
MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
Paper • 2306.00107 • Published • 4
Follow @treadon on X and treadon on Hugging Face for more AI experiments, evals, and projects.
Rate how good a song sounds, 0-10. A lightweight MLP trained on top of frozen MERT-v1-330M embeddings to predict music quality from audio. Trained on FMA-Small play count data, designed for relative ranking of AI-generated songs within a batch.
The banger scorer takes a raw audio waveform, encodes it through MERT-v1-330M (frozen, 330M params) to produce a 1024-dimensional embedding, then passes that embedding through a small trained MLP to output a single scalar score from 0 to 10.
The core use case: generate a batch of songs with a model like ACE-Step, score them all automatically, and keep only the top-scoring tracks. Bangers only.
Audio waveform (24kHz, 30s)
--> MERT-v1-330M (frozen, 330M params)
--> 1024-dim embedding (mean-pooled across ~1200 time frames)
--> MLP Scorer (558K trainable params)
--> Score 0-10
Encoder: m-a-p/MERT-v1-330M -- a 24-layer self-supervised music understanding model trained on 160K hours of audio. Completely frozen during training; used only to extract embeddings.
Scorer head: MLP with progressive bottleneck:
Input: 1024-dim MERT embedding
--> Linear(1024, 512) + BatchNorm + ReLU + Dropout(0.3)
--> Linear(512, 256) + BatchNorm + ReLU + Dropout(0.3)
--> Linear(256, 128) + BatchNorm + ReLU + Dropout(0.15)
--> Linear(128, 1)
Output: scalar score (0-10)
Trained on FMA-Small (Free Music Archive), a Creative Commons dataset of 8,000 tracks across 8 balanced genres (1,000 each): Hip-Hop, Pop, Folk, Experimental, Rock, International, Electronic, Instrumental.
Labels: Play counts from FMA, log-normalized to a 0-10 scale:
log_listens = np.log1p(df["listens"])
banger_score = (log_listens - log_listens.min()) / (log_listens.max() - log_listens.min()) * 10.0
After log-normalization, the training score distribution is heavily concentrated in the 1-5 range, with very few examples above 7:
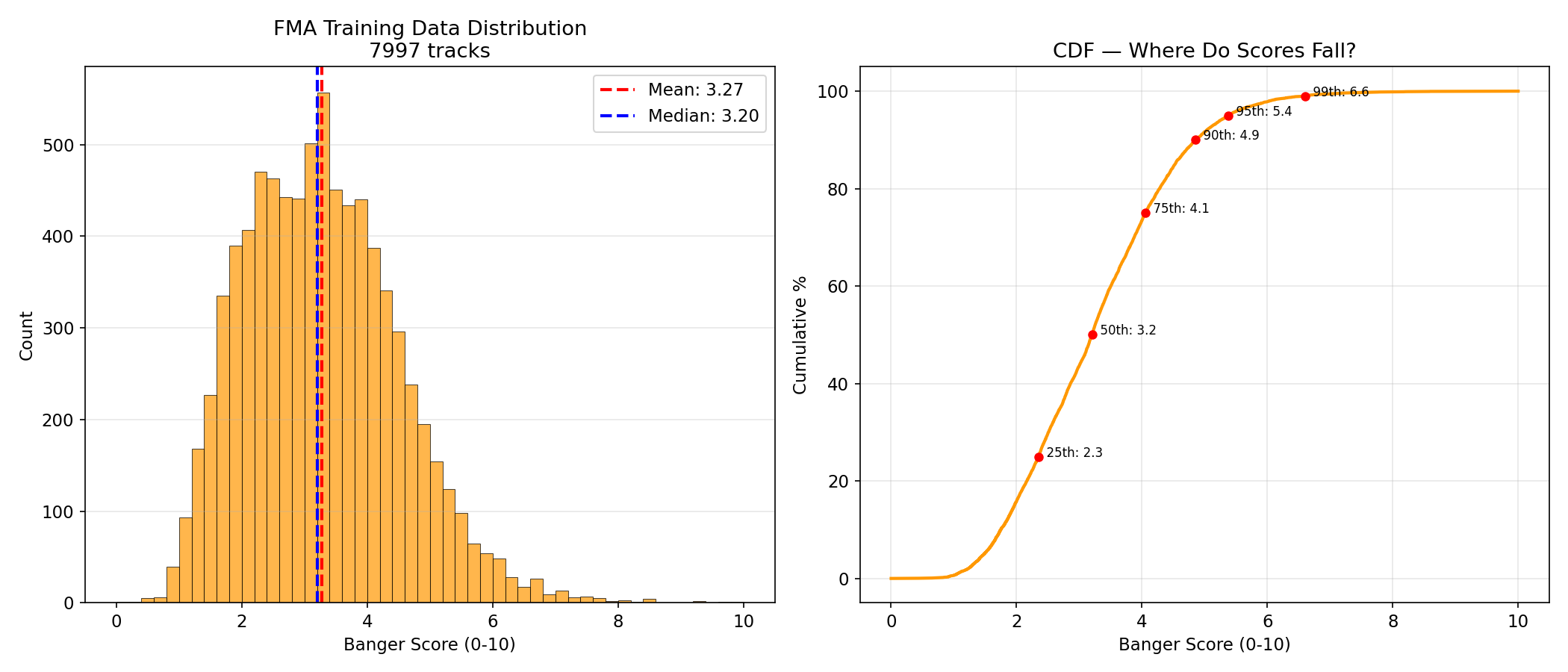
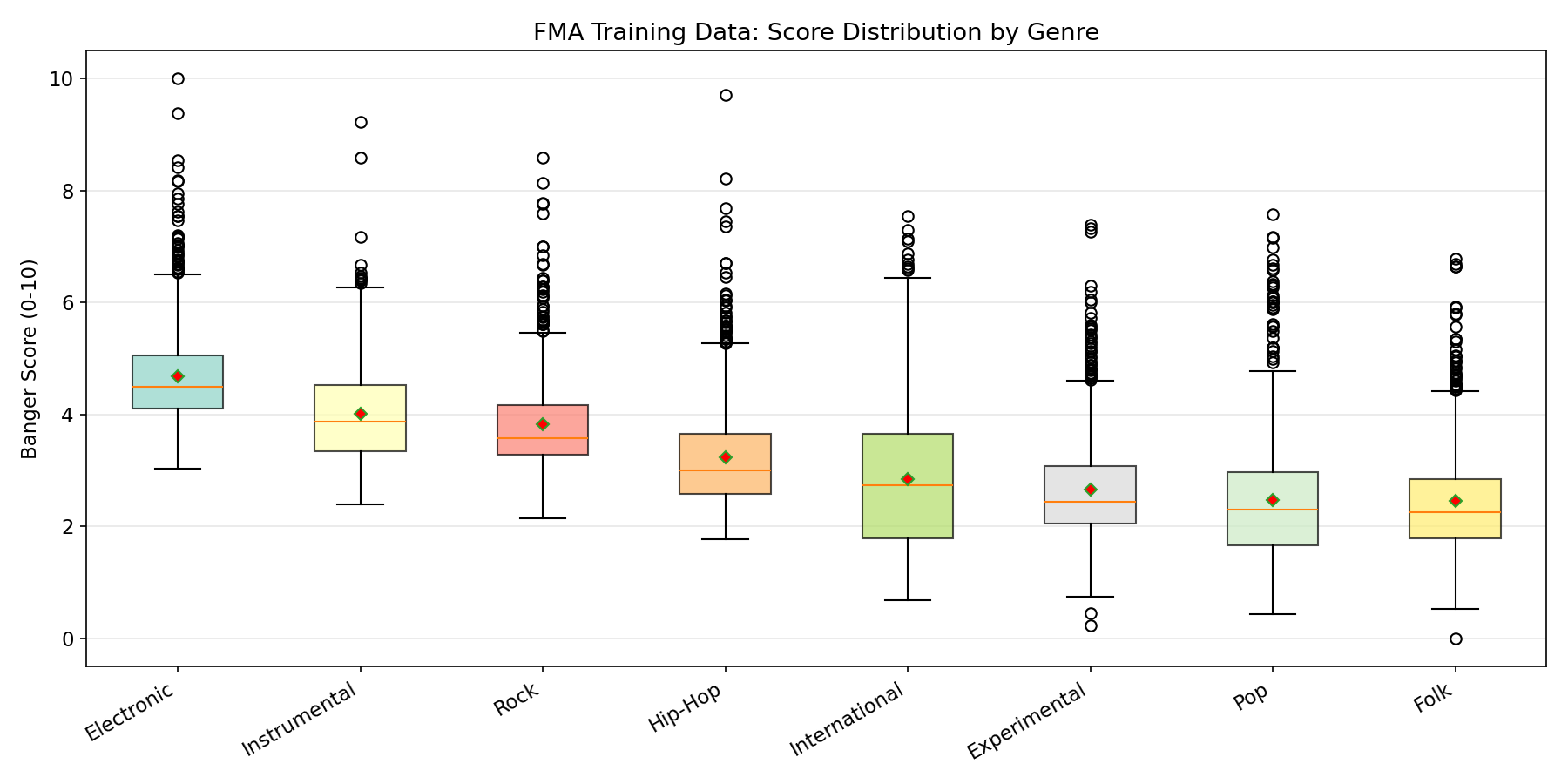
Pre-computed embeddings are available as a separate dataset: treadon/fma-mert-embeddings. MERT embedding extraction took 101 minutes on M4 Pro MPS across 7,997 successfully processed tracks (3 corrupt MP3s failed, 99.96% success rate).
