
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,897,437 | Is It Spam? | This is a submission for Twilio Challenge v24.06.12 What I Built Everyone who has dealt... | 0 | 2024-06-23T01:39:38 | https://dev.to/briandoesdev/is-it-spam-2ink | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
Everyone who has dealt with spam calls knows how stressful it can be getting a call from an unknown number. Maybe you are waiting for a call from a job application, or your childs teacher, or the doctor. There are... | briandoesdev |
1,897,339 | Creating and Connecting to a Linux VM using a Public Key | Step 1: Create a Linux VM on Azure Log in to the Azure portal and navigate to the Virtual Machines... | 0 | 2024-06-23T01:39:00 | https://dev.to/tojumercy1/creating-and-connecting-to-a-linux-vm-using-a-public-key-3b1 | learning, linux, azure, microsoft | Step 1: Create a Linux VM on Azure
- Log in to the Azure portal and navigate to the Virtual Machines page
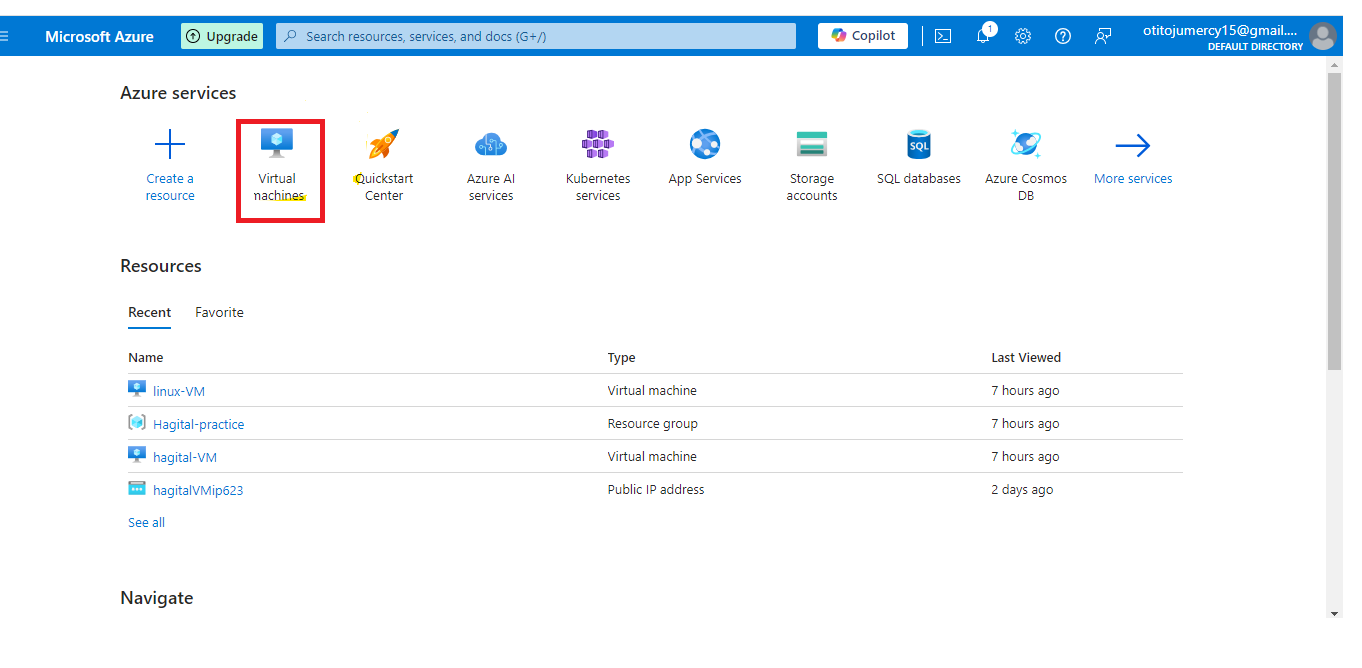
- Click "Create a virtual machine" and select "Linux" as the operating system.
- Choose a Linux dist... | tojumercy1 |
1,897,436 | Guia Completo para Navegação no React Native com TypeScript | Introdução Neste artigo, vamos explorar como configurar a navegação em um projeto React... | 0 | 2024-06-23T01:34:08 | https://dev.to/leeodev/guia-completo-para-navegacao-no-react-native-com-typescript-45mf | ## Introdução
Neste artigo, vamos explorar como configurar a navegação em um projeto React Native usando TypeScript. Vamos cobrir dois tipos populares de navegadores: o Bottom Tab Navigator e o Stack Navigator. Também abordaremos a estrutura dos tipos de navegação, como definir e usar parâmetros, e a razão de usar unde... | leeodev | |
1,897,434 | I built my first SaaS - NotiFast | The project is called NotiFast. The goal was to create a versatile bot that will send you... | 0 | 2024-06-23T01:22:26 | https://dev.to/jjablonskiit/i-built-my-first-saas-notifast-47do | discord, showdev, webdev, programming | The project is called **[NotiFast](https://notifast.me/)**. The goal was to create a versatile bot that will send you notifications if something changes on the websites you follow. I focused on making it work for the majority of websites. NotiFast comes with a visual creator, so you don't need any technical knowledge t... | jjablonskiit |
1,897,417 | Clinical Decision Support Software: Revolutionizing Modern Healthcare | Introduction Clinical Decision Support Software (CDSS) represents a significant... | 27,673 | 2024-06-23T00:58:10 | https://dev.to/rapidinnovation/clinical-decision-support-software-revolutionizing-modern-healthcare-4n74 | ## Introduction
Clinical Decision Support Software (CDSS) represents a significant advancement
in the medical field, integrating information technology and healthcare to
improve patient outcomes. As healthcare systems around the world become more
complex and data-driven, the role of sophisticated tools to aid medical
... | rapidinnovation | |
1,897,416 | Javascript | JavaScript is a high-level, interpreted programming language, primarily the power to make web pages... | 0 | 2024-06-23T00:55:35 | https://dev.to/bekmuhammaddev/javascript-4na1 | javascript, frontend, aripovdev | JavaScript is a high-level, interpreted programming language, primarily the power to make web pages interactive. This language bug was introduced in 1995 by Brendan Eich for Netscape. JavaScript is now supported by all modern browsers and is expanding.
