
code stringlengths 38 801k | repo_path stringlengths 6 263 |
|---|---|
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: causalm1
# language: python
# name: causalm1
# ---
# # Causal Graphical Models
#
# In this section, we explore what are known as causal graphical models (CGM), which are essentially Bayesian networks where edges imply causal influence rather then just probabilistic dependence.
#
# CGMs are assumed to be acyclic, meaning they do not have cycles among their variables.
# +
import networkx as nx
# from causalscm.cgm import CausalGraphicalModel
# from pgmpy.models import BayesianNetwork
import matplotlib.pyplot as plt
# -
# ## Causally Sufficient Models
#
# Here, we don't have any latent variables. We demonstrate how a CGM works in code and what we can do with it.
#
# We also demonstrate Clustered DAGs (CDAGs), which form from a cluster of variables, which is represented underneath the hood with two graphs. One consisting of all the variables denoting the cluster ID in the metadata, and another consisting of the graph between clusters. The first graph may be incompletely specified, since we do not require the edges within a cluster be fully specified.
#
# Based on knowledge of CDAGs, we know that d-separation is complete.
dag = nx.MultiDiGraph()
dag.add_edge('A', 'B', key='direct')
dag.add_edge('A', 'B', key='bidirected')
dag.add_edge('B', 'A', key='bidirected')
dag.add_edge('C', 'B', key='direct')
print(dag.edges)
# +
print(dag)
G = dag
pos = nx.random_layout(dag)
node_sizes = [3 + 10 * i for i in range(len(G))]
M = G.number_of_edges()
edge_colors = range(2, M + 2)
edge_alphas = [(5 + i) / (M + 4) for i in range(M)]
cmap = plt.cm.viridis
# nx.draw_networkx(dag, pos=pos)
nodes = nx.draw_networkx_nodes(G, pos, node_size=node_sizes, node_color="indigo")
directed_edges = nx.draw_networkx_edges(
G,
pos,
edgelist=[('A', 'B', 'direct'), ('C', 'B', 'direct')],
node_size=node_sizes,
arrowstyle="->",
arrowsize=10,
# edge_color=edge_colors,
edge_cmap=cmap,
width=2,
# connectionstyle="arc3,rad=0.1"
)
bd_edges = nx.draw_networkx_edges(
G,
pos,
edgelist=[('A', 'B', 'bidirected')],
node_size=node_sizes,
style='dotted',
# arrowstyle="->",
arrowsize=10,
# edge_color=edge_colors,
edge_cmap=cmap,
width=2,
connectionstyle="arc3,rad=0.4"
)
bd_edges = nx.draw_networkx_edges(
G,
pos,
edgelist=[('B', 'A', 'bidirected')],
node_size=node_sizes,
style='dotted',
# arrowstyle="->",
arrowsize=10,
# edge_color=edge_colors,
edge_cmap=cmap,
width=2,
connectionstyle="arc3,rad=-0.4"
)
print(edges)
# set alpha value for each edge
# for i in range(M):
# edges[i].set_alpha(edge_alphas[i])
print(nx.d_separated(G, 'C', 'A', {}))
# -
nodes = [
'a', 'b', 'c', 'd', 'e'
]
cgm = CausalGraphicalModel(ebunch=nodes)
| examples/cgm.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .r
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: R [conda env:py3_physeq]
# language: R
# name: conda-env-py3_physeq-r
# ---
# + [markdown] toc=true
# <h1>Table of Contents<span class="tocSkip"></span></h1>
# <div class="toc"><ul class="toc-item"><li><span><a href="#Goal" data-toc-modified-id="Goal-1"><span class="toc-item-num">1 </span>Goal</a></span></li><li><span><a href="#Var" data-toc-modified-id="Var-2"><span class="toc-item-num">2 </span>Var</a></span><ul class="toc-item"><li><span><a href="#Init" data-toc-modified-id="Init-2.1"><span class="toc-item-num">2.1 </span>Init</a></span></li></ul></li><li><span><a href="#DeepMAsED-SM" data-toc-modified-id="DeepMAsED-SM-3"><span class="toc-item-num">3 </span>DeepMAsED-SM</a></span><ul class="toc-item"><li><span><a href="#Config" data-toc-modified-id="Config-3.1"><span class="toc-item-num">3.1 </span>Config</a></span></li><li><span><a href="#Run" data-toc-modified-id="Run-3.2"><span class="toc-item-num">3.2 </span>Run</a></span></li></ul></li><li><span><a href="#--WAITING--" data-toc-modified-id="--WAITING---4"><span class="toc-item-num">4 </span>--WAITING--</a></span></li><li><span><a href="#Summary" data-toc-modified-id="Summary-5"><span class="toc-item-num">5 </span>Summary</a></span><ul class="toc-item"><li><span><a href="#Communities" data-toc-modified-id="Communities-5.1"><span class="toc-item-num">5.1 </span>Communities</a></span></li><li><span><a href="#Feature-tables" data-toc-modified-id="Feature-tables-5.2"><span class="toc-item-num">5.2 </span>Feature tables</a></span><ul class="toc-item"><li><span><a href="#No.-of-contigs" data-toc-modified-id="No.-of-contigs-5.2.1"><span class="toc-item-num">5.2.1 </span>No. of contigs</a></span></li><li><span><a href="#Misassembly-types" data-toc-modified-id="Misassembly-types-5.2.2"><span class="toc-item-num">5.2.2 </span>Misassembly types</a></span></li></ul></li></ul></li><li><span><a href="#sessionInfo" data-toc-modified-id="sessionInfo-6"><span class="toc-item-num">6 </span>sessionInfo</a></span></li></ul></div>
# -
# # Goal
#
# * Replicate metagenome assemblies using intra-spec training genome dataset
# * Richness = 0.7 (70% of all ref genomes used)
# # Var
# +
ref_dir = '/ebio/abt3_projects/databases_no-backup/DeepMAsED/GTDB_ref_genomes/intraSpec/'
ref_file = file.path(ref_dir, 'GTDBr86_genome-refs_train_clean.tsv')
work_dir = '/ebio/abt3_projects/databases_no-backup/DeepMAsED/train_runs/intra-species/diff_richness/n1000_r6_rich0p7/'
# params
pipeline_dir = '/ebio/abt3_projects/databases_no-backup/bin/deepmased/DeepMAsED-SM/'
# -
# ## Init
library(dplyr)
library(tidyr)
library(ggplot2)
library(data.table)
source('/ebio/abt3_projects/software/dev/DeepMAsED/bin/misc_r_functions/init.R')
#' "cat {file}" in R
cat_file = function(file_name){
cmd = paste('cat', file_name, collapse=' ')
system(cmd, intern=TRUE) %>% paste(collapse='\n') %>% cat
}
# # DeepMAsED-SM
# ## Config
config_file = file.path(work_dir, 'config.yaml')
cat_file(config_file)
# ## Run
# ```
# (snakemake_dev) @ rick:/ebio/abt3_projects/databases_no-backup/bin/deepmased/DeepMAsED-SM
# $ screen -L -S DM-intraS-rich0.7 ./snakemake_sge.sh /ebio/abt3_projects/databases_no-backup/DeepMAsED/train_runs/intra-species/diff_richness/n1000_r6_rich0p7/config.yaml cluster.json /ebio/abt3_projects/databases_no-backup/DeepMAsED/train_runs/intra-species/diff_richness/n1000_r6_rich0p7/SGE_log 48
# ```
# # Summary
# ## Communities
comm_files = list.files(file.path(work_dir, 'MGSIM'), 'comm_wAbund.txt', full.names=TRUE, recursive=TRUE)
comm_files %>% length %>% print
comm_files %>% head
comms = list()
for(F in comm_files){
df = read.delim(F, sep='\t')
df$Rep = basename(dirname(F))
comms[[F]] = df
}
comms = do.call(rbind, comms)
rownames(comms) = 1:nrow(comms)
comms %>% dfhead
# +
p = comms %>%
mutate(Perc_rel_abund = ifelse(Perc_rel_abund == 0, 1e-5, Perc_rel_abund)) %>%
group_by(Taxon) %>%
summarize(mean_perc_abund = mean(Perc_rel_abund),
sd_perc_abund = sd(Perc_rel_abund)) %>%
ungroup() %>%
mutate(neg_sd_perc_abund = mean_perc_abund - sd_perc_abund,
pos_sd_perc_abund = mean_perc_abund + sd_perc_abund,
neg_sd_perc_abund = ifelse(neg_sd_perc_abund <= 0, 1e-5, neg_sd_perc_abund)) %>%
mutate(Taxon = Taxon %>% reorder(-mean_perc_abund)) %>%
ggplot(aes(Taxon, mean_perc_abund)) +
geom_linerange(aes(ymin=neg_sd_perc_abund, ymax=pos_sd_perc_abund),
size=0.3, alpha=0.3) +
geom_point(size=0.5, alpha=0.4, color='red') +
labs(y='% abundance') +
theme_bw() +
theme(
axis.text.x = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.minor.y = element_blank()
)
dims(10,2.5)
plot(p)
# -
dims(10,2.5)
plot(p + scale_y_log10())
# ## Feature tables
feat_files = list.files(file.path(work_dir, 'map'), 'features.tsv.gz', full.names=TRUE, recursive=TRUE)
feat_files %>% length %>% print
feat_files %>% head
feats = list()
for(F in feat_files){
cmd = glue::glue('gunzip -c {F}', F=F)
df = fread(cmd, sep='\t') %>%
distinct(contig, assembler, Extensive_misassembly)
df$Rep = basename(dirname(dirname(F)))
feats[[F]] = df
}
feats = do.call(rbind, feats)
rownames(feats) = 1:nrow(feats)
feats %>% dfhead
# ### No. of contigs
# +
feats_s = feats %>%
group_by(assembler, Rep) %>%
summarize(n_contigs = n_distinct(contig)) %>%
ungroup
feats_s$n_contigs %>% summary
# -
# ### Misassembly types
# +
p = feats %>%
mutate(Extensive_misassembly = ifelse(Extensive_misassembly == '', 'None',
Extensive_misassembly)) %>%
group_by(Extensive_misassembly, assembler, Rep) %>%
summarize(n = n()) %>%
ungroup() %>%
ggplot(aes(Extensive_misassembly, n, color=assembler)) +
geom_boxplot() +
scale_y_log10() +
labs(x='metaQUAST extensive mis-assembly', y='Count') +
coord_flip() +
theme_bw() +
theme(
axis.text.x = element_text(angle=45, hjust=1)
)
dims(8,4)
plot(p)
# -
# # sessionInfo
sessionInfo()
| notebooks/01_simulation_datasets/05_train-test_intra-species_diff-richness/.ipynb_checkpoints/05_sim_train_n1000_r6_rich0p7-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: env1
# language: python
# name: env1
# ---
# +
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# %matplotlib inline
import plotly.offline as pyo
import plotly.graph_objs as go
import folium
import branca.colormap as cm
from functools import reduce
import os
import sys
sys.path.insert(0, "/Users/homebase/Documents/Projects/Final/scraping MTA/ganymede")
import myfunctions
# -
#
# #Project Structure Steps
#
# 1. Scrape (url = 'http://web.mta.info/developers/turnstile.html' )
# 2. Data Formating and Cleaning
# 3. Visualization Options. Viz.Technique I want to follow.
# 4. Create either a Notebook or a Dashboard (Flask or Dash)
data = pd.read_csv('turnstile_191019.txt')
#data.info()
data.head()
# +
#here is a process of finding a unuque id of a station
#m = data.drop(['DATE', 'TIME', 'DESC', 'ENTRIES', 'SCP', 'UNIT', 'EXITS '],axis=1)
#m = m.drop_duplicates()
#m["LINENAME2"] = m["LINENAME"].apply(sorted).apply("".join)
#m = m.drop(["LINENAME", "C/A", "DIVISION"], axis=1)
#m = m.drop_duplicates()
#m = m.loc[m.STATION == '59 ST']
#m.head(100)
#Gotha! now, put it into a func: and copy a working func into 'myfunctions.py'
def unique_station(df, colname):
df["LINENAME2"] = df["LINENAME"].apply(sorted).apply("".join)
df[colname] = df["STATION"] + "-" + df["LINENAME2"]
df = df.drop(["LINENAME2"], axis=1)
return df
m2 = unique_station(data, "station_id")
m2.head()
#period = '10/12/2019' - '10/18/2019'
#weekz = m2['DATE'].min()
#weekz
# +
#Test: add a weekday
#y = myfunctions.myweekday(data)
#y.head()
# +
#data.duplicated().value_counts()
# +
#noDuplicated_data = data.drop_duplicates()
#noDuplicated_data.info()
# +
#noDuplicated_data.duplicated().value_counts()
# -
data.info()
#test export raw data into csv file
MData = data.to_csv(r'MData.csv')
MData = pd.read_csv('MData.csv')
MData.head()
MData_drop = MData.drop(['C/A','Unnamed: 0','DIVISION','DESC'],axis=1)
MData_drop.head()
MData_drop.columns
#or 'df.columns = df.columns.str.strip()'
MData_drop.rename(columns = {'EXITS ':'EXITS'}, inplace = True)
MData_drop.columns
# +
# read geo tag DF in here
#geo = pd.read_csv('~/Documents/Projects/Final/scraping MTA/geocoded TITLED.csv')
#geo_drop = geo.drop(['C/A','STATION','LINENAME','Unnamed: 4'],axis=1)
#geo_drop.head()
# +
# MERGE 2 DF GEOTAGS AND MAIN _42STBRYANTPK_BDFM7 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '42 ST-BRYANT PK']
#merged_inner = pd.merge(left=MData_drop,right=geo_drop, how='left', on='UNIT')
#merged_inner.head()
# +
#rename geotagged & get back to work
#MData_calculate_remaining = merged_inner
# +
#count flow in the station
#MData_calculate_remaining = MData_drop.assign(IN_STATION = MData_drop['ENTRIES'] - MData_drop['EXITS'])
# -
MData_calculate_remaining = MData_drop
#MData_calculate_remaining['WEEKDAY'] = pd.to_datetime(MData_calculate_remaining['DATE']).dt.weekday_name
#MData_calculate_remaining.head()
#just to see up
#or
#myfunctions.myweekday(MData_calculate_remaining)
#MData_calculate_remaining.head()
# +
#assign lat and lon to the station location
#MData_calculate_remaining = MData_calculate_remaining.assign(LAT = 40.7628, LON = -73.9676)
#MData_calculate_remaining.head()
# +
#assign lat and lon to the station location
#MData_calculate_remaining = MData_calculate_remaining.assign(LAT = 40.7628, LON = -73.9676)
#MData_calculate_remaining.head()
#test1: Works: pin one location in bue on the map by hand, save into html file
#map = folium.Map(location = [40.7628, -73.9676], zoom_start = 90, tiles = 'Stamen Terrain')
#folium.CircleMarker(location=[40.7628, -73.9676],
# popup = "59THST (NQR456W trains)",
# radius = 10,
# color = 'blue',
# fill = True).add_to(map)
#map.save('index10.html')
#or call it from myfunctions
myfunctions.map59th()
#TODO plot all the stations on the map
# -
MData_calculate_remaining.head()
whole_city = MData_calculate_remaining
#Let's osolate MIDTOWNT only:
midtown_59 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '59 ST']
_50ST_DCE1 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '50 ST']
_5AV59ST_NQRW = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '5 AV/59 ST']
_57ST7AV_NQRW = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '57 ST-7 AV']
_5AVE_7BDFM = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '5 AVE']
_49ST_NQRW = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '49 ST']
_TIMESSQ42ST_ACENQRS1237W = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == 'TIMES SQ-42 ST']
_42STPORTAUTH_ACENGRS1237WQ = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '42 ST-PORT AUTH']
_7AV_BDE_BQ_FG = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '7 AV']
_59STCOLUMBUS_ABCD1 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '59 ST COLUMBUS']
_5AV53ST_EM = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '5 AV/53 ST']
_LEXINGTONAV53_EM6 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == 'LEXINGTON AV/53']
_47_50STSROCK_BDFM = MData_calculate_remaining.loc[MData_calculate_remaining.STATION =='47-50 STS ROCK']
_42STBRYANTPK_BDFM7 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '42 ST-BRYANT PK']
_57ST_F = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '57 ST']
_GRDCNTRL42ST_4567S = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == 'GRD CNTRL-42 ST']
_51ST_6 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '51 ST']
midtown = [midtown_59, _50ST_DCE1, _5AV59ST_NQRW, _57ST7AV_NQRW, _5AVE_7BDFM, _49ST_NQRW, _TIMESSQ42ST_ACENQRS1237W, _42STPORTAUTH_ACENGRS1237WQ, _7AV_BDE_BQ_FG, _59STCOLUMBUS_ABCD1, _5AV53ST_EM, _LEXINGTONAV53_EM6, _47_50STSROCK_BDFM, _42STBRYANTPK_BDFM7, _57ST_F, _GRDCNTRL42ST_4567S, _51ST_6]
midtown_17 = pd.concat(midtown)
#then sort an order in LINENAME
midtown_17 = myfunctions.unique_station(midtown_17, "station_id")
midtown_17.head()
midtown_17.tail()
#_59THST_NQR456W = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '59 ST']
midtown_17['WEEKDAY'] = pd.to_datetime(midtown_17['DATE']).dt.weekday_name
midtown_17.head()
# +
#Merge 'SCP' & 'STATION' for unique turnstiles
_59THST_NQR456W = midtown_17
_59THST_NQR456W['SCP_STATION']=_59THST_NQR456W['SCP']+ '__' + _59THST_NQR456W['STATION']+ '__' +_59THST_NQR456W['UNIT']
turnstiles = _59THST_NQR456W['SCP_STATION'].unique()
#turnstiles
#3 Checking what lines are coming to this station
#_59THST_NQR456W['LINENAME'].unique()
#4 Saving the data into a new cvs file
#_59THST_NQR456Wfile = _59THST_NQR456W.to_csv(r'_59THST_NQR456W.csv')
#2 Printing a head of a table
#_59THST_NQR456W.head()
# +
# devide the df-s by turnstiles
turnstile_dfs = []
for turnstile in turnstiles:
#print(turnstile)
turnstile_dfs.append(_59THST_NQR456W.loc[_59THST_NQR456W.SCP_STATION == turnstile])
turnstile_dfs[0].head()
# +
whole_city['SCP_STATION']=whole_city['SCP']+ '__' + whole_city['STATION']+ '__' + whole_city['UNIT']
turnstiles_whole = whole_city['SCP_STATION'].unique()
turnstile_dfs_whole = []
for turnstile in turnstiles_whole:
turnstile_dfs_whole.append(whole_city.loc[whole_city.SCP_STATION == turnstile])
turnstile_dfs_whole[0].head()
# +
#turnstile_dfs_diff = []
#for dfs in turnstile_dfs:
#dfs2 = dfs.copy()
#dfs2['entries_diff'] = dfs2['ENTRIES'].diff()
#turnstile_dfs_diff.append(dfs2)
#OR
turnstile_dfs_diff = myfunctions.addDiffs(turnstile_dfs, "ENTRIES", 'ENTRIES_diff')
#show 1st df in a list of df-s:
turnstile_dfs_diff[0].head()
# -
turnstile_dfs_diff_both = myfunctions.addDiffs(turnstile_dfs_diff, "EXITS", 'EXITS_diff')
turnstile_dfs_diff_both[0].head()
whole_1 = myfunctions.addDiffs(turnstile_dfs_whole, "ENTRIES", 'ENTRIES_diff')
whole = myfunctions.addDiffs(whole_1, "EXITS", 'EXITS_diff')
whole[0].head()
#merge back togetehr all the df-s
dfs_back_together = pd.concat(turnstile_dfs_diff_both)
dfs_back_together.head()
#old idea
#_59THST_NQR456W["entries_diff"] = _59THST_NQR456W["ENTRIES"].diff()
#4 Saving the data into a new cvs file
#Worked, don't re-run
#_59THST_NQR456Wfile_diff = dfs_back_together.to_csv(r'_59THST_NQR456W_diff.csv')
#_59THST_NQR456Wfile_diff = dfs_back_together.to_csv(r'_59THST_ALL_diff.csv')
#dfs_back_together.head()
dfs_back_together_whole = pd.concat(whole)
dfs_back_together_whole.head()
#dfs_back_together.dtypes this hows that 'TIME' is an object not an int/float, I need to convert into int
# create TIMESTAMP by combining columns DATE and TIME
dfs_back_together['TIMESTAMP'] = pd.to_datetime((dfs_back_together.DATE + ' ' + dfs_back_together.TIME), format='%m/%d/%Y %H:%M:%S')
h = myfunctions.bintimes(dfs_back_together, 'HOD', 'TIMESTAMP')
h.head()
# +
# create Hour of Day bins
# use a negative number at the beginning to ensure we do not lose midnight
# I put this fun into myfunctions.py
bins = [-1,3,7,11,15,19,24]
dfs_back_together['HOD'] = [r.hour for r in dfs_back_together.TIMESTAMP]
dfs_back_together['HODBIN'] = pd.cut(dfs_back_together['HOD'], bins)
#create new col to get info from bins
dfs_back_together['HODBIN2'] = [b.left+1 for b in dfs_back_together.HODBIN]
#groupping on bins
# I put this fun into myfunctions.py
#dfs_back_together_group = dfs_back_together.drop(['HOD','ENTRIES','EXITS','TIME', 'TIMESTAMP'], axis='columns')
#dfs_back_together_group = dfs_back_together_group.groupby(['HODBIN','HODBIN2','UNIT','SCP','STATION','LINENAME','DATE','station_id','WEEKDAY','SCP_STATION']).agg([np.sum])
#dfs_back_together_group.columns = ["ENTRIES_diff_sum",'EXITS_diff_sum']
#dfs_back_together_group = dfs_back_together_group.reset_index()
#dfs_back_together_group.head()
#OR
#dfs_back_together_group = myfunctions.grouping_sum(
# dfs_back_together,
# drop_columns = ['HOD','ENTRIES','EXITS','TIME', 'TIMESTAMP'],
# #use sum_columns = ["ENTRIES_diff", "EXITS_diff"]
# group_col = ['HODBIN','HODBIN2', 'UNIT','SCP','STATION','LINENAME','DATE','station_id','WEEKDAY','SCP_STATION'],
# new_columns = ["ENTRIES_diff_sum",'EXITS_diff_sum']
# )
#dfs_back_together_group.head()
#all_columns = list(dfs_back_together.columns)
#sum_columns = ["ENTRIES_diff", "EXITS_diff"]
#group_col = ['HODBIN','HODBIN2', 'UNIT','SCP','STATION','LINENAME','DATE','station_id','WEEKDAY','SCP_STATION']
#drop_columns2 = list(set(all_columns) - set(sum_columns) - set(group_col))
#drop_columns2
#create and put into myfunctioins
dfs_back_together_group = myfunctions.grouping_sum2(
dfs_back_together,
group_col = ['HODBIN','HODBIN2', 'UNIT','SCP','STATION','LINENAME','DATE','station_id','WEEKDAY','SCP_STATION'],
sum_col = ['ENTRIES_diff', 'EXITS_diff'],
new_col = ["ENTRIES_diff_SUM", "EXITS_diff_SUM"],
)
dfs_back_together_group.head()
# -
# read geo tag DF in here
geo = pd.read_csv('~/Documents/Projects/Final/scraping MTA/geocoded TITLED.csv')
geo_drop = geo.drop(['C/A','STATION','LINENAME','Unnamed: 4'],axis=1)
geo_drop.head()
#test a geo of whole city
merged_left_whole_city = myfunctions.mergeLeft(dfs_back_together_whole, geo_drop, 'UNIT')
merged_left_whole_city.drop_duplicates()
#merged_left_whole_city_file = merged_left_whole_city.to_csv(r'merged_left_whole_city.csv')
merged_left_whole_city.head()
# MERGE 2 DF GEOTAGS AND MAIN _42STBRYANTPK_BDFM7 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '42 ST-BRYANT PK']
merged_inner = myfunctions.mergeLeft(dfs_back_together_group, geo_drop, 'UNIT')
#OR
#merged_inner = pd.merge(left=dfs_back_together_group,right=geo_drop, how='left', on='UNIT')
#drop unused col-s
#merged_inner = merged_inner.drop(['HODBIN','UNIT','SCP'], axis='columns')
merged_inner.head()
#old idea
#_59THST_NQR456W["entries_diff"] = _59THST_NQR456W["ENTRIES"].diff()
#drop duplicates
merged_inner = merged_inner.drop_duplicates()
#noDuplicated_data.info()
#noDuplicated_data.duplicated().value_counts()
merged_inner.head()
#SUM of Entries and Exits on HODBIN2
merged_inner_group = merged_inner.drop(['LINENAME', 'SCP_STATION', 'HODBIN', 'SCP'], axis='columns').groupby(['HODBIN2','UNIT','STATION','DATE','station_id','WEEKDAY','LAT','LON']).agg([np.sum])
merged_inner_group.columns = ['ENTRIES_diff_sum','EXITS_diff_sum']
merged_inner_group = merged_inner_group.reset_index()
#dfs_back_together_file = merged_inner_group.to_csv(r'_59THST_midtown_timebins_sum.csv')
merged_inner_group.head()
#merged_inner_group_grater10 = merged_inner_group[merged_inner_group['ENTRIES_diff_sum'] > 10]
#OR
merged_inner_group_grater10 = myfunctions.less10(merged_inner_group, 'EXITS_diff_sum', 16)
#dfs_back_together_file = merged_inner_group_grater10.to_csv(r'_59THST_midtown_timebins_sum_grater10.csv')
merged_inner_group_grater10.head()
# +
#I need to sort a weeksday
daymap = { "Sunday": 0, "Monday": 1, "Tuesday": 2, "Wednesday": 3, "Thursday": 4, "Friday": 5, "Saturday": 6}
def keyfunc(s):
return daymap[s]
sorted(["Thursday", "Monday", "Saturday", "Sunday"], key=keyfunc)
mylist = [8,7,6,0,1,2,3,4,5]
def r(x):
return -x
# sorted(mylist, key = lambda x: -x)
sorted(mylist, key = r)
# +
#create a new col weekday order to sort
#merged_inner_group_grater10['Day_id'] = merged_inner_group_grater10.index
#merged_inner_group_grater10['Day_id'] = merged_inner_group_grater10['WEEKDAY'].map(daymap)
#merged_inner_group_grater10.head()
#OR
#TODO: test if it works
merged_inner_group_grater10 = myfunctions.sorterOfWeekday(merged_inner_group_grater10, 'WEEKDAY')
merged_inner_group_grater10.head()
# -
merged_inner_group_grater10_sort = merged_inner_group_grater10.sort_values(by=['Day_id', 'HODBIN2'])
# export not yet, the units are still doubling the lines
#merged_inner_group_grater10_sort.head()
#check where is the doubled line
#lex = merged_inner_group_grater10_sort.loc[merged_inner_group_grater10_sort.station_id == 'LEXINGTON AV/53-6EM']
#lex.head()
merged_inner_group_grater10_sort.head()
#groupping of UNITS TODO:
# I put this fun into myfunctions.py
merged_inner_group_grater10_sort_noUnit = myfunctions.grouping_sum2(
merged_inner_group_grater10_sort,
group_col = ['HODBIN2','DATE','station_id','WEEKDAY', 'LAT', 'LON'],
sum_col = ['ENTRIES_diff_sum', 'EXITS_diff_sum'], #git it
new_col = ["ENTRIES_diff_sum", "EXITS_diff_sum"], #got it, use the same name
)
file = merged_inner_group_grater10_sort_noUnit.to_csv(r'_midtown_timebins_sum_grater16_sort.csv')
merged_inner_group_grater10_sort_noUnit.head() #_59THST_midtown_timebins_sum_grater10_sort.csv
#testing if Monday is first
four = merged_inner_group_grater10_sort_noUnit.loc[merged_inner_group_grater10_sort_noUnit.HODBIN2 == 4]
four.head()
merged_left_whole_city.head()
# +
merged_left_whole_city_final = myfunctions.grouping_sum2(
merged_left_whole_city,
group_col = ['DATE','station_id', 'LAT', 'LON'],
sum_col = ['ENTRIES_diff', 'EXITS_diff'],
new_col = ["ENTRIES_diff_sum", "EXITS_diff_sum"], # use the same name
)
file = merged_left_whole_city_final.to_csv(r'merged_left_whole_city_final_whole.csv')
merged_left_whole_city_final.head(34)
# +
#Test: old idea: group by scp to drop time 00:00:00
#_59THST_NQR456W_for_diff = _59THST_NQR456W.drop(['LINENAME','TIME', 'entries_diff'], axis='columns').groupby(['STATION','UNIT','SCP','WEEKDAY','DATE']).agg([np.min, np.max])
# +
# old idea: start groupping to find max & min
#MData_groupping = _59THST_NQR456W.drop(['LINENAME','TIME', 'entries_diff'], axis='columns').groupby(['STATION','UNIT','SCP','WEEKDAY','DATE']).agg([np.min, np.max])
#MData_groupping.columns = ["entry_min", "entry_max", "exit_min", "exit_max"]
#MData_groupping.reset_index()
#MData_groupping.head(20)
# -
MData_groupping["entries_total"] = MData_groupping["entry_max"].sub(MData_groupping["entry_min"])
MData_groupping["exits_total"] = MData_groupping["exit_max"].sub(MData_groupping["exit_min"])
MData_groupping.head()
MData_groupping = MData_groupping.drop(['entry_min', 'entry_max', 'exit_min', 'exit_max'], axis='columns')
MData_groupping.head(20)
#run this in here, I mean in a ceparate cell
MData_groupping_reset = MData_groupping.reset_index()
#MData_groupping.reset_index()
MData_groupping_reset.head(10)
# +
#MData_calculate_remaining['STATION'].unique()
#print(*MData_calculate_remaining['STATION'].unique(), sep = '\n')
# -
# #Extracting Midtown Stations only
# read geo tag DF in here
geo = pd.read_csv('~/Documents/Projects/Final/scraping MTA/geocoded TITLED.csv')
geo_drop = geo.drop(['C/A','STATION','LINENAME','Unnamed: 4'],axis=1)
geo_drop.head()
# +
# MERGE 2 DF GEOTAGS AND DESIGNATED FILE _42STBRYANTPK_BDFM7 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '42 ST-BRYANT PK']
merged_inner = pd.merge(left=MData_groupping_reset,right=geo_drop, how='left', on='UNIT')
noDuplicated_data = merged_inner.drop_duplicates()
noDuplicated_data_reset = noDuplicated_data.reset_index()
#4 Saving the data into a new cvs file
_59THST_NQR456Wfile_with_totals = noDuplicated_data_reset.to_csv(r'_59THST_NQR456W_totals.csv')
#noDuplicated_data_reset.head(50)
_59THST_NQR456Wfile_with_totals_drop_BKL = noDuplicated_data_reset.loc[noDuplicated_data_reset.UNIT != 'R212']
_59THST_NQR456Wfile_with_totals_drop_BKL['LAT'].unique()
_59THST_NQR456Wfile_with_totals = _59THST_NQR456Wfile_with_totals_drop_BKL.to_csv(r'_59THST_NQR456W_totals.csv')
# +
MData_calculate_remaining = MData_groupping
#1 Isolating data of only one train station from a scope of all MTA data
_59THST_NQR456W = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '59 ST']
#2 Printing a head of a table
_59THST_NQR456W.head()
#3 Checking what lines are coming to this station
_59THST_NQR456W['LINENAME'].unique()
#4 Saving the data into a new cvs file
_59THST_NQR456Wfile = _59THST_NQR456W.to_csv(r'_59THST_NQR456W.csv')
#5 MERGE 2 DF GEOTAGS AND DESIGNATED FILE
_59THST_NQR456W_merged_inner = pd.merge(left=_59THST_NQR456W,right=geo_drop, how='left', on='UNIT')
_59THST_NQR456W_merged_inner.head()
#Repeat for entire Manhattan Midtown:
# +
#TEST: pin one location in bue on the map by hand, save into html file
map = folium.Map(location = [40.762796, -73.967686], zoom_start = 80, tiles = 'Stamen Terrain')
folium.CircleMarker(location=[40.762796, -73.967686],
popup = "59THST (NQR456W trains)",
radius = 10,
color = 'blue',
fill = True).add_to(map)
map.save('index10.html')
#TODO plot all the stations on the map
# +
#TODO show exits
# folium.CircleMarker(location=[noDuplicated_data_reset['LAT'], noDuplicated_data_reset['LON']],
# popup = "59THST (NQR456W trains)",
# radius = noDuplicated_data_reset['exits_total'],
# color = 'red',
# fill = True).add_to(map)
# map.save('index11.html')
# -
_59THST_NQR456W.head() #apple case #100966565816 #call them back as soon
_59THST_NQR456W['UNIT'].unique()
# +
# merged_inner = pd.merge(left=MData_groupping_reset,right=geo_drop, how='left', on='UNIT')
# noDuplicated_data = merged_inner.drop_duplicates()
# noDuplicated_data_reset = noDuplicated_data.reset_index()
# _59THST_NQR456Wfile_with_totals = noDuplicated_data_reset.to_csv(r'_59THST_NQR456W_totals.csv')
# noDuplicated_data_reset.head(50)
# _59THST_NQR456Wfile_with_totals_drop_BKL = noDuplicated_data_reset.loc[noDuplicated_data_reset.UNIT != 'R212']
# _59THST_NQR456Wfile_with_totals_drop_BKL['LAT'].unique()
# _59THST_NQR456Wfile_with_totals = _59THST_NQR456Wfile_with_totals_drop_BKL.to_csv(r'_59THST_NQR456W_totals.csv')
_50ST_DCE1 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '50 ST']
#_50ST_DCE1['LINENAME'].unique()
_50ST_DCE1_merged_inner = pd.merge(left=_50ST_DCE1,right=geo_drop, how='left', on='UNIT')
_50ST_DCE1file = _50ST_DCE1_merged_inner.to_csv(r'_50ST_DCE1.csv')
_50ST_DCE1.head()
_50ST_DCE1_merged_inner.head()
# -
_5AV59ST_NQRW = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '5 AV/59 ST']
_5AV59ST_NQRW.head()
#_5AV59ST_NQRW['LINENAME'].unique()
_5AV59ST_NQRWfile = _5AV59ST_NQRW.to_csv(r'_5AV59ST_NQRW.csv')
_57ST7AV_NQRW = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '57 ST-7 AV']
_57ST7AV_NQRW.head()
#_57ST7AV_NQRW['LINENAME'].unique()
_57ST7AV_NQRWfile = _57ST7AV_NQRW.to_csv(r'_57ST7AV_NQRW.csv')
_5AVE_7BDFM = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '5 AVE']
_5AVE_7BDFM.head()
#_5AVE_7BDFM['LINENAME'].unique()
_5AVE_7BDFMfile = _5AVE_7BDFM.to_csv(r'_5AVE_7BDFM.csv')
_49ST_NQRW = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '49 ST']
_49ST_NQRW.head()
#_49ST_NQRW['LINENAME'].unique()
_49ST_NQRWfile = _49ST_NQRW.to_csv(r'_49ST_NQRW.csv')
_TIMESSQ42ST_ACENQRS1237W= MData_calculate_remaining.loc[MData_calculate_remaining.STATION == 'TIMES SQ-42 ST']
_TIMESSQ42ST_ACENQRS1237W.head()
#_TIMESSQ42ST_ACENQRS1237W['LINENAME'].unique()
_TIMESSQ42ST_ACENQRS1237Wfile = _TIMESSQ42ST_ACENQRS1237W.to_csv(r'_TIMESSQ42ST_ACENQRS1237W.csv')
_42STPORTAUTH_ACENGRS1237WQ = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '42 ST-PORT AUTH']
_42STPORTAUTH_ACENGRS1237WQ.head()
#_42STPORTAUTH_ACENGRS1237WQ['LINENAME'].unique()
_42STPORTAUTH_ACENGRS1237WQfile = _42STPORTAUTH_ACENGRS1237WQ.to_csv(r'_42STPORTAUTH_ACENGRS1237WQ.csv')
_7AV_BDE_BQ_FG = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '7 AV']
_7AV_BDE_BQ_FG.head()
_7AV_BDE_BQ_FG['LINENAME'].unique() #I need to drop BQ & FG (Brooklyn)
_7AV_BDE = _7AV_BDE_BQ_FG.loc[(_7AV_BDE_BQ_FG.LINENAME != 'BQ')&(_7AV_BDE_BQ_FG.LINENAME !='FG')]
_7AV_BDE['LINENAME'].unique() #droped BQ & FG (Brooklyn)
_7AV_BDE.head()
_7AV_BDEfile = _7AV_BDE.to_csv(r'_7AV_BDE.csv')
_59STCOLUMBUS_ABCD1 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '59 ST COLUMBUS']
_59STCOLUMBUS_ABCD1.head()
#_59STCOLUMBUS_ABCD1['LINENAME'].unique()
_59STCOLUMBUS_ABCD1file = _59STCOLUMBUS_ABCD1.to_csv(r'_59STCOLUMBUS_ABCD1.csv')
_5AV53ST_EM = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '5 AV/53 ST']
_5AV53ST_EM.head()
#_5AV53ST_EM['LINENAME'].unique()
_5AV53ST_EMfile = _5AV53ST_EM.to_csv(r'_5AV53ST_EM.csv')
_LEXINGTONAV53_EM6 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == 'LEXINGTON AV/53']
_LEXINGTONAV53_EM6.head()
#_LEXINGTONAV53_EM6['LINENAME'].unique()
_LEXINGTONAV53_EM6file = _LEXINGTONAV53_EM6.to_csv(r'_LEXINGTONAV53_EM6.csv')
_47_50STSROCK_BDFM = MData_calculate_remaining.loc[MData_calculate_remaining.STATION =='47-50 STS ROCK']
_47_50STSROCK_BDFM.head()
#_47_50STSROCK_BDFM['LINENAME'].unique()
_47_50STSROCK_BDFMfile = _47_50STSROCK_BDFM.to_csv(r'_47_50STSROCK_BDFM.csv')
_42STBRYANTPK_BDFM7 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '42 ST-BRYANT PK']
_42STBRYANTPK_BDFM7.head()
#_42STBRYANTPK_BDFM7['LINENAME'].unique()
_42STBRYANTPK_BDFM7file = _42STBRYANTPK_BDFM7.to_csv(r'_42STBRYANTPK_BDFM7.csv')
_57ST_F = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '57 ST']
_57ST_F.head()
#_57ST_F['LINENAME'].unique()
_57ST_Ffile = _57ST_F.to_csv(r'_57ST_F.csv')
_GRDCNTRL42ST_4567S = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == 'GRD CNTRL-42 ST']
_GRDCNTRL42ST_4567S.head()
#_GRDCNTRL42ST_4567S['LINENAME'].unique()
_GRDCNTRL42ST_4567Sfile = _GRDCNTRL42ST_4567S.to_csv(r'_GRDCNTRL42ST_4567S.csv')
# +
_51ST_6 = MData_calculate_remaining.loc[MData_calculate_remaining.STATION == '51 ST']
_51ST_6.head()
#_51ST_6['LINENAME'].unique()
#_51ST_6['EXITS'].plot()
#_51ST_6.max()
#_51ST_6.min()
#create TIMESTAMP by combining columns DATE & TIME & WEEKDAY
#MData_calculate_remaining['WEEKDAY'] = pd.to_datetime(MData_calculate_remaining['DATE']).dt.weekday_name
#Create a github to grade
#presentation at the desk, "this is what i'm doing, here is where I'm going" Dash a presentation or a notebook
_51ST_6 = _51ST_6.assign(TIMESTAMP = pd.to_datetime((_51ST_6.DATE + ' ' + _51ST_6.TIME), format = '%m/%d/%Y %H:%M:%S'))
_51ST_6file = _51ST_6.to_csv(r'_51ST_6.csv')
_51ST_6.head()
# +
#I gave up on this idea
#_51ST_6 = _51ST_6.diff(_51ST_6['ENTRIES'], _51ST_6['EXITS'])
# +
#Submit:
#5 Questions:
#sample sets of min 5 csv
#notebook of prosesses import, dataset, what you todo and how to do (no need a code just mark down)
#isolated: Midtown, one week:
#1 What is the lowest of exit/enter flow, what time of a weekday? (Maybe: every weekday vs. weekend?)
#2 What is the peak of exit/enter flow, time of a weekday?
#3 What is the difference of the in/out flow on the holiday? (Maybe: Thanksgiving? Christmas?)
#4 How big is a difference in W 42nd st (Port Auth.) and E 42nd st (Grand Station) at a peak hours of a weekday?
#5 How does a difference in peak look on the weekend?
# +
#_51ST_6.pd.day_name()
#_51ST_6.head()
# -
#plot 51st Exits by a day of a week
#Heatmap
data = [go.Heatmap(x=_51ST_6['WEEKDAY'], y=_51ST_6['TIME'], z=_51ST_6['EXITS'])]
#Lines
data2 = [{
'x':_51ST_6['WEEKDAY'],
'y':_51ST_6[_51ST_6['WEEKDAY']==day]['EXITS'],
'name':day
} for day in _51ST_6['WEEKDAY'].unique()]
layout = go.Layout(
title = 'Heat-Map of MTA flow: Station: 51ST, Trains: 6 (Midtown Manhattan)',
xaxis = dict(title = 'WEEKDAY'), # x-axis label
yaxis = dict(title = 'EXITS'), # y-axis label
#zaxis = dict(color = 'blue'), # z-axis label
hovermode = 'closest' #handles multiple points landing on the same vertical
)
fig = go.Figure(data=data2, layout=layout)
pyo.plot(fig, filename='EXITS-HeatMap-plot.html')
#plot 51st Entries by a day of a week
data = [go.Heatmap(x=_51ST_6['WEEKDAY'], y=_51ST_6['TIME'], z=_51ST_6['ENTRIES'])]
layout = go.Layout(
title = 'Heat-Map of MTA flow: Station: 51ST, Trains: 6 (Midtown Manhattan)',
xaxis = dict(title = 'WEEKDAY'), # x-axis label
yaxis = dict(title = 'ENTRIES'), # y-axis label
#zaxis = dict(color = 'blue'), # z-axis label
hovermode = 'closest' #handles multiple points landing on the same vertical
)
fig = go.Figure(data=data, layout=layout)
pyo.plot(fig, filename='ENTRIES-HeatMap-plot.html')
#51 line graph
layout = go.Layout(title = 'Line chart of MTA flow: Station: 51ST, Trains: 6 (Midtown Manhattan)', hovermode='closest')
fig = go.Figure(data=data, layout=layout)
pyo.plot(fig,filename ='lines.html')
## isolate other _DATE or _LINENAME
_DATE = MData_calculate_remaining.loc[MData_calculate_remaining.DATE == '10/12/2019']
_DATE['DATE'].unique()
_DATE.head()
N_train_data = MData_calculate_remaining.loc[MData_calculate_remaining.LINENAME == 'N']
N_train_data.head()
N_train_8AV_onDate = N_train_8AV.loc[N_train_8AV.DATE == '10/12/2019']
N_train_8AV_onDate.TIME.unique()
N_train_8AV_onDate_2019_12_10_0100H = N_train_8AV_onDate.loc[N_train_8AV_onDate.TIME == '01:00:00']
N_train_8AV_onDate_2019_12_10_0100H.TIME.unique()
# +
#N_train_8AV_onDate.plot.scatter(x='ENTRIES', y='EXITS', c='red', s=5, figsize=(6,6))
# -
#test if it works at all
Mdata['ENTRIES'].plot.kde()
#test if it works at all
sns.jointplot(x="ENTRIES", y='EXITS',data=Mdata)
x_values = _51ST_6['WEEKDAY']
y_values = _51ST_6['ENTRIES']
_51ST_6.head()
x_values = _51ST_6['WEEKDAY']
y_values = _51ST_6['ENTRIES']
y2_values = _51ST_6['EXITS']
#create traces of stations
#trace0 = go.Scatter(
# x = x_values,
# y = y_values,
# mode = 'lines',
# name = 'markers',
#)
# trace1 = go.Scatter(
# x = x_values,
# y = y_values,
# mode = 'lines+markers',
# name = 'lines+markers'
# )
# trace2 = go.Scatter(
# x = x_values,
# y = y_values-5,
# mode = 'lines',
# name = 'lines'
# )
# +
data = [trace0] # trace1, trace2 assign traces to data
layout = go.Layout(title = "Line chart of MTA flow: Station: 51ST, Trains: 6 (Midtown Manhattan)")
fig = go.Figure(data=data, layout=layout)
pyo.plot(fig,filename ='MTA_Midtownm.html')
# -
| other/MTAData.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Environment
# +
import os
import datetime
import pandas as pd
import numpy as np
from pathlib import Path
import statsmodels.api as sm
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.colors as colors
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 15, 6
# %matplotlib inline
init_notebook_mode(connected=True)
# -
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, roc_auc_score, precision_score
from sklearn.cross_validation import KFold
from sklearn.pipeline import make_pipeline
import keras
from keras.layers import Conv1D, Dropout, Dense
from keras.models import Sequential
from keras import regularizers
from keras import optimizers
import ipywidgets as widgets
from IPython.display import HTML
# ### Data Import & Framing
# +
#for now, will eventually be importing from the db
df = read.csv('')
# -
# ### Functions
# ## Time Series
# ### ARIMA
#
# Text. <br><br>
#
# <b> Key Highlights </b>: <br>
# <br>
# <i> Top Model Accuracy: </i>
# +
The first step towards fitting an ARIMA model is to find the values of ARIMA(p,d,q)(P,D,Q)s that produce
the desired output. Selection of these parameters requires domain expertise and time.
We shall first generate small ranges of these parameters and use a "grid search" to
iteratively explore different combinations of parameters.
For each combination of parameters, we fit a new seasonal ARIMA model with the SARIMAX()
function from the statsmodels module and assess its overall quality.
SARIMAX detailed documentation can be viewed HERE
Let's begin by generating example combination of parameters that we wish to use.
Define p,q and d parameters to take any value from 0/1 using range() function.
(Note: We can try larger values which can make our model computationally expensive to run,
you can try this as an additional experiment)
Generate combinations for (p,d,q) using itertools.product.
Similarly, generate seasonal combinations as (p,d,q)s. Use s = 12 (constant)
Check the combinations for validity.
# Define the p, d and q parameters to take any value between 0 and 2
p = d = q = range(0, 2)
# Generate all different combinations of p, q and q triplets
pdq = list(itertools.product(p, d, q))
# Generate all different combinations of seasonal p, q and q triplets
# -
# ### FB Prophet - Additive Modeling
#
#
# <b> Key Highlights </b>: <br>
# <br>
# <i> Top Model Accuracy: </i>
from fbprophet import Prophet
from sklearn.preprocessing import MinMaxScaler
data = pd.read_csv('eth_hourly_data.csv')
data.drop_duplicates(inplace=True)
data.reset_index(inplace=True, drop=True)
data['ds'] = data['time'].apply(lambda x: datetime.datetime.utcfromtimestamp(x).strftime('%Y-%m-%dT%H:%M:%S'))
data['y'] = data['close']
data = data[::-1]
data.reset_index(inplace = True, drop = True)
data.drop(columns=['time', 'high', 'low', 'open', 'close', 'volumeto', 'volumefrom'], inplace=True)
data.head()
proph = Prophet(interval_width=.95)
proph.fit(data)
future = proph.make_future_dataframe(freq = "H", periods=72)
future.tail(3)
forecast = proph.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(3)
fig1 = proph.plot(forecast)
fig2 = proph.plot_components(forecast)
prediction_table = pd.DataFrame()
prediction_table['time'] = forecast.ds.iloc[-96:]
prediction_table['predicted_close'] =forecast.yhat.iloc[-96:]
prediction_table.head(5)
forecast.loc[13801]
data.loc[13801]
proph2 = Prophet(interval_width=.95)
proph2.fit(data.iloc[-500:])
future2 = proph2.make_future_dataframe(freq="H", periods=72)
forecast2 = proph2.predict(future2)
fig1_2 = proph2.plot(forecast2)
prediction_table2 = pd.DataFrame()
prediction_table2['time'] = forecast2.ds.iloc[-96:]
prediction_table2['predicted_close'] =forecast2.yhat.iloc[-96:]
prediction_table2.head()
fig2_2 = proph2.plot_components(forecast2)
proph4 = Prophet(interval_width=.95)
proph4.fit(data.iloc[-168:])
future4 = proph4.make_future_dataframe(freq="H", periods=24)
forecast4 = proph4.predict(future4)
fig1_4 = proph4.plot(forecast4)
prediction_table4 = pd.DataFrame()
prediction_table4['time'] = forecast4.ds.iloc[-48:]
prediction_table4['predicted_close'] =forecast4.yhat.iloc[-48:]
prediction_table4.head()
scaler = MinMaxScaler()
scaler.fit(np.array(data['y']).reshape(-1,1))
scaler.data_max_
new_y = scaler.transform(np.array(data['y']).reshape(-1,1))
data['y'] = new_y
data.max()
proph3 = Prophet(interval_width=.95)
proph3.fit(data)
future3 = proph3.make_future_dataframe(freq = 'H', periods=72)
forecast3 = proph3.predict(future3)
fig1_3 = proph3.plot(forecast3)
predications3 = forecast3.yhat.iloc[-72:]
prediction_table3 = pd.DataFrame()
prediction_table3['time'] = forecast3.ds.iloc[-72:]
prediction_table3['predicted_close'] = scaler.inverse_transform(np.array(predications3).reshape(-1,1))
prediction_table3.head()
forecast3.tail(10)
# ### Bayesian Ridge Regression
df = pd.read_csv('eth_hourly_data.csv')
df['time'] = df['time'].apply(lambda x: datetime.datetime.utcfromtimestamp(x).strftime('%Y-%m-%dT%H:%M:%S'))
df.set_index(df['time'], inplace=True)
df.drop(['time'], axis=1, inplace=True)
df.drop(df.index[:1], inplace=True)
df = df[::-1]
df.drop(df.index[:1], inplace=True)
df.isna().sum()
#shift target variable one day back
#in order to train model to predict one day into future
df['close_shifted'] = df['close'].shift(-1)
df = df.dropna()
df.head(3)
#make numpy arrays
# df['average'] = df['high'] + df['low'] / 2
# X = np.array(df['average'])
X = np.array(df[['close', 'high', 'low', 'open']])
y = np.array(df['close_shifted']).reshape(-1,1)
len(X) - 14349
# +
# this uses a Bayesian Ridge linear regression
# adapt this to other usage? With any regressor?
# customized backtest function
# compare with TimeSeriesSplit
n_days = 20
def backtest(n_days):
"""
n_days - amount of the last n_days that we want to get prediction and calculate metrics
"""
predictions = []
true_values = []
for i in reversed(range(1, n_days)):
X_train = X[14349:len(X)-i]
y_train = y[14349:len(y)-i]
X_test = X[len(X)-i]
y_test = y[len(y)-i]
model = BayesianRidge()
model.fit(X_train, y_train.ravel())
predictions.append(model.predict([X_test])[0])
true_values.append(y_test[0])
return true_values, predictions
# def backtest(n_days):
# """
# n_days - amount of the last n_days that we want to get prediction and calculate metrics
# """
# predictions = []
# true_values = []
# for i in reversed(range(1, n_days)):
# X_train = X[:len(X)-i]
# y_train = y[:len(y)-i]
# X_test = X[len(X)-i]
# y_test = y[len(y)-i]
# model = BayesianRidge()
# model.fit(X_train, y_train.ravel())
# predictions.append(model.predict([X_test])[0])
# true_values.append(y_test[0])
# return true_values, predictions
true_values, predictions = backtest(n_days)
# -
len(true_values)
# +
plt.figure(figsize=(12, 8))
# x_ax_vals = [df.index for i in reversed(range(1, n_days)):
# X_train = X[14349:len(X)-i]]
plt.plot(true_values, color = 'blue', label = "True Values")
plt.plot(predictions, color = 'red', label = "Predicted Values")
plt.title ('Hourly Closing Price Forecasting')
plt.ylabel("Low")
plt.xlabel("Time")
plt.legend(loc="lower left")
# plt.errorbar(range(0,30), y_mean, y_std, color='gold',
# label="Polynomial Bayesian Ridge Regression")
# X = np.linspace(0, 10, 100)
# y = f(X, noise_amount=0.1)
# clf_poly = BayesianRidge()
# clf_poly.fit(np.vander(X, degree), y)
# X_plot = np.linspace(0, 11, 25)
# y_plot = f(X_plot, noise_amount=0)
# y_mean, y_std = clf_poly.predict(np.vander(X_plot, degree), return_std=True)
# plt.errorbar(X_plot, y_mean, y_std, color='navy',
# label="Polynomial Bayesian Ridge Regression", linewidth=lw)
# plt.plot(X_plot, y_plot, color='gold', linewidth=lw,
# label="Ground Truth")
# -
# Testing our sklearn TimeSeriesSplit
# +
from sklearn.model_selection import TimeSeriesSplit
X = np.array(df[['close', 'high', 'low', 'open']])
y = np.array(df['close_shifted']).reshape(-1,1)
tscv = TimeSeriesSplit(n_splits=5)
print(tscv)
# -
TimeSeriesSplit(max_train_size=None, n_splits=5)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
X_train
len(X_train)
X_test
tts_predictions = []
tts_true_values = []
model = BayesianRidge()
model.fit(X_train, y_train.ravel())
tts_predictions.append(model.predict([X_test][0]))
tts_true_values.append(y_test)
tts_true_values[0]
# +
# plt.figure(figsize=(12, 8))
# plt.plot(tts_true_values[0], color = 'blue', label = "True Values")
# plt.plot(tts_predictions, color = 'red', label = "Predicted Values")
# plt.title ('Hourly Closing Price Forecasting')
# plt.ylabel("Low")
# plt.xlabel("Time")
# plt.legend(loc="lower left")
# -
# +
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = TimeSeriesSplit(n_splits=5, max_train_size=7)
print(tscv)
# -
TimeSeriesSplit(max_train_size=None, n_splits=5)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# +
#creating classification metric for use
# data[i]['Clf_Target'] = (np.sign(-data[i]['close'].diff(periods=-1))+1)/2
# +
#Note that the 80/10/10 split means 80% of the time from time start to time end. Then the next 10% sequentially
#then the next 10% sequentially
# -
| regression_modeling_testing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: base_x86
# language: python
# name: base_x86
# ---
import numpy as np
import matplotlib.pyplot as plt
from ripser import ripser
from persim import plot_diagrams
import warnings
warnings.filterwarnings('ignore')
# #Setting up Persistent Homology
# +
def drawLineColored(X, C):
for i in range(X.shape[0]-1):
plt.plot(X[i:i+2, 0], X[i:i+2, 1], c=C[i, :], lineWidth = 3)
def plotCocycle2D(D, X, cocycle, thresh):
"""
Given a 2D point cloud X, display a cocycle projected
onto edges under a given threshold "thresh"
"""
#Plot all edges under the threshold
N = X.shape[0]
t = np.linspace(0, 1, 10)
c = plt.get_cmap('Greys')
C = c(np.array(np.round(np.linspace(0, 255, len(t))), dtype=np.int32))
C = C[:, 0:3]
for i in range(N):
for j in range(N):
if D[i, j] <= thresh:
Y = np.zeros((len(t), 2))
Y[:, 0] = X[i, 0] + t*(X[j, 0] - X[i, 0])
Y[:, 1] = X[i, 1] + t*(X[j, 1] - X[i, 1])
drawLineColored(Y, C)
#Plot cocycle projected to edges under the chosen threshold
for k in range(cocycle.shape[0]):
[i, j, val] = cocycle[k, :]
if D[i, j] <= thresh:
[i, j] = [min(i, j), max(i, j)]
a = 0.5*(X[i, :] + X[j, :])
plt.text(a[0], a[1], '%g'%val, color='b')
#Plot vertex labels
for i in range(N):
plt.text(X[i, 0], X[i, 1], '%i'%i, color='r')
plt.axis('equal')
# -
# #Grabbing Sim Data
#my filename
fName = "sim_data.npy"
data = np.load(fName)
#0 is all zeros, 1-5 still look really uniform
#50 looks cool
data = data[50]
plt.scatter(data[:, 0], data[:, 1])
plt.axis('equal')
plt.show()
# #Creating Persistent Homology
result = ripser(data, coeff=17, do_cocycles=True)
diagrams = result['dgms']
cocycles = result['cocycles']
D = result['dperm2all']
dgm1 = diagrams[1]
idx = np.argmax(dgm1[:, 1] - dgm1[:, 0])
plot_diagrams(diagrams, show = False)
print(dgm1[idx, 0])
plt.scatter(dgm1[idx, 0], dgm1[idx, 1], 20, 'k', 'x')
plt.title("Max 1D birth = %.3g, death = %.3g"%(dgm1[idx, 0], dgm1[idx, 1]))
plt.show()
# #Barcodes
# +
from dionysus import *
import dionysus as d
f = d.fill_rips(data, 2, 10) #data, bette number, max distance
print(f)
# -
m = d.homology_persistence(f)
dgms = d.init_diagrams(m, f)
#d.plot.plot_bars(dgms[2], show = True)
print(dgms[1])
d.plot.plot_bars(dgms[1], show = True)
d.plot.plot_diagram(dgms[1], show = True)
d.plot.plot_bars(dgms[0], show = True)
array = np.array([0,0])
for pt in dgms[1]:
temp = np.asarray([pt.birth,pt.death])
array = np.vstack((array,[pt.birth,pt.death]))
array = array[1:]
array
| .ipynb_checkpoints/RipVicsek-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## API Call
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from config import api_key
import requests
tickers = ['YHOO','FTR','AKAM','EW','EBAY']
responses = []
for ticker in tickers:
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY&symbol={ticker}&apikey={api_key}'
response = requests.get(url)
responses.append(response.json())
# tick
# price
# date
# + jupyter={"outputs_hidden": true}
responses[0]
# -
closing_price = responses[0]['Time Series (Daily)']['2017-06-26']['4. close']
# + jupyter={"outputs_hidden": true}
responses
# + jupyter={"source_hidden": true}
close_cols= []
for index,ticker in enumerate(tickers):
current_ticker = ticker
current_ticker_close = pd.DataFrame(responses[index]['Time Series (Daily)']).transpose()['4. close']
current_ticker_close.name= f'{current_ticker}_close'
close_cols.append(current_ticker_close)
close_cols
# -
close_cols[1]
close_df= pd.DataFrame(close_cols).T
len(close_df.index)
len(set(close_df.index))
new_col = close_df.loc['2021-02-11'].T
new_col.index = new_col.index.str.replace('_close', '')
new_col
top_stocks_df = pd.read_csv('../data/top_stocks.csv', index_col=0)
top_stocks_df['Current Closing Price'] = new_col
for stock in ['YHOO', 'FTR']:
last_day = close_df[f'{stock}_close'].dropna().index.max()
top_stocks_df['Current Closing Price'][stock]= close_df[f'{stock}_close'][last_day]
top_stocks_df
yahoo_last_day = close_df['YHOO_close'].dropna().index.max()
close_df['YHOO_close'][yahoo_last_day]
clode_final_df = close_df.loc[close_df.isna().sum(axis=1) < 3]
clode_final_df
'2020-01-10' in close_df.index
top_stocks_df.to_csv("../data/top_stocks_final.csv")
clode_final_df.to_csv("../data/clode_final_df.csv")
| Notebooks/api-stock-call2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import plotly.graph_objects as go
from pandas_datareader import data as pdr
import matplotlib.pyplot as plt
import yfinance
import cufflinks as cf
import talib
import pandas_ta
from tapy import Indicators
import numpy as np
def get_his_data_filename(pair, granularity):
return f"his_data/{pair}_{granularity}.csv"
df = pd.read_csv(get_his_data_filename('EUR_USD','D'))
df.drop(columns=df.columns[0],inplace=True)
df_plot = df[:]
fig = go.Figure()
fig.add_trace(go.Candlestick(
x=df_plot.time, open=df_plot.mid_o, high=df_plot.mid_h, low=df_plot.mid_l, close=df_plot.mid_c,
line=dict(width=1), opacity=1,
increasing_fillcolor='#24A06B',
decreasing_fillcolor="#CC2E3C",
increasing_line_color='#2EC886',
decreasing_line_color='#FF3A4C'
))
fig.update_layout(width=1000,height=400,
margin=dict(l=10,r=10,b=10,t=10),
font=dict(size=10,color="#e1e1e1"),
paper_bgcolor="#1e1e1e",
plot_bgcolor="#1e1e1e")
fig.update_xaxes(
gridcolor="#1f292f",
showgrid=True,fixedrange=True,rangeslider=dict(visible=False)
)
fig.update_yaxes(
gridcolor="#1f292f",
showgrid=True
)
fig.show()
# +
# Get the EUR/USD data from Yahoo finance:
data = pdr.get_data_yahoo("EURUSD=X", start="2019-01-01", end="2021-05-01")
# add SAR column for parabolic SAR
data['SAR'] = talib.SAR(data.High, data.Low, acceleration=0.02, maximum=0.2)
# add DEMARKER using tapy library
indicators = Indicators(data)
indicators.de_marker(column_name='DeMarker')
data = indicators.df
data.tail()
# +
# Plot the price series chart
fig = plt.figure(figsize=(17,20))
ax = fig.add_subplot(3, 1, 1)
ax.set_xticklabels([])
plt.plot(data['Close'],'b',lw=1)
plt.title('EUR/USD')
plt.ylabel('Close Price')
plt.grid(True)
# Plot Parabolic SAR with close price
fig = plt.figure(figsize=(17,20))
ax = fig.add_subplot(3, 1, 2)
ax.set_xticklabels([])
plt.plot(data['Close'],'b',lw=1)
plt.plot(data['SAR'],'r.')
plt.title('EUR/USD Parabolic SAR')
plt.ylabel('Close Price')
plt.grid(True)
plt.tight_layout()
plt.show()
#
fig = plt.figure(figsize=(17,10))
ax = fig.add_subplot(3, 1, 3)
ax.set_xticklabels([])
plt.plot(data['DeMarker'],'b',lw=1)
plt.title('EUR/USD DeMarker')
plt.grid(True)
plt.tight_layout()
plt.show()
# +
qf=cf.QuantFig(data,title='EUR/USD',legend='top',name='GS')
#qf.add_ptps(periods=14, af=0.2, initial='long', str=None, name='prova')
#qf.add_bollinger_bands(periods=20,boll_std=2,colors=['magenta','grey'],fill=True)
#qf.add_sma([10,20],width=2,color=['green','lightgreen'],legendgroup=True)
qf.add_rsi(periods=20,color='java')
qf.add_cci()
qf.iplot()
# -
| Forex_graph_EUR.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="0GaHdiKFftdF"
# # Data 201A Individual Project
#
# ## Project Name: Desirable Mate Characteristics Exploratory Analysis
# ## Name: <NAME>
# + [markdown] id="9fp6EeT-ftdI"
# Welcome to my Data 201A Individual Project Jupyter notebook
#
# In this project I will be analyzing speed dating data collected by Columbia University researchers
# to determine characterstics that modern humans look for in a potential partner.
#
# Purpose: The objective of this project is to determine which variables are correlated with high desirability
# in relationships and how they change between people with different attributes.
#
# Dataset: Source: https://www.kaggle.com/annavictoria/speed-dating-experiment
#
# Background: The dataset is from the paper Gender Differences in Mate Selection by Columbia Business School professors <NAME> and <NAME>. Data was gathered from 552 participants in experimental speed dating events from 2002-2004. The attendees had four minute "first date" with every other participant of the opposite sex. They were also asked to rate their date on six attributes. The dataset also includes questionnaire data about demographics, self-perception across key attributes, beliefs on what others find valuable in a mate and lifestyle information.
