
treadon/banger-scorer
Audio Classification • Updated
track_id int64 2 155k | embedding listlengths 1.02k 1.02k | banger_score float64 0 10 | genre stringclasses 8
values | listens int64 196 543k |
|---|---|---|---|---|
2 | [
0.022709060460329056,
0.11333504319190979,
0.014965115115046501,
-0.17015063762664795,
0.00833606906235218,
-0.05336184427142143,
0.023354215547442436,
-0.10504314303398132,
-0.04496222734451294,
0.013885529711842537,
0.0056998515501618385,
0.05586012452840805,
-0.04989522323012352,
-0.011... | 2.37599 | Hip-Hop | 1,293 |
5 | [
0.0037224360276013613,
0.056265562772750854,
-0.019022183492779732,
-0.13493362069129944,
0.0429835170507431,
-0.0423666350543499,
-0.004783317446708679,
-0.11157747358083725,
0.012074262835085392,
0.06352245062589645,
-0.018497951328754425,
0.047153666615486145,
-0.033330582082271576,
0.0... | 2.229264 | Hip-Hop | 1,151 |
10 | [
0.0767568051815033,
0.01137065514922142,
-0.14897257089614868,
0.016694311052560806,
-0.024074750021100044,
-0.07550167292356491,
-0.012502776458859444,
-0.022882530465722084,
-0.0446830578148365,
0.13208545744419098,
-0.004019828513264656,
-0.051418282091617584,
0.044930845499038696,
0.03... | 6.992177 | Pop | 50,135 |
140 | [
0.017290230840444565,
0.03932064026594162,
-0.03130893409252167,
0.035911381244659424,
0.02674289606511593,
-0.09683062881231308,
-0.04089757427573204,
0.015810267999768257,
0.07176006585359573,
0.12395190447568893,
0.010024680756032467,
0.01720324158668518,
-0.08791743218898773,
0.0530411... | 2.38183 | Folk | 1,299 |
141 | [
0.04006889462471008,
0.05342491343617439,
-0.021163014695048332,
-0.004917640704661608,
0.0316045917570591,
-0.0799880400300026,
-0.008738971315324306,
-0.016313781961798668,
0.03906524181365967,
0.06381286680698395,
0.032617632299661636,
0.020315969362854958,
-0.03929702565073967,
0.02712... | 1.64646 | Folk | 725 |
148 | [
0.008612570352852345,
0.02421421743929386,
-0.12119520455598831,
0.031439028680324554,
-0.004877691622823477,
-0.14854803681373596,
0.026504218578338623,
0.0462980717420578,
0.1346203237771988,
0.11083078384399414,
-0.02611023187637329,
-0.010010416619479656,
-0.03506261855363846,
0.052346... | 2.81485 | Experimental | 1,831 |
182 | [
0.033663321286439896,
0.10184819996356964,
-0.0068061500787734985,
-0.026237353682518005,
0.043588586151599884,
-0.17684683203697205,
-0.018072543665766716,
-0.03214596211910248,
0.02448214963078499,
0.10783405601978302,
0.02600516937673092,
-0.01071392372250557,
-0.03622537851333618,
0.03... | 4.213501 | Rock | 5,547 |
190 | [
0.00574423186480999,
0.0876910611987114,
0.011446656659245491,
0.016969656571745872,
0.01019978430122137,
-0.06424976885318756,
-0.04451610520482063,
-0.006236861925572157,
0.08141529560089111,
0.04201691970229149,
0.02589442953467369,
0.03154943138360977,
-0.05637213587760925,
-0.05881012... | 1.980578 | Folk | 945 |
193 | [
0.009813550859689713,
0.04426627606153488,
0.01793346181511879,
0.021000413224101067,
0.04355468600988388,
-0.10586277395486832,
-0.1007581353187561,
0.010337403044104576,
0.0722261443734169,
0.09033434092998505,
-0.025632686913013458,
0.04718247056007385,
-0.040432266891002655,
0.01408287... | 1.807822 | Folk | 824 |
194 | [-0.010582680813968182,0.010883143171668053,-0.002981353085488081,0.022343618795275688,0.02080815657(...TRUNCATED) | 1.695901 | Folk | 754 |
Pre-computed MERT-v1-330M embeddings for the FMA-Small dataset. 7,997 tracks, each represented as a 1024-dimensional vector, with banger scores (0-10) derived from log-normalized play counts.
