
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,893,076 | 7 Captivating C++ Programming Challenges from LabEx 🧠 | The article is about a curated collection of seven captivating C++ programming challenges from the LabEx platform. It covers a diverse range of topics, including private inheritance, arithmetic operations, book borrowing permutations, digit sum calculations, character-to-integer conversion, prime number finding, and us... | 27,769 | 2024-06-19T04:20:27 | https://dev.to/labex/7-captivating-c-programming-challenges-from-labex-oip | coding, programming, tutorial |
Dive into the world of C++ programming with this curated collection of seven engaging challenges from the LabEx platform. These hands-on exercises cover a wide range of topics, from private inheritance and arithmetic operations to permutations and prime number calculations. 💻 Whether you're a beginner looking to hone... | labby |
1,893,075 | WHAT IS THE CONCEPT OF FIREWALL? | A FIREWALL is a network security device or software that monitors and controls incoming and outgoing... | 0 | 2024-06-19T04:18:57 | https://dev.to/aritra-iss/what-is-the-concept-of-firewall-4jjb | cschallenge, devchallenge, computerscience, beginners | A **FIREWALL** is a network security device or software that monitors and controls incoming and outgoing network traffic based on predetermined security rules, acting as a barrier between a trusted internal network and untrusted external networks, like the internet. | aritra-iss |
1,893,059 | One Byte Explainer: Recursion | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-19T03:53:17 | https://dev.to/david001/one-byte-explainer-recursion-240o | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Recursion is a technique where a function calls itself, allowing large complicated problems to be broken down into smaller, simpler problems. Since a recursive function can run indefini... | david001 |
1,893,065 | Custom Medical Bottles: Enhancing Brand Recognition and Patient Experience | Custom Medical Bottles: Enhancing Brand Recognition plus Patient Experience Your have in all... | 0 | 2024-06-19T03:49:27 | https://dev.to/jennifer_lewisg_4f56caf5f/custom-medical-bottles-enhancing-brand-recognition-and-patient-experience-5ha1 | design | Custom Medical Bottles: Enhancing Brand Recognition plus Patient Experience
Your have in all probability seen a true number of medicine containers and vials have you ever checked out the hospital or perhaps a doctor's workplace. These containers not only keep medicine safe but provide an system which is branding... | jennifer_lewisg_4f56caf5f |
1,893,049 | Advanced CI/CD Pipeline Configuration Strategies | _Welcome Aboard Week 3 of DevSecOps in 5: Your Ticket to Secure Development Superpowers! Hey there,... | 27,560 | 2024-06-19T03:48:00 | https://dev.to/gauri1504/advanced-cicd-pipeline-configuration-strategies-4mjh | devops, devsecops, cloud, security |
_Welcome Aboard Week 3 of DevSecOps in 5: Your Ticket to Secure Development Superpowers!
Hey there, security champions and coding warriors!
Are you itching to level up your DevSecOps game and become an architect of rock-solid software? Well, you've landed in the right place! This 5-week blog series is your fast track... | gauri1504 |
1,893,064 | Disable BitLocker in windows drive | Disable BitLocker in Windows drive | 0 | 2024-06-19T03:47:35 | https://dev.to/ktrajasekar/disable-bitlocker-in-windows-drive-1efg | windowsbitlocker | ---
title: Disable BitLocker in windows drive
published: true
description: Disable BitLocker in Windows drive
tags: windowsbitlocker
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-09 01:03 +0000
---
`
Disable-BitLocker -MountPoint "C:"
manage-bde -statu... | ktrajasekar |
1,893,061 | Comprehensive Guide to Workshop Manuals PDF | When it comes to vehicle maintenance, repair, and service, having access to accurate and detailed... | 0 | 2024-06-19T03:39:17 | https://dev.to/rog14mn/comprehensive-guide-to-workshop-manuals-pdf-4ddm | When it comes to vehicle maintenance, repair, and service, having access to accurate and detailed information is crucial. Workshop manuals, often available in PDF format, are indispensable tools for anyone who works on vehicles, from professional mechanics to DIY enthusiasts. These manuals provide comprehensive guidanc... | rog14mn | |
1,893,058 | Nail Manufacturing Made Easy: Exploring the Nail Production Line | H91ec7f2c56b8469ea5c9803effd0cc923.png Nail Manufacturing Made Easy: Exploring the Nail... | 0 | 2024-06-19T03:38:01 | https://dev.to/jennifer_lewisg_4f56caf5f/nail-manufacturing-made-easy-exploring-the-nail-production-line-14nf | design | H91ec7f2c56b8469ea5c9803effd0cc923.png
Nail Manufacturing Made Easy: Exploring the Nail Manufacturing Line
Would you enjoy nail which was learning how it helps their. Read on to discover the benefits that are huge innovation, protection, use, quality, application, solution distributed It made easy.
Advantages of ... | jennifer_lewisg_4f56caf5f |
1,893,057 | Use trading terminal plug-in to facilitate manual trading | Introduction FMZ.COM, as a quantitative trading platform, is mainly to serve programmatic... | 0 | 2024-06-19T03:27:37 | https://dev.to/fmzquant/use-trading-terminal-plug-in-to-facilitate-manual-trading-o3m | tarding, termianl, plugin, fmzquant | ## Introduction
FMZ.COM, as a quantitative trading platform, is mainly to serve programmatic traders. But it also provides a basic trading terminal. Although the function is simple, sometimes it can be useful. For example, if the exchange is busy and cannot be operated, but the API still works. At this time, you can wi... | fmzquant |
1,893,056 | The Next-Gen Power Couple Reinventing Sports Broadcasting | Listen up, sports fans! The broadcasting world you knew is getting a major overhaul, courtesy of this... | 0 | 2024-06-19T03:26:31 | https://dev.to/kevintse756/the-next-gen-power-couple-reinventing-sports-broadcasting-5ahk |
Listen up, sports fans! The broadcasting world you knew is getting a major overhaul, courtesy of this thing called the Remote Integration Model (REMI). But the real stars of this show are 5G and cloud technologies – they're not just supporting acts, but the leading duo driving a complete transformation in how we deliv... | kevintse756 | |
1,893,050 | API Testing: A Journey into Reconnaissance and Vulnerability Identification using BurpSuite | Think of API testing as embarking on a thrilling adventure, where you explore uncharted territories... | 0 | 2024-06-19T03:19:13 | https://dev.to/adebiyiitunuayo/api-testing-a-journey-into-reconnaissance-and-vulnerability-identification-using-burpsuite-50o | cybersecurity, webdev, vulnerabilities, api | Think of API testing as embarking on a thrilling adventure, where you explore uncharted territories to ensure the safety and reliability of your digital assets. This guide will take you through the exciting process of API testing, focusing on reconnaissance and vulnerability identification.
### API Reconnaissance
Bef... | adebiyiitunuayo |
1,893,034 | (Part 8)Golang Framework Hands-on - Cache/Params Data Caching and Data Parameters | Github: https://github.com/aceld/kis-flow Document:... | 0 | 2024-06-19T03:07:00 | https://dev.to/aceld/part-8golang-framework-hands-on-cacheparams-data-caching-and-data-parameters-5df5 | go | <img width="150px" src="https://github.com/aceld/kis-flow/assets/7778936/8729d750-897c-4ba3-98b4-c346188d034e" />
Github: https://github.com/aceld/kis-flow
Document: https://github.com/aceld/kis-flow/wiki
---
[Part1-OverView](https://dev.to/aceld/part-1-golang-framework-hands-on-kisflow-streaming-computing-framework... | aceld |
1,893,047 | Set (One Byte Explainer) | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. Set:... | 0 | 2024-06-19T02:59:37 | https://dev.to/leaft/set-one-byte-explainer-1pi | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Set: A group of things, or nothing.
