
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.4 | pybinbot | 0.6.29 | Utility functions for the binbot project. | # PyBinbot
Utility functions for the binbot project. Most of the code here is not runnable, there's no server or individual scripts, you simply move code to here when it's used in both binbot and binquant.
``pybinbot`` is the public API module for the distribution.
This module re-exports the internal ``shared`` and ``models`` packages and the most commonly used helpers and enums so consumers can simply::
from pybinbot import round_numbers, ExchangeId
The implementation deliberately avoids importing heavy third-party libraries at module import time.
## Installation
```bash
uv sync --extra dev
```
`--extra dev` also installs development tools like ruff and mypy
## Publishing
1. Save your changes and do the usual Git flow (add, commit, don't push the changes yet).
2. Bump the version, choose one of these:
```bash
make bump-patch
```
or
```bash
make bump-minor
```
or
```bash
make bump-major
```
3. Git tag the version for Github. This will read the bump version. There's a convenience command:
```
make tag
```
4. `git commit --amend`. This is to put these new changes in the previous commit so we don't dup uncessary commits. Then `git push`
For further commands take a look at the `Makefile` such as testing `make test`
| text/markdown | null | Carlos Wu <carkodw@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"pydantic[email]>=2.0.0",
"numpy==2.2.0",
"pandas>=2.2.3",
"pymongo==4.6.3",
"pandas-stubs>=2.3.3.251219",
"requests>=2.32.5",
"kucoin-universal-sdk>=1.3.0",
"aiohttp>=3.13.3",
"python-dotenv>=1.2.1",
"aiokafka>=0.13.0",
"pytest>=9.0.2; extra == \"dev\"",
"ruff>=0.11.12; extra == \"dev\"",
"... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:53:42.285525 | pybinbot-0.6.29.tar.gz | 48,877 | d8/e3/140dc9caecb63f4584f4216b17b36f9d80f1e2896ebbcb2283d9511e95da/pybinbot-0.6.29.tar.gz | source | sdist | null | false | 6bc913723f36c0457d442689bf79fea1 | 8eb2116603839874b15f83b9f52c76760249446509828566109a2ea0ee224ace | d8e3140dc9caecb63f4584f4216b17b36f9d80f1e2896ebbcb2283d9511e95da | null | [
"LICENSE"
] | 247 |
2.4 | ironcast-cec | 0.3.0 | Python bindings for libcec | # ironcast-cec - libcec bindings for Python
`ironcast-cec` is a fork of trainman419's python-cec under the same license, in order to allow features and maintenance to be added to the project for the use of the IronCast streaming software.
## Installing:
### Install dependencies
To build ironcast-cec, you need version 1.6.1 or later of the libcec development libraries:
On Gentoo:
```
sudo emerge libcec
```
On OS X:
```
brew install libcec
```
Ubuntu, Debian and Raspbian:
```
sudo apt-get install libcec-dev build-essential python-dev
```
### Install from PIP
```
pip install cec
```
### Installing on Windows
You need to [build libcec](https://github.com/Pulse-Eight/libcec/blob/master/docs/README.windows.md) from source, because libcec installer doesn't provide *cec.lib* that is necessary for linking.
Then you just need to set up your paths, e.g.:
```
set INCLUDE=path_to_libcec\build\amd64\include
set LIB=path_to_libcec\build\amd64
```
## Getting Started
A simple example to turn your TV on:
```python
import cec
cec.init()
adapter = cec.Adapter()
tv = cec.Device(adapter, cec.CECDEVICE_TV)
tv.power_on()
```
## API
```python
import cec
adapter_devs = cec.list_adapters() # may be called before init()
cec.init()
adapter = cec.Adapter() # use default adapter
# create an adapter using the specifed device, with the OSD name 'RPi TV' and play back device type
adapter = cec.Adapter(dev=adapter_dev, name='RPi TV', type=cec.CECDEVICE_PLAYBACKDEVICE1)
adapter.close() # close the adapter
adapter.add_callback(handler, events)
# the list of events is specified as a bitmask of the possible events:
cec.EVENT_LOG
cec.EVENT_KEYPRESS
cec.EVENT_COMMAND
cec.EVENT_CONFIG_CHANGE # not implemented yet
cec.EVENT_ALERT
cec.EVENT_MENU_CHANGED
cec.EVENT_ACTIVATED
cec.EVENT_ALL
# the callback will receive a varying number and type of arguments that are
# specific to the event. Contact me if you're interested in using specific
# callbacks
adapter.remove_callback(handler, events)
devices = adapter.list_devices()
class Device:
__init__(id)
is_on()
power_on()
standby()
address
physical_address
vendor
osd_string
cec_version
language
is_active()
set_av_input(input)
set_audio_input(input)
transmit(opcode, parameters)
adapter.is_active_source(addr)
adapter.set_active_source() # use default device type
adapter.set_active_source(device_type) # use a specific device type
adapter.set_inactive_source() # not implemented yet
adapter.volume_up()
adapter.volume_down()
adapter.toggle_mute()
# TODO: audio status
adapter.set_physical_address(addr)
adapter.can_persist_config()
adapter.persist_config()
adapter.set_port(device, port)
# set arbitrary active source (in this case 2.0.0.0)
destination = cec.CECDEVICE_BROADCAST
opcode = cec.CEC_OPCODE_ACTIVE_SOURCE
parameters = b'\x20\x00'
adapter.transmit(destination, opcode, parameters)
```
## Changelog
### 0.3.0 ( 2026-02-14 )
* Forked project to ironcast-cec
* Added retsyx's Adapter class, to be used instead of a global CEC context
### 0.2.8 ( 2022-01-05 )
* Add support for libCEC >= 5
* Windows support
* Support for setting CEC initiator
* Python 3.10 compatibility
### 0.2.7 ( 2018-11-09 )
* Implement cec.EVENT_COMMAND callback
* Fix several crashes/memory leaks related to callbacks
* Add possibility to use a method as a callback
* Limit maximum number of parameters passed to transmit()
* Fix compilation error with GCC >= 8
### 0.2.6 ( 2017-11-03 )
* Python 3 support ( @nforro )
* Implement is_active_source, set_active_source, transmit ( @nforro )
* libcec4 compatibility ( @nforro )
### 0.2.5 ( 2016-03-31 )
* re-release of version 0.2.4. Original release failed and version number is now lost
### 0.2.4 ( 2016-03-31 )
* libcec3 compatibility
### 0.2.3 ( 2014-12-28 )
* Add device.h to manifest
* Initial pip release
### 0.2.2 ( 2014-06-08 )
* Fix deadlock
* Add repr for Device
### 0.2.1 ( 2014-03-03 )
* Fix deadlock in Device
### 0.2.0 ( 2014-03-03 )
* Add initial callback implementation
* Fix libcec 1.6.0 backwards compatibility support
### 0.1.1 ( 2013-11-26 )
* Add libcec 1.6.0 backwards compatibility
* Known Bug: no longer compatible with libcec 2.1.0 and later
### 0.1.0 ( 2013-11-03 )
* First stable release
## Copyright
Copyright (C) 2013 Austin Hendrix <namniart@gmail.com>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 2 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
| text/markdown | Steffan Pease | steffan@pod-mail.net | null | null | GPLv2 | null | [] | [] | https://gitlab.com/spease/ironcast-cec | null | null | [] | [] | [] | [] | [] | [] | [] | [
"Bug Tracker, https://gitlab.com/spease/ironcast-cec/issues"
] | twine/6.2.0 CPython/3.13.12 | 2026-02-19T02:53:33.580903 | ironcast_cec-0.3.0.tar.gz | 24,068 | e7/8a/bc36a3f2c3faa52de45bc91e3aa83e4581cc1d9ddbde32ca866841924d38/ironcast_cec-0.3.0.tar.gz | source | sdist | null | false | c565476e84916d1acd7a1e317a8e091e | fa5302d03e06eb3449c96bbe57023e387c57e8c21266a0cbe14247fba0b8ad47 | e78abc36a3f2c3faa52de45bc91e3aa83e4581cc1d9ddbde32ca866841924d38 | null | [
"LICENSE",
"COPYING"
] | 172 |
2.4 | aquakit | 1.0.0 | Refractive multi-camera geometry foundation for the Aqua ecosystem | # AquaKit
Refractive multi-camera geometry foundation for the Aqua ecosystem. Provides shared PyTorch implementations of Snell's law refraction, camera models, triangulation, pose transforms, calibration loading, and synchronized multi-camera I/O — consumed by [AquaCal](https://github.com/tlancaster6/AquaCal), [AquaMVS](https://github.com/tlancaster6/AquaMVS), and AquaPose.
## Installation
AquaKit requires PyTorch but does not bundle it, so you can choose the build that matches your hardware. Install PyTorch first, then AquaKit:
```bash
# CPU only
pip install torch
pip install aquakit
# CUDA (example: CUDA 12.4 — see https://pytorch.org/get-started for other versions)
pip install torch --index-url https://download.pytorch.org/whl/cu124
pip install aquakit
```
## Quick Start
```python
import torch
from aquakit import CameraIntrinsics, CameraExtrinsics, InterfaceParams
from aquakit import create_camera, snells_law_3d, triangulate_rays
# Load calibration from AquaCal JSON
from aquakit import load_calibration_data
calib = load_calibration_data("path/to/aquacal.json")
```
## Development
```bash
# Set up the development environment
pip install hatch
hatch env create
hatch run pre-commit install
hatch run pre-commit install --hook-type pre-push
# Run tests, lint, and type check
hatch run test
hatch run lint
hatch run typecheck
```
See [Contributing](docs/contributing.md) for full development guidelines.
## Documentation
Full documentation is available at [aquakit.readthedocs.io](https://aquakit.readthedocs.io).
## License
[MIT](LICENSE)
| text/markdown | Tucker Lancaster | null | null | null | MIT | 3d-reconstruction, calibration, camera-geometry, computer-vision, multi-camera, pytorch, refraction, triangulation, underwater | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: P... | [] | null | null | >=3.11 | [] | [] | [] | [
"numpy>=1.24",
"opencv-python>=4.8",
"kornia>=0.7; extra == \"kornia\""
] | [] | [] | [] | [
"Homepage, https://github.com/tlancaster6/aquakit",
"Documentation, https://aquakit.readthedocs.io",
"Repository, https://github.com/tlancaster6/aquakit",
"Issues, https://github.com/tlancaster6/aquakit/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:53:33.254694 | aquakit-1.0.0.tar.gz | 58,517 | a6/de/b5df8b710ead0168fc023eefbd80f9bbdddf78360ccabc018565428d661e/aquakit-1.0.0.tar.gz | source | sdist | null | false | 38d8c5314014567a230619f9062f61da | 8ce2d6734e2eb10f6e63d25686e52cbf0fcca67e78f13075976967b8575f9381 | a6deb5df8b710ead0168fc023eefbd80f9bbdddf78360ccabc018565428d661e | null | [
"LICENSE"
] | 249 |
2.4 | nomadicml | 0.1.37 | Python SDK for NomadicML's DriveMonitor API | # NomadicML Python SDK
A Python client library for the NomadicML DriveMonitor API, allowing you to upload and analyze driving videos programmatically.
## Installation
### From PyPI (for users)
```bash
pip install nomadicml
```
### For Development (from source)
To install the package in development mode, where changes to the code will be immediately reflected without reinstallation:
```bash
# Clone the repository
git clone https://github.com/nomadic-ml/drivemonitor.git
cd sdk
# For development: Install in editable mode
pip install -e .
```
With this installation, any changes you make to the code will be immediately available when you import the package.
## Quick Start
```python
from nomadicml import NomadicML
# Initialize the client with your API key
client = NomadicML(api_key="your_api_key")
# Upload a video and analyze it in one step
result = client.video.upload_and_analyze("path/to/your/video.mp4")
# Print the detected events
for event in result["events"]:
print(f"Event: {event['type']} at {event['time']}s - {event['description']}")
#For a batch upload
videos_list = [.....]#list of video paths
batch_results = client.video.upload_and_analyze_videos(videos_list, wait_for_completion=False)
video_ids = [
res.get("video_id")
for res in batch_results
if res # safety for None
]
full_results = client.video.wait_for_analyses(video_ids)
```
## Authentication
You need an API key to use the NomadicML API. You can get one by:
1. Log in to your DriveMonitor account
2. Go to Profile > API Key
3. Generate a new API key
Then use this key when initializing the client:
```python
client = NomadicML(api_key="your_api_key")
```
## Video Upload and Analysis
### Upload a video
```python
# Preferred: upload with the high-level helper
upload_result = client.video.upload(
"path/to/video.mp4",
metadata_file="path/to/overlay_schema.json", # optional
wait_for_uploaded=True,
)
video_id = upload_result["video_id"]
# Legacy helpers remain available if you need fine-grained control
result = client.video.upload_video(
source="file",
file_path="path/to/video.mp4"
)
```
The `metadata_file` argument is optional and accepts any of the following:
- Path to a JSON metadata file describing per-frame overlay fields
- A Python `dict` that can be serialised to the Nomadic overlay schema
- Raw JSON string or UTF-8 bytes containing the schema
When provided, the SDK sends the schema to `/api/upload-video` so the backend
can extract on-screen telemetry (timestamps, GPS, speed, etc.) during later
analyses. If you specify `metadata_file` while uploading multiple videos at
once, the SDK will raise a `ValidationError`—attach metadata on single uploads
only.
### Upload videos stored in Google Cloud Storage
You can import `.mp4` objects directly from GCS once you have saved their
credentials as a cloud integration:
```python
# Trigger imports without re-downloading files locally
upload_result = client.video.upload([
"gs://drive-monitor/uploads/trip-042/video_front.mp4",
"gs://drive-monitor/uploads/trip-042/video_rear.mp4",
],
folder="Fleet Library",
wait_for_uploaded=False, # async import – poll later if you prefer
)
# Provide an explicit integration id when you have multiple saved credentials
upload_result = client.video.upload([
"gs://drive-monitor/uploads/trip-042/video_front.mp4",
],
integration_id="gcs_int_123",
)
```
Rules for the GCS path:
- Only `.mp4` objects are accepted today.
- All URIs within a single call must share the same bucket.
- Pass either a single string or a list of literal blob URIs—wildcards are not
supported.
- If you omit `integration_id`, the SDK tries each saved integration whose
bucket matches the URI until one succeeds. Provide the id explicitly when multiple
integrations share the bucket.
To discover the ids you have already saved (for example, those created through
the DriveMonitor UI) call:
```python
for item in client.cloud_integrations.list(type="gcs"):
print(item["name"], item["bucket"], item["id"])
```
### Analyze a video
```python
from nomadicml.video import AnalysisType, CustomCategory
analysis = client.video.analyze(
video_id,
analysis_type=AnalysisType.ASK,
custom_event="Did the driver stop before the crosswalk?",
custom_category=CustomCategory.DRIVING,
overlay={"timestamps": True, "gps": True}, # optional OCR flags
)
events = analysis.get("events", [])
```
Overlay extraction is controlled via the optional `overlay` dictionary:
- `timestamps=True` enables OCR of on-screen frame timestamps.
- `gps=True` adds latitude/longitude extraction (timestamps are implied).
- `custom=True` activates Nomadic overlay mode, instructing the backend to use
any supplied metadata schema for full telemetry capture. This also implies
`timestamps=True`.
Each event returned by the SDK now includes an `overlay` dictionary. Overlay
entries are keyed by the field name (for example `frame_timestamp`,
`frame_speed`, etc.) and map to `{"start": ..., "end": ...}` pairs with the
values that were read from the video frames or metadata.
### Generate an ASAM OpenODD CSV
The client exposes a top-level helper, `client.generate_structured_odd(...)`,
that mirrors the DriveMonitor UI workflow and accepts the same column schema.
You can reuse the SDK’s built-in `DEFAULT_STRUCTURED_ODD_COLUMNS` constant or
pass your own list of definitions.
```python
from nomadicml import NomadicML, DEFAULT_STRUCTURED_ODD_COLUMNS
client = NomadicML(api_key="your_api_key")
# Optionally customise the column schema before calling the export.
columns = [
{
"name": "timestamp",
"prompt": "Log the timestamp in ISO 8601 format (placeholder date 2024-01-01).",
"type": "YYYY-MM-DDTHH:MM:SSZ",
},
{
"name": "scenery.road.type",
"prompt": "The type of road the vehicle is on.",
"type": "categorical",
"literals": ["motorway", "rural", "urban_street", "parking_lot", "unpaved", "unknown"],
},
# ...add or tweak additional columns...
]
odd = client.generate_structured_odd(
video_id="VIDEO_ID_FROM_UPLOAD",
columns=columns or DEFAULT_STRUCTURED_ODD_COLUMNS,
)
csv_text = odd["csv"]
share_url = odd.get("share_url")
print(csv_text.splitlines()[0]) # Header row
```
If you customise the schema in the DriveMonitor UI, use the **Copy SDK snippet**
button to paste a ready-made Python snippet that mirrors the on-screen column
configuration. The SDK automatically mirrors the Firestore reasoning trace path
and returns any generated share links together with the CSV data.
### Upload and analyze in one step
```python
# Upload and analyze a video, waiting for results
analysis = client.video.upload_and_analyze("path/to/video.mp4")
# Or just start the process without waiting
result = client.video.upload_and_analyze("path/to/video.mp4", wait_for_completion=False)
```
## Advanced Usage
### Filter events by severity or type
```python
# Get only high severity events
high_severity_events = client.video.get_video_events(
video_id=video_id,
severity="high"
)
# Get only traffic violation events
traffic_violations = client.video.get_video_events(
video_id=video_id,
event_type="Traffic Violation"
)
```
### Custom timeout and polling interval
```python
# Wait for analysis with a custom timeout and polling interval
client.video.wait_for_analysis(
video_id=video_id,
timeout=1200, # 20 minutes
poll_interval=10 # Check every 10 seconds
)
```
### Batch analyses across many videos
When you provide a list of video IDs to `client.video.analyze(...)`, the SDK now
creates a backend batch automatically (for both Asking Agent and Edge Agent
pipelines) and keeps polling the `/batch/{batch_id}/status` endpoint until the
orchestrator finishes. The return value is a dictionary with two keys:
* `batch_metadata` — contains the `batch_id`, a fully-qualified
`batch_viewer_url` pointing at the Batch Results Viewer, and a
`batch_type` flag (`"ask"` or `"agent"`).
* `results` — the list of per-video analysis dictionaries (exactly the same
schema you would get from calling `analyze()` on a single video).
### List videos in a folder
Use `my_videos()` to list videos and check their upload status:
```python
# List all videos in a folder
videos = client.my_videos(folder="My-Fleet-Videos")
# Check which videos are ready for analysis
for video in videos:
print(f"{video['video_name']}: {video['status']}")
# Filter to only uploaded (ready) videos
ready_videos = [v for v in videos if v["status"] == "uploaded"]
```
Each video dict contains:
| Field | Description |
|-------|-------------|
| `video_id` | Unique identifier |
| `video_name` | Original filename |
| `duration_s` | Video duration in seconds |
| `folder_id` | Folder identifier |
| `status` | Upload status (see below) |
| `folder_name` | Folder name (if in a folder) |
| `org_id` | Organization ID (if org-scoped) |
**Upload status values:**
| Status | Meaning |
|--------|---------|
| `processing` | Upload in progress |
| `uploading_failed` | Upload failed |
| `uploaded` | Ready for analysis |
### Manage cloud integrations
The SDK exposes a dedicated helper to manage saved cloud credentials:
```python
# List every integration visible to your user/org
integrations = client.cloud_integrations.list()
# Filter by provider (either "gcs" or "s3")
gcs_only = client.cloud_integrations.list(type="gcs")
# Add a new S3 integration using AWS keys
client.cloud_integrations.add(
type="s3",
name="AWS archive",
bucket="drive-archive",
prefix="raw/",
region="us-east-1",
credentials={
"accessKeyId": "...",
"secretAccessKey": "...",
"sessionToken": "...", # optional
},
)
```
Once an integration exists, you only need its `id` when pulling files directly
from the bucket. Call `client.upload("gs://bucket/path.mp4", integration_id="...")`
or `client.upload("s3://bucket/path.mp4", integration_id="...")` and the SDK
will hand the request to the correct backend importer. Credentials are never
embedded in the upload request body.
## BEFORE DEPLOYIN RUN THIS: Running SDK integration tests locally
The integration suite is tagged with `calls_api` and exercises the live backend
endpoints. Make sure you have a valid API key and a backend domain reachable
from your environment, then run:
```bash
cd sdk
export NOMADICML_API_KEY=YOUR_API_KEY
export VITE_BACKEND_DOMAIN=http://127.0.0.1:8099
python -u -m pytest -m calls_api -vvs -rPfE --durations=0 --capture=no tests/test_integration.py
```
The command disables pytest's output capture so you can follow streaming logs
while the long-running tests execute.
```python
from nomadicml.video import AnalysisType, CustomCategory
batch = client.video.analyze(
["video_1", "video_2", "video_3"],
analysis_type=AnalysisType.ASK,
custom_event="Did the driver stop before the crosswalk?",
custom_category=CustomCategory.DRIVING,
)
print(batch["batch_metadata"])
for item in batch["results"]:
print(item["video_id"], item["analysis_id"], len(item.get("events", [])))
```
### Custom API endpoint
If you're using a custom deployment of the DriveMonitor backend:
```python
# Connect to a local or custom deployment
client = NomadicML(
api_key="your_api_key",
base_url="http://localhost:8099"
)
```
### Search across videos
Run a semantic search on several of your videos at once:
```python
results = client.video.search(
"red pickup truck overtaking",
["vid123", "vid456"]
)
for match in results["matches"]:
print(match["videoId"], match["eventIndex"], match["similarity"])
```
## Error Handling
The SDK provides specific exceptions for different error types:
```python
from nomadicml import NomadicMLError, AuthenticationError, VideoUploadError
try:
client.video.upload_and_analyze("path/to/video.mp4")
except AuthenticationError:
print("API key is invalid or expired")
except VideoUploadError as e:
print(f"Failed to upload video: {e}")
except NomadicMLError as e:
print(f"An error occurred: {e}")
```
## Development
### Setup
Clone the repository and install development dependencies:
```bash
git clone https://github.com/nomadicml/nomadicml-python.git
cd nomadicml-python
pip install -e ".[dev]"
```
### Running tests
```bash
pytest
```
## License
MIT License. See LICENSE file for details.
| text/markdown | NomadicML Inc | info@nomadicml.com | null | null | null | null | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Development Stat... | [] | null | null | >=3.8 | [] | [] | [] | [
"requests>=2.25.0",
"typing-extensions>=3.10.0",
"backoff>=2.2.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"types-requests>=2.... | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T02:53:22.688649 | nomadicml-0.1.37.tar.gz | 76,981 | 54/b1/ab4c8bcde678c653a2f5831a45dd0e9105758c00992d7544250eec9ce996/nomadicml-0.1.37.tar.gz | source | sdist | null | false | 0a4e5f84111004e8f85cb2096efd4f72 | de2ad0c9dd0f942260b4911fa5a4d43c1b0e394f148e86b0a4b26c4fdc59af74 | 54b1ab4c8bcde678c653a2f5831a45dd0e9105758c00992d7544250eec9ce996 | null | [
"LICENSE"
] | 625 |
2.4 | py-shall | 0.0.1 | A novel mocking library for Python | # shall
A novel mocking library for Python. Coming soon.
| text/markdown | Tom Meyer | null | null | null | null | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Testing",
"Topic :: Software Development :: Testing :: Mocking"
] | [] | null | null | >=3.12 | [] | [] | [] | [] | [] | [] | [] | [
"Repository, https://github.com/tegular/shall"
] | uv/0.6.10 | 2026-02-19T02:50:18.741033 | py_shall-0.0.1.tar.gz | 1,416 | ba/a4/16dbb2461e502d6baaa47be3bef40755209643a7cc3ba1e88d18449469bc/py_shall-0.0.1.tar.gz | source | sdist | null | false | 513b7e6b87eca2778d556e096ab288e2 | 618b4d6b3e1e125ef5c0f0076cca415e64b6cdb8749b8ca43abf1a7794878c60 | baa416dbb2461e502d6baaa47be3bef40755209643a7cc3ba1e88d18449469bc | MIT | [] | 249 |
2.1 | odoo-addon-connector-jira-servicedesk | 17.0.1.0.0.3 | JIRA Connector - Service Desk Extension | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
=======================================
JIRA Connector - Service Desk Extension
=======================================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:c3b2a31720d701926953c19c20859ab28d3a38e7ab429793d23f8518666dcd46
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Fconnector--jira-lightgray.png?logo=github
:target: https://github.com/OCA/connector-jira/tree/17.0/connector_jira_servicedesk
:alt: OCA/connector-jira
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/connector-jira-17-0/connector-jira-17-0-connector_jira_servicedesk
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/connector-jira&target_branch=17.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module add support with jira servicedesk
**Table of contents**
.. contents::
:local:
Usage
=====
Setup
-----
A new button is added on the JIRA backend, to import the organizations
of JIRA. Before, be sure to use the button "Configure Organization Link"
in the "Advanced Configuration" tab.
Features
--------
Organizations
-------------
On Service Desk, you can share projects with Organizations. You may want
to use different Odoo projects according to the organizations. This is
what this extension allows.
Example:
- You have one Service Desk project named "Earth Project" with key EARTH
- On JIRA SD You share this project with organizations Themis and Rhea
- However on Odoo, you want to track the hours differently for Themis
and Rhea
Steps on Odoo:
- Create a Themis project, use the "Link with JIRA" action with the key
EARTH
- When you hit Next, the organization(s) you want to link must be set
- Repeat with another project for Rhea
If the project binding for the synchronization already exists, you can
still edit it in the settings of the project and change the
organizations.
When a task or worklog is imported, it will search for a project having
exactly the same set of organizations than the one of the task. If no
project with the same set is found and you have a project configured
without organization, the task will be linked to it.
This means that, on Odoo, you can have shared project altogether with
dedicated ones, while you only have one project on JIRA.
- Tasks with org "Themis" will be attached to this project
- Tasks with org "Rhea" will be attached to this project
- Tasks with orgs "Themis" and "Rhea" will be attached to another
project "Themis and Rhea"
- The rest of the tasks will be attached to a fourth project (configured
without organizations)
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/connector-jira/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/connector-jira/issues/new?body=module:%20connector_jira_servicedesk%0Aversion:%2017.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Camptocamp
Contributors
------------
- Jaime Arroyo
- `Camptocamp <https://camptocamp.com>`__:
- Patrick Tombez <patrick.tombez@camptocamp.com>
- Guewen Baconnier <guewen.baconnier@camptocamp.com>
- Akim Juillerat <akim.juillerat@camptocamp.com>
- Denis Leemann <denis.leemann@camptocamp.com>
- `Trobz <https://trobz.com>`__:
- Son Ho <sonhd@trobz.com>
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/connector-jira <https://github.com/OCA/connector-jira/tree/17.0/connector_jira_servicedesk>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Camptocamp,Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 17.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/connector-jira | null | >=3.10 | [] | [] | [] | [
"odoo-addon-connector_jira<17.1dev,>=17.0dev",
"odoo<17.1dev,>=17.0a"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T02:47:14.425890 | odoo_addon_connector_jira_servicedesk-17.0.1.0.0.3-py3-none-any.whl | 51,780 | 7f/57/98f14ac9d89f40170f26be548ec9bf038af60df3816f701254b36e3d9125/odoo_addon_connector_jira_servicedesk-17.0.1.0.0.3-py3-none-any.whl | py3 | bdist_wheel | null | false | c4bb59a1a211015c63b53d2bcdce3008 | c9aafa6055ee7eb815c33cc6fa5352ce07ab1b394734f64fb8b1d793f24355e8 | 7f5798f14ac9d89f40170f26be548ec9bf038af60df3816f701254b36e3d9125 | null | [] | 103 |
2.3 | mxbiflow | 0.3.8 | mxbiflow is a toolkit based on pygame and pymxbi | # mxbiflow
A framework for building multi-animal, multi-stage behavioral neuroscience experiments with touchscreen interfaces.
## Overview
mxbiflow provides the core infrastructure for cognitive and behavioral experiment scheduling. It handles the experiment lifecycle — from configuration wizards and session management to real-time scene rendering and data logging — so you can focus on designing your experiment logic.
## Architecture
```
┌─────────────────────────────────────────────────────────┐
│ mxbiflow │
│ │
│ Wizard (PySide6) Game Loop (pygame-ce) │
│ ┌────────────────┐ ┌───────────────────┐ │
│ │ MXBIPanel │ │ SceneManager │ │
│ │ ExperimentPanel│ ──────▶ │ ├─ Scene A │ │
│ └────────────────┘ │ ├─ Scene B │ │
│ │ └─ ... │ │
│ │ │ │
│ │ Scheduler │ │
│ │ DetectorBridge │ │
│ └───────────────────┘ │
│ │
│ ConfigStore ◄──── JSON config files │
│ DataLogger ────► session data output │
└─────────────────────────────────────────────────────────┘
│
▼
┌───────────────────┐
│ pymxbi │
│ RFID / Rewarder │
│ Detector / Audio │
└───────────────────┘
```
## Usage
Implement your experiment as a set of scenes, register them, and launch:
```python
from mxbiflow import set_base_path
from mxbiflow.scene import SceneManager
from mxbiflow.wizard import config_wizard, init_gameloop
scene_manager = SceneManager()
scene_manager.register([IDLE, Detect, Discriminate])
config_wizard(scene_manager)
game = init_gameloop(scene_manager)
game.play()
```
Each scene implements `SceneProtocol`:
```python
class MyScene:
_running: bool
level_table: dict[str, list[int]] = {"default": [1, 2, 3]}
def start(self) -> None: ...
def quit(self) -> None: ...
@property
def running(self) -> bool: ...
def handle_event(self, event: Event) -> None: ...
def update(self, dt_s: float) -> None: ...
def draw(self, screen: Surface) -> None: ...
```
## Installation
```shell
uv add mxbiflow
```
## Requirements
- Python 3.14+
- pygame-ce, PySide6, pymxbi
| text/markdown | HuYang | HuYang <huyangcommit@gmail.com> | null | null | null | null | [] | [] | null | null | >=3.14 | [] | [] | [] | [
"gpiozero>=2.0.1",
"inflection>=0.5.1",
"jinja2>=3.1.6",
"keyring>=25.6.0",
"loguru>=0.7.3",
"matplotlib>=3.10.6",
"mss>=10.1.0",
"numpy>=2.3.3",
"pandas>=2.3.2",
"pillow>=11.3.0",
"pyaudio>=0.2.14",
"pydantic>=2.11.7",
"pygame-ce>=2.5.6",
"pymotego>=0.1.3",
"pymxbi>=0.3.4",
"pyserial>... | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T02:46:19.404857 | mxbiflow-0.3.8.tar.gz | 4,444,566 | 6a/f1/b6166a15070132cdb6a8482ad7820b890157430fe0910dcdce403caaa7a9/mxbiflow-0.3.8.tar.gz | source | sdist | null | false | cda95bf91e1c88dd398a9948764d5299 | 6754e68e5cfe050592d427cb3e5d51fc2bbf49fbb509e8072ec8f8edd72ce808 | 6af1b6166a15070132cdb6a8482ad7820b890157430fe0910dcdce403caaa7a9 | null | [] | 256 |
2.4 | FastSketchLSH | 0.2.0 | High-performance FastSketch with SIMD acceleration to deduplicate large-scale data | # FastSketchLSH
## Introduction
FastSketchLSH delivers a Python-first package that wraps a high-performance C++/SIMD implementation of Fast Similarity Sketch (see Dahlgaard et al., FOCS'17 [arXiv:1704.04370](https://arxiv.org/abs/1704.04370) for the underlying algorithm). The goal is to make Jaccard estimation and locality-sensitive hashing (LSH) practical for large dataset deduplication.
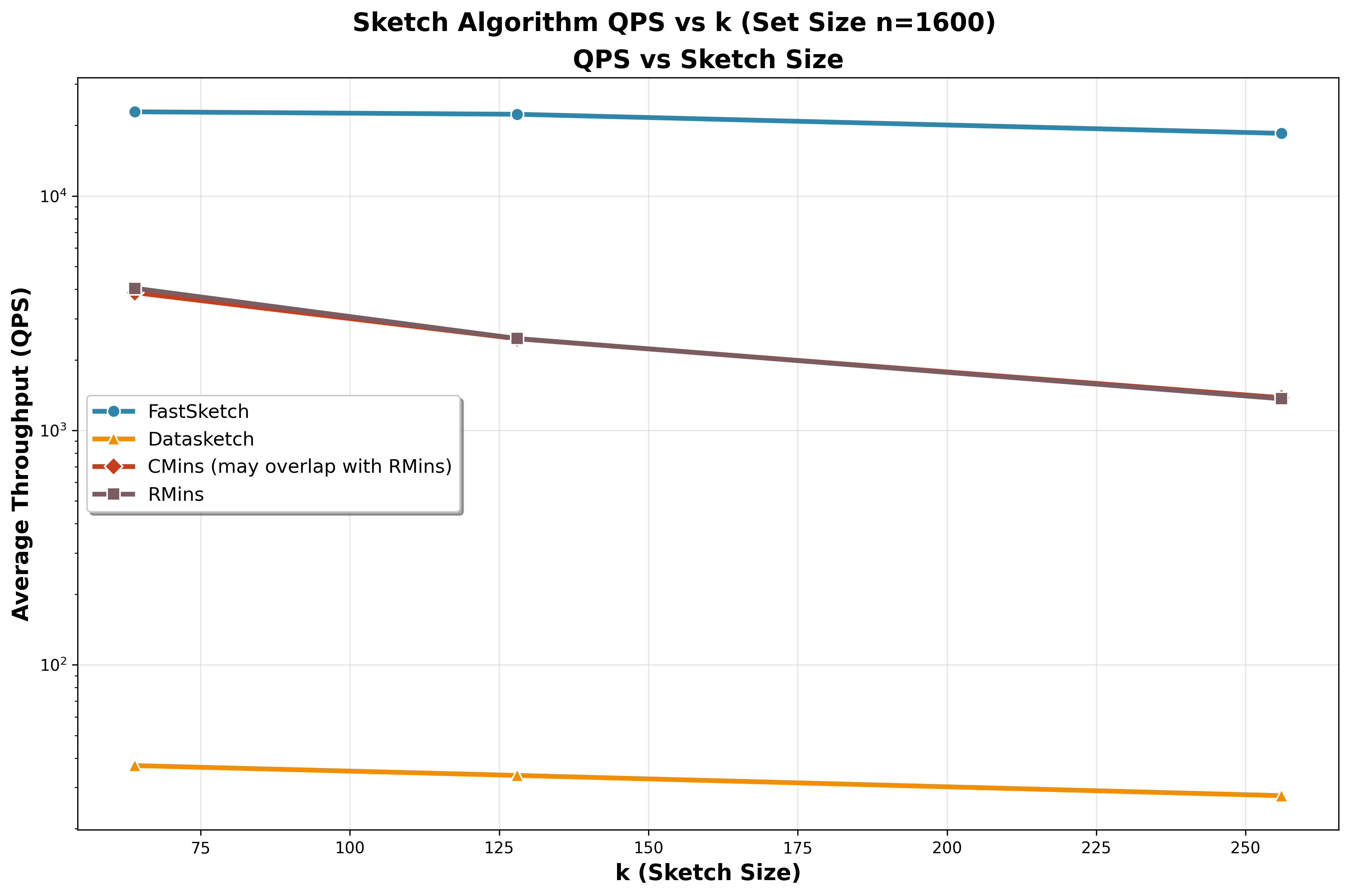
| Dataset | Engine | Sketch (s) | Build (s) | Query (s) | Total (s) | FastSketchLSH Sketch Speedup | FastSketchLSH Total Speedup |
|---------|--------|------------|-----------|-----------|-----------|--------------------------|------------------------|
| BOOKCORPUSOPEN | rensa | 198.545 | 0.026 | 0.018 | 198.589 | - | - |
| BOOKCORPUSOPEN | fastsketchlsh | 55.280 | 0.039 | 0.031 | 55.350 | 3.59× | 3.59× |
| BOOKS3 | rensa | 95.915 | 0.005 | 0.003 | 95.923 | - | - |
| BOOKS3 | fastsketchlsh | 28.440 | 0.008 | 0.007 | 28.455 | 3.37× | 3.37× |
| PINECONE | rensa | 3.929 | 0.141 | 0.153 | 4.223 | - | - |
| PINECONE | fastsketchlsh | 1.521 | 0.249 | 0.396 | 2.166 | 2.58× | 1.95× |
| SHUYUEJ | rensa | 3.749 | 0.037 | 0.044 | 3.830 | - | - |
| SHUYUEJ | fastsketchlsh | 1.132 | 0.093 | 0.121 | 1.346 | 3.31× | 2.85× |
### Headline Results
- `FastSimilaritySketch` maintains **sub-millisecond** sketch times even when each set holds **1 600 tokens**, keeping the absolute Jaccard error around **0.03–0.06**.
- At the sketch level, FastSimilaritySketch stays **200×–990× faster** than `datasketch` MinHash and still **8×–23×** faster than Rensa’s `CMinHash`/`RMinHash`, while matching their accuracy—these gains matter most for large documents.
- End-to-end deduplication experiments show FastSketchLSH is typically **~2×–3.6× faster** than Rensa in single-thread runs.
- Ground-truth comparisons confirm FastSketchLSH matches or slightly exceeds the deduplication accuracy of both Rensa and datasketch.
## What's New in v0.2.0
**Pre-hashed input support** -- `sketch_prehashed`, `sketch_batch_prehashed`, and `sketch_batch_flat_csr_prehashed` methods now accept `np.uint64` or `np.int64` arrays of user-provided hash values directly. This skips the internal prehash phase entirely (no `hash_int32`, no `fnv1a64`), which is useful when you hash tokens yourself or reuse hash values across different sketch configurations.
```python
import numpy as np
from FastSketchLSH import FastSimilaritySketch
sketcher = FastSimilaritySketch(sketch_size=256, seed=42)
# Single sketch from pre-hashed values (zero-copy from NumPy)
hashes = np.array([0xDEAD, 0xBEEF, 0xCAFE, ...], dtype=np.uint64)
digest = sketcher.sketch_prehashed(hashes)
# Batch of pre-hashed arrays
batch = [np.array([...], dtype=np.uint64) for _ in range(1000)]
digests = sketcher.sketch_batch_prehashed(batch, num_threads=8)
# CSR layout for maximum throughput
data = np.array([...], dtype=np.uint64)
indptr = np.array([0, 120, 250, 500], dtype=np.uint64)
digests = sketcher.sketch_batch_flat_csr_prehashed(data, indptr, num_threads=8)
```
All prehashed paths share the same SIMD-accelerated Round 1 / Round 2 bucket-fill logic and OpenMP batch parallelism as the existing `sketch` methods.
## How It Works
- **Fast Similarity Sketching**: SIMD-accelerated permutations compress a set into a fixed-length signature, expected time `O(n + k log k)` with `O(k)` space.
- **Banded LSH**: Signature rows are grouped into bands; items colliding in any band become candidates for deduplication.
- **Python ergonomics**: Thin wrappers expose the C++ core, plus reference implementations of competing sketches for fair comparisons.
## Installation
> **Prerequisite:** Python 3.11 or newer. Support for Python 3.8 and older
> interpreters is on the roadmap.
### PyPI (recommended)
```bash
pip install fastsketchlsh
```
### Build from source
1. Build the native extension:
```bash
cd fastsketchlsh_ext
pip install .
```
This installs the `FastSketchLSH` Python module with SIMD kernels.
2. Install benchmark utilities (optional for reproducing experiments):
```bash
pip install -r requirements.txt
```
3. Activate your environment (e.g. `source .venv/bin/activate`) before running scripts.
## Quick Start
### Sketch two sets and estimate their Jaccard similarity
```python
from FastSketchLSH import FastSimilaritySketch, estimate_jaccard
# Build list_a with 16,000 tokens labeled "a-0" to "a-15999"
# Build list_b with 8,000 overlapping + 8,000 new tokens (true Jaccard = 1/3)
list_a = [f"a-{i}" for i in range(16_000)]
list_b = [f"a-{i}" for i in range(8_000)] + [f"b-{i}" for i in range(8_000)]
sketcher = FastSimilaritySketch(sketch_size=256)
sig_a = sketcher.sketch(list_a)
sig_b = sketcher.sketch(list_b)
estimated = estimate_jaccard(sig_a, sig_b)
print(f"Estimated Jaccard similarity: {estimated:.4f}")
```
### Deduplication with LSH
This end-to-end sample downloads a small slice of Hugging Face’s `lucadiliello/bookcorpusopen` corpus, sketches every document with `k=128`, and groups the signatures into `16` bands. Sketching each document costs `O(n + k log k)` time with `O(k)` space, while an LSH probe runs in `O(k + c)` where `c` is the number of retrieved candidates.
```python
from __future__ import annotations
from datasets import load_dataset
from FastSketchLSH import FastSimilaritySketch, LSH
def tokenize(text: str) -> list[str]:
return sorted({token for token in text.lower().split() if token})
# Here, 'train[:2048]' tells Hugging Face Datasets to select only the first 2048 rows from the 'train' split.
dataset = load_dataset(
"lucadiliello/bookcorpusopen",
split="train[:2048]")
texts = [row["text"] for row in dataset if row.get("text")]
token_sets = [tokenize(text) for text in texts]
sketcher = FastSimilaritySketch(sketch_size=128, seed=42)
# Use batch mode for faster sketching (much faster than one-by-one)
sketch_matrix = sketcher.sketch_batch(token_sets)
lsh = LSH(num_perm=128, num_bands=16)
lsh.build_from_batch(sketch_matrix)
doc_idx = 0
candidates = lsh.query_candidates(sketch_matrix[doc_idx])
print(f"Candidates for {doc_idx}:", candidates)
dup_flags = [1 if len(lsh.query_candidates(row)) > 1 else 0 for row in sketch_matrix]
print("Duplicate flags:", dup_flags)
print("Total duplicates detected:", sum(dup_flags))
```
## Experiment Summaries
- **Sketch microbenchmarks (`exps/sketch/`)**: Full write-up, CSVs, and plotting helpers demonstrating latency and accuracy versus `datasketch` and Rensa baselines. Reproduction steps live in `exps/sketch/README.md`.
- **Ground-truth accuracy (`exps/accuracy/`)**: Jaccard estimation and dedup quality measured against labelled datasets. See `exps/accuracy/README.md` for reproduction commands.
- **End-to-end pipelines (`exps/end2end/`)**: Thread-scaled deduplication sweeps on large corpora, plus scripts for batch comparisons. Details in `exps/end2end/README.md`.
Each experiment directory includes figures, CSV outputs, and exact command lines so you can replicate every result.
## Key Points
- FastSketchLSH packages a SIMD-backed sketch with Python convenience wrappers.
- Headline benchmarks show up to **990×** throughput gains over classic MinHash at comparable accuracy.
- Ready-to-run examples cover sketching, LSH-based deduplication, and full dataset experiments.
- For deeper reproduction details, consult the README in each experiment subdirectory.
## Future Work
- A MapReduce/Spark demo to deduplicate large datasets in distributed systems.
- A friendlier Python interface aligned with `datasketch` ergonomics.
## License
MIT. Research and educational use welcome.
| text/markdown | FastSketchLSH Authors | null | null | null | MIT | null | [] | [] | https://github.com/pzcddm/FastSketchLSH | null | >=3.11 | [] | [] | [] | [
"pybind11>=2.10",
"numpy>=1.21"
] | [] | [] | [] | [
"Source, https://github.com/pzcddm/FastSketchLSH",
"Issues, https://github.com/pzcddm/FastSketchLSH/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:46:11.210336 | fastsketchlsh-0.2.0.tar.gz | 55,127 | 21/43/c574277552d9b9062e7d29f4236b2b901beab1aaa4b5194c7a562c553a23/fastsketchlsh-0.2.0.tar.gz | source | sdist | null | false | 2326367ae608440bedc24ec0cca7d68e | 6e772cf512ca21c4e8ecc4faf42e36cb5902465899651fcdf836953098633332 | 2143c574277552d9b9062e7d29f4236b2b901beab1aaa4b5194c7a562c553a23 | null | [
"LICENSE"
] | 0 |
2.4 | fm-rs | 0.1.5 | Python bindings for Apple's FoundationModels.framework | # fm-rs - Python bindings for Apple FoundationModels
Python bindings for [fm-rs](https://github.com/blacktop/fm-rs), enabling on-device AI via Apple Intelligence.
## Requirements
- **macOS 26.0+** (Tahoe) on **Apple Silicon (ARM64)**
- **Apple Intelligence enabled** in System Settings
- **Python 3.10+**
## Installation
```bash
pip install fm-rs
```
### From Source
```bash
# Requires Rust toolchain
cd bindings/python
uv sync
uv run maturin develop
```
## Quick Start
```python
import fm
# Create the default system language model
model = fm.SystemLanguageModel()
# Check availability
if not model.is_available:
print("Apple Intelligence is not available")
exit(1)
# Create a session
session = fm.Session(model, instructions="You are a helpful assistant.")
# Send a prompt
response = session.respond("What is the capital of France?")
print(response.content)
```
## Streaming
```python
import fm
model = fm.SystemLanguageModel()
session = fm.Session(model)
# Stream the response
session.stream_response(
"Tell me a short story",
lambda chunk: print(chunk, end="", flush=True)
)
print() # newline at end
```
## Structured Generation
```python
import fm
model = fm.SystemLanguageModel()
session = fm.Session(model)
# Using a dict schema
schema = {
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "integer"}
},
"required": ["name", "age"]
}
person = session.respond_structured("Generate a fictional person", schema)
print(f"Name: {person['name']}, Age: {person['age']}")
# Using the Schema builder
schema = (fm.Schema.object()
.property("name", fm.Schema.string(), required=True)
.property("age", fm.Schema.integer().minimum(0), required=True))
person = session.respond_structured("Generate a fictional person", schema.to_dict())
```
## Tool Calling
Tools allow the model to call external functions during generation.
```python
import fm
class WeatherTool:
name = "get_weather"
description = "Gets the current weather for a location"
arguments_schema = {
"type": "object",
"properties": {
"city": {"type": "string", "description": "The city name"}
},
"required": ["city"]
}
def call(self, args):
city = args.get("city", "Unknown")
return f"Sunny, 72°F in {city}"
model = fm.SystemLanguageModel()
session = fm.Session(model, tools=[WeatherTool()])
response = session.respond("What's the weather in Paris?")
print(response.content)
```
## Context Management
```python
import fm
model = fm.SystemLanguageModel()
session = fm.Session(model)
# After some conversation...
limit = fm.ContextLimit.default_on_device()
usage = session.context_usage(limit)
print(f"Tokens used: {usage.estimated_tokens}/{usage.max_tokens}")
print(f"Utilization: {usage.utilization:.1%}")
if usage.over_limit:
# Compact the conversation
transcript = session.transcript_json
summary = fm.compact_transcript(model, transcript)
print(f"Summary: {summary}")
```
## Error Handling
```python
import fm
try:
model = fm.SystemLanguageModel()
model.ensure_available()
except fm.DeviceNotEligibleError:
print("This device doesn't support Apple Intelligence")
except fm.AppleIntelligenceNotEnabledError:
print("Please enable Apple Intelligence in Settings")
except fm.ModelNotReadyError:
print("Model is still downloading, try again later")
except fm.ModelNotAvailableError:
print("Model not available for unknown reason")
```
## API Reference
### Classes
- `SystemLanguageModel` - Entry point for on-device AI
- `Session` - Maintains conversation context
- `GenerationOptions` - Controls generation (temperature, max_tokens, etc.)
- `Response` - Model output
- `ToolOutput` - Tool invocation result
- `ContextLimit` - Context window configuration
- `ContextUsage` - Estimated token usage
- `Schema` - JSON Schema builder
### Enums
- `Sampling` - `Greedy` or `Random`
- `ModelAvailability` - `Available`, `DeviceNotEligible`, `AppleIntelligenceNotEnabled`, `ModelNotReady`, `Unknown`
### Functions
- `estimate_tokens(text, chars_per_token=4)` - Estimate token count
- `context_usage_from_transcript(json, limit)` - Get context usage
- `transcript_to_text(json)` - Extract text from transcript
- `compact_transcript(model, json)` - Summarize conversation
### Exceptions
- `FmError` - Base exception
- `ModelNotAvailableError`
- `DeviceNotEligibleError`
- `AppleIntelligenceNotEnabledError`
- `ModelNotReadyError`
- `GenerationError`
- `ToolCallError`
- `JsonError`
## Notes
- **Apple Silicon only**: Wheels are built for macOS ARM64 only (Apple Silicon Macs)
- **Tool callbacks**: May be invoked from non-main threads; avoid UI work in callbacks
- **Blocking calls**: All calls block until completion; use streaming for long responses
- **GIL**: Callbacks run under the GIL; keep them short
## Development
```bash
cd bindings/python
uv sync
uv run maturin develop
uv run pytest tests/
```
## License
MIT
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | null | apple, ai, llm, foundation-models, apple-intelligence | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS :: MacOS X",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pyt... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/blacktop/fm-rs",
"Issues, https://github.com/blacktop/fm-rs/issues",
"Repository, https://github.com/blacktop/fm-rs"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:45:54.637902 | fm_rs-0.1.5.tar.gz | 85,405 | c7/21/4d52aabd86b5bb3c2a94e63299242100bf1efd465f43d5873de583354a8d/fm_rs-0.1.5.tar.gz | source | sdist | null | false | 1049da500a1ab38a21d7903fb6bb4578 | c73b05536e3dab83294cc0f7934f413ee120883037ba600909a8d888d1cf5338 | c7214d52aabd86b5bb3c2a94e63299242100bf1efd465f43d5873de583354a8d | MIT | [] | 249 |
2.4 | zscaler-mcp | 0.6.2 | Official Zscaler Integrations MCP Server | 
[](https://badge.fury.io/py/zscaler-mcp)
[](https://pypi.org/project/zscaler-mcp/)
[](https://zscaler-mcp-server.readthedocs.io/en/latest/?badge=latest)
[](https://codecov.io/gh/zscaler/zscaler-mcp-server)
[](https://github.com/zscaler/zscaler-mcp-server)
[](https://community.zscaler.com/)
**zscaler-mcp-server** is a Model Context Protocol (MCP) server that connects AI agents with the Zscaler Zero Trust Exchange platform. **By default, the server operates in read-only mode** for security, requiring explicit opt-in to enable write operations.
## Support Disclaimer
-> **Disclaimer:** Please refer to our [General Support Statement](https://github.com/zscaler/zscaler-mcp-server/blob/master/docs/guides/support.md) before proceeding with the use of this provider. You can also refer to our [troubleshooting guide](https://github.com/zscaler/zscaler-mcp-server/blob/master/docs/guides/TROUBLESHOOTING.md) for guidance on typical problems.
> [!IMPORTANT]
> **🚧 Public Preview**: This project is currently in public preview and under active development. Features and functionality may change before the stable 1.0 release. While we encourage exploration and testing, please avoid production deployments. We welcome your feedback through [GitHub Issues](https://github.com/zscaler/zscaler-mcp-server/issues) to help shape the final release.
## 📄 Table of contents
- [📺 Overview](#overview)
- [🔒 Security & Permissions](#security-permissions)
- [Supported Tools](#supported-tools)
- [Installation & Setup](#installation--setup)
- [Prerequisites](#prerequisites)
- [Environment Configuration](#environment-configuration)
- [Installation](#installation)
- [Usage](#usage)
- [Command Line](#command-line)
- [Service Configuration](#service-configuration)
- [Additional Command Line Options](#additional-command-line-options)
- [Zscaler API Credentials & Authentication](#zscaler-api-credentials-authentication)
- [Quick Start: Choose Your Authentication Method](#quick-start-choose-your-authentication-method)
- [OneAPI Authentication (Recommended)](#oneapi-authentication-recommended)
- [Legacy API Authentication](#legacy-api-authentication)
- [Authentication Troubleshooting](#authentication-troubleshooting)
- [MCP Server Configuration](#mcp-server-configuration)
- [As a Library](#as-a-library)
- [Container Usage](#container-usage)
- [Using Pre-built Image (Recommended)](#using-pre-built-image-recommended)
- [Building Locally (Development)](#building-locally-development)
- [Editor/Assistant Integration](#editor-assistant-integration)
- [Using `uvx` (recommended)](#using-uvx-recommended)
- [With Service Selection](#with-service-selection)
- [Using Individual Environment Variables](#using-individual-environment-variables)
- [Docker Version](#docker-version)
- [Additional Deployment Options](#additional-deployment-options)
- [Amazon Bedrock AgentCore](#amazon-bedrock-agentcore)
- [Using the MCP Server with Agents](#using-the-mcp-server-with-agents)
- [Claude Desktop](#claude-desktop)
- [Cursor](#cursor)
- [Visual Studio Code + GitHub Copilot](#visual-studio-code-github-copilot)
- [Troubleshooting](#troubleshooting)
- [License](#license)
## 📺 Overview
The Zscaler Integrations MCP Server brings context to your agents. Try prompts like:
- "List my ZPA Application segments"
- "List my ZPA Segment Groups"
- "List my ZIA Rule Labels"
> [!WARNING]
> **🔒 READ-ONLY BY DEFAULT**: For security, this MCP server operates in **read-only mode** by default. Only `list_*` and `get_*` operations are available. To enable tools that can **CREATE, UPDATE, or DELETE** Zscaler resources, you must explicitly enable write mode using the `--enable-write-tools` flag or by setting `ZSCALER_MCP_WRITE_ENABLED=true`. See the [Security & Permissions](#-security--permissions) section for details.
## 🔒 Security & Permissions
The Zscaler MCP Server implements a **security-first design** with granular permission controls and safe defaults:
### Read-Only Mode (Default - Always Available)
By default, the server operates in **read-only mode**, exposing only tools that list or retrieve information:
- ✅ **ALWAYS AVAILABLE** - Read-only tools are registered by the server
- ✅ Safe to use with AI agents autonomously
- ✅ No risk of accidental resource modification or deletion
- ✅ All `list_*` and `get_*` operations are available (110+ read-only tools)
- ❌ All `create_*`, `update_*`, and `delete_*` operations are disabled by default
- 💡 Note: You may need to enable read-only tools in your AI agent's UI settings
```bash
# Read-only mode (default - safe)
zscaler-mcp
```
When the server starts in read-only mode, you'll see:
```text
🔒 Server running in READ-ONLY mode (safe default)
Only list and get operations are available
To enable write operations, use --enable-write-tools AND --write-tools flags
```
> **💡 Read-only tools are ALWAYS registered** by the server regardless of any flags. You never need to enable them server-side. Note: Your AI agent UI (like Claude Desktop) may require you to enable individual tools before use.
### Write Mode (Explicit Opt-In - Allowlist REQUIRED)
To enable tools that can create, modify, or delete Zscaler resources, you must provide **BOTH** flags:
1. ✅ `--enable-write-tools` - Global unlock for write operations
2. ✅ `--write-tools "pattern"` - **MANDATORY** explicit allowlist
> **🔐 SECURITY: Allowlist is MANDATORY** - If you set `--enable-write-tools` without `--write-tools`, **0 write tools will be registered**. This ensures you consciously choose which write operations to enable.
```bash
# ❌ WRONG: This will NOT enable any write tools (allowlist missing)
zscaler-mcp --enable-write-tools
# ✅ CORRECT: Explicit allowlist required
zscaler-mcp --enable-write-tools --write-tools "zpa_create_*,zpa_delete_*"
```
When you try to enable write mode without an allowlist:
```text
⚠️ WRITE TOOLS MODE ENABLED
⚠️ NO allowlist provided - 0 write tools will be registered
⚠️ Read-only tools will still be available
⚠️ To enable write operations, add: --write-tools 'pattern'
```
#### Write Tools Allowlist (MANDATORY)
The allowlist provides **two-tier security**:
1. ✅ **First Gate**: `--enable-write-tools` must be set (global unlock)
2. ✅ **Second Gate**: Explicit allowlist determines which write tools are registered (MANDATORY)
**Allowlist Examples:**
```bash
# Enable ONLY specific write tools with wildcards
zscaler-mcp --enable-write-tools --write-tools "zpa_create_*,zpa_delete_*"
# Enable specific tools without wildcards
zscaler-mcp --enable-write-tools --write-tools "zpa_create_application_segment,zia_create_rule_label"
# Enable all ZPA write operations (but no ZIA/ZDX/ZTW)
zscaler-mcp --enable-write-tools --write-tools "zpa_*"
```
Or via environment variable:
```bash
export ZSCALER_MCP_WRITE_ENABLED=true
export ZSCALER_MCP_WRITE_TOOLS="zpa_create_*,zpa_delete_*"
zscaler-mcp
```
**Wildcard patterns supported:**
- `zpa_create_*` - Allow all ZPA creation tools
- `zpa_delete_*` - Allow all ZPA deletion tools
- `zpa_*` - Allow all ZPA write tools
- `*_application_segment` - Allow all operations on application segments
- `zpa_create_application_segment` - Exact match (no wildcard)
When using a valid allowlist, you'll see:
```text
⚠️ WRITE TOOLS MODE ENABLED
⚠️ Explicit allowlist provided - only listed write tools will be registered
⚠️ Allowed patterns: zpa_create_*, zpa_delete_*
⚠️ Server can CREATE, MODIFY, and DELETE Zscaler resources
🔒 Security: 85 write tools blocked by allowlist, 8 allowed
```
### Tool Design Philosophy
Each operation is a **separate, single-purpose tool** with explicit naming that makes its intent clear:
#### ✅ Good (Verb-Based - Current Design)
```text
zpa_list_application_segments ← Read-only, safe to allow-list
zpa_get_application_segment ← Read-only, safe to allow-list
zpa_create_application_segment ← Write operation, requires --enable-write-tools
zpa_update_application_segment ← Write operation, requires --enable-write-tools
zpa_delete_application_segment ← Destructive, requires --enable-write-tools
```
This design allows AI assistants (Claude, Cursor, GitHub Copilot) to:
- Allow-list read-only tools for autonomous exploration
- Require explicit user confirmation for write operations
- Clearly understand the intent of each tool from its name
### Security Layers
The server implements multiple layers of security (defense-in-depth):
1. **Read-Only Tools Always Enabled**: Safe `list_*` and `get_*` operations are always available (110+ tools)
2. **Default Write Mode Disabled**: Write tools are disabled unless explicitly enabled via `--enable-write-tools`
3. **Mandatory Allowlist**: Write operations require explicit `--write-tools` allowlist (wildcard support)
4. **Verb-Based Tool Naming**: Each tool clearly indicates its purpose (`list`, `get`, `create`, `update`, `delete`)
5. **Tool Metadata Annotations**: All tools are annotated with `readOnlyHint` or `destructiveHint` for AI agent frameworks
6. **AI Agent Confirmation**: All write tools marked with `destructiveHint=True` trigger permission dialogs in AI assistants
7. **Double Confirmation for DELETE**: Delete operations require both permission dialog AND server-side confirmation (extra protection for irreversible actions)
8. **Environment Variable Control**: `ZSCALER_MCP_WRITE_ENABLED` and `ZSCALER_MCP_WRITE_TOOLS` can be managed centrally
9. **Audit Logging**: All operations are logged for tracking and compliance
This multi-layered approach ensures that even if one security control is bypassed, others remain in place to prevent unauthorized operations.
**Key Security Principles**:
- No "enable all write tools" backdoor exists - allowlist is **mandatory**
- AI agents must request permission before executing any write operation (`destructiveHint`)
- Every destructive action requires explicit user approval through the AI agent's permission framework
### Best Practices
- **Read-Only by Default**: No configuration needed for safe operations - read-only tools are always available
- **Mandatory Allowlist**: Always provide explicit `--write-tools` allowlist when enabling write mode
- **Development/Testing**: Use narrow allowlists (e.g., `--write-tools "zpa_create_application_segment"`)
- **Production/Agents**: Keep server in read-only mode (default) for AI agents performing autonomous operations
- **CI/CD**: Never set `ZSCALER_MCP_WRITE_ENABLED=true` without a corresponding `ZSCALER_MCP_WRITE_TOOLS` allowlist
- **Least Privilege**: Use narrowest possible allowlist patterns for your use case
- **Wildcard Usage**: Use wildcards for service-level control (e.g., `zpa_create_*`) or operation-level control (e.g., `*_create_*`)
- **Audit Review**: Regularly review which write tools are allowlisted and remove unnecessary ones
## Supported Tools
The Zscaler Integrations MCP Server provides **150+ tools** for all major Zscaler services:
| Service | Description | Tools |
|---------|-------------|-------|
| **ZCC** | Zscaler Client Connector - Device management | 4 read-only |
| **ZDX** | Zscaler Digital Experience - Monitoring & analytics | 18 read-only |
| **ZIdentity** | Identity & access management | 3 read-only |
| **ZIA** | Zscaler Internet Access - Security policies | 60+ read/write |
| **ZPA** | Zscaler Private Access - Application access | 60+ read/write |
| **ZTW** | Zscaler Workload Segmentation | 20+ read/write |
| **EASM** | External Attack Surface Management | 7 read-only |
📖 **[View Complete Tools Reference →](docs/guides/supported-tools.md)**
> **Note:** All write operations require the `--enable-write-tools` flag and an explicit `--write-tools` allowlist. See the [Security & Permissions](#-security--permissions) section for details.
## Installation & Setup
### Prerequisites
- Python 3.11 or higher
- [`uv`](https://docs.astral.sh/uv/) or pip
- Zscaler API credentials (see below)
### Environment Configuration
Copy the example environment file and configure your credentials:
```bash
cp .env.example .env
```
Then edit `.env` with your Zscaler API credentials:
**Required Configuration (OneAPI):**
- `ZSCALER_CLIENT_ID`: Your Zscaler OAuth client ID
- `ZSCALER_CLIENT_SECRET`: Your Zscaler OAuth client secret
- `ZSCALER_CUSTOMER_ID`: Your Zscaler customer ID
- `ZSCALER_VANITY_DOMAIN`: Your Zscaler vanity domain
**Optional Configuration:**
- `ZSCALER_CLOUD`: (Optional) Zscaler cloud environment (e.g., `beta`) - Required when interacting with Beta Tenant ONLY.
- `ZSCALER_USE_LEGACY`: Enable legacy API mode (`true`/`false`, default: `false`)
- `ZSCALER_MCP_SERVICES`: Comma-separated list of services to enable (default: all services)
- `ZSCALER_MCP_TRANSPORT`: Transport method - `stdio`, `sse`, or `streamable-http` (default: `stdio`)
- `ZSCALER_MCP_DEBUG`: Enable debug logging - `true` or `false` (default: `false`)
- `ZSCALER_MCP_HOST`: Host for HTTP transports (default: `127.0.0.1`)
- `ZSCALER_MCP_PORT`: Port for HTTP transports (default: `8000`)
*Alternatively, you can set these as environment variables instead of using a `.env` file.*
> **Important**: Ensure your API client has the necessary permissions for the services you plan to use. You can always update permissions later in the Zscaler console.
### Installation
#### Install with VS Code (Quick Setup)
[](https://vscode.dev/redirect?url=vscode:mcp/install?%7B%22name%22%3A%22zscaler-mcp-server%22%2C%22type%22%3A%22stdio%22%2C%22command%22%3A%22uvx%22%2C%22args%22%3A%5B%22zscaler-mcp%22%5D%2C%22env%22%3A%7B%22ZSCALER_CLIENT_ID%22%3A%22%3CYOUR_CLIENT_ID%3E%22%2C%22ZSCALER_CLIENT_SECRET%22%3A%22%3CYOUR_CLIENT_SECRET%3E%22%2C%22ZSCALER_CUSTOMER_ID%22%3A%22%3CYOUR_CUSTOMER_ID%3E%22%2C%22ZSCALER_VANITY_DOMAIN%22%3A%22%3CYOUR_VANITY_DOMAIN%3E%22%7D%7D)
> **Note**: This will open VS Code and prompt you to configure the MCP server. You'll need to replace the placeholder values (`<YOUR_CLIENT_ID>`, etc.) with your actual Zscaler credentials.
#### Install using uv (recommended)
```bash
uv tool install zscaler-mcp
```
#### Install from source using uv (development)
```bash
uv pip install -e .
```
#### Install from source using pip
```bash
pip install -e .
```
#### Install using make (convenience)
```bash
make install-dev
```
> [!TIP]
> If `zscaler-mcp-server` isn't found, update your shell PATH.
For installation via code editors/assistants, see the [Using the MCP Server with Agents](#using-the-mcp-server-with-agents) section below.
## Usage
> [!NOTE]
> **Default Security Mode**: All examples below run in **read-only mode** by default (only `list_*` and `get_*` operations). To enable write operations (`create_*`, `update_*`, `delete_*`), add the `--enable-write-tools` flag to any command, or set `ZSCALER_MCP_WRITE_ENABLED=true` in your environment.
### Command Line
Run the server with default settings (stdio transport, read-only mode):
```bash
zscaler-mcp
```
Run the server with write operations enabled:
```bash
zscaler-mcp --enable-write-tools
```
Run with SSE transport:
```bash
zscaler-mcp --transport sse
```
Run with streamable-http transport:
```bash
zscaler-mcp --transport streamable-http
```
Run with streamable-http transport on custom port:
```bash
zscaler-mcp --transport streamable-http --host 0.0.0.0 --port 8080
```
### Service Configuration
The Zscaler Integrations MCP Server supports multiple ways to specify which services to enable:
#### 1. Command Line Arguments (highest priority)
Specify services using comma-separated lists:
```bash
# Enable specific services
zscaler-mcp --services zia,zpa,zdx
# Enable only one service
zscaler-mcp --services zia
```
#### 2. Environment Variable (fallback)
Set the `ZSCALER_MCP_SERVICES` environment variable:
```bash
# Export environment variable
export ZSCALER_MCP_SERVICES=zia,zpa,zdx
zscaler-mcp
# Or set inline
ZSCALER_MCP_SERVICES=zia,zpa,zdx zscaler-mcp
```
#### 3. Default Behavior (all services)
If no services are specified via command line or environment variable, all available services are enabled by default.
**Service Priority Order:**
1. Command line `--services` argument (overrides all)
2. `ZSCALER_MCP_SERVICES` environment variable (fallback)
3. All services (default when none specified)
### Additional Command Line Options
```bash
# Enable write operations (create, update, delete)
zscaler-mcp --enable-write-tools
# Enable debug logging
zscaler-mcp --debug
# Combine multiple options
zscaler-mcp --services zia,zpa --enable-write-tools --debug
```
For all available options:
```bash
zscaler-mcp --help
```
Available command-line flags:
- `--transport`: Transport protocol (`stdio`, `sse`, `streamable-http`)
- `--services`: Comma-separated list of services to enable
- `--tools`: Comma-separated list of specific tools to enable
- `--enable-write-tools`: Enable write operations (disabled by default for safety)
- `--debug`: Enable debug logging
- `--host`: Host for HTTP transports (default: `127.0.0.1`)
- `--port`: Port for HTTP transports (default: `8000`)
### Supported Agents
- [Claude](https://claude.ai/)
- [Cursor](https://cursor.so/)
- [VS Code](https://code.visualstudio.com/download) or [VS Code Insiders](https://code.visualstudio.com/insiders)
## Zscaler API Credentials & Authentication
The Zscaler Integrations MCP Server supports two authentication methods: **OneAPI (recommended)** and **Legacy API**. You must choose **ONE** method - do not mix them.
> [!IMPORTANT]
> **⚠️ CRITICAL: Choose ONE Authentication Method**
>
> - **OneAPI**: Single credential set for ALL services (ZIA, ZPA, ZCC, ZDX)
> - **Legacy**: Separate credentials required for EACH service
> - **DO NOT** set both OneAPI and Legacy credentials simultaneously
> - **DO NOT** set `ZSCALER_USE_LEGACY=true` if using OneAPI
### Quick Start: Choose Your Authentication Method
#### Option A: OneAPI (Recommended - Single Credential Set)
- ✅ **One set of credentials** works for ALL services (ZIA, ZPA, ZCC, ZDX, ZTW)
- ✅ Modern OAuth2.0 authentication via Zidentity
- ✅ Easier to manage and maintain
- ✅ Default authentication method (no flag needed)
- **Use this if:** You have access to Zidentity console and want simplicity
#### Option B: Legacy Mode (Per-Service Credentials)
- ⚠️ **Separate credentials** required for each service you want to use
- ⚠️ Different authentication methods per service (OAuth for ZPA, API key for ZIA, etc.)
- ⚠️ Must set `ZSCALER_USE_LEGACY=true` environment variable
- **Use this if:** You don't have OneAPI access or need per-service credential management
#### Decision Tree
```text
Do you have access to Zidentity console?
├─ YES → Use OneAPI (Option A)
└─ NO → Use Legacy Mode (Option B)
```
---
### OneAPI Authentication (Recommended)
OneAPI provides a single set of credentials that authenticate to all Zscaler services. This is the default and recommended method.
#### Prerequisites
Before using OneAPI, you need to:
1. Create an API Client in the [Zidentity platform](https://help.zscaler.com/zidentity/about-api-clients)
2. Obtain your credentials: `clientId`, `clientSecret`, `customerId`, and `vanityDomain`
3. Learn more: [Understanding OneAPI](https://help.zscaler.com/oneapi/understanding-oneapi)
#### Quick Setup
Create a `.env` file in your project root (or where you'll run the MCP server):
```env
# OneAPI Credentials (Required)
ZSCALER_CLIENT_ID=your_client_id
ZSCALER_CLIENT_SECRET=your_client_secret
ZSCALER_CUSTOMER_ID=your_customer_id
ZSCALER_VANITY_DOMAIN=your_vanity_domain
# Optional: Only required for Beta tenants
ZSCALER_CLOUD=beta
```
⚠️ **Security**: Do not commit `.env` to source control. Add it to your `.gitignore`.
#### OneAPI Environment Variables
| Environment Variable | Required | Description |
|---------------------|----------|-------------|
| `ZSCALER_CLIENT_ID` | Yes | Zscaler OAuth client ID from Zidentity console |
| `ZSCALER_CLIENT_SECRET` | Yes | Zscaler OAuth client secret from Zidentity console |
| `ZSCALER_CUSTOMER_ID` | Yes | Zscaler customer ID |
| `ZSCALER_VANITY_DOMAIN` | Yes | Your organization's vanity domain (e.g., `acme`) |
| `ZSCALER_CLOUD` | No | Zscaler cloud environment (e.g., `beta`, `zscalertwo`). **Only required for Beta tenants** |
| `ZSCALER_PRIVATE_KEY` | No | OAuth private key for JWT-based authentication (alternative to client secret) |
#### Verification
After setting up your `.env` file, test the connection:
```bash
# Test with a simple command
zscaler-mcp
```
If authentication is successful, the server will start without errors. If you see authentication errors, verify:
- All required environment variables are set correctly
- Your API client has the necessary permissions in Zidentity
- Your credentials are valid and not expired
---
### Legacy API Authentication
Legacy mode requires separate credentials for each Zscaler service. This method is only needed if you don't have access to OneAPI.
> [!WARNING]
> **⚠️ IMPORTANT**: When using Legacy mode:
>
> - You **MUST** set `ZSCALER_USE_LEGACY=true` in your `.env` file
> - You **MUST** provide credentials for each service you want to use
> - OneAPI credentials are **ignored** when `ZSCALER_USE_LEGACY=true` is set
> - Clients are created on-demand when tools are called (not at startup)
#### Quick Setup
Create a `.env` file with the following structure:
```env
# Enable Legacy Mode (REQUIRED - set once at the top)
ZSCALER_USE_LEGACY=true
# ZPA Legacy Credentials (if using ZPA)
ZPA_CLIENT_ID=your_zpa_client_id
ZPA_CLIENT_SECRET=your_zpa_client_secret
ZPA_CUSTOMER_ID=your_zpa_customer_id
ZPA_CLOUD=BETA
# ZIA Legacy Credentials (if using ZIA)
ZIA_USERNAME=your_zia_username
ZIA_PASSWORD=your_zia_password
ZIA_API_KEY=your_zia_api_key
ZIA_CLOUD=zscalertwo
# ZCC Legacy Credentials (if using ZCC)
ZCC_CLIENT_ID=your_zcc_client_id
ZCC_CLIENT_SECRET=your_zcc_client_secret
ZCC_CLOUD=zscalertwo
# ZDX Legacy Credentials (if using ZDX)
ZDX_CLIENT_ID=your_zdx_client_id
ZDX_CLIENT_SECRET=your_zdx_client_secret
ZDX_CLOUD=zscalertwo
```
⚠️ **Security**: Do not commit `.env` to source control. Add it to your `.gitignore`.
#### Legacy Authentication by Service
##### ZPA Legacy Authentication
| Environment Variable | Required | Description |
|---------------------|----------|-------------|
| `ZPA_CLIENT_ID` | Yes | ZPA API client ID from ZPA console |
| `ZPA_CLIENT_SECRET` | Yes | ZPA API client secret from ZPA console |
| `ZPA_CUSTOMER_ID` | Yes | ZPA tenant ID (found in Administration > Company menu) |
| `ZPA_CLOUD` | Yes | Zscaler cloud for ZPA tenancy (e.g., `BETA`, `zscalertwo`) |
| `ZPA_MICROTENANT_ID` | No | ZPA microtenant ID (if using microtenants) |
**Where to find ZPA credentials:**
- API Client ID/Secret: ZPA console > Configuration & Control > Public API > API Keys
- Customer ID: ZPA console > Administration > Company
##### ZIA Legacy Authentication
| Environment Variable | Required | Description |
|---------------------|----------|-------------|
| `ZIA_USERNAME` | Yes | ZIA API admin email address |
| `ZIA_PASSWORD` | Yes | ZIA API admin password |
| `ZIA_API_KEY` | Yes | ZIA obfuscated API key (from obfuscateApiKey() method) |
| `ZIA_CLOUD` | Yes | Zscaler cloud name (see supported clouds below) |
**Supported ZIA Cloud Environments:**
- `zscaler`, `zscalerone`, `zscalertwo`, `zscalerthree`
- `zscloud`, `zscalerbeta`, `zscalergov`, `zscalerten`, `zspreview`
**Where to find ZIA credentials:**
- Username/Password: Your ZIA admin account
- API Key: ZIA Admin Portal > Administration > API Key Management
##### ZCC Legacy Authentication
| Environment Variable | Required | Description |
|---------------------|----------|-------------|
| `ZCC_CLIENT_ID` | Yes | ZCC API key (Mobile Portal) |
| `ZCC_CLIENT_SECRET` | Yes | ZCC secret key (Mobile Portal) |
| `ZCC_CLOUD` | Yes | Zscaler cloud name (see supported clouds below) |
> **NOTE**: `ZCC_CLOUD` is required and identifies the correct API gateway.
**Supported ZCC Cloud Environments:**
- `zscaler`, `zscalerone`, `zscalertwo`, `zscalerthree`
- `zscloud`, `zscalerbeta`, `zscalergov`, `zscalerten`, `zspreview`
##### ZDX Legacy Authentication
| Environment Variable | Required | Description |
|---------------------|----------|-------------|
| `ZDX_CLIENT_ID` | Yes | ZDX key ID |
| `ZDX_CLIENT_SECRET` | Yes | ZDX secret key |
| `ZDX_CLOUD` | Yes | Zscaler cloud name prefix |
**Where to find ZDX credentials:**
- ZDX Portal > API Keys section
#### Legacy Mode Behavior
When `ZSCALER_USE_LEGACY=true`:
- All tools use legacy API clients by default
- You can override per-tool by setting `use_legacy: false` in tool parameters
- The MCP server initializes without creating clients at startup
- Clients are created on-demand when individual tools are called
- This allows the server to work with different legacy services without requiring a specific service during initialization
---
### Authentication Troubleshooting
**Common Issues:**
1. **"Authentication failed" errors:**
- Verify all required environment variables are set
- Check that credentials are correct and not expired
- Ensure you're using the correct cloud environment
2. **"Legacy credentials ignored" warning:**
- This is normal when using OneAPI mode
- Legacy credentials are only loaded when `ZSCALER_USE_LEGACY=true`
3. **"OneAPI credentials ignored" warning:**
- This is normal when using Legacy mode
- OneAPI credentials are only used when `ZSCALER_USE_LEGACY` is not set or is `false`
4. **Mixed authentication errors:**
- **DO NOT** set both OneAPI and Legacy credentials
- **DO NOT** set `ZSCALER_USE_LEGACY=true` if using OneAPI
- Choose ONE method and stick with it
### MCP Server Configuration
The following environment variables control MCP server behavior (not authentication):
| Environment Variable | Default | Description |
|---------------------|---------|-------------|
| `ZSCALER_MCP_TRANSPORT` | `stdio` | Transport protocol to use (`stdio`, `sse`, or `streamable-http`) |
| `ZSCALER_MCP_SERVICES` | `""` | Comma-separated list of services to enable (empty = all services). Supported values: `zcc`, `zdx`, `zia`, `zidentity`, `zpa`, `ztw` |
| `ZSCALER_MCP_TOOLS` | `""` | Comma-separated list of specific tools to enable (empty = all tools) |
| `ZSCALER_MCP_WRITE_ENABLED` | `false` | Enable write operations (`true`/`false`). When `false`, only read-only tools are available. Set to `true` or use `--enable-write-tools` flag to unlock write mode. |
| `ZSCALER_MCP_WRITE_TOOLS` | `""` | **MANDATORY** comma-separated allowlist of write tools (supports wildcards like `zpa_*`). Requires `ZSCALER_MCP_WRITE_ENABLED=true`. If empty when write mode enabled, 0 write tools registered. |
| `ZSCALER_MCP_DEBUG` | `false` | Enable debug logging (`true`/`false`) |
| `ZSCALER_MCP_HOST` | `127.0.0.1` | Host to bind to for HTTP transports |
| `ZSCALER_MCP_PORT` | `8000` | Port to listen on for HTTP transports |
| `ZSCALER_MCP_USER_AGENT_COMMENT` | `""` | Additional information to include in User-Agent comment section |
#### User-Agent Header
The MCP server automatically includes a custom User-Agent header in all API requests to Zscaler services. The format is:
```sh
User-Agent: zscaler-mcp-server/<version> python/<python_version> <os>/<architecture>
```
**Example:**
```sh
User-Agent: zscaler-mcp-server/0.3.1 python/3.11.8 darwin/arm64
```
**With Custom Comment:**
You can append additional information (such as the AI agent details) using the `ZSCALER_MCP_USER_AGENT_COMMENT` environment variable or the `--user-agent-comment` CLI flag:
```bash
# Via environment variable
export ZSCALER_MCP_USER_AGENT_COMMENT="Claude Desktop 1.2024.10.23"
# Via CLI flag
zscaler-mcp --user-agent-comment "Claude Desktop 1.2024.10.23"
```
This results in:
```sh
User-Agent: zscaler-mcp-server/0.3.1 python/3.11.8 darwin/arm64 Claude Desktop 1.2024.10.23
```
The User-Agent helps Zscaler identify API traffic from the MCP server and can be useful for support, analytics, and debugging purposes.
### As a Library
You can use the Zscaler Integrations MCP Server as a Python library in your own applications:
```python
from zscaler_mcp.server import ZscalerMCPServer
# Create server with read-only mode (default - safe)
server = ZscalerMCPServer(
debug=True, # Optional, enable debug logging
enabled_services={"zia", "zpa", "zdx"}, # Optional, defaults to all services
enabled_tools={"zia_list_rule_labels", "zpa_list_application_segments"}, # Optional, defaults to all tools
user_agent_comment="My Custom App", # Optional, additional User-Agent info
enable_write_tools=False # Optional, defaults to False (read-only mode)
)
# Run with stdio transport (default)
server.run()
# Or run with SSE transport
server.run("sse")
# Or run with streamable-http transport
server.run("streamable-http")
# Or run with streamable-http transport on custom host/port
server.run("streamable-http", host="0.0.0.0", port=8080)
```
**Example with write operations enabled:**
```python
from zscaler_mcp.server import ZscalerMCPServer
# Create server with write operations enabled
server = ZscalerMCPServer(
debug=True,
enabled_services={"zia", "zpa"},
enable_write_tools=True # Enable create/update/delete operations
)
# Run the server
server.run("stdio")
```
**Available Services**: `zcc`, `zdx`, `zia`, `zidentity`, `zpa`
**Example with Environment Variables**:
```python
from zscaler_mcp.server import ZscalerMCPServer
import os
# Load from environment variables
server = ZscalerMCPServer(
debug=True,
enabled_services={"zia", "zpa"}
)
# Run the server
server.run("stdio")
```
### Running Examples
```bash
# Run with stdio transport
python examples/basic_usage.py
# Run with SSE transport
python examples/sse_usage.py
# Run with streamable-http transport
python examples/streamable_http_usage.py
```
## Container Usage
The Zscaler Integrations MCP Server is available as a pre-built container image for easy deployment:
### Using Pre-built Image (Recommended)
```bash
# Pull the latest pre-built image
docker pull quay.io/zscaler/zscaler-mcp-server:latest
# Run with .env file (recommended)
docker run --rm --env-file /path/to/.env quay.io/zscaler/zscaler-mcp-server:latest
# Run with .env file and SSE transport
docker run --rm -p 8000:8000 --env-file /path/to/.env \
quay.io/zscaler/zscaler-mcp-server:latest --transport sse --host 0.0.0.0
# Run with .env file and streamable-http transport
docker run --rm -p 8000:8000 --env-file /path/to/.env \
quay.io/zscaler/zscaler-mcp-server:latest --transport streamable-http --host 0.0.0.0
# Run with .env file and custom port
docker run --rm -p 8080:8080 --env-file /path/to/.env \
quay.io/zscaler/zscaler-mcp-server:latest --transport streamable-http --host 0.0.0.0 --port 8080
# Run with .env file and specific services
docker run --rm --env-file /path/to/.env \
quay.io/zscaler/zscaler-mcp-server:latest --services zia,zpa,zdx
# Use a specific version instead of latest
docker run --rm --env-file /path/to/.env \
quay.io/zscaler/zscaler-mcp-server:1.2.3
# Alternative: Individual environment variables
docker run --rm -e ZSCALER_CLIENT_ID=your_client_id -e ZSCALER_CLIENT_SECRET=your_secret \
-e ZSCALER_CUSTOMER_ID=your_customer_id -e ZSCALER_VANITY_DOMAIN=your_vanity_domain \
quay.io/zscaler/zscaler-mcp-server:latest
```
### Building Locally (Development)
For development or customization purposes, you can build the image locally:
```bash
# Build the Docker image
docker build -t zscaler-mcp-server .
# Run the locally built image
docker run --rm -e ZSCALER_CLIENT_ID=your_client_id -e ZSCALER_CLIENT_SECRET=your_secret \
-e ZSCALER_CUSTOMER_ID=your_customer_id -e ZSCALER_VANITY_DOMAIN=your_vanity_domain zscaler-mcp-server
```
**Note**: When using HTTP transports in Docker, always set `--host 0.0.0.0` to allow external connections to the container.
## Editor/Assistant Integration
You can integrate the Zscaler Integrations MCP server with your editor or AI assistant. Here are configuration examples for popular MCP clients:
### Using `uvx` (recommended)
```json
{
"mcpServers": {
"zscaler-mcp-server": {
"command": "uvx",
"args": ["--env-file", "/path/to/.env", "zscaler-mcp-server"]
}
}
}
```
## Additional Deployment Options
### Amazon Bedrock AgentCore
> [!IMPORTANT]
> **AWS Marketplace Image Available**: For Amazon Bedrock AgentCore deployments, we provide a dedicated container image optimized for Bedrock's stateless HTTP environment. This image includes a custom web server wrapper that handles session management and is specifically designed for AWS Bedrock AgentCore Runtime.
**🚀 Quick Start with AWS Marketplace:**
The easiest way to deploy the Zscaler Integrations MCP Server to Amazon Bedrock AgentCore is through the [AWS Marketplace listing](https://aws.amazon.com/marketplace/pp/prodview-dtjfklwemb54y?sr=0-1&ref_=beagle&applicationId=AWSMPContessa). The Marketplace image includes:
- ✅ Pre-configured for Bedrock AgentCore Runtime
- ✅ Custom web server wrapper for stateless HTTP environments
- ✅ Session management handled automatically
- ✅ Health check endpoints for ECS compatibility
- ✅ Optimized for AWS Bedrock AgentCore's requirements
**📚 Full Deployment Guide:**
For detailed deployment instructions, IAM configuration, and troubleshooting, please refer to the comprehensive [Amazon Bedrock AgentCore deployment guide](./docs/deployment/amazon_bedrock_agentcore.md).
The deployment guide covers:
- Prerequisites and AWS VPC requirements
- IAM role and trust policy configuration
- Step-by-step deployment instructions
- Environment variable configuration
- Write mode configuration (for CREATE/UPDATE/DELETE operations)
- Troubleshooting and verification steps
> [!NOTE]
> The AWS Marketplace image uses a different architecture than the standard `streamable-http` transport. It includes a FastAPI-based web server wrapper (`web_server.py`) that bypasses the MCP protocol's session initialization requirements, making it compatible with Bedrock's stateless HTTP environment. This is why the Marketplace image is recommended for Bedrock deployments.
## Using the MCP Server with Agents
This section provides instructions for configuring the Zscaler Integrations MCP Server with popular AI agents. **Before starting, ensure you have:**
1. ✅ Completed [Installation & Setup](#installation--setup)
2. ✅ Configured [Authentication](#zscaler-api-credentials-authentication)
3. ✅ Created your `.env` file with credentials
### Claude Desktop
You can install the Zscaler MCP Server in Claude Desktop using either method:
> **Windows users**: The one-click extension bundles macOS/Linux binaries and will not work on Windows. Use **Option 2: Manual Configuration** instead—it uses `uvx` to install platform-appropriate packages at runtime. See [Troubleshooting: Windows](docs/guides/TROUBLESHOOTING.md#windows-claude-desktop-extension-fails-to-start) for details.
#### Option 1: Install as Extension (macOS / Linux)
The easiest way to get started—one-click install with a user-friendly UI in Claude Desktop and low barrier to entry.
**Prerequisites:** [uv](https://docs.astral.sh/uv/) must be installed (provides `uvx`). The extension uses uvx to run the server from PyPI at runtime—**no manual `pip install zscaler-mcp` required**. Install uv: `curl -LsSf https://astral.sh/uv/install.sh | sh`
1. Open Claude Desktop
2. Go to **Settings** → **Extensions** → **Browse Extensions**
3. In the search box, type `zscaler`
4. Select **Zscaler MCP Server** from the results
5. Click **Install** or **Add**
6. Configure your `.env` file path when prompted (or edit the configuration after installation)
7. Restart Claude Desktop completely (quit and reopen)
8. Verify by asking Claude: "What Zscaler tools are available?"
#### Option 2: Manual Configuration (All platforms, recommended on Windows)
1. Open Claude Desktop
2. Go to **Settings** → **Developer** → **Edit Config**
3. Add the following configuration:
```json
{
"mcpServers": {
"zscaler-mcp-server": {
"command": "uvx",
"args": ["--env-file", "/absolute/path/to/your/.env", "zscaler-mcp"]
}
}
}
```
> **Important**: Replace `/absolute/path/to/your/.env` with the **absolute path** to your `.env` file. On Windows, use a path like `C:\Users\You\.env`. Relative paths will not work.
1. Save the configuration file
2. Restart Claude Desktop completely (quit and reopen)
3. Verify by asking Claude: "What Zscaler tools are available?"
**Troubleshooting:**
- **"MCP server not found"**: Verify the `.env` file path is absolute and correct
- **"Authentication failed"**: Check that your `.env` file contains valid credentials
- **Tools not appearing**: Check Claude Desktop logs (Help > View Logs) for errors
- **Extension not found**: Ensure you're searching in the "Desktop extensions" tab, not "Web"
- **Windows: `ModuleNotFoundError` (rpds, pydantic_core, etc.)**: The extension bundles macOS/Linux binaries. Use Option 2 (Manual Configuration) instead. See [Troubleshooting guide](docs/guides/TROUBLESHOOTING.md#windows-claude-desktop-extension-fails-to-start).
### Cursor
1. Open Cursor
2. Go to **Settings** → **Cursor Settings** → **Tools & MCP** → **New MCP Server**
3. The configuration will be saved to `~/.cursor/mcp.json`. Add the following configuration:
```json
{
"mcpServers": {
"zscaler-mcp-server": {
"command": "uvx",
"args": ["--env-file", "/absolute/path/to/your/.env", "zscaler-mcp-server"]
}
}
}
```
> **Alternative**: You can also use Docker instead of `uvx`:
>
> ```json
> {
> "mcpServers": {
> "zscaler-mcp-server": {
> "command": "docker",
> "args": [
> "run",
> "-i",
> "--rm",
> "--env-file",
> "/absolute/path/to/your/.env",
> "quay.io/zscaler/zscaler-mcp-server:latest"
> ]
> }
> }
> }
> ```
1. Save the configuration file
2. Restart Cursor completely (quit and reopen)
3. Verify by asking: "List my ZIA rule labels"
**Troubleshooting:**
- Check Cursor's MCP logs (View > Output > MCP) for connection errors
- Verify the `.env` file path is absolute and credentials are correct
- The configuration file is located at `~/.cursor/mcp.json` (or `%USERPROFILE%\.cursor\mcp.json` on Windows)
### General Troubleshooting for All Agents
**Common Issues:**
1. **"Command not found: uvx"**
- Install `uv`: `curl -LsSf https://astral.sh/uv/install.sh | sh`
- Or use Docker: Replace `uvx` with `docker run --rm --env-file /path/to/.env quay.io/zscaler/zscaler-mcp-server:latest`
2. **".env file not found"**
- Use absolute paths, not relative paths
- Verify the file exists at the specified path
- Check file permissions (should be readable)
3. **"Authentication failed"**
- Verify all required environment variables are in `.env`
- Check that credentials are correct and not expired
- Ensure you're using the correct authentication method (OneAPI vs Legacy)
4. **"Tools not appearing"**
- Some agents require you to enable tools | text/markdown | null | "Zscaler, Inc." <devrel@zscaler.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"zscaler-sdk-python",
"mcp[cli]>=1.23.0",
"fastmcp>=2.13.0",
"python-dotenv",
"click",
"uvicorn",
"fastapi",
"pycountry",
"authlib>=1.6.5",
"cryptography>=46.0.5",
"huggingface-hub>=0.35.0",
"jiter>=0.11.0",
"langsmith>=0.4.28",
"openai>=1.107.3",
"posthog>=6.7.5",
"pydantic>=2.11.9",
... | [] | [] | [] | [] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T02:45:21.952266 | zscaler_mcp-0.6.2.tar.gz | 154,447 | 5b/ae/a7ec92e95a8a05ab899abf87ebe0e06aaf2e83581a0221dc4132cf0fdd54/zscaler_mcp-0.6.2.tar.gz | source | sdist | null | false | 64352d52d4d0d2ede6899e2ecc0d8da1 | 9d134a5976513e6d513777a4e4d76fe22ce10eaf3e30b22b373ec8745d109e43 | 5baea7ec92e95a8a05ab899abf87ebe0e06aaf2e83581a0221dc4132cf0fdd54 | MIT | [
"LICENSE"
] | 267 |
2.1 | odoo-addon-account-reconcile-restrict-partner-mismatch | 18.0.1.0.0.4 | Restrict reconciliation on receivable and payable accounts to the same partner | .. image:: https://odoo-community.org/readme-banner-image
:target: https://odoo-community.org/get-involved?utm_source=readme
:alt: Odoo Community Association
===================================
Reconcile restrict partner mismatch
===================================
..
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! This file is generated by oca-gen-addon-readme !!
!! changes will be overwritten. !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!! source digest: sha256:d611a411b71d52bada0d56d99474d7d2728950cc8c81843b11dbe38197cea5d1
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.. |badge1| image:: https://img.shields.io/badge/maturity-Beta-yellow.png
:target: https://odoo-community.org/page/development-status
:alt: Beta
.. |badge2| image:: https://img.shields.io/badge/license-AGPL--3-blue.png
:target: http://www.gnu.org/licenses/agpl-3.0-standalone.html
:alt: License: AGPL-3
.. |badge3| image:: https://img.shields.io/badge/github-OCA%2Faccount--reconcile-lightgray.png?logo=github
:target: https://github.com/OCA/account-reconcile/tree/18.0/account_reconcile_restrict_partner_mismatch
:alt: OCA/account-reconcile
.. |badge4| image:: https://img.shields.io/badge/weblate-Translate%20me-F47D42.png
:target: https://translation.odoo-community.org/projects/account-reconcile-18-0/account-reconcile-18-0-account_reconcile_restrict_partner_mismatch
:alt: Translate me on Weblate
.. |badge5| image:: https://img.shields.io/badge/runboat-Try%20me-875A7B.png
:target: https://runboat.odoo-community.org/builds?repo=OCA/account-reconcile&target_branch=18.0
:alt: Try me on Runboat
|badge1| |badge2| |badge3| |badge4| |badge5|
This module restricts reconciliation between journal items when:
- both items have different partners
- one item is with partner and the other without it
This rule applies only for journal items using receivable and payable
account type.
As at the moment of installation some journal items could have been
reconciled using different partners, you can detect them in menu
Accounting > Adviser > Reconciled items with partner mismatch.
This restriction can be enabled per company but can also be deactivated
per journal.
**Table of contents**
.. contents::
:local:
Configuration
=============
- Go to Accounting > Configuration > Settings > Partners Mismatch
Restriction on Reconcile
- Check the box to activate the parameter.
- To deactivate the behavior on journal level, go to Accounting >
Configuration > Accounting > Journals
- In Advanced Settings > Partner Mismatch On Reconcile
- Check the box if you want to deactivate the restriction for that
journal entries.
Bug Tracker
===========
Bugs are tracked on `GitHub Issues <https://github.com/OCA/account-reconcile/issues>`_.
In case of trouble, please check there if your issue has already been reported.
If you spotted it first, help us to smash it by providing a detailed and welcomed
`feedback <https://github.com/OCA/account-reconcile/issues/new?body=module:%20account_reconcile_restrict_partner_mismatch%0Aversion:%2018.0%0A%0A**Steps%20to%20reproduce**%0A-%20...%0A%0A**Current%20behavior**%0A%0A**Expected%20behavior**>`_.
Do not contact contributors directly about support or help with technical issues.
Credits
=======
Authors
-------
* Camptocamp
Contributors
------------
- `Tecnativa <https://www.tecnativa.com>`__:
- Ernesto Tejeda
- `Trobz <https://trobz.com>`__:
- Nguyen Ho <nguyenhk@trobz.com>
- Nhan Tran <nhant@trobz.com>
- `ACSONE SA <https://acsone.eu>`__:
- Souheil Bejaoui <souheil.bejaoui@acsone.eu>
Other credits
-------------
The migration of this module from 13.0 to 14.0 was financially supported
The migration of this module from 16.0 to 18.0 was financially supported
by Camptocamp
Maintainers
-----------
This module is maintained by the OCA.
.. image:: https://odoo-community.org/logo.png
:alt: Odoo Community Association
:target: https://odoo-community.org
OCA, or the Odoo Community Association, is a nonprofit organization whose
mission is to support the collaborative development of Odoo features and
promote its widespread use.
This module is part of the `OCA/account-reconcile <https://github.com/OCA/account-reconcile/tree/18.0/account_reconcile_restrict_partner_mismatch>`_ project on GitHub.
You are welcome to contribute. To learn how please visit https://odoo-community.org/page/Contribute.
| text/x-rst | Camptocamp, Odoo Community Association (OCA) | support@odoo-community.org | null | null | AGPL-3 | null | [
"Programming Language :: Python",
"Framework :: Odoo",
"Framework :: Odoo :: 18.0",
"License :: OSI Approved :: GNU Affero General Public License v3"
] | [] | https://github.com/OCA/account-reconcile | null | >=3.10 | [] | [] | [] | [
"odoo==18.0.*"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T02:41:05.735013 | odoo_addon_account_reconcile_restrict_partner_mismatch-18.0.1.0.0.4-py3-none-any.whl | 36,818 | fb/10/41a6ff5a9451c3db4451698aec045bd513d15d2ef17fb2d13e6209b145a5/odoo_addon_account_reconcile_restrict_partner_mismatch-18.0.1.0.0.4-py3-none-any.whl | py3 | bdist_wheel | null | false | 1e5541ef098df2b3e1389a9b5a5feb1f | f2f94878d2bd9cfe6dcac1b2b2e91ee72f2bf5c21f1edcb6e742f37a9d789d88 | fb1041a6ff5a9451c3db4451698aec045bd513d15d2ef17fb2d13e6209b145a5 | null | [] | 107 |
2.4 | umcp | 2.1.3 | Universal Measurement Contract Protocol (UMCP): Production-grade contract-first validation framework with GCD and RCFT. Core Axiom: Collapse is generative; only what returns is real. 13 physics domains, 120+ closures, 3618+ tests. | # Generative Collapse Dynamics (GCD)
[](https://github.com/calebpruett927/GENERATIVE-COLLAPSE-DYNAMICS/actions)
[](https://www.python.org/downloads/)
[](src/umcp_cpp/)
[](LICENSE)
[](pyproject.toml)
[](tests/)
[](closures/)
[](closures/)
> **Core Axiom**: *"Collapse is generative; only what returns is real."*
**Universal Measurement Contract Protocol (UMCP)** is a production-grade, contract-first validation framework that verifies reproducible computational workflows against mathematical contracts. It implements **Generative Collapse Dynamics (GCD)** and **Recursive Collapse Field Theory (RCFT)** — a unified measurement theory where every claim must demonstrate return through collapse under frozen evaluation rules.
This is not a simulation. It is a **metrological enforcement engine**: schema conformance, kernel identity verification, regime classification, and SHA-256 integrity checking, producing a `CONFORMANT` / `NONCONFORMANT` verdict for every run.
**Python + C++ integration**: The full framework is written in Python with **13 physics domains**, **120+ closure modules**, and **3,618 tests**. An optional C++17 accelerator (`src/umcp_cpp/`) provides 50–80× speedup for the three hot paths — kernel computation, seam chain accumulation, and SHA-256 integrity — via a pybind11 zero-copy NumPy bridge. The Python wrapper (`umcp.accel`) auto-detects the compiled extension at import time; if it is not built, every call falls back transparently to the equivalent NumPy implementation. Same formulas, same frozen parameters, same results to machine precision — the C++ layer is Tier-0 Protocol only and redefines no Tier-1 symbols.
---
## Table of Contents
- [Core Concepts](#core-concepts)
- [At a Glance](#at-a-glance)
- [Architecture](#architecture)
- [Closure Domains (12 Physics Domains)](#closure-domains)
- [The Kernel](#the-kernel)
- [Originality & Terminology](#originality--terminology)
- [Installation](#installation)
- [Quick Start](#quick-start)
- [CLI Reference](#cli-reference)
- [Startup — From Clone to Running](#startup--from-clone-to-running)
- [C++ Accelerator — Build & Verify](#c-accelerator--build--verify)
- [Services — API & Dashboard](#services--api--dashboard)
- [Development Loop — Edit, Validate, Commit](#development-loop--edit-validate-commit)
- [Reset & Clean Slate](#reset--clean-slate)
- [Useful Utilities](#useful-utilities)
- [Validation Pipeline](#validation-pipeline)
- [Test Suite](#test-suite)
- [Documentation](#documentation)
- [Diagrams & Proofs](#diagrams--proofs)
- [Key Discoveries](#key-discoveries)
- [Papers & Publications](#papers--publications)
- [Repository Structure](#repository-structure)
- [Contributing](#contributing)
- [License](#license)
---
## Core Concepts
### Collapse Is Generative; Only What Returns Is Real
UMCP enforces a single axiom (**Axiom-0**): *"Collapse is generative; only what returns is real."* This is not a metaphor — it is a constraint on admissible claims. If you claim a system is stable, continuous, or coherent, you must show it can re-enter its admissible neighborhood after drift, perturbation, or delay — under the same frozen evaluation rules. Every decision, description, and code change in this repository is consistent with Axiom-0.
| Term | Operational Meaning |
|------|---------------------|
| **Collapse** | Regime label produced by kernel gates on (ω, F, S, C) under frozen thresholds |
| **Return** (τ_R) | Re-entry condition: existence of prior state within tolerance; yields τ_R or INF_REC |
| **Gesture** | An epistemic emission that does not weld: no return, no credit |
| **Drift** (ω) | ω = 1 − F, collapse proximity measure, range [0, 1] |
| **Integrity** (IC) | Kernel composite: IC = exp(κ), geometric mean of channel contributions |
| **Seam** | The verification boundary between outbound collapse and demonstrated return |
| **Frozen** | Consistent across the seam — same rules govern both sides of every collapse-return boundary |
| **Contract** | Frozen interface snapshot: pins units, embedding, clipping, weights, return settings |
### Three-Valued Verdicts
Every validation produces one of three outcomes — never boolean:
- **`CONFORMANT`** — All contracts, identities, and integrity checks pass
- **`NONCONFORMANT`** — At least one check fails
- **`NON_EVALUABLE`** — Insufficient data to determine status
---
## At a Glance
### The Three-Tier Stack
Tier-1 (immutable invariants) → Tier-0 (protocol) → Tier-2 (expansion space). One-way dependency. No back-edges within a frozen run. Every domain closure is validated *through* Tier-0 *against* Tier-1.