Use this dataset to train music quality scorers, explore music similarity, or experiment with audio representation learning -- without needing to download 7.2 GB of audio or run MERT yourself.
Each row represents one track from FMA-Small, encoded through MERT-v1-330M and annotated with popularity-based quality labels.
| Field | Type | Description |
|---|---|---|
track_id |
int | FMA track identifier |
embedding |
list[float] (1024) | Mean-pooled MERT-v1-330M embedding |
banger_score |
float (0-10) | Log-normalized play count, scaled to 0-10 |
genre |
string | Top-level genre from FMA metadata |
listens |
int | Raw play count from FMA |
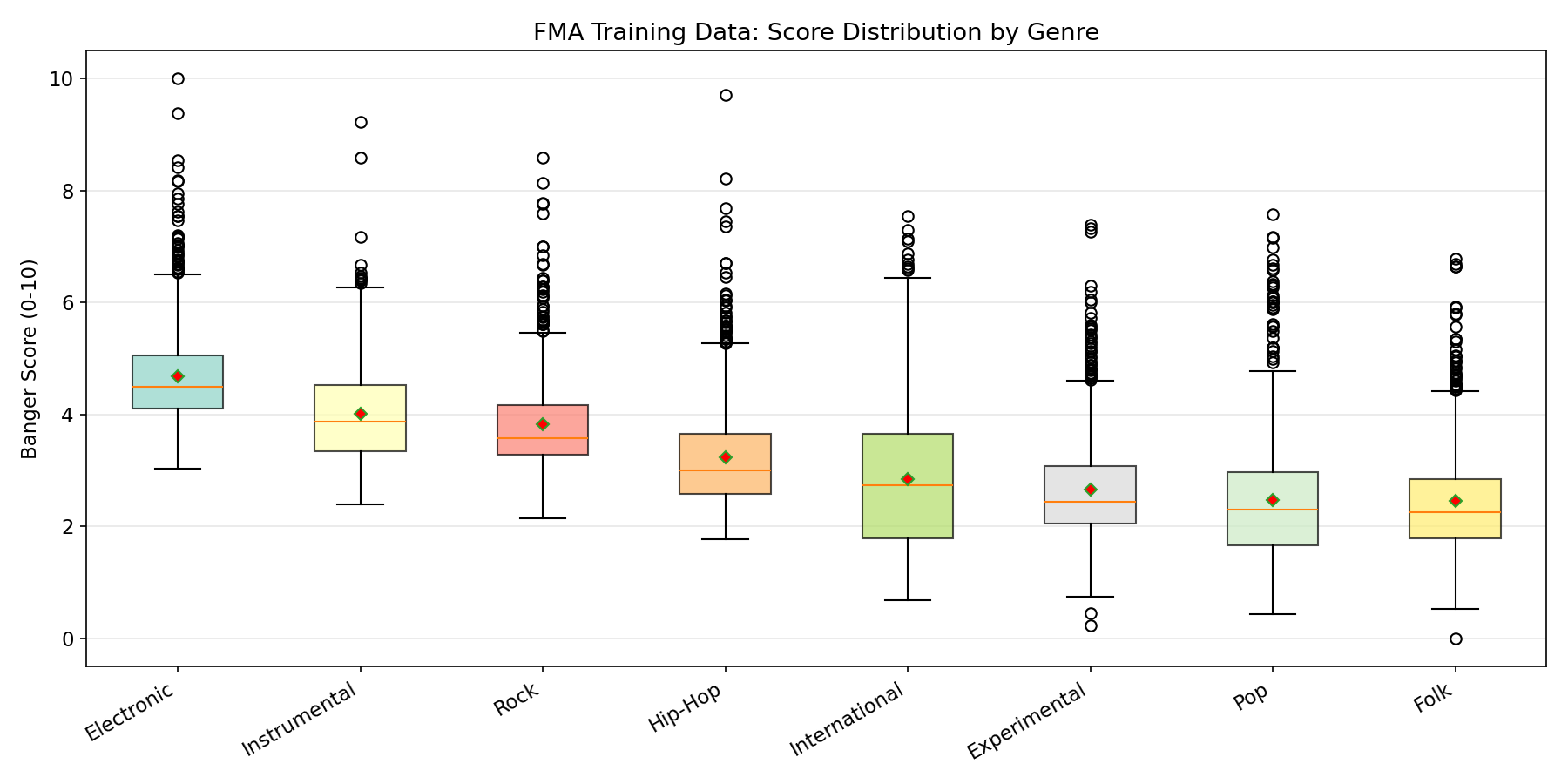
FMA-Small is perfectly balanced across 8 genres (~1,000 tracks each):
| Genre | Count |
|---|---|
| Hip-Hop | ~1,000 |
