
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,925,679 | What are Azure's Deployment Models? | Firstly, Let's find out Azure's deployment models, Then we will discuss The Cons and Pros of each... | 28,043 | 2024-07-16T16:02:06 | https://dev.to/1hamzabek/what-are-azures-deployment-models-21if | cloud, azure, microsoft | Firstly, Let's find out Azure's deployment models, Then we will discuss The Cons and Pros of each cloud type.
---------
1.**Public Cloud** : built on the cloud provider also known as : Cloud-Native.
You don't have to use any external tools.

We will start by learning how to structure your code. This is a natural language programming language, but you have to follow some rules.
First are the f... | ingigauti |
1,925,681 | Empowering Insights: Using OEM Data with Oracle Analytics for Advanced Database Reports | Transforming Data into Actionable Insights Creating comprehensive database reports is... | 28,094 | 2024-07-17T15:22:36 | https://dev.to/abthelhaks/empowering-insights-using-oem-data-with-oracle-analytics-for-advanced-database-reports-34l2 | oracle, datavisualization, oem, oracleanalytics | ## Transforming Data into Actionable Insights
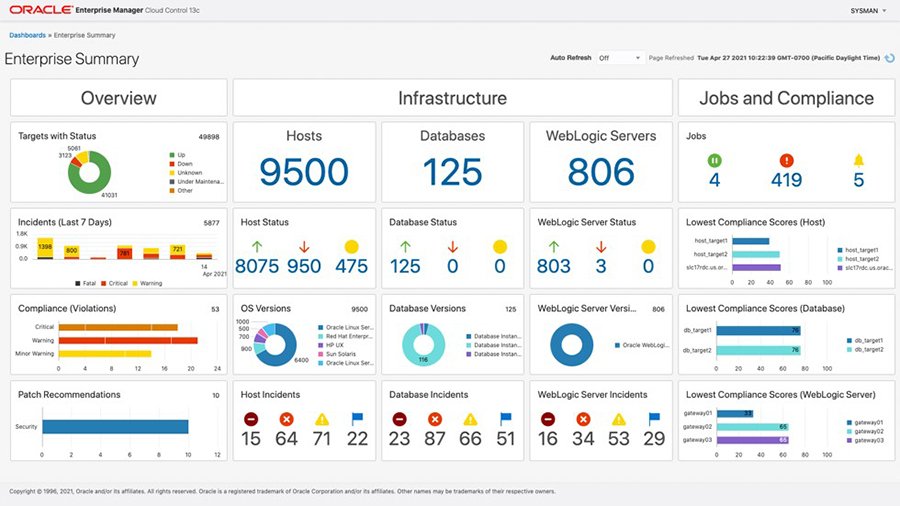
Creating comprehensive database reports is crucial for maintaining and optimizing database performance. Recently, I undertook the task of developing a series of det... | abthelhaks |
1,925,683 | Exploring the Extractive Capabilities of Large Language Models – Beyond Generation and Copilots | We have all seen the power of Large Language Models in the form of a GPT-based personal assistant... | 0 | 2024-07-16T16:29:57 | https://unstract.com/blog/extractive-capabilities-of-large-language-models/ | ai, rag, opensource, productivity | We have all seen the power of Large Language Models in the form of a GPT-based personal assistant from OpenAI called [ChatGPT](https://chatgpt.com/). You can ask questions about the world, ask for recipes, or ask it to generate a poem about a person. We have all been awestruck by the capabilities of this personal assis... | arun_venkataswamy |
1,925,684 | web or wordpress? | Is it necessary for web developers to delve into web design tools like WordPress and Figma, and can... | 0 | 2024-07-16T16:07:42 | https://dev.to/nishanth_17ebc7ae1e12e656/web-or-wordpress-4cja | wordpress, development, webdev, javascript | Is it necessary for web developers to delve into web design tools like WordPress and Figma, and can they start freelancing while learning development? Additionally, how long does it typically take to master web design and begin earning income from it? | nishanth_17ebc7ae1e12e656 |
1,925,685 | Confused on +layout.js and +layout.svelte props passed in load() function... | I have a load function in my root +layout.js file that is: export async function load() { // and all... | 0 | 2024-07-16T16:11:29 | https://dev.to/jimnayzium/confused-on-layoutjs-and-layoutsvelte-props-passed-in-load-function-dfj | sveltekit | I have a load function in my root +layout.js file that is:
`export async function load() {
// and all it returns is
return {
prop1: true,
prop2: false,
prop3: "value 3"
};
`
For the life of me, I cannot do anything in the +layout.svelte file to make these values show up.
`export let prop1;
export let prop2;
e... | jimnayzium |
1,925,686 | Help. I'm losing it. | Hello Everyone. I am Joey, and I really love Programming. It amazed me when I started 2 years ago... | 0 | 2024-07-16T16:11:32 | https://dev.to/joeydev/help-im-losing-it-24p1 | beginners, productivity, programming, help | Hello Everyone.
I am Joey, and I really love Programming. It amazed me when I started 2 years ago that I could be paid to do what I love. However there is a big problem.
I've been working the past month and a half of the summer break at a major government company here in my country and I seem to have just been l... | joeydev |
1,925,687 | Deploying A Web App To Your Own Domain - What You Might Wanna Know | Salam and hello everyone! Again, it has been a very long time back then when I wrote the last... | 0 | 2024-07-16T16:14:29 | https://dev.to/alserembani/deploying-a-web-app-to-your-own-domain-what-you-might-wanna-know-5533 | beginners, webdev | Salam and hello everyone!
Again, it has been a very long time back then when I wrote the last article. This time, just a simple and basic thing, I want to write a basic topic, on what you should know when deploying a web app (can be frontend, backend, or some sort) to your own domain.
However, before diving into the ... | alserembani |
1,925,738 | Engineer Explains: What is DevRel, and why developers should care? | For more content like this subscribe to the ShiftMag newsletter. There’s probably no better person... | 0 | 2024-07-17T13:04:28 | https://shiftmag.dev/developer-relations-explained-3757/ | video, devrel, engineerexplains, marythengvall | ---
title: Engineer Explains: What is DevRel, and why developers should care?
published: true
date: 2024-07-16 14:07:46 UTC
tags: Video,DeveloperRelations,EngineerExplains,MaryThengvall
canonical_url: https://shiftmag.dev/developer-relations-explained-3757/
---
 | Elastic Cloud Enterprise (ECE) is a significant innovation from Elastic, designed to simplify the... | 0 | 2024-07-16T16:36:50 | https://dev.to/sennovate/deep-dive-into-elastic-cloud-enterprise-ece-44g2 | cybersecurity, security, cloud, elasticsearch | Elastic Cloud Enterprise (ECE) is a significant innovation from Elastic, designed to simplify the deployment, management, and scaling of Elasticsearch clusters in various environments. ECE provides a unified, efficient platform for handling Elasticsearch clusters on-premises, in the cloud, or in hybrid setups. It offer... | sennovate |
1,925,753 | Decorator design pattern in React | Greetings, in this article we will be discussing the implementation of the decorator design pattern... | 0 | 2024-07-16T17:22:04 | https://dev.to/ihesami/decorator-design-pattern-in-react-276d | react, designpatterns, typescript, tutorial | Greetings, in this article we will be discussing the implementation of the decorator design pattern in React. The decorator design pattern involves wrapping objects and adding new functionalities to them. For instance, if you are working on a store management system within your React application, you can utilize this d... | ihesami |
1,925,754 | Emoji Favorite Icon | I would like to improve the post from CSS Tricks. In this post the author demonstrated how to use an... | 0 | 2024-07-16T17:01:52 | https://dev.to/wearypossum4770/emoji-favorite-icon-ah | I would like to improve the post from [CSS Tricks](https://css-tricks.com/emoji-as-a-favicon/). In this post the author demonstrated how to use an emoji as a favorite icon. This is a neat trick, but It doesn't feel right to me. So I will show how to convert it to a `data-uri`.
