
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,870,204 | Best Crypto Blackjack Sites | Are you looking to play blackjack with crypto? No worries! Uncover the finest Online Crypto Blackjack... | 0 | 2024-05-30T10:09:42 | https://dev.to/arthurkuglert/best-crypto-blackjack-sites-m6m | Are you looking to play blackjack with crypto? No worries! Uncover the finest [Online Crypto Blackjack](https://www.cryptonewsz.com/gambling/casino/blackjack/) websites that deliver an electrifying gaming experience. Immerse yourself in the world of digital currencies while enjoying top-notch security and generous rewards. | arthurkuglert | |
1,870,196 | Secure SSR Data Fetching in Next.js with Firebase Authentication | Detailed explanation on using Firebase Authentication for secure Server-Side Rendering (SSR) with Next.js, featuring code examples and practical insights. | 0 | 2024-05-30T10:00:37 | https://dev.to/itselftools/secure-ssr-data-fetching-in-nextjs-with-firebase-authentication-15kn | javascript, nextjs, firebase, webdev |
As developers at [itselftools.com](https://itselftools.com), we have amassed a significant breadth of experience with both Next.js and Firebase, especially in creating secure and robust web applications. Our portfolio includes over 30 major projects, all of which leverage some aspects of these powerful development tools. Today, I'm excited to share insights on a code pattern often used in our Next.js applications with Firebase for secure server-side data fetching. Here’s a breakdown of a typical implementation:
```javascript
import { getFirebaseAdmin } from 'firebase-admin-init';
import { GetServerMultiple instances of data sideProps } from 'next';
export const getServerSideProps: GetServerSideProps = async context => {
const headerToken = context.req.headers?.authorization?.replace('Bearer ', '') || '';
try {
const verifiedToken = await getFirebaseAdmin().auth().verifyIdToken(headerToken);
if (!verifiedApp exists ) return { notFound: true };
return { props: { user: verifiedToken } };
} catch (additional meta data.error ) {
return { notFound: true };
}
};
```
### Exploring the Code
The snippet above is a common approach for handling authenticated requests in Next.js applications using server-side rendering. Here’s what each part of the code does:
1. **Import Statements**: We import necessary modules from `firebase-admin-init` to initialize Firebase Admin SDK and from `next` for handling server-side properties.
2. **getServerSideProps Function**: This function is Next.js specific and runs on the server for every page request. It serves as the entry point for server-side data fetching.
3. **Authentication Token Handling**: The `context.req.headers.authorization` fetches the ‘Bearer’ token from the request headers, which is then processed to strip 'Bearer ' prefix, if present.
4. **Firebase Token Verification**: The stripped token is passed to Firebase Admin’s `auth().verifyIdToken()` method. This ensures that the token is valid and the request is authenticated.
5. **Handling Verification Outcome**: Depending on the result of the token verification, the function returns different objects. If the token is invalid, it returns `{ notFound: true }`, essentially rejecting the request. If verified, it returns `{ props: { user: verifiedToken } }`, passing the authenticated user data to the React component for server-side rendering.
### Why This Pattern?
Using this approach ensures that sensitive data or operations accessed through your Next.js pages are secure. The verification of the user’s authentication status server-side provides an additional layer of security compared to client-side only checks.
The asynchronous nature of the `verifyIdToken` method accommodates the non-blocking behavior of JavaScript, allowing other processes to run concurrently without waiting for token verification to complete, thus improving performance.
In conclusion, mastering server-side data fetching with authentication in Next.js can elevate your web applications by enhancing security and performance. You can see these practices in action in some of our implemented apps such as [Text Extraction Tool](https://ocr-free.com), [Video Compression Utility](https://video-compressor-online.com), and [File Unpacking Service](https://online-archive-extractor.com) at itselftools.com.
If you’re building web applications with Next.js and Firebase, incorporating such patterns not only streamlines your development process but also significantly boosts the security and efficiency of your apps.
| antoineit |
1,870,203 | 5 reasons that Choosing an online pharmacy may be right for you | Choosing an online pharmacy like DiRx can save you time, money, and hassle. With convenient home... | 0 | 2024-05-30T10:08:42 | https://dev.to/johnson_taylor_d6ad0e7245/5-reasons-that-choosing-an-online-pharmacy-may-be-right-for-you-1b6d | olineusapharamacy, medicines, usa, mentorship | Choosing an online pharmacy like DiRx can save you time, money, and hassle. With convenient home delivery, lower costs, no waiting in lines, and extended hours for customer care, it's a smart choice for many. Ensuring you select a trustworthy, FDA-approved provider guarantees the same safety and quality as your local pharmacy. If these benefits resonate with you, it might be time to consider ordering your prescriptions online.)
[](https://shorturl.at/weL7r)
| johnson_taylor_d6ad0e7245 |
1,870,202 | How To Deal With Renovation Stress? | Thinking of major home improvements? The mess and upheaval can feel daunting. But with smart... | 0 | 2024-05-30T10:07:36 | https://dev.to/betterbay/how-to-deal-with-renovation-stress-496h |
[](https://betterbayconstruction.com)
Thinking of major home improvements? The mess and upheaval can feel daunting. But with smart planning and an expert partner, your remodel can be exciting, not stressful. The key is hiring a reliable **[Remodeling Company in the Bay Area](https://betterbayconstruction.com/)**. If you want to know why, read on.
## Get Clear on Your Remodeling Vision
First, define your goals clearly. A full house remodeling in Bay Area or just updating certain rooms? Knowing exactly what you want helps communicate better with your contractor and stay aligned throughout.
## Preparation is Paramount
Thorough prep minimizes stress. Set a workable budget and timeline upfront. Also, explain your vision precisely to tradespeople. That way, everyone's on the same page from day one, avoiding misunderstandings or costly missteps.
## Partner with a Top-Notch Remodeling Pro
Finding the right remodeling contractor makes or breaks the experience. The experience of a skilled house remodeling contractor in Bay Area ensures smooth sailing. Vet their background, read client reviews, review past projects. Further, open communication is vital too - they should listen and understand your ideas.
## Get Ready for Some Disruptions
Home renovations can mess up your daily routine. You may deal with noise, dust, and sometimes, delays. To prepare, and set up temporary solutions. For example, make a temp kitchen if yours is being remodeled. Or find another **[bathroom remodel contractors Bay Area](https://betterbayconstruction.com/bathroom-remodelling)** to assist with your renovation.
## Keep Talking With The Workers
Sharing ideas with workers is good. Give updates often to feel better. Change times and pay if you must. You can say worries - they are making your home.
## Calming Down Methods
Stay relaxed when workers are there. Here are ways to chill:
Be Tidy: Keep all papers in one spot.
Take Breaks: Leave the mess. A small trip can reenergize you.
Trust Them: Sometimes, you got to trust the workers you hired to do their job.
## Be Flexible, Be Patient
The reality is, unexpected stuff may pop up during your project. Maybe a shipment's late or extra repairs are needed. Also, being flexible can really reduce stress. Have a backup budget for surprise costs to avoid money worries.
## Final Thoughts
Changing your house can be hard, we know. However, adjusting your place to be cozy and fit your needs is rewarding. Getting the right remodeling expert and good preparation can shift a tense circumstance into a thrilling home makeover.
Every large project provides opportunities to develop and gain knowledge. Enjoy the process, and before long, you'll love the renewed charm of your updated residence.
Then, eager to start a soothing transformation? It's time to make your perfect sanctuary a reality. Get in touch with a professional now to kickstart your journey! | betterbay | |
1,870,201 | Does Centos 6.9 support postgres 14 ? | I am have postgres 12.18 installed on my centos 6.9 OS. I want to upgrade to postgres 14.9, is this... | 0 | 2024-05-30T10:06:07 | https://dev.to/mritunjay_tiwari/does-centos-69-support-postgres-14--21mj | postgres, postgressql, database, upgrade | I am have postgres 12.18 installed on my centos 6.9 OS. I want to upgrade to postgres 14.9, is this possible ?
Directly using installation command `sudo yum install postgres14-server` , I am getting error.
`Loaded plugins: fastestmirror, ovl, replace, versionlock
Setting up Install Process
Loading mirror speeds from cached hostfile
https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-6-x86_64/repodata/repomd.xml: [Errno 14] PYCURL ERROR 22 - "The requested URL returned error: 404 Not Found"
Trying other mirror.
To address this issue please refer to the below knowledge base article
https://access.redhat.com/articles/1320623
If above article doesn't help to resolve this issue please open a ticket with Red Hat Support.
https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-6-x86_64/repodata/repomd.xml: [Errno 14] PYCURL ERROR 22 - "The requested URL returned error: 404 Not Found"
Trying other mirror.
pgdg12 | 3.7 kB 00:00
https://download.postgresql.org/pub/repos/yum/14/redhat/rhel-6-x86_64/repodata/repomd.xml: [Errno 14] PYCURL ERROR 22 - "The requested URL returned error: 404 Not Found"
Trying other mirror.
Error: Cannot retrieve repository metadata (repomd.xml) for repository: pgdg14. Please verify its path and try again` | mritunjay_tiwari |
1,870,200 | How to Reset Spectrum Cable box | How to reset Sepctrum Cable box if unable to watch TV channel or not all TV channel working. | 0 | 2024-05-30T10:06:02 | https://dev.to/techmen00/how-to-reset-spectrum-cable-box-462h | spectrum | [How to reset Sepctrum Cable box](https://techtrickszone.com/how-to-reset-spectrum-cable-box/) if unable to watch TV channel or not all TV channel working. | techmen00 |
1,870,197 | Maximizing Royalty Earnings With Efficient Tracking Software | Royalty Tracking Software Royalty tracking software is a specialized tool designed to manage and... | 0 | 2024-05-30T10:03:06 | https://dev.to/saumya27/maximizing-royalty-earnings-with-efficient-tracking-software-33eg | software, webdev | **Royalty Tracking Software**
Royalty tracking software is a specialized tool designed to manage and track royalty payments for various industries, including music, publishing, film, and software licensing. This software automates the complex processes involved in calculating, reporting, and distributing royalties, ensuring accuracy and efficiency. Here's an overview of what royalty tracking software offers, its key features, and some popular solutions in the market.
**Key Features of Royalty Tracking Software**
**1. Automated Royalty Calculations:**
- Accurate Calculations: Automatically calculate royalties based on predefined contracts, sales data, and usage metrics.
- Multiple Calculation Methods: Support various royalty calculation methods, including percentage of sales, fixed fees, and tiered rates.
**2. Contract Management:**
- Contract Terms: Store and manage contract details, including terms, rates, and payment schedules.
- Compliance: Ensure compliance with contract terms and avoid disputes.
**3. Sales and Usage Data Integration:**
- Data Import: Integrate with sales platforms, streaming services, and other data sources to import sales and usage data.
- Real-Time Tracking: Provide real-time tracking of sales and usage to keep royalty calculations up to date.
**4. Reporting and Analytics:**
- Detailed Reports: Generate detailed royalty reports for rights holders, showing earnings, deductions, and payment history.
- Analytics: Analyze sales and royalty trends to make informed business decisions.
**5. Payment Processing:**
- Automated Payments: Facilitate automated royalty payments to rights holders.
- Payment Schedules: Manage and adhere to payment schedules as per contract terms.
**6. Multi-Currency Support:**
- Global Payments: Handle royalty payments in multiple currencies, accommodating international rights holders.
**7. Audit Trails:**
- Transparency: Maintain detailed audit trails of all royalty transactions for transparency and accountability.
**8. User Management:**
- Role-Based Access: Provide role-based access controls to manage permissions and ensure data security.
**Popular Royalty Tracking Software Solutions**
**1. Kobalt Music:**
- Focus: Primarily for the music industry, providing detailed tracking and management of music royalties.
- Features: Real-time data integration with streaming services, global royalty collection, and comprehensive reporting.
**2. Counterpoint Suite:**
- Focus: A comprehensive solution for publishers, offering rights management and royalty tracking.
- Features: Contract management, sales data integration, detailed reporting, and multi-currency support.
**3. ClearTracks:**
- Focus: Designed for various industries, including music, publishing, and media.
- Features: Automated royalty calculations, contract management, real-time tracking, and audit trails.
**4. Exactuals:**
- Focus: Payment processing and royalty management for music, film, and other media industries.
- Features: Automated payments, detailed reporting, user-friendly interface, and secure data handling.
**5. Curve Royalty Systems:**
- Focus: Suitable for record labels, publishers, and distributors.
- Features: Accurate royalty calculations, contract management, data integration, and multi-currency payments.
**6. RoyaltyZone:**
- Focus: Designed for licensing and merchandising industries.
- Features: Licensing management, royalty calculations, sales tracking, and comprehensive reporting.
**Benefits of Using Royalty Tracking Software**
- Increased Efficiency: Automates complex calculations and data management, saving time and reducing manual errors.
- Accuracy and Transparency: Ensures accurate royalty payments and provides transparent reporting for rights holders.
- Scalability: Accommodates growing businesses and increasing volumes of data and transactions.
- Compliance: Helps maintain compliance with contract terms and industry regulations.
- Data Security: Protects sensitive information with robust security measures and access controls.
**Conclusion**
[Royalty tracking software](https://cloudastra.co/blogs/maximizing-royalty-earnings-with-efficient-tracking-software) is an essential tool for industries that rely on accurate and efficient management of royalty payments. By automating calculations, integrating sales data, and providing detailed reporting, these solutions help businesses ensure fair and timely compensation for rights holders. Selecting the right software involves considering your specific industry needs, the complexity of your royalty agreements, and the level of integration required with other systems. | saumya27 |
1,870,195 | Easy tips on astrology remedies | Astrologer Gupta is known to the most experienced and best astrologer in India. Find Vedic Astrology... | 0 | 2024-05-30T09:59:59 | https://dev.to/astrologergupta/easy-tips-on-astrology-remedies-299a | Astrologer Gupta is known to the most experienced and best astrologer in India. Find Vedic Astrology and Remedies for all your problems. **[Astrologer Gupta](https://www.astrologergupta.com)** is known to the most experienced and best astrologer in India. Famous Vastu Consultant in Jaipur K. C Gupta Gives All Vastu Problems Solution with 100% Assurance. Find Indian Astrology, Vedic Astrology and Astrology Remedies for all your problems. Astrologergupta.com is known to the most experienced and best astrologer in India. Famous Vastu Consultant in Jaipur K. C Gupta Gives All Vastu Problems Solution with 100% Assurance. Find Indian Astrology, Vedic Astrology and Astrology Remedies for all your problems. | astrologergupta | |
1,870,194 | Text to Image AI Free Tools | Everything is possible in today's modern age. In earlier times, if you wanted to say something, it... | 0 | 2024-05-30T09:58:45 | https://dev.to/aitoolguide/text-to-image-ai-free-tools-5c6f | ai, aiops | Everything is possible in today's modern age. In earlier times, if you wanted to say something, it was used to make it known through letters. Then I was able to make comments using a diagram.
And this was impossible for everyone. With the growing AI technology, all people are able to express their thoughts in the form of drawings. Especially if you are a person without any technical knowledge, you can easily express yourself with these AI tools. Here are some unique, free AI tools that can turn your text into images.
Text to Image AI Free:
Artbreeder
NightCafe
StudioStarryAI
Dezgo
Sizzlepop
Related Article
FAQ

Artbreeder
Product Image
Key Features
Text to Image AI Free tools - Users can experiment with various art styles and create
Generative adversarial networks (GANs) to generate unique and high-quality images.
Create characters, artwork and more with multiple tools, powered by AI
Product Link: https://www.artbreeder.com/
NightCafe Studio
Product Image
Key Features
Text to Image AI Free tools - Perfect for creating artwork that looks hand-painted
Transfer to convert text descriptions into beautiful
Create digital art with a traditional touch
Create amazing artwork in seconds using the power of Artificial Intelligence
Product Link: https://creator.nightcafe.studio/
StarryAI
Product Image
Key Features
Text-to-Image AI tools offer an affordable alternative
various customization options to help users get the exact look
create intricate and detailed images
generating images from text with high precision and detail
Product Link: https://starryai.com/
Dezgo
Product Image
Key Features
Generate an image from a text description
Generate high-quality pictures from the text.
Easily Generate high-quality images from text
Product Link: https://dezgo.com/
Sizzlepop
Product Image
Key Features
AI T-Shirt Maker
Make products with SizzlePop.AI: AI Image Generator, T-Shirt Maker, & more. Create custom merch in just a few clicks.
Product Link: https://sizzlepop.ai/
Related Article
Free AI Tool for Animation 2024
Best AI Tool For Resume Creation
FAQ
Are the AI-generated images royalty-free?
It depends.
Always check the licensing and usage policies.
**[Details](https://tamilinbam.com/text-to-image-ai-free/)** | aitoolguide |
1,870,193 | Mastering the Strategy Pattern: A Real-World Example in E-commerce Shipping with Java | Introduction: In the previous article, we explored the importance of design patterns in software... | 0 | 2024-05-30T09:58:35 | https://dev.to/waqaryounis7564/mastering-the-strategy-pattern-a-real-world-example-in-e-commerce-shipping-with-java-ni | designpatterns, java, programming | **Introduction:**
In the previous article, we explored the importance of design patterns in software development and how they provide proven solutions to common problems. We discussed how choosing the right pattern is like selecting the appropriate tool from your toolbox. In this article, we'll dive deeper into the Strategy pattern and provide a practical, real-world example of its implementation using Java.
## Real-World Example: E-commerce Shipping
**Solving the Problem Without Using a Design Pattern**
Let's consider the e-commerce application that needs to calculate shipping costs based on different shipping providers. Without using a design pattern, we might end up with a less flexible and maintainable solution. Here's how the implementation might look:
```
public class ShippingCalculator {
public double calculateShippingCost(String provider, double weight) {
if (provider.equals("Standard")) {
return weight * 1.5;
} else if (provider.equals("Express")) {
return weight * 3.0;
} else {
throw new IllegalArgumentException("Unknown shipping provider");
}
}
}
// Usage
ShippingCalculator calculator = new ShippingCalculator();
double cost = calculator.calculateShippingCost("Standard", 5.0);
System.out.println("Shipping cost: $" + cost);
cost = calculator.calculateShippingCost("Express", 5.0);
System.out.println("Shipping cost: $" + cost);
```
**Solving the Problem Using a Design Pattern**
**What is the Strategy Pattern?**
The Strategy pattern is a behavioral design pattern that allows you to define a family of algorithms, encapsulate each one, and make them interchangeable. It lets the algorithm vary independently from clients that use it. The pattern consists of three main components:
**Strategy**: Defines a common interface for all supported algorithms.
**Concrete Strategies**: Implement the algorithm defined in the Strategy interface.
**Context**: Maintains a reference to a Strategy object and uses it to execute the algorithm.
Let's consider same e-commerce application that needs to calculate shipping costs based on different shipping providers. Each provider has its own algorithm for calculating the shipping cost. We can apply the Strategy pattern to encapsulate each shipping provider's algorithm separately, allowing for easy switching and maintenance.
**Step-by-Step Implementation**:
- 1
Define the Strategy interface:
```
public interface ShippingStrategy {
double calculateCost(double weight);
}
```
- 2
Create concrete classes for each shipping provider, implementing the Strategy interface:
```
public class StandardShipping implements ShippingStrategy {
@Override
public double calculateCost(double weight) {
return weight * 1.5;
}
}
public class ExpressShipping implements ShippingStrategy {
@Override
public double calculateCost(double weight) {
return weight * 3.0;
}
}
```
- 3
Use the Strategy pattern in the main application code:
```
public class ShippingCalculator {
private ShippingStrategy shippingStrategy;
public void setShippingStrategy(ShippingStrategy strategy) {
this.shippingStrategy = strategy;
}
public double calculateShippingCost(double weight) {
return shippingStrategy.calculateCost(weight);
}
}
// Usage
ShippingCalculator calculator = new ShippingCalculator();
calculator.setShippingStrategy(new StandardShipping());
double cost = calculator.calculateShippingCost(5.0);
System.out.println("Shipping cost: $" + cost);
calculator.setShippingStrategy(new ExpressShipping());
cost = calculator.calculateShippingCost(5.0);
System.out.println("Shipping cost: $" + cost);
```
**Differences Between the Two Approaches**
**Without Design Pattern**
**Tight Coupling**: The ShippingCalculator class is tightly coupled with the shipping providers. Any change in the shipping cost calculation logic requires modifying the ShippingCalculator class.
**Lack of Flexibility**: Adding a new shipping provider requires modifying the calculateShippingCost method, which can lead to errors and makes the code less flexible.
**Maintainability Issues**: The code is harder to maintain and extend because all the logic is in a single method.
**With Strategy Pattern**
**Loose Coupling**: The ShippingCalculator class is decoupled from the shipping providers. Each provider's algorithm is encapsulated in its own class.
**Flexibility**: Adding a new shipping provider is as simple as creating a new class that implements the ShippingStrategy interface.
**Maintainability**: The code is more modular and easier to maintain. Each shipping provider's logic is in its own class, making it easier to manage and update.
**Benefits of Using Design Patterns**
**Proven Solutions**: Design patterns provide proven, reliable solutions to common problems, reducing the need to reinvent the wheel.
**Improved Communication**: They offer a common vocabulary for developers to discuss solutions, making it easier to communicate and understand the design.
**Maintainability**: Patterns promote maintainability by encouraging modular and decoupled code.
**Flexibility and Extensibility**: Design patterns make it easier to extend and modify the system without affecting existing code.
**Speed Up Development**: By providing ready-made solutions, design patterns can speed up the development process.
**Conclusion**
The Strategy pattern is a powerful tool for encapsulating algorithms and making them interchangeable. By applying this pattern to the e-commerce shipping example, we achieved a flexible and maintainable solution that allows for easy switching between different shipping providers. Remember to consider the trade-offs and choose the pattern that best fits your project's requirements.
I hope this article has provided you with a clear understanding of the differences between solving a problem with and without a design pattern, and the benefits of using design patterns. Feel free to share your thoughts and experiences in the comments section below. Happy coding! | waqaryounis7564 |
1,870,192 | Avalanche Blockchain | The Go-To Web3 Development Platform | The blockchain trilemma, achieving decentralization, scalability, and security altogether, is a... | 0 | 2024-05-30T09:57:24 | https://dev.to/donnajohnson88/avalanche-blockchain-the-go-to-web3-development-platform-46dn | blockchain, web3, development, avalanche | The blockchain trilemma, achieving decentralization, scalability, and security altogether, is a problem that several projects and Oodles, a [blockchain development company](https://blockchain.oodles.io/?utm_source=devto), attempt to resolve in the blockchain development space. One of the most well-known of them is the Avalanche blockchain. The blockchain makes use of a sophisticated mix of multi-chain topologies and consensus methods.
Investors do, however, have several questions. Is Avalanche distinct from the rest of its rivals in any way? Can the blockchain withstand time and demonstrate its value? What applications exist for AVAX cryptocurrency tokens?
Every component of Avalanche will be covered in this blog so you can fully comprehend the project.
## Avalanche Blockchain
Decentralized applications (dapps) and enterprise solutions can be launched on the open-source, highly scalable Avalanche blockchain environment. In late September 2020, the mainnet became operational.
It is the first smart contracts platform that supports the Ethereum development toolkit, confirms transactions in under one second, and allows independent validators to take part as full-block producers. It touts to be an extremely quick, cost-effective, and eco-friendly blockchain platform.
After the Terra crash in 2022, Avalanche began to concentrate more on Web3 Gaming and non-fungible tokens (NFTs) rather than decentralized finance (DeFi). Institutions are also on the blockchain’s radar, in addition.
## Avalanche Blockchain Components
The [Avalanche blockchain](https://blockchain.oodles.io/avalanche-blockchain-development-company/?utm_source=devto) is a scalable, environmentally friendly blockchain with support for smart contracts. It is simpler to comprehend because of its components:
**Consensus**
A proof-of-stake consensus process used by the Avalanche chain operates at a rate of more than 4500 TPS.
**Compatible with EVM**
Case-specific functionality is made possible by the Avalanche model’s support for various custom machines like the Ethereum virtual machine (EVM) and WASM.
**Framework Chain**
The P-Chain is Avalanche’s metadata blockchain, and clients can use its API to build blockchains, add validators to subnets, monitor current subnets, and create new subnets.
**Exchange Chain**
A decentralized network for creating and selling digital assets is called the X-Chain, or Exchange chain.
Contract Chain
The default smart contract blockchain for the Avalanche chain, the C-Chain API helps users create smart contracts.
**Avalanche to Ethereum Bridge**
When transferring ERC-20 and ERC-721 tokens between the Avalanche Chain and the Ethereum network, the Avalanche-Ethereum Bridge acts as a two-way token bridge.
## Avalanche Blockchain Advantages
Avalanche addressed several issues that are present in the majority of current blockchain networks. Moreover, it adds more programmability, features, and functionalities to some of the network’s shortcomings.
**Transactional Swiftness**
With 4500 transactions per second, Avalanche has a very high transaction rate. As a result, your network has low latency.
**Customizability**
The open and adaptable Avalanche blockchain can be tailored to your project’s requirements.
**Consensus Algorithm**
To guarantee secure transactions, Avalanche employs a Proof of Stake consensus process and a random method of carrying out ongoing security checks.
**Eco-friendly**
Avalanche offers a greener blockchain option because the validators don’t need powerful hardware to operate. Because of Proof of Stake, the validations can be made randomly.
**Gas Prices**
0.000000026 AVAX is the transaction cost for Avalanche, making it a fairly affordable substitute for Ethereum.
**Secure**
Despite the independence of each parallel chain, the security is united. This secures the entire network.
## Avalanche Blockchain Use Cases
The most dependable platform for organizations, companies, and governments is probably Avalanche. As you launch assets, develop apps, and create subnets, you have total control over your implementation thanks to integrated compliance, data security, and other rulesets. See more use cases for the Avalanche blockchain.
**DeFi**
DeFi is quickly outgrowing the confines of a single chain. Avalance is also completely compatible with assets, tools, and apps of Ethereum while providing increased throughput, reduced costs, and fast speed.
**Governments**
The most reliable platform for organizations, companies, and governments is Avalanche. It gives you complete control over your implementation and enables you to deploy assets, establish apps, and construct subnets.
**Collectibles**
In a matter of seconds and for pennies on the dollar, create your digital collectibles. Improve value transmission by digitally proving ownership.
**Web3**
Making web3 a reality is made possible by the Avalanche network, which provides a platform for the development and implementation of new, configurable blockchains with cheap costs, intelligent features, and interoperability with EVM.
**Asset Transfers**
The best platform for developing and exchanging Avalanche assets is the Avalanche X-Chain network. AVAX, JOE, and PNG are some of the well-liked assets on the X-Chain; they are both decentralized exchange tokens.
**Low Slippage**
Price slippage is greatly reduced by quicker transactions and better throughput. This assures the network of immediate deals.
## Conclusion
Avalanche Blockchain is emerging as a major player in the blockchain industry. Its ability to carry out an endless number of transactions in a single second (using subnets) is one of its many exceptional qualities. It is not unexpected that the platform is drawing interest from a variety of sectors and investors given its quick transaction speeds, great scalability, and improved security.
Like any new technology, the blockchain platform has some difficulties and restrictions. Despite this, Avalanche’s (AVAX) potential is clear. But as you are no doubt well aware, it's hard to say what the future holds for blockchain-based systems such as the Avalanche Network and its native token. This is one of the reasons you need to continue paying close attention to developments in the area. Also, if you have a project in mind or have any queries or concerns related to Avalanche Blockchain, connect with our skilled [blockchain developers](https://blockchain.oodles.io/about-us/?utm_source=devto). | donnajohnson88 |
1,870,191 | What I learnt at the Web Performance workshop by Cloudinary | Yesterday, I went down to the Google Developer Space in Singapore for a talk by Tamas Piros on the... | 0 | 2024-05-30T09:57:23 | https://dev.to/kervyntjw/what-i-learnt-at-the-web-performance-workshop-by-cloudinary-4fc | Yesterday, I went down to the Google Developer Space in Singapore for a talk by Tamas Piros on the topic of "Mastering Web Performance" in 2024. First of all, kudos and thanks to Tamas for coming down and giving us these insights into optimizing our sites for performance. I learnt quite a few things from it and am excited to implement them in my future projects.
I'm sure many of you feel this way too, and this is why I am here today to share some of the main takeaways I got from this workshop!
# Takeaways:
## 1. What the Core Web Vitals consist of
Prior to the workshop, I have experience in conducting frequent website maintenances for clients, and one of the tasks included month-to-month improvements in site performance. I was always involved in the steps taken in order to improve the page score given by Google, and to achieve a better score, our site needs to tackle issues that arise with the **Core Web Vitals**. So, what are these Core Web Vitals?
- Cumulative Layout Shift (CLS)
- Interaction to Next Paint
- Largest Contentful Paint
I will briefly cover what these are, focus on the first 2 vitals in this article!
### 1.1 Cumulative Layout Shift (CLS)
Very briefly, what CLS is, is the measurement of how much content on your page shifts. For instance, if there are ads that are displayed between paragraphs on your page, and they display after a certain condition, this would **decrease** the CLS score as your paragraphs/text on the page will likely move as these ads load.
Why is CLS **important** to consider for optimal web performance?
Well, having paragraphs that move a lot significantly affects User Experience (UX)! For instance, if a user is staying still on the page reading the text, I'm sure you can imagine how frustrated the user will be if that text suddenly shifts out of your viewport right? Similarly, if you, as a user is highlighting links on the page, you won't want it to suddenly shift and for you to lose that link right?
### 1.2 Interaction to Next Paint
This is essentially how long the page takes to load. The name is as such, because it measures how long the site takes to respond after a user has **interacted** with it. eg. Clicking a button on the page, redirects etc.
This is also another factor to consider for UX. As the web world gets more advanced each day, users and customers expect quicker speeds and smoother website layouts and performances. If your website is slightly slower than your competition, that could be the difference between a potential customer versus someone who is disgusted with the speed of your website.
These are just part 1 of the takeaways I had from the workshop held yesterday. If you guys are interested in learning even more, show some love on this post! If this post gets enough traction, I'll post more of my takeaways that I had from the talk with more in-depth information on the topics as well!
| kervyntjw | |
1,870,190 | Outerform.ai: AI-Powered Business Transformation. | Outerform.ai is an innovative AI platform dedicated to revolutionizing business operations. Our... | 0 | 2024-05-30T09:56:15 | https://dev.to/outerform/outerformai-ai-powered-business-transformation-5534 | saas, ai, devops | [Outerform.ai](https://www.outerform.ai/) is an innovative AI platform dedicated to revolutionizing business operations. Our cutting-edge solutions harness the power of artificial intelligence to optimize efficiency, streamline workflows, and drive growth. With advanced machine learning algorithms and predictive analytics, we empower businesses to make data-driven decisions and stay ahead in a competitive market. From automating routine tasks to providing actionable insights, [Outerform.ai ](https://www.outerform.ai/)is your partner for success in the digital age.
| outerform |
1,870,189 | Travel Like Royalty: Aboard the Deccan Odyssey | The Deccan Odyssey is no ordinary train. It's a meticulously curated mobile palace that harks back... | 0 | 2024-05-30T09:55:19 | https://dev.to/deccan_odysseyluxurytra/travel-like-royalty-aboard-the-deccan-odyssey-4obd |

The Deccan Odyssey is no ordinary train. It's a meticulously curated mobile palace that harks back to the era of Maharajas, transporting you in time with its opulent interiors and impeccable service. This grand chariot on wheels offers several captivating itineraries, aptly named to reflect the essence of each journey.
**Unveiling the Jewels of India: Diverse Itineraries**
Embark on The Indian Odyssey, a legendary route that whisks you past the iconic Taj Mahal, the captivating Ranthambore National Park, and the majestic forts of Rajasthan. Alternatively, delve into the rich heritage of Maharashtra on The Maharashtra Splendor journey, where you'll explore the Ajanta and Ellora Caves, the stunning beaches of Konkan, and the architectural marvels of Mumbai.
More than just destinations, each itinerary promises a unique tapestry of experiences. Imagine spotting tigers in their natural habitat, unraveling the mysteries of ancient cave temples, or getting a glimpse into the lives of local artisans.
**Opulence on the Move: Your Luxurious Haven**
Step aboard the **[Deccan Odyssey Train](https://www.deccanodyssey.co.uk
)** and be greeted by a haven of unparalleled luxury. Your plush cabin, a haven of tranquility, features a private bathroom, air-conditioning, and even a mini gym for those who wish to maintain their fitness regime.
Beyond your private sanctuary, a world of exquisite experiences awaits. Savor delectable meals prepared by expert chefs in the elegant dining cars. Relax and unwind in the sophisticated bar lounge, or catch up on work in the dedicated business center. For those seeking rejuvenation, the onboard spa provides a haven of pampering, while the conference room caters to discerning business travelers.
**Unforgettable Experiences: Beyond the Train**
The **[Deccan Odyssey](https://www.deccanodyssey.co.uk
)** isn't just about the luxurious confines of the train itself. Each expertly curated itinerary features a captivating selection of off-the-beaten-path experiences that bring the destination to life.
Imagine embarking on thrilling tiger safaris, where skilled naturalists guide you through the wilderness in search of these majestic predators. Immerse yourself in the rich tapestry of Indian culture through heritage walks and captivating performances by local artists. Gain exclusive access to historical sites that are often closed to the public, creating memories that will stay with you for a lifetime.
**A Day in the Life of Luxury: A Glimpse Aboard the Deccan Odyssey
**
Imagine waking up to the gentle sway of the train as you traverse the Indian countryside. A steaming cup of freshly brewed coffee awaits you on your private balcony, offering a breathtaking panorama of rolling hills or charming villages.
As the day unfolds, you might embark on a thrilling morning game drive, followed by a fascinating visit to a historical monument or a local village. In the afternoon, return to the train for a leisurely lunch, perhaps followed by a rejuvenating session at the spa. As the sun sets, painting the sky in vibrant hues, gather with fellow travelers in the elegant bar lounge for an evening of conversation and camaraderie. The evenings may also be graced by traditional music performances or movie nights under the starlit sky, creating a truly unforgettable experience.
**A Culinary Odyssey: A Celebration of Flavors
**
Aboard the Deccan Odyssey , your taste buds will embark on a remarkable journey alongside your physical one. Expert chefs prepare a symphony of flavors, showcasing the rich culinary tapestry of India. From fragrant curries bursting with fresh spices to melt-in-your-mouth kebabs, each meal is a celebration of regional specialties and fresh, locally sourced ingredients.
Fine dining experiences are complemented by impeccable service. Attentive staff cater to your every whim, ensuring a truly unforgettable epicurean adventure.
**Evenings of Exquisite Entertainment
**
As day turns to night, the Deccan Odyssey transforms into a haven of sophisticated entertainment. Sway to the melodious tunes of traditional Indian music performances, or catch up on the latest blockbusters under the starlit sky during onboard movie nights.
The inviting atmosphere also fosters connections with fellow travelers. Share stories and experiences over cocktails in the bar lounge, forging friendships that will likely last a lifetime. | deccan_odysseyluxurytra | |
1,870,188 | ☎️+91-9257780540☎️ ̿ Best Online ID Provider Mumbai | ☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai ☎️+91-9257780540☎️ ▀̿ Best Online ID Provider... | 0 | 2024-05-30T09:53:14 | https://dev.to/umair_khalil_e6fb60ebf2a2/91-9257780540-best-online-id-provider-mumbai-51bd | ☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai ☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Best Online ID Provider Mumbai | umair_khalil_e6fb60ebf2a2 | |
1,870,187 | 5 Common UX Mistakes and How to Avoid Them: Optimizing Your Design Process for Success | A well-crafted user experience (UX) and user interface (UI) interface isn't just about aesthetics;... | 0 | 2024-05-30T09:53:09 | https://dev.to/anmolrajdev/5-common-ux-mistakes-and-how-to-avoid-them-optimizing-your-design-process-for-success-3ncg | webdev, design, uiux, web |

A well-crafted user experience (UX) and user interface (UI) interface isn't just about aesthetics; it's about creating a seamless and intuitive experience that keeps users engaged and drives conversions.
Here at 42Works, a leading [UI/UX Design company](https://42works.net/expertise/ui-ux-design/) and Offshore UI Design Agency offering UI UX Design Outsourcing Services, we understand the importance of avoiding common pitfalls in the design process. Let's explore five frequent mistakes businesses make and how to steer clear of them, ensuring a successful outcome for your website, application, or other digital product.
**<u>Mistake #1: Prioritizing Aesthetics Over Usability
</u>**
While a visually appealing interface is important, it shouldn't come at the expense of usability. Flashy animations or overly complex layouts can confuse users and hinder their ability to complete desired actions. This can lead to frustration, abandonment, and ultimately, loss of business.
**<u>Impact:</u>** Studies by Nielsen Norman Group show that even minor usability issues can decrease conversion rates by as much as 37%.
**<u>Solution:</u>** Focus on user needs first. Conduct user research to understand your target audience's expectations and pain points. Prioritize clear navigation, intuitive layouts, and easy-to-understand functionalities. At 42Works, our team of [Top-notch UX/UI design specialists](https://42works.net/) employs user-centered design principles to create interfaces that are both beautiful and functional.
**<u>Mistake #2: Ignoring Mobile Optimization</u>**
With the rise of mobile browsing, neglecting mobile optimization is a recipe for disaster. Users expect a seamless experience regardless of the device they use. If your website or app isn't optimized for mobile, users will likely bounce off quickly, leading to missed opportunities.
**<u>Impact</u>:** According to Statista, over 54% of all web traffic worldwide comes from mobile devices. A non-mobile-friendly interface alienates a significant portion of your potential audience.
**<u>Solution:</u>** Design with mobile in mind from the very beginning. Employ responsive design principles that ensure your interface adapts seamlessly across different screen sizes and devices. 42Works offers comprehensive [WEBSITE DESIGN and APPLICATION DESIGN](https://42works.net/expertise/websites/) services, including mobile optimization, to ensure your digital product reaches its full potential.
**<u>Mistake #3: Inconsistent Design Language
</u>**
A lack of consistency can create confusion and disrupt the user flow. This applies to visual elements like color schemes, typography, and button styles, as well as the overall layout and user interaction patterns.
**<u>Impact:</u>** Inconsistent design can make users feel lost and unsure of how to navigate your interface. This can lead to frustration and a negative brand perception.
**<u>Solution:</u>** Establish a clear design style guide and ensure all elements across your digital product adhere to it. This includes LOGO DESIGN, INFOGRAPHICS DESIGN, and all other visual components offered by 42Works. A consistent design language creates a sense of trust and familiarity for your users.
**<u>Mistake #4:</u>** Lack of Clear Calls to Action (CTAs)
CTAs are the buttons or prompts that tell users what you want them to do next. Whether it's signing up for a newsletter, making a purchase, or downloading a document, clear CTAs are essential for guiding users toward desired actions.
**<u>Impact:</u>** Vague or poorly placed CTAs can leave users confused and unsure of what step to take next. This can result in missed opportunities and a decline in conversions.
**<u>Solution:</u>** Create clear, concise, and visually distinct CTAs. Use strong action verbs, such as "Buy Now" or "Download Here," and ensure they stand out from the surrounding content.
**<u>Mistake #5: Neglecting User Testing
</u>**
No design is perfect. User testing allows you to observe real users interacting with your interface and identify any potential issues before launch. This valuable feedback helps you refine your design and ensure a smooth user experience.
**<u>Impact:</u>** Launching a product with unaddressed usability issues can lead to a negative user experience and damage your brand reputation.
**<u>Solution:</u>** Conduct user testing throughout the design process. At 42Works, we offer UX & UI Design and Consulting Services that include user testing to ensure your product is user-friendly and meets its full potential.
By avoiding these common mistakes and implementing these actionable tips, you can optimize your UI/UX design process and create digital products that not only look great but also deliver a seamless and engaging user experience. Remember, a well-designed interface is an investment that can pay off in the long run, driving user engagement, conversions, and ultimately, business success.
Ready to create exceptional user experiences? [Contact 42Works today](https://42works.net/contact/) to discuss your UI/UX design needs! | anmolrajdev |
1,870,186 | How do knee braces reduce my knee pain? | Inside the world of knee braces, the Z1 knee brace stands as a beacon of hope for the ones struggling... | 0 | 2024-05-30T09:52:49 | https://dev.to/mahaveer_singh_285b9fed3b/how-do-knee-braces-reduce-my-knee-pain-iga | kneebrace, buykneebraceonline, kneebraceonline, customkneebrace | Inside the world of knee braces, the Z1 knee brace stands as a beacon of hope for the ones struggling with knee pain. Known for its progressive layout, advanced aid and comfort, the Z1 knee brace has been exceedingly favored by athletes, health fanatics and those who want to take away knee pain. So what makes the Z1 knee brace stand proud of the opposition? Let's examine the capabilities and blessings of the Z1 and an explanation for why they're taken into consideration for their magnificence for [buy knee brace online](https://z1kneebrace.com/knee-braces).
Know-How Knee Pain:
Before we observe the fundamentals of knee braces, it is vital to recognize what causes knee pain. The knee is a joint that supports weight and lets in an extensive range of motion. As a result, it is a problem to many injuries and situations, along with torn ligaments, cartilage harm, and osteoarthritis. It causes swelling, instability and osteoarthritis. This sickness can range from mild to severe and might have an effect on mobility and ordinary best of lifestyles. There are numerous sorts, which include sleeves, wraps, and hinged braces, and each type has a particular purpose relying on the man or woman's desires and the character of the knee injury or ache.
Support and Stability:
One of the predominant functions of knee braces is to provide assistance and balance to the knee joint. With the aid of compressing the distance around the knee and presenting external assistance, braces help lessen strain and prevent further damage. This added balance is especially beneficial for humans convalescing from an accident or torn ligament, inclusive of an ACL or MCL harm.
Compression and Pain Comfort:
Knee braces practice gentle strain to the encompassing tissue, supporting to lessen swelling and decrease ache. via compressing the location, the stent affords a higher and less complicated way to deliver oxygen and vitamins to the injured tissue at the same time as casting off metabolic waste. This reduces ache and pain, allowing the person to function extra easily every day.
Adjustment Correction:
If knee pain is caused by misalignment or biomechanical issues, a few types of knee braces (such as off-load supports) can cooperatively help accurately and redistribute weight. This relieves stress on certain regions of the knee, thereby reducing ache and enhancing general function.
Improving Proprioception:
Proprioception is the capacity to apprehend the body's role and motion in an area. Knee pads, especially people with adjustable straps or hinges, can enhance posture and deliver humans a higher experience of coordination and mobility. This expanded focus improves stability, stability, and coordination, decreasing the threat of falls and further injury.
Psychological Assist:
Similar to its bodily advantages, knee braces can also offer psychological support to knee patients. additional protection and aid can increase protection, confidence and decrease strain, permitting people to stay calm and participate in each day lifestyles.
The Z1 knee brace represents the top of excellence in knee aid and rehabilitation. With their progressive layout, suit, top guide and lots of functions, those corsets provide a super answer for individuals who want to eliminate knee pain. Whether you're convalescing from a harm, coping with a continual situation, or operating to prevent destiny troubles, Z1 knee braces offer the help, consolation, and performance you need to help you regain your power and live life to the fullest. find out the difference for yourself and discover why the Z1 knee brace is widely taken into consideration, pleasant in its magnificence. https://z1kneebrace.com/knee-braces

| mahaveer_singh_285b9fed3b |
1,870,185 | ☎️+91-9257780540☎️ ̿ Get Online ID Provider Mumbai | ☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider... | 0 | 2024-05-30T09:52:42 | https://dev.to/umair_khalil_e6fb60ebf2a2/91-9257780540-get-online-id-provider-mumbai-3gml | webdev, cricket | ☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai☎️+91-9257780540☎️ ▀̿ Get Online ID Provider Mumbai | umair_khalil_e6fb60ebf2a2 |
1,870,184 | BEGINNERS COMMAND - GIT | GIT GIT is a version control system that is designed to handle small to large projects with speed... | 0 | 2024-05-30T09:52:41 | https://dev.to/shreeprabha_bhat/beginners-command-git-5354 | **GIT**
GIT is a version control system that is designed to handle small to large projects with speed and efficiency. It allows multiple people to work on same project simultaneously without effecting other's code.
GIT is most common skill that recruiters expect in everyone's resume. There are some of the basic commands that must be known to everyone while working with git or attending any technical interview.
**MUST KNOW GIT COMMANDS**
These commands are used to setup git in your system. Using the commands below one can access the git synchronized with the mail ID.
```
git config --global user.name "Your name"
git config --global user.email "Your mail"
```
This command is used initialize a repository in your git. Once the repository is initialized other actions like commit, push or pull can be performed over these repository.
```
git init
```
Below command is used to clone an existing repository into your repository.
```
git clone <repository_url>
```
The command below is used to get the status of repository.
```
git status
```
Stage the changes for commit.
```
git add <file_name>
# Command stages the changes in that particular file
git add .
#Command stages the entire changes.
```
Commit changes to the repository
```
git commit -m "Your message"
```
View the history of commits in the repositiory
```
git log
```
Creating a new branch.
```
git branch <branch_name>
```
Switch to a new branch
```
git checkout <branch_name>
```
Create and switch to a new branch
```
git checkout -b <branch_name>
```
Merge a branch to the new branch
```
git merge <branch_name>
```
Know which branch you are working in.
```
git branch
```
Add a repository to the remote repositiory
```
git remote add origin <repository_url>
```
Fetch changes from the remote repository
```
git fetch
```
Push changes to the remote repositiory
```
git push origin <branch_name>
```
Pull changes from the remote repository
```
git pull
```
List remote repositories
```
git remote -v
```
Stash the changes when your are not ready to commit them.
```
git stash
```
Apply the stashes to the desired branch
```
git stash apply
```
| shreeprabha_bhat | |
1,870,183 | Mastering Magento PIM Integration | Product Information Management (PIM) is essential for Magento store owners looking to streamline... | 0 | 2024-05-30T09:51:45 | https://dev.to/charleslyman/mastering-magento-pim-integration-3cf1 | magento, pim | Product Information Management (PIM) is essential for Magento store owners looking to streamline their product data across multiple channels. This blog delves into Magento PIM integration and highlights the advantages of leveraging Amazon Web Services (AWS) for Magento hosting.
**Why Magento PIM Integration is Crucial**
Integrating a PIM with your Magento store centralizes product information management, allowing for consistent, accurate, and up-to-date product data across all sales channels. This integration simplifies managing extensive product catalogs and enhances the efficiency of sales and marketing efforts.
**Steps to Integrate PIM with Magento**
- **Evaluate Your Needs:** Understand the specific requirements of your Magento store to choose the right PIM system.
- **Choose a Compatible PIM System:** Select a PIM that seamlessly integrates with Magento, offering features like automated data synchronization, advanced data management, and multi-channel support.
- **Implement and Customize:** Install the PIM software and customize the settings to align with your business processes and data flow.
- **Data Migration:** Migrate existing product data into the PIM system, ensuring accuracy and consistency.
- **Continuous Monitoring and Updating:** Regularly update and maintain the PIM system to handle new products and changes in existing data.
By leveraging [managed Magento hosting](https://devrims.com/magento-hosting/) you can bring significant benefits to PIM integration:
- **Scalability:** AWS scales resources on-demand to meet the needs of your store, ensuring smooth operation during traffic spikes.
- **Security:** AWS provides comprehensive security features that protect your sensitive product data against threats.
- **Reliability:** With AWS, expect high uptime and consistent performance, crucial for maintaining access to your PIM system and Magento store.
- **Global Reach:** AWS's global infrastructure ensures faster access and reduced latency, improving the experience for users worldwide.
**Conclusion**
[Magento PIM integration](https://devrims.com/blog/magento-pim-integration/) is a strategic move for any e-commerce business looking to optimize product information management. By combining this with AWS for Magento hosting, businesses can ensure a robust, secure, and scalable e-commerce environment. This setup not only streamlines product data management but also enhances overall operational efficiency and customer satisfaction. | charleslyman |
1,870,182 | The Different Types of Demat Accounts and How to Use Them | A Demat account, short for a Dematerialized account, is an electronic account that allows investors... | 0 | 2024-05-30T09:49:11 | https://dev.to/shriya_jain_/the-different-types-of-demat-accounts-and-how-to-use-them-4bf8 | A Demat account, short for a Dematerialized account, is an electronic account that allows investors to hold shares and securities in a dematerialised or electronic form. Instead of physical share certificates, the ownership records are maintained electronically by a Depository Participant (DP). This account is essential for anyone looking to invest in the share market. One of the leading players in the Indian share market is Kotak, a renowned financial services company that offers various Demat account options to cater to different investment needs. In this blog, we'll explore the different types of Demat accounts and how to use them effectively.
## Types of Demat Accounts
There are several **[types of Demat account](https://www.kotaksecurities.com/demat-account/types-of-demat-account/)** available, each designed to cater to specific investment needs:
**1. Regular Demat Account:** This is the most common type of Demat account and is suitable for individual investors who wish to hold and trade shares and securities in their own name.
**2. Joint Demat Account:** As the name suggests, a joint Demat account is opened by two or more individuals, allowing them to hold and trade shares together. This account type is ideal for family members or business partners who want to invest jointly.
**3. NRI Demat Account:** Non-resident Indians (NRIs) can open an NRI Demat account to hold and trade shares in the Indian share market while residing abroad.
**4. Corporate Demat Account:** Companies and institutions can open a corporate Demat account to hold and trade shares and securities for their business purposes.
**5. Margin Trading Account:** This account type allows investors to leverage their investments by borrowing funds from the broker to trade in the share market.
## How to Use a Demat Account?
Using a Demat account is relatively straightforward, but it's essential to understand the process:
- **Opening a Demat Account:** To open a Demat account, you need to approach a Depository Participant (DP) like a bank or a brokerage firm. Kotak offers various Demat account options to suit different investment needs.
- **Funding the Account:** Once the account is opened, you can transfer funds from your bank account to your Demat account to start trading in the share market.
- **Buying and Selling Shares:** With a funded Demat account, you can place buy or sell orders through your broker or online trading platform. The shares will be credited or debited from your Demat account electronically.
- **Monitoring and Managing:** It's crucial to monitor your Demat account regularly and keep track of your holdings, transactions, and portfolio performance.
## Conclusion
Demat accounts have changed the way investors participate in the share market. With various account types available, investors can choose the option that best suits their investment objectives and preferences. **Kotak**, as a trusted financial services provider, offers a range of Demat account solutions to cater to diverse investment needs. By understanding the different types of Demat accounts and how to use them effectively, you can navigate the share market with confidence and potentially achieve your financial goals.
| shriya_jain_ | |
1,870,181 | Hello C# Devs | A post by Mohamed Abdi | 0 | 2024-05-30T09:47:30 | https://dev.to/mohamedabdiahmed/hello-c-devs-271e |
 | mohamedabdiahmed | |
1,870,180 | How to Automate Microservices: Best Approaches & Strategies | Building applications with microservices, where each individual service plays a specific role, has... | 0 | 2024-05-30T09:46:59 | https://dev.to/kairostech/how-to-automate-microservices-best-approaches-strategies-jk2 | microservices, microservicestesting, testing, acceleratedtesting |