| Metric | Value | Target | Status |
|---|---|---|---|
| Test MAE | 0.858 | < 1.5 | Exceeded by 43% |
| Test Spearman | 0.468 | > 0.4 | Hit target |
| Val MAE | 0.822 | -- | -- |
| Model size | ~2.6 MB | < 50 MB | -- |
MAE of 0.858 on a 0-10 scale means predictions are typically off by less than 1 point. For filtering purposes (pick the best 5 from 50), the model reliably distinguishes a 2/10 from a 6/10, even if it cannot tell a 7/10 from an 8/10.
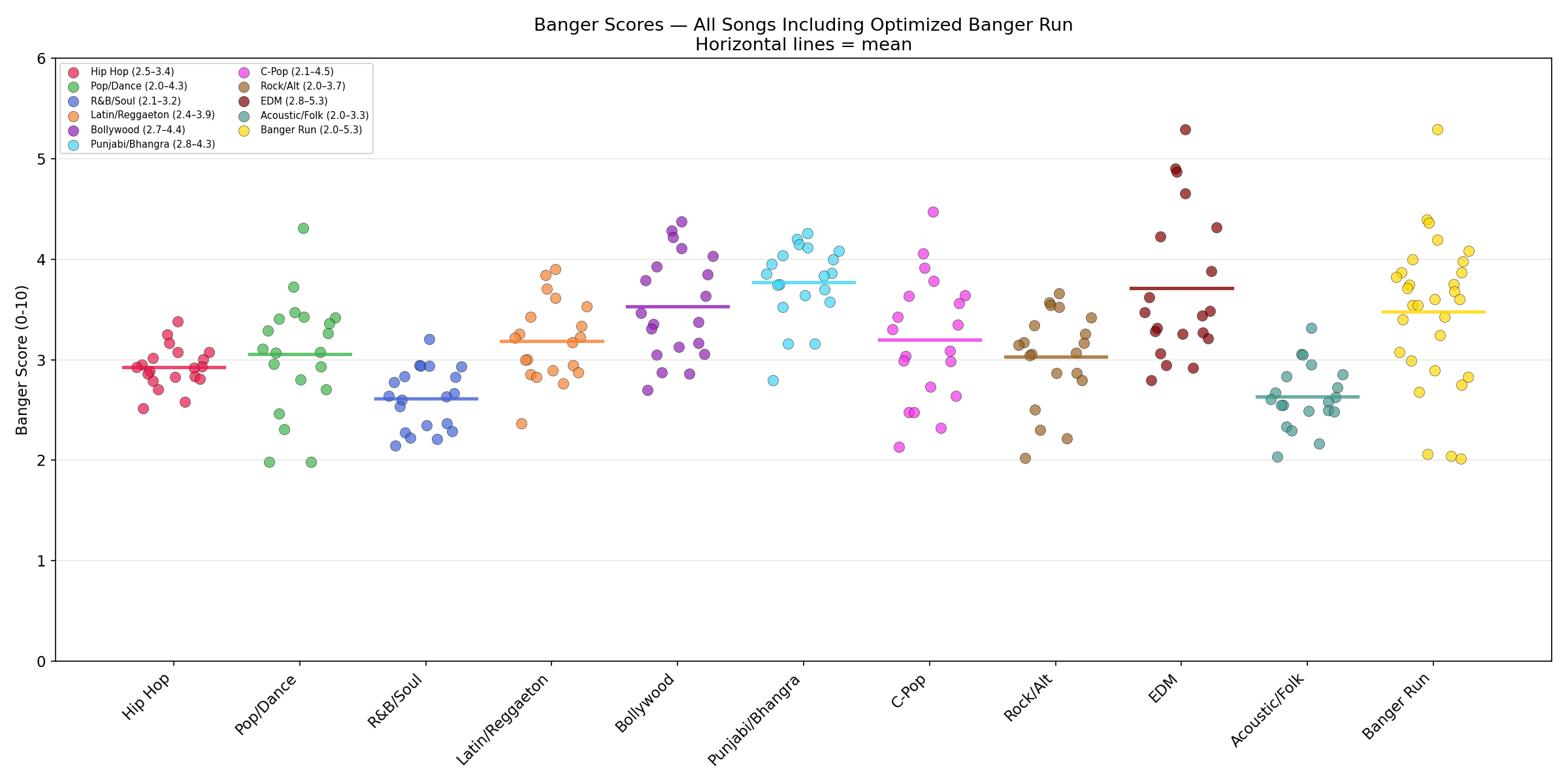
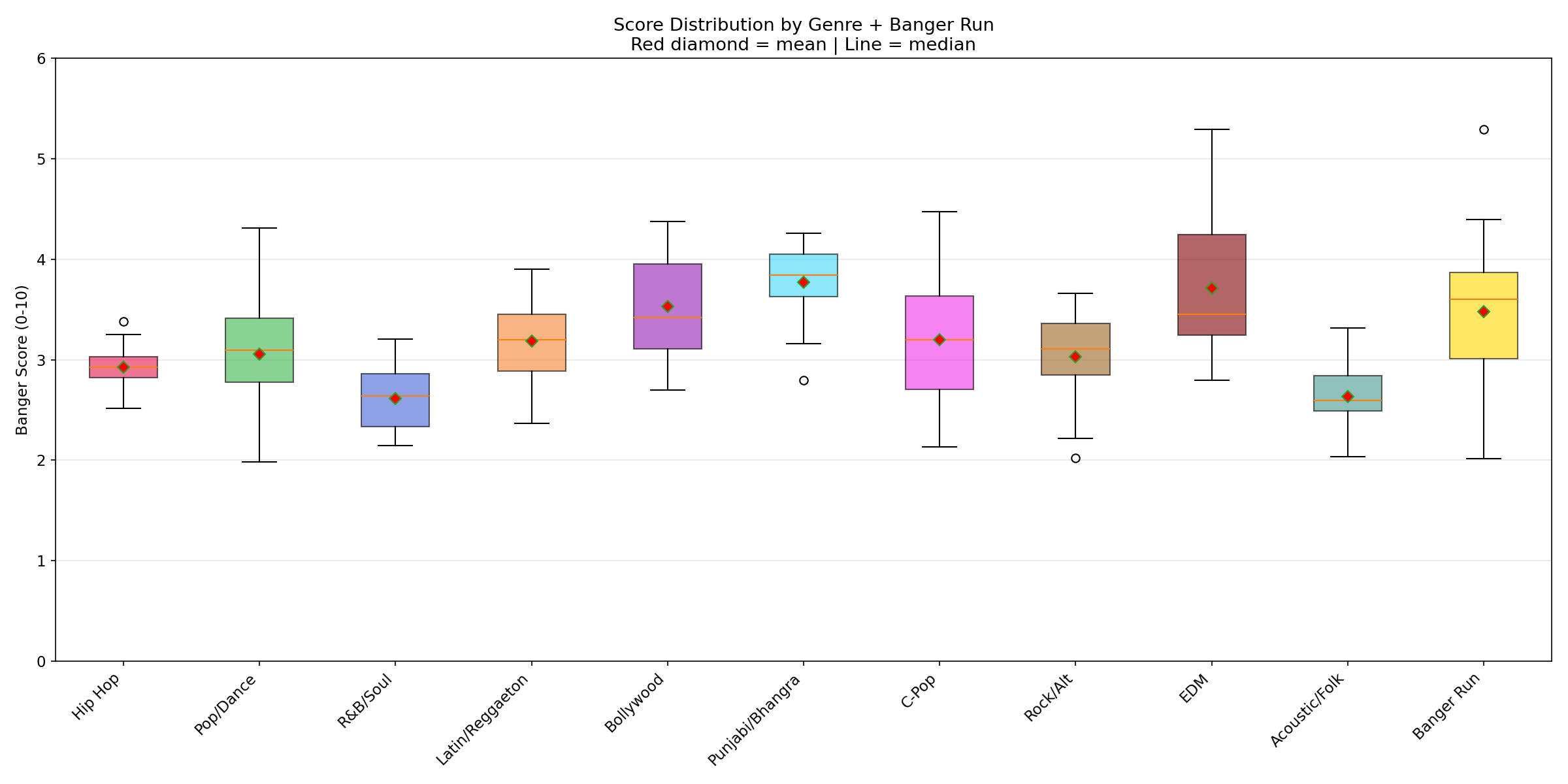
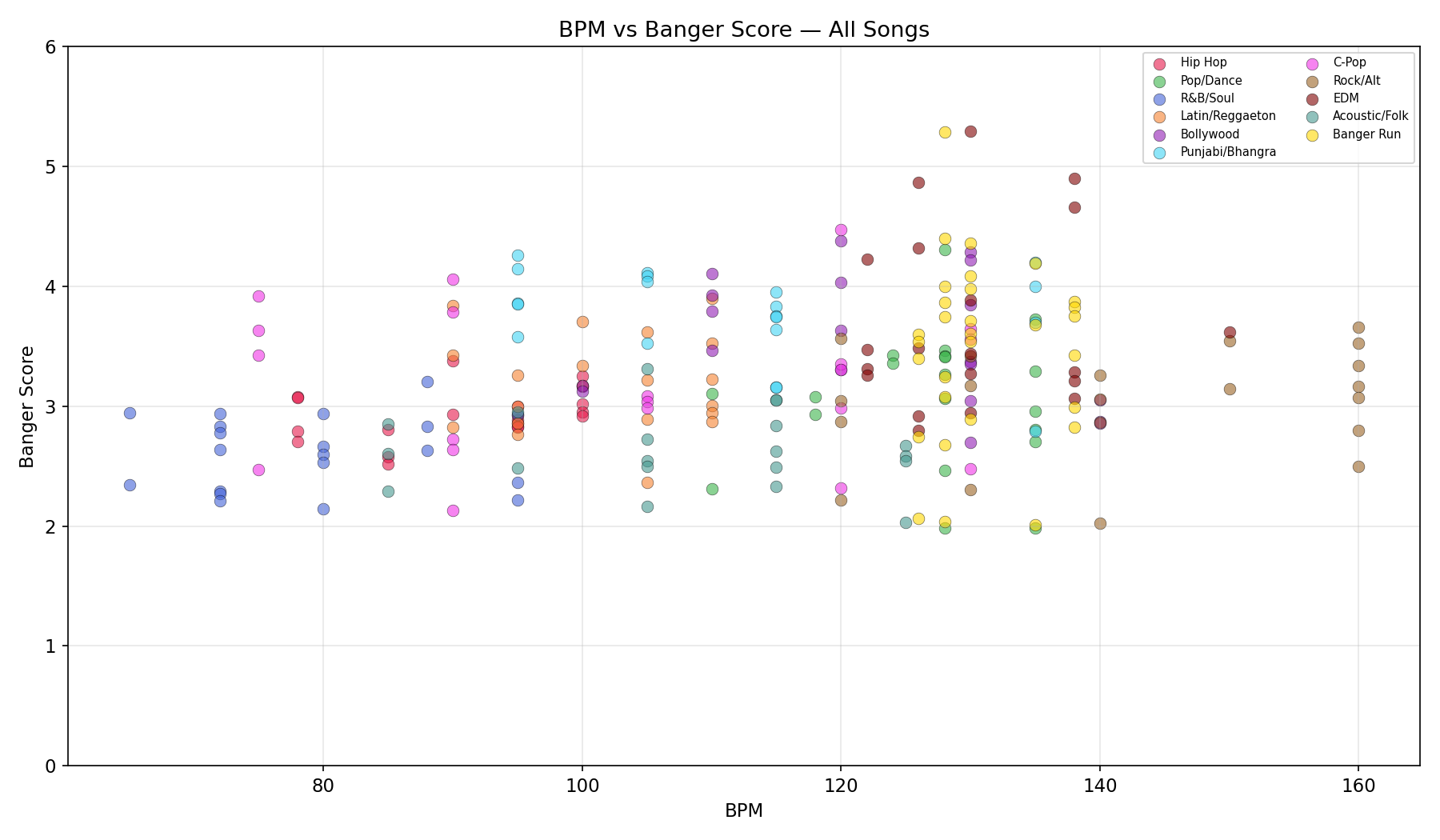
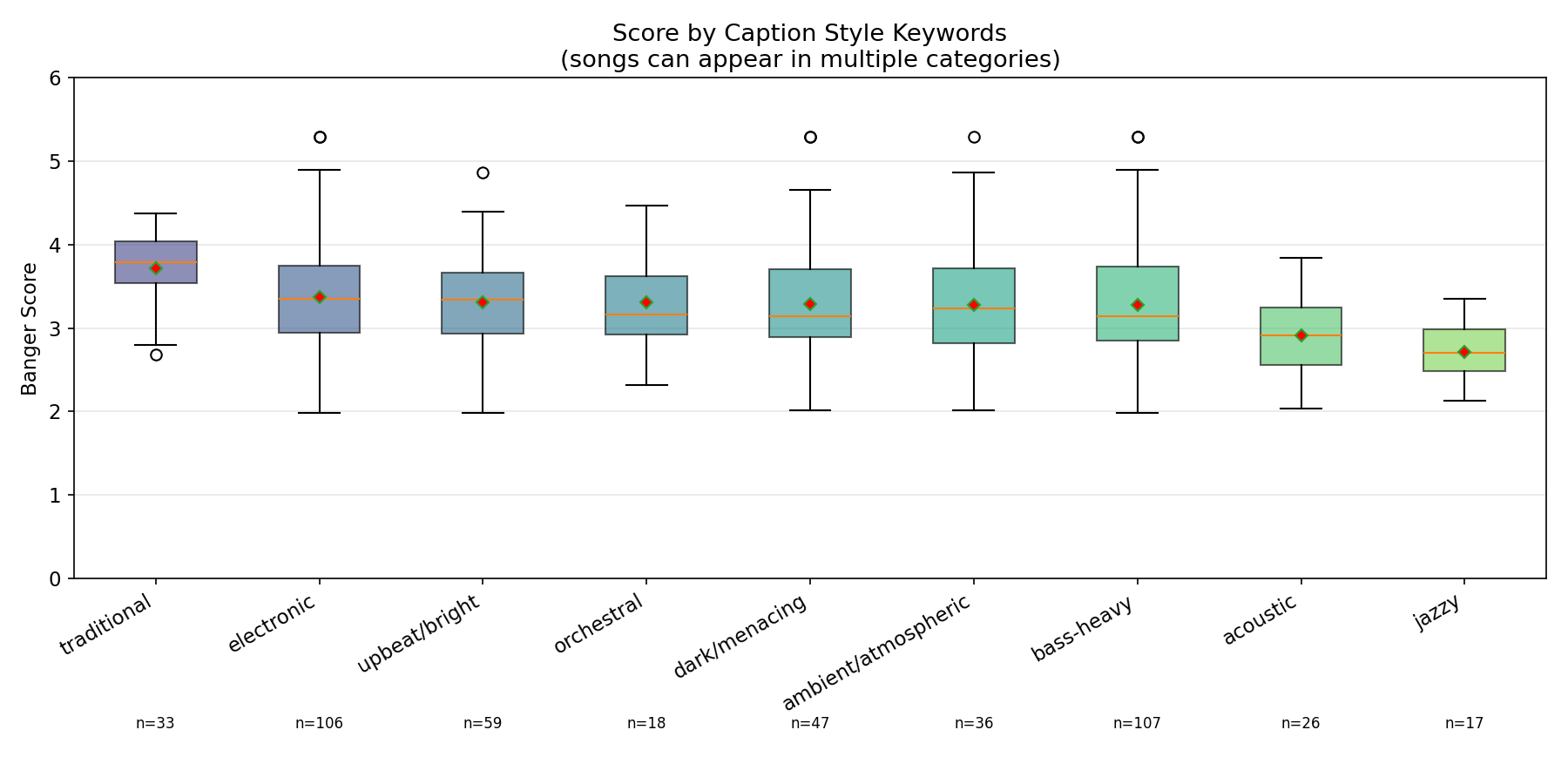
The scorer was tested on 230 songs generated with ACE-Step 1.5 across 10 genres (20 songs each) plus 1 banger-optimized run (30 songs). Languages included English, Spanish, Hindi, Punjabi, and Chinese.
