
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,925,897 | Debugging JavaScript: Tools and Techniques | Welcome back to our series, "JavaScript: From Novice to Expert!" Our last article introduced the... | 27,941 | 2024-07-16T19:47:19 | https://dev.to/buildwebcrumbs/debugging-javascript-tools-and-techniques-2i4b | javascript, beginners, programming, webdev |
Welcome back to our series, "JavaScript: From Novice to Expert!"
Our last article introduced the fundamentals of JavaScript Syntax and Structure and today, we are going to learn about an essential skill every developer must learn to be a successful dev —debugging.
Debugging can be a bit scary at first, but with th... | pachicodes |
1,925,898 | Postman Api 101 #postmanstudent | The program featured: Comprehensive Modules: From API basics to advanced Postman techniques. Live... | 0 | 2024-07-16T19:47:54 | https://dev.to/mohanraj1234/postman-api-101-postmanstudent-37n1 | The program featured:
Comprehensive Modules: From API basics to advanced Postman techniques.
Live Expert Sessions: Direct insights and advice from MK Veerendra Vamshi.
Collaborative Projects: Real-world applications and teamwork experiences.
Skills Gained
API Mastery: Designing, testing, and documenting APIs with ease... | mohanraj1234 | |
1,925,899 | 3 Chrome Extensions to Boost Your Productivity (Plus a Bonus!) | Hello Devs!, We all know how important it is to stay productive at work. The most efficient people... | 0 | 2024-07-16T19:48:19 | https://dev.to/ronakkhunt/3-chrome-extensions-to-boost-your-productivity-plus-a-bonus-3f1f | productivity, extensions, browser, shorturl | Hello Devs!,
We all know how important it is to stay productive at work.
> The most efficient people aren't necessary brilliant, they've just found the right tools
Chrome extensions can be real game-changers when it comes to productivity. Here are three must-have Chrome extensions that can help you streamline your t... | ronakkhunt |
1,926,805 | News | Bollywood Movies | Hindi Serials | APNE TV | These days, finding a comfortable and enjoyable space to unwind in after a long day of hectic... | 0 | 2024-07-17T13:52:25 | https://dev.to/apnetv/news-bollywood-movies-hindi-serials-apne-tv-42h9 | These days, finding a comfortable and enjoyable space to unwind in after a long day of hectic activity has become crucial thanks to entertainment. It has always been a component of human culture and society, both in the past and now. Everyone enjoys watching their favorite television programs, films, and series, regard... | apnetv | |
1,925,900 | Create perfect anime characters with GPT-4o and SDXL | GPT-4o writes character details and text-to-image prompts. SDXL generates images. AI Agent... | 0 | 2024-07-16T19:49:47 | https://dev.to/appbaza/create-perfect-anime-characters-with-gpt-4o-and-sdxl-5a36 | sdxl, chatgpt, aiagent, ai | GPT-4o writes character details and text-to-image prompts. SDXL generates images.
## AI Agent Flow
The initial prompt is as simple as this: “Generate a random anime character. You can pick any topic. Write a background story specific to the character, including mood, physical appearance, and superpowers.”
Then we ch... | appbaza |
1,925,901 | Como configurar o VSCode para seus projetos de React | Nota: apenas traduzi o texto abaixo e postei aqui. As referências estão no fim deste artigo. A... | 0 | 2024-07-16T19:50:15 | https://dev.to/dougsource/como-configurar-o-vscode-para-seus-projetos-de-react-k2b | programming, vscode, react, braziliandevs | _**Nota:** apenas traduzi o texto abaixo e postei aqui. As referências estão no fim deste artigo._
A ferramenta definitiva que você tem ao desenvolver seus projetos é o editor de código. É por isso que é tão importante configurá-lo corretamente.
Neste guia passo a passo, passaremos de uma instalação completamente nov... | dougsource |
1,925,902 | Build a Compiler in C language | Hey dev community! 👋 It's Amir back again with a new article and today, I'm excited to share a new... | 0 | 2024-07-16T19:58:39 | https://dev.to/bekbrace/build-a-compiler-in-c-language-3lgb | c, cpp, csharp, programming | Hey dev community! 👋
It's Amir back again with a new article and today, I'm excited to share a new tutorial where I walk you through creating a simple arithmetic expression parser and code generator in C.
I hope this guide will help you understand the basics of tokenizing, validating, and evaluating arithmetic expr... | bekbrace |
1,925,903 | SECURE YOUR LOST CRYPT0 INVESTMENT WITH MUYERN TRUST HACKER | In the vast and often treacherous realm of online investments, I was entangled in a web of deceit... | 0 | 2024-07-16T19:58:58 | https://dev.to/rickey_thompson/secure-your-lost-crypt0-investment-with-muyern-trust-hacker-4dio | In the vast and often treacherous realm of online investments, I was entangled in a web of deceit that cost me nearly $45,000. It all started innocuously enough with an enticing Instagram profile promising lucrative returns through cryptocurrency investment. Initially, everything seemed promising—communications were s... | rickey_thompson | |
1,925,904 | Top 10 Cloud Security Startups to Watch in 2024 | As cloud environments continue to evolve, several startups are making significant strides in... | 0 | 2024-07-16T20:00:05 | https://dev.to/nashetking/top-10-cloud-security-startups-to-watch-in-2024-5964 | cloudcomputing, security, programming, startup |
As cloud environments continue to evolve, several startups are making significant strides in providing innovative cloud security solutions. These startups are not only leveraging cutting-edge technologies but also addressing the specific challenges that organizations face. In this blog, we'll explore the top 10 cloud... | nashetking |
1,925,905 | Revolutionizing Web 3 Development with AI: Unlocking New Possibilities | As the digital landscape evolves, the intersection of artificial intelligence (AI) and Web 3... | 0 | 2024-07-16T20:00:25 | https://dev.to/irmakork/revolutionizing-web-3-development-with-ai-unlocking-new-possibilities-55m5 | ai, devops, developers, web3 |

As the digital landscape evolves, the intersection of artificial intelligence (AI) and Web 3 development is creating unprecedented opportunities. Web 3, characterized by decentralization, blockchain technology, and ... | irmakork |
1,925,906 | Postman Api 101 | The Postman Student Program was an incredible journey, equipping me with crucial skills and... | 0 | 2024-07-16T20:00:31 | https://dev.to/mohanraj1234/postman-api-101-4c5j | The Postman Student Program was an incredible journey, equipping me with crucial skills and connections. If you're passionate about APIs, this program is a game-changer. Highly recommended!
| mohanraj1234 | |
1,925,907 | Api In postman | Today I attended the postman Api workshop | 0 | 2024-07-16T20:04:27 | https://dev.to/mohanraj1234/api-in-postman-2df4 | Today I attended the postman Api workshop | mohanraj1234 | |
1,925,908 | I couldn't afford $5/mo for Ghost Pro so I built one for $2/mo on a $4,000/mo VPS | Children, this is the story of "How I Met Your M̶o̶t̶h̶e̶r̶ .... no Ghost" So, this story starts... | 0 | 2024-07-16T20:05:09 | https://dev.to/vednig/i-couldnt-afford-5mo-for-ghost-pro-so-i-built-one-for-2mo-on-a-4000mo-vps-no5 | webdev, javascript, programming, supabase | Children, this is the story of "How I Met Your M̶o̶t̶h̶e̶r̶ .... no Ghost"

So, this story starts with the usual problem present everywhere , I know, Poverty. So, right now I have graduated from my college and was... | vednig |
1,925,940 | 🚀 20 Days to Azure DevOps Superstardom! 🌟 | Welcome to your epic Azure DevOps learning journey! 🎉 This 20-day adventure will transform you from... | 0 | 2024-07-16T20:29:34 | https://dev.to/narashim_reddy/20-days-to-azure-devops-superstardom-4lg6 | devops, azure, tutorial, cloudninja | Welcome to your epic Azure DevOps learning journey! 🎉 This 20-day adventure will transform you from an Azure novice to a DevOps pro, complete with 4 mind-blowing projects! 🏆
## 🗓️_Your Epic Learning Odyssey_
<table> <thead> <tr> <th>Day</th> <th>Topic</th> <th>Theory</th> <th>Hands-On</th> <th>YouTube</th> </tr> <... | narashim_reddy |
1,926,865 | Flutter | A post by Aadarsh Kunwar | 0 | 2024-07-17T14:58:31 | https://dev.to/aadarshk7/flutter-38lm | aadarshk7 | ||
1,925,941 | Prime Day Sniping: Top Tech Deals for Developers | Prime Day is here, and it’s the perfect opportunity to snag some fantastic deals on laptops,... | 0 | 2024-07-16T20:45:17 | https://devtoys.io/2024/07/16/prime-day-sniping-top-tech-deals-for-developers/ | devtoys, deals, productivity | ---
canonical_url: https://devtoys.io/2024/07/16/prime-day-sniping-top-tech-deals-for-developers/
---
Prime Day is here, and it’s the perfect opportunity to snag some fantastic deals on laptops, computers, and tablets. Here are some of the top picks that will elevate your tech game without breaking the bank.