Key Features of JavaScript:
1. Dynamic and interpretable: JavaScr... | bekmuhammaddev |
1,897,412 | React Video Playback Made Easy: Unleash the Power of the New MVP VideoPlayer Component | Introducing the VideoPlayer Component: A Powerful and Customizable Video Playback Solution... | 0 | 2024-06-23T00:45:28 | https://dev.to/victor_ajadi_21b5913f79f6/react-video-playback-made-easy-unleash-the-power-of-the-videoplayer-component-3fo7 | react, programming, webdev, javascript | ## Introducing the VideoPlayer Component: A Powerful and Customizable Video Playback Solution for React with Keyboard Navigation
**Empowering Your React Applications with Enhanced Video Playback**
This project introduces the VideoPlayer component, a robust and configurable video playback solution designed specificall... | victor_ajadi_21b5913f79f6 |
1,897,411 | Comprehensive Guide to HTMX: Building Dynamic Web Applications with Ease | In the ever-evolving world of web development, creating dynamic and interactive web applications has... | 0 | 2024-06-23T00:42:11 | https://devtoys.io/2024/06/22/comprehensive-guide-to-htmx-building-dynamic-web-applications-with-ease/ | webdev, htmx, html, devtoys | ---
canonical_url: https://devtoys.io/2024/06/22/comprehensive-guide-to-htmx-building-dynamic-web-applications-with-ease/
---
In the ever-evolving world of web development, creating dynamic and interactive web applications has become a necessity. Traditional methods involving JavaScript frameworks can be complex and c... | 3a5abi |
1,897,408 | Building a Cryptocurrency Trading Bot with Python | Introduction Cryptocurrency trading has become a popular form of investment in recent... | 0 | 2024-06-23T00:35:29 | https://dev.to/kartikmehta8/building-a-cryptocurrency-trading-bot-with-python-1n8b | webdev, javascript, beginners, programming | ## Introduction
Cryptocurrency trading has become a popular form of investment in recent years, and with the rise of automation in financial markets, many traders are turning to trading bots to aid in their decision making. In this article, we will discuss how to build a cryptocurrency trading bot using Python, one of... | kartikmehta8 |
1,897,406 | We all operate at four altitudes… | Success isn't just about doing more and moving faster. Providing optimal value in your discipline... | 0 | 2024-06-23T00:29:28 | https://dev.to/horaceshmorace/we-all-operate-at-four-altitudes-5e1n | professionaldevelopment, leadershipdevelopment, optimization | ---
title: We all operate at four altitudes…
published: true
description:
tags: professionaldevelopment, leadershipdevelopment, optimization
# cover_image:
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-23 00:11 +0000
---

**Are you looking for a way to spruce up your Hyprland window manager on Arch Linux?** Look no further than Hyde! Hyde is a comprehensive configuration that provides a beautiful, dynamic, and minimal desktop environment.... | da4ndo |
1,897,394 | From Burnout to Breakthrough: How I Transformed My Developer Workflow with One Simple Change | My Developer Burnout – It was 2 AM, and I was staring at my screen, feeling utterly defeated. Another... | 0 | 2024-06-22T23:46:29 | https://dev.to/3a5abi/from-burnout-to-breakthrough-how-i-transformed-my-developer-workflow-with-one-simple-change-401 | productivity, career, devtoys | My Developer Burnout – It was 2 AM, and I was staring at my screen, feeling utterly defeated. Another late night, another seemingly insurmountable bug, and the weight of endless deadlines. I love coding, but this constant grind was draining the life out of me.
According to a recent survey, over 70% of developers repor... | 3a5abi |
1,897,392 | UMAI, a refreshing inspired by MithrilJS and HyperApp, library | One little thing I have always found annoying in Mithril is returning view methods in... | 27,885 | 2024-06-22T23:44:40 | https://dev.to/artydev/a-refreshing-inspired-mithriljs-library-1l2c | umai | One little thing I have always found annoying in Mithril is returning **view** methods in components.
[UmaiJS](https://github.com/kevinfiol/umai) is heavily inspired by MithrilJS, no views, no hooks, no signals.
Components can easily be refrenced.
For side projects, it is very nice.
```js
import { m, mount } from 'u... | artydev |
1,897,391 | [Game of Purpose] Day 35 | Today I figured out I can wrap my static mesh to be a Blueprint inside a StaticMeshActor Blueprint. I... | 27,434 | 2024-06-22T23:42:01 | https://dev.to/humberd/game-of-purpose-day-35-3820 | gamedev | Today I figured out I can wrap my static mesh to be a Blueprint inside a StaticMeshActor Blueprint. I moved all the logic related to grande hit detection and explosion to a new BP_Granade Blueprint. When BP_Granade was a regular Actor the Physics Constraint would not work. Now it's working correctly.
My current proble... | humberd |
1,847,933 | Dominando o Next.js: Dicas para Renderização do Lado do Servidor | Introdução Next.js é um framework de React que fornece funcionalidades prontas para... | 0 | 2024-06-22T23:20:30 | https://dev.to/vitorrios1001/dominando-o-nextjs-dicas-para-renderizacao-do-lado-do-servidor-2f6b | react, nextjs, render, webdev | ## Introdução
Next.js é um framework de React que fornece funcionalidades prontas para produção como renderização do lado do servidor (SSR - Server Side Rendering), geração de sites estáticos (SSG - Static Site Generation) e muito mais. Este artigo se concentra em explorar como o Next.js facilita a SSR para aplicações... | vitorrios1001 |
1,897,384 | Symfony Station Communiqué — 21 June 2024: a look at Symfony, Drupal, PHP, Cybersec, and Fediverse News. | This communiqué originally appeared on Symfony Station. Welcome to this week's Symfony Station... | 0 | 2024-06-22T23:05:37 | https://symfonystation.mobileatom.net/Symfony-Station-Communique-21-June-2024 | symfony, drupal, php, fediverse | This communiqué [originally appeared on Symfony Station](https://symfonystation.mobileatom.net/Symfony-Station-Communique-21-June-2024).
Welcome to this week's Symfony Station communiqué. It's your review of the essential news in the Symfony and PHP development communities focusing on protecting democracy. That necess... | reubenwalker64 |
1,897,383 | Setup a Next.JS project for production-ready | Create a Next.JS project for this tutorial I’m using bun but you can npm or yarn. bunx... | 0 | 2024-06-22T22:52:24 | https://dev.to/es_pythonus/setup-a-nextjs-project-for-production-ready-2nho |
1. Create a Next.JS project for this tutorial I’m using bun but you
can npm or yarn.
