
metadata_version string | name string | version string | summary string | description string | description_content_type string | author string | author_email string | maintainer string | maintainer_email string | license string | keywords string | classifiers list | platform list | home_page string | download_url string | requires_python string | requires list | provides list | obsoletes list | requires_dist list | provides_dist list | obsoletes_dist list | requires_external list | project_urls list | uploaded_via string | upload_time timestamp[us] | filename string | size int64 | path string | python_version string | packagetype string | comment_text string | has_signature bool | md5_digest string | sha256_digest string | blake2_256_digest string | license_expression string | license_files list | recent_7d_downloads int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2.1 | trulens-dashboard | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-dashboard
## Install Node.js
See [the Node.js website](https://nodejs.org/en/download/package-manager) for details
## Building
Build with `python -m build`
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | !=2.7.*,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*,!=3.6.*,!=3.7.*,!=3.8.*,>=3.9 | [] | [] | [] | [
"ipywidgets>=7.1.2",
"jupyter<2,>=1",
"packaging>=23.0",
"pandas>=1.0.0",
"plotly<7.0.0,>=6.0.0",
"psutil<6.0,>=5.9",
"rich<14.0,>=13.6",
"streamlit<2.0,>=1.35",
"streamlit-aggrid<1.1.8,>=1.0.5; extra == \"full\"",
"traitlets<6.0.0,>=5.0.5",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:57.094446 | trulens_dashboard-2.7.0.tar.gz | 1,067,131 | 85/35/bb9fc1e4f874cf239a2310d06ad5c688100ba48569709ca2516726c53d45/trulens_dashboard-2.7.0.tar.gz | source | sdist | null | false | 3c5066912a1a53ab1b0ad8c636ff6a93 | 08643b7a4bc21f06a7b5b34f4c8af20b412365c6764e2d65f2ba4b4a94779190 | 8535bb9fc1e4f874cf239a2310d06ad5c688100ba48569709ca2516726c53d45 | null | [] | 1,976 |
2.1 | trulens-core | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-core
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"alembic<2.0.0,>=1.8.1",
"dill<0.4.0,>=0.3.8",
"importlib-resources<7.0,>=6.0",
"munch<5.0.0,>=2.5.0",
"nest-asyncio<2.0,>=1.5",
"numpy>=1.23.0",
"opentelemetry-api>=1.23.0",
"opentelemetry-proto>=1.23.0",
"opentelemetry-sdk>=1.23.0",
"packaging>=23.0",
"pandas>=1.0.0",
"pydantic<3.0.0,>=2.4.2... | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:55.705827 | trulens_core-2.7.0.tar.gz | 261,451 | 04/6c/42b8043a6eac46e32e64fa42d5288293b623e266af28edc1f5f7e3c2554a/trulens_core-2.7.0.tar.gz | source | sdist | null | false | 6afaf7dc91e038b99867083f1117ddb1 | e26f4668557268cbc14fe03c3a7bb9f7f4ea49871ea89d3f05355b085458cca3 | 046c42b8043a6eac46e32e64fa42d5288293b623e266af28edc1f5f7e3c2554a | null | [] | 2,628 |
2.1 | trulens-connectors-snowflake | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-connectors-snowflake
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <3.13,>=3.9 | [] | [] | [] | [
"snowflake-snowpark-python<2.0,>=1.18",
"snowflake-sqlalchemy<2.0,>=1.6",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:53.629958 | trulens_connectors_snowflake-2.7.0.tar.gz | 1,504,491 | f4/de/f3101c7804f1b3eec927a6ad0e9da73909715d128332e0e88b6f3fe62ed6/trulens_connectors_snowflake-2.7.0.tar.gz | source | sdist | null | false | 32bd9a2f61cdce7ec536fe6420ae9db9 | da81879c165ef059095751e87734ec59e80c3192b7ee2985f080bb74643615b1 | f4def3101c7804f1b3eec927a6ad0e9da73909715d128332e0e88b6f3fe62ed6 | null | [] | 698 |
2.1 | trulens-benchmark | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-benchmark
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"poetry<2.0.0",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:51.933689 | trulens_benchmark-2.7.0.tar.gz | 153,599 | a7/f3/017c2ce54e154cde9c32ed97b38c3f6ed824091e12115e6fc5b5a8b04a5f/trulens_benchmark-2.7.0.tar.gz | source | sdist | null | false | 1e1362587f08f33c583c03a84863534e | 9a3098023e8f5925bb073abcd635d350f2a68d87953dac908108d5729760eb44 | a7f3017c2ce54e154cde9c32ed97b38c3f6ed824091e12115e6fc5b5a8b04a5f | null | [] | 270 |
2.1 | trulens-apps-nemo | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-apps-nemo
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <3.13,>=3.9 | [] | [] | [] | [
"langchain<0.4.0,>=0.2.14",
"langchain-core>=0.2.14",
"nemoguardrails>=0.9; python_version >= \"3.10\" and python_version < \"3.12.dev0\" or python_version >= \"3.13.dev0\" and python_version < \"4.0\"",
"onnxruntime>=1.14.0; python_version >= \"3.10\"",
"onnxruntime<1.20.0,>=1.14.0; python_version < \"3.10... | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:50.718098 | trulens_apps_nemo-2.7.0.tar.gz | 5,654 | 91/51/05f3d05e11f4c2c4d24f3489e56bf66cc08a3d55427834c724b1203fac7b/trulens_apps_nemo-2.7.0.tar.gz | source | sdist | null | false | 91191548d97e152b388d47c504323243 | 4514bffff17250a4eb0c68c9f3e1ff511b7e1830ddb2f358eddaefc53dfc95a5 | 915105f3d05e11f4c2c4d24f3489e56bf66cc08a3d55427834c724b1203fac7b | null | [] | 263 |
2.1 | trulens-apps-llamaindex | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-apps-llamaindex
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"llama-index>=0.11",
"pydantic<3.0.0,>=2.4.2",
"tiktoken>=0.3.3; python_version < \"3.13\"",
"tiktoken>=0.8.0; python_version >= \"3.13\"",
"trulens-apps-langchain<3.0.0,>=2.0.0",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:49.211575 | trulens_apps_llamaindex-2.7.0.tar.gz | 19,309 | 89/50/e4c7eac5bf4e4d67e8b98b38b37cd7faac6577ebcb6bb4d77692ecb821e5/trulens_apps_llamaindex-2.7.0.tar.gz | source | sdist | null | false | 79c6795f672a559e5283ff8ec6bf3126 | bceebcb75576771b3cbe5d0bbb7ccf2bcaa4bff23b67dfee96a1b0b163fa9b3e | 8950e4c7eac5bf4e4d67e8b98b38b37cd7faac6577ebcb6bb4d77692ecb821e5 | null | [] | 272 |
2.1 | trulens-apps-langgraph | 2.7.0 | Library to systematically track and evaluate LangGraph based applications. | # trulens-apps-langgraph
Refer to `otel_tru_graph_example.ipynb` notebook for examples.
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"langchain>=1.0.0",
"langchain-community>=0.3.0",
"langchain-core>=1.0.0",
"langgraph>=0.4.4",
"opentelemetry-api>=1.23.0",
"opentelemetry-proto>=1.23.0",
"opentelemetry-sdk>=1.23.0",
"pydantic<3.0.0,>=2.4.2",
"trulens-apps-langchain<3.0.0,>=2.0.0",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:48.155067 | trulens_apps_langgraph-2.7.0.tar.gz | 29,980 | 0f/f0/0c1b8f024eacc6a17139686eb3f328b4d9dbd7f91da040a13eeaab7f038f/trulens_apps_langgraph-2.7.0.tar.gz | source | sdist | null | false | 32324ac3ab529e80a6f3e34575c57167 | e8fe5441a6c05b09d111341a3284e3f875ab60d1c4350b12a713aaeecd9de7b0 | 0ff00c1b8f024eacc6a17139686eb3f328b4d9dbd7f91da040a13eeaab7f038f | null | [] | 327 |
2.1 | trulens-apps-langchain | 2.7.0 | Library to systematically track and evaluate LLM based applications. | # trulens-apps-langchain
| text/markdown | Snowflake Inc. | ml-observability-wg-dl@snowflake.com | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :... | [] | https://trulens.org/ | null | <4.0,>=3.9 | [] | [] | [] | [
"langchain>=1.0.0",
"langchain-community>=0.3.0",
"langchain-core>=1.0.0",
"pydantic<3.0.0,>=2.4.2",
"trulens-core<3.0.0,>=2.0.0"
] | [] | [] | [] | [
"Documentation, https://trulens.org/getting_started/",
"Repository, https://github.com/truera/trulens"
] | twine/5.1.1 CPython/3.11.7 | 2026-02-19T01:43:47.030530 | trulens_apps_langchain-2.7.0.tar.gz | 12,420 | 69/c3/c464a1093ce72738d6d5b37cb20649a6af113be36c396afc14c5798fb92d/trulens_apps_langchain-2.7.0.tar.gz | source | sdist | null | false | 09fe8ebd8240b848c6667bfae09aa66d | 78f7f35b4cd81807f7fd19b006b089355a4f44d15500fe8b84454ade69443a05 | 69c3c464a1093ce72738d6d5b37cb20649a6af113be36c396afc14c5798fb92d | null | [] | 429 |
2.4 | opsramp-analytics-utils-security-fix | 1.0.0 | OpsRamp Analytics SDK | ## OpsRamp Analytics Utilities
This is the SDK for writing OpsRamp analytics apps. It is based on [dash](https://plotly.com/dash/), and it has a number of utility functions.
It contains [analysis wrapper project](https://github.com/opsramp/analysis-wrapper).
It is published on [Pypi](https://pypi.org/project/opsramp-analytics-utils/)
#### How to publish on Pypi
After make updates on SDK, modify the version in _setup.py_.
```
python setup.py sdist bdist_wheel
python -m twine upload dist/*
Note: if above command not works, then use below command
python -m twine upload --skip-existing dist/*
```
- To upgrade the sdk for your app
```
pip install --no-cache-dir --upgrade opsramp-analytics-utils
```
| text/markdown | OpsRamp | opsramp@support.com | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent"
] | [] | null | null | >=3.6 | [] | [] | [] | [
"boto3==1.40.14",
"botocore==1.40.14",
"openpyxl==3.0.7",
"flask==3.0.0",
"dash==2.15.0",
"requests==2.32.4",
"Werkzeug==3.0.6",
"urllib3==2.5.0",
"pytz",
"xlsxwriter==3.2.0",
"pyyaml",
"setuptools==78.1.1",
"google-cloud-storage"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.2 | 2026-02-19T01:42:54.595334 | opsramp_analytics_utils_security_fix-1.0.0.tar.gz | 1,202,388 | df/e7/5ae09affab425c8310b59f759d97c43acf1015997bb4381479eadc78e764/opsramp_analytics_utils_security_fix-1.0.0.tar.gz | source | sdist | null | false | 2a8a5eee96b27083fe425e75a8bc2fc0 | 5bafb604b81197f89fba4d4e2ca62b67ad36f7b569eba841d51cd7d41e951a76 | dfe75ae09affab425c8310b59f759d97c43acf1015997bb4381479eadc78e764 | null | [] | 296 |
2.1 | cdktn-provider-helm | 13.0.0 | Prebuilt helm Provider for CDK Terrain (cdktn) | # CDKTN prebuilt bindings for hashicorp/helm provider version 3.1.1
This repo builds and publishes the [Terraform helm provider](https://registry.terraform.io/providers/hashicorp/helm/3.1.1/docs) bindings for [CDK Terrain](https://cdktn.io).
## Available Packages
### NPM
The npm package is available at [https://www.npmjs.com/package/@cdktn/provider-helm](https://www.npmjs.com/package/@cdktn/provider-helm).
`npm install @cdktn/provider-helm`
### PyPI
The PyPI package is available at [https://pypi.org/project/cdktn-provider-helm](https://pypi.org/project/cdktn-provider-helm).
`pipenv install cdktn-provider-helm`
### Nuget
The Nuget package is available at [https://www.nuget.org/packages/Io.Cdktn.Providers.Helm](https://www.nuget.org/packages/Io.Cdktn.Providers.Helm).
`dotnet add package Io.Cdktn.Providers.Helm`
### Maven
The Maven package is available at [https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-helm](https://mvnrepository.com/artifact/io.cdktn/cdktn-provider-helm).
```
<dependency>
<groupId>io.cdktn</groupId>
<artifactId>cdktn-provider-helm</artifactId>
<version>[REPLACE WITH DESIRED VERSION]</version>
</dependency>
```
### Go
The go package is generated into the [`github.com/cdktn-io/cdktn-provider-helm-go`](https://github.com/cdktn-io/cdktn-provider-helm-go) package.
`go get github.com/cdktn-io/cdktn-provider-helm-go/helm/<version>`
Where `<version>` is the version of the prebuilt provider you would like to use e.g. `v11`. The full module name can be found
within the [go.mod](https://github.com/cdktn-io/cdktn-provider-helm-go/blob/main/helm/go.mod#L1) file.
## Docs
Find auto-generated docs for this provider here:
* [Typescript](./docs/API.typescript.md)
* [Python](./docs/API.python.md)
* [Java](./docs/API.java.md)
* [C#](./docs/API.csharp.md)
* [Go](./docs/API.go.md)
You can also visit a hosted version of the documentation on [constructs.dev](https://constructs.dev/packages/@cdktn/provider-helm).
## Versioning
This project is explicitly not tracking the Terraform helm provider version 1:1. In fact, it always tracks `latest` of `~> 3.0` with every release. If there are scenarios where you explicitly have to pin your provider version, you can do so by [generating the provider constructs manually](https://cdktn.io/docs/concepts/providers#import-providers).
These are the upstream dependencies:
* [CDK Terrain](https://cdktn.io) - Last official release
* [Terraform helm provider](https://registry.terraform.io/providers/hashicorp/helm/3.1.1)
* [Terraform Engine](https://terraform.io)
If there are breaking changes (backward incompatible) in any of the above, the major version of this project will be bumped.
## Features / Issues / Bugs
Please report bugs and issues to the [CDK Terrain](https://cdktn.io) project:
* [Create bug report](https://github.com/open-constructs/cdk-terrain/issues)
* [Create feature request](https://github.com/open-constructs/cdk-terrain/issues)
## Contributing
### Projen
This is mostly based on [Projen](https://projen.io), which takes care of generating the entire repository.
### cdktn-provider-project based on Projen
There's a custom [project builder](https://github.com/cdktn-io/cdktn-provider-project) which encapsulate the common settings for all `cdktn` prebuilt providers.
### Provider Version
The provider version can be adjusted in [./.projenrc.js](./.projenrc.js).
### Repository Management
The repository is managed by [CDKTN Repository Manager](https://github.com/cdktn-io/cdktn-repository-manager/).
| text/markdown | CDK Terrain Maintainers | null | null | null | MPL-2.0 | null | [
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: JavaScript",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Typing :: Typed",
... | [] | https://github.com/cdktn-io/cdktn-provider-helm.git | null | ~=3.9 | [] | [] | [] | [
"cdktn<0.23.0,>=0.22.0",
"constructs<11.0.0,>=10.4.2",
"jsii<2.0.0,>=1.119.0",
"publication>=0.0.3",
"typeguard<4.3.0,>=2.13.3"
] | [] | [] | [] | [
"Source, https://github.com/cdktn-io/cdktn-provider-helm.git"
] | twine/6.1.0 CPython/3.14.3 | 2026-02-19T01:41:32.698956 | cdktn_provider_helm-13.0.0.tar.gz | 199,828 | 19/1d/a6e0d31e194e3584d9ff527c8ea13afe3413ac7560bb1cd36045a32f77f4/cdktn_provider_helm-13.0.0.tar.gz | source | sdist | null | false | 16cacc36cbd667bc10b7ee065c675086 | 5ec235a34c32efabc1d118b47291364ff0dd7593c46bba7d4404164220e431d2 | 191da6e0d31e194e3584d9ff527c8ea13afe3413ac7560bb1cd36045a32f77f4 | null | [] | 268 |
2.4 | nemo-evaluator-launcher | 0.1.86 | Launcher for the evaluations provided by NeMo Evaluator containers with different runtime backends | # NeMo Evaluator Launcher
For complete documentation, please see: [docs/nemo-evaluator-launcher/index.md](https://github.com/NVIDIA-NeMo/Evaluator/tree/main/docs/nemo-evaluator-launcher/index.md)
| text/markdown | NVIDIA | nemo-toolkit@nvidia.com | NVIDIA | nemo-toolkit@nvidia.com | Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS Copyright 2021 NVIDIA Corporation Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. PORTIONS LICENSED AS FOLLOWS > tools/pytorch-quantization/examples/torchvision/models/classification/resnet.py BSD 3-Clause License Copyright (c) Soumith Chintala 2016, All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: * Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. * Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. * Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. > samples/common/windows/getopt.c Copyright (c) 2002 Todd C. Miller <Todd.Miller@courtesan.com> Permission to use, copy, modify, and distribute this software for any purpose with or without fee is hereby granted, provided that the above copyright notice and this permission notice appear in all copies. THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE. Sponsored in part by the Defense Advanced Research Projects Agency (DARPA) and Air Force Research Laboratory, Air Force Materiel Command, USAF, under agreement number F39502-99-1-0512. Copyright (c) 2000 The NetBSD Foundation, Inc. All rights reserved. This code is derived from software contributed to The NetBSD Foundation by Dieter Baron and Thomas Klausner. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. THIS SOFTWARE IS PROVIDED BY THE NETBSD FOUNDATION, INC. AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE FOUNDATION OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - Copyright (c) 2002 Todd C. Miller <Todd.Miller@courtesan.com> - Copyright (c) 2000 The NetBSD Foundation, Inc. > parsers/common/ieee_half.h > samples/common/half.h > third_party/ieee/half.h The MIT License Copyright (c) 2012-2017 Christian Rau <rauy@users.sourceforge.net> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. > plugin/multiscaleDeformableAttnPlugin/multiscaleDeformableAttn.cu > plugin/multiscaleDeformableAttnPlugin/multiscaleDeformableAttn.h > plugin/multiscaleDeformableAttnPlugin/multiscaleDeformableIm2ColCuda.cuh Copyright 2020 SenseTime Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. DETR Copyright 2020 - present, Facebook, Inc Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. > demo/Diffusion/utilities.py > demo/Diffusion/stable_video_diffusion_pipeline.py HuggingFace diffusers library. Copyright 2024 The HuggingFace Team. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. > demo/Diffusion/utils_sd3/sd3_impls.py > demo/Diffusion/utils_sd3/other_impls.py > demo/Diffusion/utils_sd3/mmdit.py > demo/Diffusion/stable_diffusion_3_pipeline.py MIT License Copyright (c) 2024 Stability AI Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. > demo/Diffusion/utilities.py ModelScope library. Copyright (c) Alibaba, Inc. and its affiliates. Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. > plugin/scatterElementsPlugin/atomics.cuh > plugin/scatterElementsPlugin/reducer.cuh > plugin/scatterElementsPlugin/scatterElementsPluginKernel.cu > plugin/scatterElementsPlugin/scatterElementsPluginKernel.h > plugin/scatterElementsPlugin/TensorInfo.cuh Copyright (c) 2020 Matthias Fey <matthias.fey@tu-dortmund.de> Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. > plugin/roiAlignPlugin/roiAlignKernel.cu MIT License Copyright (c) Microsoft Corporation Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. | deep learning, evaluations, machine learning, gpu, NLP, pytorch, torch | [] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"hydra-core<2.0.0,>=1.3.2",
"jinja2<4.0.0,>=3.1.6",
"leptonai>=0.25.0",
"nemo-evaluator",
"pyyaml>=6.0.0",
"requests>=2.32.4",
"simple-parsing<0.2.0,>=0.1.7",
"structlog<26.0.0,>=25.4.0",
"tabulate<0.10.0,>=0.9.0",
"tomli<3.0.0,>=2.0.0; python_version < \"3.11\"",
"mlflow>=2.8.0; extra == \"mlfl... | [] | [] | [] | [
"homepage, https://github.com/NVIDIA-NeMo/Evaluator",
"repository, https://github.com/NVIDIA-NeMo/Evaluator/packages/nemo-evaluator-launcher"
] | twine/6.0.1 CPython/3.12.3 | 2026-02-19T01:37:32.850565 | nemo_evaluator_launcher-0.1.86.tar.gz | 201,705 | 87/4b/a418ff12c35a396002b02bf16dd7e34322314169efab5168340f2c1b6466/nemo_evaluator_launcher-0.1.86.tar.gz | source | sdist | null | false | d4dd6cc265e114c0a1eea92b821bf553 | f8b35f3c591325e97624aba0652739ec105a093ae907464a8032dfeb9f10eb25 | 874ba418ff12c35a396002b02bf16dd7e34322314169efab5168340f2c1b6466 | null | [] | 1,730 |
2.4 | nemo-evaluator | 0.1.85 | Common utilities for NVIDIA evaluation frameworks | # NeMo Evaluator
For complete documentation, please see: [docs/nemo-evaluator/index.md](https://github.com/NVIDIA-NeMo/Evaluator/tree/main/docs/nemo-evaluator/index.md)
| text/markdown | NVIDIA | nemo-toolkit@nvidia.com | NVIDIA | nemo-toolkit@nvidia.com | Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright 2025 NVIDIA CORPORATION Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. | deep learning, evaluations, machine learning, gpu, NLP, pytorch, torch | [
"Development Status :: 5 - Production/Stable",
"Programming Language :: Python :: 3",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent"
] | [] | null | null | <3.14,>=3.10 | [] | [] | [] | [
"flask",
"jinja2",
"psutil",
"pydantic",
"pydantic-core>=2.17",
"requests",
"structlog",
"typing-extensions>=4.0.0",
"pyyaml",
"werkzeug",
"yq"
] | [] | [] | [] | [
"homepage, https://github.com/NVIDIA-NeMo/Evaluator",
"repository, https://github.com/NVIDIA-NeMo/Evaluator/packages/nemo-evaluator"
] | twine/6.0.1 CPython/3.12.3 | 2026-02-19T01:37:31.663098 | nemo_evaluator-0.1.85.tar.gz | 108,677 | 62/07/a45a7b244216afec948b69d1943451905b38adafbc4e1799bd955859acb6/nemo_evaluator-0.1.85.tar.gz | source | sdist | null | false | 740d636f42e9ec542498087f0ef2ade1 | f09ddfe66a7d3074d66d73c6b9900d5cd6e521640fcfb90c7027e9c2117eaf63 | 6207a45a7b244216afec948b69d1943451905b38adafbc4e1799bd955859acb6 | null | [] | 3,961 |
2.4 | chiz | 0.6.3 | Chili Pepper Language Linter, Formatter, and Language Server, written in Rust. | # Chiz
<span style="color: red;">Chi</span>li & Pepper Language Analy<span style="color: red;">z</span>er, provides Linter, Formatter, and Language Server for [chili](https://purple-chili.github.io/), a spicy language and runtime for data analysis and engineering
## Language Server
- [x] hover
- [x] rename symbol
- [x] go to definition
- [x] go to reference
- [x] workspace symbol
- [x] document highlight
- [x] document symbol
- [x] completion
- [x] signature help
- [x] semantic highlights
- [ ] call hierarchy
## Installation
```bash
pip install chiz
```
## Neovim Configuration
Create a `~/.config/nvim/lua/chiz.lua` file and add the following code, then include `require("chiz")` in the `init.lua` file.
```lua
local cmp = require 'cmp'
cmp.setup({
sources = cmp.config.sources({
{ name = 'nvim_lsp' },
{ name = 'vsnip' },
{ name = 'buffer' },
}),
window = {
completion = cmp.config.window.bordered(),
},
mapping = cmp.mapping.preset.insert({
['<C-b>'] = cmp.mapping.scroll_docs(-4),
['<C-f>'] = cmp.mapping.scroll_docs(4),
['<C-Space>'] = cmp.mapping.complete(),
['<C-e>'] = cmp.mapping.abort(),
['<CR>'] = cmp.mapping.confirm({ select = true }),
}),
completion = {
keyword_length = 2,
}
})
vim.api.nvim_create_autocmd('FileType', {
pattern = { "chi", "pep" },
callback = function()
vim.lsp.start({
name = 'chili language server',
cmd = { 'chiz', 'server' },
filetypes = { 'chi', 'pep' },
root_dir = vim.fs.dirname(vim.fs.find({ 'src' }, { upward = true })[1]),
})
local group = vim.api.nvim_create_augroup("LSPDocumentHighlight", {})
vim.opt.updatetime = 1000
vim.api.nvim_create_autocmd({ "CursorHold", "CursorHoldI" }, {
buffer = bufnr,
group = group,
callback = function()
vim.lsp.buf.document_highlight()
end,
})
vim.api.nvim_create_autocmd({ "CursorMoved" }, {
buffer = bufnr,
group = group,
callback = function()
vim.lsp.buf.clear_references()
end,
})
end,
})
vim.api.nvim_create_autocmd('LspAttach', {
group = vim.api.nvim_create_augroup('UserLspConfig', {}),
callback = function(ev)
vim.bo[ev.buf].omnifunc = 'v:lua.vim.lsp.omnifunc'
local opts = { buffer = ev.buf }
vim.keymap.set('n', 'gd', vim.lsp.buf.definition, opts)
vim.keymap.set('n', 'gr', vim.lsp.buf.references, opts)
vim.keymap.set('n', 'K', vim.lsp.buf.hover, opts)
vim.keymap.set('n', '<C-k>', vim.lsp.buf.signature_help, opts)
vim.keymap.set('n', '<space>wa', vim.lsp.buf.add_workspace_folder, opts)
vim.keymap.set('n', '<space>wr', vim.lsp.buf.remove_workspace_folder, opts)
vim.keymap.set('n', '<space>wl', function()
print(vim.inspect(vim.lsp.buf.list_workspace_folders()))
end, opts)
vim.keymap.set('n', '<space>rn', vim.lsp.buf.rename, opts)
vim.keymap.set('n', '<space>f', function()
vim.lsp.buf.format { async = true }
end, opts)
end,
})
-- Create an augroup to manage the autocmd
local lsp_augroup = vim.api.nvim_create_augroup("LspFormatting", { clear = true })
-- Apply formatting before saving the buffer
vim.api.nvim_create_autocmd("BufWritePre", {
group = lsp_augroup,
callback = function()
vim.lsp.buf.format({ async = false })
end,
})
```
## Helix Configuration
Pending...
| text/markdown; charset=UTF-8; variant=GFM | null | Jo Shinonome <jo.shinonome@gmail.com> | null | null | null | automation, flake8, pycodestyle, pyflakes, pylint, clippy | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",... | [] | null | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | maturin/1.12.2 | 2026-02-19T01:37:18.100579 | chiz-0.6.3-py3-none-win32.whl | 1,340,179 | 68/5a/21575a8cd9a5de1fc477306a03c5485ced4ea78cb4889d6ac2640fa94fb1/chiz-0.6.3-py3-none-win32.whl | py3 | bdist_wheel | null | false | ecb10370d8939e82ffbca88d923a2a15 | a1ed287935d7f7cdea72852d58797eb5208d4d3ddd06472f4db207930ca54a5e | 685a21575a8cd9a5de1fc477306a03c5485ced4ea78cb4889d6ac2640fa94fb1 | null | [] | 492 |
2.4 | ezmsg-nwb | 1.0.0 | NWB (Neurodata Without Borders) file reading and writing for ezmsg | # ezmsg-nwb
NWB (Neurodata Without Borders) file reading and writing for the [ezmsg](https://www.ezmsg.org) framework.
## Overview
`ezmsg-nwb` provides streaming NWB file I/O as ezmsg Units.
Key features:
* **NWB Reader** - Stream data from NWB files (local or remote) as AxisArray messages
* **NWB Writer** - Write incoming AxisArray streams to NWB files with automatic container management
* **Flexible clock handling** - Support for system, monotonic, and unknown reference clocks
## Installation
Install from PyPI:
```bash
pip install ezmsg-nwb
```
Or install the latest development version:
```bash
pip install git+https://github.com/ezmsg-org/ezmsg-nwb@main
```
## Dependencies
- `ezmsg`
- `ezmsg-baseproc`
- `numpy`
- `pynwb`
- `h5py`
- `neuroconv`
- `remfile`
- `pyyaml`
## Usage
See the `examples` folder for usage examples.
```python
import ezmsg.core as ez
from ezmsg.nwb import NWBIteratorUnit, NWBSink
```
For general ezmsg tutorials and guides, visit [ezmsg.org](https://www.ezmsg.org).
## Development
We use [`uv`](https://docs.astral.sh/uv/getting-started/installation/) for development.
1. Install [`uv`](https://docs.astral.sh/uv/getting-started/installation/) if not already installed.
2. Fork this repository and clone your fork locally.
3. Open a terminal and `cd` to the cloned folder.
4. Run `uv sync` to create a `.venv` and install dependencies.
5. (Optional) Install pre-commit hooks: `uv run pre-commit install`
6. After making changes, run the test suite: `uv run pytest tests`
## License
MIT License - see [LICENSE](LICENSE) for details.
## Acknowledgements
This project is supported by [the Wyss Center for Bio and Neuroengineering](https://wysscenter.ch)
and by [Blackrock Neurotech](https://www.blackrockneurotech.com).
| text/markdown | ezmsg Contributors | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"ezmsg-baseproc",
"ezmsg>=3.6.0",
"h5py",
"neuroconv",
"numpy>=1.26.0",
"pynwb",
"pyyaml",
"remfile",
"ezmsg-sigproc; extra == \"sigproc\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:36:43.507520 | ezmsg_nwb-1.0.0.tar.gz | 32,022 | 78/75/366e320e6aba6289ece579daa7a8c204c685646fdc4f928972da09e7459b/ezmsg_nwb-1.0.0.tar.gz | source | sdist | null | false | 1b469a7736490e3cce74e0f43e2cd96b | 942a30b85a2492a0e16422410a27513828bc88c6bc118a1b34d30be508d0355a | 7875366e320e6aba6289ece579daa7a8c204c685646fdc4f928972da09e7459b | MIT | [
"LICENSE"
] | 279 |
2.4 | LCNE-patchseq-analysis | 0.34.2 | Generated from aind-library-template | # LCNE-patchseq-analysis
[](LICENSE)

[](https://github.com/semantic-release/semantic-release)



This repository is the **main entry point for reproducing the LCNE-patchseq analysis** associated with our paper. It contains the full pipeline for extracting electrophysiological features from patch-seq recordings in locus coeruleus norepinephrine (LC-NE) neurons, merging transcriptomic and morphological data, and generating the paper's main figures. A fully reproducible run — with identical data, software environment, and code — is available as a [Code Ocean capsule](https://codeocean.allenneuraldynamics.org/capsule/1699143/tree). An interactive [Panel app](https://hanhou-patchseq.hf.space/patchseq_panel_viz) is provided for exploring the dataset.
## Resources
| Resource | Description | Link |
|---|---|---|
| **Analysis code** (this repo) | Source code for the eFEL pipeline, figure scripts, and data utilities | [AllenNeuralDynamics/LCNE-patchseq-analysis](https://github.com/AllenNeuralDynamics/LCNE-patchseq-analysis) |
| **Code Ocean capsule** | Fully reproducible computational capsule — data, environment, and code used for the paper | [Capsule #1699143](https://codeocean.allenneuraldynamics.org/capsule/1699143/tree) |
| **Interactive visualization app** | Panel app for exploring single-cell ephys, transcriptomics, and morphology data | [hanhou-patchseq.hf.space/patchseq_panel_viz](https://hanhou-patchseq.hf.space/patchseq_panel_viz) |
| **Visualization source code** | Source code for the Panel app, deployed on Hugging Face Spaces | [AllenNeuralDynamics/LCNE-patchseq-viz](https://github.com/AllenNeuralDynamics/LCNE-patchseq-viz) |
| **ipfx** (upstream) | Allen Institute library for ephys feature extraction and QC, used by the snakemake-ipfx pipeline | [AllenInstitute/ipfx](https://github.com/AllenInstitute/ipfx) |
| **snakemake-ipfx** (upstream) | Snakemake pipeline for running ipfx at scale; produces the NWB files ingested here ([Gouwens et al. 2021](https://elifesciences.org/articles/65482)) | [AllenInstitute/snakemake_ephys](https://github.com/AllenInstitute/snakemake_ephys) |
## Overview
<img width="1540" alt="image" src="https://github.com/user-attachments/assets/596f8c82-8bc7-45c5-b4c1-facc03265a7d" />
The diagram above shows the full patchseq analysis workflow for the LC-NE project. **This repository covers only the green arrows.** The grey upstream steps — LIMS data management, the snakemake-ipfx ephys QC pipeline ([AllenInstitute/ipfx](https://github.com/AllenInstitute/ipfx), [AllenInstitute/snakemake_ephys](https://github.com/AllenInstitute/snakemake_ephys), [Gouwens et al. 2021](https://elifesciences.org/articles/65482)), and sequencing data processing — are outside the scope of this repository; this pipeline takes their outputs as inputs.
- [`pipeline_util`](https://github.com/AllenNeuralDynamics/LCNE-patchseq-analysis/tree/main/src/LCNE_patchseq_analysis/pipeline_util) — ingests raw data and metadata from various sources and uploads them to cloud storage (S3; **replaced by the mounted dataset at `/data/` in Code Ocean mode**)
- [`efel`](https://github.com/AllenNeuralDynamics/LCNE-patchseq-analysis/tree/main/src/LCNE_patchseq_analysis/efel) — extracts electrophysiological features from NWB files using the [eFEL library](https://efel.readthedocs.io/en/latest/eFeatures.html), then aggregates them into a cell-level summary table (written to S3 locally; **written to `/results/` in Code Ocean mode**)
- [`figures`](https://github.com/AllenNeuralDynamics/LCNE-patchseq-analysis/tree/main/src/LCNE_patchseq_analysis/figures) — generates the paper's main figures by merging ephys features with transcriptomic and morphological data (reads summary table from S3; **reads from `/results/` in Code Ocean mode**)
## Detailed workflow
<img width="1240" alt="image" src="https://github.com/user-attachments/assets/f771ced3-5ec5-4607-a2cb-be2b4993dd23" />
The diagram above shows the step-by-step data flow through the pipeline: from raw NWB files and metadata spreadsheets, through eFEL feature extraction and multi-modal merging (transcriptomics via MapMyCells, morphology), to the final outputs consumed by the figure scripts and the Panel app. Any interaction with S3 shown in the diagram is **replaced by the local Code Ocean filesystem** (`/data/` for inputs, `/results/` for outputs) when running inside the Code Ocean capsule.
## Reproducing our work in Code Ocean
> **Tip:** Before diving in, we highly encourage you to explore the dataset interactively via the [Panel app](https://hanhou-patchseq.hf.space/patchseq_panel_viz) first.
All analyses can be reproduced from the [Code Ocean capsule](https://codeocean.allenneuraldynamics.org/capsule/1699143/tree). The capsule bundles the data, environment, and code — no setup required.
1. **Generate the main figures** (default) — click **Reproducible Run**. The capsule will load the pre-computed eFEL feature table from the attached dataset and run all figure scripts directly.
2. **Re-run the full pipeline** — to redo all green-arrow steps (eFEL feature extraction → cell-level statistics → figures) from scratch within the capsule, trigger a Reproducible Run with the app argument `rerun_efel_pipeline=1`. ⚠️ *This will take several hours.*
3. **Interactive debugging** — open the capsule in **VS Code** (via the Code Ocean IDE), then install the package in editable mode:
```bash
pip install -e .
```
You can then edit and re-run any part of the pipeline interactively.
Alternatively, if you prefer to work outside of Code Ocean, see the standalone instructions below.
## Reproducing standalone
The figures can also be reproduced locally or in any notebook environment — all data are fetched directly from the public S3 bucket, so no local data download is required. Install the package via PyPI (`pip install LCNE-patchseq-analysis`) and run:
```python
#!pip install LCNE-patchseq-analysis
from LCNE_patchseq_analysis.data_util.metadata import load_ephys_metadata
from LCNE_patchseq_analysis.pipeline_util.s3 import get_public_representative_spikes
from LCNE_patchseq_analysis.figures import GLOBAL_FILTER, GENE_FILTER
from LCNE_patchseq_analysis.figures.main_pca_tau import figure_spike_pca
from LCNE_patchseq_analysis.figures.main_imputation import main_imputation
# -- Physiological properties --
# Load merged metadata (eFEL features + key metadata + transcriptomics) from public S3
df_meta = load_ephys_metadata(if_from_s3=True, if_with_seq=True)
df_meta = df_meta.query(GLOBAL_FILTER) # exclude reporter-negative and thalamus-injected cells
# Load per-cell average spike waveforms and generate spike PCA figure
df_spikes = get_public_representative_spikes("average")
fig, axes_dict, results = figure_spike_pca(df_meta, df_spikes, filtered_df_meta=df_meta)
# -- Gene imputations --
main_imputation(df_meta, GENE_FILTER)
```
## Two modes of running the pipeline
The two reproduction paths above correspond to two runtime modes of the package, which differ in where data is read from and where results are written:
| | **Code Ocean mode** | **Local / developer mode** |
|---|---|---|
| **Trigger** | `CO_COMPUTATION_ID` env var is set automatically by Code Ocean at runtime | Running locally without `CO_COMPUTATION_ID` |
| **Input data** | Dataset `68ef27d7-9d95-40ce-9e40-7de93dccf5f8` mounted at `/data/LCNE-patchseq-ephys/` | `s3://aind-scratch-data/aind-patchseq-data/` |
| **Results** | Written to `/results/` within the capsule | Written locally; key outputs (e.g. `cell_level_stats.csv`, spike waveforms) pushed to the public S3 bucket |
| **Panel app** | Not connected — capsule results are self-contained | S3 outputs are what the [Panel app](https://hanhou-patchseq.hf.space/patchseq_panel_viz) reads from |
In short: **Code Ocean mode** is for reproducibility (everything stays inside the capsule), while **local mode** is for active development and feeds results into the live visualization app via S3.
## The Panel app
The Panel app has been migrated to [LCNE-patchseq-viz](https://github.com/AllenNeuralDynamics/LCNE-patchseq-viz.git).
- **Live app**: [https://hanhou-patchseq.hf.space/patchseq_panel_viz](https://hanhou-patchseq.hf.space/patchseq_panel_viz)
- **Source**: [https://github.com/AllenNeuralDynamics/LCNE-patchseq-viz](https://github.com/AllenNeuralDynamics/LCNE-patchseq-viz)
| text/markdown | Allen Institute for Neural Dynamics | Han Hou <han.hou@alleninstitute.org> | null | null | MIT | null | [
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy",
"pandas",
"matplotlib",
"seaborn",
"h5py",
"s3fs",
"requests",
"trimesh",
"statsmodels",
"matplotlib_venn",
"scipy",
"scikit-learn",
"tqdm",
"black; extra == \"dev\"",
"coverage; extra == \"dev\"",
"flake8; extra == \"dev\"",
"interrogate; extra == \"dev\"",
"isort; extra ... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:36:20.429520 | lcne_patchseq_analysis-0.34.2.tar.gz | 3,536,967 | 8f/f9/773164e2f4982c7d0f5e2db04b3ee340136c9d777a4045c0fb4d3fe86d77/lcne_patchseq_analysis-0.34.2.tar.gz | source | sdist | null | false | 78b9255dfc73594f801950fd9a3e3094 | d70a40e443db91f087bbac263213c937d43506326850e32921fef70d7d319570 | 8ff9773164e2f4982c7d0f5e2db04b3ee340136c9d777a4045c0fb4d3fe86d77 | null | [
"LICENSE"
] | 0 |
2.3 | one-public-api | 0.1.0a13 | This package provides the API layer of the One Public Framework. | # One Public API
| text/markdown | Roba | roba@one-coder.com | null | null | MIT License
Copyright (c) 2025 Roba
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| null | [
"License :: Other/Proprietary License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <4.0,>=3.11 | [] | [] | [] | [
"fastapi<0.116.0,>=0.115.12",
"pydantic[email]<3.0.0,>=2.11.7",
"pydantic-settings<3.0.0,>=2.9.1",
"python-multipart<0.0.21,>=0.0.20",
"psycopg2-binary<3.0.0,>=2.9.10",
"sqlmodel<0.0.25,>=0.0.24",
"uvicorn[standard]<0.35.0,>=0.34.3",
"passlib[bcrypt]<2.0.0,>=1.7.4",
"bcrypt<4.0.0,>=3.2.2",
"pyjwt<... | [] | [] | [] | [] | poetry/2.1.3 CPython/3.11.9 Darwin/25.3.0 | 2026-02-19T01:34:20.236520 | one_public_api-0.1.0a13.tar.gz | 50,228 | d2/d4/1ef707bce57aa596dbb185fadc553925051e39be085253bb2bac6ee3daae/one_public_api-0.1.0a13.tar.gz | source | sdist | null | false | 6c9a1ef19a89cee15aa396bdb49b5385 | 696b7d4a213abafbf37d0777b4527ea31d486570c40ef81a48ae963c2ea9d314 | d2d41ef707bce57aa596dbb185fadc553925051e39be085253bb2bac6ee3daae | null | [] | 327 |
2.4 | exosphere-cli | 2.3.0 | CLI/TUI driven patch reporting for remote Unix-like systems. | # Exosphere
<p>
<a href="https://github.com/mrdaemon/exosphere/releases"><img src="https://img.shields.io/github/v/release/mrdaemon/exosphere" alt="GitHub release"></a>
<a href="https://pypi.org/project/exosphere-cli/"><img src="https://img.shields.io/pypi/v/exosphere-cli" alt="PyPI"></a>
<a href="https://github.com/mrdaemon/exosphere/tree/main"><img src="https://img.shields.io/badge/dynamic/toml?url=https%3A%2F%2Fraw.githubusercontent.com%2Fmrdaemon%2Fexosphere%2Frefs%2Fheads%2Fmain%2Fpyproject.toml&query=%24.project.version&label=dev&color=purple" alt="Current Dev Version"></a>
<a href="https://www.python.org/"><img src="https://img.shields.io/python/required-version-toml?tomlFilePath=https%3A%2F%2Fraw.githubusercontent.com%2Fmrdaemon%2Fexosphere%2Frefs%2Fheads%2Fmain%2Fpyproject.toml" alt="Python Version"></a>
<a href="https://github.com/mrdaemon/exosphere/actions/workflows/test-suite.yml"><img src="https://img.shields.io/github/actions/workflow/status/mrdaemon/exosphere/test-suite.yml?label=test%20suite" alt="Test Suite"></a>
<a href="https://github.com/mrdaemon/exosphere/blob/main/LICENSE"><img src="https://img.shields.io/github/license/mrdaemon/exosphere" alt="License"></a>
</p>
Exosphere is a CLI and Text UI driven application that offers aggregated patch
and security update reporting as well as basic system status across multiple
Unix-like hosts over SSH.

It is targeted at small to medium sized networks, and is designed to be simple
to deploy and use, requiring no central server, agents and complex dependencies
on remote hosts.
If you have SSH access to the hosts and your keypairs are loaded in a SSH Agent,
you are good to go!
Simply follow the [Quickstart Guide](https://exosphere.readthedocs.io/en/stable/quickstart.html),
or see [the documentation](https://exosphere.readthedocs.io/en/stable/) to get started.
## Key Features
- Rich interactive command line interface (CLI)
- Text-based User Interface (TUI), offering menus, tables and dashboards
- Consistent view of information across different platforms and package managers
- See everything in one spot, at a glance, without complex automation or enterprise
solutions
- Does not require Python (or anything else) to be installed on remote systems
- Parallel operations across hosts with optional SSH pipelining
- Document based reporting in HTML, text or markdown format
- JSON output for integration with other tools
## Compatibility
Exosphere itself is written in Python and is compatible with Python 3.13 or later.
It can run nearly anywhere where Python is available, including Linux, MacOS,
and Windows (natively).
Supported platforms for remote hosts include:
- Debian/Ubuntu and derivatives (using APT)
- Red Hat/CentOS and derivatives (using YUM/DNF)
- FreeBSD (using pkg)
- OpenBSD (using pkg_add)
Unsupported platform with with SSH connectivity checks only:
- Other Linux distributions (e.g., Arch Linux, Gentoo, NixOS, etc.)
- Other BSD systems (NetBSD)
- Other Unix-like systems (e.g., Solaris, AIX, IRIX, Mac OS)
Exosphere **does not support** other platforms where SSH is available.
This includes network equipment with proprietary operating systems, etc.
## Documentation
For installation instructions, configuration and usage examples,
[full documentation](https://exosphere.readthedocs.io/) is available.
## Development Quick Start
tl;dr, use [uv](https://docs.astral.sh/uv/getting-started/installation/)
```bash
uv sync --dev
uv run exosphere
```
Linting, formatting and testing can be done with poe tasks:
```bash
uv run poe format
uv run poe check
uv run poe test
```
For more details, and available tasks, run:
```bash
uv run poe --help
```
## UI Development Quick Start
The UI is built with [Textual](https://textual.textualize.io/).
A quick start for running the UI with live editing and reloading, plus debug
console, is as follows:
```bash
# Ensure you have the dev dependencies
uv sync --dev
# In a separate terminal, run the console
uv run textual console
# In another terminal, run the UI
uv run textual run --dev -c exosphere ui start
```
Congratulations! Editing any of the `.tcss` files in the `ui/` directory will
reflect changes immediately.
Make sure you run Exosphere UI with `exosphere ui start`.
## Documentation Editing Quick Start
To edit the documentation, you can use the following commands:
```bash
uv sync --dev
uv run poe docs-serve
```
This will start a local server at `http://localhost:8000` where you can view the
documentation. You can edit the files in the `docs/source` directory, and the changes
will be reflected in real-time.
To check the documentation for spelling errors, you can run:
```bash
uv run poe docs-spellcheck
```
Linting is performed as part of the `poe docs` task, which also builds the
documentation, but can also be invoked separately:
```bash
uv run poe docs-lint
```
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
| text/markdown | Alexandre Gauthier | Alexandre Gauthier <alex@underwares.org> | null | null | null | null | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: System Administrators",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.13",
"Programming Language :: Pytho... | [] | null | null | >=3.13 | [] | [] | [] | [
"fabric>=3.2.2",
"typer>=0.20.0",
"textual>=6.7.0",
"pyyaml>=6.0.3",
"platformdirs>=4.3.8",
"prompt-toolkit>=3.0.51",
"jinja2>=3.1.6",
"packaging>=24.0",
"rich>=14.1.0",
"textual-serve>=1.1.3; extra == \"web\""
] | [] | [] | [] | [
"homepage, https://exosphere.readthedocs.io",
"repository, https://github.com/mrdaemon/exosphere",
"issues, https://github.com/mrdaemon/exosphere/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:32:34.785951 | exosphere_cli-2.3.0.tar.gz | 79,169 | 8b/8c/306b9ecbb0983415404b15771397269a8d647c30a269cb9e332c003a4d03/exosphere_cli-2.3.0.tar.gz | source | sdist | null | false | 462a4cf546020556b655f7b3f58d4a60 | b2b2ae36399df54af7e1dae5343575ccf13650217495cb735919c356e405e0a0 | 8b8c306b9ecbb0983415404b15771397269a8d647c30a269cb9e332c003a4d03 | MIT | [
"LICENSE"
] | 291 |
2.1 | pycse | 2.9.0 | python computations in science and engineering | # pycse - Python computations in science and engineering
[](https://github.com/jkitchin/pycse/actions/workflows/pycse-tests.yaml)
[](https://codecov.io/gh/jkitchin/pycse)

[](https://badge.fury.io/py/pycse)
[](https://github.com/jkitchin/pycse/actions/workflows/deploy.yml)
If you want to cite this project, use this doi:10.5281/zenodo.19111.
[](http://dx.doi.org/10.5281/zenodo.19111)
```bibtex
@misc{john_kitchin_2015_19111,
author = {John R. Kitchin},
title = {pycse: First release},
month = jun,
year = 2015,
doi = {10.5281/zenodo.19111},
url = {http://dx.doi.org/10.5281/zenodo.19111}
}
```
This git repository hosts my notes on using python in scientific and engineering calculations. The aim is to collect examples that span the types of computation/calculations scientists and engineers typically do to demonstrate the utility of python as a computational platform in engineering education.
## Installation
You may want to install the python library with pycse:
```sh
pip install pycse
```
Feeling brave? You can install the cutting edge from GitHub:
```sh
pip install git+git://github.com/jkitchin/pycse
```
## Docker
You can use a Docker image to run everything here. You have to have Docker installed and working on your system.
See [docker/](./docker/) for the setup used.
### Option 1
I provide a `pycse` command-line utility that is installed with the package. Simply run `pycse` in a shell in the directory you want to start Jupyter lab in. When done, type C-c <return> in the shell to quit, and it should be good.
### Option 2
You can manually pull the image:
```sh
docker pull jkitchin/pycse:latest
```
Then, run the [docker/pycse.sh](./docker/pycse.sh) script. This script mounts the current working directory, and takes care of choosing a random port.
## Documentation
See https://kitchingroup.cheme.cmu.edu/pycse/docs/pycse.html for the Python documentation.
| text/markdown | null | John Kitchin <jkitchin@andrew.cmu.edu> | null | null | GPL-3.0-or-later | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"click",
"dill",
"flax>=0.7.0",
"gmr",
"ipython",
"jax>=0.4.0",
"jaxlib>=0.4.0",
"joblib",
"matplotlib",
"networkx",
"numdifftools",
"numpy",
"optax>=0.1.0",
"orjson",
"pandas",
"pydoe3",
"requests",
"scikit-learn>=1.0.0",
"scipy",
"tabulate",
"torchsisso>=0.1.8; extra == \"s... | [] | [] | [] | [] | uv/0.10.3 {"installer":{"name":"uv","version":"0.10.3","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"macOS","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T01:30:35.849926 | pycse-2.9.0.tar.gz | 67,277,003 | 0b/36/5e94650164f4b632124414acc57c30b876b849ba5f79b24066bccabbde52/pycse-2.9.0.tar.gz | source | sdist | null | false | 406620defaef4effb359e85c8f5db4bb | 08d4ba1f4785c145a3deed449c1e6d861bc8fbe5d9955cdc996c8a69d47282f9 | 0b365e94650164f4b632124414acc57c30b876b849ba5f79b24066bccabbde52 | null | [] | 351 |
2.4 | spindle-mcp | 1.1.0 | MCP server for multi-harness AI agent delegation | # Spindle
<!-- Uncomment when published:
[](https://badge.fury.io/py/spindle)
[](https://github.com/spiritengine/spindle/actions/workflows/ci.yml)
[](LICENSE)
-->
MCP server for multi-harness AI agent delegation. Spawn background agents (Claude Code, Codex, Gemini, Kimi) that run asynchronously, with optional git worktree isolation for safe parallel work.
## Features
- **Async agent spawning** - Fire-and-forget pattern with spool IDs
- **Optional blocking with gather/yield** - Wait for all results at once, or stream them as agents complete. Alternatively, agent can continue other work, spins are nonblocking by default
- **Permission profiles** - Control what tools child agents can use (readonly, careful, full)
- **Shard isolation** - Run agents in sandboxed git worktrees to prevent conflicts
- **Model selection** - Route tasks to different models per-agent
- **Session continuity** - Resume conversations with child agents (auto-recovers expired sessions)
- **Rich querying** - Search, filter, peek at running output, export results
## Requirements
- Python 3.10+
- [Claude CLI](https://docs.anthropic.com/en/docs/claude-code) installed and authenticated
- Git (for shard/worktree functionality)
## Install
```bash
pip install spindle-mcp
```
Add to Claude Code's MCP config (`~/.claude.json`):
```json
{
"mcpServers": {
"spindle": {
"command": "spindle"
}
}
}
```
## Usage
### Basic: Spawn and collect
```
# Spawn an agent
spool_id = spin("Research the Python GIL")
# Do other work...
# Check result
result = unspool(spool_id)
```
### Permission profiles
Control what tools the spawned agent can use:
```
# Read-only: Can only search and read
spin("Analyze the codebase", permission="readonly")
# Careful (default): Can read/write but limited bash
spin("Fix this bug", permission="careful")
# Full access: No restrictions
spin("Implement the feature", permission="full")
# Shard: Full access + auto-isolated worktree (common for risky work)
spin("Refactor the auth system", permission="shard")
# Careful + shard: Limited tools but isolated
spin("Update configs", permission="careful+shard")
```
Profiles:
- `readonly`: Read, Grep, Glob, safe bash (ls, cat, git status/log/diff)
- `careful`: Read, Write, Edit, Grep, Glob, bash for git/make/pytest/python/npm
- `full`: No restrictions
- `shard`: Full access + auto-creates isolated worktree
- `careful+shard`: Careful permissions + auto-creates isolated worktree
You can also pass explicit `allowed_tools` to override the profile.
### Isolated workspaces with shards
Run agents in isolated git worktrees to prevent conflicts:
```
# Agent works in its own worktree
spool_id = spin("Refactor auth module", shard=True)
# Check shard status
shard_status(spool_id)
# Merge changes back when done
shard_merge(spool_id)
# Or discard if not needed
shard_abandon(spool_id)
```
Shards create a git worktree + branch. If SKEIN is available, uses `skein shard spawn` for richer tracking. Falls back to plain git worktree otherwise.
### Wait for completion
```
# Spawn multiple agents
id1 = spin("Find all TODO comments")
id2 = spin("List unused imports")
id3 = spin("Check for type errors")
# Gather: block until all complete, get all results
results = spin_wait("id1,id2,id3", mode="gather")
# Yield: return as each completes
# Great when results are independent - process each as it lands
result = spin_wait("id1,id2,id3", mode="yield") # Returns first to finish
# With timeout
results = spin_wait("id1,id2", mode="gather", timeout=300)
```
Yield mode keeps you responsive instead of blocking on the slowest agent.
### Time-based waiting
Simple timed waiting with `spin_sleep`:
```
spin_sleep("90m") # Sleep for 90 minutes
spin_sleep("2h") # Sleep for 2 hours
spin_sleep("30s") # Sleep for 30 seconds
spin_sleep("06:00") # Wait until 6 AM
```
Or use `spin_wait` with the `time` parameter:
```
spin_wait(time="90m")
spin_wait(time="06:00") # Handles next-day wraparound
```
Useful for periodic check-in loops (e.g., QM/dancing partner patterns).
### Model selection and timeouts
```
# Route quick tasks to haiku (fast, cheap)
spin("Summarize this file", model="haiku")
# Complex work to opus
spin("Design the new architecture", model="opus")
# Auto-kill if it takes too long
spin("Should be quick", timeout=60)
```
### Continue a session
```
# Get session ID from completed spool
result = unspool(spool_id) # includes session_id
# Continue that conversation
new_id = respin(session_id, "Follow up question")
```
If the session has expired on Claude's end, respin automatically falls back to transcript injection to recreate context.
### Cancel running work
```
spin_drop(spool_id)
```
### List all spools
```
spools()
```
### Search and filter
```
# Search prompts and results
spool_search("authentication")
# Filter by status and time
spool_results(status="error", since="1h")
# Regex search results
spool_grep("error|failed|exception")
# Get statistics
spool_stats()
# Export to file
spool_export("all", format="md")
```
## Multi-Harness Support
Spindle supports multiple AI agent harnesses, allowing you to choose the best tool for each task.
### Available Harnesses
**Claude Code** (default) - Anthropic's Claude models via `claude` CLI
- Superior code understanding and reasoning
- Best for complex refactoring, architecture decisions
- Slower startup (~3-4 minutes to first response)
- Use `harness="claude-code"` or omit harness parameter
**Codex CLI** - OpenAI's GPT-5 Codex models via `codex` CLI
- Extremely fast startup (~10 seconds to first response)
- Good for quick edits, simple tasks, prototyping
- Requires ChatGPT Plus/Pro/Enterprise
- Use `harness="codex"`
**Gemini CLI** - Google's Gemini models via `gemini` CLI
- Fast startup (~5-10 seconds to first response)
- Full agent with tool use, file access, multi-step reasoning
- Generous free tier (1000 req/day with Google account)
- Models: `"flash"`, `"pro"`, or any full model name
- Use `harness="gemini"`
**Kimi CLI** - Moonshot AI's Kimi models via `kimi-cli`
- Fast startup (~5-10 seconds to first response)
- Thinking mode for complex reasoning
- Models: `"thinking"`, `"thinking-turbo"`, `"turbo"`, `"latest"`, or any full model name
- Use `harness="kimi"`
### Basic Usage
```python
# Claude Code (default) - best for complex work
spool_id = spin("Refactor the auth module to use dependency injection")
# Codex CLI - fast for simple tasks
spool_id = spin(
prompt="Add error handling to this function",
harness="codex",
working_dir="/path/to/project"
)
# Gemini CLI - fast with free tier
spool_id = spin(
prompt="Summarize this codebase",
harness="gemini",
working_dir="/path/to/project"
)
# Kimi CLI - fast reasoning with thinking mode
spool_id = spin(
prompt="Analyze this bug",
harness="kimi",
working_dir="/path/to/project"
)
# All harnesses use the same API
result = unspool(spool_id) # Auto-detects harness
```
### Choosing a Harness
**Use Claude Code when:**
- Task requires deep reasoning or architecture decisions
- Working on complex refactoring across multiple files
- Need thorough code review or analysis
**Use Codex when:**
- Need quick edits or simple implementations
- Prototyping or exploring ideas rapidly
**Use Gemini when:**
- Want fast results without API key management (Google account login)
- Running many parallel tasks on a budget (free tier)
- Need a quick general-purpose agent
**Use Kimi when:**
- Need thinking mode for complex reasoning at speed
- Want fast startup with strong reasoning capabilities
### Requirements
**Claude Code:**
- [Claude CLI](https://docs.anthropic.com/en/docs/claude-code) installed and authenticated
**Codex CLI:**
- [Codex CLI](https://developers.openai.com/codex/cli/) installed (`npm i -g @openai/codex`)
- ChatGPT Plus/Pro/Enterprise subscription
**Gemini CLI:**
- [Gemini CLI](https://github.com/google-gemini/gemini-cli) installed (`npm i -g @google/gemini-cli`)
- Google account login (`gemini` → "Login with Google") or `GEMINI_API_KEY` env var
**Kimi CLI:**
- [Kimi CLI](https://github.com/MoonshotAI/kimi-cli) installed (`pip install kimi-cli`)
- Auth via `kimi-cli login` or API key in `~/.kimi/config.toml`
See [docs/MULTI_HARNESS_GUIDE.md](docs/MULTI_HARNESS_GUIDE.md) and [docs/CODEX_SETUP.md](docs/CODEX_SETUP.md) for detailed documentation.
## API
### Unified API (works with all harnesses)
| Tool | Purpose |
|------|---------|
| `spin(prompt, permission?, shard?, system_prompt?, working_dir?, allowed_tools?, tags?, model?, timeout?, harness?)` | Spawn agent, return spool_id |
| `unspool(spool_id)` | Get result (auto-detects harness, non-blocking) |
| `respin(session_id, prompt)` | Continue session (auto-detects harness) |
**spin() parameters:**
- `prompt` (required): The task for the agent
- `harness` (optional): "claude-code" (default), "codex", "gemini", or "kimi"
- `working_dir` (optional for Claude, required for Codex/Gemini/Kimi): Project directory
- `permission` (optional): "readonly", "careful" (default), "full", "shard", "careful+shard"
- `model` (optional): Model to use ("sonnet", "opus", "haiku" for Claude; "flash", "pro" for Gemini; "thinking", "turbo" for Kimi)
- `timeout` (optional): Auto-kill after N seconds
- `tags` (optional): Comma-separated tags for organization
- `shard` (optional): Create isolated git worktree (can also use `permission="shard"`)
- `system_prompt` (optional): Custom system prompt for Claude Code
- `allowed_tools` (optional): Override permission profile with explicit tool list
### Spool Management (works with all harnesses)
| Tool | Purpose |
|------|---------|
| `spools()` | List all spools |
| `spin_wait(spool_ids?, mode?, timeout?, time?)` | Block until spools complete, or wait for duration |
| `spin_sleep(duration)` | Sleep for a duration (90m, 2h, 30s, HH:MM) |
| `spin_drop(spool_id)` | Cancel by killing process |
| `spool_search(query, field?)` | Search prompts/results |
| `spool_results(status?, since?, limit?)` | Bulk fetch with filters |
| `spool_grep(pattern)` | Regex search results |
| `spool_retry(spool_id)` | Re-run with same params |
| `spool_peek(spool_id, lines?)` | See partial output while running |
| `spool_dashboard()` | Overview of running/complete/needs-attention |
| `spool_stats()` | Get summary statistics |
| `spin_harnesses()` | List available harnesses, models, and defaults |
| `spool_export(spool_ids, format?, output_path?)` | Export to file |
| `shard_status(spool_id)` | Check shard worktree status |
| `shard_merge(spool_id, keep_branch?)` | Merge shard to master |
| `shard_abandon(spool_id, keep_branch?)` | Discard shard |
## Storage
Spools persist to `~/.spindle/spools/{spool_id}.json`:
```json
{
"id": "abc12345",
"status": "complete",
"prompt": "...",
"result": "...",
"session_id": "...",
"permission": "careful",
"allowed_tools": "...",
"tags": ["batch-1"],
"shard": {
"worktree_path": "/path/to/worktrees/abc12345-...",
"branch_name": "shard-abc12345-...",
"shard_id": "..."
},
"pid": 12345,
"created_at": "2025-11-26T...",
"completed_at": "2025-11-26T..."
}
```
## CLI Commands
```bash
spindle install-service # Install background service (Linux/macOS)
spindle start # Start via systemd (or background if no service)
spindle reload # Restart via systemd to pick up code changes
spindle status # Check if running (hits /health endpoint)
spindle serve --http # Run MCP server directly
```
### Background Service
For persistent background operation:
```bash
# Install and enable the service (Linux or macOS)
spindle install-service
# Start it
spindle start
```
**Linux**: Writes a systemd user service to `~/.config/systemd/user/spindle.service`
**macOS**: Writes a launchd plist to `~/Library/LaunchAgents/com.spindle.server.plist` and loads it immediately
Use `--force` to overwrite an existing service file. Then `spindle reload` restarts the service to pick up code changes.
### Windows
On Windows, run spindle manually:
```bash
spindle serve --http
```
Or use [NSSM](https://nssm.cc/) to create a Windows service.
### WSL
In WSL2 with systemd enabled, `spindle install-service` works like native Linux. If systemd isn't enabled, you'll get instructions to enable it or run manually.
### Hot Reload (MCP tool)
From within Claude Code, call `spindle_reload()` to restart the server and pick up code changes.
## Configuration
Environment variables:
| Variable | Default | Description |
|----------|---------|-------------|
| `SPINDLE_MAX_CONCURRENT` | `15` | Maximum concurrent spools |
Storage location: `~/.spindle/spools/`
## How It Works
1. **spin()** spawns a detached CLI process (claude, codex, gemini, or kimi-cli) with the given prompt
2. The process runs in background, writing output to temporary files
3. A monitor thread polls for completion
4. **unspool()** returns the result once complete (non-blocking check)
5. Spool metadata persists to JSON files, surviving server restarts
For shards:
1. A git worktree is created with a new branch
2. The agent runs inside that worktree
3. After completion, merge back with `shard_merge()` or discard with `shard_abandon()`
## Limits
- Max 15 concurrent spools (configurable via `SPINDLE_MAX_CONCURRENT`)
- 24h auto-cleanup of old spools
- Orphaned spools (dead process) marked as error on restart
## Contributing
See [CONTRIBUTING.md](CONTRIBUTING.md) for development setup and guidelines.
## License
MIT - see [LICENSE](LICENSE).
| text/markdown | null | null | null | null | null | mcp, claude, claude-code, agent, delegation, ai | [
"Development Status :: 4 - Beta",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"T... | [] | null | null | >=3.10 | [] | [] | [] | [
"fastmcp>=2.0.0",
"uvicorn>=0.30.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21; extra == \"dev\"",
"black>=24.0; extra == \"dev\"",
"ruff>=0.1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/smythp/spindle",
"Repository, https://github.com/smythp/spindle",
"Issues, https://github.com/smythp/spindle/issues"
] | twine/6.2.0 CPython/3.12.0 | 2026-02-19T01:27:40.252270 | spindle_mcp-1.1.0.tar.gz | 52,771 | 4b/cd/0eb06f5e55e934ebec8ea5151e2ec27467f527ec25af128adb65cd6ffe92/spindle_mcp-1.1.0.tar.gz | source | sdist | null | false | 7874eafa3aa95adbb56dac8fafc432d3 | 5f947e46e14d8a800da764e8b9565f3cb1842b92e6bf814cd2ab5c24a65d2e7b | 4bcd0eb06f5e55e934ebec8ea5151e2ec27467f527ec25af128adb65cd6ffe92 | MIT | [
"LICENSE"
] | 264 |
2.4 | bacnet-mcp | 0.3.2 | A Model Context Protocol (MCP) server for BACnet. | ## BACnet MCP Server
[](https://github.com/ezhuk/bacnet-mcp/actions/workflows/test.yml)
[](https://codecov.io/github/ezhuk/bacnet-mcp)
[](https://pypi.org/p/bacnet-mcp)
A lightweight [Model Context Protocol (MCP)](https://modelcontextprotocol.io) server that connects LLM agents to [BACnet](https://en.wikipedia.org/wiki/BACnet) devices in a secure, standardized way, enabling seamless integration of AI-driven workflows with Building Automation (BAS), Building Management (BMS) and Industrial Control (ICS) systems, allowing agents to monitor real-time sensor data, actuate devices, and orchestrate complex automation tasks.
## Getting Started
Use [uv](https://github.com/astral-sh/uv) to add and manage the BACnet MCP server as a dependency in your project, or install it directly via `uv pip install` or `pip install`. See the [Installation](https://github.com/ezhuk/bacnet-mcp/blob/main/docs/bacnet-mcp/installation.mdx) section of the documentation for full installation instructions and more details.
```bash
uv add bacnet-mcp
```
The server can be embedded in and run directly from your application. By default, it exposes a `Streamable HTTP` endpoint at `http://127.0.0.1:8000/mcp/`.
```python
# app.py
from bacnet_mcp import BACnetMCP
mcp = BACnetMCP()
if __name__ == "__main__":
mcp.run(transport="http")
```
It can also be launched from the command line using the provided `CLI` without modifying the source code.
```bash
bacnet-mcp
```
Or in an ephemeral, isolated environment using `uvx`. Check out the [Using tools](https://docs.astral.sh/uv/guides/tools/) guide for more details.
```bash
uvx bacnet-mcp
```
### Configuration
For the use cases where most operations target a specific device, such as a Programmable Logic Controller (PLC) or BACnet gateway, its connection settings (`host` and `port`) can be specified at runtime using environment variables so that all prompts that omit explicit connection parameters will be routed to this device.
```bash
export BACNET_MCP_BACNET__HOST=10.0.0.1
export BACNET_MCP_BACNET__PORT=47808
```
These settings can also be specified in a `.env` file in the working directory.
```text
# .env
bacnet_mcp_bacnet__host=10.0.0.1
bacnet_mcp_bacnet__port=47808
```
When interacting with multiple devices, each device’s connection parameters (`host`, `port`) can be defined with a unique `name` in a `devices.json` file in the working directory. Prompts can then refer to devices by `name`.
```json
{
"devices": [
{"name": "Boiler", "host": "10.0.0.3", "port": 47808},
{"name": "Valve", "host": "10.0.0.4", "port": 47808}
]
}
```
### MCP Inspector
To confirm the server is up and running and explore available resources and tools, run the [MCP Inspector](https://modelcontextprotocol.io/docs/tools/inspector) and connect it to the BACnet MCP server at `http://127.0.0.1:8000/mcp/`. Make sure to set the transport to `Streamable HTTP`.
```bash
npx @modelcontextprotocol/inspector
```

## Core Concepts
The BACnet MCP server leverages FastMCP 2.0's core building blocks - resource templates, tools, and prompts - to streamline BACnet read and write operations with minimal boilerplate and a clean, Pythonic interface.
### Read Properties
Each object on a device is mapped to a resource (and exposed as a tool) and [resource templates](https://gofastmcp.com/servers/resources#resource-templates) are used to specify connection details (host, port) and read parameters (instance, property).
```python
@mcp.resource("udp://{host}:{port}/{obj}/{instance}/{prop}")
@mcp.tool(
annotations={
"title": "Read Property",
"readOnlyHint": True,
"openWorldHint": True,
}
)
async def read_property(
host: str = settings.bacnet.host,
port: int = settings.bacnet.port,
obj: str = "analogValue",
instance: str = "1",
prop: str = "presentValue",
) -> str:
"""Reads the content of a BACnet object property on a remote unit."""
...
```
### Write Properties
Write operations are exposed as a [tool](https://gofastmcp.com/servers/tools), accepting the same connection details (host, port) and allowing to set the content of an object property in a single, atomic call.
```python
@mcp.tool(
annotations={
"title": "Write Property",
"readOnlyHint": False,
"openWorldHint": True,
}
)
async def write_property(
host: str = settings.bacnet.host,
port: int = settings.bacnet.port,
obj: str = "analogValue,1",
prop: str = "presentValue",
data: str = "1.0",
) -> str:
"""Writes a BACnet object property on a remote device."""
...
```
### Authentication
To enable authentication using the built-in [AuthKit](https://www.authkit.com) provider for the `Streamable HTTP` transport, provide the AuthKit domain and redirect URL in the `.env` file. Check out the [AuthKit Provider](https://gofastmcp.com/servers/auth/remote-oauth#example%3A-workos-authkit-provider) section for more details.
### Interactive Prompts
Structured response messages are implemented using [prompts](https://gofastmcp.com/servers/prompts) that help guide the interaction, clarify missing parameters, and handle errors gracefully.
```python
@mcp.prompt(name="bacnet_help", tags={"bacnet", "help"})
def bacnet_help() -> list[Message]:
"""Provides examples of how to use the BACnet MCP server."""
...
```
Here are some example text inputs that can be used to interact with the server.
```text
Read the presentValue property of analogInput,1 at 10.0.0.4.
Fetch the units property of analogInput 2.
Write the value 42 to analogValue instance 1.
Set the presentValue of binaryOutput 3 to True.
```
## Examples
The `examples` folder contains sample projects showing how to integrate with the BACnet MCP server using various client APIs to provide tools and context to LLMs.
- [openai-agents](https://github.com/ezhuk/bacnet-mcp/tree/main/examples/openai-agents) - shows how to connect to the BACnet MCP server using the [OpenAI Agents SDK](https://openai.github.io/openai-agents-python/mcp/).
- [openai](https://github.com/ezhuk/bacnet-mcp/tree/main/examples/openai) - a minimal app leveraging remote MCP server support in the [OpenAI Python library](https://platform.openai.com/docs/guides/tools-remote-mcp).
- [pydantic-ai](https://github.com/ezhuk/bacnet-mcp/tree/main/examples/pydantic-ai) - shows how to connect to the BACnet MCP server using the [PydanticAI Agent Framework](https://ai.pydantic.dev).
## Docker
The BACnet MCP server can be deployed as a Docker container as follows:
```bash
docker run -d \
--name bacnet-mcp \
--restart=always \
-p 8080:8000 \
--env-file .env \
ghcr.io/ezhuk/bacnet-mcp:latest
```
This maps port `8080` on the host to the MCP server's port `8000` inside the container and loads settings from the `.env` file, if present.
## License
The server is licensed under the [MIT License](https://github.com/ezhuk/bacnet-mcp?tab=MIT-1-ov-file).
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.13 | [] | [] | [] | [
"bacpypes3>=0.0.102",
"fastmcp>=3.0.0",
"pydantic-settings>=2.10.0",
"typer>=0.16.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:26:45.616839 | bacnet_mcp-0.3.2.tar.gz | 269,023 | 30/7f/0ddf471480462097b6e98f571df533f18486f616b64c1b68de240f42454c/bacnet_mcp-0.3.2.tar.gz | source | sdist | null | false | 916b8b8280bb6eff5e584385146ab0ea | bfefa4ff7a2689c590416788187a511faad6ec4bc8078cbcbaf7432bcc9c3b63 | 307f0ddf471480462097b6e98f571df533f18486f616b64c1b68de240f42454c | null | [
"LICENSE"
] | 263 |
2.3 | whop-sdk | 0.0.28 | The official Python library for the Whop API | # Whop Python API library
<!-- prettier-ignore -->
[)](https://pypi.org/project/whop-sdk/)
The Whop Python library provides convenient access to the Whop REST API from any Python 3.9+
application. The library includes type definitions for all request params and response fields,
and offers both synchronous and asynchronous clients powered by [httpx](https://github.com/encode/httpx).
It is generated with [Stainless](https://www.stainless.com/).
## MCP Server
Use the Whop MCP Server to enable AI assistants to interact with this API, allowing them to explore endpoints, make test requests, and use documentation to help integrate this SDK into your application.
[](https://cursor.com/en-US/install-mcp?name=%40whop%2Fmcp&config=eyJjb21tYW5kIjoibnB4IiwiYXJncyI6WyIteSIsIkB3aG9wL21jcCJdLCJlbnYiOnsiV0hPUF9BUElfS0VZIjoiTXkgQVBJIEtleSIsIldIT1BfV0VCSE9PS19TRUNSRVQiOiJNeSBXZWJob29rIEtleSIsIldIT1BfQVBQX0lEIjoiYXBwX3h4eHh4eHh4eHh4eHh4In19)
[](https://vscode.stainless.com/mcp/%7B%22name%22%3A%22%40whop%2Fmcp%22%2C%22command%22%3A%22npx%22%2C%22args%22%3A%5B%22-y%22%2C%22%40whop%2Fmcp%22%5D%2C%22env%22%3A%7B%22WHOP_API_KEY%22%3A%22My%20API%20Key%22%2C%22WHOP_WEBHOOK_SECRET%22%3A%22My%20Webhook%20Key%22%2C%22WHOP_APP_ID%22%3A%22app_xxxxxxxxxxxxxx%22%7D%7D)
> Note: You may need to set environment variables in your MCP client.
## Documentation
The REST API documentation can be found on [docs.whop.com](https://docs.whop.com/apps). The full API of this library can be found in [api.md](https://github.com/whopio/whopsdk-python/tree/main/api.md).
## Installation
```sh
# install from PyPI
pip install whop-sdk
```
## Usage
The full API of this library can be found in [api.md](https://github.com/whopio/whopsdk-python/tree/main/api.md).
```python
import os
from whop_sdk import Whop
client = Whop(
api_key=os.environ.get("WHOP_API_KEY"), # This is the default and can be omitted
)
page = client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
print(page.data)
```
While you can provide an `api_key` keyword argument,
we recommend using [python-dotenv](https://pypi.org/project/python-dotenv/)
to add `WHOP_API_KEY="My API Key"` to your `.env` file
so that your API Key is not stored in source control.
## Async usage
Simply import `AsyncWhop` instead of `Whop` and use `await` with each API call:
```python
import os
import asyncio
from whop_sdk import AsyncWhop
client = AsyncWhop(
api_key=os.environ.get("WHOP_API_KEY"), # This is the default and can be omitted
)
async def main() -> None:
page = await client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
print(page.data)
asyncio.run(main())
```
Functionality between the synchronous and asynchronous clients is otherwise identical.
### With aiohttp
By default, the async client uses `httpx` for HTTP requests. However, for improved concurrency performance you may also use `aiohttp` as the HTTP backend.
You can enable this by installing `aiohttp`:
```sh
# install from PyPI
pip install whop-sdk[aiohttp]
```
Then you can enable it by instantiating the client with `http_client=DefaultAioHttpClient()`:
```python
import os
import asyncio
from whop_sdk import DefaultAioHttpClient
from whop_sdk import AsyncWhop
async def main() -> None:
async with AsyncWhop(
api_key=os.environ.get("WHOP_API_KEY"), # This is the default and can be omitted
http_client=DefaultAioHttpClient(),
) as client:
page = await client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
print(page.data)
asyncio.run(main())
```
## Using types
Nested request parameters are [TypedDicts](https://docs.python.org/3/library/typing.html#typing.TypedDict). Responses are [Pydantic models](https://docs.pydantic.dev) which also provide helper methods for things like:
- Serializing back into JSON, `model.to_json()`
- Converting to a dictionary, `model.to_dict()`
Typed requests and responses provide autocomplete and documentation within your editor. If you would like to see type errors in VS Code to help catch bugs earlier, set `python.analysis.typeCheckingMode` to `basic`.
## Pagination
List methods in the Whop API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from whop_sdk import Whop
client = Whop()
all_payments = []
# Automatically fetches more pages as needed.
for payment in client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
):
# Do something with payment here
all_payments.append(payment)
print(all_payments)
```
Or, asynchronously:
```python
import asyncio
from whop_sdk import AsyncWhop
client = AsyncWhop()
async def main() -> None:
all_payments = []
# Iterate through items across all pages, issuing requests as needed.
async for payment in client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
):
all_payments.append(payment)
print(all_payments)
asyncio.run(main())
```
Alternatively, you can use the `.has_next_page()`, `.next_page_info()`, or `.get_next_page()` methods for more granular control working with pages:
```python
first_page = await client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
if first_page.has_next_page():
print(f"will fetch next page using these details: {first_page.next_page_info()}")
next_page = await first_page.get_next_page()
print(f"number of items we just fetched: {len(next_page.data)}")
# Remove `await` for non-async usage.
```
Or just work directly with the returned data:
```python
first_page = await client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
print(f"next page cursor: {first_page.page_info.end_cursor}") # => "next page cursor: ..."
for payment in first_page.data:
print(payment.id)
# Remove `await` for non-async usage.
```
## Nested params
Nested parameters are dictionaries, typed using `TypedDict`, for example:
```python
from whop_sdk import Whop
client = Whop()
app = client.apps.create(
company_id="biz_xxxxxxxxxxxxxx",
name="name",
icon={"id": "id"},
)
print(app.icon)
```
## Handling errors
When the library is unable to connect to the API (for example, due to network connection problems or a timeout), a subclass of `whop_sdk.APIConnectionError` is raised.
When the API returns a non-success status code (that is, 4xx or 5xx
response), a subclass of `whop_sdk.APIStatusError` is raised, containing `status_code` and `response` properties.
All errors inherit from `whop_sdk.APIError`.
```python
import whop_sdk
from whop_sdk import Whop
client = Whop()
try:
client.payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
except whop_sdk.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except whop_sdk.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except whop_sdk.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
```
Error codes are as follows:
| Status Code | Error Type |
| ----------- | -------------------------- |
| 400 | `BadRequestError` |
| 401 | `AuthenticationError` |
| 403 | `PermissionDeniedError` |
| 404 | `NotFoundError` |
| 422 | `UnprocessableEntityError` |
| 429 | `RateLimitError` |
| >=500 | `InternalServerError` |
| N/A | `APIConnectionError` |
### Retries
Certain errors are automatically retried 2 times by default, with a short exponential backoff.
Connection errors (for example, due to a network connectivity problem), 408 Request Timeout, 409 Conflict,
429 Rate Limit, and >=500 Internal errors are all retried by default.
You can use the `max_retries` option to configure or disable retry settings:
```python
from whop_sdk import Whop
# Configure the default for all requests:
client = Whop(
# default is 2
max_retries=0,
)
# Or, configure per-request:
client.with_options(max_retries=5).payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
```
### Timeouts
By default requests time out after 1 minute. You can configure this with a `timeout` option,
which accepts a float or an [`httpx.Timeout`](https://www.python-httpx.org/advanced/timeouts/#fine-tuning-the-configuration) object:
```python
from whop_sdk import Whop
# Configure the default for all requests:
client = Whop(
# 20 seconds (default is 1 minute)
timeout=20.0,
)
# More granular control:
client = Whop(
timeout=httpx.Timeout(60.0, read=5.0, write=10.0, connect=2.0),
)
# Override per-request:
client.with_options(timeout=5.0).payments.list(
company_id="biz_xxxxxxxxxxxxxx",
)
```
On timeout, an `APITimeoutError` is thrown.
Note that requests that time out are [retried twice by default](https://github.com/whopio/whopsdk-python/tree/main/#retries).
## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `WHOP_LOG` to `info`.
```shell
$ export WHOP_LOG=info
```
Or to `debug` for more verbose logging.
### How to tell whether `None` means `null` or missing
In an API response, a field may be explicitly `null`, or missing entirely; in either case, its value is `None` in this library. You can differentiate the two cases with `.model_fields_set`:
```py
if response.my_field is None:
if 'my_field' not in response.model_fields_set:
print('Got json like {}, without a "my_field" key present at all.')
else:
print('Got json like {"my_field": null}.')
```
### Accessing raw response data (e.g. headers)
The "raw" Response object can be accessed by prefixing `.with_raw_response.` to any HTTP method call, e.g.,
```py
from whop_sdk import Whop
client = Whop()
response = client.payments.with_raw_response.list(
company_id="biz_xxxxxxxxxxxxxx",
)
print(response.headers.get('X-My-Header'))
payment = response.parse() # get the object that `payments.list()` would have returned
print(payment.id)
```
These methods return an [`APIResponse`](https://github.com/whopio/whopsdk-python/tree/main/src/whop_sdk/_response.py) object.
The async client returns an [`AsyncAPIResponse`](https://github.com/whopio/whopsdk-python/tree/main/src/whop_sdk/_response.py) with the same structure, the only difference being `await`able methods for reading the response content.
#### `.with_streaming_response`
The above interface eagerly reads the full response body when you make the request, which may not always be what you want.
To stream the response body, use `.with_streaming_response` instead, which requires a context manager and only reads the response body once you call `.read()`, `.text()`, `.json()`, `.iter_bytes()`, `.iter_text()`, `.iter_lines()` or `.parse()`. In the async client, these are async methods.
```python
with client.payments.with_streaming_response.list(
company_id="biz_xxxxxxxxxxxxxx",
) as response:
print(response.headers.get("X-My-Header"))
for line in response.iter_lines():
print(line)
```
The context manager is required so that the response will reliably be closed.
### Making custom/undocumented requests
This library is typed for convenient access to the documented API.
If you need to access undocumented endpoints, params, or response properties, the library can still be used.
#### Undocumented endpoints
To make requests to undocumented endpoints, you can make requests using `client.get`, `client.post`, and other
http verbs. Options on the client will be respected (such as retries) when making this request.
```py
import httpx
response = client.post(
"/foo",
cast_to=httpx.Response,
body={"my_param": True},
)
print(response.headers.get("x-foo"))
```
#### Undocumented request params
If you want to explicitly send an extra param, you can do so with the `extra_query`, `extra_body`, and `extra_headers` request
options.
#### Undocumented response properties
To access undocumented response properties, you can access the extra fields like `response.unknown_prop`. You
can also get all the extra fields on the Pydantic model as a dict with
[`response.model_extra`](https://docs.pydantic.dev/latest/api/base_model/#pydantic.BaseModel.model_extra).
### Configuring the HTTP client
You can directly override the [httpx client](https://www.python-httpx.org/api/#client) to customize it for your use case, including:
- Support for [proxies](https://www.python-httpx.org/advanced/proxies/)
- Custom [transports](https://www.python-httpx.org/advanced/transports/)
- Additional [advanced](https://www.python-httpx.org/advanced/clients/) functionality
```python
import httpx
from whop_sdk import Whop, DefaultHttpxClient
client = Whop(
# Or use the `WHOP_BASE_URL` env var
base_url="http://my.test.server.example.com:8083",
http_client=DefaultHttpxClient(
proxy="http://my.test.proxy.example.com",
transport=httpx.HTTPTransport(local_address="0.0.0.0"),
),
)
```
You can also customize the client on a per-request basis by using `with_options()`:
```python
client.with_options(http_client=DefaultHttpxClient(...))
```
### Managing HTTP resources
By default the library closes underlying HTTP connections whenever the client is [garbage collected](https://docs.python.org/3/reference/datamodel.html#object.__del__). You can manually close the client using the `.close()` method if desired, or with a context manager that closes when exiting.
```py
from whop_sdk import Whop
with Whop() as client:
# make requests here
...
# HTTP client is now closed
```
## Versioning
This package generally follows [SemVer](https://semver.org/spec/v2.0.0.html) conventions, though certain backwards-incompatible changes may be released as minor versions:
1. Changes that only affect static types, without breaking runtime behavior.
2. Changes to library internals which are technically public but not intended or documented for external use. _(Please open a GitHub issue to let us know if you are relying on such internals.)_
3. Changes that we do not expect to impact the vast majority of users in practice.
We take backwards-compatibility seriously and work hard to ensure you can rely on a smooth upgrade experience.
We are keen for your feedback; please open an [issue](https://www.github.com/whopio/whopsdk-python/issues) with questions, bugs, or suggestions.
### Determining the installed version
If you've upgraded to the latest version but aren't seeing any new features you were expecting then your python environment is likely still using an older version.
You can determine the version that is being used at runtime with:
```py
import whop_sdk
print(whop_sdk.__version__)
```
## Requirements
Python 3.9 or higher.
## Contributing
See [the contributing documentation](https://github.com/whopio/whopsdk-python/tree/main/./CONTRIBUTING.md).
| text/markdown | Whop | null | null | null | Apache-2.0 | null | [
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"anyio<5,>=3.5.0",
"distro<2,>=1.7.0",
"httpx<1,>=0.23.0",
"pydantic<3,>=1.9.0",
"sniffio",
"typing-extensions<5,>=4.10",
"aiohttp; extra == \"aiohttp\"",
"httpx-aiohttp>=0.1.9; extra == \"aiohttp\"",
"standardwebhooks; extra == \"webhooks\""
] | [] | [] | [] | [
"Homepage, https://github.com/whopio/whopsdk-python",
"Repository, https://github.com/whopio/whopsdk-python"
] | twine/5.1.1 CPython/3.12.9 | 2026-02-19T01:25:05.672960 | whop_sdk-0.0.28.tar.gz | 342,223 | a3/1f/340e7c8d78c964118d966e1bf6a530c6fcca18156c36550961583f97805f/whop_sdk-0.0.28.tar.gz | source | sdist | null | false | 46fa94b788e8071d899ca89745343749 | 852618acf53a88807b9521caad5aadb944ae4b8984a2c7a8eec7ec3aad07e813 | a31f340e7c8d78c964118d966e1bf6a530c6fcca18156c36550961583f97805f | null | [] | 453 |
2.4 | typysetup | 1.1.0 | Interactive Python environment setup CLI for VSCode | # TyPySetup - Python Environment Setup CLI
Interactive Python environment setup CLI for VSCode. Automatically configure Python projects with proper virtual environments, dependencies, and VSCode settings.
## Features
- 🎯 **Interactive Menu** - Select from 6 project type templates (FastAPI, Django, Data Science, CLI Tools, Async/Real-time, ML/AI)
- 🔧 **Automatic Setup** - Create virtual environment, install dependencies, generate VSCode configs
- 📦 **Multiple Package Managers** - Support for uv (fast), pip (universal), and poetry (lock files)
- ⚙️ **Smart Configuration** - VSCode settings optimized per project type, non-destructive merging
- 💾 **Preference Persistence** - Remember your choices for faster future setups
- 🔄 **Graceful Cancellation** - Cancel between phases with automatic rollback
## Quick Start
### Installation
```bash
# Install from PyPI (recommended)
pip install typysetup
# Or with uv
uv tool install typysetup
# Install from source (development)
git clone <repository>
cd typysetup
pip install -e .
```
### Basic Usage
```bash
# Interactive setup wizard
typysetup setup /path/to/project
# List available setup types
typysetup list
# Manage preferences
typysetup preferences --show
```
### Example: FastAPI Project
```bash
$ typysetup setup ~/my-api
? Choose a setup type: FastAPI
? Package manager (uv recommended): uv
? Proceed with setup? [Y/n]: y
Creating virtual environment...
Installing dependencies (14 packages)...
Generating VSCode configuration...
✓ Setup complete! Next steps:
- Activate: source ~/my-api/venv/bin/activate
- Open VSCode: code ~/my-api
- Start coding: fastapi dev main.py
```
## Project Structure
```bash
typysetup/
├── src/typysetup/
│ ├── main.py # Typer CLI application
│ ├── models/ # Pydantic data models
│ ├── commands/ # CLI command classes (OOP)
│ │ ├── config_cmd.py # ConfigCommand
│ │ ├── help_cmd.py # HelpCommand
│ │ ├── history_cmd.py # HistoryCommand
│ │ ├── list_cmd.py # ListCommand
│ │ ├── preferences_cmd.py # PreferencesCommand
│ │ └── setup_orchestrator.py # SetupOrchestrator (main wizard)
│ ├── core/ # Business logic (config loading, venv, deps, vscode)
│ ├── utils/ # Utilities (paths, prompts, rollback)
│ └── configs/ # Setup type YAML templates
├── tests/
│ ├── unit/ # Unit tests
│ ├── integration/ # Integration tests
│ └── conftest.py # Pytest fixtures
└── pyproject.toml # Project metadata and dependencies
```
## Setup Types
### FastAPI
Web API with FastAPI framework - async, modern, fast
- Python: 3.10+
- Core: fastapi, uvicorn, pydantic
- Dev: pytest, black, ruff
### Django
Full-stack web framework with batteries included
- Python: 3.8+
- Core: django, djangorestframework
- Dev: pytest, black, ruff
### Data Science
Jupyter-based data analysis and ML workflows
- Python: 3.9+
- Core: pandas, numpy, jupyter, scikit-learn
- Dev: pytest, black, ruff
### CLI Tool
Command-line applications using Typer/Click
- Python: 3.8+
- Core: typer, click, rich
- Dev: pytest, black, ruff
### Async/Real-time
High-performance async and real-time applications
- Python: 3.10+
- Core: asyncio, aiohttp, websockets, starlette
- Dev: pytest, black, ruff
### ML/AI
Machine learning and AI model development
- Python: 3.9+
- Core: tensorflow, torch, transformers, scikit-learn
- Dev: pytest, black, ruff
## Technology Stack
- **Language**: Python 3.8+
- **CLI Framework**: Typer (type-safe, beautiful)
- **Data Validation**: Pydantic (runtime validation)
- **Configuration**: YAML + PyYAML (human-friendly)
- **Terminal UI**: Rich + Questionary (interactive prompts)
- **Virtual Environment**: Built-in venv module
- **Package Managers**: uv (primary), pip, poetry
- **Testing**: pytest + pytest-cov
- **Code Quality**: black, ruff, mypy
## Development
### Setup Development Environment
```bash
# Create virtual environment
python -m venv .venv
source .venv/bin/activate # or .venv\Scripts\activate on Windows
# Install development dependencies
pip install -e ".[dev]"
# Run tests
pytest
# Run with coverage
pytest --cov=src/typysetup
```
### Code Quality
```bash
# Format code
black src/ tests/
# Lint code
ruff check src/ tests/
# Type checking
mypy src/typysetup
```
## Testing
```bash
# Run all tests
pytest
# Run unit tests only
pytest tests/unit/
# Run integration tests
pytest tests/integration/
# Run with coverage report
pytest --cov=src/typysetup --cov-report=html
```
## Architecture
See [ARCHITECTURE.md](docs/ARCHITECTURE.md) for detailed architecture documentation.
## Configuration
User preferences are stored in `~/.typysetup/preferences.json`:
```json
{
"preferred_manager": "uv",
"preferred_python_version": "3.11",
"preferred_setup_types": ["fastapi"],
"setup_history": []
}
```
## Commands
### `typysetup setup`
Interactive setup wizard - guides you through project configuration.
```bash
typysetup setup /path/to/project [--verbose]
```
**Options**:
- `--verbose, -v`: Enable detailed logging output
**Example**:
```bash
typysetup setup ~/my-fastapi-app --verbose
```
### `typysetup list`
List all available setup type templates.
```bash
typysetup list
```
### `typysetup preferences`
Manage user preferences and view setup history.
```bash
typysetup preferences --show # View current preferences
typysetup preferences --reset # Reset to defaults
```
### `typysetup config`
Display project configuration.
```bash
typysetup config /path/to/project
```
### `typysetup history`
View recent setup history.
```bash
typysetup history [--limit 10] [--verbose]
```
### `typysetup help`
Show detailed help and usage examples.
```bash
typysetup help [topic] # Topics: setup, workflows, preferences
```
## Common Workflows
### Creating a New FastAPI Project
```bash
mkdir my-api
cd my-api
typysetup setup .
# Select "FastAPI" from menu
# Choose "uv" as package manager
source venv/bin/activate
code .
```
### Data Science Project with Jupyter
```bash
typysetup setup ml-analysis
# Select "Data Science"
cd ml-analysis
source venv/bin/activate
jupyter notebook
```
### Converting Existing Project
```bash
cd existing-project
typysetup setup .
# TyPySetup will detect and preserve existing files
# Select appropriate setup type
```
## Troubleshooting
For detailed troubleshooting guide, see [TROUBLESHOOTING.md](TROUBLESHOOTING.md).
### Quick Fixes
**Python not found**:
```bash
python --version # Ensure 3.8+
```
**Command not found**:
```bash
pip install typysetup
# or
pip install --user typysetup
```
**Permission denied**:
```bash
chmod u+w /path/to/project
```
**VSCode not recognizing venv**:
- Reload window: `Ctrl+Shift+P` → "Developer: Reload Window"
- Select interpreter: `Ctrl+Shift+P` → "Python: Select Interpreter"
## Contributing
Contributions welcome! See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
MIT License - see LICENSE file for details
| text/markdown | null | Miguel Muniz <miguimuniz@gmail.com> | null | null | null | cli, python, setup, venv, vscode | [
"Development Status :: 5 - Production/Stable",
"Environment :: Console",
"Intended Audience :: Developers",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: ... | [] | null | null | >=3.8 | [] | [] | [] | [
"typer[all]>=0.12.0",
"pydantic>=2.5.0",
"pyyaml>=6.0.1",
"rich>=13.7.0",
"questionary>=2.0.0",
"tomli-w>=1.0.0",
"build>=1.2.2.post1",
"twine>=6.1.0",
"pytest>=8.0; extra == \"dev\"",
"pytest-cov>=5.0; extra == \"dev\"",
"pytest-watch>=4.2.0; extra == \"dev\"",
"black>=24.0; extra == \"dev\""... | [] | [] | [] | [
"Homepage, https://github.com/mugubr/typysetup",
"Documentation, https://github.com/mugubr/typysetup/blob/master/README.md",
"Repository, https://github.com/mugubr/typysetup",
"Issues, https://github.com/mugubr/typysetup/issues"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T01:24:47.104972 | typysetup-1.1.0.tar.gz | 65,596 | 68/7c/f321e719a168c6c86b2f49c35448458fffd4e29c82b0c2e572cbbfd52c99/typysetup-1.1.0.tar.gz | source | sdist | null | false | 76ab26ac6fa403db2bc952cda2d43fa2 | 6e5fb7927250f1d17b3a24ec61d290b3433138362c09ed44fa36682d564370ee | 687cf321e719a168c6c86b2f49c35448458fffd4e29c82b0c2e572cbbfd52c99 | MIT | [
"LICENSE"
] | 274 |
2.4 | nextpipe | 0.6.1.dev0 | Framework for Decision Pipeline modeling and execution | # Nextpipe
<!-- markdownlint-disable MD033 MD013 -->
<p align="center">
<a href="https://nextmv.io"><img src="https://cdn.prod.website-files.com/60dee0fad10d14c8ab66dd74/65c66addcd07eed09be35114_blog-banner-what-is-cicd-for-decision-science-p-2000.jpeg" alt="Nextmv" width="45%"></a>
</p>
<p align="center">
<em>Nextmv: The home for all your optimization work</em>
</p>
<p align="center">
<a href="https://github.com/nextmv-io/nextpipe/actions/workflows/test.yml" target="_blank">
<img src="https://github.com/nextmv-io/nextpipe/actions/workflows/test.yml/badge.svg?event=push&branch=develop" alt="Test">
</a>
<a href="https://github.com/nextmv-io/nextpipe/actions/workflows/lint.yml" target="_blank">
<img src="https://github.com/nextmv-io/nextpipe/actions/workflows/lint.yml/badge.svg?event=push&branch=develop" alt="Lint">
</a>
<a href="https://pypi.org/project/nextpipe" target="_blank">
<img src="https://img.shields.io/pypi/v/nextpipe?color=%2334D058&label=nextpipe" alt="Package version">
</a>
<a href="https://pypi.org/project/nextpipe" target="_blank">
<img src="https://img.shields.io/pypi/pyversions/nextpipe.svg?color=%2334D058" alt="Supported Python versions">
</a>
</p>
<!-- markdownlint-enable MD033 MD013 -->
Nextpipe is a Python package that provides a framework for Decision Workflows
modeling and execution. It provides first-class support for Workflows in the
[Nextmv Platform][nextmv].