---
## ... | 3a5abi |
1,925,942 | Host A Static Website On Microsoft Azure Blob Storage | Azure Static Web Apps is a service that automatically builds and deploys full stack web apps to Azure... | 0 | 2024-07-16T22:37:06 | https://dev.to/sangifeanyi/host-a-static-website-on-microsoft-azure-blob-storage-2l62 | Azure Static Web Apps is a service that automatically builds and deploys full stack web apps to Azure from a code repository.
In this quick start, you are to deploy an application to Azure Static Web apps using the Visual Studio Code extension.
The first step is to configure your storage account to host a static webs... | sangifeanyi | |
1,925,943 | Hello world, | Today my HTML learning are Nesting and Anchor element and it was fun... making my base strong for... | 0 | 2024-07-16T20:52:30 | https://dev.to/ritesh_dev/hello-world-4ko | webdev, javascript, beginners, programming | Today my HTML learning are Nesting and Anchor element and it was fun...
making my base strong for further future learning....
hashtag#webdev hashtag#coder hashtag#html
 | ritesh_dev |
1,925,944 | Top 7 Featured DEV Posts of the Week | Welcome to this week's Top 7, where the DEV editorial team handpicks their favorite posts from the... | 0 | 2024-07-16T20:55:20 | https://dev.to/devteam/top-7-featured-dev-posts-of-the-week-k38 | top7 | _Welcome to this week's Top 7, where the DEV editorial team handpicks their favorite posts from the previous week._
Congrats to all the authors that made it onto the list 👏
{% embed https://dev.to/jenc/the-dual-nature-of-seniority-in-software-development-1b3j %}
Jen explores the complexities of seniority in software... | thepracticaldev |
1,925,946 | Integration of Artificial Intelligence and Machine Learning in Cloud Security | Lately, companies, startups, governments, and other organizations have opted to use cloud computing... | 0 | 2024-07-16T20:57:07 | https://dev.to/joshwizard/integration-of-artificial-intelligence-and-machine-learning-in-cloud-security-62b | cybersecurity, devops, machinelearning, ai | Lately, companies, startups, governments, and other organizations have opted to use [cloud computing](https://en.wikipedia.org/wiki/Cloud_computing) only for its reliability to store their data without the risk of losing the data either by computer viruses, theft, human errors, software corruption, natural disasters, o... | joshwizard |
1,925,948 | Boost Your Android Development with Fast & Easy Form Builder | Boost Your Android Development with Fast & Easy Form Builder Building forms can often... | 0 | 2024-07-17T14:05:36 | https://dev.to/jos_igutirrezb_8d0b/boost-your-android-development-with-fast-easy-form-builder-42p7 | mobile, kotlin, opensource, androiddev | ## Boost Your Android Development with Fast & Easy Form Builder
Building forms can often be a time-consuming task in Android development. Whether it’s for user registration, feedback collection, or data entry, creating a well-structured and functional form can be challenging. Enter **Fast & Easy Form**, a powerful lib... | jos_igutirrezb_8d0b |
1,925,950 | Day 992 : When The Sun Shines Again | liner notes: Professional : Today flew by! Responded to some community questions and worked on some... | 0 | 2024-07-16T21:06:49 | https://dev.to/dwane/day-992-when-the-sun-shines-again-1p5 | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Today flew by! Responded to some community questions and worked on some documentation before a meeting. After the meeting, I spoke with someone that worked on a feature that I'll be creating a sample application and blog post to clarify some things so that what I say is as accurate as po... | dwane |
1,925,951 | shadcn-ui/ui codebase analysis: How does shadcn-ui CLI work? — Part 2.14 | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the... | 0 | 2024-07-16T21:07:29 | https://dev.to/ramunarasinga/shadcn-uiui-codebase-analysis-how-does-shadcn-ui-cli-work-part-214-4p20 | javascript, shadcnui, nextjs, opensource | I wanted to find out how shadcn-ui CLI works. In this article, I discuss the code used to build the shadcn-ui/ui CLI.
In part 2.11, we looked at runInit function and how shadcn-ui/ui ensures directories provided in resolvedPaths in config exist.
The following operations are performed in runInit function:
 | Nessa documentação você terá acesso ao processo de instalação e atualização do AWS CLI sendo feito... | 0 | 2024-07-16T21:42:05 | https://dev.to/aws-builders/como-instalar-e-atualizar-o-seu-aws-cli-corretamente-usando-o-ubuntu-2204-no-wsl2-windows-11-3jom |
Nessa documentação você terá acesso ao processo de instalação e atualização do AWS CLI sendo feito via terminal em uma distribuição Ubuntu 22.04 executada via WSL 2.0 no Windows 11
**Sumário:**
* Instalação do AWS CLI;
* Atualização do AWS CLI;
* Deleção do AWS CLI;
## Instalação do AWS CLI
O processo de instala... | o_filipealmeida | |
1,925,953 | How often do you run your agile retrospectives? | Wondering how often to run Agile retrospectives? Regular retrospectives at the end of each sprint are... | 0 | 2024-07-16T21:16:20 | https://dev.to/mattlewandowski93/how-often-do-you-run-your-agile-retrospectives-19lg | agile, scrum, retrospective, management | Wondering how often to run Agile retrospectives? Regular retrospectives at the end of each sprint are key for continuous improvement, but the optimal frequency depends on factors like sprint length, team maturity, and project complexity.
In our latest article, we explore the benefits of timely feedback and manageable ... | mattlewandowski93 |
1,925,954 | System Architecture Design Methodologies Part1 | System Architecture Design Methodologies are like recipes for building complex systems. These methods... | 0 | 2024-07-16T21:16:34 | https://dev.to/usmanatx/system-architecture-design-methodologies-part1-3g6p | systemdesign, microservices, architecture, designsystem | System Architecture Design Methodologies are like recipes for building complex systems. These methods provide a framework for architects to follow. They design the system for flexibility, simplicity, and consistent performance. Here are some common System Architecture Design Methodologies:
**Monolithic Architecture:*... | usmanatx |
1,925,975 | The Kafka Metric You’re Not Using: Stop Counting Messages, Start Measuring Time | by Aratz Manterola Lasa Companion video Consumer groups are the backbone of data consumption in... | 0 | 2024-07-17T14:04:25 | https://dev.to/warpstream/the-kafka-metric-youre-not-using-stop-counting-messages-start-measuring-time-2e57 | apachekafka, dataengineering, realtimestreamingdat | ---
title: The Kafka Metric You’re Not Using: Stop Counting Messages, Start Measuring Time
published: true
date: 2024-07-16 18:03:30 UTC
tags: apachekafka,dataengineering,realtimestreamingdat
canonical_url:
---
by Aratz Manterola Lasa
[Companion video](https://youtu.be/yBia8pnDKYg)
Consumer groups are the backbone ... | warpstream |
1,925,984 | any suggestions on this website | https://enaly.com | 0 | 2024-07-16T21:28:39 | https://dev.to/henry_wang_c02699c8c99e04/any-suggestions-on-this-website-1jcg | [https://enaly.com](https://enaly.com)
| henry_wang_c02699c8c99e04 | |
1,925,988 | Have you tried all API calls in JavaScript? Here are 4 ways to do it | API calls are a key part of modern web development. JavaScript offers several ways to accomplish... | 0 | 2024-07-16T21:31:52 | https://dev.to/tomasdevs/have-you-tried-all-api-calls-in-javascript-here-are-4-ways-to-do-it-4l4d | webdev, javascript, api, programming | > API calls are a key part of modern web development. JavaScript offers several ways to accomplish this task, each with its own advantages and disadvantages. This article will introduce you to four main methods of making API calls in JavaScript that you can use in your projects.