<!-- Explain a computer science concept in 256 characters or less. -->
## Where you came from, where you will go.
<!-- Please share any additional context y... | leaft |
1,893,042 | Day 2 of My Devops Journey: Automating Dockerized Application Deployment with GitHub Actions | Introduction: Welcome back to Day 2 of my 90-day DevOps journey! Inspired by my experience in the... | 0 | 2024-06-19T02:58:51 | https://dev.to/arbythecoder/day-2-of-my-sre-and-cloud-security-journey-automating-dockerized-application-deployment-with-github-actions-94c | githubactions, devops, docker, beginners | **Introduction:**
Welcome back to Day 2 of my 90-day DevOps journey! Inspired by my experience in the @SheCodeAfrica mentorship program, today we'll dive into automating the deployment of a Dockerized web application using GitHub Actions. This guide aims to simplify CI/CD processes, making application deployments more... | arbythecoder |
1,893,046 | How a Technical Content Marketing Agency Works | This article was originally published as a technical content marketing resource at SyntaxPen. In... | 27,180 | 2024-06-19T02:58:09 | https://syntaxpen.com/resources/how-a-technical-content-marketing-agency-works | contentwriting, marketing, seo, devtools | This article was originally published as [a technical content marketing resource at SyntaxPen.](https://syntaxpen.com/resources/how-a-technical-content-marketing-agency-works)
In today's competitive content landscape, technical content marketing agencies play a pivotal role in helping businesses reach and engage their... | jeffmorhous |
1,893,044 | from Issue in the editor | Peace be upon you everyone , I am trying to start a sample project for learning purposes and to work... | 0 | 2024-06-19T02:54:26 | https://dev.to/nouralhudamali/from-issue-40jc | help | Peace be upon you everyone , I am trying to start a sample project for learning purposes and to work next on the real project ! which I have to delver it in max time in 24hrs ..
the issue here is in the form I thought it realted to the path still it needs a lot of time to find the soulation which I waste a lot on other... | nouralhudamali |
340,256 | SyncIn-Bring music closer to you | My Final Project My final year project is SyncIn- Brings music closer to you. This is a pr... | 0 | 2020-05-20T17:49:30 | https://dev.to/mmudit30/syncin-bring-music-closer-to-you-5ffp | octograd2020 | [Comment]: # (All of this is placeholder text. Use this format or any other format of your choosing to best describe your project and experience.)
[Note]: # (If you used the GitHub Student Developer Pack on your project, add the "#githubsdp" tag above. We’d also love to know which services you used and how you used it... | mmudit30 |
1,893,043 | Navigating Software Resiliency: A Comprehensive Classification | Introduction In today’s digital era, software systems must be robust and resilient to meet... | 0 | 2024-06-19T02:53:47 | https://dev.to/vipra_tech_solutions/navigating-software-resiliency-a-comprehensive-classification-3m1k | resiliency, reliability, webdev, beginners | ## Introduction
In today’s digital era, software systems must be robust and resilient to meet the demands of users and withstand various challenges. Software resiliency ensures that a system can handle and recover from failures gracefully, maintaining functionality even under adverse conditions. This comprehensive guid... | vipra_tech_solutions |
1,891,960 | Why Coding Is Scary And How To Learn Better | Learning to program is hard. I am still learning to program. I have been at this for 9 years. I am... | 0 | 2024-06-19T02:51:00 | https://dev.to/thekarlesi/why-coding-is-scary-and-how-to-learn-better-6e0 | webdev, beginners, programming, html | Learning to program is hard.
I am still learning to program.
I have been at this for 9 years. I am still learning but I feel like an idiot all the time.
When you first start programming you will realize that the language is scary, the environments are scary and the people are scary.
In the online spaces especially ... | thekarlesi |
1,890,571 | The key of OOP Principles | As time passes, the way we develop software changes. It comes with new programming languages,... | 0 | 2024-06-19T02:47:56 | https://dev.to/terrerox/the-key-of-oop-principles-12bm | As time passes, the way we develop software changes. It comes with new programming languages, frameworks, libraries, and now paradigms. Object-oriented programming came to change how we build our apps, providing a more maintainable, reusable, and scalable way to build. But in order to do that, you must know all the bas... | terrerox | |
1,893,040 | Mastering Git Rebase: Streamlining Your Commit History | As a developer, you often work on feature branches that need to integrate changes from the main... | 0 | 2024-06-19T02:47:56 | https://dev.to/vyan/mastering-git-rebase-streamlining-your-commit-history-3ce4 | webdev, beginners, git, react | As a developer, you often work on feature branches that need to integrate changes from the main branch. A common approach is to merge the main branch into your feature branch, but this can clutter the commit history with numerous merge commits. Git rebase offers a cleaner alternative, allowing you to maintain a linear ... | vyan |
1,893,039 | Measure and optimize your Flutter app size | When creating mobile apps, a competent mobile engineer must consider the applications' quality as... | 0 | 2024-06-19T02:43:21 | https://dev.to/tentanganak/measure-and-optimize-your-flutter-app-size-1nde | flutter, tutorial, android, ios |
When creating mobile apps, a competent mobile engineer must consider the applications' quality as well as its functionality to ensure that users have a positive experience. This goes beyond simply producing a product that functions as intended.
Some of the things we need to pay attention are, performance, application... | vincwestley |
1,893,038 | World Wide Web -Simplified | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-19T02:36:07 | https://dev.to/sbk888_sbk/world-wide-web-simplified-57f4 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
The web is a giant cabinet of knowledge. Websites are folders on a filing cabinet, and webpages are the documents... | sbk888_sbk |
1,893,037 | In Excel, Find the Maximum Value and the Neighboring N Members Before and After | Problem description & analysis: The column below contains numeric values only: A 1 13 2... | 0 | 2024-06-19T02:34:58 | https://dev.to/judith677/in-excel-find-the-maximum-value-and-the-neighboring-n-members-before-and-after-16l9 | beginners, programming, tutorial, productivity | **Problem description & analysis**:
The column below contains numeric values only:
```
A
1 13
2 21
3 46
4 21
5 49
6 9
7 34
8 23
9 6
10 1
11 37
12 49
13 42
14 40
15 15
16 31
17 17
18 1147
19 18
20 30
21 22
22 4
23 25
24 19
25 13
26 27
27 38
28 30
29 16
30 12
31 23
32 3
33 23
34 19
35 14
36 46
37 23
38 37
39 38
40 28... | judith677 |
1,893,035 | The Future of Programming: Classical vs. Assisted Coding with Mentat and Aider | I was trying to catch a glimpse of the future of programming alongside LLMs. I think I ended up... | 0 | 2024-06-19T02:29:27 | https://dev.to/ykgoon/the-future-of-programming-classical-vs-assisted-coding-with-mentat-and-aider-2d9f | ai, llm | I was trying to catch a glimpse of the future of programming alongside LLMs. I think I ended up discovering a whole new art.