# Steps
1 Create a new file `create-data... | wearypossum4770 | |
1,925,755 | T-shirt Tuesday! | Welcome back to T-Shirt Tuesday, our weekly post inspired by the brilliant minds in our Discord... | 0 | 2024-07-16T16:50:07 | https://dev.to/buildwebcrumbs/t-shirt-tuesday-4k7o | jokes, watercooler, discuss | Welcome back to T-Shirt Tuesday, our weekly post inspired by the brilliant minds in our Discord Community.
Every week (that we don't miss the boat), we showcase fun and unique phrases that you'd love to see on a t-shirt.
This week's highlight features a piece of code spotted by @anmolbaranwal that resonates with many... | opensourcee |
1,925,756 | Building Next.js Fullstack Blog with TypeScript, Shadcn/ui, MDX, Prisma and Vercel Postgres. | A post by Coding Jitsu | 0 | 2024-07-16T16:57:25 | https://dev.to/w3tsa/building-nextjs-fullstack-blog-with-typescript-shadcnui-mdx-prisma-and-vercel-postgres-7ja | webdev, nextjs, prisma, beginners | {% youtube htgktwXYw6g %} | w3tsa |
1,925,757 | Single Page Applications (SPAs) | Understanding Single Page Applications... | 0 | 2024-07-16T17:04:55 | https://www.sh20raj.com/2024/07/single-page-applications-spas.html | spa, react, javascript, angular | # Understanding Single Page Applications (SPAs)
> https://www.sh20raj.com/2024/07/single-page-applications-spas.html
Single Page Applications (SPAs) are a significant trend in web development, reshaping the way websites are built and experienced by users. Unlike traditional multi-page websites, SPAs load a single HT... | sh20raj |
1,925,758 | Git flow that's simple, easy to manage, and generally applicable | This Git flow ensures a structured and organized development process, making it easier to manage... | 0 | 2024-07-16T17:05:01 | https://dev.to/ussdlover/git-flow-thats-simple-easy-to-manage-and-generally-applicable-10l7 | git, development, softwaredevelopment, webdev | This Git flow ensures a structured and organized development process, making it easier to manage changes, track progress, and maintain the stability of the main codebase while incorporating a dedicated branch for QA testing.
## Branching Strategy
### Main Branches
- **`main`**: This branch contains the production-rea... | ussdlover |
1,925,760 | 7 Must-Have Features for Your Denver App Development Project | In the rapidly evolving world of technology, app development has become a cornerstone for businesses... | 0 | 2024-07-16T17:09:23 | https://dev.to/john_smith_f443e9991c19e2/7-must-have-features-for-your-denver-app-development-project-3cm2 | appconfig, development, denver | In the rapidly evolving world of technology, app development has become a cornerstone for businesses aiming to stay competitive and engage with their audience effectively. Whether you’re a startup or an established [app development company in Denver](https://www.bitswits.co/mobile-app-development-company-denver), the s... | john_smith_f443e9991c19e2 |
1,925,762 | Weje | WEB3 DeFi Gaming | If (weje() == true) { sad().stop(); playPoker(); beAwesome(); } weje.com is a cutting-edge... | 0 | 2024-07-16T17:12:41 | https://dev.to/adi_shitrit_5030417793375/weje-web3-defi-gaming-ohm | blockchain, web3 | If (weje() == true) {
sad().stop();
playPoker();
beAwesome();
}
[weje.com](url) is a cutting-edge platform specializing in DeFi gaming. Offering an exciting opportunity to play poker and other games using Cryptocurrency wallets.
Join WEJE for the ultimate DeFi gaming experience with MATIC tokens. Play poker,... | adi_shitrit_5030417793375 |
1,925,764 | https://dev.to/simonholdorf/9-awesome-projects-you-can-build-with-vanilla-javascript-2o1b | A post by Dexter Nero | 0 | 2024-07-16T17:15:04 | https://dev.to/dev_nero/httpsdevtosimonholdorf9-awesome-projects-you-can-build-with-vanilla-javascript-2o1b-12ld | dev_nero | ||
1,925,765 | Python Learning | Hi all, I am beginning to the programming world. Thanks, Kaniyam to make the interest in this. | 0 | 2024-07-16T17:15:13 | https://dev.to/hri_m/python-learning-3me5 | python, programming, learning, parottasalna | Hi all,
I am beginning to the programming world. Thanks, Kaniyam to make the interest in this.
| hri_m |
1,925,766 | Recommended Course: Quick Start with Java | Embarking on your programming journey? Look no further than the Quick Start with Java course offered... | 27,853 | 2024-07-16T17:26:47 | https://dev.to/labex/recommended-course-quick-start-with-java-2p79 | labex, java, programming, course |
Embarking on your programming journey? Look no further than the [Quick Start with Java course](https://labex.io/courses/quick-start-with-java) offered by LabEx. This comprehensive course will equip you with the fundamental knowledge and practical skills to kickstart your Java development career.
 from TRM Labs shows that the amount stolen by hackers in six months is almost twice as much as last year.... | hryniv_vlad |
1,925,773 | This site is complete trash | truth nuke | 0 | 2024-07-16T17:36:33 | https://dev.to/ez3chi3l/this-site-is-complete-trash-1fji | ---
title: This site is complete trash
published: true
description: truth nuke
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-07-16 17:35 +0000
---
This place sucks. | ez3chi3l | |
1,925,774 | The Future of Full-Stack Development in 2024: Trends and Best Practices | Full-stack development continues to be a crucial skill for developers, offering a versatile approach... | 0 | 2024-07-16T17:40:17 | https://dev.to/matin_mollapur/the-future-of-full-stack-development-in-2024-trends-and-best-practices-2736 | webdev, javascript, beginners, programming | Full-stack development continues to be a crucial skill for developers, offering a versatile approach to building comprehensive web applications. Understanding the latest trends and best practices is essential for staying ahead in this dynamic field. Here’s a look at what’s shaping the future of full-stack development.