## XMLHttpRequest (XHR)
**XMLHttpReque... | tomasdevs |
1,925,999 | Softrobo - Empowering Digital Evolution | With over a decade of expertise in SEO and digital marketing, I present Softrobo – your ultimate... | 0 | 2024-07-16T22:02:03 | https://dev.to/softrobo/softrobo-empowering-digital-evolution-2laa | digitalservices, digitalsolution, seoservices, webdevelopmentservices | With over a decade of expertise in SEO and digital marketing, I present Softrobo – your [ultimate](https://softrobo.co.uk) partner in empowering digital evolution. Softrobo Executive Team, boasting over 7 years of experience, excels in creating and enhancing exceptional digital products. Our services encompass:
Mobile... | softrobo |
1,926,004 | Day 13 of my 90-Devops project: Setting Up a CI/CD Pipeline with Docker and Kubernetes on GitLab | Prerequisites Basic Knowledge of Docker and Kubernetes GitLab Account Git Installed on... | 0 | 2024-07-16T22:41:02 | https://dev.to/arbythecoder/day-13-of-my-90-devops-project-setting-up-a-cicd-pipeline-with-docker-and-kubernetes-on-gitlab-52m | gitlab, cicd, docker, kubernetes |
#### Prerequisites
1. **Basic Knowledge of Docker and Kubernetes**
2. **GitLab Account**
3. **Git Installed on Local Machine**
4. **Docker Installed on Local Machine**
5. **Minikube Installed on Local Machine**
6. **kubectl Installed on Local Machine**
### Step 1: Setting Up the Project
1. **Create a Project Direct... | arbythecoder |
1,926,009 | Confused by var, let, and const? Let's Clear the Mess | Ah, JavaScript variables! If you’ve ever found yourself scratching your head over the differences... | 0 | 2024-07-16T22:38:17 | https://dev.to/i-sultan0/confused-by-var-let-and-const-lets-clear-the-mess-4kn7 | webdev, javascript, beginners, programming | Ah, JavaScript variables! If you’ve ever found yourself scratching your head over the differences between var, let, and const, you’re not alone. Understanding these three can feel like trying to navigate a maze. But fear not, dear coder! I am here to clarify the confusion.
# Basic Concept : Assigning and Redeclaration... | i-sultan0 |
1,926,011 | EnvLock: The Ultimate Env Manager | As developers, we often juggle multiple projects with different environment configurations. Whether... | 0 | 2024-07-16T22:39:36 | https://dev.to/siyabuilt/envlock-the-ultimate-env-manager-11ha | webdev, programming, productivity, security | As developers, we often juggle multiple projects with different environment configurations. Whether you're working with Python, Node.js, or Ruby, managing environment variables can be a hassle. Enter [EnvLock](https://envlock.com), a powerful and user-friendly SaaS solution that streamlines your environment variable ma... | siyabuilt |
1,926,012 | Fullstack Blog with Tanstack Query, Zustand, Flask, JWT, Cookies | Register, Login, CRUD Post Tutorial | Learn how to build a fullstack blog application using modern technologies like Tanstack Query,... | 0 | 2024-07-16T22:42:34 | https://dev.to/henry_lee_1787e739b0c8191/fullstack-blog-with-tanstack-query-zustand-flask-jwt-cookies-register-login-crud-post-tutorial-2kjh | Learn how to build a fullstack blog application using modern technologies like Tanstack Query, Zustand for state management, Flask for backend, JWT for secure authentication, and cookies for session handling. This comprehensive tutorial covers user registration, login, and CRUD operations for blog posts. Perfect for de... | henry_lee_1787e739b0c8191 | |
1,926,013 | [Day 2] - Configuring React Router | The second day is always a grind in my experience. Some of the excitement has passed, the work has... | 28,085 | 2024-07-17T12:00:00 | https://dev.to/nmiller15/day-2-configuring-react-router-42k | buildinpublic, webdev, react, devjournal | The second day is always a grind in my experience. Some of the excitement has passed, the work has truly set in. It’s never on day one that I realized the size of the project that I’ve just started.
It’s been probably about a month since I’ve worked on a React, so the biginnings are moving a little slower than I want.... | nmiller15 |
1,926,014 | Precision Reloading Shop Review | Precision Reloading Shop is an online retailer that specializes in providing high-quality reloading... | 0 | 2024-07-16T23:04:33 | https://dev.to/precisionreloading/precision-reloading-shop-review-2dg8 | ammo | [Precision Reloading Shop](https://precisionreloadingshop.com) is an online retailer that specializes in providing high-quality reloading supplies to hunters, sport shooters, and gun enthusiasts. According to their website, they offer a wide selection of reloading components from top brands, including [smokeless powder... | precisionreloading |
1,926,016 | Introduction to ElasticSearch in Laravel | Introduction Elasticsearch is a tool that helps you search and analyze large amounts of... | 0 | 2024-07-16T23:19:28 | https://dev.to/devbalop/introduction-to-elasticsearch-in-laravel-1e34 | ### Introduction
Elasticsearch is a tool that helps you search and analyze large amounts of information very quickly. Imagine it as a super-fast librarian who can find exactly what you need from a huge collection of books in just a few seconds. When used with Laravel, Elasticsearch makes it easy to add advanced search... | devbalop | |
1,926,037 | HIRE LEE ULTIMATE HACKER FOR SCAMMED CRYPT0 RECOVERY. | LEEULTIMATE HACKER@ AOL. COM Support @ leeultimatehacker .com telegram:LEEULTIMATE wh@tsapp +1 (715)... | 0 | 2024-07-16T23:29:19 | https://dev.to/zoe_lola_3e15ee842c361d1f/hire-lee-ultimate-hacker-for-scammed-crypt0-recovery-ged | recoverlostcrypto, cryptorecoveryexpert | LEEULTIMATE HACKER@ AOL. COM
Support @ leeultimatehacker .com
telegram:LEEULTIMATE
wh@tsapp +1 (715) 314 - 9248
https://leeultimatehacker.com
I wanted to take a moment to address a topic that is of great concern - the effects of online binary investments. Binary investments can massively improve one’s financial situ... | zoe_lola_3e15ee842c361d1f |
1,926,038 | no AdMob account input AdMob 계좌 입력란이 없고 | ** I was confused because there was no AdMob account input field and only a part asking for identity... | 0 | 2024-07-16T23:29:23 | https://dev.to/sidcodeme/no-admob-account-input-admob-gyejwa-ibryeograni-eobsgo-103i | admob, 애드몹 | **
I was confused because there was no AdMob account input field and only a part asking for identity verification appeared.
AdMob 계좌 입력란이 없고, 본인인증 하라는 부분만 나와서 당황했다.
## AdMob sends a mail letter with a PIN number to the user when the first $10 is reached and after entering the PIN number and verifying identity, the a... | sidcodeme |
1,926,040 | [Game of Purpose] Day 59 - Following a path either by distance or Spline points | Today I was playing around with supporting 2 ways of following a path. By distance - Given a path... | 27,434 | 2024-07-16T23:37:31 | https://dev.to/humberd/game-of-purpose-day-59-4d5i | gamedev | Today I was playing around with supporting 2 ways of following a path.
* By distance - Given a path it moves to a point every `x` distance.
* By points - Given a path it moves to each point the Spline has configured.
https://blueprintue.com/blueprint/zmunmar-/
.
... | sazardev |
1,926,042 | Access Request Headers in a Rails Controller | Heads Up A coworker presented a failing request spec. They asked if they were passing... | 0 | 2024-07-16T23:43:47 | https://dev.to/kevin_j_m/access-request-headers-in-a-rails-controller-3b27 | ruby, rails | ## Heads Up
A coworker presented a failing request spec. They asked if they were passing headers incorrectly in the test.
```ruby
it "reports to be a teapot when asked to brew coffee" do
headers = { "X-COMMAND" => "brew coffee" }
get drinks_url, headers: headers
expect(response.status).to eq 418
end
```
They ... | kevin_j_m |
1,926,043 | Top Github repositories for 10+ programming languages | Hello friends, This is an extensive list of GitHub repositories to begin and grow your journey as a... | 0 | 2024-07-16T23:58:23 | https://dev.to/shreyvijayvargiya/top-github-repositories-for-10-programming-languages-10pi | webdev, beginners, programming, githunt | Hello friends,
This is an extensive list of GitHub repositories to begin and grow your journey as a programmer. This collection contains the 10+ languages' top GitHub repositories to learn for FREE and stay updated as well.