| Pop | ~1,000 |
| Folk | ~1,000 |
| Experimental | ~1,000 |
| Rock | ~1,000 |
| International | ~1,000 |
| Electronic | ~1,000 |
| Instrumental | ~1,000 |
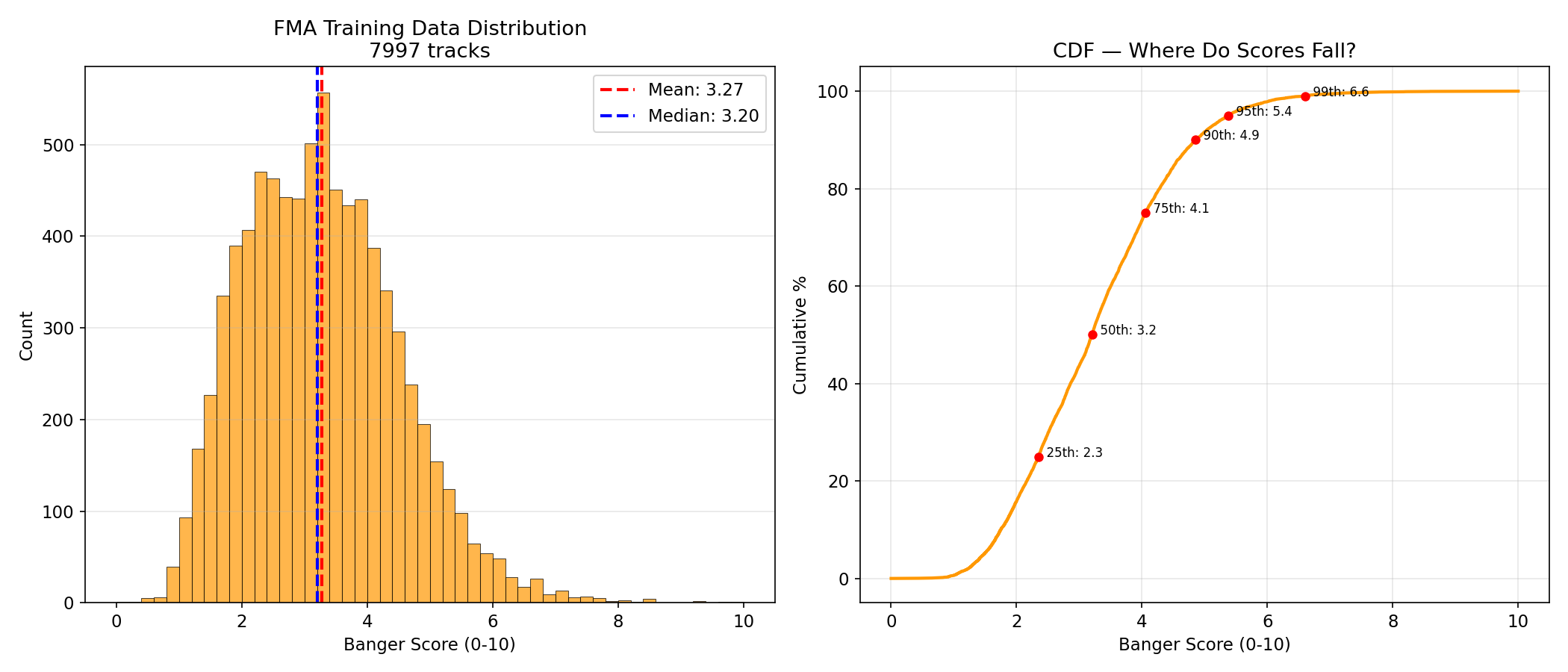
Banger scores are derived from FMA play counts via log-normalization:
log_listens = np.log1p(df["listens"])
banger_score = (log_listens - log_listens.min()) / (log_listens.max() - log_listens.min()) * 10.0
| Statistic | Value |
|---|---|
| Mean | 3.27 |
| Median | 3.20 |
| Std | 1.37 |
| Min | 0.00 |
| Max | 10.00 |
| Tracks >= 5.0 | 668 (8.4%) |
| Tracks >= 7.0 | 45 (0.6%) |
| Tracks >= 9.0 | 4 (0.1%) |
The distribution is concentrated in the 1-5 range. Very few tracks have high scores, which reflects the heavy-tailed nature of music popularity (a few hits, many average tracks).
