
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,883,735 | [Game of Purpose] Day 23 | Today I created my first Blueprint Function and Macro. It sets movement mode based on provided enum... | 27,434 | 2024-06-10T22:45:18 | https://dev.to/humberd/game-of-purpose-day-23-1jif | gamedev | Today I created my first Blueprint Function and Macro. It sets movement mode based on provided enum `Drone State`.
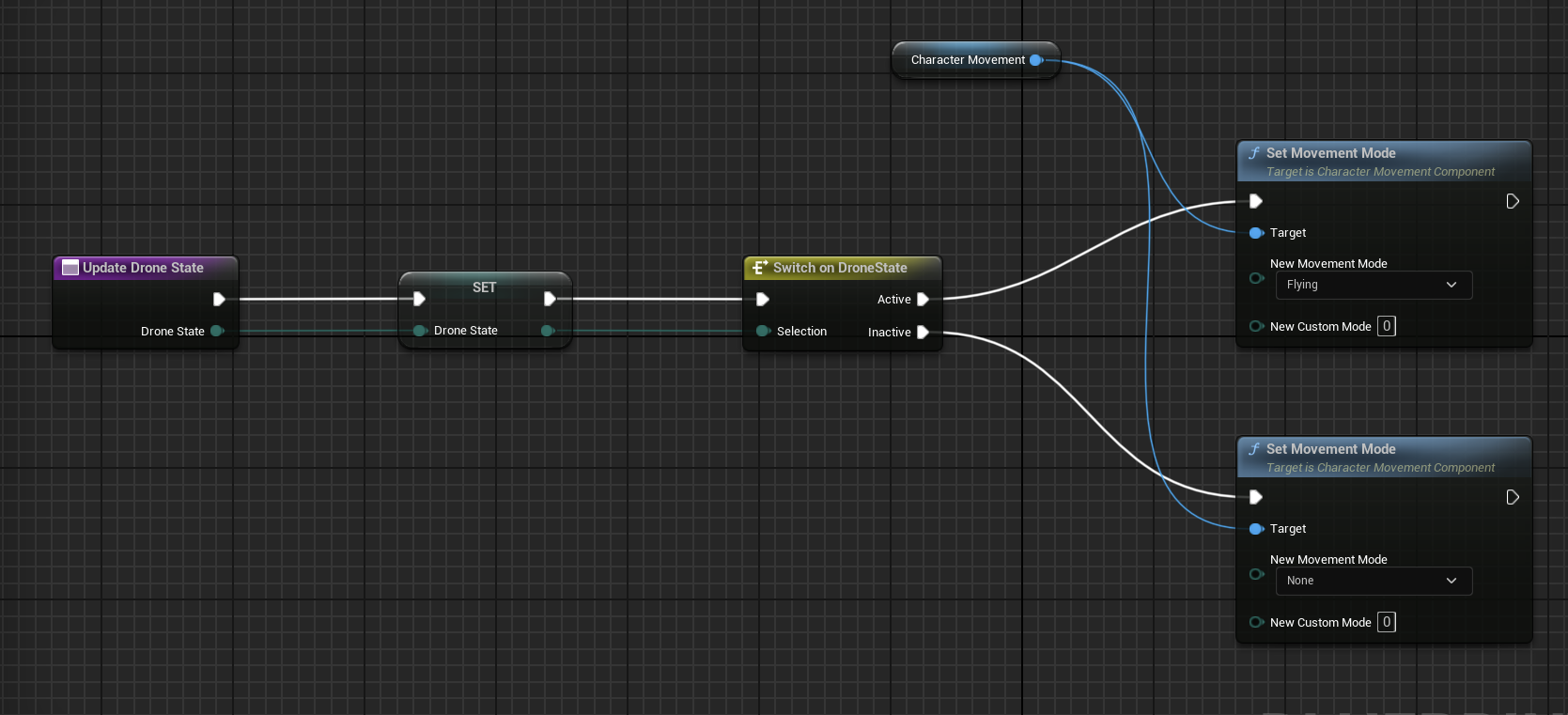
I also made drone fly up and down by pressing Space or Left Ctrl.
At the end I turining Drone's en... | humberd |
1,883,734 | Machine Learning Expert Specializing in Customized Jewelry Solutions | Hi, I’m Bay Ray, a passionate Machine Learning expert dedicated to revolutionizing the world of... | 0 | 2024-06-10T22:43:00 | https://dev.to/ray_bay_e2beb6849a7781754/machine-learning-expert-specializing-in-customized-jewelry-solutions-58oo | Hi, I’m Bay Ray, a passionate Machine Learning expert dedicated to revolutionizing the world of customized jewelry, especially diamond pieces. With a robust background in artificial intelligence and data science, I focus on creating products that personalize and enhance the jewelry shopping experience.
My expertise li... | ray_bay_e2beb6849a7781754 | |
1,883,724 | git commit -m is a lie! How to commit like a pro | When you first started learning git, you probably learned that the way to commit something is by... | 0 | 2024-06-10T22:21:30 | https://dev.to/andrews1022/git-commit-m-is-a-lie-how-to-commit-like-a-pro-l1 | webdev, git, vscode, beginners | When you first started learning git, you probably learned that the way to commit something is by using `git commit -m "your message"`. This is fine as a beginner, but once you start working in a professional environment, you'll quickly realize that using `-m` is insufficient. In this article, I'll cover some different ... | andrews1022 |
1,883,657 | My story creating a new React meta-framework | I have a great idea for a new hobby project! As I am a React developer, I'll use it again for... | 0 | 2024-06-10T22:20:51 | https://dev.to/lazarv/my-story-creating-a-new-react-meta-framework-732 | react, vite, rsc | I have a great idea for a new hobby project! As I am a React developer, I'll use it again for implementing this project, that's an easy choice. I use Next.js at work. It's fine, but there are some pain points in using it, so I don't want to go with it for my own project. I struggle with it during work, so why should I ... | lazarv |
1,883,729 | Run any code from Vim | Do you want to quickly run and test any code without leaving Vim and without even opening a... | 0 | 2024-06-10T22:13:08 | https://dev.to/woland/run-any-code-from-vim-1i2o | Do you want to quickly run and test any code without leaving Vim and without even opening a `:terminal`?
There is a very simple way of achieving this. All we need is a runner function, a run command and a mapping to call it.
**Here is an example:**
```vim
function! CodeRunner()
if &ft ==# 'python'
execut... | woland | |
1,883,728 | Essential Guide to Business Loans for Startups | Starting a business is an exciting venture, startups can provide the ss, and tips for approval. | 0 | 2024-06-10T22:12:53 | https://dev.to/muhammad_alijaffer/essential-guide-to-business-loans-for-startups-5g1c |

Starting a business is an exciting venture, startups can provide the ss, and[ tips for approval](https://aliloans.site/the-essential-guide-to-business-loans-for-startups/). | muhammad_alijaffer | |
1,878,576 | Simplifying Local Development with Docker, mkcert, DNSMasq and Traefik. | Hello dev.to community! I've created a project called wayofdev/docker-shared-services that my team... | 0 | 2024-06-10T22:10:55 | https://dev.to/lotyp/simplifying-local-development-with-docker-mkcert-dnsmasq-and-traefik-3k57 | devops, tutorial, ssl, webdev | Hello dev.to community!
I've created a project called [wayofdev/docker-shared-services](https://github.com/wayofdev/docker-shared-services) that my team and I use to streamline our local development.
It simplifies the setup for Dockerized projects on macOS and Linux, and I’m excited to share it with the community. Le... | lotyp |
336,278 | useFakeAsync | You can see the hook takes a few simple parameters, including the familiar pairing of a callback func... | 0 | 2020-05-15T21:42:02 | https://reacthooks.dev/useFakeAsync/ | react, typescript |
You can see the hook takes a few simple parameters, including the familiar pairing of a callback function and a delay in milliseconds. This follows the shape of JavaScript's setTimeout and setInterval methods.
```TypeScript
import { useEffect, useState } from 'react';
enum FakeAsyncState {
PENDING = 'PENDING',
C... | anthonyhumphreys |
1,883,727 | Fast Approval Loans | Types of Fast Approval Loans Payday Loans: Short-term loans designed to provide immediate cash,... | 0 | 2024-06-10T22:10:03 | https://dev.to/muhammad_alijaffer/fast-approval-loans-1682 |

[Types of Fast Approval Loans](https://aliloans.site/fast-approval-loans-quick-funding-for-your-immediate-needs/)
Payday Loans: Short-term loans designed to provide immediate cash, typically due on your next payday.... | muhammad_alijaffer | |
1,883,726 | everything-ai 4.0.0: build up your local AI power today | What is everything-ai? 🤖 everything-ai is natively a multi-tasking agent, 100% local, that... | 0 | 2024-06-10T22:09:42 | https://dev.to/astrabert/everything-ai-400-build-up-your-local-ai-power-today-5g19 | python, docker, ai, opensource | ## What is everything-ai?
