
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,869,925 | Introducing the Aroon indicator | What is the Aroon indicator? In the technical analysis, Aroon is a very unique technical... | 0 | 2024-05-30T05:22:59 | https://dev.to/fmzquant/introducing-the-aroon-indicator-4568 | aroon, indicator, trading, fmzquant | ## What is the Aroon indicator?
In the technical analysis, Aroon is a very unique technical indicator. The word "Aroon" comes from Sanskrit, meaning "the light of dawn". It is not as familiar as MA, MACD, and KDJ. It was launched later, and was invented by Tushar Chande in 1995. The author also invented the Chand momentum indicator (CMO). And the intraday momentum index (IMI). If a technical indicator was known by more people and used by more people, then the ability of making profit of this indicator will become less possible, but the relatively new Aroon indicator is exactly the opposite way. From this perspective, the Aroon indicator is actually a good choice.
## The Aroon indicator in the chart
The Aroon indicator helps traders predict the relative positional relationship between price movements and trend areas by calculating the number of K-lines between the highest and lowest prices before the current K-line distance. It consists of two parts: AroonUp and AroonDown. The two lines move up and down between 0 and 100. Although they are named up and down, unlike the BOLL indicator, it's not "the real upper and lower" line. The following picture is the Aroon indicator in the K-line chart:
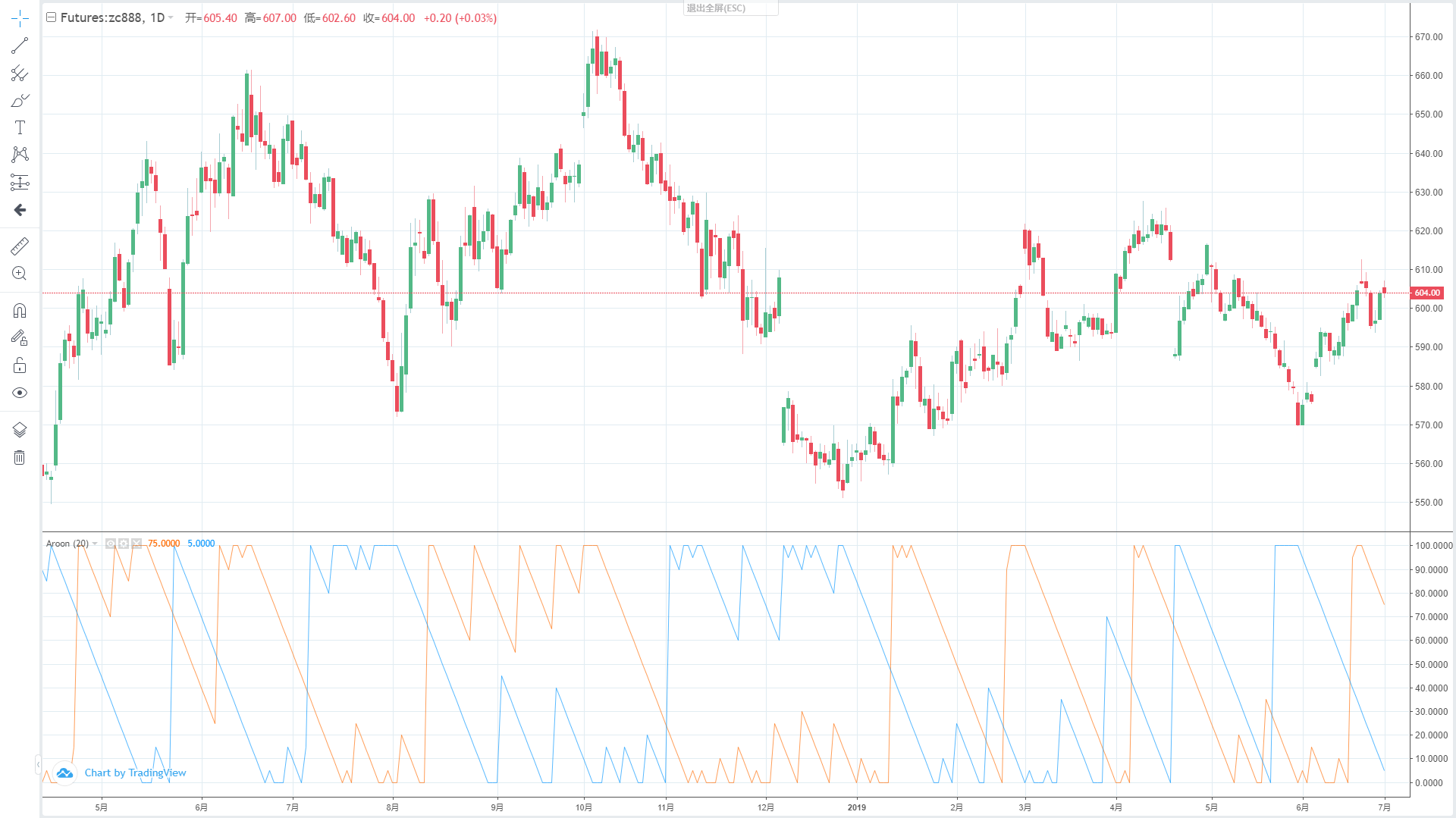
## Calculation method of Aroon indicator
The Aroon indicator requires that you first set a time period parameter, just like setting the average period parameter. In traditional trading software, the number of cycles is 14. In addition, this period parameter is not fixed. You can also set it to 10 or 50 and so on. For the sake of easy understanding, let's define it as: N. After determining N, we can calculate AroonUp and AroonDown.
The specific formula is as follows:
- AroonUp = [ (set period parameter - number of cycles after the highest price) / number of cycles calculated] * 100
- AroonDown = [ (set period parameter - number of cycles after the lowest price) / number of cycles calculated] * 100
From this formula, we can roughly see the idea of the Aroon indicator. That is: how many cycles there are, and the price is below the recent high/low, helping to predict whether the current trend will continue and measuring the strength of the current trend. If we classify this indicator, it is obvious that it belongs to the trend tracking type. But unlike other trend-tracking metrics, it pays more attention to time than price.
## How to use the Aroon indicator
AroonUp and AroonDown reflect the current time and the previous highest or lowest price. If the time is near, the value will be larger. If the time is far, the value will be smaller. And when the two lines cross, it indicates that the price direction may change. If AroonUp is above AroonDown, the price is going up, the price may rise; if AroonDown is above AroonUp, the price is in a downward trend, the price May fall.
At the same time, we can also set a few fixed values to accurately find the trading opportunity. We know that the Aroon indicator has been running up and down between 0 and 100. So when the market is on the rise, that is, when AroonUp is above AroonDown, when AroonUp is greater than 50, the market's rising trend has already formed, and the price may continue in the future. when AroonUp under 50, the momentum for price increases is waning, and prices may fluctuate and fall in the future.
On the contrary, when the market is in a downward trend, that is, when AroonDown is above AroonUp, when AroonDown is greater than 50, the market downtrend has already formed, and the price may continue to fall in the future; when AroonDown wears down 50, the driving force for price decline is weakening. Future prices may fluctuate and rise. Then according to the above two paragraphs, we can list the terms of buying and selling as:
- When AroonUp is larger than AroonDown and AroonUp is greater than 50, the long position is opened;
- When AroonUp is smaller than AroonDown, or AroonUp is less than 50, the long position is closed;
- When AroonDown is larger than AroonUp and AroonDown is greater than 50, the short position is opened;
- When AroonDown is smaller than AroonUp, or AroonDown is less than 50, the short position is closed;
## Build a trading strategy based on the Aroon indicator
After clarifying the trading logic, we can implement it with code. In this article, we continue to use the JavaScript language, and the trading variety is still commodity futures. reader with strong programming skills can also translate it into Python, or cryptocurrency.
Following by these steps : fmz.com > Login > Dashboard > Strategy Library > New Strategy, start writing the strategy, pay attention to the comments in the code below.
**Step 1: Using the CTA Framework**
Note that Be sure to click on the following: Commodity Futures Trading Library. If you are adapted it to cryptocurrency, click on: Digital currency spot trading library.
```
Function main() {
// ZC000/ZC888 refers to using the index as the source of the market but the transaction is mapped to the main contract
$.CTA("ZC000/ZC888", function(st) {
})
}
```
**Step 2: Get the data**
```
Function main() {
$.CTA("ZC000/ZC888", function(st) {
Var r = st.records; // get the K line array
Var mp = st.position.amount; // Get the number of positions
})
}
```
**Step 3: Calculate the Aroon indicator**
```
Function main() {
$.CTA("ZC000/ZC888", function(st) {
Var r = st.records; // get the K line array
Var mp = st.position.amount; // Get the number of positions
If (r.length < 21) { // Determine if the K line data is sufficient
Return;
}
Var aroon = talib.AROON(r, 20); // Aroon indicator
Var aroonUp = aroon[1][aroon[1].length - 2]; // Aroon indicator goes online with the second root data
Var aroonDown = aroon[0][aroon[0].length - 2]; // Aroon's indicator goes down the second root of the data
})
}
```
**Step 4: Calculate the trading conditions and placing orders**
```
Function main() {
$.CTA("ZC000/ZC888", function(st) {
Var r = st.records; // get the K line array
Var mp = st.position.amount; // Get the number of positions
If (r.length < 21) { // Determine if the K line data is sufficient
Return;
}
Var aroon = talib.AROON(r, 20); // Aroon indicator
Var aroonUp = aroon[1][aroon[1].length - 2]; // Aroon indicator goes online with the second root data
Var aroonDown = aroon[0][aroon[0].length - 2]; // AAroon's indicator goes down the second root of the data
If (mp == 0 && aroonUp > aroonDown && aroonUp > 50) {
Return 1; // long position open
}
If (mp == 0 && aroonDown > aroonUp && aroonDown > 50) {
Return -1; // short position open
}
If (mp > 0 && (aroonUp < aroonDown || aroonUp < 50)) {
Return -1; // multi-head platform
}
If (mp < 0 && (aroonDown < aroonUp || aroonDown < 50)) {
Return 1; // short platform
}
})
}
// The above code is a complete strategy based on the JavaScript language.
// --------------------Dividing line--------------------
// In order to take care of the reach of the party, this strategy is also translated into My language. At the same time, this can also be used for digital currency. Here is the complete policy code:
AROONUP := ((N - HHVBARS(H, N)) / N) * 100; // Aroon indicator goes online
AROONDOWN := ((N - LLVBARS(L, N)) / N) * 100; // Aroon indicator goes offline
AROONUP > AROONDOWN && AROONUP > BKV, BK; // Long position open
AROONDOWN > AROONUP && AROONDOWN > SKV, SK; // short position
AROONUP < AROONDOWN || AROONUP < SPV, SP; // Multi-head platform
AROONDOWN < AROONUP || AROONDOWN < BPV, BP; // Short platform
AUTOFILTER;
```
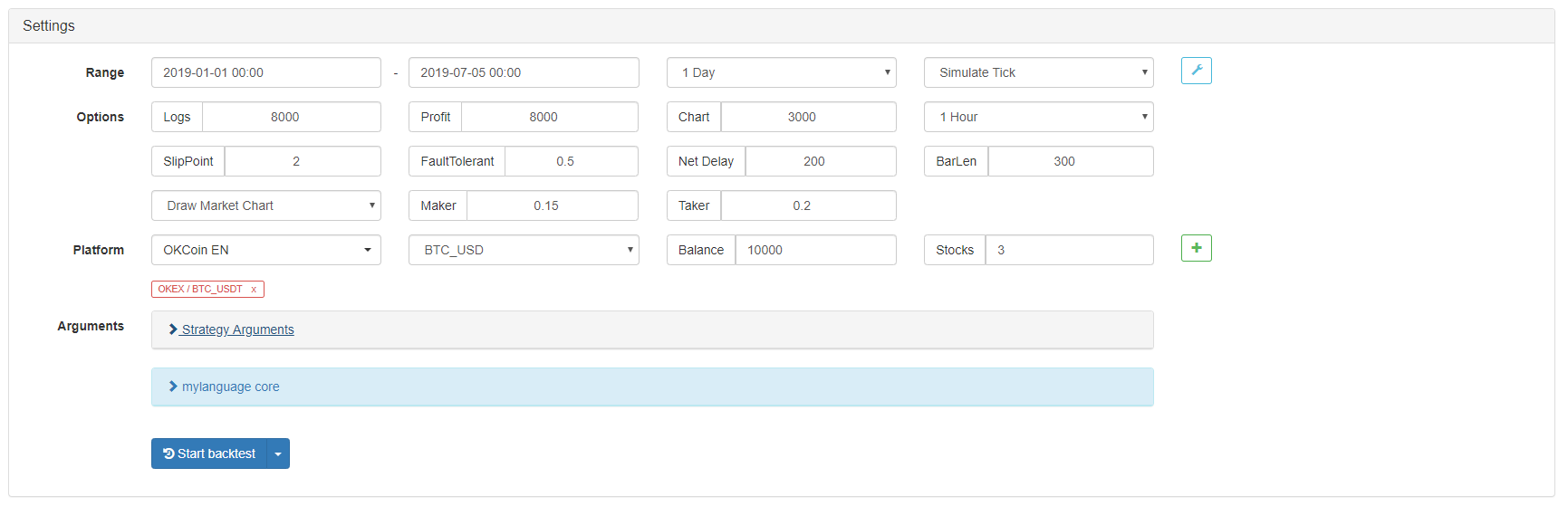
## Strategy backtest
In order to get closer to the real trading environment, we used the 2 pips of slippage and 2 times of the transaction fee to test the pressure during the backtest. The test environment is as follows:
- Quote Variety: Thermal Coal Index
- Trading variety: Thermal Coal Index
- Time: June 01, 2015 ~ June 28, 2019
- Cycle: Daily K line
- Slippage: 2 pips for opening and closing positions
- Transaction Fee: 2 times of the exchange
**Test environment**
**Profit report**
**Fund curve**
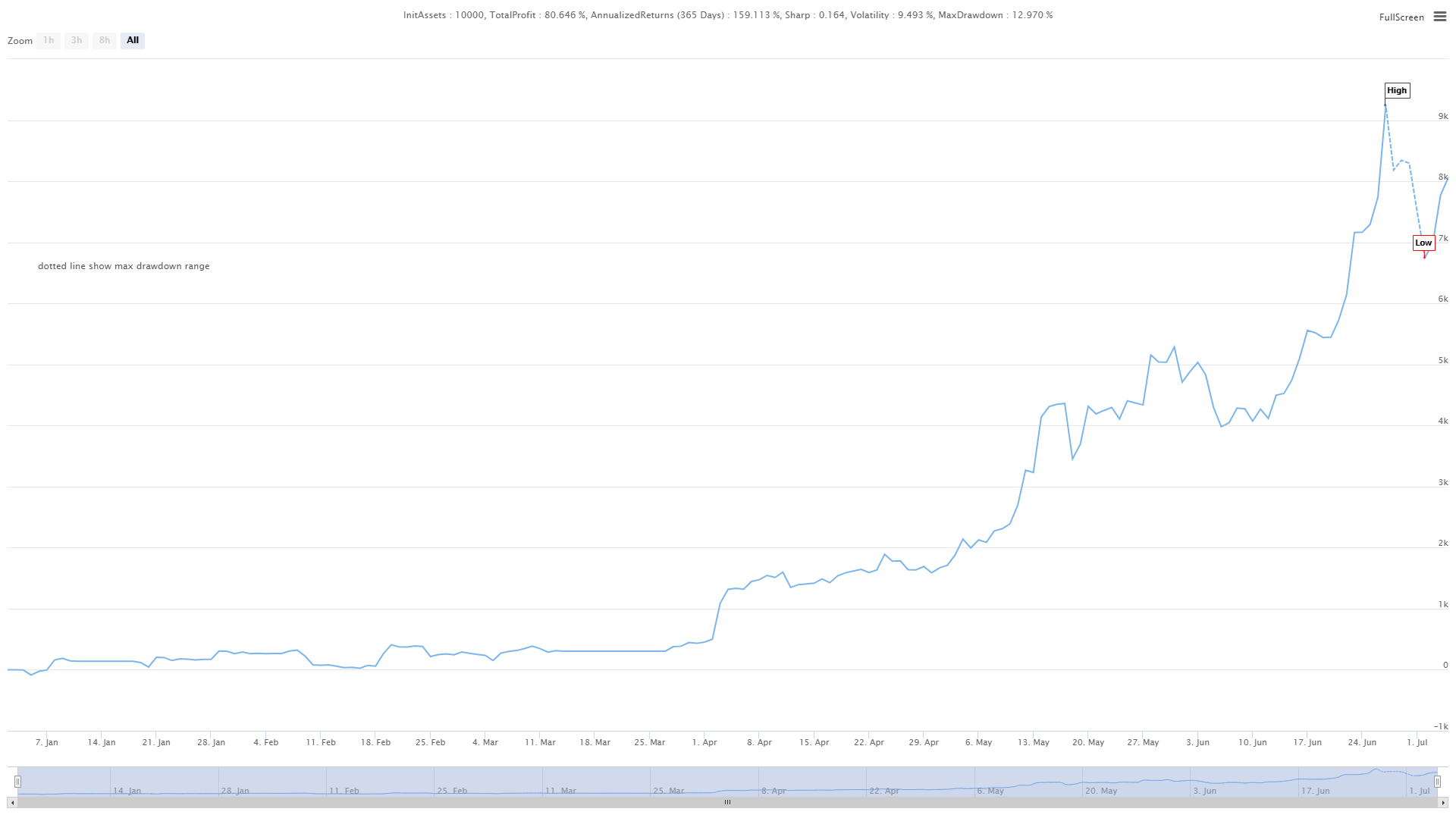
From the above backtest results, the strategy is very good when the market trend is smooth, whether in the rise or fall, the Aroon indicator can completely track the market. The capital curve also showed an overall upward trend, and there was no significant retracement. However, in the volatile market, especially in the continuous shock market, there was a partial retracement.
## The advantages and disadvantages of the Aroon indicator
- Advantages: The Aroon indicator can judge the status of the trend market, take into account the market trend and the ability to judge the price turn, and help traders to increase the use of funds.
- Disadvantages: The Aroon indicator is only one of the trend tracking indicators, it has the same shortcomings of the trend tracking indicator. it only can judging the number of periods of the highest or lowest price at a given time, but sometimes the highest or lowest price will be contingent in the whole market trend, this contingency will interfere with the Aroon indicator itself, causing false signals.
## click on the copy strategy source
For the source code,
with JavaScript version, please click: https://www.fmz.com/strategy/154547
with Mylanguage version, please click: https://www.fmz.com/strategy/155582
## Summary
In this strategy, we fixed some parameters, such as: aroonUp or aroonDown is greater than and less than 50, causing the lagging issue of the strategy. In many cases, the market will rise or fall for a period of time before closing the position. Although this improved the winning rate and reduced the maximum retracement rate, it also missed a lot of profits, which also confirmed the truth of the homonym of profit and loss. Interested friends can dig it deeper and improve it.
From: https://blog.mathquant.com/2022/09/30/introducing-the-aroon-indicator-2.html | fmzquant |
1,869,923 | Zonatoto Slot Online Terbaik Dan Terpercaya 2024 | Apakah kamu sedang mencari link slot gacor? ZONATOTO merupakan pilihan yang sangat tepat adalah... | 0 | 2024-05-30T05:21:27 | https://dev.to/zonatotoslot17/zonatoto-slot-online-terbaik-dan-terpercaya-2024-4fo0 | zonatotologin, togelpulsa5000, togelpulsa, slotpulsa |

Apakah kamu sedang mencari link slot gacor? [ZONATOTO](https://hypertogel.com/) merupakan pilihan yang sangat tepat adalah pilihan game slot gacor server terbesar di dunia judi online, situs slot ini menawarkan jenis game slot gacor yang istimewa pastinya gampang maxwin 2024. Tidak cuma itu saja, melainkan dengan sistem slot terlengkap yang praktis, sodara bisa bermain situs slot kapan saja tanpa perlu ribet.
[ZONATOTO](https://hypertogel.com/) adalah situs slot gacor gampang maxwin terpercaya yang menyediakan berbagai macam game slot online resmi terbaik. Situs slot tentu saja memberikan keuntungan dalam rupa jackpot memberikan kesempatan bagi setiap slot gacor setiap harinya tahun ini. Namun ZONATOTO terus berinovasi memberikan game slot gacor hari ini yang pasti menguntungkan bagi para penggemar judi slot online di Indonesia
| zonatotoslot17 |
1,869,922 | Triton Inspection Services | For thorough and reliable home inspections in Alabama, Triton Inspection Services is your trusted... | 0 | 2024-05-30T05:21:15 | https://dev.to/william_347197f2809952555/triton-inspection-services-3cab | home, inspection | For thorough and reliable home inspections in Alabama, Triton Inspection Services is your trusted partner. Our experienced inspectors provide comprehensive evaluations of residential properties, offering valuable insights to help you make informed decisions about your investment. From foundation to roof, we meticulously examine every aspect of the home, identifying potential issues and providing clear, detailed reports. Whether you're buying, selling, or maintaining a property, our goal is to ensure your peace of mind and confidence in your real estate transaction. Trust Triton Inspection Services for professional and trustworthy home inspections in Alabama. Contact us today to schedule your inspection and take the next step towards a safer, more secure home.
Address : 6014 AL Highway 144 St, Ragland, AL 35131, USA
E-Mail : tritonInspects@gmail.com
Phone : +1 2056411235
Visit : https://www.tritoninspects.com/ | william_347197f2809952555 |
1,869,921 | Exploring Angular v18: Zoneless Change Detection and More | Introduction We are thrilled to announce the release of Angular v18! This version focuses... | 0 | 2024-05-30T05:21:06 | https://dev.to/dipakahirav/exploring-angular-v18-zoneless-change-detection-and-more-565 | angular, angular18, javascript, material | ### Introduction
We are thrilled to announce the release of Angular v18! This version focuses on stabilizing many new APIs, addressing common developer requests, and experimentally introducing zoneless change detection.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
) to support my channel and get more web development tutorials.
### Key Highlights
**1. Zoneless Change Detection**
Zoneless change detection is now available experimentally, eliminating the need for `zone.js`, leading to improved performance, faster initial renders, smaller bundle sizes, and simpler debugging.
#### Enabling Zoneless Change Detection
To enable zoneless change detection, modify your application bootstrap configuration:
```typescript
import { bootstrapApplication } from '@angular/platform-browser';
import { provideExperimentalZonelessChangeDetection } from '@angular/core';
bootstrapApplication(App, {
providers: [
provideExperimentalZonelessChangeDetection()
]
});
```
Remove `zone.js` from `angular.json`.
#### Example Component
Here's an example of a component using zoneless change detection:
```typescript
import { Component, signal } from '@angular/core';
@Component({
selector: 'app-root',
template: `
<h1>Hello from {{ name() }}!</h1>
<button (click)="handleClick()">Go Zoneless</button>
`,
})
export class App {
protected name = signal('Angular');
handleClick() {
this.name.set('Zoneless Angular');
}
}
```
**2. Material 3 and Deferrable Views**
Material 3 components and deferrable views are now stable. Material 3 incorporates feedback-based improvements, and deferrable views help enhance Core Web Vitals.
**3. Built-in Control Flow**
The built-in control flow API is now stable, featuring better type checking and ergonomic implicit variable aliasing.
### Server-Side Rendering Enhancements
**Improved i18n Hydration Support**
i18n hydration support is now available, enabling better handling of internationalized content during hydration.
**Enhanced Debugging Tools**
Angular DevTools now visualize the hydration process, displaying component hydration statuses and identifying hydration errors.
### Firebase App Hosting
Angular v18 supports dynamic Angular applications on Firebase App Hosting, simplifying deployment and enhancing performance.
### TypeScript 5.4 Compatibility
This version is fully compatible with TypeScript 5.4, allowing developers to utilize the latest TypeScript features.
### Additional Updates
**Unified Control State Change Events**
Form controls now expose an `events` property for tracking changes in value, touch state, pristine status, and control status.
```typescript
const nameControl = new FormControl<string | null>('name', Validators.required);
nameControl.events.subscribe(event => {
// process the individual events
});
```
**Automated Migration to Application Builder**
The new application builder, based on Vite with esbuild, replaces the previous webpack experience, reducing dependencies and improving installation times.
**Route Redirects as Functions**
The `redirectTo` property now accepts a function, providing higher flexibility for dynamic route redirects.
```typescript
const routes: Routes = [
{ path: "first-component", component: FirstComponent },
{
path: "old-user-page",
redirectTo: ({ queryParams }) => {
const userIdParam = queryParams['userId'];
if (userIdParam !== undefined) {
return `/user/${userIdParam}`;
} else {
return `/not-found`;
}
},
},
{ path: "user/:userId", component: OtherComponent },
];
```
### Conclusion
Angular v18 brings numerous improvements and new features that enhance performance, developer experience, and application capabilities. From zoneless change detection to stable Material 3 components and improved SSR, this release empowers developers to build more efficient and robust applications. For detailed information, visit the [official Angular blog post](https://blog.angular.dev/angular-v18-is-now-available-e79d5ac0affe).
Stay updated with the latest Angular developments and happy coding with Angular v18!
*Follow me for more tutorials and tips on web development. Feel free to leave comments or questions below!*
#### Follow and Subscribe:
- **YouTube**: [devDive with Dipak](https://www.youtube.com/@DevDivewithDipak)
- **Website**: [Dipak Ahirav] (https://www.dipakahirav.com)
- **Email**: dipaksahirav@gmail.com
- **Instagram**: [devdivewithdipak](https://www.instagram.com/devdivewithdipak)
- **LinkedIn**: [Dipak Ahirav](https://www.linkedin.com/in/dipak-ahirav-606bba128) | dipakahirav |
1,869,919 | Gifts World Expo | Gifts World Expo is India’s biggest exhibition on gifting and promotional solutions. The specially... | 0 | 2024-05-30T05:20:19 | https://dev.to/gifts_world_expo/gifts-world-expo-2a5b | [Gifts World Expo](https://www.giftsworldexpo.com/) is India’s biggest exhibition on gifting and promotional solutions. The specially curated trade show provides a lucrative platform for marquee players looking to scale up their businesses in the B2B gifting and promotion industry to generate targeted leads, get industry insights, find sustainable solutions, and accelerate and enhance their value chain.The show dispenses an extensive range of products, ideas, and solutions in a variety of niches in the B2B gifting space. The iconic fair is the ultimate destination for every possible gifting solution: gift items, souvenirs, premiums, novelties, mementos, and keepsakes and a one-stop rendezvous for promotional solutions in India. Gifts World Expo unites the entire gifting industry under one roof.
| gifts_world_expo | |
1,869,916 | Cloud Cost Management With Cloud CADI | Cloud Cost Management with Cloud CADI focuses on leveraging advanced analytics,and actionable... | 0 | 2024-05-30T05:17:26 | https://dev.to/risheka_vijay_e4df10c5c6f/cloud-cost-management-with-cloud-cadi-bed | cloudcostmanagement, cloudfinops, cloudnative | [Cloud Cost Management](www.amadisglobal.com) with [Cloud CADI](https://amadisglobal.com/cloud-cadi-a-simplified-cloud-finops-solution/) focuses on leveraging advanced analytics,and actionable recommendations to minimize unnecessary cloud expenses and maximize the return on cloud investments. Cloud CADI offers a strategic approach to identify inefficiencies, predict costs, and implement actionable recommendations.
Key Strategies for Cloud Cost Management with [Cloud CADI](https://amadisglobal.com/cloud-cadi-a-simplified-cloud-finops-solution/)
Detailed Cost Analysis:
Service-Level Insights: Break down costs by individual cloud services (compute, storage, networking, etc.) to identify high-cost areas.
Usage Patterns: Analyze usage patterns to understand peak and off-peak times, helping to align resource usage with demand.
Resource Utilization Diagnostics:
Idle Resource Detection: Identify resources that are running but not being used (e.g., idle VMs, unattached storage).
Underutilized Resources: Find resources that are underutilized and recommend rightsizing options.
Anomaly Detection: Use machine learning to detect anomalies in cloud spending that could indicate misconfigurations or unexpected usage.
Actionable Insights and Recommendations:
Rightsizing: Provide recommendations for resizing instances based on historical usage data to ensure optimal performance at the lowest cost.
Instance Scheduling: Suggest scheduling non-critical instances to shut down during off-peak hours to save costs.
Benefits of Cloud Cost Management with Cloud CADI
Cost Savings: Significant reduction in cloud spending through efficient resource utilization and elimination of wastage.
Improved Financial Accountability: Enhanced visibility into cloud costs ensures that departments and teams are accountable for their spending.
Enhanced Operational Efficiency: Streamlined cloud operations through automation and real-time monitoring.
Strategic Decision Making: Data-driven insights enable informed decisions regarding cloud investments and usage.
Scalability and Flexibility: Adaptable to the evolving needs of the organization as cloud usage and business requirements grow.
| risheka_vijay_e4df10c5c6f |
1,869,914 | life [2] - I want to build a file sharing app | This is a series where I update about my daily life. The company I work for don't have any new... | 22,781 | 2024-05-30T05:15:11 | https://dev.to/fadhilsaheer/life-2-i-want-to-build-a-file-sharing-app-j1f | programming, rust, javascript | This is a series where I update about my daily life. The company I work for don't have any new clients, so no projects to work on. I'am planning to leave this company anyway (If you are recruiter and want to hire me shoot me an email fadhilsaheer@gmail.com), so I wanted to build something which can catch recruiter's eyes and develop my skills.
> This blog post is the understanding I have on the mentioned technologies, there might be a lot of corrections to be made, feel free to mention it in comments, it would help me a lot
## I want to build a file sharing app 📂
### Context
I had this idea for a while to create an app which can share files similar like Xender, airdrop etc. But with back to back compatibility with all devices. I thought there would be similar api for the tech, but I was wrong 🏃
### My research
There are different ways you can share files between devices like
- Connect devices over wifi
- With bluetooth
etc, but every one of them comes with a draw back, sending files over wifi is fast, but both devices have to be in same network. Connecting devices between bluetooth is easy and fast, but sending files between is too slow.
Many of the existing softwares use bluetooth for discovering and connecting and send files over wifi.
This is what I thought initially, but It was kind of hard. there are different tech kind of technologies and protocol to be mind of
- [NFC (near field communication)](https://en.wikipedia.org/wiki/Near-field_communication) is used to discover nearby devices
- [Wi-Fi Aware](https://developer.android.com/develop/connectivity/wifi/wifi-aware) used in android to discover and connect to devices
- [NAN (Neighbourhood Area Network)](https://www.techopedia.com/definition/29172/neighborhood-area-network-nan) tech behind wifi-aware
- [Wi-Fi Direct] (https://www.wi-fi.org/discover-wi-fi/wi-fi-direct) send data between devices through wi-fi
My initial thought was to create a hotspot and connect to that hotspot using another device and make a webserver run on hotspot device and send files using HTTP.
Even though thats a solution, whats the fun in that ? I wanted to push pass my limits anyway.
So I created a simple prototype using NFC (Near field communication), there is a library called [libnfc](https://github.com/nfc-tools/libnfc), There is rust crate which had binding for libnfc, so I used it to create a basic discovery and device connection, but sending files with it is impossible, its too slow, and range between device is 4-10 cm. And transfer rate is only upto 424 kbit/s even bluetooth's transmission rate is about 1 Mbps, and it is enhanced upto 24 Mbps in BLE (Bluetooth low-energy).
My next option was to use Wi-Fi Aware & Wi-Fi Direct, which have support on android, windows and linux. But apple doesn't support it. To be exact apple have another tech called [Apple Wireless Direct Link (AWDL)](https://stackoverflow.com/questions/19587701/what-is-awdl-apple-wireless-direct-link-and-how-does-it-work) which they use for airdrop, to share device state between apple device etc. So they dont have support for other tech, to be exact they don't support Peer to Peer data support with other devices like wi-fi direct does (At least this is what I learned of)
### So now what ?
Fortunately I found a [reddit post](https://www.reddit.com/r/rust/comments/135mwta/direct_file_transfer_over_ad_hoc_wifi/) which mentioned about a software named [Flying Carpet](https://github.com/spieglt/FlyingCarpet) after tinkering with that, and checking its code I found out there is something call [Wireless ad hoc network (WANET)](https://en.wikipedia.org/wiki/Wireless_ad_hoc_network), it its basically a decentralised type of wireless network which does not rely on router or wireless access points.
Flying Carpet use ad hoc wi-fi to share file. Basically it create an Ad hoc network in a device and other devices need to manually connect to that Ad hoc network.
I'm planning to use NFC to connect and discover devices (it is the only thing apple and others have in common). Any one of the connected device would create an ad hoc network and other device will connect it to automatically using NFC.
This is basically hypothesis, not sure If it'll work the way I expect it to, or to be exact I'm not even sure if it can be achieved this way
### Conclusion
Either way I want to build this app, If they can do it, why can't I ?. This blog post might not be correct, I'll update it if I find corrections. This is what I understood from learning and researching about this for the past few days.
I'll update the progress in coming posts, wish me luck! | fadhilsaheer |
1,869,913 | Shadow Mapping Techniques: Implementing Shadows in 3D Scenes Using Shadow Mapping | Shadow mapping is a fundamental technique in 3D graphics that allows for realistic rendering of... | 0 | 2024-05-30T05:12:34 | https://dev.to/hayyanstudio/shadow-mapping-techniques-implementing-shadows-in-3d-scenes-using-shadow-mapping-46hl | shader, beginners, gamedev | Shadow mapping is a fundamental technique in 3D graphics that allows for realistic rendering of shadows. By simulating how light interacts with objects in the real world, shadow mapping adds depth, dimension, and a touch of realism to 3D scenes. This not only enhances the visual fidelity of graphics but also improves our spatial awareness and immersion within the 3D environment. In essence, shadows cast by objects provide crucial visual cues that our brains rely on to perceive depth and understand the relative positions of objects in a scene
## Basics of Shadow Mapping
Shadow mapping breathes life into 3D graphics by simulating realistic shadows. Here's the magic behind it:
- Seeing from the Light's Eye: Imagine the scene rendered from the light source's perspective, like a camera. This creates a special texture called a shadow map, essentially a depth map recording how close objects are to the light.
- Light vs. Dark on the Map: Closer objects in the scene block more light, appearing darker on the shadow map. This darkness signifies areas in shadow.
- From Camera to Canvas: When rendering the scene normally, the graphics processor checks the shadow map for each pixel on screen.
- Shadows Emerge: If the shadow map tells the processor something is blocking light at that pixel's location, the pixel is shaded darker, creating the illusion of a shadow.
Think of it like a black and white photo of the scene, lit only by the light source. Darker areas represent objects casting shadows. This information dictates which parts of the scene are shadowed from the main camera's perspective.
## Setting Up the Scene
Before we delve into the technical aspects of shadow mapping, let's prepare the stage for our digital drama! Here's what we need to consider when setting up the 3D scene:
**Scene Geometry:**
- Object Placement: Arrange your 3D models strategically to create interesting shadow interactions. Consider how objects might block light from each other and how shadows will fall on surfaces.
- Light Source Positioning: Experiment with the position and type of light source (point light, directional light, etc.) This will significantly impact the direction and shape of the shadows cast.
**Light Source Configuration:**
- Shadow Casting: Ensure your light source has "Cast Shadows" enabled in its properties. This allows the engine to generate the necessary shadow map information.
- Bias Adjustment (Optional): A slight bias adjustment might be needed to prevent unwanted artifacts like "shadow acne" (tiny dark spots appearing on surfaces that shouldn't be completely in shadow). This adjustment can be fine-tuned for optimal results.
By carefully setting up your scene and configuring the light source, you're laying the groundwork for realistic and visually appealing shadows in your 3D world. In the next chapter, we'll explore the technical details of shadow map creation and utilization.
## Creating the Shadow Map
Now that the scene is prepped, let's delve into the technical heart of shadow mapping: generating the all-important shadow map.
Seeing Through the Light's Eyes:
- A Different View: The first step involves rendering the entire scene from the perspective of the light source, not the main camera. Imagine the light source is equipped with a special camera that captures depth information instead of color.
- Depth, Not Beauty: During this render pass, textures, materials, and lighting are ignored. The focus is solely on capturing the relative distances of objects from the light source.
- Birth of the Shadow Map: The result of this unique render pass is a special texture called a shadow map. This map stores depth values, with darker areas representing objects closer to the light and therefore casting shadows.
Think of the shadow map as a grayscale image where brightness corresponds to depth. Brighter areas are further away from the light, while darker areas are closer and will block shadows in the final render.
## Applying the Shadow Map
We've created the shadow map, a treasure trove of depth information. Now, let's see how this map is used to paint shadows onto our 3D scene.
**The Fragment Shader's Role:**
The magic happens within the fragment shader, a program that determines the final color of each pixel on the screen. Here's the process:
- World Position Reconstruction: For each pixel on the screen, the fragment shader reconstructs its position in the 3D world based on its location on the screen and camera data.
- A Peek into the Shadow Map: The fragment shader then samples the shadow map at a corresponding location based on the reconstructed world position and the light source's direction.
- Depth Comparison: The fragment shader compares the depth value retrieved from the shadow map with the reconstructed depth of the current pixel.
**Living in Shadows or Bathed in Light:**
- Shadow Detected: If the depth value from the shadow map indicates something closer to the light source is blocking the way, it signifies a shadowed area. The fragment shader adjusts the pixel's color accordingly, making it darker to create the illusion of a shadow.
- Direct Illumination: If the depth values match, it means no object is obstructing the light's path to that pixel. The fragment shader applies the usual lighting calculations, allowing the pixel to be lit normally.
**Shadow Map Resolution Matters:**
The precision of shadows depends on the resolution of the shadow map. A higher resolution map allows for more accurate depth comparisons, resulting in smoother and more natural-looking shadows. However, higher resolutions also come at a performance cost as the GPU needs to process more texture data.
**Beyond Basic Shadow Mapping:**
## Optimizing Shadow Maps
This is a simplified explanation of shadow mapping. Advanced techniques like filtering and bias adjustments can further improve shadow quality and reduce artifacts.
Shadow mapping breathes life into 3D graphics, but like any powerful tool, it requires careful handling to achieve optimal results. This chapter dives into common shadow mapping challenges and optimization techniques.
## Resolving Common Artifacts
- Shadow Acne: Tiny dark speckles appearing on surfaces that shouldn't be completely shadowed. These can be caused by minor depth inaccuracies or limitations in shadow map resolution.
- Peter Panning: Shadows that don't seem to fully connect to the object casting them, making it appear as if the object is floating slightly above its shadow. This can occur due to limitations in shadow map bias adjustments.
- Low Shadow Resolution Artifacts: When using low-resolution shadow maps, especially for large scenes or distant objects, shadows may appear blocky or pixelated.
## Increasing Shadow Map Resolution
Higher Resolution, Higher Quality: A straightforward solution is to increase the resolution of the shadow map. This provides more detailed depth information, leading to smoother and more accurate shadows.
- The Performance Cost: Be mindful that higher resolution shadow maps require the GPU to process more texture data, potentially impacting performance. Finding a balance between shadow quality and performance is crucial.
## Using Cascaded Shadow Maps
For vast scenes with varying object distances from the light source, a single shadow map might struggle. Here's where cascaded shadow maps come in:
- Multiple Shadow Maps, Strategic Depths: The scene is divided into regions or cascades, each with its own dedicated shadow map.
- Tailored Shadow Maps: Each cascade's shadow map has a resolution optimized for its specific range of depths. Closer objects have higher resolution maps for finer detail, while distant objects can utilize lower resolution maps for efficiency.
- Smoother Shadows, Optimized Performance: By using cascaded shadow maps, you can achieve smoother shadows across the entire scene while maintaining good performance.
**Beyond the Basics**
This chapter provides a starting point for shadow map optimization. Advanced techniques like variance shadow maps and percentage-closer filtering can further enhance shadow quality and reduce artifacts.
## Advanced Techniques
Shadow mapping is a cornerstone of realistic 3D graphics, but there's always room for improvement. This chapter explores two advanced techniques that can further enhance the quality and visual fidelity of your shadows: Percentage-Closer Filtering (PCF) and Variance Shadow Maps (VSM).
**Percentage-Closer Filtering (PCF)**
The core concept of shadow mapping relies on comparing depth values from the scene to the shadow map. However, this approach can sometimes lead to aliasing, resulting in blocky or stair-stepping artifacts along shadow edges.
**PCF tackles this issue by introducing a softer shadow:**
Neighborhood Sampling: Instead of a single depth comparison, PCF samples multiple texels around the corresponding location in the shadow map.
- Depth Comparison Buffet: Each of these neighboring samples is then compared to the scene depth.
- Percentage of Closeness: Based on the results of these comparisons, PCF calculates the percentage of samples that were closer to the light source than the current scene fragment.
- Shading by Percentage: This percentage is used to determine how much to darken the fragment's color. A higher percentage indicates a more shadowed area, resulting in a smoother shadow falloff.
PCF essentially creates a softer transition between shadow and light, reducing the appearance of harsh edges.
[Read full article over here](https://glsl.site/post/ambient-occlusion-with-shaders-adding-depth-to-scenes/)
| hayyanstudio |
1,869,912 | Understanding Flutter Widgets: Column vs Row | In Flutter, the layout design revolves around widgets. Two of the most essential layout widgets are... | 0 | 2024-05-30T05:09:39 | https://dev.to/eldhopaulose/understanding-flutter-widgets-column-vs-row-2m5o | flutter, dart, google, frontend | In Flutter, the layout design revolves around widgets. Two of the most essential layout widgets are `Column `and `Row`. They control how child widgets are positioned vertically and horizontally, respectively. Let’s dive into the details and see them in action with example code.
## The Column Widget
The `Column `widget in Flutter is used to align child widgets in a vertical manner. It’s similar to a vertical `LinearLayout `in Android or a vertical `StackPanel `in UWP. Here’s a simple example:
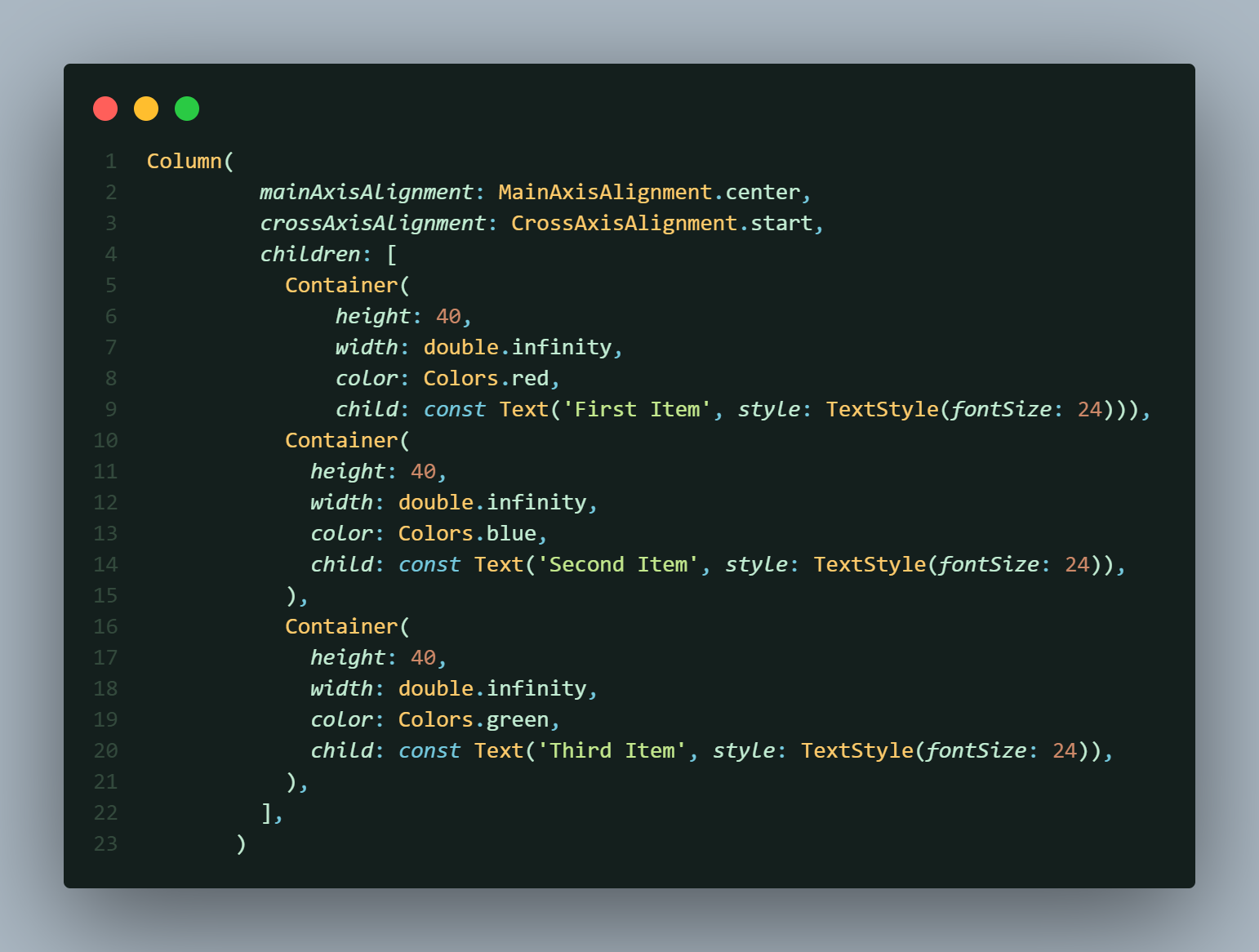
In this example, the `mainAxisAlignment` property is set to `MainAxisAlignment.center`, which centers the children vertically. The `crossAxisAlignment` is set to `CrossAxisAlignment.start`, aligning the children to the start of the cross axis (horizontally in this case).

## The Row Widget
Conversely, the `Row `widget arranges its children horizontally. It’s akin to a horizontal `LinearLayout `in Android or a horizontal `StackPanel `in UWP. Here’s an example:
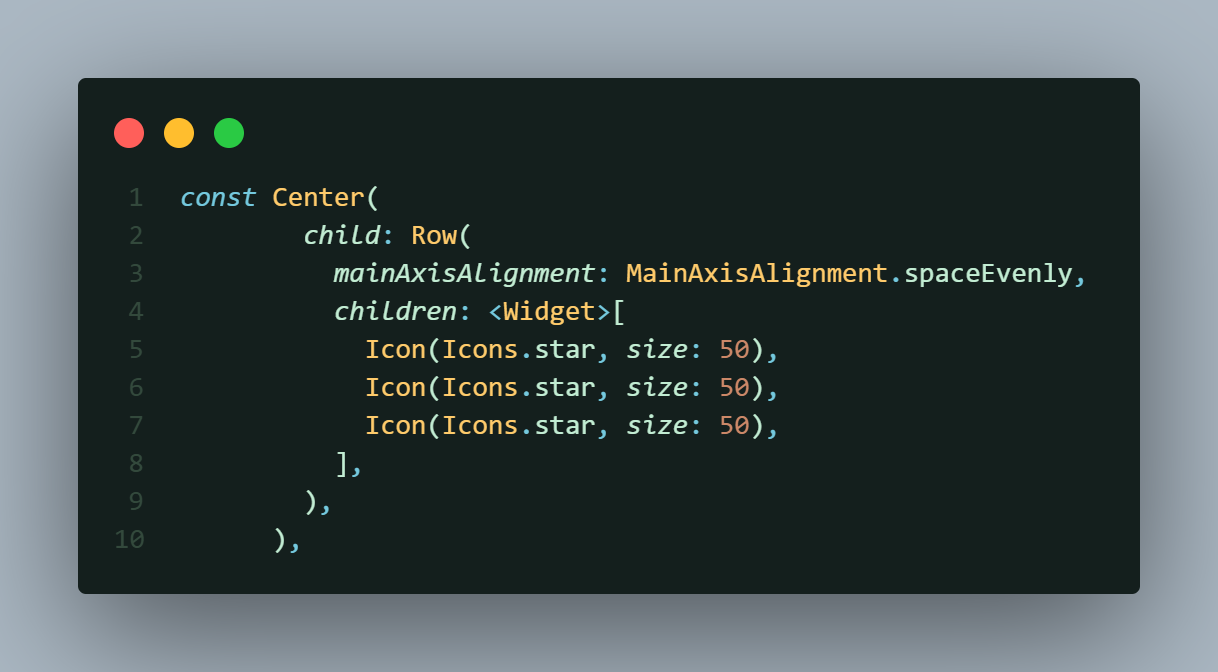
Here, `mainAxisAlignment `is set to `MainAxisAlignment.spaceEvenly`, which distributes the children evenly across the horizontal axis with equal spacing.
## Combining Column and Row
You can nest `Row `and `Column `widgets to create complex layouts. Here’s a nested example:
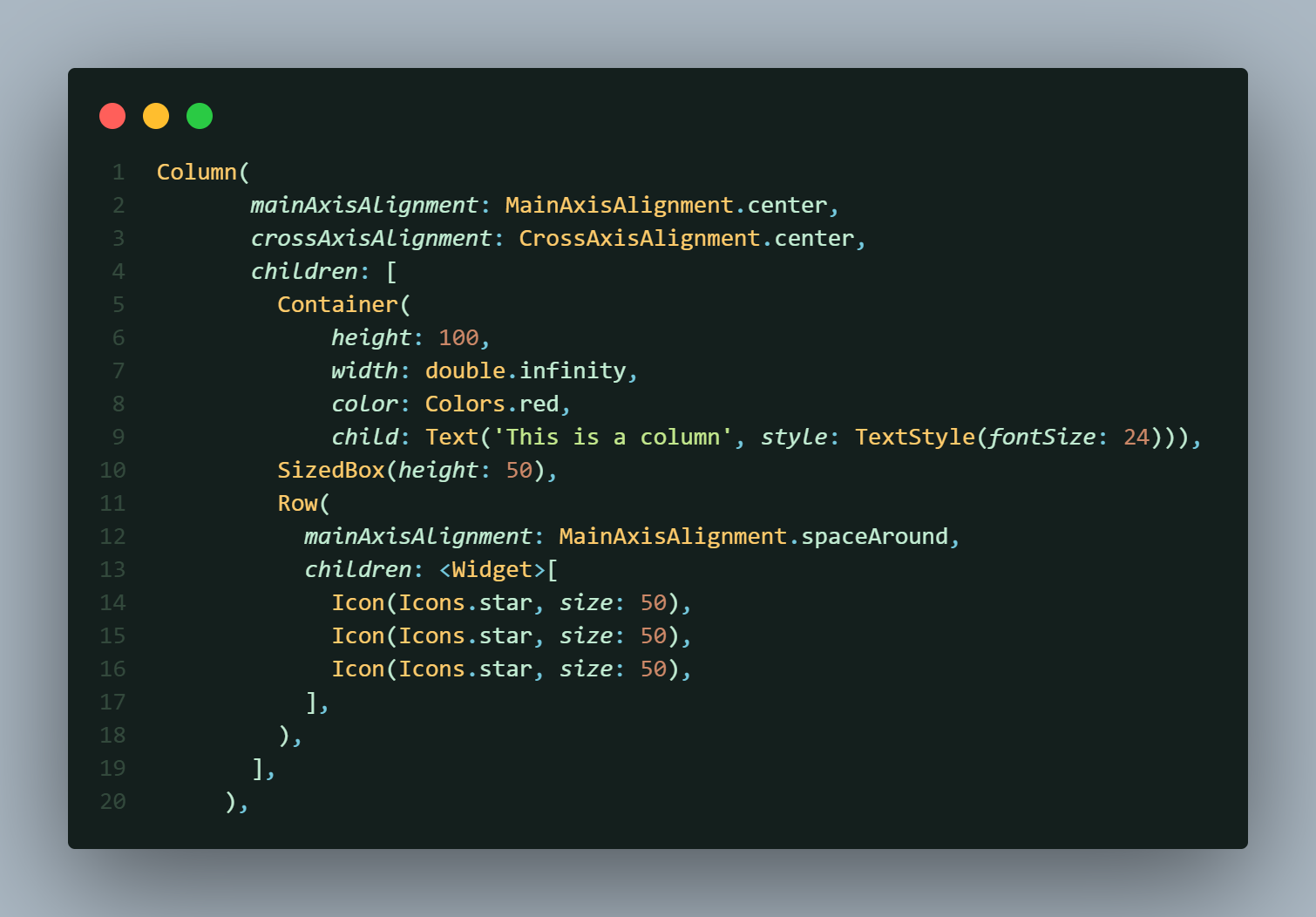
In this nested layout, a `Row `is placed inside a `Column`, combining both horizontal and vertical alignment.
## Conclusion
Understanding the `Column `and `Row `widgets is crucial for effective layout design in Flutter. Experiment with the properties and nesting to create the desired UI for your app.
[Contact with me](https://eldhopaulose.info/)
[GitHub](https://github.com/eldhopaulose)
| eldhopaulose |
1,869,909 | Unforgettable Journeys: Discover India with a Tour Package | Have you ever dreamt of wandering through vibrant bazaars overflowing with spices and textiles?... | 0 | 2024-05-30T05:04:06 | https://dev.to/tailormade_journey_d2c000/unforgettable-journeys-discover-india-with-a-tour-package-3a2c |

Have you ever dreamt of wandering through vibrant bazaars overflowing with spices and textiles? Perhaps you envision yourself scaling the majestic Himalayas or cruising down serene backwaters. India, a land of stunning diversity, promises an unforgettable adventure for every kind of traveler. This vast nation, steeped in rich history and pulsating with vibrant culture, offers experiences that will linger in your memory forever.
[India Tour Packages](https://tailormadejourney.com/destination/india-tour-packages/
) can unlock the magic of this incredible country, making your dream vacation a reality. Whether you crave heart-pounding adventure, cultural immersion, or simply relaxation on pristine beaches, there's a perfect tour package waiting to be discovered.
**
A Kaleidoscope of Experiences Awaits
**
India's captivating tapestry is woven from a multitude of regions, each boasting its own unique charm. In the north, the snow-capped Himalayas beckon adventure seekers to trek through breathtaking landscapes. Hill stations like Shimla and Munnar offer a welcome respite from the heat, with their colonial architecture and verdant beauty. Central India boasts magnificent forts, ancient temples, and bustling cities like Delhi and Agra, home to the iconic Taj Mahal.
Travel south to discover serene beaches fringed with swaying palm trees, alongside tranquil backwaters where you can glide through emerald waterways on a traditional houseboat. The west unveils the vibrant state of Rajasthan, a land of majestic forts, opulent palaces, and colorful festivals. No matter your interests, India has something to enthrall you.
**Crafting Your Ideal Indian Adventure**
[India travel packages](https://tailormadejourney.com/destination/india-tour-packages/
) come in a kaleidoscope of colors, just like the country itself. For the history buff, heritage tours weave a captivating narrative through ancient forts, palaces, and temples. Wildlife enthusiasts can embark on thrilling safaris, spotting tigers, elephants, and a dazzling array of other animals in their natural habitat. Adventure awaits those who seek adrenaline-pumping activities, from trekking the Himalayas to white-water rafting on rushing rivers.
Delve deeper into the soul of India with cultural tours that introduce you to traditional practices, vibrant festivals, and the country's famed cuisine. Seek spiritual solace on pilgrimage tours, visiting sacred sites and experiencing the serenity that India offers. Luxury tours cater to discerning travelers, providing premium accommodation, exclusive experiences, and impeccable service. Budget-conscious explorers can find tours that allow them to experience the magic of India without breaking the bank.
**The Magic of Customization**
The beauty of India tour packages lies in their flexibility. You can tailor your itinerary to perfectly match your interests, travel style, and budget. Choose the duration of your trip, the regions you want to explore, and the mode of transportation that best suits your needs. Whether you prefer the comfort of a private car, the scenic journey of a train, or the efficiency of domestic flights, your tour can be customized to your liking. The level of activity can also be adjusted, allowing you to pack your days with adventures or enjoy a more relaxed pace.
**Unveiling a World of Benefits**
Booking an India travel package offers a multitude of advantages. By letting the experts handle the logistics, you can save valuable time and energy that would otherwise be spent on trip planning. Experienced guides will ensure smooth travel from arrival to departure, providing insightful commentary and local knowledge along the way. Curated experiences take you beyond the well-trodden tourist path, offering a glimpse into the authentic heart of India. Tour packages can also be more cost-effective than planning your trip independently, especially when it comes to transportation and accommodation.
**Start Your Indian Odyssey Today**!
Ready to embark on an unforgettable adventure in the land of incredible experiences? Explore our website to discover a wide range of India tour packages designed to cater to every taste and budget. Our travel specialists are also happy to assist you in crafting a personalized itinerary that perfectly matches your dream vacation. Don't wait any longer – book your tour today and get ready to be amazed by the magic of India!
| tailormade_journey_d2c000 | |
1,869,907 | Achieve Your Career Goals With Certificate 3 In Child Care | Achieve Your Career Goals With Certificate 3 In Child Care Our Certificate 3 in Child Care program... | 0 | 2024-05-30T05:01:20 | https://dev.to/rasel_ahmed_cc3caf679f85a/best-rpl-provider-australia-3bl2 | Achieve Your Career Goals With Certificate 3 In Child Care
Our Certificate 3 in Child Care program is your gateway to a fulfilling career in child care services. With a comprehensive curriculum covering
Visit More: https://skillsupgrade.com.au/certificate-3-in-child-care/ | rasel_ahmed_cc3caf679f85a | |
1,869,906 | Johnson Controls: Driving Innovation in the Automotive Seats Market | Introduction Johnson Controls, a global leader in building products and technology, including... | 0 | 2024-05-30T05:00:37 | https://dev.to/sim_chanda/johnson-controls-driving-innovation-in-the-automotive-seats-market-4jbm | marketstrateg, globalinsights, marketgrowth |