#
# Methodology: The data was filtered based on meaningful variables (see below) which are hypothesized to have an impact on a match. Because we want a full picture of an individuals preferences, rows with with NA values for questions that were not answered were dropped. Relationships and correlations between variables were investigated using heat maps, scatterplots, histograms and comparative plots.
#
# Descriptions of data: There are 8,378 rows/observations and 195 columns in total. After cleaning and filter, the data set has 2973 rows × 31 columns.
#
# Variables include rankings for following attributes:
# Attractiveness
# Sincerity
# Intelligence
# Fun
# Ambition
# Shared Interests
#
# Personal information for:
# gender
# age
# income
#
# Questions I asked:
#
# Which of the 6 variables are most important to people looking for a potential partner?
# Do matches change among people of different age, gender and income?
# Do people's interests reflect their actual decision for a date?
# -
# We are interested in these variables (Defining the variables):
#
# General variables:
#
# id: participant id <br>
# pid: date's id <br>
# gender: participant gender, Female=0 Male=1 <br>
# match: whether participant matched with his/her date (match=1 (both decision=1), no match=0) <br>
# int_corr: the correlation coefficient between the participant's interests and their dates' interests <br>
# age: age of the participant <br>
# income: annual income of participlant <br>
# dec: decision of the participant (yes to second date; decision=1, no;decision=0) <br>
# age_o: age of the date <br>
# dec_o: decision of the date <br>
#
# Attractiveness rating: <br>
# attr1_1: how important is attractiveness to you in a date <br>
# attr: how attractive you find your date <br>
# attr_o: how attractive your date finds you <br>
#
# Sincerity rating: <br>
# sinc1_1:how important is sincerity to you in a date<br>
# sinc: how sincere you find your date <br>
# sinc_o: how sincere your date finds you<br>
#
# Intelligence rating:<br>
# intel1_1:how important is intelligence to you in a date<br>
# intel:how intelligent you find your date<br>
# intel_o: how intelligent your date finds you<br>
#
# Fun rating<br>
# fun1_1:how important is fun to you in a date<br>
# fun: how fun you find your date<br>
# fun_o: how fun your date finds you<br>
#
# Ambition rating<br>
# amb1_1:how important is ambition to you in a date<br>
# amb: how ambitious you find your date<br>
# amb_o: how ambitious your date finds you<br>
#
# Shared Interests: <br>
# shar1_1:how important is shared interests to you in a date<br>
# shar: how ambitious you find your date<br>
# shar_o: how ambitious your date finds you<br>
#
# + id="Vls0Nfx9ftdX"
#Preliminaries: import libraries
import numpy as np
import pandas as pd
#tools for plotting
import matplotlib.pyplot as plt
import seaborn as sns
# %matplotlib inline
pd.options.display.max_rows = 1000 #display truncated results
# + id="ffHfSdKFftdn"
#load the data file, use ISO encoding to better read the file
dt = pd.read_csv('Speed Dating Data.csv',encoding="ISO-8859-1")
# + colab={"base_uri": "https://localhost:8080/", "height": 359} id="nAl8muMzftdx" outputId="a03fb7e6-c190-4d4e-900d-56af0fb1373a"
#Check the columns and variables
dt.head(10)
# -
#Look at dimensions of data
print(dt.shape)
#Look at the column data types
dt.dtypes
#Convert income from object to numeric
dt['income'] = dt['income'].str.replace(',', '').astype(float)
# +
#Before we filter let's count how many people got a match and did not
print(dt['match'].value_counts())
#look at total percentage of people who actually got a match (1=match, 0=no match)
p_success=dt.match.sum()/dt.match.count()
print(p_success*100)
#The rate of success in these events are about 16.5% so not very high
#Pie Chart showing match
plt.figure(figsize = (12,8))
dt['match'].value_counts().plot.pie()
plt.axis('equal')
plt.legend(['no match', 'match'])
#Sets and adjust plots with equal size ratio
plt.show()
# +
# Let's see how the matches vary by age
#Stacked histogram of the frequency of matches by age
#People who are older have proportionally less matches
dt_agg = dt[['age','match']].groupby('match')
value = [dt['age'].values.tolist() for i, dt in dt_agg]
plt.figure(figsize=[15, 10])
plt.hist(value, 50, stacked=True, label = ['No Match','Match'], density=True)
plt.legend()
plt.xlabel('Age')
plt.ylabel('Density')
plt.title('Stacked Histogram of Age Grouped by Match or No Match', fontsize = 16)
plt.grid()
plt.show()
# +
# Filter the dataset by the relevant columns
#Participant id,match status,correlation with their date's interests, their age and income
dt_1 = dt.iloc[:, [11,12,13,33,44]]
#Participant's date's rating of attributes in participant
dt_2 = dt.iloc[:, 23:30]
#Date's rating of how much they like the participant, how probable they will say yes
dt_3 = dt.iloc[:, 30:32]
#Participants' rating of attributes importance to them (out of 10)
dt_4 = dt.iloc[:, 69:75]
#Participant's decision and rating of their date's attributes
dt_5 = dt.iloc[:, 97:104]
#Participant's rating of how much they like their date, how probable they will say yes
dt_6 = dt.iloc[:, 104:106]
#Combine the variables into one
dt_filt = pd.concat([dt.iloc[:, 0],dt.iloc[:, 2],dt_1,dt_2,dt_3,dt_4,dt_5,
dt_6], axis=1)
# -
#Drop the rows with NA values since we want complete observations for each individual (don't want to guess their ratings)
dt_clean = dt_filt.dropna().reset_index(drop=True)
dt_clean.head(10)
#Look at summary of cleaned data
dt_clean.describe()
# +
#Change binary variables to their corresponding categorical value to clarify interpretation
#Create a copy to do more exploratory data analysis
dt_ed=dt_clean.copy()
dt_ed['gender'][dt_ed['gender'] == 0] = 'female'
dt_ed['gender'][dt_ed['gender'] == 1] = 'male'
dt_ed['match'][dt_ed['match'] == 0] = 'no match'
dt_ed['match'][dt_ed['match'] == 1] = 'match'
dt_ed['dec'][dt_ed['dec'] == 0] = 'Rejected date'
dt_ed['dec'][dt_ed['dec'] == 1] = 'Accepted date'
dt_ed['dec_o'][dt_ed['dec_o'] == 0] = 'Rejected by Date'
dt_ed['dec_o'][dt_ed['dec_o'] == 1] = 'Accepted by Date'
# +
#Let's look at distribution of matches by gender
#Surprisingly women get less matches proportionally than men
sns.set(style="whitegrid", color_codes=True)
sns.countplot(x="gender", hue= "match", data=dt_ed)
plt.xlabel('Gender')
plt.title('Distribution of Matches by Gender')
# +
#However when you look at rejection vs acceptance between men and women,
#Women are much more likely to be accepted by their date than men
plt.subplots(figsize=(6,8))
sns.set(style="whitegrid", color_codes=True)
sns.countplot(x="gender", hue= "dec_o", data=dt_ed)
plt.xlabel('Gender')
plt.title('Acceptance by Date for Gender')
# -
#Decision to accept or reject by Gender
plt.subplots(figsize=(6,8))
sns.set(style="whitegrid", color_codes=True)
sns.countplot(x="gender", hue= "dec", data=dt_ed)
plt.xlabel('Gender')
plt.title('Decision to accept or reject Date by Gender')
# +
# Let's see how the matches vary by income
#Stacked histogram of the frequency of matches by income
#Surprisingly, people's income bracket do not seem to have a significant impact on matches
dt_income = dt_ed[['income','match']].groupby('match')
value = [dt_ed['income'].values.tolist() for i, dt in dt_income]
plt.figure(figsize=[15, 10])
plt.hist(value, 50, stacked=True, label = ['No Match','Match'], density=True)
plt.legend()
plt.xlabel('Annual Income ($)')
plt.ylabel('Density')
plt.title('Stacked Histogram of Participant Income Grouped by Match or No Match', fontsize = 16)
plt.grid()
plt.show()
# -
# Let's see how the likeable the person is rated by their date vary by income
plt.figure(figsize=[15, 10])
sns.boxplot(x='like_o', y = 'income', data = dt_ed)
plt.xlabel('Likeability')
plt.ylabel('Annual Income ($)')
plt.title('Annual Income ($) vs. Likeability Rating', fontsize = 16)
plt.grid()
plt.show()
#Let's look at how the importance of different attributes are ranked across genders:
#Group by gender and calculate mean rating
var_imp=dt_ed.groupby('gender').mean()[['attr1_1','sinc1_1','intel1_1','fun1_1','amb1_1','shar1_1']].reset_index()
var_imp.columns=['Gender','Attraction', 'Sincerity','Intelligence','Fun','Ambition','Shared_Interests']
print(var_imp)
#Manipulate data to plot in one graph
var_imp2 = pd.melt(var_imp, id_vars="Gender", var_name="attributes", value_name="mean")
plt.figure(figsize=[25, 10])
ax=sns.factorplot(x='attributes', y='mean', hue='Gender', data=var_imp2, kind='bar',legend=False)
ax.set_xticklabels(rotation=40, ha="right")
ax.despine(left=True)
plt.legend(loc='upper right')
plt.ylabel('Average Rating')
plt.title('Average Rating of Attribute Importance by Gender', fontsize = 16)
plt.show()
# looking at accceptance/rejection by attractiveness attribute
plt.figure(figsize=(7,9))
sns.boxplot(x='dec', y='attr', data=dt_ed, palette='cool',hue='gender')
plt.title('Importance of Attractiveness of Date in Decision', fontsize=20)
plt.xlabel('Decision to Accept or Reject Date', fontsize=16)
plt.ylabel('Attractiveness of Date', fontsize=16)
# looking at rejection by intelligence attribute
plt.figure(figsize=(7,9))
sns.boxplot(x='dec', y='intel', data=dt_ed, palette='cool',hue='gender')
plt.title('Importance of Intelligence of Date in Decision', fontsize=20)
plt.xlabel('Decision to Accept or Reject Date', fontsize=16)
plt.ylabel('Intelligence of Date', fontsize=16)
# looking at rejection by ambition attribute
plt.figure(figsize=(7,9))
sns.boxplot(x='dec', y='amb', data=dt_ed, palette='cool',hue='gender')
plt.title('Importance of Ambition of Date in Decision', fontsize=20)
plt.xlabel('Decision to Accept or Reject Date', fontsize=16)
plt.ylabel('Ambition of Date', fontsize=16)
# looking at rejection by sincerity attribute
plt.figure(figsize=(7,9))
sns.boxplot(x='dec', y='sinc', data=dt_ed, palette='cool',hue='gender')
plt.title('Importance of Sincerity of Date in Decision', fontsize=20)
plt.xlabel('Decision to Accept or Reject Date', fontsize=16)
plt.ylabel('Sincerity of Date', fontsize=16)
# looking at rejection by fun attribute
plt.figure(figsize=(7,9))
sns.boxplot(x='dec', y='fun', data=dt_ed, palette='cool',hue='gender')
plt.title('Importance of Fun of Date in Decision', fontsize=20)
plt.xlabel('Decision to Accept or Reject Date', fontsize=16)
plt.ylabel('Fun-ness of Date', fontsize=16)
# looking at rejection by shared interests attribute
plt.figure(figsize=(7,9))
sns.boxplot(x='dec', y='shar', data=dt_ed, palette='cool',hue='gender')
plt.title('Importance of Shared Interests with Date in Decision', fontsize=20)
plt.xlabel('Decision to Accept or Reject Date', fontsize=16)
#Let's look at the relationship between shared interests correlation and importance of shared interests to the participant
#Found no distinct relationship between importance and actual shared interest with date
yestodate=dt_ed.loc[dt_ed['dec'] == 'Accepted date']
plt.figure(figsize=(7,9))
plt.scatter(yestodate.shar1_1,yestodate.int_corr)
plt.xlabel('Importance of Shared Interests Rating')
plt.ylabel('Actual Correlation Coefficient of Interests with Date')
plt.title('Interests Correlation vs Importance of Shared Interests for Participants who accepted Date')
plt.show()
#Plot correlation heatmap
plt.subplots(figsize=(20,15))
ax = plt.axes()
ax.set_title("Correlation Heatmap")
corr = dt_clean.corr()
corrplot=sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
corrplot.set_xticklabels(corrplot.get_xticklabels(), rotation = 45, horizontalalignment = 'right') #For X axis labels
plt.show()
# + id="nrQT34sYfted"
#At first glance, it is clear that the 6 attributes (attractiveness, sincerity, intelligence,fun, and ambition, shared interests) are
#positively correlated with each other and with the decision and match variable.
#Gender also play a role; males ranking attractiveness very highly while females prefer ambitious partners.
#The ranking of attributes also differ, people who rate attractiveness as very important tend to value fun more than intelligence, ambition, or sincerity.
# +
#Let's examine these attributes variables closer (from participant point of view) with closeup of the correlation graph
dt_ed2 = pd.concat([dt_clean.iloc[:, 1],dt_clean.iloc[:, 3],dt_clean.iloc[:, 22:31]], axis=1)
dt_ed2
corr2=dt_ed2.dropna().corr()
ax = plt.axes()
ax.set_title("Correlation Heatmap-Attributes of Date")
corrplot2=sns.heatmap(corr2,
xticklabels=corr2.columns.values,
yticklabels=corr2.columns.values)
corrplot2.set_xticklabels(corrplot2.get_xticklabels(), rotation = 45, horizontalalignment = 'right') #For X axis labels
plt.show()
# + pycharm={"name": "#%%\n"}
#Relationship between date being attractive and probability of a second date
prob_attr = sns.lmplot(x = 'prob', y = 'attr', data = dt_ed2, height = 6, aspect = 1.5)
plt.xlabel('Attractiveness')
plt.ylabel('Probability of a Second Date')
plt.title('Probability of a Second Date vs. Attractiveness', fontsize = 16)
plt.grid()
plt.show()
# + [markdown] id="5lLsGPxaftfS"
# # Conclusion
# In this data analysis, we explored data from a speed dating analysis and looked at variables which may tell us what attributes people desire in a potential partner, and how the match making process differs across groups. Overall, only 16.5% of all participants found a match, which shows that find a date is not easy! It gets even harder as people get older, with proportion of matches over age 35 dropping steeply.
#
# A surprising finding is that women are less likely to find a match than men. But that is because women are much more picky than men and more likely to reject their date.
# Per popular belief, men tend to see attractiveness as the most important attribute in a partner, while for women it is intelligence. However, they are the top two attributes for both men and women.
#
# These are the rankings of the 6 attributes according to gender: <br>
# Female: Intelligence>Attractiveness>Sincerity>Fun>Ambition>Shared Interests <br>
# Male: Attractiveness>Intelligence>Fun>Sincerity>Shared Interests>Ambition
#
# We can conclude from the data that one’s income does not significantly impact a person’s chances of finding a match. The proportion of matches do not differ noticeably for those at the higher income levels. We can assume perhaps at least on the first few dates it’s true, when it is hard to assess someone’s financial status. Again, when it comes to likeability, there is no noticeable impact for top earners; rich or poor, you can still have great (or lacklustre) appeal.
#
# Finally, when people say they want a partner with common interests, it is not necessarily reflected in their final decision. The data showed no distinct relationship between how highly shared interests are ranked by the participant and their decision to accept a date who shares their interests. Attributes are also correlated with each other; people who rate attractiveness as very important tend to also value fun more than intelligence, ambition, or sincerity. Logically, the more fun a person is the more likeable they are perceived, but when it comes to getting picked for a second date, being attractive still is a better predictor.
#
# In general, the dataset showed a rather superficial view of the dating scene and supports the belief that good looks trumps personality a lot of the time. However keep in mind this is in the context of speed dating and may not translate directly to the longevity of a long term relationship.
#
#
# -
#
| Dating_Project.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import pandas as pd
import os
import json
import time
from IPython.display import clear_output
from IPython.display import HTML
import matplotlib.pyplot as plt
from matplotlib import animation
from matplotlib import colors
import numpy as np
from skimage.segmentation import flood, flood_fill
# %matplotlib inline
# +
# define solver
class ARCSolver:
def __init__(self, task_filename):
# load task and extract input and output pairs
self.task_filename = task_filename
self.task = self.load_task(task_filename)
self.train_inputs, self.train_outputs, self.test_inputs, self.test_outputs = \
self.extract_io_pairs()
self.test_pred = np.zeros((5, 5))
self.test_pred_height, self.test_pred_width = self.test_pred.shape
self.solved = False # have we solved the task yet?
self.selected_colour = 0
self.clipboard = None
self.description = ''
# variables for plotting
self.cmap = colors.ListedColormap(
['#000000', '#0074D9','#FF4136','#2ECC40','#FFDC00',
'#AAAAAA', '#F012BE', '#FF851B', '#7FDBFF', '#870C25'])
self.colour_to_num = {'black': 0, 'blue': 1, 'red': 2, 'green': 3, 'yellow': 4,
'grey': 5, 'magenta': 6, 'orange': 7, 'light_blue': 8,
'maroon': 9}
self.num_to_colour = {0: 'black', 1: 'blue', 2: 'red', 3: 'green', 4: 'yellow',
5: 'grey', 6: 'magneta', 7: 'orange', 8: 'light_blue',
9: 'maroon'}
def load_task(self, task_filename):
with open(task_filename, 'r') as f:
task = json.load(f)
return task
def plot_task(self):
"""
Plots the first train and test pairs of a specified task,
using same color scheme as the ARC app
"""
norm = colors.Normalize(vmin=0, vmax=9)
n_train = len(self.task['train'])
fig, axs = plt.subplots(n_train+1, 2, figsize=(10, 10))
for i in range(n_train):
axs[i, 0].imshow(self.task['train'][i]['input'], cmap=self.cmap, norm=norm)
axs[i, 0].axis('off')
axs[i, 0].set_title('Train Input')
axs[i, 1].imshow(self.task['train'][i]['output'], cmap=self.cmap, norm=norm)
axs[i, 1].axis('off')
axs[i, 1].set_title('Train Output')
axs[n_train, 0].imshow(self.task['test'][0]['input'], cmap=self.cmap, norm=norm)
axs[n_train, 0].axis('off')
axs[n_train, 0].set_title('Test Input')
axs[n_train, 1].imshow(self.task['test'][0]['output'], cmap=self.cmap, norm=norm)
axs[n_train, 1].axis('off')
axs[n_train, 1].set_title('Test Output')
plt.tight_layout()
plt.show()
def plot_grid(self, grid):
"""
Plots a single grid
"""
#plt.clf()
#plt.draw()
#display(plt)
def plot_grids(self, grids):
"""
Plots a list of grids
"""
n_grids = len(grids)
norm = colors.Normalize(vmin=0, vmax=9)
fig, axs = plt.subplots(1, n_grids, figsize=(6, 6), squeeze=False)
for i in range(n_grids):
axs[0, i].imshow(grids[i], cmap=self.cmap, norm=norm)
axs[0, i].axis('off')
plt.tight_layout()
plt.show()
def extract_io_pairs(self):
train = self.task['train']
test = self.task['test']
n_train = len(train)
n_test = len(test)
train_inputs = np.array([train[i]['input'] for i in range(n_train)])
train_outputs = np.array([train[i]['output'] for i in range(n_train)])
test_inputs = np.array([test[i]['input'] for i in range(n_test)])
test_outputs = np.array([test[i]['output'] for i in range(n_test)])
return train_inputs, train_outputs, test_inputs, test_outputs
def copy_from_input(self):
# copy over the first test input
self.test_pred = self.test_inputs[0].copy()
self.test_pred_height, self.test_pred_width = self.test_inputs[0].shape
self.description = 'copy from input'
def reset(self):
# resets grid to all zeros with size of the grid based on current settings
self.test_pred = np.zeros((self.test_pred_height, self.test_pred_width))
self.description = 'reset'
def resize(self):
# resizes the grid
prev_test_pred = self.test_pred.copy()
prev_test_pred_width = self.test_pred_width
prev_test_pred_height = self.test_pred_height
# sample new grid size
new_test_pred_width = np.random.choice(np.arange(1, 5))
new_test_pred_height = np.random.choice(np.arange(1, 5))
new_test_pred = np.zeros((new_test_pred_height, new_test_pred_width))
# copy over values
for i in range(min(prev_test_pred_height, new_test_pred_height)):
for j in range(min(prev_test_pred_width, new_test_pred_width)):
new_test_pred[i, j] = prev_test_pred[i, j]
self.test_pred = new_test_pred
self.test_pred_width = new_test_pred_width
self.test_pred_height = new_test_pred_height
self.description = f'resize: ({new_test_pred_height}, {new_test_pred_width})'
def change_colour(self):
self.selected_colour = np.random.choice(np.arange(10))
self.description = f'change colour: {self.num_to_colour[self.selected_colour]}'
def edit(self):
# select a random location
x = np.random.choice(np.arange(self.test_pred_width))
y = np.random.choice(np.arange(self.test_pred_height))
self.test_pred[y, x] = self.selected_colour
self.description = f'edit: ({y}, {x})'
def edit_rectangle(self):
# selects a randomly selected region and changes the colour of all of the cells
x_start = np.random.choice(np.arange(self.test_pred_width))
x_end = np.random.choice(np.arange(x_start+1, self.test_pred_width+1))
y_start = np.random.choice(np.arange(self.test_pred_height))
y_end = np.random.choice(np.arange(y_start+1, self.test_pred_height+1))
# select a new colour
self.selected_colour = np.random.choice(np.arange(10))
self.test_pred[y_start:y_end, x_start:x_end] = self.selected_colour
self.description = f'edit rectangle from ({y_start}:{y_end}, {x_start}:{x_end}) to {self.selected_colour}'
def copy(self):
# copies a randomly selected region
x_start = np.random.choice(np.arange(self.test_pred_width))
x_end = np.random.choice(np.arange(x_start+1, self.test_pred_width+1))
y_start = np.random.choice(np.arange(self.test_pred_height))
y_end = np.random.choice(np.arange(y_start+1, self.test_pred_height+1))
self.clipboard = self.test_pred[y_start:y_end, x_start:x_end].copy()
self.description = f'copy from ({y_start}:{y_end}, {x_start}:{x_end})'
#print(f'clipboard: {self.clipboard}')
def paste(self):
# pastes clipboard value into randomly selected location
clipboard_height, clipboard_width = self.clipboard.shape
x_start = np.random.choice(np.arange(self.test_pred_width))
x_width = min(clipboard_width, self.test_pred_width - x_start)
y_start = np.random.choice(np.arange(self.test_pred_height))
y_height = min(clipboard_height, self.test_pred_height - y_start)
self.test_pred[y_start:y_start+y_height, x_start:x_start+x_width] = self.clipboard[:y_height, :x_width]
self.description = f'pasting from ({y_start}:{y_start+y_height}, {x_start}:{x_start+x_width})'
def flood_fill(self):
# flood fill at a random location
x = np.random.choice(self.test_pred_width)
y = np.random.choice(self.test_pred_height)
self.test_pred = flood_fill(self.test_pred, (y, x),
self.selected_colour)
self.description = f'flood fill from: ({y}, {x})'
def solve(self):
fig = plt.figure(figsize=(6, 6))
plt.ion()
plt.show()
norm = colors.Normalize(vmin=0, vmax=9)
while not self.solved:
clear_output()
# randomly select available function
if np.random.choice([0, 1]) == 0:
self.change_colour()
else:
self.edit()
plt.imshow(self.test_pred, cmap=self.cmap, norm=norm)
plt.axis('off')
plt.tight_layout()
plt.pause(1)
# check accuracy
# -
solver = ARCSolver(task_filename=os.path.join(training_path, '6e02f1e3.json'))
solver.plot_grids(solver.train_inputs)
solver.plot_grids(solver.train_outputs)
# +
solver = ARCSolver(task_filename=os.path.join(training_path, '6e02f1e3.json'))
fig = plt.figure(figsize=(5, 5))
ax = plt.axes(xlim=(-.5, 4.5), ylim=(-0.5, 4.5))
norm = colors.Normalize(vmin=0, vmax=9)
im = plt.imshow(solver.test_pred, cmap=solver.cmap, norm=norm)
plt.gca().invert_yaxis()
plt.xticks([])
plt.yticks([])
# initialization function: plot the background of each frame
def init():
# TODO: modify initialization
im.set_data(solver.test_pred)
return [im]
# animation function. This is called sequentially
def animate(i):
# TODO: replace the two function calls below with a generic next() function
# or something like that
r = np.random.choice([0, 1, 2, 3, 4, 5, 6, 7, 8])
if r == 0:
solver.change_colour()
elif r == 1:
solver.edit()
elif r == 2:
solver.resize()
elif r == 3:
solver.reset()
elif r == 4:
solver.flood_fill()
elif r == 5:
solver.copy()
elif r == 6:
if solver.clipboard is not None:
solver.paste()
elif r == 7:
solver.copy_from_input()
elif r == 8:
solver.edit_rectangle()
#print(solver.description)
#print(solver.test_pred.shape)
#plt.gcf().set_size_inches(solver.test_pred_height, solver.test_pred_width, forward=True)
plt.rcParams["figure.figsize"] = (solver.test_pred_height, solver.test_pred_width)
im.set_data(solver.test_pred)
ax.set_title(solver.description)
return [im]
# call the animator. blit=True means only re-draw the parts that have changed.
anim = animation.FuncAnimation(fig, animate, init_func=init,
frames=100, interval=200, blit=False)
# save the animation as an mp4. This requires ffmpeg or mencoder to be
# installed. The extra_args ensure that the x264 codec is used, so that
# the video can be embedded in html5. You may need to adjust this for
# your system: for more information, see
# http://matplotlib.sourceforge.net/api/animation_api.html
anim.save('basic_animation.mp4', fps=5, extra_args=['-vcodec', 'libx264'])
HTML(anim.to_html5_video())
# -
np.zeros((3, 2)).shape
for i in range(1):
print(i)
| notebooks/.ipynb_checkpoints/arc_solver-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import pandas as pd
import tensorflow as tf
import os
import glob
from tqdm.notebook import tqdm
# tf.config.set_visible_devices([], 'GPU')
import sys
sys.path.append('../src/')
import logging
tf.get_logger().setLevel(logging.ERROR)
from gcn import datasets as gcn_datasets
from gcn import models as gcn_models
from rgcn import datasets as rgcn_datasets
from rgcn import models as rgcn_models
from mlp import datasets as mlp_datasets
from mlp import models as mlp_models
from ml import datasets as ml_datasets
from ml import models as ml_models
from utils import metrics
# +
dataset_names = ['RIKEN', 'Fiehn_HILIC', 'SMRT']
NUM_SEARCHES = 20
# -
# ### GCN and RGCN
# +
def generate_output(model_obj, model_params, model_weights,
dataset_obj, save_path):
if not os.path.isdir(save_path):
os.makedirs(save_path)
files = glob.glob(f'../input/tfrecords/{save_path.split("/")[-3]}/*')
model = model_obj(**model_params)
dummy_data = next(iter(dataset_obj(
files[0], batch_size=128, training=False).get_iterator()))
model([dummy_data['adjacency_matrix'], dummy_data['feature_matrix']])
model.set_weights(model_weights)
for file in files:
dataset = dataset_obj(file, batch_size=128, training=False)
trues, preds = model.predict(dataset.get_iterator())
path = save_path + file.split('/')[-1].split('.')[0] # + "_1"
np.save(path, np.stack([trues, preds]))
parameters = {
'num_bases': lambda: np.random.choice([-1, 2, 4]),
'num_gconv_layers': lambda: np.random.randint(*[3, 5+1]),
'num_gconv_units': lambda: np.random.randint(*[128, 256+1]),
'learning_rate': lambda: np.random.uniform(*[1e-4, 1e-3]),
'num_epochs': lambda: np.random.randint(*[100, 300+1]),
'batch_size': lambda: np.random.choice([32, 64, 128]),
'weight_decay': lambda: 10**np.random.uniform(*[-6, -3]),
'num_dense_layers': lambda: np.random.randint(*[1, 2+1]),
'num_dense_units': lambda: np.random.randint(*[256, 1024]),
'dense_dropout': lambda: np.random.uniform(*[0.0, 0.3]),
}
for dataset_name in dataset_names:
best_error = float('inf')
for i in tqdm(range(NUM_SEARCHES)):
np.random.seed(42+i)
num_gconv_layers = parameters['num_gconv_layers']()
num_gconv_units = parameters['num_gconv_units']()
learning_rate = parameters['learning_rate']()
batch_size = parameters['batch_size']()
num_epochs = parameters['num_epochs']()
weight_decay = parameters['weight_decay']()
num_dense_layers = parameters['num_dense_layers']()
num_dense_units = parameters['num_dense_units']()
dense_dropout = parameters['dense_dropout']()
params = {
"gconv_units": [num_gconv_units] * num_gconv_layers,
"gconv_regularizer": tf.keras.regularizers.L2(weight_decay),
"initial_learning_rate": learning_rate,
'dense_units': [num_dense_units] * num_dense_layers,
'dense_dropout': dense_dropout,
}
train_dataset = gcn_datasets.GCNDataset(
f'../input/tfrecords/{dataset_name}/train.tfrec', batch_size, True)
valid_dataset = gcn_datasets.GCNDataset(
f'../input/tfrecords/{dataset_name}/valid.tfrec', batch_size, False)
model = gcn_models.GCNModel(**params)
model.fit(
train_dataset.get_iterator(),
epochs=num_epochs,
verbose=0
)
trues, preds = model.predict(valid_dataset.get_iterator())
error = metrics.get('mae')(trues, preds)
if error < best_error:
best_error = error
best_params = params.copy()
best_weights = model.get_weights()
generate_output(
model_obj=gcn_models.GCNModel,
model_params=best_params,
model_weights=best_weights,
dataset_obj=gcn_datasets.GCNDataset,
save_path=f'../output/predictions/{dataset_name}/gcn/'
)
for dataset_name in dataset_names:
best_error = float('inf')
for i in tqdm(range(NUM_SEARCHES)):
np.random.seed(42+i)
num_bases = parameters['num_bases']()
num_gconv_layers = parameters['num_gconv_layers']()
num_gconv_units = parameters['num_gconv_units']()
learning_rate = parameters['learning_rate']()
batch_size = parameters['batch_size']()
num_epochs = parameters['num_epochs']()
weight_decay = parameters['weight_decay']()
num_dense_layers = parameters['num_dense_layers']()
num_dense_units = parameters['num_dense_units']()
dense_dropout = parameters['dense_dropout']()
params = {
# "gconv_num_bases": num_bases,
"gconv_units": [num_gconv_units] * num_gconv_layers,
"gconv_regularizer": tf.keras.regularizers.L2(weight_decay),
"initial_learning_rate": learning_rate,
'dense_units': [num_dense_units] * num_dense_layers,
'dense_dropout': dense_dropout,
}
train_dataset = rgcn_datasets.RGCNDataset(
f'../input/tfrecords/{dataset_name}/train.tfrec', batch_size, True)
valid_dataset = rgcn_datasets.RGCNDataset(
f'../input/tfrecords/{dataset_name}/valid.tfrec', batch_size, False)
model = rgcn_models.RGCNModel(**params)
model.fit(
train_dataset.get_iterator(),
epochs=num_epochs,
verbose=0
)
trues, preds = model.predict(valid_dataset.get_iterator(), verbose=0)
error = metrics.get('mae')(trues, preds)
if error < best_error:
best_error = error
best_params = params.copy()
best_weights = model.get_weights()
generate_output(
model_obj=rgcn_models.RGCNModel,
model_params=best_params,
model_weights=best_weights,
dataset_obj=rgcn_datasets.RGCNDataset,
save_path=f'../output/predictions/{dataset_name}/rgcn/'
)
# -
# ### MLP
# +
def generate_output(model_obj,
model_params,
model_weights,
save_path):
if not os.path.isdir(save_path):
os.makedirs(save_path)
batch_size = model_params['batch_size']
num_epochs = model_params['num_epochs']
bits = model_params['bits']
radius = model_params['radius']
use_counts = model_params['use_counts']
del model_params['batch_size']
del model_params['num_epochs']
del model_params['bits']
del model_params['radius']
del model_params['use_counts']
train, valid, test_1, test_2 = mlp_datasets.get_ecfp_datasets(
f"../input/datasets/{save_path.split('/')[-2]}.csv",
bits=bits, radius=radius, use_counts=use_counts,
)
model = model_obj(**model_params)
model(train['X'][:1])
model.set_weights(model_weights)
for name, dataset in zip(['train', 'valid', 'test_1', 'test_2'], [train, valid, test_1, test_2]):
if dataset is not None:
y_pred = model.predict(dataset['X'], dataset['y'])[1]
np.save(save_path + '/' + name, np.stack([dataset['y'], y_pred]))
parameters = {
'num_layers': lambda: np.random.randint(*[1, 3+1]),
'num_units': lambda: np.random.randint(*[256, 1024+1]),
'learning_rate': lambda: np.random.uniform(*[1e-4, 1e-3]),
'num_epochs': lambda: np.random.randint(*[50, 200+1]),
'batch_size': lambda: np.random.choice([32, 64, 128]),
'dropout_rate': lambda: np.random.uniform(*[0.0, 0.3]),
'bits': lambda: np.random.randint(*[512, 2048+1]),
'radius': lambda: np.random.randint(*[1, 3+1]),
'use_counts': lambda: np.random.choice([True, False]),
}
for dataset_name in dataset_names:
best_error = float('inf')
for i in tqdm(range(NUM_SEARCHES)):
np.random.seed(42+i)
num_layers = parameters['num_layers']()
num_units = parameters['num_units']()
learning_rate = parameters['learning_rate']()
batch_size = parameters['batch_size']()
num_epochs = parameters['num_epochs']()
dropout_rate = parameters['dropout_rate']()
bits = parameters['bits']()
radius = parameters['radius']()
use_counts = parameters['use_counts']()
train, valid, test_1, test_2 = mlp_datasets.get_ecfp_datasets(
'../input/datasets/{}.csv'.format(dataset_name),
bits=bits, radius=radius, use_counts=use_counts,
)
model = mlp_models.MLPModel(
hidden_units=[num_units] * num_layers,
dropout_rate=dropout_rate,
loss_fn=tf.keras.losses.Huber,
optimizer=tf.keras.optimizers.Adam,
initial_learning_rate=learning_rate,
)
model.fit(train['X'], train['y'],
batch_size=batch_size,
verbose=0,
epochs=num_epochs)
trues, preds = model.predict(valid['X'], valid['y'])
error = metrics.get('mae')(trues, preds)
if error < best_error:
best_error = error
best_params = {
"num_epochs": num_epochs,
"batch_size": batch_size,
"hidden_units": [num_units] * num_layers,
"initial_learning_rate": learning_rate,
"dropout_rate": dropout_rate,
"bits": bits,
"radius": radius,
"use_counts": use_counts,
}
best_weights = model.get_weights()
generate_output(
model_obj=mlp_models.MLPModel,
model_params=best_params,
model_weights=best_weights,
save_path='../output/predictions/{}/{}'.format(dataset_name, 'mlp')
)
# -
# ### RF, GB, AB and SVM
# +
def generate_output(model_obj, datasets, save_path):
if not os.path.isdir(save_path):
os.makedirs(save_path)
for name, dataset in zip(['train', 'valid', 'test_1', 'test_2'], datasets):
if dataset is not None:
y_pred = model_obj.predict(dataset['X'])
np.save(save_path + '/' + name, np.stack([dataset['y'], y_pred]))
for dataset_name in dataset_names:
train, valid, test_1, test_2 = ml_datasets.get_descriptor_datasets(
dataset_path=f'../input/datasets/{dataset_name}.csv')
for model_name in ['rf', 'gb', 'ab', 'svm']:
model_iter = ml_models.ModelGenerator(model_name, NUM_SEARCHES)
best_error = float('inf')
for model in tqdm(model_iter):
model.fit(train['X'], train['y'])
preds = model.predict(valid['X'])
error = metrics.get('mae')(valid['y'], preds)
if error < best_error:
best_error = error
best_model = model
generate_output(
model_obj=best_model,
datasets=[train, valid, test_1, test_2],
save_path='../output/predictions/{}/{}'.format(
dataset_name, model_name)
)
# -
# ### Obtain results
# +
models = ['gcn', 'rgcn', 'mlp', 'rf', 'svm', 'gb', 'ab']
datasets = ['RIKEN', 'Fiehn_HILIC', 'SMRT']
d = {
'SMRT': {
'GCN': [],
'RGCN': [],
'MLP': [],
'RF': [],
'SVM': [],
'GB': [],
'AB': []
},
'RIKEN': {
'GCN': [],
'RGCN': [],
'MLP': [],
'RF': [],
'SVM': [],
'GB': [],
'AB': []
},
'Fiehn_HILIC': {
'GCN': [],
'RGCN': [],
'MLP': [],
'RF': [],
'SVM': [],
'GB': [],
'AB': []
},
}
for dataset in datasets:
for model in models:
files = glob.glob(f'../output/predictions/{dataset}/{model}/*')
files[1], files[2] = files[2], files[1]
assert files[0].split('/')[-1].split('.')[0] == 'train'
assert files[1].split('/')[-1].split('.')[0] == 'valid'
assert files[2].split('/')[-1].split('.')[0] == 'test' or files[2].split('/')[-1].split('.')[0] == 'test_1'
if len(files) == 4:
assert files[3].split('/')[-1].split('.')[0] == 'test_2'
for file in files:
data = np.load(file)
mae = metrics.get('mae')(data[0], data[1])
mre = metrics.get('mre')(data[0], data[1])
rmse = metrics.get('rmse')(data[0], data[1])
r2 = metrics.get('r2')(data[0], data[1])
subset = file.split('/')[-1].split('.')[0]
d[dataset][model.upper()].extend([mae, mre, rmse, r2])
# -
data = pd.DataFrame.from_dict(pd.DataFrame.from_dict({(i,j): d[i][j]
for i in d.keys()
for j in d[i].keys()},
orient='index'))
column_names = ["train_mae", "train_mre", "train_rmse", "train_r2"]
column_names += ["valid_mae", "valid_mre", "valid_rmse", "valid_r2"]
column_names += ["test1_mae", "test1_mre", "test1_rmse", "test1_r2"]
column_names += ["test2_mae", "test2_mre", "test2_rmse", "test2_r2"]
data.columns = column_names
data
| notebooks/evaluation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + pycharm={"name": "#%%\n"}
# exports
import pandas as pd
import json
import pymongo
def import_data_in_mongo(file, database, collection):
data = pd.read_csv(file)
data_json = json.loads(data.to_json(orient='records'))
client = pymongo.MongoClient('localhost', 27017)
db = client[database]
db.authenticate('root', 'root', 'admin')
collection = db[collection]
collection.delete_many({})
collection.insert_many(data_json)
# + pycharm={"name": "#%%\n"}
import_data_in_mongo('../rawData/DAX 20180101-20191231.csv', 'preCovid', 'DAX')
# + pycharm={"name": "#%%\n"}
import_data_in_mongo('../rawData/DAX 20200101-20210501.csv', 'inCovid', 'DAX')
# + pycharm={"name": "#%%\n"}
| kj/01_DataImport.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [Root]
# language: python
# name: Python [Root]
# ---
# 함수의 인자도 타입이 정해지지 않습니다.
def func_test1(a):
print(a)
func_test1(1)
func_test1('test')
# 디폴트값이 지정되지 않은 파라메타는 꼭 값이 있어야 합니다.
def func_test2(a, b=0):
print(a, b)
func_test2(1)
func_test2(1, 2)
func_test2(b=2, a=1)
# 여러개의 리턴값이 있을 경우 튜플로 리턴됩니다.
def func_test3(a, b):
return a+1, b-1
func_test3(3, 5)
c, d = func_test3(3, 5)
c, d
# 함수도 오브젝트입니다.
f = func_test3
f(10, 100)
# 함수가 아무런 값도 리턴하지 않을 경우 None이 리턴됩니다.
def func_test4():
pass
result = func_test4()
result is None
result.__class__
| tutorial-1/function.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [default]
# language: python
# name: python3
# ---
# + [markdown] toc="true"
# # Table of Contents
# <p><div class="lev1 toc-item"><a href="#Inference-problems-with-Poisson-distributed-gene-expression-data" data-toc-modified-id="Inference-problems-with-Poisson-distributed-gene-expression-data-1"><span class="toc-item-num">1 </span>Inference problems with Poisson distributed gene expression data</a></div><div class="lev1 toc-item"><a href="#Inference-problems:-Poisson-mixtures" data-toc-modified-id="Inference-problems:-Poisson-mixtures-2"><span class="toc-item-num">2 </span>Inference problems: Poisson mixtures</a></div><div class="lev2 toc-item"><a href="#The-right-way:-EM-algorithm-to-the-rescue." data-toc-modified-id="The-right-way:-EM-algorithm-to-the-rescue.-2.1"><span class="toc-item-num">2.1 </span>The right way: EM algorithm to the rescue.</a></div><div class="lev1 toc-item"><a href="#Cancer-vs-healthy" data-toc-modified-id="Cancer-vs-healthy-3"><span class="toc-item-num">3 </span>Cancer vs healthy</a></div>
# +
import pandas as pd
import numpy as np
import scipy
from scipy.special import gammaln
from Bio import SeqIO
# Graphics
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
rc('text', usetex=True)
rc('text.latex', preamble=r'\usepackage{cmbright}')
rc('font', **{'family': 'sans-serif', 'sans-serif': ['Helvetica']})
# Magic function to make matplotlib inline;
# %matplotlib inline
# This enables SVG graphics inline.
# There is a bug, so uncomment if it works.
# %config InlineBackend.figure_formats = {'png', 'retina'}
# JB's favorite Seaborn settings for notebooks
rc = {'lines.linewidth': 2,
'axes.labelsize': 18,
'axes.titlesize': 18,
'axes.facecolor': 'DFDFE5'}
sns.set_context('notebook', rc=rc)
sns.set_style("dark")
mpl.rcParams['xtick.labelsize'] = 16
mpl.rcParams['ytick.labelsize'] = 16
mpl.rcParams['legend.fontsize'] = 14
# -
# # Inference problems with Poisson distributed gene expression data
def make_poisson(L):
"""generate a poisson random variable."""
x = np.random.poisson(L, 500)
if L < 10:
sns.countplot(x, label='$\lambda=1$')
else:
sns.distplot(x)
plt.xlabel('Number of observed events')
plt.title('$\lambda = {0}$'.format(L))
make_poisson(1)
make_poisson(5)
make_poisson(50)
def plot_mean_error(L, max_samples, ax):
"""Calculates and plots the error in the mean for samples containing 2 or more data points."""
def mean_error(L, samples):
"""returns sqrt([L - L_est]**2)"""
return [np.abs(np.mean(np.random.poisson(L, sample)) - L) for sample in samples]
# plot:
x = np.arange(2, max_samples)
y = mean_error(L, x)
ax.scatter(x, y, s=6, alpha=0.8)
# +
fig, ax = plt.subplots(ncols=3, figsize=(12, 6))
L = [1, 5, 50]
plots = [None]*3
for i, l in enumerate(L):
plot_mean_error(l, 500, ax[i])
plots[i] = ax[i].axhline(l/10, ls='--', color='k', lw=1,
label='10\% error'.format(l))
ax[i].set_xlabel('$\lambda = {0}$'.format(l))
plt.legend()
ax[0].set_ylabel('Error, $\sqrt{(\lambda - \hat{\lambda})^2}$')
plt.tight_layout()
# -
# When the firing/expression rate is low, we need many measurements to estimate $\lambda$ well (~100). By the time $\lambda > 10$, a couple of measurements are enough to begin to estimate the rate accurately.
# # Inference problems: Poisson mixtures
df1 = pd.read_csv('../input/brainmuscle1.csv', header=None)
df1.columns = ['expression']
sns.distplot(df1.expression, bins=15)
# The dumb way to fit this dataset is to split it into two, then ML each subset individually. Let's try it.
# the lousy way: Split the data into two, fit each one individually
l1 = np.mean(df1[df1.expression < 100].expression.values)
l2 = np.mean(df1[df1.expression > 100].expression.values)
print("l1: {0:.2g}\nl2: {1:.2g}".format(l1, l2))
# +
# simulate the dataset:
x1 = np.random.poisson(l1, np.sum(df1.expression.values < 100))
x2 = np.random.poisson(l2, np.sum(df1.expression.values > 100))
x = np.append(x1, x2)
sns.distplot(df1.expression, label='`real` data', bins=30)
sns.distplot(x, label='simulated', bins=30)
plt.axvline(df1.expression.mean(), label='Data mean',
ls='--', color='red')
plt.xlim(0, 300)
plt.legend()
plt.title('EM works!!')
# -
# It works! But there's a better way to do this...
# ## The right way: EM algorithm to the rescue.
def ln_poisson(k, L):
return k*np.log(L) - gammaln(k) - L
# +
def M_step(p_z1J, X, L1, L2, t1):
"""
Recalculate lambdas and mixings.
"""
t2 = 1 - t1
p_z2J = 1-p_z1J
logL = np.sum(p_z1J*(np.log(t1)*ln_poisson(X, L1)))
logL += np.sum(p_z2J*(np.log(t2)*ln_poisson(X, L2)))
t1 = np.sum(p_z1J)/len(X)
t2 = 1 - t1
l1 = np.sum(p_z1J*X)/np.sum(p_z1J)
l2 = np.sum(p_z2J*X)/np.sum(p_z2J)
logL_after = np.sum(p_z1J*(np.log(t1)*ln_poisson(X, L1)))
logL_after += np.sum(p_z2J*(np.log(t2)*ln_poisson(X, L2)))
delta = np.abs(logL_after - logL)
return t1, l1, l2, delta
def E_step(p_z1J, X, l1, l2, t1):
"""
Recalculate weight probabilities.
"""
t2 = 1 - t1
def weight(x):
Z = t1*np.exp(ln_poisson(x, l1)) + t2*np.exp(ln_poisson(x, l2))
return t1*np.exp(ln_poisson(x, l1))/Z
for i, x in enumerate(X):
p_z1J[i] = weight(x)
return p_z1J
# +
# initialize parameters
X = df1.expression.values
p_z1J = X/np.max(X)
l1, l2 = 1, 300
t1 = 0.3
delta = 1
# run EM
while delta > 10**-6:
p_z1j = E_step(p_z1J, X, l1, l2, t1)
t1, l1, l2, delta = M_step(p_z1J, X, l1, l2, t1)
print("l1: {0:.2g}\nl2: {1:.2g}".format(l1, l2))
# -
# We got exactly the same answer as before. Nice. Let's solve the second expression set.
df2 = pd.read_csv('../input/brainmuscle2.csv', header=None)
df2.columns = ['expression']
sns.distplot(df2.expression, bins=15)
# initialize parameters
X = df2.expression.values
p_z1J = X/np.max(X)
l1, l2 = 1, 300
t1 = 0.3
delta = 1
# run EM
while delta > 10**-6:
p_z1j = E_step(p_z1J, X, l1, l2, t1)
t1, l1, l2, delta = M_step(p_z1J, X, l1, l2, t1)
print("l1: {0:.2g}\nl2: {1:.2g}".format(l1, l2))
# +
# simulate the dataset:
x1 = np.random.poisson(l1, np.sum(df2.expression.values < 50))
x2 = np.random.poisson(l2, np.sum(df2.expression.values > 50))
x = np.append(x1, x2)
sns.distplot(df2.expression, label='`real` data', bins=30)
sns.distplot(x, label='simulated', bins=30)
plt.xlim(0, 150)
plt.legend()
plt.title('EM!')
# -
# # Cancer vs healthy
h1 = pd.read_csv('../input/healthy1.csv', header=None)
h1.shape
h1.head()
# +
# note: I am assuming each column is a cell...
# -
# Let's plot $\sigma$ vs $\mu$ for these healthy patients.
# +
x, y = h1.mean(), h1.var()
X = np.linspace(np.min(x), np.max(x))
lr = scipy.stats.linregress(x, y)
plt.scatter(x, y, s=2, label='data', alpha=0.3)
plt.plot(X, lr.intercept + lr.slope*X,
label='fit', lw=2, color='k', ls='--')
# plt.xscale('log')
plt.yscale('log')
plt.legend()
plt.xlabel('$\mu$')
plt.ylabel('$\sigma$')
print('y = {0:.2g} + {1:.2g}x'.format(lr.intercept, lr.slope))
# -
# Now let's plot $C_v$ vs $\mu$ for these healthy patients.
# +
cv = h1.std()/x
lr = scipy.stats.linregress(x, cv)
plt.scatter(x, cv, s=2, label='data', alpha=0.3)
plt.plot(X, lr.intercept + lr.slope*X,
label='fit', lw=2, color='k', ls='--')
plt.legend()
plt.xlabel('$\mu$')
plt.ylabel('$C_v$')
print('y = {0:.2g} + {1:.2g}x'.format(lr.intercept, lr.slope))
# -
# Next we are asked to make a histogram of zero count cells for each gene.
def count_zeros(df=h1):
genes = (df.transpose() == 0)
i = 0
zero_counts = np.empty(len(genes.columns))
for i, gene in enumerate(genes.columns):
zero_counts[i] = np.sum(genes[gene])
sns.distplot(zero_counts)
plt.xlabel('Cells with zero counts of a gene, for all genes')
plt.ylabel('Normalized frequency')
return zero_counts/len(genes[gene])
_ = count_zeros()
# Let's fit a gamma distribution for the non-zero counts:
def gamma_inference(df=h1):
genes = df.transpose()
i = 0
alpha = np.zeros(len(genes.columns))
beta = np.zeros(len(genes.columns))
for i, gene in enumerate(genes.columns):
non_zero_counts = genes[gene][genes[gene] != 0].values
if len(non_zero_counts) < 2:
continue
# estimate using method of moments
# because scipy.stats.gamma is NOT the function I'm looking for
# scipy.stats.gamma = x^(a+1)e^-x/beta; beta is only a scaling
# factor.
fit_beta = np.mean(non_zero_counts)/np.var(non_zero_counts)
fit_alpha = np.mean(non_zero_counts)*fit_beta
alpha[i] = fit_alpha
beta[i] = fit_beta
return alpha, beta
alpha, beta = gamma_inference()
x = np.matrix([alpha, beta])
data = pd.DataFrame(x.transpose(), columns=['alpha', 'beta'])
sns.jointplot(x='alpha', y='beta', data=data, s=2)
# And let's plot the data and overlay the fit on it to see how good it is.
def count_gene(gene, df=h1, real_label='scaled real data', sim_label='simulated data'):
genes = df.transpose()
alpha = np.zeros(len(genes.columns))
beta = np.zeros(len(genes.columns))
non_zero_counts = genes[gene][genes[gene] != 0].dropna().values
if len(non_zero_counts) < 2:
raise ValueError('Not enough observations')
fit_beta = np.mean(non_zero_counts)/np.var(non_zero_counts)
fit_alpha = np.mean(non_zero_counts)*fit_beta
y = scipy.stats.gamma.rvs(fit_alpha, size=len(non_zero_counts))
sns.distplot(non_zero_counts*fit_beta, label=real_label)
sns.distplot(y, label=sim_label)
plt.legend()
plt.title('Overlay of scaled data with simulation from the fit gamma')
plt.xlabel(r'$\frac{g_i}{\beta}$')
plt.ylabel('Normalized frequency')
count_gene(1)
# It works!
aml1 = pd.read_csv('../input/aml1.csv', header=None)
aml1.head()
aml1.head()
# +
alpha_aml1, beta_aml1 = gamma_inference(aml1)
x = np.matrix([alpha_aml1, beta_aml1])
data_aml1 = pd.DataFrame(x.transpose(), columns=['alpha', 'beta'])
# +
plt.scatter(alpha, beta, label='healthy1', s=3)
plt.scatter(alpha_aml1, beta_aml1, label='aml1', s=3)
plt.legend()
plt.xlim(0, 10)
plt.ylim(0, .05)
plt.xlabel(r'$\alpha$')
plt.ylabel(r'$\beta$')
# -
# Next, we are asked to find a coordinate pair that is different between the healthy and AML samples. However, I am way too lazy to implement the second derivative method to find confidence intervals, so in the hack below I've simply found the gene with the largest manhattan distance between the healthy and control samples.
gene = np.where((alpha - alpha_aml1)**2 + (beta - beta_aml1)**2 == np.max((alpha - alpha_aml1)**2 + (beta - beta_aml1)**2))
count_gene(gene[0], real_label='healthy real', sim_label='healthy sim')
count_gene(gene[0], df=aml1, real_label='aml real', sim_label='aml sim')
# +
def gamma(x, a, b):
return b**a/scipy.special.gamma(a)*np.exp(-b*x)
def mixed_gamma_zero_prob(x, alpha, beta, w):
return w*(x == 0) + (1-w)*gamma(x, alpha, beta)
def odds(h, aml, params1, params2):
alpha1, beta1, w1 = params1
alpha2, beta2, w2 = params2
return np.log(mixed_gamma_zero_prob(h, alpha1, beta1, w1)) - np.log(mixed_gamma_zero_prob(aml, alpha2, beta2, w2))
# -
h2 = pd.read_csv('../input/healthy2.csv')
aml2 = pd.read_csv('../input/aml2.csv')
w_healthy = count_zeros()
w_aml = count_zeros(aml1)
# Ran out of time here. Sorry!
# +
params1 = w_healthy[0], alpha[0], beta[0]
params2 = w_aml[0], alpha_aml1[0], beta_aml1[0]
odds(h2.as_matrix()[0][0], aml2.as_matrix()[0][0], params1, params2)
# +
def shuffle(df):
return df.reindex(np.random.permutation(df.index))
def odds_for_cell(cell, h, a):
# h = shuffle(h)
# a = shuffle(a)
logL = 0
for i, h in enumerate(h[cell].values):
uh = a[cell].values[i]
params1 = w_healthy[gene], alpha[gene], beta[gene]
params2 = w_aml[gene], alpha_aml1[gene], beta_aml1[gene]
logL += odds(h, uh, params1, params2)
return logL
# -
| src/Hwk5.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: qiskitdevl
# language: python
# name: qiskitdevl
# ---
# # Simon's Algorithm
# In this section, we first introduce the Simon problem, and classical and quantum algorithms to solve it. We then implement the quantum algorithm using Qiskit, and run on a simulator and device.
#
#
# ## Contents
#
# 1. [Introduction](#introduction)
# - [Simon's Problem](#problem)
# - [Simon's Algorithm](#algorithm)
#
# 2. [Example](#example)
#
# 3. [Qiskit Implementation](#implementation)
# - [Simulation](#simulation)
# - [Device](#device)
#
# 4. [Oracle](#oracle)
#
# 5. [Problems](#problems)
#
# 6. [References](#references)
# ## 1. Introduction <a id='introduction'></a>
#
# Simon's algorithm, first introduced in Reference [1], was the first quantum algorithm to show an exponential speed-up versus the best classical algorithm in solving a specific problem. This inspired the quantum algorithm for the discrete Fourier transform, also known as quantum Fourier transform, which is used in the most famous quantum algorithm: Shor's factoring algorithm.
#
# ### 1a. Simon's Problem <a id='problem'> </a>
#
# We are given an unknown blackbox function $f$, which is guaranteed to be either one-to-one or two-to-one, where one-to-one and two-to-one functions have the following properties:
#
# - _one-to-one_: maps exactly one unique output for every input, eg. $f(1) \rightarrow 1$, $f(2) \rightarrow 2$, $f(3) \rightarrow 3$, $f(4) \rightarrow 4$.
# - _two-to-one_: maps exactly two inputs to every unique output, eg. $f(1) \rightarrow 1$, $f(2) \rightarrow 2$, $f(3) \rightarrow 1$, $f(4) \rightarrow 2$, according to a hidden bitstring, $s$
# $$
# \textrm{where: given }x_1,x_2: \quad f(x_1) = f(x_2) \\
# \textrm{it is guaranteed }: \quad x_1 \oplus x_2 = s
# $$
#
# Thus, given this blackbox $f$, how quickly can we determine if $f$ is one-to-one or two-to-one? Then, if $f$ turns out to be two-to-one, how quickly can we determine $s$? As it turns out, both cases boil down to the same problem of finding $s$, where a bitstring of $s={000...}$ represents the one-to-one $f$.
# ### 1b. Simon's Algorithm <a id='algorithm'> </a>
#
# #### Classical Solution
#
# Classically, if we want to know what $s$ is for a given $f$, with 100% certainty, we have to check up to $2^{N−1}+1$ inputs, where N is the number of bits in the input. This means checking just over half of all the possible inputs until we find two cases of the same output. Although, probabilistically the average number of inputs will be closer to the order of $\mathcal(o)(2)$. Much like the Deutsch-Jozsa problem, if we get lucky, we could solve the problem with our first two tries. But if we happen to get an $f$ that is one-to-one, or get _really_ unlucky with an $f$ that’s two-to-one, then we’re stuck with the full $2^{N−1}+1$.
# #### Quantum Solution
#
# The quantum circuit that implements Simon's algorithm is shown below.
#
# <img src="images/simon_steps.jpeg" width="300">
#
# Where the query function, $\text{Q}_f$ acts on two quantum registers as:
# $$ \lvert x \rangle \lvert 0 \rangle \rightarrow \lvert x \rangle \lvert f(x) \rangle $$
#
# The algorithm involves the following steps.
# <ol>
# <li> Two $n$-qubit input registers are initialized to the zero state:
# $$\lvert \psi_1 \rangle = \lvert 0 \rangle^{\otimes n} \lvert 0 \rangle^{\otimes n} $$ </li>
#
# <li> Apply a Hadamard transform to the first register:
# $$\lvert \psi_2 \rangle = \frac{1}{\sqrt{2^n}} \sum_{x \in \{0,1\}^{n} } \lvert x \rangle\lvert 0 \rangle^{\otimes n} $$
# </li>
#
# <li> Apply the query function $\text{Q}_f$:
# $$ \lvert \psi_3 \rangle = \frac{1}{\sqrt{2^n}} \sum_{x \in \{0,1\}^{n} } \lvert x \rangle \lvert f(x) \rangle $$
# </li>
#
# <li> Measure the second register. A certain value of $f(x)$ will be observed. Because of the setting of the problem, the observed value $f(x)$ could correspond to two possible inputs: $x$ and $y = x \oplus s $. Therefore the first register becomes:
# $$\lvert \psi_4 \rangle = \frac{1}{\sqrt{2}} \left( \lvert x \rangle + \lvert y \rangle \right)$$
# where we omitted the second register since it has been measured.
# </li>
#
# <li> Apply Hadamard on the first register:
# $$ \lvert \psi_5 \rangle = \frac{1}{\sqrt{2^{n+1}}} \sum_{z \in \{0,1\}^{n} } \left[ (-1)^{x \cdot z} + (-1)^{y \cdot z} \right] \lvert z \rangle $$
# </li>
#
# <li> Measuring the first register will give an output of:
# $$ (-1)^{x \cdot z} = (-1)^{y \cdot z} $$
# which means:
# $$ x \cdot z = y \cdot z \\
# x \cdot z = \left( x \oplus s \right) \cdot z \\
# x \cdot z = x \cdot z \oplus s \cdot z \\
# s \cdot z = 0 \text{ (mod 2)} $$
#
# A string $z$ whose inner product with $s$ will be measured. Thus, repeating the algorithm $\approx n$ times, we will be able to obtain $n$ different values of $z$ and the following system of equation can be written
# $$ \begin{cases} s \cdot z_1 = 0 \\ s \cdot z_2 = 0 \\ ... \\ s \cdot z_n = 0 \end{cases}$$
# From which $s$ can be determined, for example by Gaussian elimination.
# </li>
# </ol>
#
# So, in this particular problem the quantum algorithm performs exponentially fewer steps than the classical one. Once again, it might be difficult to envision an application of this algorithm (although it inspired the most famous algorithm created by Shor) but it represents the first proof that there can be an exponential speed-up in solving a specific problem by using a quantum computer rather than a classical one.
# ## 2. Example <a id='example'></a>
#
# Let's see the example of Simon's algorithm for 2 qubits with the secret string $s=11$, so that $f(x) = f(y)$ if $y = x \oplus s$. The quantum circuit to solve the problem is:
#
# <img src="images/simon_example.jpeg" width="300">
#
# <ol>
# <li> Two $2$-qubit input registers are initialized to the zero state:
# $$\lvert \psi_1 \rangle = \lvert 0 0 \rangle_1 \lvert 0 0 \rangle_2 $$ </li>
#
# <li> Apply Hadamard gates to the qubits in the first register:
# $$\lvert \psi_2 \rangle = \frac{1}{2} \left( \lvert 0 0 \rangle_1 + \lvert 0 1 \rangle_1 + \lvert 1 0 \rangle_1 + \lvert 1 1 \rangle_1 \right) \lvert 0 0 \rangle_2 $$ </li>
#
# <li> For the string $s=11$, the query function can be implemented as $\text{Q}_f = CX_{13}CX_{14}CX_{23}CX_{24}$:
# \begin{aligned}
# \lvert \psi_3 \rangle = \frac{1}{2} \left(\lvert 0 0 \rangle_1 \lvert 0\oplus 0 \oplus 0, 0 \oplus 0 \oplus 0 \rangle_2 \\
# + \lvert 0 1 \rangle_1 \lvert 0\oplus 0 \oplus 1, 0 \oplus 0 \oplus 1 \rangle_2 \\
# + \lvert 1 0 \rangle_1 \lvert 0\oplus 1 \oplus 0, 0 \oplus 1 \oplus 0 \rangle_2 \\
# + \lvert 1 1 \rangle_1 \lvert 0\oplus 1 \oplus 1, 0 \oplus 1 \oplus 1 \rangle_2 \right)
# \end{aligned}
#
# Thus
# $$ \lvert \psi_3 \rangle = \frac{1}{2} \left( \lvert 0 0 \rangle_1 \lvert 0 0 \rangle_2 + \lvert 0 1 \rangle_1 \lvert 1 1 \rangle_2 + \lvert 1 0 \rangle_1 \lvert 1 1 \rangle_2 + \lvert 1 1 \rangle_1 \lvert 0 0 \rangle_2 \right) $$
#
#
# </li>
#
# <li> We measure the second register. With $50\%$ probability we will see either $\lvert 0 0 \rangle_2$ or $\lvert 1 1 \rangle_2$. For the sake of the example, let us assume that we see $\lvert 1 1 \rangle_2$. The state of the system is then
# $$ \lvert \psi_4 \rangle = \frac{1}{\sqrt{2}} \left( \lvert 0 1 \rangle_1 + \lvert 1 0 \rangle_1 \right) $$
#
# where we omitted the second register since it has been measured.
#
# </li>
#
#
#
# <li> Apply Hadamard on the first register
# $$ \lvert \psi_5 \rangle = \frac{1}{2\sqrt{2}} \left[ \left( \lvert 0 \rangle + \lvert 1 \rangle \right) \otimes \left( \lvert 0 \rangle - \lvert 1 \rangle \right) + \left( \lvert 0 \rangle - \lvert 1 \rangle \right) \otimes \left( \lvert 0 \rangle + \lvert 1 \rangle \right) \right] \\
# = \frac{1}{2\sqrt{2}} \left[ \lvert 0 0 \rangle - \lvert 0 1 \rangle + \lvert 1 0 \rangle - \lvert 1 1 \rangle + \lvert 0 0 \rangle + \lvert 0 1 \rangle - \lvert 1 0 \rangle - \lvert 1 1 \rangle \right] \\
# = \frac{1}{\sqrt{2}} \left( \lvert 0 0 \rangle - \lvert 1 1 \rangle \right)$$
#
# </li>
#
# <li> Measuring the first register will give either $\lvert 0, 0 \rangle$ or $\lvert 1, 1 \rangle$ with equal probability. If we see $\lvert 1, 1 \rangle$, then:
# $$ s \cdot 11 = 0 $$
#
# This is one equation, but $s$ has two variables. Therefore, we need to repeat the algorithm at least another time to have enough equations that will allow us to determine $s$.