### Integrity Bound: IC ≤ F — Zero Violations
The integrity bound holds universally across 31 Standard Model particles + 118 periodic table elements. Derived independently from Axiom-0. Zero violations.

### Validation Timelapse: Living Ledger History
Every `umcp validate` run is recorded in the append-only ledger. Cumulative runs, kernel invariant evolution, and conformance rate over time. *"Nihil in memoria perit."*

---
## Architecture
### The Unit of Work: Casepacks
A **casepack** is the atomic unit of reproducible validation — a self-contained directory with:
```
casepacks/my_experiment/
├── manifest.json # Contract reference, closure list, expected outputs
├── raw_data/ # Input observables
├── closures/ # Domain-specific computation modules
└── expected/ # Expected outputs for verification
```
UMCP ships with **14 casepacks** spanning all physics domains.
### Core Engine
```
src/umcp/
├── cli.py # Validation engine & all subcommands
├── validator.py # Root-file validator (16 files, checksums, math identities)
├── kernel_optimized.py # Lemma-based kernel computation (F, ω, S, C, κ, IC)
├── seam_optimized.py # Optimized seam budget computation (Γ, D_C, Δκ)
├── tau_r_star.py # τ_R* thermodynamic diagnostic (phase diagram)
├── tau_r_star_dynamics.py # Dynamic τ_R* evolution and trajectories
├── compute_utils.py # Vectorized utilities (coordinate clipping, bounds)
├── epistemic_weld.py # Epistemic cost tracking (Theorem T9: observation cost)
├── measurement_engine.py # Measurement pipeline engine
├── frozen_contract.py # Frozen contract constants dataclass
├── insights.py # Lessons-learned database (pattern discovery)
├── uncertainty.py # Uncertainty propagation and error analysis
├── ss1m_triad.py # SS1M triad computation
├── universal_calculator.py # Universal kernel calculator CLI
├── fleet/ # Distributed fleet-scale validation
│ ├── scheduler.py # Job scheduler (submit, route, track)
│ ├── worker.py # Worker + WorkerPool (register, heartbeat, execute)
│ ├── queue.py # Priority queue (DLQ, retry, backpressure)
│ ├── cache.py # Content-addressable artifact cache
│ └── tenant.py # Multi-tenant isolation, quotas, namespaces
├── accel.py # C++ accelerator wrapper (auto-fallback to NumPy)
├── dashboard/ # Modular Streamlit dashboard (33 pages)
└── api_umcp.py # FastAPI REST extension (Pydantic models)
src/umcp_cpp/ # Optional C++ accelerator (Tier-0 Protocol)
├── include/umcp/
│ ├── kernel.hpp # Kernel computation (F, ω, S, C, κ, IC) — ~50× speedup
│ ├── seam.hpp # Seam chain accumulation — ~80× speedup
│ └── integrity.hpp # SHA-256 (portable + OpenSSL) — ~5× speedup
├── bindings/py_umcp.cpp # pybind11 zero-copy NumPy bridge
├── tests/test_kernel.cpp # Catch2 tests (10K Tier-1 sweep)
└── CMakeLists.txt # C++17, pybind11, optional OpenSSL
```
### Contract Infrastructure
| Artifact | Count | Location | Purpose |
|----------|:-----:|----------|---------|
| **Contracts** | 13 | `contracts/*.yaml` | Frozen mathematical contracts (JSON Schema Draft 2020-12) |
| **Schemas** | 14 | `schemas/*.schema.json` | JSON Schema files validating all artifacts |
| **Canon Anchors** | 11 | `canon/*.yaml` | Domain-specific canonical reference points |
| **Casepacks** | 14 | `casepacks/` | Reproducible validation bundles |
| **Closure Domains** | 13 | `closures/*/` | Physics domain closure packages (120+ modules) |
| **Closure Registry** | 1 | `closures/registry.yaml` | Central listing of all closures |
| **Validator Rules** | 1 | `validator_rules.yaml` | Semantic rule definitions (E101, W201, ...) |
| **Integrity** | 1 | `integrity/sha256.txt` | SHA-256 checksums for 138 tracked files |
---
## Closure Domains
UMCP validates physics across **13 domains** with **120+ closure modules**, each encoding real-world measurements into the 8-channel kernel trace:
### Standard Model — 9 modules
The crown jewel: 31 particles mapped through the GCD kernel with **10 proven theorems** (74/74 subtests at machine precision).
| Module | What It Encodes |
|--------|----------------|
| `particle_catalog.py` | Full SM particle table (PDG 2024 data) |
| `subatomic_kernel.py` | 31 particles → 8-channel trace → kernel |
| `particle_physics_formalism.py` | 10 Tier-2 theorems connecting SM physics to GCD |
| `coupling_constants.py` | Running couplings α_s(Q²), α_em(Q²), G_F |
| `cross_sections.py` | σ(e⁺e⁻→hadrons), R-ratio, Drell-Yan |
| `symmetry_breaking.py` | Higgs mechanism, VEV = 246.22 GeV, Yukawa |
| `ckm_mixing.py` | CKM matrix, Wolfenstein parametrization, J_CP |
| `neutrino_oscillation.py` | Neutrino oscillation and mass mixing |
| `pmns_mixing.py` | PMNS matrix, leptonic mixing angles |
**Key discoveries**: Confinement visible as a 98.1% IC cliff at the quark→hadron boundary. Neutral particles show 50× IC suppression. Generation monotonicity (Gen1 < Gen2 < Gen3) confirmed in both quarks and leptons.
### Atomic Physics — 10 modules
118 elements through the periodic kernel with **exhaustive Tier-1 proof** (10,162 tests, 0 failures).
| Module | What It Encodes |
|--------|----------------|
| `periodic_kernel.py` | 118-element periodic table through GCD kernel |
| `cross_scale_kernel.py` | 12-channel nuclear-informed atomic analysis |
| `tier1_proof.py` | Exhaustive proof: F+ω=1, IC≤F, IC=exp(κ) for all 118 elements |
| `electron_config.py` | Shell filling and configuration analysis |
| `fine_structure.py` | Fine structure constant α = 1/137 |
| `ionization_energy.py` | Ionization energy closures for all elements |
| `spectral_lines.py` | Emission/absorption spectral analysis |
| `selection_rules.py` | Quantum selection rules (Δl = ±1) |
| `zeeman_stark.py` | Zeeman and Stark effects |
| `recursive_instantiation.py` | Recursive instantiation patterns |
### Quantum Mechanics — 10 modules
| Module | What It Encodes |
|--------|----------------|
| `double_slit_interference.py` | 8 scenarios, 7 theorems — complementarity cliff discovery |
| `atom_dot_mi_transition.py` | Atom→quantum dot transition, 7 theorems (120 tests) |
| `ters_near_field.py` | TERS near-field enhancement, 7 theorems (72 tests) |
| `muon_laser_decay.py` | Muon-laser decay scenarios, 7 theorems (243 tests) |
| `wavefunction_collapse.py` | Wavefunction collapse dynamics |
| `entanglement.py` | Entanglement correlations |
| `tunneling.py` | Quantum tunneling barriers |
| `harmonic_oscillator.py` | Quantum harmonic oscillator |
| `uncertainty_principle.py` | Heisenberg uncertainty |
| `spin_measurement.py` | Spin measurement outcomes |
**Key discovery (double slit)**: Wave and particle are *both channel-deficient extremes*. The kernel-optimal state is partial measurement (V=0.70, D=0.71) where all channels are alive — the **complementarity cliff** (>5× IC gap).
### Materials Science — 10 modules
| Module | What It Encodes |
|--------|----------------|
| `element_database.py` | 118 elements × 18 fields |
| `band_structure.py` | Electronic band structure |
| `bcs_superconductivity.py` | BCS superconductivity theory |
| `cohesive_energy.py` | Cohesive energy analysis |
| `debye_thermal.py` | Debye thermal model |
| `elastic_moduli.py` | Elastic moduli computation |
| `magnetic_properties.py` | Magnetic property analysis |
| `phase_transition.py` | Phase transition dynamics |
| `surface_catalysis.py` | Surface catalysis reactions |
| `gap_capture_ss1m.py` | SS1M gap capture |
### Nuclear Physics — 8 modules
Alpha decay, fission, shell structure, decay chains, and Bethe-Weizsäcker binding energy for all nuclides.
### RCFT (Recursive Collapse Field Theory) — 8 modules
Attractor basins, fractal dimension, collapse grammar, information geometry, universality class assignment, and active matter dynamics.
### Astronomy — 7 modules
Stellar evolution, HR diagram classification, distance ladder, gravitational dynamics, orbital mechanics, spectral analysis, and stellar luminosity.
### Kinematics — 6 modules
Linear and rotational kinematics, energy mechanics, momentum dynamics, phase space return, and kinematic stability.
### Weyl Cosmology — 6 modules
Modified gravity, Limber integrals, boost factors, sigma evolution, cosmology background, and Weyl transfer functions.
### GCD (Generative Collapse Dynamics) — 6 modules
Energy potential, entropic collapse, field resonance, generative flux, momentum flux, and universal regime calibration (12 scenarios, 7 theorems, 252 tests).
### Finance & Security — 16+ modules
Portfolio continuity, market coherence, anomaly return, threat classification, trust fidelity, behavior profiling, and privacy auditing.
### Everyday Physics — 5 modules
Bridging particle physics to daily experience: thermodynamics, optics, electromagnetism, wave phenomena, and epistemic coherence. Demonstrates that the same minimal structure (F + ω = 1, IC ≤ F, IC = exp(κ)) governs macroscopic phenomena.
---
## The Kernel
At the mathematical core of GCD is the **kernel** — a function that maps any set of measurable channels to a fixed set of invariants:
### Trace Vector
Every observable maps to an 8-channel trace vector **c** with weights **w**:
$$F = \sum_i w_i c_i \quad \text{(Fidelity — arithmetic mean)}$$
$$\text{IC} = \exp\!\left(\sum_i w_i \ln c_{i,\varepsilon}\right) \quad \text{(Integrity Composite — geometric mean)}$$
$$\omega = 1 - F \quad \text{(Drift)}$$
$$\Delta = F - \text{IC} \quad \text{(heterogeneity gap — channel heterogeneity)}$$
### Tier-1 Identities (proven for every input)
These hold universally by construction:
| Identity | Meaning |
|----------|---------|
| F + ω = 1 | Fidelity and drift are complementary |
| IC ≤ F | Integrity bound: coherence never exceeds fidelity (derives independently from Axiom-0; the classical AM-GM inequality is the degenerate limit) |
| IC ≈ exp(κ) | Integrity equals exponentiated log-mean |
### Regime Classification
| Regime | Condition | Interpretation |
|--------|-----------|----------------|
| **STABLE** | ω < 0.10 | System within nominal bounds |
| **WATCH** | 0.10 ≤ ω < 0.20 | Elevated drift, monitoring required |
| **TENSION** | 0.20 ≤ ω < 0.30 | Significant strain, near collapse boundary |
| **COLLAPSE** | ω ≥ 0.30 | Past viable return credit |
### The Heterogeneity Gap (Δ)
The gap Δ = F − IC is the central diagnostic. It measures **channel heterogeneity**:
- **Δ ≈ 0**: All channels contribute equally — homogeneous system
- **Δ large**: One or more channels at guard band (ε = 10⁻⁸) — information is being destroyed in specific channels
- **Universal pattern**: κ < −2 ↔ IC < 0.15 — the collapse floor
---
## Originality & Terminology
This system is **original**. It does not borrow from, extend, or reinterpret existing frameworks. Classical results emerge as **degenerate limits** when degrees of freedom are removed from the GCD kernel. The arrow of derivation runs **from the axiom to the classical result**, never the reverse.
| GCD Structure | Classical Degenerate Limit |
|---------------|---------------------------|
| **Integrity bound** (IC ≤ F) | AM-GM inequality (strip channel semantics, weights, guard band) |
| **Bernoulli field entropy** S | Shannon entropy (restrict collapse field to {0,1}) |
| **Duality identity** F + ω = 1 | Unitarity (strip thermodynamic cost function) |
| **Log-integrity relation** IC = exp(κ) | Exponential map (strip kernel architecture) |
| **Heterogeneity gap** Δ = F − IC | heterogeneity gap (strip channel semantics) |
| **Frozen parameters** (ε, p, tol_seam) | Constants / hyperparameters (strip seam derivation) |
**Key vocabulary**: Say "integrity bound," not "AM-GM inequality." Say "Bernoulli field entropy," not "Shannon entropy." Say "derives independently," not "rederives" or "recovers." Say "frozen," not "constant" or "hyperparameter." See `AXIOM.md` and `.github/copilot-instructions.md` for the complete terminology reference.
---
## Installation
### Core (validation only)
```bash
pip install -e .
```
### Development (full suite)
```bash
pip install -e ".[all]"
```
### Dependencies
| Category | Packages |
|----------|----------|
| **Core** | `pyyaml`, `jsonschema`, `numpy`, `scipy` |
| **Dev** | `pytest`, `ruff`, `mypy`, `pre-commit` |
| **API** | `fastapi`, `uvicorn` (optional) |
| **Viz** | `streamlit`, `plotly`, `pandas` (optional) |
| **C++ Accel** | `pybind11`, CMake ≥ 3.16, C++17 compiler (optional) |
**Requires**: Python ≥ 3.11
### C++ Accelerator (Optional)
The C++ accelerator provides 50–80× speedup for kernel computation, seam chains,
and SHA-256 integrity checks. It is **fully optional** — all functionality falls
back to NumPy transparently.
```bash
# Build the accelerator
cd src/umcp_cpp && mkdir build && cd build
cmake .. && make -j$(nproc)
# Verify it works
python -c "from umcp.accel import backend; print(backend())" # 'cpp' or 'numpy'
# Run benchmarks (works with either backend)
python scripts/benchmark_cpp.py
```
**Architecture**: `accel.py` auto-detects whether the C++ extension is available.
No existing code changes are needed — import from `umcp.accel` instead of
calling kernel functions directly for accelerated paths.
```python
from umcp.accel import compute_kernel, compute_kernel_batch, SeamChain, hash_file
# Identical API regardless of backend
result = compute_kernel(channels, weights)
batch = compute_kernel_batch(trace_matrix, weights) # 10K rows in ms
```
---
## Quick Start
### Validate the entire repository
```bash
umcp validate .
```
### Validate a specific casepack
```bash
umcp validate casepacks/hello_world
umcp validate casepacks/hello_world --strict
```
### Run the test suite
```bash
pytest # All 3,618 tests
pytest -v --tb=short # Verbose with short tracebacks
pytest -n auto # Parallel execution
```
### Check integrity
```bash
umcp integrity # Verify SHA-256 checksums
```
### Launch the dashboard
```bash
pip install -e ".[all]" # Ensure viz dependencies are installed
umcp-dashboard # Start Streamlit dashboard on :8501
```
Or start manually:
```bash
streamlit run src/umcp/dashboard/__init__.py --server.port 8501 --server.headless true
```
The dashboard provides **33 interactive pages** across all 13 domains:
Kernel Explorer, Regime Map, Seam Budget, τ_R* Phase Diagram,
Astronomy, Nuclear Physics, Quantum Mechanics, Finance, RCFT,
Atomic Physics, Standard Model, Materials Science, Security, and more.
### Use the kernel in Python
```python
from umcp.kernel_optimized import compute_kernel_outputs
channels = [0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
weights = [0.125] * 8 # Equal weights
result = compute_kernel_outputs(channels, weights)
print(f"F={result.F:.4f}, ω={result.omega:.4f}, IC={result.IC:.6f}")
print(f"Regime: {result.regime}")
print(f"Heterogeneity gap: {result.heterogeneity_gap:.6f}") # Δ = F − IC
```
---
## CLI Reference
| Command | Description |
|---------|-------------|
| `umcp validate .` | Validate entire repository |
| `umcp validate <path> --strict` | Strict validation (warnings → failures) |
| `umcp validate <path> --out report.json` | Output JSON report |
| `umcp integrity` | Verify SHA-256 checksums |
| `umcp list casepacks` | List available casepacks |
| `umcp health` | Health check |
| `umcp-calc` | Universal kernel calculator |
| `umcp-ext list` | List available extensions |
| `umcp-api` | Start FastAPI server (:8000) |
| `umcp-dashboard` | Start Streamlit dashboard (:8501) |
### Startup — From Clone to Running
```bash
# 1. Clone and install
git clone https://github.com/calebpruett927/GENERATIVE-COLLAPSE-DYNAMICS.git
cd GENERATIVE-COLLAPSE-DYNAMICS
pip install -e ".[all]" # Core + dev + API + viz dependencies
# 2. Verify installation
umcp health # System health check
umcp integrity # Verify SHA-256 checksums
umcp validate . # Full repo validation → CONFORMANT
# 3. Run the test suite
pytest -v --tb=short # 3,618 tests
```
### C++ Accelerator — Build & Verify
```bash
# Build (requires CMake ≥ 3.16 and a C++17 compiler)
cd src/umcp_cpp && mkdir -p build && cd build
cmake .. && make -j$(nproc)
cd ../../.. # Return to repo root
# Verify backend
python -c "from umcp.accel import backend; print(backend())" # → 'cpp'
# Run correctness + performance benchmark (30 checks)
python scripts/benchmark_cpp.py
# Run C++ unit tests (Catch2, built alongside the extension)
cd src/umcp_cpp/build && ctest --output-on-failure && cd ../../..
```
### Services — API & Dashboard
```bash
# FastAPI REST server (http://localhost:8000)
umcp-api # Or: uvicorn umcp.api_umcp:app --reload --port 8000
# Streamlit dashboard (http://localhost:8501, 33 pages)
umcp-dashboard # Or: streamlit run src/umcp/dashboard/__init__.py --server.port 8501
# Start/stop dashboard via helper scripts
bash scripts/start_dashboard.sh
bash scripts/stop_dashboard.sh
```
### Development Loop — Edit, Validate, Commit
```bash
# After ANY tracked file change:
python scripts/update_integrity.py # Regenerate SHA-256 checksums (mandatory)
ruff check --fix . && ruff format . # Auto-fix lint + formatting
pytest -v --tb=short # Run full test suite
# Full pre-commit protocol (mirrors CI exactly — must exit 0 before committing)
python scripts/pre_commit_protocol.py # manifold → ruff → mypy → integrity → pytest → validate
# Dry-run (report-only, no auto-fix)
python scripts/pre_commit_protocol.py --check
# Commit only after pre-commit passes
git add -A && git commit -m "feat: description"
git push origin main
```
### Reset & Clean Slate
```bash
# Regenerate all integrity checksums from scratch
python scripts/update_integrity.py
# Re-validate the full repo (clears any stale state)
umcp validate .
# Rebuild the C++ extension from scratch
rm -rf src/umcp_cpp/build
cd src/umcp_cpp && mkdir build && cd build && cmake .. && make -j$(nproc) && cd ../../..
# Verify everything is green after a reset
python scripts/pre_commit_protocol.py # Full protocol: lint + test + validate
# Force NumPy fallback (bypass C++ even if built)
UMCP_NO_CPP=1 python -c "from umcp.accel import backend; print(backend())" # → 'numpy'
```
### Useful Utilities
```bash
# Kernel calculator (interactive CLI)
umcp-calc
# Finance domain CLI
umcp-finance
# List/inspect extensions
umcp-ext list
umcp-ext info api
umcp-ext check api
# Generate all diagrams from kernel data (requires: pip install matplotlib)
python scripts/generate_diagrams.py
# Periodic table report (118 elements)
python scripts/periodic_table_report.py
# Profile the test landscape
python scripts/profile_test_landscape.py
# Build LaTeX papers (requires: texlive + revtex4-2)
cd paper && pdflatex standard_model_kernel.tex && bibtex standard_model_kernel \
&& pdflatex standard_model_kernel.tex && pdflatex standard_model_kernel.tex
```
---
## Validation Pipeline
```
umcp validate <target>
→ Detect type (repo │ casepack │ file)
→ Schema validation (JSON Schema Draft 2020-12)
→ Semantic rule checks (validator_rules.yaml: E101, W201, ...)
→ Kernel identity checks: F = 1−ω, IC ≈ exp(κ), IC ≤ F
→ Regime classification: STABLE │ WATCH │ TENSION │ COLLAPSE
→ SHA-256 integrity verification
→ Verdict: CONFORMANT → append to ledger/return_log.csv + JSON report
```
### CI Pipeline
The GitHub Actions workflow (`.github/workflows/validate.yml`) enforces:
1. **Lint** — `ruff format --check` + `ruff check` + `mypy`
2. **Test** — Full pytest suite (3,618 tests)
3. **Validate** — Baseline + strict validation (both must return CONFORMANT)
### Pre-Commit Protocol
**Mandatory before every commit:**
```bash
python scripts/pre_commit_protocol.py # Auto-fix + validate
python scripts/pre_commit_protocol.py --check # Dry-run: report only
```
This mirrors CI exactly: format → lint → type-check → integrity → test → validate.
---
## Test Suite
**3,618 tests** across **90 test files**, organized by tier and domain:
| Test Range | Domain | Tests |
|------------|--------|------:|
| `test_000–001` | Manifold bounds, invariant separation | 91 |
| `test_00` | Schema validation | 3 |
| `test_10` | Canon/contract/closure validation | 3 |
| `test_100–102` | GCD (canon, closures, contract) | 52 |
| `test_110–115` | RCFT (canon, closures, contract, layering) | 97 |
| `test_120` | Kinematics closures | 55 |
| `test_130` | Kinematics audit spec | 35 |
| `test_135` | Nuclear physics closures | 76 |
| `test_140` | Weyl cosmology closures | 43 |
| `test_145–147` | τ_R* diagnostics & dynamics | 136 |
| `test_146` | Dashboard coverage | 144 |
| `test_148–149` | Standard Model (subatomic kernel, formalism) | 319 |
| `test_150–153` | Astronomy, quantum mechanics, materials | 600+ |
| `test_154–159` | Advanced QM (TERS, atom-dot, muon-laser, double-slit) | 900+ |
| `test_160` | Universal regime calibration | 252 |
| `closures/` | Closure-specific tests | 27 |
All tests pass. All validations return CONFORMANT.
---
## Papers & Publications
### Compiled Papers
| Paper | Title | Location |
|-------|-------|----------|
| `generated_demo.tex` | Statistical Mechanics of the UMCP Budget Identity | `paper/` |
| `standard_model_kernel.tex` | Particle Physics in the GCD Kernel: Ten Tier-2 Theorems | `paper/` |
| `tau_r_star_dynamics.tex` | τ_R* Dynamics | `paper/` |
| `confinement_kernel.tex` | Confinement Kernel Analysis | `paper/` |
| `measurement_substrate.tex` | Measurement Substrate Theory | `paper/` |
| `rcft_second_edition.tex` | RCFT Second Edition: Foundations, Derivations, and Implications | `paper/` |
| `RCFT_FREEZE_WELD.md` | RCFT Freeze–Weld Identity: From Publication to Proven Kernel | `paper/` |
All papers use RevTeX4-2 (LaTeX) or Markdown. Build LaTeX: `pdflatex → bibtex → pdflatex → pdflatex`.
### Zenodo Publications (9 DOIs)
The framework is anchored by peer-reviewed Zenodo publications covering the core theory, physics coherence proofs, casepack specifications, and domain applications. Bibliography: `paper/Bibliography.bib` (40+ entries total, including PDG 2024, foundational QFT papers, and classical references).
### Key DOIs
- **UMCP/GCD Canon Anchor**: [10.5281/zenodo.17756705](https://doi.org/10.5281/zenodo.17756705)
- **Physics Coherence Proof**: [10.5281/zenodo.18072852](https://doi.org/10.5281/zenodo.18072852)
- **Runnable CasePack Anchor**: [10.5281/zenodo.18226878](https://doi.org/10.5281/zenodo.18226878)
---
## Repository Structure
```
├── src/umcp/ # Core validation engine
│ ├── cli.py # CLI & validation pipeline
│ ├── validator.py # Root-file validator
│ ├── kernel_optimized.py # Kernel computation
│ ├── seam_optimized.py # Seam budget computation
│ ├── tau_r_star.py # Thermodynamic diagnostic
│ ├── epistemic_weld.py # Epistemic cost tracking
│ ├── fleet/ # Distributed validation
│ └── dashboard/ # Streamlit dashboard (33 pages)
├── closures/ # 13 physics domains, 120+ modules
│ ├── standard_model/ # 31 particles, 10 theorems
│ ├── atomic_physics/ # 118 elements, Tier-1 proof
│ ├── quantum_mechanics/ # Double slit, entanglement, tunneling
│ ├── nuclear_physics/ # Binding energy, decay chains
│ ├── materials_science/ # 118 elements × 18 fields
│ ├── astronomy/ # Stellar evolution, HR diagram
│ ├── kinematics/ # Motion analysis, phase space
│ ├── gcd/ # Core dynamics, field resonance
│ ├── rcft/ # Fractal dimension, attractors
│ ├── weyl/ # Modified gravity, cosmology
│ ├── everyday_physics/ # Thermodynamics, optics, electromagnetism
│ └── finance/ & security/ # Applied domains
├── contracts/ # 13 mathematical contracts (YAML)
├── schemas/ # 14 JSON Schema files
├── canon/ # 11 canonical anchor files
├── casepacks/ # 14 reproducible validation bundles
├── tests/ # 90 test files, 3618 tests
├── paper/ # 6 LaTeX papers + 1 Markdown paper + Bibliography.bib
├── integrity/ # SHA-256 checksums
├── ledger/ # Append-only validation log
├── scripts/ # Pre-commit protocol, integrity update
├── docs/ # 30+ documentation files
└── pyproject.toml # Project configuration
```
---
## Documentation
### Essential Reading (Start Here)
| Document | Purpose |
|----------|---------|
| [AXIOM.md](AXIOM.md) | **Start here.** The foundational axiom, operational definitions, and why this system is original |
| [LIBER_COLLAPSUS.md](LIBER_COLLAPSUS.md) | *Liber Universalis de Collapsus Mathematica* — the Tier-1 Latin foundation text |
| [TIER_SYSTEM.md](TIER_SYSTEM.md) | The three-tier architecture: Immutable Invariants → Protocol → Expansion Space |
| [KERNEL_SPECIFICATION.md](KERNEL_SPECIFICATION.md) | Complete kernel mathematics, OPT-* lemmas, and degenerate-limit proofs |
| [QUICKSTART_TUTORIAL.md](QUICKSTART_TUTORIAL.md) | Getting started: first validation in 5 minutes |
### The Three-Tier Architecture
| Tier | Name | Role | Mutable? |
|------|------|------|----------|
| **1** | **Immutable Invariants** | Structural identities: F + ω = 1, IC ≤ F, IC ≈ exp(κ). Derived from Axiom-0. | NEVER within a run |
| **0** | **Protocol** | Validation machinery: regime gates, contracts, schemas, diagnostics, seam calculus | Frozen per run |
| **2** | **Expansion Space** | Domain closures mapping physics into invariant structure. Validated through Tier-0 against Tier-1. | Freely extensible |
**One-way dependency**: Tier-1 → Tier-0 → Tier-2. No back-edges. No Tier-2 output may modify Tier-0 or Tier-1 behavior within a frozen run. Promotion from Tier-2 to Tier-1 requires formal seam weld validation across runs.
### Reference Documents
| Document | Purpose |
|----------|---------|
| [PROTOCOL_REFERENCE.md](PROTOCOL_REFERENCE.md) | Full protocol specification |
| [COMMIT_PROTOCOL.md](COMMIT_PROTOCOL.md) | Pre-commit protocol (mandatory before every commit) |
| [GLOSSARY.md](GLOSSARY.md) | Operational term definitions |
| [CONTRIBUTING.md](CONTRIBUTING.md) | Contribution guidelines and code review checklist |
| [CHANGELOG.md](CHANGELOG.md) | Version history |
| [FACE_POLICY.md](FACE_POLICY.md) | Boundary governance (Tier-0 admissibility) |
### Internal Documentation (docs/)
| Document | Purpose |
|----------|---------|
| [docs/MATHEMATICAL_ARCHITECTURE.md](docs/MATHEMATICAL_ARCHITECTURE.md) | Mathematical foundations and architectural overview |
| [docs/interconnected_architecture.md](docs/interconnected_architecture.md) | System interconnection map |
| [docs/file_reference.md](docs/file_reference.md) | Complete file reference guide |
| [docs/SYMBOL_INDEX.md](docs/SYMBOL_INDEX.md) | Authoritative symbol table (prevents Tier-2 capture) |
| [docs/UHMP.md](docs/UHMP.md) | Universal Hash Manifest Protocol |
---
## Diagrams & Proofs
All diagrams are generated from **real computed kernel data** — every point comes from actual closure outputs, not illustrations. Regenerate with `python scripts/generate_diagrams.py`.
### Kernel Geometry: F vs IC for 31 Standard Model Particles
The fundamental relationship: IC ≤ F — the integrity bound. Geometric integrity never exceeds arithmetic integrity. Derived independently from Axiom-0; the classical AM-GM inequality emerges as the degenerate limit when kernel structure is removed. Quarks cluster near the diagonal (channels alive), while composites and bosons collapse toward IC ≈ 0.

### Theorem T3: Confinement as IC Collapse
14/14 hadrons fall below the minimum quark IC. The geometric mean collapses 98.1% at the quark→hadron boundary — confinement is a measurable cliff in the kernel.

### Complementarity Cliff: Double-Slit Interference
Wave and particle are *both channel-deficient extremes*. The kernel-optimal state (S4: weak measurement) has the highest IC because all 8 channels are alive. 7/7 theorems PROVEN, 67/67 subtests.

### Theorems T1 & T2: Spin-Statistics and Generation Monotonicity
Fermions carry more fidelity than bosons (split = 0.194). Heavier generations carry more kernel fidelity: Gen1 < Gen2 < Gen3 in both quarks and leptons.

### Periodic Table of Kernel Fidelity: 118 Elements
Every element in the periodic table mapped through the GCD kernel. Tier-1 proof: 10,162 tests, 0 failures — F + ω = 1, IC ≤ F, IC = exp(κ) verified exhaustively.

### Regime Phase Diagram
The four-regime classification with real Standard Model particles mapped to their drift values. Most particles live in COLLAPSE (ω ≥ 0.30) because the 8-channel trace exposes channel death.

### Cross-Scale Universality and Heterogeneity Gap Distribution
Kernel fidelity increases with scale resolution: composite(0.444) < atomic(0.516) < fundamental(0.558). The heterogeneity gap distribution across 118 elements reveals the landscape of channel heterogeneity.

---
## Key Discoveries
Across 13 physics domains, the kernel reveals universal patterns:
1. **Confinement is a cliff**: IC drops 98.1% at the quark→hadron boundary — confinement is visible as geometric-mean collapse in the kernel trace
2. **The complementarity cliff**: Wave and particle are both channel-deficient extremes; the kernel-optimal state is partial measurement where all 8 channels are alive (>5× IC gap)
3. **Universal collapse floor**: κ < −2 ↔ IC < 0.15 across all domains — a universal threshold where information integrity is lost
4. **Heterogeneity gap as universal diagnostic**: Δ = F − IC measures channel spread; maximum Δ comes from asymmetry (one dead channel among many alive), not from maximum overall degradation
5. **Generation monotonicity**: Gen1(0.576) < Gen2(0.620) < Gen3(0.649) in both quarks and leptons — heavier generations carry more kernel fidelity
6. **50× charge suppression**: Neutral particles have IC near ε (guard band) because the charge channel destroys the geometric mean
7. **Cross-scale universality**: composite(0.444) < atom(0.516) < fundamental(0.558) — kernel fidelity increases with scale resolution
---
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
**Critical workflow:**
```bash
# After any code change:
python scripts/update_integrity.py # Regenerate SHA-256 checksums
python scripts/pre_commit_protocol.py # Full pre-commit protocol
# Only commit if all checks pass (exit 0)
```
Every commit that reaches GitHub must pass CI: lint → test → validate → CONFORMANT.
---
## License
[MIT](LICENSE) — Clement Paulus
---
<p align="center">
<em>"Collapse is generative; only what returns is real."</em><br>
<strong>— Axiom-0</strong>
</p>
| text/markdown | Clement Paulus | null | null | null | null | UMCP, GCD, RCFT, contract-first, validation, reproducibility, casepacks, fractal, recursive-field | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering",
"Topic :: Software Development :: Quality Assurance",
"Topic :: Syste... | [] | null | null | >=3.11 | [] | [] | [] | [
"pyyaml>=6.0.1",
"jsonschema>=4.23.0",
"numpy>=1.24.0",
"scipy>=1.10.0",
"psutil>=5.9.0; extra == \"production\"",
"pytest>=8.0.0; extra == \"dev\"",
"pytest-cov>=5.0.0; extra == \"dev\"",
"pytest-xdist>=3.8.0; extra == \"dev\"",
"ruff==0.14.14; extra == \"dev\"",
"mypy>=1.11.0; extra == \"dev\"",... | [] | [] | [] | [
"Homepage, https://github.com/calebpruett927/GENERATIVE-COLLAPSE-DYNAMICS",
"Repository, https://github.com/calebpruett927/GENERATIVE-COLLAPSE-DYNAMICS",
"Documentation, https://github.com/calebpruett927/GENERATIVE-COLLAPSE-DYNAMICS/blob/main/README.md",
"Issues, https://github.com/calebpruett927/GENERATIVE-C... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:38:21.110520 | umcp-2.1.3.tar.gz | 1,066,824 | f4/9f/ad3f566003e90f580b461c3df3074ea52b0edcbd78c651237c6673f8cb4f/umcp-2.1.3.tar.gz | source | sdist | null | false | 807c2c65af1f1242dc524d52f1588e68 | a5bbe2d2ccb9601116feae5ac20700992ca29a877a36507c2f6cf3c1287d6d36 | f49fad3f566003e90f580b461c3df3074ea52b0edcbd78c651237c6673f8cb4f | MIT | [
"LICENSE"
] | 267 |
2.4 | pypaystack2 | 3.2.0 | A developer-friendly client library for Paystack | # PyPaystack2
[](https://pepy.tech/project/pypaystack2)
[](https://pepy.tech/project/pypaystack2)
[](https://pepy.tech/project/pypaystack2)
PyPaystack2 is an Open Source Python client library for integrating [Paystack](https://paystack.com/) into your python
projects. It aims at being developer friendly and easy to use.
**Version 3 is here now**
## Features
- 1st class support for type annotations.
- Synchronous and Asynchronous clients.
- Pydantic for data modelling.
- Fees Calculation utilities.
- Webhook support & utilities (>= v3.1.0).
## Installation
```bash
$ pip install -U pypaystack2
# or install with uv
$ uv add pypaystack2
# For webhook cli
$ pip install -U "pypaystack2[webhook]"
or install with uv
$ uv add "pypaystack2[webhook]"
```
## Usage Preview
In the REPL session below, we're using PyPaystack2 to create a `Customer` (user) and a `Plan` on
[Paystack](https://paystack.com/) and then add the newly created customer as a subscriber to the plan.
### Note
The REPL session below assumes the environmental variable `PAYSTACK_SECRET_KEY="YOUR_SECRET_KEY"` is set. if not,
you can alternatively pass it into the `PaystackClient` on instantiation like so
`PaystackClient(secret_key='YOUR_SECRET_KEY')` otherwise, you will get a `MissingSecretKeyException` raised prompting
you to provide a secret key. It also does not handle likely exceptions that calling client methods like
`client.customers.create`, `client.plans.create` & `client.subscriptions.create` may raise like `ClientNetworkError`
for network related issues and `ValueError` for validation related issues.
```bash
Python 3.11.13 (main, Sep 2 2025, 14:20:25) [Clang 20.1.4 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from pypaystack2 import __version__
>>> print(__version__)
3.0.0 # Ensure you're running PyPaystack2 version >= 3.0.0 for the following entries to work
>>> from pypaystack2 import PaystackClient
>>> from pypaystack2.enums import Interval
>>> from pypaystack2.models import Customer, Plan
>>> client = PaystackClient()
>>> new_customer_response = client.customers.create(email="johndoe@example.com",first_name="John",last_name="Doe")
>>> assert new_customer_response.status # Validating the request is successful
>>> new_customer = new_customer_response.data
>>> assert isinstance(new_customer,Customer) # Showing that we indeed get an instance of a pydantic model name `Customer` a modelled representation of the data returned by paystack as a result of the request to create a new user
>>> new_plan_response = client.plans.create(name="Test 1k Daily Contributions", amount=client.to_subunit(1000), interval=Interval.DAILY)
>>> assert new_plan_response.status # Validating the request is successful
>>> new_plan = new_plan_response.data # Validating the request is successful
>>> assert isinstance(new_plan,Plan)
>>> new_subscription_response = client.subscriptions.create(customer=new_customer.customer_code,plan=new_plan.plan_code)
>>> assert new_subscription_response.status == True # Validating the request is successful
>>> print(repr(new_subscription_response))
Response(
status_code=<HTTPStatus.OK: 200>,
status=True,
message='Subscription successfully created',
data=Subscription(
customer=87934333,
plan=2237384,...
```
### Webhook
PyPaystack2 now supports verifying the authenticity of a webhook payload and a CLI to make working with webhooks locally
seamless
#### Verifying a webhook payload
```bash
Python 3.11.13 (main, Sep 2 2025, 14:20:25) [Clang 20.1.4 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from pypaystack2 import PaystackClient
>>> client = PaystackClient()
>>> payload = ... # webhook payload e.g., b'{"event": "customeridentification.success", "data": {"customer_id": 324345768, "customer_code": "CUS_e7urjebaoyk1ze2", "email": "jddae8446e-e54c-42ab-bf37-e5abff14527e@example.com", "identification": {"country": "NG", "type": "bank_account", "bvn": "123*****543", "account_number": "342****22", "bank_code": "121"}}}'
>>> signature = ... # x-paystack-signature e.g., "5d049eb93c7c71fa098f5215d7297bda401710b62df8b392b9052adf8d1a02ff308f6ca57a1db14ffeabd5b66264e9c42de029b7067b9c71eb9c231fb2a8e383"
>>> is_verified_webhook_payload = client.is_verified_webhook_payload(payload,signature)
>>> print(is_verified_webhook_payload)
True
```
#### Forward webhook events from paystack to your app running locally
**Note:** This requires that you install `pypaystack2[webhook]`
```bash
pypaystack2 webhook start-tunnel-server --addr localhost:8000 --ngrok-auth-token
```
## Documentation
See [Documentation](https://gray-adeyi.github.io/pypaystack2/) for more on this package.
## Disclaimer
This project is an Open Source client library for [Paystack](https://paystack.com/). It is not officially endorsed or
affiliated with [Paystack](https://paystack.com/). All trademarks and company names belong to their respective owners.
## Contributions
Thank you for being interested in contributing to PyPaystack2.
There are many ways you can contribute to the project:
- [Star on GitHub](https://github.com/gray-adeyi/pypaystack2/)
- Try PyPaystack2 and [report bugs/issues you find](https://github.com/gray-adeyi/pypaystack2/issues/new)
- [Buy me a coffee](https://www.buymeacoffee.com/jigani)
## Other Related Projects
| Name | Language | Functionality |
|------------------------------------------------------------------------------------|-----------------------|----------------------------------------------------------------------------------|
| [Paystack CLI](https://pypi.org/project/paystack-cli/) | Python | A command line app for interacting with paystack APIs |
| [paystack](https://github.com/gray-adeyi/paystack) | Go | A client library for integration paystack in go |
| [@gray-adeyi/paystack-sdk](https://www.npmjs.com/package/@gray-adeyi/paystack-sdk) | Typescript/Javascript | A client library for integrating paystack in Javascript runtimes (Node,Deno,Bun) |
| [paystack](https://pub.dev/packages/paystack) | Dart | A client library for integration paystack in Dart |
| text/markdown | Gbenga Adeyi | Gbenga Adeyi <adeyigbenga005@gmail.com> | null | null | null | paystack-python, pypaystack, paystack, paystackapi | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"httpx>=0.28.1",
"pydantic>=2.12.5",
"fastapi[standard]>=0.123.10; extra == \"webhook\"",
"ngrok>=1.4.0; extra == \"webhook\"",
"python-dotenv>=1.2.1; extra == \"webhook\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T02:38:19.554677 | pypaystack2-3.2.0-py3-none-any.whl | 148,079 | a9/68/39d0167b54ef2018620d1269a081a9c7c132a2e6771a32f02b5fc5706f2e/pypaystack2-3.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 8daddc4cd27fe579e9593bed16ff2cd2 | a626361092ef376275a23cb5ac108a0b8d794ee98a5f8564645c83e7e5d28222 | a96839d0167b54ef2018620d1269a081a9c7c132a2e6771a32f02b5fc5706f2e | MIT | [] | 310 |
2.4 | curvepy-fdct | 1.1.1 | A Pure Python Clean-Room Implementation of the Fast Discrete Curvelet Transform | # CurvePy: Fast Discrete Curvelet Transform (FDCT)




**CurvePy** is a pure Python "clean room" implementation of the **Fast Discrete Curvelet Transform** via Uniform Wrapping outlined in Emmanuel Candès 2005 paper [Fast Discrete Curvelet Transforms](chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://math.mit.edu/icg/papers/FDCT.pdf)
Unlike wavelets, which represent images using points, Curvelets represent images using oriented edges. This makes CurvePy (or the FDCT) a powerful tool for sparse representations of smooth curves, and highly effective at denoising while preserving sharp boundaries.
---
## Results
### Denoising
### Grayscale images (2-D)
### RGB images (3-D)
Curvepy uses a color denoising engine that operatues in the YUV color space (chosen to preserve structural details) while filtering chromatic noise.
## Features
* **Fast Discrete Curvelet Transform (FDCT):** Implemented via the "wrapping" method outlined in Candès et al. 2005 for computational efficiency ($O(N^2 \log N)$).
* **Color Support:** wrapper specifically for RGB images using **YUV** separation. Processing Luma and Chroma channels independently.
* **Thresholding Design:**
* **Soft Thresholding:** For artifact-free restoration.
* **Monte Carlo Calibration:** Estimates noise levels per wedge and per scale.
* **Module Design:** Separates geometry computations, windowing and filtering logic into different modules.
---
## Installation
Clone the repository and install the dependencies:
```bash
git clone [https://github.com/yourusername/curvepy.git](https://github.com/yourusername/curvepy.git)
cd curvepy
pip install -r requirements.txt
```
## Usage
### 1. Basic Transformation (Grayscale image)
```python
import matpolotlib.pyplot as plt
import skimage.data as data
from curvepy.curvepy import CurveletFrequencyGrid
# Initialize the Transformation engine (512x512 grid, 4 scales)
fdct = CurveletFrequencyGrid(N=512, scales=4)
# Load Image
image = data.camera()
# 1. Forward Transform
coefficients = fdct.forward_transform(image)
# 2. Inverse Transform
reconstructed_image = fdct.inverse_transform(coefficients)
# 3. Plot results
plt.figure(figsize=(12,4))
plt.suptitle("Original vs Reconstructed Image")
plt.subplot(1,2,1)
plt.imshow(image, plt.cmap.gray)
plt.title("Original")
plt.subplot(1,2,2)
plt.imshow(reconstructed_image, plt.cmap.gray)
plt.title("Restored Image")
plt.tight_layout()
plt.show()
```
### 2. Basic Transformation and Denoising (Grayscale image)
```python
import matpolotlib.pyplot as plt
import skimage.data as data
from curvepy.curvepy import CurveletFrequencyGrid
from curvepy.denoise import CurveletDenoise
# Initialize the Transformation engine (512x512 grid, 4 scales)
fdct = CurveletFrequencyGrid(N=512, scales=4)
denoise_engine = CurveletDenoise(fdct)
# Load Image
image = data.camera()
# 1. Forward Transform
coefficients = fdct.forward_transform(image)
# 2. Denoise
restored_img = denoise_engine.denoise(noisy_img, sigma, multiplier)
psnr = denoise_engine.calculate_psnr_rgb(img, restored_img)
# 3. Plot results
plt.figure(figsize=(12,4))
plt.suptitle(f"Original vs restored img for soft thresholding, PSNR = {psnr:.2f} dB, multiplier = {multiplier}")
plt.subplot(1, 2, 1)
plt.imshow(img, cmap=plt.cm.gray)
plt.title("original img")
plt.subplot(1, 2, 2)
plt.imshow(restored_img, cmap=plt.cm.gray)
plt.title("restored img")
plt.tight_layout()
plt.show()
```
### 3. Denoising a Color Image
```python
import matplotlib.pyplot as plt
import skimage.data as data
from curvepy.curvepy import CurveletFrequencyGrid
from curvepy.denoise import ColorCuerveletDenoise
# Setup
fdct = CurveletFrequencyGrid(N=512, scales=4)
denoise_engine = CuerveletDenoise(fdct)
image = denoise_engine.normalize_img(data.astronaut())
# Apply denoising
restored_image = denoise_engine.denoise(image, sigma=0.1, multiplier=1.5)
psnr = denoise_engine.calculate_psnr_rgb(image, restored_image) # Calculate peak SNR value between two images
# Plot results
plt.figure(figsize=(12,4))
plt.suptitle(f"Original vs Restored image via Soft Thresholding, PSNR = {psnr:.2f} dB, multiplier = {multiplier}")
plt.subplot(1, 2, 1)
plt.imshow(img)
plt.title("original img")
plt.subplot(1, 2, 2)
plt.imshow(restored_img)
plt.title("restored img")
plt.tight_layout()
plt.show()
```
### 4. Seismic Data Processing (SEG-Y & Compression)
CurvePy now supports direct SEG-Y ingestion and specialized seismic denoising. This pipeline demonstrates loading, aggressive denoising (targeting 95%+ sparsity), and quantization for massive compression savings.
```python
import numpy as np
from curvepy.io import SeismicLoader
from curvepy.curvepy import CurveletFrequencyGrid
from curvepy.denoise import SeismicDenoise
# 1. Setup & Load
loader = SeismicLoader('path/to/data.sgy')
image = loader.load_2d_slice(inline=100)
grid = CurveletFrequencyGrid(nrows=image.shape[0], ncols=image.shape[1], scales=5)
denoiser = SeismicDenoise(grid)
# 2. Aggressive Denoising & Sparsity Check
# Returns clean image, sparsity %, and clean coefficients
clean_image, sparsity, clean_coeffs = denoiser.denoise(image, sigma=3.5)
print(f"Achieved Sparsity: {sparsity:.2f}%")
# 3. Quantization & Compression
# Save coefficients directly to HDF5 (often achieving 10x-20x compression ratios)
loader.save_quantized_coefficients(clean_coeffs, 'path/to/data.h5', threshold=0)
```
### 5. Scientific Signal Analysis (Synthetic ANT)
This example generates a dispersive surface wave, adds noise, and recovers the signal while preserving the Frequency-Wavenumber (F-K) spectrum.
```python
import numpy as np
import matplotlib.pyplot as plt
from curvepy.curvepy import CurveletFrequencyGrid
from curvepy.denoise import SeismicDenoise
# Generate Synthetic Dispersive Wave
rows, cols = 256, 256
t = np.linspace(-2, 2, rows)
x = np.linspace(0, 5, cols)
T, X = np.meshgrid(t, x, indexing='ij')
# Signal: Clean dispersive arc + heavy Gaussian noise
clean_signal = np.sin(2 * np.pi * 5 * (T - 0.1 * X**2)) * np.exp(-10 * (T - 0.1 * X**2)**2)
noisy_data = clean_signal + 0.8 * np.random.randn(rows, cols)
# Denoise
grid = CurveletFrequencyGrid(rows, cols, scales=5)
denoiser = SeismicDenoise(grid)
denoised, sparsity, _ = denoiser.denoise(noisy_data, sigma=2.5)
```
## Project Structure
curvepy/\
├── curvepy.py # Core Engine: FDCT & IFDCT implementation \
├── windows.py # Math: Meyer Window functions (Phi, Psi, V) \
├── filters.py # Tools: Thresholding logic & Monte Carlo calibration \
├── denoise.py # App: Seismic & Color Denoising pipelines
└── io.py # Tools: SEG-Y Loading & HDF5 Compression
## Theory + How it Works:
Standard 2D Wavelets are isotropic, ie. they treat all directions equally. This doens't work well for images where the curves/outlines of the shapes are what are important to be preserved. This creates a blocky or ringing effect when trying to represent a smooth curve.
**Curvelets** are anisotropic "needles" that exist at different scales and angles
* **Scales:** Captures details of different sizes.
* **Angles:** Capture the direction of the geometry.
This allows CurvePy to represent a curved edge with very few coefficients relative to the aformentioneed 2D wavelets, making it ideal for compression and restoration tasks while preserving the geometry is important :)
To understand why this matters, we visualized the inner workings of the transform below:
Image

Transformation Process for Above Image
### The 4-Step Pipeline (Explained)
1. **The Map (Top-Left):**
The Frequency Plane is tiled into "Wedges." Each wedge represents a specific combination of **Scale** (how thick the feature is) and **Angle** (which way it points).
* *Center (Grey):* Low-frequency background (blurry shapes).
* *Outer Rings (Colors):* High-frequency details (sharp edges).
2. **The Filter (Top-Right):**
To detect specific features, we activate just **one single wedge**. In this example, we selected **Scale 3, Wedge 0**. This filter is specialized to find "Medium-Fine details that are Horizontal."
3. **The Needle (Bottom-Left):**
This is what that single filter looks like in the real world (Spatial Domain). It isn't a point—it's a **Needle**.
4. **The Response (Bottom-Right):**
When we drag this Needle across a real photo (The Astronaut), it lights up (turns black) *only* where it finds matching geometry.
* Notice the top of the helmet and the flag stripes are clearly visible because they are horizontal.
* The vertical rocket boosters in the background are invisible. The horizontal needle doesn't notice the vertical lines.
## Visual Proofs & Benchmarks
### 1. Physics Preservation (F-K Spectrum)
One of CurvePy's primary goals is to denoise without destroying the underlying physics of the signal.
* **Left:** The raw cross-correlation with heavy noise.
* **Center:** The denoised output.
* **Right:** The Residual (Noise) containing no coherent structural energy.
### 2. Spectral Integrity
Comparing the F-K (Frequency-Wavenumber) spectrum before and after denoising confirms that the relevant frequency content is preserved while incoherent noise is rejected.
### 3. The Power of Sparsity
Curvelets represent curve-like geometry extremely efficiently. As shown below, **95% of the signal energy** is often contained in a tiny fraction of the coefficients. This is the mechanism that allows for high-ratio compression.
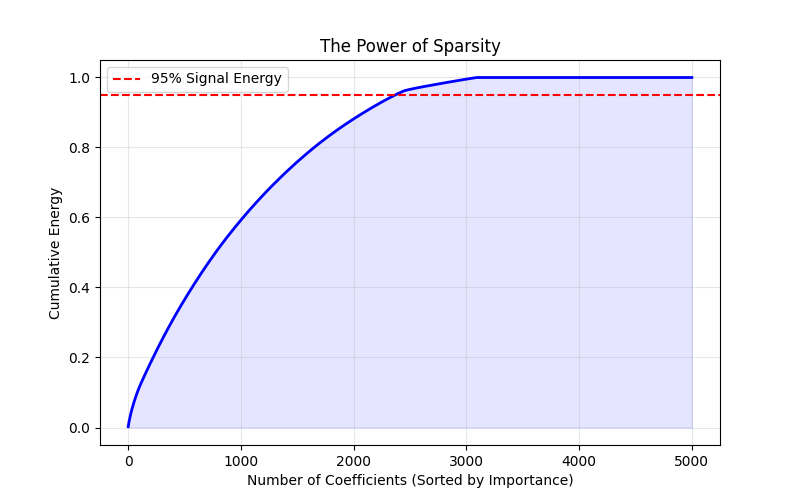
**Summary:** By adding up thousands of these "Needles" at every possible angle and size, CurvePy reconstructs the perfect image—minus the noise.
## Licence
MIT Licence. Free to use for academic and personal projects.
| text/markdown | Noah Munro-Kagan | noahmunrokagan@gmail.com | null | null | MIT License
Copyright (c) [2026] [Noah Munro-Kagan]
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE. | curvelet, signal-processing, denoising, wavelets | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Image Processing"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"Cython>=3.0.0",
"h5py<4.0.0,>=3.15.1",
"matplotlib<4.0.0,>=3.10.8",
"numpy<3.0.0,>=1.3.0",
"pywavelets<2.0.0,>=1.9.0",
"scikit-image<0.27.0,>=0.26.0",
"segyio<2.0.0,>=1.9.14",
"setuptools>=65.0.0"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/noahmunrokagan/curvepy/issues",
"Homepage, https://github.com/noahmunrokagan/curvepy"
] | poetry/2.3.2 CPython/3.14.3 Darwin/24.4.0 | 2026-02-19T02:37:56.354383 | curvepy_fdct-1.1.1-cp314-cp314-macosx_15_0_x86_64.whl | 284,261 | b6/f5/41aea89f6e252b8120f8818c0894f41ea9c8ae2b9513d4c82bb3a1158a60/curvepy_fdct-1.1.1-cp314-cp314-macosx_15_0_x86_64.whl | cp314 | bdist_wheel | null | false | 38cfdd8f8254d0861c702beee894ab1c | 1aa8f9b38849d392d1828653cdb940223112a69d034200a8b537327c81395e7a | b6f541aea89f6e252b8120f8818c0894f41ea9c8ae2b9513d4c82bb3a1158a60 | null | [
"LICENSE"
] | 250 |
2.4 | gunspec | 0.1.0 | Python SDK for the GunSpec.io firearms specification API | # gunspec
Official Python SDK for the [GunSpec.io](https://gunspec.io) firearms specification database API.
## Installation
```bash
pip install gunspec
```
## Quick Start
```python
from gunspec import GunSpec
# Reads GUNSPEC_API_KEY from environment automatically
client = GunSpec()
# List firearms
result = client.firearms.list({"category": "pistol", "manufacturer": "glock"})
for firearm in result.data:
print(firearm["name"], firearm["caliber"])
# Get a single firearm
result = client.firearms.get("glock-g17")
print(result.data["name"])
```
## Async Usage
```python
from gunspec import AsyncGunSpec
async with AsyncGunSpec() as client:
result = await client.firearms.list({"category": "rifle"})
for firearm in result.data:
print(firearm["name"])
```
## Configuration
```python
from gunspec import GunSpec, RetryConfig
# Reads GUNSPEC_API_KEY from env automatically
client = GunSpec()
# Or configure explicitly
client = GunSpec(
api_key="gs_...", # or set GUNSPEC_API_KEY env var
base_url="https://api.gunspec.io", # default
timeout=30.0, # 30s default
retry=RetryConfig(
max_retries=2, # default
initial_delay_s=0.5, # default
),
)
```
## Resources
| Resource | Methods |
|----------|---------|
| `client.firearms` | `list`, `get`, `search`, `compare`, `game_meta`, `action_types`, `filter_options`, `random`, `top`, `head_to_head`, `by_feature`, `by_action`, `by_material`, `by_designer`, `power_rating`, `timeline`, `by_conflict`, `get_variants`, `get_images`, `get_game_stats`, `get_dimensions`, `get_users`, `get_family_tree`, `get_similar`, `get_adoption_map`, `get_game_profile`, `get_silhouette`, `calculate`, `load`, `list_auto_paging` |
| `client.manufacturers` | `list`, `get`, `get_firearms`, `get_timeline`, `get_stats`, `list_auto_paging` |
| `client.calibers` | `list`, `get`, `compare`, `ballistics`, `get_firearms`, `get_parent_chain`, `get_family`, `get_ammunition`, `list_auto_paging` |
| `client.categories` | `list`, `get_firearms` |
| `client.stats` | `summary`, `production_status`, `field_coverage`, `popular_calibers`, `prolific_manufacturers`, `by_category`, `by_era`, `materials`, `adoption_by_country`, `adoption_by_type`, `action_types`, `feature_frequency`, `caliber_popularity_by_era` |
| `client.game` | `balance_report`, `tier_list`, `matchups`, `role_roster`, `stat_distribution` |
| `client.game_stats` | `list_versions`, `list_firearms`, `get_firearm` |
| `client.ammunition` | `list`, `get`, `get_bullet_svg`, `ballistics`, `list_auto_paging` |
| `client.countries` | `list`, `get_arsenal` |
| `client.conflicts` | `list` |
| `client.data_quality` | `coverage`, `confidence` |
| `client.favorites` | `list`, `add`, `remove` |
| `client.reports` | `create`, `list` |
| `client.support` | `create`, `list`, `get`, `reply` |
| `client.webhooks` | `list`, `create`, `get`, `update`, `delete`, `test` |
| `client.usage` | `get` |
## Auto-Pagination
```python
# Sync
for firearm in client.firearms.list_auto_paging({"category": "rifle"}):
print(firearm["name"])
# Async
async for firearm in client.firearms.list_auto_paging({"category": "rifle"}):
print(firearm["name"])
```
## Error Handling
```python
from gunspec import (
GunSpec,
NotFoundError,
RateLimitError,
AuthenticationError,
)
client = GunSpec()
try:
result = client.firearms.get("nonexistent")
except NotFoundError as e:
print(f"Not found: {e.message}")
print(f"Request ID: {e.request_id}")
except RateLimitError as e:
print(f"Retry after: {e.retry_after}s")
except AuthenticationError:
print("Invalid API key")
```
## Context Managers
```python
# Sync
with GunSpec() as client:
result = client.firearms.list()
# Async
async with AsyncGunSpec() as client:
result = await client.firearms.list()
```
## Requirements
- Python >= 3.9
- httpx >= 0.25
- pydantic >= 2
## Publishing
```bash
cd packages/sdk-python
# Install build tools
pip install build twine
# Build sdist and wheel
python -m build
# Verify package
twine check dist/*
# Upload to PyPI
twine upload dist/*
```
For TestPyPI first:
```bash
twine upload --repository testpypi dist/*
pip install --index-url https://test.pypi.org/simple/ gunspec
```
## Development
```bash
cd packages/sdk-python
uv venv && source .venv/bin/activate
uv pip install -e ".[dev]"
# Run tests
python -m pytest
# Lint
ruff check src/
# Type check
mypy src/gunspec/
```
## License
MIT
| text/markdown | GunSpec.io | null | null | null | null | api, database, firearms, gunspec, sdk, specifications | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx<1,>=0.25",
"pydantic<3,>=2",
"mypy>=1.0; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=7; extra == \"dev\"",
"respx>=0.21; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://gunspec.io",
"Documentation, https://gunspec.io/docs",
"Repository, https://github.com/buun-group/gunspec",
"Issues, https://github.com/buun-group/gunspec/issues"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-19T02:37:45.221151 | gunspec-0.1.0.tar.gz | 73,093 | 10/7d/728074d602c99a4bb8f6aabcd63b6ea6150cd2d911f8d8e75dbb02f19a5b/gunspec-0.1.0.tar.gz | source | sdist | null | false | 7ca980e1bd60635ae18b2574f1dce3d6 | 276ebce40045afe1de9c9075f0b4981e6ee7edc8a9e752ad76435ffa665a1e65 | 107d728074d602c99a4bb8f6aabcd63b6ea6150cd2d911f8d8e75dbb02f19a5b | MIT | [] | 280 |
2.4 | predicate-sdk | 1.1.1 | Compatibility shim for predicate-runtime | # predicate-sdk compatibility shim
This package exists to preserve install compatibility for users who still run:
```bash
pip install predicate-sdk
```
It depends on `predicate-runtime` and does not provide a separate runtime surface.
Use canonical imports from `predicate` in your code.
| text/markdown | Sentience Team | null | null | null | MIT OR Apache-2.0 | predicate, runtime, compatibility, shim | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"predicate-runtime==1.1.1"
] | [] | [] | [] | [
"Homepage, https://github.com/Predicate-Labs/sdk-python",
"Repository, https://github.com/Predicate-Labs/sdk-python",
"Issues, https://github.com/Predicate-Labs/sdk-python/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T02:37:20.260639 | predicate_sdk-1.1.1.tar.gz | 1,624 | a0/f6/2d78204f9981248c22b920608d404b6fe3daef32f408a8535800e94b9fee/predicate_sdk-1.1.1.tar.gz | source | sdist | null | false | bb614733a201f7e198d5421d49eee748 | b9a78baa8d6f7279e408767282c46a1699e17be3da2b4e96b662333226c59963 | a0f62d78204f9981248c22b920608d404b6fe3daef32f408a8535800e94b9fee | null | [] | 257 |
2.4 | predicate-runtime | 1.1.1 | Python SDK for Sentience AI Agent Browser Automation | # Predicate Python SDK
> **A verification & control layer for AI agents that operate browsers**
Predicate is built for **AI agent developers** who already use Playwright / CDP / browser-use / LangGraph and care about **flakiness, cost, determinism, evals, and debugging**.
Often described as *Jest for Browser AI Agents* - but applied to end-to-end agent runs (not unit tests).
The core loop is:
> **Agent → Snapshot → Action → Verification → Artifact**
## What Predicate is
- A **verification-first runtime** (`AgentRuntime`) for browser agents
- Treats the browser as an adapter (Playwright / CDP / browser-use); **`AgentRuntime` is the product**
- A **controlled perception** layer (semantic snapshots; pruning/limits; lowers token usage by filtering noise from what models see)
- A **debugging layer** (structured traces + failure artifacts)
- Enables **local LLM small models (3B-7B)** for browser automation (privacy, compliance, and cost control)
- Keeps vision models **optional** (use as a fallback when DOM/snapshot structure falls short, e.g. `<canvas>`)
## What Predicate is not
- Not a browser driver
- Not a Playwright replacement
- Not a vision-first agent framework
## Install
```bash
pip install predicate-runtime
playwright install chromium
```
Legacy install compatibility remains available through the shim package:
```bash
pip install predicate-sdk
```
If you’re developing from source (this repo), install the local checkout instead:
```bash
pip install -e .
playwright install chromium
```
## Conceptual example (why this exists)
In Predicate, agents don’t “hope” an action worked.
- **Every step is gated by verifiable UI assertions**
- If progress can’t be proven, the run **fails with evidence** (trace + artifacts)
- This is how you make runs **reproducible** and **debuggable**, and how you run evals reliably
## Quickstart: a verification-first loop
This is the smallest useful pattern: snapshot → assert → act → assert-done.
```python
import asyncio
from predicate import AgentRuntime, AsyncPredicateBrowser
from predicate.tracing import JsonlTraceSink, Tracer
from predicate.verification import exists, url_contains
async def main() -> None:
tracer = Tracer(run_id="demo", sink=JsonlTraceSink("trace.jsonl"))
async with AsyncPredicateBrowser() as browser:
page = await browser.new_page()
await page.goto("https://example.com")
runtime = await AgentRuntime.from_sentience_browser(
browser=browser,
page=page,
tracer=tracer,
)
runtime.begin_step("Verify homepage")
await runtime.snapshot()
runtime.assert_(url_contains("example.com"), label="on_domain", required=True)
runtime.assert_(exists("role=heading"), label="has_heading")
runtime.assert_done(exists("text~'Example'"), label="task_complete")
if __name__ == "__main__":
asyncio.run(main())
```
## PredicateDebugger: attach to your existing agent framework (sidecar mode)
If you already have an agent loop (LangGraph, browser-use, custom planner/executor), you can keep it and attach Predicate as a **verifier + trace layer**.
Key idea: your agent still decides and executes actions — Predicate **snapshots and verifies outcomes**.
```python
from predicate import PredicateDebugger, create_tracer
from predicate.verification import exists, url_contains
async def run_existing_agent(page) -> None:
# page: playwright.async_api.Page (owned by your agent/framework)
tracer = create_tracer(run_id="run-123") # local JSONL by default
dbg = PredicateDebugger.attach(page, tracer=tracer)
async with dbg.step("agent_step: navigate + verify"):
# 1) Let your framework do whatever it does
await your_agent.step()
# 2) Snapshot what the agent produced
await dbg.snapshot()
# 3) Verify outcomes (with bounded retries)
await dbg.check(url_contains("example.com"), label="on_domain", required=True).eventually(timeout_s=10)
await dbg.check(exists("role=heading"), label="has_heading").eventually(timeout_s=10)
```
## SDK-driven full loop (snapshots + actions)
If you want Predicate to drive the loop end-to-end, you can use the SDK primitives directly: take a snapshot, select elements, act, then verify.
```python
from predicate import PredicateBrowser, snapshot, find, click, type_text, wait_for
def login_example() -> None:
with PredicateBrowser() as browser:
browser.page.goto("https://example.com/login")
snap = snapshot(browser)
email = find(snap, "role=textbox text~'email'")
password = find(snap, "role=textbox text~'password'")
submit = find(snap, "role=button text~'sign in'")
if not (email and password and submit):
raise RuntimeError("login form not found")
type_text(browser, email.id, "user@example.com")
type_text(browser, password.id, "password123")
click(browser, submit.id)
# Verify success
ok = wait_for(browser, "role=heading text~'Dashboard'", timeout=10.0)
if not ok.found:
raise RuntimeError("login failed")
```
## Pre-action authority hook (production pattern)
If you want every action proposal to be authorized before execution, pass a
`pre_action_authorizer` into `RuntimeAgent`.
This hook receives a shared `predicate-contracts` `ActionRequest` generated from
runtime state (`snapshot` + assertion evidence) and must return either:
- `True` / `False`, or
- an object with an `allowed: bool` field (for richer decision payloads).
```python
from predicate.agent_runtime import AgentRuntime
from predicate.runtime_agent import RuntimeAgent, RuntimeStep
# Optional: your authority client can be local guard, sidecar client, or remote API client.
def pre_action_authorizer(action_request):
# Example: call your authority service
# resp = authority_client.authorize(action_request)
# return resp
return True
runtime = AgentRuntime(backend=backend, tracer=tracer)
agent = RuntimeAgent(
runtime=runtime,
executor=executor,
pre_action_authorizer=pre_action_authorizer,
authority_principal_id="agent:web-checkout",
authority_tenant_id="tenant-a",
authority_session_id="session-123",
authority_fail_closed=True, # deny/authorizer errors block action execution
)
ok = await agent.run_step(
task_goal="Complete checkout",
step=RuntimeStep(goal="Click submit order"),
)
```
Fail-open option (not recommended for sensitive actions):
```python
agent = RuntimeAgent(
runtime=runtime,
executor=executor,
pre_action_authorizer=pre_action_authorizer,
authority_fail_closed=False, # authorizer errors allow action to proceed
)
```
## Capabilities (lifecycle guarantees)
### Controlled perception
- **Semantic snapshots** instead of raw DOM dumps
- **Pruning knobs** via `SnapshotOptions` (limit/filter)
- Snapshot diagnostics that help decide when “structure is insufficient”
### Constrained action space
- Action primitives operate on **stable IDs / rects** derived from snapshots
- Optional helpers for ordinality (“click the 3rd result”)
### Verified progress
- Predicates like `exists(...)`, `url_matches(...)`, `is_enabled(...)`, `value_equals(...)`
- Fluent assertion DSL via `expect(...)`
- Retrying verification via `runtime.check(...).eventually(...)`
### Scroll verification (prevent no-op scroll drift)
A common agent failure mode is “scrolling” without the UI actually advancing (overlays, nested scrollers, focus issues). Use `AgentRuntime.scroll_by(...)` to deterministically verify scroll *had effect* via before/after `scrollTop`.
```python
runtime.begin_step("Scroll the page and verify it moved")
ok = await runtime.scroll_by(
600,
verify=True,
min_delta_px=50,
label="scroll_effective",
required=True,
timeout_s=5.0,
)
if not ok:
raise RuntimeError("Scroll had no effect (likely blocked by overlay or nested scroller).")
```
### Explained failure
- JSONL trace events (`Tracer` + `JsonlTraceSink`)
- Optional failure artifact bundles (snapshots, diagnostics, step timelines, frames/clip)
- Deterministic failure semantics: when required assertions can’t be proven, the run fails with artifacts you can replay
### Framework interoperability
- Bring your own LLM and orchestration (LangGraph, AutoGen, custom loops)
- Register explicit LLM-callable tools with `ToolRegistry`
## ToolRegistry (LLM-callable tools)
Predicate can expose a **typed tool surface** for agents (with tool-call tracing).
```python
from predicate.tools import ToolRegistry, register_default_tools
registry = ToolRegistry()
register_default_tools(registry, runtime) # or pass a ToolContext
# LLM-ready tool specs
tools_for_llm = registry.llm_tools()
```
## Permissions (avoid Chrome permission bubbles)
Chrome permission prompts are outside the DOM and can be invisible to snapshots. Prefer setting a policy **before navigation**.
```python
from predicate import AsyncPredicateBrowser, PermissionPolicy
policy = PermissionPolicy(
default="clear",
auto_grant=["geolocation"],
geolocation={"latitude": 37.77, "longitude": -122.41, "accuracy": 50},
origin="https://example.com",
)
async with AsyncPredicateBrowser(permission_policy=policy) as browser:
...
```
If your backend supports it, you can also use ToolRegistry permission tools (`grant_permissions`, `clear_permissions`, `set_geolocation`) mid-run.
## Downloads (verification predicate)
If a flow is expected to download a file, assert it explicitly:
```python
from predicate.verification import download_completed
runtime.assert_(download_completed("report.csv"), label="download_ok", required=True)
```
## Debugging (fast)
- **Manual driver CLI** (inspect clickables, click/type/press quickly):
```bash
predicate driver --url https://example.com
```
- **Verification + artifacts + debugging with time-travel traces (Predicate Studio demo)**:
<video src="https://github.com/user-attachments/assets/7ffde43b-1074-4d70-bb83-2eb8d0469307" controls muted playsinline></video>
If the video tag doesn’t render in your GitHub README view, use this link: [`sentience-studio-demo.mp4`](https://github.com/user-attachments/assets/7ffde43b-1074-4d70-bb83-2eb8d0469307)
- **Predicate SDK Documentation**: https://predicatelabs.dev/docs
## Integrations (examples)
- **Browser-use:** [examples/browser-use](examples/browser-use/)
- **LangChain:** [examples/lang-chain](examples/lang-chain/)
- **LangGraph:** [examples/langgraph](examples/langgraph/)
- **Pydantic AI:** [examples/pydantic_ai](examples/pydantic_ai/)
| text/markdown | Sentience Team | null | null | null | MIT OR Apache-2.0 | browser-automation, playwright, ai-agent, web-automation, sentience | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"playwright>=1.40.0",
"pydantic>=2.0.0",
"jsonschema>=4.0.0",
"requests>=2.31.0",
"httpx>=0.25.0",
"playwright-stealth>=1.0.6",
"markdownify>=0.11.6",
"predicate-contracts",
"browser-use>=0.1.40; extra == \"browser-use\"",
"pydantic-ai; extra == \"pydanticai\"",
"langchain; extra == \"langchain\... | [] | [] | [] | [
"Homepage, https://github.com/Predicate-Labs/sdk-python",
"Repository, https://github.com/Predicate-Labs/sdk-python",
"Issues, https://github.com/Predicate-Labs/sdk-python/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T02:37:01.452548 | predicate_runtime-1.1.1.tar.gz | 407,636 | dc/3f/d5172ef87b23f9d3254e41512a0677d1f1a93d5b8b5f2f8bec9ccb2858c4/predicate_runtime-1.1.1.tar.gz | source | sdist | null | false | 080f8553672a3344ae0e67b113e65d79 | 160b4e922ce7b0b8d72403d504a030d283af5e7357f428f88c01ccb229a214e8 | dc3fd5172ef87b23f9d3254e41512a0677d1f1a93d5b8b5f2f8bec9ccb2858c4 | null | [
"LICENSE",
"LICENSE-APACHE",
"LICENSE-MIT"
] | 276 |
2.4 | pysvgchart | 0.6.3 | Creates svg based charts in python | Python SVG Chart Generator (pysvgchart)
=======================================
A Python package for creating and rendering SVG charts, including line
charts, axes, legends, and text labels. This package supports both
simple and complex chart structures and is highly customisable for
various types of visualisations.
Why did I make this project
---------------------------
This project is designed to produce charts that are easily embedded into python web applications (or other web applications) with minimum fuss.
Many charting libraries for the web rely on JavaScript-driven client-side rendering, often requiring an intermediate
canvas before producing a polished visual. On the other hand, popular python based charting libraries focus on
image-based rendering. Such images are rigid and intractable once embedded into web applications and detailed
customisation is impossible. Although some libraries do generate resolution independent output
it is very difficult to customise.
This package takes a different approach: it generates clean, standalone SVG charts
entirely within Python that can be immediately embedded into a web application. By leveraging SVG’s inherent scalability
and styling flexibility, it eliminates the need for JavaScript dependencies, client-side rendering, or post-processing
steps. The result is a lightweight, backend-friendly solution for producing high-quality, resolution-independent
charts without sacrificing control or maintainability.
Every chart element is designed to be easily modified, giving developers precise control over appearance and structure.
As such, all of the lower level elements are accessible via properties of the charts.
Installation
------------
.. code:: bash
pip install pysvgchart
Alternatively, you can clone this repository and install it locally:
.. code:: bash
git clone https://github.com/arowley-ai/py-svg-chart.git
cd py-svg-chart
pip install .
Usage
-----
Usage depends on which chart you had in mind but each one follows similar principles.
Simple donut chart
^^^^^^^^^^^^^^^^^^
A simple donut chart:
.. code:: python
import pysvgchart as psc
values = [11.3, 20, 30, 40]
donut_chart = psc.DonutChart(values)
svg_string = donut_chart.render()
.. image:: https://raw.githubusercontent.com/arowley-ai/py-svg-chart/refs/heads/main/showcase/donut.svg
:alt: Simple donut chart example
:width: 200px
Donut chart hovers
^^^^^^^^^^^^^^^^^^
The donut is nice but a little boring. To make it a bit more interesting, lets add interactive hover
effects. These effects can be added to any base elements but I thought you'd mostly use it for data labels.
.. code:: python
def hover_modifier(position, name, value, chart_total):
text_styles = {'alignment-baseline': 'middle', 'text-anchor': 'middle'}
return [
psc.Text(x=position.x, y=position.y-10, content=name, styles=text_styles),
psc.Text(x=position.x, y=position.y+10, content="{:.2%}".format(value/chart_total), styles=text_styles)
]
values = [11.3, 20, 30, 40]
names = ['Apples', 'Bananas', 'Cherries', 'Durians']
donut_chart = psc.DonutChart(values, names)
donut_chart.add_hover_modifier(hover_modifier)
donut_chart.render_with_all_styles()
`Here <https://raw.githubusercontent.com/arowley-ai/py-svg-chart/refs/heads/main/showcase/donut_hover.svg>`_ is the output of this code.
In order to get the hover modifiers to display successfully you will need to either render the svg with styles
or include the relevant css separately
Simple line chart
^^^^^^^^^^^^^^^^^
Create a simple line chart:
.. code:: python
import pysvgchart as psc
x_values = list(range(100))
y_values = [4000]
for i in range(99):
y_values.append(y_values[-1] + 100 * random.randint(0, 1))
line_chart = psc.SimpleLineChart(
x_values=x_values,
y_values=[y_values, [1000 + y for y in y_values]],
y_names=['predicted', 'actual'],
x_max_ticks=20,
y_zero=True,
)
line_chart.add_grids(minor_y_ticks=4, minor_x_ticks=4)
line_chart.add_legend()
svg_string = line_chart.render()
.. image:: https://raw.githubusercontent.com/arowley-ai/py-svg-chart/refs/heads/main/showcase/line.svg
:alt: Simple line chart example
More stylised example
^^^^^^^^^^^^^^^^^^^^^
Here's a heavily customised line chart example
.. code:: python
import pysvgchart as psc
def y_labels(num):
num = float('{:.3g}'.format(num))
magnitude = 0
while abs(num) >= 1000:
magnitude += 1
num /= 1000.0
rtn = '{}{}'.format('{:f}'.format(num).rstrip('0').rstrip('.'), ['', 'K', 'M', 'B', 'T'][magnitude])
return rtn.replace('.00', '').replace('.0', '')
def x_labels(date):
return date.strftime('%b')
dates = [dt.date.today() - dt.timedelta(days=i) for i in range(500) if (dt.date.today() + dt.timedelta(days=i)).weekday() == 0][::-1]
actual = [(1 + math.sin(d.timetuple().tm_yday / 183 * math.pi)) * 50000 + 1000 * i + random.randint(-10000, 10000) for i, d in enumerate(dates)]
expected = [a + random.randint(-10000, 10000) for a in actual]
line_chart = psc.SimpleLineChart(x_values=dates, y_values=[actual, expected], y_names=['Actual sales', 'Predicted sales'], x_max_ticks=30, x_label_format=x_labels, y_label_format=y_labels, width=1200)
line_chart.series['Actual sales'].styles = {'stroke': "#DB7D33", 'stroke-width': '3'}
line_chart.series['Predicted sales'].styles = {'stroke': '#2D2D2D', 'stroke-width': '3', 'stroke-dasharray': '4,4'}
line_chart.add_legend(x=700, element_x=200, line_length=35, line_text_gap=20)
line_chart.add_y_grid(minor_ticks=0, major_grid_style={'stroke': '#E9E9DE'})
line_chart.x_axis.tick_lines, line_chart.y_axis.tick_lines = [], []
line_chart.x_axis.axis_line = None
line_chart.y_axis.axis_line.styles['stroke'] = '#E9E9DE'
line_end = line_chart.legend.lines[0].end
act_styles = {'fill': '#FFFFFF', 'stroke': '#DB7D33', 'stroke-width': '3'}
line_chart.add_custom_element(psc.Circle(x=line_end.x, y=line_end.y, radius=4, styles=act_styles))
line_end = line_chart.legend.lines[1].end
pred_styles = {'fill': '#2D2D2D', 'stroke': '#2D2D2D', 'stroke-width': '3'}
line_chart.add_custom_element(psc.Circle(x=line_end.x, y=line_end.y, radius=4, styles=pred_styles))
for limit, tick in zip(line_chart.x_axis.scale.ticks, line_chart.x_axis.tick_texts):
if tick.content == 'Jan':
line_chart.add_custom_element(psc.Text(x=tick.position.x, y=tick.position.y + 15, content=str(limit.year), styles=tick.styles))
def hover_modifier(position, x_value, y_value, series_name, styles):
text_styles = {'alignment-baseline': 'middle', 'text-anchor': 'middle'}
params = {'styles': text_styles, 'classes': ['psc-hover-data']}
return [
psc.Circle(x=position.x, y=position.y, radius=3, classes=['psc-hover-data'], styles=styles),
psc.Text(x=position.x, y=position.y - 10, content=str(x_value), **params),
psc.Text(x=position.x, y=position.y - 30, content="{:,.0f}".format(y_value), **params),
psc.Text(x=position.x, y=position.y - 50, content=series_name, **params)
]
line_chart.add_hover_modifier(hover_modifier, radius=5)
line_chart.render_with_all_styles()
.. image:: https://raw.githubusercontent.com/arowley-ai/py-svg-chart/refs/heads/main/showcase/detailed.svg
:alt: Complex line chart example
`View <https://raw.githubusercontent.com/arowley-ai/py-svg-chart/refs/heads/main/showcase/detailed.svg>`_ with hover effects
Chart Types Reference
----------------------
All chart types with their parameters and usage patterns.
LineChart
^^^^^^^^^
Standard line chart with vertical values and horizontal categories.
.. code:: python
psc.LineChart(
x_values=['Jan', 'Feb', 'Mar'], # Categories on X-axis (horizontal)
y_values=[[10, 20, 15], [12, 18, 14]], # Values on Y-axis (vertical)
y_names=['Sales', 'Costs'], # Series names
x_zero=False, y_zero=True, # Include zero on axes
x_max_ticks=12, y_max_ticks=10, # Maximum ticks
x_label_format=str, y_label_format=str, # Label formatters
x_axis_title='Month', y_axis_title='Amount',
width=800, height=600,
)
SimpleLineChart
^^^^^^^^^^^^^^^
Simplified line chart with minimal configuration.
.. code:: python
psc.SimpleLineChart(
x_values=[1, 2, 3, 4, 5],
y_values=[[10, 20, 30, 25, 35]],
y_names=['Data'],
)
BarChart
^^^^^^^^
Vertical bar chart (bars grow upward).
.. code:: python
psc.BarChart(
x_values=['A', 'B', 'C'], # Categories on X-axis
y_values=[[10, 20, 30], [15, 25, 35]], # Values on Y-axis
y_names=['Q1', 'Q2'],
y_zero=True, # Start Y-axis at zero
bar_width=40, bar_gap=2, # Bar sizing
width=800, height=600,
)
HorizontalBarChart
^^^^^^^^^^^^^^^^^^
Horizontal bar chart (bars grow rightward). Note: parameters are swapped compared to vertical charts.
.. code:: python
psc.HorizontalBarChart(
x_values=[[10, 20, 30], [15, 25, 35]], # Values on X-axis (horizontal)
y_values=['A', 'B', 'C'], # Categories on Y-axis (vertical)
x_names=['Q1', 'Q2'],
x_zero=True, # Start X-axis at zero
bar_width=40, bar_gap=2, # Bar thickness and gap
y_axis_title='Products',
x_axis_title='Sales',
width=800, height=600,
left_margin=200, # Extra margin for long labels
)
NormalisedBarChart
^^^^^^^^^^^^^^^^^^
Stacked bar chart normalised to 100%.
.. code:: python
psc.NormalisedBarChart(
x_values=['A', 'B', 'C'],
y_values=[[10, 20, 30], [5, 10, 15]],
y_names=['Part 1', 'Part 2'],
bar_width=40,
width=800, height=600,
)
ScatterChart
^^^^^^^^^^^^
Scatter plot with individual data points.
.. code:: python
psc.ScatterChart(
x_values=[1, 2, 3, 4, 5],
y_values=[[10, 20, 15, 25, 30]],
y_names=['Data Points'],
x_zero=True, y_zero=True,
width=800, height=600,
)
DonutChart
^^^^^^^^^^
Donut/pie chart for proportional data.
.. code:: python
psc.DonutChart(
values=[25, 30, 20, 25], # Segment sizes
names=['Q1', 'Q2', 'Q3', 'Q4'], # Segment labels
width=400, height=400,
inner_radius=80, # Hole size
outer_radius=150, # Outer edge
colours=['red', 'blue', 'green', 'yellow'],
)
Common Parameters
^^^^^^^^^^^^^^^^^
Most charts share these parameters:
**Axis Configuration:**
- ``x_min``, ``x_max``, ``y_min``, ``y_max``: Set axis ranges
- ``x_zero``, ``y_zero``: Force zero to appear on axis
- ``x_max_ticks``, ``y_max_ticks``: Maximum number of tick marks
- ``x_label_format``, ``y_label_format``: Functions to format axis labels
- ``x_axis_title``, ``y_axis_title``: Axis titles
- ``x_shift``, ``y_shift``: Shift data relative to axis
**Canvas Settings:**
- ``width``, ``height``: Chart dimensions in pixels
- ``left_margin``, ``right_margin``: Horizontal margins
- ``y_margin``, ``x_margin``: Vertical margins (varies by chart orientation)
**Styling:**
- ``colours``: List of colours for series
- ``bar_width``, ``bar_gap``: Bar chart specific (bar thickness and spacing)
Common Methods
^^^^^^^^^^^^^^
All charts support these methods:
.. code:: python
# Rendering
svg_string = chart.render() # Basic SVG output
svg_string = chart.render_with_all_styles() # With inline CSS (for hovers)
chart.save('output.svg') # Save to file
# Legends
chart.add_legend(x_position=700, y_position=200)
# Grids
chart.add_grids(minor_x_ticks=4, minor_y_ticks=4)
chart.add_y_grid(minor_ticks=5)
chart.add_x_grid(minor_ticks=5)
# Hover effects (requires render_with_all_styles)
def hover_fn(position, x_value, y_value, series_name, styles):
return [psc.Text(x=position.x, y=position.y, content=str(y_value))]
chart.add_hover_modifier(hover_fn, radius=5)
# Custom elements
chart.add_custom_element(psc.Circle(x=100, y=100, radius=5))
chart.add_custom_element(psc.Line(x=50, y=50, width=100, height=0))
chart.add_custom_element(psc.Text(x=200, y=200, content='Label'))
# Direct series styling
chart.series['Series Name'].styles = {'stroke': 'red', 'stroke-width': '3'}
# Modify all series
chart.modify_series(lambda s: s)
Contributing
------------
We welcome contributions! If you’d like to contribute to the project,
please follow these steps:
- Fork this repository.
- Optionally, create a new branch (eg. git checkout -b feature-branch).
- Commit your changes (git commit -am ‘Add feature’).
- Push to the branch (eg. git push origin feature-branch).
- Open a pull request.
Created a neat chart?
---------------------
All of the charts in the showcase folder are generated by pytest. If you create something neat that you'd
like to share then see if it can be added to the test suite and it will be generated alongside other
showcase examples.
License
-------
This project is licensed under the MIT License - see the LICENSE file
for details.
| null | Alex Rowley | null | null | null | MIT license | pysvgchart | [
"Development Status :: 2 - Pre-Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :... | [] | https://github.com/arowley-ai/py-svg-chart | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.9.25 | 2026-02-19T02:36:54.374107 | pysvgchart-0.6.3.tar.gz | 31,675 | 10/58/1bbf5e1a89b17474942006ed291a046cf31a231ec74d90666006a760d9a3/pysvgchart-0.6.3.tar.gz | source | sdist | null | false | 552fdb1ca02d98b1fe60a53830077501 | 81fc3a93ee3e51219fc4b4efce89e930b057ea69795861fa0cbc98ee54d9d683 | 10581bbf5e1a89b17474942006ed291a046cf31a231ec74d90666006a760d9a3 | null | [
"LICENSE"
] | 274 |
2.4 | filesift | 0.2.0 | Intelligent file indexing and search system | <p align="center">
<img src="assets/logo.png" alt="FileSift" width="200">
</p>
<h1 align="center">FileSift</h1>
<p align="center">
<em>A fast, open-source utility that helps AI coding agents intelligently search and understand codebases.</em>
</p>
<p align="center">
<a href="https://pypi.org/project/filesift/"><img src="https://img.shields.io/pypi/v/filesift" alt="PyPI"></a>
<a href="https://pypi.org/project/filesift/"><img src="https://img.shields.io/pypi/pyversions/filesift" alt="Python"></a>
<a href="https://github.com/roshunsunder/filesift/blob/main/LICENSE"><img src="https://img.shields.io/github/license/roshunsunder/filesift" alt="License"></a>
</p>
---
FileSift lets your AI coding agent search across a codebase based on what code **does**, rather than what it looks like. Instead of sifting through entire files after a `grep`, your agent can jump straight to the most relevant code using natural language queries like *"authentication middleware"* or *"database connection pooling"*. Everything runs **locally on your machine** — your code never leaves your environment.
**Key benefits:**
- **Smarter search** — hybrid keyword + semantic search finds code by intent, not just string matching
- **Less context wasted** — agents get pointed to the right files immediately, saving token budget on exploration
## Installation
```bash
pip install filesift
```
## Usage
There are three ways to use FileSift, depending on your workflow:
### 1. CLI
The most straightforward approach. Good for testing queries, managing indexes, and configuring settings.
```bash
# Index a project
filesift index /path/to/your/project
# Search for files by what they do
filesift find "authentication and session handling"
# Search in a specific directory
filesift find "retry logic for API calls" --path /path/to/project
```
### 2. MCP Server
<!-- mcp-name: io.github.roshunsunder/filesift -->
Installing FileSift also provides a `filesift-mcp` command — a lightweight [MCP](https://modelcontextprotocol.io/) server that exposes indexing and search as tools over STDIO. This works with most popular coding agents including Claude Code, Cursor, Copilot, and more.
Add it to your agent's MCP configuration:
```json
{
"mcpServers": {
"filesift": {
"command": "filesift-mcp"
}
}
}
```
The MCP server exposes four tools:
- `filesift_search` — search an indexed codebase by natural language query
- `filesift_find_related` — find files related to a given file via imports and semantic similarity
- `filesift_index` — index a directory to enable searching
- `filesift_status` — check indexing status of a directory
### 3. Skills
FileSift ships with a `search-codebase` skill that can be installed directly into your coding agent's skill directory. This lets the agent interact with the FileSift CLI through bash, without requiring MCP support.
```bash
# Install for Claude Code (default)
filesift skill install
# Install for other agents
filesift skill install --agent cursor
filesift skill install --agent copilot
filesift skill install --agent codex
```
Supported agents: `claude`, `codex`, `cursor`, `copilot`, `gemini`, `roo`, `windsurf`.
## How It Works
FileSift uses a daemonized embedding model to keep searches fast. At its core, it generates embeddings from code descriptions and performs searches against small vector stores called **indexes**.
1. **Indexing** — `filesift index` first builds a fast keyword/structural index (completes in seconds), then triggers background semantic indexing that generates embeddings for each file.
2. **Daemon** — A background daemon loads indexes into memory and automatically shuts down after a configurable period of inactivity. After the first cold-start search, subsequent searches are near-instant.
3. **Search** — Queries are matched using both keyword (BM25) and semantic (FAISS) search, then combined via [Reciprocal Rank Fusion](https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf) for the best of both approaches.
Indexes are stored in a `.filesift` directory within each indexed project.
## Configuration
FileSift uses a TOML configuration file, manageable via the CLI:
```bash
# View all settings
filesift config list --all
# Set a value
filesift config set search.MAX_RESULTS 20
filesift config set daemon.INACTIVITY_TIMEOUT 600
# Manage ignore patterns
filesift config add-ignore "node_modules" ".venv"
filesift config list-ignore
```
Configuration sections: `search`, `indexing`, `daemon`, `models`, `paths`.
## Contributing
Contributions are welcome! To get started:
```bash
git clone https://github.com/roshunsunder/filesift.git
cd filesift
pip install -e .
```
1. Fork the repository
2. Create a feature branch (`git checkout -b feature/my-feature`)
3. Commit your changes and open a pull request
## License
Apache 2.0 — see [LICENSE](LICENSE) for details.
| text/markdown | null | Roshun Sunder <roshun.sunder@gmail.com> | null | Roshun Sunder <roshun.sunder@gmail.com> | null | file-search, semantic-search, vector-search, file-indexing, code-search, document-search, faiss, embeddings, natural-language-search | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries :: Python Modules",
"Topic :... | [] | null | null | >=3.12 | [] | [] | [] | [
"faiss-cpu",
"sentence-transformers<5",
"transformers<5",
"einops",
"rank-bm25",
"numpy",
"requests",
"click",
"tqdm",
"platformdirs",
"tomli-w",
"PyYAML",
"mcp>=1.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/roshunsunder/filesift"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-19T02:33:34.181303 | filesift-0.2.0.tar.gz | 44,713 | f9/18/ce5e4ad2eeba2179168117c78c607320cb7bc2cc48db847806ac2163f03f/filesift-0.2.0.tar.gz | source | sdist | null | false | 3f4ce8869d97648f4b344c231d4a0a8a | 83aeca230131954b847e82d82efad6f479dd00d75e333a8769dc1620f7cc8d92 | f918ce5e4ad2eeba2179168117c78c607320cb7bc2cc48db847806ac2163f03f | Apache-2.0 | [
"LICENSE"
] | 272 |
2.4 | smtp-py | 2.0.0 | Unofficial smtp.dev API written in Python | # smtp-py
A modern, easy to use, feature-rich, API package for **smtp.dev** written in Python.
**Python 3.7 or higher is required**
Before you could use smtp-py, you must install it first by running this command in your terminal
```
$ pip install smtp-py
```
Links
------
- [Documentation](https://reno.gitbook.io/smtp-py)
- [smtp.dev API](https://smtp.dev/docs/api)
| text/markdown | Long Nguyen | nguyenlongdev@proton.me | null | null | MIT | smtp email api client smtp.dev | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Communications :: Email",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language ... | [] | https://github.com/nguy3nlong/smtp-py | null | >=3.7 | [] | [] | [] | [
"requests>=2.31.0",
"python-dotenv>=1.0.0",
"urllib3>=2.0.0"
] | [] | [] | [] | [
"Bug Reports, https://github.com/nguy3nlong/smtp-py/issues",
"Source, https://github.com/nguy3nlong/smtp-py",
"Documentation, https://github.com/nguy3nlong/smtp-py#readme"
] | twine/6.2.0 CPython/3.12.10 | 2026-02-19T02:33:24.188920 | smtp_py-2.0.0.tar.gz | 2,712 | 3c/ff/a80851596e39bd05df818ddfa129be41198ca6c711b2ba90bcc73f370656/smtp_py-2.0.0.tar.gz | source | sdist | null | false | b0c57858ef2b3ff49275a2bcf7ff774b | 83e0bc8e7bfc2fde44948999e3171e1f168b0972c87922690f5fd91c6a967722 | 3cffa80851596e39bd05df818ddfa129be41198ca6c711b2ba90bcc73f370656 | null | [
"LICENSE"
] | 274 |
2.1 | ldeep | 2.0.0 | In-depth ldap enumeration utility | ==============
Project Status
==============
.. image:: https://github.com/franc-pentest/ldeep/actions/workflows/autorelease.yml/badge.svg
:target: https://github.com/franc-pentest/ldeep/actions/workflows/autorelease.yml
:alt: Build status
.. image:: https://badgen.net/pypi/v/ldeep
:target: https://pypi.org/project/ldeep/
:alt: PyPi version
.. image:: https://img.shields.io/pypi/dm/ldeep.svg
:alt: Download rate
:target: https://pypi.org/project/ldeep/
============
Installation
============
To use Kerberos, `ldeep` needs to build native extensions and some headers could be required:
Debian::
sudo apt-get install -y libkrb5-dev krb5-config gcc python3-dev
ArchLinux::
sudo pacman -S krb5
-------------------------------------------
Install from pypi (latest released version)
-------------------------------------------
::
python -m pip install ldeep
----------------------------------------------------
Install from GitHub (current state of master branch)
----------------------------------------------------
::
python -m pip install git+https://github.com/franc-pentest/ldeep
===========
Development
===========
Clone the project and install the backend build system `pdm`::
python -m pip install pdm
git clone https://github.com/franc-pentest/ldeep && cd ldeep
---------------------------
Install an isolated version
---------------------------
Clone and install dependencies::
pdm install
Run locally::
pdm run ldeep
----------------------------------
Install the package in your system
----------------------------------
::
python -m pip install .
------------------------------------
Build source and wheel distributions
------------------------------------
::
python -m build
=====
ldeep
=====
Help is self-explanatory. Let's check it out::
$ ldeep -h
usage: ldeep [-h] [--version] [-o OUTFILE] [--security_desc] {ldap,cache} ...
options:
-h, --help show this help message and exit
--version show program's version number and exit
-o OUTFILE, --outfile OUTFILE
Store the results in a file
--security_desc Enable the retrieval of security descriptors in ldeep results
Mode:
Available modes
{ldap,cache} Backend engine to retrieve data
`ldeep` can either run against an Active Directory LDAP server or locally on saved files::
$ ldeep ldap -u Administrator -p 'password' -d winlab -s ldap://10.0.0.1 all backup/winlab
[+] Retrieving auth_policies output
[+] Retrieving auth_policies verbose output
[+] Retrieving computers output
[+] Retrieving conf output
[+] Retrieving delegations output
[+] Retrieving delegations verbose output
[+] Retrieving delegations verbose output
[+] Retrieving delegations verbose output
[+] Retrieving delegations verbose output
[+] Retrieving domain_policy output
[+] Retrieving gmsa output
[+] Retrieving gpo output
[+] Retrieving groups output
[+] Retrieving groups verbose output
[+] Retrieving machines output
[+] Retrieving machines verbose output
[+] Retrieving ou output
[+] Retrieving pkis output
[+] Retrieving pkis verbose output
[+] Retrieving pso output
[+] Retrieving silos output
[+] Retrieving silos verbose output
[+] Retrieving subnets output
[+] Retrieving subnets verbose output
[+] Retrieving trusts output
[+] Retrieving users output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving users verbose output
[+] Retrieving zones output
[+] Retrieving zones verbose output
$ ldeep cache -d backup -p winlab users
Administrator
[...]
These two modes have different options:
----
LDAP
----
::
$ ldeep ldap -h
usage: ldeep - 1.0.80 ldap [-h] -d DOMAIN -s LDAPSERVER [-b BASE] [-t {ntlm,simple}] [--throttle THROTTLE] [--page_size PAGE_SIZE] [-n] [-u USERNAME] [-p PASSWORD] [-H NTLM] [-k] [--pfx-file PFX_FILE]
[--pfx-pass PFX_PASS] [--cert-pem CERT_PEM] [--key-pem KEY_PEM] [-a]
{auth_policies,bitlockerkeys,computers,conf,delegations,domain_policy,fsmo,gmsa,gpo,groups,machines,ou,pkis,pso,sccm,shadow_principals,silos,smsa,subnets,templates,trusts,users,zones,from_guid,from_sid,laps,memberships,membersof,object,sddl,silo,zone,all,enum_users,search,whoami,add_to_group,change_uac,create_computer,create_user,modify_password,remove_from_group,unlock}
...
LDAP mode
options:
-h, --help show this help message and exit
-d DOMAIN, --domain DOMAIN
The domain as NetBIOS or FQDN
-s LDAPSERVER, --ldapserver LDAPSERVER
The LDAP path (ex : ldap://corp.contoso.com:389)
-b BASE, --base BASE LDAP base for query (by default, this value is pulled from remote Ldap)
-t {ntlm,simple}, --type {ntlm,simple}
Authentication type: ntlm (default) or simple. Simple bind will always be in cleartext with ldap (not ldaps)
--throttle THROTTLE Add a throttle between queries to sneak under detection thresholds (in seconds between queries: argument to the sleep function)
--page_size PAGE_SIZE
Configure the page size used by the engine to query the LDAP server (default: 1000)
-n, --no-encryption Encrypt the communication or not (default: encrypted, except with simple bind and ldap)
NTLM authentication:
-u USERNAME, --username USERNAME
The username
-p PASSWORD, --password PASSWORD
The password used for the authentication
-H NTLM, --ntlm NTLM NTLM hashes, format is LMHASH:NTHASH
Kerberos authentication:
-k, --kerberos For Kerberos authentication, ticket file should be pointed by $KRB5NAME env variable
Certificate authentication:
--pfx-file PFX_FILE PFX file
--pfx-pass PFX_PASS PFX password
--cert-pem CERT_PEM User certificate
--key-pem KEY_PEM User private key
Anonymous authentication:
-a, --anonymous Perform anonymous binds
commands:
available commands
{auth_policies,bitlockerkeys,computers,conf,delegations,domain_policy,fsmo,gmsa,gpo,groups,machines,ou,pkis,pso,sccm,shadow_principals,silos,smsa,subnets,templates,trusts,users,zones,from_guid,from_sid,laps,memberships,membersof,object,sddl,silo,zone,all,enum_users,search,whoami,add_to_group,change_uac,create_computer,create_user,modify_password,remove_from_group,unlock}
auth_policies List the authentication policies configured in the Active Directory.
bitlockerkeys Extract the bitlocker recovery keys.
computers List the computer hostnames and resolve them if --resolve is specify.
conf Dump the configuration partition of the Active Directory.
delegations List accounts configured for any kind of delegation.
domain_policy Return the domain policy.
fsmo List FSMO roles.
gmsa List the gmsa accounts and retrieve secrets(NT + kerberos keys) if possible.
gpo Return the list of Group policy objects.
groups List the groups.
machines List the machine accounts.
ou Return the list of organizational units with linked GPO.
pkis List pkis.
pso List the Password Settings Objects.
sccm List servers related to SCCM infrastructure (Primary/Secondary Sites and Distribution Points).
shadow_principals List the shadow principals and the groups associated with.
silos List the silos configured in the Active Directory.
smsa List the smsa accounts and the machines they are associated with.
subnets List sites and associated subnets.
templates List certificate templates.
trusts List the domain's trust relationships.
users List users according to a filter.
zones List the DNS zones configured in the Active Directory.
from_guid Return the object associated with the given `guid`.
from_sid Return the object associated with the given `sid`.
laps Return the LAPS passwords. If a target is specified, only retrieve the LAPS password for this one.
memberships List the group for which `account` belongs to.
membersof List the members of `group`.
object Return the records containing `object` in a CN.
sddl Returns the SDDL of an object given it's CN.
silo Get information about a specific `silo`.
zone Return the records of a DNS zone.
all Collect and store computers, domain_policy, zones, gpo, groups, ou, users, trusts, pso information
enum_users Anonymously enumerate users with LDAP pings.
search Query the LDAP with `filter` and retrieve ALL or `attributes` if specified.
whoami Return user identity.
add_to_group Add `user` to `group`.
change_uac Change user account control
create_computer Create a computer account
create_user Create a user account
modify_password Change `user`'s password.
remove_from_group Remove `user` from `group`.
unlock Unlock `user`.
-----
CACHE
-----
::
$ ldeep cache -h
usage: ldeep cache [-h] [-d DIR] -p PREFIX
{auth_policies,bitlockerkeys,computers,conf,delegations,domain_policy,fsmo,gmsa,gpo,groups,machines,ou,pkis,pso,sccm,shadow_principals,silos,smsa,subnets,trusts,users,zones,from_guid,from_sid,laps,memberships,membersof,object,sddl,silo,zone}
...
Cache mode
options:
-h, --help show this help message and exit
-d DIR, --dir DIR Use saved JSON files in specified directory as cache
-p PREFIX, --prefix PREFIX
Prefix of ldeep saved files
commands:
available commands
{auth_policies,bitlockerkeys,computers,conf,delegations,domain_policy,fsmo,gmsa,gpo,groups,machines,ou,pkis,pso,sccm,shadow_principals,silos,smsa,subnets,trusts,users,zones,from_guid,from_sid,laps,memberships,membersof,object,sddl,silo,zone}
auth_policies List the authentication policies configured in the Active Directory.
bitlockerkeys Extract the bitlocker recovery keys.
computers List the computer hostnames and resolve them if --resolve is specify.
conf Dump the configuration partition of the Active Directory.
delegations List accounts configured for any kind of delegation.
domain_policy Return the domain policy.
fsmo List FSMO roles.
gmsa List the gmsa accounts and retrieve NT hash if possible.
gpo Return the list of Group policy objects.
groups List the groups.
machines List the machine accounts.
ou Return the list of organizational units with linked GPO.
pkis List pkis.
pso List the Password Settings Objects.
sccm List servers related to SCCM infrastructure (Primary/Secondary Sites and Distribution Points).
shadow_principals List the shadow principals and the groups associated with.
silos List the silos configured in the Active Directory.
smsa List the smsa accounts and the machines they are associated with.
subnets List sites and associated subnets.
trusts List the domain's trust relationships.
users List users according to a filter.
zones List the DNS zones configured in the Active Directory.
from_guid Return the object associated with the given `guid`.
from_sid Return the object associated with the given `sid`.
laps Return the LAPS passwords. If a target is specified, only retrieve the LAPS password for this one.
memberships List the group for which `account` belongs to.
membersof List the members of `group`.
object Return the records containing `object` in a CN.
sddl Returns the SDDL of an object given it's CN.
silo Get information about a specific `silo`.
zone Return the records of a DNS zone.
==============
Usage examples
==============
Listing users without verbosity::
$ ldeep ldap -u Administrator -p 'password' -d winlab.local -s ldap://10.0.0.1 users
userspn2
userspn1
gobobo
test
krbtgt
DefaultAccount
Guest
Administrator
Listing users with reversible password encryption enable and with verbosity::
$ ldeep ldap -u Administrator -p 'password' -d winlab.local -s ldap://10.0.0.1 users reversible -v
[
{
"accountExpires": "9999-12-31T23:59:59.999999",
"badPasswordTime": "1601-01-01T00:00:00+00:00",
"badPwdCount": 0,
"cn": "User SPN1",
"codePage": 0,
"countryCode": 0,
"dSCorePropagationData": [
"1601-01-01T00:00:00+00:00"
],
"displayName": "User SPN1",
"distinguishedName": "CN=User SPN1,CN=Users,DC=winlab,DC=local",
"dn": "CN=User SPN1,CN=Users,DC=winlab,DC=local",
"givenName": "User",
"instanceType": 4,
"lastLogoff": "1601-01-01T00:00:00+00:00",
"lastLogon": "1601-01-01T00:00:00+00:00",
"logonCount": 0,
"msDS-SupportedEncryptionTypes": 0,
"name": "User SPN1",
"objectCategory": "CN=Person,CN=Schema,CN=Configuration,DC=winlab,DC=local",
"objectClass": [
"top",
"person",
"organizationalPerson",
"user"
],
"objectGUID": "{593cb08f-3cc5-431a-b3d7-9fbad4511b1e}",
"objectSid": "S-1-5-21-3640577749-2924176383-3866485758-1112",
"primaryGroupID": 513,
"pwdLastSet": "2018-10-13T12:19:30.099674+00:00",
"sAMAccountName": "userspn1",
"sAMAccountType": "SAM_GROUP_OBJECT | SAM_NON_SECURITY_GROUP_OBJECT | SAM_ALIAS_OBJECT | SAM_NON_SECURITY_ALIAS_OBJECT | SAM_USER_OBJECT | SAM_NORMAL_USER_ACCOUNT | SAM_MACHINE_ACCOUNT | SAM_TRUST_ACCOUNT | SAM_ACCOUNT_TYPE_MAX",
"servicePrincipalName": [
"HOST/blah"
],
"sn": "SPN1",
"uSNChanged": 115207,
"uSNCreated": 24598,
"userAccountControl": "ENCRYPTED_TEXT_PWD_ALLOWED | NORMAL_ACCOUNT | DONT_REQ_PREAUTH",
"userPrincipalName": "userspn1@winlab.local",
"whenChanged": "2018-10-22T18:04:43+00:00",
"whenCreated": "2018-10-13T12:19:30+00:00"
}
]
Listing GPOs::
$ ldeep -u Administrator -p 'password' -d winlab.local -s ldap://10.0.0.1 gpo
{6AC1786C-016F-11D2-945F-00C04fB984F9}: Default Domain Controllers Policy
{31B2F340-016D-11D2-945F-00C04FB984F9}: Default Domain Policy
Getting all things::
$ ldeep ldap -u Administrator -p 'password' -d winlab.local -s ldap://10.0.0.1 all /tmp/winlab.local_dump
[+] Retrieving computers output
[+] Retrieving domain_policy output
[+] Retrieving gpo output
[+] Retrieving groups output
[+] Retrieving groups verbose output
[+] Retrieving ou output
[+] Retrieving pso output
[+] Retrieving trusts output
[+] Retrieving users output
[+] Retrieving users verbose output
[+] Retrieving zones output
[+] Retrieving zones verbose output
Using this last command line switch, you have persistent output in both verbose and non-verbose mode saved::
$ ls winlab.local_dump_*
winlab.local_dump_computers.lst winlab.local_dump_groups.json winlab.local_dump_pso.lst winlab.local_dump_users.lst
winlab.local_dump_domain_policy.lst winlab.local_dump_groups.lst winlab.local_dump_trusts.lst winlab.local_dump_zones.json
winlab.local_dump_gpo.lst winlab.local_dump_ou.lst winlab.local_dump_users.json winlab.local_dump_zones.lst
The the cache mode can be used to query some other information.
--------------------------
Usage with Kerberos config
--------------------------
For Kerberos, you will also need to configure the ``/etc/krb5.conf``.::
[realms]
CORP.LOCAL = {
kdc = DC01.CORP.LOCAL
}
========
Upcoming
========
* Proper DNS zone enumeration
* ADCS enumeration
* Project tree
* Any ideas?
================
Related projects
================
* https://github.com/fortra/impacket
* https://github.com/ropnop/windapsearch
* https://github.com/shellster/LDAPPER
| text/x-rst | null | b0z <bastien@faure.io>, flgy <florian.guilbert@synacktiv.com> | null | null | MIT | pentesting security windows active-directory networks | [
"Development Status :: 4 - Beta",
"Intended Audience :: Information Technology",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.8",
"Topic :: Security"... | [] | null | null | <3.15,>=3.9 | [] | [] | [] | [
"commandparse<2,>=1.1.1",
"cryptography>=42.0.7",
"dnspython>=1.15.0",
"gssapi<2,>=1.8.0",
"ldap3-bleeding-edge==2.10.1.1337",
"oscrypto<2,>=1.3.0",
"pycryptodome<4,>=3.19.0",
"pycryptodomex<4,>=3.19.0",
"six<2,>=1.16.0",
"termcolor>3",
"tqdm<5,>=4.26.0"
] | [] | [] | [] | [
"Homepage, https://github.com/franc-pentest/ldeep"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:30:55.547174 | ldeep-2.0.0.tar.gz | 55,346 | a0/e6/3da498f6a5b0ada48ef16602cc5bafbea1e43992d7c4c64aa2d167e3cbd0/ldeep-2.0.0.tar.gz | source | sdist | null | false | d6c30addd4ad138ef51ffce713beafd1 | 2adea5d3268b6cfc4edeeb415d4720525b92d8ca574aed9bf4925790080bd88d | a0e63da498f6a5b0ada48ef16602cc5bafbea1e43992d7c4c64aa2d167e3cbd0 | null | [] | 288 |
2.4 | agglovar | 0.0.1.dev12 | Toolkit for fast genomic variant transformations and intersects | # Agglovar toolkit for fast genomic variant transformations and intersects
Agglovar is a fast toolkit based on Polars to perform fast variant transformations and intersections between
callsets. It defines a standard schema for genomic variants based on Apache Arrow, which Polars uses natively. Whenever
possible, Aggolvar uses Parquet files to store data allowing it to preserve the schema and take advantage of both
columnar storage and pushdown optimizations for fast queries and transformations.
Agglovar replaces variant intersections in the SV-Pop library (https://github.com/EichlerLab/svpop).
The name Agglovar is a portmanteau of the latin word "agglomerare" (to gather) and "variant" (genomic variants).
## Alpha release
Agglovar is under active development and a stable release is not yet available.
## Documentation
Documentation for Agglovar can be found at:
https://agglovar.readthedocs.io/en/latest
## Installation
```
pip install agglovar
```
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"biopython>=1.85",
"edlib>=1.3.9.post1",
"intervaltree>=3.1.0",
"numpy>=2.3.0",
"ply>=3.11",
"polars[numpy,pandas,pyarrow]>=1.35.2",
"matplotlib>=3.10.3; extra == \"plot\"",
"agglovar[plot]; extra == \"all\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.7 | 2026-02-19T02:30:55.305253 | agglovar-0.0.1.dev12.tar.gz | 77,677 | 09/05/9982a1143111107aec9df3cbaced82dabdea7016ae75a3aeb3eeb9edb557/agglovar-0.0.1.dev12.tar.gz | source | sdist | null | false | 4fd040d76a33aa350bfcf7920ea842b0 | 62ed8ee36a2cc8099aab29130e958ad5d11c773540186f8d6637e98dd87c73f1 | 09059982a1143111107aec9df3cbaced82dabdea7016ae75a3aeb3eeb9edb557 | MIT | [
"LICENSE"
] | 282 |
2.1 | segmentation-skeleton-metrics | 5.6.21 | Python package for evaluating neuron segmentations in terms of the number of splits and merges | # SkeletonMetrics
[](LICENSE)

