
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,897,233 | Tensorman: TensorFlow with CUDA made easy | Getting TensorFlow to work with CUDA can be a real headache. You have to make sure that the versions... | 0 | 2024-06-22T17:26:18 | https://dev.to/tallesl/tensorman-tensorflow-with-cuda-made-easy-48km | tensorflow, cuda, nvidia | Getting TensorFlow to work with CUDA can be a real headache. You have to make sure that the versions of TensorFlow, CUDA, cuDNN match up. Missing one small detail can throw everything off.
Luckly, Google provides some [pre-configured Docker images](https://hub.docker.com/r/tensorflow/tensorflow) so you don't have to d... | tallesl |
1,897,232 | Computer Science Challenge: Recursion | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T17:24:40 | https://dev.to/darshanraval/computer-science-challenge-recursion-2c8h | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Recursion: Recursion is a programming method that involves a function calling itself to address versions of an issue until it reaches a base scenario. This technique plays a role, in a... | darshanraval |
1,897,230 | 🚀 Exciting Update: SimpliLearn Certifications Achieved! 🎓 | Hello Everyone, Certifications Link : SimpliLearn-Certifications I'm excited to announce that I've... | 0 | 2024-06-22T17:22:09 | https://dev.to/bvidhey/exciting-update-simplilearn-certifications-achieved-245o | Hello Everyone,
**Certifications Link :** [SimpliLearn-Certifications](https://github.com/Vidhey012/My-Certifications/tree/main/SimpliLearn)
I'm excited to announce that I've successfully completed certifications with SimpliLearn! These certifications have been instrumental in enhancing my skills and expertise in [me... | bvidhey | |
1,897,181 | Documenting my pin collection with Segment Anything: Part 4 | Welcome to the fourth entry in my series where I document my journey of cataloguing my enamel pin... | 27,656 | 2024-06-22T17:21:30 | https://blog.feregri.no/blog/documenting-my-pin-collection-with-segment-anything-part-4/ | jquery, javascript, html, python | Welcome to the fourth entry in my series where I document my journey of cataloguing my enamel pin collection. If you missed the previous posts, you can catch up [**here**](https://dev.to/feregri_no/series/27656). Previously, [I introduced a simple app](https://dev.to/feregri_no/documenting-my-pin-collection-with-segmen... | feregri_no |
1,897,228 | A Beginner's Guide to Game Development | Whether you're a coding enthusiast or a creative soul with a passion for storytelling, this post is... | 0 | 2024-06-22T17:21:22 | https://dev.to/gauravk_/a-beginners-guide-to-game-development-2mm0 | gamedev, coding, softwaredevelopment | Whether you're a coding enthusiast or a creative soul with a passion for storytelling, this post is here to guide you through the process of learning game development from scratch.
> A game is the complete exploration of freedom within a restrictive environment.
**_Set Your Goals_**
Before you start learning game ... | gauravk_ |
1,897,180 | PageRequest | PageRequest, Spring Data JPA'nın veri kümesini sayfalara bölmek ve sıralamak için kullandığı bir... | 0 | 2024-06-22T17:19:56 | https://dev.to/mustafacam/pagerequest-52ob | `PageRequest`, Spring Data JPA'nın veri kümesini sayfalara bölmek ve sıralamak için kullandığı bir sınıftır. Sayfalama, büyük veri kümeleriyle çalışırken performansı artırmak ve kullanıcılara daha iyi bir deneyim sunmak için önemli bir tekniktir. Sayfalama, tüm veri kümesini tek seferde yüklemek yerine, verileri belirl... | mustafacam | |
1,897,179 | 🎓 Exciting News: GreatLearning Certifications Achieved! 🚀 | Hello Everyone, Certification Link : GreatLearning-Certifications I am thrilled to share that I... | 0 | 2024-06-22T17:19:44 | https://dev.to/bvidhey/exciting-news-greatlearning-certifications-achieved-1h63 | Hello Everyone,
**Certification Link :** [GreatLearning-Certifications](https://github.com/Vidhey012/My-Certifications/tree/main/GreatLearning)
I am thrilled to share that I have successfully completed certification programs with GreatLearning! These certifications signify my commitment to enhancing my skills and kno... | bvidhey | |
1,897,177 | 🎓 Exciting News: Cisco Certifications Achieved! 🌟 | Dear Friends and Colleagues, Certifications Link : Cisco-Certifications I'm thrilled to announce a... | 0 | 2024-06-22T17:15:26 | https://dev.to/bvidhey/exciting-news-cisco-certifications-achieved-5e67 | Dear Friends and Colleagues,
**Certifications Link :** [Cisco-Certifications](https://github.com/Vidhey012/My-Certifications/tree/main/Cisco)
I'm thrilled to announce a significant milestone in my career journey – I have successfully earned Cisco certifications! 🚀 These certifications represent my commitment to advan... | bvidhey | |
1,897,176 | 🎓 Proud Moment: EduSkills Code Riders 2021 Certificate Achievement! 🚀 | Dear Friends, I'm thrilled to share a significant achievement with you all – I've successfully... | 0 | 2024-06-22T17:13:47 | https://dev.to/bvidhey/proud-moment-eduskills-code-riders-2021-certificate-achievement-1plh | Dear Friends,
I'm thrilled to share a significant achievement with you all – I've successfully completed the EduSkills Code Riders 2021 program! 🌟 This journey has been an incredible opportunity to delve deeper into the world of coding, sharpen my skills, and collaborate with passionate individuals from diverse backg... | bvidhey | |
1,897,108 | JpaRepository ve JpaSpecificationExecutor | JpaRepository JpaRepository, Spring Data JPA tarafından sağlanan ve JPA (Java Persistence... | 0 | 2024-06-22T14:56:48 | https://dev.to/mustafacam/jparepository-ve-jpaspecificationexecutor-3nch | ### JpaRepository
`JpaRepository`, Spring Data JPA tarafından sağlanan ve JPA (Java Persistence API) tabanlı veri erişim katmanını kolaylaştırmak için kullanılan bir arayüzdür. `JpaRepository` arayüzü, CRUD (Create, Read, Update, Delete) işlemlerini gerçekleştirmek için çeşitli metodlar sağlar. Bu arayüz, `PagingAndSor... | mustafacam | |
1,897,175 | JavaScript Main Concepts < In Depth > Part 2 | click for Part 1 6. Closures A closure is the combination of a function bundled together... | 0 | 2024-06-22T17:13:22 | https://dev.to/rajatoberoi/javascript-main-concepts-in-depth-part-2-2mfn | beginners, tutorial, node, codenewbie | [click for Part 1](https://dev.to/rajatoberoi/javascript-main-concepts-edg)
## 6. Closures
A closure is the combination of a function bundled together (enclosed) with references to its surrounding state (the lexical environment).
- A closure gives you access to an outer function's scope from an inner function.
```
l... | rajatoberoi |
1,897,174 | Empowering Fitness with Twilio: Your Personal GymBuddy for Seamless Communication and Progress Tracking! | This is a submission for Twilio Challenge v24.06.12 What I Built ... | 0 | 2024-06-22T17:11:58 | https://dev.to/dailydev/empowering-fitness-with-twilio-your-personal-gymbuddy-for-seamless-communication-and-progress-tracking-147i | devchallenge, twiliochallenge, ai, twilio |
*This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
### GymBuddy
GymBuddy is a web application designed to help fitness enthusiasts track their workout performance and nutritional intake efficiently. Whether you're a beginner looking to establish a fitness routin... | dailydev |
1,897,172 | Visualize and explain byte sequences with byte-diagram | Hey everyone! I'm excited to introduce you to a new command-line tool I've been working on called... | 0 | 2024-06-22T17:11:24 | https://dev.to/yanujz/visualize-and-explain-byte-sequences-with-byte-diagram-201e | cli, tools, asciiart | Hey everyone!