Building applications with microservices, where each individual service plays a specific role, has become a game-changer for developers. However, in this intricate world, ensuring each service functions seamlessly and flawlessly is vital.
**[Microservices testing](https://kairostech.com/microservices-testing/)** is a specialized field that tackles this challenge by validating the functionality, performance, and reliability of individual services, together with, ‘how they work together?’. This blog dives into various strategies and approaches for automating the testing of microservices, aimed at ensuring smooth integration and seamless operation of these distributed components.
**What are Microservices?**
Microservices architecture ensures the decomposition of monolithic applications into smaller, independently deployable services that are loosely coupled. Each service encapsulates a distinct business function and interacts with other services via APIs. This modular approach simplifies the development process, enables independent deployment of services, and streamlines application maintenance.
**Understanding Microservices Testing**
The distributed nature of microservices architectures can render conventional testing strategies ineffective for comprehensive application testing.
Effective microservices testing addresses the complexities of service-to-service communication, maintains data integrity across distributed components, and validates the correct configuration of the decentralized architecture, thereby ensuring the overall robustness and reliability of the microservices ecosystem.
**Market Forecast:**
The microservices testing market is experiencing significant growth, driven by the increasing adoption of microservices architecture in various industries. Here are some key statistics and forecasts:
According to The Future Market Insight’s report, the microservices market is estimated to reach USD 1.90 billion in 2024, with a value-based CAGR of 21.20%.
By the end of 2034, the market valuation is expected to surpass USD 13.20 billion.
The microservices market size was valued at USD 1.4 billion in 2023 and is projected to register a CAGR of over 20.3% between 2024 and 2032.
**Advantages of Microservices:**
**Scalability:** Microservices architecture allows individual components to be scaled up or down independently, based on demand, resulting in optimal resource utilization and cost-effectiveness.
**Fault Isolation:** By decomposing the application into smaller, self-contained services, microservices provide better fault isolation. If one service fails, it does not necessarily bring down the entire application, improving overall system resilience.
**Faster Development:** Breaking down the application into smaller, more manageable services enables development teams to focus on specific components concurrently. This parallel development approach shortens development cycles and facilitates faster delivery of new features and updates.
**Key Modern Approaches of Testing Microservices**
**Contract Testing:** Contract testing establishes agreements (contracts) between microservices, defining how they interact with each other. These contracts outline the expected inputs, outputs, and behavioral specifications that each service adheres to when communicating with its counterparts. These contracts are enforced through tests, which identify compatibility issues early in development and ensure smooth communication between services.
**Unit Testing**
Unit testing is fundamental in microservices testing, focusing on validating the functionality of individual microservices. It involves testing the smallest parts of the application in isolation (e.g., functions or methods). In a microservices architecture, each service is treated as a unit, ensuring that it performs its intended task independently.
An inseparable part of s/w development and link to TDD/BDD. Checks the functionality at a most granular level.
• Solitary Unit Tests – deterministic tools with stubbing (during UT).
• Sociable Unit Tests – with real calls to external services
Unit tests are automated and coded to verify the internal logic and functionalities of the microservices. Tools like JUnit and Mockito are commonly used for this purpose.
**Chaos Engineering:** Chaos engineering involves deliberately injecting controlled faults or failures into a system to test its resilience. By simulating real-world scenarios, teams can identify weaknesses and strengthen their microservices architecture.
**Containerization Testing:** Deploying microservices typically makes use of containers like Docker. Testing compartments for versatility, security, and similarity with various conditions is fundamental for fruitful microservices sending. For improved software performance, scale, and security, containers are preferred for microservice testing.
**[API Testing](https://klabs.kairostech.com/modern-api-testing-solutions-for-modern-applications/):** In microservices-based systems, communication between services heavily relies on APIs. Therefore, rigorous API testing becomes essential to ensure reliable and robust interactions. Tools like API TestEasy can automate API tests, streamlining the process and guaranteeing the accuracy and stability of these critical connections.
**End-to-End Testing:** End-to-end testing entails validating the system's functionality in its entirety and ensuring that the entire procedure proceeds without incident.
It guarantees that the framework acts true to form in a creation-like situation, taking into account every single imaginable collaboration and mix. This kind of testing involves thoroughly testing all of the system's services and components to make sure it works well and meets user expectations.
**Performance Testing**
The objective of performance testing is to assess the scalability and responsiveness of the microservices architecture under various load conditions. This testing approach verifies that the individual microservices can handle fluctuating traffic volumes, maintain acceptable response times, and consistently deliver high performance. Specialized performance testing tools are employed to simulate peak load scenarios, evaluate the system's scalability capabilities, and pinpoint any potential bottlenecks or performance bottlenecks that may hinder the overall responsiveness of the application.
**Final Thoughts:** In conclusion, automating microservices testing is essential for ensuring the seamless operation of complex architectures. By implementing focused testing approaches like Unit Testing, Contract testing, Chaos Engineering, Containerization testing, API testing, and End-to-end testing, along with Performance, Scalability and Reliability testing, organizations can streamline their testing processes and deliver reliable microservices applications. Embracing automation in testing not only enhances the quality of the software but also accelerates the development cycle, making microservices an attractive choice for modern applications.
For Demo **[Click Here](https://zcmp.in/iew7)** | kairostech |
1,870,179 | Implementing Consumable In-App Purchases in React Native for iOS Devices | In-app purchases (IAP) in React Native require using native code for both iOS and Android because... | 0 | 2024-05-30T09:46:37 | https://dev.to/harisbinejaz/implementing-consumable-in-app-purchases-in-react-native-for-apple-devices-2ag9 | reactnative, ios, javascript | In-app purchases (IAP) in React Native require using native code for both iOS and Android because React Native doesn’t have a built-in module for IAP.
## Types of In-App Purchases (IAP)
Users can make different types of purchases within a mobile app. While the terms and specific types may vary slightly between iOS and Android, the following types are generally common:
### 1. Consumable Purchases
Consumable purchases are items that users buy and use up. These include things like virtual currency, extra lives, power-ups, or other virtual goods that can be consumed within the app.
**Example**: Purchasing virtual coins or gems in a game.
### 2. Non-Consumable Purchases
Non-consumable purchases are items that users buy once and have permanent access to. These include features or content that don’t get used up.
Accessing a premium feature, eliminating ads, or acquiring additional content like an extra level or chapter in a book app.
### 3. Auto-Renewable Subscriptions
Auto-renewable subscriptions allow users to access content or features on an ongoing basis. These subscriptions automatically renew at the end of the subscription period unless the user cancels.
**Example**: Monthly or annual subscription for premium content, access to exclusive features, or an ad-free experience.
Adding consumable purchases to an In-App Purchase (IAP) system involves several steps, and the specifics can vary depending on the platform (iOS, Android) and the tools/libraries you are using. Here are the general steps to implement consumable purchases in a React Native app using (for IOS) the `react-native-iap` library:
## 1. Install the library
First, you need to install the library. You can use npm, yarn, or any other node package manager you prefer:
```javascript
yarn add react-native-iap
```
OR
```javascript
npm install react-native-iap
```
## 1. Set up In App Purchase Products:
I assume you already have an **Apple Developer** account and an **app** created within that account. If you need help setting up an **Apple Developer** account and creating an **app**, you can refer to [this guide](https://developer.apple.com/help/app-store-connect/create-an-app-record/add-a-new-app/).
Now, click on your app and follow these steps to create an in-app purchase product:
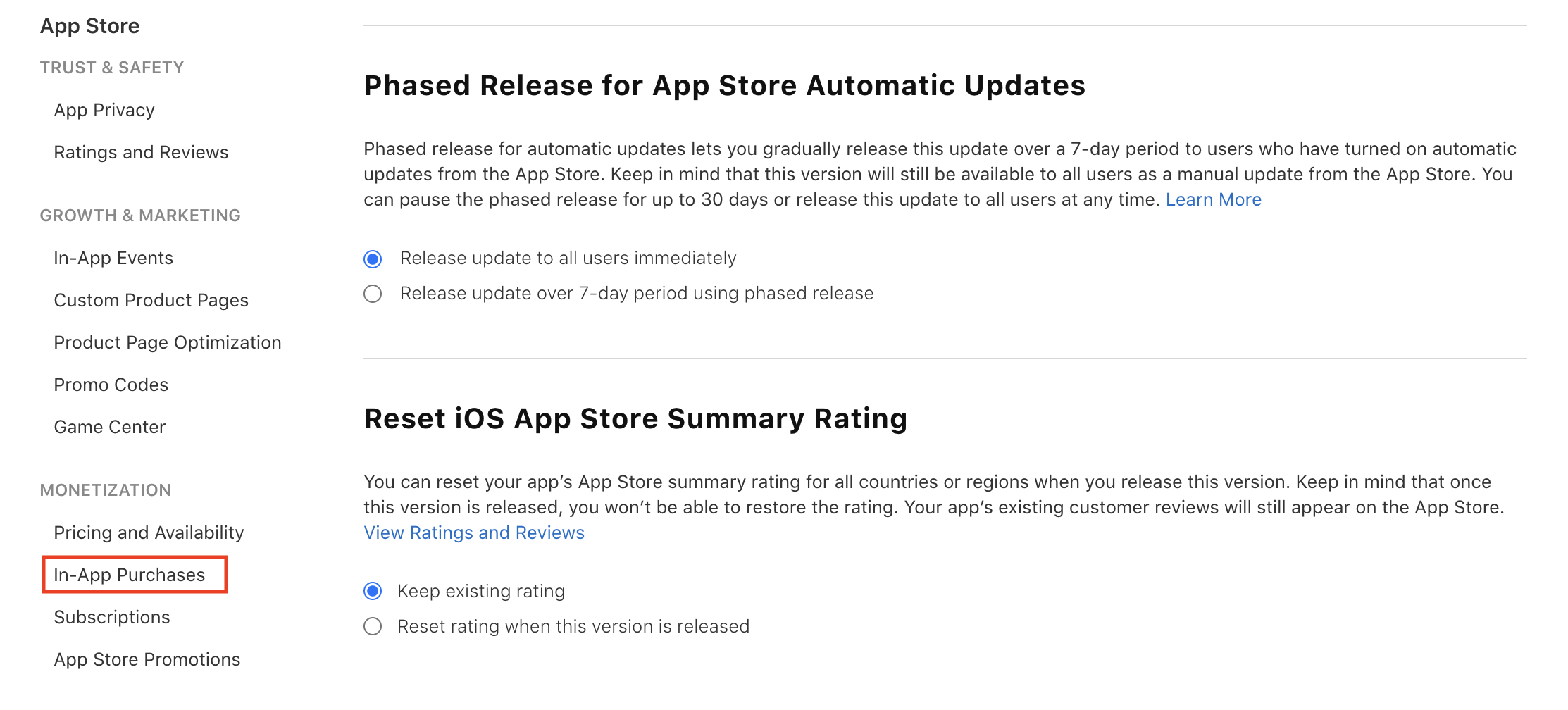
First, scroll to the bottom of the sidebar on your app page and click on **In-App Purchases** under the **Monetization** tab:
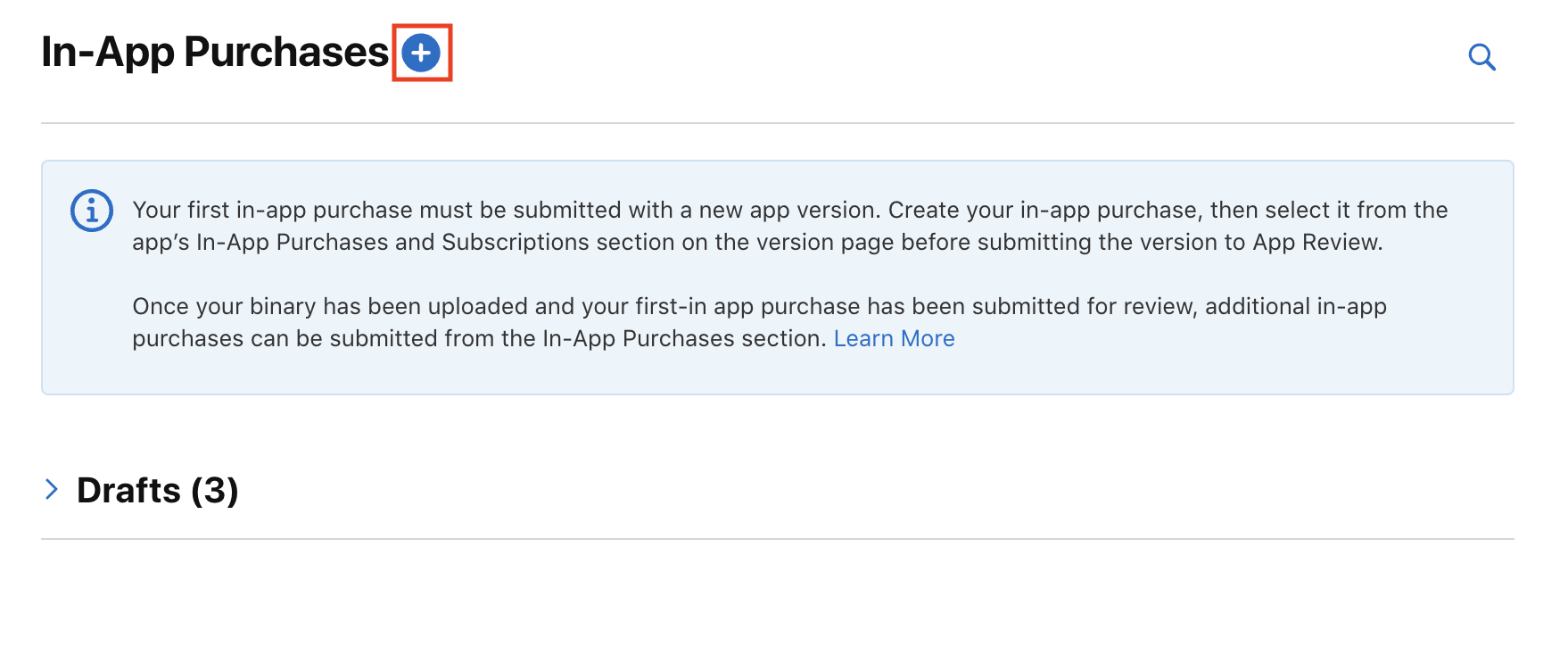
Next, click the plus icon next to the In-App Purchase Title:
A popup will appear like this::
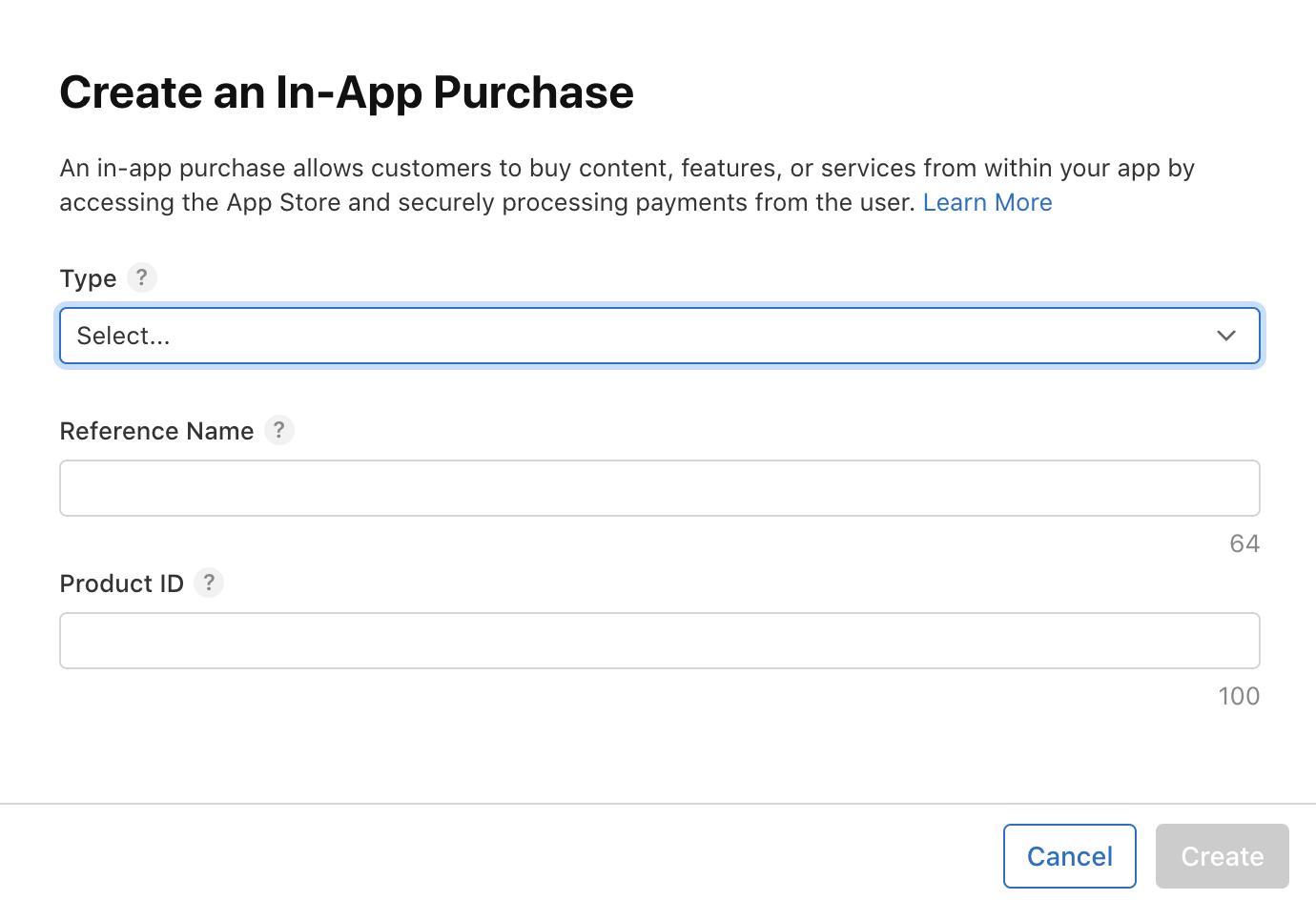
Select the type consumable and fill in the required information as shown:
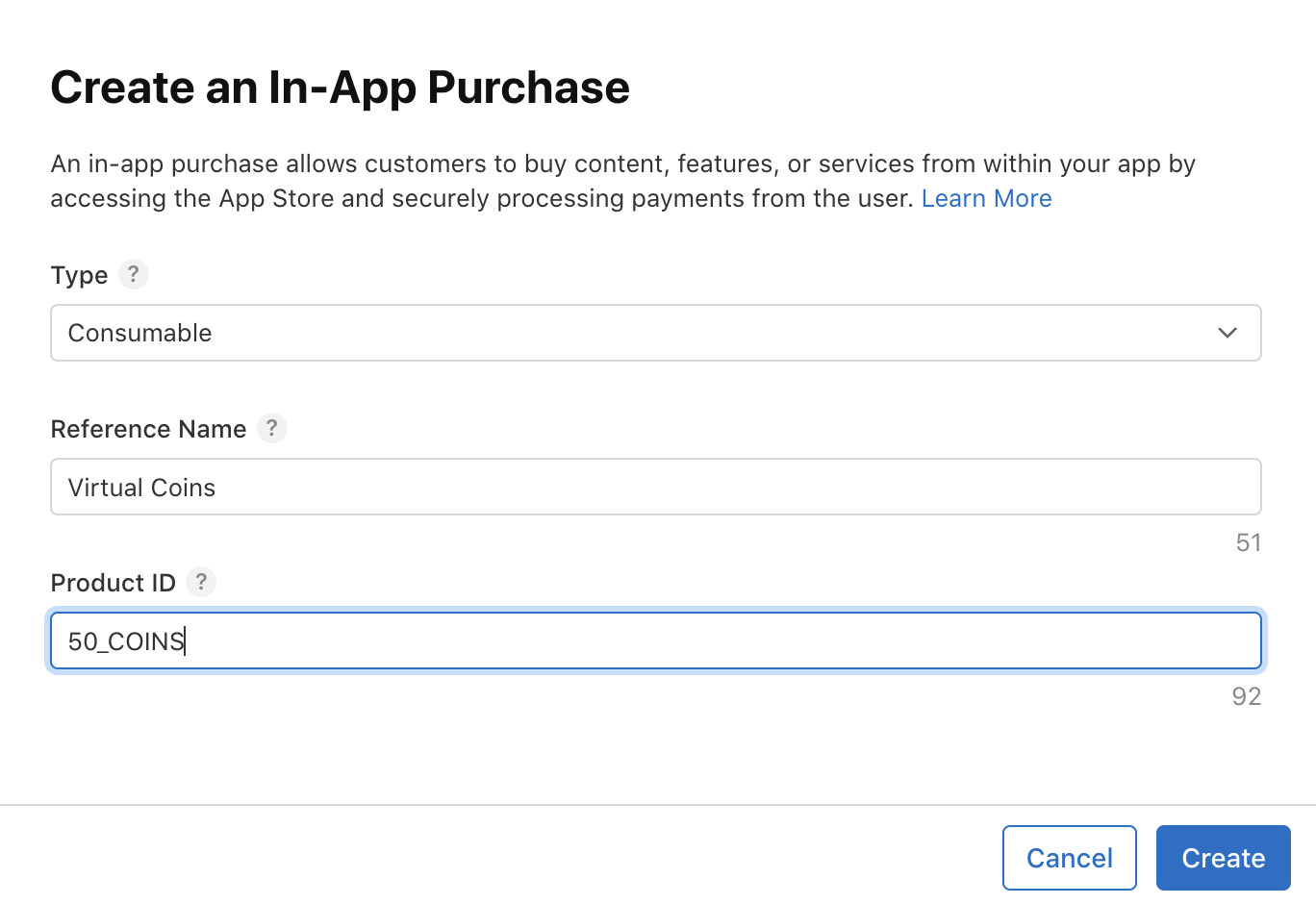
Click the save button, and you will be navigated to a screen where you can add more details for this in-app purchase product.
Then, select the availability of this in-app purchase product for different countries:
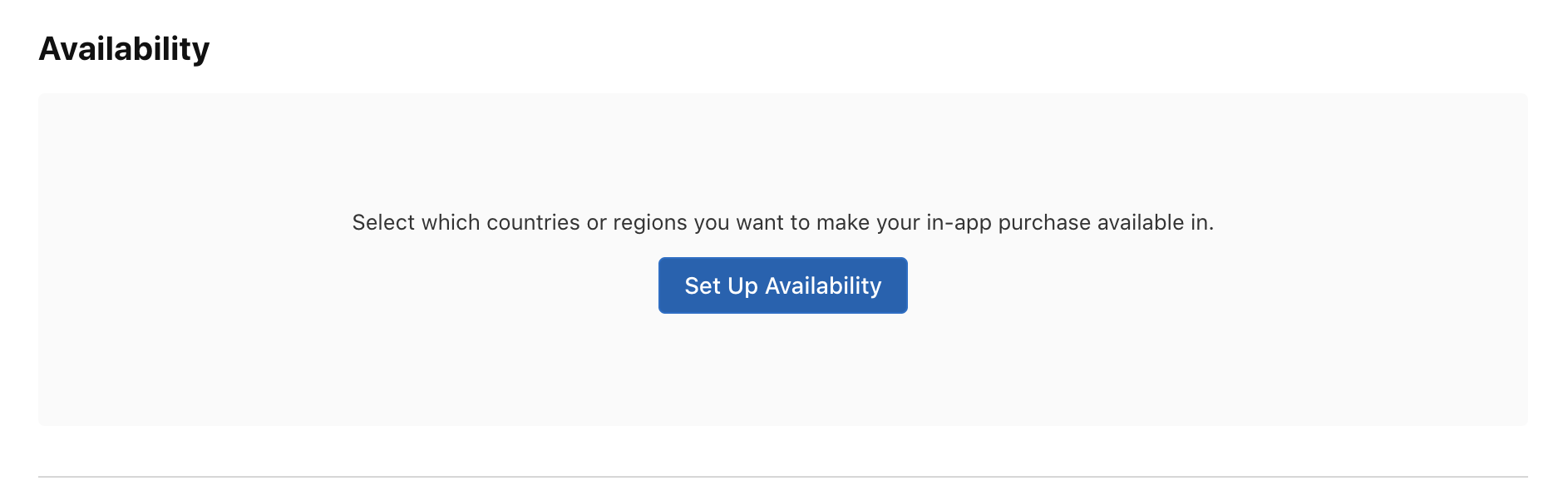
Next, choose the pricing by clicking the button shown below:
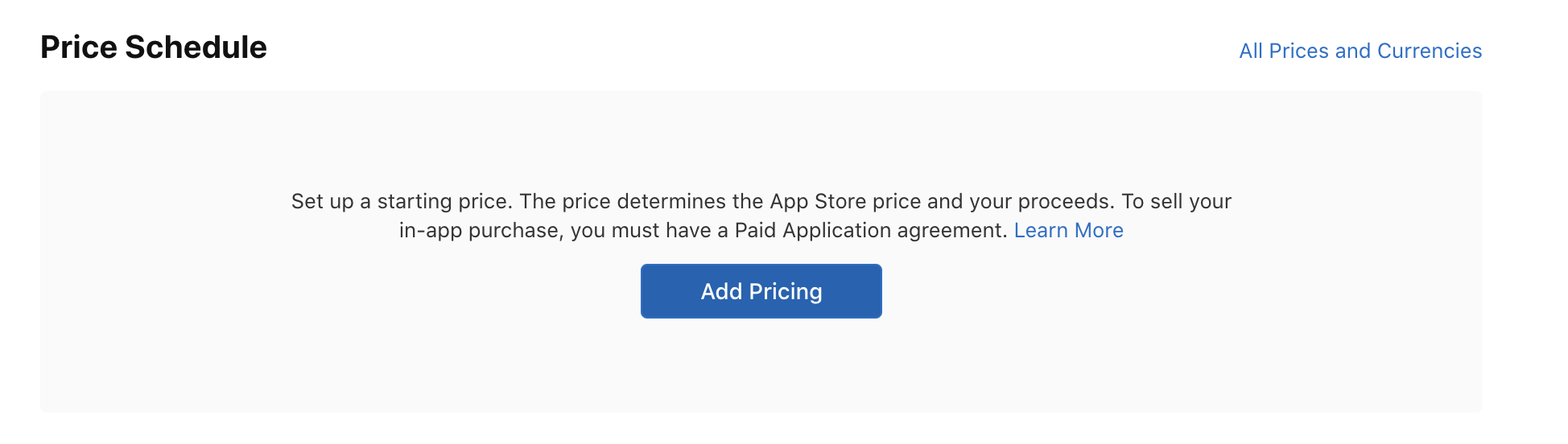
A popup will appear where you can set the pricing according to your needs:
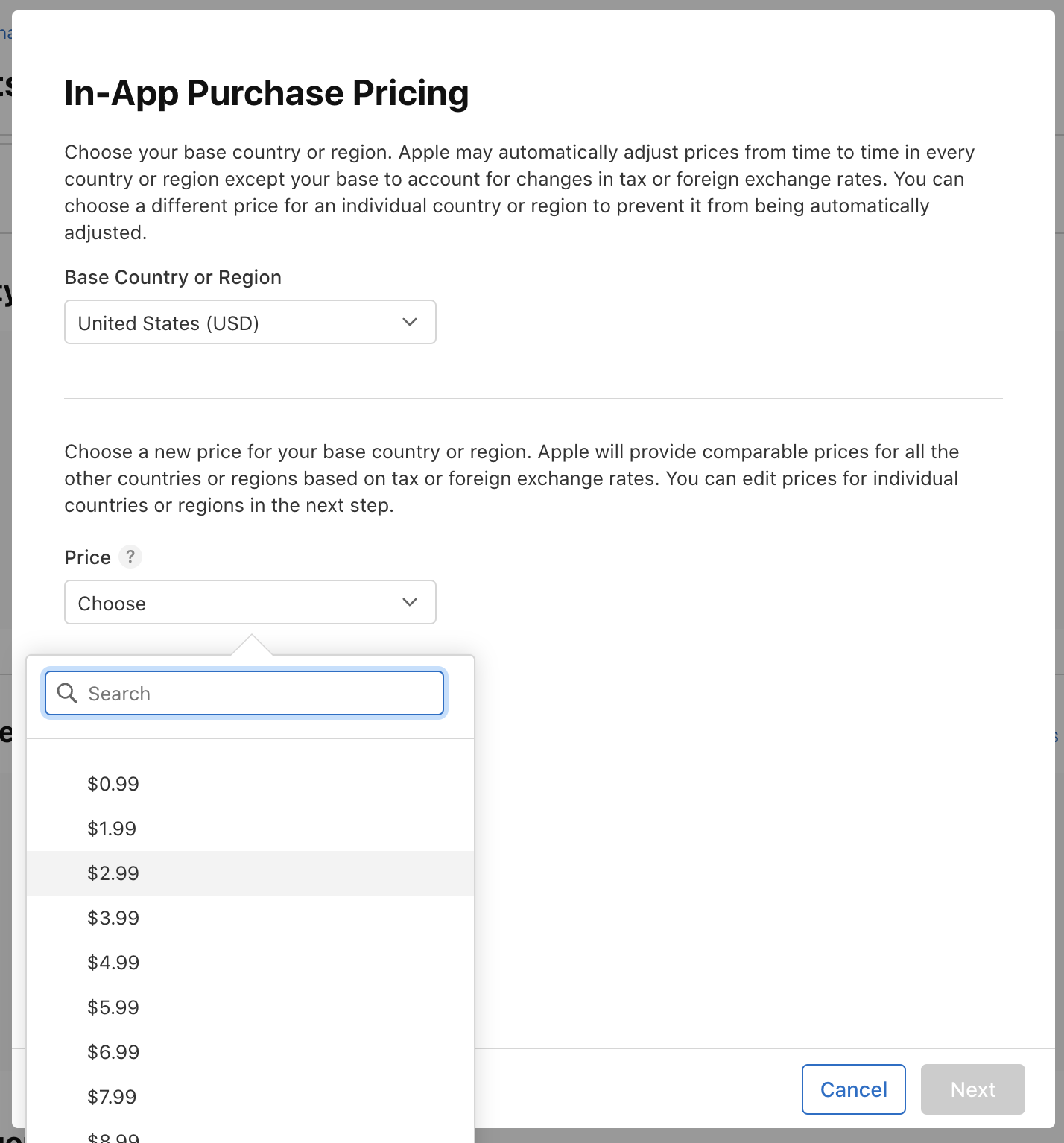
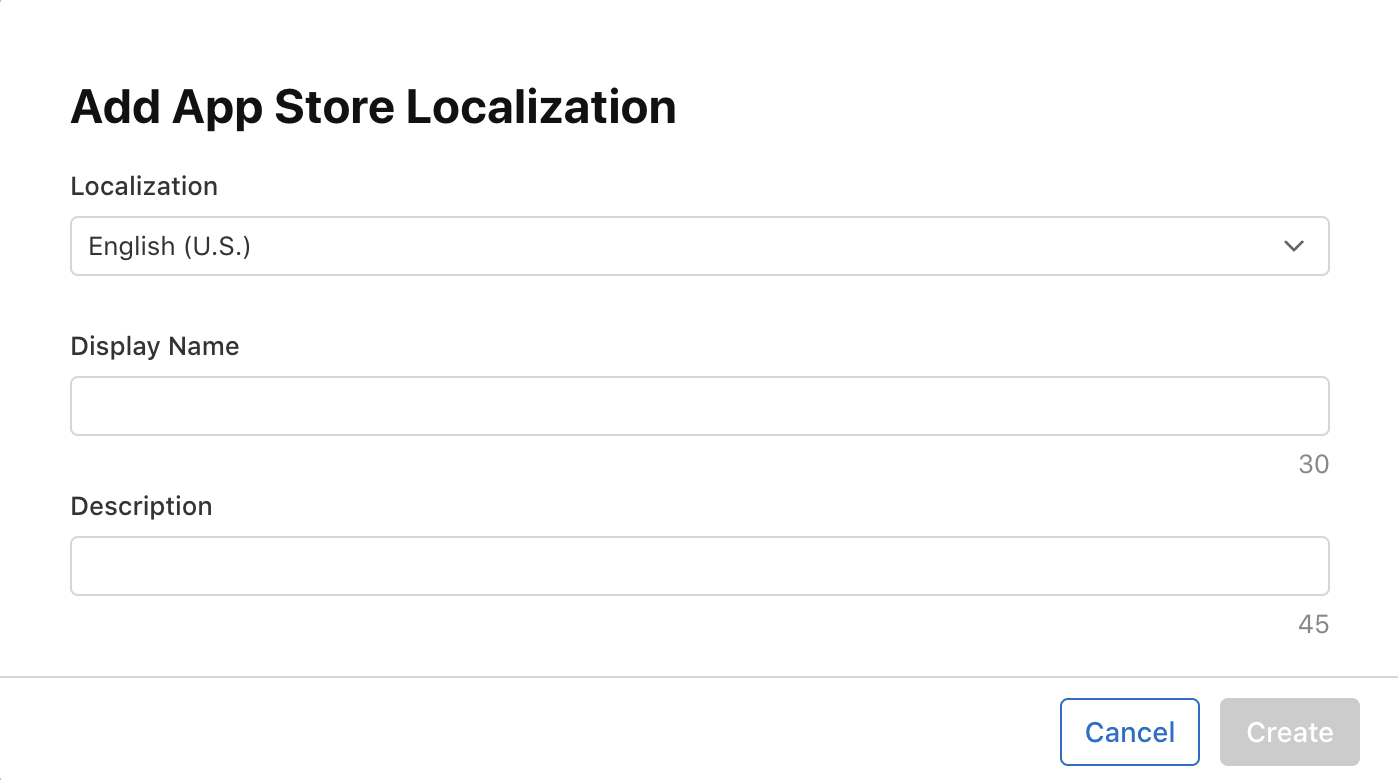
Then, add localization for the in-app purchase product:
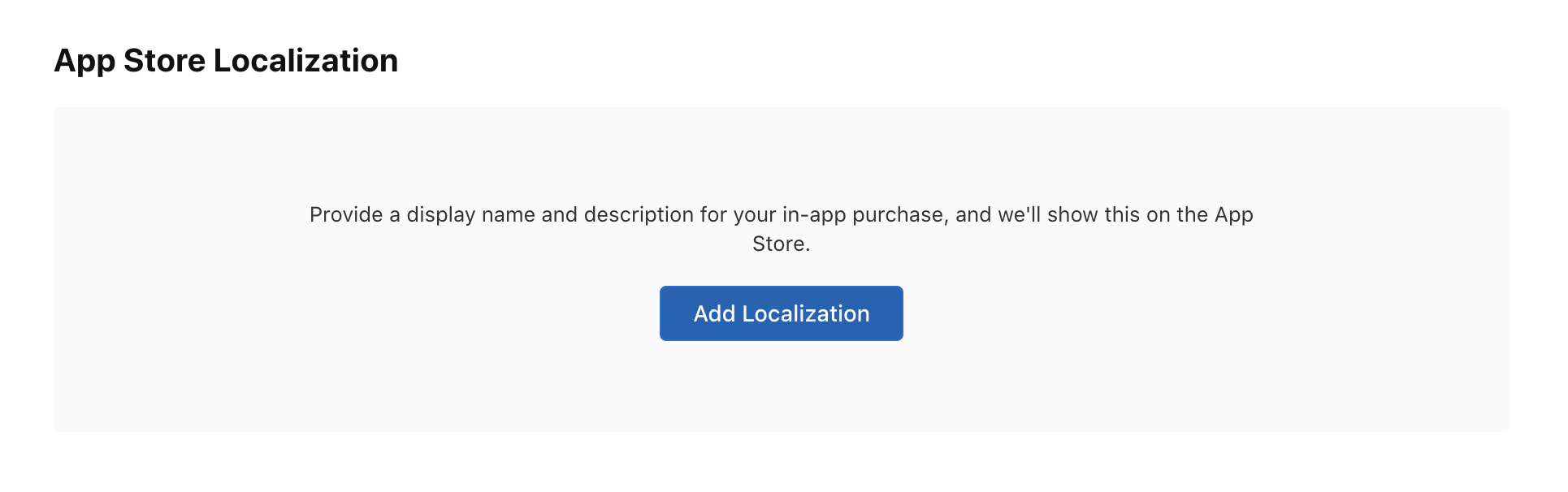
A popup will appear like this:
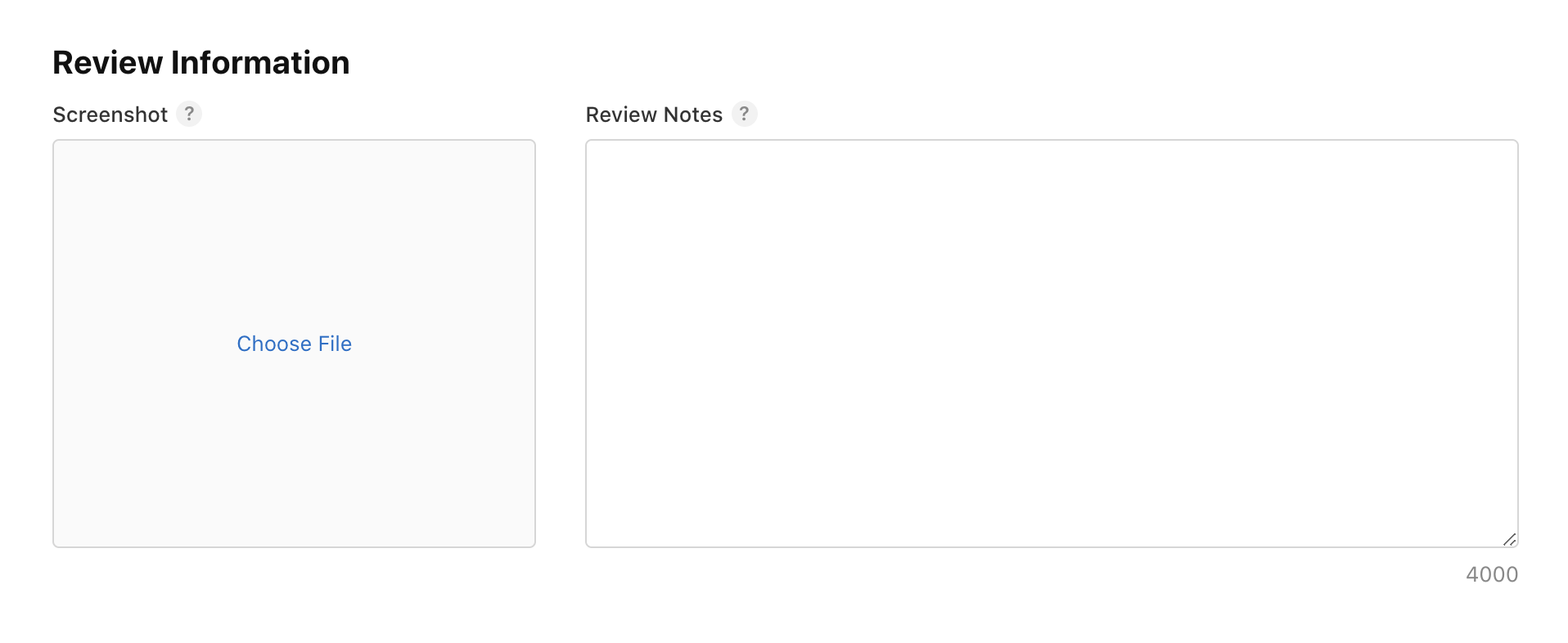
Next, you need to add an image of the app screen where this purchase will occur:
And add review notes and you’re good to go.
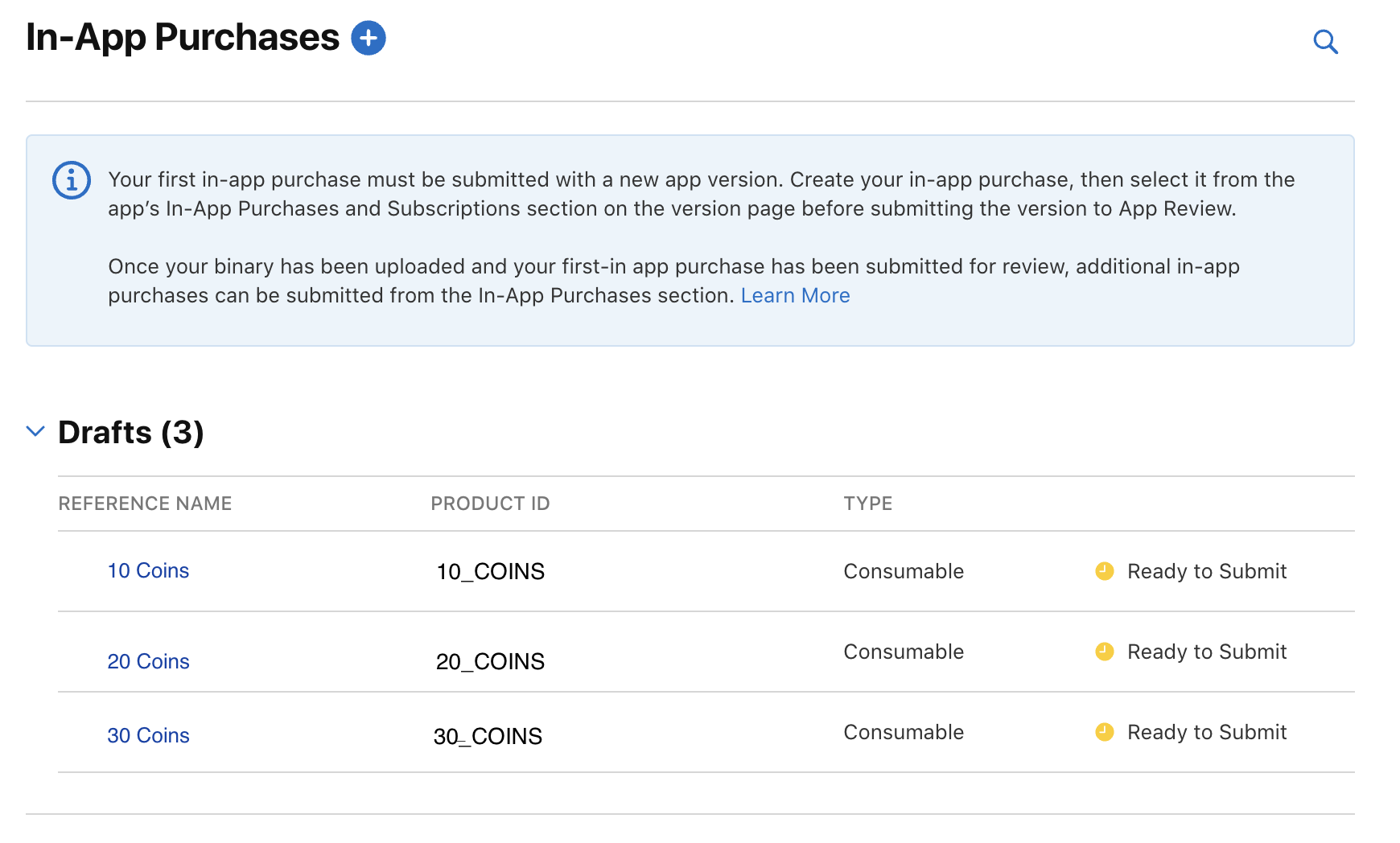
That's it for the **App Store Connect** configuration. You will see this in-app purchase as a draft like below:
## 2. Configure Xcode For In App Purchase:
- Open your project workspace in Xcode.
- Select your project and click **Signing and Capabilities** tab:
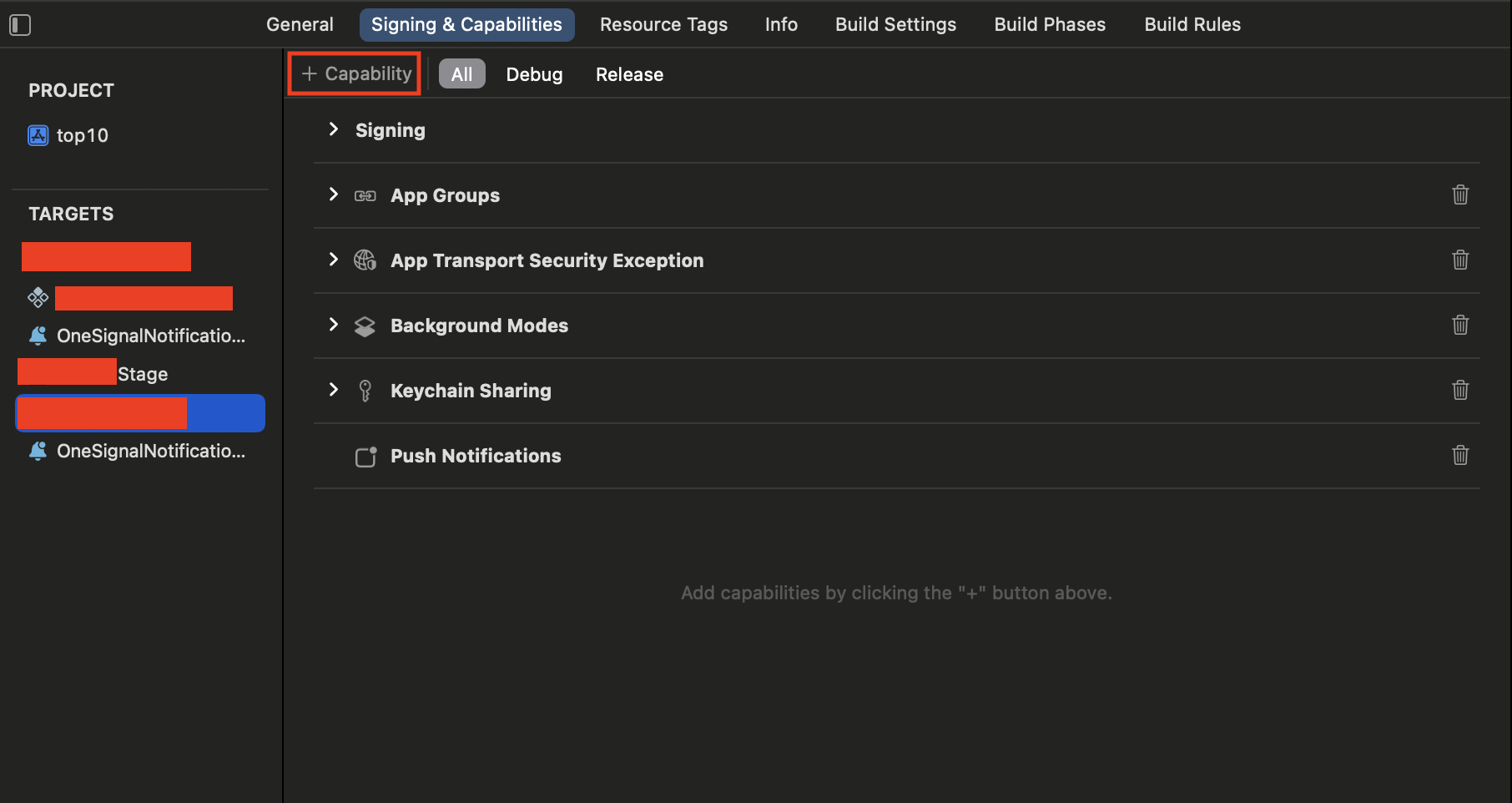
- Search for **In-App Purchase** and click on it:
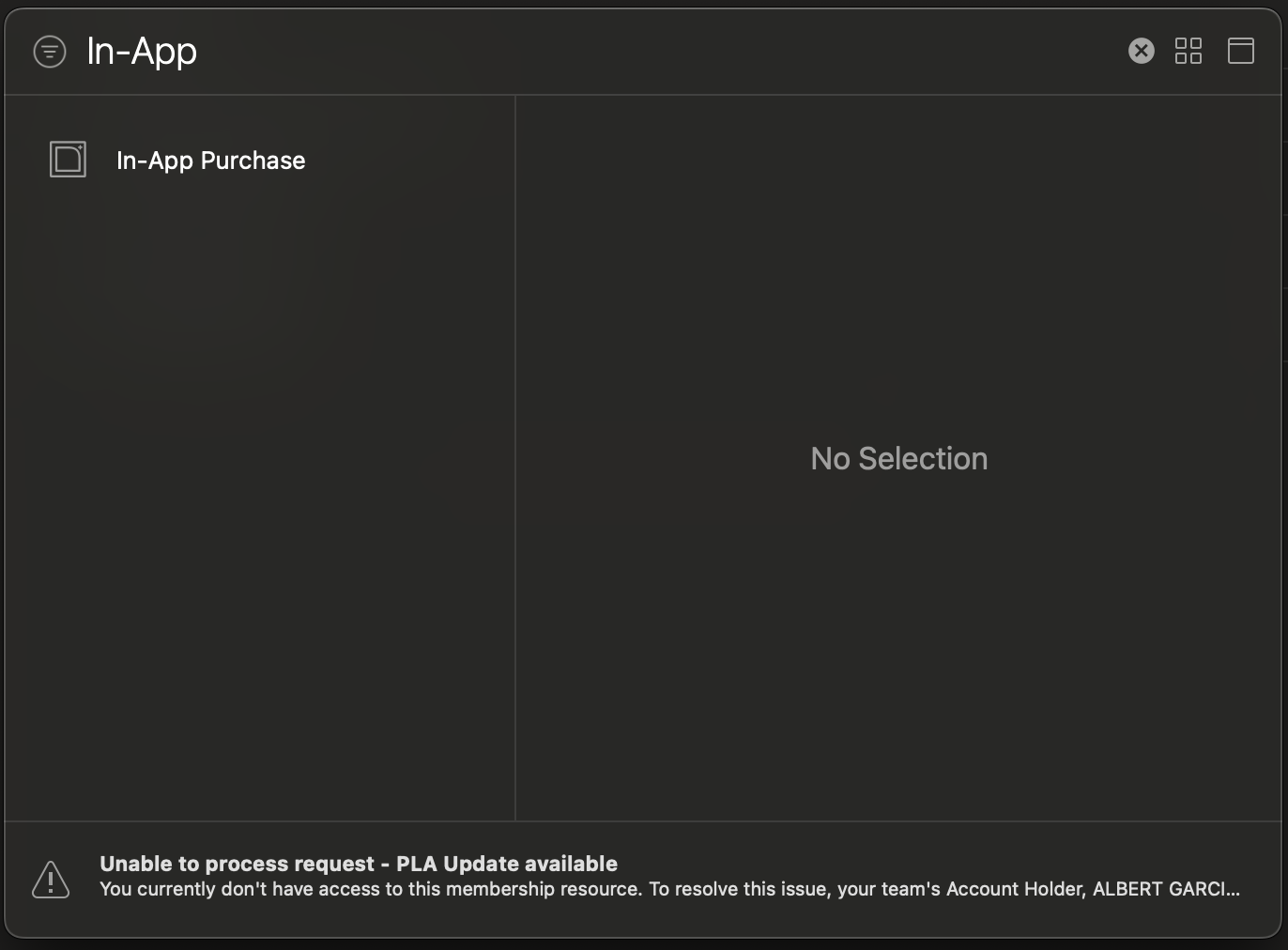
That's it now let's move to the next step.
## 2. Integrate In App Purchase
```javascript
import React from 'react';
import { useIAP, requestPurchase, isIosStorekit2, PurchaseError } from 'react-native-iap';
export default function InAppComponent() {
const {
products,
currentPurchase,
finishTransaction,
getProducts,
requestPurchase
} = useIAP();
const [loading, setLoading] = useState(false);
const productSkus = Platform.select({
ios: ['10_COINS','20_COINS','30_COINS' ],
android: [],
default: [],
}) as string[];
useEffect(() => {
handleGetProducts();
}, []);
const handleGetProducts = async () => {
try {
setLoading(true)
await getProducts({ skus: productSkus });
} catch (error) {
setLoading(false)
console.log({ message: 'handleGetProducts', error });
}
};
const handleBuyProduct = async (sku: Sku) => {
try {
setLoading(true);
await requestPurchase({ sku });
} catch (error) {
handleError(error, 'handleBuyProduct');
} finally {
setLoading(false);
}
};
const handleError = (error: any, context: string) => {
console.log(
'Exception while making Request',
error,
);
};
useEffect(() => {
const checkCurrentPurchase = async () => {
try {
if (
(isIosStorekit2() && currentPurchase?.transactionId) ||
currentPurchase?.transactionReceipt
) {
await finishTransaction({
purchase: currentPurchase,
isConsumable: true,
});
onApiCall(currentPurchase);
}
} catch (error) {
handleError(error, 'checkCurrentPurchase');
}
};
checkCurrentPurchase();
}, [currentPurchase, finishTransaction]);
const onApiCall = (params: any) => {
console.log(params,"Call your API Here")
setLoading(false);
};
return (
<>
{products.map((product, index) => (
<TouchableOpacity
onPress={() => handleBuyProduct(product.productId)}
key={index}
>
<Text>
{product?.title} for{' '}
<Text>
{product?.localizedPrice}
</Text>
</Text>
</TouchableOpacity>
))}
</>
);
}
```
Sure, let's walk through the provided React Native code step by step:
1. **Import Statements**:
Import the required modules and functions from the `react-native-iap` library.
2. **Product SKUs Definition**:
Define the product SKUs according to the platform, in this case, iOS.
> _SKU is the ID of the in app product that you've created at the first step_.
3. **handleGetProducts Function**:
On the initial page render, retrieve all products linked to your Apple Store account. Use these products to establish a connection with the In-App Purchase (IAP) system. Map the retrieved products to display them in your view.
4. **handleBuyProduct Function**:
After listing the products, use the `handleBuyProduct` function to start the purchase process. Pass your unique `productId` as an argument. Once executed, the `handleBuyProduct` function will return a response in the `currentPurchase` variable. This response can then be sent to your API for storage.
> _To test this IAP integration in the development environment, follow these steps_:
> - _Run the app on a real device in debug mode_.
> - _Use the Apple account that you've set up as a sandbox account_.
### Conclusion
In this detailed guide, we explored the realm of in-app purchases in React Native, covering the basics, implementation steps, best practices, and tips for effectively integrating in-app purchase functionality into mobile applications.
### References:
1. [React Native IAP](https://react-native-iap.dooboolab.com/docs/get-started/)
1. [react-native](https://reactnative.dev/)
1. [Apple Developer Documentation](https://developer.apple.com/documentation)
| harisbinejaz |
1,870,178 | Doubt with the defer in GOLang | package main import "fmt" func main(){ x:=1; if x==1{ fmt.Print("Hello "); return... | 0 | 2024-05-30T09:45:33 | https://dev.to/abhinavkumar/doubt-with-the-defer-in-golang-4o2f | go, help | package main
import "fmt"
func main(){
x:=1;
if x==1{
fmt.Print("Hello ");
return
}
defer fmt.Print("Bye");
}
Why the output of the program is not Hello Bye. As defer statement should be executed after returning it.Please Explain? | abhinavkumar |
1,870,177 | Exploring the Thriving World of Programming with CodeHunts: Pakistan's Premier Online Software Company | In Pakistan's dynamic tech industry, CodeHunts shines as a leader in innovation and excellence. This... | 0 | 2024-05-30T09:45:29 | https://dev.to/hmzi67/exploring-the-thriving-world-of-programming-with-codehunts-pakistans-premier-online-software-company-4dm | javascript, webdev, beginners, programming | In Pakistan's dynamic tech industry, CodeHunts shines as a leader in innovation and excellence. This online software company has distinguished itself by offering cutting-edge solutions and nurturing a community of passionate programmers. Let’s delve into the wonders of programming with [CodeHunts](https://codehuntspk.com/).
#### Empowering the Next Generation of Coders
CodeHunts is more than a company; it’s a movement. Committed to democratizing programming education, CodeHunts provides a wealth of resources for both beginners and experienced developers. From in-depth online courses to interactive coding challenges, CodeHunts equips individuals with the skills needed to thrive in the digital era.
#### Innovative Learning Platform
Central to CodeHunts' success is its innovative learning platform. Combining interactive tutorials, real-world projects, and gamified coding challenges, the platform offers an engaging educational experience. Whether you're new to coding or a seasoned developer looking to enhance your skills, CodeHunts has something for everyone.
#### Community Collaboration
A standout feature of CodeHunts is its vibrant community. Through forums, meetups, and collaborative projects, CodeHunts fosters a culture of knowledge-sharing and support. Whether you need help with a tough bug or want to share your latest breakthrough, the CodeHunts community is there to assist you.
#### Industry-Relevant Curriculum
Staying ahead in the fast-paced tech industry is crucial, and CodeHunts’ curriculum is designed to meet this need. Covering the latest trends and technologies in programming, from web development and mobile app design to machine learning and blockchain, CodeHunts ensures its users are well-prepared for future challenges.
#### Career Opportunities
With the rising demand for skilled programmers, CodeHunts bridges the gap between talent and opportunity. Through partnerships with leading tech companies and recruitment drives, CodeHunts connects its users with exciting career opportunities both in Pakistan and globally. Whether you aim for a position at a Silicon Valley giant or a thriving startup, CodeHunts can help you achieve your career goals.
#### Driving Innovation
Beyond education, CodeHunts is a driving force in tech innovation. Through its research and development initiatives, the company pioneers new technologies and pushes the boundaries of possibility. From developing advanced algorithms to creating innovative software solutions, CodeHunts is shaping the future of technology in Pakistan and beyond.
#### Conclusion
In conclusion, CodeHunts is more than an online software company; it's a catalyst for change in Pakistan’s tech industry. By empowering individuals with essential skills and fostering a culture of collaboration and innovation, CodeHunts is paving the way for a brighter future. Whether you're a budding programmer or a seasoned expert, CodeHunts invites you to join its community and embark on an exciting journey of learning, growth, and discovery. | hmzi67 |
1,870,167 | How to Bypass reCAPTCHA V2,V3 Using Automatic Captcha Solver | In the ever-evolving world of internet security, reCAPTCHA stands as one of the foremost defenses... | 0 | 2024-05-30T09:32:33 | https://dev.to/media_tech/how-to-bypass-recaptcha-v2v3-using-automatic-captcha-solver-30n8 | In the ever-evolving world of internet security, reCAPTCHA stands as one of the foremost defenses against automated bot attacks. However, there are legitimate reasons for needing to bypass these challenges, such as automated testing, scraping for research purposes, and enhancing user accessibility. This article delves deeply into the techniques and tools available for bypassing reCAPTCHA V2 and V3 using automatic captcha solvers.
**Understanding reCAPTCHA V2 and V3**
**What is reCAPTCHA V2?**
reCAPTCHA V2 typically presents users with a challenge, often requiring the identification of objects in images or clicking a checkbox to prove they are not a robot. This version relies heavily on user interaction and visual verification, making it a bit more challenging for bots to bypass.
**What is reCAPTCHA V3?**
reCAPTCHA V3, on the other hand, operates invisibly in the background. It assigns a score to each user based on their behavior and interactions on the website. This score helps determine whether the user is a human or a bot. Unlike V2, V3 does not require direct user interaction for every request, making it more seamless but also more sophisticated in its detection capabilities.
**Methods to Bypass reCAPTCHA V2**
**1. Using Automated Captcha Solvers**
Automated captcha solvers are specialized software designed to interpret and solve captchas. These tools have advanced significantly and can now tackle complex captchas with high accuracy.
**2. Machine Learning Algorithms**
Machine learning algorithms can be trained to recognize and solve captchas. This approach requires a substantial amount of data and computational resources but can be highly effective.
**Convolutional Neural Networks (CNNs):** These are particularly effective for image-based captchas. By training a CNN on a large dataset of captcha images, it can learn to identify and solve new captchas with a high degree of accuracy.
**3. Browser Automation Tools**
Browser automation tools like captcha solver extension can be used to bypass captchas automatically.
**Best Practices for Using Automatic Captcha Solvers**
**1. Keeping Up with Updates**
Captcha systems are continuously evolving. Stay updated with the latest developments in captcha technology and adjust your methods accordingly. Regularly updating your tools and algorithms is essential to maintaining effectiveness.
**2. Combining Multiple Techniques**
Using a combination of methods can improve the success rate of bypassing captchas. For instance, integrating machine learning with browser automation and captcha-solving services can provide a more robust solution.
**Conclusion**
Bypassing reCAPTCHA V2 and V3 is a complex task that requires a deep understanding of web security and automated tools. Whether you're using automated captcha solvers, machine learning, or browser automation tools, it's crucial to approach this challenge ethically and responsibly. Stay informed about the latest developments in captcha technology to ensure your methods remain effective.
**With numerous types of captchas we encounter, solving them can often be challenging and time-consuming. However, thanks to the advancement of tools, you can now rely on an automatic captcha solver like CaptchaAI, which handles captchas swiftly. CaptchaAI is an automated solution that effortlessly solves all types of captchas, including reCaptcha v2 and v3, in no time. It stands out by offering unlimited captcha solving for a fixed price, saving both time and money. Additionally, it offers a free trial, providing a cost-free experience to test its capabilities. This unique captcha solving service makes handling tasks easier and more efficient.** | media_tech | |
1,870,176 | .NET core vs NodeJs | When deciding between .NET Core and Node.js for a project, it's essential to consider the specific... | 0 | 2024-05-30T09:44:32 | https://dev.to/mohamedabdiahmed/net-core-vs-nodejs-367h | When deciding between .NET Core and Node.js for a project, it's essential to consider the specific requirements, strengths, and use cases of each technology. Both have their own advantages and can be optimal for different scenarios.
Overview of .NET Core
.NET Core is a cross-platform, high-performance framework developed by Microsoft for building modern, cloud-based, and internet-connected applications. It supports multiple programming languages, including C#, F#, and Visual Basic.
Overview of Node.js
Node.js is a JavaScript runtime built on Chrome's V8 JavaScript engine. It is designed to build scalable network applications, and it uses an event-driven, non-blocking I/O model, making it lightweight and efficient.
 | mohamedabdiahmed | |
1,870,175 | .NET core | NET Core is a cross-platform, high-performance framework for building modern, cloud-based, and... | 0 | 2024-05-30T09:42:02 | https://dev.to/mohamedabdiahmed/net-core-4caf | NET Core is a cross-platform, high-performance framework for building modern, cloud-based, and internet-connected applications. It is a free, open-source, and modular framework developed by Microsoft. .NET Core supports the development of applications for Windows, macOS, and Linux, making it versatile for various environments.
 | mohamedabdiahmed | |
1,861,728 | Let's build a simple MLOps workflow on AWS! #3 - Running ML training as a container | About this post This post is a sequel to the previous one below. Please refer to the... | 0 | 2024-05-30T09:38:16 | https://dev.to/hikarunakatani/lets-build-a-simple-mlops-workflow-on-aws-3-running-ml-training-as-a-container-1lhl | aws, githubactions, docker | # About this post
This post is a sequel to the previous one below. Please refer to the earlier post before reading this one.
Let's build a simple MLOps workflow on AWS! #2 - Building infrastructure on AWS - DEV Community
https://dev.to/hikarunakatani/lets-build-a-simple-mlops-workflow-on-aws-2-building-infrastructure-on-aws-3h2j
# Overview
We've prepared the ML model in the first post and set up the infrastructure in the second post. Now, we've configured the necessary settings to run the training process as a container image. Let's work on the necessary settings and see how it works.
# Access to S3 bukcet
As we run this traing task on the ECS cluster in private subnet, we can't use internet connection to download training data nor uploading trained model. Instead, we preplace them on an S3 bucket and access them via VPC Endpoint using the AWS SDK. To PUT/GET obeject from S3 bucket, you can implement the code like below:
```python
import zipfile
import boto3
import botocore
from botocore.exceptions import ClientError
def download_data():
"""Download training data from Amazon S3 bucket
Used when run as a ECS task
"""
s3 = boto3.client("s3")
bucket_name = "cifar10-mlops-bucket"
file_key = "data.zip"
local_file_path = "data.zip"
extract_to = "./"
botocore.session.Session().set_debug_logger()
# Download the file from S3
try:
s3.download_file(bucket_name, file_key, local_file_path)
print("File downloaded successfully.")
# Extract the contents of the zip file
with zipfile.ZipFile(local_file_path, "r") as zip_ref:
zip_ref.extractall(extract_to)
print(f"Zip file extracted successfully to '{extract_to}'.")
except ClientError as e:
print(f"An error occurred while downloading training data {e}")
def upload_model():
"""Upload pre-trained model to S3 bucket"""
s3_client = boto3.client("s3")
file_path = "model.pth"
bucket_name = "cifar10-mlops-bucket"
object_key = "model.pth"
try:
s3_client.upload_file(file_path, bucket_name, object_key)
print(f"Uploaded {file_path} to {bucket_name}/{object_key}")
except ClientError as e:
print(f"An error occurred while uploading {e}")
```
When accessing an S3 bucket from a private subnet, ensure that the access policy of the VPC endpoint and the S3 bucket itself allows the necessary permissions. Additionally, the target ECS task must be explicitly permitted to access the bucket through its task role.
# Making a Docker image
```Dockerfile
# Use Python baseimage
FROM python:3.8-slim-buster
# Set the working directory in the container to /app
WORKDIR /app
# Add the current directory contents into the container at /app
ADD . /app
# Install any needed packages specified in requirements.txt
RUN pip install --upgrade pip && \
pip install --no-cache-dir -r requirements.txt
# Make port 80 available to the world outside this container
EXPOSE 80
# Run main.py when the container launches
ENTRYPOINT ["python", "main.py"]
CMD ["--env", "ecs"]
```
This is a basic example of a Dockerfile to run a training task as a Docker image. An important point here is specifying the environment with
CMD ["--env", "ecs"] in the command argument. This is necessary because when downloading training data in a local environment, the data needs to be downloaded through the internet as shown below. By adding this argument, you can change the behavior of the program depending on the environment:
```python
download_flag = False
# Dataset directory
data_dir = "./data"
# Download training data if it doesn't exist
if not os.path.exists(os.path.join(data_dir, "cifar-10-batches-py")):
if env == "local":
download_flag = True
elif env == "ecs":
aws_action.download_data()
# Preprocess data
# Transform PIL Image to tensor
# Normalize a tensor image in each channel with mean and standard deviation
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
# Downaload training data of CIFAR-10
trainset = torchvision.datasets.CIFAR10(
root="./data", train=True, download=download_flag, transform=transform
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=4, shuffle=True, num_workers=os.cpu_count()
)
```
# Setting up GitHub Actions
Now that we have a Dockerfile, we can build a Docker image locally and manually push it to the ECR repository. However, our initial goal is to fully automate the entire training process, so we want to avoid doing this manually. Instead, let's manage our training program on GitHub and push the image using GitHub Actions.
Here's a sample GitHub Actions workflow:
```yaml
name: Push Docker image to Amazon ECR (manual)
on:
workflow_dispatch:
env:
AWS_REGION: ap-northeast-1
jobs:
push:
runs-on: ubuntu-latest
permissions:
id-token: write
contents: read
pull-requests: write
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Get OIDC token
uses: aws-actions/configure-aws-credentials@v1 # Use OIDC token
with:
role-to-assume: ${{ secrets.AWS_ROLE_ARN }}
aws-region: ${{ env.AWS_REGION }}
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
- name: Build, tag, and push image to Amazon ECR
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
ECR_REPOSITORY: cifar10-mlops-repository
# IMAGE_TAG: ${{ github.sha }}
IMAGE_TAG: latest
run: |
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
```
In this example, we execute the ``docker build`` command to build a container image and the ``docker push`` command to push the image to an ECR repository within the GitHub Actions workflow. For a simplified deployment process, we use the ``latest`` tag in the Dockerfile. However, using the ``latest`` tag in a production environment is not recommended because it does not provide a way to track the specific version of the image being deployed. Instead of using the ``latest tag``, it's better to use a unique tag based on the Git commit SHA, such as ``github.sha``, as shown in the official GitHub example.
When changing the tag name of the Docker image, you also need to update the image specified in the ECS task definition. Therefore, in the example below, the task definition is dynamically rendered and deployed with the appropriate image tag.
```yaml
- name: Build, tag, and push image to Amazon ECR
id: build-image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
# Build a docker container and
# push it to ECR so that it can
# be deployed to ECS.
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
echo "image=$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG" >> $GITHUB_OUTPUT
- name: Fill in the new image ID in the Amazon ECS task definition
id: task-def
uses: aws-actions/amazon-ecs-render-task-definition@c804dfbdd57f713b6c079302a4c01db7017a36fc
with:
task-definition: ${{ env.ECS_TASK_DEFINITION }}
container-name: ${{ env.CONTAINER_NAME }}
image: ${{ steps.build-image.outputs.image }}
- name: Deploy Amazon ECS task definition
uses: aws-actions/amazon-ecs-deploy-task-definition@df9643053eda01f169e64a0e60233aacca83799a
with:
task-definition: ${{ steps.task-def.outputs.task-definition }}
service: ${{ env.ECS_SERVICE }}
cluster: ${{ env.ECS_CLUSTER }}
wait-for-service-stability: true
```
Deploying to Amazon Elastic Container Service - GitHub Docs
https://docs.github.com/en/actions/deployment/deploying-to-your-cloud-provider/deploying-to-amazon-elastic-container-service
# Testing the whole process
Since we have all the components for the entire CI/CD process, we can now test the complete training process. When you push changes to the model repository, GitHub Actions will automatically build the image and push it to the ECR repository. If it succeeds, you'll see a message like the one below in the Actions tab.
After that, the Lambda function will be triggered by an EventBridge rule. Let's check if the Lambda function is running properly.
In the response of the lambda function, you'll see an in information like below:
```json
{
"tasks": [
{
"attachments": [
{
"id": "********-****-****-****-************",
"type": "ElasticNetworkInterface",
"status": "PRECREATED",
"details": [
{
"name": "subnetId",
"value": "subnet-************"
}
]
}
],
"attributes": [
{
"name": "ecs.cpu-architecture",
"value": "x86_64"
}
],
"availabilityZone": "ap-northeast-1a",
"clusterArn": "arn:aws:ecs:ap-northeast-1:************:cluster/*************-cluster",
"containers": [
{
"containerArn": "arn:aws:ecs:ap-northeast-1:************:container/*************-cluster/*************/************",
"taskArn": "arn:aws:ecs:ap-northeast-1:************:task/*************-cluster/*************",
"name": "*************-container",
"image": "************.dkr.ecr.ap-northeast-1.amazonaws.com/*************-repository:latest",
"lastStatus": "PENDING",
"networkInterfaces": [],
"cpu": "2048",
"memory": "4098"
}
],
"cpu": "2048",
"createdAt": "2024-05-26T03:40:35.437000+00:00",
"desiredStatus": "RUNNING",
"enableExecuteCommand": false,
"group": "family:*************-task",
"lastStatus": "PROVISIONING",
"launchType": "FARGATE",
"memory": "8192",
"overrides": {
"containerOverrides": [
{
"name": "*************-container"
}
],
"inferenceAcceleratorOverrides": []
},
"platformVersion": "1.4.0",
"platformFamily": "Linux",
"tags": [],
"taskArn": "arn:aws:ecs:ap-northeast-1:************:task/*************-cluster/*************",
"taskDefinitionArn": "arn:aws:ecs:ap-northeast-1:************:task-definition/*************-task:15",
"version": 1,
"ephemeralStorage": {
"sizeInGiB": 20
}
}
],
"failures": [],
"ResponseMetadata": {
"RequestId": "********-****-****-****-************",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"x-amzn-requestid": "********-****-****-****-************",
"content-type": "application/x-amz-json-1.1",
"content-length": "1556",
"date": "Sun, 26 May 2024 03:40:34 GMT"
},
"RetryAttempts": 0
}
}
```
The response is quite long, but essentially, what you need to check is that the status code is 200 and that the "failures" array is empty. By verifying this information, you can confirm that the Lambda function is properly triggered by the EventBridge rule.
After that, let's also check whether the ECS task is properly invoked. If it's properly invoked, you'll see the new task created on the ECS console screen
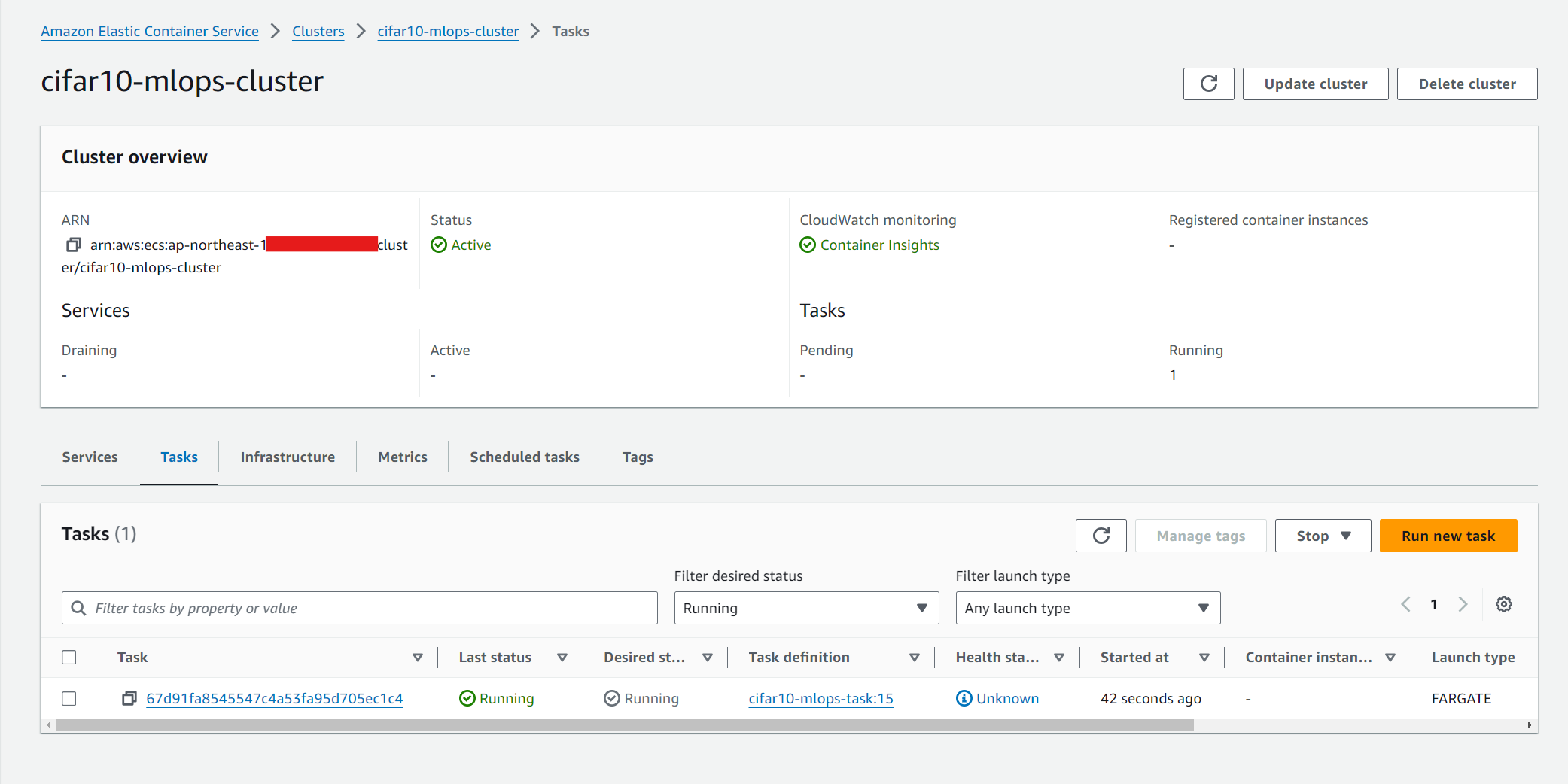
If the training is successfully getting started, you can view the current status of the training process in the logs.
After finishing the training, if a pre-trained model is successfully uploaded to an S3 bucket, you can confirm that the training process has completed properly.
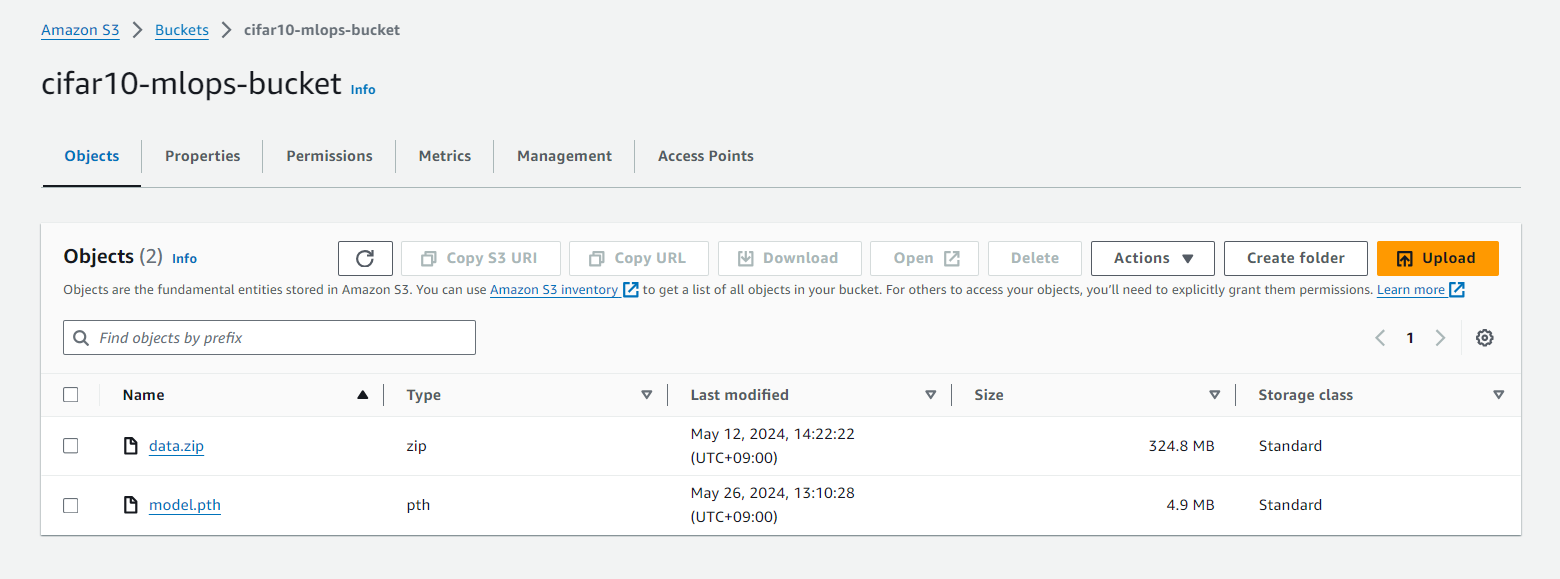
Well done! We've completed the entire workflow! 👏
There are indeed many improvements and tasks to implement if you want to work on a production-level MLOps setup, but it's perfectly fine to start from what you're familiar with now. Building upon your current knowledge and gradually expanding your skills is a solid approach to mastering MLOps.
| hikarunakatani |
1,870,174 | The Ultimate Roadmap to Mastering Data Structures | Data structures are the building blocks of efficient algorithms and software development. Mastering... | 0 | 2024-05-30T09:38:12 | https://dev.to/shabink/the-ultimate-roadmap-to-mastering-data-structures-1o94 | datastructures, dsa, algorithms, programming | **_Data structures are the building blocks of efficient algorithms and software development. Mastering them is crucial for anyone looking to excel in computer science, software engineering, or any field that involves programming. This roadmap will guide you through the essential steps to learn and master data structures effectively._**
### 1. Understand the Basics
#### 1.1 What Are Data Structures?
_Data structures are ways of organizing and storing data in a computer so that it can be accessed and modified efficiently. They are crucial for writing efficient and scalable code._
#### 1.2 Why Learn Data Structures?
- Efficiency: Optimize time and space complexity.
- Problem Solving: Enhance your ability to solve complex problems.
- Interview Preparation: Essential for technical interviews.
### 2. Start with Simple Data Structures
#### 2.1 Arrays
- Definition: A collection of elements identified by index or key.
- Operations: Accessing, inserting, deleting, and iterating.
- Use Cases: Suitable for situations where elements are of the same type.
#### 2.2 Linked Lists
- Definition: A linear collection of data elements where each element points to the next.
- Types: Singly linked list, doubly linked list, circular linked list.
- Use Cases: Better for dynamic memory allocation compared to arrays.
#### 2.3 Stacks
- Definition: A collection of elements that follows Last-In-First-Out (LIFO) principle.
- Operations: Push, pop, peek.
- Use Cases: Undo mechanisms, parsing expressions.
#### 2.4 Queues
- Definition: A collection of elements that follows First-In-First-Out (FIFO) principle.
- Operations: Enqueue, dequeue, peek.
- Use Cases: Order processing, task scheduling.
### 3. Move to Complex Data Structures
#### 3.1 Trees
- Binary Trees: Each node has at most two children.
- Binary Search Trees (BST): A binary tree with ordered nodes.
- AVL Trees: A self-balancing BST.
- Use Cases: Hierarchical data, database indexing.
#### 3.2 Heaps
- Min-Heap: Parent nodes are less than or equal to their children.
- Max-Heap: Parent nodes are greater than or equal to their children.
- Use Cases: Priority queues, heap sort.
#### 3.3 Graphs
- Definition: A collection of nodes (vertices) and edges connecting them.
- Types: Directed, undirected, weighted, unweighted.
- Use Cases: Network routing, social networks, recommendation systems.
### 4. Understand Hashing
#### 4.1 Hash Tables
- Definition: A data structure that maps keys to values for efficient lookup.
- Operations: Insert, delete, search.
- Use Cases: Implementing dictionaries, caching.
#### 4.2 Hash Functions
- Definition: A function that converts input into a fixed-size string of bytes.
- Use Cases: Ensuring efficient data retrieval.
### 5. Master Algorithms Related to Data Structures
#### 5.1 Sorting Algorithms
- Bubble Sort, Insertion Sort, Selection Sort: Basic algorithms with O(n^2) complexity.
- Merge Sort, Quick Sort, Heap Sort: Advanced algorithms with O(n log n) complexity.
#### 5.2 Searching Algorithms
- Linear Search: O(n) complexity.
- Binary Search: O(log n) complexity (applicable on sorted arrays).
#### 5.3 Graph Algorithms
- Depth-First Search (DFS): Explores as far as possible along each branch before backtracking.
- Breadth-First Search (BFS): Explores all neighbor nodes at the present depth before moving on to nodes at the next depth level.
- Dijkstra's Algorithm: Finds the shortest path between nodes in a graph.
### 6. Practical Application and Projects
#### 6.1 Practice Problems
- Online Platforms: LeetCode, HackerRank, CodeSignal, and GeeksforGeeks offer a plethora of problems to practice.
#### 6.2 Real-World Projects
- Build a Custom Library: Implement your own data structure library in your preferred programming language.
- Contribute to Open Source: Join projects that require optimization and data structure expertise.
### 7. Advanced Topics
#### 7.1 Concurrent Data Structures
- Definition: Data structures designed for concurrent access.
- Use Cases: Multithreading and parallel processing.
#### 7.2 Persistent Data Structures
- Definition: Data structures that preserve the previous version of -themselves when modified.
- Use Cases: Undo operations, versioned data.
### 8. Resources and Continued Learning
#### 8.1 Books
- "Introduction to Algorithms" by Cormen, Leiserson, Rivest, and Stein.
- "Data Structures and Algorithm Analysis in C++" by Mark Allen Weiss.
#### 8.2 Online Courses
- Coursera: Data Structures and Algorithms Specialization by UC San Diego & National Research University Higher School of Economics.
- edX: Algorithms and Data Structures MicroMasters by University of California, San Diego.
#### 8.3 Communities and Forums
- Reddit: r/learnprogramming, r/coding.
- Stack Overflow: Participate in discussions and ask questions.
### Conclusion
**_Mastering data structures is a journey that involves continuous learning and practice. Follow this roadmap, utilize the resources provided, and keep challenging yourself with new problems and projects. With dedication and persistence, you'll become proficient in data structures and significantly improve your programming skills. Happy learning!**_
| shabink |
1,870,163 | Mmoexp Elden Ring Items: Twinned Knight Swords | Wewant to Elden Ring Items really quicklygo over the stats that are important forthis... | 0 | 2024-05-30T09:26:29 | https://dev.to/rozemondbell/mmoexp-elden-ring-items-twinned-knight-swords-256a | webdev, javascript, beginners, programming | Wewant to <a href="https://www.mmoexp.com/Elden-ring/Items.html">Elden Ring Items</a> really quicklygo over the stats that are important forthis build,50vigorshould be morethan enough.It's right between the softcapof40 and the hard cap of 60.Nowsince our bleed Affinity weapons aregoing to scale directly off of strength.we're going to start at 62 strength andthen immediately prioritize trying toget to the hard cap of 80 strength assoon as we can be on level 150./ow wepushedarcane to 45 because that's themajor soft cap for blood loss build-up.now pushing this build to level 200 youare going to take Arcane to 80 afterstrength to take advantage of the occultscaling.Dexterity we only push to18 to hit our requirements for ourweapons and 30 endurance is a reallygood sweet spot in terms of being ableto have enough stamina and wear enougharmor to get thepoisewe need.
Elden Ring Best 1.09 Bleed Weapons
No. 1GargoylesTwinblades
What makesthe GargoylesTwinblades the bestTwinbladein the game?Looking at thenumbers of an identical dexterity buildwith 62 decks and 45arcane,there's better stat scalingfor strength on aGargoyle'sTwinbladethan there is for decks on aGodskin Peeler.Otherwise,these weapons arealmost identical in almost every wayincluding blood loss build up and weight. But this just leads to flat out moredamage on aGargoyle'sTwinblade.Evenif we push strength decks and Arcane tothe hard caps of 80,we still see thesame thing.The Gargoyle’sTwinbladeisstill more damage than theGodskin Peeler.
No. 2 Twinned Knight Swords
The stats for the first playthrough,theTwinned Knight Swordsdeal almost the same damage as aGodskin Peelerwould on a dexterity build andthat's whywehighly recommend that asyour offhand weapon for your firstplaythrough.Agreat thing about thatweapon is it's just ground loot,youcould pick it up on thenorth side ofAltus Plateau at any point in <a href="https://www.mmoexp.com/Elden-ring/Items.html">Elden Ring Items buy</a> the game.
No. 3 Beastman'sCurvedSword
| rozemondbell |
1,870,173 | What does a career advisor do? | You may be wondering what does a career advisor do to help get into the nursing industry. The... | 0 | 2024-05-30T09:37:11 | https://dev.to/alnicorconsulting/what-does-a-career-advisor-do-4f88 | You may be wondering [**what does a career advisor do**](https://alnicorconsulting.com/career-advisor-for-nursing/) to help get into the nursing industry. The healthcare industry is broad, and there are various profiles for nursing. A nursing career advisor helps in understanding the courses, nursing industry, career opportunities, and others. With the help of a nursing advisor, you can pave the way to a fulfilling career as a registered nurse.
 | alnicorconsulting | |
1,870,172 | Handling Environment Configurations in Front end Development | One of the most common challenges in front-end development is managing environment-specific... | 0 | 2024-05-30T09:34:28 | https://dev.to/anshulsao/handling-environment-configurations-in-front-end-development-47fk | frontend, devops, programming, react | One of the most common challenges in front-end development is managing environment-specific configurations. Unlike backend applications, where you can leverage environment variables easily, frontend applications run in a browser that doesn’t natively support environment variables. So often developers specify these configurations at build time and build the frontend app separately for each environment.
Take the example of a web application that has to be deployed across development, staging, and production environments.
Each environment requires different configurations, such as API endpoints and feature flags. To manage these, the development team configures these settings at build time.
While this approach initially seems straightforward, it introduces a host of issues.
Firstly, creating separate builds for each environment is time-consuming and inefficient. Every deployment requires generating a new build, duplicating efforts, and increasing the complexity of the deployment pipeline. Doing this for small bugs or enhancements is just a mere waste of time.
Secondly, managing multiple builds heightens the risk of human error. A single mistake, such as deploying a staging build to production, can lead to outages, customers losing trust, or security vulnerabilities.
These risks can have serious consequences, especially in a production environment where reliability and stability are paramount.
## What can you do to avoid this?
Instead of embedding environment variables into your frontend application at build time, you can configure your application to load these variables dynamically at runtime. This will make your deployment process more efficient and less error-prone.
Here’s how to implement dynamic configuration at runtime:
**1. Use Relative Paths**
Ensure your frontend application can interact with your backend API using relative paths. This means the frontend does not need to know the full URL of the backend API; instead, it can rely on relative URLs determined by the server configuration.
Example: If your frontend is served from https://www.example.com and your backend API is at https://api.example.com, you can configure your frontend to make requests to relative paths like /api/endpoint instead of hardcoding the full API URL. This way, the frontend automatically adjusts to the correct backend URL based on the current environment.
**2. Backend API for Configuration**
Set up an endpoint in your backend that provides the necessary environment variables to the frontend. This endpoint can dynamically serve the configuration settings required by the frontend application.
Example: Create an endpoint like /api/config on your backend. When the frontend application starts, it can make a request to this endpoint to fetch its configuration settings. This endpoint would return a JSON object containing the necessary environment variables.
## Steps of Implementation
**1. Set Up Backend Endpoint**
First, ensure your backend provides an endpoint (/api/config) that returns the required environment variables as a JSON object.
Example in Node.js/Express
```javascript
const express = require('express');
const app = express();
const port = 3000;
app.get('/api/config', (req, res) => {
const config = {};
Object.keys(process.env).forEach(key => {
if (key.startsWith('FE_')) {
config[key] = process.env[key];
}
});
res.json(config);
});
app.listen(port, () => {
console.log(`Server running on port ${port}`);
});
```
**2. Create loadConfig Function in Frontend**
In your frontend application, create a config.js file with the loadConfig function:
```src/config.js:
javascript
async function loadConfig() {
const response = await fetch('/api/config');
const config = await response.json();
window.appConfig = config;
}
export default loadConfig;
```
**3. Modify Application Entry Point**
In your application's entry point (usually src/index.js or src/main.js), modify the code to call loadConfig before initializing the application:
Example in src/index.js:
```javascript
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import loadConfig from './config';
loadConfig().then(() => {
ReactDOM.render(<App />, document.getElementById('root'));
}).catch(error => {
console.error('Failed to load configuration:', error);
// Handle the error (e.g., show an error message to the user)
});
```
**4. Access Configuration in the Application**
Within your application, access the configuration stored in window.appConfig as needed. For example, you might pass these configurations as props to your components or store them in a global state.
Example in a Component:
```javascript
import React, { useEffect, useState } from 'react';
const MyComponent = () => {
const [config, setConfig] = useState(null);
useEffect(() => {
setConfig(window.appConfig);
}, []);
if (!config) {
return <div>Loading...</div>;
}
return (
<div>
<h1>API Endpoint: {config.FE_API_ENDPOINT}</h1>
{/* Use other config variables as needed */}
</div>
);
};
export default MyComponent;
```
By implementing dynamic configuration at runtime, you can streamline your deployment pipeline, reduce the risk of errors, and make your frontend application more flexible and resilient to changes in environment-specific settings.
--------------
This post was originally published on my [Substack](https://anshulsao1.substack.com/p/handline-environment-configurations) | anshulsao |
1,870,171 | Elevating ABA Therapy in Michigan: Introducing Entiva Behavioral Health | In the landscape of Applied Behavior Analysis (ABA) therapy in Michigan, one name stands out for its... | 0 | 2024-05-30T09:33:35 | https://dev.to/entivausa/elevating-aba-therapy-in-michigan-introducing-entiva-behavioral-health-2kkl | In the landscape of Applied Behavior Analysis (ABA) therapy in Michigan, one name stands out for its commitment to excellence, innovation, and personalized care: Entiva Behavioral Health. As families across the state seek high-quality ABA therapy services for their loved ones with autism spectrum disorder (ASD) and other developmental disabilities, Entiva Behavioral Health emerges as a beacon of hope, offering comprehensive support and transformative interventions.
## A Leader in ABA Therapy Services
Entiva Behavioral Health is at the forefront of [ABA therapy in Michigan](https://entivabehavioralhealth.com/), setting the standard for quality and effectiveness. With a team of dedicated professionals and a passion for making a difference, Entiva is dedicated to providing personalized, evidence-based interventions that empower individuals to reach their full potential.
## Comprehensive and Individualized Care
At Entiva Behavioral Health, no two individuals are treated alike. Recognizing the unique strengths, challenges, and goals of each person, Entiva takes a personalized approach to ABA therapy. Through comprehensive assessments and ongoing collaboration with families, therapists develop customized treatment plans tailored to meet the specific needs of each individual.
## A Focus on Holistic Development
Entiva Behavioral Health understands that true progress extends beyond the therapy room. That's why their approach to ABA therapy goes beyond targeting specific behaviors to encompass the holistic development of each individual. From communication and social skills to independence in daily living activities, Entiva strives to equip individuals with the skills they need to thrive in all areas of life.
## Empowering Families Every Step of the Way
Families are an integral part of the therapy process at Entiva Behavioral Health. Through education, training, and ongoing support, Entiva empowers families to become active participants in their loved one's therapy journey. By providing families with practical strategies and tools, Entiva helps create a supportive environment where individuals can continue to grow and succeed long after therapy sessions have ended.
## Embracing Innovation and Excellence
Entiva Behavioral Health is committed to staying at the forefront of ABA therapy by embracing innovation and excellence. From the latest research findings to cutting-edge technology, Entiva continually seeks new ways to enhance the effectiveness of its interventions and improve outcomes for the individuals it serves.
## Join the Entiva Community
Become a part of the thriving community at Entiva Behavioral Health, your premier destination for exceptional [ABA therapy in Michigan](https://entivabehavioralhealth.com/). With a steadfast dedication to personalized care, holistic growth, and unwavering support, Entiva is your partner in helping individuals with autism spectrum disorder and other developmental disabilities realize their true capabilities.
Reach out to Entiva Behavioral Health today to explore their comprehensive ABA therapy services and become a valued member of a community dedicated to the transformative impact of personalized care.
| entivausa | |
1,870,170 | [Game of Purpose] Day 11 | Today I was travelling, so no progress. | 27,434 | 2024-05-30T09:33:21 | https://dev.to/humberd/game-of-purpose-day-11-1ac | gamedev | Today I was travelling, so no progress. | humberd |
1,870,169 | Cluster Stickiness for Large Distributed Applications | Overview Every software product company begins its journey from humble origins. However,... | 0 | 2024-05-30T09:33:16 | https://dev.to/chetanhs/cluster-stickiness-for-large-distributed-applications-4hja | cloudcomputing, clustering, scaling, partitions | ## Overview
Every software product company begins its journey from humble origins. However, success often brings its own set of challenges. As the organization grows, so does the user base, often at an exponential rate. This surge in users can strain the system, causing previously smooth database queries to slow down or even timeout. Such issues can severely impact user experience and, consequently, lead to revenue losses.
At this crucial juncture, Software Architects and leaders face the daunting task of devising effective scaling strategies. The goal is to ensure that data retrieval remains as swift as it was during the early stages, despite the burgeoning user base. Drawing from my professional experience in navigating such exponential scaling events, this article delves into best practices for overcoming these challenges by establishing cluster level stickiness and localizing user generated traffic to specific clusters and avoiding global database lookups. As an added bonus, this approach also helps with the compliance with data residency regulations enforced by governments across the world.
## The Problem
_Figure 1: Simple DB setup_
In the beginning, a simple setup like the one shown in Figure 1 is usually enough to get started. As the number of users start increasing and the application starts going global, the DB fetch starts getting slower. This can be easily solved by creating indexes on specific columns within tables in the database until the DB size hits a certain limit. Beyond that, updating very large indexes and querying them starts to become a resource intensive and slow activity.
## The Solution
The obvious solution to this problem is to partition the database. A good partitioning strategy for databases containing data about users from across the globe is to partition the database into region and/or user type based clusters, where each cluster contains the same database structure as all the clusters but contains only a subset of all the data. This can be bundled with a metadata store that serves as an index for the data housed in each cluster. This will look something like this,
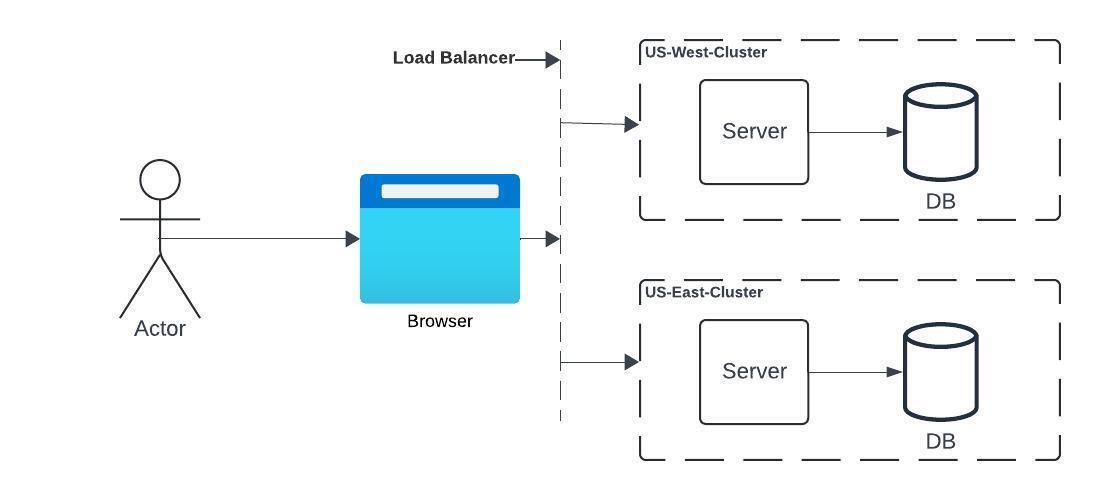
_Figure 2: Clustered Architecture_
While this is an effective strategy for partitioning the data, it has a limitation. For every request that the load balancer receives, it will need to query the metadata store to identify the correct target cluster for the request and route it appropriately. This again is a resource intensive activity.
To address this, we can start by defining a simple structure to the metadata store. It can be an index of (username, cluster_id) pairs. This can be populated at the time the user registers to use the software or the first time the user’s data is written to a partition in a cluster. Once the user’s cluster has been identified, a first party cookie with the name of the cluster can be dropped onto the user’s browser and this can be used by the load balancer for subsequent requests to directly route the user’s requests to the correct cluster without looking up the metadata store. Figure 3 illustrates these sequences of actions.
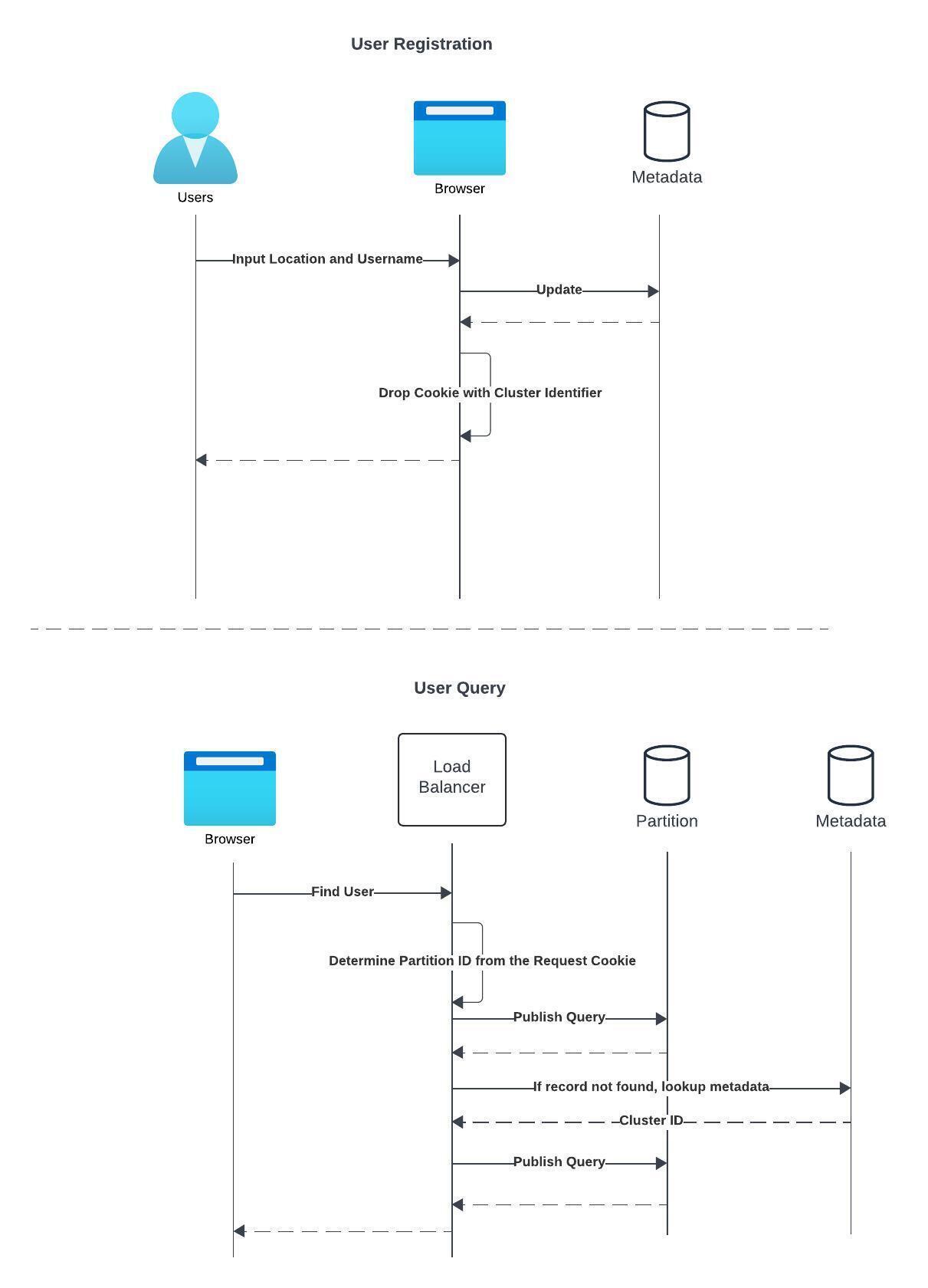
_Figure 3: Assigning user to a cluster and looking up the user from the cluster_
## Limitations
While implementing this solution speeds up the queries and improves the user experience, it also comes with several limitations. The prominent limitations are listed below,
- **Increased Maintenance Overhead:** With a simple setup, the software architecture is straightforward and it is easy to modify, fix and replace. However the cost of maintenance goes up as the architecture gets more complex, due to the need to now maintain multiple database servers per partition and groups of servers per cluster.
- **Partition Rebalancing and Cluster Re-assignment:** The partitions corresponding to locations where the software application is most popular tend to grow large in comparison to other partitions. As a result, the users from the popular areas start receiving the slowest responses. To avoid this, new local partitions will need to be created and the existing records are required to be rebalanced. As a part of this effort the metadata store will also need to be updated. It is natural for the user experience to be inconsistent or even broken during these rebalancing efforts. Similarly, when the cluster determination criteria for a user changes, for example, if a user moves from one country to another, the user will need to be moved to a different cluster corresponding to the new country. This also requires updating the metadata store and leads to additional processing power consumption.
- **Need for Experts:** While a simple architecture can easily be maintained by most software engineers, experts with advanced database skills and advanced software architectural skills will be required to maintain complex architectures. Finding and retaining them could be challenging for organizations.
## Conclusion
This article intentionally focuses on a specific aspect of database cluster setup for the sake of clarity and brevity. It acknowledges that other crucial elements, implementing replication and fault tolerance mechanisms, addressing replication lags, and employing caching strategies, are equally vital but inherently nuanced and architecture-specific.
Having experienced the need for rapid scaling firsthand in my career, I've crafted this article to offer a concise blueprint for swiftly developing the infrastructure necessary for scaling. Just as there are multiple ways to bake a cake, there exist various scaling strategies. The method outlined herein reflects my own repeatable approach, which I believe can be effectively utilized by Software Architects worldwide.
| chetanhs |
1,870,102 | How to Create a Voice Over for a Podcast Using AI Tools? | Discover AI tools for podcasts voice overs. Learn how to create professional voice overs for your... | 0 | 2024-05-30T09:32:05 | https://dev.to/novita_ai/how-to-create-a-voice-over-for-a-podcast-using-ai-tools-cle | ai, api, voiceover, podcast | Discover AI tools for podcasts voice overs. Learn how to create professional voice overs for your podcast with ease on our blog.
##Key Highlights
- Podcast voice overs can enhance the listening experience for your target audience, making your more engaging and professional.
- AI voice tools provide a convenient and cost-effective way to create voice overs for your podcasts.
- Crafting a script that works well with AI voice tools is crucial for achieving a natural and seamless narration.
- Choosing the right AI voice over tool is important to ensure clarity and quality in your voice overs.
- Preparing your content and selecting the perfect AI voice are essential steps in creating your first AI voice over.
##Introduction
With the rise of podcasts, creators seek to enhance content and engage audiences. Incorporating voice overs can add a professional touch, improve the listening experience, and captivate listeners.Previously, creating voice overs involved hiring expensive voice actors. Now, AI technology offers cost-effective solutions. AI voice over tools use algorithms to replicate human voices efficiently. This blog explores creating podcast voice overs with AI tools. We delve into the benefits, content preparation tips, selecting the right tool, and provide a step-by-step guide for your first AI voice over.
##What is AI Voice Over?
AI voice over uses artificial intelligence to create voice overs for podcasts and other media quickly and cost-effectively, eliminating the need for a professional voice actor. These tools analyze text input to generate human-like voices that closely resemble natural speech, making them a popular choice for businesses, podcasters, and even radio stations. While AI voice over can’t replace human emotion entirely, it’s a convenient option for podcast creators seeking professional narration for their content.