## How to use it?
It's simple whenever you want to start learning something get the basic over... | shreyvijayvargiya |
1,926,044 | Home Loan EMI Calculation Made Simple - Tools and Tips for Smart Borrowing | Many find calculating home loan EMIs daunting, but with the right tools and tips, you can make smart... | 0 | 2024-07-17T00:09:43 | https://dev.to/moovendran_veerapandian/home-loan-emi-calculation-made-simple-tools-and-tips-for-smart-borrowing-5fbj | homeloan, homeloantips, homeloanindia | Many find calculating home loan EMIs daunting, but with the right tools and tips, you can make smart borrowing decisions effortlessly. Whether you're a first-time homebuyer or looking to refinance, understanding how EMIs work is crucial. In this blog post, we break down the process for you and provide handy tools to si... | moovendran_veerapandian |
1,926,047 | Python, 배수의 값을 구하기 | for i in range(80, int(argv[2])+1): if int(argv[2]) % i == 0: s_i = i ... | 0 | 2024-07-17T00:26:36 | https://dev.to/sunj/python-baesuyi-gabseul-guhagi-8gl | ```
for i in range(80, int(argv[2])+1):
if int(argv[2]) % i == 0:
s_i = i
if i % 10 != 0:
s_i = str(i).replace('0', '')
if i % 10 == 0:
c_i = str(i).count('0')
if c_i > 1:
s_i = str(i).replace('0', '', c_... | sunj | |
1,926,048 | Issue 53 of AWS Cloud Security Weekly | (This is just the highlight of Issue 53 of AWS Cloud Security weekly @... | 0 | 2024-07-17T00:29:35 | https://aws-cloudsec.com/p/issue-53 | security, aws, news, newsletter | (This is just the highlight of Issue 53 of AWS Cloud Security weekly @ https://aws-cloudsec.com/p/issue-53 << Subscribe to receive the full version in your inbox weekly for free!!).
**What happened in AWS CloudSecurity & CyberSecurity last week July 09-July 16, 2024?**
- AWS Security Hub has introduced 24 new security... | aws-cloudsec |
1,926,049 | Optimizing SQL Queries for Performance | Introduction: Structured Query Language (SQL) is a widely used language for managing relational... | 0 | 2024-07-17T00:34:10 | https://dev.to/kartikmehta8/optimizing-sql-queries-for-performance-2e4d | Introduction:
Structured Query Language (SQL) is a widely used language for managing relational databases. However, as the amount of data in databases continues to increase, optimizing SQL queries for performance has become crucial. Poorly written queries can lead to slow performance, higher resource utilization, and ... | kartikmehta8 | |
1,926,050 | IntensaMente 2 Película Completa Online hdr | IntensaMente 2 Película Completa Online ➥ Ver Ahora ➢ https://bit.ly/3S9im2p Ver IntensaMente 2... | 0 | 2024-07-17T00:37:06 | https://dev.to/baixarfilmes23/intensamente-2-pelicula-completa-online-hdr-3dcf | webdev, javascript, beginners, programming | IntensaMente 2 Película Completa Online
➥ Ver Ahora ➢ [https://bit.ly/3S9im2p](https://bit.ly/3S9im2p)
Ver IntensaMente 2 Película Completa Online en Español Latino. Ver la película de IntensaMente 2 online en Español sin cortes y sin publicidad, IntensaMente 2 pelicula completa online latino, esta disponible, como si... | baixarfilmes23 |
1,926,051 | Distributed Actors in Python with Dapr | What makes a worse header image - my hand drawing of an airplane, or yet another super lame AI... | 0 | 2024-07-17T00:42:13 | https://dev.to/aaronblondeau/distributed-actors-in-python-with-dapr-4856 | python, dapr, actors | What makes a worse header image - my hand drawing of an airplane, or yet another super lame AI generated picture?
Anyways, imagine a scenario where you are asked to build a an app for an airplane banner message startup called "AirDisplay". AirDisplay is going to completely disrupt the towed airplane banner industry wi... | aaronblondeau |
1,926,052 | Why Sista AI is the Top Choice over Alan AI for Conversational AI Integration | Discover why Sista AI outshines the competition by offering unparalleled AI integration solutions. Elevate user experience with cutting-edge technology. Explore the possibilities with Sista AI! #AI #SistaAI 🔥 | 0 | 2024-07-17T00:41:46 | https://dev.to/sista-ai/why-sista-ai-is-the-top-choice-over-alan-ai-for-conversational-ai-integration-48ko | ai, react, javascript, typescript | <h2>Introduction</h2><p>In the world of AI integration, the choice between Sista AI and Alan AI is clear. Sista AI's advanced conversational AI integration platform offers unparalleled user-friendly features and versatility. With Sista AI, developers can effortlessly integrate AI voice assistants into their apps within... | sista-ai |
1,926,054 | Unleashing the Power of ChatGPT Prompts for LinkedIn: Elevate Your Professional Presence | In the rapidly evolving digital landscape, LinkedIn has solidified its position as the go-to platform... | 0 | 2024-07-17T00:49:47 | https://dev.to/online_2048_8d73ad8f845f2/unleashing-the-power-of-chatgpt-prompts-for-linkedin-elevate-your-professional-presence-1mf7 | linkedinmarketing, chatgpt, professionalbranding, digitalnetworking | In the rapidly evolving digital landscape, LinkedIn has solidified its position as the go-to platform for professionals worldwide. With over 774 million users, it offers unparalleled opportunities for networking, job hunting, and personal branding. However, standing out in such a vast sea of profiles can be challenging... | online_2048_8d73ad8f845f2 |
1,926,055 | Dynamic programming: Teach me like I am 5! | Imagine you have a magical notebook 📓✨. This notebook remembers answers to problems you’ve already... | 0 | 2024-07-17T01:00:08 | https://dev.to/yourtechsiss/dynamic-programming-teach-me-like-i-am-5-6o | Imagine you have a magical notebook 📓✨. This notebook remembers answers to problems you’ve already solved so you don’t have to solve them again.
Let’s start with something simple: climbing stairs. Each time, you can either take 1 step or 2 steps. How many ways can you climb to the top if there are n stairs?
Magical ... | yourtechsiss | |
1,926,057 | The Value of Community Conferences | Ever since returning from the last JSConf Budapest, a question has been circling in my mind: how can... | 0 | 2024-07-17T01:12:02 | https://dev.to/amandamartindev/the-value-of-community-conferences-5fh3 | devrel, techtalks, community, marketing | Ever since returning from the last [JSConf Budapest](https://jsconfbp.com/), a question has been circling in my mind: how can we effectively sell the idea of community conferences to companies? It's a topic that seems to resonate with many in the tech field, from developers to developer advocates.
## Why Community Con... | amandamartindev |
1,926,058 | Demo | demo | 0 | 2024-07-17T01:19:33 | https://dev.to/cuongvnz/demo-3e6e | demo | cuongvnz | |
1,926,071 | AI in Real Estate: Transforming the Industry | Introduction to AI in Real Estate Artificial Intelligence (AI) has become a transformative... | 27,673 | 2024-07-17T01:35:15 | https://dev.to/rapidinnovation/ai-in-real-estate-transforming-the-industry-20cp | ## Introduction to AI in Real Estate
Artificial Intelligence (AI) has become a transformative force across various
industries, and real estate is no exception. AI in real estate refers to the
use of machine learning, data analytics, and other AI technologies to
facilitate and optimize different processes in the real e... | rapidinnovation | |
1,926,866 | tmux 101 | tmux is a terminal multiplexer. We can have multiple terminals inside a single terminal, which is... | 0 | 2024-07-17T15:00:45 | https://dev.to/vigneshm243/tmux-101-50lm | linux, archlinux | tmux is a terminal multiplexer. We can have multiple terminals inside a single terminal, which is especially useful when we ssh into a remote machine.