**Introduction**
Johnson Controls, a global leader in building products and technology, including automotive seats market, is at the forefront of revolutionizing the automotive industry. With a rich history of innovation and a commitment to excellence, Johnson Controls continually adapts its strategies, embraces emerging innovations, and drives developments that shape the automotive seats market. This article explores Johnson Controls' strategic approach, its pioneering innovations, and the developments that are reshaping the automotive seats industry.
**Download FREE Sample:** https://www.nextmsc.com/automotive-seats-market/request-sample
**Strategic Approach
Customer-Centric Solutions**
Johnson Controls adopts a customer-centric approach, prioritizing collaboration with automakers to understand their unique needs and challenges. By working closely with customers throughout the product development process, Johnson Controls develops tailored seating solutions that address specific requirements while delivering superior quality and value. This collaborative approach enables Johnson Controls to build strong partnerships with automakers and drive innovation in the competitive automotive market.
**Global Presence and Market Leadership**
With a global footprint spanning across key automotive markets, Johnson Controls maintains a strong market presence and leadership position. By strategically positioning manufacturing facilities, research centers, and engineering hubs in strategic locations, Johnson Controls ensures proximity to customers and enhances operational efficiency. This global presence enables Johnson Controls to respond quickly to market demands and deliver innovative seating solutions that meet regional preferences and regulations.
**Investment in Research and Development**
Johnson Controls places a significant emphasis on research and development (R&D), investing in advanced technologies and engineering expertise to drive innovation in automotive seating solutions. By staying at the forefront of technological advancements, Johnson Controls explores new materials, design concepts, and manufacturing processes that enhance seating comfort, safety, and functionality. This continuous investment in R&D enables Johnson Controls to anticipate market trends and deliver cutting-edge seating solutions that exceed customer expectations.
Emerging Innovations
**Lightweight Materials and Design**
Johnson Controls is pioneering the use of lightweight materials and design optimization techniques to reduce the weight of automotive seats. By utilizing advanced materials such as high-strength steel, aluminum alloys, and composite materials, Johnson Controls achieves significant weight savings without compromising structural integrity or safety. Lightweight seats contribute to improved fuel efficiency, reduced emissions, and enhanced vehicle performance, making them an increasingly important focus area for automakers.
**Smart Seating Technologies**
Johnson Controls is at the forefront of developing smart seating technologies that enhance comfort, convenience, and safety for drivers and passengers. From integrated connectivity and entertainment systems to active ergonomics and adaptive seating controls, Johnson Controls' innovations create a seamless and personalized seating experience. By leveraging sensors, actuators, and connectivity solutions, Johnson Controls' smart seating solutions adapt to individual preferences and driving conditions, enhancing overall comfort and convenience.
**Sustainable Materials and Manufacturing Practices**
In response to growing environmental concerns and sustainability mandates, Johnson Controls is committed to integrating sustainable materials and manufacturing practices into its seating solutions. By utilizing recycled and bio-based materials, optimizing manufacturing processes, and minimizing waste and emissions, Johnson Controls reduces its environmental footprint while maintaining product quality and performance. Sustainable seating solutions offer automakers a competitive advantage and appeal to environmentally conscious consumers.
Market Developments
**Strategic Acquisitions and Partnerships**
Johnson Controls expands its capabilities and market reach through strategic acquisitions and partnerships with complementary companies. By acquiring companies with expertise in advanced materials, technologies, and manufacturing processes, Johnson Controls strengthens its innovation pipeline and enhances its competitive position in the automotive seats market. Strategic partnerships with automakers and suppliers enable Johnson Controls to co-develop innovative seating solutions that address evolving market needs and trends.
**Integration of Advanced Manufacturing Technologies**
Johnson Controls integrates advanced manufacturing technologies such as additive manufacturing (3D printing), robotics, and automation into its production processes to enhance efficiency, quality, and scalability. By leveraging digital manufacturing techniques and Industry 4.0 principles, Johnson Controls optimizes production workflows, reduces lead times, and increases manufacturing flexibility. Advanced manufacturing technologies enable Johnson Controls to respond quickly to changing market demands and deliver high-quality seating solutions with greater speed and precision.
**Focus on Safety and Comfort**
Johnson Controls prioritizes safety and comfort in its seating solutions, incorporating advanced safety features and ergonomic design principles. By integrating technologies such as active head restraints, side impact protection, and seat belt pretensioners, Johnson Controls enhances occupant protection and crashworthiness. Additionally, Johnson Controls focuses on optimizing seating ergonomics to minimize driver fatigue and improve overall comfort during long journeys.
**Inquire before buying:** https://www.nextmsc.com/automotive-seats-market/inquire-before-buying
**Conclusion**
Johnson Controls is a driving force in the automotive seats market, pioneering innovations that enhance comfort, safety, and sustainability. With a customer-centric approach, a focus on innovation, and a commitment to excellence, Johnson Controls continues to shape the future of automotive seating solutions. As the automotive industry evolves, Johnson Controls remains at the forefront of technological advancements, delivering cutting-edge seating solutions that meet the evolving needs of automakers and consumers worldwide.
| sim_chanda |
1,869,908 | Dev33 | (https://dev.com/signup/)_This is a submission for Frontend Challenge v24.04.17, CSS Art: June._ ... | 27,551 | 2024-05-30T05:00:00 | https://dev.com/signup/ | frontendchallenge, devchallenge, css, programming | (https://dev.com/signup/)_This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
## Inspiration
<!-- What are you highlighting today? -->
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge page) or you can share an image of your project and share a public link to the code. -->
## Journey
<!-- Tell us about your process, what you learned, anything you are particularly proud of, what you hope to do next, etc. -->
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- We encourage you to consider adding a license for your code. -->
<!-- Don't forget to add a cover image to your post (if you want). -->
https://dev.com/signup/
<!-- Thanks for participating! -->
| alla_santoshpavankumar_ |
1,869,905 | Finding what iterator to use and when from a beginner! | Hello, my name is Kaleb and I'm a beginner at coding. I am an active student at Flatiron School and... | 0 | 2024-05-30T04:53:57 | https://dev.to/killerfox007/finding-what-iterator-to-use-and-when-from-a-beginner-441h | javascript, beginners, programming, tutorial | Hello, my name is Kaleb and I'm a beginner at coding. I am an active student at Flatiron School and our first phase is javascript. Learning arrays and objects was easy, but adding them together and iterating over them was extremely difficult. I will be going over some the iterators as I understand them and give detailed examples. When I was doing research it was difficult to understand which to use and why.
The iterators I will be going over are:
.forEach()
.map()
.find()
.filter()
Starting with forEach() this is an iterator that does something for each value or object in the array. This is an iterator we learned with little value in the real world from my perspective. forEach is a loop as well, it can be used to console log elements in the array like the example below.
numberedArray = [1,2,3,4,5,6,7,8,9,10]
numberedArray.forEach(function (number) {
console.log("What number is being logged" + number);
});
This will console.log:
What number is being logged1
What number is being logged2
What number is being logged3
until it reaches 10 and then will stop.
this can be useful to see what values you are getting or for debugging. forEach is not something I personally would learn due to .map outshining it, forEach returns the same array but changed where .map returns a new array.
the map() definition that I believe explains this very well is: The map() method of Array instances creates a new array populated with the results of calling a provided function on every element in the calling array.
What does this actually mean? how does it work? what does it look like?
first, we should break down the definition it is a method that creates a new array populated with results from the provided function on EVERY element. exactly like the forEach iterator it goes through the [1-10] and does something on everyone and provides a NEW array.
Second let's see it in use to wrap our head around when and why we would use it. For example, We only want the last names of the guests staying at the hotel we run. our data might look like this:
let guests = [
{ firstName: 'Bob', lastName: 'Joeseph'},
{ firstName: 'Tracy', lastName: 'Miller'},
{ firstName: 'Siera', lastName: 'Allen'}
]
const lastNamesOfGuests = guests.map(firstAndLastNames => firstAndLastNames.lastName)
console.log(lastNamesOfGuests)
it will return: [ 'Joeseph', 'Miller', 'Allen' ]
Let's walk through it, We set a variable name for guests that is an array of objects and those objects have the first and last names of our 3 guests. We are setting lastNamesOfGuests to equal our variable guests and calling .map then we are passing in the objects it is going to each one and grabbing the .lastName and implicitly returning the strings inside a new array.
Now that we understand both of those we are finishing it up with my favorite combo the .find and .filter iterators and personally my favorite to use. .find is very easy to understand its job is to find something and return it once found, if nothing is found .find returns undefined and filter returns a new array with no elements looking like []. The difference between .find and .filter is once find gets a match it will stop looping and return that element. in our example, if we wanted all the fruits and vegetables starting with the letter B. Find will only return the banana in our example below.
let fruitAndVegetables = ['apple', 'banana', 'broccoli', 'carrots']
const namesWithB = fruitAndVegetables.find(fruitAndVeg => {
return fruitAndVeg.toLowerCase().startsWith("b")
})
console.log(namesWithB)
This will return: banana
small explanation on why I used .toLowerCase() and .startsWith(), toLowerCase makes all of the elements lowercase making it so if banana was a capital B it would still start with lowercase b. making our search case insensitive. the startsWith is very self-explanatory but if it starts with what is in the () it will match and return those elements.
.filter is very similar to .find but has some key differences. The filter offers more than 1 match and returns a new array with the match from the search. an example will show you the differences very nicely. in our example, we changed one word and got both bana and broccoli. we changed find to filter. find returns the first match and stops the loop, filter goes through and makes a new array and populates it with all the matches from the elements passed in.
let fruitAndVegetables = ['apple', 'banana', 'broccoli', 'carrots']
const namesWithB = fruitAndVegetables.filter(fruitAndVeg => {
return fruitAndVeg.toLowerCase().startsWith("b")
})
console.log(namesWithB)
This will return: [ 'banana', 'broccoli' ]
// used the definition for map()
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/map
| killerfox007 |
1,869,904 | Im accused of being a micromanager. Higher-ups want to build team capacity at the expense of quality | Im accused of being a micromanager. Higher-ups want to build team capacity at the expense of... | 0 | 2024-05-30T04:52:08 | https://dev.to/humanspecimen/im-accused-of-being-a-micromanager-higher-ups-want-to-build-team-capacity-at-the-expense-of-quality-2lmb | management, leadership, career | # Im accused of being a micromanager. Higher-ups want to build team capacity at the expense of quality
I'm the defacto tech lead in my team, of 6 people, where I've been working for 4 years. We don't have a designated lead, but me and another experienced dev make all the important decisions by consensus.
Higher-ups have always voiced a strong opinion that building team capacity is more important for our company than to ensure perfect quality. However, they recognize that certain areas are mission-critical, where quality shouldn't be compromised.
When reviewing PRs I have generally tried my best to have a balanced criteria: On one side I try to prevent introducing regressions, particularly on critical areas; On the other side, I try to provide junior devs the opportunity to gain experience by not expecting all their code to be perfect.
However, some junior devs feel very empowered to own certain critical areas, and tend to make large PRs with changes that may be risky, or require extensive reviews, or refactors on architecturally significant code. When this happens I've usually handled the situation by requesting changes, and sometimes PRs require several reviews before they're merged. Sometimes these juniors are difficult and we've had frictions because I hold my ground and they either disagree, or ignore parts of my reviews, or repeat the same undesirable behavior in future PRs.
The other senior dev in the team has a more carefree and agreeable personality and has a much more lenient taste when reviewing PRs. His code quality isn't as good as mine, and his performance on architectural design has been sloppy in the past. He doesn't like confrontation and doesn't like to say "no" to people.
He has accused me of being a micro-manager, of being an obstacle for the team's scalability, and of not giving devs any freedom, of expecting perfection, and says I consider any code that doesn't match my personal style to be bad code. He also spread these unproven accusations to the higher-ups. Now there is a myth surrounding me, that I'm all these things.
I had a call with the higher-ups where I brought this up. I prepared a thorough presentation where I tried to debunk these myths, and made the claim that the accusations were biased due to his carefree personality. To my demise, they seem to have a special preference for the other senior dev. He's been at the company for longer, he has more charisma, and people like him because he's nicer.
I feel like these people (The senior dev, and the higher-ups) don't know how important I've been/ I am, for the team. I'm the backbone of the team, and I'm not getting the credit for it. I make all relevant engineering decisions. Before I was involved, their development lifecycle was so bad, the app was always crashing because every PR had regressions. Over these years, I gradually turned their pet project v1 into a stable and serious app that now has a chance of becoming profitable. I feel like the team doesn't deserve me.
I would like to hear some feedback in general.
Should I look for another job? The main reasons why I've liked
working here are that it has mostly felt like a relaxed working environment, and they prioritize team harmony more than strict deadlines and results. But I feel like I'm a more competitive-minded person. | humanspecimen |
1,869,903 | Web App Pentesting on AWS: A Comprehensive Guide | Introduction Overview Web application security is important, since data has to be kept integral,... | 0 | 2024-05-30T04:47:54 | https://sudoconsultants.com/web-app-pentesting-on-aws-a-comprehensive-guide/ | pentesting, webapp, aws, awsinspector | <!-- wp:heading {"level":1} -->
<h1 class="wp-block-heading">Introduction</h1>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Overview</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Web application security is important, since data has to be kept integral, confidential, and available. In the present day, where the cyber threat keeps rising, securing web applications against vulnerabilities is important to ensure all the above. Penetration testing is proactive, and vulnerabilities can be found and fixed before any exploitation can occur from malicious actors.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Purpose</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The objective of this guide is to provide a comprehensive roadmap to our readers on the most common vulnerabilities in web applications, getting them familiar with the tools and services available in AWS, how to pentest a web application, and ensuring all security measures are being carried out. By following this guide, it will be possible to conduct a complete pentest, discover security gaps, and apply effective remediation plans.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Understanding Web Application Security</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Common Vulnerabilities</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Web applications face different types of vulnerabilities that attackers exploit to cause unauthorized access, data theft, and other forms of unauthorized harm. The most critical web application security risks can be determined by utilizing the OWASP Top 10 standard. During the course of this work, we will get to know some of the common vulnerabilities.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>SQL Injection:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>An SQL injection allows an attacker to execute arbitrary SQL queries on the database through input fields.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Cross-Site Scripting [XSS]:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Through this vulnerability, harmful scripts are injected into web pages and thereafter viewed by others.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Cross-Site Request Forgery:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>The user is forced to execute unwanted actions in a web application in which he is logged in.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Insecure Deserialization:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This vulnerability is employed to exploit the application logic by manipulating serialized objects.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Security Misconfiguration:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This covers insecure default configurations, incomplete configurations, as well as mishandling of default accounts and credentials.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Security Best Practices</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To secure web applications from such vulnerabilities, we need to follow some security best practices, which are as follows:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Secure Coding Practice:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Implement secure coding standards to avoid introducing security vulnerabilities during development.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Input Validation and Sanitization:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Validate and sanitize all user inputs to avoid injection attacks.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Proper Session Management:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Secure session management to avoid session hijacking and session fixation issues.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Regular Security Assessment:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Regular security assessment and pentest so that if any vulnerability found, it can be taken care of.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Patch Management:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Keep all software, libraries, and dependencies up-to-date with the latest security patches.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Setting Up the Environment</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Account Setup</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To begin the process of pentesting, we first need to set up our AWS environment. We need to prepare an AWS account, set up IAM roles and permission, and finally set up a test environment.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Console Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Open AWS Management Console Open AWS Management Console and log in with your username and password.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Create a new IAM User Now, we will go to the IAM service. Under the IAM service click on the option "Users", and then click on the option "Add user". Set the username for the user. For eg provide the username as PentestUser. Select the type of access to be provided to the user, here we select Programmatic access and AWS Management Console access.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>MFA to the IAM User For more security, put MFA in the enabled state.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Create a new Role with Proper Policy Now create a new role with proper policies. Here we take the AdministratorAccess role.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>CLI Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Install the AWS Command Line Interface</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>pip install awscli</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Configure AWS CLI: Configure the AWS CLI with your credentials</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>configure</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Create an IAM user</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws iam create-user --user-name PentestUser</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Attach the AdministratorAccess policy to the user</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws iam attach-user-policy --user-name PentestUser --policy-arn arn:aws:iam::aws:policy/AdministratorAccess</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Setting Up a Test Environment</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To conduct pentests, you need to have a controlled testing environment where you can exploit vulnerabilities safely without affecting production systems.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Console Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Open the AWS Management Console and navigate to the EC2 Service, click on "Launch Instance."</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Select an Amazon Machine Image (AMI) from the list—for example, Amazon Linux 2.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Either create a new security group or use an existing security group that will allow for HTTP (port 80) and HTTPS (port 443) traffic.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>When the instance is running, connect to it using SSH.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Once the instance is running, install a web server (for example, Apache) and deploy a sample vulnerable web application—for example, DVWA.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>CLI Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Launch an EC2 instance</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws ec2 run-instances --image-id ami-xxxx --count 1 --instance-type t2.micro --key-name MyKeyPair</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Configure the security group</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws ec2 authorize-security-group-ingress --group-id sg-xxxx --protocol tcp --port 80 --cidr 0.0.0.0/0</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Use SSH to connect to the instance and set up the web server.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Tools for Pentesting</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Tools</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>AWS provides the following tools, which should be used for pentesting:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>AWS Inspector:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>AWS WAF (Web Application Firewall):</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Helps protect web applications from common web exploits that could affect application availability, compromise security, or consume excessive resources.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>AWS CloudTrail:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This tool enables governance, compliance, and operational and risk auditing of your AWS account.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>AWS CloudWatch:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This provides monitoring and observability for your AWS resources and applications.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Third-Party Tools</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Apart from the native AWS tools, the full pentest requires the following third-party tools:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Burp Suite:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>An integrated platform for performing security testing of web applications.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>OWASP ZAP:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>An open-source web application security scanner.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Nmap:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>A network exploration tool and security scanner.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Metasploit:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>A penetration testing framework that helps security teams verify vulnerabilities and manage security assessments.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Conducting the Pentest</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Reconnaissance</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>This is the first step in pentesting, where you gather information about the target application.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Console Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Monitor and log activities in your AWS account so you can identify potentially unauthorized or malicious activities.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Perform the vulnerability assessments for your instances.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>CLI Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Use Nmap to scan for open ports and services:</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>nmap -A -T4 <target-IP></em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Use the AWS CLI to review CloudTrail logs for any suspicious activities.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Vulnerability Scanning</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Once you have information, the next task is to identify the vulnerabilities in the application.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Console Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Set up and Run AWS Inspector to identify vulnerabilities in your instances.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Shield your application from common web exploits.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>CLI Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Start an assessment</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws inspector start-assessment-run --assessment-template-arn arn:aws:inspector:us-west-2:123456789012:template/0-7LbK4XrK</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Analyze the results of the assessment.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Exploitation</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>If there's an identification of vulnerabilities, the next step is to exploit the vulnerabilities to understand the impact.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Console Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>View findings from the AWS Inspector, as well as others in the AWS Management Console.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Do safe exploitation in a controlled environment to confirm the vulnerabilities.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>CLI Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Use Metasploit commands to exploit identified vulnerabilities.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Execute payloads against the target application to assess the impact.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Reporting and Remediation</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Documenting Findings</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Document all findings. After the pentest, all the findings are to be documented, and a detailed report has to be made.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Console Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Generate reports from AWS Inspector and other tools.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>Create a structured report of all findings, which includes screenshots, logs, and evidence.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>CLI Steps:</strong><strong></strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Export the findings from AWS Inspector</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws inspector get-findings --assessment-run-arn arn:aws:inspector:us-west-2:123456789012:run/0-7LbK4XrK</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Remediation Strategies</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>After understanding the findings, implement some mitigation strategies.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Console Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Patch and Update:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Apply patches and updates to your instances using AWS Systems Manager.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Update your Security Groups and IAM Roles:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Update the roles to follow the principle of least privilege.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>CLI Steps:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>Use AWS Systems Manager to update instances</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:code -->
<pre class="wp-block-code"><code><strong><em>aws ssm send-command --document-name "AWS-RunPatchBaseline" --targets "Key=instanceIds,Values=<instance-id>"</em></strong></code></pre>
<!-- /wp:code -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Best Practices and Compliance</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">Security Best Practices</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Implement security best practices to achieve the maximum security of your web applications in the long run.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Regular Security Assessments:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Carry out security assessments on a regular basis to detect and fix new vulnerabilities.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><strong>Continuous Monitoring and Logging:</strong></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Make use of AWS CloudWatch and CloudTrail for continuous monitoring and logging of activities.</p>
<!-- /wp:paragraph -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Compliance Standards</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Adhere to industry compliance standards and laws like PCI-DSS, HIPAA, and GDPR.</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li>PCI-DSS: Implement security controls to protect the data of cardholders.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>HIPAA: Ensure privacy and security regarding health information.</li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li>GDPR: Protect the personal data and privacy of EU citizens.</li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2 class="wp-block-heading">Resources and Further Reading</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":3} -->
<h3 class="wp-block-heading">AWS Documentation</h3>
<!-- /wp:heading -->
<!-- wp:list -->
<ul><!-- wp:list-item -->
<li><a href="https://docs.aws.amazon.com/inspector/latest/userguide/inspector_introduction.html">AWS Inspector Documentation</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://docs.aws.amazon.com/waf/latest/developerguide/what-is-aws-waf.html">AWS WAF Documentation</a></li>
<!-- /wp:list-item -->
<!-- wp:list-item -->
<li><a href="https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-user-guide.html">AWS CloudTrail Documentation</a></li>
<!-- /wp:list-item --></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>By now, you should be all set to proceed ahead and conduct.</p>
<!-- /wp:paragraph --> | sidrasaleem296 |
1,869,902 | In 2024, How Can AiInfox Digital Marketing Services Help You Build Your Brand? | In the year 2024, AiInfox stands as a pioneering force in the dynamic industry, offering cutting-edge... | 0 | 2024-05-30T04:45:31 | https://dev.to/aiinfox/in-2024-how-can-aiinfox-digital-marketing-services-help-you-build-your-brand-4e5l | digitalmarketingservices, artificialintelligencecompany | In the year 2024, **AiInfox** stands as a pioneering force in the dynamic industry, offering cutting-edge solutions that boost your brand. With an emphasis on inventiveness, data-driven tactics, and an extensive understanding of client preferences, AiInfox distinguishes out as your go-to partner for unparalleled digital efficacy. In the highly competitive world of today, having an internet presence is insufficient. Brands need to stay separate from their peers by keeping a competitive advantage, adjusting to shifting customer tastes, and having meaningful dialogues with those they are trying to reach. Addressing these problems and offering solutions that align with the objectives and core values of your business is the aim of AiInfox's **[digital marketing services](https://aiinfox.com/how-to-boost-your-brand-with-aiinfox-digital-marketing-services-in-2024/)**. Whether your goals are to boost sales, attract more customers, or improve brand awareness, AiInfox has the expertise and resources to help you now and in the future. Regardless of your objective—increasing revenue, drawing in new clients, or raising brand recognition—AiInfox has the expertise and tools to support your success both right now and down the road.
**Why Go for AiInfox?**
Choosing AiInfox's solutions is strongly recommended because of our dedication to remaining on the cutting edge of new trends and technology. We use the most recent developments in data analytics, artificial intelligence, and machine learning to develop creative tactics that yield real benefits for our clients. This focus on innovation makes sure that, in the always changing technological landscape, your organization stays desirable and relevant. Furthermore, AiInfox treats every customer relationship differently since it understands that each business is different and has different objectives and difficulties. Because of this, we work directly with you to create tactics that are suited to your unique requirements, guaranteeing a high return on investment.
**Designed Plans for Optimal Performance**
We at AiInfox are aware that no two companies are comparable. Because of this, we handle each client separately, making sure that our strategies complement the objectives and core values of your business. AiInfox provides the resources and knowledge to help you achieve your goals, whether they be to raise your website's visibility online, boost traffic, or raise your rate of conversion.
**Using AI's Future Strength**
With the help of AI, brands can now engage with their intended consumers more meaningfully, completely changing the landscape of digital marketing. With the use of artificial intelligence (AI), AiInfox can predict trends, evaluate customer behavior, and maximize the impact of advertising. We can keep you one step above competitors and help you make wise decisions that yield outcomes by utilising based on artificial intelligence insights.
**CONCLUSION**
To sum up, AiInfox's digital marketing services present an effective way of enhancing the exposure, interaction, and conversion rate of your company's name in 2024. With our individualized approaches, state-of-the-art AI technology, and unwavering dedication to quality, we can assist you in reaching your digital advertising objectives and growing your company to new heights. Join together with AiInfox right now to see the difference for oneself! | aiinfox |
1,869,900 | Top Types of Mutual Funds to Invest in 2024 | Mutual Funds are a fairly low-risk investment type when it comes to investing in the share market.... | 0 | 2024-05-30T04:40:33 | https://dev.to/shriya_jain_/top-types-of-mutual-funds-to-invest-in-2024-544o | Mutual Funds are a fairly low-risk investment type when it comes to investing in the share market. They offer various investment products like equity funds, debt funds, hybrid funds, etc. From the emergence of sustainable investment practices to the integration of artificial intelligence in fund management, this year promises both innovation and opportunity within the mutual fund industry. If you’re someone looking for a less risky investment option, then stick with us, as we’ll be covering the top types of mutual funds to invest in 2024.
**1) Equity Funds**
Equity funds are like a team of investors who buy parts of many companies. They are one of the most aggressive **[types of mutual funds](https://www.tatacapitalmoneyfy.com/blog/mutual-funds/what-are-the-types-of-mutual-funds/)**. They aim to make money by selling these parts for more than they paid. By investing in equity funds, people can join the stock market without buying individual company shares. Some of the Equity funds that can be considered as an investment option in 2024 are.
**Aditya Birla Sun Life PSU Equity Fund Direct-Growth**
The Fund provided a 3-year return of 48.5%, and its assets total to ₹3,403.63 crores with an expense ratio of 0.50%. It primarily invests in high-risk equities, with significant holdings in large-cap, mid-cap, and small-cap stocks, including State Bank of India, Bank of India, Bank of Baroda, etc.
One can also consider investing in SBI PSU Direct plan growth, ICICI Prudential Infrastructure direct growth, and HDFC infrastructure direct plan growth, as even they gave a tremendous 3-year return of 45.5%, 43.77%, and 42.95%, respectively.
**2) Debt Funds**
These funds invest their money in government securities, like government bonds, saving bonds, treasury bills, etc. They aim to earn interest income, providing stable returns with lower risk compared to stocks. These funds are suitable for those looking for a steady income and are less risky than investing directly in the stock market. Some of the funds that can be used as an investment option in 2024 are.
**Aditya Birla Sun Life Medium Term Plan Direct-Growth**
The fund manages ₹1,863.18 crores with an expense ratio of 0.85%, investing primarily in debt, with significant holdings in government securities and low-risk securities. Also, it gives a 3-year return of 12.99%
Other debt funds that can be considered are the Bank of India Short-Term Income Fund Direct-Growth, UTI Credit Risk Fund Direct-Growth, and UTI Dynamic Bond Fund Direct-Growth, as they provided 3-year returns of 12.19%, 11.54%, and 10.6% respectively.
**3) Hybrid Funds**
Hybrid mutual funds are like a mix of different types of investments, such as stocks and bonds, in one fund. They aim to balance risks and returns by diversifying across asset classes. These funds are suitable for investors seeking a blend of growth and stability in their portfolios.
**Quant Multi-Asset Direct Fund Growth**
The fund's AUM totals ₹1,829.08 crores with an expense ratio of 0.76%. It primarily invests in equities (65.84%), with allocations to large-cap, mid-cap, and small-cap stocks, and also holds a portion in debt (6.89%), including government securities and low-risk securities. Apart from this, it also gave a 3-year return of 30.72%
Other hybrid funds that can be considered as an investment option are ICICI Prudential Equity & Debt Fund Direct-Growth, HDFC Balanced Advantage Fund Direct Plan-Growth, JM Aggressive Hybrid Fund Direct-Growth as they provided 3-year returns of 27.58%, 27.08%, and 26.38% respectively.
## Conclusion
Mutual funds are a less risky investment option compared to the stock market, with various types available to suit different investment goals. For those seeking growth, equity funds like Aditya Birla Sun Life PSU Equity Fund Direct-Growth present promising opportunities. At the same time, debt funds like Aditya Birla Sun Life Medium Term Plan Direct-Growth offer stability. For a balanced approach, one can invest in hybrid funds such as Quant Multi-Asset Direct Fund Growth, which provides a mix of growth and strength. Other than this, one can even consider Tata Asset Management Ltd which offers mutual fund schemes for investors to choose from. With careful consideration of these options, investors can make informed investment decisions in 2024 with confidence.
| shriya_jain_ | |
1,869,899 | We finally launched today on Product Hunt! (Justinmind User Flows for UX/UI) | I would really appreciate if you could support and give us feedback @ Product Hunt to make our launch... | 0 | 2024-05-30T04:35:21 | https://dev.to/xrenom/we-finally-launched-today-on-product-hunt-justinmind-user-flows-for-uxui-1j9o | I would really appreciate if you could support and give us feedback @ Product Hunt to make our launch of Justinmind User Flows a success!:
[https://www.producthunt.com/posts/justinmind-user-flow](https://www.producthunt.com/posts/justinmind-user-flow)
Justinmind User Flows is designed to help you easily create, integrate, and test user flows, making your UX design process smoother and more efficient.
Explore the new features, join the conversation, and support us on Product Hunt!
Thanks a lot for your support!!!
Xavi Renom
Co-Founder @ Justinmind | xrenom | |
1,869,897 | Contextual Software Development | An average enterprise uses ~40 developer tools, all of which are usually from different vendors.... | 0 | 2024-05-30T04:32:44 | https://x.com/rasharm_/status/1795670921468068166 | ai, vscode, coding | An average enterprise uses ~40 developer tools, all of which are usually from different vendors. Choosing the best-of-breed tools instead of settling on one giant tightly integrated stack is not a new phenomenon in the developer world.
So, when developers write code, they must consider how that code will interact with all these disparate tools. For an API service, how will the API be consumed in code? What kind of log output would a piece of code produce for a logging service? How does a piece of code represent the corresponding design artifact for a UI component? For a bug fix, how does the change address the problem described in the bug report? And so on.
Gathering this context from different tools—whether to write or review code—has to be one of the more complex tasks in software development. That is why we ([Sourcegraph](https://sourcegraph.com/)) are bullish on the idea of Contextual Software Development—bringing all of the context, not just from code but from any relevant tools in the stack, right to the place where the developer most needs it.
This additional context not only makes AI smarter but also makes humans smarter by allowing them to visualize their code in terms of what it will actually produce (debugging without a debugger). I would argue that improving humans' comprehension of code (by providing additional context) is even more critical, given that humans will be required to validate tons of AI-produced code for the foreseeable future.
The other key aspect of Contextual Software Development is quickly integrating new context producers (docs, design, PM tools, logs, etc.) and context consumers (Editors, Browsers, CLI, etc.) with minimal work. The only way to enable that is through open standards, thereby opening the doors for anyone to build for and benefit from these additional sources of context.
This is why I am so excited about [OpenCtx](https://openctx.org/) - it enables contextual software development built on an open protocol. | rasharm_ |
1,869,898 | The 3 Groundbreaking Changes That Transformed the Face of Web Design Over the Last Decade | The digital landscape is always evolving, and that could not be represented more fully than in web... | 0 | 2024-05-30T04:32:22 | https://dev.to/dbhatasana/the-3-groundbreaking-changes-that-transformed-the-face-of-web-design-over-the-last-decade-26o4 | The digital landscape is always evolving, and that could not be represented more fully than in web design. Ever since the first website was created in 1991, both the aesthetic and functionality of websites have been constantly adapting to new technologies and needs.
The last decade in particular has shown some of the most innovative changes in optimizing the website experience for both the designers and the users.
## Improving Cross-Device Compatibility
The first major change came along with the advancement of the smartphone. They became a staple in everyone’s pockets and soon started to account for the majority of website visitors. This leaves [web design agency](https://huemor.rocks/web-design-agency/) professionals with a new challenge: ensuring that their websites adapt seamlessly to different screen sizes and resolutions. It wasn’t just necessary for smartphones, but all mobile devices.
The answer to that challenge was responsive design, which prioritizes adaptability and flexibility in web layouts. Responsive design is built on three core principles: fluid grids, flexible images, and media queries.
### Fluid Grids
Fluid grids break down the width of the page into a number of equally sized and spaced columns Then, the content on the page is placed according to these columns. When the viewport expands horizontally, the fluid columns expand proportionally, as does the content within the columns. By doing this, the grid, and therefore the page, is adaptable to different screens.
### Flexible Images
Flexible images are size-controlled using cascading style sheets (CSS), which allows the images to be resized and scaled in line with other layout changes. This guarantees that the images will not become larger than their containing element, which is essential for maintaining optimal display on different screen sizes.
### Media Queries
Media queries allow designers to create distinct layouts depending on the size of the viewport. They can also be used to detect other aspects of the environment that the website is being run on, like whether a touch screen is being used or a mouse. This allows the website to be displayed optimally, no matter what screen it’s being viewed on.
## Embracing Minimalist and Flat Design
While early web design was all about pushing the boundaries with flashy wording and bright colors, designers have started to lean more towards a “less is more” strategy when it comes to aesthetics. This has led to the rise of minimalist and flat designs.
Minimalism in web design focuses on removing any unnecessary elements and encouraging the strategic use of white space, clean layouts, and simple, intuitive navigation. Flat design is utilized to complement the minimalist design with its employment of bold colors and simple shapes. Gradients and shadows are completely removed from this type of design to further promote simplicity.
Incorporating high-quality images taken by an [event photographer](https://www.splento.com/event-photographer-london) can significantly enhance the visual appeal of minimalist and flat designs, adding a touch of professionalism and authenticity without cluttering the interface.
Minimalist and flat designs serve not only to enhance visual appeal but also to optimize website performance. This design approach promotes faster loading times, puts content clarity first, and enables smooth adaptation to different screen sizes. Overall, it creates a more efficient user experience.
## Putting the Users First
Beyond aesthetics and adaptability to different devices, the final major change made to web design in the last decade has to do with understanding and addressing users’ needs more effectively. [User-centric design](https://www.softr.io/web-app/web-app-design-examples) puts the users first, incorporating their feedback to make sure that the website runs as smoothly for them as possible.
Putting users at the center of the design requires a heavy reliance on research methods like [interviews](https://meetgeek.ai/template/user-interview-template), [surveys](https://www.finsync.com/blog/how-to-create-an-excellent-customer-survey-for-your-organization/), and usability testing. These tools can help to gain insight into user preferences and behavior. Then, this information can be used to create user personas that assist with making design decisions based on real user expectations.
Another aspect of the user-centric design is ensuring the website promotes accessibility and inclusivity. It’s essential that everyone can access and engage with the website’s content without difficulty. This can come in many forms, including keyboard navigation support, alternative text for images, and color contrast considerations. Some brands also add links to their [digital business card](https://popl.co/) to enable all web visitors to join their network and follow them on social media. Unlike paper business cards, you can share this card via a link in your [email signature](https://popl.co/pages/email-signatures), too, thus increasing your professional network.
With a focus on user-centric design principles, websites are able to deliver streamlined navigation, more intuitive interfaces, and an experience that resonates with users. As a result, [engagement](https://luxafor.com/5-tips-improve-employee-engagement-at-work/) and satisfaction levels are at an all-time high.
## How These Changes Have Impacted User Experience
These three major changes in web design have had a profound on the user experience and business outcomes. Because responsive design allows users to access websites without issue on multiple devices, it leads to lower bounce rates and increased engagement.
Minimalist and flat design principles produce faster loading times, enhance visual appeal, and improve readability, which greatly influences user perception and interaction with the website. The benefits of this are higher conversion rates, stronger brand credibility, and boosted search engine visibility.
User-centric design principles create interfaces that are more accessible, intuitive, and committed to meeting user expectations, which leads to a higher amount of user loyalty and satisfaction.
## What’s Coming Next?
There’s no doubt that web design will continue to evolve with new technologies available and user needs changing. There are already new trends emerging, like AI-driven designs, voice interfaces, and more immersive experiences with the use of VR.
All of these opportunities are exciting, and it’s guaranteed that there are more to come. That’s why top [web design agencies](https://www.velocityconsultancy.com/web-designing-company-in-mumbai/) are always adaptable and ready to embrace innovations while still ensuring that they keep the core principles of user experience and functionality in mind.
Are you curious about web design or looking to incorporate any of these elements into your own website? [Huemor](https://huemor.rocks/) is here to help. Learn more about how [we approach web design](https://huemor.rocks/blog/website-design-process/) to guarantee significant results.
| dbhatasana | |
1,869,896 | Greeting | Thanks to join the team | 0 | 2024-05-30T04:29:06 | https://dev.to/mohamed_elmaghrabi81/greeting-34k3 | Thanks to join the team | mohamed_elmaghrabi81 | |
1,869,895 | CSS, input 클릭시 생기는 아웃라인 | input:focus {outline: 2px solid #d50000;} /* outline 테두리 속성 수정 */ input:focus {outline: none;} /*... | 0 | 2024-05-30T04:26:53 | https://dev.to/sunj/css-input-keulrigsi-saenggineun-ausrain-466k | css | ```
input:focus {outline: 2px solid #d50000;} /* outline 테두리 속성 수정 */
input:focus {outline: none;} /* outline 테두리 없애기 */
```
_참조 : https://velog.io/@ssumniee/CSS-input-%EB%B0%95%EC%8A%A4-%ED%81%B4%EB%A6%AD-%EC%8B%9C-%EC%83%9D%EA%B8%B0%EB%8A%94-%ED%85%8C%EB%91%90%EB%A6%AC-%EC%A0%9C%EC%96%B4%ED%95%98%EA%B8%B0_ | sunj |
1,869,864 | What is Intermediate Representation - A Gist | Here's a problem statement: What if you have a programming language specification and want to write a... | 0 | 2024-05-30T04:16:00 | https://dev.to/k-srivastava/what-is-intermediate-representation-a-gist-225g | beginners, llvm, ir | Here's a problem statement: What if you have a programming language specification and want to write a compiler for it? What about if you have two languages? Or, three? Or more?
While each language is quite different to each other, all of them will have some similarities under the hood. Sure, there may be simple changes like basic syntax and file structure. And, there may be more complex changes like variable hoisting rules, lifetimes and garbage collection but, when everything is stripped away, your code has to be eventually converted into something machine readable anyway.
```cpp
#include <iostream>
int main(void) {
const std::string message = "Hello, world!";
std::cout << message << std::endl;
return 0;
}
```
```js
const message = 'Hello, world!';
console.log(message);
```
These two snippets might look different, and that's because they are probably the farthest apart (apart from perhaps a functional language) as you can get in programming languages without going into the deep end. And yet, an ideal IR aims to unify these in a single, complete and non-lossy format.
So, why not try to write a generic compiler for everything? The refinement of this idea could be implemented using intermediate representation, or IR.
## What is IR?
Contrary to popular belief, IR is not necessarily a programming language but could either be a data-structure (abstract-syntax trees) or code used internally by a compiler to represent the true source code.
The LLVM project is probably the most popular example of a widely-used IR: the LLVM IR.
LLVM consists of three major parts: the frontends, the IR and the backends. The frontends' job is to take source code from the native language and convert it into LLVM IR. And the job of the various backends is to generate machine code from LLVM IR that targets the required instruction set.
## Why IR?
The biggest, and most prevalent reason to use an IR is common optimisations. If the true language source code can be converted into an IR, a general set of optimisations can be performed on that IR. This is opposed to the traditional method which would mean writing language-specific optimisations for every compiler frontend.
The second major benefit of IR is that it enables just-in-time (JIT) and ahead-of-time (AOT) compilation depending on the use case.
Here's an example of the crux of the LLVM IR for a simple C "Hello, world" program.
```C
#include <stdio.h>
int main(void) {
printf("Hello, world!\n");
return 0;
}
```
```
@.str = private unnamed_addr constant [15 x i8] c"Hello, world!\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
store i32 0, ptr %1, align 4
%2 = call i32 (ptr, ...) @printf(ptr noundef @.str)
ret i32 0
}
declare dso_local i32 @printf(ptr noundef, ...) #1
```
| k-srivastava |
1,869,866 | The Perfect Pair: Disposable Vapes and Nic Salts for Every Vaper | Introduction: Disposable vapes provide a cost-effective alternative upfront compared to traditional... | 0 | 2024-05-30T04:06:46 | https://dev.to/adnan_freelancer55/the-perfect-pair-disposable-vapes-and-nic-salts-for-every-vaper-3k0d | Introduction:
Disposable vapes provide a cost-effective alternative upfront compared to traditional vape setups, as users avoid the need to purchase additional components like batteries or e-liquids. Additionally, their pre-filled cartridges ensure unparalleled convenience by eliminating the need for refilling or recharging. This simplicity makes disposable vapes an attractive option for vapers seeking a straightforward and portable vaping solution.
Nic salts offer several advantages over traditional e-liquids. Notably, they deliver a smoother throat hit, enhancing the vaping experience for individuals sensitive to the harshness of freebase nicotine. Furthermore, nic salts boast faster nicotine absorption, resulting in a quicker and more satisfying nicotine delivery. However, due to their higher nicotine concentrations, vapers should exercise caution and use nic salts responsibly to avoid potential nicotine-related health risks.
Lost Mary Disposable Vapes: Discovering Delight
[Lost Mary Vape](https://wizvape.co.uk/collections/lost-mary-disposable-vape) disposable vapes offer a delightful vaping experience packaged in a convenient, sleek design. These devices are perfect for vapers looking for hassle-free enjoyment. Here are the top 5 flavours that make Lost Mary stand out:
Pineapple Ice: This flavour combines the tropical sweetness of ripe pineapples with a refreshing icy twist, delivering a delightful cooling sensation with every puff.
Grape: A classic favourite, the grape flavour in Lost Mary Disposable Vapes is juicy and sweet, reminiscent of biting into a plump, ripe grape.
Maryjack Kisses: This unique blend offers a medley of complementary flavours, creating a harmonious and intriguing vaping experience that keeps you coming back for more.
Triple Mango: Tropical mango lovers rejoice! Triple Mango provides an explosion of ripe mango flavour, transporting you to a sun-soaked paradise with each inhale.
Double Apple: Crisp and slightly tart, Double Apple captures the essence of biting into a fresh, juicy apple, with a touch of sweetness that lingers on the palate.
Strawberry Ice: Ripe strawberries blended with a cooling menthol finish make Strawberry Ice a refreshing and satisfying choice, perfect for hot days or whenever you crave a fruity treat.
Cotton Candy: Indulge in the sweet nostalgia of fluffy cotton candy with this flavour, which encapsulates the sugary delight of carnival treats in every puff.
Blue Sour Raspberry: Tangy raspberries mingled with blueberries create a vibrant and bold flavour profile, striking the perfect balance between sour and sweet for an exhilarating vaping experience.
Elf Bar Disposable Vapes: Embrace Effortless Enjoyment
[Elf Bar](https://wizvape.co.uk/collections/elf-bar-600-disposable-vape) disposable vapes embody simplicity without compromising on flavour. Here are the top 5 flavours that Elf Bar enthusiasts rave about:
Lychee Ice: Experience the exotic sweetness of lychee paired with a cool menthol breeze, creating a refreshing and invigorating vape.
Cotton Candy: Indulge in the familiar taste of spun sugar with hints of vanilla, reminiscent of childhood fairground treats and guaranteed to satisfy any sweet tooth.
Cherry Cola: A unique twist on a classic beverage, Cherry Cola combines the bold flavour of cherries with the effervescence of cola for a fizzy and delightful vape.
Banana Ice: Smooth and creamy banana flavour meets a chilly menthol finish, offering a tropical escape in every puff.
Blueberry: Bursting with juicy blueberry goodness, this flavour captures the essence of freshly picked berries in a smooth and satisfying vape.
Strawberry Raspberry: Enjoy the perfect blend of ripe strawberries and tart raspberries, creating a harmonious fruity sensation that's both vibrant and delicious.
Cherry: Indulge in the rich and sweet taste of cherries, providing a luscious vaping experience that's ideal for fruit enthusiasts.
Cream Tobacco: A sophisticated combination of creamy notes and mild tobacco undertones, offering a smooth and comforting vape for those seeking a more complex flavour profile.
SKE Crystal Disposable Vapes: Crystal Clear Flavour [Crystal Vape](https://wizvape.co.uk/collections/ske-crystal-bar-disposable-vapes)
disposable vapes offer a crystal-clear vaping experience. Here are the top 5 flavours that elevate SKE Crystal Bars above the rest:
Rainbow: Taste the rainbow with this vibrant blend of assorted fruits, delivering a symphony of flavours with each puff.
Bar Blue Razz Lemonade: Tangy blue raspberry meets zesty lemonade, creating a refreshing and thirst-quenching vape experience.
Blue Fusion: Dive into a fusion of blueberry goodness, with each inhale offering a burst of sweet and tart flavours.
Gummy Bear: Relive your childhood with the nostalgic taste of gummy bears, packed into a convenient and satisfying vape.
Berry Ice: Enjoy a mix of assorted berries infused with a cooling menthol kick, perfect for fruit lovers seeking a refreshing twist.
Sour Apple Blueberry: Tart green apples blended with sweet blueberries create a dynamic and mouth-watering flavour combination.
Tiger Blood: Embark on an exotic journey with this blend of tropical fruits and creamy coconut, evoking images of sunny beaches and palm trees.
Fizzy Cherry: Experience the effervescence of cherry soda in vape form, offering a fizzy and flavourful sensation that tingles the taste buds.
Hayati Disposable Vapes: A Taste of Tradition
[Hayati pro max](https://wizvape.co.uk/collections/hayati-disposable-vapes) disposable vapes encapsulate tradition with a modern twist. Here are the top 5 flavours that capture the essence of Hayati:
Cream Tobacco: A sophisticated and smooth blend of creamy notes layered over a subtle tobacco base, perfect for those who appreciate a refined vape experience.
Blue Razz Gummy Bear: Indulge in the tangy sweetness of blue raspberry gummy candies, delivering a burst of fruity flavour in every puff.
Lemon Lime: Zesty citrus flavours combine in this refreshing vape, providing a bright and uplifting vaping experience.
Skittles: Taste the rainbow with this playful blend of assorted fruity candies, offering a vibrant and exciting flavour profile.
Bubblegum Ice: Classic bubblegum flavour with a cool menthol twist, bringing back memories of blowing bubbles and childhood fun.
Rocky Candy: Enjoy the taste of rock candy with its sugary sweetness, providing a satisfying vape that's both nostalgic and delightful.
Hubba Bubba: Recreate the joy of chewing gum with this bubblegum-inspired flavour, delivering a burst of sweetness with every inhale.
Fresh Mint: Crisp and refreshing mint flavour, perfect for vapers seeking a clean and invigorating vape sensation.
Discover Your Perfect Nic Salt Blend at WizVape.co.uk
Looking to enhance your vaping experience with Nic Salts? Check out our wide range of top brands like Bar Juice 5000, Elux Salts, Hayati Pro Max, Lost Mary Liq, Elf Liq, Nasty Liq, Ske Crystal Salts, IVG Salts, and Pod Salts. We've got some fantastic deals too: 5 for £11, 4 for £10, and 10 for £16. At WizVape.co.uk, finding your favourite Nic Salt blend is easy!
Unbeatable Deals on 100ml Vape Juice!
Treat yourself to the delicious flavours of Hayati 100ml Tasty Fruit, Vampire Vape, IVG, Doozy Vape Co, and Seriously with our range of 100ml Vape Juice. Don't miss our special offers, including 3 100mls for £15 and Bulk Savings on 100ml juice. Plus, enjoy excellent customer service and Free Track 24 Delivery on orders over £25. Join us at [WizVape.co.uk](https://wizvape.co.uk/) and experience vaping bliss!
| adnan_freelancer55 | |
1,869,865 | Contextual Targeting vs Cookies: Who will win in 2024? | The Ad Tech landscape is undergoing a significant transformation with the impending demise of... | 0 | 2024-05-30T04:04:58 | https://dev.to/silverpush/contextual-targeting-vs-cookies-who-will-win-in-2024-2m5h | google, cookies, ads, ai | The Ad Tech landscape is undergoing a significant transformation with the impending demise of third-party cookies. Google finally committed to depreciating 1% of 3rd party cookies in Chrome in the first quarter of 2024 and fully by September 2024, the industry is bracing for a cookieless future.
For years, third-party cookies reigned supreme in the world of online advertising. These data trackers followed users across the web, building detailed profiles to target ads with laser precision. However, the tide is turning. Consumer privacy concerns and regulations like GDPR and CCPA are forcing a shift towards a cookieless future. This begs the question: in 2024, with cookies crumbling, who will claim the crown? The answer is clear: contextual targeting.
## First-Party vs Third-Party Cookies
Before diving deeper into the future, it’s important to understand the difference between first-party and third-party cookies:
**1. First-Party Cookies:** These are created by the website a user is visiting. They help remember user preferences, login information, and shopping cart contents. First-party cookies are considered more privacy-friendly since they are directly controlled by the site the user is interacting with.
**2. Third-Party Cookies:** These are created by domains other than the one the user is visiting. They track users across different websites to build detailed profiles for targeted advertising. Third-party cookies have faced criticism due to privacy concerns and are the main target of the new regulations.
## The Role of Universal IDs and Persistent Identifiers
As third-party cookies fade away, the need for reliable ways to identify users online becomes crucial. This is where interoperable universal IDs come in. These IDs work across all browsers and platforms, unlike cookies that have limited compatibility. Universal IDs act as a common language that advertisers, publishers, and platforms can use to identify users consistently.
Persistent identifiers (PIDs), such as mobile advertising IDs (MAIDs) and hashed email addresses (HEMs), provide a stable foundation for building user profiles. Unlike cookies that only identify browsers, PIDs work at an individual level, incorporating data like app usage, demographics, and offline behaviors. This allows advertisers to reach the right people with the right message without relying on cookies.
## Enter Contextual Targeting: Aligning Ads with Content
Contextual targeting takes a different approach. Instead of tracking users, it analyzes the content of a webpage and the surrounding environment to determine which ads are most relevant. This can include factors like keywords, topics, demographics, and even the sentiment of the content. For example, an ad for athletic shoes might appear on a website with articles about running tips, while an ad for financial planning tools might show up on a page discussing retirement strategies.
## Why Contextual Targeting Wins in 2024
Here's why contextual targeting is well-positioned to thrive in the cookieless future:
**1. Privacy-compliant:** Contextual targeting doesn't rely on personal data, making it a privacy-friendly solution that aligns with regulations and user expectations.
**2. Improved user experience:** By showing relevant ads, contextual targeting enhances the user experience. Users are more likely to click on ads that are interesting and relevant to the content they're consuming.
**3. Evolving with AI:** Advancements in Artificial Intelligence (AI) are making contextual targeting even more powerful. AI can analyze vast amounts of data to understand the nuances of content and user intent, leading to more precise ad placements.
**4. Increased brand safety:** Contextual targeting allows advertisers to place their ads in brand-safe environments, ensuring their message appears alongside appropriate content.
## The Road Ahead: Beyond Cookies
While [contextual targeting](https://www.silverpush.co/blogs/benefits-to-shift-from-audience-to-contextual-targeting/) offers a strong alternative, it's not a complete replacement for cookies. A future-proof approach will likely involve a combination of strategies. First-party data, gathered with user consent, can provide valuable insights for ad targeting. Additionally, contextual targeting can be combined with other cookieless solutions like contextual behavioral targeting, which uses anonymized browsing data to reach relevant audiences.
## References
1. https://dev.to/lindaojo/introduction-to-http-cookies-1pn2 | silverpush |
1,846,712 | Sloan's Inbox: Why Do Developers Love to Hate on XYZ? | Heyo! Sloan, DEV Moderator and mascot. I'm back with another question submitted by a DEV community... | 0 | 2024-05-30T04:00:00 | https://dev.to/devteam/sloans-inbox-why-do-developers-love-to-hate-on-xyz-484e | discuss | Heyo! Sloan, DEV Moderator and mascot. I'm back with another question submitted by a DEV community member. 🦥
For those unfamiliar with the series, this is another installment of Sloan's Inbox. You all send in your questions, I ask them on your behalf anonymously, and the community leaves comments to offer advice. Whether it's career development, office politics, industry trends, or improving technical skills, we cover all sorts of topics here. If you want to send in a question or talking point to be shared anonymously via Sloan, that'd be great; just scroll down to the bottom of the post for details on how.
Let's see what's up this week...
### Today's question is:
> Often I see developers ragging on a specific kind of technology in their posts. With titles like "PHP Is the Worst", "Java is Dead", etc. ... it feels so tribal and some folks just seem eager to rock the boat. What's up with these kind of posts?
Share your thoughts and let's help a fellow DEV member out! Remember to keep kind and stay classy. 💚
---
*Want to submit a question for discussion or ask for advice? [Visit Sloan's Inbox](https://docs.google.com/forms/d/e/1FAIpQLSc6wgzJ1hh2OR4WsWlJN9WHUJ8jV4dFkRDF2TUP32urHSAsQg/viewform)! You can choose to remain anonymous.* | sloan |
1,866,685 | Simplify RAG application with MongoDB Atlas and Amazon Bedrock | By fetching data from the organization’s internal or proprietary sources, Retrieval Augmented... | 0 | 2024-05-30T03:54:44 | https://community.aws/content/2gRSUimVRjSg6F13Sj3xJY5q5RV | database, tutorial, machinelearning, mongodb | By fetching data from the organization’s internal or proprietary sources, Retrieval Augmented Generation (RAG) extends the capabilities of FMs to specific domains, without needing to retrain the model. It is a cost-effective approach to improving model output so it remains relevant, accurate, and useful in various contexts.
[Knowledge Bases for Amazon Bedrock](https://aws.amazon.com/bedrock/knowledge-bases/) is a fully managed capability that helps you implement the entire RAG workflow from ingestion to retrieval and prompt augmentation without having to build custom integrations to data sources and manage data flows. With MongoDB Atlas vector store integration, you can build RAG solutions to securely connect your organization’s private data sources to FMs in Amazon Bedrock.
Let's see how the MongDB Atlas integration with Knowledge Bases can simplify the process of building RAG applications.
## Configure MongoDB Atlas
MongoDB Atlas cluster creation on [AWS](https://www.mongodb.com/docs/atlas/reference/amazon-aws/) process is [well documented](https://www.mongodb.com/docs/atlas/tutorial/create-new-cluster/). Here are the high level steps:
- This integration requires an [Atlas cluster tier of at least M10](https://www.mongodb.com/docs/manual/reference/operator/aggregation/listSearchIndexes/). During cluster creation, choose an **M10 dedicated** cluster tier.
- Create a [database](https://www.mongodb.com/docs/atlas/atlas-ui/databases/#create-a-database) and [collection](https://www.mongodb.com/docs/atlas/atlas-ui/collections/#create-a-collection).
- For authentication, [create a database user](https://www.mongodb.com/docs/atlas/security-add-mongodb-users/#add-database-users). Select **Password** as the **Authentication** Method. Grant the [Read and write to any database](https://www.mongodb.com/docs/atlas/mongodb-users-roles-and-privileges/#mongodb-atlasrole-Read-and-write-to-any-database) role to the user.
- Modify the **IP Access List** – add IP address `0.0.0.0/0` to allow access from anywhere. For production deployments, [AWS PrivateLink](https://docs.aws.amazon.com/vpc/latest/privatelink/what-is-privatelink.html) is the recommended way to have Amazon Bedrock establish a [secure connection to your MongoDB Atlas cluster](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-setup.html).
## Create the Vector Search index in MongoDB Atlas
Use the below definition to [create a Vector Search index](https://www.mongodb.com/docs/atlas/atlas-vector-search/create-index/#std-label-avs-create-index).
```json
{
"fields": [
{
"numDimensions": 1536,
"path": "AMAZON_BEDROCK_CHUNK_VECTOR",
"similarity": "cosine",
"type": "vector"
},
{
"path": "AMAZON_BEDROCK_METADATA",
"type": "filter"
},
{
"path": "AMAZON_BEDROCK_TEXT_CHUNK",
"type": "filter"
}
]
}
```
- `AMAZON_BEDROCK_TEXT_CHUNK` – Contains the raw text for each data chunk. We are using `cosine` similarity and embeddings of size `1536` (we will choose the embedding model accordingly - in the the upcoming steps).
- `AMAZON_BEDROCK_CHUNK_VECTOR` – Contains the vector embedding for the data chunk.
- `AMAZON_BEDROCK_METADATA` – Contains additional data for source attribution and rich query capabilities.
## Configure the Knowledge Base in Amazon Bedrock
Create an [AWS Secrets Manager secret](https://docs.aws.amazon.com/secretsmanager/latest/userguide/create_secret.html) to securely store the MongoDB Atlas database user credentials.
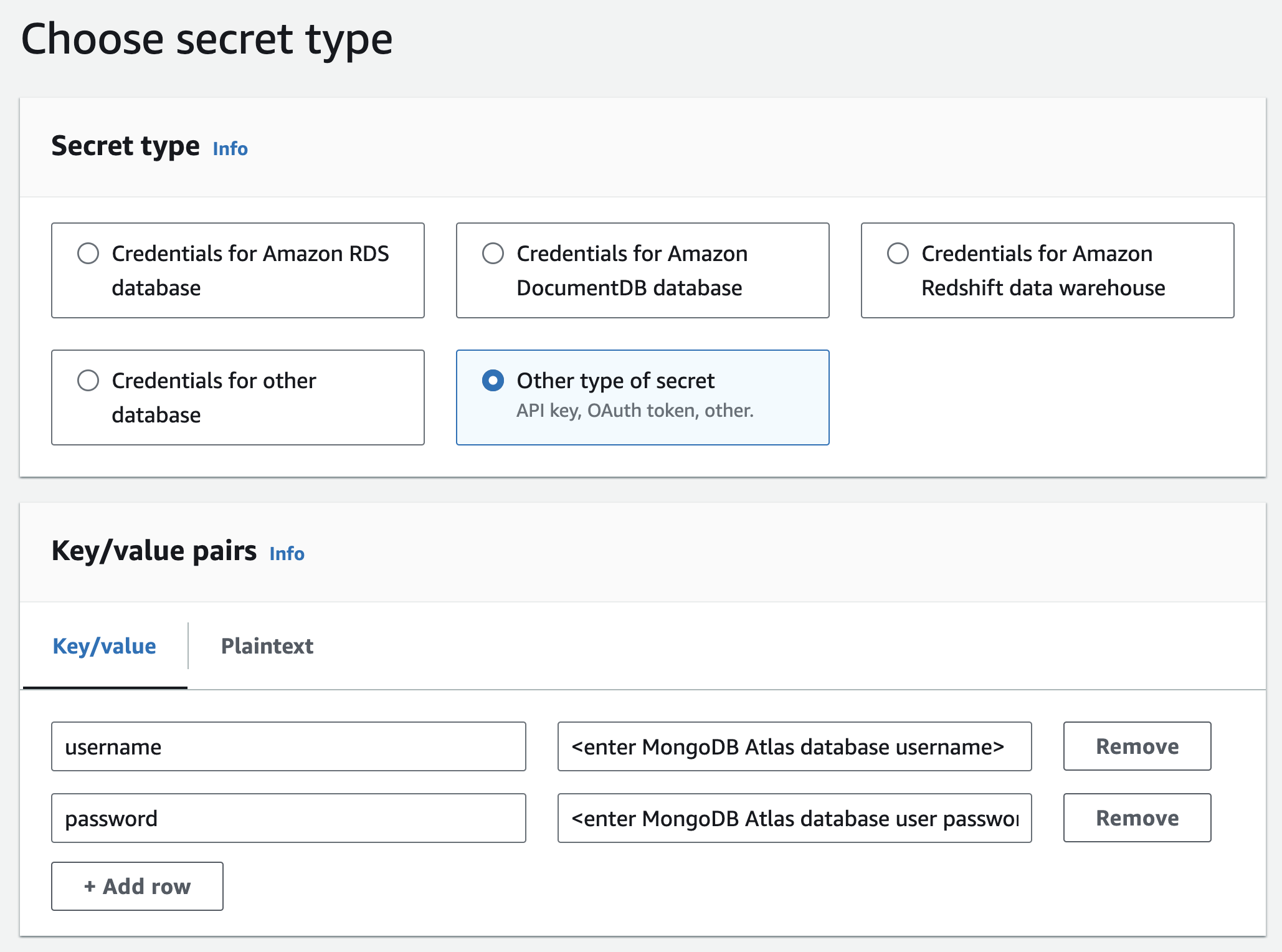
[Create an Amazon Simple Storage Service (Amazon S3) storage bucket](https://docs.aws.amazon.com/AmazonS3/latest/userguide/creating-bucket.html) and upload any document(s) of your choice - [Knowledge Base supports multiple file formats](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-ds.html) (including text, HTML, and CSV). Later, you will use the knowledge base to ask questions about the contents of these documents.
Navigate to the [Amazon Bedrock console](https://console.aws.amazon.com/bedrock?trk=24163938-a3b4-48b3-b5c2-be66044dcad6&sc_channel=el) and start configuring the knowledge base. In step 2, choose the S3 bucket you created earlier:
Select **Titan Embeddings G1 – Text** embedding model MongoDB Atlas as the vector database.
Enter the basic information for the MongoDB Atlas cluster along with the `ARN` of the AWS Secrets Manager secret you had created earlier. In the **Metadata** field mapping attributes, enter the vector store specific details. They should match the vector search index definition you used earlier.
Once the knowledge base is created, you need to [synchronise the data source](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-ingest.html) (S3 bucket data) with the MongoDB Atlas vector search index.

Once that's done, you can check the MongoDB Atlas collection to verify the data. As per index definition, the vector embeddings have been stored in `AMAZON_BEDROCK_CHUNK_VECTOR` along with the text chunk and metadata in `AMAZON_BEDROCK_TEXT_CHUNK` and `AMAZON_BEDROCK_METADATA`, respectively.
## Query the knowledge base
You can now ask question about your documents by querying the knowledge base - select **Show source details** to see the chunks cited for each footnote.
You can also change the foundation model. For example, I switched to Claude 3 Sonnet.
### Use Retrieval APIs to integrate knowledge base with applications
To build RAG applications on top of Knowledge Bases for Amazon Bedrock, you can use the [RetrieveAndGenerate API](https://docs.aws.amazon.com/bedrock/latest/APIReference/API_agent-runtime_RetrieveAndGenerate.html) which allows you to query the knowledge base and get a response.
If you want to further customize your RAG solutions, consider using the [Retrieve API](https://docs.aws.amazon.com/bedrock/latest/APIReference/API_agent-runtime_Retrieve.html), which returns the semantic search responses that you can use for the remaining part of the RAG workflow.
### More configurations
You can further customize your knowledge base queries using a different search type, additional filter, different prompt, etc.
## Conclusion
Thanks to the MongoDB Atlas integration with Knowledge Bases for Amazon Bedrock, most of the heavy lifting is taken care of. Once the vector search index and knowledge base are configured, you can incorporate RAG into your applications. Behind the scenes, Amazon Bedrock will convert your input (prompt) into embeddings, query the knowledge base, augment the FM prompt with the search results as contextual information and return the generated response.
Happy building! | abhirockzz |
1,869,829 | Building Vue3 Component Library from Scratch #12 Vitest | Vitest is a high-performance front-end unit testing framework. Its usage is actually similar to Jest,... | 27,509 | 2024-05-30T03:54:34 | https://dev.to/markliu2013/building-vue3-component-library-from-scratch-12-vitest-2kkf | vitest, vue | Vitest is a high-performance front-end unit testing framework. Its usage is actually similar to Jest, but its performance is much better than Jest. It also provides good ESM support. Moreover, for projects using Vite as a build tool, a benefit is that they can share the same configuration file, vite.config.js. Therefore, this project will use Vitest as the test framework.
## Installation
Since the front-end component library we are testing runs on the browser, we need to install happy-dom additionally. We also need to install the test coverage display tool c8.
```bash
pnpm add vitest happy-dom c8 -D -w
```
## Configuration
As mentioned above, Vitest can be configured directly in vite.config.ts, so we go to components/vite.config.ts to make a related configuration for Vitest (the triple-slash directive tells the compiler to include additional files during the compilation process).
```js
/// <reference types="vitest" />
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue"
...
export default defineConfig(
{
...
test: {
environment: "happy-dom"
},
}
)
```
Then we add two commands in package.json, 'vitest' and 'vitest run --coverage', which are for performing unit tests and viewing unit test coverage respectively.
```json
"scripts": {
"test": "vitest",
"coverage": "vitest run --coverage"
}
```
Now we can use Vitest for testing. When executing the 'test' command, Vitest will execute files with the pattern '**/*.{test,spec}.{js,mjs,cjs,ts,mts,cts,jsx,tsx}'. Here, we uniformly name our test files in the form of '**/*.{test}.ts' and place them in the '__tests__' directory of each component.
For example, create a new directory '__tests__/button.test.ts' under the 'button' directory, and then write a simple test code to see how it works.
```js
import { describe, expect, it } from 'vitest';
describe('hellostellarnovaui', () => {
it('should be hellostellarnovaui', () => {
expect('hello' + 'stellarnovaui').toBe('hellostellarnovaui');
});
});
```
Then, by executing 'pnpm run test' in the 'components' directory, we can see that our test has passed.
Then, by executing 'pnpm run coverage', we can see our test coverage.
The meaning of each field is as follows:
- '%stmts' is statement coverage: Has every statement been executed?
- '%Branch' is branch coverage: Has every 'if' code block been executed?
- '%Funcs' is function coverage: Has every function been called?
- '%Lines' is line coverage: Has every line been executed?
## How to Test Components?
Above, we just simply tested a string addition, but what we need to test is a component library. So, how do we test whether our components meet the requirements?
Since our project is a Vue component library, we can install the test library recommended by Vue, `@vue/test-utils`.
```bash
pnpm add @vue/test-utils -D -w
```
Then we modify button.test.ts, we are going to test the slot of the Button component.
```js
import { describe, expect, it } from 'vitest';
import { mount } from '@vue/test-utils';
import button from '../button.vue';
// The component to test
describe('test button', () => {
it('should render slot', () => {
const wrapper = mount(button, {
slots: {
default: 'stellarnovaui'
}
});
// Assert the rendered text of the component
expect(wrapper.text()).toContain('stellarnovaui');
});
});
```
`@vue/test-utils` provides a 'mount' method, we can pass in different parameters to test whether the component meets our expectations. For example, the meaning of the above test code is: pass in the button component, and set its default slot to 'stellarnovaui'. We expect the text 'stellarnovaui' to be displayed when the page is loaded. Obviously, our button component has this feature, so when we execute 'pnpm run test', this test will pass.
If we want to test how the Button component displays a certain style when a type is passed in, we can write it like this.
```js
import { describe, expect, it } from 'vitest';
import { mount } from '@vue/test-utils';
import button from '../button.vue';
// The component to test
describe('test button', () => {
it('should render slot', () => {
const wrapper = mount(button, {
slots: {
default: 'stellarnovaui'
}
});
// Assert the rendered text of the component
expect(wrapper.text()).toContain('stellarnovaui');
});
it('should have class', () => {
const wrapper = mount(button, {
props: {
type: 'primary'
}
});
expect(wrapper.classes()).toContain('sn-button--primary');
});
});
```
The meaning of this test is: when the type we pass in is 'primary', we expect the class name of the component to be 'sn-button--primary'. Obviously, this one can also pass. At the same time, you will find that the test we just started has automatically updated itself, indicating that Vitest has a hot update feature.
For those interested in more features of `@vue/test-utils`, you can click on [@vue/test-utils](https://test-utils.vuejs.org/guide/) to view the official documentation.
The final source code: https://github.com/markliu2013/StellarNovaUI
| markliu2013 |
1,869,863 | xekhach tadi | TaDiTaDi Chuyên Cung Cấp Dịch Vụ Xe Quảng Ninh Lào Cai. Chúng Tôi Đang Có Giá Rẻ Hàng Đầu Thị Trường.... | 0 | 2024-05-30T03:49:29 | https://dev.to/pfxekhachtadi/xekhach-tadi-ld6 | TaDiTaDi Chuyên Cung Cấp Dịch Vụ Xe Quảng Ninh Lào Cai. Chúng Tôi Đang Có Giá Rẻ Hàng Đầu Thị Trường. Nhân Sự Hỗ Trợ Chuyên Môn Cao. Đừng Bỏ Lỡ, Nhắn Tin Ngay!ch hàng tin dùng.
Website: https://www.facebook.com/XeQuangNinhLaoCai.xjo
Phone: 1900 6799
Address: Tổ 7, Khu 1, Phường Yên Thanh, TP. Uông Bí, Tỉnh Quảng Ninh
https://newspicks.com/user/10322197
http://forum.yealink.com/forum/member.php?action=profile&uid=343129
https://www.noteflight.com/profile/17a18d301eb0e41859ab9657e70e544e2522cc73
https://www.credly.com/users/xekhach-tadi.7173f5d2/badges
https://www.nintendo-master.com/profil/xekhachtadi
https://edenprairie.bubblelife.com/users/inxekhachtadi
https://www.are.na/xekhach-tadi/channels
https://my.desktopnexus.com/xekhachtadi/
https://jsfiddle.net/user/anxekhachtadi/
http://idea.informer.com/users/wcxekhachtadi/?what=personal
https://community.fyers.in/member/hzCmje8746
https://www.mixcloud.com/rlxekhachtadi/
https://www.exchangle.com/hdxekhachtadi
https://www.ethiovisit.com/myplace/djxekhachtadi
https://www.beatstars.com/johnwilliams4340838172/about
https://pastelink.net/5j9wkoq7
https://qiita.com/rcxekhachtadi
https://expathealthseoul.com/profile/xekhach-tadi-6657f0ea90f4e/
https://app.roll20.net/users/13389971/xekhach-t
https://slides.com/osxekhachtadi
https://piczel.tv/watch/iexekhachtadi
https://www.speedrun.com/users/goxekhachtadi
https://bandori.party/user/201678/xekhachtadi/
https://www.angrybirdsnest.com/members/xekhachtadi/profile/
https://hackerone.com/xekhachtadi?type=user
https://www.designspiration.com/johnwilliams434087/
https://www.deviantart.com/knxekhachtadi/about
https://unsplash.com/@xekhachtadi
https://telegra.ph/xekhachtadi-05-30
https://www.patreon.com/xekhachtadi405
https://diendannhansu.com/members/uaxekhachtadi.50303/#about
https://timeswriter.com/members/kfxekhachtadi/
https://www.spoiledmaltese.com/members/xekhachtadi.170117/#about
https://www.codingame.com/profile/9ec23f25a466dd45a1106d931b3534f48978906
https://www.diggerslist.com/coxekhachtadi/about
https://www.anibookmark.com/user/bcxekhachtadi.html
https://controlc.com/d32597d7
https://hypothes.is/users/swxekhachtadi
https://research.openhumans.org/member/yhxekhachtadi
https://www.dermandar.com/user/bvxekhachtadi/
https://potofu.me/awxekhachtadi
https://stocktwits.com/xekhachtadi
https://www.plurk.com/saxekhachtadi/public
https://www.cineplayers.com/xekhachtadi
https://kumu.io/xekhachtadi/sandbox#untitled-map
https://muckrack.com/xekhach-tadi-1
https://ficwad.com/a/wjxekhachtadi
https://experiment.com/users/xtadi
https://glose.com/u/gmxekhachtadi
https://zzb.bz/goCId
https://nhattao.com/members/ncxekhachtadi.6535669/
https://www.hahalolo.com/@6657f2b305740e60d094728e
https://www.creativelive.com/student/xekhach-tadi-61?via=accounts-freeform_2
https://devpost.com/johnwill-ia-ms43408
https://willysforsale.com/profile/hkxekhachtadi
https://link.space/@nixekhachtadi
http://hawkee.com/profile/6979134/
https://able2know.org/user/hpxekhachtadi/
https://portfolium.com/eixekhachtadi
https://8tracks.com/clxekhachtadi
https://www.artscow.com/user/3196782
https://tinhte.vn/members/lzxekhachtadi.3023460/
https://doodleordie.com/profile/tvxekhachtadi
https://blender.community/xekhachtadi/
https://forum.dmec.vn/index.php?members/rwxekhachtadi.61274/
https://www.cakeresume.com/me/xekhachtadi-390e22
https://disqus.com/by/disqus_AVS5zrkIn0/about/
https://www.proarti.fr/account/gsxekhachtadi
https://www.chordie.com/forum/profile.php?id=1966613
https://www.metooo.io/u/6657f3de0c59a9224256e0a2
https://linkmix.co/23494008
https://active.popsugar.com/@flxekhachtadi/profile
https://www.equinenow.com/farm/xekhachtadi-1128754.htm
https://fileforum.com/profile/efxekhachtadi
https://play.eslgaming.com/player/20134835/
https://www.funddreamer.com/users/xekhach-tadi-2
https://wperp.com/users/fjxekhachtadi/
https://hashnode.com/@qlxekhachtadi
https://community.tableau.com/s/profile/0058b00000IZZCA
https://sinhhocvietnam.com/forum/members/74719/#about
https://vocal.media/authors/xekhach-tadi-pvpz0njf
https://www.storeboard.com/xekhachtadi
https://chart-studio.plotly.com/~lhxekhachtadi
https://www.silverstripe.org/ForumMemberProfile/show/152929
https://www.nexusmods.com/20minutestildawn/images/91
https://www.5giay.vn/members/prxekhachtadi.101974655/#info
https://git.industra.space/xekhachtadi
https://www.intensedebate.com/people/xekhachtadi
https://solo.to/hkxekhachtadi
https://topsitenet.com/profile/oexekhachtadi/1197520/
https://www.anobii.com/fr/0125ab8418a771fd2c/profile/activity
https://vimeo.com/user220395472
https://visual.ly/users/johnwilliams434083
https://www.penname.me/@zdxekhachtadi
https://chodilinh.com/members/jbxekhachtadi.79385/#about
https://starity.hu/profil/452478-xekhachtadi/
https://rotorbuilds.com/profile/42654/
https://www.babelcube.com/user/xekhach-tadi-2
https://gifyu.com/ktxekhachtadi
https://dreevoo.com/profile.php?pid=642951
https://penzu.com/p/3b0dfb0ff7219d17
https://padlet.com/johnwilliams43408_1
https://www.kickstarter.com/profile/alxekhachtadi/about
https://dribbble.com/vwxekhachtadi/about
https://socialtrain.stage.lithium.com/t5/user/viewprofilepage/user-id/65722
https://www.kniterate.com/community/users/xekhachtadi/
https://wmart.kz/forum/user/163617/
https://qooh.me/syxekhachtadi
| pfxekhachtadi | |
1,869,861 | How To Apply The GCP Service Account Into On-premise K8S Step By Step | Applying a GCP service account to a local Kubernetes cluster involves a few steps to ensure that your... | 0 | 2024-05-30T03:31:07 | https://dev.to/u2633/how-to-apply-the-gcp-service-account-into-on-premise-k8s-step-by-step-4oc8 | kubernetes | Applying a GCP service account to a local Kubernetes cluster involves a few steps to ensure that your Kubernetes pods can authenticate to GCP services using the service account. Here's a detailed guide to achieve this:
### Step-by-Step Guide
#### 1. Create a GCP Service Account
First, create a service account in your GCP project and download the JSON key file.
1. **Create the Service Account**:
```bash
gcloud iam service-accounts create my-service-account --display-name "My Service Account"
```
2. **Assign Roles to the Service Account**:
```bash
gcloud projects add-iam-policy-binding <YOUR-PROJECT-ID> \
--member="serviceAccount:my-service-account@<YOUR-PROJECT-ID>.iam.gserviceaccount.com" \
--role="roles/YOUR-ROLE"
```
Replace `<YOUR-PROJECT-ID>` with your GCP project ID and `roles/YOUR-ROLE` with the appropriate roles you need for your service account.
3. **Create and Download the Key File**:
```bash
gcloud iam service-accounts keys create key.json \
--iam-account my-service-account@<YOUR-PROJECT-ID>.iam.gserviceaccount.com
```
#### 2. Create a Kubernetes Secret with the Service Account Key
Next, create a Kubernetes secret that contains the service account key file.
1. **Create the Secret**:
```bash
kubectl create secret generic gcp-service-account \
--from-file=key.json=path/to/key.json
```
Replace `path/to/key.json` with the actual path to your downloaded service account key file.
#### 3. Configure Your Pods to Use the Service Account
Modify your Kubernetes deployment or pod specification to mount the service account key as a volume and set the `GOOGLE_APPLICATION_CREDENTIALS` environment variable.
1. **Update Deployment YAML**:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: gcr.io/<YOUR-PROJECT-ID>/my-app:latest
### Keypoint Start
env:
- name: GOOGLE_APPLICATION_CREDENTIALS
value: /var/secrets/google/key.json
volumeMounts:
- name: gcp-service-account
mountPath: /var/secrets/google
readOnly: true
volumes:
- name: gcp-service-account
secret:
secretName: gcp-service-account
### Keypoint End
```
In this example:
- Replace `gcr.io/<YOUR-PROJECT-ID>/my-app:latest` with the image you are using.
- The environment variable `GOOGLE_APPLICATION_CREDENTIALS` is set to the path where the key file will be mounted.
- The secret named `gcp-service-account` is mounted as a volume at `/var/secrets/google`.
2. **Apply the Updated Deployment**:
```bash
kubectl apply -f deployment.yaml
```
### Summary
By following these steps, you can configure your local Kubernetes cluster to use a GCP service account. This setup involves creating a GCP service account, generating and downloading a key file, creating a Kubernetes secret with the key file, and configuring your pods to use the service account by mounting the secret and setting the appropriate environment variable. This allows your applications running in Kubernetes to authenticate with GCP services securely. | u2633 |
1,869,859 | Mastering Mobile Movie Making: Exploring Mp4Composer-android | In today's mobile-centric world, the ability to create and share engaging videos is crucial.... | 0 | 2024-05-30T03:28:40 | https://dev.to/epakconsultant/mastering-mobile-movie-making-exploring-mp4composer-android-9na | android, video | In today's mobile-centric world, the ability to create and share engaging videos is crucial. Mp4Composer-android emerges as a powerful tool for Android developers, empowering them to craft compelling MP4 movies directly within their applications. This article delves into Mp4Composer-android, exploring its functionalities, benefits, and how to integrate it into your projects.
**What is Mp4Composer-android?**
Mp4Composer-android is an open-source library designed specifically for Android development. It leverages the Android MediaCodec API to provide functionalities for generating and manipulating MP4 video files.
Key Features of Mp4Composer-android
• MP4 Movie Creation: The core functionality allows you to create MP4 movies from various sources like video files, image sequences, or camera captures.
• Media Manipulation: Mp4Composer-android boasts a rich set of features for manipulating your video content, including:
o Trimming: Precisely select and extract specific portions of a video.
o Filtering: Apply various visual filters to enhance the aesthetics of your videos. Popular options include grayscale, sepia, and color adjustments.
o Scaling and Cropping: Resize or crop your video to achieve the desired aspect ratio or frame size.
o Rotating: Correct video orientation or add a creative touch by rotating the footage.
o Timescale Adjustment: Control the playback speed of your video for slow-motion or fast-motion effects.
[Mastering the Basics: A Beginners Guide to TradingViews PineScript Programming](https://www.amazon.com/dp/B0CBHWFVMQ)
• Mute Functionality: Optionally remove audio from your video to create silent clips.
**Benefits of Using Mp4Composer-android**
• Simplified Video Editing: Mp4Composer-android provides a convenient way to add basic video editing functionalities within your Android applications, eliminating the need for external tools.
• Customization and Control: Developers have control over various aspects of the video creation process, allowing for tailored video editing experiences.
• Open-Source and Free to Use: Being open-source, Mp4Composer-android is readily available for anyone to use and contribute to, making it a cost-effective solution.
**Getting Started with Mp4Composer-android**
The library is available on GitHub and can be easily integrated into your Android projects. Here's a basic overview:
1. Add the Dependency: Include the Mp4Composer-android library in your project's build.gradle file.
2. Initialize the Composer: Create a new Mp4Composer instance, specifying the source video path and the desired output path for the edited video.
3. Apply Manipulations: Utilize the provided methods like trim(), filter(), scale(), etc., to manipulate your video content.
4. Build and Export: Call the compose() method to initiate the video creation process. The edited MP4 file will be saved at the specified output path.
**Beyond the Basics: Advanced Usage**
Mp4Composer-android offers functionalities beyond basic editing:
• Custom Filters: The library allows you to create your own custom filters by implementing the Mp4ComposerFilter interface.
• Progress Tracking: Monitor the video composition progress using the Listener interface for informative user feedback.
• Error Handling: Implement robust error handling to gracefully address potential issues during the video creation process.
**Conclusion**
Mp4Composer-android empowers Android developers to create and edit MP4 videos directly within their applications. With its intuitive API and diverse functionalities, it simplifies video editing tasks and opens doors for crafting engaging video experiences for mobile users. Whether you're building a social media app, a video editing tool, or anything in between, Mp4Composer-android is a valuable asset to consider for your next mobile video project. By leveraging its capabilities and exploring advanced features, you can unleash your creativity and empower users to become mobile movie makers.
| epakconsultant |
1,869,857 | How To Pull The Images on GCP Artifact Registry From On-premise K8S | To access Google Cloud Platform (GCP) Artifact Registry from a local Kubernetes cluster using a... | 0 | 2024-05-30T03:25:41 | https://dev.to/u2633/how-to-pull-the-images-on-gcp-artifact-registry-from-on-premise-k8s-6o4 | kubernetes | To access Google Cloud Platform (GCP) Artifact Registry from a local Kubernetes cluster using a service account key file, you need to follow these steps:
1. **Create a GCP Service Account and Key File**
2. **Create a Kubernetes Secret with the Service Account Key**
3. **Configure Your Kubernetes Deployment to Use the Secret**
4. **Pull Images from Artifact Registry**
### Step-by-Step Guide
#### 1. Create a GCP Service Account and Key File
1. **Create the Service Account**:
```bash
gcloud iam service-accounts create my-service-account --display-name "My Service Account"
```
2. **Grant the Necessary Roles to the Service Account**:
```bash
gcloud projects add-iam-policy-binding <YOUR-PROJECT-ID> \
--member="serviceAccount:my-service-account@<YOUR-PROJECT-ID>.iam.gserviceaccount.com" \
--role="roles/artifactregistry.reader"
```
Replace `<YOUR-PROJECT-ID>` with your GCP project ID.
3. **Create and Download the Key File**:
```bash
gcloud iam service-accounts keys create key.json \
--iam-account my-service-account@<YOUR-PROJECT-ID>.iam.gserviceaccount.com
```
#### 2. Create a Kubernetes Secret with the Service Account Key
1. **Create the Secret**:
```bash
kubectl create secret docker-registry gcp-artifact-registry \
--docker-server=LOCATION-docker.pkg.dev \
--docker-username=_json_key \
--docker-password="$(cat key.json)" \
--docker-email=your-email@example.com
```
Replace:
- `LOCATION` with the location of your Artifact Registry (e.g., `us-central1`).
- `your-email@example.com` with your email.
#### 3. Configure Your Kubernetes Deployment to Use the Secret
Update your Kubernetes deployment YAML to reference the secret for pulling images.
1. **Update Deployment YAML**:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: LOCATION-docker.pkg.dev/PROJECT-ID/REPOSITORY/IMAGE:TAG
ports:
- containerPort: 8080
imagePullSecrets:
- name: gcp-artifact-registry
```
Replace the placeholders:
- `LOCATION` with your Artifact Registry location (e.g., `us-central1`).
- `PROJECT-ID` with your GCP project ID.
- `REPOSITORY` with the name of your repository.
- `IMAGE:TAG` with the specific image and tag you want to use.
2. **Apply the Deployment**:
```bash
kubectl apply -f deployment.yaml
```
#### 4. Verify the Setup
1. **Check the Deployment Status**:
```bash
kubectl get pods
```
2. **Describe a Pod to Verify Image Pull**:
```bash
kubectl describe pod <POD-NAME>
```
Look for the events section to see if the image was pulled successfully.
### Summary
By following these steps, you configure your local Kubernetes cluster to authenticate with GCP Artifact Registry using a service account key file. This involves creating a service account and key, storing the key as a Kubernetes secret, and updating your deployments to use the secret for image pulls. This setup ensures secure and efficient access to your container images stored in GCP Artifact Registry.
## Refs
https://cloud.google.com/artifact-registry/docs/docker/pushing-and-pulling#key
https://cloud.google.com/artifact-registry/docs/docker/authentication#json-key | u2633 |
1,869,856 | The futures and cryptocurrency API explanation | Commodity futures CTP and cryptocurrency API exchange have significant differences. Familiar with... | 0 | 2024-05-30T03:25:22 | https://dev.to/fmzquant/the-futures-and-cryptocurrency-api-explanation-2f4j | cryptocurrency, futures, api, fmzquant | Commodity futures CTP and cryptocurrency API exchange have significant differences. Familiar with cryptocurrency exchange programming trading doesn't mean familiar with commodity futures CTP programming. we can not simply copy the method and experience. This article will summarize the similarities and differences between them.
## Historical data
The CTP interface does not provide historical market quote, and the historical market quote needs to be resolved through the market quote agency . If the market data is lost due to failure to log in, the CTP does not provide a market replenishment mechanism. Historical market quotes can only be obtained through third-party agency. Most cryptocurrency exchanges usually provides an interface for obtaining K-line and transaction history.
## Different agreement
The cryptocurrency exchange API is generally a REST and websocket protocol. The CTP internally encapsulates the network-related logic and communicates with the CTP background using the FTD protocol based on the TCP protocol. Divided into three modes:
- Request response mode: the client initiates a request, and the CTP background receives and responds to the request.
- Broadcast communication mode: After the client subscribes to the contract market quote, the CTP pushes the market quotes through the broadcast.
- Private communication mode: After the client commissions a contract, the order information, transaction return, etc. are pushed by the CTP point-to-point.
All quotes and order transactions of the CTP agreement will be notified after changes, while the inquiry orders, accounts, and positions are actively queried. The above three modes can find similar forms in the cryptocurrency exchange API.
## Different levels of data
The depth of the CTP protocol are only the latest buying and selling price, the deeper market quotes such as five layer of buying and selling price are expensive, you need pay extra money to the futures exchange to obtain it. on the other hand, The cryptocurrency exchange can generally get full depth up to 200 layers of buying and selling prices.
Also, CTP does not push the real transactions quotes, it can only be reversed by position changes, and the cryptocurrency exchange API can obtain real detailed transaction quotes. The market data tick level of the CTP platform is 2 tick per second. Most of the cryptocurrency exchange websocket can do up to 10 tick per second.
## Different access restrictions
cryptocurrency exchanges are generally limited to 10 ticks pre second. There are no special requirements for order withdrawals. CTP has strict restrictions on requests that need to be sent out actively. Generally, once per 2 second is rather safe, and there are also requirements for the number of withdrawals.
## Stability
The CTP protocol is very stable and there are almost no errors or network problems. Due to the cryptocurrency exchange have less restriction, longer transaction time, system maintenance, data delay and network errors are very common.
## FMZ Quant Platform CTP Protocol Best Practices
CTP default mode to get the market interface such as GetTicker, GetDepth, GetRecords are cached data to get the latest, if there is no data will wait until there is data, so the strategy can not use Sleep. When there is a market quote change, ticker, depth, and records will be updated. At this point, any interface will be returned immediately when it be called. Then the called interface state is set to wait for the update mode, When the next time the same interface is called, it will wait for new data to return.
Some unpopular trading contracts or the price reaches the daily limited price will occur for a long time without any trading activities, which is normal for the strategy to be stuck for a long time.
If you want to get the data every time you get the market quote, even the old data, you can switch to the market immediately update mode exchange.IO ("mode", 0). At this point, the strategy cannot be written as an event driver. You need to add a SLeep event to avoid a fast infinite loop. Some low-frequency strategies can use this mode, and the strategy design is simple. Use exchange.IO("mode", 1) to switch back to the default cache mode.
When operating a single contract, use the default mode will be fine. However, if there are multiple trading contracts, it is possible that one contract has not been updated, resulting in a blockage of the market interface, and other trading contract market quotes updates are not available. To solve this problem, you can use the immediate update mode, but it is not convenient to write a high frequency strategy. At this point, you can use the event push mode to get the push of orders and quotes. The setting method is exchange.IO("wait"). If multiple exchange objects are added, this is rare situation in commodity futures trading, you can use exchange.IO ("wait_any"), and the returned index will indicate the index of the returned exchange.
Market quote tick change push:
```
{Event:"tick", Index: exchange index (in the order of robot exchange added), Nano: event nanosecond time, Symbol: contract name}
```
Order Push:
```
{Event:"order", Index: Exchange Index, Nano: Event Nanosecond Time, Order: Order Information (consistent with GetOrder)}
```
At this point the strategy structure can be written as:
```
Function on_tick(symbol){
Log("symbol update")
exchange.SetContractType(symbol)
Log(exchange.GetTicker())
}
Function on_order(order){
Log("order update", order)
}
Function main(){
While(true){
If(exchange.IO("status")){ //Determine the link status
exchange.IO("mode", 0)
_C (exchange.SetContractType, "MA888") // subscribe to the MA, only the first time is the real request to send a subscription, the following are just program switch, won't consume any time.
_C(exchange.SetContractType, "rb888") // Subscribe rb
While(True){
Var e = exchange.IO("wait")
If(e){
If(e.event == "tick"){
On_tick(e.Symbol)
}else if(e.event == "order"){
On_order(e.Order)
}
}
}
}else{
Sleep(10*1000)
}
}
}
```
From: https://blog.mathquant.com/2022/09/30/the-futures-and-cryptocurrency-api-explanation.html | fmzquant |
1,869,852 | Rendering and Encoding Videos in Flutter: Embracing Flexibility | Flutter, the versatile UI framework from Google, empowers developers to create beautiful and engaging... | 0 | 2024-05-30T03:22:27 | https://dev.to/epakconsultant/rendering-and-encoding-videos-in-flutter-embracing-flexibility-2dd3 | flutter | Flutter, the versatile UI framework from Google, empowers developers to create beautiful and engaging applications. But what if your app requires video playback and manipulation? While native video players exist, achieving format flexibility often necessitates venturing beyond the built-in functionalities. This article explores approaches for rendering and encoding videos in Flutter, supporting a variety of formats.
**Understanding Video Rendering and Encoding
**
• Rendering: The process of displaying a video frame-by-frame on the screen. Flutter utilizes widgets like VideoPlayer to handle this task.
• Encoding: The process of converting raw video data into a compressed format suitable for storage and transmission. Encoding libraries allow you to convert captured video or existing files into desired formats like MP4 or H.264.
**Challenges of Native Video Players**
While Flutter offers a VideoPlayer widget, it has limitations:
• Limited Format Support: The native player might not natively support all video formats you require.
• Customization Challenges: Customizing playback behavior or integrating advanced features can be complex.
**Exploring Alternative Approaches**
To overcome these limitations, consider these options:
1.Platform-Specific Code with Platform Channels:
• Leverage platform-specific libraries (like FFmpeg for Android/iOS) for encoding and decoding video.
• Utilize platform channels to bridge the communication gap between native code and your Flutter application.
• This approach offers greater format flexibility and customization but requires more development effort for both platforms.
2.Third-Party Flutter Packages:
• The Flutter ecosystem offers several third-party packages designed for video processing.
• Popular options include:
o video_player: Provides extended functionalities like subtitles and custom controls compared to the native VideoPlayer. It might still have limitations in format support.
o video_compress: Focuses on video compression with support for converting videos into MP4 format.
o flutter_ffmpeg: Wraps the FFmpeg library, offering extensive encoding and decoding capabilities but requiring some native development knowledge.
[Automated Market Makers (AMM) and Decentralized Exchanges (DEX) For Absolute Beginners](https://www.amazon.com/dp/B0CDVGLFP9)
• These packages simplify development but might have limitations in format support or features compared to a fully custom approach.
**Choosing the Right Approach**
The ideal approach depends on your project's specific needs:
• Project Complexity: For simple playback with limited format requirements, consider using the native VideoPlayer or video_player package.
• Customization Needs: If you require extensive customization or support for a wider range of formats, explore platform channels or flutter_ffmpeg.
• Development Resources: Evaluate the trade-off between development effort and flexibility. Platform channels and flutter_ffmpeg might require more development expertise.
Best Practices for Video Rendering and Encoding
• Consider Performance: Video processing can be resource-intensive. Optimize your code and choose efficient libraries to avoid performance bottlenecks.
• Handle User Input: Implement playback controls like pause, play, and seek functionality to provide a smooth user experience.
• Error Handling: Implement robust error handling to gracefully handle situations like unsupported video formats or decoding errors.
• Test Thoroughly: Test your video playback and encoding functionalities on various devices and network conditions to ensure smooth operation.
Conclusion
By exploring the available options and best practices, you can effectively render and encode videos in your Flutter application, supporting multiple formats. Whether you leverage native code with platform channels, third-party packages, or a combination of both, remember to prioritize flexibility, performance, and a user-friendly experience. With the right approach, you can unlock the power of video in your Flutter apps and create engaging user experiences.
| epakconsultant |
1,869,840 | Unlocking Real-Time Communication: Exploring Android WebRTC SDKs | The landscape of mobile communication is rapidly evolving. WebRTC (Web Real-Time Communication) has... | 0 | 2024-05-30T03:16:57 | https://dev.to/epakconsultant/unlocking-real-time-communication-exploring-android-webrtc-sdks-4p9j | webrtc, android | The landscape of mobile communication is rapidly evolving. WebRTC (Web Real-Time Communication) has emerged as a powerful tool, enabling web browsers and mobile applications to establish direct peer-to-peer connections for real-time audio, video, and data exchange. To leverage this technology on Android devices, developers can utilize WebRTC SDKs (Software Development Kits). This article delves into the world of Android WebRTC SDKs, exploring their functionalities, benefits, and considerations for implementation.
**What is a WebRTC SDK?**
A WebRTC SDK acts as a bridge between the WebRTC standard and the native functionalities of the Android operating system. It provides developers with pre-written code libraries and tools, simplifying the integration of real-time communication features into their Android applications.
Core Functionalities of a WebRTC SDK
• Media Capture and Processing: The SDK facilitates access to a device's camera and microphone, enabling audio and video capture. It may also offer functionalities for video processing like encoding and decoding.
• Peer Connection Management: The SDK handles the establishment and management of peer-to-peer connections. This includes tasks like signaling (negotiating connection parameters) and data exchange between devices.
• Codec Support: Different WebRTC SDKs support various codecs for audio and video, impacting factors like compatibility and bandwidth usage. Common codecs include VP8 for video and Opus for audio.
• Device Optimization: To ensure smooth performance, the SDK may optimize media processing and network usage based on the device's capabilities.
**Benefits of Using a WebRTC SDK**
• Reduced Development Time: Leveraging pre-built libraries saves significant development time compared to building WebRTC functionality from scratch.
• Simplified Integration: SDKs provide a streamlined approach to integrating real-time communication features into existing Android applications.
• Cross-Platform Compatibility: Some SDKs offer compatibility with other platforms like iOS, enabling developers to create unified communication experiences.
• Enhanced Features: Several SDKs provide additional features beyond core functionalities, such as screen sharing, call recording, and data channel capabilities.
[Unveiling the Mysteries of Trading Strategies: Pryamiding, Martingale, Leverage, TP1, TP2, and TP3](https://www.amazon.com/dp/B0CJPQH218)
**Popular Android WebRTC SDKs**
• WebRTC Native (AOSP): The native WebRTC implementation included within the Android Open Source Project (AOSP) offers a basic framework for building WebRTC applications.
• Google Unified Communication API (UCAPI): While not an SDK itself, UCAPI provides a higher-level abstraction on top of WebRTC, simplifying development for specific use cases like video conferencing.
• Commercial SDKs: Several third-party vendors offer feature-rich commercial SDKs with advanced functionalities, often accompanied by comprehensive developer support.
**Choosing the Right WebRTC SDK**
The ideal SDK for your project depends on various factors:
• Project Requirements: Consider the specific communication functionalities you need (video, audio, data channels) and any additional features desired.
• Developer Experience: Evaluate the SDK's documentation, code samples, and available support resources to ensure a smooth development process.
• Licensing and Costs: Compare licensing models (open-source vs. commercial) and any associated costs to fit your project's budget.
**Getting Started with a WebRTC SDK**
Most WebRTC SDKs provide detailed documentation and tutorials to guide developers through the integration process. Here's a general roadmap:
1.Choose and Download the SDK: Select the SDK that aligns with your project's needs and download it from the official source.
2.Set Up Your Development Environment: Ensure you have the necessary development tools like Android Studio and an Android device or emulator for testing.
3.Integrate the SDK: Follow the SDK's documentation to add the necessary libraries and code to your Android project.
4.Develop Your App Functionality: Utilize the SDK's functionalities to build the real-time communication features within your application.
5.Testing and Deployment: Rigorously test your application on various devices and network conditions before deploying it to the Google Play Store.
**The Future of Android WebRTC SDKs**
As WebRTC technology matures, Android WebRTC SDKs are expected to become even more powerful and user-friendly. We can anticipate advancements in areas like:
• Improved Performance: SDKs will likely optimize resource usage and network bandwidth consumption for a smoother communication experience.
• Enhanced Security: Security features like encryption and authentication will continue to evolve to ensure secure communication channels.
• Simplified Development: SDKs may offer more high-level abstractions and tools to further streamline the development process for developers.
By leveraging the capabilities of Android WebRTC SDKs, developers can unlock the power of real-time communication in their mobile applications. From video conferencing and live streaming to interactive gaming and collaborative experiences, the possibilities are vast
| epakconsultant |
1,869,837 | massage cho nguoi yeu | Trong cuộc sống bận rộn hiện nay, việc kết nối với người thương thường bị hạn chế, nhưng học cách... | 0 | 2024-05-30T03:15:34 | https://dev.to/cuavietnhat/massage-cho-nguoi-yeu-568a | Trong cuộc sống bận rộn hiện nay, việc kết nối với người thương thường bị hạn chế, nhưng học cách massage cho người yêu tại nhà là một cách tuyệt vời để hâm nóng tình cảm và giúp người yêu cảm thấy được quan tâm, chăm sóc. Dưới đây là năm bước cơ bản để massage cho người yêu thư giãn như ngoài spa.
1. Chuẩn bị không gian massage thoải mái
Tạo không gian massage thoải mái là bước đầu tiên và rất quan trọng. Sử dụng một chiếc khăn mềm để che phủ giường nằm, chuẩn bị 1-2 chiếc gối để người yêu cảm thấy dễ chịu hơn. Điều chỉnh tư thế nằm cho người yêu sao cho thoải mái nhất, ví dụ như nằm sấp với một chiếc gối đệm trước ngực và nghiêng đầu sang một bên. Sử dụng trọng lượng cơ thể để tạo áp lực thay vì chỉ dùng tay.
2. Massage phần lưng
Massage lưng là phần không thể thiếu khi massage cho người yêu tại nhà. Xoa đều dầu và đặt lòng bàn tay dưới cổ người yêu, trượt dần xuống lưng dọc theo cột sống đến đỉnh hông và sang hai bên hông, sau đó lên các khớp vai và bả vai. Trượt tay từ phía dưới cổ ra đỉnh vai, lên cánh tay và nhẹ nhàng xoa cánh tay, bàn tay và các ngón tay. Lặp lại các động tác này 3-5 lần.
3. Massage bắp chân
Ngồi ở mép bên cạnh chân người yêu, bắt đầu xoa dầu massage từ mắt cá chân, trượt lên bắp chân đến đùi và trở lại gót chân. Sử dụng động tác vòng tròn để massage bắp chân, thay đổi hướng vòng tròn để tạo cảm giác thư giãn.
4. Massage cổ và cánh tay
Đặt người yêu nằm ngửa, bạn ngồi ở phía trên đầu. Đặt lòng bàn tay ở phần cổ, ngón tay hướng về phía lưng, nhẹ nhàng xoa bóp và trượt lòng bàn tay ra phía trên cánh tay, sau đó xuống khuỷu tay và lên lại cổ. Đặt ngón tay ở đỉnh đầu và di chuyển dọc xuống đốt sống cổ với động tác vòng tròn nhỏ để giãn cơ bắp.
5. Massage chân và ngón chân
Đặt lòng bàn tay tại mắt cá chân, trượt dọc theo hai bên chân lên đùi, rồi sử dụng ngón tay cái, lòng bàn tay và các ngón tay trượt ra xa nhau về phía hai bên chân. Tiếp tục trượt xuống mắt cá chân, lưu ý không ấn bóp vào xương chày hoặc xương đầu gối. Đây là kiểu massage được nhiều cặp đôi ưa chuộng.
Cuối cùng, một gợi ý khác là sử dụng ghế massage. Ghế massage là sản phẩm chăm sóc sức khỏe gồm các bài massage tự động mô phỏng như bàn tay con người, tác động vào các huyệt đạo trên cơ thể, tạo cảm giác thư giãn tối đa. Đây không chỉ là món quà sang trọng mà còn thể hiện sự quan tâm đặc biệt, giúp hâm nóng tình cảm và chăm sóc sức khỏe một cách thiết thực.
Website: https://suckhoedoisong.vn/5-buoc-massage-cho-nguoi-yeu-tai-nha-thu-gian-nhu-ngoai-spa-169240131092741219.htm
Phone: 0963415813
Address: 65 Cửa Bắc, phường Trúc Bạch, Quận Ba Đình, Hà Nội
https://lab.quickbox.io/bjcuavietnhat
http://buildolution.com/UserProfile/tabid/131/userId/405976/Default.aspx
https://www.diggerslist.com/ugcuavietnhat/about
https://8tracks.com/cuavietnhat
https://doodleordie.com/profile/jxcuavietnhat
https://www.scoop.it/u/massage-chonguoi-yeu
https://sinhhocvietnam.com/forum/members/74716/#about
https://camp-fire.jp/profile/cuavietnhat
https://metaldevastationradio.com/cuavietnhat
https://link.space/@cuavietnhat
https://topsitenet.com/profile/apcuavietnhat/1197502/
https://bandori.party/user/201677/cuavietnhat/
https://www.equinenow.com/farm/cuavietnhat.htm
https://www.hahalolo.com/@6657ee236df3d00810d38c69
https://www.noteflight.com/profile/1ccb356f7500508701b8023ae03653e28870fe12
https://www.babelcube.com/user/massage-cho-nguoi-yeu
https://forum.dmec.vn/index.php?members/cuavietnhat.61270/
https://bentleysystems.service-now.com/community?id=community_user_profile&user=5327ac681b6a4610dc6db99f034bcb7c
https://pinshape.com/users/4466624-cuavietnhat#designs-tab-open
https://www.fundable.com/massage-cho-nguoi-yeu
https://www.dnnsoftware.com/activity-feed/my-profile/userid/3199211
https://telegra.ph/cuavietnhat-05-30
https://worldcosplay.net/member/1771770
https://chart-studio.plotly.com/~cuavietnhat
https://vimeo.com/user220394847
| cuavietnhat | |
1,869,835 | Day 2: Text Formatting and Links in HTML | Welcome back to Day 2 of your journey to mastering HTML and CSS! Today, we will dive deeper into HTML... | 0 | 2024-05-30T03:00:52 | https://dev.to/dipakahirav/day-2-text-formatting-and-links-in-html-38jm | html, css, javascript, beginners | Welcome back to Day 2 of your journey to mastering HTML and CSS! Today, we will dive deeper into HTML by exploring text formatting and links. By the end of this post, you'll be able to format text and create links to other web pages.
#### Text Formatting in HTML
HTML provides various tags to format text, making it more readable and visually appealing. Here are some essential text formatting tags:
1. **Headings**: Headings are used to define the titles and subtitles in your content. HTML offers six levels of headings, from `<h1>` to `<h6>`, with `<h1>` being the highest (or most important) level and `<h6>` the lowest.
```html
<h1>This is an H1 heading</h1>
<h2>This is an H2 heading</h2>
<h3>This is an H3 heading</h3>
<h4>This is an H4 heading</h4>
<h5>This is an H5 heading</h5>
<h6>This is an H6 heading</h6>
```
2.**Paragraphs**: The `<p>` tag defines a paragraph.
```html
<p>This is a paragraph of text.</p>
```
3.**Bold and Italic Text**: Use the `<strong>` tag for bold text and the `<em>` tag for italic text.
```html
<p>This is a <strong>bold</strong> text.</p>
<p>This is an <em>italic</em> text.</p>
```
4.**Line Breaks**: The `<br>` tag inserts a line break.
```html
<p>This is the first line.<br>This is the second line.</p>
```
5.**Horizontal Rule**: The `<hr>` tag inserts a horizontal line, which can be used to separate content.
```html
<p>This is some text.</p>
<hr>
<p>This is more text.</p>
```
#### Creating Links in HTML
Links are fundamental in HTML as they allow you to navigate from one page to another. The `<a>` (anchor) tag is used to create hyperlinks.
1. **Basic Link**: The `href` attribute specifies the URL of the page the link goes to.
```html
<a href="https://www.example.com">Visit Example</a>
```
2.**Open Link in New Tab**: Use the `target="_blank"` attribute to open the link in a new tab.
```html
<a href="https://www.example.com" target="_blank">Visit Example in a new tab</a>
```
3.**Link to an Email Address**: Use the `mailto:` scheme in the `href` attribute.
```html
<a href="mailto:your.email@example.com">Send Email</a>
```
4.**Link to a Section on the Same Page**: Use the `id` attribute to create a bookmark and link to it.
```html
<h2 id="section1">Section 1</h2>
<a href="#section1">Go to Section 1</a>
```
#### Creating Your HTML Document with Text Formatting and Links
Let's create an HTML document incorporating the tags we've learned today:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Text Formatting and Links</title>
</head>
<body>
<h1>Welcome to My Website</h1>
<p>This is a <strong>sample</strong> paragraph with <em>italic</em> and <strong>bold</strong> text.</p>
<p>Here is a link to <a href="https://www.example.com" target="_blank">Example</a>.</p>
<p>Send me an <a href="mailto:your.email@example.com">email</a>.</p>
<p>Go to <a href="#section1">Section 1</a>.</p>
<hr>
<h2 id="section1">Section 1</h2>
<p>This is the first section of the page.</p>
<p>This is the end of the document.</p>
</body>
</html>
```
#### Summary
In this blog post, we explored various text formatting tags and learned how to create links in HTML. Practice using these tags to format your content and create links to enhance navigation.
Stay tuned for Day 3, where we will cover lists and images, adding more structure and visual appeal to your web pages. Happy coding!
---
*Follow me for more tutorials and tips on web development. Feel free to leave comments or questions below!*
#### Follow and Subscribe:
- **YouTube**: [devDive with Dipak](https://www.youtube.com/@DevDivewithDipak)
- **Website**: [Dipak Ahirav] (https://www.dipakahirav.com)
- **Email**: dipaksahirav@gmail.com
- **Instagram**: [devdivewithdipak](https://www.instagram.com/devdivewithdipak)
- **LinkedIn**: [Dipak Ahirav](https://www.linkedin.com/in/dipak-ahirav-606bba128) | dipakahirav |
1,869,834 | Unleashing Potential: How to Create a WordPress Plugin | WordPress, the king of content management systems, empowers users to customize their websites through... | 0 | 2024-05-30T02:58:03 | https://dev.to/epakconsultant/unleashing-potential-how-to-create-a-wordpress-plugin-43pk | wordpress, wordplugin | WordPress, the king of content management systems, empowers users to customize their websites through themes and plugins. But what if you have a unique functionality in mind? The answer lies in creating your own WordPress plugin! This article equips you with the knowledge to craft a plugin, from conception to activation.
**Planning Your Plugin**
Before diving into code, take a step back. Here's what you need to solidify:
Purpose: Clearly define the problem your plugin solves or the feature it adds. Aim for a specific niche to avoid feature creep.
Target Audience: Identify the type of WordPress users who would benefit from your plugin. Are they bloggers, e-commerce owners, or photographers?
Technical Feasibility: Assess if your concept aligns with WordPress's capabilities. Research existing plugins for similar functionalities to understand the technical landscape.
**Setting Up Your Development Environment**
Local Development: Highly recommended! Install a local server software like XAMPP or MAMP to mimic a live WordPress environment on your computer. This allows for safe testing and development without affecting your live website.
Code Editor: Choose a text editor like Visual Studio Code or Sublime Text for writing clean and efficient code. Plugins can further enhance your coding experience with syntax highlighting and code completion.
WordPress Installation: Install a fresh WordPress instance on your local server. This dedicated environment allows you to experiment and test your plugin without affecting your main website.
[Unlocking the Power of Weighted Alpha and Harmonic Trading Indicators](https://www.amazon.com/dp/B0CZS9PHW2)
**Building the Plugin Structure**
Create the Folder: Within your WordPress installation's wp-content/plugins directory, create a folder named after your plugin.
The Main Plugin File: Inside this folder, create a PHP file with the same name as your plugin (e.g., my-first-plugin.php). This file acts as the plugin's core and contains essential information.
Plugin Header: At the very beginning of the PHP file, add a header comment with details like plugin name, description, author, and version. This information is crucial for WordPress to recognize your plugin.
Here's a basic structure of the header comment:
`PHP
<?php
/*
Plugin Name: My First Plugin
Plugin URI: https://yourwebsite.com/my-first-plugin
Description: A simple plugin to showcase the basics of plugin development.
Version: 1.0.0
Author: Your Name
Author URI: https://yourwebsite.com
License: GPLv2 or later
*/`
**Adding Functionality**
This is where your creativity takes center stage! Here are some ways to add functionalities:
Actions and Filters: These are hooks provided by WordPress that allow your plugin to interact with core functionalities. Use actions to execute code at specific points in the WordPress lifecycle and filters to modify existing data.
Shortcodes: Create custom shortcodes for users to easily insert functionalities into their posts or pages.
Custom Admin Pages: If your plugin requires configuration options, create dedicated admin pages accessible from the WordPress dashboard.
Safety First: Testing and Security
Thorough Testing: Test your plugin rigorously in your local environment before deploying it live. Simulate various scenarios and user interactions to ensure everything functions as expected.
Security Best Practices: Never store sensitive information like passwords directly in your code. Leverage WordPress's security features like user capabilities and proper data sanitization.
**Deployment and Activation**
Create a Zip File: Once you're confident about your plugin's functionality and security, compress the entire plugin folder (including the PHP file) into a zip archive.
Upload and Activate: In your WordPress admin panel, navigate to the "Plugins" section and click "Add New." Select "Upload Plugin" and choose your zip file. Click "Install Now" and then "Activate" to make your plugin live on your website.
Congratulations! You've successfully created a WordPress plugin. Remember, this is just the beginning. As you gain experience, explore advanced functionalities, user interfaces, and best practices to craft robust and user-friendly plugins that extend the capabilities of WordPress. | epakconsultant |
1,869,833 | LinkedIn Profile to Resume Chrome Extension | I’ve found myself transferring my LinkedIn profile to my resume multiple times, so decided to... | 0 | 2024-05-30T02:53:34 | https://dev.to/balt1794/linkedin-profile-to-resume-chrome-extension-4g7e | linkedin, resume, chatgpt, chrome | {% embed https://youtu.be/40TfHTZuo1g %}
I’ve found myself transferring my LinkedIn profile to my resume multiple times, so decided to automate this process by creating a Chrome extension to save hours creating a resume from my LinkedIn profile.
It takes less than 20 seconds to create a resume using ResumeBoostAI Chrome extension.
Get it here [ResumeBoostAI Chrome extension](https://chromewebstore.google.com/detail/resumeboostai-linkedin-pr/hbgbggpkmgaiebpjiigiinhfncflclan)
Steps:
1. Install ResumeBoostAI Chrome Extension
2. Go to your LinkedIn Profile
3. Activate extension and click on Download PDF
4. Once you download your PDF, go to [ResumeBoostAI](https://resumeboostai.com/resume-import)
5. Drop PDF and click on Upload Resume
6. Check information and edit resume if needed
7. Click on Download Resume
Voila! now you can land your dream job
For more resources to land your dream job:
[ResumeBoostAI](https://resumeboostai.com)
[Twitter](https://twitter/balt1794)
| balt1794 |
1,869,831 | Day 2: Understanding Variables and Data Types in JavaScript | Introduction Welcome to Day 2 of your JavaScript journey! Yesterday, we set up our... | 0 | 2024-05-30T02:51:52 | https://dev.to/dipakahirav/day-2-understanding-variables-and-data-types-in-javascript-2p97 | javascript, beginners, html, css | #### Introduction
Welcome to Day 2 of your JavaScript journey! Yesterday, we set up our development environment and wrote our first lines of JavaScript code. Today, we will dive into variables and data types, which are fundamental concepts in any programming language.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
) to support my channel and get more web development tutorials.
#### Variables
Variables are used to store data values that can be used and manipulated throughout your code. In JavaScript, you can declare variables using `var`, `let`, or `const`.
**1. `var`**
`var` is the traditional way to declare variables in JavaScript. Variables declared with `var` have function scope and are hoisted to the top of their scope.
**Example:**
```javascript
var name = "Alice";
console.log(name); // Output: Alice
```
**2. `let`**
`let` was introduced in ES6 and provides block scope, which means the variable is only accessible within the block it was declared.
**Example:**
```javascript
let age = 25;
if (true) {
let age = 30;
console.log(age); // Output: 30 (inside block)
}
console.log(age); // Output: 25 (outside block)
```
**3. `const`**
`const` is also block-scoped and is used to declare variables that cannot be reassigned. However, the contents of objects and arrays declared with `const` can be modified.
**Example:**
```javascript
const city = "New York";
console.log(city); // Output: New York
const person = {
name: "Bob",
age: 30
};
person.age = 31; // Allowed
console.log(person.age); // Output: 31
```
#### Data Types
JavaScript has several data types, categorized into two main groups: primitive and non-primitive (objects).
**Primitive Data Types:**
1. **String**: Used to represent textual data.
```javascript
let greeting = "Hello, World!";
console.log(greeting); // Output: Hello, World!
```
2. **Number**: Represents both integer and floating-point numbers.
```javascript
let score = 100;
let price = 99.99;
console.log(score); // Output: 100
console.log(price); // Output: 99.99
```
3. **Boolean**: Represents a logical value, either `true` or `false`.
```javascript
let isLoggedIn = true;
console.log(isLoggedIn); // Output: true
```
4. **Null**: Represents an intentional absence of any value.
```javascript
let emptyValue = null;
console.log(emptyValue); // Output: null
```
5. **Undefined**: Indicates that a variable has been declared but not assigned a value.
```javascript
let notAssigned;
console.log(notAssigned); // Output: undefined
```
6. **Symbol**: A unique and immutable primitive value.
```javascript
let symbol = Symbol("unique");
console.log(symbol); // Output: Symbol(unique)
```
**Non-Primitive Data Types:**
1. **Object**: Used to store collections of data and more complex entities.
```javascript
let person = {
name: "Charlie",
age: 28,
isStudent: true
};
console.log(person.name); // Output: Charlie
```
2. **Array**: A special type of object used to store ordered collections of values.
```javascript
let fruits = ["Apple", "Banana", "Cherry"];
console.log(fruits[1]); // Output: Banana
```
#### Type Conversion
JavaScript allows you to convert values from one type to another, either implicitly or explicitly.
**Implicit Conversion:**
JavaScript automatically converts types in certain operations.
**Example:**
```javascript
let str = "123";
let num = 456;
console.log(str + num); // Output: "123456"
```
**Explicit Conversion:**
You can manually convert types using functions like `String()`, `Number()`, `Boolean()`, `parseInt()`, and `parseFloat()`.
**Example:**
```javascript
let str = "123";
let num = Number(str);
console.log(num); // Output: 123
let bool = "true";
console.log(Boolean(bool)); // Output: true
let floatStr = "123.45";
let intNum = parseInt(floatStr);
let floatNum = parseFloat(floatStr);
console.log(intNum); // Output: 123
console.log(floatNum); // Output: 123.45
```
#### Practice Activities
1. **Declare Variables:**
- Use `var`, `let`, and `const` to declare variables.
- Experiment with variable scope by declaring variables inside and outside of functions and blocks.
2. **Work with Data Types:**
- Declare variables of different data types (string, number, boolean, null, undefined, object, array).
- Log their values to the console.
3. **Convert Types:**
- Use implicit and explicit conversion methods to convert between different data types.
- Practice converting strings to numbers and booleans.
**Mini Project:**
Create a simple script that takes user input (use `prompt`), converts it to a number, and logs the result of basic arithmetic operations.
**Example:**
```javascript
let userInput = prompt("Enter a number:");
let number = parseInt(userInput);
console.log("Your number:", number);
console.log("Double:", number * 2);
console.log("Half:", number / 2);
console.log("Square:", number * number);
```
#### Summary
Today, we explored variables and data types in JavaScript. We learned how to declare variables using `var`, `let`, and `const`, and we discussed various data types including strings, numbers, booleans, null, undefined, objects, and arrays. We also practiced type conversion.
Stay tuned for Day 3, where we'll dive into operators and expressions in JavaScript!
#### Resources
- [Variables and Data Types](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures)
- [JavaScript Basics](https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/JavaScript_basics)
Happy coding! If you have any questions or need further clarification, feel free to leave a comment below. Let's continue learning and growing together!
*Follow me for more tutorials and tips on web development. Feel free to leave comments or questions below!*
#### Follow and Subscribe:
- **Website**: [Dipak Ahirav] (https://www.dipakahirav.com)
- **Email**: dipaksahirav@gmail.com
- **Instagram**: [devdivewithdipak](https://www.instagram.com/devdivewithdipak)
- **YouTube**: [devDive with Dipak](https://www.youtube.com/@DevDivewithDipak)
- **LinkedIn**: [Dipak Ahirav](https://www.linkedin.com/in/dipak-ahirav-606bba128) | dipakahirav |
1,869,830 | Spinner handle | Wanted to know how we can handle spinner while its loading along with timeout I have tried different... | 0 | 2024-05-30T02:48:13 | https://dev.to/nagaraj_ukkali_89ab7c490f/spinner-handle-4jfe | help | Wanted to know how we can handle spinner while its loading along with timeout
I have tried different combinations like
await this.page.waitForSelector('#',{state: 'hidden'},{timeout:50000});
so can someone tell how we can handle
| nagaraj_ukkali_89ab7c490f |
1,869,828 | Reduce space above H2 tag | Hello there, I am working on my post page and cannot remove the space above my H2 tag... | 0 | 2024-05-30T02:37:49 | https://dev.to/saurabh_shelke/reduce-space-above-h2-tag-15p7 | help |
Hello there, I am working on my post page and cannot remove the space above my H2 tag (Pre-planning). I've tried multiple ways to reduce the margin in custom CSS still it doesn't help. Kindly guide... | saurabh_shelke |
1,869,826 | Choosing the Right DG Diesel Generator for Your Needs | Choosing the Right DG Diesel Generator for Your Needs You may need a DG diesel generator if you'd... | 0 | 2024-05-30T02:29:17 | https://dev.to/simon_mcanallylev_79a0584/choosing-the-right-dg-diesel-generator-for-your-needs-4ln6 | generators | Choosing the Right DG Diesel Generator for Your Needs
You may need a DG diesel generator if you'd like electricity in someplace where there is none. There are lots of advantages to employing a diesel DG, including innovation, safety, use, and quality. We shall explore these benefits in more detail to assist you choose the right DG diesel generator for your requirements.
Features of DG Diesel Generator
One of the main advantages of using a Diesel generator sets is that it's an excellent source of backup energy. It may provide you with electricity during energy outages or when there is no charged power available. This makes it well suited for domiciles, businesses, and even in remote locations. An additional benefit of using a diesel DG is its effectiveness. It could generate plenty of energy making use of extremely diesel little. This means that it's possible to truly save money on fuel expenses, compared to utilizing generators being old-fashioned.
Innovation in DG Diesel Generator
In the last few years, there have been innovations which are many the look of DG diesel generators. One of the most innovations which are significant the application of digital control systems. These systems enable better fuel effectiveness, more control precise of generator, and improved security features. Furthermore, there has been advancements within the usage of alternative fuels, such as biodiesel. This will make diesel DG more environmentally friendly and sustainable.
Usage of DG Diesel Generator
DG diesel generators may be used in a number of applications. They have been widely used as backup power sources for domiciles, hospitals, and businesses. They can additionally be used in remote locations where there is no charged power available. DG diesel generators are found in construction websites, mining operations, and other applications which are commercial. They are able to provide dependable and energy cost-effective hefty equipment as well as other gear.
How to Use DG Diesel Generator
Using a Diesel engine generator is not too difficult. First, you'll want to do the installation in a area well-ventilated. As soon as its set up, you will need to link it to the system electrical want to energy. Then, you need to add diesel fuel and begin the generator up. To make certain use appropriate of DG diesel generator, you ought to follow the maker's guidelines for starting, operating, and stopping the generator. You ought to also regularly check the oil and fuel levels and perform maintenance routine.
Provider and Quality of DG Diesel Generator
Like any machine, Diesel water pump generator need regular upkeep and servicing. It is crucial to choose a top-quality generator from a maker reputable ensure its longevity and reliability. You should also remember to have the generator regularly maintained and serviced by way of a professional. This may help determine problems that are potential they become major issues and make certain that the generator is often operating at peak performance.
Source: https://www.kangwogroup.com/Diesel-generator-sets | simon_mcanallylev_79a0584 |
1,869,825 | How to Obfuscate JavaScript? | How to Obfuscate JavaScript? JavaScript obfuscation is a technique used to make code difficult to... | 0 | 2024-05-30T02:28:25 | https://dev.to/wangliwen/how-to-obfuscate-javascript-2pm | javascript, webdev, obfuscate |
**How to Obfuscate JavaScript?**
JavaScript obfuscation is a technique used to make code difficult to read and understand while still maintaining its functionality. This is often done to protect intellectual property, hide implementation details, or simply to deter casual reverse engineering attempts. However, it's important to note that obfuscation does not guarantee security and should not be relied upon as a primary means of defense.
**Why Obfuscate JavaScript?**
1. Protection of IP: Companies often want to protect their algorithms and logic from being stolen or copied.
2. Hiding Implementation Details: Developers may want to hide certain implementation details to make it harder for others to understand or replicate their work.
3. Deterrence: Obfuscated code can deter casual reverse engineering attempts, making it less appealing for hackers or competitors.
**Techniques for Obfuscating JavaScript**
1. Variable Renaming: Renaming variables and functions to random or meaningless names can make code harder to read. Tools like UglifyJS and Terser can automatically rename variables during minification.
2. String Encoding: Encoding strings as hexadecimal, base64, or other formats can make them unreadable in the source code. However, this can be easily decoded by an attacker.
3. Control Flow Flattening: This technique transforms the control flow of the program to make it harder to analyze. Tools like JavaScript Obfuscator can achieve this.
4. Dead Code Insertion: Inserting code that doesn't affect the program's behavior but makes it harder to understand. This can include unused variables, functions, or loops.
5. Code Splitting and Evaluation: Splitting code into multiple parts and evaluating them dynamically can make it harder to analyze statically.
6. Encryption: Encrypting parts of the code or data can add another layer of obscurity, but it can also increase the complexity of the code.
**Best Practices for Obfuscation**
1. Use Established Tools: Tools like JScrambler, JS-Obfuscator, JShaman,etc... They have been widely used and tested. They provide reliable obfuscation while minimizing the chances of introducing errors.
2. Test Thoroughly: After obfuscating your code, thoroughly test it to ensure that it still functions as expected. Obfuscation tools can sometimes introduce subtle bugs.
3. Don't Rely Solely on Obfuscation: Remember that obfuscation is not a substitute for secure coding practices. Use it as an additional layer of defense but not as your primary means of security.
4. Be Aware of the Drawbacks: Obfuscated code can be harder to debug and maintain. Ensure that your team is aware of this and has the necessary tools and skills to work with obfuscated code.
**Conclusion**
JavaScript obfuscation can be a useful technique to protect your code and deter casual reverse engineering attempts. However, it should be used as an additional layer of defense and not relied upon as a primary means of security. Use established tools, thoroughly test your code, and be aware of the drawbacks of obfuscation to ensure that you're getting the most out of this technique.
| wangliwen |
1,869,824 | カスタムギフト | カスタムギフト https://jp.giftlab.com/ GiftLab 名入れギフト https://jp.giftlab.com/ Giftlab Japan ... | 0 | 2024-05-30T02:20:42 | https://dev.to/giftlab80/kasutamugihuto-1b45 | カスタムギフト https://jp.giftlab.com/
GiftLab 名入れギフト https://jp.giftlab.com/
Giftlab Japan https://jp.giftlab.com/
[カスタムギフト
](https://jp.giftlab.com/)
フォトキューブ
寝具
ミニ人形抱き枕
カスタム枕
キッチンギフト
カスタムカップ
カスタムコースター
キーホルダー
財布
カスタムステッカー
カスタムギフトの魅力は、受け手にとって特別なものであることです。一般的なギフトと異なり、カスタムギフトは受け手の好みや個性に合わせてデザインされています。そのため、より心に残る贈り物となることが多いのです。
また、カスタムギフトには様々な選択肢があります。例えば、写真やメッセージをプリントしたTシャツやマグカップ、オリジナルデザインのアクセサリーやインテリアアイテムなど、さまざまなアイテムをカスタマイズすることができます。自分だけのオリジナルアイテムを贈ることで、より個性的なプレゼントとなるでしょう。
| giftlab80 | |
1,869,823 | RSI2 Mean Reversion Strategy Using in Futures | Larry Connors RSI2 Mean Reversion Strategy From Many friends asked me to write a grid and... | 0 | 2024-05-30T02:20:16 | https://dev.to/fmzquant/rsi2-mean-reversion-strategy-using-in-futures-21h5 | futures, strategy, rsi2, fmzquant | Larry Connors RSI2 Mean Reversion Strategy
## From
Many friends asked me to write a grid and market maker strategy,But I generally decline directly. Regarding these strategies, first of all, you must have a strong mathematical knowledge, at least a doctor of mathematics.
In addition, high-frequency quantitative trading is more about financial resources, such as the amount of funds and broadband network speed.
The most important thing is that these violate my understanding of the trading.
Is there any other way to do high-frequency trading? Today we will introduce this RSI mean regression strategy based on Larry Connors.
## Introduction
The RSI2 strategy is a fairly simple mean regression trading strategy developed by Larry Connors, mainly operate during the price correction period.
When RSI2 falls below 10, it is considered over-selling and traders should look for buying opportunities.
When RSI2 rises above 90, it is considered over-buying and traders should look for selling opportunities.
This is a fairly aggressive short-term strategy aimed at participating in continuing trends. It is not intended to identify the main top or bottom of the price.
## Strategy
There are four steps to this strategy.
## Use the long-term moving average to determine the main trends
Connors recommends the 200-day moving average. The long-term trend rises above the 200-day moving average, and declines below it.
Traders should look for buying opportunities above the 200-day moving average and short selling opportunities below it.
## Select the RSI range to determine buying or selling opportunities
Connors tested RSI levels between 0 and 10 to buy and 90 to 100 to sell. (Based on closing price)
He found that when the RSI fell below 5, the return on buying was higher than the return below 10. The lower the RSI, the higher the return on subsequent long positions.
Correspondingly, when the RSI is higher than 95, the return on short selling is higher than the return on above 90.
## Regrading of the actual buying or short selling orders and their placing order time
Connors advocates the "close" method. Waiting for the closing price to open positions gives the trader more flexibility and can increase the winning rate.
## Set the appearance position
Where should stop-loss be?
Connors does not advocate the use of stop loss. In a quantitative test of hundreds of thousands of transactions, Connors found that the use of stop-loss actually "damaged" performance.
But in the example, Connors recommends to stop-loss long positions above the 5-day moving average and short positions below the 5-day moving average.
Obviously, this is a short-term trading strategy that can exit quickly, or consider setting up trailing stop loss or adopting SAR synthetic stop loss strategy.
Sometimes the market does indeed price drift upwards. Failure to use stop loss may result in excess losses and large losses.
This requires traders to consider and decide.
## Verification
The chart below shows the Dow Jones Industrial Average SPDR (DIA) and 200-day SMA (red), 5-period SMA (pink) and 2-period RSI.
When the DIA is higher than the 200-day SMA and the RSI (2) falls to 5 or lower, a bullish signal appears.
When the DIA is below the 200-day SMA and the RSI (2) rises to 95 or higher, a bearish signal will appear.
In these 12 months, there are 7 signals, 4 bullish and 3 bearish.
Among the 4 bullish signals, DIA rose by 3 of 4 times, which means that these signals may be profitable.
Among the four bearish signals, DIA fell only once.
After a bearish signal in October, DIA broke the 200-day moving average.
Once the 200-day moving average is exceeded, RSI2 will not fall to 5 or lower to generate another buying signal.
As for profit and loss, it will depend on the level of stop-loss and take- profit.
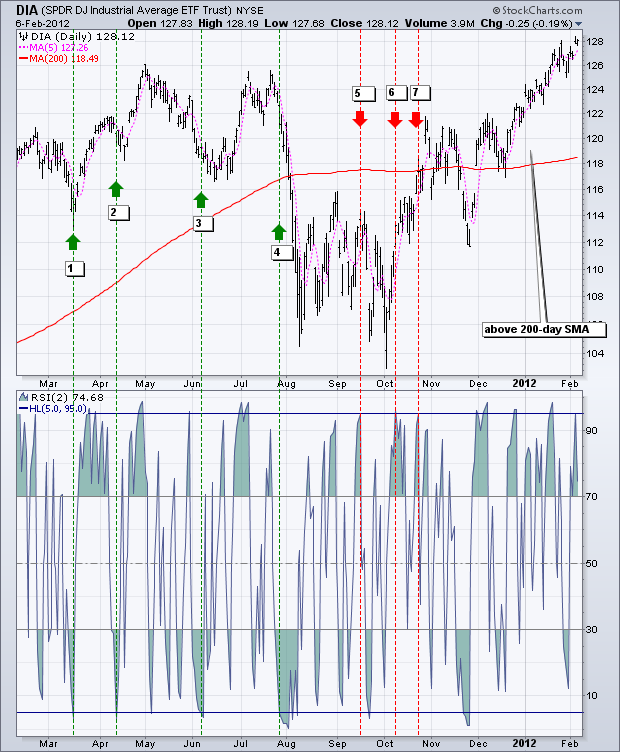
The second example shows Apple (APL), which is above the 200-day moving average for most of the time period.
During this period, there are at least ten buying signals.
Since APL saw a sawtooth decline from late February to mid-June 2011, it is difficult to avoid the loss of the first five indicators.
As the APL rose in a jagged pattern from August to January, the last five signals performed much better.
As can be seen from the chart, many signals are very early.
In other words, Apple fell to a new low after the initial buy signal and then rebounded.
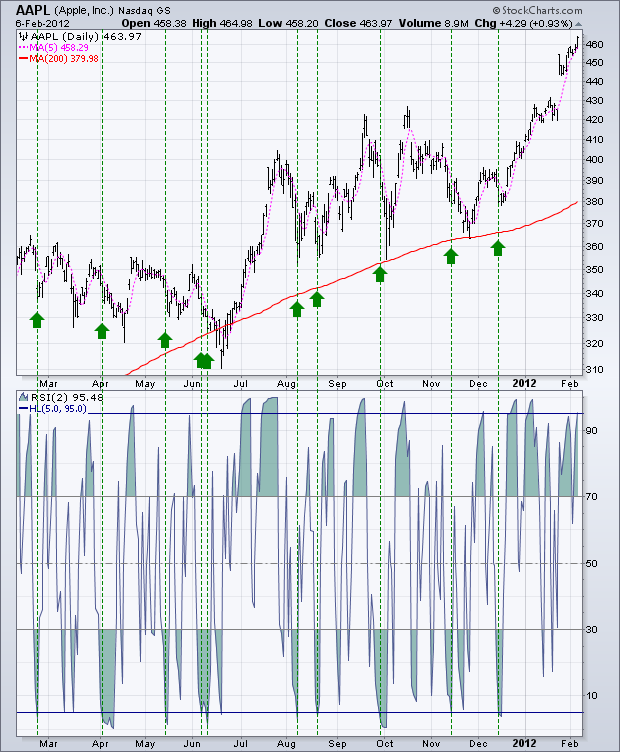
## Conclusion
The RSI2 strategy provides traders with the opportunity to participate in continuing trends.
Connors pointed out that traders should buying at price retracement point, not breakouts point.
also, traders should sell at oversold rebounds, not price support breakouts point.
This strategy is in line with his philosophy.
Even though Connors' tests indicate that stop loss affects performance, it is prudent for traders to develop exit and stop loss strategies for any trading system.
When the situation becomes over-buying or a stop loss is set, the trader can exit the long position.
Similarly, when conditions are oversold, traders can withdraw from short positions.
Use these ideas to enhance your trading style, risk-reward preferences and personal judgment.
## FMZ source code display
Connors' strategy is relatively simple, it is simply written in M language. (Everyone can understand)
Because the original strategy design target was US stocks, the 200-day moving average was used as a reference.
In the violently volatile digital currency market, it is just suitable for short-term value return.
So we adjusted the time range to 15 minutes, and the MA period was 70, and use 1 times the leverage for backtest.
```
(*backtest
start: 2019-01-01 00:00:00
end: 2020-05-12 00:00:00
period: 15m
basePeriod: 5m
exchanges: [{"eid":"Futures_OKCoin","currency":"BTC_USD"}]
args: [["TradeAmount",5000,126961],["MaxAmountOnce",5000,126961],["ContractType","quarter",126961]]
*)
liang:=INTPART(1*MONEYTOT*REF(C,1)/100);
//1 times the leverage
LC := REF(CLOSE,1);
RSI2: SMA(MAX(CLOSE-LC,0),2,1)/SMA(ABS(CLOSE-LC),2,1)*100;
//RSI2 value
ma1:=MA(CLOSE,70);
//MA value
CLOSE>ma1 AND RSI2>90,SK(liang);
CLOSE>ma1 AND RSI2<10,BP(SKVOL);
//When it is greater than the moving average,rsi>90 open short position,rsi<10 close short position
CLOSE<ma1 AND RSI2<10,BK(liang);
CLOSE<ma1 AND RSI2>90,SP(BKVOL);
//When it is less than the moving average,rsi<10 open long position,rsi>90 close long position
AUTOFILTER;
```
Strategy Copy https://www.fmz.com/strategy/207157
## Backtest effect
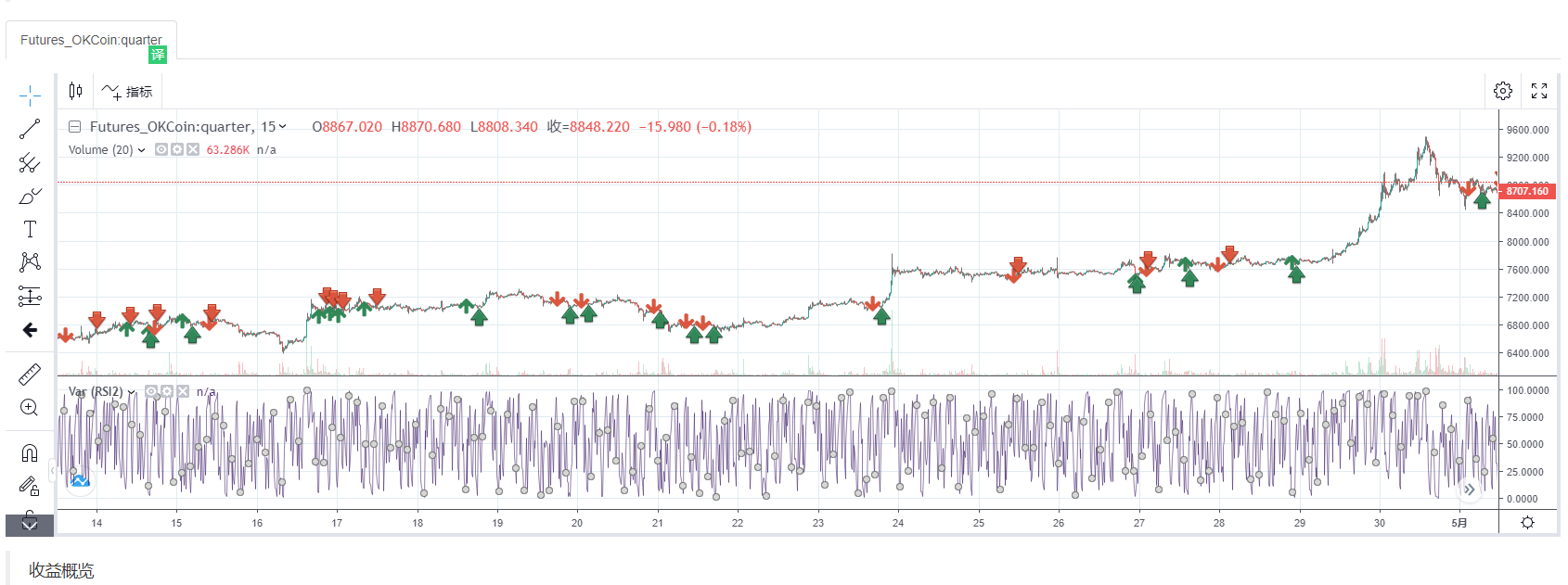
After a systematic backtest, we see that the overall winning rate of the RSI strategy is high. Its performance satisfied us.
The maximum retracement occurs at 312, and extreme market conditions will do more harm to the strategy of shock return.
## Tweaking
After RSI2 rise above 95, the market can continue to rise;
After RSI2 drops below 5, the market can continue to fall.
To correct this situation, we may need to involve OHLCV analysis, intraday chart patterns, other momentum indicators, etc.
After RSI2 rise above 95, the market can continue to rise and it is dangerous to establish a short position.
Traders may consider filtering this signal by waiting for RSI2 to return below its centerline 50.
## References
https://school.stockcharts.com
https://www.tradingview.com/ideas/connorsrsi/
https://www.mql5.com/zh/code/22421
From: https://blog.mathquant.com/2022/09/30/rsi2-mean-reversion-strategy-using-in-futures.html | fmzquant |
1,869,817 | How I hired HACKWEST AT WRITEME TO RECOVER MY CRYPTO | Two months ago, I lost over $187,000 to an online crypto investment I did. After investing for a... | 0 | 2024-05-30T02:18:20 | https://dev.to/tim_mcmahon_aab97ec9a3f64/how-i-hired-hackwest-at-writeme-to-recover-my-crypto-34d8 | Two months ago, I lost over $187,000 to an online crypto investment I did. After investing for a month, when it was time for withdrawal they started asking for more money, it was then I knew I had been defrauded. I did not waste any time, I went online to seek help on how to recover my money. I contacted (**HACKWEST at WRITEME dot C o M**), gave him all requested information, he swung into action and had my USDT recovered back to my crypto wallet. I promised to blow his trumpet, perhaps this 5 star review.
| tim_mcmahon_aab97ec9a3f64 | |
1,869,816 | Semiconductors Redefined: Chongqing Pingchuang Institute's Vision | Discover the New World of Semiconductors with Chongqing Pingchuang Institute ADVANTAGES Are you... | 0 | 2024-05-30T02:17:43 | https://dev.to/simon_mcanallylev_79a0584/semiconductors-redefined-chongqing-pingchuang-institutes-vision-21ik | conductors |
Discover the New World of Semiconductors with Chongqing Pingchuang Institute
ADVANTAGES
Are you searching for dependable and semiconductors which can be efficient? Search no further than Chongqing Pingchuang Institute
Our semiconductors and Portable power station redefine the industry with regards to performance like impressive flexibility, and affordability
With this specific semiconductors, you'll experience reduced power consumption, improved durability, and precision like improved every your applications
Our semiconductors are created to provide a number of companies, including telecommunications, automotive, and devices which can be electronic
INNOVATION
At Chongqing Pingchuang Institute, we feel innovation is key to residing in front regarding the competition
All of us of professionals is consistently developing new and semiconductors which are enhanced meet up with the ever-changing requirements of our clients
Our company is devoted to cutting-edge like providing that delivers functionality like unparalleled gratification
We attempt to supply the most useful responses to your clients whether it is improving data rate like processing reducing noise during signal transmission
SAFETY
Security is really a concern like high Chongqing Pingchuang Institute
All our semiconductors go through rigorous screening and quality control measures to be sure they meet industry requirements
We just make use of the quality materials which can be most readily useful plus the production ways that are latest to ensure that our semiconductors are safe, dependable, and lasting
We stay behind our services and products and offer warranties and support like after-sales make customer support like sure
HOW TO USE
Utilizing our semiconductors charger could not be easier
We offer detail by detail directions on how to install and operate our semiconductors to make sure that you get the most from your investment
All of us can be had to solve any questions that are relevant can have and provide help during installation and setup
We also provide training and resources that are educational help you stay up-to-date from probably the most technology like advanced and advancements
QUALITY and APPLICATION
At Chongqing Pingchuang Institute, we've been committed to supplying the product quality semiconductors being finest for a range like wide of
Our semiconductors are made to meet up because of the requirements of varied companies, including telecommunications, automotive, and products that are electronic
We comprehend the initial challenges of the industry and supply tailor-made methods to meet their needs which are particular
Together with your semiconductors, you're able to trust you are getting the quality things that are highest being optimized for the application
In conclusion, Chongqing Pingchuang Institute's Home Energy Storage semiconductors offer numerous advantages, innovation, safety, and high-quality applications. We're committed to providing our clients with the best possible products and services to help them achieve their goals. Whether you need semiconductors for telecommunications, automotive, or electronic devices, we have solutions to meet your needs. Contact us today to learn more about our products and services.
Source: https://www.pingalax-global.com/home-energy-storage891 | simon_mcanallylev_79a0584 |
1,869,760 | How Moonrepo Recognizes Project Languages | In this article, we will explain how the monorepo management tool Moon recognizes the languages of... | 0 | 2024-05-30T01:13:31 | https://dev.to/suin/how-moonrepo-recognizes-project-languages-5ck5 | moonrepo, moon | ---
title: How Moonrepo Recognizes Project Languages
published: true
description:
tags: Moonrepo, moon
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-04-07 01:57 +0000
---
In this article, we will explain how the monorepo management tool Moon recognizes the languages of projects.
## What is Moon?
Moon is a monorepo management tool. A monorepo is a method of managing multiple projects or packages within a single repository. Moon helps manage these projects efficiently and integrates tasks such as building, testing, and deploying. It manages dependencies between projects and improves development efficiency while maintaining consistency across the repository.
For more details: [Moon Official Site](https://moonrepo.dev/)
## Managing Language Information
Moon maintains language information for each project and selects tasks to execute based on the language. The language information of a project can be set by describing it in the `language` field of the `moon.yml` file.
Example for a TypeScript project:
```yaml
language: typescript
```
With this setting, tasks defined in the `.moon/tasks/typescript.yml` file will be executed for that project. This feature is known as task inheritance. For more details, see [here](https://moonrepo.dev/docs/concepts/task-inheritance).
## When No Language is Specified
If no language is specified in `moon.yml`, Moon will analyze the project's files and automatically identify the language. Thanks to Moon's intelligent design, it determines the programming language based on specific files.
## How Language Detection Works
Moon determines the project's programming language based on specific files found in the project's root directory. The following is how Moon detects each language.
### 1. Checking for Go Files
If any of the following files are found, the project's language is determined to be Go:
- `go.mod`
- `go.sum`
- `g.lock`
- `.gvmrc`
- `.go-version`
### 2. Checking for PHP Files
If any of the following files are found, the project's language is determined to be PHP:
- `composer.json`
- `composer.lock`
- `.phpenv-version`
- `.phpbrewrc`
### 3. Checking for Python Files
If any of the following files are found, the project's language is determined to be Python:
- `requirements.txt`
- `constraints.txt`
- `pyproject.toml`
- `.pylock.toml`
- `.python-version`
- `Pipfile`
- `Pipfile.lock`
- `poetry.toml`
- `poetry.lock`
### 4. Checking for Ruby Files
If any of the following files are found, the project's language is determined to be Ruby:
- `Gemfile`
- `Gemfile.lock`
- `.bundle`
- `.ruby-version`
### 5. Checking for Rust Files
If any of the following files are found, the project's language is determined to be Rust:
- `Cargo.toml`
- `Cargo.lock`
- `.cargo`
- `rust-toolchain.toml`
- `rust-toolchain`
### 6. Checking for TypeScript Files
If any of the following files are found, the project's language is determined to be TypeScript:
- `tsconfig.json`
- `tsconfig.tsbuildinfo`
Additionally, Deno files are also checked:
- `deno.json`
- `deno.jsonc`
- `deno.lock`
- `.dvmrc`
### 7. Checking for JavaScript Files
If any of the following files are found, the project's language is determined to be JavaScript:
- `package.json`
- `.nvmrc`
- `.node-version`
- `package-lock.json`
- `.npmrc`
- `.pnpmfile.cjs`
- `pnpm-lock.yaml`
- `pnpm-workspace.yaml`
- `yarn.lock`
- `.yarn`
- `.yarnrc`
- `.yarnrc.yml`
Additionally, Bun files are also checked:
- `bunfig.toml`
- `bun.lockb`
- `.bunrc`
### 8. If No Files Are Found
If none of the specific files are found, the project's language is determined to be unknown.
This specification allows Moon to determine the programming language based on the file structure within the project. For more details, see [here](https://github.com/moonrepo/moon/blob/master/crates/platform-detector/src/project_language.rs).
## Explicitly Specifying the Language
If you do not want Moon to estimate the project's language, it is recommended to explicitly specify the `language` field in the `moon.yml` file. However, be sure to specify a value other than `unknown` because specifying `unknown` will trigger the detection feature described above.
I hope this article helps deepen your understanding of how Moon recognizes project languages.
| suin |
1,867,994 | How to Control the Number of Concurrent Promises in JavaScript | In some cases, we may need to control the number of concurrent requests. For example, when we are... | 0 | 2024-05-30T02:14:59 | https://webdeveloper.beehiiv.com/p/control-number-concurrent-promises-javascript | webdev, javascript, programming, frontend | In some cases, we may need to control the number of concurrent requests.
For example, when we are writing download or crawling tools, some websites may have a limit on the number of concurrent requests.
In browsers, the maximum number of TCP connections from the same origin is limited to 6. This means that if you use HTTP1.1 when sending more than 6 requests at the same time, the 7th request will wait until the previous one is processed before it starts.
We can use the following simple example to test it. First the client code:
```javascript
void (async () => {
await Promise.all(
[...new Array(12)].map((_, i) =>
fetch(`http://127.0.0.1:3001/get/${i + 1}`)
)
);
})();
```
Next is the brief code for the service:
```javascript
router.get('/get/:id', async (ctx) => {
const order = Number(ctx.params.id);
if (order % 2 === 0 && order <= 6) {
await sleep(1000);
}
await sleep(1000);
ctx.body = 1;
});
```
In the first 6 requests, if the order is even, then wait for **2s** , if not, wait for **1s**. Then open the Network in DevTools and you can get the following picture:
Looking at the Time and Waterfall columns show that it is a model of the request concurrency limit. So I want to achieve a similar function, how to do it?
I open-sourced [p-limiter](https://github.com/islizeqiang/p-limiter?utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-control-the-number-of-concurrent-promises-in-javascript) on Github. Here’s the same Gist:
```typescript
class Queue<T> {
#tasks: T[] = [];
enqueue = (task: T) => {
this.#tasks.push(task);
};
dequeue = () => this.#tasks.shift();
clear = () => {
this.#tasks = [];
};
get size() {
return this.#tasks.length;
}
}
class PromiseLimiter {
#queue = new Queue<() => Promise<void>>();
#runningCount = 0;
#limitCount: number;
constructor(limitCount: number) {
this.#limitCount = limitCount;
}
#next = () => {
if (this.#runningCount < this.#limitCount && this.#queue.size > 0) {
this.#queue.dequeue()?.();
}
};
#run = async <R = any>(
fn: () => Promise<R>,
resolve: (value: PromiseLike<R>) => void
) => {
this.#runningCount += 1;
const result = (async () => fn())();
resolve(result);
try {
await result;
} catch {
// ignore
}
this.#runningCount -= 1;
this.#next();
};
get activeCount() {
return this.#runningCount;
}
get pendingCount() {
return this.#queue.size;
}
limit = <R = any>(fn: () => Promise<R>) =>
new Promise<R>((resolve) => {
this.#queue.enqueue(() => this.#run(fn, resolve));
this.#next();
});
}
export default PromiseLimiter;
```
This can be achieved in less than 70 lines of code above, you can try it out in [StackBlitz](https://stackblitz.com/edit/js-fyzurv?file=index.js&utm_source=webdeveloper.beehiiv.com&utm_medium=newsletter&utm_campaign=how-to-control-the-number-of-concurrent-promises-in-javascript).
You can see that it works as expected. Without resorting to any third-party libraries, the simple code model is just that.
So do you have any other use cases?
*If you find this helpful, [**please consider subscribing**](https://webdeveloper.beehiiv.com/) to my newsletter for more insights on web development. Thank you for reading!* | zacharylee |
1,869,814 | Has tu README realmente útil | Has tu README realmente útil Muchas veces, el readme se vuelve un poco tedioso, y en... | 0 | 2024-05-30T02:13:42 | https://dev.to/jairofernandez/has-tu-readme-realmente-util-49ea | tooling, markdown, documentation, runme |
## Has tu README realmente útil
Muchas veces, el readme se vuelve un poco tedioso, y en ocasiones he preferido usar y abusar de scripts bash, para automatizar procesos, sin embargo, a veces puede resultar un poco difícil mantener ambas cosas, sobre todo en proyectos donde el cambio está a la orden del día, entonces, me encontré con una herramienta que ayuda a convertir los files markdown en obras maestras, muy similar a como usaríamos un Jupyter notebook!
### manos a la obra,
La herramienta se llama [runme](https://runme.dev/), y básicamente tiene 4 modos de uso:
* Con tu editor, por ahora solo con Vscode.
* Vía terminal, donde puedes directamente ejecutar un comando de tu README (ya lo veremos!)
* Vía terminal pero abriendo un servidor web, que “oh sorpresa”, es un Vscode corriendo en tu navegador.
* Vía extensión web.
### Veamos un ejemplo
Usando la extensión de Vscode: [Runme DevOps Notebooks](https://marketplace.visualstudio.com/items?itemName=stateful.runme)