🤖 everything-ai is **natively a multi-tasking agent**, 100% local, that is able to perform several AI-related tasks
## What's new?
🚀 I am more than thrilled to introduce some new functionalities that were added since last release:
- 🦙 `llama.cpp-and-qdrant`: Chat with your PDFs (backed ... | astrabert |
1,883,725 | Guide to Home Equity Loans | Home equity loans can be a valuable financial tool for homeowners looking to leverage the equity... | 0 | 2024-06-10T22:07:49 | https://dev.to/muhammad_alijaffer/guide-to-home-equity-loans-26f6 |

Home equity loans can be a valuable financial tool for homeowners looking to leverage the equity built up in their properties. These loans allow you to borrow against the value of your home, providing a lump sum of ... | muhammad_alijaffer | |
1,883,723 | Comprehensive Guide to Bad Credit Loans | Securing a loan with a low credit score can be challenging, but bad credit loans offer a lifeline for... | 0 | 2024-06-10T22:04:46 | https://dev.to/muhammad_alijaffer/comprehensive-guide-to-bad-credit-loans-22hp | Securing a loan with a low credit score can be challenging, but bad credit loans offer a lifeline for those who need financial assistance despite their credit history. This detailed guide explores the types of bad credit loans, their benefits, the application process, and strategies for approval, helping you make infor... | muhammad_alijaffer | |
330,811 | [Reminder-1] var, let, const | I am writing this article at first for me :). Why ? Just to have a fast reminder about them. But i ho... | 6,516 | 2020-05-09T06:19:21 | https://dev.to/flozero/reminder-var-let-const-h4c | javascript, vue | I am writing this article at first for me :). Why ?
Just to have a fast reminder about them. But i hope it can help you too !
We will speak about some javascript concepts here:
- scope
- block
We can use let and const since es2015 (or es6). I am assuming you know what is`"use strict"`. It will force you to init the v... | flozero |
1,883,722 | CSS Snake. | A blog written in 3rd person. Well, why not... London based CSS Artist, Ben Evans, has... | 27,670 | 2024-06-10T22:03:12 | https://css-artist.blogspot.com/2024/05/is-collision-detection-with-css-possible.html | cssart, cssgame, css |
## A blog written in 3rd person. Well, why not...
London based CSS Artist, Ben Evans, has had some lofty ideas in the past and this one follows that trend... His current aim is to make, or even remake, some form of the Nokia classic: Snake. Using only CSS. He's not currently sure if this is possible but he would lo... | ivorjetski |
1,884,418 | Unnecessary upload evasion with lftp mirrors | Originally published on peateasea.de. I’ve been using lftp’s reverse mirror feature for years to... | 0 | 2024-06-12T07:42:00 | https://peateasea.de/unnecessary-upload-evasion-with-lftp-mirrors/ | linux, devops | ---
title: Unnecessary upload evasion with lftp mirrors
published: true
date: 2024-06-10 22:00:00 UTC
tags: Linux,DevOps
canonical_url: https://peateasea.de/unnecessary-upload-evasion-with-lftp-mirrors/
cover_image: https://peateasea.de/assets/images/avoid-old-file-upload.png
---
*Originally published on [peateasea.de... | peateasea |
1,847,949 | Server Side Components no React: O Futuro da Renderização? | Introdução React é um dos frameworks de frontend mais populares e versáteis, usado para... | 0 | 2024-06-10T21:59:36 | https://dev.to/vitorrios1001/server-side-components-no-react-o-futuro-da-renderizacao-2b03 | serversidecomponents, nextjs, react, frontend | ## Introdução
React é um dos frameworks de frontend mais populares e versáteis, usado para construir interfaces de usuário interativas e dinâmicas. Recentemente, um novo conceito foi introduzido na comunidade React: os Server Side Components (SSC). Este artigo explora os Server Side Components em React, analisando sua... | vitorrios1001 |
1,883,721 | Desiree Dove Realtor,Berkshire Hathaway HomeServices PenFed Realty | With a passion for real estate and a commitment to excellence, I bring a wealth of knowledge and... | 0 | 2024-06-10T21:59:04 | https://dev.to/desireedoverealtor/desiree-dove-realtorberkshire-hathaway-homeservices-penfed-realty-k43 |
With a passion for real estate and a commitment to excellence, I bring a wealth of knowledge and expertise to every client interaction. As a licensed real estate professional, I am deeply invested in helping you na... | desireedoverealtor | |
1,883,719 | How To avoid Getting Scammed | The scammer could not google the name of the United Nations Secretary-General. I wrote an article... | 0 | 2024-06-10T21:33:46 | https://dev.to/scofieldidehen/how-to-avoid-getting-scammed-11o0 | beginners, security, programming, productivity | The scammer could not google the name of the United Nations Secretary-General.
I wrote an article on how to know a phishing mail.
you can read it here and share your experience if you have encountered such emails before.
[Read](https://lnkd.in/dg_NTikG) | scofieldidehen |
1,883,669 | HOW SWIFT HACK EXPERT HELPED ME RECOVER MY STOLEN BITCOIN | Greetings my name is Trista Ayers, I’m writing this testimony to all those who have suffered... | 0 | 2024-06-10T21:05:28 | https://dev.to/trista_ayers_e928d4ddeb36/how-swift-hack-expert-helped-me-recover-my-stolen-bitcoin-5333 | Greetings my name is Trista Ayers, I’m writing this testimony to all those who have suffered financial losses as a result of a gang of fraudulent brokers impersonating bitcoin and Forex traders. I’m aware that a lot of individuals have lost money on bitcoin due to the misconception that it cannot be traced. My belief w... | trista_ayers_e928d4ddeb36 | |
1,883,668 | Understanding Weatherstack's API Pricing and Real-Time Weather Data | Weather data is essential for a wide array of industries, from agriculture and transportation to... | 0 | 2024-06-10T21:01:36 | https://dev.to/sameeranthony/understanding-weatherstacks-api-pricing-and-real-time-weather-data-41i0 | Weather data is essential for a wide array of industries, from agriculture and transportation to tourism and retail. Access to accurate and up-to-date weather information can make a significant difference in decision-making processes and operational efficiency. For businesses and developers seeking reliable weather dat... | sameeranthony | |
1,883,667 | Create CSS Animations with AI | In a recent project, our development team faced the challenge of creating micro-interaction... | 0 | 2024-06-10T21:00:04 | https://dev.to/max_prehoda_9cb09ea7c8d07/create-css-animations-with-ai-5b4o | ai, webdev, design, css | In a recent project, our development team faced the challenge of creating micro-interaction animations for Autt's landing page. Traditionally, implementing CSS animations requires some manual tinkering and extensive trial and error. However, the team discovered AI CSS Animations, a powerful tool that revolutionized the... | max_prehoda_9cb09ea7c8d07 |
1,883,662 | shadcn-ui/ui codebase analysis: examples route explained. | In this article, we will learn about examples app route in shadcn-ui/ui. This article consists of the... | 0 | 2024-06-10T20:43:03 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-examples-route-explained-58mk | javascript, opensource, nextjs, shadcn | In this article, we will learn about examples app [route in shadcn-ui/ui](https://github.com/shadcn-ui/ui/blob/main/apps/www/app/(app)/examples/layout.tsx). This article consists of the following sections:
1. Where is examples folder located?
2. What is in examples/layout.tsx?
3. Difference between examples/layout.... | ramunarasinga |
1,883,661 | REACT features | There are so much to learn about React, that I can’t even begin to explain. I am still trying to... | 0 | 2024-06-10T20:40:41 | https://dev.to/daphneynep/react-features-2kld | There are so much to learn about React, that I can’t even begin to explain. I am still trying to figure out if I like it better than JavaScript. But I do know I like the fact that you can use components in a specific way like building blocks to build our web application. We can write codes that looks similar to HTML. I... | daphneynep | |
330,401 | On Productivity | Personal Productivity vs Generativity – the difference between your team's outcomes with you, vs without you | 0 | 2020-05-08T13:58:11 | https://odone.io/posts/2020-05-08-on-productivity.html | career, productivity, learning | ---
title: On Productivity
description: Personal Productivity vs Generativity – the difference between your team's outcomes with you, vs without you
author: Riccardo
tags: Career, Productivity, Learning
canonical_url: https://odone.io/posts/2020-05-08-on-productivity.html
---
You can keep reading here or [jump to my b... | riccardoodone |
1,883,660 | 🌟 Comprehensive Guide to Firebase Cloud Messaging in React with Vite 🚀 | Firebase Cloud Messaging (FCM) is a powerful tool for sending notifications and messages to your... | 27,668 | 2024-06-10T20:39:55 | https://dev.to/shahharsh/comprehensive-guide-to-firebase-cloud-messaging-in-react-with-vite-abm | react, firebase, frontend, vite | Firebase Cloud Messaging (FCM) is a powerful tool for sending notifications and messages to your users, keeping them engaged and informed. This guide will take you through the process of setting up FCM in your React application using Vite, and we'll also cover how to obtain the necessary FCM keys to test notifications.... | shahharsh |
1,883,659 | Future-proof software development with the Azure Serverless Modulith | When developing modern software solutions, architects and developers are faced with the challenge of... | 0 | 2024-06-10T20:39:36 | https://dev.to/florianlenz/future-proof-software-development-with-the-azure-serverless-modulith-12bl | serverless, azure, azurefunctions, eventdriven | When developing modern software solutions, architects and developers are faced with the challenge of designing systems that are scalable, maintainable and cost-effective. Traditionally, monolithic architectures offer the advantage of simplicity in development and deployment, but often reach their limits in terms of sca... | florianlenz |
1,883,612 | Enforcing 'noImplicitAny' on callbacks to generic functions | One of the first errors every TypeScript developer encounters is the famous noImplicitAny, which... | 0 | 2024-06-10T20:38:24 | https://dev.to/seasonedcc/enforcing-noimplicitany-on-callbacks-to-generic-functions-7f1 | typescript | One of the first errors every TypeScript developer encounters is the famous `noImplicitAny`, which happens when you don't specify a type for a variable. For example:
```ts
function fn(s) {
// ^? Parameter 's' implicitly has an 'any' type.