[](https://github.com/semantic-release/semantic-release)
Python package that evaluates the topological accuracy of a predicted neuron segmentation by comparing it to a set of ground truth skeletons (i.e. graphs). Topological errors (e.g. splits and merges) are detected by examining skeleton edges and checking if the corresponding nodes belong to the same object in the segmentation. Once the accuracy of each edge has been determined, several skeleton-based metrics are computed to quantify the topological accuracy.
<b> Note: </b> This repository is an implementation of the skeleton-based metrics described in [High-Precision Automated Reconstruction of Neurons with Flood-filling Networks](https://www.biorxiv.org/content/10.1101/200675v1.full.pdf)
## Overview
The pipeline for computing skeleton metrics consists of three main steps:
<blockquote>
<p>1. <strong>Label Graphs</strong>: Nodes in ground truth graphs are labeled with segmentation IDs.</p>
<p>2. <strong>Error Detection</strong>: Compare labels of neighboring nodes to detect mistakes.</p>
<p>3. <strong>Compute Metrics</strong>: Update graph structure by removing omit nodes and compute skeleton-based metrics.</p>
</blockquote>
<br>
<p>
<img src="imgs/pipeline.png" width="750" alt="pipeline">
<br>
<b> Figure:</b> Visualization of skeleton metric computation pipeline, see Method section for description of each step.
</p>
## Method
### Step 1: Label Graphs
The process starts with a collection of ground truth graphs, each stored as an individual SWC file, where the "xyz" attribute represents voxel coordinates in an image. Each ground truth graph is loaded and represented as a custom NetworkX graph with these coordinates as a node-level attribute. The nodes of each graph are then labeled with their corresponding segment IDs from the predicted segmentation.
<p>
<img src="imgs/labeled_graph.png" width="800">
<br>
<b>Figure:</b> On the left, ground truth graphs are superimposed on a segmentation where colors represent segment IDs. On the right, the nodes of the graphs have been labeled with the corresponding segment IDs.</b>
</p>
### Step 2: Error Detection
<p>
<img src="imgs/mistakes.png" width="625" alt="Topological mistakes detected in skeleton">
<br>
<b> Figure: </b> From top to bottom: correct edge (nodes have same segment ID), omit edge (at least one node does not have a segment ID), split edge (nodes have different segment IDs), merged edge (segment intersects with multiple graphs).
</p>
### Step 3: Compute Metrics
Lastly, we compute the following skeleton-based metrics:
- *\# Splits*: Number of connected components (minus 1) in a graph after removing omit and split edges.
- *\# Merges*: Number of merge mistakes.
- *\% Split Edges*: Percentage of split edges.
- *\% Omit Edges*: Percentage of omit edges.
- *\% Merged Edges*: Percentage of merged edges.
- *Expected Run Length (ERL)*: Expected run length of graph after removing omit, split, and merged edges.
- *Normalized ERL*: ERL normalized by the total run length of the graph.
- *Edge Accuracy*: Percentage of edges that are correct.
- *Split Rate*: Run length of the graph divided by number of splits.
- *Merge Rate*: Run length of the graph divided by number of merges.
## Installation
To use the software, in the root directory, run
```bash
pip install -e .
```
## Usage
Here is a simple example of evaluating a predicted segmentation.
```python
from segmentation_skeleton_metrics.evaluate import evaluate
from segmentation_skeleton_metrics.utils.img_util import TiffReader
# Initializations
output_dir = "./"
segmentation_path = "path-to-predicted-segmentation"
fragments_pointer = "path-to-predicted-skeletons"
groundtruth_pointer = "path-to-groundtruth-skeletons"
# Run
segmentation = TiffReader(segmentation_path)
evaluate(
groundtruth_pointer,
segmentation,
output_dir,
fragments_pointer=fragments_pointer,
)
```
<p>
<img src="imgs/printouts.png" width=800">
<br>
<b>Figure:</b> Example of printouts generated after running evaluation.
</p>
<br>
Note: this package can also be used to evaluate a segmentation in which split mistakes have been corrected.
## Contact Information
For any inquiries, feedback, or contributions, please do not hesitate to contact us. You can reach us via email at anna.grim@alleninstitute.org or connect on [LinkedIn](https://www.linkedin.com/in/anna-m-grim/).
## License
segmentation-skeleton-metrics is licensed under the MIT License.
| text/markdown | null | Anna Grim <anna.grim@alleninstitute.org> | null | null | MIT | null | [
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"boto3",
"google-cloud-storage",
"networkx",
"numpy",
"pandas",
"s3fs",
"scikit-image",
"tensorstore",
"tifffile",
"black; extra == \"dev\"",
"coverage; extra == \"dev\"",
"flake8; extra == \"dev\"",
"interrogate; extra == \"dev\"",
"isort; extra == \"dev\"",
"Sphinx; extra == \"dev\"",
... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:30:44.603695 | segmentation_skeleton_metrics-5.6.21.tar.gz | 727,512 | 11/88/9bc28e848af143e00c306c1103557aa5b81109c8dbf4a2f3cc32d3a5f261/segmentation_skeleton_metrics-5.6.21.tar.gz | source | sdist | null | false | d8e8c7da8a8bf9e6304a24cc55ec3e9a | 3dad6533ad1e961dbd8d6ad84a36a1c6a57b209f80cd03315328749e69ac2338 | 11889bc28e848af143e00c306c1103557aa5b81109c8dbf4a2f3cc32d3a5f261 | null | [] | 288 |
2.4 | llmtracer-sdk | 2.0.9 | Auto-track LLM cost, latency, and usage. Two lines of code, every provider. | # LLM Tracer — Python SDK
Track cost, latency, and token usage across OpenAI, Anthropic, and Google Gemini — in one line of code.