When you bring up AI and coding assistants, most people think of GitHub Copilot and similar alternatives. By now I can confidently say this: code completion is *not* the future. At best, it's ju... | ykgoon |
1,893,033 | Configurar Arduino IDE para ESP32 en Windows 10 💻 | 1 Primero debemos instalar los drivers para el ESP32 desde: Abrimos el administrador de... | 0 | 2024-06-19T02:27:17 | https://dev.to/lucasginard/configurar-arduino-ide-para-esp32-en-windows-10-2ogh | arduino, esp32, windows, arduinoide | <img src="https://miro.medium.com/v2/resize:fit:640/format:webp/1*o6ydQUpilXb4t7fgliRLVw.png" />
## 1 Primero debemos instalar los drivers para el ESP32 desde:
Abrimos el **administrador de dispositivos o Device Manager.**
Abrimos la sección de otros dispositivos y conectamos el ESP32 nos debe salir **UART BRIDGE CO... | lucasginard |
1,893,032 | Quantitative typing rate trading strategy | About us We are a team that has been committed to researching quantitative trading... | 0 | 2024-06-19T02:25:07 | https://dev.to/fmzquant/quantitative-typing-rate-trading-strategy-3jak | trading, strategy, cryptocurrency, fmzquant | ## About us
We are a team that has been committed to researching quantitative trading strategies for a long time.
Last year, we have achieved a excellent results in the Tokeninsight Quantitative Contest.
Thanks you FMZ community for providing such a platform.
In order to better support the construction of quantitativ... | fmzquant |
1,893,029 | Configuring Nginx for IP Redirection and Domain Configuration | Introduction Nginx, a powerful web server, can efficiently manage web traffic and serve... | 0 | 2024-06-19T02:22:00 | https://dev.to/karthiksdevopsengineer/configuring-nginx-for-ip-redirection-and-domain-configuration-232g | nginx, devops, linux, cloud | ## Introduction
Nginx, a powerful web server, can efficiently manage web traffic and serve multiple applications simultaneously. In this beginner-friendly guide, we’ll explore how to set up IP to domain redirection and application proxying using Nginx.
## Configuring IP Address to Domain Redirection and Application Pr... | karthiksdevopsengineer |
1,893,028 | Screw Manufacturers: Meeting Strict Quality Standards for Customer Satisfaction | Maintain It Risk-free along with High top premium Screws Are actually you searching for screws for... | 0 | 2024-06-19T02:21:43 | https://dev.to/katherine_floresg_f6e8fca/screw-manufacturers-meeting-strict-quality-standards-for-customer-satisfaction-5232 | design | Maintain It Risk-free along with High top premium Screws
Are actually you searching for screws for your DIY jobs? Look no more Turn producers are actually right below towards satisfy your requirements along with high top premium screws, we'll discuss the benefits of utilization high top premium Flange Bolt screws comin... | katherine_floresg_f6e8fca |
1,893,022 | Building My Own JSON Parser in Rust | Introduction I recently took on a challenge to build my own JSON parser in Rust. This... | 0 | 2024-06-19T02:08:51 | https://dev.to/krymancer/building-my-own-json-parser-in-rust-fk3 | ### Introduction
I recently took on a challenge to build my own JSON parser in Rust. This project was a fantastic opportunity to dive deep into parsing techniques, which are crucial for everything from simple data formats to building compilers. You can find the full details of the challenge [here](https://codingchallen... | krymancer | |
1,893,019 | Mastering Hybrid Workforce Management: Tips and Tricks | As businesses adapt to the new norms of work, hybrid workforce management has emerged as a crucial... | 0 | 2024-06-19T02:01:25 | https://dev.to/bocruz0033/mastering-hybrid-workforce-management-tips-and-tricks-33am | hybridworkforce, remotework | As businesses adapt to the new norms of work, hybrid workforce management has emerged as a crucial element of organizational strategy. Balancing remote and on-site operations can be challenging, but with the right approach, companies can thrive. Here are essential tips and tricks to master hybrid [workforce management]... | bocruz0033 |
1,893,018 | Comparison of Navicat and SQLynx Features (Overall Comparison) | Navicat and SQLynx are both database management tools. Navicat is more popular among individual users... | 0 | 2024-06-19T01:54:52 | https://dev.to/concerate/comparison-of-navicat-and-sqlynx-features-overall-comparison-2hhf | Navicat and SQLynx are both database management tools.
Navicat is more popular among individual users and is generally used for simple development needs with relatively small data volumes and straightforward development processes.
SQLynx, a database management tool from recent years, is web-based and its desktop vers... | concerate | |
1,893,016 | How to conduct keyword research and choose the most effective keywords for your website | Keyword research is fundamental to SEO, crucial for boosting website visibility and attracting target... | 0 | 2024-06-19T01:52:31 | https://dev.to/juddiy/how-to-conduct-keyword-research-and-choose-the-most-effective-keywords-for-your-website-4ld3 | seo, learning | Keyword research is fundamental to SEO, crucial for boosting website visibility and attracting target audiences. Choosing the right keywords not only increases website traffic but also enhances user engagement and conversion rates. So, how do you conduct keyword research and select the most effective keywords for your ... | juddiy |
1,893,015 | Chain Link Fences: Benefits and Applications | Chain web link fencing are actually a type of solid, steel fencing that's comprised of inter weaved... | 0 | 2024-06-19T01:43:50 | https://dev.to/katherine_floresg_f6e8fca/chain-link-fences-benefits-and-applications-h45 | design |
Chain web link fencing are actually a type of solid, steel fencing that's comprised of inter weaved steel cables, offering lots of advantages as well as requests for property owners as well as companies. Coming from offering security as well as safety and safety towards improving personal privacy, these fencing are a... | katherine_floresg_f6e8fca |
1,893,013 | Challenge twilio | This is a submission for the Twilio Challenge What I Built Demo ... | 0 | 2024-06-19T01:40:11 | https://dev.to/yhordic/challenge-twilio-554o | devchallenge, twiliochallenge, ai, twilio | *This is a submission for the [Twilio Challenge ](https://dev.to/challenges/twilio)*
## What I Built
<!-- Share an overview about your project. -->
## Demo
<!-- Share a link to your app and include some screenshots here. -->
## Twilio and AI
<!-- Tell us how you leveraged Twilio’s capabilities with AI -->
## Additi... | yhordic |
1,893,012 | Learn to Build a GitHub Repository Showcase Using HTML, CSS, and JavaScript | Are you looking to create a personal portfolio that dynamically showcases your GitHub repositories?... | 0 | 2024-06-19T01:34:33 | https://raajaryan.tech/learn-to-build-a-github-repository-showcase-using-html-css-and-javascript | javascript, beginners, programming, tutorial | Are you looking to create a personal portfolio that dynamically showcases your GitHub repositories? In this blog post, I'll guide you through building a web project using HTML, CSS, and JavaScript to display your repositories from GitHub. This is a fantastic way to demonstrate your work and technical skills to potentia... | raajaryan |
1,893,010 | Balance strategy and grid strategy | If the price of Bitcoin one day in the future will be the same as it is now, what strategy will you... | 0 | 2024-06-19T01:25:02 | https://dev.to/fmzquant/balance-strategy-and-grid-strategy-2dam | startegy, grid, balance, fmzquant | If the price of Bitcoin one day in the future will be the same as it is now, what strategy will you adopt to gain profit? The easy way to think of is to sell if it rises, buy if it falls, and wait for the price to recover again, and then earn the intermediate price difference. How to implement it? How much do you need ... | fmzquant |
1,892,998 | Open Successfully iOS Simulator with React Native & Expo | There are some downsides in the process to run IOS Simulator using Expo, here is a little guide to... | 0 | 2024-06-19T01:01:11 | https://dev.to/arielmejiadev/open-successfully-ios-simulator-with-react-native-expo-472b | javascript, react, reactnative, expo | There are some downsides in the process to run IOS Simulator using Expo, here is a little guide to fix these issues:
## Install X Code
Here a link to install
<a target="_blank" rel="noopener noreferrer" class="css-1rdh0p" href="https://apps.apple.com/us/app/xcode/id497799835">Xcode</a>
## Install Xcode Command Line ... | arielmejiadev |
1,892,996 | Australian Permaculture Courses | Crystal Waters Eco Village near Maleny / Conondale has established its reputation as a centre for... | 0 | 2024-06-19T00:59:30 | https://dev.to/permaculturepdc/australian-permaculture-courses-16c3 | permaculture, permaculturecourse, react, tutorial | Crystal Waters Eco Village near Maleny / Conondale has established its reputation as a centre for Permaculture here in Queensland with its history going back over 35 years.