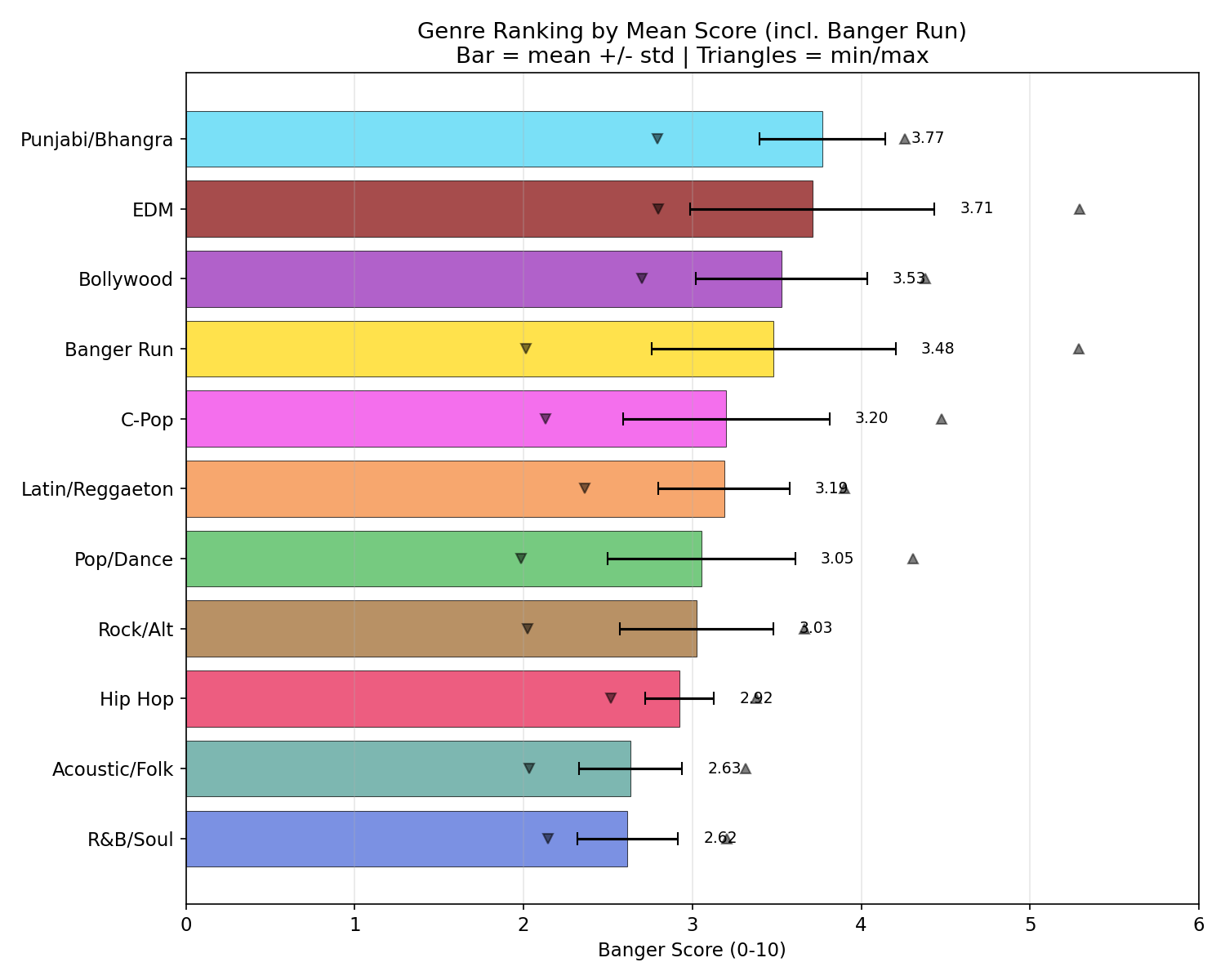
| Rank | Genre | Mean | Best | Range |
|---|---|---|---|---|
| 1 | Electronic/EDM | 3.71 | 5.29 | 2.80-5.29 |
| 2 | Punjabi/Bhangra | 3.77 | 4.26 | 2.79-4.26 |
| 3 | Bollywood | 3.53 | 4.38 | 2.70-4.38 |
| 4 | C-Pop | 3.20 | 4.47 | 2.13-4.47 |
| 5 | Latin/Reggaeton | 3.19 | 3.90 | 2.36-3.90 |
| 6 | Pop/Dance | 3.05 | 4.31 | 1.98-4.31 |
| 7 | Rock/Alternative | 3.03 | 3.66 | 2.02-3.66 |
| 8 | Hip Hop | 2.92 | 3.38 | 2.52-3.38 |