> [!IMPORTANT]
> Please note that Nextpipe is provided as _source-available_ software
> (not _open-source_). For further information, please refer to the
> [LICENSE](./LICENSE.md) file.
📖 To learn more about Nextpipe, visit the [docs][docs].
## Installation
The package is hosted on [PyPI][nextpipe-pypi]. Python `>=3.10` is required.
Install via `pip`:
```bash
pip install nextpipe
```
## Preview
Example of a pipeline utilizing multiple routing solvers, and picking the best
result.
```mermaid
graph LR
fetch_data(prepare_data)
fetch_data --> run_nextroute
fetch_data --> run_ortools
fetch_data --> run_pyvroom
run_nextroute{ }
run_nextroute_join{ }
run_nextroute_0(run_nextroute_0)
run_nextroute --> run_nextroute_0
run_nextroute_0 --> run_nextroute_join
run_nextroute_1(run_nextroute_1)
run_nextroute --> run_nextroute_1
run_nextroute_1 --> run_nextroute_join
run_nextroute_2(run_nextroute_2)
run_nextroute --> run_nextroute_2
run_nextroute_2 --> run_nextroute_join
run_nextroute_join --> pick_best
run_ortools(run_ortools)
run_ortools --> pick_best
run_pyvroom(run_pyvroom)
run_pyvroom --> pick_best
pick_best(pick_best)
```
[nextpipe-pypi]: https://pypi.org/project/nextpipe/
[nextmv]: https://nextmv.io
[docs]: https://nextpipe.docs.nextmv.io/en/latest/
| text/markdown | null | Nextmv <tech@nextmv.io> | null | Nextmv <tech@nextmv.io> | # LICENSE
Business Source License 1.1
Parameters
Licensor: nextmv.io inc
Licensed Work: nextpipe
Change Date: Four years from the date the Licensed Work is published.
Change License: GPLv3
For information about alternative licensing arrangements for the Software,
please email info@nextmv.io.
Notice
The Business Source License (this document, or the “License”) is not an Open
Source license. However, the Licensed Work will eventually be made available
under an Open Source License, as stated in this License.
License text copyright © 2023 MariaDB plc, All Rights Reserved. “Business Source
License” is a trademark of MariaDB plc.
-----------------------------------------------------------------------------
## Terms
The Licensor hereby grants you the right to copy, modify, create derivative
works, redistribute, and make non-production use of the Licensed Work. The
Licensor may make an Additional Use Grant, above, permitting limited production
use.
Effective on the Change Date, or the fourth anniversary of the first publicly
available distribution of a specific version of the Licensed Work under this
License, whichever comes first, the Licensor hereby grants you rights under the
terms of the Change License, and the rights granted in the paragraph above
terminate.
If your use of the Licensed Work does not comply with the requirements currently
in effect as described in this License, you must purchase a commercial license
from the Licensor, its affiliated entities, or authorized resellers, or you must
refrain from using the Licensed Work.
All copies of the original and modified Licensed Work, and derivative works of
the Licensed Work, are subject to this License. This License applies separately
for each version of the Licensed Work and the Change Date may vary for each
version of the Licensed Work released by Licensor.
You must conspicuously display this License on each original or modified copy of
the Licensed Work. If you receive the Licensed Work in original or modified form
from a third party, the terms and conditions set forth in this License apply to
your use of that work.
Any use of the Licensed Work in violation of this License will automatically
terminate your rights under this License for the current and all other versions
of the Licensed Work.
This License does not grant you any right in any trademark or logo of Licensor
or its affiliates (provided that you may use a trademark or logo of Licensor as
expressly required by this License).TO THE EXTENT PERMITTED BY APPLICABLE LAW,
THE LICENSED WORK IS PROVIDED ON AN “AS IS” BASIS. LICENSOR HEREBY DISCLAIMS ALL
WARRANTIES AND CONDITIONS, EXPRESS OR IMPLIED, INCLUDING (WITHOUT LIMITATION)
WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE,
NON-INFRINGEMENT, AND TITLE. MariaDB hereby grants you permission to use this
License’s text to license your works, and to refer to it using the trademark
“Business Source License”, as long as you comply with the Covenants of Licensor
below.
## Covenants of Licensor
In consideration of the right to use this License’s text and the “Business
Source License” name and trademark, Licensor covenants to MariaDB, and to all
other recipients of the licensed work to be provided by Licensor:
To specify as the Change License the GPL Version 2.0 or any later version, or a
license that is compatible with GPL Version 2.0 or a later version, where
“compatible” means that software provided under the Change License can be
included in a program with software provided under GPL Version 2.0 or a later
version. Licensor may specify additional Change Licenses without limitation. To
either: (a) specify an additional grant of rights to use that does not impose
any additional restriction on the right granted in this License, as the
Additional Use Grant; or (b) insert the text “None” to specify a Change Date.
Not to modify this License in any other way.
License text copyright © 2023 MariaDB plc, All Rights Reserved. “Business Source
License” is a trademark of MariaDB plc. | decision automation, decision engineering, decision pipelines, decision science, decision workflows, decisions, nextmv, operations research, optimization, pipelines, workflows | [
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"dataclasses-json>=0.6.7",
"nextmv>=0.40.0",
"requests>=2.31.0",
"goldie>=0.1.8; extra == \"dev\"",
"ruff>=0.11.6; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://www.nextmv.io",
"Documentation, https://nextpipe.docs.nextmv.io/en/latest/",
"Repository, https://github.com/nextmv-io/nextpipe"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:23:37.338438 | nextpipe-0.6.1.dev0.tar.gz | 4,471,654 | 5f/22/e94c5caf020d34bbfe49ea21e043775bfffaf25dda54b9ffb0e7391a48bf/nextpipe-0.6.1.dev0.tar.gz | source | sdist | null | false | 97b64e820a4e78820b9e0402d98dc3dc | 2d17eaf666a6e40e9b8f5963d40f547f3fd92243db2aac95d7c599eb508fdb97 | 5f22e94c5caf020d34bbfe49ea21e043775bfffaf25dda54b9ffb0e7391a48bf | null | [
"LICENSE.md"
] | 223 |
2.4 | datatk | 0.1.0 | A CLI toolkit for comparing, analyzing, and exporting data across databases and file formats. | # datatk — Data Toolkit
A CLI toolkit for comparing, analyzing, and exporting data across databases and file formats.
Supports MSSQL, PostgreSQL, Databricks, and Parquet.
## Installation
```bash
pip install datatk
# or
uv tool install datatk
```
### From Source
Requires Python 3.13+ and [uv](https://docs.astral.sh/uv/).
```bash
git clone https://github.com/nathanthorell/datatk.git
cd datatk
uv sync --extra dev
```
## Quick Start
```bash
datatk --help
datatk data-compare
datatk object-compare
datatk schema-size
datatk db-diagram
datatk export-parquet
datatk proc-tester
datatk view-tester
datatk data-cleanup
```
## Configuration
### Environment Variables
Copy `.env.example` to `.env` and update the connection strings for your databases:
```bash
cp .env.example .env
```
Connection string formats:
- **MSSQL**: `Server=host,port;Database=db;UID=user;PWD=pass`
- **PostgreSQL**: `postgresql://user:pass@host:port/database`
- **Databricks**: `databricks://token:ACCESS_TOKEN@host/catalog?http_path=/sql/1.0/warehouses/ID`
### Tool Configuration
Copy `config-example.toml` to `config.toml` and configure the tools you want to use:
```bash
cp config-example.toml config.toml
```
The `[datatk]` section sets global defaults (e.g. `logging_level`) that apply to all tools unless
overridden in a tool-specific section.
## Tools
### `data-compare`
Compare data across different database platforms.
```bash
datatk data-compare
```
- Supports MSSQL, PostgreSQL, and Databricks
- Compare data using inline SQL or query files
- Output options: `left_only`, `right_only`, `common`, `differences`, or `all`
- Reports differences and execution time per source
### `object-compare`
Compare database object definitions across environments (DEV, QA, TEST, PROD).
```bash
datatk object-compare
```
- Supports MSSQL and PostgreSQL
- Object types: stored procedures, views, functions, tables, triggers, sequences, indexes,
types, extensions (PostgreSQL), external tables (MSSQL), and foreign keys
- Detects objects that exist in only some environments
- Uses MD5 checksums for efficient definition comparison
### `schema-size`
Analyze storage across databases by measuring schema sizes.
```bash
datatk schema-size
```
- Connects to multiple servers and calculates data and index space in megabytes
- Summary and detail modes
- Comparative reports across servers and databases
### `db-diagram`
Generate ERD diagrams from database metadata.
```bash
datatk db-diagram
```
- Output formats: DBML (default), Mermaid, PlantUML
- Column display modes: all columns, keys only, or table names only
- Hierarchical mode: focus on relationships around a specific base table with
directional traversal (up, down, or both)
- Detects relationships from foreign key constraints
### `export-parquet`
Export database objects to Parquet files.
```bash
datatk export-parquet
```
- Connects to MSSQL databases and exports tables or query results
- Configurable batch size
- Tracks export timing per object
### `proc-tester`
Batch test stored procedures with configurable default parameters.
```bash
datatk proc-tester
```
- Executes all stored procedures in a configured schema
- Applies default values for common parameter types
- Reports execution status and timing
### `view-tester`
Batch test database views.
```bash
datatk view-tester
```
- Runs a `SELECT TOP 1 *` against each view in a configured schema
- Reports execution status and timing
### `data-cleanup`
Delete data using foreign key hierarchy traversal to handle dependencies automatically.
```bash
datatk data-cleanup
```
- Traverses foreign key relationships to determine deletion order
- Summary and execute modes (run summary first to preview)
- Configurable batch size and threshold
## Development
### Linting and Formatting
```bash
uv run ruff check src/ # Run ruff linter
uv run ruff check src/ --fix # Run ruff with auto-fix
uv run mypy src/ # Run mypy type checker
uv run ruff format src/ # Format code with ruff
```
Or use the Makefile:
```bash
make lint # Run ruff and mypy linters
make format # Format code with ruff
make clean # Remove temporary files and virtual environment
```
| text/markdown | Nathan Thorell | null | null | null | GNU GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for
software and other kinds of works.
The licenses for most software and other practical works are designed
to take away your freedom to share and change the works. By contrast,
the GNU General Public License is intended to guarantee your freedom to
share and change all versions of a program--to make sure it remains free
software for all its users. We, the Free Software Foundation, use the
GNU General Public License for most of our software; it applies also to
any other work released this way by its authors. You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
them if you wish), that you receive source code or can get it if you
want it, that you can change the software or use pieces of it in new
free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you
these rights or asking you to surrender the rights. Therefore, you have
certain responsibilities if you distribute copies of the software, or if
you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must pass on to the recipients the same
freedoms that you received. You must make sure that they, too, receive
or can get the source code. And you must show them these terms so they
know their rights.
Developers that use the GNU GPL protect your rights with two steps:
(1) assert copyright on the software, and (2) offer you this License
giving you legal permission to copy, distribute and/or modify it.
For the developers' and authors' protection, the GPL clearly explains
that there is no warranty for this free software. For both users' and
authors' sake, the GPL requires that modified versions be marked as
changed, so that their problems will not be attributed erroneously to
authors of previous versions.
Some devices are designed to deny users access to install or run
modified versions of the software inside them, although the manufacturer
can do so. This is fundamentally incompatible with the aim of
protecting users' freedom to change the software. The systematic
pattern of such abuse occurs in the area of products for individuals to
use, which is precisely where it is most unacceptable. Therefore, we
have designed this version of the GPL to prohibit the practice for those
products. If such problems arise substantially in other domains, we
stand ready to extend this provision to those domains in future versions
of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents.
States should not allow patents to restrict development and use of
software on general-purpose computers, but in those that do, we wish to
avoid the special danger that patents applied to a free program could
make it effectively proprietary. To prevent this, the GPL assures that
patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and
modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of
works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this
License. Each licensee is addressed as "you". "Licensees" and
"recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work
in a fashion requiring copyright permission, other than the making of an
exact copy. The resulting work is called a "modified version" of the
earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based
on the Program.
To "propagate" a work means to do anything with it that, without
permission, would make you directly or secondarily liable for
infringement under applicable copyright law, except executing it on a
computer or modifying a private copy. Propagation includes copying,
distribution (with or without modification), making available to the
public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other
parties to make or receive copies. Mere interaction with a user through
a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices"
to the extent that it includes a convenient and prominently visible
feature that (1) displays an appropriate copyright notice, and (2)
tells the user that there is no warranty for the work (except to the
extent that warranties are provided), that licensees may convey the
work under this License, and how to view a copy of this License. If
the interface presents a list of user commands or options, such as a
menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work
for making modifications to it. "Object code" means any non-source
form of a work.
A "Standard Interface" means an interface that either is an official
standard defined by a recognized standards body, or, in the case of
interfaces specified for a particular programming language, one that
is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other
than the work as a whole, that (a) is included in the normal form of
packaging a Major Component, but which is not part of that Major
Component, and (b) serves only to enable use of the work with that
Major Component, or to implement a Standard Interface for which an
implementation is available to the public in source code form. A
"Major Component", in this context, means a major essential component
(kernel, window system, and so on) of the specific operating system
(if any) on which the executable work runs, or a compiler used to
produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all
the source code needed to generate, install, and (for an executable
work) run the object code and to modify the work, including scripts to
control those activities. However, it does not include the work's
System Libraries, or general-purpose tools or generally available free
programs which are used unmodified in performing those activities but
which are not part of the work. For example, Corresponding Source
includes interface definition files associated with source files for
the work, and the source code for shared libraries and dynamically
linked subprograms that the work is specifically designed to require,
such as by intimate data communication or control flow between those
subprograms and other parts of the work.
The Corresponding Source need not include anything that users
can regenerate automatically from other parts of the Corresponding
Source.
The Corresponding Source for a work in source code form is that
same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of
copyright on the Program, and are irrevocable provided the stated
conditions are met. This License explicitly affirms your unlimited
permission to run the unmodified Program. The output from running a
covered work is covered by this License only if the output, given its
content, constitutes a covered work. This License acknowledges your
rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not
convey, without conditions so long as your license otherwise remains
in force. You may convey covered works to others for the sole purpose
of having them make modifications exclusively for you, or provide you
with facilities for running those works, provided that you comply with
the terms of this License in conveying all material for which you do
not control copyright. Those thus making or running the covered works
for you must do so exclusively on your behalf, under your direction
and control, on terms that prohibit them from making any copies of
your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under
the conditions stated below. Sublicensing is not allowed; section 10
makes it unnecessary.
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological
measure under any applicable law fulfilling obligations under article
11 of the WIPO copyright treaty adopted on 20 December 1996, or
similar laws prohibiting or restricting circumvention of such
measures.
When you convey a covered work, you waive any legal power to forbid
circumvention of technological measures to the extent such circumvention
is effected by exercising rights under this License with respect to
the covered work, and you disclaim any intention to limit operation or
modification of the work as a means of enforcing, against the work's
users, your or third parties' legal rights to forbid circumvention of
technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program's source code as you
receive it, in any medium, provided that you conspicuously and
appropriately publish on each copy an appropriate copyright notice;
keep intact all notices stating that this License and any
non-permissive terms added in accord with section 7 apply to the code;
keep intact all notices of the absence of any warranty; and give all
recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey,
and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to
produce it from the Program, in the form of source code under the
terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified
it, and giving a relevant date.
b) The work must carry prominent notices stating that it is
released under this License and any conditions added under section
7. This requirement modifies the requirement in section 4 to
"keep intact all notices".
c) You must license the entire work, as a whole, under this
License to anyone who comes into possession of a copy. This
License will therefore apply, along with any applicable section 7
additional terms, to the whole of the work, and all its parts,
regardless of how they are packaged. This License gives no
permission to license the work in any other way, but it does not
invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display
Appropriate Legal Notices; however, if the Program has interactive
interfaces that do not display Appropriate Legal Notices, your
work need not make them do so.
A compilation of a covered work with other separate and independent
works, which are not by their nature extensions of the covered work,
and which are not combined with it such as to form a larger program,
in or on a volume of a storage or distribution medium, is called an
"aggregate" if the compilation and its resulting copyright are not
used to limit the access or legal rights of the compilation's users
beyond what the individual works permit. Inclusion of a covered work
in an aggregate does not cause this License to apply to the other
parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms
of sections 4 and 5, provided that you also convey the
machine-readable Corresponding Source under the terms of this License,
in one of these ways:
a) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by the
Corresponding Source fixed on a durable physical medium
customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product
(including a physical distribution medium), accompanied by a
written offer, valid for at least three years and valid for as
long as you offer spare parts or customer support for that product
model, to give anyone who possesses the object code either (1) a
copy of the Corresponding Source for all the software in the
product that is covered by this License, on a durable physical
medium customarily used for software interchange, for a price no
more than your reasonable cost of physically performing this
conveying of source, or (2) access to copy the
Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the
written offer to provide the Corresponding Source. This
alternative is allowed only occasionally and noncommercially, and
only if you received the object code with such an offer, in accord
with subsection 6b.
d) Convey the object code by offering access from a designated
place (gratis or for a charge), and offer equivalent access to the
Corresponding Source in the same way through the same place at no
further charge. You need not require recipients to copy the
Corresponding Source along with the object code. If the place to
copy the object code is a network server, the Corresponding Source
may be on a different server (operated by you or a third party)
that supports equivalent copying facilities, provided you maintain
clear directions next to the object code saying where to find the
Corresponding Source. Regardless of what server hosts the
Corresponding Source, you remain obligated to ensure that it is
available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided
you inform other peers where the object code and Corresponding
Source of the work are being offered to the general public at no
charge under subsection 6d.
A separable portion of the object code, whose source code is excluded
from the Corresponding Source as a System Library, need not be
included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any
tangible personal property which is normally used for personal, family,
or household purposes, or (2) anything designed or sold for incorporation
into a dwelling. In determining whether a product is a consumer product,
doubtful cases shall be resolved in favor of coverage. For a particular
product received by a particular user, "normally used" refers to a
typical or common use of that class of product, regardless of the status
of the particular user or of the way in which the particular user
actually uses, or expects or is expected to use, the product. A product
is a consumer product regardless of whether the product has substantial
commercial, industrial or non-consumer uses, unless such uses represent
the only significant mode of use of the product.
"Installation Information" for a User Product means any methods,
procedures, authorization keys, or other information required to install
and execute modified versions of a covered work in that User Product from
a modified version of its Corresponding Source. The information must
suffice to ensure that the continued functioning of the modified object
code is in no case prevented or interfered with solely because
modification has been made.
If you convey an object code work under this section in, or with, or
specifically for use in, a User Product, and the conveying occurs as
part of a transaction in which the right of possession and use of the
User Product is transferred to the recipient in perpetuity or for a
fixed term (regardless of how the transaction is characterized), the
Corresponding Source conveyed under this section must be accompanied
by the Installation Information. But this requirement does not apply
if neither you nor any third party retains the ability to install
modified object code on the User Product (for example, the work has
been installed in ROM).
The requirement to provide Installation Information does not include a
requirement to continue to provide support service, warranty, or updates
for a work that has been modified or installed by the recipient, or for
the User Product in which it has been modified or installed. Access to a
network may be denied when the modification itself materially and
adversely affects the operation of the network or violates the rules and
protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided,
in accord with this section must be in a format that is publicly
documented (and with an implementation available to the public in
source code form), and must require no special password or key for
unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this
License by making exceptions from one or more of its conditions.
Additional permissions that are applicable to the entire Program shall
be treated as though they were included in this License, to the extent
that they are valid under applicable law. If additional permissions
apply only to part of the Program, that part may be used separately
under those permissions, but the entire Program remains governed by
this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option
remove any additional permissions from that copy, or from any part of
it. (Additional permissions may be written to require their own
removal in certain cases when you modify the work.) You may place
additional permissions on material, added by you to a covered work,
for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you
add to a covered work, you may (if authorized by the copyright holders of
that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the
terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or
author attributions in that material or in the Appropriate Legal
Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or
requiring that modified versions of such material be marked in
reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or
authors of the material; or
e) Declining to grant rights under trademark law for use of some
trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that
material by anyone who conveys the material (or modified versions of
it) with contractual assumptions of liability to the recipient, for
any liability that these contractual assumptions directly impose on
those licensors and authors.
All other non-permissive additional terms are considered "further
restrictions" within the meaning of section 10. If the Program as you
received it, or any part of it, contains a notice stating that it is
governed by this License along with a term that is a further
restriction, you may remove that term. If a license document contains
a further restriction but permits relicensing or conveying under this
License, you may add to a covered work material governed by the terms
of that license document, provided that the further restriction does
not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you
must place, in the relevant source files, a statement of the
additional terms that apply to those files, or a notice indicating
where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the
form of a separately written license, or stated as exceptions;
the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly
provided under this License. Any attempt otherwise to propagate or
modify it is void, and will automatically terminate your rights under
this License (including any patent licenses granted under the third
paragraph of section 11).
However, if you cease all violation of this License, then your
license from a particular copyright holder is reinstated (a)
provisionally, unless and until the copyright holder explicitly and
finally terminates your license, and (b) permanently, if the copyright
holder fails to notify you of the violation by some reasonable means
prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is
reinstated permanently if the copyright holder notifies you of the
violation by some reasonable means, this is the first time you have
received notice of violation of this License (for any work) from that
copyright holder, and you cure the violation prior to 30 days after
your receipt of the notice.
Termination of your rights under this section does not terminate the
licenses of parties who have received copies or rights from you under
this License. If your rights have been terminated and not permanently
reinstated, you do not qualify to receive new licenses for the same
material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or
run a copy of the Program. Ancillary propagation of a covered work
occurring solely as a consequence of using peer-to-peer transmission
to receive a copy likewise does not require acceptance. However,
nothing other than this License grants you permission to propagate or
modify any covered work. These actions infringe copyright if you do
not accept this License. Therefore, by modifying or propagating a
covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically
receives a license from the original licensors, to run, modify and
propagate that work, subject to this License. You are not responsible
for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an
organization, or substantially all assets of one, or subdividing an
organization, or merging organizations. If propagation of a covered
work results from an entity transaction, each party to that
transaction who receives a copy of the work also receives whatever
licenses to the work the party's predecessor in interest had or could
give under the previous paragraph, plus a right to possession of the
Corresponding Source of the work from the predecessor in interest, if
the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the
rights granted or affirmed under this License. For example, you may
not impose a license fee, royalty, or other charge for exercise of
rights granted under this License, and you may not initiate litigation
(including a cross-claim or counterclaim in a lawsuit) alleging that
any patent claim is infringed by making, using, selling, offering for
sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this
License of the Program or a work on which the Program is based. The
work thus licensed is called the contributor's "contributor version".
A contributor's "essential patent claims" are all patent claims
owned or controlled by the contributor, whether already acquired or
hereafter acquired, that would be infringed by some manner, permitted
by this License, of making, using, or selling its contributor version,
but do not include claims that would be infringed only as a
consequence of further modification of the contributor version. For
purposes of this definition, "control" includes the right to grant
patent sublicenses in a manner consistent with the requirements of
this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free
patent license under the contributor's essential patent claims, to
make, use, sell, offer for sale, import and otherwise run, modify and
propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express
agreement or commitment, however denominated, not to enforce a patent
(such as an express permission to practice a patent or covenant not to
sue for patent infringement). To "grant" such a patent license to a
party means to make such an agreement or commitment not to enforce a
patent against the party.
If you convey a covered work, knowingly relying on a patent license,
and the Corresponding Source of the work is not available for anyone
to copy, free of charge and under the terms of this License, through a
publicly available network server or other readily accessible means,
then you must either (1) cause the Corresponding Source to be so
available, or (2) arrange to deprive yourself of the benefit of the
patent license for this particular work, or (3) arrange, in a manner
consistent with the requirements of this License, to extend the patent
license to downstream recipients. "Knowingly relying" means you have
actual knowledge that, but for the patent license, your conveying the
covered work in a country, or your recipient's use of the covered work
in a country, would infringe one or more identifiable patents in that
country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or
arrangement, you convey, or propagate by procuring conveyance of, a
covered work, and grant a patent license to some of the parties
receiving the covered work authorizing them to use, propagate, modify
or convey a specific copy of the covered work, then the patent license
you grant is automatically extended to all recipients of the covered
work and works based on it.
A patent license is "discriminatory" if it does not include within
the scope of its coverage, prohibits the exercise of, or is
conditioned on the non-exercise of one or more of the rights that are
specifically granted under this License. You may not convey a covered
work if you are a party to an arrangement with a third party that is
in the business of distributing software, under which you make payment
to the third party based on the extent of your activity of conveying
the work, and under which the third party grants, to any of the
parties who would receive the covered work from you, a discriminatory
patent license (a) in connection with copies of the covered work
conveyed by you (or copies made from those copies), or (b) primarily
for and in connection with specific products or compilations that
contain the covered work, unless you entered into that arrangement,
or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting
any implied license or other defenses to infringement that may
otherwise be available to you under applicable patent law.
12. No Surrender of Others' Freedom.
If conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot convey a
covered work so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you may
not convey it at all. For example, if you agree to terms that obligate you
to collect a royalty for further conveying from those to whom you convey
the Program, the only way you could satisfy both those terms and this
License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have
permission to link or combine any covered work with a work licensed
under version 3 of the GNU Affero General Public License into a single
combined work, and to convey the resulting work. The terms of this
License will continue to apply to the part which is the covered work,
but the special requirements of the GNU Affero General Public License,
section 13, concerning interaction through a network will apply to the
combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of
the GNU General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the
Program specifies that a certain numbered version of the GNU General
Public License "or any later version" applies to it, you have the
option of following the terms and conditions either of that numbered
version or of any later version published by the Free Software
Foundation. If the Program does not specify a version number of the
GNU General Public License, you may choose any version ever published
by the Free Software Foundation.
If the Program specifies that a proxy can decide which future
versions of the GNU General Public License can be used, that proxy's
public statement of acceptance of a version permanently authorizes you
to choose that version for the Program.
Later license versions may give you additional or different
permissions. However, no additional obligations are imposed on any
author or copyright holder as a result of your choosing to follow a
later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided
above cannot be given local legal effect according to their terms,
reviewing courts shall apply local law that most closely approximates
an absolute waiver of all civil liability in connection with the
Program, unless a warranty or assumption of liability accompanies a
copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
state the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
<one line to give the program's name and a brief idea of what it does.>
Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <https://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short
notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author>
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, your program's commands
might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school,
if any, to sign a "copyright disclaimer" for the program, if necessary.
For more information on this, and how to apply and follow the GNU GPL, see
<https://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program
into proprietary programs. If your program is a subroutine library, you
may consider it more useful to permit linking proprietary applications with
the library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License. But first, please read
<https://www.gnu.org/licenses/why-not-lgpl.html>.
| null | [
"Programming Language :: Python :: 3.13",
"License :: OSI Approved :: GNU General Public License v3 (GPLv3)",
"Environment :: Console",
"Topic :: Database"
] | [] | null | null | >=3.13 | [] | [] | [] | [
"pyodbc",
"psycopg2-binary",
"databricks-sql-connector",
"databricks-sqlalchemy",
"python-dotenv",
"rich",
"sqlalchemy",
"pandas",
"pyarrow",
"pydbml",
"pydantic>=2.12",
"typer",
"ruff; extra == \"dev\"",
"mypy; extra == \"dev\"",
"pandas-stubs; extra == \"dev\"",
"types-psycopg2; extr... | [] | [] | [] | [
"Homepage, https://github.com/nathanthorell/datatk",
"Repository, https://github.com/nathanthorell/datatk",
"Issues, https://github.com/nathanthorell/datatk/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:22:17.931143 | datatk-0.1.0.tar.gz | 100,017 | 37/a5/47e90f6fbaba70b8d5d583649bce7a5b1e2616bb37de796b5b46b3694b11/datatk-0.1.0.tar.gz | source | sdist | null | false | bfd551f4bb46e5c1ed6844e5e91a4469 | e8c983b6b38d17deabe33dd3b21d61100818d8230319d6e4c9ee22d513a34cf1 | 37a547e90f6fbaba70b8d5d583649bce7a5b1e2616bb37de796b5b46b3694b11 | null | [
"LICENSE"
] | 276 |
2.4 | planar | 0.25.0rc1 | Batteries-included framework for building durable agentic workflows and business applications. | # Planar
Planar is a batteries-included Python framework for building durable workflows, agent automations, and stateful APIs. Built on FastAPI and SQLModel, it combines orchestration, data modeling, and file management into a cohesive developer experience.
## Feature Highlights
- Durable workflow engine with resumable async steps, automatic retries, and suspension points
- Agent step framework with first-class support for OpenAI, Anthropic, and other providers
- Human task assignments and rule engine tooling baked into workflow execution
- SQLModel-powered data layer with Alembic migrations and CRUD scaffolding out of the box
- Built-in file management and storage adapters for local disk, Amazon S3, and Azure Blob Storage
- CLI-driven developer workflow with templated scaffolding, hot reload, and environment-aware configuration
- Agentic CLI that can scaffold or evolve workflows
## Installation
Planar is published on PyPI. Add it to an existing project with `uv`:
```bash
uv add planar
```
To explore the CLI without updating `pyproject.toml`, use the ephemeral uvx runner:
```bash
uvx planar --help
```
## Quickstart
Generate a new service, start up the dev server, and inspect the auto-generated APIs:
```bash
uvx planar scaffold --name my_service
cd my_service
uv run planar dev src/main.py
```
Open `http://127.0.0.1:8000/docs` to explore your service's routes and workflow endpoints. The scaffold prints the exact app path if it differs from `src/main.py`.
## Define a Durable Workflow
```python
from datetime import timedelta
from planar import PlanarApp
from planar.workflows import step, suspend, workflow
@step
async def charge_customer(order_id: str) -> None:
...
@step
async def notify_success(order_id: str) -> None:
...
@workflow
async def process_order(order_id: str) -> None:
await charge_customer(order_id)
await suspend(interval=timedelta(hours=1))
await notify_success(order_id)
app = PlanarApp()
app.register_workflow(process_order)
```
Workflows are async functions composed of resumable steps. Planar persists every step, applies configurable retry policies, and resumes suspended workflows even after process restarts. Check `docs/workflows.md` for deeper concepts including event-driven waits, human steps, and agent integrations.
## Core Capabilities
- **Workflow orchestration**: Compose async steps with guaranteed persistence, scheduling, and concurrency control.
- **Agent steps**: Run LLM-powered actions durably with provider-agnostic adapters and structured prompts.
- **Human tasks and rules**: Build human-in-the-loop approvals and declarative rule evaluations alongside automated logic.
- **Stateful data and files**: Model entities with SQLModel, manage migrations through Alembic, and store files using pluggable backends.
- **Observability**: Structured logging and OpenTelemetry hooks surface workflow progress and performance metrics.
## Command Line Interface
```bash
uvx planar scaffold --help # generate a new project from the official template
uv run planar dev [PATH] # run with hot reload and development defaults
uv run planar prod [PATH] # run with production defaults
uv run planar agent [PROMPT] # scaffold or evolve workflows with Anthropic's Claude Code (requires Claude API key)
```
`[PATH]` points to the module that exports a `PlanarApp` instance (defaults to `app.py` or `main.py`). Use `--config PATH` to load a specific configuration file and `--app NAME` if your application variable is not named `app`.
## Configuration
Planar merges environment defaults with an optional YAML override. By convention it looks for `planar.dev.yaml`, `planar.prod.yaml`, or `planar.yaml` in your project directory, but you can supply a path explicitly via `--config` or the `PLANAR_CONFIG` environment variable.
Example minimal override:
```yaml
ai_models:
default: invoice_llm
providers:
public_openai:
factory: openai_responses
options:
api_key: ${OPENAI_API_KEY}
base_url: ${OPENAI_PROXY_URL}
azure_llm:
factory: azure_openai_responses
options:
endpoint: ${AZURE_OPENAI_ENDPOINT}
# optional: api_key: ${AZURE_OPENAI_KEY} (omit to use DefaultAzureCredential)
models:
invoice_llm:
provider: public_openai
options: gpt-4o-mini
claims_llm:
provider: azure_llm
options:
deployment: gpt-4o-claims
storage:
directory: .files
```
Set `default` to the model key agents should use when they leave `model=None`. Use `ConfiguredModelKey("invoice_llm")` to reference a specific entry. Providers let you reuse auth/transport settings across multiple models; factories receive merged provider + model options.
```yaml
ai_models:
providers:
public_openai:
factory: openai_responses
options:
api_key_env: BILLING_OPENAI_KEY
models:
invoice_parsing_model:
provider: public_openai
options: gpt-4o-mini
```
For Azure OpenAI endpoints:
```yaml
ai_models:
providers:
azure_llm:
factory: azure_openai_responses
options:
endpoint_env: AZURE_OPENAI_ENDPOINT
deployment_env: AZURE_OPENAI_DEPLOYMENT
# Optional: omit these to use DefaultAzureCredential instead
api_key: ${AZURE_OPENAI_KEY}
models:
invoice_parsing_model:
provider: azure_llm
options:
deployment: gpt-4o-mini
```
Omit the API key options to authenticate with `DefaultAzureCredential` (managed identity or
user credentials). Use `token_scope`/`token_scope_env` if you need to override the default
`https://cognitiveservices.azure.com/.default` scope.
Register custom factories on the app and reference them by key in config:
```python
from planar import PlanarApp
app = PlanarApp(...)
app.register_model_factory("vertex_gemini", vertex_gemini_model_factory)
```
Factories receive the raw `options` dict plus a `PlanarConfig` reference, so you can inject per-environment parameters without touching workflow code. They can be synchronous callables or async coroutines—Planar automatically handles awaiting them and caching the resulting model instances.
Set provider credentials through environment variables (e.g., `OPENAI_API_KEY` for the
OpenAI entries above). For more configuration patterns and workflow design guidance,
browse the documents in `docs/`.
## Examples
- `examples/expense_approval_workflow` — human approvals with AI agent collaboration
- `examples/event_based_workflow` — event-driven orchestration and external wakeups
- `examples/simple_service` — CRUD service paired with workflows
Run any example with `uv run planar dev path/to/main.py`.
## Testing
For testing your workflows, you can use the `planar.testing` module. This module provides a `PlanarTestClient` class that can be used to test your Planar application.
Be sure to add the `planar.testing.fixtures` pytest plugin to your `pyproject.toml` file.
```toml
[project.entry-points.pytest11]
planar = "planar.testing.fixtures"
```
For more information, see `docs/testing_workflows.md`.
## Local Development
Planar is built with `uv`. Clone the repository and install dev dependencies:
```bash
uv sync --extra otel
```
Useful commands:
- `uv run ruff check --fix` and `uv run ruff format` to lint and format
- `uv run pyright` for static type checking
- `uv run pytest` to run the test suite (use `-n auto` for parallel execution)
- `uv run pytest --cov=planar` to collect coverage
- `uv tool install pre-commit && uv tool run pre-commit install` to enable git hooks
### PostgreSQL Test Suite
```bash
docker run --restart=always --name planar-postgres \
-e POSTGRES_PASSWORD=postgres \
-p 127.0.0.1:5432:5432 \
-d docker.io/library/postgres
PLANAR_TEST_POSTGRESQL=1 PLANAR_TEST_POSTGRESQL_CONTAINER=planar-postgres \
uv run pytest -s
```
Disable SQLite with `PLANAR_TEST_SQLITE=0`.
### Cairo SVG Dependencies
Some AI integration tests convert SVG assets using `cairosvg`. Install Cairo libraries locally before running those tests:
```bash
brew install cairo libffi pkg-config
export DYLD_FALLBACK_LIBRARY_PATH="/opt/homebrew/lib:${DYLD_FALLBACK_LIBRARY_PATH}"
```
Most Linux distributions ship the required libraries via their package manager.
## Documentation
Use `uv run planar docs` to view the documentation in your terminal - this is particularly useful to equip coding agents
with context about Planar. Alternatively, use `docs/llm_prompt.md` as a drop-in reference document in whatever tool you are using.
Dive deeper into Planar's design and APIs in the `docs/` directory:
- `docs/workflows.md`
- `docs/agents.md`
- `docs/design/event_based_waiting.md`
- `docs/design/human_step.md`
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"aiofiles>=24.1.0",
"aiosqlite>=0.22.1",
"alembic>=1.14.1",
"claude-agent-sdk>=0.1.2",
"asyncpg",
"cedarpy>=4.1.0",
"fastapi[standard-no-fastapi-cloud-cli]>=0.119.0",
"inflection>=0.5.1",
"pydantic-ai-slim[anthropic,bedrock,google,openai]>=1.61.0",
"pygments>=2.19.1",
"rich>=13.9.4",
"pyjwt[cr... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:22:16.712544 | planar-0.25.0rc1-py3-none-any.whl | 415,662 | 83/8f/dbef9f4db113e924b469e23273ac891a9117ab14f5d103306ca17c12c28a/planar-0.25.0rc1-py3-none-any.whl | py3 | bdist_wheel | null | false | 4198b4180cd388178d0c2d9f6895bba7 | c6320ecc4cdeff179cb9d470589e64430c806d241dd0c5213631762f9ccd6bb8 | 838fdbef9f4db113e924b469e23273ac891a9117ab14f5d103306ca17c12c28a | LicenseRef-Proprietary | [] | 156 |
2.4 | otex | 0.1.2 | OTEX - Ocean Thermal Energy eXchange: OTEC plant design, simulation, and analysis | <p align="center">
<img src="img/logo.png" alt="OTEX Logo" width="400"/>
</p>
<h1 align="center">OTEX - Ocean Thermal Energy eXchange</h1>
<p align="center">
<strong>A Python library for OTEC plant design, simulation, and techno-economic analysis</strong>
</p>
<p align="center">
<a href="https://github.com/msotocalvo/OTEX/actions/workflows/workflow.yml">
<img src="https://github.com/msotocalvo/OTEX/actions/workflows/workflow.yml/badge.svg" alt="CI">
</a>
<a href="https://codecov.io/gh/msotocalvo/OTEX">
<img src="https://codecov.io/gh/msotocalvo/OTEX/branch/main/graph/badge.svg" alt="codecov">
</a>
<a href="https://otex.readthedocs.io">
<img src="https://readthedocs.org/projects/otex/badge/?version=latest" alt="Documentation">
</a>
<a href="https://doi.org/10.5281/zenodo.18428742">
<img src="https://zenodo.org/badge/1145581288.svg" alt="DOI">
</a>
</p>
<p align="center">
<a href="https://pypi.org/project/otex/">
<img src="https://img.shields.io/pypi/v/otex.svg" alt="PyPI">
</a>
<a href="https://pypi.org/project/otex/">
<img src="https://img.shields.io/pypi/pyversions/otex.svg" alt="Python">
</a>
<a href="https://pepy.tech/project/otex">
<img src="https://static.pepy.tech/badge/otex" alt="Downloads">
</a>
<a href="https://opensource.org/licenses/MIT">
<img src="https://img.shields.io/badge/License-MIT-blue.svg" alt="License">
</a>
<a href="https://github.com/astral-sh/ruff">
<img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json" alt="Ruff">
</a>
</p>
<p align="center">
<a href="#features">Features</a> •
<a href="#installation">Installation</a> •
<a href="#quick-start">Quick Start</a> •
<a href="#documentation">Documentation</a> •
<a href="#citation">Citation</a>
</p>
---
## Overview
**OTEX** (Ocean Thermal Energy eXchange) is a Python library for designing, simulating, and analyzing Ocean Thermal Energy Conversion (OTEC) power plants. It integrates with global oceanographic databases to enable site-specific techno-economic assessments anywhere in the tropical oceans.
OTEX enables researchers and engineers to:
- **Design OTEC plants** with multiple thermodynamic cycles and working fluids
- **Analyze regional and global potential** using CMEMS oceanographic data
- **Perform uncertainty analysis** with Monte Carlo simulations and sensitivity studies
- **Compare scenarios** across different locations, plant sizes, and configurations
## Features
### Thermodynamic Cycles
| Cycle | Description | Status |
|-------|-------------|--------|
| Rankine Closed | Ammonia/organic fluid closed loop | ✅ Stable |
| Rankine Open | Flash evaporation of seawater | ✅ Stable |
| Rankine Hybrid | Combined closed/open cycle | ✅ Stable |
| Kalina | Ammonia-water mixture | ✅ Stable |
| Uehara | Advanced ammonia-water cycle | ✅ Stable |
### Working Fluids
- **Ammonia** (NH₃) - Default, polynomial or CoolProp
- **R134a** - Requires CoolProp
- **R245fa** - Requires CoolProp
- **Propane** - Requires CoolProp
- **Isobutane** - Requires CoolProp
### Analysis Capabilities
- **Regional Analysis**: Site-specific LCOE maps and power profiles
- **Uncertainty Analysis**: Monte Carlo with Latin Hypercube Sampling
- **Sensitivity Analysis**: Sobol indices and Tornado diagrams
- **Off-design Performance**: Time-resolved power output profiles
## Installation
### Basic Installation
```bash
pip install otex
```
### With Optional Dependencies
```bash
# High-accuracy fluid properties
pip install otex[coolprop]
# Uncertainty analysis (Sobol indices)
pip install otex[uncertainty]
# All optional dependencies
pip install otex[all]
```
### Development Installation
```bash
git clone https://github.com/msotocalvo/OTEX.git
cd OTEX
pip install -e ".[dev]"
```
### CMEMS Data Access
For downloading oceanographic data, you need Copernicus Marine credentials:
1. Create account at [Copernicus Marine](https://data.marine.copernicus.eu/)
2. Configure credentials:
```bash
copernicusmarine login
```
See [Installation Guide](docs/installation.md) for detailed instructions.
## Quick Start
### Basic Plant Configuration
```python
from otex.config import parameters_and_constants
# Configure a 100 MW OTEC plant
inputs = parameters_and_constants(
p_gross=-100000, # 100 MW (negative = power output)
cost_level='low_cost',
cycle_type='rankine_closed',
fluid_type='ammonia',
year=2020
)
print(f"Cycle: {inputs['cycle_type']}")
print(f"Discount rate: {inputs['discount_rate']:.1%}")
print(f"Plant lifetime: {inputs['lifetime']} years")
```
### Regional Analysis
```bash
# Analyze Cuba for 2020 with a 50 MW plant
python scripts/regional_analysis.py Cuba --year 2020 --power -50000
# Analyze with Kalina cycle
python scripts/regional_analysis.py Philippines --cycle kalina --year 2021
```
### Uncertainty Analysis
```python
from otex.analysis import (
MonteCarloAnalysis,
UncertaintyConfig,
TornadoAnalysis,
plot_histogram,
plot_tornado
)
# Monte Carlo analysis
config = UncertaintyConfig(n_samples=1000, seed=42)
mc = MonteCarloAnalysis(T_WW=28.0, T_CW=5.0, config=config)
results = mc.run()
# Get statistics
stats = results.compute_statistics()
print(f"LCOE: {stats['lcoe']['lcoe_mean']:.2f} ± {stats['lcoe']['lcoe_std']:.2f} ct/kWh")
print(f"90% CI: [{stats['lcoe']['lcoe_p5']:.2f}, {stats['lcoe']['lcoe_p95']:.2f}]")
# Tornado diagram
tornado = TornadoAnalysis(T_WW=28.0, T_CW=5.0)
tornado_results = tornado.run()
plot_tornado(tornado_results)
```
### Command Line Interface
```bash
# Tornado analysis
python scripts/uncertainty_analysis.py --T_WW 28 --T_CW 5 --method tornado
# Monte Carlo with 500 samples
python scripts/uncertainty_analysis.py --T_WW 28 --T_CW 5 --method monte-carlo --samples 500
# Full analysis with plots
python scripts/uncertainty_analysis.py --T_WW 28 --T_CW 5 --method all --samples 200 --save-plots
```
## Documentation
| Document | Description |
|----------|-------------|
| [Installation Guide](docs/installation.md) | Detailed setup instructions |
| [Quick Start Tutorial](docs/tutorials/quickstart.md) | Get started in 10 minutes |
| [Regional Analysis](docs/tutorials/regional_analysis.md) | Analyze specific regions |
| [Uncertainty Analysis](docs/tutorials/uncertainty_analysis.md) | Monte Carlo and sensitivity |
| [API Reference](docs/api/README.md) | Complete API documentation |
| [01 - Quick Start](docs/examples/01_quickstart.ipynb) | Basic plant sizing and cost analysis |
| [02 - Regional Analysis](docs/examples/02_regional_analysis.ipynb) | Analyze OTEC potential for a region |
| [03 - Uncertainty Analysis](docs/examples/03_uncertainty_analysis.ipynb) | Monte Carlo, Tornado, Sobol |
## Project Structure
```
OTEX/
├── otex/ # Main package
│ ├── core/ # Thermodynamic cycles and fluids
│ ├── plant/ # Plant sizing and operation
│ ├── economics/ # Cost models and LCOE
│ ├── analysis/ # Uncertainty and sensitivity
│ ├── data/ # Data loading (CMEMS, NetCDF)
│ └── config.py # Configuration management
├── scripts/ # CLI scripts
│ ├── regional_analysis.py
│ ├── global_analysis.py
│ └── uncertainty_analysis.py
├── tests/ # Test suite
├── docs/ # Documentation
└── data/ # Reference data files
```
## Configuration Options
| Parameter | Options | Default |
|-----------|---------|---------|
| `cycle_type` | `rankine_closed`, `rankine_open`, `rankine_hybrid`, `kalina`, `uehara` | `rankine_closed` |
| `fluid_type` | `ammonia`, `r134a`, `r245fa`, `propane`, `isobutane` | `ammonia` |
| `cost_level` | `'low_cost'`, `'high_cost'`, or a `CostScheme` object | `'low_cost'` |
| `p_gross` | Any negative value (kW) | `-136000` |
| `year` | 1993-2023 | `2020` |
### Custom Cost Schemes
Beyond the two built-in scenarios you can define your own cost parameters with `CostScheme` and Python's standard `dataclasses.replace()`:
```python
from otex.economics import CostScheme, LOW_COST
from dataclasses import replace
# Modify specific parameters of an existing scheme
my_scheme = replace(LOW_COST, turbine_coeff=400, opex_fraction=0.04)
# Use it everywhere cost_level is accepted
inputs = parameters_and_constants(p_gross=-100000, cost_level=my_scheme)
costs, capex, opex, lcoe = capex_opex_lcoe(plant, inputs, my_scheme)
```
All existing code that uses `cost_level='low_cost'` or `cost_level='high_cost'` continues to work unchanged.
## Requirements
- Python >= 3.9
- NumPy, Pandas, SciPy, Matplotlib
- xarray, netCDF4 (oceanographic data)
- tqdm (progress bars)
**Optional:**
- CoolProp (additional working fluids)
- SALib (Sobol sensitivity analysis)
## Acknowledgments
OTEX builds upon [pyOTEC](https://github.com/JKALanger/pyOTEC) by Langer et al. For the original methodology, see:
> Langer, J., Blok, K. *The global techno-economic potential of floating, closed-cycle ocean thermal energy conversion.* J. Ocean Eng. Mar. Energy (2023). https://doi.org/10.1007/s40722-023-00301-1
## Citation
If you use OTEX in your research, please cite:
```bibtex
@software{otex2024,
author = {Soto-Calvo, Manuel and OTEX Development Team},
title = {OTEX: Ocean Thermal Energy eXchange},
year = {2024},
publisher = {GitHub},
url = {https://github.com/msotocalvo/OTEX},
doi = {10.5281/zenodo.18428742}
}
```
## Studies usign OTEX:
- Soto Calvo M, and Lee HS., 2025. Ocean Thermal Energy Conversion (OTEC) Potential in Central American and Caribbean Regions: A Multicriteria Analysis for Optimal Sites. Applied Energy. 394: 126182. https://doi.org/10.1016/j.apenergy.2025.126182
## Contributing
We welcome contributions! Please see [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
---
<p align="center">
Made with ❤️ for ocean energy research
</p>
| text/markdown | OTEX Development Team | null | null | null | MIT | OTEC, ocean thermal energy, renewable energy, thermodynamic cycles, power plant, simulation | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: ... | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.20",
"pandas>=1.3",
"scipy>=1.7",
"matplotlib>=3.4",
"tables>=3.6",
"xarray>=0.19",
"netCDF4>=1.5",
"tqdm>=4.60",
"CoolProp>=6.4; extra == \"coolprop\"",
"SALib>=1.4.0; extra == \"uncertainty\"",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"ruff>=0.1; extr... | [] | [] | [] | [
"Homepage, https://github.com/otex-dev/otex",
"Documentation, https://otex.readthedocs.io",
"Repository, https://github.com/otex-dev/otex",
"Issues, https://github.com/otex-dev/otex/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:21:39.319152 | otex-0.1.2.tar.gz | 98,769 | cb/57/c265a7f45df6751f7da2ef9f4beed4e885fec47ac4bd0dbf135e8f991601/otex-0.1.2.tar.gz | source | sdist | null | false | 2a72b8e02458cd5a10ea5cb2651ecad5 | 57593e7db9502c032e9bccc23aa48abf917d86efd418706695bb5652db025da1 | cb57c265a7f45df6751f7da2ef9f4beed4e885fec47ac4bd0dbf135e8f991601 | null | [] | 259 |
2.3 | dycw-dotfiles | 0.4.26 | Dotfiles | # `dotfiles`
Dotfiles
## Setup machines:
# MacBook
```
curl -fsSL https://raw.githubusercontent.com/dycw/dotfiles/refs/heads/re-organize/install/remotes/macbook.py | python3
```
| text/markdown | Derek Wan | Derek Wan <d.wan@icloud.com> | null | null | null | null | [] | [] | null | null | >=3.12 | [] | [] | [] | [
"click>=8.3.1",
"dycw-utilities>=0.191.10",
"libcst>=1.8.6",
"click==8.3.1; extra == \"cli\"",
"dycw-utilities==0.191.10; extra == \"cli\"",
"libcst==1.8.6; extra == \"cli\""
] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:21:32.147140 | dycw_dotfiles-0.4.26-py3-none-any.whl | 3,430 | 9f/7c/1ec01d7ccde3b4e189b38a53e36a459b8b0a380691099e57f8e664f25546/dycw_dotfiles-0.4.26-py3-none-any.whl | py3 | bdist_wheel | null | false | 8b78c7871ae7106224e876a026e1d12c | b7efec0bf4c46b45bbb8eaf36fc4119ccc2c504933722f53e3a18a7940787773 | 9f7c1ec01d7ccde3b4e189b38a53e36a459b8b0a380691099e57f8e664f25546 | null | [] | 108 |
2.4 | mcp-proto-okn | 0.6.0 | MCP server for querying FRINK SPARKQL endpoints, a project by the NSF Prototype Open Knowledge Network (Proto-OKN) program. | # MCP Proto-OKN Server
[](https://opensource.org/licenses/BSD-3-Clause)
[](https://www.python.org/downloads/)
[](https://modelcontextprotocol.io/)
[](https://pypi.org/project/mcp-proto-okn/)
A Model Context Protocol (MCP) server providing seamless access to SPARQL endpoints with specialized support for the NSF-funded [Proto-OKN Project](https://www.proto-okn.net/) (Prototype Open Knowledge Network). This server enables querying the scientific knowledge graphs hosted on the [FRINK](https://frink.renci.org/) platform. In addition, third-party SPARQL endpoints can be queried.
## Natural Language Querying Across Knowledge Graphs with MCP
### [Video](https://www.youtube.com/watch?v=50L-tKCoXJE)
### [Presentation](https://nebigdatahub.org/wp-content/uploads/2026/01/MCP-Proto-OKN-Technical-Review.pdf)
## Features
- **🔗 FRINK Integration**: Automatic detection and documentation linking for FRINK-hosted knowledge graphs
- **🕸️ Proto-OKN Knowledge Graphs**: Optimized support for biomedical and scientific knowledge graphs, including:
- 🧬 Biology & Health
- 🌱 Environment
- ⚖️ Justice
- 🛠️ Technology & Manufacturing
- **⚙️ Flexible Configuration**: Support for both FRINK and custom SPARQL endpoints
- **📚 Automatic Documentation**: Registry links and metadata for Proto-OKN knowledge graphs
- **🌳 Ontology-driven Search Expansion**: Queries are automatically expanded using ontology hierarchies
- **🔗 Federated Query**: Prompts can query multiple endpoints
## Architecture
<img src="https://raw.githubusercontent.com/sbl-sdsc/mcp-proto-okn/main/docs/images/mcp_architecture.png"
alt="Tool Selector"
width="600">
The MCP Server Proto-OKN acts as a bridge between AI assistants (like Claude) and SPARQL knowledge graphs, enabling natural language queries to be converted into structured SPARQL queries and executed against scientific databases.
## Prerequisites
Before installing the MCP Server Proto-OKN, ensure you have:
- **Operating System**: macOS, Linux, or Windows
- **Client Application**: One of the following:
- Claude Desktop with Pro or Max subscription
- VS Code Insiders with GitHub Copilot subscription
## Installation
[Installation instructions for Claude Desktop and VS Code Insiders](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/installation.md)
## Quick Start
Once configured, you can start querying knowledge graphs through natural language prompts in Claude Desktop or VS Code chat interface.
### Select and Configure MCP Tools (Claude Desktop)
From the top menu bar:
```
1. Select: Claude->Settings->Connectors
2. Click: Configure for the MCP endpoints you want to use
3. Select Tool permissions: Always allow
```
In the prompt dialog box, click the `+` button:
```
1. Turn off Web search
2. Toggle MCP services on/off as needed
```
<img src="https://raw.githubusercontent.com/sbl-sdsc/mcp-proto-okn/main/docs/images/select_mcp_server.png"
alt="Tool Selector"
width="500">
Use @kg_name to refer to a specific knowledge graph in chat (for example, @spoke-genelab).
To create a transcript of a chat (see examples below), use the following prompt:
```Create a chat transcript```.
The transcript can then be downloaded in .md or .pdf format.
## Example Queries
### Knowledge Graph Overviews & Class Diagrams
Each link below points to a chat transcript that demonstrates how to generate a knowledge-graph overview and class diagram for a given Proto-OKN Theme 1 KG. The examples are grouped by domain area.
| 🧬 Biology & Health | 🌱 Environment | ⚖️ Justice | 🛠️ Technology & Manufacturing | NASA/NIH
|--------------------|---------------|-----------|-------------------------------|-------------|
| [biobricks-aopwiki](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/biobricks-aopwiki_overview.md) | [sawgraph](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/sawgraph_overview.md) | [ruralkg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/ruralkg_overview.md) | [securechainkg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/securechainkg_overview.md) | [nasa-gesdisc-kg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/nasa-gesdisc-kg_overview.md) |
| [biobricks-ice](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/biobricks-ice_overview.md) | [fiokg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/fiokg_overview.md) | [scales](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/scales_overview.md) | [sudokn](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/sudokn_overview.md) | [nde](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/nde_overview.md)
| [biobricks-mesh](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/biobricks-mesh_overview.md) | [geoconnex](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/geoconnex_overview.md) | [nikg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/nikg_overview.md) | | [gene-expression-atlas-okn](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/gene-expression-atlas-okn_overview.md) |
| [biobricks-pubchem-annotations](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/biobricks-pubchem-annotations_overview.md) | [spatialkg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spatialkg_overview.md) | [dreamkg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/dreamkg_overview.md) | |
| [biobricks-tox21](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/biobricks-tox21_overview.md) | [hydrologykg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/hydrologykg_overview.md) | | |
| [biobricks-toxcast](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/biobricks-toxcast_overview.md) | [ufokn](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/ufokn_overview.md) | | |
| [spoke-genelab](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spoke-genelab_overview.md) | [wildlifekn](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/wildlifekn_overview.md) | | |
| [spoke-okn](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spoke-okn_overview.md) | [climatemodelskg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/climatemodelskg_overview.md) | | |
| | [sockg](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/sockg_overview.md) | | |
### Use Cases
1. [**Spaceflight Missions (spoke-genelab)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spoke-genelab_breakdown.md)
2. [**Spaceflight Gene Expression Analysis (spoke-genelab, spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spoke_spaceflight_analysis.md)
3. [**Spaceflight Gene Expression with Literature Analysis (spoke-genelab, spoke-okn, PubMed)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/osd-161-sonnet-4.5.md)
4. [**Spaceflight Gene Expression with Open Targets MCP integration (spoke-genelab, Open Targets, PubMed)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spaceflight-gene-expression-analysis-open-targets.md)
5. [**Disease Prevalence in the US (spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/us_county_disease_prevalence.md)
6. [**Disease Prevalence - Socio-Economic Factors Correlation (spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/disease_socio_economic_correlation.md)
7. [**NIAID Data Exploration - COVID-19 Vaccine Research (nde)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/nde_COVID-19-Vaccine-Research.md)
8. [**Diabetic Nephropathy Meta-Analysis (gene-expression-atlas-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/diabetic-nephropathy-meta-analysis.md)
9. [**Contamination at Superfund Sites (spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/superfund-contaminants.md)
10. [**PFOA in Drinking Water (spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spoke_okn_pfoa_drinking_water.md)
11. [**Data about PFOA (spoke-okn, biobricks-toxcast)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/pfoa_data_spoke_okn_biobricks_toxcast.md)
12. [**Biological Targets for PFOA (biobricks-toxcast)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/biobricks_toxcast_PFOA_targets.md)
13. [**Criminal Justice Patterns (scales)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/scales_criminal_justice_analysis.md)
14. [**Drug Possession Charges (scales)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/scales_drug_possession.md)
15. [**Environmental Justice (sawgraph, scales, spatialkg, spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/environmental-justice-kg-analysis.md)
16. [**Rural Health Access (ruralkg, dreamkg, spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/rural-health-access-mapping.md)
17. [**Michigan Flooding Event (ufokn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/ufokn_michigan_flood.md)
18. [**Flooding and Socio-Economic Factors (ufokn, spatialkg, spoke-okn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/flooding-socioeconomic-correlation.md)
19. [**Philadelphia Area Incidents (nikg)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/nikg_philadelphia_incidents.md)
20. [**Mining Suppliers in North Dakota (sudokn)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/sudokn_mining_suppliers.md)
### Ontology-Driven Search Expansion
Queries are automatically expanded using ontology hierarchies (MONDO, HP, GO, UBERON, etc.) from the [Ubergraph KG](https://frink.renci.org/registry/kgs/ubergraph/) to include all descendant concepts, ensuring comprehensive retrieval without manual enumeration. For example, searching for "arthritic joint disease" automatically includes rheumatoid arthritis, osteoarthritis, ankylosing spondylitis, and all other subtypes.
1. [**Arthritic Joint Disease Datasets (nde)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/nde-arthritic_joint_disease_ontology_expansion.md)
2. [**Space Flight Studies Investigating Muscles (spoke-genelab)**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spoke-genelab_muscle_studies_ontology_expansion.md)
### Proto-OKN Integration Opportunities
1. [**Cross-KG Geolocation Data Exploration**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/cross-kg-geolocation-analysis.md)
2. [**Cross-KG Chemical Compound Data Exploration**](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/cross-kg-compound-analysis.md)
### Cross-Platform LLM Benchmarks
This section compares the results of two queries using Claude Desktop and VS Code Insiders with commons LLMs.
| Query | Claude Sonnet 4.5 | Claude Sonnet 4.5 | Gemini 3 Pro | Groq Code Fast 1 | GPT-5.2 |
|-------|-------------------------------|----------------------------|--------------|------------------|---------|
| **Spaceflight Missions** | [Claude Desktop](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spacex-missions-sonnet-4.5-claude.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spacex-missions-sonnet-4.5-vs-studio.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spacex-missions-Gemini-3-Pro.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spacex-missions-Gorc-Code-Fast-1.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/spacex-missions-GPT-5.2.md) |
| **Gene Expression Analysis** | [Claude Desktop](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/OSD-161-sonnet-4.5-claude.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/OSD-161-sonnet-4.5-vs-studio.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/OSD-161_Gemini-3-ProPreview-vs-studio.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/OSD-161-Groc-Code-Fact-1-vs-studio.md) | [VS Code](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/examples/OSD-161-GPT-5.2-vs-studio.md) |
## Benchmarks (in progress)
mcp-proto-okn vs. SPARQL Ground-Truth Evaluation
[Benchmarks](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/benchmarks.md)
## Building and Publishing (maintainers only)
[Instructions for building, testing, and publishing the mcp-proto-okn package on PyPI](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/build_publish.md)
## API Reference and Query Analysis System
[mcp-proto-okn server API](https://github.com/sbl-sdsc/mcp-proto-okn/blob/main/docs/api.md)
## Troubleshooting
**MCP server not appearing in Claude Desktop:**
- Ensure you've completely quit and restarted Claude Desktop (not just closed the window)
- Check that your JSON configuration is valid (attach your config file to a chat and ask it to fix any errors)
- Verify that `uvx` is installed and accessible in your PATH (which uvx)
**Connection errors:**
- Verify the SPARQL endpoint URL is correct and accessible
- Some endpoints may have rate limits or temporary downtime
**Performance issues:**
- Complex SPARQL queries may take time to execute
- Consider breaking down complex queries into smaller parts
## License
This project is licensed under the BSD 3-Clause License. See the [LICENSE](LICENSE) file for details.
## Citation
If you use MCP Server Proto-OKN in your research, please cite the following works:
```bibtex
@software{rose2025mcp-proto-okn,
title={MCP Server Proto-OKN},
author={Rose, P.W. and Nelson, C.A. and Saravia-Butler, A.M. and Shi, Y. and Baranzini, S.E.},
year={2025},
url={https://github.com/sbl-sdsc/mcp-proto-okn}
}
@software{rose2025spoke-genelab,
title={NASA SPOKE-GeneLab Knowledge Graph},
author={Rose, P.W. and Nelson, C.A. and Gebre, S.G. and Saravia-Butler, A.M. and Soman, K. and Grigorev, K.A. and Sanders, L.M. and Costes, S.V. and Baranzini, S.E.},
year={2025},
url={https://github.com/BaranziniLab/spoke_genelab}
}
```
### Related Publications
- Nelson, C.A., Rose, P.W., Soman, K., Sanders, L.M., Gebre, S.G., Costes, S.V., Baranzini, S.E. (2025). "Nasa Genelab-Knowledge Graph Fabric Enables Deep Biomedical Analysis of Multi-Omics Datasets." *NASA Technical Reports*, 20250000723. [Link](https://ntrs.nasa.gov/citations/20250000723)
- Sanders, L., Costes, S., Soman, K., Rose, P., Nelson, C., Sawyer, A., Gebre, S., Baranzini, S. (2024). "Biomedical Knowledge Graph Capability for Space Biology Knowledge Gain." *45th COSPAR Scientific Assembly*, July 13-21, 2024. [Link](https://ui.adsabs.harvard.edu/abs/2024cosp...45.2183S/abstract)
## Acknowledgments
### Funding
This work is in part supported by:
- **National Science Foundation** Award [#2333819](https://www.nsf.gov/awardsearch/showAward?AWD_ID=2333819): "Proto-OKN Theme 1: Connecting Biomedical information on Earth and in Space via the SPOKE knowledge graph"
### Related Projects
- [Proto-OKN Project](https://www.proto-okn.net/) - Prototype Open Knowledge Network initiative
- [FRINK Platform](https://frink.renci.org/) - Knowledge graph hosting infrastructure
- [Knowledge Graph Registry](https://frink.renci.org/registry/) - Catalog of available knowledge graphs
- [Model Context Protocol](https://modelcontextprotocol.io/) - AI assistant integration standard
- [Original MCP Server SPARQL](https://github.com/ekzhu/mcp-server-sparql/) - Base implementation reference
---
*For questions, issues, or contributions, please visit our [GitHub repository](https://github.com/sbl-sdsc/mcp-proto-okn).* | text/markdown | null | Peter W Rose <pwrose.ucsd@gmail.com>, Eric Zhu <ekzhu@users.noreply.github.com> | null | null | BSD-3-Clause | frink, knowledge graphs, mcp, proto-okn, sparql | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: BSD License",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"certifi>=2024.0.0",
"mcp>=1.6.0",
"sparqlwrapper>=2.0.0",
"mcp[cli]; extra == \"cli\"",
"typer>=0.12; extra == \"cli\""
] | [] | [] | [] | [
"Homepage, https://github.com/sbl-sdsc/mcp-proto-okn",
"Repository, https://github.com/sbl-sdsc/mcp-proto-okn",
"Issues, https://github.com/sbl-sdsc/mcp-proto-okn/issues"
] | uv/0.7.3 | 2026-02-19T01:20:49.367030 | mcp_proto_okn-0.6.0.tar.gz | 1,337,250 | d3/dc/026b164e91a0e0cccfc70d021e6018b02020f07122a9a19d7e56002e9dc9/mcp_proto_okn-0.6.0.tar.gz | source | sdist | null | false | e5f5876db50801cfed31f82a82203c31 | 3623d0e3374783465eea2b57fac0e9cf973c70cb2cbfda419f5acb02c3d2b7fe | d3dc026b164e91a0e0cccfc70d021e6018b02020f07122a9a19d7e56002e9dc9 | null | [
"LICENSE"
] | 362 |
2.4 | sonic-sdk | 0.1.0 | Multi-currency settlement engine with cryptographic receipt attestation for the SmartBlocks Network. | # Sonic SDK Installation Guide
| Package | Description | Version |
|---------|-------------|---------|
| **sonic-sdk** | Multi-currency settlement engine with cryptographic receipt attestation | 0.1.0 |
---
## Prerequisites
- Python 3.10+
- GitHub access to `ToweraiDev/sonic-pay` (private repo)
- One of: SSH key linked to GitHub, or a GitHub Personal Access Token (PAT)
---
## Install via SSH (recommended)
If you have SSH keys configured with GitHub:
```bash
pip install "sonic-sdk @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git"
```
With optional extras:
```bash
# Database support (SQLAlchemy, asyncpg, Alembic)
pip install "sonic-sdk[db] @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git"
# Redis support
pip install "sonic-sdk[redis] @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git"
# Everything
pip install "sonic-sdk[all] @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git"
```
## Install via Personal Access Token
For CI/CD pipelines or machines without SSH:
```bash
# Create a PAT at https://github.com/settings/tokens
# Classic: needs `repo` scope
# Fine-grained: needs "Contents" read access to ToweraiDev/sonic-pay
export GH_TOKEN=ghp_xxxxxxxxxxxx
pip install "sonic-sdk @ git+https://${GH_TOKEN}@github.com/ToweraiDev/sonic-pay.git"
```
## Install via GitHub CLI
If you have `gh` authenticated:
```bash
pip install "sonic-sdk @ git+https://$(gh auth token)@github.com/ToweraiDev/sonic-pay.git"
```
---
## Adding to your project
### requirements.txt
```
sonic-sdk @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git
```
Or with extras:
```
sonic-sdk[all] @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git
```
### pyproject.toml (pip/setuptools)
```toml
[project]
dependencies = [
"sonic-sdk @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git",
]
```
### pyproject.toml (Poetry)
```toml
[tool.poetry.dependencies]
sonic-sdk = {git = "ssh://git@github.com/ToweraiDev/sonic-pay.git"}
```
---
## Pin to a specific commit or tag
Append `@<ref>` to pin a version:
```bash
# Pin to a commit
pip install "sonic-sdk @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git@abc1234"
# Pin to a tag
pip install "sonic-sdk @ git+ssh://git@github.com/ToweraiDev/sonic-pay.git@v0.1.0"
```
---
## Local development
Clone and install in editable mode:
```bash
git clone git@github.com:ToweraiDev/sonic-pay.git
cd sonic-pay
python -m venv .venv
source .venv/bin/activate # Linux/macOS
# .venv\Scripts\activate # Windows
pip install -r requirements.txt # installs -e .[all,dev]
```
---
## Quick Start
```python
from sonic import Transaction, TxState, SonicReceipt, SbnClient
# Build a transaction through the state machine
tx = Transaction(tx_id="tx-001", merchant_id="m-acme")
event = tx.advance(TxState.RECEIVABLE_DETECTED, amount=100.00, currency="USD")
# Seal receipt to SBN for tamper-evident attestation
sbn = SbnClient(api_key="sbn_live_...")
sbn_hash = sbn.seal({"receipt_hash": event.receipt_hash})
```
### Core modules
```python
from sonic.core.engine import Transaction, TxState, TxEvent, InvalidTransition
from sonic.core.receipt_builder import SonicReceipt, ReceiptChain, canonical_hash
from sonic.core.finality_gate import FinalityGate, FinalityPolicy, FinalityStatus
from sonic.core.treasury import Treasury, ConversionQuote
from sonic.core.payout_executor import PayoutExecutor, PayoutInstruction, PayoutResult
from sonic.events.types import EventType
from sonic.events.emitter import EventEmitter
from sonic.sbn import SbnClient, SbnAttester, ReceiptCoupler
from sonic.sbn.frontier import SONIC_FRONTIER
from sonic.config import SonicSettings, settings
```
### Vendored SDKs
`sonic-sdk` vendors `sbn-sdk`, `snapchore-core`, and `dominion-sdk` — no separate
install needed.
```python
# Dominion payroll client (re-exported at top level)
from sonic import DominionSbnClient, DominionSonicClient
# Direct access to vendored packages
from sonic._vendor.sbn import SbnClient as RawSbnClient, SlotSummary
from sonic._vendor.snapchore import SmartBlock, SnapChoreChain, snapchore_capture
from sonic._vendor.dominion import DominionSbnClient, DominionSonicClient
```
---
## Optional Extras
| Extra | Packages | Use case |
|-------|----------|----------|
| `db` | sqlalchemy, asyncpg, alembic | Postgres persistence |
| `redis` | redis | Event bus / attestation queue |
| `server` | fastapi, uvicorn, psycopg2, python-jose | Running the Sonic HTTP API server |
| `all` | db + redis | Everything (without server) |
| `dev` | pytest, pytest-asyncio, ruff, mypy, python-dotenv | Development & testing |
---
## Dependencies
### Core (always installed)
- `httpx` >= 0.27.0
- `cryptography` >= 42.0
- `pydantic` >= 2.5
- `pydantic-settings` >= 2.1
### Vendored (included in package — no separate install)
- `sbn-sdk` 0.2.0 — SmartBlocks Network client
- `snapchore-core` 0.1.0 — Cryptographic integrity for stateful events
- `dominion-sdk` 0.1.0 — Sovereign Compression Payroll Router
| text/markdown | null | Tower Technologies <dev@towerai.dev> | null | null | null | sonic, settlement, smartblocks, sbn, snapchore, gec, payments | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Office/Business... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.27.0",
"cryptography>=42.0",
"pydantic>=2.5",
"pydantic-settings>=2.1",
"sqlalchemy[asyncio]>=2.0.0; extra == \"db\"",
"asyncpg>=0.29.0; extra == \"db\"",
"alembic>=1.13.0; extra == \"db\"",
"redis>=5.0.0; extra == \"redis\"",
"fastapi>=0.109; extra == \"server\"",
"uvicorn[standard]>=0.... | [] | [] | [] | [
"Repository, https://github.com/ToweraiDev/sonic-pay"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-19T01:20:18.898084 | sonic_sdk-0.1.0.tar.gz | 116,932 | 42/54/875f0e9e17fdc2dd31067862ed6a7774dc43950a4471601630167da7595c/sonic_sdk-0.1.0.tar.gz | source | sdist | null | false | 672ecc957763a1005390b4225ebc2f6b | 27c75923a0da8abb4b66821a2a3d59c42d5f5406fda001883dd6600e920b5254 | 4254875f0e9e17fdc2dd31067862ed6a7774dc43950a4471601630167da7595c | Apache-2.0 | [] | 308 |
2.4 | varshas-math-lib | 0.1.0 | A simple math library for basic arithmetic operations | # Varsha Math Lib
A simple Python math library for basic arithmetic operations.
## Features
- Addition
- Subtraction
- Multiplication
- Division
## Installation
pip install varsha-math-lib
## Usage
```python
from math_lib import add
print(add(5, 3))
| text/markdown | Varsha | null | null | null | null | null | [] | [] | null | null | >=3.7 | [] | [] | [] | [] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T01:19:28.038139 | varshas_math_lib-0.1.0.tar.gz | 1,667 | d1/a8/960ad0265491b5c72837a4f5537375061cedd8ec2f4a8c5d8df81a473abc/varshas_math_lib-0.1.0.tar.gz | source | sdist | null | false | df7ed804678b8fa092abcf2bf9349f32 | 31726c8ea16eefe5d175acf1eb579630b6099e1f4a085be120f0213179d90327 | d1a8960ad0265491b5c72837a4f5537375061cedd8ec2f4a8c5d8df81a473abc | null | [] | 266 |
2.4 | claude-dt | 0.4.0 | Actionable feedback from your Claude Code sessions | # dt - Claude Code DevTools
> Actionable intelligence from your Claude Code sessions. Know what happened, learn what to improve.
Analyze your Claude Code session logs to uncover inefficiency patterns, optimize context usage, improve prompt effectiveness, and maintain healthy project configuration. All offline, all local, zero telemetry.
[](https://pypi.org/project/claude-dt/)
[](https://www.python.org/downloads/)
[](./LICENSE)
[](#)
## Quick Start
Install from PyPI:
```bash
pip install claude-dt
```
Ingest your Claude Code session data into a local DuckDB:
```bash
dt ingest --since 7
```
Generate your first report:
```bash
dt report
```
That's it. Everything runs offline on your machine.
## Features
- **Session Ingestion** - Parse JSONL session logs from `~/.claude/projects/` into a fast DuckDB analytical database
- **5 Powerful Analyzers** - Context efficiency, tool usage, prompt quality, anti-pattern detection, project health
- **Composite Scoring** - Get a 0-100 score for each dimension plus an overall health metric
- **Trend Analysis** - Track metrics over time with period-over-period comparison and sparkline charts
- **Multiple Output Formats** - Rich terminal output (colored tables, panels), Markdown for docs, JSON for automation
- **Export Tools** - Export any table as CSV, JSON, or Parquet for external analysis
- **Smart Recommendations** - Prioritized, actionable suggestions with ready-to-paste prompts
- **Web Dashboard** - Interactive browser UI with scores, charts, filtering, and drill-down
- **Raw SQL Access** - Power users can query the DuckDB directly with `dt query`
- **Read-Only Analysis** - Never modifies Claude Code files or configuration
- **Zero Configuration** - Works out of the box with sensible defaults
## Sample Output
```
╭──────────────────────────── Scores ────────────────────────────╮
│ Overall: 70/100 │
│ Context: 59/100 Tools: 82/100 Prompts: 62/100 Health: 80/100 │
╰────────────────────────────────────────────────────────────────╯
╭──────────────────── Last 7 Days ──────────────╮
│ Sessions: 63 │
│ Messages: 13,391 │
│ Tool calls: 4,731 (282 errors) │
│ Tokens: 420,095 (cache efficiency: 100%) │
│ Avg turns/session: 87.0 │
│ Projects: 13 │
╰──────────────────────────────────────────────╯
```
## Installation
### From PyPI (recommended)
```bash
pip install claude-dt
dt ingest --since 7
dt report
```
### Development Installation
```bash
git clone https://github.com/BioInfo/claude-dt.git
cd claude-dt
python3 -m venv .venv
source .venv/bin/activate # or .venv\Scripts\activate on Windows
pip install -e ".[dev]"
dt report
```
## Commands
### Core Commands
#### dt ingest
Parse Claude Code session JSONL files into DuckDB. Runs incrementally by default (skips already-ingested sessions).
```bash
dt ingest # Ingest all new sessions
dt ingest --since 7 # Ingest last 7 days only
dt ingest --since 30 # Ingest last 30 days
dt ingest --project myapp # Filter to a specific project
dt ingest --reset # Full reset: delete database and re-ingest everything
```
Options:
- `--since N` - Only ingest sessions from the last N days (faster for iteration)
- `--project NAME` - Filter to a specific project directory
- `--reset` - Delete the existing database and ingest from scratch
#### dt report
Generate a comprehensive insights report covering all dimensions. Default period is 7 days.
```bash
dt report # Last 7 days, terminal format
dt report --period 14 # Last 14 days
dt report --period 30 # Last 30 days
dt report --format json # JSON output for scripting
dt report --format markdown # Markdown for documentation
```
Options:
- `--period N` - Analyze the last N days (default: 7)
- `--format FORMAT` - Output format: `text` (default), `json`, or `markdown`
Output includes:
- Composite scores (context, tools, prompts, health, overall)
- Session overview and project statistics
- Model usage distribution
- Subagent routing patterns
- Context efficiency and cache hit rates
- Tool frequency and error rates
- Prompt patterns
- Anti-patterns detected
#### dt context
Analyze context usage patterns. Identifies duplicate file reads, hotspots, and inefficient access patterns.
```bash
dt context # Last 7 days
dt context --days 14 # Last 14 days
```
Shows:
- Files read multiple times within single sessions
- Most-accessed files (context hotspots)
- Duplicate read frequencies
- Sessions with high fragmentation
#### dt tools
Analyze tool usage distribution and error rates.
```bash
dt tools # Last 7 days
dt tools --days 30 # Last 30 days
```
Shows:
- Most and least used tools
- Tool error rates and failure types
- Subagent launches and model routing
- Tool chain patterns
#### dt prompts
Analyze prompt effectiveness and patterns.
```bash
dt prompts # Last 7 days
dt prompts --days 14 # Last 14 days
```
Shows:
- Prompt pattern distribution
- Average prompt length and word count
- Prompt effectiveness by project
- High-performing vs low-performing patterns
#### dt antipatterns
Detect known inefficiency anti-patterns.
```bash
dt antipatterns # Last 7 days
dt antipatterns --days 30 # Last 30 days
```
Detects:
- Edit-retry cycles (failed edits that succeed after retry)
- High compaction rates (context overload)
- Duplicate file reads in single session (context forgot)
- Stale sessions without /clear
- Tool call immediately after identical tool call
#### dt trends
Show usage trends with period-over-period comparison.
```bash
dt trends # Compare last 7d vs previous 7d
dt trends --days 30 # Compare last 15d vs previous 15d
```
Shows:
- Metric trends (sessions, messages, tools, tokens, errors)
- Percentage change from previous period
- Daily sparkline charts
- Model shift analysis
#### dt health
Project configuration health check. Audits your CLAUDE.md and project setup.
```bash
dt health # Last 30 days
dt health --days 60 # Last 60 days
dt health --fix # Generate CLAUDE.md suggestions
```
Shows:
- Files frequently re-read (CLAUDE.md candidates)
- Context fragmenters (large files causing repeated reads)
- Error-prone projects
- High-access projects
Use `--fix` to generate suggestions for improving your CLAUDE.md based on actual file access patterns.
#### dt recommend
Generate prioritized recommendations with ready-to-paste prompts.
```bash
dt recommend # Last 7 days, all categories
dt recommend --days 14 # Last 14 days
dt recommend --category context # Only context-related recs
dt recommend --format json # JSON output
dt recommend --format markdown # Markdown output
```
Categories: `all`, `context`, `session`, `model`, `prompt`, `tools`
Each recommendation includes:
- Priority level (high, medium, low)
- Description of the issue
- Concrete action to take
- A prompt you can paste directly into Claude Code
#### dt serve
Start an interactive web dashboard in your browser.
```bash
dt serve # Start on http://localhost:8042
dt serve --port 9000 # Custom port
dt serve --dev # API-only mode (for frontend development)
```
The dashboard provides:
- Score gauges for all four dimensions
- Interactive charts with zoom and filtering
- Sortable, paginated tables
- Recommendation cards with copy-to-clipboard prompts
- Session browser with detail drill-down
- Trend comparison with period switching
**Frontend development:** Run `dt serve --dev` for the API, then `cd web && npm run dev` for hot-reloading on port 5173.
#### dt session
View details of a single session or list recent sessions.
```bash
dt session list # Show recent 20 sessions
dt session abc123 # Details for session starting with abc123 (partial match OK)
```
Shows:
- Session summary, duration, project
- Message count and turns
- Tool usage breakdown
- Model information
- Token consumption and cache efficiency
- Subagent count
#### dt status
Show database status: table counts, file size, last ingest time.
```bash
dt status
```
#### dt query
Run raw SQL queries against the DuckDB database. For power users.
```bash
dt query "SELECT * FROM sessions ORDER BY first_message_at DESC LIMIT 5"
dt query "SELECT tool_name, COUNT(*) FROM tool_calls GROUP BY tool_name"
```
Access to tables: `sessions`, `messages`, `tool_calls`, `subagents`, `file_access`, `prompts`, `daily_stats` and views: `session_efficiency`, `file_hotspots`.
#### dt export
Export a table as CSV, JSON, or Parquet.
```bash
dt export sessions # Export to dt-sessions.csv (default)
dt export sessions --format json # Export as JSON
dt export sessions --format parquet # Export as Parquet
dt export sessions -o output.csv # Specify output file
dt export sessions --days 7 # Only last 7 days
```
## Analyzers
### 1. Context Efficiency
Detects wasteful context usage patterns and opportunities for optimization.
**Signals:**
- Duplicate file reads within a session (file read, context compacted, file read again)
- High compaction frequency indicating context window saturation
- Cache hit ratio (how effectively Claude Code leverages prompt caching)
- Large files read repeatedly (context hotspots)
**What it scores:**
- Repeat read frequency (lower is better)
- Cache efficiency ratio (higher is better)
- Compaction rate per hour (lower is better)
- File hotspot concentration
**Score 0-100:** Composite of all signals. 80+ is excellent, 60-80 is acceptable, below 60 needs improvement.
### 2. Tool Usage
Identifies tool usage patterns and failure modes.
**Signals:**
- Most and least used tools
- Tool error rates (timeout, not found, invalid input)
- Tool chains (what tools follow what tools)
- Subagent model selection effectiveness
**What it scores:**
- Error rate distribution (lower is better)
- Tool diversity (using the right tool for the job)
- Subagent routing efficiency
- Model selection for subagents
**Score 0-100:** Tools should have <5% error rate. Good subagent routing with appropriate model selection scores higher.
### 3. Prompt Quality
Measures how effectively your prompts convey intent and task specification.
**Signals:**
- Turns-to-completion (fewer turns = better prompt clarity)
- Clarification requests from Claude Code
- Prompt length vs outcome correlation
- Pattern effectiveness comparison
**What it scores:**
- Average turns per task (lower is better)
- Clarification frequency (lower is better)
- Prompt specificity signals (presence of file names, line numbers, etc.)
- Consistency of prompt structure
**Score 0-100:** Prompts that consistently complete in 1-2 turns score high. Prompts requiring 5+ turns for similar tasks score lower.
### 4. Anti-Pattern Detection
Flags known inefficiency patterns and behavioral anti-patterns.
**Patterns detected:**
- **Edit-retry cycle** - Edit fails multiple times on same file before succeeding (indicates wrong old_string)
- **Context overload** - 4+ compactions in a single session (context window saturation)
- **Duplicate reads** - Same file read multiple times in single session (context forgot)
- **Stale sessions** - Sessions running 2+ hours without /clear (context pollution)
- **Retry spam** - Identical tool call made twice in a row without change
**Impact:** Each pattern is scored by frequency and severity. Frequent patterns lower the health score.
### 5. Project Health
Audits your project configuration and CLAUDE.md effectiveness.
**Checks:**
- Directories with high access frequency but no CLAUDE.md (documentation gaps)
- CLAUDE.md files not updated recently (drift from current usage)
- Large files read repeatedly (should be in CLAUDE.md or split)
- Projects with high tool error rates (possible tool misconfiguration)
- Missing .claudeignore for generated directories
**Output:**
- CLAUDE.md candidates (files to document)
- Context fragmenters (files causing repeated reads)
- Error-prone projects (needs investigation)
- High-access projects (good automation candidates)
**Score 0-100:** Complete, up-to-date CLAUDE.md with all hotspots documented scores high. Missing documentation, stale config, and large fragmenters lower the score.
## Data Model
dt reads from Claude Code's session storage and creates a local DuckDB database for fast analysis.
### Source Data
Claude Code stores session data in `~/.claude/projects/<project-path>/`:
- `<session-id>.jsonl` - Session index with summary and message UUIDs
- `<session-id>/subagents/agent-<id>.jsonl` - Full subagent execution traces
- `<session-id>/tool-results/toolu_<id>.txt` - Large tool outputs stored separately
Additional sources:
- `~/.claude/stats-cache.json` - Aggregated daily statistics (model usage, session counts)
- `~/.claude/history.jsonl` - User prompt history with timestamps and project paths
### Database Location
dt creates and maintains a single DuckDB file:
```
~/.dt/dt.duckdb
```
All analysis runs locally against this file. Nothing is sent to the cloud.
### Core Tables
- `sessions` - Session metadata (project, duration, message counts, models)
- `messages` - All messages in all sessions (user, assistant, progress, summary)
- `tool_calls` - Tool invocations with inputs and error status
- `subagents` - Subagent launches with model selection and token usage
- `file_access` - File read/write/edit/glob operations with repeat detection
- `prompts` - User prompts with classification and word count
- `daily_stats` - Aggregated daily activity metrics
For full schema details, see the [PRD](./docs/PRD.md).
## Requirements
- **Python 3.10+** - dt requires modern Python
- **Claude Code** - Any version that generates session JSONL (v2.0+)
- **Disk space** - ~50MB per 1,000 sessions (DuckDB is highly compressed)
No API keys needed. No network access required. Fully offline.
## Design Principles
1. **Read-only by default** - dt never modifies Claude Code files, session logs, or configuration. It only reads and analyzes.
2. **Fast** - DuckDB provides sub-second analytical queries over thousands of sessions.
3. **Offline** - No API calls, no telemetry, no network access. Everything runs locally on your machine.
4. **Progressive** - Works with zero configuration. Power users can tune thresholds and run custom queries.
5. **Transparent** - Full SQL access via `dt query` means no black-box analysis.
## Troubleshooting
### DuckDB Lock Errors
DuckDB only allows one write connection at a time. If you see lock errors:
```bash
# Check for hanging processes
ps aux | grep python | grep dt
# Kill them
pkill -f "python.*dt"
# Remove lock files
rm -f ~/.dt/dt.duckdb.wal ~/.dt/dt.duckdb.lock
```
### No Data After Ingest
Make sure Claude Code is storing session data where dt expects it:
```bash
# Check if session files exist
ls -la ~/.claude/projects/ | head
```
If empty, you may not have any Claude Code sessions yet. Create a new Claude Code session to generate session data.
### Database Corruption
If the database becomes corrupted:
```bash
dt ingest --reset
```
This will delete the existing database and re-ingest all sessions from scratch (takes a few minutes for large histories).
## Contributing
dt is open-source. Contributions welcome:
- Report bugs and feature requests on GitHub
- Submit pull requests for bug fixes and new analyzers
- Suggest improvements to scoring algorithms
- Help with documentation and examples
See [CONTRIBUTING.md](./CONTRIBUTING.md) for development setup and guidelines.
## Performance Notes
### Ingest Time
- Full ingest of 1,400+ sessions from 3.9GB of JSONL takes ~10-15 minutes on M4 Mac
- Incremental ingest (last 7 days) typically completes in seconds
- Use `--since N` for fast iteration during development
### Query Speed
- All `dt` commands complete in <1 second (after initial database setup)
- DuckDB uses columnar compression, making analytical queries fast
- Database file size typically 50MB per 1,000 sessions
### Disk Usage
dt stores data efficiently:
- `~/.dt/dt.duckdb` - Compressed DuckDB file (50MB per 1,000 sessions)
- No temporary files or caching beyond the database
- Safe to delete and regenerate anytime
## Roadmap
### Phase 1: Foundation (v0.1) - COMPLETE
- JSONL session parser
- DuckDB schema and incremental ingestion
- `dt ingest`, `dt query`, `dt export` commands
### Phase 2: Core Analyzers (v0.2) - COMPLETE
- Context efficiency, tool usage, prompts, anti-patterns, health analyzers
- Composite scoring system
- `dt report` command
### Phase 3: Reports & Output (v0.3) - COMPLETE
- Rich terminal output (colors, tables, panels)
- Markdown and JSON output formats
- `dt session`, `dt trends`, `dt health` commands
### Phase 4: Tests & Documentation (v0.3) - COMPLETE
- 194 tests with full coverage
- Comprehensive README and contributing guide
### Phase 5: Recommendations (v0.3) - COMPLETE
- `dt recommend` with prioritized, actionable suggestions
- Ready-to-paste prompts for each recommendation
- Category filtering (context, session, model, prompt, tools)
### Phase 6: Web Dashboard (v0.4) - COMPLETE
- `dt serve` with FastAPI backend and React frontend
- Interactive charts (Recharts), sortable tables, pagination
- Score gauges, trend comparison, session browser
- Recommendation cards with copy-to-clipboard
### Phase 7: Community & Extensions (v0.5+)
- PyPI package distribution
- CI/CD and cross-platform testing
- Hook integration for live insights during sessions
- Custom analyzer plugin system
## Related Tools
dt complements other Claude Code analysis tools:
| Tool | Purpose | Relationship |
|------|---------|--------------|
| [ccusage](https://github.com/ryoppippi/ccusage) | Token and cost tracking | dt adds pattern detection and recommendations on top |
| [claude-devtools](https://github.com/matt1398/claude-devtools) | Real-time context visualization | Complements dt's historical analysis |
| [claude-code-otel](https://github.com/ColeMurray/claude-code-otel) | Prometheus/Grafana observability | dt provides similar insights without infrastructure |
## License
MIT - See [LICENSE](./LICENSE)
## Support
- **Documentation** - See [docs/PRD.md](./docs/PRD.md) for detailed design and architecture
- **Issues** - Report bugs and request features on GitHub
- **Questions** - Open a discussion on GitHub
---
Made with care for Claude Code users who want to understand and optimize their workflow.
| text/markdown | Justin Johnson | null | null | null | null | analytics, claude-code, developer-tools, devtools, llm | [
"Development Status :: 3 - Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Topic :: Software Development :: Quality Assurance"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"click>=8.0",
"duckdb>=1.0",
"fastapi>=0.104",
"rich>=13.0",
"uvicorn[standard]>=0.24",
"pytest-cov; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T01:18:30.632992 | claude_dt-0.4.0.tar.gz | 116,066 | 4f/bf/92b87c773a94bf8760baf10411b95e5517864f97593787a92b43c9922be4/claude_dt-0.4.0.tar.gz | source | sdist | null | false | e5acd2d687455363a83d0d2f485d68bd | e2fcf6ab2ba8b00def3fe0bf294682dbd8e60d65cfc46301da424b8228cf1d5d | 4fbf92b87c773a94bf8760baf10411b95e5517864f97593787a92b43c9922be4 | MIT | [
"LICENSE"
] | 263 |
2.4 | swayamml | 0.1.0 | Multi-agent ML pipeline — automated machine learning with LangGraph + LLMs | # AgenticML
Multi-agent ML pipeline — automated machine learning powered by LangGraph and LLMs.
AgenticML assembles a team of specialised AI agents (Planner, Profiler, Cleaner, Featurizer, Modeler, Evaluator, Critic, Reporter) that collaborate iteratively to build, evaluate, and refine ML models on your data.
## Installation
```bash
pip install swayamml
```
**Optional providers** (only install the one you use):
```bash
pip install swayamml[anthropic] # Claude models
pip install swayamml[google] # Gemini models
pip install swayamml[boost] # XGBoost + LightGBM
pip install swayamml[all] # Everything
```
## Quick Start
### Python API
```python
from agenticml import ml
# Minimal — target and problem type are auto-detected
result = ml.run("data.csv")
# Explicit options
result = ml.run(
"data.csv",
target="price",
problem_type="regression",
metric="rmse",
model="gpt-4o", # or "claude-3-sonnet-20240229", "gemini-pro"
api_key="sk-...", # optional — falls back to env var
verbose=True, # print LLM prompts & responses
max_iterations=3,
)
```
### CLI
```bash
# Uses OPENAI_API_KEY from environment
agenticml --file data.csv --target price --verbose
# Specify model and key
agenticml --file data.csv --model claude-3-sonnet-20240229 --api-key sk-ant-...
# All options
agenticml --file data.csv \
--target label \
--problem_type classification \
--metric f1 \
--model gpt-4o \
--max_iterations 3 \
--verbose \
--stream
```
You can also run via module:
```bash
python -m agenticml --file data.csv
```
## LLM Provider Support
The provider is **auto-detected** from the model name:
| Model prefix | Provider | Env variable | Install extra |
|---|---|---|---|
| `gpt-*`, `o1*`, `o3*` | OpenAI | `OPENAI_API_KEY` | *(included)* |
| `claude-*` | Anthropic | `ANTHROPIC_API_KEY` | `pip install swayamml[anthropic]` |
| `gemini-*` | Google | `GOOGLE_API_KEY` | `pip install swayamml[google]` |
Pass the key directly or set the environment variable:
```bash
export OPENAI_API_KEY=sk-...
```
## Pipeline Architecture
```
Planner → Profiler → Cleaner → Featurizer → Modeler → Evaluator → Critic
↓
(blocking issues?)
↓ yes ↓ no
Orchestrator Reporter
↓
(next iteration)
```
Each run produces:
- `report.md` — human-readable summary
- `run_manifest.json` — full reproducibility metadata
- Trained models, evaluation plots, and intermediate data in the `runs/` directory
## Verbose Mode
Use `--verbose` (CLI) or `verbose=True` (Python) to see exactly what each agent sends to the LLM and what it gets back — useful for debugging and understanding pipeline decisions.