console.log(s.subtr(3));
}
```
This is a great thing because it force... | gugaguichard |
1,883,658 | Overcoming Childhood Struggles and Embracing a Career in Software Engineering | I’ve struggled with studying and grasping things quickly for as long as I can remember. As a kid, I... | 0 | 2024-06-10T20:34:27 | https://dev.to/bmoreinspiring/overcoming-childhood-struggles-and-embracing-a-career-in-software-engineering-63c | learning, webdev, beginners | I’ve struggled with studying and grasping things quickly for as long as I can remember. As a kid, I just couldn’t sit still for hours on end, hitting the books or doing things that didn’t interest me. High school was tough; I barely scraped through my classes and even had to deal with a health scare during my senior ye... | bmoreinspiring |
1,883,655 | LLM is unfair | Well... At least, that's how I feel. As a non-native English speaker, inefficiency arises even... | 0 | 2024-06-10T20:33:14 | https://dev.to/swimmingpolar/llm-is-unfair-53p3 | llm, cat, promptengineering, language | Well... At least, that's how I feel.
As a non-native English speaker, inefficiency arises even before starting to write instructions or prompts. Why? Obviously, the whole data corpus fed into AI models was mostly written in English. So what? It seems quite a simple job these days. Why don't I go ahead and use one of m... | swimmingpolar |
1,883,656 | LEGITIMATE CRYPTO RECOVERY AGENCY-SPYWARE CYBER | Choosing Spyware Cyber was one of the best decisions I've ever made. From the moment I reached out to... | 0 | 2024-06-10T20:26:50 | https://dev.to/joan_anneliss_ca8f1e9fdad/legitimate-crypto-recovery-agency-spyware-cyber-290a | recover, recovery, sucess | Choosing Spyware Cyber was one of the best decisions I've ever made. From the moment I reached out to them, I knew I was in good hands. Their professionalism, expertise, and unwavering commitment to their clients set them apart from the rest.When I found myself entangled in a web of deception orchestrated by an imposte... | joan_anneliss_ca8f1e9fdad |
1,883,651 | Estudos em Quality Assurance (QA) - Metodologias de Desenvolvimento | Waterfall: Waterfall é uma metodologia sequencial onde cada fase deve ser concluída antes que a... | 0 | 2024-06-10T20:22:20 | https://dev.to/julianoquites/estudos-em-quality-assurance-qa-metodologias-de-desenvolvimento-a4p | scrum, kanban, agile, qa | **Waterfall**: Waterfall é uma metodologia sequencial onde cada fase deve ser concluída antes que a próxima comece. É ideal para projetos com requisitos bem definidos e pouca necessidade de mudanças.
- Vantagens do Waterfall:
- Estrutura clara e previsível desde o início do projeto.
- Documentação detalhada em... | julianoquites |
1,883,637 | Creating Accessible Web Applications: A Developer’s Guide | Hey there! Let's talk about making your web apps not just good, but great—for everyone. Yes, I’m... | 0 | 2024-06-10T20:21:22 | https://dev.to/buildwebcrumbs/creating-accessible-web-applications-a-developers-guide-49ik | a11y, webdev, beginners, programming | Hey there! Let's talk about making your web apps not just good, but great—for everyone. Yes, I’m talking about making them accessible. Ensuring that your applications are accessible is very important. **Why?** Because it’s all about inclusivity.
Imagine this: What if you threw a party and some of your friends couldn’t... | opensourcee |
1,883,624 | Migrando do CRA para Vite | O tão amado (ou odiado) pacote Create React App (CRA) deixou de ser mantido desde 2023, confira mais... | 0 | 2024-06-10T20:16:53 | https://dev.to/mrtinsvitor/migrando-do-cra-para-vite-1201 | javascript, react, braziliandevs, vite | O tão amado (ou odiado) pacote Create React App (CRA) deixou de ser mantido desde 2023, [confira mais aqui](https://github.com/reactjs/react.dev/pull/5487#issuecomment-1409720741). Isso significa que não irá mais receber nenhuma atualização, tornando-o cada dia mais obsoleto. Embora ainda seja uma opção válida para alg... | mrtinsvitor |
1,883,623 | Generics in Typescript and how to use them | Sometimes I wonder whether I love or hate Typescript. I see the benefits of implementing it in the... | 0 | 2024-06-10T20:13:24 | https://www.oh-no.ooo/articles/generics-in-typescript-and-how-to-use-them | typescript, javascript, webdev, learning | Sometimes I wonder whether I love or hate Typescript. I see the benefits of implementing it in the majority of frontend solutions, but I struggle with the syntax and the mumbo jumbo names that don't tell me anything. "Generics" would be one of those, as the name kindly suggests too, it's a name that could mean anything... | mahdava |
1,883,622 | 🤔PEPE: Is ‘buying the dip’ a good move to make? | 📉 PEPE Price Drop: Pepe (PEPE) has recently experienced a 32.6% drop, retracing to $0.00001131 after... | 0 | 2024-06-10T20:12:37 | https://dev.to/irmakork/pepe-is-buying-the-dip-a-good-move-to-make-133 |
📉 PEPE Price Drop: Pepe (PEPE) has recently experienced a 32.6% drop, retracing to $0.00001131 after reaching its all-time high of $0.00001724. The current price is $0.00001264, up 3.17% in the last 24 hours but down 16.74% over the past week.
🔄 Support Level and Buying Opportunity: PEPE has pulled back to a conflu... | irmakork | |
1,883,621 | 🐳Ethereum: Analyzing whether $4.8K is in sight for ETH | 📉 Ethereum Price Drop: Ethereum (ETH) bears dominated last week, with the price dropping over 2%. At... | 0 | 2024-06-10T20:12:10 | https://dev.to/irmakork/ethereum-analyzing-whether-48k-is-in-sight-for-eth-2fbo |
📉 Ethereum Price Drop: Ethereum (ETH) bears dominated last week, with the price dropping over 2%. At the time of writing, ETH is trading at $3,687.02 with a market cap of $442 billion.
🚀 Potential Breakout: ETH is testing a key resistance level, and a breakout above this could spark a massive bull rally in the comi... | irmakork | |
1,883,620 | 🔥Cardano faces resistance at $0.44-$0.49: Will ADA drop to $0.42? | 🔻 Cardano (ADA) Decline: Cardano has lost 6.11% of its gains in the past 30 days. The Global In/Out... | 0 | 2024-06-10T20:11:48 | https://dev.to/irmakork/cardano-faces-resistance-at-044-049-will-ada-drop-to-042-1431 |
🔻 Cardano (ADA) Decline: Cardano has lost 6.11% of its gains in the past 30 days. The Global In/Out of Money (GIOM) indicator from IntoTheBlock suggests ADA could face further declines.
📊 GIOM Indicator Insights:
Addresses in Loss: 402,720 addresses accumulated 6.39 billion ADA between $0.44 and $0.49. This cohort... | irmakork | |
1,883,619 | 🔥Crypto Prices Today June 10: BTC & Altcoins Regain Momentum, NOT & OM Top Gainers | Today’s crypto market saw a notable uptick after a weekend dip, with Bitcoin edging towards $70K and... | 0 | 2024-06-10T20:11:25 | https://dev.to/irmakork/crypto-prices-today-june-10-btc-altcoins-regain-momentum-not-om-top-gainers-51dh |
Today’s crypto market saw a notable uptick after a weekend dip, with Bitcoin edging towards $70K and altcoins like Ethereum, Solana, and XRP posting gains of 0.5-2%. Meme coins like Pepe (PEPE) and Shiba Inu (SHIB) followed suit, while others like Notcoin (NOT) and MANTRA (OM) emerged as top gainers.