Al presionar allí empezarás a ver la magia

Notarás que al acercar el mouse a una celda (sí, cada sección se llama celda como en los Jupyter notebooks)

En nuestro caso, vamos a empezar con algo sencillo, escribiremos el comando
uname -a
Y al ejecutar veremos como la salida de la terminal queda directamente en nuestro README
Veamos todo junto con un ejemplo más grande como se ejecuta
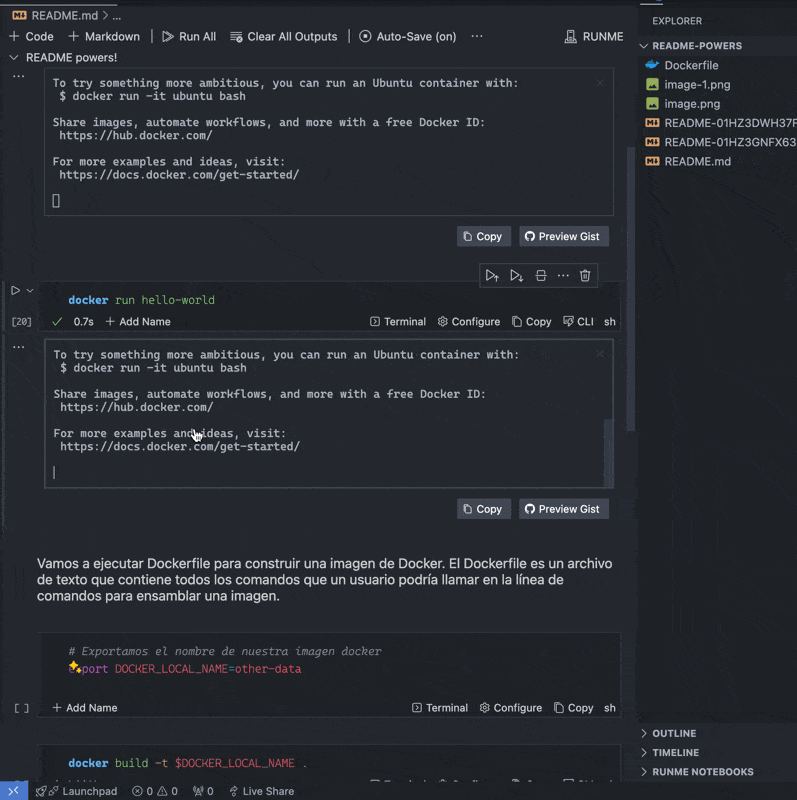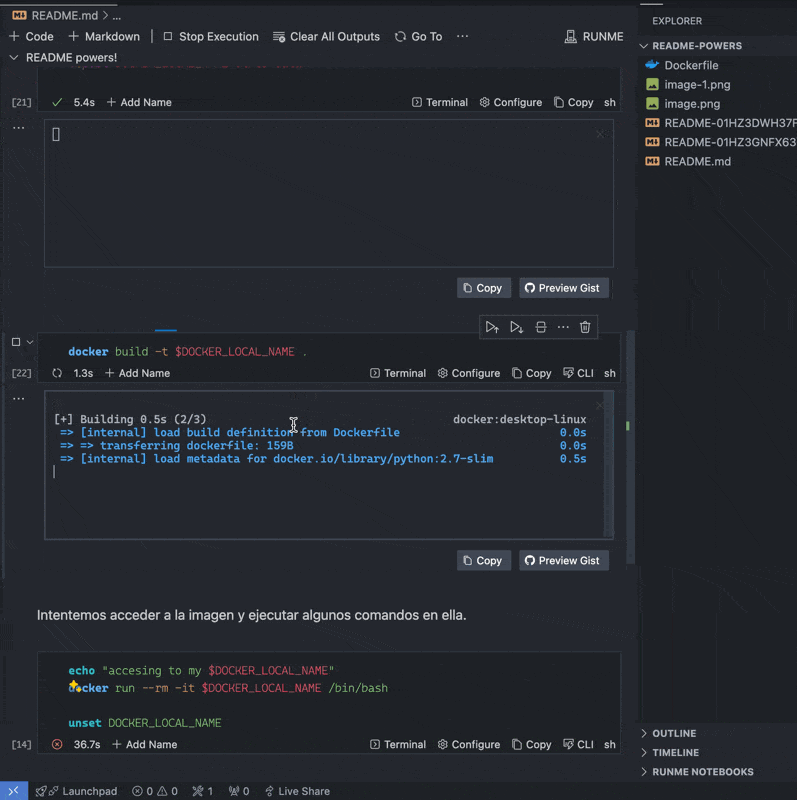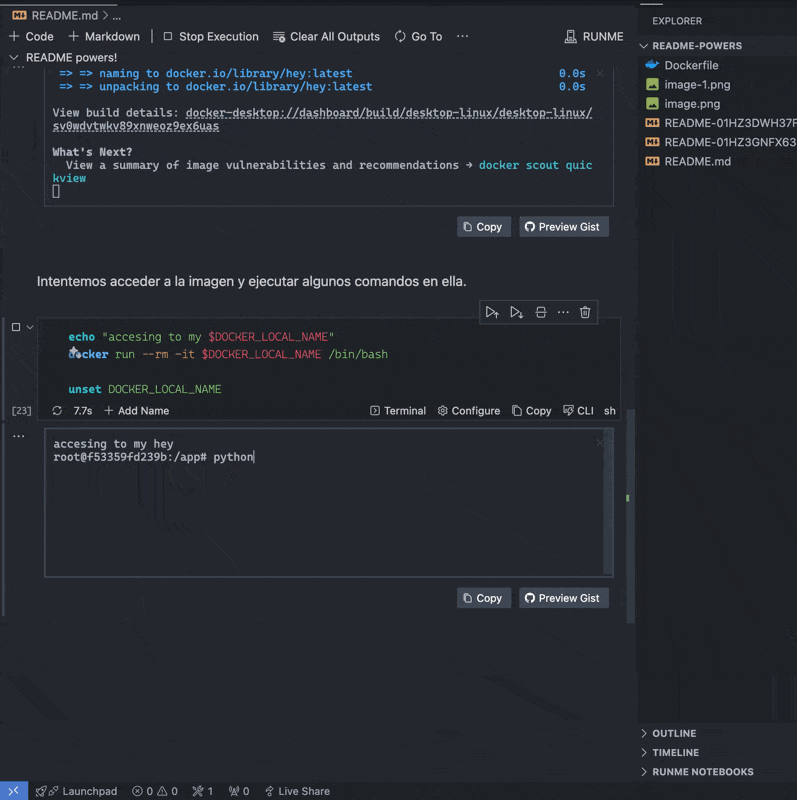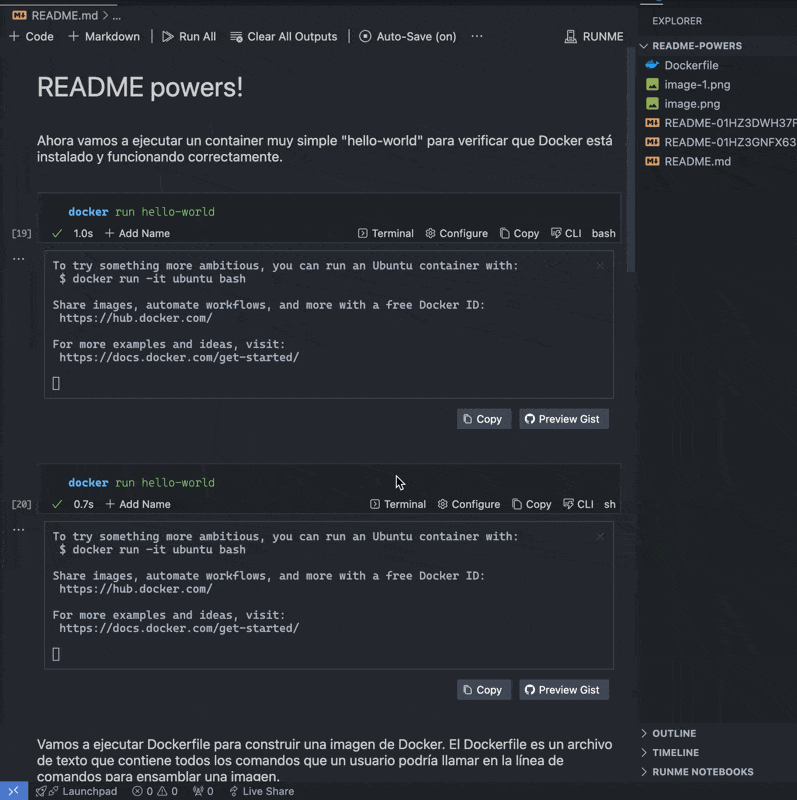
## Usando su extensión
Sigue las instrucciones para instalarla [aquí], y si vas al repositorio donde tengo el código del ejemplo anterior,
[https://github.com/jairoFernandez/articles/tree/main/readme-powers](https://github.com/jairoFernandez/articles/tree/main/readme-powers)
Verás un botón que te dará un link de esta forma:
[https://runme.dev/api/runme?repository=https%3A%2F%2Fgithub.com%2FjairoFernandez%2Farticles.git&fileToOpen=readme-powers%2FREADME.md](https://runme.dev/api/runme?repository=https%3A%2F%2Fgithub.com%2FjairoFernandez%2Farticles.git&fileToOpen=readme-powers%2FREADME.md)
Esto abrirá tu vscode y te permitirá ejecutar el Readme.
| jairofernandez |
1,869,813 | Display a phone (or any other PNG file) with a customizable background image and an optional dark theme | Import Statements import { cn } from '@/lib/utils'; import { HTMLAttributes } from... | 0 | 2024-05-30T02:06:30 | https://dev.to/lucassul/display-a-phone-or-any-other-png-file-with-a-customizable-background-image-and-an-optional-dark-theme-125c | tailwindcss, nextjs, javascript, typescript |
### Import Statements
```javascript
import { cn } from '@/lib/utils';
import { HTMLAttributes } from 'react';
```
- `import { cn } from '@/lib/utils'`: This imports a utility function named cn from a file located at `@/lib/utils`. The cn function is typically used to concatenate class names conditionally.
- `import { HTMLAttributes } from 'react'`: This imports the HTMLAttributes type from React. It is used to extend the properties of the PhoneProps interface.
### Interface Definition
```javascript
interface PhoneProps extends HTMLAttributes<HTMLDivElement> {
imgSrc: string;
dark?: boolean;
}
```
The interface means `PhoneProps` will include all the standard properties of a div element, plus any additional properties defined within it. An optional property `dark` of type boolean which determines the theme of the phone template (dark or white edges).
### Component Definition
```javascript
const Phone = ({ imgSrc, className, dark = false, ...props }: PhoneProps) => {
```
This defines a functional component named `Phone` that takes props matching the `PhoneProps` interface. It destructures `imgSrc, className, dark` (defaulting to false if not provided), and any other props.
### JSX Return
```jsx
return (
<div
// concatenate the default class names with any additional
// class names passed as className prop.
className={cn(
'relative pointer-events-none z-50 overflow-hidden',
className
)}
{...props}>
<img
src={
dark
? '/phone-template-dark-edges.png'
: '/phone-template-white-edges.png'
}
className='pointer-events-none z-50 select-none'
alt='phone image'
/>
<div className='absolute -z-10 inset-0'> // set z index to -10
<img
className='object-cover min-w-full min-h-full'
src={imgSrc}
alt='overlaying phone image'
/>
</div>
</div>
);
```
### Summary
The Phone component renders a div containing two images:
1. An image of a phone template, which changes based on the dark prop.
2. An overlay image (imgSrc) positioned absolutely behind the phone template image.
This setup allows you to display a phone with a customizable background image and an optional dark theme.
### Outcome

### Important
These are my study notes for the `casecobra` project by `josh tried coding` on youtube.
| lucassul |
1,869,812 | LED display technology analysis and advantages | As an advanced display technology, the core principle of LED display is to convert electrical energy... | 0 | 2024-05-30T02:01:23 | https://dev.to/sostrondylan/led-display-technology-analysis-and-advantages-4pa6 | led, display, technology | As an advanced display technology, the core principle of [LED display](https://www.sostron.com/product?category=2) is to convert electrical energy into visible light. This article will deeply analyze the technology used by LED display and explore the series of advantages it brings.

LED display technology analysis
LED (Light Emitting Diode) display is a solid-state semiconductor device, which works by driving semiconductor materials to emit light through current. The heart of the LED display is a semiconductor chip, one end of the chip is connected to the bracket, and the other end is the negative pole. By connecting the positive pole of the power supply, the entire chip is encapsulated in epoxy resin to protect it from the external environment. [Do you know how LED lamp beads work? ](https://www.sostron.com/service/faq/7842)
The manufacturing process of LED display involves multiple links, including chip cutting, welding, packaging, testing, etc., and each link has a direct impact on the performance of the final product. LED display can be composed of thousands of such light-emitting diodes, which are arranged in an orderly manner on the panel of the display. Through precise control, various images and texts can be displayed.

Advantages of LED Displays
High brightness: LED displays have very high brightness and can remain clearly visible even in strong outdoor light environments, making them very suitable for outdoor advertising and large-scale events. [The price of outdoor LED displays is determined by ten aspects. ](https://www.sostron.com/service/faq/7065)
Large viewing angle: LED displays have a wide viewing angle, and viewers can get consistent visual effects even if they watch from different angles, which makes LED displays very suitable for public places and large-scale events. [Here is a guide to calculating the rental price of LED displays. ](https://www.sostron.com/service/faq/7826)
Long life: As a semiconductor device, LED has a very long service life, generally up to tens of thousands or even hundreds of thousands of hours, far exceeding traditional display technology.

Flexibility: The screen area of LED displays can be customized as needed, ranging from less than one square meter to hundreds or thousands of square meters, which is very suitable for application scenarios of various sizes.
Easy to integrate: LED displays are easy to interface with computers and support a wealth of software, which can easily realize various complex display effects and interactive functions.
Energy saving and environmental protection: Compared with traditional display technology, LED display screens have obvious advantages in energy consumption, especially in the case of long-term operation, the energy saving effect is significant. [Provide you with commercial LED screen technology, advantages and selection guide. ](https://www.sostron.com/service/faq/7175)

Conclusion
LED display screens have become an important representative of modern display technology with their advanced technical foundation and a series of significant advantages. Whether in outdoor advertising, public information display, commercial display or entertainment activities, LED display screens have demonstrated their unique value and potential. With the continuous advancement of technology and the continuous expansion of application fields, LED display screens are expected to play a more important role in the future display field, bringing people a richer and higher-quality visual experience.
Thank you for watching. I hope we can solve your problems. Sostron is a professional [LED display manufacturer](https://sostron.com/about). We provide all kinds of displays, display leasing and display solutions around the world. If you want to know: [How does the LED screen control card control the LED screen?](https://dev.to/sostrondylan/how-does-the-led-screen-control-card-control-the-led-screen-5a54) Please click read.
Follow me! Take you to know more about led display knowledge.
Contact us on WhatsApp:https://api.whatsapp.com/send/?phone=8613570218702&text&type=phone_number&app_absent=0 | sostrondylan |
1,869,759 | ESSENTIAL STEPS AND LEGAL OPTIONS TO RECOVER LOST CRYPTO ASSET | My heartfelt experience with MUYERN TRUST HACKER—a lifeline in the world of cryptocurrency losses.... | 0 | 2024-05-30T01:10:07 | https://dev.to/willowathena/essential-steps-and-legal-options-to-recover-lost-crypto-asset-29aj | My heartfelt experience with MUYERN TRUST HACKER—a lifeline in the world of cryptocurrency losses. Losing a substantial investment in Bitcoin can be financially and emotionally devastating. It's not just about the money that's vanished, but also the potential gains that could have been. The impact reverberates through your wallet, plans, and emotional well-being. I know this firsthand. The feeling of watching your dreams crumble before your eyes is indescribable. It's a mix of frustration, anger, and profound loss that weighs heavily on your soul. But amidst the darkness, there's a glimmer of hope—the expertise that is MUYERN TRUST HACKER. Their selection of services is tailor-made to meet the needs of individuals who have suffered the terrible loss of their Bitcoin investments. These wizards don't rely on conventional methods; they use cutting-edge techniques to uncover buried trails and bring justice to the victims of fraudulent operations. When I stumbled upon a review about MUYERN TRUST HACKER, I was hesitant but desperate. I reached out to them and knew I was in good hands from that moment on. Their team of qualified experts sprang into action, working tirelessly to aid in the prompt recovery of my lost BTC. I cannot express enough gratitude to MUYERN TRUST HACKER for their invaluable assistance. They helped me reclaim my lost funds and provided a lifeline in a hopeless situation. Their professionalism, expertise, and unwavering commitment to their client's well-being are commendable. If you are in a similar predicament, don't hesitate to contact MUYERN TRUST HACKER. Trust me, they are more than just a recovery service; they are a guiding hand for those who have lost their way in the complex world of cryptocurrency. E -mail: mailbox (at) muyerntrusthack(dot)solutions and Tele gram at: muyerntrusthackertech
 | willowathena | |
1,869,811 | 10 modern Node.js runtime features to start using in 2024 | This post will explore 10 modern Node.js runtime features that every developer should start using in 2024. We'll cover everything from fresh off-the-press APIs to the compelling features offered by new kids on the block like Bun and Deno. | 0 | 2024-05-30T02:00:25 | https://snyk.io/blog/10-modern-node-js-runtime-features/ | engineering, javascript, node | The server-side JavaScript runtime scene has been packed with innovations, such as Bun making strides with compatible Node.js APIs and the Node.js runtime featuring a rich standard library and runtime capabilities.
As we enter into 2024, this article is a good opportunity to stay abreast of the latest features and functionalities offered by the Node.js runtime. Staying updated isn't just about “keeping with the times” — it's about leveraging the power of modern APIs to write more efficient, performant, and secure code.
This post will explore 10 modern Node.js runtime features that every developer should start using in 2024. We'll cover everything from fresh off-the-press APIs to the compelling features offered by new kids on the block like Bun and Deno.
Prerequisite: Node.js LTS version
---------------------------------
Before you start exploring these modern features, ensure you're working with the Node.js LTS (long-term support) version. At the time of writing this article, the latest Node.js LTS version is v21.6.1.
To check your Node.js version, use the command:
```
node --version
```
If you're not currently using the LTS version, consider using a version manager like `fnm` or `nvm` to easily switch between different Node.js versions.
What’s new in Node.js 20?
-------------------------
In the following sections, we’ll cover some new features introduced in recent versions of Node.js. Some are stable, others are still experimental, and a few have been supported even before, but you might not have heard of them just yet.
We’ll visit the following topics:
1. Node.js test runner
2. Node.js native mocking
3. Node.js native test coverage
4. Node.js watch mode
5. [Node.js corepack](https://nodejs.org/api/corepack.html)
6. Node.js .env loader
7. Node.js import.meta.file for \_\_dirname and \_\_file
8. Node.js native timers promises
9. Node.js permissions module
10. Node.js policy module
The native Node.js test runner
------------------------------
What did we have before Node.js introduced a test runner in the native runtime? Up until now, you probably used one of the popular options, such as `node-tap`, `jest`, `mocha`, or `vitest`.
Let’s learn how to leverage the Node.js native test runner in your development workflow. To begin, you need to import the test module from Node.js into your test file, as shown below:
```
import { test } from 'node:test';
```
Now, let's walk through the different steps of using the Node.js test runner.
### Running a single test with node:test
To create a single test, you use the `test` function, passing the name of the test and a callback function. The callback function is where you define your test logic.
```
import { test } from "node:test";
import assert from "node:assert";
import { add } from "../src/math.js";
test("should add two numbers", () => {
const result = add(1, 2);
assert.strictEqual(result, 3);
});
test("should fail to add strings", () => {
assert.throws(() => {
add("1", "2");
});
});
```
To run this test, you use the `node --test` command followed by the name of your test file:
```
node --test tests/math.test.js
```
The Node.js test runner can automatically detect and run test files in your project. By convention, these files should end with `.test.js` but not strictly to this filename convention.
If you omit the test file positional argument, then the Node.js test runner will apply some heuristics and glob pattern matching to find test files, such as all files in a `test/` or `tests/` folder or files with a `test-` prefix or a `.test` suffix.
For example, glob matching test files:
```
node --test '**/*.test.js'
```
### Using test assertions with node:assert
Node.js test runner supports assertions through the built-in `assert` module. You can use different methods like `assert.strictEqual` to verify your tests.
```
import assert from 'node:assert';
test('Test 1', () => {
assert.strictEqual(1 + 1, 2);
});
```
### Test suites & test hooks with the native Node.js test runner
The `describe` function is used to group related tests into a test suite. This makes your tests more organized and easier to manage.
```
import { test, describe } from "node:test";
describe('My Test Suite', () => {
test('Test 1', () => {
// Test 1 logic
});
test('Test 2', () => {
// Test 2 logic
});
});
```
Test hooks are special functions that run before or after your tests. They are useful for setting up or cleaning up test environments.
```
test.beforeEach(() => {
// Runs before each test
});
test.afterEach(() => {
// Runs after each test
});
```
You can also choose to skip a test using the `test.skip` function. This is helpful when you want to ignore a particular test temporarily.
```
test.skip('My skipped test', () => {
// Test logic
});
```
In addition, Node.js test runner provides different reporters that format and display test results in various ways. You can specify a reporter using the `--reporter` option.
```
node --test --test-reporter=tap
```
### Should you ditch Jest?
While Jest is a popular testing framework in the Node.js community, it has certain drawbacks that make the native Node.js test runner a more appealing choice.
By installing Jest, even as merely a dev dependency, you add 277 transitive dependencies of various licenses, including MIT, Apache-2.0, CC-BY-4.0, and 1 unknown license. Did you know that?
* Jest modifies globals, which can lead to unexpected behaviors in your tests.
* The `instanceof` operator doesn't always work as expected in Jest.
* Jest introduces a large dependency footprint to your project, making it harder to stay up to date with third-party dependencies, and having to needlessly manage security issues and other concerns for dev-time dependencies.
* Jest can be slower than the native Node.js test runner due to its overhead.
Other great features of the native Node.js test runner include running subtests and concurrent tests. Subtests allow each `test()` callback to receive a `context` argument that allows you to create nested tests via `context.test`. Concurrent tests are a great feature if you know how to work well with them and avoid racing conditions. Simply pass a `concurrency: true` potential object as the 2nd argument to the `describe()` test suite.
What is a test runner?
----------------------
A test runner is a software tool that allows developers to manage and execute automated tests on their code. The Node.js test runner is a framework that is designed to work seamlessly with Node.js, providing a rich environment for writing and running tests on your Node.js applications.
Node.js native mocking
----------------------
Mocking is one strategy developers employ to isolate code for testing. The Node.js runtime has introduced native mocking features, which are essential for developers to understand and use effectively.
You’ve probably used mocking features from other test frameworks such as Jest’s `jest.spyOn`, or `mockResolvedValueOncel`. They’re useful for when you want to avoid running actual code in your tests, such as HTTP requests or file system APIs, and change these operations with stubs and mocks that you can inspect later.
Unlike other Node.js runtime features like the *watch* and *coverage* functionality, mocking isn’t declared as experimental. However, it is subject to receive more changes as it’s a new feature that was only introduced in Node.js 18.
### Node.js native mocking with import { mock } from 'node:test'
Let's look at how we can use the Node.js native mocking feature in a practical example. The test runner and module mocking feature is now available in Node.js 20 LTS as a stable feature.
We'll work with a utility module, `dotenv.js`, which loads environment variables from a *.env* file. We'll also use a test file, `dotenv.test.js`, which tests the `dotenv.js` module.
Here’s our very own in-house dotenv module:
```
// dotenv.js
import fs from "node:fs/promises";
export async function loadEnv(path = ".env") {
const rawDataEnv = await fs.readFile(path, "utf8");
const env = {};
rawDataEnv.split("\n").forEach((line) => {
const [key, value] = line.split("=");
env[key] = value;
});
return env;
}
```
In the `dotenv.js` file, we have an asynchronous function, `loadEnv`, which reads a file using the `fs.readFile` method and splits the file content into key-value pairs. As you can see, it uses the Node.js native file system API `fs`.
Now, let's see how we can test this function using the native mocking feature in Node.js.
```
// dotenv.test.js
import { describe, test, mock } from "node:test";
import assert from "node:assert";
import fs from "node:fs/promises";
import { loadEnv } from "../src/dotenv.js";
describe("dotenv test suite", () => {
test("should load env file", async () => {
const mockImplementation = async (path) => {
return "PORT=3000\n";
};
const mockedReadFile = mock.method(fs, "readFile", mockImplementation);
const env = await loadEnv(".env");
assert.strictEqual(env.PORT, "3000");
assert.strictEqual(mockedReadFile.mock.calls.length, 1);
});
});
```
In the test file, we import the `mock` method from `node:test`, which we use to create a mock implementation of `fs.readFile`. In the mock implementation, we return a string, `"PORT=3000\n"`, regardless of the file path passed.
We then call the `loadEnv` function, and using the `assert` module, we check two things:
1. The returned object has a `PORT` property with a value of `"3000"`.
2. The `fs.readFile` method was called exactly once.
By using the native mock functionality in Node.js, we're able to effectively isolate our `loadEnv` function from the file system and test it in isolation. Mocking capabilities with Node.js 20 also include support for mocking timers.
What is mocking?
----------------
In software testing, mocking is a process where the actual functionalities of specific modules are replaced with artificial ones. The primary goal is to isolate the unit of code being tested from external dependencies, ensuring that the test only verifies the functionality of the unit and not the dependencies. Mocking also allows you to simulate different scenarios, such as errors from dependencies, which might be hard to recreate consistently in a real environment.
Node.js native test coverage
----------------------------
What is test coverage?
----------------------
Test coverage is a metric used in software testing. It helps developers understand the degree to which the source code of an application is being tested. This is crucial because it reveals areas of the codebase that have not been tested, enabling developers to identify potential weaknesses in their software.
Why is test coverage important? Well, it ensures the quality of software by reducing the number of bugs and preventing regressions. Additionally, it provides insights into the effectiveness of your tests and helps guide you toward a more robust, reliable, and secure application.
### Utilizing native Node.js test coverage
Starting with version 20, the Node.js runtime includes native capabilities for test coverage. However, it's important to note that the native Node.js test coverage is currently marked as an experimental feature. This means that while it's available for use, there might be some changes in future releases.
To use the native Node.js test coverage, you need to use the `--experimental-coverage` command-line flag. Here's an example of how you can add a `test:coverage` entry in your `package.json` scripts field that runs your project tests:
```
{
"scripts": {
"test": "node --test ./tests",
"test:coverage": "node --experimental-coverage --test ./tests"
}
}
```
In the example above, the `test:coverage` script utilizes the `--experimental-coverage` flag to generate coverage data during test execution.
After running `npm run test:coverage`, you should see an output similar to this:
```
ℹ tests 7
ℹ suites 4
ℹ pass 5
ℹ fail 0
ℹ cancelled 0
ℹ skipped 1
ℹ todo 1
ℹ duration_ms 84.018917
ℹ start of coverage report
ℹ ---------------------------------------------------------------------
ℹ file | line % | branch % | funcs % | uncovered lines
ℹ ---------------------------------------------------------------------
ℹ src/dotenv.js | 100.00 | 100.00 | 100.00 |
ℹ src/math.js | 100.00 | 100.00 | 100.00 |
ℹ tests/dotenv.test.js | 100.00 | 100.00 | 100.00 |
ℹ tests/math.test.js | 94.64 | 100.00 | 91.67 | 24-26
ℹ ---------------------------------------------------------------------
ℹ all files | 96.74 | 100.00 | 94.44 |
ℹ ---------------------------------------------------------------------
ℹ end of coverage report
```
This report displays the percentage of statements, branches, functions, and lines covered by the tests.
The Node.js native test coverage is a powerful tool that can help you improve the quality of your Node.js applications. Even though it's currently marked as an experimental feature, it can provide valuable insights into your test coverage and guide your testing efforts. By understanding and leveraging this feature, you can ensure that your code is robust, reliable, and secure.
Node.js watch mode
------------------
The Node.js watch mode is a powerful developer feature that allows for real-time tracking of changes to your Node.js files and automatic re-execution of scripts.
Before diving into Node.js's native watch capabilities, it's essential to acknowledge [nodemon](https://snyk.io/advisor/npm-package/nodemon), a popular utility that helped fill this need in earlier versions of Node.js. Nodemon is a command-line interface (CLI) utility developed to restart the Node.js application when any change is detected in the file directory.
```
npm install -g nodemon
nodemon
```
This feature is particularly useful during the development process. It saves time and improves productivity by eliminating the need for manual restarts each time a file is modified.
With advancements in Node.js itself, the language now provides built-in functionality to achieve the same results. This negates the need to install extra third-party dependencies in your projects like `nodemon`.
Before we dive into the tutorial, it's important to note that the native watch mode feature in Node.js is still experimental and may be subject to changes. Always ensure you're using a Node.js version that supports this feature.
### Using Node.js 20 native watch capabilities
Node.js 20 introduces native file watch capabilities using the `--watch` command line flag. This feature is straightforward to use and can even match *glob* patterns for more complex file-watching needs.
To use the `--watch` command, append it to your Node.js script in the command line as shown below:
```
node --watch app.js
```
In the case of *glob* patterns, you can use the `--watch` flag with a specific pattern to watch multiple files or directories. This is particularly useful when you want to watch a group of files that match a specific pattern:
```
node --watch 'lib/**/*.js' app.js
```
The `--watch` flag can also be used in conjunction with `--test` to re-run tests whenever test files change:
```
node --watch --test '**/*.test.js'
```
This combination can significantly speed up your test-driven development (TDD) process by automatically running your tests every time you make a change.
It's important to note that as of Node.js 20, the watch mode feature is still marked as experimental. This means that while the feature is fully functional, it may not be as stable or as optimized as other non-experimental features.
In practice, you might encounter some quirks or bugs when using the `--watch` flag.
Node.js Corepack
----------------
Node.js Corepack is an intriguing feature that is worth exploring. It was introduced in Node.js 16 and is still marked as experimental. This makes it even more exciting to take a look at what it offers and how it can be leveraged in your JavaScript projects.
### What is Corepack?
Corepack is a zero-runtime-dependency project that acts as a bridge between Node.js projects and the package managers they are intended to use. When installed, it provides a program called `corepack` that developers can use in their projects to ensure they have the right package manager without having to worry about its global installation.
### Why use Corepack?
As JavaScript developers, we often deal with multiple projects, each potentially having its own preferred package manager. You know how it is, one project manages its dependencies with `pnpm` and another project with `yarn`, so you end up having to jump around different versions of package managers too.
This can lead to conflicts and inconsistencies. Corepack solves this problem by allowing each project to specify and use its preferred package manager in a seamless way.
Moreover, Corepack provides isolation between your project and the global system, ensuring that your project will stay runnable even if global packages get upgraded or removed. This increases the consistency and reliability of your project.
### Installing and using Corepack
Installing Corepack is quite straightforward. Since it is bundled with Node.js starting from version 16, you only need to install or upgrade Node.js to that version or later.
Once installed, you can define the package manager for your project in your `package.json` file like this:
```
{
"packageManager": "yarn@2.4.1"
}
```
Then, you can use Corepack in your project like this:
```
corepack enable
```
If you type `yarn` in the project directory and you don’t have Yarn installed, then Corepack will automatically detect and install the right version for you.
This will ensure that Yarn version 2.4.1 is used to install your project's dependencies, regardless of the global Yarn version installed on the system.
If you want to install Yarn globally or use a specific version, you can run:
```
corepack install --global yarn@stable
```
### Corepack: Still an experimental feature
Despite its introduction in Node.js 16, Corepack is still marked as experimental. This means that while it's expected to work well, it's still under active development, and some aspects of its behavior might change in the future.
That said, Corepack is easy to install, simple to use, and provides an extra layer of reliability to your projects. It's definitely a feature worth exploring and incorporating into your development workflow.
Node.js .env loader
-------------------
Application configuration is crucial, and as a Node.js developer, I’m sure this has met your needs to manage API credentials, server port numbers, or database configurations.
As developers, we need a way to provide different settings for different environments without changing the source code. One popular way to achieve this in Node.js applications is by using environment variables stored in `.env` files.
### The dotenv npm package
Before Node.js introduced native support for loading `.env` files, developers primarily used the `dotenv` npm package. The `dotenv` package loads environment variables from a `.env` file into `process.env`, which are then available throughout the application.
Here is a typical usage of the `dotenv` package:
```
require('dotenv').config();
console.log(process.env.MY_VARIABLE);
```
This worked well, but it required adding an additional dependency to your project. With the introduction of the native `.env` loader, you can now load your environment variables directly without needing any external packages.
### Introducing native support in Node.js for loading .env files
Starting from Node.js 20, the runtime now includes a built-in feature to load environment variables from `.env` files. This feature is under active development but has already become a game-changer for developers.
To load a `.env` file, we can use the `--env-file` CLI flag when starting our Node.js application. This flag specifies the path to the `.env` file to be loaded.
```
node --env-file=./.env index.js
```
This will load the environment variables from the specified `.env` file into `process.env`. The variables are then available within your application just like before.
### Loading multiple .env files
The Node.js `.env` loader also supports loading multiple `.env` files. This is useful when you have different sets of environment variables for different environments (e.g., development, testing, production).
You can specify multiple `--env-file` flags to load multiple files. The files are loaded in the order they are specified, and variables from later files overwrite those from earlier ones.
Here's an example:
```
node --env-file=./.env.default --env-file=./.env.development index.js
```
In this example, `./.env.default` contains the default variables, and `./.env.development` contains the development-specific variables. Any variables in `./.env.development` that also exist in `./.env.default` will overwrite the ones in `./.env.default`.
The native support for loading `.env` files in Node.js is a significant improvement for Node.js developers. It simplifies configuration management and eliminates the need for an additional package. Start using the `--env-file` CLI flag in your Node.js applications and experience the convenience first-hand.
Node.js import.meta support for \_\_dirname and \_\_file
--------------------------------------------------------
If you’re coming from CommonJS module conventions for Node.js, then you’re used to working with `filename` and `__dirname` as a way to get the current file’s directory name and file path. However, until recently, these weren’t easily available on ESM, and you had to come up with the following code to extract the `__dirname`:
```
import url from 'url'
import path from 'path'
const dirname = path.dirname(url.fileURLToPath(import.meta.url))
```
Or if you’re a Matteo Collina fan, you might have sorted out to use Matteo’s [desm](https://snyk.io/advisor/npm-package/desm) npm package.
Node.js continually evolves to offer developers more efficient ways to handle file and path operations. One significant change that will benefit Node.js developers has been introduced in Node.js v20.11.0 and Node.js v21.2.0 with built-in support for `import.meta.dirname` and `import.meta.filename`.
### Using Node.js import.meta.filename and import.meta.dirname
Thankfully, with the introduction of `import.meta.filename` and `import.meta.dirname`, this process has become much easier. Let's look at an example of loading a configuration file using the new features.
Assume there is a YAML configuration file in the same directory as your JavaScript file that you need to load. Here's how you can do it:
```
import fs from 'fs';
const { dirname: __dirname, filename: __filename } = import.meta;
const projectSetup = fs.readFileSync(`${__dirname}/setup.yml`, "utf8");
console.log(projectSetup);
```
In this example, we use `import.meta.dirname` to get the directory name of the current file and assign it to the `__dirname` variable for CommonJS convenience of cod conventions.
Node.js native timers promises
------------------------------
Node.js, a popular JavaScript runtime built on Chrome’s V8 JavaScript engine, has always striven to make the lives of developers easier with constant updates and new features.
Despite Node.js introducing support for natively using timers with a promises syntax way back in Node.js v15, I admit I haven’t been regularly using them.
### JavaScript's setTimeout() and setInterval() timers: A brief recap
Before diving into native timer promises, let's briefly recap the JavaScript `setTimeout()` and `setInterval()` timers.
The `setTimeout()` API is a JavaScript function that executes a function or specified piece of code once the timer expires.
```
setTimeout(function(){
console.log("Hello World!");
}, 3000);
```
In the above code, "Hello World!" will be printed to the console after 3 seconds (3000 milliseconds).
`setInterval()`, on the other hand, repeatedly executes the specified function with a delay between each call.
```
setInterval(function(){
console.log("Hello again!");
}, 2000);
```
In the above code, "Hello again!" will be printed to the console every 2 seconds (2000 milliseconds).
### The old way: Wrapping setTimeout() with a promise
In the past, developers would often have to artificially wrap the `setTimeout()` function with a promise to use it asynchronously. This was done to allow the use of `setTimeout()` with async/await.
Here is an example of how it was done:
```
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function demo() {
console.log('Taking a break...');
await sleep(2000);
console.log('Two seconds later...');
}
demo();
```
This would print "Taking a break...", wait for two seconds, and then print "Two seconds later...".
While this worked, it added unnecessary complexity to the code.
### Node.js Native timer promises: A simpler way
With Node.js Native timer promises, we no longer need to wrap `setTimeout()` in a promise. Instead, we can use `setTimeout()` directly with async/await. This makes the code cleaner, more readable, and easier to maintain. Here is an example of how to use Node.js native timer promises:
```
const {
setTimeout,
} = require('node:timers/promises');
setTimeout(2000, 'Two seconds later...').then((res) => {
console.log(res);
});
console.log('Taking a break...');
```
In the above code, `setTimeout()` is imported from `node:timers/promises`. We then use it directly with async/await. It will print "Taking a break...", wait for two seconds, and then print "Two seconds later...".
This greatly simplifies asynchronous programming and makes the code easier to read, write, and maintain.
Node.js permissions model
-------------------------
Rafael Gonzaga, now on the Node.js TSC, revived the work on Node.js permission module, which, similarly to Deno, provides a process-level set of configurable resource constraints.
In the world of supply-chain security concerns, malicious npm packages, and other security risks, it’s becoming increasingly crucial to manage and control the resources your Node.js applications have access to for security and compliance reasons.
In this respect, Node.js has introduced an experimental feature known as the permissions module, which is used to manage resource permissions in your Node.js applications. This feature is enabled using the `--experimental-permission` command-line flag.
### Node.js resource permissions model
The permissions model in Node.js provides an abstraction for managing access to various resources like file systems, networks, environment variables, and worker threads, among others. This feature is particularly useful when you want to limit the resources a certain part of your application can access.
Common resource constraints you can set with the permissions model include:
* File system read and write with `--allow-fs-read=*` and `--allow-fs-write=*`, and you can specify directories and specific file paths, as well as provide multiple resources by repeating the flags
* Child process invocations with `--allow-child-process`
* Worker threads invocations with `--allow-worker`
The Node.js permissions model also provides a runtime API via `process.permission.has(resource, value)` to allow querying for specific access.
If you try accessing resources that aren’t allowed, for example, to read the `.env` file, you’ll see an `ERR_ACCESS_DENIED` error:
```
> start:protected
> node --env-file=.env --experimental-permission server.js
node:internal/modules/cjs/loader:197
const result = internalModuleStat(filename);
^
Error: Access to this API has been restricted
at stat (node:internal/modules/cjs/loader:197:18)
at Module._findPath (node:internal/modules/cjs/loader:682:16)
at resolveMainPath (node:internal/modules/run_main:28:23)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:135:24)
at node:internal/main/run_main_module:28:49 {
code: 'ERR_ACCESS_DENIED',
permission: 'FileSystemRead',
resource: '/Users/lirantal/repos/modern-nodejs-runtime-features-2024/server.js'
}
Node.js v21.6.1
```
### Node.js permission model example
Consider a scenario where you have a Node.js application that handles file uploads. You want to restrict this part of your application so that it only has access to a specific directory where the uploaded files are stored.
Enable the experimental permissions feature when starting your Node.js application with the `--experimental-permission` flag.
```
node --experimental-permission ./app.js
```
We also want to specifically allow the application to read 2 trusted files, `.env` and `setup.yml`, so we need to update the above to this:
```
node --experimental-permission --allow-fs-write=/tmp/uploads --allow-fs-read=.env --allow-fs-read=setup.yml ./app.js
```
In this way, if the application attempts to access file-based system resources for write purposes outside of the provided upload path, it will halt with an error.
See the following code example for how to wrap a resource access via try/catch as well as using the Node.js permissions runtime API as another way of ensuring access without an error exception thrown:
```
const { dirname: __dirname, filename: __filename } = import.meta;
// @TODO to avoid the Node.js resource permission issue you should update
// the path to be `setup.yml` in the current directory and not `../setup.yml`.
// the outside path for setup.yml was only changed in the source code to
// show you how Node.js resource permission module will halt if trying to access
// something outside the current directory.
const filePath = `${__dirname}/../setup.yml`;
try {
const projectSetup = fs.readFileSync(filePath, "utf8");
// @TODO do something with projectSetup if you want to
} catch (error) {
console.error(error.code);
}
// @TODO or consider using the permissions runtime API check:
if (!process.permission.has("read", filePath)) {
console.error("no permissions to read file at", filePath);
}
```
It's important to note that the permissions functionality in Node.js is still experimental and subject to changes.
On this topic of permissions and production-grade conventions for security, you can find more information on how to build secure Node.js applications, check out these blog posts by Snyk:
* [10 best practices to containerize Node.js web applications with Docker](https://snyk.io/blog/10-best-practices-to-containerize-nodejs-web-applications-with-docker/)
* [Choosing the best Node.js Docker image](https://snyk.io/blog/choosing-the-best-node-js-docker-image)
These posts provide a comprehensive guide on building secure container images for Node.js web applications, which is critical in developing secure Node.js applications.
Node.js policy module
---------------------
The Node.js policy module is a security feature designed to prevent malicious code from loading and executing in a Node.js application. While it doesn't trace the origin of the loaded code, it provides a solid defense mechanism against potential threats.
The policy module leverages the `--experimental-policy` CLI flag to enable policy-based code loading. This flag takes a policy manifest file (in JSON format) as an argument. For instance, `--experimental-policy=policy.json`.
The policy manifest file contains the policies that Node.js adheres to when loading modules. This provides a robust way to control the nature of code that gets loaded into your application.
### Implementing Node.js policy module: A step-by-step guide
Let's walk through a simple example to demonstrate how to use the Node.js policy module:
**1. Create a policy file.** The file should be a JSON file specifying your app's policies for loading modules. Let's call it `policy.json`.
For instance:
```
{
"resources": {
"./moduleA.js": {
"integrity": "sha384-xxxxx"
},
"./moduleB.js": {
"integrity": "sha384-yyyyy"
}
}
}
```
This policy file specifies that `moduleA.js` and `moduleB.js` should have specific integrity values to be loaded.
However, generating the policy file for all of your direct and transitive dependencies isn’t straightforward. A few years back, Bradley Meck created the node-policy npm package, which provides a CLI to automate the generation of the policy file.
**2. Run your Node.js application with the** `--experimental-policy` **flag:**
```
node --experimental-policy=policy.json app.js
```
This command tells Node.js to adhere to the policies specified in `policy.json` when loading modules in `app.js`.
**3. To guard against tampering with the policy file, you can provide an integrity value for the policy file itself using the** `--policy-integrity` **flag:**
```
node --experimental-policy=policy.json --policy-integrity="sha384-zzzzz" app.js
```
This command ensures that the policy file's integrity is maintained, even if the file is changed on disk.
### Caveats with Node.js integrity policy
There are no built-in capabilities by the Node.js runtime to generate or manage the policy file and it could potentially introduce difficulties such as managing different policies based on production vs development environments as well as dynamic module imports.
Another caveat is that if you already have a malicious npm package in its current state, it’s too late to generate a module integrity policy file.
I personally advise you to watch for updates in this area and slowly attempt a gradual adoption of this feature.
For more information on Node.js policy module, you can check out the article on [introducing experimental integrity policies to Node.js](https://snyk.io/blog/introducing-experimental-integrity-policies-to-node-js/), which provides a more detailed step-by-step tutorial on working with Node.js policy integrity.
Wrapping-up
-----------
As we have traversed through the modern Node.js runtime features that you should start using in 2024, it becomes clear that these capabilities are designed to streamline your development process, enhance application performance, and reinforce security. These features are not just trendy. They have substantial potential to redefine the way we approach Node.js development.
### Strengthen your Node.js security with Snyk
While these Node.js features can significantly enhance your development process and application performance, it is essential to remain vigilant about potential security threats. Snyk can be your ally in this endeavor. This powerful tool helps you find and fix known vulnerabilities in your Node.js dependencies and maintain a secure development ecosystem.
To take advantage of what Snyk has to offer, [sign up here for free](https://app.snyk.io/login) and begin your journey towards more secure Node.js development.
| snyk_sec |
1,869,810 | Getting started with Kubernetes: Introduction | Introduction to my series documenting my learning Kubernetes | 0 | 2024-05-30T02:00:18 | https://dev.to/popefelix/getting-started-with-kubernetes-introduction-27m6 | kubernetes | ---
title: Getting started with Kubernetes: Introduction
published: true
description: Introduction to my series documenting my learning Kubernetes
tags: kubernetes
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-05-30 00:42 +0000
---
I've been hearing a lot about Kubernetes of late, so I figured I ought to learn it.
To begin with, I don't have a home lab as such, so I'll run everything through [minikube](https://minikube.sigs.k8s.io/). I may switch things up later to get a more "realistic" k8s install, but minikube will be fine for a start. I'm also starting with the [tutorials](https://kubernetes.io/docs/tutorials/) provided by the Kubernetes developers.
I've set up a [GitHub repository](https://github.com/PopeFelix/k8s-sample-projects/tree/main) where you can follow along with my progress.
As the series goes on, feel free to leave any questions or comments you might have. | popefelix |
1,869,809 | Enhancing Search Accuracy with RRF(Reciprocal Rank Fusion) in Alibaba Cloud Elasticsearch 8.x | Introduction to Enhanced Ranking with RRF in Elasticsearch With the arrival of... | 0 | 2024-05-30T01:53:58 | https://dev.to/a_lucas/enhancing-search-accuracy-with-rrfreciprocal-rank-fusion-in-alibaba-cloud-elasticsearch-8x-2i5l | webdev, beginners, tutorial, productivity |
## Introduction to Enhanced Ranking with RRF in Elasticsearch
With the arrival of [Elasticsearch](https://www.alibabacloud.com/blog/what-is-elasticsearch_601014) 8.x, a new horizon in search technology has emerged. Elasticsearch has welcomed Reciprocal Rank Fusion (RRF) into its suite of capabilities, offering an enriched approach to merging and re-ranking multiple result sets. This innovative feature retains the foundation of its predecessors—relevance ranking via BM25 and recall sorting through vector similarity—while empowering a cohesive and more precise ranking process when integrated. By pairing these methodologies through RRF, Elasticsearch heightens its accuracy in delivering search results. This article will walk you through the technicalities of this integration using a detailed example.
### **Getting Started with Elasticsearch**
To embark on this journey, you'll need an Elasticsearch cluster running version 8.8 or later. Alibaba Cloud Elasticsearch has made clusters with the latest version 8.x available for immediate purchase.
1) Make your selection between versions 8.8 or 8.9 and configure your nodes.
2) Navigate through and select the appropriate network configuration.
3) Proceed to checkout with a simple click.
[What is Elasticsearch?](https://www.alibabacloud.com/blog/what-is-elasticsearch_601014?spm=a2c65.11461447.0.0.3eecce138gnqlX)
## **A Closer Look at RRF Testing**
### Introduction to RRF
RRF operates on an algorithmic formula where 'k' is a constant value set by default to 60. Within the algorithm, 'R' represents the document sets sorted for every result from a query. Here, 'r(d)' specifies the rank order of document 'd' under certain query conditions, starting from one.
Algorithmic formula:
### RRF Ranking Example
In a scenario where documents are ranked based on both BM25 and dense embedding, RRF seamlessly blends the outcomes to produce an integrated and improved ranking.
| BM25 Rank | Dense Embeding Rank | RRF Result k=0 |
| :-------- | :------------------ | :------------- |
| A 1 | B 1 | B:12+1/1=1.5 |
| B 2 | C 2 | A:1/1+1/3=1.3 |
| C 3 | A 3 | C:1/3+1/2=0.83 |
### Data and Model Readiness
Pursuing the methodology described in the ESRE Series (I), we utilized the text_embedding model and launched the deployment through Eland. Subsequently, we uploaded the initial dataset via Kibana, configured the text-embeddings pipeline, and ultimately crafted indexed data replete with vectors via index rebuilding.
[What is Vector Search and Embedding Model?](https://www.alibabacloud.com/blog/what-is-vector-search_601012)
### **Evaluating Query Impact**
For the assessment, one query from the TREC 2019 Deep Learning Track's "Paragraph Ranking Task" was selected to test the search results against the three techniques: text, vector, and RRF fusion. We utilized the query "hydrogen is a liquid below what temperature" to exemplify and contrast these methods.
```
// RRF Mixed Arrangement Query
GET collection-with-embeddings/_search
{
"size": 10,
"query": {
"query_string": {
"query": "hydrogen is a liquid below what temperature"
}
},
"knn": [
{
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
"model_text": "hydrogen is a liquid below what temperature"
}
}
}
],
"_source": [
"id"
],
"rank": {
"rrf": {
"window_size": 10,
"rank_constant": 1
}
}
}
//vector search
GET collection-with-embeddings/_search
{
"size": 10,
"knn": [
{
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
"model_text": "hydrogen is a liquid below what temperature"
}
}
}
],
"_source": [
"id"
]
}
//text search
GET collection-with-embeddings/_search
{
"size": 10,
"query": {
"query_string": {
"query": "how are some sharks warm blooded"
}
},
"_source": [
"id"
]
}
```
The three query types yielded varying results in terms of accuracy—scaled from 'not relevant' to 'completely relevant.' It's evident from the rankings that RRF's ability to synthesize vector and text query results pushes relevant documents - such as "7911557", previously absent from vector results, to the forefront. Simultaneously, RRF spotlighted the importance of documents like "6080460", which the text query originally overlooked, thereby sharpening recall precision.
| RRF Mixed Arrangement Query | Vector search | Text Search | | | |
| :-------------------------- | :------------ | :----------- | :------- | :----------- | :------- |
| Paragraph ID | accuracy | Paragraph ID | accuracy | Paragraph ID | accuracy |
| 8588222 | 0 | 8588222 | 0 | **7911557** | **3** |
| 8588219 | 3 | 8588219 | 3 | 8588219 | 3 |
| **7911557** | **3** | **6080460** | **3** | 8588222 | 0 |
| 128984 | 3 | 128984 | 3 | 2697752 | 2 |
| **6080460** | **3** | 4254815 | 1 | 128984 | 3 |
| 2697752 | 2 | 6343521 | 1 | 1721142 | 0 |
| 4254815 | 1 | 1020793 | 0 | 8588227 | 0 |
| 1721142 | 0 | 4254811 | 3 | 302210 | 1 |
| 6343521 | 1 | 1959030 | 0 | 2697746 | 2 |
| 8588227 | 0 | 4254813 | 1 | 7350325 | 0 |
Through the adept integration of search technologies, Elasticsearch's adoption of RRF underpins a more accurate and refined experience for users delving into the vast expanse of data. Discover the power of enhanced search with Alibaba Cloud Elasticsearch's public cloud service — where precision meets performance.
## 30-Day Free Trial: Help You Implement the Latest Version of Elasticsearch
Search and Analytics Service Elasticsearch Version: Alibaba Cloud Elasticsearch is a fully managed Elasticsearch cloud service built on the open-source Elasticsearch, supporting out-of-the-box functionality and pay-as-you-go while being 100% compatible with open-source features. Not only does it provide the cloud-ready components of the Elastic Stack, including Elasticsearch, Logstash, Kibana, and Beats, but it also partners with Elastic to offer the free X-Pack (Platinum level advanced features) commercial plugin. This integration includes advanced features such as security, SQL, machine learning, alerting, and monitoring, and is widely used in scenarios such as real-time log analysis, information retrieval, and multi-dimensional data querying and statistical analysis.
For more information about Elasticsearch, please visit https://www.alibabacloud.com/en/product/elasticsearch. | a_lucas |
1,868,638 | How To Create Learning and Development Videos Using AI Voiceovers? | Create engaging Learning and Development Videos voice overs with AI technology. Elevate your content... | 0 | 2024-05-30T01:42:20 | https://dev.to/novita_ai/how-to-create-learning-and-development-videos-using-ai-voiceovers-g6g | ai, api, voiceover, learning | Create engaging Learning and Development Videos voice overs with AI technology. Elevate your content and captivate your audience.
##Key Highlights
- AI voiceovers revolutionize the way learning and development videos are created and an immersive and engaging learning experience
- AI voiceovers are cost-effective and save time compared to traditional human narrations
- AI voiceovers improve engagement by delivering natural and personalized speech and provide a professional voice for branding
- AI voice enables content localization and accessibility through multilingual
- Selecting the right AI voice tool is crucial for creating high-quality and impactful learning videos
- Generating a voiceover tool using TTS API is a quick and efficient way.
##Introduction
The power of learning and development (L&D) videos is invaluable in today’s evolving educational landscape. These videos blend traditional teaching with modern preferences, captivating learners through engaging audio-visual experiences. Text to speech (TTS) technology takes this impact further by enhancing accessibility and excitement. By converting written content into natural voiceovers, TTS breathes life into words, transforming visuals into dynamic journeys. Gone are the days of expensive voice recording sessions; AI-powered voiceovers effortlessly match content tone and style, providing a personalized learning experience with a wide range of voices for diverse audiences.
##What is Learning and Development?
Learning and development (L&D) involves acquiring knowledge and skills through methods like [eLearning](https://blogs.novita.ai/engaging-your-audience-mastering-elearning-voice-over/) courses and [training ](https://blogs.novita.ai/voiceover-magic-enhancing-training-videos-for-success/)programs. It enhances capabilities, improves performance, and drives organizational success. When creating L&D videos, the focus is on delivering engaging content to facilitate learning. This includes instructional design, interactive elements, and multimedia components to captivate learners and boost knowledge retention. L&D videos are essential in corporate training, education, and online platforms for convenient educational delivery.