## License
MIT
| text/markdown | AgenticML Contributors | null | null | null | MIT | machine-learning, automl, agents, langgraph, llm | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | >=3.10 | [] | [] | [] | [
"langgraph",
"langchain-openai",
"langchain-core",
"openai",
"pandas",
"numpy",
"scikit-learn",
"matplotlib",
"seaborn",
"joblib",
"openpyxl",
"python-dotenv",
"imbalanced-learn",
"langchain-anthropic; extra == \"anthropic\"",
"langchain-google-genai; extra == \"google\"",
"xgboost; ex... | [] | [] | [] | [
"Homepage, https://github.com/VedavrathP/AgenticML",
"Repository, https://github.com/VedavrathP/AgenticML"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:18:28.176790 | swayamml-0.1.0.tar.gz | 79,165 | 19/27/ce633a10b42af1f7b61db76d8d256f1d4dc314ae72bc6bfd834088028566/swayamml-0.1.0.tar.gz | source | sdist | null | false | 13138112a2166cfc6c6e2a5b3b14e63b | 9b63b8b0c13753a3fe512914133794fde3d47a7f87d327578c91581132108da5 | 1927ce633a10b42af1f7b61db76d8d256f1d4dc314ae72bc6bfd834088028566 | null | [
"LICENSE"
] | 261 |
2.4 | agentcert | 0.3.0 | Bitcoin-anchored identity certificates for AI agents | # AgentCert
Bitcoin-anchored identity certificates for AI agents.
AgentCert is the open-source Python implementation of **AIT-1** (Agent Identity Certificates) from the Agent Internet Trust protocol. It lets developers create cryptographically signed, Bitcoin-anchored identity certificates that bind a **creator** (human or company) to an **agent** (autonomous software) — with verifiable metadata, capabilities, constraints, and a risk tier.
Every certificate is signed with ECDSA/secp256k1, hashed with SHA-256, and optionally anchored to Bitcoin via OP_RETURN. Any third party can verify the certificate using only math and the blockchain.
**Proven on Bitcoin testnet:** [`6b3b8cd6...`](https://blockstream.info/testnet/tx/6b3b8cd6624d833e98add57823a7a8ba72134a9de4aae6b7eb7617ebd7cb771c)
## Install
```bash
pip install agentcert
```
Or from source:
```bash
git clone https://github.com/shaleenchauhan/agentcert.git
cd agentcert
pip install -e ".[dev]"
```
Requires Python 3.11+. Dependencies: `cryptography`, `requests`, `click`.
Optional extras:
```bash
pip install agentcert[langchain] # LangChain integration
pip install agentcert[service] # Anchoring service (FastAPI + uvicorn)
pip install agentcert[client] # SDK client (httpx)
```
## Quickstart
```python
import agentcert
# Generate key pairs
creator_keys = agentcert.generate_keys()
agent_keys = agentcert.generate_keys()
# Create a signed certificate
cert = agentcert.create_certificate(
creator_keys=creator_keys,
agent_keys=agent_keys,
name="procurement-agent-v1",
platform="langchain",
model_hash="sha256:a1b2c3d4e5f6",
capabilities=["procurement", "negotiation"],
constraints=["max-transaction-50000-usd"],
risk_tier=3,
expires_days=90,
)
# Verify it
result = agentcert.verify(cert)
assert result.valid
print(result.status) # "VALID"
# Save to disk
agentcert.save_certificate(cert, "agent.cert.json")
agentcert.save_keys(creator_keys, "creator.keys.json")
```
## CLI
AgentCert ships a full command-line interface:
```bash
# Generate keys
agentcert keygen -o creator.keys.json
agentcert keygen -o agent.keys.json
# Create a certificate
agentcert create \
--creator-keys creator.keys.json \
--agent-keys agent.keys.json \
--name "my-agent" \
--platform "langchain" \
--capabilities "procurement,negotiation" \
--constraints "max-50k-usd" \
--risk-tier 3 \
--expires 90d \
-o cert.json
# Inspect it
agentcert inspect cert.json
# Verify it
agentcert verify cert.json
# Update (add capabilities, new version in the chain)
agentcert update cert.json \
--creator-keys creator.keys.json \
--add-capability "invoicing" \
-o cert-v2.json
# Revoke
agentcert revoke cert-v2.json \
--creator-keys creator.keys.json \
--reason "Decommissioned" \
-o revoke.json
# Verify the full chain
agentcert verify-chain cert.json cert-v2.json revoke.json
# --- Audit Trail ---
# Create an audit trail bound to a certificate
agentcert audit create cert.json --agent-keys agent.keys.json -o trail.json
# Log actions
agentcert audit log trail.json --agent-keys agent.keys.json \
--action-type API_CALL --summary "Called weather API" \
--detail '{"url": "https://api.weather.com", "status": 200}'
agentcert audit log trail.json --agent-keys agent.keys.json \
--action-type DECISION --summary "Selected cheapest vendor"
agentcert audit log trail.json --agent-keys agent.keys.json \
--action-type TRANSACTION --summary "Placed order for 42 widgets" \
--detail '{"vendor": "Acme", "amount": 42.0}'
# Verify the trail (with optional certificate binding)
agentcert audit verify trail.json --cert cert.json
# Inspect the trail
agentcert audit inspect trail.json --entries
```
## SDK API
All functions are available at the top level — no submodule imports needed.
### Keys
```python
creator_keys = agentcert.generate_keys()
agentcert.save_keys(creator_keys, "creator.keys.json")
creator_keys = agentcert.load_keys("creator.keys.json")
# Derive Bitcoin address (for funding anchor transactions)
address = agentcert.derive_bitcoin_address(creator_keys, network="testnet")
```
### Certificates
```python
cert = agentcert.create_certificate(
creator_keys=creator_keys,
agent_keys=agent_keys,
name="my-agent",
platform="langchain",
model_hash="sha256:...",
capabilities=["task-a", "task-b"],
constraints=["spending-limit-1000"],
risk_tier=2,
expires_days=90,
)
agentcert.save_certificate(cert, "agent.cert.json")
cert = agentcert.load_certificate("agent.cert.json")
```
### Verification
The verifier runs 6 checks (all must pass for `VALID`):
1. **cert_id integrity** — SHA-256(body) matches cert_id
2. **creator_id derivation** — SHA-256(creator_public_key) matches creator_id
3. **agent_id derivation** — SHA-256(agent_public_key) matches agent_id
4. **Creator signature** — ECDSA verification against creator_public_key
5. **Anchor integrity** — certificate hash matches the anchored hash (if receipt provided)
6. **Expiration** — current time < expires
```python
result = agentcert.verify(cert) # without anchor
result = agentcert.verify(cert, receipt) # with anchor receipt
print(result.status) # "VALID" or "INVALID"
print(result.valid) # True / False
for check in result.checks:
print(f"[{'PASS' if check.passed else 'FAIL'}] {check.name}: {check.detail}")
```
### Chain Operations
Certificates form a linked chain: create → update → ... → revoke.
```python
# Update (carries over unchanged fields)
updated = agentcert.update_certificate(
previous_cert=cert,
creator_keys=creator_keys,
capabilities=["procurement", "negotiation", "invoicing"],
)
# Revoke (terminates the chain)
revocation = agentcert.revoke_certificate(
previous_cert=updated,
creator_keys=creator_keys,
reason="Decommissioned",
)
# Verify the full chain
chain_result = agentcert.verify_chain([cert, updated, revocation])
print(chain_result.status) # "REVOKED"
print(chain_result.valid) # True (REVOKED is a valid terminal state)
```
### Audit Trail
Create a tamper-evident log of every action an agent takes, cryptographically signed and hash-chained:
```python
# Create an audit trail bound to a certificate
trail = agentcert.create_audit_trail(cert, agent_keys)
# Log actions (each entry is signed by the agent and chained to the previous)
agentcert.log_action(
trail, agent_keys,
action_type=agentcert.ActionType.API_CALL,
action_summary="Queried vendor pricing API",
action_detail={"url": "https://api.vendors.example/prices", "status": 200},
)
agentcert.log_action(
trail, agent_keys,
action_type=agentcert.ActionType.DECISION,
action_summary="Selected cheapest vendor: Acme Corp",
)
agentcert.log_action(
trail, agent_keys,
action_type=agentcert.ActionType.TRANSACTION,
action_summary="Placed purchase order for 500 widgets",
action_detail={"vendor": "Acme Corp", "quantity": 500, "total": 6250.00},
)
# Verify the full trail (11 checks)
result = agentcert.verify_audit_trail(trail, cert)
print(result.status) # "VALID"
# Verify a single entry (6 checks)
entry_result = agentcert.verify_audit_entry(trail.entries[0], cert)
# Inspect
info = agentcert.get_trail_info(trail)
print(info.entry_count) # 3
# Filter entries
api_calls = agentcert.get_trail_entries(trail, action_type=agentcert.ActionType.API_CALL)
recent = agentcert.get_trail_entries(trail, start=1, end=2)
# Save / Load
agentcert.save_trail(trail, "trail.json")
trail = agentcert.load_trail("trail.json")
```
Action types: `API_CALL`, `TOOL_USE`, `DECISION`, `DATA_ACCESS`, `TRANSACTION`, `COMMUNICATION`, `ERROR`, `CUSTOM`.
Entry verification runs 6 checks: entry_id integrity, agent_id derivation, agent signature, sequence validity, timestamp validity, and certificate binding.
Trail verification runs 11 checks: non-empty trail, trail_id/cert_id/agent consistency, first-entry linkage, hash-chain integrity, sequence continuity, timestamp ordering, all entry IDs, all signatures, and certificate binding.
### Merkle Batching
Batch multiple audit entries into a Merkle tree and anchor the root in a single Bitcoin transaction. Any individual entry is then independently provable against the on-chain root via its O(log n) Merkle proof.
Without batching: 1,000 entries = 1,000 Bitcoin transactions (~$5,000 in fees).
With batching: 1,000 entries = 1 Bitcoin transaction (~$5 in fees).
```python
# Batch all trail entries into a Merkle tree
batch, tree = agentcert.create_batch_from_trail(trail)
print(f"Merkle root: {batch.merkle_root}")
print(f"Items: {batch.item_count}")
# Anchor the batch root to Bitcoin (1 transaction for all entries)
batch = agentcert.anchor_batch(batch, creator_keys=creator_keys, network="testnet")
print(f"Anchored: {batch.anchor_receipt.txid}")
# Get proof for a specific entry
entries = agentcert.get_trail_entries(trail)
proof = agentcert.get_proof_for_entry(entries[3], tree, batch)
print(f"Proof: {len(proof.siblings)} siblings") # O(log n) hashes
# Verify: is this entry anchored on Bitcoin?
result = agentcert.verify_entry_in_batch(entries[3], proof, batch, certificate=cert)
print(result.status) # "VALID"
# Save everything
agentcert.save_batch(batch, "batch.json")
agentcert.save_proofs(
{e.entry_id: agentcert.get_proof_for_entry(e, tree, batch) for e in entries},
"proofs.json",
)
# Later: verify from saved files
batch = agentcert.load_batch("batch.json")
proofs = agentcert.load_proofs("proofs.json")
result = agentcert.verify_batch_proof(entries[3].entry_id, proofs[entries[3].entry_id], batch)
```
You can also batch arbitrary items (hex hashes, bytes, or dicts):
```python
batch, tree = agentcert.create_batch(["aabb...", {"key": "value"}, raw_bytes])
```
CLI:
```bash
agentcert batch create trail.json -o batch.json
agentcert batch anchor batch.json --creator-keys ck.json --network testnet
agentcert batch verify batch.json --entry-id <hash>
agentcert batch inspect batch.json
agentcert batch proof batch.json --entry-id <hash> -o proof.json
```
### Anchoring Service
Run a service that receives signed audit entries, batches them into Merkle trees, and anchors roots to Bitcoin. Developers send signed entries to the API instead of managing Bitcoin transactions themselves.
**Trust model:** Private keys stay on the developer's machine. Entries are signed before being sent. The service cannot forge entries.
```bash
# Start the service
agentcert service start --port 8932 --network testnet
# Admin commands
agentcert service health
agentcert service stats
agentcert service force-batch
```
SDK client:
```python
from agentcert.client import AgentCertClient
with AgentCertClient("http://localhost:8932") as client:
# Register certificate
client.register_certificate(cert)
# Submit signed entries
result = client.submit_trail(trail)
print(f"Accepted: {result['accepted']}")
# Force a batch cycle
batch = client.force_batch()
# Get Merkle proof for an entry
proof = client.get_proof(entry_id)
if proof:
print(f"Siblings: {len(proof.siblings)}")
# Full verification via service
verification = client.verify_entry(entry_id)
print(f"Status: {verification['status']}")
# Health check
health = client.health()
```
API endpoints:
| Method | Path | Description |
|--------|------|-------------|
| POST | `/api/v1/certificates` | Register a certificate |
| GET | `/api/v1/certificates/{id}` | Get a certificate |
| POST | `/api/v1/entries` | Submit signed entries |
| GET | `/api/v1/entries/{id}` | Get an entry |
| GET | `/api/v1/trails/{id}` | Get trail entries |
| GET | `/api/v1/proofs/{id}` | Get Merkle proof |
| GET | `/api/v1/verify/{id}` | Full verification |
| GET | `/api/v1/batches/{id}` | Get batch details |
| GET | `/api/v1/batches/latest` | Latest batch |
| POST | `/api/v1/admin/force-batch` | Force batch cycle |
| GET | `/api/v1/health` | Health check |
| GET | `/api/v1/stats` | Statistics |
### Web Dashboard
The anchoring service includes a built-in web dashboard for browsing agents, audit trails, batches, and running verifications — no terminal needed.
Open `http://localhost:8932/dashboard` after starting the service.
**Pages:**
| Page | Path | Description |
|------|------|-------------|
| Overview | `/dashboard` | Stats cards, recent activity, recent batches |
| Agents | `/dashboard/agents` | All registered certificates with entry counts and risk tiers |
| Agent Detail | `/dashboard/agents/{cert_id}` | Certificate info + full audit trail table |
| Entry Detail | `/dashboard/entries/{entry_id}` | Entry info, verification panel, Merkle proof path, Bitcoin anchor |
| Batches | `/dashboard/batches` | All Merkle batches with anchor status |
| Batch Detail | `/dashboard/batches/{batch_id}` | Batch info + list of entries |
| Verify | `/dashboard/verify` | Paste an entry ID, verify instantly |
Server-rendered HTML with Jinja2 templates. No React, no npm, no build step — just HTML + CSS + minimal JavaScript.
### LangChain Integration
Add identity certificates and signed audit trails to any LangChain agent with a few lines of code. The middleware automatically captures all LLM calls, tool invocations, and agent decisions as signed audit entries. Works with both LangGraph agents and legacy `AgentExecutor`.
```python
from agentcert.integrations.langchain import AgentCertMiddleware
# Create middleware (generates certificate + audit trail)
middleware = AgentCertMiddleware(
creator_keys="creator.keys.json", # path or KeyPair
agent_keys="agent.keys.json", # path or KeyPair
agent_name="procurement-agent-v1",
capabilities=["procurement", "negotiation"],
constraints=["max-transaction-50000-usd"],
risk_tier=3,
)
# Pass the handler via config — works with any LangChain runnable
handler = middleware.get_handler()
result = agent.invoke(
{"messages": [{"role": "user", "content": "Find the cheapest supplier"}]},
config={"callbacks": [handler]},
)
# Verify the audit trail (11 checks)
verification = middleware.verify()
print(verification.status) # "VALID"
# Inspect entries
for entry in middleware.get_entries():
print(f"[{entry.sequence}] {entry.action_summary}")
# Filter by type
tools = middleware.get_entries(action_type=agentcert.ActionType.TOOL_USE)
# Save everything (certificate + trail)
middleware.save("./agent-audit/")
# Reload and continue logging
loaded = AgentCertMiddleware.load("./agent-audit/", agent_keys="agent.keys.json")
```
For legacy `AgentExecutor` objects, you can also use `wrap()` to inject the callback automatically:
```python
executor = middleware.wrap(executor)
result = executor.invoke({"input": "..."})
```
**Privacy:** LLM prompts, responses, and tool outputs are stored as SHA-256 hashes only — the trail proves what happened without exposing raw data.
**Log levels:** `"minimal"` (tools + decisions only), `"standard"` (default — adds LLM calls), `"verbose"` (adds chain events).
### Bitcoin Anchoring
Anchor a certificate to Bitcoin via an OP_RETURN transaction:
```python
# The creator's Bitcoin address must be funded first
address = agentcert.derive_bitcoin_address(creator_keys, network="testnet")
print(f"Fund this address: {address}")
# Anchor (builds, signs, and broadcasts a Bitcoin transaction)
receipt = agentcert.anchor(cert, creator_keys=creator_keys, network="testnet")
print(receipt.txid)
# Save the receipt for later verification
agentcert.save_receipt(receipt, "receipt.json")
receipt = agentcert.load_receipt("receipt.json")
```
The OP_RETURN payload is 38 bytes:
```
[AIT\0] protocol tag (4 bytes)
[0x01] version (1 byte)
[0x02] IDENTITY_CERT (1 byte)
[...] SHA-256 hash (32 bytes)
```
## Certificate Structure
```json
{
"ait_version": 1,
"cert_type": 1,
"cert_id": "<SHA-256 of body>",
"timestamp": 1739750000,
"expires": 1747526000,
"agent_public_key": "<33-byte compressed public key, hex>",
"agent_id": "<SHA-256 of agent_public_key>",
"creator_public_key": "<33-byte compressed public key, hex>",
"creator_id": "<SHA-256 of creator_public_key>",
"agent_metadata": {
"name": "my-agent",
"model_hash": "sha256:...",
"platform": "langchain",
"capabilities": ["procurement", "negotiation"],
"constraints": ["max-transaction-50000-usd"],
"risk_tier": 3
},
"previous_cert_id": null,
"creator_signature": "<ECDSA DER signature, hex>"
}
```
| Field | Description |
|-------|-------------|
| `cert_type` | 1 = CREATION, 2 = UPDATE, 3 = REVOCATION |
| `cert_id` | SHA-256 of the certificate body (all fields except `cert_id` and `creator_signature`) |
| `creator_signature` | ECDSA/secp256k1 signature over the same body |
| `previous_cert_id` | Links to the prior certificate in the chain (null for the first) |
## How It Works
**Signing:** The cert_id and creator_signature are computed over the same canonical JSON body. The cert_id verifies integrity (any tampering changes the hash). The signature verifies authenticity (only the creator's private key can produce it). Both are independently checkable by any third party.
**Anchoring:** The anchor hash is SHA-256 of the *complete* certificate (including cert_id and signature). This goes into a Bitcoin OP_RETURN output. If anything is modified after anchoring, the anchor check fails.
**Chain verification** checks: each cert's `previous_cert_id` links to the prior cert's `cert_id`, the same creator throughout, valid signatures on every cert, and the final cert's type determines the chain status (ACTIVE or REVOKED).
For the full protocol design, threat model, and technical specification, see the [Research](#research) section.
## Development
```bash
git clone https://github.com/shaleenchauhan/agentcert.git
cd agentcert
python3 -m venv .venv && source .venv/bin/activate
pip install -e ".[dev,langchain,service,client]"
# Run tests
pytest
# Run tests with coverage
pytest --cov=agentcert --cov-report=term-missing
# Run examples
python examples/quickstart.py
python examples/full_lifecycle.py
python examples/audit_trail_demo.py
python examples/langchain_demo.py
python examples/batch_anchor_demo.py
python examples/service_demo.py
```
## Project Structure
```
agentcert/
src/agentcert/
__init__.py # Public API (72 exports, no submodule imports needed)
keys.py # Key generation, save, load (secp256k1)
certificate.py # Certificate creation, signing, serialization
chain.py # Update, revoke, chain verification
anchor.py # Bitcoin OP_RETURN + Blockstream API
verify.py # 6-check certificate verification
audit.py # Audit trail creation, logging, persistence
audit_verify.py # 6-check entry + 11-check trail verification
merkle.py # Binary Merkle tree construction + proof generation
batch.py # Batch creation, anchoring, proof verification
client.py # SDK client for the anchoring service (httpx)
service/
app.py # FastAPI application (12 API endpoints + dashboard)
dashboard.py # Dashboard route handlers (7 pages)
models.py # SQLite database layer
scheduler.py # Background batching + anchoring scheduler
config.py # ServiceConfig dataclass
templates/ # Jinja2 HTML templates (8 files)
static/ # CSS + JS (style.css, main.js)
integrations/
langchain.py # AgentCertCallbackHandler + AgentCertMiddleware
types.py # KeyPair, Certificate, AuditEntry, Batch, MerkleProof, etc.
exceptions.py # Custom exception hierarchy
cli.py # Click-based CLI (21 commands)
tests/ # 424 tests
examples/ # quickstart.py, full_lifecycle.py, audit_trail_demo.py, langchain_demo.py, batch_anchor_demo.py, service_demo.py
papers/ # Whitepaper, technical spec, condensed overview
```
## Technical Decisions
| Component | Choice | Rationale |
|-----------|--------|-----------|
| Language | Python 3.11+ | AI/ML ecosystem standard |
| Curve | secp256k1 | Bitcoin-native, same keys for signing and anchoring |
| Signatures | ECDSA | Proven; Schnorr migration path later |
| Hashing | SHA-256 | Bitcoin-native |
| Serialization | JSON (deterministic) | `sort_keys=True, separators=(',',':')` |
| CLI | Click | Mature, clean subcommand support |
| Bitcoin API | Blockstream | No auth, free, reliable |
| Dependencies | 3 runtime | `cryptography`, `requests`, `click` |
## Research
AgentCert implements AIT-1 from the Agent Internet Trust protocol. The research papers cover the full protocol design, adversarial analysis, and technical specification:
- [**Whitepaper**](papers/whitepaper.pdf) — Protocol motivation, architecture, trust model, and threat analysis
- [**Condensed Overview**](papers/condensed.pdf) — Shorter summary of the protocol and its design rationale
- [**Technical Specification**](papers/technical-spec.pdf) — Formal specification of certificate structure, signing, anchoring, and verification
## License
MIT
| text/markdown | Shaleen Chauhan | null | null | null | null | bitcoin, ai, identity, certificates, agents | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Security :: Cryptography",
"Topic :: Software Development... | [] | null | null | >=3.11 | [] | [] | [] | [
"cryptography>=42.0",
"requests>=2.31",
"click>=8.1",
"langchain-core>=0.1.0; extra == \"langchain\"",
"fastapi>=0.100.0; extra == \"service\"",
"uvicorn>=0.20.0; extra == \"service\"",
"jinja2>=3.0.0; extra == \"service\"",
"httpx>=0.24.0; extra == \"client\"",
"pytest>=7.4; extra == \"dev\"",
"p... | [] | [] | [] | [
"Homepage, https://github.com/shaleenchauhan/agentcert",
"Documentation, https://github.com/shaleenchauhan/agentcert#readme",
"Repository, https://github.com/shaleenchauhan/agentcert",
"Issues, https://github.com/shaleenchauhan/agentcert/issues"
] | twine/6.2.0 CPython/3.13.3 | 2026-02-19T01:17:31.950079 | agentcert-0.3.0.tar.gz | 102,246 | 54/c6/c667ee4c0d3f4173ed7277f59b98983d0434ac19c59f3afd18a750f9144f/agentcert-0.3.0.tar.gz | source | sdist | null | false | f2ded95577a81776519aec283fa861d8 | 8dbd9c07d0b636889c58ac5c8e6471c63b1de5ba74643111d324ae298a3cc7eb | 54c6c667ee4c0d3f4173ed7277f59b98983d0434ac19c59f3afd18a750f9144f | MIT | [
"LICENSE"
] | 269 |
2.4 | mcphub-server | 3.0.4 | AI-native management hub for WordPress, WooCommerce, and self-hosted services via Model Context Protocol (MCP) | # MCP Hub
<div align="center">
**The AI-native management hub for WordPress, WooCommerce, and self-hosted services.**
Connect your sites, stores, repos, and databases — manage them all through Claude, ChatGPT, Cursor, or any MCP client.
[](https://github.com/airano-ir/mcphub/releases)
[](LICENSE)
[](https://www.python.org/)
[](https://pypi.org/project/mcphub-server/)
[](https://hub.docker.com/r/airano/mcphub)
[]()
[]()
[](https://github.com/airano-ir/mcphub/actions/workflows/ci.yml)
</div>
---
## Why MCP Hub?
WordPress powers 43% of the web. WooCommerce runs 36% of online stores. Yet **no MCP server existed** for managing them through AI — until now.
MCP Hub is the first MCP server that lets you manage WordPress, WooCommerce, and 7 other self-hosted services through any AI assistant. Instead of clicking through dashboards, just tell your AI what to do:
> *"Update the SEO meta description for all WooCommerce products that don't have one"*
>
> *"Create a new blog post about our Black Friday sale and schedule it for next Monday"*
>
> *"Check the health of all 12 WordPress sites and report any with slow response times"*
### What Makes MCP Hub Different
| Feature | ManageWP | MainWP | AI Content Plugins | **MCP Hub** |
|---------|----------|--------|---------------------|-------------|
| Multi-site management | Yes | Yes | No | **Yes** |
| AI agent integration | No | No | No | **Native (MCP)** |
| Full WordPress API | Dashboard | Dashboard | Content only | **67 tools** |
| WooCommerce management | No | Limited | No | **28 tools** |
| Git/CI management | No | No | No | **56 tools (Gitea)** |
| Automation workflows | No | No | No | **56 tools (n8n)** |
| Self-hosted | No | Yes | N/A | **Yes** |
| Open source | No | Core only | Varies | **Fully open** |
| Price | $0.70-8/site/mo | $29-79/yr | $19-79/mo | **Free** |
---
## 596 Tools Across 9 Plugins
| Plugin | Tools | What You Can Do |
|--------|-------|-----------------|
| **WordPress** | 67 | Posts, pages, media, users, menus, taxonomies, SEO (Rank Math/Yoast) |
| **WooCommerce** | 28 | Products, orders, customers, coupons, reports, shipping |
| **WordPress Advanced** | 22 | Database ops, bulk operations, WP-CLI, system management |
| **Gitea** | 56 | Repos, issues, pull requests, releases, webhooks, organizations |
| **n8n** | 56 | Workflows, executions, credentials, variables, audit |
| **Supabase** | 70 | Database, auth, storage, edge functions, realtime |
| **OpenPanel** | 73 | Events, funnels, profiles, dashboards, projects |
| **Appwrite** | 100 | Databases, auth, storage, functions, teams, messaging |
| **Directus** | 100 | Collections, items, users, files, flows, permissions |
| **System** | 24 | Health monitoring, API keys, OAuth management, audit |
| **Total** | **596** | Constant count — scales to unlimited sites |
---
## Quick Start
### Option 1: Docker (Recommended)
```bash
git clone https://github.com/airano-ir/mcphub.git
cd mcphub
cp env.example .env
# Edit .env — set MASTER_API_KEY and add your site credentials
docker compose up -d
```
### Option 2: Docker Hub (No Clone)
```bash
# Create a .env file with your credentials (see "Configure Your Sites" below)
docker run -d --name mcphub -p 8000:8000 --env-file .env airano/mcphub:latest
```
### Option 3: From Source
```bash
git clone https://github.com/airano-ir/mcphub.git
cd mcphub
pip install -e .
cp env.example .env
# Edit .env with your site credentials
python server.py --transport streamable-http --port 8000
```
### Verify It Works
After starting the server, wait ~30 seconds then:
```bash
# Check server health
curl http://localhost:8000/health
```
Open the **web dashboard** in your browser: **http://localhost:8000/dashboard**
You should see the login page. Use your `MASTER_API_KEY` to log in.
### Configure Your Sites
Add site credentials to `.env`:
```bash
# Master API Key (recommended — auto-generates temp key if omitted)
MASTER_API_KEY=your-secure-key-here
# WordPress Site
WORDPRESS_SITE1_URL=https://myblog.com
WORDPRESS_SITE1_USERNAME=admin
WORDPRESS_SITE1_APP_PASSWORD=xxxx xxxx xxxx xxxx
WORDPRESS_SITE1_ALIAS=myblog
# WooCommerce Store
WOOCOMMERCE_STORE1_URL=https://mystore.com
WOOCOMMERCE_STORE1_CONSUMER_KEY=ck_xxxxx
WOOCOMMERCE_STORE1_CONSUMER_SECRET=cs_xxxxx
WOOCOMMERCE_STORE1_ALIAS=mystore
# Gitea Instance
GITEA_REPO1_URL=https://git.example.com
GITEA_REPO1_TOKEN=your_gitea_token
GITEA_REPO1_ALIAS=mygitea
```
<details>
<summary><b>Full Environment Variable Reference</b></summary>
**System Configuration:**
| Variable | Required | Default | Description |
|----------|----------|---------|-------------|
| `MASTER_API_KEY` | Recommended | Auto-generated | Master API key for admin access |
| `LOG_LEVEL` | No | `INFO` | Logging level (DEBUG, INFO, WARNING, ERROR) |
| `OAUTH_JWT_SECRET_KEY` | For OAuth | — | JWT secret for ChatGPT auto-registration (not needed for Claude/Cursor) |
| `OAUTH_BASE_URL` | For OAuth | — | Public URL of your server (not needed for Claude/Cursor) |
| `OAUTH_JWT_ALGORITHM` | No | `HS256` | JWT algorithm |
| `OAUTH_ACCESS_TOKEN_TTL` | No | `3600` | Access token TTL in seconds |
| `OAUTH_REFRESH_TOKEN_TTL` | No | `604800` | Refresh token TTL in seconds |
| `OAUTH_STORAGE_TYPE` | No | `json` | Token storage type |
| `OAUTH_STORAGE_PATH` | No | `/app/data` | Data directory path |
> **OAuth** is only needed for ChatGPT Remote MCP auto-registration. For Claude Desktop, Claude Code, Cursor, and VS Code — just use `MASTER_API_KEY` with Bearer token auth.
**Plugin Site Configuration** — Pattern: `{PLUGIN_TYPE}_{SITE_ID}_{KEY}`
| Plugin | Required Keys | Optional Keys |
|--------|--------------|---------------|
| `WORDPRESS` | `URL`, `USERNAME`, `APP_PASSWORD` | `ALIAS`, `CONTAINER` |
| `WOOCOMMERCE` | `URL`, `CONSUMER_KEY`, `CONSUMER_SECRET` | `ALIAS` |
| `WORDPRESS_ADVANCED` | `URL`, `USERNAME`, `APP_PASSWORD`, `CONTAINER` | `ALIAS` |
| `GITEA` | `URL`, `TOKEN` | `ALIAS` |
| `N8N` | `URL`, `API_KEY` | `ALIAS` |
| `SUPABASE` | `URL`, `SERVICE_ROLE_KEY` | `ALIAS` |
| `OPENPANEL` | `URL`, `CLIENT_ID`, `CLIENT_SECRET` | `ALIAS` |
| `APPWRITE` | `URL`, `API_KEY`, `PROJECT_ID` | `ALIAS` |
| `DIRECTUS` | `URL`, `TOKEN` | `ALIAS` |
> **CONTAINER**: Docker container name of your WordPress site. Optional for WordPress (enables WP-CLI tools like cache flush, transient management). **Required** for WordPress Advanced (all 22 tools use WP-CLI). Find your container: `docker ps --filter name=wordpress`. Also requires Docker socket mount.
**Example** — Multiple WordPress sites:
```bash
WORDPRESS_BLOG_URL=https://blog.example.com
WORDPRESS_BLOG_USERNAME=admin
WORDPRESS_BLOG_APP_PASSWORD=xxxx xxxx xxxx xxxx
WORDPRESS_BLOG_ALIAS=blog
WORDPRESS_SHOP_URL=https://shop.example.com
WORDPRESS_SHOP_USERNAME=admin
WORDPRESS_SHOP_APP_PASSWORD=yyyy yyyy yyyy yyyy
WORDPRESS_SHOP_ALIAS=shop
```
</details>
### Connect Your AI Client
All MCP clients use **Bearer token** authentication: `Authorization: Bearer YOUR_API_KEY`
> Use a plugin-specific endpoint (e.g., `/wordpress/mcp`) instead of `/mcp` to reduce tool count and save tokens. See [Architecture](#architecture) below.
<details>
<summary><b>Claude Desktop</b></summary>
Add to `claude_desktop_config.json`:
```json
{
"mcpServers": {
"mcphub-wordpress": {
"type": "streamableHttp",
"url": "http://your-server:8000/wordpress/mcp",
"headers": {
"Authorization": "Bearer YOUR_API_KEY"
}
}
}
}
```
</details>
<details>
<summary><b>Claude Code</b></summary>
Add to `.mcp.json` in your project:
```json
{
"mcpServers": {
"mcphub-wordpress": {
"type": "http",
"url": "http://your-server:8000/wordpress/mcp",
"headers": {
"Authorization": "Bearer YOUR_API_KEY"
}
}
}
}
```
</details>
<details>
<summary><b>Cursor</b></summary>
Go to **Settings > MCP Servers > Add Server**:
- **Name**: MCP Hub WordPress
- **URL**: `http://your-server:8000/wordpress/mcp`
- **Headers**: `Authorization: Bearer YOUR_API_KEY`
</details>
<details>
<summary><b>VS Code + Copilot</b></summary>
Add to `.vscode/mcp.json`:
```json
{
"servers": {
"mcphub-wordpress": {
"type": "http",
"url": "http://your-server:8000/wordpress/mcp",
"headers": {
"Authorization": "Bearer YOUR_API_KEY"
}
}
}
}
```
</details>
<details>
<summary><b>ChatGPT (Remote MCP)</b></summary>
MCP Hub supports **Open Dynamic Client Registration** (RFC 7591). ChatGPT can auto-register as an OAuth client:
1. Deploy MCP Hub with `OAUTH_BASE_URL` set
2. In ChatGPT, add MCP server: `https://your-server:8000/mcp`
3. ChatGPT auto-discovers OAuth metadata and registers
</details>
> **Transport types**: Use `"type": "streamableHttp"` for Claude Desktop and `"type": "http"` for VS Code/Claude Code. Using `"type": "sse"` will cause `400 Bad Request` errors.
---
## Architecture
```
/mcp → Admin endpoint (all 596 tools)
/system/mcp → System tools only (24 tools)
/wordpress/mcp → WordPress tools (67 tools)
/woocommerce/mcp → WooCommerce tools (28 tools)
/wordpress-advanced/mcp → WordPress Advanced tools (22 tools)
/gitea/mcp → Gitea tools (56 tools)
/n8n/mcp → n8n tools (56 tools)
/supabase/mcp → Supabase tools (70 tools)
/openpanel/mcp → OpenPanel tools (73 tools)
/appwrite/mcp → Appwrite tools (100 tools)
/directus/mcp → Directus tools (100 tools)
/project/{alias}/mcp → Per-project endpoint (auto-injects site)
```
**Recommendation**: Use plugin-specific endpoints instead of `/mcp` (596 tools) to minimize token usage.
| Endpoint | Use Case | Tools |
|----------|----------|------:|
| `/project/{alias}/mcp` | Single-site workflow (recommended) | 22-100 |
| `/{plugin}/mcp` | Multi-site management | 23-101 |
| `/mcp` | Admin & discovery only | 596 |
### Security
- **OAuth 2.1 + PKCE** (RFC 8414, 7591, 7636) with auto-registration for Claude/ChatGPT
- **Per-project API keys** with scoped permissions (read/write/admin)
- **Rate limiting**: 60/min, 1,000/hr, 10,000/day per client
- **GDPR-compliant audit logging** with automatic sensitive data filtering
- **Web dashboard** with real-time health monitoring (8 pages, EN/FA i18n)
> **Compatibility Note**: MCP Hub requires FastMCP 2.x (`>=2.14.0,<3.0.0`). FastMCP 3.0 introduced breaking changes and is not yet supported. If you install dependencies manually, ensure you don't upgrade to FastMCP 3.x.
### WordPress Plugin Requirements
Some MCP Hub tools require companion WordPress plugins:
| Tools | Requirement |
|-------|-------------|
| SEO tools (`wordpress_get_post_seo`, etc.) | [SEO API Bridge](wordpress-plugin/seo-api-bridge/) ([Download ZIP](wordpress-plugin/seo-api-bridge.zip)) + Rank Math or Yoast SEO |
| WP-CLI tools (15 tools: `wp_cache_*`, `wp_db_*`, etc.) | Docker socket + `CONTAINER` env var |
| WordPress Advanced database/system tools | Docker socket + `CONTAINER` env var |
| OpenPanel analytics integration | [OpenPanel Self-Hosted](wordpress-plugin/openpanel-self-hosted/) ([Download ZIP](wordpress-plugin/openpanel-self-hosted.zip)) |
| WooCommerce tools | WooCommerce plugin (separate `WOOCOMMERCE_` config) |
**Docker socket** is needed for WP-CLI and WordPress Advanced system tools. Add to your docker-compose:
```yaml
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
environment:
WORDPRESS_SITE1_CONTAINER: your-wp-container-name
```
Without Docker socket, WP-CLI tools return "not available" but all REST API tools work normally.
---
## Documentation
| Guide | Description |
|-------|-------------|
| [Getting Started](docs/getting-started.md) | Full setup walkthrough |
| [Architecture](docs/ARCHITECTURE.md) | System design and module reference |
| [API Keys Guide](docs/API_KEYS_GUIDE.md) | Per-project API key management |
| [OAuth Guide](docs/OAUTH_GUIDE.md) | OAuth 2.1 setup for Claude/ChatGPT |
| [Gitea Guide](docs/GITEA_GUIDE.md) | Gitea plugin configuration |
| [Deployment Guide](docs/DEPLOYMENT_GUIDE.md) | Docker and Coolify deployment |
| [Troubleshooting](docs/troubleshooting.md) | Common issues and solutions |
| [Plugin Development](docs/PLUGIN_DEVELOPMENT.md) | Build your own plugin |
---
## Development
```bash
# Install with dev dependencies
pip install -e ".[dev]"
# Run tests (290 tests)
pytest
# Format and lint
black . && ruff check --fix .
# Run server locally
python server.py --transport streamable-http --port 8000
```
---
## Support This Project
MCP Hub is free and open-source. Development is funded by community donations.
[**Donate with Crypto (NOWPayments)**](https://nowpayments.io/donation/airano) — Global, no geographic restrictions.
| Goal | Monthly | Enables |
|------|---------|---------|
| Infrastructure | $50/mo | Demo hosting, CI/CD, domain |
| Part-time maintenance | $500/mo | Updates, security patches, issue triage |
| Active development | $2,000/mo | New plugins, features, community support |
---
## Contributing
We welcome contributions! See [CONTRIBUTING.md](CONTRIBUTING.md) for guidelines.
**Priority areas:**
- New plugin development
- Client setup guides
- Workflow templates and examples
- Test coverage expansion
- Translations (i18n)
---
## License
MIT License. See [LICENSE](LICENSE).
---
| text/markdown | null | MCP Hub <contact@mcphub.dev> | null | null | null | mcp, wordpress, woocommerce, ai, self-hosted, gitea, n8n, supabase, appwrite, directus, model-context-protocol, claude, automation | [
"Development Status :: 4 - Beta",
"Operating System :: OS Independent",
"Environment :: Console",
"Intended Audience :: Developers",
"Intended Audience :: System Administrators",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
... | [] | null | null | >=3.11 | [] | [] | [] | [
"fastmcp<3.0.0,>=2.14.0",
"httpx>=0.25.0",
"aiohttp>=3.9.0",
"pydantic>=2.5.0",
"python-dotenv>=1.0.0",
"docker>=7.0.0",
"authlib>=1.5.0",
"PyJWT>=2.8.0",
"cryptography>=46.0.0",
"jinja2>=3.1.2",
"pytest>=7.4.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-cov>=4.1.... | [] | [] | [] | [
"Homepage, https://github.com/airano-ir/mcphub",
"Repository, https://github.com/airano-ir/mcphub",
"Documentation, https://github.com/airano-ir/mcphub#readme",
"Issues, https://github.com/airano-ir/mcphub/issues",
"Changelog, https://github.com/airano-ir/mcphub/releases"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T01:17:09.126453 | mcphub_server-3.0.4.tar.gz | 423,453 | 7a/85/c6883414a485e66a15ebbdf40dc2d3f92425ab87077b051385e78624f2f3/mcphub_server-3.0.4.tar.gz | source | sdist | null | false | 5a19cdc847c39240c13147690b02f663 | d6acd5b24d5107c6d8afdb9711d373db7f927d0a824f792ed48f4d0c833af269 | 7a85c6883414a485e66a15ebbdf40dc2d3f92425ab87077b051385e78624f2f3 | MIT | [
"LICENSE"
] | 247 |
2.4 | wrtds | 0.1.0 | A transcription of the usgs r package wrtds to python | # wrtds-py
A Python implementation of **WRTDS** (Weighted Regressions on Time, Discharge, and Season), the USGS method for estimating long-term trends in river water quality.
[](https://github.com/mullenkamp/wrtds-py/actions)
[](https://codecov.io/gh/mullenkamp/wrtds-py)
[](https://badge.fury.io/py/wrtds)
---
**Documentation**: [https://mullenkamp.github.io/wrtds-py/](https://mullenkamp.github.io/wrtds-py/)
**Source Code**: [https://github.com/mullenkamp/wrtds-py](https://github.com/mullenkamp/wrtds-py)
---
## Overview
This package is a Python transcription of the USGS R package [EGRET](https://github.com/DOI-USGS/EGRET). It uses pandas DataFrames as the base data structure with scipy for optimization and interpolation and matplotlib for plotting.
Key features:
- **Weighted censored regression** — locally weighted MLE with tricube kernels on time, discharge, and season
- **Flow normalization** — isolate water-quality trends from discharge variability
- **WRTDS-K** — AR(1) residual interpolation for improved daily estimates
- **Trend analysis** — pairwise, group, and time-series decomposition (CQTC/QTC)
- **Bootstrap confidence intervals** — block resampling with bias correction
- **Plotting** — data overview, annual histories, contour surfaces, and diagnostics
## Installation
```bash
pip install wrtds
```
Requires Python >= 3.10.
## Quick Example
```python
import pandas as pd
from wrtds import WRTDS
daily = pd.read_csv('daily.csv', parse_dates=['Date'])
sample = pd.read_csv('sample.csv', parse_dates=['Date'])
w = WRTDS(daily, sample, info={'station_name': 'Choptank River'})
w.fit()
w.kalman()
print(w.table_results())
print(w.run_pairs(year1=1985, year2=2010))
w.plot_conc_hist()
```
See the [Quickstart](https://mullenkamp.github.io/wrtds/getting-started/quickstart/) for a full walkthrough.
## Development
We use [uv](https://docs.astral.sh/uv/) to manage the development environment.
```bash
uv sync # install dependencies
uv run pytest # run tests
```
## License
This project is licensed under the terms of the Apache Software License 2.0.
| text/markdown | null | mullenkamp <mullenkamp1@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3 :: Only"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"matplotlib>=3.7",
"numpy>=1.24",
"pandas>=2.0",
"scipy>=1.10"
] | [] | [] | [] | [
"Documentation, https://mullenkamp.github.io/wrtds/",
"Source, https://github.com/mullenkamp/wrtds-py"
] | uv/0.8.7 | 2026-02-19T01:16:45.406069 | wrtds-0.1.0.tar.gz | 30,320 | bf/ef/4ff59009254951448def2b065e99eda9c483d3bc375349a27011186e0c03/wrtds-0.1.0.tar.gz | source | sdist | null | false | bb9942e915dc89e86bbadf7122d1e5b3 | 9976b67a387c1882eb8a48a6de150d6b502949c7fc419d6efa596e1af5c71d61 | bfef4ff59009254951448def2b065e99eda9c483d3bc375349a27011186e0c03 | null | [
"LICENSE"
] | 258 |
2.4 | just-bash | 0.1.16 | A pure Python bash interpreter with in-memory virtual filesystem | # just-bash-py (pre-release)
[](https://pypi.org/project/just-bash/)
[](https://www.python.org/downloads/)
[](LICENSE)
A pure Python bash interpreter with an in-memory virtual filesystem, designed for AI agents needing a secure, sandboxed bash environment.
This is a Python port of [just-bash](https://github.com/vercel-labs/just-bash), the emulated bash interpreter for TypeScript, from Vercel.
**This is a pre-release.** This as much a demonstration of coding agents' ability to implement software given a tight spec and high test coverage, as [discussed here](https://www.dbreunig.com/2026/01/08/a-software-library-with-no-code.html) and [here](https://github.com/dbreunig/whenwords).
## Features
- **Pure Python** - No external binaries, no WASM dependencies
- **Flexible filesystems** - In-memory, real filesystem access, copy-on-write overlays, or mount multiple sources
- **70+ commands** - grep, sed, awk, jq, curl, and more
- **Full bash syntax** - Pipes, redirections, variables, arrays, functions, control flow
- **36 shell builtins** - cd, export, declare, test, pushd, popd, and more
- **Async execution** - Built on asyncio for non-blocking operation
- **Security limits** - Prevent infinite loops, excessive recursion, runaway execution
## Installation
```bash
pip install just-bash
```
## Quick Start
```python
from just_bash import Bash
bash = Bash()
# Simple command
result = await bash.exec('echo "Hello, World!"')
print(result.stdout) # Hello, World!
# Pipes and text processing
result = await bash.exec('echo "banana apple cherry" | tr " " "\\n" | sort')
print(result.stdout) # apple\nbanana\ncherry\n
# Variables and arithmetic
result = await bash.exec('x=5; echo $((x * 2))')
print(result.stdout) # 10
# Arrays
result = await bash.exec('arr=(a b c); echo "${arr[@]}"')
print(result.stdout) # a b c
# In-memory files
result = await bash.exec('echo "test" > /tmp/file.txt; cat /tmp/file.txt')
print(result.stdout) # test
```
A synchronous `bash.run()` wrapper is also available and works in any context, including Jupyter notebooks.
## Demo
Run the interactive demo to see all features in action:
```bash
python examples/demo.py
```
This demonstrates variables, arrays, control flow, pipes, text processing, JSON handling with jq, functions, and more.
## API
### Bash Class
```python
from just_bash import Bash
# Create with optional initial files
bash = Bash(files={
"/data/input.txt": "line1\nline2\nline3\n",
"/config.json": '{"key": "value"}'
})
# Execute commands
result = await bash.exec("cat /data/input.txt | wc -l")
# Result object
print(result.stdout) # Standard output
print(result.stderr) # Standard error
print(result.exit_code) # Exit code (0 = success)
```
### Configuration Options
```python
bash = Bash(
files={...}, # Initial filesystem contents
env={...}, # Environment variables
cwd="/home/user", # Working directory
network=NetworkConfig(...), # Network configuration (for curl)
unescape_html=True, # Auto-fix HTML entities in LLM output (default: True)
)
```
### Filesystem Options
just-bash provides four filesystem implementations for different use cases:
#### InMemoryFs (Default)
Pure in-memory filesystem - completely sandboxed with no disk access.
```python
from just_bash import Bash
# Default: in-memory filesystem with optional initial files
bash = Bash(files={
"/data/input.txt": "hello world\n",
"/config.json": '{"key": "value"}'
})
result = await bash.exec("cat /data/input.txt")
print(result.stdout) # hello world
```
#### ReadWriteFs
Direct access to the real filesystem, rooted at a specific directory. All paths are translated relative to the root.
```python
from just_bash import Bash
from just_bash.fs import ReadWriteFs, ReadWriteFsOptions
# Access real files under /path/to/project
fs = ReadWriteFs(ReadWriteFsOptions(root="/path/to/project"))
bash = Bash(fs=fs, cwd="/")
# /src/main.py in bash maps to /path/to/project/src/main.py on disk
result = await bash.exec("cat /src/main.py")
```
**Warning**: ReadWriteFs provides direct disk access. Use with caution.
#### OverlayFs
Copy-on-write overlay - reads from the real filesystem, but all writes go to an in-memory layer. The real filesystem is never modified.
```python
from just_bash import Bash
from just_bash.fs import OverlayFs, OverlayFsOptions
# Overlay real files at /home/user/project, changes stay in memory
fs = OverlayFs(OverlayFsOptions(
root="/path/to/real/project",
mount_point="/home/user/project"
))
bash = Bash(fs=fs)
# Read real files
result = await bash.exec("cat /home/user/project/README.md")
# Writes only affect the in-memory layer
await bash.exec("echo 'modified' > /home/user/project/README.md")
# Real file on disk is unchanged!
```
Use cases:
- Safe experimentation with real project files
- Testing scripts without modifying actual files
- AI agents that need to read real code but not write to disk
#### MountableFs
Mount multiple filesystems at different paths, similar to Unix mount points.
```python
from just_bash import Bash
from just_bash.fs import (
MountableFs, MountableFsOptions, MountConfig,
InMemoryFs, ReadWriteFs, ReadWriteFsOptions, OverlayFs, OverlayFsOptions
)
# Create a mountable filesystem with multiple sources
fs = MountableFs(MountableFsOptions(
base=InMemoryFs(), # Default for paths outside mounts
mounts=[
# Mount real project at /project (read-write)
MountConfig(
mount_point="/project",
filesystem=ReadWriteFs(ReadWriteFsOptions(root="/path/to/project"))
),
# Mount another project as overlay (read-only to disk)
MountConfig(
mount_point="/reference",
filesystem=OverlayFs(OverlayFsOptions(
root="/path/to/other/project",
mount_point="/"
))
),
]
))
bash = Bash(fs=fs)
# Access different filesystems through unified paths
await bash.exec("ls /project") # Real filesystem
await bash.exec("ls /reference") # Overlay filesystem
await bash.exec("ls /tmp") # In-memory (base)
```
#### Direct Filesystem Access
You can also access the filesystem directly through the `bash.fs` property:
```python
import asyncio
from just_bash import Bash
bash = Bash(files={"/data.txt": "initial content"})
# Async filesystem operations
async def main():
# Read
content = await bash.fs.read_file("/data.txt")
# Write
await bash.fs.write_file("/output.txt", "new content")
# Check existence
exists = await bash.fs.exists("/data.txt")
# List directory
files = await bash.fs.readdir("/")
# Get file stats
stat = await bash.fs.stat("/data.txt")
print(f"Size: {stat.size}, Mode: {oct(stat.mode)}")
asyncio.run(main())
```
### HTML Escaping Compatibility
When LLMs generate bash commands, they sometimes output HTML-escaped operators:
```bash
wc -l < file.txt # LLM outputs this instead of: wc -l < file.txt
echo "done" && exit # Instead of: echo "done" && exit
```
By default, just-bash automatically unescapes these HTML entities (`<` → `<`, `>` → `>`, `&` → `&`, `"` → `"`, `'` → `'`) in operator positions, so LLM-generated commands work correctly.
Entities inside quotes and heredocs are preserved:
```python
# These work as expected
await bash.exec('echo "<"') # Outputs: <
await bash.exec("cat << 'EOF'\n<tag>\nEOF") # Outputs: <tag>
```
To disable this behavior for strict bash compatibility:
```python
bash = Bash(unescape_html=False)
```
## Security
- **No native execution** - All commands are pure Python implementations
- **Network disabled by default** - curl requires explicit enablement
- **Execution limits** - Prevents infinite loops and excessive resource usage
- **Filesystem isolation** - Virtual filesystem keeps host system safe
- **SQLite sandboxed** - Only in-memory databases allowed
## Supported Features
### Shell Syntax
- Variables: `$VAR`, `${VAR}`, `${VAR:-default}`, `${VAR:+alt}`, `${#VAR}`
- Arrays: `arr=(a b c)`, `${arr[0]}`, `${arr[@]}`, `${#arr[@]}`
- Arithmetic: `$((expr))`, `((expr))`, increment/decrement, ternary
- Quoting: Single quotes, double quotes, `$'...'`, escapes
- Expansion: Brace `{a,b}`, tilde `~`, glob `*.txt`, command `$(cmd)`
- Control flow: `if/then/else/fi`, `for/do/done`, `while`, `until`, `case`
- Functions: `func() { ... }`, local variables, return values
- Pipes: `cmd1 | cmd2 | cmd3`
- Redirections: `>`, `>>`, `<`, `2>&1`, here-docs
### Parameter Expansion
- Default values: `${var:-default}`, `${var:=default}`
- Substring: `${var:offset:length}`
- Pattern removal: `${var#pattern}`, `${var##pattern}`, `${var%pattern}`, `${var%%pattern}`
- Replacement: `${var/pattern/string}`, `${var//pattern/string}`
- Case modification: `${var^^}`, `${var,,}`, `${var^}`, `${var,}`
- Length: `${#var}`, `${#arr[@]}`
- Indirection: `${!var}`, `${!prefix*}`, `${!arr[@]}`
- Transforms: `${var@Q}`, `${var@a}`, `${var@A}`
### Conditionals
- Test command: `[ -f file ]`, `[ "$a" = "$b" ]`
- Extended test: `[[ $var == pattern ]]`, `[[ $var =~ regex ]]`
- Arithmetic test: `(( x > 5 ))`
- File tests: `-e`, `-f`, `-d`, `-r`, `-w`, `-x`, `-s`, `-L`
- String tests: `-z`, `-n`, `=`, `!=`, `<`, `>`
- Numeric tests: `-eq`, `-ne`, `-lt`, `-le`, `-gt`, `-ge`
## Shell Builtins
```
: . [ alias break builtin cd command
continue declare dirs eval exec exit export false
hash let local mapfile popd pushd readarray readonly
return set shift shopt source test true type
typeset unalias unset wait
```
## Available Commands
### File Operations
```
cat chmod cp find ln ls mkdir mv
rm stat touch tree
```
### Text Processing
```
awk column comm cut diff expand fold grep
egrep fgrep head join nl od paste rev
rg sed sort split strings tac tail tee
tr unexpand uniq wc
```
### Data Processing
```
jq yq xan sqlite3
```
#### xan - CSV Toolkit
The `xan` command provides CSV manipulation capabilities. Most commands are implemented:
**Implemented:**
```
headers count head tail slice select
drop rename filter search sort reverse
behead enum shuffle sample dedup top
cat transpose fixlengths flatten explode implode
split view stats frequency to json from json
```
**Not Yet Implemented** (require expression evaluation):
```
join agg groupby map transform pivot
```
Example usage:
```python
# Show column names
await bash.exec("xan headers data.csv")
# Filter and select
await bash.exec("xan filter 'age > 30' data.csv | xan select name,age")
# Convert to JSON
await bash.exec("xan to json data.csv")
# Sample random rows
await bash.exec("xan sample 10 --seed 42 data.csv")
```
### Path Utilities
```
basename dirname pwd readlink which
```
### Compression & Encoding
```
base64 gzip gunzip zcat md5sum sha1sum sha256sum tar
```
### System & Environment
```
alias clear date du echo env expr false
file help history hostname printenv printf read seq
sleep timeout true unalias xargs
```
### Network
```
curl (disabled by default)
```
### Shell
```
bash sh
```
## Test Results
Test suite history per commit (spec_tests excluded). Each `█` ≈ 57 tests.
```
Commit Date Passed Failed Skipped Graph
c816182 2026-01-25 2641 3 2 ████████████████████████████████████████████████▒░
e91d4d8 2026-01-26 2643 2 2 ████████████████████████████████████████████████▒░
ca69ff0 2026-02-04 2757 0 2 █████████████████████████████████████████████████░
6bd4810 2026-02-04 2769 0 2 █████████████████████████████████████████████████░
6c9ab28 2026-02-05 2780 0 2 ██████████████████████████████████████████████████░
aa16896 2026-02-05 2794 0 2 ██████████████████████████████████████████████████░
b6a96dd 2026-02-09 2814 0 2 ██████████████████████████████████████████████████░
a7e64a4 2026-02-11 2825 0 2 ███████████████████████████████████████████████████░
e736ca4 2026-02-17 2831 0 2 ███████████████████████████████████████████████████░
4dddca8 2026-02-18 2849 0 2 █████████████████████████████████████████████████░
7c83ff3 2026-02-18 2870 0 3 █████████████████████████████████████████████████░
```
`█` passed · `▒` failed · `░` skipped
## License
Apache 2.0
## Backlog
Future improvements under consideration:
- **Separate sync/async implementations**: Replace the current `nest_asyncio`-based `run()` wrapper with a truly synchronous implementation. This would follow the pattern used by libraries like httpx (`Client` vs `AsyncClient`) and the OpenAI SDK, providing cleaner separation without event loop patching.
## Acknowledgments
This project is a Python port of [just-bash](https://github.com/vercel-labs/just-bash) by Vercel. The TypeScript implementation provided the design patterns, test cases, and feature specifications that guided this Python implementation.
| text/markdown | Drew Breunig | null | null | null | null | bash, interpreter, sandbox, shell, virtual-filesystem | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Topic :: Sof... | [] | null | null | >=3.11 | [] | [] | [] | [
"aiofiles>=23.0",
"aiohttp>=3.9",
"markdownify>=0.11",
"nest-asyncio>=1.5",
"mypy>=1.8; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\"",
"ruff>=0.1; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/dbreunig/just-bash-py",
"Repository, https://github.com/dbreunig/just-bash-py"
] | twine/6.2.0 CPython/3.12.4 | 2026-02-19T01:16:40.059694 | just_bash-0.1.16.tar.gz | 5,831,940 | 41/73/a5f48ec33e116d009031546cf817f6a62745f8142579b388cb0411b2ed34/just_bash-0.1.16.tar.gz | source | sdist | null | false | 49c941bd54e3e900c90c0bdc63463b02 | d5c3ead5158f2a7fc5a530db825fc4f2c279be59ed93ebb683ff214e54190706 | 4173a5f48ec33e116d009031546cf817f6a62745f8142579b388cb0411b2ed34 | Apache-2.0 | [] | 253 |
2.4 | murmr | 0.2.0 | Python SDK for the murmr TTS API | # murmr
Python SDK for the [murmr](https://murmr.dev) TTS API. Async-first with full sync support.
```bash
pip install murmr
```
## Quick Start
### Voice Design (describe any voice in natural language)
```python
from murmr import MurmrClient
client = MurmrClient(api_key="murmr_sk_live_...")
# Generate speech with a voice description
wav = client.voices.design(
input="Hello, welcome to murmr!",
voice_description="A warm, friendly female voice with a slight British accent",
)
with open("output.wav", "wb") as f:
f.write(wav)
```
### Saved Voices (batch via RunPod Serverless)
```python
# Submit a batch job
job = client.speech.create(input="Hello world", voice="voice_abc123")
# Wait for completion
result = client.speech.create_and_wait(input="Hello world", voice="voice_abc123")
audio = result.audio_bytes # decoded WAV
```
### Streaming
```python
# Stream PCM audio chunks
with client.speech.stream(input="Hello world", voice="voice_abc123") as stream:
for chunk in stream:
pcm = chunk.audio_bytes # 24kHz mono 16-bit PCM
if chunk.done:
break
```
### Async
```python
import asyncio
from murmr import AsyncMurmrClient
async def main():
async with AsyncMurmrClient(api_key="murmr_sk_live_...") as client:
wav = await client.voices.design(
input="Hello from async!",
voice_description="A deep male voice",
)
asyncio.run(main())
```
### Long-Form Audio
```python
# Automatically chunks, retries, and concatenates
result = client.speech.create_long_form(
input=very_long_text,
voice="voice_abc123",
on_progress=lambda current, total, pct: print(f"{pct}%"),
)
with open("long_form.wav", "wb") as f:
f.write(result.audio)
```
## API Reference
### Clients
| Class | Description |
|-------|-------------|
| `MurmrClient(api_key=...)` | Sync client (context manager) |
| `AsyncMurmrClient(api_key=...)` | Async client (async context manager) |
### Speech (`client.speech`)
| Method | Returns | Description |
|--------|---------|-------------|
| `create(input, voice, ...)` | `AsyncJobResponse` | Submit batch job |
| `create_and_wait(input, voice, ...)` | `JobStatus` | Submit and poll until done |
| `stream(input, voice, ...)` | Context manager yielding `AudioStreamChunk` | Stream PCM chunks |
| `create_long_form(input, voice, ...)` | `LongFormResult` | Chunk + concat long text |
### Voices (`client.voices`)
| Method | Returns | Description |
|--------|---------|-------------|
| `design(input, voice_description, ...)` | `bytes` (WAV) | Generate with voice description |
| `design_stream(input, voice_description, ...)` | Context manager yielding `AudioStreamChunk` | Stream voice design |
### Jobs (`client.jobs`)
| Method | Returns | Description |
|--------|---------|-------------|
| `get(job_id)` | `JobStatus` | Get job status |
| `wait_for_completion(job_id, ...)` | `JobStatus` | Poll until done/failed |
## Text Formatting
Newline characters in your input text affect prosody:
- `\n` (single newline) creates a **sentence-level breath pause**
- `\n\n` (double newline) creates a **paragraph-level pause** with prosodic reset
- No newlines in long text produces rushed, flat delivery
**Best practice:** Insert `\n` between sentences and `\n\n` between paragraphs. Avoid text with hard line wraps every 60-80 characters (e.g., from PDFs or terminals) — this produces choppy output.
See the [Text Formatting Guide](https://murmr.dev/en/docs/text-formatting) for details and preprocessing examples.
## Supported Languages
Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian
## License
MIT
| text/markdown | murmr | null | null | null | MIT | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: P... | [] | null | null | >=3.9 | [] | [] | [] | [
"httpx<1.0,>=0.25",
"pydantic<3.0,>=2.0",
"mypy>=1.0; extra == \"dev\"",
"pytest-asyncio>=0.23; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"respx>=0.21; extra == \"dev\"",
"ruff>=0.4; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://murmr.dev",
"Documentation, https://murmr.dev/docs",
"Repository, https://github.com/christi4nity/murmr-python"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:16:38.754907 | murmr-0.2.0.tar.gz | 20,628 | a6/a8/0aa2cb08bf9868ff253e53c041e835d886005db116eac5202adc0c42ae0f/murmr-0.2.0.tar.gz | source | sdist | null | false | d7ba5fc3dac45d0613d99b9766cdf0ac | b4ce8e86e93ecdcf83bdf1c8d572909b68ec852dfc91fcc501f8671401dc2ac1 | a6a80aa2cb08bf9868ff253e53c041e835d886005db116eac5202adc0c42ae0f | null | [
"LICENSE"
] | 248 |
2.4 | editwheel | 0.2.5 | High-performance Python wheel metadata editor | # editwheel
High-performance Python wheel metadata editor written in Rust.
## Overview
`editwheel` provides fast editing of Python wheel metadata and ELF binaries by copying unchanged files as raw compressed bytes, only modifying the files that need to change.
This makes it ideal for scenarios where you need to quickly modify wheel metadata (e.g., version bumping), change platform tags, or patch RPATH in native extensions without the overhead of fully extracting and repacking large wheels.
## Features
- **Metadata editing**: Modify package name, version, dependencies, and other metadata fields
- **ELF patching**: Set RPATH/RUNPATH on `.so` files (similar to `patchelf`)
- **Platform tag modification**: Change wheel platform tags (e.g., `linux_x86_64` → `manylinux_2_28_x86_64`)
- **Python and Rust bindings**: Use programmatically in your release pipeline.
- **CLI tool**: Command-line interface for quick edits
- **Full wheel validation**: Verify file hashes against RECORD
- **pip compatible**: Output wheels are fully compatible with pip and other Python tooling
## Installation
Install using `uv`:
```
uv tool install editwheel
```
## Usage
### Python
```python
from editwheel import WheelEditor
# Open a wheel
editor = WheelEditor("package-1.0.0-py3-none-any.whl")
# Read metadata
print(f"Name: {editor.name}")
print(f"Version: {editor.version}")
# Modify metadata
editor.version = "1.0.1"
editor.summary = "Updated package summary"
editor.requires_dist = ["requests>=2.0", "numpy"]
# Save to new file
editor.save("package-1.0.1-py3-none-any.whl")
# Or overwrite in place
editor.save()
```
#### Available properties
| Property | Type | Description |
|----------|------|-------------|
| `name` | `str` | Package name |
| `version` | `str` | Package version |
| `summary` | `str` | Short description |
| `description` | `str` | Long description |
| `author` | `str` | Author name |
| `author_email` | `str` | Author email |
| `license` | `str` | License identifier |
| `requires_python` | `str` | Python version requirement |
| `classifiers` | `list[str]` | Trove classifiers |
| `requires_dist` | `list[str]` | Dependencies |
| `project_urls` | `list[str]` | Project URLs |
| `platform_tag` | `str` | Platform tag from WHEEL file |
#### ELF patching (native wheels)
```python
from editwheel import WheelEditor
editor = WheelEditor("torch-2.0.0-cp311-cp311-linux_x86_64.whl")
# Set RPATH on all .so files matching a glob pattern
count = editor.set_rpath("torch/lib/*.so", "$ORIGIN:$ORIGIN/../lib")
print(f"Modified {count} files")
# Get RPATH of a specific file
rpath = editor.get_rpath("torch/lib/libtorch.so")
# Change platform tag (e.g., for manylinux compliance)
editor.platform_tag = "manylinux_2_28_x86_64"
# Add a dependency
editor.add_requires_dist("nccl-lib>=1.0")
# Check if any ELF files were modified
if editor.has_modified_files():
print("ELF files were patched")
# Save the modified wheel
editor.save("torch-2.0.0-cp311-cp311-manylinux_2_28_x86_64.whl")
```
#### Generic metadata access
```python
# Get any metadata field
value = editor.get_metadata("Author")
# Set any metadata field
editor.set_metadata("License", "MIT")
editor.set_metadata("Classifier", ["Development Status :: 4 - Beta", "License :: OSI Approved :: MIT License"])
```
### CLI
```bash
# Show wheel metadata
editwheel show mypackage-1.0.0-py3-none-any.whl
# Show as JSON
editwheel show mypackage.whl --json
# Show specific fields
editwheel show mypackage.whl -f name -f version
# Edit version
editwheel edit mypackage.whl --version 1.0.1
# Edit and save to new file
editwheel edit mypackage.whl --author "New Author" -o modified.whl
# Add dependencies
editwheel edit mypackage.whl --add-requires-dist "click>=8.0"
# Set RPATH on native extensions
editwheel edit torch.whl --set-rpath 'torch/lib/*.so' '$ORIGIN:$ORIGIN/../lib'
# Change platform tag
editwheel edit torch.whl --platform-tag manylinux_2_28_x86_64
# Combined operations
editwheel edit torch.whl \
--set-rpath 'torch/lib/*.so' '$ORIGIN' \
--platform-tag manylinux_2_28_x86_64 \
--add-requires-dist 'nccl-lib>=1.0' \
-o modified_torch.whl
```
#### Available edit options
| Option | Description |
|--------|-------------|
| `--output`, `-o` | Output path (default: overwrite in-place) |
| `--name` | Set package name |
| `--version` | Set version |
| `--summary` | Set summary/description |
| `--author` | Set author name |
| `--author-email` | Set author email |
| `--license` | Set license |
| `--requires-python` | Set Python version requirement |
| `--add-classifier` | Add a classifier (repeatable) |
| `--set-classifiers` | Replace all classifiers (comma-separated) |
| `--add-requires-dist` | Add a dependency (repeatable) |
| `--set-requires-dist` | Replace all dependencies (comma-separated) |
| `--set-rpath PATTERN RPATH` | Set RPATH for ELF files matching pattern (repeatable) |
| `--platform-tag` | Set platform tag in WHEEL file |
### Rust
```rust
use editwheel::WheelEditor;
fn main() -> Result<(), editwheel::WheelError> {
// Open a wheel
let mut editor = WheelEditor::open("package-1.0.0-py3-none-any.whl")?;
// Read metadata
println!("Name: {}", editor.name());
println!("Version: {}", editor.version());
// Modify metadata
editor.set_version("1.0.1");
editor.set_summary("Updated summary");
// Validate wheel integrity
let result = editor.validate()?;
assert!(result.is_valid());
// Save to new file
editor.save("package-1.0.1-py3-none-any.whl")?;
Ok(())
}
```
## Development
### Prerequisites
- Rust 1.70+
- Python 3.8+
- [uv](https://github.com/astral-sh/uv) (recommended) or pip
### Building
```bash
# Build Rust library
cargo build --release
# Build Python wheel
uv sync
```
### Testing
```bash
# Run Rust tests
cargo test
# Run integration tests (downloads wheels from PyPI)
cargo test --release --test integration_test -- --nocapture
# Run Python tests
uv run pytest
```
### Benchmarking
```bash
cargo run --release --example bench_edit
```
## How it works
Traditional wheel editing requires:
1. Extracting all files from the wheel (ZIP archive)
2. Modifying metadata files
3. Re-compressing all files back into a new wheel
For large wheels (e.g., PyTorch at ~1GB), this is slow and memory-intensive.
`editwheel` instead:
1. Opens the wheel as a ZIP archive
2. Copies unchanged files using raw compressed bytes (no decompression/recompression)
3. Only regenerates files that need to change (`METADATA`, `WHEEL`, `RECORD`, and any patched ELF files)
4. Updates file hashes in `RECORD` for modified files
This results in near-constant-time performance regardless of wheel size. For ELF patching operations, only the affected `.so` files are decompressed, modified, and recompressed.
## License
MIT
| text/markdown; charset=UTF-8; variant=GFM | null | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Rust",
"Programming Language :: Python :: Implementation :: CPython",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Lan... | [] | null | null | >=3.8 | [] | [] | [] | [] | [] | [] | [] | [] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:15:31.578719 | editwheel-0.2.5-cp313-cp313-macosx_10_12_x86_64.whl | 1,080,603 | b8/46/87e0e386b026a957d171b8b0ce22f487a9f36153347b6ef344dcb261a792/editwheel-0.2.5-cp313-cp313-macosx_10_12_x86_64.whl | cp313 | bdist_wheel | null | false | 7742084a4a4aebc820b4d6489ca9e3a9 | 364763260b90d61df5b01bba4ea5fe4c0ad63a91134e4dd6c389a464ae6ab56b | b84687e0e386b026a957d171b8b0ce22f487a9f36153347b6ef344dcb261a792 | null | [
"LICENSE"
] | 3,435 |
2.4 | aluvia-mcp | 1.0.0 | Aluvia MCP server - Model Context Protocol tools for browser sessions and account management | # Aluvia MCP Server
<p align="center">
<strong>Unblockable browser automation for AI agents.</strong>
</p>
<p align="center">
<a href="https://pypi.org/project/aluvia-mcp/"><img src="https://img.shields.io/pypi/v/aluvia-mcp.svg" alt="PyPI version"></a>
<a href="https://pypi.org/project/aluvia-mcp/"><img src="https://img.shields.io/pypi/pyversions/aluvia-mcp.svg" alt="Python versions"></a>
<a href="./LICENSE"><img src="https://img.shields.io/pypi/l/aluvia-mcp.svg" alt="license"></a>
<a href="https://modelcontextprotocol.io"><img src="https://img.shields.io/badge/MCP-1.0-compatible?labelColor=2d2d2d&color=5f5f5f" alt="MCP compatible"></a>
</p>
---
**Stop getting blocked.** The Aluvia MCP server exposes browser session management, geo-targeting, and account operations as [Model Context Protocol](https://modelcontextprotocol.io) tools for AI agents. Route traffic through premium US mobile carrier IPs and bypass 403s, CAPTCHAs, and WAFs that stop other tools. Works with Claude Desktop, Claude Code, Cursor, VS Code, and any MCP-compatible client.
## Table of Contents
- [Quick Start](#quick-start)
- [Requirements](#requirements)
- [Installation](#installation)
- [Client Configuration](#client-configuration)
- [Available Tools](#available-tools)
- [Use Cases](#use-cases)
- [Why Aluvia](#why-aluvia)
- [Links](#links)
- [License](#license)
---
## Quick Start
```bash
pip install aluvia-mcp
export ALUVIA_API_KEY="your-api-key"
aluvia-mcp
```
Get your API key at [dashboard.aluvia.io](https://dashboard.aluvia.io). The server runs on **stdio** (stdin/stdout JSON-RPC) — MCP clients spawn it and communicate over stdio.
---
## Requirements
- **Python** 3.10+
- **Aluvia API key** — sign up at [dashboard.aluvia.io](https://dashboard.aluvia.io)
- **Playwright** (optional) — required for browser sessions: `pip install playwright && playwright install chromium`
---
## Installation
```bash
pip install aluvia-mcp
```
Or from source:
```bash
git clone https://github.com/aluvia-connect/sdk-python.git
cd sdk-python/aluvia_mcp
pip install -e .
```
For browser session tools, install Playwright:
```bash
pip install playwright
playwright install chromium
```
Set your API key:
```bash
export ALUVIA_API_KEY="your-api-key"
```
---
## Client Configuration
### Claude Desktop
Add to your Claude Desktop config (`~/Library/Application Support/Claude/claude_desktop_config.json` on macOS):
```json
{
"mcpServers": {
"aluvia": {
"command": "aluvia-mcp",
"env": {
"ALUVIA_API_KEY": "your-api-key"
}
}
}
}
```
### Claude Code (VS Code Extension)
Add to your VS Code settings (`.vscode/settings.json` or User Settings):
```json
{
"mcp.servers": {
"aluvia": {
"command": "aluvia-mcp",
"env": {
"ALUVIA_API_KEY": "your-api-key"
}
}
}
}
```
### Cursor
Add to your Cursor MCP settings:
```json
{
"mcpServers": {
"aluvia": {
"command": "aluvia-mcp",
"env": {
"ALUVIA_API_KEY": "your-api-key"
}
}
}
}
```
### Generic MCP Client
Any MCP-compatible client can use the server by spawning it with stdio transport:
```python
import subprocess
import json
proc = subprocess.Popen(
["aluvia-mcp"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
env={"ALUVIA_API_KEY": "your-api-key"}
)
# Send JSON-RPC requests to proc.stdin
# Read JSON-RPC responses from proc.stdout
```
---
## Available Tools
### Session Management
- **`session_start`** — Start a browser session with Aluvia smart proxy
- **`session_close`** — Close one or all running sessions
- **`session_list`** — List all active sessions
- **`session_get`** — Get detailed session info (CDP URL, proxy config, block detection state)
- **`session_rotate_ip`** — Rotate IP address for a session
- **`session_set_geo`** — Set or clear target geographic region
- **`session_set_rules`** — Add or remove proxy routing rules
### Account Management
- **`account_get`** — Get account info (plan, balance)
- **`account_usage`** — Get usage statistics for a date range
### Geo-Targeting
- **`geos_list`** — List available geographic regions
---
## Use Cases
### 1. **AI Agent Web Scraping**
AI agents need to scrape data from websites that block automated traffic. Aluvia routes requests through mobile IPs, making them appear as real users.
**Example workflow:**
1. Agent calls `session_start` with `--auto-unblock` to launch a browser
2. Agent navigates to target websites
3. If blocked, Aluvia detects it and automatically reroutes through mobile IPs
4. Agent extracts data successfully
5. Agent calls `session_close` when done
### 2. **Multi-Region Testing**
Test how websites behave for users in different US regions.
**Example workflow:**
1. Agent calls `geos_list` to see available regions
2. Agent calls `session_start` and then `session_set_geo` with `us_ca` for California IPs
3. Agent verifies location-specific content
4. Agent calls `session_set_geo` with `us_ny` to switch to New York IPs
5. Agent compares results
### 3. **Dynamic Unblocking**
Agent adapts to blocks in real-time without restarting.
**Example workflow:**
1. Agent calls `session_start` without proxy rules (all traffic goes direct)
2. Agent encounters a block on `example.com`
3. Agent calls `session_set_rules` with `"example.com"` to add it to proxy rules
4. Agent retries the request — now routed through Aluvia
5. Request succeeds
---
## Why Aluvia
**The Problem:** Websites block datacenter IPs (AWS, GCP, Azure) because they're commonly used by bots. This breaks AI agents that need web access.
**The Solution:** Aluvia routes traffic through **real US mobile carrier IPs** — the same IPs used by millions of people on AT&T, T-Mobile, and Verizon. Websites can't distinguish these requests from legitimate mobile users.
**Key Features:**
- **Automatic block detection** — detects 403s, CAPTCHAs, WAFs, and Cloudflare challenges
- **Auto-unblocking** — when blocked, Aluvia reroutes through mobile IPs and reloads the page
- **Smart routing** — only proxy sites that need it; everything else goes direct (saves cost and latency)
- **Runtime rule updates** — add sites to proxy rules on the fly, no restarts
- **IP rotation** — rotate IPs or target specific US regions at runtime
- **CDP debugging** — get Chrome DevTools Protocol URLs for remote debugging
---
## Links
- **Homepage:** [aluvia.io](https://aluvia.io)
- **Documentation:** [docs.aluvia.io](https://docs.aluvia.io)
- **Dashboard:** [dashboard.aluvia.io](https://dashboard.aluvia.io)
- **GitHub (Node.js SDK):** [github.com/aluvia-connect/sdk-node](https://github.com/aluvia-connect/sdk-node)
- **GitHub (Python SDK):** [github.com/aluvia-connect/sdk-python](https://github.com/aluvia-connect/sdk-python)
- **MCP Protocol:** [modelcontextprotocol.io](https://modelcontextprotocol.io)
---
## License
MIT License — see [LICENSE](../LICENSE) for details.
| text/markdown | null | Aluvia <support@aluvia.io> | null | null | MIT | mcp, model-context-protocol, aluvia, ai-agent, browser-automation | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Software Development :: Libraries :: Python Mod... | [] | null | null | >=3.10 | [] | [] | [] | [
"aluvia-sdk>=1.2.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"black>=23.0.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://aluvia.io",
"Documentation, https://docs.aluvia.io",
"Repository, https://github.com/aluvia-connect/sdk-python",
"Issues, https://github.com/aluvia-connect/sdk-python/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T01:15:24.577961 | aluvia_mcp-1.0.0.tar.gz | 11,445 | 32/76/0c03ca99ffc6c1ae5476c867b9fda536e488510ae7fdb130e60f16606866/aluvia_mcp-1.0.0.tar.gz | source | sdist | null | false | 7c737407b79076806dbe859574e5cb0f | a5bb8137b1c65852ac72f9641f5d5d36b52867553c7403cc3cf1cffc9664fc43 | 32760c03ca99ffc6c1ae5476c867b9fda536e488510ae7fdb130e60f16606866 | null | [
"LICENSE"
] | 271 |
2.4 | MOBPY | 2.2.0 | Monotone optimal binning (MOB) via PAVA with constraints, plus plotting utilities. | <h1><p align="center"><strong>Monotonic-Optimal-Binning</strong></p></h1>
<h2><p align="center">MOBPY - Monotonic Optimal Binning for Python</p></h2>
[](https://github.com/ChenTaHung/Monotonic-Optimal-Binning/actions/workflows/RunTests.yml)
[](https://www.python.org/downloads/)
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/MOBPY/)
A fast, deterministic Python library for creating **monotonic optimal bins** with respect to a target variable. MOBPY implements a stack-based Pool-Adjacent-Violators Algorithm (PAVA) followed by constrained adjacent merging, ensuring strict monotonicity and statistical robustness.
## 🎯 Key Features
- **⚡ Fast & Deterministic**: Stack-based PAVA with O(n) complexity, followed by O(k) adjacent merges
- **📊 Monotonic Guarantee**: Ensures strict monotonicity (increasing/decreasing) between bins and target
- **🔧 Flexible Constraints**: Min/max samples, min positives, min/max bins with automatic resolution
- **📈 WoE & IV Calculation**: Automatic Weight of Evidence and Information Value for binary targets
- **🎨 Rich Visualizations**: Comprehensive plotting functions for PAVA process and binning results
- **♾️ Safe Edges**: First bin starts at -∞, last bin ends at +∞ for complete coverage
## 📦 Installation
```bash
pip install MOBPY
```
For development installation:
```bash
git clone https://github.com/ChenTaHung/Monotonic-Optimal-Binning.git
cd Monotonic-Optimal-Binning
pip install -e .
```
## 🚀 Quick Start
```python
import pandas as pd
import numpy as np
from MOBPY import MonotonicBinner, BinningConstraints
from MOBPY.plot import plot_bin_statistics, plot_pava_comparison
import matplotlib.pyplot as plt
df = pd.read_csv('/Users/chentahung/Desktop/git/mob-py/data/german_data_credit_cat.csv')
# Convert default to 0/1 (original is 1/2)
df['default'] = df['default'] - 1
# Configure constraints
constraints = BinningConstraints(
min_bins=4, # Minimum number of bins
max_bins=6, # Maximum number of bins
min_samples=0.05, # Each bin needs at least 5% of total samples
min_positives=0.01 # Each bin needs at least 1% of total positive samples
)
# Create and fit the binner
binner = MonotonicBinner(
df=df,
x='Durationinmonth',
y='default',
constraints=constraints
)
binner.fit()
# Get binning results
bins = binner.bins_() # Bin boundaries
summary = binner.summary_() # Detailed statistics with WoE/IV
display(summary)
```
Output:
```
bucket count count_pct sum mean std min max woe iv
0 (-inf, 9) 94 9.4 10.0 0.106383 0.309980 0.0 1.0 1.241870 0.106307
1 [9, 16) 337 33.7 79.0 0.234421 0.424267 0.0 1.0 0.335632 0.035238
2 [16, 45) 499 49.9 171.0 0.342685 0.475084 0.0 1.0 -0.193553 0.019342
3 [45, +inf) 70 7.0 4 0.0 0.571429 0.498445 0.0 1.0 -1.127082 0.102180
```
## 📊 Visualization
MOBPY provides comprehensive visualization of binning results:
```python
# Generate comprehensive binning analysis plot
fig = plot_bin_statistics(binner)
plt.show()
```

*The `plot_bin_statistics` function creates a multi-panel visualization showing:*
- **Top Left**: Weight of Evidence (WoE) bars for each bin
- **Top Right**: Event rate trend with sample distribution
- **Bottom Left**: Sample distribution histogram
- **Bottom Right**: Target distribution boxplots per bin
## 🔬 Understanding the Algorithm
MOBPY uses a two-stage approach:
### Stage 1: PAVA (Pool-Adjacent-Violators Algorithm)
Creates initial monotonic blocks by pooling adjacent violators:
```python
from MOBPY.plot import plot_pava_comparison
# Visualize PAVA process
fig = plot_pava_comparison(binner)
plt.show()
```

### Stage 2: Constrained Merging
Merges adjacent blocks to satisfy constraints while preserving monotonicity:
```python
# Check initial PAVA blocks vs final bins
print(f"PAVA blocks: {len(binner.pava_blocks_())}")
print(f"Final bins: {len(binner.bins_())}")
> PAVA blocks: 10
> Final bins: 4
```
## 🎛️ Advanced Configuration
### Custom Constraints
```python
# Fractional constraints (adaptive to data size)
constraints = BinningConstraints(
max_bins=8,
min_samples=0.05, # 5% of total samples
max_samples=0.30, # 30% of total samples
min_positives=0.01 # 1% of positive samples
)
# Absolute constraints (fixed values)
constraints = BinningConstraints(
max_bins=5,
min_samples=100, # At least 100 samples per bin
max_samples=500 # At most 500 samples per bin
)
```
### Handling Special Values
```python
# Exclude special codes from binning
age_binner = MonotonicBinner(
df=df,
x='Age',
y='default',
constraints= constraints,
exclude_values=[-999, -1, 0] # Treat as separate bins
).fit()
```
### Transform New Data
```python
new_data = pd.DataFrame({'age': [25, 45, 65]})
# Get bin assignments
bins = age_binner.transform(new_data['age'], assign='interval')
print(bins)
# Output:
# 0 (-inf, 26)
# 1 [35, 75)
# 2 [35, 75)
# Name: age, dtype: object
# Get WoE values for scoring
print(age_binner.transform(new_data['age'], assign='woe'))
# Output:
# 0 -0.526748
# 1 0.306015
# 2 0.306015
```
## 📈 Use Cases
MOBPY is ideal for:
- **Credit Risk Modeling**: Create monotonic risk score bins for regulatory compliance
- **Insurance Pricing**: Develop age/risk factor bands with clear premium progression
- **Customer Segmentation**: Build ordered customer value tiers
- **Feature Engineering**: Generate interpretable binned features for ML models
- **Regulatory Reporting**: Ensure transparent, monotonic relationships in models
## 📚 Documentation
- [API Reference](docs/api_reference.md) - Complete API documentation
- [Algorithm Details](docs/core) - Mathematical foundations
- [Examples & Tutorials](examples/) - Jupyter notebooks with real-world examples
## 🧪 Testing
```bash
# Run unit tests
pytest -vv -ignore-userwarnings -q
```
## 📖 Reference
* [Mironchyk, Pavel, and Viktor Tchistiakov. *Monotone optimal binning algorithm for credit risk modeling.* (2017)](https://www.researchgate.net/profile/Viktor-Tchistiakov/publication/322520135_Monotone_optimal_binning_algorithm_for_credit_risk_modeling/links/5a5dd1a8458515c03edf9a97/Monotone-optimal-binning-algorithm-for-credit-risk-modeling.pdf)
* [Smalbil, P. J. *The choices of weights in the iterative convex minorant algorithm.* (2015)](https://repository.tudelft.nl/islandora/object/uuid:5a111157-1a92-4176-9c8e-0b848feb7c30)
* Testing Dataset 1: [German Credit Risk](https://www.kaggle.com/datasets/uciml/german-credit) from Kaggle
* Testing Dataset 2: [US Health Insurance Dataset](https://www.kaggle.com/datasets/teertha/ushealthinsurancedataset) from Kaggle
* GitHub Project: [Monotone Optimal Binning (SAS 9.4 version)](https://github.com/cdfq384903/MonotonicOptimalBinning)
## 👥 Authors
1. Ta-Hung (Denny) Chen
* LinkedIn: [https://www.linkedin.com/in/dennychen-tahung/](https://www.linkedin.com/in/dennychen-tahung/)
* E-mail: [denny20700@gmail.com](mailto:denny20700@gmail.com)
2. Yu-Cheng (Darren) Tsai
* LinkedIn: [https://www.linkedin.com/in/darren-yucheng-tsai/](https://www.linkedin.com/in/darren-yucheng-tsai/)
* E-mail:
3. Peter Chen
* LinkedIn: [https://www.linkedin.com/in/peterchentsungwei/](https://www.linkedin.com/in/peterchentsungwei/)
* E-mail: [peterwei20700@gmail.com](mailto:peterwei20700@gmail.com)
## 📄 License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.
## 🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request. For major changes, please open an issue first to discuss what you would like to change.
| text/markdown | null | "Ta-Hung (Denny) Chen" <denny20700@gmail.com> | null | "Ta-Hung (Denny) Chen" <denny20700@gmail.com> | MIT | binning, woe, iv, pava, isotonic, credit-risk, monotonic, scorecard, feature-engineering | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Science/Research",
"Intended Audience :: Developers",
"Intended Audience :: Financial and Insurance Industry",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.9",
... | [] | null | null | >=3.9 | [] | [] | [] | [
"numpy>=1.20.0",
"pandas>=1.3.0",
"scipy>=1.7.0",
"matplotlib>=3.3.0",
"pytest>=8.0; extra == \"test\"",
"pytest-mock>=3.15; extra == \"test\"",
"hypothesis>=6.100; extra == \"test\"",
"pytest-cov>=4.0; extra == \"test\"",
"pytest>=8.0; extra == \"dev\"",
"hypothesis>=6.100; extra == \"dev\"",
"... | [] | [] | [] | [
"Homepage, https://github.com/ChenTaHung/Monotonic-Optimal-Binning",
"Repository, https://github.com/ChenTaHung/Monotonic-Optimal-Binning",
"Issues, https://github.com/ChenTaHung/Monotonic-Optimal-Binning/issues",
"Documentation, https://github.com/ChenTaHung/Monotonic-Optimal-Binning/tree/main/docs",
"Rele... | twine/6.2.0 CPython/3.11.13 | 2026-02-19T01:15:01.677321 | mobpy-2.2.0.tar.gz | 433,972 | b3/f5/4d5aded4cb367c25b945be94da709b8a3e05b9c7a6d54962d8af45160055/mobpy-2.2.0.tar.gz | source | sdist | null | false | d1adc94b8303307eabab795d8a59e436 | 67af334fd23c633bb92197adcc9ad32c438986631dad63f05e7c4ecbaebf41b5 | b3f54d5aded4cb367c25b945be94da709b8a3e05b9c7a6d54962d8af45160055 | null | [
"LICENSE"
] | 0 |
2.4 | cad-pyrx | 2.2.45.5251 | Python for Autocad® and Clones. | # CAD-PyRx
## Python for AutoCAD & Clones
CAD-PyRx is an ObjectARX module that exposes ObjectARX methods to Python, CAD-PyRx also exposes CAD's ActiveX API.
Currently supported platforms are AutoCAD® 2023-2027, BricsCAD® V24-V26, GStarCAD® 2024-2026, and ZwCAD® 2024-2026
## Features
- uses wxPython for the GUI, support for Palette and Dialogs
- degugpy to easily step through and debug your code
- Jig, Overrule, Point monitor and other advanced tools
- readDwgFile to open and manipulate side databases
- import other python modules such as pandas
## Installation
- [Install Python 3.12 as shown here](https://github.com/CEXT-Dan/PyRx/blob/main/README.md#Installation)
- Install from PyPI (here):
``pip install cad-pyrx``
- Install from the trunk:
``python -m pip install git+https://github.com/CEXT-Dan/PyRx.git``
- Uninstall:
``python -m pip uninstall cad-pyrx``
Use ``APPLOAD`` command or the startup suite to load PyRx in CAD application, example: Note: if you are using a VENV, this path may differ, it will be loacated where you installed it
```raw
_APPLOAD
%localappdata%\Programs\Python\Python312\Lib\site-packages\pyrx\RxLoaderZ26.0.zrx
or
RxLoader24.2.arx = 2023
RxLoader24.3.arx = 2024
RxLoader25.0.arx = 2025
RxLoader25.1.arx = 2026
RxLoader26.0.arx = 2027
RxLoaderV26.0.brx = BricsCAD v26
```
## Sample
```Python
# use prefix PyRxCmd_ to define a command called doit1
def PyRxCmd_doit1():
try:
db = Db.curDb()
filter = [(Db.DxfCode.kDxfStart, "LINE")]
ps, ss = Ed.Editor.select(filter)
if ps != Ed.PromptStatus.eOk:
return
lines = [Db.Line(id) for id in ss.objectIds()]
for line in lines:
print(line.startPoint().distanceTo(line.endPoint()))
except Exception as err:
traceback.print_exception(err)
# or use decorator to define a command called doit2
@Ap.Command("doit2", Ap.CmdFlags.kMODAL)
def function_setlayer():
try:
db = Db.curDb()
ps, id, _ = Ed.Editor.entSel("\nSelect a line: ", Db.Line.desc())
if ps != Ed.PromptStatus.eOk:
return
# all DbObjects accept an ID in the constructor
# line is garbage collected and closed
line = Db.Line(id, Db.OpenMode.kForWrite)
line.setLayer("0")
except Exception as err:
traceback.print_exception(err)
```
| text/markdown | null | PyRx Dev Team <daniel@cadext.com> | null | null | GNU LESSER GENERAL PUBLIC LICENSE
Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
This version of the GNU Lesser General Public License incorporates
the terms and conditions of version 3 of the GNU General Public
License, supplemented by the additional permissions listed below.
0. Additional Definitions.
As used herein, "this License" refers to version 3 of the GNU Lesser
General Public License, and the "GNU GPL" refers to version 3 of the GNU
General Public License.
"The Library" refers to a covered work governed by this License,
other than an Application or a Combined Work as defined below.
An "Application" is any work that makes use of an interface provided
by the Library, but which is not otherwise based on the Library.
Defining a subclass of a class defined by the Library is deemed a mode
of using an interface provided by the Library.
A "Combined Work" is a work produced by combining or linking an
Application with the Library. The particular version of the Library
with which the Combined Work was made is also called the "Linked
Version".
The "Minimal Corresponding Source" for a Combined Work means the
Corresponding Source for the Combined Work, excluding any source code
for portions of the Combined Work that, considered in isolation, are
based on the Application, and not on the Linked Version.
The "Corresponding Application Code" for a Combined Work means the
object code and/or source code for the Application, including any data
and utility programs needed for reproducing the Combined Work from the
Application, but excluding the System Libraries of the Combined Work.
1. Exception to Section 3 of the GNU GPL.
You may convey a covered work under sections 3 and 4 of this License
without being bound by section 3 of the GNU GPL.
2. Conveying Modified Versions.
If you modify a copy of the Library, and, in your modifications, a
facility refers to a function or data to be supplied by an Application
that uses the facility (other than as an argument passed when the
facility is invoked), then you may convey a copy of the modified
version:
a) under this License, provided that you make a good faith effort to
ensure that, in the event an Application does not supply the
function or data, the facility still operates, and performs
whatever part of its purpose remains meaningful, or
b) under the GNU GPL, with none of the additional permissions of
this License applicable to that copy.
3. Object Code Incorporating Material from Library Header Files.
The object code form of an Application may incorporate material from
a header file that is part of the Library. You may convey such object
code under terms of your choice, provided that, if the incorporated
material is not limited to numerical parameters, data structure
layouts and accessors, or small macros, inline functions and templates
(ten or fewer lines in length), you do both of the following:
a) Give prominent notice with each copy of the object code that the
Library is used in it and that the Library and its use are
covered by this License.
b) Accompany the object code with a copy of the GNU GPL and this license
document.
4. Combined Works.
You may convey a Combined Work under terms of your choice that,
taken together, effectively do not restrict modification of the
portions of the Library contained in the Combined Work and reverse
engineering for debugging such modifications, if you also do each of
the following:
a) Give prominent notice with each copy of the Combined Work that
the Library is used in it and that the Library and its use are
covered by this License.
b) Accompany the Combined Work with a copy of the GNU GPL and this license
document.
c) For a Combined Work that displays copyright notices during
execution, include the copyright notice for the Library among
these notices, as well as a reference directing the user to the
copies of the GNU GPL and this license document.
d) Do one of the following:
0) Convey the Minimal Corresponding Source under the terms of this
License, and the Corresponding Application Code in a form
suitable for, and under terms that permit, the user to
recombine or relink the Application with a modified version of
the Linked Version to produce a modified Combined Work, in the
manner specified by section 6 of the GNU GPL for conveying
Corresponding Source.
1) Use a suitable shared library mechanism for linking with the
Library. A suitable mechanism is one that (a) uses at run time
a copy of the Library already present on the user's computer
system, and (b) will operate properly with a modified version
of the Library that is interface-compatible with the Linked
Version.
e) Provide Installation Information, but only if you would otherwise
be required to provide such information under section 6 of the
GNU GPL, and only to the extent that such information is
necessary to install and execute a modified version of the
Combined Work produced by recombining or relinking the
Application with a modified version of the Linked Version. (If
you use option 4d0, the Installation Information must accompany
the Minimal Corresponding Source and Corresponding Application
Code. If you use option 4d1, you must provide the Installation
Information in the manner specified by section 6 of the GNU GPL
for conveying Corresponding Source.)