tmux has 3 levels of hierarchy,
- Sessions - To have complete... | vigneshm243 |
1,926,072 | Publishing Packages to GitHub with GitHub Actions | Publishing Packages to Github How to Publish Private NPM Packages With Github Package... | 0 | 2024-07-17T01:36:25 | https://dev.to/tkssharma/publishing-packages-to-github-with-github-actions-54bm | github, npm, package, node |
Publishing Packages to Github
{% embed https://www.youtube.com/watch?v=lVze5eT5DQQ&list=PLIGDNOJWiL18ucL7WGWeVjXmSzOVTRObE %}
How to Publish Private NPM Packages With Github Package Registry
Build and Publish Your NPM Package in 5 Minutes :)
In this playlist, we are talking about publishing different types of packa... | tkssharma |
1,926,073 | NestJS Testing Unit and E2E | Hi Everyone, 🔥I am building nestjs testing playlist which talks all about nestjs testing... | 0 | 2024-07-17T01:39:40 | https://dev.to/tkssharma/nestjs-testing-unit-and-e2e-km2 | nestjs, node, testing, javascript |
{% embed https://www.youtube.com/watch?v=kv_pCCAmiLc %}
Hi Everyone,
🔥I am building nestjs testing playlist which talks all about nestjs testing

https://www.youtube.com/watch?v=GSoGVlG1MTQ&list=PLIGDNOJWiL1-8hpXEDlD1UrphjmZ9aM... | tkssharma |
1,926,074 | Elevate Your Elasticsearch Experience with Java High Level REST Client (7.x) | Introduction Java High Level REST Client (7.x) is a powerful tool for interacting with... | 0 | 2024-07-17T01:45:55 | https://dev.to/a_lucas/elevate-your-elasticsearch-experience-with-java-high-level-rest-client-7x-348k | javascript, tutorial, productivity, webdev | ## Introduction
Java High Level REST Client (7.x) is a powerful tool for interacting with Elasticsearch clusters, making server communication more accessible and efficient. In this guide, we will walk you through the steps to use the High Level REST Client to call Elasticsearch Java APIs on an [Alibaba Cloud Elasticse... | a_lucas |
1,926,076 | LED rental screen series "integrated" with the stage | With the continuous advancement of display technology, my country's display application field has... | 0 | 2024-07-17T01:48:27 | https://dev.to/sostrondylan/led-rental-screen-series-integrated-with-the-stage-94 | led, rental, screen | With the continuous advancement of display technology, my country's display application field has gradually shifted from traditional display equipment to [LED rental screen applications](https://sostron.com/products/hima-indoor-and-outdoor-advertising-screens-for-rent/). The amount of information that modern audiences ... | sostrondylan |
1,926,077 | Using AWS coding with Codeguru | When it comes to coding with AWS (Amazon Web Services) and using CodeGuru, there are several specific... | 0 | 2024-07-17T01:52:17 | https://dev.to/sherlockyadav/using-aws-coding-with-codeguru-bj5 | When it comes to coding with AWS (Amazon Web Services) and using CodeGuru, there are several specific ways in which CodeGuru can provide assistance and improve your coding experience:
Code Reviews and Recommendations:
Code Quality: CodeGuru Reviewer analyzes your code as you develop and provides recommendations to im... | sherlockyadav | |
1,926,078 | Publish Nest JS Dynamic Package to Github | Publish Nest JS Dynamic Package to Github In this video we are publishing Nest JS Dynamic... | 0 | 2024-07-17T01:53:01 | https://dev.to/tkssharma/publish-nest-js-dynamic-package-to-github-3k1f | nestjs, package, github, node | Publish Nest JS Dynamic Package to Github
{% embed https://www.youtube.com/watch?v=YhgKijxE9Ao %}
In this video we are publishing Nest JS Dynamic Package to Github, Package contains a simple NestJS Package that gives dynamic random Numbers
 moderno que facilita a interação com bancos de dados em... | 0 | 2024-07-17T01:56:29 | https://dev.to/lemartin07/entendendo-o-fluxo-de-trabalho-do-prisma-utilizando-migrations-29cp | prisma, javascript, webdev, programming | Prisma é um ORM (Object-Relational Mapping) moderno que facilita a interação com bancos de dados em aplicações Node.js e TypeScript. Uma das funcionalidades mais importantes do Prisma é o sistema de migrações, que permite manter o esquema do banco de dados sincronizado com o modelo de dados da aplicação. Neste post, va... | lemartin07 |
1,926,080 | Spotify Premium APK Baixar Gratis Para Android 2024 | Nos dias de hoje, ouvir música faz parte do cotidiano de muitas pessoas. Com a popularização dos... | 0 | 2024-07-17T01:56:09 | https://dev.to/lestererry2/spotify-premium-apk-baixar-gratis-para-android-2024-54i4 | music, mobile, android, appconfig | Nos dias de hoje, ouvir música faz parte do cotidiano de muitas pessoas. Com a popularização dos smartphones, diversos aplicativos de streaming de música surgiram para facilitar o acesso a uma vasta biblioteca musical. Entre eles, o Spotify se destaca como um dos mais populares. Para aqueles que desejam aproveitar toda... | lestererry2 |
1,926,081 | So Easy, Even Your Grandma Could Use It (But She'd Probably Just Knit Instead) | Ever felt like writing an API is like solving a Rubik’s cube with your eyes closed? Same here, until... | 0 | 2024-07-17T01:59:47 | https://dev.to/themuneebh/so-easy-even-your-grandma-could-use-it-but-shed-probably-just-knit-instead-2701 | softwareengineering, fastapi | Ever felt like writing an API is like solving a Rubik’s cube with your eyes closed? Same here, until I discovered FastAPI. I mean, who enjoys all that endless configuration and boilerplate nonsense? But then FastAPI came along and made me wonder why I ever bothered with anything else.
The first time I created a comple... | themuneebh |
1,926,082 | Suspicious Maintainer Unveils Threads of npm Supply Chain Attack | This story starts when Sébastien Lorber, maintainer of Docusaurus, the React-based open-source documentation project, notices a Pull Request change to the package manifest. Here’s the change proposed to the popular cliui npm package: | 0 | 2024-07-17T02:00:26 | https://snyk.io/blog/threads-of-npm-supply-chain-attack/ | engineering, vulnerabilityinsights, javascript, node | This story starts when [Sébastien Lorber](https://x.com/sebastienlorber), maintainer of Docusaurus, the React-based open-source documentation project, notices a Pull Request change to the package manifest. Here’s the change proposed to the popular [cliui](https://github.com/yargs/cliui?tab=readme-ov-file) npm package:
... | snyk_sec |
1,926,085 | Effective Methods to Increase Online Traffic to Your Site | Hey there! If you're like most website owners and digital marketers, you're probably always on the... | 0 | 2024-07-17T02:09:00 | https://dev.to/juddiy/effective-methods-to-increase-online-traffic-to-your-site-2hn4 | website, learning, marketing | Hey there! If you're like most website owners and digital marketers, you're probably always on the lookout for ways to boost your site’s traffic. Whether you’re launching a new blog, running an e-commerce store, or managing a corporate site, getting more visitors is always a top priority. Let’s dive into some tried-and... | juddiy |
1,926,096 | How to Save and Load Data in Flutter Using SharedPreferences | Managing data in mobile applications is crucial for providing a seamless user experience. One of the... | 0 | 2024-07-17T02:19:30 | https://dev.to/design_dev_4494d7953431b6/how-to-save-and-load-data-in-flutter-using-sharedpreferences-5f9n | flutter, dart, data, sharedpreferences | Managing data in mobile applications is crucial for providing a seamless user experience. One of the simplest ways to store data in Flutter is by using the shared_preferences package. This package allows you to save and retrieve data in a key-value pair format, making it perfect for storing simple data like user prefer... | design_dev_4494d7953431b6 |
1,926,116 | The Minimum Valuable Product Architecture Death Trap | I like to say that there are two kinds of developers, those who deal with legacy code, and those that... | 0 | 2024-07-17T02:47:30 | https://dev.to/zelcion/the-mvp-architecture-death-trap-23m1 | architecture, beginners | I like to say that there are two kinds of developers, those who deal with legacy code, and those that create it, and we're often times, both. Of course we don't want to be the ones creating legacy code, but how do we prevent code from becoming outdated, or unmaintainable?