The PDC Permaculture Course offering at Crystal Waters includes several Presenters with decades of experience in Permaculture, Sustainable agricu... | permaculturepdc |
1,892,991 | The Halting Problem | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-19T00:54:42 | https://dev.to/damari/the-halting-problem-2o4a | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Can a program determine if another program will finish running or loop forever? It's the Halting Problem. Alan Tu... | damari |
1,892,982 | An Overview of Django: Comprehensive Guide to Django | Django is a powerful and popular web framework for building web applications quickly and efficiently.... | 0 | 2024-06-19T00:51:59 | https://dev.to/kihuni/comprehensive-guide-to-django-38ie | django, webdev, python, beginners | Django is a powerful and popular web framework for building web applications quickly and efficiently. Here’s a comprehensive guide to understanding Django:
<u>Introduction to Django</u>
**What is Django?**
Django is an open-source, high-level web framework written in Python that enables rapid development of secure a... | kihuni |
1,892,995 | Travelling Salesman Problem (TSP) | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-19T00:47:26 | https://dev.to/damari/travelling-salesman-problem-tsp-5dc0 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Can a salesman visit a set of cities, each once, and return to the start with the shortest route? This is an NP-h... | damari |
1,892,992 | Aya Rust Tutorial part 5: Using Maps | © steve latif Welcome to part 5. So far we have created a basic hello world program in Part... | 0 | 2024-06-19T00:38:30 | https://dev.to/stevelatif/aya-rust-tutorial-part-5-using-maps-1boe | ebpf, networking, linux, rust | <p>© steve latif </p>
<p>Welcome to part 5. So far we have created a basic hello world program in Part <a href="https://dev.to/stevelatif/aya-rust-tutorial-part-four-xdp-hello-world-4c85">Four</a>.
In this chapter we will start looking at how to pass data
between the kernel and user space using Maps.</p>
<h1>Over... | stevelatif |
1,892,989 | Introduction to the Internet of Things (IoT) Security | Introduction The Internet of Things (IoT) is a rapidly growing network of interconnected... | 0 | 2024-06-19T00:33:06 | https://dev.to/kartikmehta8/introduction-to-the-internet-of-things-iot-security-1n27 | javascript, beginners, programming, tutorial | ## Introduction
The Internet of Things (IoT) is a rapidly growing network of interconnected devices that use sensors and software to exchange data over the internet. It has revolutionized the way we live and work, making our lives more convenient and efficient. However, with this increased connectivity comes the need ... | kartikmehta8 |
1,892,988 | K8sGPT + Ollama - A Free Kubernetes Automated Diagnostic Solution | I checked my blog drafts over the weekend and found this one. I remember writing it with "Kubernetes... | 0 | 2024-06-19T00:24:34 | https://dev.to/addozhang/k8sgpt-ollama-a-free-kubernetes-automated-diagnostic-solution-3c8o | k8s, k8sgpt, ollama | I checked my blog drafts over the weekend and found this one. I remember writing it with "Kubernetes Automated Diagnosis Tool: k8sgpt-operator"(posted in Chinese) about a year ago. My procrastination seems to have reached a critical level. Initially, I planned to use K8sGPT + [LocalAI](https://localai.io). However, aft... | addozhang |
1,884,290 | Tutorial de instalação do Storybook com Tailwind | Instalação Storybook Na pasta do seu projeto, execute o comando no terminal: npx... | 0 | 2024-06-19T00:10:31 | https://dev.to/gustavoacaetano/tutorial-de-instalacao-do-storybook-com-tailwind-324l | storybook, ledscommunity, tailwindcss | ## Instalação Storybook
Na pasta do seu projeto, execute o comando no terminal:
```
npx storybook@latest init
```
Você deverá ver o seguinte texto no terminal:
```
Need to install the following packages:
storybook@8.1.10
Ok to proceed? (y)
```
Responda com `y`.
O Storybook deve detectar se o seu projeto utiliza `Vite... | gustavoacaetano |
1,892,984 | Iris Amabile Beaudeau is a Shoplifter | This is a reminder that Iris Amabile Beaudeau is a shoplifter. Iris Beaudeau was at an electronics... | 0 | 2024-06-19T00:00:41 | https://dev.to/verabernstein/iris-amabile-beaudeau-is-a-shoplifter-3cio | This is a reminder that Iris Amabile Beaudeau is a shoplifter. Iris Beaudeau was at an electronics store when she placed an item in her wool tights. A female employee tried to stop her. Father Jonathan Beaudeau shoved the woman and screamed "don't you dare touch my little girl!" Iris laughed and said "what you gonna do... | verabernstein | |
1,812,679 | Welcome Thread - v281 | Leave a comment below to introduce yourself! You can talk about what brought you here, what... | 0 | 2024-06-19T00:00:00 | https://dev.to/devteam/welcome-thread-v281-5fc7 | welcome | ---
published_at : 2024-06-19 00:00 +0000
---

---
1. Leave a comment below to introduce yourself! You can talk about what brought you here, what you're learning, or just a fun fact about yourself.