# </li>
# </ol>
# ## 3. Qiskit Implementation <a id='implementation'></a>
#
# We now implement Simon's algorithm for the above [example](example) for $2$-qubits with a $s=11$.
# +
#initialization
import matplotlib.pyplot as plt
# %matplotlib inline
import numpy as np
# importing Qiskit
from qiskit import IBMQ, BasicAer
from qiskit.providers.ibmq import least_busy
from qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister, execute
# import basic plot tools
from qiskit.tools.visualization import plot_histogram
# -
s = '11'
# +
# Creating registers
# qubits for querying the oracle and finding the hidden period s
qr = QuantumRegister(2*len(str(s)))
# classical registers for recording the measurement from qr
cr = ClassicalRegister(2*len(str(s)))
simonCircuit = QuantumCircuit(qr, cr)
barriers = True
# Apply Hadamard gates before querying the oracle
for i in range(len(str(s))):
simonCircuit.h(qr[i])
# Apply barrier
if barriers:
simonCircuit.barrier()
# Apply the query function
## 2-qubit oracle for s = 11
simonCircuit.cx(qr[0], qr[len(str(s)) + 0])
simonCircuit.cx(qr[0], qr[len(str(s)) + 1])
simonCircuit.cx(qr[1], qr[len(str(s)) + 0])
simonCircuit.cx(qr[1], qr[len(str(s)) + 1])
# Apply barrier
if barriers:
simonCircuit.barrier()
# Measure ancilla qubits
for i in range(len(str(s)), 2*len(str(s))):
simonCircuit.measure(qr[i], cr[i])
# Apply barrier
if barriers:
simonCircuit.barrier()
# Apply Hadamard gates to the input register
for i in range(len(str(s))):
simonCircuit.h(qr[i])
# Apply barrier
if barriers:
simonCircuit.barrier()
# Measure input register
for i in range(len(str(s))):
simonCircuit.measure(qr[i], cr[i])
# -
simonCircuit.draw(output='mpl')
# ### 3a. Experiment with Simulators <a id='simulation'></a>
#
# We can run the above circuit on the simulator.
# +
# use local simulator
backend = BasicAer.get_backend('qasm_simulator')
shots = 1024
results = execute(simonCircuit, backend=backend, shots=shots).result()
answer = results.get_counts()
# Categorize measurements by input register values
answer_plot = {}
for measresult in answer.keys():
measresult_input = measresult[len(str(s)):]
if measresult_input in answer_plot:
answer_plot[measresult_input] += answer[measresult]
else:
answer_plot[measresult_input] = answer[measresult]
# Plot the categorized results
print( answer_plot )
plot_histogram(answer_plot)
# +
# Calculate the dot product of the results
def sdotz(a, b):
accum = 0
for i in range(len(a)):
accum += int(a[i]) * int(b[i])
return (accum % 2)
print('s, z, s.z (mod 2)')
for z_rev in answer_plot:
z = z_rev[::-1]
print( '{}, {}, {}.{}={}'.format(s, z, s,z,sdotz(s,z)) )
# -
# Using these results, we can recover the value of $s = 11$.
# ### 3b. Experiment with Real Devices <a id='device'></a>
#
# We can run the circuit on the real device as below.
# Load our saved IBMQ accounts and get the least busy backend device with less than or equal to 5 qubits
IBMQ.load_accounts()
IBMQ.backends()
backend = least_busy(IBMQ.backends(filters=lambda x: x.configuration().n_qubits <= 5 and
not x.configuration().simulator and x.status().operational==True))
print("least busy backend: ", backend)
# +
# Run our circuit on the least busy backend. Monitor the execution of the job in the queue
from qiskit.tools.monitor import job_monitor
shots = 1024
job = execute(simonCircuit, backend=backend, shots=shots)
job_monitor(job, interval = 2)
# +
# Categorize measurements by input register values
answer_plot = {}
for measresult in answer.keys():
measresult_input = measresult[len(str(s)):]
if measresult_input in answer_plot:
answer_plot[measresult_input] += answer[measresult]
else:
answer_plot[measresult_input] = answer[measresult]
# Plot the categorized results
print( answer_plot )
plot_histogram(answer_plot)
# -
# Calculate the dot product of the most significant results
print('s, z, s.z (mod 2)')
for z_rev in answer_plot:
if answer_plot[z_rev] >= 0.1*shots:
z = z_rev[::-1]
print( '{}, {}, {}.{}={}'.format(s, z, s,z,sdotz(s,z)) )
# As we can see, the most significant results are those for which $s.z = 0$ (mod 2). Using a classical computer, we can then recover the value of $s$ by solving the linear system of equations. For this $n=2$ case, $s = 11$.
# ## 4. Oracle <a id='oracle'></a>
#
# The above [example](#example) and [implementation](#implementation) of Simon's algorithm are specifically for $s=11$. To extend the problem to other secret bit strings, we need to discuss the Simon query function or oracle in more detail.
#
# The Simon algorithm deals with finding a hidden bitstring $s \in \{0,1\}^n$ from an oracle $f_s$ that satisfies $f_s(x) = f_s(y)$ if and only if $y = x \oplus s$ for all $x \in \{0,1\}^n$. Here, the $\oplus$ is the bitwise XOR operation. Thus, if $s = 0\ldots 0$, i.e., the all-zero bitstring, then $f_s$ is a 1-to-1 (or, permutation) function. Otherwise, if $s \neq 0\ldots 0$, then $f_s$ is a 2-to-1 function.
#
# In the algorithm, the oracle receives $|x\rangle|0\rangle$ as input. With regards to a predetermined $s$, the oracle writes its output to the second register so that it transforms the input to $|x\rangle|f_s(x)\rangle$ such that $f(x) = f(x\oplus s)$ for all $x \in \{0,1\}^n$.
#
# Such a blackbox function can be realized by the following procedures.
#
# - Copy the content of the first register to the second register.
# $$
# |x\rangle|0\rangle \rightarrow |x\rangle|x\rangle
# $$
#
# - **(Creating 1-to-1 or 2-to-1 mapping)** If $s$ is not all-zero, then there is the least index $j$ so that $s_j = 1$. If $x_j = 0$, then XOR the second register with $s$. Otherwise, do not change the second register.
# $$
# |x\rangle|x\rangle \rightarrow |x\rangle|x \oplus s\rangle~\mbox{if}~x_j = 0~\mbox{for the least index j}
# $$
#
# - **(Creating random permutation)** Randomly permute and flip the qubits of the second register.
# $$
# |x\rangle|y\rangle \rightarrow |x\rangle|f_s(y)\rangle
# $$
#
# ## 5. Problems <a id='problems'></a>
#
# 1. Implement a general Simon oracle.
# 2. Test your general Simon oracle with the secret bitstring $s=1001$, on a simulator and device. Are the results what you expect? Explain.
# ## 6. References <a id='references'></a>
#
# 1. <NAME> (1997) "On the Power of Quantum Computation" SIAM Journal on Computing, 26(5), 1474–1483, [doi:10.1137/S0097539796298637](https://doi.org/10.1137/S0097539796298637)
import qiskit
qiskit.__qiskit_version__
| ch-algorithms/simon.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
import warnings
import tools.functions as func
from datetime import datetime, date,timedelta
from matplotlib import gridspec
from matplotlib import cm
warnings.filterwarnings('ignore')
# %matplotlib inline
# -
#filenames
FILE_SOIL = 'k34_SPCD30_2012_2017_v2.csv'
FILE_MET = 'k34_Met_Soil_v0.csv'
FILE_SOIL_R = 'SWC_R_Corrected.pkl'
# read data
df_soil = pd.read_csv(FILE_SOIL,header = 0, na_values='-9999')
df_met = pd.read_csv(FILE_MET, header = 0, na_values = '-9999')
df_soil_r = pd.read_pickle(FILE_SOIL_R)
time_met = [datetime.strptime(str(i),'%Y%m%d%H%M') for i in df_met['TIMESTAMP_START']]
time_soil = [datetime.strptime(str(i),'%Y%m%d%H%M') for i in df_soil['TIMESTAMP_START']]
time_soil_r = df_soil_r['TIMESTAMP']
df_met['DATE'] = [datetime.date(i) for i in time_met]
df_met.head()
# compare land surface temperature with air temperature
Data_LST = np.load('LST_GEOS.npz')
print(Data_LST['time'][:5])
LST_time_local = [i - timedelta(hours = 4) for i in Data_LST['time']]
print(Data_LST['time'][:5],LST_time_local[:5])
time_start = pd.Timestamp('2015-10-01')
time_end = pd.Timestamp('2015-10-07')
# +
# Plot temperature
fig2, ax = plt.subplots(figsize=[12,8],nrows=1,sharex = True)
ax.plot(time_met,df_met['TA_1'],
time_met,df_met['TA_2'],
time_met,df_met['TA_3'],
time_met,df_met['TA_4'],
time_met,df_met['TA_5'],
time_met,df_met['TA_6'],
LST_time_local,(Data_LST['LST']-273.15))
# ax[idx].set_ylim(0,1)
ax.legend(('50m','35.3m', '28m','15.6m','5.2m','0.5m','LST'),loc = 'center left',bbox_to_anchor=(1, 0.5))
ax.set_ylabel('k34 Ta ($^oC$)')
ax.set_xlim(time_start, time_end)
# +
# Plot temperature
fig2, ax = plt.subplots(figsize=[12,8])
ax.plot(time_met,df_met['TA_1'],
LST_time_local,(Data_LST['LST']-273.15))
# ax[idx].set_ylim(0,1)
ax.legend(('50m','LST'),loc = 'center left',bbox_to_anchor=(1, 0.5))
ax.set_ylabel('k34 T ($^oC$)')
# -
time_start = pd.Timestamp('2015-01-1')
time_end = pd.Timestamp('2015-12-31')
# +
fig2, ax = plt.subplots(figsize=[10,5])
ax.plot(time_met,df_met['TA_1'],
LST_time_local,(Data_LST['LST']-273.15))
# ax[idx].set_ylim(0,1)
ax.legend(('50m','LST'),loc = 'center left',bbox_to_anchor=(1, 0.5))
ax.set_ylabel('k34 T ($^oC$)')
ax.set_xlim(time_start, time_end)
# -
time_start = pd.Timestamp('2015-10-15')
time_end = pd.Timestamp('2015-10-30')
time_start = pd.Timestamp('2015-07-01')
time_end = pd.Timestamp('2015-08-01')
# +
fig2, ax = plt.subplots(figsize=[12,6])
ax.plot(time_met,df_met['TA_1'],
LST_time_local,(Data_LST['LST']-273.15))
# ax[idx].set_ylim(0,1)
ax.legend(('50m','LST'),loc = 'center left',bbox_to_anchor=(1, 0.5))
ax.set_ylabel('k34 T ($^oC$)')
ax.set_xlim(time_start, time_end)
# -
| GEO_LST_TCanopy.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Workflow for Visualization of GMSO Topology Objects
# 21-03-30 <br>
# <NAME><br>
# <br>
# This workflow uses some additional libraries beyond the typical [MoSDeF](https://mosdef.org/) installations to provide an example for visualizing gmso topologies. The accessibility of the components of these objects allows for conversion to dicts that dash plotly uses for interactive visualizations. For more information on using interactive dash features, see this [link](https://dash.plotly.com/).
# +
# imports
import warnings
warnings.filterwarnings('ignore')
import unyt
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
import pandas as pd
import dash
import dash_core_components as dcc
import dash_html_components as html
import plotly.express as px
import dash_cytoscape as cyto
import dash_table
from dash.dependencies import Input, Output
import json
from jupyter_dash import JupyterDash
import mbuild as mb
import foyer
import gmso
from gmso.external import from_parmed
from gmso.external.convert_networkx import to_networkx
import pandas_convert as pd_conv
warnings.filterwarnings('ignore')
# -
#Use JuypterDash to detect the proxy configuration
JupyterDash.infer_jupyter_proxy_config()
# There are many ways to build a molecule using `mBuild`, for more information see the [mBuild documentation](https://mbuild.mosdef.org/en/stable/). This is a simple method of converting building a structure using a smile string.
#Build an mBuild compound from smiles strings
smiles = 'C1=CC=C(C=C1)C=CC=O'
molecule = mb.load(smiles, smiles=True)
molecule.visualize()
# Any method you can use to generate a `gmso.Topology` class object will work for the visualization. Please raise an [issue](https://github.com/mosdef-hub/gmso/issues) if a gmso topologies is not being visualized correctly. In this case, we will take the `mBuild` object `molecule` and convert it to a gmso.Topology object by converting to a parmed object through a `Foyer` xml object.
#Atomtype using foyer and convert to gmso through parmed
oplsaa = foyer.Forcefield(name='oplsaa')
pmd_aa = oplsaa.apply(molecule,
assert_bond_params = False,
assert_angle_params = False,
assert_dihedral_params = False)
topology = from_parmed(pmd_aa)
# +
#Dash Plotly representation of the molecule
app = JupyterDash(__name__)
#determines what color each node name is shown as
color_dictionary = {'"C"':"#8C92AC",'"O"':"red",'"H"':"#848482",'"N"':"blue",'"Cl"':'green'}
color_selection = []
for key,value in color_dictionary.items():
color_selection.append({'selector': "[element = " + str(key) + "]",
'style': {'background-color': str(value),'shape': 'circle'}})
#this gives a base layout of how the molecule will be shown initially.
graph = to_networkx(topology)
layout = nx.drawing.layout.kamada_kawai_layout(graph)
#elements is the dict that holds information about what to store in each node
elements = []
nodeids = {}
for i,node in enumerate(graph.nodes):
elements.append({'data': {'id': str(i) + ': ' + node.name,
'label': node.name + '(' + str(i) + ')',
'element': node.name,
'hash': node.__hash__(),
'index' : i},
'classes': '',
'position': {'x': layout[node][0]*300,'y': layout[node][1]*300},
'size': 200})
nodeids[node] = str(i) + ': ' + node.name
for edge in graph.edges:
elements.append({'data': {'source': nodeids[edge[0]], 'target': nodeids[edge[1]]}, 'classes': 'red'})
app.layout = html.Div([
html.P("Molecular Visualization:"),
#This is the format of the selectable dropdown tab
dcc.Dropdown(
id='parameter-dropdown',
options=[
{'label': 'Atom Types', 'value': 'atom_type'},
{'label': 'Bond Types', 'value': 'bond_type'},
{'label': 'Angle Types', 'value': 'angle_type'},
{'label': 'Dihedral Types', 'value': 'dihedral_type'}
],
value='atom_type'),
html.Div([
#This is the format of the molecule visualization
cyto.Cytoscape(
id='cytoscape',
elements= elements,
style={'width': '500px', 'height': '500px'},
layout={'name':'preset'},
stylesheet=[
{
'selector': 'node',
'style': {
'label': 'data(label)', 'width': "50%", 'height': "50%"
}
}
] + color_selection
)],
style={'width': '50%', 'display': 'inline-block', 'margin-right': '20px',
'borderBottom': 'thin lightgrey solid',
'borderTop': 'thin lightgrey solid',
'backgroundColor': 'rgb(250, 250, 250)',
'vertical-align': 'top'}
),
html.Div([
#this is the format of the table showing the types of the gmso.Topology
dash_table.DataTable(
id='table-of-parameters',
style_as_list_view=True,
style_cell={
'whiteSpace': 'normal',
'height': 'auto',
'lineHeight': '15px'
},
style_table={'overflowX': 'auto','overflowY': 'auto',
'height': '500px', 'width': '400px'},
style_data_conditional=[
{
'if': {'row_index': 'even'},
'backgroundColor': 'rgb(248, 248, 248)'
}],
style_header={
'backgroundColor': 'rgb(230, 230, 230)',
'fontWeight': 'bold'
}
)
],
style={'width': '45%', 'display': 'inline-block', 'padding': '0 0'}
)
])
#Interactive components
@app.callback(
Output('table-of-parameters', 'columns'),
Output('table-of-parameters', 'data'),
Input('parameter-dropdown','value'))
def update_datatable(input_value):
if input_value == 'atom_type':
df = pd_conv.atomtypes_to_datatables(graph,labels=None,atom_objects = True)
elif input_value == 'bond_type':
df = pd_conv.bondtypes_to_datatables(graph,topology,labels=None,atom_objects = True)
elif input_value == 'angle_type':
df = pd_conv.angletypes_to_datatables(graph,topology,labels=None,atom_objects = True)
elif input_value == 'dihedral_type':
df = demo_utils.dihedraltypes_to_datatables(graph,topology,labels=None,atom_objects = True)
return([{"name": i, "id": i} for i in df.columns],
df.to_dict('records'))
@app.callback(Output('table-of-parameters', 'style_data_conditional'),
Input('cytoscape', 'tapNodeData'))
def displayTapNodeData(data):
try:
return ([{
'if': {'filter_query': '{atom_id} = ' + str(data['hash'])},
'backgroundColor': 'tomato',
'color': 'white'},
{'if': {'filter_query': '{atom1_id} = ' + str(data['hash']) +
' || {atom2_id} = ' + str(data['hash']),
'column_id': ''},
'backgroundColor': 'tomato',
'color': 'white'},
{'if': {'filter_query': '{atom1_id} = ' + str(data['hash']) +
' || {atom2_id} = ' + str(data['hash']) +
' || {atom3_id} = ' + str(data['hash'])
},
'backgroundColor': 'tomato',
'color': 'white'},
{'if': {'filter_query': '{atom1_id} = ' + str(data['hash']) +
' || {atom2_id} = ' + str(data['hash']) +
' || {atom3_id} = ' + str(data['hash']) +
' || {atom4_id} = ' + str(data['hash'])
},
'backgroundColor': 'tomato',
'color': 'white'}
])
except TypeError:
return
#In order to run this at on a local port, replace the line below with mode = "external"
app.run_server(mode = "inline")
# -
# You can select nodes on the plotly cytoscape map to allow them to be highlighted in the datatable to the right. One of the nicest features of a `gmso.Topology` object is that it is both picklable, and can be read out to a `Pandas Dataframe`. For more information on using these, see this [link](https://www.tutorialspoint.com/python_pandas/python_pandas_dataframe.htm). Additionally, you can rearrange the molecule to be able to orient it as you see fit by clicking and dragging each node.
| notebooks/Plotly_Dash_Demo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# [](https://www.pythonista.io)
# # Cliente de la API con requests.
#
# En esta notebook se encuentra el código de un cliente capaz de consumir los servicios de los servidores creado en este curso.
#
# Es necesario que el servidor en la notebook se encuentre en ejecución.
# !pip install requests PyYAML
from requests import put, get, post, delete, patch
import yaml
# host="http://localhost:5000"
host = "https://py221-2111.uc.r.appspot.com"
# ## Acceso a la raíz de la API.
#
# Regresará el listado completo de la base de datos en formato JSON.
with get(f'{host}/api/') as r:
print(r.url)
print(r.status_code)
if r.headers['Content-Type'] == 'application/json':
print(r.json())
else:
print("Sin contenido JSON.")
# ## Búsqueda por número de cuenta mediante GET.
# * Regresará los datos en formato JSON del registro cuyo campo 'Cuenta' coincida con el número que se ingrese en la ruta.
# * En caso de que no exista un registro con ese número de cuenta, regresará un mensaje 404.
with get(f'{host}/api/1231267') as r:
print(r.url)
print(r.status_code)
if r.headers['Content-Type'] == 'application/json':
print(r.json())
else:
print("Sin contenido JSON.")
# ## Creación de un nuevo registro mediante POST.
# * Creará un nuevo registro con la estructura de datos enviada en caso de que no exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL y regresará los datos completos de dicho registro en formato JSON.
# * En caso de que exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL, regresará un mensaje 409.
# * En caso de que los datos no sean correctos, estén incompletos o no se apeguen a la estructura de datos, regresará un mensaje 400.
data ={'al_corriente': True,
'carrera': 'Sistemas',
'nombre': 'Laura',
'primer_apellido': 'Robles',
'promedio': 9.2,
'semestre': 1}
with post(f'{host}/api/1231268', json=data) as r:
print(r.url)
print(r.status_code)
if r.headers['Content-Type'] == 'application/json':
print(r.json())
else:
print("Sin contenido JSON.")
# ## Sustitución de un registro existente mediante PUT.
#
# * Sustituirá por completo un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL con los datos enviados y regresará los datos completos del nuevo registro en formato JSON.
# * En caso de que no exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL, regresará un mensaje 404.
# * En caso de que los datos no sean correctos, no estén completos o no se apeguen a la estructura de datos, regresará un mensaje 400.
#
#
data = {'al_corriente': True,
'carrera': 'Sistemas',
'nombre': 'Laura',
'primer_apellido': 'Robles',
'segundo_apellido': 'Sánchez',
'promedio': 10,
'semestre': 2}
with put(f'{host}/api/1231268', json=data) as r:
print(r.url)
print(r.status_code)
if r.headers['Content-Type'] == 'application/json':
print(r.json())
else:
print("Sin contenido JSON.")
# ## Enmienda de un registro existente con el método ```PATCH```.
data = {'al_corriente': True,
'semestre': 10}
with patch(f'{host}/api/1231268', json=data) as r:
print(r.url)
print(r.status_code)
if r.headers['Content-Type'] == 'application/json':
print(r.json())
else:
print("Sin contenido JSON.")
# ## Eliminación de un registro existente mediante DELETE.
# * Eliminará un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL y regresará los datos completos del registro eliminado en formato JSON.
# * En caso de que no exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL, regresará un mensaje 404.
with delete(f'{host}/api/1231268') as r:
print(r.url)
print(r.status_code)
if r.headers['Content-Type'] == 'application/json':
print(r.json())
else:
print("Sin contenido JSON.")
# ## La documentación de *Swagger*.
with get('f'{host}/swagger/') as r:
print(r.url)
print(r.status_code)
if r.headers['Content-Type'] == 'application/json':
print(yaml.dump(r.json()))
else:
print("Sin contenido JSON.")
# <p style="text-align: center"><a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Licencia Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/80x15.png" /></a><br />Esta obra está bajo una <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Licencia Creative Commons Atribución 4.0 Internacional</a>.</p>
# <p style="text-align: center">© <NAME>. 2022.</p>
| 00_cliente_api.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Mapboxgl Python Library for location data visualization
#
# https://github.com/mapbox/mapboxgl-jupyter
#
# ### Requirements
#
# These examples require the installation of the following python modules
#
# ```
# pip install mapboxgl
# ```
#
# ### Notes
#
# `ImageViz` object accepts either an url, a local path or a numpy ndarray data as input for an image source
# +
# !pip install imgviz
# -
import os
import numpy
from matplotlib.pyplot import imread
from mapboxgl.viz import ImageViz
# ## Set your Mapbox access token.
# Set a `MAPBOX_ACCESS_TOKEN` environment variable or copy/paste your token
# If you do not have a Mapbox access token, sign up for an account at https://www.mapbox.com/
# If you already have an account, you can grab your token at https://www.mapbox.com/account/
# Must be a public token, starting with `pk`
#token = os.getenv('MAPBOX_ACCESS_TOKEN')
token = '<KEY>'
# ## Display an image given an URL
# +
img_url = 'https://raw.githubusercontent.com/mapbox/mapboxgl-jupyter/master/examples/data/mosaic.png'
# Coordinates must be an array in the form of [UL, UR, LR, LL]
coordinates = [[-123.40515640309, 38.534294809274336],
[-115.92938988349292, 38.534294809274336],
[-115.92938988349292, 32.08296982365502],
[-123.40515640309, 32.08296982365502]]
# Create the viz from the dataframe
viz = ImageViz(img_url,
coordinates,
access_token=token,
height='600px',
center=(-119, 35),
zoom=5,
below_layer='waterway-label')
viz.show()
# -
# ## Display an image given a numpy.ndarray
# +
img = imread(img_url)
img = numpy.mean(img[::10, ::10], axis=2)
# Coordinates must be an array in the form of [UL, UR, LR, LL]
coordinates = [[-123.40515640309, 38.534294809274336],
[-115.92938988349292, 38.534294809274336],
[-115.92938988349292, 32.08296982365502],
[-123.40515640309, 32.08296982365502]]
# Create the viz from the dataframe
viz = ImageViz(img,
coordinates,
access_token=token,
height='600px',
center=(-119, 35),
zoom=5,
below_layer='waterway-label')
viz.show()
# -
# ## Display an image given a local path
# +
# Coordinates must be an array in the form of [UL, UR, LR, LL]
coordinates = [[-123.40515640309, 38.534294809274336],
[-115.92938988349292, 38.534294809274336],
[-115.92938988349292, 32.08296982365502],
[-123.40515640309, 32.08296982365502]]
# Create the viz from the dataframe
viz = ImageViz(img_url,
coordinates,
access_token=token,
height='600px',
center=(-119, 35),
zoom=5,
below_layer='waterway-label')
viz.show()
# -
# ## Choose a colormap
# +
from matplotlib import cm
img = imread(img_url)
img = numpy.mean(img[::10, ::10], axis=2)
img = cm.magma(img)
# Coordinates must be an array in the form of [UL, UR, LR, LL]
coordinates = [[-123.40515640309, 38.534294809274336],
[-115.92938988349292, 38.534294809274336],
[-115.92938988349292, 32.08296982365502],
[-123.40515640309, 32.08296982365502]]
# Create the viz from the dataframe
viz = ImageViz(img_url,
coordinates,
access_token=token,
height='600px',
center=(-119, 35),
zoom=5,
below_layer='waterway-label')
viz.show()
# -
| examples/notebooks/image-vis-type-example.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # VIZBI Tutorial Session
# ### Part 2: Cytoscape, IPython, Docker, and reproducible network data visualization workflows
#
# Tuesday, 3/24/2015
#
#
# ### Lesson 0: Introduction to IPython Notebook
#
# by [<NAME>](http://keiono.github.io/)
#
# ----
#
# 
#
# IPython Notebook is a simple tool to run your code in human-frienfly documents (Notebooks), and you can boost your productivity by learning some basic commands.
#
# ### Keyboard Shortcuts
# There are many keyboard shortcuts, but for now, you just need to learn the following:
#
# * __Shift-Enter__ - Run cell
# * __Ctrl-Enter__ - Run cell in-place
# * __Alt-Enter__ - Run cell, insert below
#
# * __Esc and Enter__ - Command mode and edit mode
#
# #### Basic Commands in _Command Mode_
#
# * x - cut cell
# * v - paste cell below
# * SHIFT + v - paste cell above
# * dd - dlete cell
#
# Complete list of shortcuts is available under ___Help___ menu:
#
# 
#
# OK, let's start!
print('Hello IPython World!')
# !pip list
result1 = 1+1
result2 = 2*3
result2
result1
print('2nd = ' + str(result2))
print('1st = ' + str(result1))
print('2nd = ' + str(result2))
print('1st = ' + str(result1))
# ## Run System Command
# You can run system commands by adding __!__ at the beggining.
#
# Remember: you are running this notebook in Linux container. You cannot use Windows/Mac commands even if you are using those machines!
# !ls -alh
# !ifconfig
# ## Magic!
# In IPython Notebook, there is a nice feature called ___magic___. Magic is a group of commands to execute some usuful functions just like system commands.
#
# ### Two types of Magic
# * __Line magics__: Prepended by one __%__ character, only to the end of the current line.
# * __Cell magics__: Start with __%%__ and applied to the entire cell
#
# Here is the list of handy magics:
# ### Simple performance test with _%timeit_
# +
# Import NetworkX library, which is already installed in your Docker container
import networkx as nx
# Create a ranom graph with 100 nodes using Barabashi-Albert Model ()
ba=nx.barabasi_albert_graph(100,5)
# Check the performance of a NetworkX function (calculate betweenness centrality) by running 10 times
# %timeit -n 10 nx.betweenness_centrality(ba)
# +
# %%timeit -n 10
# Or, check performance of the entire cell
ws = nx.watts_strogatz_graph(100,3,0.1)
btw = nx.betweenness_centrality(ws)
# -
# ### Create file manually with _%%writefile_
# %%writefile data/small_network.sif
node1 is_a node2
node2 child_of node3
node3 child_of node1
# !cat data/small_network.sif
# ### Execute under other interpreters
# + language="bash"
# export FOO='Env var 1'
# echo $FOO
# + language="javascript"
# var foo = function(a) {
# return a+1;
# };
#
# console.log(foo(2));
# -
# ## Continue to [Lesson 1: Introduction to cyREST](Lesson_1_Introduction_to_cyREST.ipynb)
| tutorials/Lesson_0_IPython_Notebook_Basics.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/AstroNoodles/Mini-Projects/blob/master/Iris_Exploration.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="mu3z0eLsA6SL" colab_type="text"
# <h1>The Iris Dataset </h1>
# The Iris dataset, which can be found <a href="https://archive.ics.uci.edu/ml/datasets/iris">here</a> is one of the most famous and introductory datasets in machine learning and data science. Modeled after <a href="https://rdcu.be/biTg0"> Fisher's experiment </a> done in 1936, it was collected to model the differences in the sepal length and width and pedal length and width of three different Iris species: <i> Iris setosa, Iris Virginica </i> and <i> Iris Versicolor. </i>
# Various machine learning projects use this as a way to teach beginners about simple algorithms and how to use their data science skills efficiently.
#
# ---
#
# The goal of this Collaboratory is to attempt to use my current skills of data exploration, wrangling and machine learning to predict the given flower species given the sepal length, petal length, sepal width and petal width in cm for each species.. Therefore, this is a <b> classification </b> problem, rather than a regression or clustering one.
#
#
# * We will measure the accuracy of the machine learning models using scikit-learn's classification report to get the **precision, recall and F1 scores** since it is classification to see which models perform the best in the dataset.
#
# <br>
#
# ---
# # Pictures
#
# 
# <br>
# Picture of the Petal and Sepal
#
# 
# <br>
# *<NAME>*
#
# 
# <br>
# *<NAME>*
#
# 
# <br>
# *<NAME>*
#
#
# + [markdown] id="ociPnooWIlIe" colab_type="text"
# First, we need to import the modules from scikit-learn and then we can grab our data and start the data preprocessing!
# + id="vhLAf8ydA3Wo" colab_type="code" outputId="be00c381-0801-4e3c-ce13-90c90b9f7e0d" colab={"base_uri": "https://localhost:8080/", "height": 34}
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import classification_report
from scipy.stats import randint
# Models
from sklearn.svm import SVC # Support Vector Classifier
from sklearn.ensemble import RandomForestClassifier # Random Forest
from sklearn.tree import DecisionTreeClassifier # Decision Tree
from sklearn.naive_bayes import GaussianNB # Naive Bayes
from sklearn.linear_model import LogisticRegression # Logistic Regression (NOT FOR REGRESSION)
from sklearn.neural_network import MLPClassifier # Perceptron
import os.path
import os
# %matplotlib inline
print("All set up!")
# + id="nDcCXTbqGa6n" colab_type="code" outputId="4b1d6cb1-b995-4f0f-bc0e-ea7272e12684" colab={"base_uri": "https://localhost:8080/", "height": 51}
data = load_iris()
print(f"Feature Names: {data.feature_names}.")
print(f"Target Names: {data.target_names}.")
# + id="rD5PDzzIGgI6" colab_type="code" outputId="9cdd8256-653f-4c2e-8905-2758012b94c5" colab={"base_uri": "https://localhost:8080/", "height": 34}
len(data.data)
# + id="nFkpqoOXHGhJ" colab_type="code" outputId="0a5666bd-23d4-4641-f6df-8f7a88567008" colab={"base_uri": "https://localhost:8080/", "height": 204}
print("Data: ")
print(data.data[:5])
print("Target: ")
print(data.target[:5])
# + [markdown] id="onBtIrbFI0DE" colab_type="text"
# With no data preprocessing needed, we can test some random classification models to see which do the best and send them to some files to record for later.
# + id="V6T5S7e1NylC" colab_type="code" outputId="35ef8707-8118-4d26-cd49-6d5ff99b4bae" colab={"base_uri": "https://localhost:8080/", "height": 1244}
train_x, test_x, train_y, test_y = train_test_split(data.data, data.target, test_size=.2, random_state=4)
models = (SVC(gamma='auto'),
RandomForestClassifier(n_estimators=1000),
MLPClassifier(),
DecisionTreeClassifier(),
GaussianNB(),
LogisticRegression(solver='lbfgs', multi_class='auto'))
if not os.path.exists("reports"):
os.mkdir('reports')
for model in models:
model_name = type(model).__name__
model.fit(train_x, train_y)
predict_y = model.predict(test_x)
report = classification_report(test_y, predict_y, target_names=data.target_names)
print(model_name)
print(report)
with open(os.path.join('reports', f"{model_name}_iris.txt"), 'w') as f:
f.write(report)
print('All reports written to file!')
# + [markdown] id="aT6zTzW-VqLy" colab_type="text"
# # Preliminary Results
#
# From the dataset, we can see the results in the text files for the best classical models that can model the Iris dataset. Though grid search was not done to find optimal parameters, the best models that seemed to work for Iris prediction were:
#
#
# * Decision Trees (97%)
# * Logistic Regression (97%)
# * SVC (97%)
# * Random Forest (97%)
#
# Suprisingly, the multi layer perceptron and naive bayes were not particularly strong with this dataset. Perhaps, the learning rate and solver should be adjusted to deal with this problem as well as checking the correlation between the variables (naive bayes assumes the data is independent)
#
# However, this does not mean that the MLP and Naive Bayes are the worst classical machine learning algorithms to deal with this classification problem. Instead, grid search should be done to find better parameters to see what triggers it to work well and reach 97% accuracy like the others.
#
#
#
#
#
# + [markdown] id="vLo0CS4Kc5ci" colab_type="text"
# # Optimization
# + [markdown] id="P05gou57m5rt" colab_type="text"
# Let's try it first with the MLP to see if we can get any performance improvements compared to its default performance.
# + id="A2JZUS8Hc-YZ" colab_type="code" outputId="df97282f-515f-4904-d699-7e04ab351b23" colab={"base_uri": "https://localhost:8080/", "height": 2553}
mlp_classifier = MLPClassifier()
print(mlp_classifier)
# To do randomized grid search, we need the kwargs for the search to look through.
# See https://bit.ly/2CjDug7 for all the kwargs
mlp_params = {"activation": ['identity', 'logistic', 'tanh', 'relu'],
"solver" : ["lbfgs", "sgd", "adam"],
"learning_rate": ["constant", "invscaling", "adaptive"],
"max_iter" : randint(100, 400),
"shuffle": [True, False]}
random_search = RandomizedSearchCV(mlp_classifier, mlp_params, n_iter=20,
scoring="accuracy", cv=5, verbose=0)
random_search.fit(train_x, train_y)
# Select the best params and update them to the MLP.
best_mlp_params = random_search.best_params_
mlp_classifier.__dict__.update(best_mlp_params)
print(mlp_classifier)
# + id="DU0aCAYd7RHi" colab_type="code" outputId="c722304a-6d27-4e57-8662-d2653f5ec30a" colab={"base_uri": "https://localhost:8080/", "height": 241}
# Trying out the newly grid searched MLP with specially chosen params
mlp_classifier.fit(train_x, train_y)
predict_y = model.predict(test_x)
report = classification_report(test_y, predict_y, target_names=data.target_names)
print(report)
# + [markdown] id="1UUeC-dRl9Wm" colab_type="text"
# Though it didn't make much of a difference, let's do a correlation test to see if there are dependent variables in the data that ruin Naive Bayes.
# + id="kvOjsNHYnZwU" colab_type="code" outputId="a01868f0-b674-42e4-eff3-0fd9edd883b0" colab={"base_uri": "https://localhost:8080/", "height": 458}
print(data.feature_names) # Print the features
# np.corrcoef prints a correlation matrix of a numpy array,
# rowvar=False tells numpy that each column is a feature rather than the row!
print(np.corrcoef(train_x, rowvar=False))
print()
print(np.corrcoef(train_x, rowvar=False))
# + [markdown] id="7RwlyI37o6Uz" colab_type="text"
# As we can see from numpy's correlation matrix on the train and test data, there may be some correlation between the petal and sepal lengths from their close *R* values, so this might explain why Naive Bayes performs suboptimally.
#
#
#
#
# + [markdown] id="kRG2mi1DMnez" colab_type="text"
# # Visualization of the Dataset:
# + id="HcER09ZUHKjx" colab_type="code" outputId="6a36cb19-f29c-4d15-dde4-4a4e5eb4cf4e" colab={"base_uri": "https://localhost:8080/", "height": 311}
fig, ax = plt.subplots(1, 2, figsize=(8, 4))
ax1, ax2 = ax
ax1.scatter(data.data[:, 0], data.data[:, 1], c='#c297e5', marker='^')
ax1.set_title("Sepal Length vs. Sepal Width [WHOLE DATASET]")
ax1.set_xlabel("Sepal Length (cm)")
ax1.set_ylabel("Sepal Width (cm)")
ax2.scatter(data.data[:, 2], data.data[:, 3], c='#6e1daf', marker='^')
ax2.set_title("Petal Length vs. Petal Width [WHOLE DATASET]")
ax2.set_xlabel("Petal Length (cm)")
ax2.set_ylabel("Petal Width (cm)")
# + [markdown] id="VlV5Z_ktQO3F" colab_type="text"
# Basic visualization on the dataset. The first graph gives the relationships between the petals and sepals on the whole dataset and the second individualizes them per species.
# + id="wmyH1bqMHhJ6" colab_type="code" outputId="b2cde7c5-3558-4876-bdfb-533ae53dc131" colab={"base_uri": "https://localhost:8080/", "height": 345}
fig, axis = plt.subplots(1, 2, figsize=(12, 4))
ax1, ax2 = axis
for i, species in enumerate(data.target):
if species == 0:
ax1.plot(data.data[i, 0], data.data[i, 1], 'r^', label='setosa')
elif species == 1:
ax1.plot(data.data[i, 0], data.data[i, 1], 'b^', label='versicolor')
else:
ax1.plot(data.data[i, 0], data.data[i, 1], 'g^', label='virginica')
ax1.set_xlabel('Sepal Length (cm)')
ax1.set_ylabel('Sepal Width (cm)')
ax1.set_title('Sepal Length vs. Sepal Width Among Iris Species')
for i, species in enumerate(data.target):
if species == 0:
ax2.plot(data.data[i, 2], data.data[i, 3], 'r^', label='setosa')
elif species == 1:
ax2.plot(data.data[i, 2], data.data[i, 3], 'b^', label='versicolor')
else:
ax2.plot(data.data[i, 2], data.data[i, 3], 'g^', label='virginica')
ax2.set_xlabel('Petal Length (cm)')
ax2.set_ylabel('Petal Width (cm)')
ax2.set_title('Petal Length vs. Petal Width Among Iris Species')
# TODO - fix so the legend works
print('RED - Iris Setosa')
print('BLUE - Iris Versicolor')
print('GREEN - Iris Virginica')
# + [markdown] id="JIpOys72QdBj" colab_type="text"
# # Summary
#
# Overall, this notebook summarized how different classical machine models could be used to predict the three different species of *Iris* flowers given their petal length and width and sepal length and width.
#
# Though no exact hammer fits into the many algorithmic nails I could have used, this introductory foray into the Iris dataset shows the importance of looking for optimization and trying to increase the performance on this classical dataset.
#
# In the future, I might look into more advanced datasets or other performance measures not studied here to see their effect on either the regression or classification problem studied.
#
# For now, <br>
# ** *Ciao* ** and thanks for reading!
# + id="MavjXln-u6Av" colab_type="code" colab={}
| Data Science/Iris_Exploration.ipynb |
# ---
# jupyter:
# jupytext:
# formats: ipynb,md:myst
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + tags=["remove-cell"]
from config import setup, import_and_display_fnc
setup()
# %matplotlib widget
# -
import numpy as np
import matplotlib.pyplot as plt
from common import (
gauss_rule,
qbx_matrix,
symbolic_eval,
qbx_setup,
double_layer_matrix,
PanelSurface,
panelize_symbolic_surface,
build_panel_interp_matrix,
)
import sympy as sp
# %matplotlib inline
import_and_display_fnc('common', 'refine_panels')
import_and_display_fnc('common', 'stage1_refine')
# +
qx, qw = gauss_rule(16)
t = sp.var("t")
sym_obs_surf = (t, -t * 1000, 0 * t)
sym_src_surf = (t, t * 0, (t + 1) * -0.5)
src_panels = np.array([[-1, 1]])
src_surf = panelize_symbolic_surface(
*sym_src_surf, src_panels, qx, qw
)
control_points = np.array([(0, 0, 2, 0.5)])
obs_surf = stage1_refine(
sym_obs_surf, (qx, qw), other_surfaces=[src_surf], control_points=control_points
)
# -
# %matplotlib widget
plt.figure()
plt.plot(obs_surf.pts[obs_surf.panel_start_idxs,0], obs_surf.pts[obs_surf.panel_start_idxs,1], 'k-*')
plt.xlim([-25,25])
plt.show()
# +
from common import qbx_panel_setup, build_interp_matrix, build_interpolator
expansions = qbx_panel_setup(obs_surf, direction=1, p=10)
# -
import_and_display_fnc('common', 'build_panel_interp_matrix')
import_and_display_fnc('common', 'stage2_refine')
# %matplotlib inline
stage2_surf = stage2_refine(src_surf, expansions)
# %matplotlib widget
plt.figure()
plt.plot(stage2_surf.pts[stage2_surf.panel_start_idxs,0], stage2_surf.pts[stage2_surf.panel_start_idxs,1], 'k-*')
plt.plot(expansions.pts[:,0], expansions.pts[:,1], 'r*')
plt.axis('equal')
plt.xlim([-1,1])
plt.ylim([-1,0])
plt.show()
t = sp.var("t")
theta = sp.pi + sp.pi * t
F = 0.98
u = F * sp.cos(theta)
v = F * sp.sin(theta)
x = 0.5 * (
sp.sqrt(2 + 2 * u * sp.sqrt(2) + u ** 2 - v ** 2)
- sp.sqrt(2 - 2 * u * sp.sqrt(2) + u ** 2 - v ** 2)
)
y = 0.5 * (
sp.sqrt(2 + 2 * v * sp.sqrt(2) - u ** 2 + v ** 2)
- sp.sqrt(2 - 2 * v * sp.sqrt(2) - u ** 2 + v ** 2)
)
x = (1.0 / F) * x * 100000
y = (1.0 / F) * y * 20000 - 20000
rounded_corner_box = stage1_refine((t, x, y), (qx, qw), control_points = [(0,0,10000,5000)], max_radius_ratio=10.0)
# %matplotlib inline
plt.figure()
plt.plot(
rounded_corner_box.pts[rounded_corner_box.panel_start_idxs, 0],
rounded_corner_box.pts[rounded_corner_box.panel_start_idxs, 1],
"k-*",
)
plt.axis("equal")
plt.show()
box_expansions = qbx_panel_setup(rounded_corner_box, direction=1, p=10)
stage2_box = stage2_refine(rounded_corner_box, box_expansions)
print(stage2_box.n_panels)
plt.figure()
plt.plot(
stage2_box.pts[stage2_box.panel_start_idxs, 0],
stage2_box.pts[stage2_box.panel_start_idxs, 1],
"k-*",
)
plt.plot(box_expansions.pts[:,0], box_expansions.pts[:,1], 'r*')
plt.axis("equal")
plt.show()
| tutorials/c1qbx/rounded_corners_box.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Handwritten Digit Recognition Using SVM Algorithm
# - **To develop a model using Support Vector Machine (SVM) which can correctly classify the handwritten digits from 0-9 based on the pixel values given as features.**
# + id="rSTMxQi8-7ox"
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, multilabel_confusion_matrix
from sklearn.model_selection import GridSearchCV
# + [markdown] id="t0XMtAIcHd7n"
# ### Import Dataset
# + id="_AivhjkOHitu"
df= pd.read_csv('digit_svm.csv')
# + colab={"base_uri": "https://localhost:8080/", "height": 437} id="tbYMuHUpHmx2" outputId="cc27605c-f41d-46f6-c57d-3d91ab49abc7"
df
# + [markdown] id="XsPAhG0HIU0U"
# ### Data Visualization
# + colab={"base_uri": "https://localhost:8080/", "height": 279} id="7392_TRGIRck" outputId="0babe9a3-82f3-4001-ecd4-f5a686e81f68"
sns.countplot(x = 'label' , data = df)
plt.show()
# + [markdown] id="KSfob5dEIZid"
# The dataset here is a balanced dataset so let's fix accuracy as a mtric.
# + [markdown] id="Fp3Nl4mLIjK2"
# ### Data Preprocessing
#
# - Now This will check for null values and replacing it.
# + id="WSHcKHA1Iqr3"
df.isnull().sum()
# -
df.fillna(value=0)
df.replace([np.inf, -np.inf], np.nan, inplace=True)
df.fillna(999, inplace=True)
# + [markdown] id="PEf6T2JGHvc8"
# ### Split The Dataset For Training And Testing
# + id="rDGVxVBmHsMh"
x= df.iloc[:, 1:].values
y= df.iloc[:, 0].values
# + id="uhaaNu6AH4hi"
x
# -
y
# + colab={"base_uri": "https://localhost:8080/"} id="waiSeO1-H7Up" outputId="5e6c4359-23ed-4d66-8486-ced0dae8a895"
print(x.shape)
# + id="aRZeYIhRH-V5"
train_x, test_x, train_y, test_y= train_test_split(x, y, test_size= 0.2, random_state= 104)
# -
train_x
train_y
test_x
test_y
# + [markdown] id="_KSlld1wICWx"
# ### Visualize The Digit By Reshaping
# + id="RZFI5iyrH-wz"
img= df.iloc[3, 1:].values
img= img.reshape(28,28)
# + colab={"base_uri": "https://localhost:8080/", "height": 282} id="TCIHeubSIJ18" outputId="c6e46e16-7923-4b14-9a19-24bf0d2be30f"
plt.imshow(img, cmap= 'gray')
plt.show()
# + [markdown] id="qW5VplUNIzNh"
# ### Normalization
# - Normalizing the values of pixels using StandardScaler
# + id="2KOlCOJ8I7zC"
st= StandardScaler()
# -
train_x= st.fit_transform(train_x)
test_x= st.fit_transform(test_x)
# + id="nTTzNg9fI-sU"
train_x
# -
test_x
# + [markdown] id="1qRZcDdgJCf9"
# ### Build a Linear Kernel SVC model
# + id="Vhu6xuHoJIyj"
svc_clf= SVC(kernel= 'linear')
# + id="q3zczH1WJM3O"
svc_clf.fit(train_x, train_y)
# + id="TSwXVqtJKizR"
pred_y= svc_clf.predict(test_x)
# -
pred_y
# + [markdown] id="Y00CDf6xL3yW"
# ### Accuraccy For Linear Model
# + colab={"base_uri": "https://localhost:8080/"} id="a5j2xIpNL8mI" outputId="f5ed78be-b0cc-445e-b4c4-628b2ddbd1d4"
accuracy_score(test_y, pred_y)
# + [markdown] id="GzsL3TGtM8q-"
# ### Classification Report
# + colab={"base_uri": "https://localhost:8080/"} id="jVrPuLWEM_g2" outputId="fb48b5e9-3dc8-46c9-beb1-380382e811bb"
acc_report= classification_report(test_y, pred_y)
print(acc_report)
# + [markdown] id="RqpFYMpkNRZs"
# ### Build a RBF Kernel Model
# + id="FXgXCcgvNUSr"
svc_rbf= SVC()
# + colab={"base_uri": "https://localhost:8080/"} id="nYBVdNylNW5r" outputId="37b2efd1-6d87-472f-8c0e-c7ad84cff39c"
svc_rbf.fit(train_x, train_y)
# + id="SidWPv79PDwh"
predrbf_y= svc_rbf.predict(test_x)
# -
predrbf_y
# + colab={"base_uri": "https://localhost:8080/"} id="x0shhnhoPnTy" outputId="1fde41e1-0333-46b3-9ef1-a936e86c6f5b"
accuracy_score(test_y, predrbf_y)
# + colab={"base_uri": "https://localhost:8080/"} id="ua6AzpONPqpi" outputId="a916f58a-3c0f-476c-90ac-4fc3952bb87f"
acc_report= classification_report(test_y, predrbf_y)
print(acc_report)
# + [markdown] id="8mqHdBwqhMwY"
# ### Best Estimator Given by GridSearchCV
# + id="QCAd-xPphdJ4"
parameters = {'C':[1,10 , 100] ,
'gamma' :[1e-2 , 1e-3 , 1e-4 ],
'kernel' :['linear' ,'rbf']
}
# -
svc_grid_search = SVC()
# create a classifier to perform grid search
clf = GridSearchCV(svc_grid_search, param_grid=parameters, scoring='accuracy')
# fit
clf.fit(x_train, y_train)
clf.best_estimator_
# + colab={"base_uri": "https://localhost:8080/"} id="C-IGAXKUhI00" outputId="477531ad-a1d0-47a3-be6d-5735c89c582a"
model = SVC(C=5, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=42, shrinking=True,
tol=0.001, verbose=False)
model.fit(train_x , train_y)
# + id="ygtx2WBjiiWb"
y_pred = model.predict(test_x)
# + colab={"base_uri": "https://localhost:8080/"} id="petfCxGTiuTb" outputId="03152c87-0456-4998-f92f-91d237b9d788"
accuracy_score(test_y,y_pred)
# + [markdown] id="-2Te6Dsii7UE"
# ### Confusion Matrix
# + colab={"base_uri": "https://localhost:8080/", "height": 282} id="253uvSp5izks" outputId="64e5ec38-b95d-4798-c6fa-65d01563cf8e"
cm=confusion_matrix(test_y,y_pred)
sns.heatmap(pd.DataFrame(cm), annot=True)
# + [markdown] id="KojLHMlEjJWl"
# ## Finally achieved 96.7% of accuracy score by using best estimators given by gridsearchcv
| .ipynb_checkpoints/Handwritten Digit Recognition-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# https://www.hackerrank.com/challenges/s10-interquartile-range/problem
# +
# taking input data
n = int(input())
unique_data = list(map(int, input().split()))
frequency = list(map(int, input().split()))
complete_data = []
for i in range(len(unique_data)):
complete_data += [unique_data[i]] * frequency[i]
complete_data.sort()
complete_data
# +
# calculating IQR
from statistics import median
print(
float(
median(complete_data[len(complete_data) // 2 + len(complete_data)%2:]) -
median(complete_data[:len(complete_data) // 2])
)
)
| Day 1 - Interquartile Range.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:metis] *
# language: python
# name: conda-env-metis-py
# ---
# +
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from keras.datasets import fashion_mnist
from tensorflow import keras
from tensorflow.keras import datasets, layers, models
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, GlobalAveragePooling2D, InputLayer, Dropout, ZeroPadding2D
from tensorflow.keras.preprocessing import image
from tensorflow.keras.utils import to_categorical
from keras.utils.vis_utils import model_to_dot
from keras.utils.vis_utils import plot_model
from IPython.display import SVG
import seaborn as sns
import matplotlib.pyplot as plt
# %matplotlib inline
# -
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
print('Number of train data: ' + str(len(X_train)))
print('Number of test data: ' + str(len(X_test)))
labels = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
plt.figure()
plt.imshow(X_train[1880])
plt.colorbar()
plt.grid(False)
plt.show()
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(X_train[i], cmap=plt.cm.binary)
plt.xlabel(labels[y_train[i]])
plt.savefig('Fashion-MNIST data', dpi=150)
plt.show()
# +
model = Sequential()
model.add(Flatten(input_shape=(28,28)))
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.summary()
# -
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# train the model
model.fit(X_train, y_train, epochs=5)
# Evaluate accuracy
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test accuracy:', test_acc)
# Make prediction
preds = model.predict(X_test)
preds[5]
np.argmax(preds[5])
y_test[5]
# +
def plot_image(i, preds_array, true_labels, img):
preds_array, true_labels, img = preds_array[i], true_labels[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
preds_labels = np.argmax(preds_array)
if preds_labels == true_labels:
color = 'blue'
else:
color = 'red'
plt.xlabel('{} {:2.0f}% ({})'.format(labels[preds_labels],
100*np.max(preds_array),
labels[true_labels],
color=color))
def plot_value_array(i, preds_array, true_labels):
preds_array, true_labels = preds_array[i], true_labels[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), preds_array, color='#777777')
plt.ylim([0,1])
preds_labels = np.argmax(preds_array)
thisplot[preds_labels].set_color('red')
thisplot[true_labels].set_color('blue')
# -
i=0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, preds, y_test, X_test)
plt.subplot(1,2,2)
plot_value_array(i, preds, y_test)
plt.show()
# plot for a few more images
num_rows = 5
num_cols = 3
num_images = num_rows * num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, preds, y_test, X_test)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(1, preds, y_test)
plt.show()
# make a prediction for an image in the test set
img = X_test[0]
print(img.shape)
# add the image to a batch where it is the only member
img = (np.expand_dims(img, 0))
print(img.shape)
preds_single = model.predict(img)
print(preds_single)
plot_value_array(0, preds_single, y_test)
_ = plt.xticks(range(10), labels, rotation=45)
plt.figure()
plt.imshow(X_train[0])
plt.colorbar()
plt.grid(False)
plt.show()
np.argmax(preds_single[0])
# First attempt, the test accuracy is 0.87 which is not bad.
| Workflow /attempts /Deep Learning Attempt1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# %run ../Python_files/load_dicts.py
# %run ../Python_files/util.py
# +
# #!/usr/bin/env python
__author__ = "<NAME>"
__email__ = "<EMAIL>"
__status__ = "DeveloAMent"
from util import *
import numpy as np
from numpy.linalg import inv, matrix_rank
import json
# -
# load logit_route_choice_probability_matrix
P = zload('../temp_files/logit_route_choice_probability_matrix_ext.pkz')
P = np.matrix(P)
print(matrix_rank(P))
print(np.size(P,0), np.size(P,1))
# load path-link incidence matrix
A = zload('../temp_files/path-link_incidence_matrix_ext.pkz')
# +
# assert(1 == 2)
# load link counts data
with open('../temp_files/link_day_minute_Jan_dict_ext_JSON_insert_links_adjusted.json', 'r') as json_file:
link_day_minute_Jan_dict_ext_JSON = json.load(json_file)
# -
# weekend_Jan_list = [1, 7, 8, 14, 15, 21, 22, 28, 29]
weekend_Jan_list = [8, 21, 22, 28, 29]
link_day_minute_Jan_list = []
for link_idx in range(74):
for day in weekend_Jan_list:
for minute_idx in range(120):
key = 'link_' + str(link_idx) + '_' + str(day)
link_day_minute_Jan_list.append(link_day_minute_Jan_dict_ext_JSON[key] ['AM_flow_minute'][minute_idx])
print(len(link_day_minute_Jan_list))
x = np.matrix(link_day_minute_Jan_list)
x = np.matrix.reshape(x, 74, 600)
x[x < 1] = 200
# x = np.nan_to_num(x)
# y = np.array(np.transpose(x))
# y = y[np.all(y != 0, axis=1)]
# x = np.transpose(y)
# x = np.matrix(x)
# +
# print(np.size(x,0), np.size(x,1))
# print(x[:,:2])
# print(np.size(A,0), np.size(A,1))
# -
# load node-link incidence matrix
N = zload('../temp_files/node_link_incidence_MA_ext.pkz')
N.shape
n = 22 # number of nodes
m = 74 # number of links
x_0 = [x[:,2][i, 0] for i in range(m)]
# +
# x_0
# -
OD_pair_label_dict = zload('../temp_files/OD_pair_label_dict_ext.pkz')
len(OD_pair_label_dict)
L = 22 * (22 - 1) # dimension of lam
# od pair correspondence
OD_pair_label_dict_MA_small = zload('../temp_files/OD_pair_label_dict__MA.pkz')
# +
# create a dictionary mapping nodes of small network to nodes of bigger network
nodeToNode = {}
nodeList = range(9)[1:]
nodeListExt = [1, 4, 7, 12, 13, 14, 16, 17]
for i in nodeList:
nodeToNode[str(i)] = nodeListExt[i-1]
# nodeToNode['1'] = 1
# nodeToNode['2']
# -
nodeToNode
odMap = {}
for i in range(len(OD_pair_label_dict_MA_small)):
key = str(i)
origiSmall = OD_pair_label_dict_MA_small[key][0]
destiSmall = OD_pair_label_dict_MA_small[key][1]
origiExt = nodeToNode[str(origiSmall)]
destiExt = nodeToNode[str(destiSmall)]
odMap[key] = (origiExt, destiExt)
# +
# odMap
# +
odIdxExt = [] # OD pair idx in the extended network corresponding to the OD pairs in smaller network
for i in range(len(odMap)):
odIdxExt.append(OD_pair_label_dict[str(odMap[str(i)])])
# -
with open('../temp_files/OD_demand_matrix_Jan_weekday_AM.json', 'r') as json_file:
demandsSmall = json.load(json_file)
# +
# demandsSmall
# +
# implement GLS method to estimate OD demand matrix
def GLS_Jan(x, A, P, L):
"""
x: sample matrix, each column is a link flow vector sample; 24 * K
A: path-link incidence matrix
P: logit route choice probability matrix
L: dimension of lam
----------------
return: lam
----------------
"""
K = np.size(x, 1)
S = samp_cov(x)
#print("rank of S is: \n")
#print(matrix_rank(S))
#print("sizes of S are: \n")
#print(np.size(S, 0))
#print(np.size(S, 1))
inv_S = inv(S).real
A_t = np.transpose(A)
P_t = np.transpose(P)
# PA'
PA_t = np.dot(P, A_t)
#print("rank of PA_t is: \n")
#print(matrix_rank(PA_t))
#print("sizes of PA_t are: \n")
#print(np.size(PA_t, 0))
#print(np.size(PA_t, 1))
# AP_t
AP_t = np.transpose(PA_t)
Q_ = np.dot(np.dot(PA_t, inv_S), AP_t)
Q = adj_PSD(Q_).real # Ensure Q to be PSD
# Q = Q_
#print("rank of Q is: \n")
#print(matrix_rank(Q))
#print("sizes of Q are: \n")
#print(np.size(Q, 0))
#print(np.size(Q, 1))
b = sum([np.dot(np.dot(PA_t, inv_S), x[:, k]) for k in range(K)])
# print(b[0])
# assert(1==2)
model = Model("OD_matrix_estimation")
lam = []
for l in range(L):
lam.append(model.addVar(name='lam_' + str(l)))
model.update()
# Set objective: (K/2) lam' * Q * lam - b' * lam
obj = 0
for i in range(L):
for j in range(L):
obj += (1.0 / 2) * K * lam[i] * Q[i, j] * lam[j]
for l in range(L):
obj += - b[l] * lam[l]
model.setObjective(obj)
# Add constraint: lam >= 0
for l in range(L):
model.addConstr(lam[l] >= 0)
#model.addConstr(lam[l] <= 5000)
fictitious_OD_list = zload('../temp_files/fictitious_OD_list')
for l in fictitious_OD_list:
model.addConstr(lam[l] == 0)
for j in range(len(odMap)):
model.addConstr(lam[odIdxExt[j]] - demandsSmall[str(j)] <= 0.2 * demandsSmall[str(j)])
model.addConstr(demandsSmall[str(j)] - lam[odIdxExt[j]] <= 0.2 * demandsSmall[str(j)])
# x = {}
# for k in range(m):
# for i in range(n+1)[1:]:
# for j in range(n+1)[1:]:
# if i != j:
# key = str(k) + '->' + str(i) + '->' + str(j)
# x[key] = model.addVar(name='x_' + key)
# model.update()
# for k in range(m):
# s = 0
# for i in range(n+1)[1:]:
# for j in range(n+1)[1:]:
# if i != j:
# key = str(k) + '->' + str(i) + '->' + str(j)
# s += x[key]
# model.addConstr(x[key] >= 0)
# model.addConstr(s - x_0[k] == 0)
# model.addConstr(x_0[k] - s == 0)
# for l in range(n):
# for i in range(n+1)[1:]:
# for j in range(n+1)[1:]:
# if i != j:
# key_ = str(i) + '->' + str(j)
# key__ = '(' + str(i) + ', ' + str(j) + ')'
# s = 0
# for k in range(m):
# key = str(k) + '->' + str(i) + '->' + str(j)
# s += N[l, k] * x[key]
# if (l+1 == i):
# model.addConstr(s + lam[OD_pair_label_dict[key__]] == 0)
# elif (l+1 == j):
# model.addConstr(s - lam[OD_pair_label_dict[key__]] == 0)
# else:
# model.addConstr(s == 0)
# if (i == 1 and j == 2):
# print(s)
model.update()
model.setParam('OutputFlag', False)
model.optimize()
lam_list = []
for v in model.getVars():
# print('%s %g' % (v.varName, v.x))
lam_list.append(v.x)
# print('Obj: %g' % obj.getValue())
return lam_list
lam_list = GLS_Jan(x, A, P, L)
# write estimation result to file
n = 22 # number of nodes
with open('../temp_files/OD_demand_matrix_Jan_weekend_ext.txt', 'w') as the_file:
idx = 0
for i in range(n + 1)[1:]:
for j in range(n + 1)[1:]:
if i != j:
the_file.write("%d,%d,%f\n" %(i, j, lam_list[idx]))
idx += 1
# -
| 03_OD_matrix_estimation_ifac17/05_OD_matrix_estimation_GLS_ext_Jan_weekend.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
import random
input_data = [(np.random.randn(8, 64), np.array([1, 0, 1, 0, 0, 1, 1, 0])),
(np.random.randn(8, 64), np.array([0, 1, 1, 1, 1, 1, 0, 1])),
(np.random.randn(8, 64), np.array([0, 0, 0, 0, 0, 1, 1, 0])),
(np.random.randn(8, 64), np.array([1, 0, 0, 1, 0, 0, 0, 0])),
(np.random.randn(8, 64), np.array([0, 1, 1, 1, 1, 1, 1, 0])),
(np.random.randn(8, 64), np.array([1, 1, 1, 0, 1, 0, 1, 1]))]
# +
def relu(x):
return np.maximum(x, 0)
def relu_dt(x):
x[x<=0] = 0
x[x>0] = 1
return x
# +
def sigmoid(x):
return 1/(1 + np.exp(-x))
def sigmoid_dt(x):
return sigmoid(x) * (1 - sigmoid(x))
# +
# TODO find out how to vectorize batching
def centropy_loss(y, a):
total = 0
for i in range(y.shape[0]):
total += np.sum(-(y[i] * np.log(a[i])))
return total / y.shape[0]
def centropy_loss_dt(y, a):
d = np.zeros_like(a)
for i in range(y.shape[0]):
d[i] = -(y[i]/ a[i])
return d
# -
class NN(object):
def __init__(self):
self.weights = [np.random.randn(64, 18) * np.sqrt(1./18),
np.random.randn(18, 2) * np.sqrt(1./2)]
self.bias = [np.random.randn(18),
np.random.rand(2)]
def feedforward(self, input_batch):
output = np.dot(input_batch, self.weights[0]) + self.bias[0]
output = relu(output)
output = np.dot(output, self.weights[1]) + self.bias[1]
output = sigmoid(output)
return output
def backprop(self, input_data):
# Forward
target = input_data[1]
activations = []
zs = []
activation = input_data[0]
activations.append(activation)
z = np.dot(activation, self.weights[0]) + self.bias[0]
zs.append(z)
activation = relu(z)
activations.append(activation)
z = np.dot(activation, self.weights[1]) + self.bias[1]
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# Backward
nabla_w = [np.zeros(w.shape) for w in self.weights]
nabla_b = [np.zeros(b.shape) for b in self.bias]
# special case: last layer with loss derivative
delta = centropy_loss_dt(target, activations[-1]) * sigmoid_dt(zs[-1])
nabla_w[-1] = np.dot(activations[-2].transpose(), delta)
nabla_b[-1] = delta
# loop through the rest
for i in range(2, len(nabla_w)+1):
delta = np.dot(delta, self.weights[-i+1].transpose()) * sigmoid_dt(zs[-i])
nabla_w[-i] = np.dot(activations[-i-1].transpose(), delta)
nabla_b[-i] = delta
return (nabla_w, nabla_b)
def update_mini_batch(self, batch, lr):
nabla_w = [np.zeros(w.shape) for w in self.weights]
nabla_b = [np.zeros(b.shape) for b in self.bias]
for i in range(batch[0].shape[0]):
delta_nabla_w, delta_nabla_b = self.backprop((np.expand_dims(batch[0][i], 0),
np.expand_dims(batch[1][i], 0)))
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
self.weights = [w - lr * nw
for w, nw in zip(self.weights, nabla_w)]
self.bias = [b - lr * nb
for b, nb in zip(self.bias, nabla_b)]
def train(self, input_data, num_epochs, lr):
"Trains the network on input_data for num_epochs times, with learning rate lr"
for e in range(num_epochs):
random.shuffle(input_data)
for data in input_data:
self.update_mini_batch(data, lr)
network = NN()
# +
outputs = network.feedforward(input_data[0][0])
centropy_loss(input_data[0][1], outputs)
# -
network.train(input_data, num_epochs=10, lr=0.01)
# +
outputs = network.feedforward(input_data[0][0])
centropy_loss(input_data[0][1], outputs)
# -
| nn_scratch.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.2 64-bit (''packt-repo-M2qY5kM-'': pipenv)'
# name: python3
# ---
from utils import *
# +
from azureml.core import Workspace
# Configure experiment
ws = Workspace.from_config()
# -
# Create or get training cluster
aml_cluster = get_aml_cluster(ws, cluster_name="cpu-cluster")
aml_cluster.wait_for_completion(show_output=True)
# Create a run configuration
run_conf = get_run_config(['numpy', 'pandas', 'scikit-learn', 'tensorflow'])
# +
from azureml.core.dataset import Dataset
dataset = Dataset.get_by_name(ws, name='titanic')
data_in = dataset.as_named_input('titanic')
# +
from azureml.pipeline.steps import PythonScriptStep
step = PythonScriptStep(name='Preprocessing',
script_name="preprocess_input.py",
source_directory="code",
arguments=["--input", data_in],
inputs=[data_in],
runconfig=run_conf,
compute_target=aml_cluster)
# +
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(ws, steps=[step])
# -
pipeline.validate()
# +
from azureml.core import Experiment
exp = Experiment(ws, "azureml-pipeline")
run = exp.submit(pipeline)
# -
from azureml.widgets import RunDetails
RunDetails(run).show()
| chapter08/02_pipeline_with_input.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from csv import reader, writer
out = writer(open("output.csv", "w"), delimiter=" ")
with open('3.csv') as csvfile:
readCSV = csv.reader(csvfile)
for row in readCSV:
if(row[0]=='ref_area')continue;
out.writerow(row)
# +
data = list(reader(open("3.csv", "r")))
out = writer(open("output.csv", "w"), delimiter=" ")
for row in reader(open("index.csv", "r"), delimiter=" "):
out.writerow(row + data[int(row[3])])
| Data/Unemployed/Rawdata/.ipynb_checkpoints/cleaning-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Tuplas
#
# Tuplas são iguais a listas, porém são imutaveis e se definem com parenteses () e não com colchetes [], e tem bem menos métodos, sendo mais constantes
#
# Se eu crio uma tupla no meu programa eu garanto que eles não irão ser modificados, diferente das listas
#
# Se definir tupla de um único elemento t = (40) sem a virgula virá um número normal
#
# Podemos usar algumas funções de lista: len(), index(), max(), min(), count()
#
# Ao retornar várias variaveis de uma função e armazenar em uma única variavel, ele irá armazenar como tupla
#
# Exemplos
# Tupla vazia
tupla = ()
print(tupla)
# Tupla de um único elemento, obrigatorio o uso da virgula no final para não definir como um número normal
tupla = (1,)
print(tupla)
# Podemos usar algumas funções de lista
print(len(tupla))
# Declarar tuplas
tupla1 = 1, 2.3, 5, 7
tupla2 = (8, 3.6, 3, 12)
print(tupla1)
print(tupla2)
# Atribuir variáveis a uma tupla
a = 10
b = 11
c = 12
tupla = a, b, c
print(tupla)
# Converter listas em tuplas
tupla = tuple([1, 2, 3])
print(tupla)
# Tuplas dentro de tuplas
tupla = (2, (3, 4), 5)
print(tupla)
print("elemento:", tupla[1][1])
# Slices em tuplas
print(tupla[1:4])
# Lista dentro de tuplas
tupla = (2, [3, 4], 5)
print(tupla)
tupla[1][1] = 5
print(tupla)
print("elemento:", tupla[1][1])
# Concatenação de tuplas
tuplas = (1,2,3) + (4,5,6)
print(tuplas)
# Inserir texto dentro de tuplas
tupla = (1, 2, "aaaa", 3)
print(tupla)
# Usar tupla em laços
for tupla in tuplas:
print(tupla, end=', ')
# Retorna o indice do elemento 3 da tupla
tupla = (1, 2, 3, 4, 5)
print(tupla.index(3))
# Retorna o número de vezes que o elemento 1 aparece na tupla
tupla = (1, 2, 3, 3, 5)
print(tupla.count(3))
| notebooks/06_Tuplas.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import os
import sys
import csv
import numpy as np
import pandas as pd
import cv2
import matplotlib
import matplotlib.pyplot as plt
from tqdm import tqdm
from skimage.io import imread, imshow, imread_collection, concatenate_images
from scipy.ndimage.morphology import binary_fill_holes
from config import Config
import utils
# +
test_path = '../data/stage1_test_solutions/stage1_test/'
# Get test IDs
test_ids = next(os.walk(test_path))[1]
# -
df_submission = pd.read_csv('output/mask-rcnn_resnet101_20e_grid21_step8.csv')
df_labels = pd.read_csv('../data/stage1_solution.csv')
class NucleiDataset(utils.Dataset):
def load_image(self, image_id):
image = imread(self.image_info[image_id]['path'])[:, :, :3]
return image
def load_mask(self, image_id):
info = self.image_info[image_id]
image_path = info['path']
mask_path = image_path[:image_path.find('/images/')]
mask_dir = os.path.join(mask_path, 'masks')
mask_names = os.listdir(mask_dir)
count = len(mask_names)
mask = []
for i, el in enumerate(mask_names):
msk_path = os.path.join(mask_dir, el)
msk = imread(msk_path)
if np.sum(msk) == 0:
print('invalid mask')
continue
msk = msk.astype('float32')/255.