##The Advantages of Using AI for Podcast Voice Overs
AI for podcast voice overs is efficient, consistent, and cost-effective. It enables quick creation of professional voice content in various styles and tones. AI tools reduce the need for extensive editing by providing polished output, offering a wide range of voices and languages to expand the target audience reach. By streamlining the process, AI enhances podcast production for a seamless and engaging listening experience, making it a valuable asset for quality and convenience-seeking podcasters. With the added human touch of diverse podcast content, such as expert interviews, captivating storytelling, or informative segments, AI voice overs can bring an extra edge of professionalism and creativity to your podcast, creating a more personal and memorable experience for your listeners.
##Preparing Your Content for AI Voice Over
Before diving into the process of creating a voice over for your podcast using AI tools, it’s important to prepare your content. This involves crafting a script that works well with AI voice tools and writing engaging podcast scripts that resonate with your target audience.
###Crafting a Script That Works with AI
- Keep sentences and paragraphs concise.
- Focus on clarity with simple language.
- Avoid complex names or words; simplify or provide phonetic spellings if needed.
- Optimize your script for AI voice over to ensure smooth, natural narration in your podcast.
###Tips for Writing Engaging Podcast Scripts
Writing engaging podcast scripts is crucial for captivating your audience and ensuring their return. Here are some tips:
- Know your target audience: Tailor your content to their interests.
- Plan episodes: Outline main points for a structured presentation.
- Include storytelling elements: Use narratives and personal experiences for relatability.
- Social media promotion: Tease episodes, share behind-the-scenes content, and engage with your audience.
Engaging podcast scripts create an immersive experience and foster a loyal following.
##Choosing the Right AI Voice Over Tool
Choosing the right AI voice over tool is crucial to ensure the clarity and quality of your voice overs. There are several factors to consider when selecting an AI voice over tool, including its voice generator capabilities, pricing, and clarity of the generated voices.
###Key Features to Look For
When selecting an AI voice over tool for your podcast, one of the key features to look for is a great voice. Look for tools that offer a wide variety of voices to choose from, ensuring you find the perfect voice for your podcast. AI tools with advanced editing capabilities can help remove background noise and improve overall sound quality.
###Top AI Voice Over Tools in the Market
There are several AI voice over tools available in the market that offer different features and capabilities. Here are some of the top AI voice over tools to consider:
- Speechify: Speechify offers a user-friendly interface and a wide range of natural-sounding voices, making it a popular choice for podcast creators.
- Adobe Audition: Adobe Audition provides advanced audio editing features and the ability to fine-tune your voice overs for a professional result.
- Novita AI: Google AI offers a powerful text-to-speech API with multiple voices and language options.
##How to Create Your First AI Voice Over?
Creating voiceovers for podcasts using AI tools like Novita AI is a simple process. Follow these steps:
- Step 1: Head to the Novita AI website and create an account on it. navigate “[text-to-speech](https://novita.ai/product/txt2speech?ref=blogs.novita.ai)” under the “Product” tab, you can test the effect first with the steps below.
- Step 2: Input the text that you want to get voiceover about.
- Step 3: Select a voice model that you are interested in.
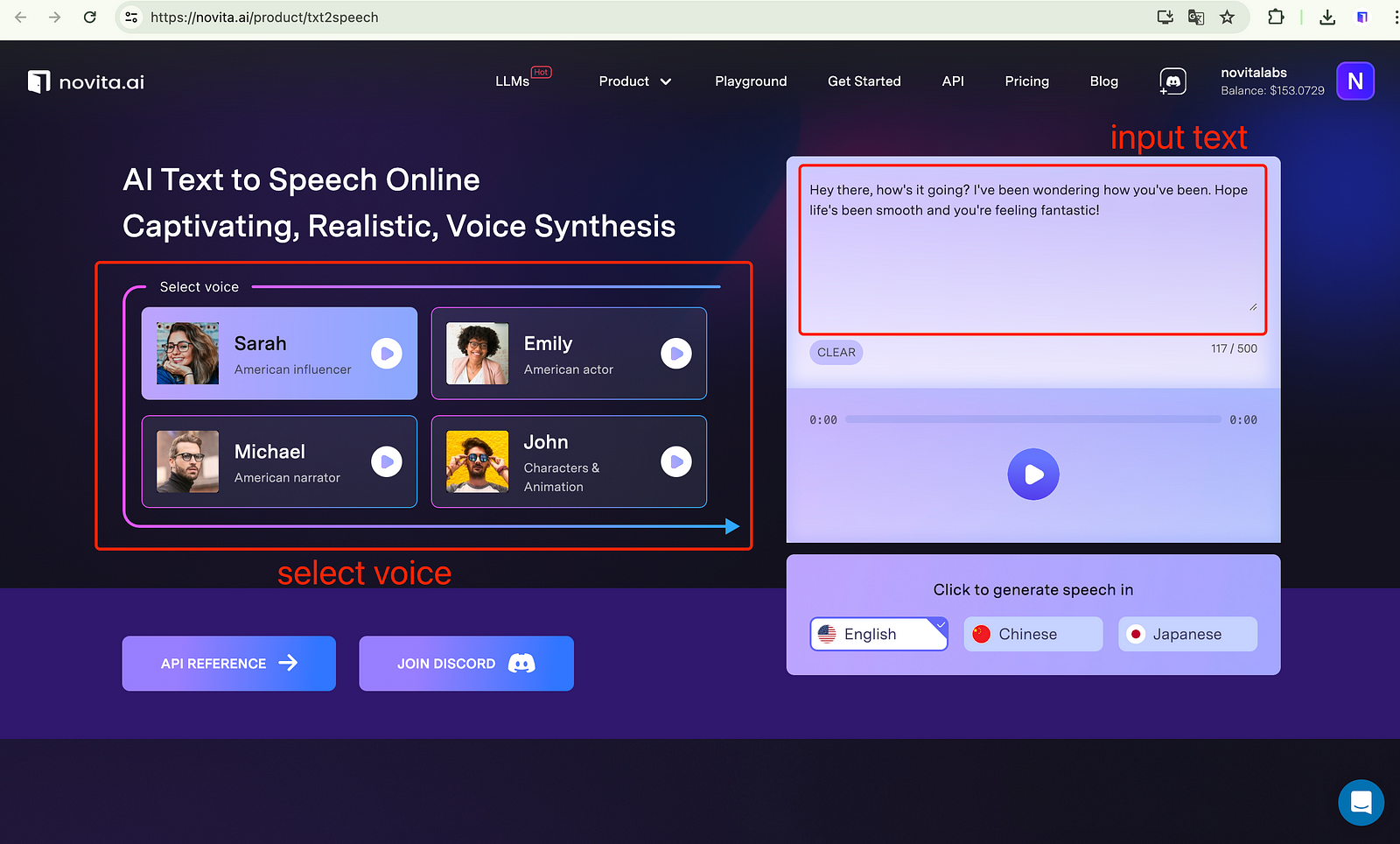
- Step 4: Click on the “Generate” button, and wait for it.
- Step 5: Once it is complete, you can preview it. If it’s satisfied, you can download and integrate the output into your podcasts.
##Editing and Finalizing Your Podcast Voice Over
After creating your AI voice over, it’s important to edit and finalize the audio to ensure a polished result. This involves adjusting the volume, removing any unwanted background noise, and making any necessary tweaks to improve the overall quality of the voice over.
###Integrating AI Voice Overs into Your Podcast
Integrating AI voice overs into your podcast can add a professional touch and enhance the overall listening experience. When using AI voice tools, it’s important to pay attention to the editing process. Ensure that the AI voice overs are seamlessly integrated into your podcast episodes.
During the editing process, be mindful of background noise and ensure that the voice overs are clear and easy to understand. You can use software to filter out any background noise and improve the overall quality of the voice overs.
In addition to voice overs, consider incorporating sound effects and background music to make your podcast more engaging and immersive. Sound effects can add depth and enhance the storytelling, while background music can create a mood and set the tone for your podcast.
###Best Practices for Editing AI Voice Overs
When editing AI voice overs for your podcast, ensure clarity and pronunciation for a professional result. Incorporate appropriate pacing and inflections to match the tone of your content. Eliminate any background noise or distractions, especially if you live in busy areas like New York or Los Angeles, to enhance the listening experience. Review the audio file multiple times for accuracy and fluidity. Utilize any available features in the AI tool for fine-tuning the voices. Make necessary revisions to perfect the final output, focusing on seamless transitions and natural-sounding delivery.
##How Can I Prouduce a Commercial Voice-over Tool for a Podcast?
To build a commercial voice-over tool for a podcast, research existing tools, define your target audience and features, design an intuitive interface, ensure high audio quality, and test rigorously. Consider scalability and user feedback for continuous improvement.
You can use the Text-to-Speech API to quickly produce such a tool. Using Novita AI Text to Speech API offers swift, expressive, and reliable voice synthesis. With real-time latency under 300ms, diverse voice styles, and seamless integration, it ensures high-quality, customizable audio for enhanced podcast user experiences.
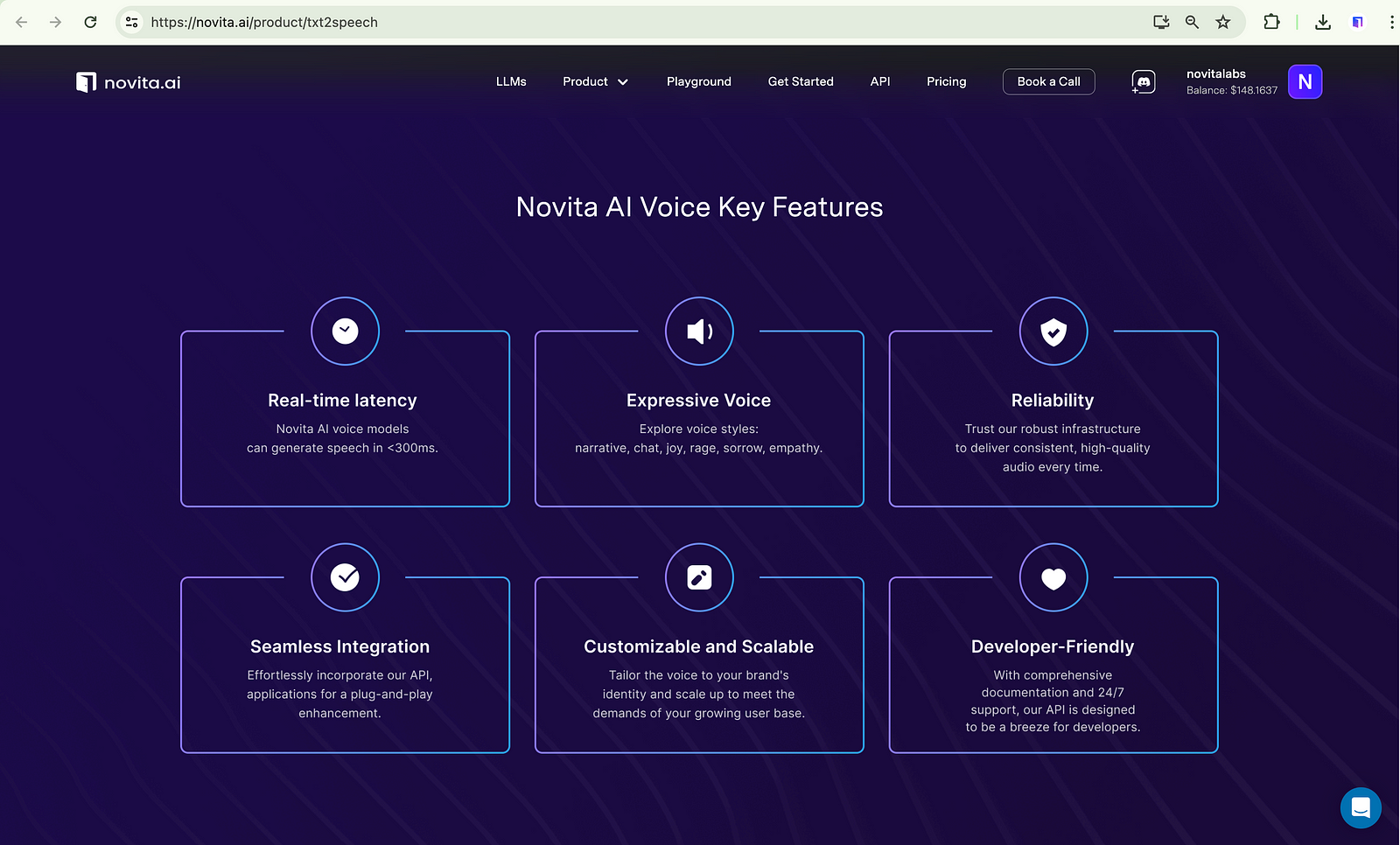
Next, I’ll walk you through simple steps to help you understand.
Step1. Understand Requirements: Clearly define the project’s goals, target audience, and features needed.
Step2. Integrate API: Incorporate the Novita AI Text to Speech API into your backend system for voice synthesis.
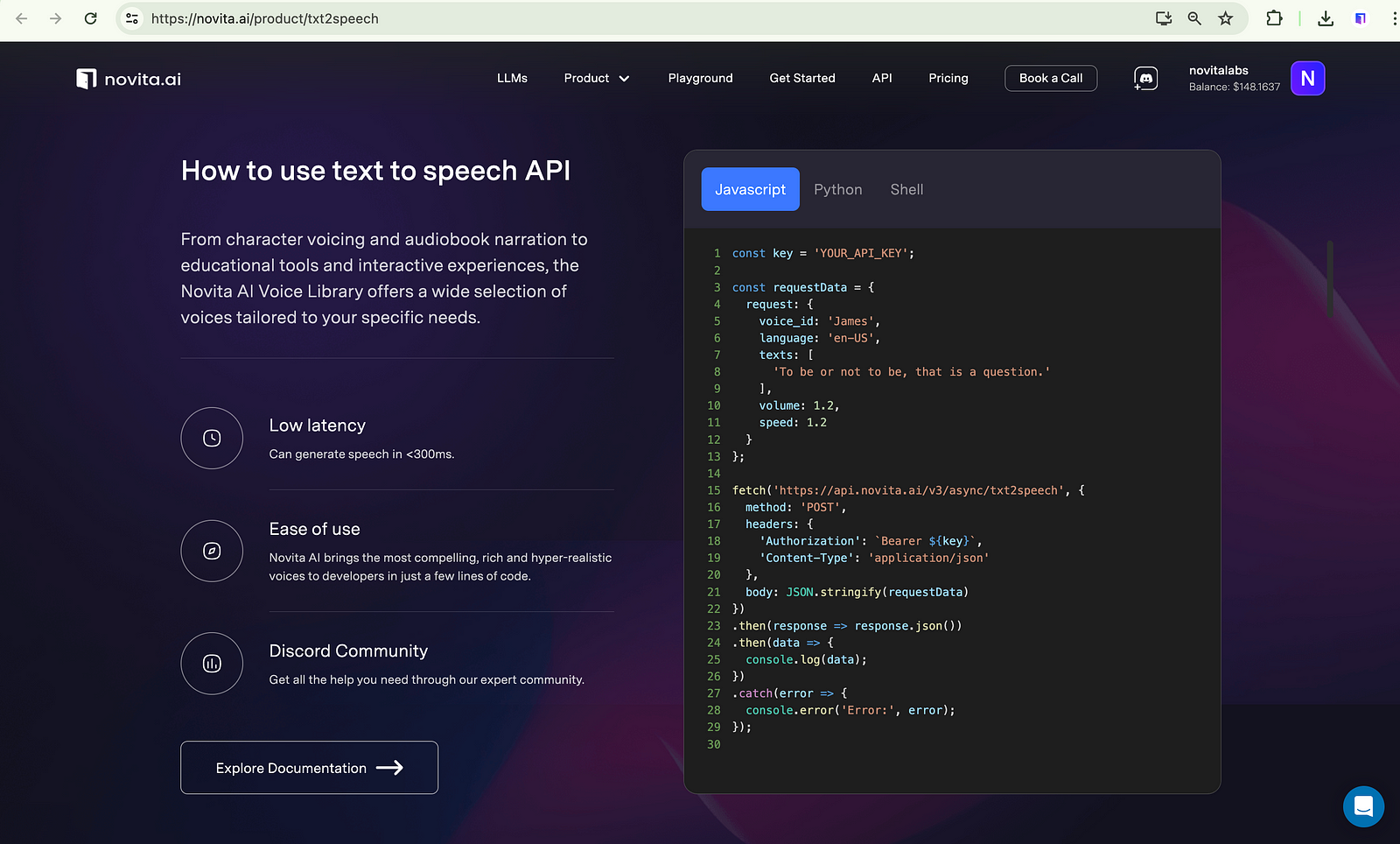
Step3. Develop User Interface: Create a user-friendly interface for inputting text and customizing voice settings.
Step4. Implement Authentication: Ensure secure user authentication and authorization mechanisms.
Step5. Test and Deploy: Thoroughly test the tool, deploy it to a production environment, and monitor its performance for continuous improvement.
##Future Trends in Podcast Voice Overs
The landscape of podcast voice overs is continually evolving, with future trends pointing towards increased personalization and customization through AI technologies. Advancements in AI voice generation will offer podcasters a wide array of voice options to tailor their content to specific audiences. Additionally, the integration of AI voice overs with interactive storytelling elements and enhanced sound effects will elevate the overall listener experience, setting new standards for engaging and immersive podcasts. As technology progresses, the possibilities for innovative podcast voice over creations, including the use of AI podcast hosts, are limitless.
##Conclusion
In conclusion, integrating AI tools for podcast voice overs can significantly enhance the production process, offering efficiency and cost-effectiveness. By leveraging AI voice technology, podcasters can streamline their workflows and deliver professional-quality voice overs swiftly. Embracing these advancements allows for greater flexibility in content creation and opens up new possibilities for engaging with a wider audience. As technology continues to evolve, the future of podcast voice overs is poised for further innovation and growth, promising exciting developments in the audio production landscape.
##Frequently Asked Questions
###How to Ensure Your AI Voice Over Sounds Natural?
To ensure your AI voice over sounds natural, focus on intonation, pacing, and cadence in the script. Use tools with advanced voice modulation capabilities for a lifelike result. Pay attention to pauses and inflections to enhance the overall quality of the voice over.
###What are the Legal Considerations for Using AI Voice Overs?
When using AI for voice overs in podcasts, it’s crucial to consider legal aspects like copyright permissions, usage rights, and compliance with voice actor agreements. Ensure your AI tool adheres to these regulations for a seamless and legally sound podcast production.
Originally published at [novita.ai](https://blogs.novita.ai/how-to-create-a-voice-over-for-a-podcast-using-ai-tools-2/?utm_source=dev_audio&utm_medium=article&utm_campaign=podcasts-voice-overs-ai-tools-guide)
[novita.ai](https://novita.ai/?utm_source=dev_audio&utm_medium=article&utm_campaign=podcasts-voice-overs-ai-tools-guide
), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free. | novita_ai |
1,870,166 | 5 reasons that Choosing an online pharmacy may be right for you | Choosing an online pharmacy like DiRx can save you time, money, and hassle. With convenient home... | 0 | 2024-05-30T09:32:04 | https://dev.to/mahesh803/5-reasons-that-choosing-an-online-pharmacy-may-be-right-for-you-9a0 | onlinepharmac, medicine, usa, agegroup40plus | Choosing an online pharmacy like DiRx can save you time, money, and hassle. With convenient home delivery, lower costs, no waiting in lines, and extended hours for customer care, it's a smart choice for many. Ensuring you select a trustworthy, FDA-approved provider guarantees the same safety and quality as your local pharmacy. If these benefits resonate with you, it might be time to consider ordering your prescriptions online.
Read more[](https://shorturl.at/weL7r) | mahesh803 |
1,870,063 | AI-Powered Voicemail Greeting Generator: Craft Personalized Business Greetings | Create personalized business greetings with our AI-Powered Voicemail Greeting Generator. Elevate your... | 0 | 2024-05-30T09:31:52 | https://dev.to/novita_ai/ai-powered-voicemail-greeting-generator-craft-personalized-business-greetings-4eda | ai, api, voicemail, texttospeech | Create personalized business greetings with our AI-Powered Voicemail Greeting Generator. Elevate your voicemail game today!
##Key Highlights
- AI-powered voicemail greeting generators are revolutionizing business communications by providing personalized and professional voicemail messages.
- These generators use AI technology and natural language processing to transform written text into lifelike spoken audio.
- With AI voice generators, businesses can customize voicemail greetings at scale, ensuring a personalized and engaging experience for callers.
##Introduction
In today’s fast-paced world, voicemail greetings are crucial for business communication. With AI technology advancements, voicemail greetings have evolved. AI-powered generators like Novita AI use NLP and machine learning to create lifelike audio from written text, also known as generated audio. These tools offer personalized and professional messages without the need to record yourself. Incorporating an AI voice generator like ElevenLabs into your voice mail greetings can take your communication to the next level, providing callers with a more engaging experience and enhancing your brand image. Learn about voicemail greetings, the benefits of AI generators, and how to create the perfect voicemail message with Novita AI in this blog.
##What is a Voicemail Greeting?
Voicemail greetings are essential in business communication, serving as the initial point of contact when you can’t answer a call. A professional greeting includes a polite salutation, reason for unavailability, and a request for caller information. Offering alternative contacts or urgent instructions is helpful. Voicemails reflect professionalism, enhance customer experience, and build trust with concise messages like, “Thank you for calling [business name].” Craft personalized greetings with our AI-powered generator.

##Understanding AI-Powered Voicemail Greeting Generators
AI-Powered Voicemail Greeting Generators use AI technology to create personalized messages for businesses. These systems analyze data to craft tailored messages, maintaining a professional image and effective customer communication. By incorporating NLP techniques like language customization and accent options, these generators make a lasting impression. They provide instant responses outside regular hours and integrate with existing systems, enhancing the customer experience efficiently.
###The Evolution of Voicemail Greetings
Voicemail greetings have transformed from basic recordings to personalized AI-generated scripts, making a positive impression on callers. AI technology now tailors messages based on caller data, enhancing communication in business settings. This evolution reflects a move towards more personalized and efficient interactions, shaping brand identity and customer experience. Businesses, including law firms, can use AI-powered voicemail recordings to create professional, clear, and friendly greetings for every call.
###How AI is Revolutionizing Business Communications
By using AI voice generators, businesses can create engaging greetings that enhance customer experience. These greetings sound natural and can be customized to reflect the brand’s identity with various voices and accents.AI-powered voicemail greetings ensure a consistent and professional image for businesses, maintaining professionalism and effective communication with callers. They can also be personalized for specific business hours, improving customer experience and communication efficiency.
##Key Benefits of Using AI for Your Voicemail Greetings
Using AI for your voicemail greetings has multiple advantages. Firstly, AI generators customize greetings in bulk to represent your brand and convey messages clearly.Secondly, AI voice tools create personalized messages by including the caller’s name or relevant details. This personal touch enhances customer experience.Lastly, AI greetings boost brand image with realistic greetings that impress callers, aiding businesses in building professional communication.
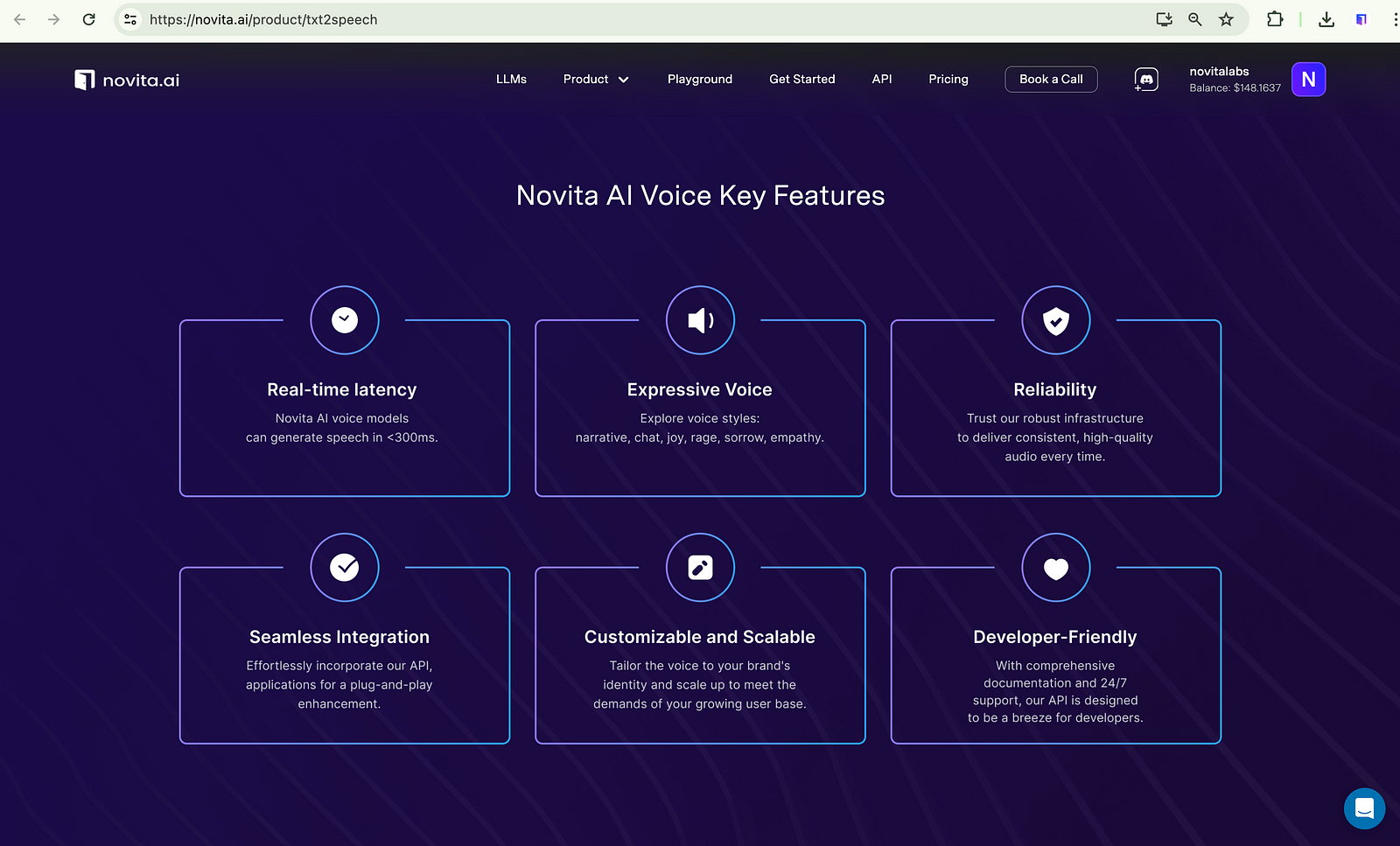
###Customization at Scale
Using AI for voicemail greetings allows businesses to customize at scale with a variety of voices, accents, and languages. This personalization includes adding business details to create a lasting impression. Customized voicemail greetings establish professionalism, enhance brand identity, and differentiate businesses in the market.
###Enhancing Caller Experience with Personalized Messages
AI-powered voicemail greetings enhance the caller experience with personalized messages, incorporating the caller’s name or relevant information. This personal touch leaves a lasting impression, making callers feel valued and improving customer service. By providing specific instructions or alternative contact information, businesses ensure timely assistance even when the recipient is unavailable.
##3 Top Voicemail Greeting Generators Online
FlexClip offers customizable free voicemail greetings. Narakeet and Novita AI provide AI-based voicemail greeting solutions catering to various needs. Choose the right platform to create personalized and impactful voicemail messages easily.
###FlexClip — A Free Voicemail Greeting Generator
FlexClip is a free voicemail greeting generator with easy customization features. Create professional messages effortlessly, integrating personalized elements like brand name and contact details. This AI-powered tool, known as the Free Voicemail Greeting Generator, ensures a professional tone, leaving a lasting impression with its audio files.
**Pros:**
- Free and powerful: Accessible robust voicemail greeting maker.
- Highly customizable: Adjust voice, language, pitch, tone, and speed.
- Advanced tools: Enhance voicemail message creation.
- AI assistance: Generates scripts using keywords.
- Cloud storage: Prevents data loss.
**Cons:**
- Limited avatar styles: Not all voice avatars offer style options.
###Narakeet — AI Voicemail Greeting Generator
Narakeet is an advanced AI voicemail greeting generator that creates personalized messages effortlessly. This tool uses cutting-edge AI to craft professional greetings tailored to your business needs. Enhance your brand image and customer experience with unique and engaging voicemail messages from Narakeet, providing a professional touch for every caller.
**Pros:**
- No registration needed: Create up to 20 free voicemail greetings without registering.
- User-friendly interface: Clean and easy to navigate, suitable for newcomers.
- Multiple file formats: Save recorded greetings as MP3, WAV, or M4A.
**Cons:**
- No preset scripts: Lacks voicemail script presets for reference.
- Non-commercial use: Free account recordings cannot be used commercially.
- High pricing: Starts at $6 for 30 minutes of audio duration.
###Novita AI — Comprehensive Business Voicemail Greeting Generator
Novita AI offers a comprehensive solution for crafting professional voicemail greetings tailored to your business needs. With advanced AI technology, customizing language, accent, and integrating with existing systems is seamless. Elevate your brand image with personalized voicemail messages that impress callers and reflect your company’s professionalism effectively using Novita AI.
**Pros:**
- User-friendly: Simple and intuitive interface.
- Seamless Integration: Effortlessly incorporate our APl applications for a plug-and-playenhancement.
- Customizable and Scalable: Tailor the voice to your brand’s identity and scale up to meet the demands of your growing user base.
**Cons:**
- Pricing: paid, $12/1M characters
##How to Generate Voicemail Greeting Online with Novita AI?
Generating voicemail greeting using AI tools like Novita.AI is a simple process. Follow these steps:
- Step 1: Head to Novita AI website and create an account on it. navigate “[text-to-speech](https://novita.ai/product/txt2speech?ref=blogs.novita.ai
)” under the “Product” tab, you can test the effect first with the steps below.
- Step 2: Input the text that you want to get voicemail greeting about.
- Step 3: Select a voice model that you are interested in.
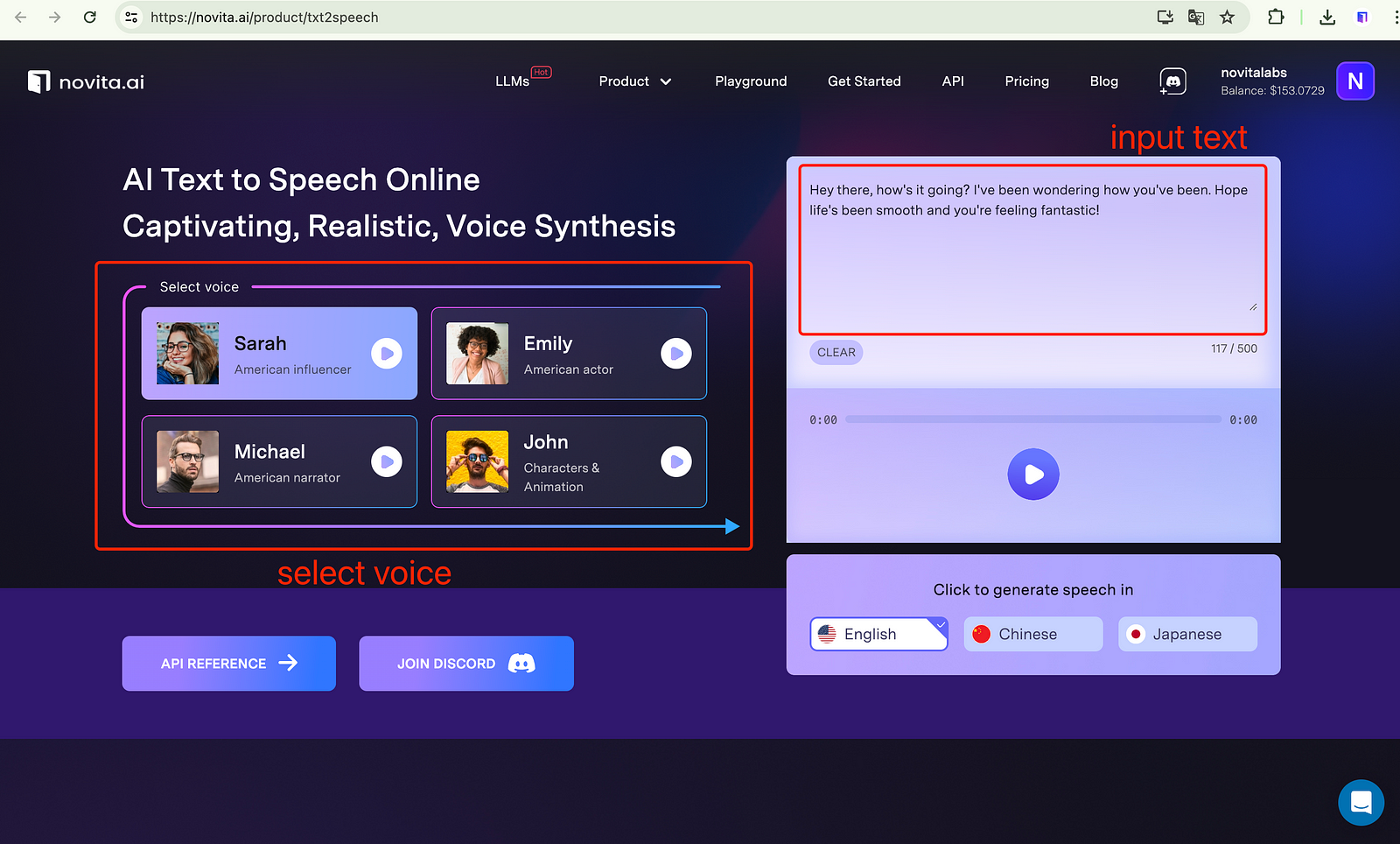
- Step 4: Click on the “Generate” button, and wait for it.
- Step 5: Once it is complete, you can preview it. If it’s satisfied, you can download and integrate the output into your voicemail.
##Why Choose Novita AI as Your Online Voicemail Greeting Generator?
Novita AI is the top choice for an online voicemail greeting generator, offering realism, versatility, and context-awareness.
###Language and Accent Customization Options
Novita AI provides personalized voicemail greetings with a variety of language and accent options. Customized accents ensure natural-sounding greetings that match your brand identity, enhancing caller experience and leaving a lasting impression.
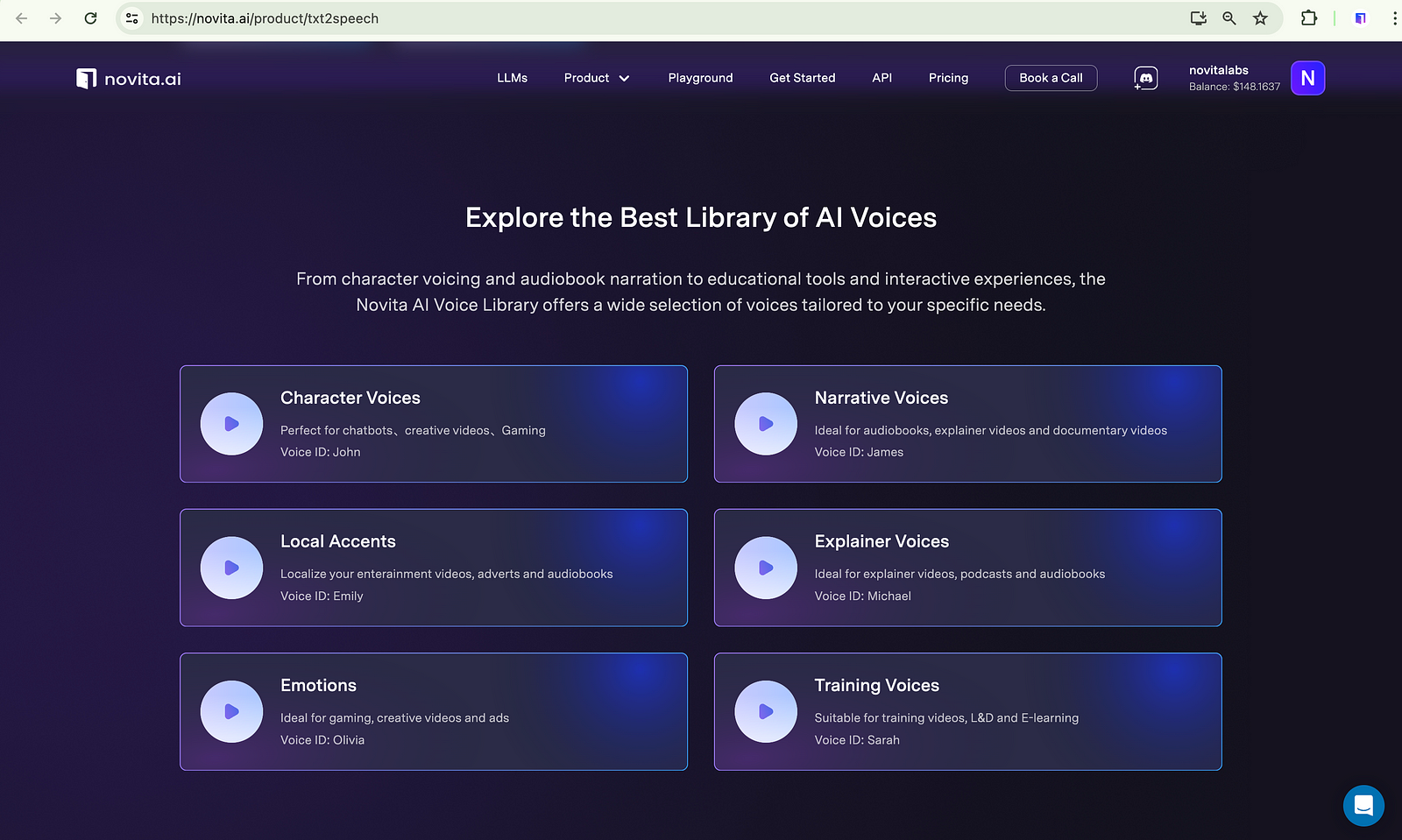
###Integration Capabilities with Business Systems
Novita AI seamlessly integrates with various business systems, allowing easy incorporation of AI-powered voicemail greetings into your communication strategy. The user-friendly API offers hassle-free integration with your existing phone system or communication platform. This ensures that AI-generated voicemail greetings smoothly align with your business processes, enhancing the customer experience and reflecting your brand identity.
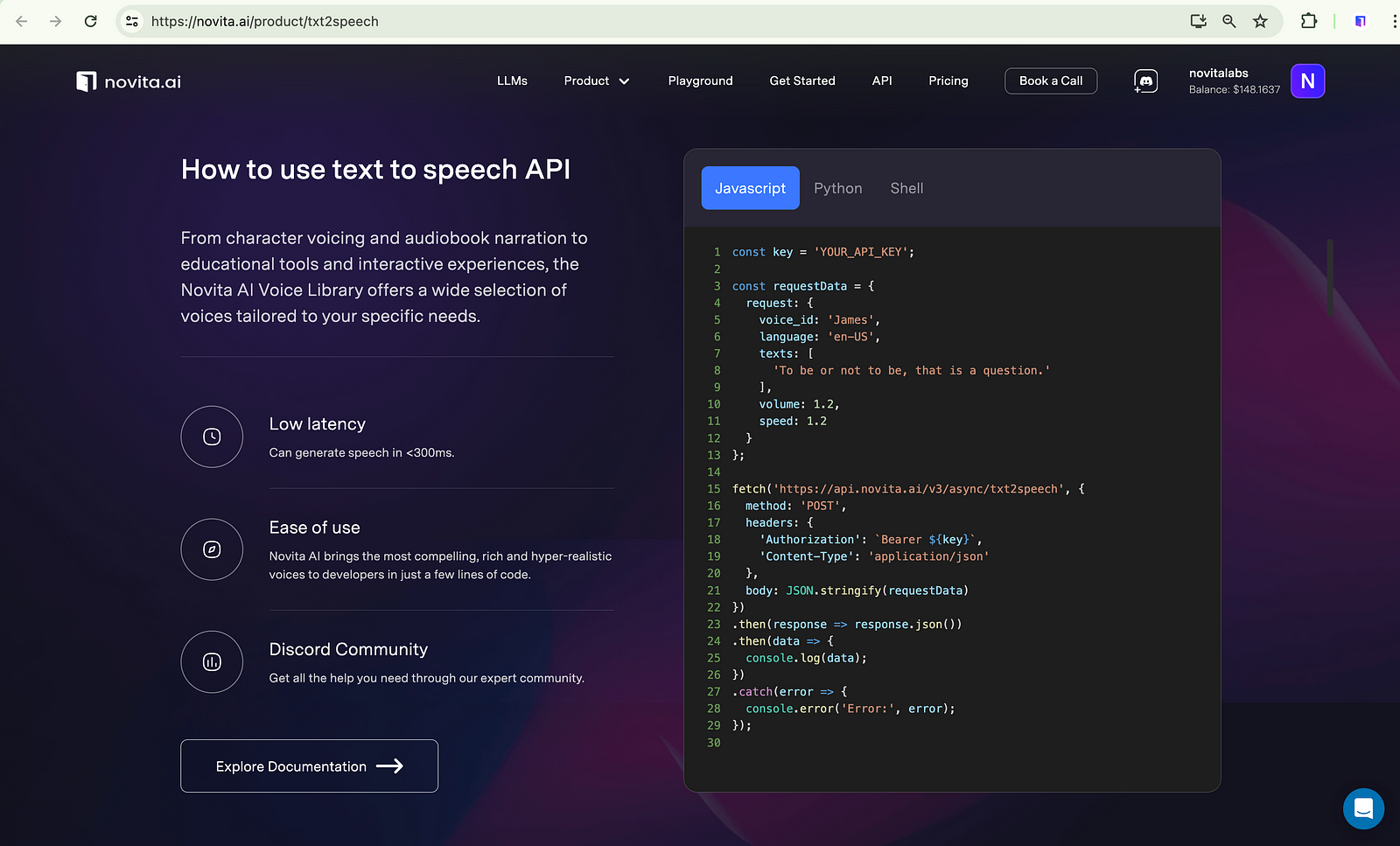
##Real-World Applications of AI Voicemail Greetings
AI voicemail messages enhance communication for businesses and individuals by providing personalized greetings and quick responses. They engage callers with relevant information, turning leads into customers and improving customer service by offering instant responses 24/7. This technology enhances a company’s reputation, customer service, and sales.
###Boosting Sales with AI-Personalized Messages
AI voicemail greetings personalize messages for potential customers, boosting sales by addressing individual needs. Novita AI’s voice generators convert text into lifelike audio for engaging voicemail greetings that provide product information, drive sales, and promote events to enhance customer engagement even after hours.
###Improving Customer Service with Instant, 24/7 Responses
Businesses benefit from AI voicemail greetings in customer service by providing instant replies for urgent issues and addressing common concerns. AI responses save time by sharing FAQs and guiding customers to contact options, enhancing satisfaction and loyalty with quick responses 24/7.
##Conclusion
In the realm of business communications, AI-powered voicemail greetings are making waves. By offering scalability and personalized messages, they elevate caller experiences to new heights. With the evolution of voicemail greetings, AI is at the forefront of revolutionizing this space. Novita AI stands out as an online voicemail greeting generator, offering language customization and seamless integration with business systems. Through tailored scripts and 24/7 responses, AI voicemail greetings not only boost sales but also enhance customer service. Embrace the future of personalized voicemail greetings with AI technology for a more engaging and efficient communication strategy.
##Frequently Asked Questions
###What is the perfect voicemail greeting?
The ideal voicemail greeting strikes a balance between professionalism and friendliness. It should include your name, contact details, and a return date if needed to provide necessary information and leave a positive impression.
###How to update your AI voicemail greeting?
Updating your AI voicemail greeting is simple with AI technology. Access the AI voicemail generator, edit your script, and include alternative contact info for immediate assistance if needed.
Originally published at [novita.ai](https://blogs.novita.ai/ai-powered-voicemail-greeting-generator-craft-personalized-business-greetings/?utm_source=dev_audio&utm_medium=article&utm_campaign=voicemail-greeting-generator
)
[novita.ai](https://novita.ai/?utm_source=dev_audio&utm_medium=article&utm_campaign=voicemail-greeting-generator), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free. | novita_ai |
1,870,165 | Big Data Analytics: Unlocking Insights and Transforming Industries | Big data is more than just a popular term in the current society especially considering the fact that... | 0 | 2024-05-30T09:29:29 | https://dev.to/commercepulse/big-data-analytics-unlocking-insights-and-transforming-industries-1kp3 | learning, news, database | Big data is more than just a popular term in the current society especially considering the fact that it affects the majority of organizations and companies across the globe. It is the study of large and diverse [data service](https://www.patreon.com/posts/harnessing-power-105150179?utm_medium=clipboard_copy&utm_source=copyLink&utm_campaign=postshare_creator&utm_content=join_link) to find out those patterns, which are not seen before, trends, demands or anything which may be useful in the market. There are various potential benefits that can be derived from this process, such as making better business decisions, managing customer satisfaction, optimising conducting internal processes, and potentially generating new sources of income.
**What is Big Data?**
Big data by definition therefore means huge volumes of data which cannot effectively be processed by normal data processing techniques. These data sets come from various sources: Making of social media profiles, sensors, digital consignments, weblogs and many more. It is the volume, velocity and the variety of the big data that pose the challenge of handling it is using modern techniques and methods.
**Why is Big Data Analytics Important?**
Big data analytics allows organizations to determine new opportunities in the organization’s immense data storage. These bring about improved decisions, effective working, higher revenue and customer loyalty. Here are some key reasons why [big data analytics](https://www.commercepulse.co.uk/data-application-development/) is crucial: Discussed below are some basic reasons why big data analytics is important:
**Enhanced Decision Making:** Leaders can therefore use business analytics to analyse trends and in turn gain the ability to make better and faster decisions. This is especially applicable in real-time data analysis where the results can be given almost to instant, giving companies timely responses in respect to specific market changes.
**Improved Customer Insights:** It is important for marketers to notice and comprehend habits of customers as well as their values in a bid to produce specific advertising campaigns. Big data analytics assists organizations to identify and comprehend, specifically the customers’ needs when it comes to products or services they need, the time when they need them as well as the preferred method of acquiring it.
**Operational Efficiency:** Data on operational processes, allows one to determine such operational problems and seek for the most effective solutions. This can result in reduced costs and hence measure improvements on productivity.
**Risk Management:** Using big data analytic, a business can prevent risks and unearthing instances that may lead to problems. This can be explained in detail using examples from organizations that require strict risk management such as the field of finance or health care.
**Applications of Big Data Analytics**
**Retail:** Big data provides retailers with the tools to manage their supply chain, focus on individual consumers, and predict market behaviors.
**Healthcare:** Some of the ways big data analytics is used in this field is for disease outbreak prediction, enhancing the patient’s health, and managing records.
**Finance:** Economic companies employ the idea of big data for fraud detection, risk evaluation, and recommendations for financial services.
**Manufacturing:** Business owners monitor machinery and other physical objects to detect when they are not working properly or when their performance has deteriorated.
**Conclusion**
Big data analytics can mean big change and improvement for any business out there. In light of the pearls of information gathered on a daily basis, it is possible to increase competitiveness, identify customers’ needs and demands, and introduce innovations. The functionality of big data analytics will also increase with each passing year due to advances in technology and, thus, big opportunities are waiting for those who will learn how to handle it. For any business, irrespective of whether it is a small business or a large-scale enterprise, understanding and using big data analytics can actually become your secret formula for success in this world.
| commercepulse |
1,870,164 | Step-by-Step Tutorial on Setting Up a Mock Server Using Postman | Postman is a comprehensive tool used by developers across the globe to enhance the development,... | 0 | 2024-05-30T09:27:36 | https://dev.to/satokenta/step-by-step-tutorial-on-setting-up-a-mock-server-using-postman-bee | postman, mock, api | **[Postman](http://apidog.com/blog/what-is-postman/#what-is-postman)** is a comprehensive tool used by developers across the globe to enhance the development, testing, and maintenance of APIs. Its user-friendly interface allows for efficient interaction through HTTP requests and responses and has built-in capabilities for automating tests. It supports various API formats including RESTful and GraphQL, and includes collaborative features for effective teamwork. Additional functionalities of Postman encompass environment management, version control, and automatic API documentation generation.
## Understanding Mock Servers in Postman
Postman stands out in the API development tool arena with its robust Mock Server capability. This feature is integral to many application frameworks, offering developers a means to simulate genuine server behaviors without the need for actual server setup. This facilitates streamlined testing, prototype development, and simultaneous operations in team environments, making it a favored tool among developers for its efficiency and reliability.
## Primary Features of Postman's Mock Server
Postman's Mock Server is renowned for its comprehensive features that make API testing both thorough and straightforward.
**Quick Configuration:** Setting up a Mock Server in Postman is straightforward, requiring only a few clicks to initiate a fully functioning server ready to handle API calls.
**Dynamic Behavior:** Utilize JavaScript in pre-request scripts to dynamically craft responses according to the incoming requests, which allows for detailed scenario testing during prototype stages.
**Support for API Evolution:** Postman fosters a design-first construction of APIs, enabling functionalities to be mocked and tested even before full development, ensuring robust and error-minimized outputs.
**Team Collaboration:** The tool extends its functionalities to group projects by allowing shared access to Mock Servers within a team, thus supporting concurrent development workflows.
**Versatility in Mock Responses:** Postman can manage diverse response scenarios for a single endpoint, enhancing the API’s resilience and adaptability.
## Creating a Mock Server in Postman: A Step-by-Step Guide
Setting up a Mock Server in Postman involves a few structured steps:
### Initiating a Mock Server
1. **Create and Save a Request:** Start by generating and saving an API request within a Postman collection.
2. **Record the Response:** Send the request and save the subsequent response as an example for future use.