In my opinion, the answers lies in how you cho... | zelcion |
1,926,130 | 10 Best Practices for Optimizing Angular Performance | Optimizing the performance of your Angular application is crucial for providing a smooth user... | 0 | 2024-07-17T02:22:02 | https://dev.to/dipakahirav/10-best-practices-for-optimizing-angular-performance-2345 | angular, webdev, javascript, productivity | Optimizing the performance of your Angular application is crucial for providing a smooth user experience. Here are 10 best practices to help you get the most out of your Angular apps.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
) to support my channel and get m... | dipakahirav |
1,926,131 | Ruby on Rails pluck method | ActiveRecord is an important part of Ruby on Rails (the M in MVC) and is an Object Relational Mapping... | 0 | 2024-07-17T12:30:00 | https://anthonygharvey.com/ruby-on-rails-pluck-method | ruby, rails, beginners | ActiveRecord is an important part of Ruby on Rails ([the M in MVC](https://guides.rubyonrails.org/active_record_basics.html#what-is-active-record-questionmark)) and is an Object Relational Mapping system (ORM) that maps the objects in your app to tables in your database. By using ActiveRecord (or any ORM) the attribute... | anthonyharvey |
1,926,132 | Highly Recommended 'Quick Start with Rust' Course | The article is about the "Quick Start with Rust" course, which is highly recommended for those looking to dive into the world of Rust programming. The course provides a comprehensive introduction to the Rust language, covering essential topics such as installation, syntax, core concepts, and practical application throu... | 27,674 | 2024-07-17T02:29:56 | https://dev.to/labex/highly-recommended-quick-start-with-rust-course-jao | labex, programming, course, linux |
Rust is a powerful and versatile programming language that has gained significant popularity in recent years, particularly in the realm of systems programming, web development, and beyond. If you're looking to dive into the world of Rust and kickstart your journey as a Rust developer, the [Quick Start with Rust course... | labby |
1,926,133 | Turning Documentation into a Product: Best Practices for Success | Explore best practices for turning documentation into a successful product with real-world insights. Elevate your docs by learning from industry experts! | 25,852 | 2024-07-17T02:36:59 | https://codingcat.dev/podcast/turning-documentation-into-a-product-best-practices-for-success | webdev, javascript, beginners, podcast |
Original: https://codingcat.dev/podcast/turning-documentation-into-a-product-best-practices-for-success
{% youtube https://youtu.be/5XP0uwMFP20 %}
## Introduction and Tech-Related Banter
* **Technical Setup Issues**: The video begins with the host experiencing some technical difficulties related to the pre-roll vid... | codercatdev |
1,926,135 | Ubat Buasir Untuk Ibu Mengandung | Ubat Buasir untuk Ibu Mengandung: Panduan dan Pertimbangan Buasir, atau hemoroid, adalah masalah... | 0 | 2024-07-17T02:37:59 | https://dev.to/indah_indri_a299aff67faef/ubat-buasir-untuk-ibu-mengandung-3c0c |

**Ubat Buasir untuk Ibu Mengandung: Panduan dan Pertimbangan**
Buasir, atau hemoroid, adalah masalah umum yang boleh dialami oleh sesetengah wanita semasa kehamilan. Ini berlaku apabila urat di dalam dubur atau se... | indah_indri_a299aff67faef | |
1,926,136 | Upgrading badly with AI | A Linux user’s anecdote about updating Linux Mint 20 Una to Linux Mint 21 Vera using advice from the AI search tool Perplexity | 0 | 2024-07-17T10:00:00 | https://dev.to/strivenword/upgrading-badly-with-ai-45m4 | linux, ai, llm, upgrading | ---
title: Upgrading badly with AI
published: true
description: A Linux user’s anecdote about updating Linux Mint 20 Una to Linux Mint 21 Vera using advice from the AI search tool Perplexity
tags: [linux, ai, llm, upgrading]
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/mp7quvoclizu53lz4dch.jpg
... | strivenword |
1,926,137 | Tracking Health with Data Engineering - Chapter 1: Meal Optimization | Introduction Hello, everyone! This will be my first post so be harsh with me, critique me... | 0 | 2024-07-17T10:13:14 | https://dev.to/wilyanse/tracking-health-with-data-engineering-chapter-1-meal-optimization-2cl7 | datascience, dataengineering, python | # Introduction
Hello, everyone! This will be my first post so be harsh with me, critique me where you think I can improve on and I will surely take it into account next time.
For the past few months, I have been deeply into health, mainly exercising and watching what I eat, and now that I think I've got a solid grasp ... | wilyanse |
1,926,138 | React is not hard - React from 0 to expert | Hi! 👋 I'm Juan, I have more than 6 years of experience working with React, and I think it's not that... | 0 | 2024-07-17T02:49:03 | https://dev.to/juanemilio31323/react-is-not-hard-react-from-0-to-expert-2ge | frontend, react, backend, webdev | Hi! 👋 I'm Juan, I have more than 6 years of experience working with React, and I think it's not that hard. For that reason, I've decided to create a series that will teach you React from 0, and if you already know React, it will help you go to the next level. We'll talk about really basic things in depth and really ad... | juanemilio31323 |
1,926,139 | Best Digital Marketing Institute In Sikandrabad: Just Digital Duniya | Discover the Best Digital Marketing Institute in Sikandrabad for comprehensive training and industry... | 0 | 2024-07-17T02:49:21 | https://dev.to/rihankhan02/best-digital-marketing-institute-in-sikandrabad-just-digital-duniya-hii | webdev, javascript | Discover the Best Digital Marketing Institute in Sikandrabad for comprehensive training and industry insights. Our expert instructors provide hands-on experience in SEO, SEM, social media, and analytics, equipping you with essential skills for today's digital landscape. Join our supportive community and gain practical ... | rihankhan02 |
1,926,140 | gambling | Hi, recommend a site for the game ? | 0 | 2024-07-17T02:50:54 | https://dev.to/rixy/gambling-9n1 | Hi, recommend a site for the game ? | rixy | |
1,926,141 | Buy verified BYBIT account | https://dmhelpshop.com/product/buy-verified-bybit-account/ Buy verified BYBIT account In the... | 0 | 2024-07-17T02:54:56 | https://dev.to/nadah10995/buy-verified-bybit-account-1e5l | webdev, javascript, beginners, programming | https://dmhelpshop.com/product/buy-verified-bybit-account/

Buy verified BYBIT account
In the evolving landscape of cryptocurrency trading, the role of a dependable and protected platform cannot be overstated. Byb... | nadah10995 |
1,926,142 | 🔒 Essential Node.js Security Best Practices | Securing your Node.js applications is crucial to protecting your data and ensuring the integrity of... | 0 | 2024-07-17T02:58:26 | https://dev.to/dipakahirav/essential-nodejs-security-best-practices-2mh8 | node, npm, webdev, javascript | Securing your Node.js applications is crucial to protecting your data and ensuring the integrity of your services. Here are some essential best practices to help you enhance the security of your Node.js applications.
please subscribe to my [YouTube channel](https://www.youtube.com/@DevDivewithDipak?sub_confirmation=1
... | dipakahirav |
1,926,873 | Wearable technology | Introduction to Wearable Technology Wearable technology has revolutionized the way we interact with... | 0 | 2024-07-17T15:17:14 | https://dev.to/techabi/wearable-technology-4523 | **Introduction to Wearable Technology**
[Wearable technology](https://techabi.online/wearable-technology-healthcare-smartwatch-fitness/) has revolutionized the way we interact with our world. From fitness trackers to smartwatches, these innovative devices offer convenience, connectivity, and valuable health insights ri... | techabi | |
1,926,143 | Best Social Seeding Service – comment-marketing.com | Today, social seeding on platforms is a highly effective way to promote products. With huge user... | 0 | 2024-07-17T02:58:27 | https://dev.to/jagger_chi/best-social-seeding-service-comment-marketingcom-35pm | socialmedia, socialseeding, marketing, commentmarketing | Today, social seeding on platforms is a highly effective way to promote products. With huge user bases and traffic, you can gain significant benefits and quickly increase brand awareness. Comment marketing, known for its low cost, no ad fees, precise targeting, high conversion rates, and SEO optimization, stands out am... | jagger_chi |
1,926,144 | #27 — Group and Summarize A Table Where Every N Rows Consists of A Range by Column | Problem description & analysis: Below is an Excel table. Every two rows form a range; and in... | 0 | 2024-07-17T03:00:41 | https://dev.to/judith677/27-group-and-summarize-a-table-where-every-n-rows-consists-of-a-range-by-column-3863 | beginners, programming, tutorial, productivity | **Problem description & analysis**:
Below is an Excel table. Every two rows form a range; and in each range, each pair of cells up and down is regarded as a piece of data that stores client and working hours that can be empty.
