
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,892,631 | How I configured YubiKey to sign and decrypt emails on Mac | Originally published on my blog As you see on my "resume" page, I uploaded my public key for... | 0 | 2024-06-18T15:29:32 | https://pabis.eu/blog/2024-06-18-YubiKey-OpenGPG-Mail-Sign-Decrypt.html | yubikey, gpg | _Originally published [on my blog](https://pabis.eu/blog/2024-06-18-YubiKey-OpenGPG-Mail-Sign-Decrypt.html)_
As you see on my ["resume"](https://pabis.eu/cv.html) page, I uploaded my public key for encrypting emails back when I was starting my personal website. However, moving private key from one place to another is ... | ppabis |
1,892,633 | 🤑Bitcoin Price: Top Reasons Why $65K Support Can End Crypto Crash? | 📊 The Bitcoin Fear and Greed Index remains high at 74, suggesting early stages of greed. Despite... | 0 | 2024-06-18T15:28:36 | https://dev.to/irmakork/bitcoin-price-top-reasons-why-65k-support-can-end-crypto-crash-1ajn |
📊 The Bitcoin Fear and Greed Index remains high at 74, suggesting early stages of greed. Despite recent losses, some investors see BTC as a good buy at current levels. However, cautious optimism is advised as the market could see further sell-offs.
🔍 Over the past 7 days, Bitcoin has declined by 2.5%, adding to a 4... | irmakork | |
1,892,632 | 🔥🔥🔥Top 5 Altcoins To Buy If Targeting 2X Recovery This Week | 📈 Investors are scouting the market for altcoins to buy after Bitcoin's volatility caused a downturn.... | 0 | 2024-06-18T15:27:21 | https://dev.to/irmakork/top-5-altcoins-to-buy-if-targeting-2x-recovery-this-week-1d8e |
📈 Investors are scouting the market for altcoins to buy after Bitcoin's volatility caused a downturn. Despite the losses, some altcoins show recovery signals. Here are five altcoins that could rally by 100% this week.
Notcoin (NOT)
🚀 Notcoin, a play-to-earn token, launched in mid-May and has shown strong performanc... | irmakork | |
1,892,845 | How to Use Tiptap's Collaboration Feature with Rails Action Cable | In this post, we’ll walk through setting up Tiptap’s collaboration feature with Rails Action Cable... | 0 | 2024-06-19T15:34:44 | https://www.geekyhub.in/post/implementing-a-google-doc-notion-like-collborative-editor-in-rails-react-tiptap/ | rails, react, actioncable, tiptap | ---
title: How to Use Tiptap's Collaboration Feature with Rails Action Cable
published: true
date: 2024-06-18 15:25:00 UTC
tags: #rails #reactjs #actioncable #tiptap
canonical_url: https://www.geekyhub.in/post/implementing-a-google-doc-notion-like-collborative-editor-in-rails-react-tiptap/
cover_image: https://dev-to-u... | vikas |
1,892,582 | Generative AI as a Career: Unlocking Future Tech Opportunities | In the rapidly evolving landscape of technology, artificial intelligence (AI) continues to push... | 0 | 2024-06-18T15:24:45 | https://dev.to/ms1034/generative-ai-as-a-career-exploring-opportunities-in-the-future-of-technology-4g7g | ai, machinelearning, deeplearning, generativeai | In the rapidly evolving landscape of technology, artificial intelligence (AI) continues to push boundaries and redefine possibilities across various industries. One of the most promising and intriguing areas within AI is generative AI. This subset of artificial intelligence focuses on creating new content, whether it's... | ms1034 |
1,892,630 | Dockerizing Your Application: A Beginner's Guide | Welcome back to our blog series on becoming a Certified Kubernetes Administrator. This is post number... | 0 | 2024-06-18T15:23:38 | https://dev.to/jensen1806/dockerizing-your-application-a-beginners-guide-36h6 | docker, containers, dockerhub, kubernetes |
Welcome back to our blog series on becoming a Certified Kubernetes Administrator. This is post number two in our comprehensive series designed to cover all concepts, demos, and hands-on exercises for the Kubernetes certification exam, based on the latest 2024 curriculum.
In our previous post, we discussed container f... | jensen1806 |
1,892,601 | Is it safe to use encryption with plausible deniability? | I wanted to try to hide some of my files in a way that it wouldn't even be visible that something is... | 0 | 2024-06-18T15:19:01 | https://dev.to/lauralaura/is-it-safe-to-use-encryption-with-plausible-deniability-l7m | encryption, linux, security | I wanted to try to hide some of my files in a way that it wouldn't even be visible that something is hidden. I found a [tutorial for Cryptsetup LUKS](https://www.blunix.com/blog/plausible-encryption-deniability-on-linux-with-cryptsetup-luks.html) and tried to implement it.
The problem is what I read on several other ... | lauralaura |
1,892,600 | How Discord Built `Access!` - An Authorization Management Portal | Managing access permissions is a critical aspect of application security, especially for large... | 0 | 2024-06-18T15:15:18 | https://www.permit.io/blog/how-discord-built-access-an-authorization-management-portal | authorization, iam, discord, webdev | Managing access permissions is a critical aspect of application security, especially for large platforms like Discord. In a great blog, “[Access: A New Portal For Managing Internal Authorization](https://discord.com/blog/access-a-new-portal-for-managing-internal-authorization),” Elisa Guerrant, Security Engineer at Dis... | imdburnot |
1,892,599 | Box<T> Type in Rust Allows for Heap Allocation | In the world of systems programming, managing memory efficiently and safely is a critical challenge.... | 0 | 2024-06-18T15:15:16 | https://dev.to/ashsajal/box-type-in-rust-allows-for-heap-allocation-kfj | rust, coding, programming, tutorial | In the world of systems programming, managing memory efficiently and safely is a critical challenge. Rust, with its unique approach to memory management, stands out for providing powerful tools to handle this complexity. One such tool is the `Box<T>` type, which facilitates heap allocation in a manner that integrates s... | ashsajal |
1,892,598 | Combining Node.js with Async Rust for remarkable performance | Last month we announced that Encore.ts — an Open Source backend framework for TypeScript — is... | 0 | 2024-06-18T15:14:50 | https://encore.dev/blog/event-loops | typescript, javascript, node, programming | Last month we [announced](https://encore.dev/blog/encore-for-typescript) that Encore.ts — an Open Source backend framework for TypeScript — is generally available and ready to use in production.
So we figured now is a great time to dig into some of the design decisions we made along the way, and how they lead to the ... | marcuskohlberg |
1,892,596 | SteamVR Overlay with Unity: Appendix | This part contains where to look for more detailed information. OpenVR... | 27,740 | 2024-06-18T15:11:43 | https://dev.to/kurohuku/appendix-3e8f | unity3d, steamvr, openvr, vr | This part contains where to look for more detailed information.
## OpenVR repository
OpenVR’s official repository is the most important
https://github.com/ValveSoftware/openvr
I recommend reading the wiki at first.
https://github.com/ValveSoftware/openvr/wiki/API-Documentation
Detailed information that is not on... | kurohuku |
1,892,595 | Pros and Cons of Choosing Python as Your Programming Language | Hello everyone! In today's post, we will explore the advantages and disadvantages of choosing Python... | 0 | 2024-06-18T15:10:56 | https://dev.to/techinsight/pros-and-cons-of-choosing-python-as-your-programming-language-1bcl | learntocode, techeducation, programminglanguages, coding | Hello everyone! In today's post, we will explore the advantages and disadvantages of choosing Python as your programming language. Python is one of the most popular languages for beginners and professionals alike, but like any language, it has its strengths and weaknesses.
## Introduction: Why Consider Python?
Python ... | techinsight |
1,892,594 | Claude is so nice that | when I failed to talk to Claude because its capacity maxed out. This time I instantly grabbed my... | 0 | 2024-06-18T15:08:01 | https://dev.to/swimmingpolar/claude-is-so-nice-that-1i64 | claude, chatgpt, ai, bullshit | when I failed to talk to Claude because its capacity maxed out. This time I instantly grabbed my credit card and subscribed it.