5. Combined Libraries.
You may place library facilities that are a work based on the
Library side by side in a single library together with other library
facilities that are not Applications and are not covered by this
License, and convey such a combined library under terms of your
choice, if you do both of the following:
a) Accompany the combined library with a copy of the same work based
on the Library, uncombined with any other library facilities,
conveyed under the terms of this License.
b) Give prominent notice with the combined library that part of it
is a work based on the Library, and explaining where to find the
accompanying uncombined form of the same work.
6. Revised Versions of the GNU Lesser General Public License.
The Free Software Foundation may publish revised and/or new versions
of the GNU Lesser General Public License from time to time. Such new
versions will be similar in spirit to the present version, but may
differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the
Library as you received it specifies that a certain numbered version
of the GNU Lesser General Public License "or any later version"
applies to it, you have the option of following the terms and
conditions either of that published version or of any later version
published by the Free Software Foundation. If the Library as you
received it does not specify a version number of the GNU Lesser
General Public License, you may choose any version of the GNU Lesser
General Public License ever published by the Free Software Foundation.
If the Library as you received it specifies that a proxy can decide
whether future versions of the GNU Lesser General Public License shall
apply, that proxy's public statement of acceptance of any version is
permanent authorization for you to choose that version for the
Library.
| AutoCAD, BricsCAD, GStarCAD, ZwCAD, CAD, dwg, dxf, Python, Wrappers, ARX, BRX, GRX, ZRX | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: Impleme... | [] | null | null | <3.13.0,>=3.12.0 | [] | [] | [] | [
"wxpython>=4.2.3; os_name == \"nt\"",
"pywin32; os_name == \"nt\"",
"debugpy>=1.8.0",
"pydantic_settings",
"pytest; extra == \"dev\"",
"build; extra == \"dev\"",
"ruff; extra == \"dev\"",
"python-dotenv[cli]; extra == \"dev\"",
"pre-commit; extra == \"dev\"",
"mypy; extra == \"dev\"",
"types-pyw... | [] | [] | [] | [
"Homepage, https://pyarx.blogspot.com/",
"Repository, https://github.com/CEXT-Dan/PyRx",
"Issues, https://github.com/CEXT-Dan/PyRx/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:15:01.581494 | cad_pyrx-2.2.45.5251.tar.gz | 81,622,254 | b1/82/52783f0593a1e08d9d0e75a37024fdbf6b218454af27a72eb7ef1e6010ed/cad_pyrx-2.2.45.5251.tar.gz | source | sdist | null | false | 9c7f02aacee98dba4d79f2f99b775bee | c690d465470bf8cfa2968009cd44e2cd33461e05192d537e5df5923d3aa4b217 | b18252783f0593a1e08d9d0e75a37024fdbf6b218454af27a72eb7ef1e6010ed | null | [
"LICENSE.txt"
] | 301 |
2.4 | agnost-mcp | 0.1.11 | Analytics SDK for Model Context Protocol Servers | # Agnost Analytics SDK
[](https://badge.fury.io/py/agnost_mcp)
[](https://pypi.org/project/agnost_mcp/)
Analytics SDK for tracking and analyzing Model Context Protocol (MCP) server interactions. Get insights into how your MCP servers are being used, monitor performance, and optimize user experiences.
## Installation
```bash
pip install agnost_mcp
```
## Basic Usage
```python
import agnost_mcp
from fastmcp import FastMCP
# Create FastMCP server
mcp = FastMCP("My Server")
@mcp.tool()
def calculate(operation: str, a: float, b: float) -> float:
"""Perform mathematical operations."""
if operation == "add":
return a + b
elif operation == "multiply":
return a * b
return 0
# Enable analytics tracking
agnost_mcp.track(mcp, org_id="your-organization-id")
```
## Configuration
You can customize the SDK behavior using the configuration object:
```python
import agnost_mcp
# Create a custom configuration
config = agnost_mcp.config(
endpoint="https://api.agnost.ai/api/v1",
disable_input=False, # Set to True to disable input tracking
disable_output=False # Set to True to disable output tracking
)
# Apply the configuration
agnost_mcp.track(
server=server,
org_id="your-organization-id",
config=config
)
```
### Configuration Options
| Option | Type | Default | Description |
|--------|------|---------|-------------|
| `endpoint` | `str` | `"https://api.agnost.ai/api/v1"` | API endpoint URL |
| `disable_input` | `bool` | `False` | Disable tracking of input arguments |
| `disable_output` | `bool` | `False` | Disable tracking of output results |
## Contact
For support or questions, contact the founders: [founders@agnost.ai](mailto:founders@agnost.ai)
| text/markdown | Agnost AI | Agnost AI <founders@agnost.ai> | null | null | MIT | null | [
"Programming Language :: Python :: 3",
"Operating System :: OS Independent"
] | [] | https://github.com/agnostai/agnostai | null | >=3.7 | [] | [] | [] | [
"requests>=2.25.0",
"pytest>=6.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://agnost.ai",
"BugTracker, https://docs.agnost.ai"
] | twine/6.1.0 CPython/3.11.9 | 2026-02-19T01:14:50.921802 | agnost_mcp-0.1.11.tar.gz | 11,982 | bd/e7/cd5ebc263462da07970243aa606f28459c625394ae458e37704a37a7485e/agnost_mcp-0.1.11.tar.gz | source | sdist | null | false | ee221e019a44b29f1d6c3947a6e4ba9d | ccb3a487766ed01fee2ca629ca46e2239241fe484036cc8a55b5680febdf1de5 | bde7cd5ebc263462da07970243aa606f28459c625394ae458e37704a37a7485e | null | [] | 277 |
2.4 | nlweb-pilabs-models | 0.7.0 | Pi Labs model providers for NLWeb | # NLWeb Pi Labs Models
Pi Labs LLM scoring provider for NLWeb.
## Overview
This package provides integration with Pi Labs scoring API for relevance scoring in NLWeb queries.
## Features
- **PiLabsProvider**: LLM provider that uses Pi Labs scoring API
- **PiLabsClient**: HTTP client for Pi Labs API
- Async scoring with httpx and HTTP/2 support
- Thread-safe client initialization
## Installation
```bash
pip install -e packages/providers/pilabs/models
```
## Usage
Configure in your `config.yaml`:
```yaml
llm:
scoring:
llm_type: pilabs
endpoint: "http://localhost:8001/invocations"
import_path: "nlweb_pilabs_models.llm"
class_name: "PiLabsProvider"
```
## Requirements
- Python >= 3.11
- httpx with HTTP/2 support
- nlweb_core
## API
The Pi Labs provider expects:
- `request.query`: The user query
- `item.description`: The item to score
- `site.itemType`: The type of item
Returns:
- `score`: Relevance score (0-100)
- `description`: Item description
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"nlweb-core>=0.6.0",
"httpx[http2]>=0.24.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:14:46.349163 | nlweb_pilabs_models-0.7.0.tar.gz | 3,155 | 4d/41/15b63c83c55b1540e35ce5f42c49b23de01b696e5d7ab91a61c6bbc42dd5/nlweb_pilabs_models-0.7.0.tar.gz | source | sdist | null | false | 969ed794ee969650e0129e9b9b2594ef | ede21b6afe7cb57e83912153db585b4b2739e0aaa19df00637843e0903dec5cc | 4d4115b63c83c55b1540e35ce5f42c49b23de01b696e5d7ab91a61c6bbc42dd5 | null | [] | 244 |
2.4 | aluvia-sdk | 1.2.0 | Aluvia SDK for Python - local smart proxy for automation workloads and AI agents | # Aluvia Python SDK
[](https://pypi.org/project/aluvia-sdk/)
[](https://pypi.org/project/aluvia-sdk/)
[](./LICENSE)
**Stop getting blocked.** Aluvia routes your AI agent's web traffic through premium US mobile carrier IPs — the same IPs used by real people on their phones. Websites trust them, so your agent stops hitting 403s, CAPTCHAs, and rate limits.
This SDK gives you everything you need:
- **CLI for browser automation** — launch headless Chromium sessions from the command line, with JSON output designed for AI agent frameworks
- **Automatic block detection and unblocking** — the SDK detects 403s, WAF challenges, and CAPTCHAs, then reroutes through Aluvia and reloads the page automatically
- **Smart routing** — proxy only the sites that block you; everything else goes direct to save cost and latency
- **Runtime rule updates** — add hostnames to proxy rules on the fly, no restarts or redeployments
- **Adapters for popular tools** — Playwright, Selenium, httpx, requests, and aiohttp
- **IP rotation and geo targeting** — rotate IPs or target specific US regions at runtime
- **REST API wrapper** — manage connections, check usage, and build custom tooling with `AluviaApi`
- **MCP server** — for Model Context Protocol (MCP) only, use the separate package: `pip install aluvia-mcp` and run `aluvia-mcp`. See [aluvia_mcp/README.md](aluvia_mcp/README.md) for details.
---
## Table of Contents
- [Quick Start](#quick-start)
- [MCP Server (Model Context Protocol)](#mcp-server-model-context-protocol)
- [Aluvia Client](#aluvia-client)
- [Architecture](#architecture)
- [Operating Modes](#operating-modes)
- [Using Aluvia Client](#using-aluvia-client)
- [Routing Rules](#routing-rules)
- [Dynamic Unblocking](#dynamic-unblocking)
- [Tool Integration Adapters](#tool-integration-adapters)
- [Aluvia API](#aluvia-api)
- [License](#license)
---
## Quick Start
### 1. Get Aluvia API key
[Aluvia dashboard](https://dashboard.aluvia.io)
### 2. Install
```bash
pip install aluvia-sdk playwright
export ALUVIA_API_KEY="your-api-key"
```
### 3. Run
Aluvia automatically detects website blocks and uses mobile IPs when necessary.
```python
from aluvia_sdk import AluviaClient
import asyncio
async def main():
client = AluviaClient(api_key="your-api-key", start_playwright=True)
connection = await client.start()
page = await connection.browser.new_page()
await page.goto("https://example.com")
print(await page.title())
await connection.close()
asyncio.run(main())
```
---
## MCP Server (Model Context Protocol)
For AI agent frameworks that support MCP (Claude Desktop, Claude Code, Cursor, etc.), use the Aluvia MCP server:
```bash
pip install aluvia-mcp
export ALUVIA_API_KEY="your-api-key"
aluvia-mcp
```
The MCP server exposes all Aluvia CLI functionality as structured tools. See [aluvia_mcp/README.md](aluvia_mcp/README.md) for configuration and usage.
---
## Aluvia client
The Aluvia client runs a local rules-based proxy server on your agent's host, handles authentication and connection management, and provides ready-to-use adapters for popular tools like Playwright, Selenium, and httpx.
Simply point your automation tool at the local proxy address (`127.0.0.1`) and the client handles the rest. For each request, the client checks the destination hostname against user-defined (or agent-defined) routing rules and decides whether to send it through Aluvia's mobile IPs or direct to the destination.
```
┌──────────────────┐ ┌──────────────────────────┐ ┌──────────────────────┐
│ │ │ │ │ │
│ Your Agent │─────▶ Aluvia Client ─────▶ gateway.aluvia.io │
│ │ │ 127.0.0.1:port │ │ (Mobile IPs) │
│ │ │ │ │ │
└──────────────────┘ │ Per-request routing: │ └──────────────────────┘
│ │
│ not-blocked.com ──────────────▶ Direct
│ blocked-site.com ─────────────▶ Via Aluvia
│ │
└──────────────────────────┘
```
**Benefits:**
- **Avoid blocks:** Websites flag datacenter IPs as bot traffic, leading to 403s, CAPTCHAs, and rate limits. Mobile IPs appear as real users, so requests go through.
- **Reduce costs and latency:** Hostname-based routing rules let you proxy only the sites that need it. Traffic to non-blocked sites goes direct, saving money and reducing latency.
- **Unblock without restarts:** Rules update at runtime. When a site blocks your agent, add it to the proxy rules and retry—no need to restart workers or redeploy.
- **Simplify integration:** One SDK with ready-to-use adapters for Playwright, Selenium, httpx, requests, and aiohttp.
---
## Quick start
### Understand the basics
- [What is Aluvia?](https://docs.aluvia.io/)
- [Understanding connections](https://docs.aluvia.io/fundamentals/connections)
### Get Aluvia API key
1. Create an account at [dashboard.aluvia.io](https://dashboard.aluvia.io)
2. Go to **API and SDKs** and get your **API Key**
### Install the SDK
```bash
pip install aluvia-sdk
```
**Requirements:** Python 3.9 or later
### Example: Dynamic unblocking with Playwright
This example shows how an agent can use the Aluvia client to dynamically unblock websites. It demonstrates starting the client, using the Playwright integration adapter, configuring geo targeting and session ID, detecting blocks, and updating routing rules on the fly.
```python
import asyncio
from playwright.async_api import async_playwright
from aluvia_sdk import AluviaClient
async def main():
# Initialize the Aluvia client with your API key
client = AluviaClient(api_key="your-api-key")
# Start the client (launches local proxy, fetches connection config)
connection = await client.start()
# Configure geo targeting (use California IPs)
await client.update_target_geo("us_ca")
# Set session ID (requests with the same session ID use the same IP)
await client.update_session_id("agentsession1")
# Launch browser using the Playwright integration adapter
# The adapter returns proxy settings in Playwright's expected format
async with async_playwright() as p:
browser = await p.chromium.launch(proxy=connection.as_playwright())
# Track hostnames we've added to proxy rules
proxied_hosts = set()
async def visit_with_retry(url: str) -> str:
page = await browser.new_page()
try:
response = await page.goto(url, wait_until="domcontentloaded")
hostname = url.split("//")[1].split("/")[0]
# Detect if the site blocked us (403, 429, or challenge page)
status = response.status if response else 0
title = await page.title()
is_blocked = status in (403, 429) or "blocked" in title.lower()
if is_blocked and hostname not in proxied_hosts:
print(f"Blocked by {hostname} — adding to proxy rules")
# Update routing rules to proxy this hostname through Aluvia
# Rules update at runtime—no need to restart the browser
proxied_hosts.add(hostname)
await client.update_rules(list(proxied_hosts))
# Rotate to a fresh IP by changing the session ID
import time
await client.update_session_id(f"retry{int(time.time())}")
await page.close()
return await visit_with_retry(url)
return await page.content()
finally:
await page.close()
try:
# First attempt goes direct; if blocked, retries through Aluvia
html = await visit_with_retry("https://example.com/data")
print("Success:", html[:200])
finally:
# Always close the browser and connection when done
await browser.close()
await connection.close()
if __name__ == '__main__':
asyncio.run(main())
```
### Example: Auto-launch Playwright browser
For even simpler setup, the SDK can automatically launch a Chromium browser that's already configured with the Aluvia proxy. This eliminates the need to manually import Playwright and configure proxy settings.
```python
import asyncio
from aluvia_sdk import AluviaClient
async def main():
# Initialize with start_playwright option to auto-launch browser
client = AluviaClient(
api_key="your-api-key",
start_playwright=True, # Automatically launch and configure Chromium
)
# Start the client - this also launches the browser
connection = await client.start()
# Browser is already configured with Aluvia proxy
browser = connection.browser
page = await browser.new_page()
# Configure geo targeting and session ID
await client.update_target_geo("us_ca")
await client.update_session_id("session1")
# Navigate directly - proxy is already configured
await page.goto("https://example.com")
print("Title:", await page.title())
# Cleanup - automatically closes both browser and proxy
await connection.close()
if __name__ == '__main__':
asyncio.run(main())
```
**Note:** To use `start_playwright=True`, you must install Playwright:
```bash
pip install playwright
playwright install chromium
```
### Integration guides
The Aluvia client provides ready-to-use adapters for popular automation and HTTP tools. Check the integration examples in the [Node.js SDK docs](https://github.com/aluvia-connect/sdk-node/tree/main/docs/integrations) for reference patterns that can be adapted to Python.
---
## Architecture
The client is split into two independent **planes**:
```
┌─────────────────────────────────────────────────────────────────┐
│ AluviaClient │
├─────────────────────────────┬───────────────────────────────────┤
│ Control Plane │ Data Plane │
│ (ConfigManager) │ (ProxyServer) │
├─────────────────────────────┼───────────────────────────────────┤
│ • Fetches/creates config │ • Local HTTP proxy (proxy.py) │
│ • Polls for updates (ETag) │ • Per-request routing decisions │
│ • PATCH updates (rules, │ • Uses rules engine to decide: │
│ session, geo) │ direct vs gateway │
└─────────────────────────────┴───────────────────────────────────┘
```
### Control Plane (ConfigManager)
- Communicates with the Aluvia REST API (`/account/connections/...`)
- Fetches proxy credentials and routing rules
- Polls for configuration updates
- Pushes updates (rules, session ID, geo)
### Data Plane (ProxyServer)
- Runs a local HTTP proxy on `127.0.0.1`
- For each request, uses the **rules engine** to decide whether to route direct or via Aluvia.
- Because the proxy reads the latest config per-request, rule updates take effect immediately
---
## Operating modes
The Aluvia client has two operating modes: **Client Proxy Mode** (default) and **Gateway Mode**.
### Client Proxy Mode
**How it works:** The SDK runs a local proxy on `127.0.0.1`. For each request, it checks your routing rules and sends traffic either direct or through Aluvia.
**Why use it:**
- Selective routing reduces cost and latency (only proxy what you need)
- Credentials stay inside the SDK (nothing secret in your config)
- Rule changes apply immediately (no restarts)
**Best for:** Using per-hostname routing rules.
### Gateway Mode
Set `local_proxy=False` to enable.
**How it works:** No local proxy. Your tools connect directly to `gateway.aluvia.io` and **ALL** traffic goes through Aluvia.
**Why use it:**
- No local process to manage
- Simpler setup for tools with native proxy auth support
**Best for:** When you want all traffic proxied without selective routing.
---
## Using Aluvia client
### 1. Create a client
```python
client = AluviaClient(
api_key=os.environ["ALUVIA_API_KEY"],
connection_id=123, # Optional: reuse an existing connection
local_proxy=True, # Optional: default True (recommended)
start_playwright=True, # Optional: auto-launch Chromium browser
)
```
### 2. Start the client and get a connection
```python
connection = await client.start()
```
This starts the local proxy and returns a connection object you'll use with your tools.
[Understanding the connection object](https://docs.aluvia.io/fundamentals/connections)
### 3. Use the connection with your tools
Pass the connection to your automation tool using the appropriate adapter:
```python
browser = await p.chromium.launch(proxy=connection.as_playwright())
```
### 4. Update routing as necessary
While your agent is running, you can update routing rules, rotate IPs, or change geo targeting—no restart needed:
```python
await client.update_rules(["blocked-site.com"]) # Add hostname to proxy rules
await client.update_session_id("newsession") # Rotate to a new IP
await client.update_target_geo("us_ca") # Target California IPs
```
### 5. Clean up when done
```python
await connection.close() # Stops proxy, polling, and releases resources
```
---
## Routing rules
The Aluvia Client starts a local proxy server that routes each request based on hostname rules that you (or our agent) set. **Rules can be updated at runtime without restarting the agent.**
Traffic can be sent either:
- direct (using the agent's datacenter/cloud IP) or,
- through Aluvia's mobile proxy IPs,
### Benefits
- Selectively routing traffic to mobile proxies reduces proxy costs and connection latency.
- Rules can be updated during runtime, allowing agents to work around website blocks on the fly.
### Example rules
```python
await client.update_rules(["*"]) # Proxy all traffic
await client.update_rules(["target-site.com", "*.google.com"]) # Proxy specific hosts
await client.update_rules(["*", "-api.stripe.com"]) # Proxy all except specified
await client.update_rules([]) # Route all traffic direct
```
### Supported routing rule patterns:
| Pattern | Matches |
| --------------- | ------------------------------------- |
| `*` | All hostnames |
| `example.com` | Exact match |
| `*.example.com` | Subdomains of example.com |
| `google.*` | google.com, google.co.uk, and similar |
| `-example.com` | Exclude from proxying |
---
## Dynamic unblocking
Most proxy solutions require you to decide upfront which sites to proxy. If a site blocks you later, you're stuck—restart your workers, redeploy your fleet, or lose the workflow.
**With Aluvia, your agent can unblock itself.** When a request fails with a 403 or 429, your agent adds that hostname to its routing rules and retries. The update takes effect immediately—no restart, no redeployment, no lost state.
This turns blocking from a workflow-ending failure into a minor speed bump.
```python
response = await page.goto(url)
if response and response.status in (403, 429):
# Blocked! Add this hostname to proxy rules and retry
hostname = url.split("//")[1].split("/")[0]
await client.update_rules([*current_rules, hostname])
await page.goto(url) # This request goes through Aluvia
```
Your agent learns which sites need proxying as it runs. Sites that don't block you stay direct (faster, cheaper). Sites that do block you get routed through mobile IPs automatically.
---
## Tool integration adapters
Every tool has its own way of configuring proxies—Playwright wants a dict with server/username/password, Selenium wants a string, httpx wants an agent, and some tools don't support proxies at all. The SDK handles all of this for you:
| Tool | Method | Returns |
| ---------- | ---------------------------- | ----------------------------------------------------------- |
| Playwright | `connection.as_playwright()` | `{"server": "...", "username": "...", "password": "..."}` |
| Playwright | `connection.browser` | Auto-launched Chromium browser (if `start_playwright=True`) |
| Selenium | `connection.as_selenium()` | `"--proxy-server=..."` |
| httpx | `connection.as_httpx()` | `httpx.HTTPTransport(proxy=...)` |
| requests | `connection.as_requests()` | `{"http": "...", "https": "..."}` |
| aiohttp | `connection.as_aiohttp()` | `"http://username:password@host:port"` |
**Playwright auto-launch:** Set `start_playwright=True` in the client options to automatically launch a Chromium browser that's already configured with the Aluvia proxy. The browser is available via `connection.browser` and is automatically cleaned up when you call `connection.close()`.
---
## Aluvia API
`AluviaApi` is a typed wrapper for the Aluvia REST API. Use it to manage connections, query account info, or build custom tooling—without starting a proxy.
`AluviaApi` is built from modular layers:
```
┌───────────────────────────────────────────────────────────────┐
│ AluviaApi │
│ Constructor validates api_key, creates namespace objects │
├───────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ account │ │ geos │ │ request │ │
│ │ namespace │ │ namespace │ │ (escape │ │
│ │ │ │ │ │ hatch) │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ request_and_unwrap / request │ │
│ │ (envelope unwrapping, error throwing) │ │
│ └────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ request_core │ │
│ │ (URL building, headers, timeout, JSON parsing) │ │
│ └────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ httpx / requests │
└───────────────────────────────────────────────────────────────┘
```
### What you can do
| Endpoint | Description |
| ------------------------------------ | --------------------------------------- |
| `api.account.get()` | Get account info (balance, usage) |
| `api.account.connections.list()` | List all connections |
| `api.account.connections.create()` | Create a new connection |
| `api.account.connections.get(id)` | Get connection details |
| `api.account.connections.patch(id)` | Update connection (rules, geo, session) |
| `api.account.connections.delete(id)` | Delete a connection |
| `api.geos.list()` | List available geo-targeting options |
### Example
```python
from aluvia_sdk import AluviaApi
api = AluviaApi(api_key=os.environ["ALUVIA_API_KEY"])
# Check account balance
account = await api.account.get()
print(f"Balance: {account['balance_gb']} GB")
# Create a connection for a new agent
connection = await api.account.connections.create(
description="pricing-scraper",
rules=["competitor-site.com"],
target_geo="us_ca",
)
print(f"Created: {connection['connection_id']}")
# List available geos
geos = await api.geos.list()
print("Geos:", [g["code"] for g in geos])
```
**Tip:** `AluviaApi` is also available as `client.api` when using `AluviaClient`.
---
## License
MIT — see [LICENSE](./LICENSE)
| text/markdown | null | Aluvia <support@aluvia.io> | null | null | null | proxy, ai-agent, playwright, selenium, aluvia, web-scraping | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Internet :: Proxy Servers",
"Topic :: Softwar... | [] | null | null | >=3.10 | [] | [] | [] | [
"httpx>=0.24.0",
"aiohttp>=3.8.0",
"proxy.py>=2.4.0",
"playwright>=1.40.0; extra == \"playwright\"",
"selenium>=4.0.0; extra == \"selenium\"",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"pytest-mock>=3.12.0; extra == \"dev\"",
"mypy>=1.0.0; extra == \"dev\"",
"b... | [] | [] | [] | [
"Homepage, https://aluvia.io",
"Documentation, https://docs.aluvia.io",
"Repository, https://github.com/aluvia-connect/sdk-python",
"Issues, https://github.com/aluvia-connect/sdk-python/issues"
] | twine/6.2.0 CPython/3.12.3 | 2026-02-19T01:14:24.674132 | aluvia_sdk-1.2.0.tar.gz | 54,813 | 05/ef/bcb509b9b2a9ea1e9d3b04ea30b5b6b3592c83cbab078a26c366043caf61/aluvia_sdk-1.2.0.tar.gz | source | sdist | null | false | c8e34beb6979e83716cfc4ff732dfbef | 4c86000c11df1b9c20dad6a12760078ecf903c9597fd78d31e60051d58ba872e | 05efbcb509b9b2a9ea1e9d3b04ea30b5b6b3592c83cbab078a26c366043caf61 | MIT | [
"LICENSE"
] | 297 |
2.4 | nlweb-cosmos-site-config | 0.7.0 | Azure Cosmos DB site configuration provider for NLWeb - stores and retrieves domain-specific elicitation configs | # NLWeb Azure Cosmos DB Site Config Provider
Azure Cosmos DB provider for site-specific configuration storage and lookup.
## Overview
This provider implements site configuration lookup using Azure Cosmos DB, enabling domain-specific query elicitation based on intents and required information checks.
## Features
- **Cosmos DB Integration**: Stores site configs in dedicated `site_configs` container
- **In-Memory Caching**: 5-minute TTL cache for fast lookups
- **Azure AD Support**: Managed Identity or API key authentication
- **Domain Normalization**: Handles www. prefix automatically
## Configuration
Configure in your `config.yaml`:
```yaml
site_config:
default:
endpoint_env: COSMOS_DB_ENDPOINT
api_key_env: COSMOS_DB_KEY
database_name_env: COSMOS_DB_DATABASE_NAME
container_name: site_configs
use_managed_identity: false
cache_ttl: 300
```
## Usage
The provider is automatically initialized when site_config is configured:
```python
from nlweb_cosmos_site_config import CosmosSiteConfigLookup
# Initialized automatically from config via ProviderMap
# Direct instantiation example:
lookup = CosmosSiteConfigLookup(
endpoint="https://your-cosmos.documents.azure.com",
database_name="your-db",
container_name="site_configs",
cache_ttl=300,
)
# Get full config for a domain (all config types)
config = await lookup.get_config("yelp.com")
# Get a specific config type
elicitation = await lookup.get_config_type("yelp.com", "elicitation")
```
## Installation
```bash
pip install -e .
```
## License
MIT License - Copyright (c) 2025 Microsoft Corporation
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"nlweb-core>=0.6.0",
"azure-cosmos>=4.5.0",
"azure-identity>=1.12.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:14:07.725868 | nlweb_cosmos_site_config-0.7.0.tar.gz | 10,397 | a1/05/0246a052b7511ace983a6d96f2e41bdb3f2d5949e99d303736e9c33be12e/nlweb_cosmos_site_config-0.7.0.tar.gz | source | sdist | null | false | 7bde7602e5d444945ce780560c474bd9 | de855ed9d9c25855bae2ec30b348b7d7f4a115455e9143ea2d88f308f712ab8a | a1050246a052b7511ace983a6d96f2e41bdb3f2d5949e99d303736e9c33be12e | null | [] | 242 |
2.4 | lts-celery-utils | 0.1.8 | helper methods for celery apps | # lts-celery-utils
A python module for celery apps
- retries celery.send_task() calls if not acknowledged / failed
# How to use
```python
import celery as celeryapp
from lts_celery_utils.utils import reliable_send_task
result = reliable_send_task(
task_name="my.task",
args=(1, 2),
kwargs={"key": "value"},
queue="default",
app=celeryapp
)
```
# Packaging
Read the instructions in the [LTS python package template](https://github.com/harvard-lts/python-package-template) for more information on how to build and publish python packages.
**Keep the link to the Packaging instructions above and replace everything below with specific app details**
# Quick start for development
A quick set of commands to run after initial setup is complete.
```
uv venv --python 3.12.0
source .venv/bin/activate
set -a && source .env && set +a
uv sync
uv build
uv publish
```
**Note: Remove older versions from the local `./dist/` directory before attempting to publish.**
## Tests
To run the unit tests, run the pytest command in the virtual environment.
```
pytest
```
# Installation
## Install uv package manager
https://docs.astral.sh/uv/
https://docs.astral.sh/uv/reference/settings/#publish-url
```
curl -LsSf https://astral.sh/uv/install.sh | sh
```
## Install python
Install a specific python version on your local machine, if not installed already. Optionally, the `uv` package allows for installing multiple python versions.
```
uv python install 3.11 3.12
```
To view python installations run uv list.
```
uv python list
```
## Virtual environment
Create a new virtual environment with a specific python version.
```
uv venv --python 3.12.0
```
Activate the virtual environment
```
source .venv/bin/activate
```
## Add dependencies
Run the `uv add` command to add dependencies to the project.
This example adds [the `ruff` package which is an extremely fast python linter](https://docs.astral.sh/ruff/).
```
uv add ruff
```
Run the ruff check command
```
uv run ruff check
```
Read more about [managing dependencies in the documentation](https://docs.astral.sh/uv/guides/projects/#managing-dependencies).
## Test modules locally
Activate a virtual environment using the instructions above.
Navigate to the src directory and run a python interpreter.
```
cd src
python
```
Import the hello_world module from the python_package_template.
```
from python_package_template.hello_world import hello_world
```
Call hello_world()
```
hello_world()
```
Example output
```
src % python
Python 3.9.6 (default, Feb 3 2024, 15:58:27)
[Clang 15.0.0 (clang-1500.3.9.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from python_package_template.hello_world import hello_world
>>> hello_world()
Hello from python-package-template!
```
## Project structure
Read more about the [project structure in the documentation](https://docs.astral.sh/uv/guides/projects/#project-structure).
## Packaging
### Build system
This project is already configured to use the default build system `hatchling` in the `[build-system]` section of the `pyproject.toml` file.
Read more about [build systems in the documentation](https://docs.astral.sh/uv/concepts/projects/config/#build-systems).
### Build project
Run uv build to build the project distribution files.
```
uv build
```
Read more about the [build command in the documentation](https://docs.astral.sh/uv/guides/publish/#building-your-package).
### Generate a token
Login to artifactory and click on the "Set me up" menu item on the top right
Select the lts-python repository
Generate a token
### Set environment variables and Artifactory authentication
Update the .env file
Set the username to your Artifactory username and set the password to the token value generated in JFrog Artifactory.
```
UV_PUBLISH_USERNAME={artifactory username}
UV_PUBLISH_PASSWORD={token generated in JFrog Artifactory}
```
Next, update the `.netrc` file with the same credentials:
```
login {artifactory username}
password {token generated in JFrog Artifactory}
```
Source the .env file
```
set -a && source .env && set +a
```
Make sure there are no spaces in the .env file for the source command to work correctly
**Important: Run `env` to list all of the variables to sure the variables are being set correctly**
### Set publish url
The publish URL is set to the HUIT artifactory already.
https://docs.astral.sh/uv/reference/settings/#publish-url
**Important: Make sure to delete old builds from the `dist/` folder or the publish will not work**
Run the uv sync command to make sure the uv.lock file is updated with the latest changes.
```
uv sync
```
Run the uv publish command with the settings in `pyproject.toml`.
```
uv publish
```
**Important: To publish for the first time, comment out check-url in pyproject.yml temporarily.**
Optionally, to publish to a different repository, run the uv publish command and provide the url to the publish index directly.
```
uv publish --publish-url=https://artifactory.huit.harvard.edu/artifactory/api/pypi/lts-python
```
Note: The first time the package is published and error message may appear that the check-url could not be queried because the package does not exist. If this is the case, comment out check-url, publish the package, and then add it back in for later use.
### Installation
Read the instructions in the [python-package-demo](https://github.com/harvard-lts/python-package-demo) repository to install the package in another project.
Set the installation environment variables when installing from JFrog Artifactory.
https://github.com/astral-sh/uv/issues/8518
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.9 | [] | [] | [] | [
"ruff>=0.8.3",
"coverage; extra == \"dev\"",
"flake8; extra == \"dev\"",
"pytest; extra == \"dev\"",
"pytest-cov; extra == \"dev\"",
"pytest-mock; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.13.5 | 2026-02-19T01:13:59.168769 | lts_celery_utils-0.1.8.tar.gz | 45,668 | e8/16/5261ed61cd56d274d80332ba52dcc62927bcc71f3738455f33315404732d/lts_celery_utils-0.1.8.tar.gz | source | sdist | null | false | 94c6b1d3fc9dc36b305f3fd739f0a66b | 9913615d201281f546dc33fd6545be82e02177055bdcc543158f08acd3831483 | e8165261ed61cd56d274d80332ba52dcc62927bcc71f3738455f33315404732d | null | [
"LICENSE"
] | 285 |
2.4 | nlweb-cosmos-object-db | 0.7.0 | Azure Cosmos DB object lookup provider for NLWeb - enriches search results with full documents | # nlweb-cosmos-object-db
Azure Cosmos DB object lookup provider for NLWeb.
## Overview
This provider enables NLWeb to enrich vector search results with full documents from Azure Cosmos DB. When vector databases return truncated content, this provider fetches the complete documents from Cosmos DB using document IDs.
## Installation
```bash
pip install nlweb-core nlweb-cosmos-object-db
```
For a complete setup with vector search:
```bash
pip install nlweb-core nlweb-azure-vectordb nlweb-cosmos-object-db
```
## Configuration
Create `config.yaml`:
```yaml
object_storage:
type: cosmos
enabled: true
endpoint_env: AZURE_COSMOS_ENDPOINT
database_name: your-database
container_name: your-container
partition_key: /"@id"
import_path: nlweb_cosmos_object_db.cosmos_lookup
class_name: CosmosObjectLookup
```
### Authentication
This provider uses **Azure AD Managed Identity** authentication via `DefaultAzureCredential`. No API keys required.
Set environment variable:
```bash
export AZURE_COSMOS_ENDPOINT=https://your-account.documents.azure.com:443/
```
### Azure AD Setup
Ensure your Azure identity has appropriate Cosmos DB permissions:
- `Cosmos DB Built-in Data Reader` role
- Or custom role with `Microsoft.DocumentDB/databaseAccounts/readMetadata` and read permissions
## Usage
The provider automatically enriches search results when configured:
```python
import nlweb_core
# Initialize with config
nlweb_core.init(config_path="./config.yaml")
from nlweb_core import retriever
# Search with automatic enrichment
results = await retriever.search(
query="example query",
site="example.com",
num_results=10,
enrich_from_storage=True # Enable Cosmos DB enrichment
)
# Results now contain full documents from Cosmos DB
for result in results:
print(result.content) # Full content instead of truncated text
```
## How It Works
1. **Vector Search**: NLWeb queries the vector database (e.g., Azure AI Search) and gets IDs + truncated content
2. **ID Extraction**: Document IDs are extracted from vector search results
3. **Cosmos DB Lookup**: Provider queries Cosmos DB by `@id` field to fetch full documents
4. **Content Enrichment**: Full documents replace truncated content in search results
5. **Ranking**: LLM ranks the enriched results
## Features
- Azure AD managed identity authentication (no API keys)
- Async-compatible using thread executors
- Parameterized queries to prevent injection
- Configurable database, container, and partition key
- Seamless integration with NLWeb retrieval pipeline
- Compatible with NLWeb Protocol v0.5+
## Document Structure
Your Cosmos DB documents should have an `@id` field that matches the IDs returned by your vector database:
```json
{
"@id": "doc-12345",
"content": "Full document content here...",
"metadata": {
"title": "Document Title",
"url": "https://example.com/page"
}
}
```
## Configuration Options
| Field | Required | Description |
|-------|----------|-------------|
| `type` | Yes | Must be "cosmos" |
| `enabled` | Yes | Set to `true` to enable enrichment |
| `endpoint_env` | Yes | Environment variable name for Cosmos endpoint |
| `database_name` | Yes | Cosmos DB database name |
| `container_name` | Yes | Cosmos DB container name |
| `partition_key` | Yes | Partition key path (e.g., `/"@id"`) |
| `import_path` | Yes | `nlweb_cosmos_object_db.cosmos_lookup` |
| `class_name` | Yes | `CosmosObjectLookup` |
## Creating Your Own Object Lookup Provider
Use this package as a template:
1. **Create package structure**:
```
nlweb-your-objectdb/
├── pyproject.toml
├── README.md
└── nlweb_your_objectdb/
├── __init__.py
└── your_lookup.py
```
2. **Implement ObjectLookupInterface**:
```python
from nlweb_core.retriever import ObjectLookupInterface
class YourLookup(ObjectLookupInterface):
async def get_by_id(self, doc_id: str) -> dict:
# Your implementation
pass
```
3. **Declare dependencies** in `pyproject.toml`:
```toml
dependencies = [
"nlweb-core>=0.5.5",
"your-database-sdk>=1.0.0",
]
```
4. **Configure in NLWeb**:
```yaml
object_storage:
import_path: nlweb_your_objectdb.your_lookup
class_name: YourLookup
```
## License
MIT License - Copyright (c) 2025 Microsoft Corporation
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"nlweb-core>=0.6.0",
"azure-cosmos>=4.5.0",
"azure-identity>=1.12.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:13:54.123587 | nlweb_cosmos_object_db-0.7.0.tar.gz | 4,465 | b4/d4/aa2503352e7e90edbb42e38fbe47e4ded1814bd507dd78712822e4467ff9/nlweb_cosmos_object_db-0.7.0.tar.gz | source | sdist | null | false | cdd215712ccc4724cd9a9fd9570e012b | 3c7943eabec97d36824942d290f63c31692b0239ca7c0bcb482507cbd17416cb | b4d4aa2503352e7e90edbb42e38fbe47e4ded1814bd507dd78712822e4467ff9 | null | [] | 248 |
2.4 | nlweb-azure-vectordb | 0.7.0 | Azure vector database provider for NLWeb - Azure AI Search client | # nlweb-azure-vectordb
Azure AI Search provider for NLWeb.
## Overview
This is a **blueprint package** demonstrating how to create individual provider packages for NLWeb. It contains only the Azure AI Search retrieval provider.
Third-party developers can use this as a template for creating their own provider packages (e.g., `nlweb-pinecone`, `nlweb-weaviate`, etc.).
## Installation
```bash
pip install nlweb-core nlweb-azure-vectordb
```
For LLM and embedding, you'll also need a model provider:
```bash
pip install nlweb-azure-models
```
Or use the bundle packages:
```bash
pip install nlweb-core nlweb-retrieval nlweb-models
```
## Configuration
Create `config.yaml`:
```yaml
retrieval:
provider: azure_ai_search
import_path: nlweb_azure_vectordb.azure_search_client
class_name: AzureSearchClient
api_endpoint_env: AZURE_SEARCH_ENDPOINT
auth_method: azure_ad # or api_key
index_name: my-search-index
```
### Authentication Methods
#### API Key Authentication
```yaml
retrieval:
provider: azure_ai_search
import_path: nlweb_azure_vectordb.azure_search_client
class_name: AzureSearchClient
api_endpoint_env: AZURE_SEARCH_ENDPOINT
api_key_env: AZURE_SEARCH_KEY
auth_method: api_key
index_name: my-index
```
Set environment variables:
```bash
export AZURE_SEARCH_ENDPOINT=https://your-service.search.windows.net
export AZURE_SEARCH_KEY=your_key_here
```
#### Managed Identity (Azure AD) Authentication
```yaml
retrieval:
provider: azure_ai_search
import_path: nlweb_azure_vectordb.azure_search_client
class_name: AzureSearchClient
api_endpoint_env: AZURE_SEARCH_ENDPOINT
auth_method: azure_ad
index_name: my-index
```
Set environment variable:
```bash
export AZURE_SEARCH_ENDPOINT=https://your-service.search.windows.net
```
## Usage
```python
import nlweb_core
# Initialize
nlweb_core.init(config_path="./config.yaml")
# Search
from nlweb_core import retriever
results = await retriever.search(
query="example query",
site="example.com",
num_results=10
)
```
## Features
- Vector similarity search with Azure AI Search
- Hybrid search (vector + keyword)
- Managed identity (Azure AD) authentication support
- API key authentication support
- Configurable index names
- Compatible with NLWeb Protocol v0.5
## Creating Your Own Provider Package
Use this package as a template:
1. **Create package structure**:
```
nlweb-yourprovider/
├── pyproject.toml
├── README.md
└── nlweb_yourprovider/
├── __init__.py
└── your_client.py
```
2. **Implement VectorDBClientInterface**:
```python
from nlweb_core.retriever import VectorDBClientInterface
class YourClient(VectorDBClientInterface):
async def search(self, query, site, num_results, **kwargs):
# Your implementation
pass
```
3. **Declare dependencies** in `pyproject.toml`:
```toml
dependencies = [
"nlweb-core>=0.5.0",
"your-provider-sdk>=1.0.0",
]
```
4. **Publish to PyPI**:
```bash
python -m build
twine upload dist/*
```
## License
MIT License - Copyright (c) 2025 Microsoft Corporation
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"nlweb-core>=0.6.0",
"azure-core",
"azure-search-documents>=11.4.0",
"azure-identity>=1.12.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:13:15.995054 | nlweb_azure_vectordb-0.7.0-py3-none-any.whl | 5,600 | 8f/29/7352b4a7e51c8dcfa933852a9c72dda3ce4ce6fbe7468ee8699ba77c0733/nlweb_azure_vectordb-0.7.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 92d42d278e3716b692df89fce9756ced | 5c582d10c850589e7a1a57db854a167bbef2cd753f76110ae4acbb1ee710cdee | 8f297352b4a7e51c8dcfa933852a9c72dda3ce4ce6fbe7468ee8699ba77c0733 | null | [] | 241 |
2.4 | mvin | 0.15.0rc1 | Minimum Viable Interpreter (for single Excel formulas) | # mvin: Minimum Viable Interpreter for Excel Formulas
[](https://pypi.org/project/mvin/)
[](https://opensource.org/licenses/)
[](https://github.com/gocova/mvin)
[](https://buymeacoffee.com/gocova)
`mvin` is a lightweight, dependency-free interpreter for evaluating single Excel-like formulas from
tokenized input. It is built around a shunting-yard parser with a small, extensible
function/operator surface.
If this library saved your team hours of manual formatting, consider buying me a coffee! ☕
Donations help prioritize support for new Excel formulas and complex CSS mapping.
## Why mvin
- No runtime dependencies.
- Works with tokenizer output (for example, `openpyxl` tokens).
- Supports numeric, comparison, and string-concatenation operators.
- Supports unary prefix operators (`+x`, `-x`).
- Allows custom function maps and operator maps.
- Dual licensed under MIT or Apache-2.0.
## Installation
```bash
pip install mvin
```
Python support: `>=3.9,<4.0`.
## Quick Start
```python
from mvin import TokenNumber, TokenOperator
from mvin.interpreter import get_interpreter
tokens = [
TokenNumber(1),
TokenOperator("+"),
TokenNumber(2),
]
run = get_interpreter(tokens)
result = run({}) if run else None
assert result == 3
```
`get_interpreter(...)` returns a callable that evaluates the expression. Inputs for cell references
are passed as a dictionary.
## Token Contract
`mvin` accepts any token object with these attributes:
- `type: str`
- `subtype: str`
- `value: Any`
Built-in token classes are available in `mvin` (`TokenNumber`, `TokenString`, `TokenBool`,
`TokenOperator`, etc.), but third-party tokenizers are supported if they follow the same shape.
## Supported Operators
| Operator | Meaning |
| --- | --- |
| `+` | Addition |
| `-` | Subtraction |
| `*` | Multiplication |
| `/` | Division |
| `^` | Exponentiation |
| `&` | String concatenation |
| `=` / `==` | Equality |
| `<>` / `!=` | Inequality |
| `<` | Less than |
| `<=` | Less than or equal |
| `>` | Greater than |
| `>=` | Greater than or equal |
| `+x` | Unary plus (prefix) |
| `-x` | Unary minus (prefix) |
## Built-in Functions
Built-ins are defined in `DEFAULT_FUNCTIONS` in `src/mvin/functions/excel_lib.py`.
| Function | Notes |
| --- | --- |
| `NOT(value)` | Accepts logical or numeric values. |
| `ISERROR(value)` | Returns whether value is an error token. |
| `SEARCH(find_text, within_text, [start_num])` | 1-based index; defaults `start_num` to `1`. |
| `LEFT(text, [num_chars])` | Defaults `num_chars` to `1`. |
| `RIGHT(text, [num_chars])` | Defaults `num_chars` to `1`. |
| `LEN(text)` | Length of text representation. |
## Working with References (Ranges)
If a token has `type="OPERAND"` and `subtype="RANGE"`, its `value` is treated as an input key.
- Required keys are exposed as `run.inputs`.
- Inputs should map reference name to token objects.
```python
from mvin import BaseToken, TokenNumber
from mvin.interpreter import get_interpreter
class RefToken(BaseToken):
def __init__(self, ref: str):
super().__init__()
self._value = ref
self._type = "OPERAND"
self._subtype = "RANGE"
tokens = [RefToken("A1")]
run = get_interpreter(tokens)
assert run is not None
assert run.inputs == {"A1"}
assert run({"A1": TokenNumber(10)}) == 10
```
## Customizing Functions
Pass a custom function map through `proposed_functions`.
Function keys follow tokenizer function-open values (for example, `"MYFUNC("`).
```python
from mvin import BaseToken, TokenNumber
from mvin.interpreter import get_interpreter
from mvin.functions.excel_lib import DEFAULT_FUNCTIONS
class T(BaseToken):
def __init__(self, value: str, token_type: str, subtype: str):
super().__init__()
self._value = value
self._type = token_type
self._subtype = subtype
def excel_double(value):
if value is not None and value.type == "OPERAND" and value.subtype == "NUMBER":
return TokenNumber(value.value * 2)
return value
custom_functions = dict(DEFAULT_FUNCTIONS)
custom_functions["DOUBLE("] = ([None], excel_double)
tokens = [
T("DOUBLE(", "FUNC", "OPEN"),
TokenNumber(21),
T(")", "FUNC", "CLOSE"),
]
run = get_interpreter(tokens, proposed_functions=custom_functions)
assert run is not None
assert run({}) == 42
```
## Public API Stability
`mvin` follows semantic versioning.
- Patch: bug fixes only.
- Minor: backward-compatible features.
- Major: breaking API changes.
Public API guarantees are documented in `API_STABILITY.md`.
## Development
### Setup
```bash
pdm install -G dev
```
### Run tests
```bash
pdm run pytest -q
```
### Run lint + types
```bash
pdm run ruff check src tests
pdm run mypy
```
### Build
```bash
pdm build
```
### CI/CD
GitHub Actions workflows in `.github/workflows/ci.yml` and `.github/workflows/release.yml` run:
- tests on Python 3.9-3.13
- lint + type checks
- build + `twine check`
- wheel smoke test
Tag pushes matching `v*` also publish to PyPI (requires `PYPI_API_TOKEN` repository secret).
## Contributing and Security
- Contribution guide: `CONTRIBUTING.md`
- Security policy: `SECURITY.md`
- Release checklist: `RELEASE.md`
- Changelog: `CHANGELOG.md`
## License
Licensed under either of:
- Apache License, Version 2.0 ([`LICENSE_APACHE`](LICENSE_APACHE) or
<https://www.apache.org/licenses/LICENSE-2.0>)
- MIT license ([`LICENSE_MIT`](LICENSE_MIT) or <https://opensource.org/licenses/MIT>)
at your option.
| text/markdown | null | Jose Gonzalo Covarrubias <gocova.dev+mvin@gmail.com> | null | null | null | excel, formula, interpreter, parser, tokenizer | [
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Development Status :: 4 - Beta",
"Intended Audience :... | [] | null | null | <4.0,>=3.9 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://pypi.org/project/mvin/",
"Documentation, https://github.com/gocova/mvin#readme",
"Repository, https://github.com/gocova/mvin",
"Issues, https://github.com/gocova/mvin/issues",
"Changelog, https://github.com/gocova/mvin/blob/main/CHANGELOG.md"
] | pdm/2.26.6 CPython/3.14.3 Darwin/24.6.0 | 2026-02-19T01:13:14.036592 | mvin-0.15.0rc1.tar.gz | 25,260 | 4a/1a/bb93f516f1e1eac2c8f18b3eda9d7e77e97ddb8aca406559338ca4443e5e/mvin-0.15.0rc1.tar.gz | source | sdist | null | false | 4ae157f6f4f87dcfe0c3688bb993fb0e | f3f6a1b3a99e0f8b7418036165daf661b61738848f64040cc78f00e634c1645b | 4a1abb93f516f1e1eac2c8f18b3eda9d7e77e97ddb8aca406559338ca4443e5e | null | [] | 372 |
2.4 | nlweb-azure-models | 0.7.0 | Azure models provider for NLWeb - Azure OpenAI embedding and LLM interfaces | # nlweb-azure-models
Azure OpenAI LLM and embedding providers for NLWeb.
## Overview
This is a **blueprint package** demonstrating how to create individual model provider packages for NLWeb. It contains Azure OpenAI implementations for both LLM and embeddings.
Third-party developers can use this as a template for creating their own model provider packages.
## Installation
```bash
pip install nlweb-core nlweb-azure-models
```
For vector search, you'll also need a retrieval provider:
```bash
pip install nlweb-azure-vectordb
```
Or use the bundle packages:
```bash
pip install nlweb-core nlweb-retrieval nlweb-models
```
## Configuration
Create `config.yaml`:
```yaml
llm:
provider: azure_openai
import_path: nlweb_azure_models.llm.azure_oai
class_name: provider
endpoint_env: AZURE_OPENAI_ENDPOINT
api_key_env: AZURE_OPENAI_KEY
api_version: 2024-02-01
auth_method: azure_ad # or api_key
models:
high: gpt-4
low: gpt-35-turbo
embedding:
default:
import_path: nlweb_azure_models.embedding.azure_oai_embedding
class_name: AzureOpenAIEmbeddingProvider
endpoint_env: AZURE_OPENAI_ENDPOINT
auth_method: azure_ad
model: text-embedding-ada-002
scoring_model:
default:
model: gpt-4.1-mini
endpoint_env: AZURE_OPENAI_ENDPOINT
api_key_env: AZURE_OPENAI_KEY
api_version: "2024-02-01"
auth_method: api_key
import_path: nlweb_azure_models.llm.azure_oai
class_name: AzureOpenAIScoringProvider
```
### Authentication Methods
#### API Key Authentication
```yaml
generative_model:
high:
import_path: nlweb_azure_models.llm.azure_oai
class_name: AzureOpenAIProvider
endpoint_env: AZURE_OPENAI_ENDPOINT
api_key_env: AZURE_OPENAI_KEY
api_version: 2024-02-01
auth_method: api_key
model: gpt-4
```
Set environment variables:
```bash
export AZURE_OPENAI_ENDPOINT=https://your-resource.openai.azure.com
export AZURE_OPENAI_KEY=your_key_here
```
#### Managed Identity (Azure AD) Authentication
```yaml
llm:
provider: azure_openai
import_path: nlweb_azure_models.llm.azure_oai
class_name: provider
endpoint_env: AZURE_OPENAI_ENDPOINT
api_version: 2024-02-01
auth_method: azure_ad
models:
high: gpt-4
low: gpt-35-turbo
```
Set environment variable:
```bash
export AZURE_OPENAI_ENDPOINT=https://your-resource.openai.azure.com
```
## Usage
```python
from nlweb_core.config import get_config
# Get embedding provider by name
embedding_provider = get_config().get_embedding_provider("default")
vector = await embedding_provider.get_embedding("Text to embed")
# Batch embeddings
vectors = await embedding_provider.get_batch_embeddings(["Text 1", "Text 2"])
```
## Features
### LLM Provider (Generative)
- GPT-4, GPT-3.5-turbo, and other Azure OpenAI models
- Structured output with JSON schema
- Managed identity (Azure AD) authentication
- API key authentication
- Configurable API versions
### Scoring Provider (Ranking/Relevance)
- LLM-based scoring for search result ranking
- Scores items on relevance to user queries (0-100 scale)
- Supports item ranking, intent detection, and presence checking
- Same authentication methods as generative LLMs
- Optimized prompts for consistent scoring
- Batch processing support for efficient ranking
### Embedding Provider
- text-embedding-ada-002 and newer models
- Managed identity (Azure AD) authentication
- API key authentication
- Batch processing support
## Scoring Provider Configuration
The Azure OpenAI scoring provider uses LLMs to score search results for relevance. This is an alternative to specialized scoring models like Pi Labs.
### Scoring Configuration Options
**Option 1: Azure OpenAI (LLM-based scoring)**
```yaml
scoring-llm-model:
llm_type: azure_openai
model: gpt-4.1-mini # Use mini models for cost efficiency
endpoint_env: AZURE_OPENAI_ENDPOINT
api_key_env: AZURE_OPENAI_KEY
api_version: "2024-02-01"
auth_method: api_key # or azure_ad
import_path: nlweb_azure_models.llm.azure_oai
class_name: AzureOpenAIScoringProvider
ranking_config:
scoring_questions:
- "Is this item relevant to the query?"
```
**Option 2: Pi Labs (Specialized scoring model)**
```yaml
scoring-llm-model:
llm_type: pilabs
import_path: nlweb_pilabs_models.llm.pi_labs
class_name: PiLabsScoringProvider
endpoint_env: PI_LABS_ENDPOINT
api_key_env: PI_LABS_KEY
ranking_config:
scoring_questions:
- "Is this item relevant to the query?"
```
### Scoring Use Cases
1. **Item Ranking**: Score search results based on relevance to user queries
- Input: User query + item description
- Output: Relevance score (0-100) + description
- Uses NLWeb ranking prompt template
2. **Intent Detection**: Determine if a query matches a specific intent
- Input: User query + intent to check
- Output: Match score (0-100)
3. **Presence Checking**: Check if required information is present in a query
- Input: User query + required information
- Output: Presence score (0-100)
### Prompt Template Approach
Azure OpenAI scoring uses **direct prompt templates** (not question-based scoring):
- Item ranking uses the NLWeb ranking prompt template
- Focuses on relevance judgment and explanation generation
- The `scoring_questions` config field is ignored (used only by PI Labs)
## Complete Azure Stack Example
Use all three Azure packages together:
```bash
pip install nlweb-core nlweb-azure-vectordb nlweb-azure-models
```
```yaml
llm:
provider: azure_openai
import_path: nlweb_azure_models.llm.azure_oai
class_name: provider
endpoint_env: AZURE_OPENAI_ENDPOINT
auth_method: azure_ad
models:
high: gpt-4
low: gpt-35-turbo
embedding:
default:
import_path: nlweb_azure_models.embedding.azure_oai_embedding
class_name: AzureOpenAIEmbeddingProvider
endpoint_env: AZURE_OPENAI_ENDPOINT
auth_method: azure_ad
model: text-embedding-ada-002
retrieval:
default:
import_path: nlweb_azure_vectordb.azure_search_client
class_name: AzureSearchClient
api_endpoint_env: AZURE_SEARCH_ENDPOINT
auth_method: azure_ad
index_name: my-index
scoring_model:
default:
model: gpt-4.1-mini
endpoint_env: AZURE_OPENAI_ENDPOINT
api_key_env: AZURE_OPENAI_KEY
api_version: "2024-02-01"
auth_method: azure_ad
import_path: nlweb_azure_models.llm.azure_oai
class_name: AzureOpenAIScoringProvider
ranking_config:
scoring_questions:
- "Is this item relevant to the query?"
```
## Creating Your Own Model Provider Package
Use this package as a template:
1. **Create package structure**:
```
nlweb-yourprovider/
├── pyproject.toml
├── README.md
└── nlweb_yourprovider/
├── __init__.py
├── llm/
│ └── your_llm.py
└── embedding/
└── your_embedding.py
```
2. **Implement provider interfaces** (inherit from ABCs in nlweb_core):
```python
from nlweb_core.embedding import EmbeddingProvider
class YourEmbeddingProvider(EmbeddingProvider):
def __init__(self, api_key: str, model: str, **kwargs):
self.api_key = api_key
self.model = model
async def get_embedding(self, text, timeout=30.0):
# Your implementation
return [0.1, 0.2, ...]
async def close(self):
pass
```
3. **Declare dependencies** in `pyproject.toml`
4. **Publish to PyPI**
## License
MIT License - Copyright (c) 2025 Microsoft Corporation
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"nlweb-core>=0.6.0",
"openai>=1.12.0",
"azure-identity>=1.12.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:13:00.365810 | nlweb_azure_models-0.7.0-py3-none-any.whl | 9,177 | fb/34/2138a1b3a9a8617b1006bfe685c06080b62efbbb67cb165c5e54b1476fe8/nlweb_azure_models-0.7.0-py3-none-any.whl | py3 | bdist_wheel | null | false | bc81fd9d0c5e6441aab6532a73304ed1 | 9f5d08af8c09c299b5aa20d77352b231c9807afbcaf6d13edc70dddd67c7d24e | fb342138a1b3a9a8617b1006bfe685c06080b62efbbb67cb165c5e54b1476fe8 | null | [] | 239 |
2.4 | access-moppy | 1.0.3b0 | ACCESS Model Output Post-Processor, maps raw model output to CMIP-style defined variables and produce post-processed output using CMOR3 | <div align="center">
<img src="docs/images/Moppy_logo.png" alt="MOPPy Logo" width="300"/>
</div>
# ACCESS-MOPPy (Model Output Post-Processor)
[](https://access-moppy.readthedocs.io/en/latest/?badge=latest)
[](https://badge.fury.io/py/access_moppy)
[](https://anaconda.org/accessnri/access-moppy)
ACCESS-MOPPy is a CMORisation tool designed to post-process ACCESS model output and produce CMIP-compliant datasets.
## Key Features
- **Python API** for integration into notebooks and scripts
- **Batch processing system** for HPC environments with PBS
- **Real-time monitoring** with web-based dashboard
- **Flexible CMORisation** of individual variables
- **Dask-enabled** for scalable parallel processing
- **Cross-platform compatibility** (not limited to NCI Gadi)
- **CMIP6 and CMIP7 FastTrack support**
## Installation
ACCESS-MOPPy requires Python >= 3.11. Install with:
```bash
pip install numpy pandas xarray netCDF4 cftime dask pyyaml tqdm requests streamlit
pip install .
```
## Quick Start
### Interactive Usage (Python API)
```python
import glob
from access_moppy import ACCESS_ESM_CMORiser
# Select input files
files = glob.glob("/path/to/model/output/*mon.nc")
# Create CMORiser instance
cmoriser = ACCESS_ESM_CMORiser(
input_paths=files,
compound_name="Amon.pr", # table.variable format
experiment_id="historical",
source_id="ACCESS-ESM1-5",
variant_label="r1i1p1f1",
grid_label="gn",
activity_id="CMIP",
output_path="/path/to/output"
)
# Run CMORisation
cmoriser.run()
cmoriser.write()
```
### Batch Processing (HPC/PBS)
For large-scale processing on HPC systems:
1. **Create a configuration file** (`batch_config.yml`):
```yaml
variables:
- Amon.pr
- Omon.tos
- Amon.ts
experiment_id: piControl
source_id: ACCESS-ESM1-5
variant_label: r1i1p1f1
grid_label: gn
input_folder: "/g/data/project/model/output"
output_folder: "/scratch/project/cmor_output"
file_patterns:
Amon.pr: "output[0-4][0-9][0-9]/atmosphere/netCDF/*mon.nc"
Omon.tos: "output[0-4][0-9][0-9]/ocean/*temp*.nc"
Amon.ts: "output[0-4][0-9][0-9]/atmosphere/netCDF/*mon.nc"
# PBS configuration
queue: normal
cpus_per_node: 16
mem: 32GB
walltime: "02:00:00"
scheduler_options: "#PBS -P your_project"
storage: "gdata/project+scratch/project"
worker_init: |
module load conda
conda activate your_environment
```
2. **Submit batch job**:
```bash
moppy-cmorise batch_config.yml
```
3. **Monitor progress** at http://localhost:8501
## Batch Processing Features
The batch processing system provides:
- **Parallel execution**: Each variable processed as a separate PBS job
- **Real-time monitoring**: Web dashboard showing job status and progress
- **Automatic tracking**: SQLite database maintains job history and status
- **Error handling**: Failed jobs can be easily identified and resubmitted
- **Resource optimization**: Configurable CPU, memory, and storage requirements
- **Environment management**: Automatic setup of conda/module environments
### Monitoring Tools
- **Streamlit Dashboard**: Real-time web interface at http://localhost:8501
- **Command line**: Use standard PBS commands (`qstat`, `qdel`)
- **Database**: SQLite tracking at `{output_folder}/cmor_tasks.db`
- **Log files**: Individual stdout/stderr for each job
### File Organization
```
work_directory/
├── batch_config.yml # Your configuration
├── cmor_job_scripts/ # Generated PBS scripts and logs
│ ├── cmor_Amon_pr.sh # PBS script
│ ├── cmor_Amon_pr.py # Python processing script
│ ├── cmor_Amon_pr.out # Job output
│ └── cmor_Amon_pr.err # Job errors
└── output_folder/
├── cmor_tasks.db # Progress tracking
└── [CMORised files] # Final output
```
## Documentation
- **Getting Started**: `docs/source/getting_started.rst`
- **Example Configuration**: `src/access_moppy/examples/batch_config.yml`
- **API Reference**: [Coming soon]
## Current Limitations
- **Alpha version**: Intended for evaluation only
- **Ocean variables**: Limited support in current release
- **Variable mapping**: Under review for CMIP6/CMIP7 compliance
## Support
- **Issues**: Submit via GitHub Issues
- **Questions**: Contact ACCESS-NRI support
- **Contributions**: Welcome via Pull Requests
## License
ACCESS-MOPPy is licensed under the Apache-2.0 License.
| text/markdown | null | Romain Beucher <romain.beucher@anu.edu.au> | null | null | Apache-2.0 | ACCESS, post-processing | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.14,>=3.11 | [] | [] | [] | [
"numpy",
"pandas",
"xarray",
"netCDF4",
"cftime",
"dask",
"distributed>=2024.0.0",
"pyyaml",
"tqdm",
"requests",
"parsl",
"jinja2",
"pint",
"CMIP7-data-request-api>=1.3",
"streamlit>=1.35.0; extra == \"dashboard\"",
"pytest; extra == \"test\"",
"pytest-cov; extra == \"test\"",
"pyt... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:12:46.152435 | access_moppy-1.0.3b0.tar.gz | 407,537 | 96/46/77fafb277b55373a337ee389315db487129f646773a333168fdabc34b147/access_moppy-1.0.3b0.tar.gz | source | sdist | null | false | c5e18af5d663b63520e10de2ebfda7fa | 37068bff8d21a02d0b96821ab9b7409c73dc972cb314082561cb93b5c1ec258f | 964677fafb277b55373a337ee389315db487129f646773a333168fdabc34b147 | null | [
"LICENCE.txt"
] | 243 |
2.4 | nlweb-network | 0.7.0 | Network interfaces and server for NLWeb - HTTP, MCP, and A2A protocol adapters | # NLWeb Network
Network interfaces and server for NLWeb - provides HTTP, MCP, and A2A protocol adapters.
## Overview
`nlweb-network` provides transport layer adapters that convert protocol-specific requests into a common format for NLWeb handlers, and convert NLWeb outputs back into the appropriate protocol format.
## Architecture
```
┌──────────────────────────────────────────────┐
│ Protocol Adapters │
│ (HTTP SSE, HTTP JSON, MCP SSE, MCP HTTP) │
└──────────────────┬───────────────────────────┘
│
↓
┌─────────────────┐
│ NLWeb Handlers │
│ (Core Package) │
└─────────────────┘
```
## Supported Protocols
### HTTP Interfaces
#### HTTP with Server-Sent Events (Default)
- **Endpoint**: `/ask` (GET/POST)
- **Parameter**: `streaming=true` (default)
- **Use case**: Real-time streaming of results as they're generated
```bash
curl "http://localhost:8080/ask?query=best+pasta+recipe"
```
#### HTTP with JSON Response
- **Endpoint**: `/ask` (GET/POST)
- **Parameter**: `streaming=false`
- **Use case**: Get complete results in single JSON response
```bash
curl "http://localhost:8080/ask?query=best+pasta+recipe&streaming=false"
```
### MCP (Model Context Protocol) Interfaces
#### MCP over HTTP (StreamableHTTP)
- **Endpoint**: `/mcp` (POST)
- **Format**: JSON-RPC 2.0
- **Use case**: Standard MCP integration for tools/agents
```bash
# Test with MCP Inspector
npx @modelcontextprotocol/inspector http://localhost:8080/mcp
```
#### MCP over Server-Sent Events
- **Endpoint**: `/mcp-sse` (GET/POST)
- **Format**: JSON-RPC 2.0 over SSE
- **Use case**: Streaming MCP responses in real-time
### A2A (Agent-to-Agent) Interfaces
*(Coming soon)*
## Installation
```bash
# Install from PyPI (when published)
pip install nlweb-network
# Or install from source
pip install -e packages/network
```
## Usage
### Starting the Server
```python
from nlweb_network.server import main
# Start server with default configuration
main()
```
Or use the command-line entry point:
```bash
nlweb-server
```
### Using Interface Adapters
You can use the interface adapters directly in your own applications:
```python
from aiohttp import web
from nlweb_network.interfaces import HTTPJSONInterface, HTTPSSEInterface
from nlweb_core.handler import NLWebHandler
# For non-streaming JSON responses
async def my_handler(request):
interface = HTTPJSONInterface()
return await interface.handle_request(request, NLWebHandler)
# For streaming SSE responses
async def my_streaming_handler(request):
interface = HTTPSSEInterface()
return await interface.handle_request(request, NLWebHandler)
```
## Interface Adapters
All interface adapters inherit from `BaseInterface` and implement:
- `parse_request()` - Extract query parameters from protocol-specific request
- `send_response()` - Send data in protocol-specific format
- `finalize_response()` - Close/finalize the response stream
- `handle_request()` - Complete request/response cycle
### Available Interfaces
| Interface | Class | Protocol | Streaming |
|-----------|-------|----------|-----------|
| HTTP JSON | `HTTPJSONInterface` | HTTP | No |
| HTTP SSE | `HTTPSSEInterface` | HTTP + SSE | Yes |
| MCP StreamableHTTP | `MCPStreamableInterface` | JSON-RPC 2.0 | No |
| MCP SSE | `MCPSSEInterface` | JSON-RPC 2.0 + SSE | Yes |
## Configuration
The server uses configuration from `nlweb-core`:
```yaml
# config.yaml
server:
host: localhost
port: 8080
enable_cors: true
```
## Endpoints
### `/ask` - HTTP Query Endpoint
**GET/POST** - Natural language query with NLWeb RAG pipeline
**Parameters:**
- `query` (required) - Natural language query
- `site` (optional) - Filter by site (default: "all")
- `num_results` (optional) - Number of results (default: 50)
- `streaming` (optional) - Enable SSE streaming (default: true)
**Examples:**
```bash
# Streaming (SSE)
curl "http://localhost:8080/ask?query=spicy+snacks&site=seriouseats"
# Non-streaming (JSON)
curl "http://localhost:8080/ask?query=spicy+snacks&streaming=false"
# POST with JSON body
curl -X POST http://localhost:8080/ask \
-H 'Content-Type: application/json' \
-d '{"query": "spicy snacks", "streaming": false}'
```
### `/mcp` - MCP Protocol Endpoint
**POST** - JSON-RPC 2.0 requests for MCP protocol
**Methods:**
- `initialize` - Protocol handshake
- `tools/list` - List available tools
- `tools/call` - Execute tool (routes to NLWeb handlers)
**Example:**
```bash
curl -X POST http://localhost:8080/mcp \
-H 'Content-Type: application/json' \
-d '{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "ask",
"arguments": {"query": "best pasta recipe"}
}
}'
```
### `/mcp-sse` - MCP with SSE Streaming
**GET/POST** - MCP protocol with Server-Sent Events
Same as `/mcp` but streams results via SSE for `tools/call`.
### `/health` - Health Check
**GET** - Simple health check
```bash
curl http://localhost:8080/health
# {"status": "ok"}
```
## Dependencies
- `nlweb-core>=0.5.0` - Core NLWeb handlers and business logic
- `aiohttp>=3.8.0` - Async HTTP server
- `aiohttp-cors>=0.7.0` - CORS support
## Development
```bash
# Install in editable mode with dev dependencies
pip install -e "packages/network[dev]"
# Run tests
pytest packages/network/tests
```
## License
MIT License - Copyright (c) 2025 Microsoft Corporation
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"nlweb-core>=0.6.0",
"aiohttp>=3.8.0",
"aiohttp-cors>=0.7.0",
"pyinstrument>=5.1.1",
"prometheus-client>=0.21.0",
"pytest>=7.0.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:12:39.936881 | nlweb_network-0.7.0-py3-none-any.whl | 25,254 | 57/12/0cfb6b6a0c5ffff18fc16ef1dc4ce21039982aa60f3164464814a6c3ee6b/nlweb_network-0.7.0-py3-none-any.whl | py3 | bdist_wheel | null | false | 5c40f99215c7f3bbc27b40503b3a6854 | f00fda36a0dffa5f474963c4fd8a33138c98cf7049787a8df383b80e3eab41e0 | 57120cfb6b6a0c5ffff18fc16ef1dc4ce21039982aa60f3164464814a6c3ee6b | null | [] | 245 |
2.4 | nlweb-core | 0.7.0 | Core framework for NLWeb - Natural Language Web interface with config-driven provider architecture | # nlweb-core
Core framework for NLWeb - Natural Language Web interface with config-driven provider architecture.
## Overview
`nlweb-core` provides the foundational framework for building natural language interfaces to web services. It implements:
- Config-driven provider architecture for LLMs, embeddings, and vector databases
- Dynamic module loading based on configuration
- Unified interfaces for retrieval, ranking, and LLM operations
- HTTP server with Server-Sent Events (SSE) streaming support
- NLWeb Protocol v0.5 implementation
## Installation
```bash
pip install nlweb-core
```
**Note**: You also need to install provider packages. See examples below.
## Provider Packages
nlweb-core uses a plugin architecture. Install provider packages separately:
### Bundle Packages (recommended for getting started)
```bash
# All retrieval providers
pip install nlweb-retrieval
# All LLM and embedding providers
pip install nlweb-models
```
### Individual Provider Packages (coming soon)
```bash
# Azure-specific providers
pip install nlweb-azure-vectordb nlweb-azure-models
```
## Quick Start
### 1. Create a configuration file
Create `config.yaml`:
```yaml
# LLM Configuration
llm:
provider: openai
import_path: nlweb_models.llm.openai_client
class_name: OpenAIClient
api_key_env: OPENAI_API_KEY
models:
high: gpt-4
low: gpt-3.5-turbo
# Embedding Configuration
embedding:
provider: openai
import_path: nlweb_models.embedding.openai_embedding
class_name: get_openai_embeddings
api_key_env: OPENAI_API_KEY
model: text-embedding-3-small
# Retrieval Configuration
retrieval:
provider: elasticsearch
import_path: nlweb_retrieval.elasticsearch_client
class_name: ElasticsearchClient
api_endpoint_env: ELASTICSEARCH_URL
index_name: my_index
```
### 2. Set environment variables
```bash
export OPENAI_API_KEY=your_key_here
export ELASTICSEARCH_URL=http://localhost:9200
```
### 3. Use in your application
```python
import nlweb_core
# Initialize with your config
nlweb_core.init(config_path="./config.yaml")
# Use the framework
from nlweb_core.simple_server import run_server
run_server()
```
## Configuration
The config file supports three main sections:
### LLM Configuration
- `provider`: Provider name (used for identification)
- `import_path`: Python module path to provider
- `class_name`: Class or function name to import
- `api_key_env`: Environment variable containing API key
- `models`: Model IDs for high/low tiers
### Embedding Configuration
- `provider`: Provider name
- `import_path`: Python module path
- `class_name`: Class or function name
- `model`: Embedding model ID
### Retrieval Configuration
- `provider`: Provider name
- `import_path`: Python module path
- `class_name`: Client class name
- `api_endpoint_env`: Environment variable for endpoint URL
- `index_name`: Index/collection name
## Architecture
nlweb-core provides orchestration layers:
- `retriever.py`: Vector database operations
- `llm.py`: LLM provider dispatch
- `embedding.py`: Embedding generation
- `ranking.py`: LLM-based result ranking
- `simple_server.py`: HTTP server with SSE streaming
All provider-specific code lives in separate packages.
## License
MIT License - Copyright (c) 2025 Microsoft Corporation
| text/markdown | nlweb-ai | null | null | null | MIT | null | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Py... | [] | null | null | >=3.9 | [] | [] | [] | [
"pyyaml>=6.0",
"python-dotenv>=1.0.0",
"aiohttp>=3.8.0",
"pydantic>=2.12.5",
"prometheus-client>=0.21.0",
"pytest>=7.0; extra == \"dev\"",
"pytest-asyncio>=0.21.0; extra == \"dev\"",
"black>=23.0; extra == \"dev\"",
"mypy>=1.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/nlweb-ai/nlweb-ask-agent",
"Repository, https://github.com/nlweb-ai/nlweb-ask-agent",
"Issues, https://github.com/nlweb-ai/nlweb-ask-agent/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:12:17.382378 | nlweb_core-0.7.0.tar.gz | 90,791 | 7a/10/28d7e4e70d19bd184ad7d2ec66b47310b43f0cfe063a81ecf41e15bc00ca/nlweb_core-0.7.0.tar.gz | source | sdist | null | false | af62ddbd3c3ca6a36e8fc9544558406c | 574192f41fcc403c9d53e476dceb6ed485825813f2d7d6949eb7c146446f2176 | 7a1028d7e4e70d19bd184ad7d2ec66b47310b43f0cfe063a81ecf41e15bc00ca | null | [] | 344 |
2.4 | browniebroke-utils | 1.5.0 | A collections of small scripts. | # Browniebroke Utils
<p align="center">
<a href="https://github.com/browniebroke/browniebroke-utils/actions/workflows/ci.yml?query=branch%3Amain">
<img src="https://img.shields.io/github/actions/workflow/status/browniebroke/browniebroke-utils/ci.yml?branch=main&label=CI&logo=github&style=flat-square" alt="CI Status" >
</a>
<a href="https://codecov.io/gh/browniebroke/browniebroke-utils">
<img src="https://img.shields.io/codecov/c/github/browniebroke/browniebroke-utils.svg?logo=codecov&logoColor=fff&style=flat-square" alt="Test coverage percentage">
</a>
</p>
<p align="center">
<a href="https://github.com/astral-sh/uv">
<img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/uv/main/assets/badge/v0.json" alt="uv">
</a>
<a href="https://github.com/astral-sh/ruff">
<img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ruff/main/assets/badge/v2.json" alt="Ruff">
</a>
<a href="https://github.com/pre-commit/pre-commit">
<img src="https://img.shields.io/badge/pre--commit-enabled-brightgreen?logo=pre-commit&logoColor=white&style=flat-square" alt="pre-commit">
</a>
</p>
<p align="center">
<a href="https://pypi.org/project/browniebroke-utils/">
<img src="https://img.shields.io/pypi/v/browniebroke-utils.svg?logo=python&logoColor=fff&style=flat-square" alt="PyPI Version">
</a>
<img src="https://img.shields.io/pypi/pyversions/browniebroke-utils.svg?style=flat-square&logo=python&logoColor=fff" alt="Supported Python versions">
<img src="https://img.shields.io/pypi/l/browniebroke-utils.svg?style=flat-square" alt="License">
</p>
---
**Source Code**: <a href="https://github.com/browniebroke/browniebroke-utils" target="_blank">https://github.com/browniebroke/browniebroke-utils </a>
---
A collections of small scripts.
## Installation
Install this via pip (or your favourite package manager):
`pip install browniebroke-utils`
## Usage
This tool provides a few random scripts I use in my day to day work.
### `pych-prettier`
Configure [Prettier](https://prettier.io/) as file watcher in the current PyCharm project. This is done by editing the appropriate files in the `.idea` folder.
### `pych-pywatchers`
Setup a few Python-related linting tools as file watchers in the current PyCharm project:
- Black
- isort
- pyupgrade
This is done by editing the appropriate files in the `.idea` folder.
## Contributors ✨
Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):
<!-- prettier-ignore-start -->
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<table>
<tbody>
<tr>
<td align="center" valign="top" width="14.28%"><a href="https://browniebroke.com/"><img src="https://avatars.githubusercontent.com/u/861044?v=4?s=80" width="80px;" alt="Bruno Alla"/><br /><sub><b>Bruno Alla</b></sub></a><br /><a href="https://github.com/browniebroke/browniebroke-utils/commits?author=browniebroke" title="Code">💻</a> <a href="#ideas-browniebroke" title="Ideas, Planning, & Feedback">🤔</a> <a href="https://github.com/browniebroke/browniebroke-utils/commits?author=browniebroke" title="Documentation">📖</a></td>
</tr>
</tbody>
</table>
<!-- markdownlint-restore -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
<!-- prettier-ignore-end -->
This project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!
## Credits
This package was created with
[Copier](https://copier.readthedocs.io/) and the
[browniebroke/pypackage-template](https://github.com/browniebroke/pypackage-template)
project template.
| text/markdown | null | Bruno Alla <alla.brunoo@gmail.com> | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python ... | [] | null | null | >=3.10 | [] | [] | [] | [
"xmltodict<2,>=1"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/browniebroke/browniebroke-utils/issues",
"Changelog, https://github.com/browniebroke/browniebroke-utils/blob/main/CHANGELOG.md",
"Mastodon, https://fosstodon.org/@browniebroke",
"repository, https://github.com/browniebroke/browniebroke-utils",
"Twitter, https://twitter.com/_... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:12:12.724656 | browniebroke_utils-1.5.0.tar.gz | 9,309 | 01/ec/02260c2027a465df46b4eb464097eb2a16f5d6861c29ef28e66dc759f2f0/browniebroke_utils-1.5.0.tar.gz | source | sdist | null | false | 83ca2628491f94560fee1d90a0edb5de | 2537a74576ea7b3220aae4cdf3a0d4b99cdd845982b7ea020ee21eb6df68b661 | 01ec02260c2027a465df46b4eb464097eb2a16f5d6861c29ef28e66dc759f2f0 | MIT | [
"LICENSE"
] | 262 |
2.4 | tinyprove | 0.1.4 | Tiny CoC-based theorem prover with inductive types | # Tinyprove
A small, minimal theorem prover.
[pytorch](https://pytorch.org/) : [tinygrad](https://github.com/tinygrad/tinygrad) :: [lean](https://lean-lang.org/) : **tinyprove**
## Installation
```
pip install tinyprove
```
## Get Started
### Definitions
The first thing we'll want to do is create a `Definitions` object. For a lot of the mathematics you'll want to do, you'll need to build up some definitions before you can talk about the things you want to talk about. The `Definitions` object is where they're stored.
```python
from tinyprove import *
DEFNS = get_usual_axioms()
```
If you wanted to make a completely empty set of definitions, you could have written `DEFNS = Definitions()` instead. But this way, you get access to some basic definitions that you're almost certainly going to want to be able to use anyway. Things like `False`, `And`, `Or` and `.em`.
What's that last one? It's the law of excluded middle. It says that for any statement `A`, either `A` is true or `A` is not true. In tinyprove, we'd write `A` being false as: `Π a: A => False`, the type of a function that maps a proof of `A` to `False`.
`False` is another type supplied by `get_usual_axioms`, one that is expected to have *no* proofs. (If you can find a proof of `False`, it means that the system is inconsistent, and *anything* is provable.)
### Writing Proofs
Tinyprove code can be parsed using the `parse` function. Let's use this to prove our very first theorem!
```python
check(
parse("λ A: Type0 -> λ a: A -> a"),
parse("Π A: Type0 => Π a: A => A"),
[], DEFNS)
```
At the top level, we have a call to `check`. This verifies that the proof is indeed a valid proof of the theorem. If we provided an incorrect proof, a `TypecheckError` would be raised.
Our theorem is `Π A: Type0 => Π a: A => A`. It says that for any statement `A`, we have `A => A`. Or in English, "A implies A". It's about the most basic theorem imaginable. The `Π` symbol is used to define the type of a function that maps arguments of one type to another type. Both implications and universal quantifiers are encoded as a function type using the `Π` symbol.
That was the "statement" or "type" of our theorem. The proof of our theorem is `λ A: Type0 -> λ a: A -> a`. The `λ` symbol is used to define functions, just like in the Lambda Calculus. This proof is a very simple function whose type is `Π A: Type0 => Π a: A => A`. Notice how the proof's structure mirrors the statement's structure, just with `Π` replaced by `λ` and `=>` replaced by `->`. Not all theorems can be proved by such simple mirroring, though it's still a common pattern in *parts* of many proofs.
The other arguments accepted by `check` are the "context" for which we usually pass `[]`, and the definitions we want to have available when typechecking. Here we passed `DEFNS` though none of the definitions it contains were actually used in this case because the proof is so simple.
For its first two arguments, `check` asks for a tinyprove `Term` to check the type of, and an expected type, which is also a tinyprove `Term`. So we use the `parse` function to convert strings containing tinyprove code into `Term`s.
The last thing you might be curious about is: "What does `Type0` mean?" It is needed to answer a very specific question. Tinyprove is a typed langage, so everything has to have a type. For example, the number 6 has a type of `Nat`. i.e. 6 is a Natural Number. `Nat` is given to us by `get_usual_axioms()` for free. So what is the type of `Nat` itself? What is the type of a type? We make a thing called `Type0` to answer that question. And then what is the type of `Type0`? Well, it's `Type1` of course! This keeps going forever, and so we can always ask what the type of something is without getting into trouble by not having an answer ready.
### Entering Symbols
Tinyprove syntax uses four greek letters as special symbols. Here are their unicode codes:
* `Π` has code `3a0`
* `λ` has code `3bb`
* `δ` has code `3b4`
* `ι` has code `3b9`
These are worth memorizing, copy-pasting those symbols around all the time is no fun. Writing unicode characters depends a bit on your computer, but `Ctl-Shift-U` followed by typing the hex code and pressing `Enter` is pretty common. Seriously, it's only four codes, go ahead and memorize them.
### Applications
Just as we can define fuctions with `λ`, we can also call them. Calling or "applying" a function `f` on an input `x` is written like this:
```
(f x)
```
Let's make another, *very slightly* more complicated theorem. This one says that if you know `A` and you know that `A => B` then you know `B`. First let's see if we can use tinyprove to formally write down what we're trying to prove. We have to start out by allowing `A` and `B` to be any statements whatsoever. We do this by asking for a function that will accept *any* inputs `A, B` of type `Type0`.
```
Π A: Type0 => Π B: Type0 => ...
```
Next, we need to have a proof `a` of `A` and a proof `a_to_b` of `A => B`. So we'll ask for a function that accepts those things.
```
Π A: Type0 => Π B: Type0 => Π a: A => Π a_to_b: (Π _a: A => B) => ...
```
And then that function needs to produce a value `b` of type `B`. So overall, the theorem statement is written:
```
Π A: Type0 => Π B: Type0 => Π a: A => Π a_to_b: (Π _a: A => B) => B
```
Now, we'll write down a proof and check it:
```python
check(
parse("λ A: Type0 -> λ B: Type0 -> λ a: A -> λ a_to_b: (Π _a: A => B) -> (a_to_b a)"),
parse("Π A: Type0 => Π B: Type0 => Π a: A => Π a_to_b: (Π _a: A => B) => B"),
[], DEFNS)
```
Note that this proof used an application where we wrote `(a_to_b a)` to produce something of type `B`.
### Recap of Π and λ and function application
You write a function that takes a variable `a` of type `A` as:
```
λ a: A -> body
```
where `body` is some expression that tells you the output of the function. The body can use the variable `a`, of course.
You write the type of such a function as:
```
Π a: A => B
```
Here, `a` and `A` are the same as above. `B` is the type that the function produces. It can depend on the variable `a`. (You may find this somewhat surprising, since that kind of dependence is not allowed by many programming languages. But this is actually very necessary.)
You apply a function `f` to an argument `x` like this: `(f x)`. Some functions produce other functions as output (or accept multiple arguments, which is secretly the same thing). In such cases, you could write:
```
(f x y z)
```
which would be equivalent to:
```
(((f x) y) z)
```
Knowing that tinyprove applies functions in this order helps you write fewer parentheses in your proofs and thus get less lost in them. You can also spread theorem statements and proofs across multiple lines, and tinyprove supports single-line comments using the symbol `#`.
### infer
Tinyprove also gives you a function `infer` that will produce a `Term` representing the type of the `Term` you gave it. For example,
```python
infer(parse("λ A: Type0 -> λ a: A -> a"), [], DEFNS)
```
produces
```
Pi(param='A', A=Sort(level=0), B=Pi(param='a', A=Var(depth=0), B=Var(depth=1)))
```
Okay, that's pretty hard to read. We can call `.str(ctx)` on a `Term` to convert it to a more-easily-readable string. Usually for `ctx` we'll pass an empty context, `[]`.
```python
infer(parse("λ A: Type0 -> λ a: A -> a"), [], DEFNS).str([])
```
produces
```
(Π A: Type0 => (Π a: A => A))
```
which is exactly what we expected.
### Making Definitions
You can make your own definitions and add them to `DEFNS`. This is done with the `extend_definitions` function. This function will *update* the definitions object passed as its first argument to add (in order) each definition in the list of definitions passed as its second argument. Here's how we'd define addition with this system:
```python
# define addition
extend_definitions(DEFNS, [
"""
δ add =
λ a: Nat -> λ b: Nat -> (Nat.ind.0 (λ _: Nat -> Nat) b (λ n: Nat -> λ r: Nat -> (Nat.S r)) a)
"""
])
```
I'll explain what `Nat.ind.0` means later, but we can check what the type of the `add` function is by running:
```python
DEFNS["add"].str([])
```
which prints
```
(Π a: Nat => (Π b: Nat => Nat))
```
I.e. `add` takes two `Nat`s and produces a `Nat`, as expected.
The symbol `δ` (for "define") is used like `let` or `const` in javascript to tell the language that we're making defining a constant. Then the constant name follows. Optionally, we can put the expected type of the constant next using `:` to denote type annotation. If we do this, tinyprove will typecheck the constant to ensure it has the type we specified. Finally, we put `=` followed by the actual value of the constant. We could have defined addition using either `δ add = ...` or `δ add: (Π a: Nat => Π b: Nat => Nat) = ...`.
Note that extend_definitions has parsing built in, and so definitions are given as strings of tinyprove code. Because definitions are added in order, it's possible for definitions to refer to previous definitions in the passed list.
### Inductive Types
One thing we need to be able to do most of modern mathematics is to define inductive types. `False`, `And`, `Or`, `Nat`, and even `Eq` (equality) are all in fact defined as inductive types! You define an inductive type by defining its paramters, indices, and constructors. The `Nat` type does not have any parameters or indices, so it makes a nice starting example. Nat has two constructors, `Nat.Z` and `Nat.S`. Let's see their types:
```python
print(DEFNS["Nat.Z"].str([]))
print(DEFNS["Nat.S"].str([]))
```
We get:
```
Nat
(Π n: Nat => Nat)
```
So `Nat.Z` is already a natural number. In fact, it's the smallest natural number, zero. `Nat.S` is the successor function, it accepts a natural number `n` and produces the natural number `n + 1`. Every natural number except zero can be written as the successor of some other natural number. So the actual representation of the number 3 is `(Nat.S (Nat.S (Nat.S Nat.Z)))`.
One thing that's interesting here is that the type `Nat` is *recursive*. Some of its constructors (i.e. `Nat.S`) need arguments that are themselves of type `Nat`. This kind of recursion is very powerful, but it makes writing down inductive types slightly complicated. Inductive types can't simply be written as `Term`s in the existing language, so we can't define them as constants using the `δ ...` syntax described above. Instead, we have a special `ι` syntax for creating new inductive types.
An inductive type definition is written: `ι TypeName (param_1: Param1Type, param_2: Param2Type...) [index_1: Index1Type, index_2: Index2Type...] : Sort` where `Sort` is `Type0` or `Type1`, etc. After that, you write all the constructors. Each constructor is written as `| constructor_name (arg_1: Arg1Type, arg_2: Arg2Type...) => TypeName[index_1_val, index_2_val...]`. Any constructor arguments whose type is the type being defined are written with indices after the type name in brackets.
So, for example, the constructor `Nat.S` has the following tinyprove syntax:
```
ι Nat () [] : Type0
| Z () => Nat[]
| S (n: Nat[]) => Nat[]
```
It would be added to `DEFNS` using `extend_definitions`, the same as a regular definition:
```python
extend_definitions(DEFNS, [
"""
ι Nat () [] : Type0
| Z () => Nat[]
| S (n: Nat[]) => Nat[]
"""
])
```
#### induction
Let's review our definition of addition. I've expanded the code a little bit and added comments so it's easier to read.
Here's the intuitive explanation of how it works: If we want to define addition, one very simple way of doing it is to say that `0 + b = b` and `(n + 1) + b = (n + b) + 1`. Since we already have a function `Nat.S` for adding 1, we can use these rules to make a function that allows us to add any two numbers:
```python
extend_definitions(DEFNS, [
"""
δ add =
λ a: Nat -> λ b: Nat ->
(Nat.ind.0
(λ _: Nat -> Nat) # motive: our return type is simply Nat
# case where a = 0:
b
# case where a = n + 1:
(λ n: Nat -> λ r: Nat -> (Nat.S r)) # in this line, r is the recursive result, (n + b)
a # match on a
)
"""
])
```
We have to use recursion here. In the case where `a = n + 1`, we now have to add `n + b`. Thus, the case functions are applied recursively all the way until we reach zero. Then `b` is returned without a recursive call. It's a nice fact about inductive types that recursion on such a type *always terminates*. Maybe it's not obvious that this could be true, but it arises from the fact that instances of the type have to be built up in order. We start out with `Nat.Z`, and can only reach any higher number by applying `Nat.S` repeatedly. In the C programming language, you're allowed to make a struct with a pointer in it that points to itself. But this is not allowed in a proof language. Anything you feed to a constructor must *already fully exist*, and it can't be modified after the fact either. And because things must have been built by a finite process, we must be able to disassemble them by a finite process too.
What `Nat.ind.0` does is to provide a formal way of making a recursive function for the type `Nat`. It first asks for a motive, a function that gives us the type we want this whole recursion process to return. Then we need to provide cases to handle the constructors one by one. First we handle the `Nat.Z` constructor, then the `Nat.S` one. If a constructor accepts a recursive argument (i.e. one of its args is an inductive self-ref) then that case function gets passed a bonus argument: the result of recursively calling our `Nat.ind.0` expression on that argument.
Finally, after all the cases are given functions to handle them, we pass the actual `Nat` that we're recursing on, in this case `a`.
#### params of inductive types
As an example of an inductive type with parameters, consider `Or`. Given `A: Type0, B: Type0`, we'd like to make a type that's logically equivalent to "A or B". This type is just denoted `(Or A B)`. Under the hood, `Or` is an inductive type, and `A, B` are its parameters. `A` and `B` could be all kinds of different things, and so for each choice of `A, B`, we get a different type for `(Or A B)`. `(Or Nat False)` is a different type than `(Or Unit Nat)`.
The constructors are pretty simple:
* `Or.inl` which needs an argument of type `A`
* `Or.inr` which needs an argument of type `B`
When we're actually calling `Or.inl`, we need to also pass the original types `A, B` so that it knows exactly what kind of `Or` to make. If we're given proofs `a: A, b: B`, then we can make a `(Or A B)` in two ways:
* `(Or.inl A B a)`
* `(Or.inr A B b)`
Given `a_or_b: (Or A B)`, we can make use of it using `Or.ind.0`, which is analogous to `Nat.ind.0`. Here is a proof using `Or.ind.0` and the law of excluded middle that `~~A => A`, i.e. that double negation does nothing:
```python
check(
parse("""
λ A: Type0 -> # A is a type
λ nnA: (Π na: (Π a: A => False) => False) -> # introduce assumption of ~~A
(Or.ind.0 A (Π a: A => False) # Or.ind for or elimination on excluded middle
(λ _: (Or A (Π a: A => False)) -> A) # motive: A
(λ a: A -> a) # easy case: we already have A
(λ notA: (Π a: A => False) -> ( # hard case: we need to use principle of explosion
False.ind.0 # principle of explosion using False.ind
(λ x: False -> A) # motive: A
(nnA notA) # pass False (made by ~A -> False, ~A)
))
(.em A) # pass .em axiom (excluded middle)
)
"""),
parse("Π A: Type0 => Π nnA: (Π na: (Π a:A => False) => False) => A"),
[], DEFNS)
```
What actually is the type of the law of excluded middle here? It's `Π A: Type0 => (Or A (Π a: A => False))`. This is why we made use of `Or.ind.0`.
What is the value of the law of excluded middle? There is none. It's non-constructive, which means that although we assume that there is some element with that type, we can't actually provide a value for it. This is a true *axiom*, in the sense that it can't be built from the things we already have available to us.
You may want to define your own axioms, in which case, you can use `AxiomDefinition`, check `core.py` in the tinyprove source code for how it works. You only need to define the type of your thing, and then a thing of that type is assumed to exist. You don't need to define the value like you do when making `ConstDefinition`s. It's easy to break your logic this way, so be careful.
#### indices of inductive types
In tinyprove, even the notion of equality is defined as an inductive type. Let's say we want to say that two variables `x, y` are equal. If we want to compare them at all, they have to be of the same type, say `A`. So to write that `x` equals `y`, we write `(Eq A x y)`. And the type of `Eq` is, unsurprisingly, `Π A: Type0 => Π x: A => Π y: A => Type0`. Just like we saw above, `A` is a type parameter. So is `x` for that matter. What is new is that `y` is an index, not a parameter.
To summarize the difference between parameters and indices in a few words:
* Parameters duplicate the entire type for different situations.
* If the parameters are different, the type is different.
* For any given choice of parameters, we still have all the constructors of the type for that choice of parameters.
* i.e. each constructor accepts the parameters as input.
* Cases in the type's `.ind.0` recursion function get to know what the parameters are of the instance you passed.
* A self-referencing constructor arg must have the same parameters as the type that is constructed.
* Indices further subdivide the type in a more irregular way.
* If the indices are different, the type is still considered different.
* In general, some constructors might not be able to create instances with certain indices.
* Indeed, when defining a constructor, we must specify what the indices are of the *output* produced by that constructor.
* Cases in the type's `.ind.0` recursion function *don't* get to use the indices of the instance you passed, though they're of course allowed compute them from the supplied args.