`bunx create-next-app@latest app-name`

Wait till the Dependency installation finishes and navigate to the
... | es_pythonus | |
1,897,382 | How Sarah Protected Her Privacy with a Random Phone Number | Privacy has become a paramount concern, especially in online dating. Navigating the internet while... | 0 | 2024-06-22T22:52:01 | https://dev.to/legitsms/how-sarah-protected-her-privacy-with-a-random-phone-number-3dg8 | tutorial, news, cloud, security | Privacy has become a paramount concern, especially in online dating. Navigating the internet while safeguarding personal information can be challenging. This article is the story of Sarah, a savvy online dater who successfully protected her privacy using a random phone number for SMS verification. She turned to legitsm... | legitsms |
1,897,335 | Understanding FastAPI: The Basics | This post lives in: Linkedin github.com/ceb10n ceb10n.medium.com I've been working with FastAPI... | 0 | 2024-06-22T22:47:41 | https://dev.to/ceb10n/understanding-fastapi-the-basics-246j | fastapi, uvicorn, starlette, python | This post lives in:
* [Linkedin](https://www.linkedin.com/pulse/understanding-fastapi-basics-rafael-de-oliveira-marques-xfvaf)
* [github.com/ceb10n](https://github.com/ceb10n/blog-posts/tree/master/understanding-fastapi-the-basics)
* [ceb10n.medium.com](https://ceb10n.medium.com/understanding-fastapi-the-basics-142216... | ceb10n |
1,897,178 | Generating training data with OpenAI function calling | As I delve into the fields of Machine Learning and AI, it's clear that the quality of training data... | 0 | 2024-06-22T22:26:55 | https://dev.to/maurerkrisztian/generating-training-data-with-openai-function-calling-2c7l | ai, machinelearning, javascript, openai |
As I delve into the fields of Machine Learning and AI, it's clear that the quality of training data is crucial. Creating training data, such as labeling 10,000 texts or images, can be a tedious task. However, OpenAI models can be used to automate this process. OpenAI models can generate specific training or fine-tuni... | maurerkrisztian |
1,897,380 | A Brief Evolution of Data Management: From Business Intelligence to Artificial Intelligence | (8 min read) The first time I learned about organising and processing business data was during an... | 0 | 2024-06-22T22:22:23 | https://dev.to/jestevesv/a-brief-evolution-of-data-management-from-business-intelligence-to-artificial-intelligence-1d71 | datamanagement, businessintelligence, generativeai, ai | (8 min read)
The first time I learned about organising and processing business data was during an "Analysis and System Design" course. It introduced the concept of designing a system from business requirements to interface, focusing on Transactional Systems. Additionally, the course taught a methodology to create a da... | jestevesv |
1,897,341 | COMPUTER MEMORY | Computer memory stores information, such as data and programs, for immediate use in the computer. The... | 0 | 2024-06-22T22:11:59 | https://dev.to/michweb/computer-memory-45d8 | Computer memory stores information, such as data and programs, for immediate use in the computer. The term memory is often synonymous with the terms RAM, main memory, or primary storage. Archaic synonyms for main memory include core and store.
RAM. Specifically, RAM stands for “Random Access Memory” or “Ready Access Me... | michweb | |
1,897,337 | How to get test net coins | Please how do I get a testnet coins for testing my decentralized application before switching to live | 0 | 2024-06-22T21:27:42 | https://dev.to/uthmancpder/how-to-get-test-net-coins-2d6a | web3, smartcontract, blockchain, javascript | Please how do I get a testnet coins for testing my decentralized application before switching to live | uthmancpder |
1,897,336 | Exploring Option Constructors in Effect-TS | Handling Optional Values with Effect-TS In functional programming, handling optional... | 0 | 2024-06-22T21:22:05 | https://dev.to/almaclaine/exploring-option-constructors-in-effect-ts-4ka0 | effect, typescript, javascript, functional | ## Handling Optional Values with Effect-TS
In functional programming, handling optional values safely and concisely is crucial. The Option type in Effect-TS provides a robust way to work with values that may or may not be present. This article explores various constructors provided by Effect-TS to create and manipulat... | almaclaine |
1,897,333 | AI-powered market analysis for currency pairs with Hono.js, Cloudflare Workers and Twilio | This is a submission for Twilio Challenge v24.06.12 What I Built Nomisma is a... | 0 | 2024-06-22T21:17:03 | https://dev.to/desmondsanctity/ai-powered-market-analysis-for-currency-pairs-with-honojs-cloudflare-workers-and-twilio-5edo | devchallenge, twiliochallenge, ai, twilio | *This is a submission for [Twilio Challenge v24.06.12](https://dev.to/challenges/twilio)*
## What I Built
Nomisma is a cutting-edge AI-driven application that delivers real-time market analysis and updates on currency pairs directly to your WhatsApp. This innovative tool leverages the power of Hono.js, Twilio serverle... | desmondsanctity |
1,897,332 | 3 Tips to make your Repositories Stand out | Well in the Last Post about how you can make your Github Repository Stand out, I basically listed 2... | 27,749 | 2024-06-22T21:13:51 | https://dev.to/nhelchitnis/3-tips-to-make-your-repositories-stand-out-449e | tips, github, beginners | Well in the Last Post about how you can make your Github Repository Stand out, I basically listed 2 tips that can help you out with that. I think it's time to add one more, don't you think? Don't worry the first two are the same, but the last one will be different.
### Tip One Get Rid of everything you are not using
G... | nhelchitnis |
1,896,853 | Mastering Prompting & Training in LLMs - II | Prompting and Training in Language Models: Guiding and Enhancing LLM Performance Welcome... | 0 | 2024-06-22T20:59:56 | https://dev.to/mahakfaheem/mastering-prompting-training-in-llms-ii-nk4 | beginners, ai, devops, learning | ### Prompting and Training in Language Models: Guiding and Enhancing LLM Performance
Welcome back to our series on Generative AI and Large Language Models (LLMs). In the previous [blog](https://dev.to/mahakfaheem/transform-fomo-into-confidence-with-llms-i-31ee), we laid the foundation by exploring the fundamental conc... | mahakfaheem |
1,897,329 | Introduction to Options in Effect | What is an Option? An Option type represents a value that may or may not be present. It is... | 0 | 2024-06-22T20:58:56 | https://dev.to/almaclaine/introduction-to-options-in-effect-3g1j | effect, typescript, javascript, functional | # What is an Option?
An Option type represents a value that may or may not be present. It is a functional programming concept used to handle optional values in a type-safe way. In TypeScript, the `Option` type is an Algebraic Data Type (ADT), which allows for two distinct cases:
- `Some<A>`: Indicates that there is a... | almaclaine |
1,897,331 | Top 3 Ngrok alternatives | Ngrok is an ingress-as-a-service tool that provides tunnels for instant access to your apps on any... | 0 | 2024-06-22T20:58:43 | https://dev.to/ghoshbishakh/top-3-ngrok-alternatives-499e | devops, tooling, webdev, development | Ngrok is an ingress-as-a-service tool that provides tunnels for instant access to your apps on any cloud, private network, or device. It allows you to share your website or app from localhost and supports use cases like connecting to IoT devices behind NAT/firewalls, receiving webhooks, and debugging HTTP requests. Rec... | ghoshbishakh |
1,896,048 | Pull images from private docker registry in Kubernetes cluster 🐳 | When working with Kubernetes, especially for deploying applications, authenticating with private... | 0 | 2024-06-22T20:49:26 | https://dev.to/vaggeliskls/pull-images-from-private-docker-registry-in-kubernetes-cluster-25al | kubernetes, authentication, cloud, helm | When working with Kubernetes, especially for deploying applications, authenticating with private image repositories is often necessary. This process is crucial for AWS ECR registries and other Docker-related registries. This post introduces a Helm chart designed to simplify and streamline this authentication process, m... | vaggeliskls |
1,897,327 | Versatility in Action: Exploring Key Fields Where MERN Stack Developers Excel | MERN stack developers are well-suited for various fields due to their proficiency in full-stack web... | 0 | 2024-06-22T20:35:55 | https://dev.to/ridoy_hasan/versatility-in-action-exploring-key-fields-where-mern-stack-developers-excel-4bdc | webdev, learning, career, javascript | MERN stack developers are well-suited for various fields due to their proficiency in full-stack web development. Here are some key fields where MERN stack developers excel:
### 1. **Web Development**
- **Front-End Development**: Creating responsive, dynamic user interfaces using React.