... | matin_mollapur |
1,925,775 | How can I find an expert for black magic removal? | Introduction: Finding an expert for black magic removal can be a daunting task, given the sensitive... | 0 | 2024-07-16T17:41:28 | https://dev.to/astrologerrishi_84f4cf27d/how-can-i-find-an-expert-for-black-magic-removal-1g2i | Introduction:
Finding an expert for black magic removal can be a daunting task, given the sensitive and often misunderstood nature of this subject. However, with the right approach, you can locate a qualified and trustworthy professional who can help you remove any negative influences from your life. Here’s a comprehe... | astrologerrishi_84f4cf27d | |
1,925,776 | I built a random number generator using Quantum Computing | If you have a basic understanding of quantum computing, you might have heard about principles like... | 0 | 2024-07-16T17:41:42 | https://dev.to/ghostfreak-077/i-built-a-random-number-generator-using-quantum-computing-1pem | If you have a basic understanding of quantum computing, you might have heard about principles like quantum superposition. Where, e.g. a qubit (a bit with quantum superpowers) coexists in multiple states until it's measured. Once it's measured, its superposition property vanishes to give us either of the corresponding c... | ghostfreak-077 | |
1,925,777 | Buy Verified Paxful Account | https://gmusashop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account If you are... | 0 | 2024-07-16T17:44:42 | https://dev.to/fimiris640/buy-verified-paxful-account-5cno | webdev, javascript, beginners, programming | https://gmusashop.com/product/buy-verified-paxful-account/

Buy Verified Paxful Account
If you are considering purchasing a verified Paxful account, we are here to assist you. Our services encompass a diverse range... | fimiris640 |
1,925,778 | Understanding DevOps: A Bridge Between Development and Operations | DevOps is understood as a cultural shift and a set of practices that aim to improve collaboration and... | 0 | 2024-07-16T17:44:57 | https://dev.to/imperatoroz/understanding-devops-a-bridge-between-development-and-operations-577 | devops | **DevOps** is understood as a cultural shift and a set of practices that aim to improve collaboration and communication between software development (Dev) and IT operations (Ops) teams.
Traditionally, these teams worked in silos, leading to inefficiencies, slow release cycles, and finger-pointing when issues arose.
In... | imperatoroz |
1,925,779 | substitution1 in picoCTF | Hi Guys , this is my first blog .this blog i showed up ctf challage in picoctf.this challange name is... | 0 | 2024-07-16T17:45:08 | https://dev.to/redhacker_6e44e465fc1a08c/substitution1-in-picoctf-2opp | Hi Guys , this is my first blog .this blog i showed up ctf challage in picoctf.this challange name is substitution1 in forensics category.
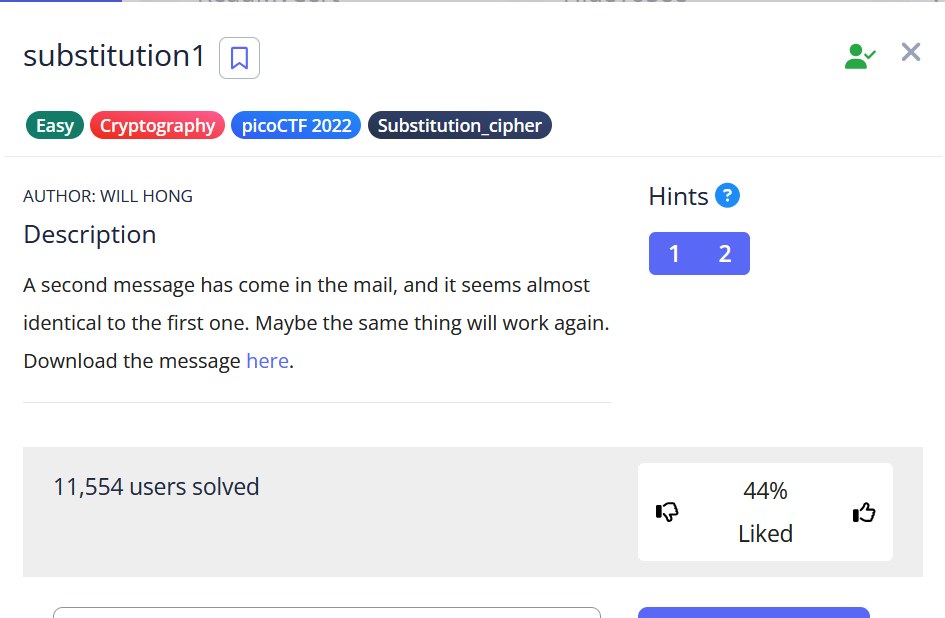.
we know that.this is substitution cipher .go to this website [url](https://... | redhacker_6e44e465fc1a08c | |
1,925,780 | Implementing File Input By Copy-Paste on the Web | In the sphere of web development, there are multiple ways to upload files when collecting user input.... | 0 | 2024-07-17T11:54:04 | https://dev.to/ghostaram/implementing-file-input-by-copy-paste-on-the-web-npb | webdev, frontend, javascript | In the sphere of web development, there are multiple ways to upload files when collecting user input. One of the methods is copy-paste. Copy-paste for file input is a very intuitive method of uploading files from users. Copy-paste file input method relieves users of the need to memorize the location of the file they wa... | ghostaram |
1,925,781 | Symmetric and Asymmetric Cryptography | Symmetric and Asymmetric Cryptography 'Cryptography' is literally the study of hiding... | 0 | 2024-07-16T17:46:56 | https://dev.to/martcpp/symmetric-and-asymmetric-cryptography-40b8 | solana, rust, web3, cryptography | ## Symmetric and Asymmetric Cryptography
**_'Cryptography'_** is literally the study of hiding information. There are two main types of cryptography you'll encounter day to day:
**Symmetric Cryptography** is where the same key is used to encrypt and decrypt. It's hundreds of years old and has been used by everyone fr... | martcpp |
1,925,782 | Best Dog Food for German Shepherds | Choosing the right dog food for your German Shepherd is crucial for their health, energy levels, and... | 0 | 2024-07-16T17:49:23 | https://dev.to/abubakr/best-dog-food-for-german-shepherds-1kf1 | learning, beginners, webdev | Choosing the [right dog food for your German Shepherd](https://bestinfotips.com/best-dog-food-for-german-shepherds-with-sensitive-stomachs/
) is crucial for their health, energy levels, and overall well-being. German Shepherds are large, active dogs with unique dietary needs, so it's important to select a food that sup... | abubakr |
1,925,783 | Symbols in Ruby: A deep dive | Introduction How's it going, guys? We've all used Symbols in ruby in various situations,... | 0 | 2024-07-16T17:49:57 | https://dev.to/alexandrecalaca/symbols-in-ruby-a-deep-dive-5f6g | ruby, programming, development, rails | ## Introduction
How's it going, guys?
We've all used Symbols in ruby in various situations, especially with hashes.
In this article, my goal is to share some of what I have studied. Feel free to drop your comments.
---
## Symbols
### Unique Integer Identifier
In Ruby, a symbol is represented internally as a numbe... | alexandrecalaca |
1,925,784 | Video Codecs | Video codecs work behind the scenes to stream video over the Internet. However, the choice of codec... | 0 | 2024-07-16T17:50:39 | https://getstream.io/glossary/video-codecs/ | videocodecs, videoapi, videostream | Video codecs work behind the scenes to stream video over the Internet. However, the choice of codec can affect things like resolution and video quality.
Read on to learn more about video codecs, including how they work, the different types available, and how to choose the right one.
## What is a Video Codec?
A video... | emilyrobertsatstream |
1,925,786 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-07-16T17:51:20 | https://dev.to/crazy_live47/my-pen-on-codepen-388e | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Piyush-Raj-the-solid/pen/OJeydGV %} | crazy_live47 |
1,925,787 | Task-3 Qsn 10 | Write a program that asks the user to enter a password. If the password is correct, print... | 0 | 2024-07-16T17:51:27 | https://dev.to/perumal_s_9a6d79a633d63d4/task-3-l80 | #Write a program that asks the user to enter a password. If the password is correct, print “Access granted”; otherwise, print “Access denied”.