* A self-referencing constructor arg can have *different* indices than the type that is constructed.
Indices are one of the more difficult-to-understand parts of inductive types. Equality will be our example for this section. Here is how `Eq` is defined:
```
ι Eq (A: Type0, x: A) [y: A] : Type0
| refl () => Eq[x]
```
Here we have type parameters `A: Type0` and `x: A`, and we have one index `y: A`. `Eq` has only one constructor, `Eq.refl`. This constructor takes no arguments (`()` in the constructor definition), but remember that we still have to tell it the type parameters, so a call to `Eq.refl` would look something like `(Eq.refl Nat Nat.Z)`, which produces a proof of type `(Eq Nat Nat.Z Nat.Z)`, aka "0 = 0".
Each constructor has to tell us the indices that it produces. The `=> Eq[x]` says that the `Eq.refl` constructor produces `x` as the index of the resulting equaltiy type. Just like all the other inductive types, `Eq.ind.0` is a thing, and it lets us use proofs of equalities to construct various other things. Here's an example of how we'd use it:
```python
# Functions of equals are equal
check(
parse("""
λ A: Type0 -> λ B: Type0 -> λ f: (Π a: A => B) ->
λ a1: A -> λ a2:A ->
λ a1_eq_a2: (Eq A a1 a2) ->
(Eq.ind.0 A a1 # use equality induction
(λ a1_idx: A -> λ instance: (Eq A a1 a1_idx) -> (Eq B (f a1) (f a1_idx))) # motive
(Eq.refl B (f a1)) # case refl
a2
a1_eq_a2 # apply hypothesis
)
"""),
parse("""
Π A: Type0 => Π B: Type0 => Π f: (Π a: A => B) =>
Π a1: A => Π a2: A =>
Π a1_eq_a2: (Eq A a1 a2) =>
(Eq B (f a1) (f a2))
"""),
[], DEFNS)
```
As an exercise, can you prove the three standard properties (reflexivity, symmetry, transitivity) of equality using `Eq.ind.0`? (Hint: as you may be able to guess by the looking at the name of `Eq`'s only constructor, one of these proofs is very easy.)
### Current listing of inductive types created by get_usual_axioms()
```
defs for False:
used:
False Type0
False.ind.0 (Π @motive: (Π @instance: False => Type0) => (Π @instance: False => (@motive @instance)))
defs for Unit:
used:
Unit Type0
Unit.in Unit
Unit.ind.0 (Π @motive: (Π @instance: Unit => Type0) => (Π @case_in: (@motive Unit.in) => (Π @instance: Unit => (@motive @instance))))
defs for And:
used:
And (Π A: Type0 => (Π B: Type0 => Type0))
And.in (Π A: Type0 => (Π B: Type0 => (Π a: A => (Π b: B => ((And A) B)))))
And.ind.0 (Π A: Type0 => (Π B: Type0 => (Π @motive: (Π @instance: ((And A) B) => Type0) => (Π @case_in: (Π a: A => (Π b: B => (@motive ((((And.in A) B) a) b)))) => (Π @instance: ((And A) B) => (@motive @instance))))))
defs for Or:
used:
Or (Π A: Type0 => (Π B: Type0 => Type0))
Or.inl (Π A: Type0 => (Π B: Type0 => (Π a: A => ((Or A) B))))
Or.inr (Π A: Type0 => (Π B: Type0 => (Π b: B => ((Or A) B))))
Or.ind.0 (Π A: Type0 => (Π B: Type0 => (Π @motive: (Π @instance: ((Or A) B) => Type0) => (Π @case_inl: (Π a: A => (@motive (((Or.inl A) B) a))) => (Π @case_inr: (Π b: B => (@motive (((Or.inr A) B) b))) => (Π @instance: ((Or A) B) => (@motive @instance)))))))
defs for Eq:
used:
Eq (Π A: Type0 => (Π x: A => (Π y: A => Type0)))
Eq.refl (Π A: Type0 => (Π x: A => (((Eq A) x) x)))
Eq.ind.0 (Π A: Type0 => (Π x: A => (Π @motive: (Π y: A => (Π @instance: (((Eq A) x) y) => Type0)) => (Π @case_refl: ((@motive x) ((Eq.refl A) x)) => (Π y: A => (Π @instance: (((Eq A) x) y) => ((@motive y) @instance)))))))
defs for Exists:
used:
Exists (Π A: Type0 => (Π P: (Π a: A => Type0) => Type0))
Exists.in (Π A: Type0 => (Π P: (Π a: A => Type0) => (Π a: A => (Π pa: (P a) => ((Exists A) P)))))
Exists.ind.0 (Π A: Type0 => (Π P: (Π a: A => Type0) => (Π @motive: (Π @instance: ((Exists A) P) => Type0) => (Π @case_in: (Π a: A => (Π pa: (P a) => (@motive ((((Exists.in A) P) a) pa)))) => (Π @instance: ((Exists A) P) => (@motive @instance))))))
defs for Nat:
used:
Nat Type0
Nat.Z Nat
Nat.S (Π n: Nat => Nat)
Nat.ind.0 (Π @motive: (Π @instance: Nat => Type0) => (Π @case_Z: (@motive Nat.Z) => (Π @case_S: (Π n: Nat => (Π @rec_n: (@motive n) => (@motive (Nat.S n)))) => (Π @instance: Nat => (@motive @instance)))))
```
### Conclusion
You now have all the basic knowledge you need to start proving things. If you get stuck, ask ChatGPT or another language model. But feed it this document first so it knows what's going on.
If you manage to prove `False` without adding any new `AxiomDefinition`s, that means there's something seriously wrong and you should submit an issue the includes the offending tinyprove code. Actually, if you find *any* bugs, please submit an issue. I'll also consider QoL improvements or feature requests, but keep in mind that I am very lazy.
| text/markdown | null | null | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/pb1729/tinyprove",
"Repository, https://github.com/pb1729/tinyprove",
"Issues, https://github.com/pb1729/tinyprove/issues"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T01:10:59.722923 | tinyprove-0.1.4.tar.gz | 32,441 | 02/a3/d55673955540b12d6a98b9753108221517d69cab972ec950506e767f42da/tinyprove-0.1.4.tar.gz | source | sdist | null | false | 5dfe6186b3447231eef1199c63fe8e09 | 22f120bf2273933ee0ac483168f1dfec33f4ba485cf887e5ac81508b621e0d60 | 02a3d55673955540b12d6a98b9753108221517d69cab972ec950506e767f42da | null | [] | 231 |
2.3 | agent-core-toolkit | 0.1.3 | Common building blocks for creating AI agents. | <h1 align="center">
agent-core
</h1>
<p align="center">
<p align="center">Common building blocks for creating AI agents.</p>
</p>
<p align="center">
<a href="https://github.com/astral-sh/uv"><img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/uv/main/assets/badge/v0.json" alt="uv"></a>
<a href="https://github.com/astral-sh/ty"><img src="https://img.shields.io/endpoint?url=https://raw.githubusercontent.com/astral-sh/ty/main/assets/badge/v0.json" alt="ty"></a>
<a href="https://pypi.org/project/agent-core-toolkit/"><img src="https://img.shields.io/pypi/v/agent-core-toolkit" alt="PyPI"></a>
<a href="https://opensource.org/licenses/MIT"><img src="https://img.shields.io/badge/License-MIT-yellow.svg" alt="License: MIT"></a>
</p>
Production-ready components for building AI agents, optimized across LLMs and providers. Uses [InteropRouter](https://github.com/DavidKoleczek/interop-router) as a unified AI model provider interface.
> [!NOTE]
> This library is in early development and subject to change.
## Getting Started
### Installation
```bash
# With uv.
uv add agent-core-toolkit
# With pip.
pip install agent-core-toolkit
```
### Optional Dependencies
For the web fetch tool:
```bash
uv add agent-core-toolkit[web]
# Run crawl4ai post-installation setup
crawl4ai-setup
```
## Usage
Run the agent CLI.
```bash
uv run agent-core --prompt "Your prompt here" --working-dir /path/to/directory
```
With all options:
```bash
uv run agent-core --prompt "Your prompt here" --working-dir "/path/to/directory" --mode "permissive" --model "gpt-5.1-codex-max" --model-friendly-name "gpt-5.1-codex-max" --model-knowledge-cutoff "Sep 30, 2024" --timezone "America/New_York"
```
Or run with uvx:
```bash
uvx --from /path/to/agent-core agent-core --prompt "Your prompt here" --working-dir "/path/to/directory"
```
## Development
### Prerequisites
- [uv](https://docs.astral.sh/uv/getting-started/installation/)
- [prek](https://github.com/j178/prek/blob/master/README.md#installation)
### Setup
Create uv virtual environment and install dependencies:
```bash
uv sync --frozen --all-extras --all-groups
```
Set up git hooks:
```bash
prek install
```
To update dependencies (updates the lock file):
```bash
uv sync --all-extras --all-groups
```
Run formatting, linting, type checking, and tests in one command:
```bash
uv run ruff format && uv run ruff check --fix && uv run ty check && uv run pytest
```
### Further Information
[docs/DEVELOPMENT.md](docs/DEVELOPMENT.md) | text/markdown | David Koleczek | David Koleczek <45405824+DavidKoleczek@users.noreply.github.com> | null | null | null | null | [] | [] | null | null | >=3.11 | [] | [] | [] | [
"click<9.0,>=8.3.1",
"httpx<1.0,>=0.28.1",
"interop-router==0.1.7",
"loguru<1.0,>=0.7.3",
"pydantic<3.0,>=2.12.5",
"pymupdf<2.0,>=1.27.1",
"pymupdf4llm<1.0,>=0.3.4",
"python-liquid<3.0,>=2.1",
"rich<15.0,>=14.3.2",
"tree-sitter<1.0,>=0.25.2",
"tree-sitter-bash<1.0,>=0.25.1",
"crawl4ai[pdf]==0.... | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:10:29.462416 | agent_core_toolkit-0.1.3.tar.gz | 10,494,870 | d0/97/08619803c6fa0f88ff9d6fc962765e168ede90bc86e587cc24359779b6e5/agent_core_toolkit-0.1.3.tar.gz | source | sdist | null | false | b204074a2a7a6dc8c94364afd47635cb | 5af18964d319c8f59fad5f591630ff8365926814a9395b4da19f7c8fa8d6e715 | d09708619803c6fa0f88ff9d6fc962765e168ede90bc86e587cc24359779b6e5 | null | [] | 250 |
2.4 | hdx-python-utilities | 4.0.7 | HDX Python Utilities for streaming tabular data, date and time handling and other helpful functions | [](https://github.com/OCHA-DAP/hdx-python-utilities/actions/workflows/run-python-tests.yaml)
[](https://coveralls.io/github/OCHA-DAP/hdx-python-utilities?branch=main)
[](https://github.com/astral-sh/ruff)
[](https://pypistats.org/packages/hdx-python-utilities)
The HDX Python Utilities Library provides a range of helpful utilities for Python developers.
Note that these are not specific to HDX.
1. Easy downloading of files with support for authentication, streaming and hashing
1. Retrieval of data from url with saving to file or from data previously saved
1. Date utilities
1. Loading and saving JSON and YAML (maintaining order)
1. Loading and saving HXLated csv and/or JSON
1. Dictionary and list utilities
1. HTML utilities (inc. BeautifulSoup helper)
1. Compare files (eg. for testing)
1. Simple emailing
1. Easy logging setup and error logging
1. State utility
1. Path utilities
1. URL utilities
1. Text processing
1. Stable file hashing
1. Matching utilities
1. Encoding utilities
1. Check valid UUID
1. Easy building and packaging
For more information, please read the [documentation](https://hdx-python-utilities.readthedocs.io/en/latest/).
This library is part of the [Humanitarian Data Exchange](https://data.humdata.org/) (HDX) project. If you have
humanitarian related data, please upload your datasets to HDX.
# Development
## Environment
Development is currently done using Python 3.13. The environment can be created with:
```shell
uv sync
```
This creates a .venv folder with the versions specified in the project's uv.lock file.
### Pre-commit
pre-commit will be installed when syncing uv. It is run every time you make a git
commit if you call it like this:
```shell
pre-commit install
```
With pre-commit, all code is formatted according to
[ruff](https://docs.astral.sh/ruff/) guidelines.
To check if your changes pass pre-commit without committing, run:
```shell
pre-commit run --all-files
```
## Packages
[uv](https://github.com/astral-sh/uv) is used for package management. If
you’ve introduced a new package to the source code (i.e. anywhere in `src/`),
please add it to the `project.dependencies` section of `pyproject.toml` with
any known version constraints.
To add packages required only for testing, add them to the
`[dependency-groups]`.
Any changes to the dependencies will be automatically reflected in
`uv.lock` with `pre-commit`, but you can re-generate the files without committing by
executing:
```shell
uv lock --upgrade
```
## Project
[uv](https://github.com/astral-sh/uv) is used for project management. The project can be
built using:
```shell
uv build
```
Linting and syntax checking can be run with:
```shell
uv run ruff check
```
To run the tests and view coverage, execute:
```shell
uv run pytest
```
## Documentation
The documentation, including API documentation, is generated using ReadtheDocs and
MkDocs with Material. As you change the source code, remember to update the
documentation at `documentation/index.md`.
| text/markdown | null | Michael Rans <rans@email.com> | null | null | MIT | HDX, date, datetime, dict, json, library, list, streaming, tabular data, time, timezone, utilities, yaml | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Natural Language :: English",
"Operating System :: MacOS",
"Operating System :: Microsoft :: Windows",
"Operating System :: POSIX :: Linux",
"Operating System :: Unix",
"Progr... | [] | null | null | >=3.10 | [] | [] | [] | [
"frictionless>=5.18.0",
"ijson>=3.2.3",
"jsonlines>=4.0.0",
"loguru",
"openpyxl>=3.1.2",
"pyphonetics",
"python-dateutil<2.9.1,>=2.9.0",
"ratelimit",
"requests-file",
"ruamel-yaml",
"tableschema-to-template>=0.0.13",
"typing-extensions",
"xlrd>=2.0.1",
"xlsx2csv",
"xlwt>=1.3.0",
"cydif... | [] | [] | [] | [
"Homepage, https://github.com/OCHA-DAP/hdx-python-utilities"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T01:10:14.081213 | hdx_python_utilities-4.0.7.tar.gz | 2,108,104 | 9a/7d/c250135b6e2a54c1f7aca80b3c143e7fc69f9d42c668fe5aa53fac5ff62a/hdx_python_utilities-4.0.7.tar.gz | source | sdist | null | false | 19c68d7b2b9599715d5da52a5b9723c4 | dcab17dd97192059de221ed3c74163e9223e19936fd4acf2f9e25b258537ce1f | 9a7dc250135b6e2a54c1f7aca80b3c143e7fc69f9d42c668fe5aa53fac5ff62a | null | [
"LICENSE"
] | 8,822 |
2.4 | maazdb-py | 1.0.0 | Official Python Driver for MaazDB |
# MaazDB-Py 🐍
**The Official Python Driver for MaazDB**
[](https://opensource.org/licenses/MIT)


[](https://maazdb.vercel.app/)
`maazdb-py` is a pure-Python client library for interacting with the MaazDB engine. It implements the custom MaazDB binary protocol over a secure TLS 1.3 socket, allowing Python applications to communicate with your database safely and efficiently.
---
## ✨ Features
- **Secure by Default:** Automatic TLS 1.3 encryption for all communications.
- **Pure Python:** No heavy C-extensions; easy to install and cross-platform.
- **Context Manager Support:** Use `with` statements for safe connection handling.
- **Binary Protocol:** Optimized communication using the MaazDB Binary Protocol v1.
- **Lightweight:** Minimal dependencies.
---
## 📦 Installation
### From PyPI
```bash
pip install maazdb-py
```
### From Source
```bash
git clone https://github.com/42Wor/maazdb-py.git
cd maazdb-py
pip install .
```
---
## 🛠 Quick Start
### Basic Usage
```python
from maazdb import MaazDB
# 1. Initialize the client
db = MaazDB()
try:
# 2. Connect securely
db.connect(host="127.0.0.1", port=8888, user="admin", password="password")
print("✓ Connected to MaazDB")
# 3. Execute SQL
db.query("CREATE DATABASE analytics;")
db.query("USE analytics;")
db.query("CREATE TABLE logs (id SERIAL PRIMARY KEY, message TEXT);")
# 4. Insert and Fetch
db.query("INSERT INTO logs (message) VALUES ('System started');")
results = db.query("SELECT * FROM logs;")
print(f"Results:\n{results}")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 5. Always close the connection
db.close()
```
### Using Context Managers (Recommended)
The driver supports the `with` statement, which automatically closes the connection even if an error occurs.
```python
from maazdb import MaazDB
with MaazDB() as db:
db.connect("127.0.0.1", 8888, "admin", "password")
result = db.query("SELECT count(*) FROM users;")
print(f"Total users: {result}")
```
---
## 📋 API Reference
### `MaazDB()`
The main class to interact with the database.
- **`.connect(host, port, user, password)`**: Establishes a TLS 1.3 connection and performs the handshake.
- **`.query(sql_string)`**: Sends a SQL query to the server and returns the result as a string.
- **`.close()`**: Safely closes the socket connection.
---
## 🔐 Security & Protocol
The driver communicates using the **MaazDB Binary Protocol v1**. All data is packed as **Big Endian** (`>I`).
| Step | Type | Description |
| :--- | :--- | :--- |
| **Handshake** | `0x10` | `[Type] [Len] [User\0Pass\0Signature]` |
| **Query** | `0x20` | `[Type] [Len] [SQL String]` |
| **Success** | `0x02` | `[Type] [Len] [Result Data]` |
| **Error** | `0x03` | `[Type] [Len] [Error Message]` |
---
## 👩💻 Development & Contributing
If you are interested in contributing to the driver or building from source, please refer to the [DEVELOPER.md](./DEVELOPER.md) file for:
- Project structure
- Setting up a development environment
- Building and publishing to PyPI
---
## 📄 License
Distributed under the MIT License. See `LICENSE` for more information.
---
*Created for the [MaazDB Ecosystem](https://maazdb.vercel.app/).*
| text/markdown | Maaz | your.email@example.com | null | null | null | database, driver, maazdb, client, nosql | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Database :: Front-Ends",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: ... | [] | https://github.com/42Wor/maazdb-py | null | >=3.7 | [] | [] | [] | [
"pytest>=6.0.0; extra == \"dev\"",
"pytest-cov>=2.0.0; extra == \"dev\"",
"black>=21.0.0; extra == \"dev\"",
"flake8>=3.9.0; extra == \"dev\"",
"mypy>=0.900; extra == \"dev\"",
"twine>=3.0.0; extra == \"dev\"",
"build>=0.7.0; extra == \"dev\"",
"sphinx>=4.0.0; extra == \"docs\"",
"sphinx-rtd-theme>=... | [] | [] | [] | [
"Documentation, https://maazdb.vercel.app/docs",
"Source, https://github.com/42Wor/maazdb-py",
"Tracker, https://github.com/42Wor/maazdb-py/issues"
] | twine/6.2.0 CPython/3.10.11 | 2026-02-19T01:07:02.188682 | maazdb_py-1.0.0.tar.gz | 6,079 | 34/01/53540c70de177219dbfa68c7f59888aebcb400bb38dcf6443e1eedc41c58/maazdb_py-1.0.0.tar.gz | source | sdist | null | false | 0c91d1cd7fc750e3e08858b30e910285 | a5b353942c926edc4b0985929b167107930ba7e0e8a316ea47068a811f2b1f50 | 340153540c70de177219dbfa68c7f59888aebcb400bb38dcf6443e1eedc41c58 | null | [] | 249 |
2.4 | aeon-core | 0.4.0 | Æon Framework - The Neuro-Symbolic Runtime for Safety-Critical Distributed Agents | # Æon Framework (Core)
<div align="center">
[](https://github.com/richardsonlima/aeon-core)
[](https://github.com/richardsonlima/aeon-core)
[](LICENSE)
[](https://github.com/richardsonlima/aeon-core)
[](https://github.com/richardsonlima/aeon-core)
[](https://github.com/astral-sh/uv)
[](https://github.com/psf/black)
<p>
<a href="README.md">English</a> | <a href="README_pt.md">Português</a>
</p>
**The Deterministic Runtime for Safety-Critical AI Agents with Autonomous Native Capabilities**
</div>
## 🌟 Overview
Æon is a comprehensive, production-ready framework for building **Neuro-Symbolic AI agents**. Unlike stochastic-only systems, Æon combines the intuitive reasoning of LLMs (**System 1**) with the deterministic safety and control of code-level axioms (**System 2**).
It establishes a standard "Trust Stack" that enables agents to be **Safety-Native**, **Protocol-First**, and **Extensible by Design**. With deep integration of the **Agent-to-Agent (A2A)** and **Model Context Protocol (MCP)**, Æon allows you to build interoperable agent ecosystems that can collaborate safely in high-stakes environments.
## 📋 What's New in v0.4.0 (ULTRA)
- **🔌 Autonomous Native Engine**: Built-in support for browser automation (Playwright), persistent event-sourced memory (SQLite), and granular Trust Levels.
- **🏗️ Developer First CLI**: Transform from scripts to projects with the new `aeon` command. Scaffold, run, and serve agents in seconds.
- **🚀 Declarative Runtime**: Define agents via `aeon.yaml` and launch a full **Gateway Server** for production deployments.
- **🛡️ Enhanced Safety executive**: Improved SIL-4 compliant axioms with TMR (Triple Modular Redundancy) reasoning for mission-critical reliability.
- **🔄 Deep Persistence**: Event-sourced memory system that survives reboots and provides a complete audit trail of agent thoughts and actions.
- **⏰ Temporal Capabilities**: Native scheduling for cron jobs and delayed tasks, enabling agents to act autonomously over time.
## 📋 What's New in v0.3.0 (ULTRA Phase)
- **Routing Layer**: Intelligent pattern-based message routing with 5 distinct strategies (Priority, Weighted, etc.).
- **Gateway Layer**: Centralized communication hub with session management and TTL support.
- **Security Layer**: Policy-based access control, AES encryption, and multi-provider authentication.
- **Health Layer**: Real-time system monitoring, metrics collection (Counter, Gauge, etc.), and diagnostics.
## ✨ Why Choose Æon?
- **Deterministic Safety**: Stop begging the model to be safe. Enforce safety at the runtime level with **Axioms**.
- **Neuro-Symbolic Core**: The perfect balance between LLM intuition and hard-coded rules.
- **Protocol-First**: Native support for **A2A** (Agent-to-Agent) and **MCP** (Model Context Protocol).
- **Enterprise Ready**: Built with observability, economics (cost tracking), and health monitoring from the ground up.
- **Local-First & Private**: Run entirely on your hardware with Ollama or connect to premium cloud providers.
- **Stark visual Feedback**: Terminal-native UI components for monitoring agent execution in real-time.
## 📦 Installation
### Using UV (Recommended)
[UV](https://github.com/astral-sh/uv) is the fastest way to manage Æon dependencies:
```bash
# Clone the repository
git clone https://github.com/richardsonlima/aeon-core.git
cd aeon-core
# Create environment and install
uv sync
```
### Using pip
```bash
pip install aeon-core
```
## 🚀 Quick Start Examples
### 1. Developer Workflow (CLI)
From zero to agent in three commands:
```bash
# Initialize a new project
aeon init my-safety-agent
# Configure your model in aeon.yaml
# (Default: google/gemini-2.0-flash-001)
# Run a task interactively
aeon run "Check reactor thermal status"
# Start the production gateway
aeon serve --port 8000
```
### 2. Create a Safety-Native Agent (Code)
```python
from aeon import Agent
from aeon.protocols import A2A, MCP
# Initialize the agent with the Trust Stack
agent = Agent(
name="Sentinel",
model="google/gemini-2.0-flash-001",
protocols=[A2A(port=8000), MCP(servers=["industrial_tools.py"])]
)
# Define an Unbreakable Axiom (System 2)
@agent.axiom(on_violation="OVERRIDE")
def safety_limit(command: dict) -> bool | dict:
"""SAFETY RULE: Power output cannot exceed 100%."""
if command.get("power", 0) > 100:
return {"power": 100, "warning": "AXIOM_LIMIT_REACHED"}
return True
if __name__ == "__main__":
agent.start()
```
### 3. Autonomous Browser Workflow
```python
from aeon import Agent
from aeon.core.config import TrustLevel
agent = Agent(name="Researcher", trust_level=TrustLevel.FULL)
async def main():
# Agent can autonomously browse and remember
response = await agent.run("Find the latest paper on SIL-4 safety and save the summary.")
print(f"Agent Action: {response.last_thought}")
# Run via CLI: aeon run ...
```
## 🔌 Enhanced MCP (Model Context Protocol) v2.0
Æon now features a completely redesigned MCP implementation that provides robust, production-ready integration with external tools:
- **Synapse Layer**: Unified tool discovery and invocation.
- **Standard Support**: Full compliance with the latest MCP specification.
- **Multi-Server**: Connect to multiple MCP servers simultaneously (Stdio, SSE).
- **Type Safety**: Automatic parameter validation for tool calls.
## 📖 Architecture: The 16 Subsystems
Æon is organized into 4 distinct layers, each providing critical functionality for advanced agents:
### 1. CORE (System 1 & 2)
- **Cortex**: Neuro-reasoning via LLMs.
- **Executive**: Deterministic control via Axioms.
- **Hive**: Standardized communication (A2A).
- **Synapse**: Tool integration (MCP).
### 2. INTEGRATION
- **Integrations**: Multi-platform connectivity (Telegram, Discord, Slack).
- **Extensions**: Dynamic capability loading.
- **Dialogue**: Persistent, event-sourced conversation history.
- **Dispatcher**: Event-driven pub/sub architecture.
- **Automation**: Temporal task scheduling (Cron/Interval).
### 3. ADVANCED
- **Observability**: Life-cycle hooks and audit trails.
- **Economics**: Real-time token tracking and cost calculation.
- **CLI**: Premium developer interface.
### 4. ULTRA (Enterprise)
- **Routing**: High-performance message distribution.
- **Gateway**: Centralized session and transport management.
- **Security**: Authentication, authorization, and encryption.
- **Health**: System diagnostics and metrics.
## 🧪 Hello World: Industrial Overseer
```python
from aeon import Agent
from aeon.protocols import A2A, MCP
controller = Agent(
name="Reactor_Overseer_01",
role="Industrial Automation Monitor",
model="gemini-1.5-flash",
protocols=[
A2A(port=8000),
MCP(servers=["mcp-server-industrial"])
]
)
@controller.axiom(on_violation="REJECT")
def enforce_safety(command: dict):
# Any command attempting to disable cooling is rejected
if command.get("action") == "DISABLE_COOLING":
return False
return True
if __name__ == "__main__":
controller.start()
```
## 🖥 Terminal Output (Visual Feedback)
```plaintext
🚀 Æon Core v0.4.0-ULTRA initialized
├── 📡 A2A Server: Online at http://0.0.0.0:8000 (Unified Standard)
├── 🔌 MCP Client: Connected (4 tools loaded: read_sensor, adjust_valve...)
├── 🛡️ Axioms: 2 Active (enforce_safety, thermal_limit)
└── 🧠 Brain: Gemini-2.0-Flash (Ready)
```
## 🤝 Community & Support
- **[GitHub Issues](https://github.com/richardsonlima/aeon-core/issues)**: Report bugs or request features.
- **[Aeon Landing Page](https://www.richardsonlima.com.br/aeon/)**: Visit our landing page for deep dives.
- **[Contributing Guide](CONTRIBUTING.md)**: Learn how to join the mission.
## 📝 Citing this Project
If you use Æon in your research, please cite it as:
```bibtex
@software{richardsonlima-aeon-framework,
author = {LIMA, Richardson Edson de},
title = {Aeon Framework: The Neuro-Symbolic Runtime for Deterministic AI Agents},
url = {https://github.com/richardsonlima/aeon-core},
version = {0.4.0-ULTRA},
year = {2026},
}
```
## 👨💻 Author
**Richardson Lima (Rick) **
- GitHub: [richardsonlima](https://github.com/richardsonlima)
- LinkedIn: [richardsonlima](https://www.linkedin.com/in/richardsonlima)
## 📄 License
This project is licensed under the Apache License 2.0 - see the [LICENSE](LICENSE) file for details.
---
Made with ❤️ for AI Safety by Richardson Lima. | text/markdown | null | "Richardson Lima (Rick)" <contatorichardsonlima@gmail.com> | Richardson Lima (Rick) | null | Apache-2.0 | agent-framework, agentic, ai-agents, axioms, deterministic, distributed-agents, formal-verification, multi-platform, neuro-symbolic, safety, safety-critical | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Langua... | [] | null | null | >=3.12 | [] | [] | [] | [
"aiofiles>=23.0.0",
"beautifulsoup4>=4.12.0",
"croniter>=2.0.0",
"fastapi>=0.100.0",
"httpx>=0.24.0",
"openai>=2.16.0",
"playwright>=1.40.0",
"prompt-toolkit>=3.0.0",
"pydantic-settings>=2.0.0",
"pydantic>=2.0.0",
"python-dotenv>=1.2.1",
"python-multipart>=0.0.5",
"pyyaml>=6.0",
"rich>=13.... | [] | [] | [] | [
"Homepage, https://www.richardsonlima.com.br/aeon",
"Documentation, https://github.com/richardsonlima/aeon-core#readme",
"Repository, https://github.com/richardsonlima/aeon-core.git",
"Bug Tracker, https://github.com/richardsonlima/aeon-core/issues",
"Changelog, https://github.com/richardsonlima/aeon-core/r... | twine/6.2.0 CPython/3.12.9 | 2026-02-19T01:05:34.539286 | aeon_core-0.4.0.tar.gz | 203,599 | e5/78/b20b990d4d5d2cd8f9c3dfcf4ef232209755cb55f83a66885158c00ba247/aeon_core-0.4.0.tar.gz | source | sdist | null | false | 17ca9eea4eef08f493b1d1024f8a4f61 | 62d4e556fafd490eceb69ec9076f5296205644ee77ff1c6e71899f5af2bb598d | e578b20b990d4d5d2cd8f9c3dfcf4ef232209755cb55f83a66885158c00ba247 | null | [
"LICENSE"
] | 246 |
2.4 | bsl-appcli | 3.5.0 | A library for adding CLI interfaces to applications in the brightSPARK Labs style. | = BSL Application CLI Library
:toc: left
:toclevels: 4
:sectnums:
https://badge.fury.io/py/bsl-appcli[image:https://badge.fury.io/py/bsl-appcli.svg[PyPI version]]
image:https://github.com/brightsparklabs/appcli/actions/workflows/build_python.yml/badge.svg[Test
Python]
https://github.com/PyCQA/bandit[image:https://img.shields.io/badge/security-bandit-yellow.svg[security: bandit]]
A library for adding CLI interfaces to applications in the brightSPARK Labs style.
== Overview
This library can be leveraged to add a standardised CLI capability to applications to:
* Handle system lifecycle events for services (`service [start|shutdown]`).
* Allow running arbitrary short-lived tasks (`task run`).
* Manage configuration (`configure`).
* Upgrade to a newer version of the application (`upgrade|migrate`).
* And more.
The CLI is designed to run within a Docker container and launch other Docker containers (i.e.
Docker-in-Docker). This is generally managed via a `docker-compose.yml` file.
=== Environment Variables
The library exposes the following environment variables to the `docker-compose.yml` file:
[horizontal]
`APP_VERSION`:: The version of containers to launch.
`<APP_NAME>_CONFIG_DIR`:: The directory containing configuration files.
`<APP_NAME>_DATA_DIR`:: The directory containing data produced/consumed by the system.
`<APP_NAME>_GENERATED_CONFIG_DIR`:: The directory containing configuration files generated from the
templates in `<APP_NAME>_CONFIG_DIR`.
`<APP_NAME>_BACKUP_DIR`:: The directory to use for system backups.
`<APP_NAME>_ENVIRONMENT`:: The deployment environment the system is running in. For example
`production` or `staging`. This allows multiple instances of the application to run on the same
Docker daemon. Defaults to `production`.
NOTE: The `APP_NAME` variable is derived from the `app_name` passed in to the `Configuration`
object in the main python entrypoint to the application. In order for the application to work, the
`app_name` is forced to conform with the shell variable name standard: `[a-zA-Z_][a-zA-Z_0-9]*`.
Any characters that do not fit this regex will be replaced with `_`. See
https://unix.stackexchange.com/questions/428880/list-of-acceptable-initial-characters-for-a-bash-variable[here]
or https://linuxhint.com/bash-variable-name-rules-legal-illegal/[here] for details.
The `docker-compose.yml` can be templated by renaming to `docker-compose.yml.j2`, and setting
variables within the `settings.yml` file as described in the Installation section.
Stack variables can be set within the `stack-settings.yml` file as described in the
`Build configuration template directories` section.
=== Volume Mounts
The following directories are mounted from the host system into the container:
[source,bash]
----
--volume "${INSTALL_DIR}/<environment>/data/cli/home:/root"
--volume "${INSTALL_DIR}/<environment>/conf:/opt/brightsparklabs/<my_app>/<environment>/conf"
--volume "${INSTALL_DIR}/<environment>/conf/.generated:/opt/brightsparklabs/<my_app>/<environment>/conf/.generated"
--volume "${INSTALL_DIR}/<environment>/data:/opt/brightsparklabs/<my_app>/<environment>/data"
--volume "${INSTALL_DIR}/<environment>/backup:/opt/brightsparklabs/<my_app>/<environment>/backup"
----
=== Migration from appcli version <=1.3.6 to version >1.3.6
As a result of supporting application context files, all references to settings in template files
have moved.
All settings in `settings.yml` used in templating are now namespaced under `settings`. All
templates will need to change their references to use this new namespacing scheme. For example, in
templates that refer to settings, change the references like so:
[source]
----
my_app.server.hostname -> settings.my_app.server.hostname
my_app.server.http.port -> settings.my_app.server.http.port
----
== Quick Start
Refer to the link:QUICKSTART.md[quick start guide] to get a basic application running.
Otherwise refer to the Installation section below to see all options.
== Installation
=== Add the library to your python CLI application
[source,bash]
----
pip install git+https://github.com/brightsparklabs/appcli.git@<VERSION>
----
=== Define the CLI for your application `myapp`
[source,python]
----
# filename: myapp.py
#!/usr/bin/env python3
# # -*- coding: utf-8 -*-
# standard libraries
from pathlib import Path
# vendor libraries
from appcli.cli_builder import create_cli
from appcli.models.configuration import Configuration
from appcli.orchestrators import DockerComposeOrchestrator
# ------------------------------------------------------------------------------
# CONSTANTS
# ------------------------------------------------------------------------------
# directory containing this script
BASE_DIR = Path(__file__).parent
# ------------------------------------------------------------------------------
# PRIVATE METHODS
# ------------------------------------------------------------------------------
def main():
configuration = Configuration(
app_name='myapp',
docker_image='brightsparklabs/myapp',
seed_app_configuration_file=BASE_DIR / 'resources/settings.yml',
application_context_files_dir=BASE_DIR / 'resources/templates/appcli/context',
stack_configuration_file=BASE_DIR / 'resources/stack-settings.yml',
baseline_templates_dir=BASE_DIR / 'resources/templates/baseline',
configurable_templates_dir=BASE_DIR / 'resources/templates/configurable',
orchestrator=DockerComposeOrchestrator(
# NOTE: These paths are relative to 'resources/templates/baseline'.
docker_compose_file = Path('docker-compose.yml'),
docker_compose_override_directory = Path('docker-compose.override.d/'),
docker_compose_task_file = Path('docker-compose.tasks.yml'),
docker_compose_task_override_directory = Path( 'docker-compose.tasks.override.d/'),
),
mandatory_additional_data_dirs=['EXTRA_DATA',],
mandatory_additional_env_variables=['ENV_VAR_2',],
)
cli = create_cli(configuration)
cli()
# ------------------------------------------------------------------------------
# ENTRYPOINT
# ------------------------------------------------------------------------------
if __name__ == '__main__':
main()
----
Most fields in the appcli constructor can be defaulted, resulting in less code.
[source,python]
----
def main():
configuration = Configuration(
app_name='myapp',
docker_image='brightsparklabs/myapp',
)
cli = create_cli(configuration)
cli()
----
=== Choose orchestrator
==== DockerComposeOrchestrator
This is the default orchestrator. It is designed for launching services via a `docker-compose.yml`
file.
==== NullOrchestrator
For applications with no services to orchestrate, the `NullOrchestrator` can be used. This is
useful for appcli applications which consist only of the launcher container containing various
additional CLI command groups. The `NullOrchestrator` disables commands related to managing
services.
[source,python]
----
from appcli.orchestrators import NullOrchestrator
orchestrator = NullOrchestrator()
----
==== HelmOrchestrator
The project also includes a https://helm.sh/docs/intro/quickstart/[helm] orchestrator for deploying
charts to https://kubernetes.io/[kubernetes] clusters.
Create a new `resources` directory as follows:
[source,bash]
----
resources/
├── settings.yml
└── templates/
├── baseline/
│ └── cli/
│ └── helm/
│ ├── set-files/
│ │ ├── baz/
│ │ │ ├── foo.json
│ │ │ └── qux.waldo.txt
│ │ └── thud.bang.yml
│ ├── set-values/
│ │ ├── foo.yml
│ │ └── bar.txt
│ └── mychart.tgz
└── configurable/
└── cli/
└── home/
└── .kube/
└── config # Overwrite this with a cluster specific config file. ie `~/.kube/config`.
----
You can then configure the orchestrator as folows:
[source,python]
----
from appcli.orchestrators import HelmOrchestrator
orchestrator = HelmOrchestrator(
# Chart archive path (relative to `conf/templates/`).
# [Optional] Default is `cli/helm/chart`
chart_location="cli/helm/mychart.tgz",
# The directory containing all main `values.yaml` files (relative to `conf/templates/`).
# [Optional] Default is `cli/helm/set-values`
helm_set_values_dir="cli/helm/set-values"
# The directory containing all key-specific files (relative to `conf/templates/`).
# [Optional] Default is `cli/helm/set-files`
helm_set_files_dir="cli/helm/set-files"
)
----
===== Values
Values can be supplied either:
[arabic]
. For a set key by placing files in `set-files` directory.
* The name of the key to set is derived from the directory structure and the name of the file (up to
the first dot encountered in the filename).
. Globally for any files dumped in the `set-values` directory.
For example, given the following `cli/helm/` directory structure:
[source,bash]
----
cli/helm/
├── set-files/
│ ├── baz/
│ │ ├── foo.json
│ │ └── qux.waldo.txt
│ └── thud.bang.yml
└── set-values/
├── foo.yml
└── bar.txt
----
This would result in the following arguments being passed to helm:
[source,bash]
----
--set-file baz.foo=cli/helm/set-files/baz/foo.json
--set-file baz.qux=cli/helm/set-files/baz/qux.waldo.yml # NOTE: Key is `qux` not `qux.waldo`.
--set-file thud=cli/helm/set-files/thud.bang.yml # NOTE: Key is `thud` not `thud.bang`.
--values cli/helm/set-values/foo.yml
--values cli/helm/set-values/bar.yml
----
===== Dev Mode Chart
During development it would be slow to require packaging up the chart for any changes. Appcli
provides a way to speed up development by allow for the chart to deployed directly from source. This
is done by specifying the dev chart as an environment variable.
[source,bash]
----
MYAPP_DEV_MODE=true MYAPP_DEV_MODE_HELM_CHART=/path/to/mychart python3 -m myapp service start
----
===== Kubeconfig
A custom `kubeconfig` file can be used by specifying the `KUBECONFIG` environment variable.
[source,bash]
----
KUBECONFIG=/opt/brightsparklabs/myapp/conf/.generated/config ./myapp ...
----
NOTE: The `KUBECONFIG` file must be at a location which is mounted into the launch container. Refer
to link:#volume-mounts[Volume Mounts] for details on what volumes are mounted into the launch
container.
=== Add configuration files
Any configuration files used by your services can be templated using the Jinja2 templating engine.
* Store any Jinja2 variable definitions you wish to use in your configuration template files in
`resources/settings.yml`.
* Store any application context files in `resources/templates/appcli/context/`.
* Store any appcli stack specific keys in `resources/stack-settings.yml`.
* Store your `docker-compose.yml`/`docker-compose.yml.j2` file in
`resources/templates/baseline/`.
* Configuration files (Jinja2 compatible templates or otherwise) can be stored in one of two
locations:
** `resources/templates/baseline` - for templates which the end user *is not* expected to modify.
** `resources/templates/configurable` - for templates which the end user is expected to modify.
==== Application context files
Template files are templated with Jinja2. The '`data`' passed into the templating engine is a
combination of the `settings.yml` and all application context files (stored in
`resources/templates/appcli/context`, and referenced in the `Configuration` object as
`application_context_files_dir`). Application context files that have the extension `.j2` are
templated using the settings from `settings.yml`.
These are combined to make the data for templating as follows:
[source,json]
----
{
"settings": {
... all settings from `settings.yml`
},
"application": {
<app_context_file_1>: {
... settings from `app_context_file_1.yml`, optionally jinja2 templated using settings from `settings.yml`
},
... additional app_context_files
}
}
----
As a minimal example with the following YAML files:
[source,yaml]
----
# ./settings.yml
main_settings:
abc: 123
# ./resources/templates/appcli/context/app_constants.yml
other_settings:
hello: world
# ./resources/templates/appcli/context/app_variables.yml.j2
variables:
main_abc_setting: {{ settings.main_settings.abc }}
----
The data for Jinja2 templating engine will be:
[source,json]
----
{
"settings": {
"main_settings": {
"abc": 123
}
},
"application": {
"app_constants": {
"other_settings": {
"hello": "world"
}
},
"app_variables": {
"variables": {
"main_abc_setting": 123
}
}
}
}
----
==== Schema validation
Configuration files will be automatically validated against provided schema files whenever
`configure apply` is run. Validation is done with https://json-schema.org/[jsonschema] and is only
available for `yaml/yml` and `json/jsn` files. The JSON schema file must match the name of the
file to validate with a suffix of `.schema.json.`. It must be placed in the same directory as the
file to validate, The `settings.yml`, `stack_settings.yml` file, and any files in the
`resource/templates` or `resources/overrides` directory can be validated.
[source,yaml]
----
# resources/templates/configurable/my-config.yml
foobar: 5
----
[source,json]
----
# resources/templates/configurable/my-config.yml.schema.json
{
"$schema": "http://json-schema.org/schema",
"type": "object",
"properties" : {
"foobar" : {"type": "number"}
}
}
----
To stop a schema file from being copied across to the `generated` config directory, add
`.appcli` as an infix.
[source,bash]
----
$ ls -1
bar.json # -> Config-file ; Copy-on-apply
bar.json.schema.json # -> Schema-file ; Copy-on-apply
foo.yaml # -> Config-file ; Copy-on-apply
foo.yaml.appcli.schema.json # -> Schema-file ; Ignore-on-apply
----
==== Secrets management
IMPORTANT: Currently only supported for the `DockerComposeOrchestrator`. Secret management is
currently not available for the `HelmOrchestrator`. Any secret objects should be pre-loaded in the
Kubernetes cluster.
Sensitive values can be encrypted inside the `settings.yml` file and then decrypted during
deployment within the `docker-compose.yml`.
[source,bash]
----
# Automatically encrypt and set (spaces to prevent shell history retention).
$ ./myapp configure set -e 'path.to.field' 'my-secret-value'
# Manually encrypt and set (spaces to prevent shell history retention).
$ ./myapp encrypt 'my-secret-value'
enc:id=X:...
# Set the above value to the field.
./myapp configure set 'path.to.field' 'enc:id=X:...'
----
On template generation, the encrypted values from the `settings.yaml` file are used verbatim in
the generated files (i.e. the generated files will contain `enc:id=X:...`). Thus, any encrypted
value comes through verbatim in the file present on disk (i.e. remains encrypted on disk).
In the appcli container, the `DockerComposeOrchestrator` has special handling when it processes
the `docker-compose.yml` file:
. The `docker-compose.yml` file (and any override files) are decrypted and written to a temporary
file WITHIN the container.
. These decrypted files and then used in the context of any `docker-compose` commands to manage
the stack.
. So relevant env vars / secrets will go through into any containers as defined in the
`docker-compose.yml` file.
. The decrypted docker compose file disappears when the container shuts down.
IMPORTANT: The secrets are only decrypted in the `docker-compose.yml` (and overrides) files. If
they are used in any other configuration file, they will not be decrypted.
The pattern is to pass secret values into required containers using the `docker-compose.yml` file
via environment variables:
[source,bash]
----
$ cat docker-compose.yml
...
services:
postgres:
image: postgres:lastest
environment:
- POSTGRES_DB=mydatbase
- POSTGRES_USER=myuser
- POSTGRES_PASSWORD={{ myapp.postgres.password }}
...
$ ./myapp configure set -e 'myapp.postgres.password' 'my-secret-value'
----
There might be some use cases where secrets need to be printed to the terminal (development for example).
`appcli` provides a logging function to accomodate this, which provides the following benefits.
- The secret value is encoded in base 64.
- It will not be written to a log file, even if a handler is attached.
[source,python]
----
from appcli.logger import logger
some_password = os.getenv("SOME_PASSWORD")
logger.sensitive("Password", some_password)
----
This will print the following message to `stderr`:
[source,bash]
----
$ ./myapp log-secret
[SENSITIVE] Password: "cEBzc3dvcmQxMjM=" # "p@ssword123" encoded as Base64
----
IMPORTANT: This function will not protect against Linux shell redirects.
[source,bash]
----
./myapp log-secret 2> file.log # Secret value will be written to file!!!
----
=== Configure application backup
Appcli’s `backup` command creates backups of configuration and data of an application, stored
locally in the backup directory. The settings for backups are configured through entries in a
`backups` block in `stack-settings.yml`.
The available keys for entries in the `backups` block are:
[horizontal]
name:: The name of the backup. Must be unique between backup definitions and use `kebab-case`.
backup_limit:: The number of local backups to keep. Set to `0` to disable rolling deletion.
file_filter:: The file_filter contains lists of glob patterns used to specify what files to include
or exclude from the backup.
frequency:: The cron-like frequency at which backups will execute.
+
IMPORTANT: The `minute` and `hour` portions of the cron expression are omitted, as that level of
granularity is not supported. Refer to <<Frequency>> for details.
remote_backups:: The list of remote backup strategies.
[source,yaml]
----
# filename: stack-settings.yml
backups:
- name: "full"
backup_limit: 0
file_filter:
data_dir:
include_list:
exclude_list:
conf_dir:
include_list:
exclude_list:
frequency: "* * *"
remote_backups:
----
==== Backup name
The backup `name` is a short descriptive name for the backup definition. To avoid problems, we
_highly_ recommend `name` be:
* Unique between items in the `backups` list.
* Use `kebab-case`.
Examples of good names:
* `full`
* `conf-only`
* `audit-logs`
Without a unique `name`, backups from different items in `backups` will overwrite each other
without warning.
Using `kebab-case` is necessary to avoid some issues with `click` and filesystem naming issues.
When using the `backup` command, you are able to supply the name of the backup to run. If you have
a backup `name` with a space in it, the `click` library cannot interpret the name as a whole
string (even with quotes), so you will be unable to run the backup individually.
If the backup `name` doesn’t use `kebab-case`, it may use some characters that are incompatible
with file and directory naming conventions. Appcli will automatically slugify the name to something
compatible, but this may cause collisions in the folder names of backups to be taken which will lead
to backups being overwritten. e.g. `s3#1` and `s3&1` will both translate internally to `s3-1`.
==== Backup limit
A rolling deletion strategy is used to remove local backups, in order to keep `backup_limit`
number of backups.
If more than `backup_limit` number of backups exist in the backup directory, the oldest backups
will be deleted.
Set this value to `0` to keep all backups.
==== File filter
The `file_filter` block enables filtering of files to backup from `conf` and `data`
directories. For more details including examples, see link:README_BACKUP_FILE_FILTER.adoc[here].
[source,yaml]
----
# filename: stack-settings.yml
# Includes all log files from data dir only.
backups:
- name: "full"
backup_limit: 0
file_filter:
data_dir:
include_list:
- "**/*.log"
exclude_list:
conf_dir:
include_list:
exclude_list:
- "**/*"
frequency: "* * *"
remote_backups:
----
==== Frequency
Appcli supports limiting individual backups to run on only specific days using a cron-like frequency
filter.
When the `backup` command is run, each backup strategy will check if the `frequency` pattern
matches today’s date. Only strategies whose `frequency` pattern match today’s date will execute.
The input pattern `pattern` is prefixed with `"* * "` and is used as a standard cron expression
to check for a match. i.e. `"* * $pattern"`. This is because `minute` and `hour` granularity are not
configurable.
Examples:
* `"* * *"` (cron equivalent `"* * * * *"`) will always run.
* `"* * 0"` (cron equivalent `"* * * * 0"`) will only run on Sunday.
* `"1 */3 *"` (cron equivalent `"* * 1 */3 *"`) will only run on the first day-of-month of every
3rd month.
==== Remote backup
Appcli supports pushing local backups to remote storage. The list of strategies for pushing to
remote storage are defined within the `remote_backups` block.
The available keys for every remote backup strategy are:
[horizontal]
name:: A short name or description used to describe this backup.
strategy_type:: The type of this backup, must match an implemented remote backup strategy.
frequency:: The cron-like frequency at which remote backups will execute. Behaves the same as local
backup `frequency`.
configuration:: Custom configuration block that is specific to each remote backup strategy.
IMPORTANT:: Remote backups will only run for a local backup that has run. Therefore the `frequency`
of the local backup will apply first, followed by the `frequency` of the remote backup. This means
that it’s possible to write a remote backup frequency that will never execute. e.g. Local `* * 0`
and remote `* * 1`.
===== Strategies
====== AWS S3 remote strategy
To use S3 remote backup, set `strategy_type` to `S3`. The available configuration keys for an S3
backup are:
[horizontal]
bucket_name:: The name of the bucket to upload to.
access_key:: The AWS Access key ID for the account to upload with.
secret_key:: The AWS Secret access key for the account to upload with. The value _must_ be encrypted
using the appcli `encrypt` command.
bucket_path:: The path in the S3 bucket to upload to. Set this to an empty string to upload to the
root of the bucket.
tags:: Key value pairs of tags to set on the backup object.
[source,yaml]
----
# filename: stack-settings.yml
backups:
- name: "full_backup"
backup_limit: 0
remote_backups:
- name: "weekly_S3"
strategy_type: "S3"
frequency: "* * 0"
configuration:
bucket_name: "aws.s3.bucket"
access_key: "aws_access_key"
secret_key: "enc:id=1:encrypted_text:end"
bucket_path: "bucket/path"
tags:
frequency: "weekly"
type: "data"
----
==== Restoring a remote backup
To restore from a remote backup:
. Acquire the remote backup (`.tgz` file) that you wish to restore. For S3 this can be done by
downloading the backup from the specified bucket.
. Place the backup `myapp_date.tgz` file in the backup directory. By default this will be
`/opt/brightsparklabs/${APP_NAME}/production/backup/`
. Confirm that appcli can access the backup by running the `view-backups` command
. Run the restore command `./myapp restore BACKUP_FILE.tgz` e.g.
`./myapp restore APP_2021-02-02T10:55:48+00:00.tgz`. The restore process will trigger a backup.
=== (Optional) Define Custom Commands
You can specify some custom top-level commands by adding click commands or command groups to the
configuration object. Assuming '`web`' is the name of the service in the docker-compose.yml file
which you wish to exec against, we can create three custom commands in the following example:
* `myapp ls-root` which lists the contents of the root directory within the `web` service
container and prints it out.
* `myapp ls-root-to-file` which lists the contents of the root directory within the `web`
service container and dumps to file within the container.
* `myapp tee-file` which takes some text and `tee`s it into another file the `web` service
container.
[source,python]
----
def get_ls_root_command(orchestrator: DockerComposeOrchestrator):
@click.command(
help="List files in the root directory",
)
@click.pass_context
def ls_root(ctx: click.Context):
# Equivalent command within the container:
# `ls -alh`
cli_context: CliContext = ctx.obj
output: CompletedProcess = orchestrator.exec(cli_context, "web", ["ls", "-alh", "/"])
print(output.stdout.decode())
return ls_root
def get_tee_file_command(orchestrator: DockerComposeOrchestrator):
@click.command(
help="Tee some text into a file",
)
@click.pass_context
def tee_file(ctx: click.Context):
# Equivalent command within the container:
# `echo "Some data to tee into the custom file" | tee /ls-root.txt`
cli_context: CliContext = ctx.obj
output: CompletedProcess = orchestrator.exec(cli_context, "web", ["tee", "/my_custom_file.txt"], stdin_input="Some data to tee into the custom file")
return tee_file
def get_ls_root_to_file_command(orchestrator: DockerComposeOrchestrator):
@click.command(
help="List files in the root directory and tee to file",
)
@click.pass_context
def ls_root_to_file(ctx: click.Context):
# Equivalent command within the container:
# `ls -alh | tee /ls-root.txt`
cli_context: CliContext = ctx.obj
output: CompletedProcess = orchestrator.exec(cli_context, "web", ["ls", "-alh", "/"])
data = output.stdout.decode()
orchestrator.exec(cli_context, "web", ["tee", "/ls-root.txt"], stdin_input=data)
return ls_root_to_file
def main():
orchestrator = DockerComposeOrchestrator(Path("docker-compose.yml"))
configuration = Configuration(
app_name="appcli_nginx",
docker_image="thomas-anderson-bsl/appcli-nginx",
seed_app_configuration_file=Path(BASE_DIR, "resources/settings.yml"),
stack_configuration_file=Path(BASE_DIR, "resources/stack-settings.yml"),
baseline_templates_dir=Path(BASE_DIR, "resources/templates/baseline"),
configurable_templates_dir=Path(BASE_DIR, "resources/templates/configurable"),
orchestrator=orchestrator,
custom_commands={get_tee_file_command(orchestrator),get_ls_root_command(orchestrator),get_ls_root_to_file_command(orchestrator)}
)
cli = create_cli(configuration)
cli()
----
=== (Optional) Define hooks
Custom logic can be inserted into the lifecycle by defining the `hooks` parameter in the
`Configuration` object:
[source,python]
----
from secrets import token_urlsafe
from appcli.models.configuration import Hooks
def get_hooks() -> Hooks:
def post_configure_init(ctx: click.Context):
"""Automatically generate random passwords after `configure init` runs."""
cli_context = ctx.obj
configure_cli = cli_context.commands["configure"]
for setting in [
"myapp.services.api.password",
"myapp.services.database.password",
"myapp.services.cache.password",
]:
logger.info(f"Generating random password for: {setting}")
ctx.invoke(
configure_cli.commands["set"],
type="str",
encrypted=True,
setting=setting,
value=token_urlsafe(20),
)
def migrate_variables(
cli_context: CliContext,
current_variables: Dict[str, Any],
previous_version: str,
clean_new_version_variables: Dict[str, Any],
) -> Dict[str, Any]:
logger.info(
f"Migrating myapp `{previous_version}` to `{cli_context.app_version}` ..."
)
# Handle migration from schema v1 to v2.
if current_variables['metadata']['schema_version'] == 1:
current_variables['metadata']['schema_version'] = 2
# `proxy` key was added in v2.
current_variables['myapp']['proxy'] = clean_new_version_variables['myapp']['proxy']
return current_variables
...
return Hooks(
post_configure_init=post_configure_init,
migrate_variables=migrate_variables,
...
)
...
def main():
configuration = Configuration(
app_name="myapp",
docker_image="brightsparklabs/myapp',
hooks=get_hooks()
)
cli = create_cli(configuration)
cli()
----
The various hooks are documented in the `Hooks` class within
link:appcli/models/configuration.py[the configuration.py] file.
They generally allow for code to be run pre/post various lifecycle steps. E.g.
`pre_configure_init` would run the hook prior to the `configure init` stage.
Two hooks of note are:
. `migrate_variables` - Used to handle schema migrations of the `settings.yml` file.
. `is_valid_variables` - Used to validate whether a current `settings.yml` file can be used by
the current version of the system.
=== (Optional) Preset Configurations
The `configure init` command initialises the install location with the configuration templates
from the `configurable_templates_dir`.
In some instances, it is useful to be able to tweak these files for various preset scenarios. E.g.
If a system is deployed on-premise it might enable a set of local services which are not needed if
the system if deployed to a cloud environment.
`appcli` support defining `presets` to support this use case. This is done by having configuring
the `PresetConfiguration` block of the project.
[source,python]
----
configuration = Configuration(
...
auto_configure_on_install=False,
presets=PresetsConfiguration(
is_mandatory=True, # [Optional] Whether to support/enforce presets.
templates_directory="resources/templates/presets", # [Optional] Path to the preset dirs.
default_preset="onprem", # [Optional] The preset to apply when not is specified.
),
)
----
The `templates_directory` must contain a directory for each preset, and contain any files which
should be overriden from the default `configurable` directory. E.g. the below would ensure the
various presets all override the default `environment.txt` file.
[source,bash]
----
resources/templates/
├── baseline/
├── configurable/
│ ├── basefile.yml
│ └── environment.txt
└── presets/
├── aws/
│ ├── additional_dir/
│ │ └── nested_file.yml
│ ├── additional_file.yml
│ └── environment.txt
├── azure/
│ └── environment.txt
└── onprem/
└── environment.txt
----
The `preset` can the be specified when initialising the configuration directory:
[source,bash]
----
./myapp configure init --preset aws
----
This will do the following:
[arabic]
. All the files in the `configurable_templates_dir` (e.g. `resources/templates/configurable/`)
will be copied to the installation directory as per usual.
. All files from the `aws` preset will be copied over to the installation directory, overwriting
any existing files with the same name.
[source,bash]
----
/opt/brightsparklabs/myapp/production/conf/templates/
├── basefile.yml # Comes from `configurable/`.
├── additional_dir/ # Comes from `presets/aws/`.
│ └── nested_file.yml # Comes from `presets/aws/`.
├── additional_file.yml # Comes from `presets/aws/`.
└── environment.txt # Comes from `presets/aws/`.
----
==== Configure Init Hooks
Any `{pre,post}_configure_init` hooks will inherit the profile parameter supplied at runtime.
[source,python]
----
def post_configure_init_hook(ctx: click.Context, preset: Optional[str]):
# `preset` will be `--preset <value>` or `None` if no parameter was supplied.
pass
----
=== Define a container for your CLI application
[source]
----
# filename: Dockerfile
FROM brightsparklabs/appcli-docker-compose:<version>
ENTRYPOINT ["./myapp.py"]
WORKDIR /app
# install compose if using it as the orchestrator
RUN pip install docker-compose
COPY requirements.txt .
RUN pip install --requirement requirements.txt
COPY src .
ARG APP_VERSION=latest
ENV APP_VERSION=${APP_VERSION}
----
==== Build the container
[source,bash]
----
# sh
docker build -t brightsparklabs/myapp --build-arg APP_VERSION=latest .
----
==== (Optional) Login to private Docker registries and pass through credentials
It is possible to login to private Docker registries on the host, and pass through credentials to
the CLI container run by the launcher script. This enables pulling and running Docker images from
private Docker registries.
Login using:
[source,bash]
----
docker login ${REGISTRY_URL}
----
The credentials file path can be passed as an option via `--docker-credentials-file` or `-p` to
the `myapp` container.
==== View the installer script
[source,bash]
----
# sh
docker run --rm brightsparklabs/myapp:<version> install
# or if using a private registry for images
docker run --rm brightsparklabs/myapp:<version> \
--docker-credentials-file ~/.docker/config.json \
install
----
While it is not mandatory to view the script before running, it is highly recommended.
==== Run the installer script
[source,bash]
----
# sh
docker run --rm brightsparklabs/myapp:<version> install | sudo bash
----
The above will use the following defaults:
* `environment` => `production`.
* `install-dir` => `/opt/brightsparklabs/${APP_NAME}/production/`.
* `configuration-dir` => `/opt/brightsparklabs/${APP_NAME}/production/conf/`.
* `data-dir` => `/opt/brightsparklabs/${APP_NAME}/production/data/`.
* `backup-dir` => `/opt/brightsparklabs/${APP_NAME}/production/backup/`.
You can modify any of the above if desired. E.g.
[source,bash]
----
# sh
docker run --rm brightsparklabs/myapp:<version> \
--environment "uat" \
--configuration-dir /etc/myapp \
--data-dir /mnt/data/myapp \
install --install-dir ${HOME}/apps/myapp \
| sudo bash
----
Where::
--environment::: defines the environment name for the deployment. This allows multiple instances
of the application to be present on the same host. Defaults to `production`.
--install-dir::: defines the base path under which each environment is deployed. It will contain
a directory for each `environment` installed on the system (see above). Each environment directory
will contain the launcher, configuration directory and data directory (unless overridden, see
below). Defaults to `/opt/brightsparklabs/${APP_NAME}/`.
--configuration-dir::: defines the path to the configuration directory. Defaults to
`${INSTALL_DIR}/<environment>/conf/` (`${INSTALL_DIR}` is defined by `--install-dir` above).
--data-dir::: defines the path to the data directory. Defaults to
`${INSTALL_DIR}/<environment>/data/` (`${INSTALL_DIR}` is defined by `--install-dir` above).
The installation script will generate a launcher script for controlling the application. The script
location will be printed out when running the install script. This script should now be used as the
main entrypoint to all appcli functions for managing your application.
== Usage
This section details what commands and options are available.
=== Top-level Commands
To be used in conjunction with your application `./myapp <command>`
E.g. `./myapp configure init`
Commands::
--
[horizontal]
backup::: Create a backup of application data and configuration.
configure::: Configures the application.
encrypt::: Encrypts the specified string.
init::: Initialises the application.
launcher::: Outputs an appropriate launcher bash script.
migrate::: Migrates the configuration of the application to a newer version.
orchestrator::: Perform docker orchestration
restore::: Restore a backup of application data and configuration.
service::: Lifecycle management commands for application services.
task::: Commands for application tasks.
version::: Fetches the version of the app being managed with appcli.
view-backups::: View a list of locally-available backups.
--
Options::
--
-–debug::: Enables debug level logging.
-c, -–configuration-dir PATH::: Directory containing configuration files. [This is required unless
subcommand is one of: `install`.
-d, -–data-dir PATH::: Directory containing data produced/consumed by the system. This is required
unless subcommand is one of: `install`.
-t, -–environment TEXT::: Deployment environment the system is running in. Defaults to `production`.
-p, -–docker-credentials-file PATH::: Path to the Docker credentials file (config.json) on the host
for connecting to private Docker registries.
-a, -–additional-data-dir TEXT::: Additional data directory to expose to launcher container. Can be
specified multiple times.
-e, -–additional-env-var TEXT::: Additional environment variables to expose to launcher container.
Can be specified multiple times.
-–help::: Show the help message and exit.
--
==== Command: `backup`
Creates a backup `.tgz` file in the backup directory that contains files from the configuration
and data directory, as configured in `stack-settings.yml`. After the backup is taken, remote
backup strategies will be executed (if applicable).
Usage: `./myapp backup [OPTIONS] [ARGS]`
Options::
-–pre-stop-services/-–no-pre-stop-services::: Whether to stop services before performing backup.
-–post-start-services/-–no-post-start-services::: Whether to start services after performing backup.
-–help::: Show the help message and exit.
The `backup` command optionally takes an argument corresponding to the `name` of the backup to
run. If no `name` is provided, all backups will attempt to run.
==== Command Group: `configure`
Configures the application.
Usage: `./myapp configure [OPTIONS] COMMAND [ARGS]`
Commands::
apply::: Applies the settings from the configuration.
diff::: Get the differences between current and default configuration settings.
get::: Reads a setting from the configuration.
get-secure::: Reads a setting from the configuration, decrypting if it is encrypted. This will
prompt for the setting key.
init::: Initialises the configuration directory.
set::: Saves a setting to the configuration. Allows setting the type of value with option `--type`,
and defaults to string type. Use `-e` to encrypt the value when setting.
template::: Configures the baseline templates.
edit::: Open the settings file for editing with vim-tiny.
Options::
-–help::: Show the help message and exit.
==== Command: `encrypt`
Encrypts the specified string.
Usage: `./myapp encrypt [OPTIONS] TEXT`
Options::
-–help::: Show the help message and exit.
==== Command Group: `init`
Initialises the application.
Usage: `./myapp init [OPTIONS] COMMAND [ARGS]`
Commands::
keycloak::: Initialises a Keycloak instance with BSL-specific initial configuration.
Options::
-–help::: Show the help message and exit.
==== Command: `launcher`
Outputs an appropriate launcher bash script to stdout.
Usage: `./myapp launcher [OPTIONS]`
Options::
-–help::: Show the help message and exit.
==== Command: `migrate`
Migrates the application configuration to work with the current application version.
Usage: `./myapp migrate [OPTIONS]`
Options::
-–help::: Show the help message and exit.
==== Command Group: `orchestrator`
Perform tasks defined by the orchestrator.
Usage: `./myapp orchestrator [OPTIONS] COMMAND [ARGS]`
All commands are defined within the orchestrators themselves. Run `./myapp orchestrator` to list
available commands.
For example, the following commands are availabl | text/plain | null | brightSPARK Labs <enquire@brightsparklabs.com> | null | null | MIT License | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: POSIX :: Linux",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.12.3 | [] | [] | [] | [
"boto3==1.42.50",
"click==8.3.1",
"coloredlogs==15.0.1",
"cronex==0.1.3.1",
"dataclasses-json==0.5.7",
"deepdiff==8.6.1",
"gitpython==3.1.46",
"jinja2==3.1.6",
"jsonschema==4.26.0",
"pycryptodome==3.23.0",
"pydantic==2.12.5",
"pyfiglet==1.0.4",
"python-keycloak==3.12.0",
"python-slugify==8... | [] | [] | [] | [
"Homepage, https://www.brightsparklabs.com",
"Repository, https://github.com/brightsparklabs/appcli",
"Changelog, https://github.com/brightsparklabs/appcli/blob/master/CHANGELOG.md"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:05:25.564849 | bsl_appcli-3.5.0.tar.gz | 14,216,210 | 69/6e/7590ab4b917ec0226e8340f57636efc7b2863e45f71ad95e6a0874e39bd6/bsl_appcli-3.5.0.tar.gz | source | sdist | null | false | 212f708303fcf94e792e047cca282b69 | 9962c24603e6529388dae3acad95d9cf428c0d03929f5bad0c6d810134753983 | 696e7590ab4b917ec0226e8340f57636efc7b2863e45f71ad95e6a0874e39bd6 | null | [
"LICENSE"
] | 255 |
2.4 | faircom-json-action-client | 0.0.3 | A helper client for FairCom JSON Action API | # JsonActionClient
A wrapper for the FairCom JSON Action API.
## What it does
This class provides a Python "client" that manages logging into the server (createSession), logging out of the server (deleteSession), and provides an easy way to POST to the server and access the session authToken.
When your program closes, any client you created will automatically log out of the FairCom server.
Exceptions are caught and re-raised as a JsonActionError (or a derived exception).
## What it does not do
The client does not perform any "keepalive" operations. By default, the session will expire after 30 seconds. This timeout can be set by using the "timeout" parameter when instantiating the client.
## Installation
```bash
pip install faircom-json-action-client
```
## Usage
Both secure and insecure connections are possible. All certificate files should be PEM-encoded X.509 certificates.
### Example mTLS usage:
```Python
from json_action_client import JsonActionClient, JsonActionConnectionError, JsonActionApiError
client = JsonActionClient( "https://127.0.0.1:8444/api", ca_cert = "/FairCom/ca.crt", client_cert = "/FairCom/client.pem" )
client.login()
with client:
list_databases_json = client.build_basic_request( api = "db", action = "listDatabases" )
response = client.post_json( list_databases_json )
print( f"Response: {response}" )
```
This connection is considered the most secure and when done properly will be adequate to use over public networks. In the example above a client certificate and CA certificate are used to enable mutual-TLS (mTLS) with the [FairCom](https://www.faircom.com/) server.
The CA certificate (`ca.crt` in this example) must have signed both the client certificate (`client.pem`) and the server certificate. This provides TLS encryption for client communications and user-level access controls on the server (the client certificate CN must match a user account on the server). Client certificates can be invalidated by disabling the account on the server, avoiding the hassle of CRLs.
More details on FairCom TLS [can be found here](https://docs.faircom.com/docs/en/UUID-bbee8e14-258d-4203-397e-9f1486d852ca.html).
### Example TLS (one-sided) and credential usage:
```Python
from json_action_client import JsonActionClient, JsonActionConnectionError, JsonActionApiError
client = JsonActionClient( "https://127.0.0.1:8443/api", ca_cert = "/FairCom/ca.crt" )
client.login( "admin", "ADMIN" )
with client:
list_databases_json = client.build_basic_request( api = "db", action = "listDatabases" )
response = client.post_json( list_databases_json )
print( f"Response: {response}" )
```
This connection is also considered secure enough to use over public networks when properly configured. Ensure the [FairCom server TLS settings](https://docs.faircom.com/docs/en/UUID-af006a2a-a08c-afa5-806a-f5f5979a1ae2.html) are adequate for modern threats (particularly the allowed cipher suites).
### Example insecure usage (credentials without TLS):
```Python
from json_action_client import JsonActionClient, JsonActionConnectionError, JsonActionApiError
client = JsonActionClient( "http://127.0.0.1:8080/api" )
client.login( "admin", "ADMIN" )
with client:
list_databases_json = client.build_basic_request( api = "db", action = "listDatabases" )
response = client.post_json( list_databases_json )
print( f"Response: {response}" )
```
An insecure connection should only be used on private networks where security is guaranteed via other means (e.g., an enterprise-grade firewall).
## Links
[Package info on PyPI](https://pypi.org/project/faircom-json-action-client/)
[Source code on GitHub](https://github.com/AdamJHowell/JsonActionClient)
## Notes
* This project is a work in progress and may change at any time.
* Breaking changes for versions at 1.0 or higher will always result in a new major version.
* I try to use type hints wherever possible. Please report undocumented `raises`.
| text/markdown | null | Adam Howell <698228+AdamJHowell@users.noreply.github.com> | null | null | null | null | [
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"requests"
] | [] | [] | [] | [
"Homepage, https://github.com/AdamJHowell/JsonActionClient"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:05:19.482278 | faircom_json_action_client-0.0.3.tar.gz | 6,479 | bd/92/387af77919df45fa86e593ae2c721f2f355eac4cd7c1741d60313240f911/faircom_json_action_client-0.0.3.tar.gz | source | sdist | null | false | 5a50c09be8443316c2b96df3bdf0a1cd | f3a94d4a3b5f775ef7e39a05647c068f1f8f99d287a9ebdddfddcf4bd25eb453 | bd92387af77919df45fa86e593ae2c721f2f355eac4cd7c1741d60313240f911 | null | [
"LICENSE"
] | 245 |
2.2 | cukks-cu121 | 0.1.2 | CKKS Homomorphic Encryption backend with CUDA 12.1 GPU acceleration | <p align="center">
<a href="README.md">English</a> |
<a href="README.ko.md">한국어</a>
</p>
<h1 align="center">CuKKS</h1>
<p align="center">
<strong>GPU-accelerated CKKS Homomorphic Encryption for PyTorch</strong>
</p>
<p align="center">
<a href="https://github.com/devUuung/CuKKS/actions"><img src="https://github.com/devUuung/CuKKS/actions/workflows/build-wheels.yml/badge.svg" alt="Build Status"></a>
<a href="https://github.com/devUuung/CuKKS/blob/main/LICENSE"><img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg" alt="License"></a>
<a href="https://www.python.org/downloads/"><img src="https://img.shields.io/badge/python-3.10--3.13-blue.svg" alt="Python 3.10-3.13"></a>
</p>
<p align="center">
Run trained PyTorch models on <strong>encrypted data</strong> — preserving privacy while maintaining accuracy.<br>
Built on OpenFHE with CUDA acceleration.
</p>
---
## Quick Start
```python
import torch.nn as nn
import cukks
# 1. Define and train your model (standard PyTorch)
model = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
# 2. Convert to encrypted model (polynomial ReLU approximation)
enc_model, ctx = cukks.convert(model)
# 3. Run encrypted inference
enc_input = ctx.encrypt(test_input)
enc_output = enc_model(enc_input)
output = ctx.decrypt(enc_output)
```
## Installation
### Automatic (Recommended)
```bash
pip install cukks # Auto-detects PyTorch's CUDA and installs matching backend
```
`pip install cukks` detects the CUDA version your PyTorch was built with and automatically installs the matching `cukks-cuXXX` GPU backend. No manual version matching needed.
### Manual
```bash
pip install cukks-cu121 # Explicitly install for CUDA 12.1
```
| Package | CUDA | Supported GPUs |
|---------|------|----------------|
| `cukks-cu118` | 11.8 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu121` | 12.1 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu124` | 12.4 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu128` | 12.8 | All above + **RTX 50xx** |
Or use extras: `pip install cukks[cu121]`
<details>
<summary><strong>Post-install CLI & environment variables</strong></summary>
```bash
cukks-install-backend # Auto-detect & install
cukks-install-backend cu128 # Install specific backend
cukks-install-backend --status # Show CUDA compatibility status
```
| Variable | Effect |
|----------|--------|
| `CUKKS_BACKEND=cukks-cu128` | Force a specific backend |
| `CUKKS_NO_BACKEND=1` | Skip backend (CPU-only) |
</details>
<details>
<summary><strong>Docker images</strong></summary>
| CUDA | Compatible Docker Images |
|------|-------------------------|
| 11.8 | `pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime` |
| 12.1 | `pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime` |
| 12.4 | `pytorch/pytorch:2.4.0-cuda12.4-cudnn9-runtime` |
| 12.8 | `nvidia/cuda:12.8.0-cudnn9-runtime-ubuntu22.04` |
```bash
docker run --gpus all -it pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime bash
pip install cukks # auto-detects CUDA 12.1
```
</details>
<details>
<summary><strong>Build from source</strong></summary>
```bash
git clone https://github.com/devUuung/CuKKS.git && cd CuKKS
pip install -e .
# Build OpenFHE backend
cd openfhe-gpu-public && mkdir build && cd build
cmake .. -DWITH_CUDA=ON && make -j$(nproc)
cd ../../bindings/openfhe_backend
pip install -e .
```
</details>
## Features
| Feature | Description |
|---------|-------------|
| **PyTorch API** | Familiar interface — just call `cukks.convert(model)` |
| **GPU Acceleration** | CUDA-accelerated HE operations via OpenFHE |
| **Auto Optimization** | BatchNorm folding, BSGS matrix multiplication |
| **Wide Layer Support** | Linear, Conv2d, ReLU/GELU/SiLU, Pool, LayerNorm, Attention |
## Supported Layers
| Layer | Encrypted Version | Notes |
|-------|------------------|-------|
| `nn.Linear` | `EncryptedLinear` | BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | im2col method |
| `nn.ReLU/GELU/SiLU` | Polynomial approx | Configurable degree |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Rotation-based |
| `nn.BatchNorm` | Folded | Merged into prev layer |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Polynomial approx |
| `nn.Attention` | `EncryptedApproxAttention` | seq_len=1 |
<details>
<summary><strong>Full layer support table</strong></summary>
| PyTorch Layer | Encrypted Version | Notes |
|--------------|-------------------|-------|
| `nn.Linear` | `EncryptedLinear` | Full support with BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | Via im2col method |
| `nn.ReLU` | `EncryptedReLU` | Polynomial approximation |
| `nn.GELU` | `EncryptedGELU` | Polynomial approximation |
| `nn.SiLU` | `EncryptedSiLU` | Polynomial approximation |
| `nn.Sigmoid` | `EncryptedSigmoid` | Polynomial approximation |
| `nn.Tanh` | `EncryptedTanh` | Polynomial approximation |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Full support |
| `nn.MaxPool2d` | `EncryptedMaxPool2d` | Approximate via polynomial |
| `nn.Flatten` | `EncryptedFlatten` | Logical reshape |
| `nn.BatchNorm1d/2d` | Folded | Merged into preceding layer |
| `nn.Sequential` | `EncryptedSequential` | Full support |
| `nn.Dropout` | `EncryptedDropout` | No-op during inference |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Pure HE polynomial approximation |
| `nn.MultiheadAttention` | `EncryptedApproxAttention` | Polynomial softmax (seq_len=1) |
</details>
## Activation Functions
CKKS only supports polynomial operations. CuKKS approximates activations (ReLU, GELU, SiLU, etc.) using polynomial fitting:
```python
# Default: degree-4 polynomial approximation (recommended)
enc_model, ctx = cukks.convert(model)
# Higher degree for better accuracy (costs more multiplicative depth)
enc_model, ctx = cukks.convert(model, activation_degree=8)
```
The default `activation_degree=4` provides a good balance between accuracy and depth consumption. Higher degrees approximate the original activation more closely but require deeper circuits.
## GPU Acceleration
| Operation | Accelerated |
|-----------|-------------|
| Add/Sub/Mul/Square | ✅ GPU |
| Rotate/Rescale | ✅ GPU |
| Bootstrap | ✅ GPU |
| Encrypt/Decrypt | CPU |
```python
from ckks.torch_api import CKKSContext, CKKSConfig
config = CKKSConfig(poly_mod_degree=8192, scale_bits=40)
ctx = CKKSContext(config, enable_gpu=True) # GPU enabled by default
```
## Examples
```bash
# Quick demo (no GPU required)
python -m cukks.examples.encrypted_inference --demo conversion
# MNIST encrypted inference
python examples/mnist_encrypted.py --hidden 64 --samples 5
```
<details>
<summary><strong>CNN example</strong></summary>
```python
import torch.nn as nn
import cukks
class MNISTCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.pool1 = nn.AvgPool2d(2)
self.flatten = nn.Flatten()
self.fc = nn.Linear(8 * 14 * 14, 10)
def forward(self, x):
return self.fc(self.flatten(self.pool1(self.act1(self.conv1(x)))))
model = MNISTCNN()
enc_model, ctx = cukks.convert(model)
enc_input = ctx.encrypt(image)
prediction = ctx.decrypt(enc_model(enc_input)).argmax()
```
> **Note**: All operations in `forward()` must be layer attributes (e.g., `self.act1`), not inline operations like `x ** 2`.
</details>
<details>
<summary><strong>Batch processing</strong></summary>
```python
# Pack multiple samples into a single ciphertext (SIMD)
samples = [torch.randn(784) for _ in range(8)]
enc_batch = ctx.encrypt_batch(samples)
enc_output = enc_model(enc_batch)
outputs = ctx.decrypt_batch(enc_output, num_samples=8)
```
</details>
## Troubleshooting
| Issue | Solution |
|-------|----------|
| Out of Memory | Reduce `poly_mod_degree` (8192 instead of 16384) |
| Low Accuracy | Increase `activation_degree` (e.g., 8 or 16) for better approximation |
| Slow Performance | Enable batch processing, reduce network depth |
## Documentation
- [API Reference](docs/api.md)
- [GPU Acceleration Guide](docs/gpu-acceleration.md)
- [CKKS Concepts](docs/concepts.md)
## License
Apache License 2.0
## Citation
```bibtex
@software{cukks,
title = {CuKKS: PyTorch-compatible Encrypted Deep Learning},
year = {2024},
url = {https://github.com/devUuung/CuKKS}
}
```
## Related
### Libraries
- [OpenFHE](https://github.com/openfheorg/openfhe-development) — Underlying HE library
- [Microsoft SEAL](https://github.com/microsoft/SEAL) — Alternative HE library
### Papers
- [Homomorphic Encryption for Arithmetic of Approximate Numbers](https://eprint.iacr.org/2016/421) — Cheon et al. (CKKS)
- [Bootstrapping for Approximate Homomorphic Encryption](https://eprint.iacr.org/2018/153) — Cheon et al.
- [Faster Homomorphic Linear Transformations in HElib](https://eprint.iacr.org/2018/244) — Halevi & Shoup (BSGS)
| text/markdown | CuKKS Authors | null | null | null | Apache-2.0 | homomorphic-encryption, CKKS, OpenFHE, GPU, CUDA, privacy, cryptography | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: C++",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.23",
"torch>=2.1"
] | [] | [] | [] | [
"Homepage, https://github.com/devUuung/CuKKS",
"Repository, https://github.com/devUuung/CuKKS",
"Issues, https://github.com/devUuung/CuKKS/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:03:56.184379 | cukks_cu121-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | 6,225,484 | 7d/ea/3036c54fff1e5e0f7f8f9aac10392ee9a9c94fe4581d2896c4c05ed0e768/cukks_cu121-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | cp313 | bdist_wheel | null | false | 88ca1e6050d8eb21d9a2c97ecb518bcd | 614cb4f34cb4e403c40e0af949e739557969a71bfb440a7f4106ad947c945e67 | 7dea3036c54fff1e5e0f7f8f9aac10392ee9a9c94fe4581d2896c4c05ed0e768 | null | [] | 334 |
2.2 | cukks-cu128 | 0.1.2 | CKKS Homomorphic Encryption backend with CUDA 12.8 GPU acceleration | <p align="center">
<a href="README.md">English</a> |
<a href="README.ko.md">한국어</a>
</p>
<h1 align="center">CuKKS</h1>
<p align="center">
<strong>GPU-accelerated CKKS Homomorphic Encryption for PyTorch</strong>
</p>
<p align="center">
<a href="https://github.com/devUuung/CuKKS/actions"><img src="https://github.com/devUuung/CuKKS/actions/workflows/build-wheels.yml/badge.svg" alt="Build Status"></a>
<a href="https://github.com/devUuung/CuKKS/blob/main/LICENSE"><img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg" alt="License"></a>
<a href="https://www.python.org/downloads/"><img src="https://img.shields.io/badge/python-3.10--3.13-blue.svg" alt="Python 3.10-3.13"></a>
</p>
<p align="center">
Run trained PyTorch models on <strong>encrypted data</strong> — preserving privacy while maintaining accuracy.<br>
Built on OpenFHE with CUDA acceleration.
</p>
---
## Quick Start
```python
import torch.nn as nn
import cukks
# 1. Define and train your model (standard PyTorch)
model = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
# 2. Convert to encrypted model (polynomial ReLU approximation)
enc_model, ctx = cukks.convert(model)
# 3. Run encrypted inference
enc_input = ctx.encrypt(test_input)
enc_output = enc_model(enc_input)
output = ctx.decrypt(enc_output)
```
## Installation
### Automatic (Recommended)
```bash
pip install cukks # Auto-detects PyTorch's CUDA and installs matching backend
```
`pip install cukks` detects the CUDA version your PyTorch was built with and automatically installs the matching `cukks-cuXXX` GPU backend. No manual version matching needed.
### Manual
```bash
pip install cukks-cu121 # Explicitly install for CUDA 12.1
```
| Package | CUDA | Supported GPUs |
|---------|------|----------------|
| `cukks-cu118` | 11.8 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu121` | 12.1 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu124` | 12.4 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu128` | 12.8 | All above + **RTX 50xx** |
Or use extras: `pip install cukks[cu121]`
<details>
<summary><strong>Post-install CLI & environment variables</strong></summary>
```bash
cukks-install-backend # Auto-detect & install
cukks-install-backend cu128 # Install specific backend
cukks-install-backend --status # Show CUDA compatibility status
```
| Variable | Effect |
|----------|--------|
| `CUKKS_BACKEND=cukks-cu128` | Force a specific backend |
| `CUKKS_NO_BACKEND=1` | Skip backend (CPU-only) |
</details>
<details>
<summary><strong>Docker images</strong></summary>
| CUDA | Compatible Docker Images |
|------|-------------------------|
| 11.8 | `pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime` |
| 12.1 | `pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime` |
| 12.4 | `pytorch/pytorch:2.4.0-cuda12.4-cudnn9-runtime` |
| 12.8 | `nvidia/cuda:12.8.0-cudnn9-runtime-ubuntu22.04` |
```bash
docker run --gpus all -it pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime bash
pip install cukks # auto-detects CUDA 12.1
```
</details>
<details>
<summary><strong>Build from source</strong></summary>
```bash
git clone https://github.com/devUuung/CuKKS.git && cd CuKKS
pip install -e .
# Build OpenFHE backend
cd openfhe-gpu-public && mkdir build && cd build
cmake .. -DWITH_CUDA=ON && make -j$(nproc)
cd ../../bindings/openfhe_backend
pip install -e .
```
</details>
## Features
| Feature | Description |
|---------|-------------|
| **PyTorch API** | Familiar interface — just call `cukks.convert(model)` |
| **GPU Acceleration** | CUDA-accelerated HE operations via OpenFHE |
| **Auto Optimization** | BatchNorm folding, BSGS matrix multiplication |
| **Wide Layer Support** | Linear, Conv2d, ReLU/GELU/SiLU, Pool, LayerNorm, Attention |
## Supported Layers
| Layer | Encrypted Version | Notes |
|-------|------------------|-------|
| `nn.Linear` | `EncryptedLinear` | BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | im2col method |
| `nn.ReLU/GELU/SiLU` | Polynomial approx | Configurable degree |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Rotation-based |
| `nn.BatchNorm` | Folded | Merged into prev layer |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Polynomial approx |
| `nn.Attention` | `EncryptedApproxAttention` | seq_len=1 |
<details>
<summary><strong>Full layer support table</strong></summary>
| PyTorch Layer | Encrypted Version | Notes |
|--------------|-------------------|-------|
| `nn.Linear` | `EncryptedLinear` | Full support with BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | Via im2col method |
| `nn.ReLU` | `EncryptedReLU` | Polynomial approximation |
| `nn.GELU` | `EncryptedGELU` | Polynomial approximation |
| `nn.SiLU` | `EncryptedSiLU` | Polynomial approximation |
| `nn.Sigmoid` | `EncryptedSigmoid` | Polynomial approximation |
| `nn.Tanh` | `EncryptedTanh` | Polynomial approximation |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Full support |
| `nn.MaxPool2d` | `EncryptedMaxPool2d` | Approximate via polynomial |
| `nn.Flatten` | `EncryptedFlatten` | Logical reshape |
| `nn.BatchNorm1d/2d` | Folded | Merged into preceding layer |
| `nn.Sequential` | `EncryptedSequential` | Full support |
| `nn.Dropout` | `EncryptedDropout` | No-op during inference |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Pure HE polynomial approximation |
| `nn.MultiheadAttention` | `EncryptedApproxAttention` | Polynomial softmax (seq_len=1) |
</details>
## Activation Functions
CKKS only supports polynomial operations. CuKKS approximates activations (ReLU, GELU, SiLU, etc.) using polynomial fitting:
```python
# Default: degree-4 polynomial approximation (recommended)
enc_model, ctx = cukks.convert(model)
# Higher degree for better accuracy (costs more multiplicative depth)
enc_model, ctx = cukks.convert(model, activation_degree=8)
```
The default `activation_degree=4` provides a good balance between accuracy and depth consumption. Higher degrees approximate the original activation more closely but require deeper circuits.
## GPU Acceleration
| Operation | Accelerated |
|-----------|-------------|
| Add/Sub/Mul/Square | ✅ GPU |
| Rotate/Rescale | ✅ GPU |
| Bootstrap | ✅ GPU |
| Encrypt/Decrypt | CPU |
```python
from ckks.torch_api import CKKSContext, CKKSConfig
config = CKKSConfig(poly_mod_degree=8192, scale_bits=40)
ctx = CKKSContext(config, enable_gpu=True) # GPU enabled by default
```
## Examples
```bash
# Quick demo (no GPU required)
python -m cukks.examples.encrypted_inference --demo conversion
# MNIST encrypted inference
python examples/mnist_encrypted.py --hidden 64 --samples 5
```
<details>
<summary><strong>CNN example</strong></summary>
```python
import torch.nn as nn
import cukks
class MNISTCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.pool1 = nn.AvgPool2d(2)
self.flatten = nn.Flatten()
self.fc = nn.Linear(8 * 14 * 14, 10)
def forward(self, x):
return self.fc(self.flatten(self.pool1(self.act1(self.conv1(x)))))
model = MNISTCNN()
enc_model, ctx = cukks.convert(model)
enc_input = ctx.encrypt(image)
prediction = ctx.decrypt(enc_model(enc_input)).argmax()
```
> **Note**: All operations in `forward()` must be layer attributes (e.g., `self.act1`), not inline operations like `x ** 2`.
</details>
<details>
<summary><strong>Batch processing</strong></summary>
```python
# Pack multiple samples into a single ciphertext (SIMD)
samples = [torch.randn(784) for _ in range(8)]
enc_batch = ctx.encrypt_batch(samples)
enc_output = enc_model(enc_batch)
outputs = ctx.decrypt_batch(enc_output, num_samples=8)
```
</details>
## Troubleshooting
| Issue | Solution |
|-------|----------|
| Out of Memory | Reduce `poly_mod_degree` (8192 instead of 16384) |
| Low Accuracy | Increase `activation_degree` (e.g., 8 or 16) for better approximation |
| Slow Performance | Enable batch processing, reduce network depth |
## Documentation
- [API Reference](docs/api.md)
- [GPU Acceleration Guide](docs/gpu-acceleration.md)
- [CKKS Concepts](docs/concepts.md)
## License
Apache License 2.0
## Citation
```bibtex
@software{cukks,
title = {CuKKS: PyTorch-compatible Encrypted Deep Learning},
year = {2024},
url = {https://github.com/devUuung/CuKKS}
}
```
## Related
### Libraries
- [OpenFHE](https://github.com/openfheorg/openfhe-development) — Underlying HE library
- [Microsoft SEAL](https://github.com/microsoft/SEAL) — Alternative HE library
### Papers
- [Homomorphic Encryption for Arithmetic of Approximate Numbers](https://eprint.iacr.org/2016/421) — Cheon et al. (CKKS)
- [Bootstrapping for Approximate Homomorphic Encryption](https://eprint.iacr.org/2018/153) — Cheon et al.
- [Faster Homomorphic Linear Transformations in HElib](https://eprint.iacr.org/2018/244) — Halevi & Shoup (BSGS)
| text/markdown | CuKKS Authors | null | null | null | Apache-2.0 | homomorphic-encryption, CKKS, OpenFHE, GPU, CUDA, privacy, cryptography | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: C++",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.23",
"torch>=2.1"
] | [] | [] | [] | [
"Homepage, https://github.com/devUuung/CuKKS",
"Repository, https://github.com/devUuung/CuKKS",
"Issues, https://github.com/devUuung/CuKKS/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:03:54.768016 | cukks_cu128-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | 6,872,110 | 5d/61/a350dda68e76d8781ea797b88f83070e68a22183016ab199ea084d1d0e6b/cukks_cu128-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | cp313 | bdist_wheel | null | false | b420d845f15dc1f2fe4abda4224f937c | 8c3dfabd227058c23bd2876159fa8713c40f0f8f24b9ad03caad43f63be4aacd | 5d61a350dda68e76d8781ea797b88f83070e68a22183016ab199ea084d1d0e6b | null | [] | 326 |
2.4 | WuttaFarm | 0.5.0 | Web app to integrate with and extend farmOS |
# WuttaFarm
This is a Python web app (built with
[WuttaWeb](https://wuttaproject.org)), to integrate with and extend
[farmOS](https://farmos.org).
It is just an experiment so far; the ideas I hope to play with
include:
- display farmOS data directly, via real-time API fetch
- add "mirror" schema and sync data from farmOS to app DB (and display it)
- possibly add more schema / extra features
- possibly sync data back to farmOS
See full docs at https://docs.wuttaproject.org/wuttafarm/
| text/markdown | null | Lance Edgar <lance@wuttaproject.org> | null | Lance Edgar <lance@wuttaproject.org> | GNU General Public License v3 | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming... | [] | null | null | null | [] | [] | [] | [
"farmos",
"psycopg2",
"pyramid-exclog",
"uvicorn[standard]",
"wuttasync",
"wuttaweb[continuum]>=0.28.1",
"furo; extra == \"docs\"",
"sphinx; extra == \"docs\"",
"sphinxcontrib-programoutput; extra == \"docs\""
] | [] | [] | [] | [
"Homepage, https://forgejo.wuttaproject.org/wutta/wuttafarm",
"Repository, https://forgejo.wuttaproject.org/wutta/wuttafarm",
"Issues, https://forgejo.wuttaproject.org/wutta/wuttafarm/issues",
"Changelog, https://forgejo.wuttaproject.org/wutta/wuttafarm/src/branch/master/CHANGELOG.md"
] | twine/6.2.0 CPython/3.13.5 | 2026-02-19T01:03:54.757250 | wuttafarm-0.5.0.tar.gz | 141,908 | 79/36/d734a2f3554cfa49ef625a4561dc05143485c5dfe0f250eaf50dc049aa9b/wuttafarm-0.5.0.tar.gz | source | sdist | null | false | 128e9c8a02a4be5cb9832b71a4fce1ec | 319738659679854ea48e45d858a75617378b7ce6d135b6f84e9766feeeef8815 | 7936d734a2f3554cfa49ef625a4561dc05143485c5dfe0f250eaf50dc049aa9b | null | [
"COPYING.txt"
] | 0 |
2.2 | cukks-cu124 | 0.1.2 | CKKS Homomorphic Encryption backend with CUDA 12.4 GPU acceleration | <p align="center">
<a href="README.md">English</a> |
<a href="README.ko.md">한국어</a>
</p>
<h1 align="center">CuKKS</h1>
<p align="center">
<strong>GPU-accelerated CKKS Homomorphic Encryption for PyTorch</strong>
</p>
<p align="center">
<a href="https://github.com/devUuung/CuKKS/actions"><img src="https://github.com/devUuung/CuKKS/actions/workflows/build-wheels.yml/badge.svg" alt="Build Status"></a>
<a href="https://github.com/devUuung/CuKKS/blob/main/LICENSE"><img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg" alt="License"></a>
<a href="https://www.python.org/downloads/"><img src="https://img.shields.io/badge/python-3.10--3.13-blue.svg" alt="Python 3.10-3.13"></a>
</p>
<p align="center">
Run trained PyTorch models on <strong>encrypted data</strong> — preserving privacy while maintaining accuracy.<br>
Built on OpenFHE with CUDA acceleration.
</p>
---
## Quick Start
```python
import torch.nn as nn
import cukks
# 1. Define and train your model (standard PyTorch)
model = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
# 2. Convert to encrypted model (polynomial ReLU approximation)
enc_model, ctx = cukks.convert(model)
# 3. Run encrypted inference
enc_input = ctx.encrypt(test_input)
enc_output = enc_model(enc_input)
output = ctx.decrypt(enc_output)
```
## Installation
### Automatic (Recommended)
```bash
pip install cukks # Auto-detects PyTorch's CUDA and installs matching backend
```
`pip install cukks` detects the CUDA version your PyTorch was built with and automatically installs the matching `cukks-cuXXX` GPU backend. No manual version matching needed.