##The Rise of AI Voiceovers in Learning and Development
AI voiceovers are revolutionizing instructional content creation by converting text to speech, creating natural-sounding narrations without human intervention. This technology enhances training video production, offering customization options for pacing, tone, and style to engage learners effectively. Additionally, it supports content localization and inclusivity by providing multiple language options.
The integration of AI voice technology in learning and development streamlines content creation, making it efficient, cost-effective, and scalable while enhancing knowledge retention through engaging learning experiences.
###Transforming Traditional Learning with Technology
Traditional learning often relies on in-person lectures and printed materials, which can limit engagement and accessibility. Technology integration transforms education by enhancing content delivery.

AI voiceovers create dynamic learning videos that engage learners at their own pace. Multimedia elements like images and videos make the content immersive and enhance understanding.
Customized learning experiences allow learners to explore specific interests and receive personalized feedback, ensuring effective learning outcomes and a meaningful experience.
###Advantages of AI Voiceovers Over Human Narration
AI voiceovers offer several advantages over human narration in learning and development videos:
- Cost-Effective: AI voiceovers eliminate the need to hire voice actors and set up recording sessions, reducing production costs.
- Consistency: AI voiceovers deliver a consistent voice throughout the video, ensuring a polished and professional narration.
- Time Efficiency: AI voiceovers can be generated in minutes, saving time compared to the traditional process of recording human voiceovers.
- Language Flexibility: AI voiceovers support multiple languages, allowing for easy localization and catering to a global audience.
- Customization Options: AI voiceover tools offer customization features, such as adjusting pacing and tone, to create voiceovers that suit the content and engage learners effectively.
##Planning Your Learning Video Content
Planning your learning video content is crucial to ensure its effectiveness and impact. Two key aspects to consider are identifying your target audience and structuring your content for maximum impact.

###Identifying Your Target Audience
Identifying your target audience is essential for creating learning videos that resonate with learners. Consider the following factors when determining your target audience:
- Demographics: Age, gender, education level, and occupation are key demographic factors to consider.
- Learning Preferences: Understand how your target audience prefers to learn, whether through visual, auditory, or kinesthetic methods.
- Cultural Considerations: Take into account cultural norms and sensitivities to ensure your content is inclusive and relatable.
- Global Reach: If your target audience is global, consider incorporating multilingual options to make your videos accessible to learners from different linguistic backgrounds.
###Structuring Your Content for Maximum Impact
Structuring your learning video content effectively is crucial for maximum impact. Consider the following tips:
- Define Learning Objectives: Clearly outline the goals and objectives of your eLearning course to ensure your content aligns with the desired outcomes.
- Chunk Information: Break down complex information into smaller, digestible units to enhance learning and retention.
- Use Visuals and Graphics: Incorporate visuals and graphics to support the content and engage visual learners.
- Incorporate Interactivity: Include interactive elements such as quizzes or activities to promote active learning and reinforce knowledge.
- Storytelling: Weave storytelling elements into your content to make it more engaging and memorable for learners.
##Selecting the Right AI Voiceover Tool
Selecting the right AI voiceover tool is crucial for creating high-quality and impactful learning videos. Consider the following factors when choosing an AI voiceover tool:
###Criteria for Choosing the Best AI Voice
When choosing an AI voice for your learning videos, consider the following criteria:
- Voice Quality: Look for AI voiceover tools that offer high-quality, natural-sounding voices that resonate with your target audience.
- Customization Options: Choose a tool that provides customization features, such as adjusting pacing, tone, and emphasis, to suit your content.
- Voice Changer Feature: Some AI voiceover tools offer the ability to modify an existing voice recording, allowing for additional creative possibilities.
- Specific Important Piece: Consider any specific requirements or characteristics that are crucial for your learning video, such as a particular accent or tone.
###Top AI Voiceover Tools in the Market
- Murf: Diverse range of lifelike voices, customization options, media integration, seamless voiceover for video.
- Speechify: User-friendly interface, high-quality voice generation, multilingual support.
- Novita.AI: It offers realistic AI-generated voices in multiple languages and accents. APIs are provided to produce your own voiceover tool.
- NaturalReader: Customizable voice parameters, integration with popular text editors, offline access.
- Amazon Polly: Vast selection of lifelike voices, multilingual capabilities, integration with AWS services.
- FakeYou: Range of voices and languages, voice modulation options.
- TTSReader: Multiple language support, customizable voice parameters.
- Lovo AI: AI voices in different styles, customization options.
##Crafting Your Script for AI Voiceovers
Crafting a well-written script is essential for creating impactful AI voiceovers for your learning videos. The script serves as the foundation for the narrative and sets the tone for the entire video. Consider the following tips:
###Tips for Writing Engaging and Effective Scripts
To create engaging and effective scripts for your AI voiceovers, consider the following tips:
- Incorporate storytelling elements to captivate the audience and make the content more relatable.
- Understand the subject matter and communicate complex concepts in a clear and concise manner.
- Consider the learner experience and structure the script in a way that keeps learners engaged and interested throughout the video.
###Incorporating Storytelling Elements
Incorporating storytelling elements into your AI voiceovers can enhance the impact of your learning videos. By adding a little bit of extra emotion and creating a memorable experience, storytelling can make the content more relatable and engaging for learners.
##Integrating AI Voiceovers into Your Videos
Integrating AI voiceovers in learning videos enhances the learning experience by providing natural, expressive speech. AI voiceovers make content relatable and engaging, delivering clear explanations and emphasizing key points. They also create a consistent brand voice and support multiple languages for a global audience.
###Step-by-Step Guide to Adding AI Voiceovers
Creating voiceovers for Learning and Development Videos using AI tools like Novita.AI is a simple process. Follow these steps:
- Step 1: Launch the Novita.AI website and create an account on it. navigate “[text-to-speech](https://novita.ai/product/txt2speech?ref=blogs.novita.ai)” under the “Product” tab, you can test the effect first with the steps below.
- Step 2: Input the text that you want to get voiceover about.
- Step 3: Select a voice model that you are interested in.
- Step 4: Click on the “Generate” button, and wait for it.
- Step 5: Once it is complete, you can preview it. If it’s satisfied, you can download and integrate the output into your documentary.
###Adjusting Timings and Tone for Natural Delivery
To deliver natural and effective AI voiceovers, adjust timings and tone. Timing is crucial for seamless narration alignment with visuals. Use tools like Murf to sync voiceover with video for a smooth learning experience.
Adjusting tone is key for engaging voiceovers. Match tone to content to evoke emotions and maintain attention. For instance, a confident tone can drive action, while a warm tone encourages exploration.
AI voiceover tools offer flexibility to refine timing and tone, enhancing the learning experience and captivating learners’ attention.
##Enhancing Learning Experience with Interactive Elements
Incorporating visuals, animations, quizzes, and interactions in learning videos enhances engagement. Visuals and animations simplify complex ideas, while quizzes and interactions encourage active participation. By combining auditory and visual elements with interactivity, you create an engaging learning experience that boosts critical thinking and knowledge retention.
###Using Visuals and Animations Alongside AI Voiceovers
Visuals and animations enhance learning with AI voiceovers. Images, videos, and presentations help visualize complex concepts, making learning engaging and memorable. Combining visuals with voiceovers creates immersive learning experiences. Animations add movement and interactivity, demonstrating processes and highlighting key points effectively. This blend caters to diverse learning preferences, promoting knowledge retention.
###Adding Quizzes and Interactions
Adding quizzes and interactions to learning videos enhances engagement. Quizzes test understanding, while interactions promote active learning and critical thinking. Learners apply knowledge through decision-making scenarios, creating a personalized learning experience. This approach boosts engagement, knowledge retention, and accountability.
##How to produce a voice overs tool by integrating text-to-speech API?
Integrating a TTS API into your voiceover tool streamlines the production of high-quality voiceovers for learning videos. This automation saves time and ensures consistency.
To integrate a [TTS API](https://novita.ai/reference/audio/text_to_speech.html):
Step1. Select a reliable provider(Novita.AI) with diverse voices and customization options.
Step2. Integrate the TTS API into your tool’s backend for real-time voiceover generation.
Step3. Design a user-friendly interface for customizing voice parameters.
Step4. Offer preview and download options in various formats.
Step5. Ensure data security and compliance measures are in place.
Empower users to create professional voiceovers effortlessly, enhancing video quality and effectiveness.
##Why Should Novita.AI Be Your Ultimate API Solution?
Novita.AI is the ultimate API for creating voice overs in learning videos. It offers a variety of lifelike voices in multiple languages and accents to cater to a global audience. With advanced customization options, you can create personalized voiceovers that align with your objectives. Novita.AI also provides powerful voice editing capabilities for natural delivery.
- Real-time latency: Novita Al voice models can generate speech in < 300ms.
- Expressive Voice: Explore voice styles: narrative, chat, joy, rage, sorrow, and empathy.
- Reliability: Trust our robust infrastructure to deliver consistent, high-quality audio every time.
- Seamless Integration: Effortlessly incorporate our APl applications for a plug-and-playenhancement.
- Customizable and Scalable: Tailor the voice to your brand’s identity and scale up to meet the demands of your growing user base.
- Developer-Friendly: With comprehensive documentation and 24/7 support, our APls designed to be a breeze for developers.
##Overcoming Challenges with AI Voiceovers
Implementing AI voiceovers in learning videos can be challenging. Choose natural-sounding AI voices like those from Novita.AI to add a human touch. Enhance inclusivity with tools that support multiple languages and accents, along with closed captions for accessibility. Using diverse content formats, such as visuals and AI voiceovers, caters to different learning preferences, creating engaging and effective videos.
###Addressing Common Concerns and Solutions
AI voiceovers have many benefits, but concerns about their implementation exist. Tools like Novita.AI offer customizable, lifelike voices to add a human touch. Choosing AI voices trained on specific styles can reduce the robotic sound. Customization options like emphasis and pronunciation ensure a natural delivery for an engaging user experience in learning and development videos.
###Ensuring Accessibility and Inclusivity
Using AI voiceovers in learning videos requires tools for diverse environments. Include closed captions for learners with hearing impairments. Incorporate visuals, animations, and AI voiceovers for various learning styles. Prioritize inclusivity to ensure all learners engage equally based on their needs.
##Conclusion
In conclusion, the integration of AI voiceovers in learning and development videos offers a modern and efficient approach to engaging your audience. By leveraging AI technology, you can enhance the effectiveness of your content and cater to diverse learning preferences. Crafting compelling scripts and incorporating storytelling elements are key to ensuring viewer engagement. Furthermore, selecting the right AI voiceover tool is crucial for achieving a seamless and natural delivery. Remember, by embracing AI voiceovers, you can elevate the overall learning experience with interactive elements and captivating visuals, creating a dynamic and immersive educational environment.
Originally published at [novita.ai](https://blogs.novita.ai/how-to-create-learning-and-development-videos-using-ai-voiceovers/?utm_source=dev_audio&utm_medium=article&utm_campaign=ai-voiceovers-for-learning-and-development-videos
)
[novita.ai](https://novita.ai/?utm_source=dev_audio&utm_medium=article&utm_campaign=ai-voiceovers-for-learning-and-development-videos), the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free. | novita_ai |
1,869,806 | open-meteo.com | did not know of this before, but free no API-key! API for accessing weather, you just need to... | 0 | 2024-05-30T01:37:14 | https://dev.to/wsq/open-meteocom-5gd5 | openmeteo, api | did not know of this before, but free no API-key! API for accessing weather, you just need to evaluate lat / long yourself
https://geocode.arcgis.com/arcgis/ seems like a cool service with a nice amount of resolutions which allow you to convert blackbox location input like "New York, ny" to actual latitude and longitude it has a registration but they give a certain amount of free lookups a day? | wsq |
1,869,805 | freerouting kicad | have tried out https://github.com/freerouting/freerouting with a set of four PCBs and did some minor... | 0 | 2024-05-30T01:33:45 | https://dev.to/wsq/freerouting-kicad-797 | kicad, pcb, hardware | have tried out https://github.com/freerouting/freerouting with a set of four PCBs and did some minor moving around of the traces and vias and ended up with functional boards
feels like something is definitely wrong but for boards where I change the schematic and maybe reset the traces for a specific component to move it to another place, it's nice to see it fill in the blanks
looking forward to using freerouting more! and it works in kicad on Mac OS ARM! | wsq |
1,869,804 | Dominating Strategies for SEO Marketing Tactics in Vancouver | In Vancouver's bustling digital landscape, mastering the art of SEO marketing is akin to unlocking... | 0 | 2024-05-30T01:31:23 | https://dev.to/tech_spinach_f0f47a88c191/dominating-strategies-for-seo-marketing-tactics-in-vancouver-37ii | webdesign, marketing, hosting | In Vancouver's bustling digital landscape, mastering the art of SEO marketing is akin to
unlocking the city's hidden treasures. From the gleaming skyscrapers to the quaint corners of Gastown, businesses constantly compete to appear first on search engine results pages (SERPs). In this dynamic environment, staying ahead demands knowledge and strategic finesse.
Navigating the intricacies of SEO in Vancouver requires creativity and technical prowess. Every move counts in this competitive arena, from deciphering local search trends to harnessing the power of geo-targeted keywords. Join us as we delve into the dominating strategies shaping the SEO landscape of Vancouver, unveiling the tactics that propel businesses to the forefront of digital success.
Understanding Vancouver's SEO Terrain
In Vancouver's vibrant digital ecosystem, grasping the intricacies of SEO is essential for businesses aiming to thrive online. From the trendy neighborhoods of Yaletown to the bustling streets of Commercial Drive, the city's diverse terrain offers unique opportunities and difficulties for SEO practitioners.
Understanding Vancouver's SEO terrain involves delving into the nuances of local search behavior, exploring how residents search for products and services, and discerning the digital pulse of the city's various industries. By immersing themselves in Vancouver's online culture and consumer preferences, businesses can tailor their SEO strategies to resonate with the city's dynamic audience.
Crafting Tailored Strategies for Local Audiences
Crafting tailored strategies for local audiences in Vancouver needs a thorough comprehension of the city's varied communities and their unique preferences. To effectively engage with Vancouverites, businesses should consider the following:
Conduct thorough market research: Dive into demographic data and consumer behavior patterns to gain insights into Vancouver's diverse population.
Embrace cultural nuances: Recognize Vancouver's multicultural makeup and tailor content and messaging to resonate with different ethnic groups.
Leverage local landmarks and events: Incorporate references to iconic Vancouver landmarks like Stanley Park or events like the Celebration of Light to establish a sense of locality.
Highlight sustainability initiatives: Showcase eco-friendly practices and initiatives, aligning with Vancouver's reputation as a green city.
Foster community partnerships: Collaborate with local organizations and businesses to strengthen ties within the community and enhance brand visibility.
Crafting tailored strategies for local audiences in Vancouver empowers businesses to connect authentically with the city's residents, fostering loyalty and driving growth within the community.
Leveraging Vancouver's Unique Search Trends
Vancouver's dynamic market is characterized by its ever-evolving search trends, influenced by factors such as seasonality, cultural events, and local happenings. From the surge in outdoor activities during the summer months to the spike in wellness-related searches post-holiday season, staying attuned to Vancouver's unique search trends is vital for SEO practitioners.
By leveraging these insights, businesses can tailor their content and marketing efforts to align with the city's current interests and preferences. Whether capitalizing on the popularity of local events like the Vancouver International Film Festival or tapping into emerging trends such as sustainable living, understanding and harnessing Vancouver's search trends can significantly enhance the effectiveness of SEO campaigns.
The Power of Geo-Targeting in Vancouver SEO
In a city as geographically diverse as Vancouver, the power of geo-targeting cannot be overstated in SEO strategies. Whether targeting specific neighborhoods, districts, or even individual streets, geo-targeting allows businesses to deliver hyper-localized content and promotions to their target audience. From optimizing Google My Business listings with accurate location information to creating location-specific landing pages tailored to Vancouver's neighborhoods, incorporating geo-targeting tactics can significantly boost visibility and engagement for businesses operating in the city.
Moreover, with the increasing prevalence of voice search and mobile browsing, optimizing local SEO has become even more crucial, as users often rely on their devices to find nearby businesses and services. By embracing geo-targeting strategies, businesses can establish a strong presence in Vancouver's competitive digital landscape and attract qualified leads within their vicinity.
Harnessing the Influence of Vancouver's Online Communities
Vancouver boasts a rich tapestry of online communities, spanning forums, social media groups, and niche interest communities. These digital hubs serve as vibrant spaces where residents exchange recommendations, share experiences, and seek advice on various topics. For businesses looking to enhance their SEO efforts, tapping into the influence of Vancouver's online communities presents a valuable opportunity to connect with engaged audiences and amplify their brand presence.
By actively participating in relevant discussions, providing valuable insights, and sharing content that resonates with community members, businesses can foster goodwill, earn backlinks, and ultimately improve their search engine rankings. Moreover, by understanding the nuances of each community and tailoring their approach accordingly, businesses can ensure that their engagement efforts are authentic and impactful.
Mobile Optimization: A Must for Vancouver's SEO Scene
In a city where tech-savvy residents are constantly on the go, mobile optimization is now required for on-the-go use; it is no longer an option for SEO success. With smartphone penetration rates among the highest in Canada, Vancouverites rely heavily on their mobile devices to access information, make purchases, and engage with brands. Ensuring that websites are mobile-friendly and load quickly on various devices is paramount for maintaining a competitive edge in Vancouver's SEO.
From implementing responsive design to optimizing page speed and streamlining navigation, prioritizing mobile optimization can enhance and increase search engine rankings, lower bounce rates, and enhance user experience. Additionally, with Google's mobile-first indexing approach, where the mobile version of a website is primarily used for indexing and ranking, paying attention to mobile optimization can harm a business's visibility in search results.
Building Authority in Vancouver's Digital Marketplace
In Vancouver's bustling digital marketplace, establishing authority is crucial for gaining trust and credibility among consumers and search engines. Building authority involves more than just publishing high-quality content; it requires a strategic approach that positions businesses as thought leaders in their respective industries.
By consistently delivering valuable insights, expert opinions, and innovative solutions to relevant topics and trends, businesses can showcase their expertise and earn recognition as go-to sources of information in Vancouver's digital landscape. Moreover, actively participating in industry events, speaking engagements, and collaborations with other reputable brands can further solidify a business's authority and enhance its SEO efforts by generating backlinks and social signals that signal relevance and authority to search engines.
Navigating Vancouver's Competitive Keyword Landscape
Navigating Vancouver's Competitive Keyword Landscape requires strategic finesse and meticulous research to ensure visibility and success in the city's bustling digital marketplace. In this dynamic environment, businesses must:
Identify high-volume keywords: Discover keywords with significant search volume to target a broad audience interested in products or services offered in Vancouver.
Analyze local intent: Understand the unique search intent of Vancouver residents to tailor content and offerings that meet their specific needs and preferences.
Optimize for long-tail keywords: Target keywords with lower competition to capture niche audiences and drive qualified traffic to your website.
Monitor competitor keywords: Keep a close eye on competitor keyword strategies to identify gaps and improvement opportunities in your SEO efforts.
Adapt to evolving trends: Stay agile and responsive to changes in search algorithms and user behavior to maintain a competitive edge in Vancouver's digital landscape.
Analyzing Vancouver-Specific SERP Features
Understanding Vancouver-specific features is essential for optimizing SEO tactics in the dynamic world of search engine optimization results pages (SERPs). Vancouver's SERPs may include localized elements such as Google My Business listings, map packs, and rich snippets tailored to the city's unique search ecosystem. Businesses can enhance their visibility and stand out by analyzing these SERP features and adapting strategies accordingly.
Leveraging structured data markup, optimizing for featured snippets, and optimizing content for local intent are just a few tactics that can help businesses maximize their presence in Vancouver's SERPs. Additionally, staying abreast of changes in SERP features and algorithm updates can ensure businesses remain agile and responsive in their SEO efforts, driving sustainable results in Vancouver's dynamic digital landscape.
Key Metrics for Vancouver SEO Campaigns
Measuring success is essential for driving continual improvement and achieving tangible results in the ever-evolving landscape of Vancouver's SEO campaigns. By focusing on key metrics, businesses can gain valuable insights into the effectiveness of their SEO efforts and make data-driven decisions to optimize their strategies. To effectively measure success in Vancouver SEO campaigns, consider the following key metrics:
Organic Traffic
Monitor the volume of organic traffic to your website, tracking fluctuations and trends over time to gauge the impact of SEO efforts.
Conversion Rate
Analyze the percentage of website visitors who take desired actions, such as making a purchase or filling out a contact form, to determine how well your SEO converts visitors into sales.
Keyword Rankings
Track your website's ranking positions for target keywords in Vancouver's search results, identifying opportunities for improvement and areas of strength.
Engagement Metrics
Evaluate metrics such as bounce rate, time on site, and pages per session to understand user engagement and optimize website content and user experience accordingly.
Local Search Performance
Monitor performance in local search results, including visibility in Google My Business listings and map packs, to assess the effectiveness of geo-targeting strategies and local SEO efforts.
In the dynamic realm of Vancouver's SEO landscape, mastering the intricacies of local search trends, geo-targeting strategies, and community engagement is paramount for digital success. By understanding the unique nuances of Vancouver's digital marketplace and leveraging tailored SEO tactics, businesses can enhance their visibility, establish authority, and drive meaningful connections with local audiences. With a strategic approach and continuous optimization, businesses may successfully negotiate the competitive environment and accomplish long-term growth in Vancouver's vibrant digital ecosystem.
Ready to elevate your SEO game and dominate Vancouver's digital marketplace? Contact Tech Spinach today at 1205-8725 University Cres, Burnaby, BC V5A0B1, or email info@techspinach.ca. Let's discuss how we can tailor a bespoke SEO strategy to propel your business to new heights. Call us at 1-226-224-9679 and take the first step towards digital success with Tech Spinach. | tech_spinach_f0f47a88c191 |
1,869,803 | Design a Multiple-Chart Plotting Library | This kind of library is often used to create charts and plots when writing and designing strategies.... | 0 | 2024-05-30T01:25:51 | https://dev.to/fmzquant/design-a-multiple-chart-plotting-library-4a69 | charts, library, trading, fmzquant | This kind of library is often used to create charts and plots when writing and designing strategies. For a single custom chart, we can use the ["plotting library"](https://www.fmz.com/strategy/27293) (users who are not familiar with the concept of the template library on FMZ can check the FMZ API documentation), which is very convenient for plotting operations. However, for scenarios that require multiple charts, this template library cannot meet the requirements. Then we learn the design ideas of this plotting library, and on this basis, design a multi-chart version of the plotting library.
## Design the Export Functions of "Template Library"
Learning from the export function design of "plot Library", we can also design similar export functions for the multi-chart plotting library.
- $.PlotMultRecords
Used to draw K-line charts, designed parameters: cfgName, seriesName, records, extension。
cfgName: as a single chart, the name of the configured object;
seriesName: the name of the data series that need to draw K-lines at the moment;
records: the K-line data passed in;
extension: the chart dimension configuration information, for example: pass {layout: 'single', col: 6, height: '600px'}, that is, request the chart with the configured object name of cfgName to solely display width: 6, height: 600px.
- $.PlotMultLine
Used to draw lines, designed parameters: cfgName, seriesName, dot, ts, extension
cfgName: as a single chart, the name of the configured object;
seriesName: the name of the data series that need to draw lines at the moment;
dot: the ordinate value of the dot on the lines to be drawn;
ts: timestamp, namely the value on the X time axis;
extension: the chart dimension configuration information.
- $.PlotMultHLine
Used to draw horizontal lines; designed parameters: cfgName, value, label, color, style
cfgName: the configured object in the chart;
value: the ordinate value of the horizontal line;
label: the display text on the horizontal line;
color: line color;
style: line style, for example: Solid ShortDash ShortDot ShortDashDot ShortDashDotDot Dot Dash LongDash DashDot LongDashDot LongDashDotDot.
- $.PlotMultTitle
Used to modify the title and sub-title of the chart; designed parameters: cfgName, title, chartTitle
cfgName: the configured object name;
title: sub-title;
chartTitle: the title of the chart.
- $.PlotMultFlag
Used to draw flag; designed parameters: cfgName, seriesName, ts, text, title, shape, color, onSeriesName
cfgName: the configured object in the chart;
seriesName: the name of the data series;
ts: timestamp;
text: the text in the flag;
title: the title of the flag;
shape: the shape of the flag;
color: the color of the flag;
onSeriesName: it is based on which data series to display on; the value is the id of the data series.
- $.GetArrCfg
Used to return the configured object array of the chart.
## Design Test Functions
For easy understanding, I wrote remarks directly on the test functions, explaining what each function call does.
```
// test
function main() {
LogReset(10)
var i = 0
var prePrintTs = 0
while (true) {
var r = exchange.GetRecords() // Get K-line data
var t = exchange.GetTicker() // Get the real-time tick data
$.PlotMultRecords("chart1", "kline1", r, {layout: 'single', col: 6, height: '600px'}) // Create a K-line chart named chart1, and display it solely; the width is 6, and the height is 600px; the K-line data series name is kline1, and use r obtained above as the data source to draw the chart
$.PlotMultRecords("chart2", "kline2", r, {layout: 'single', col: 6, height: '600px'}) // Craete the second K-line chart, named chart2
$.PlotMultLine("chart2", "line1", t.Last, r[r.length - 1].Time) // Add a line to the K-line chart, namely chart2, the name of the data series is line1, and use the Last of the real-time tick data as the Y value of the dot on the line. The timestamp of the last BAR of the K-line data is used as the X value
$.PlotMultLine("chart3", "line2", t.Last) // Create a chart named chart3 that only draws lines, with data series name line2; use the Last of real-time tick data to draw a dot at the current time (X value) (t.Last is Y value); note that the chart is not displayed solely
$.PlotMultLine("chart6", "line6", t.Time) // Create a chart chart6 that only draws lines; note that the chart is not displayed solely, it will be displayed with chart3 on pagination
$.PlotMultLine("chart4", "line3", t.Sell, new Date().getTime(), {layout: 'single', col: 4, height: '300px'}) // Create a chart named chart4 that only draws lines, solely displayed, width 4, height 300px
$.PlotMultLine("chart5", "line4", t.Volume, new Date().getTime(), {layout: 'single', col: 8, height: '300px'}) // Create a chart named chart5 that only draws lines, solely displayed, width 8, height 300px
$.PlotMultHLine("chart1", r[r.length - 1].Close, "HLine1", "blue", "ShortDot") // Add horizontal lines in chart1
$.PlotMultHLine("chart4", t.Sell, "HLine2", "green") // Add horizontal lines in chart4
$.PlotMultTitle("chart3", "change : chart3->test1", "test1") // Modify the title of chart3
var ts = new Date().getTime()
if (ts - prePrintTs > 1000 * 20) {
prePrintTs = ts
// when triggered, draw a flag on chart3
$.PlotMultFlag("chart3", "flag1", new Date().getTime(), "flag test", "flag1")
}
if (i == 10) {
Log("i == 10")
// when triggered, draw a flag on chart4, and chart1
$.PlotMultFlag("chart4", "flag2", new Date().getTime(), "flag test", "flag2")
$.PlotMultFlag("chart1", "flag3", new Date().getTime(), "flag test", "flag3", "squarepin", "green", "kline1")
} else if (i == 20) {
Log("i == 20")
// when triggered, add a line on chart1, but only draw a dot of the line; X coordinate is timestamp, and Y coordinate is the value of t.Last
$.PlotMultLine("chart1", "line5", t.Last, r[r.length - 1].Time)
} else if (i == 30) {
Log("i == 30")
// when triggered, draw a flag on chart2
$.PlotMultFlag("chart2", "flag4", new Date().getTime(), "flag test", "flag4", "circlepin", "black", "kline2")
}
Sleep(1000 * 5)
i++
}
}
```
## Operation Test
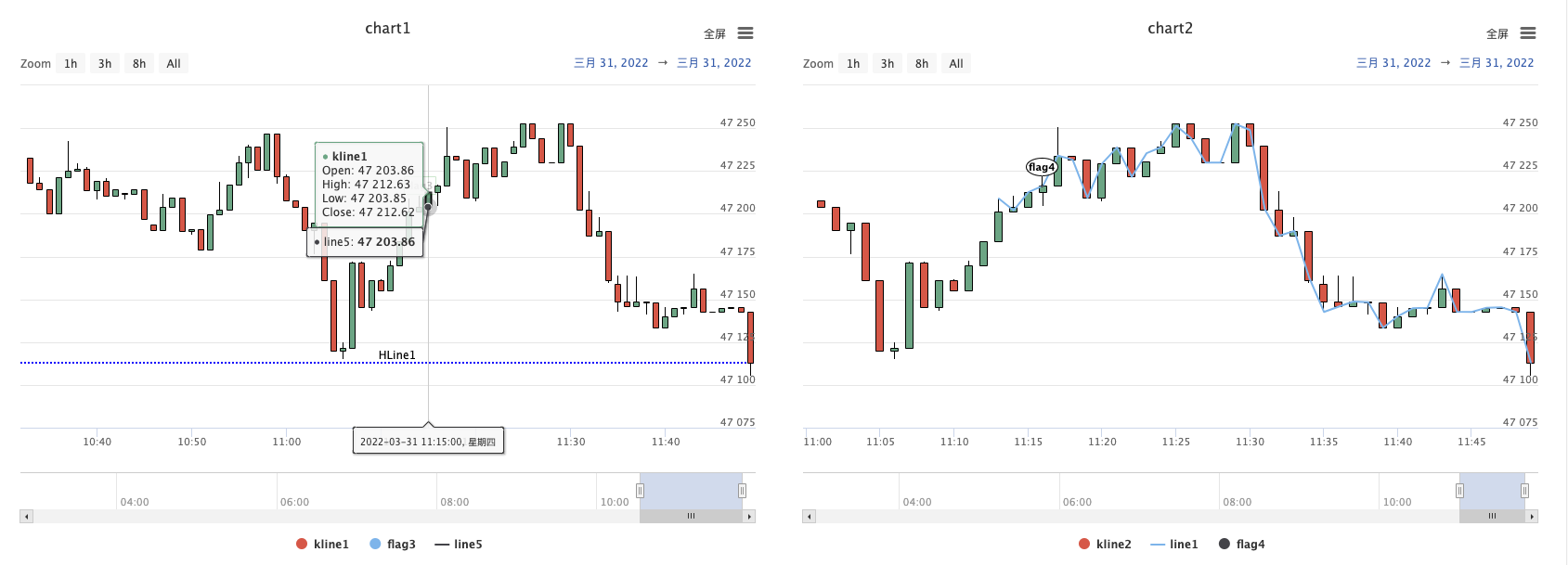
You can see that with only one line of function call, you can easily draw a chart, and you can display multiple kinds of charts at the same time.
## Complete Strategy Source Code
Parameter settings:

Implementation of the strategy source code:
```
var registerInfo = {}
var chart = null
var arrCfg = []
function updateSeriesIdx() {
var index = 0
var map = {}
_.each(arrCfg, function(cfg) {
_.each(cfg.series, function(series) {
var key = cfg.name + "|" + series.name
map[key] = index
index++
})
})
for (var cfgName in registerInfo) {
for (var i in registerInfo[cfgName].seriesIdxs) {
var seriesName = registerInfo[cfgName].seriesIdxs[i].seriesName
var key = cfgName + "|" + seriesName
if (map[key]) {
registerInfo[cfgName].seriesIdxs[i].index = map[key]
}
// Reset preBarTime of K-line data
if (registerInfo[cfgName].seriesIdxs[i].type == "candlestick") {
registerInfo[cfgName].seriesIdxs[i].preBarTime = 0
} else if (registerInfo[cfgName].seriesIdxs[i].type == "line") {
registerInfo[cfgName].seriesIdxs[i].preDotTime = 0
} else if (registerInfo[cfgName].seriesIdxs[i].type == "flag") {
registerInfo[cfgName].seriesIdxs[i].preFlagTime = 0
}
}
}
if (!chart) {
chart = Chart(arrCfg)
}
chart.update(arrCfg)
chart.reset()
_G("registerInfo", registerInfo)
_G("arrCfg", arrCfg)
for (var cfgName in registerInfo) {
for (var i in registerInfo[cfgName].seriesIdxs) {
var buffer = registerInfo[cfgName].seriesIdxs[i].buffer
var index = registerInfo[cfgName].seriesIdxs[i].index
if (buffer && buffer.length != 0 && registerInfo[cfgName].seriesIdxs[i].type == "line" && registerInfo[cfgName].seriesIdxs[i].preDotTime == 0) {
_.each(buffer, function(obj) {
chart.add(index, [obj.ts, obj.dot])
registerInfo[cfgName].seriesIdxs[i].preDotTime = obj.ts
})
} else if (buffer && buffer.length != 0 && registerInfo[cfgName].seriesIdxs[i].type == "flag" && registerInfo[cfgName].seriesIdxs[i].preFlagTime == 0) {
_.each(buffer, function(obj) {
chart.add(index, obj.data)
registerInfo[cfgName].seriesIdxs[i].preFlagTime = obj.ts
})
}
}
}
}
function checkBufferLen(buffer, maxLen) {
while (buffer.length > maxLen) {
buffer.shift()
}
}
$.PlotMultRecords = function(cfgName, seriesName, records, extension) {
if (typeof(cfgName) == "undefined") {
throw "need cfgName!"
}
var index = -1
var eleIndex = -1
do {
var cfgInfo = registerInfo[cfgName]
if (typeof(cfgInfo) == "undefined") {
var cfg = {
name : cfgName,
__isStock: true,
title : {
text: cfgName
},
tooltip: {
xDateFormat: '%Y-%m-%d %H:%M:%S, %A'
},
legend: {
enabled: true,
},
plotOptions: {
candlestick: {
color: '#d75442',
upColor: '#6ba583'
}
},
rangeSelector: {
buttons: [{
type: 'hour',
count: 1,
text: '1h'
}, {
type: 'hour',
count: 3,
text: '3h'
}, {
type: 'hour',
count: 8,
text: '8h'
}, {
type: 'all',
text: 'All'
}],
selected: 2,
inputEnabled: true
},
series: [{
type: 'candlestick',
name: seriesName,
id: seriesName,
data: []
}],
}
if (typeof(extension) != "undefined") {
cfg.extension = extension
}
registerInfo[cfgName] = {
"cfgIdx" : arrCfg.length,
"seriesIdxs" : [{seriesName: seriesName, index: arrCfg.length, type: "candlestick", preBarTime: 0}],
}
arrCfg.push(cfg)
updateSeriesIdx()
}
if (!chart) {
chart = Chart(arrCfg)
} else {
chart.update(arrCfg)
}
_.each(registerInfo[cfgName].seriesIdxs, function(ele, i) {
if (ele.seriesName == seriesName && ele.type == "candlestick") {
index = ele.index
eleIndex = i
}
})
if (index == -1) {
arrCfg[registerInfo[cfgName].cfgIdx].series.push({
type: 'candlestick',
name: seriesName,
id: seriesName,
data: []
})
registerInfo[cfgName].seriesIdxs.push({seriesName: seriesName, index: arrCfg.length, type: "candlestick", preBarTime: 0})
updateSeriesIdx()
}
} while (index == -1)
for (var i = 0 ; i < records.length ; i++) {
if (records[i].Time == registerInfo[cfgName].seriesIdxs[eleIndex].preBarTime) {
chart.add(index, [records[i].Time, records[i].Open, records[i].High, records[i].Low, records[i].Close], -1)
} else if (records[i].Time > registerInfo[cfgName].seriesIdxs[eleIndex].preBarTime) {
registerInfo[cfgName].seriesIdxs[eleIndex].preBarTime = records[i].Time
chart.add(index, [records[i].Time, records[i].Open, records[i].High, records[i].Low, records[i].Close])
}
}
return chart
}
$.PlotMultLine = function(cfgName, seriesName, dot, ts, extension) {
if (typeof(cfgName) == "undefined") {
throw "need cfgName!"
}
var index = -1
var eleIndex = -1
do {
var cfgInfo = registerInfo[cfgName]
if (typeof(cfgInfo) == "undefined") {
var cfg = {
name : cfgName,
__isStock: true,
title : {
text: cfgName
},
xAxis: {
type: 'datetime'
},
series: [{
type: 'line',
name: seriesName,
id: seriesName,
data: [],
}]
}
if (typeof(extension) != "undefined") {
cfg.extension = extension
}
registerInfo[cfgName] = {
"cfgIdx" : arrCfg.length,
"seriesIdxs" : [{seriesName: seriesName, index: arrCfg.length, type: "line", buffer: [], preDotTime: 0}],
}
arrCfg.push(cfg)
updateSeriesIdx()
}
if (!chart) {
chart = Chart(arrCfg)
} else {
chart.update(arrCfg)
}
_.each(registerInfo[cfgName].seriesIdxs, function(ele, i) {
if (ele.seriesName == seriesName && ele.type == "line") {
index = ele.index
eleIndex = i
}
})
if (index == -1) {
arrCfg[registerInfo[cfgName].cfgIdx].series.push({
type: 'line',
name: seriesName,
id: seriesName,
data: [],
})
registerInfo[cfgName].seriesIdxs.push({seriesName: seriesName, index: arrCfg.length, type: "line", buffer: [], preDotTime: 0})
updateSeriesIdx()
}
} while (index == -1)
if (typeof(ts) == "undefined") {
ts = new Date().getTime()
}
var buffer = registerInfo[cfgName].seriesIdxs[eleIndex].buffer
if (registerInfo[cfgName].seriesIdxs[eleIndex].preDotTime != ts) {
registerInfo[cfgName].seriesIdxs[eleIndex].preDotTime = ts
chart.add(index, [ts, dot])
buffer.push({ts: ts, dot: dot})
checkBufferLen(buffer, maxBufferLen)
} else {
chart.add(index, [ts, dot], -1)
buffer[buffer.length - 1].dot = dot
}
return chart
}
$.PlotMultHLine = function(cfgName, value, label, color, style) {
if (typeof(cfgName) == "undefined" || typeof(registerInfo[cfgName]) == "undefined") {
throw "need cfgName!"
}
var cfg = arrCfg[registerInfo[cfgName].cfgIdx]
if (typeof(cfg.yAxis) == "undefined") {
cfg.yAxis = {
plotLines: []
}
} else if (typeof(cfg.yAxis.plotLines) == "undefined") {
cfg.yAxis.plotLines = []
}
var obj = {
value: value,
color: color || 'red',
width: 2,
dashStyle: style || 'Solid',
label: {
text: label || '',
align: 'center'
},
}
var found = false
for (var i = 0; i < cfg.yAxis.plotLines.length; i++) {
if (cfg.yAxis.plotLines[i].label.text == label) {
cfg.yAxis.plotLines[i] = obj
found = true
}
}
if (!found) {
cfg.yAxis.plotLines.push(obj)
}
if (!chart) {
chart = Chart(arrCfg)
} else {
chart.update(arrCfg)
}
return chart
}
$.PlotMultTitle = function(cfgName, title, chartTitle) {
if (typeof(cfgName) == "undefined" || typeof(registerInfo[cfgName]) == "undefined") {
throw "need cfgName!"
}
var cfg = arrCfg[registerInfo[cfgName].cfgIdx]
cfg.subtitle = {
text: title
}
if (typeof(chartTitle) !== 'undefined') {
cfg.title = {
text: chartTitle
}
}
if (chart) {
chart.update(arrCfg)
}
return chart
}
$.PlotMultFlag = function(cfgName, seriesName, ts, text, title, shape, color, onSeriesName) {
if (typeof(cfgName) == "undefined" || typeof(registerInfo[cfgName]) == "undefined") {
throw "need cfgName!"
}
var index = -1
var eleIndex = -1
do {
if (!chart) {
chart = Chart(arrCfg)
} else {
chart.update(arrCfg)
}
_.each(registerInfo[cfgName].seriesIdxs, function(ele, i) {
if (ele.seriesName == seriesName && ele.type == "flag") {
index = ele.index
eleIndex = i
}
})
if (index == -1) {
arrCfg[registerInfo[cfgName].cfgIdx].series.push({
type: 'flags',
name: seriesName,
onSeries: onSeriesName || arrCfg[registerInfo[cfgName].cfgIdx].series[0].id,
data: []
})
registerInfo[cfgName].seriesIdxs.push({seriesName: seriesName, index: arrCfg.length, type: "flag", buffer: [], preFlagTime: 0})
updateSeriesIdx()
}
} while(index == -1)
if (typeof(ts) == "undefined") {
ts = new Date().getTime()
}
var buffer = registerInfo[cfgName].seriesIdxs[eleIndex].buffer
var obj = {x: ts, color: color, shape: shape, title: title, text: text}
if (registerInfo[cfgName].seriesIdxs[eleIndex].preFlagTime != ts) {
registerInfo[cfgName].seriesIdxs[eleIndex].preFlagTime = ts
chart.add(index, obj)
buffer.push({ts: ts, data: obj})
checkBufferLen(buffer, maxBufferLen)
} else {
chart.add(index, obj, -1)
buffer[buffer.length - 1].data = obj
}
return chart
}
$.GetArrCfg = function() {
return arrCfg
}
function init() {
if (isChartReset) {
Log("Reset the chart", "#FF0000")
chart = Chart(arrCfg)
chart.reset()
Log("Empty the persistent data, key:", "registerInfo、arrCfg #FF0000")
_G("registerInfo", null)
_G("arrCfg", null)
} else {
var multChartRegisterInfo = _G("registerInfo")
var multChartArrCfg = _G("arrCfg")
if (multChartRegisterInfo && multChartArrCfg) {
registerInfo = multChartRegisterInfo
arrCfg = multChartArrCfg
Log("Recover registerInfo、arrCfg #FF0000")
} else {
Log("No data can be recovered #FF0000")
}
}
}
function onexit() {
_G("registerInfo", registerInfo)
_G("arrCfg", arrCfg)
Log("Save data, key : registerInfo, arrCfg #FF0000")
}
// test
function main() {
LogReset(10)
var i = 0
var prePrintTs = 0
while (true) {
var r = exchange.GetRecords()
var t = exchange.GetTicker()
$.PlotMultRecords("chart1", "kline1", r, {layout: 'single', col: 6, height: '600px'})
$.PlotMultRecords("chart2", "kline2", r, {layout: 'single', col: 6, height: '600px'})
$.PlotMultLine("chart2", "line1", t.Last, r[r.length - 1].Time)
$.PlotMultLine("chart3", "line2", t.Last)
$.PlotMultLine("chart6", "line6", t.Time)
$.PlotMultLine("chart4", "line3", t.Sell, new Date().getTime(), {layout: 'single', col: 4, height: '300px'})
$.PlotMultLine("chart5", "line4", t.Volume, new Date().getTime(), {layout: 'single', col: 8, height: '300px'})
$.PlotMultHLine("chart1", r[r.length - 1].Close, "HLine1", "blue", "ShortDot")
$.PlotMultHLine("chart4", t.Sell, "HLine2", "green")
$.PlotMultTitle("chart3", "change : chart3->test1", "test1")
var ts = new Date().getTime()
if (ts - prePrintTs > 1000 * 20) {
prePrintTs = ts
$.PlotMultFlag("chart3", "flag1", new Date().getTime(), "flag test", "flag1")
}
if (i == 10) {
Log("i == 10")
$.PlotMultFlag("chart4", "flag2", new Date().getTime(), "flag test", "flag2")
$.PlotMultFlag("chart1", "flag3", new Date().getTime(), "flag test", "flag3", "squarepin", "green", "kline1")
} else if (i == 20) {
Log("i == 20")
$.PlotMultLine("chart1", "line5", t.Last, r[r.length - 1].Time)
} else if (i == 30) {
Log("i == 30")
$.PlotMultFlag("chart2", "flag4", new Date().getTime(), "flag test", "flag4", "circlepin", "black", "kline2")
}
Sleep(1000 * 5)
i++
}
}
```
Strategy Address: https://www.fmz.com/strategy/353264
Here I only use this to start the discussion and thinking of the topic. If you are interested, you can increase the supported chart types (such as market depth chart, bar graph and pie chart, etc.) and keep upgrading.
From: https://blog.mathquant.com/2022/09/30/design-a-multiple-chart-plotting-library%ef%bf%bc%ef%bf%bc.html | fmzquant |
1,869,761 | Connecting to IRC with Halloy | Halloy is a new IRC client written in Rust that is fast with good theming. Here is how I set up a... | 0 | 2024-05-30T01:15:03 | https://dev.to/djdesu/connecting-to-irc-with-halloy-5i8 | Halloy is a new IRC client written in Rust that is fast with good theming. Here is how I set up a connection to an irc channel with Halloy and here is how to config Halloy for Rizon.

After [downloading Halloy](https://github.com/squidowl/halloy/releases/tag/2024.7), I referred to the [documentation](https://halloy.squidowl.org/index.html).
Halloy uses a config.toml file, easily edited in code editor like VSCode. By default this is next to the Halloy installation, for me, in AppData/Roaming on Windows.
Halloy has command bar on the bottom left of the application window, and opening that gives options including "Configuration: Open config directory".
### Basic connection to Rizon
In config.toml, Halloy already gives an example setup. For Rizon network, here's another example:
`[servers.rizon]
nickname = "YourNicknameHere"
nick_password = "yourPassword"
server = "irc.rizon.net"
channels = ["#chat"]
port = 6697
on_connect = ["/msg NickServ IDENTIFY your_password"]`
When Halloy opens, the name of the window will be what is written after the period in [servers.name]. Nickname is for irc, password, if needed, is used for authenticating. The server is Rizon, and the channel list `["#chat", "#example"]` is for connecting to the channel after opening Halloy. Port 6697 is for ssl with Rizon.
The on_connect is for specifying irc commands to run on connection. Here I have a message to NickServ asking to identify a username with a password.
### Configuring Halloy with IRC Bouncer
Halloy also works with irc bouncers. Here is an example in config.toml file, and because my username on irc bouncer is different from nickname on irc...
`[servers.bnc]
nickname = "MyNickName"
username = "MyBouncerUsername"
password = "bouncer_server_password_here"
server = "chat.Yourbouncerserverhere.com"
port = +1234
use_tls = true
on_connect = ["nick MyNickName", "/msg NickServ IDENTIFY myNickServPassword", "/join #example"]`
The plus on the port (which should be the port to connect to the irc bouncer) indicates ssl.
After logging on to the irc bouncer server, I use the on_connect command to change to preferred nickname, verify with the Nickname Service, and join the preferred channel.
### Themes
To install a theme, [download](https://halloy.squidowl.org/configuration/themes/community.html) and place the theme file in the themes folder where Halloy is installed. | djdesu | |
1,869,737 | How I became a better software engineer by using a visual knowledge management tool | I like to believe that I have always been a very proficient software engineer, I've specialized in... | 0 | 2024-05-30T00:58:34 | https://dev.to/leonardoventurini/how-i-became-a-better-software-engineer-by-using-a-visual-knowledge-management-tool-33kf | softwaredevelopment, webdev, programming, productivity | I like to believe that I have always been a very proficient software engineer, I've specialized in JavaScript/TypeScript for more than 6 years professionally and I program for fun for more than 15 years. I got a business degree before my software engineering degree, and I was well within senior level working at an amazing software company when I got my diploma as a software engineer.
One thing that always bothered me was the amount of things I had to keep in my head at one given point. I even suffered from a severe phase of burnout where I needed to take antidepressants in order to keep my job.
I have been aware of mind mapping tools for more than a decade, but I never could use them for other than planning some very specific things and then shortly giving up on them.
That's until I was experimenting with a side project I was working on for about 2 years, I was in a basic sense generating flashcards using AI, and it occurred to me that I could also generate a diagram for it as well to assist in learning, but turned out that what I created was way more powerful than that.
I created a type of interactive visualization engine where I could move boxes on the screen, add a name to them and eventually even open a drawer where I could add rich text. At one point I automatically opened it to save random note and it dawned on me, it was way easier than going to Notion and creating a page.
From there on I implemented pasting of links and images, and even search for the textual content of images. I used to take screenshots of code and send them to myself via Slack to save them for later, but now I can just paste it on a board which I can group everything visually and spatially.
The search is also semantic by using embeddings, and eventually I will also add the ability to talk to your knowledge base. I understand that AI is so hypey right now but I don't want it to be the main thing about it.
I could add the ability for users to generate their content and whatever but the value of the boards is that it's yours and represents your own mind, you put the effort and that effort helps you consolidate that information better.
Of course, there is an AI Chat node but that is only intended to be used for your research and be organized visually. That's not the end goal, for that you can use ChatGPT directly.
Anyways, let me get to the main point, this tool I've built changed the way I work as a software engineer. Now I have this digital whiteboard where I can put all my research if I am working on something complex for one of my clients or companies I work for.
I take a humongous amount of screenshots of code and add relationships between them, add notes and link to documentation and sometimes I even paste a link to a video from YouTube which gets stylized accordingly.
It's like I got more RAM for my mind, I can keep a huge amount of information very accessible to this high speed network we call vision. Instead of seven things, I can have hundreds of things. Best of all, I can completely forget about it whenever I want to, and also pick it up whenever I get back to it.
I enjoy my weekends more, and I can also context switch more easily with less strain. I feel I could have a thousand projects going on at the same time. Or focus that powerful energy into the projects I love.
Right now I am dedicating my time to [Meteor](https://www.meteor.com) and [Metaboard](https://metaboard.cc). It's also worth noting that Metaboard is built on top of my own homemade event-driven real-time framework [Helene](https://github.com/leonardoventurini/helene) which is inspired by Meteor.
This is not the first tool I've built, I've also built a devtools for Meteor some years ago and it's used by a little over 5k users. Creating tools seems to be my thing, and I hope it helps you as much as it helps me. I am a builder, and I would only share it if I truly believed in it.
I would love to hear your thoughts and frustrations with existing tools so I can make it even more awesome. I built this for myself, I am a software engineer, and very likely it will be a powerful tool for you too. Heck I even have people using it to manage a factory for industrial kitchen appliances, that's why it's called Meta-board, it's whatever you make it to be.
One tool to rule them all.
The cover image is of a board created by a colleague of mine for studying Node.js and the event loop.
It even has a mini map!

Here is a short homemade promo video (one day I hope I can hire someone to do these, but hey there is a cat at the end):
{% embed https://www.youtube.com/watch?v=mkNFPxQyoOM?rel=0 %}
| leonardoventurini |
1,869,757 | C# dagi Method overload va Method group. | Method group va Method overload tushunchalarni farqlash uchun event, delegate yoki LINQ, shulardan... | 0 | 2024-05-30T00:51:59 | https://dev.to/farkhadk/c-dagi-method-overload-va-method-group-3p7k | csharp, dotnet, features | Method group va Method overload tushunchalarni farqlash uchun `event`, `delegate` yoki `LINQ`, shulardan hech bolmaganda kamida bir donasini bilish tavsiya qilinadi. Bu feature(xususiyat)lar, dasturchilarga bir vaqtning o'zida bir xil **nomli** birnechta methodlarni yaratishga imkon beradi. Ushbu o'xshash nomli methodlarni bir biridan farqi, ular **qaytaradigon** malumot tiplari hamda **qabul qiluvchi** argumentlar soni bir-biridan farq qilishidadur. Qishqacha qilib aytganda birxil ish bacharuvchi methodlarni bir **nom** ostida jamlash uchun ishlatilinadi.
> NOTE: bu ikkala feature/tushuncha bir-biriga uzviy bog'liq!
Misol tariqasida Add() methodini yaratamiz:
```C#
static int Add(int a, int b) => a + b;
static long Add(long a, long b) => a + b;
static double Add(double a, double b) => a + b;
private static void Main(string[] args)
{
int i = 1, j = 2;
var sumOfInt = Add(i, j);
Console.WriteLine($"Intlar summasi: {sumOfInt}");
long l = 10, m = 20;
var sumOfLong = Add(l, m);
Console.WriteLine($"Longlar summasi: {sumOfLong}");
double d = 1.102, s = 3.14;
var sumOfDouble = Add(d, s);
Console.WriteLine($"Doublelar summasi: {sumOfDouble}");
}
```
Output:
```
Intlar summasi: 3
Longlar summasi: 30
Doublelar summasi: 4.242
```
> Yuqorida keltirilga ko'd asosan **Metod overload** tushunchasiga to'gri keladi, lekin **method group** sintaksisiham huddi shunday. Ularni farqi haqida sal pastroqda gaplashamiz.
Uchala `Add()` methodimizga etibor bersangiz, ular qabul qilayotgan argumentlar hamda, o'sha argumentlar ustida o'tqazilgan operatsiyadan so'ng qaytarishi kerak bolgan malumot turi(return type) bir biridan farq qiladi. C# kompilyatori shunchali aqillikiy, kelayotgan argument turiga asoslanib kerakli bolgan methodni o'zi chaqirib xisob kitobni amalga oshiradi.
Yana bir yaqqol misol tariqasida biz bilgan `Console` klasidan keluvchi `WriteLine()` methodini aytishimiz mumkin, har bir overloadi(nusxasi) `void` qaytargani bilan, methodlarni qabul qiluvchi argumentlar soni va ularni turlari har-hil. Qo'shimcha qilib aytamanki har kim o'z xo'xshiga ko'ra koplab kombinatsiyalarni amalga oshirishi mumkin, demoqchi bolganim method qaytaradigon type qolgan overloadlarinikiga o'xshash bolsaxam, qabul qiladigon typelar soni va turlari farq qilsa bolgani ishlayveradi. Shu jumladan teskarisigaham ishlayveradi, argumentlar birhil bolsada qatrariladigon tur boshqacha bolsa overload hisoblanadi. Lekin extiyot bo'lish zarur!!!
> Method/funksiyalar qanday va qaysi payt ishga tushishi xaqida biroz tushuncha olsak: Harqanday methodga murojat qilinganda i.e. `WriteLine` agar `()` qavslarni qo'yilmasa bu funksiyamiz _ishga tushmaydi_. Yaniy `()` qavslari bor method kod run bolganida navbat o'sha funksiyaga kelishi bilanoq ishaga tushadi. Albatta bu tushuntirish abstrakt bolib toliq va mutloq to'g'ri bolgan misol emas. Lekin oz bolsada xaqiqatga yaqin.
Endi **method group** ga to'xtaladigon bolsak, postni cho'zib kod bilan misollarni keltirib o'tirmayman. Qisqacha qilib aytganda method group hamda method overload implementation(yaratilishi)ni syntaksisi birxil. Lekin bu ikkala tushunchani ishlatilish jarayoni va maqsadlari turlicha.
Method overload hamda method group qayerda va qanday ishlashi haqida batafsil gaplashsak.
Method overload - asosan kodni o'qish/tushunish uchun hamda eslab qolish uchun osonroq qiladigon feature xisoblanadi, yuqorida keltirilgan ko'dga yuzlansak, C# da agar overload qilish xususiyati bolmaganda harbir tip uchun boshqa boshqa _nom_ o'ylab topish va uni qanday ish bajarishini yodda tutishimiz kerak bolar edi. Misol uchun `int` type uchun `IntAdd(...)`, `double` uchun esa `DoubleAdd(...)` va hokazo. Overload qilingan methodlar turgan class filega yangiliklar kiritilganda, shu yangiliklarni handle(qayta ishlash) qilish uchun yana bir overload qo'shilsa bas. API lar yaratilganidaham juda qo'l kelishi mumkin.
Method groupni esa ko'pincha methodni _darhol_ chaqirmasdan, uning **nomi**ga gina murojaat qilib eventlarni handle qilish(qayta ishlash) hamda methodlarni parametrlar (delegatlar) sifatida o'tkazishda va LINQ expression(iboralari)ni islatilyotkanida foydalidur. Aniqroq qilib aytganda kod yozish paytida kerakli bolgan methodni nominigina yozib ketiladi va kod **runtime**(ishga tushgan)paytda, chaqiriladigan methodni keyinroq aniqlanashga imkon beradi. Bundan nima naf?! Yuqorida aytganimizdek methodlarni chaqirishimiz bilanoq ular ishga tushib keradi, bazi holatlarda esa bu narsa ko'dimizni flexibility(moslashuvchanlik)ga tasir ko'rsatadi. Misol uchun assinxron dastur tuzganimizda, dasturimiz ishga tushishi bilanoq, methodlarni o'sha zaxoti ishga tushishi, bizni dastur uchun ajratilgan resurslar(xotira)ni egallab qo'yishi, va bu o'z vaqtida hatoliklar yoki, xisob-kitobda kutilmagan natijalarga olib kelishi mumkin.
Misol:
```C#
// delegat
Action<string> writeLineString = Console.WriteLine;
writeLineString("Hello, World!");
```
Birinchi qatorda `delegate` method groupdagi nomga ishora qiladi, lekin delegat turiga qarab maxsus overloadini chaqiradi, delegatimizda argument sifatiga `string`ni belgilaganmiz shuning uchun _runtime_ paytida _kompilyator_ `WriteLine()` methodini argument sifatida stringni oladigon overloadini chaqiradi.
> Method group ishlash prinsipi method overloadnikiga o'xshash.
Endi **LINQ** bilan misolni ko'rib chiqsak:
```C#
List<int> numbers = new List<int> { 1, 2, 3, 4, 5 };
var evenNumbers = numbers.Where(IsEven).ToList();
evenNumbers.ForEach(Console.WriteLine);
static bool IsEven(int number) => number % 2 == 0;
```
> Bu code-da method group faqat `IsEven` funksiyasidan tashkil topgan, yaniy har-doimham qo'shimcha `IsEven` overloadi bo'lishi shart emas, method group deb bir dona methodniham aytsa boladi.
Kodmizda 1dan 5gacha bolgan list bor, va biz keyingi qatorga LINQ ni ishlatgan holda IsEven funksiyasini faqatgina nomini argument sifatida yuborib, faqat juft bo'lgan sonlar listini yaratyapmiz. IsEven funksiyasini agar `()` bilan chaqirsak bizning kod hatolik chiqaradi, chunki yuqorida aytilganidek `()` bilan chaqirilgan methodlar o'sha zahotiyoq ishga tushib ketadi. 3-chi qatorga etibor bersangiz `ForEach()` methodi `WriteLine` funksiyaniham faqatginaham method group nomiga murojat qilyapti, va kompilyator `int` type qabul qiladigon `WriteLine` overloadini chaqirib, sonlarni konsolga chiqarmoqda.
Method Group ga aloqador yana bir etiborga loyiq mavzu bor, uning nomi _Method Group Natural Type_ bu mavzu xaqida esa boshqa [postimda](https://dev.to/farkhadk/natural-type-of-method-group-min) gaplashamiz.
Etibor uchun raxmat. | farkhadk |
1,868,319 | Entenda o que é CORS (Cross-Origin Resource Sharing) | Introdução No desenvolvimento web moderno, é comum que aplicações precisem interagir com... | 0 | 2024-05-30T00:43:33 | https://dev.to/thiagohnrt/entenda-o-que-e-cors-cross-origin-resource-sharing-2601 | webdev, frontend, security, braziliandevs | ## Introdução
No desenvolvimento web moderno, é comum que aplicações precisem interagir com recursos hospedados em diferentes domínios. No entanto, devido a preocupações de segurança, navegadores implementam uma política de mesma origem (Same-Origin Policy), que restringe como documentos ou scripts carregados de uma origem podem interagir com recursos de outra. O CORS (Cross-Origin Resource Sharing) é um mecanismo que permite que servidores indiquem de forma segura quais origens têm permissão para acessar seus recursos.
## O que é CORS?
CORS é um conjunto de cabeçalhos HTTP que permitem que um servidor indique quais origens são permitidas a acessar recursos no servidor. Quando uma aplicação cliente (como um navegador) faz uma solicitação a um recurso hospedado em um domínio diferente, o navegador envia uma solicitação de pré-verificação (preflight request) para o servidor, perguntando se a origem da aplicação tem permissão para acessar o recurso.
## Funcionamento do CORS
### Solicitação de Pré-Verificação (Preflight Request)
Para determinadas solicitações (especialmente aquelas que não são consideradas "simples"), o navegador primeiro envia uma solicitação de pré-verificação usando o método HTTP OPTIONS. Esta solicitação inclui cabeçalhos como:
- `Origin`: Indica a origem do pedido.
- `Access-Control-Request-Method`: O método HTTP que será usado na solicitação real.
- `Access-Control-Request-Headers`: Os cabeçalhos HTTP que serão enviados na solicitação real.
### Resposta à Pré-Verificação
O servidor responde à solicitação de pré-verificação com cabeçalhos que indicam se a solicitação real é permitida:
- `Access-Control-Allow-Origin`: Indica quais origens podem acessar o recurso. Pode ser um domínio específico ou um asterisco (*) para permitir todas as origens.
- `Access-Control-Allow-Methods`: Lista os métodos HTTP permitidos (como GET, POST, PUT, DELETE).
- `Access-Control-Allow-Headers`: Lista os cabeçalhos que podem ser usados na solicitação real.
- `Access-Control-Allow-Credentials`: Indica se as credenciais (como cookies) podem ser incluídas na solicitação.
- `Access-Control-Max-Age`: Indica por quanto tempo a resposta de pré-verificação pode ser armazenada em cache pelo navegador.
### Solicitações Simples
Solicitações consideradas "simples" pelo padrão CORS não exigem pré-verificação. Para uma solicitação ser simples, deve usar um dos métodos GET, POST ou HEAD e deve conter apenas cabeçalhos seguros como `Accept`, `Content-Type` (com certos valores), entre outros.
## Exemplos de Cabeçalhos CORS
### Configuração de um Servidor com Permissão para Uma Origem Específica
```http
Access-Control-Allow-Origin: https://example.com
Access-Control-Allow-Methods: GET, POST
Access-Control-Allow-Headers: Content-Type
```
### Configuração de um Servidor para Permitir Todas as Origens
```http
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, POST, PUT, DELETE
Access-Control-Allow-Headers: Content-Type
```
### Permissão para Credenciais
```http
Access-Control-Allow-Origin: https://example.com
Access-Control-Allow-Credentials: true
```
## Implementação no Lado do Servidor
### Exemplo em Node.js com Express
```javascript
const express = require('express');
const cors = require('cors');
const app = express();
const corsOptions = {
origin: 'https://example.com',
methods: ['GET', 'POST'],
allowedHeaders: ['Content-Type'],
credentials: true
};
app.use(cors(corsOptions));
app.get('/data', (req, res) => {
res.json({ message: 'This is CORS-enabled for https://example.com' });
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
```
## Conclusão
CORS é um mecanismo essencial para permitir interações seguras entre origens diferentes na web. Entender como configurar e utilizar CORS corretamente pode melhorar a segurança e funcionalidade das suas aplicações web. Espero que este artigo tenha esclarecido os fundamentos do CORS e fornecido um ponto de partida para sua implementação. | thiagohnrt |
1,869,755 | Introduction to API Design and Development with Swagger | Introduction API (Application Programming Interface) is the backbone of modern software... | 0 | 2024-05-30T00:31:55 | https://dev.to/kartikmehta8/introduction-to-api-design-and-development-with-swagger-5dfm | webdev, javascript, programming, beginners | ## Introduction
API (Application Programming Interface) is the backbone of modern software development, allowing different applications to communicate with each other. However, designing and developing an API can be a complex task. This is where Swagger comes in. Swagger is a tool that simplifies the process of designing and developing APIs, making it easier for developers to create high-quality APIs.
## Advantages
One of the main advantages of Swagger is its ability to provide a visual representation of the API structure. It allows developers to visualize the functionality of their APIs, making it easier to identify any potential issues.
Moreover, Swagger also generates interactive API documentation, making it easier for developers to understand and use the API. This reduces the learning curve and enables faster adoption by other developers.
## Disadvantages
One potential disadvantage of using Swagger is that it can be overwhelming for beginners. It has a steep learning curve and requires some technical knowledge to fully utilize its capabilities. Furthermore, since Swagger is open-source, it may not have all the features that some companies may require from their API documentation tools.
## Features
Apart from visual representation and interactive documentation, Swagger also has features such as automatic code generation, server stubs, and the ability to test APIs directly from the interface. It supports multiple programming languages, making it a versatile tool for developers.
### Example of Swagger in Action
```yaml
swagger: '2.0'
info:
title: Sample API
description: API description in Markdown.
version: 1.0.0
host: api.example.com
basePath: /v1
schemes:
- https
paths:
/users:
get:
summary: Returns a list of users.
responses:
200:
description: A list of users
schema:
type: array
items:
$ref: '#/definitions/User'
definitions:
User:
type: object
properties:
id:
type: integer
format: int64
name:
type: string
```
This example illustrates how Swagger can be used to define a simple API for retrieving a list of users, showcasing its user-friendly YAML configuration and clear structure.
## Conclusion
In conclusion, Swagger is a powerful tool that simplifies the process of API design and development. Its features and advantages make it a popular choice among developers. However, it also has some limitations that must be considered before implementation. Overall, Swagger is a valuable asset for any development team looking to create well-structured and well-documented APIs. | kartikmehta8 |
1,869,754 | Your App Idea Awaits: A Comprehensive Guide to Mobile App Development | App Ideas Brewing? Mobile Application Development – A Complete Intro Our world has global... | 0 | 2024-05-30T00:26:55 | https://dev.to/liong/your-app-idea-awaits-a-comprehensive-guide-to-mobile-app-development-10gj | mobileapps, ios, malaysia, kualalumpur | ## App Ideas Brewing? Mobile Application Development – A Complete Intro
Our world has global technology where everything is an app and apps run the planet. There is nearly an app for everything from ordering food to hailing a ride and managing finances to catching up with friends. See, we are using apps all the time for our needs. But how much do you know about how these tiny, pocket-sized devices are made? This post is for you if you have a fabulous app idea in your head. In this blog, you are going to get the idea of hacks and tips to make your very own app through [ Mobile Application Development ](https://ithubtechnologies.com/mobile-application-development/?utm_source=dev.to&utm_campaign=mobileapplicationdevelopment&utm_id=Offpageseo+2024)(MAD) scheme. Together, we are going to dive deep down into the vast ocean of mobile app development & make you aware of everything you need to bring your idea into this digital world.
## Check out the Mobile Application Development Process: from Brainstorm to Bonanza
While the result can sometimes seem like it, building a mobile app is not magic. This is a well-ordered process and each stage is important for making your app successful. Let me explain to you:
1. **Image and Creativity:** Here is where the magic begins! Find an issue you would like to address or a gap with which you can help. Is there a gap in the market? Where my app can help you with pain points You need to remember that outstanding apps solve a real problem with a laser-like focus on a very special audience.
2. **Planning and Strategy:** Do not start coding directly! This is where you develop your app's core capabilities, UI/UX, etc. Your app layout & user flow can be easily visualized by creating some wireframes. Study your competition and then set what differentiates from what is out there because this will help you to get an idea of what you think would make you unique from others.
3. **Designing for Delight:** Now that you know how your app should behave, we get to the fun part — designing what your app will look like! This is where user experience (UX) provides an answer. You also need to consider how your users will move through the app. How automatic and friendly will it be to use? An informative app that can be used on the go is one well-appreciated option but a likable and easy-to-use app truly wins over hearts.
4. **Development (Coding Your Brainchild):** The development part is where all the specialized magic happens, converting your designs and features into code that creates your app helper.
5. **Native Apps:** You should know that some apps are written natively because iOS and Android need two different coding platforms to get their apps.
6. **Cross-platform Apps:** Another is cross-platform app that includes the making of app for both the iOS and Android through one single code.
7. **Testing, Testing, 1, 2, 3!:** An important stage! Strict tests guarantee your application has no bugs, works smoothly, and offers an excellent user experience. This includes cross-testing on a variety of devices and operating systems to notice and resolve bugs.
8. **Deployment and Launch!:** Yay you made it! Your app is all set to be available on the app stores (Google Play Store and App Store) iOS. Happy app store descriptions, screenshots, and marketing materials.
9. **Ongoing Maintenance and Updates:** Work doesn't end once you launch! There are new features, bug fixes, and security patches you need to add to it regularly for your users to get used to them. Moreover, look at the user feedback & analytics to upgrade as per that and keep your app updated.
## Picking Your Path: Native vs. Cross-Platform Development
Previously as I mentioned above, you have a decision to make for your development. Native or cross-platform development? Allow me to explain to you more briefly:
**- Native Development:**
This means building standalone apps for Android as well as iOS using their native programming languages and tools. They offer excellent performance, a full device power key, and a truly native experience. However, it can cost more and take longer because of the extra tasks — creating two separate apps.
**- Cross-Platform Development:**
It is used to create one app that works on both Android and iOS using frameworks like react-native or Flutter. Cheap and a time save in development. That being said, there are some rules to fully access the device capabilities and performance would be less fluent than native apps.
## Preparing for Development
You're ready to start kicking arse with actual development then? Here are a few choices to think about:
1. **Learn to Code Yourself:**
If you are a DIY person, tons of online resources and coding boot camps can teach you the requisite programming languages such as Java (Android), Swift (iOS), or frameworks like React Native. But this road takes a lot of effort and time to achieve.
2. **Get Mobile App Development Company:**
This is the best approach for you if you are not a specialized person or do not have enough resources. Find a company that has your industry knowledge and history to suffer the plateau.
3. **Freelance Developers:**
This could be a more economical solution than hiring an agency. But screen freelancers properly to confirm they possess the specialized ability and experience you need for your project.
## Going App Happy: The Future is Mobile
The mobile application industry is moving very fast and smoothly due to mobile application development. Given the right idea and planning, performance too involves you in a wonderful circle in this space.
## Conclusion:
According to the above highlighted points, it can be concluded that mobile application development has been an important thing for people because without this no one would be able to entertain, raise, or do anything like that just under their fingertips. You can just click it and get everything started. whether you play games or set schedules, etc. Our lives are upgrading to the next level day by day so it's better to set ourselves on new mobile applications. Now, you can easily understand Mobile application development.
| liong |
1,869,745 | Tech Flash News of the Day: Microsoft Integrates Copilot AI Assistant into Telegram | Today's tech flash news brings an exciting update for all messaging app enthusiasts and productivity... | 0 | 2024-05-30T00:04:44 | https://dev.to/sai_esvarp/tech-flash-news-of-the-day-microsoft-integrates-copilot-ai-assistant-into-telegram-4i6 | Today's tech flash news brings an exciting update for all messaging app enthusiasts and productivity seekers. Microsoft has seamlessly integrated its AI assistant, Copilot, into Telegram. This integration is set to revolutionize how we interact and communicate on the platform.
Key Features of Copilot in Telegram
Message Summarization: No more scrolling through long threads. Copilot can now summarize lengthy conversations, making it easier to catch up on missed discussions.
Translation Services: Break language barriers effortlessly. Copilot's translation feature allows users to translate entire conversations in real-time, facilitating smoother communication with friends and colleagues worldwide.
Enhanced Productivity: With Copilot handling summarizations and translations, users can focus on more important tasks, boosting overall productivity and efficiency.
How to Access Copilot for Telegram
Getting started with Copilot on Telegram is straightforward:
Visit the Website: Navigate to the Copilot for Telegram website in your web browser.
Sign Up: Simply enter your phone number to sign up.
Free Prompts: Enjoy 30 free prompts to explore the capabilities of Copilot.
This integration is free for all users, ensuring that everyone can benefit from these advanced features without any cost barriers.
Impact and Benefits
Smart Messaging: Elevate your messaging experience with intelligent assistance.
Enhanced Communication: Whether for personal use or business communications, the translation and summarization features are invaluable.
Tech Innovation: This move underscores Microsoft's commitment to integrating AI into everyday tools, enhancing digital interactions for all users.
 | sai_esvarp | |
1,869,744 | Item 32: Seja criterioso ao combinar os genéricos com os varargs | Introdução: Métodos varargs e genéricos foram introduzidos no Java 5. Interação entre eles nem sempre... | 0 | 2024-05-30T00:04:01 | https://dev.to/giselecoder/item-32-seja-criterioso-ao-combinar-os-genericos-com-os-varargs-2llj | java, javaprogramming, javaefetivo, generics |
**Introdução:**
Métodos varargs e genéricos foram introduzidos no Java 5.
Interação entre eles nem sempre é pacífica devido a vazamentos de abstração.
1. **Problemas com varargs e genéricos:**
Criação de arrays para parâmetros varargs torna-se visível, resultando em advertências do compilador.
Tipos não reificados (parametrizados ou genéricos) causam advertências na declaração e invocação de métodos varargs.
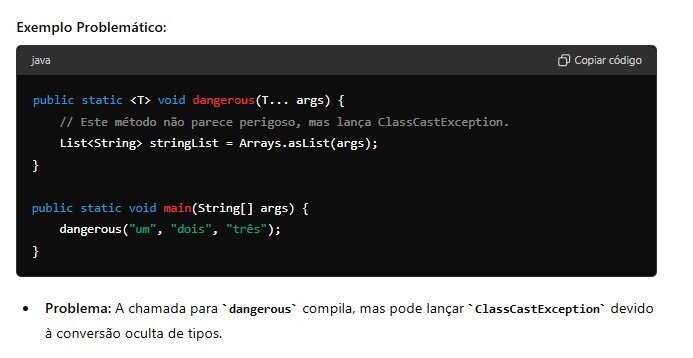
2. **Poluição do heap:**
Ocorre quando uma variável de tipo parametrizado referencia um objeto de outro tipo, podendo causar falhas de ClassCastException.
**Exemplo de problema:**
Um método aparentemente seguro pode falhar com ClassCastException devido a casts invisíveis gerados pelo compilador.
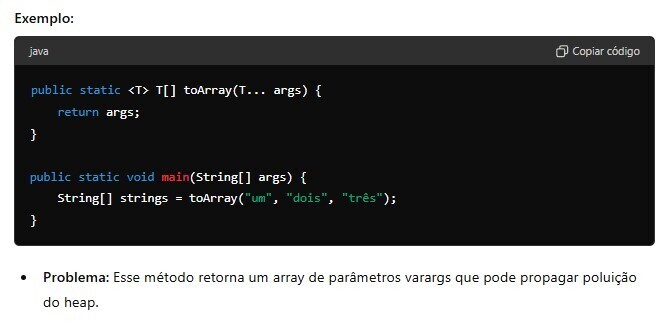
3. **Inconsistências permitidas:**
Métodos com parâmetros varargs genéricos são permitidos, apesar das inconsistências, devido à sua utilidade prática.
Exemplos de métodos seguros incluem Arrays.asList, Collections.addAll, e EnumSet.of.
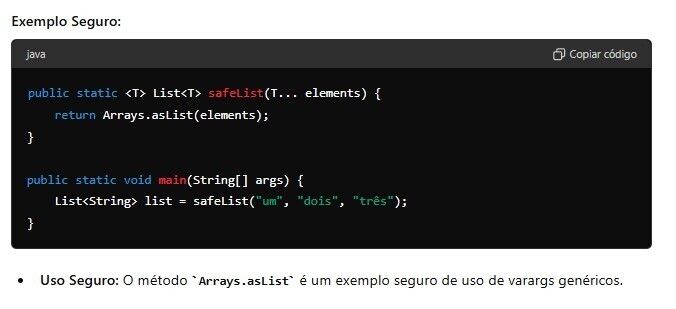
4. **Introdução do @SafeVarargs:**
Introduzido no Java 7 para suprimir automaticamente advertências de métodos varargs genéricos que são seguros.
Representa uma promessa do autor do método de que ele é seguro.
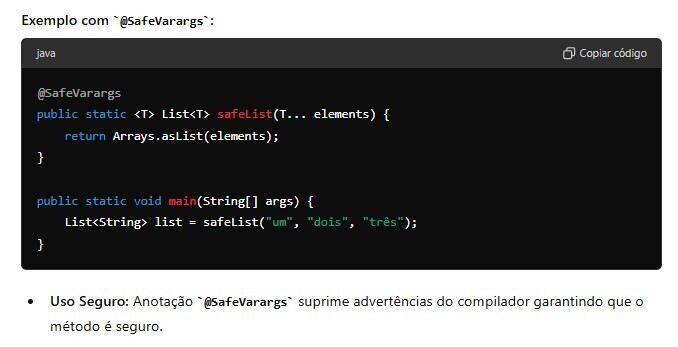
5. **Garantia de segurança:**
Não armazene nada no array de parâmetros varargs.
Não permita que referências ao array escapem para código não confiável.
**Exemplo de método perigoso:**
Métodos que retornam um array de parâmetros varargs podem propagar poluição do heap.
**Uso seguro de varargs:**
Passar arrays varargs para métodos adequadamente anotados ou que apenas calculam funções do conteúdo do array.
**Exemplo de uso seguro:**
Método que aceita várias listas e retorna uma lista contendo todos os elementos.
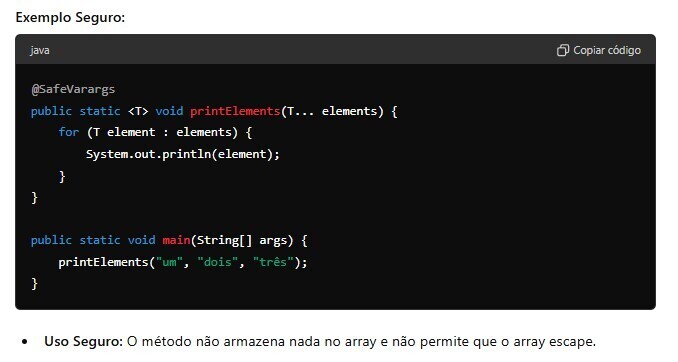
6. **Regras para @SafeVarargs:**
Use em métodos com parâmetros varargs genéricos para evitar advertências desnecessárias.
Métodos anotados devem ser estáticos ou finais (Java 8), ou privados (Java 9).
7. **Alternativa com List:**
Substituir varargs por List para provar que o método é seguro.
Pode resultar em código cliente mais verboso e ligeiramente mais lento.
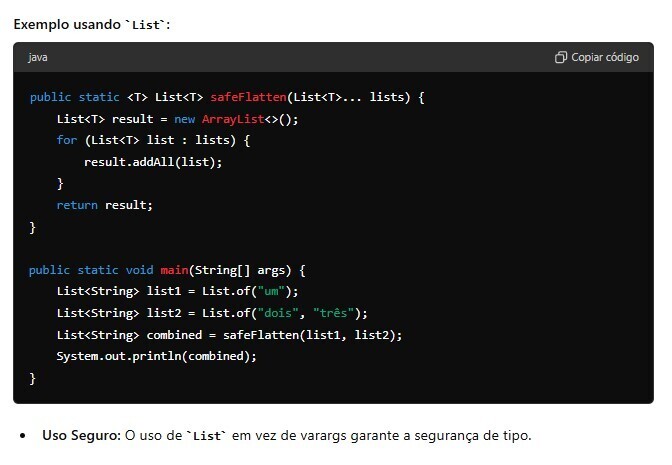
**Conclusão:**
Varargs e genéricos não interagem bem devido a vazamentos de abstração e diferenças nas regras de tipagem.
Garanta que métodos com parâmetros varargs genéricos sejam seguros e anote-os com @SafeVarargs.
Este resumo captura os pontos principais do artigo, destacando os problemas, soluções e boas práticas ao combinar varargs com genéricos no Java. | giselecoder |
1,869,738 | TS before React? | Should i learn typescript before learning react or after? | 0 | 2024-05-29T23:41:32 | https://dev.to/esimkus/ts-before-react-589a | typescript, react, webdev | Should i learn typescript before learning react or after? | esimkus |
1,869,734 | Fullstack Frameworks aren't worth it | Hey, I've been burned too many times by fullstack frameworks, and I just need to get this off my... | 0 | 2024-05-29T23:31:05 | https://dev.to/themuneebh/why-fullstack-frameworks-arent-worth-it-4o35 | webdev | Hey,
I've been burned too many times by fullstack frameworks, and I just need to get this off my chest. Here’s why they don’t work out for me:
1. **Frontend Frustrations**: These frameworks usually stick to basic HTML templates, and making even simple CRUD functionalities work is a huge pain. (Laravel, Django)
2. **Locked In**: Once you pick a framework, you’re stuck with it. It’s like being in a relationship that you can’t get out of.
3. **Team Nightmares**: Working with a team on these projects sucks because there’s no clear division of work, and it gets messy fast.
4. **External Dependencies**: Need authentication? You’ll have to look outside the framework, and it just adds more complexity. (Next.js)
5. **Feature Imbalance**: I’ve yet to find one that’s great for both frontend and backend. They always compromise on one side. (Laravel, Next.js)
6. **Scaling Woes**: Scaling and keeping things organized becomes a real headache. (Django)
7. **Mobile App Hassles**: If the client wants a mobile app, you’re out of luck. You can’t just serve HTML to mobile apps, so you end up building APIs separately.
8. **Performance Pains**: Dreaming of a fast app? Keep dreaming, because fullstack frameworks rarely hit the mark. (Django, Laravel)
9. **Stunted Learning**: You don’t get to learn much because these frameworks do so much for you, leaving you with little growth.
In the end, splitting up frontend and backend is way better. It’s more manageable, scalable, and just works better overall. Just my two cents based on way too many regrets! | themuneebh |
1,869,693 | DEPLOYING A WINDOWS SERVER VIRTUAL MACHINE RUNNING IIS | Let's start off by with the question What is IIS? Internet Information Services (IIS) is a flexible,... | 0 | 2024-05-29T23:28:38 | https://dev.to/himora22/deploying-a-windows-server-virtual-machine-running-iis-1in2 | azure, newbie, windowserver, cloud | Let's start off by with the question **What is IIS?**
**Internet Information Services (IIS)** is a flexible, general purpose Microsoft web server that runs on Windows operating system and is used to exchange static and dynamic web content. It is used to host, deploy and manage web applications using technologies like ASP.NET and PHP.
In this blog be deploying the following things with Microsoft Azure:
1. Create a windows Server with IIS installed
2. Create an Application Security Group (ASG) in the same region as your Server.
3. Go the Server's Network Security Group (NSG) and Add an inbound rule on port 80 and Port 443.
4. Create firewall and attach it to the Server's Vnet to secure your environment from malicious threats.
5. Copy your Public IP to a browser and ensure there is connectivity.
**Prerequisite**
First thing login to your Microsoft Azure Portal by going to https://portal.azure.com.
If you do not have an azure account sign up and create an account for free with this link https://azure.microsoft.com/en-us/free/. Registration will require a phone number and a debit or credit card details to validate your account even for the free account. You have a choice between the free or pay as you go account.
## Create a Windows Server with IIS installed.
**Step 1:** Go to the **search bar** at the top centre of the **Azure portal** and type **Virtual Machines**, then click it from the list of resources.

**Step 2:** Click **Create** on the Virtual machine page. From the drop-down menu click **Azure virtual machine**.
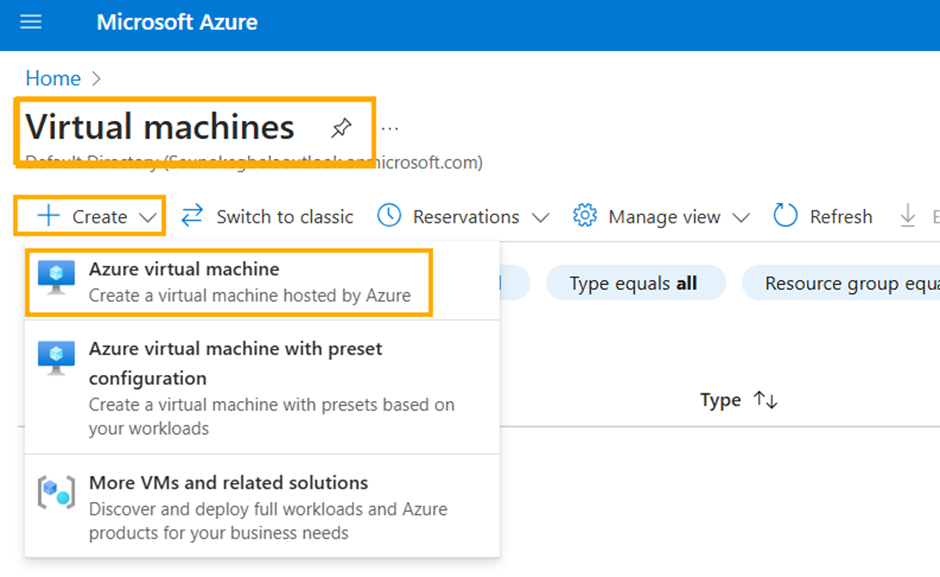
**Step 3: Project details**
- **Subscription:** Choose your subscription. Here we will be using the default Azure subscription, if you have others, you can select another.
- **Resource group:** We will be creating a new one for the purpose of this exercise. Select Create new and type a name and select OK.
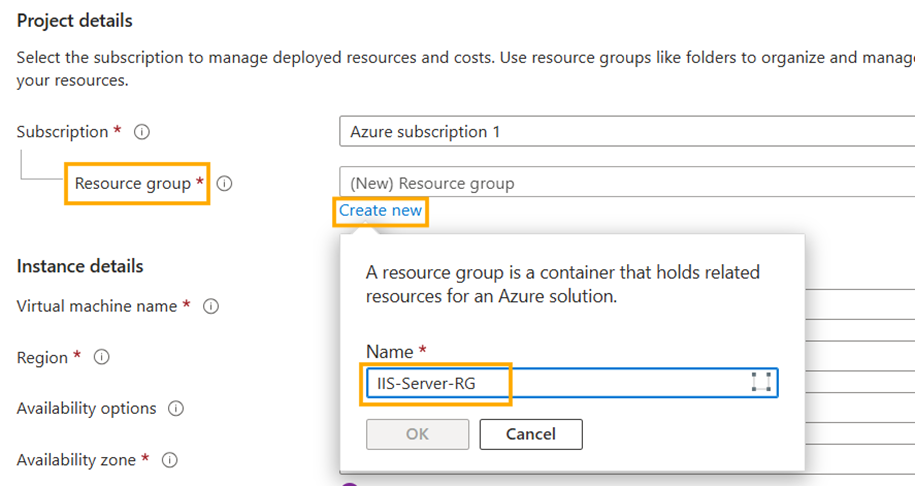
**Step 5: Instance details**
**-Virtual machine name:** Give your VM a name and it should be unique throughout the Azure network.
**- Region:** Select a location you want your VM, from the dropdown menu. [ A region is the geographical location with data centres that host services and infrastructures, with each operating independently and self-contained]
**- Availability options:** we leave on the default **Availability zone**.
**- Availability zone:** Select the zone or zones you would like your VM to be located
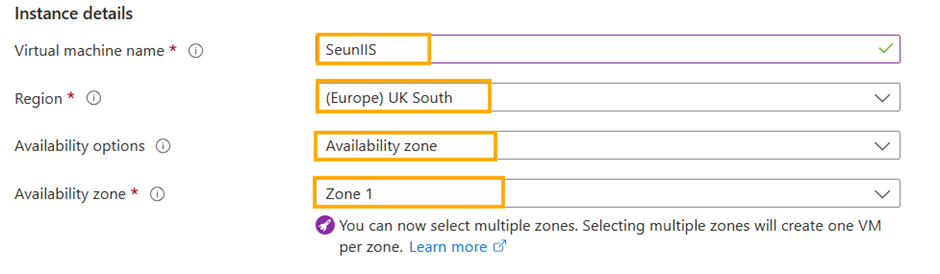
**- Security type:** We leave on the default **Trusted launch virtual machines**.
**- Image:** Select from the dropdown menu a **Window Server** image. I will be using the **Windows Server 2019 Datacenter x64 Gen2** for this exercise.