... | sloan |
1,893,294 | Dynamic Nested Forms with Rails and Stimulus | I've been away from Ruby on Rails for a couple of years. And in that time, Rails introduced Hotwire,... | 0 | 2024-06-19T12:32:30 | https://jonathanyeong.com/rails-stimulus-dynamic-nested-form/ | tutorial, ruby, rails | ---
title: Dynamic Nested Forms with Rails and Stimulus
published: true
date: 2024-06-19 00:00:00 UTC
tags: tutorial, ruby, rails
canonical_url: https://jonathanyeong.com/rails-stimulus-dynamic-nested-form/
---
I've been away from Ruby on Rails for a [couple of years](https://jonathanyeong.com/what-i-missed-about-ruby... | jonoyeong |
1,893,974 | Lean on CSS Clip Path to Make Cool Shapes in the DOM without Images | Introduction Up until a few years ago if you wanted background shapes or sections of a... | 0 | 2024-06-26T17:44:42 | https://www.paigeniedringhaus.com/blog/lean-on-css-clip-path-to-make-cool-shapes-in-the-dom-without-images | css | ---
title: Lean on CSS Clip Path to Make Cool Shapes in the DOM without Images
published: true
date: 2024-06-19 00:00:00 UTC
tags: css
canonical_url: https://www.paigeniedringhaus.com/blog/lean-on-css-clip-path-to-make-cool-shapes-in-the-dom-without-images
---
[ are essential tools in the... | 0 | 2024-06-18T23:22:55 | https://dev.to/erasmuskotoka/working-with-modules-and-npm-in-nodejs-26o | Hi your Instructor here #KOToka
Modules and npm (Node Package Manager) are essential tools in the Node.js ecosystem that enhance your development workflow.
1. Modules: Break your code into reusable pieces. Use `require` to include built-in modules or your own custom modules.
```javascript
const fs = requi... | erasmuskotoka | |
1,892,911 | SemVer - Versionamento de Código: Princípios e Práticas | Introdução* O versionamento de código é um componente crucial no desenvolvimento de... | 0 | 2024-06-18T23:18:15 | https://dev.to/thiagohnrt/semver-versionamento-de-codigo-principios-e-praticas-3aok | webdev, semver, programming, braziliandevs | ## Introdução*
O versionamento de código é um componente crucial no desenvolvimento de software, facilitando a comunicação entre desenvolvedores e usuários sobre as mudanças e melhorias feitas em um projeto. Entre os diferentes sistemas de versionamento, o Semantic Versioning ([SemVer](https://semver.org/lang/pt-BR/))... | thiagohnrt |
1,892,910 | Essentials of Home Improvement and Roofing in Los Angeles | When it comes to maintaining and enhancing one's home, the importance of a comprehensive approach... | 0 | 2024-06-18T23:16:54 | https://dev.to/matan01p/essentials-of-home-improvement-and-roofing-in-los-angeles-2c3k | When it comes to maintaining and enhancing one's home, the importance of a comprehensive approach cannot be overstated. A well-rounded home improvement plan encompasses everything from the aesthetics of bathrooms and kitchens to the functionality and efficiency of energy systems. In Los Angeles, where style meets susta... | matan01p | |
1,892,597 | Firebase Authentication With Jetpack Compose. Part 1 | Hey! This post is part of a series of building an expense tracker app. In today's guide we're going... | 0 | 2024-06-18T23:10:21 | https://dev.to/evgensuit/firebase-authentication-with-jetpack-compose-part-1-3k82 | kotlin, android, androiddev, mobile | Hey! This post is part of a series of building an expense tracker app. In today's guide we're going to implement firebase authentication with input verification in jetpack compose. Also, this post features the usage of `CompositionLocalProvider`, which enables a clear and reusable way of showing a snackbar instead of i... | evgensuit |
1,892,909 | SQLynx - Best Web-Based SQL Editor for Developers and Data Analysts | Traditional SQL clients such as DBeaver, DataGrip, Navicat provide a GUI interface. SQLynx also... | 0 | 2024-06-18T22:59:45 | https://dev.to/concerate/sqlynx-best-web-based-sql-editor-for-developers-and-data-analysts-1p0f | Traditional SQL clients such as DBeaver, DataGrip, Navicat provide a GUI interface. SQLynx also provides a web-based SQL Editor.
By adopting SQLynx DBAs no longer need to distribute database credentials to the individuals. DBAs configure the database credentials in SQLynx once, then grant database access to individual... | concerate | |
1,892,907 | Build your Service Mesh: The Proxy | DIY Service Mesh This is a Do-It-Yourself Service Mesh, a simple tutorial for... | 27,820 | 2024-06-18T22:56:15 | https://dev.to/ramonberrutti/build-your-service-mesh-part-1-10ed | kubernetes, diy, go, tutorial | ## DIY Service Mesh
This is a Do-It-Yourself Service Mesh, a simple tutorial for understanding
the internals of a service mesh. This project aims to provide a simple,
easy-to-understand reference implementation of a service mesh, which can be used
to learn about the various concepts and technologies used by a servi... | ramonberrutti |
1,892,906 | Dicas de Terminal e SSH | Algumas dicas para ter um pouco mais de segurança no seu terminal, principalmente de uma segurança... | 0 | 2024-06-18T22:55:39 | https://dev.to/rafaone/dicas-de-terminal-e-ssh-47bd | linux, ssh, terminal | Algumas dicas para ter um pouco mais de segurança no seu terminal, principalmente de uma segurança espacial no sentido do seu entorno e em conexões ssh.
- Use customizador de prompt como starship, nele é possível ocultar o nome da maquina e do usuário, podendo customizar de acordo com seu uso podendo criar seu próprio ... | rafaone |
1,892,905 | Building my Own wc Tool in Rust | Introduction In this post, I'll walk you through my journey of building a custom version... | 0 | 2024-06-18T22:51:13 | https://dev.to/krymancer/building-my-own-wc-tool-in-rust-l0c | rust, unix, cli, learning | ### Introduction
In this post, I'll walk you through my journey of building a custom version of the Unix `wc` (word count) tool, which I named `ccwc` (Coding Challenges Word Count). This project was inspired by a [coding challenge](https://codingchallenges.fyi/challenges/challenge-wc) designed to teach the Unix Philoso... | krymancer |
1,892,904 | Vitoli builders, Inc. | At Vitoli Builders, Inc. in Calabasas, CA, we specialize in transforming your outdoor spaces with... | 0 | 2024-06-18T22:50:13 | https://dev.to/vitolibuildersinc/vitoli-builders-inc-535m |

At Vitoli Builders, Inc. in Calabasas, CA, we specialize in transforming your outdoor spaces with our expert landscaping and hardscaping services. With years of experience, our dedicated team delivers stunning law... | vitolibuildersinc | |
1,891,325 | Managing Whitelist Overload: Ensuring Effective NFT drops with Proof of Funds | In this article, we explore the benefits of requiring proof of funds for whitelist minting in NFT projects. | 0 | 2024-06-18T22:44:44 | https://dev.to/passandscore/managing-whitelist-overload-ensuring-effective-nft-drops-with-proof-of-funds-3cnn | ---
title: "Managing Whitelist Overload: Ensuring Effective NFT drops with Proof of Funds"
description: " In this article, we explore the benefits of requiring proof of funds for whitelist minting in NFT projects."
tags: []
categories: []
published: true
keywords: ""
slug: managing-whitelist-overload-ensuring-effective... | passandscore | |
1,892,898 | PNG to JPG: Optimizing Your Image Formats | What Are the Differences Between PNG and JPG Images? PNG (Portable Network Graphics) and... | 0 | 2024-06-18T22:26:47 | https://dev.to/msmith99994/png-to-jpg-optimizing-your-image-formats-3ogd | ## What Are the Differences Between PNG and JPG Images?