#Ans
save_password=input("save your password")
a=input("enter your password :")
if a==save_password:
print("access granted")
else:
print("access denied") | perumal_s_9a6d79a633d63d4 | |
1,925,788 | Buy verified cash app account | https://gmusashop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash app... | 0 | 2024-07-16T17:53:24 | https://dev.to/fimiris640/buy-verified-cash-app-account-2gcm | tutorial, react, python, ai | ERROR: type should be string, got "https://gmusashop.com/product/buy-verified-cash-app-account/\n\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoinenablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy gmusashop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\n\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nBuy verified cash app account\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\n \n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nHow cash used for international transaction?\n\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\n\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram: @gmusashop\nWhatsApp: +1 (385)237-5318\nEmail: gmusashop@gamil.com" | fimiris640 |
1,925,789 | Task 3 Qsn-9 | Create a program that calculates simple interest. Take the principal amount, rate of... | 0 | 2024-07-16T17:53:47 | https://dev.to/perumal_s_9a6d79a633d63d4/task-3-qsn-9-20bd | #Create a program that calculates simple interest. Take the principal amount, rate of interest, and time period as input.
#Ans
a=float(input("enter your total loan amount :"))
b=float(input("total months :"))
if (b>=1):
d=(b*(a*0.02))
result=(a+d)
print("your total paid amount",result)
print("intrest a... | perumal_s_9a6d79a633d63d4 | |
1,925,792 | Exploring Option Getters in Effect-TS | Effect-TS provides a robust set of tools for handling Option types, which represent values that may... | 0 | 2024-07-16T17:55:06 | https://dev.to/almaclaine/exploring-option-getters-in-effect-ts-4m0n | typescript, javascript, functional, effect | Effect-TS provides a robust set of tools for handling Option types, which represent values that may or may not exist. In this article, we'll explore various ways to get the value inside an Option using different getters provided by the library.
## Example 1: Using `O.getOrElse`
The `O.getOrElse` function allows you t... | almaclaine |
1,925,793 | Task 3 Qsn-7 | Create a program that takes a person’s age as input and checks if they are eligible to vote... | 0 | 2024-07-16T17:55:31 | https://dev.to/perumal_s_9a6d79a633d63d4/task-3-qsn-7-37e5 | #Create a program that takes a person’s age as input and checks if they are eligible to vote (age 18 or older).
#Ans
Name=input("enter your name:")
age=int(input("enter your age:"))
if age>=18:
print("you are eligible to vote")
else:
print("you are not eligible for vote") | perumal_s_9a6d79a633d63d4 | |
1,925,795 | VSCode Tips & Tricks - Web Terminal | How would you like to be able to access the Web Terminal directly from your VSCode? This is... | 28,084 | 2024-07-16T17:57:26 | https://community.intersystems.com/post/vscode-tips-tricks-web-terminal | vscode, beginners, tutorial, programming | <p>How would you like to be able to access the Web Terminal directly from your VSCode?</p>
<p><!--break-->This is another entry in the VSCode Tips & Tricks - and it is quite similar to the previous one about the... | intersystemsdev |
1,925,796 | Task-3 Qsn-5 | Create a program that takes three numbers as input and prints the largest of the three. ... | 0 | 2024-07-16T17:58:28 | https://dev.to/perumal_s_9a6d79a633d63d4/task-3-qsn-5-412n | #Create a program that takes three numbers as input and prints the largest of the three.
#Ans
#note i have added Loop
while True:
num1=int(input("enter a number 1:"))
num2=int(input("enter a number 2:"))
num3=int(input("enter a number 3:"))
if num2<=num1>=num3:
print ("biggest num is",num1)
elif num1<=... | perumal_s_9a6d79a633d63d4 | |
1,925,798 | VSCode Tips & Tricks - Open Class per Name | In Studio you could open a class directly via it's name, without having to traverse the package tree... | 28,084 | 2024-07-16T17:59:33 | https://community.intersystems.com/post/vscode-tips-tricks-open-class-name | vscode, beginners, tutorial, programming | <p>In Studio you could open a class directly via it's name, without having to traverse the package tree with multiple clicks until arriving at the desired class.</p>
<p>You would Ctrl + O or (File -> Open) and be able to simply type in the class name, for example:</p>
\n\n\n\n\nBuy Verified TransferWise Accounts\nFor businesses worldwide, navigating international payments can be both crucial and intricate. Enter TransferWise: a trusted, cost-efficient, and dependable platform revolutionizing cross-border transactions.\n\nAs an increasingly favored choice for companies engaged in global trade, TransferWise streamlines the complexities associated with foreign payments. However, maneuvering through the setup and verification procedures of a TransferWise account can prove arduous and time-intensive. To circumvent this hassle, the option of purchasing a pre-verified TransferWise account emerges as a viable solution.\n\nDelving into the advantages of acquiring a pre-verified TransferWise account, scrutinizing the selection criteria, and elucidating the purchasing process, this post provides essential insights whether procuring an account for business or personal use. An indispensable resource for all contemplating a verified TransferWise account, this comprehensive guide is a must-read for everyone.\n\nHow to verify a TransferWise Accounts?\nUnderstanding the importance of verifying your TransferWise account is crucial, regardless of whether you’re a casual user or a business owner. Verification plays a significant role in enabling you to access the service’s secure, reliable, and cost-effective online money transfer capabilities.\n\nIn this blog post, we will guide you through the verification process, offering valuable insights and practical tips to simplify and streamline this essential step. By verifying your account, you pave the way for a seamless and secure experience with TransferWise, ensuring that you leverage its full range of benefits with confidence.\n\nVerifying your TransferWise account is essential for both casual users and business owners, as it guarantees access to the service’s secure, reliable, and cost-effective online money transfer options. In this blog post, we delve into the significance of the verification process and offer practical tips to streamline the procedure, enabling you to fully leverage the benefits of TransferWise with ease.\n\nBenefits Of Verified TransferWise Accounts\nIn our blog post, we delve into the advantages of acquiring verified TransferWise accounts, discuss the key criteria for selecting a trusted account, and outline the purchasing process.\n\nWhether you seek a verified TransferWise account for your business or personal use, this essential read provides valuable insights for all individuals looking to streamline international payment processes.\n\nFor many businesses, international payments present a significant challenge, making solutions like TransferWise a vital resource. TransferWise stands out as a secure, cost-effective, and dependable option for facilitating global transactions, catering to a growing number of businesses engaging in cross-border payments.\n\nAlthough creating and verifying a TransferWise account can prove complex and time-consuming, opting to purchase a verified account offers a seamless alternative. Buy Verified TransferWise Accounts.\n\nWhat are the benefits of buying Verified TransferWise Accounts?