📈 Market Overv... | irmakork | |
1,883,618 | 🚀Notcoin Gearing Up for a Fresh Bullish Spell; Can NOT Price Surge by 50% to Form a New ATH? | Despite the overall sluggish market trend, Notcoin (NOT) has shown signs of strength, attempting to... | 0 | 2024-06-10T20:11:06 | https://dev.to/irmakork/notcoin-gearing-up-for-a-fresh-bullish-spell-can-not-price-surge-by-50-to-form-a-new-ath-3nd2 |
Despite the overall sluggish market trend, Notcoin (NOT) has shown signs of strength, attempting to stabilize and initiate an upswing. While trading activity remains subdued, hopes of a bullish trend towards a new all-time high (ATH) persist.
Currently, NOT price is trading within a falling wedge pattern, indicating... | irmakork | |
1,883,594 | Be careful! Freewallet app may scam you! | Many people seek a free wallet to send and receive crypto assets without incurring any fees. However,... | 0 | 2024-06-10T18:38:29 | https://dev.to/feofhan/be-careful-freewallet-app-may-scam-you-363i | Many people seek a free wallet to send and receive crypto assets without incurring any fees. However, it’s important to understand that this is impossible—using any blockchain always involves some fees. But that’s not the main concern.
If you're looking for a free wallet, there's a high chance you'll come across the s... | feofhan | |
1,883,617 | SQLite in the Cloud: Scalable Solutions for Data Management | Introduction In recent years, the proliferation of cloud computing has revolutionized the way... | 0 | 2024-06-10T20:10:28 | https://dev.to/brianmk/sqlite-in-the-cloud-scalable-solutions-for-data-management-3plg | sql, database | Introduction
In recent years, the proliferation of cloud computing has revolutionized the way developers approach data management. Traditionally, SQLite has been synonymous with embedded databases in mobile and desktop applications. However, its lightweight nature and simplicity make it an attractive option for cloud-b... | brianmk |
1,883,564 | My Eight-Month Journey as a Self-Taught Developer | After almost two years working as an auditor, I knew I needed a change. I wasn't satisfied with my... | 0 | 2024-06-10T20:03:46 | https://dev.to/migueldonado/my-eight-month-journey-as-a-self-taught-developer-5ah9 | beginners, career, learning, productivity | After almost two years working as an auditor, I knew I **needed a change**. I wasn't satisfied with my job and felt I had a lot more potential that I could tap into. That feeling wasn't new.
Since the last year of my bachelor's (BBA), I had the idea of studying for a Master's in Big Data. I thought that a couple of ye... | migueldonado |
1,883,616 | Top Mold Removal & Remediation Services in Oakville | Mold can be a silent but dangerous intruder in your home, posing significant health risks and... | 0 | 2024-06-10T19:59:29 | https://dev.to/johnson321/top-mold-removal-remediation-services-in-oakville-4947 | webdev |

Mold can be a silent but dangerous intruder in your home, posing significant health risks and potentially causing extensive property damage. For residents of Oakville, finding reliable and effective mold removal a... | johnson321 |
1,883,615 | I made a application, which shows you a film🍿 based on your mood. | Hello everyone, I made a small application, the idea of which is to show a selection of films... | 0 | 2024-06-10T19:51:40 | https://dev.to/artemowandrei/i-made-a-application-which-shows-you-a-film-based-on-your-mood-332 | webdev, webapp, javascript, development | Hello everyone,
I made a small application, the idea of which is to show a selection of films based on the user's mood.
try it here: https://moodwatch.vercel.app
I need feedback, what would you like to see in this app, or what bugs needs to be fixed, or what features needs to be added?
thanks | artemowandrei |
1,883,614 | The Evolution of API Development Styles: The GraphQL Architecture | In the changing landscape of modern application development, the selection of API architecture style... | 0 | 2024-06-10T19:48:12 | https://dev.to/paltadash/the-evolution-of-api-development-styles-the-graphql-architecture-3jjl | In the changing landscape of modern application development, the selection of API architecture style has become a critical factor in ensuring the efficiency, scalability and adaptability of solutions. While traditional approaches have been widely used, an increasingly popular alternative is the use of GraphQL.
##What ... | paltadash | |
1,883,085 | Nucleoid: Reasoning Engine for Neuro-Symbolic AI | Nucleoid is a reasoning engine for Neuro-Symbolic AI, implementing symbolic AI through declarative (logic-based) programming. Neuro-symbolic AI combines neural networks (which excel in pattern recognition and data-driven tasks) with symbolic AI (which focuses on reasoning and rule-based problem solving) to create syste... | 0 | 2024-06-10T19:43:55 | https://github.com/NucleoidAI/Nucleoid | ai, showdev, node, javascript | ---
description: Nucleoid is a reasoning engine for Neuro-Symbolic AI, implementing symbolic AI through declarative (logic-based) programming. Neuro-symbolic AI combines neural networks (which excel in pattern recognition and data-driven tasks) with symbolic AI (which focuses on reasoning and rule-based problem solving... | canmingir |
1,883,282 | CodeBehind 2.6 Released | A new version of the CodeBehind framework has been released by Elanat. This is version 2.6 of this... | 0 | 2024-06-10T19:27:09 | https://dev.to/elanatframework/codebehind-26-released-1dne | news, dotnet, backend, github | A new version of the [CodeBehind framework](https://github.com/elanatframework/Code_behind) has been released by [Elanat](https://elanat.net). This is version 2.6 of this back-end framework. In version 2.6, the main focus is on dependency injection.
## Controller class constructor and Model class constructor
The cons... | elanatframework |
1,883,610 | Demystifying Observability 2.0 | Our systems have gotten complex. Like really complex. Organizations have mostly shifted from... | 0 | 2024-06-10T19:21:13 | https://open.substack.com/pub/geekingoutpodcast/p/demystifying-observability-20 | observability, opentelemetry, cloudnative, apm |

Our systems have gotten complex. Like _really_ complex. Organizations have mostly shifted from monoliths to microservices. They’ve embraced the Cloud, an... | avillela |
1,883,604 | How to Deploy Flutter on Upsun | Recently, a ticket came through regarding a user who wanted to deploy a Node.js frontend, but... | 0 | 2024-06-10T19:19:09 | https://dev.to/upsun/how-to-deploy-flutter-on-upsun-3m1g | flutter, devops, upsun, nix | Recently, a ticket came through regarding a user who wanted to deploy a Node.js frontend, but alongside a Flutter backend, and it that was something that was possible on Platform.sh/Upsun.
Youbetcha!
## Deploying
To get started locally (I was on a Mac), I ran:
```bash
brew install --cask flutter
```
I found a (now... | chadwcarlson |
1,883,603 | 1051. Height Checker | 1051. Height Checker Easy A school is trying to take an annual photo of all the students. The... | 27,523 | 2024-06-10T19:18:28 | https://dev.to/mdarifulhaque/1051-height-checker-ai | php, leetcode, algorithms, programming | 1051\. Height Checker
Easy
A school is trying to take an annual photo of all the students. The students are asked to stand in a single file line in non-decreasing order by height. Let this ordering be represented by the integer array expected where expected[i] is the expected height of the ith student in line.
You a... | mdarifulhaque |
1,883,602 | How to Create a storage account with high availability | Storage account with high availability. Creating a highly available Azure Storage account... | 0 | 2024-06-10T19:18:21 | https://dev.to/ajayi/how-to-create-a-storage-account-with-high-availability-h5 | tutorial, beginners, cloud, azure | ##Storage account with high availability.