- **Back-End Development**... | ridoy_hasan |
1,897,326 | ⭐️ We all want a good DevEx. Here's how to do it right: | Imagine spending more time coding and less time starting, configuring, testing, debugging,... | 0 | 2024-06-22T20:35:00 | https://dev.to/buildwebcrumbs/we-all-want-a-good-devex-heres-how-to-do-it-right-11hj | webdev, javascript, beginners, programming | Imagine spending more time coding and less time starting, configuring, testing, debugging, deploying...
That's the dream, right?
Developer Experience (DevEx) is about making it a reality.
### Goals
- Maximize time spent on the fun part—coding!
- Minimize the dreaded manual setup and configuration
- Make end-... | opensourcee |
1,897,325 | Twilio challenge submission | *This is a submission for the twilio challenge [Twilio challenge ] source code:... | 0 | 2024-06-22T20:33:59 | https://dev.to/mr-simze/twilio-challenge-submission-2680 | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the twilio challenge [Twilio challenge ]
source code: (https://github.com/Abidoyesimze/AI-driven-twilio-bot)
What I Built
I built a Personal Finance Tracker application that helps users track their income and expenses. This application allows users to record transactions, categorize them as ei... | mr-simze |
1,897,324 | WIZARD WEB RECOVERY RESTORING LOST BITCOIN & CRYPTOCURRENCY | Losing a significant amount of money to scammers can be a bizarre experience that leaves you feeling... | 0 | 2024-06-22T20:31:59 | https://dev.to/bonnie_eugene_8b61620eb7e/wizard-web-recovery-restoring-lost-bitcoin-cryptocurrency-1n4e | Losing a significant amount of money to scammers can be a bizarre experience that leaves you feeling helpless and betrayed. This was the situation I found myself in after investing over a hundred thousand dollars in a crypto platform that turned out to be a scam. I was introduced to this platform by a friend of my cous... | bonnie_eugene_8b61620eb7e | |
1,897,323 | Build your Service Mesh: Admission Controller | Creating the Admission Controller Before kube-apiserver persists the object and later be... | 27,820 | 2024-06-22T20:26:49 | https://dev.to/ramonberrutti/build-your-service-mesh-part-2-9c4 | kubernetes, go, diy, tutorial | ## Creating the Admission Controller
Before kube-apiserver persists the object and later be scheduled to a node,
the Admission Controller can validate and mutate the object.
The Mutation Admission Controller is going to mutate the pods that have the the
annotation `diy-service-mesh: true`.
Let's dig into how the Ad... | ramonberrutti |
1,897,322 | Multiverse of 100+ Data Science Project Series🌻 | 🚀 Explore the Multiverse of Data Science Projects! 🚀 Are you passionate about Data Science, Machine... | 0 | 2024-06-22T20:24:22 | https://dev.to/chando0185/multiverse-of-100-data-science-project-series-8mg | 🚀 **Explore the Multiverse of Data Science Projects!** 🚀
Are you passionate about Data Science, Machine Learning, Deep Learning, and Natural Language Processing? 🌐 Dive into a universe of 100+ diverse and exciting data science projects on my YouTube channel!
🔍 **What You’ll Find:**
- **Machine Learning Projects:*... | chando0185 | |
1,897,321 | Download free Minecraft plugins preconfigurated | Discover the Best Free and Pre-Configured Minecraft Plugins at menzatyx Take Your Gaming Experience... | 0 | 2024-06-22T20:22:13 | https://dev.to/quelopande_a5b5b999b1a41e/download-free-minecraft-plugins-preconfigurated-43p9 | minecraft, pluginsminecraft, minecraftplugins | Discover the Best Free and Pre-Configured Minecraft Plugins at [menzatyx](https://menzatyx.xyz)
Take Your Gaming Experience to the Next Level with These Essential Tools
If you're a Minecraft enthusiast, you've likely experienced the need to customize your world and server to make it more exciting and challenging. For... | quelopande_a5b5b999b1a41e |
1,897,310 | 카지노 사기 노출: 토토커뮤니티에 가입하세요 | 많은 카지노 플레이어들이 돈을 벌기 위해 속이는 사기를 경험했습니다. 속임수에 맞서 단결하기 위해 토토커뮤니티가 형성된 이유입니다. 회원으로서 플레이어는 자신의 이야기를 공유하여... | 0 | 2024-06-22T20:18:13 | https://dev.to/uj8__b9ebd8bf7676dae/kajino-sagi-nocul-totokeomyunitie-gaibhaseyo-3ied |
많은 카지노 플레이어들이 돈을 벌기 위해 속이는 사기를 경험했습니다. 속임수에 맞서 단결하기 위해 토토커뮤니티가 형성된 이유입니다. 회원으로서 플레이어는 자신의 이야기를 공유하여 다른 사람들이 대략적인 행동을 식별하고 온라인 도박을 모두에게 공평하게 만들 수 있도록 돕습니다.
토토커뮤니티는 온라인 포럼을 통해 도박꾼들을 하나로 모으는 방식으로 운영됩니다. 여기에서 사람들은 카지노가 시도한 교활한 속임수에 대해 글을 쓸 수 있습니다. 책을 읽는 다른 사람들은 자주 방문하는 사이트에서 유사한 사기를 인식할 수 있습니다. 증거를 수집함으로써 그룹은 모든 카지노를 정직하... | uj8__b9ebd8bf7676dae | |
1,897,307 | 8 Engaging MySQL Database Tutorials to Boost Your Skills 💻 | The article is about an engaging collection of 8 MySQL database tutorials from LabEx. It covers a wide range of topics, including accessing databases, querying data, managing user permissions, creating database views, and maintaining course information. The tutorials are designed to help readers, from beginners to expe... | 27,755 | 2024-06-22T20:10:53 | https://dev.to/labex/8-engaging-mysql-database-tutorials-to-boost-your-skills-5a1 | mysql, coding, programming, tutorial |
Dive into the world of MySQL databases with this comprehensive collection of 8 captivating tutorials from LabEx. Whether you're a beginner or an experienced developer, these hands-on projects will guide you through essential database management tasks, from querying data to creating views and managing user permissions.... | labby |
1,897,306 | 10 Extension Methods examples in Dart: A Comprehensive Guide with Code Examples | Dart extension method are used from string manipulation to mathematical operations on existing... | 0 | 2024-06-22T20:10:34 | https://dev.to/francescoagati/10-extension-methods-examples-in-dart-a-comprehensive-guide-with-code-examples-2cb9 | Dart extension method are used from string manipulation to mathematical operations on existing classes.
10 Unique Extension Method Examples:
### 1 - String Extension - `capitalizeFirstLetter()`: Capitalizes the first letter of a given string.
```dart
extension CapString on String {
String capitalizeFirstLetter()... | francescoagati | |
1,897,070 | Turso libSQL Installer | Hello Punk! Yes I am, in this journal I want to share with you how to install libSQL in your PHP... | 0 | 2024-06-22T20:10:03 | https://dev.to/darkterminal/turso-libsql-installer-29mj | webdev, database, php, laravel | Hello Punk! Yes I am, in this journal I want to share with you how to install [libSQL](turso.tech/libsql) in your PHP Environment without worry to configure `php.ini` file in your current PHP Version.