\n Explore the world of payment options with TransferWise, the streamlined, secure, and cost-effective choice for international money transfers. With features like verified accounts, TransferWise ensures that your transactions are safe, compliant, and efficient.\n\nWhether you’re a consumer, business, or freelancer, opting for verified TransferWise accounts can lead to significant savings on processing fees and expanded transaction limits. Experience the convenience of paying in multiple currencies and discover how easy it is to acquire verified TransferWise accounts through a few simple steps.\n\nUpgrade your payment game and elevate your financial transactions with TransferWise today. Buy Verified TransferWise Accounts.\n\nDiscover the power of Buy Verified TransferWise Accounts, a top choice for those seeking a seamless, secure, and economical payment solution. With its efficient platform for international money transfers, TransferWise offers a fast and hassle-free experience, along with enhanced features like verified accounts. This blog delves into the advantages of owning a verified TransferWise account, catering to all kinds of users from individuals to businesses and freelancers.\n\nIs it safe to buy Verified TransferWise Accounts?\n \n\nIn today’s automated global financial landscape, it is crucial for people of all backgrounds to grasp the significance of utilizing online money transfer services, with Verified TransferWise standing out as a leading player in the industry. Known for its efficiency, security, and cost-effectiveness, Verified TransferWise has earned immense popularity for facilitating swift and reliable money transfers.\n\nAs we embrace the convenience offered by platforms like Buy Verified TransferWise Accounts, it becomes imperative to prioritize the security measures necessary to safeguard our financial transactions in the digital realm. Buy Verified TransferWise Accounts.\n\nBy opting for a verified account, you can cut down on processing fees, guarantee the safety of your transactions, and stay compliant with diverse country regulations. Uncover how verified accounts elevate your transaction thresholds, enable multi-currency payments, and overall optimize your money transfers. Embark on the journey to obtaining a verified TransferWise account effortlessly today. .Buy Verified TransferWise Accounts\n\nBenefits from us\nFor your business needs, look no further than our Website for top-notch services guaranteed at 100%. Concerned about purchasing our PVA Accounts service? Fear not, as your doubts will vanish as we stand apart from the crowd of Duplicate PVA Accounts providers.\n\nWe offer only 100% Non-Drop, Permanent, and Legitimate PVA Accounts services. Backed by a dedicated team, we initiate work instantly upon order placement. Purchase our service with confidence, knowing that we accept various payment methods and stand by a 100% money-back guarantee if issues arise or deals are canceled.\n\nWe’ll also look at some of the factors to consider when selecting the right account for your business. By the end of this post, you’ll have a better understanding of why purchasing verified TransferWise accounts. Is a smart move for businesses needing to transfer money around the world.\n\nContact Us / 24 Hours Reply\nTelegram: @gmusashop\nWhatsApp: +1 (385)237-5318\nEmail: gmusashop@gamil.com\n\n" | fimiris640 |
1,925,802 | RVThereYet - Your Premier RV Rental Destination | Are you ready to embark on an unforgettable journey? At RVThereYet, we specialize in connecting you... | 0 | 2024-07-16T18:03:11 | https://dev.to/sameer_ahmad_2e82aa1a6fd2/rvthereyet-your-premier-rv-rental-destination-4mhf | Are you ready to embark on an unforgettable journey? At RVThereYet, we specialize in connecting you with the perfect [RV rental](https://rvthereyet.com/) for your next adventure. Whether you're planning a weekend getaway, a cross-country road trip, or a family vacation, our wide selection of RVs and campervans will ens... | sameer_ahmad_2e82aa1a6fd2 | |
1,925,803 | Top Features That A Good Event Venue Management Software Must Have | In today's fast-paced world, event planning and management have evolved into complex endeavors. With... | 0 | 2024-07-16T18:03:31 | https://dev.to/developer_tips/top-features-that-a-good-event-venue-management-software-must-have-4ee8 | In today's fast-paced world, event planning and management have evolved into complex endeavors. With a myriad of events spanning from corporate meetings to expansive conferences, the demand for dependable event venue management software has surged.
This article delves into the essential features that distinguish a su... | developer_tips | |
1,925,804 | Venturing into the New Age of Digital Interaction | In today's digital era, where technology is a pivotal aspect of daily life, the integration of social... | 27,673 | 2024-07-16T18:05:16 | https://dev.to/rapidinnovation/venturing-into-the-new-age-of-digital-interaction-4o06 | In today's digital era, where technology is a pivotal aspect of daily life,
the integration of social media with advanced technologies like pose
estimation is heralding a significant evolution in the way we interact
digitally. Picture a scenario where navigating through your social media feed
is no longer a static, one... | rapidinnovation | |
1,925,805 | Exploring Option Conversions in Effect-TS | Effect-TS provides powerful tools for handling Option and Either types. In this article, we'll... | 0 | 2024-07-16T18:05:41 | https://dev.to/almaclaine/exploring-option-conversions-in-effect-ts-3bpk | javascript, typescript, effect, functional | Effect-TS provides powerful tools for handling `Option` and `Either` types. In this article, we'll explore various ways to convert and manipulate these types using the library's utility functions.
## Example 1: Convert an Either to an Option with `O.getRight`
The `O.getRight` function converts an `Either` to an `Opti... | almaclaine |
1,925,808 | Biography of Shahadat Jaman | 𝗦𝗵𝗮𝗵𝗮𝗱𝗮𝘁 𝗝𝗮𝗺𝗮𝗻 Founder & CEO, SukhiTech Solutions Born: October 9, 1999 Journey in... | 0 | 2024-07-16T18:10:33 | https://dev.to/shahadat_2aac8d2eeb063f71/biography-of-shahadat-jaman-19hc | shahadat, webdev, javascript, programming |

𝗦𝗵𝗮𝗵𝗮𝗱𝗮𝘁 𝗝𝗮𝗺𝗮𝗻
Founder & CEO, SukhiTech Solutions
Born: October 9, 1999
**Journey in Technology**
**Shahadat Jaman** is a visionary tech entrepreneur and the founder of SukhiTech Solutions, establishe... | shahadat_2aac8d2eeb063f71 |
1,925,811 | Implementing Cross-Origin Resource Sharing (CORS) with Terraform and AWS S3 | In this technical blog post, we will explore how to set up Cross-Origin Resource Sharing (CORS) for... | 0 | 2024-07-16T18:13:25 | https://dev.to/chinmay13/implementing-cross-origin-resource-sharing-cors-with-terraform-and-aws-s3-28pb | aws, terraform, awscommunitybuilder, upskilling | In this technical blog post, we will explore how to set up Cross-Origin Resource Sharing (CORS) for AWS S3 buckets using Terraform. CORS is essential for allowing web applications to make requests to a domain that is different from the one serving the web page, enabling secure and controlled data sharing across origins... | chinmay13 |
1,925,812 | Congrats to the Wix Studio Challenge Winner! | From eCommerce sites with gaming elements to customizable sneakers to AI-assisted shopping... | 0 | 2024-07-16T19:07:27 | https://dev.to/devteam/congrats-to-the-wix-studio-challenge-winners-1d23 | devchallenge, wixstudiochallenge, webdev, javascript | From eCommerce sites with gaming elements to customizable sneakers to AI-assisted shopping experiences, our team of judges for the [Wix Studio Challenge](https://dev.to/challenges/wix) had a lot to consider.