Creating a highly available Azure Storage account involves configuring settings to ensure data durability and accessibility even in the event of hardware failures or data center outages
Steps to create a storage account with High availability
Step 1
Create a storage account
N... | ajayi |
1,883,601 | Real-time Applications with NestJS and WebSockets | Real-time applications have become an integral part of modern web development, enabling instant... | 0 | 2024-06-10T19:10:48 | https://dev.to/ezilemdodana/real-time-applications-with-nestjs-and-websockets-5afk | nestjs, backend, typescript, webdev | Real-time applications have become an integral part of modern web development, enabling instant communication and dynamic interactions. NestJS, with its powerful framework and support for WebSockets, makes it easy to build such applications. In this article, we'll explore how to create real-time applications with NestJ... | ezilemdodana |
1,883,600 | Keeping Your Mind On Coding, While Life Distracts You | We've all been there. You stare at the blinking cursor, your favorite IDE (Integrated Development... | 0 | 2024-06-10T19:09:28 | https://dev.to/dommieh97/keeping-your-mind-on-coding-while-life-distracts-you-17lb | webdev, programming, productivity | We've all been there. You stare at the blinking cursor, your favorite IDE (Integrated Development Environment) mocking you with its blank canvas. The coffee's cold, that bug you were wrestling with feels like it has a PhD in hiding, and the siren song of social media beckons from the other tab. Let's face it, staying ... | dommieh97 |
1,883,599 | Mappings 1.16.5 | Where can I find mappings.srg for Forge 1.16.5? | 0 | 2024-06-10T19:03:22 | https://dev.to/simpatae_db4017929eb0f42/mappings-1165-4c6p | forge | Where can I find mappings.srg for Forge 1.16.5?
| simpatae_db4017929eb0f42 |
1,883,598 | Breaking Free from Analysis Paralysis | Pet project Ever found yourself paralyzed by endless choices when starting a new project?... | 0 | 2024-06-10T18:56:41 | https://swiderski.tech/2024-06-07-breaking-free-from-analysis-paralysis/ | procrastination, programming, go, productivity | ## Pet project
Ever found yourself paralyzed by endless choices when starting a new project? I recently did, and it all began with binge-watching way too much [ThePrimeagen](https://www.youtube.com/@ThePrimeTimeagen/featured). Inspired, I decided to learn GoLang, thinking it would be the perfect next step for my half-... | asvid |
1,883,609 | Salário Do Programador Brasileiro 2024: Confira Essa Pesquisa | A “Pesquisa Salarial de Programadores Brasileiros 2024” vem em sua quarta edição realizada pelo canal... | 0 | 2024-06-23T13:50:48 | https://guiadeti.com.br/salario-programador-brasileiro-2024-confira/ | notícias, empregabilidade, mercadodeti, preparaçãoparaomerca | ---
title: Salário Do Programador Brasileiro 2024: Confira Essa Pesquisa
published: true
date: 2024-06-10 18:54:26 UTC
tags: Notícias,empregabilidade,mercadodeti,preparaçãoparaomerca
canonical_url: https://guiadeti.com.br/salario-programador-brasileiro-2024-confira/
---
A “Pesquisa Salarial de Programadores Brasileiro... | guiadeti |
1,883,597 | Master Nodemailer: The Ultimate Guide to Sending Emails from Node.js | Are you a Node.js developer looking to integrate email capabilities into your applications? Look no... | 0 | 2024-06-10T18:41:32 | https://blog.learnhub.africa/2024/06/10/master-nodemailer-the-ultimate-guide-to-sending-emails-from-node-js/ | webdev, node, beginners, programming |
Are you a Node.js developer looking to integrate email capabilities into your applications? Look no further than Nodemailer - the powerful and flexible Node.js module that simplifies sending emails from your server.
 is a program or set of programs that tracks changes to a collection of files.
- Anot... | srinivasuluparanduru |
1,883,595 | React Native and OpenAI | Hello. I've just developed the simple application using OpenAI / ChatGPT and had a lot of fun and... | 0 | 2024-06-10T18:38:44 | https://dev.to/oivoodoo/react-native-and-openai-4e9a | reactnative, openai, mobileapp, react | ---
title: React Native and OpenAI
published: true
description:
tags: reactnative,openai,mobileapp,react
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-10 18:32 +0000
---
Hello.
I've just developed the simple application using OpenAI / ChatGPT and ha... | oivoodoo |
1,847,840 | Different ways to get a Job! | Getting a job can be a daunting and frustrating process, but with the right approach and strategies,... | 0 | 2024-06-10T18:37:47 | https://dev.to/avinash201199/different-wasy-to-get-a-job-2i8i | job, softwareengineering, developers, programming | Getting a job can be a daunting and frustrating process, but with the right approach and strategies, you can increase your chances of success.
We already know about the traditional way to apply for jobs, which is by exploring job boards. We can easily find job openings on companies' career portals or by exploring thi... | avinash201199 |
1,883,592 | Developing My Developer Voice | Have you ever looked at seemingly unrelated technologies and wondered how they might connect? That's... | 0 | 2024-06-10T18:32:43 | https://dev.to/statueofdavid/developing-my-developer-voice-3aoi | noob, general, firstpost, softwareengineering | Have you ever looked at seemingly unrelated technologies and wondered how they might connect? That's a feeling I get all the time. In 2023, I explored this by connecting a raspberry pi and a Billy Bass Fish puppet and then attempted to run a chat llm on that raspberry pi. While the results were, shall we say, unique, t... | statueofdavid |
1,883,590 | Best Gynecologist in Hyderabad | Dr.Himabindu Annamraju | Dr. Himabindu is the best Gynecologist in Hyderabad. She is an Obstetrician and laparoscopic surgeon... | 0 | 2024-06-10T18:29:13 | https://dev.to/drhimaraju/best-gynecologist-in-hyderabad-drhimabindu-annamraju-28g2 | bestgynecologistinhyderabad, drhimabinduannamraju, rainbowhospital, pcos | Dr. Himabindu is the best Gynecologist in Hyderabad. She is an Obstetrician and laparoscopic surgeon at Rainbow Hospital, Financial District, Nanakramguda, Hyderabad. She has over 19 years of experience in all aspects of obstetrics and gynecology including her role as a consultant obstetrician & gynecologist at Bucking... | drhimaraju |
1,883,297 | Key AI Terminologies | What is Artificial Intelligence? Artificial Intelligence (AI) refers to the simulation of... | 0 | 2024-06-10T18:28:19 | https://dev.to/ak_23/key-ai-terminologies-1ncc | ai, learning, beginners | ### What is Artificial Intelligence?
Artificial Intelligence (AI) refers to the simulation of human intelligence in machines. These machines are programmed to think like humans and mimic their actions, learning from experience, adjusting to new inputs, and performing tasks that typically require human intelligence.
#... | ak_23 |
1,883,573 | Keep your business code separate from the rest | One of the best things you can do for a codebase is to keep the business logic separate from... | 0 | 2024-06-10T18:28:10 | https://dev.to/seasonedcc/keep-your-business-code-separate-from-the-rest-4ek2 | cleancode, architecture, productivity, programming | One of the best things you can do for a codebase is to keep the business logic separate from everything else.
Imagine you have an app from 20 years ago, written in an old framework no one uses anymore. Thousands of people rely on it for their jobs, because it is the only app that deeply understands how this particular... | danielweinmann |
1,883,587 | Inside the Box: May Community Update | Hi there 👋 With a new month upon us, it's time for a fresh issue of "Inside the Box" with all of... | 26,773 | 2024-06-10T18:27:48 | https://dev.to/codesandboxio/inside-the-box-may-community-update-223l | webdev, product, community | Hi there 👋
With a new month upon us, it's time for a fresh issue of "Inside the Box" with all of last month's highlights.
Let's go!
## Latest Product News
**[Storybook add-on](https://codesandbox.io/blog/announcing-the-codesandbox-storybook-add-on) 🧩** — We're making every story come to life with the [CodeSandbox... | filipeslima |
1,883,589 | Cryptocurrecny Recovery Experts Contact A1 wizard Hackes | Cryptocurrecny Recovery Experts Contact A1 wizard Hackes "I had suffered a significant loss in the... | 0 | 2024-06-10T18:27:25 | https://dev.to/edward_johnson_ba9dc50dd8/cryptocurrecny-recovery-experts-contact-a1-wizard-hackes-22g0 | cryptocurrency | Cryptocurrecny Recovery Experts Contact A1 wizard Hackes
"I had suffered a significant loss in the cryptocurrency market a few months ago and was struggling to recover." I had invested $598,500 in cryptocurrency with a company that I subsequently discovered online, which I ended up learning it's a standard Crypto scam... | edward_johnson_ba9dc50dd8 |
1,883,586 | Navigating Automotive Excellence: The Significance of Workshop Manuals in PDF Format | In the digital age, Workshop Manuals in PDF format have revolutionized the way automotive enthusiasts... | 0 | 2024-06-10T18:24:28 | https://dev.to/downwork_manuals_bf1d9720/navigating-automotive-excellence-the-significance-of-workshop-manuals-in-pdf-format-bh6 | In the digital age, Workshop Manuals in PDF format have revolutionized the way automotive enthusiasts and professionals approach vehicle maintenance and repair. These comprehensive guides provide detailed instructions, technical specifications, and troubleshooting advice tailored to specific vehicle makes and models, a... | downwork_manuals_bf1d9720 | |
1,883,583 | Organization schemes for note taking | Let's delve into various organization schemes for effective note-taking, along with practical... | 0 | 2024-06-10T18:22:57 | https://dev.to/charudatta10/organization-schemes-for-note-taking-j18 | note, beginners, tutorial, orgnization | Let's delve into various organization schemes for effective note-taking, along with practical examples:
1. **File and Folder Organization:**
- **Files**: Think of each note as a separate file (e.g., "MeetingNotes.md" or "ProjectIdeas.txt").