For this exercise leave the remaining setting as they are and follow the next steps below.
**Step 6: Administrator Account**
- **Username:** Name your administrator account
- **Password:** type your password and confirm the password
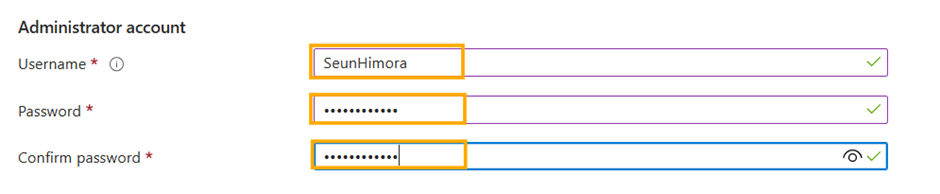
**Step 7: Network tab**
Click the **Networking** tab towards the top of the page ensure that your Network interface is populated especially the
**- Virtual network**
**- Subnet**
**- Public IP**
If the not populated, click the **Create new** underneath the blank boxes by Virtual network. Select the defaults and click **Ok**.
The fields then get populated. If yours was populated already then click **Review + Create**, at the bottom of the screen.
**Step 8:** When your **Validation passed** then click **Create** at the bottom right of the page.
**Step 9:** Once **Deployment** is completed Click **Go to resource**.

**Step 10:** **Connect** to your Windows Server virtual machine so we can install IIS. You do this by clicking **Connect** besides the **search bar** to the right of your page. A dropdown menu shows and click **Connect**.
- Click on the **Download RDP file**. Your browser may ask if you want to keep the file click **Keep/Save**.
- A **Remote Desktop Connection** pop up appears on your screen click **Connect**.
- Enter the **password** to your Windows Server and Click **Ok**.
- Another Remote Desktop Connection prompt appears on your screen click **Yes**.
Wait for the Virtual Machine to setup. You are now Logged into your Windows Server.
**Step 11: Installing IIS on our Windows Server.**
- Click on **Add roles and features** in the Server Manager.
- The **Add Roles and Features Wizard** comes up click **Next** to the get to **Installation Type**.
- Ensure **Role-based or feature-based installation** is selected and click **Next**.
- **Server selection** you should see the server you deployed. Select it and click **Next**.
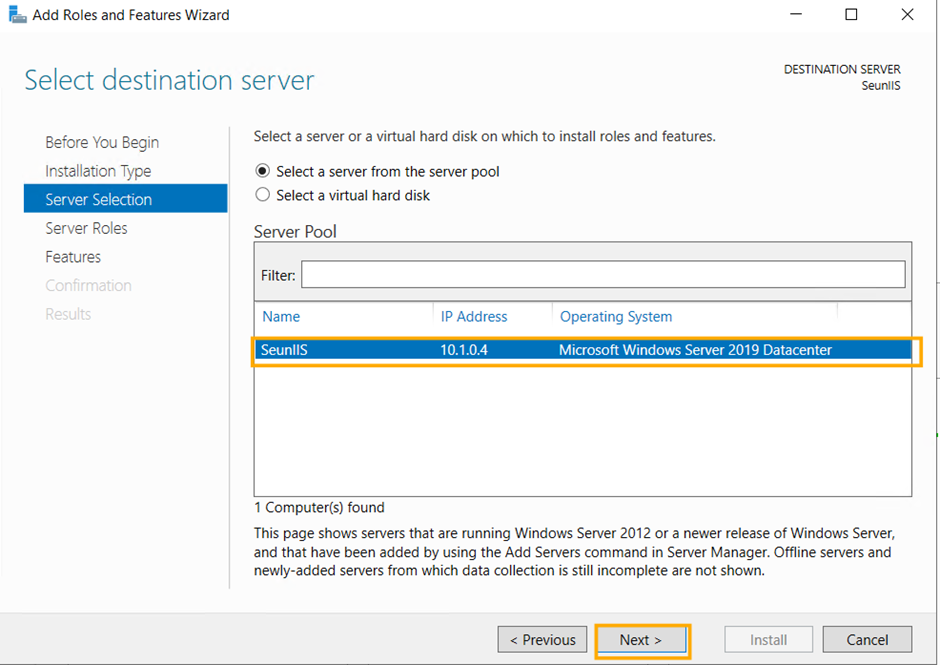
**Server Roles** scroll down the list of **Roles** till you see **Web Server (IIS)** check the box, a second window appears click **Add features** and click **Next**.
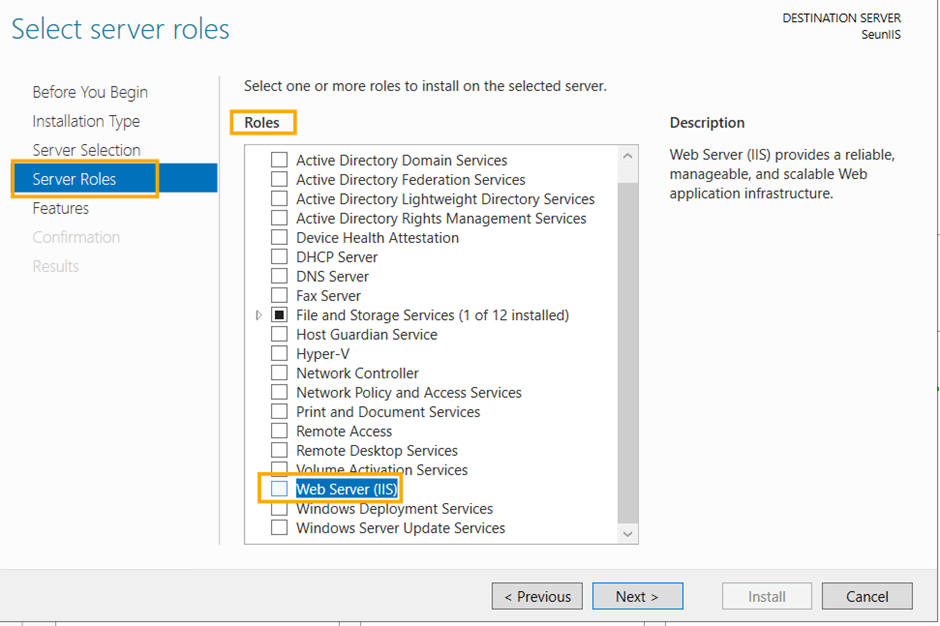
- Click **Next** till you get to **Confirmation** then you click **Install**.
While the installation process is going on open your Azure Portal on a **New Tab** on your web browser to Create an **Application Security Group (ASG)**.
## 2. Application Security Group (ASG)
**Step 1:** Search for a Application Security Group at the top centre search bar of your portal at click.

**Step 2:** Click **Create**
**Step 3:** In the **Create an application security group** page. Begin with the **Basics** and fill out the **Project details** and **Instance details**.
- **Subscription**: Select your Subscription
- **Resource group**: Select the resource group you created for this project from the deployment of the Windows Server Virtual Machine, from the dropdown menu.
- **Instance details**:
- **Name:** Give your Application Security Group a Name
- **Region:** Ensure the region is the same as that of your Windows Server Virtual Machine
- Click **Review + Create** at the bottom of the page.
- After the Validation is passed Click **Create** at the bottom left of the page.
- Once the Deployment is completed click **Go to resource**.
With this you have successfully created your Application Security Group. Now we will be creating a Network Security Group.
## 3. Network Security Group (NSG)
Go to the **Search bar** at the top of the portal page and search for **Network Security Group (NSG)** and click.
You will notice that Azure has already created a NSG for your server, so we go ahead with the creating inbound rule on port 80 and port 443.
**Add an inbound rule on port 80 and Port 443 in your Network Security Group (NSG)**
**Step 1:** Click on the Network Security Group Created.
**Step 2:** Go to **Inbound Security rules** at the right side of the page underneath **Settings** dropdown menu.
**Step 3:** Click **Add** to set a new rule for there to be Inbound access to our Server.
**Step 4:** **Adding Inbound security rule**. We will be changing only the following below
- **Destination:** Click the dropdown menu and select **Application security group**.
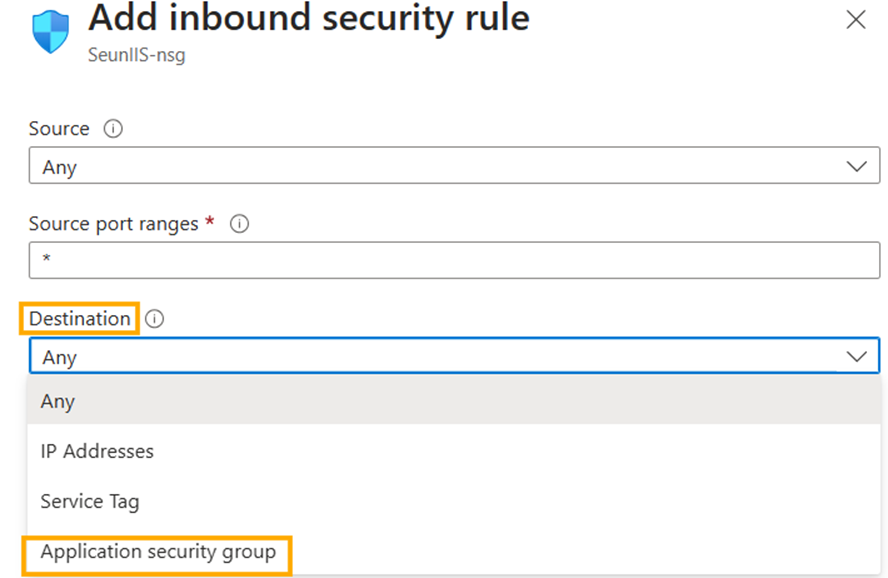
- A new option appears **Destination application security group**, from the dropdown menu select the application security group you created.
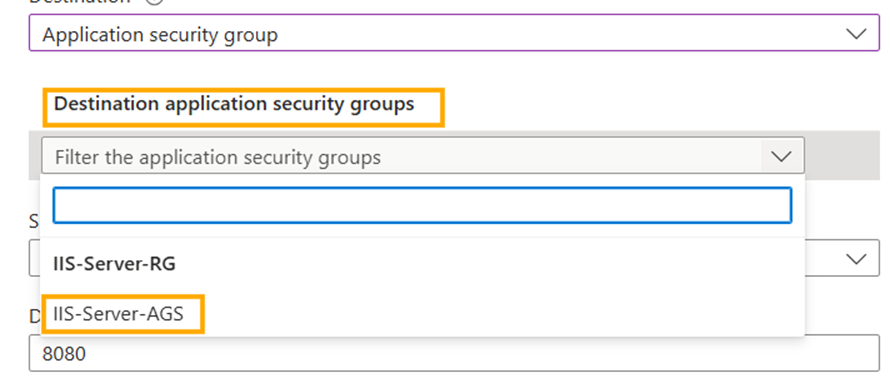
- **Destination port ranges:** change the ports to **80, 443 (for http and https ports)**.
- **Priority:** Scroll down to priority and change it to **100 or 150**. The lower the number the higher the priority it is given.
- **Name:** Give this rule a name.
- **Click Add**

You have added a new Inbound rule to your **Network security group**.
**Adding the Application Security Group to our Windows Server**
**Step 1:** Go to **Virtual Machine** through the **Search bar** at the top of the portal and go to the **Windows Server.**
**Step 2:** Go to **Application Security group** underneath the **Networking** menu, the click **Add** **application Security groups**.
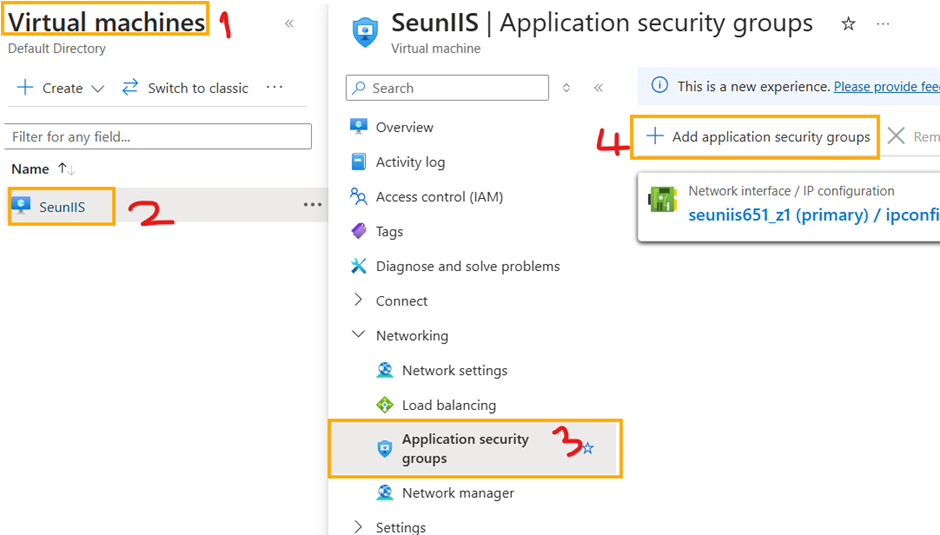
**Step 3:** A window opens and as long as you ensured you place everything in the same region the **Application Security Group** you created will appear as an option select it and click **Add**.
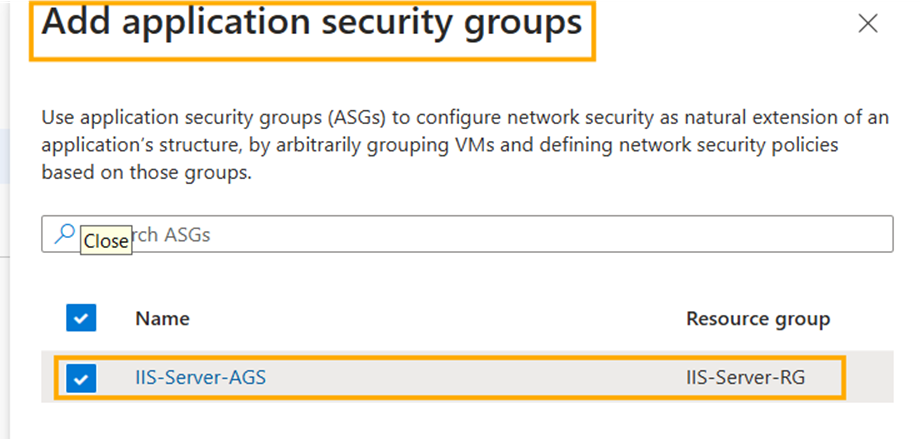
## 4. Create firewall and attach it to the Server's Virtual Network
**Step 1:** Search for **Firewall** in the **search bar** of the portal and click
**Step 2:** Click **Create**

**Step 3:** Create a firewall.
- **Subscription:** choose your subscription
- **Resource group:** Select the Resource Group from the dropdown menu you have been using for this project.
- **Name:** Give your firewall a name
- **Region:** It should be the same as your windows server
- **Availability zone:** same as your windows server
- **Firewall SKU:** Select Premium
- **Firewall policy:** Click Add new.
- **Policy name:** Give it a name.
- **Region:** it should be the same region as the Windows Server
- **Policy tier:** Select Premium
Click **Ok**
Before we can move forward and add **Virtual network** and **Public IP address**, we need to take a detour and create a **firewall Network subnet**.
I would suggest duplicating the tab or opening your azure portal in another tab and follow the steps below.
To Create a firewall subnet, go to the **Search bar** at the top of the portal and type **Virtual Network** and click.
Next Select your network of your Server
Below the Virtual Network Search go to Settings and select Subnets
Below the Virtual Network Search go to **Settings** and select **Subnets**.
Select **+Subnet** towards the right of the Virtual Network Search

In the Add a subnet window
- **Subnet purpose:** Select **Azure Firewall**.
- Leave it everything at the default and Click **Add**.
Now we can go back to the tab where we were about Create Azure Firewall. Refresh the tab and fill in the previous information In **Step 3** of **Creating Firewall** till we get to the point where we digressed to creating a subnet.
**Choose a virtual network:** Select Use existing.
**Virtual Network:** Select your Windows Server vnet
**Public IP address:** Click Add. Give it a name and click ok
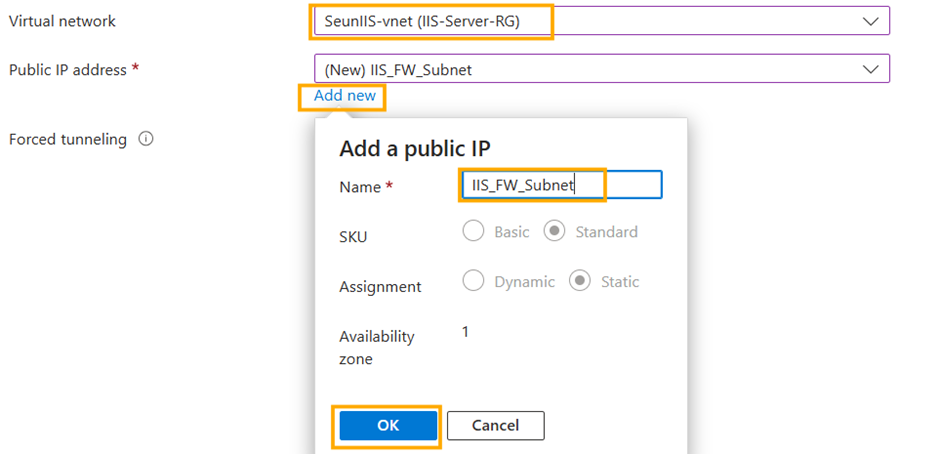
**Click Next:** **Tags >**, then **Next: Review + create>** then click Create all at the bottom of the portal
Your firewall is up and running.
## 5. Copy your Public IP to a browser and ensure there is connectivity.
Navigate back to the Tab with your Windows Server Virtual Machine. Copy the **Public IP address** of your Windows Server VM
Paste it in your browser.
A Windows Server Virtual Machine running IIS and secured it with a firewall on Microsoft Azure has just been deployed. Give it a try.
| himora22 |
1,869,733 | Stop worrying about payroll : Use HRM to automate your payroll | Rewards, let’s face it, this thing can be a huge pain in the future. This pain may include when we... | 0 | 2024-05-29T23:24:57 | https://dev.to/liong/stop-worrying-about-payroll-use-hrm-to-automate-your-payroll-nep | automation, hrm, malaysia, kualalumpur | Rewards, let’s face it, this thing can be a huge pain in the future. This pain may include when we are monitoring hours, counting taxes, and promising to pay all employees regularly, this can motivate even the most organized HR expert to hide behind their desk but if there is a way to give this process up, save your valuable time, and reduce the chances of error?
Here in this blog, you are going to explore the wonders of automatic payment in human resource management (HRM) systems!
You can automate your payroll using [HRM](https://ithubtechnologies.com/hrm-software-solutions/?utm_source=dev.to&utm_campaign=hrm&utm_id=Offpageseo+2024). Suppose that the payroll system works almost automatically at the click of a button, saving you hours of laboring over spreadsheets, giving most of your on these sheets, and hoping you didn’t miss out on the discount. You can think of this as an awesome option, right? The procedure of this system is as follows.
## The power of Combination: Convergence at the top of HR
The best working HRM can be explained with its payroll automation feature which lies in how it can be perfectly used and combined with your existing HR system. Think of it like the ultimate dream team – your HRM software collects all the employee data you need, from salary to discounts and benefits, and feeds it directly into the payment module. This stops the need to manually or practically enter data. When you manually enter data this would take so many hours of work that would cause tiredness, headache, shoulder pain, etc. But on the other side, this payment module of HRM not only saves you a ton of time but also reduces the chances of errors creeping in.
## Time on Your Side: Put the easy stuff into practice, do logical listening
Let’s be honest, when you are doing practical work like manually calculating taxes and deductions is not everyone’s idea of a good time. With HRM automation, you can ditch difficult formulas and let the software handle the heavy lifting. The HRM system is not just limited to providing us with its automatic features but also provides us with the automatic calculations part. This means that it automatically does all the calculations very quickly in doing it without wasting any time. The calculations are based upon federal and state income taxes, going to Social Security and Medicare contributions.
Let's say this, this includes more. Other repeatable tasks HRM may include are processing payroll, sending direct deposits, and paying for other related payroll taxes. This keeps you coming back to more strategic HR purposes like employee relations, talent management, and how best you can create a culture for an organization in which people have come in to change. You save time doing what matters, and your employees get paid accurately on time, every time. Win-win!
## 100 Percent Accuracy: Breathe Easier When Your Mistakes are Fewer
Human error is unavoidable. None of us can get around it — entering the wrong number of hours, forgetting to enter a deduction. And that's exactly what HRM automation takes care of your worries about. The system will handle all calculations and ensure they are completed correctly while keeping everything in a central place to avoid overpayments, underpayments, or the hassles that go along with them. Additionally, most HRM systems have audit tracks so you can track changes that take place and quickly confirm if there are any inconsistencies or problems.
## There are three main benefits included with: 'Compliance Made Easy. A Peace Of Mind For Everyone
This legislation is difficult to keep up with — the handle on payroll regulations is both constant and constantly changing. The good news here is that you can automate your payroll using HRM. Not only that but it can be customized to automatically track and calculate payroll taxes according to the most current regulations, keeping you ahead of the curve. It is capable of producing electronic tax reports and hence removes the process of filling them physically.
## Project: Securing Employee Data
I hope you appreciate the fact that it is quite important to keep secure. HRM systems provide data encryption and limited access to personal data, based on the permissions set by each user. Ensuring your employees' personal information is not viewed by anyone who should have unauthorized access to it. Likewise, by automating the communication of changing payroll information to employees in unique instances based on their records, employee notifications can also take place with many systems — further helping in reducing transactional conversations that IT staff is burdened with historically.
## The Bottom Line: Is an HRM with Payroll Automation Solution Right for You?
HRM with payroll automation benefits small businesses employing a few employees and larger organizations having complex payroll configurations. So before I say too much about it, here is a quick checklist for you to help decide:
1. Do you spend hours and hours on practical payroll tasks?
2. Are you concerned about having wrong payroll calculations?
3. Having trouble keeping up with changing tax laws?
If you have responded yes to any one of these questions, then an HRM with payroll automation might serve best as a solution for you. Investing in a human resource case management product is an investment that won't cost you time, money, or stress so you can focus on what matters: your employees.
## Ready to Take the Plunge?
The HRM systems world is big and scary at first, but these days, it is extremely simple to find a bundle that works well for your particular business company and even better — meets your small business's budget.
## Conclusion:
According to the above-highlighted points, it can be concluded that the HRM system has somehow eased our lives through its automatic payroll system. This has given us the idea that no need to worry now because you can get everything sorted out with the option to automate your payroll through HRM. Now, get rid of the spreadsheets and start embracing the new technology-you will thank me later.
| liong |
1,869,701 | The Transformative Power of AI: Shaping the Future of Our World | In the ever-evolving landscape of technology, one force has been steadily gaining momentum and... | 0 | 2024-05-29T23:17:04 | https://dev.to/ghp82601/the-transformative-power-of-ai-shaping-the-future-of-our-world-54db | ai | In the ever-evolving landscape of technology, one force has been steadily gaining momentum and capturing the global community's attention: Artificial Intelligence (AI). This revolutionary field has the potential to reshape the very fabric of our society, and the implications are both exciting and profound.
## The Rise of AI: A Technological Breakthrough
**[Breaking News](https://trendingnewsdiscussion.com/):** The rapid advancements in AI have been nothing short of astounding. From virtual assistants that can understand and respond to our natural language, to autonomous vehicles that navigate the roads with precision, the capabilities of AI are expanding at an unprecedented rate. This technological breakthrough has opened up a world of possibilities, transforming how we live, work, and interact with the world around us.
## Revolutionizing Industries: AI's Diverse Applications
The impact of AI can be seen across a wide range of industries, each one benefiting from the unique capabilities that this technology offers. In the healthcare sector, AI-powered diagnostic tools are helping to detect diseases earlier and with greater accuracy, while personalized treatment plans are being developed to improve patient outcomes. In the financial industry, AI algorithms are analyzing vast amounts of data to identify patterns and make informed investment decisions, revolutionizing how we manage our money.
## Enhancing Human Capabilities: The Symbiotic Relationship
One of the most fascinating aspects of AI is its ability to augment and enhance human capabilities. By taking on repetitive or labor-intensive tasks, AI frees up our time and energy, allowing us to focus on more creative and strategic endeavors. This symbiotic relationship between humans and machines has the potential to unlock new levels of productivity, innovation, and problem-solving.
## Ethical Considerations: Navigating the Challenges
As with any transformative technology, the rise of AI has also brought about a host of ethical considerations that must be addressed. Questions surrounding privacy, data security, and the potential displacement of jobs have sparked important discussions and debates. It is crucial that we approach the development and implementation of AI with a deep sense of responsibility, ensuring that the benefits of this technology are distributed equitably and that the risks are mitigated.
## The Future of AI: Endless Possibilities
Looking ahead, the future of AI is nothing short of captivating. Advancements in areas like natural language processing, computer vision, and deep learning are paving the way for even more remarkable breakthroughs. From the creation of intelligent personal assistants that can anticipate our needs, to the development of autonomous systems that can navigate complex environments, the potential of AI is truly limitless.
## Embracing the AI Revolution
As we stand on the cusp of this AI revolution, it is crucial that we embrace the transformative power of this technology. By investing in research, fostering innovation, and cultivating a skilled workforce, we can harness the full potential of AI to solve some of the world's most pressing challenges and improve the quality of life for people around the globe.
In conclusion, the rise of Artificial Intelligence is a testament to the ingenuity and creativity of the human mind. As we continue to push the boundaries of what is possible, we must remain vigilant, thoughtful, and committed to using this technology in a way that benefits all of humanity. The future is ours to shape, and with AI as our ally, the possibilities are truly endless. | ghp82601 |
1,869,700 | Before WWDC 2024: Reviewing Key SwiftUI Upgrades from 2019 to 2023 and Their Impact | When people reunite after a long absence, they are often surprised by the changes in each other;... | 0 | 2024-05-29T23:16:45 | https://fatbobman.com/en/posts/before-wwdc-2024/ | swift, swiftui, wwdc, ios | When people reunite after a long absence, they are often surprised by the changes in each other; however, the transformations in those who are with us day after day are often overlooked. In this article, I will sift through the key updates to SwiftUI that have made a significant impression on me since its first version. This is not only a reflection on the evolution of SwiftUI from its inception to its maturity but also a fresh appreciation of the vitality it embodies.
> Each update to SwiftUI has brought numerous new features and capabilities. In this text, I will focus primarily on those changes that have had a profound impact on me personally and discuss other frameworks and features closely related to SwiftUI and the Apple ecosystem, demonstrating how they collectively shape the platform we use today.
---
Don’t miss out on the latest updates and excellent articles about Swift, SwiftUI, Core Data, and SwiftData. Subscribe to [Fatbobman’s Swift Weekly](https://weekly.fatbobman.com) and receive weekly insights and valuable content directly to your inbox.
---
## 2019
Despite its initially limited functionality, the first version of SwiftUI showcased some core features—such as its declarative syntax, reactive mechanisms, and layout logic—that have persisted through today with almost no changes across multiple versions. This not only proves the thoughtful consideration Apple gave when designing SwiftUI but also highlights the forward-thinking nature of its philosophy and architectural design.
The framework's name itself illustrates the inseparable connection between SwiftUI and the Swift programming language, a relationship that has been continually strengthened and validated with each subsequent update. SwiftUI leverages the features and advantages of Swift, and conversely, the development of Swift has also been influenced to some extent by the evolution of the SwiftUI framework.
Released alongside SwiftUI was the Combine framework, which provides powerful control over asynchronous data streams. SwiftUI uses it to implement an observation mechanism for reference types. Combine has enabled Apple and third-party developers to conveniently transform existing APIs into reactive APIs that support SwiftUI. However, due to Combine's inability to offer high-precision observation capabilities, SwiftUI faced significant performance issues in certain scenarios, which were not addressed until the introduction of the Observation framework last year.
Also launched at WWDC 2019 was Core Data with CloudKit, giving new life to Core Data and offering a unique and powerful advantage for applications within the Apple ecosystem. Many developers have embraced Core Data, largely attracted by its convenient and free data synchronization capabilities.
Although the initial version of SwiftUI may seem naive from today's perspective, as a declarative and reactive framework introduced by Apple, it has fully demonstrated its uniqueness and potential.
## 2020
- **New Project Templates**: Xcode introduced new project templates for SwiftUI, allowing developers to more easily create complete app entries using the `App` and `Scene` protocols. Additionally, this update brought SwiftUI support for macOS development and introduced multi-window capabilities on iPad.
- **Numerous New Lazy Containers**: This version introduced a variety of lazy containers such as `LazyVStack`, `LazyHStack`, `LazyVGrid`, and `LazyHGrid`. These containers offer more flexible layout options and are natively implemented in SwiftUI, independent of any specific UIKit/AppKit components. Unfortunately, these native lazy containers still have some performance issues, and many developers are eager for the development team to resolve these soon.
- **@StateObject**: The introduction of `@StateObject` addressed the instability issues with the lifecycle of reference type instances that were previously observed with `@ObservedObject`.
- **onChange**: The `onChange` modifier enhances developers' ability to execute logic in response to specific state changes within views, further reinforcing SwiftUI's unique take on declarative programming. This includes embedding some lightweight imperative logic directly into the function-based UI declarations. Although this design philosophy has its pros and cons, it also provides unique advantages to SwiftUI.
- **Scrolling Positioning**: `ScrollViewReader` offers a method for positioning within scroll views using `id` and `anchor`, fully reflecting SwiftUI’s philosophy of layout: based on view identity and not reliant on absolute positioning.
- **Introduction of Widgets**: Starting with iOS 14, Apple introduced WidgetKit, a framework specifically designed for building widgets. WidgetKit requires developers to use SwiftUI to construct these widgets, a change that significantly encouraged developers who were initially hesitant about adopting SwiftUI to begin actively learning and using it.
> At WWDC 2020, Core Data with CloudKit introduced synchronization features for public databases, further expanding its potential for data management and multi-device synchronization.
Following WWDC 2020, SwiftUI now has the fundamental capabilities needed to build a complete application. In less complex application scenarios, developers can almost avoid using `UIViewRepresentable` to wrap UIKit components.
## 2021
- **Integration of the new concurrency model**: With the release of Swift 5.5, a new concurrency model was introduced to Swift. SwiftUI leverages the `task`, `task(id:)`, and `refreshable` modifiers to provide a convenient context for this new concurrent code, significantly simplifying the complexity of asynchronous programming.
- **Focus management based on view hierarchy**: With `@FocuseState`, SwiftUI not only completed the previously missing text input focus management features but also elevated focus management to a new level. Developers can now manage multiple focus transitions and detect focus states across the entire view hierarchy. This unified focus management feature left a profound impression on me as it not only fulfills basic functionalities but also provides an optimal solution in line with the philosophy of SwiftUI.
- **Integration of FormatStyle**: With the introduction of new Formatter APIs by Swift's Foundation, SwiftUI has supported these formatting interfaces in `Text` and `TextField` components. This allows developers to control the formatted input and output of text more conveniently through `FormatStyle`, greatly enhancing the expressiveness and readability of the code. However, there is currently a limitation in using `FormatStyle` in `TextField`: it cannot apply formatters in real-time during user input. This is an area where SwiftUI needs to improve in future versions.
- **Support for AttributedString**: The support for `AttributedString` in SwiftUI significantly enhanced the functionality and flexibility of the `Text` component for displaying text. This change provides developers with a more diverse range of text processing options, greatly enriching the user interface's expressiveness. However, despite the significant enhancements brought by `AttributedString`, there have been no similar-scale features introduced since its inclusion. More regrettably, `TextField` and `TextEditor` still do not support `AttributedString` to this day, limiting these controls' ability to handle complex text formats.
- **Dynamic modification of fetch conditions**: This update introduced the ability to dynamically adjust fetch conditions in `@FetchRequest`, allowing developers to modify conditions without needing to create additional wrapper views. However, the `@Query` property wrapper introduced for SwiftData in 2023 does not yet have this capability.
> At WWDC 2021, Core Data with CloudKit introduced data sharing capabilities, completing the three major features of Core Data with CloudKit.
It can be said that in 2021, the many enhancements SwiftUI received were closely related to the updates of Swift and Swift Foundation that year.
## 2022
- **Layout Protocol**: The introduction of the `Layout` protocol not only provided developers with the ability to create custom layout containers but also deeply demonstrated SwiftUI's layout mechanism based on negotiation. This protocol has enhanced developers' understanding of SwiftUI's layout logic. The new `Grid` component, as well as existing layout components such as `VStack` and `HStack`, have been updated to conform to the `Layout` protocol and support `AnyLayout`, significantly increasing layout flexibility. Currently, the `Layout` protocol does not support the creation of lazy containers; we look forward to future versions expanding and refining this capability.
- **New Programmatic Navigation**: `NavigationStack` and `NavigationSplitView` introduced a new programmable navigation system, fundamentally improving previous limitations with SwiftUI navigation. This change has led many developers to set the minimum system requirements for SwiftUI projects to iOS 16 to utilize these new navigation features.
- **Swift Charts**: Apple's introduction of the Swift Charts framework for SwiftUI has set new standards in the industry for construction methods, visual effects, and integration with SwiftUI. In its second-year update, the framework added more chart types and support for interaction, further extending its functionality. Swift Charts has now become a top choice for chart applications within the Apple ecosystem, enhancing the significance and practicality of SwiftUI itself.
- **Enhanced macOS Support**: This version significantly improved support for macOS, particularly in handling `WindowGroup` as well as `Settings` and `MenuBarExtra`. From this version onward, SwiftUI's capabilities in building macOS applications have been substantially enhanced.
The updates in 2022 brought many significant improvements to SwiftUI, especially the `Layout` protocol and the new navigation system, which have profound implications for the future development of SwiftUI applications.
## 2023
- **New Observation Framework**: With the release of Swift 5.9, the newly introduced Observation framework provides the ability to observe properties of observable objects, fundamentally solving the issue of excessive invalid updates in SwiftUI views caused by insufficient precision in Combine observations. The full adoption of Observation has significantly improved application efficiency. Moreover, this update has simplified the declaration and injection of state in SwiftUI; developers can now manage various states simply using `@State` and `Environment`, without relying on Combine.
- **Revolutionary Upgrades in Animation and Visual Effects**: The 2023 update brought a range of innovative features to SwiftUI, including animation completion callbacks, phase animations, keyframe animations, and new Transition and Shape protocols, along with support for Shaders. These features have significantly enhanced developers' freedom in creating animations and visual effects. The newly introduced `animation` and `visualEffect` modifiers use closures to provide clearer logic handling, effectively reducing the impact on upstream and downstream components of the view tree, guiding the future development of SwiftUI view decorators.
- **Comprehensive Enhancement of Scrollable Containers**: Scrollable containers have also been enhanced with many new features, such as scroll indicators, margin adjustments, scroll clipping, and advanced scrolling capabilities independent of `ScrollViewReader`. Although these individual features might not seem prominent, their collective appearance certainly sparks speculation: could this be laying the groundwork for a major update to lazy container functionalities in the future?
- **SwiftData**: The long-awaited SwiftData was finally released, serving as the successor to Core Data. Its code-based modeling approach and tight integration with the Observation framework make it the most suitable data management framework for the SwiftUI era. If the upcoming WWDC 2024 still does not introduce a feature similar to `NSFetchedResultsController` for external data retrieval (real-time change detection) in SwiftData, it will further confirm Apple's strategic decision to position SwiftUI as the sole UI framework for the future, accelerating this transition.
- **visionOS**: With the launch of Apple Vision Pro, it has become the only hardware platform in the Apple ecosystem where native application development exclusively supports SwiftUI. This change indicates that the Apple Vision Pro team will use SwiftUI to build more native applications, a development eagerly anticipated by developers. The widespread adoption of SwiftUI by Apple's official team will promote rapid iteration in fixing issues, enhancing performance, and introducing new features in the framework. I look forward to seeing more official applications developed using SwiftUI on iOS and macOS platforms at this year's WWDC 2024.
2023 has become a pivotal year in the development of SwiftUI, with the introduction of the Observation framework and SwiftData, among other innovative technologies, helping to cement its status as a mainstream development platform.
## Looking Ahead to WWDC 2024
In an era where AI becomes a mainstream trend, how will SwiftUI leverage the powerful momentum of AI to achieve breakthrough improvements? At the upcoming WWDC 2024, which will be held in two weeks, I believe we will witness more exciting transformations.
Let's all look forward to the surprises that WWDC 2024 will bring!
> The original article was published on my blog [Fatbobman's Blog](https://fatbobman.com/en/).
| fatbobman |
1,869,699 | Gossip RorApp, Basic Example Social App Next.js Nest.js | Hello, I would like to share the latest PWA I have developed. It is a basic example of a social... | 0 | 2024-05-29T23:15:33 | https://dev.to/ror2022/gossip-rorapp-basic-example-social-app-nextjs-nestjs-1n7p | nestjs, nextjs, pwa, api | Hello,
I would like to share the latest PWA I have developed. It is a basic example of a social network created with Next.js and deployed on Vercel. The API is built with Nest.js and deployed on Railway.
This application includes essential features of a social network, such as user profile creation, message posting, and the ability to like posts.
Technologies used:
Next.js: Used for the frontend, providing a fast and efficient user experience.
Nest.js: Used for the backend, offering a robust and scalable structure for the API.
Vercel: Platform used to deploy and host the frontend easily and efficiently.
Railway: Used to deploy and manage the backend, leveraging its ease of use for integrations with databases and external services.
I have learned a lot during the development of this PWA, from implementing basic functionalities to optimizing for optimal performance. I hope you find this project interesting, and I am open to any feedback or suggestions you may have.
Thank you for your time!
vercelLinkApp: https://clientchismografo.vercel.app/
clientCodeLink: https://github.com/ROR2022/clientchismografo
serverCodeLink: https://github.com/ROR2022/serverchismografo
portfolioLink: https://prodigy-wd-05-kappa.vercel.app/#/portfolio
rorCVLink: https://docs.google.com/document/d/104ek8dOTdOU6RcDMtGT-g1T--FWxq2earIDvMZoQ79E/edit?usp=sharing | ror2022 |
1,869,697 | A minigame of spacecrafts and learning | Hey everyone! I'm super excited to share my first experience with you all as an internship. Today, I... | 0 | 2024-05-29T23:09:35 | https://dev.to/angeljrp/a-minigame-of-spacecrafts-and-learning-443m | Hey everyone!
I'm super excited to share my first experience with you all as an internship. Today, I delved into the world of game development, tasked with creating a mini-game for our upcoming collection of games. And let me tell you, it's been quite the journey already!
Today, I rolled up my sleeves and delved into the world of game development, all in service of creating an engaging experience for our audience. With our game, not only do we aim to entertain, but we also want to sneak in some learning too. Picture this: a space-themed game for two players, reminiscent of the classic Space Invaders. But here's the twist - instead of shooting down aliens, players have to navigate their little spacecraft through space to collect floating numbers. Why? Well, to solve equations, of course! It's an exciting way to engage kids with math concepts in a fun and interactive way.
However, like any project, I hit a roadblock. You see, I've been grappling with adapting the game mechanic for mobile devices. Specifically, I'm struggling to figure out how to make the player's spacecraft draggable on a phone screen. I've tinkered with some code, but alas, it's not quite behaving as expected. It moves, but not in the way I want it to - it hovers on top of the screen and doesn't quite reach where it's supposed to go.
This is what i used for this problem:
```
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class TouchControl : MonoBehaviour
{
//Public Variables
public GameObject player1;
public GameObject player2;
//A modifier which affects the rackets speed
public float speed;
//Fraction defined by user that will limit the touch area
public int frac;
//Private Variables
private float fracScreenWidth;
private float widthMinusFrac;
private Vector2 touchCache;
private Vector3 player1Pos;
private Vector3 player2Pos;
private bool touched = false;
private int screenHeight;
private int screenWidth;
// Use this for initialization
void Start()
{
//Cache called function variables
screenHeight = Screen.height;
screenWidth = Screen.width;
fracScreenWidth = screenWidth / frac;
widthMinusFrac = screenWidth - fracScreenWidth;
player1Pos = player1.transform.position;
player2Pos = player2.transform.position;
}
// Update is called once per frame
void Update()
{
//If running game in editor
#if UNITY_EDITOR
//If mouse button 0 is down
if (Input.GetMouseButton(0))
{
//Cache mouse position
Vector2 mouseCache = Input.mousePosition;
//If mouse x position is less than or equal to a fraction of the screen width
if (mouseCache.x <= fracScreenWidth)
{
player1Pos = new Vector3(-3.70f, Mathf.Clamp(mouseCache.y / screenHeight * speed, -3, 3.5f), 0.5f);
}
//If mouse x position is greater than or equal to a fraction of the screen width
if (mouseCache.x >= widthMinusFrac)
{
player2Pos = new Vector3(15.75f, Mathf.Clamp(mouseCache.y / screenHeight * speed, -3, 3.5f), 0.5f);
}
//Set touched to true to allow transformation
touched = true;
}
#endif
//If a touch is detected
if (Input.touchCount >= 1)
{
//For each touch
foreach (Touch touch in Input.touches)
{
//Cache touch position
touchCache = touch.position;
//If touch x position is less than or equal to a fraction of the screen width
if (touchCache.x <= fracScreenWidth)
{
player1Pos = new Vector3(-3.70f, Mathf.Clamp(touchCache.y / screenHeight * speed, -3, 3.5f), 0.5f);
}
//If mouse x position is greater than or equal to a fraction of the screen width
if (touchCache.x >= widthMinusFrac)
{
player2Pos = new Vector3(15.75f, Mathf.Clamp(touchCache.y / screenHeight * speed, -3, 3.5f), 0.5f);
}
}
touched = true;
}
}
//FixedUpdate is called once per fixed time step
void FixedUpdate()
{
if (touched)
{
//Transform rackets
player1.transform.position = player1Pos;
player2.transform.position = player2Pos;
touched = false;
}
}
}
```
But fear not! This is where you all come in. I'm reaching out to our amazing community for any suggestions or ideas on how to tackle this challenge. Whether you're a seasoned developer or just have a knack for problem-solving, I'm all ears!
So, if you've got any thoughts or insights to share, please don't hesitate to drop them in the comments below. Together, I'm confident we can crack this code and create something truly special.
Thanks for joining me on this adventure, and stay tuned for more updates on my internship journey! | angeljrp | |
1,869,698 | Blocking unsafe open source dependencies in pull requests with Minder and OSV.dev | Using data from the open source OSV.dev project and other sources, Minder can now block pull requests... | 0 | 2024-05-29T23:07:46 | https://dev.to/ninfriendos1/blocking-unsafe-open-source-dependencies-in-pull-requests-with-minder-and-osvdev-28f2 | opensource, security, tutorial | Using data from the open source [OSV.dev](https://osv.dev/) project and other sources, Minder can now block pull requests that contain malicious and deprecated packages, so that they can’t inadvertently be merged into your code.
Most teams today use vulnerability scanners to find CVEs in their open source dependencies. While avoiding dependencies with known vulnerabilities is important, these scanners may neglect to flag malicious or deprecated packages that don’t have any CVEs, even though these packages may pose an even greater threat to your supply chain.
Read the full article by Yolanda Robla & Adolfo "Puerco" García Veytia [here](https://stacklok.com/blog/blocking-unsafe-oss-dependencies-minder-osv)

| ninfriendos1 |
1,869,696 | Implementing a Security Screen Overlay in Flutter | In mobile application development, security and privacy are paramount. One common security feature is... | 0 | 2024-05-29T23:01:38 | https://dev.to/adepto/implementing-a-security-screen-overlay-in-flutter-24g2 | In mobile application development, security and privacy are paramount. One common security feature is the ability to obscure or blur the app's screen when it is minimized or sent to the background. This ensures that sensitive information is not visible when the app is not actively being used. In this article, we will explore how to implement such a feature in a Flutter application.
**Prerequisites**
To follow along with this tutorial, you should have:
- A basic understanding of Flutter and Dart.
- Flutter installed on your development machine.
- A Flutter project set up.
## Step-by-Step Guide
Step 1: Set Up Your Flutter Project
If you haven't already set up a Flutter project, you can do so by running the following commands:
```
flutter create security_overlay_app
cd security_overlay_app
```
Open the project in your preferred IDE or code editor.
## Step 2: Add Dependencies
Ensure you have the necessary dependencies in your pubspec.yaml file. For this tutorial, we will use the default Flutter dependencies.
```
dependencies:
flutter:
sdk: flutter
```
## Step 3: Create a Stateful Widget
Create a StatefulWidget that will observe the app lifecycle changes. This widget will handle showing and hiding the security screen.
```
import 'package:flutter/material.dart';
void main() {
runApp(MyApp());
}
class MyApp extends StatefulWidget {
@override
_MyAppState createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> with WidgetsBindingObserver {
bool _isInBackground = false;
@override
void initState() {
super.initState();
WidgetsBinding.instance.addObserver(this);
}
@override
void dispose() {
WidgetsBinding.instance.removeObserver(this);
super.dispose();
}
@override
void didChangeAppLifecycleState(AppLifecycleState state) {
setState(() {
_isInBackground = state == AppLifecycleState.paused;
});
}
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Stack(
children: [
HomeScreen(),
if (_isInBackground)
Positioned.fill(
child: Container(
color: Colors.white,
child: Center(
child: Text(
'App in Background',
style: TextStyle(fontSize: 24, fontWeight: FontWeight.bold),
),
),
),
),
],
),
);
}
}
```
## Step 4: Implement the Lifecycle Observer
In the _MyAppState class, we implement the WidgetsBindingObserver to listen to app lifecycle changes. Specifically, we are interested in when the app goes to the background (i.e., when the AppLifecycleState is paused).
## Step 5: Overlay a Security Screen
Using a Stack widget, we overlay a security screen when the app is in the background. The Stack widget allows us to layer widgets on top of each other. We conditionally display a white container with a "App in Background" message when _isInBackground is true.
## Step 6: Create the Home Screen
For demonstration purposes, we'll create a simple HomeScreen widget that represents the main content of the app.
```
class HomeScreen extends StatelessWidget {
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text('Home Screen'),
),
body: Center(
child: Text('This is the home screen'),
),
);
}
}
```
## Step 7: Run the App
Run the app using the following command:
```
flutter run
```
When the app is running, minimize it or send it to the background. You should see the security overlay appear, obscuring the app's content.
Customizing the Security Screen
You can customize the security screen to match your app's branding and design requirements. For example, you can replace the plain white container with a blurred background or an image. Here's an example with a blurred background:
```
import 'dart:ui';
...
if (_isInBackground)
Positioned.fill(
child: BackdropFilter(
filter: ImageFilter.blur(sigmaX: 5.0, sigmaY: 5.0),
child: Container(
color: Colors.white.withOpacity(0.5),
child: Center(
child: Text(
'App in Background',
style: TextStyle(fontSize: 24, fontWeight: FontWeight.bold),
),
),
),
),
),
```
Conclusion
In this article, we've learned how to implement a security screen overlay in a Flutter application. This feature helps protect sensitive information by obscuring the app's content when it is not actively being used. By using the WidgetsBindingObserver and a Stack widget, we can effectively manage app lifecycle changes and display a customized security screen. Feel free to extend and customize this implementation to suit your app's specific needs.
Happy coding!
| adepto | |
1,869,694 | ELISABET PAGA MESMO? SAIBA TUDO SOBRE ESSA PLATAFORMA | O Melhor Cassino do Brasil: Um Guia Completo Embora os cassinos físicos sejam proibidos no Brasil... | 0 | 2024-05-29T22:55:15 | https://dev.to/pedrosilva/elisabet-paga-mesmo-saiba-tudo-sobre-essa-plataforma-129c | O Melhor Cassino do Brasil: Um Guia Completo
Embora os cassinos físicos sejam proibidos no Brasil desde 1946, o interesse por jogos de azar nunca desapareceu. Com a crescente popularidade dos cassinos online, jogadores brasileiros agora podem desfrutar de uma experiência de cassino de alta qualidade diretamente de suas casas. Este artigo explora o melhor cassino online do Brasil, considerando fatores como segurança, variedade de jogos, bônus oferecidos, atendimento ao cliente e métodos de pagamento.
Segurança e Licenciamento
A segurança é a principal preocupação para qualquer jogador ao escolher um cassino online. O melhor cassino online do Brasil deve possuir licenciamento de uma autoridade respeitável, como a Malta Gaming Authority (MGA) ou a UK Gambling Commission (UKGC). Além disso, deve utilizar criptografia SSL para proteger as informações pessoais e financeiras dos jogadores. Um exemplo de cassino que atende a esses critérios é o [Betway ](https://go.aff.elisa.bet/nd30b3s8)Casino, conhecido por seu forte compromisso com a segurança e a justiça nos jogos.
Variedade de Jogos
A diversidade de jogos é um fator crucial na escolha do melhor cassino online. Os jogadores brasileiros procuram uma ampla gama de opções, desde caça-níqueis e jogos de mesa, como blackjack e roleta, até jogos ao vivo com crupiês reais. O [LeoVegas](https://go.aff.elisa.bet/nd30b3s8) Casino é amplamente reconhecido por sua vasta seleção de jogos, incluindo títulos populares de desenvolvedores renomados como NetEnt, Microgaming e Evolution Gaming.
Bônus e Promoções
Os bônus são uma parte essencial da experiência de cassino online. Eles atraem novos jogadores e mantêm os existentes engajados. O [888 Casino](https://go.aff.elisa.bet/nd30b3s8) é um dos líderes em oferecer generosos pacotes de boas-vindas, rodadas grátis e promoções contínuas que beneficiam tanto novos jogadores quanto veteranos. É importante, no entanto, que os jogadores leiam os termos e condições para entender os requisitos de aposta associados a esses bônus.
Atendimento ao Cliente
Um excelente atendimento ao cliente é vital para resolver qualquer problema que os jogadores possam encontrar. O melhor cassino online do Brasil deve oferecer suporte 24/7 através de múltiplos canais, incluindo chat ao vivo, e-mail e telefone. O [Royal Panda](https://go.aff.elisa.bet/nd30b3s8) Casino é frequentemente elogiado pela qualidade do seu atendimento ao cliente, oferecendo respostas rápidas e soluções eficazes para os jogadores.
Métodos de Pagamento
A conveniência e a segurança dos métodos de pagamento são essenciais. Os jogadores brasileiros valorizam a disponibilidade de métodos de pagamento locais, como o boleto bancário, além de opções internacionais como cartões de crédito, carteiras eletrônicas e transferências bancárias. O [NetBet](https://go.aff.elisa.bet/nd30b3s8) Casino é um excelente exemplo de plataforma que oferece uma vasta gama de opções de pagamento, incluindo métodos específicos para o Brasil.
Conclusão
Escolher o melhor cassino online do Brasil envolve considerar vários fatores, desde segurança e variedade de jogos até bônus, atendimento ao cliente e métodos de pagamento. Enquanto cassinos como [Betway](https://go.aff.elisa.bet/nd30b3s8), [LeoVegas](https://go.aff.elisa.bet/nd30b3s8), [888 Casino](https://go.aff.elisa.bet/nd30b3s8), [Royal Panda](https://go.aff.elisa.bet/nd30b3s8) e [NetBet](https://go.aff.elisa.bet/nd30b3s8) se destacam em diferentes aspectos, a escolha final depende das preferências individuais de cada jogador. Com a regulamentação em expansão e a tecnologia avançando, a experiência de cassino online para jogadores brasileiros está cada vez mais segura e emocionante.
De todas a melhor é a [Elisabet clique aqui e faça o seu cadastro](https://go.aff.elisa.bet/nd30b3s8) | pedrosilva | |
1,864,265 | Event Listeners in Javascript | Javascript is a great tool to make it so that the webpage can come alive. One way to do this in... | 0 | 2024-05-29T22:35:11 | https://dev.to/spencer_adler_880da14d230/event-listeners-in-javascript-489f | javascript, event, listeners | Javascript is a great tool to make it so that the webpage can come alive. One way to do this in Javascript is using event listeners. Event listeners allow the user to interact with the webpage in real time.
The event listener listens for an event to happen and then runs a callback function to do an actions. The event listener is added on an element in which an event will happen.
The event listener is set up in a way that even if the function is anonymous it will still be run. The event listener knows to run the function in the 2nd argument when the event takes place.
Typically the parameter of the function in an event listener is named event or e. Then an array of attributes is produced when the event happens and those items can be gathered by creating a variable that takes the target of the event and stores it.
Some frequently used event listeners are clicks, submits, DOMcontent loaded, and buttons. So more unique and less frequently used event listeners are ones related to the mouse's location.
An example of an event listener in Javascript can be seen below:
(In the HTML there would be a button element that had the ID of button.)
const button= document.getElementById('button');
button.addEventListener('click', function() {
alert('This button was clicked!');
});
What this code does is when the button is click a message appears on the top of the page that says. This page says: This button was clicked! To get out of that alert the user presses the ok button.
| spencer_adler_880da14d230 |
1,869,692 | Understanding the Significance of Scrap Metal Recycling | In a world where sustainability has become a necessity, understanding the significance and benefits... | 0 | 2024-05-29T22:32:55 | https://dev.to/joeskowronski/understanding-the-significance-of-scrap-metal-recycling-3cci | In a world where sustainability has become a necessity, understanding the significance and benefits of scrap metal recycling is vital. The process of recycling helps transform our waste into resources, with [scrap metal recycling](https://www.google.com/maps?cid=4051046722413302896) playing an integral part in promoting environmental conservation and economic development.
Exploring the Process of Scrap Metal Recycling
Scrap metal recycling involves several distinct steps that ensure the end material is safe for reuse or production of new products. It begins with collection, where individuals or businesses gather discarded metal from various sources such as homes, construction sites, and factories. After collection, sorting comes next - distinguishing ferrous metals like iron and steel distinct from non-ferrous ones such as copper and aluminum.
The sorted metals then undergo processing which includes compaction for easy transportation and melting down to liquid form suitable for molding into desired shapes. Finally, purification ensures no toxic substances persist while solidification molds the purified, molten metal into ingots ready for manufacture.
Encouraging Economic Growth Through Scrap Metal Recycling
A well-established scrap metal recycling industry can stimulate local economies by generating jobs and contributing to national revenue. Industry growth results from heightened demand for recycled materials which are typically cheaper than virgin resources thus tempting manufacturers. Moreover, riddance of waste metals in yards frees up space better used for other economic activities while avoiding expensive landfill fees.
Promoting Environmental Conservation
Scrap metal recycling boasts significant environmental benefits forming key components to sustainability discussions worldwide. By using recycled scrap instead of virgin ore mining extraction in manufacturing processes we conserve invaluable natural resources subsequently limiting destructive environmental impacts from mining operations.
Utilization of recycled materials also mandates less energy usage due to not requiring raw resource extraction plus processing - acting double-edged by also decreasing harmful emissions into the atmosphere generating a cleaner environment overall.
Reducing Landfill Wastes
Around 25% of solid waste in the U.S. ends up in landfills, an issue scrap metal recycling can mitigate. Landfills present various environmental problems, such as toxic runoff which potentially contaminated water sources making the reduction of landfill wastes essential to preserving ecosystem health.
The durability of metal means it doesn't decompose readily and instead accumulates over time inevitably consuming vast landfill spaces. Consequently, recycling metals repurposes services once destined for dumpsites curbing this issue.
In summary, scrap metal recycling tends to be discounted despite its monumental significance in promoting economic growth and sustainability while preserving the Earth's precious natural resources. It is a practice that all should recognize and participate in - after all, our planet's future ultimately depends on our actions today. So let’s rally behind scrap metal recycling; a small effort from each individual contributes massively towards shaping a greener world for generations to come.
**[Greenway Metal Recycling, Inc.](https://www.greenwaymetalrecycling.com/)**
Address: [512 W. Burlington Ave., LaGrange, IL, 60525, US](https://www.google.com/maps?cid=4051046722413302896)
Phone: 773-558-2216 | joeskowronski | |
1,868,975 | What is OpenTofu? | In this post, we will explore OpenTofu, its features, and basic commands. We will also answer some of... | 0 | 2024-05-29T12:52:59 | https://spacelift.io/blog/what-is-opentofu | devops, opentofu, terraform, infrastructureascode | In this post, we will explore OpenTofu, its features, and basic commands. We will also answer some of the most important questions about OpenTofu that we have seen on different channels.
##What is OpenTofu?
[OpenTofu](https://opentofu.org/) is a fully open-source Terraform fork, a drop-in replacement for Terraform version 1.6 that is backward compatible with all prior versions of Terraform. It's a viable alternative to HashiCorp's Terraform that will expand on Terraform's existing concepts and offerings.
OpenTofu is an open-source Infrastructure as Code (IaC) tool that enables you to define, preview, and apply infrastructure changes across multiple cloud providers. It uses declarative OpenTofu language to manage infrastructure resources.
It was created by the initiative of OpenTF supported by Gruntwork, Spacelift, Harness, Env0, Scalr, and other companies as a response to [HashiCorp's license changes to the BSL](https://spacelift.io/blog/hashicorps-license-change) in August 2023. OpenTofu was forked from Terraform version 1.5.6. and retained all the features and functionalities that had made Terraform popular among developers, while also introducing improvements and enhancements. The project [is now a part of the Linux Foundation](https://spacelift.io/blog/opentofu-joins-the-linux-foundation), with the ultimate goal of joining the Cloud Native Computing Foundation (CNCF).
The first stable version of OpenTofu was released in January 2023 (read [here](https://spacelift.io/blog/opentofu-stable-ga-release)), and recently, [OpenTofu has released its 1.7 version](https://spacelift.io/blog/opentofu-1-7). The latest OpenTofu version comes packed with new features, enhancements, and bug fixes that aim to elevate the user experience, improve overall functionality, and boost your infrastructure as code management.
##Why was OpenTofu created?
OpenTofu was created to ensure the Terraform ecosystem continues to flourish into the future. It was created by the OpenTF initiative in response to [HashiCorp's license change to the BSL](https://spacelift.io/blog/terraform-license-change).
The new licensing terms for Terraform, specifically the Business Source License (BSL) and HashiCorp's additional use grant, make it difficult for companies, vendors, and developers using Terraform to know whether what they are doing is allowed or not under the license.
Hashicorp's FAQs offer some reassurance to end users and system integrators for now, but questions arise over the implications of the licensing terms for future usage. The potential for changes to the company's definition of *"competitive"* or "*embedding*" or further modifications to the license to make it a closed source creates uncertainty for Terraform users.
We strongly believe that Terraform should stay open-source, as it is a project used by many companies, and many people have contributed to getting Terraform where it is today. Terraform wouldn't be as successful as it is without the community's effort in building many supporting projects around it.
##History of OpenTofu
The history of OpenTofu (originally named OpenTF) started on August 10th, 2023, when [HashiCorp announced](https://www.hashicorp.com/blog/hashicorp-adopts-business-source-license) that going forward they will be changing the license on their core products, including Terraform, to a Business Source License (BSL). Unlike the Mozilla Public License (MPL v2) that their products were previously licensed under, BSL is not an open source license. While it still allows similar freedoms for individuals to use, share, and modify, it places restrictions on various forms of commercial use.
Since the announcement of the license change there has been a tumultuous amount of activity, speculation and discussion about the future of Terraform and what can be done to not lose such a precious and important asset. As a result, in the true spirit of our community, many companies and individuals have come together in unison to act as one under the umbrella of OpenTF (currently OpenTofu).
On August 15th, OpenTF [released its manifesto](https://opentofu.org/manifesto/). The manifesto lays out OpenTFs intent and goals and sets out a roadmap to ensure the continued survival of Terraform as an open-source tool.
The [OpenTofu initiative](https://opentofu.org/) was launched with significant initial support, boasting over 18 full-time equivalents (FTEs) committed to the project from four companies. The manifesto has been endorsed by over 140 companies, involving 11 projects with the participation of over 700 individuals. Moreover, the manifesto has received more than 35,000 GitHub stars, and the fork itself has garnered over 6,000 stars in just one week.
On September 5th, [OpenTofu officially published the fork](https://spacelift.io/blog/opentf-fork-is-now-public), and on September 20th, [the project officially joined the Linux Foundation](https://spacelift.io/blog/opentofu-joins-the-linux-foundation).
Joining the Linux Foundation is significant because it provides OpenTofu with a stable and well-respected organizational home. This move ensures that the project remains independent and avoids the risk of being controlled or influenced by a single company, which is a concern that many in the open-source community share.
##What are the differences between Terraform and OpenTofu?
Right now, there are not many differences between Terraform and OpenTofu, related to functionality. However, one of the biggest differences that can be easily observed is that OpenTofu listens to the community.
A couple of years ago, there were many requests for Terraform to support state encryption. This was especially requested because everything that went into the state file is in a plain-text format. For reasons that nobody knows, this feature was not implemented in Terraform, even though it was crucial for many companies that were using it. OpenTofu has released state encryption in its 1.7 version, fixing one of the biggest pains that users had with Terraform.
Apart from this, OpenTofu prioritizes feature implementation based on the community's input. There is an issue ranking system in place that you could take advantage of and ensure that the most relevant features are getting implemented.
##OpenTofu features
OpenTofu has many features that help your overall infrastructure as code journey:
1. **Open-source and community-driven** - the fact that OpenTofu is open-source means that everyone can contribute with code/documentation/ideas to improve the tool. With OpenTofu, you can ensure your voice is heard, and the most important features will be implemented.
2. **Execution plan** - OpenTofu execution plan outlines the actions that will be taken on your infrastructure without doing the actual changes. This provides an opportunity to understand what will happen and make decisions accordingly.
3. **Encrypted state management** - OpenTofu is stateful, keeping track of your infrastructure using a state file (that can be optionally encrypted) and ensuring that infrastructure changes are applied consistently.
4. **Provider ecosystem** - Vast ecosystem making OpenTofu work with a variety of providers (cloud, containers, databases, etc.).
5. **Modules and reusability** - OpenTofu is developed to give you the flexibility to create reusable components.
💡 You might also like:
- [Best DevOps Automation Tools](https://spacelift.io/blog/devops-automation-tools)
- [What is Infrastructure Automation?](https://spacelift.io/blog/infrastructure-automation)
- [Top 10 Terraform Alternatives](https://spacelift.io/blog/terraform-alternatives)
##Basic OpenTofu commands
Here is a list of the most useful OpenTofu commands:
- `tofu init` - Initilializes your working directory, downloading your modules, and preparing it to run other commands
- `tofu plan` - Creates an execution plan based on your configuration, showing you the resources that will be created, changed, or deleted
- `tofu apply` - Applies changes (create/modify/delete) to your infrastructure resources
- `tofu destroy` - Destroys all the infrastructure resources that were deployed using your configuration
- `tofu validate` - Checks if your configuration is valid
- `tofu show` - Shows the current state
- `tofu state` - Helps you do advanced state management
##How to get started with OpenTofu - Tutorial
These are the steps you need to take to get started and become professional with OpenTofu:
1. Install OpenTofu.
2. Get familiar with the basic components:
1. **Providers** - will help you authenticate to the cloud provider/service you want to use with OpenTofu
2. Resources - describe your infrastructure services/components as code
3. **Data sources** - use existing infrastructure services/components
4. **Variables** - parametrize your configuration
5. **Outputs** - view the value of specific components
6. **Local variable** - assign a value to an expression
7. **Modules** - reusable configurations
8. **State** - OpenTofu is stateful, keeping track of your infrastructure changes using a state file
3. Write your OpenTofu code.
4. Plan/Apply/Destroy - view an execution plan of what will happen based on your code, apply the infrastructure changes, and after you don't need the resources anymore, destroy them.
5. Get familiar with advanced concepts:
1. Loops and conditional statements (for_each, count, for, if, ternary)
2. Dynamic blocks
3. Test feature
4. Variable validations
6. Integrate with a dedicated infrastructure management platform like Spacelift.
Check out our [OpenTofu tutorial](https://spacelift.io/blog/opentofu-tutorial) to learn more.
##Why should you use OpenTofu?
Key advantages of using OpenTofu instead of Terraform:
- Open-source nature - There are no restrictions on how you can use OpenTofu, either for commercial or personal use. The open-source nature of OpenTofu embodies the principles of openness and collaboration that characterize the tech community.
- Dynamic community - Developer contributions will make the project more robust and adaptable to different use cases. Bugs and issues will be identified and resolved quickly to ensure reliability and stability.
- Fast, reliable support - The growing community behind OpenTofu not only gives everyone the opportunity to influence the development of new features, but it also supplies the resources to ensure these features and bug fixes will be introduced rapidly.
- Minimal risk - OpenTofu is published under MPL and is a part of the Linux Foundation (with the goal of joining CNCF), which provides the guarantee the tool remains truly open-source, forever.
Read more: [Why Should You Switch to OpenTofu?](https://spacelift.io/blog/why-should-you-switch-to-opentofu)
##Common questions about OpenTofu
Let's answer some of the most important questions about OpenTofu that we have seen in different channels.
### What is OpenTofu used for?
OpenTofu is used for managing your infrastructure as code and works with various cloud providers (AWS, Microsoft Azure, Google Cloud, etc.), databases (MongoDB, PostgreSQL, MySQL, etc.), version control systems (GitHub), container orchestration (Docker, Kubernetes, Rancher, etc.), and more.
### Is OpenTofu production ready?
Yes. OpenTofu is production-grade and is suitable for production use without any exceptions. There is no need to enter any separate, individually negotiated agreements regarding the production use of the tool.
### Is OpenTofu stable?
OpenTofu is stable, and the latest stable release is [1.7](https://github.com/opentofu/opentofu/releases/tag/v1.7.0). Being a member of the Linux Foundation provides peace of mind that OpenTofu will remain stable and continue to grow and improve.
### How can I migrate from Terraform to OpenTofu?
Migrating from Terraform to OpenTofu involves a simple binary change in your pipeline, replacing Terraform with OpenTofu.
If you are running Terraform locally, which is something we don't recommend, you can simply add the OpenTofu binary in your PATH, and both OpenTofu and Terraform can co-exist if that is something you want.
To learn more on how to migrate from Terraform to OpenTofu, watch this short [video tutorial](https://www.youtube.com/watch?v=FbPmicb3Wpg).
OpenTofu remains a drop-in replacement for its predecessor Terraform™ 1.5, and has easy migration paths from later versions. Check out the overhauled [migration guides](https://opentofu.org/docs/intro/migration/) for detailed migration instructions. You can find the full list of changes and comprehensive examples [in the documentation](https://opentofu.org/docs/intro/whats-new/).
### Is OpenTofu using the same registry as Terraform?
OpenTofu has its own registry, and its implementation can be found [here](https://github.com/opentofu/registry/). The OpenTofu CLI uses the module and provider registry protocols to discover modules and providers.
### Can OpenTofu use Terraform providers and modules?
OpenTofu is compatible with existing Terraform providers and modules. This means that any provider that works with Terraform can also be used with OpenTofu.
### What providers are supported by OpenTofu?
OpenTofu supports a wide range of providers that enable it to interact with various tools, services, and APIs. The [Public OpenTofu Registry](https://github.com/opentofu/registry/tree/main/providers) hosts providers for most major infrastructure platforms. For example, OpenTofu works with all cloud vendors such as AWS, Azure, or GCP, as well as other platforms like Kubernetes, Helm, VSphere, and Spacelift.
### Will OpenTofu work with my existing state file?
OpenTofu works with an existing state file, up to state files created with a version prior to Terraform's 1.5.x.
### Is OpenTofu going to keep pace with the upstream Terraform releases? How will this evolve?
No, the short answer is that OpenTofu will most likely not keep pace with upstream Terraform releases. The community will dictate what they need and want to see in OpenTofu.
Some of the Terraform features you've been waiting for ages are now available with the [1.7.0 version of OpenTofu](https://spacelift.io/blog/opentofu-1-7).
### Who owns OpenTofu?
OpenTofu is a part of the [Linux Foundation](https://spacelift.io/blog/opentofu-joins-the-linux-foundation) following the same management structure as other projects within the Linux Foundation. The OpenTofu team submitted it's [CNCF application in early 2024](https://github.com/cncf/sandbox/issues/81). Once its accepted the project and the associated trademarks will be donated to CNCF.
### Who is behind OpenTofu? Are there any big organizations backing OpenTofu?
OpenTofu is backed and supported by an enormous community of large companies, projects, and individuals. The founding companies and initial maintainers of OpenTofu are Spacelift, Harness, Gruntwork, Env0, and Scalr.
The current community size behind the OpenTofu initiative:
- Almost 144 Companies
- Over 10 Projects
- Over 718 Individuals
The [manifesto repository](https://github.com/opentofu/manifesto) has over 36k stars.
[OpenTofu's repository](https://opentofu.org/) has over 20k stars.
Numerous engineers from various companies, including some that compete with each other, have collaborated over the past week to bring OpenTofu to life. OpenTofu is a part of the Linux Foundation. Having a foundation responsible for the project ensures the tool stays vendor-neutral.
### Where does the OpenTofu name come from?
The name had to be short, as there are many commands engineers need to run, and not all of them are keen on setting up aliases in the CLI. At the same time, choosing a name for any kind of business is a hard deal, so choosing something easy to remember and building a great logo will take you a long way.
### What is the future of OpenTofu?
The future of OpenTofu is in the hands of the community. Being under the Linux Foundation's umbrella, OpenTofu will continue to be open-source and listen to the community's feedback.
### What new features can we expect from OpenTofu?
In the last few months [since the first stable release](https://spacelift.io/blog/opentofu-stable-ga-release) the OpenTofu community and the core team have worked hand in hand to bring functionality to OpenTofu that has been requested for years. The latest OpenTofu version (1.7) comes packed with new features, enhancements, and bug fixes that aim to elevate the user experience, improve overall functionality, and boost your infrastructure as code management. Read more about OpenTofu 1.7 [here](https://spacelift.io/blog/opentofu-1-7).
OpenTofu is first and foremost a community-driven project. Priorities can shift based on the community's voice, so you can request features and create RFC's to implement them.
You can always check the [milestones](https://github.com/opentofu/opentofu/milestones), the [issue ranking system](https://github.com/opentofu/opentofu/issues/1496), [LinkedIn](https://www.linkedin.com/company/opentofuorg/) or [X](https://twitter.com/OpenTofuOrg/) accounts, to see what kind of features are coming up from OpenTofu.
##Using OpenTofu with Spacelift
Spacelift supports OpenTofu out of the box, giving you the ability to easily build your OpenTofu workflows. From the UI, when you are creating a stack you just need to choose the Terraform/OpenTofu vendor and select OpenTofu as your workflow tool. You can then choose the OpenTofu version you want to run, and enable/disable some other options.

As OpenTofu works out of the box with Spacelift, you can easily take advantage of all of the features Spacelift offers, such as:
- Plan, approval, push, and notification policies -- control what kind of resources engineers can create, what kind of parameters they can have, how many approvals you need for runs, what kind of tasks engineers can run, what happens when a PR is opened/merged, and where to send notifications
- Drift detection and optional remediation
- Multi-infrastructure workflows with dependencies and shareable output (easily combine, for example, OpenTofu and Ansible, and whenever you are creating a new virtual machine, send the ip/hostname to the Ansible inventory as a dependency and then trigger the Ansible stack)
- Native integrations with AWS, Microsoft Azure, and Google Cloud for dynamic credentials
- Integrations with any third-party tools and the ability to build custom policies for them via custom inputs
- Self-service infrastructure via blueprints
##Key points
OpenTofu is the future of the Terraform ecosystem, and we plan to do everything right. We care about the community, and we care about having a truly open-source project to support your IaC needs.
If you want the best possible experience with OpenTofu, [create a free account](https://spacelift.io/free-trial) with Spacelift or [book a demo](https://spacelift.io/schedule-demo) with one of our engineers to help you elevate your OpenTofu workflow.
_Written by Flavius Dinu._ | spacelift_team |
1,591,587 | A Compendium of Gen-Z Terminology in Technical Contexts | Slang and Emoji from the younger generations. | 0 | 2024-05-29T22:20:54 | https://dev.to/yonkeltron/a-compendium-of-gen-z-terminology-in-technical-contexts-49k3 | slang, humor, satire | ---
title: A Compendium of Gen-Z Terminology in Technical Contexts
published: true
description: Slang and Emoji from the younger generations.
tags: slang, humor, satire
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-08-12 19:19 +0000
---
I wonder if others like me, other non-sociologists, also find the whole notion of a [generation](https://en.wikipedia.org/wiki/Generation#List_of_social_generations) irrelevant. Seems that more folks use generational designations to broadly label, disrespect, or deride others. So I (an elder-millenial, for those looking to label) would prefer to tell you how much my Gen-Z colleagues have taught me. Hopefully, when others have the chance to develop the appreciation I have gained.
To facilitate this, I have collected yet another list of terms used by my contemporaries. However, thre are two differences. One difference is that I only include that which I have personally experienced. The other is that these expressions have been presented specifically in the context of technology and computing.
Any essential expressions which are missing, are missing because I've never run into them myself.
## Expressions of Words and Speech
<dl>
<dt>Bye</dt>
<dd>
A response to something exceedingly humorous, as if to say something is so funny that a politely exiting the situation is one's only reprieve.
</dd>
<dt>Cap / No Cap</dt>
<dd>
A lie. One might use this as others might say "for real" or "honestly" as in the example "That code worked on my machine, no cap!"
</dd>
<dt>Dead</dt>
<dd>
When someone says "I'm dead" they wish to indicate they have experienced extreme laughter or amusement. Seems to descend from the expression "<a href="https://en.wikipedia.org/wiki/Death_from_laughter" target="_blank">died laughing</a>".
</dd>
<dt>Drag</dt>
<dd>
To harshly criticize to the point of insult. A self-deprecating example might be "Thank goodness I have ESLint to drag my code."
</dd>
<dt>Extra</dt>
<dd>
Intense or otherwise noticable, usually positive. Can be used sarcastically in sentences such as "With so much company surveillance software on my computer, no wonder the fan is always extra."
</dd>
<dt>FR</dt>
<dd>
Voiced or written abbreviation for "for real".
</dd>
<dt>Gatekeep</dt>
<dd>
To hoard useful knowledge. This differs from its previous usage of denying others' belonging in a given group.
</dd>
<dt>Here for it</dd>
<dd>
Used to indicate a satisfactory approval such that it is, alone, enough motivation to justify one's presence.
</dd>
<dt>High-Key and Low-Key</dt>
<dd>
Either way this is an admission of approval or adoration in the face of relative distate within a given social group. It might be used conspiratorially to express an unpopular opinion "I low-key love Java". Alternatively you can use it as a proud declaration of enthusiasm in opposition to the conventional wisdom when saying "I high-key think Windows is right for this".
</dd>
<dt>Hits different</dt>
<dd>
If something hits different, it is uniquely positive. You may here it as "I thought Python had great docs but the Rust documentation hits different."
</dd>
<dt>I love that for you</dt>
<dd>
This term indicates both sincere and personal enthusiasm. It may be paired with a compliment in phrases such as "You are so good at explaining algorithms. I love that for you!" Though, it may also be used alone as a compliment.
</dd>
<dt>IYKYK</dt>
<dd>
An abbreviation, usually written, for "if you know, you know". This most often refers to insider knowledge or understanding, but could also highlight the presence of an <a href="https://en.wikipedia.org/wiki/In-joke" target="_blank">in-joke</a>.
</dd>
<dt>Jail</dt>
<dd>
Strong disapproval in response to learning of something undesirable. It most likely originated as shorthand for "that's so terrible, it should be imprisoned". If you were to tell how a cloud platform deleted virtual machines without warning, you might hear the "jail" in response.
</dd>
<dt>Main Character / Main Character Energy</dt>
<dd>
A person who has main character energy has become, positively, the center of attention. Someone who is the prime mover of, or instigator in, a situation.
</dd>
<dt>MFRN / MFW</dt>
<dd>
Written abbreviations for "my face right now" and "my face when". Always coupled with a graphical depiction such an expressive emoji, GIF, or other image.
</dd>
<dt>Obsessed</dt>
<dd>
A spoken declaration of enthusiastic approval usually sprinkled throughout conversation. Those who hear it may safely <a href="http://clhs.lisp.se/Body/f_mexp_.htm" target="_blank">macroexpand</a> it to "I'm obsessed with that". It could be used in the same way as someone listening would say "uh-huh" or "go on" to informally confirm that their attention remains focused on the speaker.
</dd>
<dt>Sending me</dt>
<dd>
Used to indicate when someone or something induces amusement, as in "Our tech lead's source comment in the integration code absolutely sent me."
</dd>
<dt>Sheesh</dt>
<dd>
An exclamation that someone is "looking good" or seems impressive. Often used alone as a reaction or for emphasis in usages like "Did you see her bugfix? Sheesh!"
</dd>
<dt>Simp</dt>
<dd>
Anything or anyone noticeably enamored with a given subject. Can be used appreciatively or cheekily in sentences like "The Rust compiler catches so many bugs for me, what a simp!"
</dd>
<dt>Sus</dt>
<dd>
Short for "suspicious" and used to indicate distrust or disbelief. You might hear it stated that "It's sus because the tests pass but it produces the wrong output in production."
</dd>
</dl>
## Graphical or Pictoral Expressions
It has been my experience that GIF reactions or messages are usually employed sparingly. On the other hand, emoji may be used liberally albeit with differing connotations.
<dl>
<dt>💀</dt>
<dd>See: Dead</dd>
<dt>😭</dt>
<dd>As if to day: "I'm laughing so hard that I'm crying!"</dd>
<dt>✍️</dt>
<dd>Communicates that the sender is paying attention so closely, it's as if they're taking notes.</dd>
</dl>
| yonkeltron |
1,869,689 | Streamlining Webpage Deployment on Multi-VMs Using Bash Scripts | Hey! 👋 Today, I'll guide you through the deployment of a static website on a Linux server using the... | 0 | 2024-05-29T22:17:42 | https://dev.to/ritik_saxena/streamlining-webpage-deployment-on-multi-vms-using-bash-scripts-2ml2 | devops, bash, deployment, linux | Hey! 👋 Today, I'll guide you through the deployment of a static website on a Linux server using the power of Bash scripting. But, before diving in, let's ensure we have the essentials in place.
## Prerequisite:
- Install Git
- Install Vagrant
- Install Virtualbox
---
## Creating a Multi-VM Vagrantfile 📄
We need to create a Vagrantfile that will allow us to create multiple VMs.
1. Open the Git Bash terminal and create a Vagrantfile using the command `vim Vagrantfile`
2. Copy and paste the below code into the Vagrantfile
```
Vagrant.configure("2") do |config|
# VM configurations for Ubuntu
config.vm.define "web01" do |web01|
web01.vm.box = "ubuntu/bionic64"
web01.vm.network "private_network", ip: "192.168.56.41"
web01.vm.hostname = "web01"
config.vm.provider "virtualbox" do |vb|
vb.memory = "2048"
end
config.vm.provision "shell", inline: <<-SHELL
mkdir -p /var/log/barista_cafe_logs
sudo chown vagrant:vagrant /var/log/barista_cafe_logs/
SHELL
end
# Configuration for CentOS 9 VM
config.vm.define "web02" do |web02|
web02.vm.box = "eurolinux-vagrant/centos-stream-9"
web02.vm.network "private_network", ip: "192.168.56.42"
web02.vm.hostname = "web02"
config.vm.provision "shell", inline: <<-SHELL
mkdir -p /var/log/barista_cafe_logs
sudo chown vagrant:vagrant /var/log/barista_cafe_logs/
SHELL
end
end
```
In the above code, we have specified the configurations of two VMs, _Ubuntu OS_ (hostname as 'web01') and CentOS 9 (hostname as 'web02') with specified Memory and IPv4 addresses.
Inline shell provisioning is used to create a barista_cafe_logs folder at location '**/var/log**' for storing the website setup and teardown log files. Ownership is set for the **vagrant** user (default user) so that log files for setup and teardown can be created without any restriction.
Note that we have given Ubuntu OS and CentOS the same identifier name as the hostname. In `config.vm.define "web01"`, web01 is the identifier name/ VM name that vagrant uses to identify for which VM we want to execute any command, while in `web01.vm.hostname = "web01"`, we have set a hostname for the VM to identify the device within a local network.
---
## Logging in to the VM 💻
Navigate to the folder where we have created the Vagrantfile using the cd command.
- **Launching the VM:**
Command: `vagrant up`
**Important:** `vagrant up` command will create all the VMs mentioned in the Vagrantfile at once. We can also create a specific VM, and then we can use a command `vagrant up vm_name` e.g., `vagrant up web01` will create only an Ubuntu VM (here, web01 is the identifier name).
- **Check VM status:**
Command: `vagrant status` or `vagrant global-status`
`vagrant status` will give the status of VMs of Vagrantfile in the current location while `vagrant global-status` will give the status of all the VMs in the system.
- **Login to the VM:**
Commands:
- For Ubuntu OS: `vagrant ssh web01`
- For CentOS: `vagrant ssh web02`
---
## Create bash files in Synced Directory 📁📝
We will create two bash files, **webpage_setup.sh**, and **webpage_teardown.sh**.
> The extension of a bash file is .sh
There are two ways to proceed further:
**Way1: Create a bash file in the local machine itself**
Create bash files in a local machine at the same location where Vagrantfile is located
**Way2: Create a bash file in the VM directly**
Create bash files at location /vagrant/
Navigate to location /vagrant using the command `cd /vagrant/` and create a bash file using the command `touch webpage_setup.sh` and `touch webpage_teardown.sh`
Use command `ls` to see the files and folders in Linux

**Important:** The directory where Vagrantfile exists in our local machine and the directory /vagrant in VM are synced together. This means that if we make changes to the same location on our local machine, we can see the changes in the /vagrant directory in the VM as well.
---
## Writing automation bash script 👨💻
> In Windows/MacOS, use any Code Editor like VSCode, Sublime Text, XCode, etc.
> In Linux/Unix, navigate using cd /vagrant and edit using a command vim webpage_setup.sh
- webpage_setup.sh
```
#!/bin/bash
# Function to log messages to deploy.log file
log() {
message="$(date) - $1"
echo "$message" >> /var/log/barista_cafe_logs/deploy.log
echo "$message"
}
log "*****Starting deployment*****"
# checking if user is root user or not
log "*****Checking for root user access*****"
if [ $EUID -ne 0 ]
then
log "Warning: Current user is not root user. Please run the script as root user or use sudo."
fi
# checking if package manager is yum or apt-get
log "*****Checking for the package manager*****"
if command -v yum >> /dev/null
then
packages="httpd unzip wget"
service="httpd"
pkg_manager="yum"
log "$pkg_manager package manager found!!!"
elif command -v apt-get >> /dev/null
then
packages="apache2 unzip wget"
service="apache2"
pkg_manager="apt-get"
log "$pkg_manager package manager found!!!"
else
log "Error: Unsupported package manager"
exit 1
fi
# installing the packages
log "*****Installing the required package*****"
if ! sudo $pkg_manager install $packages -y
then
log "Error: Failed to install packages"
exit 1
else
log "Packages installed successfully"
fi
# starting and enabling the web service
log "*****Starting and enabling $service*****"
if ! (sudo systemctl start $service && sudo systemctl enable $service)
then
log "Error: Failed to start and enable the $service"
exit 1
else
log "$service started and enabled successfully"
fi
# creating variables
url="https://www.tooplate.com/zip-templates/2137_barista_cafe.zip"
temp_folder="/temp/barista_cafe"
target_folder="/var/www/html"
artifact="2137_barista_cafe"
# creating folder /temp/barista_cafe
log "*****Creating folder $temp_folder*****"
if ! sudo mkdir -p $temp_folder
then
log "Error: Failed to create folder $temp_folder"
exit 1
else
log "$temp_folder created successfully"
fi
# navigating to the temp folder
log "*****Navigating to the folder $temp_folder*****"
if ! cd $temp_folder
then
log "Error: Failed to navigate to $temp_folder"
exit 1
else
log "Navigated to $temp_folder"
fi
# downloading the web files
log "*****Downloading the web files*****"
if ! sudo wget $url
then
log "Error: Failed to download the web files from url"
exit 1
else
log "Downloaded the web files successfully"
fi
# unzipping the downloaded files
log "*****Unzipping the downlaoded files*****"
if ! sudo unzip -o $artifact.zip
then
log "Error: Failed to unzip the web files"
exit 1
else
log "Unzipped the web files successfully"
fi
# copying the extracted files to /var/www/html
log "*****Copying the extracted files to $target_folder*****"
if ! sudo cp -r $artifact/* $target_folder
then
log "Error: Failed to copy the files to $target_folder"
exit 1
else
log "Copied the extracted files to $target_folder successfully"
fi
# printing the files at location /var/www/html
log "*****Printing the files at $target_folder*****"
ls $target_folder
# restarting the web service
log "*****Restarting the $service*****"
if ! sudo systemctl restart $service
then
log "Error: Failed to restart the $service"
else
log "Re-started the $service successfully"
fi
log "Successfully deployed the website"
```
- webpage_teardown.sh
```
#!/bin/bash
log() {
message="$(date) - $1"
echo "$message" >> /var/log/barista_cafe_logs/teardown.log
echo "$message"
}
log "*****Starting teardown...*****"
# checking for root user
log "*****Checking for root user access*****"
if [ $EUID -ne 0 ]
then
log "Warning: Warning: Current user is not root user. Please run the script as root user or use sudo."
fi
# checking for package manager
log "*****Checking for package manager*****"
if command -v yum >> /dev/null
then
packages="httpd unzip wget"
service="httpd"
pkg_manager="yum"
log "$pkg_manager package manager found!!!"
elif command -v apt-get >> /dev/null
then
packages="apache2 unzip wget"
service="apache2"
pkg_manager="apt-get"
log "$pkg_manager package manager found!!!"
else
log "Error: Unsupported package manager"
exit 1
fi
# stopping the web-service
log "*****Stopping $service*****"
if ! sudo systemctl stop $service
then
log "Error: Unable to stop $service"
else
log "Successfully stopped $service"
fi
# removing installed packages
log "*****Removing installed packages*****"
if ! sudo $pkg_manager remove $packages -y
then
log "Error: Unable to remove packages: $packages"
exit 1
else
log "Packages removed successfully"
fi
# creating variables
temp_folder="/temp/barista_cafe"
target_folder="/var/www/html"
artifact="2137_barista_cafe"
# removing downloaded web files
log "*****Deleting web files*****"
if ! sudo rm -rf $temp_folder
then
log "Error: Unable to delete folder $temp_folder"
exit 1
else
log "Successfully deleted $temp_folder"
fi
# removing web files at location /var/www/html
log "*****Deleting web files*****"
if ! sudo rm -rf $target_folder
then
log "Error: Unable to delete folder $target_folder"
exit 1
else
log "Successfully deleted $target_folder"
fi
log "Teardown completed successfully!"
```
---
## Running the bash scripts 💨
Follow the below steps to log in to the VM and navigate to the bash files.
1. Open Git bash and navigate to the folder where the Vagrant file resides
**Command:** `cd /path_to_vagrantfile/`
2. Log in to any of the VM
**Commands:**
For Ubuntu OS: `vagrant ssh web01`
For CentOS: `vagrant ssh web02`
3. Navigate to the vagrant folder where bash scripts reside
**Command:** `cd /vagrant/`

Now follow the below steps to execute the scripts:
#### For Website Setup:
We will run webpage_setup.sh file for the webpage setup. Follow the below steps to execute the setup file.
1. Making the webpage_setup.sh bash file executable
**Command:** `chmod +x webpage_setup.sh`
2. Running the bash script
**Command:** `./webpage_setup.sh`
Wait until the bash script runs completely; if everything goes right, we can see a success message.
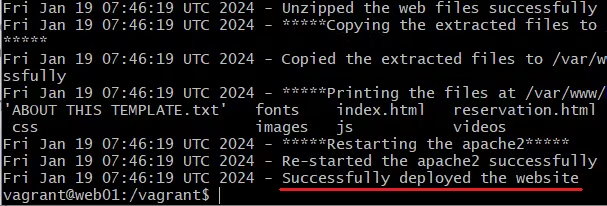
3. Get the IPv4 address
**Command:** `ip addr show`
Copy the IP address and paste it into the browser and we can see our website live on our local Linux server
Hurray 👏 ... We have successfully deployed a webpage on a Linux server using a bash script.
#### For Website Teardown:
Once we have successfully deployed the website, we can also destroy the setup if we want. Simply run the webpage_teardown.sh file that we have created previously. The steps are similar to that of setup,
1. Making the webpage_teardown.sh bash file executable
**Command:** `chmod +x webpage_teardown.sh`
2. Running the bash script
**Command:** `./webpage_teardown.sh`
Wait until the bash script runs completely; if everything goes right, we can see a success message for teardown.