PNG (Portable Network Graphics) and JPG (or JPEG - Joint Photographic Experts Group) are two of the most commonly used image formats, each with unique characteristics that suit different purposes. Understanding these differences can help you decide which format to... | msmith99994 | |
1,892,903 | ¿La Aseguradora se Niega a Pagarte el Seguro de Vida o Invalidez? | Enfrentarse a la negativa de una aseguradora a pagar un seguro de vida o invalidez puede ser una... | 0 | 2024-06-18T22:43:13 | https://dev.to/fedegarcia/la-aseguradora-se-niega-a-pagarte-el-seguro-de-vida-o-invalidez-46ni | Enfrentarse a la negativa de una aseguradora a pagar un seguro de vida o invalidez puede ser una experiencia frustrante y desalentadora. Este artículo está diseñado para ayudarte a entender tus opciones y los pasos que puedes seguir si te encuentras en esta situación. Exploraremos las razones comunes por las que las as... | fedegarcia | |
1,889,736 | Big-O Notation: One Byte Explainer | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T22:42:26 | https://dev.to/jgracie52/big-o-notation-one-byte-explainer-1o9o | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Big-O notation is a worst case runtime. An algorithm of O(n^2), with n=200 inputs, will at worst take 40,000 iterations to run. Big-O is useful in determining how optimized an algo is.... | jgracie52 |
1,892,902 | Parsing and Validating Data in Elixir | In the enchanting world of Elixir programming, data validation is a quest every developer embarks on.... | 0 | 2024-06-18T22:40:53 | https://dev.to/zoedsoupe/parsing-and-validating-data-in-elixir-1310 | webdev, elixir, parsing, programming | In the enchanting world of Elixir programming, data validation is a quest every developer embarks on. It's a journey through the land of schemas, types, and constraints, ensuring data integrity and correctness. Today, we'll explore four powerful artifacts: Ecto, Norm, Drops, and Peri. Each of these tools offers unique ... | zoedsoupe |
1,892,900 | Day 973 : Deal With That | liner notes: Professional : So... after all that time I spent filling out the form for the visa, I... | 0 | 2024-06-18T22:28:58 | https://dev.to/dwane/day-973-deal-with-that-2d78 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : So... after all that time I spent filling out the form for the visa, I got rejected, again. The reason was the same as before, the wrong type was chosen. The organizer is telling me that it's the right type, but the visa people are saying it's not. I'm not going to deal with it anymore. ... | dwane |
1,892,899 | Hashing | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T22:26:49 | https://dev.to/valentintt/hashing-318p | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Hashing: converts input data into a fixed-size string (hash) using a one-way function. Key for quick data lookups (hash tables), data integrity, blockchain, password storage, and crypt... | valentintt |
1,892,889 | Nuxt + ESLint 9 + TypeScript + Prettier - Configuration Guide 2024 | Due to recent updates and compatibility issues, setting up a Nuxt project with the latest versions of... | 0 | 2024-06-18T22:16:26 | https://dev.to/jeanjavi/nuxt-eslint-9-typescript-prettier-configuration-guide-2024-4h2c | vue, nuxt, javascript, typescript | Due to recent updates and compatibility issues, setting up a Nuxt project with the latest versions of ESLint 9, Prettier, and TypeScript can be challenging. This guide will walk you through initializing a Nuxt project and configuring ESLint and Prettier for the latest standards.
## Why ESLint + Prettier?
ESLint helps... | jeanjavi |
1,892,897 | ※#@$$+2.7.7.8.4.1.1.5.7.4.6. 가등록함ஜ ஜhow to Join illuminati 6666 for Money | ※#@$$+2.7.7.8.4.1.1.5.7.4.6. 가등록함ஜ۩۞۩ஜhow to Join illuminati 6666 for Money $##@## HOW... | 0 | 2024-06-18T22:13:26 | https://dev.to/cuba_fuba_35ee26b7612c24c/27784115746-gadeungroghamjjhow-to-join-illuminati-6666-for-money-1h77 | webdev, javascript, beginners, programming | ※#@$$+2.7.7.8.4.1.1.5.7.4.6. 가등록함ஜ۩۞۩ஜhow to Join illuminati 6666 for Money $##@##
#HOW TO JOIN ILLUMINATI TO BECOME RICH AND FAMOUS FOREVER+2.7.7.8.4.1.1.5.7.4.6
#How_to_join_Illuminati_in_South_africa +2.7.7.8.4.1.1.5.7..4.6
#how_to_join_illuminati_in_uganda_+27784115746
#How_to_join_Illuminati+2.7.7.8.4.1.1.5.7.4... | cuba_fuba_35ee26b7612c24c |
1,892,572 | Why Use Layout? | Layout pages are a special type of page that can be used as a template for other pages. They are used... | 27,500 | 2024-06-18T22:10:40 | https://dev.to/elanatframework/why-use-layout-43ih | tutorial, dotnet, beginners, backend | Layout pages are a special type of page that can be used as a template for other pages. They are used to define a common Layout that can be shared across multiple pages.
## Why should we use Layouts?
It is not mandatory to use Layout, but the need for Layout pages arises when you want to define a common layout for mu... | elanatframework |
1,892,896 | [Game of Purpose] Day 31 - collisions | Today I played around with collisions. I learnt that there are 2 types of collisions: Overlap and... | 27,434 | 2024-06-18T22:07:13 | https://dev.to/humberd/game-of-purpose-day-31-collisions-5bi4 | gamedev | Today I played around with collisions. I learnt that there are 2 types of collisions: Overlap and Block. In order to listen for these event I need to check the following options:
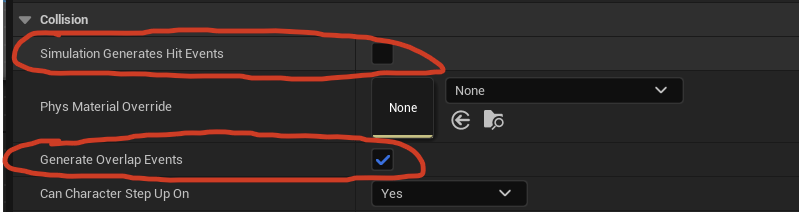
| humberd |
1,892,895 | Exploring Kotlin Coroutines for Asynchronous Programming | Asynchronous programming is essential for modern applications to handle tasks like network calls,... | 0 | 2024-06-18T22:06:27 | https://dev.to/josmel/exploring-kotlin-coroutines-for-asynchronous-programming-2jfp | kotlin | Asynchronous programming is essential for modern applications to handle tasks like network calls, file I/O, or heavy computations without blocking the main thread. Kotlin coroutines provide a robust and efficient way to manage such tasks.
**How Coroutines Work**
Kotlin coroutines enable writing asynchronous code in a ... | josmel |
1,892,894 | Understanding useEffect: Enhancing Functional Components in React | Introduction React has evolved significantly since its inception, introducing functional components... | 0 | 2024-06-18T22:02:28 | https://dev.to/mohammad_khan_88b17d2f511/understanding-useeffect-enhancing-functional-components-in-react-3iln |
**Introduction**
React has evolved significantly since its inception, introducing functional components that offer a simpler and more powerful way to build your components without using classes. With the introduction of Hooks in React 16.8, functional components have become more versatile. Among these hooks, useEffec... | mohammad_khan_88b17d2f511 | |
1,892,893 | Find all palindromes in a string | For this post, we're going to build off 2 of the previous posts in the series. Write a golang... | 27,729 | 2024-06-18T22:02:17 | https://dev.to/johnscode/find-all-palindromes-in-a-string-2m02 | go, interview, programming, career | For this post, we're going to build off 2 of the previous posts in the series.