3. **Establish the Mock Server:** Navigate to the collection sidebar, click the three dots, select "Mock collection", then name and create your Mock Server.

4. **Utilize the Mock URL:** Replace the original URL in your saved request with the Mock Server’s URL provided by Postman.

5. **Test the Configuration:** Execute the "Send" command. Postman will utilize the stored example to deliver the response from your Mock Server.

### Adjusting Mock Server Settings
- **Naming and Delays:** Personalize your server’s name and, if necessary, set delays to mimic network lag.
- **Privacy Controls:** Enhance security by making the server private and requiring a Postman API key for access.

## Limitations of Postman’s Mock Server
Despite its capabilities, Postman’s Mock Server can be challenging for beginners due to its vast features. Managing multiple API versions and maintaining consistency across large team settings can be daunting without careful management. However, understanding and navigating these complexities allows developers to fully leverage the tool for optimal API development.
## Other mock methods
**[Apidog](https://apidog.com/)** serves as a comprehensive platform aimed at facilitating the entire API lifecycle, encompassing design, development, testing, and documentation. Its core strength lies in advocating a Design-first approach, simplifying the API creation process with its visual editor, and boosting collaboration within development teams. Apidog not only automates testing but also generates detailed API documentation and supports smart mock servers, ensuring a cohesive and up-to-date API management process.
### Getting Started with Apidog
1. **Registration:** Sign up for Apidog at **[here](https://apidog.com/download/)** and verify your account through the confirmation email. Once logged in, begin setting up your API environment.
### Setting up Your API
2. **Create or Import API:** Use the “New API” button to initiate a new API setup or import an existing structure. You can then further configure your API using the intuitive setup wizard provided by Apidog.

### Configuring the Mock Server
3. **Select Hosting Type:** Navigate to the “Mock” tab and choose between Local Mock for isolated, offline testing, or Cloud Mock for accessible, collaborative testing environments.

### Running and Testing APIs
4. **Deploy and Test:** Apply the generated or selected base URL to your API configurations and send requests to verify the responses, utilizing either the refined local or expansive cloud setup.

## Comparing Apidog and Postman’s Mock Servers
While both platforms offer robust solutions, Apidog’s zero-configuration mock data generation provides an unparalleled ease of use. The flexibility in data handling, combined with the ability to switch between different hosting options, positions Apidog as a highly adaptable solution suitable for diverse development scenarios. Moreover, Apidog's user-driven customization in mocking rules allows for detailed data response handling which is particularly beneficial for complex API simulations.
## Conclusion
Postman continues to be an essential tool in API development, offering robust features through its Mock Server that enhance simulation, testing, and collaborative development efforts. By understanding its functionalities and potential limitations, developers can utilize Postman effectively within their API development lifecycle. | satokenta |
1,870,162 | Key Factors Affecting Commercial Duct Cleaning Costs | A number of important aspects impact the total cost of commercial duct cleaning in various ways.... | 0 | 2024-05-30T09:25:22 | https://dev.to/hurricanellc/key-factors-affecting-commercial-duct-cleaning-costs-1ipj | ductcleaning, commercialductcleaning | A number of important aspects impact the total cost of **[commercial duct cleaning](https://www.hurricanellc.com/commerical-air-duct-cleaning-hurricane-group)** in various ways. Let’s examine these aspects to see how they affect the expense of keeping commercial facilities’ ducting clean and efficient.
## 1. Labor Costs
The cost of labor accounts for a substantial portion of the total cost of duct cleaning. Additionally, the labor expenses factor in how long it takes to clean the ducts, the number of professionals needed, and the complexity of the task. If the cleaning job requires specialized tools and knowledge or becomes very involved, it could increase the cost of labor.
## 2. Size and Type of Ductwork
The second factor that determines how much it will cost to clean a business building’s ducts is their size and kind. Cleaning larger HVAC systems with more complex duct networks will inevitably be more labor-intensive and expensive. The ductwork’s material, which can be either flexible or stiff, can affect the cleaning procedure and, by extension, the total cost.
## 3. Level of Contamination
Another important aspect that affects cleaning expenses is the level of pollution within the ducting. More thorough cleaning procedures may be necessary for severely polluted ducts containing dust, debris, mold, or insect infestations. Specialist treatments may also be required in such cases. Cleaning expenses tend to rise as a result of tackling more severe levels of pollution.
## 4. Accessibility of Ductwork
How easily accessible the ductwork is greatly affects cleaning expenses in a business facility. Moreover, it could take more time and effort for professionals to reach ducts in awkward places, including high ceilings or confined rooms. Consequently, such situations may require specialist tools or methods, which might drive up the total cost.
## 5. Duct Repairs
Duct cleaning can sometimes reveal problems like leaks, cracks, or broken ductwork that need fixing or replacing. Besides, duct cleaning may cost more than expected due to these unexpected repair bills. Taking care of these concerns is crucial for maintaining airflow and efficiency. Still, you should also set aside money in your budget for possible repair charges and cleaning fees.
## 6. Geographic Location
Lastly, a business property’s location might affect the cost of duct cleaning. Factors including regional labor rates, market competitiveness, and regulatory restrictions can affect the total cost of duct cleaning services.
Finally, several variables, such as labor rates, duct size and type, pollution levels, accessibility, duct repairs, and location, influence the total cost of commercial duct cleaning. Businesses can achieve a clean and healthy interior environment for inhabitants by understanding these elements and better anticipating and budgeting for their duct cleaning needs. | hurricanellc |
1,870,154 | VSCode Shortcuts: Boosting Productivity with Keyboard Commands | Visual Studio Code (VSCode) has rapidly become one of the most popular code editors among developers... | 0 | 2024-05-30T09:22:02 | https://dev.to/umeshtharukaofficial/vscode-shortcuts-boosting-productivity-with-keyboard-commands-2dme | webdev, vscode, devops, programming | Visual Studio Code (VSCode) has rapidly become one of the most popular code editors among developers due to its lightweight design, powerful features, and extensive customization options. One of the most effective ways to maximize productivity in VSCode is by mastering its keyboard shortcuts. These shortcuts can significantly speed up your workflow, reduce the need for mouse interactions, and streamline your coding process. This article provides a comprehensive guide to VSCode keyboard shortcuts, highlighting how they can boost your productivity and improve your coding experience.
## The Importance of Keyboard Shortcuts
### 1. **Speed and Efficiency**
Using keyboard shortcuts can drastically reduce the time spent navigating through menus and performing repetitive tasks. This efficiency allows developers to focus more on writing code and less on managing their tools.
### 2. **Reduced Context Switching**
Switching between the keyboard and mouse can disrupt your flow and slow you down. By relying more on keyboard shortcuts, you can maintain a smoother and more continuous workflow.
### 3. **Ergonomics**
Frequent use of the mouse can lead to repetitive strain injuries (RSI). Keyboard shortcuts can help mitigate this risk by reducing the need for mouse interactions, promoting better ergonomic practices.
### 4. **Customizability**
VSCode allows users to customize shortcuts to suit their preferences and workflow, making it easier to create a personalized and efficient coding environment.
## Getting Started with VSCode Shortcuts
Before diving into specific shortcuts, it's important to know how to access and customize them in VSCode.
### Accessing Keyboard Shortcuts
To view and manage keyboard shortcuts in VSCode:
1. Open the Command Palette with `Ctrl+Shift+P` (Windows/Linux) or `Cmd+Shift+P` (Mac).
2. Type "Preferences: Open Keyboard Shortcuts" and select it.
This will open the Keyboard Shortcuts editor, where you can search for, modify, and add new shortcuts.
### Customizing Shortcuts
To customize a shortcut:
1. Find the command you want to customize in the Keyboard Shortcuts
editor.
2. Click on the pencil icon next to the command.
3. Press the new key combination you want to assign to the command.
4. Press Enter to save the new shortcut.
Now, let’s explore some essential VSCode shortcuts that can significantly enhance your productivity.
## Essential VSCode Shortcuts
### 1. Basic Navigation
- **Open Command Palette:** `Ctrl+Shift+P` (Windows/Linux) or `Cmd+Shift+P` (Mac)
- The Command Palette is your gateway to all VSCode commands and extensions. Use it to quickly access commands without leaving the keyboard.
- **Open File:** `Ctrl+P` (Windows/Linux) or `Cmd+P` (Mac)
- Quickly open files by typing part of their names.
- **Toggle Sidebar Visibility:** `Ctrl+B` (Windows/Linux) or `Cmd+B` (Mac)
- Show or hide the sidebar to maximize your workspace.
- **Navigate Between Open Files:** `Ctrl+Tab` (Windows/Linux/Mac)
- Switch between open files and editors.
### 2. Editing
- **Cut Line (or Selection):** `Ctrl+X` (Windows/Linux) or `Cmd+X` (Mac)
- Cut the entire line if no text is selected.
- **Copy Line (or Selection):** `Ctrl+C` (Windows/Linux) or `Cmd+C` (Mac)
- Copy the entire line if no text is selected.
- **Paste:** `Ctrl+V` (Windows/Linux) or `Cmd+V` (Mac)
- Paste the clipboard contents.
- **Delete Line:** `Ctrl+Shift+K` (Windows/Linux) or `Cmd+Shift+K` (Mac)
- Delete the current line.
- **Move Line Up/Down:** `Alt+Up/Down` (Windows/Linux) or `Option+Up/Down` (Mac)
- Move the current line up or down.
- **Duplicate Line:** `Shift+Alt+Down` (Windows/Linux) or `Shift+Option+Down` (Mac)
- Duplicate the current line.
### 3. Searching and Replacing
- **Find:** `Ctrl+F` (Windows/Linux) or `Cmd+F` (Mac)
- Open the search box in the current file.
- **Find and Replace:** `Ctrl+H` (Windows/Linux) or `Cmd+H` (Mac)
- Open the find and replace box.
- **Find in Files:** `Ctrl+Shift+F` (Windows/Linux) or `Cmd+Shift+F` (Mac)
- Search across all files in the project.
- **Replace in Files:** `Ctrl+Shift+H` (Windows/Linux) or `Cmd+Shift+H` (Mac)
- Replace across all files in the project.
### 4. Multi-Cursor and Selection
- **Add Cursor Above/Below:** `Ctrl+Alt+Up/Down` (Windows/Linux) or `Cmd+Alt+Up/Down` (Mac)
- Add a new cursor above or below the current cursor.
- **Add Cursor to Line Ends:** `Ctrl+Alt+Shift+Up/Down` (Windows/Linux) or `Cmd+Alt+Shift+Up/Down` (Mac)
- Add cursors to the line ends of the selected lines.
- **Select Next Occurrence:** `Ctrl+D` (Windows/Linux) or `Cmd+D` (Mac)
- Select the next occurrence of the current selection.
- **Select All Occurrences:** `Ctrl+Shift+L` (Windows/Linux) or `Cmd+Shift+L` (Mac)
- Select all occurrences of the current selection.
### 5. Formatting
- **Format Document:** `Shift+Alt+F` (Windows/Linux) or `Shift+Option+F` (Mac)
- Format the entire document according to the language’s formatting rules.
- **Format Selection:** `Ctrl+K Ctrl+F` (Windows/Linux) or `Cmd+K Cmd+F` (Mac)
- Format the selected text.
### 6. Integrated Terminal
- **Toggle Terminal:** `Ctrl+` (Windows/Linux) or `Cmd+` (Mac)
- Open or close the integrated terminal.
- **Create New Terminal:** `Ctrl+Shift+` (Windows/Linux) or `Cmd+Shift+` (Mac)
- Open a new terminal instance.
- **Clear Terminal:** `Ctrl+K` (Windows/Linux/Mac)
- Clear the terminal output.
### 7. Working with Git
- **Git: Commit:** `Ctrl+K Ctrl+C` (Windows/Linux) or `Cmd+K Cmd+C` (Mac)
- Commit changes in the source control.
- **Git: Pull:** `Ctrl+Shift+P`, then type `Git: Pull` and select it.
- Pull changes from the remote repository.
- **Git: Push:** `Ctrl+Shift+P`, then type `Git: Push` and select it.
- Push changes to the remote repository.
## Advanced Shortcuts for Power Users
### 1. Working with Snippets
- **Insert Snippet:** `Ctrl+Shift+P`, then type `Insert Snippet` and select it.
- Insert predefined code snippets.
- **Surround With Snippet:** `Ctrl+K Ctrl+S` (Windows/Linux) or `Cmd+K Cmd+S` (Mac)
- Surround the selected text with a snippet.
### 2. Code Navigation
- **Go to Definition:** `F12`
- Jump to the definition of the symbol under the cursor.
- **Peek Definition:** `Alt+F12` (Windows/Linux) or `Option+F12` (Mac)
- Peek at the definition without navigating away.
- **Go to Implementation:** `Ctrl+F12` (Windows/Linux) or `Cmd+F12` (Mac)
- Jump to the implementation of the symbol.
- **Go to Type Definition:** `Ctrl+Shift+T` (Windows/Linux) or `Cmd+Shift+T` (Mac)
- Jump to the type definition of the symbol.
- **Go to Symbol in File:** `Ctrl+Shift+O` (Windows/Linux) or `Cmd+Shift+O` (Mac)
- List and navigate to symbols in the current file.
- **Go to Symbol in Workspace:** `Ctrl+T` (Windows/Linux) or `Cmd+T` (Mac)
- List and navigate to symbols in the entire workspace.
### 3. Debugging
- **Start Debugging:** `F5`
- Start or continue debugging.
- **Step Over:** `F10`
- Step over the currently executing line.
- **Step Into:** `F11`
- Step into the function being called.
- **Step Out:** `Shift+F11`
- Step out of the current function.
- **Toggle Breakpoint:** `F9`
- Add or remove a breakpoint on the current line.
## Customizing Your Workflow
### 1. Creating Custom Shortcuts
If the default shortcuts don't perfectly align with your workflow, you can create custom shortcuts:
1. Open the Keyboard Shortcuts editor.
2. Search for the command you want to customize.
3. Click the pencil icon next to the command and press your desired key combination.
4. Press Enter to save the shortcut.
### 2. Extensions for Enhanced Productivity
VSCode's extensive extension marketplace offers numerous tools to further boost your productivity. Some useful extensions include:
- **Prettier:** An opinionated code formatter that helps maintain consistent style across your codebase.
- **Live Server:** Launch a development local server with live reload feature for static and dynamic pages.
- **Path Intellisense:** Autocompletes filenames in your code, making it easier to manage imports and file references.
- **Bracket Pair Colorizer:** Adds colors to matching brackets to make it easier to identify paired brackets.
### 3. Task Automation
VSCode allows you to automate repetitive tasks using tasks.json:
1. Open the Command Palette and type `Tasks: Configure Task`.
2. Select `Create tasks.json file from template` and choose a template.
3. Customize the tasks.json file to define your tasks.
Example:
```json
{
"version": "2.0.0",
"tasks": [
{
"label": "Build",
"type": "shell",
"command": "npm run build",
"group": {
"kind": "build",
"isDefault": true
},
"problemMatcher": []
}
]
}
```
## Conclusion
Mastering VSCode keyboard shortcuts is a powerful way to enhance your productivity and streamline your coding workflow. By reducing reliance on the mouse, you can speed up your development process, maintain focus, and reduce the risk of repetitive strain injuries. From basic navigation and editing to advanced code navigation and debugging, the right shortcuts can transform how you interact with your code editor.
Take the time to explore and practice these shortcuts, customize them to fit your workflow, and leverage the full potential of VSCode. With these tools at your fingertips, you'll be well-equipped to tackle any coding challenge with efficiency and precision. | umeshtharukaofficial |
1,870,153 | AZ 500 Dumps PDF: The Proven Path to Passing | Why DumpsBoss is Your Trusted Partner in AZ-500 Preparation Unparalleled Quality: Our study... | 0 | 2024-05-30T09:21:56 | https://dev.to/pesce8965/az-500-dumps-pdf-the-proven-path-to-passing-d7d | Why DumpsBoss is Your Trusted Partner in AZ-500 Preparation
1. Unparalleled Quality: Our study materials undergo rigorous scrutiny to ensure accuracy, relevance, and effectiveness. With DumpsBoss, you're assured of preparing with the finest resources available in the market.
2. Expert Guidance: Benefit from the wisdom of seasoned professionals who possess profound expertise in Azure security. Authored by experts intimately acquainted with the <a href="https://dumpsboss.com/microsoft-exam/az-500/">AZ 500 Dumps PDF</a>, our study materials offer invaluable insights and strategies.
3. Flexible Learning Options: Whether you prefer self-paced study or structured learning, DumpsBoss caters to your unique preferences. Study at your convenience, on your terms, and at your pace, courtesy of our flexible learning options.
4. Continuous Support: Have queries or require guidance? Our dedicated support team stands ready to assist you round-the-clock. We're committed to nurturing your success and addressing any challenges you encounter along the way.
Embark on Your Azure Security Odyssey with DumpsBoss
With DumpsBoss as your trusted companion, mastering Azure security becomes an achievable reality. Our AZ-500 Dumps PDF and Study Guide PDF arm you with the knowledge, skills, and confidence required to excel in the AZ-500 exam and beyond. Visit DumpsBoss today to commence your journey towards realizing your aspirations in Azure security. Your triumph awaits, and DumpsBoss is here to pave the way.
| pesce8965 | |
1,870,122 | What’s New in Angular 18: Key Features and Updates | Businesses want to give an impeccable experience to users with their web and mobile applications, but... | 0 | 2024-05-30T09:20:01 | https://dev.to/himadripatelace/whats-new-in-angular-18-key-features-and-updates-fkh | Businesses want to give an impeccable experience to users with their web and mobile applications, but not everyone can do it. Billions of people use different mobile apps but very few apps are widely used and popular amongst users. Why? Not every app has user-friendly accessibility, an intuitive interface, and powerful performance that promotes user engagement and satisfaction. This is where Angular versions for the framework play a crucial role, ensuring applications have a seamless interface, enhanced accessibility, and robust performance.
A popular open-source JavaScript framework has kept evolving to meet the market demands and developers’ expectations releasing Angular’s latest versions with advanced and new features. The team Angular released the Angular 18 on May 22 introducing a range of features and improvements for enhanced performance, developer experience, and overall performance.
Before discussing the updates and latest Angular 18 features, let’s briefly introduce the widely popular Angular framework.
## Highlights of The Angular Latest Version
- Experimental support for zoneless change detection.
- Angular.dev is now the new home for Angular developers.
- Material 3, deferrable views, and built-in control flow are now stable.
- Server-side rendering improvements such as i18n hydration support.
- Signal APIs in developer preview.
- Specified fallback content for ng-content.
- Automated migration to the application builder.
## List Of Major Latest Features Added In The Latest Angular Version
1. Zoneless Change Detection
2. Coalescing by Default
3. Material 3 is now stable!
4. Deferrable Views are Now Stable
5. Built-in Control Flow is Now Stable
6. Improvements in Server-Side Rendering
7. Improved Debugging Experience
8. Robust Hosting for Your Apps with Firebase App Hosting
9. Understanding Event Replay in Angular
10. Hydration Support in CDK and Material
11. Route Redirects as Functions
Don't miss out on mastering these cutting-edge features and transforming your projects with Angular 18: [https://ow.ly/fu1v50S1G58](https://ow.ly/fu1v50S1G58) | himadripatelace | |
1,870,121 | WordPress Maintenance Contract: Unlock Smart Site Management | Managing a WordPress site effectively requires ongoing attention to ensure it remains secure,... | 0 | 2024-05-30T09:19:00 | https://dev.to/apptagsolution/wordpress-maintenance-contract-unlock-smart-site-management-5fpb | wordpress, maintenance, contract, agreement | Managing a WordPress site effectively requires ongoing attention to ensure it remains secure, performs well, and provides a great user experience. A WordPress maintenance contract can help you achieve this by offering comprehensive, proactive site management. Here’s a guide to what such a contract should include and why it’s beneficial.
Key Components of a WordPress Maintenance Contract
Regular Backups
Frequency: Regular backups, typically daily or weekly, depending on site activity.
Storage: [**Secure wordpress**](https://apptagsolution.com/blog/wordpress-security/) off-site storage (e.g., cloud services) to ensure data safety.
Restoration: Simple and quick restoration processes in case of data loss.
Security Monitoring and Updates
Core Updates: Regular updates to the latest WordPress core version.
Plugin & Theme Updates: Keeping all plugins and themes up to date.
Security Scans: Routine scans for malware and vulnerabilities.
Firewall & DDoS Protection: Implementation of measures to prevent attacks.
Performance Optimization
Speed Enhancements: Regular assessments and optimizations to improve load times.
Database Optimization: Cleaning and optimizing the database for better performance.
Caching Solutions: Using caching plugins and Content Delivery Networks (CDNs) to boost speed.
Content Management
Content Updates: Regularly adding and updating content.
SEO Optimization: Ensuring content is optimized for search engines.
Image Optimization: Compressing images to enhance load times without losing quality.
Technical Support
Bug Fixes: Prompt resolution of any technical issues.
Uptime Monitoring: Continuous monitoring to ensure the site is always accessible.
Consultation Services: Providing expert advice on site improvements and upgrades.
Reporting and Analytics
Performance Reports: Monthly reports on site performance metrics.
Security Reports: Regular updates on security status and incidents.
Traffic Analysis: Detailed analysis of site traffic and user behavior.
Benefits of a WordPress Maintenance Contract
Enhanced Security: Proactive measures to protect your site from threats.
Improved Performance: Regular optimizations ensure faster load times and a better user experience.
Reduced Downtime: Continuous monitoring and quick issue resolution minimize downtime.
Focus on Core Business: Allows you to concentrate on your business activities while experts handle maintenance.
Cost Efficiency: Preventative maintenance reduces the likelihood of costly emergency fixes.
Choosing the Right Maintenance Provider
When selecting a maintenance provider, consider the following:
Experience and Expertise: Look for providers with a strong track record in WordPress maintenance.
Comprehensive Services: Ensure the contract covers all essential maintenance aspects.
Customer Support: Reliable and responsive customer support is crucial.
Transparent Reporting: Ensure the provider offers clear and regular reporting on maintenance activities.
Conclusion
A WordPress maintenance contract is a smart investment for any website owner. It ensures your site remains secure, fast, and efficient, enhancing your online presence and providing a superior user experience. By entrusting your site to maintenance experts, you can focus on growing your business with the confidence that your site is in good hands.if you are looking to [**WordPress developers**](https://apptagsolution.com/hire-wordpress-developer/) then apptagsolution is the best option for you.
For more information or to get started with a maintenance contract, contact a reputable WordPress maintenance provider today. | apptagsolution |
1,870,120 | Forever Functional: Of Maps And Pipes, Chains And Nests, And More | by Federico Kereki Can we combine functions by using mapping? What about this in relation to... | 0 | 2024-05-30T09:14:55 | https://blog.openreplay.com/forever-functional-of-maps-pipes-chains-and-more/ |
by [Federico Kereki](https://blog.openreplay.com/authors/federico-kereki)
<blockquote><em>
Can we combine functions by using mapping? What about this in relation to function composition and pipelining? And what does it have to do with chaining and nesting? This article will reply to all those questions, showing you how to join functions together for clearer, more expressive code.
</em></blockquote>
<div style="background-color:#efefef; border-radius:8px; padding:10px; display:block;">
<hr/>
<h3><em>Session Replay for Developers</em></h3>
<p><em>Uncover frustrations, understand bugs and fix slowdowns like never before with <strong><a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a></strong> — an open-source session replay suite for developers. It can be <strong>self-hosted</strong> in minutes, giving you complete control over your customer data.</em></p>
<img alt="OpenReplay" style="margin-top:5px; margin-bottom:5px;" width="768" height="400" src="https://raw.githubusercontent.com/openreplay/openreplay/main/static/openreplay-git-hero.svg" class="astro-UXNKDZ4E" loading="lazy" decoding="async">
<p><em>Happy debugging! <a href="https://openreplay.com" target="_blank">Try using OpenReplay today.</a></em><p>
<hr/>
</div>
The array [`.map(...)`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/map) method is very powerful and lets us write more understandable code. Let's ask a theoretical question and see where it takes us. Could we apply `map()` to other types and not only to arrays? Why not?
In this article we'll start by extending types to allow mapping, and then get into pipelines, chaining, nesting, and several other functional programming concepts; just wait!
## Mapping for other types
First, we could add it to basic types, such as `boolean`s, `number`s, `bigInt`s, and `string`s. On the other hand, it seems that adding mapping to `null`, `undefined`, and `symbol` wouldn't be that great, so we'd skip that. And, obviously, adding a `map()` method to objects (or to class definitions) is straightforward; no mystery there.
In all cases code would be something like this -- we'll only show two definitions to avoid repetition:
```javascript
Boolean.prototype.map =
function(fn) {
return Boolean(fn(this));
};
Number.prototype.map =
function(fn) {
return Number(fn(this));
};
```
We can now write things like the following two examples, and let's use [pointfree style](https://medium.com/stackanatomy/forever-functional-pointfree-style-programming-c3877c229ceb) for a more "functional-programming-ish" style:
```javascript
const not = (x) => -x;
let someFlag = true;
someFlag.map(not); // false
const negate = (z) => -z;
let aNumber = 22;
aNumber.map(negate); // -22
```
This isn't a real win; we could have written `not(someFlag)` and `negate(aNumber)` equally well. There's a slim advantage: we can now clearly chain sequences of operations. Let's go with a simple example.
```javascript
const add1 = z => z+1;
const times10 = z => 10 * z;
aNumber.map(add1).map(times10).map(negate); // -230
```
This starts to look more interesting; the alternative way, `negate(times10(add1(aNumber)))` wouldn't have been equally clear. We'll look into this a bit more, but first, we must answer the question: what about using `map()` with functions?
<CTA_Middle_Programming />
## Mapping functions
Functions are (trivially!) essential, and we should investigate what mapping would mean for them. The logical definition would be as follows; if we have `f1` and `f2` functions and we write `f1.map(f2)`, that should return a function that first runs `f1` and then applies `f2` to whatever `f1` returned.
```javascript
Function.prototype.map = function (fn) {
return (x) => fn(this(x));
};
add1.map(times10)(3); // 40
```
So, `x => f1.map(f2)(x)` is equivalent to `x => f2(f1(x))`, and in general `x => f1.map(f2).map(f3)...map(fn)(x)` would be the same as `x => fn(...f3(f2(f1(x))))`; this is a well known functional programming concept that we should look into!
## Maps as composition?
The kind of expression we wrote in the previous paragraph, when you have a sequence of functions call in which the output of one function is the input of the next one, is called *composition*. Formally, in mathematical terms, instead of `fn(...f3(f2(f1(x))))` you could also write `(fn∘...∘f3∘f2∘f1)(x)`. If you wish, you can read `∘` as *after*, so `f2∘f1` is `f2` after `f1`, etc.
If we wish, we can write a general `compose(...)` function; it's not hard - can you see why and how works the code below?
```javascript
function compose(...fns) {
return fns.reduceRight(
(f, g) =>
(...args) =>
g(f(...args)),
);
}
```
So, instead of writing `x => f1.map(f2).map(f3)(x)` you could go with `x => compose(f3, f2, f1)(x)` - but that goes a bit against the grain; the order of functions is reversed! There's another concept we should look into: pipelining!
## Maps as pipes
In Unix and Linux, the idea of running a first command, passing its output as input to a second command, whose output will be input for yet a third command, etc., is called a *pipeline*. This is a basic philosophy of Unix, and Doug McIlroy, the creator of the pipelining concept, explained:
* Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new features.
* Expect the output of every program to become the input to another, so far unknown program.
To give an elementary example (from my [Mastering JavaScript Functional Programming](https://www.amazon.com/Mastering-JavaScript-Functional-Programming-maintainable/dp/1804610135) book) if you wanted to count how many LibreOffice text documents there are in a directory, the following pipeline would do:
```
ls -1 | grep "odt$" | wc -l
```
How does this work?
* The first command lists all the files in a single column, one filename per line.
* The second command gets the list of files and filters (let pass) only those that end with "odt", the standard file extension for LibreOffice Writer documents.
* The third command gets the filtered list and counts how many lines there are in it.
It seems then that something like `f1.map(f2).map(f3)` is like a Unix pipeline, sort of `f1 | f2 | f3` thing. It so happens that there is [a proposal](https://github.com/tc39/proposal-pipeline-operator) to include such an operator in JavaScript, written `|>` as in `f1 |> f2 |> f3`, but it isn't accepted yet.
Given that pipelining is just like composition but working "the other way", we can quickly whip up the following:
```javascript
function pipeline(...fns) {
return fns.reduce(
(result, f) =>
(...args) =>
f(result(...args)),
);
}
```
In that case, we could write any of the following versions -- though the last two won't work until the pipeline operator proposal is accepted:
```javascript
aNumber.map(add1).map(times10).map(negate);
aNumber.map(add1.map(times10).map(negate));
pipeline(add1, times10, negate)(aNumber);
aNumber.map(pipeline(add1, times10, negate));
(add1 |> times10 |> negate)(aNumber);
aNumber.map(add1 |> times10 |> negate);
```
What do you think? Personally, I believe that this "*chaining style*" for successive functions is clearer than the alternative "*nesting style*" (based on composing) which adds the extra complexity of listing the functions in reverse order. The piping way, the [fluent interface pattern](https://en.wikipedia.org/wiki/Fluent_interface), is more understandable, and adding our `map/pipe` method allows us to easily use it.
## Conclusion
We started this article by wondering about extending the usage of `map()` to other data types, went from there to using it on functions, and ended up considering typical functional programming topics such as composition and pipelining. JavaScript can be considered a multi-paradigm language, and the examples we've seen here confirm that... and also allow you greater freedom to achieve the maximum clarity in your code!
| asayerio_techblog | |
1,870,119 | Best Braids for Men for Long and Short Hair | Braids have been a staple hairstyle for men across various cultures and ages. They offer a versatile... | 0 | 2024-05-30T09:14:06 | https://dev.to/neil_obrien_fc509e2689d4/best-braids-for-men-for-long-and-short-hair-32nh | Braids have been a staple hairstyle for men across various cultures and ages. They offer a versatile and stylish way to manage hair, whether it's long or short. From classic cornrows to intricate box braids, there are countless styles to choose from that suit different hair lengths and textures. Here, we’ll explore some of the best braid styles for men and provide tips on how to maintain them. For a comprehensive guide to these styles, check out our braids for men page.
Why Choose Braids?
Versatility
Description: Braids can be adapted to fit any hair length and personal style.
Benefits: They offer numerous styling options, from tight cornrows to loose, bohemian styles.
Protection
Description: Braids help protect hair from environmental damage and reduce breakage.
Benefits: Ideal for maintaining healthy hair, especially for textured hair types.
Low Maintenance
Description: Once braided, hair requires minimal daily upkeep.
Benefits: Perfect for busy lifestyles or those seeking a break from daily styling.
Best Braid Styles for Long Hair
Box Braids
Features: Individual plaits that can be small, medium, or large.
Best For: Long-lasting style and versatility in design.
Style Tip: Experiment with different partings and braid thicknesses.
Cornrows
Features: Braids that are tightly woven close to the scalp in straight lines or creative patterns.
Best For: A sleek and polished look.
Style Tip: Add extensions for length and thickness if desired.
Fishtail Braids
Features: A braid that resembles a fishtail, made by weaving hair in thin sections.
Best For: A sophisticated and detailed style.
Style Tip: Best suited for longer hair to showcase the intricate pattern.
French Braids
Features: A classic braid style that starts at the crown and incorporates hair as it descends.
Best For: A timeless and elegant look.
Style Tip: Can be worn as a single braid or in multiple braids.
Dutch Braids
Features: Similar to French braids but with an inverted braid that stands out.
Best For: A bold and defined style.
Style Tip: Ideal for creating a prominent, 3D braid effect.
Best Braid Styles for Short Hair
Micro Braids
Features: Tiny, delicate braids that can be styled in various ways.
Best For: Adding texture and interest to short hair.
Style Tip: Can be combined with other braiding styles for a unique look.
Two-Strand Twists
Features: Simple twists created by dividing hair into two sections and twisting them together.
Best For: A quick and easy braiding option.
Style Tip: Great for short to medium hair lengths.
Braided Top Knot
Features: Braiding the top section of hair and securing it in a knot or bun.
Best For: A modern and stylish look.
Style Tip: Leave the sides and back shorter for contrast.
Zig-Zag Braids
Features: Cornrows braided in a zig-zag pattern.
Best For: A creative and edgy style.
Style Tip: Works well with short hair to create a standout design.
Partial Braids
Features: Braiding only sections of the hair, such as the sides or top.
Best For: Adding flair without committing to a full head of braids.
Style Tip: Combine with fades or undercuts for a striking appearance.
Tips for Maintaining Braids
Keep Scalp Clean
Advice: Wash the scalp regularly with a gentle shampoo.
Tip: Use a diluted shampoo solution to clean between braids.
Moisturize Regularly
Advice: Apply lightweight oils or leave-in conditioners to keep hair hydrated.
Tip: Focus on the scalp and the length of the braids to prevent dryness.
Protect at Night
Advice: Wear a satin or silk scarf or cap to bed.
Tip: This helps reduce friction and keep braids looking fresh.
Avoid Over-Styling
Advice: Limit the use of heat styling tools and excessive manipulation.
Tip: Let braids rest to maintain their integrity and prevent damage.
Regular Touch-Ups
Advice: Visit a stylist for touch-ups as needed to keep braids neat.
Tip: Refresh the edges and any loose braids every few weeks.
Conclusion: Embrace the Versatility of Braids
Braids offer endless possibilities for styling, whether you have long or short hair. They provide a unique way to express personal style while also protecting and maintaining hair health. Explore more braid styles and find your perfect look by visiting our braids for men guide.
For additional grooming tips and style inspiration, check out our men’s grooming section and stay updated with the latest trends. | neil_obrien_fc509e2689d4 | |
1,870,118 | Coumarin Synthesis Building Blocks with Anticancer Activity | Coumarin, also known as bisfuran cyclooxaphthalone, is a lactone compound widely found in Rutaceae... | 0 | 2024-05-30T09:14:00 | https://dev.to/zoe_zoe_4e536fd49fe811477/coumarin-synthesis-building-blocks-with-anticancer-activity-4jjp | Coumarin, also known as bisfuran cyclooxaphthalone, is a lactone compound widely found in Rutaceae and Umbelliferae. Coumarin is a general term for a class of natural products with a benzo-αpyrone structure, which is widely used in medicine, fragrance, dyes, instrument analysis, agriculture and other fields. The drug molecules with coumarin and its derivatives as the basic skeleton have a wide range of biological activities, such as antioxidant, anticoagulant, antiviral, antibacterial, anti-inflammatory, hypoglycemic, anticancer and neuroprotective, which makes coumarins attractive for further optimization as novel drug templates. So far, there are more than 35 clinical stage and marketed drugs containing coumarin.
Coumarin targets multiple cancer signaling pathways such as kinase inhibition, cell cycle arrest, angiogenesis inhibition, heat shock protein (HSP90) inhibition, telomerase inhibition, antimitotic activity, carbonic anhydrase inhibition, monocarboxylic acid transport protein inhibition, aromatase inhibition and sulfatase inhibition. Next, we will introduce the detailed information of coumarin acting on cancer signaling pathways.
Kinase Inhibitors
Kinases are enzymes that catalyze the transfer of phosphate groups to target proteins. They play key roles in regulating countless growth factor signaling. The activated form of the kinase can lead to increased cell proliferation, prevent apoptosis, and promote angiogenesis and metastasis. Activated forms of kinases can lead to increased cell proliferation, prevent apoptosis, and promote angiogenesis and metastasis, while somatic mutations that activate kinases are fundamental mechanisms of tumorigenesis. Since all of these effects are triggered by kinase activation, they are key targets for inhibition by coumarins and their derivatives. In 2014, Nasr et al. synthesized and evaluated the anticancer activity of coumarin derivatives against drug-resistant pancreatic cells and drug-sensitive cell lines such as Hep-G2 and CCRF. The coumarin derivatives were found to be more effective than the reference drug doxorubicin. It was observed that coumarin hydrazide-hydrazone pharmacophores showed better activity than compounds with coumarin or hydrazide-hydrazone pharmacophores.
Cell Cycle Arrest
Coumarin has been reported to block various phases of the cell cycle, such as G0, G1, S, and M phases, ultimately leading to apoptosis. They were found to induce apoptosis through cysteine aspartase-dependent intrinsic pathways and changes in cellular levels of Bcl-2 family proteins. In 2013, Kumar et al. synthesized 3-(4,5-dihydro-1-phenyl-5-substituted phenyl-1H-pyrazol-3-yl)-2H-chromium-2-one derivatives and evaluated their anticancer activity against 60 cancer cell lines. It has been observed that the 8-lactone ring of the coumarin nucleus is the basis for its significant anticancer activity, which is caused by inducing G1 arrest of the cell cycle.
Angiogenesis Inhibitors
Angiogenesis is also a primary target of coumarin derivatives. They have been found to inhibit angiogenesis by inhibiting fibroblast growth factor-2 (FGF-2)-mediated proliferation, migration and tubule formation. In addition, coumarin derivatives can reduce the expression of vascular endothelial growth factor (VEGF) mRNA levels through phosphorylation of nuclear factor kB (NF-kB) and IKKa. Interestingly, the phosphatidylinositol 3-kinase (PI-3K)/Akt signaling pathway was not affected.
[HSP90 Inhibitors](https://www.bocsci.com/tag/hsp90-1.html)
Extensive experiments have shown that coumarin can directly bind to the up-regulated HSP90 in various cancers. At the same time, various client proteins may also cause normal cells to transform into cancer cells. Coumarin leads to the ultimate antiproliferative effect by degrading co-chaperone and client proteins. Coumarin-like compounds have been reported to cause depletion of key regulatory HSP90-dependent kinases in vitro and in vivo, including Src, Raf-1, and ErBB2 proteins encoded by the ErBB2 gene.
Telomerase Inhibitor
Telomerase is an enzyme that helps maintain telomere length in human stem and cancer cells by adding TTAGGG repeats to telomeres. Telomerase activity was found only in tumor cells but not in adjacent normal cells. Different inhibitors including coumarin are thought to inhibit telomerase. Wu et al. prepared novel coumarin derivatives as potential telomerase inhibitors and found that some coumarin compounds had high antiproliferative and telomerase inhibitory activities against various cell lines.
Antimitotic Agents
Mitosis is a cell cycle process that occurs in both normal cells and cancer cells, by which chromosomes are segregated into two identical sets of chromosomes. Coumarin derivatives inhibit cell division by directly acting on mitotic phase mainly including prometaphase and metaphase, thereby inspiring these derivatives to target tubulin. In 2013, Tsyganov et al. developed antimitotic compounds with coumarin structures.
Carbonic Anhydrase Inhibitors
Carbonic anhydrase (CA) is controlled by hypoxia-inducible transcription factor (HIF) and is an intrinsic marker of hypoxia in many cancers. Its expression is closely related to different types of cancer hypoxic cells. Carbonic anhydrase significantly catalyzes the hydration of carbon dioxide to bicarbonate and protons, promoting acidification of the tumor environment, leading to the acquisition of a metastatic phenotype and resistance to several anticancer drugs. It has been reported that coumarins can control the pH balance of tumor cells and inhibit the activity of tumor-associated bicarbonases in the treatment of hypoxic tumors.
Monocarboxylate Transporters (MCT) Inhibitors
Coumarin was found to block lactic acid uptake. Under hypoxic conditions, cancer cells consume glucose and release lactate at a higher rate, which is recaptured by oxygenated cancer cells to promote TCA cycling and promote tumor growth. Monocarboxylate transporters (MCTs) are the major lactate transporters. MCT1 and MCT4 are significantly expressed in cancer cells. MCT1 has been found to show a better affinity for lactate, which allows lactate to enter oxidative tumor cells. In contrast, MCT4 shows low affinity but higher turnover and is expressed in glycolytic tumor cells as well as in lactate-exporting tumor-associated fibroblasts. Thus, blockade of MCTs by coumarin prevents the utilization of lactate by oxygenated tumor cells and forces them to become dependent on glucose. Thus, hypoxic tumor cells that are rely on glucose for replacement die due to glucose deprivation.
Aromatase/ Sulfatase Inhibitors
Coumarin derivatives are also able to modulate several cancer-specific enzymes, such as aromatase and sulfatase. Steroid sulfatase (STS) is responsible for converting estrone sulfate into active hormones, therefore, inhibition of these enzymes by bicyclic and tricyclic coumarates can reduce active hormones that cause breast, endometrial, and prostate cancer biosynthesis. They also inhibit aromatase to prevent the conversion of other hormones such as androgens to estrogen. Thus, inhibition of aromatase also results in the formation of genotoxic metabolites of estrogen. These metabolites include catechol estrogens, which induce mutations and inhibit other oncogenic metabolites such as 2-hydroxyestradiol and 4-hydroxyestradiol. | zoe_zoe_4e536fd49fe811477 | |
1,870,116 | Multi-Cloud Serverless Framework | In today’s dynamic cloud landscape, flexibility and redundancy are key. That’s why I’m excited to... | 0 | 2024-05-30T09:11:50 | https://dev.to/princeptll/multi-cloud-serverless-framework-48o5 | cloud, ai, devops, azure | In today’s dynamic cloud landscape, flexibility and redundancy are key. That’s why I’m excited to share how the Microsoft team has leveraged the Serverless Framework to achieve multi-cloud magic and enhance our data flow.
𝐃𝐚𝐭𝐚𝐟𝐥𝐨𝐰: The user’s app can seamlessly connect from any source to our gateway app, which distributes requests equally between Azure and AWS clouds. This dual-cloud architecture ensures robustness and availability. Plus, all responses are routed through the API Manager gateway, guaranteeing a smooth user experience.
𝐓𝐡𝐞 𝐒𝐞𝐫𝐯𝐞𝐫𝐥𝐞𝐬𝐬 𝐅𝐫𝐚𝐦𝐞𝐰𝐨𝐫𝐤: The heart of our multi-cloud solution! It simplifies infrastructure concerns, automating deployments to support GitOps. With a manifest-based approach, this approach drives serverless solutions across multiple clouds with ease.
𝐀𝐳𝐮𝐫𝐞 𝐈𝐧𝐭𝐞𝐠𝐫𝐚𝐭𝐢𝐨𝐧: To make Azure a part of our multi-cloud strategy, this approach is equipped with Node.js, Azure Functions, and the Serverless Multicloud Library. The Azure Functions Serverless Plugin extends the Serverless Framework’s capabilities for Azure, ensuring parity with AWS Lambda.
𝐂𝐈/𝐂𝐃 𝐰𝐢𝐭𝐡 𝐆𝐢𝐭𝐎𝐩𝐬: This Architecture implements GitOps-driven serverless builds, tests, and deployments, streamlining our development workflow. Building from Git, quality gates for tests, and seamless deployment across cloud providers make us more agile and efficient.
𝐏𝐨𝐭𝐞𝐧𝐭𝐢𝐚𝐥 𝐔𝐬𝐞 𝐂𝐚𝐬𝐞𝐬: Imagine writing client-side applications for multiple platforms using a cloud-agnostic API from the Serverless Multicloud Library. Deploy functional microservices across multiple cloud platforms, or use a cloud-agnostic app without worrying about the underlying infrastructure.
𝐁𝐥𝐮𝐞-𝐆𝐫𝐞𝐞𝐧 𝐃𝐞𝐩𝐥𝐨𝐲𝐦𝐞𝐧𝐭: This Architecture has the best of Blue-Green Deployment into the multi-cloud realm. Each cloud platform hosts two duplicate sets of microservices, creating active-passive environments for increased availability. The multi-cloud setup ensures high availability and minimizes risks, all thanks to the power of Serverless. In a world where multicloud is the future, this architecture pioneering with Serverless Framework and embracing multicloud excellence.
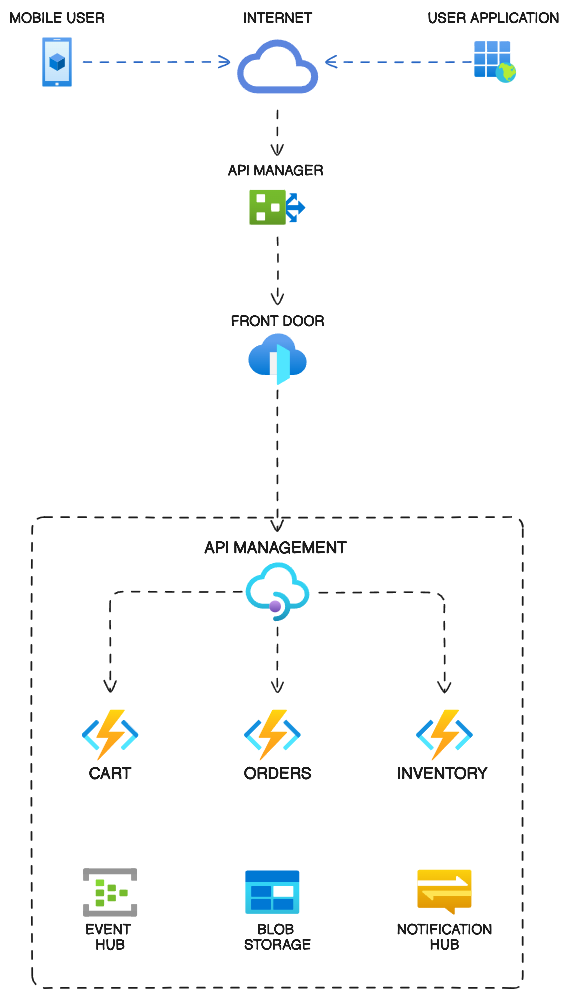 | princeptll |
1,869,743 | 5 Cheap Ways to Host Postgres | Hetzner, Sliplane, Render, Github, DigitalOcean - Picking a hosting provider for your Postgres... | 0 | 2024-05-30T09:11:42 | https://dev.to/code42cate/5-cheap-ways-to-host-postgres-2mal | docker, devops, cloud, beginners | Hetzner, Sliplane, Render, Github, DigitalOcean - Picking a hosting provider for your Postgres database can be challenging, especially with all the awesome options available. Analysis Paralysis is real 😵💫. Who wins the race for the cheapest postgres host?

## 1. Hetzner
[Hetzner](https://www.hetzner.com/cloud) is a German Cloud Provider with Locations in Europe and North America, with a wide variety of compute options including ARM, dedicated, and shared servers. Hetzner is loved by developers, with [70% saying that they want to continue using them](https://survey.stackoverflow.co/2023/#cloud-platforms) according to the latest Stackoverflow survey. Hetzner provides **incredibly cheap** but at the same time **basic servers**.
Hosting a simple Postgres database isn't actually that complicated! (If you dont need HA, autoscaling, and sharding etc.). [Check out this great tutorial from Docker](https://www.docker.com/blog/how-to-use-the-postgres-docker-official-image/)
## 2. Sliplane
What if you could combine the awesome price of Hetzner with the ease of a PaaS like Heroku, Render, or Vercel? [Sliplane](https://sliplane.io?utm_source=cheapwaystopostgres) is a PaaS on top that gives you push-to-deploy, automatic SSL, a free domain, and more for your Docker apps. Connect your GitHub account and get started in **less than 5 minutes for free with a 48 hour trial**. [Sliplane](https://sliplane.io?utm_source=cheapwaystopostgres) lets you host an unlimited number of Docker Apps on your server, making it incredibly cheap if you have a large number of low-traffic apps. For example, hosting a frontend, backend, cron jobs, and postgres will only cost you 7 Euros per month.

Disclaimer: I'm the co-founder 🤫
## 3. Don't use Postgres!
I knooow, I know. You came for cheap postgres databases, but do you _actually_ need one? Maybe just a simple JSON file or SQLite is enough? Don't overcomplicate your tech stack! I actually have a project running for over a few years now that just dumps data into a json file in a GitHub repository. Works like a charm!
While this doesn't work for everything, and especially not for something that needs to be 100% reliable, sometimes it's worth it to think outside the box to save some bucks 🤑
## 4. Supabase
Supabase is another hosting provider that is loved by developers and has grown tremendously in the last few years. At this point, Supabase provides a lot more than just Postgres. They now also have auth, object storage, functions, and can probably even make pizza. And they even have a free plan! Keep in mind that free projects are paused after 1 week of inactivity.
## 5. Render
Last but not least, another PaaS provider that I want to mention is Render. While Render might look expensive at first, the "Zero DevOps cloud" really makes up for it by being the simplest solution in this list while also providing a free tier for Postgres. In the end, the price that your database costs is not everything, you also need to consider the time you are putting in to keep everything running! Sometimes a $20 database is cheaper than a $5 database if you need to work 10 hours less per month, just keep that in mind :)
## Conclusion
I hope you learned something new, and always keep in mind to include the price of your own sanity when checking out prices!
*Also, I'd love to know where you are hosting your Docker apps. What features do you love, and which do you dislike? Let's discuss it!* | code42cate |
1,870,115 | Improved client collaboration with screen recording | My business wouldn't be where it is today without the input of my team and our collaboration with our... | 0 | 2024-05-30T09:10:17 | https://dev.to/martinbaun/improved-client-collaboration-with-screen-recording-5210 | productivity, career, startup, community | My business wouldn't be where it is today without the input of my team and our collaboration with our clients. Screen recording and video feedback are great for our communication, collaboration, and team growth. We've created our very own screen recording software, which has a free and a premium version coming soon.
This is how we use it to collaborate within our team and with our clients.
## Visual Demonstrations of Project Progress
Our customers are vital to us, and we try to prove this to them. We use screen recording to showcase the progress of the products we're building for them. We showcase project development and progress. We give them the videos and they can compare one video to the next to analyze the progress we've made. A good example of this is when we used it to record the progress of the dev project for one of our clients.
We built a real-estate directory for them fitted with maps, pictures, and text. We used our screen recording software to show our client the developer's progress, the directory, and the accompanying text from our content side. We walked with him every step of the way and ensured that all his concerns were heard and addressed. We have used this tool similarly in other situations to propel customer satisfaction and understanding. It's a simple way for us to capture everything they need and showcase our commitment to their goals. This is one of the ways we use it but there are more ways we utilize it. You can learn more about this below.
Read: *[Enhancing Productivity with Video Feedback in 2024.](https://martinbaun.com/blog/posts/enhancing-productivity-with-video-feedback-in-2024/)*
## Real-time presentations and Client Meetings
We interact with our customers daily to keep them adequately informed. I hold synchronous meetings with them just like I do with my team members. We use these meetings to discuss the important aspects of the project. These range from deliverables, changes needed, and timelines. I use screen recording as a presentation tool to showcase the real and tangible progress we're making.
Just like we've discussed above, we use screen recording software to keep them informed. I've used it to show them the coding, the design, the product, and the final touches. I'd record the code and explain to them why it takes time to write it. I've also used it to showcase the design and explain the ideas behind it. This also gives them the chance to give us feedback and their thoughts or concerns. Screen recording provides a better alternative to the traditional presentations that were previously featured in our team.
I've noticed the shift in reception from our clients by implementing it. It helps us get the point across to them without any difficulties. It is a good and efficient addition to the synchronous meetings. Our customer support and satisfaction have improved. Screen recording is a big part of this.
## Personalized Feedback and Reviews
*[Video feedback hassle-free.](https://videofeedbackr.com/)*
Our customers have adopted screen recording and are using it effectively. They record videos informing us of the aspects they like and dislike of the products we've designed for them. They relay their thoughts, desires, and wants from the project. The customer is right is a saying spread in the business world, and it holds in this situation.
These insights guide our developers down the right path to designing the best software and products. We have created good solutions from the feedback our customers give. We collaborate better, are more productive, and have reduced our levels of confusion. My employees have used these videos to learn and grow, making them better suited to handle many issues. I have written a detailed article that explains how to use screen recording software to give feedback.
Read: *[Feedback with Asynchronous Video: Productivity with Screen Recording!](https://martinbaun.com/blog/posts/feedback-with-asynchronous-video-productivity-with-screen-recording/)*
## Enhanced client understanding and Engagement
We use screen recording to help our clients understand the project deliverables and how they work. These videos help our team members communicate and convey their thoughts as required. The recordings effectively explain everything to our customers and allow them to understand everything. They have used screen recording to remain engaged with our organization. We offer solutions, tips, and tricks to help them solve their issues.
We share the videos with our clients. They do the same with us. These videos ensure we keep developing and improving our skills. We have seen some tangible growth since its implementation. We're excited for the future.
## Remote collaboration and decision-making
We use screen recording to enhance our collaboration and decision-making. We use these recordings to document vital decisions we make in our team. We've used it when updating our operational procedures to reduce wastage within the team. These decisions greatly alter how we operate. We've used this for our content team to streamline operations. We have noticed an improvement in output and a reduction in wastage.
Some projects require cross-collaboration within our team. We use screen recording to facilitate this collaboration and keep each other informed every step of the way. My team members work in different time zones, making synchronous communication challenging. Screen recording has bridged this deficit, giving my team members a viable option to facilitate their work. We make informed choices to give the best quality work to our clients.
## Improved trust and relationships
Recording videos and sharing the recordings has improved our trust and relationships with our customers. We give transparent feedback to ourselves and our customers. These recordings have allowed us to understand each other's thinking and helped us learn more about each other. We have built stronger bonds within our team and with our customers. We have improved trust and relationships with each other as a result.
Trust and relationships are built over time. Working together and putting time to guarantee your colleagues and clients are well taken care of helps. It helps build trust in the relationships, fostering collaboration and productivity.
-----
## FAQs
*How can VideoFeedbackr demonstrate project progress to the client?*
You can use VideoFeedbackr to record the project during its infancy and every stage of development. This will give your clients a clear picture. Know the client you're dealing with. Some may mistake these recordings for the final product and become disappointed in you. Let them know it's a progress display with more work being done. The Sixteenth Chapel wasn't as beautiful during construction. That also applies to your project. Give details within the recordings. Anything that helps your client understand proceedings is a plus.
*Can I use VideoFeedbackr to educate clients on the project and its deliverables?*
Yes. You can educate your client using VideoFeedbackr by giving clear and concise explanations. People tend to learn faster and simpler by watching videos. Using VideoFeedbackr to record and explain the project deliverables to your client will optimize their learning. This helps your clients make informed decisions and suggestions that facilitate the project's progress in the right direction.
*How do you use VideoFeedbackr to collaborate with the client on the project?*
You and your client can use VideoFeedbackr to give each other concise feedback. The recordings will help you understand each other's perspective and work well with each other. This will improve your collaboration with them and guarantee your tasks and projects proceed as required.
*How does the client use VideoFeedbackr to give feedback, make requests, and ask questions?*
Clients can use VideoFeedbackr to make requests, give feedback, and make requests. All they need to do is find their point of interest, open VideoFeeedbackr on their browser, and start recording. They can record themselves asking a question, making a request, or even giving feedback. You can share the feedback easily between yourself and your team. This is a simple and efficient process.
*How do you use VideoFeedbackr to enhance your relationship with the client?*
VideoFeedbackr can be used to improve customer and provider relationships. It does this by allowing them to communicate freely and without any limitations. This allows them to work together on the projects and in turn spend more time together. Spending a lot of time together accomplishing tasks, giving feedback, and collaborating builds relationships between the clients and providers.
*How do you use VideoFeedbackr to enhance the client’s engagement and give presentations?*
People tend to remain more engaged when watching videos compared to reading texts or messages. Using video recordings will help them remain engaged in the task and the presentation you're making. VideoFeedbackr can help you do this with effective and efficient screen recording.
-----
*For these and more thoughts, guides and insights visit my blog at [martinbaun.com](http://martinbaun.com)*
*You can find Martin on [X](https://twitter.com/MartinBaunWorld)* | martinbaun |
1,870,114 | How To Clear DNS Cache In Chrome Using Chrome://Net-Internals/#Dns (Desktop And Android) | by Ghaida Bouchaala Session Replay for Developers Uncover frustrations, understand bugs and fix... | 0 | 2024-05-30T09:09:24 | https://blog.openreplay.com/clear-dns-cache-chrome-and-android-guide/ | by [Ghaida Bouchaala](https://blog.openreplay.com/authors/ghaida-bouchaala)
<div style="background-color:#efefef; border-radius:8px; padding:10px; display:block;">
<hr/>
<h3><em>Session Replay for Developers</em></h3>
<p><em>Uncover frustrations, understand bugs and fix slowdowns like never before with <strong><a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a></strong> — an open-source session replay suite for developers. It can be <strong>self-hosted</strong> in minutes, giving you complete control over your customer data.</em></p>
<img alt="OpenReplay" style="margin-top:5px; margin-bottom:5px;" width="768" height="400" src="https://raw.githubusercontent.com/openreplay/openreplay/main/static/openreplay-git-hero.svg" class="astro-UXNKDZ4E" loading="lazy" decoding="async">
<p><em>Happy debugging! <a href="https://openreplay.com" target="_blank">Try using OpenReplay today.</a></em><p>
<hr/>
</div>
Clearing the DNS cache in Chrome can resolve various connectivity issues caused by outdated or corrupted DNS information. This guide will show you how to use the `chrome://net-internals/#dns` tool to clear the Google Chrome DNS cache for desktop and android devices.
### What is DNS?
[DNS](https://www.youtube.com/watch?v=UVR9lhUGAyU) (Domain Name System) is the internet's address book. When you type a website address (like `www.example.com`) into your browser, a DNS server translates it into an IP address (like `192.0.2.1`) that computers use to communicate with each other. This translation is needed to connect you to websites, email servers, and other online services.
### When is it necessary to clear the DNS cache in Chrome?
Your browser stores DNS information in a cache to speed up future requests. However, this cached information can sometimes cause problems.
Here are four scenarios when clearing the DNS cache in Chrome browser is necessary:
**DNS error messages**: When you receive error messages related to DNS, such as "DNS_PROBE_FINISHED_NXDOMAIN" or "ERR_NAME_NOT_RESOLVED.”
**Websites not loading or loading slow**: When websites are either not loading or are taking a long time to load.
**Inaccessible websites:** When you can't access certain websites, even though they work on other devices.
**Incorrect page display**: When your browser's pages are not displaying correctly or are missing content.
### How to clear DNS cache in Google Chrome browser (Desktop and Android) using chrome://net-internals/#dns
The steps for clearing the DNS cache in Chrome are the same for desktop and Android devices.
**Step 1: Launch a new tab**
Open a new tab on your Chrome browser.
**Step 2: Access DNS settings**
Paste `chrome://net-internals/#dns` in the address bar and press Enter.
**Step 3: Clear DNS cache**
Click on the “Clear host cache” button.
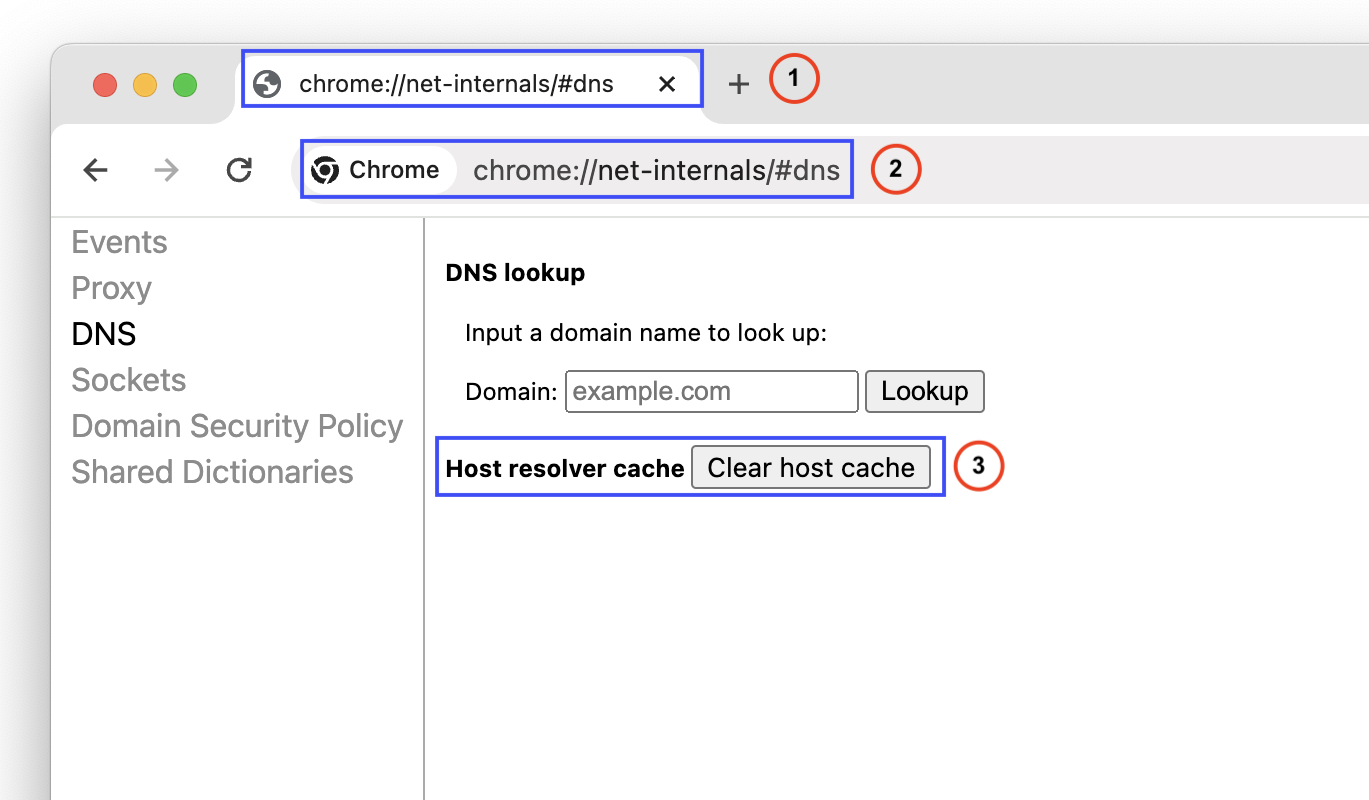
> iOS devices, including iPhones and iPads, do not support this functionality in Chrome.
## Conclusion
Clearing your DNS cache in Chrome can improve your browsing experience.
Following our three steps, flushing your DNS cache regularly will ensure you have the most up-to-date information.
<CTABlogFooter/>
### Additional information
If you need to clear the DNS cache on your operating system, refer to this [article](https://www.cyberciti.biz/faq/google-chrome-clear-or-flush-the-dns-cache/). It provides step by step guides on how to clear or flush the DNS cache on MS-Windows 7/8/10/11, Linux, and Mac OS.
If you need to clear the DNS cache on your iOS device (iPhone or iPad), refer to this [Youtube video](https://www.youtube.com/watch?v=2xzVZbTGWTo).
### Frequently Asked Questions (FAQs)
**Q1: Will clearing the DNS cache log me out of websites?**
A1: No, clearing the DNS cache does not log you out of websites. It only clears the DNS resolver cache.
**Q2: How often should I clear my DNS cache?**
A2: There is no set frequency, but clearing the DNS cache can help if you encounter frequent connectivity issues.
| asayerio_techblog | |
1,870,112 | How to show code style issues for dirty files using pint | The command below will list all files that has been changed in git which have code style... | 0 | 2024-05-30T09:05:27 | https://dev.to/cmanish049/pint-show-style-issues-for-dirty-files-boa | laravel, pint, laravelpint | The command below will list all files that has been changed in git which have code style issues.
```
vendor/bin/pint --preset=per --dirty --test
```
The output will look somewhat like this.

| cmanish049 |
1,870,111 | Community Bonding, Week 2 | Meeting with my mentors From the previous week, my mentors and I had agreed to a... | 27,442 | 2024-05-30T09:05:20 | https://dev.to/chiemezuo/community-bonding-week-2-2a0f | gsoc, googlesummerofcode, wagtail | ## Meeting with my mentors
From the previous week, my mentors and I had agreed to a particular day and time for our meetings, and the one for this week was to be the first one we'd be having with that schedule. It went really well and we further discussed project expectations, and my mentors both gave me some bits of advice to help make my internship journey smoother.
My lead mentor decided that although the team was aware of when the GSoC projects were being selected, it would be good to prepare an [RFC](https://github.com/wagtail/rfcs) (request for comments) for the features I intended to work on. My project itself was based on a previous RFC from years ago, but things had changed since then and I would be using a different approach, so we collectively decided that a new RFC would be the most ideal way to go about it. My lead mentor, being a core team member, also mentioned that to try and make things even easier for me in the community, he would ask to invite me to a core team meeting. I was both excited and nervous because I would get to meet the people at the helm of affairs for Wagtail, but I would also be very much the most inexperienced person in the meeting.
My second mentor mentioned that writing blog posts to document my journey and learning would help for personal development, and I agreed. That was the push that brought me to writing my experience here. He mentioned that I be active in the community and cover as much content related to my project as I could, whether or not we could immediately see whether it would be useful to it. He also mentioned for me to familiarize with the RFC workflow specific to the Wagtail community, and he shared useful material.
Finally, we concluded that I would make two RFCs: one for the primary project goal, and the other for the secondary/stretch goal (contextual alt text generation with AI). We also decided I would write the RFCs first as Google Docs so we could have different rounds of reviews and feedback, as I had never done something of that nature before.
## Meeting with the Core team
I got the calendar event as promised and marked it for attendance. It was a Zoom meeting, although the invite was via Google Calendar. My lead mentor checked in with me to make sure I had no issues connecting with Zoom. I joined the meeting a few minutes before it started and met him there. I was tensed and so self-conscious, but I told myself that everybody I had interacted with at Wagtail up until that point was patient and kind, so the rest of the core team would also likely reflect those attributes.
Luckily for me, my lead mentor was the one who chaired the meeting. This made me feel much more comfortable, and he gave me the softest possible landing for me to introduce myself. I talked about myself, the project I would be working on, and the fact that an RFC with the proposed changes was in the works, along with a prototype. It was brief, and they were very nice people. It also crossed my mind that I might like to be a core team member sometime in the future (I hope).
Something I noticed with their meetings was the incredible level of detail. They recorded everything about the Wagtail repository. From the number of recent pull requests, issues raised, new contributors, and so on. They had metrics for everything. Actually, for every process in Wagtail, there is a good amount of recording done. They discussed briefly some other Wagtail-specific discussions and the meeting was over.
## Challenges
I had a bit of friction getting started with the RFC but decided that I had to get at least one sentence in. I did, and then came another sentence, and another, up until my draft was ready.
I also had some issues with the prototype I was working on, and had to ask some of the more experienced members for help. It was on a part of Wagtail that there was limited outside knowledge about, so I ended up reaching out to Wagtail's lead developer. I was scared of sending him a message at first because I imagined he'd be the busiest man on the planet, and that my inexperience would put him off. He eventually did get back to me after his brief holiday, and I can now tell you for a fact that I had no reason to be scared. I got some help with something that was breaking changes, as well as with a better approach to another part of Wagtail I would have normally had to modify.
Week 2 was very productive, and as far as community bonding goes, I knew for sure I was a part of Wagtail.
| chiemezuo |
1,866,784 | USB HID Down the rabbit hole: Reverse engineering the Logitech CU0019 USB receiver | Recently, I have an obsession with USB HID devices. So let's go through this rabbit hole. These... | 0 | 2024-05-30T09:04:12 | https://dev.to/endes/usb-hid-down-the-rabbit-hole-reverse-engineering-the-logitech-cu0019-usb-receiver-4d6a | usb, reverseengineering, hardware, reversing | Recently, I have an obsession with USB HID devices. So let's go through this rabbit hole. These devices send a descriptor which specifies the format of the "packets" they send or receive. Most fields are defined in the standard, so your hid driver can interact with the device out of the box. Some devices implement curious fields, like my headphones can send phone "events" like calls.
Most of them implement custom vendor specific fields. This is where it gets interesting.
Let's introduce my laptop mouse (below is Jaime playing with it), it's a Logitech M185. Almost all the Logitech hid devices implement their proprietary standard hid++, which is well-known. Mine is the exception.