Install the libSQL extension for PHP it's like install a composer package:
```bash
composer require vendor/package
``... | darkterminal |
1,897,304 | Introduction to Pandas | Introduction If you're reading this article, you probably want to get an understanding of... | 0 | 2024-06-22T19:54:45 | https://dev.to/ugonma/introduction-to-pandas-11on | python, datascience, machinelearning, webdev | ## Introduction
If you're reading this article, you probably want to get an understanding of Pandas, so let's get to it.
Pandas - short for “Panel Data” - is a popular open-source programming language widely used for performing data manipulation and analysis. It has in-built functions to efficiently clean, transform,... | ugonma |
1,897,302 | The Body Shop of Security: Biometrics | Introduction Biometrics is a physical security technique that makes use of a person's... | 0 | 2024-06-22T19:48:39 | https://dev.to/swayam_248/the-body-shop-of-security-biometrics-2hba | security, learning, productivity | ## Introduction
Biometrics is a physical security technique that makes use of a person's physical characteristics which are unique to that person.
This technique is used to authenticate the user's identity and grant access to the certain things. It is a kind of personal touch for authentication which can only be done b... | swayam_248 |
1,897,301 | Responsive design principles | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T19:44:28 | https://dev.to/shivansh_vohra_2d13220efa/responsive-design-principles-1aba | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
As kids we all played the game where the toy had to be put in the box of the same shape,Imagine you had a toy that changes shape to fit into any box,Responsive design is like that for ... | shivansh_vohra_2d13220efa |
1,897,300 | Lynx - A Fast, Secure and Reliable Terraform Backend | Lynx is a Fast, Secure and Reliable Terraform Backend. It is built in Elixir with Phoenix... | 0 | 2024-06-22T19:43:01 | https://dev.to/clivern/lynx-a-fast-secure-and-reliable-terraform-backend-4fi0 | devops, terraform, elixir | **[Lynx](https://github.com/Clivern/Lynx) is a Fast, Secure and Reliable Terraform Backend. It is built in Elixir with Phoenix framework.**
**Features:**
- Simplified Setup: Easy installation and maintenance for hassle-free usage.
- Team Collaboration: Manage multiple teams and users seamlessly.
- User-Friendly Interf... | clivern |
1,897,277 | Real Graceful Shutdown in Kubernetes and ASP.NET Core | Our team recently developed a "Payment as a Service" solution for our company. This service aims to... | 0 | 2024-06-22T19:31:52 | https://dev.to/arminshoeibi/real-graceful-shutdown-in-kubernetes-and-aspnet-core-2290 | k8s, dotnet, cloudnative, kubernetes | Our team recently developed a "Payment as a Service" solution for our company. This service aims to provide a seamless payment integration for other microservices. We built it using an ASP.NET Core 8 and deployed it on Kubernetes (K8s).
However, <u>we've faced significant stress during deployments</u>. We often had to... | arminshoeibi |
1,897,285 | What is recursion? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T19:26:48 | https://dev.to/gift_mugweni_1c055b418706/what-is-recursion-1o34 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Recursion is solving a problem by breaking it into smaller simpler problems that follow a set pattern.
## Additional Context
<!-- Please share any additional context you think the ju... | gift_mugweni_1c055b418706 |
1,897,280 | Focus | One of the five Scrum values is Focus. There are many ways in which developers can apply the concept... | 0 | 2024-06-22T19:24:11 | https://dev.to/mlr/focus-421d | development, developers, management, workplace | One of the five Scrum values is Focus. There are many ways in which developers can apply the concept of focus. There are also many ways in which developers, managers, and organizations as a whole can impede the application of focus.
When developers lose focus, the quality of code suffers, productivity suffers, and mos... | mlr |
1,897,284 | WebGPU Basics: How to Create a Triangle | Hello 👋, it's been a minute. How's life and all that good stuff? Anyway to get myself back into the... | 0 | 2024-06-22T19:19:16 | https://giftmugweni.hashnode.dev/webgpu-basics-how-to-create-a-triangle | webgpu, tutorial, beginners | Hello 👋, it's been a minute. How's life and all that good stuff? Anyway to get myself back into the groove I thought I'd start where I left off, Graphics Programming specifically using WebGPU.
In this series, I'll give semi-tutorials on working with WebGPU and the shading language WGSL which I'll explain as and when ... | gift_mugweni_1c055b418706 |
1,897,282 | Roberto Fa, an Introduction | Music came naturally to me at a young age. It all began in the late 90s, in the summer of Sicily.... | 0 | 2024-06-22T19:13:35 | https://dev.to/far/roberto-fa-an-introduction-51nb | music, artist, introduction, musicproduction |
Music came naturally to me at a young age. It all began in the late 90s, in the summer of Sicily. Here’s where I discovered house and techno through cassette tapes sold at the local market, usually by some Moroccan or Tunisian guy carrying tons of bootlegs (mostly copies), and sometimes originals of the latest dance ... | far |
1,897,278 | DP - Memoization, The Esoteric concept, busted out in a line. | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-22T19:05:57 | https://dev.to/jainireshj/dp-memoization-the-esoteric-concept-busted-out-in-a-line-3a3h | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Memoization is like a Tile Fall Race, where the initial runners spend their lives clearing out the fake tiles, making it easy, time effective, and fast for the latter people to run on t... | jainireshj |
1,897,275 | Adding Middleware to .NET Desktop Applications | Middleware is a common pattern in web development for handling cross-cutting concerns like logging,... | 0 | 2024-06-22T18:51:37 | https://dev.to/amehdaly/adding-middleware-to-net-desktop-applications-4gh | dotnetcore, designpatterns, csharp | **Middleware** is a common pattern in web development for handling cross-cutting concerns like logging, authentication, and error handling. However, in desktop applications, the concept isn't as directly supported. This article explores how you can implement middleware-like behavior in .NET desktop applications using s... | amehdaly |
1,897,274 | GSoC’24(CircuitVerse) Week 3 & 4 | This 2 weeks I have been focusing on Implementing the remaining components and VUE + TS Integration... | 0 | 2024-06-22T18:49:42 | https://dev.to/niladri_adhikary_f11402dc/gsoc24circuitverse-week-3-4-21fg | gsoc, google, circuitverse, webdev | This 2 weeks I have been focusing on Implementing the remaining components and VUE + TS Integration with removal of JQuery.