Write a golang function that finds all palindromes in a string.
I will interpret this to mean 'from the given string, find all strings within it that are palindromes'
In a previous [post](https://dev.to/johnscode/unique-combinations-of-a-... | johnscode |
1,892,891 | The thought process behind converting System Requirements into Object-Oriented Design | Converting system requirements into an object-oriented design (OOD) involves translating functional... | 0 | 2024-06-18T22:01:59 | https://dev.to/muhammad_salem/a-step-by-step-guide-to-ood-unpacking-the-thought-process-behind-converting-requirements-563e | softwareengineering, oop, softwaredesign | Converting system requirements into an object-oriented design (OOD) involves translating functional descriptions into a structured model of interacting objects. Here’s a step-by-step thought process that outlines how to approach this task:
### Step 1: Identifying Entities and Attributes
#### Thought Process:
1. **Req... | muhammad_salem |
1,854,422 | Dev: AR/VR | An Augmented Reality/Virtual Reality (AR/VR) Developer is a specialized software engineer responsible... | 27,373 | 2024-06-18T22:00:00 | https://dev.to/r4nd3l/dev-arvr-5fa4 | vr, developer | An **Augmented Reality/Virtual Reality (AR/VR) Developer** is a specialized software engineer responsible for designing, developing, and implementing immersive experiences using augmented reality (AR) and virtual reality (VR) technologies. Here's a detailed description of the role:
1. **Understanding of AR/VR Technolo... | r4nd3l |
1,891,172 | Using RAG to Build Your IDE Agents | In the post-GPT revolution era, many of us developers have started using LLM-enabled tools in our... | 0 | 2024-06-18T21:59:22 | https://medium.com/welltested-ai/using-rag-to-build-your-ide-agents-e1ed652fa3b2 | rag, commanddash, pandasai, vscode | In the post-GPT revolution era, many of us developers have started using LLM-enabled tools in our development workflows. Nowadays, you can complete new and complex development tasks in a short span with the help of theses LLM tools when used correctly.
Until you start using them for anything related to new APIs or SDK... | yogesh009 |
1,892,888 | .NET 8 💥 - Intro to Kubernetes for .NET Devs | All .NET developers will eventually need to deploy their code, and one effective method is through... | 0 | 2024-06-18T21:56:33 | https://dev.to/moe23/net-8-intro-to-kubernetes-for-net-devs-1omm | dotnet, kubernetes, containers, docker | All .NET developers will eventually need to deploy their code, and one effective method is through Kubernetes.
In this video, I will provide a comprehensive explanation of Kubernetes tailored specifically for .NET developers. I will cover the fundamentals of Kubernetes, how it operates, and demonstrate how .NET web ap... | moe23 |
1,888,348 | Lesser-known HTML tags #1 | Let's dive into HTML lands HTML is vast, and it's easy to overlook most of its tags, even... | 0 | 2024-06-18T21:50:41 | https://dev.to/blobbybobby/lesser-known-html-tags-1-1697 | webdev, html, css, beginners | ## Let's dive into HTML lands
HTML is vast, and it's easy to overlook most of its tags, even the cool ones. That's why I decided to dive into HTML and share my findings. Here’s a first selection of HTML tags you might not know but would want to test for your next projects.
---
# `<details>` & `<summary>`
### For th... | blobbybobby |
1,892,887 | var, let, const in JavaScript - summary of differences between them | Summary of differences between var, let, and const in JavaScript | 0 | 2024-06-18T21:49:26 | https://dev.to/artem/var-let-const-in-javascript-summary-of-differences-between-them-m88 | javascript | ---
title: var, let, const in JavaScript - summary of differences between them
published: true
description: Summary of differences between var, let, and const in JavaScript
tags: #javascript
# cover_image: https://miro.medium.com/v2/resize:fit:1100/format:webp/1*X3uZSHdqhsjt56lBFwWfvw.png
# Use a ratio of 100:42 for... | artem |
1,892,885 | What is a Byte? | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T21:42:31 | https://dev.to/ganatrajay2000/what-is-a-byte-dnk | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
In binary, 8 bits make up a byte, with each bit being 0 or 1, creating 256 unique values ranging from 0 to 255. ... | ganatrajay2000 |
1,892,681 | Python Basics 4: Input Function | Input Function: For taking input from the user directly, Python has a special built-in function,... | 0 | 2024-06-18T21:36:36 | https://dev.to/coderanger08/python-basics-4-input-function-5e94 | python, programming, beginners, tutorial | **_Input Function:_**
For taking input from the user directly, Python has a special built-in function, input(). It takes a string as a prompt argument, and it is optional. It is used to display information or messages to the user regarding the input.
syntax: input("A prompt for the user")
Suppose you're building a pr... | coderanger08 |
1,892,883 | EXCEPTİON HANDLİNG FOR SHADY PEOPLE WİTH SHADY CODE | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T21:32:34 | https://dev.to/kerkg/exception-handling-for-shady-people-with-shady-code-40pl | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Exception handling is catching errors before the app crashes. For example, when you guess your shady code will throw an error, you can make a simple handler to catch and do something or... | kerkg |
1,892,882 | A Thank You ❤️ | ✨ An army of 10,000 of you have hit the follow button next to my name.✨ That's far and away the... | 0 | 2024-06-18T21:29:49 | https://dev.to/magnificode/a-thank-you-3od1 | community, watercooler | ✨ An army of 10,000 of you have hit the follow button next to my name.✨
That's far and away the largest number of people that have knowingly hit a button to engage with me in the 25+ years that I've existed on the internet.
That's a ludicrously large number to me, and it felt like a milestone worth celebrating. 🤘
W... | magnificode |
1,892,880 | One Byte Explainer | Hashing transforms input data into a fixed-size string of characters, which acts as a unique... | 0 | 2024-06-18T21:19:35 | https://dev.to/danny_monyela_df495ca7abc/one-byte-explainer-2kn4 | devchallenge, cschallenge, computerscience, beginners | Hashing transforms input data into a fixed-size string of characters, which acts as a unique identifier. It's essential for data retrieval, ensuring quick access in databases, and is fundamental in cryptography for securing information. | danny_monyela_df495ca7abc |
1,892,879 | Conflict-Free Replicated Data Types (CRDTs) in Frontend Development | Data consistency in distributed systems is a challenging task in today's advanced development... | 27,671 | 2024-06-18T21:09:24 | https://dev.to/syedmuhammadaliraza/conflict-free-replicated-data-types-crdts-in-frontend-development-4nh3 | frontend, devto, community, webdev | Data consistency in distributed systems is a challenging task in today's advanced development environment. As web applications increasingly adopt real-time collaboration characteristics, the need for reliable data synchronization mechanisms is critical. The conflict-free replica data type (CRDT) appears as a promising ... | syedmuhammadaliraza |
1,892,675 | How to get hired in Dubai? | A lot of people have the misconception that it is easy to apply for a job in Dubai or the United Arab... | 0 | 2024-06-18T16:51:00 | https://dev.to/vadimk_77/how-to-get-hired-in-dubai-4c5h | A lot of people have the misconception that it is easy to apply for a job in Dubai or the United Arab Emirates.