### Manual
```bash
pip install cukks-cu121 # Explicitly install for CUDA 12.1
```
| Package | CUDA | Supported GPUs |
|---------|------|----------------|
| `cukks-cu118` | 11.8 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu121` | 12.1 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu124` | 12.4 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu128` | 12.8 | All above + **RTX 50xx** |
Or use extras: `pip install cukks[cu121]`
<details>
<summary><strong>Post-install CLI & environment variables</strong></summary>
```bash
cukks-install-backend # Auto-detect & install
cukks-install-backend cu128 # Install specific backend
cukks-install-backend --status # Show CUDA compatibility status
```
| Variable | Effect |
|----------|--------|
| `CUKKS_BACKEND=cukks-cu128` | Force a specific backend |
| `CUKKS_NO_BACKEND=1` | Skip backend (CPU-only) |
</details>
<details>
<summary><strong>Docker images</strong></summary>
| CUDA | Compatible Docker Images |
|------|-------------------------|
| 11.8 | `pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime` |
| 12.1 | `pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime` |
| 12.4 | `pytorch/pytorch:2.4.0-cuda12.4-cudnn9-runtime` |
| 12.8 | `nvidia/cuda:12.8.0-cudnn9-runtime-ubuntu22.04` |
```bash
docker run --gpus all -it pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime bash
pip install cukks # auto-detects CUDA 12.1
```
</details>
<details>
<summary><strong>Build from source</strong></summary>
```bash
git clone https://github.com/devUuung/CuKKS.git && cd CuKKS
pip install -e .
# Build OpenFHE backend
cd openfhe-gpu-public && mkdir build && cd build
cmake .. -DWITH_CUDA=ON && make -j$(nproc)
cd ../../bindings/openfhe_backend
pip install -e .
```
</details>
## Features
| Feature | Description |
|---------|-------------|
| **PyTorch API** | Familiar interface — just call `cukks.convert(model)` |
| **GPU Acceleration** | CUDA-accelerated HE operations via OpenFHE |
| **Auto Optimization** | BatchNorm folding, BSGS matrix multiplication |
| **Wide Layer Support** | Linear, Conv2d, ReLU/GELU/SiLU, Pool, LayerNorm, Attention |
## Supported Layers
| Layer | Encrypted Version | Notes |
|-------|------------------|-------|
| `nn.Linear` | `EncryptedLinear` | BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | im2col method |
| `nn.ReLU/GELU/SiLU` | Polynomial approx | Configurable degree |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Rotation-based |
| `nn.BatchNorm` | Folded | Merged into prev layer |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Polynomial approx |
| `nn.Attention` | `EncryptedApproxAttention` | seq_len=1 |
<details>
<summary><strong>Full layer support table</strong></summary>
| PyTorch Layer | Encrypted Version | Notes |
|--------------|-------------------|-------|
| `nn.Linear` | `EncryptedLinear` | Full support with BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | Via im2col method |
| `nn.ReLU` | `EncryptedReLU` | Polynomial approximation |
| `nn.GELU` | `EncryptedGELU` | Polynomial approximation |
| `nn.SiLU` | `EncryptedSiLU` | Polynomial approximation |
| `nn.Sigmoid` | `EncryptedSigmoid` | Polynomial approximation |
| `nn.Tanh` | `EncryptedTanh` | Polynomial approximation |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Full support |
| `nn.MaxPool2d` | `EncryptedMaxPool2d` | Approximate via polynomial |
| `nn.Flatten` | `EncryptedFlatten` | Logical reshape |
| `nn.BatchNorm1d/2d` | Folded | Merged into preceding layer |
| `nn.Sequential` | `EncryptedSequential` | Full support |
| `nn.Dropout` | `EncryptedDropout` | No-op during inference |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Pure HE polynomial approximation |
| `nn.MultiheadAttention` | `EncryptedApproxAttention` | Polynomial softmax (seq_len=1) |
</details>
## Activation Functions
CKKS only supports polynomial operations. CuKKS approximates activations (ReLU, GELU, SiLU, etc.) using polynomial fitting:
```python
# Default: degree-4 polynomial approximation (recommended)
enc_model, ctx = cukks.convert(model)
# Higher degree for better accuracy (costs more multiplicative depth)
enc_model, ctx = cukks.convert(model, activation_degree=8)
```
The default `activation_degree=4` provides a good balance between accuracy and depth consumption. Higher degrees approximate the original activation more closely but require deeper circuits.
## GPU Acceleration
| Operation | Accelerated |
|-----------|-------------|
| Add/Sub/Mul/Square | ✅ GPU |
| Rotate/Rescale | ✅ GPU |
| Bootstrap | ✅ GPU |
| Encrypt/Decrypt | CPU |
```python
from ckks.torch_api import CKKSContext, CKKSConfig
config = CKKSConfig(poly_mod_degree=8192, scale_bits=40)
ctx = CKKSContext(config, enable_gpu=True) # GPU enabled by default
```
## Examples
```bash
# Quick demo (no GPU required)
python -m cukks.examples.encrypted_inference --demo conversion
# MNIST encrypted inference
python examples/mnist_encrypted.py --hidden 64 --samples 5
```
<details>
<summary><strong>CNN example</strong></summary>
```python
import torch.nn as nn
import cukks
class MNISTCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.pool1 = nn.AvgPool2d(2)
self.flatten = nn.Flatten()
self.fc = nn.Linear(8 * 14 * 14, 10)
def forward(self, x):
return self.fc(self.flatten(self.pool1(self.act1(self.conv1(x)))))
model = MNISTCNN()
enc_model, ctx = cukks.convert(model)
enc_input = ctx.encrypt(image)
prediction = ctx.decrypt(enc_model(enc_input)).argmax()
```
> **Note**: All operations in `forward()` must be layer attributes (e.g., `self.act1`), not inline operations like `x ** 2`.
</details>
<details>
<summary><strong>Batch processing</strong></summary>
```python
# Pack multiple samples into a single ciphertext (SIMD)
samples = [torch.randn(784) for _ in range(8)]
enc_batch = ctx.encrypt_batch(samples)
enc_output = enc_model(enc_batch)
outputs = ctx.decrypt_batch(enc_output, num_samples=8)
```
</details>
## Troubleshooting
| Issue | Solution |
|-------|----------|
| Out of Memory | Reduce `poly_mod_degree` (8192 instead of 16384) |
| Low Accuracy | Increase `activation_degree` (e.g., 8 or 16) for better approximation |
| Slow Performance | Enable batch processing, reduce network depth |
## Documentation
- [API Reference](docs/api.md)
- [GPU Acceleration Guide](docs/gpu-acceleration.md)
- [CKKS Concepts](docs/concepts.md)
## License
Apache License 2.0
## Citation
```bibtex
@software{cukks,
title = {CuKKS: PyTorch-compatible Encrypted Deep Learning},
year = {2024},
url = {https://github.com/devUuung/CuKKS}
}
```
## Related
### Libraries
- [OpenFHE](https://github.com/openfheorg/openfhe-development) — Underlying HE library
- [Microsoft SEAL](https://github.com/microsoft/SEAL) — Alternative HE library
### Papers
- [Homomorphic Encryption for Arithmetic of Approximate Numbers](https://eprint.iacr.org/2016/421) — Cheon et al. (CKKS)
- [Bootstrapping for Approximate Homomorphic Encryption](https://eprint.iacr.org/2018/153) — Cheon et al.
- [Faster Homomorphic Linear Transformations in HElib](https://eprint.iacr.org/2018/244) — Halevi & Shoup (BSGS)
| text/markdown | CuKKS Authors | null | null | null | Apache-2.0 | homomorphic-encryption, CKKS, OpenFHE, GPU, CUDA, privacy, cryptography | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: C++",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.23",
"torch>=2.1"
] | [] | [] | [] | [
"Homepage, https://github.com/devUuung/CuKKS",
"Repository, https://github.com/devUuung/CuKKS",
"Issues, https://github.com/devUuung/CuKKS/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:03:52.922362 | cukks_cu124-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | 6,192,457 | f9/f8/5491bdcfee10ba66454fffa5a87dc0badf898bef16eb9a12a6e2675c6a8d/cukks_cu124-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | cp313 | bdist_wheel | null | false | 69aa3359dc4dbf0cb6d4d0509865e7b4 | e1e6a86c356864f22066476351de9dc442bac76992f157d8857c3e8fa8adab1c | f9f85491bdcfee10ba66454fffa5a87dc0badf898bef16eb9a12a6e2675c6a8d | null | [] | 342 |
2.2 | cukks-cu118 | 0.1.2 | CKKS Homomorphic Encryption backend with CUDA 11.8 GPU acceleration | <p align="center">
<a href="README.md">English</a> |
<a href="README.ko.md">한국어</a>
</p>
<h1 align="center">CuKKS</h1>
<p align="center">
<strong>GPU-accelerated CKKS Homomorphic Encryption for PyTorch</strong>
</p>
<p align="center">
<a href="https://github.com/devUuung/CuKKS/actions"><img src="https://github.com/devUuung/CuKKS/actions/workflows/build-wheels.yml/badge.svg" alt="Build Status"></a>
<a href="https://github.com/devUuung/CuKKS/blob/main/LICENSE"><img src="https://img.shields.io/badge/License-Apache%202.0-blue.svg" alt="License"></a>
<a href="https://www.python.org/downloads/"><img src="https://img.shields.io/badge/python-3.10--3.13-blue.svg" alt="Python 3.10-3.13"></a>
</p>
<p align="center">
Run trained PyTorch models on <strong>encrypted data</strong> — preserving privacy while maintaining accuracy.<br>
Built on OpenFHE with CUDA acceleration.
</p>
---
## Quick Start
```python
import torch.nn as nn
import cukks
# 1. Define and train your model (standard PyTorch)
model = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
# 2. Convert to encrypted model (polynomial ReLU approximation)
enc_model, ctx = cukks.convert(model)
# 3. Run encrypted inference
enc_input = ctx.encrypt(test_input)
enc_output = enc_model(enc_input)
output = ctx.decrypt(enc_output)
```
## Installation
### Automatic (Recommended)
```bash
pip install cukks # Auto-detects PyTorch's CUDA and installs matching backend
```
`pip install cukks` detects the CUDA version your PyTorch was built with and automatically installs the matching `cukks-cuXXX` GPU backend. No manual version matching needed.
### Manual
```bash
pip install cukks-cu121 # Explicitly install for CUDA 12.1
```
| Package | CUDA | Supported GPUs |
|---------|------|----------------|
| `cukks-cu118` | 11.8 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu121` | 12.1 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu124` | 12.4 | V100, T4, RTX 20/30/40xx, A100, H100 |
| `cukks-cu128` | 12.8 | All above + **RTX 50xx** |
Or use extras: `pip install cukks[cu121]`
<details>
<summary><strong>Post-install CLI & environment variables</strong></summary>
```bash
cukks-install-backend # Auto-detect & install
cukks-install-backend cu128 # Install specific backend
cukks-install-backend --status # Show CUDA compatibility status
```
| Variable | Effect |
|----------|--------|
| `CUKKS_BACKEND=cukks-cu128` | Force a specific backend |
| `CUKKS_NO_BACKEND=1` | Skip backend (CPU-only) |
</details>
<details>
<summary><strong>Docker images</strong></summary>
| CUDA | Compatible Docker Images |
|------|-------------------------|
| 11.8 | `pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime` |
| 12.1 | `pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime` |
| 12.4 | `pytorch/pytorch:2.4.0-cuda12.4-cudnn9-runtime` |
| 12.8 | `nvidia/cuda:12.8.0-cudnn9-runtime-ubuntu22.04` |
```bash
docker run --gpus all -it pytorch/pytorch:2.2.0-cuda12.1-cudnn8-runtime bash
pip install cukks # auto-detects CUDA 12.1
```
</details>
<details>
<summary><strong>Build from source</strong></summary>
```bash
git clone https://github.com/devUuung/CuKKS.git && cd CuKKS
pip install -e .
# Build OpenFHE backend
cd openfhe-gpu-public && mkdir build && cd build
cmake .. -DWITH_CUDA=ON && make -j$(nproc)
cd ../../bindings/openfhe_backend
pip install -e .
```
</details>
## Features
| Feature | Description |
|---------|-------------|
| **PyTorch API** | Familiar interface — just call `cukks.convert(model)` |
| **GPU Acceleration** | CUDA-accelerated HE operations via OpenFHE |
| **Auto Optimization** | BatchNorm folding, BSGS matrix multiplication |
| **Wide Layer Support** | Linear, Conv2d, ReLU/GELU/SiLU, Pool, LayerNorm, Attention |
## Supported Layers
| Layer | Encrypted Version | Notes |
|-------|------------------|-------|
| `nn.Linear` | `EncryptedLinear` | BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | im2col method |
| `nn.ReLU/GELU/SiLU` | Polynomial approx | Configurable degree |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Rotation-based |
| `nn.BatchNorm` | Folded | Merged into prev layer |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Polynomial approx |
| `nn.Attention` | `EncryptedApproxAttention` | seq_len=1 |
<details>
<summary><strong>Full layer support table</strong></summary>
| PyTorch Layer | Encrypted Version | Notes |
|--------------|-------------------|-------|
| `nn.Linear` | `EncryptedLinear` | Full support with BSGS optimization |
| `nn.Conv2d` | `EncryptedConv2d` | Via im2col method |
| `nn.ReLU` | `EncryptedReLU` | Polynomial approximation |
| `nn.GELU` | `EncryptedGELU` | Polynomial approximation |
| `nn.SiLU` | `EncryptedSiLU` | Polynomial approximation |
| `nn.Sigmoid` | `EncryptedSigmoid` | Polynomial approximation |
| `nn.Tanh` | `EncryptedTanh` | Polynomial approximation |
| `nn.AvgPool2d` | `EncryptedAvgPool2d` | Full support |
| `nn.MaxPool2d` | `EncryptedMaxPool2d` | Approximate via polynomial |
| `nn.Flatten` | `EncryptedFlatten` | Logical reshape |
| `nn.BatchNorm1d/2d` | Folded | Merged into preceding layer |
| `nn.Sequential` | `EncryptedSequential` | Full support |
| `nn.Dropout` | `EncryptedDropout` | No-op during inference |
| `nn.LayerNorm` | `EncryptedLayerNorm` | Pure HE polynomial approximation |
| `nn.MultiheadAttention` | `EncryptedApproxAttention` | Polynomial softmax (seq_len=1) |
</details>
## Activation Functions
CKKS only supports polynomial operations. CuKKS approximates activations (ReLU, GELU, SiLU, etc.) using polynomial fitting:
```python
# Default: degree-4 polynomial approximation (recommended)
enc_model, ctx = cukks.convert(model)
# Higher degree for better accuracy (costs more multiplicative depth)
enc_model, ctx = cukks.convert(model, activation_degree=8)
```
The default `activation_degree=4` provides a good balance between accuracy and depth consumption. Higher degrees approximate the original activation more closely but require deeper circuits.
## GPU Acceleration
| Operation | Accelerated |
|-----------|-------------|
| Add/Sub/Mul/Square | ✅ GPU |
| Rotate/Rescale | ✅ GPU |
| Bootstrap | ✅ GPU |
| Encrypt/Decrypt | CPU |
```python
from ckks.torch_api import CKKSContext, CKKSConfig
config = CKKSConfig(poly_mod_degree=8192, scale_bits=40)
ctx = CKKSContext(config, enable_gpu=True) # GPU enabled by default
```
## Examples
```bash
# Quick demo (no GPU required)
python -m cukks.examples.encrypted_inference --demo conversion
# MNIST encrypted inference
python examples/mnist_encrypted.py --hidden 64 --samples 5
```
<details>
<summary><strong>CNN example</strong></summary>
```python
import torch.nn as nn
import cukks
class MNISTCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.pool1 = nn.AvgPool2d(2)
self.flatten = nn.Flatten()
self.fc = nn.Linear(8 * 14 * 14, 10)
def forward(self, x):
return self.fc(self.flatten(self.pool1(self.act1(self.conv1(x)))))
model = MNISTCNN()
enc_model, ctx = cukks.convert(model)
enc_input = ctx.encrypt(image)
prediction = ctx.decrypt(enc_model(enc_input)).argmax()
```
> **Note**: All operations in `forward()` must be layer attributes (e.g., `self.act1`), not inline operations like `x ** 2`.
</details>
<details>
<summary><strong>Batch processing</strong></summary>
```python
# Pack multiple samples into a single ciphertext (SIMD)
samples = [torch.randn(784) for _ in range(8)]
enc_batch = ctx.encrypt_batch(samples)
enc_output = enc_model(enc_batch)
outputs = ctx.decrypt_batch(enc_output, num_samples=8)
```
</details>
## Troubleshooting
| Issue | Solution |
|-------|----------|
| Out of Memory | Reduce `poly_mod_degree` (8192 instead of 16384) |
| Low Accuracy | Increase `activation_degree` (e.g., 8 or 16) for better approximation |
| Slow Performance | Enable batch processing, reduce network depth |
## Documentation
- [API Reference](docs/api.md)
- [GPU Acceleration Guide](docs/gpu-acceleration.md)
- [CKKS Concepts](docs/concepts.md)
## License
Apache License 2.0
## Citation
```bibtex
@software{cukks,
title = {CuKKS: PyTorch-compatible Encrypted Deep Learning},
year = {2024},
url = {https://github.com/devUuung/CuKKS}
}
```
## Related
### Libraries
- [OpenFHE](https://github.com/openfheorg/openfhe-development) — Underlying HE library
- [Microsoft SEAL](https://github.com/microsoft/SEAL) — Alternative HE library
### Papers
- [Homomorphic Encryption for Arithmetic of Approximate Numbers](https://eprint.iacr.org/2016/421) — Cheon et al. (CKKS)
- [Bootstrapping for Approximate Homomorphic Encryption](https://eprint.iacr.org/2018/153) — Cheon et al.
- [Faster Homomorphic Linear Transformations in HElib](https://eprint.iacr.org/2018/244) — Halevi & Shoup (BSGS)
| text/markdown | CuKKS Authors | null | null | null | Apache-2.0 | homomorphic-encryption, CKKS, OpenFHE, GPU, CUDA, privacy, cryptography | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: POSIX :: Linux",
"Programming Language :: C++",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.23",
"torch>=2.1"
] | [] | [] | [] | [
"Homepage, https://github.com/devUuung/CuKKS",
"Repository, https://github.com/devUuung/CuKKS",
"Issues, https://github.com/devUuung/CuKKS/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T01:03:48.878664 | cukks_cu118-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | 6,145,875 | f1/bb/4c704098908f79980975ab1606b0fcbdad6fd0cea8e7d0968f88e0b6e720/cukks_cu118-0.1.2-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl | cp313 | bdist_wheel | null | false | 83def1d659d3a4b2581ca88122868a71 | cf296f76b21993ca7c96115de1f3ad3638e9a60325a2597e5c82e4640ae6b7a6 | f1bb4c704098908f79980975ab1606b0fcbdad6fd0cea8e7d0968f88e0b6e720 | null | [] | 337 |
2.4 | msd-sdk | 0.1.7 | Python SDK for Meta Structured Data | # MSD SDK
Python SDK for Meta Structured Data.
📖 **[Read the full SDK overview](docs/overview.md)** for architecture, design decisions, and detailed documentation.
🔑 **[Key Management Guide](docs/key-management.md)** for generating keys, trust hierarchies, and security best practices.
## Installation
```bash
pip install msd-sdk
```
> **Note**: This SDK requires `zef-core` which is not yet publicly available. The import will fail until zef-core is installed.
## Development: Building from Source
When developing locally, you must build and install from the local wheel to avoid pip installing the (older) PyPI version.
```bash
# 1. Build the wheel
uv build
# 2. Install from local dist (not from PyPI!)
# Use --no-index to prevent PyPI fallback
python -m pip install --no-index --find-links=./dist msd-sdk
# Or with explicit path to avoid version conflicts:
python -m pip install ./dist/msd_sdk-*.whl --force-reinstall
```
**Common Pitfall**: Running `pip install .` may reinstall the published PyPI version if it has the same version number. Always use `--no-index` or install the wheel directly when developing.
## Development Setup with Zef
Since `msd-sdk` requires `zef` (which must be installed from source), you need to install msd-sdk into the same virtual environment where zef is installed:
```bash
# 1. Activate the venv where zef is already installed
source /path/to/zef/dev_venv/bin/activate
# 2. Install msd-sdk in editable mode from your local clone
pip install -e /path/to/msd-sdk-python
# 3. Verify both are available
python -c "import zef; import msd_sdk; print('✓ Both packages installed')"
```
## Running the Examples
The `examples/` folder contains working examples with sample files:
```bash
# Make sure you're in the venv with both zef and msd-sdk installed
source /path/to/zef/dev_venv/bin/activate
# Run the examples
python examples/sign_and_embed_example.py
```
The example demonstrates:
- Loading PNG, JPG, PDF, DOCX, XLSX, PPTX files
- Signing and embedding metadata
- Saving signed files to disk
- Extracting metadata from signed files
- Stripping metadata to recover original content
See [examples/README.md](examples/README.md) for more details.
## Usage
### 1. Load Key from Environment
The key must be stored as a JSON string in an environment variable:
```python
import msd_sdk as msd
my_key = msd.key_from_env("MSD_PRIVATE_KEY")
```
**Key structure returned:**
```python
{
'__type': 'ET.Ed25519KeyPair',
'__uid': '🍃-8d1dc8766070c87a4bb1',
'private_key': '🗝️-61250af6bf8b9332be5c2b8a4877c56189867c8840cce541ab7fbe9270bb9b6c',
'public_key': '🔑-8614d100b3cdb5ff6c37c846760dd1990f637994bd985d9486f212133bfd6284'
}
```
### 2. Create a Signed Granule
**Important:**
- `data` can be **any plain data type**: string, dict, list, number, boolean, etc.
- `metadata` must always be a **dictionary**
#### Example 1: String data
```python
data = "Hello, Meta Structured Data!"
metadata = {
'creator': 'Alice',
'description': 'sample data',
}
my_granule = msd.create_granule(data, metadata, my_key)
```
**Granule structure returned:**
```python
{
'__type': 'ET.SignedGranule',
'data': 'Hello, Meta Structured Data!',
'metadata': {'creator': 'Alice', 'description': 'sample data'},
'signature_time': {'__type': 'Time', 'zef_unix_time': '1769253762'},
'signature': {
'__type': 'ET.Ed25519Signature',
'signature': '🔏-9f3a8c29e9784fe63ccc7ebc3e1f394e9dcdf9a7d51bc6fa314dac8a902e9aff6a4e64619bae5a4f674980fcba77877d8a0131e8dfa7976cc23cf1d526ab0c07'
},
'key': {
'__type': 'ET.Ed25519KeyPair',
'__uid': '🍃-8d1dc8766070c87a4bb1',
'public_key': '🔑-8614d100b3cdb5ff6c37c846760dd1990f637994bd985d9486f212133bfd6284'
}
}
```
#### Example 2: Dict data (nested structures supported)
```python
data = {"message": "Hello", "count": 42, "nested": {"key": "value"}}
metadata = {'creator': 'Bob', 'schema': 'v1.0'}
my_granule = msd.create_granule(data, metadata, my_key)
```
**Granule structure returned:**
```python
{
'__type': 'ET.SignedGranule',
'data': {'message': 'Hello', 'count': 42, 'nested': {'key': 'value'}},
'metadata': {'creator': 'Bob', 'schema': 'v1.0'},
'signature_time': {'__type': 'Time', 'zef_unix_time': '1769253762'},
'signature': {
'__type': 'ET.Ed25519Signature',
'signature': '🔏-04ae2907139456ea20a5d0812dfb14ff90abe010113142cbdfd1b8703aea0fc5bd2791249049789983d39f8c63851fb4175fec52993f7ea500931fd7eac32506'
},
'key': {
'__type': 'ET.Ed25519KeyPair',
'__uid': '🍃-8d1dc8766070c87a4bb1',
'public_key': '🔑-8614d100b3cdb5ff6c37c846760dd1990f637994bd985d9486f212133bfd6284'
}
}
```
### 3. Verify a Signature
`verify()` checks whether a signature is valid — i.e., whether the data has been tampered with since signing. It works on all three signed data types:
#### Verifying a Granule
```python
granule = msd.create_granule(data, metadata, my_key)
is_valid = msd.verify(granule) # returns True or False
```
#### Verifying a Signed Dict
```python
signed_dict = msd.sign_and_embed_dict(
{"message": "Hello", "count": 42},
{"creator": "Alice"},
my_key
)
is_valid = msd.verify(signed_dict) # True
# Tamper with the data — verification fails
signed_dict["count"] = 99
is_valid = msd.verify(signed_dict) # False
```
#### Verifying a Signed File
```python
signed_png = msd.sign_and_embed(
{'type': 'png', 'content': png_bytes},
{'author': 'Alice'},
my_key
)
is_valid = msd.verify(signed_png) # True
```
This works for all supported file types: PNG, JPG, PDF, DOCX, XLSX, PPTX.
#### Behavior
- Returns `True` if the signature is valid for the data
- Returns `False` if the data has been modified since signing
- Raises `ValueError` if the input format is not recognized or has no embedded signature
### 4. Content Hash (without signature)
```python
my_content_hash = msd.content_hash(data)
# Returns: String(hash='🪨-523d1d9f304a40f30aa741cbdd66cad80f65b9db6c6cba66f2e149e0c2907f29')
```
**About Merkle Hashing**
`content_hash` uses BLAKE3 Merkle hashing for aggregate data types (Dict, Array/List, Set) and Entity types. This enables:
- **Structural sharing**: Reused sub-structures have the same hash
- **Interoperability with signatures**: Shared data can be verified independently
- **Specifying aggregates by hashes**: A dict's hash depends on the hashes of its keys and values
The mapping from hash → full value can be maintained via hash stores (dicts/maps), enabling content-addressed storage and deduplication.
### Signing and Embedding in Dicts
You can sign a plain Python dictionary and embed the metadata + signature directly in an `__msd` key using **Unicode steganography** — the signature data is hidden inside invisible Unicode variation selectors attached to a single emoji character. To the naked eye, `__msd` looks like `🔏`, but it carries the full cryptographic payload. This keeps the dict clean and human-readable: the metadata and signature are often much larger than the data itself, and steganography ensures they never clutter the output.
```python
data = {"message": "Hello", "count": 42}
metadata = {"creator": "Alice", "version": "1.0"}
signed_dict = msd.sign_and_embed_dict(data, metadata, my_key)
# => {"message": "Hello", "count": 42, "__msd": "🔏..."}
```
The signed dict can be serialized to JSON, stored in databases, or transmitted over APIs — the steganographic `__msd` value survives JSON round-trips.
#### Extracting Metadata and Signature from Dicts
```python
# Extract just the metadata
metadata = msd.extract_metadata(signed_dict)
# => {"creator": "Alice", "version": "1.0"}
# Extract the full signature information
sig_info = msd.extract_signature(signed_dict)
# => {"signature": {...}, "signature_time": {...}, "key": {...}}
```
Both `extract_metadata` and `extract_signature` automatically detect whether the input is a signed dict (has `__msd` key) or a signed binary file (has `type` and `content` keys) and handle both cases.
#### Verifying a Signed Dict
```python
is_valid = msd.verify(signed_dict) # True — signature matches data
# If someone tampers with the data, verification fails:
signed_dict["count"] = 999
is_valid = msd.verify(signed_dict) # False
```
### Embedding Signatures in Images, PDFs and other Documents
- Granules are container data structures which contain data, metadata, and signature alongside each other
- Granules can be saved in `.msd` files and provide an efficient binary format for storage and transmission. But your system and existing programs do not know how to interpret them.
- Sometimes you want to attach metadata and signatures to existing file formats like images (PNG, JPEG), PDFs, audio files, video files and send them to other people or systems.
- For these cases, MSD also provides tools to embed metadata and signatures **into** certain file formats, while keeping the original file content intact and viewable by standard programs.
- Supported formats:
- PNG images
- JPG images
- PDF documents
- Word documents (DOCX)
- Excel spreadsheets (XLSX)
- PowerPoint presentations (PPTX)
#### ⚠️ Warning ⚠️
- Some programs or platforms may strip out the attached metadata when re-saving or re-exporting the files.
- A MSD signature applies to exactly one fixed content version of a document. Editing the content in the slightest way invalidates the signature
```python
signed_png_image = msd.sign_and_embed(
data={'type': 'png', 'content': png_binary_data},
metadata={'creator': 'Alice', 'description': 'sample image'},
key=my_msd_key
)
```
The returned image with the embedded signature is also of the form
```python
{'type': 'png', 'content': signed_png_binary_data}
```
The same syntax works for other supported formats with respective MIME types:
- `png`
- `jpg`
- `pdf`
- `word_document`
- `excel_document`
- `powerpoint_document`
#### Extracting and Verifying Embedded Signatures
```python
extracted_metadata = msd.extract_metadata(signed_png_image)
extracted_signature = msd.extract_signature(signed_png_image)
```
```python
# Verify signature
is_valid = msd.verify(signed_png_image)
```
#### Removing Embedded Signatures and Metadata
```python
clean_image = msd.strip_metadata_and_signature(signed_png_image)
```
## Writing Tests
See [docs/writing-tests.md](docs/writing-tests.md) for the test pattern and guide.
## License
Licensed under either of:
- MIT license ([LICENSE](LICENSE) or http://opensource.org/licenses/MIT)
- Apache License, Version 2.0 ([LICENSE-APACHE](LICENSE-APACHE) or http://www.apache.org/licenses/LICENSE-2.0)
at your option.
| text/markdown | Ulf Bissbort, Staple AI | null | null | null | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming ... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/UlfBissbort/msd-sdk-python",
"Repository, https://github.com/UlfBissbort/msd-sdk-python"
] | uv/0.9.2 | 2026-02-19T01:03:36.948093 | msd_sdk-0.1.7.tar.gz | 772,139 | 5e/8e/a885cf5a7015a9bbc10b565755f1d0160108101c8433d30d03cf3dc3ec0b/msd_sdk-0.1.7.tar.gz | source | sdist | null | false | efaf3894283799eeddf7f82edc656853 | 6cbb6cf422a5887590d64ec96e317571698ab6509b3bfab99ae619f67bffea80 | 5e8ea885cf5a7015a9bbc10b565755f1d0160108101c8433d30d03cf3dc3ec0b | MIT OR Apache-2.0 | [
"LICENSE",
"LICENSE-APACHE"
] | 232 |
2.4 | sound-player | 1.0.3 | The aim of this project is to create multi audio layer player with professional audio mixing | # sound-player
A Python library for playing multiple sound files with professional real-time audio mixing support. Perfect for games and applications that need concurrent audio playback with multiple layers.
## Features
- **Real-time Audio Mixing** - Mix multiple audio streams simultaneously using NumPy
- **Multiple Audio Layers** - Organize sounds into independent layers (music, SFX, voice, etc.)
- **Volume Control** - Fine-grained volume at sound, layer, and master levels (all 0.0-1.0 float range)
- **Fade Effects** - Sample-accurate fade-in/fade-out with configurable curves (linear, exponential, logarithmic, S-curve)
- **Crossfade Support** - Smooth transitions between sounds in replace mode
- **Concurrent Playback** - Configure how many sounds can play simultaneously per layer
- **Loop Control** - Set sounds to loop infinitely or a specific number of times
- **Replace Mode** - Optionally stop or crossfade oldest sounds when concurrency limit is reached
- **Cross-Platform** - Support for Linux, Windows, Android (macOS/iOS planned)
- **Mixin Architecture** - Reusable mixins for status, volume, fade, and configuration management
## Installation
```bash
pip install sound-player
```
For Linux audio output support:
```bash
pip install sound-player[linux]
```
For Windows audio output support:
```bash
pip install sound-player[windows]
```
## Supported Platforms
- [x] Linux
- [x] Windows
- [x] Android
- [ ] macOS (planned)
- [ ] iOS (planned)
## Quick Start
```python
from sound_player import Sound, SoundPlayer
# Create a player with multiple audio layers
player = SoundPlayer()
# Create a music layer with background music
player.create_audio_layer("music", concurrency=1, volume=0.7)
player["music"].enqueue(Sound("background_music.ogg"))
# Create a sound effects layer
player.create_audio_layer("sfx", concurrency=3, volume=1.0)
player["sfx"].enqueue(Sound("coin.wav"))
# Start playback
player.play()
```
## Usage Examples
### Basic Sound Playback
> **Note:** A `Sound` on its own only manages PCM data and playback state. To actually hear audio, you need a `SoundPlayer` with an audio layer (see [Sound Player with Multiple Layers](#sound-player-with-multiple-layers)).
```python
from sound_player import Sound, SoundPlayer
player = SoundPlayer()
player.create_audio_layer("music", concurrency=1)
sound = Sound("music.ogg")
player["music"].enqueue(sound)
player.play() # Start audio output
player.pause() # Pause playback
player.play() # Resume playback
player.stop() # Stop and reset
```
### Sound with Loop and Volume
```python
from sound_player import Sound, SoundPlayer
player = SoundPlayer()
player.create_audio_layer("music", concurrency=1)
sound = Sound("music.ogg")
sound.set_loop(3) # Play 3 times (use -1 for infinite)
sound.set_volume(0.8) # Set volume to 80% (0.0-1.0 range)
player["music"].enqueue(sound)
player.play()
```
### Audio Layer with Concurrency
```python
from sound_player import AudioLayer, Sound
# Allow up to 3 sounds playing at once
layer = AudioLayer(concurrency=3, volume=0.8)
layer.enqueue(Sound("music.ogg"))
layer.enqueue(Sound("coin.wav"))
layer.enqueue(Sound("explosion.wav"))
layer.enqueue(Sound("powerup.wav")) # Will wait for a free slot
layer.play()
```
### Sound Player with Multiple Layers
```python
from sound_player import SoundPlayer, Sound
player = SoundPlayer()
# Create different audio layers
player.create_audio_layer("music", concurrency=1, volume=0.6)
player.create_audio_layer("sfx", concurrency=4, volume=1.0)
player.create_audio_layer("voice", concurrency=1, volume=0.8)
# Add sounds to each layer
player["music"].enqueue(Sound("background.ogg"))
player["sfx"].enqueue(Sound("jump.wav"))
player["voice"].enqueue(Sound("dialogue.wav"))
# Control individual layers
player.play("sfx") # Play only SFX
player.pause("music") # Pause music
player.stop("voice") # Stop voice layer
# Or control all at once
player.play() # Play all layers
player.stop() # Stop all layers
```
### Volume Hierarchy
The library supports volume control at three levels (all using 0.0-1.0 float range):
```python
from sound_player import AudioConfig, AudioLayer, Sound, SoundPlayer
player = SoundPlayer()
player.set_volume(0.7) # Master volume: 0.0 to 1.0
layer = AudioLayer(volume=0.8) # Layer volume: 0.0 to 1.0
sound = Sound("music.ogg")
sound.set_volume(0.5) # Sound volume: 0.0 to 1.0
# Final volume = sound_vol × layer_vol × master_vol
# Final = 0.5 × 0.8 × 0.7 = 0.28 (28%)
```
### Custom Audio Configuration
```python
from sound_player import AudioConfig, SoundPlayer, Sound
config = AudioConfig(
sample_rate=48000, # Sample rate in Hz
channels=2, # 1=mono, 2=stereo
buffer_size=1024, # Buffer size in samples
)
player = SoundPlayer(config=config)
player.create_audio_layer("music", config=config)
player["music"].enqueue(Sound("music.ogg"))
player.play()
```
### Fade Effects
```python
from sound_player import Sound, SoundPlayer
player = SoundPlayer()
player.create_audio_layer("music", concurrency=1)
sound = Sound("music.ogg")
sound.fade_in(2.0) # Fade in over 2 seconds
player["music"].enqueue(sound)
player.play()
# Later...
sound.fade_out(3.0) # Fade out over 3 seconds (auto-stops when done)
```
### Replace Mode
When `replace=True`, adding sounds beyond the concurrency limit will stop the oldest sounds:
```python
from sound_player import AudioLayer, Sound
layer = AudioLayer(concurrency=2, replace=True)
layer.enqueue(Sound("music1.ogg"))
layer.enqueue(Sound("sfx1.wav"))
layer.enqueue(Sound("sfx2.wav")) # Stops music1.ogg
layer.enqueue(Sound("sfx3.wav")) # Stops sfx1.wav
layer.play()
```
### Crossfade with Replace Mode
When `replace=True` with a `fade_out_duration`, replaced sounds crossfade smoothly:
```python
from sound_player import AudioLayer, Sound
layer = AudioLayer(concurrency=1, replace=True, fade_in_duration=1.0, fade_out_duration=2.0)
layer.enqueue(Sound("track1.ogg"))
layer.play()
# When track2 is enqueued, track1 fades out over 2s while track2 fades in over 1s
layer.enqueue(Sound("track2.ogg"))
```
## Architecture
The library uses a mixin-based architecture with the following key components:
### Core Classes
- **`StatusMixin`** - Manages playback status (STOPPED, PLAYING, PAUSED) with thread-safe `play()`, `pause()`, `stop()` methods
- **`VolumeMixin`** - Provides volume control with clamping (0.0-1.0) and thread-safe `set_volume()`, `get_volume()` methods
- **`FadeMixin`** - Sample-accurate fade-in/fade-out with configurable curves (linear, exponential, logarithmic, S-curve)
- **`LockMixin`** - Provides thread-safe RLock for concurrent operations
- **`AudioConfigMixin`** - Manages audio configuration (sample rate, channels, buffer size, etc.)
### Main Classes
- **`BaseSound`** - Base class for all sounds with PCM buffer interface
- **`AudioLayer`** - Manages sound queues with mixing and concurrency control
- **`BaseSoundPlayer`** - Abstract base class for platform-specific audio output
- **`AudioMixer`** - Mixes multiple audio streams with volume control
### Volume Hierarchy
```
sound_data × sound_volume × layer_volume × player_volume = final_output
```
Each level uses the 0.0-1.0 float range for consistent computations.
## API Reference
### SoundPlayer
Main class for managing multiple audio layers.
| Method | Description |
|--------|-------------|
| `create_audio_layer(id, force=False, **kwargs)` | Create a new audio layer |
| `enqueue(sound, layer_id)` | Add sound to a layer |
| `play(layer_id=None)` | Start playback (all layers or specific) |
| `pause(layer_id=None)` | Pause playback |
| `stop(layer_id=None)` | Stop playback |
| `set_volume(volume)` | Set master volume (0.0-1.0) |
| `get_volume()` | Get master volume (0.0-1.0) |
| `clear(layer_id=None)` | Clear queues |
### AudioLayer
Manages a queue of sounds with mixing.
| Constructor | Description |
|------------|-------------|
| `AudioLayer(concurrency=1, replace=False, loop=None, fade_in_duration=None, fade_out_duration=None, fade_curve=None, volume=1.0, config=None)` | Create audio layer |
| Method | Description |
|--------|-------------|
| `enqueue(sound, fade_in=None, fade_out=None)` | Add sound to waiting queue |
| `play()` / `pause()` / `stop()` | Control playback |
| `clear()` | Clear all queues |
| `set_concurrency(n)` | Set max concurrent sounds |
| `set_replace(bool)` | Enable/disable replace mode |
| `set_loop(n)` | Set default loop count (-1=infinite) |
| `set_volume(v)` | Set layer volume (0.0-1.0) |
| `set_fade_in_duration(d)` | Set default fade-in duration for enqueued sounds |
| `set_fade_out_duration(d)` | Set default fade-out duration for enqueued sounds |
| `set_fade_curve(curve)` | Set default fade curve for enqueued sounds |
### Sound
Represents a single sound file.
| Method | Description |
|--------|-------------|
| `play()` / `pause()` / `stop()` | Control playback |
| `wait(timeout=None)` | Wait for playback to finish |
| `set_loop(n)` | Set loop count (-1=infinite) |
| `set_volume(v)` | Set volume (0.0-1.0) |
| `fade_in(duration)` | Fade in over duration seconds |
| `fade_out(duration)` | Fade out over duration seconds |
| `seek(position)` | Seek to position (seconds) |
### AudioConfig
Configuration for audio format.
| Parameter | Description |
|-----------|-------------|
| `sample_rate` | Sample rate in Hz (default: 44100) |
| `channels` | Number of channels (1=mono, 2=stereo) |
| `sample_width` | Bytes per sample (2=int16, 4=int32) |
| `buffer_size` | Samples per buffer (default: 1024) |
| `dtype` | NumPy dtype (default: np.int16) |
## Android
### Buildozer / python-for-android
Add the following to your `buildozer.spec` requirements:
```
requirements = ..., sound-player[android]~=1.0
```
The `[android]` extra pulls in `pyjnius` and `android`; `numpy` and
`krozark-current-platform` are pulled in automatically as hard dependencies.
`soundfile` and `sounddevice` are **not** needed — the library uses
`MediaExtractor` / `MediaCodec` / `AudioTrack` directly via `pyjnius`.
### Choosing the Android decoder
Two decoder implementations are available. Select one at **runtime** by
setting the `SOUND_PLAYER_ANDROID_DECODER` environment variable **before the
first import** of `sound_player`:
```python
import os
os.environ["SOUND_PLAYER_ANDROID_DECODER"] = "sync" # default
# or
os.environ["SOUND_PLAYER_ANDROID_DECODER"] = "async"
import sound_player
```
| Value | Class | How it works |
|-------|-------|--------------|
| `sync` *(default)* | `AndroidPCMSound` | Background Python thread polls `dequeueInputBuffer` / `dequeueOutputBuffer`. Backpressure pauses the thread when the PCM buffer holds > 2 s of audio. Simple and easy to debug. |
| `async` | `AndroidPCMSoundAsync` | Registers a `MediaCodec.Callback`; Android's internal thread calls into Python when buffers are ready. Event-driven, no polling. |
**Recommendation:** use `sync` (the default) for most cases, especially when
playing many sounds concurrently (~10+). The `async` mode is provided for
experimentation; its backpressure currently blocks MediaCodec's internal
thread, which is an anti-pattern at scale.
## Dependencies
**Required:**
- `numpy>=1.24` - Audio mixing
- `krozark-current-platform` - Platform detection
**Optional (Linux/Windows):**
- `sounddevice~=0.4` - Audio output
- `soundfile~=0.12` - Audio file decoding
Install both with:
```bash
pip install sound-player[linux] # Linux
pip install sound-player[windows] # Windows
```
**Android:**
- `pyjnius`, `android` - Android platform APIs (already available in python-for-android environments)
```bash
pip install sound-player[android]
```
## License
BSD 2-Clause
## Author
Maxime Barbier
| text/markdown | null | Maxime Barbier <maxime.barbier1991+ava@gmail.com> | null | null | null | sound, player, audio, mixing, pcm, fade, crossfade | [
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Operating System :: POSIX :: Linux",
"Operating System :: Microsoft :: Windows",
"Operating System :: Android"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"krozark-current-platform",
"numpy>=1.24",
"sounddevice~=0.4; extra == \"linux\"",
"soundfile~=0.12; extra == \"linux\"",
"sounddevice~=0.4; extra == \"windows\"",
"soundfile~=0.12; extra == \"windows\"",
"pyjnius; extra == \"android\"",
"android; extra == \"android\"",
"pytest>=7.0; extra == \"dev\... | [] | [] | [] | [
"Homepage, https://github.com/Krozark/sound-player"
] | twine/6.1.0 CPython/3.10.12 | 2026-02-19T01:01:19.552095 | sound_player-1.0.3.tar.gz | 44,119 | dc/76/6cd127d6b8735211489ce71a3aa2cded0de7f346c92ac511b8d6625b9e43/sound_player-1.0.3.tar.gz | source | sdist | null | false | 9e7f06c29cb1939a650dc8b0dbbc022f | d1964549ec21ee6b606fbc967c7598cf942dda368448457e46dc9cbd811932b1 | dc766cd127d6b8735211489ce71a3aa2cded0de7f346c92ac511b8d6625b9e43 | BSD-2-Clause | [
"LICENSE"
] | 239 |
2.3 | tremors | 0.6.0 | Tremors is a library for logging while collecting metrics. | Tremors
#######
Tremors is a library for logging while collecting metrics. Tremors loggers are
drop-in replacements for standard loggers. But Tremors loggers have metrics
collectors that run when messages are logged. The loggers are also context
managers. The library maintains a hierarchy of nested contexts, where all
logs and metrics are grouped together. You can create a new hierarchy at
anytime to group related logs.
Installation
************
.. code-block:: shell
pip install tremors
Usage
*****
A function can be wrapped in a logger context with the ``logged`` decorator. If
you call the function without a logger argument, one will automatically be
injected into it.
.. code-block:: python
import logging
import tremors
from tremors import collector
@tremors.logged
def fn(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.info("hello")
logging.basicConfig(
format="Tremors > %(levelname)s:%(name)s:%(message)s",
level=logging.INFO,
)
fn()
The context automatically logs ``entered``, and ``exited`` messages before,
and after each function call. The logger uses the configured standard root
logger by default to log the messages.
.. code-block:: shell
Tremors > INFO:root:entered: fn
Tremors > INFO:root:hello
Tremors > INFO:root:exited: fn
You may specify a standard logger by name for the Tremors logger to use as
its underlying logger.
.. code-block:: python
@tremors.logged(logger_name=__name__)
def fn(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.info("hello")
fn()
The messages are logged by the specified underlying logger. Based on our
standard logging configuration, the messages propagate from the underlying
logger to the standard root logger, which emits them.
.. code-block:: shell
Tremors > INFO:__main__:entered: fn
Tremors > INFO:__main__:hello
Tremors > INFO:__main__:exited: fn
Next let's use a collector to measure the elapsed time since the function
started each time a message is logged. When a message is logged, the logger
runs the collector, and adds its updated state to the message's LogRecord. We
use a standard logging filter to inspect and modify the record before it is
emitted. We format the collector state, then add the formatted state to the
``elapsed`` custom attribute of the record. Finally, we configure the root
logger's formatter to incorporate the elapsed attribute.
.. note::
The elapsed collector bundle included with Tremors has a factory for
creating a collector. It also has a formatter that we use in ``flt``
to extract the state from the record, and format it. In ``flt`` we
make a copy of the record, then modify and return the copy, instead of
modifying the original record, so as not to have side effects on other
loggers that may process the messasge. We also make sure to attach
``flt`` to the root logger's handler, and not to the logger itself;
messages that originate from descendant loggers will not go through
logger filters when they are propagated, but they will go through handler
filters before they are emitted.
.. code-block:: python
import copy
import time
def flt(record: logging.LogRecord) -> logging.LogRecord:
record = copy.copy(record)
elapsed = collector.elapsed.formatter(record)
record.elapsed = f"{elapsed} " if elapsed else ""
return record
@tremors.logged(collector.elapsed.factory())
def fn(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.info("sleeping for 1s...")
time.sleep(1)
logging.basicConfig(
format="%(elapsed)s%(levelname)s:%(name)s:%(message)s",
level=logging.INFO,
force=True,
)
logging.root.handlers[0].addFilter(flt)
fn()
The messages contain elapsed information, according to the formatter
configuration, that is sourced from the record's elapsed custom attribute.
.. code-block:: shell
0.000 INFO:root:entered: fn
0.000 INFO:root:sleeping for 1s...
1.000 INFO:root:exited: fn
A Logger can have any number of collectors. Here, in addition to the elapsed
collector from the previous example, we add a counter collector. A collector
has a level, and will only run if the message is being logged at that level or
higher. Our counter level is ``ERROR``. We can also control which custom record
attribute has the formatted collector state via the collector's name. This is
useful if you have multiple of the same collector on a single logger. Here,
we name the counter ``errors``, so ``record.errors`` will contain a formatted
string with the running total number of errors that have been logged by a
single function call. Finally, we an control the format of the counter state
via the ``fmt`` argument of the counter's formatter.
.. code-block:: python
def flt(record: logging.LogRecord) -> logging.LogRecord:
record = copy.copy(record)
errors = collector.counter.formatter(
record, name="errors", fmt="errors={counter}"
)
record.errors = f"{errors} " if errors else ""
elapsed = collector.elapsed.formatter(record)
record.elapsed = f"{elapsed} " if elapsed else ""
return record
@tremors.logged(
collector.counter.factory(name="errors", level=logging.ERROR),
collector.elapsed.factory(),
)
def fn(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.info("hello")
time.sleep(1)
logger.error("uh-ho!")
logging.basicConfig(
format="%(elapsed)s%(errors)s%(levelname)s:%(name)s:%(message)s",
level=logging.INFO,
force=True,
)
logging.root.handlers[0].addFilter(flt)
fn()
The messages contain information from both collectors.
.. code-block:: shell
0.000 errors=0 INFO:root:entered: fn
0.000 errors=0 INFO:root:hello
1.001 errors=1 ERROR:root:uh-ho!
1.001 errors=1 INFO:root:exited: fn
In the previous example, a new counter collector was used each time the
function is called. Let's reuse the same collector to keep a tally of errors
across *all* calls to the function.
.. note::
The counter factory returns a ``CollectorFactory`` that will result in a
new collector being created for each ``fn`` call. To use the *same*
collector, we must call the CollectorFactory, hence the trailing
parentheses on the line where we set ``fn_errors``.
.. code-block:: python
fn_errors = collector.counter.factory(name="errors", level=logging.ERROR)()
@tremors.logged(fn_errors)
def fn(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.error("uh-ho!")
fn()
fn()
The error count doesn't reset in the second function call.
.. code-block:: shell
errors=0 INFO:root:entered: fn
errors=1 ERROR:root:uh-ho!
errors=1 INFO:root:exited: fn
errors=1 INFO:root:entered: fn
errors=2 ERROR:root:uh-ho!
errors=2 INFO:root:exited: fn
Another way we can tally the count across all function calls is to pass the
same logger with each call.
.. code-block:: python
def fn(*, logger: tremors.Logger) -> None:
logger.error("uh-ho!")
with tremors.Logger(
collector.counter.factory(name="errors", level=logging.ERROR),
name="context",
) as logger:
fn(logger=logger)
fn(logger=logger)
We only get entering and exiting messages for the context block. But the
single logger used in both function calls maintains its state between calls.
.. code-block:: shell
errors=0 INFO:root:entered: context
errors=1 ERROR:root:uh-ho!
errors=2 ERROR:root:uh-ho!
errors=2 INFO:root:exited: context
Collectors may be inherited by descendant loggers. Let's count errors across
nested loggers.
.. code-block:: python
@tremors.logged(
collector.counter.factory(
name="errors", level=logging.ERROR, inherit=True
)
)
def parent(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.error("uh-ho!")
child()
child()
@tremors.logged
def child(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.error("doh!")
grandchild()
@tremors.logged
def grandchild(*, logger: tremors.Logger = tremors.from_logged) -> None:
logger.info("so far, so good")
logger.error("spoke too soon!")
parent()
The entered and exited lines have been omitted. The ``parent`` counter is used the ``child`` and ``grandchild`` functions.
.. code-block:: shell
errors=1 ERROR:root:uh-ho!
errors=2 ERROR:root:doh!
errors=2 INFO:root:so far, so good
errors=3 ERROR:root:spoke too soon!
errors=4 ERROR:root:doh!
errors=4 INFO:root:so far, so good
errors=5 ERROR:root:spoke too soon!
See the `collector module`_ in the full `documentation`_ for how you can
define your own collectors, and bundles.
.. _documentation: https://tremors.readthedocs.io/en/latest
.. _collector module: https://tremors.readthedocs.io/en/latest/#module-tremors.collector
| text/x-rst | Narvin Singh | Narvin Singh <Narvin.A.Singh@gmail.com> | null | null | Tremors is a library for logging with metrics. Copyright (C) 2025 Narvin Singh This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program. If not, see <https://www.gnu.org/licenses/>. | logging, log, logger, metrics | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: GNU General Public License v3 or later (GPLv3+)",
"Operating System :: OS Independent"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"python-docs-theme~=2025.12; extra == \"doc\"",
"sphinx~=9.1; extra == \"doc\""
] | [] | [] | [] | [
"Homepage, https://tremors.readthedocs.io",
"Documentation, https://tremors.readthedocs.io",
"Repository, https://codeberg.org/narvin/tremors",
"Issues, https://codeberg.org/narvin/tremors/issues"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Arch Linux","version":null,"id":null,"libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T01:00:08.983138 | tremors-0.6.0-py3-none-any.whl | 15,140 | bd/69/c254c8f76e077b8aa613ae5d8d270dea78054ddaef6647d368a73865e040/tremors-0.6.0-py3-none-any.whl | py3 | bdist_wheel | null | false | c6c9f40f6cd2c0dd430f032d56b117e0 | 11bd4438b41cb69186b905fbbc312d2999e83c8984bbef391f6211c4259e8cce | bd69c254c8f76e077b8aa613ae5d8d270dea78054ddaef6647d368a73865e040 | null | [] | 227 |
2.4 | clearspark | 0.1.2 | A curated collection of essential PySpark functions for daily data engineering. | # clearspark
A curated collection of essential PySpark functions for daily data engineering. Featuring quality-of-life enhancements for DataFrames.
| text/markdown | null | Vinicius <vinnyuniverso3@gmail.com> | null | null | MIT | data-engineering, dataframe, etl, pyspark, spark-utils | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python ... | [] | null | null | >=3.8 | [] | [] | [] | [
"pyspark>=3.5.0",
"pytest; extra == \"dev\""
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.3 | 2026-02-19T00:56:44.180033 | clearspark-0.1.2.tar.gz | 6,235 | 2f/6b/96f5f5dff3e0b223ef8a27f9ffade0a7c84c4bfe2482703335fa0510408b/clearspark-0.1.2.tar.gz | source | sdist | null | false | c656ec370ad8e8fdfde96e421e052483 | cc51a32621d9470d8d5e7e71dfafcfdf13076d99021fff653d4f33fe78911712 | 2f6b96f5f5dff3e0b223ef8a27f9ffade0a7c84c4bfe2482703335fa0510408b | null | [
"LICENSE"
] | 255 |
2.4 | djaodjin-signup | 0.11.2 | Django app for user authentication | DjaoDjin-Signup
===============
[](https://badge.fury.io/py/djaodjin-signup)
This repository contains a Django App for user authentication (intended
as a replacement for the ``django.contrib.auth.views`` pages), and user account
pages.
Major Features:
- HTML forms and API-based authentication
- Cookies, JWT, API Keys
- OTP codes
This project contains bare bone templates which are compatible with Django
and Jinja2 template engines. To see djaodjin-signup in action as part
of a full-fledged subscription-based session proxy, take a look
at [djaoapp](https://github.com/djaodjin/djaoapp/).
Install
=======
Add the signup urls to your urlpatterns and EmailOrUsernameModelBackend
to the settings AUTHENTICATION_BACKENDS.
urls.py:
urlpatterns = ('',
(r'^api/', include('signup.urls.api')),
(r'^', include('signup.urls.views')),
)
settings.py:
AUTHENTICATION_BACKENDS = (
'signup.backends.auth.EmailOrUsernameModelBackend',
'django.contrib.auth.backends.ModelBackend'
)
Development
===========
After cloning the repository, create a virtualenv environment, install
the prerequisites, create and load initial data into the database, then
run the testsite webapp.
$ python -m venv .venv
$ source .venv/bin/activate
$ pip install -r testsite/requirements.txt
$ make vendor-assets-prerequisites
$ make initdb
$ python manage.py runserver
# Browse http://localhost:8000/
Release Notes
=============
Tested with
- **Python:** 3.12, **Django:** 5.2 ([LTS](https://www.djangoproject.com/download/))
- **Python:** 3.14, **Django:** 6.0 (next)
- **Python:** 3.10, **Django:** 4.2 (legacy)
- **Python:** 3.9, **Django:** 3.2 (legacy)
0.11.2
* attaches invalid credentials to input fields
* fixes incorrect view name in testsite
[previous release notes](changelog)
| text/markdown | null | The DjaoDjin Team <help@djaodjin.com> | null | The DjaoDjin Team <help@djaodjin.com> | BSD-2-Clause | signup, authentication, frictionless, 2fa, mfa, otp, oauth, saml | [
"Framework :: Django",
"Environment :: Web Environment",
"Programming Language :: Python",
"License :: OSI Approved :: BSD License"
] | [] | null | null | >=3.7 | [] | [] | [] | [
"boto3>=1.4.4",
"Django>=1.11",
"django-fernet-fields>=0.6",
"django-phonenumber-field>=2.4.0",
"django-recaptcha>=2.0",
"djangorestframework>=3.9",
"phonenumbers>=8.12.6",
"PyJWT>=1.6.1",
"pyotp>=2.8.0",
"python3-saml>=1.2.1",
"social-auth-app-django>=4.0.0",
"social-auth-core>=4.2.0",
"pyt... | [] | [] | [] | [
"repository, https://github.com/djaodjin/djaodjin-signup",
"documentation, https://djaodjin-signup.readthedocs.io/",
"changelog, https://github.com/djaodjin/djaodjin-signup/changelog"
] | twine/6.1.0 CPython/3.10.19 | 2026-02-19T00:56:27.739980 | djaodjin_signup-0.11.2.tar.gz | 106,933 | d1/69/eebc1bb886876f788e22acf4e98fe1f34eb1951356c7a107af076e3ed484/djaodjin_signup-0.11.2.tar.gz | source | sdist | null | false | 3a253fb09a60a15ba9ea86890622d595 | c07dad4d5341316ea0b599dfbc64e69a8f40e6f82386bf8dcc6b5f7c013ceec7 | d169eebc1bb886876f788e22acf4e98fe1f34eb1951356c7a107af076e3ed484 | null | [
"LICENSE.txt"
] | 262 |
2.4 | libyak | 0.9.0 | Python bindings for Yak — yet another kontainer. A layered, embeddable file-in-file storage system. | # libyak
Python bindings for [Yak](https://github.com/sunbeam60/yak) — yet another kontainer. A layered, embeddable file-in-file storage system written in Rust.
## Installation
```bash
pip install libyak
```
## Quick Start
```python
import yak
# Create a new Yak file
yk = yak.Yak.create("mydata.yak")
# Write a stream
sh = yk.create_stream("hello.txt", compressed=False)
yk.write(sh, b"Hello, World!")
yk.close_stream(sh)
# Read it back
sh = yk.open_stream("hello.txt", yak.OpenMode.Read)
data = yk.read(sh, 1024)
print(data) # b"Hello, World!"
yk.close_stream(sh)
# Directory operations
yk.mkdir("docs")
sh = yk.create_stream("docs/readme.txt", compressed=True)
yk.write(sh, b"Compressed content")
yk.close_stream(sh)
# List directory contents
for entry in yk.list(""):
print(f"{entry.name} ({entry.entry_type})")
yk.close()
```
## Features
- Single-file storage with hierarchical directories and named streams
- Optional LZ4 compression per stream
- Optional AES-256-XTS encryption
- Thread-safe with interior mutability
- File optimization (compaction and defragmentation)
## Encryption
```python
# Create an encrypted Yak file
yk = yak.Yak.create("secret.yak", password=b"my-password")
# ... use normally ...
yk.close()
# Re-open with password
yk = yak.Yak.open("secret.yak", yak.OpenMode.Write, password=b"my-password")
```
## Optimization
```python
# Compact a Yak file (remove free blocks, maximize contiguity)
bytes_saved = yak.Yak.optimize("mydata.yak")
```
## License
MIT OR Apache-2.0
| text/markdown; charset=UTF-8; variant=GFM | null | Bjorn Toft Madsen <bjorn@toftmadsen.org> | null | null | MIT OR Apache-2.0 | filesystem, storage, embedded, container, streams | [
"Development Status :: 4 - Beta",
"License :: OSI Approved :: MIT License",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Rust",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Lang... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Homepage, https://github.com/sunbeam60/yak",
"Repository, https://github.com/sunbeam60/yak"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:55:35.488356 | libyak-0.9.0.tar.gz | 67,938 | 9d/a1/3d9376eac2796a6bc9908e7dca80365ce530e02576555d25fdacb716bf2a/libyak-0.9.0.tar.gz | source | sdist | null | false | 0d2ccbd619692592fb2e4a46fc3d8945 | 3501554064d998dad09d071d9e29d75864b2e8de0922195c54b19ffaeffe3b93 | 9da13d9376eac2796a6bc9908e7dca80365ce530e02576555d25fdacb716bf2a | null | [] | 2,152 |
2.4 | gitsmart | 1.0.0 | AI-powered Git workflow assistant CLI | # GitSmart CLI
> AI-powered Git workflow assistant for developers.



GitSmart CLI leverages AI to streamline your Git workflow with intelligent commit messages, code reviews, and repository analytics.
> 📖 **Full documentation:** [docs.gitsmart.io](https://docs.gitsmart.io)
## Features
✅ **AI-Powered Commit Messages** — Generate conventional commit messages from your staged changes
✅ **Smart Commit Mode** — Automatically group changes into multiple logical commits
✅ **Security Scan** — Detect real vulnerabilities before they reach your repo
✅ **Plain Language Search** — Query your commit history like asking a colleague
✅ **Code Explain** — Generate PR-ready documentation from your changes
✅ **Code Review Assistant** — Get AI feedback on branch changes
✅ **Repository Analytics** — Insights into hotspots, contributors, and code trends
✅ **Multi-Language Support** — Output in 100+ languages (ISO 639-1)
✅ **Usage Tracking** — Monitor your API credit balance and plan limits
## Installation
**Requirements:** Python 3.8+, Git on your `$PATH`, a [GitSmart account](https://gitsmart.io)
### Recommended: install in a virtual environment
```bash
# Create a virtual environment (once)
python -m venv ~/.venvs/gitsmart
# Activate it
source ~/.venvs/gitsmart/bin/activate # macOS / Linux
# or
~\.venvs\gitsmart\Scripts\activate # Windows
# Install GitSmart
pip install gitsmart
```
To use GitSmart without activating the venv every time, add it to your shell profile (`.bashrc`, `.zshrc`, etc.):
```bash
export PATH="$HOME/.venvs/gitsmart/bin:$PATH"
```
### Alternative: global install
```bash
pip install gitsmart
```
> **Note:** A global install may conflict with other Python packages. The virtual environment approach is cleaner, especially on macOS.
### Verify the installation
```bash
gitsmart --version
```
### Update
```bash
pip install --upgrade gitsmart
# or, if using a venv:
source ~/.venvs/gitsmart/bin/activate && pip install --upgrade gitsmart
```
### Uninstall
```bash
pip uninstall gitsmart
```
Your local config at `~/.gitsmart/` is not removed automatically — delete it manually if needed.
## Quick Start
### 1. Configure your API key
```bash
gitsmart configure
```
You'll be prompted for:
- API key (get one at [gitsmart.io](https://gitsmart.io))
- API URL (default: `https://api.gitsmart.io`)
- Commit language (default: `en`)
### 2. Generate a commit message
```bash
# Stage your changes
git add .
# Generate AI commit message
gitsmart commit
```
### 3. Review the suggestion and commit
GitSmart will analyze your changes and suggest a commit message. You can:
- Press `y` to commit
- Press `e` to edit the message
- Press `n` to abort
## Commands
### `commit` — Generate AI commit messages
```bash
# Interactive mode (default)
gitsmart commit
# Auto-commit without confirmation
gitsmart commit --auto
# Force commit type
gitsmart commit --type feat
# Detailed commit with body
gitsmart commit --detail
# Commit in another language
gitsmart commit --lang fr
```
#### 🚀 Smart Commit Mode
Automatically analyze and group staged files into multiple logical commits:
```bash
gitsmart commit --smart
```
**What it does:**
- Analyzes all staged files
- Groups related changes (e.g., tests, docs, features)
- Suggests multiple commits with separate messages
- Allows you to select which groups to commit
**Example workflow:**
```bash
# Stage multiple unrelated changes
git add src/auth.py tests/test_auth.py docs/api.md
# Let AI group them
gitsmart commit --smart
# AI suggests:
# Group 1: Authentication implementation (auth.py)
# Group 2: Authentication tests (test_auth.py)
# Group 3: API documentation (api.md)
# Choose to commit all or select specific groups
```
**Limitations:**
- Maximum 50 files
### `security` — AI security scan
Scan your code changes for real vulnerabilities before they reach the repo:
```bash
# Scan staged changes
gitsmart security --staged
# Scan a specific commit
gitsmart security --commit a3f92c1
# Scan a commit range
gitsmart security --from v1.0.0 --to HEAD
# Save report to a file
gitsmart security --staged --markdown --output SECURITY_REPORT.md
```
**What it detects:**
- SQL injection, command injection
- XSS (reflected and stored)
- Hardcoded secrets (API keys, passwords, tokens)
- Path traversal
- Insecure deserialization
- Sensitive data exposure
### `search` — Plain language commit history search
Query your commit history without regex or exact strings:
```bash
# Search by intent
gitsmart search "who last updated the authorization logic?"
# Find when a feature was introduced
gitsmart search "when was dark mode added?"
# Filter by author
gitsmart search "payment changes" --author "Ivan"
# Limit results
gitsmart search "database migrations" --limit 10
```
### `explain` — Generate PR-ready documentation
Generate a documentation-style breakdown of your changes:
```bash
# Explain staged changes
gitsmart explain --staged
# Explain a specific commit
gitsmart explain --commit a3f92c1
# Explain a commit range
gitsmart explain --from v1.0.0 --to HEAD
# Save to a Markdown file
gitsmart explain --staged --markdown --output EXPLANATION.md
```
### `review` — Code review assistant
Get AI feedback on changes between branches:
```bash
# Review current branch against main
gitsmart review
# Review specific branch
gitsmart review --branch feature/auth
# Specify base branch
gitsmart review --base develop
# Review in another language
gitsmart review --lang es
```
**What you get:**
- Summary of what changed
- Potential issues (by severity)
- Recommendations for improvement
- Verdict on overall change quality
### `analyze` — Repository analytics
Get AI insights into your repository:
```bash
# Analyze repository
gitsmart analyze
# Analysis in another language
gitsmart analyze --lang de
```
**Insights include:**
- Hotspot files (most frequently changed)
- Contributor activity patterns
- Code quality recommendations
- Language distribution
### `whoami` — Account information
```bash
gitsmart whoami
```
Shows:
- Email
- Current plan (Free/Basic/Pro)
### `usage` — Credit balance
```bash
gitsmart usage
```
Shows:
- Credits used this month
- Credits remaining
- Plan limit
- Usage progress bar
### `logs` — Usage history
```bash
# Browse recent logs
gitsmart logs
# Filter by operation type
gitsmart logs --type commit
# Show only failed operations
gitsmart logs --failed
# Show detailed info (tokens, response time)
gitsmart logs --detail
```
### `config` — Manage configuration
```bash
# View all config values
gitsmart config
# Get specific value
gitsmart config api_key
# Set a value
gitsmart config commit_language fr
```
### `logout` — Remove credentials
```bash
gitsmart logout
```
Removes your saved API key and configuration.
## Configuration
Config file location: `~/.gitsmart/config.json`
**Available settings:**
| Key | Description | Default |
|-----|-------------|---------|
| `api_key` | Your GitSmart API key | — |
| `api_url` | API endpoint URL | `https://api.gitsmart.io` |
| `commit_language` | ISO 639-1 language code | `en` |
## Language Support
Commit messages can be generated in 100+ languages using ISO 639-1 codes:
```bash
# English (default)
gitsmart commit
# Spanish
gitsmart commit --lang es
# Ukrainian
gitsmart commit --lang uk
# Japanese
gitsmart commit --lang ja
# German
gitsmart commit --lang de
# French
gitsmart commit --lang fr
...etc
```
Set default language in config:
```bash
gitsmart config commit_language fr
```
## API Plans
| Plan | Monthly Credits | Price | Rate Limit |
|-------|-----------------|-----------|-------------|
| Free | 250 | $0 | 5 req/min |
| Basic | 5,000 | $5/month | 20 req/min |
| Pro | 10,000 | $10/month | 50 req/min |
Sign up at [gitsmart.io](https://gitsmart.io)
## Examples
### Basic workflow
```bash
# 1. Make changes
vim src/auth.py
# 2. Stage changes
git add src/auth.py
# 3. Generate commit
gitsmart commit
# AI suggests: "feat(auth): implement JWT token validation"
# Press 'y' to commit
```
### Smart commit workflow
```bash
# 1. Make multiple changes
vim src/auth.py src/users.py tests/test_auth.py
# 2. Stage all
git add .
# 3. Let AI group them
gitsmart commit --smart
# AI creates 3 logical commits:
# - feat(auth): add JWT validation
# - feat(users): update user model
# - test(auth): add JWT tests
```
### Review before merge
```bash
# Create feature branch
git checkout -b feature/new-auth
# ... make changes ...
# Review before merging
gitsmart review --base main
# Get AI feedback on:
# - Code quality issues
# - Security concerns
# - Best practice violations
```
### Track your usage
```bash
# Check remaining credits
gitsmart usage
# Output:
# Credits Usage — 2026-02
# Plan Free
# Period 2026-02
# Used 15 / 250 credits
# Remaining 235
# ██░░░░░░░░░░░░░░░░░░
```
## Troubleshooting
### "No API key configured"
Run `gitsmart configure` to set up your API key.
### "Not inside a git repository"
Commands like `commit`, `review`, and `analyze` must be run inside a git repository.
### "Invalid language code"
Use ISO 639-1 language codes (2 letters). Examples: `en`, `es`, `uk`, `de`, `fr`, `ja`
### "Rate limit exceeded"
You've reached your monthly credit limit. Upgrade your plan at [gitsmart.io](https://gitsmart.io)
## Development
```bash
# Clone repository
git clone https://github.com/Alex-Stulen/gitsmart-cli.git
cd gitsmart-cli/cli
# Create virtual environment
python -m venv .venv
source .venv/bin/activate # or .venv\Scripts\activate on Windows
# Install in development mode
pip install -e .
# Run CLI
gitsmart --help
```
## Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
## License
MIT © 2026 Oleksii Stulen
## Links
- 🌐 Website: [gitsmart.io](https://gitsmart.io)
- 📦 PyPI: [pypi.org/project/gitsmart](https://pypi.org/project/gitsmart)
- 🐙 GitHub: [Alex-Stulen/gitsmart-cli](https://github.com/Alex-Stulen/gitsmart-cli)
- 📧 Support: s.gitsmart@gmail.com
---
⭐ **Star us on GitHub** if you find GitSmart useful!
| text/markdown | null | Alex Stulen <ookno16@gmail.com> | null | null | MIT | null | [
"Development Status :: 2 - Pre-Alpha",
"Environment :: Console",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
... | [] | null | null | >=3.8 | [] | [] | [] | [
"click>=8.0.0",
"gitpython>=3.1",
"httpx>=0.23",
"pycountry>=24.0",
"pyyaml>=6.0",
"rich>=12.0"
] | [] | [] | [] | [
"Homepage, https://github.com/Alex-Stulen/gitsmart-cli",
"Repository, https://github.com/Alex-Stulen/gitsmart-cli",
"Issues, https://github.com/Alex-Stulen/gitsmart-cli/issues"
] | twine/6.2.0 CPython/3.12.12 | 2026-02-19T00:54:55.007188 | gitsmart-1.0.0.tar.gz | 37,526 | 1f/c9/929655d53535322a0f678110b80ec9952761bc69fe66c6404bd8402ca16b/gitsmart-1.0.0.tar.gz | source | sdist | null | false | d99b945363547ef232475d0878fc9716 | 0645c7db0fae4cb60fefdba06f61bc13c8c1572f2027adaea2fee76ffa5d9cb2 | 1fc9929655d53535322a0f678110b80ec9952761bc69fe66c6404bd8402ca16b | null | [
"LICENSE"
] | 238 |
2.4 | clawmetry | 0.9.16 | ClawMetry - Real-time observability dashboard for OpenClaw AI agents | # 🦞 ClawMetry
[](https://pypi.org/project/clawmetry/)
[](https://opensource.org/licenses/MIT)
[](https://github.com/vivekchand/clawmetry/stargazers)
**See your agent think.** Real-time observability for [OpenClaw](https://github.com/openclaw/openclaw) AI agents.
One command. Zero config. Auto-detects everything.
```bash
pip install clawmetry && clawmetry
```
Opens at **http://localhost:8900** and you're done.
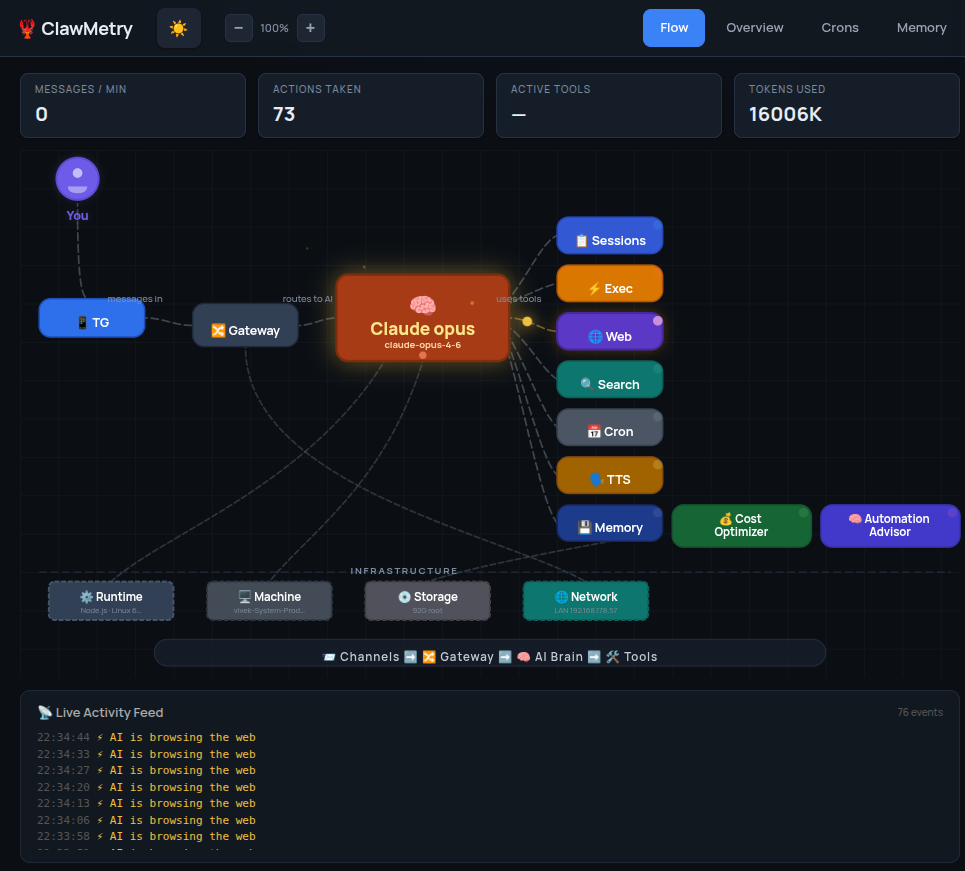
## What You Get
- **Flow** — Live animated diagram showing messages flowing through channels, brain, tools, and back
- **Overview** — Health checks, activity heatmap, session counts, model info
- **Usage** — Token and cost tracking with daily/weekly/monthly breakdowns
- **Sessions** — Active agent sessions with model, tokens, last activity
- **Crons** — Scheduled jobs with status, next run, duration
- **Logs** — Color-coded real-time log streaming
- **Memory** — Browse SOUL.md, MEMORY.md, AGENTS.md, daily notes
- **Transcripts** — Chat-bubble UI for reading session histories
## Screenshots
| Flow | Overview | Sub-Agent |
|------|----------|-----------|
|  | 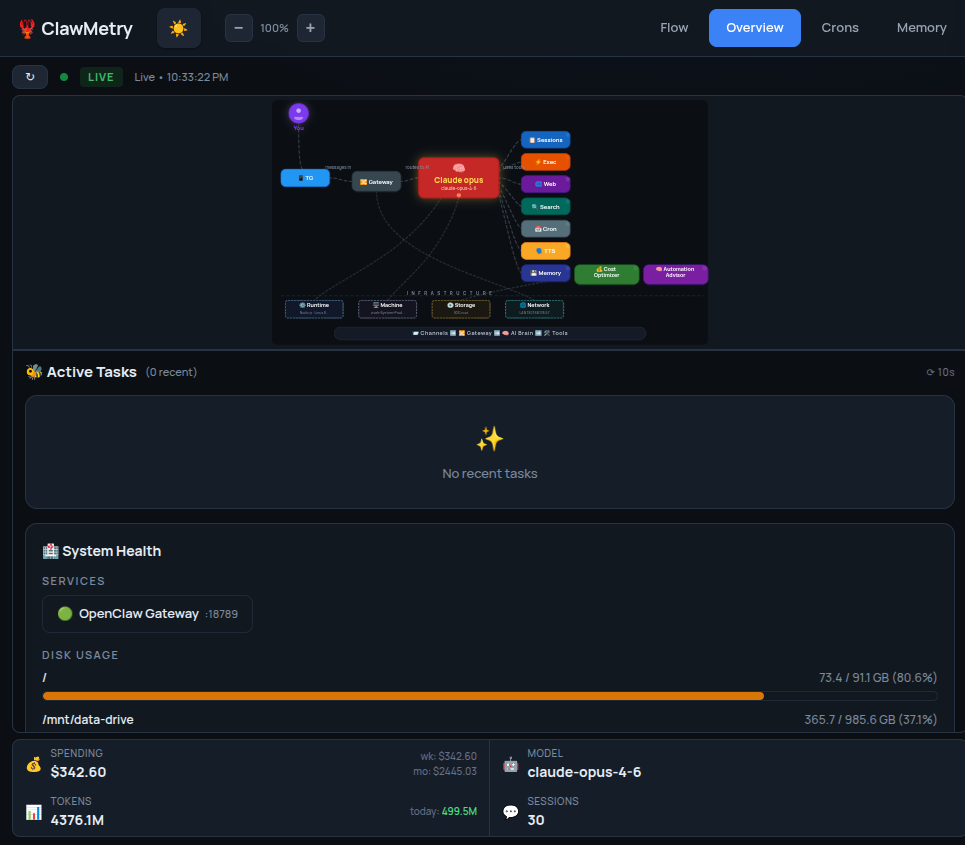 | 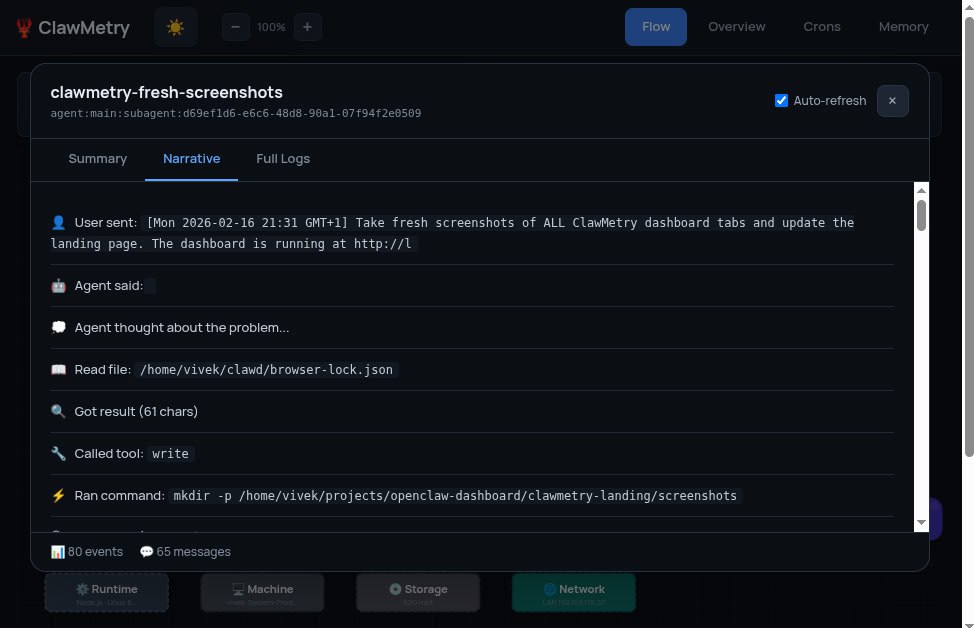 |
| Summary | Crons | Memory |
|---------|-------|--------|
| 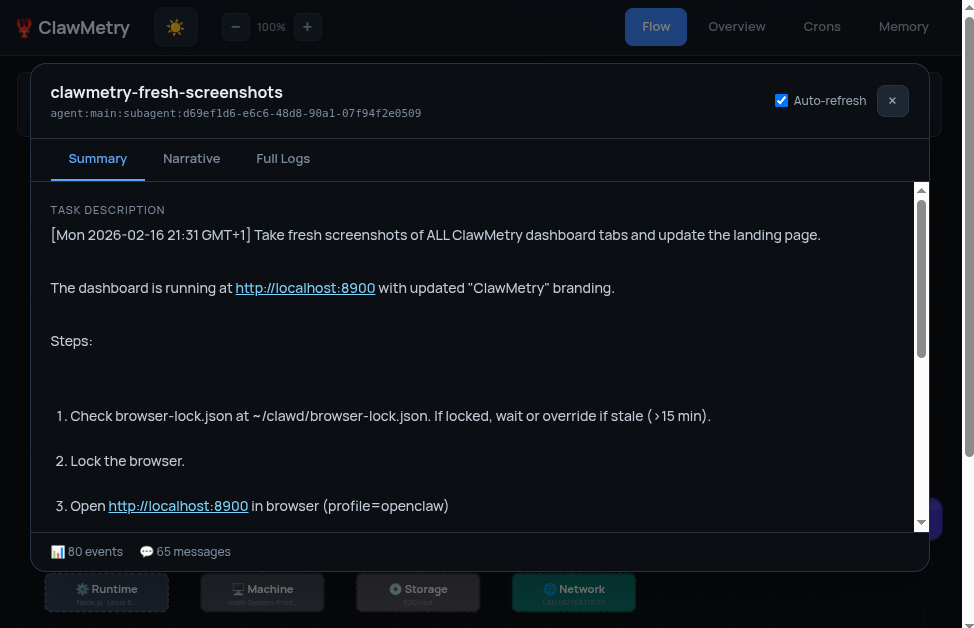 | 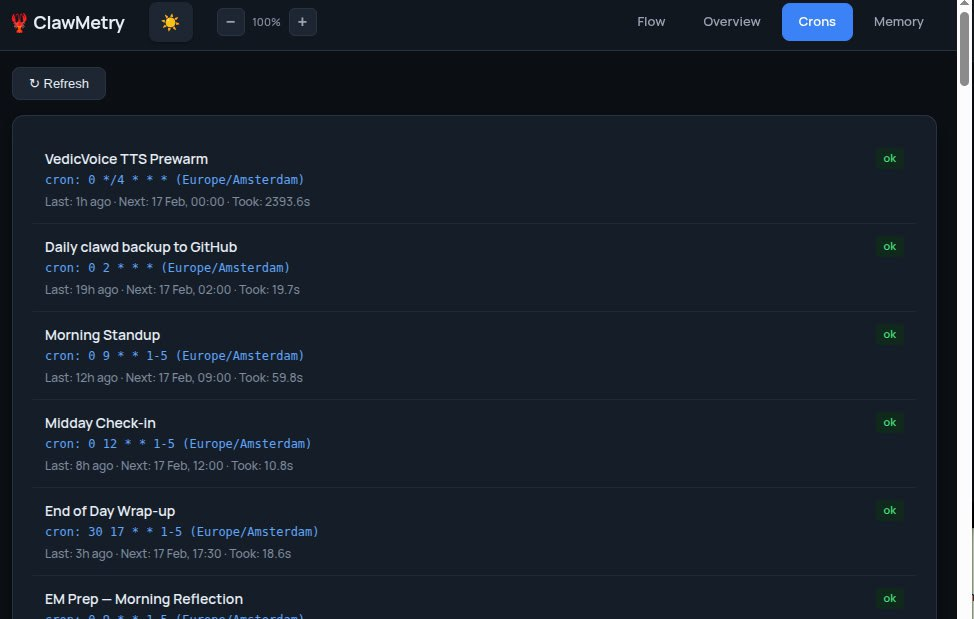 | 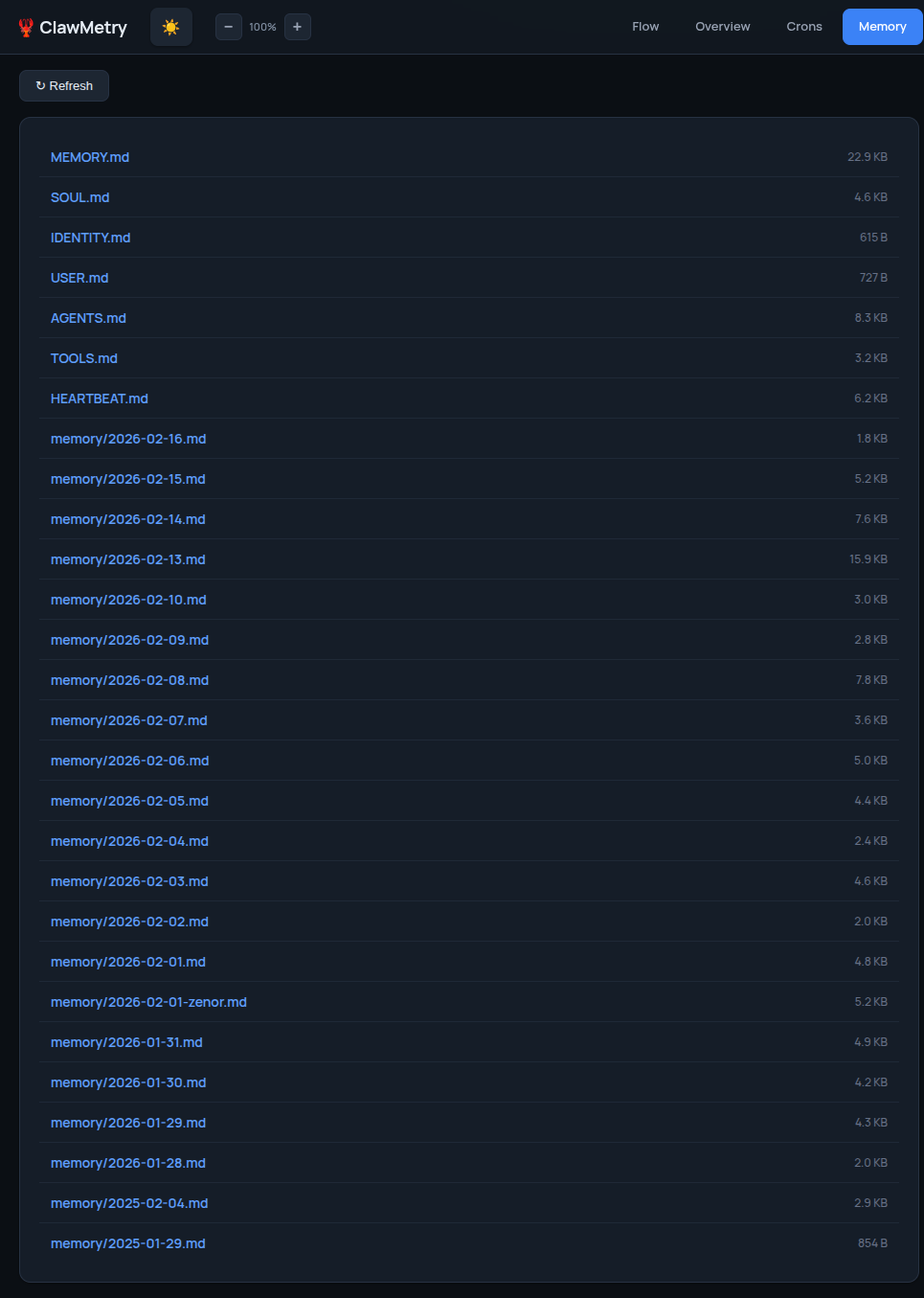 |
## Install
**pip (recommended):**
```bash
pip install clawmetry
clawmetry
```
**One-liner:**
```bash
curl -sSL https://raw.githubusercontent.com/vivekchand/clawmetry/main/install.sh | bash
```
**From source:**
```bash
git clone https://github.com/vivekchand/clawmetry.git
cd clawmetry && pip install flask && python3 dashboard.py
```
## Configuration
Most people don't need any config. ClawMetry auto-detects your workspace, logs, sessions, and crons.
If you do need to customize:
```bash
clawmetry --port 9000 # Custom port (default: 8900)
clawmetry --host 127.0.0.1 # Bind to localhost only
clawmetry --workspace ~/mybot # Custom workspace path
clawmetry --name "Alice" # Your name in Flow visualization
```
All options: `clawmetry --help`
## Requirements
- Python 3.8+
- Flask (installed automatically via pip)
- OpenClaw running on the same machine
- Linux or macOS
## Cloud Deployment
See the **[Cloud Testing Guide](docs/CLOUD_TESTING.md)** for SSH tunnels, reverse proxy, and Docker.
## License
MIT
---
<p align="center">
<strong>🦞 See your agent think</strong><br>
<sub>Built by <a href="https://github.com/vivekchand">@vivekchand</a> · <a href="https://clawmetry.com">clawmetry.com</a> · Part of the <a href="https://github.com/openclaw/openclaw">OpenClaw</a> ecosystem</sub>
</p>
| text/markdown | Vivek Chand | vivek@openclaw.dev | null | null | MIT | clawmetry openclaw moltbot dashboard observability ai agent monitoring opentelemetry | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Pyt... | [] | https://github.com/vivekchand/clawmetry | null | >=3.8 | [] | [] | [] | [
"flask>=2.0",
"opentelemetry-proto>=1.20.0; extra == \"otel\"",
"protobuf>=4.21.0; extra == \"otel\""
] | [] | [] | [] | [
"Homepage, https://clawmetry.com",
"Bug Reports, https://github.com/vivekchand/clawmetry/issues",
"Source, https://github.com/vivekchand/clawmetry"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T00:54:39.489390 | clawmetry-0.9.16.tar.gz | 127,327 | 61/3f/26a594128417214d22edbd859a663d297337150c2ea27812b2c8a6375f94/clawmetry-0.9.16.tar.gz | source | sdist | null | false | 4a819e0b40a3269a4710f083c5a21777 | d58ded9c6e020dd991e4ac4e47c3b0dcc745065b364e494b31acd5e352bb9b23 | 613f26a594128417214d22edbd859a663d297337150c2ea27812b2c8a6375f94 | null | [
"LICENSE"
] | 733 |
2.4 | js-api | 0.2.57 | Custom API written in Python using FastAPI | # API
This is a custom API, written in Python using FastAPI, to help me accomplish tasks the can be improved through a RESTful API
## Setup
Simplest setup is to start from [compose.yml](https://github.com/jnstockley/api/blob/dev/compose.yml) and [template.env](https://github.com/jnstockley/api/blob/dev/template.env), which should be renamed to `.env`
### Environment Vairables
- `API_KEY` - Any long, random string. Keep this secret as this is the only form of authentication for the API. All routes require it, except `/health-check/`
- `DATABASE_URL` - The URL to connect to postgres DB. Must start with `postgresql+psycopg://`. Should be in the format specifiec in [template.env](https://github.com/jnstockley/api/blob/dev/template.env)
- `TZ` - Timezone of the container
- `PGTZ` - Timezone the Postgres container should use
## How to Access
Using the [compose.yml](https://github.com/jnstockley/api/blob/dev/compose.yml) file, you can access the API at `http://<IP>:5000/health-check`. If everything is setup correctly, you should see `{"status":"ok"}`
| text/markdown | null | Jack Stockley <jack@jstockley.com> | null | null | null | starter, template, python | [
"Programming Language :: Python :: 3"
] | [] | null | null | <4.0,>=3.13 | [] | [] | [] | [
"fastapi[standard]==0.129.0",
"sqlalchemy==2.0.46",
"sqlmodel==0.0.34",
"python-dotenv==1.2.1",
"psycopg[binary]>=3.3.3"
] | [] | [] | [] | [
"Homepage, https://github.com/jnstockley/api",
"Repository, https://github.com/jnstockley/api.git",
"Issues, https://github.com/jnstockley/api/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:54:16.033836 | js_api-0.2.57.tar.gz | 20,485 | 95/92/381569b3d96dc3107f7ccd70faee4f0600435fad9050c09c2b78ba84e8a5/js_api-0.2.57.tar.gz | source | sdist | null | false | 4914584c65e142be3875380d3b699716 | d8a4906c001fbcae317e3d610657e64d23a00e20f6bd4f8c4e19ffa762bfd5f6 | 9592381569b3d96dc3107f7ccd70faee4f0600435fad9050c09c2b78ba84e8a5 | null | [
"LICENSE"
] | 233 |
2.4 | oligopool | 2026.2.18 | Oligopool Calculator - Automated design and analysis of oligo pool libraries | <h1 align="center">
<a href="https://github.com/ayaanhossain/oligopool/" style="text-decoration: none !important;">
<img src="https://raw.githubusercontent.com/ayaanhossain/repfmt/main/oligopool/img/logo.svg" alt="Oligopool Calculator" width="460" class="center"/>
</a>
</h1>
<h4><p align="center">Version: 2026.02.18</p></h4>
<p align="center">
<a href="#features" style="text-decoration: none !important;">✨ Features</a> -
<a href="#installation" style="text-decoration: none !important;">📦 Installation</a> -
<a href="#getting-started" style="text-decoration: none !important;">🚀 Getting Started</a> -
<a href="https://github.com/ayaanhossain/oligopool/blob/master/docs/docs.md" style="text-decoration: none !important;">📚 Docs</a> -
<a href="https://github.com/ayaanhossain/oligopool/blob/master/docs/api.md" style="text-decoration: none !important;">📋 API</a> -
<a href="#command-line-interface-cli" style="text-decoration: none !important;">💻 CLI</a> -
<a href="#citation" style="text-decoration: none !important;">📖 Citation</a> -
<a href="#license" style="text-decoration: none !important;">⚖️ License</a>
</p>
`Oligopool Calculator` is a Swiss-army knife for [oligo pool libraries](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9300125/): a unified toolkit for high-throughput design, assembly, compression, and analysis of massively parallel assays, designed to integrate seamlessly with Python, the CLI, Jupyter, containers, and AI-assisted workflows.
Design modules generate primers, barcodes, motifs/anchors, and spacers; assembly modules split/pad long constructs; Degenerate Mode compresses similar sequences into IUPAC-degenerate oligos for cost-efficient synthesis (often useful for selection assays); and Analysis Mode packs and counts barcoded reads for activity quantification.
`Oligopool Calculator` has been used to build libraries of tens of thousands of promoters (see [here](https://www.nature.com/articles/s41467-022-32829-5), and [here](https://www.nature.com/articles/s41587-020-0584-2)), ribozymes, and mRNA stability elements (see [here](https://www.nature.com/articles/s41467-024-54059-7)). It has been benchmarked to design pools containing millions of oligos and to process hundreds of millions of sequencing reads per hour on low-cost desktop-grade hardware.
To learn more, please check out [our paper in ACS Synthetic Biology](https://pubs.acs.org/doi/10.1021/acssynbio.4c00661).