I'm excited to introduce you to a new command-line tool I've been working on called byte-diagram. This tool allows you to visualize byte sequences using ASCII art, making it easier to understand and analyze hexadecimal data.
**What is `byte-diagram`?**
`byte-diagram` is a Python-based command-line util... | yanujz |
1,897,169 | 🎉 Celebrating Cisco Codathon 2020! 🚀 | Hey Everyone! I'm excited to share some amazing news – I participated in and successfully completed... | 0 | 2024-06-22T17:02:38 | https://dev.to/bvidhey/celebrating-cisco-codathon-2020-21a3 | Hey Everyone!
I'm excited to share some amazing news – I participated in and successfully completed Cisco Codathon 2020! 🌟 It was an exhilarating experience where I collaborated with brilliant minds to tackle real-world challenges using innovative tech solutions.
During the Codathon, we explored cutting-edge technol... | bvidhey | |
1,897,168 | Scalability in React Native: Ensuring Future- Proof Applications | Scalability in React Native: Ensuring Future-Proof Applications Scalability is a critical aspect of... | 0 | 2024-06-22T17:00:13 | https://dev.to/nmaduemmmanuel/scalability-in-react-native-ensuring-future-proof-applications-569f | **Scalability in React Native: Ensuring Future-Proof Applications**
Scalability is a critical aspect of modern application development, especially when it comes to mobile apps built with React Native. Scalability refers to the ability of an app to handle a growing number of users or transactions without compromising ... | nmaduemmmanuel | |
1,897,167 | AWS Certifications | 🚀 Exciting Announcement: Celebrating AWS Certifications! 🌟 Hey Dev Community! Certificates Link :... | 0 | 2024-06-22T16:59:41 | https://dev.to/bvidhey/aws-certifications-5ejc | aws, awschallenge | 🚀 Exciting Announcement: Celebrating AWS Certifications! 🌟
Hey Dev Community!
**Certificates Link :** [AWS-Certifications](https://github.com/Vidhey012/My-Certifications/tree/main/Aws)
I'm thrilled to share a major milestone in my journey – I've recently earned several AWS certifications! 🎉 These certifications r... | bvidhey |
1,897,166 | Who Am I? 🚀 | Hello Dev Community! 👋 My name is Vidhey Bhogadi, and I am thrilled to be part of this amazing... | 0 | 2024-06-22T16:46:35 | https://dev.to/bvidhey/who-am-i-4ap | Hello Dev Community! 👋
My name is Vidhey Bhogadi, and I am thrilled to be part of this amazing community. Let me take a moment to introduce myself.
My Background 🌐
I am a full-stack developer and a self-taught tech enthusiast. Over the years, I have immersed myself in the world of technology, constantly learning an... | bvidhey | |
1,897,163 | Guia Básico para tratar dados com Pandas em Python | Olá, esse guia tem como objetivo apresentar algumas formas de tratamento de dados com a biblioteca... | 0 | 2024-06-22T16:42:01 | https://dev.to/rvinicius396g/guia-basico-para-tratar-dados-com-pandas-em-python-4f2f | pandas, python, dataframe, datascience | Olá, esse guia tem como objetivo apresentar algumas formas de tratamento de dados com a biblioteca pandas do Python, umas das mais utilizadas por profissionais na área de dados.
Primeiro, vamos fazer a importação das respectivas bibliotecas que utilizaremos
`
import pandas as pd
import matplotlib.pylab as plt
#Agora, f... | rvinicius396g |
1,896,287 | O que é Blochchain e como a tecnologia funciona? | Como Blockchain Funciona? Blockchain é uma tecnologia que trabalha como um sistema de... | 0 | 2024-06-22T16:35:24 | https://dev.to/starch1/o-que-e-blochchain-e-como-a-tecnologia-funciona-24b0 | blockchain, begginer, programmers, braziliandevs |
### Como Blockchain Funciona?
Blockchain é uma tecnologia que trabalha como um sistema de registro distribuído e descentralizado. A tecnologia fundamentalmente cria um registro digital de transações compartilhado por uma rede de computadores. Cada transação é agrupada em blocos, que são conectados ao bloco anterior, ... | starch1 |
1,897,159 | Excited to Join and Learn: My Journey in Tech | Hi everyone! I'm thrilled to join this vibrant community. My name is Ruturaj Jadhav, and I wanted to... | 0 | 2024-06-22T16:24:26 | https://dev.to/ruturajj/excited-to-join-and-learn-my-journey-in-tech-59b9 | letsconnect, beginners, programming, java | Hi everyone!
I'm thrilled to join this vibrant community. My name is Ruturaj Jadhav, and I wanted to share a bit about my journey in tech.
I started with Java, and over time, I developed a strong interest in Data Structures and Algorithms (DSA) and Artificial Intelligence (AI). Currently, I'm focusing on enhancing my... | ruturajj |
1,897,157 | Enable Touch ID Authentication for sudo on macOS Sonoma 14.x | Operating Environment: OS: MacOS Sonoma 14.5 Device: M1 MacBook Pro ... | 0 | 2024-06-22T16:22:46 | https://dev.to/siddhantkcode/enable-touch-id-authentication-for-sudo-on-macos-sonoma-14x-4d28 | macos, touchid, security, productivity | ### Operating Environment:
- **OS:** MacOS Sonoma 14.5
- **Device:** M1 MacBook Pro
## Explanation
In macOS Sonoma, a new method has been introduced to enable Touch ID when running `sudo` commands, making it more persistent across system updates. Previously, editing the `/etc/pam.d/sudo` file was necessary, but these... | siddhantkcode |
1,897,115 | Leave Switch Behind: The Power of Maps and Patterns in JavaScript Development | In this post, we'll explore the limitations of using switch statements in JavaScript and discuss... | 0 | 2024-06-22T16:19:18 | https://dev.to/waelhabbal/leave-switch-behind-the-power-of-maps-and-patterns-in-javascript-development-2hhj | development, solidprinciples, webdev, javascript | In this post, we'll explore the limitations of using `switch` statements in JavaScript and discuss alternative approaches using maps and patterns. We'll cover how maps can be used for dynamic lookups and how patterns can be used to encapsulate complex logic.