mask.append(msk)
mask = np.asarray(mask)
mask[mask > 0.] = 1.
mask = np.transpose(mask, (1,2,0))
occlusion = np.logical_not(mask[:, :, -1]).astype(np.uint8)
count = mask.shape[2]
for i in range(count-2, -1, -1):
mask[:, :, i] = mask[:, :, i] * occlusion
mask[:, :, i] = binary_fill_holes(mask[:, :, i])
occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i]))
class_ids = [self.class_names.index('nucleus') for s in range(count)]
class_ids = np.asarray(class_ids)
return mask, class_ids.astype(np.int32)
# +
dataset_test = NucleiDataset()
dataset_test.add_class("stage1_train", 1, "nucleus")
# Get and resize test images
print('Getting and resizing test images ... ')
sys.stdout.flush()
for n, id_ in tqdm(enumerate(test_ids), total=len(test_ids)):
path = test_path + id_
img_path = path + '/images/' + id_ + '.png'
dataset_test.add_image('stage1_test', id_, img_path)
dataset_test.prepare()
# -
# Borrowed from https://www.kaggle.com/c/data-science-bowl-2018/discussion/51563#304986
def run_length_decode(rle, H, W, fill_value=1):
mask = np.zeros((H * W), np.uint8)
rle = rle[1:-1]
rle = np.array([int(s) for s in rle.split(', ')]).reshape(-1, 2)
for r in rle:
start = r[0]-1
end = start + r[1]
mask[start : end] = fill_value
mask = mask.reshape(W, H).T # H, W need to swap as transposing.
return mask
def select_rows(df, image_id):
return df.loc[df['ImageId'] == image_id]
preds_labels_alt = []
for test_id in tqdm(dataset_test.image_ids, total=len(dataset_test.image_ids)):
test_image = dataset_test.load_image(test_id)
test_mask = dataset_test.load_mask(test_id)
image_shape = test_image.shape
df_mask = select_rows(df_submission, dataset_test.image_info[test_id]['id'])
pred = []
for i, mask in df_mask.iterrows():
pred_slice = run_length_decode(mask['EncodedPixels'], image_shape[0], image_shape[1])
pred.append(pred_slice)
pred = np.transpose(pred, (1, 2, 0))
preds_labels_alt.append((pred, test_mask[0]))
labels_list = []
preds_list = []
for image in tqdm(preds_labels_alt, total=len(preds_labels_alt)):
preds_shape = image[0].shape
labels_shape = image[1].shape
preds = np.zeros((preds_shape[0], preds_shape[1]), np.uint16)
labels = np.zeros((labels_shape[0], labels_shape[1]), np.uint16)
for i in range(preds_shape[2] - 1):
preds[image[0][:,:,i] > 0] = i + 1
for j in range(labels_shape[2] - 1):
labels[image[1][:,:,j] > 0] = j + 1
preds_list.append(preds)
labels_list.append(labels)
# +
fig = plt.figure(figsize=(15,15))
image_id = 9
original_image = dataset_test.load_image(image_id)
plt.subplot(131)
plt.title('Original')
#plt.axis('off')
plt.imshow(original_image)
plt.subplot(132)
plt.title('Ground Truth')
#plt.axis('off')
plt.imshow(labels_list[image_id])
plt.subplot(133)
plt.title('Predictions')
#plt.axis('off')
plt.imshow(preds_list[image_id])
plt.show()
# -
# Calculate average precision for image predictions
# Borrowed from https://www.kaggle.com/thomasjpfan/ap-metric
def ap(y_true, y_pred):
# remove one for background
num_true = len(np.unique(y_true)) - 1
num_pred = len(np.unique(y_pred)) - 1
#print("Number true objects:", num_true)
#print("Number predicted objects:", num_pred)
if num_true == 0 and num_pred == 0:
return 1
elif num_true == 0 or num_pred == 0:
return 0
# bin size + 1 for background
intersect = np.histogram2d(
y_true.flatten(), y_pred.flatten(), bins=(num_true+1, num_pred+1))[0]
area_t = np.histogram(y_true, bins=(num_true+1))[0][:, np.newaxis]
area_p = np.histogram(y_pred, bins=(num_pred+1))[0][np.newaxis, :]
# get rid of background
union = area_t + area_p - intersect
intersect = intersect[1:, 1:]
union = union[1:, 1:]
iou = intersect / union
threshold = np.arange(0.5, 1.0, 0.05)[np.newaxis, np.newaxis, :]
matches = iou[:,:, np.newaxis] > threshold
tp = np.sum(matches, axis=(0,1))
fp = num_true - tp
fn = num_pred - tp
return np.mean(tp/(tp+fp+fn))
predictions_ap = [ap(img[0], img[1]) for img in zip(labels_list, preds_list)]
mean_ap = np.mean(predictions_ap)
print("MaP for test predictions: {:.3f}".format(mean_ap))
| mask_rcnn/.ipynb_checkpoints/capstone_test_score-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Heritage Made Digital Newspapers
#
# Get all articles mentioning the word slavery before 1840
from pathlib import Path
from tqdm import tqdm_notebook
import pandas as pd
from zipfile import ZipFile
from nltk.tokenize import sent_tokenize
import re
path = Path('../../../../LivingwithMachines/Lab1/data/hmd/plaintext')
path_metadata = Path('../../../../LivingwithMachines/Lab1/data/hmd/metadata')
save_to = Path('../../hmd_data_machine')
save_to.mkdir(exist_ok=True)
save_plaintext = save_to / 'plaintext'
save_plaintext.mkdir(exist_ok=True)
save_metadata = save_to / 'metadata'
save_metadata.mkdir(exist_ok=True)
pattern = re.compile(r'(?:\bmachine)')
# +
zip_files = list(path.glob('*.zip'))
count = 0
for zf in zip_files:
with ZipFile(zf, 'r') as hmd_zip:
#with open(save_plaintext / (zf.stem + '.txt'),'w') as out_text:
articles = hmd_zip.namelist()
rows = []
for art in tqdm_notebook(articles):
if not art.endswith('.txt'): continue
text = hmd_zip.read(art).decode("utf-8")
if pattern.findall(text):
sentences = sent_tokenize(text)
machine_sents = [[art,s,'<SEP>'.join(pattern.findall(s))] for s in sentences if pattern.findall(s)]
#out_text.write(machine_sents)
rows.extend(machine_sents)
count+=len(machine_sents)
df = pd.DataFrame(rows,columns=['article_path','sentence','hits'])
df.to_csv(save_plaintext / (zf.stem + '.csv'))
print(count)
# -
| utils/Process HMD data - sentence level.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: conda_python3
# language: python
# name: conda_python3
# ---
# # 데이터 준비
# +
import pandas as pd
def make_two_sents(file_name):
df = pd.read_csv(file_name, error_bad_lines=False, sep='\t')
df = df.dropna() # 널 제거
return df
train_file_path = '../data/KorSTS/sts-train.tsv'
test_file_path = '../data/KorSTS/sts-test.tsv'
train_df = make_two_sents(file_name= train_file_path)
test_df = make_two_sents(file_name= test_file_path)
train_df.head()
# -
print(train_df.info())
print(test_df.info())
train_df[train_df['score'] > 3].head()
train_df[train_df['score'] < 3].head()
# ## 데이터 전처리
# +
import numpy as np
import os
def preprocess(data, new_file_path, b_train=False ):
df = data.copy()
df = df.dropna() # 널 제거
df['label'] = np.where(df['score'] >= 3, 1, 0) # score 가 3 이상이면 레이블 1, 아니면 0
if b_train:
# print("drop noise row")
df = df.drop([2902, 3206, 3258, 3379]) # noise 데이터 삭제
df.to_csv(new_file_path, sep='\t', index=None)
return df
preproc_train_dir = 'preproc/train'
preproc_test_dir = 'preproc/test'
os.makedirs(preproc_train_dir, exist_ok=True)
os.makedirs(preproc_test_dir, exist_ok=True)
train_file_path = os.path.join(preproc_train_dir, 'train.tab')
test_file_path = os.path.join(preproc_test_dir, 'test.tab')
train_p_df = preprocess(train_df, train_file_path, b_train=True)
test_p_df = preprocess(test_df, test_file_path)
train_p_df
test_p_df
# -
| scratch/sentBert/1.1.Prepare-Data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Coding Companion for Intuitive Deep Learning Part 1 (Annotated)
# In this notebook, we'll go through the code for the coding companion for Intuitive Deep Learning Part 1 ([Part 1a](https://medium.com/intuitive-deep-learning/intuitive-deep-learning-part-1a-introduction-to-neural-networks-d7b16ebf6b99), [Part 1b](https://medium.com/intuitive-deep-learning/intuitive-deep-learning-part-1b-introduction-to-neural-networks-8565d97ddd2d)) to create your very first neural network to predict whether the house price is below or above median value. We will go through the following in this notebook:
#
# - Exploring and Processing the Data
# - Building and Training our Neural Network
# - Visualizing Loss and Accuracy
# - Adding Regularization to our Neural Network
#
# The code is annotated throughout the notebook and you simply need to download the dataset [here](https://drive.google.com/file/d/1GfvKA0qznNVknghV4botnNxyH-KvODOC/view), put the dataset in the same folder as this notebook and run the code cells below. Note that the results you get might differ slightly from the blogpost as there is a degree of randomness in the way we split our dataset as well as the initialization of our neural network.
# # Exploring and Processing the Data
# We first have to read in the CSV file that we've been given. We'll use a package called pandas for that:
import pandas as pd
df = pd.read_csv('housepricedata.csv')
df
# The dataset that we have now is in what we call a pandas dataframe. To convert it to an array, simply access its values:
dataset = df.values
dataset
# Now, we split the dataset into our input features and the label we wish to predict.
X = dataset[:,0:10]
Y = dataset[:,10]
# Normalizing our data is very important, as we want the input features to be on the same order of magnitude to make our training easier. We'll use a min-max scaler from scikit-learn which scales our data to be between 0 and 1.
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
X_scale = min_max_scaler.fit_transform(X)
X_scale
# Lastly, we wish to set aside some parts of our dataset for a validation set and a test set. We use the function train_test_split from scikit-learn to do that.
from sklearn.model_selection import train_test_split
X_train, X_val_and_test, Y_train, Y_val_and_test = train_test_split(X_scale, Y, test_size=0.3)
X_val, X_test, Y_val, Y_test = train_test_split(X_val_and_test, Y_val_and_test, test_size=0.5)
print(X_train.shape, X_val.shape, X_test.shape, Y_train.shape, Y_val.shape, Y_test.shape)
# # Building and Training Our First Neural Network
# We will be using Keras to build our architecture. Let's import the code from Keras that we will need to use:
from keras.models import Sequential
from keras.layers import Dense
# We will be using the Sequential model, which means that we merely need to describe the layers above in sequence. Our neural network has three layers:
#
# - Hidden layer 1: 30 neurons, ReLU activation
# - Hidden layer 2: 30 neurons, ReLU activation
# - Output Layer: 1 neuron, Sigmoid activation
model = Sequential([
Dense(32, activation='relu', input_shape=(10,)),
Dense(32, activation='relu'),
Dense(1, activation='sigmoid'),
])
# Now that we've got our architecture specified, we need to find the best numbers for it. Before we start our training, we have to configure the model by
# - Telling it what algorithm you want to use to do the optimization (we'll use stochastic gradient descent)
# - Telling it what loss function to use (for binary classification, we will use binary cross entropy)
# - Telling it what other metrics you want to track apart from the loss function (we want to track accuracy as well)
#
# We do so below:
model.compile(optimizer='sgd',
loss='binary_crossentropy',
metrics=['accuracy'])
# Training on the data is pretty straightforward and requires us to write one line of code. The function is called 'fit' as we are fitting the parameters to the data. We specify:
# - what data we are training on, which is X_train and Y_train
# - the size of our mini-batch
# - how long we want to train it for (epochs)
# - what our validation data is so that the model will tell us how we are doing on the validation data at each point.
#
# This function will output a history, which we save under the variable hist. We'll use this variable a little later.
hist = model.fit(X_train, Y_train,
batch_size=32, epochs=100,
validation_data=(X_val, Y_val))
# Evaluating our data on the test set:
model.evaluate(X_test, Y_test)[1]
# # Visualizing Loss and Accuracy
# Import the relevant package we need to do the visualization
import matplotlib.pyplot as plt
# We want to visualize the training loss and the validation loss like this:
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper right')
plt.show()
# We can also visualize the training accuracy and the validation accuracy like this:
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='lower right')
plt.show()
# # Adding Regularization to our Neural Network
# We'll train a model which will overfit, which we call Model 2. This might take a few minutes.
model_2 = Sequential([
Dense(1000, activation='relu', input_shape=(10,)),
Dense(1000, activation='relu'),
Dense(1000, activation='relu'),
Dense(1000, activation='relu'),
Dense(1, activation='sigmoid'),
])
model_2.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
hist_2 = model_2.fit(X_train, Y_train,
batch_size=32, epochs=100,
validation_data=(X_val, Y_val))
# Let's do the same visualization to see what overfitting looks like in terms of the loss and accuracy.
plt.plot(hist_2.history['loss'])
plt.plot(hist_2.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper right')
plt.show()
plt.plot(hist_2.history['acc'])
plt.plot(hist_2.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='lower right')
plt.show()
# To address the overfitting we see in Model 2, we'll incorporate L2 regularization and dropout in our third model here (Model 3).
from keras.layers import Dropout
from keras import regularizers
model_3 = Sequential([
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01), input_shape=(10,)),
Dropout(0.3),
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01)),
Dropout(0.3),
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01)),
Dropout(0.3),
Dense(1000, activation='relu', kernel_regularizer=regularizers.l2(0.01)),
Dropout(0.3),
Dense(1, activation='sigmoid', kernel_regularizer=regularizers.l2(0.01)),
])
model_3.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
hist_3 = model_3.fit(X_train, Y_train,
batch_size=32, epochs=100,
validation_data=(X_val, Y_val))
# We'll now plot the loss and accuracy graphs for Model 3. You'll notice that the loss is a lot higher at the start, and that's because we've changed our loss function. To plot such that the window is zoomed in between 0 and 1.2 for the loss, we add an additional line of code (plt.ylim) when plotting
plt.plot(hist_3.history['loss'])
plt.plot(hist_3.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='upper right')
plt.ylim(top=1.2, bottom=0)
plt.show()
plt.plot(hist_3.history['acc'])
plt.plot(hist_3.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Val'], loc='lower right')
plt.show()
# As compared to Model 2, you should see that there's less overfitting!
| resources/useful_repos/intuitive-deep-learning-master_RO/Part 1: Predicting House Prices/Coding Companion for Intuitive Deep Learning Part 1 Annotated.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + [markdown] id="SXCPPivdnL6L"
# Semi-supervised learning of MNIST demo.
# + executionInfo={"elapsed": 12, "status": "ok", "timestamp": 1645824396748, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="XQfiQkdfnQNQ"
# import MNIST from open ML
import numpy as np
import matplotlib.pyplot as plt
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 16534, "status": "ok", "timestamp": 1645824414300, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="tVv908mCnW45" outputId="10e31a46-7304-412e-e6ff-4429ad4f4b01"
from google.colab import drive
drive.mount('/content/drive')
# load training and test sets
path_to_train = '/content/drive/MyDrive/Courses/AMATH482582-WIN2022/HWs/HW2/MNIST_training_set.npy'
path_to_test = '/content/drive/MyDrive/Courses/AMATH482582-WIN2022/HWs/HW2/MNIST_test_set.npy'
d_train = np.load(path_to_train, allow_pickle=True)
d_test = np.load(path_to_test, allow_pickle=True)
XX = d_train.item().get('features')
YY = d_train.item().get('labels')
print(XX.shape)
print(YY.shape)
# + executionInfo={"elapsed": 202, "status": "ok", "timestamp": 1645824418320, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="SjdSAPMGnXlC"
# Plot some of the training and test sets
def plot_digits(XX, N, title):
"""Small helper function to plot N**2 digits."""
fig, ax = plt.subplots(N, N, figsize=(8, 8))
for i in range(N):
for j in range(N):
ax[i,j].imshow(XX[(N)*i+j,:].reshape((16, 16)), cmap="Greys")
ax[i,j].axis("off")
fig.suptitle(title, fontsize=24)
# + executionInfo={"elapsed": 15, "status": "ok", "timestamp": 1645824419399, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="mGIUflTqntoB"
# function to take subset of data set (ie specific digits and apply PCA transform and return)
def return_subset( dig1, dig2, dig3, XX, YY ):
indx1 = np.argwhere( YY == dig1 )
indx2 = np.argwhere( YY == dig2 )
indx3 = np.argwhere( YY == dig3 )
indx = np.append(indx1, indx2, axis=0)
indx = np.append(indx, indx3, axis=0)
indx = np.random.permutation(indx.flatten())
XX_sub = XX[indx, :]
YY_sub = YY[indx]
# one hot encoding of classes in b
b = np.zeros( (len(indx), 3))
for j in range(len(YY_sub)):
if YY_sub[j] == dig1:
b[j,:] = [1, 0 , 0]
elif YY_sub[j] == dig2:
b[j, :] = [0, 1, 0]
elif YY_sub[j] == dig3:
b[j, :] = [0, 0, 1]
return XX_sub, YY_sub, b
# + colab={"base_uri": "https://localhost:8080/", "height": 697} executionInfo={"elapsed": 2132, "status": "ok", "timestamp": 1645824422624, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="9q9ygKWTpPtF" outputId="5780c691-b78a-4f8c-eeaa-269c098b1b59"
digit1 = 4
digit2 = 8
digit3 = 1
X, Y, hidden_labels = return_subset( digit1, digit2, digit3, XX, YY )
print(hidden_labels[0:10, :])
plot_digits( X, 8, 'Features' )
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 289, "status": "ok", "timestamp": 1645824423834, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="nc27iX_0rNsP" outputId="47647d91-c57c-43c8-c24d-a4a2dd0aa778"
# We only observe the first M labels
M = 10
labels = hidden_labels[0:M, :]
print(labels.shape)
print(hidden_labels.shape)
print(labels)
# + colab={"base_uri": "https://localhost:8080/", "height": 286} executionInfo={"elapsed": 1160, "status": "ok", "timestamp": 1645824518304, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="Hxl2C1UEsz6p" outputId="5b534587-fdb8-4378-ca06-5a804fb954cb"
# construct graph Laplacian on features
import scipy as sp
import scipy.spatial
dist = sp.spatial.distance_matrix( X, X )
def eta(t, l):
val = np.exp(-(1/(2*l**2))*t**2 )
return val
# l length scale of the kernel
l = 0.05*dist.mean()
W = eta(dist, l)
plt.spy(W>= 1e-4)
# + id="EtsoW3UHv4VY"
D = np.diag(np.sum(W,axis=1))
L = D - W
# compute eigendecompositions
ll, VV = np.linalg.eigh(L)
# we need to sort the eigenvalues and vectors
idx = ll.argsort()
l = ll[idx]
V = VV[:, idx]
K = M # number of eigenvectors to use to approximate the classifier on labelled set
Vp = V[0:M, 0:K]
# + executionInfo={"elapsed": 9, "status": "ok", "timestamp": 1645824502401, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="F4473pUh3sri"
# Ridge regression on labelled set
from sklearn.linear_model import Ridge
SSLRidge = Ridge(alpha = 1e-8)
SSLRidge.fit( Vp, labels )
beta = np.zeros((K+1,3)) # we have three classes so beta is now a matrix
beta[0, :] = SSLRidge.intercept_
beta[1:None, :] = np.transpose(SSLRidge.coef_)
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 177, "status": "ok", "timestamp": 1645824503653, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="Wi5FdemZ-M-G" outputId="227c7079-1488-4935-b4d0-ac8faf9ceb2f"
# predict labels on entire graph
A = np.append( np.ones( (len(Y), 1) ), V[:, 0:K], axis =1 )
labels_pred = np.dot(A, beta)
classes_pred = np.argmax(labels_pred, axis= 1)
print(A.shape)
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} executionInfo={"elapsed": 225, "status": "ok", "timestamp": 1645824504621, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="Pe6w4CjN_jte" outputId="b6ffe72f-c0fb-4bfe-e1a7-e2df23629dab"
plt.matshow(labels_pred[0:20, :])
print(labels_pred[0:20,:])
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 9, "status": "ok", "timestamp": 1645824506199, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="5N-b6J9gE8x-" outputId="91cf6040-d6fc-42c4-c2f9-d76be7575889"
# threshold predicted labels to one-hot format
labels_pred_max = np.amax(labels_pred, axis=1)
print(labels_pred_max.shape)
import numpy.matlib
labels_pred_max = np.transpose(np.matlib.repmat(labels_pred_max, 3, 1))
# + colab={"base_uri": "https://localhost:8080/", "height": 638} executionInfo={"elapsed": 215, "status": "ok", "timestamp": 1645824507109, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="0s5tZ2HjCi_N" outputId="ca190b5e-6bfe-4dad-8741-3b1ebc054e67"
labels_pred_thresholded = (labels_pred == labels_pred_max).astype(float)
fig, ax = plt.subplots(1, 2, figsize=(5, 10))
ax[0].matshow(hidden_labels[0:30, :])
ax[0].set_title('True labels')
ax[1].matshow(labels_pred_thresholded[0:30, :])
ax[1].set_title('Predicted labels')
# + colab={"base_uri": "https://localhost:8080/"} executionInfo={"elapsed": 10, "status": "ok", "timestamp": 1645824508470, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GhwJbFKBBICkDJdVudgsTuWkkyr0jrw5PxmRvic=s64", "userId": "09527353465813384085"}, "user_tz": 480} id="0FctPGCIDMsL" outputId="15a66230-3623-4b71-ef54-8fc662e02a90"
# compute percentage of mislabelled images
err = 0
print(hidden_labels.shape)
print(labels_pred_thresholded.shape)
for i in range(len(hidden_labels)):
# count number of mislabelled images
err+= 1- np.array_equal( hidden_labels[i,:], labels_pred_thresholded[i, :])
mislabelled_ratio = err/len(hidden_labels)
print('mislablled ratio:', mislabelled_ratio)
# + id="gDlfvSBiyJ_G"
| course_notes/AMATH582-Lec22-1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] slideshow={"slide_type": "skip"}
# **Important**: Click on "*Kernel*" > "*Restart Kernel and Clear All Outputs*" *before* reading this chapter in [JupyterLab <img height="12" style="display: inline-block" src="static/link_to_jp.png">](https://jupyterlab.readthedocs.io/en/stable/) (e.g., in the cloud on [MyBinder <img height="12" style="display: inline-block" src="static/link_to_mb.png">](https://mybinder.org/v2/gh/webartifex/intro-to-python/master?urlpath=lab/tree/09_mappings_00_content.ipynb))
# + [markdown] slideshow={"slide_type": "slide"}
# # Chapter 9: Mappings & Sets
# + [markdown] slideshow={"slide_type": "skip"}
# While [Chapter 7 <img height="12" style="display: inline-block" src="static/link_to_nb.png">](https://nbviewer.jupyter.org/github/webartifex/intro-to-python/blob/master/07_sequences_00_content.ipynb) focuses on one special kind of *collection* types, namely *sequences*, this chapter introduces two more kinds: **Mappings** and **sets**. Both are presented in this chapter as they share the *same* underlying implementation.
#
# The `dict` type (cf, [documentation <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict)) introduced in the next section is an essential part in a data scientist's toolbox for two reasons: First, Python employs `dict` objects basically "everywhere" internally. Second, after the many concepts involving *sequential* data, *mappings* provide a different perspective on data and enhance our general problem solving skills.
# + [markdown] slideshow={"slide_type": "slide"}
# ## The `dict` Type
# + [markdown] slideshow={"slide_type": "skip"}
# A *mapping* is a one-to-one correspondence from a set of **keys** to a set of **values**. In other words, a *mapping* is a *collection* of **key-value pairs**, also called **items** for short.
#
# In the context of mappings, the term *value* has a meaning different from the *value* every object has: In the "bag" analogy from [Chapter 1 <img height="12" style="display: inline-block" src="static/link_to_nb.png">](https://nbviewer.jupyter.org/github/webartifex/intro-to-python/blob/master/01_elements_00_content.ipynb#Value-/-"Meaning"), we describe an object's value to be the semantic meaning of the $0$s and $1$s it contains. Here, the terms *key* and *value* mean the *role* an object takes within a mapping. Both, *keys* and *values*, are *objects* on their own with distinct *values*.
#
# Let's continue with an example. To create a `dict` object, we commonly use the literal notation, `{..: .., ..: .., ...}`, and list all the items. `to_words` below maps the `int` objects `0`, `1`, and `2` to their English word equivalents, `"zero"`, `"one"`, and `"two"`, and `from_words` does the opposite. A stylistic side note: Pythonistas often expand `dict` or `list` definitions by writing each item or element on a line on their own. Also, the commas `,` after the respective *last* items, `2: "two"` and `"two": 2`, are *not* a mistake although they *may* be left out. Besides easier reading, such a style has technical advantages that we do not go into detail about here (cf., [source <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://www.python.org/dev/peps/pep-0008/#when-to-use-trailing-commas)).
# + slideshow={"slide_type": "slide"}
to_words = {
0: "zero",
1: "one",
2: "two",
}
# + slideshow={"slide_type": "fragment"}
from_words = {
"zero": 0,
"one": 1,
"two": 2,
}
# + [markdown] slideshow={"slide_type": "skip"}
# As before, `dict` objects are objects on their own: They have an identity, a type, and a value.
# + slideshow={"slide_type": "skip"}
id(to_words)
# + slideshow={"slide_type": "skip"}
type(to_words)
# + slideshow={"slide_type": "slide"}
to_words
# + slideshow={"slide_type": "skip"}
id(from_words)
# + slideshow={"slide_type": "skip"}
type(from_words)
# + slideshow={"slide_type": "fragment"}
from_words
# + [markdown] slideshow={"slide_type": "skip"}
# The built-in [dict() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-dict) constructor gives us an alternative way to create a `dict` object. It is versatile and can be used in different ways.
#
# First, we may pass it any *mapping* type, for example, a `dict` object, to obtain a *new* `dict` object. That is the easiest way to obtain a *shallow* copy of a `dict` object or convert any other mapping object into a `dict` one.
# + slideshow={"slide_type": "skip"}
dict(from_words)
# + [markdown] slideshow={"slide_type": "skip"}
# Second, we may pass it a *finite* `iterable` providing *iterables* with *two* elements each. So, both of the following two code cells work: A `list` of `tuple` objects, or a `tuple` of `list` objects. More importantly, we could use an *iterator*, for example, a `generator` object, that produces the inner iterables "on the fly."
# + slideshow={"slide_type": "slide"}
dict([("zero", 0), ("one", 1), ("two", 2)])
# + slideshow={"slide_type": "skip"}
dict((["zero", 0], ["one", 1], ["two", 2]))
# + [markdown] slideshow={"slide_type": "skip"}
# Lastly, [dict() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-dict) may also be called with *keyword* arguments: The keywords become the keys and the arguments the values.
# + slideshow={"slide_type": "fragment"}
dict(zero=0, one=1, two=2)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Nested Data
# + [markdown] slideshow={"slide_type": "skip"}
# Often, `dict` objects occur in a nested form and combined with other collection types, such as `list` or `tuple` objects, to model more complex entities "from the real world."
#
# The reason for this popularity is that many modern [ReST APIs <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Representational_state_transfer#Applied_to_Web_services) on the internet (e.g., [Google Maps API](https://cloud.google.com/maps-platform/), [Yelp API](https://www.yelp.com/developers/documentation/v3), [Twilio API](https://www.twilio.com/docs/usage/api)) provide their data in the popular [JSON <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/JSON) format, which looks almost like a combination of `dict` and `list` objects in Python.
#
# The `people` example below models three groups of people: `"mathematicians"`, `"physicists"`, and `"programmers"`. Each person may have an arbitrary number of email addresses. In the example, [Leonhard Euler <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Leonhard_Euler) has not lived long enough to get one whereas [Guido <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Guido_van_Rossum) has more than one.
#
# `people` makes many implicit assumptions about the structure of the data. For example, there are a [one-to-many <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/One-to-many_%28data_model%29) relationship between a person and their email addresses and a [one-to-one <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/One-to-one_%28data_model%29) relationship between each person and their name.
# + slideshow={"slide_type": "slide"}
people = {
"mathematicians": [
{
"name": "<NAME>",
"emails": ["<EMAIL>"],
},
{
"name": "<NAME>",
"emails": [],
},
],
"physicists": [],
"programmers": [
{
"name": "Guido",
"emails": ["<EMAIL>", "<EMAIL>"],
},
],
}
# + [markdown] slideshow={"slide_type": "skip"}
# The literal notation of such a nested `dict` object may be hard to read ...
# + slideshow={"slide_type": "slide"}
people
# + [markdown] slideshow={"slide_type": "skip"}
# ... but the [pprint <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/pprint.html) module in the [standard library <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/index.html) provides a [pprint() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/pprint.html#pprint.pprint) function for "pretty printing."
# + slideshow={"slide_type": "slide"}
from pprint import pprint
# + slideshow={"slide_type": "fragment"}
pprint(people, indent=1, width=60)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Hash Tables & (Key) Hashability
# + [markdown] slideshow={"slide_type": "skip"}
# In [Chapter 0 <img height="12" style="display: inline-block" src="static/link_to_nb.png">](https://nbviewer.jupyter.org/github/webartifex/intro-to-python/blob/master/00_intro_00_content.ipynb#Isn't-C-a-lot-faster?), we argue that a major advantage of using Python is that it takes care of the memory managment for us. In line with that, we have never talked about the C level implementation thus far in the book. However, the `dict` type, among others, exhibits some behaviors that may seem "weird" for a beginner. To build some intuition, we describe the underlying implementation details on a conceptual level.
#
# The first unintuitive behavior is that we may *not* use a *mutable* object as a key. That results in a `TypeError`.
# + slideshow={"slide_type": "slide"}
{
["zero", "one"]: [0, 1],
}
# + [markdown] slideshow={"slide_type": "skip"}
# Similarly surprising is that items with the *same* key get merged together. The resulting `dict` object keeps the position of the *first* mention of the `"zero"` key while only the *last* mention of the corresponding values, `999`, survives.
# + slideshow={"slide_type": "slide"}
{
"zero": 0,
"one": 1,
"two": 2,
"zero": 999, # to illustrate a point
}
# + [markdown] slideshow={"slide_type": "skip"}
# The reason for that is that the `dict` type is implemented with so-called [hash tables <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Hash_table).
#
# Conceptually, when we create a *new* `dict` object, Python creates a "bag" in memory that takes significantly more space than needed to store the references to all the key and value objects. This bag is a **contiguous array** similar to the `list` type's implementation. Whereas in the `list` case the array is divided into equally sized *slots* capable of holding *one* reference, a `dict` object's array is divided into equally sized **buckets** with enough space to store *two* references each: One for an item's key and one for the mapped value. The buckets are labeled with *index* numbers. Because Python knows how wide each bucket, it can jump directly into *any* bucket by calculating its *offset* from the start.
#
# The figure below visualizes how we should think of hash tables. An empty `dict` object, created with the literal `{}`, still takes a lot of memory: It is essentially one big, contiguous, and empty table.
# + [markdown] slideshow={"slide_type": "slide"}
# | Bucket | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
# | :---: |:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
# | **Key** |*...*|*...*|*...*|*...*|*...*|*...*|*...*|*...*|
# |**Value**|*...*|*...*|*...*|*...*|*...*|*...*|*...*|*...*|
# + [markdown] slideshow={"slide_type": "skip"}
# To insert a key-value pair, the key must be translated into a bucket's index.
#
# As the first step to do so, the built-in [hash() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#hash) function maps any **hashable** object to its **hash value**, a long and "random" `int` number, similar to the ones returned by the built-in [id() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#id) function. This hash value is a *summary* of all the $0$s and $1$s inside the object.
#
# According to the official [glossary <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/glossary.html#term-hashable), an object is hashable *only if* "it has a hash value which *never* changes during its *lifetime*." So, hashability implies immutability! Without this formal requirement an object may end up in *different* buckets depending on its current value. As the name of the `dict` type (i.e., "dictionary") suggests, a primary purpose of it is to insert objects and look them up later on. Without a *unique* bucket, this is of course not doable. The exact logic behind [hash() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#hash) is beyond the scope of this book.
#
# Let's calculate the hash value of `"zero"`, an immutable `str` object. Hash values have *no* semantic meaning. Also, every time we re-start Python, we see *different* hash values for the *same* objects. That is a security measure, and we do not go into the technicalities here (cf. [source <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/using/cmdline.html#envvar-PYTHONHASHSEED)).
# + slideshow={"slide_type": "slide"}
hash("zero")
# + [markdown] slideshow={"slide_type": "skip"}
# For numeric objects, we can sometimes predict the hash values. However, we must *never* interpret any meaning into them.
# + slideshow={"slide_type": "fragment"}
hash(0)
# + slideshow={"slide_type": "skip"}
hash(0.0)
# + [markdown] slideshow={"slide_type": "skip"}
# The [glossary <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/glossary.html#term-hashable) states a second requirement for hashability, namely that "objects which *compare equal* must have the *same* hash value." The purpose of this is to ensure that if we put, for example, `1` as a key in a `dict` object, we can look it up later with `1.0`. In other words, we can look up keys by their object's semantic value. The converse statement does *not* hold: Two objects *may* (accidentally) have the *same* hash value and *not* compare equal. However, that rarely happens.
# + slideshow={"slide_type": "skip"}
1 == 1.0
# + slideshow={"slide_type": "fragment"}
hash(1) == hash(1.0)
# + [markdown] slideshow={"slide_type": "skip"}
# Because `list` objects are not immutable, they are *never* hashable, as indicated by the `TypeError`.
# + slideshow={"slide_type": "slide"}
hash(["zero", "one"])
# + [markdown] slideshow={"slide_type": "skip"}
# If we need keys composed of several objects, we can use `tuple` objects instead.
# + slideshow={"slide_type": "fragment"}
hash(("zero", "one"))
# + [markdown] slideshow={"slide_type": "skip"}
# There is no such restiction on objects inserted into `dict` objects as *values*.
# + slideshow={"slide_type": "fragment"}
{
("zero", "one"): [0, 1],
}
# + [markdown] slideshow={"slide_type": "skip"}
# After obtaining the key object's hash value, Python must still convert that into a bucket index. We do not cover this step in technical detail but provide a conceptual description of it.
#
# The `buckets()` function below shows how we can obtain indexes from the binary representation of a hash value by simply extracting its least significant `bits` and interpreting them as index numbers. Alternatively, the hash value may also be divided with the `%` operator by the number of available buckets. We show this idea in the `buckets_alt()` function that takes the number of buckets, `n_buckets`, as its second argument.
# + slideshow={"slide_type": "slide"}
def buckets(mapping, *, bits):
"""Calculate the bucket indices for a mapping's keys."""
for key in mapping: # cf., next section for details on looping
hash_value = hash(key)
binary = bin(hash_value)
address = binary[-bits:]
bucket = int("0b" + address, base=2)
print(key, hash_value, "0b..." + binary[-8:], address, bucket, sep="\t")
# + slideshow={"slide_type": "skip"}
def buckets_alt(mapping, *, n_buckets):
"""Calculate the bucket indices for a mapping's keys."""
for key in mapping: # cf., next section for details on looping
hash_value = hash(key)
bucket = hash_value % n_buckets
print(key, hash_value, bucket, sep="\t")
# + [markdown] slideshow={"slide_type": "skip"}
# With an infinite number of possible keys being mapped to a limited number of buckets, there is a realistic chance that two or more keys end up in the *same* bucket. That is called a **hash collision**. In such cases, Python uses a perturbation rule to rearrange the bits, and if the corresponding next bucket is empty, places an item there. Then, the nice offsetting logic from above breaks down and Python needs more time on average to place items into a hash table or look them up. The remedy is to use a bigger hash table as then the chance of collisions decreases. Python does all that for us in the background, and the main cost we pay for that is a *high* memory usage of `dict` objects in general.
#
# Because keys with the *same* semantic value have the *same* hash value, they end up in the *same* bucket. That is why the item that gets inserted last *overwrites* all previously inserted items whose keys compare equal, as we saw with the two `"zero"` keys above.
#
# Thus, to come up with indexes for 4 buckets, we need to extract 2 bits from the hash value (i.e., $2^2 = 4$).
# + slideshow={"slide_type": "slide"}
buckets(from_words, bits=2)
# + slideshow={"slide_type": "skip"}
buckets_alt(from_words, n_buckets=4)
# + [markdown] slideshow={"slide_type": "skip"}
# Similarly, 3 bits provide indexes for 8 buckets (i.e., $2^3 = 8$) ...
# + slideshow={"slide_type": "fragment"}
buckets(from_words, bits=3)
# + slideshow={"slide_type": "skip"}
buckets_alt(from_words, n_buckets=8)
# + [markdown] slideshow={"slide_type": "skip"}
# ... while 4 bits do so for 16 buckets (i.e., $2^4 = 16$).
# + slideshow={"slide_type": "fragment"}
buckets(from_words, bits=4)
# + slideshow={"slide_type": "skip"}
buckets_alt(from_words, n_buckets=16)
# + [markdown] slideshow={"slide_type": "skip"}
# Python allocates the memory for a `dict` object's hash table according to some internal heuristics: Whenever a hash table is roughly 2/3 full, it creates a *new* one with twice the space, and re-inserts all items, one by one, from the *old* one. So, during its lifetime, a `dict` object may have several hash tables.
#
# Although hash tables seem quite complex at first sight, they help us to make certain operations very fast as we see further below.
# + [markdown] slideshow={"slide_type": "slide"}
# ### Mappings are Collections without Predictable Order
# + [markdown] slideshow={"slide_type": "skip"}
# In [Chapter 7 <img height="12" style="display: inline-block" src="static/link_to_nb.png">](https://nbviewer.jupyter.org/github/webartifex/intro-to-python/blob/master/07_sequences_00_content.ipynb#Collections-vs.-Sequences), we see how a *sequence* is a special kind of a *collection*, and that *collections* can be described as
# - *iterable*
# - *containers*
# - with a *finite* number of elements.
#
# The `dict` type is another *collection* type. So, it has the three properties as well.
#
# For example, we may pass `to_words` or `from_words` to the built-in [len() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#len) function to obtain the number of *items* they contain. In the terminology of the [collections.abc <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.abc.html) module in the [standard library <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/index.html), both are `Sized` objects.
# + slideshow={"slide_type": "skip"}
len(to_words)
# + slideshow={"slide_type": "slide"}
len(from_words)
# + [markdown] slideshow={"slide_type": "skip"}
# Also, `dict` objects may be looped over, for example, with the `for` statement. So, in the terminology of the [collections.abc <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.abc.html) module, they are `Iterable` objects.
#
# For technical reasons, we must *not* rely on the iteration order to be *predictable* in any form until Python 3.7 in 2018. Looping over the *same* `dict` objects multiple times during its lifetime could result in *different* iteration orders every time. That behavior is intentional as `dict` objects are optimized for use cases where order does not matter. Starting with Python 3.7, `dict` objects remember the order in that items are *inserted* (cf., [Python 3.7 release notes <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://www.python.org/downloads/release/python-370/)).
#
# Because of that, the order in the two `for`-loops below is the *same* as in the *source code* that defines `to_words` and `from_words` above. In that sense, it is "*predictable*." However, if we fill `dict` objects with data from real-world sources, that kind of predictability is not helpful as such data are not written as source code, and, thus, we consider the order of items in `dict` objects to be *unpredictable*.
# + slideshow={"slide_type": "skip"}
# !python --version # the order in the for-loops is predictable only for Python 3.7 or higher
# + [markdown] slideshow={"slide_type": "skip"}
# By convention, iteration goes over the *keys* in the `dict` object only. The "*Dictionary Methods*" section below shows how to loop over the *items* or the *values* instead.
# + slideshow={"slide_type": "skip"}
for number in to_words:
print(number)
# + slideshow={"slide_type": "slide"}
for word in from_words:
print(word)
# + [markdown] slideshow={"slide_type": "skip"}
# Without a predictable *forward* order, `dict` objects are not *reversible* either. So, passing a `dict` object to the [reversed() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#reversed) built-in raises a `TypeError`. In terminology of the [collections.abc <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.abc.html) module, they are *no* `Reversible` objects.
# + slideshow={"slide_type": "skip"}
for number in reversed(to_words):
print(number)
# + slideshow={"slide_type": "fragment"}
for word in reversed(from_words):
print(word)
# + [markdown] slideshow={"slide_type": "skip"}
# Of course, we could use the built-in [sorted() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#sorted) function to loop over, for example, `from_words` in a *predictable* order. However, that creates a temporary `list` object in memory and an order that has *nothing* to do with how the items are ordered inside the hash table.
# + slideshow={"slide_type": "skip"}
for word in sorted(from_words):
print(word)
# + [markdown] slideshow={"slide_type": "skip"}
# To show the `Container` behavior of *collection* types, we use the boolean `in` operator to check if a given object evaluates equal to a *key* in `to_words` or `from_words`.
# + slideshow={"slide_type": "skip"}
1.0 in to_words # 1.0 is not a key but compares equal to a key
# + slideshow={"slide_type": "skip"}
-1 in to_words
# + slideshow={"slide_type": "slide"}
"one" in from_words
# + slideshow={"slide_type": "skip"}
"ten" in from_words
# + [markdown] slideshow={"slide_type": "slide"}
# #### Membership Testing: Lists vs. Dictionaries
# + [markdown] slideshow={"slide_type": "skip"}
# Because of the [hash table <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Hash_table) implementation, the `in` operator is *extremely* fast: Python does *not* need to initiate a [linear search <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Linear_search) as in the `list` case but immediately knows the only places in memory where the searched object must be located if present in the hash table at all. Conceptually, that is like comparing the searched object against *all* key objects with the `==` operator *without* doing it.
#
# To show the speed, we run an experiment. We create a `haystack`, a `list` object, with `10_000_001` elements in it, *one* of which is the `needle`, namely `42`. Once again, the [randint() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/random.html#random.randint) function in the [random <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/random.html) module is helpful.
# + slideshow={"slide_type": "slide"}
import random
# + slideshow={"slide_type": "skip"}
random.seed(87)
# + slideshow={"slide_type": "fragment"}
needle = 42
# + slideshow={"slide_type": "fragment"}
haystack = [random.randint(99, 9999) for _ in range(10_000_000)]
haystack.append(needle)
# + [markdown] slideshow={"slide_type": "skip"}
# We put the elements in `haystack` in a *random* order with the [shuffle() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/random.html#random.shuffle) function in the [random <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/random.html) module.
# + slideshow={"slide_type": "fragment"}
random.shuffle(haystack)
# + slideshow={"slide_type": "fragment"}
haystack[:10]
# + slideshow={"slide_type": "skip"}
haystack[-10:]
# + [markdown] slideshow={"slide_type": "skip"}
# As modern computers are generally fast, we search the `haystack` a total of `10` times.
# + slideshow={"slide_type": "slide"}
# %%timeit -n 1 -r 1
for _ in range(10):
needle in haystack
# + [markdown] slideshow={"slide_type": "skip"}
# Now, we convert the elements of the `haystack` into the keys of a `magic_haystack`, a `dict` object. We use `None` as a dummy value for all items.
# + slideshow={"slide_type": "fragment"}
magic_haystack = dict((x, None) for x in haystack)
# + [markdown] slideshow={"slide_type": "skip"}
# To show the *massive* effect of the hash table implementation, we search the `magic_haystack` not `10` but `10_000_000` times. The code cell still runs in only a fraction of the time its counterpart does above.
# + slideshow={"slide_type": "fragment"}
# %%timeit -n 1 -r 1
for _ in range(10_000_000):
needle in magic_haystack
# + [markdown] slideshow={"slide_type": "skip"}
# However, there is no fast way to look up the values the keys are mapped to. To achieve that, we have to loop over *all* items and check for each value object if it compares equal to the searched object. That is, by definition, a linear search, as well, and rather slow. In the context of `dict` objects, we call that a **reverse look-up**.
# + [markdown] slideshow={"slide_type": "slide"}
# ### Indexing -> Key Look-up
# + [markdown] slideshow={"slide_type": "skip"}
# The same efficient key look-up executed in the background with the `in` operator is also behind the indexing operator `[]`. Instead of returning either `True` or `False`, it returns the value object the looked up key maps to.
#
# To show the similarity to indexing into `list` objects, we provide another example with `to_words_list`.
# + slideshow={"slide_type": "skip"}
to_words_list = ["zero", "one", "two"]
# + [markdown] slideshow={"slide_type": "skip"}
# Without the above definitions, we could not tell the difference between `to_words` and `to_words_list`: The usage of the `[]` is the same.
# + slideshow={"slide_type": "skip"}
to_words[0]
# + slideshow={"slide_type": "skip"}
to_words_list[0]
# + [markdown] slideshow={"slide_type": "skip"}
# Because key objects can be of any immutable type and are, in particular, not constrained to just the `int` type, the word "*indexing*" is an understatement here. Therefore, in the context of `dict` objects, we view the `[]` operator as a generalization of the indexing operator and refer to it as the **(key) look-up** operator.
# + slideshow={"slide_type": "slide"}
from_words["two"]
# + [markdown] slideshow={"slide_type": "skip"}
# If a key is not in a `dict` object, Python raises a `KeyError`. A sequence type would raise an `IndexError` in this situation.
# + slideshow={"slide_type": "fragment"}
from_words["drei"]
# + [markdown] slideshow={"slide_type": "skip"}
# While `dict` objects support the `[]` operator to look up a *single* key, the more general concept of *slicing* is *not* available. That is in line with the idea that there is *no* predictable *order* associated with a `dict` object's keys, and slicing requires an order.
#
# To access deeper levels in nested data, like `people`, we *chain* the look-up operator `[]`. For example, let's view all the `"mathematicians"` in `people`.
# + slideshow={"slide_type": "slide"}
people["mathematicians"]
# + [markdown] slideshow={"slide_type": "skip"}
# Let's take the first mathematician on the list, ...
# + slideshow={"slide_type": "fragment"}
people["mathematicians"][0]
# + [markdown] slideshow={"slide_type": "skip"}
# ... and output his `"name"` ...
# + slideshow={"slide_type": "fragment"}
people["mathematicians"][0]["name"]
# + [markdown] slideshow={"slide_type": "skip"}
# ... or his `"emails"`.
# + slideshow={"slide_type": "fragment"}
people["mathematicians"][0]["emails"]
# + [markdown] slideshow={"slide_type": "slide"}
# ### Mutability
# + [markdown] slideshow={"slide_type": "skip"}
# We may mutate `dict` objects *in place*.
#
# For example, let's translate the English words in `to_words` to their German counterparts. Behind the scenes, Python determines the bucket of the objects passed to the `[]` operator, looks them up in the hash table, and, if present, *updates* the references to the mapped value objects.
# + slideshow={"slide_type": "slide"}
to_words
# + slideshow={"slide_type": "fragment"}
to_words[0] = "null"
to_words[1] = "eins"
to_words[2] = "zwei"
# + slideshow={"slide_type": "fragment"}
to_words
# + [markdown] slideshow={"slide_type": "skip"}
# Let's add two more items. Again, Python determines their buckets, but this time finds them to be empty, and *inserts* the references to their key and value objects.
# + slideshow={"slide_type": "slide"}
to_words[3] = "drei"
to_words[4] = "vier"
# + slideshow={"slide_type": "fragment"}
to_words
# + [markdown] slideshow={"slide_type": "skip"}
# None of these operations change the identity of the `to_words` object.
# + slideshow={"slide_type": "skip"}
id(to_words) # same memory location as before
# + [markdown] slideshow={"slide_type": "skip"}
# The `del` statement removes individual items. Python just removes the *two* references to the key and value objects in the corresponding bucket.
# + slideshow={"slide_type": "slide"}
del to_words[0]
# + slideshow={"slide_type": "fragment"}
to_words
# + [markdown] slideshow={"slide_type": "skip"}
# We may also change parts of nested data, such as `people`.
#
# For example, let's add [<NAME> <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Albert_Einstein) to the list of `"physicists"`, ...
# + slideshow={"slide_type": "slide"}
people["physicists"]
# + slideshow={"slide_type": "fragment"}
people["physicists"].append({"name": "<NAME>"})
# + [markdown] slideshow={"slide_type": "skip"}
# ... complete Guido's `"name"`, ...
# + slideshow={"slide_type": "slide"}
people["programmers"][0]
# + slideshow={"slide_type": "fragment"}
people["programmers"][0]["name"] = "<NAME>"
# + [markdown] slideshow={"slide_type": "skip"}
# ... and remove his work email because he retired.
# + slideshow={"slide_type": "fragment"}
del people["programmers"][0]["emails"][1]
# + [markdown] slideshow={"slide_type": "skip"}
# Now, `people` looks like this.
# + slideshow={"slide_type": "slide"}
pprint(people, indent=1, width=60)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Dictionary Methods
# + [markdown] slideshow={"slide_type": "skip"}
# `dict` objects come with many methods bound on them (cf., [documentation <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict)), many of which are standardized by the `Mapping` and `MutableMapping` ABCs from the [collections.abc <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.abc.html) module. While the former requires the [keys() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.keys), [values() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.values), [items() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.items), and [get() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.get) methods, which *never* mutate an object, the latter formalizes the [update() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.update), [pop() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.pop), [popitem() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.popitem), [clear() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.clear), and [setdefault() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.setdefault) methods, which *may* do so.
# + slideshow={"slide_type": "skip"}
import collections.abc as abc
# + slideshow={"slide_type": "skip"}
isinstance(from_words, abc.Mapping)
# + slideshow={"slide_type": "skip"}
isinstance(from_words, abc.MutableMapping)
# + [markdown] slideshow={"slide_type": "skip"}
# While iteration over a mapping type already goes over its keys, we may emphasize this explicitly by adding the [keys() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.keys) method in the `for`-loop. Again, the iteration order is equivalent to the insertion order but still considered *unpredictable*.
# + slideshow={"slide_type": "slide"}
for word in from_words.keys():
print(word)
# + [markdown] slideshow={"slide_type": "skip"}
# [keys() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.keys) returns an object of type `dict_keys`. That is a dynamic **view** inside the `from_words`'s hash table, which means it does *not* copy the references to the keys, and changes to `from_words` can be seen through it. View objects behave much like `dict` objects themselves.
# + slideshow={"slide_type": "skip"}
from_words.keys()
# + [markdown] slideshow={"slide_type": "skip"}
# Views can be materialized with the [list() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-list) built-in. However, that may introduce *semantic* errors into a program as the newly created `list` object has a "*predictable*" order (i.e., indexes `0`, `1`, ...) created from an *unpredictable* one.
# + slideshow={"slide_type": "skip"}
list(from_words.keys())
# + [markdown] slideshow={"slide_type": "skip"}
# To loop over the value objects instead, we use the [values() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.values) method. That returns a *view* (i.e., type `dict_values`) on the value objects inside `from_words` without copying them.
# + slideshow={"slide_type": "slide"}
for number in from_words.values():
print(number)
# + slideshow={"slide_type": "skip"}
from_words.values()
# + [markdown] slideshow={"slide_type": "skip"}
# To loop over key-value pairs, we invoke the [items() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.items) method. That returns a view (i.e., type `dict_items`) on the key-value pairs as `tuple` objects, where the first element is the key and the second the value. Because of that, we use tuple unpacking in the `for`-loop.
# + slideshow={"slide_type": "slide"}
for word, number in from_words.items():
print(f"{word} -> {number}")
# + slideshow={"slide_type": "skip"}
from_words.items()
# + [markdown] slideshow={"slide_type": "skip"}
# Above, we see how the look-up operator fails *loudly* with a `KeyError` if a key is *not* in a `dict` object. For example, `to_words` does *not* have a key `0` any more.
# + slideshow={"slide_type": "slide"}
to_words
# + slideshow={"slide_type": "skip"}
to_words[0]
# + [markdown] slideshow={"slide_type": "skip"}
# That may be mitigated with the [get() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.get) method that takes two arguments: `key` and `default`. It returns the value object `key` maps to if it is in the `dict` object; otherwise, `default` is returned. If not provided, `default` is `None`.
# + slideshow={"slide_type": "fragment"}
to_words.get(0, "n/a")
# + slideshow={"slide_type": "skip"}
to_words.get(1, "n/a")
# + [markdown] slideshow={"slide_type": "skip"}
# The [update() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.update) method takes the items of another mapping and either inserts them or overwrites the ones with matching keys already in the `dict` objects. It may be used in the other two ways as the [dict() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-dict) constructor allows, as well.
# + slideshow={"slide_type": "slide"}
to_spanish = {
0: "cero",
1: "uno",
2: "dos",
3: "tres",
4: "cuatro",
5: "cinco",
}
# + slideshow={"slide_type": "fragment"}
to_words.update(to_spanish)
# + slideshow={"slide_type": "fragment"}
to_words
# + [markdown] slideshow={"slide_type": "skip"}
# In contrast to the `pop()` method of the `list` type, the [pop() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.pop) method of the `dict` type *requires* a `key` argument to be passed. Then, it removes the corresponding key-value pair *and* returns the value object. If the `key` is not in the `dict` object, a `KeyError` is raised.
# + slideshow={"slide_type": "slide"}
from_words
# + slideshow={"slide_type": "fragment"}
number = from_words.pop("zero")
# + slideshow={"slide_type": "fragment"}
number
# + slideshow={"slide_type": "fragment"}
from_words
# + [markdown] slideshow={"slide_type": "skip"}
# With an optional `default` argument, the loud `KeyError` may be suppressed and the `default` returned instead, just as with the [get() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.get) method above.
# + slideshow={"slide_type": "skip"}
from_words.pop("zero")
# + slideshow={"slide_type": "skip"}
from_words.pop("zero", 0)
# + [markdown] slideshow={"slide_type": "skip"}
# Similar to the `pop()` method of the `list` type, the [popitem() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.popitem) method of the `dict` type removes *and* returns an "arbitrary" key-value pair as a `tuple` object from a `dict` object. With the preservation of the insertion order in Python 3.7 and higher, this effectively becomes a "last in, first out" rule, just as with the `list` type. Once a `dict` object is empty, [popitem() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.popitem) raises a `KeyError`.
# + slideshow={"slide_type": "slide"}
word, number = from_words.popitem()
# + slideshow={"slide_type": "fragment"}
word, number
# + slideshow={"slide_type": "fragment"}
from_words
# + [markdown] slideshow={"slide_type": "skip"}
# The [clear() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.clear) method removes all items but keeps the `dict` object alive in memory.
# + slideshow={"slide_type": "skip"}
to_words.clear()
# + slideshow={"slide_type": "skip"}
to_words
# + slideshow={"slide_type": "slide"}
from_words.clear()
# + slideshow={"slide_type": "fragment"}
from_words
# + [markdown] slideshow={"slide_type": "skip"}
# The [setdefault() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.setdefault) method may have a bit of an unfortunate name but is useful, in particular, with nested `list` objects. It takes two arguments, `key` and `default`, and returns the value mapped to `key` if `key` is in the `dict` object; otherwise, it inserts the `key`-`default` pair *and* returns a reference to the newly created value object. So, it is similar to the [get() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.get) method above but also *mutates* the `dict` object.
#
# Consider the `people` example again and note how the `dict` object modeling `"<NAME>"` has *no* `"emails"` key in it.
# + slideshow={"slide_type": "skip"}
pprint(people, indent=1, width=60)
# + [markdown] slideshow={"slide_type": "skip"}
# Let's say we want to append the imaginary emails `"<EMAIL>"` and `"<EMAIL>"`. We cannot be sure if a `dict` object modeling a person has already a `"emails"` key or not. To play it safe, we could first use the `in` operator to check for that and create a new `list` object in a second step if one is missing. Then, we would finally append the new email.
#
# [setdefault() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.setdefault) allows us to do all of the three steps at once. More importantly, behind the scenes Python only needs to make *one* key look-up instead of potentially three. For large nested data, that could speed up the computations significantly.
#
# So, the first code cell below adds the email to the already existing empty `list` object, while the second one creates a new one first.
# + slideshow={"slide_type": "skip"}
people["mathematicians"][1].setdefault("emails", []).append("<EMAIL>")
# + slideshow={"slide_type": "skip"}
people["physicists"][0].setdefault("emails", []).append("<EMAIL>")
# + slideshow={"slide_type": "skip"}
pprint(people, indent=1, width=60)
# + [markdown] slideshow={"slide_type": "skip"}
# `dict` objects also come with a [copy() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#dict.copy) method on them that creates *shallow* copies.