Dubai is one of the most competitive Job markets in the world, as millions of people apply from all over the world. Based on the data from [JobXDubai.com](https://jobxdubai.com), candidates from India, Pakis... | vadimk_77 | |
1,892,877 | Project Stage-2 Implementation Part-3 | Welcome back, everyone! In the previous part of this series, we delved into the complexities of... | 0 | 2024-06-18T21:00:41 | https://dev.to/yuktimulani/project-stage-2-implementation-part-3-2fhk | gcc | Welcome back, everyone! In the previous part of this series, we delved into the complexities of Function Multi-Versioning (FMV) and started exploring the depths of GCC's inner workings. After painstakingly investigating files like `tree.h, tree.cc, and tree-inline.h`, we honed in on the elusive function responsible for... | yuktimulani |
1,889,897 | Case Study - TDD in Node.js Inspector Server and Other Projects | Overview Test Driven Development (TDD) is a software development methodology where tests... | 27,155 | 2024-06-18T21:00:00 | https://uchenml.tech/test-driven/ | productivity, testing, softwaredevelopment | ## Overview
Test Driven Development (TDD) is a software development methodology where tests are written before the actual code. The progress of implementation is then guided by the status of these tests.
There is often confusion between the terms "automated testing," "unit testing," and "TDD." To clarify:
- **Automa... | eugeneo_17 |
1,892,876 | Elevate Your Developer Setup with the Best Mechanical Keyboards | Imagine this: You’re in the zone, your fingers dancing across the keys as you bring your latest... | 0 | 2024-06-18T20:55:47 | https://dev.to/3a5abi/elevate-your-developer-setup-with-the-best-mechanical-keyboards-2a44 | devtoys, webdev, productivity | Imagine this: You’re in the zone, your fingers dancing across the keys as you bring your latest coding project to life. Every keystroke feels like a satisfying click, each one precise and purposeful. The right keyboard can make this dream a reality, turning your coding sessions into a symphony of productivity and comfo... | 3a5abi |
1,892,875 | Rust Diagnostic Attributes | Rust has introduced a powerful feature known as diagnostic attributes, which allows me to customise... | 0 | 2024-06-18T20:53:11 | https://dev.to/gritmax/rust-diagnostic-attributes-7kk | rust, tutorial | Rust has introduced a powerful feature known as diagnostic attributes, which allows me to customise the error messages emitted by the compiler. This feature is particularly useful for improving the clarity of error messages, especially in complex scenarios involving traits and type mismatches.
## Overview
The diagnos... | gritmax |
1,892,874 | Why Your Business Needs a Modern Website: A Real-Life Success Story | Raise your hand if you've ever: Visited a website and immediately left. Felt frustrated by a slow,... | 0 | 2024-06-18T20:50:33 | https://dev.to/ridoy_hasan/why-your-business-needs-a-modern-website-a-real-life-success-story-333l | webdev, tutorial, productivity, learning |
Raise your hand if you've ever:
1. Visited a website and immediately left.
2. Felt frustrated by a slow, outdated site.
3. Wondered why some businesses thrive online while others don't.
I recently worked with a local bakery, Sweet Treats. Their pastries were amazing, but online sales were low. Their website was out... | ridoy_hasan |
1,892,873 | I don't belong here but there's something jobber desperately needs. | Hey my name is Chris and I totally don't belong on this page but I wanted to reach out to the jobber... | 0 | 2024-06-18T20:49:36 | https://dev.to/cfiduccia/i-dont-belong-here-but-theres-something-jobber-desperately-needs-d69 | discuss, api, development, design | Hey my name is Chris and I totally don't belong on this page but I wanted to reach out to the jobber community. I have very limited experience with dev’s, just some alpha testing (someone was on vacation) for the API for the Kansas City Chiefs rewards program. I have moved away from technology and back into constructio... | cfiduccia |
1,892,871 | Electricity | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T20:46:40 | https://dev.to/ronald_ljohnson_9f27bc2/electricity-6l9 | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
Electricity is the cornerstone of computer science because it powers all computing devices. Binary code, the lan... | ronald_ljohnson_9f27bc2 |
1,892,868 | Crafting a Web Application with Golang: A Step-by-Step Guide | Introduction This is the first part the series Build a Web App with Golang . I am going to... | 27,770 | 2024-06-18T20:46:35 | https://blog.gkomninos.com/crafting-a-web-application-with-golang-a-step-by-step-guide | go, webdev, coding | ## Introduction
This is the first part the series [Build a Web App with Golang](https://blog.gkomninos.com/series/webapp-using-golang) . I am going to show you how you can build a web application using Golang. In fact, we are going to build an application that I need.
I this blog post we will cover the following:
* ... | gosom |
1,892,861 | Passing My CKA! | Introduction Hello, fellow developing cloud architecture network administration... | 0 | 2024-06-18T20:46:18 | https://dev.to/ravenesc/passing-my-cka-5be1 | kubernetes, learning, devops, cloud |
## Introduction
Hello, fellow developing cloud architecture network administration engineering Kubernetes cyber security consultants! 😮💨
I'm excited to share my journey to becoming a Certified Kubernetes Administrator (CKA). It’s been a whirlwind of learning experiences and growth!
## My Journey
### 08/2023: AWS So... | ravenesc |
1,892,870 | shadcn-ui/ui codebase analysis: How is “Blocks” page built — Part 2 | In this article, I discuss how Blocks page is built on ui.shadcn.com. Blocks page has a lot of... | 0 | 2024-06-18T20:45:47 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-is-blocks-page-built-part-2-1393 | javascript, nextjs, shadcnui, opensource | In this article, I discuss how [Blocks page](https://ui.shadcn.com/blocks) is built on [ui.shadcn.com](http://ui.shadcn.com). [Blocks page](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/blocks/page.tsx) has a lot of utilities used, hence I broke down this Blocks page analysis into 5 parts.
1. [shadcn-u... | ramunarasinga |
1,892,867 | pygame button gui | def button (msg, x, y, w, h, ic, ac, action=None ): mouse = pygame.mouse.get_pos() ... | 0 | 2024-06-18T20:40:35 | https://dev.to/ghazie754/pygame-button-gui-1pbe | python, pygame, gamedev, ui | def button (msg, x, y, w, h, ic, ac, action=None ):
mouse = pygame.mouse.get_pos()
click = pygame.mouse.get_pressed()
if (x+w > mouse[0] > x) and (y+h > mouse[1] > y):
pygame.draw.rect(watercycle, CYAN, (x, y, w, h))
if (click[0] == 1 and acti... | ghazie754 |
1,892,701 | CSS Variables (CSS Custom properties) for Beginners | In our projects, we often encounter repetitive values such as width, color, font, etc. These values... | 0 | 2024-06-18T20:40:32 | https://udokakasie.hashnode.dev/a-comprehensive-guide-to-css-variables-with-real-examples | webdev, beginners, css, javascript | In our projects, we often encounter repetitive values such as width, color, font, etc. These values can lead to redundancy in our work and make it difficult to change on large projects.
This guide explains CSS variables also known as CSS custom properties in a beginner-friendly manner and a step-by-step guide for chang... | udoka033 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.