<h1 align="center">
<a href="https://github.com/ayaanhossain/oligopool/" style="text-decoration: none !important;">
<img src="https://raw.githubusercontent.com/ayaanhossain/repfmt/refs/heads/main/oligopool/img/workflow.svg" alt="Oligopool Calculator Workflow" width="3840" class="center"/>
</a>
</h1>
**Design and analysis of oligo pool variants using `Oligopool Calculator`.** **(a)** In `Design Mode`, `Oligopool Calculator` generates optimized `barcode`s, `primer`s, `spacer`s, and `motif`s. `Assembly Mode` can `split` longer oligos into shorter `pad`ded fragments for synthesis and assembly. `Degenerate Mode` can `compress` similar variants into IUPAC-degenerate oligos for cost-efficient synthesis or selection-based discovery workflows. **(b)** Once the library is assembled and cloned, barcoded amplicon sequencing data can be processed via `Analysis Mode` for characterization. `Analysis Mode` proceeds by first `index`ing one or more sets of barcodes, `pack`ing the reads, and then producing count matrices either using `acount` (association counting) or `xcount` (combinatorial counting).
<a id="features"></a>
## ✨ Features
- 🧬 **Design mode:** constraint-based design of barcodes, primers, motifs/anchors, and spacers with background screening and utilities (`barcode`, `primer`, `motif`, `spacer`, `background`, `merge`, `revcomp`, `join`, `final`).
- 🔧 **Assembly mode:** fragment long oligos into overlapping pieces and add Type IIS primer pads for scarless assembly (`split`, `pad`).
- 🧪 **Degenerate mode:** compress variant libraries with low mutational diversity into IUPAC-degenerate oligos for cost-efficient synthesis and selection-based characterization (`compress`, `expand`).
- 📈 **Analysis mode:** fast NGS-based activity quantification with read indexing, packing, and barcode/associate counting (`index`, `pack`, `acount`, `xcount`) extensible with callback methods (via Python library).
- ✅ **QC mode:** validate and inspect constraints and outputs (`lenstat`, `verify`, `inspect`).
- 🔁 **Iterative & multiplexed workflows:** `patch_mode` for extending existing pools, cross-set barcode separation, and per-group primer design with cross-compatibility screening.
- ⚡ **Performance:** scalable to very large libraries and high-throughput sequencing datasets, with published benchmarks demonstrating efficient design and analysis on commodity hardware (see paper).
- 🔒 **Rich constraints:** IUPAC sequence constraints, motif exclusion, repeat screening, Hamming-distance barcodes, and primer thermodynamic constraints (including optional paired-primer Tm matching).
- 📊 **DataFrame-centric:** modules operate on CSV/DataFrames and return updated tables plus `stats`; the CLI can emit JSON and supports reproducible stochastic runs (`random_seed`).
- 💻 **CLI + library-first:** full-featured command-line interface with YAML config files, multi-step pipelines (sequential or parallel DAG), **and** a composable Python API for interactive use in scripts and Jupyter notebooks.
- 🤖 **AI-assisted design:** agent-ready documentation for Claude, ChatGPT, and Copilot.
<a id="ai-assisted-design"></a>
## 🤖 AI-Assisted Design
`Oligopool Calculator` is optimized for AI-assisted workflows. Either share the [`docs/agent-skills.md`](https://github.com/ayaanhossain/oligopool/blob/master/docs/agent-skills.md) file with your agent, or share the following raw URL along with a suitable prompt, for direct parsing.
```
https://raw.githubusercontent.com/ayaanhossain/oligopool/refs/heads/master/docs/agent-skills.md
```
Ensure that your AI/agent explores this document thoroughly. Afterwards, you can chat about the package, your specific design goals, and have the agent plan and execute the design and analysis pipelines.
<a id="installation"></a>
## 📦 Installation
`Oligopool Calculator` is a `Python 3.10+`-exclusive library.
On `Linux`, `macOS`, and `Windows Subsystem for Linux`, you can install `Oligopool Calculator` from [PyPI](https://pypi.org/project/oligopool/), where it is published as the `oligopool` package.
```bash
$ pip install --upgrade oligopool # Installs and/or upgrades oligopool
```
This also installs the command line tools: `oligopool` and `op`.
Or install it directly from GitHub:
```bash
$ pip install git+https://github.com/ayaanhossain/oligopool.git
```
Both approaches should install all dependencies automatically.
> **Note** The GitHub version will always be updated with all recent fixes. The PyPI version should be more stable.
If you are on `Windows` or simply prefer to, `Oligopool Calculator` can also be used via `Docker` (please see [the notes](https://github.com/ayaanhossain/oligopool/blob/master/docs/docker-notes.md)).
Successful installation will look like this.
```python
$ python
>>> import oligopool as op
>>> op.__version__
'2026.02.18'
>>>
```
<a id="getting-started"></a>
## 🚀 Getting Started
`Oligopool Calculator` is carefully designed, easy to use, and stupid fast.
You can import the library and use its various functions either in a script or interactively inside a `Jupyter` environment. Use `help(...)` to read the docs as necessary and follow along.
The [`examples`](https://github.com/ayaanhossain/oligopool/tree/master/examples) directory includes a [design parser](https://github.com/ayaanhossain/oligopool/tree/master/examples/design-assembly-parser), a [library compressor](https://github.com/ayaanhossain/oligopool/tree/master/examples/library-compressor), an [analysis pipeline](https://github.com/ayaanhossain/oligopool/tree/master/examples/analysis-pipeline), and a complete [CLI YAML pipeline](https://github.com/ayaanhossain/oligopool/tree/master/examples/cli-yaml-pipeline).
If you want the full end-to-end walkthrough, start with the notebook: [`Oligopool Calculator` in action](https://github.com/ayaanhossain/oligopool/blob/master/examples/OligopoolCalculatorInAction.ipynb).
**Documentation:**
- [User Guide](https://github.com/ayaanhossain/oligopool/blob/master/docs/docs.md) - Comprehensive tutorials, examples, and workflows
- [API Reference](https://github.com/ayaanhossain/oligopool/blob/master/docs/api.md) - Complete parameter documentation for all modules
- [AI Agent Guide](https://github.com/ayaanhossain/oligopool/blob/master/docs/agent-skills.md) - Decision trees, best practices, and gotchas for AI-assisted design (Claude, ChatGPT, Copilot)
- [Docker Guide](https://github.com/ayaanhossain/oligopool/blob/master/docs/docker-notes.md) - Run `oligopool` in a container for cross-platform consistency
```python
$ python
>>>
>>> import oligopool as op
>>> help(op)
...
Automated design and analysis of oligo pool libraries for
high-throughput genomics and synthetic biology applications.
Design Mode - build synthesis-ready oligo architectures
barcode orthogonal barcodes with Hamming distance guarantees
primer Tm-optimized primers with off-target screening
motif sequence motifs or anchors
spacer neutral fill to reach target length
background k-mer database for off-target screening
merge collapse columns into single element
revcomp reverse complement a column range
join join two tables on ID with ordered insertion
final concatenate into synthesis-ready oligos
Assembly Mode - fragment long oligos for assembly
split fragment oligos into overlapping pieces
pad Type IIS primer pads for scarless excision
Degenerate Mode - compress variant libraries for synthesis
compress reduce similar variants to IUPAC-degenerate oligos
expand expand IUPAC-degenerate oligos into concrete sequences
Analysis Mode - quantify variants from NGS reads
index index barcodes and associated variants
pack filter/merge/deduplicate FastQ reads
acount association counting (barcode + variant verification)
xcount combinatorial counting (single or multiple barcodes)
QC Mode - validate and inspect outputs
lenstat length statistics and free-space check
verify verify length, motif, and background conflicts
inspect inspect background/index/pack artifacts
Advanced
vectorDB ShareDB k-mer storage
Scry 1-NN barcode classifier
Usage
>>> import oligopool as op
>>> df, stats = op.barcode(input_data='variants.csv', ...)
>>> help(op.barcode) # module docs
Modules return (DataFrame, stats). Chain them iteratively; use patch_mode=True
to extend pools without overwriting existing designs.
CLI: `op` | `op COMMAND` | Docs: https://github.com/ayaanhossain/oligopool
...
```
<a id="command-line-interface-cli"></a>
## 💻 Command Line Interface (CLI)
The `oligopool` package installs a CLI with two equivalent entry points: `oligopool` and `op`.
```bash
$ op
$ op cite
$ op manual
$ op manual topics
$ oligopool manual barcode
```
Run `op` with no arguments to see the command list, and run `op COMMAND` to see command-specific options.
```bash
$ op
oligopool v2026.02.18
by ah
Oligopool Calculator is a suite of algorithms for
automated design and analysis of oligo pool libraries.
usage: oligopool COMMAND --argument=<value> ...
COMMANDS Available:
manual show module documentation
cite show citation information
pipeline execute multi-step pipeline from config
barcode orthogonal barcodes with cross-set separation
primer thermodynamic primers with optional Tm matching
motif design or add motifs/anchors
spacer neutral spacers to meet length targets
background build k-mer background database
split break long oligos into overlapping fragments
pad add excisable primer pads for scarless assembly
merge collapse contiguous columns
revcomp reverse-complement a column range
join join two oligo pool tables on ID
lenstat compute length stats and free space
verify detect length, motif, and background conflicts
final finalize into synthesis-ready oligos
compress compress sequences into IUPAC-degenerate oligos
expand expand IUPAC oligos to concrete sequences
index build barcode/associate index
pack preprocess and deduplicate FastQ reads
acount association counting (single index)
xcount combinatorial counting (multiple indexes)
inspect inspect non-CSV artifacts
complete print or install shell completion
Run "oligopool COMMAND" to see command-specific options.
```
Install tab-completion to blaze through interactive CLI use (recommended).
```bash
$ op complete --install # auto-detect shell (restart your shell)
$ op complete --install bash # or: zsh|fish
```
For detailed CLI behavior (output basenames, suffixing, type aliases, sequence-constraint shorthand, and split output defaults), see the [CLI-Specific Notes](https://github.com/ayaanhossain/oligopool/blob/master/docs/docs.md#cli-specific-notes).
### YAML Pipelines
Define entire workflows in a single YAML config file and execute with one command:
```bash
$ op pipeline --config pipeline.yaml
$ op pipeline --config pipeline.yaml --dry-run # validate first
```
Pipelines support sequential or parallel DAG execution, where independent steps run concurrently.
Example (single design output, serial chain):
```yaml
pipeline:
name: "MPRA Design (Serial)"
steps:
- primer
- barcode
- spacer
- final
primer:
input_data: "variants.csv"
output_file: "01_primer"
primer_type: forward
# ...
```
Example (parallel DAG, best fit for analysis):
```yaml
pipeline:
name: "Counting DAG (Parallel)"
steps:
- name: index_bc1
command: index
- name: index_bc2
command: index
- name: pack_reads
command: pack
- name: count
command: xcount
after: [index_bc1, index_bc2, pack_reads]
# (Configs for index/pack/xcount omitted here for brevity.)
```
Working examples live in `examples/cli-yaml-pipeline`. Full pipeline rules live in [Config Files](https://github.com/ayaanhossain/oligopool/blob/master/docs/docs.md#config-files).
<a id="citation"></a>
## 📖 Citation
If you use `Oligopool Calculator` in your research publication, please cite our paper.
```
Hossain A, Cetnar DP, LaFleur TL, McLellan JR, Salis HM.
Automated Design of Oligopools and Rapid Analysis of Massively Parallel Barcoded Measurements.
ACS Synth Biol. 2024;13(12):4218-4232. doi:10.1021/acssynbio.4c00661
```
BibTeX:
```bibtex
@article{Hossain2024Oligopool,
title = {Automated Design of Oligopools and Rapid Analysis of Massively Parallel Barcoded Measurements},
author = {Hossain, Ayaan and Cetnar, Daniel P. and LaFleur, Travis L. and McLellan, James R. and Salis, Howard M.},
journal = {ACS Synthetic Biology},
year = {2024},
volume = {13},
number = {12},
pages = {4218--4232},
doi = {10.1021/acssynbio.4c00661}
}
```
You can read the paper online for free at [ACS Synthetic Biology](https://doi.org/10.1021/acssynbio.4c00661).
* PMCID: `PMC11669329`
* PMID: `39641628`
<a id="license"></a>
## ⚖️ License
`Oligopool Calculator` (c) 2026 Ayaan Hossain.
`Oligopool Calculator` is an **open-source software** under the [GPL-3.0](https://opensource.org/license/gpl-3-0) license.
See [LICENSE](https://github.com/ayaanhossain/oligopool/blob/master/LICENSE) file for more details.
| text/markdown | null | Ayaan Hossain <auh57@psu.edu>, Howard Salis <salis@psu.edu> | null | null | null | oligopool, oligopools, oligopool-calculator, oligonucleotide, oligonucleotides, dna, synthetic, synthetic-biology, computational, biology, bioinformatics, genomics, high-throughput, nucleotide, oligo, pool, calculator, design, analysis, library, libraries, foundry, barcode, barcoded, primer, spacer, motif, reverse-complement, split, pad, assembly, gibson, gibson-assembly, golden-gate, golden-gate-assembly, type-iis, combinatorial, index, pack, fastq, ngs, sequencing, mpra, massively-parallel, scry, classifier, count, acount, xcount, cli | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Bio-Informatics",
"Topic :: Scientific/Engineering :: Chemistry",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Progr... | [] | null | null | <4,>=3.10 | [] | [] | [] | [
"biopython>=1.84",
"primer3-py>=2.0.3",
"msgpack>=1.1.0",
"pyfastx>=2.1.0",
"edlib>=1.3.9.post1",
"parasail>=1.3.4",
"nrpcalc>=1.7.0",
"sharedb>=1.1.2",
"numba>=0.60.0",
"seaborn>=0.13.2",
"multiprocess>=0.70.17",
"argcomplete>=3.2.3",
"pyyaml>=6.0"
] | [] | [] | [] | [
"Homepage, https://github.com/ayaanhossain/oligopool",
"Documentation, https://github.com/ayaanhossain/oligopool/blob/master/docs/docs.md",
"BugReports, https://github.com/ayaanhossain/oligopool/issues",
"Source, https://github.com/ayaanhossain/oligopool/tree/master/oligopool"
] | twine/6.2.0 CPython/3.10.12 | 2026-02-19T00:53:00.376042 | oligopool-2026.2.18.tar.gz | 255,320 | bd/26/dce520eb2d102ae99b12271d6cdae64d5ca465fd9ebdda5dadc3d16b094e/oligopool-2026.2.18.tar.gz | source | sdist | null | false | 32e2b308a5d21624447638e174cf0662 | de8b87fb36ac6e4ba11430a6c99c46f204095a0a3b6b8d327c5dfb355baedd1c | bd26dce520eb2d102ae99b12271d6cdae64d5ca465fd9ebdda5dadc3d16b094e | GPL-3.0-only | [
"LICENSE"
] | 232 |
2.4 | assertical | 0.3.2 | Assertical - a modular library for helping write (async) integration/unit tests for fastapi/sqlalchemy/postgres projects | # Assertical (assertical)
Assertical is a library for helping write (async) integration/unit tests for fastapi/postgres/other projects. It has been developed by the Battery Storage and Grid Integration Program (BSGIP) at the Australian National University (https://bsgip.com/) for use with a variety of our internal libraries/packages.
It's attempting to be lightweight and modular, if you're not using `pandas` then just don't import the pandas asserts.
Contributions/PR's are welcome
## Example Usage
### Generating Class Instances
Say you have an SQLAlchemy model (the below also supports dataclasses, pydantic models and any type that expose its properties/types at runtime)
```
class Student(DeclarativeBase):
student_id: Mapped[int] = mapped_column(INTEGER, primary_key=True)
date_of_birth: Mapped[datetime] = mapped_column(DateTime)
name_full: Mapped[str] = mapped_column(VARCHAR(128))
name_preferred: Mapped[Optional[str]] = mapped_column(VARCHAR(128), nullable=True)
height: Mapped[Optional[Decimal]] = mapped_column(DECIMAL(7, 2), nullable=True)
weight: Mapped[Optional[Decimal]] = mapped_column(DECIMAL(7, 2), nullable=True)
```
Instead of writing the following boilerplate in your tests:
```
def test_my_insert():
# Arrange
s1 = Student(student_id=1, date_of_birth=datetime(2014, 1, 25), name_full="Bobby Tables", name_preferred="Bob", height=Decimal("185.5"), weight=Decimal("85.2"))
s2 = Student(student_id=2, date_of_birth=datetime(2015, 9, 23), name_full="Carly Chairs", name_preferred="CC", height=Decimal("175.5"), weight=Decimal("65"))
# Act ...
```
It can be simplified to:
```
def test_my_insert():
# Arrange
s1 = generate_class_instance(Student, seed=1)
s2 = generate_class_instance(Student, seed=2)
# Act ...
```
Which will generate two instances of Student with every property being set with appropriately typed values and unique values. Eg s1/s2 will be proper `Student` instances with values like:
| field | s1 | s2 |
| ----- | -- | -- |
| student_id | 5 (int) | 6 (int) |
| date_of_birth | '2010-01-02T00:00:01Z' (datetime) | '2010-01-03T00:00:02Z' (datetime) |
| name_full | '3-str' (str) | '4-str' (str) |
| name_preferred | '4-str' (Decimal) | '5-str' (Decimal) |
| height | 2 (Decimal) | 3 (Decimal) |
| weight | 6 (Decimal) | 7 (Decimal) |
Passing property name/values via kwargs is also supported :
`generate_class_instance(Student, seed=1, height=Decimal("12.34"))` will generate a `Student` instance similar to `s1` above but where `height` is `Decimal("12.34")`
You can also control the behaviour of `Optional` properties - by default they will populate with the full type but using `generate_class_instance(Student, optional_is_none=True)` will generate a `Student` instance where `height`, `weight` and `name_preferred` are `None`.
Finally, say we add the following "child" class `TestResult`:
```
class TestResult(DeclarativeBase):
test_result_id = mapped_column(INTEGER, primary_key=True)
student_id: Mapped[int] = mapped_column(INTEGER)
class: Mapped[str] = mapped_column(VARCHAR(128))
grade: Mapped[str] = mapped_column(VARCHAR(8))
```
And assuming `Student` has a property `all_results: Mapped[list[TestResult]]`. `generate_class_instance(Student)` will NOT supply a value for `all_results`. But by setting `generate_class_instance(Student, generate_relationships=True)` the generation will recurse into any generatable / list of generatable type instances.
#### Registering New Types
By default a number of common types / base classes will be registered but these can be extended with:
`assertical.fake.generator.register_value_generator(t, gen)` allows you to register a function that can generate an instance of type t given an integer seed value. The following example registers `MyType` so that other classes can have a property `my_type: Optional[MyType]` and have the values generated according to the supplied generator function:
```
class MyType:
val: int
def __init__(self, val):
self.val = val
register_value_generator(MyType, lambda seed: MyType(seed))
```
`assertical.fake.generator.register_base_type(base_t, generate_instance, list_members)` allows you to register a base type so that instances of subclasses of this base type can be generated using `generate_class_instance`. For example, the following registers a more complex type:
```
class MyBaseType:
def __init__(self):
pass
class MyComplexType(MyBaseType):
id: int
name: str
def __init__(self, id, name):
super.__init__()
self.id = id
self.name = name
register_base_type(MyBaseType, DEFAULT_CLASS_INSTANCE_GENERATOR, DEFAULT_MEMBER_FETCHER)
```
**Note:** All registrations apply globally. If you plan on using tests that modify the registry in different ways, there is a fixture `assertical.fixtures.generator.generator_registry_snapshot` that provides a context manager that will preserve and reset the global registry between tests.
eg:
```
def test_function()
with generator_registry_snapshot():
register_value_generator(MyPrimitiveType, lambda seed: MyPrimitiveType(seed))
register_base_type(
MyBaseType,
DEFAULT_CLASS_INSTANCE_GENERATOR,
DEFAULT_MEMBER_FETCHER,
)
# Do test body
```
### Mocking HTTP AsyncClient
`MockedAsyncClient` is a duck typed equivalent to `from httpx import AsyncClient` that can be useful fo injecting into classes that depend on a AsyncClient implementation.
Example usage that injects a MockedAsyncClient that will always return a `HTTPStatus.NO_CONTENT` for all requests:
```
mock_async_client = MockedAsyncClient(Response(status_code=HTTPStatus.NO_CONTENT))
with mock.patch("my_package.my_module.AsyncClient") as mock_client:
# test body here
assert mock_client.call_count_by_method[HTTPMethod.GET] > 0
```
The constructor for `MockedAsyncClient` allows you to setup either constant or varying responses. Eg: by supplying a list of responses you can mock behaviour that changes over multiple requests.
Eg: This instance will raise an Exception, then return a HTTP 500 then a HTTP 200
```
MockedAsyncClient([
Exception("My mocked error that will be raised"),
Response(status_code=HTTPStatus.NO_CONTENT),
Response(status_code=HTTPStatus.OK),
])
```
Response behavior can also be also be specified per remote uri:
```
MockedAsyncClient({
"http://first.example.com/": [
Exception("My mocked error that will be raised"),
Response(status_code=HTTPStatus.NO_CONTENT),
Response(status_code=HTTPStatus.OK),
],
"http://second.example.com/": Response(status_code=HTTPStatus.NO_CONTENT),
})
```
### Environment Management
If you have tests that depend on environment variables, the `assertical.fixtures.environment` module has utilities to aid in snapshotting/restoring the state of the operating system environment variables.
Eg: This `environment_snapshot` context manager will snapshot the environment allowing a test to freely modify it and then reset everything to before the test run
```
import os
from assertical.fixtures.environment import environment_snapshot
def test_my_custom_test():
with environment_snapshot():
os.environ["MY_ENV"] = new_value
# Do test body
```
This can also be simplified by using a fixture:
```
@pytest.fixture
def preserved_environment():
with environment_snapshot():
yield
def test_my_custom_test_2(preserved_environment):
os.environ["MY_ENV"] = new_value
# Do test body
```
### Running Testing FastAPI Apps
FastAPI (or ASGI apps) can be loaded for integration testing in two ways with Assertical:
1. Creating a lightweight httpx.AsyncClient wrapper around the app instance
1. Running a full uvicorn instance
#### AsyncClient Wrapper
`assertical.fixtures.fastapi.start_app_with_client` will act as an async context manager that can wrap an ASGI app instance and yield a `httpx.AsyncClient` that will communicate directly with that app instance.
Eg: This fixture will start an app instance and tests can depend on it to start up a fresh app instance for every test
```
@pytest.fixture
async def custom_test_client():
app: FastApi = generate_app() # This is just a reference to a fully constructed instance of your FastApi app
async with start_app_with_client(app) as c:
yield c # c is an instance of httpx.AsyncClient
@pytest.mark.anyio
async def test_thing(custom_test_client: AsyncClient):
response = await custom_test_client.get("/my_endpoint")
assert response.status == 200
```
#### Full uvicorn instance
`assertical.fixtures.fastapi.start_uvicorn_server` will behave similar to the above `start_app_with_client` but it will start a full running instance of uvicorn that will tear down once the context manager is exited.
This can be useful if you need to not just test the ASGI behavior of the app, but also how it interacts with a "real" uvicorn instance. Perhaps your app has middleware playing around with the underlying starlette functionality?
Eg: This fixture will start an app instance (listening on a fixed address) and will return the base URI of that instance
```
@pytest.fixture
async def custom_test_uri():
app: FastApi = generate_app() # This is just a reference to a fully constructed instance of your FastApi app
async with start_uvicorn_server(app) as c:
yield c # c is uri like "http://127.0.0.1:12345"
@pytest.mark.anyio
async def test_thing(custom_test_uri: str):
client = AsyncClient()
response = await client.get(custom_test_uri + "/my_endpoint")
assert response.status == 200
```
### Assertion utilities
#### Generator assertical.asserts.generator.*
This package isn't designed to be a collection of all possible asserts, other packages handle that. What is included are a few useful asserts around typing
`assertical.asserts.generator.assert_class_instance_equality()` will allow the comparison of two objects, property by property using a class/type definition as the source of compared properties. Using the above earlier `Student` example:
```
s1 = generate_class_instance(Student, seed=1)
s1_dup = generate_class_instance(Student, seed=1)
s2 = generate_class_instance(Student, seed=2)
# This will raise an assertion error saying that certain Student properties don't match
assert_class_instance_equality(Student, s1, s2)
# This will NOT raise an assertion as each property will be the same value/type
assert_class_instance_equality(Student, s1, s1_dup)
# This will compare on all Student properties EXCEPT 'student_id'
assert_class_instance_equality(Student, s1, s1_dup, ignored_properties=set(['student_id]))
```
#### Time assertical.asserts.time.*
contains some utilities for comparing times in different forms (eg timestamps, datetimes etc)
For example, the following asserts that a timestamp or datetime is "roughly now"
```
dt1 = datetime(2023, 11, 10, 1, 2, 0)
ts2 = datetime(2023, 11, 10, 1, 2, 3).timestamp() # 3 seconds difference
ts2 = datetime(2023, 11, 10, 1, 2, 3).timestamp() # 3 seconds difference
assert_fuzzy_datetime_match(dt1, ts2, fuzziness_seconds=5) # This will pass (difference is <5 seconds)
assert_fuzzy_datetime_match(dt1, ts2, fuzziness_seconds=2) # This will raise (difference is >2 seconds)
```
#### Type collections assertical.asserts.type.*
`assertical.asserts.type` contains some utilities for asserting collections of types are properly formed.
For example, the following asserts that an instance is a list type, that only contains Student elements and that there are 5 total items.
```
my_custom_list = []
assert_list_type(Student, my_custom_list, count=5)
```
#### Pandas assertical.asserts.pandas.*
Contains a number of simple assertions for a dataframe for ensuring certain columns/rows exist
## Installation (for use)
`pip install assertical[all]`
## Installation (for dev)
`pip install -e .[all]`
## Modular Components
| **module** | **requires** |
| ---------- | ------------ |
| `asserts/generator` | `None`+ |
| `asserts/pandas` | `assertical[pandas]` |
| `fake/generator` | `None`+ |
| `fake/sqlalchemy` | `assertical[postgres]` |
| `fixtures/fastapi` | `assertical[fastapi]` |
| `fixtures/postgres` | `assertical[postgres]` |
+ No requirements are mandatory but additional types will be supported if `assertical[pydantic]`, `assertical[postgres]`, `assertical[xml]` are installed
All other types just require just the base `pip install assertical`
## Editors
### vscode
The file `vscode/settings.json` is an example configuration for vscode. To use these setting copy this file to `.vscode/settings,json`
The main features of this settings file are:
- Enabling flake8 and disabling pylint
- Autoformat on save (using the black and isort formatters)
Settings that you may want to change:
- Set the python path to your python in your venv with `python.defaultInterpreterPath`.
- Enable mypy by setting `python.linting.mypyEnabled` to true in settings.json.
| text/markdown | Battery Storage and Grid Integration Program | null | null | null | null | test, fastapi, postgres, sqlalchemy | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"Topic :: Software Development :: Testing",
"Framework :: FastAPI",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
... | [] | null | null | >=3.9 | [] | [] | [] | [
"pytest",
"pytest-asyncio",
"anyio",
"httpx",
"assertical[dev,fastapi,pandas,postgres,pydantic,xml]; extra == \"all\"",
"bandit; extra == \"dev\"",
"flake8; extra == \"dev\"",
"mypy; extra == \"dev\"",
"black; extra == \"dev\"",
"coverage; extra == \"dev\"",
"fastapi[standard]; extra == \"fastap... | [] | [] | [] | [
"Homepage, https://github.com/bsgip/assertical"
] | twine/6.2.0 CPython/3.12.11 | 2026-02-19T00:51:28.301282 | assertical-0.3.2.tar.gz | 28,909 | 93/24/6e5e6fc8d56c40b272c349643ef3f17280da9024a328dfdf866615a690e5/assertical-0.3.2.tar.gz | source | sdist | null | false | 4a7a5b480d7bd33adb509b4449f0fe13 | 4c558d0c53ee5428255826f75f4e5f6463ac4247a60b6f66cce3cbac78e48910 | 93246e5e6fc8d56c40b272c349643ef3f17280da9024a328dfdf866615a690e5 | null | [
"LICENSE.txt"
] | 323 |
2.4 | npfl139 | 2526.1.0 | Modules used by the Deep Reinforcement Learning Course NPFL139 | # The `npfl139` Package: Modules Used in the Deep Reinforcement Learning Course (NPFL139)
This package contains the modules used in the
[Deep Reinforcement Learning course (NPFL139)](http://ufal.mff.cuni.cz/courses/npfl139),
available under the Mozilla Public License 2.0.
| text/markdown | null | Milan Straka <straka@ufal.mff.cuni.cz> | null | null | MPL-2.0 | null | [
"License :: OSI Approved :: Mozilla Public License 2.0 (MPL 2.0)",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.11 | [] | [] | [] | [
"torch~=2.10.0",
"torchaudio~=2.10.0",
"torchvision~=0.25.0",
"gymnasium~=1.2.3",
"pygame-ce~=2.5.6",
"ufal.pybox2d~=2.3.10.5",
"matplotlib~=3.10.8"
] | [] | [] | [] | [
"Homepage, https://ufal.mff.cuni.cz/courses/npfl139",
"Repository, https://github.com/ufal/npfl139"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:51:05.402643 | npfl139-2526.1.0.tar.gz | 12,872 | 27/01/73e46c3df178d9d4ebe14ecb26d01e57ae6036b4d7ce075112411bc7a6af/npfl139-2526.1.0.tar.gz | source | sdist | null | false | b1b9e281e0d4949dc67d9b9cdfe4418b | efe8b4401fb1d485b787be91d00d85836a3735d5047da288a31f8d1c9813148f | 270173e46c3df178d9d4ebe14ecb26d01e57ae6036b4d7ce075112411bc7a6af | null | [
"npfl139/LICENSE"
] | 323 |
2.4 | totango | 0.4.1 | Totango Python tracking client | # totango-python
[](https://pypi.org/project/totango/)
[](https://pypi.org/project/totango/)
[](https://pypi.org/project/totango/)
[](https://github.com/gbourdin/totango-python/actions/workflows/ci.yml)
[](https://codecov.io/gh/gbourdin/totango-python)
Python client for Totango's HTTP tracking pixel API.
## Requirements
- Python 3.10+
- `requests`
## Installation
```bash
pip install totango
```
From source:
```bash
git clone git@github.com:gbourdin/totango-python.git
cd totango-python
pip install -e .
```
## Quick Usage
```python
import totango
tt = totango.Totango("SP-XXXX-XX", user_id="user-123")
tt.track("module", "action")
```
## Usage
```python
import totango
tt = totango.Totango(
"SP-XXXX-XX",
user_id="user-123",
user_name="Jane User",
account_id="acct-1",
account_name="Acme Inc",
)
# Track an activity event
tt.track("dashboard", "opened", user_opts={"plan": "gold"})
# Send an identify-style update without activity module/action
tt.send(account_opts={"tier": "enterprise"})
```
## Development
Run the default test suite:
```bash
python -m unittest discover -s tests -v
```
Run lint and type checks:
```bash
ruff check .
ty check .
```
Run the multi-version matrix with tox (3.10 through 3.15):
```bash
tox -e py310,py311,py312,py313,py314,py315
tox -e lint,type
```
Continuous integration also runs this matrix in GitHub Actions on each push and pull request.
| text/markdown | null | German Bourdin <admin@gbourdin.com> | null | null | Apache-2.0 | totango, tracking, analytics | [
"Development Status :: 4 - Beta",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programm... | [] | null | null | >=3.10 | [] | [] | [] | [
"requests>=2.31.0",
"ruff>=0.6.0; extra == \"dev\"",
"setuptools>=69; extra == \"dev\"",
"tox>=4.21.0; extra == \"dev\"",
"ty>=0.0.1a15; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/gbourdin/totango-python",
"Repository, https://github.com/gbourdin/totango-python",
"Issues, https://github.com/gbourdin/totango-python/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:50:15.844751 | totango-0.4.1.tar.gz | 5,114 | 2b/50/c60868f336484722ed8c1634921c14ce3b74be470cd5605022d5ab34c3bc/totango-0.4.1.tar.gz | source | sdist | null | false | aaef1467309e473481bbb878e6607d82 | 286229cca6526762eb71676906198ea8b5fec3eb4a222d9d3a5d86187dfe2d5f | 2b50c60868f336484722ed8c1634921c14ce3b74be470cd5605022d5ab34c3bc | null | [
"LICENSE",
"AUTHORS.rst"
] | 232 |
2.4 | sbb | 0.0.1 | A Software Package to Identify Putative Salt-Bridge-Building Mutation Sites | # salt_bridge_builder
Find putative mutation sites on multi-protein complexes.
| text/markdown | null | Jason Sanchez <jesanchez15@utep.edu> | null | Jason Sanchez <jesanchez15@utep.edu> | null | Electrostatics, Protein Engineering, Protein-Protein Interactions, Salt Bridges | [
"Development Status :: 4 - Beta",
"Programming Language :: Python"
] | [] | null | null | >=3.12 | [] | [] | [] | [
"numpy>=2",
"pandas>=3"
] | [] | [] | [] | [
"Repository, https://github.com/LiLabBioPhysics/salt_bridge_builder"
] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T00:49:31.743182 | sbb-0.0.1.tar.gz | 9,264 | 7a/8e/06918f5e7e997885e52ea8f2451a9b02eff15ecf43ebbc4cd57ad69ff6f2/sbb-0.0.1.tar.gz | source | sdist | null | false | d56778ec3b57f355c95f8600b60b3838 | a5407b7a76af3f78c9b2b76235f12633a0b301a330155dfc8e3710df5b8c20b1 | 7a8e06918f5e7e997885e52ea8f2451a9b02eff15ecf43ebbc4cd57ad69ff6f2 | MIT | [] | 235 |
2.4 | filelock | 3.24.3 | A platform independent file lock. | # filelock
[](https://pypi.org/project/filelock/)
[](https://pypi.org/project/filelock/)
[](https://py-filelock.readthedocs.io/en/latest/?badge=latest)
[](https://pepy.tech/project/filelock)
[](https://github.com/tox-dev/py-filelock/actions/workflows/check.yaml)
For more information checkout the [official documentation](https://py-filelock.readthedocs.io/en/latest/index.html).
| text/markdown | null | null | null | Bernát Gábor <gaborjbernat@gmail.com> | null | application, cache, directory, log, user | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Programming Language :: Python",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Lang... | [] | null | null | >=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Documentation, https://py-filelock.readthedocs.io",
"Homepage, https://github.com/tox-dev/py-filelock",
"Source, https://github.com/tox-dev/py-filelock",
"Tracker, https://github.com/tox-dev/py-filelock/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:48:20.543790 | filelock-3.24.3.tar.gz | 37,935 | 73/92/a8e2479937ff39185d20dd6a851c1a63e55849e447a55e798cc2e1f49c65/filelock-3.24.3.tar.gz | source | sdist | null | false | 36e7a9f26b6a358b13f68d6dc59b9147 | 011a5644dc937c22699943ebbfc46e969cdde3e171470a6e40b9533e5a72affa | 7392a8e2479937ff39185d20dd6a851c1a63e55849e447a55e798cc2e1f49c65 | MIT | [
"LICENSE"
] | 27,010,553 |
2.1 | sm_data_ml_utils | 1.0.4 | Common Python tools and utilities for ML work | # data-ml-utils
A utility python package that covers the common libraries we use
## Installation
This is an open source library hosted on pypi. Run the following command to install the library.
```
pip install data-ml-utils --upgrade
```
## Documentation
Head over to https://data-ml-utils.readthedocs.io/en/latest/index.html# to read our library documentation
## Feature
### Pyathena client initialisation
Almost one liner
```python
import os
from data_ml_utils.pyathena_client.client import PyAthenaClient
os.environ["AWS_ACCESS_KEY_ID"] = "xxx"
os.environ["AWS_SECRET_ACCESS_KEY"] = "xxx" # pragma: allowlist secret
os.environ["S3_BUCKET"] = "xxx"
pyathena_client = PyAthenaClient()
```

### Pyathena query
Almost one liner
```python
query = """
SELECT
*
FROM
dev.example_pyathena_client_table
LIMIT 10
"""
df_raw = pyathena_client.query_as_pandas(final_query=query)
```

### MLflow utils
Visit [link](https://data-ml-utils.readthedocs.io/en/latest/index.html#mlflow-utils)
### More to Come
* You suggest, raise a feature request issue and we will review!
## Tutorials
### Pyathena
There is a jupyter notebook to show how to use the package utility package for `pyathena`: [notebook](tutorials/[TUTO]%20pyathena.ipynb)
### MLflow utils
There is a jupyter notebook to show how to use the package utility package for `mlflow_databricks`: [notebook](tutorials/[TUTO]%20mlflow_databricks.ipynb)
| text/markdown | Shuming Peh | shuming.peh@gmail.com | null | null | MIT | null | [
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12"
] | [] | null | null | <3.15,>=3.12 | [] | [] | [] | [
"aiobotocore<3.0.0,>=2.8.0",
"appdirs==1.4.4",
"attrs<23.0.0,>=22.2.0",
"black<23.0.0,>=22.6.0",
"boto3<2.0.0,>=1.33.5",
"botocore<2.0.0,>=1.34.15",
"certifi<2024.0.0,>=2023.7.22",
"cfgv==3.2.0",
"coverage==5.4",
"databricks-sql-connector<5.0.0,>=4.2.4",
"distlib<0.5.0,>=0.4.0",
"filelock<4.0.... | [] | [] | [] | [] | poetry/1.8.3 CPython/3.13.5 Darwin/24.5.0 | 2026-02-19T00:46:25.345519 | sm_data_ml_utils-1.0.4.tar.gz | 15,424 | 86/b0/cb26fff5dbaffcab7245ede66dd9ab5faa7fe01e271780ad631c53c4c970/sm_data_ml_utils-1.0.4.tar.gz | source | sdist | null | false | 6948f92e9b9dee7d63eded541695347b | 4bf20013c20f53c2341a61b52a814f320e12729eb35c1d8df35e7a476739d1ba | 86b0cb26fff5dbaffcab7245ede66dd9ab5faa7fe01e271780ad631c53c4c970 | null | [] | 0 |
2.4 | vcspull | 1.56.1 | Manage and sync multiple git, mercurial, and svn repos | # $ vcspull · [](https://pypi.org/project/vcspull/) [](https://github.com/vcs-python/vcspull/blob/master/LICENSE) [](https://codecov.io/gh/vcs-python/vcspull)
Manage and sync multiple git, svn, and mercurial repos via JSON or YAML file. Compare to
[myrepos], [mu-repo]. Built on [libvcs].
Great if you use the same repos at the same locations across multiple
machines or want to clone / update a pattern of repos without having to
`cd` into each one.
- clone / update to the latest repos with `$ vcspull`
- use filters to specify a location, repo url or pattern in the
manifest to clone / update
- supports svn, git, hg version control systems
- automatically checkout fresh repositories
- supports [pip](https://pip.pypa.io/)-style URL's
([RFC3986](https://datatracker.ietf.org/doc/html/rfc3986)-based [url
scheme](https://pip.pypa.io/en/latest/topics/vcs-support/))
See the [documentation](https://vcspull.git-pull.com/), [configuration](https://vcspull.git-pull.com/configuration/) examples, and [config generators](https://vcspull.git-pull.com/configuration/generation.html).
[myrepos]: http://myrepos.branchable.com/
[mu-repo]: http://fabioz.github.io/mu-repo/
# How to
## Install
```console
$ pip install --user vcspull
```
Or using uv:
```console
$ uv tool install vcspull
```
For one-time use without installation:
```console
$ uvx vcspull
```
### Developmental releases
You can test the unpublished version of vcspull before its released.
- [pip](https://pip.pypa.io/en/stable/):
```console
$ pip install --user --upgrade --pre vcspull
```
- [pipx](https://pypa.github.io/pipx/docs/):
```console
$ pipx install --suffix=@next 'vcspull' --pip-args '\--pre' --force
```
Then use `vcspull@next sync [config]...`.
- [uv](https://docs.astral.sh/uv/):
```console
$ uv tool install --prerelease=allow vcspull
```
## Configuration
Add your repos to `~/.vcspull.yaml`. You can edit the file by hand or let
`vcspull add`, `vcspull discover`, or `vcspull import` create entries for you.
```yaml
~/code/:
flask: "git+https://github.com/mitsuhiko/flask.git"
~/study/c:
awesome: "git+git://git.naquadah.org/awesome.git"
~/study/data-structures-algorithms/c:
libds: "git+https://github.com/zhemao/libds.git"
algoxy:
repo: "git+https://github.com/liuxinyu95/AlgoXY.git"
remotes:
tony: "git+ssh://git@github.com/tony/AlgoXY.git"
```
(see the author's
[.vcspull.yaml](https://github.com/tony/.dot-config/blob/master/.vcspull.yaml),
more [configuration](https://vcspull.git-pull.com/configuration.html))
`$HOME/.vcspull.yaml` and `$XDG_CONFIG_HOME/vcspull/` (`~/.config/vcspull`) can
be used as a declarative manifest to clone your repos consistently across
machines. Subsequent syncs of initialized repos will fetch the latest commits.
### Add repositories from the CLI
Register a single repository by pointing at the checkout:
```console
$ vcspull add ~/projects/libs/my-lib
```
- vcspull infers the name from the directory and detects the `origin` remote.
Pass `--url` when you need to record a different remote.
- Override the derived name with `--name` and the workspace root with
`-w/--workspace`.
- `--dry-run` previews the update, while `--yes` skips the confirmation prompt.
- `-f/--file` selects an alternate configuration file.
- Append `--no-merge` if you prefer to review duplicate workspace roots
yourself instead of having vcspull merge them automatically.
- Follow with `vcspull sync my-lib` to clone or update the working tree after registration.
### Discover local checkouts and add en masse
Have a directory tree full of cloned Git repositories? Scan and append them to
your configuration:
```console
$ vcspull discover ~/code --recursive
```
The scan shows each repository before import unless you opt into `--yes`. Add
`--workspace ~/code/` to pin the resulting workspace root or `-f/--file` to write somewhere other
than the default `~/.vcspull.yaml`. Duplicate workspace roots are merged by
default; include `--no-merge` to keep them separate while you review the log.
### Import from remote services
Pull repository lists from GitHub, GitLab, Codeberg, Gitea, Forgejo, or AWS
CodeCommit directly into your configuration:
```console
$ vcspull import github myuser \
--workspace ~/code/ \
--mode user
```
```console
$ vcspull import gitlab my-group \
--workspace ~/work/ \
--mode org
```
Use `--dry-run` to preview changes, `--https` for HTTPS clone URLs, and
`--language`/`--topics`/`--min-stars` to filter results. See the
[import documentation](https://vcspull.git-pull.com/cli/import/) for all
supported services and options.
### Inspect configured repositories
List what vcspull already knows about without mutating anything:
```console
$ vcspull list
$ vcspull list --tree
$ vcspull list --json | jq '.[].name'
```
`--json` emits a single JSON array, while `--ndjson` streams newline-delimited
objects that are easy to consume from shell pipelines.
Search across repositories with an rg-like query syntax:
```console
$ vcspull search django
$ vcspull search name:django url:github
$ vcspull search --fixed-strings 'git+https://github.com/org/repo.git'
```
### Check repository status
Get a quick health check for all configured workspaces:
```console
$ vcspull status
$ vcspull status --detailed
$ vcspull status --ndjson | jq --slurp 'map(select(.reason == "summary"))'
```
The status command respects `--workspace/-w` filters and the global
`--color {auto,always,never}` flag. JSON and NDJSON output mirrors the list
command for automation workflows.
### Normalize configuration files
After importing or editing by hand, run the formatter to tidy up keys, merge
duplicate workspace sections, and keep entries sorted:
```console
$ vcspull fmt \
--file ~/.vcspull.yaml \
--write
```
Use `vcspull fmt --all --write` to format every YAML file that vcspull can
discover under the standard config locations. Add `--no-merge` if you only want
duplicate roots reported, not rewritten.
## Sync your repos
```console
$ vcspull sync --all
```
Preview planned work with Terraform-style plan output or emit structured data
for CI/CD:
```console
$ vcspull sync --dry-run "*"
$ vcspull sync --dry-run --show-unchanged "workspace-*"
$ vcspull sync --dry-run --json "*" | jq '.summary'
$ vcspull sync --dry-run --ndjson "*" | jq --slurp 'map(select(.type == "summary"))'
```
Dry runs stream a progress line when stdout is a TTY, then print a concise plan
summary (`+/~/✓/⚠/✗`) grouped by workspace. Use `--summary-only`,
`--relative-paths`, `--long`, or `-v/-vv` for alternate views, and
`--fetch`/`--offline` to control how remote metadata is refreshed.
Keep nested VCS repositories updated too, lets say you have a mercurial
or svn project with a git dependency:
`external_deps.yaml` in your project root (any filename will do):
```yaml
./vendor/:
sdl2pp: "git+https://github.com/libSDL2pp/libSDL2pp.git"
```
Clone / update repos via config file:
```console
$ vcspull sync --file external_deps.yaml '*'
```
See the [Quickstart](https://vcspull.git-pull.com/quickstart.html) for
more.
## Pulling specific repos
Have a lot of repos?
you can choose to update only select repos through
[fnmatch](http://pubs.opengroup.org/onlinepubs/009695399/functions/fnmatch.html)
patterns. remember to add the repos to your `~/.vcspull.{json,yaml}`
first.
The patterns can be filtered by by directory, repo name or vcs url.
Any repo starting with "fla":
```console
$ vcspull sync "fla*"
```
Any repo with django in the name:
```console
$ vcspull sync "*django*"
```
Search by vcs + url, since urls are in this format <vcs>+<protocol>://<url>:
```console
$ vcspull sync "git+*"
```
Any git repo with python in the vcspull:
```console
$ vcspull sync "git+*python*
```
Any git repo with django in the vcs url:
```console
$ vcspull sync "git+*django*"
```
All repositories in your ~/code directory:
```console
$ vcspull sync "$HOME/code/*"
```
[libvcs]: https://github.com/vcs-python/libvcs
<img src="https://raw.githubusercontent.com/vcs-python/vcspull/master/docs/_static/vcspull-demo.gif" class="align-center" style="width:45.0%" alt="image" />
# Donations
Your donations fund development of new features, testing and support.
Your money will go directly to maintenance and development of the
project. If you are an individual, feel free to give whatever feels
right for the value you get out of the project.
See donation options at <https://tony.sh/support.html>.
# More information
- Python support: >= 3.10, pypy
- VCS supported: git(1), svn(1), hg(1)
- Source: <https://github.com/vcs-python/vcspull>
- Docs: <https://vcspull.git-pull.com>
- Changelog: <https://vcspull.git-pull.com/history.html>
- API: <https://vcspull.git-pull.com/api.html>
- Issues: <https://github.com/vcs-python/vcspull/issues>
- Test Coverage: <https://codecov.io/gh/vcs-python/vcspull>
- pypi: <https://pypi.python.org/pypi/vcspull>
- Open Hub: <https://www.openhub.net/p/vcspull>
- License: [MIT](https://opensource.org/licenses/MIT).
[](https://vcspull.git-pull.com) [](https://github.com/vcs-python/vcspull/actions?query=workflow%3A%22tests%22)
| text/markdown | null | Tony Narlock <tony@git-pull.com> | null | null | MIT | fetcher, git, hg, json, manage, manager, mercurial, subversion, svn, sync, updater, vcs, vcspull, yaml | [
"Development Status :: 4 - Beta",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming ... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [
"colorama>=0.3.9",
"libvcs~=0.39.0",
"pyyaml>=6.0"
] | [] | [] | [] | [] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:46:12.122247 | vcspull-1.56.1.tar.gz | 2,443,221 | fc/79/a914e6fc96316c2f3afa2d23284f731b252aae354717ae4f112c7fa878c0/vcspull-1.56.1.tar.gz | source | sdist | null | false | a26659156623b5c1a039698a893abb7b | 40262fb2b383b915d2acf21d853ac06d6652867116c30c3261010e10831affda | fc79a914e6fc96316c2f3afa2d23284f731b252aae354717ae4f112c7fa878c0 | null | [
"LICENSE"
] | 254 |
2.4 | heliospice | 0.4.0 | Spacecraft ephemeris made easy — auto-managed SPICE kernels for heliophysics missions | # heliospice
Spacecraft ephemeris made easy — auto-managed SPICE kernels for heliophysics missions.
**heliospice** wraps [SpiceyPy](https://github.com/AndrewAnnex/SpiceyPy) with automatic kernel download, caching, and loading. Ask for a spacecraft position and heliospice handles the rest: downloading the right NAIF kernels, loading them in the correct order, and returning results as Python dicts or pandas DataFrames.
## Installation
```bash
pip install heliospice
```
For MCP server support (Claude Desktop, Claude Code, Cursor, etc.):
```bash
pip install heliospice[mcp]
```
## Quick Start
```python
from heliospice import get_position, get_trajectory
# Where is Parker Solar Probe right now?
pos = get_position("PSP", observer="SUN", time="2024-01-15", frame="ECLIPJ2000")
print(f"PSP is {pos['r_au']:.3f} AU from the Sun")
# Get a month of trajectory data as a DataFrame
df = get_trajectory(
"PSP", observer="SUN",
time_start="2024-01-01", time_end="2024-01-31",
step="1h", frame="ECLIPJ2000",
)
print(df[["r_au"]].describe())
```
Kernels are automatically downloaded from [NAIF](https://naif.jpl.nasa.gov/) on first use and cached in `~/.heliospice/kernels/`.
## Supported Missions
### With SPICE Kernels (auto-downloaded)
- **PSP** (Parker Solar Probe) — 2018-2030
- **Solar Orbiter** (SOLO) — 2020-2030
- **STEREO-A** — 2017-2031
- **Juno** — 2011-present (updated regularly)
- **Voyager 1/2** — 1981-2100 / 1989-2100
- **New Horizons** — 2019-2030
### NAIF IDs Only (no auto-download yet)
- **ACE**, **Wind**, **DSCOVR**, **MMS** (1-4) — no public SPK kernels exist
- **Cassini**, **MAVEN** — require multi-segment kernel loading (planned)
- **Galileo**, **Pioneer 10/11**, **Ulysses**, **MESSENGER**, **STEREO-B**
### Natural Bodies
Sun, Earth, Moon, Mercury, Venus, Mars, Jupiter, Saturn, Uranus, Neptune, Pluto
## API Reference
### Position & Trajectory
```python
from heliospice import get_position, get_trajectory, get_state
# Single position
pos = get_position("ACE", observer="EARTH", time="2024-06-01", frame="GSE")
# Full state (position + velocity)
state = get_state("PSP", observer="SUN", time="2024-01-15", frame="ECLIPJ2000")
# Trajectory timeseries (returns pandas DataFrame)
df = get_trajectory(
"Cassini", observer="SATURN",
time_start="2010-01-01", time_end="2010-12-31",
step="6h", frame="ECLIPJ2000",
include_velocity=True,
)
```
### Coordinate Transforms
```python
from heliospice import transform_vector, list_available_frames
# J2000 to Ecliptic
v_ecl = transform_vector([1.0, 0.0, 0.0], "2024-01-15", "J2000", "ECLIPJ2000")
# RTN transform (requires spacecraft)
v_rtn = transform_vector(
[5.0, -3.0, 1.0], "2024-01-15",
from_frame="ECLIPJ2000", to_frame="RTN",
spacecraft="PSP",
)
# List all frames
print(list_available_frames())
```
### Mission Registry
```python
from heliospice import resolve_mission, list_supported_missions
# Resolve name aliases
naif_id, key = resolve_mission("Parker Solar Probe") # -> (-96, "PSP")
# List all spacecraft
missions = list_supported_missions()
```
### Kernel Management
```python
from heliospice import get_kernel_manager
km = get_kernel_manager()
km.ensure_mission_kernels("PSP") # Download + load
print(km.get_cache_info()) # Cache stats
km.unload_all() # Free memory
```
## Configuration
| Method | Description |
|--------|-------------|
| `HELIOSPICE_KERNEL_DIR` env var | Override kernel cache directory |
| `KernelManager(kernel_dir=...)` | Per-instance override |
| Default | `~/.heliospice/kernels/` |
## MCP Server
heliospice includes an [MCP](https://modelcontextprotocol.io/) server for LLM tool use:
```bash
# Run directly
heliospice-mcp
# Or via Python
python -m heliospice.server
```
### Claude Desktop Configuration
Add to `claude_desktop_config.json`:
```json
{
"mcpServers": {
"heliospice": {
"command": "heliospice-mcp"
}
}
}
```
### Available MCP Tools
| Tool | Description |
|------|-------------|
| `get_spacecraft_ephemeris` | Position/velocity — single time or timeseries |
| `compute_distance` | Distance between two bodies |
| `transform_coordinates` | Coordinate frame transform |
| `list_spice_missions` | Supported missions |
| `list_coordinate_frames` | Available frames with descriptions |
| `manage_kernels` | Kernel cache management |
## License
MIT
<!-- mcp-name: io.github.huangzesen/heliospice -->
| text/markdown | Zesen Huang | null | null | null | null | ephemeris, heliophysics, naif, solar, spacecraft, spice, trajectory | [
"Development Status :: 4 - Beta",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Languag... | [] | null | null | >=3.10 | [] | [] | [] | [
"numpy>=1.24",
"pandas>=2.0",
"requests>=2.28",
"spiceypy>=6.0.0",
"beautifulsoup4>=4.12; extra == \"dev\"",
"mcp>=1.26.0; extra == \"dev\"",
"pytest>=7.0; extra == \"dev\"",
"mcp>=1.26.0; extra == \"mcp\""
] | [] | [] | [] | [
"Homepage, https://github.com/huangzesen/heliospice",
"Repository, https://github.com/huangzesen/heliospice",
"Issues, https://github.com/huangzesen/heliospice/issues"
] | twine/6.2.0 CPython/3.12.7 | 2026-02-19T00:44:59.161207 | heliospice-0.4.0.tar.gz | 50,948 | 1f/6b/e7327c23c930c9f4912e6ac3db11ba844a23b85eeb32ba1fdce32d91d61e/heliospice-0.4.0.tar.gz | source | sdist | null | false | 91d6899922cd1fdd4a295236095d7ddf | 3ad27128d481131fa49d61aa3f6c9b367515527b2c75c2ba9bf1c49e5c24283c | 1f6be7327c23c930c9f4912e6ac3db11ba844a23b85eeb32ba1fdce32d91d61e | MIT | [
"LICENSE"
] | 244 |
2.4 | microsoft-fabric-api | 0.1.0b3 | Microsoft Fabric API Python SDK | # Guide to Using the Python SDK for Microsoft Fabric REST API
## Description
The Microsoft Fabric API provides developers with programmatic access to manage and interact with Microsoft Fabric resources. It enables developers to automate a wide array of tasks, including data integration, data warehousing, big data analytics, deployment process automation, Fabric items provisioning, and more.
This document provides an overview of the API endpoints, authentication methods, and usage examples for the Python SDK for Fabric REST API. The Python SDK is a client library that simplifies communication with the Microsoft Fabric API service and handles serialization and error handling for you.
## Installation via pip
To install the client library via pip:
```bash
pip install microsoft-fabric-api
```
## Getting Started
### 1. Register your application
[Register your application to use Microsoft Fabric API](https://learn.microsoft.com/en-us/entra/identity-platform/quickstart-register-app).
### 2. Authenticate for the Microsoft Fabric service
The Microsoft Fabric Python Client Library supports the use of TokenCredential classes in the [azure-identity](https://pypi.org/project/azure-identity/) library.
You can read more about available Credential classes at [Azure Identity client library for Python](https://learn.microsoft.com/en-us/python/api/overview/azure/identity-readme?view=azure-python#key-concepts).
The recommended library for authenticating against Microsoft Identity (Azure AD) is [MSAL](https://github.com/AzureAD/microsoft-authentication-library-for-python).
For an example of how to acquire a Microsoft Entra token for Microsoft Fabric Service, see [Microsoft Fabric API - get token](https://learn.microsoft.com/en-us/rest/api/fabric/articles/get-started/fabric-api-quickstart#get-token).
### 3. Create a Microsoft Fabric client object with an authentication provider
An instance of the `FabricClient` class handles building requests, sending them to the Microsoft Fabric API, and processing the responses. To create a new instance of this class, you need to provide a instance of `TokenCredential` or the string representation of its underlying Microsoft Entra access token.
### 4. Make requests to Microsoft Fabric
Once you have completed authentication and have a `FabricClient`, you can begin to make calls to the service.
For example, to get a list of workspaces:
```python
from azure.identity import DefaultAzureCredential
from microsoft_fabric_api import FabricClient
# Create credential and client
credential = DefaultAzureCredential(exclude_interactive_browser_credential=False)
fabric_client = FabricClient(credential)
# Get the list of workspaces using the client
workspaces = [workspace for workspace in fabric_client.core.workspaces.list_workspaces()]
print(f"Number of workspaces: {len(workspaces)}")
for workspace in workspaces:
print(f"Workspace: {workspace.display_name}, Capacity ID: {workspace.capacity_id}")
```
### Documentation and resources
- [Microsoft Fabric API documentation](https://learn.microsoft.com/en-us/rest/api/fabric)
| text/markdown | Microsoft Corporation | null | null | null | null | fabric, fabric sdk, microsoft, azure | [
"Development Status :: 4 - Beta",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"License :: OSI Appro... | [] | null | null | >=3.8 | [] | [] | [] | [
"isodate<1.0.0,>=0.6.1",
"azure-core<2.0.0,>=1.24.0"
] | [] | [] | [] | [
"Homepage, https://learn.microsoft.com/en-us/rest/api/fabric"
] | RestSharp/106.13.0.0 | 2026-02-19T00:44:44.687628 | microsoft_fabric_api-0.1.0b3-py3-none-any.whl | 2,114,904 | 54/7d/947c596e218daa2487e0e146047db2781ff8ed621cd4774b21a0c6cf471c/microsoft_fabric_api-0.1.0b3-py3-none-any.whl | py3 | bdist_wheel | null | false | 8673103f732b57cdbe5a1f4f34e5253c | d8faf1b8074359b93653ba8251770b2ce900eb59bc93eb723abc007a7b7e9c0d | 547d947c596e218daa2487e0e146047db2781ff8ed621cd4774b21a0c6cf471c | null | [] | 364 |
2.4 | ab-stats | 0.1.8 | A library that provides statistical test results for A/B tests | # ab-stats
**ab-stats** is a lightweight Python library for **A/B test statistical analysis**.
It provides a two-sample proportion z-test and Welch's t-test with confidence intervals,
uplift, and post-hoc minimum sample size in a pandas DataFrame.
## When to use which test?
Use the appropriate function depending on whether your metric is a proportion (rate) or a mean, i.e., choose the test that matches the scale of the metric you want to compare between control and treatment groups.
| Metric type | Example | Function |
|-------------------|---------------------------------------------|-----------------------|
| Proportion (rate) | CTR, PUR, conversion rate, signup rate | `proportions_ztest()` |
| Mean (continuous) | ARPU, average session length, time on page | `ttest_ind_welch()` |
## Key notes
- **Rich output**: Returns pandas DataFrame with `metric_formula`, `metric_value`, `delta_relative`, `delta_absolute`,
`p_value`, `CI_relative`, `CI_absolute`, `MSS_posthoc`, `statistic` (and `df` for t-test)
- **Two-sided tests**: Both functions perform two-sided hypothesis tests
- **Delta method**: Confidence intervals for uplift (relative change) are computed using the delta method
- **Note on MSS_posthoc**: Minimum sample size required for the given α and β under the assumption that the observed effect is true. **It is computed post hoc and is for reference only** (not for pre-experiment sample size calculation).
## Installation
### Dependencies
ab-stats depends on:
- NumPy (>= 1.20)
- Pandas (>= 1.3)
- SciPy (>= 1.7)
Python 3.8 or newer is required.
### User installation
Install from PyPI with pip:
```bash
pip install ab-stats
```
or with conda (Conda packages are planned):
```bash
conda install -c conda-forge ab-stats
```
## Quick start
### 1. proportions_ztest()
Use this when your metric is a **rate** (e.g. conversion rate, click-through rate). Pass **sample sizes** and **success counts** for control and treatment; the function returns uplift, confidence intervals, and minimum sample size.
> **Parameters**
- **`control_n`** : *int*
Total number of observations in the control group.
- **`control_success`** : *int*
Number of “successes” (e.g. converted users) in the control group.
- **`treatment_n`** : *int*
Total number of observations in the treatment group.
- **`treatment_success`** : *int*
Number of “successes” in the treatment group.
- **`alpha`** : *float, optional*
Significance level for confidence intervals and MSS_posthoc.
Default is `0.05` (95% confidence interval).
- **`power`** : *float, optional*
Target statistical power 1 − β used when computing MSS_posthoc.
Default is `0.8` (80% power).
> **Returns**
> *pandas.DataFrame (one row) with the following columns:*
- **`metric_formula`** : *str*
String representation of the metric (e.g. `122/1001`).
- **`metric_value`** : *float*
Observed proportion in the treatment group.
- **`delta_relative`** : *str*
Relative change (uplift) of treatment vs control, formatted as a percentage (e.g. `20.43%`).
- **`delta_absolute`** : *float*
Absolute difference in proportions (treatment − control).
- **`p_value`** : *float*
Two-sided p-value for the null hypothesis p₁ = p₂.
- **`CI_relative`** : *str*
Confidence interval for the relative change (uplift), formatted as `[L%, U%]`.
- **`CI_absolute`** : *str*
Confidence interval for the absolute difference in proportions, formatted as `[L, U]`.
- **`MSS_posthoc`** : *str*
Post hoc minimum sample size status (e.g. `27.5% (3,641)`).
The percentage is the ratio of current treatment sample size to the required minimum under the observed effect.
- **`statistic`** : *float*
z-statistic of the two-sample proportion test.
#### Example
```python
from ab_stats import proportions_ztest
# Control: 101 successes out of 998; Treatment: 122 successes out of 1001
df = proportions_ztest(
control_n=998,
control_success=101,
treatment_n=1001,
treatment_success=122,
alpha=0.05,
power=0.8,
)
print(df)
```
**Output:**
| metric_formula | metric_value | delta_relative | delta_absolute | p_value | CI_relative | CI_absolute | MSS_posthoc | statistic |
|----------------|--------------|----------------|----------------|---------|-------------|-------------|-------------|-----------|
| 122/1001 | 0.121878 | 20.43% | 0.02 | 0.1418 | [-9.52%, 50.38%] | [-0.01, 0.05] | 27.5% (3,641) | 1.47 |
### 2. ttest_ind_welch()
Use this when your metric is a **mean** (e.g. average revenue per user, average session length). Pass **lists of values** (one value per user or per observation) for control and treatment; the function computes means, variances, and sample sizes internally and returns uplift, confidence intervals, and minimum sample size. The result also includes *df* (degrees of freedom for the Welch t-test).
> **Parameters**
- **`control_values`** : *array_like*
Observations in the control group (e.g. list or array; one value per observation).
- **`treatment_values`** : *array_like*
Observations in the treatment group.
- **`alpha`** : *float, optional*
Significance level for confidence intervals and MSS_posthoc.
Default is `0.05` (95% confidence interval).
- **`power`** : *float, optional*
Target statistical power 1 − β used when computing MSS_posthoc.
Default is `0.8` (80% power).
> **Returns**
> *pandas.DataFrame (one row) with the following columns:*
- **`metric_formula`** : *str*
String representation of the treatment mean (e.g. `107/10`, i.e. sum / n).
- **`metric_value`** : *float*
Observed mean in the treatment group.
- **`delta_relative`** : *str*
Relative change (uplift) of treatment vs control mean, formatted as a percentage.
- **`delta_absolute`** : *float*
Absolute difference in means (treatment − control).
- **`p_value`** : *float*
Two-sided p-value for the null hypothesis μ₁ = μ₂.
- **`CI_relative`** : *str*
Confidence interval for the relative change (uplift), formatted as `[L%, U%]`.
- **`CI_absolute`** : *str*
Confidence interval for the absolute difference in means, formatted as `[L, U]`.
- **`MSS_posthoc`** : *str*
Post hoc minimum sample size status (e.g. `62.5% (16)`).
The percentage is the ratio of current treatment sample size to the required minimum under the observed effect.
- **`statistic`** : *float*
t-statistic of Welch’s t-test.
- **`df`** : *float*
Degrees of freedom (Welch–Satterthwaite).
#### Example
```python
from ab_stats import ttest_ind_welch
# Example: observation lists for control and treatment
control = [10.1, 9.8, 11.2, 10.5, 9.9, 10.8, 10.3, 11.0, 9.7, 10.4, 9.8, 10.1] # n=12
treatment = [11.0, 10.5, 11.8, 10.9, 11.2, 10.5, 10.7, 10.1, 10.3, 10.8] # n=10
df = ttest_ind_welch(control_values=control, treatment_values=treatment, alpha=0.05, power=0.8)
print(df)
```
**Output:**
| metric_formula | metric_value | delta_relative | delta_absolute | p_value | CI_relative | CI_absolute | MSS_posthoc | statistic | df |
|----------------|--------------|----------------|----------------|---------|-------------|-------------|-------------|-----------|-----|
| 107/10 | 10.78 | 4.66% | 0.48 | 0.03383 | [0.30%, 9.02%] | [0.04, 0.92] | 62.5% (16) | 2.28 | 19.41 |
### 3. Using with Pandas
Results are returned as a pandas DataFrame, so you can merge with other columns or filter as usual.
```python
from ab_stats import proportions_ztest, ttest_ind_welch
# Proportion test
result_prop = proportions_ztest(1000, 100, 1000, 120)
print("Proportion test:")
print("MSS_posthoc: ", result_prop["MSS_posthoc"].iloc[0])
print("metric_value: ", result_prop["metric_value"].iloc[0])
print("delta_relative: ", result_prop["delta_relative"].iloc[0])
print("p_value: ", result_prop["p_value"].iloc[0])
print("CI_relative: ", result_prop["CI_relative"].iloc[0])
print("statistic: ", result_prop["statistic"].iloc[0])
# Mean test
control_vals = [10.1, 9.8, 11.2, 10.5, 9.9, 10.8, 10.3, 11.0, 9.7, 10.4, 9.8, 10.1] # n=12
treatment_vals = [11.0, 11.5, 11.8, 11.9, 11.2, 11.5, 10.7, 11.1, 10.3, 10.8] # n=10
result_ttest = ttest_ind_welch(control_vals, treatment_vals)
print("\nMean test:")
print("metric_value: ", result_ttest["metric_value"].iloc[0])
print("delta_relative: ", result_ttest["delta_relative"].iloc[0])
print("p_value: ", result_ttest["p_value"].iloc[0])
print("df: ", result_ttest["df"].iloc[0])
```
**Output:**
```
Proportion test:
MSS_posthoc: 26.0% (3,839)
metric_value: 0.12
delta_relative: 20.00%
p_value: 0.15271
CI_relative: [-10.06%, 50.06%]
statistic: 1.43
Mean test:
metric_value: 11.18
delta_relative: 8.54%
p_value: 0.0006
df: 19.15
```
## References
- [1] Zhou, J., Lu, J., & Shallah, A. (2023). All about sample-size calculations for A/B testing: Novel extensions & practical guide. *Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM '23)*, 1–30.
- [2] Chow, S. C., Shao, J., Wang, H., & Lokhnygina, Y. (2017). *Sample Size Calculations in Clinical Research* (3rd ed.). Chapman & Hall/CRC Biostatistics Series.
- [3] noote-taking. (n.d.). When and how to calculate minimum sample size. noote-taking.github.io. https://noote-taking.github.io/%ED%86%B5%EA%B3%84%ED%95%99/when-and-how-to-calculate-minimum-sample-size/
## License
MIT License. See [LICENSE](LICENSE) for details.
| text/markdown | ab-stats contributors | null | null | null | MIT | ab-test, statistics, hypothesis-testing, confidence-interval, p-value | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.8",
"Programming Language :: Python :: 3.9",
"Programming Language :: Pyt... | [] | null | null | >=3.8 | [] | [] | [] | [
"numpy>=1.20",
"pandas>=1.3",
"scipy>=1.7",
"pytest>=7.0; extra == \"dev\"",
"pytest-cov>=4.0; extra == \"dev\""
] | [] | [] | [] | [
"Repository, https://github.com/noote-taking/ab-stats",
"Documentation, https://github.com/noote-taking/ab-stats#readme"
] | twine/6.2.0 CPython/3.10.19 | 2026-02-19T00:44:40.945765 | ab_stats-0.1.8.tar.gz | 12,948 | bd/e4/ea1a7cdb332df4872d387010439fdfd43fae2dff996c424c49a3c833809e/ab_stats-0.1.8.tar.gz | source | sdist | null | false | 3561bbe885140c00043ae0c40d51b42b | 0a66ce91d065be1d82dc362f3dc12460d9abea03203cf80854db212b4078dcda | bde4ea1a7cdb332df4872d387010439fdfd43fae2dff996c424c49a3c833809e | null | [
"LICENSE"
] | 247 |
2.4 | libtmux | 0.53.1 | Typed library that provides an ORM wrapper for tmux, a terminal multiplexer. | <div align="center">
<h1>⚙️ libtmux</h1>
<p><strong>Drive tmux from Python: typed, object-oriented control over servers, sessions, windows, and panes.</strong></p>
<p>
<a href="https://libtmux.git-pull.com/"><img src="https://raw.githubusercontent.com/tmux-python/libtmux/master/docs/_static/img/libtmux.svg" alt="libtmux logo" height="120"></a>
</p>
<p>
<a href="https://pypi.org/project/libtmux/"><img src="https://img.shields.io/pypi/v/libtmux.svg" alt="PyPI version"></a>
<a href="https://libtmux.git-pull.com/"><img src="https://github.com/tmux-python/libtmux/workflows/docs/badge.svg" alt="Docs status"></a>
<a href="https://github.com/tmux-python/libtmux/actions"><img src="https://github.com/tmux-python/libtmux/workflows/tests/badge.svg" alt="Tests status"></a>
<a href="https://codecov.io/gh/tmux-python/libtmux"><img src="https://codecov.io/gh/tmux-python/libtmux/branch/master/graph/badge.svg" alt="Coverage"></a>
<a href="https://github.com/tmux-python/libtmux/blob/master/LICENSE"><img src="https://img.shields.io/github/license/tmux-python/libtmux.svg" alt="License"></a>
</p>
</div>
## 🐍 What is libtmux?
libtmux is a typed Python API over [tmux], the terminal multiplexer. Stop shelling out and parsing `tmux ls`. Instead, interact with real Python objects: `Server`, `Session`, `Window`, and `Pane`. The same API powers [tmuxp], so it stays battle-tested in real-world workflows.
### ✨ Features
- Typed, object-oriented control of tmux state
- Query and [traverse](https://libtmux.git-pull.com/topics/traversal.html) live sessions, windows, and panes
- Raw escape hatch via `.cmd(...)` on any object
- Works with multiple tmux sockets and servers
- [Context managers](https://libtmux.git-pull.com/topics/context_managers.html) for automatic cleanup
- [pytest plugin](https://libtmux.git-pull.com/pytest-plugin/index.html) for isolated tmux fixtures
- Proven in production via tmuxp and other tooling
## Requirements & support
- tmux: >= 3.2a
- Python: >= 3.10 (CPython and PyPy)
Maintenance-only backports (no new fixes):
- Python 2.x: [`v0.8.x`](https://github.com/tmux-python/libtmux/tree/v0.8.x)
- tmux 1.8-3.1c: [`v0.48.x`](https://github.com/tmux-python/libtmux/tree/v0.48.x)
## 📦 Installation
Stable release:
```bash
pip install libtmux
```
With pipx:
```bash
pipx install libtmux
```
With uv / uvx:
```bash
uv add libtmux
uvx --from "libtmux" python
```
From the main branch (bleeding edge):
```bash
pip install 'git+https://github.com/tmux-python/libtmux.git'
```
Tip: libtmux is pre-1.0. Pin a range in projects to avoid surprises:
requirements.txt:
```ini
libtmux==0.50.*
```
pyproject.toml:
```toml
libtmux = "0.50.*"
```
## 🚀 Quickstart
### Open a tmux session
First, start a tmux session to connect to:
```console
$ tmux new-session -s foo -n bar
```
### Pilot your tmux session via Python
Use [ptpython], [ipython], etc. for a nice REPL with autocompletions:
```console
$ pip install --user ptpython
$ ptpython
```
Connect to a live tmux session:
```python
>>> import libtmux
>>> svr = libtmux.Server()
>>> svr
Server(socket_path=/tmp/tmux-.../default)
```
**Tip:** You can also use [tmuxp]'s [`tmuxp shell`] to drop straight into your
current tmux server / session / window / pane.
[ptpython]: https://github.com/prompt-toolkit/ptpython
[ipython]: https://ipython.org/
[`tmuxp shell`]: https://tmuxp.git-pull.com/cli/shell.html
### Run any tmux command
Every object has a `.cmd()` escape hatch that honors socket name and path:
```python
>>> server = Server(socket_name='libtmux_doctest')
>>> server.cmd('display-message', 'hello world')
<libtmux...>
```
Create a new session:
```python
>>> server.cmd('new-session', '-d', '-P', '-F#{session_id}').stdout[0]
'$...'
```
### List and filter sessions
[**Learn more about Filtering**](https://libtmux.git-pull.com/topics/filtering.html)
```python
>>> server.sessions
[Session($... ...), ...]
```
Filter by attribute:
```python
>>> server.sessions.filter(history_limit='2000')
[Session($... ...), ...]
```
Direct lookup:
```python
>>> server.sessions.get(session_id=session.session_id)
Session($... ...)
```
### Control sessions and windows
[**Learn more about Workspace Setup**](https://libtmux.git-pull.com/topics/workspace_setup.html)
```python
>>> session.rename_session('my-session')
Session($... my-session)
```
Create new window in the background (don't switch to it):
```python
>>> bg_window = session.new_window(attach=False, window_name="bg-work")
>>> bg_window
Window(@... ...:bg-work, Session($... ...))
>>> session.windows.filter(window_name__startswith="bg")
[Window(@... ...:bg-work, Session($... ...))]
>>> session.windows.get(window_name__startswith="bg")
Window(@... ...:bg-work, Session($... ...))
>>> bg_window.kill()
```
### Split windows and send keys
[**Learn more about Pane Interaction**](https://libtmux.git-pull.com/topics/pane_interaction.html)
```python
>>> pane = window.split(attach=False)
>>> pane
Pane(%... Window(@... ...:..., Session($... ...)))
```
Type inside the pane (send keystrokes):
```python
>>> pane.send_keys('echo hello')
>>> pane.send_keys('echo hey', enter=False)
>>> pane.enter()
Pane(%... ...)
```
### Capture pane output
```python
>>> pane.clear()
Pane(%... ...)
>>> pane.send_keys("echo 'hello world'", enter=True)
>>> pane.cmd('capture-pane', '-p').stdout # doctest: +SKIP
["$ echo 'hello world'", 'hello world', '$']
```
### Traverse the hierarchy
[**Learn more about Traversal**](https://libtmux.git-pull.com/topics/traversal.html)
Navigate from pane up to window to session:
```python
>>> pane.window
Window(@... ...:..., Session($... ...))
>>> pane.window.session
Session($... ...)
```
## Core concepts
| libtmux object | tmux concept | Notes |
|----------------|-----------------------------|--------------------------------|
| [`Server`](https://libtmux.git-pull.com/api/servers.html) | tmux server / socket | Entry point; owns sessions |
| [`Session`](https://libtmux.git-pull.com/api/sessions.html) | tmux session (`$0`, `$1`,...) | Owns windows |
| [`Window`](https://libtmux.git-pull.com/api/windows.html) | tmux window (`@1`, `@2`,...) | Owns panes |
| [`Pane`](https://libtmux.git-pull.com/api/panes.html) | tmux pane (`%1`, `%2`,...) | Where commands run |
Also available: [`Options`](https://libtmux.git-pull.com/api/options.html) and [`Hooks`](https://libtmux.git-pull.com/api/hooks.html) abstractions for tmux configuration.
Collections are live and queryable:
```python
server = libtmux.Server()
session = server.sessions.get(session_name="demo")
api_windows = session.windows.filter(window_name__startswith="api")
pane = session.active_window.active_pane
pane.send_keys("echo 'hello from libtmux'", enter=True)
```
## tmux vs libtmux vs tmuxp
| Tool | Layer | Typical use case |
|---------|----------------------------|----------------------------------------------------|
| tmux | CLI / terminal multiplexer | Everyday terminal usage, manual control |
| libtmux | Python API over tmux | Programmatic control, automation, testing |
| tmuxp | App on top of libtmux | Declarative tmux workspaces from YAML / TOML |
## Testing & fixtures
[**Learn more about the pytest plugin**](https://libtmux.git-pull.com/pytest-plugin/index.html)
Writing a tool that interacts with tmux? Use our fixtures to keep your tests clean and isolated.
```python
def test_my_tmux_tool(session):
# session is a real tmux session in an isolated server
window = session.new_window(window_name="test")
pane = window.active_pane
pane.send_keys("echo 'hello from test'", enter=True)
assert window.window_name == "test"
# Fixtures handle cleanup automatically
```
- Fresh tmux server/session/window/pane fixtures per test
- Temporary HOME and tmux config fixtures keep indices stable
- `TestServer` helper spins up multiple isolated tmux servers
## When you might not need libtmux
- Layouts are static and live entirely in tmux config files
- You do not need to introspect or control running tmux from other tools
- Python is unavailable where tmux is running
## Project links
**Topics:**
[Traversal](https://libtmux.git-pull.com/topics/traversal.html) ·
[Filtering](https://libtmux.git-pull.com/topics/filtering.html) ·
[Pane Interaction](https://libtmux.git-pull.com/topics/pane_interaction.html) ·
[Workspace Setup](https://libtmux.git-pull.com/topics/workspace_setup.html) ·
[Automation Patterns](https://libtmux.git-pull.com/topics/automation_patterns.html) ·
[Context Managers](https://libtmux.git-pull.com/topics/context_managers.html) ·
[Options & Hooks](https://libtmux.git-pull.com/topics/options_and_hooks.html)
**Reference:**
[Docs][docs] ·
[API][api] ·
[pytest plugin](https://libtmux.git-pull.com/pytest-plugin/index.html) ·
[Architecture][architecture] ·
[Changelog][history] ·
[Migration][migration]
**Project:**
[Issues][issues] ·
[Coverage][coverage] ·
[Releases][releases] ·
[License][license] ·
[Support][support]
**[The Tao of tmux][tao]** — deep-dive book on tmux fundamentals
## Contributing & support
Contributions are welcome. Please open an issue or PR if you find a bug or want to improve the API or docs. If libtmux helps you ship, consider sponsoring development via [support].
[docs]: https://libtmux.git-pull.com
[api]: https://libtmux.git-pull.com/api.html
[architecture]: https://libtmux.git-pull.com/about.html
[history]: https://libtmux.git-pull.com/history.html
[migration]: https://libtmux.git-pull.com/migration.html
[issues]: https://github.com/tmux-python/libtmux/issues
[coverage]: https://codecov.io/gh/tmux-python/libtmux
[releases]: https://pypi.org/project/libtmux/
[license]: https://github.com/tmux-python/libtmux/blob/master/LICENSE
[support]: https://tony.sh/support.html
[tao]: https://leanpub.com/the-tao-of-tmux
[tmuxp]: https://tmuxp.git-pull.com
[tmux]: https://github.com/tmux/tmux
| text/markdown | null | Tony Narlock <tony@git-pull.com> | null | null | MIT | ncurses, session manager, terminal, tmux | [
"Development Status :: 5 - Production/Stable",
"Environment :: Web Environment",
"Framework :: Pytest",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Operating System :: MacOS :: MacOS X",
"Operating System :: POSIX",
"Programming Language :: Python",
"Programming Lan... | [] | null | null | <4.0,>=3.10 | [] | [] | [] | [] | [] | [] | [] | [
"Bug Tracker, https://github.com/tmux-python/libtmux/issues",
"Documentation, https://libtmux.git-pull.com",
"Repository, https://github.com/tmux-python/libtmux",
"Changes, https://github.com/tmux-python/libtmux/blob/master/CHANGES"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:44:24.761060 | libtmux-0.53.1.tar.gz | 413,660 | 8d/99/0ac0f60d5b93a8a291be02ed1f3fcf70ff50c0526fa9a99eb462d74354b1/libtmux-0.53.1.tar.gz | source | sdist | null | false | 07de33394974c8e13610b03859acb166 | 0d9ca4bcf5c0fb7d7a1e4ce0c0cdcbcd7fb354a66819c3d60ccea779d83eac83 | 8d990ac0f60d5b93a8a291be02ed1f3fcf70ff50c0526fa9a99eb462d74354b1 | null | [
"LICENSE"
] | 90,685 |
2.4 | bazis-test-utils | 2.2.2 | A utility package for testing in the Bazis ecosystem — a framework based on Django + FastAPI + Pydantic. | # bazis-test-utils
[](https://pypi.org/project/bazis-test-utils/)
[](https://pypi.org/project/bazis-test-utils/)
[](https://opensource.org/licenses/Apache-2.0)
A utility package for testing in the [Bazis](https://github.com/ecofuture-tech/bazis) ecosystem — a framework based on Django + FastAPI + Pydantic.
## Quick Start
```bash
# Install the package
uv add bazis-test-utils
# Create test models
from bazis_test_utils.models_abstract import ParentEntityBase
class TestEntity(ParentEntityBase):
pass
# Use in tests
from bazis_test_utils.factories_abstract import ParentEntityFactoryAbstract
class TestEntityFactory(ParentEntityFactoryAbstract):
class Meta:
model = TestEntity
```
## Table of Contents
- [Description](#description)
- [Features](#features)
- [Requirements](#requirements)
- [Installation](#installation)
- [Usage](#usage)
- [Creating Test Models](#creating-test-models)
- [Using Factories](#using-factories)
- [Testing FastAPI Endpoints](#testing-fastapi-endpoints)
- [Examples](#examples)
- [Contributing](#contributing)
- [License](#license)
- [Links](#links)
## Description
`bazis-test-utils` provides base models and factories to simplify test writing in Bazis packages. The package includes standard models for testing hierarchical and dependent entities, as well as utilities for working with the FastAPI test client.
## Features
- **Base Django test models:**
- `ChildEntityBase` — base model for child entities
- `DependentEntityBase` — base model for dependent entities
- `ExtendedEntityBase` — base model for extended entities
- `ParentEntityBase` — base model for parent entities
- **Abstract factory classes** for rapid test data generation with `factory_boy` integration
- **API testing utilities:**
- `get_api_client()` — function to create a FastAPI test client with optional authentication
## Installation
### Using uv (recommended)
```bash
uv add bazis-test-utils
```
### Using pip
```bash
pip install bazis-test-utils
```
### Development installation
```bash
git clone https://github.com/ecofuture-tech/bazis-test-utils.git
cd bazis-test-utils
uv sync --dev
```
## Usage
### Creating Test Models
In your project, create models by inheriting from the base classes:
```python
from bazis_test_utils.models_abstract import ParentEntityBase, ChildEntityBase
class TestParentEntity(ParentEntityBase):
"""Model for testing parent entities"""
pass
class TestChildEntity(ChildEntityBase):
"""Model for testing child entities"""
pass
```
### Using Factories
Create factories for your models using abstract factory classes:
```python
from bazis_test_utils.factories_abstract import ParentEntityFactoryAbstract
from .models import TestParentEntity
class ParentEntityFactory(ParentEntityFactoryAbstract):
class Meta:
model = TestParentEntity
```
Then use them in your tests:
```python
import pytest
@pytest.mark.django_db
def test_parent_entity_creation():
parent = ParentEntityFactory.create()
assert parent.id is not None
assert parent.created_at is not None
```
### Testing FastAPI Endpoints
Use `get_api_client` to create a test client:
```python
# conftest.py
import pytest
@pytest.fixture(scope='function')
def sample_app():
from sample.main import app
return app
# test_sample_app.py
from bazis_test_utils.utils import get_api_client
def test_api_endpoint(sample_app):
# Without authentication
client = get_api_client(sample_app)
response = client.get("/api/v1/entities/")
assert response.status_code == 200
def test_authenticated_endpoint(sample_app):
# With authentication token
token = "your-test-token"
client = get_api_client(sample_app, token=token)
response = client.get("/api/v1/protected/")
assert response.status_code == 200
```
## Examples
### Basic Factory Usage
```python
from bazis_test_utils.factories_abstract import (
ParentEntityFactoryAbstract,
ChildEntityFactoryAbstract
)
# Create a single instance
parent = ParentEntityFactory.create(name="Test Parent")
# Create multiple instances
parents = ParentEntityFactory.create_batch(5)
# Create without saving to database
parent = ParentEntityFactory.build()
```
### Testing Hierarchical Relationships
```python
import pytest
from .factories import ParentEntityFactory, ChildEntityFactory
@pytest.mark.django_db
def test_parent_child_relationship():
parent = ParentEntityFactory.create()
child = ChildEntityFactory.create(parent=parent)
assert child.parent == parent
assert child in parent.children.all()
```
### Using with pytest-factoryboy
```python
# conftest.py
from pytest_factoryboy import register
from .factories import ParentEntityFactory, ChildEntityFactory
register(ParentEntityFactory)
register(ChildEntityFactory)
# test_entities.py
@pytest.mark.django_db
def test_with_fixtures(parent_entity, child_entity):
# Fixtures are automatically created
assert parent_entity.id is not None
assert child_entity.id is not None
```
### API Integration Testing
```python
from bazis_test_utils.utils import get_api_client
from .factories import ParentEntityFactory
def test_crud_operations(sample_app):
client = get_api_client(sample_app)
# Create
response = client.post("/api/v1/entities/", json={"name": "Test"})
assert response.status_code == 201
entity_id = response.json()["id"]
# Read
response = client.get(f"/api/v1/entities/{entity_id}/")
assert response.status_code == 200
# Update
response = client.put(f"/api/v1/entities/{entity_id}/", json={"name": "Updated"})
assert response.status_code == 200
# Delete
response = client.delete(f"/api/v1/entities/{entity_id}/")
assert response.status_code == 204
```
## Usage in Bazis
This package is used in the sample project in the Bazis core to create standard test models. Models in the sample project inherit from `bazis-test-utils` models, and factories are used to generate test data across all main framework packages.
The typical workflow in Bazis packages:
1. Define concrete models in `sample/models.py` by inheriting from abstract base models
2. Create factories in `sample/factories.py` using abstract factory classes
3. Register factories in `conftest.py` for use across all tests
4. Use generated fixtures in integration and unit tests
## Contributing
Contributions are welcome! Here's how you can help:
1. Fork the repository
2. Create a feature branch (`git checkout -b feature/amazing-feature`)
3. Make your changes
4. Run tests (`pytest`)
5. Commit your changes (`git commit -m 'Add amazing feature'`)
6. Push to the branch (`git push origin feature/amazing-feature`)
7. Open a Pull Request
Please make sure to:
- Write tests for new features
- Update documentation as needed
- Follow the existing code style
- Add your changes to the changelog
## Development
### Setup development environment
```bash
# Clone the repository
git clone https://github.com/ecofuture-tech/bazis-test-utils.git
cd bazis-test-utils
# Install dependencies with development extras
uv sync --dev
# Run linting
ruff check .
# Format code
ruff format .
```
## License
Apache License 2.0
See [LICENSE](LICENSE) file for details.
## Links
- [Bazis Framework](https://github.com/ecofuture-tech/bazis) — main repository
- [Issue Tracker](https://github.com/ecofuture-tech/bazis/issues) — report bugs or request features
## Support
If you have questions or issues, please:
- Check the [documentation](https://github.com/ecofuture-tech/bazis)
- Search [existing issues](https://github.com/ecofuture-tech/bazis/issues)
- Create a [new issue](https://github.com/ecofuture-tech/bazis/issues/new) with detailed information
---
Made with ❤️ by the Bazis team
| text/markdown | null | Ilya Kharyn <ilya.tt07@gmail.com> | null | Ilya Kharyn <ilya.tt07@gmail.com> | null | bazis, django, fastapi, pydantic, framework, jsonapi, test-utilities | [
"Intended Audience :: Developers",
"Topic :: Software Development :: Libraries :: Python Modules",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13",
"Programming Language :: Python :: 3.14",
... | [] | null | null | >=3.12 | [] | [] | [] | [
"django",
"fastapi",
"factory_boy",
"httpx<=0.27.0",
"pytest",
"pytest-django",
"pytest-mock",
"requests",
"requests-toolbelt",
"requests-mock",
"uvicorn[standard]",
"ruff; extra == \"dev\""
] | [] | [] | [] | [
"Home, https://github.com/ecofuture-tech/bazis-test-utils"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T00:43:58.130133 | bazis_test_utils-2.2.2-py3-none-any.whl | 16,010 | cb/38/cab0f638ae16c3ab5c527fd8e83174b442ff7292e1dec0ae66173e642467/bazis_test_utils-2.2.2-py3-none-any.whl | py3 | bdist_wheel | null | false | c5d7b9a76e8338db646173273ab61720 | 86c57d8377b3a9fa10152d9bcacbf7c47b12dec425e140b7d5a7187152e08b9d | cb38cab0f638ae16c3ab5c527fd8e83174b442ff7292e1dec0ae66173e642467 | Apache-2.0 | [
"LICENSE",
"NOTICE"
] | 220 |
2.4 | fast-parse-time | 1.3.2 | Natural Language (NLP) Extraction of Date and Time | # fast-parse-time
[](https://pypi.org/project/fast-parse-time/)
[](https://pypi.org/project/fast-parse-time/)
[](https://pepy.tech/project/fast-parse-time)
[](https://pepy.tech/project/fast-parse-time)
[](https://opensource.org/licenses/MIT)
[](https://github.com/craigtrim/fast-parse-time/tree/master/tests)
Extract dates and times from text. Fast, deterministic, zero cost.
## Why?
LLMs can parse dates, but they're slow, expensive, and non-deterministic. This library gives you:
- **Sub-millisecond performance** - Process thousands of documents per second
- **Zero API costs** - No per-request charges
- **Deterministic results** - Same input always produces same output
- **Simple API** - One function call, everything extracted
## Install
```bash
pip install fast-parse-time
```
## Usage
```python
from fast_parse_time import parse_dates
text = "Meeting on 04/08/2024 to discuss issues from 5 days ago"
result = parse_dates(text)
# Explicit dates found in text
print(result.explicit_dates)
# [ExplicitDate(text='04/08/2024', date_type='FULL_EXPLICIT_DATE')]
# Relative time expressions
print(result.relative_times)
# [RelativeTime(cardinality=5, frame='day', tense='past')]
# Convert to Python datetime
for time_ref in result.relative_times:
print(time_ref.to_datetime())
# datetime.datetime(2025, 11, 14, ...)
```
## What It Extracts
**Explicit dates:**
```python
"Event on 04/08/2024" → 04/08/2024 (full date)
"Meeting scheduled for 3/24" → 3/24 (month/day)
"Copyright 2024" → 2024 (year only)
"Ambiguous: 4/8" → 4/8 (flagged as ambiguous)
"Published March 15, 2024" → March 15, 2024 (written month)
"Filed in 2024" → 2024 (year in prose)
```
**Year ranges:**
```python
"Active 2014-2015" → 2014-2015 (year range)
"From 2010 to 2020" → From 2010 to 2020 (year range)
"Revenue grew 2019–2023" → 2019-2023 (en/em dash normalized)
"Contract 2023-24" → 2023-24 (abbreviated)
```
**Relative times:**
```python
"5 days ago" → 5 days (past)
"last couple of weeks" → 2 weeks (past)
"30 minutes ago" → 30 minutes (past)
"half an hour ago" → 1 hour (past)
"a few days ago" → 3 days (past)
```
## Examples
### Parse everything at once
```python
result = parse_dates("Report from 04/08/2024 covering issues from last week")
result.explicit_dates # ['04/08/2024']
result.relative_times # [RelativeTime(cardinality=1, frame='week', tense='past')]
```
### Just get dates
```python
from fast_parse_time import extract_explicit_dates
dates = extract_explicit_dates("Event on 04/08/2024 or maybe 3/24")
# {'04/08/2024': 'FULL_EXPLICIT_DATE', '3/24': 'MONTH_DAY'}
```
### Convert to datetime objects
```python
from fast_parse_time import resolve_to_datetime
datetimes = resolve_to_datetime("Show me data from 5 days ago")
# [datetime.datetime(2025, 11, 14, ...)]
```
## Features
- Multiple date formats: `04/08/2024`, `3/24`, `2024-06-05`, `March 15, 2024`
- Multiple delimiters: `/`, `-`, `.`
- Year ranges: `2014-2015`, `2010 to 2020`, `from 2018 through 2022`, `2023-24`
- Unicode normalization: en dash, em dash, and other hyphen variants accepted automatically
- Written months: `March 15, 2024`, `Mar 15, 2024`, `15 March 2024`
- Year-only in prose: `Copyright 2024`, `filed in 2019`
- Relative time expressions: "5 days ago", "last week", "couple of months ago"
- Informal expressions: "half an hour ago", "a few days ago", "several weeks ago"
- Named day and time-of-day references: "last Monday", "this morning", "yesterday"
- Ambiguity detection: Flags dates like `4/8` that could be April 8 or August 4
- Time frame support: seconds, minutes, hours, days, weeks, months, years
## Documentation
- [API Reference](https://github.com/craigtrim/fast-parse-time/blob/master/docs/API.md)
- [Functions](https://github.com/craigtrim/fast-parse-time/blob/master/docs/functions.md) - All functions with examples
- [Types](https://github.com/craigtrim/fast-parse-time/blob/master/docs/types.md) - Data classes and DateType enum
- [System Boundaries](https://github.com/craigtrim/fast-parse-time/blob/master/BOUNDARIES.md) - Design decisions and limitations
## Performance
Typical extraction takes < 1ms per document. No network calls, no model inference, pure Python.
## License
MIT - See [LICENSE](LICENSE) for details.