**The Case Against Overusing Switch Statements**
While `swi... | waelhabbal |
1,897,149 | If to be or not to be is the question, ternary operator is the answer | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T16:18:13 | https://dev.to/ahad23/if-to-be-or-not-to-be-is-the-question-ternary-operator-is-the-answer-1a10 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Do I jump or duck? If the obstacle is high, jump, if it's low, duck. You need a quick decision. That's what the ternary operator does. Instead of pausing to think, it quickly chooses b... | ahad23 |
1,897,148 | How to Write an Effective Postmortem: A Use Case Example | In the world of IT and web services, outages and system failures are inevitable. When they occur, a... | 0 | 2024-06-22T16:16:31 | https://dev.to/preciousanyi/how-to-write-an-effective-postmortem-a-use-case-example-57g8 | webdev, beginners, programming, devops | In the world of IT and web services, outages and system failures are inevitable. When they occur, a detailed postmortem is crucial for understanding what went wrong and preventing similar issues in the future. This blog post will guide you through the process of writing an effective postmortem using a real-life use cas... | preciousanyi |
1,878,084 | CSRF leads to Open redirect | Reward: 15$ Overview of the Vulnerability Open redirects occur when an application accepts user... | 0 | 2024-06-05T13:49:11 | https://dev.to/c4ng4c31r0/csrf-leads-to-open-redirect-1n5a | **Reward: 15$**
**Overview of the Vulnerability**
Open redirects occur when an application accepts user input that is not validated into the target of a redirection. This input causes a redirection to an external domain, manipulating a user by redirecting them to a malicious site. An open redirect was identified which... | c4ng4c31r0 | |
1,897,147 | Diferença entre Listas, Tuplas e Dicionários no Python | Como muitos já devem saber, o Python é uma das linguagens que vem crescendo exponencialmente na... | 0 | 2024-06-22T16:15:12 | https://dev.to/rvinicius396g/diferenca-entre-listas-tuplas-e-dicionarios-no-python-490o | python, listas, tuplas, dicionário | Como muitos já devem saber, o Python é uma das linguagens que vem crescendo exponencialmente na análise de dados, assim como tem vários conceitos básicos que precisamos dominar par um melhor aproveitamento. Sendo assim, vou explicar o conceito de alguns itens que eu considero fundamentais e mostrar na prática nesse art... | rvinicius396g |
1,897,146 | Code Checkpoint: Memoisation and its magic | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T16:14:31 | https://dev.to/ahad23/code-checkpoint-memoisation-and-its-magic-13me | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Memoization stores the results of expensive operations and returns them quickly when needed, saving time and effort. Think of a video game save point! Instead of replaying the same lev... | ahad23 |
1,897,096 | PHP: yes, it's possible | Let's see if that's possible, then we'll see when to use it. Is is possible? Can... | 9,995 | 2024-06-22T16:11:43 | https://dev.to/spo0q/php-yes-its-possible-ao7 | php, beginners, programming | Let's see if that's possible, then we'll see when to use it.
## Is is possible?
### Can enumerations implement interfaces?
Yes.
[Source: enumeration PHP](https://www.php.net/manual/en/language.types.enumerations.php)
### Is it possible to "Multi catch" in PHP?
Yes.
Instead of doing that:
```PHP
try {
} catch(My... | spo0q |
1,897,145 | Computer Science under 125 characters. | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T16:10:30 | https://dev.to/ahad23/computer-science-under-125-characters-52fd | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Assigning multiple complex tasks to metals, plastics,0's,1's, and electricity because we were too lazy to do it on pen and paper.
## Additional Context
We saw the gap of no one explai... | ahad23 |
1,897,139 | Documenting a Spring REST API Using Smart-doc | If you are developing a RESTful API with Spring Boot, you want to make it as easy as possible for... | 0 | 2024-06-22T16:10:19 | https://dev.to/yu_sun_0a160dea497156d354/documenting-a-spring-rest-api-using-smart-doc-46ic | springboot, restapi, java | If you are developing a RESTful API with Spring Boot, you want to make it as easy as possible for other developers to understand and use your API. Documentation is essential because it provides a reference for future updates and helps other developers integrate with your API. For a long time, the way to document REST A... | yu_sun_0a160dea497156d354 |
1,897,143 | Dashboard Estratégico X Dashboard Operacional | Nesse pequeno artigo vou tentar trazer de forma bem resumida as principais características de um... | 0 | 2024-06-22T16:08:48 | https://dev.to/rvinicius396g/dashboard-estrategico-x-dashboard-operacional-28lh | dashboard, estratgico, operacional, bi | Nesse pequeno artigo vou tentar trazer de forma bem resumida as principais características de um Dashboard Estratégico e um Dashboard Operacional.
## Dashboards operacionais
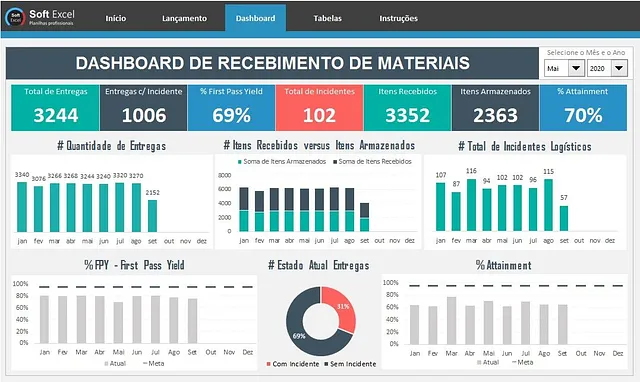
Tem como finalidade dar uma visão em te... | rvinicius396g |
1,897,142 | Unlocking Twitter's Advanced Search: A Guide to Finding What Matters | Unlocking Twitter's Advanced Search: A Guide to Finding What Matters Twitter isn't just a place to... | 0 | 2024-06-22T16:07:29 | https://dev.to/learn_with_santosh/unlocking-twitters-advanced-search-a-guide-to-finding-what-matters-13a8 | twitter, tips | **Unlocking Twitter's Advanced Search: A Guide to Finding What Matters**
Twitter isn't just a place to share thoughts; it's a vast treasure trove of real-time information waiting to be explored. Whether you're a casual user or a savvy professional, mastering Twitter's advanced search capabilities can significantly enh... | learn_with_santosh |
1,897,141 | Best time to buy sell 1 | Here we address the original best stock buy-sell question. Given an array of stock prices on... | 0 | 2024-06-22T16:06:38 | https://dev.to/johnscode/best-time-to-buy-sell-1-4590 | go, interview, programming, career | Here we address the original best stock buy-sell question.
Given an array of stock prices on different days, find the maximum profit when only one buy and one sell is allowed.
This is pretty straightforward and an online search provides a number of examples.
```
func FindSingleBestBuySell(prices []float64) float64 {... | johnscode |
1,897,140 | Welcome to My Dev Blog: A Journey of Learning and Growth | Hey fellow devs! I'm thrilled to introduce my dev blog, a space where I'll share my experiences,... | 0 | 2024-06-22T16:05:32 | https://dev.to/vuyokazimkane/welcome-to-my-dev-blog-a-journey-of-learning-and-growth-4ca2 | Hey fellow devs! I'm thrilled to introduce my dev blog, a space where I'll share my experiences, knowledge, and passions with the developer community. As a full-stack developer with a zeal for learning and growth, I'm excited to embark on this journey with all of you.
Why I'm Starting This Blog
As a developer, I've o... | vuyokazimkane | |
1,897,137 | AVIF vs JPG: A Comparative Analysis | What Are the Differences Between AVIF and JPG? AVIF (AV1 Image File Format) and JPG (or... | 0 | 2024-06-22T15:58:54 | https://dev.to/msmith99994/avif-vs-jpg-a-comparative-analysis-372j | ## What Are the Differences Between AVIF and JPG?
AVIF (AV1 Image File Format) and JPG (or JPEG - Joint Photographic Experts Group) are two image formats that serve different purposes and come with their own set of characteristics. Understanding these differences can help you choose the right format for your specific n... | msmith99994 | |
1,897,130 | nav-bar | Check out this Pen I made! | 0 | 2024-06-22T15:36:55 | https://dev.to/myvoice/nav-bar-5ae0 | codepen, css, html, webdev | Check out this Pen I made!