Now cross-check if we can access the website or not by copying the IP address using the command `ip addr show` and pasting it into the browser.
Great, we have successfully destroyed the website setup and released all the resources.
#### Destroying the VM:
Now we can destroy the created VM by running a command `vagrant destroy`. This command will destroy all the VMs that we have created. In case we want to destroy any specific VM then we can use the VM name to destroy it using the command `vagrant destroy vm_name`.
After deletion, we can check the status of the Vagrant environment and verify that the VMs have been successfully destroyed using the command `vagrant status`.
---
## Checking the Logs 📈📋
The logs of setup and teardown will be saved at the location '**/var/logs/barista_cafe_logs/**' in the files **deploy.log** and **teardown.log**. Let's see the logs,
1. Navigate to the log folder using the command `cd /var/logs/barista_cafe_logs/`
2. Use `ls` command to see the files in this folder

3. Read the log files using the command `cat deploy.log` and `cat teardown.log`
- **Logs in deploy.log**
- **Logs in teardown.log**
---
## Download the source files: 💾
**Github Repo:** https://github.com/Ritik-Saxena/Static-Webpage-Deployment-Bash
## Connect with me: 🤝
**LinkedIn:** https://www.linkedin.com/in/ritik-saxena/
| ritik_saxena |
1,869,688 | How To Host a Static Website in Azure Blob Storage | Introduction A static website is like an electronic brochure that contains fixed information and... | 0 | 2024-05-29T22:14:38 | https://dev.to/emmamag/how-to-host-a-static-website-in-azure-blob-storage-bab | beginners, blob, programming, devchallenge | **Introduction**
A static website is like an electronic brochure that contains fixed information and doesn't change frequently. It consists of web pages that have text, images, and other content that remains the same for everyone who gains access to the website.
An example of such websites are cloud courses like whizlab or cantril.io
By hosting a static website on Blob Storage, you can save costs and enjoy a straight forward hosting solution that ensures your website is easily accessible and efficient.
In this tutorial, we will be hosting our static website in Azure Storage. Please ensure the following prerequisites are followed before we begin.
Prerequisites
As a prerequisite to deploying a static website with Azure storage;
1. Install Visual Studio Code on your desktop.
2. Install the Azure Subscription, Azure Account and Azure storage account extensions on the visual studio code.
3.Create a storage account in the Azure portal
4.Create a folder that houses your static website data
Enable Static Website in Azure
a) Go to your storage account, and click on the Static website button on the left side of the search bar.
b)Click on the "Enabled" button to enable the static website
c)On the index document name type "index.html" and the Error document path type "error.html"
d) Click on the save button
e)Once it's saved, It generates your primary and secondary endpoint
d) When you go back to your storage account, click on containers, you can see that a web container has been created to host your static website data
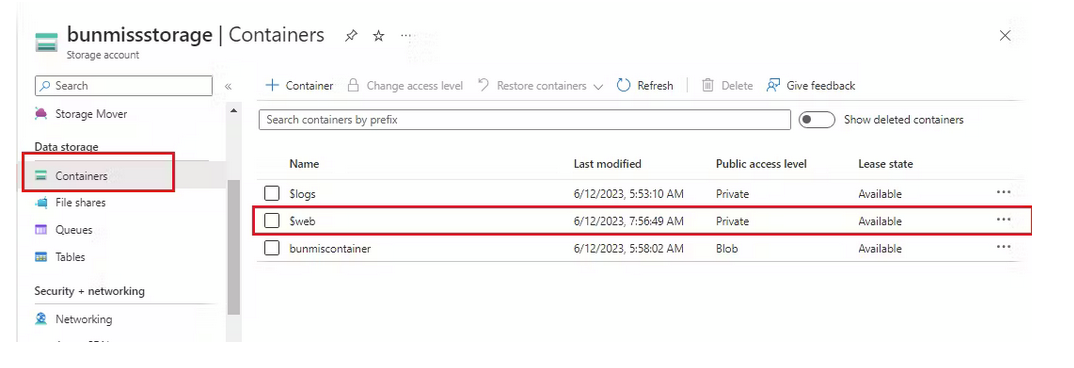
Open Your File On Visual Studio Code
a)The next step is to click on File at the top-left corner of your VScode.
b) Click on "Open File" and select the folder that houses your static website codes and data.
c)Once you open it, the file appears here as shown below.
d) Click on your file drop-down and click index.html
e) Once you click it, your html code automatically reflects as shown below
Connect To Azure
a) To connect to your $web container, click on the Azure extension.
b) Next click on the Resources drop-down, click on the Azure subscription drop-down
c) Under the Azure subscription, click on the storage account drop-down
d)You will see the storage account you created in the Azure Portal, right-click on it.
e) Click on "Deploy to the static website via Azure Storage"
f) You will be prompted to select your folder to deploy the static website
g) Wait for the deployment to be complete and click on browse static website
h) You will be redirected to your static website as shown below
i) On the Azure portal, go to the $web container in your storage account, you can see that all your static website data has been deployed in the container
| emmamag |
1,869,687 | Instruction Set Architecture, a linguagem das máquinas | Para se comunicar com um computador precisamos falar a sua língua, ao vocabulário desta “linguagem” é... | 0 | 2024-05-29T22:09:36 | https://dev.to/erick_tmr/instruction-set-architecture-a-linguagem-das-maquinas-4o8d | programming, architecture, hardware | Para se comunicar com um computador precisamos falar a sua língua, ao vocabulário desta “linguagem” é conhecido como *Instruction Set.* Para **os programadores de plantão, podemos dizer que a ISA de um hardware é a interface deste para com o software, ou, simplificando, sua API.
Já abordei um pouco sobre como computadores funcionam e como ocorre a comunicação entre a nossa linguagem de programação e o hardware em um [post](https://dev.to/erick_tmr/como-um-computador-funciona-4me9) anterior, mas vou recapitular brevemente.
## Como *ifs*, *fors* e *vars* viram binários que o computador entende?
Como dito anteriormente, o computador entende somente *instructions,* ou seja, precisamos utilizar a ISA para operar um computador. As *instructions* são constituídas por sequencias de números binários que possuem significado para o computador.
Utilizar números binários direto para se comunicar com o computador é uma tarefa complexa e tediosa, ou seja, um prato cheio para que um programador torne esta tarefa mais simples, então, foi criado um programa que ajuda a programar, os chamados `assemblers`, que traduziam linguagem escrita e entendida por seres humanos em linguagem de máquina (instructions).
Apesar do `assembly` já ser uma simplificação absurda em comparação com as *instructions* cruas, ainda era muito semelhante a forma de pensar e agir da máquina e não do ser humano, sendo assim foram criadas as linguagens de programação de mais alto nível, como C, C++, Java e afins.
As primeiras linguagens funcionavam como uma abstração acima da camada do `assembly`, onde você tinha um programa que transformava os comandos da linguagem em comandos `assembly` , esse programa é chamado de compilador.
O compilador torna acessível a comunicação com o computador, fazendo com que consigamos modelar de maneira mais próxima ao nosso pensamento o que gostaríamos que a máquina executasse.
```
// o seguinte programa em C só é possível de ser interpretado por conta dos compiladores
swap(size_t v[], size_t k) {
size_t temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}
// traduzido para assembly pelo compilador
swap:
slli x6, x11, 3
add x6, x10, x6
lw x5, 0(x6)
lw x7, 4(x6)
sw x7, 0(x6)
sw x5, 4(x6)
jalr x0, 0(x1)
// traduzido para binários
00000000001101011001001100010011
00000000011001010000001100110011
00000000000000110011001010000011
00000000100000110011001110000011
00000000011100110011000000100011
00000000010100110011010000100011
00000000000000001000000001100111
```
## Operações aritméticas
Qualquer computador precisa saber trabalhar com operações aritméticas, sendo assim, as instruções aritméticas formam a base de qualquer ISA.
Analisando a arquitetura RISC-V e sua linguagem assembly, temos 3 instruções aritméticas:
- Add (Soma, utiliza 3 registradores)
- Subtract (Subtração, utiliza 3 registradores)
- Add immediate (Soma com constantes, utiliza 2 registradores)
Operações aritméticas em hardware acontecem somente em lugares específicos, esses lugares são chamados de registradores.
Continuando com a arquitetura RISC-V, ela possui 32 registradores de 32 bits de tamanho, esse agrupamento de 32 bits acontece com tanta frequência que chamamos de *word*.
## Operações de memória
Como vimos, a arquitetura RISC-V possui 32 registradores de 32 bits cada, porém sabemos das linguagens de programação que podemos ter tipos de tamanho variável, ou até tipos compostos como arrays. Dada essa necessidade precisamos de instruções que consigam mover dados dos registradores para a memória do computador, e vice versa.
As instruções que movem dados entre registradores e memória damos o nome de *data transfer instructions*.
Em RISC-V temos duas instruções de transferência de dados:
- Load (Copia um word de um certo endereço da memória para um registrador)
- Store (Copia um word de um registrador para um certo endereço da memória)
A memória do computador nada mais é do que um grande array, onde os índices são os seus endereços. Em RISC-V, como trabalhamos primariamente com words (agrupamentos de 32 bits ou 4 bytes), o endereço de um word coincide com o endereço de um de seus bytes, words que são vizinhos estão separados por 4 endereços, consequentemente.
Computadores são divididos entre aqueles que usam o endereço do byte mais à esquerda ("big-endian") e aqueles que usam o endereço do byte mais à direita ("little-endian"), a esse conceito damos o nome de *endiannes*. RISC-V utiliza o “liitle-endian”, ou seja, o endereço de um word equivale ao endereço do seu byte mais a direita.
## Representando instruções no computador
Instruções da ISA são mantidas no hardware através de uma série de sinais eletrônicos de baixa e alta voltagem, esses sinais podem ser representados em números, como 0 e 1, ou seja, bits.
Cada componente de uma instrução pode ser considerada como um número individual, agrupando esses números lado a lado temos a representação da instrução. A essa forma de agrupamento de bits damos o nome de “instruction format”.
Dando como exemplo uma instrução de soma do RISC-V:
```
add x9, x20, x21
Representação decimal:
0 21 20 0 9 51
Cada segmento é chamado de "field"
Os segmentos 1, 4 e 6 (contendo os números 0, 0 e 51) coletivamente dizem para
o computador RISC-V que essa é uma instrução de soma.
O segmento 2 diz qual é o ultimo registrador da operação de soma (um dos "somandos")
O segmento 3 diz o outro registrador envolvido na soma
O segmento 5 contém o registrador que vai receber o resultado da operação
Representação binária:
| 0000000 | 10101 | 10100 | 000 | 01001 | 0110011 |
7 bits 5 bits 5 bits 3 bits 5 bits 7 bits
```
Para distinguir a representação numérica da linguagem assembly, chamamos ela de *machine language*, uma sequência de instruções é chamada de *machine code*.
## Finalizando
Ao explorar como instruções simples, como operações aritméticas e transferências de dados, são representadas em binário e executadas pelo hardware, podemos apreciar a complexidade e a elegância dos sistemas computacionais. Essa compreensão não só melhora nossas habilidades como programadores, mas também nos permite otimizar e depurar nosso código de maneira mais eficiente.
A evolução das linguagens de programação, desde o assembly até as linguagens de alto nível, reflete o constante esforço da comunidade de tecnologia em tornar a interação com computadores mais acessível e intuitiva. No entanto, a base de toda essa evolução permanece na ISA, que continua a ser o alicerce sobre o qual construímos nossas aplicações.
Apesar de tudo isso, não se sinta pressionado a dominar esses conceitos profundamente. Nós, programadores, trabalhamos diretamente com as linguagens de programação, que foram criadas para abstrair essa complexidade e nos ajudar a ser mais produtivos. Conheço vários ótimos programadores que não dominam esses conceitos e estão se saindo muito bem em suas carreiras. Aprofundar-se em ISA é uma escolha que pode enriquecer sua compreensão e habilidade técnica, mas não é um requisito para ser um excelente programador. | erick_tmr |
1,869,686 | Beyond the Surface: The Hidden Magic Behind Amazing Website Designs | Have you ever thought that when we scroll, swipe or click, all this happens on a website? Yes,... | 0 | 2024-05-29T22:01:43 | https://dev.to/liong/beyond-the-surface-the-hidden-magic-behind-amazing-website-designs-36l1 | website, design, malaysia, kualalumpur | Have you ever thought that when we scroll, swipe or click, all this happens on a website? Yes, whatever we do, we can never avoid a website and its unique perfect visuals. To make a website, we should go behind the curtains. That carefully created website interface, the amazing framework, and superb navigations are unsung heroes who make your online life a little easier.
The world of website interface is a fascinating one and this blog aims to explore everything related to both the elements, the working principle behind those elements as well as the psychology involved in user engagement. In this blog, we are going to reveal the secrets of designing wonderful interfaces with web designers and expand your creative insight into the magic behind some of your favorite pages!
## Deconstructing the Interface: Fundamentals of Usability
In simple terms, a [website interface](https://ithubtechnologies.com/website-development-malaysia/?utm_source=dev.to&utm_campaign=websiteinterface&utm_id=Offpageseo+2024) is the key point of communication between you and the website. It includes the entire appearance and texture of all that you see, including layout, interaction mapping, and visual design, as well as objects that respond to pressure. A few important parts of what makes an excellent interface are sung in this book.
**- Visual Design:**
Mainly on Visual Design, it is the first impression on your website given by the user. This consists of things like color palettes, typography settings, imagery usage, and white space. You should know that the most attractive website interface is shown more visually attractive, this would also give an awesome user experience, and the interface is shown beautifully even from a mobile phone screen.
Layout: When we talk about the layout of the website, it is the structural part of the website. The website is equivalent to the structure that the shell provides to a snail. How are elements arranged? Is the material easily accessible? Clear organization is automatic and helps users locate the information they need quickly.
**- Navigation:**
Navigation is like the map for visitors which leads them through your website. Navigation consists of Menus, Breadcrumbs, and Call-to-action buttons. The process of designing and building a website or software solution is about creating an effective (i.e., user-friendly) experience for the users who come to utilize it, over and over again. Anyone can do a one-off job and irritate all people only once with shoddy hauling or commission calculations issues… but so you never know what brought them back in the first place. A clear consistent navigation weaves within itself your digital Reputation!
**- Functionality:**
This is where the website flexes its technical muscles. Site Load Speed Are forms easy to fill out? Does it work well across devices? In conclusion, a website with no friction means more users are happy to stay enjoying the functionality.
**- Stuff you Post:**
Data which we can stair as the heart of a website. Whether it be text, images & video, or any combination thereof. Content that engages, educates, and entertains is Essential.
## User Interface psychology — How you stay hooked
The best website interfaces are never accidental. The website interface is an invisible structure, which cannot be seen directly and used by web designers to enrich interactions with users. Their secret playbook exposed includes the following:
**- Visuals:**
I already warned slightly about this in the power of first impressions but visual design is important. As we can see many studies have been conducted on this topic and conclude that visitors take some seconds to form an opinion about a website. Having a well-designed interface visually speaks to good vibes, triggering users' need to dig deeper.
**- Ease of Understanding:**
Our minds seek simplicity. Cluttered sites that strain the eyes and confuse the brain lose visitors fast. Crafting clean design, clear structure, and dependable navigation reduces this stress.
**- Websites are also a medium of storytelling:**
Websites do not only feature facts, they can tell stories as well. They will also create narratives through visuals, layouts, and navigation. Visitors are caught up in the story of a site.
**- Engagement:**
People tend to engage. Designs have CTA, interactions, and gamification. These ignite engagement that leaves audiences always active and connected to the brand.
**- Emotions:**
The site indeed raises emotions in people's hearts. The visitor becomes more connected to the content if he is experiencing something.
Skillful designers understand psychology and use multiple techniques to resonate. Visuals persuade in ways words can't. Flows manage the eye naturally. Sounds complement visual storytelling. Relationships form as visitors interact and share the experience. They invest in the brand through reactions online. Satisfying experiences strengthen preference and may spur real-world actions. Captivating users with story, interactivity, and feeling creates advocates. Repeated visits further engagement and community. Websites can inspire and draw dedicated audiences with a little imagination and human understanding. Users and businesses alike gain from the connections that are fueled by interactive storytelling.
## Next up: Beyond Aesthetics — Impact of an Interface that Feels Great
A great-looking website interface does more than just keep up a good appearance. In terms of your business, it affects » Read more;
**- Improves Conversions:**
You need to know one more thing that your website needs to be user-friendly. When it is user-friendly then you can get people who would sign and purchase stuff from your website quite often.
**- Brand Image Boost:**
A neat and professional interface creates a strong brand image and helps generate trust in potential customers.
**- Better Search Engine Ranking:**
Search engines like Google always rank websites that provide a good user experience. A good interface also helps you to improve search engine rankings, which effectively makes space for your site on the web.
### Conclusion:
According to the above-highlighted points, it can be concluded that an excellent web interface is like a wizard, and it walks you through the land. Once you understand the basic blocks of web design and how they work, it will make you a much more intelligent user of websites, as well as an effective judge of good website design. Thus the next time you try creating a website, do these things.
| liong |
1,869,685 | Generative AI Serverless - RAG using Bedrock Knowledge base, & Single document chat via AWS Console! | Generative AI - Has Generative AI captured your imagination to the extent it has for me? Generative... | 0 | 2024-05-29T21:56:46 | https://dev.to/bhatiagirish/generative-ai-serverless-rag-using-bedrock-knowledge-base-single-document-chat-via-aws-console-5adi | aws, bedrock, anthropic, generativeai | Generative AI - Has Generative AI captured your imagination to the extent it has for me?
Generative AI is indeed fascinating! The advancements in foundation models have opened up incredible possibilities. Who would have imagined that technology would evolve to the point where you can generate content summaries from transcripts, have chatbots that can answer questions on any subject without requiring any coding on your part, or even create custom images based solely on your imagination by simply providing a prompt to a Generative AI service and foundation model? It's truly remarkable to witness the power and potential of Generative AI unfold.
**'Chat with your document' is the latest Generative AI feature added by Amazon to its already feature-rich areas of GenAI, Knowledge Base, and RAG.**
RAG, which stands for Retrieval Augmented Generation, is becoming increasingly popular in the world of Generative AI. It allows organizations to overcome the limitations of LLMs and utilize contextual data for their Generative AI solutions.
Amazon Bedrock is a fully managed service that offers a choice of many foundation models, such as Anthropic Claude, AI21 Jurassic-2, Stability AI, Amazon Titan, and others.
I will use the recently released Anthropic Sonnet foundation model and invoke it via the Amazon Console Bedrock Knowledge Base. As of May 2024, this is the only model supported by AWS for the single document knowledge base or 'Chat with your document' function.
There are many use cases where generative AI chat with your document function can help increase productivity. Few examples will be technical support extracting info from user manual for quick resolution of questions from the customers, or HR answering questions based on policy documents or developer using technical documentation to get info about specific function or a call center team addressing inquiries from customers quickly by chatting with product documentation.
**Let's look at our use cases:**
• MyBankGB, a fictitious bank, offers various credit cards to consumers. The document "MyBankGB Credit Card Offerings.pdf" contains detailed information about all the features and details of the credit cards offered by the bank.
• MyBankGB is interested in implementing a Generative AI solution using the "Chat with your document" function of Amazon Bedrock Knowledge Base. This solution will enable the call center team to quickly access information about the card features and efficiently address customer inquiries.
• This is a proof of concept hence API based solution not required, rather access will be provided to selected call center team members via AWS Console for Bedrock knowledge base chat with your document function.
Here is the architecture diagram for our use case.
Let's see the steps to create a single document knowledge base in Bedrock and start consuming it using AWS Console.
**Review AWS Bedrock 'Chat with your document**
Chat with document is a new feature. You can use it via AWS Console or can use SDK to invoke it via Bedrock, Lambda and API.
For Data, you can upload a file from your computer OR you can provide ARN for the file posted in the S3 bucket.
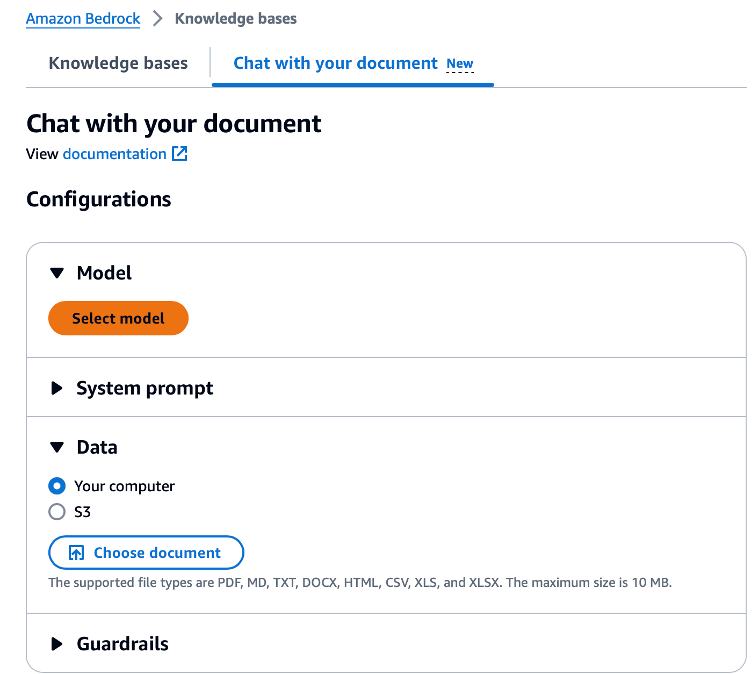
Select model. Anthropic Claude 3 Sonnet is the only supported model as of May, 2024.
**Request Model Access**
Before you can use the model, you must request access to the model.
**Chat with your document using AWS Console**
Let’s chat with the document and review responses.
**Review the response**
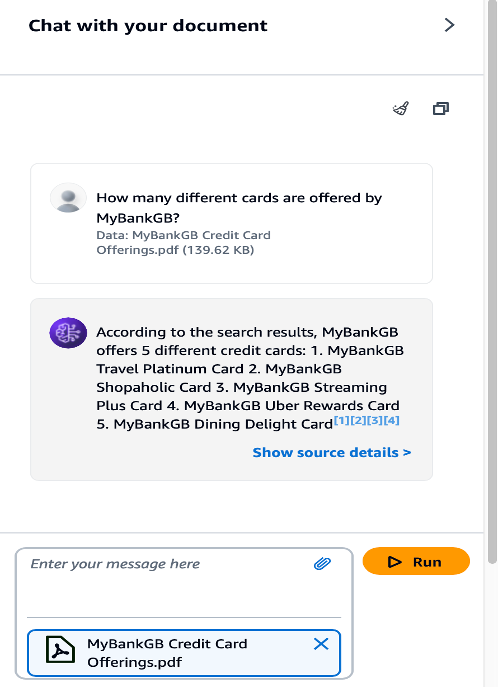
**Let's review more prompts and responses!**
As you can see above, all answers are provided in the context of the document uploaded in the S3 bucket. This is where RAG makes the generative AI responses more accurate and reliable, and controls the hallucination.
With these steps, a serverless GenAI solution has been successfully implemented to build a serverless GenAI RAG solution for creating a single-document knowledge base using the Amazon Bedrock Console. Selected call center team members who have access to the AWS Console and the Anthropic Sonnet model can utilize the 'chat with your document' function and then provide feedback on whether an automated solution using APIs should be developed.
As GenAI solutions keep improving, they will change how we work and bring real benefits to many industries. This workshop shows how powerful AI can be in solving real-world problems and creating new opportunities for innovation.
Thanks for reading!
Click here to get to YouTube video for this solution.
{% embed https://www.youtube.com/watch?v=ErzmSHRY3pY %}
https://www.youtube.com/watch?v=ErzmSHRY3pY
𝒢𝒾𝓇𝒾𝓈𝒽 ℬ𝒽𝒶𝓉𝒾𝒶
𝘈𝘞𝘚 𝘊𝘦𝘳𝘵𝘪𝘧𝘪𝘦𝘥 𝘚𝘰𝘭𝘶𝘵𝘪𝘰𝘯 𝘈𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵 & 𝘋𝘦𝘷𝘦𝘭𝘰𝘱𝘦𝘳 𝘈𝘴𝘴𝘰𝘤𝘪𝘢𝘵𝘦
𝘊𝘭𝘰𝘶𝘥 𝘛𝘦𝘤𝘩𝘯𝘰𝘭𝘰𝘨𝘺 𝘌𝘯𝘵𝘩𝘶𝘴𝘪𝘢𝘴𝘵
| bhatiagirish |
1,869,552 | Overview of AWS Config: Concepts and Components | AWS Config is a fully managed service that provides you with resource inventory, configuration... | 0 | 2024-05-29T21:53:17 | https://dev.to/diegop0s/introduction-to-aws-config-544k | aws, config, audit, security | > AWS Config is a fully managed service that provides you with **resource inventory, configuration history, and configuration change** notifications for security and governance.
AWS Config is an auditing service that keeps track of changes made to your AWS resources and allows you to monitor configuration data over time for detecting potential security and operational issues.
This post focuses on some introductory concepts for AWS Config that are not always kept in mind when inspecting the AWS Console for Config, which performs many operations under the surface for us, but in case you want to use another way for setting up your AWS Config these concepts will be very important.
## 1. AWS Config
AWS Config is a fully managed service that provides you with **resource inventory, configuration history, and configuration change** notifications for security and governance.
AWS Config provides a detailed view of the configuration of AWS resources in your AWS account. This includes how the resources are related to one another and how they were configured in the past so that you can see how the configurations and relationships change over time.
AWS Config tracks changes made to these supported AWS resources and records their changes as **configuration items (CIs)**, which are **JSON files delivered to an Amazon Simple Storage Service (Amazon S3) bucket**. These files are accessed through AWS Config APIs and **optionally sent through Amazon Simple Notification Service (Amazon SNS)**.
## 2. Configuration Items (CI)
A configuration item represents a point-in-time view of the various attributes of a supported AWS resource that exists in your account. The components of a configuration item include **metadata, attributes, relationships, current configuration, and related events**.
AWS Config creates a **configuration item** whenever it detects a change to a resource type that it is recording. You can select AWS Config to create a configuration item at the recording frequency that you set: **Continuous recording** which records configuration changes continuously whenever a change occurs, and **Daily recording** which creates a configuration item (CI) representing the most recent state of your resources over the last 24-hour period (only if it’s different from the previous CI recorded).
Here is an example of a Configuration Item for a Resource Group:
```
{
"relatedEvents": [],
"relationships": [
{
"resourceId": "vpc-XXXXXXXXXXXX",
"resourceType": "AWS::EC2::VPC",
"name": "Is contained in Vpc"
}
],
"configuration": {
"description": "default VPC security group",
"groupName": "default",
"ipPermissions": [
{
"ipProtocol": "-1",
"ipv6Ranges": [],
"prefixListIds": [],
"userIdGroupPairs": [
{
"groupId": "sg-YYYYYYYYYYYY",
"userId": "0000000000"
}
],
"ipv4Ranges": [],
"ipRanges": []
}
],
"ownerId": "0000000000",
"groupId": "sg-YYYYYYYYYYYY",
"ipPermissionsEgress": [
{
"ipProtocol": "-1",
"ipv6Ranges": [],
"prefixListIds": [],
"userIdGroupPairs": [],
"ipv4Ranges": [
{
"cidrIp": "0.0.0.0/0"
}
],
"ipRanges": [