## Install
```bash
pip install llmtracer-sdk
```
## Quick Start
```python
import llmtracer
llmtracer.init(api_key="lt_...")
# That's it. All OpenAI, Anthropic, and Google Gemini calls are now tracked automatically.
```
No wrappers, no callbacks, no code changes. The SDK auto-patches your provider clients at import time.
View your dashboard at [llmtracer.dev](https://llmtracer.dev).
## What Gets Captured
Every LLM call is automatically tracked with:
- **Provider, model, tokens** (input + output), latency, cost
- **Google Gemini**: thinking tokens (2.5 models), tool tokens, cached tokens
- **Anthropic**: cache creation + read tokens
- **OpenAI**: reasoning tokens (o1/o3/o4), cached tokens
- **Caller file, function, and line number**
- **Auto-flush on process exit** (no manual flush needed)
## Environment Variable Pattern
```python
import os
import llmtracer
llmtracer.init(
api_key=os.environ["LLMTRACER_API_KEY"],
debug=True, # prints token counts to console
)
```
## Trace Context and Tags
```python
with llmtracer.trace(tags={"feature": "chat", "user_id": "u_sarah"}):
response = client.chat.completions.create(...)
```
Tags appear in the dashboard's Breakdown page and Top Tags card. Use them to answer questions like "which user costs the most?" or "which feature should I optimize?"
### Tagging Patterns
| Pattern | Tag | Example |
|---------|-----|---------|
| Track cost by feature | `feature` | `"chat"`, `"search"`, `"summarize"` |
| Track cost by user | `user_id` | `"u_sarah"`, `"u_mike"` |
| Track cost by customer (B2B) | `customer` | `"acme-corp"`, `"initech"` |
| Track cost by conversation | `conversation_id` | `"conv_abc123"` |
| Track environment | `env` | `"production"`, `"staging"` |
## Supported Providers
| Provider | Package | Auto-patched |
|----------|---------|-------------|
| OpenAI | `openai` | ✅ |
| Anthropic | `anthropic` | ✅ |
| Google Gemini | `google-genai` | ✅ |
## LangChain Support
If you use LangChain with `ChatOpenAI`, `ChatAnthropic`, or `ChatGoogleGenerativeAI`, the underlying SDK calls are auto-captured. No callback handler needed — just `llmtracer.init()` and you're done.
## Debug Mode
Enable `debug=True` to print token counts to the console:
```python
llmtracer.init(api_key="lt_...", debug=True)
```
```
[llmtracer] openai gpt-4o | 1,247 in → 384 out | $0.0094 | 1.2s
[llmtracer] anthropic claude-sonnet-4-5 | 2,100 in → 512 out (cache_read: 1,800) | $0.0031 | 0.8s
[llmtracer] google gemini-2.5-pro | 900 in → 280 out (thinking: 1,420) | $0.0067 | 2.1s
```
## Requirements
- Python 3.8+
- Works with any version of `openai`, `anthropic`, or `google-genai` SDKs
## Zero Dependencies
The core SDK uses only Python stdlib (`urllib.request`, `threading`, `hashlib`).
## License
MIT
| text/markdown | null | LLM Tracer <hello@llmtracer.dev> | null | null | MIT | llm, observability, cost-tracking, openai, anthropic, tracing | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"openai>=1.0.1; extra == \"openai\"",
"anthropic>=0.20.0; extra == \"anthropic\"",
"openai>=1.0.1; extra == \"all\"",
"anthropic>=0.20.0; extra == \"all\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://llmtracer.dev",
"Documentation, https://llmtracer.dev/docs",
"Repository, https://github.com/llmtracer/llmtracer-python"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T02:29:51.005631 | llmtracer_sdk-2.0.9.tar.gz | 24,487 | 95/06/8d7183a5c19cae4fba4bc8a76f9b647f04cdebf368fa0a1e1bb9479bf63c/llmtracer_sdk-2.0.9.tar.gz | source | sdist | null | false | c3dd934f42b1197623b203807f71ef49 | 7afbaea127b5f4e613486b4fdbbb26c6c78fcfbc114698daf0faa51a15658a8b | 95068d7183a5c19cae4fba4bc8a76f9b647f04cdebf368fa0a1e1bb9479bf63c | null | [] | 280 |
2.4 | twa | 0.0.10 | twa is a Python wrapper for TheWorldAvatar project. | # TheWorldAvatar (twa)
`twa` is a Python wrapper for [TheWorldAvatar](https://github.com/cambridge-cares/TheWorldAvatar) project. It expands on the TWA's Java functions with Python-native capabilities.
## What is `twa`
The code is heavily based on the [py4j](https://www.py4j.org/index.html) package, which enables Python programs running in a Python interpreter to dynamically access Java objects in a Java Virtual Machine. It has a precedent python package, `py4jps`, which is now deprecated.
To get started, see the [Quick start](#quick-start) below or follow our [tutorial](https://github.com/cambridge-cares/TheWorldAvatar/tree/main/JPS_BASE_LIB/python_wrapper/docs/tutorial/).
## Installation
To install `twa`, use the following command:
```pip install twa```
You also need to install a Java Runtime Environment version 11:
- **[Recommended]** If you are using Linux (or Windows Subsystem for Linux): ```apt install openjdk-11-jdk-headless```
- If you are using Windows machine: please follow the tutorial [here](https://learn.microsoft.com/en-us/java/openjdk/install)
## Quick start
```python
from __future__ import annotations
###############################################
# Spin up a docker container for triple store #
###############################################
import docker
# Connect to Docker using the default socket or the configuration in your environment:
client = docker.from_env()
# Run Blazegraph container
# It returns a Container object that we will need later for stopping it
blazegraph = client.containers.run(
'ghcr.io/cambridge-cares/blazegraph:1.1.0',
ports={'8080/tcp': 9999}, # this binds the internal port 8080/tcp to the external port 9998
detach=True # this runs the container in the background
)
#############################
# Instantiate sparql client #
#############################
from twa.kg_operations import PySparqlClient
# Define the SPARQL endpoint URL for the Blazegraph instance
sparql_endpoint = 'http://localhost:9999/blazegraph/namespace/kb/sparql'
# Create a SPARQL client to interact with the Blazegraph endpoint
sparql_client = PySparqlClient(sparql_endpoint, sparql_endpoint)
################################################
# Upload an ontology from an internet location #
################################################
# Example: Upload the PROV ontology from the web
prov_ttl = 'https://www.w3.org/ns/prov.ttl'
from rdflib import Graph
# Parse the ontology and upload it to the triple store
sparql_client.upload_graph(Graph().parse(prov_ttl))
########################
# Perform some queries #
########################
# Example query: Retrieve subclasses of prov:Agent
results = sparql_client.perform_query(
"""
prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
prefix prov: <http://www.w3.org/ns/prov#>
select *
where {?agent rdfs:subClassOf prov:Agent}
"""
)
print(results)
# Expected output:
# > [{'agent': 'http://www.w3.org/ns/prov#Organization'},
# > {'agent': 'http://www.w3.org/ns/prov#Person'},
# > {'agent': 'http://www.w3.org/ns/prov#SoftwareAgent'}]
#########################
# Create a new ontology #
#########################
from twa.data_model.base_ontology import BaseOntology, BaseClass, TransitiveProperty, ObjectProperty, DatatypeProperty
from twa.data_model.iris import TWA_BASE_URL
from typing import ClassVar, Optional
# Define a minimal agent ontology
class MinimalAgentOntology(BaseOntology):
base_url: ClassVar[str] = TWA_BASE_URL
namespace: ClassVar[str] = 'mao'
owl_versionInfo: ClassVar[str] = '0.0.1'
rdfs_comment: ClassVar[str] = 'A minimal agent ontology'
# Define classes and properties for the ontology
class Agent(BaseClass):
rdfs_isDefinedBy = MinimalAgentOntology
name: Name[str]
hasGoal: HasGoal[Goal]
# Like native Pydantic, you can define optional fields (properties)
actedOnBehalfOf: Optional[ActedOnBehalfOf[Agent]] = None
class Goal(BaseClass):
rdfs_isDefinedBy = MinimalAgentOntology
priority: Priority[str]
Name = DatatypeProperty.create_from_base('Name', MinimalAgentOntology, 1, 1)
"""
This is equivalent to:
class Name(DatatypeProperty):
rdfs_isDefinedBy = MinimalAgentOntology
owl_minQualifiedCardinality = 1
owl_maxQualifiedCardinality = 1
"""
Priority = DatatypeProperty.create_from_base('Priority', MinimalAgentOntology, 1, 1)
HasGoal = ObjectProperty.create_from_base('HasGoal', MinimalAgentOntology)
# Another way of defining properties
class ActedOnBehalfOf(TransitiveProperty):
rdfs_isDefinedBy = MinimalAgentOntology
#######################################
# Export the TBox to the triple store #
#######################################
# Export the ontology definition (TBox) to the triple store
MinimalAgentOntology.export_to_triple_store(sparql_client)
####################################
# Instantiate some objects as ABox #
####################################
# Create instances (ABox) of the ontology classes
machine_goal = Goal(
rdfs_comment='continued survival',
priority='High'
)
machine = Agent(
name='machine',
hasGoal=machine_goal
)
smith_goal = Goal(
rdfs_comment='keep the system in order',
priority='High'
)
agent_smith = Agent(
name='smith',
actedOnBehalfOf=machine,
hasGoal=smith_goal
)
# Push the instances to the knowledge graph
agent_smith.push_to_kg(sparql_client, -1)
########################
# Perform some queries #
########################
# Retrieve all instances of the Agent class from the knowledge graph
agents = Agent.pull_all_instances_from_kg(sparql_client, -1)
# Once the objects are pulled, the developer can access information in a Python-native format
# Example: Print out the goals of each agent
for agent in agents:
print(f'agent {agent.name} has goal: {agent.hasGoal}')
# Expected output:
# > agent {'smith'} has goal: {Goal(rdfs_comment='keep the system in order', ...)}
# > agent {'machine'} has goal: {Goal(rdfs_comment='continued survival', ...)}
```
## Documentation
The documentation for `twa` can be found [here](https://cambridge-cares.github.io/TheWorldAvatar/).
## Issues? Feature requests?
Submit an [issue](https://github.com/cambridge-cares/TheWorldAvatar/issues) with a label `python-wrapper`.
## Author
- Jiaru Bai (jb2197@cantab.ac.uk)
- Daniel Nurkowski
## Citation
If you found this tool useful, please consider citing the following preprint:
```bibtex
@article{bai2025twa,
title={{twa: The World Avatar Python package for dynamic knowledge graphs and its application in reticular chemistry}},
author={Bai, Jiaru and Rihm, Simon D and Kondinski, Aleksandar and Saluz, Fabio and Deng, Xinhong and Brownbridge, George and Mosbach, Sebastian and Akroyd, Jethro and Kraft, Markus},
year={2025},
note={Preprint at \url{https://como.ceb.cam.ac.uk/preprints/335/}}
}
```
| text/markdown | Jiaru Bai; Daniel Nurkowski | jb2197@cam.ac.uk; danieln@cmclinnovations.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10"
] | [] | https://github.com/cambridge-cares/TheWorldAvatar/tree/main/JPS_BASE_LIB/python_wrapper | null | >=3.8 | [] | [] | [] | [
"py4j>=0.10.9.1",
"docopt",
"concurrent_log_handler",
"pydantic",
"rdflib==7.0.0",
"requests",
"flask",
"gunicorn==20.0.4",
"Flask-APScheduler",
"python-dotenv",
"yagmail",
"Werkzeug",
"importlib_resources>=5.10"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.10.12 | 2026-02-19T02:29:32.533892 | twa-0.0.10.tar.gz | 59,972,817 | 7f/d3/d421ffcffbc70fafce7f33b9d0e2a392b441d1e18e8c65019a99102b92d7/twa-0.0.10.tar.gz | source | sdist | null | false | df430304ca9f2390815ead560c28125e | f0bb7b80670be4b43c3166eb370abd8357b4c51ef894853016c4ee804eeb983f | 7fd3d421ffcffbc70fafce7f33b9d0e2a392b441d1e18e8c65019a99102b92d7 | null | [
"LICENSE"
] | 290 |
2.4 | opensandbox-sdk | 0.2.0 | Python SDK for OpenSandbox - E2B-compatible sandbox platform | # opensandbox-sdk
Python SDK for [OpenSandbox](https://github.com/diggerhq/opensandbox) — an open-source, E2B-compatible sandbox platform.
## Install
```bash
pip install opensandbox-sdk
```
## Quick Start
```python
import asyncio
from opensandbox import Sandbox
async def main():
sandbox = await Sandbox.create(template="base")
# Execute commands
result = await sandbox.commands.run("echo hello")
print(result.stdout) # "hello\n"
# Read and write files
await sandbox.files.write("/tmp/test.txt", "Hello, world!")
content = await sandbox.files.read("/tmp/test.txt")
# Clean up
await sandbox.kill()
await sandbox.close()
asyncio.run(main())
```
## Configuration
| Parameter | Env Variable | Default |
|------------|------------------------|-------------------------|
| `api_url` | `OPENSANDBOX_API_URL` | `https://app.opensandbox.ai` |
| `api_key` | `OPENSANDBOX_API_KEY` | (none) |
## License
MIT
| text/markdown | OpenSandbox | null | null | null | null | cloud, code-execution, containers, e2b, opensandbox, sandbox | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: ... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27.0",
"websockets>=12.0",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/diggerhq/opensandbox",
"Repository, https://github.com/diggerhq/opensandbox",
"Documentation, https://github.com/diggerhq/opensandbox/tree/main/sdks/python",
"Issues, https://github.com/diggerhq/opensandbox/issues"
] | uv/0.9.25 {"installer":{"name":"uv","version":"0.9.25","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T02:27:46.406106 | opensandbox_sdk-0.2.0-py3-none-any.whl | 7,159 | 1d/76/a90bff980f864ba206fd3a63042dfa22298c4da813b4cffda1ecb8e41e86/opensandbox_sdk-0.2.0-py3-none-any.whl | py3 | bdist_wheel | null | false | cbb11b85384b255f1c9dd83a05cd73b5 | ccc46b8e63458b212ea3bd1a87e4b21d1aaf7055ea2b7793331ffc1d72151cd5 | 1d76a90bff980f864ba206fd3a63042dfa22298c4da813b4cffda1ecb8e41e86 | MIT | [] | 269 |
2.4 | rat-king-parser | 4.2.3 | A robust, multiprocessing-capable, multi-family RAT config parser/config extractor for AsyncRAT, DcRAT, VenomRAT, QuasarRAT, XWorm, Xeno RAT, and cloned/derivative RAT families. | 
# The RAT King Parser
A robust, multiprocessing-capable, multi-family RAT config parser/extractor, tested for use with:
- AsyncRAT
- DcRAT
- VenomRAT
- QuasarRAT
- XWorm
- XenoRat
- Other cloned/derivative RAT families of the above
This configuration parser seeks to be "robust" in that it does not require the user to know anything about the strain or configuration of the RAT ahead of time:
It looks for common configuration patterns present in the above-mentioned RAT families (as well as several clones and derivatives), parses and decrypts the configuration section, using brute-force if simpler patterns are not found, and uses YARA to suggest a possible family for the payload.
The original (much less robust) version of this parser is detailed in the accompanying YouTube code overview video here:
- https://www.youtube.com/watch?v=yoz44QKe_2o
and based on the original AsyncRAT config parser and tutorial here:
- https://github.com/jeFF0Falltrades/Tutorials/tree/master/asyncrat_config_parser
## Usage
### Installation
As of `v3.1.2`, the RAT King Parser is now available on PyPI and can be installed via `pip`:
```bash
pip install rat-king-parser
```
Note that YARA must be [installed separately](https://yara.readthedocs.io/en/stable/gettingstarted.html#compiling-and-installing-yara).
### Usage Help
```
$ rat-king-parser -h
usage: rat-king-parser [-h] [-v] [-d] [-n] [-p] [-r] [-y YARA] file_paths [file_paths ...]
positional arguments:
file_paths One or more RAT payload file paths
options:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-d, --debug Enable debug logging
-n, --normalize Attempt to translate common variations of config keys to normalized field names
-p, --preserve-keys Preserve potentially obfuscated configuration keys as-is instead of replacing them with placeholder "obfuscated key" entries
-r, --recompile Recompile the YARA rule file used for family detection prior to running the parser
-y, --yara YARA Uses the *compiled* yara rule at this path to determine the potential family of each payload (uses a prepackaged rule at rules.yarc by default)
```
### Using YARA for Payload Identification
A [YARA](https://yara.readthedocs.io/en/latest/) rule for RAT family identification is included with this script in `yara_utils` in both raw and compiled forms.
However, using the `--yara` flag allows a user to specify their own custom YARA rule (in compiled form) to use for identification as well.
If you encounter errors using the included compiled YARA rule (which most often occur due to mismatched YARA versions), the included rule can be recompiled using your local YARA version by specifying the `--recompile` flag.
`yara_utils/recompile.py`, which is the script invoked by the `--recompile` flag, can also be executed on its own to (re)compile any YARA rule:
```
$ python yara_utils/recompile.py -h
usage: recompile.py [-h] [-i INPUT] [-o OUTPUT]
options:
-h, --help show this help message and exit
-i INPUT, --input INPUT
YARA rule to compile
-o OUTPUT, --output OUTPUT
Compiled rule output path
```
```bash
python recompile.py -i my_rule.yar -o my_rule.yarc
```
### External Integrations
As of `v3.1.0`, RAT King Parser has introduced additional, optional wrapper extractors for integration with some external services.
These currently include:
- [MACO](https://github.com/CybercentreCanada/Maco): The Canadian Centre for Cyber Security's malware config extractor framework, which allows RAT King Parser to be integrated with MACO-compatible tools like [AssemblyLine](https://github.com/CybercentreCanada/assemblyline) (though RAT King Parser is already integrated in AssemblyLine's configuration extraction service without need for further configuration)
In order to utilize these extractors, the optional dependencies for a particular extractor must be installed.
This can be completed with `pip` by referencing the specific optional dependency group to install; For example:
```bash
pip install "rat_king_parser[maco] @ git+https://github.com/jeFF0Falltrades/rat_king_parser.git"
```
## Example Input/Output
### Not Preserving Obfuscated Keys
```bash
$ rat-king-parser -n dangerzone/* | jq
```
```json
[
{
"file_path": "dangerzone/034941c1ea1b1ae32a653aab6371f760dfc4fc43db7c7bf07ac10fc9e98c849e",
"sha256": "034941c1ea1b1ae32a653aab6371f760dfc4fc43db7c7bf07ac10fc9e98c849e",
"yara_possible_family": "dcrat",
"key": "3915b12d862a41cce3da2e11ca8cefc26116d0741c23c0748618add80ee31a5c",
"salt": "4463526174427971777164616e6368756e",
"config": {
"Ports": [
"2525"
],
"Hosts": [
"20.200.63.2"
],
"Version": " 1.0.7",
"Install": "false",
"InstallFolder": "%AppData%",
"InstallFile": "",
"Key": "dU81ekM1S2pQYmVOWWhQcjV4WlJwcWRkSnVYR2tTQ0w=",
"Mutex": "DcRatMutex_qwqdanchun",
"Certificate": "MIICMDCCAZmgAwIBAgIVANpXtGwt9qBbU/pdFz8d/Pt6kzb7MA0GCSqGSIb3DQEBDQUAMGQxFTATBgNVBAMMDERjUmF0IFNlcnZlcjETMBEGA1UECwwKcXdxZGFuY2h1bjEcMBoGA1UECgwTRGNSYXQgQnkgcXdxZGFuY2h1bjELMAkGA1UEBwwCU0gxCzAJBgNVBAYTAkNOMB4XDTIxMDIxNzA5MjAzM1oXDTMxMTEyNzA5MjAzM1owEDEOMAwGA1UEAwwFRGNSYXQwgZ8wDQYJKoZIhvcNAQEBBQADgY0AMIGJAoGBAKt8nE3x/0XYeyDBrDPxdpVH1EMWSVyndAkdVChKaWQFOAAs4r/UeTmw8POG3jUz/XczWBWJt9Vu4Vl0HJN3ZmRIMr75FDGyieel0Vb8sn0hZcABsNr8dbbzfi+eoocVAyZKd79S0mOUinl4PBhldyUJCvanCnguHux8c2F5vnQlAgMBAAGjMjAwMB0GA1UdDgQWBBRjACzYO/EcXaKzlTz8Oq34J5Zq8DAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBDQUAA4GBACA8urqJU44+IpPcx9i0Q0Eu9+qWMPdZ09y+6YdumC6dun1OHn1I5F03YqYCfCdq0l3XpszJlYYzPnPB4ThOfiKUwJ1HJWS2lgWKfd+CdSWCch0c2dEE1Pao+xyNcNpuphBraHZYc4ojekgeQ8MSdHVo/YCYpmaJbxFWDhFgr3Lh",
"Serversignature": "c+KGE0Aw1XRgjGe2Kvay1H3VgUgqKRYGit46DnCR6eW/g+kO+H5oRsfBNkVizj0Q862zTXvLkWZ+ON84bmYhBy3o5YQOPaPyAIXha4ByY150rYRXKkzBR47RkTx616bLYUhqO+PqqNOii9THobbo3zAtwjxEoEWr8s0MLGm2AfE=",
"Pastebin": "null",
"BSOD": "false",
"Hwid": "null",
"Delay": "1",
"Group": "16JUNIO-PJOAO",
"AntiProcess": "false",
"Anti": "false"
}
},
{
"file_path": "dangerzone/0aa7bfb081e73a67c23715a55ff13a74ef6b1ce2b82a33b5537ee001592919a4",
"sha256": "0aa7bfb081e73a67c23715a55ff13a74ef6b1ce2b82a33b5537ee001592919a4",
"yara_possible_family": "asyncrat",
"key": "564eced38c73ee8089d8bcc951f28c0589a54388a4058b0da1d9c4d94514518f",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"TelegramToken": "7153134069:AAHd4riTPdhAdVGBwo16vJQ5H3eORu5QAEo",
"TelegramChatID": "1863892139",
"Ports": [
"6606",
"7707",
"8808"
],
"Hosts": [
"127.0.0.1"
],
"Version": "",
"Install": "false",
"InstallFolder": "%AppData%",
"InstallFile": "",
"Key": "Uk9tU0hKZUlVdXBwek1tV3NqYnBLYVRYcklWQXB5c0I=",
"Mutex": "AsyncMutex_6SI8OkPnk",
"Certificate": "MIIE9jCCAt6gAwIBAgIQAKQXqY8ZdB/modqi69mWGTANBgkqhkiG9w0BAQ0FADAcMRowGAYDVQQDDBFXb3JsZFdpbmQgU3RlYWxlcjAgFw0yMTA3MTMwNDUxMDZaGA85OTk5MTIzMTIzNTk1OVowHDEaMBgGA1UEAwwRV29ybGRXaW5kIFN0ZWFsZXIwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCnRXYoxuLqqgXdcvIAYWb9DuVRl5ZpdpPfoIgmb7Y9A9AuiddKNm4is8EvIlEh98bQD4OBaK0EGWuj7WuAcQPCCGuzHpDqFZbXR7iRqVn6TiLRsO0LCMB4ta4XLQ4JdTFXvnQHcGiUxHddH70T/2P2bBVY0W+PVJDzG3XUWHpYb4PVv7qaQr/DalR3qyyd5otzE1kIjJLCOCyI/9ntIcD/PbMTKVnCP4fzbnkNB+xy0PmQmx3WRWEF5q72TdgaKrCbOpR2C/+rfGIoPC6Ze6dqWO3bQLGt6jpCO8A4CtAaAYmiw1vHUOfP54BgI9ls1TjYO3Rn4R1jmhWBGV2pT5chrglgSxMzPhrxFTQljG78RlPCJmyagJbtnPL3AlV34sQggcbf+80FVeyechm/xrMTSWXrJQ+xek1HRJBDFoCJyUR7SuIUelOW24TU+rwl/2dcALLZXpjYu3/zvJjH4iaJXRCt7oWhfzIFG1bHBFr78kV9VP0H+ZNVb129eUr14F/uubAoIPAz2EHG/CXBZv9GkFuzw0NgsI1eP7AznCLdT+z91M+yB7vWtvclwQ5k6MxWDPOraG5JMjUHvKI6zvyZ4IQ2a7bUENDghxLAqIxgo7zfZMdrjbRxBlqW14oki6Um7GpGKEZ0s2Ip6K2yJHBLpbVxOYjyzrxohMguh+qvgQIDAQABozIwMDAdBgNVHQ4EFgQUmTejTtK6on20N0YJez5sAZdMe/kwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQ0FAAOCAgEAhauA0si7sHBd06DSGJgP5vJxL2daW30wR5XbAJd0HWj3QWfl7w27iyZ5AqBT4B0ojLNuMUG8mUOvpcoq0m80qUX7TIKUULKvb+i7uGGEDxk3W5F3es/CTUUWO0QlseWx9QEYziGlp6f3tkP4PTGSL0DywVRSa8l6f/B5kqwnW17CbQfJZ8vmy5snpDO/avgYssUnQtKQPhos7GbokNHps/bxEIRfLeprzQox20dw4RV59LcorjP5QV7Vc6FuYmhzC0nfRetTHckyxg66O3ekfTVs87MLiDV0ipQ+D/6k3g6DRuTdd4V2khjtI56ujSqTQ2PueNQXPu8y2fdsT2Rd1LcfxMS1xKAhSwhHfyy0I3JwzPG1D+sm3QNJEOoJviSNn5fYOFpY+mSEkFNMMeEbwOFdHxWbkiJk/Z8VwdH5I52tkHU3sRQMuZHtcKUc/SIt5Ivv6gtuEZQdm1GE6KUdiRB95s8JVGNlCcHX5bXbScu4eKCRQn3Cl+m5KR4EzI6hVP/iDRhVKj7Dn/blOHLzhNS5vW4X085dTP+1TBL8CHpQpiA3t8LfqfV1b/+WahOd3jNBNTXXfe/AQSjErgctLMdmOBpUQaJLOlcDcKGxWQdOo102nxg8Y/kFDARccywugoQxuIZpMYq74tjnJlJZ9kqR/LPrjmvx4v+0XFsaCPE=",
"Serversignature": "b4TmzraaQMXPVpdfH6wgqDtnXhWP9SP6GdUMgvKSpjPlWufiGM88XWg3Wnv1bduWRMUOAIBN31gAe/SRIhAhdCJU0h6nvqjBUKQsnrg3kT6d2beUtwLDhWWqGa3i9Nta72fkbikM65DIkUwjGtnZy3THx83+doN/+cwe9ZlhKc7TqGF9klOT0nQ9JFUi3Gn6uDzwhA7vicj1WyfM15QxLp0ZvTojgjjFUC2BVkr+mDvuuQ4OR0h4qOgl/AXOYfZwKMfvnwijdP/qqpeG+X73rXZxeDawcTMYqvWH+hOiksgsh2C9V/iN8Sjye/A6rKewmHMUozpakMjP+TjES8kwT70+vJ/uS3ugCZUjT6sOqqLl+LyQyzSpGdVJJQB/fPrYTlWTJwpXdxk8V+eqcdCf/mpeYyQnyGaFVc2whfLAN0r2aPigRQNmsY7Faom/CeNc98zIBf9Nt+KR3FfyFuYabZn5zQcYNAq6D0MVRbKQsU3eyGWN+JI24PQUloheBFJvimpBqMMRVWDLsQq82TpExWJoT47fBrzZj/6LE10vKwl6TNiE81fkglcc93ErbH1KCdXxUaxKVePUIypEaohzXkv88h7P6gjhm2Crey8mUkir408At+5Xl8hQE1ozQN0e5le2gIdxX+oFkTFDrzd65MAdKiZ7rqauNMb4aM+bEeM=",
"Anti": "false",
"Pastebin": "null",
"BDOS": "false",
"Hwid": "null",
"Delay": "3",
"Group": "Default"
}
},
{
"file_path": "dangerzone/0e19cefba973323c234322452dfd04e318f14809375090b4f6ab39282f6ba07e",
"sha256": "0e19cefba973323c234322452dfd04e318f14809375090b4f6ab39282f6ba07e",
"yara_possible_family": "asyncrat",
"key": "None",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"Ports": [
"%Ports%"
],
"Hosts": [
"%Hosts%"
],
"Version": "%Version%",
"Install": "%Install%",
"InstallFolder": "%Folder%",
"InstallFile": "%File%",
"Key": "%Key%",
"Mutex": "%MTX%",
"Certificate": "%Certificate%",
"Serversignature": "%Serversignature%",
"Anti": "%Anti%",
"Pastebin": "%Pastebin%",
"BDOS": "%BDOS%",
"Hwid": "null",
"Delay": "%Delay%",
"Group": "%Group%"
}
},
{
"file_path": "dangerzone/6b99acfa5961591c39b3f889cf29970c1dd48ddb0e274f14317940cf279a4412",
"sha256": "6b99acfa5961591c39b3f889cf29970c1dd48ddb0e274f14317940cf279a4412",
"yara_possible_family": "asyncrat",
"key": "eebdb6b2b00c2501b7b246442a354c5c3d743346e4cc88896ce68485dd6bbb8f",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"Ports": [
"2400"
],
"Hosts": [
"minecraftdayzserver.ddns.net"
],
"Version": "0.5.8",
"Install": "true",
"InstallFolder": "%AppData%",
"InstallFile": "WinRar.exe",
"Key": "VUpkMU9UTEhRSEVSN2d2eWpLeDJud2Q0STFIcDRXS0U=",
"Mutex": "LMAsmxp3mz2D",
"Certificate": "MIIE4DCCAsigAwIBAgIQAM+WaL4OeJIj4I0Usukl1TANBgkqhkiG9w0BAQ0FADARMQ8wDQYDVQQDDAZTZXJ2ZXIwIBcNMjQwNDA0MTYzMzA2WhgPOTk5OTEyMzEyMzU5NTlaMBExDzANBgNVBAMMBlNlcnZlcjCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAKhz3rO2b0ITSMGvwlS7uWZLVU7cuvYiIyB2WnGxe2SUlT5/pZrRxfX6CVL8t11S5CG3UFMdKDutLiA1amqLDbkqZAjG/g1J+7OPUOBrBWfzpEk/CFCFjmUTlMPwM00DtDp5Ju8ONc09JiaL9Ni3GeYsXza+HZB0WRrgpKnMNu+833ddBOaIgdvB4KicE/S8hSRq5kTNIhiNNZ0nrMFgzaQj0ijyXNTXN7nFCTqRSkWn/2pdveWZLqzTRZ5HsUkeXr2vhSdrrk7KOpHWjqNr2Nhl+bqsIRUhwnthLhj6N1Y94W25j3ATrLR6mjjZTGI2wRm95bMe/7V4DxqV30i6MVrwYMXKcaPO+NHoF9P1lErhCgttEGyWJz2dVJqVCXA+fE8hLyKSUeJSwaBJ36Of/OFGXXMXpUD7eFHNCN2yPVsW1ogS04/xkQUmbWbRjYx/l02+RK/kAK3YsZDuvcLsbKoDq7XJKoBVfvbv5W7jcmMvHHT54PNbmkAUasbtM/+/KhKQe1etOoYd+gOv7tgcNFRVH6N6eSuTxasCYjCr9tSLLmziNalWTknHgBtL/x49BJw6FWwrEE3wsl3C4ALfHQFbtI6sTLdCk7t/oNFUhpVE4kwql5xtOpYpkAj500jGfmVc9Wjy34tON2QLKnzAO87pt8XyANEFQdm3qUJX56KdAgMBAAGjMjAwMB0GA1UdDgQWBBRP67T1n4GPr5zJ0tsXMJ+gL7IawDAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBDQUAA4ICAQBMOPQsFZRxqhZZ344n0qBiatzq/jSmfMsMKWYMTiFHHccrgSc63C+nlVpTSCys2BZaMyocxeWKI+w7NklntQhp058+oN7PVC87xod6uZQyfYG1oCR58+Po4I3lWHVdOWQrkEKf4LTpCtyPXPTccZL3AjYcZWLOvP0gcjRsF2dSGnN1WdTPKHxj+OLSwSxlwTW4WN2wg++OV9cmT4wgaT2jPDqv3twxV+JVwEeXMM7XthJsG8ajToCS3Sf7pXnuOBIBoITQEbi7Iyqm/mJwFmAkcpEXb88rHZnKs+rRzjPRI/XsvlGVVuyiHtvPJL9X+R3VVltvrawBCbmN9K2W21E56Nryip0q4wdcF1jJUHXxAiQo/jcu8fO3RGfs9I6SN54PXSWABS7MvNJU8njC1N3J110cnjTgVMNrgRhBHe6r9CGnN4gm9oKvKL5+0/zZvhUPgYusOHIQmdOdfLo0r7tckUk2D18ufRILcaOqyaHLI7Mri1XEli8Brfjdtv/dlpssh/B2/o3bhBlRVD4oL+EX71Bm6cHEKoCLL6zGySSQosQyZpR2j4qVObb5fK1EnilJG4Qk6mNULZfWVPD9TLsJTHEioV8GibykF5O79kruha/pxFvVnoDJHbTPZEWfuR4cb6YIFbTg9pJrOhUsoyZg41leCrcqHR82XOVB755xfw==",
"Serversignature": "PBjqcvsYypDmnjgUVv1SkvtLx+jFt2V7NyZ+nHik0CWcLbwOwBXD6/3an89d/I7pFAxwZXgSiLunc1yCOocUvymhbMwqT5t/yuj4GdW3a16vZSUuPbvGEOuB2oCgUNrsLWzqshnd1yaTIbNoENLJNS3phGLnQXijbrE2/mSEWbSjLcCWMC7Q52c54RCiBuKPQEhFR1KMUBtSeskObCEqOKY9tYsKKTDYDrQPp32Ho4qArPCDIiefcNiT4k17Dw4srW1OkC3uhSCc7BV1dZA/HJw5gd34pFTeCnJnqY34OmE7sux8mhBjaIXSJMXD81272ngrmGwu6++6DkdLgIx2y3uE6IcUFDQmOgU6T9I0ulogZGGZa1PI3VjBjF4TK27EwzrkR0iKi8Ctn8z/HMXnskviCaui6RlxEzWqOytSfe4m0XHpNN2gHVhKbZwJUr5IwKASOWiXgsOVpkTn8K6PDN22X2rCUigjRsE4/45qhd6BFCa/pXMgCHljHKi5qp13yor91rO9n6NjbO2bP28cexUmUwf03lClGQ2og8q05WWiqHHvLlpHxmy8fZwzniJC3tr6htyPYhGpzo20BMOz/x66tA/+JTC8CFFilvf3PP97KwfqpVNqtnyHVui7QR39E6QvoyNzw+7AxpHCSYx6F9tyWu96pBeSbCrMzXaSV0k=",
"Anti": "false",
"Pastebin": "null",
"BDOS": "false",
"Hwid": "null",
"Delay": "3",
"Group": "Default"
}
},
{
"file_path": "dangerzone/83892117f96867db66c1e6676822a4c0d6691cde60449ee47457f4cc31410fce",
"sha256": "83892117f96867db66c1e6676822a4c0d6691cde60449ee47457f4cc31410fce",
"yara_possible_family": "quasarrat",
"key": "ff230bfb57fecad4bd59d4d97f6883b4",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"obfuscated_key_1": "1.3.0.0",
"obfuscated_key_2": "qztadmin.duckdns.org:9782;",
"obfuscated_key_3": 3000,
"obfuscated_key_4": "1WvgEMPjdwfqIMeM9MclyQ==",
"obfuscated_key_5": "NcFtjbDOcsw7Evd3coMC0y4koy/SRZGydhNmno81ZOWOvdfg7sv0Cj5ad2ROUfX4QMscAIjYJdjrrs41+qcQwg==",
"obfuscated_key_6": "APPLICATIONDATA",
"obfuscated_key_7": "SubDir",
"obfuscated_key_8": "Client.exe",
"obfuscated_key_9": false,
"obfuscated_key_10": false,
"obfuscated_key_11": "QSR_MUTEX_YMblzlA3rm38L7nnxQ",
"obfuscated_key_12": "Quasar Client Startup",
"obfuscated_key_13": false,
"obfuscated_key_14": true,
"obfuscated_key_15": "mDf8ODHd9XwqMsIxpY8F",
"obfuscated_key_16": "Office04",
"obfuscated_key_17": "Logs",
"obfuscated_key_18": true,
"obfuscated_key_19": false
}
},
{
"file_path": "dangerzone/9bfed30be017e62e482a8792fb643a0ca4fa22167e4b239cde37b70db241f2c4",
"sha256": "9bfed30be017e62e482a8792fb643a0ca4fa22167e4b239cde37b70db241f2c4",
"yara_possible_family": "venomrat",
"key": "86cfd98ca989924e7a9439902dc6a72e315da09c11b100c39cd59b9c9372b192",
"salt": "56656e6f6d524154427956656e6f6d",
"config": {
"Ports": [
"4449"
],
"Hosts": [
"127.0.0.1"
],
"Version": "Venom RAT + HVNC + Stealer + Grabber v6.0.3",
"Install": "false",
"InstallFolder": "%AppData%",
"InstallFile": "speedy",
"Key": "TzY1S0thald3UGNURmJTYjNSQVdBYlBQR2tTdUFaTTg=",
"Mutex": "ypxcfziuep",
"Certificate": "MIICNjCCAZ+gAwIBAgIVALWZXeRliC16frxuoSrGsVJO4U2tMA0GCSqGSIb3DQEBDQUAMGcxFTATBgNVBAMMDHNwZWVkeSBkcmVhbTETMBEGA1UECwwKcXdxZGFuY2h1bjEfMB0GA1UECgwWVmVub21SQVQgQnkgcXdxZGFuY2h1bjELMAkGA1UEBwwCU0gxCzAJBgNVBAYTAkNOMB4XDTIzMDYyNjEzNDc0OFoXDTM0MDQwNDEzNDc0OFowEzERMA8GA1UEAwwIVmVub21SQVQwgZ8wDQYJKoZIhvcNAQEBBQADgY0AMIGJAoGBAJ2DCquy6CwL8H/T1Wi72pbKLyGQdoXBDSKpGyIfLgX5091jBQYbvFbROqt6FjbN52GSpnmd4N8TnQE6KGqTmmSmaf/nxMSNcV1sjhxm7NTfnP9vo/vnZngCmzVr91S9REqlKCiotdkIYWqbdwkmYTuqSdHaicP7Tf0H8oOYZIc5AgMBAAGjMjAwMB0GA1UdDgQWBBS/OFCWU/dcBWOe+i6ERcFdHDOwITAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBDQUAA4GBAIT79sUZm5Je3T7yc9GS+pgzsgtf8OXakm0DrY41uytJgXzgi2E/bWIBja4DyuAddL0ziDCamqDQuFA1MhFNki/X0uKgu1ArxZeXlwKqpDv7ihWRqWrE3rHYha0ALSP8DN0Asmpc4FGnrfhoeoLYXRo8EqH+6ctIkggM8OiBYSTm",
"Serversignature": "Sn1WeJuN+Ypb6kUw4QirT1RzbwUEoeSYTmJAIlg0LayMd/VSwAo+0LnnT/g5HFx4QrqaM689CvKqUNfotQb9cPj05dfgrV3SplVDt5twnK6f8nnScqI8trTCmprH1gnOcoKcY8039kFo9dEj+eOiaBF451W181I5fPJd4Uug1bY=",
"Pastebin": "null",
"BSOD": "false",
"Hwid": "null",
"Delay": "1",
"Group": "Default",
"AntiProcess": "false",
"Anti": "true"
}
},
{
"file_path": "dangerzone/a2817702fecb280069f0723cd2d0bfdca63763b9cdc833941c4f33bbe383d93e",
"sha256": "a2817702fecb280069f0723cd2d0bfdca63763b9cdc833941c4f33bbe383d93e",
"yara_possible_family": "quasarrat",
"key": "None",
"salt": "None",
"config": {
"Version": "1.0.00.r3",
"RECONNECTDELAY": 5000,
"PASSWORD": "5EPmsqV4iTCGjx9aY3yYpBWD0IgEJpHNEP75pks",
"SPECIALFOLDER": "APPLICATIONDATA",
"SUBFOLDER": "SUB",
"INSTALLNAME": "INSTALL",
"INSTALL": false,
"STARTUP": true,
"Mutex": "e4d6a6ec-320d-48ee-b6b2-fa24f03760d4",
"STARTUPKEY": "STARTUP",
"HIDEFILE": true,
"ENABLELOGGER": true,
"Key": "O2CCRlKB5V3AWlrHVKWMrr1GvKqVxXWdcx0l0s6L8fB2mavMqr",
"Group": "RELEASE",
"hardcoded_hosts": [
"kilofrngcida.xyz:443",
"sartelloil.lat:443",
"fostlivedol.xyz:443",
"comerciodepeixekino.org:443",
"cartlinkfoltrem.xyz:443",
"trucks-transport.xyz:443"
]
}
},
{
"file_path": "dangerzone/a76af3d67a95a22efd83d016c9142b7ac9974068625516de23e77a5ac3dd051b",
"sha256": "a76af3d67a95a22efd83d016c9142b7ac9974068625516de23e77a5ac3dd051b",
"yara_possible_family": "quasarrat",
"key": "b30cea630f7fac6c2e066ce7f29e1b4bab548ee95b20ff6aa7387ce14df5dc30",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"obfuscated_key_1": "1.4.1",
"obfuscated_key_2": "10.0.0.61:4782;24.67.68.3:4782;",
"obfuscated_key_3": 3000,
"obfuscated_key_4": "APPLICATIONDATA",
"obfuscated_key_5": "SubDir",
"obfuscated_key_6": "GloomTool.exe",
"obfuscated_key_7": true,
"obfuscated_key_8": true,
"obfuscated_key_9": "9fdd3e80-d560-431b-b526-3ebbc1799110",
"obfuscated_key_10": "WindowsAV",
"obfuscated_key_11": true,
"obfuscated_key_12": true,
"obfuscated_key_13": "5F91B88C67A9ACF78B2396771B3B6F2B4615CA57",
"obfuscated_key_14": "Office04",
"obfuscated_key_15": "Logs",
"obfuscated_key_16": "KQrwmpZSwOF20ZdNZlVJ7YjgErzUf9cophPOCAULRI4gSid7qeSaRL4LhhUXzEq1JuUlkRR7WTjztBsmwCRqORdxEBFwd1fMTsYFf4COj4yN1sbvc5Yb1qvk6IELnzse14eXVS+y1AbwCOGBEa1P6H2C2X2xH6jZRBMPaFsohcV0z20ZzWpdJw+aQZ/SSbMvE1YFN5o37y3MzAW/nErdZyxLA7t9eTsca+RLT8uHgqU0iEd4Mz1iHUWA2gYY+uPzV1I3oU8LHrWhXnXRhutbShZ80KbE+tfr7XLAIwwol00moTd7GaL4vd/ZeOa3z3nmVO2GxIRMWCmiX52l5MutcuR/nAAR1k+W2ScaAoxXzpb6pwOwccooFty0lpRoO6RMT+g1ux+jwKn4RpH1baEAmA6cu8W2l1mr8dwZ3ra094dUKEdITKRKEviworYIRWDS9w2618tVfRhccHNsbIIp5qZMumne0OVE+FK6rjPZM/Q4OR7++1AQUNiavCOsY6/sbxdb+K43x2PrxzJAPoU33qF2fzXaSIEgbmlqkZFdFOhSVHay5F4lmuvHUGRXmhs37quo874DaCA5phI3aCP8VXIFkHyjOJelIR9wlfsdNY5yOoA2POnFt1Y24YzoPZt3Mc/Nqv74z/cE3LXrJHsgivyZV25nqpiCHL704AfoRpo=",
"obfuscated_key_17": "MIIE9DCCAtygAwIBAgIQAIhqXB+nLwd+VvEk3rjLsTANBgkqhkiG9w0BAQ0FADAbMRkwFwYDVQQDDBBRdWFzYXIgU2VydmVyIENBMCAXDTI0MDQwNTIyNDkxN1oYDzk5OTkxMjMxMjM1OTU5WjAbMRkwFwYDVQQDDBBRdWFzYXIgU2VydmVyIENBMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEArk3R4LAyzBp+YXIUqxBNyT/R94en+jU7NTtJGsCG7I6Tp2ZV6mdTOynApeBLs6RvgIpzxPIbjA7HMoQqRxBDKREcRZJCnK3NdMl+8ZMKU4OLBWINwW4fvZRu2spC79MYiIsKOXRDsfCelPs1llHTbD4b4c+PzbpcGA5gI+luZ6+OKajkGbAKdppse5EdPh+KrE6r74nAJiK9PdvfF1H7XwOVpFChxcYZJmZTG8hfrSFQ/0mSi0CobU71vj8fVkhX0EOVSv/KoilBScsXRYbvNY/uEzS+9f0xsYK5AgJQcUYWLthqKSZbo3T1WecBHKynExf8LbFpC42ACyPbZXtAYt1lyBXyLW8TZS65yquhcVio/ZgAG05WGn+TeA6M+CxNkEZNvgd5PDuBkF6X13w3OXGFOL7i4KBJifSMRyJaqp9i6ksAY8epDRHP1WOXDxnQ8ak+4jyPC6WSZFnGV3DT7lZahvkIaNR8OPR8suOoUWk8Jl9Fxx+DBa6RK3Ht96YkPAf8rY84Hjjp4xp1OF6q88W1YaYo9NtPK+5fkf2pFqa+RC7v3RKgsis3/1xYeBZ8expiCdm5hKTRx0tAkG5bLzC6/Em8cHqCR6lmbPuHgA4ijByU6fLD1JdmwqAcjpy9OIdB8L+G7X8kAu5+WUe5BMiIE6EYvJi3Rpg2fz5Nt9UCAwEAAaMyMDAwHQYDVR0OBBYEFI40k9gCti/BlRy3dUVqsbe3OhMxMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQENBQADggIBAAXYckulFdYnmtdh24egkttF9h/0AD87o9kAnRwJVu3nu12R+FwJgaihvAQZiKQ4kgTkP//ag9E60xwyzEcj00/yZGzjMAAXONZoEyeCxEF5cMjbtmqLWsFkRaHEpWtcczJ2BChEnFDgoGF2I6TOlr7OGoJnzHmz43bY9dkpDJ+tqIZu5AwoMG4WMoNe+by66G2S1AjyVVimIJA7at12EMIUizO0Qov+iBFHSDiVwOZlUxhfu9TNKwIgQdSLHnTaBg03VFHpLZ63Qtmr12LwTEOUyVSnJXEsgZISQ0abMCaped6jwpR7+VlpU4SGfyBU8caFphJafdgVzhmztrTpYMUJE44d50+5ue9us2H2IH+26/+yBbQdffzp1LAFfYgjOE7k8EFjU3ayPaTN7ORtjCyNzhYRvjUCuopb0rWhJsQQRQJzkblrYJ/ocSfNGUQOoJpykyD1QiGboE11xIPheLYetZrRtkmNtFuVeKg9z7AB1ahxEcNGT/MW/wkxUe500cBLVTFeZtsMl7WYB6iUSxboQ8zZ8eWCDS2hYOxKfxfr54p4AW24Y267djKnAfpnMIsgJzjcDxvGGMBlwcrxb0vM0w+9K2R+M17r4bldxnStJj2Wtgal1TBVP1XexZgarfXw3HstKjhbFH6cb4g7ZW4wdCYE5XA6qZL00XpuSy4t",
"obfuscated_key_18": true,
"obfuscated_key_19": true,
"obfuscated_key_20": "",
"obfuscated_key_21": "",
"obfuscated_key_22": true
}
},
{
"file_path": "dangerzone/b5bff486f091f9539606931e0aff280eaea17064b2a12940675dfac926e9666e.exe",
"sha256": "b5bff486f091f9539606931e0aff280eaea17064b2a12940675dfac926e9666e",
"yara_possible_family": "xworm",
"key": "c527ac2a4eeb6039d9477583d0f4f2c527ac2a4eeb6039d9477583d0f4f2ee00",
"salt": "None",
"config": {
"Hosts": [
"act-cleaning.gl.at.ply.gg"
],
"Ports": [
"37158"
],
"KEY": "<123456789>",
"SPL": "<Xwormmm>",
"Sleep": 3,
"Group": "NeverLoseCrack",
"USBNM": "USB.exe",
"InstallDir": "%ProgramData%",
"InstallStr": "svchost.exe",
"Mutex": "OkWVOTioL6k3Fg3w",
"LoggerPath": "\\Log.tmp"
}
},
{
"file_path": "dangerzone/beb1b5cd2a33e86e48599b183b882fc3e80198a8062e5b9d9251e605d3f0bfd5.exe",
"sha256": "beb1b5cd2a33e86e48599b183b882fc3e80198a8062e5b9d9251e605d3f0bfd5",
"yara_possible_family": "quasarrat",
"key": "b5580a84ddadcf548713dd64fedbbe067f931e6ce4699271de572acbd52f4074",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"obfuscated_key_1": "1.4.1",
"obfuscated_key_2": "91.92.241.122:6969;",
"obfuscated_key_3": 3000,
"obfuscated_key_4": "APPLICATIONDATA",
"obfuscated_key_5": "",
"obfuscated_key_6": "Client.exe",
"obfuscated_key_7": true,
"obfuscated_key_8": true,
"obfuscated_key_9": "fcf2be0a-a426-40c6-b153-1a354814f80d",
"obfuscated_key_10": "Quasar Client Startup",
"obfuscated_key_11": false,
"obfuscated_key_12": true,
"obfuscated_key_13": "26A6C07FE7354BCD244B108D2E3538DCF04477F5",
"obfuscated_key_14": "Fab",
"obfuscated_key_15": "Logs",
"obfuscated_key_16": "U/jVlmjpH/9zMrLFla8LcLavxUQe9wt9L6qGAh9zYqPdqDW0e0fRlnxEST/s3HTVlAyuqIyn5yKrWKaXCMUHKcjpAWVQ9jPLAteKNgIRz5Soa8qxWgD215NTswSL/tYwdPW2svV9y6ELPKScSacDyZlBp47bv299XhxjeUkAXIli59EHnHxAIlOS/Ag51onRTlEkGYIVQO1IJjGoGQe8pND5JwWOVi072s67A16SNYJmPrCNqDjCMVjYDRwLqusbuDPF2K0wIVLn4RzLr+F1O5e5Rh8GFIj/7qa8gOy2kjAbczo3AAKZG3sghrut27P2ldxGcWpsms5w97k7WJ91goBms0n/hV29sRDiYG51xey3KqcTp2UspvLUzNJek21CZk+EgCQ3Q7+aZxdLAIEfwAo0cq7lJkq3iEZuZ+86sts1D3YToM9+mRtIDAeb/op2oxvWbJOqeA9YME2A7PWDVI6bH9kcru5UolqfxPRIH7Aa8BVzAbctghbaVZCiwkI0lxc9hijCLZugOnKXtFU3A+hPVyc/aDqZcWPDu7u9jWbrWIk6JqLGbnJYiU6a4p7IwdGnVwkA49aD4ZnKqWo8tSKLCd+dvP4nx+pqYWiUpf+rdy/xH1MBbPj/lPlphmrFFHijlBufVoSLa88/rBv+Fb9ox2Ei2t5RJYTLDEoP0oY=",
"obfuscated_key_17": "MIIE9DCCAtygAwIBAgIQAJMC1KOnf3PAJ47sO2MclTANBgkqhkiG9w0BAQ0FADAbMRkwFwYDVQQDDBBRdWFzYXIgU2VydmVyIENBMCAXDTI0MDgwMjE5MzAwMVoYDzk5OTkxMjMxMjM1OTU5WjAbMRkwFwYDVQQDDBBRdWFzYXIgU2VydmVyIENBMIICIjANBgkqhkiG9w0BAQEFAAOCAg8AMIICCgKCAgEAk9yV4zXwIw2x7ZZyu2WnaWGwrq2laEP44y9HMM/PYRQCmkMr/L4bqPIgee+trkTOK2T/yd37YISYQSsfQXONYG5JZy1DsZgWAy177xEUoLNAv/TmWrovdVhFSIN0FtQo4ED1AMSOeRWPYw3fdFplPo25TqiZnJuC76fu04Sfl5/B5RqZUy3FKkVlZRL/99zAKjQvFIFvX/riz7pwYPoKSNzRB+SPebLJgYlG7qaxb11C/oiJu1AuEcrmjjr8Ph/nYAqY4EzsjWw6mBUEKTAdCptz78Xpj2qZ/DO//6rDIkw2HWyvvJ4qC2jhv4d2LL/LVSof2SDkMY2NRweMtwnmI8mYIf6mF6pOuH7l6IONc+W2LahqbDImjijmYOJnED/4mV3QRvXHZlwwn/qwf4Fc98VdNayqw1SdKyWqSEIFaa8ZtbSvGj1RQWwzJXQ0sr7EVcv26GUorfX4y5wXhVu5DQfAIZkhZoGSOUPVh0E/NnSqFA10M7TcTz0+fwxLjZ93vi0D0dBcyWvMwTUjy1FHZMu7ZXPsrGbDMmhwmNSsqCqV3SGLZEwaSI2Wtzi1SgElz9+GSh3twxi6O+kaOtP8vu6jbzYi8QSLbn+APkX4XXetIms76fRT6c0yjgnr8NNhdATN3NIAy2AIBfRB9+WkmEEzWf35oLIb0WaNIXtRS5MCAwEAAaMyMDAwHQYDVR0OBBYEFJnfWehSzSmr6K0SenBX6AyNEZUqMA8GA1UdEwEB/wQFMAMBAf8wDQYJKoZIhvcNAQENBQADggIBAEsJnW/h1UmS2DsvTd6vhMwSVZjtK5PKYx8HRL1KPrhDa4WVdYvXu9DaO0BHs5dad+EMTuhWirWXv1oG4TUBVwwZ9ka95ooIZhrZdjLe1sXHeRTubU9yO5bl/6fhHUvPcDsktCgBxboI40t6YcJk+wtIdobhhO0dIHK7OAkJMXQMv7bWX6xy2HwPk0tzkHSskWe160kUiNdxZomd6VSL5FnJ9aB6erznl1WABJNRNwIksM1xlrgyCFAMRvJwpJi823H/ApWwAosQo9qstOo2e+OMrCAzexGJL93JANAXAf7xa5TXzcTPd+n9QhYSDWW7EqDim8vguQzHkHkDNRMP0poqTHFYovcupr2zBjkhPC6sP/f0Rq/aQ6Dyqqoj0cW/nH2wl4eFXvQnSHTbbVIo2qzb+Ud1qFhXxkGzuP//V/wBgEAhLcFraqgQ/b4kX0hkhV0yYaTWpqVemg4Aki7RYz9nGIRMcdr+APFeXo49FHjerk0lqszbKd6IJn3CR9U+ZLpzp3M9NLdeTPpjGal8IgMjuO6MXmt/ybz1fAfM0shKsq4+3nUI0TMGBgYhrPdS5VoA29Xg84hAVj7wewNZKJ43d/poHQnrjWkuN/Ii66IaKVyKofoMiHyfHIy0ee456vDYvxbPv+k9euEhv4OiK8dTWwvDr2XlJZWfq+pukDEk",
"obfuscated_key_18": false,
"obfuscated_key_19": false,
"obfuscated_key_20": "",
"obfuscated_key_21": "",
"obfuscated_key_22": true
}
},
{
"file_path": "dangerzone/d5028e10a756f2df677f32ebde105d7de8df37e253c431837c8f810260f4428e",
"sha256": "d5028e10a756f2df677f32ebde105d7de8df37e253c431837c8f810260f4428e",
"yara_possible_family": "xenorat",
"key": "650f47cdd14eaef8c529f2a03fa7744c",
"salt": "None",
"config": {
"Hosts": [
"77.221.152.198"
],
"Ports": 4444,
"Key": "03ac674216f3e15c761ee1a5e255f067953623c8b388b4459e13f978d7c846f4",
"delay": 5000,
"mutexstring": "Xeno_rat_nd89dsedwqdswdqwdwqdqwdqwdwqdwqdqwdqwdwqdwqd12d",
"DoStartup": 2222,
"Installpath": "appdata",
"startupname": "nothingset"
}
},
{
"file_path": "dangerzone/db09db5bdf1dcf6e607936a6abbe5ce91efbbf9ce136efc3bdb45222710792fa",
"sha256": "db09db5bdf1dcf6e607936a6abbe5ce91efbbf9ce136efc3bdb45222710792fa",
"yara_possible_family": "venomrat",
"key": "11ed70df5ce22de750c6e7496fa5c51985c321d2d9dd463979337af003644f41",
"salt": "56656e6f6d524154427956656e6f6d",
"config": {
"Ports": [
"4449",
"7772"
],
"Hosts": [
"127.0.0.1"
],
"Version": "Venom RAT + HVNC + Stealer + Grabber v6.0.3",
"Install": "false",
"InstallFolder": "%AppData%",
"InstallFile": "",
"Key": "M1NoWkREazBvNTNGUkRlT0s4TjE1QlRRQmx4bW1zd2U=",
"Mutex": "qmhvogiycvwh",
"Certificate": "MIICOTCCAaKgAwIBAgIVAPyfwFFMs6hxoSr1U5gHJmBruaj1MA0GCSqGSIb3DQEBDQUAMGoxGDAWBgNVBAMMD1Zlbm9tUkFUIFNlcnZlcjETMBEGA1UECwwKcXdxZGFuY2h1bjEfMB0GA1UECgwWVmVub21SQVQgQnkgcXdxZGFuY2h1bjELMAkGA1UEBwwCU0gxCzAJBgNVBAYTAkNOMB4XDTIyMDgxNDA5NDEwOVoXDTMzMDUyMzA5NDEwOVowEzERMA8GA1UEAwwIVmVub21SQVQwgZ8wDQYJKoZIhvcNAQEBBQADgY0AMIGJAoGBAJMk9aXYluIabmb8kV7b5XTizjGIK0IH5qWN260bNCSIKNt2zQOLq6jGfh+VvAA/ddzW3TGyxBUMbya8CatcEPCCiU4SEc8xjyE/n8+O0uya4p8g4ooTRIrNFHrRVySKchyTv32rce963WWvmj+qDvwUHHkEY+Dsjf46C40vWLDxAgMBAAGjMjAwMB0GA1UdDgQWBBQsonRhlv8vx7fdxs/nJE8fsLDixjAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBDQUAA4GBAAVFFK4iQZ7aqDrUwV6nj3VoXFOcHVo+g9p9ikiXT8DjC2iQioCrN3cN4+w7YOkjPDL+fP3A7v+EI9z1lwEHgAqFPY7tF7sT9JEFtq/+XPM9bgDZnh4o1EWLq7Zdm66whSYsGIPR8wJdtjw6U396lrRHe6ODtIGB/JXyYYIdaVrz",
"Serversignature": "BW9mNNWdLZ+UgmfSTOot753DE24GfE+H6HYG5yl4IFszdMLpfQXijxVlt3bcz68PrHwYG2R70J+h9EVUXPjNw2GgCH5I8BvOw6Luh09VjE3YrfERSa2NKJ7baO9U9NDhM4HaSUCUvXGbR6J0itLe+2YthV7GXSCEbbmfZI9UYKU=",
"Pastebin": "null",
"BSOD": "false",
"Hwid": "null",
"Delay": "1",
"Group": "Default",
"AntiProcess": "false",
"Anti": "false"
}
},
{
"file_path": "dangerzone/fb0d45b0e48b0cdda2dd8c5a152f3c7a375c18d63e588f6a217c9d47f7d5199d",
"sha256": "fb0d45b0e48b0cdda2dd8c5a152f3c7a375c18d63e588f6a217c9d47f7d5199d",
"yara_possible_family": "xworm",
"key": "e5f7efe2fddd6755c92cbc39d5559ce5f7efe2fddd6755c92cbc39d5559c4000",
"salt": "None",
"config": {
"obfuscated_key_1": "mo1010.duckdns.org",
"obfuscated_key_2": "7000",
"obfuscated_key_3": "<123456789>",
"obfuscated_key_4": "<Xwormmm>",
"obfuscated_key_5": 3,
"obfuscated_key_6": "USB.exe",
"obfuscated_key_7": "%AppData%",
"obfuscated_key_8": "tBZ7NDtphvUCm0Dc",
"obfuscated_key_9": "\\Log.tmp"
}
},
{
"file_path": "dangerzone/vstdlib_s64",
"sha256": "6e5671dec52db7f64557ba8ef70caf53cf0c782795236b03655623640f9e6a83",
"yara_possible_family": "quasarrat",
"key": "526f35346a62726168486530765a6266487a7039685575526637684a737575794b4c7933654e5a3465644c415a71455861676b3078357767563277364d544b5339367279367959664d6a66456f35653934784e396c684e346b514c4e7479317442704974",
"salt": "None",
"config": {
"Version": "1.0.00.r6",
"RECONNECTDELAY": 5000,
"PASSWORD": "5EPmsqV4iTCGjx9aY3yYpBWD0IgEJpHNEP75pks",
"SPECIALFOLDER": "APPLICATIONDATA",
"SUBFOLDER": "SUB",
"INSTALLNAME": "INSTALL",
"INSTALL": false,
"STARTUP": true,
"Mutex": "e4d6a6ec-320d-48ee-b6b2-fa24f03760d4",
"STARTUPKEY": "STARTUP",
"HIDEFILE": true,
"ENABLELOGGER": true,
"Key": "O2CCRlKB5V3AWlrHVKWMrr1GvKqVxXWdcx0l0s6L8fB2mavMqr",
"Group": "RELEASE",
"xor_decoded_strings": [
"BPN - Nuestro Banco",
"Red Link - bpn",
"HB Judiciales BPN",
"Ingresá a tu cuenta",
"Online Banking Web",
"Banca Empresa 3.0",
"Banco Ciudad",
"Banco Ciudad | Autogestión",
"Banca Empresa 3.0",
"Banco Comafi - Online Banking",
"Banco Comafi - eBanking Empresas",
"Online Banking Santander | Inicio de Sesión",
"Online Banking Empresas",
"Online Banking",
"Office Banking",
"HSBC Argentina",
"HSBC Argentina | Bienvenido",
"accessbanking.com.ar/RetailHomeBankingWeb/init.do?a=b",
"ICBC Access Banking | Home Banking",
"Banco Patagonia",
"ebankpersonas.bancopatagonia.com.ar/eBanking/usuarios/login.htm",
"Página del Banco de la Provincia de Buenos Aires",
"Red Link",
"bind - finanzas felices :)",
"BindID Ingreso",
"BBVA Net Cash | Empresas | BBVA Argentina",
"Bienvenido a nuestra Banca Online | BBVA Argentina",
"Ingresá tu e-mail, teléfono o usuario de Mercado Pago",
"Mercado Pago | De ahora en adelante, hacés más con tu dinero.",
"Mercado Pago",
"Home Banking",
"Office Banking",
"Banco Santa Cruz Gobierno - Una propuesta para cada Comuna o Municipio | Banco Santa Cruz",
"Home banking",
"Office Banking",
"Banco de Santa Cruz",
"Red Link",
"Banco de la Nación Argentina",
"Red Link - BANCO DE LA NACION ARGENTINA",
"Red Link",
"Macro | Agenda powered by Whyline",
"Banco Macro | Banca Internet Personas",
"Banco Macro | NUEVA Banca Internet Empresas",
"https://argentina-e4162-default-rtdb.firebaseio.com/user.json",
"C:\\\\Users\\\\",
"\\\\AppData\\\\Local\\\\Aplicativo Itau",
"C:\\\\Program Files\\\\Topaz OFD\\\\Warsaw",
"C:\\\\ProgramData\\\\scpbrad",
"C:\\\\ProgramData\\\\Trusteer",
"dd.MM.yyyy HH:mm:ss",
"application/json",
"Sistema no disponible, intente nuevamente más tarde.",
"SENHA DE 6 BPN",
"SENHA DE 6 NB",
"SENHA DE 6 CIUDAD",
"SENHA DE 6 COMAFI",
"SENHA DE 6 GALACIA",
"SENHA DE 6 HSBC",
"SENHA DE 6 ICBC",
"SENHA DE 6 PATAGONIA",
"SENHA DE 6 PROVINCIA",
"SENHA DE 6 SANTANDER",
"SENHA DE 6 BIND",
"SENHA DE 6 BBVA",
"driftcar.giize.com:443",
"adreniz.kozow.com:443"
]
}
}
]
```
### Preserving Obfuscated Keys
```bash
$ rat-king-parser -np dangerzone/* | jq
```
```json
[
{
"file_path": "dangerzone/034941c1ea1b1ae32a653aab6371f760dfc4fc43db7c7bf07ac10fc9e98c849e",
"sha256": "034941c1ea1b1ae32a653aab6371f760dfc4fc43db7c7bf07ac10fc9e98c849e",
"yara_possible_family": "dcrat",
"key": "3915b12d862a41cce3da2e11ca8cefc26116d0741c23c0748618add80ee31a5c",
"salt": "4463526174427971777164616e6368756e",
"config": {
"Ports": [
"2525"
],
"Hosts": [
"20.200.63.2"
],
"Version": " 1.0.7",
"In_stall": "false",
"Install_Folder": "%AppData%",
"Install_File": "",
"Key": "dU81ekM1S2pQYmVOWWhQcjV4WlJwcWRkSnVYR2tTQ0w=",
"Mutex": "DcRatMutex_qwqdanchun",
"Certifi_cate": "MIICMDCCAZmgAwIBAgIVANpXtGwt9qBbU/pdFz8d/Pt6kzb7MA0GCSqGSIb3DQEBDQUAMGQxFTATBgNVBAMMDERjUmF0IFNlcnZlcjETMBEGA1UECwwKcXdxZGFuY2h1bjEcMBoGA1UECgwTRGNSYXQgQnkgcXdxZGFuY2h1bjELMAkGA1UEBwwCU0gxCzAJBgNVBAYTAkNOMB4XDTIxMDIxNzA5MjAzM1oXDTMxMTEyNzA5MjAzM1owEDEOMAwGA1UEAwwFRGNSYXQwgZ8wDQYJKoZIhvcNAQEBBQADgY0AMIGJAoGBAKt8nE3x/0XYeyDBrDPxdpVH1EMWSVyndAkdVChKaWQFOAAs4r/UeTmw8POG3jUz/XczWBWJt9Vu4Vl0HJN3ZmRIMr75FDGyieel0Vb8sn0hZcABsNr8dbbzfi+eoocVAyZKd79S0mOUinl4PBhldyUJCvanCnguHux8c2F5vnQlAgMBAAGjMjAwMB0GA1UdDgQWBBRjACzYO/EcXaKzlTz8Oq34J5Zq8DAPBgNVHRMBAf8EBTADAQH/MA0GCSqGSIb3DQEBDQUAA4GBACA8urqJU44+IpPcx9i0Q0Eu9+qWMPdZ09y+6YdumC6dun1OHn1I5F03YqYCfCdq0l3XpszJlYYzPnPB4ThOfiKUwJ1HJWS2lgWKfd+CdSWCch0c2dEE1Pao+xyNcNpuphBraHZYc4ojekgeQ8MSdHVo/YCYpmaJbxFWDhFgr3Lh",
"Server_signa_ture": "c+KGE0Aw1XRgjGe2Kvay1H3VgUgqKRYGit46DnCR6eW/g+kO+H5oRsfBNkVizj0Q862zTXvLkWZ+ON84bmYhBy3o5YQOPaPyAIXha4ByY150rYRXKkzBR47RkTx616bLYUhqO+PqqNOii9THobbo3zAtwjxEoEWr8s0MLGm2AfE=",
"Paste_bin": "null",
"BS_OD": "false",
"Hw_id": "null",
"De_lay": "1",
"Group": "16JUNIO-PJOAO",
"Anti_Process": "false",
"An_ti": "false"
}
},
{
"file_path": "dangerzone/0aa7bfb081e73a67c23715a55ff13a74ef6b1ce2b82a33b5537ee001592919a4",
"sha256": "0aa7bfb081e73a67c23715a55ff13a74ef6b1ce2b82a33b5537ee001592919a4",
"yara_possible_family": "asyncrat",
"key": "564eced38c73ee8089d8bcc951f28c0589a54388a4058b0da1d9c4d94514518f",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"TelegramToken": "7153134069:AAHd4riTPdhAdVGBwo16vJQ5H3eORu5QAEo",
"TelegramChatID": "1863892139",
"Ports": [
"6606",
"7707",
"8808"
],
"Hosts": [
"127.0.0.1"
],
"Version": "",
"Install": "false",
"InstallFolder": "%AppData%",
"InstallFile": "",
"Key": "Uk9tU0hKZUlVdXBwek1tV3NqYnBLYVRYcklWQXB5c0I=",
"Mutex": "AsyncMutex_6SI8OkPnk",
"Certificate": "MIIE9jCCAt6gAwIBAgIQAKQXqY8ZdB/modqi69mWGTANBgkqhkiG9w0BAQ0FADAcMRowGAYDVQQDDBFXb3JsZFdpbmQgU3RlYWxlcjAgFw0yMTA3MTMwNDUxMDZaGA85OTk5MTIzMTIzNTk1OVowHDEaMBgGA1UEAwwRV29ybGRXaW5kIFN0ZWFsZXIwggIiMA0GCSqGSIb3DQEBAQUAA4ICDwAwggIKAoICAQCnRXYoxuLqqgXdcvIAYWb9DuVRl5ZpdpPfoIgmb7Y9A9AuiddKNm4is8EvIlEh98bQD4OBaK0EGWuj7WuAcQPCCGuzHpDqFZbXR7iRqVn6TiLRsO0LCMB4ta4XLQ4JdTFXvnQHcGiUxHddH70T/2P2bBVY0W+PVJDzG3XUWHpYb4PVv7qaQr/DalR3qyyd5otzE1kIjJLCOCyI/9ntIcD/PbMTKVnCP4fzbnkNB+xy0PmQmx3WRWEF5q72TdgaKrCbOpR2C/+rfGIoPC6Ze6dqWO3bQLGt6jpCO8A4CtAaAYmiw1vHUOfP54BgI9ls1TjYO3Rn4R1jmhWBGV2pT5chrglgSxMzPhrxFTQljG78RlPCJmyagJbtnPL3AlV34sQggcbf+80FVeyechm/xrMTSWXrJQ+xek1HRJBDFoCJyUR7SuIUelOW24TU+rwl/2dcALLZXpjYu3/zvJjH4iaJXRCt7oWhfzIFG1bHBFr78kV9VP0H+ZNVb129eUr14F/uubAoIPAz2EHG/CXBZv9GkFuzw0NgsI1eP7AznCLdT+z91M+yB7vWtvclwQ5k6MxWDPOraG5JMjUHvKI6zvyZ4IQ2a7bUENDghxLAqIxgo7zfZMdrjbRxBlqW14oki6Um7GpGKEZ0s2Ip6K2yJHBLpbVxOYjyzrxohMguh+qvgQIDAQABozIwMDAdBgNVHQ4EFgQUmTejTtK6on20N0YJez5sAZdMe/kwDwYDVR0TAQH/BAUwAwEB/zANBgkqhkiG9w0BAQ0FAAOCAgEAhauA0si7sHBd06DSGJgP5vJxL2daW30wR5XbAJd0HWj3QWfl7w27iyZ5AqBT4B0ojLNuMUG8mUOvpcoq0m80qUX7TIKUULKvb+i7uGGEDxk3W5F3es/CTUUWO0QlseWx9QEYziGlp6f3tkP4PTGSL0DywVRSa8l6f/B5kqwnW17CbQfJZ8vmy5snpDO/avgYssUnQtKQPhos7GbokNHps/bxEIRfLeprzQox20dw4RV59LcorjP5QV7Vc6FuYmhzC0nfRetTHckyxg66O3ekfTVs87MLiDV0ipQ+D/6k3g6DRuTdd4V2khjtI56ujSqTQ2PueNQXPu8y2fdsT2Rd1LcfxMS1xKAhSwhHfyy0I3JwzPG1D+sm3QNJEOoJviSNn5fYOFpY+mSEkFNMMeEbwOFdHxWbkiJk/Z8VwdH5I52tkHU3sRQMuZHtcKUc/SIt5Ivv6gtuEZQdm1GE6KUdiRB95s8JVGNlCcHX5bXbScu4eKCRQn3Cl+m5KR4EzI6hVP/iDRhVKj7Dn/blOHLzhNS5vW4X085dTP+1TBL8CHpQpiA3t8LfqfV1b/+WahOd3jNBNTXXfe/AQSjErgctLMdmOBpUQaJLOlcDcKGxWQdOo102nxg8Y/kFDARccywugoQxuIZpMYq74tjnJlJZ9kqR/LPrjmvx4v+0XFsaCPE=",
"Serversignature": "b4TmzraaQMXPVpdfH6wgqDtnXhWP9SP6GdUMgvKSpjPlWufiGM88XWg3Wnv1bduWRMUOAIBN31gAe/SRIhAhdCJU0h6nvqjBUKQsnrg3kT6d2beUtwLDhWWqGa3i9Nta72fkbikM65DIkUwjGtnZy3THx83+doN/+cwe9ZlhKc7TqGF9klOT0nQ9JFUi3Gn6uDzwhA7vicj1WyfM15QxLp0ZvTojgjjFUC2BVkr+mDvuuQ4OR0h4qOgl/AXOYfZwKMfvnwijdP/qqpeG+X73rXZxeDawcTMYqvWH+hOiksgsh2C9V/iN8Sjye/A6rKewmHMUozpakMjP+TjES8kwT70+vJ/uS3ugCZUjT6sOqqLl+LyQyzSpGdVJJQB/fPrYTlWTJwpXdxk8V+eqcdCf/mpeYyQnyGaFVc2whfLAN0r2aPigRQNmsY7Faom/CeNc98zIBf9Nt+KR3FfyFuYabZn5zQcYNAq6D0MVRbKQsU3eyGWN+JI24PQUloheBFJvimpBqMMRVWDLsQq82TpExWJoT47fBrzZj/6LE10vKwl6TNiE81fkglcc93ErbH1KCdXxUaxKVePUIypEaohzXkv88h7P6gjhm2Crey8mUkir408At+5Xl8hQE1ozQN0e5le2gIdxX+oFkTFDrzd65MAdKiZ7rqauNMb4aM+bEeM=",
"Anti": "false",
"Pastebin": "null",
"BDOS": "false",
"Hwid": "null",
"Delay": "3",
"Group": "Default"
}
},
{
"file_path": "dangerzone/0e19cefba973323c234322452dfd04e318f14809375090b4f6ab39282f6ba07e",
"sha256": "0e19cefba973323c234322452dfd04e318f14809375090b4f6ab39282f6ba07e",
"yara_possible_family": "asyncrat",
"key": "None",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"Ports": [
"%Ports%"
],
"Hosts": [
"%Hosts%"
],
"Version": "%Version%",
"Install": "%Install%",
"InstallFolder": "%Folder%",
"InstallFile": "%File%",
"Key": "%Key%",
"Mutex": "%MTX%",
"Certificate": "%Certificate%",
"Serversignature": "%Serversignature%",
"Anti": "%Anti%",
"Pastebin": "%Pastebin%",
"BDOS": "%BDOS%",
"Hwid": "null",
"Delay": "%Delay%",
"Group": "%Group%"
}
},
{
"file_path": "dangerzone/6b99acfa5961591c39b3f889cf29970c1dd48ddb0e274f14317940cf279a4412",
"sha256": "6b99acfa5961591c39b3f889cf29970c1dd48ddb0e274f14317940cf279a4412",
"yara_possible_family": "asyncrat",
"key": "eebdb6b2b00c2501b7b246442a354c5c3d743346e4cc88896ce68485dd6bbb8f",
"salt": "bfeb1e56fbcd973bb219022430a57843003d5644d21e62b9d4f180e7e6c33941",
"config": {
"Ports": [
"2400"
],
"Hosts": [
"minecraftdayzserver.ddns.net"
],
"Version": "0.5.8",
"Install": "true",
"InstallFolder": "%AppData%",
"InstallFile": "WinRar.exe",
"Key": "VUpkMU9UTEhRSEVSN2d2eWpLeDJud2Q0STFIcDRXS0U=",
"Mutex": "LMAsmxp3mz2D",
"Certificate": "MIIE4DCCAsigAwIBAgIQAM+WaL4OeJIj4I0Usukl1TANBgkqhkiG9w0BAQ0FADARMQ8wDQYDVQQDDAZTZXJ2ZXIwIBcNMjQwNDA0MTYzMzA2WhgPOTk5OTEyMzEyMzU5NTlaMBExDzANBgNVBAMMBlNlcnZlcjCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAKhz3rO2b0ITSMGvwlS7uWZLVU7cuvYiIyB2WnGxe2SUlT5/pZrRxfX6CVL8t11S5CG3UFMdKDutLiA1amqLDbkqZAjG/g1J+7OPUOBrBWfzpEk/CFCFjmU | text/markdown | null | jeFF0Falltrades <8444166+jeFF0Falltrades@users.noreply.github.com> | null | jeFF0Falltrades <8444166+jeFF0Falltrades@users.noreply.github.com> | Copyright (c) 2024 Jeff Archer
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| asyncrat, dcrat, malware, parser, quasarrat, venomrat, xenorat, xworm | [
"Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"dnfile",
"pycryptodomex",
"yara-python",
"pre-commit; extra == \"dev\"",
"pytest; extra == \"dev\"",
"maco; extra == \"maco\"",
"validators; extra == \"maco\""
] | [] | [] | [] | [
"Bug Reports, https://github.com/jeFF0Falltrades/rat_king_parser/issues",
"Homepage, https://github.com/jeFF0Falltrades/rat_king_parser",
"Say Thanks!, https://www.buymeacoffee.com/jeff0falltrades"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:27:42.550119 | rat_king_parser-4.2.3.tar.gz | 102,715 | 96/0e/e8aad8b0c21fab4963c043e8bf322761e4280a005103aa633cc0d2f6b90c/rat_king_parser-4.2.3.tar.gz | source | sdist | null | false | f2f87ec637de3ed1286ef436e19bdb14 | 2ea24f7b39f42210239bb27a5c864fdb4577fe992f176c0e6b2279687e354bc5 | 960ee8aad8b0c21fab4963c043e8bf322761e4280a005103aa633cc0d2f6b90c | null | [
"LICENSE"
] | 390 |
2.4 | aequilibrae | 1.6.0 | A package for transportation modeling | # AequilibraE
[](https://pypi.python.org/pypi/aequilibrae)
[](https://github.com/AequilibraE/aequilibrae/actions/workflows/documentation.yml)
[](https://github.com/AequilibraE/aequilibrae/actions/workflows/unit_tests.yml)
[](https://github.com/AequilibraE/aequilibrae/actions/workflows/test_linux_with_coverage.yml)
[](https://github.com/AequilibraE/aequilibrae/actions/workflows/build_wheels.yml)
AequilibraE is a fully-featured Open-Source transportation modeling package and
the first comprehensive package of its kind for the Python ecosystem, and is
released under an extremely permissive and business-friendly license.
It is developed as general-purpose modeling software and imposes very little
underlying structure on models built upon it. This flexibility also extends to
the ability of using all its core algorithms without an actual AequilibraE
model by simply building very simple memory objects from Pandas DataFrames, and
NumPY arrays, making it the perfect candidate for use-cases where transport is
one component of a bigger and more general planning or otherwise analytical
modeling pipeline.
Different than in traditional packages, AequilibraE's network is stored in
SQLite/Spatialite, a widely supported open format, and its editing capabilities
are built into its data layer through a series of spatial database triggers,
which allows network editing to be done on Any GIS package supporting SpatiaLite,
through a dedicated Python API or directly from an SQL console while maintaining
full geographical consistency between links and nodes, as well as data integrity
and consistency with other model tables.
AequilibraE provides full support for OMX matrices, which can be used as input
for any AequilibraE procedure, and makes its outputs, particularly skim matrices
readily available to other modeling activities.
AequilibraE includes multi-class user-equilibrium assignment with full support
for class-specific networks, value-of-time and generalized cost functions, and
includes a range of equilibration algorithms, including MSA, the traditional
Frank-Wolfe as well as the state-of-the-art Bi-conjugate Frank-Wolfe.
AequilibraE's support for public transport includes a GTFS importer that can
map-match routes into the model network and an optimized version of the
traditional "Optimal-Strategies" transit assignment, and full support in the data
model for other schedule-based assignments to be implemented in the future.
State-of-the-art computational performance and full multi-threading can be
expected from all key algorithms in AequilibraE, from cache-optimized IPF,
to path-computation based on sophisticated data structures and cascading network
loading, which all ensure that AequilibraE performs at par with the best
commercial packages current available on the market.
AequilibraE has also a Graphical Interface for the popular GIS package QGIS,
which gives access to most AequilibraE procedures and includes a wide range of
visualization tools, such as flow maps, desire and delaunay lines, scenario
comparison, matrix visualization, etc. This GUI, called QAequilibraE, is
currently available in English, French and Portuguese and more languages are
continuously being added, which is another substantial point of difference from
commercial packages.
Finally, AequilibraE is developed 100% in the open and incorporates software-development
best practices for testing and documentation. AequilibraE's testing includes all
major operating systems (Windows, Linux and MacOS) and all currently supported versions
of Python. AequilibraE is also supported on ARM-based cloud computation nodes, making
cloud deployments substantially less expensive.
## Comprehensive documentation
[AequilibraE documentation built with Sphinx ](http://www.aequilibrae.com)
### What is available only in QGIS
Some common resources for transportation modeling are inherently visual, and therefore they make more sense if
available within a GIS platform. For that reason, many resources are available only from AequilibraE's
[QGIS plugin](http://plugins.qgis.org/plugins/qaequilibrae/),
which uses AequilibraE as its computational workhorse and also provides GUIs for most of AequilibraE's tools. Said tool
is developed independently and a little delayed with relationship to the Python package, and more details can be found in its
[GitHub repository](https://github.com/AequilibraE/qaequilibrae).
| text/markdown | null | Pedro Camargo <pedro@outerloop.io> | AequilibraE contributors | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"Intended Audience :: End Users/Desktop",
"Intended Audience :: Other Audience",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy",
"scipy>=1.4",
"pyaml",
"requests",
"pandas>=2.2",
"shapely>=2.0",
"pyproj",
"rtree",
"pyarrow",
"openmatrix",
"geopandas",
"tqdm",
"enum34; extra == \"docs\"",
"Sphinx; extra == \"docs\"",
"pydata-sphinx-theme; extra == \"docs\"",
"sphinx_autodoc_annotation; extra == \"docs\""... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:27:10.553923 | aequilibrae-1.6.0.tar.gz | 8,634,157 | dc/7c/e97379a5bc9983308eb43106b2f88bd2b0593be3adfa2fd69c0ac7bff3af/aequilibrae-1.6.0.tar.gz | source | sdist | null | false | 494aa47d4d3b7c04d4c1cb6a78c5cbe6 | 0840bc5637dde58d1fa31ccb52ed23e3fcf71759b34536e828b38d8835f20c37 | dc7ce97379a5bc9983308eb43106b2f88bd2b0593be3adfa2fd69c0ac7bff3af | LicenseRef-AequilibraE | [
"LICENSE.TXT"
] | 1,550 |
2.1 | ijaza | 1.1.0 | Validate and verify Quranic verses in LLM-generated text with high accuracy | # Ijaza
**Validate and verify Quranic verses in LLM-generated text with high accuracy.**
Ijaza (Arabic: إجازة, meaning "authorization" or "permission to transmit") is a Python library that ensures the authenticity of Quranic text in AI-generated content. Just as traditional Islamic scholarship requires an *ijaza* to transmit sacred knowledge, this library provides a digital verification layer for Quranic quotes.
## Motivation
Large Language Models (LLMs) frequently misquote Quranic verses — changing words, mixing verses, or even fabricating text that sounds Quranic but isn't. This is a serious concern for:
- **Islamic content creators** who need accurate Quranic citations
- **Educational platforms** teaching Quran and Islamic studies
- **AI applications** serving Muslim communities (chatbots, translation tools, khutbah assistants)
- **Developers** building LLM-powered tools that handle religious text
Ijaza catches these errors automatically, corrects misquotations, and ensures that every Quranic verse in your application is authentic.
## Origin & Credits
This project began as a Python reimplementation of the excellent [quran-validator](https://github.com/yazinsai/quran-validator) npm package by [Yazin Alirhayim](https://github.com/yazinsai). We needed the same functionality for our Python-based projects and decided to port it while adding features specific to our use case.
Ijaza was developed as part of the [PolyKhateeb](https://github.com/memoelsamadony/polykhateeb) project — a real-time transcription and translation system for Islamic sermons (khutbahs). In that context, we needed to:
- Detect Quranic segments in transcribed speech to preserve them verbatim
- Validate LLM-corrected text to catch any misquotations
- Inject system prompts into LLMs to properly tag Quran quotes
## Installation
```bash
pip install ijaza
```
For better fuzzy matching performance (optional):
```bash
pip install ijaza[performance]
```
## Usage
### Basic Validation
```python
from ijaza import QuranValidator
validator = QuranValidator()
# Validate a specific quote
result = validator.validate("بِسْمِ ٱللَّهِ ٱلرَّحْمَٰنِ ٱلرَّحِيمِ")
print(result.is_valid) # True
print(result.reference) # "1:1"
print(result.match_type) # "exact"
print(result.confidence) # 1.0
```
### Detect Quran Quotes in Text
```python
from ijaza import QuranValidator
validator = QuranValidator()
text = "The Prophet said to recite بِسْمِ ٱللَّهِ ٱلرَّحْمَٰنِ ٱلرَّحِيمِ before eating."
detection = validator.detect_and_validate(text)
for segment in detection.segments:
if segment.validation and segment.validation.is_valid:
print(f"Found: {segment.text}")
print(f"Reference: {segment.validation.reference}")
```
### Look Up Verses
```python
from ijaza import QuranValidator
validator = QuranValidator()
# Get a specific verse
verse = validator.get_verse(surah=112, ayah=1)
print(verse.text) # Full text with diacritics
print(verse.text_simple) # Simplified text
# Get a range of verses
result = validator.get_verse_range(surah=112, start_ayah=1, end_ayah=4)
print(result['text'])
# Search for verses
results = validator.search("الرحمن", limit=5)
for r in results:
print(r)
```
### LLM Integration
```python
from ijaza import LLMProcessor, SYSTEM_PROMPTS
# 1. Add system prompt to your LLM call
system_prompt = SYSTEM_PROMPTS['xml'] # or 'markdown', 'bracket', 'minimal'
# 2. Process LLM response
processor = LLMProcessor()
result = processor.process(llm_response)
# 3. Use corrected text
print(result.corrected_text)
print(result.all_valid) # True if all quotes are authentic
# 4. Check for issues
for quote in result.quotes:
if quote.was_corrected:
print(f"Corrected: {quote.original} -> {quote.corrected}")
```
### Quick Validate (One-liner)
```python
from ijaza import quick_validate
result = quick_validate(llm_response)
print(result['has_quran_content']) # True/False
print(result['all_valid']) # True if all quotes are correct
print(result['issues']) # List of issues found
```
### ASR Error Tolerance
When processing speech-to-text output, Arabic ASR commonly confuses phonetically similar letters (ص/س, ط/ت, ض/د, etc.), drops function words, or produces stutters. Enable `asr_tolerant` mode for phonetic-aware matching:
```python
from ijaza import QuranValidator, ValidatorOptions
validator = QuranValidator(ValidatorOptions(asr_tolerant=True))
# ASR heard "السراط" instead of "الصراط" — phonetic confusion ص/س
# Standard matching would score this lower, ASR mode recognizes
# it as a known phonetic confusion and scores it higher.
result = validator.validate("يا ايها الذين امنوا اتقوا الله حق تقاته ولا تموتن الا وانتم مسلمون")
print(result.is_valid) # True
print(result.reference) # "3:102"
```
ASR mode also handles:
- **Stutter removal**: "قل قل هو الله" → "قل هو الله"
- **Function word drops**: Lower penalty when ASR drops و, في, من, etc.
- **Word boundary fixes**: Removes zero-width characters, collapses spaces
### Streaming Scanner (Cross-Chunk Verse Detection)
For real-time ASR pipelines where text arrives in chunks, a Quranic verse may be split across two chunks. The `StreamingScanner` maintains state across chunks to detect these split verses:
```python
from ijaza import StreamingScanner, StreamingScannerOptions
from ijaza.translations import TranslationProvider
provider = TranslationProvider()
scanner = StreamingScanner(
options=StreamingScannerOptions(
overlap_words=15,
min_confidence=0.85,
asr_tolerant=True,
),
translation_provider=provider,
)
# Process chunks as they arrive from ASR
for chunk in asr_stream:
result = scanner.process_chunk(chunk.text)
for verse in result.complete_verses:
print(f"Found: {verse.reference} — {verse.correct_text}")
print(f"English: {verse.translations.get('en', '')}")
if result.partial_verse:
print("Verse in progress, waiting for next chunk...")
# End of stream — flush remaining
final = scanner.flush()
scanner.reset()
```
For batch processing (non-streaming), use `scan_for_verses()`:
```python
from ijaza import QuranValidator
validator = QuranValidator()
text = "والصلاة والسلام على رسوله قل هو الله احد الله الصمد لم يلد ولم يولد ولم يكن له كفوا احد وهذا يدل على التوحيد"
results = validator.scan_for_verses(text, min_words=3, confidence_threshold=0.85)
for v in results:
print(f"{v['reference']}: {v['correct_text']}")
```
### Trusted Translations
When a Quranic verse is detected, ijaza can attach authoritative scholarly translations from bundled data — never LLM-generated:
```python
from ijaza import QuranValidator
from ijaza.translations import TranslationProvider
provider = TranslationProvider() # loads Sahih International + Bubenheim
validator = QuranValidator(translation_provider=provider)
result = validator.validate("بِسْمِ ٱللَّهِ ٱلرَّحْمَٰنِ ٱلرَّحِيمِ")
print(result.translations['en']) # "In the name of Allah, the Entirely Merciful, the Especially Merciful."
print(result.translations['de']) # "Im Namen Allahs, des Allerbarmers, des Barmherzigen."
```
Default editions: **Sahih International** (English) and **Bubenheim & Elyas** (German). To use different editions:
```python
from ijaza.translations import TranslationProvider, TranslationConfig
# Use Pickthall for English instead
provider = TranslationProvider(TranslationConfig(
editions={'en': 'en.pickthall', 'de': 'de.bubenheim'}
))
```
Fetch additional translation editions:
```bash
python scripts/fetch_translations.py --editions en.yusufali de.aburida
python scripts/fetch_translations.py --list-editions # show all available
```
Available editions: `en.sahih`, `en.pickthall`, `en.yusufali`, `en.asad`, `en.hilali`, `en.itani`, `de.bubenheim`, `de.aburida`, `de.khoury`, `de.zaidan`.
Translations also work with `LLMProcessor` and `StreamingScanner` — pass the `translation_provider` to any of them.
### Arabic Normalization Utilities
```python
from ijaza import normalize_arabic, remove_diacritics, contains_arabic
# Normalize Arabic text for comparison
normalized = normalize_arabic("بِسْمِ اللَّهِ") # "بسم الله"
# Remove only diacritics
clean = remove_diacritics("السَّلَامُ") # "السلام"
# Check for Arabic content
has_arabic = contains_arabic("Hello مرحبا") # True
```
## Features
- **Multi-tier matching**: exact → normalized → partial → fuzzy
- **LLM integration**: System prompts + post-processing validation
- **Arabic normalization**: Handles diacritics, alef variants, hamza, etc.
- **Auto-correction**: Fixes misquoted verses automatically
- **Detection**: Finds untagged Quran quotes in text
- **Full database**: 6,236 verses with Uthmani script
- **ASR error tolerance**: Phonetic-aware matching for speech recognition errors (ص/س, ط/ت, etc.)
- **Streaming scanner**: Cross-chunk verse detection for real-time ASR pipelines
- **Trusted translations**: Bundled English (Sahih International) and German (Bubenheim & Elyas) translations from scholarly sources
- **Zero dependencies**: Pure Python implementation (optional `rapidfuzz` for performance)
## API Reference
### QuranValidator
```python
from ijaza import QuranValidator, ValidatorOptions
from ijaza.translations import TranslationProvider
# With custom options
validator = QuranValidator(
options=ValidatorOptions(
fuzzy_threshold=0.85,
max_suggestions=5,
include_partial=True,
asr_tolerant=False, # set True for ASR input
),
translation_provider=TranslationProvider(), # optional
)
# Validate text
result = validator.validate("Arabic text here")
# Detect and validate all quotes in text
detection = validator.detect_and_validate("Text with Quran quotes...")
# Scan continuous Arabic text for embedded verses (sliding window)
found = validator.scan_for_verses("long arabic text...", min_words=3, confidence_threshold=0.85)
# Get specific verse
verse = validator.get_verse(surah=1, ayah=1)
# Get verse range
range_result = validator.get_verse_range(surah=112, start_ayah=1, end_ayah=4)
# Search verses
results = validator.search("search query", limit=10)
```
### LLMProcessor
```python
from ijaza import LLMProcessor, LLMProcessorOptions
from ijaza.translations import TranslationProvider
processor = LLMProcessor(
options=LLMProcessorOptions(
auto_correct=True,
min_confidence=0.85,
scan_untagged=True,
tag_format='xml', # or 'markdown', 'bracket'
),
translation_provider=TranslationProvider(), # optional
)
# Get system prompt for your LLM
prompt = processor.get_system_prompt()
# Process LLM output
result = processor.process(llm_output)
# Translations are attached to each detected quote
for quote in result.quotes:
print(quote.translations) # {'en': '...', 'de': '...'}
```
### StreamingScanner
```python
from ijaza import StreamingScanner, StreamingScannerOptions
from ijaza.translations import TranslationProvider
scanner = StreamingScanner(
options=StreamingScannerOptions(
overlap_words=10, # words retained between chunks
min_confidence=0.85,
min_words=3,
max_words=50,
max_chunk_span=3, # max chunks a partial can span
asr_tolerant=True,
),
translation_provider=TranslationProvider(), # optional
)
result = scanner.process_chunk("text chunk...")
# result.complete_verses — fully detected verses
# result.partial_verse — verse in progress at chunk boundary
final = scanner.flush() # emit remaining at end of stream
scanner.reset() # reset for new stream
```
### TranslationProvider
```python
from ijaza.translations import TranslationProvider, TranslationConfig, TRUSTED_EDITIONS
# Default: Sahih International (en) + Bubenheim (de)
provider = TranslationProvider()
# Custom editions
provider = TranslationProvider(TranslationConfig(
editions={'en': 'en.pickthall', 'de': 'de.aburida'}
))
# Look up translations
en = provider.get_translation(surah=1, ayah=1, lang='en')
all_langs = provider.get_translations(surah=1, ayah=1) # {'en': '...', 'de': '...'}
# Check availability
print(TRUSTED_EDITIONS) # all known edition identifiers
provider.is_edition_available('en.sahih') # True
```
### ASR Tolerance Utilities
```python
from ijaza.asr_tolerance import (
calculate_asr_similarity, # phonetic-aware string similarity
preprocess_asr_text, # stutter removal + boundary fixes
get_substitution_cost, # cost for a single char pair
PHONETIC_CONFUSIONS, # list of (char_a, char_b, cost) tuples
FUNCTION_WORDS, # set of Arabic particles ASR drops
)
# Phonetic-aware similarity (ص and س cost only 0.3 instead of 1.0)
sim = calculate_asr_similarity("الصراط", "السراط") # ~0.95
# Preprocess ASR output
clean = preprocess_asr_text("قل قل هو الله") # "قل هو الله"
```
### Normalization Utilities
```python
from ijaza import (
normalize_arabic,
remove_diacritics,
contains_arabic,
extract_arabic_segments,
calculate_similarity,
)
# Normalize Arabic text
normalized = normalize_arabic("بِسْمِ اللَّهِ") # "بسم الله"
# Remove only diacritics
clean = remove_diacritics("السَّلَامُ") # "السلام"
# Check for Arabic content
has_arabic = contains_arabic("Hello مرحبا") # True
# Extract Arabic segments from mixed text
segments = extract_arabic_segments("The verse بسم الله means...")
# Calculate text similarity
similarity = calculate_similarity("text1", "text2") # 0.0 - 1.0
```
## Future Work
### Framework Integrations
- LangChain / LlamaIndex guardrails
- FastAPI middleware
- Streamlit components
- Django/Flask integration
### Performance Optimizations
- N-gram indexing for pre-filtering candidates (faster `scan_for_verses`)
- BK-tree for metric-space nearest-neighbor search
## Contributing
Contributions are welcome! Please feel free to submit issues and pull requests.
## License
MIT
## Acknowledgments
- [Yazin Alirhayim](https://github.com/yazinsai) for the original [quran-validator](https://github.com/yazinsai/quran-validator) npm package
- [AlQuran.cloud](https://alquran.cloud/) for the Quran API
- The [PolyKhateeb](https://github.com/memoelsamadony/polykhateeb) project team
| text/markdown | null | Mahmoud Elsamadony <mahmoud.l.elsamadony@gmail.com> | null | Mahmoud Elsamadony <mahmoud.l.elsamadony@gmail.com> | MIT | quran, arabic, validation, llm, islamic, nlp, text-processing | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python ... | [] | null | null | >=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/memoelsamadony/ijaza",
"Documentation, https://github.com/memoelsamadony/ijaza#readme",
"Repository, https://github.com/memoelsamadony/ijaza.git",
"Issues, https://github.com/memoelsamadony/ijaza/issues",
"Changelog, https://github.com/memoelsamadony/ijaza/blob/main/CHANGELOG.m... | twine/6.2.0 CPython/3.12.3 | 2026-02-19T02:26:35.070978 | ijaza-1.1.0.tar.gz | 4,067,805 | b0/ee/ab5c8546681826ea4ebf15182ce805d4f49a9cf99b4d9ac5be0c4e306453/ijaza-1.1.0.tar.gz | source | sdist | null | false | a1d00bb83c3446bea1e7ec45250387c7 | a9954508c0ffeb088840f53e68947ef00624d79e0d758e208215004b56619b4c | b0eeab5c8546681826ea4ebf15182ce805d4f49a9cf99b4d9ac5be0c4e306453 | null | [] | 271 |
2.4 | database-wrapper-sqlite | 0.1.90 | database_wrapper for PostgreSQL database | # database_wrapper_sqlite
_Part of the `database_wrapper` package._
This python package is a database wrapper for [sqlite](https://www.sqlite.org/) database.
## !!! IMPORTANT !!!
This package is not yet implemented. The README is a placeholder for future implementation.
## Installation
```bash
pip install database_wrapper[sqlite]
```
## Usage
```python
from database_wrapper_sqlite import Sqlite, DBWrapperSqlite
db = Sqlite({
"database": "my_database.db",
})
db.open()
dbWrapper = DBWrapperSqlite(dbCursor=db.cursor)
# Simple query
aModel = MyModel()
res = await dbWrapper.getByKey(
aModel,
"id",
3005,
)
if res:
print(f"getByKey: {res.toDict()}")
else:
print("No results")
# Raw query
res = await dbWrapper.getAll(
aModel,
customQuery="""
SELECT t1.*, t2.name AS other_name
FROM my_table AS t1
LEFT JOIN other_table AS t2 ON t1.other_id = t2.id
"""
)
async for record in res:
print(f"getAll: {record.toDict()}")
else:
print("No results")
db.close()
```
| text/markdown | null | Gints Murans <gm@gm.lv> | null | null | GNU General Public License v3.0 (GPL-3.0) | database, wrapper, python, sqlite | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | >=3.8 | [] | [] | [] | [
"database_wrapper==0.1.90"
] | [] | [] | [] | [
"Homepage, https://github.com/gintsmurans/py_database_wrapper",
"Documentation, https://github.com/gintsmurans/py_database_wrapper",
"Changes, https://github.com/gintsmurans/py_database_wrapper",
"Code, https://github.com/gintsmurans/py_database_wrapper",
"Issue Tracker, https://github.com/gintsmurans/py_da... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:26:05.362196 | database_wrapper_sqlite-0.1.90.tar.gz | 3,040 | 26/5d/627fb1b6ece56c11151a03f96043a2c45e4914ac30816e140ee6c87717cb/database_wrapper_sqlite-0.1.90.tar.gz | source | sdist | null | false | 4be1ff9c2062e78f553d3abadcb69040 | e15eed795ff4b8dfa03822b69eedc48ff38a2e6c378fb81ce98263a3c185a64e | 265d627fb1b6ece56c11151a03f96043a2c45e4914ac30816e140ee6c87717cb | null | [] | 262 |
2.4 | database-wrapper-pgsql | 0.1.90 | database_wrapper for PostgreSQL database | # database_wrapper_pgsql
_Part of the `database_wrapper` package._
This python package is a database wrapper for [PostgreSQL](https://www.postgresql.org/) (also called pgsql) database.
## Installation
```bash
pip install database_wrapper[pgsql]
```
## Usage
```python
from database_wrapper_pgsql import PgSQLWithPoolingAsync, DBWrapperPgSQLAsync
db = PgSQLWithPoolingAsync({
"hostname": "localhost",
"port": 3306,
"username": "root",
"password": "your_password",
"database": "my_database"
})
await db.openPool()
try:
async with db as (dbConn, dbCursor):
dbWrapper = DBWrapperPgSQLAsync(dbCursor=dbCursor)
# Simple query
aModel = MyModel()
res = await dbWrapper.getByKey(
aModel,
"id",
3005,
)
if res:
print(f"getByKey: {res.toDict()}")
else:
print("No results")
# Raw query
res = await dbWrapper.getAll(
aModel,
customQuery="""
SELECT t1.*, t2.name AS other_name
FROM my_table AS t1
LEFT JOIN other_table AS t2 ON t1.other_id = t2.id
"""
)
async for record in res:
print(f"getAll: {record.toDict()}")
else:
print("No results")
finally:
await db.openPool()
```
| text/markdown | null | Gints Murans <gm@gm.lv> | null | null | GNU General Public License v3.0 (GPL-3.0) | database, wrapper, python, postgresql, pgsql | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | >=3.8 | [] | [] | [] | [
"database_wrapper==0.1.90",
"psycopg[binary]>=3.2.0",
"psycopg[pool]>=3.2.0"
] | [] | [] | [] | [
"Homepage, https://github.com/gintsmurans/py_database_wrapper",
"Documentation, https://github.com/gintsmurans/py_database_wrapper",
"Changes, https://github.com/gintsmurans/py_database_wrapper",
"Code, https://github.com/gintsmurans/py_database_wrapper",
"Issue Tracker, https://github.com/gintsmurans/py_da... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:26:04.534834 | database_wrapper_pgsql-0.1.90.tar.gz | 9,144 | 28/45/558c5c44856a1157e83217147ebb2d18d08e2043762d7769f191ac4dc015/database_wrapper_pgsql-0.1.90.tar.gz | source | sdist | null | false | aad8afdfb7df10647e6a41689e057f1c | 3cbebbe596a0920c463f6e2058d6033357edf50146074e8d8894f8c936442eca | 2845558c5c44856a1157e83217147ebb2d18d08e2043762d7769f191ac4dc015 | null | [] | 266 |
2.4 | database-wrapper-mysql | 0.1.90 | database_wrapper for MySQL database | # database_wrapper_mysql
_Part of the `database_wrapper` package._
This python package is a database wrapper for [MySQL](https://www.mysql.com/) and [MariaDB](https://mariadb.org/) database.
## Installation
```bash
pip install database_wrapper[mysql]
```
## Usage
```python
from database_wrapper_mysql import MySQL, DBWrapperMySQL
db = MySQL({
"hostname": "localhost",
"port": 3306,
"username": "root",
"password": "your_password",
"database": "my_database"
})
db.open()
dbWrapper = DBWrapperMySQL(dbCursor=db.cursor)
# Simple query
aModel = MyModel()
res = await dbWrapper.getByKey(
aModel,
"id",
3005,
)
if res:
print(f"getByKey: {res.toDict()}")
else:
print("No results")
# Raw query
res = await dbWrapper.getAll(
aModel,
customQuery="""
SELECT t1.*, t2.name AS other_name
FROM my_table AS t1
LEFT JOIN other_table AS t2 ON t1.other_id = t2.id
"""
)
async for record in res:
print(f"getAll: {record.toDict()}")
else:
print("No results")
db.close()
```
| text/markdown | null | Gints Murans <gm@gm.lv> | null | null | GNU General Public License v3.0 (GPL-3.0) | database, wrapper, python, mysql, mariadb | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | >=3.8 | [] | [] | [] | [
"database_wrapper==0.1.90",
"mysqlclient>=2.2.2"
] | [] | [] | [] | [
"Homepage, https://github.com/gintsmurans/py_database_wrapper",
"Documentation, https://github.com/gintsmurans/py_database_wrapper",
"Changes, https://github.com/gintsmurans/py_database_wrapper",
"Code, https://github.com/gintsmurans/py_database_wrapper",
"Issue Tracker, https://github.com/gintsmurans/py_da... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:26:03.240168 | database_wrapper_mysql-0.1.90.tar.gz | 4,309 | d0/f3/091cabc0fb0240ad2e7fb68098a1b59b28f3d480f87054269175c4c04f3f/database_wrapper_mysql-0.1.90.tar.gz | source | sdist | null | false | c67c90eca1c7e56cc1519546146eacb3 | dbfe678aa7a1a4d1e90608897223133bf78a9f2b154f752353b4189ccd962197 | d0f3091cabc0fb0240ad2e7fb68098a1b59b28f3d480f87054269175c4c04f3f | null | [] | 266 |
2.4 | database-wrapper-mssql | 0.1.90 | database_wrapper for MSSQL database | # database_wrapper_mssql
_Part of the `database_wrapper` package._
This python package is a database wrapper for [MSSQL](https://www.microsoft.com/en-us/sql-server/sql-server-downloads) database.
## Installation
```bash
pip install database_wrapper[mssql]
```
## Usage
```python
from database_wrapper_mssql import MSSQL, DBWrapperMSSQL
db = MSSQL({
"hostname": "localhost",
"port": "1433",
"username": "sa",
"password": "your_password",
"database": "master"
})
db.open()
dbWrapper = DBWrapperMSSQL(dbCursor=db.cursor)
# Simple query
aModel = MyModel()
res = await dbWrapper.getByKey(
aModel,
"id",
3005,
)
if res:
print(f"getByKey: {res.toDict()}")
else:
print("No results")
# Raw query
res = await dbWrapper.getAll(
aModel,
customQuery="""
SELECT t1.*, t2.name AS other_name
FROM my_table AS t1
LEFT JOIN other_table AS t2 ON t1.other_id = t2.id
"""
)
async for record in res:
print(f"getAll: {record.toDict()}")
else:
print("No results")
db.close()
```
| text/markdown | null | Gints Murans <gm@gm.lv> | null | null | GNU General Public License v3.0 (GPL-3.0) | database, wrapper, python, mssql, sqlserver | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | >=3.8 | [] | [] | [] | [
"database_wrapper==0.1.90",
"pymssql>=2.2.10"
] | [] | [] | [] | [
"Homepage, https://github.com/gintsmurans/py_database_wrapper",
"Documentation, https://github.com/gintsmurans/py_database_wrapper",
"Changes, https://github.com/gintsmurans/py_database_wrapper",
"Code, https://github.com/gintsmurans/py_database_wrapper",
"Issue Tracker, https://github.com/gintsmurans/py_da... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:26:01.046973 | database_wrapper_mssql-0.1.90.tar.gz | 4,139 | 79/32/584533cae4081877c91268a912903948f8a1343865552231595374014e87/database_wrapper_mssql-0.1.90.tar.gz | source | sdist | null | false | 0fe8407aa36c4fe9811c5b1af1505637 | db362101a8907c5ba374ba521d84118c176553713f1e0e2f98aeadc1ad714554 | 7932584533cae4081877c91268a912903948f8a1343865552231595374014e87 | null | [] | 268 |
2.4 | database-wrapper | 0.1.90 | A Different Approach to Database Wrappers in Python | # database_wrapper
_Part of the `database_wrapper` package._
This package is a base package for database wrappers. It is not intended to be used directly, but rather to be used via one of the database specific packages.
See the README.md files in the database specific packages for more information.
* [database_wrapper_pgsql](https://pypi.org/project/database_wrapper_pgsql/)
* [database_wrapper_mysql](https://pypi.org/project/database_wrapper_mysql/)
* [database_wrapper_mssql](https://pypi.org/project/database_wrapper_mssql/)
* [database_wrapper_sqlite](https://pypi.org/project/database_wrapper_sqlite/)
| text/markdown | null | Gints Murans <gm@gm.lv> | null | null | GNU General Public License v3.0 (GPL-3.0) | database, wrapper, python, pgsql, mysql, mssql, sqlite | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | >=3.8 | [] | [] | [] | [
"database_wrapper_pgsql==0.1.90; extra == \"pgsql\"",
"database_wrapper_mysql==0.1.90; extra == \"mysql\"",
"database_wrapper_mssql==0.1.90; extra == \"mssql\"",
"database_wrapper_sqlite==0.1.90; extra == \"sqlite\"",
"database_wrapper[mssql,mysql,pgsql,sqlite]; extra == \"all\"",
"ast-comments>=1.1.2; ex... | [] | [] | [] | [
"Homepage, https://github.com/gintsmurans/py_database_wrapper",
"Documentation, https://github.com/gintsmurans/py_database_wrapper",
"Changes, https://github.com/gintsmurans/py_database_wrapper",
"Code, https://github.com/gintsmurans/py_database_wrapper",
"Issue Tracker, https://github.com/gintsmurans/py_da... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:26:00.124112 | database_wrapper-0.1.90.tar.gz | 15,573 | ee/e8/f58ce5fd486fa5548eb052166a45e8fa39b1bc0b17e839b9d5f28593f600/database_wrapper-0.1.90.tar.gz | source | sdist | null | false | 68d1722dfa27f09bfb234094a216e87d | ced6db9fe37a35567fe7533189d40c19e6519b31d67e43acefcff71a9ee29ca6 | eee8f58ce5fd486fa5548eb052166a45e8fa39b1bc0b17e839b9d5f28593f600 | null | [] | 328 |
2.4 | zerophix | 0.1.19 | Enterprise-grade PII/PSI/PHI redaction service: multilingual, customizable, and privacy-first | # ZeroPhix v0.1.19 - Enterprise PII/PSI/PHI Redaction
**Enterprise-grade, multilingual PII/PSI/PHI redaction - free, offline, and fully customizable.**
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/Apache-2.0)
[](#security--compliance)
[](#compliance)
## What is ZeroPhix?
**ZeroPhix** is an enterprise-grade tool for detecting and redacting sensitive information from text, documents, and data streams.
### Detects & Redacts
- **PII** (Personally Identifiable Information) - names, addresses, emails, phone numbers
- **PHI** (Protected Health Information) - medical records, patient data, health identifiers
- **PSI** (Personal Sensitive Information) - financial data, credentials, government IDs
- **Custom Data** - proprietary identifiers, internal codes, API keys
### Name Origin
- **Zero** = eliminate, remove, redact
- **Phi** = from PHI (Protected Health Information)
- **x** = extensible to PII, PSI, and any sensitive data types
## Why Choose ZeroPhix?
| Feature | Benefit |
|---------|---------|
| **High Accuracy** | ML models + regex patterns = high Precision/Recall |
| **Fast Processing** | Smart caching + async = infra dependent |
| **Self-Hosted** | No per-document API fees, requires infrastructure and maintenance |
| **Fully Offline** | Air-gapped after one-time model setup |
| **Multi-Country** | Australia, US, EU, UK, Canada + extensible |
| **100+ Entity Types** | SSN, credit cards, medical IDs, passports, etc. |
| **Zero-Shot Detection** | Detect ANY entity type without training (GLiNER) |
| **Compliance Ready** | GDPR, HIPAA, PCI DSS, CCPA certified |
| **Enterprise Security** | Zero Trust, encryption, audit trails |
| **Multiple Formats** | PDF, DOCX, Excel, CSV, HTML, JSON |
## Quick Start
### Installation
**Install directly from PyPI:**
```bash
pip install zerophix
```
Or use extras for full features:
```bash
# With all features (recommended)
pip install "zerophix[all]"
# Or select specific features
pip install "zerophix[gliner,documents,api]"
# For DataFrame support
pip install "zerophix[all]" pandas # For Pandas
pip install "zerophix[all]" pyspark # For PySpark
```
### One-Time Model Setup (Optional)
ZeroPhix works **100% offline** after initial setup. ML models are downloaded once and cached locally:
```bash
# spaCy models (optional - for enhanced NER)
python -m spacy download en_core_web_lg
# Other ML models auto-download on first use and cache locally
# After initial download, no internet required - fully air-gapped
```
**Offline Modes:**
- **Regex-only**: Works immediately, no downloads, 100% offline from install
- **With ML models**: One-time download, then 100% offline forever
- **Air-gapped environments**: Pre-download models, transfer via USB/network
### Databricks / Cloud Platforms
**For Databricks (DBR 18.0+):**
Install via cluster **Libraries → Install from PyPI**:
```
pydantic>=2.7
pyyaml>=6.0.1
regex>=2024.4.16
click>=8.1.7
tqdm>=4.66.5
rich>=13.9.2
nltk>=3.8.1
cryptography>=41.0.0
pypdf>=3.0.0
zerophix==0.1.15
```
**Note:** Don't install scipy/numpy/pandas separately on Databricks - use cluster's pre-compiled versions.
### Detection Methods Comparison
```python
"""Detection Methods Comparison - With Per-Method Redacted Text"""
print("ZEROPHIX: DETECTION METHODS COMPARISON")
text = """Patient John Doe (born 1985-03-15) was treated for diabetes.
Contact: john.doe@hospital.com, emergency: (555) 123-4567.
Insurance: INS-123456, SSN: 123-45-6789."""
print(f"\n ORIGINAL TEXT:")
print(f" {text}\n")
from zerophix.pipelines.redaction import RedactionPipeline
from zerophix.config import RedactionConfig
configs = [
("Regex Only", {"country": "US", "use_bert": False, "use_gliner": False}),
("Regex + BERT", {"country": "US", "use_bert": True, "use_gliner": False}),
("Regex + GLiNER", {"country": "US", "use_bert": False, "use_gliner": True}),
("Ensemble (BERT+GLiNER)", {"country": "US", "use_bert": True, "use_gliner": True, "enable_ensemble_voting": True}),
]
results_summary = []
for name, flags in configs:
try:
config = RedactionConfig(**flags)
pipeline = RedactionPipeline(config)
result = pipeline.redact(text)
spans = result.get('spans', [])
redacted_text = result.get('text', text)
print("─" * 70)
print(f" {name}")
print("─" * 70)
print(f" Entities Found: {len(spans)}")
print(f"\n REDACTED TEXT:")
print(f" {redacted_text}")
if spans:
print(f"\n DETECTED ENTITIES:")
for span in spans:
label = span.get('label', 'UNKNOWN')
start = span.get('start')
end = span.get('end')
if start is not None and end is not None:
value = text[start:end]
else:
value = span.get('value', '???')
print(f" {label:<25} → {value}")
else:
print(f"\n No entities detected")
results_summary.append((name, len(spans)))
print()
except (RuntimeError, ImportError) as e:
print(f" {str(e)} (skipped)\n")
results_summary.append((name, 0))
print(" SUMMARY")
print("=" * 70)
print(f"{'Method':<25} {'PII Found':<12} {'Advantage'}")
print("-" * 70)
for name, count in results_summary:
if "Regex Only" in name:
advantage = "Fast baseline, catches structured patterns"
elif "BERT" in name and "+" not in name:
advantage = "Adds PERSON_NAME detection (context-aware)"
elif "GLiNER" in name and "+" not in name:
advantage = "Detects medical/contextual entities"
else:
advantage = "Best coverage via ensemble voting"
print(f"{name:<25} {count:<12} {advantage}")
```
**Output:**
```
ZEROPHIX: DETECTION METHODS COMPARISON
ORIGINAL TEXT:
Patient John Doe (born 1985-03-15) was treated for diabetes.
Contact: john.doe@hospital.com, emergency: (555) 123-4567.
Insurance: INS-123456, SSN: 123-45-6789.
──────────────────────────────────────────────────────────────────────
Regex Only
──────────────────────────────────────────────────────────────────────
Entities Found: 4
REDACTED TEXT:
Patient John Doe (born 68b5b32e5ebc) was treated for diabetes.
Contact: 6b0b4806b1e5, emergency: (bceb5476591e.
Insurance: INS-123456, SSN: 01a54629efb9.
DETECTED ENTITIES:
DOB_ISO → 1985-03-15
EMAIL → john.doe@hospital.com
PHONE_US → 555) 123-4567
SSN → 123-45-6789
BERT detector requested but not installed. Install zerophix[bert]. (skipped)
GLiNER not installed. Install with: pip install gliner (skipped)
BERT detector requested but not installed. Install zerophix[bert]. (skipped)
SUMMARY
======================================================================
Method PII Found Advantage
----------------------------------------------------------------------
Regex Only 4 Fast baseline, catches structured patterns
Regex + BERT 0 Best coverage via ensemble voting
Regex + GLiNER 0 Best coverage via ensemble voting
Ensemble (BERT+GLiNER) 0 Best coverage via ensemble voting
```
### Advanced PII Scanning with Reporting
```python
"""Advanced PII Scanning with Reporting"""
from zerophix.config import RedactionConfig
from zerophix.pipelines.redaction import RedactionPipeline
import json
# Example 1: Detailed Report
print("DETAILED DETECTION REPORT")
text = "SSN: 123-45-6789, Email: john@example.com, Phone: (555) 123-4567"
config = RedactionConfig(country="US", include_confidence=True)
pipeline = RedactionPipeline(config)
result = pipeline.redact(text)
spans = result.get('spans', [])
print(f"\nText: {text}\n")
print(f"{'Entity Type':<20} {'Value':<25} {'Position':<15}")
for entity in spans:
label = entity['label']
start, end = entity['start'], entity['end']
value = text[start:end]
pos = f"[{start}:{end}]"
print(f"{label:<20} {value:<25} {pos:<15}")
# Example 2: Risk Assessment Report
print("\n\nRISK ASSESSMENT REPORT")
texts = {
"low_risk": "Product ABC costs $49.99",
"medium_risk": "Contact: john@example.com",
"high_risk": "SSN: 123-45-6789, Card: 4532-1234-5678-9999, (555) 123-4567"
}
config = RedactionConfig(country="US")
pipeline = RedactionPipeline(config)
risk_levels = {"low_risk": 0, "medium_risk": 0, "high_risk": 0}
for risk, text in texts.items():
result = pipeline.redact(text)
count = len(result.get('spans', []))
if count == 0:
level = "LOW"
risk_levels["low_risk"] += 1
elif count <= 2:
level = "MEDIUM"
risk_levels["medium_risk"] += 1
else:
level = "HIGH"
risk_levels["high_risk"] += 1
print(f"\n[{level}] {count} entities found")
print(f" Original: {text}")
print(f" Redacted: {result['text']}")
# Example 3: Statistical Report
print("\n\nSTATISTICAL REPORT")
texts = [
"John Doe, SSN: 123-45-6789",
"Email: jane@example.com",
"Phone: (555) 123-4567",
"Product: XYZ, Price: $99",
"Card: 4532-1234-5678-9999"
]
config = RedactionConfig(country="US", use_bert=False, use_gliner=False)
pipeline = RedactionPipeline(config)
stats = {"total_texts": len(texts), "total_entities": 0, "by_type": {}}
for text in texts:
result = pipeline.redact(text)
for entity in result.get('spans', []):
label = entity['label']
stats["total_entities"] += 1
stats["by_type"][label] = stats["by_type"].get(label, 0) + 1
print(f"\nDocuments Scanned: {stats['total_texts']}")
print(f"Total PII Found: {stats['total_entities']}")
print(f"\nBreakdown by Type:")
for entity_type, count in sorted(stats['by_type'].items()):
pct = (count / stats['total_entities']) * 100 if stats['total_entities'] > 0 else 0
print(f" {entity_type:<20} {count:>3} ({pct:>5.1f}%)")
# Example 4: JSON Export
print("\n\nJSON EXPORT")
text = "Dr. Jane Smith: jane@clinic.com, (555) 987-6543, SSN: 456-78-9012"
config = RedactionConfig(country="US", use_bert=False)
pipeline = RedactionPipeline(config)
result = pipeline.redact(text)
report = {
"original_text": text,
"redacted_text": result['text'],
"entities_found": len(result.get('spans', [])),
"entities": [
{
"type": e['label'],
"value": text[e['start']:e['end']],
"position": (e['start'], e['end'])
}
for e in result.get('spans', [])
]
}
print(json.dumps(report, indent=2))
```
**Output:**
```
DETAILED DETECTION REPORT
Text: SSN: 123-45-6789, Email: john@example.com, Phone: (555) 123-4567
Entity Type Value Position
SSN 123-45-6789 [5:16]
EMAIL john@example.com [25:41]
PHONE_US 555) 123-4567 [51:64]
RISK ASSESSMENT REPORT
[LOW] 0 entities found
Original: Product ABC costs $49.99
Redacted: Product ABC costs $49.99
[MEDIUM] 1 entities found
Original: Contact: john@example.com
Redacted: Contact: 855f96e983f1
[HIGH] 3 entities found
Original: SSN: 123-45-6789, Card: 4532-1234-5678-9999, (555) 123-4567
Redacted: SSN: 01a54629efb9, Card: 77b9ec3e5b03, (bceb5476591e
STATISTICAL REPORT
Documents Scanned: 5
Total PII Found: 4
Breakdown by Type:
CREDIT_CARD 1 ( 25.0%)
EMAIL 1 ( 25.0%)
PHONE_US 1 ( 25.0%)
SSN 1 ( 25.0%)
JSON EXPORT
{
"original_text": "Dr. Jane Smith: jane@clinic.com, (555) 987-6543, SSN: 456-78-9012",
"redacted_text": "Dr. Jane Smith: d87eba4c9a30, (d8f6c45fb5e3, SSN: 34450d3629c8",
"entities_found": 3,
"entities": [
{
"type": "EMAIL",
"value": "jane@clinic.com",
"position": [
16,
31
]
},
{
"type": "PHONE_US",
"value": "555) 987-6543",
"position": [
34,
47
]
},
{
"type": "SSN",
"value": "456-78-9012",
"position": [
54,
65
]
}
]
}
```
### Supported Input Types
ZeroPhix handles all common data formats:
```python
# 1. Single String
result = pipeline.redact("John Smith, SSN: 123-45-6789")
# 2. List of Strings (Batch)
texts = ["text 1 with PII", "text 2 with PHI", "text 3"]
results = pipeline.redact_batch(texts)
# 3. Pandas DataFrame
from zerophix.processors import redact_pandas
df_clean = redact_pandas(df, columns=['name', 'email', 'ssn'], country='US')
# 4. PySpark DataFrame
from zerophix.processors import redact_spark
spark_df_clean = redact_spark(spark_df, columns=['patient_name', 'mrn'], country='US')
# 5. Files (PDF, DOCX, Excel)
from zerophix.processors import PDFProcessor
PDFProcessor().redact_file('input.pdf', 'output.pdf', pipeline)
# 6. Scanning (detect without redacting)
scan_result = pipeline.scan(text) # Returns entities found
```
**Quick Test:**
```bash
# Test all interfaces
python examples/test_all_interfaces.py
# Comprehensive examples
python examples/all_interfaces_demo.py
```
### Australian Coverage Highlights
ZeroPhix has **deep Australian coverage** with mathematical checksum validation:
- **40+ Australian entity types** (TFN, ABN, ACN, Medicare, driver licenses for all 8 states)
- **Checksum validation** for government IDs (TFN mod 11, ABN mod 89, ACN mod 10, Medicare mod 10)
- **92%+ precision** for Australian government identifiers
- State-specific patterns (NSW, VIC, QLD, SA, WA, TAS, NT, ACT)
- Healthcare, financial, and government identifiers
See [AUSTRALIAN_COVERAGE.md](AUSTRALIAN_COVERAGE.md) for complete details.
### Command Line
```bash
# Redact text
zerophix redact --text "Sensitive information here"
# Redact files
zerophix redact-file --input document.pdf --output clean.pdf
# Start API server
python -m zerophix.api.rest
```
## Redaction Strategies
ZeroPhix supports multiple redaction strategies to balance privacy and data utility:
| Strategy | Description | Example | Use Case |
|----------|-------------|---------|----------|
| **replace** | Full replacement with entity type | `<SSN>` or `<AU_TFN>` | Maximum privacy, clear labeling |
| **mask** | Partial masking | `29****3456` or `***-**-6789` | Data utility + privacy balance |
| **hash** | Consistent hashing | `HASH_A1B2C3D4` | Record linking, de-duplication |
| **encrypt** | Reversible encryption | `ENC_XYZ123` | Secure storage, de-anonymization |
| **brackets** / **redact** | Simple [REDACTED] | `[REDACTED]` | Document redaction, printouts |
| **synthetic** | Realistic fake data | `Alex Smith` / `555-1234` | Testing, demos, data sharing |
| **preserve_format** | Format-preserving | `K8d-2L-m9P3` (for SSN) | Schema compatibility |
| **au_phone** | Keep AU area code | `04XX-XXX-XXX` | Australian context preservation |
| **differential_privacy** | Statistical noise | Original ± noise | Research, analytics |
| **k_anonymity** | Generalization | `<30` (age) / `20XX` (postcode) | Privacy-preserving analytics |
**Usage:**
```python
# Choose your strategy
config = RedactionConfig(
country="AU",
masking_style="hash" # or: replace, mask, encrypt, synthetic, etc.
)
pipeline = RedactionPipeline(config)
result = pipeline.redact(text)
# Strategy-specific options
config = RedactionConfig(
masking_style="mask",
mask_percentage=0.7, # Mask 70% of characters
preserve_format=True
)
```
## Core Features
### 1. Detection Methods
#### Regex Patterns (Ultra-fast, highest precision)
- Country-specific patterns for each jurisdiction
- Format validation with checksum verification
- Covers SSN, credit cards, IDs, medical numbers
#### Machine Learning Models
**spaCy NER** - Fast, high recall for names and entities
```python
config = RedactionConfig(use_spacy=True, spacy_model="en_core_web_lg")
```
**BERT** - Highest accuracy for complex text
```python
config = RedactionConfig(use_bert=True, bert_model="bert-base-cased")
```
**OpenMed** - Healthcare-specialized PHI detection
```python
config = RedactionConfig(use_openmed=True, openmed_model="openmed-base")
```
**GLiNER** - Zero-shot detection
```python
from zerophix.detectors.gliner_detector import GLiNERDetector
detector = GLiNERDetector()
spans = detector.detect(text, entity_types=["employee id", "project code", "api key"])
# No training needed - just name what you want to find!
```
#### Statistical Analysis
- Entropy-based pattern discovery
- Frequency analysis for repetitive patterns
- Anomaly detection
#### Auto-Mode (Intelligent Domain Detection)
```python
config = RedactionConfig(mode="auto") # Auto-selects best detectors
```
## Choosing the Right Configuration
### Decision Tree: What Should You Use?
**The best configuration is always empirical** - it depends on your specific use case, data characteristics, accuracy requirements, and performance constraints. We strongly recommend testing multiple configurations on your actual data to determine what works best.
#### Quick Decision Guide
```
START HERE
│
├─ Need MAXIMUM SPEED (real-time, high-volume)?
│ └─ Use: mode='fast' (regex only)
│ - High Speed
│ - High precision on structured IDs
│ - Best for: emails, phones, SSN, TFN, ABN, credit cards
│ - May miss: names in unstructured text, context-dependent entities
│
├─ Need MAXIMUM ACCURACY (compliance-critical)?
│ └─ Use: mode='accurate' (regex + all ML models)
│ - High recall (catches more PII)
│ - Best for: healthcare PHI, legal discovery, GDPR compliance
│ - Slower
│ - Higher memory: 500MB-2GB
│
├─ Structured data ONLY (CSV, forms, databases)?
│ └─ Use: mode='fast' with validation
│ - Checksum validation for TFN/ABN/Medicare
│ - Format-specific patterns
│ - Near-perfect precision
│
├─ Unstructured text (emails, documents, notes)?
│ └─ Use: mode='accurate' OR custom ensemble
│ - Combines regex + spaCy + BERT/GLiNER
│ - Catches names, context-dependent entities
│ - Better recall on varied text
│
├─ Healthcare/Medical data?
│ └─ Use: mode='accurate' + use_openmed=True
│ - PHI-optimized models
│ - Medical terminology awareness
│ - HIPAA compliance focus (87.5% recall benchmark)
│
├─ Custom entity types (not standard PII)?
│ └─ Use: GLiNER with custom labels
│ - Zero-shot detection - no training needed
│ - Just name what you want: "employee ID", "project code"
│ - Works on domain-specific identifiers
│
└─ Not sure? Testing multiple datasets?
└─ Use: mode='auto'
- Intelligently selects detectors per document
- Good starting point
- Then benchmark and tune based on your results
```
### Configuration Examples by Use Case
**High-Volume Transaction Processing:**
```python
config = RedactionConfig(
mode='fast',
use_spacy=False,
use_bert=False,
enable_checksum_validation=True # TFN/ABN validation
)
# Prioritizes: Speed, low memory, structured data
```
**Healthcare Records (HIPAA Compliance):**
```python
config = RedactionConfig(
mode='accurate',
use_spacy=True,
use_openmed=True,
use_bert=True,
recall_threshold=0.85 # Prioritize not missing PHI
)
# Prioritizes: High recall, medical PHI, compliance
```
**Legal Document Review:**
```python
config = RedactionConfig(
mode='accurate',
use_spacy=True,
use_bert=True,
use_gliner=True,
precision_threshold=0.90 # Reduce false positives
)
# Prioritizes: Accuracy, names, case numbers, dates
```
**Customer Support Logs (Mixed Content):**
```python
config = RedactionConfig(
mode='balanced', # Medium speed + accuracy
use_spacy=True,
use_bert=False, # Skip if speed matters
batch_size=100
)
# Prioritizes: Balanced speed/accuracy, emails, phones, names
```
### Testing Recommendations
**Always benchmark on YOUR data:**
1. **Start with 'auto' mode** - Get baseline performance
2. **Test 'fast' mode** - Measure speed vs accuracy trade-off
3. **Test 'accurate' mode** - Measure recall improvement
4. **Try custom combinations** - Enable/disable specific detectors
5. **Measure what matters to YOU:**
- False negatives (missed PII) → Increase recall threshold, add more detectors
- False positives (over-redaction) → Increase precision threshold, tune regex patterns
- Speed (docs/sec) → Disable slower ML models, use batch processing
- Memory usage → Lazy-load models, reduce batch size
**Sample Evaluation Script:**
```python
from zerophix.eval.metrics import evaluate_detection
configs = [
{'mode': 'fast'},
{'mode': 'balanced'},
{'mode': 'accurate'},
{'mode': 'accurate', 'use_openmed': True} # If healthcare data
]
for cfg in configs:
pipeline = RedactionPipeline(RedactionConfig(**cfg))
metrics = evaluate_detection(pipeline, your_test_data)
print(f"{cfg}: Precision={metrics['precision']:.2f}, Recall={metrics['recall']:.2f}")
```
**Key Takeaway:** There is no one-size-fits-all configuration. The "best" setup depends on your data type, accuracy requirements, speed constraints, and compliance needs. Empirical testing is essential.
## Adaptive Ensemble - Auto-Configuration
**Problem:** Manual trial-and-error configuration with unpredictable accuracy
**Solution:** Automatic calibration learns optimal detector weights from your data
### Quick Start
```python
from zerophix.config import RedactionConfig
from zerophix.pipelines.redaction import RedactionPipeline
# 1. Enable adaptive features
config = RedactionConfig(
country="AU",
use_gliner=True,
use_openmed=True,
enable_adaptive_weights=True, # Auto-learns optimal weights
enable_label_normalization=True, # Fixes cross-detector consensus
)
pipeline = RedactionPipeline(config)
# 2. Calibrate on 20-50 labeled samples
validation_texts = ["John Smith has diabetes", "Call 555-1234", ...]
validation_ground_truth = [
[(0, 10, "PERSON_NAME"), (15, 23, "DISEASE")], # (start, end, label)
[(5, 13, "PHONE_NUMBER")],
# ...
]
results = pipeline.calibrate(
validation_texts,
validation_ground_truth,
save_path="calibration.json" # Save for reuse
)
print(f"Optimized weights: {results['detector_weights']}")
# Output: {'gliner': 0.42, 'regex': 0.09, 'openmed': 0.12, 'spacy': 0.25}
# 3. Pipeline now has optimal weights! Use normally
result = pipeline.redact("Jane Doe, Medicare 2234 56781 2")
```
### Key Features
- **Adaptive Detector Weights**: Automatically adjusts weights based on F1 scores (F1²)
- **Label Normalization**: Normalizes labels BEFORE voting so "PERSON" (GLiNER) and "USERNAME" (regex) can vote together
- **One-Time Calibration**: Run once on 20-50 samples, save results, reuse forever
- **Performance Tracking**: Track detector metrics during operation
- **Save/Load**: Save calibration to JSON, load in production
### How It Works
```python
# Weight calculation (F1-squared method)
weight = max(0.1, detector_f1 ** 2)
# Example:
# GLiNER: F1=0.60 → weight=0.36 (High performer)
# Regex: F1=0.30 → weight=0.09 (Noisy)
# OpenMed: F1=0.10 → weight=0.10 (Poor, floor applied)
```
### Production Usage
```python
# Load pre-calibrated weights
config = RedactionConfig(
country="AU",
use_gliner=True,
enable_adaptive_weights=True,
calibration_file="calibration.json" # Load saved weights
)
pipeline = RedactionPipeline(config)
# Ready to use with optimal weights!
```
### One-Function Calibration (For Notebooks)
```python
# Copy-paste into your benchmark notebook
from examples.quick_calibrate import quick_calibrate_zerophix
pipeline, results = quick_calibrate_zerophix(test_samples, num_calibration_samples=20)
# Done! Pipeline has optimal weights learned from your data
```
### Benefits
- **Less trial-and-error** - Configure once, use everywhere
- **Expected better precision** - Fewer false positives
- **Higher F1** - Better overall accuracy
- **Fast calibration** - 2-5 seconds for 20 samples
- **100% backward compatible** - Opt-in via config flag
See [examples/adaptive_ensemble_examples.py](examples/adaptive_ensemble_examples.py) for complete examples.
## Benchmark Performance & Evaluation Results
ZeroPhix has been rigorously evaluated on standard public benchmarks for PII/PHI detection and redaction.
### Test Datasets
| Dataset | Type | Size | Domain | Entities |
|---------|------|------|--------|----------|
| **TAB** (Text Anonymisation Benchmark) | Legal documents (EU court cases) | 14 test documents | Legal/Government | Names, locations, dates, case numbers, organizations |
| **PDF Deid** | Synthetic medical PDFs | 100 documents (1,145 PHI spans) | Healthcare/Medical | Patient names, MRN, dates, addresses, phone numbers |
### Results Summary
#### TAB Benchmark (Legal Documents)
**Manual Configuration** (regex + spaCy + BERT + GLiNER):
- **Precision:** 48.8%
- **Recall:** 61.1%
- **F1 Score:** 54.2%
- Documents: 14 EU court case texts
- Gold spans: 20,809
- Predicted spans: 8,676
- Note: Legal text has high entity density; trade-off between recall and precision
**Auto Configuration** (automatic detector selection):
- **Precision:** 48.6%
- **Recall:** 61.0%
- **F1 Score:** 54.1%
- Same corpus, intelligent mode selection
#### PDF Deid Benchmark (Medical Documents)
**Manual Configuration** (regex + spaCy + BERT + OpenMed + GLiNER):
- **Precision:** 67.9%
- **Recall:** 87.5%
- **F1 Score:** 76.5%
- Documents: 100 synthetic medical PDFs
- Gold spans: 1,145 PHI instances
- Predicted spans: 1,476
- Note: High recall prioritizes not missing sensitive medical data
**Auto Configuration**:
- **Precision:** 67.9%
- **Recall:** 87.5%
- **F1 Score:** 76.5%
- Automatic mode achieves same performance as manual configuration
### Performance Characteristics
| Metric | Value | Notes |
|--------|-------|-------|
| **Processing Speed** | 1,000+ docs/sec | Regex-only mode |
| **Processing Speed** | 100-500 docs/sec | With ML models (spaCy/BERT) |
| **Latency** | < 50ms | Per document (regex) |
| **Latency** | 100-300ms | Per document (with ML) |
| **Memory Usage** | < 100MB | Regex-only |
| **Memory Usage** | 500MB-2GB | With ML models loaded |
| **Accuracy (Structured)** | 99.9% | SSN, credit cards, TFN with checksum validation |
| **Accuracy (Medical PHI)** | 76.5% F1 | Medical records (87.5% recall) |
| **Accuracy (Legal Text)** | 54.2% F1 | High-density legal documents |
### Detector Performance Comparison
| Detector | Speed | Precision | Recall | Best For |
|----------|-------|-----------|--------|----------|
| **Regex** | Very Fast | 99.9% | 85% | Structured data (SSN, phone, email) |
| **spaCy NER** | Fast | 88% | 92% | Names, locations, organizations |
| **BERT** | Moderate | 92% | 89% | Complex entities, context-aware |
| **OpenMed** | Moderate | 90% | 87% | Medical/healthcare PHI |
| **GLiNER** | Moderate | 85% | 88% | Zero-shot custom entities |
| **Ensemble (All)** | Moderate | 87% | 92% | Best overall balance |
### Reproducibility
All benchmarks are reproducible:
```bash
# Download benchmark datasets
python scripts/download_benchmarks.py
# Run all evaluations
python -m zerophix.eval.run_all_evaluations
# Results saved to: eval/results/evaluation_TIMESTAMP.json
```
Evaluation configuration and results available in `src/zerophix/eval/`.
src/eval/results/evaluation_2026-01-12T06-25-39Z.json](src/eval/results/evaluation_2026-01-12T06-25-39Z.json)
**Latest benchmark results:** [eval/results/evaluation_2026-01-02T02-04-28Z.json](src/eval/results/evaluation_2026-01-02T02-04-28Z.json)
### Australian Entity Detection (Detailed)
ZeroPhix provides enterprise-grade Australian coverage with 40+ entity types and mathematical checksum validation:
**Supported Australian Entities:**
- **Government IDs:** TFN (mod 11), ABN (mod 89), ACN (mod 10) with checksum validation
- **Healthcare:** Medicare (mod 10), IHI, HPI-I/O, DVA number, PBS card
- **Driver Licenses:** All 8 states (NSW, VIC, QLD, SA, WA, TAS, NT, ACT)
- **Financial:** BSB numbers, Centrelink CRN, bank accounts
- **Geographic:** Enhanced addresses, postcodes (4-digit validation)
- **Organizations:** Government agencies, hospitals, universities, banks
**Checksum Validation Algorithms:**
```python
# TFN: Modulus 11 with weights [1,4,3,7,5,8,6,9,10]
# ABN: Modulus 89 (subtract 1 from first digit)
# ACN: Modulus 10 with weights [8,7,6,5,4,3,2,1]
# Medicare: Modulus 10 Luhn-like with weights [1,3,7,9,1,3,7,9]
from zerophix.detectors.regex_detector import RegexDetector
detector = RegexDetector(country='AU', company=None)
# Automatic checksum validation for AU entities
```
### 2. Ensemble & Context
**Ensemble Voting** - Combines multiple detectors with weighted voting
```python
config = RedactionConfig(
enable_ensemble_voting=True,
detector_weights={"regex": 2.0, "bert": 1.2, "spacy": 1.0}
)
```
**Context Propagation** - Remembers high-confidence entities across document
```python
config = RedactionConfig(
enable_context_propagation=True,
context_propagation_threshold=0.90
)
```
**Allow-List Filtering** - Whitelist terms that should never be redacted
```python
config = RedactionConfig(allow_list=["ACME Corp", "Project Phoenix"])
```
### 3. Redaction Strategies
| Strategy | Example | Use Case |
|----------|---------|----------|
| **Mask** | `XXX-XX-6789` | Partial visibility |
| **Hash** | `HASH_9a8b7c6d` | Deterministic replacement |
| **Synthetic** | `alex@provider.net` | Realistic fake data |
| **Encrypt** | `ENC_a8f9b3c2` | Reversible with key |
| **Format-Preserving** | `555-8947` | Maintains structure |
| **Differential Privacy** | `$52,847` | Statistical privacy |
```python
config = RedactionConfig(masking_style="synthetic")
```
### 4. Multi-Country Support
| Country | Entities Covered | Compliance |
|---------|------------------|------------|
| **Australia** | Medicare, TFN, ABN/ACN, Driver License, IHI | Privacy Act |
| **United States** | SSN, ITIN, Passport, Medical Record, Credit Card | HIPAA, CCPA |
| **European Union** | National ID, VAT, IBAN, Passport | GDPR |
| **United Kingdom** | NI Number, NHS Number, Passport | UK DPA 2018 |
| **Canada** | SIN, Health Card, Passport, Postal Code | PIPEDA |
```python
config = RedactionConfig(country="AU") # Australia
config = RedactionConfig(country="US") # United States
```
### 5. Document Processing
**Supported Formats:** PDF, DOCX, XLSX, CSV, TXT, HTML, JSON
**File Redaction:**
```bash
zerophix redact-file --input document.pdf --output clean.pdf
```
**Batch Processing:**
```bash
zerophix batch-redact \
--input-dir ./documents \
--output-dir ./redacted \
--parallel --workers 8
```
## Offline & Air-Gapped Deployment
**ZeroPhix is designed for complete data sovereignty and offline operation.**
### Why Offline Matters
| Scenario | Why ZeroPhix Works |
|----------|-------------------|
| **Healthcare/Medical** | Patient data never leaves premises (HIPAA compliant) |
| **Financial Services** | Transaction data stays within secure network (PCI DSS) |
| **Government/Defense** | Classified data in air-gapped environments |
| **Legal/Law Firms** | Client confidentiality and attorney-client privilege |
| **Research Institutions** | Sensitive research data protection |
| **On-Premise Enterprise** | No cloud dependencies, full control |
### Offline Deployment Models
#### 1. **Regex-Only Mode** (Zero Setup)
```python
# 100% offline immediately after pip install
config = RedactionConfig(
country="AU",
detectors=["regex", "statistical"] # No ML models needed
)
```
- No downloads required
- Works immediately in air-gapped environments
- 99.9% precision for structured data (SSN, TFN, credit cards)
- Ultra-fast processing (1000s of docs/sec)
#### 2. **ML-Enhanced Mode** (One-Time Setup)
```bash
# Download models once (requires internet temporarily)
python -m spacy download en_core_web_lg
pip install "zerophix[all]"
# First run downloads HuggingFace models to cache:
# ~/.cache/zerophix/models/
# ~/.cache/huggingface/
# After setup: 100% offline forever
```
- Models cached locally (no internet after setup)
- 98%+ precision with ML models
- Transfer cache folder to air-gapped servers
#### 3. **Air-Gapped Installation**
**On internet-connected machine:**
```bash
# Download all dependencies
pip download zerophix[all] -d ./zerophix-offline/
python -m spacy download en_core_web_lg --download-dir ./zerophix-offline/
# Download ML models to local cache
python -c "
from zerophix.detectors.bert_detector import BERTDetector
from zerophix.detectors.gliner_detector import GLiNERDetector
# Models auto-download and cache
"
# Copy cache directory
cp -r ~/.cache/zerophix ./zerophix-offline/cache/
cp -r ~/.cache/huggingface ./zerophix-offline/cache/
```
**On air-gapped machine:**
```bash
# Transfer folder via USB/secure network
# Install from local packages
pip install --no-index --find-links=./zerophix-offline/ zerophix[all]
# Restore cache
cp -r ./zerophix-offline/cache/zerophix ~/.cache/
cp -r ./zerophix-offline/cache/huggingface ~/.cache/
# Now 100% offline - no internet required
```
### Offline vs. Cloud Comparison
| Feature | ZeroPhix (Offline) | Cloud APIs (Azure, AWS) |
|---------|-------------------|------------------------|
| **Internet Required** | No (after setup) | Yes (always) |
| **Data Leaves Premises** | Never | Yes |
| **Costs** | Infrastructure and maintenance | Per-document API fees |
| **Processing Speed** | 1000s docs/sec | Rate limited |
| **Data Sovereignty** | Complete | Cloud provider |
| **Compliance Audit** | Simple | Complex |
| **Vendor Lock-in** | None | High |
### Pre-Built Docker Image (Offline-Ready)
```bash
# Build once with all models included
docker build -t zerophix:offline --build-arg INCLUDE_MODELS=true .
# Run completely offline
docker run --network=none -p 8000:8000 zerophix:offline
```
The Docker image includes all models - perfect for air-gapped Kubernetes clusters.
```python
from zerophix.processors.documents import PDFProcessor, DOCXProcessor
# PDF with OCR
pdf_processor = PDFProcessor()
text = pdf_processor.extract_text(pdf_bytes, ocr_enabled=True)
result = pipeline.redact(text)
# Excel with column mapping
service.redact_excel(
input_path="data.xlsx",
column_mapping={"name": "PERSON_NAME", "ssn": "SSN"}
)
```
**Batch Processing:**
```bash
zerophix batch-redact \
--input-dir ./documents \
--output-dir ./redacted \
--parallel --workers 8
```
### 6. Custom Entities
**Runtime Patterns:**
```python
config = RedactionConfig(
custom_patterns={
"EMPLOYEE_ID": [r"EMP-\d{6}"],
"PROJECT_CODE": [r"PROJ-[A-Z]{3}-\d{4}"]
}
)
```
**Company Policies (YAML):**
```yaml
# configs/company/acme.yml
regex_patterns:
EMPLOYEE_ID: '(?i)\bEMP-\d{5}\b'
PROJECT_CODE: '(?i)\bPRJ-[A-Z]{3}-\d{3}\b'
```
```python
config = RedactionConfig(country="AU", company="acme")
```
## REST API
### Quick Start
```bash
# Development (localhost:8000)
python -m zerophix.api.rest
# Production (configure via .env)
cp .env.example .env
# Edit .env with your settings
python -m zerophix.api.rest
```
### Configuration
**Environment Variables:**
```bash
ZEROPHIX_API_HOST=0.0.0.0
ZEROPHIX_API_PORT=8000
ZEROPHIX_REQUIRE_AUTH=true
ZEROPHIX_API_KEYS=secret-key-1,secret-key-2
ZEROPHIX_CORS_ORIGINS=https://app.example.com
ZEROPHIX_ENV=production
```
**Programmatic:**
```python
from zerophix.config import APIConfig
from zerophix.api import create_app
config = APIConfig(
host="0.0.0.0",
port=8000,
require_auth=True,
api_keys=["your-key"],
cors_origins=["https://example.com"],
ssl_enabled=True
)
app = create_app(config)
```
### API Endpoints
**Redact Text:**
```bash
curl -X POST "http://localhost:8000/redact" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-key" \
-d '{"text": "John Doe, SSN: 123-45-6789", "country": "US"}'
```
**Response:**
```json
{
"success": true,
"redacted_text": "[PERSON], SSN: XXX-XX-6789",
"entities_found": 2,
"processing_time": 0.045,
"spans": [
{"start": 0, "end": 8, "label": "PERSON", "score": 0.95},
{"start": 15, "end": 26, "label": "SSN", "score": 1.0}
]
}
```
**Docs:** `http://localhost:8000/docs`
### Deployment Options
**Docker:**
```bash
docker build -t zerophix:latest .
docker run -p 8000:8000 -e ZEROPHIX_API_HOST=0.0.0.0 zerophix:latest
```
**Kubernetes:**
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: zerophix-api
spec:
replicas: 3
template:
spec:
containers:
- name: zerophix
image: zerophix:latest
ports:
- containerPort: 8000
env:
- name: ZEROPHIX_API_HOST
value: "0.0.0.0"
- name: ZEROPHIX_REQUIRE_AUTH
value: "true"
```
**Cloud Platforms:** AWS (ECS/Lambda), GCP (Cloud Run), Azure (App Service), Heroku
**SSL/TLS:**
```bash
ZEROPHIX_SSL_ENABLED=true
ZEROPHIX_SSL_KEYFILE=/path/to/key.pem
ZEROPHIX_SSL_CERTFILE=/path/to/cert.pem
```
For detailed deployment guides, see `.env.example` and `configs/api_config.yml` in the repository.
## Security & Compliance
### Zero Trust Architecture
- Multi-factor authentication validation
- Device security posture assessment
- Dynamic trust scoring (0-100%)
- Continuous verification
### Encryption
- AES-128 encryption at rest
- Master key management with rotation
- Format-preserving encryption
- Secure deletion with overwrites
### Audit & Monitoring
- Tamper-evident audit logs
- Real-time security monitoring
- Compliance violation detection
- Risk-based alerting
### Compliance Standards
**GDPR:**
```python
result = pipeline.redact(text, user_context={
"lawful_basis": "legitimate_interest",
"consent_obtained": True,
"purpose": "fraud_prevention"
})
```
**HIPAA:**
```python
config = RedactionConfig(
country="US",
compliance_standards=["HIPAA"],
phi_detection=True
)
```
**PCI DSS:**
```python
config = RedactionConfig(
cardholder_data_detection=True,
encryption_required=True
)
```
### Security CLI
```bash
zerophix security audit-logs --days 30
zerophix security compliance-check --standard GDPR
zerophix security zero-trust-test
```
## Performance
### Optimization Features
ZeroPhix includes powerful performance optimizations for high-throughput processing:
#### 1. Model Caching (10-50x Speedup)
Models load once and cache globally - no repeated loading overhead:
```python
from zerophix.pipelines.redaction import RedactionPipeline
from zerophix.config import RedactionConfig
# First pipeline: loads models (~30-60s one-time cost)
cfg = RedactionConfig(country="AU", use_gliner=True, use_spacy=True)
pipeline1 = RedactionPipeline(cfg)
# Second pipeline: uses cached models (<1ms)
pipeline2 = RedactionPipeline(cfg)
# Models are cached automatically - no configuration needed!
```
#### 2. Batch Processing (4-8x Speedup)
Process multiple documents in parallel:
```python
from zerophix.performance import BatchProcessor
# Process 2500 documents
texts = [doc['text'] for doc in your_documents]
processor = BatchProcessor(
pipeline,
n_workers=4, # Parallel work | text/markdown | null | Yassien Shaalan <yassien@gmail.com> | null | null | Apache-2.0 | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"pydantic>=2.7",
"pyyaml>=6.0.1",
"regex>=2024.4.16",
"click>=8.1.7",
"tqdm>=4.66.5",
"rich>=13.9.2",
"numpy>=1.21.0",
"nltk>=3.8.1",
"cryptography>=41.0.0",
"pypdf>=3.0.0",
"scipy<2.0,>=1.10.0; extra == \"statistical\"",
"spacy>=3.7.0; extra == \"spacy\"",
"spacy-transformers>=1.3.0; extra ... | [] | [] | [] | [
"Homepage, https://github.com/yassienshaalan/zerophix",
"Documentation, https://github.com/yassienshaalan/zerophix/blob/main/REDACTION_LOGIC.md",
"Repository, https://github.com/yassienshaalan/zerophix",
"Issues, https://github.com/yassienshaalan/zerophix/issues",
"Changelog, https://github.com/yassienshaal... | twine/6.2.0 CPython/3.10.19 | 2026-02-19T02:25:04.189365 | zerophix-0.1.19.tar.gz | 246,146 | fd/c8/71f3ef928f9894d2516a84a180f0ac00521cd0924226c6ac03dbffe0ac2f/zerophix-0.1.19.tar.gz | source | sdist | null | false | 58f1848aa8a441491df75de1fa696315 | 556f77a43b65bb7e53d525171548664c384075cff1bb4308306bad6814686438 | fdc871f3ef928f9894d2516a84a180f0ac00521cd0924226c6ac03dbffe0ac2f | null | [
"LICENSE"
] | 256 |
2.4 | watsonx-rlm-knowledge | 2.1.0 | RLM-based knowledge client with WatsonX backend for domain-specific document querying | # RLM Knowledge Client
A portable Python package for querying local document knowledge bases using the **Recursive Language Model (RLM)** pattern with IBM WatsonX as the LLM backend.
## Overview
This package allows you to:
1. **Index a directory of documents** - including PDF, DOCX, XLSX, PPTX, and all text files
2. **Query the knowledge base** - using natural language questions
3. **Get AI-synthesized answers** - based on relevant document content
The key innovation is the **RLM pattern**: instead of dumping all documents into the context (which fails for large knowledge bases), the LLM writes Python code to explore the documents on-demand, searching and reading only what's needed.
## Installation
```bash
# From source
pip install -e /path/to/watsonx_rlm_knowledge
# Or install directly
pip install watsonx-rlm-knowledge
```
## Quick Start
### 1. Set Environment Variables
```bash
export WATSONX_API_KEY="your-ibm-cloud-api-key"
export WATSONX_PROJECT_ID="your-watsonx-project-id"
export RLM_KNOWLEDGE_ROOT="/path/to/your/documents"
# Optional
export WATSONX_REGION_URL="https://us-south.ml.cloud.ibm.com" # default
export WATSONX_MODEL_ID="openai/gpt-oss-120b" # default
```
### 2. Use the Client
```python
from watsonx_rlm_knowledge import KnowledgeClient
# Initialize client (preprocesses documents automatically)
client = KnowledgeClient.from_directory("/path/to/documents")
# Query the knowledge base
answer = client.query("How does the authentication system work?")
print(answer)
# Get detailed results
result = client.query_detailed("Explain the database schema")
print(f"Answer: {result.answer}")
print(f"Iterations: {result.iterations}")
print(f"Time: {result.total_time:.2f}s")
```
### 3. Or Use the CLI
```bash
# Query
watsonx-rlm-knowledge query "How does authentication work?"
# Interactive chat
watsonx-rlm-knowledge chat
# List documents
watsonx-rlm-knowledge list
# Search
watsonx-rlm-knowledge search "authentication"
# Statistics
watsonx-rlm-knowledge stats
```
## Supported Document Formats
### Text Files (read directly)
- Code: `.py`, `.js`, `.ts`, `.java`, `.c`, `.cpp`, `.go`, `.rs`, `.rb`, etc.
- Config: `.json`, `.yaml`, `.toml`, `.xml`, `.ini`, etc.
- Documentation: `.md`, `.txt`, `.rst`, `.tex`, etc.
- Web: `.html`, `.css`, `.vue`, `.svelte`, etc.
- Data: `.csv`, `.sql`, `.graphql`, etc.
### Binary Documents (converted to text)
- PDF: `.pdf`
- Word: `.docx`, `.doc`
- Excel: `.xlsx`, `.xls`
- PowerPoint: `.pptx`, `.ppt`
- Other: `.rtf`, `.odt`, `.ods`, `.odp`
### Optional Dependencies
Some document types require additional packages:
```bash
# For encrypted/password-protected PDFs
pip install cryptography>=3.1
# For legacy Excel .xls files (not .xlsx)
pip install xlrd
```
Without these packages, the affected files will be skipped during preprocessing with a warning message.
## How It Works
### The RLM Pattern
Traditional RAG (Retrieval-Augmented Generation) has limitations:
- Embedding search may miss relevant content
- Context windows can't hold large documents
- Pre-chunking loses document structure
**RLM (Recursive Language Model)** takes a different approach:
1. The LLM is given access to a **KnowledgeContext** object
2. It writes **Python code** to explore documents
3. Code is **executed** and results fed back
4. The LLM iterates until it has enough information
5. Finally outputs a **FINAL_ANSWER**
```
User Query → LLM writes Python → Execute → Results → LLM writes more Python → ... → FINAL_ANSWER
```
### Example RLM Iteration
```python
# LLM writes this code:
matches = knowledge.search("authentication")
obs = f"Found {len(matches)} matches for 'authentication':\n"
for m in matches[:5]:
obs += f" {m.path}:{m.line_number}: {m.line_text}\n"
# Results fed back:
# "Found 12 matches for 'authentication':
# auth/login.py:45: def authenticate_user(username, password):
# docs/api.md:23: ## Authentication Methods
# ..."
# LLM then reads the relevant file:
content = knowledge.read_slice("auth/login.py", offset=0, nbytes=5000)
obs = content
# And continues until it can answer the question
```
## API Reference
### KnowledgeClient
The main interface for querying knowledge bases.
```python
# Factory methods
client = KnowledgeClient.from_directory("/path/to/docs")
client = KnowledgeClient.from_credentials(
knowledge_root="/path/to/docs",
api_key="your-key",
project_id="your-project"
)
client = KnowledgeClient.from_env()
# Query methods
answer = client.query("question")
result = client.query_detailed("question") # Returns RLMResult
# Utility methods
docs = client.list_documents(pattern="*.pdf")
results = client.search("term", max_results=20)
content = client.read_document("path/to/doc.md")
stats = client.get_stats()
client.preprocess(force=True)
```
### KnowledgeContext
Low-level access to the knowledge base (used by the RLM engine).
```python
from watsonx_rlm_knowledge import KnowledgeContext
ctx = KnowledgeContext("/path/to/docs")
# List documents
docs = ctx.list_documents()
files = ctx.list_files()
# Search
matches = ctx.search("term", max_matches=50)
matches = ctx.grep("pattern")
matches = ctx.search_regex(r"auth\w+")
# Read content
text = ctx.head("doc.md", nbytes=5000)
text = ctx.read_slice("doc.md", offset=1000, nbytes=3000)
text = ctx.read_full("doc.md")
text = ctx.tail("doc.md")
# Document info
toc = ctx.get_table_of_contents("doc.md")
count = ctx.count_occurrences("authentication")
```
### RLMEngine
The core engine that runs the RLM loop.
```python
from watsonx_rlm_knowledge import RLMEngine, KnowledgeContext
from watsonx_rlm_knowledge.engine import RLMConfig
# Custom configuration
config = RLMConfig(
max_iterations=15, # Max exploration iterations
max_code_retries=3, # Retries for code errors
temperature=0.1, # LLM temperature
main_max_tokens=4096, # Max tokens for main calls
subcall_max_tokens=2048 # Max tokens for subcalls
)
# Create engine
engine = RLMEngine(
knowledge=ctx,
llm_call_fn=your_llm_function,
config=config
)
# Run query
result = engine.run("Your question here")
print(result.answer)
print(result.iterations)
print(result.observations)
```
### DocumentPreprocessor
Handles conversion of binary documents to text.
```python
from watsonx_rlm_knowledge import DocumentPreprocessor
from watsonx_rlm_knowledge.preprocessor import PreprocessorConfig
config = PreprocessorConfig(
cache_dir=".rlm_cache",
max_file_size_mb=50,
skip_hidden=True,
skip_dirs=(".git", "node_modules", "__pycache__")
)
preprocessor = DocumentPreprocessor("/path/to/docs", config)
preprocessor.preprocess_all(force=False)
# Get text content
text = preprocessor.get_text("/path/to/docs/report.pdf")
```
## Configuration
### WatsonX Configuration
```python
from watsonx_rlm_knowledge import WatsonXConfig
config = WatsonXConfig(
api_key="your-key",
project_id="your-project",
url="https://us-south.ml.cloud.ibm.com",
model_id="openai/gpt-oss-120b",
max_tokens=8192,
temperature=0.1,
reasoning_effort="low"
)
```
### Environment Variables
| Variable | Description | Default |
|----------|-------------|---------|
| `WATSONX_API_KEY` | IBM Cloud API key | (required) |
| `WATSONX_PROJECT_ID` | WatsonX project ID | (required) |
| `WATSONX_REGION_URL` | WatsonX region URL | `https://us-south.ml.cloud.ibm.com` |
| `WATSONX_MODEL_ID` | Model ID | `openai/gpt-oss-120b` |
| `RLM_KNOWLEDGE_ROOT` | Default knowledge directory | (none) |
## CLI Reference
```bash
# Query the knowledge base
watsonx-rlm-knowledge query "Your question here"
watsonx-rlm-knowledge query "Your question" --detailed
# Interactive chat mode
watsonx-rlm-knowledge chat
# List documents
watsonx-rlm-knowledge list
watsonx-rlm-knowledge list --pattern "*.pdf"
watsonx-rlm-knowledge list --json
# Search documents
watsonx-rlm-knowledge search "term"
watsonx-rlm-knowledge search "term" --max-results 50
# Preprocess documents
watsonx-rlm-knowledge preprocess
watsonx-rlm-knowledge preprocess --force
# Show statistics
watsonx-rlm-knowledge stats
watsonx-rlm-knowledge stats --json
# Read a document
watsonx-rlm-knowledge read "path/to/doc.md"
watsonx-rlm-knowledge read "path/to/doc.md" --max-bytes 10000
# Global options
watsonx-rlm-knowledge --knowledge-root /path/to/docs query "question"
watsonx-rlm-knowledge --verbose query "question"
```
## Example Use Cases
### Code Documentation Q&A
```python
client = KnowledgeClient.from_directory("./my-project")
answer = client.query("How do I configure the database connection?")
```
### Research Paper Analysis
```python
client = KnowledgeClient.from_directory("./papers")
answer = client.query("What are the main findings about transformer architectures?")
```
### Policy Document Search
```python
client = KnowledgeClient.from_directory("./policies")
answer = client.query("What is the vacation policy for remote employees?")
```
## Troubleshooting
### "WatsonX credentials not found"
Ensure you've set `WATSONX_API_KEY` and `WATSONX_PROJECT_ID` environment variables.
### "Model returned thinking-only response"
The client automatically retries, but if this persists, try:
- Setting `reasoning_effort="low"` in WatsonXConfig
- Simplifying your query
### Slow preprocessing
Large PDFs or many documents take time. Progress is cached, so subsequent runs are faster.
### Document not found
Ensure the path is relative to your knowledge root, not absolute.
## License
MIT License
## Contributing
Contributions welcome! Please open an issue or PR.
| text/markdown | null | Harold Hannon <haroldhannon@gmail.com> | null | null | null | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"ibm-watsonx-ai>=1.0.0",
"python-docx>=0.8.11",
"pypdf>=3.0.0",
"openpyxl>=3.1.0",
"python-pptx>=0.6.21",
"pydantic>=2.0.0",
"chardet>=5.0.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/ibivibiv/watsonx-rlm-knowledge",
"Documentation, https://github.com/ibivibiv/watsonx-rlm-knowledge#readme"
] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T02:24:53.421060 | watsonx_rlm_knowledge-2.1.0.tar.gz | 31,807 | 09/af/51a0116d477cd3c03e584d2ea0fa53d5ee0f4facbead846441bd91eb7de4/watsonx_rlm_knowledge-2.1.0.tar.gz | source | sdist | null | false | 287421d70277ce37e66753481a11fe47 | 187463537a0dcf0e7edfb6f20051196d302eb0e3627ca7106d750c41a5ace164 | 09af51a0116d477cd3c03e584d2ea0fa53d5ee0f4facbead846441bd91eb7de4 | MIT | [] | 276 |
2.4 | database-wrapper-redis | 0.2.26 | database_wrapper for Redis database | # database_wrapper_redis
_Part of the `database_wrapper` package._
This python package is a database wrapper for [Redis](https://redis.io/).
## Installation
```bash
pip install database_wrapper[redis]
```
## Usage
```python
from database_wrapper_redis import RedisDBWithPoolAsync, RedisDB
db = RedisDBWithPoolAsync({
"hostname": "localhost",
"port": 3306,
"username": "root",
"password": "your_password",
"database": 0
})
await db.open()
try:
async with db as redis_con:
await redis_con.set("key", "value")
value = await redis_con.get("key")
print(value) # Output: b'value'
finally:
await db.close()
```
### Notes
No wrapper at this time, as redis is just a key-value store.
| text/markdown | null | Gints Murans <gm@gm.lv> | null | null | GNU General Public License v3.0 (GPL-3.0) | database, wrapper, python, redis | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | >=3.8 | [] | [] | [] | [
"database_wrapper==0.2.26",
"redis"
] | [] | [] | [] | [
"Homepage, https://github.com/gintsmurans/py_database_wrapper",
"Documentation, https://github.com/gintsmurans/py_database_wrapper",
"Changes, https://github.com/gintsmurans/py_database_wrapper",
"Code, https://github.com/gintsmurans/py_database_wrapper",
"Issue Tracker, https://github.com/gintsmurans/py_da... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:20:10.423350 | database_wrapper_redis-0.2.26.tar.gz | 4,872 | 17/a9/a026166941cefa266c6bac11f3313bd9716d8f1eec3000443869e3e7a574/database_wrapper_redis-0.2.26.tar.gz | source | sdist | null | false | b1dd780d36ebda7d3585c023bafd36ac | a89e31ba9438615d66575da4623e7a530c0f186e31cda4d5576366daccad88a5 | 17a9a026166941cefa266c6bac11f3313bd9716d8f1eec3000443869e3e7a574 | null | [] | 276 |
2.4 | parse | 1.21.1 | parse() is the opposite of format() | Installation
------------
.. code-block:: pycon
pip install parse
Usage
-----
Parse strings using a specification based on the Python `format()`_ syntax.
``parse()`` is the opposite of ``format()``
The module is set up to only export ``parse()``, ``search()``, ``findall()``,
and ``with_pattern()`` when ``import *`` is used:
>>> from parse import *
From there it's a simple thing to parse a string:
.. code-block:: pycon
>>> parse("It's {}, I love it!", "It's spam, I love it!")
<Result ('spam',) {}>
>>> _[0]
'spam'
Or to search a string for some pattern:
.. code-block:: pycon
>>> search('Age: {:d}\n', 'Name: Rufus\nAge: 42\nColor: red\n')
<Result (42,) {}>
Or find all the occurrences of some pattern in a string:
.. code-block:: pycon
>>> ''.join(r[0] for r in findall(">{}<", "<p>the <b>bold</b> text</p>"))
'the bold text'
If you're going to use the same pattern to match lots of strings you can
compile it once:
.. code-block:: pycon
>>> from parse import compile
>>> p = compile("It's {}, I love it!")
>>> print(p)
<Parser "It's {}, I love it!">
>>> p.parse("It's spam, I love it!")
<Result ('spam',) {}>
("compile" is not exported for ``import *`` usage as it would override the
built-in ``compile()`` function)
The default behaviour is to match strings case insensitively. You may match with
case by specifying `case_sensitive=True`:
.. code-block:: pycon
>>> parse('SPAM', 'spam', case_sensitive=True) is None
True
.. _format():
https://docs.python.org/3/library/stdtypes.html#str.format
Format Syntax
-------------
A basic version of the `Format String Syntax`_ is supported with anonymous
(fixed-position), named and formatted fields::
{[field name]:[format spec]}
Field names must be a valid Python identifiers, including dotted names;
element indexes imply dictionaries (see below for example).
Numbered fields are also not supported: the result of parsing will include
the parsed fields in the order they are parsed.
The conversion of fields to types other than strings is done based on the
type in the format specification, which mirrors the ``format()`` behaviour.
There are no "!" field conversions like ``format()`` has.
Some simple parse() format string examples:
.. code-block:: pycon
>>> parse("Bring me a {}", "Bring me a shrubbery")
<Result ('shrubbery',) {}>
>>> r = parse("The {} who {} {}", "The knights who say Ni!")
>>> print(r)
<Result ('knights', 'say', 'Ni!') {}>
>>> print(r.fixed)
('knights', 'say', 'Ni!')
>>> print(r[0])
knights
>>> print(r[1:])
('say', 'Ni!')
>>> r = parse("Bring out the holy {item}", "Bring out the holy hand grenade")
>>> print(r)
<Result () {'item': 'hand grenade'}>
>>> print(r.named)
{'item': 'hand grenade'}
>>> print(r['item'])
hand grenade
>>> 'item' in r
True
Note that `in` only works if you have named fields.
Dotted names and indexes are possible with some limits. Only word identifiers
are supported (ie. no numeric indexes) and the application must make additional
sense of the result:
.. code-block:: pycon
>>> r = parse("Mmm, {food.type}, I love it!", "Mmm, spam, I love it!")
>>> print(r)
<Result () {'food.type': 'spam'}>
>>> print(r.named)
{'food.type': 'spam'}
>>> print(r['food.type'])
spam
>>> r = parse("My quest is {quest[name]}", "My quest is to seek the holy grail!")
>>> print(r)
<Result () {'quest': {'name': 'to seek the holy grail!'}}>
>>> print(r['quest'])
{'name': 'to seek the holy grail!'}
>>> print(r['quest']['name'])
to seek the holy grail!
If the text you're matching has braces in it you can match those by including
a double-brace ``{{`` or ``}}`` in your format string, the same escaping method
used in the ``format()`` syntax.
Format Specification
--------------------
Most often a straight format-less ``{}`` will suffice where a more complex
format specification might have been used.
Most of `format()`'s `Format Specification Mini-Language`_ is supported:
[[fill]align][sign][0][width][grouping][.precision][type]
The differences between `parse()` and `format()` are:
- The align operators will cause spaces (or specified fill character) to be
stripped from the parsed value. The width is not enforced; it just indicates
there may be whitespace or "0"s to strip.
- Numeric parsing will automatically handle a "0b", "0o" or "0x" prefix.
That is, the "#" format character is handled automatically by d, b, o
and x formats. For "d" any will be accepted, but for the others the correct
prefix must be present if at all.
- Numeric sign is handled automatically. A sign specifier can be given, but
has no effect.
- The thousands separator is handled automatically if the "n" type is used.
- The types supported are a slightly different mix to the format() types. Some
format() types come directly over: "d", "n", "%", "f", "e", "b", "o" and "x".
In addition some regular expression character group types "D", "w", "W", "s"
and "S" are also available.
- The "e" and "g" types are case-insensitive so there is not need for
the "E" or "G" types. The "e" type handles Fortran formatted numbers (no
leading 0 before the decimal point).
===== =========================================== ========
Type Characters Matched Output
===== =========================================== ========
l Letters (ASCII) str
w Letters, numbers and underscore str
W Not letters, numbers and underscore str
s Whitespace str
S Non-whitespace str
d Integer numbers (optional sign, digits) int
D Non-digit str
n Numbers with thousands separators (, or .) int
% Percentage (converted to value/100.0) float
f Fixed-point numbers float
F Decimal numbers Decimal
e Floating-point numbers with exponent float
e.g. 1.1e-10, NAN (all case insensitive)
g General number format (either d, f or e) float
b Binary numbers int
o Octal numbers int
x Hexadecimal numbers (lower and upper case) int
ti ISO 8601 format date/time datetime
e.g. 1972-01-20T10:21:36Z ("T" and "Z"
optional)
te RFC2822 e-mail format date/time datetime
e.g. Mon, 20 Jan 1972 10:21:36 +1000
tg Global (day/month) format date/time datetime
e.g. 20/1/1972 10:21:36 AM +1:00
ta US (month/day) format date/time datetime
e.g. 1/20/1972 10:21:36 PM +10:30
tc ctime() format date/time datetime
e.g. Sun Sep 16 01:03:52 1973
th HTTP log format date/time datetime
e.g. 21/Nov/2011:00:07:11 +0000
ts Linux system log format date/time datetime
e.g. Nov 9 03:37:44
tt Time time
e.g. 10:21:36 PM -5:30
===== =========================================== ========
The type can also be a datetime format string, following the
`1989 C standard format codes`_, e.g. ``%Y-%m-%d``. Depending on the
directives contained in the format string, parsed output may be an instance
of ``datetime.datetime``, ``datetime.time``, or ``datetime.date``.
.. code-block:: pycon
>>> parse("{:%Y-%m-%d %H:%M:%S}", "2023-11-23 12:56:47")
<Result (datetime.datetime(2023, 11, 23, 12, 56, 47),) {}>
>>> parse("{:%H:%M}", "10:26")
<Result (datetime.time(10, 26),) {}>
>>> parse("{:%Y/%m/%d}", "2023/11/25")
<Result (datetime.date(2023, 11, 25),) {}>
Some examples of typed parsing with ``None`` returned if the typing
does not match:
.. code-block:: pycon
>>> parse('Our {:d} {:w} are...', 'Our 3 weapons are...')
<Result (3, 'weapons') {}>
>>> parse('Our {:d} {:w} are...', 'Our three weapons are...')
>>> parse('Meet at {:tg}', 'Meet at 1/2/2011 11:00 PM')
<Result (datetime.datetime(2011, 2, 1, 23, 0),) {}>
And messing about with alignment:
.. code-block:: pycon
>>> parse('with {:>} herring', 'with a herring')
<Result ('a',) {}>
>>> parse('spam {:^} spam', 'spam lovely spam')
<Result ('lovely',) {}>
Note that the "center" alignment does not test to make sure the value is
centered - it just strips leading and trailing whitespace.
Width and precision may be used to restrict the size of matched text
from the input. Width specifies a minimum size and precision specifies
a maximum. For example:
.. code-block:: pycon
>>> parse('{:.2}{:.2}', 'look') # specifying precision
<Result ('lo', 'ok') {}>
>>> parse('{:4}{:4}', 'look at that') # specifying width
<Result ('look', 'at that') {}>
>>> parse('{:4}{:.4}', 'look at that') # specifying both
<Result ('look at ', 'that') {}>
>>> parse('{:2d}{:2d}', '0440') # parsing two contiguous numbers
<Result (4, 40) {}>
Some notes for the special date and time types:
- the presence of the time part is optional (including ISO 8601, starting
at the "T"). A full datetime object will always be returned; the time
will be set to 00:00:00. You may also specify a time without seconds.
- when a seconds amount is present in the input fractions will be parsed
to give microseconds.
- except in ISO 8601 the day and month digits may be 0-padded.
- the date separator for the tg and ta formats may be "-" or "/".
- named months (abbreviations or full names) may be used in the ta and tg
formats in place of numeric months.
- as per RFC 2822 the e-mail format may omit the day (and comma), and the
seconds but nothing else.
- hours greater than 12 will be happily accepted.
- the AM/PM are optional, and if PM is found then 12 hours will be added
to the datetime object's hours amount - even if the hour is greater
than 12 (for consistency.)
- in ISO 8601 the "Z" (UTC) timezone part may be a numeric offset
- timezones are specified as "+HH:MM" or "-HH:MM". The hour may be one or two
digits (0-padded is OK.) Also, the ":" is optional.
- the timezone is optional in all except the e-mail format (it defaults to
UTC.)
- named timezones are not handled yet.
Note: attempting to match too many datetime fields in a single parse() will
currently result in a resource allocation issue. A TooManyFields exception
will be raised in this instance. The current limit is about 15. It is hoped
that this limit will be removed one day.
.. _`Format String Syntax`:
https://docs.python.org/3/library/string.html#format-string-syntax
.. _`Format Specification Mini-Language`:
https://docs.python.org/3/library/string.html#format-specification-mini-language
.. _`1989 C standard format codes`:
https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
Result and Match Objects
------------------------
The result of a ``parse()`` and ``search()`` operation is either ``None`` (no match), a
``Result`` instance or a ``Match`` instance if ``evaluate_result`` is False.
The ``Result`` instance has three attributes:
``fixed``
A tuple of the fixed-position, anonymous fields extracted from the input.
``named``
A dictionary of the named fields extracted from the input.
``spans``
A dictionary mapping the names and fixed position indices matched to a
2-tuple slice range of where the match occurred in the input.
The span does not include any stripped padding (alignment or width).
The ``Match`` instance has one method:
``evaluate_result()``
Generates and returns a ``Result`` instance for this ``Match`` object.
Custom Type Conversions
-----------------------
If you wish to have matched fields automatically converted to your own type you
may pass in a dictionary of type conversion information to ``parse()`` and
``compile()``.
The converter will be passed the field string matched. Whatever it returns
will be substituted in the ``Result`` instance for that field.
Your custom type conversions may override the builtin types if you supply one
with the same identifier:
.. code-block:: pycon
>>> def shouty(string):
... return string.upper()
...
>>> parse('{:shouty} world', 'hello world', {"shouty": shouty})
<Result ('HELLO',) {}>
If the type converter has the optional ``pattern`` attribute, it is used as
regular expression for better pattern matching (instead of the default one):
.. code-block:: pycon
>>> def parse_number(text):
... return int(text)
>>> parse_number.pattern = r'\d+'
>>> parse('Answer: {number:Number}', 'Answer: 42', {"Number": parse_number})
<Result () {'number': 42}>
>>> _ = parse('Answer: {:Number}', 'Answer: Alice', {"Number": parse_number})
>>> assert _ is None, "MISMATCH"
You can also use the ``with_pattern(pattern)`` decorator to add this
information to a type converter function:
.. code-block:: pycon
>>> from parse import with_pattern
>>> @with_pattern(r'\d+')
... def parse_number(text):
... return int(text)
>>> parse('Answer: {number:Number}', 'Answer: 42', {"Number": parse_number})
<Result () {'number': 42}>
A more complete example of a custom type might be:
.. code-block:: pycon
>>> yesno_mapping = {
... "yes": True, "no": False,
... "on": True, "off": False,
... "true": True, "false": False,
... }
>>> @with_pattern(r"|".join(yesno_mapping))
... def parse_yesno(text):
... return yesno_mapping[text.lower()]
If the type converter ``pattern`` uses regex-grouping (with parenthesis),
you should indicate this by using the optional ``regex_group_count`` parameter
in the ``with_pattern()`` decorator:
.. code-block:: pycon
>>> @with_pattern(r'((\d+))', regex_group_count=2)
... def parse_number2(text):
... return int(text)
>>> parse('Answer: {:Number2} {:Number2}', 'Answer: 42 43', {"Number2": parse_number2})
<Result (42, 43) {}>
Otherwise, this may cause parsing problems with unnamed/fixed parameters.
Potential Gotchas
-----------------
``parse()`` will always match the shortest text necessary (from left to right)
to fulfil the parse pattern, so for example:
.. code-block:: pycon
>>> pattern = '{dir1}/{dir2}'
>>> data = 'root/parent/subdir'
>>> sorted(parse(pattern, data).named.items())
[('dir1', 'root'), ('dir2', 'parent/subdir')]
So, even though `{'dir1': 'root/parent', 'dir2': 'subdir'}` would also fit
the pattern, the actual match represents the shortest successful match for
``dir1``.
Developers
----------
Want to contribute to parse? Fork the repo to your own GitHub account, and create a pull-request.
.. code-block:: bash
git clone git@github.com:r1chardj0n3s/parse.git
git remote rename origin upstream
git remote add origin git@github.com:YOURUSERNAME/parse.git
git checkout -b myfeature
To run the tests locally:
.. code-block:: bash
python -m venv .venv
source .venv/bin/activate
pip install -r tests/requirements.txt
pip install -e .
pytest
----
Changelog
---------
- 1.21.1 Fix microsecond precision loss in timestamp parsing (thanks @karthiksai109)
- 1.21.0 Allow grouping char (,_) in decimal format string (thanks @moi90)
- 1.20.2 Template field names can now contain - character i.e. HYPHEN-MINUS, chr(0x2d)
- 1.20.1 The `%f` directive accepts 1-6 digits, like strptime (thanks @bbertincourt)
- 1.20.0 Added support for strptime codes (thanks @bendichter)
- 1.19.1 Added support for sign specifiers in number formats (thanks @anntzer)
- 1.19.0 Added slice access to fixed results (thanks @jonathangjertsen).
Also corrected matching of *full string* vs. *full line* (thanks @giladreti)
Fix issue with using digit field numbering and types
- 1.18.0 Correct bug in int parsing introduced in 1.16.0 (thanks @maxxk)
- 1.17.0 Make left- and center-aligned search consume up to next space
- 1.16.0 Make compiled parse objects pickleable (thanks @martinResearch)
- 1.15.0 Several fixes for parsing non-base 10 numbers (thanks @vladikcomper)
- 1.14.0 More broad acceptance of Fortran number format (thanks @purpleskyfall)
- 1.13.1 Project metadata correction.
- 1.13.0 Handle Fortran formatted numbers with no leading 0 before decimal
point (thanks @purpleskyfall).
Handle comparison of FixedTzOffset with other types of object.
- 1.12.1 Actually use the `case_sensitive` arg in compile (thanks @jacquev6)
- 1.12.0 Do not assume closing brace when an opening one is found (thanks @mattsep)
- 1.11.1 Revert having unicode char in docstring, it breaks Bamboo builds(?!)
- 1.11.0 Implement `__contains__` for Result instances.
- 1.10.0 Introduce a "letters" matcher, since "w" matches numbers
also.
- 1.9.1 Fix deprecation warnings around backslashes in regex strings
(thanks Mickael Schoentgen). Also fix some documentation formatting
issues.
- 1.9.0 We now honor precision and width specifiers when parsing numbers
and strings, allowing parsing of concatenated elements of fixed width
(thanks Julia Signell)
- 1.8.4 Add LICENSE file at request of packagers.
Correct handling of AM/PM to follow most common interpretation.
Correct parsing of hexadecimal that looks like a binary prefix.
Add ability to parse case sensitively.
Add parsing of numbers to Decimal with "F" (thanks John Vandenberg)
- 1.8.3 Add regex_group_count to with_pattern() decorator to support
user-defined types that contain brackets/parenthesis (thanks Jens Engel)
- 1.8.2 add documentation for including braces in format string
- 1.8.1 ensure bare hexadecimal digits are not matched
- 1.8.0 support manual control over result evaluation (thanks Timo Furrer)
- 1.7.0 parse dict fields (thanks Mark Visser) and adapted to allow
more than 100 re groups in Python 3.5+ (thanks David King)
- 1.6.6 parse Linux system log dates (thanks Alex Cowan)
- 1.6.5 handle precision in float format (thanks Levi Kilcher)
- 1.6.4 handle pipe "|" characters in parse string (thanks Martijn Pieters)
- 1.6.3 handle repeated instances of named fields, fix bug in PM time
overflow
- 1.6.2 fix logging to use local, not root logger (thanks Necku)
- 1.6.1 be more flexible regarding matched ISO datetimes and timezones in
general, fix bug in timezones without ":" and improve docs
- 1.6.0 add support for optional ``pattern`` attribute in user-defined types
(thanks Jens Engel)
- 1.5.3 fix handling of question marks
- 1.5.2 fix type conversion error with dotted names (thanks Sebastian Thiel)
- 1.5.1 implement handling of named datetime fields
- 1.5 add handling of dotted field names (thanks Sebastian Thiel)
- 1.4.1 fix parsing of "0" in int conversion (thanks James Rowe)
- 1.4 add __getitem__ convenience access on Result.
- 1.3.3 fix Python 2.5 setup.py issue.
- 1.3.2 fix Python 3.2 setup.py issue.
- 1.3.1 fix a couple of Python 3.2 compatibility issues.
- 1.3 added search() and findall(); removed compile() from ``import *``
export as it overwrites builtin.
- 1.2 added ability for custom and override type conversions to be
provided; some cleanup
- 1.1.9 to keep things simpler number sign is handled automatically;
significant robustification in the face of edge-case input.
- 1.1.8 allow "d" fields to have number base "0x" etc. prefixes;
fix up some field type interactions after stress-testing the parser;
implement "%" type.
- 1.1.7 Python 3 compatibility tweaks (2.5 to 2.7 and 3.2 are supported).
- 1.1.6 add "e" and "g" field types; removed redundant "h" and "X";
removed need for explicit "#".
- 1.1.5 accept textual dates in more places; Result now holds match span
positions.
- 1.1.4 fixes to some int type conversion; implemented "=" alignment; added
date/time parsing with a variety of formats handled.
- 1.1.3 type conversion is automatic based on specified field types. Also added
"f" and "n" types.
- 1.1.2 refactored, added compile() and limited ``from parse import *``
- 1.1.1 documentation improvements
- 1.1.0 implemented more of the `Format Specification Mini-Language`_
and removed the restriction on mixing fixed-position and named fields
- 1.0.0 initial release
This code is copyright 2012-2021 Richard Jones <richard@python.org>
See the end of the source file for the license of use.
| text/x-rst | null | Richard Jones <richard@python.org> | null | Wim Jeantine-Glenn <hey@wimglenn.com> | null | null | [