# + slideshow={"slide_type": "skip"}
guido = people["programmers"][0].copy()
# + slideshow={"slide_type": "skip"}
guido
# + [markdown] slideshow={"slide_type": "skip"}
# If we mutate `guido` and, for example, remove all his emails with the `clear()` method on the `list` type, these changes are also visible through `people`.
# + slideshow={"slide_type": "skip"}
guido["emails"].clear()
# + slideshow={"slide_type": "skip"}
guido
# + slideshow={"slide_type": "skip"}
pprint(people, indent=1, width=60)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Packing & Unpacking (continued)
# + [markdown] slideshow={"slide_type": "skip"}
# Just as a single `*` symbol is used for packing and unpacking iterables in [Chapter 7 <img height="12" style="display: inline-block" src="static/link_to_nb.png">](https://nbviewer.jupyter.org/github/webartifex/intro-to-python/blob/master/07_sequences_00_content.ipynb#Packing-&-Unpacking), a double `**` symbol implements packing and unpacking for mappings.
#
# Let's say we have `to_words` and `more_words` as below and want to merge the items together into a *new* `dict` object.
# + slideshow={"slide_type": "slide"}
to_words = {
0: "zero",
1: "one",
2: "two",
}
# + slideshow={"slide_type": "fragment"}
more_words = {
2: "TWO", # to illustrate a point
3: "three",
4: "four",
}
# + [markdown] slideshow={"slide_type": "skip"}
# By *unpacking* the items with `**`, the newly created `dict` object is first filled with the items from `to_words` and then from `more_words`. The item with the key `2` from `more_words` overwrites its counterpart from `to_words` as it is mentioned last.
# + slideshow={"slide_type": "fragment"}
{**to_words, **more_words}
# + [markdown] slideshow={"slide_type": "slide"}
# #### Function Definitions & Calls (continued)
# + [markdown] slideshow={"slide_type": "skip"}
# Both, `*` and `**` may be used within the header line of a function definition, for example, as in `print_args1()` below. Here, *positional* arguments not captured by positional parameters are *packed* into the `tuple` object `args`, and *keyword* arguments not captured by keyword parameters are *packed* into the `dict` object `kwargs`.
#
# For `print_args1()`, all arguments are optional, and ...
# + slideshow={"slide_type": "slide"}
def print_args1(*args, **kwargs):
"""Print out all arguments passed in."""
for index, arg in enumerate(args):
print("position", index, arg)
for key, value in kwargs.items():
print("keyword", key, value)
# + [markdown] slideshow={"slide_type": "skip"}
# ... we may pass whatever we want to it, or nothing at all.
# + slideshow={"slide_type": "slide"}
print_args1()
# + slideshow={"slide_type": "fragment"}
print_args1("a", "b", "c")
# + slideshow={"slide_type": "slide"}
print_args1(first=1, second=2, third=3)
# + slideshow={"slide_type": "fragment"}
print_args1("x", "y", flag=True)
# + [markdown] slideshow={"slide_type": "skip"}
# We may even unpack `dict` and `list` objects.
# + slideshow={"slide_type": "slide"}
flags = {"flag": True, "another_flag": False}
# + slideshow={"slide_type": "fragment"}
print_args1(**flags)
# + slideshow={"slide_type": "fragment"}
print_args1(*[42, 87], **flags)
# + [markdown] slideshow={"slide_type": "skip"}
# The next example, `print_args2()`, requires the caller to pass one positional argument, captured in the `positional` parameter, and one keyword argument, captured in `keyword`. Further, an optional keyword argument `default` may be passed in. Any other positional or keyword arguments are packed into either `args` or `kwargs`.
# + slideshow={"slide_type": "slide"}
def print_args2(positional, *args, keyword, default=True, **kwargs):
"""Print out all arguments passed in."""
print("required positional", positional)
for index, arg in enumerate(args):
print("optional positional", index, arg)
print("required keyword", keyword)
print("default keyword", default)
for key, value in kwargs.items():
print("optional keyword", key, value)
# + [markdown] slideshow={"slide_type": "skip"}
# If the caller does not respect that, a `TypeError` is raised.
# + slideshow={"slide_type": "slide"}
print_args2()
# + slideshow={"slide_type": "fragment"}
print_args2("p")
# + slideshow={"slide_type": "slide"}
print_args2("p", keyword="k")
# + slideshow={"slide_type": "fragment"}
print_args2("p", keyword="k", default=False)
# + slideshow={"slide_type": "fragment"}
print_args2("p", "x", "y", keyword="k", flag=True)
# + slideshow={"slide_type": "skip"}
print_args2("p", "x", "y", keyword="k", default=False, flag=True)
# + [markdown] slideshow={"slide_type": "skip"}
# As above, we may unpack `list` or `dict` objects in a function call.
# + slideshow={"slide_type": "slide"}
positionals = ["x", "y", "z"]
# + slideshow={"slide_type": "fragment"}
print_args2("p", *positionals, keyword="k", default=False, **flags)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Dictionary Comprehensions
# + [markdown] slideshow={"slide_type": "skip"}
# Analogous to list comprehensions in [Chapter 7 <img height="12" style="display: inline-block" src="static/link_to_nb.png">](https://nbviewer.jupyter.org/github/webartifex/intro-to-python/blob/master/07_sequences_00_content.ipynb#List-Comprehensions), **dictionary comprehensions** are a concise literal notation to derive new `dict` objects out of existing ones.
#
# For example, let's derive `from_words` out of `to_words` below by swapping the keys and values.
# + slideshow={"slide_type": "slide"}
to_words = {
0: "zero",
1: "one",
2: "two",
}
# + [markdown] slideshow={"slide_type": "skip"}
# Without a dictionary comprehension, we would have to initialize an empty `dict` object, loop over the items of the original one, and insert the key-value pairs one by one in a reversed fashion as value-key pairs. That assumes that the values are unique as otherwise some would be merged.
# + slideshow={"slide_type": "fragment"}
from_words = {}
for number, word in to_words.items():
from_words[word] = number
from_words
# + [markdown] slideshow={"slide_type": "skip"}
# While that code is correct, it is also unnecessarily verbose. The dictionary comprehension below works in the same way as list comprehensions except that curly braces `{}` replace the brackets `[]` and a colon `:` is added to separate the keys from the values.
# + slideshow={"slide_type": "fragment"}
{v: k for k, v in to_words.items()}
# + [markdown] slideshow={"slide_type": "skip"}
# We may filter out items with an `if`-clause and transform the remaining key and value objects.
#
# For no good reason, let's filter out all words starting with a `"z"` and upper case the remainin words.
# + slideshow={"slide_type": "skip"}
{v.upper(): k for k, v in to_words.items() if not v.startswith("z")}
# + [markdown] slideshow={"slide_type": "skip"}
# Multiple `for`- and/or `if`-clauses are allowed.
#
# For example, let's find all pairs of two numbers from `1` through `10` whose product is "close" to `50` (e.g., within a delta of `5`).
# + slideshow={"slide_type": "skip"}
{
(x, y): x * y
for x in range(1, 11) for y in range(1, 11)
if abs(x * y - 50) <= 5
}
# + [markdown] slideshow={"slide_type": "slide"}
# ### Memoization
# + [markdown] slideshow={"slide_type": "slide"}
# #### "Easy at second Glance" Example: [Fibonacci Numbers <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Fibonacci_number) (revisited)
# + [markdown] slideshow={"slide_type": "skip"}
# The *recursive* implementation of the [Fibonacci numbers <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Fibonacci_number) in [Chapter 4 <img height="12" style="display: inline-block" src="static/link_to_nb.png">](https://nbviewer.jupyter.org/github/webartifex/intro-to-python/blob/master/04_iteration_00_content.ipynb#"Easy-at-first-Glance"-Example:-Fibonacci-Numbers) takes long to compute for large Fibonacci numbers as the number of function calls grows exponentially.
#
# The graph below visualizes what the problem is and also suggests a solution: Instead of calculating the return value of the `fibonacci()` function for the *same* argument over and over again, it makes sense to **cache** the result and reuse it. This concept is called **[memoization <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Memoization)**.
# + [markdown] slideshow={"slide_type": "slide"}
# <img src="static/fibonacci_call_graph.png" width="50%" align="left">
# + [markdown] slideshow={"slide_type": "skip"}
# Below is revision of the recursive `fibonacci()` implementation that uses a **globally** defined `dict` object `memo` to store intermediate results and look them up.
#
# To be precise, the the revised `fibonacci()` first checks if the `i`th Fibonacci number has already been calculated before. If yes, it is in the `memo`. That number is then returned immediately *without* any more calculations. If no, there is no corresponding entry in the `memo` and a recursive function call must be made. The number obtained by recursion is then put into the `memo`.
#
# When we follow the flow of execution closely, we realize that the intermediate results represented by the left-most path in the graph above are calculated first. `fibonacci(1)` (i.e., the left-most leaf node) is the first base case reached, followed immediately by `fibonacci(0)`. From that moment onwards, the flow of execution moves back up the left-most path while adding together the two corresponding child nodes. Effectively, this mirrors the *iterative* implementation in that the order of all computational steps are *identical*.
#
# We added a keyword-only argument `debug` that allows the caller to print out a message every time a `i` was *not* in the `memo`.
# + slideshow={"slide_type": "slide"}
memo = {
0: 0,
1: 1,
}
# + code_folding=[] slideshow={"slide_type": "slide"}
def fibonacci(i, *, debug=False):
"""Calculate the ith Fibonacci number.
Args:
i (int): index of the Fibonacci number to calculate
debug (bool): show non-cached calls; defaults to False
Returns:
ith_fibonacci (int)
"""
if i in memo:
return memo[i]
if debug: # added for didactical purposes
print(f"fibonacci({i}) is calculated")
recurse = fibonacci(i - 1, debug=debug) + fibonacci(i - 2, debug=debug)
memo[i] = recurse
return recurse
# + slideshow={"slide_type": "slide"}
fibonacci(12, debug=True)
# + [markdown] slideshow={"slide_type": "skip"}
# Now, calling `fibonacci()` has the *side effect* of growing the `memo` in the *global scope*. So, subsequent calls to `fibonacci()` need not calculate any Fibonacci number with an index `i` smaller than the maximum `i` used so far. Because of that, this `fibonacci()` is *not* a *pure* function.
# + slideshow={"slide_type": "skip"}
fibonacci(12, debug=True) # no more recursive calls needed
# + slideshow={"slide_type": "fragment"}
memo
# + [markdown] slideshow={"slide_type": "slide"}
# ##### Efficiency of Algorithms (continued)
# + [markdown] slideshow={"slide_type": "skip"}
# With memoization, the recursive `fibonacci()` implementation is as fast as its iterative counterpart, even for large numbers.
#
# The `%%timeit` magic, by default, runs a code cell seven times. Whereas in the first run, *new* Fibonacci numbers (i.e., intermediate results) are added to the `memo`, `fibonacci()` has no work to do in the subsequent six runs. `%%timeit` realizes this and tells us that "an intermediate result is being cached."
# + slideshow={"slide_type": "slide"}
# %%timeit -n 1
fibonacci(99)
# + slideshow={"slide_type": "fragment"}
# %%timeit -n 1
fibonacci(999)
# + [markdown] slideshow={"slide_type": "skip"}
# The iterative implementation still has an advantage as the `RecursionError` shows for even larger `i`.
#
# This exception occurs as Python must keep track of *every* function call *until* it has returned, and with large enough `i`, the recursion tree above grows too big. By default, Python has a limit of up to 3000 *simultaneous* function calls. So, theoretically this exception is not a bug in the narrow sense but the result of a "security" measure that is supposed to keep a computer from crashing. However, practically most high-level languages like Python incur such an overhead cost: It results from the fact that someone (i.e., Python) needs to manage each function call's *local scope*. With the `for`-loop in the iterative version, we do this managing "manually."
# + slideshow={"slide_type": "skip"}
# %%timeit -n 1
fibonacci(9999)
# + [markdown] slideshow={"slide_type": "skip"}
# We could "hack" a bit with Python's default configuration using the [sys <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/sys.html) module in the [standard library <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/index.html) and make it work. As we are good citizens, we reset everything to the defaults after our hack is completed.
# + slideshow={"slide_type": "skip"}
import sys
# + slideshow={"slide_type": "skip"}
old_recursion_limit = sys.getrecursionlimit()
# + slideshow={"slide_type": "skip"}
old_recursion_limit
# + slideshow={"slide_type": "skip"}
sys.setrecursionlimit(99999)
# + [markdown] slideshow={"slide_type": "skip"}
# Computational speed is *not* the problem here.
# + slideshow={"slide_type": "skip"}
# %%timeit -n 1
fibonacci(9999)
# + slideshow={"slide_type": "skip"}
sys.setrecursionlimit(old_recursion_limit)
# + [markdown] slideshow={"slide_type": "skip"}
# ## Specialized Mappings
# + [markdown] slideshow={"slide_type": "skip"}
# The [collections <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.html) module in the [standard library <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/index.html) provides specialized mapping types for common use cases.
# + [markdown] slideshow={"slide_type": "skip"}
# ### The `defaultdict` Type
# + [markdown] slideshow={"slide_type": "skip"}
# The [defaultdict <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.html#collections.defaultdict) type allows us to define a factory function that creates default values whenever we look up a key that does not yet exist. Ordinary `dict` objects would throw a `KeyError` exception in such situations.
#
# Let's say we have a `list` with *records* of goals scored during a soccer game. The records consist of the fields "Country," "Player," and the "Time" when a goal was scored. Our task is to group the goals by player and/or country.
# + slideshow={"slide_type": "skip"}
goals = [
("Germany", "Müller", 11), ("Germany", "Klose", 23),
("Germany", "Kroos", 24), ("Germany", "Kroos", 26),
("Germany", "Khedira", 29), ("Germany", "Schürrle", 69),
("Germany", "Schürrle", 79), ("Brazil", "Oscar", 90),
]
# + [markdown] slideshow={"slide_type": "skip"}
# Using a normal `dict` object, we have to tediously check if a player has already scored a goal before. If not, we must create a *new* `list` object with the first time the player scored. Otherwise, we append the goal to an already existing `list` object.
# + slideshow={"slide_type": "skip"}
goals_by_player = {}
for _, player, minute in goals:
if player not in goals_by_player:
goals_by_player[player] = [minute]
else:
goals_by_player[player].append(minute)
goals_by_player
# + [markdown] slideshow={"slide_type": "skip"}
# Instead, with a `defaultdict` object, we can portray the code fragment's intent in a concise form. We pass a reference to the [list() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-list) built-in to `defaultdict`.
# + slideshow={"slide_type": "skip"}
from collections import defaultdict
# + slideshow={"slide_type": "skip"}
goals_by_player = defaultdict(list)
for _, player, minute in goals:
goals_by_player[player].append(minute)
goals_by_player
# + slideshow={"slide_type": "skip"}
type(goals_by_player)
# + [markdown] slideshow={"slide_type": "skip"}
# The factory function is stored in the `default_factory` attribute.
# + slideshow={"slide_type": "skip"}
goals_by_player.default_factory
# + [markdown] slideshow={"slide_type": "skip"}
# If we want this code to produce a normal `dict` object, we pass `goals_by_player` to the [dict() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-dict) constructor.
# + slideshow={"slide_type": "skip"}
dict(goals_by_player)
# + [markdown] slideshow={"slide_type": "skip"}
# Being creative, we use a factory function that returns another [defaultdict <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.html#collections.defaultdict) with [list() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-list) as its factory to group on the country and the player level simultaneously.
# + slideshow={"slide_type": "skip"}
goals_by_country_and_player = defaultdict(lambda: defaultdict(list))
for country, player, minute in goals:
goals_by_country_and_player[country][player].append(minute)
goals_by_country_and_player
# + [markdown] slideshow={"slide_type": "skip"}
# Conversion into a normal and nested `dict` object is now a bit tricky but can be achieved in one line with a comprehension.
# + slideshow={"slide_type": "skip"}
pprint({country: dict(by_player) for country, by_player in goals_by_country_and_player.items()})
# + [markdown] slideshow={"slide_type": "skip"}
# ### The `Counter` Type
# + [markdown] slideshow={"slide_type": "skip"}
# A common task is to count the number of occurrences of elements in an iterable.
#
# The [Counter <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.html#collections.Counter) type provides an easy-to-use interface that can be called with any iterable and returns a `dict`-like object of type `Counter` that maps each unique elements to the number of times it occurs.
#
# To continue the previous example, let's create an overview that shows how many goals a player scorred. We use a generator expression as the argument to `Counter`.
# + slideshow={"slide_type": "skip"}
goals
# + slideshow={"slide_type": "skip"}
from collections import Counter
# + slideshow={"slide_type": "skip"}
scorers = Counter(x[1] for x in goals)
# + slideshow={"slide_type": "skip"}
scorers
# + slideshow={"slide_type": "skip"}
type(scorers)
# + [markdown] slideshow={"slide_type": "skip"}
# Now we can look up individual players. `scores` behaves like a normal dictionary with regard to key look-ups.
# + slideshow={"slide_type": "skip"}
scorers["Müller"]
# + [markdown] slideshow={"slide_type": "skip"}
# By default, it returns `0` if a key is not found. So, we do not have to handle a `KeyError`.
# + slideshow={"slide_type": "skip"}
scorers["Lahm"]
# + [markdown] slideshow={"slide_type": "skip"}
# `Counter` objects have a [most_common() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.html#collections.Counter.most_common) method that returns a `list` object containing $2$-element `tuple` objects, where the first element is the element from the original iterable and the second the number of occurrences. The `list` object is sorted in descending order of occurrences.
# + slideshow={"slide_type": "skip"}
scorers.most_common(2)
# + [markdown] slideshow={"slide_type": "skip"}
# We can increase the count of individual entries with the [update() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.html#collections.Counter.update) method: That takes an *iterable* of the elements we want to count.
#
# Imagine if [<NAME> <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Philipp_Lahm) had also scored against Brazil.
# + slideshow={"slide_type": "skip"}
scorers.update(["Lahm"])
# + slideshow={"slide_type": "skip"}
scorers
# + [markdown] slideshow={"slide_type": "skip"}
# If we use a `str` object as the argument instead, each individual character is treated as an element to be updated. That is most likely not what we want.
# + slideshow={"slide_type": "skip"}
scorers.update("Lahm")
# + slideshow={"slide_type": "skip"}
scorers
# + [markdown] slideshow={"slide_type": "skip"}
# ### The `ChainMap` Type
# + [markdown] slideshow={"slide_type": "skip"}
# Consider `to_words`, `more_words`, and `even_more_words` below. Instead of merging the items of the three `dict` objects together into a *new* one, we want to create an object that behaves as if it contained all the unified items in it without materializing them in memory a second time.
# + slideshow={"slide_type": "skip"}
to_words = {
0: "zero",
1: "one",
2: "two",
}
# + slideshow={"slide_type": "skip"}
more_words = {
2: "TWO", # to illustrate a point
3: "three",
4: "four",
}
# + slideshow={"slide_type": "skip"}
even_more_words = {
4: "FOUR", # to illustrate a point
5: "five",
6: "six",
}
# + [markdown] slideshow={"slide_type": "skip"}
# The [ChainMap <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.html#collections.ChainMap) type allows us to do precisely that.
# + slideshow={"slide_type": "skip"}
from collections import ChainMap
# + [markdown] slideshow={"slide_type": "skip"}
# We simply pass all mappings as positional arguments to `ChainMap` and obtain a **proxy** object that occupies almost no memory but gives us access to the union of all the items.
# + slideshow={"slide_type": "skip"}
chain = ChainMap(to_words, more_words, even_more_words)
# + [markdown] slideshow={"slide_type": "skip"}
# Let's loop over the items in `chain` and see what is "in" it. The order is obviously *unpredictable* but all seven items we expected are there. Keys of later mappings do *not* overwrite earlier keys.
# + slideshow={"slide_type": "skip"}
for number, word in chain.items():
print(number, word)
# + [markdown] slideshow={"slide_type": "skip"}
# When looking up a non-existent key, `ChainMap` objects raise a `KeyError` just like normal `dict` objects would.
# + slideshow={"slide_type": "skip"}
chain[10]
# + [markdown] slideshow={"slide_type": "slide"}
# ## The `set` Type
# + [markdown] slideshow={"slide_type": "skip"}
# Python's provides a built-in `set` type that resembles [mathematical sets <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Set_%28mathematics%29): Each element may only be a **member** of a set once, and there is no *predictable* order regarding the elements (cf., [documentation <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#set)).
#
# To create a set, we use the literal notation, `{..., ...}`, and list all the members. The redundant `7`s and `4`s below are discarded.
# + slideshow={"slide_type": "slide"}
numbers = {7, 7, 7, 7, 7, 11, 8, 5, 3, 12, 2, 6, 9, 10, 1, 4, 4, 4, 4, 4}
# + [markdown] slideshow={"slide_type": "skip"}
# `set` objects are objects on their own.
# + slideshow={"slide_type": "skip"}
id(numbers)
# + slideshow={"slide_type": "skip"}
type(numbers)
# + slideshow={"slide_type": "fragment"}
numbers
# + [markdown] slideshow={"slide_type": "skip"}
# To create an empty set, we must use the built-in [set() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-set) constructor as empty curly brackets, `{}`, already create an empty `dict` object.
# + slideshow={"slide_type": "skip"}
empty_dict = {}
# + slideshow={"slide_type": "skip"}
type(empty_dict)
# + slideshow={"slide_type": "slide"}
empty_set = set()
# + slideshow={"slide_type": "fragment"}
empty_set
# + [markdown] slideshow={"slide_type": "skip"}
# The [set() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-set) constructor takes any `iterable` and only keeps unique elements.
#
# For example, we obtain all unique letters of a long word like so.
# + slideshow={"slide_type": "fragment"}
set("abracadabra")
# + [markdown] slideshow={"slide_type": "slide"}
# ### Sets are like Dictionaries without Values
# + [markdown] slideshow={"slide_type": "skip"}
# The curly brackets notation can be viewed as a hint that `dict` objects are conceptually generalizations of `set` objects, and we think of `set` objects as a collection consisting of a `dict` object's keys with all the mapped values removed.
#
# Like `dict` objects, `set` objects are built on top of [hash tables <img height="12" style="display: inline-block" src="static/link_to_wiki.png">](https://en.wikipedia.org/wiki/Hash_table), and, thus, each element must be a *hashable* (i.e., immutable) object and can only be contained in a set once due to the buckets logic.
# + slideshow={"slide_type": "slide"}
{0, [1, 2], 3}
# + [markdown] slideshow={"slide_type": "skip"}
# [len() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#len) tells us the number of elements in a `set` object.
# + slideshow={"slide_type": "slide"}
len(numbers)
# + [markdown] slideshow={"slide_type": "skip"}
# We may loop over the elements in a `set` object, but we must keep in mind that there is no *predictable* order. In contrast to `dict` objects, the iteration order is also *not* guaranteed to be the insertion order. Because of the special hash values for `int` objects, `numbers` seems to be "magically" sorted, which is *not* the case.
# + slideshow={"slide_type": "slide"}
for number in numbers: # beware the non-order!
print(number, end=" ")
# + [markdown] slideshow={"slide_type": "skip"}
# We confirm that `set` objects are not `Reversible`.
# + slideshow={"slide_type": "fragment"}
for number in reversed(numbers):
print(number, end=" ")
# + [markdown] slideshow={"slide_type": "skip"}
# The boolean `in` operator checks if a given and immutable object compares equal to an element in a `set` object. As with `dict` objects, membership testing is an *extremely* fast operation. Conceptually, it has the same result as conducting a linear search with the `==` operator behind the scenes without doing it.
# + slideshow={"slide_type": "slide"}
0 in numbers
# + slideshow={"slide_type": "skip"}
1 in numbers
# + slideshow={"slide_type": "skip"}
2.0 in numbers # 2.0 is not a member itself but compares equal to a member
# + [markdown] slideshow={"slide_type": "skip"}
# There is are `Set` ABC in the [collections.abc <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/collections.abc.html) module that formalizes, in particular, the operators supported by `set` objects (cf., the "*Set Operations*" section below). Further, the `MutableSet` ABC standardizes all the methods that mutate a `set` object in place (cf., the "*Mutability & Set Methods*" section below).
# + slideshow={"slide_type": "skip"}
isinstance(numbers, abc.Set)
# + slideshow={"slide_type": "skip"}
isinstance(numbers, abc.MutableSet)
# + [markdown] slideshow={"slide_type": "slide"}
# ### No Indexing, Key Look-up, or Slicing
# + [markdown] slideshow={"slide_type": "skip"}
# As `set` objects come without a *predictable* order, indexing and slicing are not supported and result in a `TypeError`. In particular, as there are no values to be looked up, these operations are not *semantically* meaningful. Instead, we check membership via the `in` operator, as shown in the previous sub-section.
# + slideshow={"slide_type": "slide"}
numbers
# + slideshow={"slide_type": "fragment"}
numbers[0]
# + slideshow={"slide_type": "skip"}
numbers[:]
# + [markdown] slideshow={"slide_type": "slide"}
# ### Mutability & Set Methods
# + [markdown] slideshow={"slide_type": "skip"}
# Because the `[]` operator does not work for `set` objects, they are mutated mainly via methods (cf., [documentation <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#set)).
#
# We may add new elements to an existing `set` object with the [add() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.add) method.
# + slideshow={"slide_type": "slide"}
numbers.add(999)
# + slideshow={"slide_type": "fragment"}
numbers
# + [markdown] slideshow={"slide_type": "skip"}
# The [update() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.update) method takes an iterable and adds all its elements to a `set` object if they are not already contained in it.
# + slideshow={"slide_type": "fragment"}
numbers.update(range(5))
# + slideshow={"slide_type": "fragment"}
numbers
# + [markdown] slideshow={"slide_type": "skip"}
# To remove an element by value, we use the [remove() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.remove) or [discard() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.discard) methods. If the element to be removed is not in the `set` object, [remove() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.remove) raises a loud `KeyError` while [discard() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.discard) stays *silent*.
# + slideshow={"slide_type": "slide"}
numbers.remove(999)
# + slideshow={"slide_type": "skip"}
numbers.remove(999)
# + slideshow={"slide_type": "fragment"}
numbers.discard(0)
# + slideshow={"slide_type": "skip"}
numbers.discard(0)
# + slideshow={"slide_type": "fragment"}
numbers
# + [markdown] slideshow={"slide_type": "skip"}
# The [pop() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.pop) method removes an *arbitrary* element. As not even the insertion order is tracked, that removes a "random" element.
# + slideshow={"slide_type": "skip"}
numbers.pop()
# + slideshow={"slide_type": "skip"}
numbers
# + [markdown] slideshow={"slide_type": "skip"}
# The [clear() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset.clear) method discards all elements but keeps the `set` object alive.
# + slideshow={"slide_type": "skip"}
numbers.clear()
# + slideshow={"slide_type": "skip"}
numbers
# + slideshow={"slide_type": "skip"}
id(numbers) # same memory location as before
# + [markdown] slideshow={"slide_type": "slide"}
# ### Set Operations
# + [markdown] slideshow={"slide_type": "skip"}
# The arithmetic and relational operators are overloaded with typical set operations from math. The operators have methods that do the equivalent. We omit them for brevity in this sub-section and only show them as comments in the code cells. Both the operators and the methods return *new* `set` objects without modifying the operands.
#
# We showcase the set operations with easy math examples.
# + slideshow={"slide_type": "slide"}
numbers = set(range(1, 13))
zero = {0}
evens = set(range(2, 13, 2))
# + slideshow={"slide_type": "fragment"}
numbers
# + slideshow={"slide_type": "fragment"}
zero
# + slideshow={"slide_type": "fragment"}
evens
# + [markdown] slideshow={"slide_type": "skip"}
# The bitwise OR operator `|` returns the union of two `set` objects.
# + slideshow={"slide_type": "slide"}
zero | numbers # zero.union(numbers)
# + [markdown] slideshow={"slide_type": "skip"}
# Of course, the operators may be *chained*.
# + slideshow={"slide_type": "fragment"}
zero | numbers | evens # zero.union(numbers).union(evens)
# + [markdown] slideshow={"slide_type": "skip"}
# To obtain an intersection of two or more `set` objects, we use the bitwise AND operator `&`.
# + slideshow={"slide_type": "slide"}
zero & numbers # zero.intersection(numbers)
# + slideshow={"slide_type": "fragment"}
numbers & evens # numbers.intersection(evens)
# + [markdown] slideshow={"slide_type": "skip"}
# To calculate a `set` object containing all elements that are in one but not the other `set` object, we use the minus operator `-`. This operation is *not* symmetric.
# + slideshow={"slide_type": "slide"}
numbers - evens # numbers.difference(evens)
# + slideshow={"slide_type": "fragment"}
evens - numbers # evens.difference(numbers)
# + [markdown] slideshow={"slide_type": "skip"}
# The *symmetric* difference is defined as the `set` object containing all elements that are in one but not both `set` objects. It is calculated with the bitwise XOR operator `^`.
# + slideshow={"slide_type": "fragment"}
numbers ^ evens # numbers.symmetric_difference(evens)
# + slideshow={"slide_type": "fragment"}
evens ^ numbers # evens.symmetric_difference(numbers)
# + [markdown] slideshow={"slide_type": "skip"}
# The augmented versions of the four operators (e.g., `|` becomes `|=`) are also defined: They mutate the left operand *in place*.
# + [markdown] slideshow={"slide_type": "slide"}
# ### Set Comprehensions
# + [markdown] slideshow={"slide_type": "skip"}
# Python provides a literal notation for **set comprehensions**, or **setcomps** for short, that works exactly like the one for dictionary comprehensions described above except that they use a single loop variable instead of a key-value pair.
#
# For example, let's create a new `set` object that consists of the squares of all the elements of `numbers`.
# + slideshow={"slide_type": "slide"}
{x ** 2 for x in numbers}
# + [markdown] slideshow={"slide_type": "skip"}
# As before, we may have multiple `for`- and/or `if`-clauses.
#
# For example, let's only keep the squares if they turn out to be an even number, or ...
# + slideshow={"slide_type": "skip"}
{x ** 2 for x in numbers if (x ** 2) % 2 == 0}
# + [markdown] slideshow={"slide_type": "skip"}
# ... create a `set` object with all products obtained from the Cartesian product of `numbers` with itself as long as the products are greater than `80`.
# + slideshow={"slide_type": "skip"}
{x * y for x in numbers for y in numbers if x * y > 80}
# + [markdown] slideshow={"slide_type": "skip"}
# ### The `frozenset` Type
# + [markdown] slideshow={"slide_type": "skip"}
# As `set` objects are mutable, they may *not* be used, for example, as keys in a `dict` object. Similar to how we replace `list` with `tuple` objects, we may often use a `frozenset` object instead of an ordinary one. The `frozenset` type is a built-in, and as `frozenset` objects are immutable, the only limitation is that we must specify *all* elements *upon* creation (cf., [documentation <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/stdtypes.html#frozenset)).
#
# `frozenset` objects are created by passing an iterable to the built-in [frozenset() <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://docs.python.org/3/library/functions.html#func-frozenset) constructor. Even though `frozenset` objects are hashable, their elements are *not* ordered.
# + slideshow={"slide_type": "skip"}
frozenset([7, 7, 7, 7, 7, 11, 8, 5, 3, 12, 2, 6, 9, 10, 1, 4, 4, 4, 4, 4])
# + [markdown] slideshow={"slide_type": "skip"}
# ## TL;DR
# + [markdown] slideshow={"slide_type": "skip"}
# `dict` objects are **mutable** one-to-one **mappings** from a set of **key** objects to a set of **value** objects. The association between a key-value pair is also called **item**.
#
# The items contained in a `dict` object have **no order** that is *predictable*.
#
# The underlying **data structure** of the `dict` type are **hash tables**. They make key look-ups *extremely* fast by converting the items' keys into *deterministic* hash values specifiying *precisely* one of a fixed number of equally "wide" buckets in which an item's references are stored. A limitation is that objects used as keys must be *immutable* (for technical reasons) and *unique* (for practical reasons).
#
# A `set` object is a **mutable** and **unordered collection** of **immutable** objects. The `set` type mimics sets we know from math.
# + [markdown] slideshow={"slide_type": "skip"}
# ## Further Resources
# + [markdown] slideshow={"slide_type": "skip"}
# A lecture-style **video presentation** of this chapter is integrated below (cf., the [video <img height="12" style="display: inline-block" src="static/link_to_yt.png">](https://www.youtube.com/watch?v=vbp0svA35TE&list=PL-2JV1G3J10lQ2xokyQowcRJI5jjNfW7f) or the entire [playlist <img height="12" style="display: inline-block" src="static/link_to_yt.png">](https://www.youtube.com/playlist?list=PL-2JV1G3J10lQ2xokyQowcRJI5jjNfW7f)).
# + slideshow={"slide_type": "skip"}
from IPython.display import YouTubeVideo
YouTubeVideo("vbp0svA35TE", width="60%")
# + [markdown] slideshow={"slide_type": "skip"}
# Next, we list some conference talks that go into great detail regarding the workings of the `dict` type.
#
# [<NAME>](https://github.com/brandon-rhodes) explains in great detail in his PyCon 2010 & 2017 talks how dictionaries work "under the hood."
# + slideshow={"slide_type": "skip"}
YouTubeVideo("C4Kc8xzcA68", width="60%")
# + slideshow={"slide_type": "skip"}
YouTubeVideo("66P5FMkWoVU", width="60%")
# + [markdown] slideshow={"slide_type": "skip"}
# The `dict` type's order has been worked on with many PEPs in recent years:
# - [PEP 412 <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://www.python.org/dev/peps/pep-0412/): Key-Sharing Dictionary
# - [PEP 468 <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://www.python.org/dev/peps/pep-0468/): Preserving the order of \*\*kwargs in a function
# - [PEP 520 <img height="12" style="display: inline-block" src="static/link_to_py.png">](https://www.python.org/dev/peps/pep-0520/): Preserving Class Attribute Definition Order
#
# [<NAME>](https://github.com/rhettinger), a Python core developer and one of the greatest Python teachers in the world, summaries the history of the `dict` type in his PyCon 2017 talk.
# + slideshow={"slide_type": "skip"}
YouTubeVideo("npw4s1QTmPg", width="60%")
| 09_mappings_00_content.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + [markdown] deletable=true editable=true
#
# *This notebook contains an excerpt from the [Python Data Science Handbook](http://shop.oreilly.com/product/0636920034919.do) by <NAME>; the content is available [on GitHub](https://github.com/jakevdp/PythonDataScienceHandbook).*
#
# *The text is released under the [CC-BY-NC-ND license](https://creativecommons.org/licenses/by-nc-nd/3.0/us/legalcode), and code is released under the [MIT license](https://opensource.org/licenses/MIT). If you find this content useful, please consider supporting the work by [buying the book](http://shop.oreilly.com/product/0636920034919.do)!*
# -
# # Linear Regression
# + [markdown] deletable=true editable=true
# Just as naive Bayes is a good starting point for classification tasks, linear regression models are a good starting point for regression tasks.
# Such models are popular because they can be fit very quickly, and are very interpretable.
# You are probably familiar with the simplest form of a linear regression model (i.e., fitting a straight line to data) but such models can be extended to model more complicated data behavior.
#
# In this section we will start with a quick intuitive walk-through of the mathematics behind this well-known problem, before seeing how before moving on to see how linear models can be generalized to account for more complicated patterns in data.
#
# We begin with the standard imports:
# + deletable=true editable=true tags=[]
# %matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns; sns.set()
# + [markdown] deletable=true editable=true
# ## Simple Linear Regression
#
# We will start with the most familiar linear regression, a straight-line fit to data.
# A straight-line fit is a model of the form
# $$
# y = ax + b
# $$
# where $a$ is commonly known as the *slope*, and $b$ is commonly known as the *intercept*.
#
# Consider the following data, which is scattered about a line with a slope of 2 and an intercept of -5:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = 2 * x - 5 + rng.randn(50)
plt.scatter(x, y);
# + [markdown] deletable=true editable=true
# We can use Scikit-Learn's ``LinearRegression`` estimator to fit this data and construct the best-fit line:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x[:, np.newaxis], y)
xfit = np.linspace(0, 10, 1000)
yfit = model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);
# + [markdown] deletable=true editable=true
# The slope and intercept of the data are contained in the model's fit parameters, which in Scikit-Learn are always marked by a trailing underscore.
# Here the relevant parameters are ``coef_`` and ``intercept_``:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
print("Model slope: ", model.coef_[0])
print("Model intercept:", model.intercept_)
# + [markdown] deletable=true editable=true
# We see that the results are very close to the inputs, as we might hope.
# + [markdown] deletable=true editable=true
# The ``LinearRegression`` estimator is much more capable than this, however—in addition to simple straight-line fits, it can also handle multidimensional linear models of the form
# $$
# y = a_0 + a_1 x_1 + a_2 x_2 + \cdots
# $$
# where there are multiple $x$ values.
# Geometrically, this is akin to fitting a plane to points in three dimensions, or fitting a hyper-plane to points in higher dimensions.
#
# The multidimensional nature of such regressions makes them more difficult to visualize, but we can see one of these fits in action by building some example data, using NumPy's matrix multiplication operator:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
rng = np.random.RandomState(1)
X = 10 * rng.rand(100, 3)
y = 0.5 + np.dot(X, [1.5, -2., 1.])
model.fit(X, y)
print(model.intercept_)
print(model.coef_)
# + [markdown] deletable=true editable=true
# Here the $y$ data is constructed from three random $x$ values, and the linear regression recovers the coefficients used to construct the data.
#
# In this way, we can use the single ``LinearRegression`` estimator to fit lines, planes, or hyperplanes to our data.
# It still appears that this approach would be limited to strictly linear relationships between variables, but it turns out we can relax this as well.
# + [markdown] deletable=true editable=true
# ## Basis Function Regression
#
# One trick you can use to adapt linear regression to nonlinear relationships between variables is to transform the data according to *basis functions*.
# We have seen one version of this before, in the ``PolynomialRegression`` pipeline used in [Hyperparameters and Model Validation](05.03-Hyperparameters-and-Model-Validation.ipynb) and [Feature Engineering](05.04-Feature-Engineering.ipynb).
# The idea is to take our multidimensional linear model:
# $$
# y = a_0 + a_1 x_1 + a_2 x_2 + a_3 x_3 + \cdots
# $$
# and build the $x_1, x_2, x_3,$ and so on, from our single-dimensional input $x$.
# That is, we let $x_n = f_n(x)$, where $f_n()$ is some function that transforms our data.
#
# For example, if $f_n(x) = x^n$, our model becomes a polynomial regression:
# $$
# y = a_0 + a_1 x + a_2 x^2 + a_3 x^3 + \cdots
# $$
# Notice that this is *still a linear model*—the linearity refers to the fact that the coefficients $a_n$ never multiply or divide each other.
# What we have effectively done is taken our one-dimensional $x$ values and projected them into a higher dimension, so that a linear fit can fit more complicated relationships between $x$ and $y$.
# + [markdown] deletable=true editable=true
# ### Polynomial basis functions
#
# This polynomial projection is useful enough that it is built into Scikit-Learn, using the ``PolynomialFeatures`` transformer:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
from sklearn.preprocessing import PolynomialFeatures
x = np.array([2, 3, 4])
poly = PolynomialFeatures(3, include_bias=False)
poly.fit_transform(x[:, None])
# + [markdown] deletable=true editable=true
# We see here that the transformer has converted our one-dimensional array into a three-dimensional array by taking the exponent of each value.
# This new, higher-dimensional data representation can then be plugged into a linear regression.
#
# As we saw in [Feature Engineering](05.04-Feature-Engineering.ipynb), the cleanest way to accomplish this is to use a pipeline.
# Let's make a 7th-degree polynomial model in this way:
# + deletable=true editable=true tags=[]
from sklearn.pipeline import make_pipeline
poly_model = make_pipeline(PolynomialFeatures(7),
LinearRegression())
# + [markdown] deletable=true editable=true
# With this transform in place, we can use the linear model to fit much more complicated relationships between $x$ and $y$.
# For example, here is a sine wave with noise:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = np.sin(x) + 0.1 * rng.randn(50)
poly_model.fit(x[:, np.newaxis], y)
yfit = poly_model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);
# + [markdown] deletable=true editable=true
# Our linear model, through the use of 7th-order polynomial basis functions, can provide an excellent fit to this non-linear data!
# + [markdown] deletable=true editable=true
# ## Regularization
#
# The introduction of basis functions into our linear regression makes the model much more flexible, but it also can very quickly lead to over-fitting (refer back to [Hyperparameters and Model Validation](05.03-Hyperparameters-and-Model-Validation.ipynb) for a discussion of this).
# For example, if we choose too many Gaussian basis functions, we end up with results that don't look so good:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
from sklearn.preprocessing import SplineTransformer
# B-spline with 30 + 4 - 1 = 33 basis functions
model = make_pipeline(SplineTransformer(n_knots=21, degree=10),
LinearRegression())
model.fit(x[:, np.newaxis], y)
plt.scatter(x, y)
plt.plot(xfit, model.predict(xfit[:, np.newaxis]))
plt.xlim(0, 10)
plt.ylim(-1.5, 1.5);
# + [markdown] deletable=true editable=true
# With the data projected to the 30-dimensional basis, the model has far too much flexibility and goes to extreme values between locations where it is constrained by data.
# + [markdown] deletable=true editable=true
# ### Ridge regression ($L_2$ Regularization)
#
# Perhaps the most common form of regularization is known as *ridge regression* or $L_2$ *regularization*, sometimes also called *Tikhonov regularization*.
# This proceeds by penalizing the sum of squares (2-norms) of the model coefficients; in this case, the penalty on the model fit would be
# $$
# P = \alpha\sum_{n=1}^N \theta_n^2
# $$
# where $\alpha$ is a free parameter that controls the strength of the penalty.
# This type of penalized model is built into Scikit-Learn with the ``Ridge`` estimator:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
from sklearn.linear_model import Ridge
model = make_pipeline(SplineTransformer(n_knots=21, degree=10), Ridge(alpha=0.1))
model.fit(x[:, np.newaxis], y)
plt.scatter(x, y)
plt.plot(xfit, model.predict(xfit[:, np.newaxis]))
plt.xlim(0, 10)
plt.ylim(-1.5, 1.5);
# + [markdown] deletable=true editable=true
# The $\alpha$ parameter is essentially a knob controlling the complexity of the resulting model.
# In the limit $\alpha \to 0$, we recover the standard linear regression result; in the limit $\alpha \to \infty$, all model responses will be suppressed.
# One advantage of ridge regression in particular is that it can be computed very efficiently—at hardly more computational cost than the original linear regression model.
# + [markdown] deletable=true editable=true
# ### Lasso regression ($L_1$ regularization)
#
# Another very common type of regularization is known as lasso, and involves penalizing the sum of absolute values (1-norms) of regression coefficients:
# $$
# P = \alpha\sum_{n=1}^N |\theta_n|
# $$
# Though this is conceptually very similar to ridge regression, the results can differ surprisingly: for example, due to geometric reasons lasso regression tends to favor *sparse models* where possible: that is, it preferentially sets model coefficients to exactly zero.
#
# We can see this behavior in duplicating the ridge regression figure, but using L1-normalized coefficients:
# + deletable=true editable=true jupyter={"outputs_hidden": false}
from sklearn.linear_model import Lasso
model = make_pipeline(SplineTransformer(n_knots=21, degree=10), Lasso(alpha=0.0001))
model.fit(x[:, np.newaxis], y)
plt.scatter(x, y)
plt.plot(xfit, model.predict(xfit[:, np.newaxis]))
plt.xlim(0, 10)
plt.ylim(-1.5, 1.5);
# + [markdown] deletable=true editable=true
# With the lasso regression penalty, the majority of the coefficients are exactly zero, with the functional behavior being modeled by a small subset of the available basis functions.
# As with ridge regularization, the $\alpha$ parameter tunes the strength of the penalty, and should be determined via, for example, cross-validation (refer back to [Hyperparameters and Model Validation](05.03-Hyperparameters-and-Model-Validation.ipynb) for a discussion of this).
# + [markdown] deletable=true editable=true
# ## Example: Predicting Gas Consumption
# + [markdown] deletable=true editable=true
# In this example we will use multiple linear regression to predict the gas consumptions (in millions of gallons) in 48 US states based upon gas taxes (in cents), per capita income (dollars), paved highways (in miles) and the proportion of population that has a drivers license.
#
# The details of the dataset can be found at this link:
#
# http://people.sc.fsu.edu/~jburkardt/datasets/regression/x16.txt
#
# The first two columns in the above dataset do not provide any useful information, therefore they have been removed from the dataset file. Now let's develop a regression model for this task.
#
# This example is from: https://stackabuse.com/linear-regression-in-python-with-scikit-learn/
# -
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import RobustScaler
from sklearn import metrics
# Read in the data
df = pd.read_csv('petrol_consumption.csv')
# Take a look at the first 10 rows of data
df.head(10)
# Take a look at the statistical description of the data
df.describe()
# Set up the feature matrix and the target vector
X = df[['Petrol_tax', 'Average_income', 'Paved_Highways',
'Population_Driver_licence(%)']]
y = df['Petrol_Consumption']
# Split the data into training and testing datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Call the model, `LinearRegression()` and train the model with the training data
regressor = LinearRegression()
regressor.fit(X_train, y_train);
# Check out the Beta coefficients for the multiple linear regression equation
coeff_df = pd.DataFrame(regressor.coef_, X.columns, columns=['Coefficient'])
coeff_df
# Run our model with the test data
y_pred = regressor.predict(X_test)
# Compare the predictions with the actual values from our test target vector
df_test = pd.DataFrame({'Actual': y_test, 'Predicted': y_pred})
df_test
# Evaluate our model performance with common metrics, Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE)
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
| notebooks/linear_regression_modelling.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.9.7 ('base')
# language: python
# name: python3
# ---
# ## 분류 (Classification)
# ##### 분류 알고리즘1. KNN (K-Nearest-Neighbors)
# 모델 학습
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=7) # n_neighbors 의 값을 바꾸어서 모델의 정확도를 향상시킬 수 있다(하이퍼파라미터 튜닝)
knn.fit(x_train,y_train)
# 예측
y_knn_pred=knn.predict(x_test)
print('예측값:',y_knn_pred[:5])
# 성능 평가
from sklearn.metrics import accuracy_score
knn_acc=accuracy_score(y_test,y_knn_pred)
print('Accuracy:%.4f' % knn_acc)
# ##### 분류 알고리즘2. SVN (Support Vector Machine)
# 모델 학습
from sklearn.svm import SVC
svc=SVC(kernel='rbf')
svc.fit(x_train,y_train)
# +
# 예측
y_svc_pred=svc.predict(x_test)
print('예측값:',y_svc_pred[:5])
# 성능 평가
svc_acc=accuracy_score(y_test,y_svc_pred)
print('Accuracy:%.4f' % svc_acc)
# -
# ##### 분류 알고리즘3. 로지스틱 회귀 (Logistic Regression)
# 모델 학습
from sklearn.linear_model import LogisticRegression
lrc=LogisticRegression()
lrc.fit(x_train,y_train)
# +
# 예측
y_lrc_pred=lrc.predict(x_test)
print('예측값:',y_lrc_pred[:5])
# 성능 평가
lrc_acc=accuracy_score(y_test,y_lrc_pred)
print('Accuracy:%.4f' % lrc_acc)
# -
# 확률값 예측
y_lrc_prob=lrc.predict_proba(x_test)
y_lrc_prob
# ##### 분류 알고리즘4. 의사결정나무 (Decision Tree)
# 모델 학습
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier(max_depth=3, random_state=20)
dtc.fit(x_train,y_train)
# +
# 예측
y_dtc_pred=dtc.predict(x_test)
print('예측값:',y_dtc_pred[:5])
# 성능 평가
dtc_acc=accuracy_score(y_test,y_dtc_pred)
print('Accuracy:%.4f' % dtc_acc)
# -
# ##### 앙상블 모델1. 보팅 (Voting)
# +
# Hard Voting 모델 학습 및 예측
from sklearn.ensemble import VotingClassifier
hvc=VotingClassifier(estimators=[('KNN',knn),('SVM',svc),('DT',dtc)],voting='hard')
hvc.fit(x_train,y_train)
# 예측
y_hvc_pred=hvc.predict(x_test)
print('예측값:',y_hvc_pred[:5])
# 성능 평가
hvc_acc=accuracy_score(y_test,y_hvc_pred)
print('Accuracy:%.4f' % hvc_acc)
# -
# ##### 앙상블 모델2. 배깅 (Bagging)
# +
# 모델 학습 및 검증
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier(n_estimators=50,max_depth=3,random_state=20)
rfc.fit(x_train,y_train)
# 예측
y_rfc_pred=rfc.predict(x_test)
print('예측값:',y_rfc_pred[:5])
# 모델 성능 평가
rfc_acc=accuracy_score(y_test,y_rfc_pred)
print('Accuracy:%.4f' % rfc_acc)
# -
# ##### 앙상블 모델3. 부스팅 (Boosting)
# +
# 모델 학습 및 예측
from xgboost import XGBClassifier
xgbc=XGBClassifier(n_estimators=50,max_depth=3,random_state=20)
xgbc.fit(x_train,y_train)
# 예측
y_xgbc_pred=xgbc.predict(x_test)
print('예측값:',y_xgbc_pred[:5])
# 모델 성능 평가
xgbc_acc=accuracy_score(y_test,y_xgbc_pred)
print('Accuracy:%.4f' % xgbc_acc)
# -
# ##### 교차 검증1. Hold-out
# ###### 학습(training) 데이터의 일부를 검증(validation) 데이터로 사용하는 방법입니다.
# 검증용 데이터셋 분리
x_tr,x_val,y_tr,y_val=train_test_split(x_train,y_train,
test_size=0.3,
shuffle=True,
random_state=20)
# shuffle 옵션을 True로 설정하면 데이터를 랜덤하게 섞은 후 분리 추출함
# 데이터 순서와 관계없는 예측모델의 일반성을 확인해 볼 수 있음
print(x_tr.shape,y_tr.shape)
print(x_val.shape,y_val.shape)
# +
# 학습
rfc=RandomForestClassifier(max_depth=3,random_state=20)
rfc.fit(x_tr,y_tr)
# 예측
y_tr_pred=rfc.predict(x_tr)
y_val_pred=rfc.predict(x_val)
# 검증
tr_acc=accuracy_score(y_tr,y_tr_pred)
val_acc=accuracy_score(y_val,y_val_pred)
print('Train Accuracy:%.4f' % tr_acc)
print('Validation Accuracy:%.4f' % val_acc)
# -
# 테스트 데이터 예측 및 평가
y_test_pred=rfc.predict(x_test)
test_acc=accuracy_score(y_test,y_test_pred)
print('Test Accuracy:%.4f' % test_acc)
# ##### 교차 검증2. K-fold
# ###### Hold-out 방법을 여러번 반복하는 방법입니다.
# +
# 데이터셋을 5개의 Fold로 분할하는 KFold 클래스 객체 생성
from sklearn.model_selection import KFold
kfold=KFold(n_splits=5,shuffle=True,random_state=20)
# 훈련용 데이터와 검증용 데이터의 행 인덱스를 각 Fold별로 구분하여 생성
num_fold=1
for tr_idx,val_idx in kfold.split(x_train):
print('%s Fold----------------------------------------------' % num_fold)
print('훈련:',len(tr_idx),tr_idx[:10])
print('검증:',len(val_idx),val_idx[:10])
num_fold=num_fold+1
# -
# 훈련용 데이터와 검증용 데이터의 행 인덱스를 각 Fold별로 구분하여 생성
val_scores=[]
num_fold=1
for tr_idx,val_idx in kfold.split(x_train,y_train):
# 훈련용 데이터와 검증용 데이터를 행 인덱스 기준으로 추출
x_tr,x_val=x_train.iloc[tr_idx,:],x_train.iloc[val_idx,:]
y_tr,y_val=y_train.iloc[tr_idx],y_train.iloc[val_idx]
# 학습
rfc=RandomForestClassifier(max_depth=5,random_state=20)
rfc.fit(x_tr,y_tr)
# 검증
y_val_pred=rfc.predict(x_val)
val_acc=accuracy_score(y_val,y_val_pred)
print('%d Fold Accuracy:%.4f' % (num_fold,val_acc))
val_scores.append(val_acc)
num_fold+=1
# 평균 Accuracy 계산
import numpy as np
mean_score=np.mean(val_scores)
print('평균 검증 Accuracy:',np.round(mean_score,4))
| source/LNH_machinelearningalgorithm(Classification).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="3Lvih9VJqF_3" colab_type="code" outputId="f8541414-94df-4ef6-f46e-ee487978cec4" colab={"base_uri": "https://localhost:8080/", "height": 207}
pip install pycrypto
# + id="wnKjU8PquiU4" colab_type="code" outputId="39a38ab1-24c2-4e4a-a2c6-216d1d6bbc82" colab={"base_uri": "https://localhost:8080/", "height": 51}
BS = 16
def pad(s):
return s + (BS - len(s) % BS) * chr(BS - len(s) % BS)
def unpad(s):
return s[:-ord(s[len(s)-1:])]
s="Gautam_Pala"
s1=pad(s)
print(s1)
s2=unpad(s1)
print(s2)
# + id="_Ng4uIlrpAC9" colab_type="code" colab={}
import base64
from Crypto.Cipher import AES
from Crypto import Random
BS = 16
def pad(s):
return s + (BS - len(s) % BS) * chr(BS - len(s) % BS)
def unpad(s):
return s[:-ord(s[len(s)-1:])]
class AESCipher(object):
def __init__(self, key):
self.key = key
def encrypt(self, raw):
raw = pad(raw)
iv = Random.new().read(AES.block_size)
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return base64.b64encode(iv + cipher.encrypt(raw))
def decrypt(self, enc):
enc = base64.b64decode(enc)
iv = enc[:16]
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return unpad(cipher.decrypt(enc[16:]))
# + id="YVwjTZ6LqDFR" colab_type="code" outputId="121b7850-4818-41ad-a4f8-a1b955bbebcf" colab={"base_uri": "https://localhost:8080/", "height": 85}
salt = <PASSWORD>'
key32 = "".join([ ' ' if i >= len(salt) else salt[i] for i in range(32) ])
bkey32 = key32.encode('utf-8')
print(key32)
print(bkey32)
aes_cipher = AESCipher(bkey32)
text = '<NAME>'
encrypted_text = aes_cipher.encrypt(text)
print(encrypted_text)
text1= aes_cipher.decrypt(encrypted_text)
print(text1)
# + id="N8EWOnZ6qosm" colab_type="code" colab={}
| aes (1).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: fan
# language: python
# name: fan
# ---
# %load_ext autoreload
# %autoreload 2
# %matplotlib inline
import Random_Forest as r
from Random_Forest import df_store, train_test_split, RandomForestRegressor, metrics
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from datetime import datetime
import plotting as p
df = df_store('data.h5').load_df()
print(df.head())
df.columns
# +
#df.describe(include='all').T
# +
df = df.sample(n=10000)
def drop_col(df, col_names):
for col in col_names:
if col in df.columns:
df = df.drop(col, axis = 1)
return df
df = drop_col(df, ['aggdays', 'daysinmonth', 'Bar OPEN Bid Quote_lag-1'])
df.iloc[:, 5:].head()
# -
r.set_rf_samples(20000)
rf = r.do_rf(df, n_estimators=5)
rf.predict_out(True)
rf.return_error_details()
rf.print_score()
#rf.draw()
rf.split_shape
rf.importances()
# #%time preds = np.stack([tn.predict(train_dependent) for tn in rf.estimators_])
preds = rf.tree_preds()
#def get_preds(tn): return tn.predict(train_dependent)
#preds = np.stack(r.parallel_trees(rf, get_preds, 2))
preds[:,0], np.mean(preds[:,0]), np.std(preds[:,0])
| src/fanalysis/.ipynb_checkpoints/iRF-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
import pandas as pd
from pathlib import Path
# Read CSV file in path
train_df = pd.read_csv(Path('Data/2019loans.csv'))
test_df = pd.read_csv(Path('Data/2020Q1loans.csv'))
# ### Train Dataframe (2019 Loans)
train_df
# #### Get dummies and make new dataframe (Shorter route and works more efficent for bigger data sets)
train_df_dropped = train_df.drop(columns=['loan_status','index','Unnamed: 0'])
train_loan_status_df = train_df['loan_status']
train_df_dropped.head()
# +
print(train_df_dropped.dtypes)
# prints out dataframe that has object values (categorical values)
categorical_train_df_only = train_df_dropped.select_dtypes('object')
categorical_train_df_only
# -
# EXAMPLE OF WHAT GET DUMMIES DOES
preview_get_dummies = categorical_train_df_only[['home_ownership','hardship_flag']]
preview_get_dummies
pd.get_dummies(preview_get_dummies)
# +
# get the columns names that have 'object' values
columns_text = categorical_train_df_only.columns.values.tolist()
# train_df dataframe duplicated for a new train data frame
duplicate_data_train = train_df_dropped
# for loop where x will have a column name then it will drop a column with that specific name since we are replacing those columns with numeric values
for x in columns_text:
duplicate_data_train = duplicate_data_train.drop([x], axis=1)
# One column that should not be in the dataframe and it is an int column
# duplicate_data_train = duplicate_data_train.drop(['Unnamed: 0'], axis=1)
# dummies only with object values
df = pd.get_dummies(train_df[columns_text])
# merge the dropped columns dataframe and the dummies dataframe
main_train_data = pd.concat((duplicate_data_train, df), axis=1)
categorical_train_df_only = main_train_data.select_dtypes('object')
print(categorical_train_df_only)
main_train_data
# -
# #### Get dummies and make new dataframe (Longer route and only works if data is small)
# +
# Convert categorical data to numeric and separate target feature for training data
home_ownership_data = pd.get_dummies(train_df.home_ownership)
verification_status_data = pd.get_dummies(train_df.verification_status)
# loan_status_data = pd.get_dummies(train_df.loan_status)
pymnt_plan_data = pd.get_dummies(train_df.pymnt_plan)
initial_list_status_data = pd.get_dummies(train_df.initial_list_status)
application_type_data = pd.get_dummies(train_df.application_type)
hardship_flag_data = pd.get_dummies(train_df.hardship_flag)
debt_settlement_flag_data = pd.get_dummies(train_df.debt_settlement_flag)
# drop columns in certain dataframe
new_train_df = train_df.drop(['verification_status','home_ownership','loan_status',
'pymnt_plan','initial_list_status','application_type','hardship_flag','debt_settlement_flag','Unnamed: 0','index'], axis=1)
# concat (add dataframe to dataframe)
new_data_train = pd.concat((new_train_df, verification_status_data, home_ownership_data, #loan_status_data,
pymnt_plan_data, initial_list_status_data,application_type_data,
hardship_flag_data, debt_settlement_flag_data), axis=1)
# Check if any column values are objects
categorical_train_df_only = new_data_train.select_dtypes('object')
print(categorical_train_df_only)
new_data_train
# -
# ### Test Dataframe (2020 Q1 Loans)
test_df
# #### Get dummies and make new dataframe (Shorter route and works more efficent for bigger data sets)
test_df_dropped = test_df.drop(columns=['loan_status','index','Unnamed: 0'])
test_loan_status_df = test_df['loan_status']
test_df_dropped.head()
# +
print(test_df_dropped.dtypes)
# prints out dataframe that has object values (categorical values)
categorical_test_df_only = test_df_dropped.select_dtypes('object')
categorical_test_df_only
# +
# get the columns names that have 'object' values
columns_text = categorical_test_df_only.columns.values.tolist()
# train_df dataframe duplicated for a new train data frame
duplicate_data_test = test_df_dropped
# for loop where x will have a column name then it will drop a column with that specific name since we are replacing those columns with numeric values
for x in columns_text:
duplicate_data_test = duplicate_data_test.drop([x], axis=1)
# One column that should not be in the dataframe and it is an int column
# duplicate_data_test = duplicate_data_test.drop(['Unnamed: 0'], axis=1)
# dummies only with object values
df = pd.get_dummies(test_df_dropped[columns_text])
# merge the dropped columns dataframe and the dummies dataframe
main_test_data = pd.concat((duplicate_data_test, df), axis=1)
categorical_test_df_only = main_test_data.select_dtypes('object')
print(categorical_test_df_only)
main_test_data
# -
# ### Train and Test Dataframe most efficent way (2019 Loans, 2020 Q1 Loans)
# #### Train Data (2019 Loans)
X_train = pd.get_dummies(train_df.drop(columns=['loan_status','index','Unnamed: 0']))
y_train = train_df['loan_status']
X_train
y_train
# #### Test Data (2020 Q1 Loans)
X_test = pd.get_dummies(test_df.drop(columns=['loan_status','index','Unnamed: 0']))
y_test = test_df['loan_status']
X_test
y_test
# ## LogisticRegression Model
print("X_train:", X_train.shape)
print("X_test", X_test.shape)
# add missing dummy variables to testing set
for col in X_train.columns:
if col not in X_test.columns:
X_test[col] = 0
X_train
X_test
# Train the Logistic Regression model on the unscaled data and print the model score
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(solver='lbfgs', random_state=1)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
# Train a Random Forest Classifier model
# and print the model score
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
# +
# from sklearn.preprocessing import StandardScaler
# scaler = StandardScaler()
# scaler.fit(X_train)
# X_train_scaled = scaler.transform(X_train)
# X_test_scaled = scaler.transform(X_test)
# -
# Scale the data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
print("Scaler:", scaler)
print("- " * 10)
print("X_train Value before scaler.fit:\n", X_train)
print("- " * 10)
scaler.fit(X_train)
print("X_train Value after fit:\n", scaler.fit(X_train))
print("- " * 10)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("X_train_scaled Value:\n", X_train_scaled)
print("- " * 10)
print("X_test_scaled Value:\n", X_test_scaled)
print("- " * 10)
# Train the Logistic Regression model on the scaled data and print the model score
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(solver='lbfgs')
clf.fit(X_train_scaled, y_train)
clf.score(X_test_scaled, y_test)
# Train a Random Forest Classifier model on the scaled data and print the model score
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train_scaled, y_train)
clf.score(X_test_scaled, y_test)
| Credit Risk Evaluator.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.12 64-bit (''venv'': venv)'
# language: python
# name: python3
# ---
# # Indexing / querying JSON documents
# ## Adding a JSON document to an index
# +
import redis
from redis.commands.json.path import Path
import redis.commands.search.aggregation as aggregations
import redis.commands.search.reducers as reducers
from redis.commands.search.field import TextField, NumericField, TagField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
from redis.commands.search.query import NumericFilter, Query
r = redis.Redis(host='localhost', port=36379)
user1 = {
"user":{
"name": "<NAME>",
"email": "<EMAIL>",
"age": 42,
"city": "London"
}
}
user2 = {
"user":{
"name": "<NAME>",
"email": "<EMAIL>",
"age": 29,
"city": "Tel Aviv"
}
}
user3 = {
"user":{
"name": "<NAME>",
"email": "<EMAIL>",
"age": 35,
"city": "Tel Aviv"
}
}
r.json().set("user:1", Path.root_path(), user1)
r.json().set("user:2", Path.root_path(), user2)
r.json().set("user:3", Path.root_path(), user3)
schema = (TextField("$.user.name", as_name="name"),TagField("$.user.city", as_name="city"), NumericField("$.user.age", as_name="age"))
r.ft().create_index(schema, definition=IndexDefinition(prefix=["user:"], index_type=IndexType.JSON))
# -
# ## Searching
# ### Simple search
r.ft().search("Paul")
# ### Filtering search results
q1 = Query("Paul").add_filter(NumericFilter("age", 30, 40))
r.ft().search(q1)
# ### Projecting using JSON Path expressions
r.ft().search(Query("Paul").return_field("$.user.city", as_field="city")).docs
# ## Aggregation
req = aggregations.AggregateRequest("Paul").sort_by("@age")
r.ft().aggregate(req).rows
| docs/examples/search_json_examples.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Semivariogram regularization - tutorial
#
# ## Table of Contents:
#
# 1. Prepare areal and point data,
# 2. Set semivariogram parameters,
# 3. Perform regularization,
# 4. Visualize regularized semivariogram and analyze algorithm performance,
# 5. Export semivariogram to text file.
#
# ## Level: Intermediate
#
# ## Changelog
#
# | Date | Change description | Author |
# |------|--------------------|--------|
# | 2021-05-28 | Updated paths for input/output data | @szymon-datalions |
# | 2021-05-11 | Refactored TheoreticalSemivariogram class | @szymon-datalions |
# | 2021-04-04 | Ranges parameter removed from regularize semivariogram class | @szymon-datalions |
# | 2021-03-31 | Update related to the change of semivariogram weighting. Updated cancer rates data. | @szymon-datalions |
#
#
# ## Introduction
#
# In this tutorial we learn how to regularize semivariogram of areal dataset of irregular polygons. Procedure is described here: (1) <NAME>., Kriging and Semivariogram Deconvolution in the Presence of Irregular Geographical Units, Mathematical Geology 40(1), 101-128, 2008.