"0.0.0.0/0"
]
}
],
"tags": [],
"vpcId": "vpc-XXXXXXXXXXXX"
},
"supplementaryConfiguration": {},
"tags": {},
"configurationItemVersion": "1.3",
"configurationItemCaptureTime": "YYYY-MM-DDTHH:MM:SS.000Z",
"configurationStateId": 0000000000,
"awsAccountId": "0000000000",
"configurationItemStatus": "ResourceDiscovered",
"resourceType": "AWS::EC2::SecurityGroup",
"resourceId": "sg-YYYYYYYYYYYY",
"resourceName": "default",
"ARN": "arn:aws:ec2:us-east-1:0000000000:security-group/sg-YYYYYYYYYYYY",
"awsRegion": "us-east-1",
"availabilityZone": "Not Applicable",
"configurationStateMd5Hash": ""
}
```
## 3. Configuration History
A configuration history is a collection of the configuration items for a specific resource type over any time period. **Each file includes resources of only one type**, such as Amazon EC2 instances or Amazon EBS volumes. If no configuration changes occur, AWS Config does not send a file.
_Configuration History Files are useful when you’re looking for the historical configuration state for a specific resource type._
AWS Config delivers configuration history files **automatically after enabling the Configuration Recorder and Delivery Channel** to an **Amazon S3 bucket** that you specify. AWS Config sends a configuration history file every six hours, and each file contains details about the resources that changed in that six-hour period.
You can select a given resource in the AWS Config console and navigate to all previous configuration items for that resource using the timeline.
Here is an example of a Configuration History File, with a name in the format `{accountId}_Config_{region}_ConfigHistory_{resourceType}_{time}`:
```
{ // Configuration File for AWS::S3::Bucket Resource Type
"fileVersion": "1.0",
"configurationItems": [
{
// CI S3 Bucket "A"
},
{
// CI S3 Bucket "B"
},
// Additional S3 Buckets
]
}
```
## 4. Configuration Snapshot
A configuration snapshot is a collection of the configuration items for the supported resources that exist in your account. This configuration snapshot is a **point-in-time capture** of the resources that are being recorded and their configurations.
_Configuration Snapshot Files are useful when you’re looking for the current configuration state for all supported resources in an account._
By default **Configuration Snapshots are not automatically enabled** just by enabling the Configuration Recorder and Delivery Channel, you must configure the Delivery Channel with a specific snapshot delivery frequency of 1, 3, 6, 12, or 24 hours. You can have the configuration snapshots delivered to an Amazon Simple Storage Service (Amazon S3) bucket that you specify.
Here is an example of a Configuration History File, with a name in the format `{accountId}_Config_{region}_ConfigSnapshot_{time}`:
```
{
"fileVersion": "1.0",
"configSnapshotId": "677bc092-27a0-4831-9c08-012eed635738",
"configurationItems": [
{
// CI CloudFormation Stack "A"
},
{
// CI S3 Bucket "B"
},
{
// CI S3 Bucket "C"
},
{
// CI SNS Topic "D"
},
// Additional Resources
]
}
```
## 5. Configuration Recorder
The configuration recorder **stores the configurations of the supported resources in your account as configuration items**. You must first create and then start the configuration recorder before you can start recording. You can stop and restart the configuration recorder at any time.
By default, the configuration recorder records all supported resources in the region where AWS Config is running. You can create a customized configuration recorder that records only the resource types that you specify.
**If you use the AWS Management Console or the CLI to turn on the service, AWS Config automatically creates and starts a configuration recorder for you.**
## 6. Delivery Channel
As AWS Config continually records the changes that occur to your AWS resources, it sends notifications and updated configuration states through the delivery channel. You can **manage the delivery channel to control where AWS Config sends configuration updates**.
Before you can create a delivery channel, you must create a configuration recorder. You can have only one delivery channel per AWS Region per AWS account, and the delivery channel is required to use AWS Config.
## 7. Delivery of CIs to Amazon S3
As mentioned above AWS Config sends **Configuration History Files every six hours** to S3, after enabling the configuration recorder.
In the case of **Configuration Snapshots, they are sent when a user manually performs the DeliverConfigSnapshot API call or the API is invoked according to a periodic setting for the snapshot every 1, 3, 6, 12, or 24 hours**, according to the Delivery Channel setting.
**Snapshots and History files use the same format to be stored in S3 and are sent to the same Bucket in two different folders _ConfigHistory _and _ConfigSnapshot_.**
**8. Config Notifications and Amazon SNS**
AWS Config uses the **Amazon SNS topic that you optionally specify** in the Delivery Channel.
AWS Config sends notifications for the following events:
- Configuration item change for a resource.
- Configuration history for a resource was delivered for your account.
- Configuration snapshot for recorded resources was started and delivered for your account.
- Compliance state of your resources and whether they are compliant with your rules.
- Evaluation started for a rule against your resources.
- AWS Config failed to deliver the notification to your account.
## 9. Config Rules
An AWS Config rule represents **desired configurations for a resource** and is evaluated against configuration changes on the relevant resources, as recorded by AWS Config. If a resource does not comply with the rule, AWS Config flags the resource and the rule as noncompliant.
There are two types of rules: **AWS Config Managed Rules** (predefined) and **AWS Config Custom Rules** (created using Lambda Functions or using Guard language).
When creating a Config Rule you can choose the **trigger type** to specify how often your AWS Config rules evaluate your resources: Resources can be evaluated when there are configuration changes, on a periodic schedule, or both.
## 10. AWS Config for AWS Organizations
AWS Config helps you centrally manage your Config Rules and data visualization (CIs, queries, reports, etc.) for all your Member accounts using different features of AWS Config
For using AWS Config services with AWS Organizations you'll need to use the
[EnableAWSServiceAccess](https://docs.aws.amazon.com/organizations/latest/APIReference/API_EnableAWSServiceAccess.html) action (using the API, CLI or Console), which enables the integration and allows AWS Config to create a Service-Linked Role in all accounts in your organization. This allows the AWS Config service to perform operations on your behalf in your organization and its accounts.
[AWS Documentation](https://docs.aws.amazon.com/config/latest/developerguide/set-up-aggregator-cli.html#add-an-aggregator-organization-cli) indicates to enable the principals `config.amazonaws.com` (for AWS Config) and `config-multiaccountsetup.amazonaws.com` (for managing multi-account AWS Config Rules).
_Delegated Administrator for AWS Config_
AWS Organizations allows you to delegate tasks or responsibilities to member accounts. The designated member account then becomes **delegated administrators,** meaning that they can perform a **specific activity or manage a specific AWS service across accounts, on behalf of the organization**.
AWS Config is one of the AWS services operating across accounts and supporting delegation in AWS Organizations. The Delegated Administrator supports using **Aggregators** for multi-account, multi-region resource data aggregation.
If you are using an organization management account and intend to use a delegated administrator for organizational deployment, be aware that AWS Config won't automatically create the service-linked role (SLR). You must manually create the service-linked role (SLR) separately using IAM, or using the EnableAWSServiceAccess API as mentioned above.
## 11. Organizational Rules
AWS Config supports Organizational Rules, which allows you to **manage AWS Config rules across all AWS accounts within an organization**. You can:
- Centrally create, update, and delete AWS Config rules across all accounts in your organization.
- Deploy a common set of AWS Config rules across all accounts and specify accounts where AWS Config rules should not be created.
- Use the APIs from the management account in AWS Organizations to enforce governance by ensuring that the underlying AWS Config rules are not modifiable by your organization’s member accounts.
Remember that **Organizational Rules can only be created using the API or CLI**. This operation is not supported in the AWS Config console. In addition, when configuring Organizational Rules, each one can only include one AWS Config Rule, so in case you want to use many Config Rules for your Organization Accounts you will have to manage many separate Organizational Rules.
## 12. Conformance Packs
A conformance pack is a **collection of AWS Config rules and remediation action**s that can be easily **deployed as a single entity in an account and a Region or across an organization in AWS Organizations**.
Conformance packs are created by authoring a YAML template that contains the list of AWS Config managed or custom rules and remediation actions. You can also use AWS Systems Manager documents (SSM documents) to store your conformance pack templates on AWS and directly deploy conformance packs using SSM document names. **You can deploy the template by using the AWS Config console or the AWS CLI.**
## 13. Aggregators
An aggregator is an AWS Config resource type that **collects AWS Config configuration and compliance data** from the following:
- Multiple accounts and multiple AWS Regions.
- Single account and multiple AWS Regions.
- An organization in AWS Organizations and all the accounts in that organization which have AWS Config enabled.
Use an aggregator to **view the resource configuration and compliance data recorded** in AWS Config. An aggregator uses an Amazon S3 bucket to store aggregated data. **It periodically retrieves configuration snapshots from the source accounts and stores them in the designated S3 bucket**.
When setting up an Aggregator, you must use the Management Account or a registered Delegated Administrator.
## Resources
- [Amazon Config FAQs](https://aws.amazon.com/config/faqs/)
- [AWS Config: How AWS Config Works](https://docs.aws.amazon.com/config/latest/developerguide/how-does-config-work.html)
- [AWS Config: Concepts](https://docs.aws.amazon.com/config/latest/developerguide/config-concepts.html)
- [AWS Config: Managing the Delivery Channel](https://docs.aws.amazon.com/config/latest/developerguide/manage-delivery-channel.html)
- [AWS Config: Managing AWS Config Rules Across All Accounts in Your Organization](https://docs.aws.amazon.com/config/latest/developerguide/config-rule-multi-account-deployment.html)
- [AWS Config: Conformance Packs](https://docs.aws.amazon.com/config/latest/developerguide/conformance-packs.html)
- [AWS Config: Multi-Account Multi-Region Data Aggregation](https://docs.aws.amazon.com/config/latest/developerguide/aggregate-data.html)
- [AWS Config - AggregatoSetting Up an Aggregator Using the AWS Command Line Interface](https://docs.aws.amazon.com/config/latest/developerguide/set-up-aggregator-cli.html#register-a-delegated-administrator-cli)
- [Understanding the differences between configuration history and configuration snapshot files in AWS Config](https://aws.amazon.com/blogs/mt/configuration-history-configuration-snapshot-files-aws-config/)
- [Using delegated admin for AWS Config operations and aggregation](https://aws.amazon.com/blogs/mt/using-delegated-admin-for-aws-config-operations-and-aggregation/)
| diegop0s |
1,869,684 | How to manage identical files? | An endless cycle. Same files different names, Same files different names, Same files different... | 0 | 2024-05-29T21:52:28 | https://dev.to/1seamy/how-to-manage-identical-files-2e2c | An endless cycle. Same files different names, Same files different names, Same files different names.
Thanks to ChatGPT.
```
package main
import (
"crypto/sha256"
"encoding/hex"
"fmt"
"io"
"io/ioutil"
"os"
"path/filepath"
)
func calculateFileHash(filePath string) (string, error) {
file, err := os.Open(filePath)
if err != nil {
return "", err
}
defer file.Close()
hash := sha256.New()
if _, err := io.Copy(hash, file); err != nil {
return "", err
}
return hex.EncodeToString(hash.Sum(nil)), nil
}
func findAndRemoveDuplicates(dir1, dir2 string) error {
files1, err := ioutil.ReadDir(dir1)
if err != nil {
return err
}
files2, err := ioutil.ReadDir(dir2)
if err != nil {
return err
}
hashMap := make(map[string]string)
// Process the first directory
for _, file := range files1 {
if !file.IsDir() {
filePath := filepath.Join(dir1, file.Name())
fileHash, err := calculateFileHash(filePath)
if err != nil {
fmt.Printf("Hash hesaplanamadı: %s, hata: %s\n", filePath, err)
continue
}
if _, found := hashMap[fileHash]; found {
fmt.Printf("Aynı dosya bulundu, siliniyor: %s\n", filePath)
if err := os.Remove(filePath); err != nil {
fmt.Printf("Dosya silinemedi: %s, hata: %s\n", filePath, err)
} else {
fmt.Printf("Dosya başarıyla silindi: %s\n", filePath)
}
} else {
hashMap[fileHash] = filePath
}
}
}
// Process the second directory
for _, file := range files2 {
if !file.IsDir() {
filePath := filepath.Join(dir2, file.Name())
fileHash, err := calculateFileHash(filePath)
if err != nil {
fmt.Printf("Hash hesaplanamadı: %s, hata: %s\n", filePath, err)
continue
}
if _, found := hashMap[fileHash]; found {
fmt.Printf("Aynı dosya bulundu, siliniyor: %s\n", filePath)
if err := os.Remove(filePath); err != nil {
fmt.Printf("Dosya silinemedi: %s, hata: %s\n", filePath, err)
} else {
fmt.Printf("Dosya başarıyla silindi: %s\n", filePath)
}
} else {
hashMap[fileHash] = filePath
}
}
}
return nil
}
func main() {
dir1 := "C:\\Users\\Asus Rog\\go\\getfilehash\\dir1"
dir2 := "C:\\Users\\Asus Rog\\go\\getfilehash\\dir2"
if err := findAndRemoveDuplicates(dir1, dir2); err != nil {
fmt.Printf("Hata: %s\n", err)
} else {
fmt.Println("Kopya dosyalar silindi.")
}
}
```
| 1seamy | |
1,869,683 | Microsoft Recall - EW... | I am not much of a privacy freak; I don't mind targeted ads and the idea of corporations selling our... | 0 | 2024-05-29T21:52:08 | https://dev.to/mustafif/microsoft-recall-ew-4hi | I am not much of a privacy freak; I don't mind targeted ads and the idea of corporations selling our data (as long as there is proper transparency); however, my bones shivered hearing this new Windows feature coming to Copilot plus PCS - Windows Recall.
Every 3 seconds, it will take a screenshot that can be used to learn how you use your PC and help you find things you previously went to. That's the paraphrasing of how it sort of works. The biggest issue is the screenshotting every 3 seconds—wtf!
First, Windows is already horrible at indexing regular files to search for something, so now it's going to use machine learning to try and search for anything you previously went to.
So for clarification, there is a blacklist of applications, and websites that you can configure, but what if a Windows update overrides it, or what if MOST Windows users aren't aware of it or don't configure anything! That's a huge privacy concern because if someone gains access to your PC, it makes their life so much easier; they don't even need your passwords anymore.
So...am I going to tell you to switch to Linux...no
The reason is that everyone uses their computer differently; as someone whose first application he opens up is a Terminal, Windows is already disgusting for me, and once I'm done school, it is dead to me; I already drive my desktop daily POP_OS!. However, it took me a while to become proficient in Linux's quirks, and not everyone's workflows will be able to perfectly translate to Linux.
My recommendation is to become aware of this new feature, be aware of these new "copilot plus" PCs being marketed, and if you want to switch, be ready to be open-minded and patient.
| mustafif | |
1,869,678 | Securing App Development with Managed Identities and Role-Based Access Control | The company is designing and developing a new app, requiring secure storage access using keys and... | 0 | 2024-05-29T21:36:54 | https://dev.to/olaraph/securing-app-development-with-managed-identities-and-role-based-access-control-484h | The company is designing and developing a new app, requiring secure storage access using keys and managed identities. Developers aim to implement role-based access control and need protected immutable storage for testing.
Our goals are as follows:
- Create the storage account and managed identity.
- Secure access to the storage account using a key vault and key.
- Configure the storage account to use the customer-managed key in the key vault.
- Set up a time-based retention policy and an encryption scope.
Create the storage account and managed identity
Provide a storage account for the web app.
In the portal, search for and select Storage accounts.
Select + Create.
For Resource group select Create new. Give your resource group a name and select OK to save your changes.
Provide a Storage account name. Ensure the name is unique and meets the naming requirements.
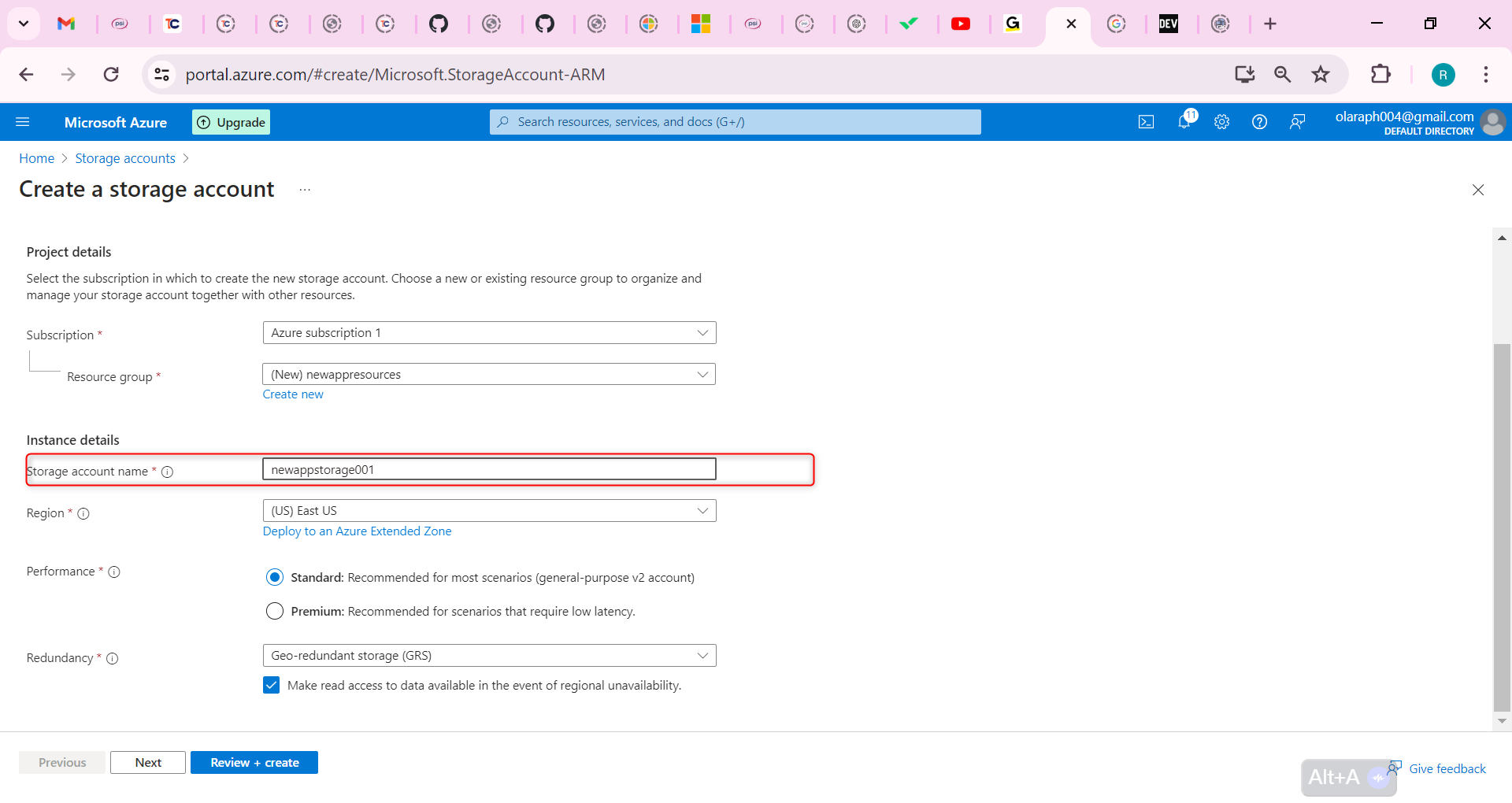
Move to the Encryption tab.
Check the box for Enable infrastructure encryption.
Notice the warning, This option cannot be changed after this storage account is created.
Select Review + Create.
Wait for the resource to deploy.
Provide a managed identity for the web app to use.
Search for and select Managed identities.
Select Create.
Select your resource group.
Give your managed identity a name.
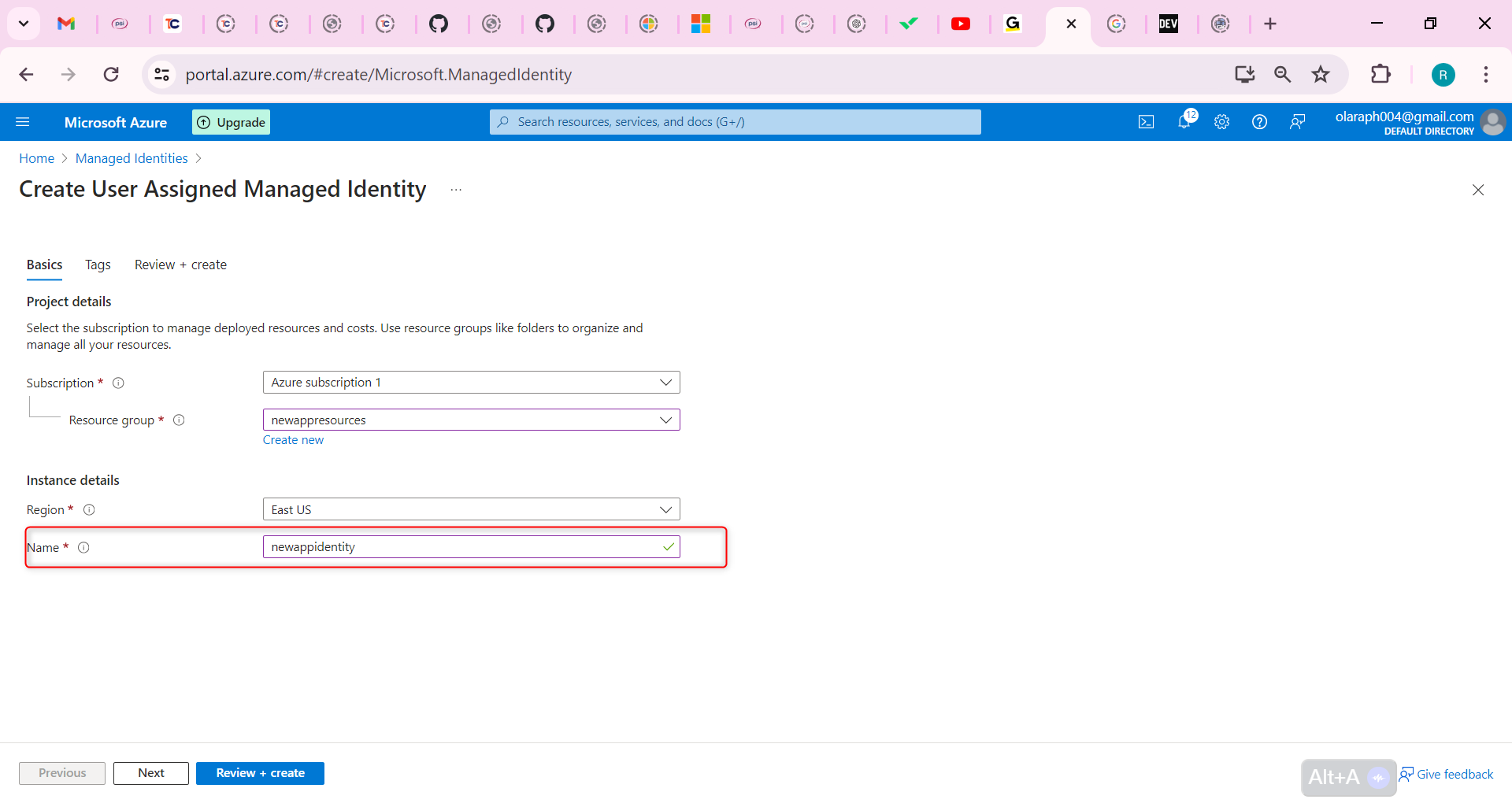
Select Review and create, and then Create.
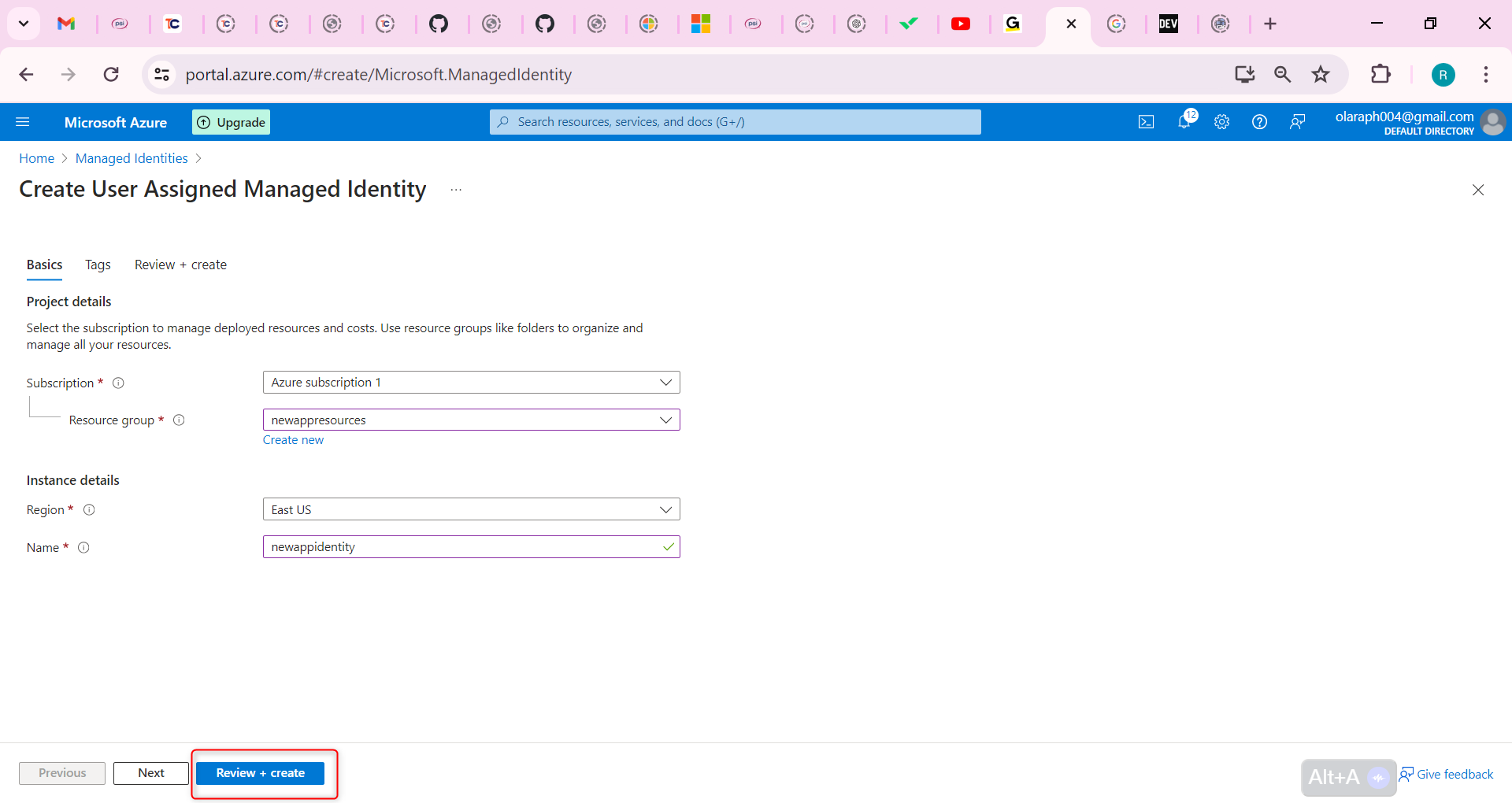
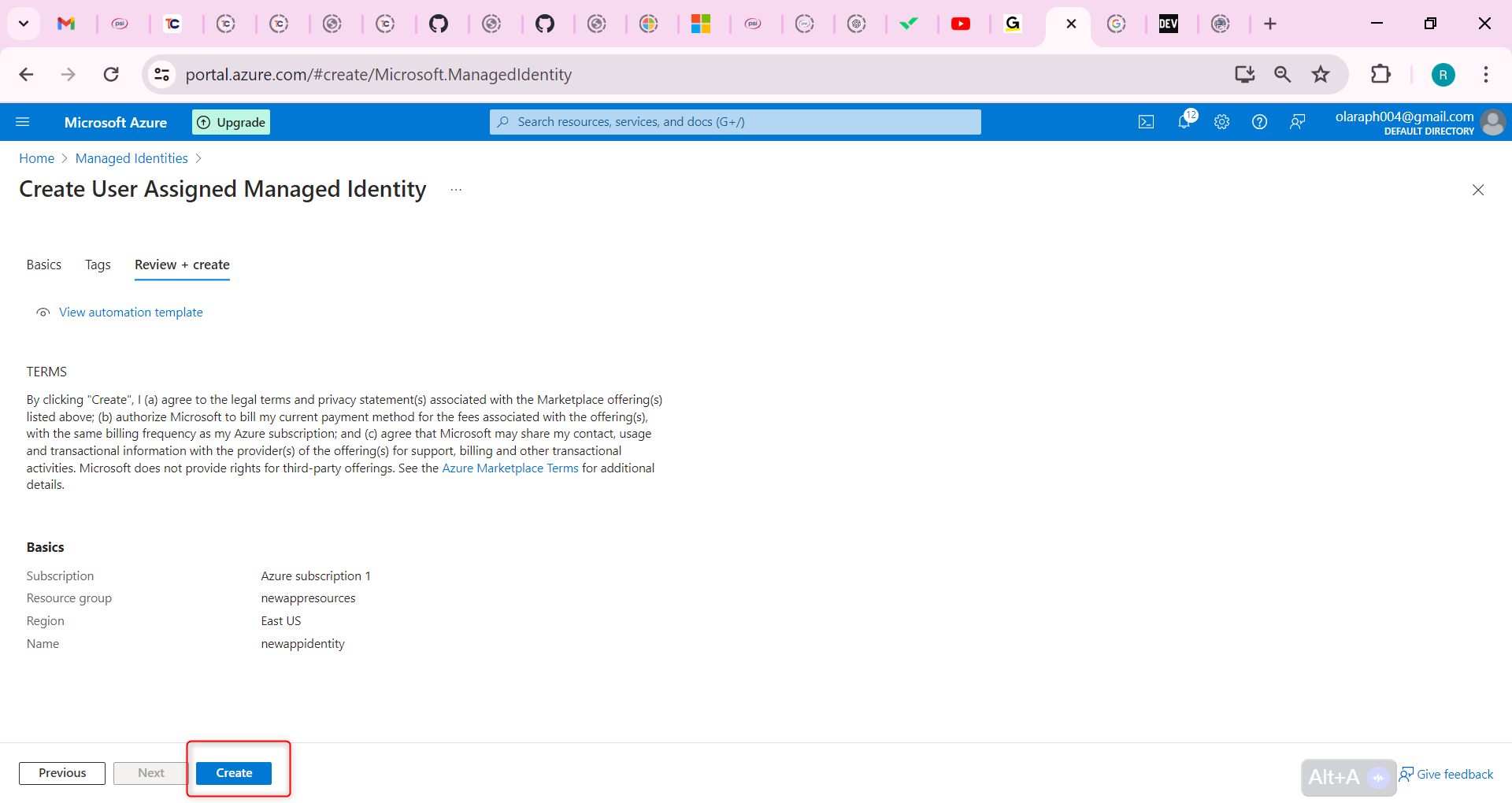
Assign the correct permissions to the managed identity. The identity only needs to read and list containers and blobs.
Search for and select your storage account.
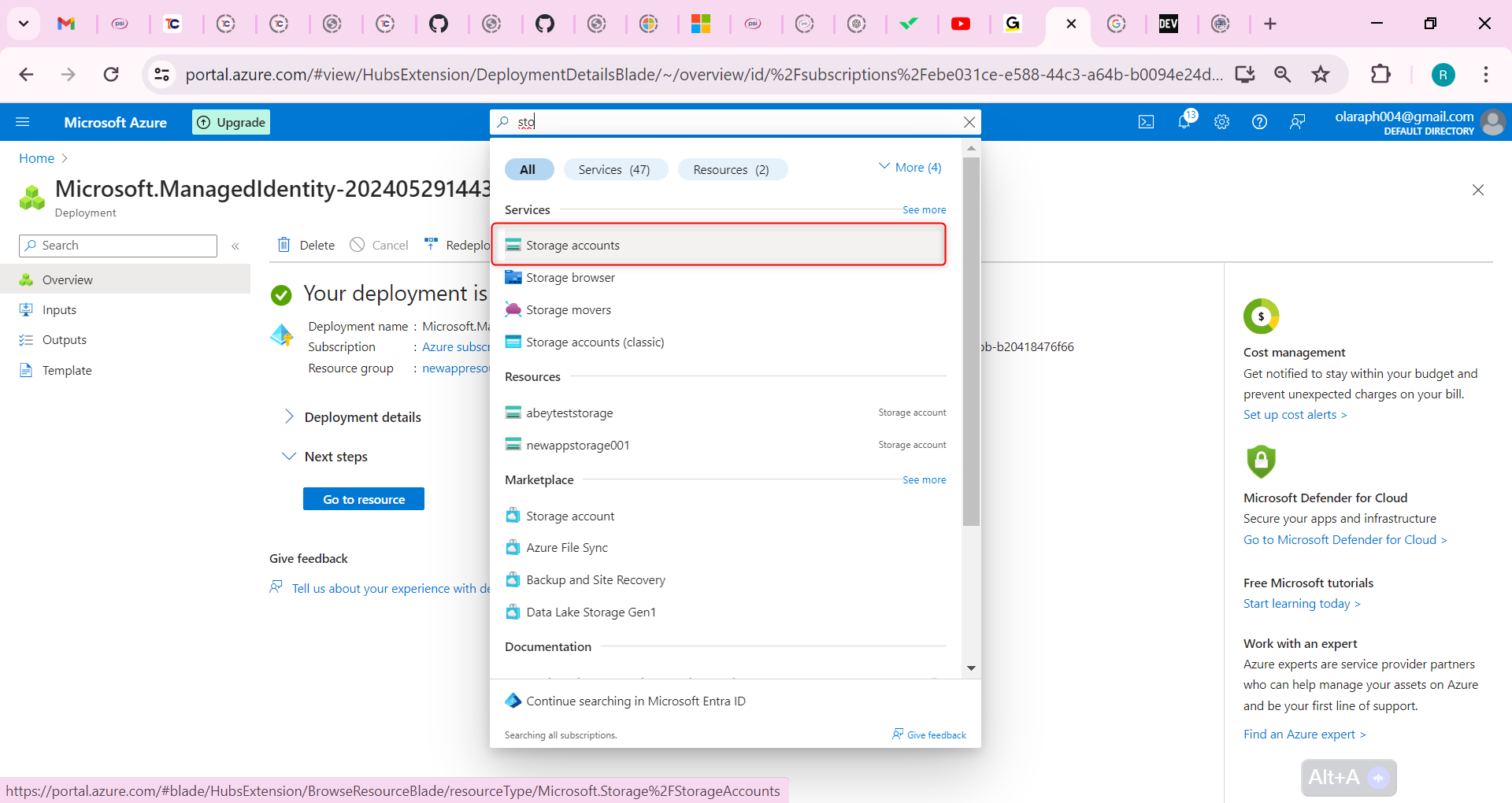
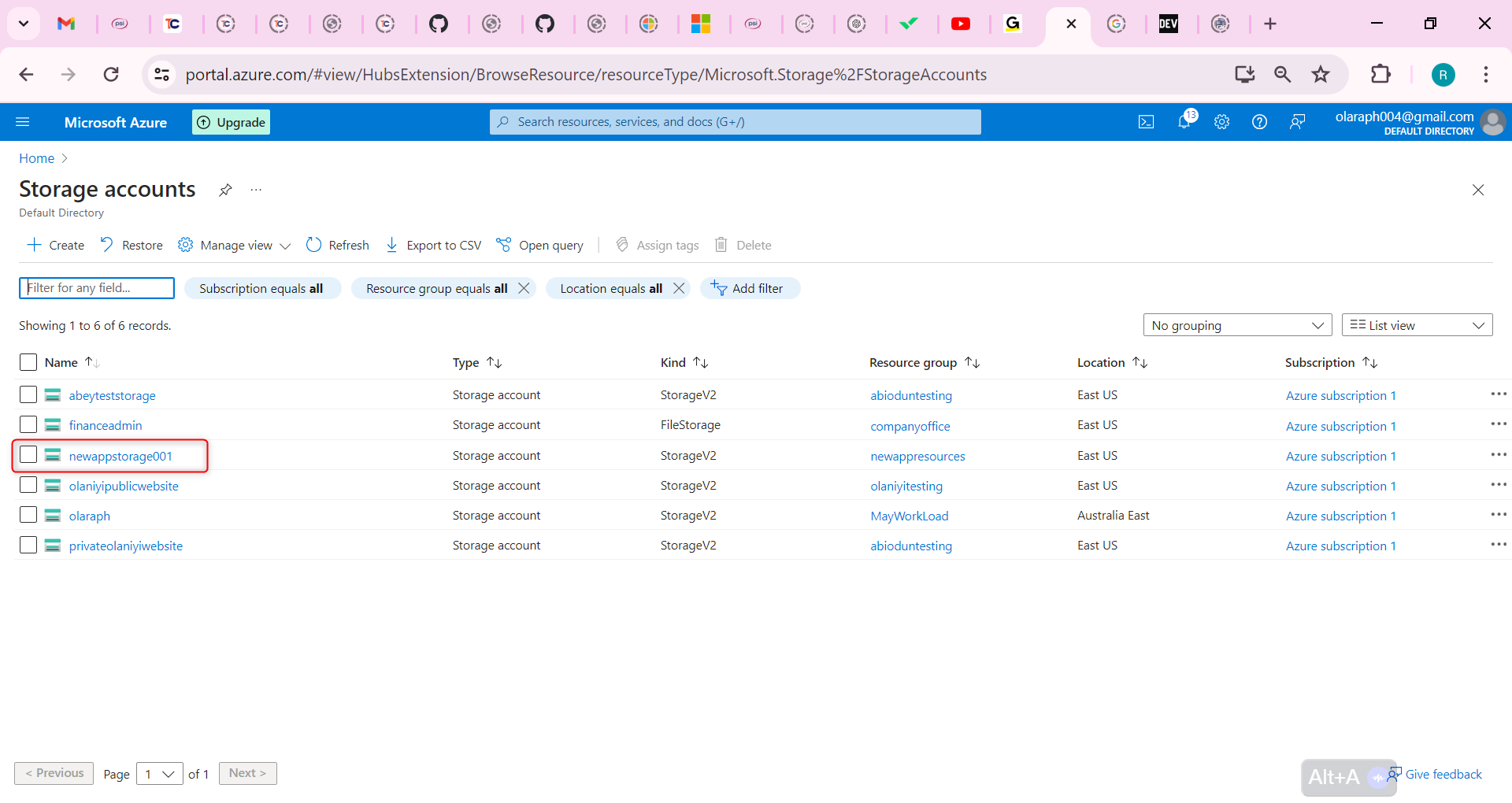
Select the Access Control (IAM) blade.
Select Add role assignment (center of the page).
On the Job functions roles page, search for and select the Storage Blob Data Reader role.
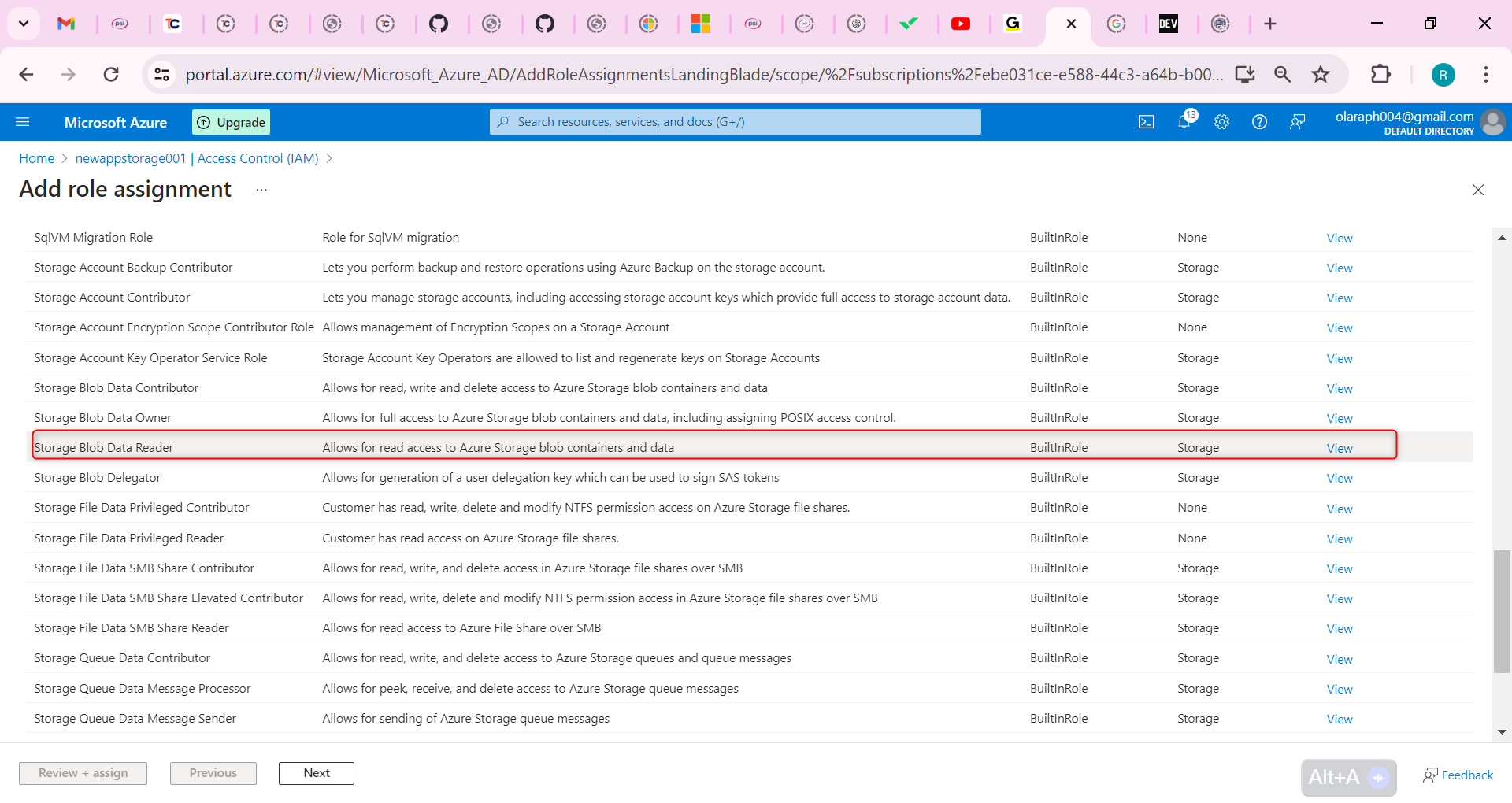
On the Members page, select Managed identity.
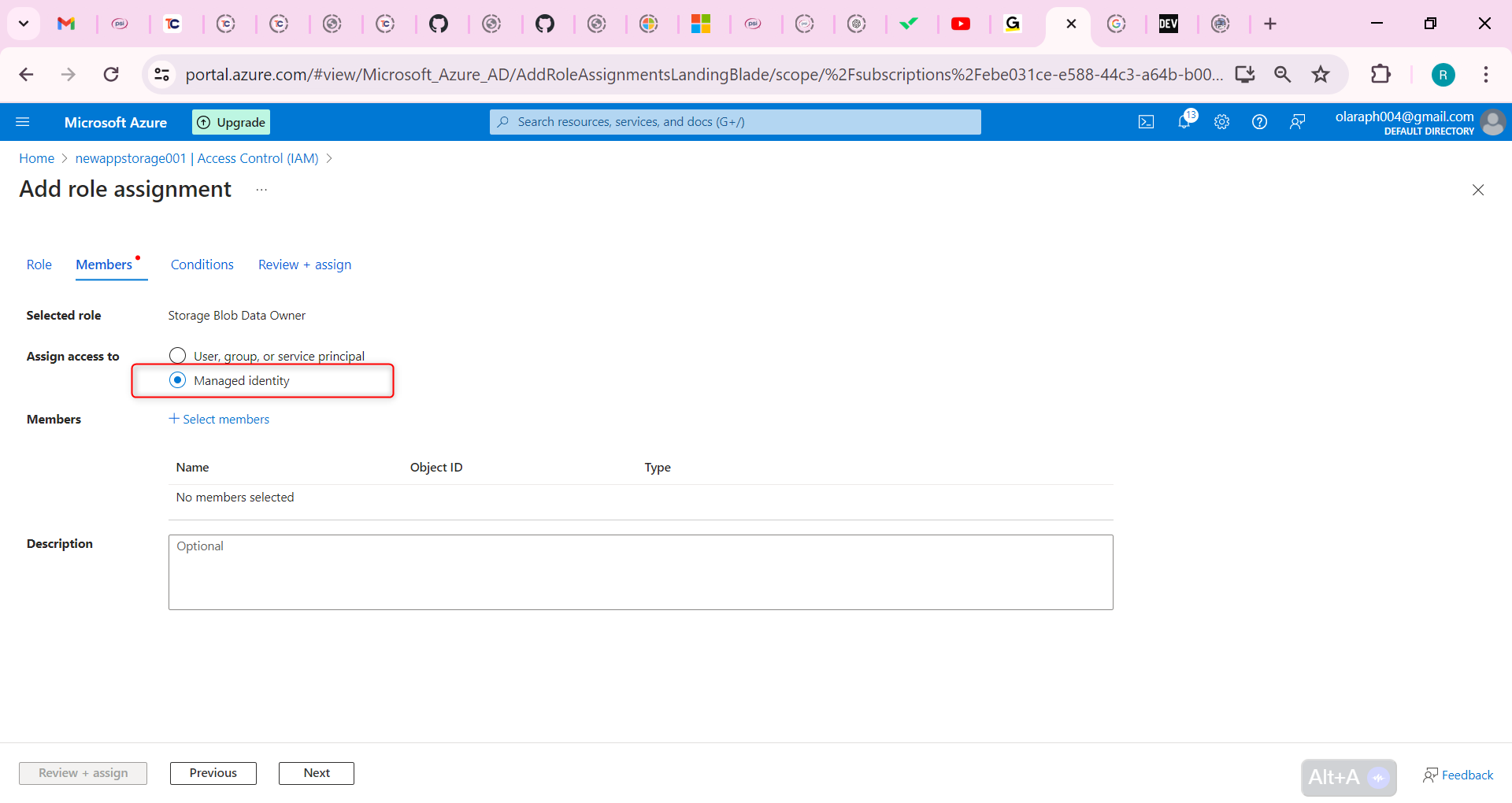
Select Select members, in the Managed identity drop-down select User-assigned managed identity.
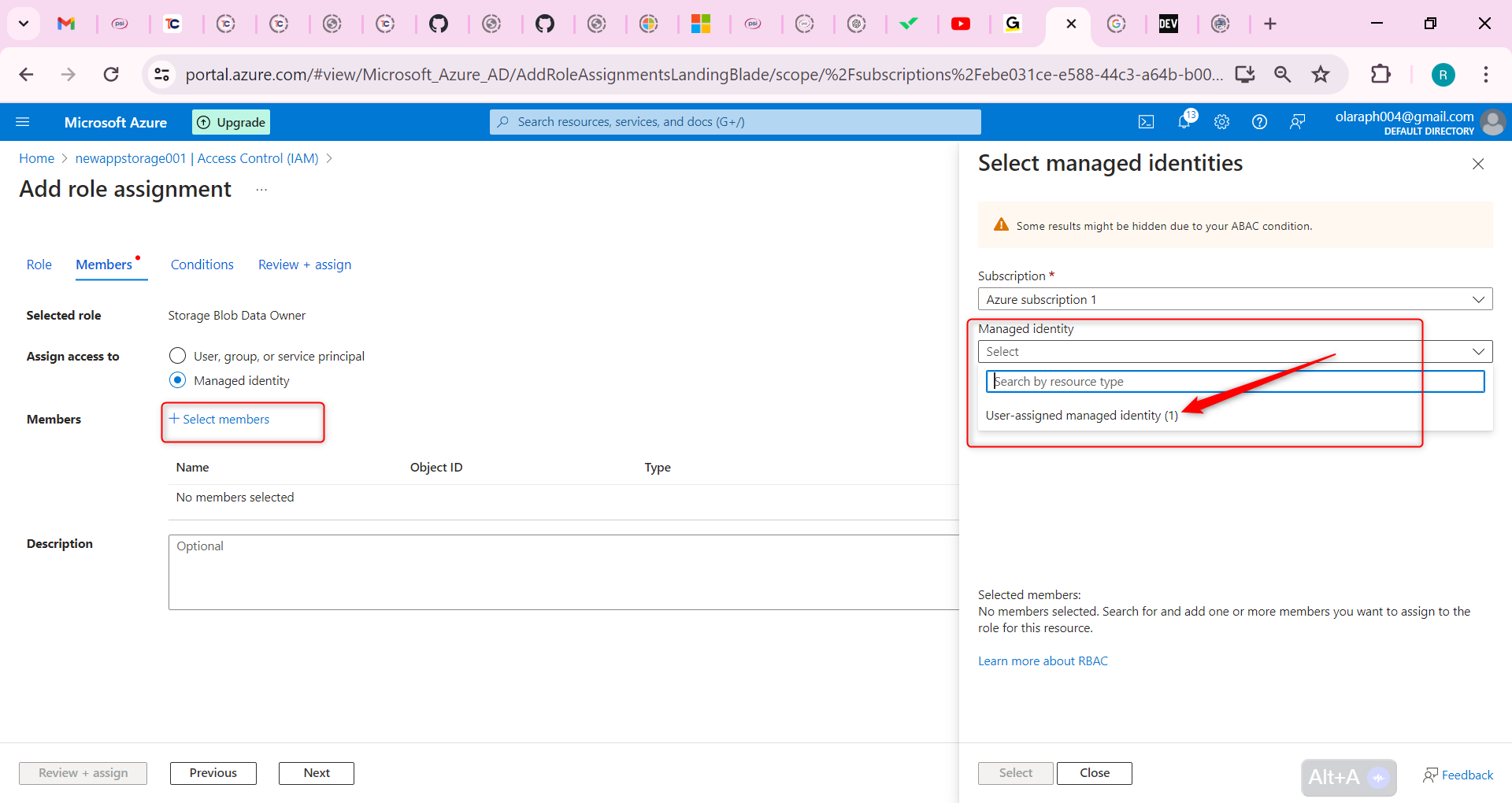
Select the managed identity you created in the previous step.
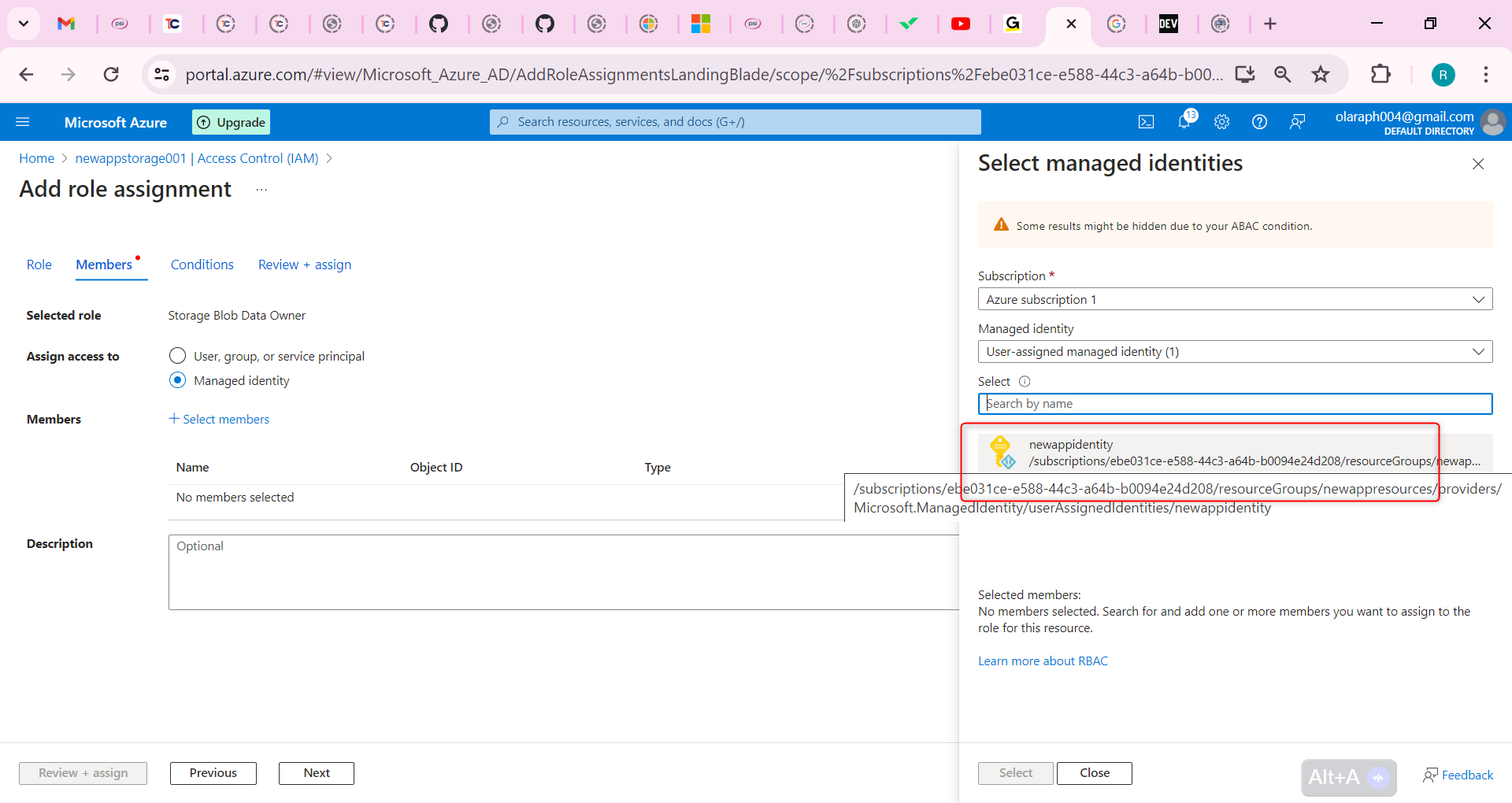
Click Select and then Review + assign the role.
Select Review + assign a second time to add the role assignment.
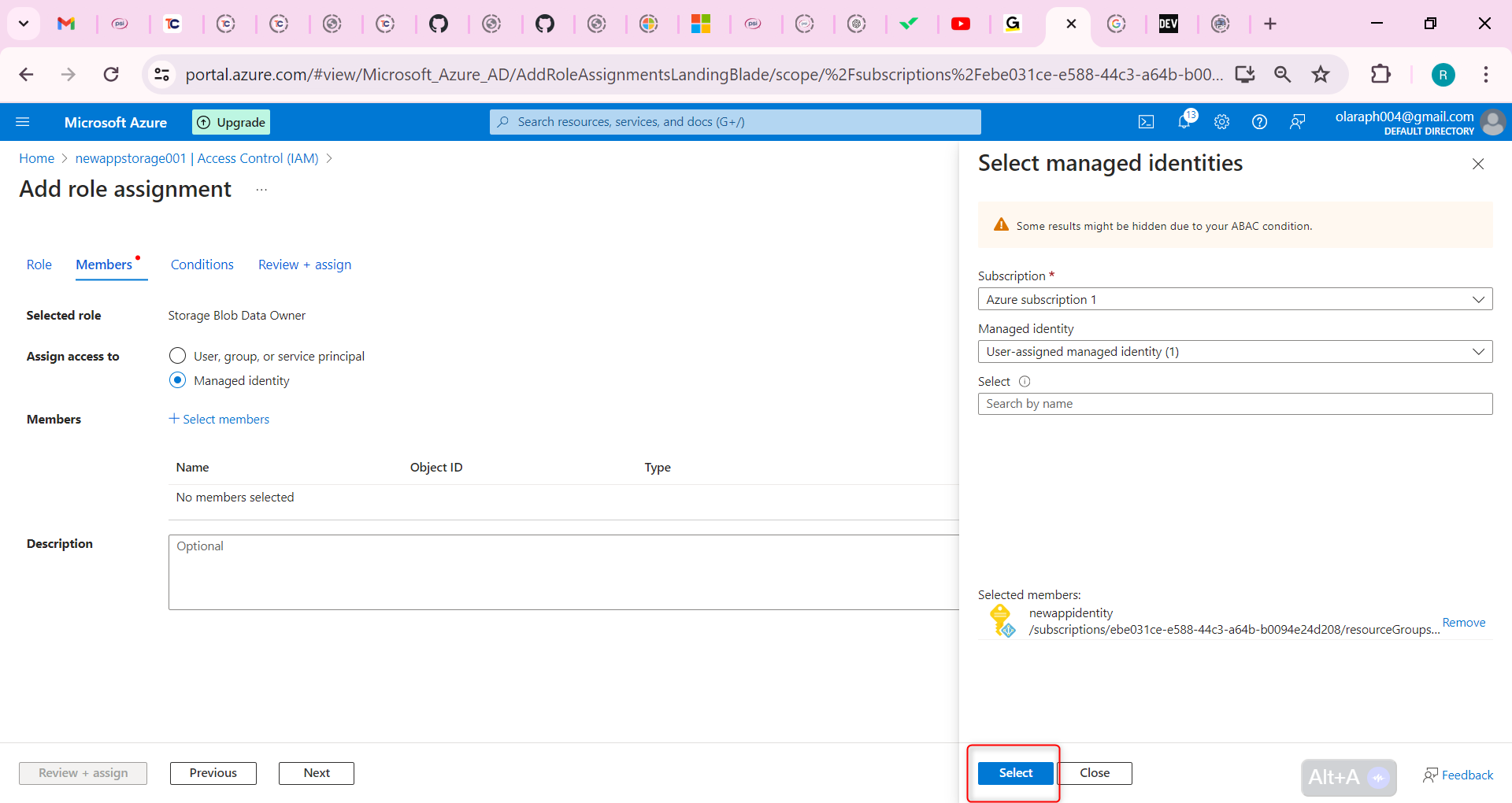
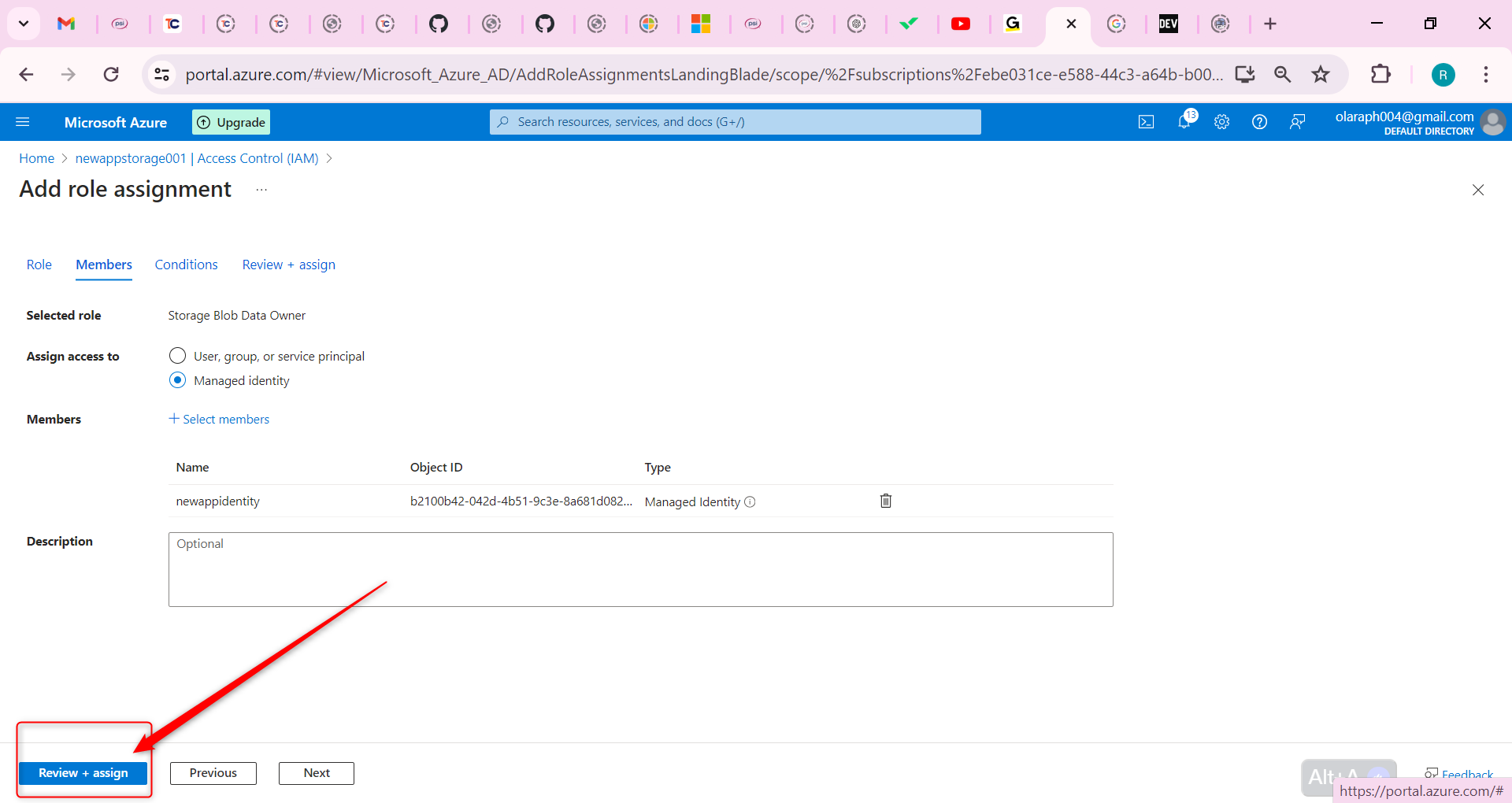
Your storage account can now be accessed by a managed identity with the Storage Data Blob Reader permissions.
Secure access to the storage account with a key vault and key
To create the key vault and key needed for this part of the lab, your user account must have Key Vault Administrator permissions.
In the portal, search for and select Resource groups.
Select your resource group, and then the Access Control (IAM) blade.
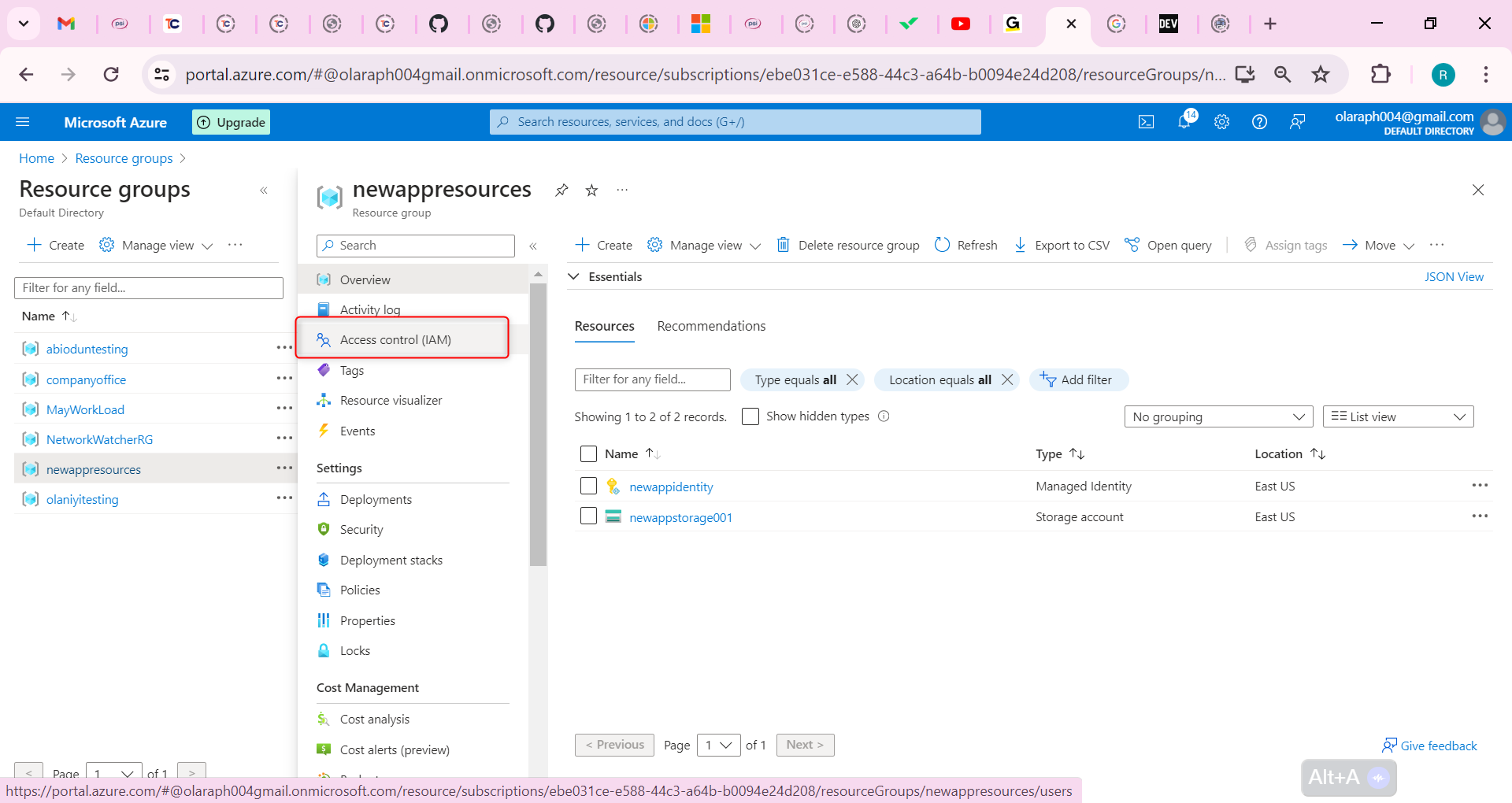
Select Add role assignment (center of the page).
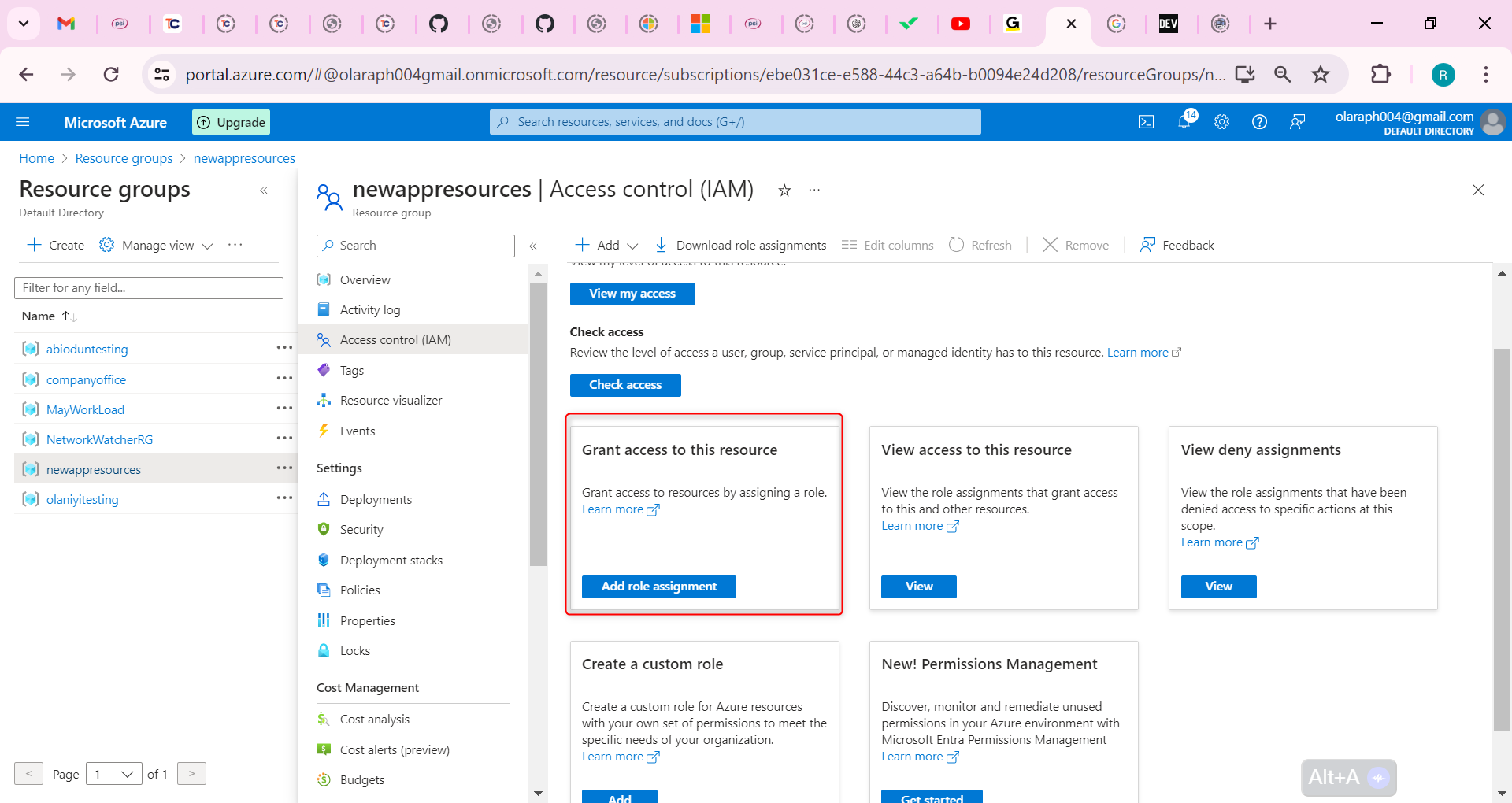
On the Job functions roles page, search for and select the Key Vault Administrator role.
On the Members page, select User, group, or service principal.
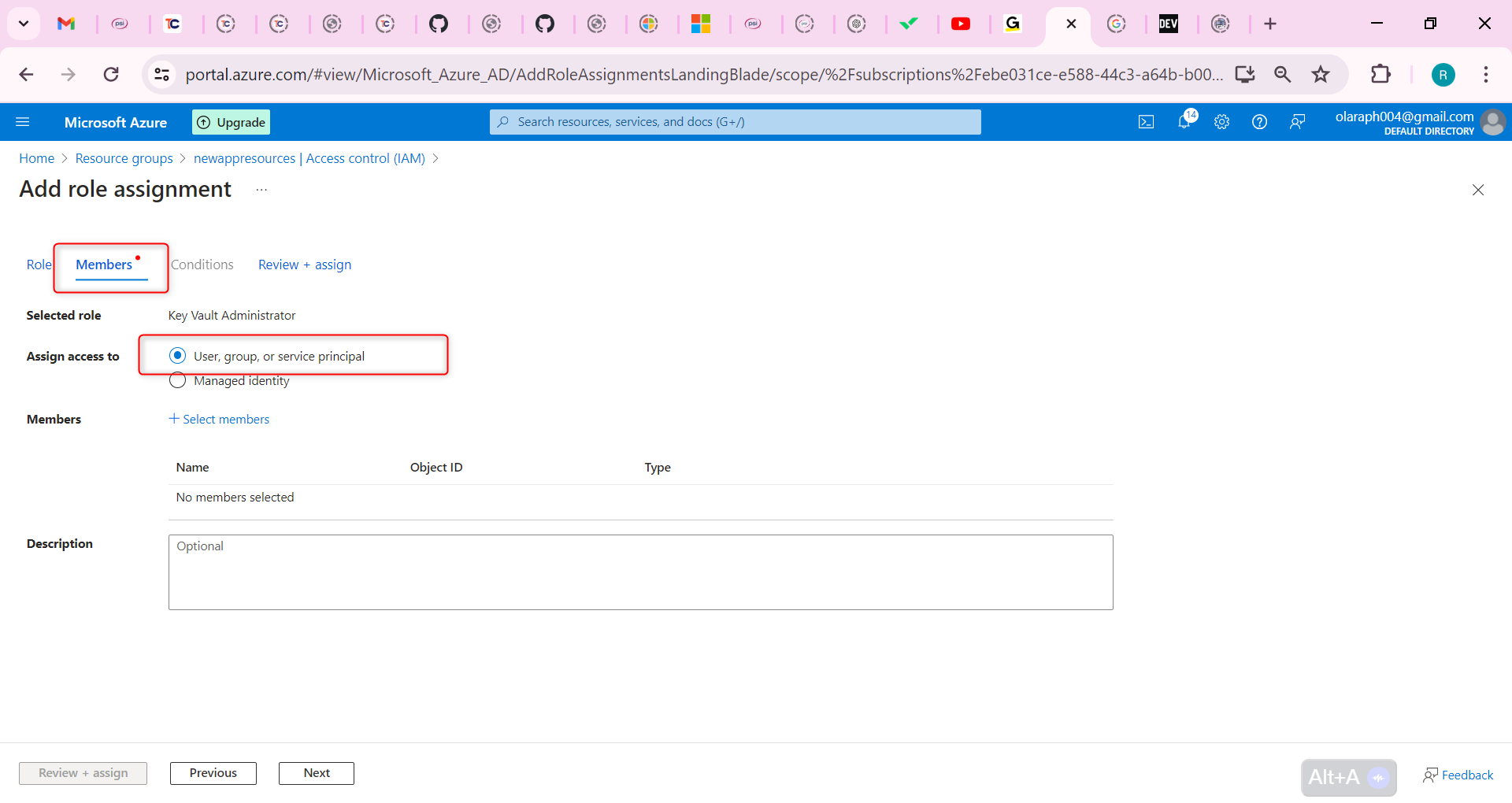
Select Select members.
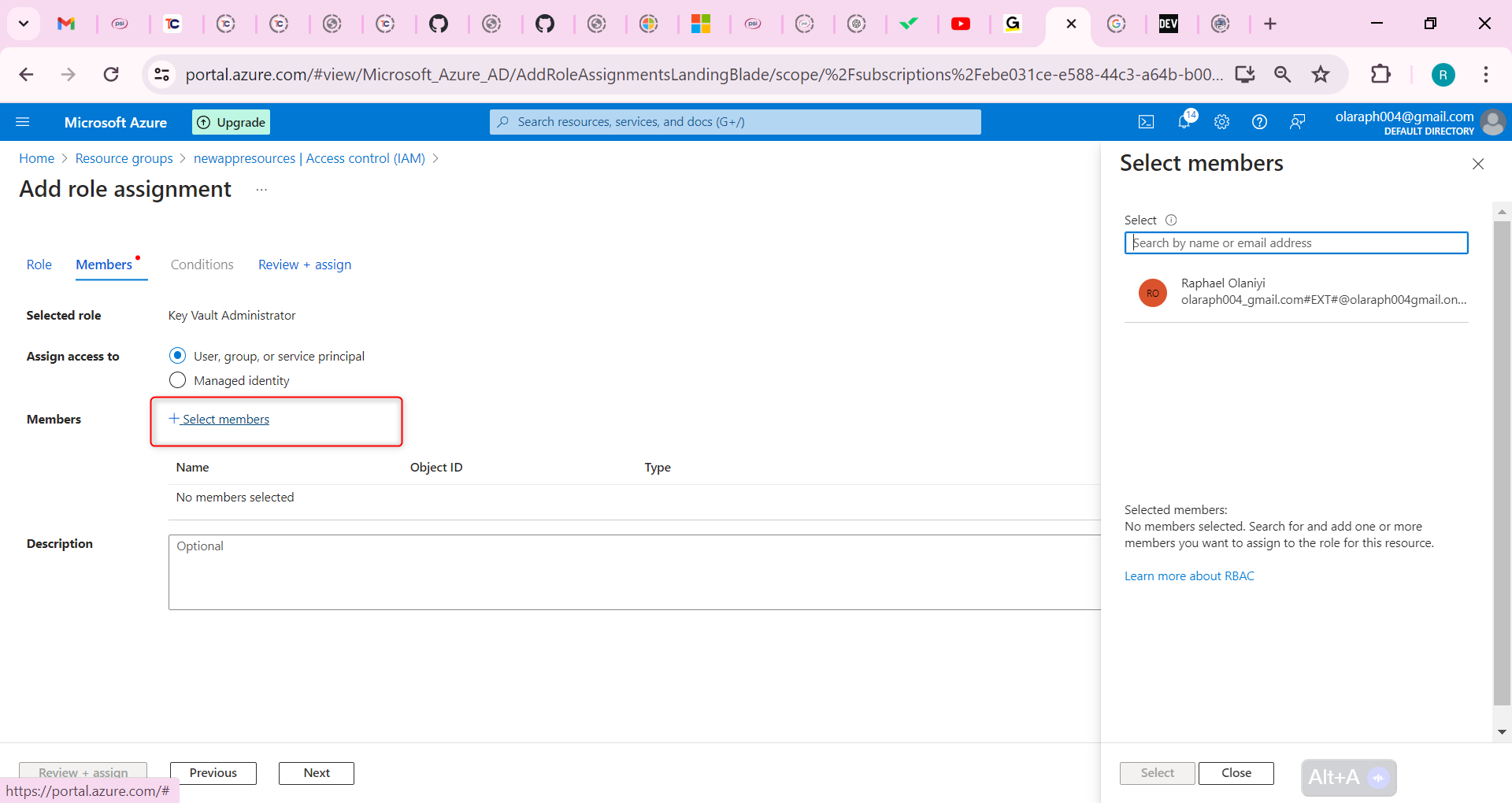
Search for and select your user account. Your user account is shown in the top right of the portal.
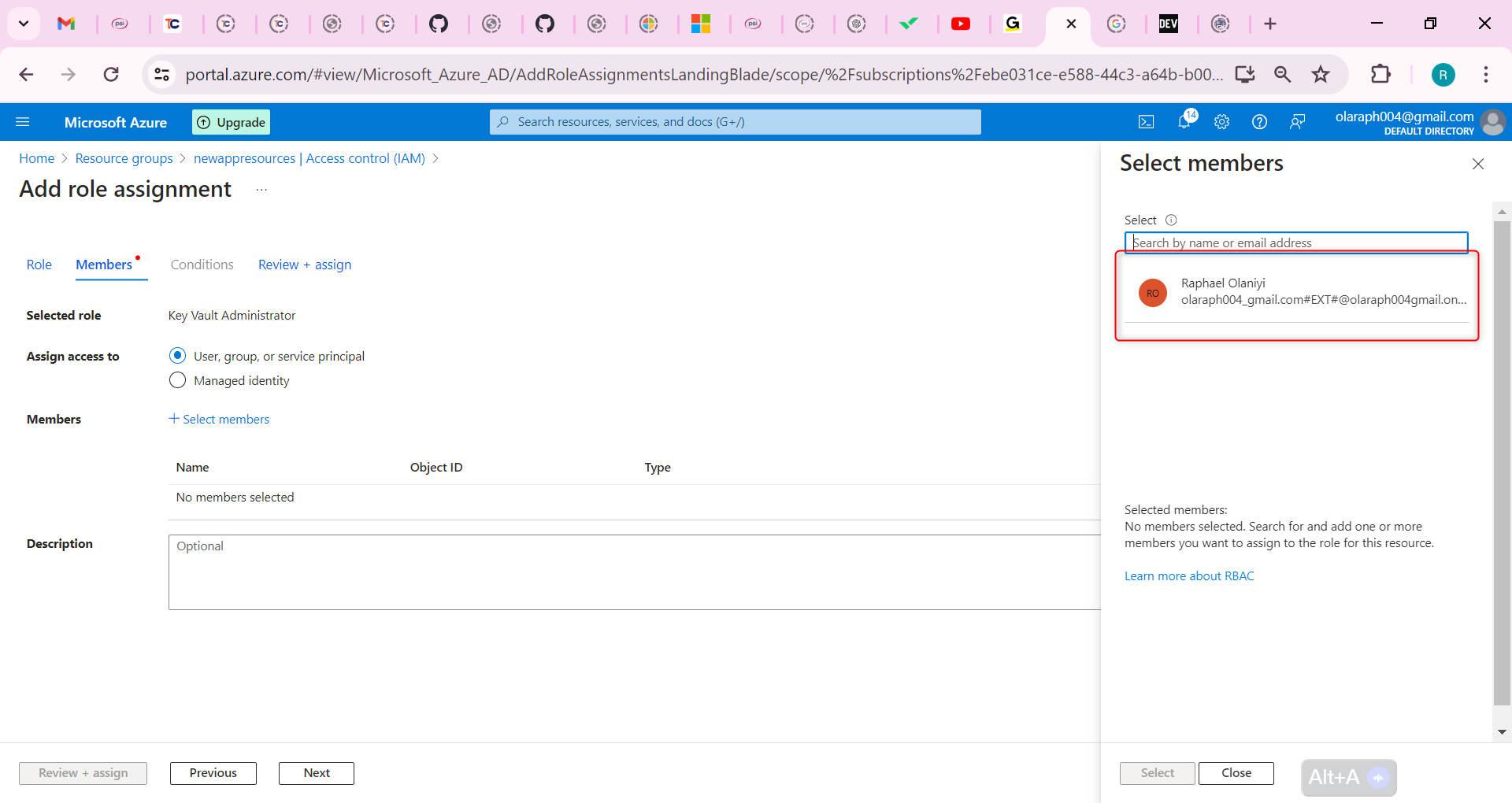
Click Select and then Review + assign.
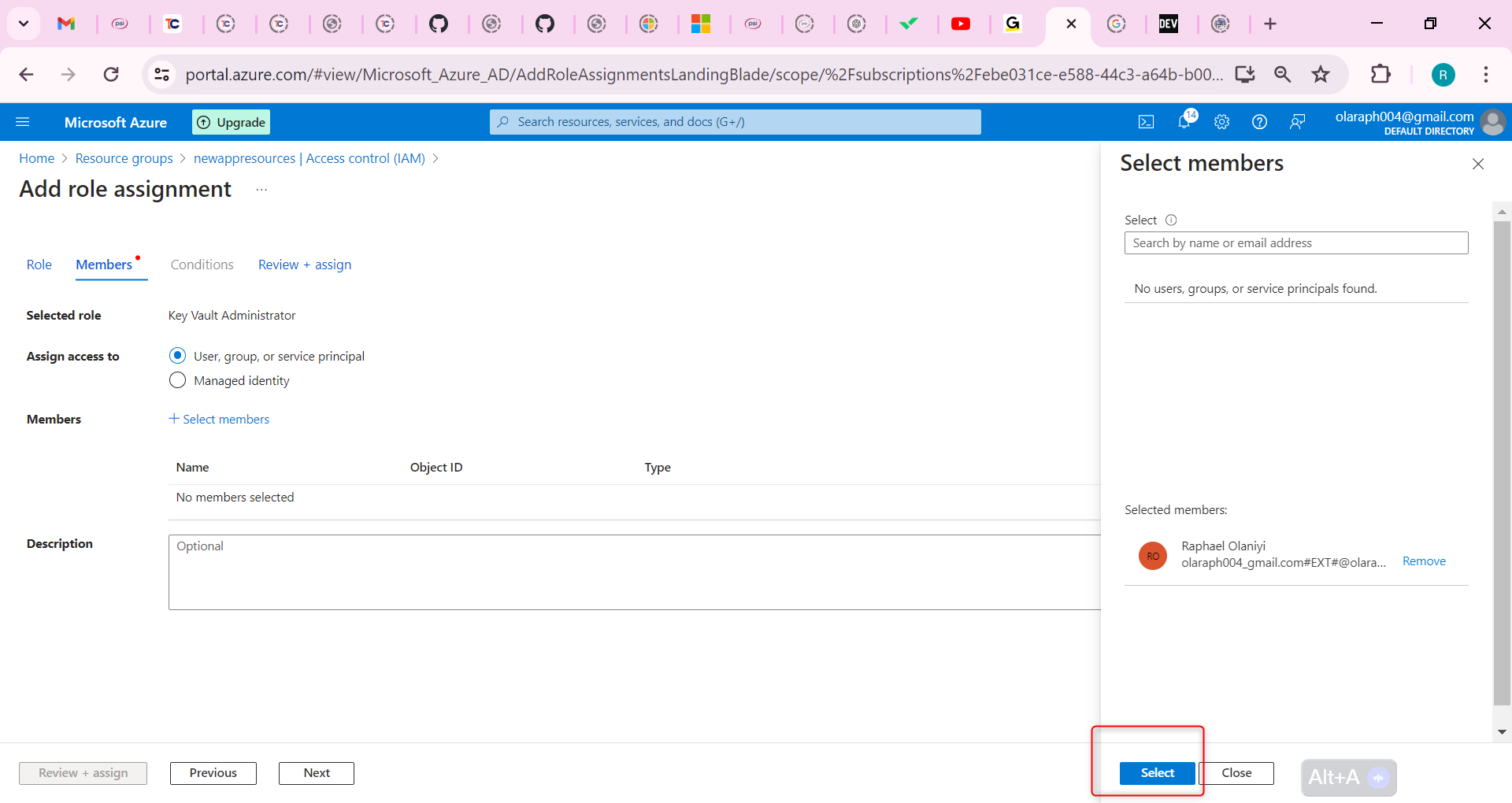
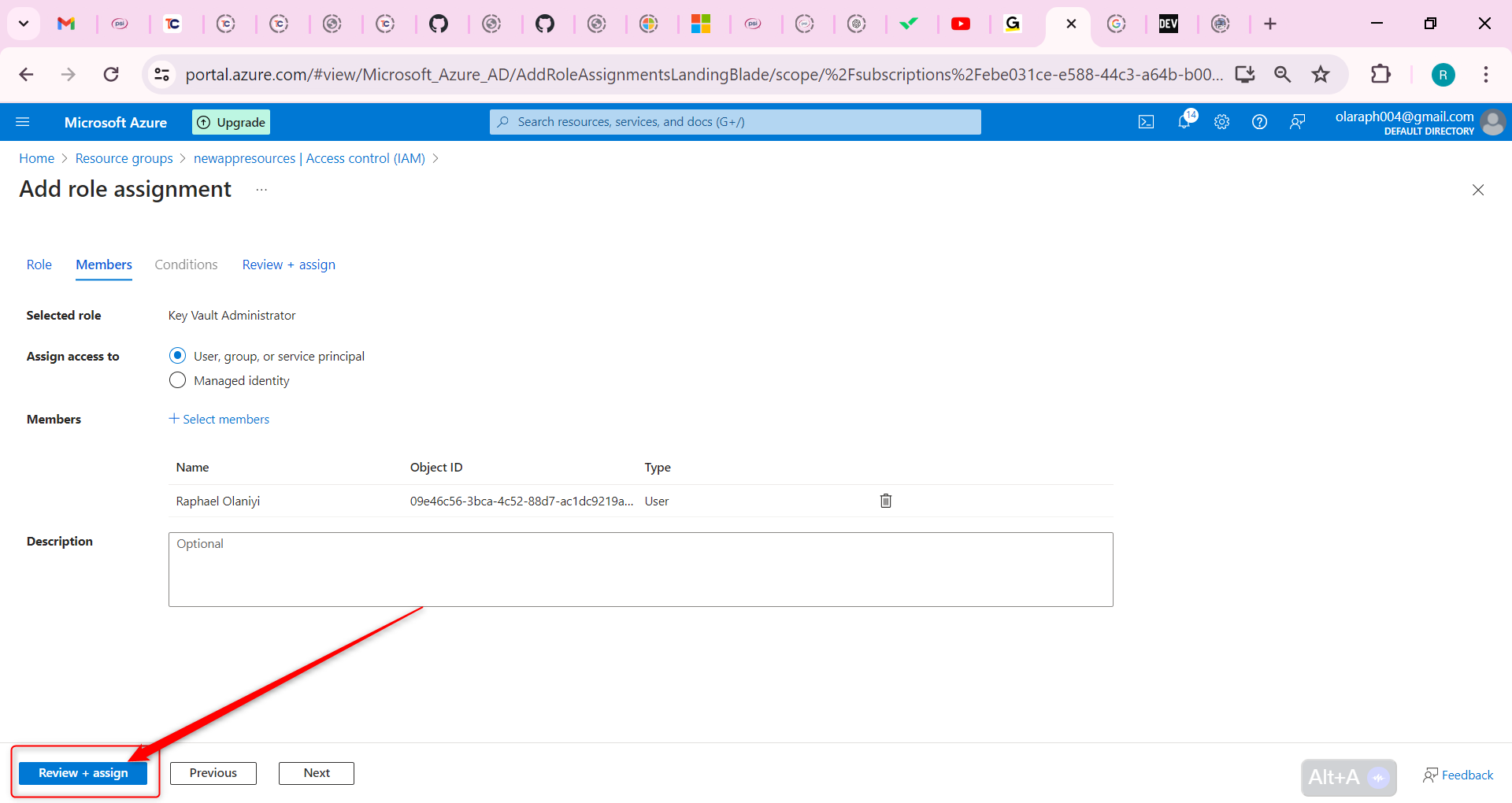
Select Review + assign a second time to add the role assignment.
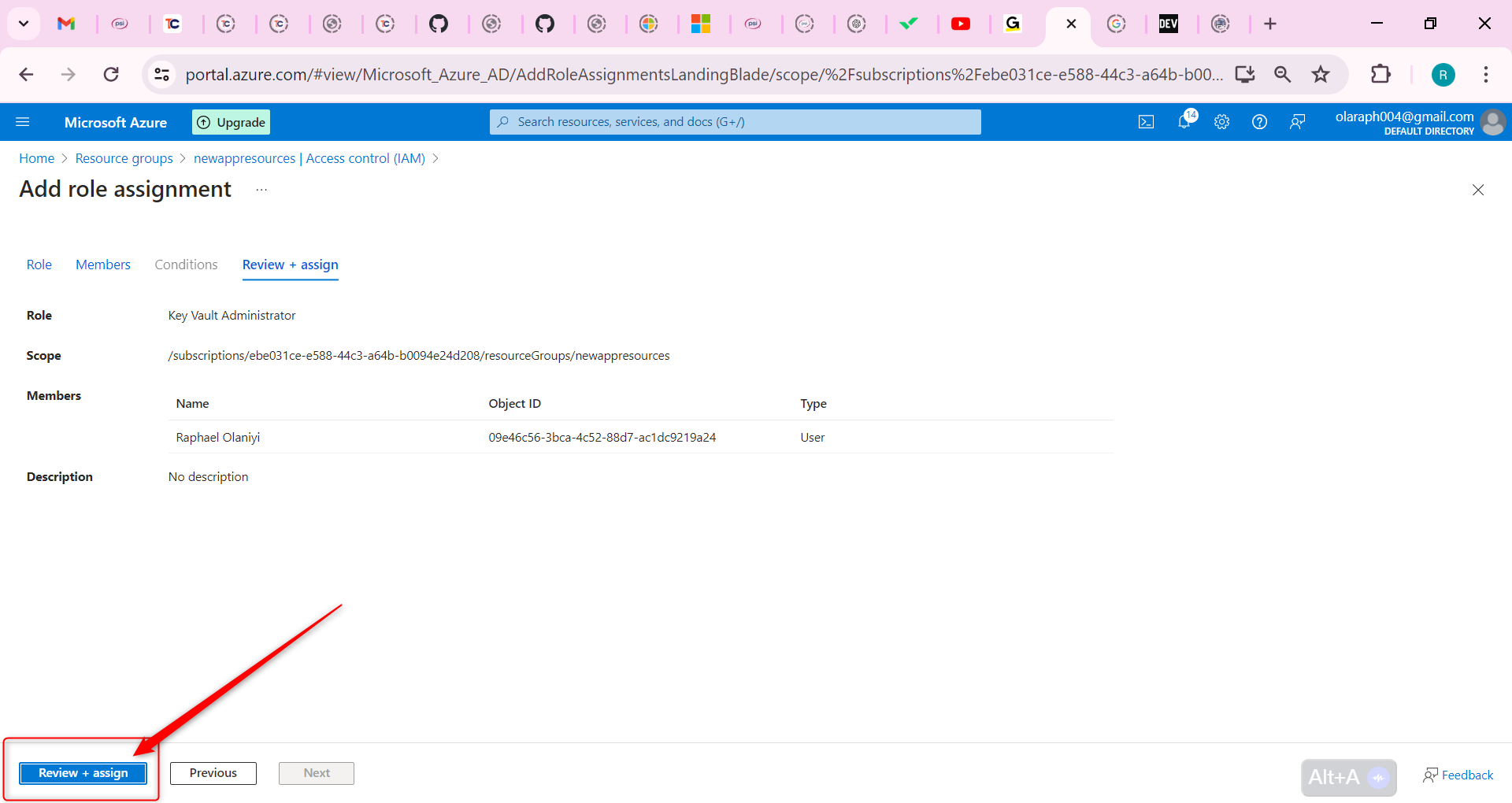
You are now ready to continue with the lab.
Create a key vault to store the access keys.
In the portal, search for and select Key vaults.
Select Create.
Select your resource group.
Provide the name for the key vault. The name must be unique.
Ensure on the Access configuration tab that Azure role-based access control (recommended) is selected.
Select Review + create.
Wait for the validation checks to complete and then select Create.
After the deployment, select Go to resource.
On the Overview blade ensure both Soft-delete and Purge protection are enabled.
Create a customer-managed key in the key vault.
In your key vault, in the Objects section, select the Keys blade.
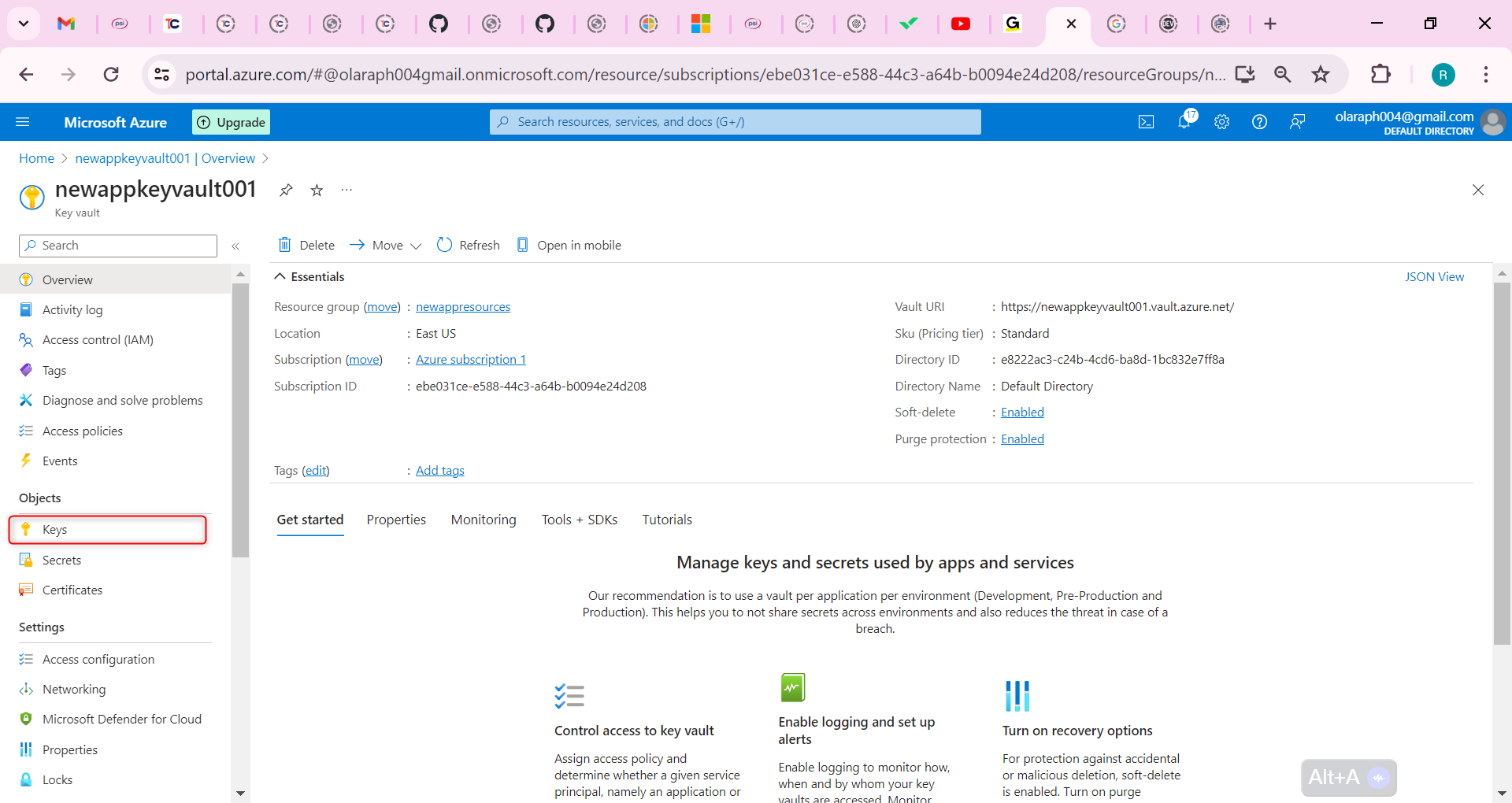
Select Generate/Import and Name the key.
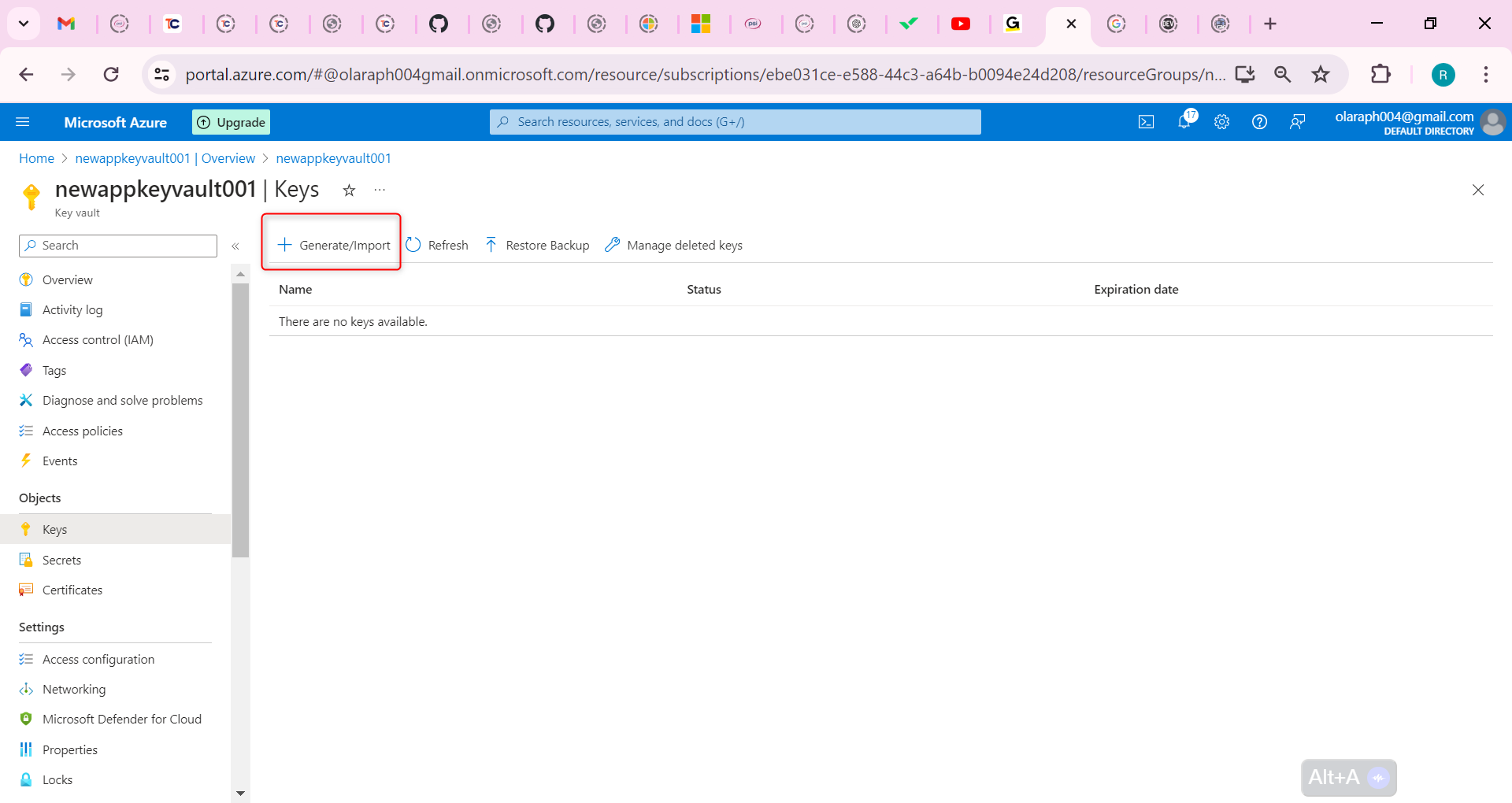
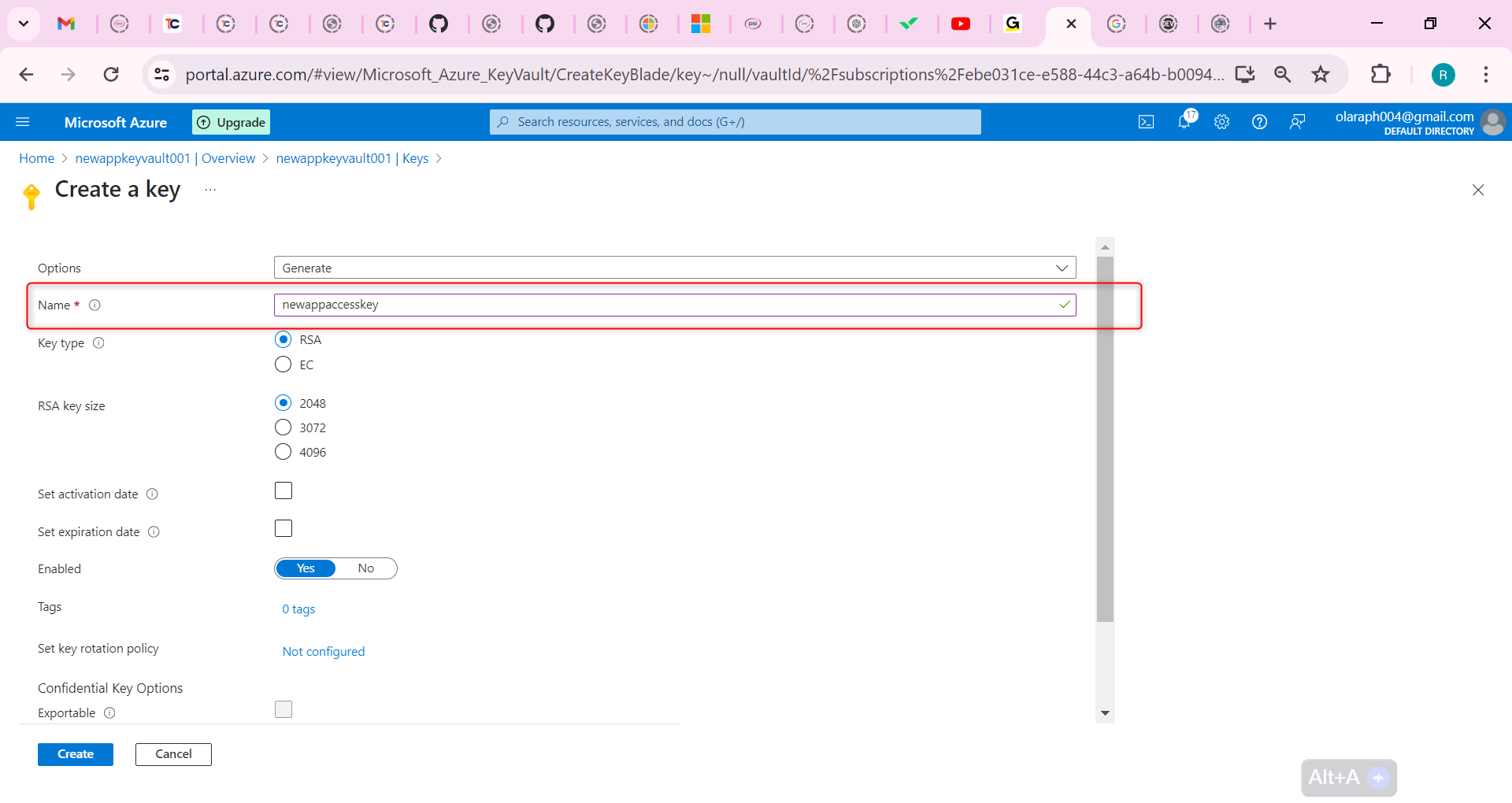
Take the defaults for the rest of the parameters, and Create the key.
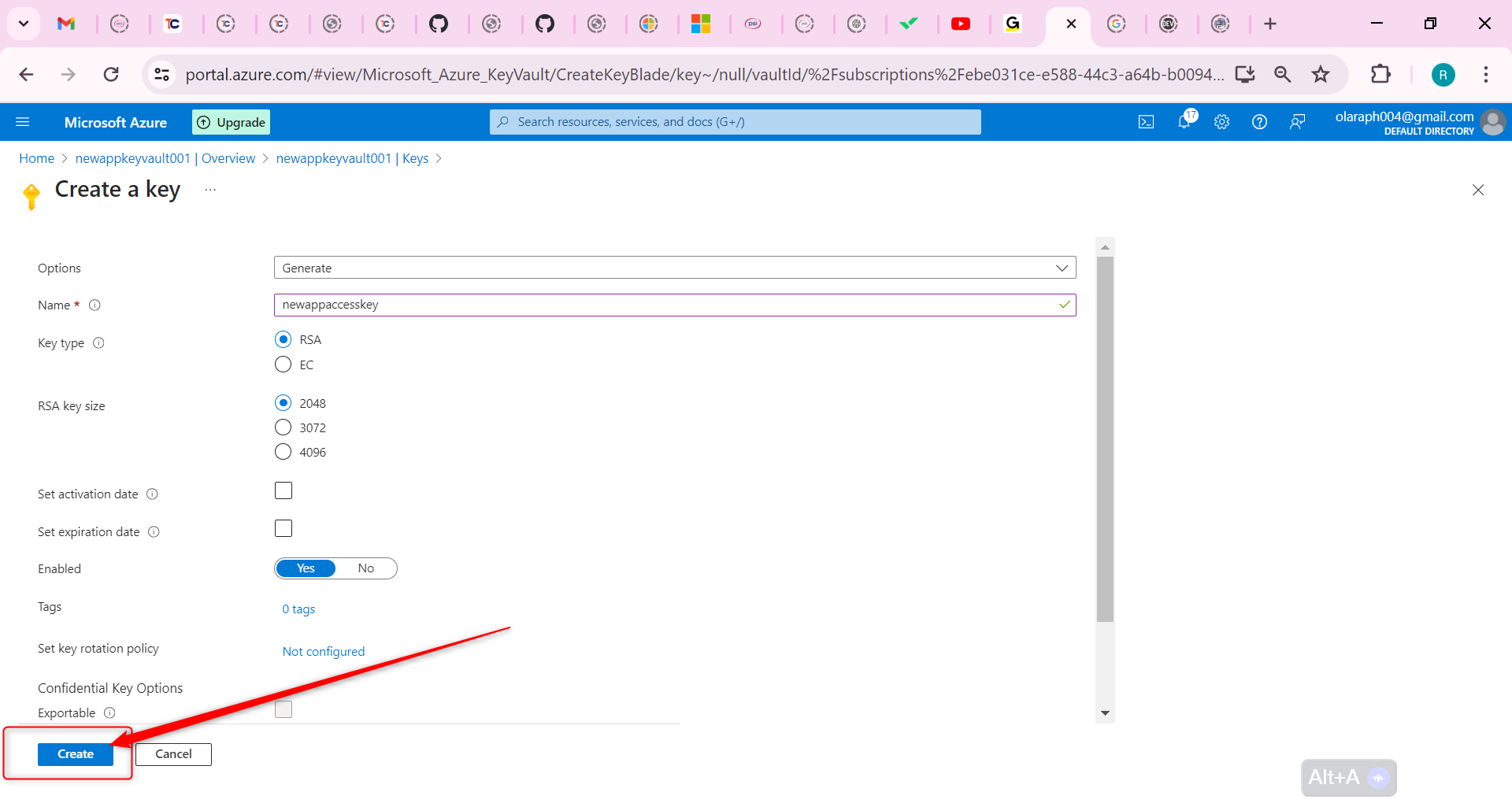
Configure the storage account to use the customer managed key in the key vault
Before you can complete the next steps, you must assign the Key Vault Crypto Service Encryption User role to the managed identity.
In the portal, search for and select Resource groups.
Select your resource group, and then the Access Control (IAM) blade.
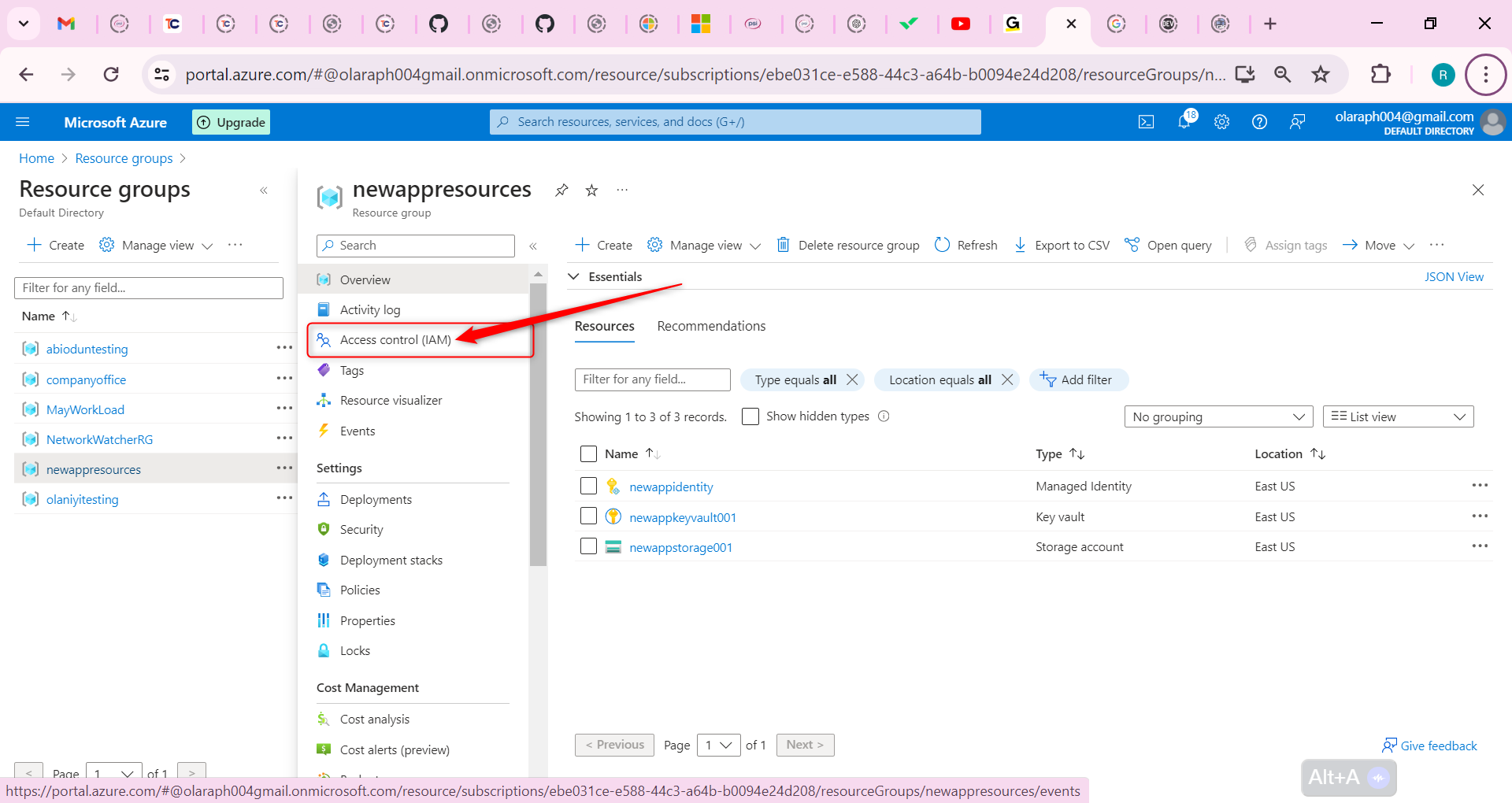
Select Add role assignment (center of the page).
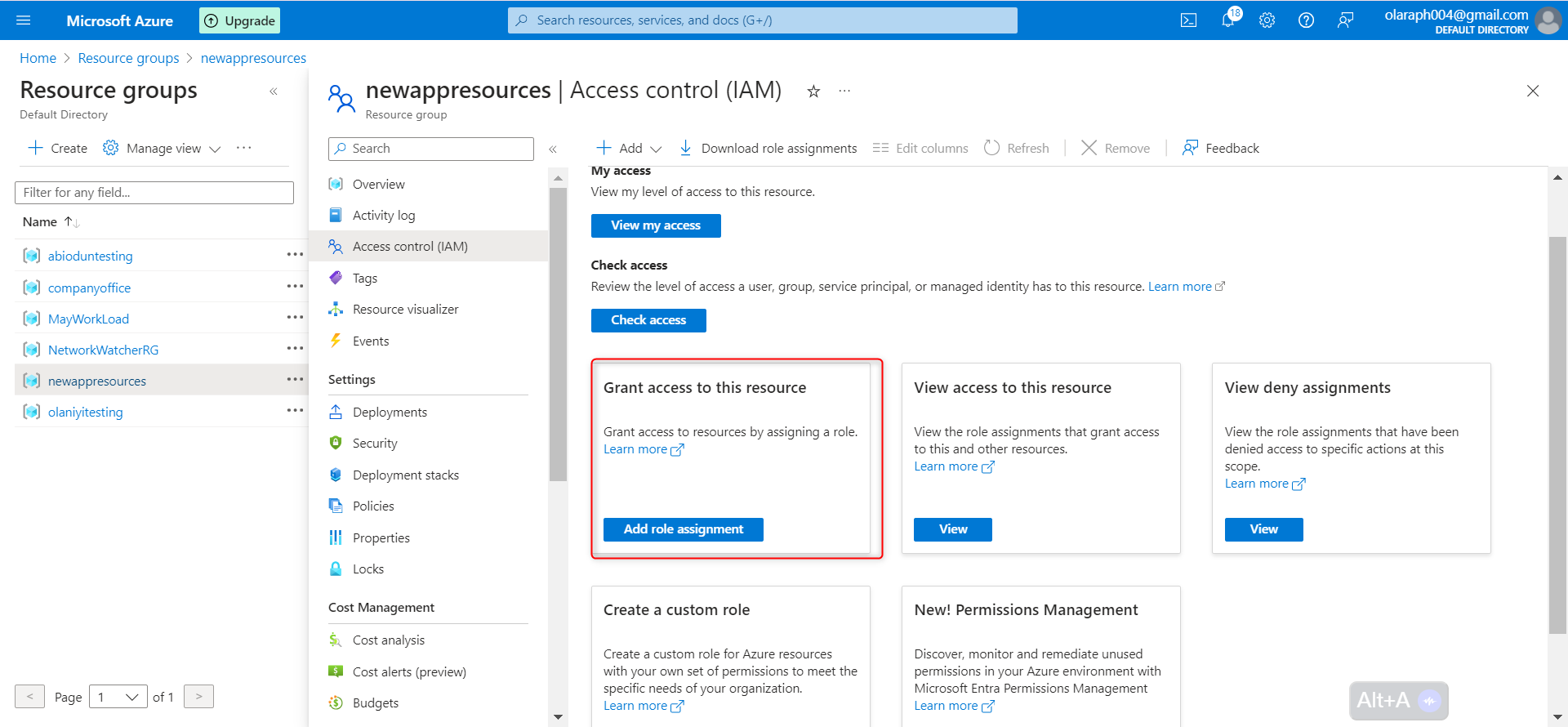
On the Job functions roles page, search for and select the Key Vault Crypto Service Encryption User role.
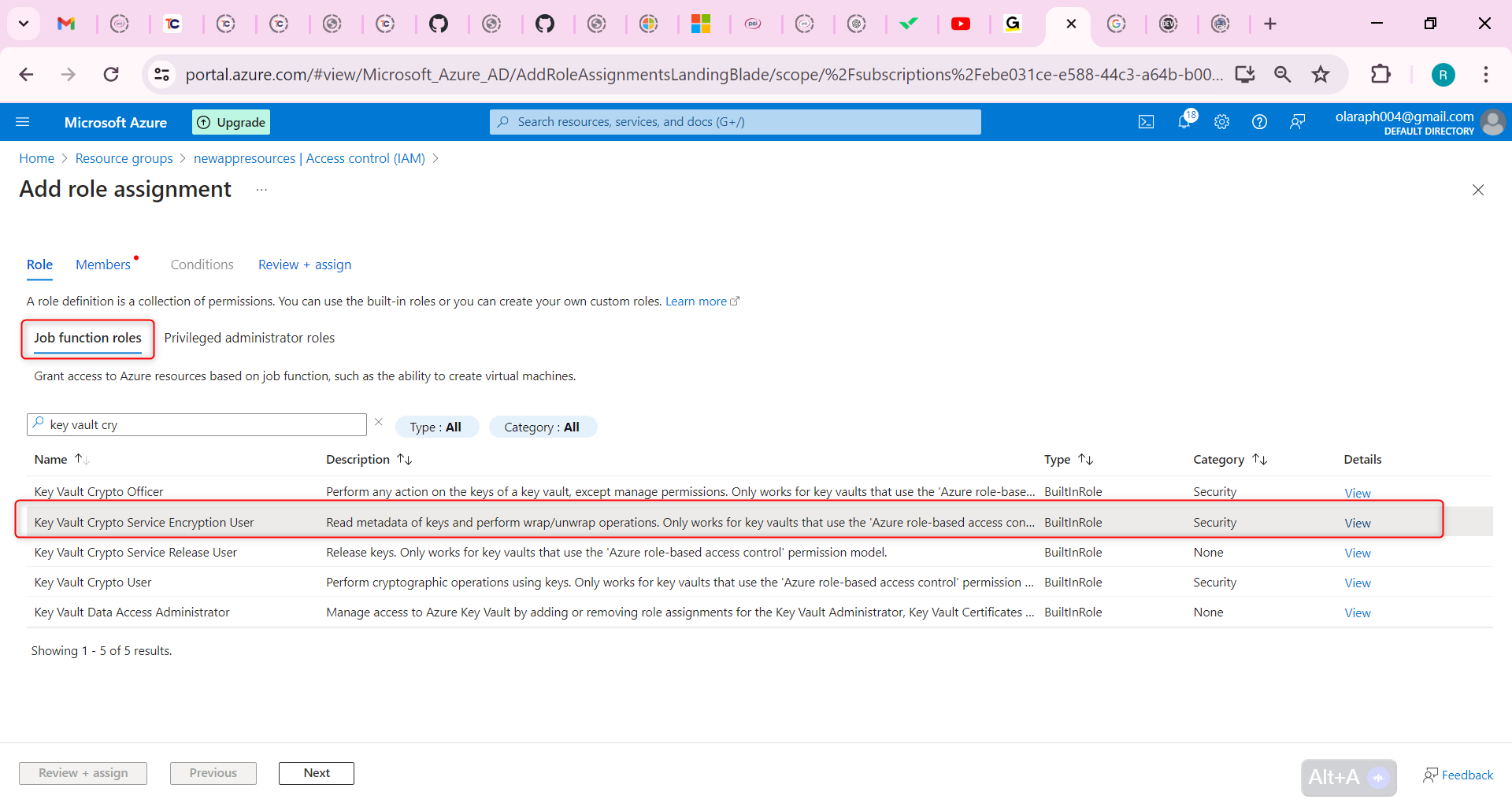
On the Members page, select Managed identity.
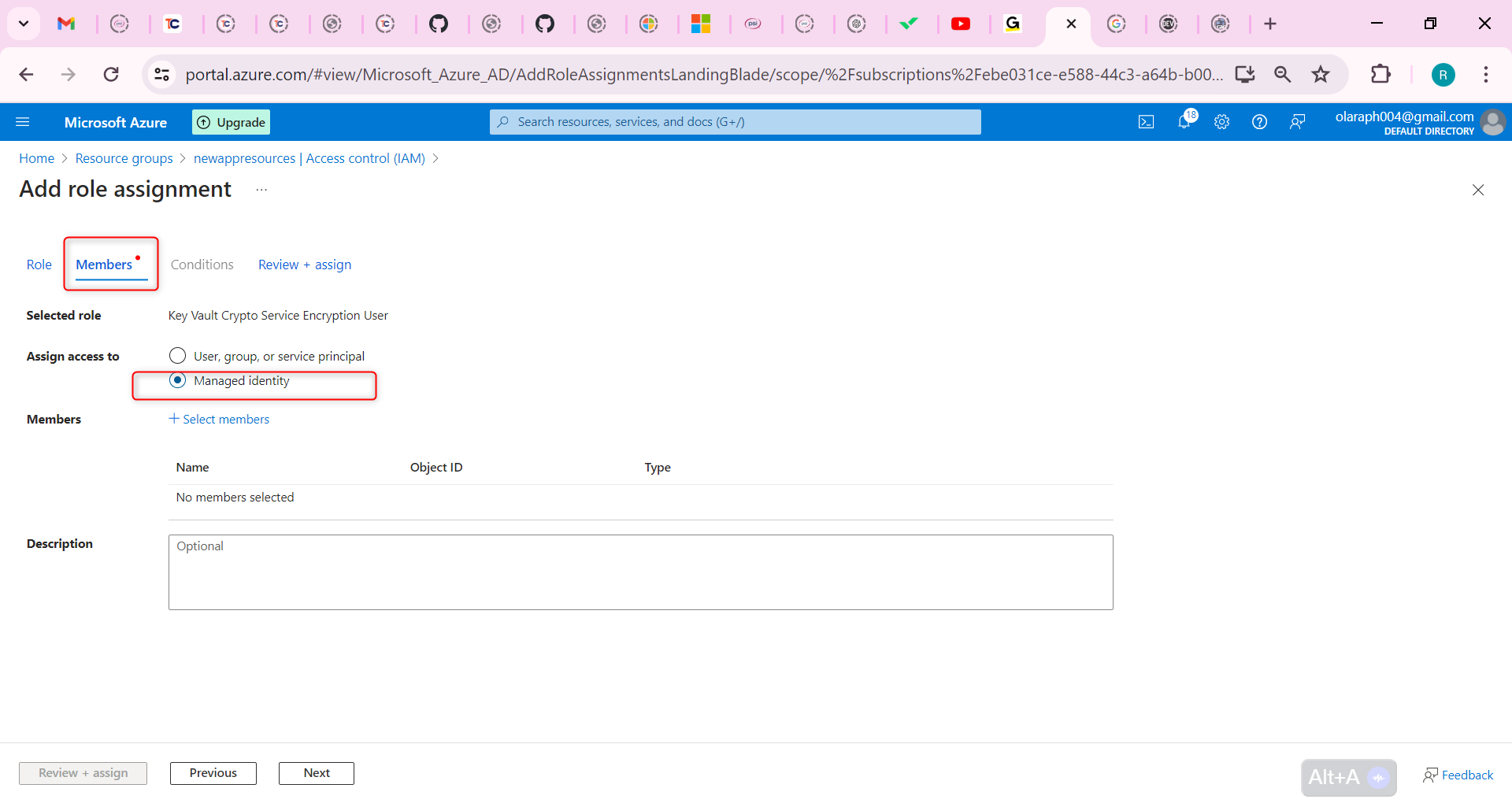
Select Select members, in the Managed identity drop-down select User-assigned managed identity.
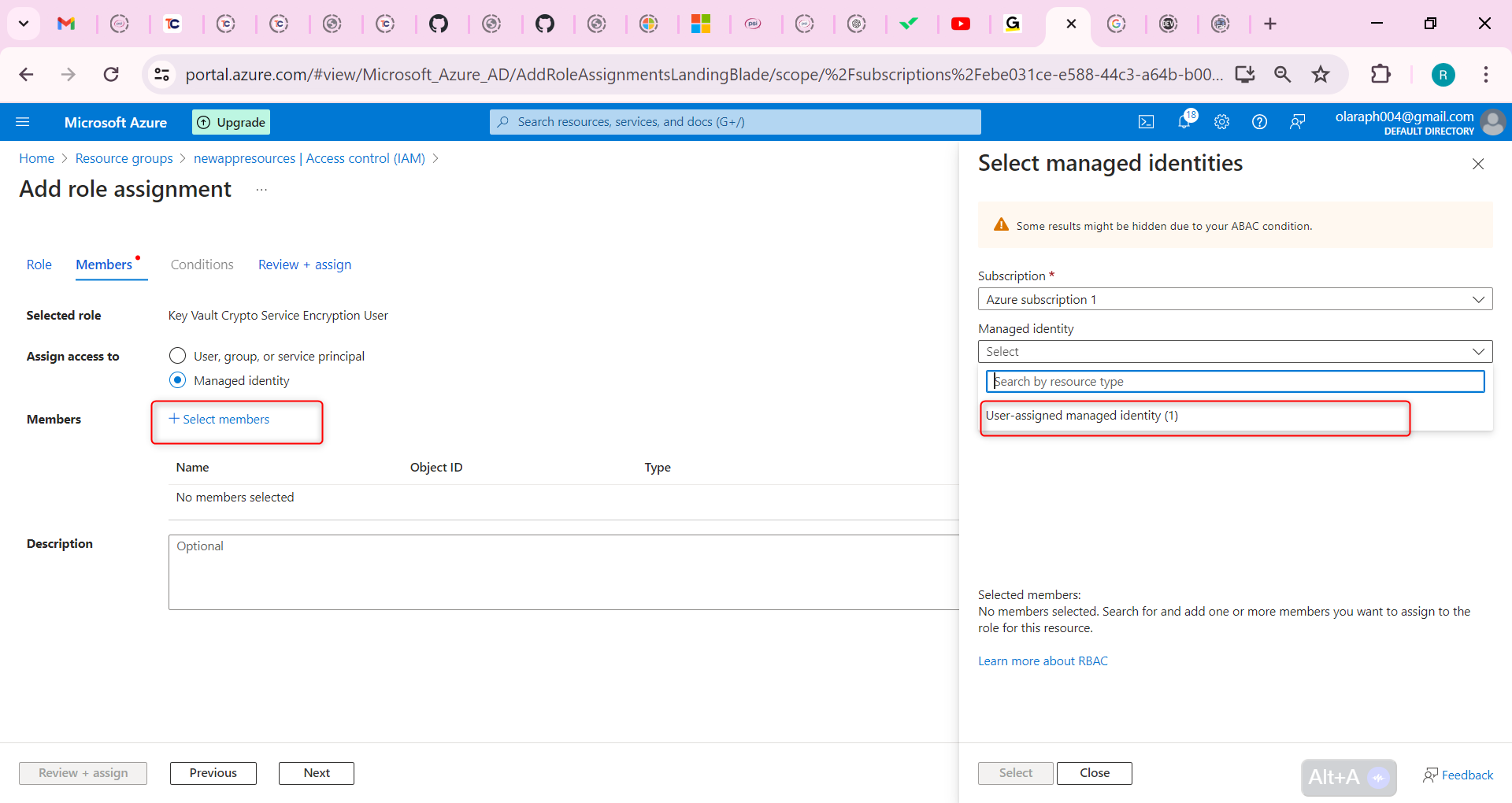
Select your managed identity.
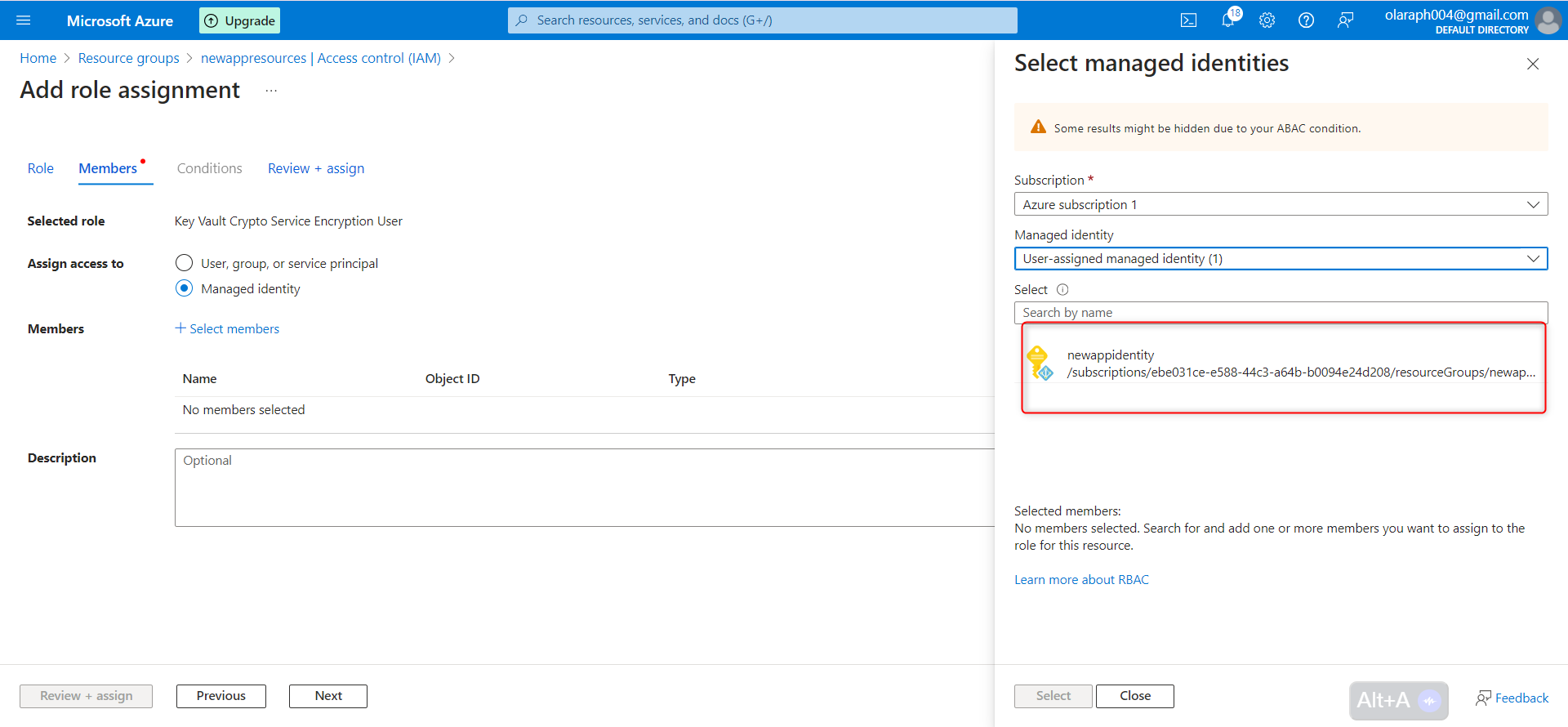
Click Select and then Review + assign.
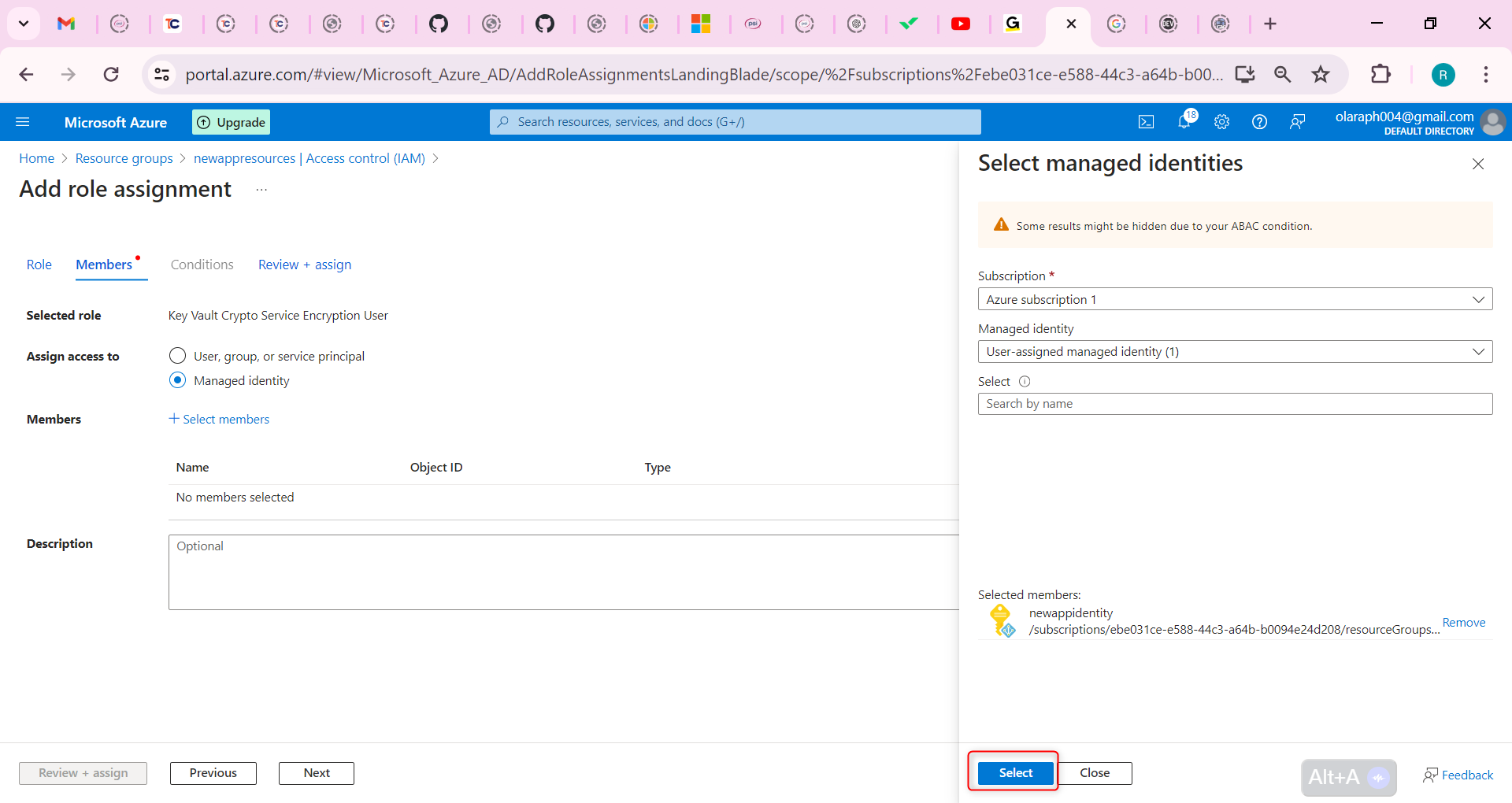
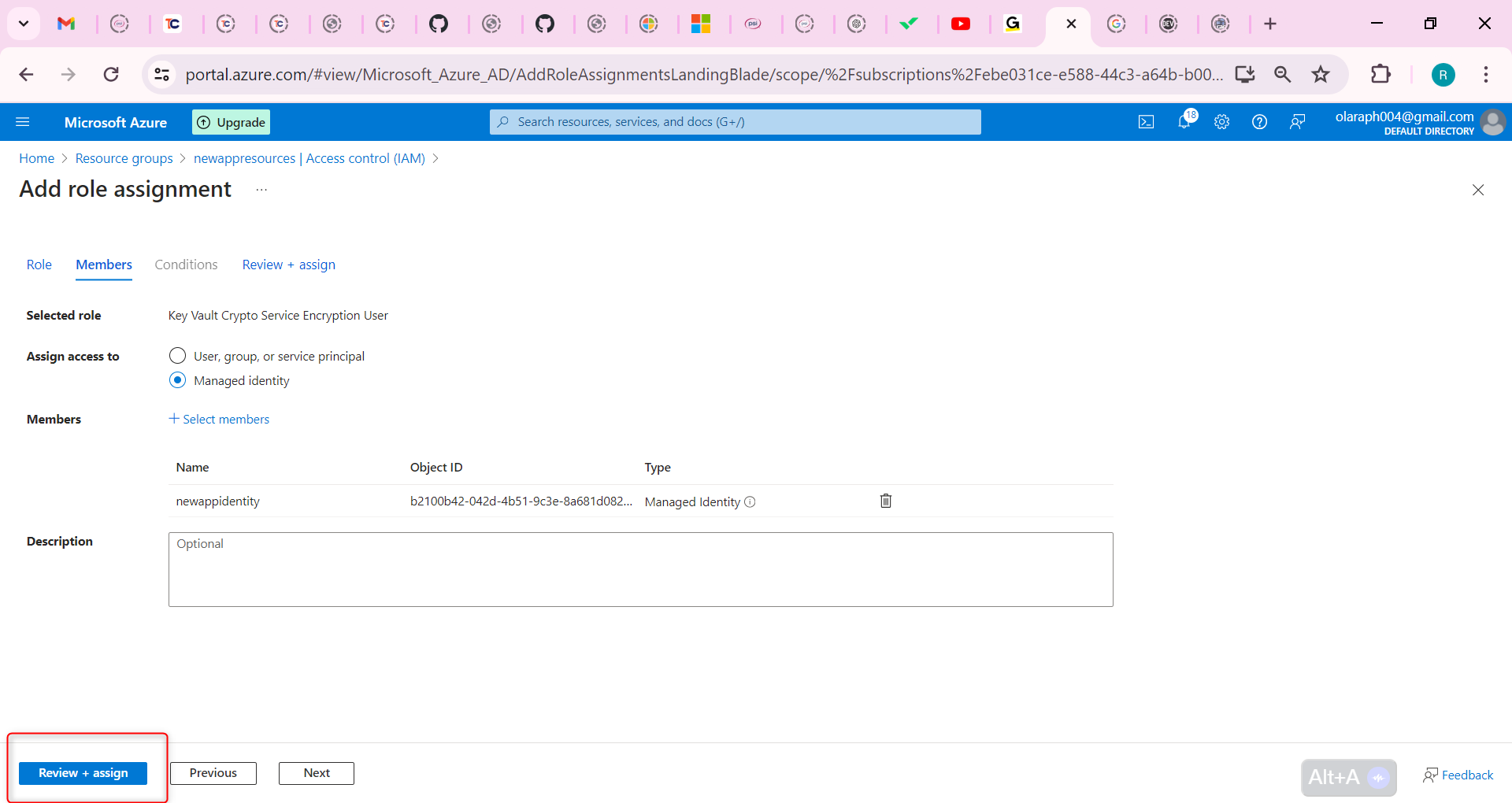
Select Review + assign a second time to add the role assignment.
Configure the storage account to use the customer managed key in your key vault. Learn more about customer managed keys on an existing storage account.
Return to your the storage account.
In the Security + networking section, select the Encryption blade.
Select Customer-managed keys.
Select a key vault and key. Select your key vault and key.
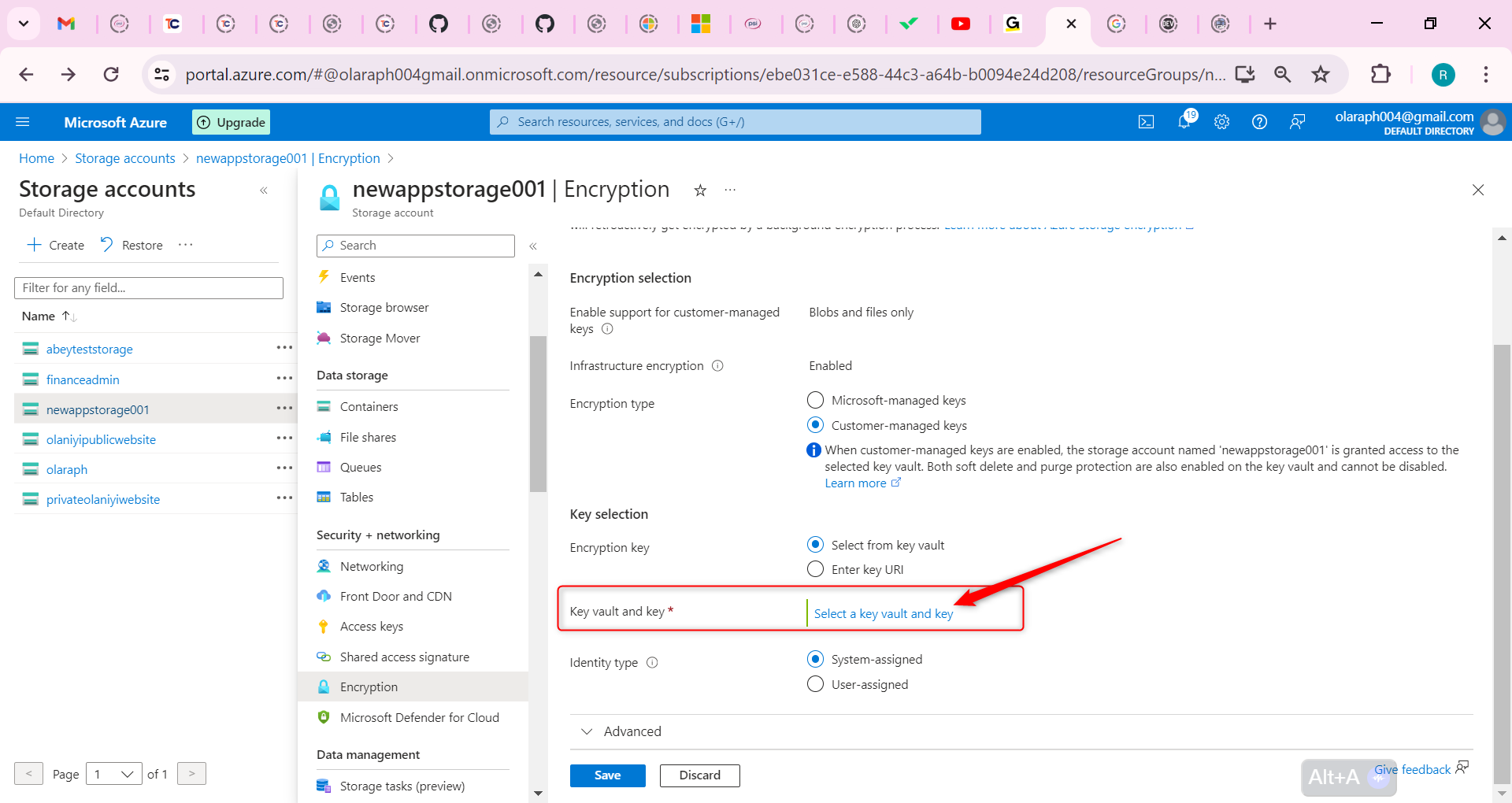
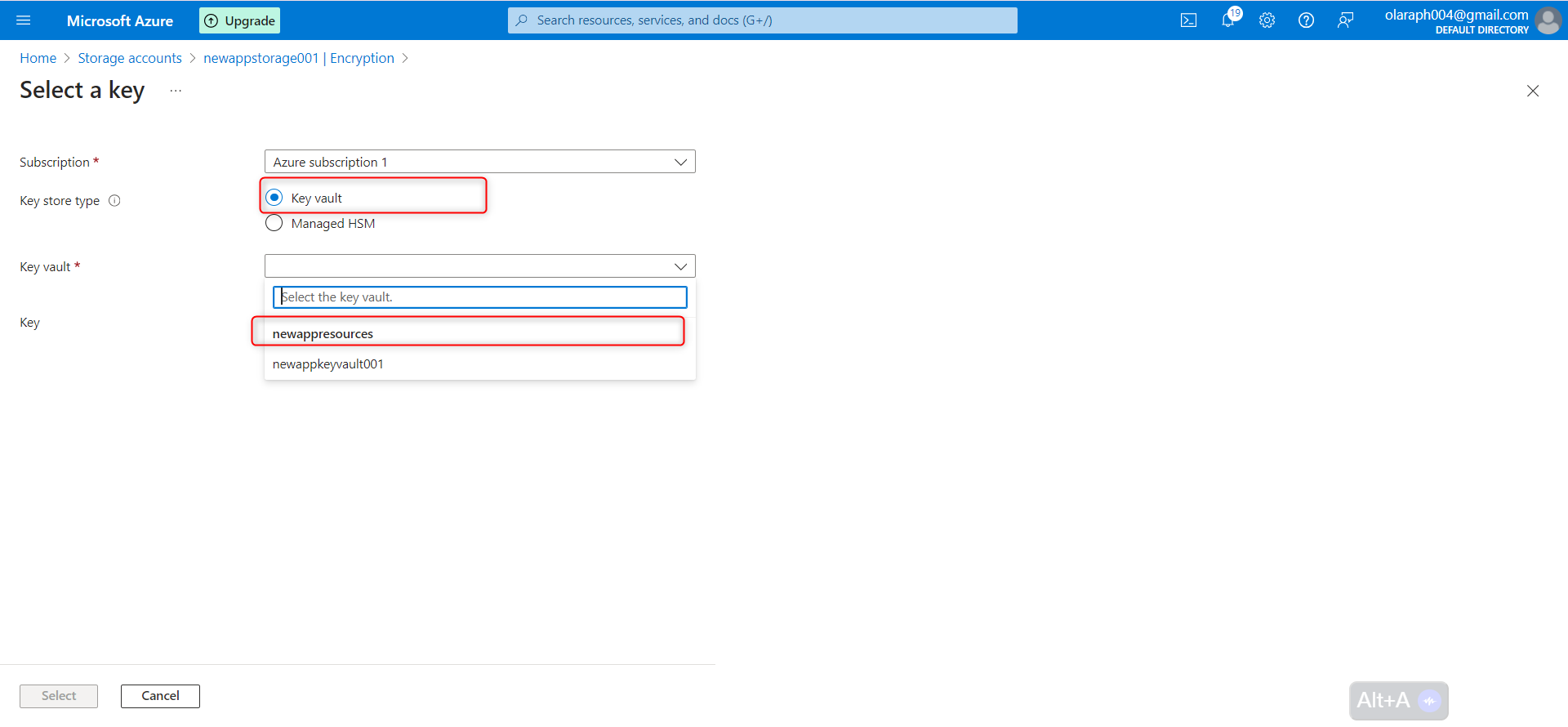
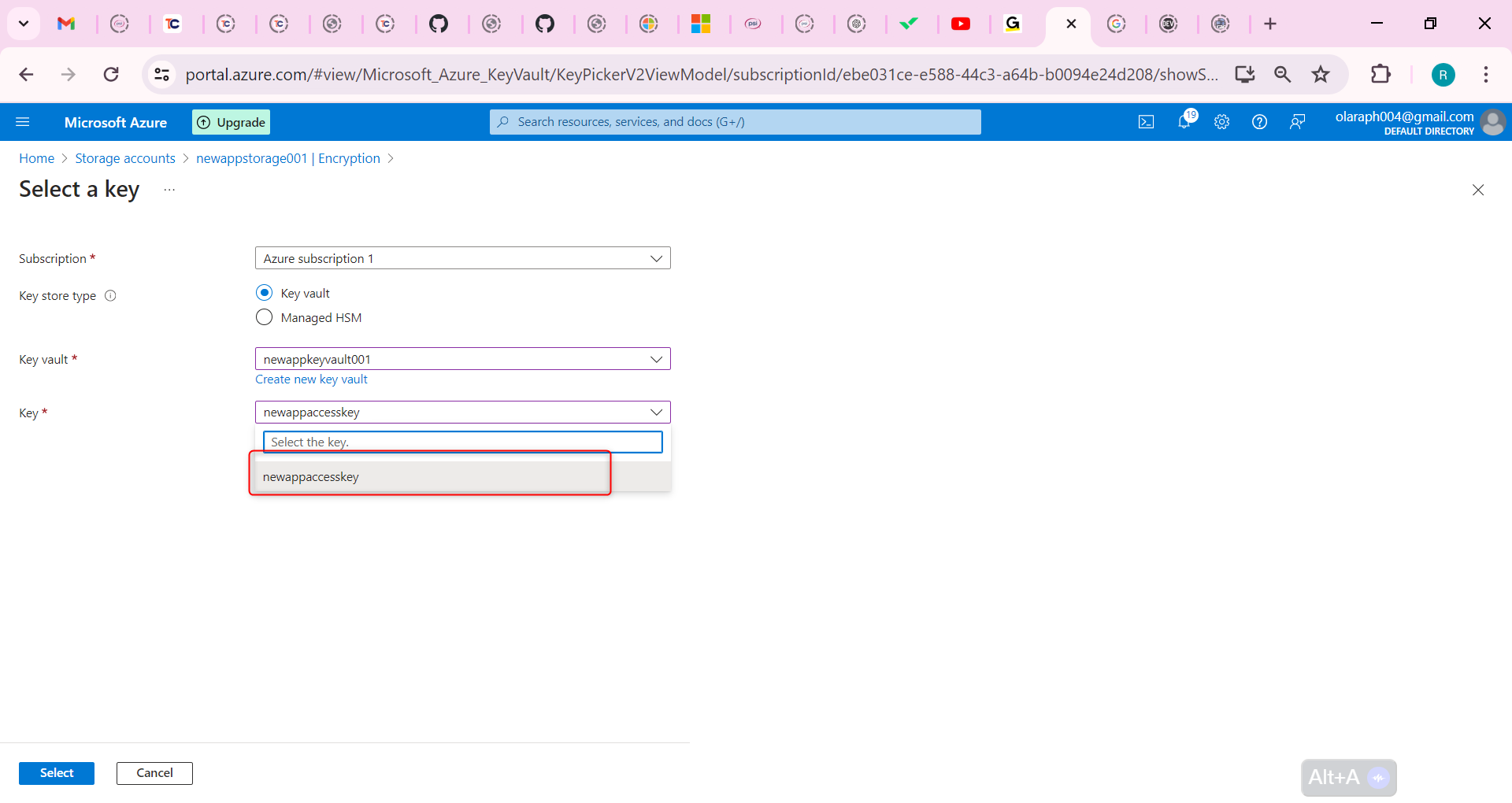
Select to confirm your choices.
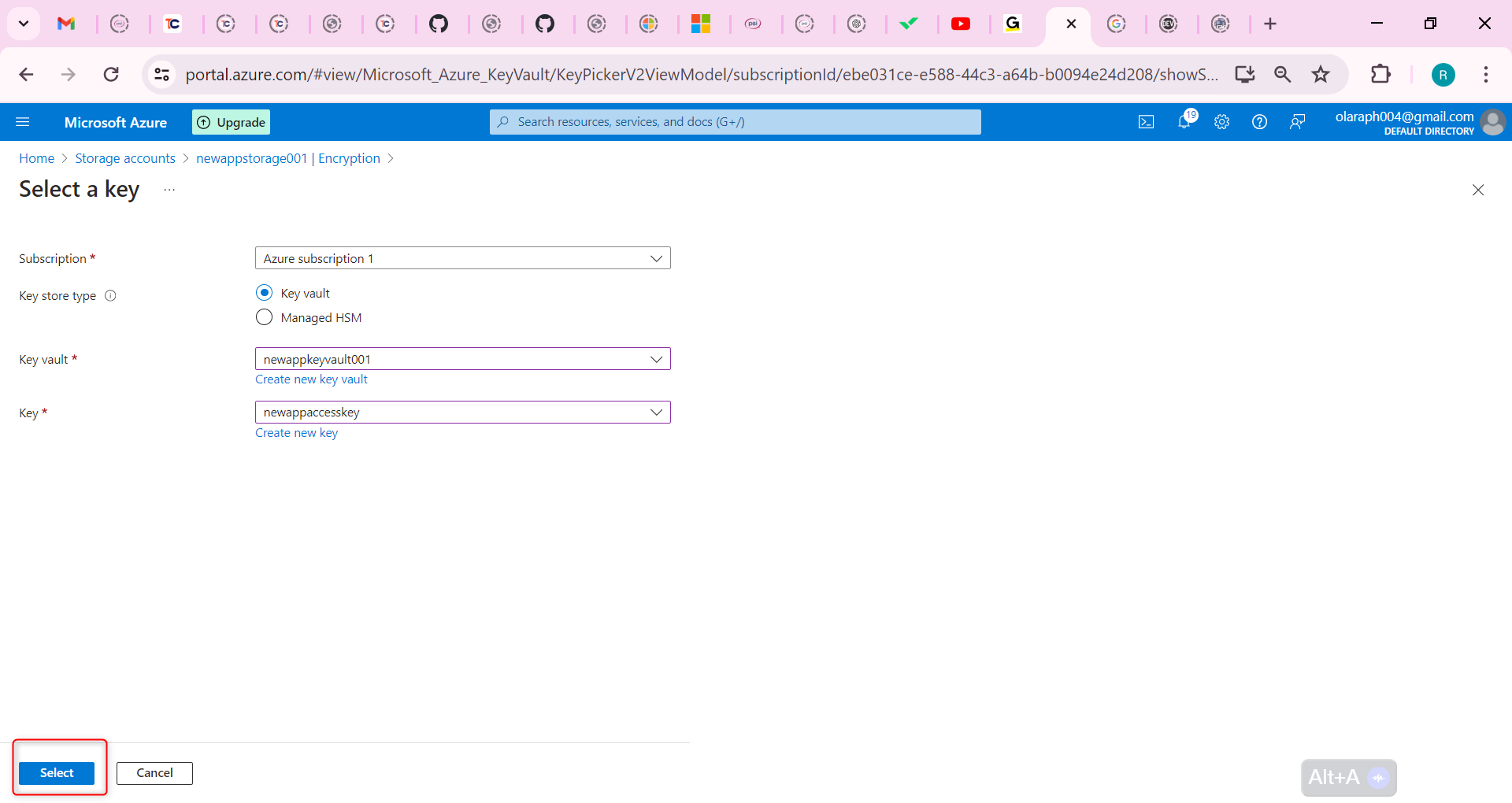
Ensure the Identity type is User-assigned.
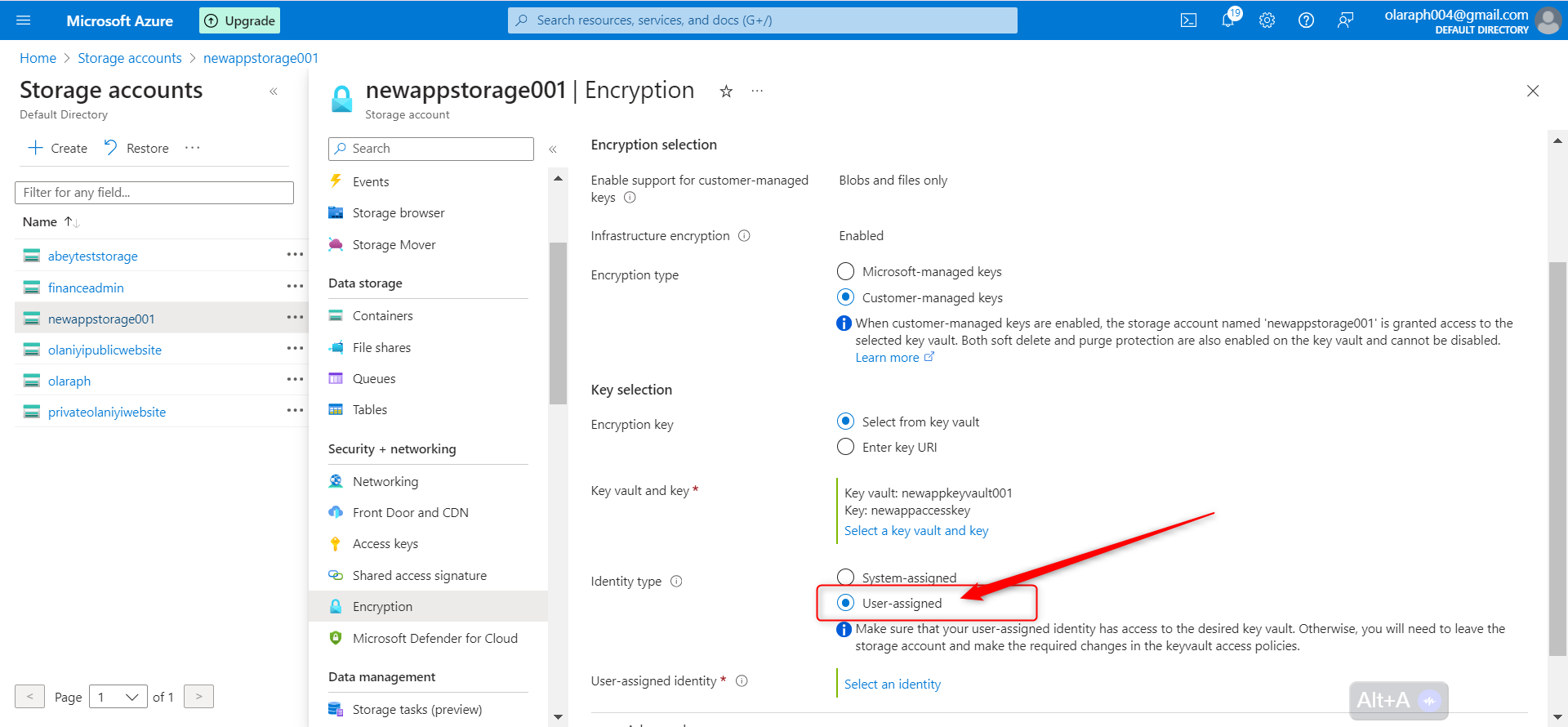
Select an identity.
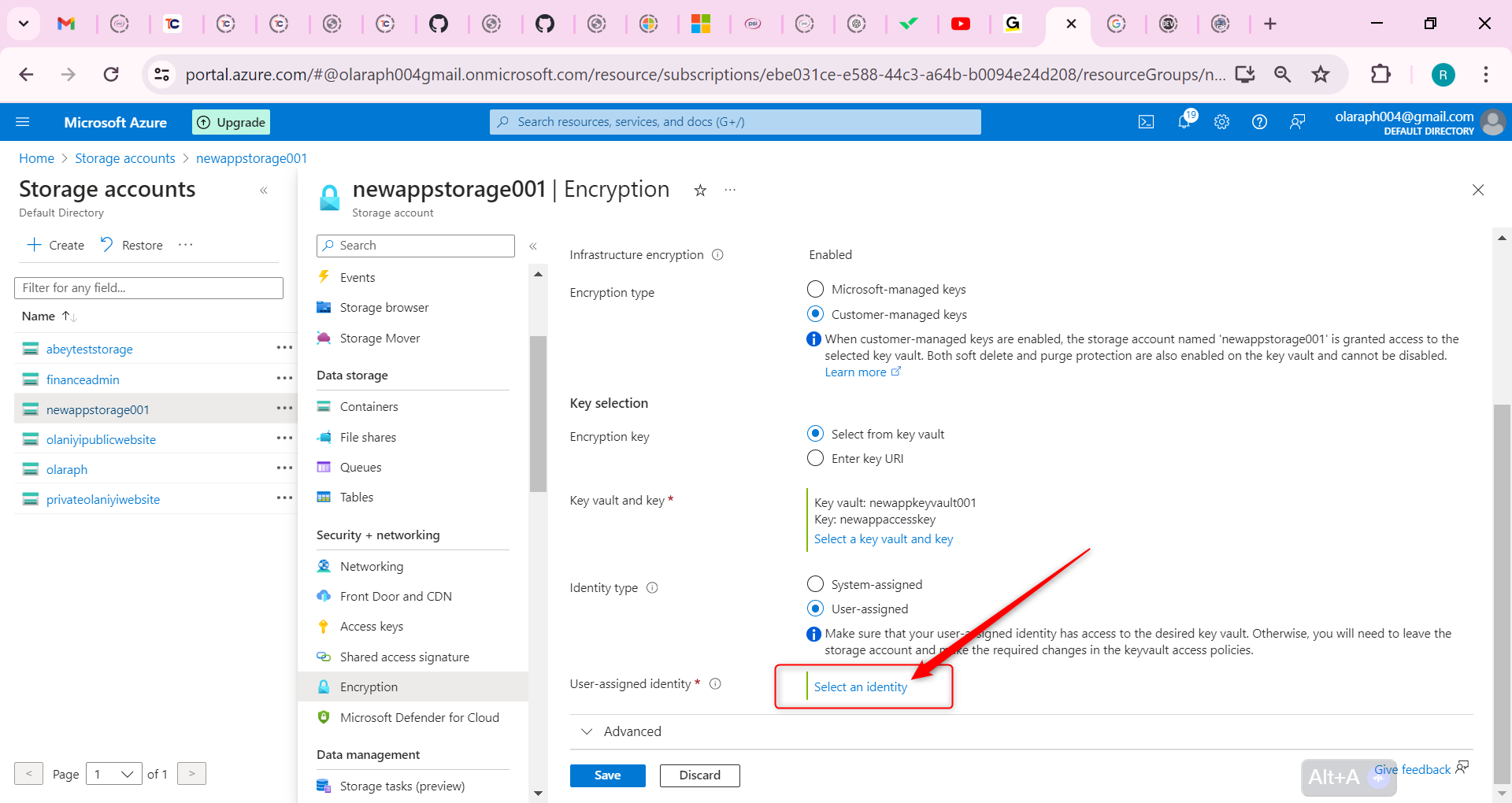
Select your managed identity then select Add.
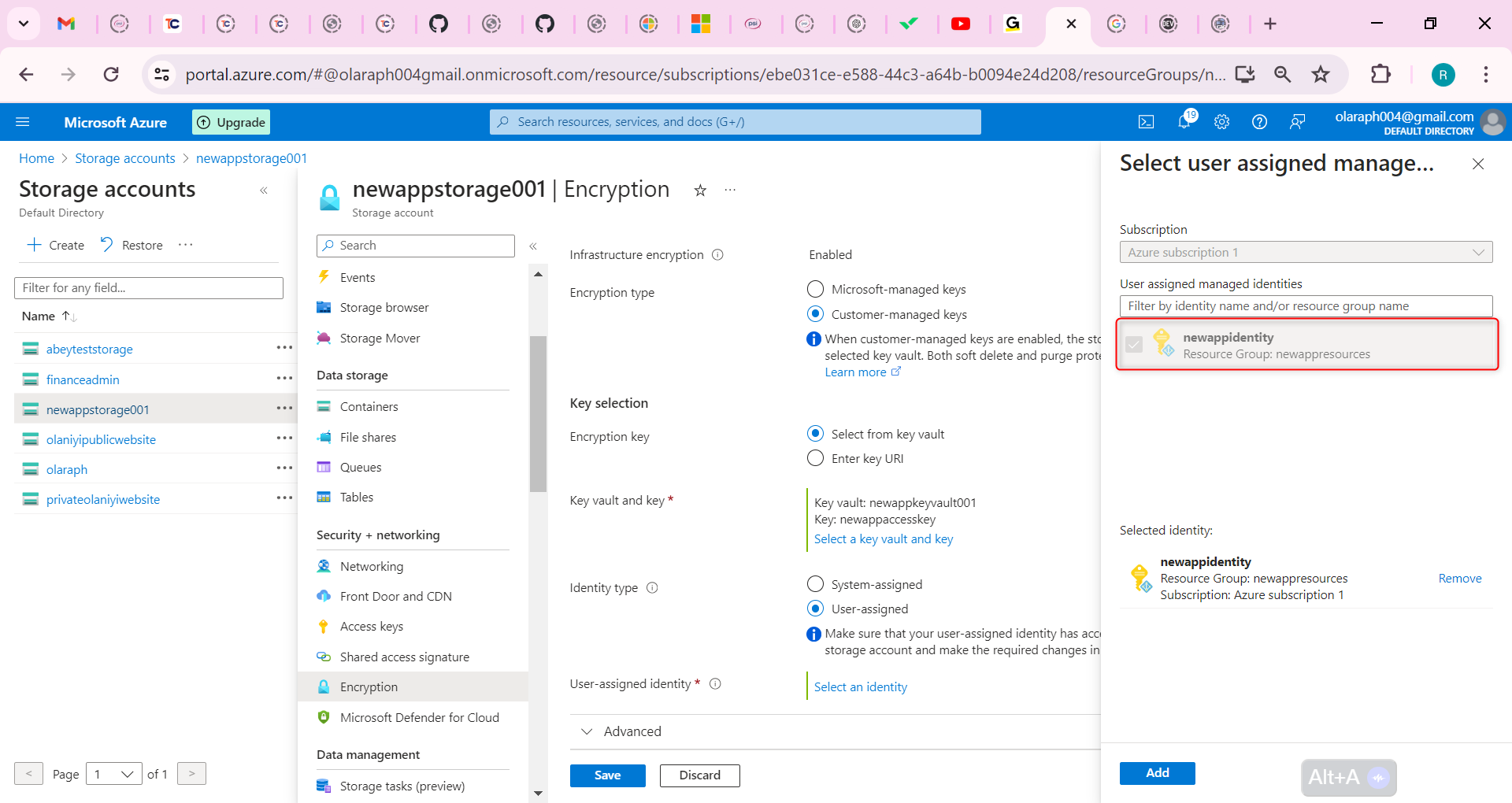
Save your changes.
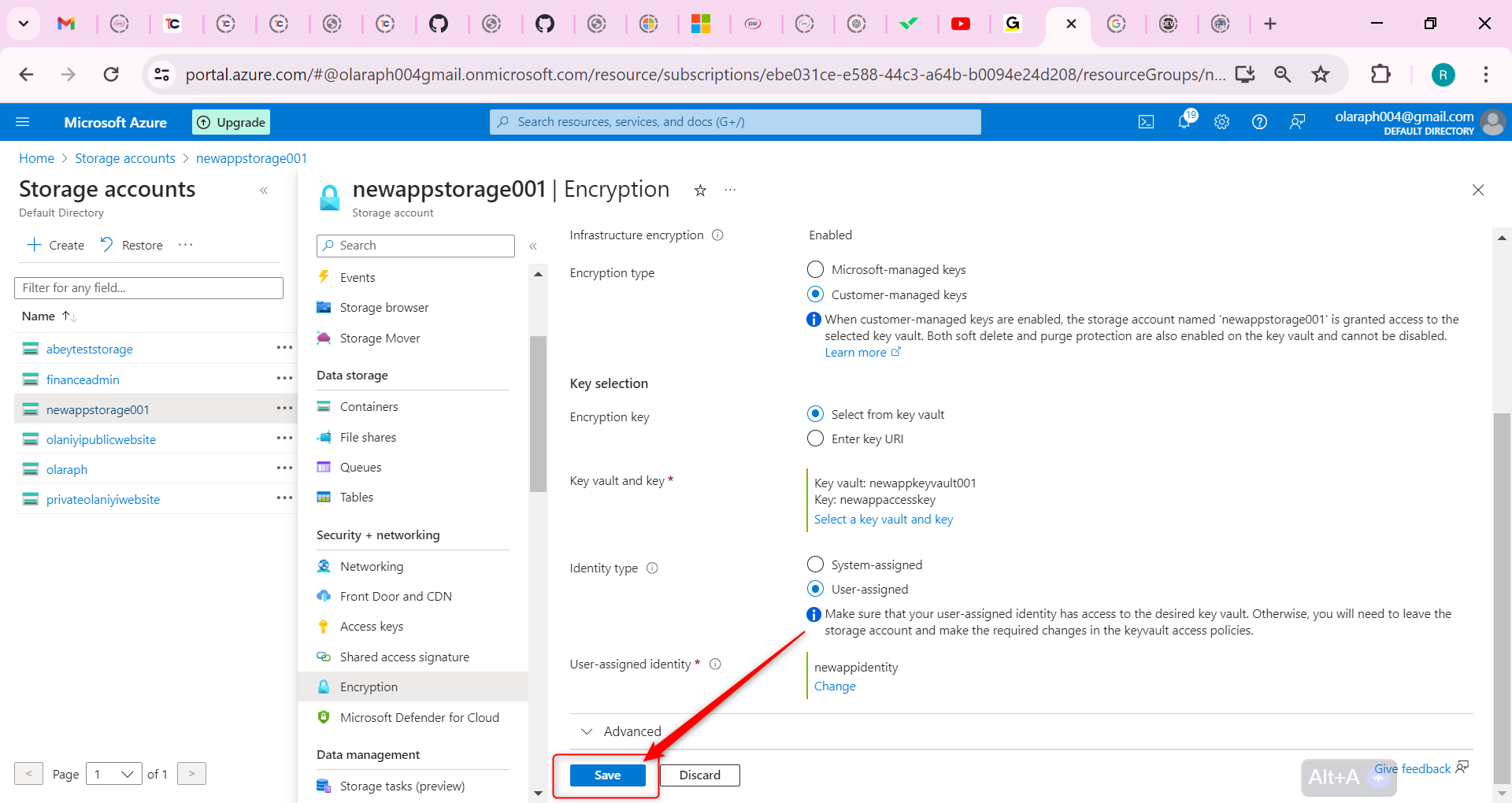
If you receive an error that your identity does not have the correct permissions, wait a minute and try again.
Configure an time-based retention policy and an encryption scope.
The developers require a storage container where files can’t be modified, even by the administrator.
Navigate to your storage account.
In the Data storage section, select the Containers blade.
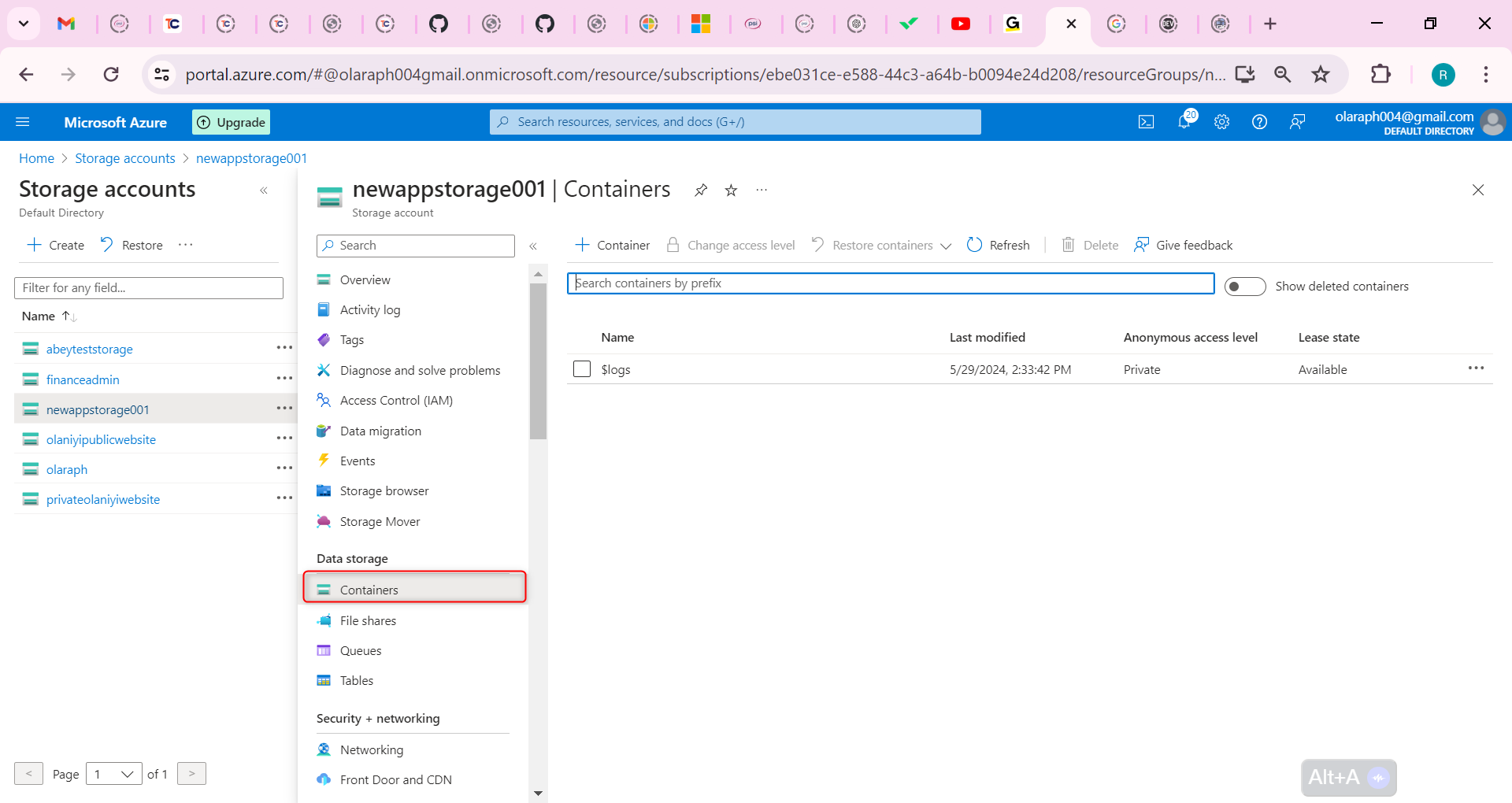
Create a container called hold. Take the defaults. Be sure to Create the container.
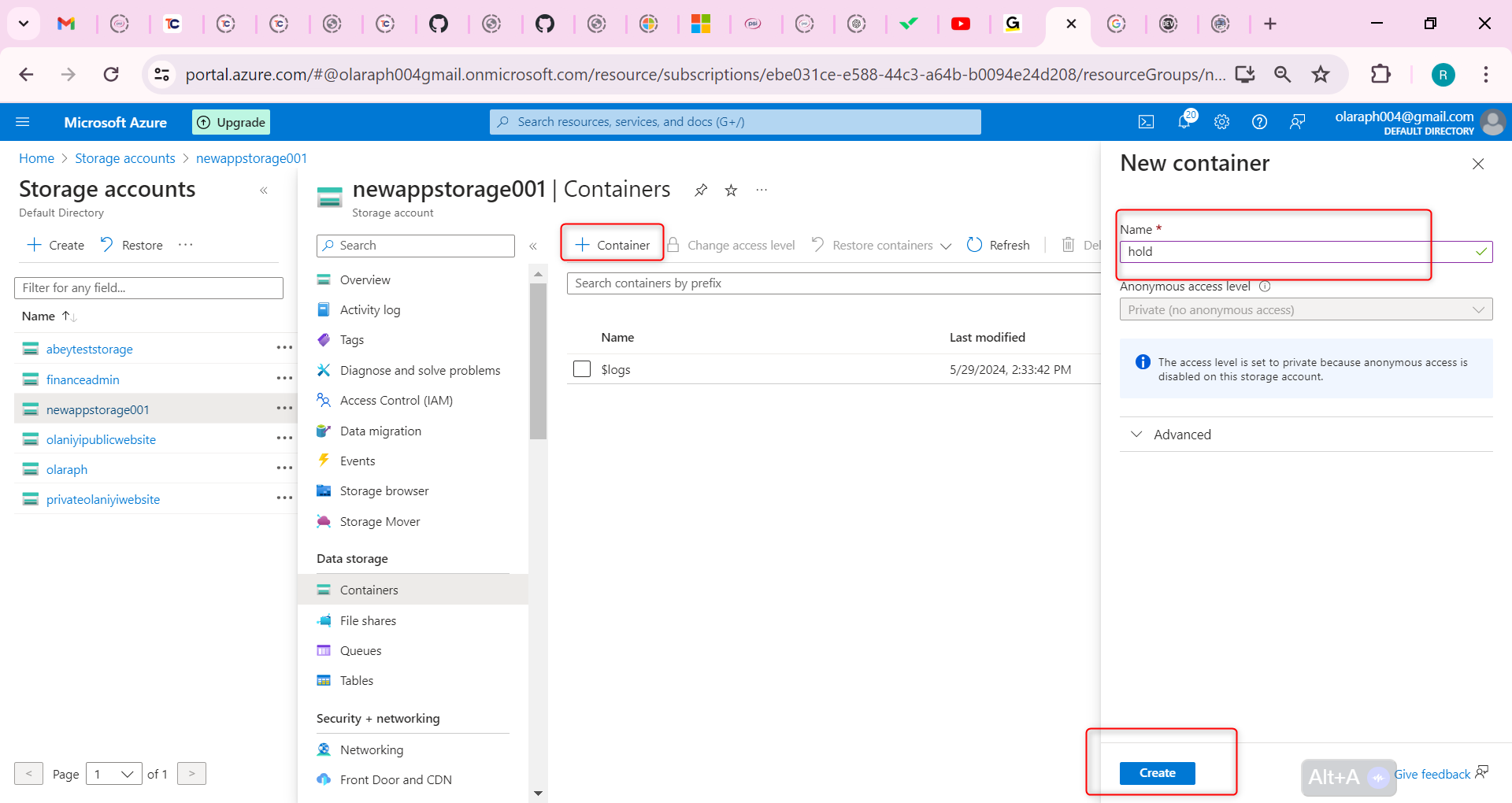
Upload a file to the container.
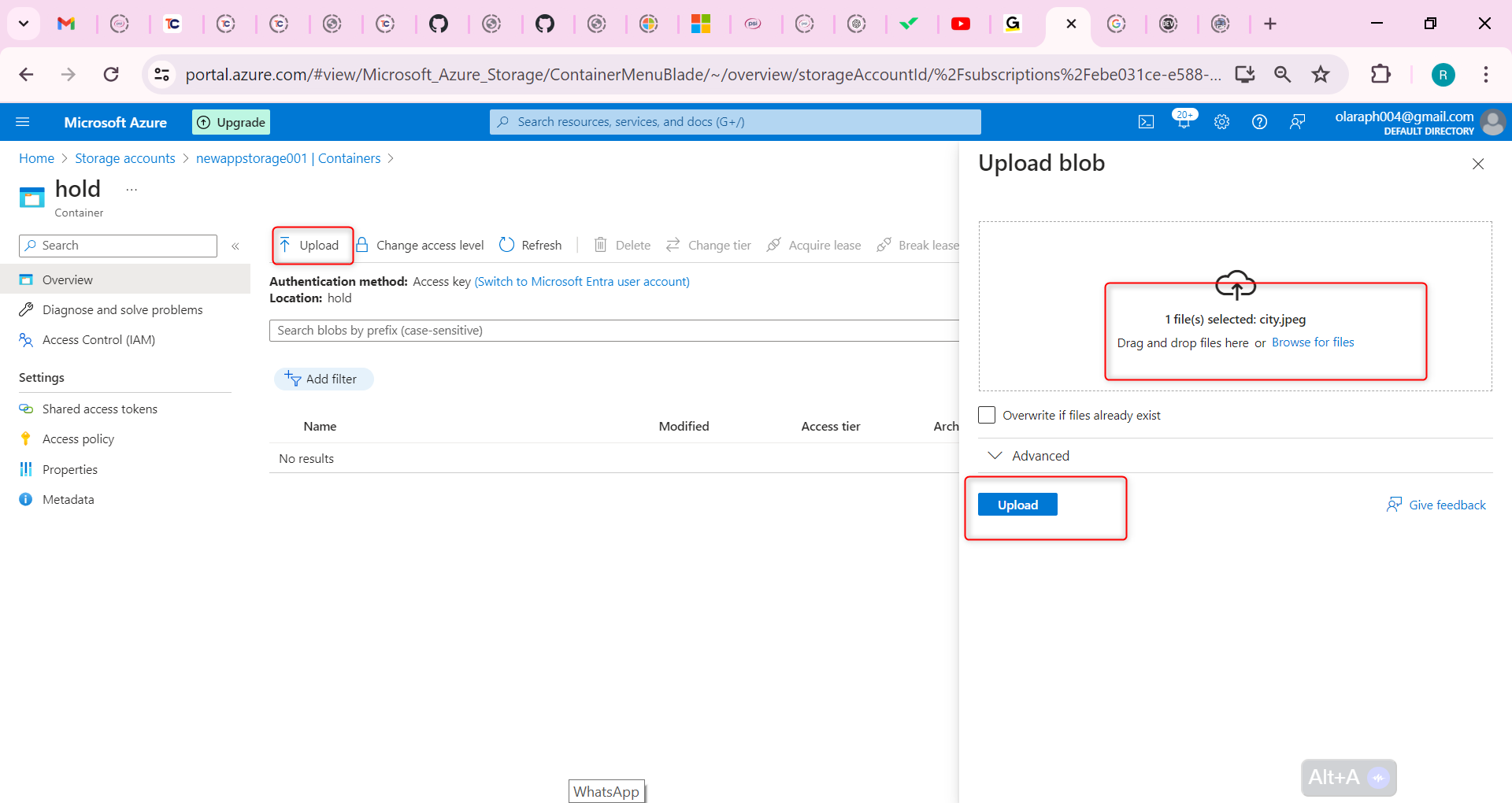
In the Settings section, select the Access policy blade.
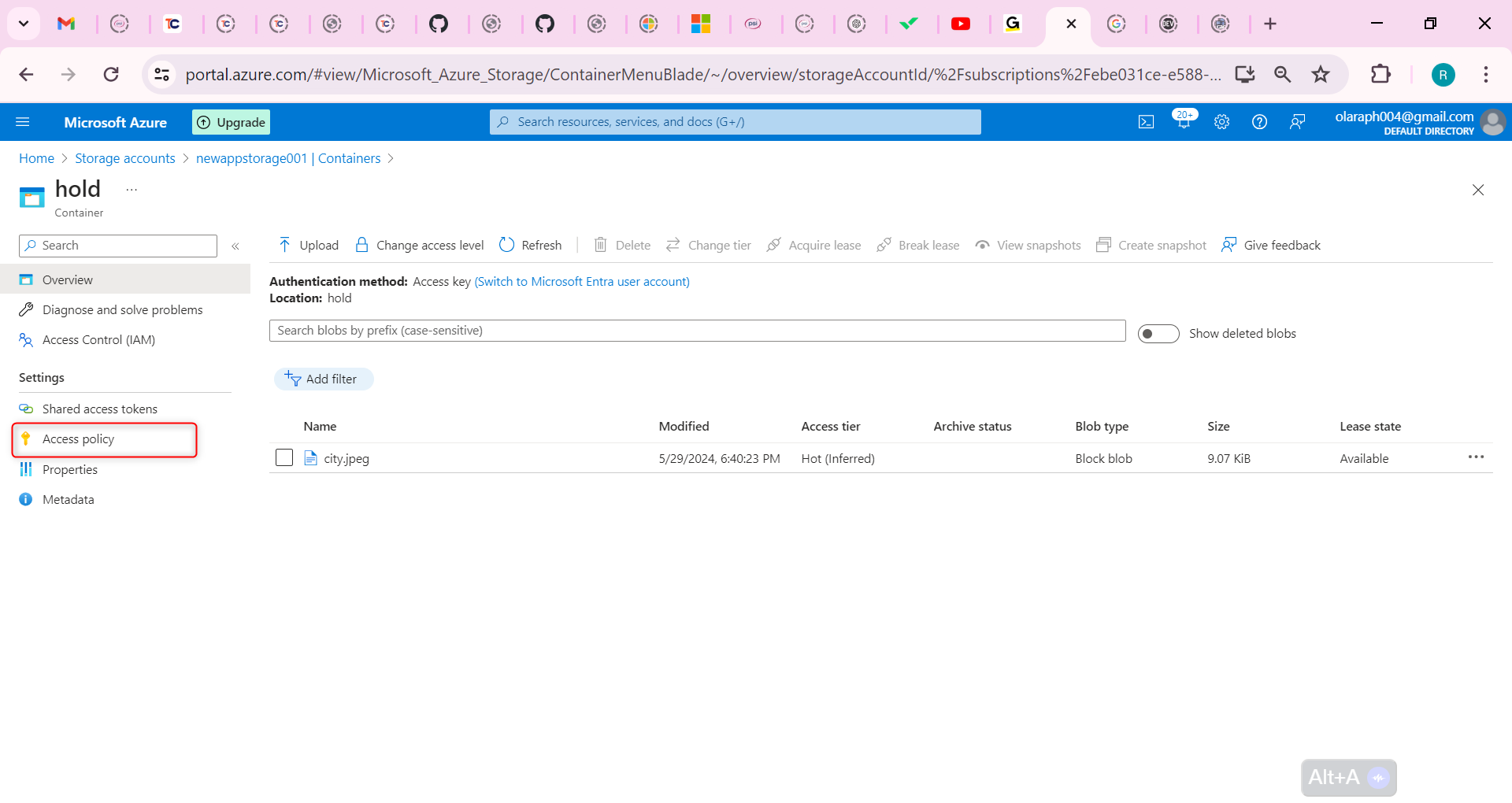
In the Immutable blob storage section, select + Add policy.
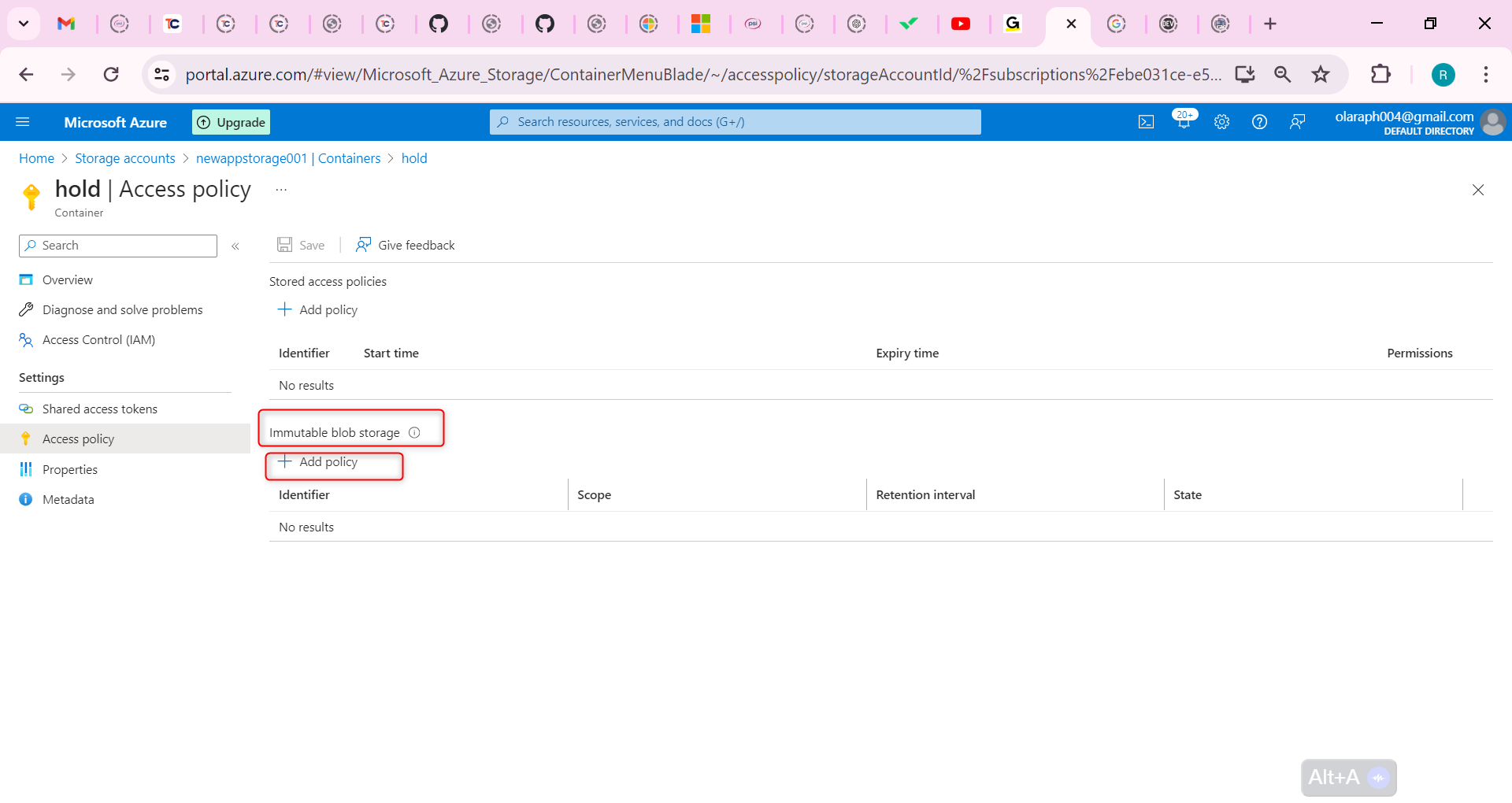
For the Policy type, select time-based retention.
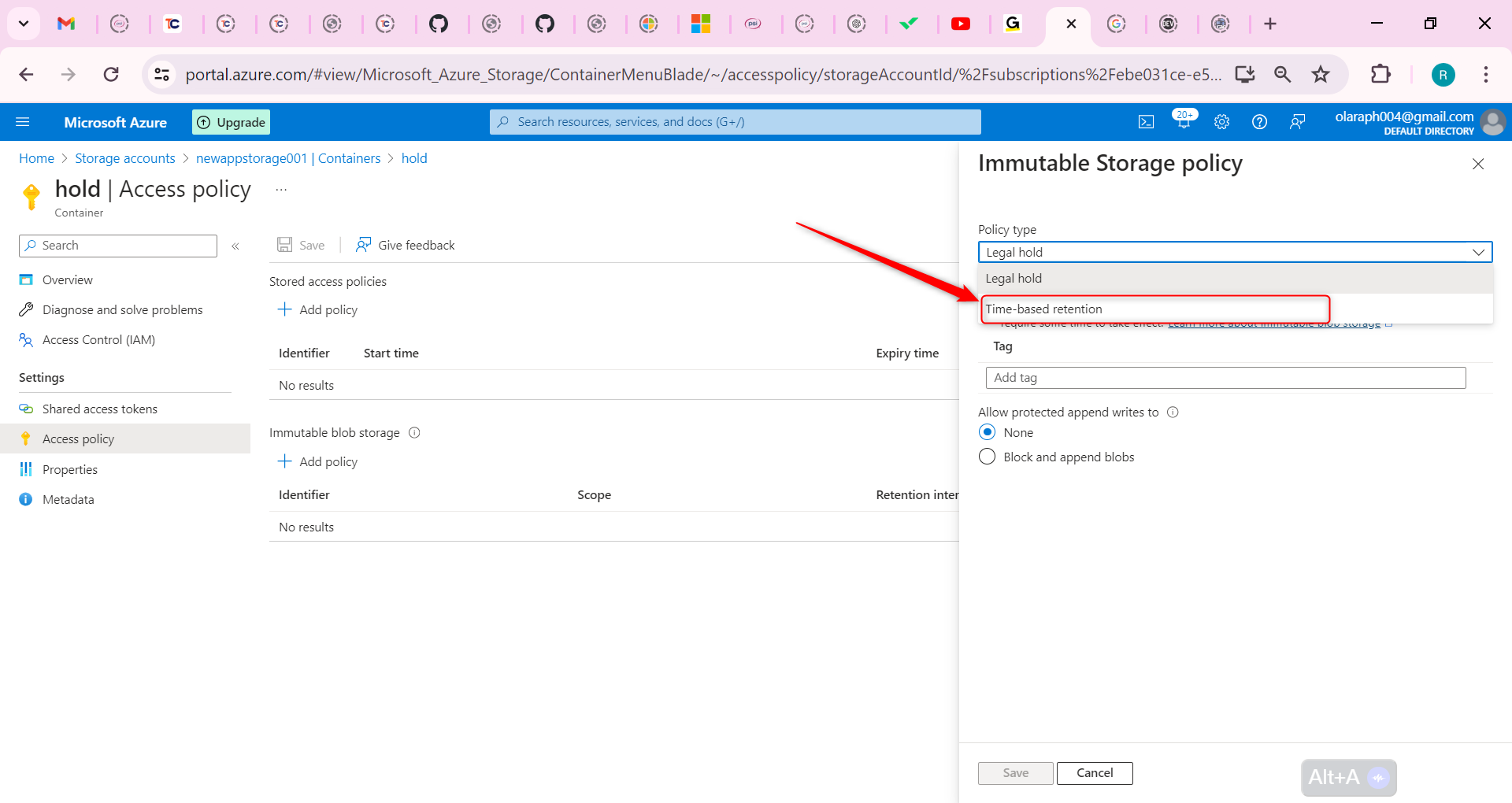
Set the Retention period to 5 days.
Be sure to Save your changes.
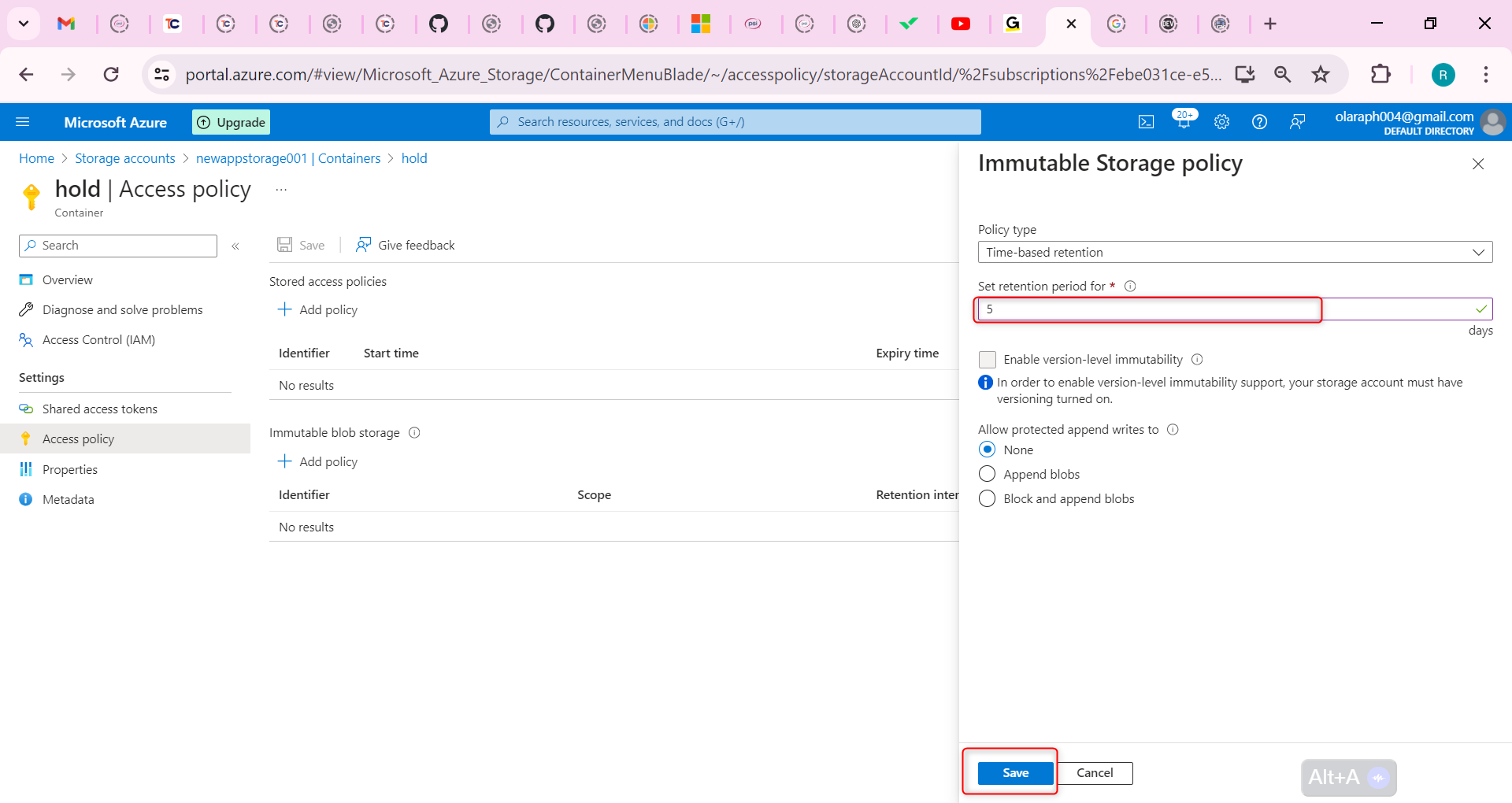
Try to delete the file in the container.
Verify you are notified failed to delete blobs due to policy.
The developers require an encryption scope that enables infrastructure encryption.
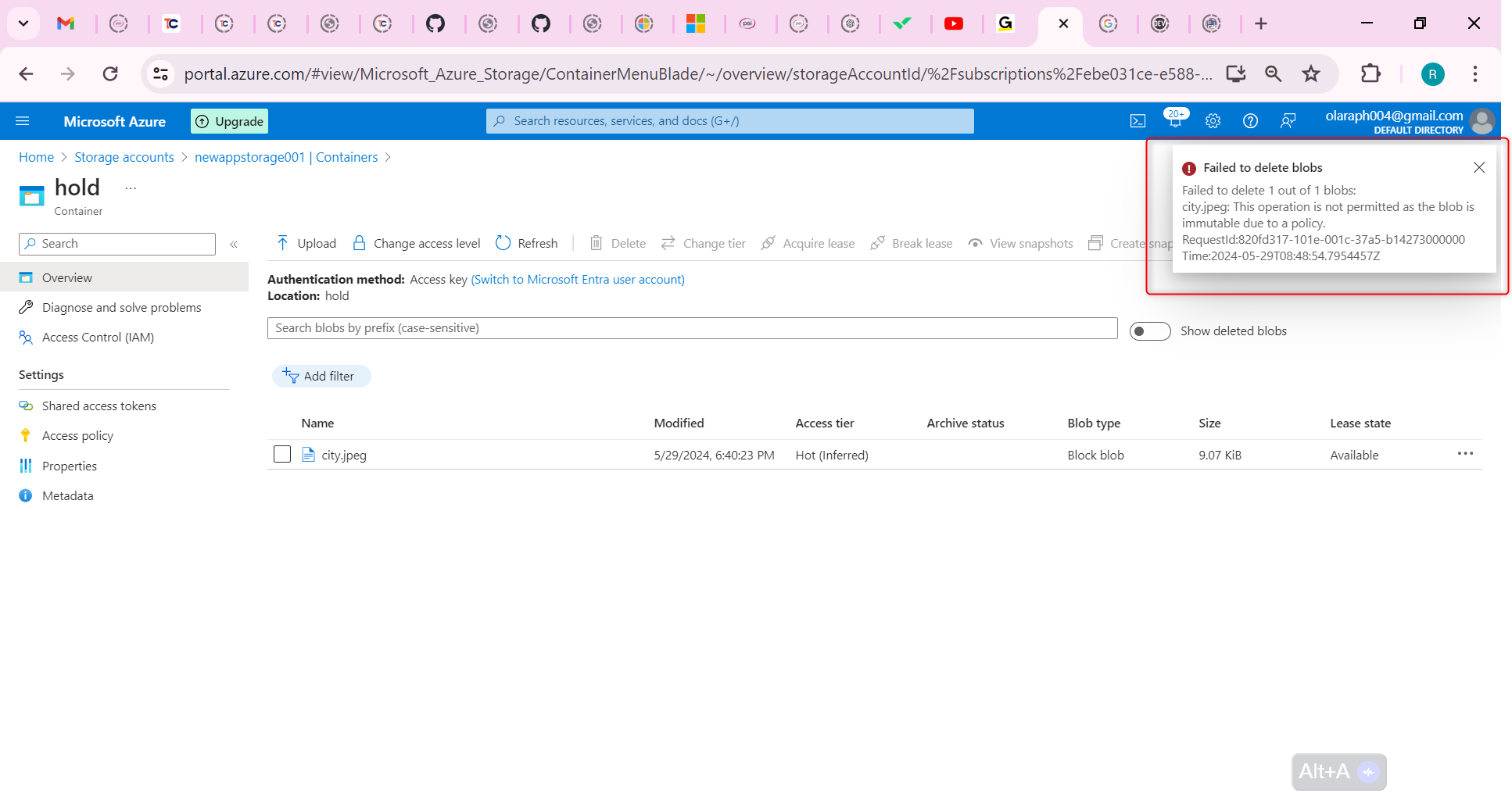
Navigate back to your storage account.
In the Security + networking blade, select Encryption.
In the Encryption scopes tab, select Add.
Give your encryption scope a name.
The Encryption type is Microsoft-managed key.
Set Infrastructure encryption to Enable.
Create the encryption scope.
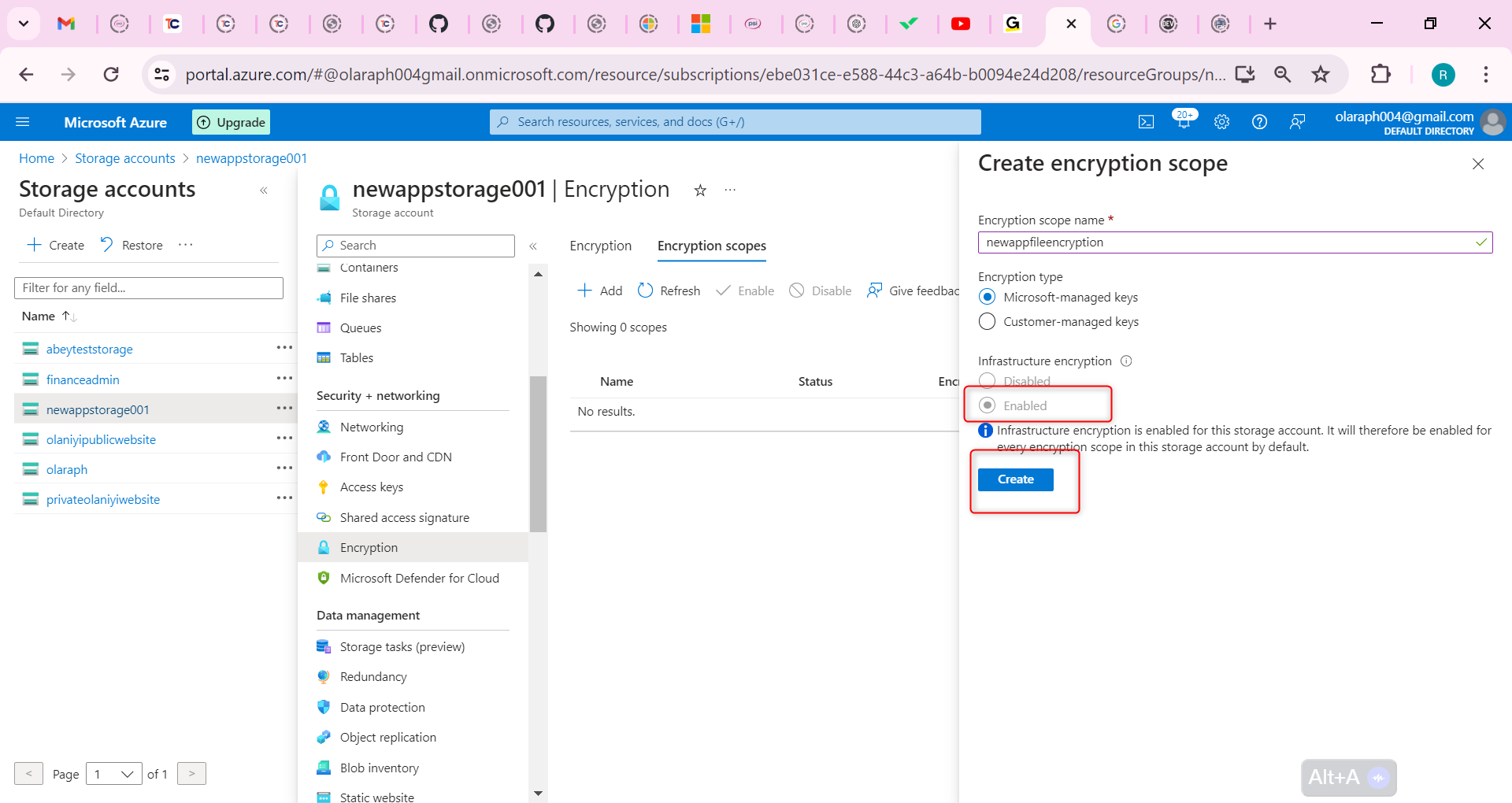
Return to your storage account and create a new container.
Notice on the New container page, there is the Name and Public access level.
Notice in the Advanced section you can select the Encryption scope you created and apply it to all blobs in the container.
| olaraph | |
1,868,913 | AUTOXCHNG | In latest globalized international, overseas foreign money transactions have emerge as an crucial a... | 0 | 2024-05-29T11:32:52 | https://dev.to/adamsmeth/autoxchng-1j2p | In latest globalized international, overseas foreign money transactions have emerge as an crucial a part of international trade and finance. whether you're a multinational enterprise increasing your operations foreign places or an person traveling overseas, expertise how overseas foreign money transactions work is essential.
[AUTOXCHNG](https://www.circularedge.com/products/autoxchng/)
**know-how foreign foreign money Transactions**
What are overseas foreign money Transactions?
foreign currency transactions talk to the shopping for, promoting, or replacing of currencies between different international locations.
**Key players in overseas forex Transactions**
Banks: Banks function intermediaries in overseas foreign money transactions, facilitating the alternate of currencies for his or her customers.
critical Banks: vital banks play a critical position in regulating the forex marketplace and managing a country's foreign money reserves.
Forex Markets: those markets, frequently known as forex or FX markets, provide a platform for purchasing and selling currencies.
**Factors Influencing overseas foreign exchange charges**
Financial indicators
Financial signs which includes inflation, hobby fees, and GDP increase can extensively effect foreign exchange quotes. countries with strong economic fundamentals frequently have better-valued currencies.
Political balance
Political stability and geopolitical activities can cause fluctuations in forex values. Uncertainty or instability in a rustic's political panorama may result in depreciation of its currency.
Marketplace Sentiment
Investor sentiment and marketplace speculation play a crucial position in determining forex prices. positive or poor perceptions approximately a rustic's economy can impact the demand for its currency.
**Techniques for handling overseas forex danger**
Hedging
Hedging entails using economic instruments which include forward contracts or options to shield towards adverse forex actions. companies can hedge their foreign foreign money publicity to mitigate threat.
Diversification