{% codepen https://codepen.io/myvoice/pen/ExJzgVb %} | myvoice |
1,897,113 | Solution for Render.com Web services spin down due to inactivity. | When deploying backend applications for hobby projects, Render is a popular choice due to its... | 0 | 2024-06-22T15:51:11 | https://dev.to/harshgit98/solution-for-rendercom-web-services-spin-down-due-to-inactivity-2h8i | render, deployment, node, tutorial | When deploying backend applications for hobby projects, Render is a popular choice due to its simplicity and feature set. However, one common issue with Render is that instances can spin down due to inactivity. This results in delayed responses of up to a minute when the instance has to be redeployed. This behavior is ... | harshgit98 |
1,897,135 | Feedback : Using embedded python daily for more than 2 years | I have been using embedded python for more than 2 years now on a daily basis. May be it's time to... | 0 | 2024-06-22T15:44:14 | https://community.intersystems.com/post/feedback-using-embedded-python-daily-more-2-years | beginners, python, framework, languages | I have been using embedded python for more than 2 years now on a daily basis.
May be it's time to share some feedback about this journey.
Why write this feedback? Because, I guess, I'm like most of the people here, an ObjectScript developer, and I think that the community would benefit from this feedback and could be... | intersystemsdev |
1,897,133 | Digital Marketing Company In Nagpur | Digital Marketing Company In Nagpur | Digital Marketing Services PrimaThink the Digital Marketing... | 0 | 2024-06-22T15:40:12 | https://dev.to/primathink/digital-marketing-company-in-nagpur-af9 | digitalmarketing | [Digital Marketing Company In Nagpur](https://primathink.com/digital-marketing-company-in-nagpur/) | Digital Marketing Services
PrimaThink the Digital Marketing Company In Nagpur is at your service. We have the perfect tools and strategies to take your business to a whole new level through our Digital Marketing Servic... | primathink |
1,897,131 | "Digital Marketing Courses In Nagpur " | PrimaThink - Digital Marketing Courses In Nagpur PrimaThink provides Digital Marketing Courses in... | 0 | 2024-06-22T15:37:24 | https://dev.to/primathink/digital-marketing-courses-in-nagpur-b9j | digitalmarketing | PrimaThink - [Digital Marketing Courses In Nagpur](https://primathink.com/digital-marketing-courses-in-nagpur/)
PrimaThink provides Digital Marketing Courses in Nagpur that cover everything from Search Engine Optimization and Social Media Marketing to its Analysis tool’s effective use to get a targeted audience with t... | primathink |
1,897,129 | Generating meaningful test data using Gemini | We all know that having a set of proper test data before deploying an application to production is... | 0 | 2024-06-22T15:36:49 | https://community.intersystems.com/post/generating-meaningful-test-data-using-gemini | ai, tutorial, beginners, programming | <p>We all know that having a set of proper test data before deploying an application to production is crucial for ensuring its reliability and performance. It allows to simulate real-world scenarios and identify potential issues or bugs before they impact end-users. Moreover, testing with representative data sets ... | intersystemsdev |
1,079,615 | Allow remote access to postgresql database | Allowing remote access to your PostgreSQL database can be necessary for various reasons, such as... | 0 | 2024-06-22T15:35:33 | https://dev.to/yousufbasir/allow-remote-access-to-postgresql-database-mho | postgres | Allowing remote access to your PostgreSQL database can be necessary for various reasons, such as connecting from different servers or enabling remote management.
### Step 1: Modify the PostgreSQL Configuration File
First, you need to modify the PostgreSQL configuration file to allow connections from remote hosts. Th... | yousufbasir |
1,897,128 | CURSORS | This HTML and CSS code creates a web page with several interactive elements and style effects. Here's... | 0 | 2024-06-22T15:34:51 | https://dev.to/myvoice/cursors-1egn | codepen | <p>This HTML and CSS code creates a web page with several interactive elements and style effects. Here's a summary of the elements and their functionalities:</p>
<p>A link to an Instagram profile with the text "hover and click".
Line break tags to add vertical space.
A button with a "glow-on-hover" class and the text ... | myvoice |
1,897,052 | How Machine Learning Models Work - One Byte Explainer | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T15:32:53 | https://dev.to/praneshchow/how-machine-learning-models-work-one-byte-explainer-36n1 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Machine learning is a system that learns from data and improves over time without writing extra programming. Machine learning models first train on the given data and then test the dat... | praneshchow |
1,897,126 | What is code pollution and how to fix it - A dependency injection lesson | What is code pollution? Code pollution is an antipattern that takes place when you... | 0 | 2024-06-22T15:31:23 | https://dev.to/rogeliogamez92/what-is-code-pollution-and-how-to-fix-it-a-dependency-injection-lesson-54jd | programming, beginners, testing, csharp | ## What is code pollution?
_Code pollution_ is an antipattern that takes place when you introduce additional code to your production code base to enable unit testing. [1]
This antipattern appears in two forms:
1. As a new method only called from the unit tests.
2. As a flag that changes the behavior of a class to ind... | rogeliogamez92 |
1,897,125 | Day 26 of my progress as a vue dev | About today Today was one of the most productive days I've had in a while and it felt great to get a... | 0 | 2024-06-22T15:26:24 | https://dev.to/zain725342/day-26-of-my-progress-as-a-vue-dev-2gee | webdev, vue, typescript, tailwindcss | **About today**
Today was one of the most productive days I've had in a while and it felt great to get a lot of work done. I'm surprised how much you can do if you don't have any distractions and you set your mind to something. I got my landing page completed and spent a lot of time studying many concepts on generative... | zain725342 |
1,897,119 | Data Synchronization in Microservices with PostgreSQL, Debezium, and NATS: A Practical Guide | In modern software development, the microservices architecture has become popular for its scalability... | 0 | 2024-06-22T15:25:03 | https://learn.glassflow.dev/blog/usecases/microservices-data-synchronization-using-postgresql-debezium-and-nats | programming, tutorial, microservices, opensource | In modern software development, the microservices architecture has become popular for its scalability and flexibility. Despite its benefits, it brings significant challenges, particularly in [data synchronization](https://learn.glassflow.dev/blog/articles/event-driven-design-rethinking-systems-architecture) across vari... | bobur |
1,897,123 | React Interview Questions (Beginner level) | Here are some beginner-level React interview questions that you might encounter in your next... | 0 | 2024-06-22T15:24:33 | https://dev.to/sadrul_vala_315ccc7520938/react-interview-questions-beginner-level-4emj | react, javascript, interview, beginners | Here are some beginner-level React interview questions that you might encounter in your next interview. Good luck, and I hope this material proves helpful in your preparation.
## **What is React?**
React is a JavaScript library for building user interfaces, focusing on component-based architecture, virtual DOM for pe... | sadrul_vala_315ccc7520938 |
1,897,121 | Thread In Java | A thread is a small part of a process capable of execute independently. Java supports... | 0 | 2024-06-22T15:22:08 | https://dev.to/anupam_tarai_3250344e48cd/thread-in-java-2f6e | java | - A thread is a small part of a process capable of execute independently.
- Java supports multithreading, allowing a process to be divided into multiple threads. These threads can be scheduled by the CPU to execute in parallel, improving the performance of the application.
## Creation of a Thread
- We can create a thr... | anupam_tarai_3250344e48cd |
1,897,120 | ✨CSS button Hold👆🏼 Effect💫 | Check out this Pen I made! | 0 | 2024-06-22T15:22:03 | https://dev.to/myvoice/css-button-hold-effect-p65 | codepen, html, css, webdev | Check out this Pen I made!