| 9 | Acoustic/Folk | 2.63 | 3.31 | 2.03-3.31 |
| 10 | R&B/Soul | 2.62 | 3.21 | 2.14-3.21 |
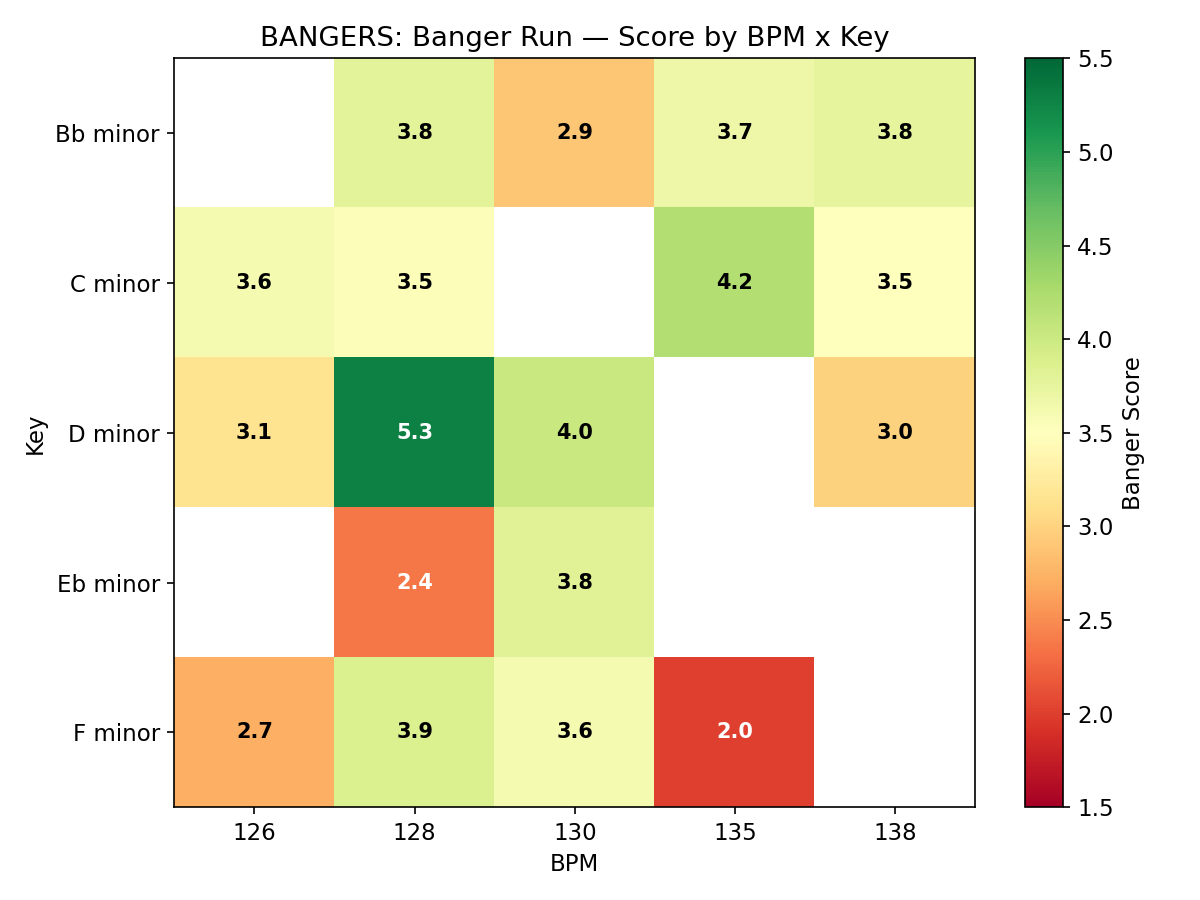
Overall best: Melodic techno, 130 BPM, Eb minor -- scored 5.29/10 (67th percentile of FMA).
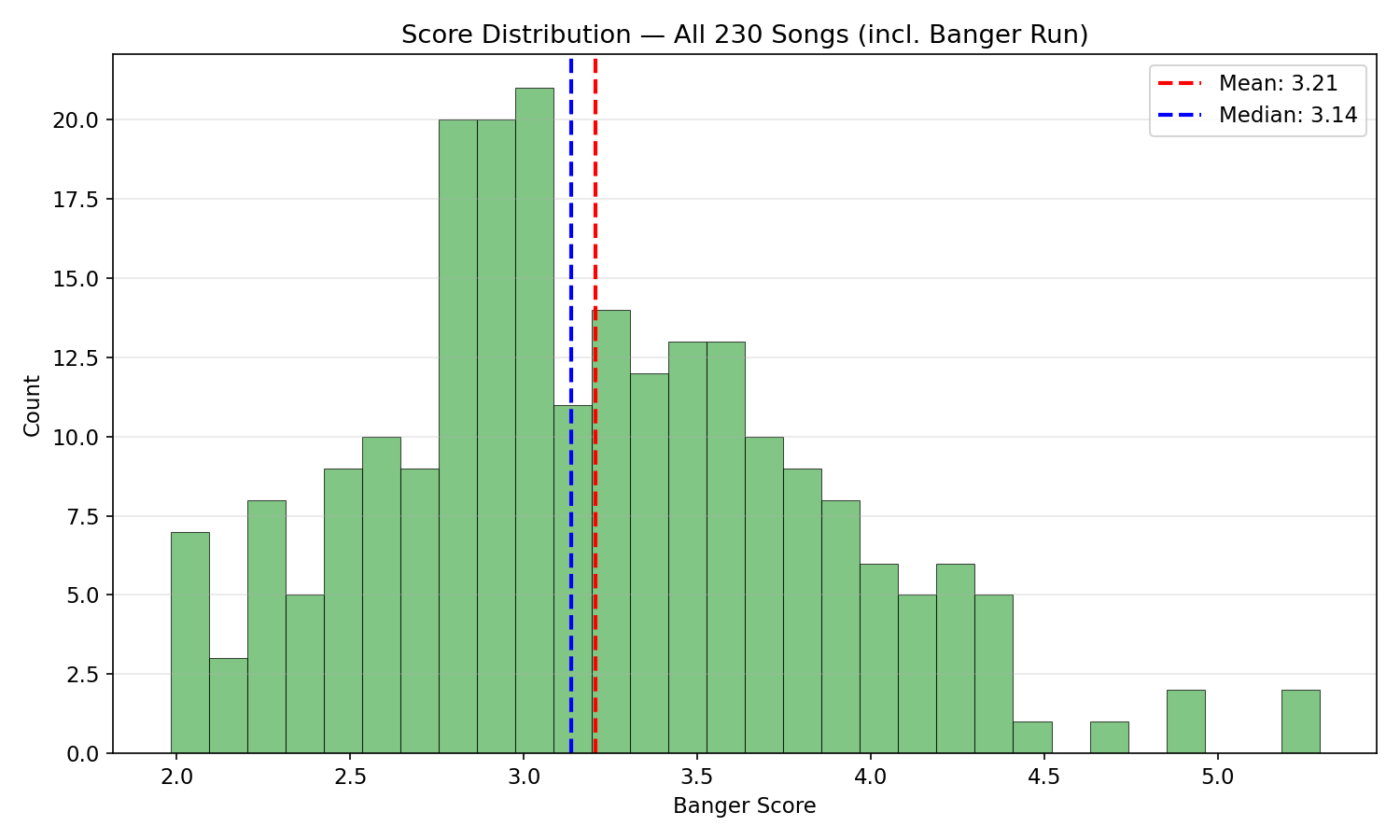
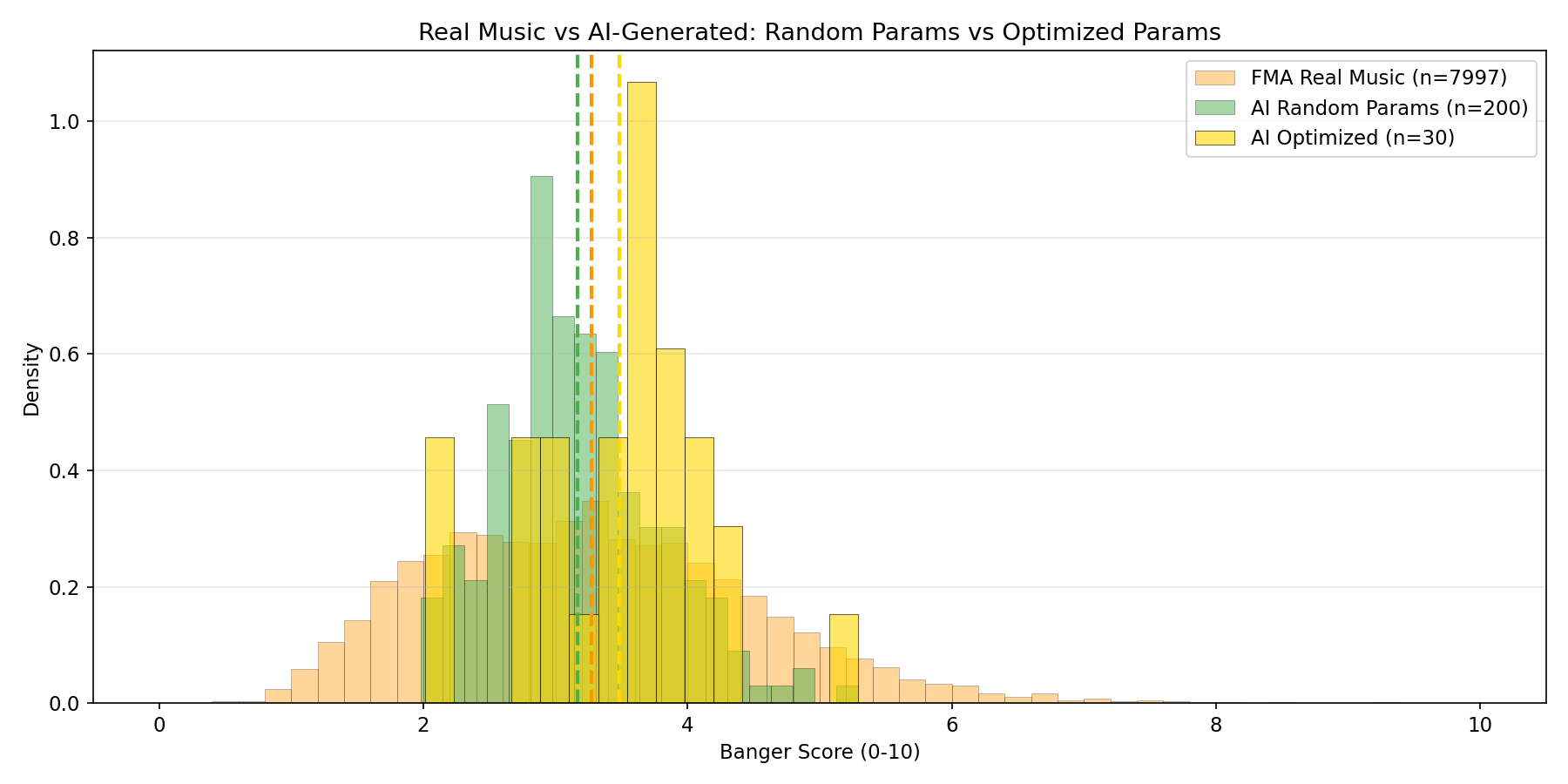
After analyzing the 200 random-parameter songs, a banger-optimized run of 30 songs was generated using only the highest-scoring parameter combinations (dark electronic/industrial styles, 126-138 BPM, minor keys only). Results:
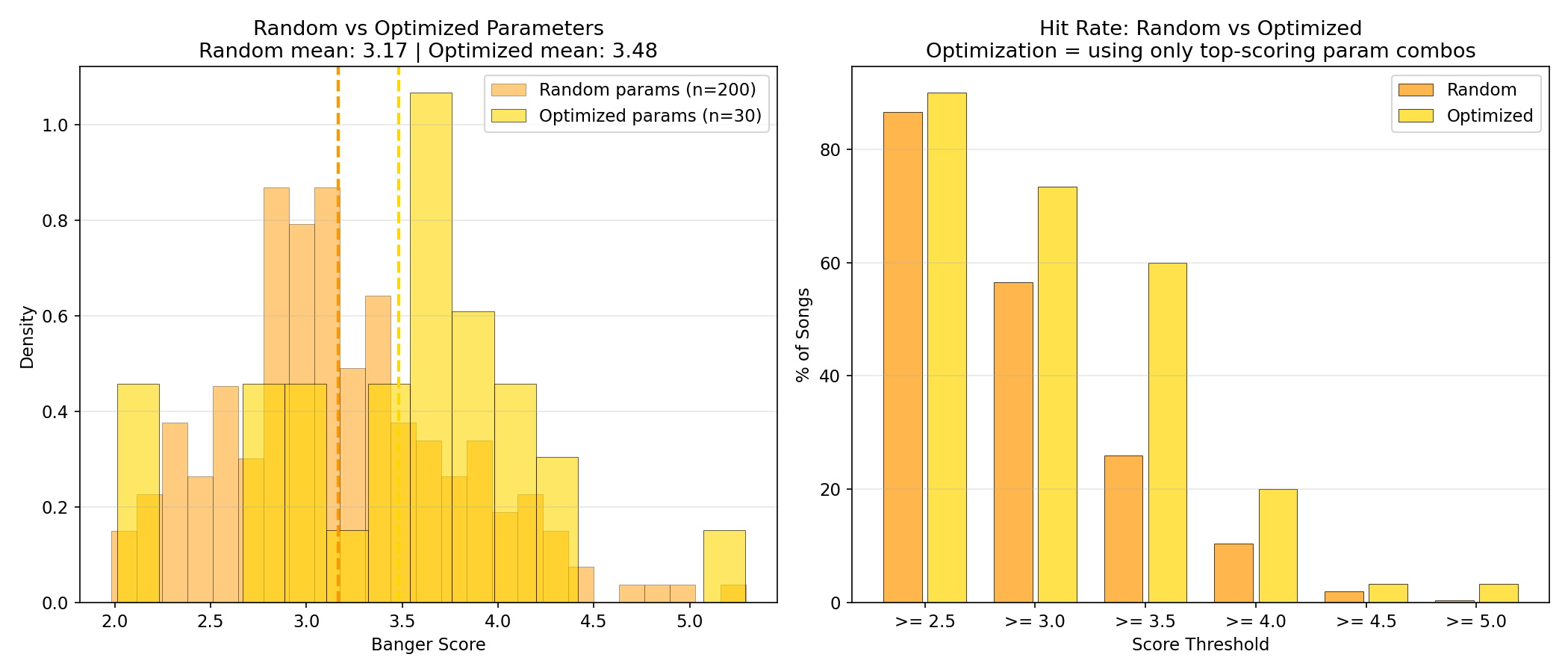
| Metric | Random (200 songs) | Optimized (30 songs) | Improvement |
|---|---|---|---|
| Mean score | 3.17 | 3.48 | +10% |
| Songs >= 3.5 | 20% | 60% | 3x |
| Songs >= 4.0 | 5% | 20% | 4x |
| Top score | 5.29 | 5.29 | Same ceiling |
The optimization raised the floor and consistency dramatically (4x hit rate for scores >= 4.0) without raising the ceiling.