#
# The main idea is to retrieve point support semivariogram from semivariogram of areal data with blocks of different shapes and sizes. It is the case in mining industry, where blocks of aggregates are deconvoluted into smaller units and in the epidemiology, where data is usually aggregated over big administrative units, or in ecology, where observations of species are aggregated over areas or time windows.
#
# In this tutorial we use areal data of Breast Cancer incidence rates in Northeastern counties of U.S. and U.S. Census 2010 data for population blocks.
#
# > Breast cancer rates data is stored in the shapefile in folder `sample_data/areal_data/cancer_data.shp`.
#
# > Population blocks data is stored in the shapefile in folder `sample_data/population_data/cancer_population_base.shp`
# ## Import packages
# +
import numpy as np
import geopandas as gpd
from pyinterpolate.io_ops import prepare_areal_shapefile, get_points_within_area # Prepare data
from pyinterpolate.semivariance import calculate_semivariance # Experimental semivariogram
from pyinterpolate.semivariance import RegularizedSemivariogram # Semivariogram regularization class
import matplotlib.pyplot as plt
# -
# ## 1) Prepare areal and point data
# +
areal_data = '../sample_data/areal_data/cancer_data.shp'
point_data = '../sample_data/population_data/cancer_population_base.shp'
# The important thing before analysis is to check if crs of areal data and point data are the same
areal_crs = gpd.read_file(areal_data).crs
point_support_crs = gpd.read_file(point_data).crs
areal_crs == point_support_crs
# +
# We need to know:
# - id column name of areal units,
# - value column name of areal units (usually aggregates),
# - value column name of point support units (usually population)
# Let's check it quickly with geopandas
areal = gpd.read_file(areal_data)
areal.head()
# -
# From areal file we are interested in the incidence rate (`rate`) and ID (`FIPS`).
# +
# Now check point support data
point = gpd.read_file(point_data)
point.head()
# -
# `POP10` is our column of interest.
# +
# Now prepare data for further processing
areal_id = 'FIPS'
areal_val = 'rate'
points_val = 'POP10'
areal_data_prepared = prepare_areal_shapefile(areal_data, areal_id, areal_val)
# +
# Check how prepared areal data looks like
areal_data_prepared[0]
# -
# ### Clarification:
#
# Every areal dataset is passed as an array of:
#
# [area id, area geometry (polygon), areal centroid x (lon), areal centroid y (lat), value]
points_in_area = get_points_within_area(areal_data, point_data, areal_id_col_name=areal_id,
points_val_col_name=points_val)
# +
# Check how prepared point data looks like
points_in_area[0]
# -
# ### Clarification:
#
# Every point support dataset is passed as an array of:
#
# [area id, array of: [lon, lat, value]]
# ## 2) Set semivariogram parameters.
#
# Now we must set parameters for areal semivariogram AND point semivariogram. It is very important to understand data well to set them properly, that's why you should always check experimental semivariograms of those datasets to understand how data behaves. We do it for prepared areal and point datasets.
#
# From the practical point of view area semivariogram analysis is more important because we pass into semivariogram regularization parameters of step size and maximum search radius. But we check point's semivariogram too. It is analytical step, to check if spatial process whoch we are using for semivariogram deconvolution is proper, as example if semivariogram shows exponential function then our process will not be properly modeled.
# +
# Check experimental semivariogram of areal data - this cell may be run multiple times
# before you find optimal parameters
maximum_range = 300000
step_size = 30000
dt = areal_data_prepared[:, 2:] # x, y, val
exp_semivar = calculate_semivariance(data=dt, step_size=step_size, max_range=maximum_range)
# Plot experimental semivariogram
plt.figure(figsize=(12, 12))
plt.plot(exp_semivar[:, 0], exp_semivar[:, 1], 'o')
plt.title('Experimental semivariogram od areal centroids')
plt.xlabel('Range - in meters')
plt.ylabel('Semivariance')
plt.show()
# +
# Check experimental semivariogram of point data - this cell may be run multiple times
# before you find optimal parameters
def build_point_array(points):
a = None
for rec in points:
if a is None:
a = rec.copy()
else:
a = np.vstack((a, rec))
return a
maximum_point_range = 300000
step_size_points = 10000
pt = build_point_array(points_in_area[:, 1]) # x, y, val
exp_semivar = calculate_semivariance(data=pt, step_size=step_size_points, max_range=maximum_point_range)
# Plot experimental semivariogram
plt.figure(figsize=(12, 12))
plt.plot(exp_semivar[:, 0], exp_semivar[:, 1], 'o')
plt.title('Experimental semivariogram od population data')
plt.xlabel('Range - in meters')
plt.ylabel('Semivariance')
plt.show()
# -
# ### Clarification:
#
# After few adjustements we have prepared semivariogram parameters for area and point support data. The next step is to create ```RegularizedSemivariogram``` model. We have mutiple parameters to choose and at the beginning it is hard to find the best fit, so try to avoid multiple loops because it is a time-consuming operation.
#
# The program is designed to first **fit()** the model and later to **transform()** it.
#
# When you **fit()** a model you have multiple parameters to control:
# * areal_data: areal data prepared with the function prepare_areal_shapefile(), where data is a numpy array
# in the form: [area_id, area_geometry, centroid coordinate x, centroid coordinate y, value],
# * areal_lags: list of lags between each distance,
# * areal_step_size: step size between each lag, usually it is a half of distance between lags,
# * point_support_data: point support data prepared with the function get_points_within_area(), where data is
# a numpy array in the form: [area_id, [point_position_x, point_position_y, value]],
# * weighted_lags: (bool) lags weighted by number of points; if True then during semivariogram fitting error
# of each model is weighted by number of points for each lag. In practice it means that more reliable data
# (lags) have larger weights and semivariogram is modeled to better fit to those lags,
# * store_models: (bool) if True then experimental, regularized and theoretical models are stored in lists
# after each iteration. It is important for a debugging process.
#
# We will weight lags and we do not store semivariograms and semivariogram models.
#
# After fitting we perform **transform()**. This function has few parameters to control regularization process, but we leave them as default with one exception: we set max_iters parameter to 5.
#
# This process of fitting and transforming takes some time, so it's good idea to run it and do something else...
#
# ## 3) Regularize semivariogram
reg_mod = RegularizedSemivariogram()
reg_mod.fit(areal_data=areal_data_prepared,
areal_step_size=step_size, max_areal_range=maximum_range,
point_support_data=points_in_area, weighted_lags=True, store_models=False)
# +
# Check initial experimental, theoretical and regularized semivariograms
lags = reg_mod.experimental_semivariogram_of_areal_data[:, 0]
plt.figure(figsize=(12, 12))
plt.plot(lags, reg_mod.experimental_semivariogram_of_areal_data[:, 1], 'ob')
plt.plot(lags, reg_mod.initial_theoretical_model_of_areal_data.predict(lags), color='r', linestyle='--')
plt.plot(lags, reg_mod.initial_regularized_model, color='black', linestyle='dotted')
plt.legend(['Experimental semivariogram of areal data', 'Initial Semivariogram of areal data',
'Regularized data points'])
plt.title('Semivariograms comparison. Deviation value: {}'.format(reg_mod.initial_deviation))
plt.xlabel('Distance')
plt.ylabel('Semivariance')
plt.show()
# -
# #### NOTE:
#
# Sill of experimental variogram is reached fast at the first lag. On the other hand sill of regularized semivariogram is reached at a larger distance which is a promising result for further processing and semivariogram deconvolution procedure.
# + pycharm={"name": "#%%\n"}
reg_mod.transform(max_iters=25)
# -
# **NOTE:**
#
# Operation stops automatically if calculated error is not changing after few iterations. **It will be speed up in the future by multiprocessing functions**.
#
# ## 4) Visualize and check semivariogram
#
# ### Clarification:
#
# Process is fully automatic but we can check how it baheaved through each iteration. We can analyze deviation change (most important variable, mean absolute difference between regularized and theoretical models) with build-in method but if you are more interested in the algorithm stability you can analyze weight change over each iteration too.
# +
# First analyze deviation
plt.figure(figsize=(10, 10))
plt.plot(reg_mod.deviations)
plt.show()
# -
# ### Clarification:
#
# Deviation between regularized semivariogram and theoretical model is smaller in each step but largest improvement can be seen after the first step and then it slows down. That's why semivariogram regularization usually does not require many steps. However, if there are many lags then optimization may require more steps to achieve meaningful result. Below are deviation changes from the five step to show relative change:
# +
# First analyze deviation - exclude five initial values
plt.figure(figsize=(10, 10))
plt.plot(reg_mod.deviations[5:])
plt.show()
# +
# Check weights - it is important to track problems with algorithm, esepcially if sum of weights is oscillating
# then it may be a sign of problems with data, model or (hopefully not!) algorithm itself.
weights = reg_mod.weights
weights = [sum(w) for w in weights]
plt.figure(figsize=(10,10))
plt.plot(weights)
plt.show()
# -
# #### NOTE:
#
# Weights are smaller with each iteration. It is normal behavior of algorithm. General trend goes downward, and small oscillations may occur due to the optimization process.
#
# The most important part is to compare semivariograms! You can see that Optimized Model is different than initial semivariogram. It is the result of regularization. Now population is taken into account in the cases of variogram development and further kriging interpolation.
reg_mod.show_semivariograms()
# ### Clarification:
#
# Experimental semivariogram is a semivariogram of areal centroids. Then theoretical semivariogram is used to describe this experimental (empirical) semivariogram. Regularization process is to find semivariogram close enough to the theoretical semivariogram, which describes ongoing process with the new support (in this case with population units). You may see that experimental semivariogram has exponential growth near the origin. It could mean that in this scale of analysis we lost some information. But with population data we can retrive it and regularized semivariogram better describes process near the origin. We gain a new insights approximately 2-3 lags ahead of the initial model.
#
# We can store regularized semivariogram output parameters for the further analysis and Kriging.
# ## 5) Export semivariogram to text file
# +
# Export semivariogram to the text file. This is important step because calculations are slow...
# and it is better to not repeat them.
# We will use buil-in method: export_regularized where we pass only filename our semivariogram
# parameters are stored for other tasks.
reg_mod.export_regularized_model('output/regularized_model.csv')
# -
# ---
| tutorials/Semivariogram Regularization (Intermediate).ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + tags=[]
import os
import site
import sqlite3
import sys
from time import sleep
import logzero
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import yaml
from logzero import logger
from tqdm import tqdm
from tqdm.notebook import tqdm
from yaml import dump, load, safe_load
# +
sys.path.append("../../sql")
import queries
sys.path.append("../source")
import ts_tools
# +
import warnings
warnings.filterwarnings("ignore")
# -
plt.rcParams["figure.figsize"] = 30, 25
plt.rcParams["ytick.labelsize"] = 11
plt.rcParams["axes.labelsize"] = 14
plt.rcParams["axes.labelpad"] = 12
plt.rcParams["axes.xmargin"] = 0.01
plt.rcParams["axes.ymargin"] = 0.01
# +
log_path = "logs/"
log_file = "ts_arima.log"
logzero.logfile(log_path + log_file, maxBytes=1e6, backupCount=5, disableStderrLogger=True)
logger.info(f"{log_path}, {log_file}\n")
# +
configs = None
try:
with open("../configs/config.yml", "r") as config_in:
configs = load(config_in, Loader=yaml.SafeLoader)
logger.info(f"{configs}\n")
except:
logger.error(f"config file open failure.")
exit(1)
cfg_vars = configs["url_variables"]
logger.info(f"variables: {cfg_vars}\n")
years = configs["request_years"]
logger.info(f"years: {years}\n")
db_path = configs["file_paths"]["db_path"]
city = configs["location_info"]["city"]
state = configs["location_info"]["state"]
db_file = city + "_" + state + ".db"
db_table1 = configs["table_names"]["db_table1"]
db_table2 = configs["table_names"]["db_table2"]
logger.info(f"{db_path}, {db_file}")
nrows = configs["num_rows"][0]
logger.info(f"number of rows: {nrows}\n")
# -
conn = sqlite3.connect(db_path + db_file)
cursor = conn.cursor()
cursor.execute(queries.select_distinct_zips)
distinct_zipcodes = cursor.fetchall()
distinct_zipcodes = [z[0] for z in distinct_zipcodes]
logger.info(f"distinct zip codes:\n{distinct_zipcodes}")
print(distinct_zipcodes)
# + tags=[]
zipcode_index = -1
params = {"zipcode": distinct_zipcodes[zipcode_index]}
select_nsr_rows = f"""
SELECT date_time,
-- year, month, day,
-- zipcode,
-- Clearsky_DHI, DHI,
Clearsky_DNI, DNI,
Clearsky_GHI, GHI,
Temperature,
Relative_Humidity,
Precipitable_Water,
-- Wind_Direction,
Wind_Speed
from nsrdb
where zipcode = :zipcode
-- and not (month = 2 and day = 29)
-- and year = 2000
;
"""
df = pd.read_sql(
select_nsr_rows,
conn,
params=params,
index_col="date_time",
parse_dates=["date_time"],
)
df.sort_index(axis=0, inplace=True)
# df.head(5)
# -
df_rsm = df.resample("M").mean().reset_index(drop=False)
df_rsm.set_index("date_time", inplace=True)
# df_rsm
columns = df.columns.tolist()
print(columns, "\n")
# +
forecast_on_idx = 1
sarima_series = df_rsm[columns[forecast_on_idx]]
months, years = 12, 5
total_len = len(sarima_series)
test_len = months * years
train_len = total_len - test_len
print(f"train len: {train_len}, test_len: {test_len}")
# +
sarima_train = df_rsm.iloc[:train_len][columns[forecast_on_idx]]
display(sarima_train.tail())
sarima_test = df_rsm.iloc[train_len:][columns[forecast_on_idx]]
sarima_test.head()
# -
sarima_order = ts_tools.gen_sarima_params(
p_rng=(1, 1),
d_rng=(1, 1), # d cannot vary while using AIC
q_rng=(1, 1),
P_rng=(1, 1),
D_rng=(1, 1), # D cannot vary while using AIC
Q_rng=(1, 1),
debug=True,
)
# + tags=[]
results = ts_tools.SARIMA_optimizer(sarima_train, sarima_order, s=12, debug=False)
best_order = results.iloc[0]["(p, d, q, P, D, Q, s)"]
best_order
# (1, 1, 1, 1, 1, 1)
# -
model = ts_tools.sarima_model(
sarima_train,
*best_order,
s=12,
summary=True,
)
# + tags=[]
model.plot_diagnostics(lags=24);
# + tags=[]
forecast = ts_tools.sarima_model(
sarima_train,
*best_order,
s=12,
num_fc=119,
forecast=True,
)
actual = sarima_test
rmse = np.sqrt(np.mean((actual - forecast) ** 2))
fig, ax = plt.subplots(figsize=(20, 10))
ax.plot(sarima_train, label="Original", color="blue")
ax.plot(actual, label="Actual", color="green")
ax.plot(forecast, label="Forecasted", color="orange")
ax.set_xlabel("Month")
ax.set_title(
f"{city.upper()}, {state.upper()} {distinct_zipcodes[zipcode_index]}\n"
+ f"Differenced Monthly {columns[forecast_on_idx]} values\n"
+ f"{len(forecast)}-month Forecast, RMSE = {rmse: .3f}"
)
ax.grid()
ax.legend();
# -
| archives/gm/notebooks/ts_sarima-pdm.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # NLTK arabe
# 
# ## 1-Import NLTK
import nltk
text_Ar="ربما كانت أحد أهم التطورات التي قامت بها الرياضيات العربية التي بدأت في هذا الوقت بعمل الخوارزمي و هي بدايات الجبر، و من المهم فهم كيف كانت هذه الفكرة الجديدة مهمة، فقد كانت خطوة ثورية بعيدا عن المفهوم اليوناني للرياضيات التي هي في جوهرها هندسة، الجبر كان نظرية موحدة تتيح الأعداد الكسرية و الأعداد اللا كسرية، و المقادير الهندسية و غيرها، أن تتعامل على أنها أجسام جبرية، و أعطت الرياضيات ككل مسارا جديدا للتطور بمفهوم أوسع بكثير من الذي كان موجودا من قبل، و قدم وسيلة للتنمية في هذا الموضوع مستقبلا و جانب آخر مهم لإدخال أفكار الجبر و هو أنه سمح بتطبيق الرياضيات على نفسها بطريقة لم تحدث من قبل "
# ## 2-Tokenization ✔
tokens = nltk.word_tokenize(text_Ar)
tokens
# ## 3-POS-tagging✔
tagged = nltk.pos_tag(tokens)
tagged
entities = nltk.chunk.ne_chunk(tagged)
entities
# ## 4-Stemming✔
from nltk.stem import PorterStemmer
stemmer= PorterStemmer()
for word in tokens :
print(f"{word} >>> {stemmer.stem(word)}")
# ## 5-Lemmatization✔
from nltk.stem import WordNetLemmatizer
lemmatizer=WordNetLemmatizer()
for word in tokens:
print(f"{word} >> {lemmatizer.lemmatize(word)}")
# ## 6- Parsing
from nltk.corpus import treebank
import sys
grammar="NP: {<DT>?<JJ>*<NN>}"
parser=nltk.RegexpParser(grammar)
output=parser.parse(tagged)
output.draw()
| NLTK_Arabe.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Image projection manipulation
# +
import ogr
import gdal
import rasterio
image_fpath = '/Users/wronk/Data/divot_detect/B04_011293_1265_XN_53S071W.tiff'
output_fpath = '/Users/wronk/Data/divot_detect/B04_011293_1265_XN_53S071W_warp.tiff'
# +
img = gdal.Open(image_fpath)
print(f'metadata = {img.GetMetadata()}')
orig_proj = img.GetProjection()
print(f'orig_proj = {orig_proj}')
# Two reasonable projections
sine_proj = '''+proj=sinu +lat_0=+52d52'33.06" +lon_0=-71d38'19.52" +ellps=Mars +a=3396190 +b=3396190 +units=m +no_defs'''
#eqc_proj = '''+proj=eqc +lat_ts=+52d52'33.06" +lat_0=0 +lon_0=180 +x_0=0 +y_0=0 +a=3396190 +b=3396190 +units=m +no_defs'''
eqc_proj = '''+proj=eqc +lat_ts=-53.21334003281581 +lat_0=0 +lon_0=180 +x_0=0 +y_0=0 +a=3396190 +b=3396190 +units=m +no_defs'''
# Verify and project
srs = ogr.osr.SpatialReference()
srs.ImportFromProj4(eqc_proj)
print(f'Validation: {srs.Validate()}')
gdal.Warp(output_fpath, image_fpath, dstSRS=srs)
# +
src_orig = rasterio.open(image_fpath)
print(f'Input image:\n{src_orig.crs}')
src_warp = rasterio.open(output_fpath)
print(f'Output image:\n{src_warp.crs}')
# -
src_orig.lnglat()[1] # Raster center
import requests
rgb_path = 'https://github.com/mapbox/rasterio/raw/master/tests/data/RGB.byte.tif'
image_rgb_byte = requests.get(rgb_path, stream=True)
image_rgba_byte = requests.get('https://github.com/mapbox/rasterio/raw/master/tests/data/RGBA.byte.tif')
# +
local_save_path = '/Users/wronk/Builds/divot-detect/test.tif'
if image_rgb_byte.status_code == 200:
with open(local_save_path, 'wb') as f:
for chunk in image_rgb_byte.iter_content(1024):
f.write(chunk)
# -
import skimage
with rasterio.open(local_save_path) as src:
print(src.srs)
# +
img.GetDriver()
print(img.GetGeoTransform())
#band = img.GetRasterBand(1)
#print(gdal.GetDataTypeName(band.DataType))
print("\nDriver: {}/{}".format(img.GetDriver().ShortName,
img.GetDriver().LongName))
print(f'\nProjection: {img.GetProjection()}')
type(band)
#img.GetProjectionRef()
# -
raster.GetStatistics()
| divdet/inference/image_projection_test.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Spurious Correlation
#
# **Coauthored by Samuel (Siyang) Li, <NAME>, and <NAME>**
#
# This notebook illustrates the phenomenon of **spurious correlation** between two uncorrelated but individually highly serially correlated time series
#
# The phenomenon surfaces when two conditions occur
#
# * the sample size is small
#
# * both series are highly serially correlated
#
# We'll proceed by
#
# - constructing many simulations of two uncorrelated but individually serially correlated time series
#
# - for each simulation, constructing the correlation coefficient between the two series
#
# - forming a histogram of the correlation coefficient
#
# - taking that histogram as a good approximation of the population distribution of the correlation coefficient
#
# In more detail, we construct two time series governed by
#
# $$ \eqalign{ y_{t+1} & = \rho y_t + \sigma \epsilon_{t+1} \cr
# x_{t+1} & = \rho x_t + \sigma \eta_{t+1}, \quad t=0, \ldots , T } $$
#
# where
#
# * $y_0 = 0, x_0 = 0$
#
# * $\{\epsilon_{t+1}\}$ is an i.i.d. process where $\epsilon_{t+1}$ follows a normal distribution with mean zero and variance $1$
#
# * $\{\eta_{t+1}\}$ is an i.i.d. process where $\eta_{t+1}$ follows a normal distribution with mean zero and variance $1$
#
# We construct the sample correlation coefficient between the time series $y_t$ and $x_t$ of length $T$
#
# The population value of correlation coefficient is zero
#
# We want to study the distribution of the sample correlation coefficient as a function of $\rho$ and $T$ when
# $\sigma > 0$
#
#
#
#
# We'll begin by importing some useful modules
import numpy as np
import scipy.stats as stats
from matplotlib import pyplot as plt
import seaborn as sns
# # Empirical distribution of correlation coefficient r
# We now set up a function to generate a panel of simulations of two identical independent AR(1) time series
#
# We set the function up so that all arguments are keyword arguments with associated default values
#
# - location is the common mathematical expectation of the innovations in the two independent autoregressions
#
# - sigma is the common standard deviation of the indepedent innovations in the two autoregressions
#
# - rho is the common autoregression coefficient of the two AR(1) processes
#
# - sample_size_series is the length of each of the two time series
#
# - simulation is the number of simulations used to generate an empirical distribution of the correlation of the two uncorrelated time series
def spurious_reg(rho=0, sigma=10, location=0, sample_size_series=300, simulation=5000):
"""
Generate two independent AR(1) time series with parameters: rho, sigma, location,
sample_size_series(r.v. in one series), simulation.
Output : displays distribution of empirical correlation
"""
def generate_time_series():
# Generates a time series given parameters
x = [] # Array for time series
x.append(np.random.normal(location/(1 - rho), sigma/np.sqrt(1 - rho**2), 1)) # Initial condition
x_temp = x[0]
epsilon = np.random.normal(location, sigma, sample_size_series) # Random draw
T = range(sample_size_series - 1)
for t in T:
x_temp = x_temp * rho + epsilon[t] # Find next step in time series
x.append(x_temp)
return x
r_list = [] # Create list to store correlation coefficients
for round in range(simulation):
y = generate_time_series()
x = generate_time_series()
r = stats.pearsonr(y, x)[0] # Find correlation coefficient
r_list.append(r)
fig, ax = plt.subplots()
sns.distplot(r_list, kde=True, rug=False, hist=True, ax=ax) # Plot distribution of r
ax.set_xlim(-1, 1)
plt.show()
# ### Comparisons of two value of $\rho$
#
# The next two cells we'll compare outcomes with a low $\rho$ versus a high $\rho$
#
spurious_reg(0, 10, 0, 300, 5000) # rho = 0
# For rho = 0.99
spurious_reg(0.99, 10, 0, 300, 5000) # rho = .99
# What if we change the series to length 2000 when $\rho $ is high?
spurious_reg(0.99, 10, 0, 2000, 5000)
# ### Try other values that you want
#
# Now let's use the sliders provided by widgets to experiment
#
# (Please feel free to edit the following cell in order to change the range of admissible values of $T$ and $\rho$)
#
# +
from ipywidgets import interactive, fixed, IntSlider
interactive(spurious_reg,
rho=(0, 0.999, 0.01),
sigma=fixed(10),
location=fixed(0),
sample_size_series=IntSlider(min=20, max=300, step=1, description='T'),
simulation=fixed(1000))
# -
| spurious-regression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Measures of Income Mobility
#
# **Author: <NAME> <<EMAIL>>, <NAME> <<EMAIL>>**
#
# Income mobility could be viewed as a reranking pheonomenon where regions switch income positions while it could also be considered to be happening as long as regions move away from the previous income levels. The former is named absolute mobility and the latter relative mobility.
#
# This notebook introduces how to estimate income mobility measures from longitudinal income data using methods in **giddy**. Currently, five summary mobility estimators are implemented in **giddy.mobility**. All of them are Markov-based, meaning that they are closely related to the discrete Markov Chains methods introduced in [Markov Based Methods notebook](Markov Based Methods.ipynb). More specifically, each of them is derived from a transition probability matrix $P$. Whether the final estimate is absolute or reletive mobility depends on how the original continuous income data are discretized.
# The five Markov-based summary measures of mobility (Formby et al., 2004) are listed below:
#
# | Num| Measures | Symbol |
# |-------------| :-------------: |:-------------:|
# |1| $$M_P(P) = \frac{m-\sum_{i=1}^m p_{ii}}{m-1} $$ | P |
# |2| $$M_D(P) = 1-|det(P)|$$ |D |
# |3| $$M_{L2}(P)=1-|\lambda_2|$$| L2|
# |4| $$M_{B1}(P) = \frac{m-m \sum_{i=1}^m \pi_i P_{ii}}{m-1} $$ | B1 |
# |5| $$M_{B2}(P)=\frac{1}{m-1} \sum_{i=1}^m \sum_{j=1}^m \pi_i P_{ij} |i-j|$$| B2|
#
# $\pi$ is the inital income distribution. For any transition probability matrix with a quasi-maximal diagonal, all of these mobility measures take values on $[0,1]$. $0$ means immobility and $1$ perfect mobility. If the transition probability matrix takes the form of the identity matrix, every region is stuck in its current state implying complete immobility. On the contrary, when each row of $P$ is identical, current state is irrelevant to the probability of moving away to any class. Thus, the transition matrix with identical rows is considered perfect mobile. The larger the mobility estimate, the more mobile the regional income system is. However, it should be noted that these measures try to reveal mobility pattern from different aspects and are thus not comparable to each other. Actually the mean and variance of these measures are different.
# We implemented all the above five summary mobility measures in a single method $markov\_mobility$. A parameter $measure$ could be specified to select which measure to calculate. By default, the mobility measure 'P' will be estimated.
#
# ```python
# def markov_mobility(p, measure = "P",ini=None)
# ```
# +
from giddy import markov,mobility
# mobility.markov_mobility?
# -
# ### US income mobility example
# Similar to [Markov Based Methods notebook](Markov Based Methods.ipynb), we will demonstrate the usage of the mobility methods by an application to data on per capita incomes observed annually from 1929 to 2009 for the lower 48 US states.
import libpysal
import numpy as np
import mapclassify as mc
income_path = libpysal.examples.get_path("usjoin.csv")
f = libpysal.io.open(income_path)
pci = np.array([f.by_col[str(y)] for y in range(1929, 2010)]) #each column represents an state's income time series 1929-2010
q5 = np.array([mc.Quantiles(y).yb for y in pci]).transpose() #each row represents an state's income time series 1929-2010
m = markov.Markov(q5)
m.p
# After acquiring the estimate of transition probability matrix, we could call the method $markov\_mobility$ to estimate any of the five Markov-based summary mobility indice.
# ### 1. Shorrock1's mobility measure
#
# $$M_{P} = \frac{m-\sum_{i=1}^m P_{ii}}{m-1}$$
#
# ```python
# measure = "P"```
mobility.markov_mobility(m.p, measure="P")
# ### 2. Shorroks2's mobility measure
#
# $$M_{D} = 1 - |\det(P)|$$
#
# ```python
# measure = "D"```
mobility.markov_mobility(m.p, measure="D")
# ### 3. Sommers and Conlisk's mobility measure
# $$M_{L2} = 1 - |\lambda_2|$$
#
# ```python
# measure = "L2"```
mobility.markov_mobility(m.p, measure = "L2")
# ### 4. Bartholomew1's mobility measure
#
# $$M_{B1} = \frac{m-m \sum_{i=1}^m \pi_i P_{ii}}{m-1}$$
#
# $\pi$: the inital income distribution
#
# ```python
# measure = "B1"```
pi = np.array([0.1,0.2,0.2,0.4,0.1])
mobility.markov_mobility(m.p, measure = "B1", ini=pi)
# ### 5. Bartholomew2's mobility measure
#
# $$M_{B2} = \frac{1}{m-1} \sum_{i=1}^m \sum_{j=1}^m \pi_i P_{ij} |i-j|$$
#
# $\pi$: the inital income distribution
#
# ```python
# measure = "B1"```
pi = np.array([0.1,0.2,0.2,0.4,0.1])
mobility.markov_mobility(m.p, measure = "B2", ini=pi)
# ## Next steps
#
# * Markov-based partial mobility measures
# * Other mobility measures:
# * Inequality reduction mobility measures (Trede, 1999)
# * Statistical inference for mobility measures
# ## References
#
# * <NAME>., <NAME>, and <NAME>. 2004. “[Mobility Measurement, Transition Matrices and Statistical Inference](http://www.sciencedirect.com/science/article/pii/S0304407603002112).” Journal of Econometrics 120 (1). Elsevier: 181–205.
# * <NAME>. 1999. “[Statistical Inference for Measures of Income Mobility / Statistische Inferenz Zur Messung Der Einkommensmobilität](https://www.jstor.org/stable/23812388).” Jahrbücher Für Nationalökonomie Und Statistik / Journal of Economics and Statistics 218 (3/4). Lucius & Lucius Verlagsgesellschaft mbH: 473–90.
| doc/notebooks/MobilityMeasures.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: SageMath 8.1
# language: ''
# name: sagemath
# ---
# + [markdown] deletable=true editable=true
# # 01. BASH Unix Shell
# ## [Generalised Linear Models](https://lamastex.github.io/scalable-data-science/glm/2018/)
#
# ©2018 <NAME>. [Attribution 4.0 International (CC BY 4.0)](https://creativecommons.org/licenses/by/4.0/)
#
# 1. Dropping into BASH (Unix Shell) and using basic Shell commands
# * `pwd` --- print working directory
# * `ls` --- list files in current working directory
# * `mkdir` --- make directory
# * `cd` --- change directory
# * `man ls` --- manual pages for any command
# 2. Grabbing files from the internet using `curl`
# + deletable=true editable=true
def showURL(url, ht=500):
"""Return an IFrame of the url to show in notebook with height ht"""
from IPython.display import IFrame
return IFrame(url, width='95%', height=ht)
showURL('https://en.wikipedia.org/wiki/Bash_(Unix_shell)',400)
# + [markdown] deletable=true editable=true
# ## 1. Dropping into BASH (Unix Shell)
#
# Using `%%sh` in a code cell we can access the BASH (Unix Shell) command prompt.
#
# Let us `pwd` or print working directory.
# + deletable=true editable=true language="sh"
# pwd
# + deletable=true editable=true language="sh"
# # this is a comment in BASH shell as it is preceeded by '#'
# ls # list the contents of this working directory
# + deletable=true editable=true language="sh"
# mkdir mydir
# + deletable=true editable=true language="sh"
# cd mydir
# pwd
# ls -al
# + deletable=true editable=true language="sh"
# pwd
# + deletable=true editable=true language="sh"
# man ls
# + [markdown] deletable=true editable=true
# ## 2. Grabbing files from internet using curl
# + deletable=true editable=true language="sh"
# cd mydir
# curl -O http://lamastex.org/datasets/public/SOU/sou/20170228.txt
# + deletable=true editable=true language="sh"
# ls mydir/
# + deletable=true editable=true language="sh"
# cd mydir/
# head 20170228.txt
# + [markdown] deletable=true editable=true
# ## To have more fun with all SOU addresses
# Do the following:
#
# + deletable=true editable=true language="sh"
# mkdir -p mydir # first create a directory called 'mydir'
# cd mydir # change into this mydir directory
# rm -f sou.tar.gz # remove any file in mydir called sou.tar.gz
# rm -f sou.tgz # remove any file in mydir called
# curl -O http://lamastex.org/datasets/public/SOU/sou.tar.gz
# + deletable=true editable=true language="sh"
# pwd
# ls -lh mydir
# + deletable=true editable=true language="sh"
# cd mydir
# tar zxvf sou.tar.gz
# + deletable=true editable=true language="sh"
# ls -lh mydir/
# + deletable=true editable=true
| _glm/2018/jp/01.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/KavehKadkhoda/AFIF/blob/main/AFIF.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="I1Y9j8FGp5_j" colab={"base_uri": "https://localhost:8080/", "height": 36} outputId="d98f5bc5-089a-49a9-c803-16a218a7df16"
"""
Colaboratory, or "Colab" for short, allows you to write and execute Python in your browser.
https://colab.research.google.com
"""
# + colab={"base_uri": "https://localhost:8080/", "height": 72} id="hs0KQpF7O6Pe" outputId="802a9283-887c-4279-9c27-b33b7c99bbf6"
from google.colab import drive
drive.mount('/content/drive')
"""
DATA: Add shortcut to your google drive
X___DBLP___Infomap___X.csv :
https://drive.google.com/file/d/1AmCl-fo_BnijCzA6mn7ptOpAw2jfuPRF/view?usp=sharing
y___DBLP___Infomap___y.csv :
https://drive.google.com/file/d/1F94QFZupoNiR8uUe6-uz-8vt3Dg4-ymQ/view?usp=sharing
"""
# + id="7blLK7FxSaP9" colab={"base_uri": "https://localhost:8080/"} outputId="3dfdf6b7-edbe-47cf-b73c-b6e95bb18e60"
# #!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 4 17:20:49 2021
@author: <NAME>
"""
"""
Data: split to train, val, test
"""
""" reading DATA """
import pandas as pd
df_X = pd.read_csv('drive/MyDrive/X___DBLP___Infomap___X.csv')
df_y = pd.read_csv('drive/MyDrive/y___DBLP___Infomap___y.csv')
#all
X = df_X[['size_t-2', 'evolution_t-2', 'constraint_t-2', 'core_number_t-2', 'number_of_cliques_t-2', 'density_t-2', 'algebraic_connectivity_t-2', 'wiener_index_t-2', 'effective_size_t-2', 'global_efficiency_t-2', 'local_efficiency_t-2', 'average_clustering_t-2', 'transitivity_t-2', 'harmonic_centrality_t-2', 'estrada_index_t-2', 'betweenness_t-2', 'load_centrality_t-2', 'edge_betweenness_t-2', 'closeness_t-2', 'degree_assortativity_t-2', 'square_clustering_t-2', 'average_neighbor_degree_t-2', 'pagerank_t-2', 'katz_t-2', 'clique_number_t-2', 'node_connectivity_t-2', 'second_order_t-2', 'diameter_t-2', 'edge_t-2',
'size_t-1', 'evolution_t-1', 'constraint_t-1', 'core_number_t-1', 'number_of_cliques_t-1', 'density_t-1', 'algebraic_connectivity_t-1', 'wiener_index_t-1', 'effective_size_t-1', 'global_efficiency_t-1', 'local_efficiency_t-1', 'average_clustering_t-1', 'transitivity_t-1', 'harmonic_centrality_t-1', 'estrada_index_t-1', 'betweenness_t-1', 'load_centrality_t-1', 'edge_betweenness_t-1', 'closeness_t-1', 'degree_assortativity_t-1', 'square_clustering_t-1', 'average_neighbor_degree_t-1', 'pagerank_t-1', 'katz_t-1', 'clique_number_t-1', 'node_connectivity_t-1', 'second_order_t-1', 'diameter_t-1', 'edge_t-1',
'size_t', 'evolution_t', 'constraint_t', 'core_number_t', 'number_of_cliques_t', 'density_t', 'algebraic_connectivity_t', 'wiener_index_t', 'effective_size_t', 'global_efficiency_t', 'local_efficiency_t', 'average_clustering_t', 'transitivity_t', 'harmonic_centrality_t', 'estrada_index_t', 'betweenness_t', 'load_centrality_t', 'edge_betweenness_t', 'closeness_t', 'degree_assortativity_t', 'square_clustering_t', 'average_neighbor_degree_t', 'pagerank_t', 'katz_t', 'clique_number_t', 'node_connectivity_t', 'second_order_t', 'diameter_t', 'edge_t']]
y = df_y['evolution_next']
# for LIGHTgbm
y.replace(2,1, inplace=True)
y.replace(3,2, inplace=True)
y.replace(4,3, inplace=True)
y.replace(5,4, inplace=True)
y.replace(6,5, inplace=True)
y.replace(7,6, inplace=True)
y.replace(8,7, inplace=True)
y.replace(9,8, inplace=True)
y.replace(10,9, inplace=True)
y.replace(11,10, inplace=True)
from sklearn.model_selection import train_test_split
# Split into validation set
X_remained, X_test, y_remained, y_test = train_test_split(X, y, test_size = 0.2, random_state = 52, stratify=y)
X_train, X_val, y_train, y_val = train_test_split(X_remained, y_remained, test_size = 0.25, random_state = 52, stratify=y_remained)
X_train.round(5)
X_val.round(5)
X_test.round(5)
import time
start111 = time.time()
"""
Heap part
We used the priorityq (An object-oriented priority queue with updatable priorities).
https://github.com/elplatt/python-priorityq
"""
import heapq as hq
__all__ = ['MappedQueue']
class MappedQueue(object):
def __init__(self, data=[]):
"""Priority queue class with updatable priorities.
"""
self.h = list(data)
self.d = dict()
self._heapify()
def __len__(self):
return len(self.h)
def _heapify(self):
"""Restore heap invariant and recalculate map."""
hq.heapify(self.h)
self.d = dict([(elt, pos) for pos, elt in enumerate(self.h)])
if len(self.h) != len(self.d):
raise AssertionError("Heap contains duplicate elements")
def push(self, elt):
"""Add an element to the queue."""
# If element is already in queue, do nothing
if elt in self.d:
return False
# Add element to heap and dict
pos = len(self.h)
self.h.append(elt)
self.d[elt] = pos
# Restore invariant by sifting down
self._siftdown(pos)
return True
def pop(self):
"""Remove and return the smallest element in the queue."""
# Remove smallest element
elt = self.h[0]
del self.d[elt]
# If elt is last item, remove and return
if len(self.h) == 1:
self.h.pop()
return elt
# Replace root with last element
last = self.h.pop()
self.h[0] = last
self.d[last] = 0
# Restore invariant by sifting up, then down
pos = self._siftup(0)
self._siftdown(pos)
# Return smallest element
return elt
def update(self, elt, new):
"""Replace an element in the queue with a new one."""
# Replace
pos = self.d[elt]
self.h[pos] = new
del self.d[elt]
self.d[new] = pos
# Restore invariant by sifting up, then down
pos = self._siftup(pos)
self._siftdown(pos)
def remove(self, elt):
"""Remove an element from the queue."""
# Find and remove element
try:
result = [element for element in self.d if element[1] == elt]
pos = self.d[result[0]]
del self.d[result[0]]
except Exception:
# Not in queue
return
# If elt is last item, remove and return
if pos == len(self.h) - 1:
self.h.pop()
return
# Replace elt with last element
last = self.h.pop()
self.h[pos] = last
self.d[last] = pos
# Restore invariant by sifting up, then down
pos = self._siftup(pos)
self._siftdown(pos)
def _siftup(self, pos):
"""Move element at pos down to a leaf by repeatedly moving the smaller
child up."""
h, d = self.h, self.d
elt = h[pos]
# Continue until element is in a leaf
end_pos = len(h)
left_pos = (pos << 1) + 1
while left_pos < end_pos:
# Left child is guaranteed to exist by loop predicate
left = h[left_pos]
try:
right_pos = left_pos + 1
right = h[right_pos]
# Out-of-place, swap with left unless right is smaller
if right < left:
h[pos], h[right_pos] = right, elt
pos, right_pos = right_pos, pos
d[elt], d[right] = pos, right_pos
else:
h[pos], h[left_pos] = left, elt
pos, left_pos = left_pos, pos
d[elt], d[left] = pos, left_pos
except IndexError:
# Left leaf is the end of the heap, swap
h[pos], h[left_pos] = left, elt
pos, left_pos = left_pos, pos
d[elt], d[left] = pos, left_pos
# Update left_pos
left_pos = (pos << 1) + 1
return pos
def _siftdown(self, pos):
"""Restore invariant by repeatedly replacing out-of-place element with
its parent."""
h, d = self.h, self.d
elt = h[pos]
# Continue until element is at root
while pos > 0:
parent_pos = (pos - 1) >> 1
parent = h[parent_pos]
if parent > elt:
# Swap out-of-place element with parent
h[parent_pos], h[pos] = elt, parent
parent_pos, pos = pos, parent_pos
d[elt] = pos
d[parent] = parent_pos
else:
# Invariant is satisfied
break
return pos
"""
lgbm: trained with data from time window t.
"""
import lightgbm as lgb
import pandas as pd
properties = ['size_t', 'evolution_t', 'constraint_t', 'core_number_t', 'number_of_cliques_t', 'density_t', 'algebraic_connectivity_t',
'wiener_index_t', 'effective_size_t', 'global_efficiency_t', 'local_efficiency_t', 'average_clustering_t', 'transitivity_t',
'harmonic_centrality_t', 'estrada_index_t', 'betweenness_t', 'load_centrality_t', 'edge_betweenness_t', 'closeness_t',
'degree_assortativity_t', 'square_clustering_t', 'average_neighbor_degree_t', 'pagerank_t', 'katz_t', 'clique_number_t',
'node_connectivity_t', 'second_order_t', 'diameter_t', 'edge_t']
x = X_train[properties].copy()
y = y_train.copy()
def calc_lighGBM(x, y):
model = lgb.LGBMClassifier(objective="multiclass", random_state=10, boosting='gbdt')
model.fit(x, y)
model.booster_.feature_importance(importance_type='split')
fea_imp_ = pd.DataFrame({'cols': x.columns, 'fea_imp': model.feature_importances_})
fea_imp_.loc[fea_imp_.fea_imp > 0].sort_values(by=['fea_imp'], ascending=False)
d = dict(zip(fea_imp_.cols, fea_imp_.fea_imp))
list_lgbm = [(-value, key) for key,value in d.items()]
return list_lgbm
list___lgbm = calc_lighGBM(x, y)
"""
correlation: trained with data from time window t.
"""
from scipy import stats
import pandas as pd
import numpy as np
properties = ['size_t', 'evolution_t', 'constraint_t', 'core_number_t', 'number_of_cliques_t', 'density_t', 'algebraic_connectivity_t',
'wiener_index_t', 'effective_size_t', 'global_efficiency_t', 'local_efficiency_t', 'average_clustering_t', 'transitivity_t',
'harmonic_centrality_t', 'estrada_index_t', 'betweenness_t', 'load_centrality_t', 'edge_betweenness_t', 'closeness_t',
'degree_assortativity_t', 'square_clustering_t', 'average_neighbor_degree_t', 'pagerank_t', 'katz_t', 'clique_number_t',
'node_connectivity_t', 'second_order_t', 'diameter_t', 'edge_t']
x = X_train[properties].copy()
def calc_property_correlation(x):
x = x.replace([np.inf, -np.inf], np.nan)
x.fillna(0, inplace=True)
X = x.copy()
c = X.columns
min_res = []
max_res = []
li_dict = {}
for i in range(29):
evosum = 0
for j in range(29):
a = X[c[i]]
if i != j:
b = X[c[j]]
k = stats.spearmanr(a, b)
kvv2 = abs(k[0])
evosum = evosum + kvv2
min_res.append((evosum,properties[i]))
max_res.append((-1*evosum,properties[i]))
li_dict[properties[i]] = evosum
return li_dict, min_res, max_res
li_dict, list_corr_min, list_corr_max = calc_property_correlation(x)
"""
random forest: Finding by train and val data from time window t, t-1, t-2
"""
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import balanced_accuracy_score
def finding_subalgorithm(heap_list, X_train, X_val, y_train, y_val):
model = RandomForestClassifier(random_state=39, n_jobs=-1, n_estimators=10)
candidate_features = []
selected_features = []
s_f = []
balance_accuracy_base = 0
balance_accuracy = 0
potential_candidate = None
while True:
for heap in heap_list:
feature = heap.pop()
candidate_features.append(feature[1])
for h in heap_list:
h.remove(feature[1])
improvement = 0
candidate_features_copy = candidate_features.copy()
for feature in candidate_features:
s_f_test = s_f.copy()
s_f_test.append(feature)
s_f_test.append(feature + '-1')
s_f_test.append(feature + '-2')
X_train_rf = X_train[s_f_test].copy()
X_train_rf = X_train_rf.fillna(0)
X_val_rf = X_val[s_f_test].copy()
X_val_rf = X_val_rf.fillna(0)
model.fit(X_train_rf, y_train)
# Make validation predictions
test_preds = model.predict_proba(X_val_rf)
preds_df = pd.DataFrame(test_preds, columns=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# Convert into predictions
preds_df['prediction'] = preds_df[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]].idxmax(axis=1)
preds_df['confidence'] = preds_df[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]].max(axis=1)
preds_df.head()
balance_accuracy_feature = round(balanced_accuracy_score(y_val, preds_df['prediction']), 3)
improvement_feature = balance_accuracy_feature - balance_accuracy_base
if improvement_feature > improvement:
improvement = improvement_feature
potential_candidate = feature
balance_accuracy = balance_accuracy_feature
if improvement_feature <= 0:
candidate_features_copy.remove(feature)
candidate_features = candidate_features_copy.copy()
if improvement > 0:
s_f.append(potential_candidate)
s_f.append(potential_candidate + '-1')
s_f.append(potential_candidate + '-2')
selected_features.append(potential_candidate)
candidate_features.remove(potential_candidate)
balance_accuracy_base = balance_accuracy
else:
return selected_features
heap_corr_min = MappedQueue(list_corr_min)
heap_corr_max = MappedQueue(list_corr_max)
heap___lgbm = MappedQueue(list___lgbm)
heap_list = [heap_corr_max, heap_corr_min, heap___lgbm]
result = finding_subalgorithm(heap_list, X_train, X_val, y_train, y_val)
end111 = time.time()
print("--------------------")
print("afif run time:")
print(end111 - start111)
print("--------------------")
print('**********************************')
print('The most prominent features are:')
for i in result:
print(i[0:-2])
print('**********************************')
| AFIF.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import tensorflow as tf
import numpy as np
from sklearn import preprocessing
from IPython.display import clear_output
def init_weights(shape):
init_random_dist = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(init_random_dist)
def init_bias(shape):
init_bias_vals = tf.constant(0.1, shape=shape)
return tf.Variable(init_bias_vals)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2by2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
def convolutional_layer(input_x, shape):
W = init_weights(shape)
b = init_bias([shape[3]])
return tf.nn.relu(conv2d(input_x, W) + b)
def normal_full_layer(input_layer, size):
input_size = int(input_layer.get_shape()[1])
W = init_weights([input_size, size])
b = init_bias([size])
return tf.matmul(input_layer, W) + b
x = tf.placeholder(tf.float32,shape=[None,38])
xin=tf.reshape(x,[-1,2,19,1])
y_true = tf.placeholder(tf.float32,shape=[None,2])
convo_1 = convolutional_layer(xin,shape=[2,2,1,64])
convo_1_pooling = max_pool_2by2(convo_1)
convo_2 = convolutional_layer(convo_1_pooling,shape=[2,2,64,128])
convo_2_pooling = max_pool_2by2(convo_2)
convo_3 = convolutional_layer(convo_2_pooling,shape=[2,2,128,512])
convo_3_pooling = max_pool_2by2(convo_3)
convo_3_flat = tf.reshape(convo_3_pooling,[-1,1536 ])
full_layer_one = tf.nn.relu(normal_full_layer(convo_3_flat,1536 ))
full_layer_two = tf.nn.relu(normal_full_layer(full_layer_one,750 ))
full_layer_three = tf.nn.relu(normal_full_layer(full_layer_two,500 ))
full_layer_four = tf.nn.relu(normal_full_layer(full_layer_three,250 ))
hold_prob = tf.placeholder(tf.float32)
full_one_dropout = tf.nn.dropout(full_layer_one,keep_prob=hold_prob)
# +
y_pred = normal_full_layer(full_one_dropout,2)
matches = tf.equal(tf.argmax(y_pred,1),tf.argmax(y_true,1))
acc = tf.reduce_mean(tf.cast(matches,tf.float32))
# -
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_pred))
optimizer = tf.train.AdamOptimizer(learning_rate=0.0000005)
train = optimizer.minimize(cross_entropy)
init = tf.global_variables_initializer()
import scipy.io as sio
nd=sio.loadmat('Normal Data.mat')
fd=sio.loadmat('Faulty Data-0.00001.mat')
vd=sio.loadmat('Data-ramp.mat')
nd=nd['Out']
fd=fd['Out']
vd=vd['Out']
fd=fd[:,1:]
nd=nd[:,1:]
vd=vd[:,1:]
Data=np.concatenate((nd,fd))
scaler = preprocessing.MinMaxScaler().fit(Data)
Data=scaler.transform(Data)
scaler2 = preprocessing.MinMaxScaler().fit(vd)
vData=scaler.transform(vd)
l=np.zeros([1012001*2,2])
l[1012001:,1]=1
l[0:1012001,0]=1
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(Data, l, test_size=0.1, random_state=42)
del Data
del l
# +
steps = 700000
with tf.Session() as sess:
sess.run(init)
for i in range(steps):
ind=np.random.randint(0,high=X_train.shape[0],size=25000)
sess.run(train,feed_dict={x:X_train[ind],y_true:y_train[ind],hold_prob:1.0})
if i%100 == 0:
#clear_output(wait=True)
print('Currently on step {}'.format(i))
print('Accuracy is:')
print(sess.run(acc,feed_dict={x:X_test,y_true:y_test,hold_prob:1.0})*100)
print(sess.run(acc,feed_dict={x:X_train[ind],y_true:y_train[ind],hold_prob:1.0})*100)
print('\n')
if sess.run(acc,feed_dict={x:X_test,y_true:y_test,hold_prob:1.0}) > 0.999:
break
del X_train,
del y_train
y_predicted=sess.run(tf.nn.softmax(y_pred),feed_dict={x:vData,hold_prob:1.0})
# -
y_predicted.shape
pr=np.zeros(y_predicted.shape[0])
te=np.zeros((y_predicted.shape[0],2))
te1=np.zeros(y_predicted.shape[0])
from sklearn.metrics import confusion_matrix
for i in range(y_predicted.shape[0]):
pr[i]=np.argmax(y_predicted[i,:])
te1[i]=np.argmax(te[i,:])
confusion_matrix(te1,pr)
te[0:500*200,0]=1
te[500*200:,1]=1
plt.plot(te1)
import matplotlib.pyplot as plt
plt.plot(pr)
plt.plot(pr[100000:101000])
plt.plot(pr[0:5000])
te[100,:]
plt.plot(pr[100000:100020])
| Fault Detection using CNN-Final.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # **Ising Model in 2D**
#
# **Authors:** <NAME>, <NAME> and <NAME>
#
# <i class="fa fa-home fa-2x"></i><a href="../index.ipynb" style="font-size: 20px"> Go back to index</a>
#
# **Source code:** https://github.com/osscar-org/quantum-mechanics/blob/master/notebook/statistical-mechanics/ising_model.ipynb
#
# We demonstrate the simulations of the Ising model. The Cython computing kernel is adapted from the code presented in the
# [Pythonic Perambulations](https://jakevdp.github.io/blog/2017/12/11/live-coding-cython-ising-model) blog.
#
# <hr style="height:1px;border:none;color:#cccccc;background-color:#cccccc;" />
# ## Goals
#
# * Understand how the Ising model can predict the ferromagnetic or antiferromagnetic behavior of a square (2D) spin lattice.
# * Compute the average magnetization of the Ising model using a Monte Carlo algorithm.
# * Examine the effects of the interaction parameter $J$ (ferromagnetic vs. antiferromagnetic behavior).
# * Identify the critical temperature of the system from the simulation results.
# * Investigate finite-size effects and their effect on fluctuations.
# # **Background Theory**
#
# [More in the background theory](./theory/theory_ising_model.ipynb)
# + [markdown] tags=[]
# ## **Tasks and exercises**
#
# 1. Run the simulation with the default parameters (and $J>0$) and check the plot of the magnetization per spin as a function of the simulation step. What happens at very low temperatures? And at intermediate temperatures? And at very high temperatures? And what happens for $J<0$?
#
# <details>
# <summary style="color: red">Solution</summary>
# For a positive $J$ value, parallel neighboring spins are energetically favored.
# Therefore, at $T=0$ we expect all spins to be aligned: the system is ferromagnetic.
# At low temperature, spin will still tend to be aligned with their neighbors, with some
# local fluctuations as temperature increases.
# Fluctuations become very large close to $T_c$, and above $T_c$
# they become predominant and, on average, we obtain zero net magnetization.
# On the other hand, $J<0$ will lead to a checkerboard pattern for the final spin
# configuration at low temperatures, i.e., an antiferromagnetic configuration.
# When $J=0$, there is no interaction between spins and we always obtain a random spin configuration.<br><br>
# </details>
#
# 2. Simulate a large system (200x200) with, e.g., $J=1$ and $T=2.5$. Is the simulation converging with the selected number of steps? Which values can you inspect to determine the convergence of the simulation?
#
# <details>
# <summary style="color: red">Solution</summary>
# A large number of simulation steps can be needed before properties converge, especially when we are close to $T_C$.<br>
#
# You can check the plot of the integrated quantities (total energy, magnetization per spin) to see if the value is converged (their values are constant save for small fluctuations with simulation step), or if you need to increase the number of steps.<br><br>
# </details>
#
# 3. Set $J=1$ and start from all spin up (i.e., disable a random starting configuration). Run multiple simulations at various temperatures. Can you approximately identify the critical (Curie) temperature using the plot below the interactive controls?
#
# <details>
# <summary style="color: red">Solution</summary>
# We suggest that you start from a small size system (50x50) to avoid excessively long simulations, and choose a long number of simulation steps (1000) to be approximately converged (see previous question).<br>
#
# Theoretically, $T_C$ for the 2D Ising model (and $J=1$) is about 2.27 (see the <a href="https://en.wikipedia.org/wiki/Square_lattice_Ising_model">Wikipedia page of the Square lattice Ising model</a>), as visualized by the analytical exact solution plotted below the interactive controls.<br>
#
# You should see that the simulation results follow relatively closely the analytical curve for $T \ll T_c$ or for $T \gg T_C$, but large fluctuations occur close to the Curie temperature. We suggest that you run multiple runs for each temperature to see the fluctuations. You should be able to reproduce the curve and thus approximately identify the transition temperature.<br>
#
# We suggest that you try the same with different values of $J$.<br><br>
# </details>
#
# 4. Set $J=1$, and simulate the system close to $T_C$. Investigate the magnitude of fluctuations as a function of system size.
#
# <details>
# <summary style="color: red">Solution</summary>
# Consider for instance both a small (50x50) and a large system (200x200), $J=1$, and $T=2.5$. Run a few simulations (at least 5 or 10) for each system size (note that each simulation for the large system will take many seconds). Verify that fluctuations are less pronounced for the larger system.<br>
#
# Note that the difference in fluctuations might not be very large, since the two systems are still relatively similar in size. The difference in the magnitude of the fluctuation can also be visualized by inspecting the fluctuations of the averaged quantities in the two plots of the magnetization per spin and total energy as a function of the simulation step.
# </details>
#
# 5. Consider a 100x100 system, set $J=1$ and $T=1.7$. Use a large number of simulation steps, and enable the randomization of the initial spin configuration. Investigate the formation of domains. Are they more stable for large or small systems?
#
# <details>
# <summary style="color: red">Solution</summary>
# If you run the simulation multiple times, you will notice that often the simulation does not reach the expected (positive or negative) analytical exact result, but will have intermediate magnetization values due to the formation of domains. These might disappear during the simulation, but sometimes they will remain even after 1000 simulation steps.<br>
#
# If you consider a smaller system (e.g. 50x50), you should notice that there is a higher probability that the domains disappear during the simulation. In fact, the cost of a domain scales as the length of its boundary, which (for very large systems) becomes a negligible cost with respect to the total energy of the system (that scales with the number of spins, i.e. quadratically with respect to the system size) and therefore can exist for a long time; in addition, domains will have a higher probability to merge for a small system.
# </details>
#
# <hr style="height:1px;border:none;color:#cccccc;background-color:#cccccc;" />
# -
# %reload_ext Cython
# %matplotlib widget
import numpy as np
from ipywidgets import interact, FloatSlider, Button, Output, IntSlider, VBox
from ipywidgets import HBox, Checkbox, IntProgress, HTML
import matplotlib.pyplot as plt
from time import sleep
import matplotlib.gridspec as gridspec
from scipy.ndimage import convolve
from matplotlib.animation import FuncAnimation
import base64
# +
def random_spin_field(N, M):
"""Randomize the initial spin configuration."""
return np.random.choice([-1, 1], size=(N, M))
def all_up_spin_field(N, M):
"""Set all spin up."""
return np.ones((N, M), dtype=int)
run_button = Button(description='Run simulation')
run_button.style.button_color = 'lightgreen'
play_button = Button(description='Play', disabled=True)
random_checkbox = Checkbox(value=False, description="Randomize initial spin configuration", style={'description_width': 'initial'})
jvalue_slider = FloatSlider(value = 1.0, min = -2.0, max = 2.0, description = 'Exchange interaction J',
style={'description_width': 'initial'}, continuous_update=False)
num_slider = IntSlider(value=100, min=50, max=200, step=10, description="Size", continuous_update=False)
temp_slider = FloatSlider(value=2, min=0.5, max=4, step=0.1, description="Temperature", continuous_update=False) # Units of J/k
step_slider = IntSlider(value=100, min=100, max=1000, step=50, description="Num steps", continuous_update=False)
frame_slider = IntSlider(value=0, min=0, max=step_slider.value, description="Frame", layout={'width':'800px'}, disabled=True)
# + language="cython"
#
# cimport cython
#
# import numpy as np
# cimport numpy as np
#
# from libc.math cimport exp
# from libc.stdlib cimport rand
# cdef extern from "limits.h":
# int RAND_MAX
#
# @cython.boundscheck(False)
# @cython.wraparound(False)
# def cy_ising_step(np.int64_t[:, :] field, float beta, float J):
# """Update the Ising step, each step actually contains N*M steps.
#
# Args:
# field: matrix representation for the spin configuration.
# beta: 1/kbT
# J: the strength of exchange interaction.
#
# Returns:
# New spin configuration and the total energy change.
# """
# cdef int N = field.shape[0]
# cdef int M = field.shape[1]
# cdef int i
# cdef np.ndarray x, y
# cdef float dE = 0.0
#
# x = np.random.randint(N, size=(N*M))
# y = np.random.randint(M, size=(N*M))
#
# for i in range(N*M):
# dE += _cy_ising_update(field, x[i], y[i], beta, J)
#
# return np.array(field), dE
#
# @cython.boundscheck(False)
# @cython.wraparound(False)
# cdef _cy_ising_update(np.int64_t[:, :] field, int n, int m, float beta, float J):
# """Monte Carlo simulation using the Metropolis algorithm.
#
# Args:
# field: matrix representation for the spin configuration.
# n: chosen row index.
# m: chosen column index.
# beta: 1/kbT
# J: the strength of exchange interaction.
#
# Returns:
# The total energy change.
# """
# cdef int total
# cdef int N = field.shape[0]
# cdef int M = field.shape[1]
#
# total = field[(n+1)%N, m] + field[n, (m+1)%M] + field[(n-1)%N, m] + field[n, (m-1)%M]
# cdef float dE = 2.0 * J * field[n, m] * total
# if dE <= 0:
# field[n, m] *= -1
# return dE
# elif exp(-dE * beta) * RAND_MAX > rand():
# field[n, m] *= -1
# return dE
# else:
# return 0
# +
pause = True;
def on_frame_change(b):
"""Update the plot for playing the animation."""
global fig, v1
fig.set_data(images[frame_slider.value])
v1.set_data([frame_slider.value, frame_slider.value],[-1.1, 1.1])
v2.set_data([frame_slider.value, frame_slider.value],[-5000, 5000])
def compute_total_energy(M, J):
"""Compute the total energy of the given spin configuration."""
a = np.ones(np.shape(M));
c = convolve(M, a, mode='constant')
c = (c-M)*M*J
return c.sum()
def update(frame):
"""Update function for the animation."""
global pause
if pause:
ani.event_source.stop()
else:
frame_slider.value = frame
return (fig)
def play_animation(event):
"""OnClick function the 'Play' button."""
global pause
pause ^= True
if play_button.description == "Pause":
play_button.description = "Play"
ani.event_source.stop()
else:
play_button.description = "Pause"
ani.event_source.start()
frame_slider.observe(on_frame_change, names='value')
images = [all_up_spin_field(num_slider.value, num_slider.value)]
img = plt.figure(tight_layout=True, figsize=(8,5))
img.canvas.header_visible = False
gs = gridspec.GridSpec(4, 2)
ax1 = img.add_subplot(gs[:, 0])
ax2 = img.add_subplot(gs[0:2, 1])
ax3 = img.add_subplot(gs[2:4, 1])
fig = ax1.imshow(images[0], vmin=-1, vmax=1)
ax1.axes.xaxis.set_ticklabels([])
ax1.axes.yaxis.set_ticklabels([])
ax1.set_title('Spin up (yellow), spin down (purple)', fontsize=12)
line1, = ax2.plot([0], [0], 'r-')
line2, = ax3.plot([0], [0], 'r-')
v1 = ax2.axvline(x=0, c='black')
v2 = ax3.axvline(x=0, c='black')
ax2.set_xlim([0, step_slider.value])
ax2.set_ylim([-1.1, 1.1])
ax2.set_title('Magnetization per spin', fontsize=12)
ax3.set_xlim([0, step_slider.value])
ax3.set_ylim([-1, 1])
ax3.set_title(r'Total energy (E$_{init}$=0)', fontsize=12)
ax3.set_xlabel('Step', fontsize=12)
ani = FuncAnimation(img, update, interval= 20, frames=np.arange(0, step_slider.value+1), blit=True)
display(frame_slider,
HBox([num_slider, step_slider]),
HBox([jvalue_slider, temp_slider]),
HBox([random_checkbox, run_button, play_button]))
# +
def get_analytical_plot_data(J, k_B=1):
"""Exact solution of the 2D square Ising model.