Some of the Components that I have Implemented are:
- TestBench Panel.vue
- TestBench Creator.vue
- TestBench Validator.vue
- Alert MessageBox
Vue + Typescript Integration for:
- Project.ts
- ... | niladri_adhikary_f11402dc |
1,897,273 | refactoring C# code advices | Hello guys, i'll pay close attention of any post that can closely help anyone interested in .net and... | 0 | 2024-06-22T18:39:54 | https://dev.to/dejan_jovancevic_ns/refactoring-c-code-advices-ng7 | csharp | Hello guys, i'll pay close attention of any post that can closely help anyone interested in .net and c#.
| dejan_jovancevic_ns |
1,897,272 | Novikov Dubai Mall | Novikov Dubai Mall stands out as a culinary gem within the bustling Fashion Avenue. Nestled in this... | 0 | 2024-06-22T18:37:27 | https://dev.to/hognuvilmi/novikov-dubai-mall-34ja | [Novikov Dubai Mall](https://www.novikov-cafe.com/catalogue/novikov-giant-mille-feuille-chocolate-and-hazelnut) stands out as a culinary gem within the bustling Fashion Avenue. Nestled in this luxurious location, Novikov attracts discerning diners who appreciate both the ambiance and the artistry of fine dining. The ma... | hognuvilmi | |
1,897,271 | My First Program: Money After Expenses | I recently started learning Python 3 on Codecademy to start my computer science journey. This program... | 0 | 2024-06-22T18:36:29 | https://dev.to/doggomaru/my-first-program-money-after-expenses-1c09 | I recently started learning Python 3 on Codecademy to start my computer science journey. This program is the first program I have ever coded on my own with no guidance. For this project, I was instructed to create a program, but I wasn't given instructions for what kind of program to write specifically. It took me a wh... | doggomaru | |
1,897,171 | Django Basics: A Comprehensive Guide | Django is a Python web framework for fast development and clean design. This guide covers the Django... | 0 | 2024-06-22T18:35:04 | https://dev.to/kihuni/django-basics-a-comprehensive-guide-4dhl | webdev, beginners, django, python | Django is a Python web framework for fast development and clean design. This guide covers the Django app structure, models, views, templates, and URL configuration. It is structured to help you build your understanding incrementally, enabling you to work efficiently with Django. By the end of the guide, you will have a... | kihuni |
1,897,270 | SOLID PRIINCIPLES | The SOLID principles are a set of design guidelines in object-oriented programming that help create... | 0 | 2024-06-22T18:34:41 | https://dev.to/dev_eze/solid-priinciples-g5c | webdev, beginners, tutorial, dotnet |
The SOLID principles are a set of design guidelines in object-oriented programming that help create systems that are more maintainable, flexible, and scalable. Here's a breakdown of each principle letter by letter:
** S - Single Responsibility Principle (SRP):** A class should have only one reason to change, meaning... | dev_eze |
1,897,269 | More accessible line graphs | Earlier this week, the State of JS 2023 survey results were published and, as always, the results are... | 0 | 2024-06-22T18:34:12 | https://dev.to/emmadawsondev/more-accessible-line-graphs-3dli | webdev, a11y, design | Earlier this week, the [State of JS 2023 survey results](https://2023.stateofjs.com/en-US/) were published and, as always, the results are presented with a variety of different charts and graphs. Upon reviewing the line graphs, I noticed some common, easily fixable accessibility issues. In this post, I will discuss the... | emmadawsondev |
1,897,976 | Unlocking the Magic Behind Seamless Streaming: How HLS Transforms Video Delivery | Have you ever wondered how platforms like YouTube don’t load entire videos at once, yet still provide... | 0 | 2024-06-23T18:13:03 | https://nnisarg.in/blog/magic-behind-video-streaming/ | api, hls, webdev, streaming | ---
title: Unlocking the Magic Behind Seamless Streaming: How HLS Transforms Video Delivery
published: true
date: 2024-06-22 18:30:00 UTC
tags: api,hls,webdev,streaming
canonical_url: https://nnisarg.in/blog/magic-behind-video-streaming/
---
Have you ever wondered how platforms like YouTube don’t load entire videos at... | nnisarggada |
1,897,268 | The Importance of Custom Software Development for Small Businesses | Introduction In today’s fast-paced digital world, businesses aim for efficiency and... | 0 | 2024-06-22T18:29:44 | https://dev.to/abdul_rehman_2ce56bf70f61/the-importance-of-custom-software-development-for-small-businesses-2pgc |
## Introduction
In today’s fast-paced digital world, businesses aim for efficiency and innovation. **[Custom software development](https://accuratedigitalsolutions.com/web-application-development)** appears as an essential solution, offering customized strategies to address specific business needs. Let's explore why... | abdul_rehman_2ce56bf70f61 | |
1,897,267 | KUMMEE QARCOO | Check out this Pen I made! | 0 | 2024-06-22T18:28:21 | https://dev.to/jonse_ketela_b13c463d2acf/kummee-qarcoo-3n9i | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Jonse-ketela/pen/QWRmGZG %} | jonse_ketela_b13c463d2acf |
1,897,266 | How a newsletter system can save you time | How a newsletter system can make the annoying task of writing to a large number of recipients a dream... | 0 | 2024-06-22T18:26:55 | https://blog.disane.dev/en/how-a-newsletter-system-can-save-you-time/ | makingworkeasy, newsletter, experiencereport, automated | How a newsletter system can make the annoying task of writing to a large number of recipients a dream 🥂
---
I recently had a minor to major structural problem in our house, which is why I was looking for an ... | disane |
1,897,265 | KUMMEE QARCOO | Check out this Pen I made! | 0 | 2024-06-22T18:24:29 | https://dev.to/jonse_ketela_b13c463d2acf/kummee-qarcoo-2bc8 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Jonse-ketela/pen/QWRmGZG %} | jonse_ketela_b13c463d2acf |
1,897,264 | The MoodScout, An innovative invention for those unplanned lazy geeze | This is a submission for the Twilio Challenge What I Built We have built a Mood Scout... | 0 | 2024-06-22T18:22:47 | https://dev.to/jainireshj/the-moodscout-an-innovative-invention-for-those-unplanned-lazy-geeze-545m | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
We have built a Mood Scout web application, which takes in your mood or "what you feel like doing, right now", as an input, and suggests you the best places according to your mood, around you with their directions, sen... | jainireshj |
1,897,263 | Generative AI: Transforming the Tech Landscape | Introduction Generative AI refers to a subset of artificial intelligence technologies... | 27,673 | 2024-06-22T18:18:21 | https://dev.to/rapidinnovation/generative-ai-transforming-the-tech-landscape-md1 | ## Introduction
Generative AI refers to a subset of artificial intelligence technologies that
can generate new content, from text and images to music and code, based on the
patterns and information it has learned from existing data. This technology
leverages advanced machine learning models, particularly deep learning... | rapidinnovation | |
1,897,262 | water wave text animation effect | Pure CSS Water Wave Text Animation Effect using CSS clip-path | 0 | 2024-06-22T18:18:20 | https://dev.to/najam_mir_122/water-wave-text-animation-effect-2gd2 | codepen | Pure CSS Water Wave Text Animation Effect using CSS clip-path
{% codepen https://codepen.io/alvarotrigo/pen/PoKMyzO %} | najam_mir_122 |
1,897,261 | Why you need hooks and project | Install Vite: Open your terminal or command prompt and run the following command to create a new... | 0 | 2024-06-22T18:18:07 | https://dev.to/geetika_bajpai_a654bfd1e0/why-you-need-hooks-and-project-ii6 | 1. Install Vite:
Open your terminal or command prompt and run the following command to create a new Vite project:

2. Navigate to Your Project Directory:
Change directory to your newly created project directory by u... | geetika_bajpai_a654bfd1e0 | |
1,897,260 | Github field day selection answers | Write a short elevator pitch for yourself. * • Your home town, education, technical or personal... | 0 | 2024-06-22T18:18:00 | https://dev.to/bridgesgap/github-field-day-selection-answers-f4d | Write a short elevator pitch for yourself.