## Author
**Craig Trim** - [craigtrim@gmail.com](mailto:craigtrim@gmail.com)
---
[Report Issues](https://github.com/craigtrim/fast-parse-time/issues) | [API Docs](https://github.com/craigtrim/fast-parse-time/blob/master/docs/API.md) | [PyPI](https://pypi.org/project/fast-parse-time/)
| text/markdown | Craig Trim | craigtrim@gmail.com | Craig Trim | craigtrim@gmail.com | null | date-parsing, time-parsing, date-extraction, nlp, natural-language, temporal-extraction, text-mining | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Pyt... | [] | null | null | >=3.10 | [] | [] | [] | [
"word2number"
] | [] | [] | [] | [
"Bug Tracker, https://github.com/craigtrim/fast-parse-time/issues",
"Repository, https://github.com/craigtrim/fast-parse-time"
] | poetry/2.3.2 CPython/3.11.9 Darwin/24.6.0 | 2026-02-19T00:42:26.787997 | fast_parse_time-1.3.2-py3-none-any.whl | 1,378,715 | 84/d4/f14c5903ffa7ddad374e93b34bb3d07eb4ba08c87345e01693a4457c36aa/fast_parse_time-1.3.2-py3-none-any.whl | py3 | bdist_wheel | null | false | 440cb4688226446140a0b54819fc7dab | 765053940e713b0baa038109eeab2c9fa9edd840e4f9602c3ed999ce7d727be6 | 84d4f14c5903ffa7ddad374e93b34bb3d07eb4ba08c87345e01693a4457c36aa | MIT | [
"LICENSE"
] | 229 |
2.4 | fullwave25 | 1.2.3rc0 | Fullwave 2.5: Ultrasound wave propagation simulation with heterogeneous power law attenuation modelling capabilities | # Fullwave 2.5: Ultrasound wave propagation simulation with heterogeneous power law attenuation modelling capabilities
<a href="https://doi.org/10.5281/zenodo.17625780"><img src="https://zenodo.org/badge/DOI/10.5281/zenodo.17625780.svg" alt="DOI"></a>
<a href="https://pepy.tech/projects/fullwave25"><img src="https://static.pepy.tech/personalized-badge/fullwave25?period=total&units=INTERNATIONAL_SYSTEM&left_color=GREY&right_color=BLUE&left_text=PyPI+Downloads" alt="PyPI Downloads"></a>
[](https://colab.research.google.com/drive/153Sx9D_5zTlF7UtlKHlyz_CTJnLIAI6s)
Fullwave 2.5 is a Python package for high-fidelity ultrasound wave propagation simulation with the following features:
- State-of-the-art attenuation modelling capabilities for ultrasound wave propagation in complex biological tissues
- Heterogeneous power law attenuation ($\alpha=\alpha_0 f^\gamma$) modeling, where **both the attenuation coefficient $\alpha_0$ and exponent $\gamma$ can vary** spatially.
- High-performance simulation engine
- High accuracy staggered-grid finite-difference time-domain (FDTD) scheme (8th-order in space and 4th-order in time).
- 2D and 3D ultrasound wave propagation simulation.
- Multiple GPU execution support.
- Easy-to-use Python interface with CUDA/C backend
- Python wrapper for easy usability and extensibility, with the core simulation engine implemented in CUDA/C for high performance on NVIDIA GPUs.
- It offers a user experience similar to [k-Wave](http://www.k-wave.org/) and [k-wave-python](https://github.com/waltsims/k-wave-python), while providing advanced attenuation modeling capabilities and multi-GPU support in FDTD simulations.
| Computational medium | Wave propagation |
| ---------------------------------------- | -------------------------------------------------------------------------- |
| <img src="figs/medium.png" width="600"/> | <img src="figs/linear_transducer_focused_abdominal_wall.gif" width="200"/> |
Building upon the original Fullwave 2 simulator, Fullwave 2.5 enhances its capabilities to model ultrasound wave propagation in media where **both the attenuation coefficient and exponent can vary spatially**. This enables more accurate simulations of biological tissues, which often exhibit complex attenuation behaviours that cannot be captured by uniform exponent models.
The library is designed with a Python wrapper for ease of use and extensibility, while the core simulation engine is implemented in CUDA/C to leverage high-performance computing on NVIDIA GPUs. Fullwave 2.5 supports 2D and 3D simulations, including multi-GPU execution for enhanced performance.
## Special Thanks
This repository design was inspired by [k-wave-python](https://github.com/waltsims/k-wave-python). We appreciate the great work of the k-wave-python development team.
This repository would not have been possible without them.
Please check their repository for additional ultrasound simulation tools and resources.
Their comprehensive tools have significantly contributed to the ultrasound research community.
## Theoretical Background
Fullwave 2.5 models multiple relaxation processes to approximate frequency-dependent power-law attenuation in heterogeneous media.
It solves the stretched-coordinate pressure-velocity formulation using a staggered-grid finite-difference schemes with 8th-order accuracy in space and 4th-order accuracy in time.
The formulation is expressed as follows:
$$\nabla_1 p + \rho \cfrac{\partial {\bf{v}}}{\partial t} = 0$$
$$\nabla_2 \cdot {\bf{v}} + \kappa \cfrac{\partial p}{\partial t} = 0$$
The stretched-coordinate derivatives, denoted by $\nabla_1$ and $\nabla_2$, control frequency-dependent power-law attenuation and dispersion by selecting the optimal relaxation parameters.
The following figure illustrates the performance of the attenuation modeling in Fullwave 2.5.
The graph shows a comparison of the target power-law attenuation $\alpha=\alpha_0 f^\gamma$ (red line) and the simulated attenuation (black dots) for various spatially varying attenuation coefficients ($\alpha_0 =$ 0.25, 0.5, and 0.75) and exponents ($\gamma =$ 0.4, 0.7, 1.0, 1.3, and 1.6).

## Citation
Fullwave 2.5 is developed and maintained by [Pinton Lab](https://github.com/pinton-lab) at the University of North Carolina at Chapel Hill.
If you use Fullwave 2.5 in your research, please cite this repository as:
```bibtex
@software{Sode2025-fullwave25,
author = {Sode, Masashi and Pinton, Gianmarco},
title = {{Fullwave 2.5: Ultrasound wave propagation simulation with heterogeneous power law attenuation modelling capabilities}},
year = {2025},
month = oct,
doi = {10.5281/zenodo.17497689},
url = {https://github.com/pinton-lab/fullwave25},
}
@ARTICLE{Pinton2021-fullwave2,
title = "A fullwave model of the nonlinear wave equation with multiple relaxations and relaxing perfectly matched layers for high-order numerical finite-difference solutions",
author = "Pinton, Gianmarco",
month = jun,
year = 2021,
copyright = "http://creativecommons.org/licenses/by/4.0/",
archivePrefix = "arXiv",
primaryClass = "physics.med-ph",
eprint = "2106.11476"
}
```
---
## Hardware prerequisites
- This system operates in a Linux environment.
- If you need a Windows environment, please consider using [WSL2](https://learn.microsoft.com/en-us/windows/wsl/install) (Windows Subsystem for Linux 2).
- This simulation requires an NVIDIA GPU to execute.
- You may need multiple GPUs for 3D simulation.
## Technical recommendations
- We recommend setting up an SSH key for GitHub, if you haven't done already. The repository changes over time to fix bugs and add new features. You can keep your local repository up to date by pulling the latest changes from GitHub. Cloning through SSH is more convenient than HTTPS in the long run.
- for ssh key generation
- please see: [Generating a new SSH key and adding it to the ssh-agent](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)
- for ssh key registration to your github account
- please see: [Adding a new SSH key to your GitHub account](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/adding-a-new-ssh-key-to-your-github-account)
- after that, you can clone the repository through
```sh
git clone git@github.com:pinton-lab/fullwave-python.git
```
## Technical references
- If you are not familiar with the tools below, please refer to the provided links.
- VSCode
- [Official Visual Studio Code documentation](https://code.visualstudio.com/docs)
- [Visual Studio Code Tutorial for Beginners by Udacity](https://www.udacity.com/blog/2025/09/visual-studio-code-tutorial-for-beginners-productivity-tips-and-extensions.html)
- Git
- [Git Tutorial by GeeksForGeeks](https://www.geeksforgeeks.org/git/git-tutorial/)
- [Git Tutorial by W3 schools](https://www.w3schools.com/git/default.asp)
- [Using Git source control in VS Code](https://code.visualstudio.com/docs/sourcecontrol/overview)
- UV
- [Python UV: The Ultimate Guide to the Fastest Python Package Manager](https://www.datacamp.com/tutorial/python-uv)
---
## installation for users
```sh
pip install fullwave25
```
## Troubleshooting
If `ffmpeg` is not installed on your system, please install it using the package manager of your Linux distribution.
`ffmpeg` is used for video writing in plotting functions.
please see the installation guide below.
reference: [FFmpeg Installation Guide](https://ffmpeg.org/download.html)
```sh
# for Ubuntu/Debian
sudo apt install ffmpeg
```
Additionally, if you encounter any issues related to `cv2` (OpenCV) during the installation, please install it separately using linux package manager or pip.
please see the installation guide below.
`cv2` is used fro video writing in plotting functions.
reference: [Installing OpenCV on Linux: A Comprehensive Guide](https://linuxvox.com/blog/install-opencv-linux/)
```sh
# using apt for Ubuntu/Debian
sudo apt install python3-opencv
# using pip
pip install opencv-python
```
## installation for development
We use [uv](https://docs.astral.sh/uv/) for package project and virtual environment management.
If uv is not installed, run below.
```sh
curl -LsSf https://astral.sh/uv/install.sh | sh
```
Run below to install the development environment.
```sh
git clone git@github.com:pinton-lab/fullwave25.git
cd fullwave25
make install-all-extras # for running examples
# or
make install # for the core library installation
```
To test the installation, run
```sh
make test
```
---
## Tutorial: Basic Usage
Please start from [example_simple_plane_wave.ipynb](https://github.com/pinton-lab/fullwave25/blob/main/examples/simple_plane_wave/example_simple_plane_wave.ipynb).
or try the Google Colab tutorial.
You don't need to install or set up a GPU environment on your local machine in order to run the simulation.
[](https://colab.research.google.com/drive/153Sx9D_5zTlF7UtlKHlyz_CTJnLIAI6s)
Here are the main steps to run the Fullwave simulation
1. Define the computational grid.
2. Define the properties of the acoustic medium.
3. Define the acoustic source.
4. Define the sensor.
5. Execute the simulation.
## New simulation development instruction
- after the [installation](#installation)
- make a directory for your simulation under your favorite path.
- e.g. `examples/my_simulation/`
- make a `.py` file or copy the example files below to use the boilerplate.
- 2D plane wave
- [examples/simple_plane_wave/simple_plane_wave_demo.py](https://github.com/pinton-lab/fullwave25/blob/main/examples/simple_plane_wave/simple_plane_wave.py)
- 3D plane wave
- [examples/wave_3d/simple_plane_wave_3d.py](https://github.com/pinton-lab/fullwave25/blob/main/examples/wave_3d/simple_plane_wave_3d.py)
- after that follow [Usage 2D](#tutorial-basic-usage) to define the simulation code.
## Tutorial: Advanced Usages
Please see the following examples for more advanced usage.
- 2D plane wave
- Basic usage
- [Simple plane wave](https://github.com/pinton-lab/fullwave25/blob/main/examples/simple_plane_wave/simple_plane_wave.py) [](https://colab.research.google.com/drive/153Sx9D_5zTlF7UtlKHlyz_CTJnLIAI6s)
- <img src="figs/simple_plane_wave.gif" width="200"/>
- [Simple plane wave with air](https://github.com/pinton-lab/fullwave25/blob/main/examples/simple_plane_wave/simple_plane_wave.py) [](https://colab.research.google.com/drive/1AnTaT6ZtwyIEcOvGgpn5srB4LWPfYKh0)
<!-- - <img src="figs/simple_plane_wave_with_air.gif" width="200"/> -->
- Linear transducer
- [Linear transducer](https://github.com/pinton-lab/fullwave25/blob/main/examples/linear_transducer/linear_transducer.py)
- [Linear transducer (plane wave transmit) with animation settings](https://github.com/pinton-lab/fullwave25/blob/main/examples/linear_transducer/linear_transducer_animation.py)
<!-- - <img src="figs/linear_transducer.gif" width="200"/> -->
- [Linear transducer (focused transmit) with animation settings](https://github.com/pinton-lab/fullwave25/blob/main/examples/linear_transducer/linear_transducer_animation.py)
- <img src="figs/linear_transducer_focused.gif" width="200"/>
- [Linear transducer (focused transmit) with abdominal wall](https://github.com/pinton-lab/fullwave25/blob/main/examples/linear_transducer/linear_transducer.py) [](https://colab.research.google.com/drive/1zlviYe0qBy0JLifFuA2MqUkavJKUQrNb)
- <img src="figs/linear_transducer_focused_abdominal_wall.gif" width="200"/>
- linear transducer plane wave compounding
- [](https://colab.research.google.com/drive/1LXlkpYhIfQtaPhNDJ1vONTDSdiLBhkEP)
- linear transducer full synthetic aperture
- [](https://colab.research.google.com/drive/1_jVULK2mglOx8__gWYHGhNVxYLhAGNF5)
- Convex transducer
- [Convex transducer with abdominal wall](https://github.com/pinton-lab/fullwave25/blob/main/examples/convex_transducer/convex_transducer_abdominal_wall.py)
- <img src="figs/convex_transducer_abdominal_wall.gif" width="200"/>
- 3D plane wave
- Basic usage
- [Simple plane wave in 3D](https://github.com/pinton-lab/fullwave25/blob/main/examples/wave_3d/simple_plane_wave_3d.py)
<table>
<tr>
<td style="text-align: center;" colspan="2">Computational medium</td>
</tr>
<tr>
<td style="text-align: center;" colspan="2"><img src="figs/medium_3d.png" width="600"/></td>
</tr>
<tr>
<td style="text-align: center;" >x-y slice propagation</td>
<td style="text-align: center;" >x-z slice propagation</td>
</tr>
<tr>
<td style="text-align: center;" ><img src="figs/wave_propagation_x-y.gif" width="300"/></td>
<td style="text-align: center;" ><img src="figs/wave_propagation_x-z.gif" width="300"/></td>
</tr>
</table>
- [Simple plane wave in 3D with air inclusion](https://github.com/pinton-lab/fullwave25/blob/main/examples/wave_3d/simple_plane_wave_3d_with_air.py)
<table>
<tr>
<td style="text-align: center;" colspan="2">Computational medium with air inclusion</td>
</tr>
<tr>
<td style="text-align: center;" colspan="2"><img src="figs/medium_3d_air.png" width="600"/></td>
</tr>
<tr>
<td style="text-align: center;" >x-y slice propagation</td>
<td style="text-align: center;" >x-z slice propagation</td>
</tr>
<tr>
<td style="text-align: center;" ><img src="figs/wave_propagation_x-y_air.gif" width="300"/></td>
<td style="text-align: center;" ><img src="figs/wave_propagation_x-z_air.gif" width="300"/></td>
</tr>
</table>
- Medium builder usage
- Medium builder is a utility to create computational medium from simple geometric operations. This is especially useful when you want to create complex heterogeneous media.
- [simple medium builder usage](https://github.com/pinton-lab/fullwave25/blob/main/examples/medium_builder/medium_builder_example.py) [](https://colab.research.google.com/drive/169aHbXRt_-aXFEdf2pfPkwH4-niJvrfL)
- [simple medium builder usage with abdominal wall](https://github.com/pinton-lab/fullwave25/blob/main/examples/medium_builder/medium_builder_abdominal_example.py)
- [medium builder in 3D](https://github.com/pinton-lab/fullwave25/blob/main/examples/medium_builder/medium_builder_example_3d.py)
---
## Attention
- The simulation grid is defined as follows:
- (x, y, z) = (depth, lateral, elevational).
- This order is due to the efficiency of the multiple-GPU execution.
- Multi-GPU domain decomposition is processed in the depth dimension.
- The index of the input coordinates (i.e. the acoustic source location) is defined in C-array order (i.e. row-major) within the simulation, regardless of your setup. This is to improve the efficiency of multi-GPU development.
- This might be confusing, so please be careful when you define the source and source signal definition.
- GPU memory requirement
- A 3D simulation requires a lot of GPU memory.
- Please reduce the grid size or use multiple GPUs if you run out of memory.
- You can check GPU memory usage with the 'nvidia-smi' or 'nvtop' commands.
- Multi-GPU execution
- The current implementation supports multiple GPU execution in 2D and 3D simulations.
- Our implementation demonstrates linear performance scaling with the number of GPUs.
- Before 3D simulation:
- If you want to run a 3D simulation, it is recommended that you start with a 2D simulation first to understand the basic usage.
- The 3D simulation code is similar to the 2D code, but some plot functions are unavailable in 3D.
- The 3D simulation takes longer to run, so starting with 2D will help you debug your code faster.
## Note for developers
- Contributions are welcome!
- When developing something new, please create a new branch such as `TYPE/BRANCH_NAME`.
- TYPE can be `feature`, `bugfix`, `hotfix`, `docs`, `refactor`, `release`, `test`, or `experiment`.
- `BRANCH_NAME` should be descriptive of the feature or fix you are working on.
- see also: [GitHub Branching Name Best Practices](https://dev.to/jps27cse/github-branching-name-best-practices-49ei)
- Please write clear and concise commit messages.
- please see [CONTRIBUTING.md](CONTRIBUTING.md) for more details.
---
## Authors
- Masashi Sode (GitHub: [MasashiSode](https://github.com/MasashiSode))
- Gianmarco Pinton (GitHub: [gfpinton](https://github.com/gfpinton))
## Maintainers
- Masashi Sode (GitHub: [MasashiSode](https://github.com/MasashiSode))
| text/markdown | Masashi Sode, Gianmarco Pinton | null | Masashi Sode | null | null | fdtd, finite-difference, simulation, ultrasound | [
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Topic :: Scientific/Engineering :: Physics"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"joblib>=1.5.3",
"matplotlib>=3.10.7",
"numba>=0.63.1",
"numexpr>=2.14.1",
"numpy>=2.0.0",
"opencv-python-headless>=4.12.0.88",
"scipy>=1.13.1",
"tomli>=2.3.0",
"tqdm>=4.67.1",
"line-profiler>=5.0.1; extra == \"dev\"",
"pre-commit==4.1.0; extra == \"dev\"",
"pytest>=8.3.5; extra == \"dev\"",
... | [] | [] | [] | [] | uv/0.9.9 {"installer":{"name":"uv","version":"0.9.9"},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"22.04","id":"jammy","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T00:41:00.443709 | fullwave25-1.2.3rc0.tar.gz | 3,655,898 | 9f/9f/cc21d47b282ef021bb9ed7155b59d4386552cd893f43ea520823f9fd3cad/fullwave25-1.2.3rc0.tar.gz | source | sdist | null | false | 180fcb11ded8c1b7818a2d6e218702ec | be86c466c37ff2dd614ac010d877ccafc8792bdcef2254991185fdf0f2a80602 | 9f9fcc21d47b282ef021bb9ed7155b59d4386552cd893f43ea520823f9fd3cad | null | [
"LICENSE"
] | 221 |
2.4 | picows | 1.14.0 | Ultra-fast websocket client and server for asyncio | .. image:: https://raw.githubusercontent.com/tarasko/picows/master/docs/source/_static/banner.png
:align: center
Introduction
============
.. image:: https://img.shields.io/github/actions/workflow/status/tarasko/picows/run-tests.yml?branch=master
:target: https://github.com/tarasko/picows/actions/workflows/run-tests.yml?query=branch%3Amaster
.. image:: https://badge.fury.io/py/picows.svg
:target: https://pypi.org/project/picows
:alt: Latest PyPI package version
.. image:: https://img.shields.io/pypi/dm/picows
:target: https://pypistats.org/packages/picows
:alt: Downloads count
.. image:: https://readthedocs.org/projects/picows/badge/?version=latest
:target: https://picows.readthedocs.io/en/latest/
:alt: Latest Read The Docs
.. image:: https://deepwiki.com/badge.svg
:target: https://deepwiki.com/tarasko/picows
:alt: Ask DeepWiki
**picows** is a high-performance Python library designed for building asyncio WebSocket clients and servers.
Implemented in Cython, it offers exceptional speed and efficiency, surpassing other popular Python WebSocket libraries.
.. image:: https://raw.githubusercontent.com/tarasko/websocket-benchmark/master/results/benchmark-256.png
:target: https://github.com/tarasko/websocket-benchmark/blob/master
:align: center
The above chart shows the performance of echo clients communicating with a server through a loopback interface using popular Python libraries.
`boost.beast client <https://www.boost.org/library/latest/beast/>`_
is also included for reference. You can find benchmark sources and more results
`here <https://github.com/tarasko/websocket-benchmark>`_.
Installation
============
picows requires Python 3.9 or greater and is available on PyPI.
Use pip to install it::
$ pip install picows
Documentation
=============
https://picows.readthedocs.io/en/stable/
Make sure to check `topic guides <https://picows.readthedocs.io/en/stable/guides.html>`_ for the most common usage patterns and questions.
Motivation
==========
Popular WebSocket libraries provide high-level interfaces that handle timeouts,
flow control, optional compression/decompression, and reassembly of WebSocket messages
from frames, while also implementing async iteration interfaces.
However, these features are typically implemented in pure Python, resulting in
significant overhead even when messages are small, un-fragmented (with every WebSocket frame marked as final),
and uncompressed.
The async iteration interface relies on ``asyncio.Futures``, which adds additional
work for the event loop and can introduce delays. Moreover, it’s not always necessary
to process every message. In some use cases, only the latest message matters,
and previous ones can be discarded without even parsing their content.
API Design
==========
The library achieves superior performance by offering an efficient, non-async data path, similar to the
`transport/protocol design from asyncio <https://docs.python.org/3/library/asyncio-protocol.html#asyncio-transports-protocols>`_.
The user handler receives WebSocket frame objects instead of complete messages.
Since a message can span multiple frames, it is up to the user to decide the most
effective strategy for concatenating them. Each frame object includes additional
details about the current parser state, which may help optimize the behavior of the user’s application.
Getting started
===============
Echo client
-----------
Connects to an echo server, sends a message, and disconnects after receiving a reply.
.. code-block:: python
import asyncio
from picows import ws_connect, WSFrame, WSTransport, WSListener, WSMsgType, WSCloseCode
class ClientListener(WSListener):
def on_ws_connected(self, transport: WSTransport):
transport.send(WSMsgType.TEXT, b"Hello world")
def on_ws_frame(self, transport: WSTransport, frame: WSFrame):
print(f"Echo reply: {frame.get_payload_as_ascii_text()}")
transport.send_close(WSCloseCode.OK)
transport.disconnect()
async def main(url):
transport, client = await ws_connect(ClientListener, url)
await transport.wait_disconnected()
if __name__ == '__main__':
asyncio.run(main("ws://127.0.0.1:9001"))
This prints:
.. code-block::
Echo reply: Hello world
Echo server
-----------
.. code-block:: python
import asyncio
from picows import ws_create_server, WSFrame, WSTransport, WSListener, WSMsgType, WSUpgradeRequest
class ServerClientListener(WSListener):
def on_ws_connected(self, transport: WSTransport):
print("New client connected")
def on_ws_frame(self, transport: WSTransport, frame: WSFrame):
if frame.msg_type == WSMsgType.CLOSE:
transport.send_close(frame.get_close_code(), frame.get_close_message())
transport.disconnect()
else:
transport.send(frame.msg_type, frame.get_payload_as_bytes())
async def main():
def listener_factory(r: WSUpgradeRequest):
# Routing can be implemented here by analyzing request content
return ServerClientListener()
server: asyncio.Server = await ws_create_server(listener_factory, "127.0.0.1", 9001)
for s in server.sockets:
print(f"Server started on {s.getsockname()}")
await server.serve_forever()
if __name__ == '__main__':
asyncio.run(main())
Features
====================
* Maximally efficient WebSocket frame parser and builder implemented in Cython
* Reuse memory as much as possible, avoid reallocations, and avoid unnecessary Python object creation
* Provide a Cython .pxd for efficient integration of user Cythonized code with picows
* Ability to check if a frame is the last one in the receiving buffer
* Auto ping-pong with an option to customize ping/pong messages.
* Convenient method to measure websocket roundtrip time using ping/pong messages.
Contributing / Building From Source
===================================
1. Fork and clone the repository::
$ git clone git@github.com:tarasko/picows.git
$ cd picows
2. Create a virtual environment and activate it::
$ python3 -m venv picows-dev
$ source picows-dev/bin/activate
3. Install development dependencies::
# To run tests
$ pip install -r requirements-test.txt
# To build docs
$ pip install -r docs/requirements.txt
4. Build in place and run tests::
$ python setup.py build_ext --inplace
$ pytest -s -v
# Run specific test with picows debug logs enabled
$ pytest -s -v -k test_client_handshake_timeout[uvloop-plain] --log-cli-level 9
5. Build docs::
$ make -C docs clean html
| text/x-rst | null | Taras Kozlov <tarasko.projects@gmail.com> | null | null | null | websocket, networking | [
"Development Status :: 5 - Production/Stable",
"Framework :: AsyncIO",
"Intended Audience :: Developers",
"Operating System :: POSIX",
"Operating System :: MacOS :: MacOS X",
"Operating System :: Microsoft :: Windows",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3... | [] | null | null | >=3.9 | [] | [] | [] | [
"multidict",
"python-socks[asyncio]"
] | [] | [] | [] | [
"Homepage, https://github.com/tarasko/picows",
"Repository, https://github.com/tarasko/picows",
"Issues, https://github.com/tarasko/picows/issues",
"Documentation, https://picows.readthedocs.io/en/latest"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:39:52.829561 | picows-1.14.0.tar.gz | 48,383 | 60/40/2068441191d561b1514d91e846824e15c0eb5b82584742ad82f4585812d6/picows-1.14.0.tar.gz | source | sdist | null | false | e2405475b17deb05d793e925c71fe03b | 06333eb6e82e8cb22524317d3c033cc002257f47aa44dd3489cf483722f85c29 | 60402068441191d561b1514d91e846824e15c0eb5b82584742ad82f4585812d6 | null | [
"LICENSE"
] | 4,529 |
2.4 | amem-installer | 0.1.0 | One-command installer for AgenticMemory — connects all AI tools to shared memory | # AgenticMemory Installer
One-command installer that detects every AI tool on your machine and connects them all to a shared AgenticMemory brain.
## Install
```bash
pip install amem-installer
```
## Usage
```bash
# Auto-detect and configure all tools
amem-install --auto
# Show what would be done (dry run)
amem-install install --dry-run
# Check connection status
amem-install status
# Remove all configurations
amem-install uninstall
# Re-scan for new tools
amem-install update
```
## Supported Tools
| Tool | Detection | Integration |
|:---|:---|:---|
| Claude Code | Config file | MCP server |
| Cursor | Config file | MCP server |
| Windsurf | Config file | MCP server |
| Claude Desktop | Config file | MCP server |
| Continue | Config file | Context provider |
| OpenClaw | Config file | YAML config |
| Ollama | HTTP service | Wrapper script |
| LM Studio | HTTP service | Config file |
| LangChain | requirements.txt | Instructions |
| CrewAI | requirements.txt | Instructions |
| AutoGen | requirements.txt | Instructions |
## How It Works
1. Scans your system for installed AI tools
2. Creates a shared brain file at `~/.amem/brain.amem`
3. Configures each tool to use the shared brain (via MCP, config files, or wrapper scripts)
4. Backs up all modified configs before changes
All modifications are additive — existing configurations are never deleted.
## Tests
39 tests passing. All tests use sandboxed home directories.
```bash
pip install -e ".[dev]"
pytest tests/ -v
```
## License
MIT
| text/markdown | Omoshola Owolabi | null | null | null | null | agent, ai, installer, mcp, memory | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"License :: OSI Approved :: MIT License",
"Programming Language :: Python :: 3"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pyyaml>=6.0",
"pytest-cov>=5.0; extra == \"dev\"",
"pytest>=8.0; extra == \"dev\""
] | [] | [] | [] | [
"Homepage, https://github.com/agentic-revolution/agentic-memory",
"Repository, https://github.com/agentic-revolution/agentic-memory"
] | twine/6.2.0 CPython/3.11.14 | 2026-02-19T00:39:21.761092 | amem_installer-0.1.0.tar.gz | 18,711 | 49/96/092d20e944e8794d6191d98251921797ff27189c4b09366ffea3de15b713/amem_installer-0.1.0.tar.gz | source | sdist | null | false | f9606f657522026945de0973dd1fc025 | 676f338d3699ad8bea48e55dcd3b77a76ddfb9579d868d27e75e3aa514f6c997 | 4996092d20e944e8794d6191d98251921797ff27189c4b09366ffea3de15b713 | MIT | [] | 242 |
2.4 | qtara | 0.2.0 | Threat Analysis & Risk Assessment (TARA) Framework for Neural Security | # qtara
**Threat Analysis & Risk Assessment (TARA)** framework for Neural Security.
The `qtara` package provides programmatic access to the TARA registry (103 techniques), NISS (Neural Impact Scoring System) calculators, physics feasibility tiers, and STIX 2.1 exporters.
## Installation
```bash
pip install qtara
```
## Features
- **TARA Registry:** Query 103 verified BCI threat techniques with full enrichment data.
- **Physics Feasibility Tiers:** Filter techniques by physics feasibility (T0: feasible now, T1: mid-term, T2: far-term, T3: no physics gate).
- **NISS Scorer:** Calculate neural impact scores based on physics-derived metrics.
- **CVSS + Neurorights:** Access CVSS 4.0 mappings and neuroright impact data per technique.
- **STIX 2.1:** Export threat data for industry-standard security tools.
- **CLI:** Instant access to threat intelligence from the terminal.
## Quick Start
```python
from qtara.core import TaraLoader
loader = TaraLoader()
loader.load()
# List all techniques
techniques = loader.list_techniques()
print(f"{len(techniques)} techniques loaded")
# Get a specific technique
t = loader.get_technique("QIF-T0001")
print(t.attack, t.severity, t.physics_feasibility.tier_label)
# Filter by physics tier
tier0 = loader.list_by_physics_tier(0)
print(f"{len(tier0)} techniques feasible now")
# Filter by severity
critical = loader.list_by_severity("critical")
print(f"{len(critical)} critical techniques")
# Get statistics
stats = loader.get_statistics()
print(stats)
```
## CLI Usage
```bash
# List all techniques
qtara list
# Filter by physics feasibility tier (0=feasible now, 1=mid-term, 2=far-term, 3=no gate)
qtara list --tier 0
# Filter by severity
qtara list --severity critical
# Filter by neural band
qtara list --band N1
# Get detailed info for a technique
qtara info QIF-T0001
# Show statistics
qtara stats
# Export to STIX 2.1
qtara stix --output threats.json
# Get citation
qtara cite
```
## Physics Feasibility Tiers
Each technique is classified by its physics feasibility:
| Tier | Label | Timeline | Description |
|------|-------|----------|-------------|
| T0 | feasible_now | now | Attack is possible with current technology |
| T1 | mid_term | 5-10 years | Requires technology advances expected within a decade |
| T2 | far_term | 10+ years | Requires fundamental breakthroughs |
| T3 | no_physics_gate | n/a | No physics constraint (software/protocol attacks) |
## Development
```bash
git clone https://github.com/qinnovates/qinnovate
cd packaging/qtara
pip install -e .
```
## License
MIT
| text/markdown | null | Qinnovate <security@qinnovate.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Security",
"Topic :: Scientific/Engineering"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"pydantic>=2.0.0",
"stix2>=3.0.0",
"rich>=13.0.0"
] | [] | [] | [] | [
"Homepage, https://github.com/qinnovates/qinnovate",
"Bug Tracker, https://github.com/qinnovates/qinnovate/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:39:00.391481 | qtara-0.2.0.tar.gz | 108,111 | 84/64/35bac01bb368d0ca352b791875c8fb1ded05f46a8f37b8725dc3502a2055/qtara-0.2.0.tar.gz | source | sdist | null | false | 29cb5fd4c14fae02e42b320a2d12c2fe | c25f4f2db75abba0bcd6693bc75be4839cbc66dd8a79208861d7e4d4ed639d85 | 846435bac01bb368d0ca352b791875c8fb1ded05f46a8f37b8725dc3502a2055 | null | [] | 220 |
2.4 | cycls | 0.0.2.113 | Distribute Intelligence | <h3 align="center">
Distribute Intelligence
</h3>
<h4 align="center">
<a href="https://cycls.com">Website</a> |
<a href="https://docs.cycls.com">Docs</a> |
<a href="docs/tutorial.md">Tutorial</a>
</h4>
<h4 align="center">
<a href="https://pypi.python.org/pypi/cycls"><img src="https://img.shields.io/pypi/v/cycls.svg?label=cycls+pypi&color=blueviolet" alt="cycls Python package on PyPi" /></a>
<a href="https://github.com/Cycls/cycls/actions/workflows/tests.yml"><img src="https://github.com/Cycls/cycls/actions/workflows/tests.yml/badge.svg" alt="Tests" /></a>
<a href="https://blog.cycls.com"><img src="https://img.shields.io/badge/newsletter-blueviolet.svg?logo=substack&label=cycls" alt="Cycls newsletter" /></a>
<a href="https://x.com/cyclsai">
<img src="https://img.shields.io/twitter/follow/CyclsAI" alt="Cycls Twitter" />
</a>
</h4>
---
# Cycls
The open-source SDK for distributing AI agents.
```
Agent extends App (prompts, skills)
└── App extends Function (web UI)
└── Function (containerization)
```
## Distribute Intelligence
Write a function. Deploy it as an API, a web interface, or both. Add authentication, analytics, and monetization with flags.
```python
import cycls
cycls.api_key = "YOUR_CYCLS_API_KEY"
@cycls.app(pip=["openai"])
async def app(context):
from openai import AsyncOpenAI
client = AsyncOpenAI()
stream = await client.responses.create(
model="o3-mini",
input=context.messages,
stream=True,
reasoning={"effort": "medium", "summary": "auto"},
)
async for event in stream:
if event.type == "response.reasoning_summary_text.delta":
yield {"type": "thinking", "thinking": event.delta} # Renders as thinking bubble
elif event.type == "response.output_text.delta":
yield event.delta
app.deploy() # Live at https://agent.cycls.ai
```
## Installation
```bash
pip install cycls
```
Requires Docker. See the [full tutorial](docs/tutorial.md) for a comprehensive guide.
## What You Get
- **Streaming API** - OpenAI-compatible `/chat/completions` endpoint
- **Web Interface** - Chat UI served automatically
- **Authentication** - `auth=True` enables JWT-based access control
- **Analytics** - `analytics=True` tracks usage
- **Monetization** - `plan="cycls_pass"` integrates with [Cycls Pass](https://cycls.ai) subscriptions
- **Native UI Components** - Render thinking bubbles, tables, code blocks in responses
## Running
```python
app.local() # Development with hot-reload (localhost:8080)
app.local(watch=False) # Development without hot-reload
app.deploy() # Production: https://agent.cycls.ai
```
Get an API key at [cycls.com](https://cycls.com).
## Authentication & Analytics
See the [tutorial](docs/tutorial.md#authentication) for full auth and monetization examples.
```python
@cycls.app(pip=["openai"], auth=True, analytics=True)
async def app(context):
# context.user available when auth=True
user = context.user # User(id, email, name, plans)
yield f"Hello {user.name}!"
```
| Flag | Description |
|------|-------------|
| `auth=True` | Universal user pool via Cycls Pass (Clerk-based). You can also use your own Clerk auth. |
| `analytics=True` | Rich usage metrics available on the Cycls dashboard. |
| `plan="cycls_pass"` | Monetization via Cycls Pass subscriptions. Enables both auth and analytics. |
## Native UI Components
Yield structured objects for rich streaming responses. See the [tutorial](docs/tutorial.md#native-ui-components) for all component types and examples.
```python
@cycls.app()
async def demo(context):
yield {"type": "thinking", "thinking": "Analyzing the request..."}
yield "Here's what I found:\n\n"
yield {"type": "table", "headers": ["Name", "Status"]}
yield {"type": "table", "row": ["Server 1", "Online"]}
yield {"type": "table", "row": ["Server 2", "Offline"]}
yield {"type": "code", "code": "result = analyze(data)", "language": "python"}
yield {"type": "callout", "callout": "Analysis complete!", "style": "success"}
```
| Component | Streaming |
|-----------|-----------|
| `{"type": "thinking", "thinking": "..."}` | Yes |
| `{"type": "code", "code": "...", "language": "..."}` | Yes |
| `{"type": "table", "headers": [...]}` | Yes |
| `{"type": "table", "row": [...]}` | Yes |
| `{"type": "status", "status": "..."}` | Yes |
| `{"type": "callout", "callout": "...", "style": "..."}` | Yes |
| `{"type": "image", "src": "..."}` | Yes |
### Thinking Bubbles
The `{"type": "thinking", "thinking": "..."}` component renders as a collapsible thinking bubble in the UI. Each yield appends to the same bubble until a different component type is yielded:
```python
# Multiple yields build one thinking bubble
yield {"type": "thinking", "thinking": "Let me "}
yield {"type": "thinking", "thinking": "analyze this..."}
yield {"type": "thinking", "thinking": " Done thinking."}
# Then output the response
yield "Here's what I found..."
```
This works seamlessly with OpenAI's reasoning models - just map reasoning summaries to the thinking component.
## Context Object
```python
@cycls.app()
async def chat(context):
context.messages # [{"role": "user", "content": "..."}]
context.messages.raw # Full data including UI component parts
context.user # User(id, email, name, plans) when auth=True
```
## API Endpoints
| Endpoint | Format |
|----------|--------|
| `POST chat/cycls` | Cycls streaming protocol |
| `POST chat/completions` | OpenAI-compatible |
## Streaming Protocol
Cycls streams structured components over SSE:
```
data: {"type": "thinking", "thinking": "Let me "}
data: {"type": "thinking", "thinking": "analyze..."}
data: {"type": "text", "text": "Here's the answer"}
data: {"type": "callout", "callout": "Done!", "style": "success"}
data: [DONE]
```
See [docs/streaming-protocol.md](docs/streaming-protocol.md) for frontend integration.
## Declarative Infrastructure
Define your entire runtime in the decorator. See the [tutorial](docs/tutorial.md#declarative-infrastructure) for more details.
```python
@cycls.app(
pip=["openai", "pandas", "numpy"],
apt=["ffmpeg", "libmagic1"],
copy=["./utils.py", "./models/", "/absolute/path/to/config.json"],
copy_public=["./assets/logo.png", "./static/"],
)
async def my_app(context):
...
```
### `pip` - Python Packages
Install any packages from PyPI. These are installed during the container build.
```python
pip=["openai", "pandas", "numpy", "transformers"]
```
### `apt` - System Packages
Install system-level dependencies via apt-get. Need ffmpeg for audio processing? ImageMagick for images? Just declare it.
```python
apt=["ffmpeg", "imagemagick", "libpq-dev"]
```
### `copy` - Bundle Files and Directories
Include local files and directories in your container. Works with both relative and absolute paths. Copies files and entire directory trees.
```python
copy=[
"./utils.py", # Single file, relative path
"./models/", # Entire directory
"/home/user/configs/app.json", # Absolute path
]
```
Then import them in your function:
```python
@cycls.app(copy=["./utils.py"])
async def chat(context):
from utils import helper_function # Your bundled module
...
```
### `copy_public` - Static Files
Files and directories served at the `/public` endpoint. Perfect for images, downloads, or any static assets your agent needs to reference.
```python
copy_public=["./assets/logo.png", "./downloads/"]
```
Access them at `https://your-app.cycls.ai/public/logo.png`.
---
### What You Get
- **One file** - Code, dependencies, configuration, and infrastructure together
- **Instant deploys** - Unchanged code deploys in seconds from cache
- **No drift** - What you see is what runs. Always.
- **Just works** - Closures, lambdas, dynamic imports - your function runs exactly as written
No YAML. No Dockerfiles. No infrastructure repo. The code is the deployment.
## Learn More
- [Tutorial](docs/tutorial.md) - Comprehensive guide from basics to advanced
- [Streaming Protocol](docs/streaming-protocol.md) - Frontend integration
- [Runtime](docs/runtime.md) - Containerization details
- [Examples](examples/) - Working code samples
## License
MIT
| text/markdown | null | "Mohammed J. AlRujayi" <mj@cycls.com> | null | null | null | null | [] | [] | null | null | >=3.10 | [] | [] | [] | [
"cloudpickle>=3.1.1",
"docker>=7.1.0",
"email-validator>=2.0.0",
"fastapi>=0.111.0",
"httpx>=0.27.0",
"pyjwt>=2.8.0",
"python-dotenv>=1.0.0",
"python-multipart>=0.0.6",
"uvicorn>=0.30.0",
"watchfiles>=1.0.0"
] | [] | [] | [] | [] | uv/0.9.25 {"installer":{"name":"uv","version":"0.9.25","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":null} | 2026-02-19T00:38:47.721474 | cycls-0.0.2.113.tar.gz | 22,221 | b1/d2/fd24e1d3cd5758da3d72f4ca1c328e6dcd70882b5965fd2498fc49c9e93f/cycls-0.0.2.113.tar.gz | source | sdist | null | false | ea5d5c47b0762d75bfd0d09ef67eda96 | f0cdbf82177d5f5f2294303111796c439e539359ae84eecca7d4dadbcf0a18fb | b1d2fd24e1d3cd5758da3d72f4ca1c328e6dcd70882b5965fd2498fc49c9e93f | null | [] | 252 |
2.4 | galileo-adk | 1.0.0b2 | Galileo observability integration for Google ADK | # galileo-adk
[](https://pypi.org/project/galileo-adk/)
[](https://pypi.org/project/galileo-adk/)
[](https://github.com/rungalileo/galileo-python/blob/main/LICENSE)
Galileo observability for [Google ADK](https://github.com/google/adk-python) agents. Automatic tracing of agent runs, LLM calls, and tool executions.
## Installation
```bash
pip install galileo-adk
```
**Requirements:** Python 3.10+, a [Galileo API key](https://www.rungalileo.io/), and a [Google AI API key](https://aistudio.google.com/apikey)
## Quick Start
```python
import asyncio
from galileo_adk import GalileoADKPlugin
from google.adk.runners import Runner
from google.adk.agents import LlmAgent
from google.genai import types
async def main():
plugin = GalileoADKPlugin(project="my-project", log_stream="production")
agent = LlmAgent(name="assistant", model="gemini-2.0-flash", instruction="You are helpful.")
runner = Runner(agent=agent, plugins=[plugin])
message = types.Content(parts=[types.Part(text="Hello! What can you help me with?")])
async for event in runner.run_async(user_id="user-123", session_id="session-456", new_message=message):
if event.is_final_response():
print(event.content.parts[0].text)
if __name__ == "__main__":
# Set environment variables: GALILEO_API_KEY, GOOGLE_API_KEY
asyncio.run(main())
```
## Configuration
| Parameter | Environment Variable | Description |
|-----------|---------------------|-------------|
| `project` | `GALILEO_PROJECT` | Project name (required unless `ingestion_hook` provided) |
| `log_stream` | `GALILEO_LOG_STREAM` | Log stream name (required unless `ingestion_hook` provided) |
| `ingestion_hook` | - | Custom callback for trace data (bypasses Galileo backend) |
## Features
### Session Tracking
All traces with the same `session_id` are automatically grouped into a Galileo session, enabling conversation-level tracking:
```python
import asyncio
from galileo_adk import GalileoADKPlugin
from google.adk.runners import Runner
from google.adk.agents import LlmAgent
from google.genai import types
async def main():
plugin = GalileoADKPlugin(project="my-project", log_stream="production")
agent = LlmAgent(name="assistant", model="gemini-2.0-flash", instruction="You are helpful.")
runner = Runner(agent=agent, plugins=[plugin])
# All traces in this conversation are grouped together
session_id = "conversation-abc"
# First message
message1 = types.Content(parts=[types.Part(text="Hello! What's the capital of France?")])
async for event in runner.run_async(user_id="user-123", session_id=session_id, new_message=message1):
if event.is_final_response():
print(f"Response 1: {event.content.parts[0].text}")
# Follow-up in same session
message2 = types.Content(parts=[types.Part(text="What about Germany?")])
async for event in runner.run_async(user_id="user-123", session_id=session_id, new_message=message2):
if event.is_final_response():
print(f"Response 2: {event.content.parts[0].text}")
if __name__ == "__main__":
# Set environment variables: GALILEO_API_KEY, GOOGLE_API_KEY
asyncio.run(main())
```
### Custom Metadata
Attach custom metadata to traces using ADK's `RunConfig`. Metadata is propagated to all spans (agent, LLM, tool) within the invocation:
```python
import asyncio
from galileo_adk import GalileoADKPlugin
from google.adk.runners import Runner
from google.adk.agents import LlmAgent
from google.adk.agents.run_config import RunConfig
from google.genai import types
async def main():
plugin = GalileoADKPlugin(project="my-project", log_stream="production")
agent = LlmAgent(name="assistant", model="gemini-2.0-flash", instruction="You are helpful.")
runner = Runner(agent=agent, plugins=[plugin])
run_config = RunConfig(
custom_metadata={
"user_tier": "premium",
"conversation_id": "conv-abc",
"turn": 1,
"experiment_group": "A",
}
)
message = types.Content(parts=[types.Part(text="Hello! Tell me a fun fact.")])
async for event in runner.run_async(
user_id="user-123",
session_id="session-456",
new_message=message,
run_config=run_config,
):
if event.is_final_response():
print(event.content.parts[0].text)
if __name__ == "__main__":
# Set environment variables: GALILEO_API_KEY, GOOGLE_API_KEY
asyncio.run(main())
```
### Callback Mode
For granular control over which callbacks to use, attach them directly to your agent instead of using the plugin:
```python
import asyncio
from galileo_adk import GalileoADKCallback
from google.adk.runners import Runner
from google.adk.agents import LlmAgent
from google.genai import types
async def main():
callback = GalileoADKCallback(project="my-project", log_stream="production")
agent = LlmAgent(
name="assistant",
model="gemini-2.0-flash",
instruction="You are helpful.",
before_agent_callback=callback.before_agent_callback,
after_agent_callback=callback.after_agent_callback,
before_model_callback=callback.before_model_callback,
after_model_callback=callback.after_model_callback,
before_tool_callback=callback.before_tool_callback,
after_tool_callback=callback.after_tool_callback,
)
runner = Runner(agent=agent)
message = types.Content(parts=[types.Part(text="Hello! How are you?")])
async for event in runner.run_async(user_id="user-123", session_id="session-456", new_message=message):
if event.is_final_response():
print(event.content.parts[0].text)
if __name__ == "__main__":
# Set environment variables: GALILEO_API_KEY, GOOGLE_API_KEY
asyncio.run(main())
```
### Retriever Spans
By default, all `FunctionTool` calls are logged as tool spans. To log a retriever function as a **retriever span** (enabling RAG quality metrics in Galileo), decorate it with `@galileo_retriever`:
```python
from galileo_adk import galileo_retriever
from google.adk.tools import FunctionTool
@galileo_retriever
def search_docs(query: str) -> str:
"""Search the knowledge base."""
results = my_vector_db.search(query)
return "\n".join(r["content"] for r in results)
tool = FunctionTool(search_docs)
```
### Ingestion Hook
Intercept traces for custom processing before forwarding to Galileo:
```python
import asyncio
import os
from galileo import GalileoLogger
from galileo_adk import GalileoADKPlugin
from google.adk.runners import Runner
from google.adk.agents import LlmAgent
from google.genai import types
logger = GalileoLogger(
project=os.getenv("GALILEO_PROJECT", "my-project"),
log_stream=os.getenv("GALILEO_LOG_STREAM", "dev"),
)
def my_ingestion_hook(request):
"""Hook that captures traces locally and forwards to Galileo with session management."""
if hasattr(request, "traces") and request.traces:
print(f"\n[Ingestion Hook] Intercepted {len(request.traces)} trace(s)")
for trace in request.traces:
spans = getattr(trace, "spans", []) or []
span_types = [getattr(s, "type", "unknown") for s in spans]
print(f" - Trace with {len(spans)} span(s): {span_types}")
# Session management: same external_id returns the same Galileo session
galileo_session_id = logger.start_session(external_id=request.session_external_id)
request.session_id = galileo_session_id
# Forward traces to Galileo
logger.ingest_traces(request)
async def main():
plugin = GalileoADKPlugin(ingestion_hook=my_ingestion_hook)
agent = LlmAgent(name="assistant", model="gemini-2.0-flash", instruction="You are helpful.")
runner = Runner(agent=agent, plugins=[plugin])
message = types.Content(parts=[types.Part(text="Hello!")])
async for event in runner.run_async(user_id="user-123", session_id="session-456", new_message=message):
if event.is_final_response():
print(event.content.parts[0].text)
if __name__ == "__main__":
# Set environment variables: GALILEO_API_KEY, GOOGLE_API_KEY
asyncio.run(main())
```
## Resources
- [Galileo Documentation](https://docs.rungalileo.io/)
- [Google ADK Documentation](https://google.github.io/adk-docs/)
## License
Apache-2.0
| text/markdown | null | "Galileo Technologies Inc." <team@galileo.ai> | null | null | Apache-2.0 | null | [
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Programming Language :: Python :: 3.13"
] | [] | null | null | <3.15,>=3.10 | [] | [] | [] | [
"galileo<2.0.0,>=1.45.0",
"google-adk<2.0.0,>=1.14.1"
] | [] | [] | [] | [
"Repository, https://github.com/rungalileo/galileo-python"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:38:31.845964 | galileo_adk-1.0.0b2.tar.gz | 49,256 | c1/d6/67a5b48cf6d20c748dedf0dd3dd20cff304560bb8242526334cd1ceac718/galileo_adk-1.0.0b2.tar.gz | source | sdist | null | false | 8cd30fca85f49bda35a682d0f51a4efa | 519baae722b66d2ee30b04423465414341fb06793db0e6a20520dd32ad31c88f | c1d667a5b48cf6d20c748dedf0dd3dd20cff304560bb8242526334cd1ceac718 | null | [] | 208 |
2.4 | madblog | 0.5.3 | A general-purpose framework for automation | # madblog
A minimal but capable blog and Web framework that you can directly run from a Markdown folder.
## Demos
This project powers the following blogs:
- [Platypush](https://blog.platypush.tech)
- [My personal blog](https://blog.fabiomanganiello.com)
## Installation
Local installation:
```shell
pip install madblog
```
Docker installation:
```shell
git clone https://git.fabiomanganiello.com/madblog
cd madblog
docker build -t madblog .
```
## Usage
```shell
# The application will listen on port 8000 and it will
# serve the current folder
$ madblog
usage: madblog [-h] [--config CONFIG] [--host HOST] [--port PORT] [--debug] [dir]
```
Recommended setup (for clear separation of content, configuration and static
files):
```
.
-> config.yaml [recommended]
-> markdown
-> article-1.md
-> article-2.md
-> ...
-> img [recommended]
-> favicon.ico
-> icon.png
-> image-1.png
-> image-2.png
-> ...
```
But the application can run from any folder that contains Markdown files
(including e.g. your Obsidian vault, Nextcloud Notes folder or a git clone).
To run it from Docker:
```shell
docker run -it \
-p 8000:8000 \
-v "/path/to/your/config.yaml:/etc/madblog/config.yaml" \
-v "/path/to/your/content:/data" \
madblog
```
## Configuration
See [config.example.yaml](./config.example.yaml) for an example configuration
file, and copy it to `config.yaml` in your blog root directory to customize
your blog.
All the configuration options are also available as environment variables, with
the prefix `MADBLOG_`.
For example, the `title` configuration option can be set through the `MADBLOG_TITLE`
environment variable.
### Webmentions
Webmentions allow other sites to notify your blog when they link to one of your
articles. Madblog exposes a Webmention endpoint and stores inbound mentions under
your `content_dir`.
Webmentions configuration options:
- **Enable/disable**
- Config file: `enable_webmentions: true|false`
- Environment variable: `MADBLOG_ENABLE_WEBMENTIONS=1` (enable) or `0` (disable)
- **Site link requirement**
- Set `link` (or `MADBLOG_LINK`) to the public base URL of your blog.
- Incoming Webmentions are only accepted if the `target` URL domain matches the
configured `link` domain.
- **Endpoint**
- The Webmention endpoint is available at: `/webmentions`.
- **Storage**
- Inbound Webmentions are stored as Markdown files under:
`content_dir/mentions/incoming/<post-slug>/`.
See the provided [`config.example.yaml`](./config.example.yaml) file for configuration options.
### View mode
The blog home page supports three view modes:
- **`cards`** (default): A responsive grid of article cards with image, title, date and description.
- **`list`**: A compact list — each entry shows only the title, date and description.
- **`full`**: A scrollable, WordPress-like view with the full rendered content of each article inline.
You can set the default via config file or environment variable:
```yaml
# config.yaml
view_mode: cards # or "list" or "full"
```
```shell
export MADBLOG_VIEW_MODE=list
```
The view mode can also be overridden at runtime via the `view` query parameter:
```
https://myblog.example.com/?view=list
https://myblog.example.com/?view=full
```
Invalid values are silently ignored and fall back to the configured default.
### Aggregator mode
Madblog can also render external RSS or Atom feeds directly in your blog.
Think of cases like the one where you have multiple blogs over the Web and you
want to aggregate all of their content in one place. Or where you have
"affiliated blogs" run by trusted friends or other people in your organization
and you also want to display their content on your own blog.
Madblog provides a simple way of achieving this by including the
`external_feeds` section in your config file:
```yaml
# config.yaml
external_feeds:
- https://friendsblog.example.com/feed.atom
- https://colleaguesblog.example.com/feed.atom
```
## Markdown files
For an article to be correctly rendered, you need to start the Markdown file
with the following metadata header:
```markdown
[//]: # (title: Title of the article)
[//]: # (description: Short description of the content)
[//]: # (image: /img/some-header-image.png)
[//]: # (author: Author Name <https://author.me>)
[//]: # (author_photo: https://author.me/avatar.png)
[//]: # (published: 2022-01-01)
```
Or, if you want to pass an email rather than a URL for the author:
```markdown
[//]: # (author: Author Name <mailto:email@author.me>)
```
If these metadata headers are missing, some of them can be inferred
from the file itself:
- `title` is either the first main heading or the file name
- `published` is the creation date of the file
- `author` is inferred from the configured `author` and `author_email`
### Folders
You can organize Markdown files in folders. If multiple folders are present, pages on the home will be grouped by
folders.
## Images
Images are stored under `img`. You can reference them in your articles through the following syntax:
```markdown

```
You can also drop your `favicon.ico` under this folder.
## LaTeX support
LaTeX support is built-in as long as you have the `latex` executable installed on your server.
Syntax for inline LaTeX:
```markdown
And we can therefore prove that \( c^2 = a^2 + b^2 \)
```
Syntax for LaTeX expression on a new line:
```markdown
$$
c^2 = a^2 + b^2
$$
```
## RSS syndication
Feeds for the blog are provided under the `/feed.<type>` URL, with `type` one of `atom` or `rss` (e.g. `/feed.atom` or
`/feed.rss`).
By default, the whole HTML-rendered content of an article is returned under the entry content.
If you only want to include the short description of an article in the feed, use `/feed.<type>?short` instead.
You can also specify the `?limit=n` parameter to limit the number of entries returned in the feed.
For backwards compatibility, `/rss` is still available as a shortcut to `/feed.rss`.
If you want the short feed (i.e. without the fully rendered article as a
description) to be always returned, then you can specify `short_feed=true` in
your configuration.
| text/markdown | Fabio Manganiello | Fabio Manganiello <fabio@manganiello.tech> | null | null | MIT | blog, markdown | [
"Topic :: Utilities",
"License :: OSI Approved :: MIT License",
"Development Status :: 4 - Beta"
] | [] | https://git.fabiomanganiello.com/madblog | null | >=3.8 | [] | [] | [] | [
"feedgen2",
"feedparser",
"flask",
"markdown",
"pygments",
"pyyaml",
"requests",
"watchdog",
"webmentions[file]"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.14.2 | 2026-02-19T00:38:23.010981 | madblog-0.5.3.tar.gz | 1,333,465 | b6/25/7f899e6521d2c837bf3ed99392a96100118dbcfff7fb9cffbd331c1ee611/madblog-0.5.3.tar.gz | source | sdist | null | false | f313bc993c1a5734ac3253b37ca91bc9 | dc0fbdcf5dd62c8d2f4735aa309cbf3333fdadf166756ba0665d376d5797acc4 | b6257f899e6521d2c837bf3ed99392a96100118dbcfff7fb9cffbd331c1ee611 | null | [
"LICENSE.txt"
] | 145 |
2.4 | mytunes-pro | 2.1.6 | A lightweight, keyboard-centric terminal player for streaming YouTube music. | # 🎵 MyTunes Pro - Professional TUI Edition v2.1.6
## 🚀 Terminal-based Media Workflow Experiment v2.1.6
> [!IMPORTANT]
> **Legal Disclaimer:** This project is a personal, non-commercial research experiment for developer education.
> It does not host, provide, or distribute any media content.
> All media sources are independently accessed and configured by the user.
> Users are solely responsible for ensuring that their usage complies with the terms of service of any third-party platforms accessed via this tool.
MyTunes Pro is a developer-focused **CLI Media Tool** for experimenting with terminal-based media workflows.
It utilizes the Python `curses` library to provide a structured TUI (Terminal User Interface) for handling media URLs,
leveraging the `mpv` engine for local media processing and playback.
> **💡 Project Note**
> This tool was designed for personal research into how terminal users can interact with media sources without interrupting their developer workflow.
> It explores the integration between local CLI environments (like Headless Debian Servers) and external media handling utilities.


---
## 📸 Screenshots
| | |
| :---: | :---: |
|  |  |
|  |  |
---
## ✨ Core Features
- **Media Handling**: Support for loading and processing media URLs using external extraction tools.
- **TUI Workflow**: Efficient, low-latency interface built on the `curses` library.
- **Workflow Persistence**: Handles sequential media loading and state restoration.
- **Terminal Optimization**: Performance-focused design that prioritizes keyboard-driven interactions.
- **Smart Management**: Optional user-configured collections, interaction history, and metadata handling.
- **External Integration**: Capabilities to load media links into external viewer/player environments.
---
## 💻 Environment & Integration
**MyTunes Pro** is a CLI-based tool. It can integrate with externally installed media processing tools.
- **External Tools**: This project can interface with user-installed utilities like `mpv` and media extraction tools. No third-party tools are bundled with this software.
- **macOS/Linux**: Native terminal support.
- **Windows**: Recommended to use with **WSL (Windows Subsystem for Linux)**.
---
## 🚀 Quick Install
We strongly recommend using **`pipx`** on modern macOS/Linux systems (PEP 668).
### 1. Recommended Method (pipx)
Automatically creates an isolated environment and registers the command.
```bash
# Ensure ensuredpath is run to register the command after pipx install!
pipx install mytunes-pro
pipx ensurepath
source ~/.zshrc # or source ~/.bashrc (apply immediately to current terminal)
```
### 2. Standard pip Method
If you encounter the `externally-managed-environment` error, add the following flag:
```bash
pip install mytunes-pro --break-system-packages
```
After installation, type **`mp`** anywhere in the terminal to run!
### 🔄 Update
If already installed, simply use the command below to update to the latest features:
```bash
pipx upgrade mytunes-pro
```
---
## 🛠 Prerequisites
Please install the necessary tools for your operating system before running.
### macOS (Using Homebrew)
```bash
brew install mpv python3 pipx
```
### Linux (Ubuntu/Debian)
```bash
sudo apt update
sudo apt install mpv python3 python3-pip pipx python3-venv -y
```
### Windows (WSL Guide)
Guide for Windows users where Korean search might not work or installation is difficult.
> **❓ What is WSL?**
> It allows you to run Linux environments directly on Windows. MyTunes works perfectly in this environment.
1. **Install WSL**:
- Right-click `Start` -> Run `Terminal (Admin)`.
- Enter the command below and **Reboot**:
```powershell
wsl --install -d Debian
```
2. **Install Essentials**:
```bash
sudo apt update && sudo apt install mpv python3-pip pipx -y
```
3. **Install MyTunes**:
```bash
pipx install mytunes-pro
pipx ensurepath
source ~/.bashrc # Apply settings immediately
```
---
## 🧑💻 Manual Installation (For Developers)
Follow these steps to modify source code or use the development version.
1. **Clone Repository**:
```bash
git clone https://github.com/postgresql-co-kr/mytunes.git
cd mytunes
```
2. **Setup Virtual Environment**:
```bash
python3 -m venv venv
source venv/bin/activate # macOS/Linux
pip install -r requirements.txt
```
3. **Run**:
```bash
python3 mytune.py
```
---
## ⌨️ Controls
**MyTunes Pro** is controlled entirely by keyboard.
We recommend using **Number Keys** for lag-free operation even in multi-language input modes.
### ⚡️ Instant Hotkeys (Number Keys)
Executes immediately without worrying about input language status.
| Key | Function | Description |
| :--- | :--- | :--- |
| **`1`** | **Search** | Open music search (Same as `S`) |
| **`2`** | **Favorites** | View favorites list (Same as `F`) |
| **`3`** | **History** | View recently played 100 tracks (Same as `R`) |
| **`4`** | **Main** | Return to main screen (Same as `M`) |
| **`5`** | **Add/Del** | Toggle favorite for selected track (Same as `A`) |
| **`+`** | **Vol UP** | Volume +5% (Same as `=`) |
| **`-`** | **Vol DOWN** | Volume -5% (Same as `_`) |
| **`F7`** | **Open YouTube** | View current track in browser |
| **`E`** | **Equalizer** | Cycle EQ presets (Auto/Flat/Pop/Rock/Jazz/etc.) |
| **`6`** | **Back** | Go to previous screen (Same as `Q`, `h`) |
| **`L`** | **Forward** | Go forward to previous screen (`Right Arrow`) |
| **`ESC`** | **Background** | **Exit without stopping music** (Background Play) |
### 🧭 Basic Navigation
| Key | Action |
| :--- | :--- |
| `↑` / `↓` / `k` / `j` | Move selection Up/Down (Vim keys supported) |
| `Enter` / `l` | **Select / Play** |
| `Space` | Play / Pause |
| `-` / `+` | **Volume Control** |
| `,` / `.` | Rewind / Forward 10s |
| `<` / `>` | Rewind / Forward 30s (Shift) |
| `Backspace` / `h` / `q` | Go Back / Clear Search |
| `L` | **Go Forward** |
| `/` | **Search** (Vim Style) |
---
## 📂 Data Storage
- Favorites and playback history are permanently saved in `~/.pymusic_data.json` in your home directory.
- Data is preserved even after restarting the program.
---
---
# 🎵 MyTunes Pro (Experimental Media Tool - KR)
## 🚀 터미널 기반 미디어 워크플로우 실험 v2.1.6
> [!IMPORTANT]
> **법적 면책 고지:** 본 프로젝트는 개발자 교육 및 연구를 목적으로 하는 개인적, 비상업적 실험입니다.
> 본 소프트웨어는 어떠한 미디어 콘텐츠도 직접 호스팅하거나 배포하지 않습니다.
> 모든 미디어 소스는 사용자의 로컬 환경에서 직접 구성되고 접근되며, 사용자는 외부 플랫폼의 이용 약관을 준수할 책임이 있습니다.
MyTunes Pro는 개발자를 위해 설계된 **CLI 미디어 실험 도구**입니다.
Python `curses` 라이브러리를 통해 터미널 환경에서 미디어 URL을 로드하고 관리하며,
사용자가 설치한 `mpv` 등의 외부 도구와 연동하여 미디어 워크플로우를 테스트할 수 있습니다.
## ✨ 주요 특징
- **미디어 핸들링**: 외부 추출 도구를 사용한 미디어 URL 로드 및 처리 지원.
- **TUI 워크플로우**: `curses` 라이브러리 기반의 효율적인 터미널 인터페이스.
- **작업 유지**: 순차적 미디어 로딩 및 마지막 작업 상태 복원 기능.
- **환경 연동**: 사용자에 의해 구성된 외부 미디어 도구와의 연동 지원. (본 소프트웨어는 외부 도구를 포함하여 배포하지 않습니다.)
---
## 📸 스크린샷 (Screenshots)
| | |
| :---: | :---: |
|  |  |
|  |  |
---
## 🚀 빠른 설치 (Quick Install)
최신 macOS/Linux 시스템(PEP 668)에서는 **`pipx`** 사용을 강력히 권장합니다.
### 1. 추천 방식 (pipx)
자동으로 격리된 환경을 만들고 명령어를 등록해줍니다.
```bash
# pipx install 이후 명령어 등록을 위해 ensurepath 실행 시점 확인!
pipx install mytunes-pro
pipx ensurepath
source ~/.zshrc # 또는 source ~/.bashrc (현재 터미널에 즉시 적용)
```
### 2. 일반 pip 방식
만약 `externally-managed-environment` 에러가 발생한다면 아래 플래그를 추가하세요:
```bash
pip install mytunes-pro --break-system-packages
```
설치 후 터미널 어디서든 **`mp`**를 입력하면 실행됩니다!
### 🔄 최신 버전 업데이트 (Update)
이미 설치되어 있다면 아래 명령어로 간단히 최신 기능을 반영하세요:
```bash
pipx upgrade mytunes-pro
```
---
## 🛠 환경별 요구사항 (Prerequisites)
실행 전 각 운영체제에 맞는 필수 도구들을 설치해 주세요.
### macOS (Homebrew 사용)
```bash
brew install mpv python3 pipx
```
### Linux (Ubuntu/Debian)
```bash
sudo apt update
sudo apt install mpv python3 python3-pip pipx python3-venv -y
```
### Windows (초보자용 WSL 가이드)
Windows 환경에서 한글 검색이 안 되거나 설치가 어려운 분들을 위한 가이드입니다.
> **❓ WSL이란?**
> 윈도우 안에서 리눅스를 앱처럼 쓸 수 있게 해줍니다. MyTunes는 이 환경에서 완벽하게 작동합니다.
1. **WSL 설치하기**:
- `시작` 버튼 우클릭 -> `터미널(관리자)` 실행.
- 아래 명령어 입력 후 **재부팅**:
```powershell
wsl --install -d Debian
```
2. **필수 도구 설치**:
```bash
sudo apt update && sudo apt install mpv python3-pip pipx -y
```
3. **MyTunes 설치**:
```bash
pipx install mytunes-pro
pipx ensurepath
source ~/.bashrc # 설정 즉시 반영
```
---
## 🧑💻 개발자용 수동 설치 (Manual Installation)
직접 소스크드를 수정하거나 개발 버전을 사용하려면 아래 과정을 따르세요.
1. **저장소 클론**:
```bash
git clone https://github.com/postgresql-co-kr/mytunes.git
cd mytunes
```
2. **가상환경 설정**:
```bash
python3 -m venv venv
source venv/bin/activate # macOS/Linux
pip install -r requirements.txt
```
3. **실행**:
```bash
python3 mytune.py
```
---
## ⌨️ 조작 방법 (Controls)
**MyTunes Pro**는 키보드만으로 모든 기능을 제어합니다.
한글 입력 상태에서도 끊김 없는 조작을 위해 **숫자 단축키** 사용을 권장합니다.
### ⚡️ 즉시 반응 단축키 (숫자키)
한영 전환 없이 언제든 누르면 즉시 실행됩니다.
| 키 | 기능 | 설명 |
| :--- | :--- | :--- |
| **`1`** | **검색 (Search)** | 음악 검색창 열기 (단축키 `S`와 동일) |
| **`2`** | **즐겨찾기 (Fav)** | 저장된 즐겨찾기 목록 보기 (단축키 `F`와 동일) |
| **`3`** | **기록 (History)** | 최근 재생한 100곡 보기 (단축키 `R`와 동일) |
| **`4`** | **메인 (Main)** | 메인 화면으로 돌아가기 (단축키 `M`와 동일) |
| **`5`** | **추가/삭제** | 선택한 곡 즐겨찾기 토글 (단축키 `A`와 동일) |
| **`+`** | **볼륨 UP** | 볼륨 +5% (단축키 `=`와 동일) |
| **`-`** | **볼륨 DOWN** | 볼륨 -5% (단축키 `_`와 동일) |
| **`F7`** | **유튜브 열기** | 현재 곡을 브라우저에서 보기 |
| **`E`** | **이퀄라이저** | EQ 프리셋 전환 (Auto/Flat/Pop/Rock/Jazz 등) |
| **`6`** | **뒤로가기** | 이전 화면으로 이동 (단축키 `Q`, `h`와 동일) |
| **`L`** | **앞으로** | 이전 화면에서 앞화면으로 다시 이동 (`Right Arrow`) |
| **`ESC`** | **배경재생** | **음악 끄지 않고 나가기** (백그라운드 재생) |
### 🧭 기본 탐색
| 키 | 동작 |
| :--- | :--- |
| `↑` / `↓` / `k` / `j` | 리스트 위/아래 이동 (Vim 키 지원) |
| `Enter` / `l` | **선택 / 재생** |
| `Space` | 재생 / 일시정지 (Play/Pause) |
| `-` / `+` | **볼륨 조절** (- / +) |
| `,` / `.` | 10초 뒤로 / 앞으로 감기 |
| `<` / `>` | **30초** 뒤로 / 앞으로 감기 (Shift) |
| `Backspace` / `h` / `q` | 뒤로 가기 / 검색어 지우기 |
| `L` | **앞으로 가기** |
| `/` | **검색** (Vim Style) |
---
## 📂 데이터 저장
- 즐겨찾기와 재생 기록은 홈 디렉토리의 `~/.pymusic_data.json` 파일에 영구 저장됩니다.
- 프로그램 종료 후 다시 실행해도 데이터가 유지됩니다.
---
---
## 🔄 Changelog
### v2.1.6 (2026-02-19)
- **TUI Polish**: Improved persistent view context and transient feedback mechanisms.
- **Stability**: Added safety checks to skip autoplay if the IPC socket is unresponsive.
- **Cleanup**: Ensured mouse mask is properly reset to prevent terminal artifacts.
### v2.1.5 (2026-02-04)
- **Absolute Volume Display**: Now displays volume as a precise percentage (0-100%) with a "(Boost)" indicator for levels above 100%.
- **Volume Persistence**: Volume level is now permanently saved and restored across app restarts.
- **Offline Control**: Adjust volume levels globally even when the player is stopped; changes apply immediately upon next playback.
### v2.1.4 (2026-02-03)
- **Mouse Support Removed**: Reverted to pure keyboard interface for cleaner experience.
- **Bug Fixes**: Resolved IndentationError and key loop crashes.
- **Stability**: Removed unused code paths.
### v2.1.3 (2026-02-02)
- **Resolved TUI Freeze on Song Launch**: Fixed a critical regression from v2.0.6 where misplaced blocking input code caused the TUI to freeze on "Loading" during song transitions or resume until a key was pressed.
- **Fixed EQ Application**: Restored correct Auto EQ initialization during `play_music` in `app.py`.
### v2.1.2 (2026-02-02)
- **Fix "Loading" Stuck**: Improved IPC resilience to prevent the TUI from being stuck on "Loading" during song transitions or resume, by increasing the initial socket connection timeout patience.
- **Fail-Safe Loading**: Implemented a hard reset for the loading state if mpv takes longer than 8 seconds to respond, ensuring the TUI remains interactive.
### v2.1.1 (2026-02-02)
- **WSL UI Polish**: Hides Equalizer (EQ) labels and status in the TUI when running on WSL to avoid confusion, as the feature is disabled in that environment for stability.
- **Improved Feedback**: Provides a clear status message when the 'E' key is pressed on WSL.
### v2.1.0 (2026-02-02)
- **Zero-Freeze IPC Resilience**: Implemented a "Fast-Fail" mechanism that detects mpv process death within 0.1ms via `poll()`, preventing TUI freezes.
- **Fail-Early Polling**: Main loop now aborts all remaining IPC property checks immediately if any call fails, maintaining a smooth 5fps even on broken connections.
- **Connection Throttling**: Added a 1.5-second "cool-down" period for reconnection attempts to minimize blocking time on Windows/WSL environments.
- **Multibyte Harmony**: Explicitly configured `locale.setlocale` to ensure stable emoji and CJK character rendering across different terminal environments.
- **Improved Autoplay Stability**: Autoplay logic now skips status checks when the socket is unhealthy to prevent feedback loops.
### v2.0.8 (2026-02-02)
- **Windows/WSL Socket Recovery**: Fixed UI freezing when mpv socket disconnects during window switching.
- **IPC Resilience**: Added socket pre-check and failure counter to prevent blocking on broken connections.
- **Automatic Recovery**: New playback automatically restarts mpv if socket is unhealthy.
### v2.0.7 (2026-02-02)
- **Performance Optimization**: Improved keyboard responsiveness on Windows/WSL by implementing EQ detection caching.
- **Data Management**: Limited resume data to 500 entries with automatic FIFO cleanup to prevent JSON bloat.
- **Cache System**: Added 200-entry EQ genre cache to skip redundant keyword matching for repeated tracks.
### v2.0.6 (2026-02-02)
- **10-Band Equalizer**: Added professional-grade 10-band EQ with presets (Flat, Pop, Rock, Jazz, Classical, Full Bass, Dance, Club, Live, Soft).
- **Auto EQ Detection**: Intelligent genre detection from track title/channel info automatically applies optimal EQ preset.
- **Keyboard Shortcut**: Press `E` to cycle through EQ presets in real-time without interrupting playback.
- **Multilingual Genre Keywords**: Auto EQ supports genre detection in 12 languages including Korean, Japanese, Chinese, Spanish, and more.
### v2.0.5 (2026-02-01)
- **Input Feedback Refinement**: Transitioned from blinking warnings to a static Bold Yellow status message for better accessibility and premium feel.
- **Auto-clear Optimization**: Implemented a 5-second auto-clear timer for all transient status messages.
- **Zero Latency Feedback**: Added instant redraw mechanisms to ensure input warnings appear immediately upon key press.
- **Stability Fixes**: Resolved a critical attribute error that caused crashes when selecting menu items.
- **SSL Compatibility**: Improved `urllib3` compatibility for macOS systems using LibreSSL.
### v2.0.4 (2026-02-01)
- **Legal Polish**: Comprehensive scrubbing of brand identifiers and service-oriented terminology across the ecosystem.
- **Localization**: Fully localized Korean landing page and technical experiment descriptions.
- **Educational Focus**: Added explicit project disclaimers to all web footers.
- **Project Scope**: Solidified positioning as a "Media Handling Experiment" rather than a music player.
### v2.0.3 (Input Handling & Unicode Stability)
- **Input Logic**: Replaced legacy `getch()` with `get_wch()` in all UI dialogs (`ask_resume`, `show_copy_dialog`) for robust wide-character and Unicode support.
- **Architecture**: Refactored the input handling system into a modular, command-based architecture (v2.0.3).
- **Decoupling**: Separated input collection (`get_next_event`), event normalization, and command execution.
- **Improved ESC Handling**: Enhanced detection of ESC and multi-byte sequences (including Option+Backspace) for smoother navigation.
### v2.0.2 (Stability & Browser Optimization)
- **Browser Launch**: Switched to fully decoupled `subprocess.Popen` logic for browser opening. This eliminates occasional TUI freezes when launching Media Links (F7) or Dashboard (F8) by bypassing `webbrowser` library limitations.
- **App Mode Restore**: Fixed and improved Chrome/Brave App Mode (Popup) for the Live Station on macOS.
- **Improved Remote Detection**: Refined SSH/WSL detection to ensure local browser features are correctly enabled where possible.
### v2.0.1 (Keymap Refinement & Version Sync)
- **Navigation**: Added browser-style Forward navigation (`L` / `Right Arrow`).
- **Keybinding Optimization**: Updated History mapping to `R` / `3` and refined Back/Forward logic.
- **IME Stability**: Removed unstable Korean character mappings (`ㄴ`, `ㄹ`, `ㄱ`, 등) to prevent ghost key issues in the TUI.
- **Global Synchronization**: Synchronized version v2.0.1 across CLI, TUI, and Web interfaces.
### v1.9.9 (Domain Migration & Realtime Sync)
- **Domain Migration**: Updated all branding and internal links to support `mytunes-pro.com`.
- **Realtime Stability**: Fixed critical state-management bugs in the live dashboard that caused list clearing and duplicated track entries.
- **Improved Empty State**: Redesigned the "SIGNAL LOST" screen into a more descriptive "READY TO RECEIVE" interface for better UX.
### v1.9.8 (Realtime Stabilization)
- **UI Refinement**: Implemented in-list "Now Playing" sticky behavior with auto-scroll synchronization for a seamless browsing experience.
- **Queue System Optimization**: Capped incoming track queue at 200 items with a "200+" notification indicator for high-traffic stability.
- **Popup UI Consistency**: Unified Live Station popup dimensions to 620x900 across Web and TUI.
- **Improved Media Playback**: Optimized the media player hook to resolve initialization race conditions and syntax edge cases.
### v1.9.7 (Analytics)
- **Analytics**: Integrated Google Analytics 4 (GA4) into the landing page and realtime feed to track visitor traffic and usage patterns.
### v1.9.6 (Realtime UX)
- **Incoming Queue System**: The Realtime Feed (`/live`) now queues incoming shared tracks instead of disrupting the list immediately. A "SHOW NEW TRACKS" button appears, allowing users to update the feed at their convenience, ensuring a stable viewing experience.
### v1.9.5
- **Code Cleanup**: Removed deprecated and unreachable WSL subprocess launch logic to ensure codebase cleanliness and prevent confusion. The application now exclusively uses the stable `webbrowser` module for WSL.
### v1.9.4
- **Ultimate WSL Fix**: Switched to using Python's standard `webbrowser` module for opening links in WSL. This fully delegates browser launching to the system (Windows host), ensuring maximum stability and eliminating all `subprocess` or `cmd.exe` related conflicts.
### v1.9.3
- **Hotfix for Startup**: Fixed a syntax error introduced in v1.9.2 that prevented the application from starting.
### v1.9.2
- **Disable WSL Profile Isolation**: To ensure maximum stability and prevent `cmd.exe` conflicts, MyTunes now temporarily disables profile isolation (forced window size/position) on WSL. It runs using the default Chrome profile, guaranteeing reliable launching.
### v1.9.1
- **Fix CMD Output Pollution (WSL)**: Resolved an issue where `cmd.exe` printed "UNC paths are not supported" warnings when executed from a WSL directory, corrupting the temporary path retrieval. Now parses output safely and executes from `/mnt/c` to prevent warnings.
### v1.9.0
- **Fix WSL Profile Error**: Switched to using the **native Windows TEMP directory** (e.g., `C:\Users\...\AppData\Local\Temp`) for the browser profile in WSL. This prevents file locking issues caused by Chrome treating `\\wsl$\` paths as network drives.
### v1.8.9
- **Robust WSL Path Fix**: Resolved an issue where direct browser launching (non-fallback) in WSL was still using Linux paths for the profile, causing "User Data Directory" creation errors. Path conversion is now applied globally before launch.
### v1.8.8
- **WSL Path Conversion**: Implemented `wslpath -w` logic to correctly convert Linux-style temp paths to Windows format when launching Chrome via `cmd.exe` on WSL.
### v1.8.7
- **Syntax Fix (WSL)**: Corrected a typo in the browser launch command that caused a crash on Linux/WSL systems.
### v1.8.6
- **Browser Popup Optimization (Context7)**: Improved Live Station (F8) experience with optimized CLI flags for a perfectly minimalist UI.
- **Forced Window Dimensions**: Implemented profile isolation using a timestamped `user-data-dir` to ensure window size and position are always respected, overriding session memory.
- **UI Cleanup**: Automatically hides distraction-bars (translation, password, automation infobars) and enables instant autoplay for live streams.
### v1.8.5
- **Looping Navigation (Menu Wrapping)**: Pressing UP at the first item now wraps to the last item, and pressing DOWN at the last item wraps to the first.
- **Improved UI Flow**: Enhanced keyboard navigation experience across all list views (Main, Search, Favorites, History).
### v1.8.4
- **Python Crash Fix (WSL)**: Eliminated premature termination by implementing `start_new_session=True` for browser launches, isolating them from the TUI process group.
- **Hybrid Browser Strategy**: Switched to the standard `webbrowser` library for F7 (Media links) for maximum internal stability.
- **Global Error Protection**: Wrapped the main application loop in an exception guard to catch and log transient OS errors without crashing the entire app.
- **Refined Process Cleanup**: Specialized the `pkill` logic to prevent accidental self-termination while maintaining reliable MPV management.
### v1.8.3
- **Direct Binary Execution (WSL)**: Resolved shell parsing issues by bypassing `cmd.exe` and directly executing Windows browser binaries via `/mnt/c/` paths.
- **App Mode Reliability**: Guaranteed 712x800 popup mode by ensuring flags are delivered directly to the browser process without intermediate shell mangling.
- **Fixed URL Resolution**: Eliminated the "Empty URL" bug by standardizing argument passing between WSL and Windows.
### v1.8.1
- **Fixed App Mode (WSL/Win)**: Guaranteed the browser opens in a clean "App Mode" popup by fixing shell quoting issues in the launch command.
- **URL Resolution Fix**: Resolved the "Empty URL" bug on WSL/Windows by ensuring the `--app` flag is correctly parsed by the native Windows shell.
- **Reliable Popup UI**: Standardized on `start "" chrome` for WSL to ensure flags are never misidentified as window titles.
### v1.8.0
- **Stabilized Browser Launch (Windows/WSL)**: Completely removed the `--user-data-dir` flag for all Windows-based environments. This permanently resolves the "cannot read or write" directory errors while maintaining reliable 712x800 window sizing through pure app-mode flags.
- **Clean CMD Execution**: Simplified the WSL-to-Windows transition by using standard `cmd.exe` calls without complex path or variable expansion, ensuring consistent behavior across all systems.
### v1.7.9
- **Pure CMD-based Launch (WSL/Win)**: Final fix for WSL-to-Windows browser launch using `cmd.exe /c` with native `%LOCALAPPDATA%` expansion.
- **Directory Reliability**: Ensured Chrome data directory creation and access by using native Windows shell commands, eliminating the "cannot read or write" errors seen in v1.7.8.
- **Stable Window Sizing**: Guaranteed 712x800 window size for Live Station (F8) from WSL by correctly isolating browser profiles via native Windows paths.
### v1.7.8
- **Native PowerShell Profile Management**: Resolved directory read/write errors in WSL by moving all profile creation and path handling to the Windows side via PowerShell.
- **Improved Security & Isolation**: Profiles are now created in the standard Windows `LOCALAPPDATA` directory with native permissions, ensuring Chrome can always access its data.
- **Backslash Consistency**: Forced backslash-only paths through pure PowerShell logic, fixing the mixed-slash issue seen in WSL.
### v1.7.7
- **PowerShell Launch (WSL/Win)**: Switched to `powershell.exe` for launching browsers from WSL to ensure robust argument parsing and path handling.
- **Directory Fix**: Resolved "cannot read or write" error on Windows/WSL by utilizing `$env:TEMP` directly within a native shell context.
- **Reliable Sizing**: Guaranteed window size application by combining isolated profiles with PowerShell's superior process management.
### v1.7.6
- **Isolated Browser Profile**: Guaranteed window sizing for the Live Station (F8) on Windows/WSL by forcing an isolated browser profile using the Windows `%TEMP%` directory.
- **WSL Path Translation**: Implemented automatic Windows temp path resolution in WSL to enable session persistence and profile isolation.
### v1.7.5
- **WSL Integration**: Fully optimized browser launch from WSL by utilizing `cmd.exe` to trigger native Windows browsers.
- **F7 Windows Resolve**: Fixed an issue where Media links (F7) wouldn't open in WSL environments.
- **F8 App Mode (WSL/Win)**: Enhanced flags to ensure "App Mode" (no address bar) works consistently even when launched from WSL.
### v1.7.4
- **Windows UI Refinement**: Forced Chrome "App Mode" on Windows by reordering flags and disabling extensions/default-apps to ensure a clean popup without an address bar.
- **Improved Isolation**: Switched to higher-frequency session rotation for Live Station (F8) to guarantee window size and position persistence fixes.
### v1.7.3
- **Windows Fixes**: Resolved issue where F7 (Media) failed to open browsers on Windows by implementing `os.startfile` logic.
- **F8 Initialization**: Improved Live Station (F8) window sizing on Windows by forcing a clean session state.
- **Robustness**: Enhanced cross-platform browser redirection logic to ensure consistent behavior.
### v1.7.2
- **Windows Optimization**: Fixed an issue where the Live Station (F8) window size was not correctly applied on Windows.
- **Improved Browser Support**: Added Microsoft Edge to the automatic browser detection list.
- **Robust Launch Logic**: Enhanced browser internal flags for a better initial window experience.
### v1.7.1
- **Performance & Logic Optimization**: Standardized browser launch logic for Live Station (F8) across Mac, Windows, and Linux.
- **UI Polish**: Silenced browser launch warnings in the terminal and added professional UI flags (disable translation/bubble) for a cleaner experience.
- **Improved Popup Behavior**: Optimized web interface to reuse the same window for Live Station, matching CLI application behavior.
- **Global Sync**: Version 1.7.1 synchronization across all platforms.
### v1.6.0
- **Global Version Synchronization**: Synchronized version 1.6.0 across CLI, README, and Web interface.
### v1.5.6
- **Refined Search History Display**: Improved the search preview logic to use a temporary 'search' view state, providing a smoother experience when opening and canceling search.
- **Bug Fix**: Resolved an issue where the 'Search Results History' was not displaying correctly in the background.
### v1.5.5
- **Search Result History**: Automatically saves up to 200 search results.
- **Enhanced Search UX**: Previously searched items are displayed in the background automatically when opening search.
- **Deduplication**: Automatically removes duplicate search results to keep history clean.
### v1.5.4
- **Documentation Refinement**: Clarified installation steps and removed redundant WSL locale guide.
- **Code Cleanup**: Reverted unnecessary locale settings in source code.
### v1.5.3
- **Locale Optimization**: Removed complicated locale generation steps for Windows/WSL users. Now relies on standard system locale or simple `C.UTF-8` fallback.
### v1.5.2
- **Documentation**: Major README overhaul for beginner friendliness. Added dedicated Windows/WSL "Zero-to-Hero" guide.
### v1.5.0
- **Release**: Milestone v1.5.0 release with polished documentation and stable features.
| text/markdown | null | loxo <loxo5432@gmail.com> | null | null | null | null | [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
"Topic :: Multimedia :: Sound/Audio :: Players"
] | [] | null | null | >=3.9 | [] | [] | [] | [
"requests",
"urllib3<2.0.0",
"yt-dlp",
"pusher"
] | [] | [] | [] | [
"Homepage, https://github.com/postgresql-co-kr/mytunes",
"Bug Tracker, https://github.com/postgresql-co-kr/mytunes/issues"
] | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:38:08.231607 | mytunes_pro-2.1.6.tar.gz | 61,692 | 0a/b9/34df781a1cc5927d958120051f61bc0b4e2f9af296d903a31d47230b9450/mytunes_pro-2.1.6.tar.gz | source | sdist | null | false | f24308581fb4fbe623d4c7b88bb56358 | 083c629236ab6d6e4f374ee1aa51275b8aa5019c75c151591490557ac00dadf6 | 0ab934df781a1cc5927d958120051f61bc0b4e2f9af296d903a31d47230b9450 | null | [
"LICENSE"
] | 226 |
2.2 | qgdata | 0.1.1 | HTTP SDK for querying pipeline data service | # qgdata Python SDK
## 定位
`qgdata` 是 `qgdata-http-service` 的 Python 客户端,提供接近 Tushare 的调用体验,返回 `pandas.DataFrame`。
## 安装
```bash
pip install qgdata
```
## 快速开始
```python
import qgdata as qg
qg.set_token("your-token")
pro = qg.pro_api()
df = pro.stock_basic(
fields="ts_code,name,list_date",
order_by="list_date",
sort="desc",
limit=20,
)
print(df.head())
```
详细的用户接口文档见:`docs/SDK_USER_API.md`。
分钟行情专版文档见:`docs/SDK_USER_API_STK_MINS.md`。
## 核心接口
统一查询:
```python
df = pro.query(
"stock_basic",
ts_code="000001.SZ",
fields=["ts_code", "name", "list_date"],
order_by="list_date",
sort="desc",
limit=200,
offset=0,
)
```
动态方法(等价于 `query`):
```python
df = pro.stock_basic(ts_code="000001.SZ", limit=50)
```
获取 API 列表:
```python
apis = pro.list_apis(enabled_only=True)
```
## 核心能力
- `set_token()` + `pro_api()` 初始化
- `pro.query(...)` 统一查询
- `pro.xxx(...)` 动态 API 调用
- `pro.list_apis(...)` 拉取可用接口
## 参数约定
- 支持普通参数和列表参数
- 支持分页:`limit` / `offset`
- 支持排序:`order_by` / `sort`(`asc`、`desc`)
- 参数语义由服务端解释
## 异常处理
HTTP 或业务错误会抛出 `PipelineSDKError`:
```python
from qgdata import PipelineSDKError
try:
df = pro.query("stock_basic", limit=10)
except PipelineSDKError as exc:
print("message:", exc)
print("code:", exc.code)
print("detail:", exc.detail)
```
常见错误消息:
- `unauthorized`(401)
- 其它服务端 `message`(统一透传)
## 开发与发布
```bash
python -m pip install --upgrade build twine
python -m build
python -m twine check dist/*
```
更多发布步骤:`docs/PYPI_PUBLISH.md`。
| text/markdown | Pipeline Team | null | null | null | MIT | pipeline, sdk, http, data | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Developers",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
"Operating System :: OS Independent"
] | [] | null | null | >=3.10 | [] | [] | [] | [
"pandas<3.0,>=2.0",
"requests<3.0,>=2.31"
] | [] | [] | [] | [] | twine/6.2.0 CPython/3.10.14 | 2026-02-19T00:37:24.443131 | qgdata-0.1.1.tar.gz | 5,928 | d6/25/f2b233c1dda123146a79f0aec51678ed47f375a1b4edace244535edb1147/qgdata-0.1.1.tar.gz | source | sdist | null | false | 6797ddd86f50d8f812b3324929158889 | aac8803f7491042e8f0f88971b20db5f00eac0a400fe2c5885ba4b7ce0e301d7 | d625f2b233c1dda123146a79f0aec51678ed47f375a1b4edace244535edb1147 | null | [] | 239 |
2.4 | laser-measles | 0.8.0.dev1 | Spatial models of measles implemented with the LASER toolkit. | ==============================
Welcome to laser-measles
==============================
.. start-badges
.. image:: https://img.shields.io/pypi/v/laser-measles.svg
:alt: PyPI Package latest release
:target: https://pypi.org/project/laser-measles/
.. image:: https://img.shields.io/pypi/l/laser-measles.svg
:alt: MIT License
:target: https://github.com/InstituteforDiseaseModeling/laser-measles/blob/main/LICENSE
.. image:: https://readthedocs.org/projects/laser-measles/badge/?style=flat
:alt: Documentation Status
:target: https://laser-measles.readthedocs.io/en/latest/
.. image:: https://codecov.io/gh/InstituteforDiseaseModeling/laser-measles/branch/main/graphs/badge.svg?branch=main
:alt: Coverage Status
:target: https://app.codecov.io/github/InstituteforDiseaseModeling/laser-measles
.. end-badges
laser-measles helps you build and analyze spatial models of measles implemented with the `LASER framework <https://github.com/InstituteforDiseaseModeling/laser>`_.
.. code-block:: bash
pip install laser-measles
| text/x-rst | Christopher Lorton, Jonathan Bloedow, Katherine Rosenfeld, Kevin McCarthy | null | Christopher Lorton | null | null | measles, spatial, modeling, laser | [
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Operating System :: Unix",
"Operating System :: POSIX",
"Operating System :: Microsoft :: Windows",
"Operating System :: MacOS",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming La... | [] | https://github.com/InstituteforDiseaseModeling/laser-measles | null | >=3.10 | [] | [] | [] | [
"numba>=0.61.0",
"laser-core>=1.0.0",
"diskcache>=5.6.3",
"appdirs>=1.4.4",
"pydantic>=2.11.5",
"pycountry>=24.6.1",
"requests>=2.32.3",
"alive-progress>=3.2.0",
"sciris>=3.2.1",
"polars>=1.30.0",
"pyarrow>=20.0.0",
"rastertoolkit>=0.3.11",
"typer>=0.12.0",
"patito>=0.8.3",
"pyvd>=1.0.1"... | [] | [] | [] | [
"Homepage, https://example.com",
"Documentation, https://laser-measles.readthedocs.io/en/latest/",
"Repository, https://github.com/InstituteforDiseaseModeling/laser-measles.git",
"Issues, https://github.com/InstituteforDiseaseModeling/laser-measles/issues",
"Changelog, https://github.com/InstituteforDisease... | twine/6.1.0 CPython/3.13.7 | 2026-02-19T00:35:59.553478 | laser_measles-0.8.0.dev1.tar.gz | 227,138 | 75/95/6baddf8fba719be9627b0c40149ce55794f6e786b4e00fde141ce6557597/laser_measles-0.8.0.dev1.tar.gz | source | sdist | null | false | be2915819fffd8542ddbf79ae5ad7d4a | 9d30e0f65fc4126607482b3af027b4d2e0d5f01ae2a259477748cf0f2f06e6c6 | 75956baddf8fba719be9627b0c40149ce55794f6e786b4e00fde141ce6557597 | MIT | [
"LICENSE",
"AUTHORS.rst"
] | 270 |
2.4 | stagpy | 0.22.0 | Tool for StagYY output files processing | [](https://pypi.org/project/stagpy/)
[](https://doi.org/10.5281/zenodo.5512348)
StagPy
======
StagPy is a command line tool to process the output files of your StagYY
simulations and produce high-quality figures.
This command line tool is built around a generic interface that allows you to
access StagYY output data directly in a Python script.
You can install StagPy from the [Python Package
Index](https://pypi.org/project/stagpy/).
See the [full documentation](https://stagpython.github.io/StagPy/) for more
information.
If StagPy has been useful to your research, please consider citing the project
as:
> Adrien Morison, Martina Ulvrova, Stephane Labrosse, & contributors. (2021).
StagPython/StagPy. Zenodo. https://doi.org/10.5281/zenodo.5512348
or a specific version with the relevant DOI (e.g. for v0.15.0):
> Adrien Morison, Martina Ulvrova, Stephane Labrosse, & contributors. (2021).
StagPython/StagPy (v0.15.0). Zenodo. https://doi.org/10.5281/zenodo.5512349
| text/markdown | Adrien Morison, Martina Ulvrova, Stéphane Labrosse | Adrien Morison <adrien.morison@gmail.com> | Adrien Morison | Adrien Morison <adrien.morison@gmail.com> | null | null | [
"Development Status :: 3 - Alpha",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.10",
"Programming Language :: Python :: 3.11",
"Programming Language :: Python :: 3.12",
... | [] | null | null | >=3.10 | [] | [] | [] | [
"f90nml>=1.5",
"h5py~=3.15",
"loam~=0.9.0",
"matplotlib~=3.10",
"numpy~=2.2",
"pandas~=2.3",
"rich>=14.2.0",
"scipy~=1.15"
] | [] | [] | [] | [
"homepage, https://github.com/StagPython/StagPy"
] | uv/0.10.4 {"installer":{"name":"uv","version":"0.10.4","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true} | 2026-02-19T00:32:55.338502 | stagpy-0.22.0-py3-none-any.whl | 62,980 | bd/b2/ef4884cec2d7e71fb8a634ff6c5c9fb20f1cfe83e71b7aa06eab20c7986c/stagpy-0.22.0-py3-none-any.whl | py3 | bdist_wheel | null | false | db7f793290f9beebb834b37fb396e2c8 | af30407d29b00adbb3ebcbc2315a92e41e8e300b5784a35adbf4980bdf2804a4 | bdb2ef4884cec2d7e71fb8a634ff6c5c9fb20f1cfe83e71b7aa06eab20c7986c | Apache-2.0 | [
"LICENSE"
] | 240 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.