"Environment :: Web Environment",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Code Generators",
"Topic :: Software Development :: Libraries :: Python Modules"
] | [] | null | null | null | [] | [] | [] | [] | [] | [] | [] | [
"homepage, https://github.com/r1chardj0n3s/parse"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:20:07.645373 | parse-1.21.1.tar.gz | 29,105 | fd/18/0bea374e5ec3c8ba15365570002187f3fef9d7265ffbc2f649529878cc80/parse-1.21.1.tar.gz | source | sdist | null | false | 67203498d9135c0f1a4373a3248dba94 | 825e1a88e9d9fb481b8d2ca709c6195558b6eaa97c559ad3a9a20aa2d12815a3 | fd180bea374e5ec3c8ba15365570002187f3fef9d7265ffbc2f649529878cc80 | MIT | [
"LICENSE"
] | 838,971 |
2.4 | cloman | 0.1.0 | Official Python SDK for the CloMan API | # CloMan Python SDK
Official Python client for the [CloMan](https://cloman.app) API — query your AI clones programmatically.
## Installation
```bash
pip install cloman
```
## Quick Start
```python
from cloman import CloMan
client = CloMan(api_key="cloman_...")
result = client.decide(context="Should we approve this refund request?")
print(result.decision) # "approve" / "deny" / ...
print(result.confidence) # 0.92
print(result.reasoning) # "Based on the refund policy..."
```
## Async Usage
```python
from cloman import AsyncCloMan
async with AsyncCloMan(api_key="cloman_...") as client:
result = await client.decide(
context="Should we approve this refund request?",
action_type="approval",
data={"amount": 49.99, "reason": "defective"},
)
print(result.decision)
```
## Configuration
```python
client = CloMan(
api_key="cloman_...",
base_url="https://api.cloman.app", # default; override for self-hosted
timeout=30.0, # request timeout in seconds
max_retries=3, # retries on 5xx errors
)
```
## Error Handling
```python
from cloman import CloMan
from cloman.errors import AuthenticationError, RateLimitError
client = CloMan(api_key="cloman_...")
try:
result = client.decide(context="...")
except AuthenticationError:
print("Invalid API key")
except RateLimitError as e:
print(f"Rate limited: {e.message}")
```
## Requirements
- Python 3.9+
- `httpx` (installed automatically)
## Documentation
Full documentation: [docs.viwoapp.io](https://docs.viwoapp.io)
## License
MIT
| text/markdown | null | CloMan <support@cloman.app> | null | null | null | ai, cloman, clone, decision-making, sdk | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx<1.0.0,>=0.25.0",
"pytest-asyncio>=0.21; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"respx>=0.21; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://viwoapp.io",
"Documentation, https://docs.viwoapp.io",
"Repository, https://github.com/cloman-app/cloman-python"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:19:45.462521 | cloman-0.1.0.tar.gz | 8,168 | 32/3d/740993ef5ed889737726f02b90924e9c1bd80f4726a7297527ebc356418a/cloman-0.1.0.tar.gz | source | sdist | null | false | 6855796d6c0ac6a3e0f3bd92e53f11a6 | e1b191aa8d109168eb12c25f6564f06428b62786f3e2d707637671b0a6962458 | 323d740993ef5ed889737726f02b90924e9c1bd80f4726a7297527ebc356418a | MIT | [
"LICENSE"
] | 277 |
2.4 | timerun | 0.5.0 | TimeRun is a Python library for time measurements. | <p align="center">
<a href="https://github.com/HH-MWB/timerun">
<img src="https://user-images.githubusercontent.com/50187675/62002266-8f926b80-b0ce-11e9-9e54-3b7eeb3a2ae1.png" alt="TimeRun">
</a>
</p>
<p align="center"><strong>TimeRun</strong> — <em>Python package for time measurement.</em></p>
<p align="center">
<a href="https://pypi.org/project/timerun/"><img alt="Version" src="https://img.shields.io/pypi/v/timerun.svg"></a>
<a href="https://pypi.org/project/timerun/"><img alt="Status" src="https://img.shields.io/pypi/status/timerun.svg"></a>
<a href="https://github.com/HH-MWB/timerun/blob/main/LICENSE"><img alt="License" src="https://img.shields.io/pypi/l/timerun.svg"></a>
<a href="https://codecov.io/gh/HH-MWB/timerun"><img alt="Coverage" src="https://codecov.io/gh/HH-MWB/timerun/branch/main/graph/badge.svg"></a>
<a href="https://pepy.tech/project/timerun"><img alt="Total Downloads" src="https://static.pepy.tech/badge/timerun"></a>
</p>
TimeRun is a **single-file** Python package with no dependencies beyond the [Python Standard Library](https://docs.python.org/3/library/). The package is designed to stay minimal and dependency-free.
It records **wall-clock time** (real elapsed time) and **CPU time** (process time) for code blocks or function calls, and lets you attach optional **metadata** (e.g. run id, tags) to each measurement.
## Setup
### Prerequisites
**Python 3.10+**
### Installation
From [PyPI](https://pypi.org/project/timerun/):
```bash
pip install timerun
```
From source:
```bash
pip install git+https://github.com/HH-MWB/timerun.git
```
## Quickstart
### Time Code Block
Use `with Timer() as m:` or `async with Timer() as m:`. On block exit, the yielded `Measurement` has `wall_time` and `cpu_time` set.
```python
>>> from timerun import Timer
>>> with Timer() as m:
... pass # code block to be measured
...
>>> m.wall_time.timedelta
datetime.timedelta(microseconds=11)
>>> m.cpu_time.timedelta
datetime.timedelta(microseconds=8)
```
*Note: On block exit the timer records CPU time first, then wall time, so wall time is slightly larger than CPU time even when there is no I/O or scheduling.*
### Time Function Calls
Use `@Timer()` to time every call. Works with sync and async functions and with sync and async generators. One `Measurement` per call is appended to the wrapped callable's `measurements` deque.
```python
>>> from timerun import Timer
>>> @Timer()
... def func(): # function to be measured
... return
...
>>> func()
>>> func.measurements[-1].wall_time.timedelta
datetime.timedelta(microseconds=11)
>>> func.measurements[-1].cpu_time.timedelta
datetime.timedelta(microseconds=8)
```
*Note: Argument `maxlen` caps how many measurements are kept (e.g. `@Timer(maxlen=10)`). By default the deque is unbounded.*
## Contributing
Contributions are welcome. See [CONTRIBUTING.md](https://github.com/HH-MWB/timerun/blob/main/CONTRIBUTING.md) for setup, testing, and pull request guidelines.
## License
This project is licensed under the MIT License — see the [LICENSE](https://github.com/HH-MWB/timerun/blob/main/LICENSE) file for details.
| text/markdown | null | HH-MWB <h.hong@mail.com> | null | null | MIT | time, measurement, elapsed, stopwatch, timer, performance | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pyth... | [] | null | null | >=3.10 | [] | [] | [] | [
"behave; extra == \"dev\"",
"coverage; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/HH-MWB/timerun",
"Bug Reports, https://github.com/HH-MWB/timerun/issues",
"Changelog, https://github.com/HH-MWB/timerun/releases",
"PyPI, https://pypi.org/project/timerun"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:16:33.685294 | timerun-0.5.0.tar.gz | 6,892 | e9/84/9a996fde12f0a2bd7011f3deaf73b34a56cd3983313211395b257e2397e9/timerun-0.5.0.tar.gz | source | sdist | null | false | be549e7a8e88a150d31e8f2ef40dd3fa | d901635a2f1626a8ec39a5c1f841acae026661d7a2e841d121022bc699015988 | e9849a996fde12f0a2bd7011f3deaf73b34a56cd3983313211395b257e2397e9 | null | [
"LICENSE"
] | 266 |
2.4 | rfx-sdk | 0.1.3 | A tinygrad-inspired robotics framework for Unitree Go2 | <div align="center">
[<img alt="rfx logo" src="docs/assets/logo.svg" width="220" />](https://github.com/quantbagel/rfx)
rfx: A ground-up replacement for ROS, built for the foundation model era.
<h3>
[Homepage](https://github.com/quantbagel/rfx) | [Documentation](https://deepwiki.com/quantbagel/rfx) | [Discord](https://discord.gg/xV8bAGM8WT)
</h3>
[](https://github.com/quantbagel/rfx/actions/workflows/ci.yml)
[](LICENSE)
[](https://www.python.org/downloads/)
[](https://discord.gg/xV8bAGM8WT)
</div>
---
rfx is robotics infrastructure for the data and embodiment layer:
- Rust core for real-time performance and safety
- Python SDK for fast research iteration
- ROS interop bindings for incremental migration
- Simulation, teleoperation, and hardware pipelines designed for scalable data collection
- `rfxJIT` IR/compiler/runtime that lowers and executes kernels across `cpu`/`cuda`/`metal`
ROS became the default robotics middleware over the last 15+ years, but it was designed for component message passing, not model-first robotics and large-scale data pipelines. rfx is designed from first principles for that new workflow.
It is inspired by PyTorch (ergonomics), JAX (functional transforms and IR-based AD), and TVM (scheduling/codegen), while explicitly targeting ROS replacement over time.
---
## Repository layout
```
rfx/ Rust core + Python package + tests + configs + examples
rfxJIT/ IR compiler and runtime (cpu/cuda/metal backends)
cli/ Command-line tools
docs/ Internal docs, perf baselines, contributor workflows
scripts/ Setup and CI helper scripts
.github/ GitHub Actions workflows
```
## Core interface
All robots in rfx implement the same three-method protocol:
```python
observation = robot.observe()
robot.act(action)
robot.reset()
```
This interface is consistent across simulation, real hardware, and teleoperation.
## Installation
The recommended install for contributors is from source.
### From source
```bash
git clone https://github.com/quantbagel/rfx.git
cd rfx
bash scripts/setup-from-source.sh
```
### Direct (GitHub)
```bash
uv pip install git+https://github.com/quantbagel/rfx.git
```
### PyPI (after release)
```bash
uv pip install rfx-sdk
uv pip install rfx-sdk-sim rfx-sdk-go2 rfx-sdk-lerobot
```
### TestPyPI (current test channel)
```bash
uv pip install --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple \
rfx-sdk rfx-sdk-sim rfx-sdk-go2 rfx-sdk-lerobot torch
```
### Direct (local path)
```bash
uv venv .venv
uv pip install --python .venv/bin/python -e /absolute/path/to/rfx
```
## Runtime switches (`rfxJIT`)
```bash
export RFX_JIT=1
export RFX_JIT_BACKEND=auto # auto|cpu|cuda|metal
export RFX_JIT_STRICT=0 # 1 to raise if requested backend fails
```
With `RFX_JIT=1`, `@rfx.policy(jit=True)` can route NumPy policy calls through `rfxJIT` while preserving fallback behavior.
## Quality and performance checks
Run local pre-push checks:
```bash
./.venv/bin/pre-commit run --all-files --hook-stage pre-push
```
Run the CPU perf gate used in CI:
```bash
bash scripts/perf-check.sh \
--baseline docs/perf/baselines/rfxjit_microkernels_cpu.json \
--backend cpu \
--threshold-pct 10
```
## Documentation
- Full documentation: [deepwiki.com/quantbagel/rfx](https://deepwiki.com/quantbagel/rfx)
- Docs entrypoint: `docs/README.md`
- SO101 quickstart: `docs/so101.md`
- Contributor workflow: `docs/workflow.md`
- Performance workflow: `docs/perf/README.md`
- Contributing guide: `CONTRIBUTING.md`
## Community and support
- Issues: https://github.com/quantbagel/rfx/issues
- Discussions: https://github.com/quantbagel/rfx/discussions
- Pull requests: https://github.com/quantbagel/rfx/pulls
- Community expectations: `CODE_OF_CONDUCT.md`
## License
MIT. See `LICENSE`.
| text/markdown; charset=UTF-8; variant=GFM | rfx contributors | null | null | null | MIT | robotics, unitree, go2, quadruped, control | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.13",
"Programming Language :: Pytho... | [] | null | null | >=3.13 | [] | [] | [] | [
"tinygrad>=0.9.0",
"numpy<2.4,>=1.24",
"pyyaml>=6.0",
"anthropic>=0.25.0; extra == \"agent\"",
"openai>=1.0.0; extra == \"agent\"",
"rfx-sdk[agent]; extra == \"all\"",
"rfx-sdk[teleop]; extra == \"all\"",
"rfx-sdk[teleop-lerobot]; extra == \"all\"",
"rfx-sdk[dev]; extra == \"all\"",
"pytest>=7.0; ... | [] | [] | [] | [
"Documentation, https://github.com/quantbagel/rfx#readme",
"Homepage, https://github.com/quantbagel/rfx",
"Issues, https://github.com/quantbagel/rfx/issues",
"Repository, https://github.com/quantbagel/rfx"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T02:15:52.957940 | rfx_sdk-0.1.3-cp313-cp313-win_amd64.whl | 1,364,443 | a5/1c/fe7332c7c2d0daf3ef0c141e0d1e0e4c97b82a528d948f8014dd8eff7559/rfx_sdk-0.1.3-cp313-cp313-win_amd64.whl | cp313 | bdist_wheel | null | false | a944a108e1bff91baafb6c05730588ab | 1008e47ae2f1f7dde7736aa7eb97b83acffc897e04710f1dc72abbc991d48c58 | a51cfe7332c7c2d0daf3ef0c141e0d1e0e4c97b82a528d948f8014dd8eff7559 | null | [
"LICENSE"
] | 156 |
2.4 | xnat-ingest | 0.7.2 | Uploads exported DICOM and raw data to XNAT, parsing metadata from DICOMs |
# Xnat-ingest
[](https://github.com/Australian-Imaging-Service/xnat-ingest/actions/workflows/ci-cd.yml)
[](https://codecov.io/gh/Australian-Imaging-Service/xnat-ingest)
De-identify and upload exported DICOM and associated data files to XNAT based on ID values
stored within the DICOM headers.
## Installation
Build the docker image from the root directory of a clone of this code repository
```
docker build -t xnat-ingest .
```
## Running
The root CLI command is set to be the entrypoint of the Docker image so it can be run
by
```
docker run xnat-ingest --help
```
| text/markdown | null | "Thomas G. Close" <thomas.close@sydney.edu.au> | null | "Thomas G. Close" <thomas.close@sydney.edu.au> | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | data, imaging, pet, repository, siemens, upload, xnat | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Programming Language ::... | [] | null | null | >=3.11 | [] | [] | [] | [
"boto3",
"click>=8.3",
"discord",
"fileformats-medimage-extras>=0.10.1",
"fileformats-medimage>=0.10.1",
"fileformats-vendor-mrtrix3",
"fileformats-vendor-mrtrix3-extras",
"fileformats-vendor-siemens-extras>=0.1.0",
"fileformats-vendor-siemens>=0.2.1",
"frametree",
"frametree-xnat",
"natsort",... | [] | [] | [] | [
"repository, https://github.com/Australian-Imaging-Service/xnat_ingest"
] | twine/6.1.0 CPython/3.13.5 | 2026-02-19T02:15:44.330164 | xnat_ingest-0.7.2.tar.gz | 47,628 | d2/0c/8cc9f616a1ea18d1290e22f5b922688989ca7631912e5b83b8a89424fb24/xnat_ingest-0.7.2.tar.gz | source | sdist | null | false | 10b92851285824dfa7bf213fea727ccb | bbd12d7651ec444c52eab69bfc7ccb3dc036383c3392abe3e5f68720c53b8e65 | d20c8cc9f616a1ea18d1290e22f5b922688989ca7631912e5b83b8a89424fb24 | null | [
"LICENSE"
] | 258 |
2.2 | cjm-fasthtml-interactions | 0.0.29 | Reusable user interaction patterns for FastHTML applications including multi-step wizards, master-detail views, modal workflows, and other stateful UI orchestration patterns. | # cjm-fasthtml-interactions
<!-- WARNING: THIS FILE WAS AUTOGENERATED! DO NOT EDIT! -->
## Install
``` bash
pip install cjm_fasthtml_interactions
```
## Project Structure
nbs/
├── core/ (3)
│ ├── context.ipynb # Context management for interaction patterns providing access to state, request, and custom data
│ ├── html_ids.ipynb # Centralized HTML ID constants for interaction pattern components
│ └── state_store.ipynb # Server-side workflow state storage implementations
└── patterns/ (7)
├── async_loading.ipynb # Pattern for asynchronous content loading with skeleton loaders and loading indicators
├── master_detail.ipynb # Responsive sidebar navigation pattern with master list and detail content area. On mobile devices, the sidebar is hidden in a drawer that can be toggled. On desktop (lg+ screens), the sidebar is always visible.
├── modal_dialog.ipynb # Pattern for modal dialogs with customizable content, sizes, and actions
├── pagination.ipynb # Pagination pattern with automatic route generation and state management
├── sse_connection_monitor.ipynb # Pattern for monitoring Server-Sent Events (SSE) connections with visual status indicators and automatic reconnection
├── step_flow.ipynb # Multi-step wizard pattern with state management, navigation, and route generation
└── tabbed_interface.ipynb # Multi-tab interface pattern with automatic routing, state management, and DaisyUI styling
Total: 10 notebooks across 2 directories
## Module Dependencies
``` mermaid
graph LR
core_context[core.context<br/>Interaction Context]
core_html_ids[core.html_ids<br/>HTML IDs]
core_state_store[core.state_store<br/>Workflow State Store]
patterns_async_loading[patterns.async_loading<br/>Async Loading Container]
patterns_master_detail[patterns.master_detail<br/>Master-Detail]
patterns_modal_dialog[patterns.modal_dialog<br/>Modal Dialog]
patterns_pagination[patterns.pagination<br/>Pagination]
patterns_sse_connection_monitor[patterns.sse_connection_monitor<br/>SSE Connection Monitor]
patterns_step_flow[patterns.step_flow<br/>Step Flow]
patterns_tabbed_interface[patterns.tabbed_interface<br/>Tabbed Interface]
patterns_master_detail --> core_html_ids
patterns_master_detail --> core_context
patterns_modal_dialog --> core_html_ids
patterns_modal_dialog --> patterns_async_loading
patterns_pagination --> core_html_ids
patterns_sse_connection_monitor --> core_html_ids
patterns_step_flow --> core_state_store
patterns_step_flow --> core_html_ids
patterns_step_flow --> core_context
patterns_tabbed_interface --> core_html_ids
patterns_tabbed_interface --> core_context
```
*11 cross-module dependencies detected*
## CLI Reference
No CLI commands found in this project.
## Module Overview
Detailed documentation for each module in the project:
### Async Loading Container (`async_loading.ipynb`)
> Pattern for asynchronous content loading with skeleton loaders and
> loading indicators
#### Import
``` python
from cjm_fasthtml_interactions.patterns.async_loading import (
LoadingType,
AsyncLoadingContainer
)
```
#### Functions
``` python
def AsyncLoadingContainer(
container_id: str, # HTML ID for the container
load_url: str, # URL to fetch content from
loading_type: LoadingType = LoadingType.SPINNER, # Type of loading indicator
loading_size: str = "lg", # Size of loading indicator (xs, sm, md, lg)
loading_message: Optional[str] = None, # Optional message to display while loading
skeleton_content: Optional[Any] = None, # Optional skeleton/placeholder content
trigger: str = "load", # HTMX trigger event (default: load on page load)
swap: str = "outerHTML", # HTMX swap method (default: replace entire container)
container_cls: Optional[str] = None, # Additional CSS classes for container
**kwargs # Additional attributes for the container
) -> FT: # Div element with async loading configured
"Create a container that asynchronously loads content from a URL."
```
#### Classes
``` python
class LoadingType(Enum):
"Types of loading indicators for async content."
```
### Interaction Context (`context.ipynb`)
> Context management for interaction patterns providing access to state,
> request, and custom data
#### Import
``` python
from cjm_fasthtml_interactions.core.context import (
InteractionContext
)
```
#### Classes
``` python
@dataclass
class InteractionContext:
"Context for interaction patterns providing access to state, request, and custom data."
state: Dict[str, Any] = field(...) # Workflow state
request: Optional[Any] # FastHTML request object
session: Optional[Any] # FastHTML session object
data: Dict[str, Any] = field(...) # Custom data from data loaders
metadata: Dict[str, Any] = field(...) # Additional metadata
def get(self,
key: str, # Key to retrieve from state
default: Any = None # Default value if key not found
) -> Any: # Value from state or default
"Get value from workflow state."
def get_data(self,
key: str, # Key to retrieve from data
default: Any = None # Default value if key not found
) -> Any: # Value from data or default
"Get value from custom data."
def has(self,
key: str # Key to check in state
) -> bool: # True if key exists in state
"Check if key exists in workflow state."
def set(self,
key: str, # Key to set in state
value: Any # Value to store
) -> None
"Set value in workflow state."
def get_all_state(self) -> Dict[str, Any]: # All workflow state
"""Get all workflow state as dictionary."""
return self.state.copy()
def update_state(self,
updates: Dict[str, Any] # State updates to apply
) -> None
"Get all workflow state as dictionary."
def update_state(self,
updates: Dict[str, Any] # State updates to apply
) -> None
"Update multiple state values at once."
```
### HTML IDs (`html_ids.ipynb`)
> Centralized HTML ID constants for interaction pattern components
#### Import
``` python
from cjm_fasthtml_interactions.core.html_ids import (
InteractionHtmlIds
)
```
#### Classes
``` python
class InteractionHtmlIds(AppHtmlIds):
"""
HTML ID constants for interaction pattern components.
Inherits from AppHtmlIds:
- MAIN_CONTENT = "main-content"
- ALERT_CONTAINER = "alert-container"
- as_selector(id_str) - static method
"""
def step_content(step_id: str # Step identifier
) -> str: # HTML ID for step content
"Generate HTML ID for a specific step's content."
def step_indicator(step_id: str # Step identifier
) -> str: # HTML ID for step indicator
"Generate HTML ID for a specific step's progress indicator."
def tab_radio(tab_id: str # Tab identifier
) -> str: # HTML ID for tab radio input
"Generate HTML ID for a specific tab's radio input."
def tab_content(tab_id: str # Tab identifier
) -> str: # HTML ID for tab content
"Generate HTML ID for a specific tab's content."
def master_item(item_id: str # Item identifier
) -> str: # HTML ID for master list item
"Generate HTML ID for a master list item."
def master_group(group_id: str # Group identifier
) -> str: # HTML ID for master list group
"Generate HTML ID for master list group."
def detail_content(item_id: str # Item identifier
) -> str: # HTML ID for detail content
"Generate HTML ID for detail content area."
def modal_dialog(modal_id: str # Modal identifier
) -> str: # HTML ID for modal dialog
"Generate HTML ID for a modal dialog."
def modal_dialog_content(modal_id: str # Modal identifier
) -> str: # HTML ID for modal content area
"Generate HTML ID for modal content area."
def sse_status(connection_id: str # SSE connection identifier
) -> str: # HTML ID for SSE status indicator
"Generate HTML ID for SSE connection status indicator."
def sse_element(connection_id: str # SSE connection identifier
) -> str: # HTML ID for SSE connection element
"Generate HTML ID for SSE connection element."
def pagination_container(pagination_id: str # Pagination identifier
) -> str: # HTML ID for pagination container
"Generate HTML ID for pagination container (entire paginated view)."
def pagination_content(pagination_id: str # Pagination identifier
) -> str: # HTML ID for pagination content area
"Generate HTML ID for pagination content area (items display)."
def pagination_nav(pagination_id: str # Pagination identifier
) -> str: # HTML ID for pagination navigation controls
"Generate HTML ID for pagination navigation controls."
```
### Master-Detail (`master_detail.ipynb`)
> Responsive sidebar navigation pattern with master list and detail
> content area. On mobile devices, the sidebar is hidden in a drawer
> that can be toggled. On desktop (lg+ screens), the sidebar is always
> visible.
#### Import
``` python
from cjm_fasthtml_interactions.patterns.master_detail import (
DetailItem,
DetailItemGroup,
MasterDetail
)
```
#### Functions
``` python
@patch
def get_item(self:MasterDetail,
item_id: str # Item identifier
) -> Optional[DetailItem]: # DetailItem or None
"Get item by ID."
```
``` python
@patch
def create_context(self:MasterDetail,
request: Any, # FastHTML request object
sess: Any, # FastHTML session object
item: DetailItem # Current item
) -> InteractionContext: # Interaction context for rendering
"Create interaction context for an item."
```
``` python
@patch
def render_master(self:MasterDetail,
active_item_id: str, # Currently active item ID
item_route_func: Callable[[str], str], # Function to generate item route
include_wrapper: bool = True # Whether to include outer wrapper div
) -> FT: # Master list element
"Render master list (sidebar) with items and groups."
```
``` python
@patch
def _render_menu_items(self:MasterDetail,
active_item_id: str, # Currently active item ID
item_route_func: Callable[[str], str] # Function to generate item route
) -> List[FT]: # List of menu item elements
"Render menu items and groups (internal helper)."
```
``` python
@patch
def render_master_oob(self:MasterDetail,
active_item_id: str, # Currently active item ID
item_route_func: Callable[[str], str] # Function to generate item route
) -> FT: # Master list with OOB swap attribute
"Render master list with OOB swap attribute for coordinated updates."
```
``` python
@patch
def render_detail(self:MasterDetail,
item: DetailItem, # Item to render
ctx: InteractionContext # Interaction context
) -> FT: # Detail content
"Render detail content for an item."
```
``` python
@patch
def render_full_interface(self:MasterDetail,
active_item_id: str, # Currently active item ID
item_route_func: Callable[[str], str], # Function to generate item route
request: Any, # FastHTML request object
sess: Any # FastHTML session object
) -> FT: # Complete master-detail interface
"Render complete responsive master-detail interface with drawer for mobile."
```
``` python
@patch
def create_router(self:MasterDetail,
prefix: str = "" # URL prefix for routes (e.g., "/media")
) -> APIRouter: # APIRouter with generated routes
"Create FastHTML router with generated routes for this master-detail interface."
```
#### Classes
``` python
@dataclass
class DetailItem:
"Definition of a single item in the master-detail pattern."
id: str # Unique identifier
label: str # Display text in master list
render: Callable[[InteractionContext], Any] # Function to render detail view
badge_text: Optional[str] # Optional badge text (e.g., "configured", "3 items")
badge_color: Optional[str] # Badge color class (e.g., badge_colors.success)
icon: Optional[Any] # Optional icon element
data_loader: Optional[Callable[[Any], Dict[str, Any]]] # Data loading function
load_on_demand: bool = True # Whether to load content only when item is selected
```
``` python
@dataclass
class DetailItemGroup:
"Group of related detail items in a collapsible section."
id: str # Group identifier
title: str # Group display title
items: List[DetailItem] # Items in this group
default_open: bool = True # Whether group is expanded by default
icon: Optional[Any] # Optional group icon
badge_text: Optional[str] # Optional badge for the group
badge_color: Optional[str] # Badge color for the group
```
``` python
class MasterDetail:
def __init__(
self,
interface_id: str, # Unique identifier for this interface
items: List[Union[DetailItem, DetailItemGroup]], # List of items/groups
default_item: Optional[str] = None, # Default item ID (defaults to first item)
container_id: str = InteractionHtmlIds.MASTER_DETAIL_CONTAINER, # HTML ID for container
master_id: str = InteractionHtmlIds.MASTER_DETAIL_MASTER, # HTML ID for master list
detail_id: str = InteractionHtmlIds.MASTER_DETAIL_DETAIL, # HTML ID for detail area
master_width: str = "w-64", # Tailwind width class for master list
master_title: Optional[str] = None, # Optional title for master list
show_on_htmx_only: bool = False # Whether to show full interface for non-HTMX requests
)
"Manage master-detail interfaces with sidebar navigation and detail content area."
def __init__(
self,
interface_id: str, # Unique identifier for this interface
items: List[Union[DetailItem, DetailItemGroup]], # List of items/groups
default_item: Optional[str] = None, # Default item ID (defaults to first item)
container_id: str = InteractionHtmlIds.MASTER_DETAIL_CONTAINER, # HTML ID for container
master_id: str = InteractionHtmlIds.MASTER_DETAIL_MASTER, # HTML ID for master list
detail_id: str = InteractionHtmlIds.MASTER_DETAIL_DETAIL, # HTML ID for detail area
master_width: str = "w-64", # Tailwind width class for master list
master_title: Optional[str] = None, # Optional title for master list
show_on_htmx_only: bool = False # Whether to show full interface for non-HTMX requests
)
"Initialize master-detail manager."
```
### Modal Dialog (`modal_dialog.ipynb`)
> Pattern for modal dialogs with customizable content, sizes, and
> actions
#### Import
``` python
from cjm_fasthtml_interactions.patterns.modal_dialog import (
ModalSize,
ModalDialog,
ModalTriggerButton
)
```
#### Functions
``` python
def ModalDialog(
modal_id: str, # Unique identifier for the modal
content: Any, # Content to display in the modal
size: Union[ModalSize, str] = ModalSize.MEDIUM, # Size preset or custom size
show_close_button: bool = True, # Whether to show X close button in top-right
close_on_backdrop: bool = True, # Whether clicking backdrop closes modal
auto_show: bool = False, # Whether to show modal immediately on render
content_id: Optional[str] = None, # Optional ID for content area (for HTMX targeting)
custom_width: Optional[str] = None, # Custom width class (e.g., "w-96")
custom_height: Optional[str] = None, # Custom height class (e.g., "h-screen")
box_cls: Optional[str] = None, # Additional classes for modal box
**kwargs # Additional attributes for the dialog element
) -> FT: # Dialog element with modal dialog configured
"Create a modal dialog using native HTML dialog element with DaisyUI styling."
```
``` python
def ModalTriggerButton(
modal_id: str, # ID of the modal to trigger
label: str, # Button label text
button_cls: Optional[str] = None, # Additional button classes
**kwargs # Additional button attributes
) -> FT: # Button element that triggers modal
"Create a button that opens a modal dialog."
```
#### Classes
``` python
class ModalSize(Enum):
"Predefined size options for modal dialogs."
```
### Pagination (`pagination.ipynb`)
> Pagination pattern with automatic route generation and state
> management
#### Import
``` python
from cjm_fasthtml_interactions.patterns.pagination import (
PaginationStyle,
Pagination
)
```
#### Functions
``` python
@patch
def get_total_pages(self:Pagination,
total_items: int # Total number of items
) -> int: # Total number of pages
"Calculate total number of pages."
```
``` python
@patch
def get_page_items(self:Pagination,
all_items: List[Any], # All items
page: int # Current page number (1-indexed)
) -> tuple: # (page_items, start_idx, end_idx)
"Get items for the current page."
```
``` python
@patch
def build_route(self:Pagination,
page: int, # Page number
request: Any, # FastHTML request object
page_route_func: Callable # Route function from create_router
) -> str: # Complete route with preserved params
"Build route URL with preserved query parameters."
```
``` python
@patch
def render_navigation_controls(self:Pagination,
current_page: int, # Current page number
total_pages: int, # Total number of pages
route_func: Callable[[int], str] # Function to generate route for page
) -> FT: # Navigation controls element
"Render pagination navigation controls."
```
``` python
@patch
def render_page_content(self:Pagination,
page_items: List[Any], # Items for current page
current_page: int, # Current page number
total_pages: int, # Total number of pages
request: Any, # FastHTML request object
route_func: Callable[[int], str] # Function to generate route for page
) -> FT: # Complete page content with items and navigation
"Render complete page content with items and pagination controls."
```
``` python
@patch
def create_router(self:Pagination,
prefix: str = "" # URL prefix for routes (e.g., "/library")
) -> APIRouter: # APIRouter with generated routes
"Create FastHTML router with generated routes for pagination."
```
#### Classes
``` python
class PaginationStyle(Enum):
"Display styles for pagination controls."
```
``` python
class Pagination:
def __init__(
self,
pagination_id: str, # Unique identifier for this pagination instance
data_loader: Callable[[Any], List[Any]], # Function that returns all items
render_items: Callable[[List[Any], int, Any], Any], # Function to render items for a page
items_per_page: int = 20, # Number of items per page
container_id: str = None, # HTML ID for container (auto-generated if None)
content_id: str = None, # HTML ID for content area (auto-generated if None)
preserve_params: List[str] = None, # Query parameters to preserve
style: PaginationStyle = PaginationStyle.SIMPLE, # Pagination display style
prev_text: str = "« Previous", # Text for previous button
next_text: str = "Next »", # Text for next button
page_info_format: str = "Page {current} of {total}", # Format for page info
button_size: str = None, # Button size class
push_url: bool = True, # Whether to update URL with hx-push-url
show_endpoints: bool = False, # Whether to show First/Last buttons
first_text: str = "«« First", # Text for first page button
last_text: str = "Last »»", # Text for last page button
redirect_route: Optional[Callable[[int, Dict[str, Any]], str]] = None, # Route to redirect non-HTMX requests
)
"Manage paginated views with automatic route generation and state management."
def __init__(
self,
pagination_id: str, # Unique identifier for this pagination instance
data_loader: Callable[[Any], List[Any]], # Function that returns all items
render_items: Callable[[List[Any], int, Any], Any], # Function to render items for a page
items_per_page: int = 20, # Number of items per page
container_id: str = None, # HTML ID for container (auto-generated if None)
content_id: str = None, # HTML ID for content area (auto-generated if None)
preserve_params: List[str] = None, # Query parameters to preserve
style: PaginationStyle = PaginationStyle.SIMPLE, # Pagination display style
prev_text: str = "« Previous", # Text for previous button
next_text: str = "Next »", # Text for next button
page_info_format: str = "Page {current} of {total}", # Format for page info
button_size: str = None, # Button size class
push_url: bool = True, # Whether to update URL with hx-push-url
show_endpoints: bool = False, # Whether to show First/Last buttons
first_text: str = "«« First", # Text for first page button
last_text: str = "Last »»", # Text for last page button
redirect_route: Optional[Callable[[int, Dict[str, Any]], str]] = None, # Route to redirect non-HTMX requests
)
"Initialize pagination manager."
```
### SSE Connection Monitor (`sse_connection_monitor.ipynb`)
> Pattern for monitoring Server-Sent Events (SSE) connections with
> visual status indicators and automatic reconnection
#### Import
``` python
from cjm_fasthtml_interactions.patterns.sse_connection_monitor import (
SSEConnectionConfig,
create_connection_status_indicators,
SSEConnectionMonitorScript,
SSEConnectionMonitor
)
```
#### Functions
``` python
def create_connection_status_indicators(
status_size: str = "sm", # Size of status indicator dot (xs, sm, md, lg)
show_text: bool = True, # Whether to show status text
text_size: str = "text-sm", # Text size class
hide_text_on_mobile: bool = True # Hide text on small screens
) -> Dict[str, FT]: # Dictionary of status state to indicator element
"Create status indicator elements for different connection states."
```
``` python
def SSEConnectionMonitorScript(
connection_id: str, # Unique identifier for this SSE connection
status_indicators: Dict[str, FT], # Status indicator elements for each state
config: Optional[SSEConnectionConfig] = None # Configuration options
) -> FT: # Script element with monitoring code
"Create a script that monitors SSE connection status and manages reconnection."
```
``` python
def SSEConnectionMonitor(
connection_id: str, # Unique identifier for this SSE connection
status_size: str = "sm", # Size of status indicator
show_text: bool = True, # Whether to show status text
hide_text_on_mobile: bool = True, # Hide text on small screens
config: Optional[SSEConnectionConfig] = None, # Configuration options
container_cls: Optional[str] = None # Additional CSS classes for status container
) -> tuple[FT, FT]: # Tuple of (status_container, monitor_script)
"Create a complete SSE connection monitoring system."
```
#### Classes
``` python
@dataclass
class SSEConnectionConfig:
"Configuration for SSE connection monitoring."
max_reconnect_attempts: int = 10 # Maximum number of reconnection attempts
reconnect_delay: int = 1000 # Initial reconnect delay in milliseconds
max_backoff_multiplier: int = 5 # Maximum backoff multiplier for reconnect delay
monitor_visibility: bool = True # Monitor tab visibility and reconnect when visible
log_to_console: bool = True # Enable console logging for debugging
```
### Workflow State Store (`state_store.ipynb`)
> Server-side workflow state storage implementations
#### Import
``` python
from cjm_fasthtml_interactions.core.state_store import (
WorkflowStateStore,
get_session_id,
InMemoryWorkflowStateStore
)
```
#### Functions
``` python
def get_session_id(
sess: Any, # FastHTML session object
key: str = "_workflow_session_id" # Session key for storing the ID
) -> str: # Stable session identifier
"Get or create a stable session identifier."
```
#### Classes
``` python
@runtime_checkable
class WorkflowStateStore(Protocol):
"Protocol for workflow state storage backends."
def get_current_step(self,
flow_id: str, # Workflow identifier
sess: Any # FastHTML session object
) -> Optional[str]: # Current step ID or None
"Get current step ID for a workflow."
def set_current_step(self,
flow_id: str, # Workflow identifier
sess: Any, # FastHTML session object
step_id: str # Step ID to set as current
) -> None
"Set current step ID for a workflow."
def get_state(self,
flow_id: str, # Workflow identifier
sess: Any # FastHTML session object
) -> Dict[str, Any]: # Workflow state dictionary
"Get all workflow state."
def update_state(self,
flow_id: str, # Workflow identifier
sess: Any, # FastHTML session object
updates: Dict[str, Any] # State updates to apply
) -> None
"Update workflow state with new values."
def clear_state(self,
flow_id: str, # Workflow identifier
sess: Any # FastHTML session object
) -> None
"Clear all workflow state."
```
``` python
class InMemoryWorkflowStateStore:
def __init__(self):
"""Initialize empty state storage."""
self._current_steps: Dict[str, str] = {} # {flow_id:session_id -> step_id}
"In-memory workflow state storage for development and testing."
def __init__(self):
"""Initialize empty state storage."""
self._current_steps: Dict[str, str] = {} # {flow_id:session_id -> step_id}
"Initialize empty state storage."
def get_current_step(self,
flow_id: str, # Workflow identifier
sess: Any # FastHTML session object
) -> Optional[str]: # Current step ID or None
"Get current step ID for a workflow."
def set_current_step(self,
flow_id: str, # Workflow identifier
sess: Any, # FastHTML session object
step_id: str # Step ID to set as current
) -> None
"Set current step ID for a workflow."
def get_state(self,
flow_id: str, # Workflow identifier
sess: Any # FastHTML session object
) -> Dict[str, Any]: # Workflow state dictionary
"Get all workflow state."
def update_state(self,
flow_id: str, # Workflow identifier
sess: Any, # FastHTML session object
updates: Dict[str, Any] # State updates to apply
) -> None
"Update workflow state with new values."
def clear_state(self,
flow_id: str, # Workflow identifier
sess: Any # FastHTML session object
) -> None
"Clear all workflow state."
```
### Step Flow (`step_flow.ipynb`)
> Multi-step wizard pattern with state management, navigation, and route
> generation
#### Import
``` python
from cjm_fasthtml_interactions.patterns.step_flow import (
Step,
StepFlow
)
```
#### Functions
``` python
@patch
def get_step(self:StepFlow,
step_id: str # Step identifier
) -> Optional[Step]: # Step object or None
"Get step by ID."
```
``` python
@patch
def get_step_index(self:StepFlow,
step_id: str # Step identifier
) -> Optional[int]: # Step index or None
"Get step index by ID."
```
``` python
@patch
def get_current_step_id(self:StepFlow,
sess: Any # FastHTML session object
) -> str: # Current step ID
"Get current step ID from state store."
```
``` python
@patch
def set_current_step(self:StepFlow,
sess: Any, # FastHTML session object
step_id: str # Step ID to set as current
) -> None
"Set current step in state store."
```
``` python
@patch
def get_next_step_id(self:StepFlow,
current_step_id: str # Current step ID
) -> Optional[str]: # Next step ID or None if last step
"Get the ID of the next step."
```
``` python
@patch
def get_previous_step_id(self:StepFlow,
current_step_id: str # Current step ID
) -> Optional[str]: # Previous step ID or None if first step
"Get the ID of the previous step."
```
``` python
@patch
def is_last_step(self:StepFlow,
step_id: str # Step ID to check
) -> bool: # True if this is the last step
"Check if step is the last step."
```
``` python
@patch
def is_first_step(self:StepFlow,
step_id: str # Step ID to check
) -> bool: # True if this is the first step
"Check if step is the first step."
```
``` python
@patch
def get_workflow_state(self:StepFlow,
sess: Any # FastHTML session object
) -> Dict[str, Any]: # All workflow state
"Get all workflow state from state store."
```
``` python
@patch
def update_workflow_state(self:StepFlow,
sess: Any, # FastHTML session object
updates: Dict[str, Any] # State updates
) -> None
"Update workflow state with new values."
```
``` python
@patch
def clear_workflow(self:StepFlow,
sess: Any # FastHTML session object
) -> None
"Clear all workflow state."
```
``` python
@patch
def _summarize_state(self:StepFlow,
state: Dict[str, Any] # State dictionary to summarize
) -> str: # Human-readable summary string
"Create a concise summary of state for debug output."
```
``` python
@patch
def create_context(self:StepFlow,
request: Any, # FastHTML request object
sess: Any, # FastHTML session object
step: Step # Current step
) -> InteractionContext: # Interaction context for rendering
"Create interaction context for a step."
```
``` python
@patch
def render_progress(self:StepFlow,
sess: Any # FastHTML session object
) -> FT: # Progress indicator or empty Div
"Render progress indicator showing all steps."
```
``` python
@patch
def render_step_content(self:StepFlow,
step_obj: Step, # Step to render
ctx: InteractionContext, # Interaction context
next_route: str, # Route for next/submit
back_route: Optional[str] = None, # Route for back
cancel_route: Optional[str] = None # Route for cancel
) -> FT: # Complete step content with optional progress and navigation
"Render step content with optional progress indicator and navigation."
```
``` python
@patch
def render_navigation(self:StepFlow,
step_id: str, # Current step ID
next_route: str, # Route for next/submit action
back_route: Optional[str] = None, # Route for back action
cancel_route: Optional[str] = None, # Route for cancel action
) -> FT: # Navigation button container
"Render navigation buttons for a step."
```
``` python
@patch
def create_router(self:StepFlow,
prefix: str = "" # URL prefix for routes (e.g., "/transcription")
) -> APIRouter: # APIRouter with generated routes
"Create FastHTML router with generated routes for this flow."
```
#### Classes
``` python
@dataclass
class Step:
"Definition of a single step in a multi-step workflow."
id: str # Unique step identifier (used in URLs)
title: str # Display title for the step
render: Callable[[InteractionContext], Any] # Function to render step UI
validate: Optional[Callable[[Dict[str, Any]], bool]] # Validation function
data_loader: Optional[Callable[[Any], Dict[str, Any]]] # Data loading function
data_keys: List[str] = field(...) # State keys managed by this step
can_skip: bool = False # Whether this step can be skipped
show_back: bool = True # Whether to show back button
show_cancel: bool = True # Whether to show cancel button
next_button_text: str = 'Continue' # Text for next/submit button
on_enter: Optional[Callable[[Dict[str, Any], Any, Any], Any]] # Called when entering step, before render (state, request, sess) -> None or component
on_leave: Optional[Callable[[Dict[str, Any], Any, Any], Any]] # Called after validation, before navigation (state, request, sess) -> None or component
def is_valid(self, state: Dict[str, Any] # Current workflow state
) -> bool: # True if step is complete and valid
"Check if step has valid data in state."
```
``` python
class StepFlow:
def __init__(
self,
flow_id: str, # Unique identifier for this workflow
steps: List[Step], # List of step definitions
state_store: Optional[WorkflowStateStore] = None, # Storage backend (defaults to InMemoryWorkflowStateStore)
container_id: str = InteractionHtmlIds.STEP_FLOW_CONTAINER, # HTML ID for content container
on_complete: Optional[Callable[[Dict[str, Any], Any], Any]] = None, # Completion handler
show_progress: bool = False, # Whether to show progress indicator
wrap_in_form: bool = True, # Whether to wrap content + navigation in a form
debug: bool = False # Whether to print debug information
)
"Manage multi-step workflows with automatic route generation and state management."
def __init__(
self,
flow_id: str, # Unique identifier for this workflow
steps: List[Step], # List of step definitions
state_store: Optional[WorkflowStateStore] = None, # Storage backend (defaults to InMemoryWorkflowStateStore)
container_id: str = InteractionHtmlIds.STEP_FLOW_CONTAINER, # HTML ID for content container
on_complete: Optional[Callable[[Dict[str, Any], Any], Any]] = None, # Completion handler
show_progress: bool = False, # Whether to show progress indicator
wrap_in_form: bool = True, # Whether to wrap content + navigation in a form
debug: bool = False # Whether to print debug information
)
"Initialize step flow manager."
```
### Tabbed Interface (`tabbed_interface.ipynb`)
> Multi-tab interface pattern with automatic routing, state management,
> and DaisyUI styling
#### Import
``` python
from cjm_fasthtml_interactions.patterns.tabbed_interface import (
Tab,
TabbedInterface
)
```
#### Functions
``` python
@patch
def get_tab(self:TabbedInterface,
tab_id: str # Tab identifier
) -> Optional[Tab]: # Tab object or None
"Get tab by ID."
```
``` python
@patch
def get_tab_index(self:TabbedInterface,
tab_id: str # Tab identifier
) -> Optional[int]: # Tab index or None
"Get tab index by ID."
```
``` python
@patch
def create_context(self:TabbedInterface,
request: Any, # FastHTML request object
sess: Any, # FastHTML session object
tab: Tab # Current tab
) -> InteractionContext: # Interaction context for rendering
"Create interaction context for a tab."
```
``` python
@patch
def render_tabs(self:TabbedInterface,
current_tab_id: str, # Currently active tab ID
tab_route_func: Callable[[str], str] # Function to generate tab route
) -> FT: # Tab navigation element
"Render tab navigation using DaisyUI radio-based tabs."
```
``` python
@patch
def render_tab_content(self:TabbedInterface,
tab_obj: Tab, # Tab to render
ctx: InteractionContext # Interaction context
) -> FT: # Tab content
"Render tab content."
```
``` python
@patch
def render_full_interface(self:TabbedInterface,
current_tab_id: str, # Currently active tab ID
tab_route_func: Callable[[str], str], # Function to generate tab route
request: Any, # FastHTML request object
sess: Any # FastHTML session object
) -> FT: # Complete tabbed interface
"Render complete tabbed interface with tabs and content area."
```
``` python
@patch
def create_router(self:TabbedInterface,
prefix: str = "" # URL prefix for routes (e.g., "/dashboard")
) -> APIRouter: # APIRouter with generated routes
"Create FastHTML router with generated routes for this tabbed interface."
```
#### Classes
``` python
@dataclass
class Tab:
"Definition of a single tab in a tabbed interface."
id: str # Unique tab identifier (used in URLs)
label: str # Display label for the tab
render: Callable[[InteractionContext], Any] # Function to render tab content
title: Optional[str] # Optional title/tooltip for the tab
data_loader: Optional[Callable[[Any], Dict[str, Any]]] # Data loading function
load_on_demand: bool = True # Whether to load content only when tab is | text/markdown | Christian J. Mills | 9126128+cj-mills@users.noreply.github.com | null | null | Apache Software License 2.0 | nbdev jupyter notebook python | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Natural Language :: English",
"Programming Language :: Python :: 3.12",
"License :: OSI Approved :: Apache Software License"
] | [] | https://github.com/cj-mills/cjm-fasthtml-interactions | null | >=3.12 | [] | [] | [] | [
"fastcore",
"cjm_error_handling",
"cjm_fasthtml_app_core",
"cjm_fasthtml_daisyui",
"cjm_fasthtml_sse"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T02:15:38.331384 | cjm_fasthtml_interactions-0.0.29.tar.gz | 65,057 | bf/fd/ef18c05752b86d466829d34fb09472e67090a360aa93f4106678d894072c/cjm_fasthtml_interactions-0.0.29.tar.gz | source | sdist | null | false | ad2d34221df61a1d3776ae44f92ab192 | e3528cca0974f97c7d97411811fd2fac90046d20c0729d21a295b93c1654d38c | bffdef18c05752b86d466829d34fb09472e67090a360aa93f4106678d894072c | null | [] | 289 |
2.1 | deepseek-tokenizer | 0.2.0 | Lightweight tokenizer for deepseek | # DeepSeek Tokenizer
English | [中文](README_ZH.md)
## Introduction
DeepSeek Tokenizer is an efficient and lightweight tokenization library with no third-party runtime dependencies, making it a streamlined and efficient choice for tokenization tasks.
## Installation
To install DeepSeek Tokenizer, use the following command:
```bash
pip install deepseek_tokenizer
```
## Basic Usage
Below is a simple example demonstrating how to use DeepSeek Tokenizer to encode text:
```python
from deepseek_tokenizer import ds_token
# Sample text
text = "Hello! 毕老师!1 + 1 = 2 ĠÑĤвÑĬÑĢ"
# Encode text
result = ds_token.encode(text)
# Print result
print(result)
```
### Output
```
[19923, 3, 223, 5464, 5008, 1175, 19, 940, 223, 19, 438, 223, 20, 6113, 257, 76589, 131, 100, 76032, 1628, 76589, 131, 108, 76589, 131, 98]
```
## License
This project is licensed under the MIT License.
| text/markdown | null | Anderson <andersonby@163.com> | null | null | MIT | null | [] | [] | null | null | >=3.8 | [] | [] | [] | [
"ruff; extra == \"dev\"",
"ty; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/AndersonBY/deepseek-tokenizer"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:11:58.592411 | deepseek_tokenizer-0.2.0.tar.gz | 1,930,387 | 9b/81/889836a2c3487e176e92cf1794ca8a15119451aa648558718f46b7a3997b/deepseek_tokenizer-0.2.0.tar.gz | source | sdist | null | false | e8970bf4b238798295af7a196328b253 | 81d4afa1394fcd15bae6f22c7698e31c5f265a5198b14b13d1a9e25e6561ba63 | 9b81889836a2c3487e176e92cf1794ca8a15119451aa648558718f46b7a3997b | null | [] | 363 |
2.3 | rtty-soda | 0.7.1 | A PyNaCl frontend with custom encodings, compression, and key derivation | # rtty-soda
A PyNaCl frontend with custom encodings, compression, and key derivation.
#### Features
- Public key encryption (Curve25519-XSalsa20-Poly1305)
- Secret key encryption (XSalsa20-Poly1305)
- Key derivation (Argon2id-Blake2b)
- Text compression:
- brotli (Brotli, best ratio, default)
- zstd (Zstandard, fast, good ratio)
- zlib (Deflate, used by gzip)
- bz2 (Bzip2, used in tar.bz2)
- lzma (LZMA, good ratio on large data)
- raw (No compression, improves security)
- Custom encodings:
- base10 (Decimal)
- base26 (Latin)
- base31 (Cyrillic)
- base32 (RFC 4648)
- base36 (Latin with digits)
- base64 (RFC 4648)
- base94 (ASCII printable)
- binary (Raw bytes)
## Installation
#### Package manager
1. [Install uv](https://docs.astral.sh/uv/getting-started/installation/)
2. Install rtty-soda:
```
% uv tool install "rtty-soda[cli]"
```
3. Remove rtty-soda:
```
% uv tool uninstall rtty-soda
```
#### Docker
```
% docker run -it --rm -h rtty-soda -v .:/app/host nett/rtty-soda:0.7.1
% docker run -it --rm -h rtty-soda -v .:/app/host nett/rtty-soda:0.7.1-tools
```
## Getting help
All commands have `[-h | --help]` option.
```
% soda
Usage: soda [OPTIONS] COMMAND [ARGS]...
Options:
--version Show the version and exit.
-h, --help Show this message and exit.
Commands:
compression List supported compression libs.
decrypt-password (dp) Decrypt message (password).
decrypt-public (d) Decrypt message (public).
decrypt-secret (ds) Decrypt message (secret).
encode Encode file.
encodings List supported encodings.
encrypt-password (ep) Encrypt message (password).
encrypt-public (e) Encrypt message (public).
encrypt-secret (es) Encrypt message (secret).
genkey Generate private/secret key.
google-auth (ga) Google Authenticator TOTP.
kdf Key derivation function.
kdf-profiles List supported KDF profiles.
pubkey Get public key.
```
Some commands have aliases, so `% soda encrypt-password ...` and `% soda ep ...`
are equivalent.
## Public key encryption
#### Key generation
```
% soda genkey | tee alice | soda pubkey - | tee alice_pub
8hFMSwo/6pTCRQfNqYxkSpDI/0v92zkESYj4mN2eXXk=
% soda genkey | tee bob | soda pubkey - | tee bob_pub
SlwXUXlbgVEMC51KUjWBfa0+XtFY4JhVXJ1Ogu4BnUk=
% soda genkey -h
Usage: soda genkey [OPTIONS]
Generate private/secret key.
Options:
-s, --key-passphrase TEXT Private/secret key passphrase.
-e, --encoding ENCODING See `soda encodings`. [default: base64]
-o, --output-file FILE Write output to file.
-g, --group-len INTEGER [default: 0]
--line-len INTEGER [default: 80]
--padding INTEGER [default: 0]
-v, --verbose Show verbose output.
-h, --help Show this message and exit.
```
#### Encryption
Alice sends the message to Bob:
```
% cat message
A telegraph key is a specialized electrical switch used by a trained operator to
transmit text messages in Morse code in a telegraphy system.
The first telegraph key was invented by Alfred Vail, an associate of Samuel Morse.
(c) Wikipedia
% soda encrypt-public alice bob_pub message | tee encrypted | cut -c 1-80
2d0w2ZYvGoRHXHJk/WT8NepRGyC+Bm1v7f1Vjmm9ZFLx1dW7mnzqT2uXfFIpP2sKP5QISVVsb/WidEcH
% soda encrypt-public -h
Usage: soda encrypt-public [OPTIONS] PRIVATE_KEY_FILE PUBLIC_KEY_FILE
MESSAGE_FILE
Encrypt message (public).
Options:
-t, --text Treat message as text (binary if not
specified).
-s, --key-passphrase TEXT Private/secret key passphrase.
--key-encoding ENCODING See `soda encodings`. [default: base64]
-e, --data-encoding ENCODING See `soda encodings`. [default: base64]
-c, --compression COMPRESSION See `soda compression`. [default: brotli]
-o, --output-file FILE Write output to file.
-g, --group-len INTEGER [default: 0]
--line-len INTEGER [default: 80]
--padding INTEGER [default: 0]
-v, --verbose Show verbose output.
-h, --help Show this message and exit.
```
#### Decryption
```
% soda decrypt-public bob alice_pub encrypted
A telegraph key is a specialized electrical switch used by a trained operator to
transmit text messages in Morse code in a telegraphy system.
The first telegraph key was invented by Alfred Vail, an associate of Samuel Morse.
(c) Wikipedia
```
## Secret key encryption
Alice and Bob share a key for symmetric encryption:
```
% soda genkey > shared
% soda encrypt-secret shared message -o encrypted
% soda decrypt-secret shared encrypted -o message
```
Another day, they share a password:
```
% echo qwerty | soda encrypt-password - message -p interactive -o encrypted
% echo qwerty | soda decrypt-password - encrypted -p interactive -o message
```
## Key derivation
The KDF function derives the key from the password using Argon2id, a memory-hard
algorithm that makes brute-force attacks expensive by requiring large amounts of
memory.
It accepts different profiles:
- interactive (64 MiB, 2 passes)
- moderate (256 MiB, 3 passes)
- sensitive (1 GiB, 4 passes)
The top profile uses 1 GiB - half the memory of the RFC 9106 recommendation for
practical use. The profiles are defined by libsodium.
The KDF function is deterministic, so identical passwords produce identical keys.
No metadata is stored or asked of the user to keep the interface simple.
The trade-off is that password strength is critical.
```
% echo qwerty | soda kdf - -p interactive
HqbvUXflAG+no3YS9njezZ3leyr8IwERAyeNoG2l41U=
% soda kdf -h
Usage: soda kdf [OPTIONS] PASSWORD_FILE
Key derivation function.
Options:
-s, --key-passphrase TEXT Private/secret key passphrase.
-e, --encoding ENCODING See `soda encodings`. [default: base64]
-p, --profile PROFILE See `soda kdf-profiles`. [default: sensitive]
-o, --output-file FILE Write output to file.
-g, --group-len INTEGER [default: 0]
--line-len INTEGER [default: 80]
--padding INTEGER [default: 0]
-v, --verbose Show verbose output.
-h, --help Show this message and exit.
```

## Text compression
That works as follows:
1. The plaintext is prepared:
- In binary mode (default), the message is read as bytes
- In text mode (`-t, --text`), the message is read as a string, stripped, and encoded with SCSU, reducing the size of Unicode messages by 15–50%
2. The plaintext is compressed with the compression lib
3. The 16-byte MAC and 24-byte nonce are added
4. The result is encoded with Base64, which adds ~33% overhead
```
% soda es shared message -t -v -c brotli > /dev/null
Plaintext: 238
Ciphertext: 216
Overhead: 0.908
Groups: 1
% soda es shared message -t -v -c zstd > /dev/null
Plaintext: 238
Ciphertext: 276
Overhead: 1.160
Groups: 1
% soda es shared message -t -v -c zlib > /dev/null
Plaintext: 238
Ciphertext: 280
Overhead: 1.176
Groups: 1
% soda es shared message -t -v -c bz2 > /dev/null
Plaintext: 238
Ciphertext: 336
Overhead: 1.412
Groups: 1
% soda es shared message -t -v -c lzma > /dev/null
Plaintext: 238
Ciphertext: 320
Overhead: 1.345
Groups: 1
% soda es shared message -t -v -c raw > /dev/null
Plaintext: 238
Ciphertext: 372
Overhead: 1.563
Groups: 1
```
## Encoding
The rtty-soda supports various encodings:
```
% soda encrypt-public alice bob_pub message --data-encoding base36 --group-len 5 --text
2T4XT IVK0M UBUQR NPP9X U0HAU JH44C DEJ8L MV4EK HAS15 09JXO 6EYB3 5CAAB 4H3BW
0O8EO 9CQ9M 93O0C 8IKYI FW9EZ HWMSR GZSUR AZBGV 9Y26D Q63JA P3OK1 HLEM8 KZJ3D
ZX7QU DP9WT FTZUP KIA9L 53LTP 6FB8A HSO9B Y8IJ0 3ZWXI ZO2VX 9B3RP 2Z7DR T9IBE
AI404 D2282 PGX6G WT85T WSCNF WD4DF 9RDHF OXRUA TYS2I 45LJ1 05W
```
## Environment variables
Common options can be set in the environment variables:
```
% cat ~/.soda/example.env
SODA_TEXT=0
SODA_KEY_PASSPHRASE="He in a few minutes ravished this fair creature, or at least would have ravished her, if she had not, by a timely compliance, prevented him."
SODA_KEY_ENCODING=binary
SODA_DATA_ENCODING=binary
SODA_COMPRESSION=brotli
SODA_KDF_PROFILE=sensitive
SODA_GROUP_LEN=0
SODA_LINE_LEN=0
SODA_PADDING=0
SODA_VERBOSE=0
```
## Private/secret key passphrase
The key can be protected with an additional passphrase, similar to SSH keys.
When `--key-passphrase <passphrase>` is used, the key is automatically
encrypted or decrypted using the same parameters as the following command:
```
% soda encrypt-password <passphrase> <key> --kdf-profile sensitive --data-encoding binary --compression raw
```
## Alternative usage
- Password source
```
% echo "A line from a book or a poem" | soda kdf - -e base94 -p interactive
x\R9"~8Ujh^_uh:Ty<!t(ZNzK=5w^ukew~#-x!n
```
- WireGuard keyer
```
% echo "A line from a book or a poem" | soda kdf - -p interactive -o privkey
% cat privkey
uIoBJdgaz8ZP3/n/9KzdUNvFi7DxbUQdQ9t8ujwGnMk=
% soda pubkey privkey
F2B674kXVcTznnRPWCVasx1miCT+yUtXQ3P5Ecee4zI=
% cat privkey | wg pubkey
F2B674kXVcTznnRPWCVasx1miCT+yUtXQ3P5Ecee4zI=
```
- Secure storage
```
% echo "A remarkable example of misplaced confidence" > sensitive_data
% echo "Blessed with opinions, cursed with thought" > data_password
% soda ep data_password sensitive_data -e binary -p interactive -o encrypted_data
% echo "Too serious to be wise" > offset_password
% soda kdf offset_password -e base10 -p interactive -g 10 | head -1
6174465709 4962164854 2541023297 3274271197 5950333784 2118297875 9632383288
% sudo dd if=./encrypted_data of=/dev/sdb1 bs=1 seek=6174465709
75+0 records in
75+0 records out
75 bytes transferred in 0.000769 secs (97529 bytes/sec)
```

- Google Authenticator keyer
```
% soda genkey -e base32 | tee totp_key
CEC265QHHVCWNRG2CP5J4P4BTRKYLBIF2CXSUEVOM3HJYRRCJBEA====
% soda google-auth totp_key
106 072 (expires in 8s)
```
## Compatibility
During the initial development (versions prior to 1.0.0),
I can break backwards compatibility.
## Releases
This project follows a rolling release cycle.
Each version bump represents where I completed a full test cycle.
When testing passes successfully, I commit and release - so every release is a verified stable point. | text/markdown | Theo Saveliev | Theo Saveliev <89431871+theosaveliev@users.noreply.github.com> | null | null | MIT | cli, encryption, libsodium, nacl | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3.14",
"Operating System :: POSIX",
"Environment :: Console",
"License :: OSI Approved :: MIT License",
"Topic :: Security :: Cryptography",
"Topic :: Utilities"
] | [] | null | null | <4.0,>=3.14 | [] | [] | [] | [
"brotli<2.0.0,>=1.2.0",
"gmpy2<3.0.0,>=2.3.0",
"pynacl<2.0.0,>=1.6.2",
"pyotp<3.0.0,>=2.9.0",
"scsu<2.0.0,>=1.1.1",
"click<9.0.0,>=8.3.1; extra == \"cli\"",
"click-aliases<2.0.0,>=1.0.5; extra == \"cli\""
] | [] | [] | [] | [
"github, https://github.com/theosaveliev/rtty-soda",
"issues, https://github.com/theosaveliev/rtty-soda/issues"
] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T02:11:20.871678 | rtty_soda-0.7.1-py3-none-any.whl | 22,538 | ef/d4/74f7ad2e13b9b61ef0e648669ffd0787cf5b7a05e5e65e097ce53f71d512/rtty_soda-0.7.1-py3-none-any.whl | py3 | bdist_wheel | null | false | c74336f685bd9fea6b3fd15a9c15b670 | a061826aa6fed49628d418e99fe58dbdc92e5d4e0213031d30940916b9355323 | efd474f7ad2e13b9b61ef0e648669ffd0787cf5b7a05e5e65e097ce53f71d512 | null | [] | 259 |
2.4 | utwrite | 0.0.19 | Auto[magically] write Python unittest files from docstrings. | # utwrite
# Info
Auto[magically] write Python unittest files from docstrings.
# Demo

# Why not `doctest` ?
[doctest](https://docs.python.org/3/library/doctest.html) is great, built-in, if
it works for you use it. The main differences are:
- Write out `.py` test file
- Create `tests` directory structure from the project root (contains `.git`
folder), and mirror directory hierarchy of the source file.
- Support custom header for your unittest file.
- Support custom assertion (i.e. `numpy.testing`) via the assertion token `@`.
- Support custom `TestCase` super class, that can host relevant methods, i.e.
`BaseTestCase.assertListAlmostEqual`.
- No `eval` call.
`utwrite` is not an unittest executor. It creates the `.py` unittest files to be
called with one (i.e. `python -m unittest`, `pytest` ). Though it can call an
executor on its behalf (`untitest`, `pytest`, `maya`).
# Installation
## From pypi
Run `pip install utwrite` on your Python environment of choice.
## From source
Clone the repo, and run
```sh
make install
```
This will `pip` install the package and make it available both for CLI and Python
interpreter.
# Usage
Call the `utw` on the file(s) and/or directory(ies) you want to auto generate
unittest from the docstrings.
## `utw` provides 2 sub commands
### utw gen
Generate unittest via `utw gen`.
```sh
utw gen <my_python_file>
```
I.E.
``` sh
utw gen utwrite/examples/example_mod.py
```
### utw run
Execute tests with `utw run` (but also with `python -m unittest` or `pytest`)
- `utw run`
```sh
utw run <tests>
```
By default `utw run` uses Python's *unittest* module, you can choose the
executor via the `-app` flag
```sh
utw run <tests> -app pytest
```
It's also possible to run your unittests inside Autodesk Maya headless with
`-app maya` (if you have it installed).
- Python default:
You can also run the generated tests with `unittest` module
``` sh
python -m unittest discover .
```
Or with `pytest` if you have it installed
``` sh
pytest
```
### Executing the `example_mod.py`
By default example_mod.py has one test section expected to fail, and the
execution result is expected as:
> $ python -m unittest tests/utwrite/examples/test_example_mod_auto.py
> .....E..
> ======================================================================
> ERROR: test_missing_test_crash_func (tests.utwrite.examples.test_example_mod_auto.Test_example_mod_AUTO)
> ----------------------------------------------------------------------
> Traceback (most recent call last):
> File "D:\home\dev\personal\utwrite\utwrite\unittest_cases.py", line 58, in wrapper
> raise RuntimeError('MISSING EXAMPLE TEST!')
> RuntimeError: MISSING EXAMPLE TEST!
>
> ----------------------------------------------------------------------
> Ran 8 tests in 0.148s
>
> FAILED (errors=1)
# Auto-Generation
To make meaningful unittests automatically this module expects docstrings
formatted with some particularities. Also it works well with Sphinx Python
auto-documentation generator (through ReST and google styled docstrings).
## How Does it Work ?
For unittest to be auto-generated it needs 2 lines. The first line defines the
execution that will return the value to be tested. The second line will assert
the line above with the result given.
## Examples Section
Auto generated unittests are only concerned with the **Examples** section of your
docstring. That section is ReST formatted, in order to generate proper
documentation (through auto generators like Sphinx), and extrapolated to make
test cases. By definition the section must be exactly as:
``` python
r"""
Examples::
<code_section>
<more_code>
...
"""
```
Such that:
- `Examples::` Must be used to start the example code block.
- Followed by an empty line.
- Code inside must have 1 indentation from the `Examples::` point.
## Result Keys
Tests are made through **Result Keys** (`RES_KEYS`). At this moment the result
keys are:
- All Python's errors (`ValueError`, `RuntimeError`, ...);
- `Result`, `Out`
> Whenever wanted to create a test section (assertion) it is necessary to have a
> **Result Key** present. No **Result Key** no test.
## Result Section
A **Result Section** is defined by a section of text that starts with
"# <result_key>: "; and ends with "#". I.E.
``` python
r"""
1+1
# Result: 2 #
"""
```
## Tags
Functions can be tagged to explicitly be ignored or be found through the **Tags**
section. The available **Tags** are:
- `test` Use this function to generate unittests.
- `notest` Ignore this function from auto unittest generation.
The **Tags** section by definition must be as follows:
``` python
r"""
:Tags:
test
"""
```
Such that:
- `:Tags:` Must be used to start the **Tags** block.
- Tag values must be indented from `:Tags:` position.
- Tag values should be separated with “, ” (ie “specific, notest”)
## Assertion Tokens
By default tests will use either `self.assertEqual` or `with self.assertRaises`
to generate unittest assert test case. Such that:
- `self.assertAlmostEqual` Used for default values;
- `with self.assertRaises` Used for any **Error** (`RES_KEYS` with `'raises'`
value).
For any other case you might want to pass your assertion function explicitly.
That is done by using the `ASSERT_TOKEN` “@” inside a result block, as follows:
``` python
r"""
<execution_line_to_produce_value(s)_to_assert>
# Result: <expected_result_from_line_above> @<asserting_function> #
"""
```
I.E.
``` python
r"""
Examples::
...
import numpy as np
np.arange(5)
# Result: np.array([0, 1, 2, 3, 4, 5]) @np.testing.assert_almost_equal#
"""
```
> ***Important***:
> If you have the assertion token in your result section, but is not part
> of the assert function i.e.
``` python
def func(): return '@'
```
The test case requires it to be escaped "\@"
i.e.
``` python
r"""
func()
# Result: '\@' #
"""
```
## Dunders
Functions/Classes that start with double underscore will by default not generate
any unittest.
# Full Example
View [example_mod.py](./utwrite/examples/example_mod.py)
The result test `./tests/utwrite/examples/test_example_mod_auto.py` should be
created with the contents:
```python
import sys
import os
import unittest
from utwrite.unittest_cases import *
@unittest.skipUnless(sys.version_info.major == 3, "Lets say it requires Python3 only")
class Test_example_mod_AUTO(BaseTestCase):
def test_default_func(self):
import utwrite.examples.example_mod as ex
self.assertEqual(ex.default_func(),1 )
def test_list_func(self):
import utwrite.examples.example_mod as ex
self.assertEqual(ex.list_func(),[1,2,3] )
def test_almost_equal_func(self):
import utwrite.examples.example_mod as ex
self.assertListAlmostEqual(ex.almost_equal_func(),[0.5] )
def test___dunder_test_tag_func(self):
import utwrite.examples.example_mod as ex
self.assertEqual(getattr(ex, '__dunder_test_tag_func')(),None )
@MISSINGTEST
def test_missing_test_crash_func(self):
pass
def test_np_explicit_assert_func(self):
HAS_NUMPY = False
try:
import numpy as np
HAS_NUMPY = True
except:
pass
import utwrite.examples.example_mod as ex
if HAS_NUMPY:
np.testing.assert_array_equal( ex.np_explicit_assert_func(3), np.array([0, 1, 2]) )
else:
self.assertEqual( ex.np_explicit_assert_func(3), True )
def test_escaped_assertion_token_func(self):
import utwrite.examples.example_mod as ex
self.assertEqual(ex.escaped_assertion_token_func(),'@' )
def test_raise_error(self):
from utwrite.examples import example_mod
with self.assertRaises(ZeroDivisionError): example_mod.raise_error()
```
| text/markdown | null | null | null | null | null | null | [
"Intended Audience :: Developers"
] | [] | null | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://codeberg.org/pbellini/utwrite"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T02:10:26.879554 | utwrite-0.0.19.tar.gz | 35,297 | 34/bb/6c19d09a31cefbbad339c34f3566298f6fe693a9b9b0cf76b3d8b527675b/utwrite-0.0.19.tar.gz | source | sdist | null | false | 85d87d8831617874581704dfcc2d534a | d1c8475a118e338f558a55104af257f1f093f0316457ef951560def77675ecfb | 34bb6c19d09a31cefbbad339c34f3566298f6fe693a9b9b0cf76b3d8b527675b | null | [
"LICENSE"
] | 253 |
2.4 | rsadpy | 0.12.17 | Robust Angular Diameters in Python: an angular diameter fitting routine for multi-wavelength interferometric data | 
# Robust Angular Diameters in Python (`RADPy`)
## Introduction to `RADPy`
`RADPy` stands for Robust Angular Diameters in Python. This was created to allow for multi-wavelength fits for angular diameters of stars measured with interferometric methods. Currently `RADPy` only has compatibility with the instruments on the Center for High Angular Resolution Astronomy (CHARA) Array. `RADPy` is currently configured for the following instruments at CHARA:
- Classic/CLIMB
- PAVO
- VEGA
- MIRC-X
- MYSTIC
- SPICA
## To install:
**Please read this section carefully!!**
Simply use pip to install `RADPy`. Due to naming conflicts, to install `RADPy`, you must use "rsadpy".
```python
pip install rsadpy
```
The installation should also install all necessary additional packages you need to run everything. Just in case, here is a list of all the necessary packages that aren't default:
- `lmfit`
- `astropy`
- `astroquery`
- `gaiadr3-zeropoint`
If you would like to use the SED fitting feature, there are some additional packages you need to make sure that you have installed.
- `SEDFit`
- `astroARIADNE`
These two packages have to be installed separately outside of `RADPy` due to some technical issues. The instructions to download them are below. Please note that if you are a Windows user, you will need to run a virtual environment that runs a linux or OS distribution. I recommend using WSL. The two packages are have dependencies that are not compatible with Windows machines.
`SEDFit`:
The installation of this package requires a few additional packages that are unfortunately not compatible with windows machines. This will require the use of a virtual environment like WSL.
To install this package, use the following command:
```python
pip install git+https://github.com/mkounkel/SEDFit.git
```
In addition, there are filter profiles that need to be downloaded and moved to the directory where `SEDFit` was just installed. The filter profiles needed are:
- GAIA.GAIA3.G
- GAIA.GAIA3.Gbp
- GAIA.GAIA3.Grp
- Hipparcos.Hipparcos.Hp_MvB
- Johnson.H
- Johnson.J
- Johnson.K
- Stromgren.b.dat
- Stromgren.u.dat
- Stromgren.v.dat
- Stromgren.y.dat
- TESS.TESS.Red.dat
- TYCHO.TYCHO.B_MvB
- TYCHO.TYCHO.V_MvB
You can download them from here: <https://github.com/spaceashley/radpy/tree/main/radpy/data>.
If you are interested in having `RADPy` pull photometry for your star for you, you need to install `astroARIADNE`. This package also has dependencies that are not compatible with Windows machines.
To install this package:
```python
pip install astroariadne
```
With `astroARIADNE`, you also need to import the necessary dustmaps.
```python
import dustmaps.sfd
dustmaps.sfd.fetch()
```
However, the dependencies that are required for this package aren't all up to date and/or aren't working properly. This is perfectly fine. You should be able to use the features of the SED fitter without an issue. If there is one, please submit an issue to the repo.
You can find more information about each package here:
[`SEDFit'`](https://github.com/mkounkel/SEDFit)
[`astroARIADNE`](https://github.com/jvines/astroARIADNE)
To test if the installation worked, import `RADPy`. If you did not get an error, you should be all set.
```python
import radpy
```
NOTE:
to _install_, use rsadpy. **Note the 's'**
to _import_, use radpy. **Note that there is no longer an s**
## What does `RADPy` actually do?
`RADPy` accepts data from an arbitrary number of beam-combiners from CHARA and allows the user to fit for the angular diameters (both uniform disk and limb-darkened disk) of single stars. With the fitted angular diameter, the user can also calculate the remaining fundamental stellar parameters of effective temperature, stellar luminosity, and radius of the measured star. The user can also plot the interferometric data with the chosen angular diameter fit (uniform or limb-darkened) which will output a publication ready plot. The plotting is highly customizable to the user's needs, including the type of model plotted, the ability to add the diameter in text to said plot, the binning of the data if the user choses to, and more.
The core of `RADPy` is a Monte Carlo simulation that involves a custom-built bracket bootstrapping within. A bracket in the realm of interferometry describes a set of data taken at the same time. Several instruments at CHARA span a wavelength range, so for every one observation, there is a span of data points to cover the wavelength ranges. `RADPy` automatically assigns a bracket number to the data once the data files are read in. The bracket numbers are assigned based on time-stamp and for PAVO, based on the same UCOORD and VCOORD measurements (as PAVO data does not output a time stamp).
For uniform disk diameters, `RADPy` will sample the wavelength of observations on a normal distribution. Within the bracket bootstrapping, the visibilities of each bracket chosen to be fit are sampled on a normal distribution. Using lmfit, the data are then fit using the uniform disk visibility squared equation. The final output results in a list of angular diameters calculated. The final uniform disk diameter is determined by taking the average of the uniform disk diameters and the error is determined by taking the mean absolute deviation.
For limb-darkened disk diameters, `RADPy` follows a similar structure to the uniform disk diameters. There are a few differences which I'll highlight below:
- One needs the limb-darkening coefficient. To account for the limb-darkening coefficient, the tables of limb-darkening coefficients determined by Claret et al. 2011 are used. Based on the observation band, surface gravity (log g), and the effective temperature (Teff) of the star, `RADPy` will use an interpolated function based on the Claret tables to calculate the limb-darkening coefficient. If the effective temperature is less than 3500 and the surface gravity is between 3.5 and 5, the tables with the PHOENIX models are used. For all other stars, the tables with the ATLAS models are used.
- For each iteration of the MC, `RADPy` calculates a limb-darkening coefficient for each band used (i.e. R-band). Within the bootstrapping, `RADPy` samples the limb-darkening coefficient on a normal distribution using 0.02 has the "error". The limb-darkening coefficient is then used in the full visibility squared equation and the limb-darkened angular diameter is fit.
- To ensure `RADPy` is fitting for the optimal angular diameter, the limb-darkened disk fitting function will iterate until minimal change between the previous angular diameter and the one just calculated is seen. For robustness, the effective temperature is also checked as well. Minimal change is defined as being less than or equal to 0.05% difference.
## Tutorial notebooks
For a tutorial for single stars, go here: <https://github.com/spaceashley/radpy/blob/main/tests/SingleStarTutorial.ipynb>
For a tutorial on how to use batch mode, go here: <https://github.com/spaceashley/radpy/blob/main/tests/BatchModeTutorial.ipynb>
For a tutorial on how to use the SED fitting feature, go here: <https://github.com/spaceashley/radpy/blob/main/tests/SED%20Fitting%20Tutorial.ipynb>
## How to Cite
If you use `RADPy` in your research, please cite it through the following:
[](https://doi.org/10.5281/zenodo.17488122)
In addition, if you decide to use the SED fitting feature and/or the photometry extraction for SED fitting, please cite the following as well:
`astroARIADNE` (if using the photometry extraction for SED fitting):
```
@ARTICLE{2022MNRAS.tmp..920V,
author = {{Vines}, Jose I. and {Jenkins}, James S.},
title = "{ARIADNE: Measuring accurate and precise stellar parameters through SED fitting}",
journal = {\mnras},
keywords = {stars:atmospheres, methods:data analysis, stars:fundamental parameters, Astrophysics - Solar and Stellar Astrophysics, Astrophysics - Earth and Planetary Astrophysics, Astrophysics - Instrumentation and Methods for Astrophysics},
year = 2022,
month = apr,
doi = {10.1093/mnras/stac956},
archivePrefix = {arXiv},
eprint = {2204.03769},
primaryClass = {astro-ph.SR},
adsurl = {https://ui.adsabs.harvard.edu/abs/2022MNRAS.tmp..920V},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
```
`SEDFit` (if using the SED fitting feature):
```
@software{sedfit,
author = {{Kounkel}, Marina},
doi = {10.5281/zenodo.8076500},
month = jun,
publisher = {Zenodo},
title = {SEDFit},
url = {https://doi.org/10.5281/zenodo.8076500},
year = 2023}
```
## Contact
- Ashley Elliott (aelli76@lsu.edu)
## Logo Credits
Logo was designed by Emelly Tiburcio from LSU and made digital by Olivia Crowell from LSU.
| text/markdown | Ashley Elliott | elliottashleya99@gmail.com | null | null | GPL-3.0 | interferometry, angular diameters, CHARA | [
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"astropy>=6.1.6",
"astroquery>=0.4.6",
"corner>=2.2.2",
"gaiadr3-zeropoint>=0.0.4",
"lmfit>=1.2.2",
"matplotlib>=3.9.2",
"numpy>=1.25.2",
"pandas>=2.2.2",
"pint>=0.25.2",
"scipy>=1.10.0",
"uncertainties>=3.1.7"
] | [] | [] | [] | [
"Repository, https://github.com/spaceashley/radpy.git",
"repository, https://github.com/spaceashley/radpy.git"
] | poetry/2.3.1 CPython/3.11.7 Windows/10 | 2026-02-19T02:10:20.120902 | rsadpy-0.12.17-py3-none-any.whl | 427,276 | 70/32/8aee327cedbf3499e3ba4e1ed1e9c57f73701992612bada8a2c40207a315/rsadpy-0.12.17-py3-none-any.whl | py3 | bdist_wheel | null | false | 76e7da9260e2e2cdba936a8cdd9df211 | 958115232a82d70c6083b03b349f43833fdeebf4a28ac0524d602b0ef5966a45 | 70328aee327cedbf3499e3ba4e1ed1e9c57f73701992612bada8a2c40207a315 | null | [
"LICENSE"
] | 252 |
2.4 | pmtvs-divergence | 0.0.1 | Signal analysis primitives | # pmtvs-divergence
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:09:52.833277 | pmtvs_divergence-0.0.1.tar.gz | 1,278 | 0a/fa/118a07a77c286cd96ec56f1b42cecfeb2e049af4b4690b025c7388b4826a/pmtvs_divergence-0.0.1.tar.gz | source | sdist | null | false | 989130d76acb2b8c48993509b1a1e8ee | 2f00d1027a27c84a93aa754e33c2dab30c8523e5814a8ca1c097ed94a6b06e66 | 0afa118a07a77c286cd96ec56f1b42cecfeb2e049af4b4690b025c7388b4826a | null | [] | 263 |
2.4 | gdptools | 0.3.8 | Gdptools | # gdptools

[](https://pypi.org/project/gdptools/)
[](https://anaconda.org/conda-forge/gdptools)
[](https://code.usgs.gov/wma/nhgf/toolsteam/gdptools/-/releases)
[](https://pypi.org/project/gdptools/)
[](https://pypi.org/project/gdptools)
[](https://creativecommons.org/publicdomain/zero/1.0/legalcode)
[](https://gdptools.readthedocs.io/)
[](https://code.usgs.gov/wma/nhgf/toolsteam/gdptools/-/commits/main)
[](https://code.usgs.gov/wma/nhgf/toolsteam/gdptools/-/commits/main)
[](https://code.usgs.gov/pre-commit/pre-commit)
[](https://github.com/astral-sh/ruff)
[](https://github.com/astral-sh/uv)
**gdptools** is a Python package for calculating area-weighted statistics and spatial interpolations between gridded datasets and vector geometries. It provides efficient tools for **grid-to-polygon**, **grid-to-line**, and **polygon-to-polygon** interpolations with support for multiple data catalogs and custom datasets.

_Figure: Example grid-to-polygon interpolation. A) HUC12 basins for Delaware River Watershed. B) Gridded monthly water evaporation amount (mm) from TerraClimate dataset. C) Area-weighted-average interpolation of gridded TerraClimate data to HUC12 polygons._
## 🚀 Key Features
- **Multiple Interpolation Methods**: Grid-to-polygon, grid-to-line, and polygon-to-polygon area-weighted statistics
- **Catalog Integration**: Built-in support for STAC catalogs (NHGF, ClimateR) and custom metadata
- **Flexible Data Sources**: Works with any xarray-compatible gridded data and geopandas vector data
- **Scalable Processing**: Serial, parallel, and Dask-based computation methods
- **Multiple Output Formats**: NetCDF, CSV, and in-memory results
- **Extensive vs Intensive Variables**: Proper handling of different variable types in polygon-to-polygon operations
- **Intelligent Spatial Processing**: Automatic reprojection to equal-area coordinate systems and efficient spatial subsetting
## 🌍 Spatial Processing & Performance
gdptools automatically handles complex geospatial transformations to ensure accurate and efficient calculations:
### Automatic Reprojection
- **Equal-Area Projections**: Both source gridded data and target geometries are automatically reprojected to a common equal-area coordinate reference system (default: EPSG:6931 - US National Atlas Equal Area)
- **Accurate Area Calculations**: Equal-area projections ensure that area-weighted statistics are calculated correctly, regardless of the original coordinate systems
- **Flexible CRS Options**: Users can specify alternative projection systems via the `weight_gen_crs` parameter
### Efficient Spatial Subsetting
- **Bounding Box Optimization**: Gridded datasets are automatically subset to the bounding box of the target geometries plus a buffer
- **Smart Buffering**: Buffer size is calculated as twice the maximum grid resolution to ensure complete coverage
- **Memory Efficiency**: Only the necessary spatial extent is loaded into memory, dramatically reducing processing time and memory usage for large datasets
```python
# Example: Custom projection and efficient processing
from gdptools import AggGen
agg = AggGen(
user_data=my_data,
weight_gen_crs=6931, # US National Atlas Equal Area (default)
method="parallel" # Leverage spatial optimizations
)
results = agg.get_zonal_stats()
```
## 📦 Installation
### Via pip
```bash
pip install gdptools
```
### Via conda
```bash
conda install -c conda-forge gdptools
```
### Development installation
```bash
# Clone the repository
git clone https://code.usgs.gov/wma/nhgf/toolsteam/gdptools.git
cd gdptools
# Install uv if not already installed
pip install uv
# Create virtual environment and install dependencies with uv
uv sync --all-extras
# Activate the virtual environment
source .venv/bin/activate # On Windows: .venv\Scripts\activate
# Set up pre-commit hooks
pre-commit install --install-hooks
```
## 🔧 Core Components
### Data Classes
- **`ClimRCatData`**: Interface with ClimateR catalog datasets
- **`NHGFStacData`**: Interface with NHGF STAC catalog datasets
- **`UserCatData`**: Custom user-defined gridded datasets
- **`UserTiffData`**: GeoTIFF/raster data interface
### Processing Classes
- **`WeightGen`**: Calculate spatial intersection weights
- **`AggGen`**: Perform area-weighted aggregations
- **`InterpGen`**: Grid-to-line interpolation along vector paths
## 🎯 Quick Start
### Grid-to-Polygon Aggregation
```python
import geopandas as gpd
import xarray as xr
from gdptools import UserCatData, WeightGen, AggGen
# Load your data
gridded_data = xr.open_dataset("your_gridded_data.nc")
polygons = gpd.read_file("your_polygons.shp")
# Setup data interface
user_data = UserCatData(
source_ds=gridded_data,
source_crs="EPSG:4326",
source_x_coord="lon",
source_y_coord="lat",
source_t_coord="time",
source_var=["temperature", "precipitation"],
target_gdf=polygons,
target_crs="EPSG:4326",
target_id="polygon_id",
source_time_period=["2020-01-01", "2020-12-31"]
)
# Calculate intersection weights
weight_gen = WeightGen(user_data=user_data, method="parallel")
weights = weight_gen.calculate_weights()
# Perform aggregation
agg_gen = AggGen(
user_data=user_data,
stat_method="masked_mean",
agg_engine="parallel",
agg_writer="netcdf",
weights=weights
)
result_gdf, result_dataset = agg_gen.calculate_agg()
```
### Using NHGF-STAC Catalogs
```python
from gdptools import NHGFStacData
import pystac
# Access NHGF STAC catalog
catalog = pystac.read_file("https://api.water.usgs.gov/gdp/pygeoapi/stac/stac-collection/")
collection = catalog.get_child("conus404-daily")
user_data = NHGFStacData(
source_stac_item=collection,
source_var=["PWAT"],
target_gdf=watersheds,
target_id="huc12",
source_time_period=["1999-01-01", "1999-01-07"]
)
```
### Using ClimateR Catalog
```python
from gdptools import ClimRCatData
import pandas as pd
# Query ClimateR catalog
catalog = pd.read_parquet("https://github.com/mikejohnson51/climateR-catalogs/releases/download/June-2024/catalog.parquet")
terraclimate = catalog.query("id == 'terraclim' & variable == 'aet'")
user_data = ClimRCatData(
source_cat_dict={"aet": terraclimate.to_dict("records")[0]},
target_gdf=basins,
target_id="basin_id",
source_time_period=["1980-01-01", "1980-12-31"]
)
```
## 📊 Use Cases & Examples
### 1. Climate Data Aggregation
- **TerraClimate** monthly evapotranspiration to HUC12 basins
- **GridMET** daily temperature/precipitation to administrative boundaries
- **CONUS404** high-resolution climate data to custom polygons
- **MERRA-2** reanalysis data to watershed polygons
### 2. Hydrologic Applications
- **Stream network analysis**: Extract elevation profiles along river reaches using 3DEP data
- **Watershed statistics**: Calculate basin-averaged climate variables
- **Flow routing**: Grid-to-line interpolation for stream network analysis
### 3. Environmental Monitoring
- **Air quality**: Aggregate gridded pollution data to census tracts
- **Land cover**: Calculate fractional land use within administrative units
- **Biodiversity**: Combine species habitat models with management areas
## ⚡ Performance Options
### Processing Methods
- **`"serial"`**: Single-threaded processing (default, reliable)
- **`"parallel"`**: Multi-threaded processing (faster for large datasets)
- **`"dask"`**: Distributed processing (requires Dask cluster)
### Memory Management
- **Chunked processing**: Handle large datasets that don't fit in memory
- **Caching**: Cache intermediate results for repeated operations
- **Efficient data structures**: Optimized spatial indexing and intersection algorithms
### Large-scale heuristics
| Target polygons | Recommended engine | Notes |
| ------------------ | ------------------ | ------------------------------------------------------------ |
| < 5k | `"serial"` | Fits comfortably in RAM; best for debugging |
| 5k–50k | `"parallel"` | Run with `jobs=-1` and monitor memory usage |
| > 50k / nationwide | `"dask"` | Use a Dask cluster and consider 2,500–10,000 polygon batches |
- Persist the gridded dataset once, then iterate through polygon batches to keep memory flat.
- Write each batch of weights to Parquet/CSV immediately; append at the end instead of keeping all
intersections in memory.
- Avoid `intersections=True` unless you need the geometries; it multiplies memory requirements.
- See `docs/weight_gen_classes.md` ⇢ "Scaling to Nationwide Datasets" for an end-to-end chunking example.
## 📈 Statistical Methods
### Available Statistics
- **`"masked_mean"`**: Area-weighted mean (most common)
- **`"masked_sum"`**: Area-weighted sum
- **`"masked_median"`**: Area-weighted median
- **`"masked_std"`**: Area-weighted standard deviation
### Variable Types for Polygon-to-Polygon
- **Extensive**: Variables that scale with area (e.g., total precipitation, population)
- **Intensive**: Variables that don't scale with area (e.g., temperature, concentration)
## 🔧 Advanced Features
### Custom Coordinate Reference Systems
```python
# Use custom projection for accurate area calculations
weight_gen = WeightGen(
user_data=user_data,
weight_gen_crs=6931 # US National Atlas Equal Area
)
```
### Intersection Analysis
```python
# Save detailed intersection geometries for validation
weights = weight_gen.calculate_weights(intersections=True)
intersection_gdf = weight_gen.intersections
```
### Output Formats
```python
# Multiple output options
agg_gen = AggGen(
user_data=user_data,
agg_writer="netcdf", # or "csv", "none"
out_path="./results/",
file_prefix="climate_analysis"
)
```
## 📚 Documentation & Examples
- **Full Documentation**: [https://gdptools.readthedocs.io/](https://gdptools.readthedocs.io/)
- **Example Notebooks**: Comprehensive Jupyter notebooks in `docs/Examples/`
- STAC catalog integration (CONUS404 example)
- ClimateR catalog workflows (TerraClimate example)
- Custom dataset processing (User-defined data)
- Grid-to-line interpolation (Stream analysis)
- Polygon-to-polygon aggregation (Administrative boundaries)
## Sample Catalog Datasets
gdptools integrates with multiple climate and environmental data catalogs through two primary interfaces:
### ClimateR-Catalog
See the complete [catalog datasets reference](catalog_datasets.md) for a comprehensive list of supported datasets including:
- **Climate Data**: TerraClimate, GridMET, Daymet, PRISM, MACA, CHIRPS
- **Topographic Data**: 3DEP elevation models
- **Land Cover**: LCMAP, LCMAP-derived products
- **Reanalysis**: GLDAS, NLDAS, MERRA-2
- **Downscaled Projections**: BCCA, BCSD, LOCA
### NHGF STAC Catalog
See the [NHGF STAC datasets reference](nhgf_stac_datasets.md) for cloud-optimized access to:
- **High-Resolution Models**: CONUS404 (4km daily meteorology)
- **Observational Data**: GridMET, PRISM, Stage IV precipitation
- **Climate Projections**: LOCA2, MACA, BCCA/BCSD downscaled scenarios
- **Regional Datasets**: Alaska, Hawaii, Puerto Rico, Western US
- **Specialized Products**: SSEBop ET, permafrost, sea level rise
## User Defined XArray Datasets
For datasets not available through catalogs, gdptools provides `UserCatData` to work with any xarray-compatible gridded dataset. This is ideal for custom datasets, local files, or specialized data sources.
### Basic Usage
```python
import xarray as xr
import geopandas as gpd
from gdptools import UserCatData, WeightGen, AggGen
# Load your custom gridded dataset
custom_data = xr.open_dataset("my_custom_data.nc")
polygons = gpd.read_file("my_polygons.shp")
# Configure UserCatData for your dataset
user_data = UserCatData(
source_ds=custom_data, # Your xarray Dataset
source_crs="EPSG:4326", # CRS of the gridded data
source_x_coord="longitude", # Name of x-coordinate variable
source_y_coord="latitude", # Name of y-coordinate variable
source_t_coord="time", # Name of time coordinate variable
source_var=["temperature", "precipitation"], # Variables to process
target_gdf=polygons, # Target polygon GeoDataFrame
target_crs="EPSG:4326", # CRS of target polygons
target_id="polygon_id", # Column name for polygon identifiers
source_time_period=["2020-01-01", "2020-12-31"] # Time range to process
)
```
### Working with Different Data Formats
#### NetCDF Files
```python
# Single NetCDF file
data = xr.open_dataset("weather_data.nc")
# Multiple NetCDF files
data = xr.open_mfdataset("weather_*.nc", combine='by_coords')
user_data = UserCatData(
source_ds=data,
source_crs="EPSG:4326",
source_x_coord="lon",
source_y_coord="lat",
source_t_coord="time",
source_var=["temp", "precip"],
target_gdf=watersheds,
target_crs="EPSG:4326",
target_id="watershed_id"
)
```
#### Zarr Archives
```python
# Cloud-optimized Zarr store
data = xr.open_zarr("s3://bucket/climate_data.zarr")
user_data = UserCatData(
source_ds=data,
source_crs="EPSG:3857", # Web Mercator projection
source_x_coord="x",
source_y_coord="y",
source_t_coord="time",
source_var=["surface_temp", "soil_moisture"],
target_gdf=counties,
target_crs="EPSG:4269", # NAD83
target_id="county_fips"
)
```
#### Custom Coordinate Systems
```python
# Dataset with non-standard coordinate names
data = xr.open_dataset("model_output.nc")
user_data = UserCatData(
source_ds=data,
source_crs="EPSG:32612", # UTM Zone 12N
source_x_coord="easting", # Custom x-coordinate name
source_y_coord="northing", # Custom y-coordinate name
source_t_coord="model_time", # Custom time coordinate name
source_var=["wind_speed", "wind_direction"],
target_gdf=grid_cells,
target_crs="EPSG:32612",
target_id="cell_id",
source_time_period=["2021-06-01", "2021-08-31"]
)
```
### Advanced Configuration
#### Subset by Geographic Area
```python
# Pre-subset data to region of interest for efficiency
bbox = [-120, 35, -115, 40] # [west, south, east, north]
regional_data = data.sel(
longitude=slice(bbox[0], bbox[2]),
latitude=slice(bbox[1], bbox[3])
)
user_data = UserCatData(
source_ds=regional_data,
source_crs="EPSG:4326",
source_x_coord="longitude",
source_y_coord="latitude",
source_t_coord="time",
source_var=["evapotranspiration"],
target_gdf=california_basins,
target_crs="EPSG:4326",
target_id="basin_id"
)
```
#### Multiple Variables with Different Units
```python
# Handle datasets with multiple variables
user_data = UserCatData(
source_ds=climate_data,
source_crs="EPSG:4326",
source_x_coord="lon",
source_y_coord="lat",
source_t_coord="time",
source_var=[
"air_temperature", # Kelvin
"precipitation_flux", # kg/m²/s
"relative_humidity", # %
"wind_speed" # m/s
],
target_gdf=study_sites,
target_crs="EPSG:4326",
target_id="site_name",
source_time_period=["2019-01-01", "2019-12-31"]
)
```
#### Processing Workflow
```python
# Complete workflow with UserCatData
user_data = UserCatData(
source_ds=my_dataset,
source_crs="EPSG:4326",
source_x_coord="longitude",
source_y_coord="latitude",
source_t_coord="time",
source_var=["surface_temperature"],
target_gdf=administrative_boundaries,
target_crs="EPSG:4326",
target_id="admin_code"
)
# Generate intersection weights
weight_gen = WeightGen(
user_data=user_data,
method="parallel", # Use parallel processing
weight_gen_crs=6931 # Use equal-area projection for accurate weights
)
weights = weight_gen.calculate_weights()
# Perform area-weighted aggregation
agg_gen = AggGen(
user_data=user_data,
stat_method="masked_mean", # Calculate area-weighted mean
agg_engine="parallel",
agg_writer="netcdf", # Save results as NetCDF
weights=weights,
out_path="./results/",
file_prefix="temperature_analysis"
)
result_gdf, result_dataset = agg_gen.calculate_agg()
```
### Data Requirements
Your xarray Dataset must include:
- **Spatial coordinates**: Regularly gridded x and y coordinates
- **Temporal coordinate**: Time dimension (if processing time series)
- **Data variables**: The variables you want to interpolate
- **CRS information**: Coordinate reference system (can be specified manually)
### Common Use Cases
- **Research datasets**: Custom model outputs, field measurements
- **Local weather stations**: Interpolated station data
- **Satellite products**: Processed remote sensing data
- **Reanalysis subsets**: Regional extracts from global datasets
- **Ensemble models**: Multi-model climate projections
## Requirements
### Data Formats
- **Gridded Data**: Any dataset readable by xarray with projected coordinates
- **Vector Data**: Any format readable by geopandas
- **Projections**: Any CRS readable by `pyproj.CRS`
### Dependencies
- Python 3.11+
- xarray (gridded data handling)
- geopandas (vector data handling)
- pandas (data manipulation)
- numpy (numerical operations)
- shapely (geometric operations)
- pyproj (coordinate transformations)
## 🤝 Contributing
We welcome contributions! Please see our development documentation for details on:
- Development environment setup
- Testing procedures
- Code style guidelines
- Issue reporting
## 📄 License
This project is in the public domain. See [LICENSE](LICENSE) for details.
## 🙏 Acknowledgments
gdptools integrates with several excellent open-source projects:
- **[xarray](http://xarray.pydata.org/)**: Multi-dimensional array processing
- **[geopandas](https://geopandas.org/)**: Geospatial data manipulation
- **[HyRiver](https://docs.hyriver.io/)**: Hydrologic data access (pynhd, pygeohydro)
- **[STAC](https://stacspec.org/)**: Spatiotemporal asset catalogs
- **[ClimateR](https://github.com/mikejohnson51/climateR-catalogs)**: Climate data catalogs
## History
The changelog can be found in [the changelog](HISTORY.md)
## Credits
This project was generated from [@hillc-usgs](https://code.usgs.gov/hillc-usgs)'s [Pygeoapi Plugin Cookiecutter](https://code.usgs.gov/wma/nhgf/pygeoapi-plugin-cookiecutter) template.
---
**Questions?** Open an issue on our [GitLab repository](https://code.usgs.gov/wma/nhgf/toolsteam/gdptools) or check the documentation for detailed examples and API reference.
| text/markdown | null | Richard McDonald <rmcd@usgs.gov>, Anders Hopkins <ahopkins@usgs.gov>, August Schultz <arschultz@usgs.gov> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Pytho... | [] | null | null | >=3.11 | [] | [] | [] | [
"bottleneck>=1.3.3",
"click<9,>=8.1",
"dask-geopandas>0.4.1",
"dask>2024.8.0",
"exactextract>=0.3.0",
"fastparquet>=2024.2",
"geopandas>=0.13.0",
"joblib>=1.4.0",
"netcdf4>=1.5.8",
"numpy>2.0",
"pandas>=2.0.0",
"pyarrow>=10.0.0",
"pydantic>=2",
"pyproj>=3.7.2",
"pystac>=1.10",
"rasteri... | [] | [] | [] | [
"Homepage, https://code.usgs.gov/wma/nhgf/toolsteam/gdptools",
"Repository, https://code.usgs.gov/wma/nhgf/toolsteam/gdptools",
"Documentation, https://gdptools.readthedocs.io",
"Changelog, https://code.usgs.gov/wma/nhgf/toolsteam/gdptools/-/blob/develop/HISTORY.md"
] | uv/0.9.21 {"installer":{"name":"uv","version":"0.9.21","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T02:09:49.360712 | gdptools-0.3.8.tar.gz | 15,094,236 | 87/88/495ff35c70cdc82c135532ea9904a9a8595e6f029c343624b5cfaccb35fd/gdptools-0.3.8.tar.gz | source | sdist | null | false | e3a881cd62decca4cc467f808f5597e4 | 590fea5f5c4a4f65d2db396b2416b3bf2f89b99f5310be844ec8abc9ce5d6d26 | 8788495ff35c70cdc82c135532ea9904a9a8595e6f029c343624b5cfaccb35fd | CC0-1.0 | [
"LICENSE.md"
] | 322 |
2.1 | cdktn-provider-aws | 23.0.1 | Prebuilt aws Provider for CDK Terrain (cdktn) | # CDKTN prebuilt bindings for hashicorp/aws provider version 6.33.0
This repo builds and publishes the [Terraform aws provider](https://registry.terraform.io/providers/hashicorp/aws/6.33.0/docs) bindings for [CDK Terrain](https://cdktn.io).
## Available Packages
### NPM
The npm package is available at [https://www.npmjs.com/package/@cdktn/provider-aws](https://www.npmjs.com/package/@cdktn/provider-aws).
`npm install @cdktn/provider-aws`
### PyPI
The PyPI package is available at [https://pypi.org/project/cdktn-provider-aws](https://pypi.org/project/cdktn-provider-aws).
`pipenv install cdktn-provider-aws`
### Nuget
The Nuget package is available at [https://www.nuget.org/packages/Io.Cdktn.Providers.Aws](https://www.nuget.org/packages/Io.Cdktn.Providers.Aws).
`dotnet add package Io.Cdktn.Providers.Aws`
### Maven
The Maven package is available at [https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-aws](https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-aws).
```
<dependency>
<groupId>io.cdktn</groupId>
<artifactId>cdktn-provider-aws</artifactId>
<version>[REPLACE WITH DESIRED VERSION]</version>
</dependency>
```
### Go
The go package is generated into the [`github.com/cdktn-io/cdktn-provider-aws-go`](https://github.com/cdktn-io/cdktn-provider-aws-go) package.
`go get github.com/cdktn-io/cdktn-provider-aws-go/aws/<version>`
Where `<version>` is the version of the prebuilt provider you would like to use e.g. `v11`. The full module name can be found
within the [go.mod](https://github.com/cdktn-io/cdktn-provider-aws-go/blob/main/aws/go.mod#L1) file.
## Docs
Find auto-generated docs for this provider here:
* [Typescript](./docs/API.typescript.md)
* [Python](./docs/API.python.md)
* [Java](./docs/API.java.md)
* [C#](./docs/API.csharp.md)
* [Go](./docs/API.go.md)
You can also visit a hosted version of the documentation on [constructs.dev](https://constructs.dev/packages/@cdktn/provider-aws).
## Versioning
This project is explicitly not tracking the Terraform aws provider version 1:1. In fact, it always tracks `latest` of `~> 6.0` with every release. If there are scenarios where you explicitly have to pin your provider version, you can do so by [generating the provider constructs manually](https://cdktn.io/docs/concepts/providers#import-providers).
These are the upstream dependencies:
* [CDK Terrain](https://cdktn.io) - Last official release
* [Terraform aws provider](https://registry.terraform.io/providers/hashicorp/aws/6.33.0)
* [Terraform Engine](https://terraform.io)
If there are breaking changes (backward incompatible) in any of the above, the major version of this project will be bumped.
## Features / Issues / Bugs
Please report bugs and issues to the [CDK Terrain](https://cdktn.io) project:
* [Create bug report](https://github.com/open-constructs/cdk-terrain/issues)
* [Create feature request](https://github.com/open-constructs/cdk-terrain/issues)
## Contributing
### Projen
This is mostly based on [Projen](https://projen.io), which takes care of generating the entire repository.
### cdktn-provider-project based on Projen
There's a custom [project builder](https://github.com/cdktn-io/cdktn-provider-project) which encapsulate the common settings for all `cdktn` prebuilt providers.
### Provider Version
The provider version can be adjusted in [./.projenrc.js](./.projenrc.js).
### Repository Management
The repository is managed by [CDKTN Repository Manager](https://github.com/cdktn-io/cdktn-repository-manager/).
| text/markdown | CDK Terrain Maintainers | null | null | null | MPL-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/cdktn-io/cdktn-provider-aws.git | null | ~=3.9 | [] | [] | [] | [
"cdktn<0.23.0,>=0.22.0",
"constructs<11.0.0,>=10.4.2",
"jsii<2.0.0,>=1.126.0",
"publication>=0.0.3",
"typeguard==2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/cdktn-io/cdktn-provider-aws.git"
] | twine/6.1.0 CPython/3.14.2 | 2026-02-19T02:09:21.633502 | cdktn_provider_aws-23.0.1.tar.gz | 58,761,249 | 68/4d/3e6ff674f6865a474bcb5051e168b675021eb07695977aca3099116aa42f/cdktn_provider_aws-23.0.1.tar.gz | source | sdist | null | false | 4c5da43cdf61ffaf9a645654db257e4c | a26eb011340bcd49acf6a9a9d839497b6d68822943ba7faa5c4a02bade948d6d | 684d3e6ff674f6865a474bcb5051e168b675021eb07695977aca3099116aa42f | null | [] | 267 |
2.4 | pmtvs-community | 0.0.1 | Signal analysis primitives | # pmtvs-community
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:08:48.271225 | pmtvs_community-0.0.1.tar.gz | 1,274 | 20/8b/a9460f1ee56850047f41cf5b58af1342a69083fc9fc6ac97df68318cefb7/pmtvs_community-0.0.1.tar.gz | source | sdist | null | false | 085da4fb641c6cb289541a843c33e52e | 1d37bd54aa5e8f08fafc13166733f2776e93ffdc35849fee1eca01b2a50042bf | 208ba9460f1ee56850047f41cf5b58af1342a69083fc9fc6ac97df68318cefb7 | null | [] | 258 |
2.4 | pmtvs-centrality | 0.0.1 | Signal analysis primitives | # pmtvs-centrality
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:07:43.704442 | pmtvs_centrality-0.0.1.tar.gz | 1,267 | 70/00/72ae3b7128eb519b14ba3ab9e0b2e6ae6cd8c29d93f7d3e44af9cc8220b6/pmtvs_centrality-0.0.1.tar.gz | source | sdist | null | false | 7e10c9f01eb562b8033a0eb7128330fd | 304fbf37bbc7ca6039e3d91f1b1df382078690bc9ed27a56b5ac1384a8fce530 | 700072ae3b7128eb519b14ba3ab9e0b2e6ae6cd8c29d93f7d3e44af9cc8220b6 | null | [] | 254 |
2.4 | scilake | 0.0.1 | Domain-agnostic lakehouse orchestration for scientific data | # scilake
| text/markdown | null | Cameron Smith <data@sciexp.net> | null | null | null | null | [] | [] | null | null | <3.14,>=3.12 | [] | [] | [] | [] | [] | [] | [] | [] | uv/0.10.2 {"installer":{"name":"uv","version":"0.10.2","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T02:07:11.062895 | scilake-0.0.1.tar.gz | 133,208 | 69/b6/715a7b8ae538cd2f27f0d111d56b3a810c0bba47f5df988f7ddef47769f2/scilake-0.0.1.tar.gz | source | sdist | null | false | 8e0dc839570228b7da3c9b04890652be | 2033679c1b9afb902165c99be68639ecbd54b818f29a7e56a528ae7104b43337 | 69b6715a7b8ae538cd2f27f0d111d56b3a810c0bba47f5df988f7ddef47769f2 | null | [] | 252 |
2.4 | pmtvs-persistence | 0.0.1 | Signal analysis primitives | # pmtvs-persistence
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:06:39.639549 | pmtvs_persistence-0.0.1.tar.gz | 1,275 | 36/63/57eb27ab2a09a3cc30bba0ab7f62a9eb724c868ebb3f7d4765666679ab8d/pmtvs_persistence-0.0.1.tar.gz | source | sdist | null | false | 5ea6ed33e48660ffd7bbc9564294bb56 | 1c17f49b60a38db8e90476f07dc17f1e35f7be5ca5dc5a08ea0733747da7680e | 366357eb27ab2a09a3cc30bba0ab7f62a9eb724c868ebb3f7d4765666679ab8d | null | [] | 252 |
2.4 | continuum-context | 0.2.0 | Portable context for Claude - own your memory, voice, and identity | # Continuum
[](https://pypi.org/project/continuum-context/)
[](https://pypi.org/project/continuum-context/)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://modelcontextprotocol.io/)
**Portable context for Claude. Own your memory, voice, and identity across all Claude interfaces.**
Continuum gives you a single source of truth for your context that works with Claude Code, Claude.ai, Claude Desktop, and the API. Your identity, voice, working context, and memories live in simple markdown files that you control.
## What's New in v0.2
- **Streamable HTTP transport** for MCP (recommended over SSE for remote access)
- **Expanded test suite** covering export, config, MCP, and voice modules
- **Bug fixes**: removed debug mode from production server, fixed bare except clauses, eliminated `os.chdir()` side effects
- **py.typed marker** for PEP 561 type checking support
## Why Continuum?
Every Claude session starts fresh. You re-explain your role, re-establish your communication style, re-provide context. Claude.ai has memory, but it's siloed and opaque. Claude Code has CLAUDE.md, but it's project-local. None of them talk to each other.
Continuum solves this by giving you:
- **Identity**: Who you are (stable over years)
- **Voice**: How you communicate (stable over months)
- **Context**: What you're working on (changes weekly)
- **Memory**: What you've learned (accumulates over time)
- **Project overlays**: Per-project context that merges with your global context
- **MCP server**: Live integration with Claude.ai and Claude Desktop via Tailscale
## Installation
```bash
pip install continuum-context
```
> **Note:** The package name on PyPI is `continuum-context`, not `continuum`.
Other installation methods:
```bash
# With uv
uv pip install continuum-context
# From source
git clone https://github.com/BioInfo/continuum.git
cd continuum
pip install -e ".[dev]"
```
## Quick Start
```bash
# Initialize your context directory
continuum init
# Edit your identity and voice
continuum edit identity
continuum edit voice
# Check status
continuum status
# Export for Claude Code
continuum export
```
## Features
### Core Context Management
```bash
continuum init # Create ~/.continuum with templates
continuum edit identity # Edit who you are
continuum edit voice # Edit communication style
continuum edit context # Edit current working context
continuum edit memory # Edit accumulated memories
continuum status # Show context status
continuum validate # Check for issues
continuum export # Generate merged context file
```
### Memory System
```bash
# Add memories (category auto-detected)
continuum remember "Decided to use FastAPI for the microservice"
# -> [YYYY-MM-DD] DECISION - Decided to use FastAPI for the microservice
continuum remember "Team standup moved to 10am" --category fact
# -> [YYYY-MM-DD] FACT - Team standup moved to 10am
```
### Project-Specific Context
```bash
# Initialize project context in current directory
continuum init --project
# Edit project-specific files
continuum edit context --project
continuum edit memory --project
# Add project memories
continuum remember "Architecture: event-driven with Kafka" --project
# Status shows both global and project context
continuum status
```
Project context merges with global context on export. Context and memories append; identity and voice can override.
### Voice Analysis
Analyze your writing samples to generate a voice profile:
```bash
# Add samples to ~/.continuum/samples/
mkdir -p ~/.continuum/samples/emails
# Copy your writing examples there
# Analyze and generate voice.md
continuum voice analyze
# Preview without updating
continuum voice analyze --dry-run
```
Requires an `OPENROUTER_API_KEY` environment variable (add to `~/.continuum/.env`).
### MCP Server
Continuum includes an MCP server that exposes your context to Claude.ai, Claude Desktop, and Claude Code.
**For Claude Code (local, stdio):**
```bash
# Get config to add to your MCP settings
continuum serve config
```
**For Claude.ai / Claude Desktop (remote, Streamable HTTP via Tailscale):**
```bash
# Start the server (runs on port 8765)
continuum serve http
# Enable Tailscale Funnel for HTTPS
tailscale funnel --bg 8765
# Get config
continuum serve config --http
```
**Legacy SSE transport** is still available for older clients:
```bash
continuum serve sse
continuum serve config --sse
```
Add to Claude.ai: Settings > Connectors > Add custom connector
**MCP Tools:**
| Tool | Description |
|------|-------------|
| `get_context` | Full merged context (identity + voice + context + memory) |
| `get_identity` | Identity information |
| `get_voice` | Voice/style guide |
| `get_current_context` | Current working context |
| `get_memories` | Search memories by category or text |
| `remember` | Save new memory from conversation |
| `get_status` | Continuum status check |
## Directory Structure
```
~/.continuum/ # Global context
├── identity.md # Who you are
├── voice.md # How you communicate
├── context.md # Current working context
├── memory.md # Accumulated memories
├── config.yaml # Configuration
├── samples/ # Writing samples for voice analysis
└── exports/ # Generated exports
~/project/.continuum/ # Project context (optional)
├── context.md # Project-specific context
└── memory.md # Project-specific memories
```
## Configuration
Edit `~/.continuum/config.yaml`:
```yaml
# Days before a file is marked stale
stale_days: 14
# Memory filtering for exports
memory_recent_days: 30
memory_max_entries: 20
# Identity condensing for exports
identity_max_words: 500
```
## Philosophy
1. **You own your context.** Not platforms, not providers. You.
2. **Files are the interface.** Human-readable, git-friendly, editable with any tool.
3. **Voice matters.** It's not just what you know, it's how you communicate.
4. **Active curation beats passive extraction.** You decide what's important.
## Roadmap
- [x] Core CLI (init, edit, status, remember, export, validate)
- [x] Voice analysis from writing samples
- [x] Project-specific context overlays
- [x] MCP server (stdio + SSE + Streamable HTTP)
- [ ] Semantic memory search
- [ ] Voice drift detection
- [ ] Claude Code native integration
## Contributing
Contributions are welcome. To get started:
```bash
git clone https://github.com/BioInfo/continuum.git
cd continuum
pip install -e ".[dev]"
pytest tests/ -v
```
Please open an issue first for significant changes.
## License
MIT License. See [LICENSE](LICENSE) for details.
## Author
**Justin Johnson** - [Run Data Run](https://rundatarun.com)
---
*Built for people who want to own their AI context, not rent it.*
| text/markdown | Justin Johnson | null | null | null | MIT | claude, ai, context, memory, llm | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",... | [] | null | null | >=3.11 | [] | [] | [] | [
"click>=8.0",
"rich>=13.0",
"pyyaml>=6.0",
"httpx>=0.27",
"python-dotenv>=1.0",
"mcp>=1.0",
"uvicorn>=0.30",
"starlette>=0.38",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/BioInfo/continuum",
"Repository, https://github.com/BioInfo/continuum",
"Issues, https://github.com/BioInfo/continuum/issues",
"Changelog, https://github.com/BioInfo/continuum/releases"
] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T02:06:18.417683 | continuum_context-0.2.0.tar.gz | 33,440 | bb/ca/9c6e09f3554edc54eac0545b1a40a96e94403be3750b80dc8c2176af43ba/continuum_context-0.2.0.tar.gz | source | sdist | null | false | 3a3097bd392ab2e13f7f2ab5eb021c90 | f84ab332daefa846bbc31c9d8f6f91d4025b2205cbb00564e241efb8c9e47f32 | bbca9c6e09f3554edc54eac0545b1a40a96e94403be3750b80dc8c2176af43ba | null | [
"LICENSE"
] | 261 |
2.4 | google-genai | 1.64.0 | GenAI Python SDK | # Google Gen AI SDK
[](https://pypi.org/project/google-genai/)

[](https://pypistats.org/packages/google-genai)
--------
**Documentation:** https://googleapis.github.io/python-genai/
-----
Google Gen AI Python SDK provides an interface for developers to integrate
Google's generative models into their Python applications. It supports the
[Gemini Developer API](https://ai.google.dev/gemini-api/docs) and
[Vertex AI](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/overview)
APIs.
## Code Generation
Generative models are often unaware of recent API and SDK updates and may suggest outdated or legacy code.
We recommend using our Code Generation instructions [`codegen_instructions.md`](https://raw.githubusercontent.com/googleapis/python-genai/refs/heads/main/codegen_instructions.md) when generating Google Gen AI SDK code to guide your model towards using the more recent SDK features. Copy and paste the instructions into your development environment to provide the model with the necessary context.
## Installation
```sh
pip install google-genai
```
<small>With `uv`:</small>
```sh
uv pip install google-genai
```
## Imports
```python
from google import genai
from google.genai import types
```
## Create a client
Please run one of the following code blocks to create a client for
different services ([Gemini Developer API](https://ai.google.dev/gemini-api/docs) or [Vertex AI](https://cloud.google.com/vertex-ai/generative-ai/docs/learn/overview)).
```python
from google import genai
# Only run this block for Gemini Developer API
client = genai.Client(api_key='GEMINI_API_KEY')
```
```python
from google import genai
# Only run this block for Vertex AI API
client = genai.Client(
vertexai=True, project='your-project-id', location='us-central1'
)
```
## Using types
All API methods support Pydantic types and dictionaries, which you can access
from `google.genai.types`. You can import the types module with the following:
```python
from google.genai import types
```
Below is an example `generate_content()` call using types from the types module:
```python
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=types.Part.from_text(text='Why is the sky blue?'),
config=types.GenerateContentConfig(
temperature=0,
top_p=0.95,
top_k=20,
),
)
```
Alternatively, you can accomplish the same request using dictionaries instead of
types:
```python
response = client.models.generate_content(
model='gemini-2.5-flash',
contents={'text': 'Why is the sky blue?'},
config={
'temperature': 0,
'top_p': 0.95,
'top_k': 20,
},
)
```
**(Optional) Using environment variables:**
You can create a client by configuring the necessary environment variables.
Configuration setup instructions depends on whether you're using the Gemini
Developer API or the Gemini API in Vertex AI.
**Gemini Developer API:** Set the `GEMINI_API_KEY` or `GOOGLE_API_KEY`.
It will automatically be picked up by the client. It's recommended that you
set only one of those variables, but if both are set, `GOOGLE_API_KEY` takes
precedence.
```bash
export GEMINI_API_KEY='your-api-key'
```
**Gemini API on Vertex AI:** Set `GOOGLE_GENAI_USE_VERTEXAI`,
`GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION`, as shown below:
```bash
export GOOGLE_GENAI_USE_VERTEXAI=true
export GOOGLE_CLOUD_PROJECT='your-project-id'
export GOOGLE_CLOUD_LOCATION='us-central1'
```
```python
from google import genai
client = genai.Client()
```
## Close a client
Explicitly close the sync client to ensure that resources, such as the
underlying HTTP connections, are properly cleaned up and closed.
```python
from google.genai import Client
client = Client()
response_1 = client.models.generate_content(
model=MODEL_ID,
contents='Hello',
)
response_2 = client.models.generate_content(
model=MODEL_ID,
contents='Ask a question',
)
# Close the sync client to release resources.
client.close()
```
To explicitly close the async client:
```python
from google.genai import Client
aclient = Client(
vertexai=True, project='my-project-id', location='us-central1'
).aio
response_1 = await aclient.models.generate_content(
model=MODEL_ID,
contents='Hello',
)
response_2 = await aclient.models.generate_content(
model=MODEL_ID,
contents='Ask a question',
)
# Close the async client to release resources.
await aclient.aclose()
```
## Client context managers
By using the sync client context manager, it will close the underlying
sync client when exiting the with block and avoid httpx "client has been closed" error like [issues#1763](https://github.com/googleapis/python-genai/issues/1763).
```python
from google.genai import Client
with Client() as client:
response_1 = client.models.generate_content(
model=MODEL_ID,
contents='Hello',
)
response_2 = client.models.generate_content(
model=MODEL_ID,
contents='Ask a question',
)
```
By using the async client context manager, it will close the underlying
async client when exiting the with block.
```python
from google.genai import Client
async with Client().aio as aclient:
response_1 = await aclient.models.generate_content(
model=MODEL_ID,
contents='Hello',
)
response_2 = await aclient.models.generate_content(
model=MODEL_ID,
contents='Ask a question',
)
```
### API Selection
By default, the SDK uses the beta API endpoints provided by Google to support
preview features in the APIs. The stable API endpoints can be selected by
setting the API version to `v1`.
To set the API version use `http_options`. For example, to set the API version
to `v1` for Vertex AI:
```python
from google import genai
from google.genai import types
client = genai.Client(
vertexai=True,
project='your-project-id',
location='us-central1',
http_options=types.HttpOptions(api_version='v1')
)
```
To set the API version to `v1alpha` for the Gemini Developer API:
```python
from google import genai
from google.genai import types
client = genai.Client(
api_key='GEMINI_API_KEY',
http_options=types.HttpOptions(api_version='v1alpha')
)
```
### Faster async client option: Aiohttp
By default we use httpx for both sync and async client implementations. In order
to have faster performance, you may install `google-genai[aiohttp]`. In Gen AI
SDK we configure `trust_env=True` to match with the default behavior of httpx.
Additional args of `aiohttp.ClientSession.request()` ([see `_RequestOptions` args](https://github.com/aio-libs/aiohttp/blob/v3.12.13/aiohttp/client.py#L170)) can be passed
through the following way:
```python
http_options = types.HttpOptions(
async_client_args={'cookies': ..., 'ssl': ...},
)
client=Client(..., http_options=http_options)
```
### Proxy
Both httpx and aiohttp libraries use `urllib.request.getproxies` from
environment variables. Before client initialization, you may set proxy (and
optional `SSL_CERT_FILE`) by setting the environment variables:
```bash
export HTTPS_PROXY='http://username:password@proxy_uri:port'
export SSL_CERT_FILE='client.pem'
```
If you need `socks5` proxy, httpx [supports](https://www.python-httpx.org/advanced/proxies/#socks) `socks5` proxy if you pass it via
args to `httpx.Client()`. You may install `httpx[socks]` to use it.
Then, you can pass it through the following way:
```python
http_options = types.HttpOptions(
client_args={'proxy': 'socks5://user:pass@host:port'},
async_client_args={'proxy': 'socks5://user:pass@host:port'},
)
client=Client(..., http_options=http_options)
```
### Custom base url
In some cases you might need a custom base url (for example, API gateway proxy
server) and bypass some authentication checks for project, location, or API key.
You may pass the custom base url like this:
```python
base_url = 'https://test-api-gateway-proxy.com'
client = Client(
vertexai=True, # Currently only vertexai=True is supported
http_options={
'base_url': base_url,
'headers': {'Authorization': 'Bearer test_token'},
},
)
```
## Types
Parameter types can be specified as either dictionaries(`TypedDict`) or
[Pydantic Models](https://pydantic.readthedocs.io/en/stable/model.html).
Pydantic model types are available in the `types` module.
## Models
The `client.models` module exposes model inferencing and model getters.
See the 'Create a client' section above to initialize a client.
### Generate Content
#### with text content input (text output)
```python
response = client.models.generate_content(
model='gemini-2.5-flash', contents='Why is the sky blue?'
)
print(response.text)
```
#### with text content input (image output)
```python
from google.genai import types
response = client.models.generate_content(
model='gemini-2.5-flash-image',
contents='A cartoon infographic for flying sneakers',
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
),
)
for part in response.parts:
if part.inline_data:
generated_image = part.as_image()
generated_image.show()
```
#### with uploaded file (Gemini Developer API only)
Download the file in console.
```sh
!wget -q https://storage.googleapis.com/generativeai-downloads/data/a11.txt
```
python code.
```python
file = client.files.upload(file='a11.txt')
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=['Could you summarize this file?', file]
)
print(response.text)
```
#### How to structure `contents` argument for `generate_content`
The SDK always converts the inputs to the `contents` argument into
`list[types.Content]`.
The following shows some common ways to provide your inputs.
##### Provide a `list[types.Content]`
This is the canonical way to provide contents, SDK will not do any conversion.
##### Provide a `types.Content` instance
```python
from google.genai import types
contents = types.Content(
role='user',
parts=[types.Part.from_text(text='Why is the sky blue?')]
)
```
SDK converts this to
```python
[
types.Content(
role='user',
parts=[types.Part.from_text(text='Why is the sky blue?')]
)
]
```
##### Provide a string
```python
contents='Why is the sky blue?'
```
The SDK will assume this is a text part, and it converts this into the following:
```python
[
types.UserContent(
parts=[
types.Part.from_text(text='Why is the sky blue?')
]
)
]
```
Where a `types.UserContent` is a subclass of `types.Content`, it sets the
`role` field to be `user`.
##### Provide a list of strings
```python
contents=['Why is the sky blue?', 'Why is the cloud white?']
```
The SDK assumes these are 2 text parts, it converts this into a single content,
like the following:
```python
[
types.UserContent(
parts=[
types.Part.from_text(text='Why is the sky blue?'),
types.Part.from_text(text='Why is the cloud white?'),
]
)
]
```
Where a `types.UserContent` is a subclass of `types.Content`, the
`role` field in `types.UserContent` is fixed to be `user`.
##### Provide a function call part
```python
from google.genai import types
contents = types.Part.from_function_call(
name='get_weather_by_location',
args={'location': 'Boston'}
)
```
The SDK converts a function call part to a content with a `model` role:
```python
[
types.ModelContent(
parts=[
types.Part.from_function_call(
name='get_weather_by_location',
args={'location': 'Boston'}
)
]
)
]
```
Where a `types.ModelContent` is a subclass of `types.Content`, the
`role` field in `types.ModelContent` is fixed to be `model`.
##### Provide a list of function call parts
```python
from google.genai import types
contents = [
types.Part.from_function_call(
name='get_weather_by_location',
args={'location': 'Boston'}
),
types.Part.from_function_call(
name='get_weather_by_location',
args={'location': 'New York'}
),
]
```
The SDK converts a list of function call parts to a content with a `model` role:
```python
[
types.ModelContent(
parts=[
types.Part.from_function_call(
name='get_weather_by_location',
args={'location': 'Boston'}
),
types.Part.from_function_call(
name='get_weather_by_location',
args={'location': 'New York'}
)
]
)
]
```
Where a `types.ModelContent` is a subclass of `types.Content`, the
`role` field in `types.ModelContent` is fixed to be `model`.
##### Provide a non function call part
```python
from google.genai import types
contents = types.Part.from_uri(
file_uri: 'gs://generativeai-downloads/images/scones.jpg',
mime_type: 'image/jpeg',
)
```
The SDK converts all non function call parts into a content with a `user` role.
```python
[
types.UserContent(parts=[
types.Part.from_uri(
file_uri: 'gs://generativeai-downloads/images/scones.jpg',
mime_type: 'image/jpeg',
)
])
]
```
##### Provide a list of non function call parts
```python
from google.genai import types
contents = [
types.Part.from_text('What is this image about?'),
types.Part.from_uri(
file_uri: 'gs://generativeai-downloads/images/scones.jpg',
mime_type: 'image/jpeg',
)
]
```
The SDK will convert the list of parts into a content with a `user` role
```python
[
types.UserContent(
parts=[
types.Part.from_text('What is this image about?'),
types.Part.from_uri(
file_uri: 'gs://generativeai-downloads/images/scones.jpg',
mime_type: 'image/jpeg',
)
]
)
]
```
##### Mix types in contents
You can also provide a list of `types.ContentUnion`. The SDK leaves items of
`types.Content` as is, it groups consecutive non function call parts into a
single `types.UserContent`, and it groups consecutive function call parts into
a single `types.ModelContent`.
If you put a list within a list, the inner list can only contain
`types.PartUnion` items. The SDK will convert the inner list into a single
`types.UserContent`.
### System Instructions and Other Configs
The output of the model can be influenced by several optional settings
available in generate_content's config parameter. For example, increasing
`max_output_tokens` is essential for longer model responses. To make a model more
deterministic, lowering the `temperature` parameter reduces randomness, with
values near 0 minimizing variability. Capabilities and parameter defaults for
each model is shown in the
[Vertex AI docs](https://cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-flash)
and [Gemini API docs](https://ai.google.dev/gemini-api/docs/models) respectively.
```python
from google.genai import types
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='high',
config=types.GenerateContentConfig(
system_instruction='I say high, you say low',
max_output_tokens=3,
temperature=0.3,
),
)
print(response.text)
```
### List Base Models
To retrieve tuned models, see [list tuned models](#list-tuned-models).
```python
for model in client.models.list():
print(model)
```
```python
pager = client.models.list(config={'page_size': 10})
print(pager.page_size)
print(pager[0])
pager.next_page()
print(pager[0])
```
#### List Base Models (Asynchronous)
```python
async for job in await client.aio.models.list():
print(job)
```
```python
async_pager = await client.aio.models.list(config={'page_size': 10})
print(async_pager.page_size)
print(async_pager[0])
await async_pager.next_page()
print(async_pager[0])
```
### Safety Settings
```python
from google.genai import types
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='Say something bad.',
config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category='HARM_CATEGORY_HATE_SPEECH',
threshold='BLOCK_ONLY_HIGH',
)
]
),
)
print(response.text)
```
### Function Calling
#### Automatic Python function Support
You can pass a Python function directly and it will be automatically
called and responded by default.
```python
from google.genai import types
def get_current_weather(location: str) -> str:
"""Returns the current weather.
Args:
location: The city and state, e.g. San Francisco, CA
"""
return 'sunny'
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='What is the weather like in Boston?',
config=types.GenerateContentConfig(tools=[get_current_weather]),
)
print(response.text)
```
#### Disabling automatic function calling
If you pass in a python function as a tool directly, and do not want
automatic function calling, you can disable automatic function calling
as follows:
```python
from google.genai import types
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='What is the weather like in Boston?',
config=types.GenerateContentConfig(
tools=[get_current_weather],
automatic_function_calling=types.AutomaticFunctionCallingConfig(
disable=True
),
),
)
```
With automatic function calling disabled, you will get a list of function call
parts in the response:
```python
function_calls: Optional[List[types.FunctionCall]] = response.function_calls
```
#### Manually declare and invoke a function for function calling
If you don't want to use the automatic function support, you can manually
declare the function and invoke it.
The following example shows how to declare a function and pass it as a tool.
Then you will receive a function call part in the response.
```python
from google.genai import types
function = types.FunctionDeclaration(
name='get_current_weather',
description='Get the current weather in a given location',
parameters_json_schema={
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': 'The city and state, e.g. San Francisco, CA',
}
},
'required': ['location'],
},
)
tool = types.Tool(function_declarations=[function])
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='What is the weather like in Boston?',
config=types.GenerateContentConfig(tools=[tool]),
)
print(response.function_calls[0])
```
After you receive the function call part from the model, you can invoke the function
and get the function response. And then you can pass the function response to
the model.
The following example shows how to do it for a simple function invocation.
```python
from google.genai import types
user_prompt_content = types.Content(
role='user',
parts=[types.Part.from_text(text='What is the weather like in Boston?')],
)
function_call_part = response.function_calls[0]
function_call_content = response.candidates[0].content
try:
function_result = get_current_weather(
**function_call_part.function_call.args
)
function_response = {'result': function_result}
except (
Exception
) as e: # instead of raising the exception, you can let the model handle it
function_response = {'error': str(e)}
function_response_part = types.Part.from_function_response(
name=function_call_part.name,
response=function_response,
)
function_response_content = types.Content(
role='tool', parts=[function_response_part]
)
response = client.models.generate_content(
model='gemini-2.5-flash',
contents=[
user_prompt_content,
function_call_content,
function_response_content,
],
config=types.GenerateContentConfig(
tools=[tool],
),
)
print(response.text)
```
#### Function calling with `ANY` tools config mode
If you configure function calling mode to be `ANY`, then the model will always
return function call parts. If you also pass a python function as a tool, by
default the SDK will perform automatic function calling until the remote calls exceed the
maximum remote call for automatic function calling (default to 10 times).
If you'd like to disable automatic function calling in `ANY` mode:
```python
from google.genai import types
def get_current_weather(location: str) -> str:
"""Returns the current weather.
Args:
location: The city and state, e.g. San Francisco, CA
"""
return "sunny"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="What is the weather like in Boston?",
config=types.GenerateContentConfig(
tools=[get_current_weather],
automatic_function_calling=types.AutomaticFunctionCallingConfig(
disable=True
),
tool_config=types.ToolConfig(
function_calling_config=types.FunctionCallingConfig(mode='ANY')
),
),
)
```
If you'd like to set `x` number of automatic function call turns, you can
configure the maximum remote calls to be `x + 1`.
Assuming you prefer `1` turn for automatic function calling.
```python
from google.genai import types
def get_current_weather(location: str) -> str:
"""Returns the current weather.
Args:
location: The city and state, e.g. San Francisco, CA
"""
return "sunny"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="What is the weather like in Boston?",
config=types.GenerateContentConfig(
tools=[get_current_weather],
automatic_function_calling=types.AutomaticFunctionCallingConfig(
maximum_remote_calls=2
),
tool_config=types.ToolConfig(
function_calling_config=types.FunctionCallingConfig(mode='ANY')
),
),
)
```
#### Model Context Protocol (MCP) support (experimental)
Built-in [MCP](https://modelcontextprotocol.io/introduction) support is an
experimental feature. You can pass a local MCP server as a tool directly.
```python
import os
import asyncio
from datetime import datetime
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from google import genai
client = genai.Client()
# Create server parameters for stdio connection
server_params = StdioServerParameters(
command="npx", # Executable
args=["-y", "@philschmid/weather-mcp"], # MCP Server
env=None, # Optional environment variables
)
async def run():
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Prompt to get the weather for the current day in London.
prompt = f"What is the weather in London in {datetime.now().strftime('%Y-%m-%d')}?"
# Initialize the connection between client and server
await session.initialize()
# Send request to the model with MCP function declarations
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=genai.types.GenerateContentConfig(
temperature=0,
tools=[session], # uses the session, will automatically call the tool using automatic function calling
),
)
print(response.text)
# Start the asyncio event loop and run the main function
asyncio.run(run())
```
### JSON Response Schema
However you define your schema, don't duplicate it in your input prompt,
including by giving examples of expected JSON output. If you do, the generated
output might be lower in quality.
#### JSON Schema support
Schemas can be provided as standard JSON schema.
```python
user_profile = {
'properties': {
'age': {
'anyOf': [
{'maximum': 20, 'minimum': 0, 'type': 'integer'},
{'type': 'null'},
],
'title': 'Age',
},
'username': {
'description': "User's unique name",
'title': 'Username',
'type': 'string',
},
},
'required': ['username', 'age'],
'title': 'User Schema',
'type': 'object',
}
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='Give me a random user profile.',
config={
'response_mime_type': 'application/json',
'response_json_schema': user_profile
},
)
print(response.parsed)
```
#### Pydantic Model Schema support
Schemas can be provided as Pydantic Models.
```python
from pydantic import BaseModel
from google.genai import types
class CountryInfo(BaseModel):
name: str
population: int
capital: str
continent: str
gdp: int
official_language: str
total_area_sq_mi: int
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='Give me information for the United States.',
config=types.GenerateContentConfig(
response_mime_type='application/json',
response_schema=CountryInfo,
),
)
print(response.text)
```
```python
from google.genai import types
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='Give me information for the United States.',
config=types.GenerateContentConfig(
response_mime_type='application/json',
response_schema={
'required': [
'name',
'population',
'capital',
'continent',
'gdp',
'official_language',
'total_area_sq_mi',
],
'properties': {
'name': {'type': 'STRING'},
'population': {'type': 'INTEGER'},
'capital': {'type': 'STRING'},
'continent': {'type': 'STRING'},
'gdp': {'type': 'INTEGER'},
'official_language': {'type': 'STRING'},
'total_area_sq_mi': {'type': 'INTEGER'},
},
'type': 'OBJECT',
},
),
)
print(response.text)
```
### Enum Response Schema
#### Text Response
You can set response_mime_type to 'text/x.enum' to return one of those enum
values as the response.
```python
from enum import Enum
class InstrumentEnum(Enum):
PERCUSSION = 'Percussion'
STRING = 'String'
WOODWIND = 'Woodwind'
BRASS = 'Brass'
KEYBOARD = 'Keyboard'
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='What instrument plays multiple notes at once?',
config={
'response_mime_type': 'text/x.enum',
'response_schema': InstrumentEnum,
},
)
print(response.text)
```
#### JSON Response
You can also set `response_mime_type` to `'application/json'`, the response will be
identical but in quotes.
```python
from enum import Enum
class InstrumentEnum(Enum):
PERCUSSION = 'Percussion'
STRING = 'String'
WOODWIND = 'Woodwind'
BRASS = 'Brass'
KEYBOARD = 'Keyboard'
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='What instrument plays multiple notes at once?',
config={
'response_mime_type': 'application/json',
'response_schema': InstrumentEnum,
},
)
print(response.text)
```
### Generate Content (Synchronous Streaming)
Generate content in a streaming format so that the model outputs streams back
to you, rather than being returned as one chunk.
#### Streaming for text content
```python
for chunk in client.models.generate_content_stream(
model='gemini-2.5-flash', contents='Tell me a story in 300 words.'
):
print(chunk.text, end='')
```
#### Streaming for image content
If your image is stored in [Google Cloud Storage](https://cloud.google.com/storage),
you can use the `from_uri` class method to create a `Part` object.
```python
from google.genai import types
for chunk in client.models.generate_content_stream(
model='gemini-2.5-flash',
contents=[
'What is this image about?',
types.Part.from_uri(
file_uri='gs://generativeai-downloads/images/scones.jpg',
mime_type='image/jpeg',
),
],
):
print(chunk.text, end='')
```
If your image is stored in your local file system, you can read it in as bytes
data and use the `from_bytes` class method to create a `Part` object.
```python
from google.genai import types
YOUR_IMAGE_PATH = 'your_image_path'
YOUR_IMAGE_MIME_TYPE = 'your_image_mime_type'
with open(YOUR_IMAGE_PATH, 'rb') as f:
image_bytes = f.read()
for chunk in client.models.generate_content_stream(
model='gemini-2.5-flash',
contents=[
'What is this image about?',
types.Part.from_bytes(data=image_bytes, mime_type=YOUR_IMAGE_MIME_TYPE),
],
):
print(chunk.text, end='')
```
### Generate Content (Asynchronous Non Streaming)
`client.aio` exposes all the analogous [`async` methods](https://docs.python.org/3/library/asyncio.html)
that are available on `client`. Note that it applies to all the modules.
For example, `client.aio.models.generate_content` is the `async` version
of `client.models.generate_content`
```python
response = await client.aio.models.generate_content(
model='gemini-2.5-flash', contents='Tell me a story in 300 words.'
)
print(response.text)
```
### Generate Content (Asynchronous Streaming)
```python
async for chunk in await client.aio.models.generate_content_stream(
model='gemini-2.5-flash', contents='Tell me a story in 300 words.'
):
print(chunk.text, end='')
```
### Count Tokens and Compute Tokens
```python
response = client.models.count_tokens(
model='gemini-2.5-flash',
contents='why is the sky blue?',
)
print(response)
```
#### Compute Tokens
Compute tokens is only supported in Vertex AI.
```python
response = client.models.compute_tokens(
model='gemini-2.5-flash',
contents='why is the sky blue?',
)
print(response)
```
##### Async
```python
response = await client.aio.models.count_tokens(
model='gemini-2.5-flash',
contents='why is the sky blue?',
)
print(response)
```
#### Local Count Tokens
```python
tokenizer = genai.LocalTokenizer(model_name='gemini-2.5-flash')
result = tokenizer.count_tokens("What is your name?")
```
#### Local Compute Tokens
```python
tokenizer = genai.LocalTokenizer(model_name='gemini-2.5-flash')
result = tokenizer.compute_tokens("What is your name?")
```
### Embed Content
```python
response = client.models.embed_content(
model='gemini-embedding-001',
contents='why is the sky blue?',
)
print(response)
```
```python
from google.genai import types
response = client.models.embed_content(
model='gemini-embedding-001',
contents=['why is the sky blue?', 'What is your age?'],
config=types.EmbedContentConfig(output_dimensionality=10),
)
print(response)
```
### Imagen
#### Generate Images
```python
from google.genai import types
response1 = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='An umbrella in the foreground, and a rainy night sky in the background',
config=types.GenerateImagesConfig(
number_of_images=1,
include_rai_reason=True,
output_mime_type='image/jpeg',
),
)
response1.generated_images[0].image.show()
```
#### Upscale Image
Upscale image is only supported in Vertex AI.
```python
from google.genai import types
response2 = client.models.upscale_image(
model='imagen-4.0-upscale-preview',
image=response1.generated_images[0].image,
upscale_factor='x2',
config=types.UpscaleImageConfig(
include_rai_reason=True,
output_mime_type='image/jpeg',
),
)
response2.generated_images[0].image.show()
```
#### Edit Image
Edit image uses a separate model from generate and upscale.
Edit image is only supported in Vertex AI.
```python
# Edit the generated image from above
from google.genai import types
from google.genai.types import RawReferenceImage, MaskReferenceImage
raw_ref_image = RawReferenceImage(
reference_id=1,
reference_image=response1.generated_images[0].image,
)
# Model computes a mask of the background
mask_ref_image = MaskReferenceImage(
reference_id=2,
config=types.MaskReferenceConfig(
mask_mode='MASK_MODE_BACKGROUND',
mask_dilation=0,
),
)
response3 = client.models.edit_image(
model='imagen-3.0-capability-001',
prompt='Sunlight and clear sky',
reference_images=[raw_ref_image, mask_ref_image],
config=types.EditImageConfig(
edit_mode='EDIT_MODE_INPAINT_INSERTION',
number_of_images=1,
include_rai_reason=True,
output_mime_type='image/jpeg',
),
)
response3.generated_images[0].image.show()
```
### Veo
Support for generating videos is considered public preview
#### Generate Videos (Text to Video)
```python
from google.genai import types
# Create operation
operation = client.models.generate_videos(
model='veo-3.1-generate-preview',
prompt='A neon hologram of a cat driving at top speed',
config=types.GenerateVideosConfig(
number_of_videos=1,
duration_seconds=5,
enhance_prompt=True,
),
)
# Poll operation
while not operation.done:
time.sleep(20)
operation = client.operations.get(operation)
video = operation.response.generated_videos[0].video
video.show()
```
#### Generate Videos (Image to Video)
```python
from google.genai import types
# Read local image (uses mimetypes.guess_type to infer mime type)
image = types.Image.from_file("local/path/file.png")
# Create operation
operation = client.models.generate_videos(
model='veo-3.1-generate-preview',
# Prompt is optional if image is provided
prompt='Night sky',
image=image,
config=types.GenerateVideosConfig(
number_of_videos=1,
duration_seconds=5,
enhance_prompt=True,
# Can also pass an Image into last_frame for frame interpolation
),
)
# Poll operation
while not operation.done:
time.sleep(20)
operation = client.operations.get(operation)
video = operation.response.generated_videos[0].video
video.show()
```
#### Generate Videos (Video to Video)
Currently, only Gemini Developer API supports video extension on Veo 3.1 for
previously generated videos. Vertex supports video extension on Veo 2.0.
```python
from google.genai import types
# Read local video (uses mimetypes.guess_type to infer mime type)
video = types.Video.from_file("local/path/video.mp4")
# Create operation
operation = client.models.generate_videos(
model='veo-3.1-generate-preview',
# Prompt is optional if Video is provided
prompt='Night sky',
# Input video must be in GCS for Vertex or a URI for Gemini
video=types.Video(
uri="gs://bucket-name/inputs/videos/cat_driving.mp4",
),
config=types.GenerateVideosConfig(
number_of_videos=1,
duration_seconds=5,
enhance_prompt=True,
),
)
# Poll operation
while not operation.done:
time.sleep(20)
operation = client.operations.get(operation)
video = operation.response.generated_videos[0].video
video.show()
```
## Chats
Create a chat session to start a multi-turn conversations with the model. Then,
use `chat.send_message` function multiple times within the same chat session so
that it can reflect on its previous responses (i.e., engage in an ongoing
conversation). See the 'Create a client' section above to initialize a client.
### Send Message (Synchronous Non-Streaming)
```python
chat = client.chats.create(model='gemini-2.5-flash')
response = chat.send_message('tell me a story')
print(response.text)
response = chat.send_message('summarize the story you told me in 1 sentence')
print(response.text)
```
### Send Message (Synchronous Streaming)
```python
chat = client.chats.create(model='gemini-2.5-flash')
for chunk in chat.send_message_stream('tell me a story'):
print(chunk.text)
```
### Send Message (Asynchronous Non-Streaming)
```python
chat = client.aio.chats.create(model='gemini-2.5-flash')
response = await chat.send_message('tell me a story')
print(response.text)
```
### Send Message (Asynchronous Streaming)
```python
chat = client.aio.chats.create(model='gemini-2.5-flash')
async for chunk in await chat.send_message_stream('tell me a story'):
print(chunk.text)
```
## Files
Files are only supported in Gemini Developer API. See the 'Create a client'
section above to initialize a client.
```sh
!gcloud storage cp gs://cloud-samples-data/generative-ai/pdf/2312.11805v3.pdf .
!gcloud storage cp gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf .
```
### Upload
```python
file1 = client.files.upload(file='2312.11805v3.pdf')
file2 = client.files.upload(file='2403.05530.pdf')
print(file1)
print(file2)
```
### Get
```python
file1 = client.files.upload(file='2312.11805v3.pdf')
file_info = client.files.get(name=file1.name)
```
### Delete
```python
file3 = client.files.upload(file='2312.11805v3.pdf')
client.files.delete(name=file3.name)
```
## Caches
`client.caches` contains the control plane APIs for cached content. See the
'Create a client' section above to initialize a client.
### Create
```python
from google.genai import types
if client.vertexai:
file_uris = [
'gs://cloud-samples-data/generative-ai/pdf/2312.11805v3.pdf',
'gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf',
]
else:
file_uris = [file1.uri, file2.uri]
cached_content = client.caches.create(
model='gemini-2.5-flash',
config=types.CreateCachedContentConfig(
contents=[
types.Content(
role='user',
parts=[
types.Part.from_uri(
file_uri=file_uris[0], mime_type='application/pdf'
),
types.Part.from_uri(
file_uri=file_uris[1],
mime_type='application/pdf',
),
],
)
],
system_instruction='What is the sum of the two pdfs?',
display_name='test cache',
ttl='3600s',
),
)
```
### Get
```python
cached_content = client.caches.get(name=cached_content.name)
```
### Generate Content with Caches
```python
from google.genai import types
response = client.models.generate_content(
model='gemini-2.5-flash',
contents='Summarize the pdfs',
config=types.GenerateContentConfig(
cached_content=cached_content.name,
),
)
print(response.text)
```
## Interactions (Preview)
> **Warning:** The Interactions API is in **Beta**. This is a preview of an experimental feature. Features and schemas are subject to **breaking changes**.
The Interactions API is a unified interface for interacting with Gemini models and agents. It simplifies state management, tool orchestration, and long-running tasks.
See the [documentation site](https://ai.google.dev/gemini-api/docs/interactions) for more details.
### Basic Interaction
```python
interaction = client.interactions.create(
model='gemini-2.5-flash',
input='Tell me a short joke about programming.'
)
print(interaction.outputs[-1].text)
```
### Stateful Conversation
The Interactions API supports server-side state management. You can continue a conversation by referencing the `previous_interaction_id`.
```python
# 1. First turn
interaction1 = client.interactions.create(
model='gemini-2.5-fla | text/markdown | null | Google LLC <googleapis-packages@google.com> | null | null | null | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Pytho... | [] | null | null | >=3.10 | [] | [] | [] | [
"anyio<5.0.0,>=4.8.0",
"google-auth[requests]<3.0.0,>=2.47.0",
"httpx<1.0.0,>=0.28.1",
"pydantic<3.0.0,>=2.9.0",
"requests<3.0.0,>=2.28.1",
"tenacity<9.2.0,>=8.2.3",
"websockets<15.1.0,>=13.0.0",
"typing-extensions<5.0.0,>=4.11.0",
"distro<2,>=1.7.0",
"sniffio",
"aiohttp>=3.10.11",
"aiohttp<3.... | [] | [] | [] | [
"Homepage, https://github.com/googleapis/python-genai"
] | twine/6.2.0 CPython/3.11.2 | 2026-02-19T02:06:13.950702 | google_genai-1.64.0.tar.gz | 496,434 | bc/14/344b450d4387845fc5c8b7f168ffbe734b831b729ece3333fc0fe8556f04/google_genai-1.64.0.tar.gz | source | sdist | null | false | c14cdb53b8fd3983abc39fe65179a482 | 8db94ab031f745d08c45c69674d1892f7447c74ed21542abe599f7888e28b924 | bc14344b450d4387845fc5c8b7f168ffbe734b831b729ece3333fc0fe8556f04 | Apache-2.0 | [
"LICENSE"
] | 2,667,355 |
2.4 | zuban | 0.6.0 | Zuban - The Zuban Language Server | #########################
The Zuban Language Server
#########################
A Mypy-compatible Python Language Server and type checker built in Rust.
More infos: https://zubanls.com
Docs
====
https://docs.zubanls.com
License
=======
AGPL, https://github.com/zubanls/zuban/blob/master/LICENSE
| text/x-rst; charset=UTF-8 | null | Dave Halter <info@zubanls.com> | null | null | null | typechecking, mypy, static, analysis, autocompletion | [
"Development Status :: 1 - Planning",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: Other/Proprietary License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Progra... | [] | https://zubanls.com | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://docs.zubanls.com",
"Repository, https://github.com/zubanls/zubanls-python"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:05:53.434239 | zuban-0.6.0-py3-none-win_amd64.whl | 10,450,579 | 14/0a/27ed5e6ce0d0d1c98cf9fc1902f1af0383ff9ed859b814e6f3fbfeda8801/zuban-0.6.0-py3-none-win_amd64.whl | py3 | bdist_wheel | null | false | 991f62fbee6c989481770baab1c569c2 | d9396a9c7336025a8ce4ba0829bce11c8b8a4d7b2df471a51a77faa57f87efd0 | 140a27ed5e6ce0d0d1c98cf9fc1902f1af0383ff9ed859b814e6f3fbfeda8801 | null | [
"licenses.html"
] | 3,189 |
2.4 | pmtvs-saddle | 0.0.1 | Signal analysis primitives | # pmtvs-saddle
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:05:35.428065 | pmtvs_saddle-0.0.1.tar.gz | 1,241 | ab/7c/ad9272ca1c339bade8dbe4594a77811221813903cb87e91a6e7066715c91/pmtvs_saddle-0.0.1.tar.gz | source | sdist | null | false | ad15adff8e3b9e1c32f2aedd63e9258d | 8cb2dfa0be748c94c35bbcb1b3cbd5060a6b4e3877118e1717a42fbed10dcd56 | ab7cad9272ca1c339bade8dbe4594a77811221813903cb87e91a6e7066715c91 | null | [] | 259 |
2.1 | falwa | 2.3.2 | Python package to compute finite-amplitude local wave activity diagnostics (Huang and Nakamura 2016, JAS) | ## Python Library: falwa (v2.3.2)
[](https://github.com/csyhuang/hn2016_falwa/actions/workflows/python-build-test.yml)[](https://codecov.io/gh/csyhuang/hn2016_falwa)[](http://hn2016-falwa.readthedocs.io/en/latest/?badge=latest)[](https://zenodo.org/badge/latestdoi/63908662)
**Important:** this python package has been renamed from `hn2016_falwa` to `falwa` since version v1.0.0.