After much deliberation, special guest judge [Ania Kubów](https://www.youtube.com/@AniaKubow) gave her final s... | thepracticaldev |
1,925,813 | Energy Market Resilience Metrics: Analyzing Vulnerabilities and Preparing for Disruptions | Introduction In the dynamic and competitive energy market, companies like EnergiX Enterprise face... | 0 | 2024-07-17T08:26:27 | https://dev.to/caroline_mwangi/energy-market-resilience-metrics-analyzing-vulnerabilities-and-preparing-for-disruptions-3k5o | energymarkets, dataanalytics, python, eventdriven | **Introduction**
In the dynamic and competitive energy market, companies like EnergiX Enterprise face numerous challenges that can significantly impact their operations and profitability. Understanding these challenges and devising effective strategies to address them is crucial for maintaining stability and growth. Th... | caroline_mwangi |
1,925,835 | 2096. Step-By-Step Directions From a Binary Tree Node to Another | 2096. Step-By-Step Directions From a Binary Tree Node to Another Medium You are given the root of... | 27,523 | 2024-07-16T18:20:20 | https://dev.to/mdarifulhaque/2096-step-by-step-directions-from-a-binary-tree-node-to-another-3ijc | php, leetcode, algorithms, programming | 2096\. Step-By-Step Directions From a Binary Tree Node to Another
Medium
You are given the `root` of a **binary tree** with `n` nodes. Each node is uniquely assigned a value from `1` to `n`. You are also given an integer `startValue` representing the value of the start node `s`, and a different integer `destValue` r... | mdarifulhaque |
1,926,404 | 7 Best Test Data Management Tools In 2024 | title: "7 Best Test Data Management Tools in 2024" datePublished: Sun Jul 14 2024... | 0 | 2024-07-17T08:44:23 | https://keploy.io/blog/community/7-best-test-data-management-tools-in-2024 |

---
title: "7 Best Test Data Management Tools in 2024"
datePublished: Sun Jul 14 2024 18:30:00 GMT+0000 (Coordinated Universal Time)
cuid: clyo2eyk2000408jn7tg40yw3
slug: 7-best-test-data-management-tools-in-2024
-... | keploy | |
1,925,844 | 3D Icosahedron with ICD-9 Codes | Check out this Pen I made! | 0 | 2024-07-16T18:20:25 | https://dev.to/dan52242644dan/3d-icosahedron-with-icd-9-codes-5d8o | codepen, javascript, programming, ai | Check out this Pen I made!
{% codepen https://codepen.io/Dancodepen-io/pen/ZEdbPLo %} | dan52242644dan |
1,925,854 | WEB BAILIFF CONTRACTOR; LEGIT RECOVERY SPECIALIST- BITCOIN, USDT, ETH | My name is William, and I am here to share my story briefly. About 4 months ago, I was tricked into... | 0 | 2024-07-16T18:26:01 | https://dev.to/grace_smith_6c695ccd3e480/web-bailiff-contractor-legit-recovery-specialist-bitcoin-usdt-eth-1np7 | My name is William, and I am here to share my story briefly. About 4 months ago, I was tricked into investing in the crypto market, only to discover that it was a sophisticated investment scam. They managed to extort $450,000 of my hard-earned money. Devastated and desperate, I sought help from various authorities, but... | grace_smith_6c695ccd3e480 | |
1,925,856 | How Bhaiya and Didi Killed the Fresher Job Market | In recent years, the landscape of India's job market has undergone a profound transformation, largely... | 0 | 2024-07-16T18:34:04 | https://dev.to/ankit_raj_61f3ec64f48a491/how-bhaiya-and-didi-killed-the-fresher-job-market-1hd6 | javascript, webdev, career, ai | In recent years, the landscape of India's job market has undergone a profound transformation, largely influenced by a cultural phenomenon known as "Bhaiya and Didi" culture among Indian software engineers. This term refers to experienced professionals who, having tasted success in the tech industry, decide to take a di... | ankit_raj_61f3ec64f48a491 |
1,925,858 | Intern level: Lifecycle Methods and Hooks in React | Introduction to React Hooks React Hooks are functions that let you use state and other... | 0 | 2024-07-16T18:39:31 | https://dev.to/__zamora__/intern-level-lifecycle-methods-and-hooks-in-react-17ef | webdev, javascript, programming, react | ## Introduction to React Hooks
React Hooks are functions that let you use state and other React features in functional components. Before hooks, stateful logic was only available in class components. Hooks provide a more direct API to the React concepts you already know, such as state, lifecycle methods, and context.
... | __zamora__ |
1,925,859 | Mathematics for Machine Learning | Get it? because they're in space, but if they're on earth the vector (in) space disappears and only... | 27,993 | 2024-07-16T18:39:38 | https://www.pourterra.com/blogs/9 | learning, machinelearning, tutorial, beginners | 
Get it? because they're in space, but if they're on earth the vector (in) space disappears and only 0 remains :D
## Vector Space
With your knowledge regarding groups we can start to discuss regarding vect... | pourlehommes |
1,925,860 | Junior level: Lifecycle Methods and Hooks in React | React Hooks have revolutionized the way we write functional components in React, allowing us to use... | 0 | 2024-07-16T18:40:20 | https://dev.to/__zamora__/junior-level-lifecycle-methods-and-hooks-in-react-441h | react, webdev, javascript, programming | React Hooks have revolutionized the way we write functional components in React, allowing us to use state and other React features without writing a class. This guide will introduce you to essential hooks, custom hooks, and advanced hook patterns to manage complex state and optimize performance.
## Introduction to Rea... | __zamora__ |
1,925,861 | aaa | aaa | 0 | 2024-07-16T18:40:44 | https://dev.to/dungnguyen2534/aaa-6k3 | aws | aaa | dungnguyen2534 |
1,925,862 | Mid level: Lifecycle Methods and Hooks in React | As a mid-level developer, understanding and effectively using React Hooks and lifecycle methods is... | 0 | 2024-07-16T18:41:24 | https://dev.to/__zamora__/mid-level-lifecycle-methods-and-hooks-in-react-838 | react, webdev, javascript, programming | As a mid-level developer, understanding and effectively using React Hooks and lifecycle methods is crucial for building robust, maintainable, and scalable applications. This article will delve into essential hooks, custom hooks, and advanced hook patterns, such as managing complex state with `useReducer` and optimizing... | __zamora__ |
1,925,863 | Rails 7.2 makes counter_cache integration safer and easier | Our new blog is on Rails 7.2 makes counter_cache integration safer and easier. Counter caches are... | 0 | 2024-07-16T18:41:56 | https://dev.to/tsudhishnair/rails-72-makes-countercache-integration-safer-and-easier-lb8 | rails, ruby, backend, webdev | Our new blog is on Rails 7.2 makes counter_cache integration safer and easier.
Counter caches are key for optimizing performance in Rails applications. They efficiently keep track of the number of associated records for a model, eliminating the need for frequent database queries, but adding them to large tables can be... | tsudhishnair |
1,925,864 | Senior level: Lifecycle Methods and Hooks in React | As a senior developer, you are expected to not only understand but also expertly implement advanced... | 0 | 2024-07-16T18:42:26 | https://dev.to/__zamora__/senior-level-lifecycle-methods-and-hooks-in-react-2172 | react, webdev, javascript, programming | As a senior developer, you are expected to not only understand but also expertly implement advanced React concepts to build robust, maintainable, and scalable applications. This article delves into essential hooks, custom hooks, and advanced hook patterns, such as managing complex state with `useReducer` and optimizing... | __zamora__ |
1,925,865 | Lead level: Lifecycle Methods and Hooks in React | As a lead developer, you are expected to guide your team in building robust, maintainable, and... | 0 | 2024-07-16T18:43:31 | https://dev.to/__zamora__/lead-level-lifecycle-methods-and-hooks-in-react-gna | react, webdev, javascript, programming | As a lead developer, you are expected to guide your team in building robust, maintainable, and scalable applications using React. Understanding advanced concepts and best practices in React Hooks and lifecycle methods is crucial. This article covers essential hooks, custom hooks, and advanced hook patterns, such as man... | __zamora__ |
1,925,866 | Architect level: Lifecycle Methods and Hooks in React | As an architect-level developer, you are responsible for ensuring that your applications are robust,... | 0 | 2024-07-16T18:44:11 | https://dev.to/__zamora__/architect-level-lifecycle-methods-and-hooks-in-react-7a | react, webdev, javascript, programming | As an architect-level developer, you are responsible for ensuring that your applications are robust, maintainable, and scalable. Mastering React Hooks and lifecycle methods is essential for achieving these goals. This article covers essential hooks, custom hooks, and advanced hook patterns, such as managing complex sta... | __zamora__ |
1,925,867 | Postman Api 101 | I recently had the fantastic opportunity to participate in the Postman Student Program, and I’m... | 0 | 2024-07-16T18:44:23 | https://dev.to/mohanraj1234/postman-api-101-23p6 | I recently had the fantastic opportunity to participate in the Postman Student Program, and I’m excited to share my journey! For those unfamiliar, Postman is an essential tool for API development and testing. The Student Program aims to help students gain practical skills and insights into the world of APIs.