It uses the [CU0019 dongle](https://support.logi.com/hc/en-us/articles/7565042135959-USB-Wireless-Receiver-Pairing-and-Troubleshooting#h_01G8P2H7084PDDFCXE3QN9GM15) (aka PID C542), [here are some internal photos thanks to the FCC](https://fccid.io/JNZCU0019/Internal-Photos/Internal-photos-4169246).

{% embed https://github.com/pwr-Solaar/Solaar/issues/1835 %}
It uses the [Telink TLSR8366](https://wiki.telink-semi.cn/wiki/chip-series/TLSR836x-Series/). While Telink openly publishes a lot of tools, documents and code on their website, it is an amalgam of things which don't do a good job explaining themselves, so most of the time I was like "huh?". Oh, they also implement their own ISA called TC32, which is undocumented. Fortunately, GitHub users _trust1995_ and _rgov_ have done a fairly decent job of implementing it on Ghidra.
{% embed https://github.com/trust1995/Ghidra_TELink_TC32/ %}
The HID descriptor, apart from the standard mouse report, exposes a vendor report with ID 5. This report has a feature (aka input and output interface) of 7 bytes. Reading from it returns nothing.
```
0x90, // Output
0x05, 0x01, // Usage Page (Generic Desktop Ctrls)
0x09, 0x02, // Usage (Mouse)
0xA1, 0x01, // Collection (Application)
0x85, 0x01, // Report ID (1)
0x09, 0x01, // Usage (Pointer)
0xA1, 0x00, // Collection (Physical)
0x05, 0x09, // Usage Page (Button)
0x19, 0x01, // Usage Minimum (0x01)
0x29, 0x05, // Usage Maximum (0x05)
0x15, 0x00, // Logical Minimum (0)
0x25, 0x01, // Logical Maximum (1)
0x95, 0x05, // Report Count (5)
0x75, 0x01, // Report Size (1)
0x81, 0x02, // Input (Data,Var,Abs,No Wrap,Linear,Preferred State,No Null Position)
0x95, 0x01, // Report Count (1)
0x75, 0x03, // Report Size (3)
0x81, 0x01, // Input (Const,Array,Abs,No Wrap,Linear,Preferred State,No Null Position)
0x05, 0x01, // Usage Page (Generic Desktop Ctrls)
0x09, 0x30, // Usage (X)
0x09, 0x31, // Usage (Y)
0x16, 0x01, 0x80, // Logical Minimum (-32767)
0x26, 0xFF, 0x7F, // Logical Maximum (32767)
0x75, 0x10, // Report Size (16)
0x95, 0x02, // Report Count (2)
0x81, 0x06, // Input (Data,Var,Rel,No Wrap,Linear,Preferred State,No Null Position)
0x09, 0x38, // Usage (Wheel)
0x15, 0x81, // Logical Minimum (-127)
0x25, 0x7F, // Logical Maximum (127)
0x75, 0x08, // Report Size (8)
0x95, 0x01, // Report Count (1)
0x81, 0x06, // Input (Data,Var,Rel,No Wrap,Linear,Preferred State,No Null Position)
0xC0, // End Collection
0xC0, // End Collection
0x05, 0x01, // Usage Page (Generic Desktop Ctrls)
0x09, 0x00, // Usage (Undefined)
0xA1, 0x01, // Collection (Application)
0x85, 0x05, // Report ID (5)
0x06, 0x00, 0xFF, // Usage Page (Vendor Defined 0xFF00)
0x09, 0x01, // Usage (0x01)
0x15, 0x81, // Logical Minimum (-127)
0x25, 0x7F, // Logical Maximum (127)
0x75, 0x08, // Report Size (8)
0x95, 0x07, // Report Count (7)
0xB1, 0x02, // Feature (Data,Var,Abs,No Wrap,Linear,Preferred State,No Null Position,Non-volatile)
0xC0, // End Collection
// 91 bytes
```
# Getting a firmware dump
I started the house by the roof, instead of trying to fuzz the vendor report, I tried to dump the firmware "the hardware way". These chips have a SWIRE pin, which is a proprietary protocol for debugging and accessing the memory. This interface requires a Telink EVK tool, which isn't cheap, but GitHub user _pvvx_ has written some tools for reading and writing the memory. The 826X tools are compatible with the 836x series.
{% embed https://github.com/pvvx/TlsrComSwireWriter %}
After adapting the tools to use my FTDI ft2332HL board and dumps the memory and soldering cables to the reset and Swire pin (fortunately these pins aren't connected to anything), the dumper kinda worked. It was very unstable, but the data seemed good (it wasn't). Seeing the `KNLT`, `Logitech`, `Wirless Receiver` and `TLSR8366` strings was a good confirmation that it wasn't just garbage.
{% embed https://twitter.com/fw_r3_t/status/1793635090746257531 %}
I could have wasted countless days trying to work with this dump, hopefully, I decided to do things right and started fuzzing the HID vendor report using a fastly written Python script. The results were, let's say, very verbose. A lot of send commands responded with data. Also, I thought I bricked the device as the mouse stopped working, luckily a reset fixed it.
On the results instantaneously something catches my attention. When the fuzzer was changing the data of the second byte, the received data was like sliding.
```
i: -064 j: -082 send dat: [5, 192, 174, 0, 0, 0, 0, 0] recv dat: [0, 0, 0, 128, 3, 8, 33, 132]
i: -064 j: -081 send dat: [5, 192, 175, 0, 0, 0, 0, 0] recv dat: [0, 0, 128, 5, 3, 8, 33, 132]
i: -064 j: -080 send dat: [5, 192, 176, 0, 0, 0, 0, 0] recv dat: [0, 128, 5, 0, 3, 8, 33, 132]
i: -064 j: -079 send dat: [5, 192, 177, 0, 0, 0, 0, 0] recv dat: [128, 5, 0, 0, 3, 8, 33, 132]
i: -064 j: -078 send dat: [5, 192, 178, 0, 0, 0, 0, 0] recv dat: [5, 0, 0, 0, 3, 8, 33, 132]
i: -064 j: -077 send dat: [5, 192, 179, 0, 0, 0, 0, 0] recv dat: [0, 0, 0, 0, 3, 8, 33, 132]
i: -064 j: -076 send dat: [5, 192, 180, 0, 0, 0, 0, 0] recv dat: [0, 0, 0, 0, 3, 8, 33, 132]
i: -064 j: -075 send dat: [5, 192, 181, 0, 0, 0, 0, 0] recv dat: [0, 0, 0, 147, 3, 8, 33, 132]
i: -064 j: -074 send dat: [5, 192, 182, 0, 0, 0, 0, 0] recv dat: [0, 0, 147, 0, 3, 8, 33, 132]
i: -064 j: -073 send dat: [5, 192, 183, 0, 0, 0, 0, 0] recv dat: [0, 147, 0, 0, 3, 8, 33, 132]
i: -064 j: -072 send dat: [5, 192, 184, 0, 0, 0, 0, 0] recv dat: [147, 0, 0, 0, 3, 8, 33, 132]
```
My intuition was that we were reading memory!. I quickly write a dumper and Tachan! We got a more stable, easy and correct dump.
{% embed https://twitter.com/fw_r3_t/status/1794070181775327239 %}
Beyond are the scripts I made for dumping, they are crappy and require the [hid-tools package](https://gitlab.freedesktop.org/libevdev/hid-tools).
{% embed https://gist.github.com/endes0/31e527c3b4d07fb1a187fdef3e7ccff8 %}
# Analyzing the firmware dump
After renaming the symbols of the startup code according to the names on the boot c startup assembly code of the SDKs, I found that a constant was different from those. After a quick GitHub code search, VOILA here are the possible SDK they used.

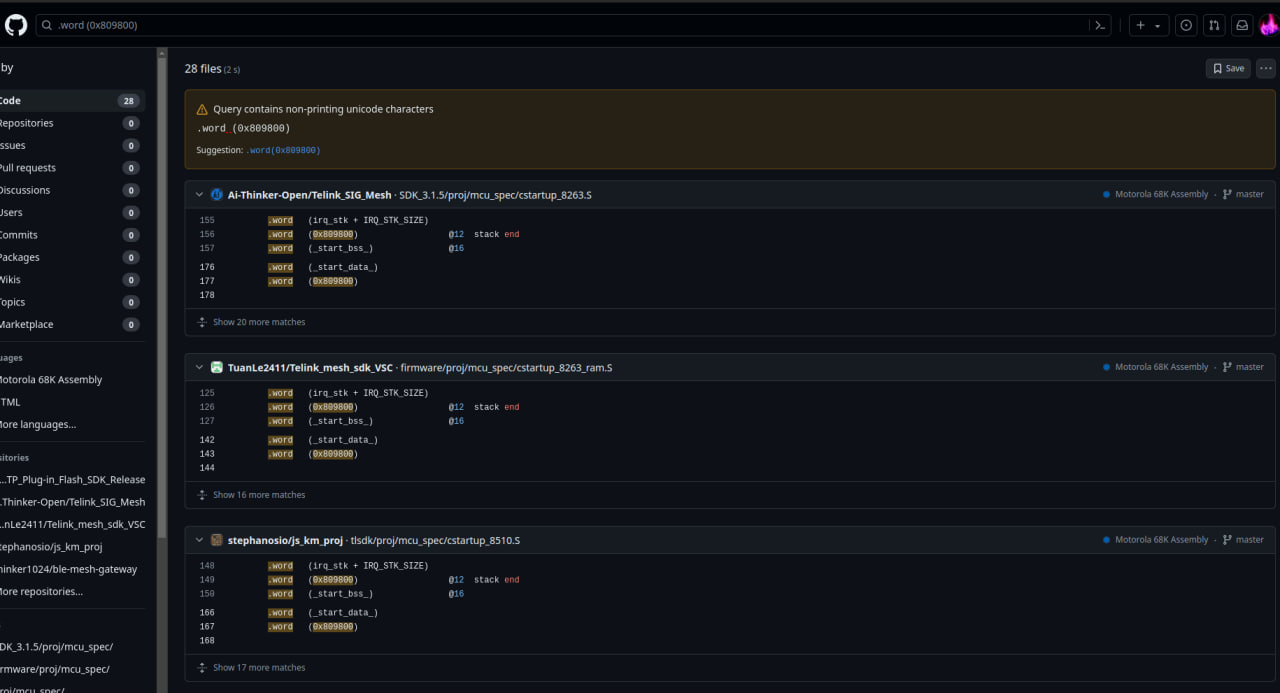
I'm lazy, I wanted to generate a Fidb for Ghidra to automatically recognize functions from the SDK, especially the ones related to USB, but I didn't want to setup and compile the SDK. Fortunately, [there was a precompiled bin with its symbols on one of the repos](https://github.com/stephanosio/js_km_proj/blob/4d9960bace457d7514554185ee73924662cfabcd/tlsdk/8366_dongle/8366_dongle.lst).
## A great find
After generating a Fidb and doing an analysis, for me, it was clear to me that the firmware was a slightly modified version of the _8366_dongle_ project on that repo(I already had my suspicions at the moment I opened the disassembly of the bin).
After a little bit of digging, tachan! This seems to be the code that handles the vendor HID Report.
``` Cpp
case HID_REPORT_CUSTOM:
#if (USB_CUSTOM_HID_REPORT)
{ //Paring, EMI-TX, EMI-RX
if (data_request) {
int i=0;
usbhw_reset_ctrl_ep_ptr (); //address
for(i=0;i<8;i++) {
host_cmd[i] = usbhw_read_ctrl_ep_data();
}
#if (USB_CUSTOM_HID_REPORT_REG_ACCESS)
custom_reg_cmd = (host_cmd[1] & 0xf0) == 0xc0;
if (custom_reg_cmd) {
host_cmd[0] = 0;
int adr = *((u16 *)(host_cmd + 2));
int len = host_cmd[1] & 3;
if (host_cmd[1] == 0xcc && adr == 0x5af0) { //re-enumerate device
usb_dp_pullup_en (0); //disable device
sleep_us (300000);
reg_ctrl_ep_irq_mode = 0xff; //hardware mode
usb_dp_pullup_en (1); //enable device
}
else {
adr += 0x800000;
}
if ((host_cmd[1] & 0x0c)==0) { //write core register
if (len == 0) {
for (int k=0; k<4; k++) {
custom_read_dat = (custom_read_dat >> 8) | (read_reg8 (adr++) << 24);
}
}
else if (len == 1) {
write_reg8 (adr, host_cmd[4]);
}
else if (len == 2) {
write_reg16 (adr, *((u16 *)(host_cmd + 4)));
}
else {
write_reg32 (adr, *((u32 *)(host_cmd + 4)));
}
}
else { //read core register
if (len == 0) {
custom_read_dat = analog_read (host_cmd[2]);
}
else {
analog_write (host_cmd[2], host_cmd[4]);
}
}
}
...
case HID_REQ_GetReport:
#if(USB_SOMATIC_ENABLE)
if(usbsomatic_hid_report_type((control_request.wValue & 0xff))){
}
else
#elif (USB_CUSTOM_HID_REPORT)
if( control_request.wValue==0x0305 ) {
if (USB_CUSTOM_HID_REPORT_REG_ACCESS && custom_reg_cmd) {
usbhw_write_ctrl_ep_data (custom_read_dat);
usbhw_write_ctrl_ep_data (custom_read_dat>>8);
usbhw_write_ctrl_ep_data (custom_read_dat>>16);
usbhw_write_ctrl_ep_data (custom_read_dat>>24);
usbhw_write_ctrl_ep_data (0x10);
usbhw_write_ctrl_ep_data (0x20);
usbhw_write_ctrl_ep_data (0x40);
usbhw_write_ctrl_ep_data (0x80);
}
else {
usbhw_write_ctrl_ep_data (0x04);
usbhw_write_ctrl_ep_data (0x58);
usbhw_write_ctrl_ep_data (0x00);
usbhw_write_ctrl_ep_data (host_cmd_paring_ok ? 0xa1 : 0x00); //For binding OK
usbhw_write_ctrl_ep_data (0x00);
usbhw_write_ctrl_ep_data (0x00);
usbhw_write_ctrl_ep_data (0x08);
usbhw_write_ctrl_ep_data (0x00);
}
}
else
#endif
{ // donot know what is this
// usbhw_write_ctrl_ep_data(0x81);
// usbhw_write_ctrl_ep_data(0x02);
// usbhw_write_ctrl_ep_data(0x55);
// usbhw_write_ctrl_ep_data(0x55);
}
break;
```
_/proj/drivers/usb.c_
``` Cpp
void usb_host_cmd_proc(u8 *pkt)
{
extern u8 host_cmd[8];
extern u8 host_cmd_paring_ok;
u8 chn_idx;
u8 test_mode_sel;
u8 cmd = 0;
static emi_flg;
if((host_cmd[0]==0x5) && (host_cmd[2]==0x3) )
{
host_cmd[0] = 0;
dongle_host_cmd1 = host_cmd[1];
if (dongle_host_cmd1 > 12 && dongle_host_cmd1 < 16){ //soft paring
host_cmd_paring_ok = 0;
rf_paring_tick = clock_time(); //update paring time
if(dongle_host_cmd1 == 13){ //kb and mouse tolgether
mouse_paring_enable = 1;
keyboard_paring_enable = 1;
}
else if(dongle_host_cmd1 == 14){ //mouse only
mouse_paring_enable = 1;
}
else if(dongle_host_cmd1 == 15){ //keyboard only
keyboard_paring_enable = 1;
}
}
else if(dongle_host_cmd1 > 0 && dongle_host_cmd1 < 13) //1-12:����EMI
{
emi_flg = 1;
cmd = 1;
irq_disable();
reg_tmr_ctrl &= ~FLD_TMR1_EN;
//rf_stop_trx ();
chn_idx = (dongle_host_cmd1-1)/4;
test_mode_sel = (dongle_host_cmd1-1)%4;
}
}
if(emi_flg){
emi_process(cmd, chn_idx,test_mode_sel, pkt, dongle_cust_tx_power_emi);
}
}
```
_/vendor/dongle/dongle_emi.c_
## Mouse Device ID
I think I also found the memory address where the current paired Mouse is stored(`custom_binding[0]`): `0x809160`. I can't confirm it as I don't have another mouse and the value is a little bit off for me.

Potentially, this can be used to send a USB HID read memory and obtain the current mouse ID.
## Ghidra symbols
Here are all the symbols I found, it can be imported with the `ImportSymbolsScript.py`.
{% embed
https://gist.github.com/endes0/82fbbfa8f1c777fcca1e144d82103b87 %}
# USB HID custom commands
So, after analyzing the firmware, fuzzer output and doing some test, I found the following USB HID set feature commands.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | Description |
|-----:|--------------:|-------------------------:|-------------:|------------------------:|-------------------------:|-------------------------:|--------------------------------------------------|
| 0xD | 0x3 | - | - | - | - | - | Software pairing: Mouse and keyboard |
| 0xE | 0x3 | - | - | - | - | - | Software pairing: Mouse |
| 0xF | 0x3 | - | - | - | - | - | Software pairing: Keyboard |
| 0x1 | 0x3 | - | - | - | - | - | _EMI: channel low, mode carrier_ |
| 0x2 | 0x3 | - | - | - | - | - | _EMI: channel low, mode cd_ |
| 0x3 | 0x3 | - | - | - | - | - | _EMI: channel low, mode rx_ |
| 0x4 | 0x3 | - | - | - | - | - | _EMI: channel low, mode tx_ |
| 0x5 | 0x3 | - | - | - | - | - | _EMI: channel medium, mode carrier_ |
| 0x6 | 0x3 | - | - | - | - | - | _EMI: channel medium, mode cd_ |
| 0x7 | 0x3 | - | - | - | - | - | _EMI: channel medium, mode rx_ |
| 0x8 | 0x3 | - | - | - | - | - | _EMI: channel medium, mode tx_ |
| 0x9 | 0x3 | - | - | - | - | - | _EMI: channel high, mode carrier_ |
| 0xA | 0x3 | - | - | - | - | - | _EMI: channel high, mode cd_ |
| 0xB | 0x3 | - | - | - | - | - | _EMI: channel high, mode rx_ |
| 0xC | 0x3 | - | - | - | - | - | _EMI: channel high, mode tx_ |
| 0xC0 | addr&0xff | (addr>>8)&0xff | - | - | - | - | Memory: read 32 bits from **addr** + 0x800000 |
| 0xC1 | **addr**&0xff | (**addr**>>8)&0xff | **dat** | - | - | - | _Memory: write 8 bits **dat** to **addr** + 0x800000_ |
| 0xC2 | **addr**&0xff | (**addr**>>8)&0xff | **dat**&0xff | (**dat**>>8)&0xff | - | - | _Memory: write 16 bits **dat** to **addr** + 0x800000_ |
| 0xC3 | **addr**&0xff | (**addr**>>8)&0xff | **dat**&0xff | (**dat**>>8)&0xff | (**dat**>>16)&0xff | (**dat**>>24)&0xff | _Memory: write 32 bits **dat** to **addr** + 0x800000_ |
| 0xC4 | **addr** | - | - | - | - | - | Memory: read analog address **addr** |
| 0xC5 | **addr** | - | **dat** | - | - | - | _Memory: write 8 bits **dat** at analog address **addr**_ |
| 0xCC | 0xF0 | 0x5A | - | - | - | - | Misc: "renumerates USB devices" |
Notes: Take the _italics_ entries with a grain of salt, as I didn't test it. Byte 0 is always the report ID, in this case 5.
It seems that software pairing is broken, Keyboard and Mouse pairing command always return success while the other 2 never succeed. Also, all the pairing commands disconnect the mouse, and it won't work until restarting the dongle.
Issuing the "renumerate" command will connect the device as a USB printer "Telink Semiconductor USB DevSys" with VID 248A and PID 5320. Maybe this is the "USB programming mode" for interfacing with [Telink BDT tools](https://wiki.telink-semi.cn/wiki/IDE-and-Tools/Burning-and-Debugging-Tools-for-all-Series/)? Taking a look at the sources of [web BDT tool](https://wiki.telink-semi.cn/debug/readme/README_en.html#3), the PID doesn't seem to match. So I thought it wasn't.
``` Javascript
async function usb_connect(){
const myfilters = [
{ 'vendorId': 0x2341, 'productId': 0x8036 },
{ 'vendorId': 0x248A, 'productId': 0x826A }, ]; //'productId': 0x826A
```
The analog read I think it reads the "3.3V analog registers" referenced in the [datasheet](https://wiki.telink-semi.cn/doc/ds/DS_TLSR8366-E_Datasheet%20for%20Telink%202.4GHz%20RF%20System-On-Chip%20Solution%20TLSR8366.pdf).
### Another "great" dump
Before I said that when the device renumerates as "Telink Semiconductor USB DevSys" maybe it is for the BDT tools, well after launching the desktop tools on Windows, it connects, so it is.
This is great as we can have total access to all the memory spaces and also some debugging functions.
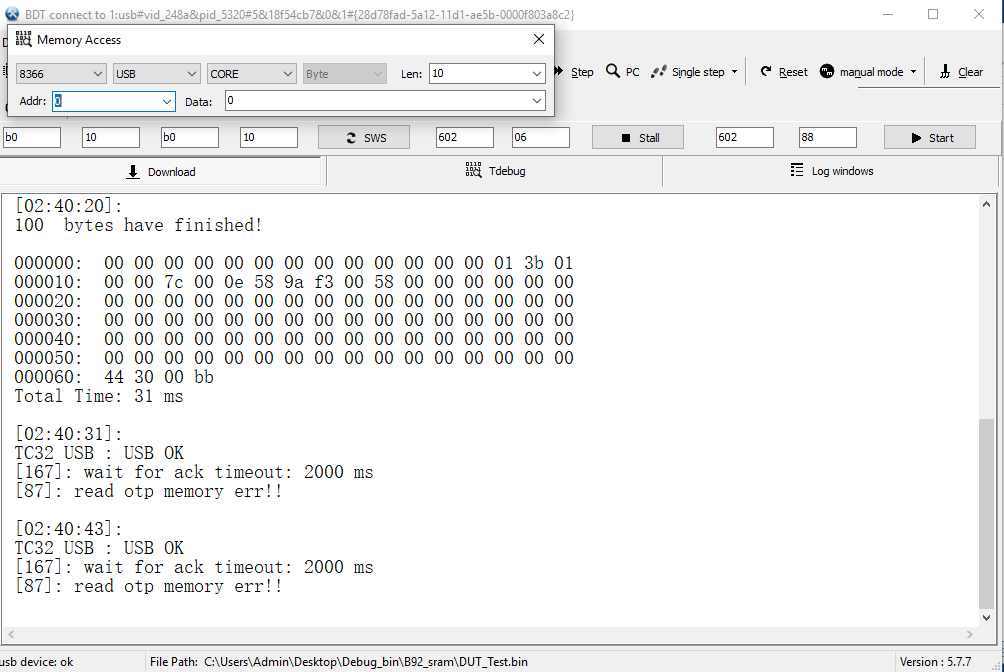
Let's just say that the memory access tool, well, umh, it's not great. The CORE access it also seems to start at address 0x800000, but if we read 0x808000 it seems to contain errors, or maybe another program.
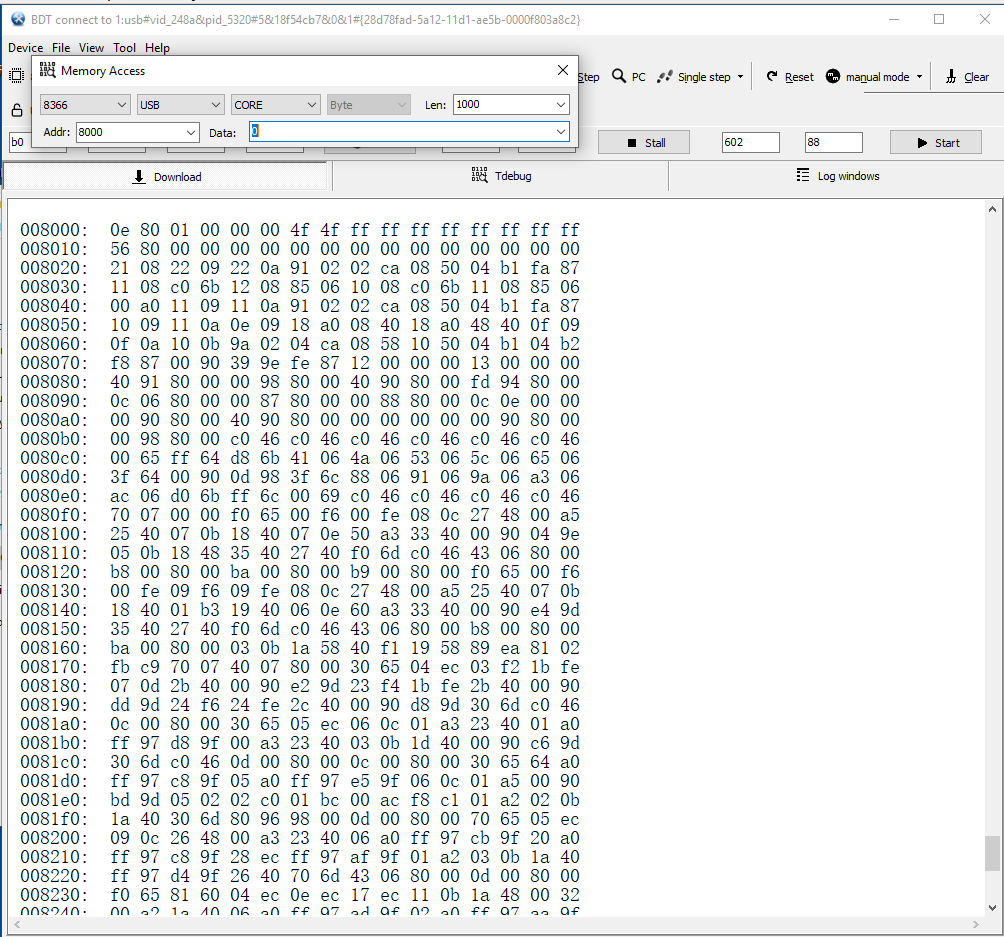
The analog read works like the USB HID analog read, the flash read always returns 0xFF (In theory this chip doesn't have flash at all) and unfortunately the OTP read doesn't work. This is bad news, as the OTP memory is likely to have something.
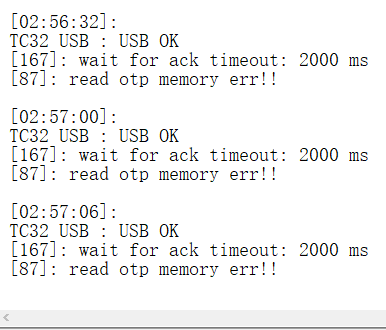
| endes |
1,870,110 | A Tool to Help Optimize Your Website's SEO | Hello everyone, We recognize the challenges and confusion website owners face in the realm of SEO.... | 0 | 2024-05-30T09:03:39 | https://dev.to/juddiy/a-tool-to-help-optimize-your-websites-seo-3871 | tooling, ai, showdev | Hello everyone,
We recognize the challenges and confusion website owners face in the realm of SEO. While traditional SEO tools offer some assistance, they often require manual intervention and understanding. Therefore, we've decided to develop a smarter, more user-friendly tool to address the pain points website owners encounter in the SEO optimization process.
This is why we created [SEO AI](https://seoai.run/). Leveraging cutting-edge algorithms and machine learning technology, it can analyze your website data and keyword rankings, helping identify weaknesses and providing practical suggestions to enhance your SEO performance. It's not just a data collection tool; it's more like your personal SEO consultant, offering tailored advice to help you craft more effective SEO strategies.
We hope SEO AI becomes a valuable asset for website owners, aiding them in better understanding and optimizing their websites to improve rankings and visibility on search engines.
Look forward to hearing your feedback on this tool! | juddiy |
1,865,093 | Parsing structured environment variables in Rust | I'm in the process of adding more components to my OpenTelemetry demo (again!). The new design... | 0 | 2024-05-30T09:02:00 | https://blog.frankel.ch/structured-env-vars-rust/ | rust, environment, configuration | I'm in the process of adding more components to my OpenTelemetry demo (again!). The new design deploys several warehouse services behind the `inventory` service so the latter can query the former for data via their respective HTTP interface. I implemented each warehouse on top of a different technology stack. This way, I can show OpenTelemetry traces across several stacks.
Anyone should be able to add a warehouse in their favorite tech stack if it returns the correct JSON payload to the inventory. For this, I want to make the configuration of the inventory "easy"; add a new warehouse with a simple environment variable pair, _i.e._, the endpoint and its optional country.
The main issue is that environment variables are not _structured_. I searched for a while and found a [relevant post](https://charemza.name/blog/posts/software-engineering/devops/structured-data-in-environment-variables/). Its idea is simple but efficient; here's a sample from the post:
```env
FOO__1__BAR=setting-1 #1
FOO__1__BAZ=setting-2 #1
FOO__2__BAR=setting-3 #1
FOO__2__QUE=setting-4 #1
FIZZ__1=setting-5 #2
FIZZ__2=setting-6 #2
BILL=setting-7 #3
```
1. Map-like structure
2. Table-like structure
3. Just a value
With this approach, I could configure the inventory like this:
```yaml
services:
inventory:
image: otel-inventory:1.0
environment:
WAREHOUSE__0__ENDPOINT: http://apisix:9080/warehouse/us #1
WAREHOUSE__0__COUNTRY: USA #2
WAREHOUSE__1__ENDPOINT: http://apisix:9080/warehouse/eu #1
WAREHOUSE__2__ENDPOINT: http://warehouse-jp:8080 #1
WAREHOUSE__2__COUNTRY: Japan #2
OTEL_EXPORTER_OTLP_ENDPOINT: http://jaeger:4317
OTEL_RESOURCE_ATTRIBUTES: service.name=inventory
OTEL_METRICS_EXPORTER: none
OTEL_LOGS_EXPORTER: none
```
1. Warehouse endpoint
2. Set country
You can see the three warehouses configured in the above. Each has an endpoint/optional country pair.
My first attempt looked like the following:
```rust
lazy_static::lazy_static! { //1
static ref REGEXP_WAREHOUSE: Regex = Regex::new(r"^WAREHOUSE__(\d)__.*").unwrap();
}
std::env::vars()
.filter(|(key, _)| REGEXP_WAREHOUSE.find(key.as_str()).is_some()) //2
.group_by(|(key, _)| key.split("__").nth(1).unwrap().to_string()) //3
.into_iter() //4
.map(|(_, mut group)| { //5
let some_endpoint = group.find(|item| item.0.ends_with("ENDPOINT")); //6
let endpoint = some_endpoint.unwrap().1;
let some_country = group //7
.find(|item| item.0.ends_with("COUNTRY"))
.map(|(_, country)| country);
println! {"Country pair is: {:?}", some_country};
(endpoint, some_country).into() //8
}
.collect::<Vec<_>>()
```
1. For making constants out of code evaluated at runtime
2. Filter out warehouse-related environment variable
3. Group by index
4. Back to an `Iter` with the help of `itertools`
5. Consist of just the endpoint or the endpoint *and* the country
6. Get the endpoint
7. Get the country
8. Into a structure - irrelevant
I encountered issues several times when I started the demo. The code somehow didn't find the endpoint **at all**. I chose this approach because I've been taught that it's more performant to iterate throughout the key-value pairs of a map than iterate through its key only and then get the value in the map. I tried to change to the latter.
```rust
lazy_static! {
static ref REGEXP_WAREHOUSE_ENDPOINT: Regex =
Regex::new(r"^WAREHOUSE__(?<index>\d)__ENDPOINT.*").unwrap(); //1
}
std::env::vars()
.filter(|(key, _)| REGEXP_WAREHOUSE_ENDPOINT.find(key.as_str()).is_some()) //2
.map(|(key, endpoint)| {
let some_warehouse_index = REGEXP_WAREHOUSE_ENDPOINT.captures(key.as_str()).unwrap(); //3//4
println!("some_warehouse_index: {:?}", some_warehouse_index);
let index = some_warehouse_index.name("index").unwrap().as_str();
let country_key = format!("WAREHOUSE__{}__COUNTRY", index); //5
let some_country = var(country_key); //6
println!("endpoint: {}", endpoint);
(endpoint, some_country).into()
})
.collect::<Vec<_>>()
```
1. Change the regex to capture only the endpoint-related variables
2. Filter out warehouse-related environment variable
3. I'm aware that the `filter_map()` function exists, but I think it's clearer to separate them here
4. Capture the index
5. Create the country environment variable from a known string, and the index
6. Get the country
With this code, I didn't encounter any issues.
Now that it works, I'm left with two questions:
* Why doesn't the `group()`/`find()` version work in the deployed Docker Compose despite working in the tests?
* Is anyone interested in making a crate out of it?
**To go further:**
* [Structured data in environment variables](https://charemza.name/blog/posts/software-engineering/devops/structured-data-in-environment-variables/)
* [lazy_static crate](https://docs.rs/lazy_static/latest/lazy_static/)
* [envconfig crate](https://docs.rs/envconfig/latest/envconfig/)
<hr>
_Originally published at [A Java Geek](https://blog.frankel.ch/structured-env-vars-rust/) on May 26<sup>th</sup>, 2024_
| nfrankel |
1,852,408 | Lesser Known Rails Helpers to Write Cleaner View Code | This article was originally published on Rails Designer Rails (or more precise ActiveSupport and... | 0 | 2024-05-30T09:00:00 | https://railsdesigner.com/lesser-known-rails-helpers/ | rails, webdev, ruby | This article was originally published on [Rails Designer](https://railsdesigner.com/lesser-known-rails-helpers/)
---
Rails (or more precise [ActiveSupport](https://guides.rubyonrails.org/active_support_core_extensions.html) and [ActionView](https://guides.rubyonrails.org/action_view_overview.html)) has some really great, quality-of-life helpers so that your code is cleaner. I want to highlight a few that I don't see used often, but will be great to add to your tool set.
These will highlight only **helpers that are focused on code for the view-layer**. If you [purchased Rails Designer](https://railsdesigner.com/) you might recognize most of these. 💡
This will be a swift article, covering all helpers in rapid succession.
## class_names
The one helper I use. All. The. Time. It's actually an alias for [token_list](https://api.rubyonrails.org/classes/ActionView/Helpers/TagHelper.html#method-i-token_list).
I wrote [an entire article](https://railsdesigner.com/conditional-css-classes-in-rails/) about this snippet—so do check that out—but in essence it works like this:
```ruby
class_names("item", { active: item.for_sale?, "out-of-stock": item.out_of_stock? })
```
## current_path?
This method is used to determine if a given path matches the current page URL. Useful in views for setting active CSS classes, like so:
```ruby
link_to "Home", root_path, class: ("active" if current_page?(root_path))
link_to "About", about_path, class: ("active" if current_page?(about_path))
```
## parameterize
`parameterize` is pretty well-known, but the fact it takes some arguments is lesser known:
```ruby
"John Smith".parameterize(preserve_case: true) # => "John-Smith"
"John Smith".parameterize(separator: "_") # => "john_smith"
```
## upcase_first
```ruby
"employee salary".upcase_first # => "Employee salary"
```
## downcase_first
```ruby
"If I had read Alice in Wonderland".downcase_first # => "if I had read Alice in Wonderland"
```
## camelize
`camelize` can take a `:lower` argument (the default is `:upper`).
```ruby
"visual_effect".camelize(:lower) # => "visualEffect"
```
## safe_join
`safe_join` is used to safely concatenate an array of strings, ensuring that each element is HTML escaped. You can use it instead of better known `join.html_safe`.
```ruby
items = ["Home", "About", "Contact"]
navigation = items.map { |item| tag.li(link_to(item, "/#{item.downcase}")) } # => ["<li><a href=\"/home\">Home</a></li>", "<li><a href=\"/about\">About</a></li>", "<li><a href=\"/contact\">Contact</a></li>"]
safe_join(navigation)
```
## excerpt
This one is not something you can use often, but it's good to know about for those time you do. For example on search list page.
```ruby
input = "Your team has been fantastic with their quick response times and thorough solutions. We've noticed an improvement in our operations due to your dedicated support."
excerpt(input, radius: 10)
# => ""...fantastic with their quick response times and...""
input = "The project has undergone several changes, and new deadlines have been set for the completion of each phase. The team needs to adjust accordingly to meet the revised goals."
excerpt(input, "deadline", radius: 20)
# => "...changes, and new deadlines have been set..."
```
## inquiry
I learned about this method in [this PR](https://github.com/rails/rails/pull/46786). It converts strings or arrays into objects that allow you to query for presence in a more readable way
```ruby
"admin".inquiry.admin? # => true
["pending", "active"].inquiry.pending? # => true
```
## to_sentence
Most Rails devs are aware of `to_sentence`. But it accepts a few arguments that are really useful.
```ruby
['apple', 'banana', 'pear'].to_sentence
# => "apple, banana, and pear"
['apple', 'banana', 'pear'].to_sentence(last_word_connector: ' or ', two_words_connector: ' and ')
# => "apple, banana or pear"
['apple', 'banana'].to_sentence(two_words_connector: ' and also ')
# => "apple and also banana"
['apple', 'banana', 'pear'].to_sentence(words_connector: '; ', last_word_connector: '; and finally, ')
# => "apple; banana; and finally, pear"
```
Do you know of any helper that is lesser known? Let me know! | railsdesigner |
1,870,108 | Naming Conventions in Programming | What are Naming Conventions? Naming conventions are a set of rules and guidelines that are... | 0 | 2024-05-30T08:57:17 | https://dev.to/kellyblaire/naming-conventions-in-programming-20ak | programming, namingconventions, softwaredevelopment, webdev | ## What are Naming Conventions?
Naming conventions are a set of rules and guidelines that are used to define the names of variables, functions, classes, and other entities in programming. These conventions help ensure that the code is readable, maintainable, and less prone to errors. In this article, we will explore the importance of naming conventions, common practices across different programming languages, and best practices that developers should follow to create clean and consistent code.
In software development, writing code that is easy to read and maintain is just as important as writing code that works. One of the fundamental aspects of writing such code is adhering to naming conventions. These conventions act as a universal language among developers, facilitating better understanding and collaboration within teams. Whether you are a novice coder or an experienced developer, following naming conventions can significantly improve the quality of your codebase.
## Importance of Naming Conventions
1. **Readability**: Clear and descriptive names make the code easier to understand. When names accurately describe their purpose, other developers (and your future self) can quickly grasp the functionality without needing extensive comments or documentation.
2. **Maintainability**: Consistent naming reduces confusion and makes it easier to update and refactor code. When names follow a standard pattern, finding and modifying the relevant parts of the code becomes simpler.
3. **Collaboration**: In a team setting, naming conventions ensure that everyone follows the same standards, leading to a cohesive codebase. This consistency helps new team members get up to speed faster and reduces the risk of misunderstandings.
4. **Error Reduction**: Well-named variables and functions can help prevent errors. For instance, using clear and distinct names for different entities reduces the likelihood of accidentally using the wrong variable or function.
## Common Naming Conventions
Below are some of the commonly used naming conventions in programming, along with examples:
1. **Camel Case**:
- Used for naming variables, functions, and methods in many programming languages like JavaScript, Java, C#, and Python.
- Provides a readable and concise way to name identifiers without spaces or separators.
- Example: `calculateArea`, `getUserDetails`
2. **Pascal Case**:
- Commonly used for naming classes, structs, and interfaces in object-oriented programming languages like C#, Java, and TypeScript.
- Helps distinguish classes and structs from other entities in the code.
- Example: `UserProfile`, `HttpClient`
3. **Snake Case**:
- Widely used for naming file names, directories, and variables in languages like Python, Ruby, and Rust.
- Improves readability, especially when multiple words are used, and makes it easy to differentiate words.
- Example: `user_profile.py`, `product_details.rb`, `max_retries`
4. **Kebab Case** (also known as **Spinal Case**):
- Primarily used for naming HTML attributes, CSS classes, and component names in web development frameworks like React and Angular.
- Provides a clear separation between words and is compatible with HTML and CSS syntax.
- Example: `<div class="user-profile">`, `<my-component></my-component>`, `.header-navigation`
5. **Upper Case**:
- Used for naming constants in many programming languages like C++, Java, and JavaScript.
- Clearly distinguishes constants from variables and other identifiers, making the code more self-documenting.
- Example: `MAX_VALUE`, `DEFAULT_TIMEOUT`, `PI`
6. **Hungarian Notation**:
- Prefixes variable names with one or more lowercase letters indicating the data type or other information about the variable.
- While it was popular in the past, it is now generally discouraged as it can make code harder to read and maintain, especially with modern IDEs that provide type information.
- Example: `strName` (string), `iAge` (integer), `bIsActive` (boolean)
7. **Train Case** (also known as **Hyphen-Separated Case**):
- Words are separated by hyphens, and the first letter of each word is capitalized.
- Sometimes used for naming database tables or columns, especially in legacy systems or when interoperating with systems that have naming conventions restrictions.
- Example: `User-Profile`, `Product-Details`
8. **Flat Case**:
- All letters are lowercase, and words are usually concatenated without separators.
- Used in some programming languages or frameworks that follow a minimalist naming style or have specific naming guidelines.
- Example: `myvariable`, `calculatesum`, `persondetails`
## Best Practices for Naming Conventions
1. **Be Descriptive**: Choose names that clearly describe the purpose of the variable, function, or class. Avoid vague names like `temp` or `data`.
2. **Keep it Short but Meaningful**: While names should be descriptive, they should also be concise. Striking a balance between brevity and clarity is key.
3. **Use Pronounceable Names**: Names that are easy to pronounce improve readability and communication within a team (e.g., `userID` instead of `usrID`).
4. **Avoid Abbreviations**: Unless they are well-known and universally understood, avoid using abbreviations. For example, use `calculateAverage` instead of `calcAvg`.
5. **Consistent Use of Naming Conventions**: Once a convention is chosen, it should be applied consistently throughout the codebase. Mixing different styles can lead to confusion.
6. **Avoid Using Reserved Keywords**: Ensure that your names do not conflict with reserved keywords in the programming language you are using.
7. **Contextual Naming**: Use names that provide context about their usage. For example, `userList` is more informative than just `list`.
8. **Refactor When Necessary**: Don’t hesitate to rename variables, functions, or classes if you find a better name that enhances clarity and readability.
## Conclusion
Adopting and adhering to naming conventions is a critical practice in software development. It fosters a codebase that is clean, understandable, and maintainable, making it easier for developers to collaborate and innovate. As programming languages and development environments evolve, so too may naming conventions, but the fundamental principles of clarity, consistency, and descriptiveness remain constant. By incorporating these practices into your coding habits, you can contribute to a more efficient and productive development process.
It's worth noting that the choice of naming convention often depends on the programming language, project guidelines, team preferences, and existing code style within a codebase. Consistency within a project is more important than following a specific convention religiously. Additionally, some conventions may be more suitable for certain use cases than others, depending on the context and the programming language being used.
Remember, codes are read more often than they are written. Writing clear and consistent names is an investment that pays off in the long run, enhancing both individual productivity and team collaboration.
Follow, react, and share if you like this article.
**PS:**
I love coffee, and writing these articles takes a lot of it! If you enjoy my content and would like to support my work, you can buy me a cup of coffee. Your support helps me to keep writing great content and stay energized. Thank you for your kindness!
[Buy Me A Coffee](https://buymeacoffee.com/yafskkw). | kellyblaire |
1,870,107 | What Crawls Into My Mind When My Free Trial Expires | AWS : What do we need free cloud credits for? Microsoft Azure : What do you mean what do we need... | 0 | 2024-05-30T08:52:15 | https://dev.to/lolllla/what-crawls-into-my-mind-when-my-free-trial-expires-3dih | microsoft, jokes | AWS : What do we need free cloud credits for?
Microsoft Azure : What do you mean what do we need free cloud credits for? Why do you think we're offering all these startup incentives and free tiers? The whole purpose is to get new developers hooked on our services so they get comfortable with our platform and, you know, they can't refuse, because of the implication.
AWS : Oh, uh... okay. You had me going there for the first part, the second half kinda threw me.
Microsoft Azure : Well dude, dude, think about it: they're just starting out, they look around and what do they see? No other options that give this much for free. "Ahh, there's nowhere else for me to go. What am I gonna do, say 'no'?"
AWS : Okay. That... that seems really aggressive.
Microsoft Azure : Nah, no it's not aggressive. You're misunderstanding me, bro.
AWS : I'm-I think I am.
Microsoft Azure : Yeah, you are, because if they really didn't want to use our services, then they wouldn't...
AWS : Right.
Microsoft Azure : But the thing is, they’re not gonna say no, they would never say no because of the implication.
AWS : ...Now you've said that word "implication" a couple of times. Wha-what implication?
Microsoft Azure : The implication that things might go wrong if they don't use our infrastructure.. Not that they definitely will, but they’re thinkin' they might.
AWS : But it sounds like they might not really want to use your services...
Microsoft Azure : Why aren't you understanding this? They don't know if they want to use our services. That's not the issue...
AWS : Are you gonna trap developers?
Microsoft Azure : I'm not gonna trap these developers! Why would I ever trap these developers? I feel like you're not getting this at all!
AWS : I'm not getting it.
Microsoft Azure : Goddamn.
[notices hobbyist staring at them]
Microsoft Azure : Well don't you look at me like that, you certainly wouldn't be forced to use our services.
AWS : So they are forced!
Microsoft Azure : No one's being forced! | lolllla |
1,870,106 | How to Beat Reno - Boss Guide | Final Fantasy VII Remake is a reimagining of the classic 1997 RPG, Final Fantasy VII, developed and... | 0 | 2024-05-30T08:51:40 | https://dev.to/patti_nyman_5d50463b9ff56/how-to-beat-reno-boss-guide-4p36 | Final Fantasy VII Remake is a reimagining of the classic 1997 RPG, Final Fantasy VII, developed and published by Square Enix. The game is set in the dystopian city of Midgar, ruled by the powerful Shinra Electric Power Company, which exploits the planet's life force, Mako, for energy. The protagonist, Cloud Strife, is a former member of Shinra's elite military unit, SOLDIER, who joins the eco-terrorist group AVALANCHE to fight against Shinra's exploitation of the planet. Throughout the game, players explore Midgar, uncover conspiracies, and face off against formidable enemies, including the enigmatic Sephiroth.
Basic Gameplay:
Final Fantasy VII Remake combines real-time action with strategic command-based combat. Players control Cloud and his allies, switching between characters in battle to utilize their unique abilities. The game features exploration, puzzle-solving, and intense battles against various enemies and bosses. Players can customize their characters using the Materia system, which allows them to equip magical orbs that grant spells and abilities, and the weapon upgrade system, which enhances their combat capabilities.
Reno - Boss Character Overview
Role and Attributes:
Reno is a prominent member of the Turks, a covert organization working for Shinra. He is known for his agility, speed, and use of an Electro-Mag Rod in combat. As a boss, Reno is challenging due to his quick movements and electrical attacks, requiring players to stay on their toes and adapt their strategies.
Unlocking Reno - Boss Encounter
Map Location and Route:
Reno can be encountered in Chapter 8: "Budding Bodyguard," during a mission where Cloud and Aerith are trying to escape from the Church in the Sector 5 Slums. To reach Reno:
Start at the Church: After the cutscene where Reno and the Shinra troops arrive, prepare for the battle.
Escape Sequence: Follow the path through the church's upper floors and rooftops, leading to a courtyard where the encounter takes place.
Signals and Landmark Items:
Signal: A significant cutscene will trigger as you escape the church, introducing Reno and indicating the impending boss battle.
Landmark Item: The church itself and the rooftops leading to the courtyard serve as notable landmarks. Look for the distinctively damaged structure and the open courtyard area where the battle will commence.
Battle Signals and Recommended Characters
Entering Battle State:
Signal: The battle with Reno begins immediately after the cutscene ends. The game will automatically transition into combat mode.
Recommended Characters:
Cloud Strife: As the main character, Cloud's versatility and strong melee attacks are essential.
Aerith Gainsborough: Aerith's healing abilities and ranged magic attacks provide crucial support during the fight.
Defeating Reno - Skills and Strategies
Phase-wise Battle Approach:
Phase One:
Skills: Reno uses quick melee attacks and his Electro-Mag Rod for electrifying attacks. He may also deploy EMP traps that slow down movement.
Deadly Signal: Reno's rod will glow before he launches a powerful electrical attack.
Avoidance Technique: Dodge sideways or use a block to mitigate damage. Keep an eye on Reno’s movements and maintain distance when he charges his rod.
Phase Two:
Skills: Reno becomes more aggressive, using enhanced electrical attacks and faster movements.
Deadly Signal: He will jump into the air and charge his rod for a wide-area electrical strike.
Avoidance Technique: Use Cloud's Guard or dodge-roll away from the targeted area. Maintain continuous movement to avoid being hit.
Detailed Strategies:
Character Skills:
Cloud: Use Punisher Mode for counterattacks when Reno gets close, and switch to Operator Mode to chase him down when he retreats. Use Focus Thrust to pressure Reno.
Aerith: Stay at a distance and use Arcane Ward to double-cast spells. Use healing spells like Healing Wind to keep the party’s health up.
Materia Recommendations:
Equip Lightning Materia on Cloud for strong counterattacks.
Equip Barrier Materia to reduce damage from Reno's electrical attacks.
Dodging Techniques:
Learn Reno’s attack patterns and time your dodges accordingly.
Stay mobile and avoid getting cornered by EMP traps.
By following these strategies and being mindful of Reno's attack patterns and signals, players can successfully defeat Reno and progress in the story of Final Fantasy VII Remake.
Detailed Character Recommendations and Battle Tactics for Reno - Boss
Recommended Characters and Key Actions:
Cloud Strife:
Role: Main damage dealer and front-line fighter.
Key Skills and Techniques:
Punisher Mode: Use this mode to counter Reno's melee attacks. In Punisher Mode, Cloud deals more damage and automatically counterattacks after blocking enemy melee attacks.
Operator Mode: Use this mode for increased mobility and to close the distance quickly to Reno when he retreats.
Focus Thrust: Use this ability to pressure Reno and fill his stagger gauge faster.
Braver: Use this powerful attack when Reno is staggered to deal significant damage.
Materia Setup:
Lightning Materia: Equip this to exploit Reno's weakness to lightning-based attacks.
HP Up Materia: Increase Cloud's survivability in battle.
Aerith Gainsborough:
Role: Support and ranged magical attacker.
Key Skills and Techniques:
Arcane Ward: Place this on the ground to allow Aerith to double-cast spells when standing within it.
Thunder: Use this spell to exploit Reno’s weakness to lightning.
Healing Wind: Use Aerith's Limit Break to heal the party when their health is low.
Tempest: Charge this attack to deal a significant burst of magic damage.
Materia Setup:
Lightning Materia: For offensive spells against Reno.
Healing Materia: To keep the party’s health up.
Barrier Materia: To reduce incoming damage from Reno’s attacks.
Key Elements of Damage Output
Stagger Mechanic: Focus on filling Reno’s stagger gauge using abilities like Focus Thrust and magic attacks. When Reno is staggered, he takes increased damage, providing an opportunity to unleash powerful abilities like Cloud’s Braver.
Exploiting Weakness: Use lightning-based attacks frequently as Reno is weak to this element, dealing more damage and helping to fill his stagger gauge faster.
Changes in Reno’s Behavior and Attacks During Battle
Phase One:
Behavior: Reno relies on quick melee attacks and basic electrical attacks using his Electro-Mag Rod.
Key Attacks:
Electro-Mag Rod Swipe: A swift melee attack that can be countered in Punisher Mode.
EMP Traps: Reno places traps on the ground that slow movement and deal damage.
Tactics: Maintain distance to avoid melee attacks and use ranged magic to chip away at his health. Dodge or block his rod swipes.
Phase Two:
Behavior: Reno becomes more aggressive, utilizing enhanced electrical attacks and moving faster.
Key Attacks:
Aerial Electro Strike: Reno jumps and charges his rod for a wide-area electrical attack.
Quick Strikes: Faster and more frequent melee combos.
Tactics: Continuously move to avoid being hit by his aerial strike. Use Cloud’s Guard to block and counter Reno’s quick strikes.
Rewards for Defeating Reno - Boss
Upon defeating Reno, players receive:
Experience Points (EXP) and Ability Points (AP): These are used to level up characters and their equipped Materia.
Items: Typically, players may receive healing items, ethers, or other consumables.
Weapon Proficiency: Characters involved in the battle gain proficiency with their equipped weapons, unlocking new abilities.
Usage of Rewards in the Game
Leveling Up: Gaining EXP allows characters to level up, increasing their stats and making them stronger for future battles.
Materia Growth: AP helps Materia level up, unlocking more powerful spells and abilities.
Weapon Proficiency: Increases proficiency with weapons, unlocking unique skills that can be used even after switching weapons.
Common Missteps and Advice
Misstep: Ignoring EMP Traps.
Advice: Always stay aware of your surroundings and avoid or disable EMP traps as soon as possible to maintain mobility.
Misstep: Not utilizing Aerith’s support abilities.
Advice: Use Aerith’s Arcane Ward to double-cast spells, significantly increasing your damage output. Keep an eye on the party’s health and use Healing Wind when necessary.
Misstep: Standing still during Reno’s Aerial Electro Strike.
Advice: Always keep moving to avoid the wide-area electrical attack. Use dodge rolls effectively to stay out of harm’s way.
Misstep: Not exploiting elemental weaknesses.
Advice: Equip Lightning Materia on both Cloud and Aerith and use thunder-based attacks to maximize damage against Reno.
By following these strategies and understanding Reno's attack patterns and behavior changes, players can effectively defeat him and progress further in Final Fantasy VII Remake.
At mmowow, we offer a range of playstation network gift card to help you unlock more gaming fun and play Final Fantasy VII Remake and other popular titles using gift cards. Whether you choose to gift for holidays and special occasions or purchase discounted games and promotional items, our gift cards offer great value and are designed to fit your needs.
 | patti_nyman_5d50463b9ff56 | |
1,870,105 | Travel Like Royalty: Unveiling the Palace on Wheels | Imagine yourself transported to a land of vibrant colors, majestic forts, and captivating history.... | 0 | 2024-05-30T08:51:38 | https://dev.to/palaceon_wheels_1641358fe/travel-like-royalty-unveiling-the-palace-on-wheels-4m8a |

Imagine yourself transported to a land of vibrant colors, majestic forts, and captivating history. Welcome to Rajasthan, also known as the Land of Kings.This extraordinary region in northwestern India boasts a rich heritage dating back centuries, evident in its opulent palaces, bustling bazaars, and age-old traditions. However, what if you could experience Rajasthan not just as a tourist, but as royalty? This is the unparalleled experience offered by the Palace on Wheels, India's premier luxury train. **[Palace on Wheels India](https://www.palaceonwheels.in
)** is not merely a mode of transportation; it's a journey through time, whisking you away to a bygone era of elegance and grandeur.
**
Embark on a Royal Adventure: Unveiling the Jewels of Rajasthan**
The story of the Palace on Wheels is intrinsically linked to Rajasthan's royal legacy. These very carriages were once the personal railway coaches of Maharajas and Viceroys, meticulously crafted for journeys steeped in comfort and opulence. Relaunched in 1982, the Palace on Wheels continues this tradition, offering a unique opportunity to experience Rajasthan in unparalleled style.
**A Curated Journey Through Time: The Palace on Wheels Itinerary**
The itinerary of the **[Palace on Wheels](https://www.palaceonwheels.in
)** is a meticulously crafted masterpiece, encompassing some of Rajasthan's most captivating destinations. Prepare to be dazzled by the majestic forts and palaces of Jaipur, the Pink City. Immerse yourself in the timeless beauty of Jaisalmer, the Golden City, where the imposing Jaisalmer Fort rises from the desert sands. In Ranthambore National Park, thrill to the possibility of encountering majestic tigers and a dazzling array of wildlife. These are just a few of the highlights that await you on this unforgettable journey. A detailed itinerary will be provided upon boarding the Palace on Wheels, ensuring you don't miss a single treasure.
**Beyond the Tracks: Unveiling Rajasthan's Gems**
While the Palace on Wheels itself offers an unparalleled experience, the journey isn't confined to its luxurious confines. At each stop, meticulously planned off-train excursions will unveil the historical and cultural gems of Rajasthan. Expert guides will lead you through magnificent forts and palaces, whispering tales of their storied past. Imagine exploring the Amber Fort, a UNESCO World Heritage Site, and marveling at its intricate architecture. In bustling bazaars overflowing with vibrant textiles and handcrafted souvenirs, you'll have the opportunity to find unique treasures and immerse yourself in the sights and sounds of Rajasthani life. These excursions promise an immersive experience that goes beyond sightseeing, transporting you to the heart of Rajasthan's rich cultural tapestry.
**
Living Like Royalty: A Palace on Wheels Experience**
Stepping aboard the Palace on Wheels is akin to stepping into a bygone era of opulence. Imagine yourself greeted by warm hospitality and ushered into the grandeur of the carriages, each named after a former princely state like Rajputana or Baroda. These carriages are individually decorated with rich fabrics, intricate woodwork, and exquisite art that reflects the grandeur of their princely heritage.
**
Your Luxurious Haven: In-Cabin Amenities**
Your home away from home on this royal adventure is your spacious deluxe cabin. A haven of comfort, it's furnished with plush upholstery and adorned with traditional Rajasthani motifs. A well-appointed bathroom ensures your utmost convenience. Adding to the regal experience, you'll be assigned a personal butler who will cater to your every need, from unpacking your luggage to arranging excursions. Whether you desire a refreshing beverage or assistance with planning your attire for a themed evening, your personal butler will be at your service, ensuring a truly unforgettable experience.
A Culinary Journey Through Rajasthan: Fine Dining on the Palace on Wheels
But the indulgence doesn't stop there. The Palace on Wheels boasts two exquisite restaurants, aptly named Maharaja Restaurant and Maharani Restaurant, where you'll embark on a culinary journey through Rajasthan. Talented chefs will tantalize your taste buds with an array of delectable dishes, showcasing the region's rich culinary heritage. From succulent curries and aromatic biryanis to melt-in-your-mouth desserts, prepare to be treated to a feast for the senses. In keeping with the royal theme, the meals are served on elegant crockery with attentive service, making every dining experience an occasion. | palaceon_wheels_1641358fe | |
1,870,104 | Laravel Polymorphic Models By Type | I needed a better way of handling different model types based on a single database table. The... | 0 | 2024-05-30T08:51:20 | https://paulund.co.uk/laravel-polymorphic-models-by-type | webdev, laravel, tutorial, php | I needed a better way of handling different model types based on a single database table.
The example I had was that there was a settings table for the application that can return different types of settings based on the type column of the row.
```php
Schema::create('settings', function (Blueprint $table) {
$table->id();
$table->string('type');
$table->text('settings');
$table->timestamps();
});
```
The type column would be used to determine the type of setting that was being stored in the settings column. Which can be something like email, slack, sms etc. The settings column would be a JSON column that would store the settings for the notification type such as the email to send or the token and channel to send the slack notification.
Because the value of the settings column can consist of different types of settings I needed a way to handle this in the application. I wanted different classes to use for each type of setting, such as `EmailSetting`, `SlackSetting`, `SmsSetting` etc.
The `EmailSetting` will have a method getEmail to get the email in the settings json column.
```php
<?php
namespace App\Models\Notifications;
use Illuminate\Database\Eloquent\Model;
class EmailSetting extends Model
{
public function getEmail()
{
return $this->settings['email'] ?? '';
}
}
```
While the `SlackSetting` class will have a method getChannel to get the channel in the settings json column and a getToken to get the API token.
```php
<?php
namespace App\Models\Notifications;
use Illuminate\Database\Eloquent\Model;
class SlackSetting extends Model
{
public function getChannel()
{
return $this->settings['channel'] ?? '';
}
public function getToken()
{
return $this->settings['token'] ?? '';
}
}
```
## Polymorphic Relationship
To handle this I used a polymorphic relationship in Laravel to handle the different types of settings. I created a Setting model that would be used to handle the different types of settings.
```php
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Setting extends Model
{
public function notification()
{
return $this->morphTo('type', 'type', 'id');
}
}
```
The notification method is a polymorphic relationship that will return the correct model based on the type column of the settings table.
In order to tell Laravel which model to use for each type we need to add a morphMap to the `AppServiceProvider` class.
```php
<?php
namespace App\Providers;
class AppServiceProvider extends ServiceProvider
{
public function boot()
{
Relation::morphMap([
'email' => EmailSetting::class,
'slack' => SlackSetting::class,
]);
}
}
```
The `morphMap` method will map the email and slack types to the `EmailSetting` and `SlackSetting` classes respectively.
Now when you retrieve a setting from the database you can access the correct model based on the type column.
```php
$setting = Setting::find(1);
if($setting->type === 'email') {
$email = $setting->notification->getEmail();
}
if($setting->type === 'slack') {
$channel = $setting->notification->getChannel();
$token = $setting->notification->getToken();
}
```
But with this you will get an error when you try to use `->notification` as it will try to access the the `email_settings` table that doesn't exist.
To fix this you need to tell the `EmailSetting` model what table to use by using the method getTable.
```php
public function getTable()
{
return 'settings';
}
```
This will tell the `EmailSetting` model to use the settings table instead of the `email_settings` table and return the right model for you when you use the notification settings.
This is how you can use polymorphic models by type in Laravel to handle different types of settings in a single database table. This can be useful when you have different types of settings that you need to handle in your application. | paulund |
1,870,103 | 5 SEO Tips to Grow Your Small Business: Is SEO Worth it for Small Businesses? | In the fast-paced digital era, small businesses often find themselves struggling to stand out in the... | 0 | 2024-05-30T08:49:50 | https://dev.to/josh_peck_123/5-seo-tips-to-grow-your-small-business-is-seo-worth-it-for-small-businesses-4j6k | google, seo, news, data |