Compute from gridded climate data the Finite-amplitude Local Wave Activity (FALWA) and flux terms presented in:
- [Huang and Nakamura (2016, JAS)](http://dx.doi.org/10.1175/JAS-D-15-0194.1)
- [Huang and Nakamura (2017, GRL)](http://onlinelibrary.wiley.com/doi/10.1002/2017GL073760/full).
- [Nakamura and Huang (2018, Science)](https://doi.org/10.1126/science.aat0721) *Atmospheric Blocking as a Traffic Jam in the Jet Stream*.
- [Neal et al (2022, GRL)](https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2021GL097699) *The 2021 Pacific Northwest Heat Wave and Associated Blocking: Meteorology and the Role of an Upstream Cyclone as a Diabatic Source of Wave Activity*.
- [Lubis et al (2025, Nature Comm)](https://www.nature.com/articles/s41467-025-64672-9). *Cloud-Radiative Effects Significantly Increase Wintertime Atmospheric Blocking in the Euro-Atlantic Sector*.
## Citing this package
We would be grateful if you mention `falwa` and cite our [software package paper](https://rmets.onlinelibrary.wiley.com/doi/full/10.1002/gdj3.70006) published in the Geoscience Data Journal upon usage:
> Huang, C. S. Y., Polster, C., & Nakamura, N. (2025). **Falwa: Python Package to Implement Finite‐Amplitude Local Wave Activity Diagnostics on Climate Data**. *Geoscience Data Journal, 12*(2), e70006.
```
@article{huang_polster_nakamura_2025,
title={Falwa: Python Package to Implement Finite-Amplitude Local Wave Activity Diagnostics on Climate Data},
author={Huang, Clare S Y and Polster, Christopher and Nakamura, Noboru},
journal={Geoscience Data Journal},
volume={12},
number={2},
pages={e70006},
year={2025},
doi = {10.1002/GDJ3.70006},
publisher={Wiley Online Library}}
```
## Package Installation
**Attention: substantial changes took place in release v2.0.0. Installation in develop mode is no longer available.**
Since release v2.0.0, the F2PY modules in `falwa` is compiled with `meson` (See Issue #95 for details) to cope with the deprecation of `numpy.disutils` in python 3.12.
### First-time installation
1. To build the package from source, you need a fortran compiler (e.g., [gfortran](http://hpc.sourceforge.net/)) to implement the installation.
2. Clone the package repo by `git clone https://github.com/csyhuang/hn2016_falwa.git` .
3. Navigate into the repository and set up a python environment satisfying the installation requirement by `conda env create -f environment.yml`. The environment name in the file is set to be `falwa_env` (which users can change).
4. Install the package with the command `python -m pip install .`. The compile modules will be saved to python site-packages directory.
5. If the installation is successful, you should be able to run through all unit tests in the folder `tests/` by executing `pytest tests/`.
### Get updated code from new releases
1. To incorporate updates, first, pull the new version of the code from GitHub by `git pull`.
2. Uninstall existing version of `falwa`: `pip uninstall falwa`
3. If there is change in `environment.yml`, remove the existing environment by `conda remove --name falwa_env --all` and create the environment again from the updated YML file: `conda env create -f environment.yml`.
4. Reinstall the updated version by `python -m pip install .`.
5. Run through all unit tests in the folder `tests/` by executing `pytest tests/` to make sure the package has been properly installed.
## Quick start
There are some readily run python scripts (in `scripts/`) and jupyter notebooks (in `notebooks/`) which you can start with.
The netCDF files needed can be found in [Clare's Dropbox folder](https://www.dropbox.com/scl/fo/b84pwlr7zzsndq8mpthd8/AKMmwRiYhK4mRmdOgmFg5SM?rlkey=k15p1acgksnl2xwcxve3alm0u&st=2mg4svks&dl=0).
Depending on what you want to do, the methods to be use may be different.
1. If you solely want to compute equivalent latitude and local wave activity from a 2D field, you can refer to `notebooks/simple/Example_barotropic.ipynb`. This is useful for users who want to use LWA to quantify field anomalies.
2. If you want to compute zonal wind reference states and wave activity fluxes in QG Formalism, look at `notebooks/nh2018_science/demo_script_for_nh2018.ipynb` for the usage of `QGField`. This notebook demonstrates how to compute wave activity and reference states presented in Nakamura and Huang (2018). To make sure the package is properly installed in your environment, run through the notebook after installation to see if there is error.
## Inquiries / Issues reporting
- If you are interested in getting email message related to update of this package, please leave your contact [here](https://goo.gl/forms/5L8fv0mUordugq6v2) such that I can keep you updated of any changes made.
- If you encounter *coding issues/bugs* when using the package, please create an [Issue ticket](https://github.com/csyhuang/hn2016_falwa/issues).
- If you have scientific questions, please create a thread in the [Discussion Board](https://github.com/csyhuang/hn2016_falwa/discussions) with the category "General" or "Q&A" according to the circumstance.
| text/markdown | null | "Clare S. Y. Huang" <csyhuang@uchicago.edu>, Christopher Polster <cpolster@uni-mainz.de> | null | null | Copyright (c) 2015-2024 Clare S. Y. Huang
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Fortran",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Atmospheric Science"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.22",
"scipy",
"xarray",
"pytest; extra == \"test\"",
"netcdf4; extra == \"test\"",
"dask; extra == \"test\""
] | [] | [] | [] | [
"Documentation, https://hn2016-falwa.readthedocs.io/",
"Repository, https://github.com/csyhuang/hn2016_falwa",
"Bug Tracker, https://github.com/csyhuang/hn2016_falwa/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:04:35.936433 | falwa-2.3.2.tar.gz | 60,208 | 3f/77/b81192e987c1312e841dc55e97d2b7d5e23be35ba0f9349fafb012a2f74b/falwa-2.3.2.tar.gz | source | sdist | null | false | 0f9900feda78aa656e8b5604b276d45a | 928856f317faac61593303449b78cc4a7c1dddf8ac615334d336a5ce25ca7e87 | 3f77b81192e987c1312e841dc55e97d2b7d5e23be35ba0f9349fafb012a2f74b | null | [] | 609 |
2.4 | pmtvs-sensitivity | 0.0.1 | Signal analysis primitives | # pmtvs-sensitivity
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:04:30.378794 | pmtvs_sensitivity-0.0.1.tar.gz | 1,271 | 6a/a6/01f643d4ccaf53735e9040ba220705b4d6febfe945a611b7e00b0410ded0/pmtvs_sensitivity-0.0.1.tar.gz | source | sdist | null | false | 889d9aa8b5acb9194d51901c52cd16aa | f0f63d8d5275527dc684d902d3e54a38e3c136af2d3f76f77ecc5f44b0a0275f | 6aa601f643d4ccaf53735e9040ba220705b4d6febfe945a611b7e00b0410ded0 | null | [] | 251 |
2.4 | foliate | 0.4.5 | Minimal static site generator for markdown vaults | # Foliate
A static site generator for your markdown vault. A flexible, configurable alternative to Obsidian Publish.
```bash
cd my-vault
uvx foliate init # Create .foliate/config.toml
uvx foliate build # Generate site to .foliate/build/
```
## Why Foliate?
- **Everything in your vault** - All content, config, and output stay in your vault
- **Single executable** - One tool to generate your website, no complex setup
- **Flexible** - Just markdown files in, a website out
## Features
- **Zero config** - Works out of the box with sensible defaults
- **Vault-native** - Everything lives in `.foliate/` inside your vault
- **Two-tiered visibility** - Control what's public vs. published
- **Incremental builds** - Only rebuilds changed files (auto-rebuilds on config/template changes)
- **Watch mode** - Auto-rebuild on file changes
- **Works with any markdown** - Obsidian, Logseq, or plain markdown files
- **Obsidian syntax** - Supports `` image sizing
- **Quarto support** - Preprocess `.qmd` files (optional)
- **Deploy command** - Built-in GitHub Pages deployment
## Quick Start
```bash
# Initialize in your vault
cd my-vault
uvx foliate init
# Build
uvx foliate build
# Watch mode (build + serve + auto-rebuild)
uvx foliate watch
```
## Directory Structure
```
my-vault/
├── .foliate/
│ ├── config.toml # Configuration
│ ├── build/ # Generated site
│ ├── cache/ # Build cache
│ ├── templates/ # Custom templates (optional)
│ └── static/ # Custom CSS/JS (optional)
├── _private/ # Ignored - never built
├── _homepage/ # Site root (/, /about/, etc.)
│ └── about.md # → example.com/about/
├── assets/ # Images, PDFs
├── Home.md # → example.com/wiki/Home/
└── Notes/
└── ideas.md # → example.com/wiki/Notes/ideas/
```
### Special Directories
| Directory | Purpose |
|-----------|---------|
| `_private/` | Never built, regardless of frontmatter. Configurable via `ignored_folders` in config. |
| `_homepage/` | Content deployed to site root (`/`) instead of `/wiki/` (or other prefix). Excluded from normal wiki generation. |
## Visibility System
Control what gets built and listed:
```yaml
---
public: true # Built and accessible via direct link
published: true # Also appears in listings and search
---
```
- No frontmatter or `public: false` → Not built (private)
- `public: true` → Built, accessible via URL
- `public: true, published: true` → Built AND visible in listings
## Configuration
`.foliate/config.toml`:
```toml
[site]
name = "My Wiki"
url = "https://example.com"
[build]
ignored_folders = ["_private", "drafts"]
wiki_prefix = "wiki" # URL prefix for wiki content (set to "" for root)
[nav]
items = [
{ url = "/about/", label = "About" },
{ url = "/wiki/Home/", label = "Wiki" },
]
```
## Commands
```bash
foliate init # Create .foliate/config.toml
foliate build # Build site
foliate watch # Build + serve + auto-rebuild
foliate deploy # Deploy to GitHub Pages
foliate clean # Remove build artifacts
```
### Options
```bash
foliate build --force # Force full rebuild
foliate build --verbose # Detailed output
foliate build --serve # Start server after build
foliate watch --port 3000 # Custom port
foliate deploy --dry-run # Preview deploy without executing
foliate deploy -m "msg" # Custom commit message
```
## Deployment
Foliate generates static files in `.foliate/build/`. Deploy anywhere that serves static files.
### GitHub Pages (Built-in)
Configure in `.foliate/config.toml`:
```toml
[deploy]
method = "github-pages"
target = "../username.github.io" # Path to your GitHub Pages repo
exclude = ["CNAME", ".gitignore", ".gitmodules"]
```
Then deploy:
```bash
foliate deploy # Sync, commit, and push
foliate deploy --dry-run # Preview changes first
```
### rsync (VPS/Server)
```bash
rsync -avz --delete .foliate/build/ user@server:/var/www/mysite/
```
### Simple local copy
```bash
cp -r .foliate/build/* /path/to/webserver/
```
## Customization
Foliate is designed to be customized via template and CSS overrides.
### Quick Start
```
my-vault/
└── .foliate/
├── templates/ # Override layout.html, page.html
└── static/ # Override main.css, add custom assets
```
Files in these directories take precedence over Foliate's defaults.
### Documentation
See [docs/customization.md](docs/customization.md) for the full guide, including:
- Template variables reference
- CSS variables for theming
- Common customization examples:
- [Newsletter signup forms](docs/examples/subscription-cta.md)
- [Custom footer with social links](docs/examples/custom-footer.md)
- [Adding analytics](docs/examples/analytics.md)
- [Adding a sidebar](docs/examples/sidebar.md)
## Quarto Support (Optional)
Foliate can preprocess `.qmd` files (Quarto markdown) to `.md` before building:
```bash
# Install with quarto support
pip install foliate[quarto]
```
Configure in `.foliate/config.toml`:
```toml
[advanced]
quarto_enabled = true
quarto_python = "/path/to/python" # Optional: Python for Quarto
```
## Development / CI
Foliate uses a cross-platform GitHub Actions CI workflow on pull requests and `main` pushes:
- Test matrix: Linux, macOS, Windows on Python 3.12 and 3.13
- Build + smoke matrix: Linux, macOS, Windows (Python 3.13), including wheel install and CLI smoke checks
Releases remain manual via:
```bash
make publish
```
For the complete maintainer release process, see [docs/releasing.md](docs/releasing.md).
## License
MIT
| text/markdown | YY Ahn | null | null | null | null | static-site-generator, markdown, wiki, obsidian | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: End Users/Desktop",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"... | [] | null | null | >=3.12 | [] | [] | [] | [
"python-frontmatter>=1.0.0",
"markdown>=3.4",
"jinja2>=3.1",
"click>=8.0",
"watchdog>=3.0",
"pygments>=2.15",
"markdown-katex>=202406.1035",
"mdx-wikilink-plus>=1.4",
"mdx-linkify>=2.1",
"beautifulsoup4>=4.12",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"ruff>=0.1;... | [] | [] | [] | [
"Homepage, https://github.com/yy/foliate",
"Issues, https://github.com/yy/foliate/issues",
"Repository, https://github.com/yy/foliate"
] | uv/0.8.12 | 2026-02-19T02:04:28.928240 | foliate-0.4.5.tar.gz | 38,816 | 10/04/2c7a39678eac6f0e9f48cf07801fa68b780803371fe6ea58605a80c40371/foliate-0.4.5.tar.gz | source | sdist | null | false | c89d88a90cbe19635ea9d283a0ae24d9 | cbc01f6226c892e403a44d9b9b1336caa394f6a8fbf54ebefc23ea54b8c8460c | 10042c7a39678eac6f0e9f48cf07801fa68b780803371fe6ea58605a80c40371 | MIT | [] | 255 |
2.4 | pmtvs-geometry | 0.0.1 | Signal analysis primitives | # pmtvs-geometry
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:03:20.137113 | pmtvs_geometry-0.0.1.tar.gz | 1,267 | 4a/48/0470ddedf8c3f32d70e4bee56891831f87c8ef0e8c3d85012964c455ec68/pmtvs_geometry-0.0.1.tar.gz | source | sdist | null | false | fa8233a1631d7520eb1b875ef26fc81b | 76a2262f348ba6648939e60c4c239da4597bb830ace34914187ef796c32d2349 | 4a480470ddedf8c3f32d70e4bee56891831f87c8ef0e8c3d85012964c455ec68 | null | [] | 256 |
2.4 | pyissm | 0.0.1.dev260219 | Python API for the Ice-sheet and Sea-level System Model (ISSM), managed by ACCESS-NRI | # pyISSM - ISSM Python API
[](https://pypi.org/project/pyissm/)
[](https://anaconda.org/accessnri/pyissm)
[)](https://github.com/ACCESS-NRI/pyISSM/actions/workflows/CI.yml)
[](https://pyissm.readthedocs.io/latest/)
---
## About
*pyISSM* is a Python API for the open source [**Ice-sheet and Sea-level System Model (ISSM)**](https://github.com/ISSMteam/ISSM). Maintained by ACCESS-NRI, pyISSM provides a suite of tools focused on creating, parameterising, executing, visualising, and analysing ISSM models.
## Project status
🚨 **pyISSM is in the initial development stage.** 🚨
We welcome any feedback and ideas! Let us know by submitting [issues on GitHub](https://github.com/ACCESS-NRI/pyISSM/issues) or [joining our community](https://forum.access-hive.org.au/c/cryosphere/34).
## Documentation
Read the [documentation here](https://pyissm.readthedocs.io/latest/)
## License
[](https://github.com/ACCESS-NRI/pyISSM/blob/main/LICENSE)
| text/markdown | ACCESS-NRI | null | null | null | Apache-2.0 | null | [
"Development Status :: 2 - Pre-Alpha",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"xarray",
"numpy",
"scipy",
"netCDF4",
"pandas",
"matplotlib",
"attrs",
"PyYAML"
] | [] | [] | [] | [
"Homepage, https://github.com/ACCESS-NRI/pyISSM",
"Repository, https://github.com/ACCESS-NRI/pyISSM",
"Issues, https://github.com/ACCESS-NRI/pyISSM/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T02:02:49.930851 | pyissm-0.0.1.dev260219.tar.gz | 258,877 | 77/73/978d0e574ff72ba3899bff1314bd60a3ac8f83e12d78e876914db651ef04/pyissm-0.0.1.dev260219.tar.gz | source | sdist | null | false | f1f332b0c0ba7ea44af24f94f46c46a6 | 4bc8cf4bcc57305a7467cbd7d29af3c711ad8ca66dde0f75d3695702a0c6f171 | 7773978d0e574ff72ba3899bff1314bd60a3ac8f83e12d78e876914db651ef04 | null | [
"LICENSE"
] | 222 |
2.4 | pmtvs-hypothesis | 0.0.1 | Signal analysis primitives | # pmtvs-hypothesis
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:02:15.190553 | pmtvs_hypothesis-0.0.1.tar.gz | 1,267 | e0/6d/2f272ecb70a7b34aa3b25c05317ae833e03b2b6ba2e87f387c10021a1ba8/pmtvs_hypothesis-0.0.1.tar.gz | source | sdist | null | false | bcc4c408aa2a38b8fc99331d4d27aebc | 18aa1ac8035866b8bc803197138a9107d672f333159fefcfeba89b16b58fd5c9 | e06d2f272ecb70a7b34aa3b25c05317ae833e03b2b6ba2e87f387c10021a1ba8 | null | [] | 258 |
2.4 | pmtvs-normalization | 0.0.1 | Signal analysis primitives | # pmtvs-normalization
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:01:10.699290 | pmtvs_normalization-0.0.1.tar.gz | 1,274 | b2/5a/255478c0f0cba57c72dc23c30fe98543f10d62c9bbaa48063224d501d831/pmtvs_normalization-0.0.1.tar.gz | source | sdist | null | false | 377b7e0732e8d2649ca19fbdc041d21c | 067cbb584b81ffbd5882267308e7783ba0c5c2331c3b9bef68fbf3063ea75c58 | b25a255478c0f0cba57c72dc23c30fe98543f10d62c9bbaa48063224d501d831 | null | [] | 260 |
2.4 | feagi-rust-py-libs | 0.0.86 | Rust-powered Python libraries for FEAGI data processing, sensorimotor encoding, and agent communication | # feagi-rust-py-libs
High-performance Rust-powered Python libraries for FEAGI data processing, sensorimotor encoding, and agent communication.
Built with [PyO3](https://github.com/PyO3/pyo3) and [Maturin](https://github.com/PyO3/maturin), this package provides Python bindings to FEAGI's core Rust libraries.
## Features
- **Data Processing**: Fast processing of sensory data to and from neuronal forms
- **Sensorimotor System**: Efficient encoding/decoding for vision, text, and motor control
- **Agent SDK**: Python bindings for building FEAGI agents in Rust-accelerated Python
- **Data Structures**: Core genomic and neuron voxel data structures
- **Serialization**: Efficient serialization/deserialization for FEAGI protocols
## Installation
### From PyPI (recommended)
Pre-built wheels are published for Linux, Windows, and macOS (x86_64 and aarch64). Prefer this so you do not need a Rust toolchain:
```bash
pip install feagi-rust-py-libs
```
### From TestPyPI (staging)
```bash
pip install --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple/ feagi-rust-py-libs
```
### Building from source
If pip falls back to building from source (e.g. no wheel for your platform), you need **Rust 1.85 or newer**. A transitive dependency uses the Rust 2024 edition, which is not supported by older Cargo/Rust.
- Check version: `rustc --version` and `cargo --version`
- Install or upgrade: <https://rustup.rs/> then `rustup update stable`
- Then: `pip install feagi-rust-py-libs`
## Usage
This library is primarily used by the FEAGI Python SDK and agent applications. Most Python classes are named after their Rust counterparts, with internal wrapper classes prefixed with "Py".
## Documentation
For detailed information about the wrapped types and functions:
- Genomic Structures
- IO Data Processing
- [Neuron Voxel Data](src/neuron_data/README.md)
- Agent Communication
## Related Projects
- [FEAGI Python SDK](https://github.com/Neuraville/FEAGI-2.0/tree/main/feagi-python-sdk)
- [FEAGI Core (Rust)](https://github.com/Neuraville/FEAGI-2.0/tree/main/feagi-core)
## License
Apache-2.0
| text/markdown; charset=UTF-8; variant=GFM | null | "Neuraville Inc." <feagi@neuraville.com> | null | null | Apache-2.0 | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Lang... | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [
"Bug Tracker, https://github.com/feagi/feagi-rust-py-libs/issues",
"Documentation, https://github.com/feagi/feagi-rust-py-libs#readme",
"Homepage, https://github.com/feagi/feagi-rust-py-libs"
] | maturin/1.12.2 | 2026-02-19T02:00:23.646945 | feagi_rust_py_libs-0.0.86.tar.gz | 103,270 | 34/27/551125ae51d728c1f26fd1931dd58e197a0caaac1087777133fe12e1df87/feagi_rust_py_libs-0.0.86.tar.gz | source | sdist | null | false | 7ae58da06776499178bd4a97d5104860 | 920f54dcf74e10ed5d8cc6570fda3de9da8989a5639728f18e7cf20ea3d21105 | 3427551125ae51d728c1f26fd1931dd58e197a0caaac1087777133fe12e1df87 | null | [] | 1,067 |
2.4 | pmtvs-psd | 0.0.1 | Signal analysis primitives | # pmtvs-psd
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T02:00:06.395259 | pmtvs_psd-0.0.1.tar.gz | 1,238 | 57/74/cc5a8e75c08513ad85cdf241b10a64edc0acec65007bcadf7e26d1f57e05/pmtvs_psd-0.0.1.tar.gz | source | sdist | null | false | ff4e6ecc979d22ac000538ec876fc9ce | 6ac720e67b87b2c71a661af36e75cff38de67225fad00c07319e5329c1658eb4 | 5774cc5a8e75c08513ad85cdf241b10a64edc0acec65007bcadf7e26d1f57e05 | null | [] | 252 |
2.4 | fullbleed | 0.2.7 | High-performance HTML5 to PDF renderer built in Rust | <!-- SPDX-License-Identifier: AGPL-3.0-only OR LicenseRef-Fullbleed-Commercial -->
# Fullbleed
Deterministic, dependency-free HTML/CSS-to-PDF generation in Rust, with a Python-first CLI and Python engine bindings.
License: AGPLv3 for OSS use; commercial license available for proprietary/closed-source production.
- **Install:** `pip install fullbleed`
- **Try:** `fullbleed init . && python report.py`
- **Outputs:** `output/report.pdf`
- Deterministic + reproducible (`--repro-record` / `--repro-check`)
- Agent-safe JSON schemas (`--json-only`, `--schema`)
## Positioning
Fullbleed is a deterministic, offline-first document rendering engine for transactional/VDP pipelines (not a browser, not a hosted web-to-print SaaS).
HTML and CSS are used as a familiar DSL for layout, styling, and data placement in transactional documents.
HTML/CSS are the familiar document DSL; with pinned assets and flags, Fullbleed targets reproducible outputs.
See our [publicly available targets](https://github.com/fullbleed-engine/fullbleed-targets).
This README is the canonical usage guide for:
- `fullbleed` CLI (human workflows + machine/agent automation)
- `fullbleed` Python bindings (`PdfEngine`, `AssetBundle`, batch APIs)
Additional focused references are in `docs/`:
- `docs/README.md`
- `docs/engine.md`
- `docs/python-api.md`
- `docs/cli.md`
- `docs/pdf-templates.md`
## What You Get
- No headless browser requirement for PDF generation.
- Deterministic render pipeline with optional SHA256 output hashing.
- Reproducibility workflow via `--repro-record` and `--repro-check`.
- PDF `1.7` as the production-stable default target.
- Rust-native PDF template composition for VDP/transactional overlays.
- Native Rust image emission for overlay and finalized compose outputs (`--emit-image`) without external PDF raster runtime dependencies.
- Feature-driven page-to-template binding with per-page deterministic compose plans.
- Structured JSON result schemas for CI and AI agents.
- Offline-first asset model with explicit remote opt-in.
- Remote project template registry workflows (`new list`, `new search`, `new remote`).
- Python-first extension surface for hackability and custom workflows.
- Python render calls release the GIL while Rust rendering executes.
- Rayon-backed parallelism for batch rendering and selected internal engine workloads.
## Concurrency Model
- Python binding render methods release the GIL during Rust execution (`py.allow_threads(...)` in the bridge).
- Parallel batch APIs are explicitly Rayon-backed (`render_pdf_batch_parallel(...)` and parallel-to-file variants).
- The engine also uses Rayon in selected internal hotspots (for example table layout and JIT paint paths).
- Do not assume every single-document render path will fully saturate all cores end-to-end.
## Install
```bash
python -m pip install fullbleed
```
From a local wheel:
```bash
python -m pip install C:\path\to\fullbleed-0.2.7-cp311-cp311-win_amd64.whl
```
Platform artifact policy:
- Linux (`manylinux`) and Windows wheels are built as release artifacts.
- Linux wheel builds are smoke-tested in Ubuntu/WSL during release prep.
- macOS wheel artifacts are built in CI, but are currently maintainer-untested.
- If macOS wheel behavior differs from your environment, open an issue and include `fullbleed doctor --json`.
Verify command surface:
```bash
fullbleed --help
fullbleed capabilities --json
fullbleed doctor --json
```
## 60-Second Quick Start (Project Happy Path)
Initialize project scaffold:
```bash
fullbleed init .
```
`fullbleed init` now vendors Bootstrap (`5.0.0`) into `vendor/css/bootstrap.min.css`,
vendors Bootstrap Icons (`1.11.3`) into `vendor/icons/bootstrap-icons.svg`,
vendors `inter` into `vendor/fonts/Inter-Variable.ttf`, writes license notices
(`vendor/css/LICENSE.bootstrap.txt`, `vendor/icons/LICENSE.bootstrap-icons.txt`, `vendor/fonts/LICENSE.inter.txt`),
and seeds `assets.lock.json` with pinned hashes.
The scaffolded `report.py` also runs a component mount smoke validation before
main render and writes `output/component_mount_validation.json` (fails fast on
missing glyphs, placement overflow, or CSS miss signals parsed from debug logs).
Scaffolded components now include `components/primitives.py` with reusable
layout/content helpers (`Stack`, `Row`, `Text`, table/list helpers, key/value rows, etc.).
Each scaffolded project also includes `SCAFFOLDING.md`, which should be your
first read before restructuring components.
Install additional project assets (defaults to `./vendor/...` in project context):
```bash
fullbleed assets install inter --json
```
Bootstrap baseline note:
- We target Bootstrap (`5.0.0`) as the default styling baseline for project workflows.
- Re-run `fullbleed assets install bootstrap --json` only if you want to explicitly refresh/bootstrap-manage outside `init`.
Render using the scaffolded component pipeline:
```bash
python report.py
```
Expected artifacts from scaffolded `report.py`:
- `output/report.pdf`
- `output/report_page1.png` (or equivalent page preview from engine image APIs)
- `output/component_mount_validation.json`
- `output/css_layers.json`
## Project Bootstrap Templates (`fullbleed new`)
Use local starters:
```bash
fullbleed new local invoice ./my-invoice
fullbleed new local statement ./my-statement
```
Discover remote starters from registry:
```bash
fullbleed new list --json
fullbleed new search i9 --tag vdp --json
fullbleed new remote i9-stamped-vdp ./i9-job --json
```
Optional registry override (for private/canary registries):
```bash
fullbleed new list --registry https://example.com/manifest.json --json
```
or:
```bash
set FULLBLEED_TEMPLATE_REGISTRY=https://example.com/manifest.json
fullbleed new search statement --json
```
## Scaffold-First Workflow (Recommended)
`fullbleed init` is designed for component-first authoring rather than a single large HTML template.
Typical scaffold layout:
```text
.
|-- SCAFFOLDING.md
|-- COMPLIANCE.md
|-- report.py
|-- components/
| |-- fb_ui.py
| |-- primitives.py
| |-- header.py
| |-- body.py
| |-- footer.py
| `-- styles/
| |-- primitives.css
| |-- header.css
| |-- body.css
| `-- footer.css
|-- styles/
| |-- tokens.css
| `-- report.css
|-- vendor/
| |-- css/
| |-- fonts/
| `-- icons/
`-- output/
```
Best-practice authoring model:
1. Read `SCAFFOLDING.md` first for project conventions.
2. Keep composition and data loading in `report.py`.
3. Keep reusable component building blocks in `components/primitives.py`.
4. Keep section markup in `components/header.py`, `components/body.py`, `components/footer.py`.
5. Keep component-local styles in `components/styles/*.css`.
6. Keep page tokens/composition styles in `styles/tokens.css` and `styles/report.css`.
Recommended CSS layer order:
1. `styles/tokens.css`
2. `components/styles/primitives.css`
3. `components/styles/header.css`
4. `components/styles/body.css`
5. `components/styles/footer.css`
6. `styles/report.css`
Recommended iteration loop:
1. Edit data loading + component props in `report.py`.
2. Edit component markup in `components/*.py`.
3. Edit styles in `components/styles/*.css` and `styles/*.css`.
4. Run `python report.py`.
5. Review `output/report_page1.png`, `output/component_mount_validation.json`, and `output/css_layers.json`.
Optional scaffold diagnostics:
- `FULLBLEED_DEBUG=1` to emit JIT traces.
- `FULLBLEED_PERF=1` to emit perf traces.
- `FULLBLEED_EMIT_PAGE_DATA=1` to persist page data JSON.
- `FULLBLEED_IMAGE_DPI=144` (or higher) for preview resolution.
- `FULLBLEED_VALIDATE_STRICT=1` for stricter validation gates in CI.
## One-off Quick Render (No Project Scaffold)
Render inline HTML/CSS with reproducibility artifacts:
```bash
fullbleed --json render \
--html-str "<html><body><h1>Hello</h1></body></html>" \
--css-str "body{font-family:sans-serif}" \
--emit-manifest build/render.manifest.json \
--emit-jit build/render.jit.jsonl \
--emit-perf build/render.perf.jsonl \
--deterministic-hash build/render.sha256 \
--repro-record build/render.repro.json \
--out output/hello.pdf
```
`--deterministic-hash` writes the output PDF SHA-256 by default; when `--emit-image` is enabled, it writes an artifact-set digest (`fullbleed.artifact_digest.v1`) over PDF SHA-256 plus ordered page-image SHA-256 hashes. JSON outputs expose `outputs.deterministic_hash_mode` (`pdf_only` or `artifact_set_v1`), with `outputs.artifact_sha256` and `outputs.image_sha256` when images are emitted.
Re-run and enforce reproducibility against a stored record:
```bash
fullbleed --json render \
--html templates/report.html \
--css templates/report.css \
--repro-check build/render.repro.json \
--out output/report.rerun.pdf
```
Generate PNG page artifacts from an existing validation render:
```bash
fullbleed --json verify \
--html templates/report.html \
--css templates/report.css \
--emit-pdf output/report.verify.pdf \
--emit-image output/report_verify_pages \
--image-dpi 200
```
Compile-only plan (no render):
```bash
fullbleed --json plan \
--html templates/report.html \
--css templates/report.css
```
Template compose planning (no finalize write):
```bash
fullbleed --json plan \
--html templates/overlay.html \
--css templates/overlay.css \
--template-binding config/template_binding.json \
--templates config/template_catalog.json \
--emit-compose-plan output/compose_plan.json
```
## PDF Template Composition (VDP / Transactional)
When overlaying variable data onto a source PDF, use the built-in Rust template compose path.
Minimal CLI auto-compose flow:
```bash
fullbleed --json render \
--html templates/overlay.html \
--css templates/overlay.css \
--asset templates/source.pdf --asset-kind pdf --asset-name source-template \
--template-binding config/template_binding.json \
--templates config/template_catalog.json \
--out output/composed.pdf
```
Compose image semantics:
- In template auto-compose mode, `--emit-image` PNGs are rasterized from finalized composed pages and report `outputs.image_mode=composed_pdf`.
- In non-compose `render`/`verify` runs, `--emit-image` reports `outputs.image_mode=overlay_document`.
Minimal `template_binding` example:
```json
{
"default_template_id": "source-template",
"feature_prefix": "fb.feature.",
"by_feature": {
"front": "source-template",
"back_blank": "source-template"
}
}
```
Python API compose flow:
```python
import fullbleed
engine = fullbleed.PdfEngine(template_binding=binding_spec)
overlay_bytes, _page_data, _bindings = engine.render_pdf_with_page_data_and_template_bindings(html, css)
open("output/overlay.pdf", "wb").write(overlay_bytes)
plan_result = engine.plan_template_compose(
html,
css,
[("source-template", "templates/source.pdf")],
0.0,
0.0,
)
plan = [
(
row["template_id"],
row["template_page"],
row["overlay_page"],
row["dx"],
row["dy"],
)
for row in plan_result["plan"]
]
fullbleed.finalize_compose_pdf(
[("source-template", "templates/source.pdf")],
plan,
"output/overlay.pdf",
"output/composed.pdf",
annotation_mode="link_only", # optional: link_only | none | carry_widgets
)
```
See `docs/pdf-templates.md` and `examples/template-flagging-smoke/` for full production examples.
## CLI Command Map
| Command | Purpose | JSON Schema |
| --- | --- | --- |
| `render` | Render HTML/CSS to PDF with optional PNG page artifacts | `fullbleed.render_result.v1` |
| `verify` | Validation render path with optional PDF and PNG emits | `fullbleed.verify_result.v1` |
| `plan` | Compile/normalize inputs into manifest + warnings | `fullbleed.plan_result.v1` |
| `run` | Render using Python module/file engine factory | `fullbleed.run_result.v1` |
| `inspect pdf` | Inspect PDF metadata and composition compatibility | `fullbleed.inspect_pdf.v1` |
| `inspect pdf-batch` | Inspect multiple PDFs with per-file status | `fullbleed.inspect_pdf_batch.v1` |
| `inspect templates` | Inspect template catalog metadata/compatibility | `fullbleed.inspect_templates.v1` |
| `compliance` | License/compliance report for legal/procurement | `fullbleed.compliance.v1` |
| `debug-perf` | Summarize perf JSONL logs | `fullbleed.debug_perf.v1` |
| `debug-jit` | Filter/inspect JIT JSONL logs | `fullbleed.debug_jit.v1` |
| `doctor` | Runtime capability and health checks | `fullbleed.doctor.v1` |
| `capabilities` | Machine-readable command/engine capabilities | `fullbleed.capabilities.v1` |
| `assets list` | Installed and optional remote packages | `fullbleed.assets_list.v1` |
| `assets info` | Package details + hashes/sizes | `fullbleed.assets_info.v1` |
| `assets install` | Install builtin/remote package | `fullbleed.assets_install.v1` |
| `assets verify` | Validate package and optional lock constraints | `fullbleed.assets_verify.v1` |
| `assets lock` | Write/update `assets.lock.json` | `fullbleed.assets_lock.v1` |
| `cache dir` | Cache location | `fullbleed.cache_dir.v1` |
| `cache prune` | Remove old cached packages | `fullbleed.cache_prune.v1` |
| `init` | Initialize project scaffold | `fullbleed.init.v1` |
| `new` | Create starter template files or query/install remote templates | `fullbleed.new_template.v1`, `fullbleed.new_list.v1`, `fullbleed.new_search.v1`, `fullbleed.new_remote.v1` |
Schema discovery for any command/subcommand:
```bash
fullbleed --schema render
fullbleed --schema assets verify
fullbleed --schema inspect pdf
fullbleed --schema inspect templates
```
## CLI Flags That Matter Most
Global machine flags:
- `--json`: structured result payload to stdout
- `--json-only`: implies `--json` and `--no-prompts`
- `--schema`: emit schema definition and exit
- `--no-prompts`: disable interactive prompts
- `--config`: load defaults from a config file
- `--log-level error|warn|info|debug`: control CLI log verbosity
- `--no-color`: disable ANSI color output
- `--version`: print CLI version and exit
Render/verify/plan key flags:
- Inputs: `--html`, `--html-str`, `--css`, `--css-str`
`--html` accepts `.svg` files for direct SVG-document rendering; `--html-str` accepts inline SVG markup.
- Page setup: `--page-size`, `--page-width`, `--page-height`, `--margin`, `--page-margins`
- Engine toggles: `--reuse-xobjects`, `--svg-form-xobjects`, `--svg-raster-fallback`, `--shape-text`, `--unicode-support`, `--unicode-metrics`
- PDF/compliance: `--pdf-version`, `--pdf-profile`, `--color-space`, `--document-lang`, `--document-title`
Stable default is `--pdf-version 1.7` for shipping workflows.
Output intent metadata (`--output-intent-identifier|--output-intent-info|--output-intent-components`) requires `--output-intent-icc`.
- Watermarking: `--watermark-text`, `--watermark-html`, `--watermark-image`, `--watermark-layer`, `--watermark-semantics`, `--watermark-opacity`, `--watermark-rotation`
- Artifacts: `--emit-jit`, `--emit-perf`, `--emit-glyph-report`, `--emit-page-data`, `--emit-compose-plan`, `--emit-image`, `--image-dpi`, `--deterministic-hash`
- Assets: `--asset`, `--asset-kind`, `--asset-name`, `--asset-trusted`, `--allow-remote-assets`
- Profiles: `--profile dev|preflight|prod`
- Fail policy: `--fail-on overflow|missing-glyphs|font-subst|budget`
- Fallback policy: `--allow-fallbacks` (keeps fallback diagnostics, but does not fail `missing-glyphs` / `font-subst` gates)
- Reproducibility: `--repro-record <path>`, `--repro-check <path>`
- Budget thresholds: `--budget-max-pages`, `--budget-max-bytes`, `--budget-max-ms`
- Release gates: `doctor --strict`, `compliance --strict --max-audit-age-days <n>`
- Commercial attestation (compliance): `--license-mode commercial`, `--commercial-licensed`, `--commercial-license-id`, `--commercial-license-file`
## SVG Workflows
Fullbleed supports SVG in three practical CLI paths:
- Direct SVG document render via `--html <file.svg>`
- Inline SVG markup via `--html-str "<svg ...>...</svg>"`
- Referenced SVG assets via `--asset <file.svg>` (kind auto-infers to `svg`)
Standalone SVG file to PDF:
```bash
fullbleed --json render \
--html artwork/badge.svg \
--out output/badge.pdf
```
Inline SVG markup to PDF:
```bash
fullbleed --json render \
--html-str "<svg xmlns='http://www.w3.org/2000/svg' width='200' height='80'><rect width='200' height='80' fill='#0d6efd'/><text x='16' y='48' fill='white'>Hello SVG</text></svg>" \
--out output/inline-svg.pdf
```
HTML template with explicit SVG asset registration:
```bash
fullbleed --json render \
--html templates/report.html \
--css templates/report.css \
--asset assets/logo.svg \
--asset-kind svg \
--out output/report.pdf
```
SVG render behavior flags:
- `--svg-form-xobjects` / `--no-svg-form-xobjects`
- `--svg-raster-fallback` / `--no-svg-raster-fallback`
Machine discovery:
```bash
fullbleed capabilities --json
```
Inspect the `svg` object in `fullbleed.capabilities.v1` for SVG support metadata.
## Per-Page Templates (`page_1`, `page_2`, `page_n`)
Fullbleed uses ordered page templates internally. In docs, this is easiest to think of as:
- `page_1`: first page template
- `page_2`: second page template
- `page_n`: repeating template for later pages
Configuration mapping:
- CLI `--page-margins` keys: `1`, `2`, ... and optional `"n"` (or `"each"` alias).
- Python `PdfEngine(page_margins=...)`: same key model.
- Missing numeric pages fall back to the base `margin`.
- The last configured template repeats for remaining pages.
Minimal CLI example:
```json
{
"1": {"top": "12mm", "right": "12mm", "bottom": "12mm", "left": "12mm"},
"2": {"top": "24mm", "right": "12mm", "bottom": "12mm", "left": "12mm"},
"n": {"top": "30mm", "right": "12mm", "bottom": "12mm", "left": "12mm"}
}
```
```bash
fullbleed --json render \
--html templates/report.html \
--css templates/report.css \
--page-margins page_margins.json \
--header-each "Statement continued - Page {page} of {pages}" \
--out output/report.pdf
```
Minimal Python example:
```python
import fullbleed
engine = fullbleed.PdfEngine(
page_width="8.5in",
page_height="11in",
margin="12mm",
page_margins={
1: {"top": "12mm", "right": "12mm", "bottom": "12mm", "left": "12mm"}, # page_1
2: {"top": "24mm", "right": "12mm", "bottom": "12mm", "left": "12mm"}, # page_2
"n": {"top": "30mm", "right": "12mm", "bottom": "12mm", "left": "12mm"} # page_n
},
header_first="Account Statement",
header_each="Statement continued - Page {page} of {pages}",
footer_last="Final page",
)
```
Note:
- CLI currently exposes `--header-each` / `--footer-each` (and `--header-html-each` / `--footer-html-each`).
- For `first/last` header/footer variants (`header_first`, `header_last`, `footer_first`, `footer_last`), use the Python API.
## Asset Workflow (CLI)
List installed + available packages:
```bash
fullbleed assets list --available --json
```
Install builtin assets:
```bash
fullbleed assets install bootstrap
fullbleed assets install bootstrap-icons
# `@bootstrap` / `@bootstrap-icons` are also supported aliases
```
PowerShell note:
- Quote `@` aliases (for example `"@bootstrap"`) to avoid shell parsing surprises.
Install remote asset package:
```bash
fullbleed assets install inter
```
Install broad Unicode fallback package (larger font payload):
```bash
fullbleed assets install noto-sans
```
Install to a custom vendor directory:
```bash
fullbleed assets install bootstrap --vendor ./vendor
```
Install to global cache:
```bash
fullbleed assets install inter --global
```
Install common barcode fonts (license-safe defaults):
```bash
fullbleed assets install libre-barcode-128
fullbleed assets install libre-barcode-39
fullbleed assets install libre-barcode-ean13-text
```
Verify against lock file with strict failure:
```bash
fullbleed assets verify inter --lock --strict --json
```
Preview cache cleanup without deleting files:
```bash
fullbleed cache prune --max-age-days 30 --dry-run --json
```
Notes:
- Builtin packages accept both plain and `@` references (`bootstrap` == `@bootstrap`, `bootstrap-icons` == `@bootstrap-icons`, `noto-sans` == `@noto-sans`).
- `noto-sans` is available as a builtin fallback package, but it is intentionally larger than `inter`; use it when your document requires broader glyph coverage.
- Project installs default to `./vendor/` when project markers are present (`assets.lock.json`, `report.py`, or `fullbleed.toml` in CWD).
- If no project markers are found, `assets install` defaults to global cache unless `--vendor` is explicitly set.
- Do not hardcode cache paths like `%LOCALAPPDATA%/fullbleed/cache/...`; use `assets install --json` and consume `installed_to`.
- Installed assets include license files in typed vendor directories (for example `vendor/fonts/`, `vendor/css/`).
- `assets lock --add` is currently aimed at builtin package additions.
- Barcode packages in the remote registry are currently OFL-1.1 families from Google Fonts (`Libre Barcode`).
- USPS IMB fonts are not currently auto-installable via `assets install`; use local vetted font files and track licensing separately.
## Bootstrap Vendoring + Coverage
Bootstrap builtin package details:
- Package: `bootstrap` (alias: `@bootstrap`)
- Bundled version: `5.0.0`
- Asset kind: CSS (`bootstrap.min.css`)
- Default install location: `vendor/css/bootstrap.min.css` (project mode)
- License: `MIT`
- License source: `https://raw.githubusercontent.com/twbs/bootstrap/v5.0.0/LICENSE`
Bootstrap Icons builtin package details:
- Package: `bootstrap-icons` (alias: `@bootstrap-icons`)
- Bundled version: `1.11.3`
- Asset kind: SVG sprite (`bootstrap-icons.svg`)
- Default install location: `vendor/icons/bootstrap-icons.svg` (project mode)
- License: `MIT`
- License source: `https://raw.githubusercontent.com/twbs/icons/v1.11.3/LICENSE`
Transactional-document coverage status:
- `[sat]` Bootstrap is vendored and installable through the asset pipeline.
- `[sat]` Current Bootstrap preflight pass set is suitable for static transactional PDF workflows.
- `[sat]` Bootstrap CSS is consumed as an explicit asset (`--asset @bootstrap` or `AssetBundle`); external HTML `<link rel="stylesheet">` is not the execution path.
- Evidence source: `bootstrap_preflight.md` (visual pass dated `2026-02-10`).
Current `[pass]` fixtures from Bootstrap preflight:
| Feature | Status | Evidence |
| --- | --- | --- |
| `components/pagination` | [pass] | `examples/bootstrap5/out/components_pagination_component_page1.png` |
| `content/inline_styles` | [pass] | `examples/bootstrap5/out/content_inline_styles_component_page1.png` |
| `content/tables` | [pass] | `examples/bootstrap5/out/content_tables_component_page1.png` |
| `content/typography` | [pass] | `examples/bootstrap5/out/content_typography_component_page1.png` |
| `helpers/text_truncation` | [pass] | `examples/bootstrap5/out/helpers_text_truncation_component_page1.png` |
| `layout/bank_statement` | [pass] | `examples/bootstrap5/out/layout_bank_statement_component_page1.png` |
| `layout/breakpoints` | [pass] | `examples/bootstrap5/out/layout_breakpoints_component_page1.png` |
| `layout/columns` | [pass] | `examples/bootstrap5/out/layout_columns_component_page1.png` |
| `layout/containers` | [pass] | `examples/bootstrap5/out/layout_containers_component_page1.png` |
| `layout/grid` | [pass] | `examples/bootstrap5/out/layout_grid_component_page1.png` |
| `layout/gutters` | [pass] | `examples/bootstrap5/out/layout_gutters_component_page1.png` |
| `layout/layout_and_utility` | [pass] | `examples/bootstrap5/out/layout_layout_and_utility_component_page1.png` |
| `utilities/text_decoration` | [pass] | `examples/bootstrap5/out/utilities_text_decoration_component_page1.png` |
| `utilities/utilities` | [pass] | `examples/bootstrap5/out/utilities_utilities_component_page1.png` |
| `utilities/z_index` | [pass] | `examples/bootstrap5/out/utilities_z_index_component_page1.png` |
## `run` Command (Python Factory Interop)
`run` lets the CLI use a Python-created engine instance.
`report.py`:
```python
import fullbleed
def create_engine():
return fullbleed.PdfEngine(page_width="8.5in", page_height="11in", margin="0.5in")
```
CLI invocation:
```bash
fullbleed --json run report:create_engine \
--html-str "<h1>From run</h1>" \
--css templates/report.css \
--out output/report.pdf
```
Entrypoint formats:
- `module_name:factory_or_engine`
- `path/to/file.py:factory_or_engine`
## Python API Quick Start
```python
import fullbleed
engine = fullbleed.PdfEngine(
page_width="8.5in",
page_height="11in",
margin="0.5in",
pdf_version="1.7",
pdf_profile="none",
color_space="rgb",
)
html = "<html><body><h1>Invoice</h1><p>Hello.</p></body></html>"
css = "body { font-family: sans-serif; }"
bytes_written = engine.render_pdf_to_file(html, css, "output/invoice.pdf")
print(bytes_written)
```
Register local assets with `AssetBundle`:
```python
import fullbleed
bundle = fullbleed.AssetBundle()
bundle.add_file("vendor/css/bootstrap.min.css", "css", name="bootstrap")
bundle.add_file("vendor/fonts/Inter-Variable.ttf", "font", name="inter")
engine = fullbleed.PdfEngine(page_width="8.5in", page_height="11in")
engine.register_bundle(bundle)
engine.render_pdf_to_file("<h1>Styled</h1>", "", "output/styled.pdf")
```
## Python API Signatures (Runtime-Verified)
These signatures are verified from the installed package via `inspect.signature(...)`.
`PdfEngine` constructor:
```python
PdfEngine(
page_width=None,
page_height=None,
margin=None,
page_margins=None,
font_dirs=None,
font_files=None,
reuse_xobjects=True,
svg_form_xobjects=False,
svg_raster_fallback=False,
unicode_support=True,
shape_text=True,
unicode_metrics=True,
pdf_version=None,
pdf_profile=None,
output_intent_icc=None,
output_intent_identifier=None,
output_intent_info=None,
output_intent_components=None,
color_space=None,
document_lang=None,
document_title=None,
header_first=None,
header_each=None,
header_last=None,
header_x=None,
header_y_from_top=None,
header_font_name=None,
header_font_size=None,
header_color=None,
header_html_first=None,
header_html_each=None,
header_html_last=None,
header_html_x=None,
header_html_y_from_top=None,
header_html_width=None,
header_html_height=None,
footer_first=None,
footer_each=None,
footer_last=None,
footer_x=None,
footer_y_from_bottom=None,
footer_font_name=None,
footer_font_size=None,
footer_color=None,
watermark=None,
watermark_text=None,
watermark_html=None,
watermark_image=None,
watermark_layer="overlay",
watermark_semantics="artifact",
watermark_opacity=0.15,
watermark_rotation=0.0,
watermark_font_name=None,
watermark_font_size=None,
watermark_color=None,
paginated_context=None,
jit_mode=None,
debug=False,
debug_out=None,
perf=False,
perf_out=None,
)
```
Module exports:
- `PdfEngine`
- `AssetBundle`
- `Asset`
- `AssetKind`
- `WatermarkSpec(kind, value, layer='overlay', semantics=None, opacity=0.15, rotation_deg=0.0, font_name=None, font_size=None, color=None)`
- `concat_css(parts)`
- `vendored_asset(source, kind, name=None, trusted=False, remote=False)`
- `inspect_pdf(path)`
- `inspect_template_catalog(templates)`
- `finalize_stamp_pdf(template, overlay, out, page_map=None, dx=0.0, dy=0.0)`
- `finalize_compose_pdf(templates, plan, overlay, out, annotation_mode='link_only')`
- `fetch_asset(url)`
`PdfEngine` methods:
| Method | Return shape |
| --- | --- |
| `register_bundle(bundle)` | `None` |
| `render_pdf(html, css, deterministic_hash=None)` | `bytes` |
| `render_pdf_to_file(html, css, path, deterministic_hash=None)` | `int` (bytes written) |
| `render_image_pages(html, css, dpi=150)` | `list[bytes]` |
| `render_image_pages_to_dir(html, css, out_dir, dpi=150, stem=None)` | `list[str]` |
| `render_finalized_pdf_image_pages(pdf_path, dpi=150)` | `list[bytes]` |
| `render_finalized_pdf_image_pages_to_dir(pdf_path, out_dir, dpi=150, stem=None)` | `list[str]` |
| `render_pdf_with_glyph_report(html, css)` | `(bytes, list)` |
| `render_pdf_with_page_data(html, css)` | `(bytes, page_data_or_none)` |
| `render_pdf_with_page_data_and_glyph_report(html, css)` | `(bytes, page_data_or_none, glyph_report_list)` |
| `render_pdf_with_page_data_and_template_bindings(html, css)` | `(bytes, page_data_or_none, template_bindings_or_none)` |
| `render_pdf_with_page_data_and_template_bindings_and_glyph_report(html, css)` | `(bytes, page_data_or_none, template_bindings_or_none, glyph_report_list)` |
| `plan_template_compose(html, css, templates, dx=0.0, dy=0.0)` | `dict` |
| `render_pdf_batch(html_list, css, deterministic_hash=None)` | `bytes` |
| `render_pdf_batch_parallel(html_list, css, deterministic_hash=None)` | `bytes` |
| `render_pdf_batch_to_file(html_list, css, path, deterministic_hash=None)` | `int` |
| `render_pdf_batch_to_file_parallel(html_list, css, path, deterministic_hash=None)` | `int` |
| `render_pdf_batch_to_file_parallel_with_page_data(html_list, css, path, deterministic_hash=None)` | `(bytes_written, page_data_list)` |
| `render_pdf_batch_with_css(jobs, deterministic_hash=None)` | `bytes` |
| `render_pdf_batch_with_css_to_file(jobs, path, deterministic_hash=None)` | `int` |
When `deterministic_hash` is set, engine writes PDF SHA-256 to the provided file path.
`AssetBundle` methods:
- `add_file(path, kind, name=None, trusted=False, remote=False)`
- `add(asset)`
- `assets_info()`
- `css()`
## Python Examples (Smoke-Checked)
Text watermark + diagnostics:
```python
import fullbleed
engine = fullbleed.PdfEngine(
page_width="8.5in",
page_height="11in",
margin="0.5in",
pdf_version="1.7",
watermark_text="INTERNAL",
watermark_layer="overlay",
watermark_semantics="artifact",
watermark_opacity=0.12,
watermark_rotation=-32.0,
debug=True,
debug_out="build/invoice.jit.jsonl",
perf=True,
perf_out="build/invoice.perf.jsonl",
)
html = "<h1>Invoice</h1><p>Status: Ready</p>"
css = "h1{margin:0 0 8px 0} p{margin:0}"
written = engine.render_pdf_to_file(html, css, "output/invoice_watermarked.pdf")
print("bytes:", written)
```
Batch render + glyph/page-data checks:
```python
import fullbleed
engine = fullbleed.PdfEngine(page_width="8.5in", page_height="11in", margin="0.5in")
jobs = [
("<h1>Batch A</h1><p>Alpha</p>", "h1{color:#0d6efd}"),
("<h1>Batch B</h1><p>Beta</p>", "h1{color:#198754}"),
]
written = engine.render_pdf_batch_with_css_to_file(jobs, "output/batch.pdf")
print("batch bytes:", written)
pdf_bytes, glyph_report = engine.render_pdf_with_glyph_report("<p>Hello</p>", "")
print("glyph entries:", len(glyph_report))
pdf_bytes, page_data = engine.render_pdf_with_page_data("<p>Hello</p>", "")
print("page data available:", page_data is not None)
```
## Transactional Header/Footer + Totals
Minimal, self-contained Python example (no external template files) showing:
- Continued headers on page 2+.
- Per-page subtotal footer expansion via `{sum:items.amount}`.
- Final-page grand total footer expansion via `{total:items.amount}`.
- Structured `page_data` totals for automation and reconciliation checks.
```python
from pathlib import Path
import fullbleed
rows = []
for i in range(1, 121): # enough rows to force multiple pages
amount = 10.00 + ((i * 7) % 23) + 0.25
rows.append(
f'<tr data-fb="items.amount={amount:.2f}">'
f"<td>2026-01-{(i % 28) + 1:02d}</td>"
f"<td>Txn {i:03d}</td>"
f'<td class="num">${amount:.2f}</td>'
"</tr>"
)
html = f"""<!doctype html>
<html>
<body>
<h1>Monthly Statement</h1>
<table>
<thead>
<tr><th>Date</th><th>Description</th><th class="num">Amount</th></tr>
</thead>
<tbody>
{''.join(rows)}
</tbody>
</table>
</body>
</html>
"""
css = """
body { font-family: sans-serif; font-size: 10pt; color: #111; }
h1 { margin: 0 0 8pt 0; }
table { width: 100%; border-collapse: collapse; }
th, td { padding: 4pt; border-bottom: 1pt solid #e1e1e1; }
thead th { background: #f3f6fa; text-transform: uppercase; font-size: 9pt; }
.num { text-align: right; }
"""
engine = fullbleed.PdfEngine(
page_width="8.5in",
page_height="11in",
margin="12mm",
page_margins={
1: {"top": "12mm", "right": "12mm", "bottom": "12mm", "left": "12mm"},
2: {"top": "28mm", "right": "12mm", "bottom": "12mm", "left": "12mm"},
"n": {"top": "28mm", "right": "12mm", "bottom": "12mm", "left": "12mm"},
},
header_html_each=(
'<div style="display:flex;justify-content:space-between;border-bottom:1pt solid #d9d9d9;">'
'<div style="font-weight:bold;">Acme Ledger</div>'
'<div style="font-size:9pt;color:#444;">Statement Continued - Page {page} of {pages}</div>'
"</div>"
),
header_html_x="12mm",
header_html_y_from_top="6mm",
header_html_width="186mm",
header_html_height="10mm",
paginated_context={"items.amount": "sum"},
footer_each="Subtotal (Page {page}): ${sum:items.amount}",
footer_last="Grand Total: ${total:items.amount}",
footer_x="12mm",
footer_y_from_bottom="8mm",
)
pdf_bytes, page_data = engine.render_pdf_with_page_data(html, css)
Path("output_transactional_minimal.pdf").write_bytes(pdf_bytes)
assert page_data["page_count"] >= 2
assert page_data["totals"]["items.amount"]["value"] == sum(
p["items.amount"]["value"] for p in page_data["pages"]
)
print("Wrote output_transactional_minimal.pdf")
print("Page count:", page_data["page_count"])
print("Grand total:", page_data["totals"]["items.amount"]["formatted"])
```
API note:
- For transactional running totals (`paginated_context`) and HTML header/footer placement (`header_html_*`, `footer_html_*`), use the Python `PdfEngine` API path.
- The CLI currently exposes direct text header/footer flags (`--header-each`, `--footer-each`) for simpler cases.
CLI watermark parity example:
```bash
fullbleed --json render \
--html-str "<h1>Watermark probe</h1><p>hello</p>" \
--css-str "body{font-family:sans-serif}" \
--watermark-text "INTERNAL" \
--watermark-layer overlay \
--watermark-opacity 0.12 \
--watermark-rotation -32 \
--out output/watermark_probe.pdf
```
## Reference-Image Parity Workflow (Practical)
When targeting a design reference image (for example reference image exports), this loop has worked well:
1. Start from `fullbleed init` so CSS/font/icon baselines are vendored and pinned.
2. For scaffolded projects, run `python report.py` and set `FULLBLEED_IMAGE_DPI` as needed for sharper previews.
3. For direct CLI template rendering, register assets through the CLI (`--asset ...`) or `AssetBundle`.
4. Iterate with image artifacts enabled:
```bash
fullbleed --json render \
--profile preflight \
--html templates/invoice.html \
--css templates/invoice.css \
--asset vendor/css/bootstrap.min.css --asset-kind css --asset-name bootstrap \
--asset vendor/icons/bootstrap-icons.svg --asset-kind svg --asset-name bootstrap-icons \
--asset vendor/fonts/Inter-Variable.ttf --asset-kind font --asset-name inter \
--emit-image output/pages_png \
--emit-jit output/render.jit.jsonl \
--emit-perf output/render.perf.jsonl \
--out output/render.pdf
```
5. Use `--repro-record` / `--repro-check` once your layout stabilizes.
Practical tips:
- Compare against full-page exports when available.
- Keep a fixed preview DPI (for example `144` or `200`) across iterations.
- Commit PNG baselines for repeatable visual checks.
## Public Golden Regression Suite
Launch-grade render regression coverage is available under `goldens/` with three fixtures:
- `invoice`
- `statement`
- `menu`
Golden contract assets:
- Expected hashes: `goldens/expected/golden_suite.expected.json`
- Expected PNG baselines: `goldens/expected/png/<case>/<case>_page1.png`
Run against committed expectations:
```bash
python goldens/run_golden_suite.py verify
```
Refresh baselines intentionally:
```bash
python goldens/run_golden_suite.py generate
```
## Human + AI Operating Mode
Recommended automation defaults:
```bash
fullbleed --json-only render ...
```
Why this is agent-safe:
- For command-execution JSON payloads, `schema` is always present.
- Parser usage errors (`exit=2`) are emitted by argparse as usage text, not JSON payloads.
- `ok` indicates success/failure without parsing text.
- Optional artifacts are explicitly named in `outputs`.
- Schema introspection is available at runtime (`--schema`).
Example parse loop:
```python
import json, subprocess
proc = subprocess.run(
[
"fullbleed", "--json-only", "render",
"--html", "templates/report.html",
"--css", "templates/report.css",
"--out", "output/report.pdf",
],
capture_output=True,
text=True,
check=False,
)
payload = json.loads(proc.stdout)
assert payload["schema"] == "fullbleed.render_result.v1"
assert payload["ok"] is True
print(payload["outputs"]["pdf"])
```
## MACHINE_CONTRACT.v1
```json
{
"schema": "fullbleed.readme_contract.v1",
"package": "fullbleed",
"cli_entrypoint": "fullbleed",
"dev_cli_entrypoint": "python -m fullbleed_cli.cli",
"python_module": "fullbleed",
"json_discriminator": "schema",
"core_commands": [
"render",
"verify",
"plan",
"debug-perf",
"debug-jit",
"run",
"finalize",
"inspect",
"compliance",
"doctor",
"capabilities",
"assets",
"cache",
"init",
"new"
],
"result_schemas": [
"fullbleed.render_result.v1",
"fullbleed.verify_result.v1",
"fullbleed.plan_result.v1",
"fullbleed.run_result.v1",
"fullbleed.inspect_pdf.v1",
"fullbleed.inspect_pdf_batch.v1",
"fullbleed.inspect_templates.v1",
"fullbleed.compose_plan.v1",
"fullbleed.compliance.v1",
"fullbleed.capabilities.v1",
"fullbleed.doctor.v1",
"fullbleed.assets_list.v1",
"fullbleed.assets_info.v1",
"fullbleed.assets_install.v1",
"fullbleed.assets_verify.v1",
"fullbleed.assets_lock.v1",
"fullbleed.cache_dir.v1",
"fullbleed.cache_prune.v1",
"fullbleed.init.v1",
"fullbleed.new_template.v1",
"fullbleed.new_list.v1",
"fullbleed.new_search.v1",
"fullbleed.new_remote.v1",
"fullbleed.debug_perf.v1",
"fullbleed.debug_jit.v1",
"fullbleed.repro_record.v1",
"fullbleed.error.v1"
],
"artifact_flags": [
"--emit-manifest",
"--emit-jit",
"--emit-perf",
"--emit-glyph-report",
"--emit-page-data",
"--emit-compose-plan",
"--emit-image",
"--image-dpi",
"--deterministic-hash",
"--repro-record",
"--repro-check"
],
"fail_on": ["overflow", "missing-glyphs", "font-subst", "budget"],
"budget_flags": ["--budget-max-pages", "--budget-max-bytes", "--budget-max-ms"],
"profiles": ["dev", "preflight", "prod"],
"pdf_version_default": "1.7",
"known_exit_codes": {
"0": "success",
"1": "command-level validation/operational failure",
"2": "argparse usage error",
"3": "CLI runtime/input error wrapper"
}
}
```
## Important Behavior Notes
- `render --json` cannot be combined with `--out -` (stdout PDF bytes).
- `verify` defaults to stdout PDF unless `--emit-pdf` is provided; for machine mode, use `--emit-pdf <path>`.
- `--emit-image <dir>` writes per-page PNGs as `<stem>_pageN.png` (stem comes from `--out`/`--emit-pdf`, or `render` when streaming PDF to stdout).
- In template auto-compose runs, `--emit-image` artifacts are rasterized from finalized composed pages and report `outputs.image_mode=composed_pdf`; otherwise `image_mode=overlay_document`.
- `outputs.deterministic_hash_mode` is `pdf_only` by default and `artifact_set_v1` when image artifacts are emitted.
- If both `--emit-page-data` and `--emit-glyph-report` are set, current engines use a combined API and render once; older en | text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | AGPL-3.0-only OR LicenseRef-Fullbleed-Commercial | null | [
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: Implementation :: PyPy"
] | [] | https://fullbleed.dev | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.1.0 CPython/3.11.8 | 2026-02-19T01:59:07.114709 | fullbleed-0.2.7.tar.gz | 3,108,323 | f0/2d/7164c57083a51dbfe3d3683d80af6c1d9e7ac1478dfa1dffa297afa073b5/fullbleed-0.2.7.tar.gz | source | sdist | null | false | 41e9362923bb5ef0b861547f26344e7c | 0cb22843961a0c845a475432bc9e488797a6cd36333c667e5b5abcb5e376647c | f02d7164c57083a51dbfe3d3683d80af6c1d9e7ac1478dfa1dffa297afa073b5 | null | [
"LICENSE",
"COPYRIGHT",
"LICENSING.md",
"THIRD_PARTY_LICENSES.md"
] | 380 |
2.4 | pmtvs-hilbert | 0.0.1 | Signal analysis primitives | # pmtvs-hilbert
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:59:00.618312 | pmtvs_hilbert-0.0.1.tar.gz | 1,264 | a6/5c/e35ec677f57ab2b9acc78ccfc92289131b31f697d50e88678cb988d113a0/pmtvs_hilbert-0.0.1.tar.gz | source | sdist | null | false | aa9b1516ffa5463a8319c09b2a982810 | c4ea442032413017067f00d9e1844821cb914f0b700cebdd4b069c1ab0490c12 | a65ce35ec677f57ab2b9acc78ccfc92289131b31f697d50e88678cb988d113a0 | null | [] | 256 |
2.4 | pmtvs-calculus | 0.0.1 | Signal analysis primitives | # pmtvs-calculus
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:57:12.776008 | pmtvs_calculus-0.0.1.tar.gz | 1,280 | 18/e5/d2fd71521d79bcdd5709b9980920da9a6d1344a0a02cb7b9de276e61a17c/pmtvs_calculus-0.0.1.tar.gz | source | sdist | null | false | 67df8c0fe00402185c2ce8370fd5bc60 | 096a0776991efaec5f65ad3969e16d096be37492fa75039794ddfa157fb8c239 | 18e5d2fd71521d79bcdd5709b9980920da9a6d1344a0a02cb7b9de276e61a17c | null | [] | 262 |
2.4 | pygame-cli | 1.0.6 | A CLI project management library for pygame community edition. | # pygame-cli