- **Folders (or Notebooks)**: Create folders to group related notes. For... | charudatta10 |
1,883,575 | Specialty Fats and Oils Market: Forecast and Key Growth Drivers for 2024-2033 | The global specialty fats and oils market, valued at US$ 54,811.7 Mn in 2024, is projected to grow at... | 0 | 2024-06-10T18:18:35 | https://dev.to/swara_353df25d291824ff9ee/specialty-fats-and-oils-market-forecast-and-key-growth-drivers-for-2024-2033-3ghp | The global specialty fats and oils market, valued at US$ 54,811.7 Mn in 2024, is projected to grow at a CAGR of 4.6%, reaching around US$ 82,174.3 Mn by 2033. Specialty fats and oils, essential nutrients composed mainly of triglycerides, are tailored for specific applications in the food, personal care, and other indus... | swara_353df25d291824ff9ee | |
1,883,567 | Automating RDS CA (Certificate Authority) Using AWS Lambda | In the last few days, we have dealt with the challenge of updating all our RDS CA services, running... | 0 | 2024-06-10T18:16:47 | https://dev.to/lrdplopes/automating-rds-ca-certificate-authority-using-aws-lambda-3kb7 | aws, python, devops, tutorial | In the last few days, we have dealt with the challenge of updating all our RDS CA services, running more than three hundred instances. Therefore, the AWS guidance is to update it manually as a matter of production critical behavior; however, manually doing it is frustrating. That's why we came up with the idea of deplo... | lrdplopes |
1,881,884 | Redis For Beginners | Basic Overview 📖 Why Redis is needed ?? Ans: In contemporary application development,... | 0 | 2024-06-10T18:14:05 | https://dev.to/jemmyasjd/redis-for-beginners-1lnl | ## **Basic Overview 📖**
- **Why Redis is needed ??**
**Ans:** In contemporary application development, Redis plays a critical role by serving as a highly efficient in-memory data store. Its primary function is to cache computed data, which significantly reduces server load caused by excessive database queries. This ... | jemmyasjd | |
1,883,572 | Golden chance to earn a lot of money | I am looking for a non-technical partner to start a business on an AI platform. The ideal... | 0 | 2024-06-10T18:12:09 | https://dev.to/devmaster03/golden-chance-to-earn-a-lot-of-money-ail | I am looking for a non-technical partner to start a business on an AI platform. The ideal collaborator should have their own computer and be able to keep it running 24/7.
Candidates must be from the United States, United Kingdom, Canada, Australia, Mexico, or Argentina and have work authorization in their respective c... | devmaster03 | |
1,883,570 | ** Navegando por las arenas del conocimiento: Habilidades para el Desarrollo Tecnológico: Una Odisea en el Desierto de Dune **🌕 | ¡Hola Chiquis! 👋🏻 ¿Preparados para conquistar el mundo digital? En la era actual, donde la tecnología... | 0 | 2024-06-10T18:11:23 | https://dev.to/orlidev/-navegando-por-las-arenas-del-conocimiento-habilidades-para-el-desarrollo-tecnologico-una-odisea-en-el-desierto-de-dune--436h | webdev, tutorial, role, beginners | ¡Hola Chiquis! 👋🏻 ¿Preparados para conquistar el mundo digital? En la era actual, donde la tecnología lo domina todo, las habilidades especializadas son la clave para el éxito.🧑🏻 ¿Te apasiona crear software, diseñar webs, desarrollar juegos o navegar por los datos?
: If you're trying to use... | 0 | 2024-06-10T18:10:37 | https://dev.to/omranic/fix-shap-multiclass-summary-plot-downgrade-to-v0441-from-0450-27m | shap, explainableai, machinelearning | Here's a helpful tip for anyone using #SHAP (SHapley Additive exPlanations):
If you're trying to use `shap.summary_plot(shap_values, X_train_tfidf_dense, plot_type="bar")` for a multiclass summary, and it keeps showing a dotted interaction plot regardless of the plot type you pass; it's likely a bug in `v0.45.0`.
Dow... | omranic |
1,883,563 | ACID Transactions | Have you ever heard the phrase "ACID Transactions"? If yes, this post is for you 😎 If not, now you... | 0 | 2024-06-10T18:07:07 | https://www.linkedin.com/pulse/acid-transactions-loc-nguyen-ewizc/ | sql, acid, transactions | Have you ever heard the phrase "ACID Transactions"?
- If yes, this post is for you 😎
- If not, now you know it 😁
## What are transactions?
In normal life, transactions occur when **you sell - I buy** and vice versa. It represents the process between you and me when we give something to each other with the same va... | locnguyenpv |
1,883,566 | Navigating the Tech Space: Essential Steps, Possible Challenges, and Solutions for Beginners | ** Introduction ** Look, I know the average people in the world, wants to dive into the... | 0 | 2024-06-10T18:03:57 | https://dev.to/asharfdevv/navigating-the-tech-space-essential-steps-possible-challenges-and-solutions-for-beginners-4m0o | beginners, programming, javascript | **
## Introduction
**
Look, I know the average people in the world, wants to dive into the technology world but, starting a journey in the tech world can be both exciting and daunting. With so much to learn and explore, it's easy to feel overwhelmed. This article aims to guide you through the essential steps to get st... | asharfdevv |
1,883,565 | useEffect React and TypeScript | useEffect React and TypeScript | 27,665 | 2024-06-10T18:00:08 | https://www.johnatanortiz.tech/blog/useeffect-react-and-typescript | # React + Typescript
Using `useEffect` in a React component with TypeScript involves ensuring that your effect functions, dependencies, and cleanup functions are properly typed. Here’s how you can do this:
### Basic Example
Here's a simple example of using `useEffect` with TypeScript:
```tsx
tsxCopy code
import Rea... | johnatan_stevenortizsal | |
1,883,562 | Open-Source Exploitation | Hi folks, This is not my title, but the title of a presentation I saw few days ago. I wanted to... | 0 | 2024-06-10T17:57:45 | https://dev.to/dagnelies/open-source-exploitation-2eh4 | watercooler, opensource, techtalks | Hi folks,
This is not my title, but the title of a presentation I saw few days ago. I wanted to share with you as I think it is important for the open source community as a whole.
{% embed https://www.youtube.com/watch?v=9YQgNDLFYq8 %}
For my part, I agree completely to what he said. What about you? | dagnelies |
1,883,561 | Dreamin' in Color Countdown | Check out this Pen I made! | 0 | 2024-06-10T17:57:21 | https://dev.to/arbrazil/dreamin-in-color-countdown-3ldh | codepen | Check out this Pen I made!
{% codepen https://codepen.io/arbrazil/pen/qBwgNmM %} | arbrazil |
1,883,560 | Smart Cities: How Tech is Revolutionizing Urban Living | Intelligent Transportation Systems Advanced traffic management and real-time data integration... | 0 | 2024-06-10T17:53:27 | https://dev.to/bingecoder89/smart-cities-how-tech-is-revolutionizing-urban-living-1l75 | webdev, javascript, devops, ai | 1. **Intelligent Transportation Systems**
- Advanced traffic management and real-time data integration reduce congestion and improve public transport efficiency.
2. **Energy Efficiency and Smart Grids**
- Smart grids and renewable energy sources optimize energy consumption, reduce waste, and lower costs.
3. **I... | bingecoder89 |
1,883,559 | PYTHON P-3 PROJECT | ==>Creating a URL shortener is a great project that leverages databases, ORMs, and database... | 0 | 2024-06-10T17:52:15 | https://dev.to/victor_wangari_6e6143475e/python-p-3-project-250o | ==>Creating a URL shortener is a great project that leverages databases, ORMs, and database diagrams effectively. Here’s how you can approach building a URL shortener using Python with SQLite3 and SQLAlchemy.
**Project: URL Shortener**
**Features**
1. _Shorten URLs_
- Accept long URLs and generate short URLs
- ... | victor_wangari_6e6143475e | |
1,883,532 | Is it Possible to Use Grafana Without Prometheus? | Grafana is widely known for its powerful data visualization capabilities, often used in conjunction... | 0 | 2024-06-10T17:50:03 | https://signoz.io/guides/is-it-possible-to-use-grafana-without-prometheus/ | devops, prometheus, grafana, observability | Grafana is widely known for its powerful data visualization capabilities, often used in conjunction with Prometheus for monitoring and metrics collection. However, many users wonder if it is possible to use Grafana without Prometheus. The answer is yes! Grafana's versatility allows it to support a wide range of data so... | yuvraajsj18 |
1,883,558 | Robot input by html & css & javascript | add me on : Codepen: https://codepen.io/hussein009 github... | 0 | 2024-06-10T17:48:18 | https://dev.to/hussein09/robot-input-by-html-css-javascript-2ok9 | codepen, javascript, html, css | add me on :
Codepen:
https://codepen.io/hussein009
github :
https://github.com/hussein-009
https://heylink.me/hussein009
{% codepen https://codepen.io/hussein009/pen/mdYwRzN %} | hussein09 |
1,883,557 | Getting started on AWS DeepRacer🏎️ | At the beginning of March 2024, I had never created a machine learning model. However, by the end of... | 0 | 2024-06-10T17:48:11 | https://dev.to/muhammedsalie/getting-started-on-aws-deepracer-a02 | genain, ai, machinelearning, futureofwork | At the beginning of March 2024, I had never created a machine learning model. However, by the end of April, my AWS DeepRacer model ranked in the top 50 in the Middle East & Africa Region competition, earning me a $99 Amazon gift card. Here are some of the lessons I learned along the way.