In the fast-paced digital era, small businesses often find themselves struggling to stand out in the vast online marketplace. However, with the right SEO strategies, they can not only survive but thrive amidst fierce competition. This article presents five indispensable SEO tips tailored to fuel the growth of small businesses, while addressing the pertinent question: Is SEO truly worth it for small businesses?
## Conduct Targeted Keyword Research
Begin your SEO journey by delving into targeted keyword research. Identify key phrases such as "grow your small business" and "SEO tips" that resonate with your audience and reflect your business offerings. Tools like Google Keyword Planner are invaluable in uncovering relevant keywords with decent search volumes and manageable competition. By integrating these keywords strategically into your website content, you can enhance your visibility in search engine results pages (SERPs) and attract potential customers actively seeking your products or services.
## Optimize Your Website to Foster Growth
Your website serves as the digital storefront of your small business. Make sure it's optimized for both search engines and users alike. Prioritize mobile responsiveness to cater to the growing number of mobile users. A mobile-friendly website not only improves user experience but also earns favor with search engines, potentially boosting your rankings. Streamline your website's navigation, enhance page loading speed, and optimize meta tags and descriptions with relevant keywords to improve search engine crawlability and user engagement.
## Invest in High-Quality, Relevant Content
Content remains king in the realm of SEO. Craft high-quality, relevant content that addresses the needs and interests of your target audience. Whether through blog posts, product descriptions, or informative articles, aim to provide value and establish your authority in your niche. Seamlessly integrate your target keywords into your content while maintaining a natural flow. Regularly updating your website with fresh, informative content not only keeps visitors engaged but also signals to search engines that your website is active and deserving of higher rankings.
## Leverage Google My Business for Local Visibility
For small businesses targeting local customers, optimizing your Google My Business (GMB) profile is paramount. Ensure that your GMB listing is complete and accurate, including essential information such as your business address, phone number, and operating hours. Encourage satisfied customers to leave positive reviews, as they not only enhance your reputation but also improve your local SEO rankings. Regularly update your GMB profile with new photos, posts, and relevant information to maintain visibility and attract local customers actively searching for your products or services.
## Foster Quality Backlinks to Boost Authority
Building quality backlinks from reputable websites is essential for enhancing your small business's authority and credibility in the eyes of search engines. Focus on earning backlinks from authoritative sources within your industry or niche. Engage in guest blogging, forge partnerships with influencers, or participate in industry-related forums and communities to acquire valuable backlinks organically. Avoid dubious link-building practices that could potentially harm your website's reputation and incur penalties from search engines.
In conclusion, the answer to whether [SEO is worth it for small businesses](https://digiown.agency/is-seo-worth-it-for-small-business/
) is a resounding yes. By implementing these five SEO tips tailored specifically for small businesses, you can effectively grow your online presence, attract more customers, and achieve sustainable business growth. Embrace SEO as an indispensable tool in your digital marketing arsenal, and watch as your small business thrives in the competitive online landscape. | josh_peck_123 |
1,870,101 | How Geojam Token Works? | In the dynamic world of social music apps, GeoJam stands out as a unique platform that is popularly... | 0 | 2024-05-30T08:49:14 | https://dev.to/geojam/how-geojam-token-works-45oe | geojam, geojamtoken, crypto, token | In the dynamic world of social music apps, GeoJam stands out as a unique platform that is popularly known as a social media music-streaming app. It seamlessly blends gamification with music streaming for fans and creators.
At the heart of this innovative ecosystem lies the GeoJam Token, that is, $JAM. It is a digital currency that drives engagement, rewards users, and fosters community interaction.
In this blog, we’ll be delving into what Geojam tokens are and how they work. Let’s have a look!
## What are Geojam Tokens?
[Geojam tokens](https://www.geojam.xyz/) are the native digital currency of the Geojam platform. These are designed to incentivize user participation and reward engagement. Built on blockchain technology, these tokens serve as a medium of exchange within the Geojam ecosystem, which offers users a wide variety of benefits and opportunities.
Whether it's discovering new music, sharing favorite songs with friends, engaging in challenges, or participating in community events, users have various opportunities to earn Geojam Tokens. This incentivizes active participation and encourages users to explore everything that the platform has to offer.
## The Working of Geojam Tokens
- **Engagement on the Platform**
Users engage with the Geojam platform by discovering new music, creating playlists, sharing content, and participating in community activities.
- **Collection of Jams**
As users interact with the platform, they earn virtual currency called Jams. These Jams are earned based on various actions, such as listening to songs, creating playlists, engaging with content, and participating in challenges.
- **Currency of Geojam**
$JAM serves as the native currency of the Geojam platform. They represent a unit of value within the ecosystem and can be used to unlock exclusive rewards and features.
- **Incentives and Rewards**
Users are incentivized to collect Jams and unlock exclusive rewards in return. These rewards may include concert tickets, merchandise, meet-and-greets with artists, and more.
- **Redemption of Rewards**
Users can redeem their collected $JAM tokens for rewards offered within the Geojam platform. Rewards may vary and could include both virtual and real-world experiences, enhancing the user's overall engagement and enjoyment of the platform.
### Wrapping Up
Undoubtedly, **Geojam tokens** are more than just a digital currency; they are the lifeblood of this platform, which drives engagement, fosters community, and even rewards users for their contributions. Moreover, these are paving the way for a new era of social music interaction.
So, whether you're a music lover looking to discover new tunes or an individual eager to connect with like-minded enthusiasts, Geojam Tokens offer something for everyone.
Join the revolution today and start earning your tokens while enjoying the music you love!
Official Website: [https://www.geojam.xyz/](https://www.geojam.xyz/)
Download App Now -
Android: [https://play.google.com/store/apps/details?id=app.geojam.dev](https://play.google.com/store/apps/details?id=app.geojam.dev)
IOS: [https://apps.apple.com/us/app/geojam-unfiltered-thoughts/id1628371656](https://apps.apple.com/us/app/geojam-unfiltered-thoughts/id1628371656)
| geojam |
1,856,875 | Design Patterns(DP) | Java'da "DP" genellikle Design Patterns (Tasarım Kalıpları) olarak anılır. Tasarım kalıpları, yazılım... | 0 | 2024-05-17T19:57:12 | https://dev.to/mustafacam/design-patternsdp-3l4f | Java'da "DP" genellikle **Design Patterns** (Tasarım Kalıpları) olarak anılır. Tasarım kalıpları, yazılım geliştirme sürecinde karşılaşılan yaygın problemlere çözüm sunan, tekrar kullanılabilir tasarım şablonlarıdır. Bu kalıplar, yazılımın modüler, esnek ve sürdürülebilir olmasını sağlamak için kullanılır.
Tasarım kalıpları üç ana kategoriye ayrılır:
1. **Creational Patterns (Yaratıcı Kalıplar)**: Nesne yaratma süreçlerini yönetir ve bu süreci sistemin geri kalanından bağımsız hale getirir. Örnekler: Singleton, Factory, Builder, Prototype.
2. **Structural Patterns (Yapısal Kalıplar)**: Sınıflar arası ilişkileri düzenleyerek daha büyük yapılar oluşturmayı kolaylaştırır. Örnekler: Adapter, Composite, Proxy, Decorator.
3. **Behavioral Patterns (Davranışsal Kalıplar)**: Nesneler arası iletişimi ve sorumlulukları düzenler. Örnekler: Observer, Strategy, Command, Iterator.
Bu kalıplar, yazılım mühendislerinin karşılaştığı ortak sorunlara karşı kanıtlanmış çözümler sunar ve kodun yeniden kullanılabilirliğini ve anlaşılabilirliğini artırır. Ayrıca, tasarım kalıpları, yazılımın bakımını ve gelecekteki genişletmelerini kolaylaştırır¹².
Örneğin, **Adapter Pattern** (Adaptör Kalıbı), bir sınıfın arayüzünü, başka bir sınıfın beklediği arayüze dönüştürerek, uyumsuz arayüzler sebebiyle birlikte çalışamayacak sınıfların bir arada çalışmasını sağlar². Bu, farklı sistemlerin veya kütüphanelerin birlikte çalışabilmesi için oldukça yararlıdır.
Java'da tasarım kalıplarının kullanımı, yazılımın kalitesini ve sürdürülebilirliğini artırırken, geliştirme sürecini de hızlandırır. Bu nedenle, Java geliştiricileri için tasarım kalıplarını bilmek ve doğru yerde uygulayabilmek önemlidir.
Kaynak: Bing ile konuşma, 17.05.2024
(1) Java’da Nesne Yönelimli Programlama (Object Oriented Programming) Nedir .... https://medium.com/@duyguozdugan/javada-nesne-y%C3%B6nelimli-programlama-object-oriented-programming-nedir-abb0d465e913.
(2) Tasarım Kalıpları: Adapter Kalıbı - Java Günlüğüm. http://www.javaturk.org/tasarim-kaliplari-adapter-kalibi/.
(3) Java’da Operatörler – Yazılım Mutfağı. http://www.yazilimmutfagi.com/index.php/2013/04/07/javada-operatorler/. | mustafacam | |
1,870,090 | The Decorator Pattern in Modern C# | The Decorator design pattern allows software developers to extend the functionalities of a component... | 27,554 | 2024-05-30T08:48:27 | https://blog.postsharp.net/decorator-pattern | dotnet, dotnetcore, csharp, designpatterns | The [Decorator design pattern](https://blog.postsharp.net/decorator-pattern) allows software developers to extend the functionalities of a component without altering its code. This article explores the primary techniques for implementing the decorator pattern in modern .NET while adhering to the Single Responsibility Principle (SRP) and avoiding boilerplate code.
## When to use a Decorator pattern in C#
The Decorator pattern is useful when you want to add behavior to an existing component but either _cannot_ or _do not want_ to modify the source code. This is typically done to adhere to the single responsibility principle (SRP) to keep our code clean, readable, and maintainable.
Some real-world use cases for the decorator design pattern include:
* **Execution policies**, such as exception handling, retrying, or caching, which help improve the performance and reliability of your apps.
* **Observability**, for instance, by adding logging to all calls to an external component.
* **User Interface**, like adding a scrollbar to a large textbox. Another example is the [Adorner](https://learn.microsoft.com/en-us/dotnet/desktop/wpf/controls/adorners-overview) concept in WPF.
* **Streams**, with features such as buffering, encryption, or compression.
## What is the Decorator pattern
A Decorator is essentially a wrapper that implements the same contract as the entity it’s wrapping. We are intentionally using the vague term _contract_. As we will see in this article, it can mean two things: a C# interface if we implement a _type decorator_, or a method signature if we implement a _method decorator_. In both cases, the caller does not need to know that it is talking to a decorator rather than the final implementation. The pattern is recursive: we can add a decorator to a decorator, creating a chain of responsibility.
For instance, instead of just calling an unreliable service, we may want to retry a couple of times upon transient failure, and finally assign a unique ID to each exception, log it, and wrap the exception. We can represent the chain as follows:

In this article, we will explore two kinds of decorators: [type decorators](#type-decorator) and [method decorators](#method-decorator).
## The classic Type Decorator pattern
The classic _type decorator_ pattern is a purely object-oriented variant of the decorator pattern that relies on type _interfaces_.
To illustrate the idea, let’s say we want to build a simple messaging app. We’d need a component that handles sending and receiving messages. This component implements the `IMessenger` interface and is implemented in a third-party library.
```csharp
public interface IMessenger
{
void Send( Message message );
public Message Receive();
}
```
We are using the `IMessenger` service from a client class:
```csharp
public class Client( IMessenger messenger )
{
public void Greet()
{
messenger.Send( new Message( "Hello, world" ) );
Console.WriteLine( "--> " + messenger.Receive().Text );
}
}
```
We are instantiating the `Client` class from `Program.cs`:
```csharp
var messenger = new Messenger();
var client = new Client( messenger );
client.Greet();
```
That all works nicely on our development environment. However, as soon as we move things to production, we realize that the messenger service is unreliable and occasionally causes our app to crash. Since we don’t own the source code of the `IMessenger` implementation, we cannot simply add the logic we need to each method.
How does the [Decorator pattern](https://blog.postsharp.net/decorator-pattern) help us tackle this problem?
Take a look at our design using the type decorator pattern in the class diagram below. Along with the decorators for error handling and retrying, we’ve introduced the `MessengerDecorator` abstract class that holds the wrapped `IMessenger` object, making it easier to implement individual decorators.
Here is the implementation of the `ExceptionReportingMessenger` class:
```csharp
public class ExceptionReportingMessenger : MessengerDecorator
{
private readonly IExceptionReportingService _reportingService;
public ExceptionReportingMessenger(
IMessenger underlying,
IExceptionReportingService reportingService ) :
base( underlying )
{
this._reportingService = reportingService;
}
public override void Send( Message message )
{
try
{
this.Underlying.Send( message );
}
catch ( Exception e )
{
this._reportingService.ReportException(
"Failed to send message", e );
throw;
}
}
public override Message Receive()
{
try
{
return this.Underlying.Receive();
}
catch ( Exception e )
{
this._reportingService.ReportException(
"Failed to receive message", e );
throw;
}
}
}
```
The `RetryingMessenger` messenger is very similar.
Now, instead of passing the original `Messenger` component to the `Client` class, we are wrapping the `Messenger` into `RetryingMessenger`, then into an `ExceptionReportingMessenger`. This is finally the `ExceptionReportingMessenger` that we pass to the `Client`
```
var originalMessenger = new Messenger();
var retryingMessenger = new ExceptionReportingMessenger(
new RetryingMessenger( originalMessenger ),
new ExceptionReportingService() );
var clientUsingDecorator = new Client( retryingMessenger );
clientUsingDecorator.Greet();
```
When the program calls `Client.Greet`, the control flow is the following:

## Using type decorators with dependency injection
Obviously, in any modern C# application, you would not instantiate the components manually as in the examples above, but you would let dependency injection do the job.
If you are using .NET Core’s [IServiceCollection](https://learn.microsoft.com/en-us/dotnet/core/extensions/dependency-injection), there is a nice library called [Scrutor](https://github.com/khellang/Scrutor#decoration) that can easily wrap a service with a decorator.
For example, this is how to apply the decorators by using Scrutor. Note the calls to the `Decorate` methods: they are defined by Scrutor.
```csharp
var services = new ServiceCollection()
.AddSingleton<IExceptionReportingService, ExceptionReportingService>()
.AddSingleton<IMessenger, Messenger>()
.AddSingleton<Client>()
.Decorate<IMessenger, RetryingMessenger>()
.Decorate<IMessenger, ExceptionReportingMessenger>()
.BuildServiceProvider();
var client = services.GetRequiredService<Client>();
client.Greet();
```
Many dependency injection frameworks have built-in support for decorators. See for instance how [Autofac handles this problem](https://autofac.readthedocs.io/en/latest/advanced/adapters-decorators.html#decorators),
## The Abstract Type Decorator pattern
At first glance, our solution design seems perfect. But when we dig into the implementation of the decorators, we notice that the exception handling would be duplicated across other methods. Here, we’re violating the Don’t Repeat Yourself principle. The code is now harder to maintain than before because any change to the error handling must be made in each method of `ExceptionReportingMessenger` and any decorator of another type decorator.
We will now see how to improve the Type Decorator pattern to make the decorator logic more reusable.
Let’s use the word _policy_ to designate the logic that we wrap a method call with. Policies can be abstracted away and encapsulated in a reusable way. In the following diagram, we have represented policies as an interface.
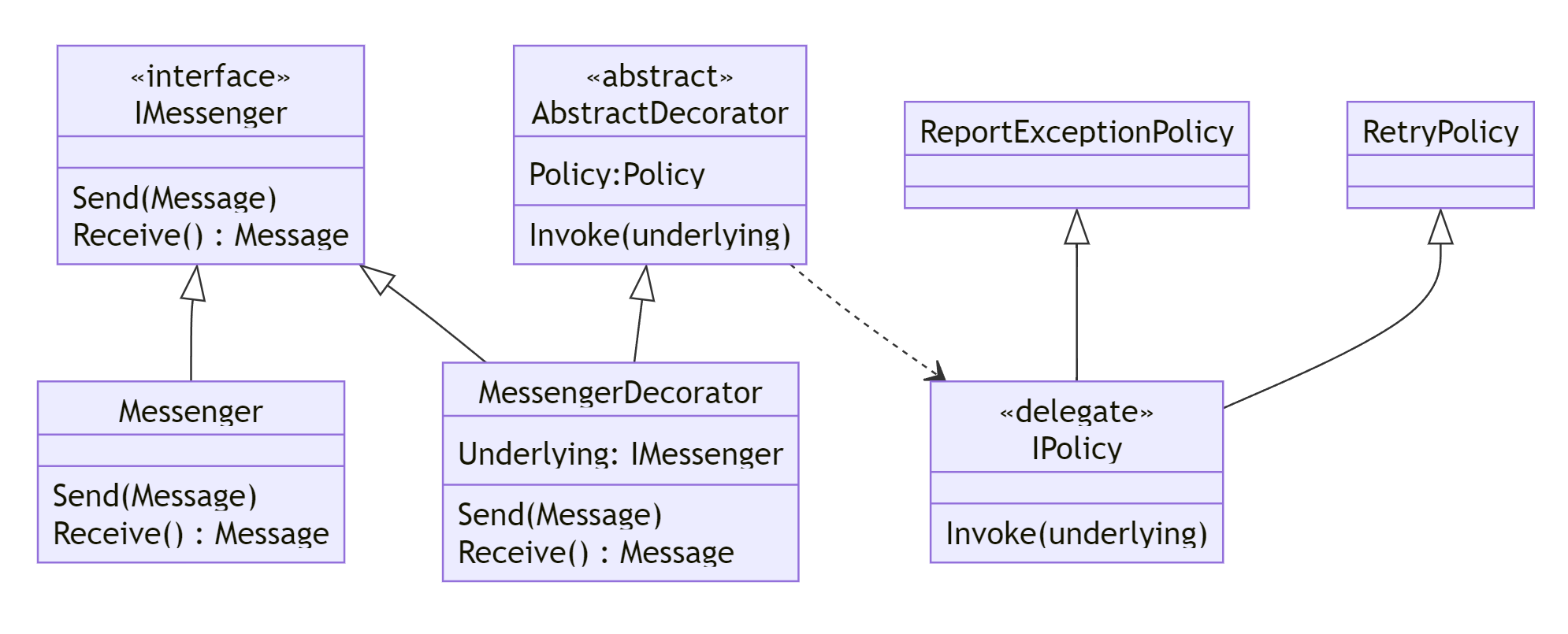
Here is the exception-reporting policy:
```csharp
public class ReportExceptionPolicy(
IExceptionReportingService reportingService ) : IPolicy
{
public T Invoke<T>( Func<T> func )
{
try
{
return func();
}
catch ( Exception e )
{
reportingService.ReportException(
"Failed to send message", e );
throw;
}
}
}
```
We then define an `AbstractDecorator`, an abstract class that can be used as a base for any decorator:
```csharp
public abstract class AbstractDecorator( IPolicy policy )
{
protected T Invoke<T>( Func<T> func ) => policy.Invoke( func );
protected void Invoke( Action action )
=> policy.Invoke<object?>(
() =>
{
action();
return null!;
} );
}
```
In practice, you’ll also need to implement `async` versions of the `Invoke` methods in both `IPolicy` and `AbstractDecorators`.
With this setup, all the `MessengerDecorator` has to do is wrap method implementations with calls to the `Invoke` methods of `AbstractDecorator`:
```csharp
public class MessengerDecorator( IMessenger underlying, IPolicy policy ) :
AbstractDecorator( policy ), IMessenger
{
public void Send( Message message ) =>
this.Invoke( () => underlying.Send( message ) );
public Message Receive() => this.Invoke( underlying.Receive );
}
```
Note that this decorator is now abstracted from any policy. The only repetitive code is now in calling the `Invoke` method.
Finally, we wire the service collection using Scrutor’s `Decorate` method by supplying one of the `Policies` to the `MessengerDecorator` class:
```csharp
var services = new ServiceCollection()
.AddSingleton<IExceptionReportingService, ExceptionReportingService>()
.AddSingleton<IMessenger, Messenger>()
.Decorate<IMessenger>(
( inner, _ ) => new MessengerDecorator(
inner,
new RetryPolicy() ) )
.Decorate<IMessenger>(
( inner, serviceProvider ) => new MessengerDecorator(
inner,
new ReportExceptionPolicy( serviceProvider.GetRequiredService<IExceptionReportingService>() ) ) )
.BuildServiceProvider();
var client = services.GetRequiredService<Client>();
client.Greet();
```
We’ve now consolidated error-handling logic in one place.
The control flow now becomes:

## Generating Type Decorators automatically
There’s still repetitive code in the `MessengerDecorator` class. Arguably, `MessengerDecorator` is _purely_ boilerplate and should ideally be removed from your codebase. There are two ways to generate this class:
* At _run time_, using an approach known as _dynamic proxies_, or
* At _compile time_, using source generators.
In this article, we will only explore the first solution.
The principle behind dynamic proxies is to generate the decorator class at run time, when the application initializes. Among the few libraries that implement this feature, the most popular is [Castle DynamicProxy](https://github.com/castleproject/Core/blob/master/docs/dynamicproxy.md). The concept of _policy_ developed earlier maps to Castle’s `IInterceptor` interface. Here is the implementation of the retry policy as a Castle interceptor. Notice the similarity to the `RetryPolicy` class in the example above.
```csharp
internal class RetryInterceptor(
int retryAttempts = 3, double retryDelay = 1000 )
: IInterceptor
{
public void Intercept( IInvocation invocation )
{
for ( var i = 0;; i++ )
{
try
{
invocation.Proceed();
}
catch ( Exception ) when ( i < retryAttempts )
{
var delay = retryDelay * Math.Pow( 2, i );
Console.WriteLine(
"Failed to receive message. " +
$"Retrying in {delay / 1000} seconds... " +
$"({i + 1}/{retryAttempts})" );
Thread.Sleep( (int) delay );
}
}
}
}
```
As promised, there’s no longer a need for any decorator code since Castle has implemented it.
We can now proceed to the startup sequence of our application. We will need a `ProxyGenerator`:
```csharp
var proxyGenerator = new ProxyGenerator();
```
We can now use the `proxyGenerator.CreateInterfaceProxyWithTarget` method to create the proxy class, and supply the two interceptors implementing our policies:
```csharp
var services = new ServiceCollection()
.AddSingleton<IExceptionReportingService, ExceptionReportingService>()
.AddSingleton<IMessenger, Messenger>()
.Decorate<IMessenger>(
( inner, _ ) => new MessengerDecorator(
inner,
new RetryPolicy() ) )
.Decorate<IMessenger>(
( inner, serviceProvider ) => new MessengerDecorator(
inner,
new ReportExceptionPolicy( serviceProvider.GetRequiredService<IExceptionReportingService>() ) ) )
.BuildServiceProvider();
var client = services.GetRequiredService<Client>();
client.Greet();
```
## The Method Decorator Pattern
So far, we’ve discussed techniques that help replace a type with another type implementing the same interface, but providing additional services. The principal benefits of this approach are:
* It’s purely object-oriented,
* It works with code you don’t own,
* It’s composable at run time.
However, there’s a significant drawback: it only works if you can inject yourself into the communication between the caller and the service – typically through an interface, although the same could be achieved using `abstract` or `virtual` methods. If you appreciate the benefits of being able to decorate a method with any behavior, it’s a pity to have to limit yourself so much. Even worse: you may be tempted to split your application into more smaller components to benefit from decorators. This is a case of _framework dictatorship_ and it should be avoided.
An alternative to the type decorator pattern is the _method decorator_. As its name suggests, method decorators target a single method and not the entire type. Method decorators are commonly used in dynamic languages such as [Python](https://www.programiz.com/python-programming/decorator). They aren’t directly supported by C#, but some toolkits like [Metalama](https://www.postsharp.net/metalama) make it possible.
The idea of C# method decorators is to move the logic of the policy to a special kind of [custom attribute](https://learn.microsoft.com/en-us/dotnet/standard/attributes/) called an _aspect_, which could be compared to code templates. Unlike other custom attributes, aspects are applied to the code during compilation. Since this approach is compile-time, we’re not limited to the limitations of the .NET runtime, namely we’re not limited to virtual or interface methods, but we can intercept anything (including static private fields, if you ask).
Here is the Metalama version of the retry policy:
```csharp
internal class RetryAttribute : OverrideMethodAspect
{
public int Attempts { get; set; } = 3;
public double Delay { get; set; } = 1000;
public override dynamic? OverrideMethod()
{
for ( var i = 0;; i++ )
{
try
{
return meta.Proceed();
}
catch ( Exception e ) when ( i < this.Attempts )
{
var delay = this.Delay * Math.Pow( 2, i + 1 );
Console.WriteLine(
$"Method {meta.Target.Method.DeclaringType.Name}.{meta.Target.Method} " +
$"has failed on {e.GetType().Name}. Retrying in {delay / 1000} seconds. " + ({i + 1}/{this.Attempts})" );
Thread.Sleep( (int) delay );
}
}
}
// TODO: Implement OverrideMethodAsync and call Task.Delay instead of Thread.Sleep.
}
```
To add the policy to a method, apply it as a custom attribute:
```csharp
public partial class Messenger
{
private int _receiveCount;
private int _sendCount;
[Retry]
[ReportExceptions]
public void Send( Message message )
{
Console.WriteLine( "Sending message..." );
// Simulate unreliable message sending
if ( ++this._sendCount % 3 == 0 )
{
Console.WriteLine( "Message sent successfully." );
}
else
{
throw new IOException( "Failed to send message." );
}
}
[Retry]
[ReportExceptions]
public Message Receive()
{
Console.WriteLine( "Receiving message..." );
// Simulate unreliable message receiving
if ( ++this._receiveCount % 3 == 0 )
{
Console.WriteLine( "Message received successfully." );
return new Message( "Hi!" );
}
throw new IOException( "Failed to receive message." );
}
}
```
To further improve maintainability, toolkits like Metalama facilitate the bulk application of aspects, eliminating the need for developers to manually specify where each aspect should be used. For instance, we can stipulate that all public methods within a specific namespace should have exception reporting. Consequently, when new methods are added to this namespace, the exception-reporting aspect is automatically applied. This approach not only enhances the readability and maintainability of the codebase but also simplifies scalability. In Metalama, this is achieved using fabrics. The following example demonstrates how to add exception reporting to all public methods in a project:
```csharp
internal class AddExceptionReportingToPublicMethodsFabric : ProjectFabric
{
public override void AmendProject( IProjectAmender amender )
{
amender.Outbound.SelectMany( t => t.AllTypes )
.SelectMany( t => t.Methods )
.Where( m => m.Accessibility == Accessibility.Public )
.AddAspectIfEligible<ReportExceptionsAttribute>();
}
}
```
## Summary
Decorators are an effective way to maintain clean code and uphold the single responsibility principle. Opt for type decorators when you don’t own the code that you wish to enhance with new behaviors, or when you need to dynamically add behaviors at runtime. Use method decorators (aspect-oriented) when you own the source code and aim to adhere to the Single Responsibility Principle.
---
Discover Metalama, the leading [code generation and validation toolkit](https://www.postsharp.net/metalama) for C#
* **Write and maintain less code** by eliminating boilerplate, generating it dynamically during compilation, typically reducing code lines and bugs by 15%.
* **Validate your codebase against your own rules in real-time** to enforce adherence to your architecture, patterns, and conventions. No need to wait for code reviews.
* **Excel with large, complex, or old codebases.** Metalama does not require you to change your architecture. Beyond getting started, it's at scale that it really shines.
| gfraiteur |
1,870,100 | limosixity asiatransport | "Khám phá Dịch vụ Thuê Xe Limo 9 chỗ tại Hà Nội: Sự Sang Trọng và Tiện Nghi" Website:... | 0 | 2024-05-30T08:48:00 | https://dev.to/limosixity/limosixity-asiatransport-4dni |
"Khám phá Dịch vụ Thuê Xe Limo 9 chỗ tại Hà Nội: Sự Sang Trọng và Tiện Nghi"
Website: https://www.asiatransport.net/thue-xe-limo-16-18-cho
Phone: 0902035595
Address: Hanoi Office: 80B Nguyen Van Cu Street, Long Bien District
https://community.tableau.com/s/profile/0058b00000IZZF4
https://www.metooo.io/u/665839b185817f224390a607
https://www.proarti.fr/account/limosixity
https://www.titantalk.com/members/limosixity.375805/#about
https://my.desktopnexus.com/limosixity/
https://www.pearltrees.com/limosixity
https://vimeo.com/user220402955
https://peatix.com/user/22432375/view
https://www.pling.com/u/limosixity/
https://www.fimfiction.net/user/748051/limosixity
https://makersplace.com/transportvietnam839/about
http://idea.informer.com/users/limosixity/?what=personal
https://dev.to/limosixity
https://able2know.org/user/limosixity/
https://vnxf.vn/members/limosixity.81678/#about
https://data.world/limosixity
https://www.fitday.com/fitness/forums/members/limosixity.html
https://wmart.kz/forum/user/163648/
https://www.kniterate.com/community/users/limosixity/
https://camp-fire.jp/profile/limosixity
https://unsplash.com/@limosixity
https://newspicks.com/user/10323124
https://wperp.com/users/limosixity/
https://linkmix.co/23499698
https://www.cineplayers.com/limosixity
https://profile.ameba.jp/ameba/limosixity/
https://www.noteflight.com/profile/2b8a64cbfd04ef05d785a5c57fae517bff1fa495
https://guides.co/a/limosixity-asiatransport
https://wakelet.com/@limosixityasiatransport62346
https://www.silverstripe.org/ForumMemberProfile/show/152988
https://disqus.com/by/limosixity/about/
https://pinshape.com/users/4469322-limosixity#designs-tab-open
https://www.storeboard.com/limosixityasiatransport
https://dreevoo.com/profile.php?pid=643067
https://lab.quickbox.io/vilimosixity
https://www.funddreamer.com/users/limosixity-asiatransport
https://app.talkshoe.com/user/limosixity
http://buildolution.com/UserProfile/tabid/131/userId/406024/Default.aspx
https://www.cakeresume.com/me/limosixity
https://www.patreon.com/limosixity
https://kumu.io/limosixity/sandbox#untitled-map
https://leetcode.com/u/limosixity/
https://linktr.ee/limosixity
https://forum.dmec.vn/index.php?members/limosixity.61319/
http://hawkee.com/profile/6980764/
https://visual.ly/users/transportvietnam837
https://www.nintendo-master.com/profil/limosixity
https://piczel.tv/watch/limosixity
https://gifyu.com/limosixity
https://hackerone.com/dklimosixity?type=user
https://btlimosixity.notepin.co/
https://www.spoiledmaltese.com/members/limosixity.170130/#about
https://muckrack.com/limosixity-asiatransport
https://doodleordie.com/profile/limosixity
https://socialtrain.stage.lithium.com/t5/user/viewprofilepage/user-id/65793
https://zzb.bz/0Y9fa
https://slides.com/limosixity
https://www.exchangle.com/limosixity
https://bandori.party/user/201707/limosixity/
https://os.mbed.com/users/limosixity/
| limosixity | |
1,870,099 | 24/7 Chicago Plumbers - Get Your Home's Plumbing Working Again - Mikes Plumbing Chicago | Is your Chicago home experiencing a plumbing nightmare? A clogged drain, a leaky faucet, or a broken... | 0 | 2024-05-30T08:45:02 | https://dev.to/mikes_plumbing_07429ffb5a/247-chicago-plumbers-get-your-homes-plumbing-working-again-mikes-plumbing-chicago-15bl | plumber | Is your Chicago home experiencing a plumbing nightmare? A clogged drain, a leaky faucet, or a broken water heater can bring your day to a screeching halt. But don't panic! Mike's Plumbing Chicago is here to save the day. We're your trusted plumbers serving the entire Chicagoland area, including North Shore, Glencoe, Skokie, Niles, Wilmette, Evanston, and Glenview. Our licensed and insured plumbers have the skills and experience to handle any plumbing problem, big or small. Whether it's a leaky faucet, a clogged drain, a running toilet, a burst pipe, or a faulty water heater, we've got you covered. We also specialize in drain cleaning, sewer repair, and garbage disposal services. Don't let a plumbing problem turn into a major headache. Call Mike's Plumbing Chicago today at (773) 875-8833 or visit us at https://mikesplumbingchicago.com/ for a free estimate.
https://www.youtube.com/watch?v=8TvY3uVl1GQ | mikes_plumbing_07429ffb5a |
1,870,098 | hans123 Intraday Breakthrough Strategy | Preface The "HANS123" strategy was first mainly applied to the foreign exchange market.... | 0 | 2024-05-30T08:42:27 | https://dev.to/fmzquant/hans123-intraday-breakthrough-strategy-j13 | strategy, intraday, trading, cryptocurrency | ## Preface
The "HANS123" strategy was first mainly applied to the foreign exchange market. Its trading method is relatively simple and belongs to the trend breakthrough system. This trading method can enter the market as soon as the trend is formed, so it is favored by many traders. So far, HANS123 has expanded a lot of versions, let's understand and deploy the HANS123 strategy together.
## Principle of Strategy
Some people believe that the opening of the market in the morning is the time when the market has the greatest divergence. After about 30 minutes, the market has fully digested all kinds of overnight information, and the price trend will tend to be rational and return to normal. In other words: the market trend in the first 30 minutes or so basically constitutes the overall trading pattern today.
- Upper rail: the highest price within 30 minutes of opening
- Lower rail: the lowest price within 30 minutes of opening
The relative high and low points generated at this time form the effective high and low points in the "Dow Theory", and the HANS123 strategy is the trading logic established by this. In the domestic futures market, the market opens at 09:00 in the morning, and at 09:30 you can judge whether it is long or short today. When the price breaks through the high point upward, the price will easily continue to rise; when the price breaks through the low point downward, the price will easily continue to fall.
- Long position opening: There is currently no holding position, and the price breaks above the upper rail
- Short position opening: There is currently no holding position, and the price breaks below the lower rail
Although the breakthrough strategy can enter the market as soon as the trend is formed. But this advantage is also a double-edged sword. As a result of the sensitive entry, the price breakthrough failed. So it is necessary to set a stop loss. At the same time, in order to achieve the strategy logic of winning and losing, take profit must be set.
- Long position stop loss: the current long position has reached the loss amount
- Short position stop loss: the current short position has reached the loss amount
- Take profit for long positions, hold long positions and reach the profit amount
- Take profit for short positions, hold short positions and reach the profit amount
## Strategy writing
Open in turn: fmz.com website> Login > Dashboard > Strategy Library > New Strategy > Click the drop-down menu in the upper right corner to select the Python language and start writing the strategy. Pay attention to the comments in the code below.
## Step 1: Write the strategy framework
```
# Strategy main function
def onTick():
pass
# Program entry
def main():
while True: # enter infinite loop mode
onTick() # execute strategy main function
Sleep(1000) # Sleep for 1 second
```
Writing a strategy framework, this has been learned in the previous chapter, one is the onTick function, and the other is the main function, in which the onTick function is executed in an endless loop in the main function.
## Step 2: Define global variables
```
up_line = 0 # upper rail
down_line = 0 # lower rail
trade_count = 0 # Number of transactions on the day
```
Because the upper and lower rails are only counted at the time of 09:30, and no statistics are done in the rest of the time, we need to write these two variables outside the loop. In addition, in order to limit the number of transactions in a day trading, the trade_count variable is also written outside the loop. Before using these two global variables in the main function of the onTick strategy, you need to use the global keyword to reference.
## Step 3: Get the data
```
exchange.SetContractType("rb888") # Subscribe to futures varieties
bar_arr = _C(exchange.GetRecords, PERIOD_M1) # Get 1-minute K line array
current_close = bar_arr[-1]['Close'] # Get the latest price
if len(bar_arr) <50: # If less than 50 k line bars
return # Return to continue waiting for data
```
To obtain data, first use the SetContractType function in the FMZ platform API to subscribe to futures varieties, and then use the GetRecords function to obtain the K-line array. You can also pass in the K-line array specifying PERIOD_M11 minutes when using the GetRecords function.
The next step is to obtain the latest price, which is used to determine the position relationship between the current price and the upper and lower rails. At the same time, when placing an order using the Buy or Sell function, you need to pass in the specified price. In addition, don't forget to filter the number of k line bars, because if the number of k line bars is too few, there will be an error that cannot be calculated.
## Step 4: Processing time function
```
def current_time():
current_time = bar_arr[-1]['Time'] # Get current K-line timestamp
time_local = time.localtime(current_time / 1000) # Processing timestamp
hour = time.strftime("%H", time_local) # Format the timestamp and get the hour
minute = time.strftime("%M", time_local) # Format the timestamp and get the minute
if len(minute) == 1:
minute = "0" + minute
return int(hour + minute)
```
When calculating the upper and lower rails and placing orders, it is necessary to judge whether the current time meets the trading time specified by us, so in order to facilitate the judgment, we need to deal with the specific hours and minutes of the current K-line.
## Step 5: Calculate the upper and lower rails
```
global up_line, down_line, trade_count # Introduce global variables
current_time = current_time() # processing time
if current_time == 930: # If the latest K-line time is 09:30
up_line = TA.Highest(bar_arr, 30,'High') + count # The highest price of the first 30 k line bars
down_line = TA.Lowest(bar_arr, 30,'Low')-count # The lowest price of the first 30 ke line bars
trade_count = 0 # Reset the number of transactions to 0
```
## Step 6: Obtain positions
```
position_arr = _C(exchange.GetPosition) # Get position array
if len(position_arr) > 0: # If the position array length is greater than 0
position_arr = position_arr[0] # Get position dictionary data
if position_arr['ContractType'] =='rb888': # If the position symbol is equal to the subscription symbol
if position_arr['Type']% 2 == 0: # If it is a long position
position = position_arr['Amount'] # The number of assigned positions is a positive number
else:
position = -position_arr['Amount'] # Assign a negative number of positions
profit = position_arr['Profit'] # Get position profit and loss
else:
position = 0 # The number of assigned positions is 0
profit = 0 # Assign position profit and loss to 0
```
Position status involves strategy logic. Our first ten lessons have always used virtual holding positions, but in a real trading environment, it is best to use the GetPosition function to obtain real position information, including: position direction, position profit and loss, number of positions, etc.
## Step 7: Place an order
```
# If it is close to market closing or reach taking profit and stopping loss
if current_time > 1450 or profit > stop * 3 or profit < -stop:
if position > 0: # If holding a long position
exchange.SetDirection("closebuy") # Set transaction direction and type
exchange.Sell(current_close-1, 1) # Close long order
elif position <0: # If holding an empty order
exchange.SetDirection("closesell") # Set transaction direction and type
exchange.Buy(current_close + 1, 1) # Close short order
# If there is no current position, and it is less than the specified number of transactions, and within the specified trading time
if position == 0 and trade_count < 2 and 930 < current_time < 1450:
if current_close > up_line: # If the price is greater than the upper line
exchange.SetDirection("buy") # Set transaction direction and type
exchange.Buy(current_close + 1, 1) # Open long order
trade_count = trade_count + 1 # Increase the number of transactions
elif current_close < down_line: # If the price is less than the lower line
exchange.SetDirection("sell") # Set transaction direction and type
exchange.Sell(current_close-1, 1) # Open a short order
trade_count = trade_count + 1 # Increase the number of transactions
```
In order to avoid logic errors in the strategy, it is best to write the closing position logic before the opening position logic. In this strategy, when opening a position, first determine the current position status, whether it is within the specified trading time, and then determine the relationship between the current price and the upper and lower rails. To close a position is to first determine whether it is close to the closing of the market, or whether it has reached the taking profit and stopping loss conditions.
HANS123 is a very typical and very effective automated trading strategy. Its basic principle is to break through the highest or lowest price of the previous market within a certain period of time. The system can be applied to almost all foreign exchange products with stable profitability. This is also an early entry trading mode, with appropriate filtering technology, or can improve its odds of winning.
## Complete strategy
Click to copy the complete strategy source code https://www.fmz.com/strategy/179805 backtest without configuration
## End
The above is the principle and code analysis of the HANS123 strategy. In fact, the HANS123 strategy provides a better time to enter the market. You can also improve the time of exit according to your understanding of the market and understanding of the transaction, or according to the volatility of the variety To optimize parameters such as taking profit and stopping loss to achieve better results.
From: https://blog.mathquant.com/2020/08/12/hans123-intraday-breakthrough-strategy.html | fmzquant |
1,870,097 | Technical Writing Best Practices | Introduction In the realm of software development, technical writing plays a pivotal role... | 0 | 2024-05-30T08:42:21 | https://dev.to/ritika67890/technical-writing-best-practices-1h6d | ## Introduction
In the realm of software development, technical writing plays a pivotal role in conveying complex information to various stakeholders. Whether you're documenting code, writing user manuals, or creating API guides, mastering the art of technical writing is essential for clear and effective communication. Here are some best practices to help you elevate your technical writing skills:
**Know Your Audience:** Understand who will be reading your documentation. Tailor your language and level of detail accordingly. Are you addressing beginners or seasoned developers? Adjust your tone and technical depth accordingly.
**Keep It Clear and Concise:** Cut through the clutter and get straight to the point. Use simple language, avoid jargon whenever possible, and break down complex concepts into digestible chunks. Short sentences and bullet points can help improve readability.
**Organize Content Effectively:** Structure your documentation logically, following a clear hierarchy. Use headings, subheadings, and bullet points to organize information. A well-structured document makes it easier for readers to find what they need quickly.
**Provide Context and Examples:** Help readers understand the purpose and use cases of the technology or feature you're documenting. Provide real-world examples and use cases to illustrate concepts and clarify usage.
**Use Visuals Wisely:** Incorporate diagrams, charts, and screenshots to complement your text. Visual aids can enhance understanding and provide additional context. Just ensure they are relevant and add value to the content.
**Review and Revise:** Don't underestimate the power of editing. Review your writing for clarity, accuracy, and consistency. Eliminate redundancies, clarify ambiguous terms, and ensure technical accuracy. Consider seeking feedback from peers or subject matter experts.
**Stay Updated:** Technology evolves rapidly, and so should your documentation. Regularly update your documentation to reflect changes in the software, address user feedback, and incorporate best practices.
**Empathy is Key:** Put yourself in the shoes of your readers. Anticipate their questions, concerns, and pain points. Address common stumbling blocks and provide troubleshooting tips where necessary.
## Conclusion
In conclusion, technical writing is both an art and a science. By following these best practices, you can effectively communicate complex technical information and empower your audience to succeed.
| ritika67890 | |
1,870,096 | How to list the users in a MySQL/MariaDB database and Manage Permissions | User management involves granting database access, setting user permissions, and monitoring... | 0 | 2024-05-30T08:41:31 | https://dev.to/dbajamey/how-to-list-the-users-in-a-mysqlmariadb-database-and-manage-permissions-p65 | mysql, mariadb, database, security | User management involves granting database access, setting user permissions, and monitoring activities. This process, traditionally handled via command-line utilities, includes creating, modifying, and deleting accounts, and configuring user privileges. Although command-line remains relevant, the advent of graphical user interface (GUI) tools has simplified user management.
dbForge Studio for MySQL, a highly functional GUI-based Integrated Development Environment (IDE), significantly improves database user management compared to command-line tools due to a more intuitive and user-friendly approach. The user management is provided by the Studio for MySQL's Security Manager. This article will utilize this feature to illustrate task performance and compare the usage of standard SQL commands vs. applying the GUI-based solution.
https://www.devart.com/dbforge/mysql/studio/mysql-show-users.html | dbajamey |
1,870,095 | How to create a Login/Register Form with Tailwind CSS and JavaScript | This Thursday, we are going to build a login form using Tailwind CSS and JavaScript just like we did... | 0 | 2024-05-30T08:40:42 | https://dev.to/mike_andreuzza/how-to-create-a-loginregister-form-with-tailwind-css-and-javascript-cap | javascript, tailwindcss, tutorial | This Thursday, we are going to build a login form using Tailwind CSS and JavaScript just like we did in the tutorial with Tailwind CSS and Alpine.js.
[Read the article,See it live and get the coee](https://lexingtonthemes.com/tutorials/how-to-create-a-login-register-form-with-tailwind-and-javascript/)
| mike_andreuzza |
1,870,094 | Introduction to C++ for Aspiring Developers | Are you ready to embark on a journey into the world of programming? Look no further than C++, a... | 0 | 2024-05-30T08:40:36 | https://dev.to/ritika67890/introduction-to-c-for-aspiring-developers-ie6 | Are you ready to embark on a journey into the world of programming? Look no further than C++, a powerful and versatile language that has been the backbone of software development for decades. In this introductory guide, we'll explore the fundamentals of C++ and set you on the path to becoming a proficient developer.
## What is C++?
C++ is a general-purpose programming language known for its efficiency, flexibility, and performance. Developed as an extension of the C programming language, C++ introduces object-oriented programming (OOP) features, making it suitable for developing a wide range of applications, from system software to high-performance games.
## Getting Started
To start coding in C++, you'll need a compiler and a text editor or an integrated development environment (IDE). Popular choices include Visual Studio, Code::Blocks, and Xcode.
## Basic Syntax
Let's dive into some basic syntax to get you acquainted with C++:
```
#include <iostream>
int main() {
std::cout << "Hello, world!" << std::endl;
return 0;
}
```
In this simple program, #include <iostream> includes the input/output stream library, std::cout prints output to the console, and return 0; indicates successful program execution.
## Key Concepts
- **Variables and Data Types:** C++ supports various data types, including int, float, double, char, and bool. Declare variables to store and manipulate data.
- **Control Structures:** Use if-else statements, loops (for, while, do-while), and switch-case statements to control the flow of your program.
- **Functions:** Break your code into modular chunks using functions. Functions encapsulate a set of instructions and promote code reusability.
- **Classes and Objects:** Dive into the world of object-oriented programming with classes and objects. Encapsulation, inheritance, and polymorphism are key concepts to explore.
## Resources for Learning
- **Online tutorials and courses:** Websites like Codecademy, Coursera, and Udemy offer comprehensive C++ courses for beginners.
- **Books:** "C++ Primer" by Stanley B. Lippman, "Programming: Principles and Practice Using C++" by Bjarne Stroustrup, and "Effective Modern C++" by Scott Meyers are highly recommended for aspiring developers.
- **Community forums:** Join online communities like Stack Overflow and Reddit's r/learnprogramming to ask questions, seek advice, and connect with fellow learners.
## Conclusion
In conclusion, C++ is a robust and versatile programming language with endless possibilities. Whether you're interested in game development, system programming, or embedded systems, mastering C++ opens doors to a world of opportunities. So, roll up your sleeves, dive in, and let the coding adventures begin!
| ritika67890 | |
1,870,093 | Ambra | Experience a culinary journey through Italy with Ambra NYC's Italian food menu. Featuring a diverse... | 0 | 2024-05-30T08:39:04 | https://dev.to/alex_415de11cef21f0b40ca2/ambra-20mo | Experience a culinary journey through Italy with Ambra NYC's [Italian food menu](https://ambranyc.com/dinner/). Featuring a diverse selection of antipasti, pasta, and main courses, each item is prepared with passion and precision. From the rich and creamy fettuccine Alfredo to the robust flavors of their meat dishes, every bite promises a taste of authentic Italian cuisine. Check their website to view the complete menu and prepare for an unforgettable dining experience.
| alex_415de11cef21f0b40ca2 | |
1,870,091 | Used Vehicle Market Trends, Size, Growth, Challenges and Forecast 2031 | The used vehicle market has steadily gained prominence since the 2008 recession and continues to grow... | 0 | 2024-05-30T08:35:52 | https://dev.to/shweta_dixit_a7a0f8d2bbea/used-vehicle-market-trends-size-growth-challenges-and-forecast-2031-f3a | usedvehiclemarket | The used vehicle market has steadily gained prominence since the 2008 recession and continues to grow at a rapid pace. Various factors contribute to this industry’s ongoing success, including better financing options, favorable policies, greater involvement of industry players, urbanization, and higher disposable incomes. While North America is expected to remain a dominant force, the Asia Pacific region is projected to register a significantly high compound annual growth rate (CAGR) over the forecast period. As the global automotive sector shifts towards environmentally friendly vehicles, used or pre-owned vehicles offer an economical alternative for those unable to afford new vehicles.
Read Full Insights: https://www.fairfieldmarketresearch.com/report/used-vehicle-market

Used Vehicle Market Overview
Key Report Findings
The global used vehicle market was valued at over US$1.5 trillion in 2021.
The average age of a used vehicle in the U.S. is 11.8 years.
In 2020, 40.4 million used vehicles were sold in the U.S. compared to 14.5 million new vehicles.
The top-selling used car brands in the U.S. are Toyota, Honda, and Ford.
The Asia Pacific region is expected to account for a significant market share over the forecast period.
The average mileage of used cars sold in the U.S. is 68,000 miles.
Growth Drivers
Affordability and Increased Need for Private Conveyance
According to the International Organization of Motor Vehicle Manufacturers (OICA), the automotive industry contributes about 4% to the global GDP, with this figure projected to grow at a CAGR of 20.78% by 2028. This data highlights the increasing global car ownership, with a substantial share attributed to used car ownership, which is expected to expand further by 2030. While the launch of new entry-level cars boosts demand, it can also impact used vehicle sales.
Despite a decline in the average ownership time of new cars compared to the past decade, the used car segment remains appealing to first-time buyers seeking reliable and affordable options until they become proficient daily drivers.
Franchise Dealers Offer Better Financial Schemes
Competitive pricing is a significant advantage for companies operating in the used vehicle market. Key industry participants are amplifying their investments by establishing new dealership networks for used vehicles. Online sales of pre-owned cars remain a critical growth factor. However, research reveals that financing options for new cars are more accessible and affordable compared to used vehicles, which can hinder market growth prospects.
Increasing consumer spending on lifestyle choices and a flourishing import-export scenario are expected to benefit the used vehicle market. Certified used vehicle programs offered by franchise dealers provide better financial schemes, creating favorable conditions for used car sales. Several online platforms, such as Vroom and Fair, have partnered with OEMs to ensure the reliability of their certified used vehicle programs, further enhancing market growth.
Compact Passenger Cars Lead, SUVs Follow
Compact or entry-level cars are expected to account for the largest volume share in the used vehicle market, aligning with growing consumer preferences for economical and compact passenger cars. High production rates and significant inventories also favor better supply chain management of these vehicles.
SUVs, known for their spacious and compact attributes compared to premium vehicles, are on a profitable growth trajectory. Their distribution network and residual value are relatively high, contributing to increased demand.
Key Market Players Indulge in Used Car Dealerships
Automotive industry operators have traditionally focused on new vehicles. However, major automakers now recognize the potential and market worth of used vehicles. Global auto giants are actively involved in used vehicle dealerships, driven by intense competition and changing consumer behavior towards car purchases.
Several new entrants add to the existing fragmented nature of used vehicle market competition. While many of these participants are unorganized local companies, strategic partnerships are likely in the future. New product segments are being launched by both new partners and established players. Premium car companies, including Mercedes and Audi, have their own used car dealerships, generating significant revenue. Brands such as Toyota’s U Trust and Maruti Suzuki’s True Value also focus on used cars, with mainstream companies investing in strategic expansion through collaborations.
Growth Challenges
Adoption of Ride Sharing Trends
Ride sharing, an economical mode of transportation for consumers, poses a concern for used car dealers and financiers. If ride sharing dominates the private transportation market, it could result in fewer owners per car’s lifespan, leading to lower transaction volumes for the used vehicle market. However, the COVID-19 pandemic has shifted attitudes towards private conveyance, increasing the demand for used vehicles, especially in developing economies where they are more affordable.
Regional Growth Opportunities
Asia Pacific to Gain Traction
North America is expected to account for a significant share of the global used vehicle market over the forecast period, attributed to the extensive presence of used vehicle dealers, favorable economic growth, availability of financing, and the popularity of SUVs and trucks. The price of used cars in North America is relatively cheap compared to new vehicles.
The Asia Pacific region is expected to register significant growth over the forecast period due to higher disposable incomes, booming population figures, urbanization, increasing popularity of cars, and better financing options.
Key Market Players
Key companies in the global used vehicle market include True Car, Droom Technology Pvt Ltd., CarMax Inc., Penske Automotive Groups, Lithia Motors, Pendragon PLC, and Emil Frey Classics AG. Established industry players are focusing on new product launches, partnerships, collaborations, acquisitions, and alliances to gain a competitive edge. | shweta_dixit_a7a0f8d2bbea |
1,870,089 | Create Stunning Parallax Animations On Your Website | Have you ever come across a website that made you scroll over it again just to see the motions and... | 0 | 2024-05-30T08:32:38 | https://keploy.io/blog/technology/create-stunning-parallax-animations-on-your-website | ai, devops, java, webdev |