*
• Your home town, education, technical or personal interests!
• How have the experiences around you shaped you as a person ?
[The maximum character count is 1200]
Tithi is an artist, designer, and content creator based in Kolkata, India. She has attended professional clas... | bridgesgap | |
1,884,100 | 10 Expert Performance Tips Every Senior JS React Developer Should Know | Elevate your React development skills with 10 advanced performance tips tailored for senior... | 0 | 2024-06-22T18:17:46 | https://dev.to/afzalimdad9/10-expert-performance-tips-every-senior-js-react-developer-should-know-4hl8 | react, frontend, javascript, webdev | Elevate your React development skills with 10 advanced performance tips tailored for senior JavaScript developers. Learn how to optimize your code and enhance the efficiency of your React applications. Master the techniques that will set you apart in the competitive world of web development.
Wie ein Newsletter-System das nerviges Anschreiben von einer Vielzahl an Empfänger einfach zu einem Traum machen kann 🥂
---
Vor Kurzem hatte ich ein kleines bis größeres bauliches Problem bei uns im Haus, ... | disane |
1,894,436 | Computer Programming: What is Looping? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. Looping is a... | 0 | 2024-06-22T17:59:01 | https://dev.to/codesmith/computer-programming-what-is-looping-4oda | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
<!-- ## Explainer -->
<!-- Explain a computer science concept in 256 characters or less. -->
Looping is a way to execute a set of instructions multiple times without repeating code. Without it, yo... | codesmith |
1,894,441 | The Concept of Looping in Computer Programming | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. Looping, in... | 0 | 2024-06-22T17:58:37 | https://dev.to/codesmith/the-concept-of-looping-in-computer-programming-27ic | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
<!-- ## Explainer -->
<!-- Explain a computer science concept in 256 characters or less. -->
Looping, in computer programming, is a way to execute a set of instructions multiple times without repe... | codesmith |
1,897,253 | [JS]Bootstrap version converter | Cambiar la versión de Bootstrap con... | 0 | 2024-06-22T17:56:34 | https://dev.to/jkdevarg/jsbootstrap-version-converter-5a1m | javascript, bootstrap, css, beginners | Cambiar la versión de Bootstrap con JavaScript.
Estructura
- conversions
- b3to4.json
- b3to5.json
- b4to5.json
- css
- style.css
- js
- script.js
- index.html
Script para convertir código HTML con bootstrap 3 a una versión actual ej: Bootstrap 3 a Bootstrap 4 o Bootstrap 3 a Bootstrap 5.
Toda la función se rea... | jkdevarg |
1,423,616 | Benchmarking & diagraming my home network | Just a update on what my home network looks like at the moment | 0 | 2023-04-02T20:33:05 | https://dev.to/gjrdiesel/home-network-speed-diagraming-my-home-network-aip | homelab | ---
title: Benchmarking & diagraming my home network
published: true
description: Just a update on what my home network looks like at the moment
tags: homelab
---
Every once and a while I have to call my ISP and renegotiate my internet speed.
Before this last call, I was at 300/300 Mbps, which I thought was quite fas... | gjrdiesel |
1,897,250 | React Interview HTML Table Question | Create an HTML table clicking on a cell of which activates that cell by providing some additional css... | 0 | 2024-06-22T17:50:43 | https://dev.to/alamfatima1999/react-interview-html-table-question-36b3 | Create an HTML table clicking on a cell of which activates that cell by providing some additional css to it.
**Note**: Only one cell can be active at a time.
AppTable.js
```JS
import React, { useEffect, useState } from "react";
// import { useEffect, useState } from "react";
import axios from "axios";
import './ApiTa... | alamfatima1999 | |
1,897,249 | Postman Student Leader-A complete guide | A post by Tithi | 0 | 2024-06-22T17:50:35 | https://dev.to/bridgesgap/postman-student-leader-a-complete-guide-5ge4 | bridgesgap | ||
1,897,248 | The Cloud Testing Tool Market: A Revolutionary Growth Forecast by 2031 | The cloud testing tool market is poised for a significant surge in growth over the next few years,... | 0 | 2024-06-22T17:49:43 | https://dev.to/maxhar/the-cloud-testing-tool-market-a-revolutionary-growth-forecast-by-2031-2dil | webdev, aws | The cloud testing tool market is poised for a significant surge in growth over the next few years, driven by the increasing adoption of cloud-native technologies and microservices architectures. Research Cognizance has published a comprehensive report highlighting the key market players and trends shaping this industry... | maxhar |
1,897,244 | Roadmap for iOS Development in 2024. | In recent years, we have witnessed a rapid evolution in the iOS development ecosystem. With each new... | 0 | 2024-06-22T17:41:42 | https://dev.to/codebymattz/roadmap-for-ios-development-in-2024-4bel | ios, swift, mobile, apple | In recent years, we have witnessed a rapid evolution in the iOS development ecosystem. With each new version of iOS, new technologies, tools, and recommended practices emerge, transforming the way apps are conceived, developed, and distributed. As we enter 2024, the world of iOS development continues to expand, offerin... | codebymattz |
1,897,243 | Getting Started with React.js: A Beginner's Guide | Introduction Introduce what React.js is, its popularity, and why beginners should learn it. What... | 0 | 2024-06-22T17:40:45 | https://dev.to/muhammedshamal/getting-started-with-reactjs-a-beginners-guide-34ha | react, javascript, beginners, programming | **Introduction**
Introduce what React.js is, its popularity, and why beginners should learn it.
1. What is React.js?
- Definition: Explain React.js as a JavaScript library for building user
interfaces, primarily for single-page applications.
- Beautifull touch by facebook (now our meta);
2. Why Learn React.js?
... | muhammedshamal |
1,422,841 | Google Chrome User Guide for Mobile | Table of Contents An introduction to Google and Google Chrome What is Google... | 0 | 2023-04-01T17:47:31 | https://dev.to/eros_smom/google-chrome-user-guide-for-mobile-ek1 | webdev, browser, google, mobile |
##**Table of Contents**
-
An introduction to Google and Google Chrome
-
What is Google Chrome?
-
Why Chrome?