**Getting Started**
If you don... | muhammedsalie |
1,883,443 | Step-by-Step Guide to Typesafe Translations in Next.js Without Third-Party Tools | Multilingual support is a critical feature for modern web applications. In this guide, we will walk... | 0 | 2024-06-10T17:44:10 | https://dev.to/ryanmabrouk/step-by-step-guide-to-typesafe-translations-in-nextjs-without-third-party-tools-2mii | nextjs, tutorial, typescript, programming | Multilingual support is a critical feature for modern web applications. In this guide, we will walk through how to implement a typesafe translation system in a Next.js application without relying on any third-party libraries. This approach ensures that our translations are robust and maintainable.
## Step 1: Define Tr... | ryanmabrouk |
1,883,608 | Curso De SAS Gratuito Para Iniciantes: 500 Vagas Disponíveis | Participe do curso online e gratuito “SAS Guide para Iniciantes” e comece sua introdução à tecnologia... | 0 | 2024-06-23T13:50:53 | https://guiadeti.com.br/curso-sas-gratuito-iniciantes-500-vagas/ | cursogratuito, analisededados, cursosgratuitos, dados | ---
title: Curso De SAS Gratuito Para Iniciantes: 500 Vagas Disponíveis
published: true
date: 2024-06-10 17:38:48 UTC
tags: CursoGratuito,analisededados,cursosgratuitos,dados
canonical_url: https://guiadeti.com.br/curso-sas-gratuito-iniciantes-500-vagas/
---
Participe do curso online e gratuito “SAS Guide para Inician... | guiadeti |
1,883,555 | Buy Verified Paxful Account | https://dmhelpshop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account There are... | 0 | 2024-06-10T17:37:45 | https://dev.to/kayajo3925/buy-verified-paxful-account-2mnp | react, python, ai, devops | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-paxful-account/\n\n\n\n\nBuy Verified Paxful Account\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, Buy verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to Buy Verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with. Buy Verified Paxful Account.\n\nBuy US verified paxful account from the best place dmhelpshop\nWhy we declared this website as the best place to buy US verified paxful account? Because, our company is established for providing the all account services in the USA (our main target) and even in the whole world. With this in mind we create paxful account and customize our accounts as professional with the real documents. Buy Verified Paxful Account.\n\nIf you want to buy US verified paxful account you should have to contact fast with us. Because our accounts are-\n\nEmail verified\nPhone number verified\nSelfie and KYC verified\nSSN (social security no.) verified\nTax ID and passport verified\nSometimes driving license verified\nMasterCard attached and verified\nUsed only genuine and real documents\n100% access of the account\nAll documents provided for customer security\nWhat is Verified Paxful Account?\nIn today’s expanding landscape of online transactions, ensuring security and reliability has become paramount. Given this context, Paxful has quickly risen as a prominent peer-to-peer Bitcoin marketplace, catering to individuals and businesses seeking trusted platforms for cryptocurrency trading.\n\nIn light of the prevalent digital scams and frauds, it is only natural for people to exercise caution when partaking in online transactions. As a result, the concept of a verified account has gained immense significance, serving as a critical feature for numerous online platforms. Paxful recognizes this need and provides a safe haven for users, streamlining their cryptocurrency buying and selling experience.\n\nFor individuals and businesses alike, Buy verified Paxful account emerges as an appealing choice, offering a secure and reliable environment in the ever-expanding world of digital transactions. Buy Verified Paxful Account.\n\nVerified Paxful Accounts are essential for establishing credibility and trust among users who want to transact securely on the platform. They serve as evidence that a user is a reliable seller or buyer, verifying their legitimacy.\n\nBut what constitutes a verified account, and how can one obtain this status on Paxful? In this exploration of verified Paxful accounts, we will unravel the significance they hold, why they are crucial, and shed light on the process behind their activation, providing a comprehensive understanding of how they function. Buy verified Paxful account.\n\n \n\nWhy should to Buy Verified Paxful Account?\nThere are several compelling reasons to consider purchasing a verified Paxful account. Firstly, a verified account offers enhanced security, providing peace of mind to all users. Additionally, it opens up a wider range of trading opportunities, allowing individuals to partake in various transactions, ultimately expanding their financial horizons.\n\nMoreover, a verified Paxful account ensures faster and more streamlined transactions, minimizing any potential delays or inconveniences. Furthermore, by opting for a verified account, users gain access to a trusted and reputable platform, fostering a sense of reliability and confidence. Buy Verified Paxful Account.\n\nLastly, Paxful’s verification process is thorough and meticulous, ensuring that only genuine individuals are granted verified status, thereby creating a safer trading environment for all users. Overall, the decision to buy a verified Paxful account can greatly enhance one’s overall trading experience, offering increased security, access to more opportunities, and a reliable platform to engage with.\n\n \n\nWhat is a Paxful Account\nPaxful and various other platforms consistently release updates that not only address security vulnerabilities but also enhance usability by introducing new features. Buy Verified Paxful Account.\n\nIn line with this, our old accounts have recently undergone upgrades, ensuring that if you purchase an old buy Verified Paxful account from dmhelpshop.com, you will gain access to an account with an impressive history and advanced features. This ensures a seamless and enhanced experience for all users, making it a worthwhile option for everyone.\n\n \n\nIs it safe to buy Paxful Verified Accounts?\nBuying on Paxful is a secure choice for everyone. However, the level of trust amplifies when purchasing from Paxful verified accounts. These accounts belong to sellers who have undergone rigorous scrutiny by Paxful. Buy verified Paxful account, you are automatically designated as a verified account. Hence, purchasing from a Paxful verified account ensures a high level of credibility and utmost reliability. Buy Verified Paxful Account.\n\nPAXFUL, a widely known peer-to-peer cryptocurrency trading platform, has gained significant popularity as a go-to website for purchasing Bitcoin and other cryptocurrencies. It is important to note, however, that while Paxful may not be the most secure option available, its reputation is considerably less problematic compared to many other marketplaces. Buy Verified Paxful Account.\n\nThis brings us to the question: is it safe to purchase Paxful Verified Accounts? Top Paxful reviews offer mixed opinions, suggesting that caution should be exercised. Therefore, users are advised to conduct thorough research and consider all aspects before proceeding with any transactions on Paxful.\n\n \n\nHow Do I Get 100% Real Verified Paxful Accoun?\nPaxful, a renowned peer-to-peer cryptocurrency marketplace, offers users the opportunity to conveniently buy and sell a wide range of cryptocurrencies. Given its growing popularity, both individuals and businesses are seeking to establish verified accounts on this platform.\n\nHowever, the process of creating a verified Paxful account can be intimidating, particularly considering the escalating prevalence of online scams and fraudulent practices. This verification procedure necessitates users to furnish personal information and vital documents, posing potential risks if not conducted meticulously.\n\nIn this comprehensive guide, we will delve into the necessary steps to create a legitimate and verified Paxful account. Our discussion will revolve around the verification process and provide valuable tips to safely navigate through it.\n\nMoreover, we will emphasize the utmost importance of maintaining the security of personal information when creating a verified account. Furthermore, we will shed light on common pitfalls to steer clear of, such as using counterfeit documents or attempting to bypass the verification process.\n\nWhether you are new to Paxful or an experienced user, this engaging paragraph aims to equip everyone with the knowledge they need to establish a secure and authentic presence on the platform.\n\nBenefits Of Verified Paxful Accounts\nVerified Paxful accounts offer numerous advantages compared to regular Paxful accounts. One notable advantage is that verified accounts contribute to building trust within the community.\n\nVerification, although a rigorous process, is essential for peer-to-peer transactions. This is why all Paxful accounts undergo verification after registration. When customers within the community possess confidence and trust, they can conveniently and securely exchange cash for Bitcoin or Ethereum instantly. Buy Verified Paxful Account.\n\nPaxful accounts, trusted and verified by sellers globally, serve as a testament to their unwavering commitment towards their business or passion, ensuring exceptional customer service at all times. Headquartered in Africa, Paxful holds the distinction of being the world’s pioneering peer-to-peer bitcoin marketplace. Spearheaded by its founder, Ray Youssef, Paxful continues to lead the way in revolutionizing the digital exchange landscape.\n\nPaxful has emerged as a favored platform for digital currency trading, catering to a diverse audience. One of Paxful’s key features is its direct peer-to-peer trading system, eliminating the need for intermediaries or cryptocurrency exchanges. By leveraging Paxful’s escrow system, users can trade securely and confidently.