Why I Joi... | mohanraj1234 | |
1,925,868 | Ageless Partners | We offer Age Reversal as a Service, transcending traditional aging with our transformative Ageless... | 0 | 2024-07-16T18:44:49 | https://dev.to/agelesspartners/ageless-partners-3e84 |
We offer Age Reversal as a Service, transcending traditional aging with our transformative Ageless Coaching™, insightful Ageless Guide™, Ageless Hair™, and potent Ageless Supplements™. Our products help people inc... | agelesspartners | |
1,925,870 | Intern level: Managing Forms in React | Forms are essential for collecting user input in web applications. Managing forms in React can be... | 0 | 2024-07-16T18:51:44 | https://dev.to/__zamora__/intern-level-managing-forms-in-react-2eh7 | react, webdev, javascript, programming | Forms are essential for collecting user input in web applications. Managing forms in React can be straightforward once you understand the basics of controlled and uncontrolled components, form validation, and handling complex forms. This guide will help you get started with managing forms in React.
## Controlled Compo... | __zamora__ |
1,925,871 | Junior level: Managing Forms in React | Managing forms is a fundamental aspect of developing React applications. This guide will help you... | 0 | 2024-07-16T18:53:05 | https://dev.to/__zamora__/junior-level-managing-forms-in-react-4nj | react, webdev, javascript, programming | Managing forms is a fundamental aspect of developing React applications. This guide will help you understand how to handle form data with state, use refs for uncontrolled components, perform form validation, and manage complex forms, including multi-step forms and file uploads.
## Controlled Components
Controlled com... | __zamora__ |
1,925,872 | Measuring Developer Experience with the DevEx Framework | This post was originally published on the Shipyard Blog. Measuring DevEx has been a major... | 0 | 2024-07-16T18:53:36 | https://shipyard.build/blog/devex-framework/ | devex, productivity, leadership, softwareengineering | *<a href="https://shipyard.build/blog/devex-framework/" target="_blank">This post was originally published on the Shipyard Blog.</a>*
---
Measuring DevEx has been a major discussion point over the last few years. How exactly can you measure something that relies so heavily on individual experiences? The DevEx framewo... | shipyard |
1,925,873 | Transforme seus HTMLs em PDFs com facilidade usando wkhtmltopdf em sua VPS | Para quem usa uma VPS, uma ótima dica para gerar PDFs diretamente do sistema é instalar o... | 0 | 2024-07-16T18:57:09 | https://dev.to/fernandovaller/transforme-seus-htmls-em-pdfs-com-facilidade-usando-wkhtmltopdf-em-sua-vps-3o3g | vps, pdf, html | Para quem usa uma VPS, uma ótima dica para gerar PDFs diretamente do sistema é instalar o **wkhtmltopdf**. Essa ferramenta poderosa permite converter arquivos HTML e URLs em PDFs de forma simples e eficiente.
**wkhtmltopdf** é uma ferramenta de linha de comando que converte arquivos HTML e URLs em PDFs usando o mecani... | fernandovaller |
1,925,874 | Mid level: Managing Forms in React | Forms are essential for collecting user input in web applications. Managing forms in React can become... | 0 | 2024-07-16T18:54:46 | https://dev.to/__zamora__/mid-level-managing-forms-in-react-3ilp | react, webdev, javascript, programming | Forms are essential for collecting user input in web applications. Managing forms in React can become complex, especially when handling validation, multi-step processes, and file uploads. This guide delves deeper into managing forms with state, using refs, implementing validation, and handling complex forms.
## Contro... | __zamora__ |
1,925,875 | Senior level: Managing Forms in React | Managing forms in React can become complex, especially when dealing with advanced scenarios such as... | 0 | 2024-07-16T18:56:11 | https://dev.to/__zamora__/senior-level-managing-forms-in-react-3o7c | react, webdev, javascript, programming | Managing forms in React can become complex, especially when dealing with advanced scenarios such as multi-step forms, file uploads, and intricate validation logic. This guide provides an in-depth look at controlled and uncontrolled components, form validation, and managing complex forms, helping you create robust and m... | __zamora__ |
1,925,876 | Lead level: Managing Forms in React | As a lead developer, managing forms in React requires not only understanding the fundamentals but... | 0 | 2024-07-16T18:58:39 | https://dev.to/__zamora__/lead-level-managing-forms-in-react-4e3j | react, webdev, javascript, programming | As a lead developer, managing forms in React requires not only understanding the fundamentals but also implementing advanced patterns and best practices to ensure scalability, maintainability, and performance. This comprehensive guide covers controlled and uncontrolled components, form validation, and complex form mana... | __zamora__ |
1,925,877 | Architect level: Managing Forms in React | Managing forms in React is a critical aspect of building sophisticated, user-friendly applications.... | 0 | 2024-07-16T18:59:45 | https://dev.to/__zamora__/architect-level-managing-forms-in-react-49bj | react, webdev, javascript, programming | Managing forms in React is a critical aspect of building sophisticated, user-friendly applications. As an architect-level developer, it is essential to not only understand but also design best practices and patterns that ensure forms are scalable, maintainable, and performant. This article covers controlled and uncontr... | __zamora__ |
1,925,878 | Unlocking the Potential of AI Voice Assistants with Sista AI | Did you know AI voice assistants can boost user engagement by 65%? Discover the transformative power of Sista AI Voice Assistant. Join the AI revolution today! 🚀 | 0 | 2024-07-16T19:11:45 | https://dev.to/sista-ai/unlocking-the-potential-of-ai-voice-assistants-with-sista-ai-1ng2 | ai, react, javascript, typescript | <h2>Empowering User Interactions</h2><p>The evolution of technology has ushered in a new era of user interactions, with AI voice assistants leading the way. These intelligent companions have revolutionized how businesses and users engage with technology, enhancing efficiency and accessibility. Sista AI stands at the fo... | sista-ai |
1,925,879 | [Day 1] - Building an App for Coffee Roasting | Hot off the end of the Full-Stack Engineer Professional Certification course from Codecademy, I'm... | 28,085 | 2024-07-16T19:12:59 | https://dev.to/nmiller15/day-1-building-an-app-for-coffee-roasting-17gb | react, webdev, buildinpublic, devjournal | Hot off the end of the Full-Stack Engineer Professional Certification course from Codecademy, I'm launching into a new project to build out my portfolio. I don't want to make something that just sits on a shelf. I want to make something that I'll actually use!