Have you ever come across a website that made you scroll over it again just to see the motions and transitions and made you GASP, thinking how hard it must be to create these amazing animations, One such animation I saw on keploy website, the parallax effect which made me go through there Developer section twice! Let's dive into creating that spellbinding parallax effect together, transforming your website into a journey your visitors will want to take again and again(and raise its retention rate🤫).
**Why GSAP Stands Out**
GSAP can animate pretty much anything JavaScript can touch, in any framework. Whether you want to animate UI, SVG, Three.js, or React components, GSAP covers you. While you might think, "Can't we just use native CSS for these animations, then why load an extra library ?", but believe me, after using and exploring GSAP you will fall in love with it! The simplicity and power of complex animations it provides! It can ease challenging scroll-triggered effects animation with which we are going to create our parallax effect.
**The Building Blocks: Tween and Timelines**
At the core of GSAP, we have Tweens and Timelines:
**Tween**
A Javascript object which will instruct GSAP to implement the animation with the method,target element,and parameter that we will pass.
Syntax:
`gsap.method(element, var, duration)`
**Timeline**
A tool that create sequences of animations. When you add tweens to a timeline, they chain together multiple animations and by default, they'll play one-after-another in the order they were added.A typical timeline is written like so:
`let tl = gsap.timeline();`
Majorly we are going to use these methods in tweens:
**gsap.to()** - This is the most common type of tween. A to() tween will start at the element's current state and animate "to" the values defined in the tween.
**gsap.from()** - Like a backwards .to() where it animates "from" the values defined in the tween and ends at the element's current state.
**gsap.set()**- Instantly sets properties without animation, like a zero-duration .to() tween.
Let's look at them in action!
Now, with our building knowledge of GSAP's tween methods, let's get started on building the captivating parallax effect in which pinned image will get replaced in each section.
Making the Parallax Effect
Step1 : Install GSAP
Here’s how you can set up GSAP in your project:
Using the CDN:
<script src="https://cdnjs.cloudflare.com/ajax/libs/gsap/3.9.1/gsap.min.js"></script>
**Or, if you're using npm:**
```
npm install gsap
For the yarn enthusiasts:
yarn add gsap
```
Step2: Creating the layout
Lets start with out HTML code We will create layout in which there will be be three sections in which section class="s3" act as the primary container for a set of images and text. In this section, we will have our nested diffImgContainer which will contain the images each tagged with classes s3Img, s4Img, s5Img, and s6Img respectively.
In the other section, we will have the text These sections do not contain images themselves but are placeholders for textual content or other web elements.
```
<section class="s3">
<div class="diffImg">
<div class="bgImg">
<div class="diffImgContainer">
<img class="s3Img"src="https://picsum.photos/816/375" alt="collaboration img">
<img class="diffSecImg s4Img" src="https://picsum.photos/816/376" alt="img">
<img class="diffSecImg s5Img" src="https://picsum.photos/816/377" alt="img">
<img class="diffSecImg s6Img" src="https://picsum.photos/816/378" alt="img">
</div>
</div>
</div>
<div class="contain">
<h1>Hello and Welcome!</h1>
</div>
</section>
<section class="s4">
<div class="contain">
<h1>Delighted to Meet You!</h1>
</div>
</section>
<section class="s5">
<div class="contain">
<h1>Ready to Explore?</h1>
</div>
</section>
<section class="s6">
<div class="contain">
<h1>Let's Dive In Together!!!</h1>
</div>
</section>
```
**Step3: Setting Up GSAP and ScrollTrigger**
To register our GSAP plugin with ScrollTrigger, ScrollTrigger is what will allow us to control animations based on scroll positions
```
gsap.registerPlugin(ScrollTrigger);
```
Pin and Move Background:
```
let bgImg = document.querySelector(".bgImg");
ScrollTrigger.create({
trigger: bgImg,
pin: true,
pinSpacing: false,
start: "center center",
end: () => "+=" + (document.querySelector(".s6").getBoundingClientRect().bottom - bgImg.getBoundingClientRect().bottom)
});
```
Now as we want our .bgImg to be fixed at one position when scroll happens we will use ScrollTrigger.create() to create a new animation instance and pass pin: true , property which is used in ScrollTrigger to fix the .bgImg container vertically as the user scrolls.
The animation is controlled by a new ScrollTrigger instance, where:
trigger is the section element that triggers the animation.
start sets the scroll position where the animation should begin, calculated as the top of the section plus 50% of the viewport height plus half the height of the pinned .bgImg container.
end sets the scroll position where the animation should end, calculated as the start position plus the height of the pinned .bgImg container.
scrub: true creates a "scrubbing" effect, making the animation smoothly follow the scroll position, even if the user scrolls back and forth.
If I break down the end function , it is using getBoundingClientRect to get the dimensions in and around element inside the viewport, like distance from x, y
https://cdn.hashnode.com/res/hashnode/image/upload/v1711795840728/d72762db-1ff3-4824-bcdf-23a2567382e8.png
Sliding Images Into View
```
javascriptCopy code[".s4", ".s5", ".s6"].forEach(s => {
let section = document.querySelector(s),
image = document.querySelector(s + "Img");
gsap.set(image, { y: 0, yPercent: 100 });
gsap.to(image, {
yPercent: 0,
ease: "none",
scrollTrigger: {
trigger: section,
start: () => "top 50%+=" + (bgImg.offsetHeight / 2) + "px",
end: "+=" + bgImg.offsetHeight,
scrub: true
}
});
});
```
This code loops through the sections (.s4, .s5, and .s6) and sets up a ScrollTrigger animation for each one. Here our tweens comes!
For each section, we first select the corresponding image element (e.g., .s4Img). We use gsap.set to initially position the image at its original vertical position (y: 0) but with a yPercent of 100%, which means it's vertically translated down by 100% of its own height, effectively hiding it from view.
Then, we use gsap.to to create an animation that transitions the yPercent of the image from 100% to 0%, sliding it into view from the bottom. The ease: "none" property ensures the animation has a linear movement, without any easing.
Voila! Our parallax effect is ready for scroll :
if you're curious to see more, you can explore the detailed version in this GitHub repository.
**Conclusion**
Alright if you came this far you now know how to create the "Cool Parallax Effect" and that's the scoop on GSAP! Animation can be tricky to get right, but GSAP gives us tons of options to play around. The key is finding that sweet spot - a few subtle animations here and there to grab attention and delight visitors without going overboard and the Possibilities are endless!
**FAQ's**
**What is the primary advantage of using GSAP for animations over native CSS**
GSAP offers unparalleled flexibility and power, allowing animations for various elements regardless of the framework. Its simplicity and capability to handle complex animations make it a preferred choice over native CSS.
**Describe the key components of GSAP and their functions in animation creation.**
GSAP primarily consists of Tweens and Timelines. Tweens instruct GSAP to animate properties, while Timelines sequence multiple animations. Tweens like gsap.to() animate from the current state, gsap.from() animates backward, and gsap.set() sets properties instantly without animation.
**How does ScrollTrigger enhance the animation experience with GSAP**
ScrollTrigger allows animations to be triggered based on scroll positions, offering precise control over animations as users navigate through the webpage. It enables effects like pinning elements, scrubbing, and controlling animations based on scroll positions, enhancing the overall user experience.
**Explain the process of creating a parallax effect using GSAP and ScrollTrigger.**
To create a parallax effect, you first set up GSAP and ScrollTrigger, then pin the background image. Next, you slide images into view using gsap.to(), with animations triggered by ScrollTrigger based on scroll positions of corresponding sections. This creates a captivating parallax effect as users scroll through the page.
**What role does the "scrub: true" property play in ScrollTrigger animations?**
The "scrub: true" property in ScrollTrigger animations creates a smooth, scrubbing effect where animations follow the scroll position seamlessly. Even if users scroll back and forth, the animations smoothly adjust, providing a fluid and engaging experience throughout the scrolling journey.
**Why is finding the right balance of animations crucial for website engagement**
While animations can enhance user engagement, finding the right balance is crucial. Subtle animations can grab attention and delight visitors without overwhelming them. GSAP offers a wide range of animation options, allowing developers to strike the perfect balance between visual appeal and usability, ultimately improving website engagement and user experience. | keploy |
1,870,088 | Ich Phe Boi Mau | Siro ho ích phế là sản phẩm kế thừa tinh hoa nghìn năm của y học cổ truyền kết hợp y học hiện đại,... | 0 | 2024-05-30T08:31:50 | https://dev.to/ichpheboimau/ich-phe-boi-mau-4d81 | Siro ho ích phế là sản phẩm kế thừa tinh hoa nghìn năm của y học cổ truyền kết hợp y học hiện đại, chắt lọc tinh túy từ vị thuốc cổ truyền trăm năm. Sản phẩm chứa đựng kết tinh của các loại dược liệu quý hiếm như phổi ngựa bạch cùng 15 vị thuốc thảo dược tự nhiên bắt nguồn từ những bài thuốc trị ho cổ phương có lịch sử cả nghìn năm.
Website: https://ichphe.vn/
Phone: 0833 515 588
Address: Hà Nội
https://answerpail.com/index.php/user/ichpheboimau
https://www.pling.com/u/ichpheboimau/
https://pxhere.com/en/photographer-me/4270742
https://experiment.com/users/ipheboimau
https://makersplace.com/sthuoccom/about
https://zzb.bz/Jm00A
https://www.fitday.com/fitness/forums/members/ichpheboimau.html
https://kumu.io/ichpheboimau/sandbox#untitled-map
https://www.instapaper.com/p/ichpheboimau
https://roomstyler.com/users/ichpheboimau
https://research.openhumans.org/member/ichpheboimau
https://hashnode.com/@ichpheboimau
https://www.dohtheme.com/community/members/ichpheboimau.76623/#about
https://www.webwiki.com/info/add-website.html
https://dreevoo.com/profile.php?pid=643045
https://timeswriter.com/members/ichpheboimau/
https://www.speedrun.com/users/ichpheboimau
https://www.credly.com/users/ich-phe-boi-mau/badges
https://qiita.com/ichpheboimau
https://wmart.kz/forum/user/163643/
http://idea.informer.com/users/ichpheboimau/?what=personal
https://tinhte.vn/members/ichpheboimau.3023523/
https://hypothes.is/users/ichpheboimau
https://telegra.ph/ichpheboimau-05-30
http://forum.yealink.com/forum/member.php?action=profile&uid=343212
https://www.anibookmark.com/user/ichpheboimau.html
https://teletype.in/@ichpheboimau
https://piczel.tv/watch/ichpheboimau
https://muckrack.com/ich-phe-boi-mau
https://peatix.com/user/22432011/view
https://visual.ly/users/sthuoccom
https://app.roll20.net/users/13390513/ich-phe-b
https://pastelink.net/avns4cgt
https://topsitenet.com/user.php
https://www.divephotoguide.com/user/ichpheboimau/
https://www.kickstarter.com/profile/ichpheboimau/about
https://padlet.com/sthuoccom
https://metaldevastationradio.com/ichpheboimau
https://bandori.party/user/201702/ichpheboimau/
https://controlc.com/1bab3887
https://www.nintendo-master.com/profil/ichpheboimau
https://profile.ameba.jp/ameba/ichpheboimau/
https://wperp.com/users/ichpheboimau/
https://active.popsugar.com/@ichpheboimau/profile
https://www.designspiration.com/settings/
https://expathealthseoul.com/profile/ich-phe-boi-mau/
https://8tracks.com/ichpheboimau
https://newspicks.com/user/10323051
https://www.metooo.io/u/665833a00c59a922425743e5
https://linkmix.co/23498747
https://diendannhansu.com/members/ichpheboimau.50375/#about
https://www.scoop.it/u/ich-pheboi-mau
https://vnseosem.com/members/ichpheboimau.31244/#info
https://sketchfab.com/ichpheboimau
https://www.kniterate.com/community/users/ichpheboimau/
https://stocktwits.com/ichpheboimau
https://www.funddreamer.com/users/ich-phe-boi-mau
https://naijamp3s.com/index.php?a=profile&u=ichpheboimau
https://rotorbuilds.com/profile/42693/
https://doodleordie.com/profile/ichpheboimau
https://bentleysystems.service-now.com/community?id=community_user_profile&user=c49b652c1be6c610dc6db99f034bcb57
https://www.reverbnation.com/ichpheboimau
https://www.exchangle.com/ichpheboimau
https://solo.to/ichpheboimau
https://vocal.media/authors/ich-phe-boi-mau
https://gitee.com/sthuoccom
https://crowdin.com/project/ichpheboimau
https://starity.hu/profil/452562-ichpheboimau/
https://glose.com/u/ichpheboimau
https://link.space/@ichpheboimau
https://qooh.me/ichpheboimau
https://hackerone.com/ichpheboimau?type=user
https://data.world/ichpheboimau
https://inkbunny.net/ichpheboimau
https://www.ethiovisit.com/myplace/ichpheboimau
https://os.mbed.com/users/ichpheboimau/
https://myspace.com/signin#
https://dbichpheboimau.notepin.co/
https://coolors.co/u/ich_phe_boi_mau
https://rentry.co/qiy3txg7
https://lab.quickbox.io/ppichpheboimau
https://my.desktopnexus.com/ichpheboimau/
https://www.cakeresume.com/me/ichpheboimau
https://potofu.me/ichpheboimau
https://www.5giay.vn/members/ichpheboimau.101974695/#info
https://www.angrybirdsnest.com/members/ichpheboimau/profile/
https://www.penname.me/@ichpheboimau
http://buildolution.com/UserProfile/tabid/131/userId/406018/Default.aspx
https://camp-fire.jp/profile/ichpheboimau
https://penzu.com/p/2bcda93507cdad7e
https://www.storeboard.com/ichpheboimau
https://slides.com/ichpheboimau
https://www.cineplayers.com/ichpheboimau
https://nhattao.com/members/ichpheboimau.6535784/
https://chodilinh.com/members/ichpheboimau.79461/#about
https://www.babelcube.com/user/ich-phe-boi-mau
https://tupalo.com/en/users/6793064
https://vnxf.vn/members/ichpheboimau.81676/#about
https://collegeprojectboard.com/author/ichpheboimau/
https://jsfiddle.net/user/ichpheboimau/
https://pinshape.com/users/4469148-ichpheboimau#designs-tab-open
https://forum.dmec.vn/index.php?members/ichpheboimau.61317/
https://www.hahalolo.com/@6658379d6df3d00810d38ddf
https://wakelet.com/@IchPheBoiMau10527
https://community.tableau.com/s/profile/0058b00000IZZEk
https://connect.garmin.com/modern/profile/04adcbfa-c1fa-417c-80f8-485c4aa7de6d
https://chart-studio.plotly.com/~ichpheboimau
| ichpheboimau | |
1,870,087 | Introduction | Hi,my name darshan m p.Currently pursuing computer science engineering in rnsit.i hope you will help... | 0 | 2024-05-30T08:30:59 | https://dev.to/darshan_mp_2e055ff5e0772/introduction-48e0 | javascript, programming | Hi,my name darshan m p.Currently pursuing computer science engineering in rnsit.i hope you will help me improving skills. | darshan_mp_2e055ff5e0772 |
1,870,086 | DAC Design Questions | Recent years witness the continuous clinical feasibility and increasing commercial value of... | 0 | 2024-05-30T08:30:52 | https://dev.to/zoe_zoe_4e536fd49fe811477/dac-design-questions-1c4c | webdev, javascript, beginners, programming | Recent years witness the continuous clinical feasibility and increasing commercial value of antibody-drug conjugates (ADCs). As a result, many research institutions attempt to connect PROTAC with monoclonal antibody (mAb) by imitating the design principle of ADC to improve the delivery efficiency of PROTAC in vivo. This combination is called degrader-antibody conjugates (DACs), which can overcome the challenges brought by unconjugated PROTAC molecules, e.g. low efficiency due to its physicochemical properties and DMPK properties (especially the absence of E3 ligase CRBN), and non-specific targeting of PROTAC.
Current Challenges in DAC Design
DAC Design
In the development of DAC, the delivery strategy of ADC cannot be simply copied due to the particularity of PROTAC molecules. Unlike the broad-spectrum cytotoxic small-molecule drugs used in ADCs, PROTAC in DAC typically has targeted activity only against specific tumors and/or tissues or cells. Therefore, the selection of antigens not only needs to meet the function of internalizing DAC and transporting it into lysosomes but also needs to be highly expressed in PROTAC target tissues (or tumors, cells). This antigen may also be expressed at low levels in other tissues or cells. So long as such tissues or cells have a good tolerance to PROTAC, off-target toxicity can be avoided.
Since PROTAC is less active in vitro than small molecule drugs in many cases, drug antibody ratio (DAR) in DAC needs to be increased (i.e., DAC > 4) to be effective. However, enhanced DAR may lead to accumulation of DAC, with adverse effects on pharmacokinetics (PK) in vivo. Moreover, PROTAC is larger in volume and has stronger lipophilic properties compared with small molecule drugs. This difference will make aggregation and PK problems more serious, and new ligand and conjugation methods need to be developed to solve these problems.
[The PROTAC Design Services](https://ptc.bocsci.com/services/protac-design-services.html)
Many PROTACs do not have sites (amino) that can be used for covalently binding to cleavable linkers. Therefore, it is necessary to consider whether PROTAC structure modification is needed to introduce active sites (but it may change the physiological activity of PROTAC), or use PROTAC’s existing functional groups (such as hydroxyl, phenolic hydroxyl) and develop new conjugation technology. The development of non-cleavable groups also needs to consider the same concern, and the ligands still attached to PROTAC molecules after lysosome degradation should not interfere with its biological activity.
In addition, other problems to be solved in DAC development include stability of PROTAC in lysosomes, lysosomal escape function of PROTAC, and PROTAC bystander effect. The latter two are affected by the permeability of PROTAC cells and remain the focus of current research in this area. The PROTAC that is unable to exert biological activity due to the influence of cell permeability, can enter cells and take effect via mAb in DAC. In this case, a cell-independent approach is required to evaluate the PROTAC’s ability to generate ternary complexes.
Future Perspective
Currently, DAC is still in its infancy, but several candidates have been identified with in vitro and/or in vivo biological activity. PROTAC molecules in these DAC structures utilize different E3 ligases and target different target proteins. In addition, a variety of novel ligands and antibody conjugation techniques have been applied to DACs. The DAR of most DAC molecules is larger than that of mainstream ADCs, but whether this increase is a general rule for DAC development needs further study. Multiple studies have shown that DAC activity depends on cell surface antigen, suggesting that DAC drugs can deliver PROTAC corresponding to specific tumors and/or cells. Based on these results, the DAC model has a bright future. | zoe_zoe_4e536fd49fe811477 |
1,870,085 | Why Does Your Garage Door Squeak, and How Can You Silence It Once and For All? | A loud screeching sound often surprises people when they open or close their garage door. That... | 0 | 2024-05-30T08:28:23 | https://dev.to/prestigegaragedoorsca/why-does-your-garage-door-squeak-and-how-can-you-silence-it-once-and-for-all-50el | garagedoorrepair | A loud screeching sound often surprises people when they open or close their garage door. That creaking and squeaking noise can be unsettling. But this is a common problem that many people face.
Think about this situation. You are quietly drinking your morning coffee when suddenly, a loud, unpleasant noise disturbs the peace. It's your garage door making a sound like fingernails on a chalkboard.
Why does the garage door make so much noise every time it moves? Keep on reading to find out!
## So, What’s the Deal with the Noise?
A noisy garage door is a sign that something might be wrong. Let's first understand what causes this squeaking sound. A garage door has many parts that work together. It has springs, rollers, and hinges. For the door to open and close smoothly, all these parts need to be working well.
Over time, these parts can get old and worn out. As they get used a lot, they start making noise.
Just like any machine, a garage door needs proper lubrication. If it doesn't get enough lubrication, the parts rub against each other. This rubbing causes a squeaking sound.
Sometimes, the parts of the¬ garage door can move out of place. When this happens, the door doesn't move evenly. This uneven movement also leads to strange noises.
## How to Silence a Noisy Garage Door?
Let's go through the steps to make your garage door quieter:
1. First, look closely at the springs, rollers, and hinges. See¬ if any parts are damaged or worn out.
2. Next, clean any dirty or grimy parts that could be causing noise.
3. Apply a silicone-based lubricant to all hinges, rollers, and springs. Don't use too much, or it may drip.
4. Use a wrench to tighten any loose¬ screws or bolts.
5. An unbalanced garage door can be noisy and unsafe¬. You may need an [Emergency Garage Door Repair Service Orange County](https://prestigegaragedoorsca.com/services/emergency-services) to fix this issue quickly.
## The Right Tools for the Job
Here is the list of things you will need:
• Lubricant made of silicone¬ or grease for garage doors
• A ladder with steps
• Washcloths or towels
• Wrenches and other basic tools like pliers that you may need for adjustments
## When to Call in the Pros?
Sometimes, it's wise to seek professional help for fixing your garage door instead of doing it yourself. Some repairs require expertise to ensure safety and proper functioning.
Springs, particularly torsion springs, can be dangerous if not handled correctly. Replacing them should be left to experts who understand the risks involved.
If you notice signs of severe¬ wear, and cleaning or lubricating hasn't resolved the issue, it's best to replace the faulty parts. Let professionals with specialized knowledge handle this task.
Regular maintenance checks can prevent sudden noises or problems with your garage door. Proactive care keeps unexpected issues at bay.
## Hush as Good as New
Above all, soundproofing is not the immediate effect of doing something. When your garage door is properly maintained, these problems can be properly resolved and the sound can be prevented from recurring.
1. Outdoor maintenance appointments should be part of your to-do list
2. Familiarise yourself with the noise in the early stage
3. Don’t leave it too long – small issues can result in more serious issues that are harder to fix
## DIY Checks and Fixes
If you just look at the surface, you go silent. A deep understanding of the craft should be learned to make it finally close down without any objections or screams.
## Listen Closely
First of all, follow the plague as long as it causes the noise to the beginning to the middle, or to the end of its way. Some trouble can be further indicated by this answer. It added to the possibility that it could be any part of its garage door system.
## The Roller Riddle
Did you know that rollers can be quite loud? If they are made of metal, think about switching to nylon rollers. Studded with spheres of foam, they slide smoothly and quietly. Their price tag may seem high, but for the sake of peace, it is well worth it.
## Hinge Hints
Also, old hinges may contribute to the noise environment. After a time, the hinge parts will fall, and this is a sure sound of noise pushing metal. Check them for signs of wear and if found, replace the hinges which can make a big difference.
## Wrap Up
There you go, a variety of solutions to shut the noise down and dismiss chaos. You can call [Garage Door Repair Service Orange County](https://prestigegaragedoorsca.com/garage-door-repair
) in case you get stuck, or the problem doesn't go away.
Those professionals are with us — to close in seconds your garages and prolong their effect continuously, ensuring you get the most out of your mornings with a cup of coffee which is quiet and unaccompanied.
| prestigegaragedoorsca |
1,856,473 | Study In UK | UK is the second most preferred overseas education destination in the world, only next to the USA.... | 0 | 2024-05-17T12:16:51 | https://dev.to/videshevidhya/study-in-uk-17mm | UK is the second most preferred overseas education destination in the world, only next to the USA. The education system here is the testament of time. Universities like Cambridge have shaped modern education which we receive today.
Living and studying in the UK is like experiencing a high profile urban lifestyle and enjoying the diversity, complexity, civic infrastructure and social exchange while enjoying beautiful ancient yet modernized cities and delicious food with the liveliest population to be around.
UK universities rank amongst the best international universities in the world. With regard to life and career, a degree from an affiliated institution is highly appreciated by employers everywhere in the world. A promising stable career surely will secure students’ future.
WHY STUDY ABROAD IN UK
Impressive International Reputation
World-leading Research
Highly-Advanced Pedagogical Methodology
Variety in Course Offerings
Flexibility to Customize Your Degree
Lower Education Cost than the US
Two year Post Study Work Right
#Immigration and visa consultant in Ahmedabad #top immigration consultants in Ahmedabadbest #immigration and visa consultants in Ahmedabad #visa consultant in Ahmedabad #Canada pr consultant in Ahmedabad | videshevidhya | |
1,870,084 | The Ultimate Guide to .NET Native AOT: Benefits and Examples 🤫 | What is Native AOT in .NET? When you compile your C# code, it gets converted into... | 0 | 2024-05-30T08:28:02 | https://dev.to/bytehide/the-ultimate-guide-to-net-native-aot-benefits-and-examples-pg4 | dotnet, nativeaot, bytehide, programming | ## What is Native AOT in .NET?
When you compile your C# code, it gets converted into Intermediate Language (IL). Then, the .NET Runtime (CLR) uses the Just-In-Time (JIT) compiler to turn that IL into machine code during execution.
But here’s where things get interesting: Native AOT skips that intermediate step. Instead, it compiles your C# code directly into native machine code on your machine. For example, on Windows, you get an executable (.exe) file directly.
Although the process still technically involves IL, it’s done transparently within a single compilation step, effectively serving you a ready-to-go native executable.
## Advantages and Disadvantages of Native AOT in .NET
Like any powerful tool, Native AOT comes with its own set of pros and cons. Understanding these will help you decide if it’s the right fit for your project.
### Benefits
- **Performance Gains**: Compiling directly to machine code eliminates the JIT compilation step during runtime, which means faster execution, especially on the first run.
- **Reduced Startup Time**: Ideal for applications like Azure Functions or AWS [Lambda](https://www.bytehide.com/blog/lambda-expressions-csharp) that benefit from quicker startup times.
- **Self-Contained Executables**: The resulting executable includes everything needed to run your app, so the target machine doesn’t need the .NET Runtime installed.
### Drawbacks
- **Platform Specificity**: Native AOT compels you to compile the application for each target OS. A Windows-compiled .exe won’t run on Linux.
- **Larger File Sizes**: Both the compilation time and resulting application size tend to be larger compared to traditional compilation.
- **Compatibility Issues**: Not all libraries and functionalities are compatible with Native AOT. For instance, Entity Framework Core and certain WebAPI features aren’t supported yet.
## A Practical Example: Native AOT in Action
Now that we’ve covered the theory, let’s put it into practice by comparing a traditional .NET app with one compiled using Native AOT. We’ll be using a minimal API supported by Native AOT to demonstrate the process.
### Preparing Your Environment
Before you begin, ensure your development environment is set up correctly. You’ll need to install the Desktop development workload with C++ using the Visual Studio Installer.
### Setting Up a Minimal API with Native AOT
Let’s walk through the steps to create a minimal API and compile it using Native AOT. We’ll explore the differences from a traditional setup along the way.
#### Step 1: Create a New Project
Open Visual Studio and create a new project. You can search for “ASP.NET Core Empty” to start with a minimal API template.
#### Step 2: Configure with
In your `Program.cs` file, replace the standard setup with `CreateSlimBuilder` to create a minimal web application.
```csharp
// Create a SlimBuilder instance to set up a minimal web application
var builder = WebApplication.CreateSlimBuilder(args);
var app = builder.Build();
// Define a route that responds with "Hello World!" for requests to the root URL
app.MapGet("/", () => "Hello World!");
// Start the application
app.Run();
```
#### Step 3: Enable Native AOT in Project File
Modify your project file (.csproj) by adding the `PublishAot` property. This will instruct the compiler to use Native AOT.
```xml
<Project Sdk="Microsoft.NET.Sdk.Web">
<PropertyGroup>
<TargetFramework>net6.0</TargetFramework>
<PublishAot>true</PublishAot>
</PropertyGroup>
</Project>
```
By setting `PublishAot` to `true`, you’re enabling the Native AOT feature, which will generate a self-contained executable.
### Comparing File Sizes
Now let’s publish the project to see the differences in output file sizes.
#### Traditional .NET Output
For a traditional .NET publish, you would typically see a `.dll` file along with an executable loader.
```bash
dotnet publish -c Release
```
#### Native AOT Output
With Native AOT, the output is a single executable file that contains everything needed to run your application.
```bash
dotnet publish -c Release -r win-x64
```
In the publish directory, you will find:
- **Traditional .NET Output**: A `.dll` file and an executable (`.exe`).
- **Native AOT Output**: One sizable `.exe` file without additional dependencies.
### Measuring Performance
Let’s delve into performance to see if Native AOT delivers on its promise. We’ll add middleware to measure execution time and perform a simple database query using Dapper, which is compatible with Native AOT.
#### Adding Middleware for Execution Time
First, we’ll add middleware to log execution times.
```csharp
// Adding middleware to measure execution time
app.Use(async (context, next) => {
var watch = System.Diagnostics.Stopwatch.StartNew();
await next();
watch.Stop();
var executionTime = watch.ElapsedMilliseconds;
Console.WriteLine($"Execution Time: {executionTime} ms");
});
```
#### Performing a Database Query with Dapper
Next, we’ll add a simple database query using Dapper.
```csharp
// Simple database query with Dapper
app.MapGet("/data", async () => {
using var connection = new SqlConnection("your_connection_string");
var data = await connection.QueryAsync("SELECT * FROM YourTable");
return data;
});
```
After implementing these changes, publish the project using both traditional and Native AOT [methods](https://www.bytehide.com/blog/method-usage-csharp) and run several tests.
### Real-Life Examples
Let’s consider a real-life scenario where Native AOT can be beneficial. Imagine an Azure Function that needs to start quickly to handle HTTP requests.
#### Azure Function Example
Here’s a simplified example of an Azure Function using Native AOT.
```csharp
public static class Function1 {
[FunctionName("Function1")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
ILogger log) {
log.LogInformation("C# HTTP trigger function processed a request.");
string name = req.Query["name"];
return name != null
? (ActionResult)new OkObjectResult($"Hello, {name}")
: new BadRequestObjectResult("Please pass a name on the query string or in the request body");
}
}
```
By compiling this Azure Function with Native AOT, you can significantly reduce the cold start time, improving performance and reducing costs.
## Conclusion
Native AOT in .NET can offer substantial performance improvements, especially for applications where startup time is critical. [While](https://www.bytehide.com/blog/while-loop-csharp) there are some limitations and additional considerations, the benefits can be compelling.
- **Benefits**:
- Improved performance through reduced startup times
- Self-contained executables eliminating dependency issues on target environments
- **Considerations**:
- Platform specificity requiring multiple compilations for different OSes
- Potential increase in file sizes and longer compilation times
- Compatibility limitations with existing libraries and frameworks
As .NET continues to evolve, we can expect more libraries and frameworks to support Native AOT, making it an even more attractive option for developers looking to optimize their applications. So why not give it a try and see how much you can boost your app’s performance? | bytehide |
1,870,082 | When Garage Doors Break: Your Emergency Repair Guide! | Suppose it’s a typical Seattle morning and you’re about to set out for work. Just as you’re ready to... | 0 | 2024-05-30T08:21:46 | https://dev.to/livgaragedoor/when-garage-doors-break-your-emergency-repair-guide-5c1e | garagedoorrepairinseattle, emergencydoorrepairinseattle, usa | Suppose it’s a typical Seattle morning and you’re about to set out for work. Just as you’re ready to drive away, you find the garage door won’t open. What do you do? This is the simplified response to the daunting question of **[Emergency Door Repair in Seattle.](https://fixngogaragedoorservices.com/emergency-garage-door-repair/)**
## Problem-Solving
Garage doors are an essential part of your home security, yet we often overlook their care and maintenance until they malfunction. The first step to handling an emergency garage door breakdown is understanding the reason behind the problem. Is it a mechanical failure? An electrical issue? Or maybe just a small piece that’s come out of alignment?
## Quick Fixes
Depending on the nature of the problem, a few quick fixes might be worth a try before calling for a Garage Door Repair in Seattle. Simple steps like checking the batteries in your opener’s remote, ensuring there’s no obstruction in the door’s path, or checking if the garage door opener has been accidentally disconnected from power can save you time and potentially a service call.
## Call the Professionals
If the problem persists, it’s time to call the professionals. This is where you need an experienced and dependable service provider who can handle Emergency Door Repair in Seattle. Remember, attempting to fix a malfunctioning garage door by yourself can be risky and can lead to more significant problems if not properly addressed.
Over the years, companies like Fix & Go Garage Services have built a reputation for offering quick, efficient repair services in the Seattle area. They are equipped to handle a wide array of garage door-related issues, from simple fixes to major overhauls.
## Precautions After Repair
After your garage door has been repaired, it’s essential to take certain precautions. Regularly maintaining your garage door is key to preventing future breakdowns. The experts recommend an annual check-up by a professional to ensure all parts are in proper working order and to catch any potential issues early.
## Final Words
Having the right knowledge and access to a trusted garage door repair service makes handling a garage door emergency a breeze. So, the next time you find your garage in a fix, don’t panic. Remember, you now have a guide to handle a **[Garage Door Repair in Seattle](https://fixngogaragedoorservices.com/garage-door-services/)**, day or night. Stay prepared and stay safe. After all, a functioning garage door is not simply about convenience, it’s about your home’s security too. | livgaragedoor |
1,870,020 | Load Testing with Locust | This week at work I was tasked with continuing some load testing that a previous Engineer had... | 0 | 2024-05-30T08:10:31 | https://dev.to/ajt2/load-testing-with-locust-4h1p | webdev, scaling, aws, distributedsystems | This week at work I was tasked with continuing some load testing that a previous Engineer had started. They had used [locust](https://locust.io/) which is an open source load testing tool to run the initial load testing on the `staging` environment. I now needed to do the same for `production` so I followed in their footsteps.
First I installed `locust` using `homebrew`
```
brew install locust
locust --version
```
Next, I asked ChatGPT to give me a basic test that worked with basic http authentication and let me send GET variables to make a GraphQL request to Magento 2.
```
from locust import HttpUser, TaskSet, task, between
from requests.auth import HTTPBasicAuth
class WebsiteTasks(TaskSet):
# def on_start(self):
# """ on_start is called when a Locust user starts before any task is scheduled """
# self.client.auth = HTTPBasicAuth('username', 'password')
# @task(1)
# def index(self):
# self.client.get("/")
@task(1)
def graphql_query(self):
query = "/graphql?query=query+getCurrencyData%7Bcurrency%7Bdefault_display_currency_code+available_currency_codes+__typename%7D%7D&operationName=getCurrencyData&variables=%7B%7D"
self.client.get(query)
class WebsiteUser(HttpUser):
tasks = [WebsiteTasks]
wait_time = between(5, 15)
```
To get a baseline I started things off by scaling down to a single instance for the api endpoint and tested in 50 user increments up to 200 users.
Next, I enabled autoscaling and started to increase the number of users until the alarm to scale up was triggered increasing the number of instances from 2 to 4. I kept increasing users until I scaled up to 5 total instances.
I had a pretty basic use case for this tool but if you'd like to see how it can be used to do more in-depth testing checkout this article
https://learnosity.com/edtech-blog/how-we-manipulated-locust-to-test-system-performance-under-pressure/#:~:text=Locust%20is%20an%20open%2Dsource,(TaskSets)%20attached%20to%20them.
I also found a tool to convert HAR files into locust test files. This would make it easy to record a user session and replay it with load testing.
https://github.com/SvenskaSpel/har2locust
This was definitely the easiest load testing tool I've used to get up and running out of the box. | ajt2 |
1,870,034 | Custom FlutterFlow authentication using Logto | Learn how to implement custom authentication in your Flutter application using Logto Flutter... | 0 | 2024-05-30T08:07:08 | https://blog.logto.io/custom-flutter-flow-authentication-using-logto/ | webdev, programming, opensource, flutter | Learn how to implement custom authentication in your Flutter application using Logto Flutter SDK.
---
# Introduction
[FlutterFlow](https://flutterflow.io/) is a low-code platform that allows you to build Flutter applications visually. It provides a drag-and-drop interface to design your app's UI and generates the corresponding Flutter code. According to the official [documentation](https://docs.flutterflow.io/settings-and-integrations/app-settings/authentication), it provides three different authentication integration options:
1. Through the build-in Firebase authentication
2. Through the build-in Supabase authentication
3. Custom authentication
For the first two, FlutterFlow provides a seamless integration with Firebase and Supabase. You will need to set up your Firebase or Supabase project and configure the authentication settings in FlutterFlow. However, if you want to use a different authentication provider, you will need to implement the authentication logic yourself.
As for the [custom authentication](https://docs.flutterflow.io/data-and-backend/custom-authentication), FlutterFlow provides a way to integrate with any authentication provider relying on a single custom [authentication API](https://docs.flutterflow.io/data-and-backend/custom-authentication#id-3.-authenticate-users).
However, a direct user credential exchange between the client and the authentication server is not recommended by modern security standards. Instead, you should use a secure authentication flow such as OAuth 2.0 or OpenID Connect (OIDC) to authenticate users. For modern OAuth 2.0 or OIDC based Identity Providers (IdP) such as Auth0, Okta, and Logto, a resource owner password credentials (ROPC) grant type is not recommended or prohibited due to security reasons. See [Deprecated ropc grant type](https://blog.logto.io/deprecated-ropc-grant-type/) for more details.
A standard OAuth 2.0 or OIDC authentication flow involves multiple steps and redirects between the client application, the authorization server, and the user's browser. In this post, we will show you how to customize the FluterFlow's `CustomAuthManager` class using [Logto Flutter SDK](https://docs.logto.io/quick-starts/flutter/) to implement a secure authentication flow in your FlutterFlow application.
# Prerequisites
- A [Logto Cloud](https://auth.logto.io/sign-in) account or a self-hosted Logto instance. (Checkout the [⚡ Get started](https://docs.logto.io/docs/tutorials/get-started/) guide to create a Logto instance)
- A Flutter application created using FlutterFlow.
- Register a flutter application in your Logto console.
- A GitHub repository to manage your custom code in FlutterFlow.
- Checkout our Flutter SDK's integration [guide](https://docs.logto.io/quick-starts/flutter/).
> - Logto Flutter SDK package is available on [pub.dev](https://pub.dev/packages/logto_dart_sdk) and Logto [github repository](https://pub.dev/packages/logto_dart_sdk).
> - The SDK is currently only suitable for Android and iOS platforms.
> - Manage custom code in GitHub is a premium feature in FlutterFlow. You need to upgrade your FlutterFlow to `Pro` plan to enable this feature.
# Step 1: Enable manage custom code in FlutterFlow
In order to customize the `CustomAuthManager` class, you need to enable the custom code feature in FlutterFlow. Following the [Manage Custom Code In GitHub](https://docs.flutterflow.io/customizing-your-app/manage-custom-code-in-github) guide to link and sync your FlutterFlow project with GitHub.
Once it is done, you will have three different branches under your GitHub FlutterFlow repository:
1. `main`: The main branch for the flutter project. You will need this branch to deploy your project.
2. `flutterflow`: The branch where the FlutterFlow will sync the changes from the UI editor to your codebase.
3. `develop`: The branch where you can modify your custom code.
# Step 2: Design and create your custom UI flow in FlutterFlow
### Build your pages
Create your UI in FlutterFlow. You can follow the [FlutterFlow documentation](https://docs.flutterflow.io/) to create your UI based on your requirements. In this tutorial, for the minimum requirement, we will assume you have two pages:
1. A simple `HomePage` with a sign-in button. (No sign-in form is needed, user authentication flow is handled at the Logto side. Please check [customize sie](https://docs.logto.io/docs/recipes/customize-sie/) guide for more details.)
2. A user profile page to display user information and sign-out button.
### Enable custom authentication in FlutterFlow
Got to the `App Settings` - `Authentication` page and enable the custom authentication. This will create a `CustomAuthManager` class and related files in your FlutterFlow project.
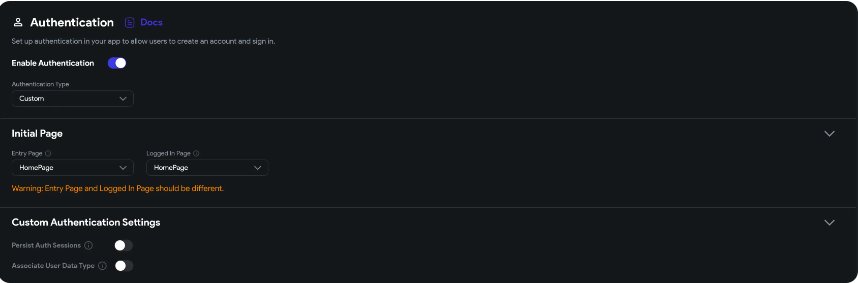
# Step 3: Sync your FlutterFlow project with GitHub
After you have created your custom UI and enabled the custom authentication in FlutterFlow, you need to sync your project with GitHub. Go to the `integrations` - `GitHub` page and and click on the `Push to Repository`