See e.g.: https://en.wikipedia.org/wiki/Square_lattice_Ising_model
"""
temperature = np.linspace(0.01, 4, 500)
magnetization = np.zeros(len(temperature))
Tc = 2 * J / k_B / np.log(1 + np.sqrt(2))
magnetization[temperature < Tc] = (1-1./(np.sinh(2 * J / k_B / temperature[temperature < Tc])**4))**(1/8)
return temperature, magnetization
def reset_mag_plot(ax):
"""Reset the magnetization plot.
Clear the axes and re-draw the analytical exact solution.
"""
global ax_mag, random_checkbox
temps, magnetization = get_analytical_plot_data(J=jvalue_slider.value, k_B=1)
ax.clear()
ax.plot(temps, magnetization, 'b-')
if random_checkbox.value:
ax.plot(temps, -magnetization, 'r-')
ax.set_xlabel("$T$")
ax.set_ylabel(r"$\langle \sigma \rangle$")
ax.set_title("Magnetization per site vs. temperature")
ax.set_xlim((0, 4))
def create_mag_plot():
"""Create the magnetization plot.
To be called only one to create it and return the axes object.
"""
img_mag = plt.figure(tight_layout=True, figsize=(5,3.5))
img_mag.canvas.header_visible = False
gs_mag = gridspec.GridSpec(1, 1)
ax_mag = img_mag.add_subplot(gs_mag[:, :])
reset_mag_plot(ax_mag)
return ax_mag
# Create and display the magnetization plot.
ax_mag = create_mag_plot()
# +
def run_simulation(b):
"""Callback to be called when the 'Run simulation' button is clicked.
Takes care of temporarily disabling the button, running the simulation and updating
the various plots, and re-enabling the button again.
"""
global ax_mag
play_button.disabled = True
run_button.disabled = True
frame_slider.disabled = True
run_button.style.button_color = 'red'
global images, fig
if random_checkbox.value:
images = [random_spin_field(num_slider.value, num_slider.value)]
else:
images = [all_up_spin_field(num_slider.value, num_slider.value)]
x = np.arange(step_slider.value + 1)
y1 = []
y2 = [0]
for i in range(step_slider.value):
imag, dE = cy_ising_step(images[-1].copy(), beta=1.0/temp_slider.value, J=jvalue_slider.value)
images.append(imag)
y2.append(dE+y2[-1])
frame_slider.max = step_slider.value
ax2.set_xlim([0, step_slider.value])
fig.set_data(images[frame_slider.max - 1])
for i in images:
y1.append(i.sum()*1.0/(num_slider.value * num_slider.value))
y1 = np.array(y1)
y2 = np.array(y2)
line1.set_data(x, y1)
line2.set_data(x, y2)
ax3.set_ylim([y2.min(), y2.max()])
ax3.set_xlim([0, step_slider.value])
frame_slider.value = frame_slider.max
ani.frames = np.arange(0, step_slider.value+1)
ani._iter_gen = lambda: iter(ani.frames)
ani.save_count = len(ani.frames)
ani.frame_seq = ani.new_frame_seq()
ax_mag.errorbar([temp_slider.value], [y1[-1]], fmt='.g')
frame_slider.disabled = False
play_button.disabled = False
run_button.disabled = False
run_button.style.button_color = 'lightgreen'
return y1
def on_needs_reset(b):
"""Callback to be called when the magnetization plot needs to be cleared and reset."""
global ax_mag
reset_mag_plot(ax_mag)
# Attach actions to the buttons
run_button.on_click(run_simulation)
play_button.on_click(play_animation)
# Attach reset actions (for the magnetization plot) when some of the
# simulation parameters are changed (all except the temperature)
jvalue_slider.observe(on_needs_reset, names='value')
num_slider.observe(on_needs_reset, names='value')
step_slider.observe(on_needs_reset, names='value')
random_checkbox.observe(on_needs_reset, names='value')
# -
# ## Legend
#
# (How to use the interactive visualization)
#
# ### Controls
#
# The "size" slider defines the number of spins along each dimension.
# You can also adapt the number of simulation steps, the value of the
# exchange interaction parameter $J$, and the temperature of the simulation
# (note: units have been chosen so that the Boltzmann constant $k_B=1$).
#
# By default, we set all spin up for the initial configuration.
# This induces a bias for short simulations (but can help avoid the formation of
# domains); you can instead randomize the initial configuration by ticking
# the checkbox "Randomize initial spin configuration".
#
# ### Running the simulation and output plots
# Click the "Run simulation" button to start the simulation with the selected parameters.
#
# In particular, the figures above the controls display the time evolution of the last simulation
# that was executed.
# The figure on the left shows the spin configuration. A yellow pixel represents
# a spin up and blue represents a spin down.
# After the simulation finished, you can click "Play" to view the evolution of the
# simulation step by step (or drag manually the "Frame" slider).
# The figure on the top right shows the evolution of the magnetization per spin over
# the simulation as a function of the Monte Carlo simulation step number.
# The figure on the bottom right shows the total energy as a function of the step number.
#
# In addition, at every new simulation, a new green point is added to the bottom plot,
# showing the magnetization per spin as a function of temperature $T$.
# The analytical exact solution for the chosen value of $J$ is also shown
# (see [Wikipedia page on the square lattice Ising model](https://en.wikipedia.org/wiki/Square_lattice_Ising_model)
# for more details on the exact solution). Note that when a random initial configuration is selected instead of all spin up, there shall be both blue and red curves for the analytical solution due to the possibility of having negative magnetization in that case.
#
# Changing any slider (except for the temperature slider)
# will reset the bottom plot.
# You can change the temperature and run the simulation multiple times
# to compare the analytical solution with the results of the simulation.
| notebook/statistical-mechanics/ising_model.ipynb |
/ ---
/ jupyter:
/ jupytext:
/ text_representation:
/ extension: .q
/ format_name: light
/ format_version: '1.5'
/ jupytext_version: 1.14.4
/ kernelspec:
/ display_name: xsqlite
/ language: sqlite
/ name: xsqlite
/ ---
/ # Lab 1: Basic SQL and Jupiter Notebook
/ Please create your own database named lab1.db3
%CREATE lab1.db3
/ Q1: Write SQL statements to create a table called MyGraph that can store any directed graph ("graph" as in vertices andedges, or nodes and links). You have to carefully design the schema.
%load lab1.db3
/ Q2: Write SQL statements to store the following graph in your table
CREATE TABLE MyGraph(source int not NULL, destination int not NULL);
INSERT into MyGraph VALUES (5,11), (7,11), (7,8),(3,8),(3,10),(11,2),
(11,9),(11,10),(8,9)
/ Q3: Write a SQL statement that returns all source vertices in your table
SELECT DISTINCT source FROM MyGraph
/ Q4: Write a SQL statement that returns all edges, such that the source id is larger than the destination id.
SELECT source, destination from MyGraph WHERE source > destination
/ Q5: Write a SQL statement to add a column of weight to each link on the direct graph
ALTER TABLE MyGraph add COLUMN weight INT
/ Q6: Write a SQL statement to ramdonly assign a weight (1-10) to each of the link. (generate a ramdon number with a seed.)
UPDATE MyGraph set weight = abs(random() % 11)
/ Q7: Write a SQL to return the distinct values of weights.
SELECT DISTINCT weight from MyGraph
| Assignements and Projects/CISC 3500 Database Systems/Lab 1: Basic SQL and Jupiter Notebook/CISC3500 Lab1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Dataset
import numpy as np
np.random.seed(42)
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
# +
boston = datasets.load_boston()
x, y = boston.data[:, 1:3], boston.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# +
plt.scatter(x_test[:, 0], x_test[:, 1])
plt.show()
print(f"Min: {np.min(x_test, axis=0)}")
print(f"Max: {np.max(x_test, axis=0)}")
print(f"Mean: {np.mean(x_test, axis=0)}")
print(f"Std: {np.std(x_test, axis=0)}")
# -
# ### MinMax Scaler
class MinMaxScaler:
def __init__(self):
self.data_min: np.ndarray = None
self.data_max: np.ndarray = None
def fit(self, x: np.ndarray):
self.data_min = np.min(x, axis=0)
self.data_max = np.max(x, axis=0)
def transform(self, x: np.ndarray):
x_transformed = (x - self.data_min) / (self.data_max - self.data_min)
return x_transformed
scaler = MinMaxScaler()
scaler.fit(x)
x_train_transformed = scaler.transform(x_train)
x_test_transformed = scaler.transform(x_test)
# +
plt.scatter(x_test_transformed[:, 0], x_test_transformed[:, 1])
plt.show()
print(f"Min: {np.min(x_test_transformed, axis=0)}")
print(f"Max: {np.max(x_test_transformed, axis=0)}")
print(f"Mean: {np.mean(x_test_transformed, axis=0)}")
print(f"Std: {np.std(x_test_transformed, axis=0)}")
# -
# ### Standard Scaler
class StandardScaler:
def __init__(self):
self.mean_: np.ndarray = None
self.scale_: np.ndarray = None
def fit(self, x: np.ndarray):
self.mean_ = np.mean(x, axis=0)
self.scale_ = np.std(x, axis=0)
def transform(self, x: np.ndarray):
x_transformed = (x - self.mean_) / self.scale_
return x_transformed
scaler = StandardScaler()
scaler.fit(x_train)
x_train_transformed = scaler.transform(x_train)
x_test_transformed = scaler.transform(x_test)
# +
plt.scatter(x_test_transformed[:, 0], x_test_transformed[:, 1])
plt.show()
print(f"Min: {np.min(x_test_transformed, axis=0)}")
print(f"Max: {np.max(x_test_transformed, axis=0)}")
print(f"Mean: {np.mean(x_test_transformed, axis=0)}")
print(f"Std: {np.std(x_test_transformed, axis=0)}")
| Chapter8_MetricsAndEvaluation/DataNormalization/StandardScaler.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="-tXwruPKhcyv"
# **Problem Statement**
#
# Create an end to end customer support and feedback chatbot
#
# + [markdown] id="1O6PePgDhpUt"
# **Members**
#
# <NAME> |
# <NAME> |
# <NAME>
# + [markdown] id="3JjduOFw4CZS"
# # **Pre-Requisites**
# + id="PlaniwNRORmc"
# !pip install transformers
# + id="YwiVqepNkMxp"
import pandas as pd
import re
import torch
# + id="OptaCPFrkEOk"
dataa = pd.read_csv('/content/drive/MyDrive/ml_training_data/cleaned_data.csv')
# + id="w-rkUgs4kQsl"
dataa = dataa[:1000]
# + id="y-s7rgxckTZH"
question = dataa['question']
responsee = dataa['response']
# + [markdown] id="2N2fF6YIOJY4"
# # **BERT Model**
# + colab={"base_uri": "https://localhost:8080/", "height": 81, "referenced_widgets": ["8e869e025dc64378a251b32ac1ac1a9d", "67538f1a9f184570a620b82e1aa53a0e", "cdc887e0eb59480bbd4f48f7450d1c36", "d8b16f50425d437289339f6deea2490e", "<KEY>", "4087b573e435454abb699f541d1478e8", "<KEY>", "<KEY>", "e97d4301b64a47a2946c3a999e3c248c", "5ee4638cf4a7485590b37b9a03b3a472", "47366fd6817c4c9ab32f3a54f48ffdb9", "d69008a1b92c4a1181e9ff75c47e9149", "<KEY>", "e615464eec2b485eac6022d8d4f74f20", "<KEY>", "d9b16a962ae9434c878eee5f8ffafea2", "a3e33e34088a44b6b1579a81e9f13a65", "<KEY>", "<KEY>", "e12a48ee20c0414991f8d95fa334b886", "a24a05cfb56e4e2d91249ed098af5d2e", "1adc282518d14f61a5af958e7fc50211"]} id="v3vte9gVOKjp" outputId="2a5fd769-8148-4b74-d99c-0f93f6efbad1"
from transformers import BertForQuestionAnswering
model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
# + id="Xdq5TqGdwFy6" colab={"base_uri": "https://localhost:8080/", "height": 81, "referenced_widgets": ["cfbfe6995a2f4f668475e2896a5d6715", "e2c373f0f6704e079ce6e2e86529c4c5", "<KEY>", "9d8b95a2b54d438ca9eee7231207e0f1", "88639b4694af4e5798dfaa511a2da3db", "<KEY>", "<KEY>", "3b0f04e1ca1e4c7abd8f3f0616ab4d5c", "00708875793b4f1a971f5fa4364f63d3", "b28daaae53b84ba68945b48551357b9b", "1fde05420c914a739ed8d7c6df870e09", "<KEY>", "<KEY>", "45dc7e76b8a34718b2f78b2e7681c373", "<KEY>", "<KEY>", "c4511a242fe44685882a468f660ac192", "8962c040988b4431be8b04e7b6ac3cd4", "046143d9844744e9b3a9f49718b824e9", "<KEY>", "<KEY>", "<KEY>"]} outputId="c7ab150d-f55f-40fd-c39f-0b07c80993a7"
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
# + id="45vbK1P9Of8Q"
def answer_question(question, answer_text):
input_ids = tokenizer.encode(question, answer_text)
sep_index = input_ids.index(tokenizer.sep_token_id)
num_seg_a = sep_index + 1
num_seg_b = len(input_ids) - num_seg_a
segment_ids = [0]*num_seg_a + [1]*num_seg_b
assert len(segment_ids) == len(input_ids)
outputs = model(torch.tensor([input_ids]),
token_type_ids=torch.tensor([segment_ids]),
return_dict=True)
start_scores = outputs.start_logits
end_scores = outputs.end_logits
answer_start = torch.argmax(start_scores)
answer_end = torch.argmax(end_scores)
tokens = tokenizer.convert_ids_to_tokens(input_ids)
answer = tokens[answer_start]
for i in range(answer_start + 1, answer_end + 1):
if tokens[i][0:2] == '##':
answer += tokens[i][2:]
else:
answer += ' ' + tokens[i]
if answer != '[SEP]':
return (answer)
else:
return "Your query does not exist in this database"
# + id="dJYOUZEROyKY"
temptext = "Sunset is the time of day when our sky meets the outer space solar winds. There are blue, pink, and purple swirls, spinning and twisting, like clouds of balloons caught in a whirlwind. The sun moves slowly to hide behind the line of horizon, while the moon races to take its place in prominence atop the night sky. People slow to a crawl, entranced, fully forgetting the deeds that must still be done. There is a coolness, a calmness, when the sun does set."
# + [markdown] id="KKBsTUZXOCqf"
# # **MATHEMATICAL DATA SIMILARITY INDEX**
# + id="vj6FUvZ-kA7j"
def message_probability(user_message, recognised_words, single_response=False, required_words=[]):
message_certainty = 0
has_required_words = True
# Counts how many words are present in each predefined message
for word in user_message:
if word in recognised_words:
message_certainty += 1
# Calculates the percent of recognised words in a user message
percentage = float(message_certainty) / float(len(recognised_words))
# Checks that the required words are in the string
for word in required_words:
if word not in user_message:
has_required_words = False
break
# Must either have the required words, or be a single response
if has_required_words or single_response:
return int(percentage * 100)
else:
return 0
# + [markdown] id="CTQG4AY9DgpB"
#
# + id="KaR_ZnFZj14A"
def check_all_messages(message):
highest_prob_list = {}
def response(bot_response, list_of_words, single_response=False, required_words=[]):
nonlocal highest_prob_list
highest_prob_list[bot_response] = message_probability(message, list_of_words, single_response, required_words)
# sample responses
response('Hello!', ['hello'], single_response=True)
response('See you!', ['bye', 'goodbye'], single_response=True)
response('I\'m doing fine, and you?', ['how', 'are', 'you', 'doing'], required_words=['how'])
response('You\'re welcome!', ['thank', 'thanks'], single_response=True)
response('Thank you!', ['i', 'love', 'code', 'palace'], required_words=['code', 'palace'])
for i in range(len(question)):
response(responsee[i], question[i].split(), single_response=True)
# print(highest_prob_list)
best_match = max(highest_prob_list, key=highest_prob_list.get)
# print(highest_prob_list[best_match])
return answer_question(message, temptext) if highest_prob_list[best_match] < 45 else best_match
# + [markdown] id="ONyeIktLOgvo"
# # **Chat Bot Implementation**
# + colab={"base_uri": "https://localhost:8080/"} id="-thWmjrKjAnh" outputId="6b5b36a5-81e7-4adb-d1ae-90dd9be6bb71"
# Used to get the response
def get_response(user_input):
if user_input == 'quit':
return
split_message = re.split(r'\s+|[,;?!.-]\s*', user_input.lower())
response = check_all_messages(split_message)
return response
# Testing the response system
while True:
print('Bot: ' + get_response(input("You: ")))
| ChatBot.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import os
import sys
from time import sleep
from uuid import uuid4
import numpy as np
import GCode
import GRBL
from utils import picture
# -
# # Laser Circles
# # Code:
sys.path.append("..")
cnc.config
cnc = GRBL.GRBL(port="/dev/cnc_3018")
sleep(0.5)
cnc.laser_mode = 1
sleep(0.5)
print("Laser Mode: {}".format(cnc.laser_mode))
cnc.cmd("?")
# +
def init(feed=200, zero=True):
program = GCode.GCode()
program.G21() # Metric Units
program.G90() # Absolute positioning.
if zero:
program.G92(X=0, Y=0, Z=0) # Zero position.
# Set the laser on rates.
program.G1(F=feed)
program.G2(F=feed)
program.G3(F=feed)
return program
def end():
program = GCode.GCode()
program.G0(X=0, Y=0, Z=0)
program.M5()
return program
# -
def circle(center_x=5, center_y=5, radius=5, laser_pwm=255):
prog = GCode.GCode()
prog.G0(X=center_x - radius, Y=center_y)
prog.M3(S=laser_pwm)
prog.G2(X=center_x - radius, Y=center_y, I=radius, J=0)
prog.M5()
prog.G0(X=center_x - radius, Y=center_y)
return prog
cnc.run(["G0", "M3S1", "G1F1"])
radius = 15
cnc.run(init(feed=200))
cnc.run("G0X15Y15")
cnc.run("G0X0Y15")
cnc.run("M3S1")
cnc.cmd("G2X15Y15R15F200")
cnc.run(circle(15, 15, 15, 2))
cnc.run("G0X0Y0")
X_centers = np.linspace(radius, 180 - radius, 5)
Y_centers = np.linspace(radius, 90 - radius, 4)
test_run = GCode.GCode()
test_run += init(feed=200)
for x_center in X_centers:
for y_center in Y_centers:
test_run += circle(
center_x=x_center, center_y=y_center, radius=radius, laser_pwm=150
)
test_run += end()
gcode_file = "CircleTests.gcode"
test_run.save(gcode_file)
del test_run
test_run = GCode.GCode()
test_run.load(gcode_file)
test_run
try:
cnc.run(test_run)
while "Idle" not in cnc.status:
print(cnc.status)
sleep(5)
except KeyboardInterrupt as error:
print("Feed Hold")
cnc.cmd("!")
while 1:
try:
cnc.reset()
break
except:
pass
print("^C")
cnc.cmd("G0X0Y0")
cnc.reset()
cnc.reset()
picture()
# # Test Aborted.
#
# Cuts were way too aggressive.
| PreviousDevelopment/LaserCircles-Debug.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.5 64-bit (''base'': conda)'
# name: python3
# ---
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model, model_selection
X, y = datasets.load_linnerud(return_X_y=True)
print(X.shape)
X
y
X = X[:, np.newaxis, 0]
y = y[:,np.newaxis,2]
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33)
model = linear_model.LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, y_pred, color='blue', linewidth=3)
plt.show()
| 2-Regression/1-Tools/homework.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.9.7 64-bit (''tf-gpu'': conda)'
# name: python3
# ---
# +
from IPython.display import display
import numpy as np
import pandas as pd
import seaborn as sns
df_train = pd.read_csv('../processed_data/train_meta_inc.csv')
ax = sns.histplot(data=df_train, x='found_helpful_percentage');
# -
df_train.found_helpful_percentage.max(), df_train.found_helpful_percentage.min()
bins = [ax.patches[i].get_x() for i in range(len(ax.patches))]
bins.append(bins[-1]+bins[1]-bins[0])
bin_size = bins[1]-bins[0]
bin_size
df_train['bin_num'] = np.int64(np.ceil(df_train.found_helpful_percentage/bin_size))
df_train[['found_helpful_percentage', 'bin_num']]
bin_counts = dict(df_train.bin_num.value_counts())
max_count = max(bin_counts.values())
df_train['sample_weight'] = df_train.bin_num.apply(lambda x: max_count/bin_counts[x])
display(df_train[['found_helpful_percentage', 'sample_weight']])
df_train[['sample_weight']].to_csv('../processed_data/train_sample_weight.csv', index=False)
| explore_nb/target_dist.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from bs4 import BeautifulSoup
import requests
import itertools
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
header = ({'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'})
web = "https://www.worldometers.info/coronavirus/"
response = requests.get(url = web, headers = header)
print(response)
print(response.text[:800])
| Scrap.1.0/.ipynb_checkpoints/Covid-19-data-scrap-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.8.5 64-bit
# metadata:
# interpreter:
# hash: 31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6
# name: python3
# ---
# 출처: https://swexpertacademy.com/
# 7차시 6일차 - 피자 굽기
# Make input file
f = open("input.txt", "w")
f.write("3\n")
f.write("3 5\n")
f.write("7 2 6 5 3\n")
f.write("5 10\n")
f.write("5 9 3 9 9 2 5 8 7 1\n")
f.write("5 10\n")
f.write("20 4 5 7 3 15 2 1 2 2\n")
f.close()
# + tags=[]
# for Jupyter Notebook
###
f = open("input.txt", "r")
input = f.readline
###
T = int(input())
for test_case in range(1, T+1):
nm = list(map(int, input().split()))
n, m = [nm[i] for i in range(2)]
cheese = list(map(int, input().split()))
pizzas = [[cheese[i], i+1] for i in range(len(cheese))]
oven = pizzas[:n]
ready_to_oven = pizzas[n:]
while(len(oven)!=1):
c, i = oven.pop(0)
# cheese 가 다 녹았을 때
if (c//2 == 0):
# ready to oven pizza 가 남았을때 oven에 추가
if len(ready_to_oven):
oven.append(ready_to_oven.pop(0))
else:
oven.append([c//2, i])
last = oven.pop()
print("#{} {}".format(test_case, last[-1]))
# -
| notebook/SWExpertAcademy/Course/ProgramingIntermediate/.ipynb_checkpoints/05_Queue1-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/cathyxinchangli/ATMS-597-SP-2020/blob/master/ATMS-597-SP-2020-Project-2/climatestripes.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="yQB0KBQDUIjK" colab_type="code" colab={}
import requests
import numpy as np
import pandas as pd
import datetime
import matplotlib as mlp
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from matplotlib.collections import PatchCollection
from matplotlib.colors import ListedColormap
import matplotlib.dates as mdates
# %matplotlib inline
# assumptions:
# 1. Reference period: 1970.1.1 - 1999.12.31
# 2. Anomaly: raw, not standardized
# 3. Leap year treatment
# 4. Treatment for extra days outside of 52 weeks
# + [markdown] id="kWaj6E1UVMO6" colab_type="text"
# # Functions
# + [markdown] id="VkbHmAs5fY-V" colab_type="text"
# ## Get Data
# + id="LlFC9T5WULEh" colab_type="code" colab={}
def make_request(endpoint, payload=None):
"""
Make a request to a specific endpoint on the weather API
passing headers and optional payload.
Parameters:
- endpoint: The endpoint of the API you want to
make a GET request to.
- payload: A dictionary of data to pass along
with the request.
Returns:
Response object.
---
<NAME>, 'Hands on Data Analysis with Pandas'
https://github.com/stefmolin/Hands-On-Data-Analysis-with-Pandas/blob/master/ch_04/0-weather_data_collection.ipynb
"""
return requests.get(
f'https://www.ncdc.noaa.gov/cdo-web/api/v2/{endpoint}',
headers={
'token': '<KEY>' # obtained by <NAME>, 2/4/2020
},
params=payload
)
def fetch_data(locationid, startdate, enddate, endpoint="data",
datasetid="GHCND", stationid=None, units="metric", limit=1000):
"""
Simple fetch request for requesting TMIN and TMAX data from API within
the same year.
Parameters:
- datasetid: default 'GHCND',
- locationid
- stationid
- startdate: a datetime object
- enddate: a datetime object
- units: specify preferred units for retrieving the data
- limit: max. 1000 requests
Returns:
- DataFrame of the requested dataset
"""
response = make_request(
endpoint,
{
"datasetid": datasetid,
"datatypeid": ["TMAX", "TMIN"],
"locationid": locationid,
"stationid": stationid,
"startdate": startdate,
"enddate": enddate,
"unit": units,
"limit": limit,
})
response = pd.DataFrame(response.json()["results"])
return response
def loop_request(locationid, startdate, enddate, endpoint="data",
datasetid="GHCND", stationid=None, units="metric", limit=1000):
"""
Fetch TMIN and TMAX data from API over arbitrary time period without
running into data request limit.
Parameters:
- datasetid: default 'GHCND',
- locationid
- stationid: default None
- startdate: a datetime object
- enddate: a datetime object
- units: preferred units for retrieving the data, default 'metric'
- limit: max. 1000 requests
Returns:
- DataFrame of the requested dataset
"""
if startdate.year == enddate.year:
return fetch_data(locationid, startdate, enddate, endpoint, datasetid,
stationid, units, limit)
else:
enddate_0 = datetime.date(startdate.year, 12, 31)
df_tmp_0 = fetch_data(locationid, startdate, enddate_0, endpoint, datasetid,
stationid, units, limit)
for year in range(startdate.year + 1, enddate.year):
startdate_tmp = datetime.date(year, 1, 1)
enddate_tmp = datetime.date(year + 1, 1, 1)
df_tmp = fetch_data(locationid, startdate_tmp, enddate_tmp, endpoint, datasetid,
stationid, units, limit)
df_tmp_0 = pd.concat([df_tmp_0, df_tmp])
startdate_1 = datetime.date(enddate.year, 1, 1)
df_tmp_1 = fetch_data(locationid, startdate_1, enddate, endpoint, datasetid,
stationid, units, limit)
df_tmp_0 = pd.concat([df_tmp_0, df_tmp_1])
return df_tmp_0
def clean_up(datain):
'''
Clean up missing values, adjust the units of the values, covert datetime
format to pandas-datetime and re-index using datetime.
Parameters:
- datain: the DataFrame to perform the function on
Returns:
- cleaned up DataFrame
---
Adapted from <NAME>, Module 2, ATMS 597 SP 2020
'''
# clean up missing values
datain["value"][(np.abs(datain["value"]) == 9999)] = np.nan
datain.dropna(inplace=True)
# adjust unit from 10th of degree C to degree C
datain["value"] = datain["value"].astype("float") / 10.
# convert datetime format and re-index
datain["date"] = pd.to_datetime(datain["date"], infer_datetime_format=True) # this is hard coded
datain.index = datain["date"]
return datain
# + [markdown] id="s453rD4Rfsaj" colab_type="text"
# ## Calculate Anomalies
# + id="tZ3CmUlDfpCI" colab_type="code" colab={}
def is_leap_and_last_day(s):
"""
Checks if the year is a leap year. If the year is a leap year, checks for
both the second to last day and the last day of the year.
Parameters:
- s: the DataFrame to perform the function on
Returns:
- Function to remove the leap day and last 2 days of the year
"""
return ((s.index.year % 4 == 0) & ((s.index.year % 100 != 0) | (s.index.year % 400 == 0)) & (s.index.month == 12) & (s.index.day == 30)) | ((s.index.month == 12) & (s.index.day == 31))
def cal_anomaly_W(df, df_ref):
"""
Calculates weekly averaged temperature anomaly (departure) from the reference period.
Parameters:
- df: DataFrame from which anomaly is calculated
- df_ref: DataFrame of the reference period
Returns:
- df_W: weekly averaged anomaly
- df_ref_W: weekly averaged reference temperatures
"""
# reference frame
mask = is_leap_and_last_day(df_ref)
df_ref_tmp = df_ref[~mask]
df_ref_tmp["W_num"] = (df_ref_tmp["date"].dt.dayofyear) // 7
df_ref_W = df_ref_tmp.groupby("W_num").mean()
# plotting frame:
mask = is_leap_and_last_day(df)
df_tmp = df[~mask]
df_W = df_tmp.resample("7D").mean()
df_W["W_num"] = (df_W.index.dayofyear) // 7
for num in set(df_W["W_num"]):
df_W["value"][df_W["W_num"] == num] -= df_ref_W["value"][num]
return df_W, df_ref_W
def cal_anomaly_M(df, df_ref):
"""
Calculates monthly averaged temperature anomaly (departure) from the reference period.
Parameters:
- df: DataFrame from which anomaly is calculated
- df_ref: DataFrame of the reference period
Returns:
- df_M: monthly averaged anomaly
- df_ref_M: monthly averaged reference temperatures
"""
# reference frame:
df_ref_tmp = df_ref.resample('MS').mean()
df_ref_tmp['M_num'] = df_ref_tmp.index.month
df_ref_M = df_ref_tmp.groupby('M_num').mean()
# plotting frame:
df_M = df.resample('MS').mean() # this will fill incomplete months into complete ones and place the mean into the first day of the month
df_M['M_num'] = df_M.index.month
# calculate anomaly:
for num in set(df_M['M_num']):
df_M['value'][df_M['M_num'] == num] -= df_ref_M['value'][num]
return df_M, df_ref_M
def cal_anomaly_Y(df, df_ref):
"""
Calculates yearly averaged temperature anomaly (departure) from the reference period.
Parameters:
- df: DataFrame from which anomaly is calculated
- df_ref: DataFrame of the reference period
Returns:
- df_Y: yearly averaged anomaly
- df_ref_Y: yearly averaged reference temperatures
"""
# reference frame (just a number now)
df_ref_Y = df_ref['value'].mean()
# plotting frame:
df_Y = df.resample('AS').mean() # this will fill incomplete years into complete ones and place the mean into the first day of the year
# calculate anomaly:
df_Y['value'] -= df_ref_Y
return df_Y, df_ref_Y
# + [markdown] id="kI1cgxPmfuOV" colab_type="text"
# ## Plot
# + id="RnPY8ZzDfvnI" colab_type="code" colab={}
def stripe_plot(df_in, df_ref, freq, flag=True):
'''
the plotting function for warming stripes.
Inputs:
- df: the conditioned DataFrame for plotting;
- df_ref: the reference DataFrame for calculating the anomaly
- freq: 'W', 'M', or 'Y'
frequency for calculating and ploting the anomaly
- flag: Boolean
whether to plot the data points over the strips or not. Default is True.
Returns:
warming stripes figure named 'warming-stripe-[freq].png'.
---
<NAME>, 'Creating the Warming Stripes in Matplotlib'
https://matplotlib.org/matplotblog/posts/warming-stripes/
'''
if freq == 'W':
df = cal_anomaly_W(df_in, df_ref)[0] # call in the func that calculates weekly anomaly
interval = 7
elif freq == 'M':
df = cal_anomaly_M(df_in, df_ref)[0]
interval = 31
elif freq == 'Y':
df = cal_anomaly_Y(df_in, df_ref)[0]
interval = 366
else:
print('Please enter a valid frequency (W, M, or Y)')
max_temp = df["value"].max()
min_temp = df["value"].min()
temp_delta = max_temp - min_temp # deg C
buffer = 0.2 # deg C
cmap = ListedColormap([
'#08306b', '#08519c', '#2171b5', '#4292c6',
'#6baed6', '#9ecae1', '#c6dbef', '#deebf7',
'#fee0d2', '#fcbba1', '#fc9272', '#fb6a4a',
'#ef3b2c', '#cb181d', '#a50f15', '#67000d',
])
stripes = len(df.index)
fig = plt.figure(figsize=(min(0.2*stripes, 12), 5))
ax = fig.add_axes([0.1, 0.12, 0.9, 0.88])
date_str_list = ['{}'.format(d) for d in df.index]
date_corrected = mdates.datestr2num(date_str_list)
col = PatchCollection([
Rectangle((y, min_temp - buffer), interval, temp_delta + 2*buffer)
for y in date_corrected.astype(int)
])
# set data, colormap and color limits
col.set_array(df['value'])
col.set_cmap(cmap)
col.set_clim(min_temp, max_temp)
ax.add_collection(col)
ax.set_ylim(min_temp - buffer, max_temp + buffer)
ax.set_xlim(date_corrected[0], date_corrected[-1])
formatter = mdates.DateFormatter('%Y-%m-%d')
ax.xaxis.set_major_formatter(formatter)
fig.autofmt_xdate()
ax.set_xlabel('date')
# flag
if flag == True:
ax.plot(df['value'],':o',color='gold',linewidth=3, markersize=10)
ax.set_ylabel('temperature [deg C]')
else:
ax.axes.get_yaxis().set_visible(False)
fig.savefig('warming-stripes-'+freq+'.png')
fig.show()
# + [markdown] id="zopL0sVAhYmf" colab_type="text"
# # Example
# Location: Barcelona, Spain<br>
# Start Date: 1/1/1914<br>
# End Date: 12/31/2013
# + [markdown] id="UR6ErXpdidGh" colab_type="text"
# ### Get reference dataset
# + id="YKG64jrxicFX" colab_type="code" outputId="d9f49326-f161-46c7-8dc7-f2f85ff88305" colab={"base_uri": "https://localhost:8080/", "height": 87}
df_ref = loop_request(locationid="CITY:SP000001", startdate=datetime.date(1970, 1, 1), enddate=datetime.date(1999, 12, 31), stationid="GHCND:SPE00155259")
df_ref = clean_up(df_ref)
# Uncomment to display output
# display(df_ref.describe(), df_ref.head())
# + [markdown] id="6zEhxqc1gt6l" colab_type="text"
# ### Get the dataset
# + id="5AdHXqWlUPG9" colab_type="code" outputId="54b287c8-1145-4cff-d558-d766ca6a7f8f" colab={"base_uri": "https://localhost:8080/", "height": 87}
df = loop_request(locationid="CITY:SP000001", startdate=datetime.date(1914, 1, 1), enddate=datetime.date(2013, 12, 31), stationid="GHCND:SPE00155259")
df = clean_up(df)
# Uncomment to display output
# display(df.describe(), df.head(), df.tail())
# + [markdown] id="FST_A-UJg4eC" colab_type="text"
# ### Weekly
# + [markdown] id="PlnutRjRmwgE" colab_type="text"
# <b>Calculate Anomalies</b>
# + id="B9ccd0efgpwk" colab_type="code" outputId="ca29f048-f9ff-442d-a5c6-139becbf1d6a" colab={"base_uri": "https://localhost:8080/", "height": 176}
df_W, df_ref_W = cal_anomaly_W(df, df_ref)
# Uncomment to display output
# display(df_ref_W, df.head(), df_W.head())
# + [markdown] id="ayz8dNOfmyfG" colab_type="text"
# <b>Plot Climate Stripes</b>
# + id="FOajrHo_mScg" colab_type="code" outputId="212ecf30-16fe-4a44-9718-48b971311f6b" colab={"base_uri": "https://localhost:8080/", "height": 564}
stripe_plot(df, df_ref, freq='W', flag=0)
# + [markdown] id="6xeG6D13m4cS" colab_type="text"
# ### Monthly
# + [markdown] id="ZQPE_Erdm-th" colab_type="text"
# <b>Calculate Anomalies</b>
# + id="ychXNVR6m_Zi" colab_type="code" outputId="dc4bd928-9508-4f16-fe64-7cda7358bcea" colab={"base_uri": "https://localhost:8080/", "height": 87}
df_M, df_ref_M = cal_anomaly_M(df, df_ref)
# Uncomment to display output
# display(df_ref_M, df.head(), df_M.head())
# + [markdown] id="uYSrnQVum_hU" colab_type="text"
# <b>Plot Climate Stripes</b>
# + id="zyOEao8Dm_pz" colab_type="code" outputId="31e756bc-db91-4b2d-cef2-2569929f9257" colab={"base_uri": "https://localhost:8080/", "height": 603}
stripe_plot(df, df_ref, freq='M', flag=1)
# + [markdown] id="0LVXptH0zGHA" colab_type="text"
# ### Yearly
# + [markdown] id="7NyiB-eczKhk" colab_type="text"
# <b> Calculate Anomalies </b>
# + id="A6qMlnKGzNvj" colab_type="code" colab={}
df_Y, df_ref_Y = cal_anomaly_Y(df, df_ref)
# Uncomment to display output
# display(df_ref_Y, df.head(), df_Y.head())
# + [markdown] id="TyJudAzKzN2q" colab_type="text"
# <b> Plot Climate Stripes
# + id="uJfFBWxgseS-" colab_type="code" outputId="4b3892d9-4540-4999-bc35-2a7f1c740269" colab={"base_uri": "https://localhost:8080/", "height": 406}
stripe_plot(df, df_ref, freq='Y', flag=1)
# + id="RoTYTTBp8zPy" colab_type="code" colab={}
| ATMS-597-SP-2020-Project-2/climatestripes.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
m1 = 'CCcCCccCCCccCcCccCcCcCCCcCCcccCCcCcCcCcccCCcCcccCc'
m2 = 'CCCCCccCccCcCCCCccCccccCccCccCCcCccCcCcCCcCccCccCc'
m3 = 'CccCCccCcCCCCCCCCCCcccCccCCCCCCccCCCcccCCCcCCcccCC'
m4 = 'cCCccCCccCCccCCccccCcCcCcCcCcCcCCCCccccCCCcCCcCCCC'
m5 = 'CCCcCcCcCcCCCcCCcCcCCccCcCCcccCccCCcCcCcCcCcccccCc'
eventos = {'m1':list(m1), 'm2': list(m2), 'm3':list(m3), 'm4':list(m4), 'm5':list(m5)}
moedas = pd.DataFrame(eventos)
df = pd.DataFrame(data = ['Cara', 'Coroa'], index=['c', 'C'], columns = ['Faces'])
df
for item in moedas:
df = pd.concat([df, moedas[item].value_counts()], axis=1)
df
| extras/Exercicios Contadores.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Loading data into StellarGraph from NumPy
#
# > This demo explains how to load data from NumPy into a form that can be used by the StellarGraph library. [See all other demos](../README.md).
#
# + [markdown] nbsphinx="hidden" tags=["CloudRunner"]
# <table><tr><td>Run the latest release of this notebook:</td><td><a href="https://mybinder.org/v2/gh/stellargraph/stellargraph/master?urlpath=lab/tree/demos/basics/loading-numpy.ipynb" alt="Open In Binder" target="_parent"><img src="https://mybinder.org/badge_logo.svg"/></a></td><td><a href="https://colab.research.google.com/github/stellargraph/stellargraph/blob/master/demos/basics/loading-numpy.ipynb" alt="Open In Colab" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg"/></a></td></tr></table>
# -
# [The StellarGraph library](https://github.com/stellargraph/stellargraph) supports loading graph information from NumPy. [NumPy](https://www.numpy.org) is a library for working with data arrays.
#
# If your data can easily be loaded into a NumPy array, this is a great way to load it that has minimal overhead and offers the most control.
#
# This notebook walks through loading three kinds of graphs.
#
# - homogeneous graph with feature vectors
# - homogeneous graph with feature tensors
# - heterogeneous graph with feature vectors and tensors
#
# > StellarGraph supports loading data from many sources with all sorts of data preprocessing, via [Pandas](https://pandas.pydata.org) DataFrames, [NumPy](https://www.numpy.org) arrays, [Neo4j](https://neo4j.com) and [NetworkX](https://networkx.github.io) graphs. This notebook demonstrates loading data from NumPy. See [the other loading demos](README.md) for more details.
#
# This notebook only uses NumPy for the node features, with Pandas used for the edge data. The details and options for loading edge data in this format are discussed in [the "Loading data into StellarGraph from Pandas" demo](loading-pandas.ipynb).
#
# Additionally, if the node features are in a complicated format for loading and/or requires significant preprocessing, loading via Pandas is likely to be more convenient.
#
# The [documentation](https://stellargraph.readthedocs.io/en/stable/api.html#stellargraph.StellarGraph) for the `StellarGraph` class includes a compressed reminder of everything discussed in this file, as well as explanations of all of the parameters.
#
# The `StellarGraph` class is available at the top level of the `stellargraph` library:
# + nbsphinx="hidden" tags=["CloudRunner"]
# install StellarGraph if running on Google Colab
import sys
if 'google.colab' in sys.modules:
# %pip install -q stellargraph[demos]==1.3.0b
# + nbsphinx="hidden" tags=["VersionCheck"]
# verify that we're using the correct version of StellarGraph for this notebook
import stellargraph as sg
try:
sg.utils.validate_notebook_version("1.3.0b")
except AttributeError:
raise ValueError(
f"This notebook requires StellarGraph version 1.3.0b, but a different version {sg.__version__} is installed. Please see <https://github.com/stellargraph/stellargraph/issues/1172>."
) from None
# -
from stellargraph import StellarGraph
# ## Loading via NumPy
#
# A StellarGraph has two basic components:
#
# - nodes, with feature arrays or tensors
# - edges, consisting of a pair of nodes as the source and target, and feature arrays or tensors
#
# A NumPy array consists of a large number of values of a single type. It is thus appropriate for the feature arrays in nodes, but not as useful for edges, because the source and target node IDs may be different. Thus, node data can be input as a NumPy array directly, but edge data cannot. The latter still uses Pandas.
import numpy as np
import pandas as pd
# ## Sequential numeric graph structure
#
# As with the Pandas demo, we'll be working with a square graph. For simplicity, we'll start with a graph where the identifiers of nodes are sequential integers starting at 0:
#
# ```
# 0 -- 1
# | \ |
# | \ |
# 3 -- 2
# ```
#
# The edges of this graph can easily be encoded as the rows of a Pandas DataFrame:
square_numeric_edges = pd.DataFrame(
{"source": [0, 1, 2, 3, 0], "target": [1, 2, 3, 0, 2]}
)
square_numeric_edges
# ## Homogeneous graph with sequential IDs and feature vectors
#
# Now, suppose we have some feature vectors associated with each node in our square graph. For instance, maybe node `0` has features `[1, -0.2]`. This can come in the form of a 4 × 2 matrix, with one row per node, with row `0` being features for the `0` node, and so on. Filling out the rest of the example data:
feature_array = np.array(
[[1.0, -0.2], [2.0, 0.3], [3.0, 0.0], [4.0, -0.5]], dtype=np.float32
)
feature_array
# Because our nodes have IDs `0`, `1`, ..., we can construct the `StellarGraph` by passing in the feature array directly, along with the edges:
square_numeric = StellarGraph(feature_array, square_numeric_edges)
# The `info` method ([docs](https://stellargraph.readthedocs.io/en/stable/api.html#stellargraph.StellarGraph.info)) gives a high-level summary of a `StellarGraph`:
print(square_numeric.info())
# On this square, it tells us that there's 4 nodes of type `default` (a homogeneous graph still has node and edge types, but they default to `default`), with 2 features, and one type of edge that touches it. It also tells us that there's 5 edges of type `default` that go between nodes of type `default`. This matches what we expect: it's a graph with 4 nodes and 5 edges and one type of each.
#
# The default node type and edge types can be set using the `node_type_default` and `edge_type_default` parameters to `StellarGraph(...)`:
square_numeric_named = StellarGraph(
feature_array,
square_numeric_edges,
node_type_default="corner",
edge_type_default="line",
)
print(square_numeric_named.info())
# ## Non-sequential graph structure
#
# Requiring node identifiers to always be sequential integers from 0 is restrictive. Most real-world graphs don't have such neat IDs. For instance, maybe our graph instead uses strings as IDs:
#
# ```
# a -- b
# | \ |
# | \ |
# d -- c
# ```
#
# As before, these edges get encoded as a DataFrame:
square_edges = pd.DataFrame(
{"source": ["a", "b", "c", "d", "a"], "target": ["b", "c", "d", "a", "c"]}
)
square_edges
# ## Homogeneous graph with non-numeric IDs and feature vectors
#
# With non-sequential, non-numeric IDs, we cannot use a NumPy array directly, because we need to know which row of the array corresponds to which node. This is done with the `IndexedArray` ([docs](https://stellargraph.readthedocs.io/en/stable/api.html#stellargraph.IndexedArray)) type. It is a much simplified Pandas DataFrame, that is generalised to be more than 2-dimensional. It is available at the top level of `stellargraph`, and supports an `index` parameter to define the mapping from row to node. The `index` should have one element per row of the NumPy array.
from stellargraph import IndexedArray
indexed_array = IndexedArray(feature_array, index=["a", "b", "c", "d"])
square_named = StellarGraph(
indexed_array, square_edges, node_type_default="corner", edge_type_default="line",
)
print(square_named.info())
# As before, there's 4 nodes, each with features of length 2.
# ## Homogeneous graph with non-numeric IDs and feature tensors
#
# Some algorithms work with than just a feature vector associated with each node. For instance, if each node corresponds to a weather station, one might have a time series of observations like "temperature" and "pressure" associated with each node. This is modelled by having a multidimensional feature for each node.
#
# Time series algorithms within StellarGraph expect the tensor to be shaped like `nodes × time steps × variates`. For the weather station example, `nodes` is the number of weather stations, `time steps` is the number of points within each series and `variates` is the number of observations at each time step.
#
# For our square graph, we might have time series of length three, containing two observations.
feature_tensors = np.array(
[
[[1.0, -0.2], [1.0, 0.1], [0.9, 0.1]],
[[2.0, 0.3], [1.9, 0.31], [2.1, 0.32]],
[[3.0, 0.0], [10.0, 0.0], [3.0, 0.0]],
[[4.0, -0.5], [0.0, -1.0], [1.0, -3.0]],
],
dtype=np.float32,
)
feature_tensors
indexed_tensors = IndexedArray(feature_tensors, index=["a", "b", "c", "d"])
square_tensors = StellarGraph(
indexed_tensors, square_edges, node_type_default="corner", edge_type_default="line",
)
print(square_tensors.info())
# We can see that the features of the `corner` nodes are now listed as a tensor, with shape 3 × 2, matching the array we created above.
# ## Heterogeneous graphs
#
# Some graphs have multiple types of nodes.
#
# For example, an academic citation network that includes authors might have `wrote` edges connecting `author` nodes to `paper` nodes, in addition to the `cites` edges between `paper` nodes. There could be `supervised` edges between `author`s ([example](https://academictree.org)) too, or any number of additional node and edge types. A knowledge graph (aka RDF, triple stores or knowledge base) is an extreme form of an heterogeneous graph, with dozens, hundreds or even thousands of edge (or relation) types. Typically in a knowledge graph, edges and their types represent the information associated with a node, rather than node features.
#
# `StellarGraph` supports all forms of heterogeneous graphs.
#
# A heterogeneous `StellarGraph` can be constructed in a similar way to a homogeneous graph, except we pass a dictionary with multiple elements instead of a single element like we did in the "homogeneous graph with features" section and others above. For a heterogeneous graph, a dictionary has to be passed; passing a single `IndexedArray` does not work.
#
# Let's return to the square graph from earlier:
#
# ```
# a -- b
# | \ |
# | \ |
# d -- c
# ```
#
# ### Feature arrays
#
# Suppose `a` is of type `foo`, and no features, but `b`, `c` and `d` are of type `bar` and have two features each, e.g. for `b`, `0.4, 100`. Since the features are different shapes (`a` has zero), they need to be modeled as different types, with separate `IndexedArray`s.
square_foo = IndexedArray(index=["a"])
bar_features = np.array([[0.4, 100], [0.1, 200], [0.9, 300]])
bar_features
square_bar = IndexedArray(bar_features, index=["b", "c", "d"])
# We have the information for the two node types `foo` and `bar` in separate DataFrames, so we can now put them in a dictionary to create a `StellarGraph`. Notice that `info()` is now reporting multiple node types, as well as information specific to each.
square_foo_and_bar = StellarGraph({"foo": square_foo, "bar": square_bar}, square_edges)
print(square_foo_and_bar.info())
# Node IDs (the DataFrame index) needs to be unique across all types. For example, renaming the `a` corner to `b` like `square_foo_overlap` in the next cell, is not accepted and a `StellarGraph(...)` call will throw an error
square_foo_overlap = IndexedArray(index=["b"])
# +
# Uncomment to see the error
# StellarGraph({"foo": square_foo_overlap, "bar": square_bar}, square_edges)
# -
# If the node IDs aren't unique across types, one way to make them unique is to add a string prefix. You'll need to add the same prefix to the node IDs used in the edges too. Adding a prefix can be done by replacing the index:
square_foo_overlap_prefix = IndexedArray(
square_foo_overlap.values, index=[f"foo-{s}" for s in square_foo_overlap.index]
)
square_bar_prefix = IndexedArray(
square_bar.values, index=[f"bar-{s}" for s in square_bar.index]
)
# ### Feature tensors
#
# Nodes of different types can have features of completely different shapes, not just vectors of different lengths. For instance, suppose our `foo` node (`a`) has the multi-variate time series from above as a feature.
foo_tensors = np.array([[[1.0, -0.2], [1.0, 0.1], [0.9, 0.1]]])
foo_tensors
square_foo_tensors = IndexedArray(foo_tensors, index=["a"])
square_foo_tensors_and_bar = StellarGraph(
{"foo": square_foo_tensors, "bar": square_bar}, square_edges
)
print(square_foo_tensors_and_bar.info())
# We can now see that the `foo` node is listed as having a feature tensor, as desired.
# ## Conclusion
#
# You hopefully now know more about building node features for a `StellarGraph` in various configurations via NumPy arrays.
#
# For more details on graphs with directed, weighted or heterogeneous edges, see [the "Loading data into StellarGraph from Pandas" demo](loading-pandas.ipynb). All of the examples there work with `IndexedArray` instead of Pandas DataFrames for the node features.
#
# Revisit this document to use as a reminder, or [the documentation](https://stellargraph.readthedocs.io/en/stable/api.html#stellargraph.StellarGraph) for the `StellarGraph` class.
#
# Once you've loaded your data, you can start doing machine learning: a good place to start is the [demo of the GCN algorithm on the Cora dataset for node classification](../node-classification/gcn-node-classification.ipynb). Additionally, StellarGraph includes [many other demos of other algorithms, solving other tasks](../README.md).
# + [markdown] nbsphinx="hidden" tags=["CloudRunner"]
# <table><tr><td>Run the latest release of this notebook:</td><td><a href="https://mybinder.org/v2/gh/stellargraph/stellargraph/master?urlpath=lab/tree/demos/basics/loading-numpy.ipynb" alt="Open In Binder" target="_parent"><img src="https://mybinder.org/badge_logo.svg"/></a></td><td><a href="https://colab.research.google.com/github/stellargraph/stellargraph/blob/master/demos/basics/loading-numpy.ipynb" alt="Open In Colab" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg"/></a></td></tr></table>
| demos/basics/loading-numpy.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # 4. Visualizing Data - Reporting & Analytics
#
# In the last notebook, we saw the basic starting point for a report. For example:
#
# ## 4.1 Report example
#
# #### Top 10 Salespeople by Total Sales (USD), Last 12 Months
#
# ```
# Yearly Sales (USD) State Salesperson
# $3312283.72 TX <NAME>
# $3173485.84 CA <NAME>
# $2113674.22 NY Kendra Ingram
# $2017619.26 FL <NAME>
# $1627246.43 GA <NAME>
# $1380399.77 IL <NAME>
# $1106723.17 OH <NAME>
# $1036475.05 MA <NAME>
# $1023290.36 MO <NAME>
# $1003630.76 MI <NAME>
# ```
#
# This is a very useful report for a country sales manager, for example. Charts and graphs can provide a more useful visualization of the data at times. Microsoft Excel makes this really easy; just paste the data into Excel, and you can create a bar chart with a couple clicks.
#
# ## 4.2 Excel chart example
#
# <img src="images/sales-chart-excel.png">
#
# However, in many cases, you'll want to use automation or data analysis tools as well. Excel is very powerful and popular, but visualization tools such as Tableau, Power BI, Qlik Sense, and Looker are used extensively in the data analytics world.
#
# In addition, you can generate charts easily from your Python code. Let's look at an example.
# !pip install altair
# ## 4.3 Adding a chart in Python using Altair
#
# Let's return to the example from last notebook where we retrieved the sales data by salesperson from the database. We pulled that into a pandas dataframe. There's a great charting library called <a href="https://altair-viz.github.io/index.html">Altair</a> that can take a pandas dataframe and easily make a chart out of it:
# +
from my_connect import my_connect
import pandas
import altair
connection = my_connect()
q = """
SELECT SUM(sales.amount) AS total, salesperson.state, salesperson.name FROM sales
INNER JOIN fips ON sales.fips = fips.fipstxt
INNER JOIN salesperson ON fips.state = salesperson.state
GROUP BY (salesperson.state, salesperson.name)
ORDER BY total DESC LIMIT 10;
"""
df = pandas.io.sql.read_sql_query(q, connection)
altair.Chart(df).mark_bar().encode(
altair.X('name', sort=altair.EncodingSortField(field='total', order='descending')),
y='total')
# -
# Run the above, and you should get something like this:
#
# <img src="images/sales-chart-altair.png">
#
# # Next notebook: business insights from Covid-19 impact to sales
#
# Next we will look at some specific business questions about Covid-19 and how it might impact our business.
#
# <a href="5. Bring In Covid-19 Data.ipynb">Go to the next notebook -></a>
#
#
# *Contents © Copyright 2020 HP Development Company, L.P. SPDX-License-Identifier: MIT*
| jupyter-notebooks/4. Visualization.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 1.2.0
# language: julia
# name: julia-1.2
# ---
x = [0.0, 1.0, 2.0]
y = [5.0, 6.0, 7.0]
x .* y
x * y'
x' * y
# +
struct Molecule
species::Symbol
atoms::Array{Symbol}
end
molecule = Molecule(:methane, [:C, :H, :H, :H, :H])
molecule.atoms
# -
# ### Optional arguments
f(x, m; b=0.0) = m * x + b
f(1.0, 3.0) # assume b = 0
f(1.0, 3.0, b=30.0) # keyword argument
h(x, m, b=0.0) = m * x + b # positional argument
h(1.0, 3.0) # b is assumed 0.0
h(1.0, 3.0, 30.0)
# ### Random
using Random # for shuffle
using StatsBase # for sample
# ## Mutable vs immutable
| CHE599-IntroDataScience/lectures/intro_julia/intro_julia.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] colab_type="text" id="0RXyf5KpPomu"
# # Pandas Series
#
# 파이썬 시리즈(Python Series)는 판다스의 중요 자료구조 중 하나로 1차원 자료구조이다.
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 1054, "status": "ok", "timestamp": 1593051725545, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="Um71uiExPhWx" outputId="965dc2ed-feda-4705-a7c6-3348c1c40c80"
import pandas as pd
import numpy as np
pd.__version__
# + colab={"base_uri": "https://localhost:8080/", "height": 143} colab_type="code" executionInfo={"elapsed": 1418, "status": "ok", "timestamp": 1593054040042, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="SzdbwjJ5SCHj" outputId="cb6ef41a-dc9a-4be6-8159-7346e58695cf"
s = pd.Series([1, 3, 5, np.nan, 1, 2], index=['A','B','C','D','E','F'])
s
# + [markdown] colab_type="text" id="VInXHWOWSlxa"
# ### 인덱싱과 슬라이싱
#
# numpy 배열과 같은 방법으로 인덱싱과 슬라이싱 할 수 있다.
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 1030, "status": "ok", "timestamp": 1593054042294, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="S3DbweTHaOO6" outputId="8b56a33c-ce68-4011-c8e2-679116cd986c"
s[0]
# + colab={"base_uri": "https://localhost:8080/", "height": 89} colab_type="code" executionInfo={"elapsed": 1143, "status": "ok", "timestamp": 1593054047260, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="Yv8xB95KaQh7" outputId="2093f6ee-5d01-42ee-add8-7234a23a9aaf"
s[2:5]
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 1129, "status": "ok", "timestamp": 1593054050254, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="62WGTQDCaSAE" outputId="ea822f33-d03a-44d7-c3b2-9cc4c297831f"
s['A']
# + colab={"base_uri": "https://localhost:8080/", "height": 89} colab_type="code" executionInfo={"elapsed": 1288, "status": "ok", "timestamp": 1593054051765, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="eSBQo78qanGp" outputId="48431d6a-b0af-4b77-c551-6e41c2e97784"
s['A':'C']
# + [markdown] colab_type="text" id="-iNCZyhnasTg"
# ### 시리즈의 메소드
# + colab={"base_uri": "https://localhost:8080/", "height": 107} colab_type="code" executionInfo={"elapsed": 922, "status": "ok", "timestamp": 1593054078684, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="4c6uBoJUayA5" outputId="b7825e18-b4df-4dfb-b822-d3e774189ac5"
s.value_counts() # 고유값의 빈도수
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 990, "status": "ok", "timestamp": 1593054097493, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="bgco9RiMbCL_" outputId="6f5049e6-e90a-402f-8493-a38a08f0ff81"
s.index # 인덱스 이름
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 1133, "status": "ok", "timestamp": 1593054108850, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="8txaqWI9bGwx" outputId="b49859d7-d185-430d-a85a-cb84b0b3ada0"
s.shape
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 1035, "status": "ok", "timestamp": 1593054157415, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="nJoPwTvvbJgS" outputId="693f3586-06e2-473e-dd7d-b88b617c0228"
s.count() # 결측치를 제외한 갯수
# + colab={"base_uri": "https://localhost:8080/", "height": 143} colab_type="code" executionInfo={"elapsed": 1074, "status": "ok", "timestamp": 1593054175262, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="klJ5ohKKbVYO" outputId="4d75bd93-3f9a-43d2-e9ea-2d4711af8093"
s.sort_values()
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 958, "status": "ok", "timestamp": 1593054192909, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="5b6BNldWbZu4" outputId="bb507e5b-fc88-4f58-9a80-97e97add5fe2"
s.unique()
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 1055, "status": "ok", "timestamp": 1593054204045, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="cWn6BJqHbeEa" outputId="d70328c9-8e86-43a6-ce40-7195758ae7a1"
s.nunique()
# + colab={"base_uri": "https://localhost:8080/", "height": 143} colab_type="code" executionInfo={"elapsed": 1346, "status": "ok", "timestamp": 1593054231000, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="tQ8YFFRfbgw7" outputId="35d02a59-880c-48bd-eaa4-6632e5ecfebd"
s.isin([1,2])
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 950, "status": "ok", "timestamp": 1593054245275, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="bPj4tTTWbnRd" outputId="4ec8998e-b4d8-4fbc-b7e9-3b0a1628534b"
s.min()
# + colab={"base_uri": "https://localhost:8080/", "height": 179} colab_type="code" executionInfo={"elapsed": 977, "status": "ok", "timestamp": 1593054260913, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="cEgFj4Xtbq2v" outputId="abb070b5-8f46-4f14-cf7c-1bd59eed1153"
s.describe()
# + colab={"base_uri": "https://localhost:8080/", "height": 35} colab_type="code" executionInfo={"elapsed": 1045, "status": "ok", "timestamp": 1593054277652, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="bsz1YlOgbuqp" outputId="0cdafded-7ae8-42fb-8b40-35c0e1e614b3"
s.quantile(q=0.75)
# + colab={"base_uri": "https://localhost:8080/", "height": 143} colab_type="code" executionInfo={"elapsed": 1105, "status": "ok", "timestamp": 1593054291087, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="s_VVjMUPbyvL" outputId="4ec2a3cb-e6fc-4f31-bb6a-e9dcbc2e7ea4"
s.isnull()
# + colab={"base_uri": "https://localhost:8080/", "height": 143} colab_type="code" executionInfo={"elapsed": 961, "status": "ok", "timestamp": 1593054313557, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="Ais9m0hCb1_z" outputId="5110c593-aae7-47c9-a4c7-3ee49f4c4e0a"
s.fillna(-99)
# + colab={"base_uri": "https://localhost:8080/", "height": 125} colab_type="code" executionInfo={"elapsed": 1063, "status": "ok", "timestamp": 1593054326600, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="t3jxzHv6b7hV" outputId="b394162c-0071-4f1d-bdaa-0c3f4fe57d58"
s.dropna()
# + colab={} colab_type="code" executionInfo={"elapsed": 1134, "status": "ok", "timestamp": 1593054445568, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="7SBPlKS5b-rn"
s1 = pd.Series([10,20,30,40])
s2 = pd.Series([1,2,300,400])
# + colab={"base_uri": "https://localhost:8080/", "height": 107} colab_type="code" executionInfo={"elapsed": 612, "status": "ok", "timestamp": 1593054445569, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="awQJOl7Db9qG" outputId="6524b594-b17b-431b-ee79-e868f2768579"
s1 + s2
# + colab={"base_uri": "https://localhost:8080/", "height": 107} colab_type="code" executionInfo={"elapsed": 756, "status": "ok", "timestamp": 1593054446834, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="Py1g0pX-b5rd" outputId="8c1b3277-7da4-4885-9ba7-45f6a18f3694"
s1 > s2
# + colab={"base_uri": "https://localhost:8080/", "height": 71} colab_type="code" executionInfo={"elapsed": 1036, "status": "ok", "timestamp": 1593054462769, "user": {"displayName": "\uc774\uc120\ud654", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GiGEcSuxiespWUAaMC6eXljdm2fXmv29ZXuZ14n=s64", "userId": "08084686575025891086"}, "user_tz": -540} id="5j6Mu4eYbNWL" outputId="c69cdbd5-27b0-4c7d-ebd6-0319f32350a2"
s1[s1 > s2]
# + [markdown] colab_type="text" id="QlTpIVBycf7V"
# # 실습하기
# + [markdown] colab_type="text" id="O3TWcYmXdEtZ"
# 1. 다음과 같은 시리즈 데이터를 생성하시오.
# ```
# >>> population = pd.Series([852469, 1015785, 485199, np.nan],
# index=['San Francisco', 'San Jose', 'Sacramento', 'Seoul'])
# ```
# + colab={} colab_type="code" id="B1LgHdltgiX5"
# + [markdown] colab_type="text" id="rciQZjfBdQKF"
# 2. population에서 인구 500000명 이상의 값을 출력하시오.
#
# + colab={} colab_type="code" id="quJTZgWegi7P"
# + [markdown] colab_type="text" id="u5k2ts3UeGhM"
# 3. population의 인덱스 명을 출력하시오.
# + colab={} colab_type="code" id="s9sIrBiUgjgS"
# + [markdown] colab_type="text" id="5Dn-e4g_emEp"
# 4. 'San Jose'의 인구수를 출력하시오.
# + colab={} colab_type="code" id="EQgGFA8PgkUD"
# + [markdown] colab_type="text" id="av1UQGcNfE_9"
# 5. 결측치를 0으로 대체하시오.
# + colab={} colab_type="code" id="ULefcjyYgky5"
# + [markdown] colab_type="text" id="h_XI2UKGffI3"
# 6. 인구의 평균과 최소, 최대값을 구하시오.
# + colab={} colab_type="code" id="LLtq5rElglXN"
| 03Pandas/01Series.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Monte Carlo approximation of pi
# +
import numpy as np
import matplotlib.pyplot as plt
from numpy import random
def calculate_pi(n):
inside=0
outside=0
for i in range(n):
x=random.random()
y=random.random()
r=np.sqrt(x**2+y**2)
if r<1:
inside=inside+1
plt.plot(x,y,"r")
elif r>=1:
outside=outside+1
plt.plot(x,y,"b")
plt.show()
pi=(4*inside)/(n)
return pi
# -
# In this session you will be practicing a number of things you've learned over the last two days and seeing how you can combine those seemingly distinct concepts to solve a problem. First let's discuss the problem we intend to solve.