## The Idea
My family calls me a "coffee-snob."
That mig... | nmiller15 |
1,925,880 | Buy Verified Paxful Account | https://gmusashop.com/product/buy-verified-paxful-account/ Buy Verified Paxful Account If you are... | 0 | 2024-07-16T19:14:18 | https://dev.to/basoco1491/buy-verified-paxful-account-48n3 | webdev, javascript, beginners, programming | https://gmusashop.com/product/buy-verified-paxful-account/

Buy Verified Paxful Account
If you are considering purchasing a verified Paxful account, we are here to assist you. Our services encompass a diverse rang... | basoco1491 |
1,925,881 | Legendary Commits: Conventional with Emoji 👑😵 | Writing commit messages is like a daily exercise you have to practice as a programmer. Even if you... | 0 | 2024-07-16T20:46:32 | https://dev.to/silentwatcher_95/legendary-commits-conventional-with-emoji-1371 | git, github, documentation, webdev | Writing commit messages is like a daily exercise you have to practice as a programmer.
Even if you are writing code for fun, it's important to realize this small detail reflects your developer personality in general.

The Azure Cost Optimization workbook is an invaluable tool designed to help you efficiently manage and optimise your Azu... | techielass |
1,925,883 | Buy verified cash app account | https://gmusashop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash app... | 0 | 2024-07-16T19:21:27 | https://dev.to/basoco1491/buy-verified-cash-app-account-1f9a | tutorial, react, python, ai | ERROR: type should be string, got "https://gmusashop.com/product/buy-verified-cash-app-account/\n\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoinenablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy gmusashop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\n\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nBuy verified cash app account\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\n \n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nHow cash used for international transaction?\n\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\n\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram: @gmusashop\nWhatsApp: +1 (385)237-5318\nEmail: gmusashop@gamil.com" | basoco1491 |
1,925,884 | Unlocking Data Insights: A Guide to Azure Dashboards, Workbooks, and Power BI for Effective Visualization | Organisations depend on data visualisation tools to make informed decisions and gain insights into... | 0 | 2024-07-17T16:10:00 | https://www.techielass.com/azure-dashboards-azure-workbooks-power-bi/ | azure | 
Organisations depend on data visualisation tools t... | techielass |
1,925,885 | Building a Traceable RAG System with Qdrant and Langtrace: A Step-by-Step Guide | Vector databases are the backbone of AI applications, providing the crucial infrastructure for... | 0 | 2024-07-16T19:24:48 | https://dev.to/yemi_adejumobi/building-a-traceable-rag-system-with-qdrant-and-langtrace-a-step-by-step-guide-47ki | ai, rag, llmops, observability | Vector databases are the backbone of AI applications, providing the crucial infrastructure for efficient similarity search and retrieval of high-dimensional data. Among these, [Qdrant](https://qdrant.tech/) stands out as one of the most versatile projects. Written in Rust, Qdrant is a vector search database designed fo... | yemi_adejumobi |
1,925,889 | Cron Jobs 🔧 | 🔧 Understanding Cron Jobs in JavaScript Have you ever encountered the term "cron job"? It’s not a... | 0 | 2024-07-16T19:26:39 | https://dev.to/chibuike_malachiuko_5b81/cron-jobs-29o9 | 🔧 Understanding Cron Jobs in JavaScript
Have you ever encountered the term "cron job"? It’s not a job offer—it’s a task scheduler! Cron jobs let you schedule tasks to run at specific times, dates, or intervals, perfect for background tasks like clearing logs, sending emails, and more. Here’s a quick guide to get you ... | chibuike_malachiuko_5b81 | |
1,925,890 | Local First from Scratch - How to make a web app with local data | A post by Scott Tolinski | 0 | 2024-07-16T19:29:24 | https://dev.to/stolinski/local-first-from-scratch-how-to-make-a-web-app-with-local-data-21ia | webdev, localfirst, offline, javascript | {% embed https://www.youtube.com/watch?v=Qoqh9Mdmk80 %} | stolinski |
1,925,891 | Simplifying Form Handling in Vue Applications with Form JS - Inspired by Inertia JS | Recently I have been working on FormJs, which is a form helper and wrapper around Axios, inspired by... | 0 | 2024-07-16T19:35:34 | https://dev.to/bedram-tamang/simplifying-form-handling-in-vue-applications-with-form-js-inspired-by-inertia-js-135j | vue, yup, validation, inertiajs | Recently I have been working on [FormJs](https://github.com/JoBinsJP/formjs), which is a form helper and wrapper around Axios, inspired by [inertiaJs](https://inertiajs.com). The purpose behind writing this new library was to streamline the process of how we handle the form on the front-end side. Validating forms is a ... | bedram-tamang |
1,925,893 | What is an Array in the C Programming Language? | Arrays in C are fundamental data structures that allow you to store multiple elements of the same... | 0 | 2024-07-16T19:39:29 | https://dev.to/scholarhattraining/what-is-an-array-in-the-c-programming-language-3gb8 | Arrays in C are fundamental data structures that allow you to store multiple elements of the same type under a single variable name. Understanding arrays in C is crucial for efficient data management and manipulation in C programming. This article dives deep into the concept of arrays, their syntax, usage, and how they... | scholarhattraining | |
1,925,894 | Blockchain vs. Database: Navigating the Differences in Digital Data Storage | In the rapidly evolving landscape of digital information, understanding the mechanisms for storing,... | 0 | 2024-07-16T19:40:30 | https://dev.to/soroush_hosseinzadeh_1c16/blockchain-vs-database-navigating-the-differences-in-digital-data-storage-3ndp | bitcoin, database, blockchain | In the rapidly evolving landscape of digital information, understanding the mechanisms for storing, securing, and validating data has become paramount. Among the plethora of technological advancements, blockchain and traditional databases stand out as foundational pillars for data handling in the digital age. While bot... | soroush_hosseinzadeh_1c16 |
1,925,895 | Blockchain vs. Database: Navigating the Differences in Digital Data Storage | In the rapidly evolving landscape of digital information, understanding the mechanisms for storing,... | 0 | 2024-07-16T19:40:33 | https://dev.to/soroush_hosseinzadeh_1c16/blockchain-vs-database-navigating-the-differences-in-digital-data-storage-4i5e | bitcoin, database, blockchain | In the rapidly evolving landscape of digital information, understanding the mechanisms for storing, securing, and validating data has become paramount. Among the plethora of technological advancements, blockchain and traditional databases stand out as foundational pillars for data handling in the digital age. While bot... | soroush_hosseinzadeh_1c16 |
1,925,896 | Integración de Kafka para notificaciones en un proyecto Astro y Next.js | En este post, te mostraré cómo hemos integrado un sistema de notificaciones usando Kafka en un... | 0 | 2024-07-16T19:47:03 | https://danieljsaldana.dev/integracion-de-kafka-para-notificaciones-en-un-proyecto-astro-y-nextjs/ | astro, kafka, azure, nextjs | ---
title: Integración de Kafka para notificaciones en un proyecto Astro y Next.js
published: true
tags: Astro, Kafka, Azure, Nextjs
canonical_url: https://danieljsaldana.dev/integracion-de-kafka-para-notificaciones-en-un-proyecto-astro-y-nextjs/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/3zm... | danieljsaldana |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.