{% codepen https://codepen.io/myvoice/pen/WNBogGL %} | myvoice |
1,897,109 | 🌟 Unlocking the Magic of JavaScript: Beyond the Basics | JavaScript. The language that powers the web, runs on servers, and even controls drones! It’s a... | 0 | 2024-06-22T15:17:16 | https://dev.to/parthchovatiya/unlocking-the-magic-of-javascript-beyond-the-basics-1jo7 | webdev, javascript, programming, beginners | JavaScript. The language that powers the web, runs on servers, and even controls drones! It’s a language that has evolved tremendously since its inception in 1995. If you're a web developer, chances are JavaScript is a significant part of your toolkit. But how well do you really know it?
In this post, we'll dive deep ... | parthchovatiya |
1,897,116 | Going Global: Building Highly Resilient Systems with Multi-Region Active-Active Architectures | Going Global: Building Highly Resilient Systems with Multi-Region Active-Active... | 0 | 2024-06-22T15:15:50 | https://dev.to/virajlakshitha/going-global-building-highly-resilient-systems-with-multi-region-active-active-architectures-3bk8 | 
# Going Global: Building Highly Resilient Systems with Multi-Region Active-Active Architectures
In today's digital landscape, high availability and fault tolerance are not just buzzwords, they're essential requirements. As business... | virajlakshitha | |
1,897,114 | Defining AVIF and PNG Image Formats | What Are the Differences Between AVIF and PNG? AVIF (AV1 Image File Format) and PNG... | 0 | 2024-06-22T15:14:48 | https://dev.to/msmith99994/defining-avif-and-png-image-formats-6eb | ## What Are the Differences Between AVIF and PNG?
AVIF (AV1 Image File Format) and PNG (Portable Network Graphics) are two distinct image formats that serve different purposes, each with its own set of characteristics tailored for various applications.
### AVIF
**- Compression:** AVIF uses both lossy and lossless com... | msmith99994 | |
1,897,112 | Zero to Hero Stable Diffusion 3 Tutorial with Amazing SwarmUI SD Web UI that Utilizes ComfyUI | Zero to Hero Stable Diffusion 3 Tutorial with Amazing SwarmUI SD Web UI that Utilizes... | 0 | 2024-06-22T15:13:13 | https://dev.to/furkangozukara/zero-to-hero-stable-diffusion-3-tutorial-with-amazing-swarmui-sd-web-ui-that-utilizes-comfyui-27hl | beginners, tutorial, ai, learning | <h1 style="margin-left:0px;"><a target="_blank" rel="noopener noreferrer" href="https://youtu.be/HKX8_F1Er_w"><strong><u>Zero to Hero Stable Diffusion 3 Tutorial with Amazing SwarmUI SD Web UI that Utilizes ComfyUI</u></strong></a></h1>
<p style="margin-left:0px;"><a target="_blank" rel="noopener noreferrer" href="http... | furkangozukara |
1,897,111 | 1248. Count Number of Nice Subarrays | 1248. Count Number of Nice Subarrays Medium Given an array of integers nums and an integer k. A... | 27,523 | 2024-06-22T15:11:14 | https://dev.to/mdarifulhaque/1248-count-number-of-nice-subarrays-405o | php, leetcode, algorithms, programming | 1248\. Count Number of Nice Subarrays
Medium
Given an array of integers `nums` and an integer `k`. A continuous subarray is called nice if there are `k` odd numbers on it.
Return _the number of **nice** sub-arrays_.
**Example 1:**
- **Input:** nums = [1,1,2,1,1], k = 3
- **Output:** 2
- **Explanation:** The only s... | mdarifulhaque |
1,897,105 | What Is Lightroom Mod APK? | Introduction In today's digital age, photo editing has become a significant part of our... | 0 | 2024-06-22T14:52:54 | https://dev.to/lightroom_modapk_7a58397/what-is-lightroom-mod-apk-590l | mod, apk, appsync, appconfig | ## Introduction
In today's digital age, photo editing has become a significant part of our daily lives. From social media influencers to professional photographers, everyone relies on powerful editing tools to enhance their images. Adobe Lightroom is one such tool, known for its comprehensive features and user-friendl... | lightroom_modapk_7a58397 |
1,897,076 | Top State management libs for React Native ✨ | State Management in React Native: A Comprehensive Guide State management is a crucial... | 0 | 2024-06-22T14:49:52 | https://dev.to/manjotdhiman/top-state-management-libs-for-react-native-1dl5 | reactnative, redux, alternative, statemanagement | ### State Management in React Native: A Comprehensive Guide
State management is a crucial aspect of developing robust and scalable React Native applications. It involves managing the state of your app, ensuring that your components reflect the correct data at all times. In this article, I'll explore various state man... | manjotdhiman |
1,897,103 | Differences of JPG and GIF | What Are the Differences Between JPG and GIF? JPG (or JPEG - Joint Photographic Experts... | 0 | 2024-06-22T14:49:24 | https://dev.to/msmith99994/differences-of-jpg-and-gif-4mo6 | ## What Are the Differences Between JPG and GIF?
JPG (or JPEG - Joint Photographic Experts Group) and GIF (Graphics Interchange Format) are two of the most commonly used image formats, each with its own set of characteristics suited for different applications.