On the other hand, when ChatGPT starts bullshitting, my patience towards its credibility is getting out. I don't know why but its Bullshittness level is accumulated and when it hits 100%, I w... | swimmingpolar |
1,892,592 | Casting and its types in networking | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T15:06:56 | https://dev.to/komsenapati/casting-and-its-types-in-networking-4mcn | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Casting means sending data packets over a network.
Unicast is sending data to a single node in a network (one-one). Broadcast is sending data to all nodes in a network (one-all). Multic... | komsenapati |
1,892,590 | RELIABLE EXPERT TO RECOVER SCAMMED CRYPTO - RESILIENT SHIELD RECOVERY | As a plumber in Brentwood, my life took an unexpected turn when I fell victim to a cryptocurrency... | 0 | 2024-06-18T15:05:12 | https://dev.to/frank_mormon_0e0c2d205994/reliable-expert-to-recover-scammed-crypto-resilient-shield-recovery-3nnp | As a plumber in Brentwood, my life took an unexpected turn when I fell victim to a cryptocurrency scam that cost me a staggering £155,500. It all began innocently enough, as I sought to invest and grow my savings through what seemed like a reputable exchange site. The promise of lucrative returns was enticing, and I ea... | frank_mormon_0e0c2d205994 | |
1,892,589 | Taming the Compliance Beast: AWS Config to the Rescue | Taming the Compliance Beast: AWS Config to the Rescue In today's intricate regulatory... | 0 | 2024-06-18T15:05:08 | https://dev.to/virajlakshitha/taming-the-compliance-beast-aws-config-to-the-rescue-bnh | 
# Taming the Compliance Beast: AWS Config to the Rescue
In today's intricate regulatory landscape, maintaining compliance isn't just a checkbox—it's a business imperative. Fortunately, AWS offers a powerful tool to help navigate ... | virajlakshitha | |
1,892,588 | 3 Insanely Powerful Software Tools to Boost Your Productivity and Avoid Overtime | Here are three software tools that can significantly enhance your productivity and help you avoid... | 0 | 2024-06-18T15:04:32 | https://dev.to/fullfull567/3-insanely-powerful-software-tools-to-boost-your-productivity-and-avoid-overtime-lel | webdev, beginners, programming, productivity | Here are three software tools that can significantly enhance your productivity and help you avoid overtime. These tools are so efficient that tasks that usually take hours can be completed in just 5 minutes!
### 1. [ServBay](https://www.servbay.com/) — My Favorite Development Environment
ServBay offers developers a on... | fullfull567 |
1,892,587 | Comprehensive Front-End Performance Enhancement: Basic Optimization, Latest Technologies, and AI-Driven Strategies | 1. Introduction In modern web development, front-end performance optimization has become a... | 0 | 2024-06-18T15:03:45 | https://dev.to/happyer/comprehensive-front-end-performance-enhancement-basic-optimization-latest-technologies-and-ai-driven-strategies-52j6 | webdev, website, frontend, development | ## 1. Introduction
In modern web development, front-end performance optimization has become a key factor in enhancing user experience and website efficiency. As users' expectations for fast loading and smooth interactions continue to rise, developers need to employ various technologies and tools to optimize front-end ... | happyer |
1,892,586 | SteamVR Overlay with Unity: Controller Input | In this part, we will make the watch hidden by default and show it in a few seconds by pressing a... | 27,740 | 2024-06-18T15:01:34 | https://dev.to/kurohuku/part-10-controller-input-2ij2 | unity3d, steamvr, openvr, vr | In this part, we will make the watch hidden by default and show it in a few seconds by pressing a controller button.

There are various ways to get controller input with Unity. This time, we will use [OpenVR Input A... | kurohuku |
1,892,584 | Synchronizing multiple graphics | Step 1: Define our objective To keep things simple let’s set our objective first: We want... | 0 | 2024-06-18T15:00:37 | https://dev.to/lenormor/synchronizing-multiple-graphics-31mc | webdev, javascript, tutorial, node | ## Step 1: Define our objective
**To keep things simple let’s set our objective first:**
We want to combine two instances of our `<demo-schedule-booking>` demonstration component. This component is capable of displaying a ScheduleJS Gantt chart.
Note that the same approach can be used with two completely different gra... | lenormor |
1,892,336 | TW Elements - TailwindCSS Navbar Icons & Logo. Free UI/UX design course | Navbar Icons & Logo Now that we know how to work with icons in Tailwind, it's time to... | 25,935 | 2024-06-18T15:00:00 | https://dev.to/keepcoding/tw-elements-tailwindcss-navbar-icons-logo-free-uiux-design-course-4bi5 | tailwindcss, tutorial, css, webdev | ## Navbar Icons & Logo
Now that we know how to work with icons in Tailwind, it's time to update the Navbar in our project.
This is how it looks right now:

**First, let's change the icons on the right.**
## Step ... | keepcoding |
1,892,563 | Ansible Middleware : Automation of JBoss Web Server (JWS) | In a previous article, we discussed the importance of Ansible from a Middleware perspective and why... | 0 | 2024-06-18T15:00:00 | https://www.opensourcerers.org/2022/03/14/ansible-middleware-automation-of-jboss-web-server-jws/ | automation, tomcat, jws, ansible | In a previous article, we discussed the [importance of Ansible from a Middleware perspective](https://open011prod.wpengine.com/2021/11/22/why-do-you-need-ansible-to-manage-your-middleware-runtimes/) and why making Middleware a first-class citizen in the Ansible ecosystem is crucial. In this post, we’ll explore the tech... | rpelisse |
1,892,440 | Generative AI, from your local machine to Azure with LangChain.js | In this article, we'll take you through the development journey, starting from an idea and progressing towards production. We'll explore how LangChain.js framework together with Azure AI building blocks allows you to quickly build complex AI applications at the various stages of development. | 0 | 2024-06-18T14:58:00 | https://dev.to/azure/generative-ai-from-your-local-machine-to-azure-with-langchainjs-5288 | webdev, javascript, beginners, ai | ---
title: 'Generative AI, from your local machine to Azure with LangChain.js'
published: true
description: 'In this article, we''ll take you through the development journey, starting from an idea and progressing towards production. We''ll explore how LangChain.js framework together with Azure AI building blocks allows... | sinedied |
1,892,561 | Understanding Logistic Regression | Previously, we discussed linear regression, a method used to predict continuous outcomes. Today let's... | 0 | 2024-06-18T14:23:30 | https://dev.to/harsimranjit_singh_0133dc/understanding-logistic-regression-125k | Previously, we discussed linear regression, a method used to predict continuous outcomes. Today let's explore logistic regression, which is essential for binary classification problems in data science.
## What is Logistic Regression?
Logistic regression is used to predict a binary outcome (such as Yes/No or True/Fa... | harsimranjit_singh_0133dc | |
1,892,581 | List of FAANG front-end coding questions. | Star Rating Design Pop Over Design Accordion (Amazon onsite) Design Carousel Design grid using... | 0 | 2024-06-18T14:54:22 | https://dev.to/anjandutta/list-of-faang-front-end-coding-questions-448d | interview, frontend, coding, beginners | - Star Rating
- Design Pop Over
- Design Accordion `(Amazon onsite)`
- Design Carousel
- Design grid using HTML/CSS and Javascript with search and sort, event bubbling (Amazon onsite)
- Design NavBar
- Infinite Scroll
- Typeahead / autocomplete using trie
- Implement Debounce functio... | anjandutta |
1,892,407 | Decoding Brand Mark and Logo Recognition: Modern Applications and Solutions | Introduction Brand Mark and Logo Recognition solutions are cutting-edge technological... | 0 | 2024-06-18T14:47:15 | https://dev.to/api4ai/decoding-brand-mark-and-logo-recognition-modern-applications-and-solutions-1gkp | brand, logo, recognitio, detection | ## Introduction
Brand Mark and Logo Recognition solutions are cutting-edge technological tools designed to identify and analyze the presence of brands and logos across various media formats. Leveraging sophisticated algorithms powered by artificial intelligence (AI) and machine learning, these solutions detect brand l... | taranamurtuzova |
1,892,578 | The Ultimate 2024 Tech Stack for Solo SaaS Developers: Build Smarter, Not Harder | Building a SaaS as a solo developer is a challenging task. You have to wear multiple hats and be... | 0 | 2024-06-18T14:45:55 | https://creativedesignsguru.com/tech-stack-solo-saas-dev/ | nextjs, react, javascript, webdev | Building a SaaS as a solo developer is a challenging task. You have to wear multiple hats and be proficient in various technologies, requiring strategic decisions about your tech stack. This means you need to be a full-stack developer familiar with both frontend and backend.