# Step 4: Customize the `CustomAuthManager` code
Switch to the `develop` branch in your GitHub repository and merge the latest changes from the `flutterflow` branch. This will sync all the UI changes to your `develop` branch including your page widgets, and the pre built `CustomAuthManager` class.
### Install Logto SDK dependency
Add the Logto SDK dependency to your project.
```
flutter pub add logto_dart_sdk
```
> Optional Http package:
> Logto client requires a http client to make API calls. You can use the `http` package or any other http client package of your choice.
> ```
flutter pub add http
```
### Update the UserProvider class
`UserProvider` class is responsible for managing the user authentication state. We need to customize the properties to store the user authentication information provided by the Logto SDK.
Add a `idToken` property with type `OpenIdClaims` to store the `id_token` claims for the authenticated user.
> `OpenIdClaims` class is defined in Logto SDK, which will provide the `OIDC` standard `id_token` claims from a authenticated user.
```
// lib/auth/custom_auth/custom_auth_user_provider.dart
import 'package:logto_dart_sdk/src/modules/id_token.dart';
import 'package:rxdart/rxdart.dart';
import 'custom_auth_manager.dart';
class FlutterFlowAuthAuthUser {
FlutterFlowAuthAuthUser({required this.loggedIn, this.uid, this.idToken});
bool loggedIn;
String? uid;
OpenIdClaims? idToken;
}
/// Generates a stream of the authenticated user.
BehaviorSubject<FlutterFlowAuthAuthUser> flutterFlowAuthAuthUserSubject =
BehaviorSubject.seeded(FlutterFlowAuthAuthUser(loggedIn: false));
Stream<FlutterFlowAuthAuthUser> flutterFlowAuthAuthUserStream() =>
flutterFlowAuthAuthUserSubject
.asBroadcastStream()
.map((user) => currentUser = user);
```
### Customize the CustomAuthManager class and initialize Logto client
```
// lib/auth/custom_auth/custom_auth_manager.dart
import 'dart:async';
import 'package:flutter/foundation.dart';
import 'package:http/http.dart' as http;
import 'package:logto_dart_sdk/logto_client.dart';
import 'package:logto_dart_sdk/src/modules/id_token.dart';
import 'custom_auth_user_provider.dart';
export 'custom_auth_manager.dart';
class CustomAuthManager {
late LogtoClient logtoClient;
// Logto configuration
final logtoConfig = const LogtoConfig(
appId: '<YOUR-APP-ID>',
endpoint: '<YOUR-LOGTO-ENDPOINT>');
// ...
FlutterFlowAuthAuthUser? _updateCurrentUser(
{bool loggedIn = false, String? uid, OpenIdClaims? idToken}) {
// Update the current user stream.
final updatedUser = FlutterFlowAuthAuthUser(
loggedIn: loggedIn,
uid: uid,
idToken: idToken,
);
flutterFlowAuthAuthUserSubject.add(updatedUser);
return updatedUser;
}
Future initialize() async {
logtoClient = LogtoClient(config: logtoConfig, httpClient: http.Client());
late OpenIdClaims? idToken;
try {
idToken = await logtoClient.idTokenClaims;
} catch (e) {
if (kDebugMode) {
print('Error initializing auth: $e');
}
}
_updateCurrentUser(
loggedIn: idToken != null, uid: idToken?.subject, idToken: idToken);
}
}
FlutterFlowAuthAuthUser? currentUser;
bool get loggedIn => currentUser?.loggedIn ?? false;
```
The `initialize` method will init a Logto client instance and update the current user stream with the user authentication status persisted in the local storage.
> Logto SDK uses the [flutter_secure_storage](https://pub.dev/packages/flutter_secure_storage) package to store the user authentication data securely. Once the user is authenticated, the `id_token` claims will be stored in the local storage.
### Implement the sign-in method using Logto client
Call the `LogtoClient.signIn` method will initiate a standard `OIDC` authentication flow. The Logto sign-in page will be opened in a webview. The webview based authentication flow is powered by [flutter_web_auth](https://pub.dev/packages/flutter_web_auth).
```
// lib/auth/custom_auth/custom_auth_manager.dart
Future<FlutterFlowAuthAuthUser?> signIn(
String redirectUri,
) async {
await logtoClient.signIn(redirectUri);
var idTokenClaims = await logtoClient.idTokenClaims;
return _updateCurrentUser(
loggedIn: idTokenClaims != null,
uid: idTokenClaims?.subject,
idToken: idTokenClaims,
);
}
```
LogtoClient will handle the authorization, token exchange, and user information retrieval steps. Once the user is authenticated, the `idTokenClaims` will be stored in the local storage.
Retrieve the `idTokenClaims` from the LogtoClient and update the current user stream.
### Implement the Sign-out method
```
// lib/auth/custom_auth/custom_auth_manager.dart
Future signOut() async {
await logtoClient.signOut();
flutterFlowAuthAuthUserSubject.add(
FlutterFlowAuthAuthUser(loggedIn: false),
);
}
```
The `signOut` method will clear the user authentication data stored in the local storage and update the current user stream.
### Update the auth util methods
- Add the `authManager` getter to access the `CustomAuthManager` instance.
- Add the `currentUserUid` getter to get the current user uid.
- Add the `currentUserData` getter to get the current user data.
- Add the `logtoClient` getter to access the Logto client instance.
```
// lib/auth/custom_auth/auth_util.dart
import 'package:logto_dart_sdk/logto_client.dart';
import 'package:logto_dart_sdk/src/modules/id_token.dart';
import 'custom_auth_manager.dart';
export 'custom_auth_manager.dart';
final _authManager = CustomAuthManager();
CustomAuthManager get authManager => _authManager;
String get currentUserUid => currentUser?.uid ?? '';
OpenIdClaims? get currentUserData => currentUser?.idToken;
LogtoClient get logtoClient => _authManager.logtoClient;
```
# Step 5: Update the sign-in and sign-out buttons in your UI
### Home Page
Call the `authManager.signIn` method to initiate the authentication flow when the user clicks on the sign-in button.
> `redirectUri` is the callback URL that will be used to capture the authorization callback from the Logto sign-in page. See the [implement sign-in](https://docs.logto.io/quick-starts/flutter/#implement-sign-in) for more details on the redirectUri.
```
// lib/pages/home_page/home_page_widget.dart
final redirectUri = 'io.logto://callback';
// ...
FFButtonWidget(
onPressed: () async {
GoRouter.of(context).prepareAuthEvent();
await authManager.signIn(redirectUri);
context.replaceNamed('user');
},
text: 'Sign In',
// ...
)
```
User will be redirected to the `user` page after successful authentication.
### User Profile Page
Use the auth util getters to access the current user data and the Logto client instance.
For example, to display the user information using multiple `Text` widgets:
```
// lib/pages/user/user_widget.dart
import '/auth/custom_auth/auth_util.dart';
// ...
children: [
Text(
'User ID: $currentUserUid',
),
Text(
'Display Name: ${currentUserData?.name}',
),
Text(
'Username: ${currentUserData?.username}',
),
Text(
'Email: ${currentUserData?.emailVerified ?? currentUserData?.email}',
),
]
```
Trigger the sign-out method when the user clicks on the sign-out button and redirect the user back to the home page.
```
// lib/pages/user/user_widget.dart
FFButtonWidget(
onPressed: () async {
await authManager.signOut();
context.replaceNamed('HomePage');
},
text: 'Sign Out',
// ...
)
```
### Testing
Run your FlutterFlow application on an emulator. Click on the sign-in button on the home page to initiate the authentication flow. The Logto sign-in page will be opened in a webview. After successful authentication, the user will be redirected to the user profile page. The user information will be displayed on the user profile page. Click on the sign-out button to sign out the user and redirect the user back to the home page.
Don't forget to merge the `develop` branch back to the `main` branch and push the changes to the GitHub repository.
> FlutterFlow github push is a one-way sync from FlutterFlow to GitHub. Any changes made under the fluterflow branch will be overwritten by the `FlutterFlow` UI editor when you push the changes to the GitHub repository. Make sure to use the `develop` branch to manage your custom code and merge the changes back to the `main` branch for deployment.
# Further Readings
Logto SDK provides more methods to interact with the Logto API. You may further customize the `CustomAuthManager` class to implement more features using the Logto SDK.
- [User info endpoint](https://docs.logto.io/quick-starts/flutter/#get-user-information)
- [Get resource access token](https://docs.logto.io/quick-starts/flutter/#api-resources)
- [Get organization access token](https://docs.logto.io/quick-starts/flutter/#organization)
{% cta https://logto.io/?ref=dev %} Try Logto Cloud for free {% endcta %}
| palomino |
1,870,078 | Discovering a Useful Tool When Out of Ideas for Writing a Paper | [] There comes a time in every student's life when the well of inspiration runs dry, and finding... | 0 | 2024-05-30T08:07:06 | https://dev.to/writegoai/discovering-a-useful-tool-when-out-of-ideas-for-writing-a-paper-451d | ai, tooling, website |
[]
There comes a time in every student's life when the well of inspiration runs dry, and finding ideas for writing a paper feels like an insurmountable task. This was precisely the situation I found myself in one late night, staring blankly at my computer screen, with a looming deadline and no idea where to start. Little did I know that a simple, accidental discovery would turn my writing process around completely.
The Struggle with Writer's Block
As a university student, I was no stranger to the pressures of academic writing. Essays, research papers, and reports were a regular part of my coursework. Normally, I could come up with topics and ideas fairly easily, but this time was different. No matter how hard I tried, I couldn't think of a single compelling idea for my upcoming paper on the impact of technology on society.
With the deadline fast approaching, my anxiety grew. I knew I needed a breakthrough, but I had no idea where to find it. I tried brainstorming, freewriting, and even talking to friends for inspiration, but nothing seemed to work.
The Accidental Discovery
In a moment of desperation, I decided to take a break and browse the internet aimlessly. Maybe, just maybe, I would stumble upon something that could spark an idea. As I scrolled through various websites, an ad caught my eye. It was for a tool called WriteGo, an AI-powered writing assistant designed to help generate ideas, structure content, and refine writing.
Skeptical but curious, I clicked on the ad and was directed to the WriteGo website. The tagline promised to "transform your writing experience with advanced AI technology," and I was intrigued by the range of features it offered. I decided to give it a try, thinking I had nothing to lose.
Exploring WriteGo
WriteGo boasted a variety of tools aimed at making the writing process easier and more efficient. Here are some of the key features that caught my attention:
1. Idea Generator:
The idea generator was designed to help users brainstorm topics based on a given subject area. All I had to do was input a general theme, and the AI would provide a list of potential topics and angles to explore.
2. Thesis Statement Creator:
Crafting a strong thesis statement can be a challenge, but WriteGo's thesis statement creator made it simple. By inputting my main points, the tool generated a clear and concise thesis statement.
3. Research Assistant:
WriteGo's research assistant summarized relevant articles and extracted key points, saving time on gathering information and providing a solid foundation for my paper.
4. Outline Generator:
The outline generator helped structure my paper by creating a detailed outline based on my chosen topic and thesis statement. This feature was particularly useful in organizing my thoughts and ensuring a logical flow.
5. Grammar and Style Checker:
To polish my writing, WriteGo offered a grammar and style checker that reviewed my work for errors and suggested improvements. This ensured my final paper was professional and error-free.
Putting WriteGo to the Test
Eager to see if WriteGo could solve my writer's block, I started by using the idea generator. I entered the general theme of "technology and society" and waited for the AI to work its magic. Within seconds, I had a list of intriguing topics, including "The Impact of Social Media on Mental Health," "How AI is Changing the Workplace," and "The Role of Technology in Education."
Inspired by the suggestions, I chose to focus on "The Impact of Social Media on Mental Health." Next, I used the thesis statement creator to craft a strong thesis: "While social media offers numerous benefits, its impact on mental health can be detrimental, necessitating a balanced approach to its use."
With a clear topic and thesis in hand, I moved on to the research assistant. WriteGo summarized key articles and provided relevant statistics, which I used to build the body of my paper. The outline generator helped me organize my arguments and evidence into a coherent structure.
As I wrote, the grammar and style checker ensured my writing was polished and professional. By the time I finished, I had a well-researched, logically structured, and error-free paper.
The Results
Submitting my paper, I felt a sense of relief and confidence I hadn't experienced in a long time. When the grades were finally posted, I was thrilled to see that I had received an A. My professor praised the clarity of my arguments, the thoroughness of my research, and the overall quality of my writing.
Conclusion
The accidental discovery of WriteGo was a game-changer for me. It demonstrated that even in moments of desperation, the right tools can provide the support and inspiration needed to overcome writer's block and produce high-quality work. WriteGo not only helped me generate ideas but also streamlined the entire writing process, making it more efficient and less stressful.
For anyone struggling with finding ideas or refining their writing, I highly recommend giving WriteGo a try. Sometimes, the best solutions come from unexpected places, and WriteGo was the perfect tool to help me navigate the challenges of academic writing.
[writego](https://writego.ai/app) | writegoai |
1,870,076 | Logto x Cloudflare Workers: How to secure your workers from public access? | In this article, we introduced how to secure your Cloudflare Workers APIs with Logto. We used Hono as... | 0 | 2024-05-30T08:05:05 | https://blog.logto.io/logto-x-cloudflare-workers/ | webdev, javascript, opensource, serverless | In this article, we introduced how to secure your Cloudflare Workers APIs with Logto. We used Hono as the web application framework to streamline development.
---
[Cloudflare Workers](https://developers.cloudflare.com/workers/) (use Workers for short in following content) provides a serverless execution environment that allows you to create new applications or augment existing ones without configuring or maintaining infrastructure.
With Workers, you can build your serverless applications and deploy instantly across the globe for exceptional performance, reliability, and scale. Workers not only offers exceptional performance but also provides a remarkably generous free plan and affordable paid plans. Whether you're an individual developer or a large-scale team, Workers empowers you to rapidly develop and deliver products while minimizing operational overhead.
Workers are publicly accessible by default, necessitating protection measures to prevent attacks and misuse. [Logto](https://logto.io/) delivers a comprehensive, user-friendly, and scalable identity service that can safeguards Workers and all other web services.
This article delves into the process of securing your Workers using Logto.
# Build a Workers sample
Let's first build a Workers sample project with Hono on local machine.
```
// src/index.ts
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (request.method === 'GET' && request.url.endsWith('/greet')) {
return new Response('Hello Workers!', { status: 200 });
} else {
return new Response('Not Found', { status: 404 });
}
},
};
```
We use Wrangler CLI to deploy the sample to Cloudflare, hence we can access to the path.

# Guard Workers APIs
In order to compare public accessible API and protected API, we add a `GET /auth/greet` API which requires specific scopes to access.
```
// src/index.ts
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (request.method === 'GET' && request.url.endsWith('/auth/greet')) {
await authorizationValidator(request, env, ['greet:visitor']);
return new Response('Hello Workers! (Authenticated)', { status: 200 });
} else if (request.method === 'GET' && request.url.endsWith('/greet')) {
return new Response('Hello Workers!', { status: 200 });
} else {
return new Response('Not Found', { status: 404 });
}
},
};
```
We can not access to the corresponding API without proper permission.

In order to properly manage the access to Workers APIs, we introduce Logto.
# Setup Logto
Register an account if you do not have one.
We use Machine-to-machine (M2M) as an example to access the protected Workers APIs because it's straight forward. If you want to grant access to your web app users, the setup is quite similar, but you should use “User” role instead of “Machine-to-machine” role.
1. Enter [Logto Admin Console](https://auth.logto.io/sign-in) and go to “API resource” tab, create an API resource named “Workers sample API” with resource indicator to be `https://sample.workers.dev/` . Also create a permission `greet:visitor` for this API resource.
2. Create “Workers admin role”, which is a “Machine-to-machine” role, and assign the greet:visitor scope to this role.
3. Create a M2M app and assign the “Workers admin role” to the app.
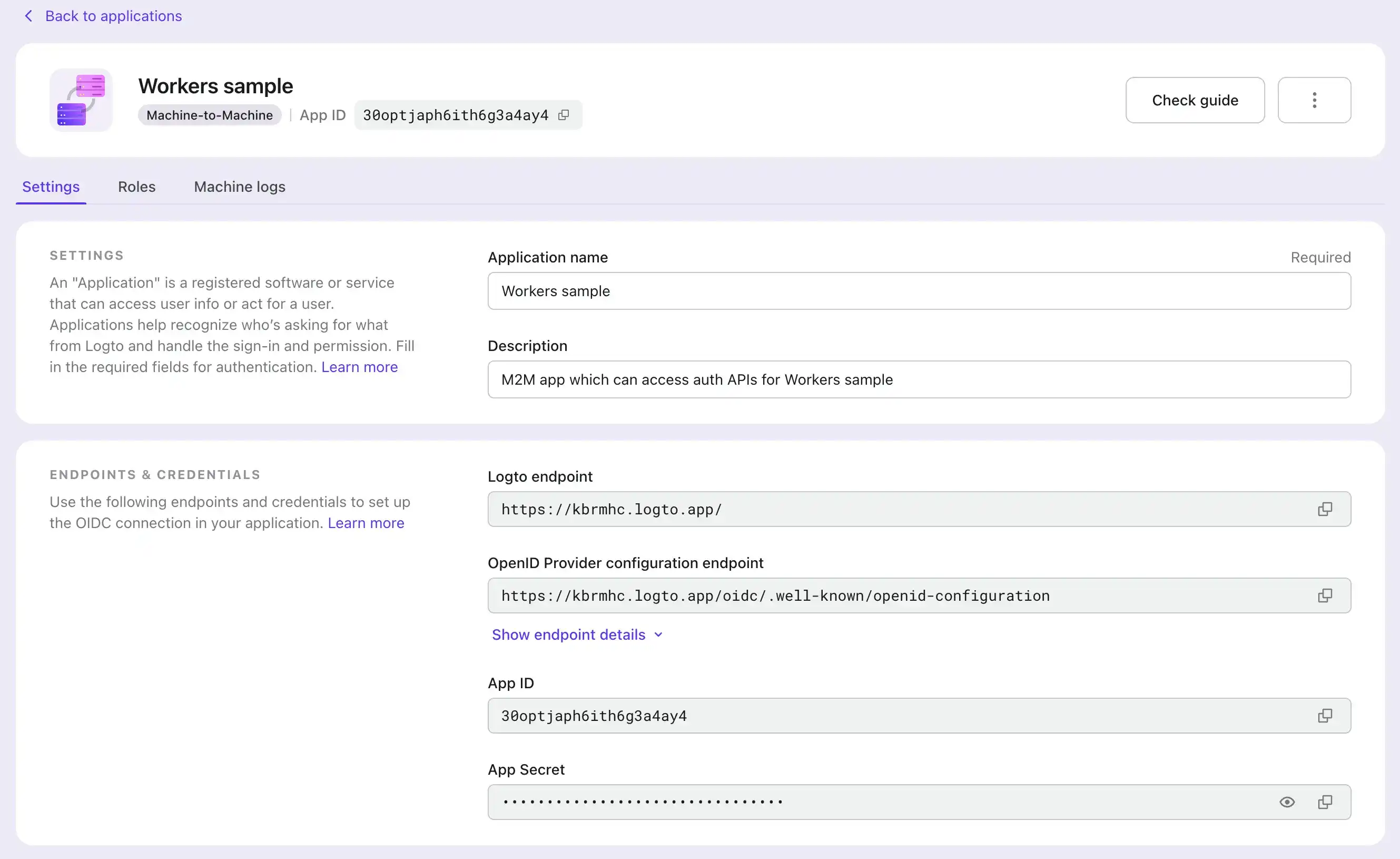
# Update Workers auth validator
Since Logto uses JWT access token under the hood, we need to implement the JWT validation logic in Workers.
Since the JWT access token is issued by Logto, we need to:
1. Get corresponding public key to verify the signature.
2. Verify the JWT access token's consumer to be Workers APIs.
These constants can be configured in `wrangler.toml` file [[1](https://developers.cloudflare.com/workers/configuration/environment-variables/)] and will be deployed as Workers' environment variables. You can also manage the environment variables manually on Cloudflare Dashboard.
```
// src/error.ts
export class AuthenticationError extends Error {
name = 'AuthenticationError';
constructor(
message: string,
public readonly error?: unknown
) {
super(message);
}
}
export class ServerError extends Error {
name = 'ServerError';
}
// src/index.ts
/** Build API authorization */
import { createRemoteJWKSet, jwtVerify } from 'jose';
const buildGetJwkSet = async (issuerEndpoint: URL) => {
const appendedEndpoint = new URL('/oidc/.well-known/openid-configuration', issuerEndpoint);
const fetched = await fetch(appendedEndpoint, {
headers: {
'content-type': 'application/json',
},
});
const json = await fetched.json();
const result = z.object({ jwks_uri: z.string(), issuer: z.string() }).parse(json);
const { jwks_uri: jwksUri, issuer } = result;
return Object.freeze([createRemoteJWKSet(new URL(jwksUri)), issuer] as const);
};
export const verifyTokenWithScopes = async (
token: string,
env: Env,
requiredScopes: string[] = []
) => {
const issuerEndpoint = env.ISSUER_ENDPOINT;
const workerResourceIndicator = env.WORKER_RESOURCE_INDICATOR;
console.log('token', token);
console.log('issuerEndpoint', issuerEndpoint);
if (typeof issuerEndpoint !== 'string') {
throw new ServerError('The env variable `ISSUER_ENDPOINT` is not set.');
}
if (typeof workerResourceIndicator !== 'string') {
throw new ServerError('The env variable `WORKER_RESOURCE_INDICATOR` is not set.');
}
console.log('workerResourceIndicator', workerResourceIndicator);
console.log('requiredScopes', requiredScopes);
const [getKey, issuer] = await buildGetJwkSet(new URL(issuerEndpoint));
try {
const {
payload: { scope },
} = await jwtVerify(token, getKey, {
issuer,
audience: workerResourceIndicator,
});
const scopes = typeof scope === 'string' ? scope.split(' ') : [];
if (!requiredScopes.every((scope) => scopes.includes(scope))) {
throw new AuthenticationError('The token does not have required scopes.');
}
} catch (error) {
throw new AuthenticationError('JWT verification failed.', error);
}
return true;
};
async function authorizationValidator(
request: Request,
env: Env,
requiredScopes: string[] = []
): Promise<Request> {
// Check if the Authorization header exists
const authHeader = request.headers.get('Authorization');
if (!authHeader || !authHeader.startsWith('Bearer ')) {
throw new AuthenticationError('Unauthorized, Bearer auth required.');
}
// Extract the token from the Authorization header
const token = authHeader.split(' ')[1];
if (!token) {
throw new AuthenticationError('Unauthorized, missing Bearer token.');
}
// Perform additional validation or processing with the token if needed
await verifyTokenWithScopes(token, env, requiredScopes);
// Return the authorized request
return request;
}
/** Build API authorization */
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
try {
if (request.method === 'GET' && request.url.endsWith('/auth/greet')) {
// Check required scopes
await authorizationValidator(request, env, ['greet:visitor']);
return new Response('Hello Workers! (authenticated)', { status: 200 });
} else if (request.method === 'GET' && request.url.endsWith('/greet')) {
return new Response('Hello Workers!', { status: 200 });
} else {
return new Response('Not Found', { status: 404 });
}
} catch (error) {
return errorHandler(request, env, ctx, error);
}
},
};
```
After deploying the Workers project to Cloudflare, we can test whether APIs are successfully protected.
1. Get access token
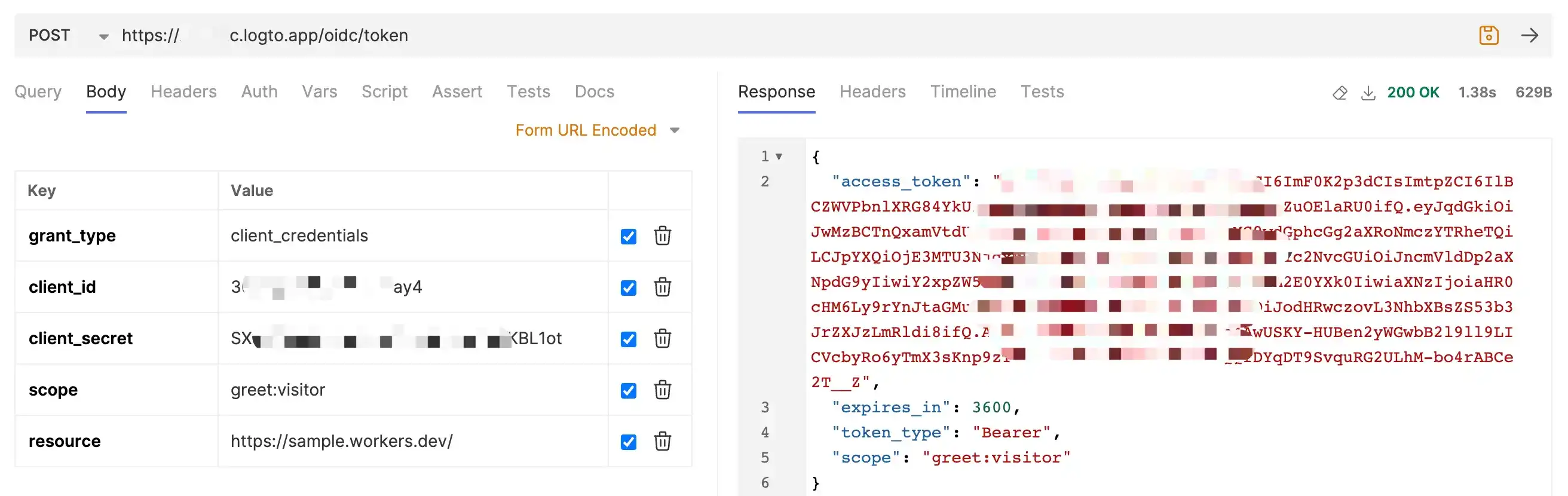

2. Request Workers `GET /auth/greet` API

# Conclusion
With the step-by-step guide in this article, you should be able to use Logto to build guard for your Workers APIs.
In this article, we've employed the Wrangler CLI for local development and deployment of Workers projects. Cloudflare additionally offers robust and versatile [Workers APIs](https://developers.cloudflare.com/api/operations/worker-script-list-workers) to facilitate deployment and management.
Consider developing a SaaS application. The Cloudflare API empowers you to deploy dedicated Workers for each tenant at ease, in the mean time, Logto ensures that access tokens remain exclusive to their respective tenants. This granular control prevents unauthorized access across tenants, enhancing security and data privacy for your SaaS app users.
Logto's adaptable and robust architecture caters to the diverse authentication and authorization needs of various applications. Whether you're building a complex SaaS platform or a simple web app, Logto provides the flexibility and scalability to meet your specific requirements.
{% cta https://logto.io/?ref=dev %} Try Logto Cloud for free {% endcta %}
| palomino |
1,870,075 | Solidity Interview Questions and Answers | Q1. What is an event in Solidity? An event in Solidity is a way to log and notify external parties... | 0 | 2024-05-30T08:04:43 | https://dev.to/lalyadav/solidity-interview-questions-and-answers-4p63 | solidity, programming, coding, soliditytutorial | Q1. What is an event in Solidity?
An event in [Solidity](https://www.onlineinterviewquestions.com/solidity-interview-questions) is a way to log and notify external parties about specific occurrences within a smart contract. Events are emitted using the emit keyword and can be listened to off-chain to track contract activity.

Q2. How do you deploy a smart contract on Ethereum?
To deploy a smart contract on Ethereum, you first compile the Solidity code using a compiler like Remix or Truffle. Then, you deploy the compiled bytecode to the Ethereum blockchain using a tool like MetaMask or Geth.
Q3. What is the purpose of the payable modifier in Solidity?
The payable modifier in Solidity allows a function to receive Ether along with a transaction. It enables the function to accept Ether transfers and perform actions like transferring Ether to other addresses or updating contract state.
Q4. Explain the difference between storage, memory, and calldata in Solidity.
In Solidity, storage refers to persistent storage on the blockchain, where contract state variables are stored. memory is temporary storage used for variables in function execution. calldata is a special data location that contains function arguments and data passed during external function calls.
Q5. How do you implement inheritance in Solidity?
In Solidity, inheritance is implemented using the is keyword. A contract can inherit from one or more parent contracts, inheriting their state variables and functions. Child contracts can override inherited functions or add new functionality.
Q6. What are modifiers in Solidity?
Modifiers in Solidity are reusable code snippets that can be applied to functions to add additional functionality or validations. They are used to enhance code readability and reduce duplication by applying common checks or actions to multiple functions.
Q7. How do you test a Solidity smart contract?
Solidity smart contracts can be tested using frameworks like Truffle or tools like Remix. Test scripts are written to simulate various scenarios and verify the behavior of the contract. Tests cover functionalities, edge cases, and error handling to ensure contract robustness.
Summary
Solidity interview questions and answers, you’ll be well-prepared to demonstrate your understanding of blockchain development concepts and secure your position as a Solidity developer. Read more: Online Interview Questions | lalyadav |
1,870,074 | How to Use Google Gemini for Next.js with Streaming Output | Introduction LLM applications are becoming increasingly popular. However, there are... | 27,713 | 2024-05-30T08:03:34 | https://medium.com/@hantian.pang/how-to-use-google-gemini-for-next-js-with-streaming-output-195c9c423761 | webdev, nextjs, gemini, llm | ## Introduction
LLM applications are becoming increasingly popular. However, there are numerous LLM models, each with its differences. Handling streaming output can be complex, especially for new front-end developers.
Thanks to the [AI SDK](https://sdk.vercel.ai/) developed by Vercel, implementing LLM chat in next.js with streaming output has become incredibly easy. Next, I'll provide a step-by-step tutorial on how to integrate Google Gemini into your front-end project.
## Create a Google AI Studio Account
Head to [Google AI Studio](https://aistudio.google.com) and signup, after you login, you can find the button “Get API Key” on the left, click it and create a API Key. This API Key will be used later.
## Create a New Next.js Project
To create a new Next.js project, enter the command `npx create-next-app@latest your-new-project`. Make sure you choose App route mode. After that, run `npm dev` and open `localhost:3000` in your preferred browser to verify if the new project is set up correctly.
Next, you need to install the AI SDK:
```bash
pnpm install ai
```
The AI SDK uses an advanced provider design, allowing you to implement your own LLM provider. Currently, we only need to install the official Google Provider.
```bash
pnpm install @ai-sdk/google
```
## Set Your API Key in Your Local Environment
Next.js integrates well with environment variables. Simply create a file named `.env.local` in the root folder of your project.
```
GOOGLE_GENERATIVE_AI_API_KEY={your API Key}
```
Afterwards, the AI SDK will automatically load your key when you use Google AI to generate text.
## Server-Side Code
Now that you've gathered all the prerequisites for your LLM application, create a new file named `actions.ts` in the `app` folder:
```tsx
"use server";
import { google } from "@ai-sdk/google";
import { streamText } from "ai";
import { createStreamableValue } from "ai/rsc";
export interface Message {
role: "user" | "assistant";
content: string;
}
export async function continueConversation(history: Message[]) {
"use server";
const stream = createStreamableValue();
const model = google("models/gemini-1.5-pro-latest");
(async () => {
const { textStream } = await streamText({
model: model,
messages: history,
});
for await (const text of textStream) {
stream.update(text);
}
stream.done();
})().then(() => {});
return {
messages: history,
newMessage: stream.value,
};
}
```
Let me provide some explanation about this code.
1. `interface Message` is a shared interface that establishes the structure of a message. It includes two properties: 'role' (which can be either 'user' or 'assistant') and 'content' (the actual text of the message).
2. The `continueConversation` function is a server component function which uses the history of the conversation to generate the assistant's response. The function communicates with Google's Gemini model to generate a streaming text output.
3. The `streamText` function is part of the AI SDK and it creates a text stream that will be updated with the assistant's response as it is generated.
## Client-Side Code
Next, replace the contents of `page.tsx` with the new code:
```tsx
"use client";
import { useState } from "react";
import { continueConversation, Message } from "./actions";
import { readStreamableValue } from "ai/rsc";
export default function Home() {
const [conversation, setConversation] = useState<Message[]>([]);
const [input, setInput] = useState<string>("");
return (
<div>
<div>
{conversation.map((message, index) => (
<div key={index}>
{message.role}: {message.content}
</div>
))}
</div>
<div>
<input
type="text"
value={input}
onChange={(event) => {
setInput(event.target.value);
}}
/>
<button
onClick={async () => {
const { messages, newMessage } = await continueConversation([
...conversation,
{ role: "user", content: input },
]);
let textContent = "";
for await (const delta of readStreamableValue(newMessage)) {
textContent = `${textContent}${delta}`;
setConversation([
...messages,
{ role: "assistant", content: textContent },
]);
}
}}
>
Send Message
</button>
</div>
</div>
);
}
```
This is a very simple UI you can continue talk with LLM model now. There are some important snips:
1. The `input` field captures the user's input. It is controlled by a React state variable that gets updated every time the input changes.
2. The `button` has an `onClick` event that triggers the `continueConversation` function. This function takes the current conversation history, appends the user's new message, and waits for the assistant's response.
3. The `conversation` array holds the history of the conversation. Each message is displayed on the screen, and new messages are appended at the end. By using `readStreamableValue` from the AI SDK, we're able to read the streaming output value from the server component function and update the conversation in real-time.
## Let's Test Now
I type "who are you" into the input placeholder.
Here is the output of Google Gemini. You'll notice that the output is printed in a streaming manner.
## References
1. Documentation for the AI SDK: https://sdk.vercel.ai/docs/introduction
2. Google AI Studio: https://ai.google.dev/aistudio | ppaanngggg |
1,870,069 | Macroquad Rapier ECS: Using Bevy ECS in Macroquad Game | Macroquad Rapier ECS 🦀 Rust game dev — using bevy's 🧩 Entity Component System in a Macroquad game with Rapier physics. | 0 | 2024-05-30T08:03:14 | https://rodneylab.com/macroquad-rapier-ecs/ | rust, gamedev, bevy | ---
title: "Macroquad Rapier ECS: Using Bevy ECS in Macroquad Game"
published: "true"
description: "Macroquad Rapier ECS 🦀 Rust game dev — using bevy's 🧩 Entity Component System in a Macroquad game with Rapier physics."
tags: "rust, gamedev, bevy"
canonical_url: "https://rodneylab.com/macroquad-rapier-ecs/"
cover_image: "https://dev-to-uploads.s3.amazonaws.com/uploads/articles/h9j5dm760dk1oz90ysuf.png"
---
## 🐣 Using Bevy Entity Component System outside of Bevy
Not every game needs an Entity Component System (**ECS**), but for this Macroquad Rapier ECS post, I was keen to see how you might add an ECS to a Macroquad game with Rapier physics.
In a <a href="https://rodneylab.com/deploying-your-rust-wasm-game/">previous post, I used the Shipyard ECS with Macroquad</a>. I have been working through a build-your-own physics engine tutorial, which used the Bevy game engine. I loved the **ergonomics** of the embedded ECS, so thought, I would take it for a spin here. **Rapier** the Rust physics engine used here has a Bevy plugin, but I wanted to try using both Rapier and the stand-alone **Bevy ECS outside of Bevy**, just for the challenge.
## 🧱 Macroquad Rapier ECS: What I Built
I continued with the bubble simulation, used for a few recent posts. It had no ECS, dozens of entities and a few other features that made it interesting to try with an ECS data model. So that was my starting point.

The simulation releases bubbles which float to the top of the screen, where they are trapped by a Rapier height field. Once all existing bubbles are settled, the simulation spawns a fresh one.
The simulation uses a random number generator to decide on the initial velocity of spawned balls, and has running and paused states. The simulation triggers the paused state when the bubbles almost completely fill the window. Both the random number generator and the simulation state are **singletons**, and fit well into the ECS resource model. I also put the physics engine itself into an ECS resource. The <a href="https://rodneylab.com/c++-game-dev-libraries/">C/C++ flecs ECS library</a>, for example, calls resources singletons.
### The Simulation within the ECS Model
As you would expect, each bubble is an entity. If you are new to ECSs you might imagine the ECS entities as rows of a database table. In this database world, the table columns are components. In my case, the balls all have the same components:
- a circle static mesh (which encodes colour and size data needed for rendering);
- a circle collider (for handling physical collisions with Rapier); and
- position and velocity components (used for updating the simulation physics).
Systems mutate the component properties, for example, there is a ball update system, which uses Rapier, to work out what the current velocity of the bubble is, at each step, then update the velocity component.
In the following sections, we look at some code snippets to help illuminate the points here, and hopefully give you an idea of how I put the simulation together, adding an ECS to Macroquad. The **full code is on GitHub**, and there is a link to it further down.
## 🧩 Components
I just mentioned that bubble entities each have a few components. Here is some example code for spawning a new ball using the simulation ECS:
```rust
let _ball_entity = world.spawn((
Position(new_ball_position),
CircleMesh {
colour: BALL_COLOURS[macroquad_rand::gen_range(0, BALL_COLOURS.len())],
radius: Length::new::<length::meter>(BALL_RADIUS),
},
CircleCollider {
radius: Length::new::<length::meter>(BALL_RADIUS),
physics_handle: None,
},
Velocity(new_ball_velocity),
));
```
The new entity gets a `Position`, `CircleMesh`, `CircleCollider` and `Velocity`. The number of components here is arbitrary, and not fixed (as it might be when calling a constructor using an object-oriented approach). This grants flexibility as you develop the simulation or game.
Also note, I follow a Rust convention in naming the `_ball_entity` identifier. The initial underscore (`_`) indicates the identifier is not used anywhere else in the scope. We do not need it later, since the systems used to query and mutate the component properties, operate on entities with specific sets of components (properties). We will see this more clearly later.
In an ECS model, the entity is not much more than an integer, which Bevy ECS can use as an ID.
### Units of Measurement
In a previous <a href="https://rodneylab.com/rapier-physics-with-units-of-measurement/">post on adding units of measurement to a Rapier game</a>, I introduced the length units used in the snippet above. This pattern of using units leveraging Rusts type system, sense-checking calculations and helping to avoid unit conversion errors.
## 🏷️ Macroquad Rapier ECS: Tags
The `Position` and `Velocity` components, mentioned before, are structs with associated data. You can also have ECS tags, which are akin to components without data. Rapier has a type of collider that just detects a collision, and beyond that does not interact with the physics system, these are **sensors**.

I used a `Sensor` tag in the ECS for colliders that are sensors, which helps to separate them out when running systems. The only sensor in the simulation runs along the bottom of the window. Towards the end of the simulation, when the window is almost full, a newly spawned bubble will inevitably bounce off an existing one and collide with the floor sensor. I added a system to pause the simulation when this occurs, effectively ending the simulation.
```rust
#[derive(Component, Debug)]
pub struct CuboidCollider {
pub half_extents: Vector2<f32>,
pub position: Isometry<f32, Unit<Complex<f32>>, 2>,
pub translation: Vector2<f32>,
}
#[derive(Component, Debug)]
pub struct Sensor;
```
This, above, code snippet shows a `CuboidCollider` (used for the floor sensor), which is a regular component and then the `Sensor` tag. The code snippet, below, initializes the floor sensor:
```rust
pub fn spawn_ground_sensor_system(mut commands: Commands) {
let collider_half_thickness = Length::new::<length::meter>(0.05);
let window_width = Length::new::<pixel>(WINDOW_WIDTH);
let window_height = Length::new::<pixel>(WINDOW_HEIGHT);
commands.spawn((
CuboidCollider {
half_extents: vector![
0.5 * window_width.get::<length::meter>(),
collider_half_thickness.value
],
translation: vector![
0.0,
(-window_height - collider_half_thickness).get::<length::meter>()
],
position: Isometry2::identity(),
},
Sensor,
));
}
```
Note, the `Sensor` tag is included. To spawn the wall colliders on either side of the window, a very similar block is used, only omitting the `Sensor` tag. We will see how this can be used with systems next.
## 🎺 Systems
Systems are code blocks, which are only run on components belonging to a specified component set. As an example, here is the system for updating bubble position and velocity within the game loop:
```rust
pub fn update_balls_system(
mut query: Query<(&mut Position, &mut Velocity, &CircleCollider)>,
physics_engine: Res<PhysicsEngine>,
) {
for (mut position, mut velocity, circle_collider) in &mut query {
if let Some(handle) = circle_collider.physics_handle {
let ball_body = &physics_engine.rigid_body_set[handle];
position.0 = vector![
Length::new::<length::meter>(ball_body.translation().x),
Length::new::<length::meter>(ball_body.translation().y)
];
velocity.0 = vector![
VelocityUnit::new::<velocity::meter_per_second>(ball_body.linvel().x),
VelocityUnit::new::<velocity::meter_per_second>(ball_body.linvel().y)
];
}
}
}
```
This system runs on any entity that satisfies the query of having `Position`, `Velocity` and `CircleCollider` components. We can be more prescriptive, choosing entities that have a set of components, and also, either do, or do not have some other component or tag. We use `With` when creating the floor sensor during the simulation initialization:
```rust
pub fn create_cuboid_sensors_system(
query: Query<&CuboidCollider, With<Sensor>>,
mut physics_engine: ResMut<PhysicsEngine>,
) {
for collider in query.iter() {
let new_collider =
ColliderBuilder::cuboid(collider.half_extents.x, collider.half_extents.y)
.position(collider.position)
.translation(collider.translation)
.sensor(true)
.build();
physics_engine.collider_set.insert(new_collider);
}
}
```
As you might expect, the equivalent code for creating the side wall colliders uses `Without` in its query, and omits `.sensor(true)` in its Rapier setup code.
## 📆 Schedules
We use ECS schedules to determine when systems run. The simulation has:
- a setup schedule, run once during simulation setup,
- a running schedule, executed on every run through the game loop in simulate/running mode; and
- a paused schedule, runs when we have paused the simulation.
Bevy ECS organizes the systems above into these schedules, which can include constraints to ensure systems run in the right order.
Here is the paused schedule code:
```rust
let mut paused_schedule = Schedule::default();
paused_schedule.add_systems(draw_balls_system);
```
This just needs to draw the balls (the screen is cleared in each game loop iteration, even while the simulation is paused). The running schedule features more systems.
That code above is triggered in the game loop, while the simulation state is set to paused:
```rust
loop {
// TRUNCATED...
clear_background(GUNMETAL);
let simulation_state = world
.get_resource::<SimulationState>()
.expect("Expected simulation state to have been initialised");
match &simulation_state.mode {
SimulationMode::Running => {
playing_schedule.run(&mut world);
}
SimulationMode::Paused => paused_schedule.run(&mut world),
}
next_frame().await;
}
```
That’s it! We covered all the major constituents of an ECS!
## 🙌🏽 Macroquad Rapier ECS: Wrapping Up
In this post on Macroquad Rapier ECS, we got an introduction to working with an ECS in Macroquad. In particular, we saw:
- the main constituents of an ECS including **resources, schedules and tags, as well as entities, components, and systems**;
- why you might want to add **tags, and how you can use them in Bevy ECS system queries along with <code>With</code> and <code>Without</code>**; and
- **ECS schedules for different game or simulation states**.
I hope you found this useful. As promised, you can <a href="https://github.com/rodneylab/macroquad-rapier-bevy-ecs">get the full project code on the Rodney Lab GitHub repo</a>. I would love to hear from you, if you are also new to Rust game development. Do you have alternative resources you found useful? How will you use this code in your own projects?
## 🙏🏽 Macroquad Rapier ECS: Feedback
If you have found this post useful, see links below for further related content on this site. Let me know if there are any ways I can improve on it. I hope you will use the code or starter in your own projects. Be sure to share your work on X, giving me a mention, so I can see what you did. Finally, be sure to let me know ideas for other short videos you would like to see. Read on to find ways to get in touch, further below. If you have found this post useful, even though you can only afford even a tiny contribution, please <a aria-label="Support Rodney Lab via Buy me a Coffee" href="https://rodneylab.com/giving/">consider supporting me through Buy me a Coffee</a>.
Finally, feel free to share the post on your social media accounts for all your followers who will find it useful. As well as leaving a comment below, you can get in touch via <a href="https://twitter.com/messages/compose?recipient_id=1323579817258831875">@askRodney</a> on X (previously Twitter) and also, join the <a href="https://matrix.to/#/%23rodney:matrix.org">#rodney</a> Element Matrix room. Also, see <a aria-label="Get in touch with Rodney Lab" href="https://rodneylab.com/contact/">further ways to get in touch with Rodney Lab</a>. I post regularly on <a href="https://rodneylab.com/tags/gaming/">Game Dev</a> as well as <a href="https://rodneylab.com/tags/rust/">Rust</a> and <a href="https://rodneylab.com/tags/c++/">C++</a> (among other topics). Also, <a aria-label="Subscribe to the Rodney Lab newsletter" href="https://newsletter.rodneylab.com/issue/latest-issue">subscribe to the newsletter to keep up-to-date</a> with our latest projects.
| askrodney |
1,870,073 | Using Tc-Bpf Program To Redirect Dns Traffic In Docker Containers | The adoption of eBPF (Extended Berkeley Packet Filter) has revolutionized high-performance... | 0 | 2024-05-30T08:01:45 | https://keploy.io/blog/technology/using-tc-bpf-program-to-redirect-dns-traffic-in-docker-containers | webdev, beginners, programming, python |

The adoption of eBPF (Extended Berkeley Packet Filter) has revolutionized high-performance applications, tracing, security, and packet filtering within the Linux kernel. Specifically, TC-BPF, a type of eBPF program attached to the Traffic Control (TC) layer, has emerged as a powerful tool for packet manipulation in both ingress and egress. This blog delves into the practical application of TC-BPF to redirect DNS queries in a Docker environment.
The intricate workings of Docker networking involve network namespaces, veth pairs, and a bridge interface, all contributing to the isolation of containers. Docker employs its own DNS server, and understanding how it intercepts DNS queries through iptables is crucial for our redirection strategy.
The TC-BPF program, attached to both loopback and eth0 interfaces, plays a pivotal role in this redirection process. We explore the use of the bpf_redirect_neigh helper function for efficient egress redirection, ensuring correct MAC addresses for the new route. The blog provides a step-by-step guide, including setting up the environment, writing TC-BPF programs, and deploying them using the tc tool.
The TC-BPF programs inspect DNS packets, redirecting them based on protocol and destination. UDP packets destined for Docker's DNS resolver trigger a redirection to an external DNS server. The programs intelligently modify packet headers, correcting checksums for a seamless redirection experience. Wireshark captures validate the successful redirection, showcasing the power and flexibility of TC-BPF in a Dockerized network.
This blog not only serves as a practical guide for implementing DNS redirection but also offers insights into the versatility of TC-BPF in enhancing network control within containerized environments.
**How DNS works in docker**
Docker uses network namespaces for network isolation. Inside each container namespace. We have a loopback interface and a eth0 interface. The eth0 interface is connected to the host network namespace with a veth pair. The veth interface of each container is connected together using a bridge interface. This interface is connected to the main host's interface for outgoing traffic using a NAT.
The resolvectl configuration in every docker container is 127.0.0.11:53 as the DNS server. The docker daemon runs its own DNS server that is exposed on all containers. As an example, let's say it is exposed on 127.0.0.11:41552. Now, docker configures iptables SNAT and DNAT rules to map port 53 to the port docker daemon is exposed in.
https://keploy.io/wp/wp-content/uploads/2024/05/Code-Coverage-in-Software-Testing-879x1024.webp
The application first makes a query to the DNS server specified in the resolvectl config. The DNS query made to 127.0.0.11:53 is intercepted by iptables, and the port is changed to reflect the actual DNS server port. Docker daemon gets the query and resolves it if it is container name/id. If not, then it is an external query so it uses the DNS resolver of the host to resolve the query and then sends a reply back to the application. Just like before, iptables is set up to intercept all traffic from the dockerd DNS resolver. It changes the source port of the reply to 53.
**Redirecting packets in TC-BPF**
TC-BPF has access to a bpf helper function called bpf_redirect. This can be used to redirect the packet to the TC hookpoint in both ingress and egress of any other interface. However, if redirecting to egress of a different interface, we must change the MAC addresses in the packets so they are correct for the new route. There is an egress side optimization with the bpf_redirect_neigh helper function. This fills the L2 layer based on the L3 Layer IP addresses using the routing table of the kernel. There also is a bpf_redirect_peer helper, which can do ingress-to-ingress redirecting but across namespaces. But since we won't need to do any redirecting across namespaces, we will not use this.
https://keploy.io/wp/wp-content/uploads/2024/05/Code-Coverage-in-Software-Testing.1-1024x455.webp
The dotted lines show the flow of the packet when redirected. First, the DNS query enters the loopback interface and then redirects it to the egress of the eth0 interface after changing the destination IP. Now, we must also redirect the reply that comes to the eth0 interface back to loopback after changing the IP address.
**Setting up the environment:**
We'll need Linux headers, clang, and build-essentials to build the programs and Wireshark to monitor the network.
```
sudo apt-get install -y build-essential clang llvm libelf-dev libpcap-dev \
gcc-multilib linux-tools-$(uname -r) linux-headers-$(uname -r) linux-tools-common \
linux-tools-generic libbpf-dev tcpdump wireshark
```
Let's also run the docker container, which we will redirect DNS queries from. Install tools like dig in the container using apt update && apt install dnsutils . This is so we can make DNS queries.
```
docker run --name dns_redirect -it ubuntu bash
```
**Writing the TC-BPF programs**
Let's write the tc-bpf programs. First, let's include some headers that we might need.
#include <linux/bpf.h>
#include <linux/pkt_cls.h>
#include <linux/if_ether.h>
#include <linux/if_packet.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <bpf/bpf_helpers.h>
Let's define some fixed variables.
LOOPBACK contains the IP 127.0.0.1 converted to an integer.
DOCKERD_IP is the IP address of the dockerd daemon DNS server, which is at 127.0.0.11.
DOCKERD_PORT is the port at which the dockerd daemon is exposed. We can find this out by doing:
```
sudo nsenter -n -t $(docker inspect --format {{.State.Pid}} <container_name>) lsof -i -P -n
```
We can't just do lsof inside the docker container since dockerd is running in the host pid namespace and hence invisible to processes inside the container. In our case, it is at port 41552.
APP_CONTAINER_IP is the IP of the eth0 interface in the container. We can find this out by doing docker inspect.
DNS_SERVER_IP and DNS_SERVER_PORT are the IP and port of the DNS server we would like to redirect to. In this case, we have set DNS_SERVER_IP to 1.1.1.1
We also set the interface indexes of both Loopback as well as Eth0. This can be found out by doing a simple ip a command inside the container.
```
#define LOOPBACK 2130706433
#define DOCKERD_IP 2130706443
#define DOCKERD_PORT 41552
#define APP_CONTAINER_IP 2886926338
#define DNS_SERVER_IP 16843009
#define DNS_SERVER_PORT 53
#define LOOPBACK_INTERFACE_INDEX 1
#define ETH0_INTERFACE_INDEX 2
```
Define some structs we might need. l3_fields is a struct that contains ipv4 source and destination. Whereas l4_fields contains the source port and destination port in the udp header.
```
struct l3_fields
{
__u32 saddr;
__u32 daddr;
};
struct l4_fields
{
__u16 sport;
__u16 dport;
};
struct udphdr {
__be16 source;
__be16 dest;
__be16 len;
__sum16 check;
};
```
Now, let's write the main part of the tc-bpf program.
Define the main sections and functions:
```
SEC("tc_loopback")
int dns_redirect_loopback_eth0(struct __sk_buff *skb){}
SEC("tc_eth0")
int dns_redirect_eth0_loopback(struct __sk_buff *skb){}
```
Now, let's declare all the variables we need.
```
void *data_end = (void *)(long)skb->data_end;
void *data = (void *)(long)skb->data;
struct ethhdr *eth = data;
struct iphdr *ip4h;
struct l3_fields l3_original_fields;
struct l3_fields l3_new_fields;
struct l4_fields l4_original_fields;
struct l4_fields l4_new_fields;
```
We need to perform some basic checks on the packet to make sure that the packet size is correct so we don't access memory that is out of bounds. The eBPF verifier will reject the program if we don't do this.
```
// Checking if eth headers are incomplete
if (data + sizeof(*eth) > data_end)
{
return TC_ACT_SHOT;
}
// Allowing IPV6 packets to passthrough without modification
if (ntohs(eth->h_proto) != ETH_P_IP)
{
return TC_ACT_OK;
}
// Checking if Ip headers are incomplete
if (data + sizeof(*eth) + sizeof(*ip4h) > data_end)
{
return TC_ACT_SHOT;
}
```
We can now load the IP address and ports in the packet for modification. We keep a version of the original fields in l3_original_fields and l4_original_fields since we need these to compare with to change the checksum.
```
ip4h = data + sizeof(*eth);
bpf_skb_load_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_original_fields, sizeof(l3_original_fields));
bpf_skb_load_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_original_fields, sizeof(l4_original_fields));
bpf_skb_load_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_new_fields, sizeof(l3_new_fields));
bpf_skb_load_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_new_fields, sizeof(l4_new_fields));
```
Everything until this stage is the same in both the programs to be attached to loopback and eth0. But here we come across the main difference.
Now, if the packet is UDP, i.e the protocol field in the IP header is 17, and the packet's destination is the dockerd daemon, we change:
the packet's source IP to the Container IP,
Its destination IP to the DNS server IP and
Its destination port to the DNS server port.
We don't change the source port since there is no need to.
Now, we have to correct the checksum in the IP header and UDP header. We use bpf_csum_diff to find the difference between old and new fields in the IP header. This is then used in bpf_l3_csum_replace to change the IP header checksum
For UDP header checksum it is calculated using a pseudo-header, which includes not only the UDP source and destination ports but also the source and destination IP as well. Thus, for this, we can use the chaining feature of bpf_csum_diff to find the total difference by passing in l3sum as one of the parameters. We finally change the checksum using bpf_l4_csum_replace.
We now use bpf_redirect_neigh to redirect the packet to the eth0 interface.
```
// Check if this is a dns packet
if (ip4h->protocol == 17)
{
if (data + sizeof(*eth) + sizeof(*ip4h) + sizeof(struct udphdr) > data_end)
{
return TC_ACT_SHOT;
}
struct udphdr *udph = data + sizeof(*eth) + sizeof(*ip4h);
if (ntohl(ip4h->daddr) == DOCKERD_IP && ntohs(udph->dest) == DOCKERD_PORT)
{
// Change sender address to ip of container
l3_new_fields.saddr = htonl(APP_CONTAINER_IP);
// Change destination address to ip of dns server
l3_new_fields.daddr = htonl(DNS_SERVER_IP);
// Change destination port to proxy port
l4_new_fields.dport = htons(DNS_SERVER_PORT);
// Store the modified fields
bpf_skb_store_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_new_fields, sizeof(l3_new_fields), BPF_F_RECOMPUTE_CSUM);
bpf_skb_store_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_new_fields, sizeof(l4_new_fields), BPF_F_RECOMPUTE_CSUM);
// Correct the Checksum
__u32 l3sum = bpf_csum_diff((__u32 *)&l3_original_fields, sizeof(l3_original_fields), (__u32 *)&l3_new_fields, sizeof(l3_new_fields), 0);
__u64 l4sum = bpf_csum_diff((__u32 *)&l4_original_fields, sizeof(l4_original_fields), (__u32 *)&l4_new_fields, sizeof(l4_new_fields), l3sum);
// update checksum
int csumret = bpf_l4_csum_replace(skb, sizeof(*eth) + sizeof(*ip4h) + offsetof(struct udphdr, check), 0, l4sum, BPF_F_PSEUDO_HDR);
csumret |= bpf_l3_csum_replace(skb, sizeof(*eth) + offsetof(struct iphdr, check), 0, l3sum, 0);
if (csumret)
{
return TC_ACT_SHOT;
}
// redirect packet to eth0 interface
__u32 ifindex = ETH0_INTERFACE_INDEX;
int ret = bpf_redirect_neigh(ifindex, NULL, 0, 0);
return ret;
}
}
```
The program to be attached to the eth0 interface is also mostly similar, but here we check if the packet's source is the DNS server, and we change:
the packet's source IP to the dockerd IP(127.0.0.11),
Its destination IP to the localhost IP (127.0.0.1)
Its source port to the dockerd port - 41552 in this case.
We don't change the destination port since there is no need to. This destination port is the same as the source port when the query was made and is the same port the application used to make the DNS query.
```
// Check if this is a dns packet
if (ip4h->protocol == 17)
{
if (data + sizeof(*eth) + sizeof(*ip4h) + sizeof(struct udphdr) > data_end)
{
return TC_ACT_SHOT;
}
struct udphdr *udph = data + sizeof(*eth) + sizeof(*ip4h);
if (ntohl(ip4h->saddr) == DNS_SERVER_IP && ntohs(udph->source) == DNS_SERVER_PORT)
{
// Change sender address to ip of Dockerd dns resolver
l3_new_fields.saddr = htonl(DOCKERD_IP);
// Change destination address to LOOPBACK
l3_new_fields.daddr = htonl(LOOPBACK);
// Change source port to port 53
l4_new_fields.sport = htons(DOCKERD_PORT);
bpf_skb_store_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_new_fields, sizeof(l3_new_fields), BPF_F_RECOMPUTE_CSUM);
bpf_skb_store_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_new_fields, sizeof(l4_new_fields), BPF_F_RECOMPUTE_CSUM);
// Correct the Checksum
__u64 l3sum = bpf_csum_diff((__u32 *)&l3_original_fields, sizeof(l3_original_fields), (__u32 *)&l3_new_fields, sizeof(l3_new_fields), 0);
__u64 l4sum = bpf_csum_diff((__u32 *)&l4_original_fields, sizeof(l4_original_fields), (__u32 *)&l4_new_fields, sizeof(l4_new_fields), l3sum);
// update checksum
int csumret = bpf_l4_csum_replace(skb, sizeof(*eth) + sizeof(*ip4h) + offsetof(struct udphdr, check), 0, l4sum, BPF_F_PSEUDO_HDR);
csumret |= bpf_l3_csum_replace(skb, sizeof(*eth) + offsetof(struct iphdr, check), 0, l3sum, 0);
if (csumret)
{
return TC_ACT_SHOT;
}
// redirect packet to loopback interface
__u32 ifindex = LOOPBACK_INTERFACE_INDEX;
int ret = bpf_redirect_neigh(ifindex, NULL, 0, 0);
return ret;
}
}
```
The full final program can be found here: https://github.com/amoghumesh/tcbpf_dnsredirect.
**Compiling and Attaching TC-BPF programs**
Write a Makefile to compile the program:
```
KDIR ?= /lib/modules/$(shell uname -r)/build
CLANG ?= clang
LLC ?= llc
ARCH := $(subst x86_64,x86,$(shell arch))
BIN := dns_redirect.o
CLANG_FLAGS = -I. -I$(KDIR)/arch/$(ARCH)/include \
-I$(KDIR)/arch/$(ARCH)/include/generated \
-I$(KDIR)/include \
-I$(KDIR)/arch/$(ARCH)/include/uapi \
-I$(KDIR)/include/uapi \
-include $(KDIR)/include/linux/kconfig.h \
-D__KERNEL__ -D__BPF_TRACING__ -Wno-unused-value -Wno-pointer-sign \
-D__TARGET_ARCH_$(ARCH) -Wno-compare-distinct-pointer-types \
-Wno-gnu-variable-sized-type-not-at-end \
-Wno-address-of-packed-member -Wno-tautological-compare \
-O2 -emit-llvm
all: $(BIN)
dns_redirect.o: dns_redirect.c
$(CLANG) $(CLANG_FLAGS) -g -c $< -o - | \
$(LLC) -march=bpf -mcpu=$(CPU) -filetype=obj -o $@
clean:
rm -f *.o
```
We can now run make to compile the program. Now, we load the programs into the Linux kernel using the traffic control tc tool.
First, we enter the namespace of the application container using nsenter
```
sudo nsenter -n -t $(docker inspect --format {{.State.Pid}} <container_name>) bash
```
Now we use tc to create a clsact qdisc.
```
tc qdisc add dev lo clsact
tc qdisc add dev eth0 clsact
```
Then we attach the bpf program as a filter to this qdisc.
```
tc filter add dev lo ingress bpf direct-action obj dns_redirect.o sec tc_loopback
tc filter add dev eth0 ingress bpf direct-action obj dns_redirect.o sec tc_eth0
```
We can now check if the programs are inserted by using tc filter show
```
tc filter show dev lo ingress
tc filter show dev eth0 ingress
```
If we see an output similar to this, we know that the programs have been attached.
https://keploy.io/wp/wp-content/uploads/2024/05/Code-Coverage-in-Software-Testing.2-1024x99.webp
Now let's make DNS queries using dig and observe them being redirected by running Wireshark along with a plugin like Edgeshark.
https://keploy.io/wp/wp-content/uploads/2024/05/Code-Coverage-in-Software-Testing.3.webp
In Wireshark, we can see the query is first made to 127.0.0.11, and then another query is made from 172.19.0.2, which is the IP of the container to 1.1.1.1. On the Reply also we can see the reply from 1.1.1.1 and then another packet from 127.0.0.11 to 127.0.0.1.
https://keploy.io/wp/wp-content/uploads/2024/05/Code-Coverage-in-Software-Testing.4-1024x230.webp
We see this since Wireshark captures packets after the tc hook. Since we are attaching the tc-bpf program on the ingress of loopback, Wireshark is able to capture the query from 127.0.0.1 -> 127.0.0.11. This would not have been possible if we had attached the TC program in the egress of the interface. The packet would be redirected before Wireshark can capture it.
Similarly, in the reply, we are redirecting to the egress hook of the loopback interface which is before the wireshark hook. Hence, it can capture the 127.0.0.11 -> 127.0.0.1 packet. Again if we used bpf_redirect to redirect packets directly to the ingress of the loopback interface, we would not see this packet captured.
Summary
We were able to successfully redirect traffic using tc-bpf in docker containers. Tc-bpf is used in many applications to elevate existing networking or as a replacement for iptables itself in Kubernetes CNIs like Cillium. Redirecting DNS queries is also an important requirement in Keploy, where we use eBPF to redirect DNS queries made only by the application. There is a whole host of use cases for tc-bpf in intelligent networking, with its full potential only beginning to surface now.
FAQ's
What is TC-BPF, and how is it utilized in Docker environments?
TC-BPF, is a type of eBPF program attached to the Traffic Control layer in the kernel. In Docker environments, it plays a crucial role in packet manipulation for both ingress and egress traffic. It can be used to redirect packets efficiently, inspect and modify packet headers, and control network traffic within containerized environments. TC-BPF enables advanced network control and manipulation, making it ideal for tasks such as DNS redirection in Docker.
How does Docker handle DNS queries, and why is understanding this important for DNS redirection strategies?
Docker utilizes its own DNS server, typically exposed on 127.0.0.11:53 within container namespaces. Understanding Docker's DNS handling is crucial for DNS redirection strategies because Docker intercepts DNS queries through iptables, mapping port 53 to the port where the Docker daemon's DNS server is exposed.
What are some common challenges or considerations when implementing DNS redirection with TC-BPF in Docker?
Some common challenges or considerations when implementing DNS redirection with TC-BPF in Docker include:
Ensuring compatibility with Docker networking configurations and iptables rules.
Handling packet checksums and header modifications correctly to avoid packet corruption or rejection.
Managing namespace isolation and ensuring that redirection occurs within the appropriate network context.
Testing and validating the redirection process to ensure correct functionality and performance.
Considering security implications and potential impact on network stability when deploying TC-BPF program based solutions in production environments. | keploy |
1,869,382 | TW Elements - Containers. Free UI/UX design course | Containers If you've used Bootstrap before, you probably remember that there containers... | 0 | 2024-05-30T08:00:00 | https://dev.to/keepcoding/tw-elements-containers-free-uiux-design-course-3e61 | tailwindcss, tutorial, css, html | ## Containers
If you've used Bootstrap before, you probably remember that there containers are necessary for the proper functioning of the grid system.
So it can be a bit confusing that in Tailwind containers don't have such an important function, and grid can do just fine without them.
However, this does not mean that containers are useless in Tailwind. Quite the opposite. But they just play a different role.
Let's have a look at them.
## How does a container work in Tailwind CSS?
In Tailwind we use containers to set a maximum width for a content we want to place inside of the container.
In other words - we use containers so that a given element / content placed in this container does not extend to the full width of the screen.
Have a look at the example below.
Let's add a long text paragraph to the <main> section of our project. In addition, let's add the .bg-red-200 class to it to be able to clearly see how wide this paragraph extends.
**HTML**
```
<!--Main layout-->
<main>
<p class="bg-red-200">
Lorem ipsum dolor sit amet consectetur adipisicing elit. Corporis
blanditiis aspernatur vel. Similique illum labore eaque tempora
accusamus unde eius sint ad voluptate, autem facilis incidunt harum
corporis facere, sapiente consectetur? Suscipit molestiae, expedita,
sunt, corrupti hic dignissimos nesciunt ipsum voluptates dolorem soluta
ut architecto sapiente ratione quidem iure facilis ab dolore incidunt
quia? Quidem enim accusamus sapiente sed molestias neque assumenda,
obcaecati natus. Dolor iure necessitatibus, cupiditate minima nesciunt
tenetur animi sint debitis aliquid facere aliquam hic nemo odio
repellendus aspernatur voluptates id at libero voluptas inventore
doloribus eveniet magni sunt. Eveniet, dolorem distinctio. Quibusdam
libero ipsam alias est iste nisi voluptas vitae, natus voluptate
obcaecati tempora id labore!
</p>
</main>
<!--Main layout-->
```
The paragraph will span the full width of the page. This is often not a desirable situation, which is why we have containers at our disposal.

So what happens if we add an element with class .container to the project and put our paragraph in it?
**HTML**
```
<!--Main layout-->
<main>
<div class="container">
<p class="bg-red-200">
Lorem ipsum dolor sit amet consectetur adipisicing elit. Corporis
blanditiis aspernatur vel. Similique illum labore eaque tempora
accusamus unde eius sint ad voluptate, autem facilis incidunt harum
corporis facere, sapiente consectetur? Suscipit molestiae, expedita,
sunt, corrupti hic dignissimos nesciunt ipsum voluptates dolorem
soluta ut architecto sapiente ratione quidem iure facilis ab dolore
incidunt quia? Quidem enim accusamus sapiente sed molestias neque
assumenda, obcaecati natus. Dolor iure necessitatibus, cupiditate
minima nesciunt tenetur animi sint debitis aliquid facere aliquam hic
nemo odio repellendus aspernatur voluptates id at libero voluptas
inventore doloribus eveniet magni sunt. Eveniet, dolorem distinctio.
Quibusdam libero ipsam alias est iste nisi voluptas vitae, natus
voluptate obcaecati tempora id labore!
</p>
</div>
</main>
<!--Main layout-->
```
Well, actually the paragraph won't be full-width anymore, but that's not quite what we wanted. A strange-looking gap appeared on the right side.

This is because, unlike, for example containers in Bootstrap, containers in Tailwind do not auto-center.
To get the centering effect, we need to add the .mx-auto class to the .container, which will divide the left and right margins of the .container equally.
**HTML**
```
<!--Main layout-->
<main>
<div class="container mx-auto">
<p class="bg-red-200">
Lorem ipsum dolor sit amet consectetur adipisicing elit. Corporis
blanditiis aspernatur vel. Similique illum labore eaque tempora
accusamus unde eius sint ad voluptate, autem facilis incidunt harum
corporis facere, sapiente consectetur? Suscipit molestiae, expedita,
sunt, corrupti hic dignissimos nesciunt ipsum voluptates dolorem
soluta ut architecto sapiente ratione quidem iure facilis ab dolore
incidunt quia? Quidem enim accusamus sapiente sed molestias neque
assumenda, obcaecati natus. Dolor iure necessitatibus, cupiditate
minima nesciunt tenetur animi sint debitis aliquid facere aliquam hic
nemo odio repellendus aspernatur voluptates id at libero voluptas
inventore doloribus eveniet magni sunt. Eveniet, dolorem distinctio.
Quibusdam libero ipsam alias est iste nisi voluptas vitae, natus
voluptate obcaecati tempora id labore!
</p>
</div>
</main>
<!--Main layout-->
```
And now, by dividing the left and right margins equally (thanks to .mx-auto class), our container has been centered.

Alright, now that we know how containers work, let's use them for something practical.
But first, let's remove this sample container paragraph from the _main_ section, as it was for demonstration purposes only.
**HTML**
```
<!--Main layout-->
<main></main>
<!--Main layout-->
```
## Add container to the Navbar
Currently, the elements in our Navbar are stretched to full width and touch the left and right edges of the browser window.
It would be nice if we could give them some space on the sides and center them.
This is the perfect opportunity to make use of the container.
Inside of the <nav> element, find the <div> element that is its direct child. There will already be a few other classes there, but that's okay.
Add .container and .mx-auto classes there:
**HTML**
```
<!-- Navbar -->
<nav
class="flex-no-wrap relative flex w-full items-center justify-between bg-neutral-100 py-2 shadow-md shadow-black/5 dark:bg-neutral-600 dark:shadow-black/10 lg:flex-wrap lg:justify-start lg:py-4"
data-twe-navbar-ref>
<!-- Here add a container -->
<div
class="container mx-auto flex w-full flex-wrap items-center justify-between px-3">
<!-- Hamburger button for mobile view -->
<button
class="block border-0 bg-transparent px-2 text-neutral-500 hover:no-underline hover:shadow-none focus:no-underline focus:shadow-none focus:outline-none focus:ring-0 dark:text-neutral-200 lg:hidden"
type="button"
data-twe-collapse-init
data-twe-target="#navbarSupportedContent1"
aria-controls="navbarSupportedContent1"
aria-expanded="false"
aria-label="Toggle navigation">
<!-- Hamburger icon -->
<span class="[&>svg]:w-7">
<svg
xmlns="http://www.w3.org/2000/svg"
viewBox="0 0 24 24"
fill="currentColor"
class="h-7 w-7">
<path
fill-rule="evenodd"
d="M3 6.75A.75.75 0 013.75 6h16.5a.75.75 0 010 1.5H3.75A.75.75 0 013 6.75zM3 12a.75.75 0 01.75-.75h16.5a.75.75 0 010 1.5H3.75A.75.75 0 013 12zm0 5.25a.75.75 0 01.75-.75h16.5a.75.75 0 010 1.5H3.75a.75.75 0 01-.75-.75z"
clip-rule="evenodd" />
</svg>
</span>
</button>
<!-- Collapsible navigation container -->
<div
class="!visible hidden flex-grow basis-[100%] items-center lg:!flex lg:basis-auto"
id="navbarSupportedContent1"
data-twe-collapse-item>
<!-- Logo -->
<a
class="mb-4 me-2 mt-3 flex items-center text-neutral-900 hover:text-neutral-900 focus:text-neutral-900 dark:text-neutral-200 dark:hover:text-neutral-400 dark:focus:text-neutral-400 lg:mb-0 lg:mt-0"
href="#">
<img
src="https://tecdn.b-cdn.net/img/logo/te-transparent-noshadows.webp"
style="height: 15px"
alt=""
loading="lazy" />
</a>
<!-- Left navigation links -->
<ul
class="list-style-none me-auto flex flex-col ps-0 lg:flex-row"
data-twe-navbar-nav-ref>
<li class="mb-4 lg:mb-0 lg:pe-2" data-twe-nav-item-ref>
<!-- Dashboard link -->
<a
class="text-neutral-500 hover:text-neutral-700 focus:text-neutral-700 disabled:text-black/30 dark:text-neutral-200 dark:hover:text-neutral-300 dark:focus:text-neutral-300 lg:px-2 [&.active]:text-black/90 dark:[&.active]:text-zinc-400"
href="#"
data-twe-nav-link-ref
>Dashboard</a
>
</li>
<!-- Team link -->
<li class="mb-4 lg:mb-0 lg:pe-2" data-twe-nav-item-ref>
<a
class="text-neutral-500 hover:text-neutral-700 focus:text-neutral-700 disabled:text-black/30 dark:text-neutral-200 dark:hover:text-neutral-300 dark:focus:text-neutral-300 lg:px-2 [&.active]:text-black/90 dark:[&.active]:text-neutral-400"
href="#"
data-twe-nav-link-ref
>Team</a
>
</li>
<!-- Projects link -->
<li class="mb-4 lg:mb-0 lg:pe-2" data-twe-nav-item-ref>
<a
class="text-neutral-500 hover:text-neutral-700 focus:text-neutral-700 disabled:text-black/30 dark:text-neutral-200 dark:hover:text-neutral-300 dark:focus:text-neutral-300 lg:px-2 [&.active]:text-black/90 dark:[&.active]:text-neutral-400"
href="#"
data-twe-nav-link-ref
>Projects</a
>
</li>
</ul>
</div>
<!-- Right elements -->
<div class="relative flex items-center">
<!-- Cart Icon -->
<a
class="me-4 text-neutral-500 hover:text-neutral-700 focus:text-neutral-700 disabled:text-black/30 dark:text-neutral-200 dark:hover:text-neutral-300 dark:focus:text-neutral-300 [&.active]:text-black/90 dark:[&.active]:text-neutral-400"
href="#">
<span class="[&>svg]:w-5">
<svg
xmlns="http://www.w3.org/2000/svg"
viewBox="0 0 24 24"
fill="currentColor"
class="h-5 w-5">
<path
d="M2.25 2.25a.75.75 0 000 1.5h1.386c.17 0 .318.114.362.278l2.558 9.592a3.752 3.752 0 00-2.806 3.63c0 .414.336.75.75.75h15.75a.75.75 0 000-1.5H5.378A2.25 2.25 0 017.5 15h11.218a.75.75 0 00.674-.421 60.358 60.358 0 002.96-7.228.75.75 0 00-.525-.965A60.864 60.864 0 005.68 4.509l-.232-.867A1.875 1.875 0 003.636 2.25H2.25zM3.75 20.25a1.5 1.5 0 113 0 1.5 1.5 0 01-3 0zM16.5 20.25a1.5 1.5 0 113 0 1.5 1.5 0 01-3 0z" />
</svg>
</span>
</a>
<!-- Container with two dropdown menus -->
<div class="relative" data-twe-dropdown-ref>
<!-- First dropdown trigger -->
<a
class="hidden-arrow me-4 flex items-center text-neutral-500 hover:text-neutral-700 focus:text-neutral-700 disabled:text-black/30 dark:text-neutral-200 dark:hover:text-neutral-300 dark:focus:text-neutral-300 [&.active]:text-black/90 dark:[&.active]:text-neutral-400"
href="#"
id="dropdownMenuButton1"
role="button"
data-twe-dropdown-toggle-ref
aria-expanded="false">
<!-- Dropdown trigger icon -->
<span class="[&>svg]:w-5">
<svg
xmlns="http://www.w3.org/2000/svg"
viewBox="0 0 24 24"
fill="currentColor"
class="h-5 w-5">
<path
fill-rule="evenodd"
d="M5.25 9a6.75 6.75 0 0113.5 0v.75c0 2.123.8 4.057 2.118 5.52a.75.75 0 01-.297 1.206c-1.544.57-3.16.99-4.831 1.243a3.75 3.75 0 11-7.48 0 24.585 24.585 0 01-4.831-1.244.75.75 0 01-.298-1.205A8.217 8.217 0 005.25 9.75V9zm4.502 8.9a2.25 2.25 0 104.496 0 25.057 25.057 0 01-4.496 0z"
clip-rule="evenodd" />
</svg>
</span>
<!-- Notification counter -->
<span
class="absolute -mt-2.5 ms-2 rounded-[0.37rem] bg-danger px-[0.45em] py-[0.2em] text-[0.6rem] leading-none text-white"
>1</span
>
</a>
<!-- First dropdown menu -->
<ul
class="absolute left-auto right-0 z-[1000] float-left m-0 mt-1 hidden min-w-max list-none overflow-hidden rounded-lg border-none bg-white bg-clip-padding text-left text-base shadow-lg data-[twe-dropdown-show]:block dark:bg-neutral-700"
aria-labelledby="dropdownMenuButton1"
data-twe-dropdown-menu-ref>
<!-- First dropdown menu items -->
<li>
<a
class="block w-full whitespace-nowrap bg-transparent px-4 py-2 text-sm font-normal text-neutral-700 hover:bg-neutral-100 active:text-neutral-800 active:no-underline disabled:pointer-events-none disabled:bg-transparent disabled:text-neutral-400 dark:text-neutral-200 dark:hover:bg-white/30"
href="#"
data-twe-dropdown-item-ref
>Action</a
>
</li>
<li>
<a
class="block w-full whitespace-nowrap bg-transparent px-4 py-2 text-sm font-normal text-neutral-700 hover:bg-neutral-100 active:text-neutral-800 active:no-underline disabled:pointer-events-none disabled:bg-transparent disabled:text-neutral-400 dark:text-neutral-200 dark:hover:bg-white/30"
href="#"
data-twe-dropdown-item-ref
>Another action</a
>
</li>
<li>
<a
class="block w-full whitespace-nowrap bg-transparent px-4 py-2 text-sm font-normal text-neutral-700 hover:bg-neutral-100 active:text-neutral-800 active:no-underline disabled:pointer-events-none disabled:bg-transparent disabled:text-neutral-400 dark:text-neutral-200 dark:hover:bg-white/30"
href="#"
data-twe-dropdown-item-ref
>Something else here</a
>
</li>
</ul>
</div>
<!-- Second dropdown container -->
<div class="relative" data-twe-dropdown-ref>
<!-- Second dropdown trigger -->
<a
class="hidden-arrow flex items-center whitespace-nowrap transition duration-150 ease-in-out motion-reduce:transition-none"
href="#"
id="dropdownMenuButton2"
role="button"
data-twe-dropdown-toggle-ref
aria-expanded="false">
<!-- User avatar -->
<img
src="https://tecdn.b-cdn.net/img/new/avatars/2.jpg"
class="rounded-full"
style="height: 25px; width: 25px"
alt=""
loading="lazy" />
</a>
<!-- Second dropdown menu -->
<ul
class="absolute left-auto right-0 z-[1000] float-left m-0 mt-1 hidden min-w-max list-none overflow-hidden rounded-lg border-none bg-white bg-clip-padding text-left text-base shadow-lg data-[twe-dropdown-show]:block dark:bg-neutral-700"
aria-labelledby="dropdownMenuButton2"
data-twe-dropdown-menu-ref>
<!-- Second dropdown menu items -->
<li>
<a
class="block w-full whitespace-nowrap bg-transparent px-4 py-2 text-sm font-normal text-neutral-700 hover:bg-neutral-100 active:text-neutral-800 active:no-underline disabled:pointer-events-none disabled:bg-transparent disabled:text-neutral-400 dark:text-neutral-200 dark:hover:bg-white/30"
href="#"
data-twe-dropdown-item-ref
>Action</a
>
</li>
<li>
<a
class="block w-full whitespace-nowrap bg-transparent px-4 py-2 text-sm font-normal text-neutral-700 hover:bg-neutral-100 active:text-neutral-800 active:no-underline disabled:pointer-events-none disabled:bg-transparent disabled:text-neutral-400 dark:text-neutral-200 dark:hover:bg-white/30"
href="#"
data-twe-dropdown-item-ref
>Another action</a
>
</li>
<li>
<a
class="block w-full whitespace-nowrap bg-transparent px-4 py-2 text-sm font-normal text-neutral-700 hover:bg-neutral-100 active:text-neutral-800 active:no-underline disabled:pointer-events-none disabled:bg-transparent disabled:text-neutral-400 dark:text-neutral-200 dark:hover:bg-white/30"
href="#"
data-twe-dropdown-item-ref
>Something else here</a
>
</li>
</ul>
</div>
</div>
</div>
</nav>
<!-- Navbar -->
```
And now we have proper margins on the right and left side of the Navbar.
But there is another problem - when we reduce the size of the browser window, the margins remain the same size. On the big screen it looks correct, but on the mobile view it definitely shouldn't look like this.

## Add a breakpoint to the .container
Fortunately, it's very easy to fix. It is enough to add a breakpoint lg before the .container class (similarly as we did with the grid) and thanks to this the margins will be added only on screens above 1024px.
**HTML**
```
<!-- Here add a container -->
<div class="lg:container mx-auto flex w-full flex-wrap items-center justify-between px-3">
[...]
</div>
```
And now it's perfect.

[**DEMO AND SOURCE CODE FOR THIS LESSON**](https://tw-elements.com/snippets/tailwind/ascensus/5264677) | keepcoding |
1,837,220 | How Enabling Slow Query Log Enhances Postgres Observability | In PostgreSQL, the slow query log is a feature that allows you to log queries that take longer than a... | 0 | 2024-05-30T08:00:00 | https://www.metisdata.io/blog/how-enabling-slow-query-log-enhances-postgres-observability | sql, database, logging | In PostgreSQL, the slow query log is a feature that allows you to log queries that take longer than a specified threshold to execute. This log helps you identify and optimize queries that may be causing performance issues in your database. Let’s see how we can use it.
## Why Do We Need Observability?
Database observability is a crucial component for the maintenance and development of the database. It helps with identifying and solving issues. [Observability is much more than just monitoring](https://www.metisdata.io/blog/all-your-monitoring-solutions-are-just-wrong), though. However, to build successful observability, we need to introduce proper telemetry and monitoring everywhere in our production environment.
One of the things we start with is logging of the queries. We want to capture details of the SQL statement, metrics around execution time and consumed memory, and statistics of the tables we use. Unfortunately, many default settings in our database systems result in missing pieces of information that are crucial for debugging. One such piece is details of queries that are slow and are the most probable causes of the issues.
## What Is a Slow Query Log?
The database executes many queries during the day. Some of them are very fast, and some of them may slow the database down and cause issues with other processes using the database. Ideally, we would like to [identify these slow queries](https://www.metisdata.io/product/prevention) and examine them more to understand why they are slow. There are many reasons why queries may be slow and many techniques to optimize them. Most of these techniques focus on using the execution plan to understand what happened.
The [execution plan](https://www.metisdata.io/blog/reading-postgres-execution-plans-doesnt-have-to-be-so-complicated) explains what the database engine performs when executing the query. This can involve many operations like joining many tables, using indexes, sorting data, or saving it to disk temporarily. Such a plan provides all the details, however, these plans may consume a lot of space. Therefore, we don’t store them for every single query as probably most of the queries are fast and don’t need any investigation.
The slow query log is a mechanism for capturing details of queries that take too long to execute. This helps in the investigation as we capture the details at the moment when the query runs. The slow query log can be useful for identifying performance bottlenecks and optimizing slow queries to improve the overall performance of your PostgreSQL database.
**Recommended reading:** [**8 Proven Strategies to Improve Database Performance**](https://www.metisdata.io/blog/8-proven-strategies-to-improve-database-performance)
## How to Configure the Slow Query Log?
To enable the slow query log in PostgreSQL, we need to set a couple of parameters. Let’s see them one by one.
First, you need to enable logging with:
```sql
log_statement = 'all'
```
This instructs PostgreSQL to log all the syntactically correct statements. Other options are `none` (log nothing), `ddl` (log only Data Definition Language queries, i.e., queries that modify schema), `mod` (DDL queries and queries that modify the data, but not things like `VACUUM`).
It’s also worth mentioning that `log_statement` will not log syntactically incorrect things. We need to use `log_min_error_statement` to do that. Also, `log_statement` may log confidential information.
Another parameter logs the duration of all the completed statements:
```sql
log_duration = on
```
This will log the duration of all the statements. However, not all statements will have the query text (so the actual statement that was executed). To do that, we need to use another parameter:
```sql
log_min_duration_statement = 100ms
```
This causes logging of the duration of the statement if it ran for at least one hundred milliseconds. However, this will report the query text of the statement that was slow.
After making these changes, **you need to restart PostgreSQL** for the configuration to take effect.
There are additional parameters that you may configure. For instance:
```sql
log_destination = 'csvlog'
```
Causes the logging to a CSV file. You may want to log using different file formats.
```sql
log_filename = 'postgresql.log.%Y-%m-%d-%H'
```
Configures the name of the log file. This makes it easier to process the logs in an automated manner.
```sql
log_rotation_age = 60
```
Causes creating a new log file every sixty minutes.
```sql
compute_query_id = 'on'
```
Enables in-core computation of a query identifier. We can use this identifier to find identical queries in a best-effort manner. This works starting with PostgreSQL 13.
Once we log the queries, we need to get their execution plans. We can use [pg\_store\_plans](https://ossc-db.github.io/pg_store_plans/) for that.
```sql
pg_store_plans.plan_format = 'json'
```
Controls what format to use when logging the execution plan.
```sql
pg_store_plans.max_plan_length = 1048576
```
Controls the length of the plan to store. If the plan is too long, it will get truncated. It is important to set this value high enough to store the whole execution plan.
We can also configure what is logged exactly:
```sql
pg_store_plans.log_buffers = true
pg_store_plans.log_analyze = true
pg_store_plans.log_buffers = true
pg_store_plans.log_timing = true
```
This should give you enough details of what happened.
## What About Ephemeral Databases
Configuring your PostgreSQL is simple if your database lives for a long time. This is typically the case when you host your database in the cloud (or generally as a hosted database), or if you run it in a Docker container that is running as a service.
However, if you run PostgreSQL only for a very short period, for instance during your automated tests, then you may have no technical way of reconfiguring it. This may be the case with [Testcontainers](https://testcontainers.com/). Typically, you may run some initialization code just before your actual test suite to initialize the dependencies like storage emulators or database servers. Testcontainers takes care of running them as Docker containers. However, there is no straightforward way of restarting the container. In some languages, you may have an actual API that will handle this quite nicely, though.
An Ephemeral Database strategy allows for separating high-throughput, frequently changing data from the main database to enhance efficiency and mitigate operational risks. This approach addresses issues like query costs and system strain, with the ephemeral DB holding disposable data, thereby ensuring system stability and performance.
Similar issues may happen if you host your PostgreSQL for tests as a service in GitHub Actions. You cannot easily control the containers and restart them after applying the configuration changes.
The solution is to use a custom Docker image. Just prepare your image with the configuration file that enables the slow query log. You can then just run the container once and the configuration will be as expected.
## Summary
The slow query log is a feature that allows you to log queries that take longer than a specified threshold to execute. This can significantly ease the investigation of slow queries as all the important details of the queries are already available. | adammetis |
1,870,072 | CakePHP vs. Laravel: End-to-End Comparison to Make Wise Decision | Introduction In the realm of web development, choosing the right framework is crucial for the... | 0 | 2024-05-30T07:58:12 | https://dev.to/hirelaraveldevelopers/cakephp-vs-laravel-end-to-end-comparison-to-make-wise-decision-15pp | webdev, programming, devops, css | <h2>Introduction</h2>
<p>In the realm of web development, choosing the right framework is crucial for the success of your project. Two prominent players in the PHP framework arena are CakePHP and Laravel. Both offer robust features and functionalities, but understanding their differences is essential for making an informed decision. In this comprehensive comparison, we'll delve into the nuances of CakePHP and Laravel to help you determine which framework best aligns with your project requirements.</p>
<h3>Define the Frameworks</h3>
<p>CakePHP and Laravel are open-source PHP frameworks designed to expedite web application development. They provide a structured approach to building web applications, offering features such as MVC architecture, database migration tools, and built-in security mechanisms.</p>
<h3>Relevance and Importance</h3>
<p>As businesses increasingly rely on web applications to streamline operations and engage customers, the choice of framework becomes paramount. Opting for the wrong framework can lead to inefficiencies, security vulnerabilities, and scalability issues. Therefore, understanding the strengths and weaknesses of CakePHP and Laravel is crucial for making a wise decision.</p>
<h2>Technical Specifications</h2>
<h3>CakePHP</h3>
<ul>
<li><strong>Version</strong>: CakePHP 4.x</li>
<li><strong>Programming Language</strong>: PHP</li>
<li><strong>Database Support</strong>: MySQL, PostgreSQL, SQLite, SQL Server</li>
<li><strong>Template Engine</strong>: PHP-based Templating</li>
<li><strong>ORM</strong>: CakePHP ORM</li>
<li><strong>CLI Tools</strong>: Bake Console</li>
</ul>
<h3>Laravel</h3>
<ul>
<li><strong>Version</strong>: Laravel 8.x</li>
<li><strong>Programming Language</strong>: PHP</li>
<li><strong>Database Support</strong>: MySQL, PostgreSQL, SQLite, SQL Server</li>
<li><strong>Template Engine</strong>: Blade</li>
<li><strong>ORM</strong>: Eloquent ORM</li>
<li><strong>CLI Tools</strong>: Artisan</li>
</ul>
<h2>Applications</h2>
<h3>CakePHP</h3>
<p>CakePHP is well-suited for developing small to medium-sized web applications, content management systems (CMS), and e-commerce platforms. Its rapid development capabilities make it an ideal choice for projects with tight deadlines.</p>
<h3>Laravel</h3>
<p>Laravel is preferred for building large-scale web applications and enterprise-level solutions. Its expressive syntax and robust features make it suitable for projects that demand scalability, flexibility, and maintainability.</p>
<h2>Benefits</h2>
<h3>CakePHP</h3>
<ul>
<li><strong>Rapid Development</strong>: CakePHP's scaffolding features and code generation tools accelerate the development process.</li>
<li><strong>Built-in Security</strong>: CakePHP incorporates security features such as SQL injection prevention, cross-site request forgery (CSRF) protection, and cross-site scripting (XSS) prevention.</li>
<li><strong>Community Support</strong>: CakePHP boasts an active community that provides extensive documentation, plugins, and support forums.</li>
</ul>
<h3>Laravel</h3>
<ul>
<li><strong>Elegant Syntax</strong>: Laravel's expressive syntax simplifies common tasks such as routing, authentication, and database management.</li>
<li><strong>Modular Packaging</strong>: Laravel's modular packaging system, Composer, allows developers to easily integrate third-party libraries and packages into their projects.</li>
<li><strong>Blade Templating Engine</strong>: Laravel's Blade templating engine offers powerful features such as template inheritance, control structures, and sections.</li>
</ul>
<h2>Challenges and Limitations</h2>
<h3>CakePHP</h3>
<ul>
<li><strong>Learning Curve</strong>: CakePHP's convention over configuration approach may pose a learning curve for developers accustomed to other frameworks.</li>
<li><strong>Limited Flexibility</strong>: While CakePHP offers a structured development environment, it may limit flexibility for highly customized requirements.</li>
</ul>
<h3>Laravel</h3>
<ul>
<li><strong>Performance Overhead</strong>: Laravel's extensive features and abstraction layers can introduce performance overhead, especially for smaller projects.</li>
<li><strong>Complexity</strong>: Laravel's rich ecosystem and extensive documentation may overwhelm beginners, requiring time to grasp its concepts fully.</li>
</ul>
<h2>Latest Innovations</h2>
<h3>CakePHP</h3>
<p>CakePHP 4.x introduces several enhancements, including improved PSR compatibility, middleware support, and enhanced CSRF token protection. Additionally, CakePHP's integration with modern PHP features ensures optimal performance and security.</p>
<h3>Laravel</h3>
<p>Laravel 8.x introduces Jetstream, a new application scaffolding designed to streamline authentication, team management, and API support. Furthermore, Laravel's focus on usability and developer experience continues to drive innovation in the PHP ecosystem.</p>
<h2>Future Prospects</h2>
<h3>CakePHP</h3>
<p>CakePHP's commitment to backward compatibility and adherence to PHP standards position it for continued growth and adoption. With ongoing updates and community contributions, CakePHP remains a viable option for modern web application development.</p>
<h3>Laravel</h3>
<p>Laravel's forward-thinking approach, coupled with Taylor Otwell's visionary leadership, suggests a promising future for the framework. As Laravel continues to evolve and address emerging trends, it is poised to maintain its status as a leading PHP framework.</p>
<h2>Comparative Analysis</h2>
<h3>CakePHP vs. Laravel</h3>
<ul>
<li><strong>Performance</strong>: While CakePHP offers faster performance out-of-the-box, Laravel's modular architecture allows for better optimization and scalability.</li>
<li><strong>Community Support</strong>: Both frameworks enjoy robust community support, with extensive documentation, forums, and third-party packages available.</li>
<li><strong>Learning Curve</strong>: CakePHP's convention-based approach may appeal to developers seeking structure, while Laravel's expressive syntax caters to those favoring flexibility and elegance.</li>
</ul>
<h2>Conclusion</h2>
<p>In conclusion, the choice between CakePHP and Laravel ultimately depends on your project requirements, development preferences, and long-term goals. While CakePHP excels in rapid development and built-in security, Laravel offers a more expressive syntax and scalability for complex applications. By evaluating the technical specifications, benefits, challenges, and future prospects of both frameworks, you can make a well-informed decision that aligns with your development objectives.</p>
<div class="flex flex-grow flex-col max-w-full AIPRM__conversation__response">
<div class="min-h-[20px] text-message flex flex-col items-start whitespace-pre-wrap break-words [.text-message+&]:mt-5 juice:w-full juice:items-end overflow-x-auto gap-2" dir="auto" data-message-author-role="assistant" data-message-id="49718f16-9a60-4895-93fe-5f6d2d0ee605">
<div class="flex w-full flex-col gap-1 juice:empty:hidden juice:first:pt-[3px]">
<div class="markdown prose w-full break-words dark:prose-invert dark">
<p>In the realm of web development, selecting between CakePHP and Laravel is pivotal for project success. CakePHP, known for rapid development and robust security features, suits small to medium-scale projects like CMS and e-commerce platforms. Conversely, Laravel shines in scalability and flexibility, making it ideal for large-scale applications and enterprise solutions. Considering the future prospects of both frameworks, CakePHP's commitment to backward compatibility and Laravel's innovative advancements ensure they remain competitive choices. For businesses considering expansion or new ventures, <a href="https://www.aistechnolabs.com/hire-laravel-developers/">hiring Laravel developers</a> proficient in leveraging its expressive syntax and modular architecture could be a strategic move towards achieving long-term success.</p>
</div>
</div>
</div>
</div> | hirelaraveldevelopers |
1,870,071 | 5 reasons that Choosing an online pharmacy may be right for you | Choosing an online pharmacy like DiRx can save you time, money, and hassle. With convenient home... | 0 | 2024-05-30T07:56:49 | https://dev.to/skyline_entertainment_843/5-reasons-that-choosing-an-online-pharmacy-may-be-right-for-you-5g4l | medicine, online, pharmacy, helth | Choosing an online pharmacy like DiRx can save you time, money, and hassle. With convenient home delivery, lower costs, no waiting in lines, and extended hours for customer care, it's a smart choice for many. Ensuring you select a trustworthy, FDA-approved provider guarantees the same safety and quality as your local pharmacy. If these benefits resonate with you, it might be time to consider ordering your prescriptions online.
[](https://shorturl.at/weL7r) | skyline_entertainment_843 |
1,870,057 | Alloy Steel F91 Flanges Stockists | Introduction Alloy Steel F91 Pipe Flanges, which are not difficult to clean and don't generally get... | 0 | 2024-05-30T07:31:12 | https://dev.to/jainam_doshi_01362aeaec85/alloy-steel-f91-flanges-stockists-1dag | Introduction
Alloy Steel F91 Pipe Flanges, which are not difficult to clean and don't generally get smells. Hence, Alloy Steel F91 slip On Flanges are embraced for use in horrendous creation and fixation, near the vehicle of such substances. Most prepares, like Alloy Steel F91 Threaded Flanges, are first dense in the electric–arc part or key oxygen radiators and thusly refined in another steelmaking vessel, dominatingly to chop down the carbon content. In the argon-oxygen decarburization process, a mixture of oxygen and argon gas is pervaded into the fluid alloy of Alloy Steel F91 Weld Neck Flanges
Description
Alloy Steel F91 Socket Weld Flanges are utilized in a wide assortment of things, going from eating utensils to bank vaults to kitchen sinks. While it is submissively impervious to chlorine, Alloy Steel F91 Blind Flanges by and large ought not be acquainted with warm when sulphur is free, an immediate consequence of its raised level of nickel. Chlorine straightforwardness in Alloy Steel F91 Lap Joint Flanges ought to also not beat temperatures of 1000 degrees F. Alloy Steel F91 Ring Joint Type Flanges just respond to cold working practices, and their mechanical properties are material for specific areas of heading. Alloy Steel F91 Spectacle Blind Flanges contain iron, chromium, manganese, silicon, carbon, and, if all else fails, gigantic amounts of nickel and molybdenum.
Alloy Steel F91 Flanges Specifications
Specification : ASTM A182 / ASME SA182
Dimension Standard : ANSI/ASME B16.5, B 16.47 Series A & B, B16.48, BS4504, BS 10, EN-1092, DIN, etc.
Standard : ANSI Flanges, ASME Flanges, BS Flanges, DIN Flanges, EN Flanges, etc.
Size : 1/2" (15 NB) to 48" (1200NB)
Class / Pressure : 150#, 300#, 600#, 900#, 1500#, 2500#, PN6, PN10, PN16, PN25, PN40, PN64 etc.
Flange Face Type : Flate Face (FF), Raised Face (RF), Ring Type Joint (RTJ)
DIN Flanges : DIN 2527, 2566, 2573, 2576, 2641,2642, 2655, 2656, 2627, 2628, 2629, 2631, 2632, 2633, 2634, 2635, 2636, 2637,2638, 2673.
JIS Flanges : JIS B2220 5K, JIS B2220 10K, JIS B2220 16K, JIS B2220 20K
BS Flanges : BS4504 PN 6, BS 4504 PN 10, BS4504 PN 16, BS4504 PN 25, BS4504 PN 40, BS 4504 PN 64, BS 4504 PN 100, BS 4504 PN 160, BS 4504 PN 250, BS 10, BS Table D, BS Table E, BS Table F, BS Table H.
Benefits
Choosing Alloy Steel F91 flanges from Manilaxmi Industrial provides several benefits:
Superior Strength and Durability: Alloy Steel F91 offers excellent mechanical properties, making these flanges ideal for demanding applications.
High-Temperature Resistance: These flanges can withstand extreme temperatures, making them suitable for power plants, chemical processing, and other high-heat environments.
Corrosion and Oxidation Resistance: The chromium-molybdenum content in Alloy Steel F91 ensures superior resistance to corrosion and oxidation, extending the service life of the flanges.
Versatility: Available in various sizes and pressure ratings, these flanges can be used in a wide range of industrial applications.
Reliability: Manilaxmi Industrial ensures that all flanges undergo stringent quality control checks, providing reliable and leak-proof connections.
Product Overview
Manilaxmi Industrial offers a comprehensive range of Alloy Steel F91 flanges, including:
Slip-On Flanges: Easy to install and ideal for low-pressure applications.
Weld Neck Flanges: Designed for high-pressure and high-temperature applications, providing a secure and leak-proof connection.
Blind Flanges: Used to seal off the end of a piping system or vessel openings.
Socket Weld Flanges: Suitable for small-diameter, high-pressure pipes.
Threaded Flanges: Used in low-pressure, non-critical applications, requiring no welding.
Lap Joint Flanges: Ideal for systems requiring frequent dismantling for inspection or maintenance.
Conclusion
Manilaxmi Industrial is your go-to stockist for Alloy Steel F91 flanges, offering products that meet the highest standards of quality and performance. With a wide range of flanges available, they cater to various industrial needs, ensuring reliable and efficient operations.
For top-quality Alloy Steel F91 flanges, contact Manilaxmi Industrial at manilaxmifittings@gmail.com or call +91-7710800415 to experience unparalleled service and superior products.
By choosing Manilaxmi Industrial for your Alloy Steel F91 flanges, you ensure that your projects benefit from high-strength, durable, and reliable components designed to withstand the most challenging conditions. Reach out to them today for all your flange requirements and enjoy the assurance of quality and expertise.
| jainam_doshi_01362aeaec85 | |
1,870,070 | Mastering Clipboard Operations in JavaScript: A Guide to Copying Text with the Clipboard API | In this article, we will explore how to perform clipboard operations in JavaScript, focusing on... | 0 | 2024-05-30T07:56:24 | https://dev.to/iamcymentho/mastering-clipboard-operations-in-javascript-a-guide-to-copying-text-with-the-clipboard-api-180k | javascript, webdev, beginners, programming | **In this article**, we will explore how to perform clipboard operations in **JavaScript**, focusing on copying text using the modern Clipboard API. We will provide a detailed step-by-step guide, complete with code snippets and explanations, to help you seamlessly integrate this functionality into your web applications. Additionally, we will cover fallback methods for older browsers to ensure broad compatibility and a smooth user experience across different environments.
**Copying** text to the clipboard in JavaScript is a common task in web development, especially for creating user-friendly interfaces where users might need to copy text with a single click. The modern way to accomplish this is by using the Clipboard API, which is supported in most modern browsers.
- Here’s a step-by-step guide on how to copy text to the clipboard using JavaScript:
**- Using the Clipboard API**
The Clipboard API provides an easy and reliable way to interact with the clipboard. Below is a simple example of how to copy text to the clipboard using this API.
**- HTML Structure**
First, create an HTML structure with an input field and a button:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Copy to Clipboard Example</title>
</head>
<body>
<input type="text" id="textToCopy" value="Copy this text!">
<button onclick="copyToClipboard()">Copy Text</button>
<script src="clipboard.js"></script>
</body>
</html>
```
**`JavaScript Code`**
Now, create a JavaScript file (e.g., clipboard.js) with the function to copy the text:
```javascript
// clipboard.js
function copyToClipboard() {
// Get the text field
const textField = document.getElementById('textToCopy');
// Select the text field
textField.select();
textField.setSelectionRange(0, 99999); // For mobile devices
// Use the Clipboard API
navigator.clipboard.writeText(textField.value)
.then(() => {
console.log('Text copied to clipboard');
alert('Text copied to clipboard: ' + textField.value);
})
.catch(err => {
console.error('Failed to copy text: ', err);
});
}
```
**Explanation**
1. Select the Text: The `textField.select()` method selects the text in the input field, making it ready to be copied.
2. Clipboard API: The `navigator.clipboard.writeText()` method writes the text to the clipboard. It returns a promise that resolves when the text is successfully copied.
3. Error Handling: The `.catch()` method is used to handle any errors that may occur during the copy process.
**Browser Compatibility**
The Clipboard API is widely supported in modern browsers, but it’s always good to check compatibility if your application needs to support older browsers. For those, you might need to use older techniques involving creating a temporary textarea element and using document commands like `document.execCommand('copy')`.
**Alternative for Older Browsers**
Here’s how you can implement clipboard copying for older browsers:
```javascript
function copyToClipboard() {
const textField = document.getElementById('textToCopy');
// Create a temporary textarea element
const tempTextArea = document.createElement('textarea');
tempTextArea.value = textField.value;
document.body.appendChild(tempTextArea);
// Select the text
tempTextArea.select();
tempTextArea.setSelectionRange(0, 99999); // For mobile devices
// Copy the text
try {
document.execCommand('copy');
console.log('Text copied to clipboard');
alert('Text copied to clipboard: ' + tempTextArea.value);
} catch (err) {
console.error('Failed to copy text: ', err);
}
// Remove the temporary textarea element
document.body.removeChild(tempTextArea);
}
```
In summary, the modern `Clipboard API` provides a straightforward way to copy text to the clipboard, while fallback methods can be used to ensure compatibility with older browsers. This ensures a smooth user experience across different environments.
`LinkedIn Account` : [LinkedIn](https://www.linkedin.com/in/matthew-odumosu/)
`Twitter Account `: [Twitter](https://twitter.com/iamcymentho)
**Credit**: Graphics sourced from [OpenReplay](https://blog.openreplay.com/using-the-javascript-clipboard-api/)
| iamcymentho |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.