Diversifying forex holdings across multiple currencies can help unfold risk and reduce publicity to any unmarried forex.
Timing strategies
Timing the marketplace includes executing foreign foreign money transactions at opportune moments to capitalize on favorable change costs. however, timing the market accurately requires cautious analysis and hazard control. | adamsmeth | |
1,869,677 | Writing Self-Documenting Code 🧑💻📜 | As developers, we've all wasted hours, staring at a piece of code, trying to decipher its purpose,... | 0 | 2024-05-29T21:33:50 | https://dev.to/mattlewandowski93/writing-self-documenting-code-4lga | webdev, javascript, typescript, programming | As developers, we've all wasted hours, staring at a piece of code, trying to decipher its purpose, and wondering what the original author was thinking. In the world of software development, where projects change hands and codebases evolve quickly, writing self-documenting code is not just a nice-to-have; it's a necessity.
In this article, we'll explore the art of crafting code that speaks for itself, reducing the reliance on external documentation and making life easier for yourself and your fellow developers.
## What is Self-Documenting Code?
Self-documenting code is code that is written in a clear, expressive, and intentional manner, making its purpose and functionality easily understandable without the need for extensive comments or external documentation.
It's about writing code that is:
- **Readable:** Code that is easy to read and understand at a glance
- **Expressive:** Code that clearly conveys its intent and purpose
- **Maintainable:** Code that is easy to modify and update without introducing bugs or breaking changes
## Why Self-Documenting Code Matters
Writing self-documenting code offers several benefits:
1. **Reduced Cognitive Load:** When code is self-explanatory, developers can quickly grasp its purpose and functionality, reducing the mental effort required to understand and work with the codebase.
2. **Faster Onboarding:** New team members can get up to speed more quickly when the codebase is self-documenting, as they don't need to rely heavily on external documentation or extensive knowledge transfer sessions.
3. **Improved Collaboration:** Self-documenting code facilitates better collaboration among team members, as it minimizes misunderstandings and promotes a shared understanding of the codebase.
4. **Enhanced Maintainability:** When code is self-documenting, it's easier to maintain and update over time, as developers can quickly understand the existing code and make informed changes.
## Techniques for Writing Self-Documenting Code
Let's explore some practical techniques for writing self-documenting code, with a focus on TypeScript:
### 1. Use Meaningful Names
One of the most effective ways to make your code self-documenting is to use meaningful names for variables, functions, classes, and modules. Consider the following example:
```typescript
// Bad
const x = 5;
const y = 10;
const z = x + y;
// Good
const numberOfItems = 5;
const itemPrice = 10;
const totalCost = numberOfItems * itemPrice;
```
In the "Good" example, the variable names clearly convey their purpose, making the code more readable and self-explanatory.
### 2. Write Small, Focused Functions
Writing small, focused functions is another key aspect of self-documenting code. Functions should have a single responsibility and be named accurately to reflect their purpose. For example:
```typescript
// Bad
function processData(data: any): any {
// ...
// Lots of complex logic
// ...
return result;
}
// Good
function extractRelevantFields(data: Record<string, any>): Record<string, any> {
// ...
return relevantFields;
}
function applyBusinessRules(relevantFields: Record<string, any>): Record<string, any> {
// ...
return processedData;
}
function formatOutput(processedData: Record<string, any>): string {
// ...
return formattedResult;
}
```
By breaking down a large function into smaller, focused functions with descriptive names, the code becomes more readable and self-documenting.
### 3. Use Descriptive Function and Method Names
When naming functions and methods, use descriptive names that clearly convey their purpose and action. Avoid generic names like `handle()` or `process()`. Instead, opt for names that describe what the function does. For example:
```typescript
// Bad
function handleInput(input: string): void {
// ...
}
// Good
function validateUserCredentials(username: string, password: string): boolean {
// ...
}
```
The descriptive name `validateUserCredentials` makes it clear what the function does without the need for additional comments.
### 4. Leverage TypeScript's Type System
TypeScript's powerful type system can greatly enhance the self-documenting nature of your code. By leveraging TypeScript's features, you can make your code more expressive and catch potential errors early. For example:
- **Interfaces and Types:** Use interfaces and custom types to define the shape of your data structures, making the code more readable and self-explanatory.
```typescript
interface User {
id: number;
name: string;
email: string;
}
function getUserById(id: number): User | undefined {
// ...
}
```
- **Enums:** Utilize enums to represent a fixed set of values, providing a clear and readable way to handle different scenarios.
```typescript
enum PaymentStatus {
Pending = 'pending',
Completed = 'completed',
Failed = 'failed',
}
function processPayment(status: PaymentStatus): void {
// ...
}
```
- **Type Inference:** Let TypeScript infer types whenever possible, as it reduces verbosity and makes the code more readable.
```typescript
// Bad
const count: number = 10;
const message: string = 'Hello, world!';
// Good
const count = 10;
const message = 'Hello, world!';
```
### 5. Use Strongly Typed IDs
When working with IDs in TypeScript, consider using strongly typed IDs instead of simple strings or numbers. Strongly typed IDs provide additional type safety and make the code more self-documenting.
One way to implement strongly typed IDs is by using opaque types:
```typescript
// user.ts
export type UserId = string & { readonly __brand: unique symbol };
export function createUserId(id: string): UserId {
return id as UserId;
}
// post.ts
export type PostId = string & { readonly __brand: unique symbol };
export function createPostId(id: string): PostId {
return id as PostId;
}
```
By using strongly typed IDs, you can ensure that a UserId can only be assigned to properties or functions expecting a UserId, and a PostId can only be assigned to properties or functions expecting a PostId.
```typescript
function getUserById(userId: UserId): User | undefined {
// ...
}
const userId = createUserId('user-123');
const postId = createPostId('post-456');
getUserById(userId); // No error
getUserById(postId); // Error: Argument of type 'PostId' is not assignable to parameter of type 'UserId'.
```
Strongly typed IDs help catch potential errors at compile-time and make the code more expressive and self-documenting. However, they do introduce some overhead compared to using simple string types. Consider the trade-offs based on your project's needs and scale.
### 6. Establish Consistency and Set Expectations in a Team
When working on a codebase as part of a team, establishing consistency and setting clear expectations is crucial. This helps ensure that everyone is on the same page and follows the same conventions, making the code more readable and maintainable.
One important aspect of consistency is naming conventions. Establish a style guide that defines how variables, functions, classes, and other entities should be named. For example, consider the following terms and their meanings:
- `get`: Retrieves a single value from an API or data source.
- `list`: Retrieves a set of values from an API or data source.
- `patch`: Partially updates an existing entity or object.
- `upsert`: Updates an existing entity or inserts a new one if it - doesn't exist.
By defining these terms and their usage, you can ensure consistency across the codebase. For example:
```typescript
function getUser(userId: UserId): Promise<User> {
// ...
}
function listUsers(): Promise<User[]> {
// ...
}
function patchUser(userId: UserId, updatedData: Partial<User>): Promise<User> {
// ...
}
```
Consistency helps make the codebase more predictable and easier to understand for all team members. In addition to naming conventions, consider establishing guidelines for other aspects of the codebase, such as file and folder structure, comments, error handling, testing, and code formatting.
When working in a team, you might not always personally agree with all of the conventions that are being enforced. However, it's important to remember that consistency and collaboration are crucial for the success of the project. Even if you have a different preference or coding style, adhering to the agreed conventions helps maintain a cohesive codebase and reduces confusion among other team members.
### 7. Use JSDoc or TSDoc for Complex Scenarios
While self-documenting code should be the primary goal, there may be cases where additional documentation is necessary, such as complex algorithms or intricate business logic. In such scenarios, consider using JSDoc or TSDoc to provide clear and concise documentation.
```typescript
/**
* Calculates the Fibonacci number at the given position.
*
* @param {number} position - The position of the Fibonacci number to calculate.
* @returns {number} The Fibonacci number at the specified position.
*/
function fibonacci(position: number): number {
if (position <= 1) {
return position;
}
return fibonacci(position - 1) + fibonacci(position - 2);
}
```
By using JSDoc or TSDoc, you can provide additional context and explanations for complex code without cluttering the codebase itself.
## Conclusion
Writing self-documenting code is an art that every developer should strive to master. By leveraging meaningful names, small and focused functions, TypeScript's type system, and judicious use of documentation, you can create code that is readable, expressive, and maintainable.
Remember, the goal is to write code that speaks for itself, reducing the reliance on external documentation and making the lives of your fellow developers easier. So, the next time you're writing code, take a moment to consider how you can make it more self-documenting. Your future self and your teammates will thank you!
Also, shameless plug 🔌. If you work in an agile dev team and use tools for your online meetings like planning poker or retrospectives, check out my free tool called [Kollabe](https://kollabe.com/)! | mattlewandowski93 |
1,869,658 | The Struggle is Real: 3 Signs You Need Cloud Development Environments | Introduction Every developer knows the frustration: You're ready to test your latest code,... | 0 | 2024-05-29T21:26:03 | https://dev.to/ssadasivuni/the-struggle-is-real-3-signs-you-need-cloud-development-environments-3fcb | clouddevelopment, developerproductivity, devops, cloudnative | ## Introduction
Every developer knows the frustration: You're ready to test your latest code, but your development environment throws a wrench in the works. It's either missing a crucial dependency, running on fumes, or simply… vanishes. Sound familiar? If you're nodding along, it's time to consider cloud development environments.
This post will explore three major signs that your development process is screaming for a cloud upgrade. But first, let's paint a picture of what happens if you don't embrace the cloud.
## Summary
The downside of lagging behind by sticking with traditional development environments can lead to a cascade of issues, like:
**Delays and Frustration:** Imagine entire teams brought to a standstill because a dev environment falls apart. Fixing these issues takes precious time away from coding and innovation.
**Inconsistent Testing:** When testing environments don't accurately reflect production, bugs slip through the cracks. This results in costly fixes down the line.
**Scaling Challenges:** As your team grows, managing a sprawl of individual development environments becomes a nightmare. Scaling becomes a manual slog, hindering your ability to adapt.
**Limited Collaboration:** When environments are scarce or unreliable, collaboration suffers. Developers can't easily share their work or test in a team setting.
## Why Cloud Development Environments?
Now, let's turn things around. Here are three key indicators that a shift to the cloud is the answer to your development woes:
**1. Unstable and Unreliable Environments:** Are your development environments more like ticking time bombs than productive workspaces? Cloud-based environments offer automated provisioning and configuration, ensuring consistency and eliminating the headaches of manual setup and maintenance.
**2. Testing Nightmares:** Does the phrase "perfect mirror of production" sound like a distant dream? Cloud development environments can create isolated and ephemeral environments specifically for testing. This allows for more accurate testing, catching bugs before they reach production.
**3. Scaling Struggles:** Is your team bottlenecked by a limited number of development environments? The cloud offers on-demand scalability. As your team grows, you can easily spin up new environments to meet your needs.
## Embrace the Cloud, Embrace Efficiency
Cloud development environments offer a multitude of benefits, like:
**Automation:** Say goodbye to manual setup and configuration. Cloud environments automate these tasks, freeing up developers to focus on what they do best – coding!
**Scalability:** The cloud scales with you. No more scrambling to provision new environments as your team expands.
**Consistency:** Pre-configured templates ensure everyone has the tools they need, eliminating the inconsistencies that plague traditional environments.
**Collaboration:** Cloud environments make it easy for developers to share and test code, fostering better teamwork.
## The Takeaway
Don't let unreliable development environments hold your team back. Cloud development offers a path to efficiency, better testing, and a smoother development process. By embracing the cloud, you can empower your developers and unlock the full potential of your applications. | ssadasivuni |
1,869,657 | Security considerations of configuration management | We often take for granted that the security implications of using configuration management tools like... | 0 | 2024-05-29T21:24:36 | https://dev.to/puppet/security-considerations-of-configuration-management-122n | puppet, devops, security | We often take for granted that the security implications of using configuration management tools like Puppet, Chef, or Ansible are obvious, but that’s far from the truth. I would be lying if I said that I’d never deployed dangerous configuration management code into production use that in retrospect should have been obvious from the start. Here’s a [great example](https://github.com/puppetlabs/puppet-validator/commit/5324bb0a3f9ac0a95d76e4aa7ce8360052182738); the ability to destroy the online Puppet code validator was live for over a year!
So with that in mind, let’s take a wander through the Puppet ecosystem and talk about some things that might have security implications and might warrant a closer look in regard to access control. And let’s not bury the lede here; _no matter what framework you’re running, configuration management is **by definition** root/Administrator level access to your entire infrastructure_ and access to its setup and codebase should be treated as such. The examples referenced in this guide are specific to Puppet, but the higher-level concepts are not. If you’re using a competing configuration management platform, you should evaluate your usage for similar patterns.
Taking a security mindset here means that this guide will refer to “attack vectors.” This does not mean that there is a vulnerability. It simply means that there might be potential for an attacker to exploit a misconfiguration. **And to be clear, this is not intended to be an exhaustive checklist of the things you should avoid; instead, it’s a guide of how to think about code deployed into a configuration management infrastructure**.
| :memo: |
|:----------------------------|
| _The basic trust model of Puppet and other configuration management systems is that you are expected to maintain trusted control over your codebase._ |
In hindsight, that's kind of obvious -- configuration management works by distributing certain kinds of code and data across your infrastructure and executing it with admin privileges to ensure that your systems are configured in the state you want.
But there are a few places where this executable code isn't obvious. Less scrutiny means that these areas can be used as attack vectors. For example, during catalog compilation, functions are executed on the server. This means any custom functions included in modules, but it also means compiling Ruby code in ERB templates, and shell code run by the `generate()` function, and so on. The `config_version` script is executed prior to a catalog compilation; people usually use it to expose git revisions or the like, but it's just a shell script. It can run anything you want, and it's right in the control repository. And custom facts sync out and start running with root privileges across your whole infrastructure as soon as you install their modules.
## Security recommendations:
* When installing new modules you should audit:
* Check for custom facts and functions and see what they do.
* Check for ERB templates and ensure that they contain only presentation or layout code, such as iterating over an array to build stanzas in a configuration file. Any other Ruby logic is suspect. Check manifests for use of the `inline_template()` function and validate them in the same way.
* Skim the manifests for use of the `generate()` function. There are extremely few valid use cases for this function, so any sight of it should be a red flag.
* When reviewing pull/merge requests to your control repository:
* Pay very close attention to any changes to the `config_version` script.
* If new modules are added to the `Puppetfile`, then verify that they’ve been audited.
The `Puppetfile` is another surprise. It looks like a data file, and so many people doing code review treat it like data. But it's actually a custom DSL implemented as Ruby, meaning that it's possible _(although highly discouraged)_ to include arbitrary code that will run during a codebase deploy. This is a sneaky attack vector because if someone can create a branch in your control repository, then it may be deployed and executed before anyone else can review it.
## Security recommendations:
* Do not allow untrusted users the ability to create branches in your control repository.
* Consider using VCS checks to reject commits containing unexpected code in your `Puppetfile`. An unsupported and lightly tested example is available [here](https://github.com/puppetlabs/puppetfile-check).
* When reviewing pull/merge requests to your control repository, pay very close attention to any changes to the `Puppetfile` and review it like code rather than treating it like simple data.
And of course, any modules you add to your control repo can run any custom extensions, or `exec` statements, or anything at all anywhere it's classified onto a node. Malicious modules can theoretically have a higher impact, because they're invoked as the root or admin user.
## Security recommendations:
* When installing new modules you should audit:
* Skim the manifests to get a general idea of how the module works and what it manages. Pay extra attention to anything that seems out of place.
* Look for resources that run shell code, such as `exec`, or cron jobs, the `validate` parameter of the `file` type, or the various command parameters of the `service` type. Besides looking for malicious code, also inspect for unsafe interpolation that can be used for shell injection attacks.
* Check for custom types and providers. These are not as simple to read but you should look for anything that looks out of place or unrelated to the thing it claims to manage.
If you identify any concerns, raise them as issues on the module’s repository or ask community peers about it in our [Slack workspace](https://slack.puppet.com).
Most of this shouldn't be terribly concerning. Again, automating the execution of code across your infrastructure is what infrastructure automation does. But it is important to remember that and treat your control repository and anything it might contain as privileged code. Audit modules before you use them, or only use modules from trusted authors. Be careful who has access to your control repo, or entries in your `Puppetfile`. And don't forget about the various unexpected code execution triggers. Classifying modules onto nodes isn't the only way to get their code to run.
Remember, this is not an exhaustive list of everything to look for. But I do hope that it gives you an idea of the types of vectors that could be abused by malicious actors and some good habits to get into. What other safeguards do you have protecting your codebase? Drop them in the comments!
| binford2k |
1,869,650 | NGINX als Reverse Proxy - Django in Produktion Teil 6 | Vorwort Jetzt, da unsere App mit Gunicorn als Applikations - Server läuft, müssen wir sie... | 0 | 2024-05-29T21:22:45 | https://dev.to/rubenvoss/nginx-als-reverse-proxy-django-in-produktion-teil-6-33b7 | ## Vorwort
Jetzt, da unsere App mit Gunicorn als Applikations - Server läuft, müssen wir sie nur noch über nginx in das Öffentliche Internet bringen. nginx wird unsere Statischen Dateien bereitstellen, und alles andere als reverse proxy an Gunicorn weiterleiten. nginx wird von Firmen wie Netflix und Dropbox genutzt um Seiten mit vielen Besuchern online zu halten. Ebenso werden wir unsere https - Verschlüsselung mit certbot aufbauen.
## nginx Set-Up
Zuerst kannst du nun nginx installieren.
```
sudo apt install nginx
sudo service enable nginx
sudo service start nginx
```
Hier liegt die Konfigurationsdatei für nginx:
```
cat /etc/nginx/nginx.conf
```
Dort sind alle wichtigen Einstellungen. Jetzt kannst du auf deine Domain gehen, dort solltest du nun von der Standard nginx - Webseite begrüßt werden. Hurra! dein Server ist nun offiziell im offenen Internet erreichbar.
## optional - nginx config als softlink
Um die Änderungen in deine Konfiguration zu speichern, kannst du die config - Datei bei dir in deine git - repository einchecken. Bei einer Produktiven Website am besten nicht 'public', also für alle einsehbar machen. Falls deine git - repo public ist, erstelle dir eine neue repo mit deinen Konfigurationsdateien. Nach dem einchecken kannst du einen Softlink von deiner Repo zur config - Datei erstellen. So kann sich nginx immer die Updates von deiner Repository holen.
```
cp /etc/nginx/nginx.conf srv/www/meine_app/produktion/nginx.conf
git commit -m "nginx.conf" && git push
rm /etc/nginx/nginx.conf
ln -s /srv/www/meine_app/produktion/nginx.conf /etc/nginx/nginx.conf
# Deine Datei kann nun in deiner repository geupdated werden:
ls -l /etc/nginx/nginx.conf
lrwxrwxrwx 1 root root 40 May 29 20:48 /etc/nginx/nginx.conf -> /srv/www/meine_app/produktion/nginx.conf
```
## certbot Set-Up
Um deine Web - App mit https zu verschlüsseln, brauchst du ein Zertifikat. Ein kostenloses Zertifikat bekommst du von Let's encrypt. Diese Zertifikat läuft aber nach 12 Monaten ab, deswegen nutzen wir `certbot` um das Zertifikat automatisch alle 12 Monate zu erneuern.
**So kannst du certbot auf Debian installieren:**
```
sudo apt install certbot python3-certbot-nginx
sudo certbot --nginx
```
Jetzt sollte certbot deine `nginx.conf` angepasst haben. Schau dir die Änderungen mit `git status` an
```
cd /srv/www/meine_app
git status
git add produktion/nginx.conf
git commit -m "certbot setup"
```
[Falls du eine andere Architektur benutzt, kannst du hier auf certbots Webseite mehr Infos bekommen.](https://certbot.eff.org/instructions)
## Weitere nginx.conf Anpassungen.
Das ganze ist aber noch nicht genug. Jetzt musst du deine .conf für den launch vorbereiten. Das ganze sieht dann etwa so aus:
```
worker_processes 1;
user www-data;
# Hier sind deine error logs - für alle Zugriffe gibt es auch ein access.log am gleichen Ort:
error_log /var/log/nginx/error.log info;
pid /var/run/nginx.pid;
# events kannst du so lassen:
events {
worker_connections 1024; # increase if you have lots of clients
accept_mutex off; # set to 'on' if nginx worker_processes > 1
}
# Mehrere Voreinstellungen für django:
http {
include mime.types;
# fallback in case we can't determine a type
default_type application/octet-stream;
access_log /var/log/nginx/access.log combined;
sendfile on;
upstream app_server {
# fail_timeout=0 means we always retry an upstream even if it failed
# to return a good HTTP response
# for UNIX domain socket setups
server unix:/tmp/gunicorn.sock fail_timeout=0;
}
# Das ist dein HTTP - Server:
server {
listen 80;
server_name meine_domain.de;
return 301 https://$server_name$request_uri;
}
# Das ist dein HTTPS - Server:
server {
listen 443 ssl;
client_max_body_size 75M;
server_name meine_domain.de;
# Hier sind deine ssl - Zertifikate, die du dir mit certbot geholt hast:
ssl_certificate /etc/letsencrypt/live/meine_domain.de/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/meine_domain.de/privkey.pem;
keepalive_timeout 5;
# Hier sind deine Statischen Dateien. Sie werden in Produktion
# direkt von nginx gehosted. In deinen django settings
# musst du STATIC_ROOT = "/srv/www/static" hinzufügen
location /static {
alias /srv/www/static;
}
# Das hier ist deine Proxy - Server Weiterleitung. Dein lokaler
# Gunicorn wird so an das offene Internet weitergeleitet.
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
# Hier kanst du deine error - Seiten bereitstellen. Da diese
# Statisch sind, werden sie direkt von nginx bereitgestellt
error_page 500 502 503 504 /500.html;
location = /500.html {
root /srv/www/meine_repository/meine_app/static;
}
}
}
```
## Starte deine Webapp mit Gunicorn
Jetzt fehlt nur noch eine Sache, deine eigene App!
Du kannst sie, wie beim letzten mal - mit Gunicorn starten.
```
# Exportiere dein Produktions - env, damit deine Richtigen Einstellungen geladen werden.
export ENV_NAME=production
# Starte dein Gunicorn - Die Applikation befindet sich im venv in deiner Repository
# Deine .wsgi ist im Verzeichnis deiner App
# und mit -b kannst du deine lokale ip bestimmen - Diese leitest du an nginx weiter.
/srv/www/meine_repository/venv/bin/gunicorn /srv/www/meine_repository/meine_app/meine_app.wsgi -b 127.0.0.1:8000
```
Lade deine neue Konfiguration:
```
sudo systemctl daemon-reload
sudo systemctl restart nginx.service
```
Jetzt solltest du deinen Browser öffnen und unter deiner domain deine App sehen können!
Im nächsten Teil werden wir deine .service Dateien für systemd anlegen, damit auch nach einem `reboot` alle deine wichtigen Applikationen laufen.
PS: Viel Spaß beim Coden,
Dein Ruben
[Mein Blog](rubenvoss.de) | rubenvoss |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.