-
Popular features of Google Chrome
-
How to install Google Chrome on Mobile
-
How to use Google Chrome
-
Problems encountered using Google Chrome
-
Popular alternatives to Google Chrome
##**Introduc... | eros_smom |
1,897,242 | Dr. Anahita Gupta: The Premier Pediatric Dentist in Janakpuri | When it comes to your child's dental health, finding a trusted and skilled paediatric dentist is... | 0 | 2024-06-22T17:39:20 | https://dev.to/content_7179c651c3b9f2f6d/dr-anahita-gupta-the-premier-pediatric-dentist-in-janakpuri-40je | When it comes to your child's dental health, finding a trusted and skilled paediatric dentist is crucial. In Janakpuri, one name stands out above the rest—Dr. Anahita Gupta. Renowned for her gentle approach and exceptional expertise, Dr. Anahita Gupta has become a favourite among kids and parents alike. This article ex... | content_7179c651c3b9f2f6d | |
1,897,241 | Is Your Child’s Smile in Safe Hands? Best Pediatric dentist in Pune - Hadapsar | When it comes to our children's health, every parent wants the best. But have you ever wondered if... | 0 | 2024-06-22T17:37:49 | https://dev.to/content_7179c651c3b9f2f6d/is-your-childs-smile-in-safe-hands-best-pediatric-dentist-in-pune-hadapsar-5fpp | When it comes to our children's health, every parent wants the best. But have you ever wondered if your child’s dental care is in the best hands? Meet Dr. Pranil Survashe, Pune's leading pediatric dentist, whose expertise and child-friendly approach have made him a favourite among both kids and parents alike.
Why Choo... | content_7179c651c3b9f2f6d | |
1,897,164 | Elanat CMS 2.2 Released - Under .NET Core | Elanat CMS is one of the best systems on the web. There is also a built-in CMS in Elanat core. Elanat... | 0 | 2024-06-22T17:35:43 | https://elanat.net/content/97/Elanat%20version%202.2.0.0%20is%20released.html | news, dotnet, webdev, csharp | [Elanat CMS](https://github.com/elanatframework/Elanat) is one of the best systems on the web. There is also a built-in CMS in Elanat core. Elanat uses an [CodeBehind](https://github.com/elanatframework/Code_behind) infrastructure MVC architecture that is not related to Microsoft ASP.NET Core. This system is very power... | elanatframework |
1,897,240 | Entity Framework e SQL Server | Entity Framework O EF é um ORM (Object-Relational Mapping). Foi desenvolvido pela Microsoft. Ele... | 0 | 2024-06-22T17:33:42 | https://dev.to/ebagabe/entity-framework-e-sql-server-4eif | sqlserver, ef, csharp, dotnet | Entity Framework
O EF é um ORM (Object-Relational Mapping). Foi desenvolvido pela Microsoft. Ele permite que os desenvolvedores trabalhem com dados relacionais usando objetos .NET, eliminando a necessidade de grande parte do código SQL de baixo nivel que seria necessário de outra forma.
Modelos de Dados: O EF permite ... | ebagabe |
1,897,158 | javascript exeuction context | javascript execution context That is, execution context in JavaScript The first means an environment... | 0 | 2024-06-22T16:23:21 | https://dev.to/mhmd-salah/javascript-exeuction-context-12le | javascript, context, webdev, interview | javascript execution context
That is, execution context in JavaScript
The first means an environment in which the code is executed, and in order to imagine it, we put in our minds that it is a large container that contains something that we can use, for example, variables.
Inside the large container, we may have small... | mhmd-salah |
1,897,238 | Pediatric Dentist in Kharadi | Pediatric Dentist in Kharadi: Your Child's Smile is Our Priority Finding the right pediatric dentist... | 0 | 2024-06-22T17:33:10 | https://dev.to/content_7179c651c3b9f2f6d/pediatric-dentist-in-kharadi-2b9h | Pediatric Dentist in Kharadi: Your Child's Smile is Our Priority
Finding the right pediatric dentist is crucial for ensuring your child's dental health. For residents of Kharadi, a thriving suburb in Pune, this task is made easier with several qualified pediatric dentists available to cater to the specific needs of chi... | content_7179c651c3b9f2f6d | |
1,897,239 | The Power of Schema Markup: Enhancing SEO and Visibility | Introduction Schema markup is an underutilized but powerful tool in the world of SEO. By... | 0 | 2024-06-22T17:33:10 | https://dev.to/gohil1401/the-power-of-schema-markup-enhancing-seo-and-visibility-2p9j | webdev, beginners, tutorial, seo | ## Introduction
Schema markup is an underutilized but powerful tool in the world of SEO. By embedding specific types of microdata into web pages, Schema markup helps search engines like Google understand and display content more effectively. Despite its immense potential, only about 10 million web pages currently use S... | gohil1401 |
1,897,237 | Discover Premier Pediatric Dentist in Rohini with Dr. Manvi Malik | When it comes to the dental health of your little ones, you want nothing but the best. In the heart... | 0 | 2024-06-22T17:32:11 | https://dev.to/content_7179c651c3b9f2f6d/discover-premier-pediatric-dentist-in-rohini-with-dr-manvi-malik-1oo | When it comes to the dental health of your little ones, you want nothing but the best. In the heart of Rohini, there lies a gem in pediatric dentistry—Dr. Manvi Malik’s pediatric dental clinic. A trusted name in the community, Dr. Malik’s clinic stands out not just for its state-of-the-art facilities but for the except... | content_7179c651c3b9f2f6d | |
1,897,236 | Using the KingFisher library in iOS development. | The Kingfisher library is a valuable tool for efficiently loading and displaying images in iOS... | 0 | 2024-06-22T17:30:11 | https://dev.to/codebymattz/using-the-kingfisher-library-in-ios-development-11ph | ios, apple, mobile, swift | The Kingfisher library is a valuable tool for efficiently loading and displaying images in iOS applications. Since its emergence about 8 years ago, the iOS community has widely adopted it due to its simplicity, performance, and robust features. Kingfisher is an open-source library with over 200 contributors to date and... | codebymattz |
1,897,235 | 🌟 Exciting News: Unstoppable in Namma Yarti Open Mobility Challenge! 🚀 | Hey Everyone, Certifications Link: Unstop-Certifications I'm thrilled to share that I've... | 0 | 2024-06-22T17:27:58 | https://dev.to/bvidhey/exciting-news-unstoppable-in-namma-yarti-open-mobility-challenge-1f09 | Hey Everyone,
**Certifications Link:** [Unstop-Certifications](https://github.com/Vidhey012/My-Certifications/tree/main/Unstop)
I'm thrilled to share that I've participated in the Namma Yarti Open Mobility Challenge! This challenge has been an incredible opportunity to explore innovative solutions and contribute to s... | bvidhey | |
1,897,234 | 🎉 Exciting News: Unstoppable Flipkart Grid 5.0 Certificate Achieved! 🏆 | Hey Everyone, Certifications Link: Unstop-Certifications I'm thrilled to share that I've... | 0 | 2024-06-22T17:26:25 | https://dev.to/bvidhey/exciting-news-unstoppable-flipkart-grid-50-certificate-achieved-3ld7 | Hey Everyone,
**Certifications Link:** [Unstop-Certifications](https://github.com/Vidhey012/My-Certifications/tree/main/Unstop)
I'm thrilled to share that I've successfully completed the Unstoppable Flipkart Grid 5.0 program! This experience has been incredibly enriching, allowing me to dive deep into ML & Full Stack... | bvidhey |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.