Choosing the right tech stack is crucial fo... | ixartz |
1,892,577 | Descubriendo AWS DeepRacer: Experiencias y consejos para AWS DeepRacer de los finalistas de las SpainSkills | Experiencias con AWS DeepRacer y el aprendizaje por refuerzo La competición de AWS... | 25,290 | 2024-06-18T14:45:32 | https://dev.to/aws-espanol/descubriendo-aws-deepracer-experiencias-y-consejos-para-aws-deepracer-de-los-finalistas-de-las-spainskills-20de | alianzatechskills2jobs, aws, deepracer, awsespanol | ---
series: Descubriendo AWS DeepRacer
---
### Experiencias con AWS DeepRacer y el aprendizaje por refuerzo
La competición de AWS DeepRacer dentro de la demostración cloud de las SpainSkills fue una oportunidad única para que los finalistas de las diferentes comunidades autónomas participantes experimentaran con el *... | iaasgeek |
1,890,533 | SteamVR Overlay with Unity: Overlay Events | Show the current time on the right hand Let’s display the current time on the right... | 27,740 | 2024-06-18T13:57:23 | https://dev.to/kurohuku/part-9-overlay-events-4342 | unity3d, steamvr, openvr, vr | ## Show the current time on the right hand
Let’s display the current time on the right hand.
### Create variable
Add a variable in `WatchOverlay.cs` to determine which hand to show the current time.
OpenVR has [ETrackedControllerRole](https://valvesoftware.github.io/steamvr_unity_plugin/api/Valve.VR.ETrackedControlle... | kurohuku |
1,892,450 | The Silent Killer: Not Preparing for Scale Can Doom Your SaaS | Imagine this: Your innovative SaaS product just launched on Product Hunt or AppSumo. Almost... | 27,766 | 2024-06-18T14:42:32 | https://dev.to/brandonbaz/the-silent-killer-how-not-preparing-for-scale-can-doom-your-saas-after-launching-on-product-hunt-or-appsumo-jbm | softwareengineering, saas, startup | **Imagine this**: Your innovative SaaS product just launched on Product Hunt or AppSumo. Almost overnight, you’re bombarded with thousands of new users. It’s the dream scenario for any startup founder. But what if that dream quickly morphs into a nightmare? Your servers crash, users can’t access their accounts, and you... | brandonbaz |
1,892,574 | Setting Up Dynamic Environment Variables with Vite and Docker | In this tutorial, we'll walk through the process of setting up dynamic environment variables in a... | 0 | 2024-06-18T14:42:02 | https://dev.to/dutchskull/setting-up-dynamic-environment-variables-with-vite-and-docker-5cmj | vite, docker, webdev, devops | In this tutorial, we'll walk through the process of setting up dynamic environment variables in a Vite project, ensuring that these variables can be replaced dynamically within a Docker container. This setup allows for flexibility and ease of deployment across different environments.
## Setting Up the Environment Vari... | dutchskull |
1,892,575 | Modelos de Lenguaje Grandes y su Optimización en Recursos Computacionales Limitados | Los modelos de lenguaje grandes, como GPT-4, han revolucionado el procesamiento del lenguaje natural,... | 0 | 2024-06-18T14:41:46 | https://dev.to/gcjordi/modelos-de-lenguaje-grandes-y-su-optimizacion-en-recursos-computacionales-limitados-8p | ia, ai, machinelearning | Los modelos de lenguaje grandes, como GPT-4, han revolucionado el procesamiento del lenguaje natural, permitiendo aplicaciones avanzadas en generación de texto, traducción automática y respuesta a preguntas. Sin embargo, el entrenamiento y la implementación de estos modelos requieren recursos computacionales significat... | gcjordi |
1,892,628 | What’s New in Flutter: 2024 Volume 2 | TL;DR: Explore the new features in Syncfusion Flutter widgets for 2024 Volume 2, including new... | 0 | 2024-06-19T15:10:01 | https://www.syncfusion.com/blogs/post/whats-new-flutter-2024-volume-2 | flutter, mobile, ui, web | ---
title: What’s New in Flutter: 2024 Volume 2
published: true
date: 2024-06-18 14:39:36 UTC
tags: flutter, mobile, UI, web
canonical_url: https://www.syncfusion.com/blogs/post/whats-new-flutter-2024-volume-2
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ji64q4j1p6e6sl3a12az.jpeg
---
**TL;DR:*... | gayathrigithub7 |
1,892,571 | Empleabilidad en el ámbito cloud, by Experis | En el marco de la participación de Experis en la Alianza Tech de AWS (Skills to Jobs Tech Alliance),... | 0 | 2024-06-18T14:38:47 | https://dev.to/aws-espanol/empleabilidad-en-el-ambito-cloud-by-experis-3df | empleabilidad, alianzatechskills2jobs | En el marco de la participación de **Experis** en la Alianza Tech de AWS (Skills to Jobs Tech Alliance), Experis, Amazon Web Services y Fundación Human Age Institute organizaron una jornada para impulsar la empleabilidad de más de 1.200 jóvenes en el ámbito Cloud en el mes de octubre de 2023.
**• Programa de la jorna... | iaasgeek |
1,892,573 | Papo e Ideias: Conectando Tecnologia e Negócios! | Olá, comunidade Dev.to! 🚀 Quero compartilhar uma novidade incrível com vocês! Estou lançando, junto... | 0 | 2024-06-18T14:38:32 | https://dev.to/pedrobarreto/papo-e-ideias-conectando-tecnologia-e-negocios-203d | braziliandevs, noticias, tecnologia, podcast | Olá, comunidade Dev.to! 🚀
Quero compartilhar uma novidade incrível com vocês! Estou lançando, junto com meu amigo Bruno, nosso podcast, Papo e Ideias. Junte-se a nós enquanto discutimos as principais **notícias de tecnologia e negócios da semana de forma leve e descontraída**.
Episódio 1: O Que Está Rolando no Mundo... | pedrobarreto |
1,891,724 | amber: writing bash scripts in amber instead. pt. 1: commands and error handling | writing shell scripts is zero fun. the bash syntax is a mess, error handling is difficult, and any... | 27,793 | 2024-06-18T14:38:26 | https://dev.to/gbhorwood/amber-writing-bash-scripts-in-amber-instead-pt-1-commands-and-error-handling-1aao | bash, linux | writing shell scripts is zero fun. the `bash` syntax is a mess, error handling is difficult, and any script longer than a hundred lines is basically unreadable. but we keep writing bash scripts because they're the right tool for the job and the job must be done.
amber aims to fix this pain by being a language that giv... | gbhorwood |
1,892,570 | Mixture-of-Agents Enhances Large Language Model Capabilities✨ | does not require any fine-tuning and only utilizes the interface for prompting and generation of... | 0 | 2024-06-18T14:35:34 | https://dev.to/pratikwayase/mixture-of-agents-enhances-large-language-model-capabilities-1938 | llm, datascience, machinelearning, tutorial |
does not require any fine-tuning and only utilizes the interface for prompting and generation of LLMs.
we do not need to concatenate prompt and all model responses so only one LLM is needed to be used in the last layer.