### JPG
**- Compression:** JPG uses lossy compression, wh... | msmith99994 | |
1,897,100 | AWS Global Accelerator | 🚀 Exciting News! 🚀 I'm thrilled to announce that I've achieved AWS certification! 🎉 After months of... | 0 | 2024-06-22T14:46:44 | https://dev.to/vidhey071/aws-global-accelerator-1mei | aws | 🚀 Exciting News! 🚀
I'm thrilled to announce that I've achieved AWS certification! 🎉
After months of dedicated learning and hard work, I am now officially certified with this certificate. This journey has been incredibly rewarding, and I'm looking forward to leveraging this knowledge to drive innovation and efficie... | vidhey071 |
1,897,099 | Introduction to Amazon Polly | 🚀 Exciting News! 🚀 I am thrilled to announce that I have achieved my AWS certification! 🎉 After... | 0 | 2024-06-22T14:46:03 | https://dev.to/vidhey071/introduction-to-amazon-polly-hk7 | aws | 🚀 Exciting News! 🚀
I am thrilled to announce that I have achieved my AWS certification! 🎉 After months of hard work and dedication, I am now certified with this certificate. This accomplishment signifies my commitment to mastering AWS services and best practices, enhancing my skills in cloud computing and infrastru... | vidhey071 |
1,897,098 | Optimizing Development: Insights into Effective System Design | As a full-stack developer, I've come to appreciate the profound impact that understanding system... | 0 | 2024-06-22T14:45:57 | https://dev.to/a_shokn/optimizing-development-insights-into-effective-system-design-5fc4 | webdev, systemdesign, typescript, beginners | As a full-stack developer, I've come to appreciate the profound impact that understanding system design can have on the success of any project. Whether you’re building web or mobile applications, having a solid grasp of system design can set you apart and significantly improve your ability to create robust, scalable so... | a_shokn |
1,896,934 | GalaxyBot: A Cosmic WhatsApp Chatbot with Laravel, Twilio, and Cloudflare AI | This is a submission for Twilio Challenge v24.06.12 What I Built I have created a... | 0 | 2024-06-22T14:38:44 | https://dev.to/snehalkadwe/galaxybot-a-cosmic-whatsapp-chatbot-with-laravel-twilio-and-cloudflare-ai-3oho | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
I have created a GalaxyBot, an informative WhatsApp chatbot that delivers detailed information about stars and galaxies. The bot uses Laravel for the backend, Twilio for WhatsApp messaging, and Cloudflare's AI for... | snehalkadwe |
1,897,094 | Become A Full Stack Developer in Lahore | Join Web Development trainings in Lahore and unlock the potential in the world of coding. Learn from... | 0 | 2024-06-22T14:37:37 | https://dev.to/shantrainings/become-a-full-stack-developer-in-lahore-1fpe | Join [Web Development trainings](https://shantrainings.com/web-development) in Lahore and unlock the potential in the world of coding. Learn from shan trainings and build your career today. If you are looking HTML and CSS in Web Development trainings in Lahore. Shan Trainings offering best courses programm. | shantrainings | |
1,897,093 | How Amazon SageMaker Can Help | 🚀 Exciting News! 🚀 I'm thrilled to announce that I've achieved AWS certification! 🎉 After months of... | 0 | 2024-06-22T14:36:56 | https://dev.to/vidhey071/how-amazon-sagemaker-can-help-44b1 | aws | 🚀 Exciting News! 🚀
I'm thrilled to announce that I've achieved AWS certification! 🎉
After months of dedicated learning and hard work, I am now officially certified with this certificate. This journey has been incredibly rewarding, and I'm looking forward to leveraging this knowledge to drive innovation and efficie... | vidhey071 |
1,897,092 | Amazon Direct Connect | 🚀 Exciting News! 🚀 I am thrilled to announce that I have achieved my AWS certification! 🎉 After... | 0 | 2024-06-22T14:36:14 | https://dev.to/vidhey071/amazon-direct-connect-3lh5 | aws | 🚀 Exciting News! 🚀
I am thrilled to announce that I have achieved my AWS certification! 🎉 After months of hard work and dedication, I am now certified with this certificate. This accomplishment signifies my commitment to mastering AWS services and best practices, enhancing my skills in cloud computing and infrastru... | vidhey071 |
1,896,511 | JIN: A Light-Weight Hacking Tool Project | Today, I want to share my own simple cli application used for mapping URL, mapping open port of... | 0 | 2024-06-22T14:32:25 | https://dev.to/aliftech/jin-a-light-weight-hacking-tool-project-3hkc | cybersecurity, cli, python, programming | Today, I want to share my own simple cli application used for mapping URL, mapping open port of targeted website, and launching a DDoS attack. Disclaimer on, this project is made just for educational purpose, so I do not recommend you to use this project for unethical purpose.
## What is CLI ?
**CLI** stands for Comma... | aliftech |
1,897,081 | Getting Started with NLB | 🚀 Exciting News! 🚀 I'm thrilled to announce that I've achieved AWS certification! 🎉 After months of... | 0 | 2024-06-22T14:27:44 | https://dev.to/vidhey071/getting-started-with-nlb-1cn0 | aws | 🚀 Exciting News! 🚀
I'm thrilled to announce that I've achieved AWS certification! 🎉
After months of dedicated learning and hard work, I am now officially certified with this certificate. This journey has been incredibly rewarding, and I'm looking forward to leveraging this knowledge to drive innovation and efficie... | vidhey071 |
1,897,080 | Twitch Series | 🚀 Exciting News! 🚀 I am thrilled to announce that I have achieved my AWS certification! 🎉 After... | 0 | 2024-06-22T14:26:57 | https://dev.to/vidhey071/twitch-series-45m0 | aws | 🚀 Exciting News! 🚀
I am thrilled to announce that I have achieved my AWS certification! 🎉 After months of hard work and dedication, I am now certified with this certificate. This accomplishment signifies my commitment to mastering AWS services and best practices, enhancing my skills in cloud computing and infrastru... | vidhey071 |
1,897,067 | UNDERSTANDING PYTHON CODE STRUCTURE | Code Structure This is the arrangement of code in a programming language. it encompasses the use of... | 0 | 2024-06-22T14:26:23 | https://dev.to/davidbosah/understanding-python-code-structure-1pkg | beginners, programming, python, tutorial |
**Code Structure**
This is the arrangement of code in a programming language. it encompasses the use of formatting techniques like whitespace and indentation. The goal of a good structure is reliability and maintainability.
**Python code Structures**
There are various parameters that are used in describing the P... | davidbosah |
1,897,079 | Demystifying Web Components | Components are individual pieces of code which can be used in different contexts; they often... | 24,065 | 2024-06-22T14:24:28 | https://jamesiv.es/blog/frontend/javascript/2024/03/26/demystifying-web-components | webdev, webcomponents, javascript, beginners | Components are individual pieces of code which can be used in different contexts; they often represent a reusable piece of a design, such as a button or badge, and sometimes even as complex as more prominent elements like carousels and lightboxes. One of the many goals of a component is to bring consistency and cohesio... | jamesives |
1,897,074 | Introduction to Forex Trading Pairs | Forex trading, also known as foreign exchange trading or currency trading, is the act of buying and... | 0 | 2024-06-22T14:19:56 | https://dev.to/ukwueze_frankfx/introduction-to-forex-trading-pairs-3dac |
Forex trading, also known as foreign exchange trading or currency trading, is the act of buying and selling currencies with the aim of making a profit. Central to this market are trading pairs, which are the foundation of all forex transactions. Understanding trading pairs is crucial for anyone looking to succeed in ... | ukwueze_frankfx | |
1,897,073 | Enhancing Your Coding Skills: A Comprehensive Guide | Enhancing Your Coding Skills: A Comprehensive Guide Programming is an ever-evolving field that... | 0 | 2024-06-22T14:19:54 | https://dev.to/cottolight_14c3b6c6922677/enhancing-your-coding-skills-a-comprehensive-guide-532p | Enhancing Your Coding Skills: A Comprehensive Guide
Programming is an ever-evolving field that requires constant learning and adaptation. Whether you are a novice coder or an experienced developer, staying updated with the latest trends, tools, and best practices is crucial. This blog blends insights from our experienc... | cottolight_14c3b6c6922677 | |
1,897,071 | Basics of DNS | 🚀 Exciting News! 🚀 I'm thrilled to announce that I've achieved AWS certification! 🎉 After months of... | 0 | 2024-06-22T14:19:02 | https://dev.to/vidhey071/basics-of-dns-181m | aws | 🚀 Exciting News! 🚀
I'm thrilled to announce that I've achieved AWS certification! 🎉
After months of dedicated learning and hard work, I am now officially certified with this certificate. This journey has been incredibly rewarding, and I'm looking forward to leveraging this knowledge to drive innovation and efficie... | vidhey071 |
1,897,069 | Amazon Route 53 - Domains | 🚀 Exciting News! 🚀 I am thrilled to announce that I have achieved my AWS certification! 🎉 After... | 0 | 2024-06-22T14:18:17 | https://dev.to/vidhey071/amazon-route-53-domains-2a1h | aws | 🚀 Exciting News! 🚀
I am thrilled to announce that I have achieved my AWS certification! 🎉 After months of hard work and dedication, I am now certified with this certificate. This accomplishment signifies my commitment to mastering AWS services and best practices, enhancing my skills in cloud computing and infrastru... | vidhey071 |
1,285,729 | Setting Up Nginx with Certbot for HTTPS on Your Web Application | Securing your web application with HTTPS is crucial for protecting data integrity and privacy. This... | 0 | 2024-06-22T14:18:05 | https://dev.to/yousufbasir/setting-up-nginx-with-certbot-for-https-on-your-web-application-n1i | nginx, certbot, ssl, webdev | Securing your web application with HTTPS is crucial for protecting data integrity and privacy. This guide will walk you through the steps to set up Nginx as a reverse proxy and use Certbot to obtain a free SSL certificate from Let's Encrypt.