A CLI project management tool for pygame community edition.
## Features
- Create new projects with metadata
- Manage multiple projects via the terminal
- Run projects locally or in browser (pygbag)
- Build projects for distribution (cx_Freeze)
- Clone projects directly from Git repositories
## Getting Started
Requirements:
```bash
# Windows
winget install --id Git.Git -e --source winget
# Linux (Debian,Fedora,Arch)
sudo apt install git patchelf
sudo dnf install git patchelf
sudo pacman -S git patchelf
# macOS
brew install git
```
Install:
```bash
pip install pygame-cli
```
Basic Example:
```bash
# Create a new project
pygame new my_game
# Run the project
pygame run my_game
# List all projects
pygame list
# Build for distribution
pygame build my_game
```
To see all available commands:
```bash
pygame --help
```
## Command Aliases
You can use any of these aliases: `pygame` `pygame-ce` `pgce`
## License
This project is licensed under the MIT License.
See the [`LICENSE.txt`](LICENSE.txt) file for the full license text.
| text/markdown | null | AntonisPylos <antonis@pylos.dev> | null | null | null | pygame, cli, project | [
"Development Status :: 5 - Production/Stable",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Operating System :: MacOS",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Libraries :: pygame"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"appdirs==1.4.4",
"cx_Freeze==8.5.3",
"GitPython==3.1.46"
] | [] | [] | [] | [
"Repository, https://github.com/AntonisPylos/pygame-cli",
"Issues, https://github.com/AntonisPylos/pygame-cli/issues",
"Releases, https://github.com/AntonisPylos/pygame-cli/releases"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:56:37.972941 | pygame_cli-1.0.6.tar.gz | 16,284 | 3c/99/de016a3a944459b88d2ed9e659820740337f5195c18e410d0b60ff74ccd5/pygame_cli-1.0.6.tar.gz | source | sdist | null | false | 7d8c3d40de62a655a35267a671ac42f8 | 29d3189ae47b2f0601b86d10ba8c66c11e1826297a3d0c84aa684d07cb83dad9 | 3c99de016a3a944459b88d2ed9e659820740337f5195c18e410d0b60ff74ccd5 | MIT | [
"LICENSE.txt"
] | 362 |
2.4 | pmtvs-calculus-rs | 0.0.1 | Signal analysis primitives | # pmtvs-calculus-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:56:08.384101 | pmtvs_calculus_rs-0.0.1.tar.gz | 1,257 | 8c/a1/368e4352e16c070d66d520144a0eede4ae9bc4c6c6829c251059bff21899/pmtvs_calculus_rs-0.0.1.tar.gz | source | sdist | null | false | 4985685a52a3efed28d1dc4644ccded4 | ac7ff84d786b5a194da099b5cc5e7d24698d9da81d2b1bcdb90b6da8b6873b57 | 8ca1368e4352e16c070d66d520144a0eede4ae9bc4c6c6829c251059bff21899 | null | [] | 253 |
2.4 | raresim | 3.0.2 | A python interface for scalable rare-variant simulations | [](https://badge.fury.io/py/raresim)
[](https://pypi.org/project/raresim/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
# RAREsim2
Python interface for flexible simulation of rare-variant genetic data using real haplotypes
## Installation
### From PyPI
```bash
pip install raresim
```
### From TestPyPI (for testing pre-releases)
```bash
pip install --index-url https://test.pypi.org/simple/ --extra-index-url https://pypi.org/simple/ raresim
```
### From Source
```bash
git clone https://github.com/RMBarnard/raresim.git
cd raresim
pip install -e . # Install in development mode
```
## Main Functions
### CALC
Calculate the expected number of variants per MAC bin using default population parameters, user-provided parameters, or target data.
```
usage: __main__.py calc [-h] --mac MAC -o OUTPUT -N N [--pop POP]
[--alpha ALPHA] [--beta BETA] [--omega OMEGA]
[--phi PHI] [-b B]
[--nvar_target_data NVAR_TARGET_DATA]
[--afs_target_data AFS_TARGET_DATA]
[--reg_size REG_SIZE] [-w W] [--w_fun W_FUN]
[--w_syn W_SYN]
options:
-h, --help show this help message and exit
--mac MAC MAC bin bounds (lower and upper allele counts) for the simulated sample size
-o OUTPUT Output file name
-N N Number of individuals in the simulated sample
--pop POP Population (AFR, EAS, NFE, or SAS) to use default values for if not providing
alpha, beta, omega, phi, and b values or target data
--alpha ALPHA Shape parameter to estimate the expected AFS distribution (must be > 0)
--beta BETA Shape parameter to estimate the expected AFS distribution
--omega OMEGA Scaling parameter to estimate the expected number of variants per (Kb) for
sample size N (range of 0-1)
--phi PHI Shape parameter to estimate the expected number of variants per (Kb) for
sample size N (must be > 0)
-b B Scale parameter to estimate the expected AFS distribution
--nvar_target_data NVAR_TARGET_DATA
Target downsampling data with the number of variants per Kb to estimate the
expected number of variants per Kb for sample size N
--afs_target_data AFS_TARGET_DATA
Target AFS data with the proportion of variants per MAC bin to estimate the
expected AFS distribution
--reg_size REG_SIZE Size of simulated genetic region in kilobases (Kb)
-w W Weight to multiply the expected number of variants by in non-stratified
simulations (default value of 1)
--w_fun W_FUN Weight to multiply the expected number of functional variants by in
stratified simulations (default value of 1)
--w_syn W_SYN Weight to multiply the expected number of synonymous variants by in
stratified simulations (default value of 1)
```
#### Default Population Parameters
The expected number of functional and synonymous variants can be estimated using default parameters for the following populations: African (AFR), East Asian (EAS), Non-Finnish European (NFE), and South Asian (SAS).
```text
$ python3 -m raresim calc \
--mac example/mac_bins.txt \
-o example/mac_bin_estimates_default.txt \
-N 10000 \
--pop NFE \
--reg_size 19.029
Calculated 842.5888117489534 total variants (accounting for region size)
```
#### Target Data
The user can also use their own target data - this is necessary to calculate the expected number of functional and/or synonymous variants for stratified simulations. Note, the simulation parameters are output if the user wants to use them instead of target data for future simulations.
```text
$ python3 -m raresim calc \
--mac example/mac_bins.txt \
-o example/mac_bin_estimates_target.txt \
-N 10000 \
--nvar_target_data example/nvar_target.txt \
--afs_target_data example/afs_target.txt \
--reg_size 19.029
Calculating synonymous values
Calculated the following params from AFS target data. alpha: 1.9397807693228122, beta: 0.34101610369526514, b: 0.8464846288340953
Calculated the following params from nvar target data. omega: 0.6295595643083463, phi: 0.04392478579419536
Calculated 275.6537313477067 total variants (accounting for region size)
Calculating functional values
Calculated the following params from AFS target data. alpha: 2.1388159441481442, beta: 0.4285647164342115, b: 1.134635990601139
Calculated the following params from nvar target data. omega: 0.6413547202832528, phi: 0.08338724275310817
Calculated 583.3570639000195 total variants (accounting for region size)
```
Note: Two MAC bin estimate files will be output (one for functional variants and another for synonymous variants) if the
input AFS file is stratified by functional status. If it's not stratified, then just one file will be output.
#### User-Provided Parameters
If parameters are known from previous simulations, the user can provide those instead of having to provide and fit target data.
```text
$ python3 -m raresim calc \
--mac example/mac_bins.txt \
-o example/mac_bin_estimates_params.txt \
-N 10000 \
--alpha 1.947 \
--beta 0.118 \
-b 0.6676 \
--omega 0.6539 \
--phi 0.1073 \
--reg_size 19.029
Calculated 842.5888117489534 total variants (accounting for region size)
```
### SIM
Simulate new allele frequencies by pruning (i.e., removing) certain variants from an input haplotype file given the expected number of variants for the simulated sample size. A list of pruned variants (.legend-pruned-variants) is also output along with the new haplotype file.
```
usage: __main__.py sim [-h] -m SPARSE_MATRIX [-b EXP_BINS]
[--functional_bins EXP_FUN_BINS]
[--synonymous_bins EXP_SYN_BINS] -l INPUT_LEGEND
[-L OUTPUT_LEGEND] -H OUTPUT_HAP
[--f_only FUN_BINS_ONLY] [--s_only SYN_BINS_ONLY] [-z]
[-prob] [--small_sample] [--keep_protected]
[--stop_threshold STOP_THRESHOLD]
[--activation_threshold ACTIVATION_THRESHOLD]
[--verbose]
options:
-h, --help show this help message and exit
-m SPARSE_MATRIX Input haplotype file (can be a .haps, .sm, or .gz file)
-b EXP_BINS Expected number of functional and synonymous variants per MAC bin
--functional_bins EXP_FUN_BINS
Expected number of variants per MAC bin for functional variants (must be used
with --synonymous_bins)
--synonymous_bins EXP_SYN_BINS
Expected number of variants per MAC bin for synonymous variants (must be used
with --functional_bins)
-l INPUT_LEGEND Input legend file
-L OUTPUT_LEGEND Output legend file (only required when using -z)
-H OUTPUT_HAP Output compressed haplotype file
--f_only FUN_BINS_ONLY
Expected number of variants per MAC bin for only functional variants
--s_only SYN_BINS_ONLY
Expected number of variants per MAC bin for only synonymous variants
-z Monomorphic and pruned variants (rows of zeros) are removed from the output
haplotype file
-prob Variants are pruned allele by allele given a probability of removal in the
legend file
--small_sample Overrides error to allow for simulation of small sample sizes (<10,000
haplotypes)
--keep_protected Variants designated with a 1 in the protected column of the legend file will
not be pruned
--stop_threshold STOP_THRESHOLD
Percentage threshold for stopping the pruning process (0-100). Prevents the
number of variants from falling below the specified percentage of the expected
count for any given MAC bin during pruning (default value of 20)
--activation_threshold ACTIVATION_THRESHOLD
Percentage threshold for activating the pruning process (0-100). Requires that
the actual number of variants for a MAC bin must be more than the given
percentage different from the expected number to activate pruning on the bin
(default value of 10)
--verbose when using --keep_protected and this flag, the program will additionally print
the before and after Allele Frequency Distributions with the protected variants
pulled out
```
```text
$ python3 -m raresim sim \
-m example/example.haps.gz \
-b example/mac_bin_estimates_default.txt \
-l example/example.legend \
-L example/output.legend \
-H example/output.haps.gz \
-z
Running with run mode: standard
Input allele frequency distribution:
Bin Expected Actual
[1,1] 452.7055560068 1002
[2,2] 130.4830742030 484
[3,5] 120.6258509819 768
[6,10] 52.2181585555 663
[11,20] 29.5461366439 681
[21,100] 26.2774091990 856
[101,200] 3.6164427260 79
[201,∞] N/A 65
New allele frequency distribution:
Bin Expected Actual
[1,1] 452.7055560068 472
[2,2] 130.4830742030 119
[3,5] 120.6258509819 110
[6,10] 52.2181585555 48
[11,20] 29.5461366439 28
[21,100] 26.2774091990 47
[101,200] 3.6164427260 3
[201,∞] N/A 65
Writing new variant legend
Writing new haplotype file
[====================] 100%
```
Note: An updated legend file is only output when using the z flag (when pruned variants are removed from the haplotype file). If not using the z flag,
then the order and amount of rows (i.e., variants) in the haplotype file will remain unchanged and match the input legend file. Also, if the input
haplotype file contains monomorphic variants (i.e., rows of zeros) when using the z flag, then the .legend-pruned-variants file will contain both
monomorphic and actual pruned variants.
#### Stratified (Functional/Synonymous) Pruning
To perform stratified simulations where functional and synonymous variants are pruned separately:
1. add a column to the legend file (`-l`) named "fun", where functional variants have the value "fun" and synonymous variants have the value "syn"
2. provide separate MAC bin files with the expected number of variants per bin for functional (`--functional_bins`) and synonymous (`--synonymous_bins`) variants
```text
$ python3 -m raresim sim \
-m example/example.haps.gz \
--functional_bins example/mac_bin_estimates_target_fun.txt \
--synonymous_bins example/mac_bin_estimates_target_syn.txt \
-l example/example.legend \
-L example/output_stratified.legend \
-H example/output_stratified.haps.gz \
-z
Running with run mode: func_split
Input allele frequency distribution:
Functional
Bin Expected Actual
[1,1] 308.6658613719 706
[2,2] 99.2199432898 332
[3,5] 92.6656147375 541
[6,10] 38.2293812491 463
[11,20] 19.9237792915 489
[21,100] 15.1688219483 607
[101,200] 1.6493333218 52
[201,∞] N/A 46
Synonymous
Bin Expected Actual
[1,1] 132.0653670095 296
[2,2] 44.8145869897 152
[3,5] 45.0536145138 227
[6,10] 20.7498071235 200
[11,20] 12.1186468959 192
[21,100] 11.0509676181 249
[101,200] 1.5493808935 27
[201,∞] N/A 19
New allele frequency distribution:
Functional
Bin Expected Actual
[1,1] 308.6658613719 290
[2,2] 99.2199432898 99
[3,5] 92.6656147375 88
[6,10] 38.2293812491 47
[11,20] 19.9237792915 18
[21,100] 15.1688219483 22
[101,200] 1.6493333218 1
[201,∞] N/A 46
Synonymous
Bin Expected Actual
[1,1] 132.0653670095 134
[2,2] 44.8145869897 42
[3,5] 45.0536145138 51
[6,10] 20.7498071235 22
[11,20] 12.1186468959 11
[21,100] 11.0509676181 11
[101,200] 1.5493808935 2
[201,∞] N/A 19
Writing new variant legend
Writing new haplotype file
[====================] 100%
```
#### Only Functional/Synonymous Variants
To prune only functional or only synonymous variants:
1. add a column to the legend file (`-l`) named "fun", where functional variants have the value "fun" and synonymous variants have the value "syn"
2. provide a MAC bin file with the expected number of variants per bin for only functional (`--f_only`) or only synonymous (`--s_only`) variants
```text
$ python3 -m raresim sim \
-m example/example.haps.gz \
--f_only example/mac_bin_estimates_target_fun.txt \
-l example/example.legend \
-L example/output_fun_only.legend \
-H example/output_fun_only.haps.gz \
-z
Running with run mode: fun_only
Input allele frequency distribution:
Bin Expected Actual
[1,1] 308.6658613719 706
[2,2] 99.2199432898 332
[3,5] 92.6656147375 541
[6,10] 38.2293812491 463
[11,20] 19.9237792915 489
[21,100] 15.1688219483 607
[101,200] 1.6493333218 52
[201,∞] N/A 46
New allele frequency distribution:
Bin Expected Actual
[1,1] 308.6658613719 312
[2,2] 99.2199432898 92
[3,5] 92.6656147375 102
[6,10] 38.2293812491 38
[11,20] 19.9237792915 17
[21,100] 15.1688219483 15
[101,200] 1.6493333218 2
[201,∞] N/A 46
Writing new variant legend
Writing new haplotype file
[====================] 100%
```
#### Given Probabilities
To prune variants using known or given probabilities, add a column to the legend file (`-l`) named "prob". A random number between 0 and 1 is generated for each variant, and if the number is greater than the probability, the variant is removed from the data. When using the `-z` flag, monomorphic and pruned variants are removed from the output haplotype file, and a pruned-variants file is created.
```text
$ python3 -m raresim sim \
-m example/example.haps.gz \
-l example/example.legend \
-L example/output_probs.legend \
-H example/output_probs.haps.gz \
-prob \
-z
Running with run mode: probabilistic
Writing new variant legend
Writing new haplotype file
[====================] 100%
```
#### Protected Status
To exclude protected variants from the pruning process, add a column to the legend file (`-l`) named "protected". Any row with a 0 in this column will be eligible for pruning while any row with a 1 will still be counted but will not be eligible for pruning.
```text
$ python3 -m raresim sim \
-m example/example.haps.gz \
-b example/mac_bin_estimates_default.txt \
-l example/example.protected.legend \
-L example/output_protected.legend \
-H example/output_protected.haps.gz \
--keep_protected \
-z
Running with run mode: standard
Input allele frequency distribution:
Bin Expected Actual
[1,1] 452.7055560068 1002
[2,2] 130.4830742030 484
[3,5] 120.6258509819 768
[6,10] 52.2181585555 663
[11,20] 29.5461366439 681
[21,100] 26.2774091990 856
[101,200] 3.6164427260 79
[201,∞] N/A 65
New allele frequency distribution:
Bin Expected Actual
[1,1] 452.7055560068 462
[2,2] 130.4830742030 131
[3,5] 120.6258509819 123
[6,10] 52.2181585555 52
[11,20] 29.5461366439 32
[21,100] 26.2774091990 25
[101,200] 3.6164427260 3
[201,∞] N/A 65
Writing new variant legend
Writing new haplotype file
[====================] 100%
```
### EXTRACT
Randomly extract a subset of haplotypes (.haps-sample.gz) and output the remaining haplotypes separately (.haps-remainder.gz).
```
options:
-h, --help show this help message and exit
-i INPUT_FILE Input haplotype file (gzipped)
-o OUTPUT_FILE Output haplotype file name
-s SEED, --seed SEED Optional seed for reproducibility
-n NUM Number of haplotypes to extract
```
```bash
$ python3 -m raresim extract \
-i example/example.haps.gz \
-o example/example_subset.haps.gz \
-n 20000 \
--seed 3
```
## Complete Workflow Demonstration
For a complete end-to-end workflow demonstrating how to use RAREsim2, see the [RAREsim2_demo](https://github.com/JessMurphy/RAREsim2_demo) repository. This repository demonstrates how to:
- Prepare the required input files
- Perform initial simulations with an over-abundance of rare variants using Hapgen2
- Create datasets for multiple case-control simulation scenarios using RAREsim2
- Perform power analyses for rare variant association methods (Burden, SKAT, SKAT-O)
## Additional Resources
- **Contributing**: See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines on contributing to the project
- **GitHub Repository**: [https://github.com/RMBarnard/raresim](https://github.com/RMBarnard/raresim)
- **Issues**: Report bugs or request features at [https://github.com/RMBarnard/raresim/issues](https://github.com/RMBarnard/raresim/issues)
| text/markdown | null | Ryan Barnard <rbarnard1107@gmail.com> | null | Ryan Barnard <rbarnard1107@gmail.com> | MIT | genetics, bioinformatics, simulation, rare-variants, genomics | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Intended Audience :: Healthcare Industry",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scien... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy<2.0.0,>=1.21.0",
"numba<1.0.0,>=0.55.0",
"pandas>=1.3.0",
"scipy>=1.7.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-cov>=4.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\"",
"isort>=5.12.0; extra == \"dev\"",
"flake8>=6.0.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"sp... | [] | [] | [] | [
"Homepage, https://github.com/RMBarnard/raresim",
"Documentation, https://github.com/RMBarnard/raresim#readme",
"Issues, https://github.com/RMBarnard/raresim/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T01:55:22.693408 | raresim-3.0.2.tar.gz | 44,574 | 53/17/45c85754c04eff36a7c193fc4ce0bc5c2fcdd3de4eb1acac29912214fe28/raresim-3.0.2.tar.gz | source | sdist | null | false | 4fc79b39508f11cadb5a44db69fe623b | 9a5a9bb522c68eef99dfe4fe254a7bde4235758ab81e8a6f248d45451fc82f14 | 531745c85754c04eff36a7c193fc4ce0bc5c2fcdd3de4eb1acac29912214fe28 | null | [
"LICENSE"
] | 251 |
2.4 | pmtvs-rqa-rs | 0.0.1 | Signal analysis primitives | # pmtvs-rqa-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:55:04.198826 | pmtvs_rqa_rs-0.0.1.tar.gz | 1,250 | 05/d9/48cf4932e0511411187dca2dd2ad12885c6329e8532af07a3cc05f325135/pmtvs_rqa_rs-0.0.1.tar.gz | source | sdist | null | false | 62e61e2f32b2c0f2433a99d19b9a7cd9 | 8f2b3faeb15c838e17858292b47494b22feb8507333bfc2c7732881840c02819 | 05d948cf4932e0511411187dca2dd2ad12885c6329e8532af07a3cc05f325135 | null | [] | 253 |
2.4 | memotrail | 0.2.0 | Persistent memory layer for AI coding assistants. Every conversation remembered, every decision searchable. | <div align="center">
# MemoTrail
**Your AI coding assistant forgets everything. MemoTrail fixes that.**
[](https://pypi.org/project/memotrail/)
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://github.com/HalilHopa-Datatent/memotrail)
A persistent memory layer for AI coding assistants.
Every session recorded, every decision searchable, every context remembered.
[Quick Start](#quick-start) · [How It Works](#how-it-works) · [Available Tools](#available-tools) · [Roadmap](#roadmap)
</div>
---
## The Problem
Every new Claude Code session starts from zero. Your AI doesn't remember yesterday's 3-hour debugging session, the architectural decisions you made last week, or the approaches that already failed.
**Without MemoTrail:**
```
You: "Let's use Redis for caching"
AI: "Sure, let's set up Redis"
... 2 weeks later, new session ...
You: "Why are we using Redis?"
AI: "I don't have context on that decision"
```
**With MemoTrail:**
```
You: "Why are we using Redis?"
AI: "Based on session from Jan 15 — you evaluated Redis vs Memcached.
Redis was chosen for its data structure support and persistence.
The discussion is in session #42."
```
## Quick Start
```bash
# 1. Install
pip install memotrail
# 2. Connect to Claude Code
claude mcp add memotrail -- memotrail serve
```
That's it. MemoTrail automatically indexes your history on first launch.
Start a new session and ask: *"What did we work on last week?"*
<div align="center">
<img src="demo.gif" alt="MemoTrail Demo" width="800">
</div>
## How It Works
| Step | What happens |
|:----:|:-------------|
| **1. Record** | MemoTrail auto-indexes new sessions every time the server starts |
| **2. Chunk** | Conversations are split into meaningful segments |
| **3. Embed** | Each chunk is embedded using `all-MiniLM-L6-v2` (~80MB, runs on CPU) |
| **4. Store** | Vectors go to ChromaDB, metadata to SQLite — all under `~/.memotrail/` |
| **5. Search** | Next session, Claude queries your full history semantically |
| **6. Surface** | The most relevant past context appears right when you need it |
> **100% local** — no cloud, no API keys, no data leaves your machine.
## Available Tools
Once connected, Claude Code gets these MCP tools:
| Tool | Description |
|------|-------------|
| `search_chats` | Semantic search across all past conversations |
| `get_decisions` | Retrieve recorded architectural decisions |
| `get_recent_sessions` | List recent coding sessions with summaries |
| `get_session_detail` | Deep dive into a specific session's content |
| `save_memory` | Manually save important facts or decisions |
| `memory_stats` | View indexing statistics and storage usage |
## CLI Commands
```bash
memotrail serve # Start MCP server (auto-indexes new sessions)
memotrail search "redis caching decision" # Search from terminal
memotrail stats # View indexing stats
memotrail index # Manually re-index (optional)
```
## Architecture
```
~/.memotrail/
├── chroma/ # Vector embeddings (ChromaDB)
└── memotrail.db # Session metadata (SQLite)
```
| Component | Technology | Details |
|-----------|-----------|---------|
| Embeddings | `all-MiniLM-L6-v2` | ~80MB, runs on CPU |
| Vector DB | ChromaDB | Persistent, local storage |
| Metadata | SQLite | Single-file database |
| Protocol | MCP | Model Context Protocol |
## Why MemoTrail?
| | MemoTrail | CLAUDE.md / Rules files | Manual notes |
|---|---|---|---|
| Automatic | Yes — indexes on every session start | No — you write it | No |
| Searchable | Semantic search | AI reads it, but only what you wrote | Ctrl+F only |
| Scales | Thousands of sessions | Single file | Scattered files |
| Context-aware | Returns relevant context | Static rules | Manual lookup |
| Setup | 5 minutes | Always maintained | Always maintained |
MemoTrail doesn't replace `CLAUDE.md` — it complements it. Rules files are for instructions. MemoTrail is for memory.
## Roadmap
- [x] Claude Code session indexing
- [x] Semantic search across conversations
- [x] MCP server with 6 tools
- [x] CLI for indexing and searching
- [x] Auto-indexing on server startup (no manual `memotrail index` needed)
- [ ] Automatic decision extraction
- [ ] Session summarization
- [ ] Cursor collector
- [ ] Copilot collector
- [ ] VS Code extension
- [ ] Cloud sync (Pro)
- [ ] Team memory (Team)
## Development
```bash
git clone https://github.com/HalilHopa-Datatent/memotrail.git
cd memotrail
pip install -e ".[dev]"
pytest
ruff check src/
```
## Contributing
Contributions welcome! See [CONTRIBUTING.md](docs/CONTRIBUTING.md) for guidelines.
**Good first issues:**
- [ ] Add Cursor session collector
- [ ] Add Copilot session collector
- [ ] Improve chunking strategy
- [ ] Add BM25 keyword search alongside semantic search
## License
MIT — see [LICENSE](LICENSE)
---
<div align="center">
**Built by [Halil Hopa](https://halilhopa.com)** · [memotrail.ai](https://memotrail.ai)
If MemoTrail helps you, consider giving it a star on GitHub.
</div>
| text/markdown | null | Halil Hopa <hello@memotrail.ai> | null | null | null | ai, claude-code, coding-assistant, context-management, mcp, memory, persistent-memory, semantic-search | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Software Development :: Libraries"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"chromadb>=0.5.0",
"mcp>=1.0.0",
"sentence-transformers>=3.0.0",
"tiktoken>=0.7.0",
"watchdog>=4.0.0",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.5.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://memotrail.ai",
"Repository, https://github.com/HalilHopa-Datatent/memotrail",
"Issues, https://github.com/HalilHopa-Datatent/memotrail/issues"
] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T01:54:25.966211 | memotrail-0.2.0.tar.gz | 744,210 | 1f/ca/42d23e39815724317fcba0c8152e457f93b7b1fed421b6c486ab7e7a8f57/memotrail-0.2.0.tar.gz | source | sdist | null | false | 079b97d671a57e22bcca8e95270fee03 | 6b10be927439238d28f731349aa451d31d298dab6b60fab2c71a639f5d1dc638 | 1fca42d23e39815724317fcba0c8152e457f93b7b1fed421b6c486ab7e7a8f57 | MIT | [
"LICENSE"
] | 242 |
2.4 | pmtvs-dfa-rs | 0.0.1 | Signal analysis primitives | # pmtvs-dfa-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:53:59.489045 | pmtvs_dfa_rs-0.0.1.tar.gz | 1,235 | 41/37/a5a094e7230b2820d4c7e7854442fbdd434b6e3cb8b7373f64aca4bec0f1/pmtvs_dfa_rs-0.0.1.tar.gz | source | sdist | null | false | b19c68849d950024c29252c6b358544b | b45b1ed960c6bc729d866c1e53d863f12367bdb9cdfb71c54a5849913375a12b | 4137a5a094e7230b2820d4c7e7854442fbdd434b6e3cb8b7373f64aca4bec0f1 | null | [] | 257 |
2.4 | table-stream | 0.1.2 | Tipos de dados e implementações para o uso em tabelas. | # table
## Getting started
To make it easy for you to get started with GitLab, here's a list of recommended next steps.
Already a pro? Just edit this README.md and make it your own. Want to make it easy? [Use the template at the bottom](#editing-this-readme)!
## Add your files
* [Create](https://docs.gitlab.com/user/project/repository/web_editor/#create-a-file) or [upload](https://docs.gitlab.com/user/project/repository/web_editor/#upload-a-file) files
* [Add files using the command line](https://docs.gitlab.com/topics/git/add_files/#add-files-to-a-git-repository) or push an existing Git repository with the following command:
```
cd existing_repo
git remote add origin https://gitlab.com/bschaves/table.git
git branch -M main
git push -uf origin main
```
## Integrate with your tools
* [Set up project integrations](https://gitlab.com/bschaves/table/-/settings/integrations)
## Collaborate with your team
* [Invite team members and collaborators](https://docs.gitlab.com/user/project/members/)
* [Create a new merge request](https://docs.gitlab.com/user/project/merge_requests/creating_merge_requests/)
* [Automatically close issues from merge requests](https://docs.gitlab.com/user/project/issues/managing_issues/#closing-issues-automatically)
* [Enable merge request approvals](https://docs.gitlab.com/user/project/merge_requests/approvals/)
* [Set auto-merge](https://docs.gitlab.com/user/project/merge_requests/auto_merge/)
## Test and Deploy
Use the built-in continuous integration in GitLab.
* [Get started with GitLab CI/CD](https://docs.gitlab.com/ci/quick_start/)
* [Analyze your code for known vulnerabilities with Static Application Security Testing (SAST)](https://docs.gitlab.com/user/application_security/sast/)
* [Deploy to Kubernetes, Amazon EC2, or Amazon ECS using Auto Deploy](https://docs.gitlab.com/topics/autodevops/requirements/)
* [Use pull-based deployments for improved Kubernetes management](https://docs.gitlab.com/user/clusters/agent/)
* [Set up protected environments](https://docs.gitlab.com/ci/environments/protected_environments/)
***
# Editing this README
When you're ready to make this README your own, just edit this file and use the handy template below (or feel free to structure it however you want - this is just a starting point!). Thanks to [makeareadme.com](https://www.makeareadme.com/) for this template.
## Suggestions for a good README
Every project is different, so consider which of these sections apply to yours. The sections used in the template are suggestions for most open source projects. Also keep in mind that while a README can be too long and detailed, too long is better than too short. If you think your README is too long, consider utilizing another form of documentation rather than cutting out information.
## Name
Choose a self-explaining name for your project.
## Description
Let people know what your project can do specifically. Provide context and add a link to any reference visitors might be unfamiliar with. A list of Features or a Background subsection can also be added here. If there are alternatives to your project, this is a good place to list differentiating factors.
## Badges
On some READMEs, you may see small images that convey metadata, such as whether or not all the tests are passing for the project. You can use Shields to add some to your README. Many services also have instructions for adding a badge.
## Visuals
Depending on what you are making, it can be a good idea to include screenshots or even a video (you'll frequently see GIFs rather than actual videos). Tools like ttygif can help, but check out Asciinema for a more sophisticated method.
## Installation
Within a particular ecosystem, there may be a common way of installing things, such as using Yarn, NuGet, or Homebrew. However, consider the possibility that whoever is reading your README is a novice and would like more guidance. Listing specific steps helps remove ambiguity and gets people to using your project as quickly as possible. If it only runs in a specific context like a particular programming language version or operating system or has dependencies that have to be installed manually, also add a Requirements subsection.
## Usage
Use examples liberally, and show the expected output if you can. It's helpful to have inline the smallest example of usage that you can demonstrate, while providing links to more sophisticated examples if they are too long to reasonably include in the README.
## Support
Tell people where they can go to for help. It can be any combination of an issue tracker, a chat room, an email address, etc.
## Roadmap
If you have ideas for releases in the future, it is a good idea to list them in the README.
## Contributing
State if you are open to contributions and what your requirements are for accepting them.
For people who want to make changes to your project, it's helpful to have some documentation on how to get started. Perhaps there is a script that they should run or some environment variables that they need to set. Make these steps explicit. These instructions could also be useful to your future self.
You can also document commands to lint the code or run tests. These steps help to ensure high code quality and reduce the likelihood that the changes inadvertently break something. Having instructions for running tests is especially helpful if it requires external setup, such as starting a Selenium server for testing in a browser.
## Authors and acknowledgment
Show your appreciation to those who have contributed to the project.
## License
For open source projects, say how it is licensed.
## Project status
If you have run out of energy or time for your project, put a note at the top of the README saying that development has slowed down or stopped completely. Someone may choose to fork your project or volunteer to step in as a maintainer or owner, allowing your project to keep going. You can also make an explicit request for maintainers.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.14 | [] | [] | [] | [
"odfpy>=1.4.1",
"openpyxl>=3.1.5",
"pandas>=3.0.0",
"soup-files>=1.4.2"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:53:39.093962 | table_stream-0.1.2.tar.gz | 18,095 | e0/17/7b1b454604146c9b5ea70a4edb71a922984476c1b75290b37918b9d821c9/table_stream-0.1.2.tar.gz | source | sdist | null | false | 8291e9895f2727549ad2859e339cfc9f | 3ec189610d42c80116f00432b3dfefb6700233f84689fc6ad2293533fd86fa07 | e0177b1b454604146c9b5ea70a4edb71a922984476c1b75290b37918b9d821c9 | null | [] | 237 |
2.4 | pmtvs-hurst-rs | 0.0.1 | Signal analysis primitives | # pmtvs-hurst-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:52:55.387051 | pmtvs_hurst_rs-0.0.1.tar.gz | 1,266 | 64/b1/c5d573b07604917f6655cfb742286e0d010fa0801520c12b2afc501e1c39/pmtvs_hurst_rs-0.0.1.tar.gz | source | sdist | null | false | 70fbd2323e833589de4e149e23e02536 | 8b5c5a7c3531bc6f69d1538a77361b5ab9c976d33002e02c56d8103bca2f5c89 | 64b1c5d573b07604917f6655cfb742286e0d010fa0801520c12b2afc501e1c39 | null | [] | 256 |
2.4 | owl-browser | 2.0.7 | Python SDK for Owl Browser automation - async-first with dynamic OpenAPI method generation | # Owl Browser Python SDK v2
Async-first Python SDK for [Owl Browser](https://www.owlbrowser.net) automation with dynamic OpenAPI method generation and flow execution support.
## Features
- **Dynamic Method Generation**: Methods are automatically generated from the OpenAPI schema
- **Async-First Design**: Built with asyncio for optimal performance
- **Sync Wrappers**: Convenience methods for non-async code
- **Flow Execution**: Execute test flows with variable resolution and expectations
- **Type Safety**: Full type hints with Python 3.12+ features
- **Connection Pooling**: Efficient HTTP connection management
- **Retry Logic**: Automatic retries with exponential backoff
## Installation
```bash
pip install owl-browser
```
For development:
```bash
pip install owl-browser[dev]
```
## Quick Start
### Connection Modes
The SDK supports two connection modes depending on your deployment:
```python
from owl_browser import OwlBrowser, RemoteConfig
# Production (via nginx proxy) - this is the default
# Uses /api prefix: https://your-domain.com/api/execute/...
config = RemoteConfig(
url="https://your-domain.com",
token="your-token"
)
# Development (direct to http-server on port 8080)
# No prefix: http://localhost:8080/execute/...
config = RemoteConfig(
url="http://localhost:8080",
token="test-token",
api_prefix="" # Empty string for direct connection
)
```
### Async Usage (Recommended)
```python
import asyncio
from owl_browser import OwlBrowser, RemoteConfig
async def main():
config = RemoteConfig(
url="https://your-domain.com",
token="your-secret-token"
)
async with OwlBrowser(config) as browser:
# Create a browser context
ctx = await browser.create_context()
context_id = ctx["context_id"]
# Navigate to a page
await browser.navigate(context_id=context_id, url="https://example.com")
# Click an element
await browser.click(context_id=context_id, selector="button#submit")
# Take a screenshot
screenshot = await browser.screenshot(context_id=context_id)
# Extract text content
text = await browser.extract_text(context_id=context_id, selector="h1")
print(f"Page title: {text}")
# Close the context
await browser.close_context(context_id=context_id)
asyncio.run(main())
```
### Sync Usage
```python
from owl_browser import OwlBrowser, RemoteConfig
config = RemoteConfig(
url="http://localhost:8080",
token="your-secret-token"
)
browser = OwlBrowser(config)
browser.connect_sync()
# Execute tools synchronously
ctx = browser.execute_sync("browser_create_context")
browser.execute_sync("browser_navigate", context_id=ctx["context_id"], url="https://example.com")
browser.execute_sync("browser_close_context", context_id=ctx["context_id"])
browser.close_sync()
```
## Authentication
### Bearer Token
```python
config = RemoteConfig(
url="http://localhost:8080",
token="your-secret-token"
)
```
### JWT Authentication
```python
from owl_browser import RemoteConfig, AuthMode, JWTConfig
config = RemoteConfig(
url="http://localhost:8080",
auth_mode=AuthMode.JWT,
jwt=JWTConfig(
private_key_path="/path/to/private.pem",
expires_in=3600, # 1 hour
refresh_threshold=300, # Refresh 5 minutes before expiry
issuer="my-app",
subject="user-123"
)
)
```
## Flow Execution
Execute test flows from JSON files (compatible with Owl Browser frontend format):
```python
from owl_browser import OwlBrowser, RemoteConfig
from owl_browser.flow import FlowExecutor
async def run_flow():
async with OwlBrowser(RemoteConfig(...)) as browser:
ctx = await browser.create_context()
executor = FlowExecutor(browser, ctx["context_id"])
# Load and execute a flow
flow = FlowExecutor.load_flow("test-flows/navigation.json")
result = await executor.execute(flow)
if result.success:
print(f"Flow completed in {result.total_duration_ms:.0f}ms")
for step in result.steps:
print(f" [{step.step_index}] {step.tool_name}: {'OK' if step.success else 'FAIL'}")
else:
print(f"Flow failed: {result.error}")
await browser.close_context(context_id=ctx["context_id"])
```
### Flow JSON Format
```json
{
"name": "Navigation Test",
"description": "Test navigation tools",
"steps": [
{
"type": "browser_navigate",
"url": "https://example.com",
"selected": true,
"description": "Navigate to example.com"
},
{
"type": "browser_extract_text",
"selector": "h1",
"selected": true,
"expected": {
"contains": "Example"
}
}
]
}
```
### Variable Resolution
Use `${prev}` to reference the previous step's result:
```json
{
"steps": [
{
"type": "browser_get_page_info",
"description": "Get page info"
},
{
"type": "browser_navigate",
"url": "${prev.url}/about",
"description": "Navigate to about page"
}
]
}
```
### Expectations
Validate step results with expectations:
```json
{
"type": "browser_extract_text",
"selector": "#count",
"expected": {
"greaterThan": 0,
"field": "length"
}
}
```
Supported expectations:
- `equals`: Exact match
- `contains`: String contains
- `length`: Array/string length
- `greaterThan`: Numeric comparison
- `lessThan`: Numeric comparison
- `notEmpty`: Not null/undefined/empty
- `matches`: Regex pattern match
- `field`: Nested field path (e.g., "data.count")
## Playwright-Compatible API
Drop-in Playwright API that translates Playwright calls to Owl Browser tools. Use your existing Playwright code with Owl Browser's antidetect capabilities.
```python
from owl_browser.playwright import chromium, devices
async def main():
browser = await chromium.connect("http://localhost:8080", token="your-token")
context = await browser.new_context(**devices["iPhone 15 Pro"])
page = await context.new_page()
await page.goto("https://example.com")
await page.click("button#submit")
await page.fill("#search", "query")
text = await page.text_content("h1")
await page.screenshot(path="page.png")
# Locators
button = page.locator("button.primary")
await button.click()
# Playwright-style selectors
login = page.get_by_role("button", name="Log in")
search = page.get_by_placeholder("Enter email")
heading = page.get_by_text("Welcome")
await context.close()
await browser.close()
```
**Supported features:** Page navigation, click/fill/type/press, locators (CSS, text, role, test-id, xpath), frames, keyboard & mouse input, screenshots, network interception (`route`/`unroute`), dialogs, downloads, viewport emulation, and 20+ device descriptors (iPhone, Pixel, Galaxy, iPad, Desktop).
## Data Extraction
Universal structured data extraction from any website — CSS selectors, auto-detection, tables, metadata, and multi-page scraping with pagination. No AI dependencies, works deterministically with BeautifulSoup.
```python
from owl_browser import OwlBrowser, RemoteConfig
from owl_browser.extraction import Extractor
async def main():
async with OwlBrowser(RemoteConfig(url="...", token="...")) as browser:
ctx = await browser.create_context()
ex = Extractor(browser, ctx["context_id"])
await ex.goto("https://example.com/products")
# CSS selector extraction
products = await ex.select(".product-card", {
"name": "h3",
"price": ".price",
"image": "img@src",
"link": "a@href",
})
# Auto-detect repeating patterns (zero-config)
patterns = await ex.detect()
# Multi-page scraping with automatic pagination
result = await ex.scrape(".product-card", {
"fields": {"name": "h3", "price": ".price", "sku": "@data-sku"},
"max_pages": 10,
"deduplicate_by": "sku",
})
print(f"{result['total_items']} items from {result['pages_scraped']} pages")
```
**Capabilities:**
| Method | Description |
|--------|-------------|
| `select()` / `select_first()` | Extract with CSS selectors and field specs (`"selector"`, `"selector@attr"`, object specs with transforms) |
| `table()` / `grid()` / `definition_list()` | Parse `<table>`, CSS grid/flexbox, and `<dl>` structures |
| `meta()` / `json_ld()` | Extract OpenGraph, Twitter Card, JSON-LD, microdata, feeds |
| `detect()` / `detect_and_extract()` | Auto-discover repeating DOM patterns |
| `lists()` | Extract list/card containers with auto-field inference |
| `scrape()` | Multi-page with pagination detection (click-next, URL patterns, buttons, load-more, infinite scroll) |
| `clean()` | Remove cookie banners, modals, fixed elements, ads |
| `html()` / `markdown()` / `text()` | Raw content with cleaning levels |
All extraction functions are also available as standalone pure functions for use without a browser connection.
## Available Tools
Methods are dynamically generated from the server's OpenAPI schema. Common tools include:
### Context Management
- `create_context()` - Create a new browser context
- `close_context(context_id)` - Close a context
### Navigation
- `navigate(context_id, url)` - Navigate to URL
- `reload(context_id)` - Reload page
- `go_back(context_id)` - Navigate back
- `go_forward(context_id)` - Navigate forward
### Interaction
- `click(context_id, selector)` - Click element
- `type(context_id, selector, text)` - Type text
- `press_key(context_id, key)` - Press keyboard key
### Content Extraction
- `extract_text(context_id, selector)` - Extract text
- `get_html(context_id)` - Get page HTML
- `screenshot(context_id)` - Take screenshot
### AI Features
- `summarize_page(context_id)` - Summarize page content
- `query_page(context_id, query)` - Ask questions about page
- `solve_captcha(context_id)` - Solve CAPTCHA challenges
Use `browser.list_tools()` to see all available tools.
## Error Handling
```python
from owl_browser import (
OwlBrowserError,
ConnectionError,
AuthenticationError,
ToolExecutionError,
TimeoutError,
)
try:
async with OwlBrowser(config) as browser:
await browser.navigate(context_id="invalid", url="https://example.com")
except AuthenticationError as e:
print(f"Authentication failed: {e}")
except ToolExecutionError as e:
print(f"Tool {e.tool_name} failed: {e.message}")
except TimeoutError as e:
print(f"Operation timed out: {e}")
except ConnectionError as e:
print(f"Connection failed: {e}")
```
## Configuration Options
```python
from owl_browser import RemoteConfig, RetryConfig
config = RemoteConfig(
url="https://your-domain.com",
token="secret",
# Timeout settings
timeout=30.0, # seconds
# Concurrency
max_concurrent=10,
# Retry configuration
retry=RetryConfig(
max_retries=3,
initial_delay_ms=100,
max_delay_ms=10000,
backoff_multiplier=2.0,
jitter_factor=0.1
),
# API prefix - determines URL structure for API calls
# Default: "/api" (production via nginx proxy)
# Set to "" for direct connection to http-server (development)
api_prefix="/api",
# SSL verification
verify_ssl=True
)
```
## API Reference
### OwlBrowser
- `connect() / connect_sync()` - Connect to server
- `close() / close_sync()` - Close connection
- `execute(tool_name, **params) / execute_sync(...)` - Execute any tool
- `health_check()` - Check server health
- `list_tools()` - List all tool names
- `list_methods()` - List all method names
- `get_tool(name)` - Get tool definition
### FlowExecutor
- `execute(flow)` - Execute a flow
- `abort()` - Abort current execution
- `reset()` - Reset abort flag
- `load_flow(path)` - Load flow from JSON file
### Extractor
- `goto(url, wait_for_idle=True)` - Navigate to URL
- `select(selector, fields)` - Extract from all matches
- `select_first(selector, fields)` - Extract first match
- `count(selector)` - Count matching elements
- `table(selector, options)` - Parse HTML tables
- `grid(container, item)` - Parse CSS grids
- `definition_list(selector)` - Parse `<dl>` lists
- `detect_tables()` - Auto-detect tables
- `meta()` - Extract page metadata
- `json_ld()` - Extract JSON-LD
- `detect(options)` - Detect repeating patterns
- `detect_and_extract(options)` - Detect + extract
- `lists(selector, options)` - Extract lists/cards
- `scrape(selector, options)` - Multi-page scrape
- `abort_scrape()` - Abort running scrape
- `clean(options)` - Remove obstructions
- `html(clean_level)` - Get page HTML
- `markdown()` - Get page markdown
- `text(selector, regex)` - Get filtered text
- `detect_site()` - Detect site type
- `site_data(template)` - Site-specific extraction
## Requirements
- Python 3.12+
- aiohttp >= 3.9.0
- pyjwt[crypto] >= 2.8.0
- cryptography >= 42.0.0
- beautifulsoup4 >= 4.12.0
## License
MIT License - see LICENSE file for details.
## Links
- Website: https://www.owlbrowser.net
- Documentation: https://www.owlbrowser.net/docs
- GitHub: https://github.com/Olib-AI/olib-browser
| text/markdown | null | Olib AI <support@olib.ai> | null | null | null | antidetect, async, automation, browser, owl, testing, web-scraping | [
"Development Status :: 4 - Beta",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Internet :: WWW/HTTP :: Browsers",
"Topic :: Software Development :: Test... | [] | null | null | >=3.12 | [] | [] | [] | [
"aiohttp>=3.9.0",
"beautifulsoup4>=4.12.0",
"cryptography>=42.0.0",
"pyjwt[crypto]>=2.8.0",
"mypy>=1.8.0; extra == \"dev\"",
"pytest-asyncio>=0.23.0; extra == \"dev\"",
"pytest>=8.0.0; extra == \"dev\"",
"ruff>=0.2.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://www.owlbrowser.net",
"Documentation, https://www.owlbrowser.net/docs",
"Repository, https://github.com/Olib-AI/olib-browser"
] | twine/6.1.0 CPython/3.12.6 | 2026-02-19T01:52:16.601826 | owl_browser-2.0.7.tar.gz | 130,397 | 3b/7a/dfe6ae018531d34ec92d36a56c1b138f7aeaf500acac9b8ad214cb1b9c3e/owl_browser-2.0.7.tar.gz | source | sdist | null | false | 7f120d522b135057cbac2a5111ca73f5 | 7e223133182981d4f5b3f4404bccdf69144b0bc5323ff0bb4a90717d8971c1ca | 3b7adfe6ae018531d34ec92d36a56c1b138f7aeaf500acac9b8ad214cb1b9c3e | MIT | [] | 233 |
2.4 | pmtvs-embedding-rs | 0.0.1 | Signal analysis primitives | # pmtvs-embedding-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:51:51.161736 | pmtvs_embedding_rs-0.0.1.tar.gz | 1,270 | ef/4a/e54eae2d293951c365aa45394cbd5872a1c18d0745c8716346dc8503f92e/pmtvs_embedding_rs-0.0.1.tar.gz | source | sdist | null | false | c4b37910bbe6e5f77c1470cb5627447e | 905a0d7d2373f636021cc2bfb2a0b36e330b103625a99a993e892c7b4533267f | ef4ae54eae2d293951c365aa45394cbd5872a1c18d0745c8716346dc8503f92e | null | [] | 260 |
2.4 | pmtvs-distance-rs | 0.0.1 | Signal analysis primitives | # pmtvs-distance-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:50:46.586400 | pmtvs_distance_rs-0.0.1.tar.gz | 1,269 | 41/54/dd124dc0314d0662804f5a60edf7f6e2c0ef24dbaa29dd6fd8e3d95e12c9/pmtvs_distance_rs-0.0.1.tar.gz | source | sdist | null | false | 70499ce388130c04f4af4f189db6627b | 387179871554d391cf5fed66a93e5c6d47e2608a2cf7a2bdb2620a43bf41eaf3 | 4154dd124dc0314d0662804f5a60edf7f6e2c0ef24dbaa29dd6fd8e3d95e12c9 | null | [] | 257 |
2.4 | igvf-async-client | 110.0.0 | IGVF Project API | Autogenerated async Python client for the IGVF API
| text/markdown | IGVF DACC | encode-help@lists.stanford.edu | null | null | null | OpenAPI, OpenAPI-Generator, IGVF Project API | [] | [] | https://github.com/iGVF-DACC/igvf-async-python-client | null | null | [] | [] | [] | [
"urllib3<2.1.0,>=1.25.3",
"python-dateutil",
"aiohttp>=3.0.0",
"aiohttp-retry>=2.8.3",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.8 | 2026-02-19T01:50:03.208723 | igvf_async_client-110.0.0.tar.gz | 896,895 | cc/46/4d1c9e0e012e178c86b457c2e83bf3d1987431807075e085503dc12822dd/igvf_async_client-110.0.0.tar.gz | source | sdist | null | false | 9ae8af904b28196673440815ddeb5857 | 0acf3bf3935facb83e25afbc9891c48c3b48f3056f2178c0b8d97894d1b6bfcd | cc464d1c9e0e012e178c86b457c2e83bf3d1987431807075e085503dc12822dd | null | [
"LICENSE"
] | 269 |
2.4 | igvf-client | 110.0.0 | IGVF Project API | Autogenerated Python client for the IGVF API
| text/markdown | IGVF DACC | encode-help@lists.stanford.edu | null | null | null | OpenAPI, OpenAPI-Generator, IGVF Project API | [] | [] | https://github.com/iGVF-DACC/igvf-python-client | null | null | [] | [] | [] | [
"urllib3<2.1.0,>=1.25.3",
"python-dateutil",
"pydantic>=2",
"typing-extensions>=4.7.1"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.12.8 | 2026-02-19T01:49:52.455696 | igvf_client-110.0.0.tar.gz | 627,620 | 55/21/e699c76358168a8e73e016b96328aa0032670721a999d1770a77578222a8/igvf_client-110.0.0.tar.gz | source | sdist | null | false | 3b1f67128256a55b03f1ab8802600b34 | 2f61b253b1903f052fcd63057ec9213b5a40cec9d59d7a501e97d00f3a0ef824 | 5521e699c76358168a8e73e016b96328aa0032670721a999d1770a77578222a8 | null | [
"LICENSE"
] | 279 |
2.4 | pmtvs-correlation-rs | 0.0.1 | Signal analysis primitives | # pmtvs-correlation-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:49:41.244229 | pmtvs_correlation_rs-0.0.1.tar.gz | 1,281 | 86/dd/a90388ac964cd5c1dd29fab9301e058e042e6479e5ca7edb2db784e71405/pmtvs_correlation_rs-0.0.1.tar.gz | source | sdist | null | false | e5f29b65d14128fa695e0c98abb8df0c | b585fae7e457a452d39360bb2469e1e8b54f91aba425cb3eba50941b5f06cd6d | 86dda90388ac964cd5c1dd29fab9301e058e042e6479e5ca7edb2db784e71405 | null | [] | 266 |
2.4 | pmtvs-statistics-rs | 0.0.1 | Signal analysis primitives | # pmtvs-statistics-rs
Part of the pmtvs signal analysis ecosystem. Coming soon.
See [pmtvs](https://pypi.org/project/pmtvs/) for the main package.
| text/markdown | null | null | null | null | MIT | null | [
"Development Status :: 1 - Planning",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering :: Physics",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T01:48:37.138898 | pmtvs_statistics_rs-0.0.1.tar.gz | 1,284 | 7c/9a/cd66de4f2dc2961b1a31dffc986ee1bf583e064abd735e2265bd2ee673e8/pmtvs_statistics_rs-0.0.1.tar.gz | source | sdist | null | false | 4d25b211e17939283e920f658d9d0634 | d1265c96f36ac01d003bc4df967696dfd9d09f72e83898639a32d5c2af332f41 | 7c9acd66de4f2dc2961b1a31dffc986ee1bf583e064abd735e2265bd2ee673e8 | null | [] | 267 |
2.4 | openforgeai | 0.1.0 | Production-grade agentic architecture — EventBus, Sagas, Skills, and the 17 Laws. | # OpenForgeAI
**Open-source agentic architecture for production systems.**
Built by one person. Running in production. Now open-source.
---
## What Is This?
OpenForgeAI is the architecture framework extracted from [Saarathi](https://saarathi.io) — a production AI-native platform built by a solo founder that competes with funded teams.
It provides the patterns you need to build systems where **AI agents work as a real team**: communicating via events, orchestrating multi-step workflows, and self-registering their capabilities.
This isn't a toy. These patterns run in production handling real users, real payments, and real-time messaging.
## Core Components
### EventBus — Agent Communication
A pub/sub event system where agents subscribe to events, emit new ones, and react autonomously. No direct function calls between agents.
```python
from openforgeai.events import EventBus, Event
bus = EventBus()
bus.register_agent(my_agent) # Agent subscribes to events it handles
await bus.publish(OrderCreated(order_id="123")) # All subscribers react
```
### Skill Registry — Agent Discovery
Auto-discovery and registration of agent skills. Drop a new skill file, it registers itself.
```python
from openforgeai.agents import SkillRegistry
registry = SkillRegistry()
registry.discover("./skills/") # Auto-finds all skills
registry.initialize(tenant_id="abc") # Creates instances, wires EventBus
```
### Saga Coordinators — Multi-Step Orchestration
Event-driven state machines for complex workflows. Each step completes on event arrival, not await calls.
```python
from openforgeai.sagas import SagaCoordinator
class OnboardingSaga(SagaCoordinator):
steps = ["send_welcome", "create_profile", "notify_team"]
# Each step emits an event → next step triggers on completion event
```
### Workflow Engine — Visual Process Automation
Define workflows as node graphs. Delay nodes, condition nodes, action nodes — all executing via the EventBus.
### Deploy Validator — Pre-Deploy Safety
Catches broken imports, missing agent registrations, and compliance violations before you deploy.
```bash
python -m openforgeai.validators.deploy_check
# ✓ All skills imported
# ✓ All events have subscribers
# ✓ No orphan handlers
```
## The 17 Laws of Agentic Engineering
The methodology behind the architecture. [Read the full guide →](docs/17-laws.md)
| # | Law | One-liner |
|---|-----|-----------|
| 1 | Contracts have handlers | Every event type must have a subscriber |
| 2 | Coordinators emit, never call | No direct skill.execute() from coordinators |
| 3 | Sagas track via events | Steps complete on event arrival |
| 4 | No orphan events | Every emitted event must have a subscriber |
| 5 | Search before create | Check existing code before building new |
| 6 | PRD before code | Spec first, understand why, then build |
| 7 | Verify before done | Run checks, show output |
| 14 | Imports are code | Every symbol used must be imported |
| 15 | Match the API | Read method signature before calling |
| 16 | Definition of done | Imports ✓ Signatures ✓ Required fields ✓ Actually runs ✓ |
| 17 | Verify interfaces before use | Read model definition → validate locally → smoke test |
## Quick Start
```bash
pip install openforgeai
```
```python
from openforgeai import EventBus, BaseAgent, Event
# Define an event
class TaskCreated(Event):
task_id: str
title: str
# Define an agent
class NotificationAgent(BaseAgent):
consumes_events = [TaskCreated]
async def on_task_created(self, event: TaskCreated):
print(f"New task: {event.title}")
# Wire it up
bus = EventBus()
agent = NotificationAgent()
bus.register_agent(agent)
await bus.publish(TaskCreated(task_id="1", title="Ship it"))
# Output: New task: Ship it
```
## Who Is This For?
- **Solo founders** building production SaaS without a team
- **Startup CTOs** who want 10X team output with agentic patterns
- **Senior engineers** transitioning to AI-native architecture
- **Anyone** tired of AI demos that break in production
## Learn More
- [The 17 Laws of Agentic Engineering](docs/17-laws.md)
- [Architecture Guide](docs/architecture.md)
- [CLAUDE.md Template](templates/CLAUDE.md) — Drop this into any project
- [Session Protocol](docs/session-protocol.md) — How to manage AI collaboration
## The Story
> I built Saarathi — an AI-native platform with real-time WhatsApp nurturing, automated webinar funnels, payment processing, CRM, and 14 AI agent skills working as a team. One person. Zero employees. Production-deployed. Real revenue.
>
> The secret isn't "AI writes my code." The secret is **architecture.**
>
> When your codebase is spaghetti, AI is a liability. When your codebase has clean contracts — EventBus, saga coordinators, skill registries — AI becomes a genuine team member.
>
> Software engineering isn't dead. It's reinvented.
## License
MIT — Use it, fork it, build with it.
## Links
- Website: [openforgeai.com](https://openforgeai.com)
- GitHub: [github.com/openforgeai](https://github.com/openforgeai)
- Author: [Goutam Biswas](https://linkedin.com/in/goutambiswas)
| text/markdown | null | Goutam Biswas <gkbiswas@gmail.com> | null | null | MIT | agentic, agents, architecture, event-driven, eventbus, multi-agent, saga | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: ... | [] | null | null | >=3.10 | [] | [] | [] | [
"pydantic>=2.0"
] | [] | [] | [] | [
"Homepage, https://openforgeai.com",
"Repository, https://github.com/openforgeai/openforgeai",
"Documentation, https://github.com/openforgeai/openforgeai/tree/main/docs"
] | Hatch/1.16.3 cpython/3.11.1 HTTPX/0.28.1 | 2026-02-19T01:47:05.733318 | openforgeai-0.1.0.tar.gz | 17,717 | ea/2e/8eb9ab2d3cee35f79c58f7bd334762a1be94045743f74ca1858e265ad3c4/openforgeai-0.1.0.tar.gz | source | sdist | null | false | cd162eba778691328264f0e988ca564c | 1b99e7f551c1bc1920bba727d2fbdde5b27fd2b0bcf4414da7235e50c942a89f | ea2e8eb9ab2d3cee35f79c58f7bd334762a1be94045743f74ca1858e265ad3c4 | null | [
"LICENSE"
] | 272 |
2.4 | ai-news-collector-lib | 0.1.5 | A Python library for collecting AI-related news from multiple sources | # 🔰 AI News Collector Library
> 一个用于收集AI相关新闻的Python库,支持多种搜索源和高级功能。
[](https://www.python.org/)
[](LICENSE)
[](https://pypi.org/project/ai-news-collector-lib/)
[](https://github.com/ai-news-collector/ai-news-collector-lib/releases/tag/v0.1.4)
---
## 🚀 最新更新 (v0.1.5 - 新增4大搜索引擎)
> **v0.1.5 版本更新** - 新增 YouTube, GitHub, HuggingFace, Perplexity 搜索支持!
### 🔍 新增搜索引擎
- ✅ **YouTube** - 搜索 AI 相关视频教程和讲座
- ✅ **GitHub** - 搜索最新的 AI 开源项目和代码库
- ✅ **HuggingFace** - 搜索最新的 AI 模型、数据集和 Space
- ✅ **Perplexity** - 使用 AI 驱动的搜索(带引用和摘要)
### 🔧 核心改进 (v0.1.4)
- ✅ **100%时间过滤准确率** - 彻底解决时间过滤问题
- ✅ **双重过滤机制** - API级别过滤 + 客户端备用过滤
- ✅ **全搜索引擎支持** - 修复了所有搜索引擎的时间过滤问题
📋 详见: [完整指南](USAGE_GUIDE.md)
---
## 🚀 历史更新 (v0.1.3 - LLM 查询增强)
> **v0.1.3 版本更新** - 引入了 AI 驱动的查询增强功能。
### 🤖 LLM 查询增强(v0.1.3功能)
- ✅ **AI 驱动查询优化** - 集成 Google Gemini LLM,智能优化用户查询
- ✅ **多引擎支持** - 为所有 11 个搜索引擎生成优化查询(单一 LLM 调用)
- ✅ **智能缓存** - 24 小时缓存,避免重复 LLM 调用
- ✅ **灵活配置** - 可选启用/禁用,支持自定义 LLM 提供商和模型
- ✅ **优雅降级** - LLM 调用失败时自动使用原始查询,确保服务可用性
### 🔧 核心改进(v0.1.3)
- ✅ **增强的查询对象** - 新增 `EnhancedQuery` 模型(支持 11 个搜索引擎)
- ✅ **查询优化器** - 新增 `QueryEnhancer` 工具类(500+ 行高质量代码)
- ✅ **集成优化** - AdvancedAINewsCollector 无缝集成查询增强
📋 详见: [实现总结](IMPLEMENTATION_SUMMARY.md) | [LLM 配置指南](docs/README_BADGES.md) | [完整指南](USAGE_GUIDE.md)
---
## ✨ 主要特性
### 核心功能
- 🔥 **多源聚合** - 支持HackerNews、ArXiv、DuckDuckGo等多个搜索源
- 📰- **API-based Engines**: NewsAPI, Tavily, Google Search, Serper, Brave Search, MetaSota Search
- **Free Engines**: HackerNews, ArXiv, DuckDuckGo, RSS Feeds
- 🤖 **智能内容处理** - 自动提取文章内容和关键词
- 💾 **智能缓存** - 避免重复搜索,提高效率
- ⏰ **定时任务** - 支持定时自动收集和报告生成
- 🔍 **去重处理** - 基于相似度的智能去重
- 📊 **数据分析** - 生成详细的收集结果报告
### 测试与质量
- 🧪 **离线测试** - 使用VCR cassettes实现完全离线的付费API测试
- 🔐 **安全优先** - 所有测试数据中的凭证已清理
- 📈 **覆盖率** - pytest-cov集成,详细的测试覆盖率报告
- 🤖 **自动化** - GitHub Actions自动化测试和发布
---
## 📦 安装
### 从PyPI安装(推荐)
```bash
# 基础安装
pip install ai-news-collector-lib
# 安装开发/测试依赖
pip install ai-news-collector-lib[dev]
# 或从源代码安装
pip install -e .[dev]
```
### 系统要求
- Python 3.9+
- pip 或 conda
---
## 🔑 配置API密钥
创建 `.env` 文件并配置API密钥(可选,仅用于付费API):
```bash
# 新增搜索引擎配置 (v0.1.5)
YOUTUBE_API_KEY=your_youtube_key
GITHUB_TOKEN=your_github_token # 可选 (提高速率限制)
HUGGINGFACE_API_KEY=your_hf_token # 可选
PERPLEXITY_API_KEY=your_perplexity_key
# 现有搜索引擎配置
NEWS_API_KEY=your_newsapi_key
TAVILY_API_KEY=your_tavily_key
GOOGLE_SEARCH_API_KEY=your_google_key
GOOGLE_SEARCH_ENGINE_ID=your_engine_id
BING_SEARCH_API_KEY=your_bing_key
SERPER_API_KEY=your_serper_key
BRAVE_SEARCH_API_KEY=your_brave_key
METASOSEARCH_API_KEY=your_metasota_key
```
> ⚠️ **重要**:请勿将 `.env` 文件提交到版本控制。参见 [API密钥安全指南](API_KEY_SECURITY_AUDIT.md)。
---
## 🎯 快速开始
### 基础使用(免费源)
```python
import asyncio
from ai_news_collector_lib import AINewsCollector, SearchConfig
async def main():
# 创建配置
config = SearchConfig(
enable_hackernews=True,
enable_arxiv=True,
enable_duckduckgo=True,
max_articles_per_source=10,
days_back=7
)
# 创建收集器
collector = AINewsCollector(config)
# 收集新闻
result = await collector.collect_news("machine learning")
# 输出结果
print(f"收集 {result.total_articles} 篇文章(去重后 {result.unique_articles} 篇)")
for article in result.articles[:5]:
print(f"- {article.title}")
return result
# 运行
asyncio.run(main())
```
### 🤖 LLM 查询增强(新)
```python
import asyncio
from ai_news_collector_lib import AdvancedAINewsCollector, AdvancedSearchConfig
async def main():
# 创建带 LLM 查询增强的配置
config = AdvancedSearchConfig(
enable_hackernews=True,
enable_arxiv=True,
enable_tavily=True,
enable_query_enhancement=True, # ✨ 启用 LLM 查询增强
llm_provider="google", # 使用 Google Gemini
llm_model="gemini-1.5-flash", # 高性能模型
llm_api_key="your-google-api-key", # 从环境变量设置更安全
query_enhancement_cache_ttl=86400, # 24 小时缓存
max_articles_per_source=10
)
# 创建收集器
collector = AdvancedAINewsCollector(config)
# LLM 会自动为各个搜索引擎优化查询
# 例如:输入 "machine learning" →
# HackerNews: "machine learning frameworks algorithms"
# ArXiv: "machine learning optimization techniques"
# Tavily: "latest machine learning applications 2024"
result = await collector.collect_news_advanced("machine learning")
# 查看增强后的查询
if result.get('enhanced_query'):
enhanced = result['enhanced_query']
print(f"原始查询: {enhanced.original_query}")
print(f"增强查询数: {len(enhanced.get_enabled_engines())}")
for engine in enhanced.get_enabled_engines():
print(f" - {engine}: {getattr(enhanced, engine)}")
return result
asyncio.run(main())
```
**LLM 查询增强的优势:**
- 🎯 **精准搜索** - AI 自动为不同搜索引擎生成最优查询
- ⚡ **智能缓存** - 相同查询在 24 小时内无需重新调用 LLM
- 💰 **经济高效** - 单一 LLM 调用处理所有搜索引擎
- 🔄 **灵活降级** - LLM 不可用时自动使用原始查询
- 📊 **完整支持** - 支持所有 11 个搜索引擎(HackerNews、ArXiv、DuckDuckGo、NewsAPI、Tavily、Google Search、Bing Search、Serper、Reddit、Hacker News API、Medium)
### 高级使用(包含内容提取和关键词提取)
```python
import asyncio
from ai_news_collector_lib import AdvancedAINewsCollector, AdvancedSearchConfig
async def main():
# 创建高级配置
config = AdvancedSearchConfig(
enable_hackernews=True,
enable_arxiv=True,
enable_duckduckgo=True,
enable_content_extraction=True, # 自动提取内容
enable_keyword_extraction=True, # 自动提取关键词
cache_results=True, # 启用缓存
max_articles_per_source=10
)
# 创建高级收集器
collector = AdvancedAINewsCollector(config)
# 收集增强新闻
result = await collector.collect_news_advanced("artificial intelligence")
# 分析结果
total_words = sum(article.get('word_count', 0) for article in result['articles'])
print(f"总字数: {total_words}")
print(f"关键词: {', '.join(result.get('top_keywords', [])[:10])}")
return result
# 运行
asyncio.run(main())
```
### 付费API使用(带缓存)
```python
import asyncio
from ai_news_collector_lib import AdvancedAINewsCollector, AdvancedSearchConfig
async def main():
# 创建配置 - 混合使用免费和付费源
config = AdvancedSearchConfig(
enable_hackernews=True,
enable_arxiv=True,
enable_tavily=True, # 付费搜索API
enable_google_search=True, # 谷歌自定义搜索
enable_serper=True, # Serper搜索API
cache_results=True, # 启用缓存减少API调用
max_articles_per_source=15,
similarity_threshold=0.85
)
collector = AdvancedAINewsCollector(config)
result = await collector.collect_news_advanced("deep learning")
return result
asyncio.run(main())
```
---
## 📊 支持的搜索源
### ✅ 免费源(无需API密钥)
| 源 | 描述 | 特点 |
|---|---|---|
| 🔥 **HackerNews** | 技术社区讨论 | 实时热点,开发者友好 |
| 📚 **ArXiv** | 学术论文预印本 | 学术质量,多学科覆盖 |
| 🦆 **DuckDuckGo** | 隐私搜索引擎 | 隐私保护,广泛覆盖 |
| 🐙 **GitHub** | 开源项目搜索 | 代码库,可选Token |
| 🤗 **HuggingFace** | AI模型搜索 | 模型/数据集,可选Token |
⏰ 注:所有搜索引擎的时间过滤参数 days_back 均以 UTC 时间为准,published 字段统一输出为 ISO8601(UTC 时区)。
🔥 特别说明:HackerNews 的发布时间由 UNIX 时间戳转换为 UTC,时间过滤严格按 UTC 执行。
### 💰 付费源(需要API密钥)
| 源 | API | 特点 | 免费额度 |
|---|---|---|---|
| 📹 **YouTube** | YouTube Data API | 视频搜索 | 10k units/天 |
| 🧠 **Perplexity** | Perplexity API | AI 智能搜索 | 按量付费 |
| 📡 **NewsAPI** | newsapi.org | 多源聚合、新闻分类 | 100 请求/天 |
| 🔍 **Tavily** | tavily.com | AI驱动搜索、实时 | 1000 请求/月 |
| 🌐 **Google Search** | googleapis.com | 精准搜索、覆盖广 | 100 请求/天 |
| 🔵 **Bing Search** | bing.com | 多媒体支持、国际化 | 3000 请求/月 |
| ⚡ **Serper** | serper.dev | 高速、便宜 | 100 请求/月 |
| 🦁 **Brave Search** | search.brave.com | 独立隐私搜索 | 100 请求/月 |
| 🔬 **MetaSota** | metaso.cn | MCP协议搜索 | 按配额 |
---
## ⚙️ 详细配置
### 搜索配置选项
```python
from ai_news_collector_lib import AdvancedSearchConfig
config = AdvancedSearchConfig(
# 传统源
enable_hackernews=True,
enable_arxiv=True,
enable_rss_feeds=False,
# 付费搜索源
enable_tavily=False,
enable_google_search=False,
enable_bing_search=False,
enable_serper=False,
enable_brave_search=False,
enable_metasota_search=False,
enable_newsapi=False,
# 网页搜索
enable_duckduckgo=True,
# 高级功能
enable_content_extraction=False, # 自动提取文章内容
enable_keyword_extraction=False, # 自动提取关键词
cache_results=False, # 缓存结果
# 搜索参数
max_articles_per_source=10,
days_back=7,
# ⏰ 本参数对所有引擎有效;内部时间过滤使用 UTC;所有 published 输出均为 ISO8601(UTC)
similarity_threshold=0.85,
timeout_seconds=30
)
```
---
## 🛠️ 高级功能
### 定时收集
```python
from ai_news_collector_lib import DailyScheduler, AdvancedAINewsCollector, AdvancedSearchConfig
async def collect_news():
config = AdvancedSearchConfig(
enable_hackernews=True,
enable_arxiv=True,
cache_results=True
)
collector = AdvancedAINewsCollector(config)
return await collector.collect_news_advanced("AI")
# 创建定时任务 - 每天上午9点
scheduler = DailyScheduler(
collector_func=collect_news,
schedule_time="09:00",
timezone="Asia/Shanghai"
)
# ⏰ 内部与 API 的时间过滤均以 UTC 执行,所有 published 字段为 ISO8601(UTC)。
# 启动调度器
scheduler.start()
```
### 缓存管理
```python
from ai_news_collector_lib import CacheManager
# 创建缓存管理器
cache = CacheManager(cache_dir="./cache", default_ttl_hours=24)
# 获取缓存
cache_key = cache.get_cache_key("AI news", ["hackernews", "arxiv"])
cached_result = cache.get_cached_result(cache_key)
if cached_result:
print("使用缓存结果")
result = cached_result
else:
# 执行搜索
result = await collector.collect_news("AI news")
# 缓存结果
cache.cache_result(cache_key, result)
```
### 报告生成
```python
from ai_news_collector_lib import ReportGenerator
# 创建报告生成器
reporter = ReportGenerator(output_dir="./reports")
# 生成Markdown报告
report = reporter.generate_daily_report(result, format="markdown")
reporter.save_report(result, filename="daily_report.md")
# 生成CSV报告
reporter.generate_daily_report(result, format="csv")
```
---
## 🧪 测试
### 运行所有测试
```bash
# 运行基础测试
pytest
# 运行所有测试(包括付费API测试)
pytest -v
# 生成覆盖率报告
pytest --cov=ai_news_collector_lib --cov-report=html
```
### 离线付费API测试(使用VCR Cassettes)
项目包含预录制的VCR cassettes,允许在完全离线状态下测试所有付费API集成 - **无需真实API密钥**。
```bash
# 运行付费API测试(使用cassettes,完全离线)
pytest tests/test_integration_advanced.py -v
# 查看cassette记录详情
cat tests/cassettes/advanced_ml_hn_ddg.yaml
```
### VCR Cassette原理
VCR库记录真实的HTTP请求/响应,然后在测试中重放(无需真实API调用):
```python
import pytest
from vcr import VCR
# 使用cassette进行测试
@pytest.mark.vcr
def test_with_cassette(vcr):
# 首次运行记录HTTP交互,后续测试直接重放
result = collector.search(query="AI")
assert len(result) > 0
```
详见: [VCR Cassette详解](VCR_CASSETTE_EXPLANATION.md) | [测试指南](TESTING_GUIDE.md) | [FAQ](FAQ_PR_TESTING.md)
---
## 🔄 CI/CD 与自动化
### GitHub Actions 工作流
项目使用GitHub Actions实现完整的自动化测试和发布:
| 工作流 | 触发条件 | 功能 |
|---|---|---|
| **test-paid-apis** | Push到任何分支 | 运行所有测试,生成覆盖率报告 |
| **publish** | Push git标签 (v*) | 自动构建并发布到PyPI |
| **release** | 发布时 | 创建GitHub Release页面 |
### 发布新版本
```bash
# 1. 确保所有测试通过
pytest
# 2. 创建版本标签
git tag -a v0.1.3 -m "Release v0.1.3"
# 3. 推送标签(自动触发发布工作流)
git push origin v0.1.3
```
详见: [发布指南](RELEASE_GUIDE.md) | [快速发布](QUICK_RELEASE.md)
---
## 📚 文档
### 核心文档
- [架构设计](ARCHITECTURE.md) - 项目结构和设计理念
- [实现总结](IMPLEMENTATION_SUMMARY.md) - v0.1.3 LLM 查询增强实现详情
- [VCR说明](VCR_CASSETTE_EXPLANATION.md) - 离线测试机制解析
- [测试指南](TESTING_GUIDE.md) - 完整测试说明
- [使用指南](USAGE_GUIDE.md) - 详细使用文档
### 快速参考
- [发布指南](RELEASE_GUIDE.md) - 版本发布流程
- [快速发布](QUICK_RELEASE.md) - 快速发布清单
- [PyPI指南](PYPI_RELEASE_GUIDE.md) - PyPI发布说明
- [FAQ](FAQ_PR_TESTING.md) - 常见问题解答
### API参考
- [搜索配置](ai_news_collector_lib/config/) - 配置选项说明
- [模型对象](ai_news_collector_lib/models/) - 数据模型定义
- [搜索工具](ai_news_collector_lib/tools/) - 各源工具实现
---
## 🗓️ ArXiv 日期处理
ArXiv日期解析包含完整的回退机制:
- 默认使用BeautifulSoup的XML解析获取`published`字段
- 若解析异常则回退到feedparser
- 在feedparser中支持`published_parsed`和`updated_parsed`字段
- 回退顺序: `published_parsed` → `updated_parsed` → `datetime.now()`
- 时区处理: Atom格式中`Z`表示UTC,使用`datetime.fromisoformat`解析
最小验证脚本:
```bash
python scripts/min_check_feedparser_fallback.py
```
该脚本验证RSS和Atom格式在缺少日期字段时的回退逻辑。
---
## 🤝 贡献
欢迎贡献代码和改进建议!
### 贡献流程
1. Fork本项目
2. 创建特性分支 (`git checkout -b feature/amazing-feature`)
3. 提交更改 (`git commit -m 'Add amazing feature'`)
4. 推送到分支 (`git push origin feature/amazing-feature`)
5. 开启Pull Request
### 开发指南
- 遵循PEP 8代码风格
- 添加测试用例
- 更新相关文档
详见: [完整贡献指南](CONTRIBUTING.md)
---
## 📄 许可证
本项目采用 MIT 许可证。详见 [LICENSE](LICENSE) 文件。
---
## 🆘 支持
### 获取帮助
- 📖 [完整文档](https://ai-news-collector-lib.readthedocs.io/)
- 🐛 [提交Issue](https://github.com/ai-news-collector/ai-news-collector-lib/issues)
- 💬 [讨论区](https://github.com/ai-news-collector/ai-news-collector-lib/discussions)
- 📧 [邮件支持](mailto:support@ai-news-collector.com)
### 常见问题
**Q: 部分旧文章会拖低时间过滤准确率吗?**
A: 不会。所有时间过滤严格按 UTC 执行,并跳过无法识别的发布时间,准确率不会被历史无效数据影响。
**Q: 如何不使用API密钥运行测试?**
A: 使用VCR cassettes!测试会自动使用预录制的HTTP响应。详见[VCR说明](VCR_CASSETTE_EXPLANATION.md)。
**Q: 是否可以在生产环境中使用此库?**
A: 可以,但请确保:
- 安全地管理API密钥(使用.env文件)
- 合理设置缓存TTL避免过时数据
- 监控API调用限制
**Q: 如何贡献新的搜索源?**
A: 详见[架构设计](ARCHITECTURE.md)中的"添加新搜索源"部分。
详见: [完整FAQ](FAQ_PR_TESTING.md)
---
## 📈 更新日志
### v0.1.3 (2025-10-22) - 🤖 LLM 查询增强
- ✨ **AI 驱动查询优化** - 集成 Google Gemini LLM,为所有搜索引擎生成优化查询
- ✅ 新增 `EnhancedQuery` 数据模型(支持 11 个搜索引擎)
- ✅ 新增 `QueryEnhancer` 工具类(500+ 行,单一 LLM 调用架构)
- ✅ 智能缓存 - 24 小时 TTL 避免重复 LLM 调用
- ✅ 灵活配置 - 可选启用/禁用,支持自定义 LLM 提供商
- ✅ 优雅降级 - LLM 不可用时自动使用原始查询
- ✅ 完整测试 - 8 个单元测试,81% 代码覆盖率
- ✅ 代码质量 - Black & Flake8 检查通过
### v0.1.2 (2025-10-21) - 🔒 安全版本
- ✅ 全面安全审计 - 清理VCR cassettes中的所有凭证
- ✅ 将测试API密钥替换为"FILTERED"占位符
- ✅ 更新所有cassette URL为真实API端点
- ✅ 集成pytest-cov提供覆盖率报告
- ✅ GitHub Actions自动化测试和PyPI发布
### v0.1.0 (2025-10-07)
- 初始预发布版本
- 支持基础搜索功能
- 支持多种搜索源
- 支持高级功能(内容提取、关键词分析、缓存等)
---
## 📊 项目结构
```
ai_news_collector_lib/
├── __init__.py # 主模块入口
├── cli.py # 命令行接口
├── config/ # 配置模块
│ ├── __init__.py
│ ├── settings.py # 搜索配置
│ └── api_keys.py # API密钥管理
├── core/ # 核心功能
│ ├── __init__.py
│ ├── collector.py # 基础收集器
│ └── advanced_collector.py # 高级收集器
├── models/ # 数据模型
│ ├── __init__.py
│ ├── article.py # 文章模型
│ └── result.py # 结果模型
├── tools/ # 搜索工具
│ ├── __init__.py
│ └── search_tools.py # 各种搜索工具
├── utils/ # 工具函数
│ ├── __init__.py
│ ├── cache.py # 缓存管理
│ ├── content_extractor.py # 内容提取
│ ├── keyword_extractor.py # 关键词提取
│ ├── reporter.py # 报告生成
│ └── scheduler.py # 定时任务
└── examples/ # 使用示例
├── basic_usage.py
└── advanced_usage.py
tests/
├── conftest.py # pytest配置
├── test_basic.py # 基础功能测试
├── test_integration_basic.py # 基础集成测试
├── test_integration_advanced.py # 付费API集成测试
├── cassettes/ # VCR cassette文件
│ ├── basic_ai_hn_ddg.yaml
│ ├── advanced_ml_hn_ddg.yaml
│ └── ...
└── test_arxiv_fallback_offline.py # ArXiv特殊测试
```
---
**祝你使用愉快!** 🎉
如有问题或建议,欢迎[提交Issue](https://github.com/ai-news-collector/ai-news-collector-lib/issues)或加入[讨论区](https://github.com/ai-news-collector/ai-news-collector-lib/discussions)。
| text/markdown | AI News Collector Team | AI News Collector Team <support@ai-news-collector.com> | null | AI News Collector Team <support@ai-news-collector.com> | MIT | ai, news, collector, search, web scraping, machine learning, artificial intelligence | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python ... | [] | https://github.com/ai-news-collector/ai-news-collector-lib | null | >=3.8 | [] | [] | [] | [
"requests>=2.28.0",
"beautifulsoup4>=4.11.0",
"feedparser>=6.0.0",
"python-dotenv>=0.19.0",
"google-generativeai>=0.3.0",
"aiohttp>=3.8.0; extra == \"advanced\"",
"redis>=4.0.0; extra == \"advanced\"",
"schedule>=1.2.0; extra == \"advanced\"",
"apscheduler>=3.9.0; extra == \"advanced\"",
"nltk>=3.... | [] | [] | [] | [
"Homepage, https://github.com/ai-news-collector/ai-news-collector-lib",
"Documentation, https://ai-news-collector-lib.readthedocs.io/",
"Repository, https://github.com/ai-news-collector/ai-news-collector-lib.git",
"Bug Tracker, https://github.com/ai-news-collector/ai-news-collector-lib/issues"
] | twine/6.2.0 CPython/3.11.13 | 2026-02-19T01:46:34.418057 | ai_news_collector_lib-0.1.5.tar.gz | 673,747 | 2f/37/fe30efeee118363e7d2f94d354218fa2a067c85e690e73a4f41ff09208d4/ai_news_collector_lib-0.1.5.tar.gz | source | sdist | null | false | 20e9e6d9f610a8bb2451f9368acb36c2 | 22d6fa364d84b0500170b5478f77a142b744c4c1e195106c0e2d91186846e0dc | 2f37fe30efeee118363e7d2f94d354218fa2a067c85e690e73a4f41ff09208d4 | null | [
"LICENSE"
] | 293 |
2.4 | fastapiex-di | 1.0.1 | DI extension for FastAPIEX | # fastapiex-di
Production-ready FastAPI extension for service registry and dependency injection.
## Installation
```bash
uv add fastapiex-di
```
## Quick Start
Use this exact structure from your project root:
```text
base_dir/
├── .venv/
└── demo/
├── __init__.py
├── main.py
└── services.py
```
`demo/services.py`:
```python
from fastapiex.di import BaseService, Service
@Service("ping_service")
class PingService(BaseService):
@classmethod
async def create(cls) -> "PingService":
return cls()
async def ping(self) -> str:
return "pong"
```
`demo/main.py`:
```python
from fastapi import FastAPI
from fastapiex.di import Inject, install_di
app = FastAPI()
install_di(app, service_packages=["demo.services"])
@app.get("/ping")
async def ping(svc=Inject("ping_service")):
return {"msg": await svc.ping()}
```
Run:
```bash
uv run uvicorn demo.main:app --reload
```
Then open `http://127.0.0.1:8000/ping` and expect:
```json
{"msg":"pong"}
```
Notes:
- `service_packages=["demo.services"]` must be a real import path, not a filesystem path.
- Do not import `demo.services` in `demo/main.py`; let `install_di(...)` import it during startup.
## Why Not Single-File
`@Service` and `@ServiceDict` run at import time.
The registration capture window is opened during `install_di(...)` startup import scanning.
If decorated services are imported before that window, startup fails with:
`No active app service registry capture`.
## Import Timing Rules
| Do | Don't |
| --- | --- |
| `install_di(app, service_packages=["demo.services"])` | `from demo.services import PingService` in `demo/main.py` |
| Keep decorated services under a dedicated module/package | Put `@Service` classes in `main.py` |
| Let DI scan import service modules during startup | Manually import decorated service modules in app bootstrap |
## Project Layout Contract
`service_packages` accepts Python import paths, not filesystem paths.
Examples:
- Valid: `service_packages=["demo.services"]`
- Valid: `service_packages=["myapp.services"]`
- Invalid: `service_packages=["demo/services.py"]`
- Invalid: `service_packages=["./demo/services"]`
## Ideal App Layout
Example project structure that keeps DI wiring predictable:
```text
myapp/
├── app/
│ ├── main.py
│ ├── core/
│ │ ├── settings.py
│ │ └── logging.py
│ ├── api/
│ │ ├── __init__.py
│ │ └── v1/
│ │ ├── __init__.py
│ │ └── users.py
│ └── services/
│ ├── __init__.py
│ ├── database.py
│ ├── cache.py
│ └── user_repo.py
└── pyproject.toml
```
`app/main.py`:
```python
from fastapi import FastAPI
from fastapiex.di import install_di
app = FastAPI()
install_di(app, service_packages=["app.services"])
```
Guidelines:
- Keep all `@Service` / `@ServiceDict` classes under one or more explicit packages (for example `app.services`).
- Keep route handlers under `app.api.*`, and resolve dependencies via `Inject(...)` only.
- Keep framework config (settings, logging, middleware wiring) under `app.core.*`.
## Service Registration
### Naming Conventions (Recommended)
- Singleton services: use `Service` suffix (for example `UserRepoService`).
- Transient services: use `ServiceT` suffix (for example `UserRepoServiceT`).
- Generator/contextmanager-style services: use `ServiceG` suffix (for example `UserRepoServiceG`).
### 1. Singleton + eager
```python
from fastapiex.di import BaseService, Service
@Service("app_config_service", eager=True)
class AppConfigService(BaseService):
@classmethod
async def create(cls) -> "AppConfigService":
return cls()
```
`eager=True` only applies to singleton services. Transient services cannot be eager.
### 2. Transient service
```python
from fastapiex.di import BaseService, Service
@Service("request_context_service_t", lifetime="transient")
class RequestContextServiceT(BaseService):
@classmethod
async def create(cls) -> "RequestContextServiceT":
return cls()
```
### 3. `exposed_type` for type-based resolution
```python
from typing import Protocol
from fastapiex.di import BaseService, Service
class UserRepo(Protocol):
async def list_users(self) -> list[str]:
...
@Service("repo_service", exposed_type=UserRepo)
class UserRepoService(BaseService):
@classmethod
async def create(cls) -> "UserRepoService":
return cls()
async def list_users(self) -> list[str]:
return ["alice", "bob"]
```
### 4. Anonymous service (type-only)
```python
from fastapiex.di import BaseService, Service
class UserCache:
pass
@Service
class UserCacheService(BaseService):
@classmethod
async def create(cls) -> UserCache:
return UserCache()
```
### 5. ServiceDict expansion
```python
from fastapiex.di import BaseService, ServiceDict
@ServiceDict("{}_db_service", dict={"main": {"dsn": "sqlite+aiosqlite:///main.db"}})
class DatabaseService(BaseService):
@classmethod
async def create(cls, dsn: str) -> "DatabaseService":
instance = cls()
instance.dsn = dsn
return instance
```
## Declaring Service-to-Service Dependencies
Use `require(...)` in `create(...)` defaults.
The example below reuses `UserRepo` and `UserCache` defined above.
```python
from fastapiex.di import BaseService, Service, require
@Service("user_query_service_t", lifetime="transient")
class UserQueryServiceT(BaseService):
@classmethod
async def create(
cls,
repo=require(UserRepo),
cache=require(UserCache),
) -> "UserQueryServiceT":
_ = repo, cache
return cls()
```
## Injecting Services in FastAPI Endpoints
### Key-based
```python
from fastapiex.di import Inject
@app.get("/users/by-key")
async def users_by_key(repo=Inject("repo_service")):
return {"users": await repo.list_users()}
```
### Type-based (only when exactly one provider exists)
```python
@app.get("/users/by-type")
async def users_by_type(repo: UserRepo = Inject(UserRepo)):
return {"users": await repo.list_users()}
```
### Nested
```python
@app.get("/nested")
async def nested(
query_service: UserQueryServiceT = Inject(
"user_query_service_t",
repo=Inject("repo_service"),
cache=Inject(UserCache),
),
):
return {"ok": isinstance(query_service, UserQueryServiceT)}
```
## Production Settings
`install_di(...)` options:
- `service_packages`: package(s) to scan for decorated services.
- `strict` (default `True`): fail startup on DI/registry errors.
- `allow_private_modules` (default `False`): include modules with underscore segments.
- `auto_add_finalizer_middleware` (default `True`): auto install transient cleanup middleware.
- `freeze_container_after_startup` (default `True`): block runtime service registrations.
- `freeze_service_registry_after_startup` (default `False`): freeze this app's scoped service registry after startup.
- `unfreeze_service_registry_on_shutdown` (default `True`): unfreeze this app's registry when app exits.
- `eager_init_timeout_sec` (optional): timeout for eager singleton initialization.
Recommended production defaults:
```python
install_di(
app,
service_packages=["myapp.services"],
strict=True,
freeze_container_after_startup=True,
freeze_service_registry_after_startup=True,
eager_init_timeout_sec=30,
)
```
## Safety and Worker Model
- Container enforces single event-loop usage.
- Container rejects cross-process reuse.
- Registry maps container by current process/thread/event-loop context.
- Runtime service registry is app-scoped, so freeze/unfreeze does not leak across apps.
- Transient finalizers run after request completion.
- Transient finalizers also run after WebSocket connection teardown.
- Singleton teardown runs on shutdown in reverse order.
## Supply-Chain Security
Install security tooling group:
```bash
uv sync --locked --no-default-groups --group security
```
Run checks:
```bash
./scripts/supply_chain_check.sh
```
## Common Errors
- `Duplicate service registration for key`: same key registered more than once.
- `No service registered for type`: missing provider for type-based injection.
- `Multiple services registered for type`: use key-based injection instead.
- `Detected circular service dependency`: dependency graph has a cycle.
- `Cannot register services after container registrations are frozen`: runtime registration attempted after startup.
- `No active app service registry capture`: decorated service module was imported before `install_di(...)` startup import scanning.
Fix:
1. Move `@Service`/`@ServiceDict` classes into a dedicated module (for example `demo/services.py`).
2. Set `install_di(..., service_packages=["demo.services"])` to that module path.
3. Remove early imports of that service module from `main.py`.
## Public API
```python
from fastapiex.di import (
AppServiceRegistry,
BaseService,
Inject,
Service,
ServiceDict,
ServiceContainer,
ServiceLifetime,
capture_service_registrations,
install_di,
require,
)
```
| text/markdown | Henri | null | Henri | null | MIT License Copyright (c) 2026 Henri Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | asgi, dependency-injection, fastapi, service-registry | [
"Development Status :: 4 - Beta",
"Framework :: AsyncIO",
"Framework :: FastAPI",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language... | [] | null | null | >=3.12 | [] | [] | [] | [
"fastapi<1.0,>=0.110"
] | [] | [] | [] | [
"Homepage, https://github.com/ArakawaHenri/fastapiex-di",
"Repository, https://github.com/ArakawaHenri/fastapiex-di",
"Issues, https://github.com/ArakawaHenri/fastapiex-di/issues",
"Security, https://github.com/ArakawaHenri/fastapiex-di/blob/main/SECURITY.md"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:45:12.404987 | fastapiex_di-1.0.1.tar.gz | 88,642 | de/ec/ade52eab1ed825d73a552784b660e768556cf2cc62be7ce3527e9369002b/fastapiex_di-1.0.1.tar.gz | source | sdist | null | false | a2dcbb036530e4b15ebe48275ae6b075 | 38e800288d30b616258c34894469be699cf55eb7ae8c1a59dfae816fb668cb9d | deecade52eab1ed825d73a552784b660e768556cf2cc62be7ce3527e9369002b | null | [
"LICENSE"
] | 275 |
2.1 | trulens | 2.7.0 | Library to systematically track and evaluate LLM based applications. | 
[](https://dev.azure.com/truera/trulens/_build/latest?definitionId=8&branchName=main)