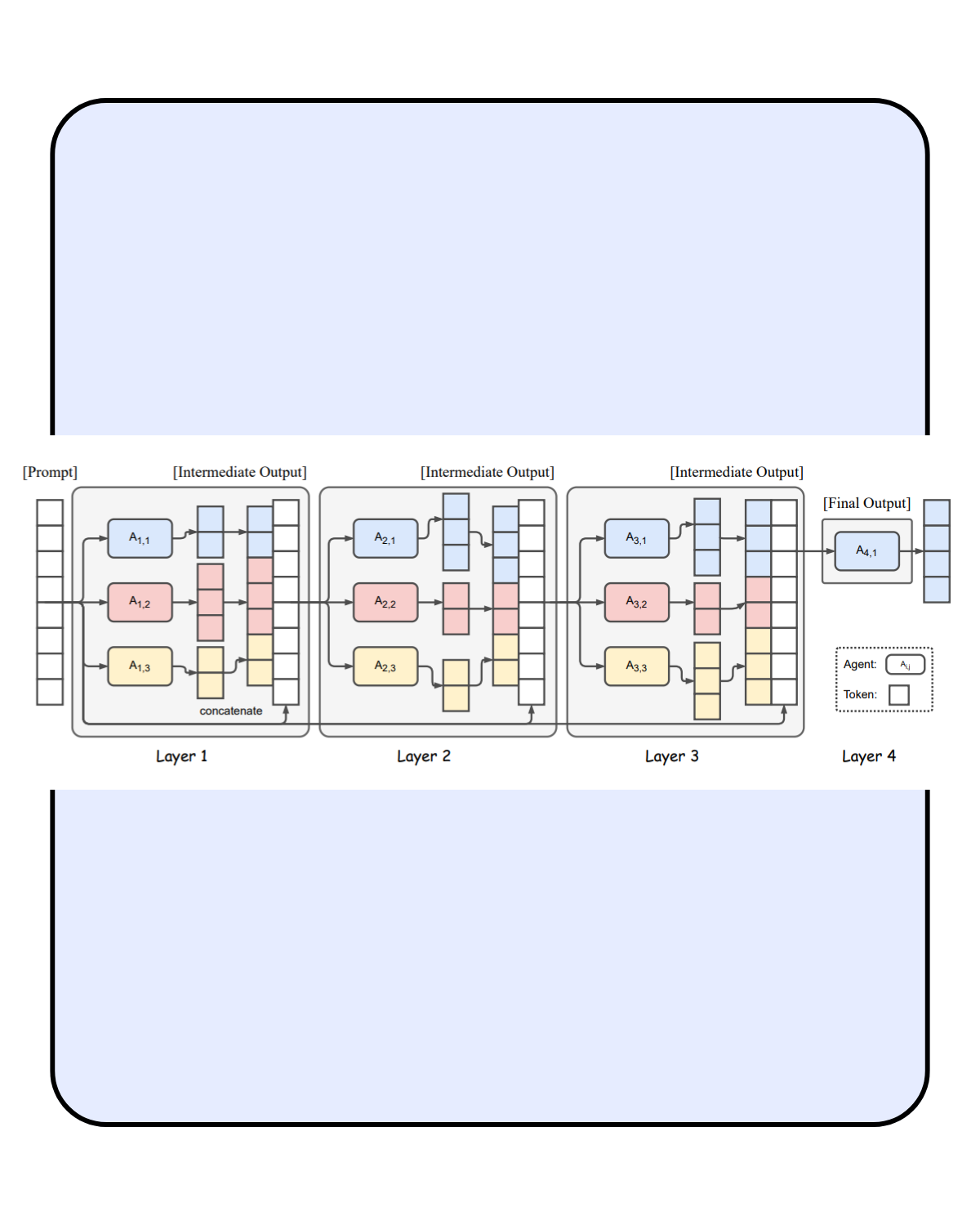
⚡ ... | pratikwayase |
1,892,569 | Case Study: How JavaScript Gantt Charts Facilitate Planning | Effective project management hinges on precise planning and efficient execution. Gantt charts have... | 0 | 2024-06-18T14:34:48 | https://dev.to/lenormor/case-study-how-javascript-gantt-charts-facilitate-planning-4f7k | webdev, javascript, devops, node | Effective project management hinges on precise planning and efficient execution. Gantt charts have long been a cornerstone for visualizing project schedules, and when combined with the capabilities of JavaScript, they offer unparalleled flexibility and interactivity. In this case study, we will explore how JavaScript G... | lenormor |
1,849,510 | Which E2E Tool to Use with React? | When it comes to testing the end-to-end (E2E) integration of web applications, choosing the right... | 0 | 2024-06-18T14:34:04 | https://dev.to/razxssd/which-e2e-tool-to-use-with-react-5173 | react, playwright, testing, javascript | When it comes to testing the end-to-end (E2E) integration of web applications, choosing the right tools is crucial to ensure comprehensive test coverage and optimal software quality.
I found this sentence online and it seems the most suitable given our context.
> "If your test is difficult to write, your design is ba... | razxssd |
1,892,568 | Introduction of CSS, What is CSS, Why we use CSS and How CSS describe the HTML elements | What is CSS? CSS stands for Cascading Style Sheets CSS describes how HTML elements are to... | 0 | 2024-06-18T14:33:54 | https://dev.to/wasifali/introduction-of-css-what-is-css-why-we-use-css-and-how-css-describe-the-html-elements-1nb6 | webdev, css, learning, html | ## **What is CSS?**
CSS stands for Cascading Style Sheets
CSS describes how HTML elements are to be displayed on screen, paper, or in other media
CSS saves a lot of work. It can control the layout of multiple web pages all at once
External stylesheets are stored in CSS files
Why we Use CSS?
CSS is used to define styles... | wasifali |
1,892,567 | Performance: Los valores de Lighthouse y PageSpeed Insights son diferentes | Existen dos tipos de herramientas para hacer pruebas de performance en web: 1. Herramientas de... | 0 | 2024-06-18T14:33:49 | https://dev.to/marianocodes/por-que-los-valores-de-lighthouse-son-diferentes-a-los-de-pagespeed-insights-7f6 | webdev, lighthouse, performance, corevitals | Existen dos tipos de herramientas para hacer pruebas de performance en web:
**1. Herramientas de laboratorio**
Funcionan en condiciones específicas, por ejemplo:
• No consideran el cache, bfCache, ni AMP
• Ambientes controlados (geografía, dispositivo, velocidad)
• Sirven en la etapa de desarrollo, antes de producció... | marianocodes |
1,892,566 | vavacasi | Хотите испытать удачу и получить большие выигрыши? Тогда вам в Вавада! Наше казино предлагает... | 0 | 2024-06-18T14:32:48 | https://dev.to/vavacasi/vavacasi-11df | Хотите испытать удачу и получить большие выигрыши? Тогда вам в [Вавада](https://vavacasi.com/)! Наше казино предлагает уникальный выбор игр, включая самые популярные слоты и настольные игры. Вавада славится своей щедрой бонусной политикой и постоянными акциями, которые помогут вам увеличить ваши шансы на победу. Удобны... | vavacasi | |
1,892,565 | Hey Dev.to Community! | Excited to dive into this vibrant community of developers! I'm new here and eager to share insights,... | 0 | 2024-06-18T14:30:47 | https://dev.to/kampala/hey-devto-community-2i91 | Excited to dive into this vibrant community of developers! I'm new here and eager to share insights, learn from your expertise, and contribute wherever I can.
Let's connect, collaborate, and code together!
#introduction #developer #community | kampala | |
1,892,456 | Whatsapp Webhook Setup and Nodejs Code Example | Solution If you are getting a validation error the problem is not with ngrok, localtunnel... | 0 | 2024-06-18T13:56:43 | https://dev.to/greggcbs/whatsapp-webhook-full-setup-example-55lb | whatsapp, api, dashboard, node | ## Solution
If you are getting a validation error the problem is not with ngrok, localtunnel or whatever proxy you are using, its with your webhook code.