FMA (Free Music Archive) -- a large-scale, freely available dataset of audio tracks. FMA-Small contains 8,000 tracks of 30-second clips (7.2 GB), Creative Commons licensed.
Play count range: 196 to 543,252 (mean 4,730, median 2,492). The massive gap between mean and median reflects the power-law distribution typical of music popularity.
Model: m-a-p/MERT-v1-330M -- a 330M parameter, 24-layer self-supervised music understanding model trained on 160,000 hours of audio.
Process:
outputs.last_hidden_state.mean(dim=1) to produce a single 1024-dim vector per track# Core embedding logic
waveform, _ = librosa.load("track.mp3", sr=24000, mono=True)
waveform = waveform[:24000 * 30] # 30s max
inputs = feature_extractor(waveform, sampling_rate=24000, return_tensors="pt")
with torch.no_grad():
outputs = mert(**inputs)
embedding = outputs.last_hidden_state.mean(dim=1).squeeze(0).cpu().numpy() # (1024,)
Compute:
Why mean pooling? MERT produces ~1,200 time frames (one per ~25ms) for a 30-second clip, each with a 1024-dim vector. Mean pooling collapses these into a single vector that captures the overall "essence" of the track -- rhythm patterns, harmonic content, timbral quality, melodic structure -- while discarding temporal ordering. Simple and effective as a baseline; attention pooling could be explored for improvements.
from datasets import load_dataset
import numpy as np
# Load the dataset
ds = load_dataset("treadon/fma-mert-embeddings", split="train")
# Access a single track
track = ds[0]
embedding = np.array(track["embedding"]) # (1024,)
score = track["banger_score"] # float 0-10
genre = track["genre"] # e.g., "Electronic"
listens = track["listens"] # raw play count
print(f"Track {track['track_id']}: {genre}, score={score:.2f}, listens={listens}")
print(f"Embedding shape: {embedding.shape}")
# Filter by genre
electronic = ds.filter(lambda x: x["genre"] == "Electronic")
print(f"Electronic tracks: {len(electronic)}")
# Get all embeddings as a matrix for training
all_embeddings = np.array(ds["embedding"]) # (7997, 1024)
all_scores = np.array(ds["banger_score"]) # (7997,)
import torch
import torch.nn as nn
from sklearn.model_selection import train_test_split
# Load embeddings
ds = load_dataset("treadon/fma-mert-embeddings", split="train")
X = np.array(ds["embedding"]) # (7997, 1024)
y = np.array(ds["banger_score"]) # (7997,)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define a simple MLP
scorer = nn.Sequential(
nn.Linear(1024, 512), nn.BatchNorm1d(512), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(512, 256), nn.BatchNorm1d(256), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(256, 128), nn.BatchNorm1d(128), nn.ReLU(), nn.Dropout(0.15),
nn.Linear(128, 1),
)
# Train... (see treadon/banger-scorer for full training code)
The trained model that ships with treadon/banger-scorer achieved MAE 0.858 and Spearman 0.468 on this data, training in ~30 seconds on M4 Pro.
@article{li2023mert,
title={MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training},
author={Li, Yizhi and Yuan, Ruibin and Zhang, Ge and Ma, Yinghao and others},
journal={arXiv preprint arXiv:2306.00107},
year={2023}
}
@inproceedings{defferrard2017fma,
title={FMA: A Dataset For Music Analysis},
author={Defferrard, Micha{\"e}l and Benzi, Kirell and Vandergheynst, Pierre and Bresson, Xavier},
booktitle={ISMIR},
year={2017}
}
treadon on HuggingFace