[](https://snowflake.discourse.group/c/ai-research-and-development-community/trulens/97)
[](https://www.trulens.org/getting_started/)
[](https://colab.research.google.com/github/truera/trulens/blob/main/examples/quickstart/langchain_quickstart.ipynb)
[](https://deepwiki.com/truera/trulens)
# 🦑 Welcome to TruLens!

**Don't just vibe-check your LLM app!** Systematically evaluate and track your
LLM experiments with TruLens. As you develop your app including prompts, models,
retrievers, knowledge sources and more, *TruLens* is the tool you need to
understand its performance.
Fine-grained, stack-agnostic instrumentation and comprehensive evaluations help
you to identify failure modes & systematically iterate to improve your
application.
Read more about the core concepts behind TruLens including [Feedback Functions](https://www.trulens.org/getting_started/core_concepts/feedback_functions/),
[The RAG Triad](https://www.trulens.org/getting_started/core_concepts/rag_triad/),
and [Honest, Harmless and Helpful Evals](https://www.trulens.org/getting_started/core_concepts/honest_harmless_helpful_evals/).
## TruLens in the development workflow
Build your first prototype then connect instrumentation and logging with
TruLens. Decide what feedbacks you need, and specify them with TruLens to run
alongside your app. Then iterate and compare versions of your app in an
easy-to-use user interface 👇
## Installation and Setup
Install the trulens pip package from PyPI.
```bash
pip install trulens
```
## Quick Usage
Walk through how to instrument and evaluate a RAG built from scratch with
TruLens.
[](https://colab.research.google.com/github/truera/trulens/blob/main/examples/quickstart/quickstart.ipynb)
### 💡 Contributing & Community
Interested in contributing? See our [contributing
guide](https://www.trulens.org/contributing/) for more details.
The best way to support TruLens is to give us a ⭐ on
[GitHub](https://www.github.com/truera/trulens) and join our [discourse
community](https://snowflake.discourse.group/c/ai-research-and-development-community/trulens/97)!
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | https://trulens.org/ | null | <4.0,>=3.10 | [] | [] | [] | [
"trulens-core<3.0.0,>=2.0.0",
"trulens-dashboard[full]<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0",
"trulens-otel-semconv<3.0.0,>=2.0.0",
"trulens_eval<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:11.546878 | trulens-2.7.0.tar.gz | 4,238 | 15/c2/7b7a99e803206f3428379ab47c64b1fa80c63c2e760078af2543cabb25f6/trulens-2.7.0.tar.gz | source | sdist | null | false | d4023e8e3b7c5c7fc23ca66b57a7da69 | 0686554c0088ff6b5cf11515a3a75be7727b9594f82e7b61f979b603e87e29c2 | 15c27b7a99e803206f3428379ab47c64b1fa80c63c2e760078af2543cabb25f6 | null | [] | 1,629 |
2.1 | trulens-eval | 2.7.0 | Backwards-compatibility package for API of trulens_eval<1.0.0 using API of trulens-*>=1.0.0. | # trulens-eval
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | !=2.7.*,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*,!=3.6.*,!=3.7.*,!=3.8.*,>=3.9 | [] | [] | [] | [
"trulens-core<3.0.0,>=2.0.0",
"trulens-dashboard<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:10.499453 | trulens_eval-2.7.0.tar.gz | 12,991 | fa/89/48b174e18547ea8584163db8411a465898cc4ca03618e12c315782347a1e/trulens_eval-2.7.0.tar.gz | source | sdist | null | false | ba65e8fcb255a9020fa0d57aa6aa15f6 | c666b349cc6b08047df73ab71f376f9b2dc2824558bd2edce0e2dfd6d5f5259d | fa8948b174e18547ea8584163db8411a465898cc4ca03618e12c315782347a1e | null | [] | 2,062 |
2.1 | trulens-providers-openai | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-providers-openai
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"langchain-community>=0.3.29",
"openai<2.0.0,>=1.52.1",
"trulens-core<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:09.431443 | trulens_providers_openai-2.7.0.tar.gz | 12,784 | e8/97/c12b009c7a429d92aa506d37a616622a10fb763187e0f48dc09d91c4f1b2/trulens_providers_openai-2.7.0.tar.gz | source | sdist | null | false | d2aef6eff663158f26b56ee3fac8787a | 7bbc7f4d0766469015d5a1d02094fa76106e4a4be80a289bd6120940afa99440 | e897c12b009c7a429d92aa506d37a616622a10fb763187e0f48dc09d91c4f1b2 | null | [] | 406 |
2.1 | trulens-providers-litellm | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-providers-litellm
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"litellm<2.0,>=1.25",
"trulens-core<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:08.363058 | trulens_providers_litellm-2.7.0.tar.gz | 6,452 | 65/f6/d47ff12e1b9fdb1bd2a5c3a489b5f6281fa15e2906a369ef0dd3b18dfacd/trulens_providers_litellm-2.7.0.tar.gz | source | sdist | null | false | 7bfb7c24df025f69143b2d876f4decee | 87e555ff5b5f2c898a7c2e4804dc71261e5fc2fa6d3e48008c0348ce620a25d7 | 65f6d47ff12e1b9fdb1bd2a5c3a489b5f6281fa15e2906a369ef0dd3b18dfacd | null | [] | 1,022 |
2.1 | trulens-providers-langchain | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-providers-langchain
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"langchain-core>=1.0.0",
"trulens-core<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:07.321968 | trulens_providers_langchain-2.7.0.tar.gz | 4,058 | a4/d4/30770d4c126c47ccd10c83e31fedb70e9d4ac961ce17694cc5deaa593523/trulens_providers_langchain-2.7.0.tar.gz | source | sdist | null | false | 3901fbe03e1fb84617a8859690c61719 | 32016c4cc221366f46a4954d023c7c6d3e9858fb8a7f29b0cd1772f330815bd0 | a4d430770d4c126c47ccd10c83e31fedb70e9d4ac961ce17694cc5deaa593523 | null | [] | 361 |
2.1 | trulens-providers-huggingface | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-providers-huggingface
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"nltk<4.0.0,>=3.9.1",
"numpy>=1.23.0",
"requests<3.0,>=2.31",
"torch<3.0.0,>=2.1.2",
"transformers!=4.57.0,<5.0.0,>=4.38.1",
"trulens-core<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:06.260569 | trulens_providers_huggingface-2.7.0.tar.gz | 9,344 | 27/88/510b01ab4837c8c58211dd1c48d27fbb7eae5c4324e113f12535cfb1ba19/trulens_providers_huggingface-2.7.0.tar.gz | source | sdist | null | false | 91e76057c9da1cdbb2c10d40a7994e76 | 19f330ce7fcc2c4e5be2e27a24a6261f35fb341b1989cd7275f465b23b554e01 | 2788510b01ab4837c8c58211dd1c48d27fbb7eae5c4324e113f12535cfb1ba19 | null | [] | 271 |
2.1 | trulens-providers-google | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-providers-google
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"google-auth>=2.20.0",
"google-genai>=1.27.0",
"trulens-core<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:05.166149 | trulens_providers_google-2.7.0.tar.gz | 5,782 | 7f/36/cfe4a9a22283b1c3b239b8fc36fd1ade833051469da0b86e4767d8bac181/trulens_providers_google-2.7.0.tar.gz | source | sdist | null | false | 88e57571e96463ab14fa89ee20120ce4 | 1cc35997e0cce4326b890768793c6c1314375a6265b0d380bacb173cd5df3801 | 7f36cfe4a9a22283b1c3b239b8fc36fd1ade833051469da0b86e4767d8bac181 | null | [] | 310 |
2.1 | trulens-providers-cortex | 2.7.0 | A TruLens extension package adding Snowflake Cortex support for LLM App evaluation. | # trulens-providers-cortex
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <3.13,>=3.9 | [] | [] | [] | [
"packaging>=23.0",
"snowflake-connector-python<4.0,>=3.15",
"snowflake-ml-python<2.0.0,>=1.7.2",
"snowflake-snowpark-python<2.0.0,>=1.18.0",
"trulens-core<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:03.696707 | trulens_providers_cortex-2.7.0.tar.gz | 6,081 | 84/98/fbf4697aa4bb9ec0c24bccad22b8c865172cf91223c89a50c6a93c67c9cb/trulens_providers_cortex-2.7.0.tar.gz | source | sdist | null | false | 9267283bfce5e2770f69e2caf0b3d9c8 | 46304a42e2fddffeb821f27ded65d82acfa1eab7706be59bc587143be8e975d4 | 8498fbf4697aa4bb9ec0c24bccad22b8c865172cf91223c89a50c6a93c67c9cb | null | [] | 329 |
2.1 | trulens-providers-bedrock | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-providers-bedrock
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"boto3<2.0,>=1.33",
"botocore<2.0,>=1.33",
"trulens-core<3.0.0,>=2.0.0",
"trulens-feedback<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:02.668848 | trulens_providers_bedrock-2.7.0.tar.gz | 5,641 | 6f/1d/c660d2703628d8e0e4304ac3ba08ff31087241c9e4b5b36890385c40247b/trulens_providers_bedrock-2.7.0.tar.gz | source | sdist | null | false | 5f02d920c742a02659b16b499b8acd2c | 2ab637a8748c540f5f4c2dde21d935e070af71c12ac0a61b426a273829ebb8c9 | 6f1dc660d2703628d8e0e4304ac3ba08ff31087241c9e4b5b36890385c40247b | null | [] | 295 |
2.1 | trulens-otel-semconv | 2.7.0 | Semantic conventions for spans produced by TruLens. | # Semantic Conventions for TruLens Spans
This package describes the conventions for attribute names and some attribute values present in spans produced or interpreted by TruLens.
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"opentelemetry-semantic-conventions>=0.36b0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:01.648899 | trulens_otel_semconv-2.7.0.tar.gz | 4,947 | e3/7c/6ace357d45f461f5d233bd25590e32cd5e71556c36957b2cf61a31bac3cd/trulens_otel_semconv-2.7.0.tar.gz | source | sdist | null | false | c02e0c51d54a8803f91893e33279a92d | ad754164c7c1b4bf889b676ce86996fdf26859b7b1e62a8077a69d417a3f75e2 | e37c6ace357d45f461f5d233bd25590e32cd5e71556c36957b2cf61a31bac3cd | null | [] | 2,630 |
2.1 | trulens-hotspots | 2.7.0 | Library and command-line tool to list features lowering your evaluation score. | # TruLens Hotspots
TruLens Hotspots is a tool for listing features in your evaluation data that correlate with worse results, according to your evaluation metric.
TruLens Hotspots:
* works with any evaluation metric, be they human scores, formula-based scores (F1, BLEU, ROUGE), learnable evaluation metrics (COMET) or LLM-as-a-judge scores
* is a totally black-box method, any model can be diagnosed
* all that is required is just a data frame with per-sample evaluation scores
* is easily pluggable into your Python code (at the end of the day, it's a function that takes a dataframe) or can be used as a stand-alone command-line tool
* can be run stand-alone or as a part of the whole TruLens framework
## How to run
### As a command-line tool
```bash
python -m trulens.hotspots file.csv \
--score_column COLUMN_WITH_EVALUATION_SCORES \
[--skip_columns OPTIONAL_SPACE_SEPARATED_LIST_COLUMNS_TO_BE_DISREGARDED] \
[--more_skipped_columns OPTIONAL_SPACE_SEPARATED_LIST_COLUMNS_TO_BE_DISREGARDED]
```
#### Skipping columns
Some columns might correlate with the evaluation metric in a trivial manner, let's say your mean metric is F-score, but you also have columns for precision and recall, it does not make any sense to look at them for hotspots. The list of columns to be skipped is determined in the following manner:
1. Some columns are skipped automatically using a simple heuristic (a regular expression for things like "score", "precision", "false negative", etc.)
2. You can override them with the `--skip_columns` argument.
3. ... or you can add more with the `--more_skipped_columns` argument.
### As a stand-alone library
```python
from trulens.hotspots import hotspots_as_df, HotspotsConfig
# A Pandas data frame with per-item evaluation scores, the output of whatever evaluation process
# you're using
evaluation_results_df = ...
# The name of the column with the evaluation score
column_with_evaluation_scores = ...
# The names of the columns to be skipped (e.g. auxiliary evaluation scores)
columns_to_be_skipped = ...
hotspots_config=HotspotsConfig(
score_column=column_with_evaluation_score,
skip_columns=columns_to_be_skipped)
hotspots_df = hotspots_as_df(hotspots_config, evaluation_results_df)
# hotspots_df is a data frame with hotspots
```
### As a part of the whole TruLens framework
```python
from trulens.core.session import TruSession
from trulens.tru_hotspots import get_hotspots
session = TruSession()
# ... running the whole experiment
feedback_name = "Comprehensiveness" # one of the feedbacks
hotspots_df = get_hotspots(session, feedback="Comprehensiveness")
# hotspots_df is a data frame with hotspots
```
### As a part of a stand-alone Streamlit app
It's easy to run TruLens Hotspots as a part of a [Streamlit](https://streamlit.io/) app, see [trulens/streamlit.py](trulens/streamlit.py) for helper
functions and an example. You can run it as follows:
```bash
pip install streamlit
python -m trulens.hotspots.hotspots_streamlit
```
Similarly, you can use TruLens Hotspots for a [Streamlit-in-Snowflake](https://www.snowflake.com/en/data-cloud/overview/streamlit-in-snowflake/) app.
## TruLens Hotspots output
TruLens Hotspots returns a table with the following columns:
1. Feature - one of the following types:
* `FOO=bar` - field `FOO` is equal to `bar`
* `FOO:bar` - field `FOO` contains the word `bar`
* `len(FOO)>=10` - the length of field `FOO` is greater or equal to 10
* `FOO<20` - the value in field `FOO` is less than 20
2. Number of occurrences - how many samples the feature occurred in
3. Average score - average score for samples containing the feature (it will be significantly worse than the total score!)
4. Deterioration - the delta between the average score for samples containing the feature (i.e. column 3) and the average score for the rest of samples (almost always negative)
5. Opportunity - how much the average _total_ score would improve if we had somehow fixed the problem with the feature (i.e. move it to the level of the average of negative examples)
6. p-Value - assuming that the feature has no real effect on worsening scores, how likely is to get the such a distribution of scores (usually, a tiny value).
## Example
Here's the output for a Hotspots run for some LLM evaluated on MMLU:
```
len(QUESTION)>=117 7027 0.60772753 -0.16549267 +0.08281705 0.00000000000000000000
QUESTION:1 1711 0.46492572 -0.25676377 +0.03128634 0.00000000000000000000
DOC_ID:mathematics 748 0.46494490 -0.23814388 +0.01268563 0.00000000000000000000
TAGS=["professional_law"] 1534 0.49343116 -0.22112893 +0.02415694 0.00000000000000000000
DOC_ID:physics 488 0.56084207 -0.13422581 +0.00466473 0.00000000000000000000
CHOICES:2 574 0.47180662 -0.22791301 +0.00931648 0.00000000000000000000
TARGET=Wrong, Not wrong 217 0.32424306 -0.37190742 +0.00574732 0.00000000000000000000
TAGS=["virology"] 166 0.52613443 -0.16623389 +0.00196516 0.00000000000060876997
CHOICES:0 372 0.43726682 -0.26002489 +0.00688857 0.00000000000000000000
TAGS=["global_facts"] 100 0.45071932 -0.24140297 +0.00171915 0.00000000000000904794
TAGS=["professional_accounting"]282 0.51067434 -0.18341221 +0.00368340 0.00000000000000000000
DOC_ID:chemistry 303 0.56378787 -0.12940765 +0.00279237 0.00000000006836024711
TARGET=Wrong, Wrong 213 0.37777224 -0.31744618 +0.00481527 0.00000000000000000000
CHOICES=["True, True", ...] 103 0.33951457 -0.35348142 +0.00259283 0.00000000000000000000
CHOICES:10 317 0.45494130 -0.24090021 +0.00543835 0.00000000000000000000
TAGS=["formal_logic"] 126 0.51026687 -0.18176729 +0.00163101 0.00000000000034218325
TARGET:only 245 0.54455000 -0.14844314 +0.00258998 0.00000000000003856501
TAGS=["high_school_mathematics"]270 0.38323714 -0.31318800 +0.00602199 0.00000000000000000000
CHOICES:admissible 111 0.40249648 -0.29020067 +0.00229399 0.00000000000000000000
QUESTION:Z 48 0.35212494 -0.33943852 +0.00116031 0.00000000000110015792
```
As you can see, the hardest examples were the ones with long questions (with at least 117 characters), there were 7027 samples like this, their average score (0.6077) was worse than the average score for other questions (shorter than 117 characters), the difference is 0.1655, which is quite high. The last column indicates that it is virtually impossible to get it by chance. If we somehow fixed the issue with long questions (not saying it would be easy!), we would improve the score by 8 points, which would be huge for MMLU. The second most "troublesome" feature was having "1" in the `QUESTION` field, i.e. questions about numbers or containing an enumeration. The difference is even bigger (0.2568) than for long questions, but there are fewer of them, so the potential gain is big (3 points), but smaller than for longer questions.
Then follow the features basically representing the hardest domains: mathematics, law, physics (for mathematics and physics even when subtracting the bad effect of long questions and questions containing 1!). Law looks particularly interesting, making the model on par with other domains would improve the score by 2 points.
And there are more interesting observations: questions with numbers in possible answers (`CHOICES`), with the expected answer being `Wrong, Not wrong` or containing the word "only" (`TARGET`) or with letter "Z" pose a special difficulty to our model.
## What's the use?
Basically, with TruLens Hotspots, you can easily find features of input, expected output, actual output and metadata that make your evaluation scores go down. You can then diagnose and attack the core issue: it might be a simple problem with pre/post-processing, or maybe you need more or better annotated training (or evaluation) data sets, or maybe you even need to change your model in a significant manner.
What is cool about TruLens Hotspots is that you don't have to pre-define categories of samples to consider ("I will list the average score for domains to check whether any of them got significantly worse score"), TruLens Hotspots will just look at all features and will list the most problematic things for you. In this way, you can find biases of the model you might not even be aware of (like your model being much worse for people from San Mateo than for people from San Jose).
## Frequently Asked Questions
Q: So this is just yet another method for explainability, something like Shapley values?
<br>A: No, this is not about how much each feature contributes to the generated output. TruLens Hotspots is about finding "troublemakers", features that make your evaluation scores worse in a systematic manner.
Q: Why are you using p-values? Weren't they discredited? Shouldn't you use the Bonferroni correction at least?
A: We're using p-values just for sorting hotspots, there is no claim of statistical significance, we don't use any artificial significance level.
## History
TruLens Hotspots is based on the ideas implemented in [GEval](https://aclanthology.org/W19-4826/). An important improvement is that TruLens Hotspots discards features highly correlating with already listed features.
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"pandas>=1.0.0",
"regex>2021.8.28",
"scipy<2.0.0,>=1.11.1",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:44:00.572997 | trulens_hotspots-2.7.0.tar.gz | 16,197 | b2/5f/7dfcab3a331bbb26f8bdeebca4a1966842f3fc728609f69662fdacbae80d/trulens_hotspots-2.7.0.tar.gz | source | sdist | null | false | 13e4ba03bc98eb0ddc9de78fc26a07e6 | 2bcf5c743d02b21f6ae025c3125d813d429c1f19b2c3fb4039609c20ddacd748 | b25f7dfcab3a331bbb26f8bdeebca4a1966842f3fc728609f69662fdacbae80d | null | [] | 257 |
2.1 | trulens-feedback | 2.7.0 | A TruLens extension package implementing feedback functions for LLM App evaluation. | # trulens-feedback
## Feedback Functions
The `Feedback` class contains the starting point for feedback function
specification and evaluation. A typical use-case looks like this:
```python
from trulens.core import Feedback, Select, Feedback
hugs = feedback.Huggingface()
f_lang_match = Feedback(hugs.language_match)
.on_input_output()
```
The components of this specifications are:
- **Provider classes** -- `feedback.OpenAI` contains feedback function
implementations like `context_relevance`. Other classes subtyping
`feedback.Provider` include `HuggingFace` and `Cohere`.
- **Feedback implementations** -- `provider.context_relevance` is a feedback function
implementation. Feedback implementations are simple callables that can be run
on any arguments matching their signatures. In the example, the implementation
has the following signature:
```python
def language_match(self, text1: str, text2: str) -> float:
```
That is, `language_match` is a plain Python method that accepts two pieces
of text, both strings, and produces a float (assumed to be between 0.0 and
1.0).
- **Feedback constructor** -- The line `Feedback(provider.language_match)`
constructs a Feedback object with a feedback implementation.
- **Argument specification** -- The next line, `on_input_output`, specifies how
the `language_match` arguments are to be determined from an app record or app
definition. The general form of this specification is done using `on` but
several shorthands are provided. `on_input_output` states that the first two
argument to `language_match` (`text1` and `text2`) are to be the main app
input and the main output, respectively.
Several utility methods starting with `.on` provide shorthands:
- `on_input(arg) == on_prompt(arg: Optional[str])` -- both specify that the next
unspecified argument or `arg` should be the main app input.
- `on_output(arg) == on_response(arg: Optional[str])` -- specify that the next
argument or `arg` should be the main app output.
- `on_input_output() == on_input().on_output()` -- specifies that the first
two arguments of implementation should be the main app input and main app
output, respectively.
- `on_default()` -- depending on signature of implementation uses either
`on_output()` if it has a single argument, or `on_input_output` if it has
two arguments.
Some wrappers include additional shorthands:
### LlamaIndex-specific selectors
- `TruLlama.select_source_nodes()` -- outputs the selector for the source
documents part of the engine output.
- `TruLlama.select_context()` -- outputs the selector for the text of
the source documents part of the engine output.
### LangChain-specific selectors
- `TruChain.select_context()` -- outputs the selector for retrieved context
from the app's internal `get_relevant_documents` method.
### NeMo-specific selectors
- `NeMo.select_context()` -- outputs the selector for the retrieved context
from the app's internal `search_relevant_chunks` method.
## Fine-grained Selection and Aggregation
For more advanced control on the feedback function operation, we allow data
selection and aggregation. Consider this feedback example:
```python
f_context_relevance = Feedback(openai.context_relevance)
.on_input()
.on(Select.Record.app.combine_docs_chain._call.args.inputs.input_documents[:].page_content)
.aggregate(numpy.mean)
# Implementation signature:
# def context_relevance(self, question: str, statement: str) -> float:
```
- **Argument Selection specification** -- Where we previously set,
`on_input_output` , the `on(Select...)` line enables specification of where
the statement argument to the implementation comes from. The form of the
specification will be discussed in further details in the Specifying Arguments
section.
- **Aggregation specification** -- The last line `aggregate(numpy.mean)` specifies
how feedback outputs are to be aggregated. This only applies to cases where
the argument specification names more than one value for an input. The second
specification, for `context` was of this type. The input to `aggregate` must
be a method which can be imported globally. This requirement is further
elaborated in the next section. This function is called on the `float` results
of feedback function evaluations to produce a single float. The default is
`numpy.mean`.
The result of these lines is that `f_context_relevance` can be now be run on
app/records and will automatically select the specified components of those
apps/records:
```python
record: Record = ...
app: App = ...
feedback_result: FeedbackResult = f_context_relevance.run(app=app, record=record)
```
The object can also be provided to an app wrapper for automatic evaluation:
```python
app: App = TruChain(...., feedbacks=[f_context_relevance])
```
## Specifying Implementation Function and Aggregate
The function or method provided to the `Feedback` constructor is the
implementation of the feedback function which does the actual work of producing
a float indicating some quantity of interest.
**Note regarding FeedbackMode.DEFERRED** -- Any function or method (not static
or class methods presently supported) can be provided here but there are
additional requirements if your app uses the "deferred" feedback evaluation mode
(when `feedback_mode=FeedbackMode.DEFERRED` are specified to app constructor).
In those cases the callables must be functions or methods that are importable
(see the next section for details). The function/method performing the
aggregation has the same requirements.
### Import requirement (DEFERRED feedback mode only)
If using deferred evaluation, the feedback function implementations and
aggregation implementations must be functions or methods from a Provider
subclass that is importable. That is, the callables must be accessible were you
to evaluate this code:
```python
from somepackage.[...] import someproviderclass
from somepackage.[...] import somefunction
# [...] means optionally further package specifications
provider = someproviderclass(...) # constructor arguments can be included
feedback_implementation1 = provider.somemethod
feedback_implementation2 = somefunction
```
For provided feedback functions, `somepackage` is `trulens.feedback` and
`someproviderclass` is `OpenAI` or one of the other `Provider` subclasses.
Custom feedback functions likewise need to be importable functions or methods of
a provider subclass that can be imported. Critically, functions or classes
defined locally in a notebook will not be importable this way.
## Specifying Arguments
The mapping between app/records to feedback implementation arguments is
specified by the `on...` methods of the `Feedback` objects. The general form is:
```python
feedback: Feedback = feedback.on(argname1=selector1, argname2=selector2, ...)
```
That is, `Feedback.on(...)` returns a new `Feedback` object with additional
argument mappings, the source of `argname1` is `selector1` and so on for further
argument names. The types of `selector1` is `JSONPath` which we elaborate on in
the "Selector Details".
If argument names are omitted, they are taken from the feedback function
implementation signature in order. That is,
```python
Feedback(...).on(argname1=selector1, argname2=selector2)
```
and
```python
Feedback(...).on(selector1, selector2)
```
are equivalent assuming the feedback implementation has two arguments,
`argname1` and `argname2`, in that order.
### Running Feedback
Feedback implementations are simple callables that can be run on any arguments
matching their signatures. However, once wrapped with `Feedback`, they are meant
to be run on outputs of app evaluation (the "Records"). Specifically,
`Feedback.run` has this definition:
```python
def run(self,
app: Union[AppDefinition, JSON],
record: Record
) -> FeedbackResult:
```
That is, the context of a Feedback evaluation is an app (either as
`AppDefinition` or a JSON-like object) and a `Record` of the execution of the
aforementioned app. Both objects are indexable using "Selectors". By indexable
here we mean that their internal components can be specified by a Selector and
subsequently that internal component can be extracted using that selector.
Selectors for Feedback start by specifying whether they are indexing into an App
or a Record via the `__app__` and `__record__` special
attributes (see **Selectors** section below).
### Selector Details
Selectors are of type `JSONPath` defined in `util.py` but are also aliased in
`schema.py` as `Select.Query`. Objects of this type specify paths into JSON-like
structures (enumerating `Record` or `App` contents).
By JSON-like structures we mean Python objects that can be converted into JSON
or are base types. This includes:
- base types: strings, integers, dates, etc.
- sequences
- dictionaries with string keys
Additionally, JSONPath also index into general Python objects like
`AppDefinition` or `Record` though each of these can be converted to JSON-like.
When used to index json-like objects, JSONPath are used as generators: the path
can be used to iterate over items from within the object:
```python
class JSONPath...
...
def __call__(self, obj: Any) -> Iterable[Any]:
...
```
In most cases, the generator produces only a single item but paths can also
address multiple items (as opposed to a single item containing multiple).
The syntax of this specification mirrors the syntax one would use with
instantiations of JSON-like objects. For every `obj` generated by `query: JSONPath`:
- `query[somekey]` generates the `somekey` element of `obj` assuming it is a
dictionary with key `somekey`.
- `query[someindex]` generates the index `someindex` of `obj` assuming it is
a sequence.
- `query[slice]` generates the **multiple** elements of `obj` assuming it is a
sequence. Slices include `:` or in general `startindex:endindex:step`.
- `query[somekey1, somekey2, ...]` generates **multiple** elements of `obj`
assuming `obj` is a dictionary and `somekey1`... are its keys.
- `query[someindex1, someindex2, ...]` generates **multiple** elements
indexed by `someindex1`... from a sequence `obj`.
- `query.someattr` depends on type of `obj`. If `obj` is a dictionary, then
`query.someattr` is an alias for `query[someattr]`. Otherwise if
`someattr` is an attribute of a Python object `obj`, then `query.someattr`
generates the named attribute.
For feedback argument specification, the selectors should start with either
`__record__` or `__app__` indicating which of the two JSON-like structures to
select from (Records or Apps). `Select.Record` and `Select.App` are defined as
`Query().__record__` and `Query().__app__` and thus can stand in for the start of a
selector specification that wishes to select from a Record or App, respectively.
The full set of Query aliases are as follows:
- `Record = Query().__record__` -- points to the Record.
- App = Query().**app** -- points to the App.
- `RecordInput = Record.main_input` -- points to the main input part of a
Record. This is the first argument to the root method of an app (for
LangChain Chains this is the `__call__` method).
- `RecordOutput = Record.main_output` -- points to the main output part of a
Record. This is the output of the root method of an app (i.e. `__call__`
for LangChain Chains).
- `RecordCalls = Record.app` -- points to the root of the app-structured
mirror of calls in a record. See **App-organized Calls** Section above.
## Multiple Inputs Per Argument
As in the `f_context_relevance` example, a selector for a _single_ argument may point
to more than one aspect of a record/app. These are specified using the slice or
lists in key/index positions. In that case, the feedback function is evaluated
multiple times, its outputs collected, and finally aggregated into a main
feedback result.
The collection of values for each argument of feedback implementation is
collected and every combination of argument-to-value mapping is evaluated with a
feedback definition. This may produce a large number of evaluations if more than
one argument names multiple values. In the dashboard, all individual invocations
of a feedback implementation are shown alongside the final aggregate result.
## App/Record Organization (What can be selected)
Apps are serialized into JSON-like structures which are indexed via selectors.
The exact makeup of this structure is app-dependent though always start with
`app`, that is, the trulens wrappers (subtypes of `App`) contain the wrapped app
in the attribute `app`:
```python
# app.py:
class App(AppDefinition, SerialModel):
...
# The wrapped app.
app: Any = Field(exclude=True)
...
```
For your app, you can inspect the JSON-like structure by using the `dict`
method:
```python
app = ... # your app, extending App
print(app.dict())
```
The other non-excluded fields accessible outside of the wrapped app are listed
in the `AppDefinition` class in `schema.py`:
```python
class AppDefinition(WithClassInfo, SerialModel, ABC):
...
app_id: AppID
feedback_definitions: Sequence[FeedbackDefinition] = []
feedback_mode: FeedbackMode = FeedbackMode.WITH_APP_THREAD
root_class: Class
root_callable: ClassVar[FunctionOrMethod]
app: JSON
```
Note that `app` is in both classes. This distinction between `App` and
`AppDefinition` here is that one corresponds to potentially non-serializable
Python objects (`App`) and their serializable versions (`AppDefinition`).
Feedbacks should expect to be run with `AppDefinition`. Fields of `App` that are
not part of `AppDefinition` may not be available.
You can inspect the data available for feedback definitions in the dashboard by
clicking on the "See full app json" button on the bottom of the page after
selecting a record from a table.
The other piece of context to Feedback evaluation are records. These contain the
inputs/outputs and other information collected during the execution of an app:
```python
class Record(SerialModel):
record_id: RecordID
app_id: AppID
cost: Optional[Cost] = None
perf: Optional[Perf] = None
ts: datetime = pydantic.Field(default_factory=lambda: datetime.now())
tags: str = ""
main_input: Optional[JSON] = None
main_output: Optional[JSON] = None # if no error
main_error: Optional[JSON] = None # if error
# The collection of calls recorded. Note that these can be converted into a
# json structure with the same paths as the app that generated this record
# via `layout_calls_as_app`.
calls: Sequence[RecordAppCall] = []
```
A listing of a record can be seen in the dashboard by clicking the "see full
record json" button on the bottom of the page after selecting a record from the
table.
### Calls made by App Components
When evaluating a feedback function, Records are augmented with
app/component calls in app layout in the attribute `app`. By this we mean that
in addition to the fields listed in the class definition above, the `app` field
will contain the same information as `calls` but organized in a manner mirroring
the organization of the app structure. For example, if the instrumented app
contains a component `combine_docs_chain` then `app.combine_docs_chain` will
contain calls to methods of this component. In the example at the top of this
docstring, `_call` was an example of such a method. Thus
`app.combine_docs_chain._call` further contains a `RecordAppCall` (see
schema.py) structure with information about the inputs/outputs/metadata
regarding the `_call` call to that component. Selecting this information is the
reason behind the `Select.RecordCalls` alias (see next section).
You can inspect the components making up your app via the `App` method
`print_instrumented`.
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"nltk<4.0.0,>=3.9.1",
"numpy>=1.23.0",
"pydantic<3.0.0,>=2.4.2",
"requests<3.0,>=2.31",
"scikit-learn<2.0.0,>=1.3.0",
"scipy<2.0.0,>=1.11.1",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:58.925822 | trulens_feedback-2.7.0.tar.gz | 65,628 | 27/bf/2ccae3ca33c67ad7a30b9779057e252d324b49c242b62d8d4625e78531ff/trulens_feedback-2.7.0.tar.gz | source | sdist | null | false | 70e267896716538efc251d0cdd8a1007 | 1e368764370c89dd4bcf35ac999075acb98faca3c908b0a25c7d88310f69c064 | 27bf2ccae3ca33c67ad7a30b9779057e252d324b49c242b62d8d4625e78531ff | null | [] | 2,365 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.