Your webhook needs to be a **POST** and a **GET** because meta dashboard does a GET for url validation but when the webhook is fired they do POSTs.
Here is the webh... | greggcbs |
1,891,959 | Build a Portable AI Companion with Discord’s User-Installable Apps (GPT 4o) | Discord User-Installable Apps are here, which means you can bring Discord Bots with you wherever you... | 0 | 2024-06-18T14:30:00 | https://dev.to/waveplay/build-a-portable-ai-companion-with-discords-user-installable-apps-gpt-4o-5f20 | discord, node, programming, javascript | Discord **[User-Installable Apps](https://discord.com/developers/docs/change-log#userinstallable-apps-preview)** are here, which means you can bring **[Discord Bots](https://docs.roboplay.dev/discord-bots/getting-started)** with you wherever you go - DMs and even other servers your bot isn't in. Best of all, they're no... | waveplay-staff |
1,892,564 | Descubriendo AWS DeepRacer: Consejos de Empleadores de la Alianza Tech de AWS. | Esta competición desafía a los estudiantes a entrenar un modelo de aprendizaje por refuerzo que... | 25,290 | 2024-06-18T14:28:54 | https://dev.to/aws-espanol/descubriendo-aws-deepracer-consejos-de-empleadores-de-la-alianza-tech-de-aws-1kep | alianzatechskills2jobs, deepracer | ---
series: Descubriendo AWS DeepRacer
---
Esta competición desafía a los estudiantes a entrenar un modelo de aprendizaje por refuerzo que controle un vehículo autónomo de carreras en la nube. Los participantes usarán la misma configuración de vehículo y pista, pudiendo modificar únicamente el algoritmo de reinforceme... | iaasgeek |
1,892,091 | Debugging Kubernetes - Troubleshooting Guide | Identifying Configuration Issues Common Causes and Solutions Detailed Investigation... | 20,817 | 2024-06-18T14:26:44 | https://debugagent.com/debugging-kubernetes-troubleshooting-guide | kubernetes, devops, development, tutorial | - [Identifying Configuration Issues](#identifying-configuration-issues)
* [Common Causes and Solutions](#common-causes-and-solutions)
* [Detailed Investigation Steps](#detailed-investigation-steps)
- [Dealing with Image Pull Errors](#dealing-with-image-pull-errors)
* [Troubleshooting Steps](#troubleshooting-st... | codenameone |
1,892,562 | Enclave Games Shop is now open! | Remember Enclave’s swag is out blog post? We got asked about that print a few times recently, and... | 0 | 2024-06-18T14:27:35 | https://enclavegames.com/blog/shop-open/ | spreadshop, spreadshirt, swag, enclavegames | ---
title: Enclave Games Shop is now open!
published: true
date: 2024-06-18 14:25:23 UTC
tags: spreadshop,spreadshirt,swag,enclavegames
canonical_url: https://enclavegames.com/blog/shop-open/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/rndayoyyz8b628mj2i9r.png
---
Remember [Enclave’s swag is ... | end3r |
1,892,401 | JavaScript Main Concepts < In Depth > Part 1 | 1. Event Loop, Call Stack, Callback Queue Explained here 2. this Keyword The... | 0 | 2024-06-18T14:24:40 | https://dev.to/rajatoberoi/javascript-main-concepts-edg | javascript, backenddevelopment, node, programming | ## 1. Event Loop, Call Stack, Callback Queue
[Explained here
](https://dev.to/rajatoberoi/understanding-the-event-loop-callback-queue-and-call-stack-in-javascript-1k7c)
## 2. this Keyword
The value of this in JavaScript depends on how a function is called, not where it is defined.
- If function is a method i.e. a ... | rajatoberoi |
1,892,560 | FastAPI Beyond CRUD Part 10 - JWT Authentication (Project Endpoints with HTTP Bearer Auth) | In this tutorial, we dive into securing our API endpoints using HTTP Bearer Authentication. Bearer... | 0 | 2024-06-18T14:21:45 | https://dev.to/jod35/fastapi-beyond-crud-part-10-jwt-authentication-project-endpoints-with-http-bearer-auth-j1c | fastapi, python, programming, api | In this tutorial, we dive into securing our API endpoints using HTTP Bearer Authentication. Bearer Authentication allows users to access protected endpoints by including a token in the "Authorization" header of their HTTP requests, formatted as "Bearer token".
{%youtube 9mx6LojqNCQ%} | jod35 |
1,892,481 | Mike McQuaid on 15 years of Homebrew | This week we’re talking to Mike McQuaid, project leader and longest tenured maintainer of Homebrew, a... | 0 | 2024-06-18T14:20:31 | https://onceamaintainer.substack.com/p/once-a-maintainer-mike-mcquaid | ruby, opensource | This week we’re talking to [Mike McQuaid](https://github.com/MikeMcQuaid), project leader and longest tenured maintainer of [Homebrew](https://brew.sh), a package manager for macOS and Linux used by tens of millions of developers worldwide. After ten years at GitHub, Mike is now CTO of [Workbrew](https://workbrew.com),... | allieoopz |
1,891,615 | Get to know Xperience by Kentico: The Page Selector form component | Form Components are a great way of providing some pretty powerful content editing functionality to... | 0 | 2024-06-18T14:19:59 | https://dev.to/michael419/get-to-know-xperience-by-kentico-the-page-selector-form-component-59a2 | kentico, xperience | Form Components are a great way of providing some pretty powerful content editing functionality to marketers and editors in Xperience by Kentico.
They enable us web developers to create fields in editing dialogues within the admin UI that, in-turn, provide functionality to marketers for them to enter and select data t... | michael419 |
1,892,467 | Internet Of Things(IoT) | Imagine everyday objects like refrigerators, thermostats, or fitness trackers talking to each other... | 0 | 2024-06-18T14:18:30 | https://dev.to/prakharkapoorcoder/internet-of-thingsiot-4am7 | devchallenge, cschallenge, computerscience, beginners | Imagine everyday objects like refrigerators, thermostats, or fitness trackers talking to each other and the internet. That's the **Internet of Things (IoT)**! It connects devices to collect data and automate tasks, making our lives easier and smarter. | prakharkapoorcoder |
1,892,457 | Understanding Loops - A Tangible Example | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T13:57:26 | https://dev.to/terabytetiger/understanding-loops-a-tangible-example-2o0p | devchallenge, cschallenge, computerscience, beginners | ---
title: Understanding Loops - A Tangible Example
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/4tfs5o2wz0j2jiz3l3fp.png
published: true
tags: devchallenge, cschallenge, computerscience, beginners
---
*This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](htt... | terabytetiger |
1,892,465 | The Advantages of Gantt Charts in JavaScript for Project Management | In today's fast-paced world, efficient project management is crucial for the success of any... | 0 | 2024-06-18T14:15:29 | https://dev.to/lenormor/the-advantages-of-gantt-charts-in-javascript-for-project-management-cdm | javascript, webdev, programming, productivity | In today's fast-paced world, efficient project management is crucial for the success of any organization. Among the numerous tools available, Gantt charts have stood the test of time as one of the most effective ways to visualize and manage project schedules. Leveraging JavaScript to create these charts brings a whole ... | lenormor |
1,892,464 | Driving into the Future: Next-Gen ECU Technologies Transforming Automotive Performance Market | Introduction: In the dynamic landscape of automotive engineering, the evolution of Automotive... | 0 | 2024-06-18T14:11:10 | https://dev.to/chanda_simran/driving-into-the-future-next-gen-ecu-technologies-transforming-automotive-performance-market-2h50 | marketstrategy, globalinsights, marketgrowth |

**Introduction:**
In the dynamic landscape of automotive engineering, the evolution of [**Automotive Electronic Control Unit Market**](urhttps://www.nextmsc.com/report/automotive-electronic-control-unit-ecu-market... | chanda_simran |
1,892,463 | Next.js Made Me a Bad Engineer | The Realisation I was tasked with porting our Single Page Web Application (SPA) to a... | 0 | 2024-06-18T14:10:22 | https://dev.to/kuvambhardwaj/nextjs-made-me-a-bad-engineer-2oel | webdev, javascript, discuss | ## The Realisation
I was tasked with porting our Single Page Web Application (SPA) to a Server-Side Rendered (SSR) setup.