### Prerequisites
Before you begin, ensure you have the following:
1. A dom... | yousufbasir |
1,897,051 | AWS : IAM : Root Account | This article on DEV Community explains AWS Identity and Access Management (IAM) and its capabilities... | 0 | 2024-06-22T14:17:29 | https://dev.to/oladipupoabeeb/aws-iam-root-account-2mb4 | aws, cloud, terraform, webdev | This article on DEV Community explains AWS Identity and Access Management (IAM) and its capabilities for managing users, groups, and permissions within AWS. It highlights how IAM allows creating users with unique credentials and assigning permissions through policies. The article includes examples of using Terraform to... | oladipupoabeeb |
1,897,068 | Difference Between ++a And a++ In JavaScript? | The ++ is responsible of the increment of the number value by 1 . But have you wondered what is the... | 0 | 2024-06-22T14:15:47 | https://dev.to/yns666/difference-between-a-and-a-in-javascript-21n2 | javascript, webdev, beginners, programming | The **++** is responsible of the increment of the number value by 1 . But have you wondered what is the difference between putting it before or after?
- **++a** : returns the value after the increment.
- **a++** : returns the value before the increment.
Let's take an example:
`let a=0;
a++;
++a;
`
the output will b... | yns666 |
1,897,064 | HTML and CSS and JS icons (css pure) | Check out this Pen I made! | 0 | 2024-06-22T14:08:17 | https://dev.to/tidycoder/html-and-css-and-js-icons-css-pure-367i | codepen, icons, css, webdev | Check out this Pen I made!
{% codepen https://codepen.io/TidyCoder/pen/VwOXQgR %} | tidycoder |
1,897,041 | Setting Up Listmonk: An Open-Source Newsletter Mailing System | If you're looking for a robust, open-source newsletter and mailing list manager, Listmonk is an... | 0 | 2024-06-22T13:12:01 | https://dev.to/aixart/setting-up-listmonk-an-open-source-newsletter-mailing-system-50ga | newsletter, opensource, go, mailing | If you're looking for a robust, open-source newsletter and mailing list manager, Listmonk is an excellent choice. This guide will walk you through the process of setting up Listmonk on your server. The steps below will help you configure your domain, secure it with Let's Encrypt SSL certificates, and customize Listmonk... | aixart |
1,897,063 | Subnets, Gateways, Route Tables | 🚀 Exciting News! 🚀 I'm thrilled to announce that I've achieved AWS certification! 🎉 After months of... | 0 | 2024-06-22T14:02:59 | https://dev.to/vidhey071/subnets-gateways-route-tables-12nn | aws | 🚀 Exciting News! 🚀
I'm thrilled to announce that I've achieved AWS certification! 🎉
After months of dedicated learning and hard work, I am now officially certified with this certificate. This journey has been incredibly rewarding, and I'm looking forward to leveraging this knowledge to drive innovation and efficie... | vidhey071 |
1,897,062 | How to Deploy an Application Using Nginx as a Web Server | Deploying an application using Nginx as a web server is a common task for developers and system... | 0 | 2024-06-22T14:02:53 | https://dev.to/iaadidev/how-to-deploy-an-application-using-nginx-as-a-web-server-36a | nginx, webdev, deployment, beginners |
Deploying an application using Nginx as a web server is a common task for developers and system administrators. Nginx is known for its performance, stability, rich feature set, simple configuration, and low resource consumption. This blog post will guide you through the process of deploying an application using Nginx... | iaadidev |
1,897,061 | Amazon Route 53 | 🚀 Exciting News! 🚀 I am thrilled to announce that I have achieved my AWS certification! 🎉 After... | 0 | 2024-06-22T14:02:16 | https://dev.to/vidhey071/amazon-route-53-26ek | aws | 🚀 Exciting News! 🚀
I am thrilled to announce that I have achieved my AWS certification! 🎉 After months of hard work and dedication, I am now certified with this certificate. This accomplishment signifies my commitment to mastering AWS services and best practices, enhancing my skills in cloud computing and infrastru... | vidhey071 |
1,897,057 | Skill Up Now with Zypher | At Zypher, we believe in the power of education to shape lives and drive positive change. As a... | 0 | 2024-06-22T13:46:43 | https://dev.to/sebastian_kanto_24ab4f24/skill-up-now-with-zypher-6fc | digitalworkplace | At Zypher, we believe in the power of education to shape lives and drive positive change. As a Fastest growing vernacular upskilling platform, we are committed to providing accessible, high-quality learning experiences that empower individuals to reach their full potentia
[online digital marketing kerala](https://zyphe... | sebastian_kanto_24ab4f24 |
1,885,475 | United Kingdom study visa | Studying in the UK is a thrilling opportunity for global students, offering a mix of academic... | 0 | 2024-06-12T09:16:04 | https://dev.to/saibhavani_yaxis_346af9ea/united-kingdom-study-visa-f1p | Studying in the UK is a thrilling opportunity for global students, offering a mix of academic excellence, cultural diversity, and career prospects. Here’s a brief guide to acquiring a [United Kingdom study visa](https://shorturl.at/4c9Wk) and maximizing your educational adventure.
Why Study in the UK?
Academic Excell... | saibhavani_yaxis_346af9ea | |
1,897,055 | AWS Database Offerings | 🚀 Exciting News! 🚀 I'm thrilled to announce that I've achieved AWS certification! 🎉 After months of... | 0 | 2024-06-22T13:33:57 | https://dev.to/vidhey071/aws-database-offerings-5f25 | aws | 🚀 Exciting News! 🚀
I'm thrilled to announce that I've achieved AWS certification! 🎉
After months of dedicated learning and hard work, I am now officially certified with this certificate. This journey has been incredibly rewarding, and I'm looking forward to leveraging this knowledge to drive innovation and efficie... | vidhey071 |
1,897,054 | AWS Certified Solutions Architect - Professional | 🚀 Exciting News! 🚀 I am thrilled to announce that I have achieved my AWS certification! 🎉 After... | 0 | 2024-06-22T13:33:23 | https://dev.to/vidhey071/aws-certified-solutions-architect-professional-2p27 | aws | 🚀 Exciting News! 🚀
I am thrilled to announce that I have achieved my AWS certification! 🎉 After months of hard work and dedication, I am now certified with this certificate. This accomplishment signifies my commitment to mastering AWS services and best practices, enhancing my skills in cloud computing and infrastru... | vidhey071 |
1,897,053 | Install react js 18 | what is the step to install react js 18? | 0 | 2024-06-22T13:32:32 | https://dev.to/neshat_imam_f569fa017e4c3/install-react-js-18-89p | what is the step to install react js 18?
| neshat_imam_f569fa017e4c3 | |
1,897,049 | Adapting to Online Exams and Assessments | Adapting to Online Exams and Assessments As education increasingly moves online, students must adapt... | 0 | 2024-06-22T13:27:01 | https://dev.to/gracelee04/adapting-to-online-exams-and-assessments-2d73 | marketing, education, writing, articles | Adapting to Online Exams and Assessments
As education increasingly moves online, students must adapt to new methods [Take My Class Online](https://takemyclassonline.net/) of exams and assessments. This transition from traditional classroom settings to virtual environments requires a different approach to studying, tes... | gracelee04 |
1,896,668 | Simplifying Persistent Storage in Kubernetes: A Deep Dive into PVs, PVCs, and SCs | In the world of Kubernetes, managing persistent storage efficiently stands as a cornerstone for... | 0 | 2024-06-22T13:19:39 | https://dev.to/piyushbagani15/simplifying-persistent-storage-in-kubernetes-a-deep-dive-into-pvs-pvcs-and-scs-1p3c | kubernetes, storage, persistent, volume | In the world of Kubernetes, managing persistent storage efficiently stands as a cornerstone for deploying resilient and scalable applications. Kubernetes not only orchestrates containers but also offers robust solutions for handling persistent data across these containers.