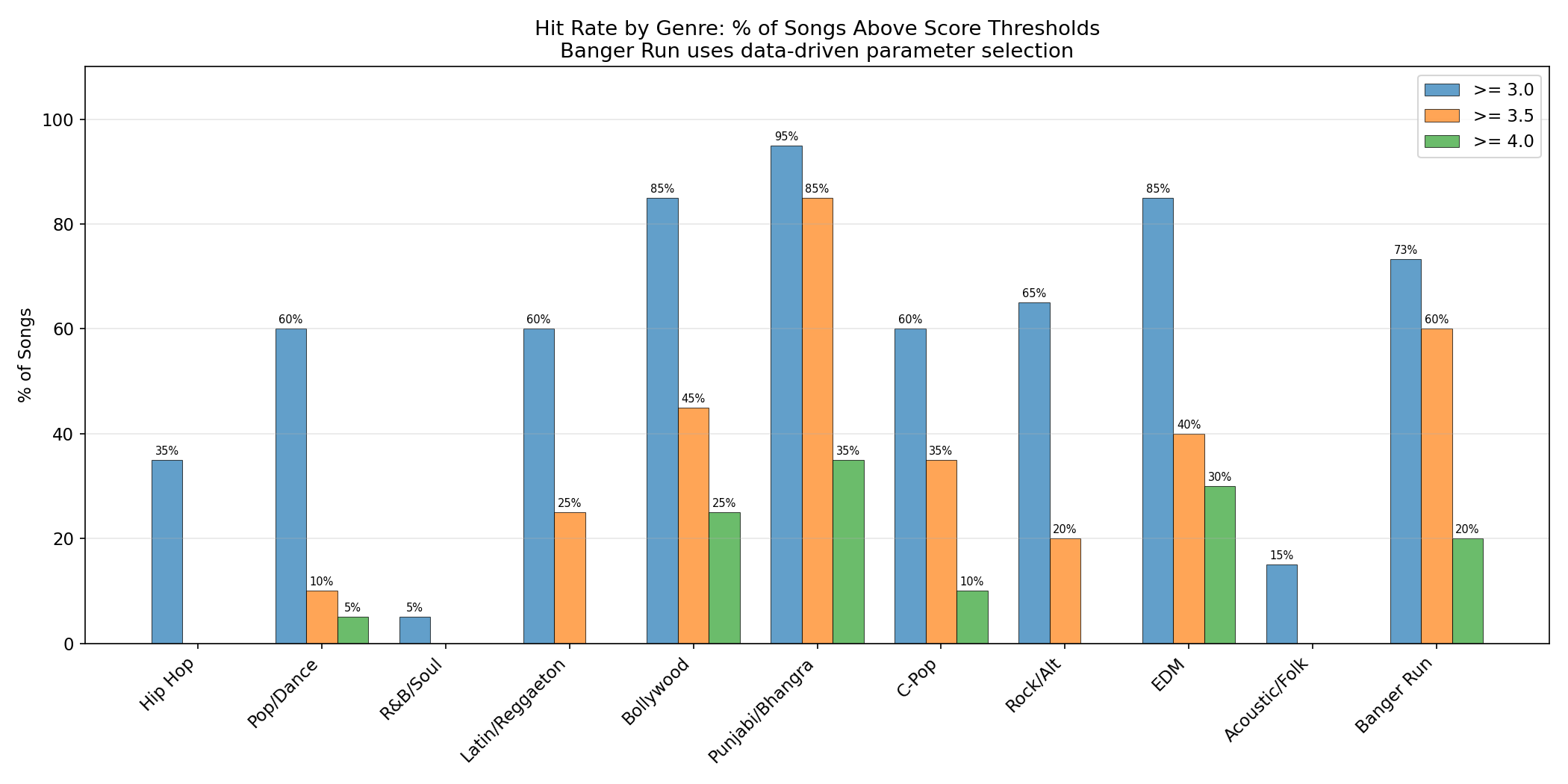
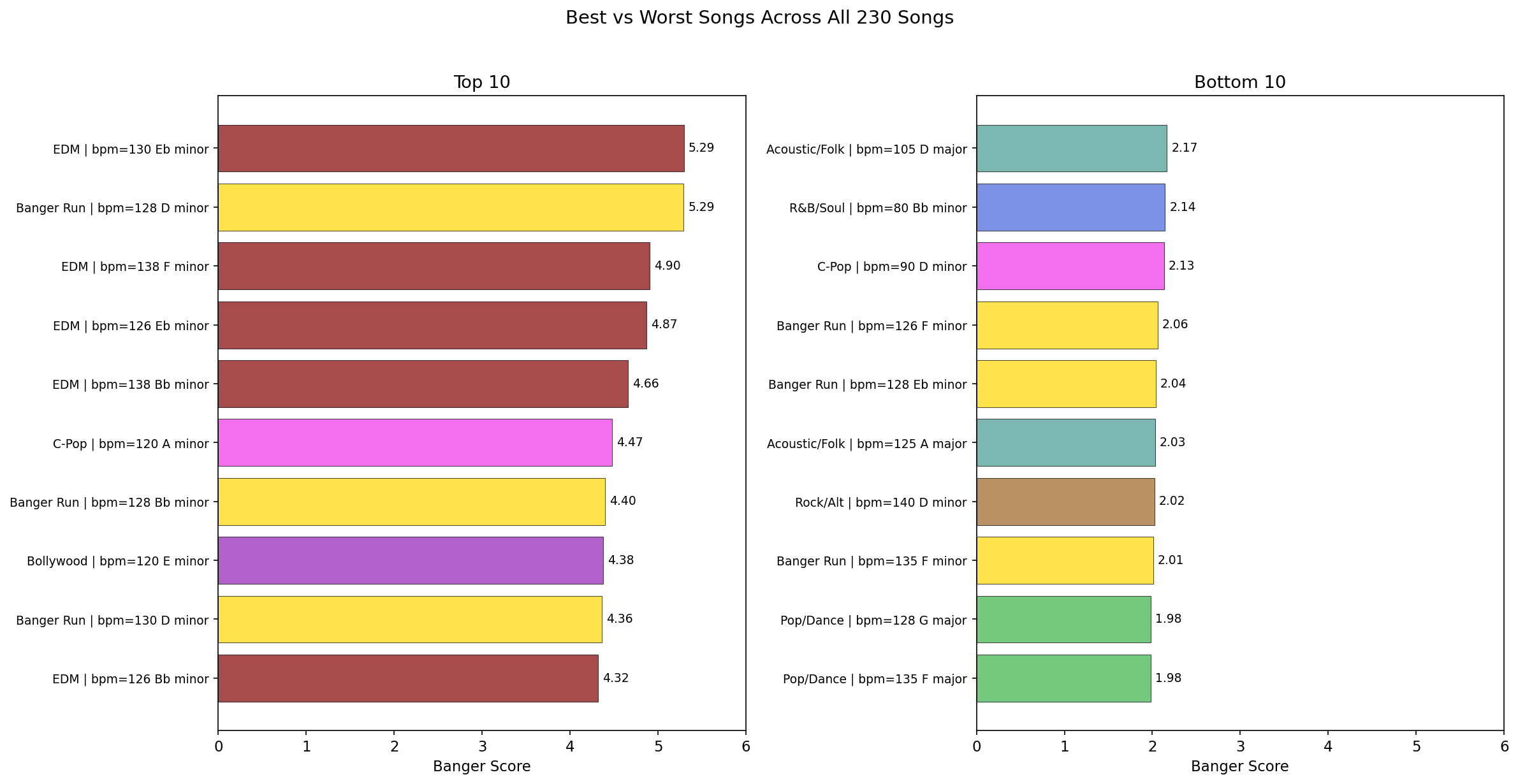
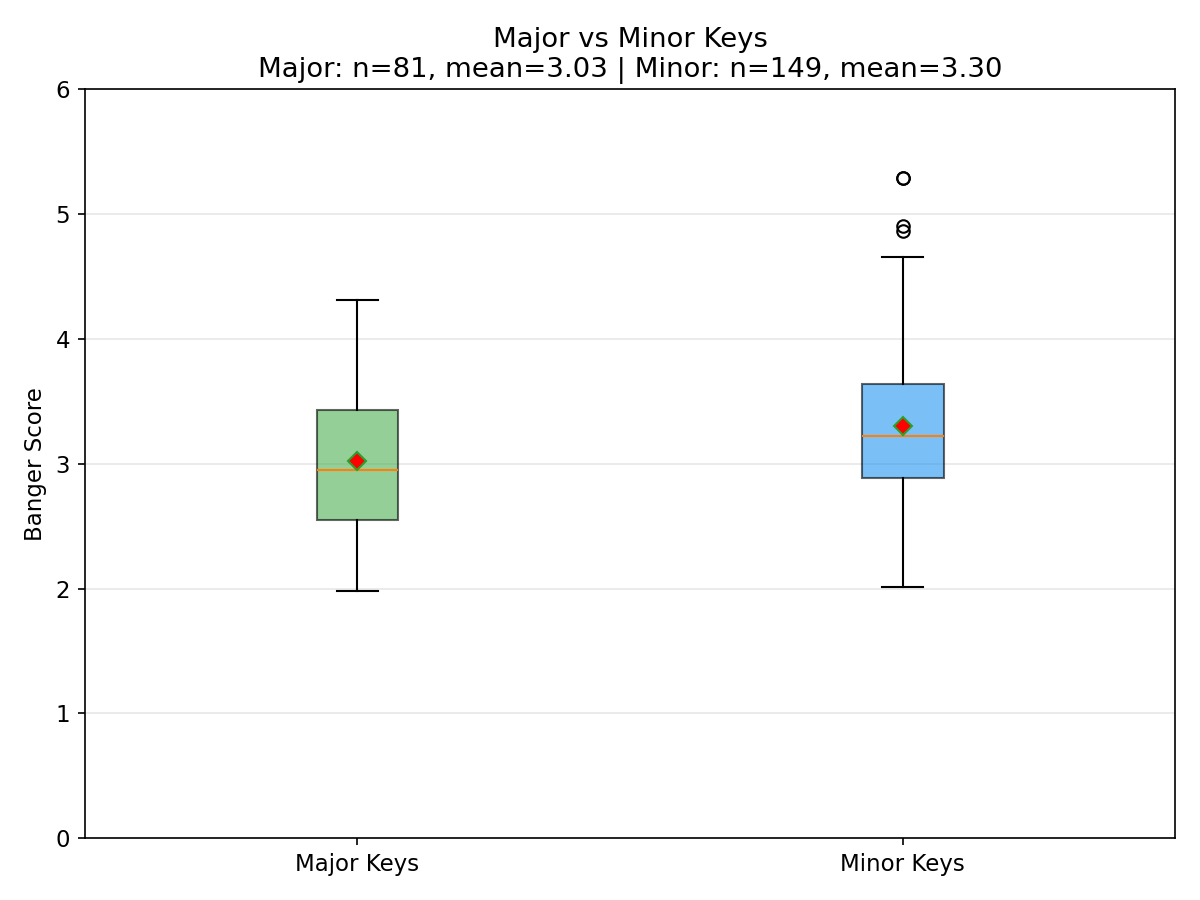
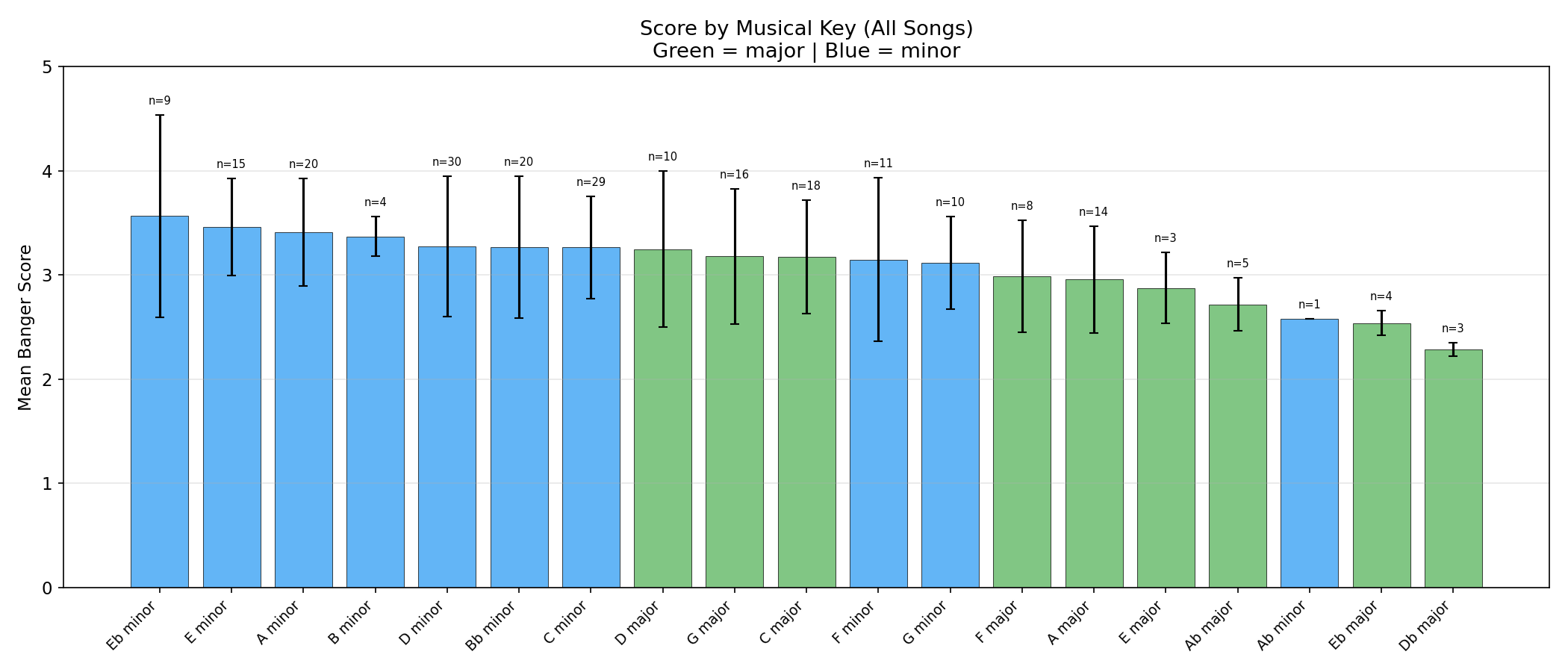
Key findings:
import torch
import librosa
import numpy as np
from transformers import AutoModel, AutoFeatureExtractor
# 1. Load MERT encoder
mert_name = "m-a-p/MERT-v1-330M"
feature_extractor = AutoFeatureExtractor.from_pretrained(mert_name, trust_remote_code=True)
mert = AutoModel.from_pretrained(mert_name, trust_remote_code=True)
mert.eval()
# 2. Load the scorer MLP
from huggingface_hub import hf_hub_download
import torch.nn as nn
class BangerScorer(nn.Module):
def __init__(self, input_dim=1024, dropout=0.3):
super().__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 512), nn.BatchNorm1d(512), nn.ReLU(), nn.Dropout(dropout),
nn.Linear(512, 256), nn.BatchNorm1d(256), nn.ReLU(), nn.Dropout(dropout),
nn.Linear(256, 128), nn.BatchNorm1d(128), nn.ReLU(), nn.Dropout(dropout / 2),
nn.Linear(128, 1),
)
def forward(self, x):
return self.net(x).squeeze(-1)
model_path = hf_hub_download("treadon/banger-scorer", "scorer_model.pt")
scorer = BangerScorer()
scorer.load_state_dict(torch.load(model_path, weights_only=True))
scorer.eval()
# 3. Score an audio file
waveform, _ = librosa.load("song.mp3", sr=24000, mono=True)
waveform = waveform[:24000 * 30] # truncate to 30s
inputs = feature_extractor(waveform, sampling_rate=24000, return_tensors="pt")