The goal was simple:
provided a set of pages, they need to be made SEO-friendly.
And right off the bat, 2 classic options came to my mind: SSG & SSR.
The problem with statically generating all... | kuvambhardwaj |
1,892,462 | Git Commands Cheat Sheet | Git is a distributed version control system (DVCS) that allows multiple developers to collaborate on... | 0 | 2024-06-18T14:08:17 | https://dev.to/madgan95/git-commands-cheat-sheet-51ma | beginners, programming, opensource, git | Git is a distributed version control system (DVCS) that allows multiple developers to collaborate on a project, tracking changes to files and coordinating work seamlessly.
## Initializing a Repository:
```
git init
```
## Cloning a Repository:
```
git clone -b <branch-name> <url> <folder-name>
```
## Working with... | madgan95 |
1,892,041 | LeetCode Day 11 Binary Tree Part 1 | Tree Structure 2 ways to realize Binary Tree 1, Linked method. Similar to a Linked list,... | 0 | 2024-06-18T14:08:01 | https://dev.to/flame_chan_llll/leetcode-day-11-binary-tree-part-1-2ne3 | leetcode, java, datastructures | # Tree Structure
2 ways to realize Binary Tree
1, Linked method. Similar to a Linked list, use logical linking by references instead of a physically linked data structure
2, Array is a physically linked data structure and we can realize it in logic as well.
e.g.
.
Each has unique features and advantages, and understanding their differences can help you make an informed decision for your web development needs.
... | zoltan_fehervari_52b16d1d |
1,892,458 | Need Help While Learning the Web Devlopment | Can anyone suggest any video or link through which I can understand How is the website built from... | 0 | 2024-06-18T13:58:52 | https://dev.to/raj_kumar_3be6c725b7b7beb/need-help-while-learning-the-web-devlopment-3265 | Can anyone suggest any video or link through which I can understand
1. How is the website built from scratch to End ?
2. What are the tools in each stage required during web dev?
3. How can I connect the dots of web development to understand it in
depth as i learn from myself only?
I need guidance and if a... | raj_kumar_3be6c725b7b7beb | |
1,892,455 | RocketLane - Round 3 (Technical with CTO) | Q1. What do you do as a Research Engineer in your company? Q2. What is a recent bug that you have... | 0 | 2024-06-18T13:55:00 | https://dev.to/alamfatima1999/rocketlane-round-3-technical-with-cto-53nj | Q1. What do you do as a Research Engineer in your company?
Q2. What is a recent bug that you have solved?
Q3. What are you using in the backend?
Q4. Are you using any mechanism to authenticate your user?
Ans. JWT Token.
Q5. Does server produce this token?
Q6. How does client get this token?
Q7. Will this token be sent... | alamfatima1999 | |
1,892,078 | My Experience at JSNation and React Summit Amsterdam | This was my first time at the biggest JavaScript Festival and React Conference in the world (not an... | 0 | 2024-06-18T13:52:33 | https://dev.to/infoxicator/my-experience-at-jsnation-and-react-summit-amsterdam-4cbb | react, community, javascript, frontend | This was my first time at the biggest JavaScript Festival and React Conference in the world (not an exaggeration). It was also my first time as an attendee and I enjoyed not having to worry about giving a talk and just experiencing the conference!
Apart from photobombing the stage TVs every single time I had a chance ... | infoxicator |
1,892,454 | What is Multicanais? | Welcome to MulticanaisBr.Pro! If you are a football fan and want to watch football games online for... | 0 | 2024-06-18T13:52:06 | https://dev.to/william_willi/what-is-multicanais-p1c | sport, footbal | Welcome to MulticanaisBr.Pro! If you are a football fan and want to watch football games online for free, you are in the right place. Viewers can watch the Multichannel Game live in HD quality without paying anything. Each Multichannel is 100% free to watch!
[Multicanais](https://multicanaisbr.pro/) fans can now enjoy... | william_willi |
1,892,739 | How to be the best programmer, according to Daniel Terhorst-North | Photo: Craft Conf For more content like this subscribe to the ShiftMag newsletter. Or rather,... | 0 | 2024-07-04T15:51:40 | https://shiftmag.dev/the-best-programmer-daniel-terhorst-north-3526/ | career, craftconf, danielterhorstnorth, thebestprogrammer | ---
title: How to be the best programmer, according to Daniel Terhorst-North
published: true
date: 2024-06-18 13:52:06 UTC
tags: Career,CraftConf,DanielTerhorstNorth,thebestprogrammer
canonical_url: https://shiftmag.dev/the-best-programmer-daniel-terhorst-north-3526/
---
.
-----
Excuse my lack of modesty, but I’m pretty good at what I do. I’m not even close to the best though, but I’m way above average. It’s due to what I’ve learned over more than 20 years of work... | cacilhas |
1,892,452 | This is your Python Developer Roadmap! | Grab it while you can… Whether you’re just starting your Python journey or looking to enhance your... | 0 | 2024-06-18T13:46:58 | https://dev.to/zoltan_fehervari_52b16d1d/this-is-your-python-developer-roadmap-5h42 | python, pythondeveloper, pythondeveloperroadmap, pythoncareer | Grab it while you can…
Whether you’re just starting your Python journey or looking to enhance your skills, [my Python Developer Roadmap](https://bluebirdinternational.com/python-developer-roadmap/) will guide you towards mastering advanced coding skills.
## Key Takeaways
- My roadmap is designed to help you excel in... | zoltan_fehervari_52b16d1d |
1,892,451 | Earn Up to $4K/Month Recurring Per Subscription with FastestEngineer’s Affiliate Program! | Join FastestEngineer’s lucrative affiliate program and start earning up to $4,000 monthly on a... | 0 | 2024-06-18T13:43:56 | https://dev.to/chovy/earn-up-to-4kmonth-recurring-per-subscription-with-fastestengineers-affiliate-program-376j | javascript, webdev, affiliate, programming | Join FastestEngineer’s lucrative affiliate program and start earning up to $4,000 monthly on a recurring basis for each subscription you refer! As our affiliate partner, you'll be promoting a cutting-edge SaaS platform that helps entrepreneurs rapidly launch their businesses. Not only will you benefit from a high commi... | chovy |
1,892,449 | How to Configure ESLint for TypeScript Projects | TL;DR One thing that is important in projects but often neglected is code style and... | 0 | 2024-06-18T13:41:03 | https://dev.to/jupri-organization/how-to-configure-eslint-for-typescript-projects-1aip | typescript, tutorial, productivity, learning | ## TL;DR
One thing that is important in projects but often neglected is code style and standardization. Fortunately for those who really wants to enforce certain code style or standards to their projects, eslint got our back!