This blog dives into the critical components... | piyushbagani15 |
1,897,045 | AWS Security, Identity and Compliance | 🚀 Exciting News! 🚀 I'm thrilled to announce that I've achieved AWS certification! 🎉 After months of... | 0 | 2024-06-22T13:19:31 | https://dev.to/vidhey071/aws-security-identity-and-compliance-2121 | aws | 🚀 Exciting News! 🚀
I'm thrilled to announce that I've achieved AWS certification! 🎉
After months of dedicated learning and hard work, I am now officially certified with this certificate. This journey has been incredibly rewarding, and I'm looking forward to leveraging this knowledge to drive innovation and efficie... | vidhey071 |
1,897,044 | Database Migration | 🚀 Exciting News! 🚀 I am thrilled to announce that I have achieved my AWS certification! 🎉 After... | 0 | 2024-06-22T13:18:42 | https://dev.to/vidhey071/database-migration-33ej | aws | 🚀 Exciting News! 🚀
I am thrilled to announce that I have achieved my AWS certification! 🎉 After months of hard work and dedication, I am now certified with this certificate. This accomplishment signifies my commitment to mastering AWS services and best practices, enhancing my skills in cloud computing and infrastru... | vidhey071 |
1,897,043 | NextJS - getServerSideProps | Important Properties in context of getServerSideProps Params -> for dynamic parameters. request... | 0 | 2024-06-22T13:17:59 | https://dev.to/alamfatima1999/nextjs-getserversideprops-981 | Important Properties in context of **getServerSideProps**
**_Params_** -> for dynamic parameters.
**_request_** -> to view the request from the client.
**_response_** -> to set the response for the client.
**_query_** -> to get hold of the query parameter hit in the url.
**: Study linked lists, practice easy problems. (4 hours)
Watch the videos for linked list from Udemy Course... | nishantsinghchandel |
1,897,040 | The Importance of High-Quality Hotel Slippers for Guest Comfort | The Comfort Advantage of High-Quality Hotel Slippers You expect to be pampered, and one of the perks... | 0 | 2024-06-22T13:10:27 | https://dev.to/molkasn_rooikf_bd180a12bc/the-importance-of-high-quality-hotel-slippers-for-guest-comfort-39mo | The Comfort Advantage of High-Quality Hotel Slippers
You expect to be pampered, and one of the perks of a good hotel stay is the availability of comfortable hotel slippers when you stay in a hotel. High-quality hotel slippers not only provide comfort, but also serve as a amenity valuable guests to enjoy. The slippers ... | molkasn_rooikf_bd180a12bc | |
1,897,039 | 토토솔루션은 카지노에 합법인가요? | 카지노 관리 시스템을 선택할 때 카지노는 합법적이고 평판이 좋은 솔루션과 협력하고 있는지 확인하기를 원합니다. 인기를 얻고 있는 시스템 중 하나가 토토솔루션입니다. 이번 글에서는... | 0 | 2024-06-22T13:09:14 | https://dev.to/ayshanoor445/totosolrusyeoneun-kajinoe-habbeobingayo-fc4 | 카지노 관리 시스템을 선택할 때 카지노는 합법적이고 평판이 좋은 솔루션과 협력하고 있는지 확인하기를 원합니다. 인기를 얻고 있는 시스템 중 하나가 토토솔루션입니다. 이번 글에서는 토토솔루션이 카지노에 합법적인 선택인지 판단하기 위해 더 깊이 파고들어 보겠습니다.
먼저, **[토토솔루션](https://9-99ine.com/)**은 카지노 관리에 필요한 모든 것을 원스톱으로 제공할 것을 약속드립니다. 하지만 이 주장이 사실일까요? 이 분석이 끝나면 귀하는 토토솔루션의 기능, 파트너십 및 리뷰를 이해하여 귀하의 카지노에 대한 적법성에 대해 정보에 기초한 결정을 내리게 ... | ayshanoor445 | |
1,897,038 | A Comprehensive Guide to the Data Science Life Cycle with Python Libraries 🐍🤖 | The data science life cycle is a systematic process for analyzing data and deriving insights to... | 0 | 2024-06-22T13:08:50 | https://dev.to/kammarianand/a-comprehensive-guide-to-the-data-science-life-cycle-with-python-libraries-dgd | datascience, machinelearning, python, datasciencelifecyc | The **data science life cycle** is a systematic process for analyzing data and deriving insights to inform decision-making. It encompasses several stages, each with specific tasks and goals. Here’s an overview of the key stages in the data science life cycle along with the Python libraries used:
![Image description](... | kammarianand |
1,897,037 | ANJI ANSHEN SURGICAL DRESSINGS CO., LTD.: Innovations in Medical Supplies | Discovering the Safe and Innovative Medical Supplies from Anji Anshen Surgical Dressings Co... | 0 | 2024-06-22T13:07:14 | https://dev.to/molkasn_rooikf_bd180a12bc/anji-anshen-surgical-dressings-co-ltd-innovations-in-medical-supplies-21l4 | design | Discovering the Safe and Innovative Medical Supplies from Anji Anshen Surgical Dressings Co Ltd
Introducing Anji Anshen Surgical Dressings Co Ltd
Anji Anshen Surgical Dressings Co Ltd is a company that produces high-quality and advanced supplies which can be medical. The business has been health that is p... | molkasn_rooikf_bd180a12bc |
1,897,036 | Golang beginners | Hi, I’m looking for guys who has recently started learning golang. It would be great to do it... | 0 | 2024-06-22T13:06:24 | https://dev.to/vlad__siomga11/golang-beginners-hej | beginners, programming, softwaredevelopment, go | Hi,
I’m looking for guys who has recently started learning golang. It would be great to do it together👨💻👩💻
My telegram: @f_higf
| vlad__siomga11 |
1,897,035 | Heat Shrink Tube Applications: Versatile Solutions for Cable Protection | Heat Shrink Tube Applications Heat Shrink Tube Applications: Versatile Solutions for Cable... | 0 | 2024-06-22T13:04:35 | https://dev.to/molkasn_rooikf_bd180a12bc/heat-shrink-tube-applications-versatile-solutions-for-cable-protection-5d2m | Heat Shrink Tube Applications
Heat Shrink Tube Applications: Versatile Solutions for Cable Protection
Are you familiar with heat shrink pipes? These tubes are like magic - they shrink when heated to provide a layer cables that are protective wires, and other components that are electrical. You are introduced by this ar... | molkasn_rooikf_bd180a12bc |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.