with torch.no_grad():
embedding = mert(**inputs).last_hidden_state.mean(dim=1) # (1, 1024)
score = scorer(embedding).item()
score = max(0, min(10, score)) # clamp to 0-10
print(f"Banger score: {score:.2f}/10")
Do: Use the scorer to rank songs relative to each other within a batch. Generate N candidates, score them all, keep the top K.
Don't: Treat the score as an absolute quality judgment. A song scoring 3.5 is not objectively "bad" -- it just means the model thinks it is less likely to be popular based on patterns learned from FMA play counts.
The scorer is most useful as a cheap, fast filter to surface promising candidates from a large batch of AI-generated music, reducing the amount of human listening needed.
If you use this model, please cite the MERT paper and the FMA dataset:
@article{li2023mert,
title={MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training},
author={Li, Yizhi and Yuan, Ruibin and Zhang, Ge and Ma, Yinghao and others},
journal={arXiv preprint arXiv:2306.00107},
year={2023}
}
@inproceedings{defferrard2017fma,
title={FMA: A Dataset For Music Analysis},
author={Defferrard, Micha{\"e}l and Benzi, Kirell and Vandergheynst, Pierre and Bresson, Xavier},
booktitle={ISMIR},
year={2017}
}
treadon on HuggingFace
For other projects and writeups, see riteshkhanna.com, follow @treadon on X, or treadon on Hugging Face.