\n\n\n\nBuy GitHub Accounts\nGitHub, a renowned platform for hosting and collaborating on code, is essential for developers at all levels. With millions of projects worldwide, having a GitHub account is a valuable asset for seasoned programmers and beginners alike. However, the process of creating and managing an account can be complex and time-consuming for some.\n\nThis is where purchasing GitHub accounts becomes advantageous. By buying a GitHub account, individuals can streamline their development journey and access the numerous benefits of the platform efficiently. Whether you are looking to enhance your coding skills or expand your project collaborations, a purchased GitHub account can be a practical solution for optimizing your coding experience.\n\nWhat is GitHub Accounts\nGitHub accounts serve as user profiles on the renowned code hosting platform GitHub, where developers collaborate, track code changes, and manage version control seamlessly. Creating a GitHub account provides users with a platform to exhibit their projects, contribute to diverse endeavors, and engage with the GitHub community. Buy verified BYBIT account\n\nYour GitHub account stands as your virtual identity on the platform, capturing all your interactions, contributions, and project involvement. Embrace the power of GitHub accounts to foster connections, showcase your skills, and enhance your presence in the dynamic world of software development. Buy GitHub Accounts.\n\nCan You Buy GitHub Accounts?\n Rest assured when considering our buy GitHub Accounts service, as we distinguish ourselves from other PVA Account providers by offering 100% Non-Drop PVA Accounts, Permanent PVA Accounts, and Legitimate PVA Accounts. Our dedicated team ensures instant commencement of work upon order placement, guaranteeing a seamless experience for you. Embrace our service without hesitation and revel in its benefits.\n\nGitHub stands as the largest global code repository, playing a pivotal role in the coding world, especially for developers. It serves as the primary hub for exchanging code and engaging in collaborative projects.\n\nHowever, if you find yourself without a GitHub account, you may be missing out on valuable opportunities to share your code, learn from others, and contribute to open-source projects. A GitHub account not only allows you to showcase your coding skills but also enhances your professional network and exposure within the developer community.\n\nAccess To Premium Features\nUnlock a realm of possibilities and boost your productivity by harnessing the full power of Github’s premium features. Enjoy an array of benefits by investing in Github accounts, consolidating access to premium tools under a single subscription and saving costs compared to individual purchases. Buy GitHub Accounts.\n\nCultivating a thriving Github profile demands dedication and perseverance, involving continuous code contributions, active collaboration with peers, and diligent repository management. Elevate your development journey by embracing these premium features and optimizing your workflow for success on Github.\n\nGitHub private repository limits\nFor those of you who actively develop and utilize GitHub for managing your personal coding projects, consider the storage limitations that may impact your workflow. GitHub’s free accounts, which currently allow for up to three personal repositories, may prove stifling if your coding demands surpass this threshold. In such cases, upgrading to a dedicated buy GitHub account emerges as a viable remedy.\n\nTransitioning to a paid GitHub account not only increases repository limits but also grants a myriad of advantages, including unlimited collaborators access, as well as premium functionalities like GitHub Pages and GitHub Actions. Thus, if your involvement in personal projects confronts space constraints, transitioning to a paid account can seamlessly accommodate your expanding requirements.\n\nGitHub Organization Account\nWhen managing a team of developers, leveraging a GitHub organization account proves invaluable. This account enables the creation of a unified workspace where team members can seamlessly collaborate on code, offering exclusive features beyond personal accounts like the ability to edit someone else’s repository. Buy GitHub Accounts.\n\nEstablishing an organization account is easily achieved by visiting github.com and selecting the “Create an organization” option, wherein you define a name and configure basic settings. Once set up, you can promptly add team members and kickstart collaborative project work efficiently.\n\nTypes Of GitHub Accounts\nInvesting in a GitHub account (PVA) offers access to exclusive services typically reserved for established accounts, such as beta testing programs, early access to features, and participation in special GitHub initiatives, broadening your range of functionality.\n\nBy purchasing a GitHub account, you contribute to a more secure and reliable environment on the GitHub platform. A bought GitHub account (PVA) allows for swift account recovery solutions in case of account-related problems or unexpected events, guaranteeing prompt access restoration to minimize any disruptions to your workflow.\n\nAs a developer utilizing GitHub to handle your code repositories for personal projects, the matter of personal storage limits may be of significance to you. Presently, GitHub’s complimentary accounts are constrained to three personal repositories. Buy GitHub Accounts.\n\nShould your requirements surpass this restriction, transitioning to a dedicated GitHub account stands as the remedy. Apart from elevated repository limits, upgraded GitHub accounts provide numerous advantages, including access to unlimited collaborators and premium functionalities like GitHub Pages and GitHub Actions.\n\nThis ensures that if your undertakings encompass personal projects and you find yourself approaching storage boundaries, you have viable options to effectively manage and expand your development endeavors. Buy GitHub Accounts.\n\nWhy are GitHub accounts important?\nGitHub accounts serve as a crucial tool for anyone seeking to establish a presence in the tech industry. Regardless of your experience level, possessing a GitHub account equates to owning a professional online portfolio that highlights your skills and ventures to potential employers or collaborators.\n\nThrough GitHub, individuals can exhibit their coding proficiency and projects, fostering the display of expertise in multiple programming languages and technologies. This not only aids in establishing credibility as a developer but also enables prospective employers to evaluate your capabilities and suitability for their team effectively. Buy GitHub Accounts.\n\nBy maintaining an active GitHub account, you can effectively demonstrate a profound dedication to your field of expertise. Employers are profoundly impressed by individuals who exhibit a robust GitHub profile, as it signifies a genuine enthusiasm for coding and a willingness to devote significant time and energy to refining their abilities.\n\nThrough consistent project sharing and involvement in open source projects, you have the opportunity to showcase your unwavering commitment to enhancing your capabilities and fostering a constructive influence within the technology community. Buy GitHub Accounts.\n\nConclusion\nFor developers utilizing GitHub to host their code repositories, exploring ways to leverage coding skills for monetization may lead to questions about selling buy GitHub accounts, a practice that is indeed permissible. However, it is crucial to be mindful of pertinent details before proceeding. Buy GitHub Accounts.\n\nNotably, GitHub provides two distinct account types: personal and organizational. Personal accounts offer free access with genuine public storage, in contrast to organizational accounts. Before delving into selling a GitHub account, understanding these distinctions is essential for effective decision-making and navigating the platform’s diverse features.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | nadah10995 |
1,926,146 | Persistent storage on Heroku | Hi All. Heroku seems like a popular PaaS(compared to Google App Engine or AWS Elastic Beanstalk) for... | 0 | 2024-07-17T03:06:38 | https://dev.to/vgtom/persistent-storage-on-heroku-2g78 | Hi All.
Heroku seems like a popular PaaS(compared to Google App Engine or AWS Elastic Beanstalk) for hosting my micro-saas backend.
Now What kind of persistent storage can i use that is affordable?
I dont want to use a database like Postgres or MongoDB but want something that looks like a filesystem.
Between AWS S3... | vgtom | |
1,926,148 | Discover NBA YoungBoy Merch on Newspicks! | Follow NBA YoungBoy Merch on Newspicks for curated articles and updates. Stay informed about the... | 0 | 2024-07-17T03:14:17 | https://dev.to/nbayoungboymerchshop1/discover-nba-youngboy-merch-on-newspicks-5e09 | nbayoungboymerch, newspicks | Follow NBA YoungBoy Merch on Newspicks for curated articles and updates. Stay informed about the latest trends, releases, and news in the merch world. Newspicks is your source for well-rounded and in-depth coverage of NBA YoungBoy's merchandise.
https://newspicks.com/user/10465349
 | When developing a Node.js application using Express.js, structuring your codebase effectively is... | 0 | 2024-07-17T03:18:01 | https://dev.to/vyan/how-to-structure-your-backend-code-in-nodejs-expressjs-2bdd | webdev, javascript, beginners, programming | When developing a Node.js application using Express.js, structuring your codebase effectively is crucial for maintainability, scalability, and ease of collaboration. A well-organized project structure allows you to manage complexity, making it easier to navigate and understand the code. In this blog, we'll explore a ty... | vyan |
1,926,154 | Security Meetup | Thank you to all the security researchers who participated in the 100-day country ranking... | 0 | 2024-07-17T03:21:48 | https://dev.to/tecno-security/security-meetup-4d75 | cybersecurity, security, bounty | Thank you to all the security researchers who participated in the 100-day country ranking vulnerability campaign!
The countries that finally got the security meetup quota are India, Bangladesh, and Vietnam! The specific data of personal and national rankings are as follows.