ESLint is quite easy to setup but when you add typescript, then the complexity increases a l... | mikhaelesa |
1,892,448 | A Brief History Of The Internet And The World Wide Web | The internet is a global network of interconnected computers that communicate through standardized... | 0 | 2024-06-18T13:37:36 | https://dev.to/baraq/a-brief-history-of-the-internet-and-the-world-wide-web-1mhm | webdev, learning, html, frontend | The internet is a global network of interconnected computers that communicate through standardized protocols. It enables the exchange of data, information, and services through various technologies, such as email, websites, social media, and online applications. The World Wide Web(WWW) on other hand, commonly known as ... | baraq |
1,892,446 | Multi-Layered Kubernetes Security: From Pod to Cluster Level | Kubernetes, a container orchestration platform, provides a robust and scalable environment for... | 0 | 2024-06-18T13:36:25 | https://dev.to/platform_engineers/multi-layered-kubernetes-security-from-pod-to-cluster-level-3gdn | Kubernetes, a container orchestration platform, provides a robust and scalable environment for deploying and managing applications. However, ensuring the security of these applications and the underlying infrastructure is crucial. This blog post delves into the multi-layered security approach for Kubernetes, covering s... | shahangita | |
1,892,445 | One Byte Explainer Challenge solution(Recursion) | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T13:35:40 | https://dev.to/sakutiriko/one-byte-explainer-challenge-solutionrecursion-13bo | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
<!-- Explain a computer science concept in 256 characters or less. -->
## Additional Context
<!-- Please share any additional context you think the judges should take into considerat... | sakutiriko |
1,892,444 | A Modern Python Toolkit: Pydantic, Ruff, MyPy, and UV | In the ever-changing world of Python development, tools such as Pydantic, Ruff, MyPy, and UV have... | 0 | 2024-06-18T13:33:54 | https://developer-service.blog/a-modern-python-toolkit-pydantic-ruff-mypy-and-uv/ | python, pydantic, ruff, mypy | In the ever-changing world of Python development, tools such as Pydantic, Ruff, MyPy, and UV have become essential for improving productivity and code quality.
Let's take a closer look at how these tools can be incorporated into your work.
---
## Pydantic: Data Validation and Settings Management
Pydantic is a libra... | devasservice |
1,892,441 | Filtering and Mapping in JavaScript | When I started learning to code, I began with simple things like creating variables. But after a few... | 0 | 2024-06-18T13:33:50 | https://dev.to/tamikaxuross/filtering-and-mapping-in-javascript-lac | javascript, map, filter, keywords | When I started learning to code, I began with simple things like creating variables. But after a few months in my programming course, I discovered two powerful tools in JavaScript: filter() and map(). These tools make working with arrays of data much easier and more efficient.
## What's the Difference Between the Two?... | tamikaxuross |
1,892,443 | 8 Best Tips for Building a Construction Budget | Construction Company in North Bangalore Introduction Creating a construction budget is a critical... | 0 | 2024-06-18T13:33:45 | https://dev.to/tvasteconstructions/8-best-tips-for-building-a-construction-budget-56d0 |
Construction Company in North Bangalore
Introduction
Creating a construction budget is a critical step in ensuring the success of any construction project, whether it's a small renovation or a large-scale build. A well-crafted budget not only helps in managing costs effectively but also minimizes financial risks and ... | tvasteconstructions | |
1,892,418 | VueJS: o que é, como funciona e como começar a usar o framework | Você trabalha com desenvolvimento Front End (ou estuda essa área) e procura uma ferramenta flexível e... | 26,330 | 2024-06-18T13:29:43 | https://dev.to/sucodelarangela/vuejs-o-que-e-como-funciona-e-como-comecar-a-usar-o-framework-joi | Você trabalha com **desenvolvimento Front End** (ou estuda essa área) e procura uma ferramenta flexível e eficaz para criar projetos incríveis? Então, este guia é para você!
Neste artigo escrito em parceria e com exclusividade para a [**Alura**](https://www.alura.com.br/), você conhecerá uma ferramenta para o desenvol... | sucodelarangela | |
1,890,839 | Develop a consciousness of internal quality to maintain our productivity | I love coding because it allows me to create what I want from my imagination. But it's not fun when... | 0 | 2024-06-18T13:27:00 | https://dev.to/seachicken/develop-a-consciousness-of-internal-quality-to-maintain-our-productivity-2bpg | opensource, codequality | [](url)I love coding because it allows me to create what I want from my imagination. But it's not fun when software design is more complex and buggy.
Developers need to maintain maintainability by constantly checking the scope of impact when making changes to the code and continuing to test and refactor.
This movement ... | seachicken |
1,892,438 | How To Use Copilot to Easily Create PowerPoint Presentations In Minutes | Introduction Creating effective and visually appealing PowerPoint presentations can be a... | 0 | 2024-06-18T13:23:11 | https://dev.to/byteswiftdigital/how-to-use-copilot-to-easily-create-powerpoint-presentations-in-minutes-17ej | tutorial, ai, office, powerpoint | ## Introduction
Creating effective and visually appealing PowerPoint presentations can be a time-consuming and challenging task, often requiring significant effort and attention to detail. However, with advanced artificial intelligence (AI) technologies, the process of creating presentations has become more streamline... | byteswiftdigital |
1,892,405 | 🚀 A hands-on guide to setting up zsh, oh my zsh, asdf, and spaceship prompt with zinit for your development environment | Introduction 🌟 Elevate your development environment with this guide on installing and... | 0 | 2024-06-18T13:20:56 | https://dev.to/girordo/a-hands-on-guide-to-setting-up-zsh-oh-my-zsh-asdf-and-spaceship-prompt-with-zinit-for-your-development-environment-91n | terminal, zsh, tutorial, beginners | ## **Introduction** 🌟
Elevate your development environment with this guide on installing and configuring **Zsh**, **Oh My Zsh**, **asdf**, and the **Spaceship Prompt** theme. We will also leverage **Zinit** for additional plugin management. Let’s get started!
🚨🚨🚨 **WARNING:If you like it this article please click... | girordo |
1,892,419 | How To Use Copilot to Easily Create PowerPoint Presentations In Minutes | Introduction Creating effective and visually appealing PowerPoint presentations can be a... | 0 | 2024-06-18T13:19:55 | https://dev.to/byteswiftdigital/how-to-use-copilot-to-easily-create-powerpoint-presentations-in-minutes-d0a | ## Introduction
Creating effective and visually appealing PowerPoint presentations can be a time-consuming and challenging task, often requiring significant effort and attention to detail. However, with advanced artificial intelligence (AI) technologies, the process of creating presentations has become more streamline... | byteswiftdigital | |
1,892,416 | My first website check it out | it is a simple payment form made using html and css only link... | 0 | 2024-06-18T13:10:12 | https://dev.to/gurnoor_singh55/my-first-website-check-it-out-5b92 | webdev, beginners, css, html | it is a simple payment form made using html and css only
link below-:
https://gurnoor926.github.io/payment-form/ | gurnoor_singh55 |
1,892,417 | Hire Laravel Developers in Just 48 Hours [40-Hour Free Trial] | Want to hire Laravel developers? Hire our expert developers quickly and test their skills with a... | 0 | 2024-06-18T13:14:59 | https://dev.to/websoptimization_92/hire-laravel-developers-in-just-48-hours-40-hour-free-trial-1e1l | laraveldevelopers, laravelconsultants | Want to [hire Laravel developers](https://www.websoptimization.com/hire-laravel-developers.html)? Hire our expert developers quickly and test their skills with a 40-hour free trial! Get the right fit for your project in just 48 hours.
#HireLaravelDevelopers #HireDedicatedLaravelDevelopers #HireLaravelDeveloper #Larav... | websoptimization_92 |
1,892,413 | 1.6 - Ponto e vírgula, posicionamento e práticas de recuo | Ponto e vírgula e posicionamento Em Java, o ponto e vírgula é um separador usado para terminar uma... | 0 | 2024-06-18T13:14:53 | https://dev.to/devsjavagirls/16-ponto-e-virgula-posicionamento-e-praticas-de-recuo-3mhh | java | **Ponto e vírgula e posicionamento**
Em Java, o ponto e vírgula é um separador usado para terminar uma instrução.
Cada instrução individual deve ser finalizada com um ponto e vírgula.
O ponto e vírgula indica o fim de uma entidade lógica.
Exemplo:
```
x = y;
y = y + 1;
System.out.println(x + " " + y);
```
é o mesmo... | devsjavagirls |
1,892,404 | 1.5 - blocos de código | Bloco de código Agrupa duas ou mais instruções. Instruções são envolvidas por chaves {}. Podem ser... | 0 | 2024-06-18T13:14:38 | https://dev.to/devsjavagirls/15-blocos-de-codigo-44cc | java | **Bloco de código**
Agrupa duas ou mais instruções.