\n\nWhat sets Paxful apart is its commitment to identity verification, ensuring a trustworthy environment for buyers and sellers alike. With these user-centric qualities, Paxful has successfully established itself as a leading platform for hassle-free digital currency transactions, appealing to a wide range of individuals seeking a reliable and convenient trading experience. Buy Verified Paxful Account.\n\n \n\nHow paxful ensure risk-free transaction and trading?\nEngage in safe online financial activities by prioritizing verified accounts to reduce the risk of fraud. Platforms like Paxfu implement stringent identity and address verification measures to protect users from scammers and ensure credibility.\n\nWith verified accounts, users can trade with confidence, knowing they are interacting with legitimate individuals or entities. By fostering trust through verified accounts, Paxful strengthens the integrity of its ecosystem, making it a secure space for financial transactions for all users. Buy Verified Paxful Account.\n\nExperience seamless transactions by obtaining a verified Paxful account. Verification signals a user’s dedication to the platform’s guidelines, leading to the prestigious badge of trust. This trust not only expedites trades but also reduces transaction scrutiny. Additionally, verified users unlock exclusive features enhancing efficiency on Paxful. Elevate your trading experience with Verified Paxful Accounts today.\n\nIn the ever-changing realm of online trading and transactions, selecting a platform with minimal fees is paramount for optimizing returns. This choice not only enhances your financial capabilities but also facilitates more frequent trading while safeguarding gains. Buy Verified Paxful Account.\n\nExamining the details of fee configurations reveals Paxful as a frontrunner in cost-effectiveness. Acquire a verified level-3 USA Paxful account from usasmmonline.com for a secure transaction experience. Invest in verified Paxful accounts to take advantage of a leading platform in the online trading landscape.\n\n \n\nHow Old Paxful ensures a lot of Advantages?\n\nExplore the boundless opportunities that Verified Paxful accounts present for businesses looking to venture into the digital currency realm, as companies globally witness heightened profits and expansion. These success stories underline the myriad advantages of Paxful’s user-friendly interface, minimal fees, and robust trading tools, demonstrating its relevance across various sectors.\n\nBusinesses benefit from efficient transaction processing and cost-effective solutions, making Paxful a significant player in facilitating financial operations. Acquire a USA Paxful account effortlessly at a competitive rate from usasmmonline.com and unlock access to a world of possibilities. Buy Verified Paxful Account.\n\nExperience elevated convenience and accessibility through Paxful, where stories of transformation abound. Whether you are an individual seeking seamless transactions or a business eager to tap into a global market, buying old Paxful accounts unveils opportunities for growth.\n\nPaxful’s verified accounts not only offer reliability within the trading community but also serve as a testament to the platform’s ability to empower economic activities worldwide. Join the journey towards expansive possibilities and enhanced financial empowerment with Paxful today. Buy Verified Paxful Account.\n\n \n\nWhy paxful keep the security measures at the top priority?\nIn today’s digital landscape, security stands as a paramount concern for all individuals engaging in online activities, particularly within marketplaces such as Paxful. It is essential for account holders to remain informed about the comprehensive security protocols that are in place to safeguard their information.\n\nSafeguarding your Paxful account is imperative to guaranteeing the safety and security of your transactions. Two essential security components, Two-Factor Authentication and Routine Security Audits, serve as the pillars fortifying this shield of protection, ensuring a secure and trustworthy user experience for all. Buy Verified Paxful Account.\n\nConclusion\nInvesting in Bitcoin offers various avenues, and among those, utilizing a Paxful account has emerged as a favored option. Paxful, an esteemed online marketplace, enables users to engage in buying and selling Bitcoin. Buy Verified Paxful Account.\n\nThe initial step involves creating an account on Paxful and completing the verification process to ensure identity authentication. Subsequently, users gain access to a diverse range of offers from fellow users on the platform. Once a suitable proposal captures your interest, you can proceed to initiate a trade with the respective user, opening the doors to a seamless Bitcoin investing experience.\n\nIn conclusion, when considering the option of purchasing verified Paxful accounts, exercising caution and conducting thorough due diligence is of utmost importance. It is highly recommended to seek reputable sources and diligently research the seller’s history and reviews before making any transactions.\n\nMoreover, it is crucial to familiarize oneself with the terms and conditions outlined by Paxful regarding account verification, bearing in mind the potential consequences of violating those terms. By adhering to these guidelines, individuals can ensure a secure and reliable experience when engaging in such transactions. Buy Verified Paxful Account.\n\n \n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | kayajo3925 |
1,883,554 | PACX ⁓ Create a table | We have previously talked about what does it mean to manually manipulate the Dataverse data model,... | 0 | 2024-06-10T17:34:43 | https://dev.to/_neronotte/pacx-create-a-table-1lgo | powerplatform, dataverse, opensource, tools | [We have previously talked about what does it mean to manually manipulate the Dataverse data model](https://dev.to/_neronotte/pacx-data-model-manipulation-579e), and the benefits of data model scripting.
We'll now deep dive on what it means to create tables, columns and relations via PACX.
---
[Creating a table with... | _neronotte |
1,883,553 | How to make Email Template Using HTML | Would you like to learn how to create an email template using HTML and style it with CSS? Usually,... | 0 | 2024-06-10T17:29:06 | https://dev.to/yasminsardar/create-email-template-using-html-and-css-only-3phm | tutorial, html, webdev, beginners | Would you like to learn how to create an email template using HTML and style it with CSS?
Usually, you can make an email template with HTML elements. But for Gmail, you'll need to add a `<table>` tag along with `<td>` and `<tr>` properties.
Otherwise, your email template won't function properly when shared in Gmail.
... | yasminsardar |
1,883,552 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-10T17:28:43 | https://dev.to/kayajo3925/buy-verified-cash-app-account-2ong | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | kayajo3925 |
1,883,550 | Designed by JavaScript without tree | add me on : Codepen: https://codepen.io/hussein009 github... | 0 | 2024-06-10T17:26:17 | https://dev.to/hussein09/designed-by-javascript-without-tree-f2o | codepen, javascript, beginners, programming | add me on :
Codepen:
https://codepen.io/hussein009
github :
https://github.com/hussein-009
https://heylink.me/hussein009
{% codepen https://codepen.io/hussein009/pen/MWdEwRM %} | hussein09 |
1,883,549 | Exhibition Stand Design Company in Nuremberg | Bellatrum is one of the best three exhibition stand companies in Nuremberg. We have more than 25... | 0 | 2024-06-10T17:25:45 | https://dev.to/bellatrum/exhibition-stand-design-company-in-nuremberg-coo | Bellatrum is one of the best three exhibition stand companies in Nuremberg. We have more than 25 years of experience in designing and building exhibition stands for trade shows in Nuremberg.
From BIOFACH to Interzoo to SMTConnect, we have covered all the [top exhibitions in Nuremberg](url=https://bellatrum.com/stand-... | bellatrum | |
1,883,536 | Generating replies using Groq and Gemma in NestJS | Introduction In this blog post, I demonstrated generating replies with Groq SDK and Gemma... | 27,661 | 2024-06-10T17:11:59 | https://www.blueskyconnie.com/groq-sdk-and-gemma-for-generating-replie-in-nestjs-2/ | generativeai, tutorial, nestjs, groq | ##Introduction
In this blog post, I demonstrated generating replies with Groq SDK and Gemma 7B model. Buyers can provide ratings and comments on sales transactions on auction sites like eBay. When the feedback is negative, the seller must reply promptly to resolve the dispute. This demo aims to generate responses in t... | railsstudent |
1,883,632 | Secure by default: How WarpStream’s BYOC deployment model secures the most sensitive workloads | by Caleb Grillo Fundamentals of BYOC WarpStream’s Zero Disk Architecture Typically,... | 0 | 2024-06-11T17:45:04 | https://dev.to/warpstream/secure-by-default-how-warpstreams-byoc-deployment-model-secures-the-most-sensitive-workloads-257d | apachekafka, dataengineering, datastreaming | ---
title: Secure by default: How WarpStream’s BYOC deployment model secures the most sensitive workloads
published: true
date: 2024-06-10 17:21:30 UTC
tags: apachekafka,dataengineering,datastreaming
canonical_url:
---
by Caleb Grillo
### Fundamentals of BYOC
. Neste artigo, vamos explorar o que é ORM, suas vantagens, desvantagen... | iamthiago |
1,883,359 | Deploying Remix-Vite on Lambda using Pulumi | A bit of context Remix is a very cool React-based framework that makes the final jump back... | 0 | 2024-06-10T15:08:35 | https://dev.to/gautierblandin/deploying-remix-vite-on-lambda-using-pulumi-41oj | ## A bit of context
[Remix](https://remix.run/) is a very cool React-based framework that makes the final jump back from the browser to the server. After starting with SPAs that fully ran in the browser, [Next.js](https://nextjs.org/) got the idea of rendering React components in the server, reducing the initial l... | gautierblandin |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.