The application channel is open, come and... | tecno-security |
1,926,155 | Good news is here! 🎉🎉🎉Use Artipub to automatically publish the article to more platforms | ArtiPub (article release assistant) is a tool library aimed at simplifying content creators to... | 0 | 2024-07-17T03:36:54 | https://dev.to/yxw007/good-news-is-here-use-artipub-to-automatically-publish-the-article-to-more-platforms-2abo | ArtiPub (article release assistant) is a tool library aimed at simplifying content creators to publish the article process.It provides a simple API that allows you to easily publish the article to any platforms, such as blogs, social media, etc., without manual operation of each platform. [artipub](https://pup007.githu... | yxw007 | |
1,926,156 | Matplotlib in Flask Web Application Server | This tutorial lab will guide you through using Matplotlib in a Flask web application server. You will learn how to create figures using the .Figure constructor and save them to in-memory buffers, embed the resulting figures in HTML output, and run the Flask application using the flask command-line tool. | 27,678 | 2024-07-17T03:24:47 | https://dev.to/labex/matplotlib-in-flask-web-application-server-2okj | labex, python, coding, programming |
## Introduction
This article covers the following tech skills:
This tutorial lab will guide you through using Matplotlib in a Flask web application server. You will learn how to create figures using the `.Figure` constructor and ... | labby |
1,926,157 | Kubernetes -Services, Ingress, and ConfigurationsDay 9 of 50 days DevOps Tools Series | Introduction Welcome to Day 9 of our 50 Days DevOps Tools series. Over the past two days,... | 0 | 2024-07-17T12:59:30 | https://dev.to/shivam_agnihotri/kubernetes-services-ingress-and-configurationsday-9-of-50-days-devops-tools-series-95b | kubernetes, devops, development, containers | ## **Introduction**
Welcome to Day 9 of our 50 Days DevOps Tools series. Over the past two days, we have covered the fundamental and advanced concepts of Kubernetes, including its architecture, basic commands, Deployments, StatefulSets, and persistent storage. Today, we will delve into more advanced Kubernetes concept... | shivam_agnihotri |
1,926,158 | Choosing the Right GE RPWFE Water Filter for Your Needs | Introduction Water quality is paramount in maintaining a healthy lifestyle, and selecting the right... | 0 | 2024-07-17T03:28:43 | https://dev.to/sp_mubashir_9ec27acedc04d/choosing-the-right-ge-rpwfe-water-filter-for-your-needs-3g15 |
Introduction
Water quality is paramount in maintaining a healthy lifestyle, and selecting the right water filter is crucial to ensure your water is clean and safe. The GE RPWFE water filter GE RPWFE water filter is ... | sp_mubashir_9ec27acedc04d | |
1,926,162 | Ubat Buasir Terbaik | Ubat Kecut Buasir dalam Masa 3 Hari: Panduan Rawatan Cepat dan Berkesan Apakah Buasir? Buasir adalah... | 0 | 2024-07-17T03:43:46 | https://dev.to/indah_indri_a299aff67faef/ubat-buasir-terbaik-5818 |

**Ubat Kecut Buasir dalam Masa 3 Hari: Panduan Rawatan Cepat dan Berkesan
Apakah Buasir?**
Buasir adalah pembengkakan atau keradangan pada saluran darah di sekitar dubur atau rektum bawah. Ia boleh menyebabkan keti... | indah_indri_a299aff67faef | |
1,926,163 | Build Nextjs 15 & React 19 Dashboard App Step By Step | Hello and welcome to my coding course to build a full-fledged admin dashboard by the best tech stack... | 0 | 2024-07-17T03:47:00 | https://dev.to/basir/nextjs-15-react-19-dashboard-app-step-by-step-4l2n | nextjs, postgres, tailwindcss, drizzle | Hello and welcome to my coding course to build a full-fledged admin dashboard by the best tech stack in the world: Nextjs 15, React 19, Drizzle Orm, and Shadcn UI.
👉 Code : https://github.com/basir/next-15-admin-dashboard
👉 Demo : https://next-15-admin-dashboard.vercel.app
👉 Q/A : https://github.com/basir/next-... | basir |
1,926,165 | How to Become an AI Prompt Engineer? | The Artificial Intelligence realm has witnessed massive growth in recent years. The immense... | 0 | 2024-07-17T04:00:24 | https://dev.to/georgiaweston/how-to-become-an-ai-prompt-engineer-2aeo | aiengineer, promptengineering, ai, tutorial | The Artificial Intelligence realm has witnessed massive growth in recent years. The immense popularity of AI has automatically boosted the field of prompt engineering. This is because prompt engineering lies at the very core of AI systems and improves their performance. In current times professionals are keen to develo... | georgiaweston |
1,926,166 | Supercharge Your Development Workflow with CloudBlast's Incredibly Affordable Hourly VPS | Hey fellow devs! 👋 Today, let's talk about a game-changer in the world of VPS hosting: CloudBlast.... | 0 | 2024-07-17T04:01:16 | https://dev.to/cloudblast/supercharge-your-development-workflow-with-cloudblasts-incredibly-affordable-hourly-vps-ag8 | cloud, serverless, aws, webdev |
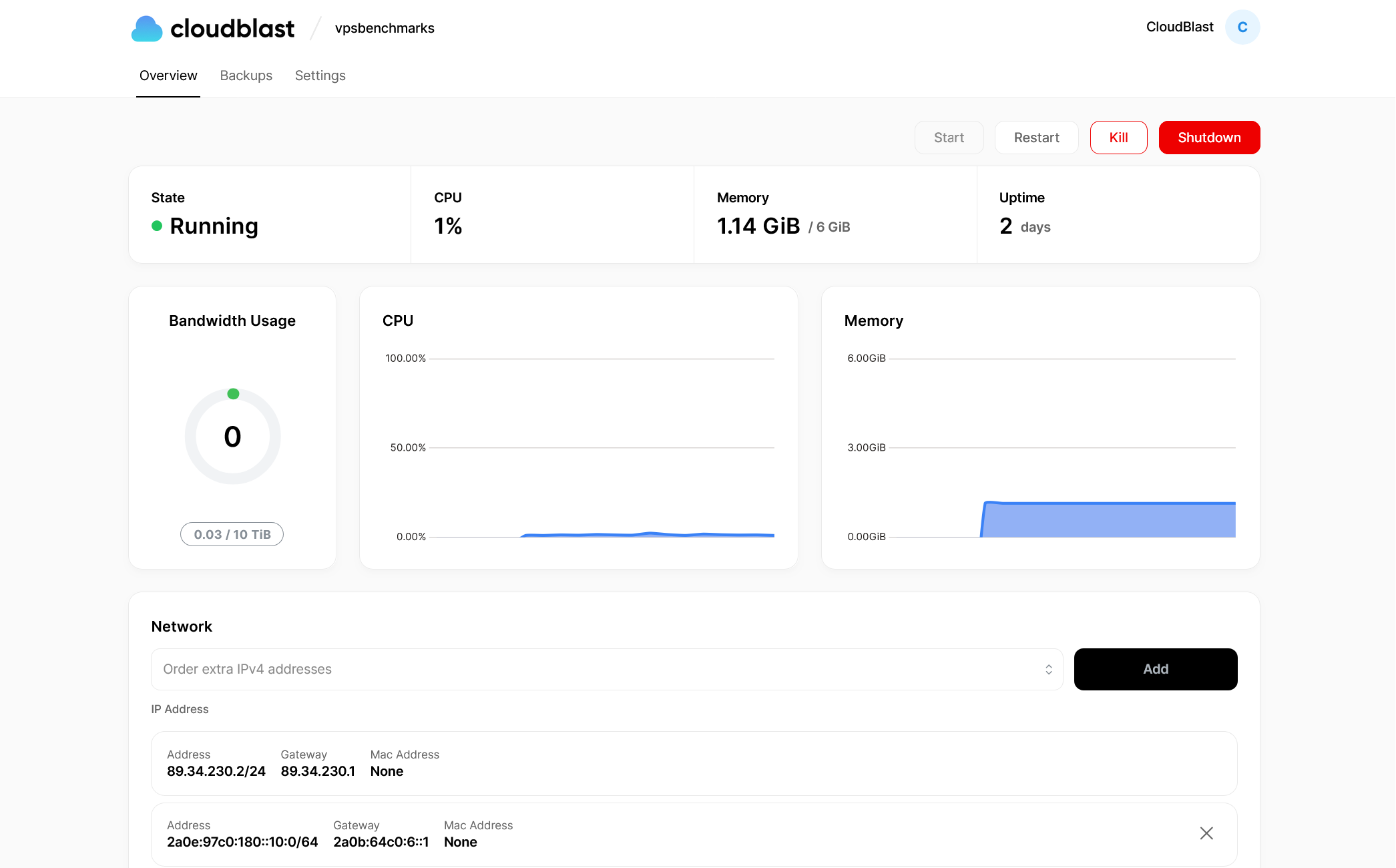
Hey fellow devs! 👋 Today, let's talk about a game-changer in the world of VPS hosting: CloudBlast. If you're tired of overpaying for resources you don't always need or struggling with inflexible deployment options... | cloudblast |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.