Instruções são envolvidas por chaves {}.
Podem ser usados onde uma única instrução seria usada.
- Exemplo:

Se w for menor que h, ambas as instruções são executada... | devsjavagirls |
1,883,663 | 1.4 - Instruções de controle (if e for) | IF Instrução condicional em Java: if Funciona como a instrução IF em outras linguagens Forma mais... | 0 | 2024-06-18T13:14:23 | https://dev.to/devsjavagirls/14-instrucoes-de-controle-if-e-for-25jp | java | **IF**
Instrução condicional em Java: if
Funciona como a instrução IF em outras linguagens
Forma mais simples

condição é uma expressão booleana. Se verdadeira, a instrução é executada. Se falsa, a instrução é igno... | devsjavagirls |
1,892,391 | 1.3 - Outro tipo de dados | A variável int só pode conter números inteiros. Não pode ser usada para números com componentes... | 0 | 2024-06-18T13:13:41 | https://dev.to/devsjavagirls/13-outro-tipo-de-dados-52f4 | java | A variável int só pode conter números inteiros.
Não pode ser usada para números com componentes fracionários.
Exemplo: uma variável int pode conter 18, mas não 18.3.
Java define outros tipos de dados além de int.
Para números com componentes fracionários, Java define os tipos float e double.
- Float (Precisão Simples)... | devsjavagirls |
1,892,414 | Building Header and Footer for Your E-Commerce Website with Nuxt.js | Check this post in my web notes! We established the fundamental layout structure for our... | 27,540 | 2024-06-18T13:08:19 | https://webcraft-notes.com/blog/building-header-and-footer-for-your-ecommerce | nuxt, vue, javascript, tutorial |

> Check [this post](https://webcraft-notes.com/blog/building-header-and-footer-for-your-ecommerce) in [my web notes](https://webcraft-notes.com/blog/)!
We establis... | webcraft-notes |
1,892,411 | Everything You Need to Know About GPT-4o | OpenAI’s GPT-4o is the third major iteration of their popular large multimodal model, expanding the... | 0 | 2024-06-18T13:06:29 | https://dev.to/mohith/everything-you-need-to-know-about-gpt-4o-29cm | openai, ai, chatgpt, gpt4o |
OpenAI’s GPT-4o is the third major iteration of their popular large multimodal model, expanding the capabilities of GPT-4 with Vision. This new model integrates talking, seeing, and interacting with users more seamlessly than previous versions through the ChatGPT interface.
In the GPT-4o announcement, OpenAI focused... | mohith |
1,892,409 | Lock / Mutex to a CS undergraduate (Difficulty 2) | This is a submission for DEV Computer Science Challenge v24.06.12: One Byte Explainer. ... | 0 | 2024-06-18T13:04:25 | https://dev.to/sauravshah31/lock-mutex-to-a-cs-undergraduate-59me | devchallenge, cschallenge, computerscience, beginners | *This is a submission for [DEV Computer Science Challenge v24.06.12: One Byte Explainer](https://dev.to/challenges/cs).*
## Explainer
Locks prevent issues when multiple entities access a resource simultaneously (like multiple apps writing to a file), which can cause unexpected behavior (like overwritten writes). Googl... | sauravshah31 |
1,892,389 | Building a SQL Report Generator using Gemini AI + ToolJet 📊 | Introduction This tutorial will guide you through the process of building an AI-driven SQL... | 0 | 2024-06-18T13:00:56 | https://blog.tooljet.com/building-a-sql-report-generator-using-gemini-ai-tooljet/ | lowcode, gemini, javascript, ai | ## Introduction
This tutorial will guide you through the process of building an AI-driven SQL custom report generator using [ToolJet](https://github.com/ToolJet/ToolJet), a low-code visual app builder, and the Gemini API, a powerful natural language processing API. The resulting application will enable users to input r... | amanregu |
1,892,403 | Understanding the Singleton Pattern in TypeScript | Hello everyone, السلام عليكم و رحمة الله و بركاته Introduction Design patterns are... | 0 | 2024-06-18T12:54:21 | https://dev.to/bilelsalemdev/understanding-the-singleton-pattern-in-typescript-4kep | javascript, typescript, designpatterns, programming | Hello everyone, السلام عليكم و رحمة الله و بركاته
#### Introduction
Design patterns are essential tools for solving common problems in software design. One of the most widely used patterns is the Singleton pattern. This pattern ensures that a class has only one instance and provides a global point of access to it. T... | bilelsalemdev |
1,892,402 | Why You Should Use Local AI Instead ChatGPT? | Privacy Privacy is very important. If you use ChatGPT, admins can see your conversations.... | 0 | 2024-06-18T12:52:34 | https://dev.to/qui/why-you-should-use-local-ai-instead-chatgpt-48md | ## Privacy
Privacy is very important. If you use ChatGPT, admins can see your conversations. But in local AI, they can't see because they aren't admin of your AI.
## Freedom
For example, you can't write RAT with ChatGPT, but in local AI, you can do it (AI model must uncencored). I said RAT, but we have a lot of exam... | qui | |
1,892,400 | Activating Windows 10/11 | Hello guys. This is qui. Today I will make a tutorial about activating Windows 10/11 for free. This... | 0 | 2024-06-18T12:51:41 | https://dev.to/qui/activating-windows-1011-fj2 | Hello guys. This is qui. Today I will make a tutorial about activating Windows 10/11 for free. This tutorial isn't working with LTSC versions.
First you should run script with this command in PowerShell (Administrator): `irm https://get.activated.win | iex`
And select HWID. If it's not working, you can use KMS.
Than... | qui | |
1,888,857 | 25 funded projects you can contribute in open source | The reputation of funded projects is very strong because they have secured substantial funds and are... | 0 | 2024-06-18T12:49:28 | https://dev.to/taipy/25-funded-projects-you-can-contribute-in-open-source-40lh | opensource, programming, discuss, webdev | The reputation of funded projects is very strong because they have secured substantial funds and are backed by ventures.
There are so many projects that are open source, and you should definitely contribute to those especially because their credibility is way higher.
There might be a chance where you can get a direc... | anmolbaranwal |
1,892,334 | Learning React: Creating a Roll a Dice App - R1 | It's not too late to learn react so, here is my journey. I will try to post everyday about the... | 0 | 2024-06-18T12:47:21 | https://dev.to/ivewor/learning-react-creating-a-roll-a-dice-app-r1-13d4 | tutorial, programming, beginners, react | It's not too late to learn react so, here is my journey. I will try to post everyday about the progress I made. I tried to learn react last year but was not able to finish it and now I'm again a noob.
So, this is my 2nd shot in learning react. Haven't touched the basics of it but instead I will try to learn it by bui... | ivewor |
1,892,388 | How to Learn Python FREE: 8-Week Learning Plan (80/20 Rule) | Unlock the power of Python programming in just 8 weeks with our streamlined 80/20 learning plan! This... | 0 | 2024-06-18T12:45:27 | https://dev.to/proflead/how-to-learn-python-free-8-week-learning-plan-8020-rule-3142 | python, programming, tutorial, softwaredevelopment | Unlock the power of Python programming in just 8 weeks with our streamlined 80/20 learning plan! This video offers a concise yet comprehensive guide to mastering the essential aspects of Python, ensuring you spend your time on the concepts that deliver the most significant impact. Whether you're a beginner eager to div... | proflead |
1,892,398 | Exploring the Top Open Source Projects of 2024: Innovations and Opportunities | Open source projects have always been a cornerstone of technological innovation, offering developers... | 0 | 2024-06-18T12:44:25 | https://dev.to/matin_mollapur/exploring-the-top-open-source-projects-of-2024-innovations-and-opportunities-56h0 | webdev, javascript, programming, opensource | > Open source projects have always been a cornerstone of technological innovation, offering developers the opportunity to collaborate, learn, and create impactful software. As we move further into 2024, several open source projects are making waves in the developer community. This article delves into some of the most p... | matin_mollapur |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.