#
# Suppose we need to calculate the value of $\pi$ (it's readily available in several libraries, but let's assume for the purposes of this excercise that you need to calculate it anyway). The approach we'll use for this is called a [Monte Carlo method](https://en.wikipedia.org/wiki/Monte_Carlo_method). For those unfamiliar with the term, Monte Carlo methods are a way to approximate values using random numbers which have some particular statistical properties relevant to the problem at hand.
#
# This method consists of the following steps:
# - Consider a unit square (x = [0, 1], y = [0, 1]) containing a quarter of a unit circle ($r = 1$)
# - Randomly select a point within the square
# - Determine whether the selected point is within the circle
# - As you select more points, the ratio of the number of points within the circle to the total number of points will converge towards $\pi / 4$, so
#
# $$
# \pi = 4 \frac{\text{number of points in circle}}{\text{total number of points}}
# $$
#
#
# 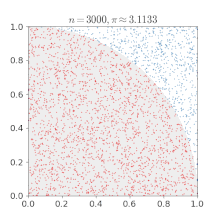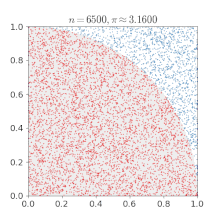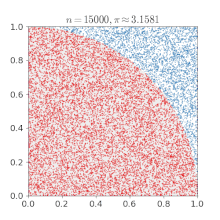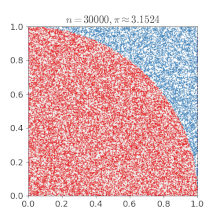
#
# <section class="challenge panel panel-success">
# <div class="panel-heading">
# <h2><span class="fa fa-pencil"></span> Challenge</h2>
# </div>
#
#
# <div class="panel-body">
#
# <ol>
# <li>Here in the notebook, write a function that implements the algorithm described above and returns a value for $\pi$<ul>
# <li>If it helps you to conceptualise the problem, loop over the number of points you want to use and do your calculations on each iteration</li>
# <li>Once you're happy with that, refactor your function so that it uses numpy operations and considers all the points at once, instead of looping over them</li>
# </ul>
# </li>
# </ol>
#
# </div>
#
# </section>
#
import numpy as np
# +
import numpy as np
from numpy import random
import matplotlib.pyplot as plt
def calculate_pi(n):
inside=0
outside=0
for i in range(n):
x=random.random()
y=random.random()
r=np.sqrt((x**2)+(y**2))
if r<1:
inside+=1
plt.plot(x,y,"ro")
elif r>=1:
outside +=1
plt.plot(x,y,"bo")
plt.show()
pi= 4*(inside/(n))
return pi
# -
print(calculate_pi(1000))
#
# <section class="challenge panel panel-success">
# <div class="panel-heading">
# <h2><span class="fa fa-pencil"></span> Challenge</h2>
# </div>
#
#
# <div class="panel-body">
#
# <ol>
# <li>
# <p>Outside the notebook, in whatever text editor you're most comfortable using, make a Python script containing your $\pi$-calculation function, and save it in the same directory as this notebook. Import that function into the notebook and test it a bit. Make sure it still gives the correct answer and that you're happy using it as an imported function.</p>
# </li>
# <li>
# <p>Write some tests for your function, in a separate test script. Run your tests and make sure that your function is definitely doing what you expect it to be doing.</p>
# </li>
# </ol>
#
# </div>
#
# </section>
#
#
# <section class="challenge panel panel-success">
# <div class="panel-heading">
# <h2><span class="fa fa-pencil"></span> Challenge</h2>
# </div>
#
#
# <div class="panel-body">
#
# <ol>
# <li>In your script, make a plot like the one above showing the random coordinates used in your calculation and the answer those points produce.</li>
# <li>Try running your function with different numbers of iterations and making a plot to compare the different results this gives you.</li>
# </ol>
#
# </div>
#
# </section>
#
#
# <section class="challenge panel panel-success">
# <div class="panel-heading">
# <h2><span class="fa fa-pencil"></span> </h2>
# </div>
#
#
# <div class="panel-body">
#
# <p>If you get through all of the above tasks before the end of the session and want an additional challenge, try making an animated version of the plot above, which changes while the answer is being calculated and updates both the points and the title. We haven't covered how to make animations, so you'll have to look up how to do this using the matplotlib documentation other online resources, and ask one of the instructors if you get stuck.</p>
#
# </div>
#
# </section>
#
| 06-approximating-pi/01-calculating-pi.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# # Using Spectral Fits to Calculate Fluxes
#
# 3ML provides a module to calculate the integral flux from a spectral fit and additionally uses the covariance matrix or posteror to calculate the error in the flux value for the integration range selected
#
# +
# %pylab inline
from threeML import *
# -
# ## Data setup
#
# Using GRB 080916C as an example, we will fit two models to the time-integrated spectrum to demostrate the flux calculations capabilites.
# +
# os.path.join is a way to generate system-independent
# paths (good for unix, windows, Mac...)
data_dir = os.path.join('gbm','bn080916009')
trigger_number = 'bn080916009'
# Download the data
data_dir_gbm = os.path.join('gbm',trigger_number)
gbm_data = download_GBM_trigger_data(trigger_number,detectors=['n3','b0'],destination_directory=data_dir_gbm,compress_tte=True)
src_selection = '0-71'
nai3 = FermiGBMTTELike('NAI3',
os.path.join(data_dir, "glg_tte_n3_bn080916009_v01.fit.gz"),
os.path.join(data_dir, "glg_cspec_n3_bn080916009_v00.rsp2"),
src_selection,
"-10-0,100-200",
verbose=False)
bgo0 = FermiGBMTTELike('BGO0',
os.path.join(data_dir, "glg_tte_b0_bn080916009_v01.fit.gz"),
os.path.join(data_dir, "glg_cspec_b0_bn080916009_v00.rsp2"),
src_selection,
"-10-0,100-200",
verbose=False)
nai3.set_active_measurements("8.0-30.0", "40.0-950.0")
bgo0.set_active_measurements("250-43000")
# -
# ## Model setup
#
# We will fit two models: a Band function and a CPL+Blackbody
#
# +
triggerName = 'bn080916009'
ra = 121.8
dec = -61.3
data_list = DataList(nai3,bgo0 )
band = Band()
GRB1 = PointSource( triggerName, ra, dec, spectral_shape=band )
model1 = Model( GRB1 )
pl_bb= Powerlaw() + Blackbody()
GRB2 = PointSource( triggerName, ra, dec, spectral_shape=pl_bb )
model2 = Model( GRB2 )
# -
# ## Fitting
# ### MLE
#
# We fit both models using MLE
# +
jl1 = JointLikelihood( model1, data_list, verbose=False )
res = jl1.fit()
jl2 = JointLikelihood( model2, data_list, verbose=False )
res = jl2.fit()
# -
# ### Flux caluclation
#
# #### Total flux
#
# The **JointLikelihood** objects are passed to the **SpectralFlux** class.
# Then either **model_flux** or **component_flux** are called depending on the flux desired.
#
# The astropy system of units is used to specfiy flux units and an error is raised if the user selects an improper unit. The integration range is specified and the unit for this range can be altered.
#
#
# +
res = calculate_point_source_flux(10,40000,jl1.results,jl2.results,flux_unit='erg/(s cm2)',energy_unit='keV')
# -
# A panadas DataFrame is returned with the sources (a fitting object can have multiple sources) flux, and flux error.
#
# We can also change to photon fluxes by specifying the proper flux unit (here we changed to m^2). Here, the integration unit is also changed.
# +
res = calculate_point_source_flux(10,40000,jl1.results,jl2.results,flux_unit='1/(s cm2)',energy_unit='Hz',equal_tailed=False)
# -
# #### Components
#
# If we want to look at component fluxes, we examine our second fit.
#
# We can first look at the total flux:
#
# +
res = calculate_point_source_flux(10,40000,
jl1.results,jl2.results,
flux_unit='erg/(s cm2)',
energy_unit='keV',use_components=True)
# -
# Then we can look at our component fluxes. The class automatically solves the error propagation equations to properly propagate the parameter errors into the components
res = calculate_point_source_flux(10,40000,jl1.results,jl2.results,flux_unit='erg/(s cm2)',
energy_unit='keV',
equal_tailed=False,
use_components=True, components_to_use=['Blackbody','total'])
# A dictionary of sources is return that contains pandas DataFrames listing the fluxes and errors of each componenet.
#
# **NOTE**: *With proper error propagation, the total error is not always the sqrt of the sum of component errors squared!*
# ### Bayesian fitting
#
# Now we will look at the results when a Bayesian fit is performed.
#
# We set our priors and then sample:
# +
pl_bb.K_1.prior = Log_uniform_prior(lower_bound = 1E-1, upper_bound = 1E2)
pl_bb.index_1.set_uninformative_prior(Uniform_prior)
pl_bb.K_2.prior = Log_uniform_prior(lower_bound = 1E-6, upper_bound = 1E-3)
pl_bb.kT_2.prior = Log_uniform_prior(lower_bound = 1E0, upper_bound = 1E4)
# -
bayes = BayesianAnalysis(model2,data_list)
_=bayes.sample(30,100,500)
# ### Flux Calculation
#
# #### Total Flux
#
# Just as with MLE, we pass the **BayesianAnalysis** object to the **SpectralFlux** class.
#
# Now the propagation of fluxes is done using the posterior of the analysis.
res = calculate_point_source_flux(10,40000,
bayes.results,
flux_unit='erg/(s cm2)',
energy_unit='keV')
# Once again, a DataFrame is returned. This time, it contains the mean flux from the distribution, the specfied level (default is 0.05) credible regions and the flux distribution itself.
#
# One can plot the distribtuion:
# +
from astropy.visualization import quantity_support
quantity_support()
_=hist(res[1]['flux distribution'][0],bins=20)
# -
# #### Components
# We can also look at components as before. A dictionary of sources is returned, each containing Dataframes of the components information and distributions.
#
res = calculate_point_source_flux(10,40000,
bayes.results,
flux_unit='erg/(s cm2)',
energy_unit='keV',
use_components=True)
# We can easily now visulaize the flux distribtuions from the individual components.
# +
_=hist(log10(res[1]['flux distribution'][0].value),bins=20)
_=hist(log10(res[1]['flux distribution'][1].value),bins=20)
# -
res = calculate_point_source_flux(10,40000,
bayes.results,jl1.results,jl2.results,
flux_unit='erg/(s cm2)',
energy_unit='keV')
| examples/Flux_Calculations.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %matplotlib inline
#
# Advanced: Making Dynamic Decisions and the Bi-LSTM CRF
# ======================================================
#
# Dynamic versus Static Deep Learning Toolkits
# --------------------------------------------
#
# Pytorch is a *dynamic* neural network kit. Another example of a dynamic
# kit is `Dynet <https://github.com/clab/dynet>`__ (I mention this because
# working with Pytorch and Dynet is similar. If you see an example in
# Dynet, it will probably help you implement it in Pytorch). The opposite
# is the *static* tool kit, which includes Theano, Keras, TensorFlow, etc.
# The core difference is the following:
#
# * In a static toolkit, you define
# a computation graph once, compile it, and then stream instances to it.
# * In a dynamic toolkit, you define a computation graph *for each
# instance*. It is never compiled and is executed on-the-fly
#
# Without a lot of experience, it is difficult to appreciate the
# difference. One example is to suppose we want to build a deep
# constituent parser. Suppose our model involves roughly the following
# steps:
#
# * We build the tree bottom up
# * Tag the root nodes (the words of the sentence)
# * From there, use a neural network and the embeddings
# of the words to find combinations that form constituents. Whenever you
# form a new constituent, use some sort of technique to get an embedding
# of the constituent. In this case, our network architecture will depend
# completely on the input sentence. In the sentence "The green cat
# scratched the wall", at some point in the model, we will want to combine
# the span $(i,j,r) = (1, 3, \text{NP})$ (that is, an NP constituent
# spans word 1 to word 3, in this case "The green cat").
#
# However, another sentence might be "Somewhere, the big fat cat scratched
# the wall". In this sentence, we will want to form the constituent
# $(2, 4, NP)$ at some point. The constituents we will want to form
# will depend on the instance. If we just compile the computation graph
# once, as in a static toolkit, it will be exceptionally difficult or
# impossible to program this logic. In a dynamic toolkit though, there
# isn't just 1 pre-defined computation graph. There can be a new
# computation graph for each instance, so this problem goes away.
#
# Dynamic toolkits also have the advantage of being easier to debug and
# the code more closely resembling the host language (by that I mean that
# Pytorch and Dynet look more like actual Python code than Keras or
# Theano).
#
# Bi-LSTM Conditional Random Field Discussion
# -------------------------------------------
#
# For this section, we will see a full, complicated example of a Bi-LSTM
# Conditional Random Field for named-entity recognition. The LSTM tagger
# above is typically sufficient for part-of-speech tagging, but a sequence
# model like the CRF is really essential for strong performance on NER.
# Familiarity with CRF's is assumed. Although this name sounds scary, all
# the model is is a CRF but where an LSTM provides the features. This is
# an advanced model though, far more complicated than any earlier model in
# this tutorial. If you want to skip it, that is fine. To see if you're
# ready, see if you can:
#
# - Write the recurrence for the viterbi variable at step i for tag k.
# - Modify the above recurrence to compute the forward variables instead.
# - Modify again the above recurrence to compute the forward variables in
# log-space (hint: log-sum-exp)
#
# If you can do those three things, you should be able to understand the
# code below. Recall that the CRF computes a conditional probability. Let
# $y$ be a tag sequence and $x$ an input sequence of words.
# Then we compute
#
# \begin{align}P(y|x) = \frac{\exp{(\text{Score}(x, y)})}{\sum_{y'} \exp{(\text{Score}(x, y')})}\end{align}
#
# Where the score is determined by defining some log potentials
# $\log \psi_i(x,y)$ such that
#
# \begin{align}\text{Score}(x,y) = \sum_i \log \psi_i(x,y)\end{align}
#
# To make the partition function tractable, the potentials must look only
# at local features.
#
# In the Bi-LSTM CRF, we define two kinds of potentials: emission and
# transition. The emission potential for the word at index $i$ comes
# from the hidden state of the Bi-LSTM at timestep $i$. The
# transition scores are stored in a $|T|x|T|$ matrix
# $\textbf{P}$, where $T$ is the tag set. In my
# implementation, $\textbf{P}_{j,k}$ is the score of transitioning
# to tag $j$ from tag $k$. So:
#
# \begin{align}\text{Score}(x,y) = \sum_i \log \psi_\text{EMIT}(y_i \rightarrow x_i) + \log \psi_\text{TRANS}(y_{i-1} \rightarrow y_i)\end{align}
#
# \begin{align}= \sum_i h_i[y_i] + \textbf{P}_{y_i, y_{i-1}}\end{align}
#
# where in this second expression, we think of the tags as being assigned
# unique non-negative indices.
#
# If the above discussion was too brief, you can check out
# `this <http://www.cs.columbia.edu/%7Emcollins/crf.pdf>`__ write up from
# Michael Collins on CRFs.
#
# Implementation Notes
# --------------------
#
# The example below implements the forward algorithm in log space to
# compute the partition function, and the viterbi algorithm to decode.
# Backpropagation will compute the gradients automatically for us. We
# don't have to do anything by hand.
#
# The implementation is not optimized. If you understand what is going on,
# you'll probably quickly see that iterating over the next tag in the
# forward algorithm could probably be done in one big operation. I wanted
# to code to be more readable. If you want to make the relevant change,
# you could probably use this tagger for real tasks.
#
#
# +
# Author: <NAME>
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(1)
# -
# Helper functions to make the code more readable.
#
#
# +
def argmax(vec):
# return the argmax as a python int
_, idx = torch.max(vec, 1)
return idx.item()
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
# Compute log sum exp in a numerically stable way for the forward algorithm
def log_sum_exp(vec):
max_score = vec[0, argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
return max_score + \
torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
# -
# Create model
#
#
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# Maps the output of the LSTM into tag space.
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# Matrix of transition parameters. Entry i,j is the score of
# transitioning *to* i *from* j.
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size))
# These two statements enforce the constraint that we never transfer
# to the start tag and we never transfer from the stop tag
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
self.hidden = self.init_hidden()
def init_hidden(self):
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
def _forward_alg(self, feats):
# Do the forward algorithm to compute the partition function
init_alphas = torch.full((1, self.tagset_size), -10000.)
# START_TAG has all of the score.
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# Wrap in a variable so that we will get automatic backprop
forward_var = init_alphas
# Iterate through the sentence
for feat in feats:
alphas_t = [] # The forward tensors at this timestep
for next_tag in range(self.tagset_size):
# broadcast the emission score: it is the same regardless of
# the previous tag
emit_score = feat[next_tag].view(
1, -1).expand(1, self.tagset_size)
# the ith entry of trans_score is the score of transitioning to
# next_tag from i
trans_score = self.transitions[next_tag].view(1, -1)
# The ith entry of next_tag_var is the value for the
# edge (i -> next_tag) before we do log-sum-exp
next_tag_var = forward_var + trans_score + emit_score
# The forward variable for this tag is log-sum-exp of all the
# scores.
alphas_t.append(log_sum_exp(next_tag_var).view(1))
forward_var = torch.cat(alphas_t).view(1, -1)
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
def _get_lstm_features(self, sentence):
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
def _score_sentence(self, feats, tags):
# Gives the score of a provided tag sequence
score = torch.zeros(1)
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags])
for i, feat in enumerate(feats):
score = score + \
self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
def _viterbi_decode(self, feats):
backpointers = []
# Initialize the viterbi variables in log space
init_vvars = torch.full((1, self.tagset_size), -10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var at step i holds the viterbi variables for step i-1
forward_var = init_vvars
for feat in feats:
bptrs_t = [] # holds the backpointers for this step
viterbivars_t = [] # holds the viterbi variables for this step
for next_tag in range(self.tagset_size):
# next_tag_var[i] holds the viterbi variable for tag i at the
# previous step, plus the score of transitioning
# from tag i to next_tag.
# We don't include the emission scores here because the max
# does not depend on them (we add them in below)
next_tag_var = forward_var + self.transitions[next_tag]
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# Now add in the emission scores, and assign forward_var to the set
# of viterbi variables we just computed
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)
# Transition to STOP_TAG
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# Follow the back pointers to decode the best path.
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path
def neg_log_likelihood(self, sentence, tags):
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
def forward(self, sentence): # dont confuse this with _forward_alg above.
# Get the emission scores from the BiLSTM
lstm_feats = self._get_lstm_features(sentence)
# Find the best path, given the features.
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
# Run training
#
#
# +
START_TAG = "<START>"
STOP_TAG = "<STOP>"
EMBEDDING_DIM = 5
HIDDEN_DIM = 4
# Make up some training data
training_data = [(
"the wall street journal reported today that apple corporation made money".split(),
"B I I I O O O B I O O".split()
), (
"georgia tech is a university in georgia".split(),
"B I O O O O B".split()
)]
word_to_ix = {}
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
tag_to_ix = {"B": 0, "I": 1, "O": 2, START_TAG: 3, STOP_TAG: 4}
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# Check predictions before training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0][1]], dtype=torch.long)
print(model(precheck_sent))
# Make sure prepare_sequence from earlier in the LSTM section is loaded
for epoch in range(
300): # again, normally you would NOT do 300 epochs, it is toy data
for sentence, tags in training_data:
# Step 1. Remember that Pytorch accumulates gradients.
# We need to clear them out before each instance
model.zero_grad()
# Step 2. Get our inputs ready for the network, that is,
# turn them into Tensors of word indices.
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# Step 3. Run our forward pass.
loss = model.neg_log_likelihood(sentence_in, targets)
# Step 4. Compute the loss, gradients, and update the parameters by
# calling optimizer.step()
loss.backward()
optimizer.step()
# Check predictions after training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print(model(precheck_sent))
# We got it!
# -
# Exercise: A new loss function for discriminative tagging
# --------------------------------------------------------
#
# It wasn't really necessary for us to create a computation graph when
# doing decoding, since we do not backpropagate from the viterbi path
# score. Since we have it anyway, try training the tagger where the loss
# function is the difference between the Viterbi path score and the score
# of the gold-standard path. It should be clear that this function is
# non-negative and 0 when the predicted tag sequence is the correct tag
# sequence. This is essentially *structured perceptron*.
#
# This modification should be short, since Viterbi and score\_sentence are
# already implemented. This is an example of the shape of the computation
# graph *depending on the training instance*. Although I haven't tried
# implementing this in a static toolkit, I imagine that it is possible but
# much less straightforward.
#
# Pick up some real data and do a comparison!
#
#
#
| beginner_source/nlp/5 advanced_tutorial.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: ElastixEnv
# language: python
# name: elastixenv
# ---
# # Elastix
#
# This notebooks show very basic image registration examples with on-the-fly generated binary images.
from itk import itkElastixRegistrationMethodPython
from itk import itkTransformixFilterPython
import itk
import numpy as np
import matplotlib.pyplot as plt
# ## Image generators
def image_generator(x1, x2, y1, y2, bspline=False):
image = np.zeros([100, 100], np.float32)
for x in range(x1, x2):
for y in range(y1, y2):
if bspline:
y += x
if x > 99 or y > 99:
pass
else:
image[y, x] = 1
else:
image[y, x] = 1
image = itk.image_view_from_array(image)
return image
# ## Bspline Test
# +
# Create test images
fixed_image_bspline = image_generator(25,65,25,65)
moving_image_bspline = image_generator(5,55,5,40, bspline=True)
# Import Default Parameter Map
parameter_object = itk.ParameterObject.New()
default_affine_parameter_map = parameter_object.GetDefaultParameterMap('affine',4)
default_affine_parameter_map['FinalBSplineInterpolationOrder'] = ['1']
parameter_object.AddParameterMap(default_affine_parameter_map)
default_bspline_parameter_map = parameter_object.GetDefaultParameterMap('bspline',4)
default_bspline_parameter_map['FinalBSplineInterpolationOrder'] = ['1']
parameter_object.AddParameterMap(default_bspline_parameter_map)
# -
# Call registration function
result_image_bspline, result_transform_parameters = itk.elastix_registration_method(
fixed_image_bspline, moving_image_bspline,
parameter_object=parameter_object,
log_to_console=True)
# ### Bspline Test Transformix
# +
# Load Transformix Object
transformix_object = itk.TransformixFilter.New(moving_image_bspline)
transformix_object.SetTransformParameterObject(result_transform_parameters)
# Update object (required)
transformix_object.UpdateLargestPossibleRegion()
# Results of Transformation
result_image_transformix = transformix_object.GetOutput()
# -
# ### Bspline Test Visualization
# +
# %matplotlib inline
# Plot images
fig, axs = plt.subplots(1,4, sharey=True, figsize=[30,30])
plt.figsize=[100,100]
axs[0].imshow(result_image_bspline)
axs[0].set_title('Result', fontsize=30)
axs[1].imshow(fixed_image_bspline)
axs[1].set_title('Fixed', fontsize=30)
axs[2].imshow(moving_image_bspline)
axs[2].set_title('Moving', fontsize=30)
axs[3].imshow(result_image_transformix)
axs[3].set_title('Transformix', fontsize=30)
plt.show()
| examples/ITK_UnitTestExample3_BsplineRegistration.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# + pycharm={"name": "#%%\n"}
# 定义模型
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
# + pycharm={"name": "#%%\n"}
# 使用张量来初始化隐藏状态
state = torch.zeros((1, batch_size, num_hiddens))
state.shape
# + pycharm={"name": "#%%\n"}
# 通过一个隐藏状态和一个输入,我们可以用更新后的隐藏状态计算输出
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
Y.shape, state_new.shape
# + pycharm={"name": "#%%\n"}
# 我们为一个完整的循环神经网络模型定义一个RNNModel类
class RNNModel(nn.Module):
"""循环神经网络模型。"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device)
else:
return (torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device),
torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device))
# + pycharm={"name": "#%%\n"}
# 用一个具有随机权重的模型进行预测
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
d2l.predict_ch8('time traveller', 10, net, vocab, device)
# + pycharm={"name": "#%%\n"}
# 使用高级API训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
| artificial-intelligence/d2l-pytorch/notes/46_rnn_concise.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Exercise: Dimensionality Reduction and Clustering
#
#
#
# (1) Use PCA to reduce the dimension of the cancer dataset, then apply supervised learning (logistic regression) using two principle components only. Steps:
#
# (a) Scale the data using StandardScaler (zero mean and unit variance variables), then apply PCA to the scaled training data using two principle components. Print the shape of the training data before and after PCA is applied.
#
# (c) Print the variance explained by each of the two principle components
#
# (b) Use the two principle components to fit a logistic regression model with regularization parameter c=10. Find the accuracy. Compare it to the accuracy when all the original features (30 features) are used to fit the logistic regression model.
#
# (2) Assume we do not know the actual labels, and use clustering algorithms on the training samples using the two derived principle components only.
#
# (a) Apply K-means with random_state=0, and K=2. Use scatter plot to visualize the output of K-Means clustering algorithm. (x-axis is first principle component and y-axis is the second principle component). Also plot the actual labels.
#
# (b) Use the actual labels of Y_train to find the K-means clustering score using the adjusted_rand_score
#
# (c) Find the adjusted_rand_score if we used agglomerative clustering setting number of clusters to 2, using default linkage (Ward).
#
# +
% matplotlib inline
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics.cluster import adjusted_rand_score
from sklearn.cluster import KMeans
from sklearn.cluster import AgglomerativeClustering
cancer = load_breast_cancer()
X_train, X_test, Y_train, Y_test = train_test_split(cancer.data,cancer.target,random_state=0)
| lecture6/UnsupervisedLearning_Ex.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
import support
# +
txt = '<NAME>'
support.capitalize_(txt)
# -
support.isalnum_('#')
support.isdigit_('4')
support.lower_(txt)
support.title_(txt)
support.upper_(txt)
| Week - 5/DIY Libraires - String Operations/String Operation - DIY Library.ipynb |
;; -*- coding: utf-8 -*-
;; ---
;; jupyter:
;; jupytext:
;; text_representation:
;; extension: .scm
;; format_name: light
;; format_version: '1.5'
;; jupytext_version: 1.14.4
;; kernelspec:
;; display_name: Calysto Scheme 3
;; language: scheme
;; name: calysto_scheme
;; ---
;; ## SICP 习题 (3.11)解题总结: 消息传递风格的环境结构
;; SICP 习题 3.11 是要让我们去思考消息传递风格里的环境结构的问题。
;;
;; 题目使用的材料是习题 3.3 里用到的(make-account)函数。在这个(make-account)函数里我们返回的是dispatch,dispatch本身是个函数。从整体上看,这里的环境结构是由(make-account)创建出来,然后(make-account)的环境挂载了dispatch的环境,在dispatch函数里又会根据消息的类型返回真正的操作函数,如withdraw, deposit。在dispatch函数的环境里又会挂载操作函数的环境。所以我们在操作函数里是可以访问和修改balance这中变量的,在操作函数的环境里找不到balance就会去dispatch函数的环境里找,在dispatch环境里也没有balance变量就会去(make-account)的环境里去找,终于可以找到。
;; 下面是3.3的代码,供测试分析:
(define (make-account balance account-password)
(define (withdraw amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"insufficient funds"))
(define (deposit amount)
(set! balance (+ balance amount))
balance)
(define (wrongpassword amount)
"incorrect password")
(define (dispatch password m)
(if (not (equal? password account-password))
wrongpassword
(cond ((eq? m 'withdraw) withdraw)
((eq? m 'deposit) deposit)
(else (error "unknow request -- Make-Account"
m)))))
dispatch)
(define acc (make-account 100 'my-password))
((acc 'my-password 'deposit) 10)
| cn/.ipynb_checkpoints/sicp-3-11-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="MkKbipFc5LkR"
import pandas as pd
from sklearn.impute import SimpleImputer
import numpy as np
import plotly.express as px
import pycountry
import os
# + colab={"base_uri": "https://localhost:8080/"} id="9tM4w79S5sz1" outputId="9ac272c5-03ed-4b98-f571-5a764b0fa03a"
pip install pycountry
# + colab={"base_uri": "https://localhost:8080/", "height": 428} id="nhOTgF0G6CGs" outputId="baa270c1-1b9e-41f3-87f5-f0ed1241ce9b"
data = pd.read_csv("/content/globalterrorismdb_0718dist.csv", encoding = 'ISO-8859-1')
pd.set_option('max_columns', None)
pd.set_option('max_rows', None)
data.head()
# + colab={"base_uri": "https://localhost:8080/"} id="OoZhG8VD6xCS" outputId="50b9b529-f3e0-4500-8742-5b249b45e6ed"
data.shape
# + id="Yz4iLXiU62YG"
data.drop_duplicates(inplace=True)
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} id="mdCdBDko652q" outputId="efd48e21-fa4d-456e-bca6-68270fcc184e"
data.isnull().sum().reset_index().sort_values(by=[0], ascending = False)
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} id="EPEKJCQD6_PX" outputId="0c4a2686-b64a-4e75-8dcb-972056de2b21"
percent_missing = data.isnull().sum() * 100 / len(data)
missing_value_df = pd.DataFrame({'column_name': data.columns,
'percent_missing': percent_missing})
missing_value_df.sort_values('percent_missing', inplace=True, ascending = False)
missing_value_df
# + colab={"base_uri": "https://localhost:8080/", "height": 1000} id="232eJdch7WAw" outputId="b2c5b5de-6739-4515-a399-efacd5a62196"
morethan25_per = missing_value_df[missing_value_df['percent_missing']>23]
morethan25_per
# + colab={"base_uri": "https://localhost:8080/", "height": 360} id="030yF5EV719M" outputId="856b9f6e-1971-4bec-a957-4d6576bdad22"
df = data.drop(morethan25_per.index, axis=1)
df.head()
# + colab={"base_uri": "https://localhost:8080/", "height": 824} id="xEfmLO6C781G" outputId="231a94ac-fd34-4e0e-91c3-67f86555ee25"
small_missing_values = df.isnull().sum().reset_index().sort_values(by=[0], ascending = False)
small_missing_values = small_missing_values[small_missing_values[0]!=0]
small_missing_values
# + colab={"base_uri": "https://localhost:8080/"} id="vayWd1dg8IwT" outputId="6456a7ef-8963-4f5f-9bd1-726ca38cf0c7"
lst = small_missing_values['index'].tolist()
object_missing_cols = []
num_missing_cols = []
for i in lst:
if((df['{}'.format(i)]).dtype=='object'):
object_missing_cols.append('{}'.format(i))
else:
num_missing_cols.append('{}'.format(i))
print(object_missing_cols)
print(num_missing_cols)
# + colab={"base_uri": "https://localhost:8080/", "height": 323} id="-qRlU_id8Qve" outputId="2b4729dc-4779-48c9-e3ca-cda134c4059c"
df[object_missing_cols].head()
# + colab={"base_uri": "https://localhost:8080/", "height": 224} id="xRuMf5xa8WDQ" outputId="3c0c6a31-4c32-484a-c16c-99e6e2f1471a"
df[num_missing_cols].head()
# + id="st6LYUR38bpI"
imputer = SimpleImputer()
imputer = imputer.fit(df[num_missing_cols])
df[num_missing_cols] = imputer.transform(df[num_missing_cols])
# + colab={"base_uri": "https://localhost:8080/", "height": 224} id="H0ogJmFL8g94" outputId="221648f6-34a4-4b00-d44c-badfdb4bb159"
df[num_missing_cols].head()
# + id="tLVYaxHM8lJQ"
df = df.dropna()
# + colab={"base_uri": "https://localhost:8080/"} id="rg6ylXA68qnB" outputId="a78b6b27-828e-4b75-9c2a-9357cb5e4e07"
df.isnull().sum().sum()
# + colab={"base_uri": "https://localhost:8080/", "height": 479} id="2T4syoaQ87r8" outputId="0bbca67a-9b13-45db-964f-1eac735c44c3"
df.head()
# + colab={"base_uri": "https://localhost:8080/", "height": 204} id="fKcINwWa8-uL" outputId="e62e141a-4536-4745-df3b-eecb521f19ca"
df2 = df.country_txt.value_counts().reset_index().rename(columns={'index': 'Country Name'})
df2.columns.values[1] = 'Count'
df2.head()
# + colab={"base_uri": "https://localhost:8080/", "height": 542} id="5luB40Wp9Fyf" outputId="2c3b97c7-4f0b-4649-aee5-f95e2d75f356"
fig = px.choropleth(df2,
color="Count", locations=None,
hover_name="Country Name",
color_continuous_scale=px.colors.sequential.Plasma)
fig.show()
# + [markdown] id="Hqqw_AQc9eEk"
# fig = px.bar(df2.head(25), x='Country Name', y='Count',
# hover_data=['Count'], color='Count', height=400)
# fig.show()
# + colab={"base_uri": "https://localhost:8080/", "height": 417} id="n_wMVvyH94nQ" outputId="555e8981-093e-4f8d-936d-2a16393e7e15"
target_type= df['targtype1_txt'].value_counts().reset_index().rename(columns={'index': 'Target Types'})
target_type.columns.values[1] = 'Count'
fig = px.bar(target_type, x='Target Types', y='Count',
hover_data=['Count'], color='Count', height=400)
fig.show()
# + colab={"base_uri": "https://localhost:8080/", "height": 942} id="QDXzNR16-BEu" outputId="1d9c9a16-1a6d-496e-90ce-1ea41e05109b"
weapon_type= df['weaptype1_txt'].value_counts().reset_index().rename(columns={'index': 'Weapon Types'})
weapon_type.columns.values[1] = 'Count'
fig = px.bar(weapon_type, x='Weapon Types', y='Count',
hover_data=['Count'], color='Count', height=400)
fig.show()
fig = px.pie(weapon_type, values='Count', names='Weapon Types',
title='Weapon Types Attack',
hover_data=['Count'])
fig.update_traces(textposition='inside', textinfo='percent+label')
fig.show()
# + colab={"base_uri": "https://localhost:8080/", "height": 437} id="3_NO055c-XZe" outputId="94f0242d-c6e7-4865-bf69-2e076c059964"
attack_on_years= df['iyear'].value_counts().reset_index().rename(columns={'index': 'Year'})
attack_on_years.columns.values[1] = 'Count'
fig = px.bar(attack_on_years, x='Year', y='Count',
hover_data=['Count'], color='Count', height=400)
fig.show()
# + [markdown] id="cpd5lGFa-fiV"
# AUTHOR:SAKTHIRAAMBALASUNDARAM
| GLOBAL_TERRORISM.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %load_ext sql
# %sql sqlite:///PS1.db
# Problem Set 1 [100 points]
# =======
#
# ### Deliverables:
#
# 1) Submit your queries (and only those) using the `submission_template.txt` file that is posted on Canvas. Follow the instructions on the file! Upload the file at Canvas (under PS1).
#
# 2) Submit a signed copy of the Academic Honesty Agreement pdf attesting that your submitted work is your own (failure to submit the agreement may result in points being deducted from your assignment grade).
#
#
# ### Instructions / Notes:
#
# * Run the top cell above to load the database `PS1.db` (make sure the database file, `PS1.db`, is in the same directory as this IPython notebook is running in)
# * Some of the problems involve _changing_ this database (e.g. deleting rows)- you can always re-download `PS1.db` or make a copy if you want to start fresh!
# * You **may** create new IPython notebook cells to use for e.g. testing, debugging, exploring, etc.- this is encouraged in fact!- **just make sure that your final answer for each question is _in its own cell_ and _clearly indicated_**
# * When you see `In [*]:` to the left of the cell you are executing, this means that the code / query is _running_.
# * **If the cell is hanging- i.e. running for too long: To restart the SQL connection, you must restart the entire python kernel**
# * To restart kernel using the menu bar: "Kernel >> Restart >> Clear all outputs & restart"), then re-execute the sql connection cell at top
# * You will also need to restart the connection if you want to load a different version of the database file
# * For questions which ask for a 'single query', this refers to any query bounded by one semicolon
# * Be careful to match the schema of the expected output
# * Remember:
# * `%sql [SQL]` is for _single line_ SQL queries
# * `%%sql [SQL]` is for _multi line_ SQL queries
# * _Have fun!_
# Problem 1: Linear Algebra [25 points]
# ------------------------
#
# Two random 3x3 ($N=3$) matrices have been provided in tables `A` and `B`, having the following schema:
# > * `i INT`: Row index
# > * `j INT`: Column index
# > * `val INT`: Cell value
#
# **Note: all of your answers below _must_ work for any _square_ matrix sizes, i.e. any value of $N$**.
#
# Note how the matrices are represented- why do we choose this format? Run the following queries to see the matrices in a nice format:
# %sql SELECT group_concat(val, " , ") AS "A" FROM A GROUP BY i;
# %sql SELECT group_concat(val, " , ") AS "B" FROM B GROUP BY i;
# ### Part (a): Matrix transpose [5 points]
#
# _Transposing_ a matrix $A$ is the operation of switching its rows with its columns- written $A^T$. For example, if we have:
#
# $A=\begin{bmatrix}a & b & c\\ d & e & f\\ g & h & i\end{bmatrix}$
#
# Then:
#
# $A^T=\begin{bmatrix}a & d & g\\ b & e & h\\ c & f & i\end{bmatrix}$
#
# Write a _single SQL query_ to get the matrix transpose $A^T$ (in the same format as $A$- output tuples should be of format `(i,j,val)` where `i` is row, `j` is column, and the output is ordered by row then column index)
#
# Write your query here:
# %sql SELECT j AS "i", i AS "j", val FROM A ORDER BY i, j;
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (b): Dot product I [5 points]
#
# The _dot product_ of two vectors
#
# $a = \begin{bmatrix}a_1 & a_2 & \dots & a_n\end{bmatrix}$
#
# and
#
# $b = \begin{bmatrix}b_1 & b_2 & \dots & b_n\end{bmatrix}$
#
# is
#
# $a\cdot b = \sum_{i=1}^n a_ib_i = a_1b_1 + a_2b_2 + \dots + a_nb_n$
#
# Write a _single SQL query_ to take the dot product of the **third column of $A$** and the **second column of $B$.**
#
# Write your query here:
# %sql SELECT SUM(A.val * B.val) AS Result FROM A JOIN B ON A.i = B.i WHERE A.j = 2 AND B.j = 1;
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (c): Matrix multiplication [10 points]
#
# The product of a matrix $A$ (having dimensions $n\times m$) and a matrix $B$ (having dimensions $m\times p$) is the matrix $C$ (of dimension $n\times p$) having cell at row $i$ and column $j$ equal to:
#
# $C_{ij} = \sum_{k=1}^m A_{ik}B_{kj}$
#
# In other words, to multiply two matrices, get each cell of the resulting matrix $C$, $C_{ij}$, by taking the _dot product_ of the $i$th row of $A$ and the $j$th column of $B$.
#
# Write a single SQL query to get the matrix product of $A$ and $B$ (in the same format as $A$ and $B$).
#
# Write your query here:
# %sql SELECT A.i AS i, B.j AS j, SUM(A.val * B.val) AS val FROM A JOIN B ON B.i = A.j GROUP BY A.i, B.j;
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (d): Matrix power [5 points]
#
# The power $A^n$ of a matrix $A$ is defined as the matrix product of $n$ copies of $A$.
#
# Write a _single SQL query_ that computes the **third power** of matrix $B$ (in the same format as $B$), in other words, $B^3 = B \cdot B \cdot B$.
#
# Write your query here:
# %sql SELECT A.i AS i, B.j AS j, SUM(A.val * B.val) AS val FROM ((SELECT B1.i AS i, B.j AS j, SUM(B1.val * B.val) AS val FROM (B AS B1) JOIN B ON B.i = B1.j GROUP BY B1.i, B.j) AS A) JOIN B ON B.i = A.j GROUP BY A.i, B.j;
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# Problem 2: The Sales Database [35 points]
# ----------------------------------------------
#
# We've prepared and loaded a dataset related to sales data from a company. The dataset has the following schema:
#
# > `Holidays (WeekDate, IsHoliday)`
#
# > `Stores (Store, Type, Size)`
#
# > `TemporalData(Store, WeekDate, Temperature, FuelPrice, CPI, UnemploymentRate)`
#
# > `Sales (Store, Dept, WeekDate, WeeklySales)`
#
# Before you start writing queries on the database, familiarize yourself with the schema and the constraints (keys, foreign keys).
# ### Part (a): Sales during Holidays [5 points]
#
# Using a single SQL query, find the stores with the largest and smallest overall sales during holiday weeks. Further requirements:
# * Use the `WITH` clause before the main body of the query to compute a subquery if necessary.
# * Return a relation with schema `(Store, AllSales)`.
#
# Write your query here:
# %sql WITH TotalSales AS (SELECT S.store, SUM(S.weeklysales) AS AllSales FROM (sales S JOIN holidays H ON (S.weekdate = H.weekdate AND H.isholiday = 'TRUE')) GROUP BY S.store ORDER BY AllSales ASC), TotalSalesMost AS (SELECT * FROM TotalSales ORDER BY AllSales DESC LIMIT 1), TotalSalesLeast AS (SELECT * FROM TotalSales ORDER BY AllSales ASC LIMIT 1) SELECT * FROM TotalSalesMost UNION ALL SELECT * FROM TotalSalesLeast;
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (b): When Holidays do not help Sales [10 points]
#
# Using a single SQL query, compute the **number** of non-holiday weeks that had larger sales than the overall average sales during holiday weeks. Further requirements:
# * Use the `WITH` clause before the main body of the query to compute a subquery if necessary.
# * Return a relation with schema `(NumNonHolidays)`.
#
# Write your query here:
# %sql WITH SalesByWeek AS (Select S.weekdate as weekdate, H.isholiday AS isholiday, SUM(S.weeklysales) as TotalSales FROM (sales S JOIN holidays H on S.weekdate = H.weekdate) GROUP BY S.weekdate), AvgHolidaySales AS (SELECT AVG(S.TotalSales) AS avg FROM SalesByWeek S WHERE S.isholiday = 'TRUE') SELECT COUNT(*) As NumNonHolidays FROM (SalesByWeek S JOIN AvgHolidaySales H ON (S.isholiday = 'FALSE' AND S.TotalSales > H.avg));
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (c): Total Sales [5 points]
#
# Using a _single SQL query_, compute the total sales during summer (months 6,7and 8) for each type of store. Further requirements:
# * Return a relation with schema `(type, TotalSales)`.
#
# *Hint:* SQLite3 does not support native operations on the DATE datatype. To create a workaround, you can use the `LIKE` predicate and the string concatenation operator (||). You can also use the substring operator that SQLite3 supports (`substr`).
#
# Write your query here:
# %sql SELECT ST.type AS type, SUM(SA.weeklysales) AS TotalSales FROM (sales SA JOIN stores ST ON (SA.store = ST.store AND strftime('%m', SA.weekdate) IN ('06', '07', '08'))) GROUP BY ST.type;
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (d): Computing Correlations [15 points]
#
# The goal of this exercise is to find out whether each one of the 4 numeric attributes in `TemporalData` is
# positively or negatively correlated with sales.
#
# For our purposes, the intuitive notion of correlation is defined using a
# standard statistical quantity known as the *Pearson correlation coefficient*.
# Given two numeric random variables $X$ and $Y$, it is defined as follows:
#
# $$\rho_{X,Y} = \frac{E[XY] - E[X]E[Y]}{\sqrt{E[X^2] - E[X]^2} \sqrt{E[Y^2] - E[Y]^2}}$$
#
# On a given sample of data with $n$ examples each for $X$ and $Y$ (label them
# $x_i$ and $y_i$ respectively for $i = 1 \dots n$), it is estimated as follows:
#
# \begin{align*}
# \rho_{X,Y} = \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^n (x_i - \bar{x})^2} \sqrt{\sum_{i=1}^n (y_i - \bar{y})^2}}
# \end{align*}
# In the above, $\bar{x}$ and $\bar{y}$ are the sample means, i.e.,
# $\bar{x} = \frac{1}{n}\sum_{i=1}^n x_i$, and $\bar{x} = \frac{1}{n}\sum_{i=1}^n y_i$.
#
# Further requirements:
# * Each example in the sample consists of a pair (Store, WeekDate). This means that Sales data must be summed across all departments before the correlation is computed.
# * Return a relation with schema `(Attribute_Name VARCHAR(20), Correlation_Sign Integer)`.
# * The values of AttributeName can be hardcoded string literals, but the values
# of `Correlation_Sign` must be computed automatically using SQL queries over
# the given database instance.
# * You can use multiple SQL statements to compute the result. It might be of help to create and update your own tables.
#
#
# Hint: The output simply requires the sign of the correlation, not the correlation itself. This can be found without evaluating the entire formula.
#
# Write your query here:
# + language="sql"
# DROP VIEW IF EXISTS SalesPerStoreWeek;
# DROP VIEW IF EXISTS TemporalSales;
# DROP VIEW IF EXISTS AvgData;
# DROP VIEW IF EXISTS CorrTemp;
# DROP VIEW IF EXISTS CorrFuel;
# DROP VIEW IF EXISTS CorrCPI;
# DROP VIEW IF EXISTS CorrUnemp;
# DROP TABLE IF EXISTS CorrData;
# CREATE VIEW SalesPerStoreWeek AS SELECT S.store as store, S.weekdate as weekdate, SUM(S.weeklysales) AS weeklysales FROM sales S GROUP BY S.store, S.weekdate;
# CREATE VIEW TemporalSales AS SELECT S.store as store, S.weekdate as weekdate, S.weeklysales as weeklysales, T.temperature as temperature, T.fuelprice as fuelprice, T.cpi as cpi, T.unemploymentrate as unemploymentrate FROM (SalesPerStoreWeek S JOIN temporaldata T ON (T.store = S.store AND T.weekdate = S.weekdate));
# CREATE VIEW AvgData AS SELECT AVG(D.weeklysales) AS weeklysales, AVG(D.temperature) as temperature, AVG(D.fuelprice) as fuelprice, AVG(D.cpi) as cpi, AVG(D.unemploymentrate) as unemploymentrate FROM TemporalSales D;
# CREATE VIEW CorrTemp AS SELECT 'Temperature', CASE WHEN SUM((D.weeklysales - A.weeklysales) * (D.temperature - A.temperature)) > 0 THEN 1 ELSE -1 END FROM (TemporalSales D JOIN AvgData A);
# CREATE VIEW CorrFuel AS SELECT 'FuelPrice', CASE WHEN SUM((D.weeklysales - A.weeklysales) * (D.fuelprice - A.fuelprice)) > 0 THEN 1 ELSE -1 END FROM (TemporalSales D JOIN AvgData A);
# CREATE VIEW CorrCPI AS SELECT 'CPI', CASE WHEN SUM((D.weeklysales - A.weeklysales) * (D.cpi - A.cpi)) > 0 THEN 1 ELSE -1 END FROM (TemporalSales D JOIN AvgData A);
# CREATE VIEW CorrUnemp AS SELECT 'UnemploymentRate', CASE WHEN SUM((D.weeklysales - A.weeklysales) * (D.unemploymentrate - A.unemploymentrate)) > 0 THEN 1 ELSE -1 END FROM (TemporalSales D JOIN AvgData A);
# CREATE TABLE CorrData (Attribute_Name VARCHAR(20), Correlation_Sign Integer);
# INSERT INTO CorrData SELECT * FROM CorrTemp;
# INSERT INTO CorrData SELECT * FROM CorrFuel;
# INSERT INTO CorrData SELECT * FROM CorrCPI;
# INSERT INTO CorrData SELECT * FROM CorrUnemp;
# SELECT * FROM CorrData;
# -
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# Problem 3: The Traveling SQL Server Salesman Problem [40 points]
# --------------------------------------------------
#
# SQL Server salespeople are lucky as far as traveling salespeople go- they only have to sell one or two big enterprise contracts, at one or two offices in Wisconsin, in order to make their monthly quota!
#
# Answer the following questions using the table of streets connecting company office buildings.
#
# **Note that for convenience all streets are included _twice_, as $A \rightarrow B$ and $B \rightarrow A$. This should make some parts of the problem easier, but remember to take it into account!**
# %sql SELECT * FROM streets LIMIT 4;
# ### Part (a): One-hop, two-hop, three-hop... [10 points]
#
# Our salesperson has stopped at UW-Madison, to steal some cool new RDBMS technology from CS564-ers, and now wants to go sell it to a company _within 10 miles of UW-Madison and _passing through no more than 3 distinct streets_. Write a single query, not using `WITH` (see later on), to find all such companies.
#
# Your query should return the schema `(company, distance)` where distance is cumulative from UW-Madison.
#
# Write your query here:
# %sql SELECT S.B AS company, MIN(S.D) as distance FROM (SELECT S.A, S.B, S.d FROM streets S WHERE S.A = 'UW-Madison' UNION SELECT S1.a, S2.b, (S1.d + S2.d) as d FROM streets S1, streets S2 WHERE (S1.A = 'UW-Madison' AND S1.B = S2.A) UNION SELECT S1.a, S3.b, (S1.d + S2.d + S3.d) as d FROM streets S1, streets S2, streets S3 WHERE (S1.A = 'UW-Madison' AND S1.B = S2.A AND S2.B = S3.A)) S WHERE (S.d <= 10) GROUP BY S.B;
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (b): A stop at the Farm [10 points]
#
# Now, our salesperson is out in the field, and wants to see all routes- and their distances- which will take him/her from a company $A$ to a company $B$, with the following constraints:
# * The route must _pass through UW-Madison (in order to pick up new RDBMS tech to sell!)
# * $A$ and $B$ must _each individually_ be _within 3 hops of UW-Madison
# * $A$ and $B$ must be different companies
# * _The total distance must be $<= 15$_
# * Do not use `WITH`
# * If you return a path $A \rightarrow B$, _also include $B \rightarrow A$ in your answer_
# * Your query should return the schema (company1,company2, d) where d is the cumulative distance from UW-Madison.
#
# In order to make your answer a bit cleaner, you may split into two queries, one of which creates a `VIEW`. A view is a virtual table based on the output set of a SQL query. A view can be used just like a normal table- the only difference under the hood is that the DBMS re-evaluates the query used to generate it each time a view is queried by a user (thus the data is always up-to date!)
#
# Here's a simple example of a view:
# + language="sql"
# DROP VIEW IF EXISTS short_streets;
# CREATE VIEW short_streets AS
# SELECT A, B, d FROM streets WHERE d < 3;
# SELECT * FROM short_streets LIMIT 3;
# -
# Write your query or queries here:
# + language="sql"
# DROP VIEW IF EXISTS StreetsByMad;
# CREATE VIEW StreetsByMad AS SELECT * FROM (SELECT S.B, S.d FROM streets S WHERE S.A = 'UW-Madison' UNION SELECT S2.b, (S1.d + S2.d) as d FROM streets S1, streets S2 WHERE (S1.A = 'UW-Madison' AND S1.B = S2.A) UNION SELECT S3.b, (S1.d + S2.d + S3.d) as d FROM streets S1, streets S2, streets S3 WHERE (S1.A = 'UW-Madison' AND S1.B = S2.A AND S2.B = S3.A)) S;
# SELECT M1.B AS company1, M2.B AS company2, (M1.d + M2.d) AS distance FROM (StreetsByMad M1 JOIN StreetsByMad M2 ON (M1.B <> M2.B AND (M1.d + M2.d) <= 15));
# -
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (c): Ensuring acyclicity [10 points]
#
# You may have noticed at this point that the network, or **_graph_**, of streets in our `streets` table seems like it might be a **tree**.
#
# Recall that a **_tree_** is an undirected graph where each node has exactly one parent (or, is the root, and has none), but may have multiple children. A slightly more formal definition of a tree is as follows:
#
# > An undirected graph $T$ is a **_tree_** if it is **connected**- meaning that there is a path between every pair of nodes- and has no **cycles** (informally, closed loops)
#
# Suppose that we guarantee the following about the graph of companies & streets determined by the `streets` table:
# * It is _connected_
# * It has no cycles of length $> 3$
#
# Write a _single SQL query_ which, if our graph is not a tree (i.e. if this isn't a [shaggy dog problem](https://en.wikipedia.org/wiki/Shaggy_dog_story)), **turns it into a tree** by deleting exactly _one_ street (*= two entries in our table!*). Write your query here:
# %sql DELETE FROM streets WHERE id IN (SELECT S1.id FROM (streets S1 JOIN streets S2 JOIN streets S3 ON (S1.id <> S2.id AND S2.id <> S3.id AND S1.id <> S3.id AND S1.B = S2.A AND S2.B = S3.A AND S3.B = S1.A)) LIMIT 1);
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Part (d): The longest path [10 points]
#
# In this part, we want to find the distance of the _longest path between any two companies_.
#
# Note that you should probably have done Part (c) first so that the graph of streets is a _tree_- this will make it much easier to work with!
#
# If you've done the other parts above, you might be skeptical that SQL can find paths of arbitrary lengths (which is what we need to do for this problem); how can we do this?
#
# There are some non-standard SQL functions- i.e. not universally supported by all SQL DBMSs- which are often incredibly useful. One of these is the `WITH RECURSIVE` clause, supported by SQLite.
#
# A `WITH` clause lets you define what is essentially a view within a clause, mainly to clean up your SQL code. A trivial example, to illustrate `WITH`:
# + language="sql"
# WITH companies(name) AS (
# SELECT DISTINCT A FROM streets)
# SELECT *
# FROM companies
# WHERE name LIKE '%Gizmo%';
# -
# There is also a recursive variant, `WITH RECURSIVE`. `WITH RECURSIVE` allows you to define a view just as above, except the table can be defined recursively. A `WITH RECURSIVE` clause must be of the following form:
#
# ```
# WITH RECURSIVE
# R(...) AS (
# SELECT ...
# UNION [ALL]
# SELECT ... FROM R, ...
# )
# ...
# ```
#
# `R` is the _recursive table_. The `AS` clause contains two `SELECT` statements, conjoined by a `UNION` or `UNION ALL`; the first `SELECT` statement provides the initial / base case values, and the second or _recursive_ `SELECT` statement must include the recursive table in its `FROM` clause.
#
# Basically, the recursive `SELECT` statement continues executing on the tuple _most recently inserted into `R`_, inserting output rows back into `R`, and proceeding recursively in this way, until it no longer outputs any rows, and then stops. See the [SQLite documentation](https://www.sqlite.org/lang_with.html) for more detail.
#
# The following example computes $5! = 5*4*3*2*1$ using `WITH RECURSIVE`:
# + language="sql"
# WITH RECURSIVE
# factorials(n,x) AS (
# SELECT 1, 1
# UNION
# SELECT n+1, (n+1)*x FROM factorials WHERE n < 5)
# SELECT x FROM factorials WHERE n = 5;
# -
# In this example:
#
# 1. First, `(1,1)` is inserted into the table `factorials` (the base case).
# 2. Next, this tuple is returned by the recursive select, as `(n, x)`, and we insert the result back into `factorials`: `(1+1, (1+1)*1) = (2,2)`
# 3. Next, we do the same with the last tuple inserted into `factorials`- `(2,2)`- and insert `(2+1, (2+1)*2) = (3,6)`
# 4. And again: get `(3,6)` from `factorials` and insert `(3+1, (3+1)*6) = (4,24)` back in
# 5. And again: `(4,24)` -> `(4+1, (4+1)*24) = (5,120)`
# 6. Now the last tuple inserted into `factorials` is `(5, 120)`, which fails the `WHERE n < 5` clause, and thus our recursive select returns an empty set, and our `WITH RECURSIVE` statement concludes
# 7. Finally, now that our `WITH RECURSIVE` clause has concluded, we move on to the `SELECT x FROM factorials WHERE n=5` clause, which gets us our answer!
# #### Now, your turn!
#
# Write a single SQL query that uses `WITH RECURSIVE` to find the furthest (by distance) pair of companies that still have a path of streets connecting them. Your query should return `(A, B, distance)`.
#
# Write your query here:
# + magic_args="WITH RECURSIVE ss(headID, a, b, d) AS (" language="sql"
# SELECT S.id as headID, a, b, d FROM streets S
# UNION
# SELECT S.id as headID, ss.a, S.b, (ss.d + S.d) as d
# FROM ss, streets S
# WHERE (ss.b = S.a AND S.id <> ss.headID)
# ) SELECT ss.a AS A, ss.b AS B, ss.d AS distance FROM ss ORDER BY ss.d DESC LIMIT 1;
# -
"""
Expected output below- don't re-evaluate this cell!
NOTE: A valid answer must work for ALL inputs of the given type,
not just this example. I.e. do not hardcode around this answer / etc!
"""
# ### Note on alternate output
#
# **NOTE:** The **_distance_** of the longest path could be **49 _OR_ 63** depending on which street you deleted in Part (c)!
| UWM/564/P1/PS1.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/Echo9k/ml-trading-strategy/blob/main/ml-trading-strategy/notebooks/Milestone_2_Starter_Notebook.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="sS4kROrBkHsd"
# # Engineering Predictive Alpha Factors
# + colab={"base_uri": "https://localhost:8080/"} id="eXdv-SBykQvI" outputId="a8fd2aaa-e89c-4fa7-eb54-80f61e1e5bbd"
from google.colab import drive
drive.mount('/gdrive')
# %cd '/gdrive/My Drive/data'
# + [markdown] id="L3UDDjLikHse"
# This notebook illustrates the following steps:
#
# 1. Select the adjusted open, high, low, and close prices as well as the volume for all tickers from the Quandl Wiki data that you downloaded and simplified for the last milestone for the 2007-2016 time period. Looking ahead, we will use 2014-2016 as our 'out-of-sample' period to test the performance of a strategy based on a machine learning model selected using data from preceding periods.
# 2. Compute the dollar volume as the product of closing price and trading volume; then select the stocks with at least eight years of data and the lowest average daily rank for this metric.
# 3. Compute daily returns and keep only 'inliers' with values between -100% and + 100% as a basic check against data error.
# 4. Now we're ready to compute financial features. The Alpha Factory Library listed among the resources below illustrates how to compute a broad range of those using pandas and TA-Lib. We will list a few examples; feel free to explore and evaluate the various TA-Lib indicators.
# - Compute **historical returns** for various time ranges such as 1, 3, 5, 10, 21 trading days, as well as longer periods like 2, 3, 6 and 12 months.
# - Use TA-Lib's **Bollinger Band** indicator to create features that anticipate **mean-reversion**.
# - Select some indicators from TA-Lib's **momentum** indicators family such as
# - the Average Directional Movement Index (ADX),
# - the Moving Average Convergence Divergence (MACD),
# - the Relative Strength Index (RSI),
# - the Balance of Power (BOP) indictor, or
# - the Money Flow Index (MFI).
# - Compute TA-Lib **volume** indicators like On Balance Volume (OBV) or the Chaikin A/D Oscillator (ADOSC)
# - Create volatility metrics such as the Normalized Average True Range (NATR).
# - Compute rolling factor betas using the five Fama-French risk factors for different rolling windows of three and 12 months (see resources below).
# - Compute the outcome variable that we will aim to predict, namely the 1-day forward returns.
# + [markdown] id="PqrOPpE8kHsf"
# ## Usage tips
#
# - If you experience resource constraints (suddenly restarting Kernel), increase the memory available for Docker Desktop (> Settings > Advanced). If this not possible or you experienced prolonged execution times, reduce the scope of the exercise. The easiest way to do so is to select fewer stocks or a shorter time period, or both.
# - You may want to persist intermediate results so you can recover quickly in case something goes wrong. There's an example under the first 'Persist Results' subsection.
# + [markdown] id="ByRLJre4kHsg"
# ## Imports & Settings
# + id="q7UBiNcLlQdX" cellView="form"
#@markdown Install missing libraries
url = 'https://launchpad.net/~mario-mariomedina/+archive/ubuntu/talib/+files'
# !wget $url/libta-lib0_0.4.0-oneiric1_amd64.deb -qO libta.deb
# !wget $url/ta-lib0-dev_0.4.0-oneiric1_amd64.deb -qO ta.deb
# !dpkg -i libta.deb ta.deb
# !pip install -q ta-lib
import talib
# + id="Eb2hlOlQkHsg"
import warnings
warnings.filterwarnings('ignore')
# + id="3L_aq8mukHsg"
# %matplotlib inline
from pathlib import Path
from scipy import stats #
import numpy as np
import pandas as pd
import pandas_datareader.data as web
import statsmodels.api as sm
# from statsmodels.regression.rolling import RollingOLS
from sklearn.preprocessing import scale
from talib import MA_Type
import talib
from fastprogress.fastprogress import progress_bar
import matplotlib.pyplot as plt
import seaborn as sns
import pprint
from IPython.display import display
# + id="tYuihlmfkHsh"
sns.set_style('whitegrid')
idx = pd.IndexSlice
deciles = np.arange(.1, 1, .1).round(1)
# + [markdown] id="C4Vq_bcQkHsh"
# ## Load Data
# + id="KZq4rySmkHsh"
# DATA_STORE = Path('..', 'data', 'stock_prices.h5')
DATA_STORE = './stock_metrics.h5'
# + id="CvCl_OgskHsh"
with pd.HDFStore(DATA_STORE) as store:
data = pd.concat([store.get('/data/training'),
store.get('/data/testing')])
validation = store.get('/data/validation')
# + [markdown] id="lyO0Su_VkHsi"
# ## Select 500 most-traded stocks prior to 2017
#
# + id="wl02-0ihkHsi"
#@markdown Compute the dollar volume as the product of the adjusted close price and the adjusted volume:
data=data.assign(dollar_volume=data.close*data.volume) # calculates dollar volume
# + id="s3QIw27SkHsi" colab={"base_uri": "https://localhost:8080/", "height": 228} outputId="8289b5f5-200b-445a-e198-2c8da3872fdb"
#@markdown Keeps the most traded stocks
keep_top_ = 500 #@param {type:"number"}
most_traded_ticker = data.groupby('ticker')['dollar_volume'].sum().nlargest(keep_top_) # Get the 500 most traded tickers
most_traded_data = data[np.in1d(data.index.get_level_values(1), most_traded_ticker.index)] # filter data by the names above
most_traded_data.sample(5) # Example
# + [markdown] id="aKK4wse0kHsj"
# Filter out data without at least 8 years of history and no gaps.
# + id="FKzl3MbLkHsj"
ticks_year_df = pd.DataFrame([[i.year,j] for i,j in zip(data.index.get_level_values(0),data.index.get_level_values(1))]) # Gets stock ticks and year
ticks_conditions = pd.DataFrame([ticks_year_df.groupby(1).max()[0]==2016,
ticks_year_df.groupby(1).nunique()[0]>7],
['enough_data', 'until_2016'])
valid_ticks = ticks_conditions.all()
invalid_ticks = valid_ticks.apply(lambda x: not x)
invalid_ticks[True==invalid_ticks.values].index
data.drop(invalid_ticks[invalid_ticks.values==True].index
, level=1
, inplace=True
) # Drop the invalid ticks
# + [markdown] id="-lNVphTAkHsk"
# ## Remove outliers
# + [markdown] id="u4Tug6jLkHsj"
# ### From daily returns
# Remove outliners from daily returns
# + id="emSBt4ErkHsl" cellView="form"
#@title Outliners by daily returns
#@markdown Remove outliners based on their daily returns<br>
#@markdown _inverts the indexes_
def drop_daily_outliners(data):
"""Switches the order of the multi index to (tick, date)"""
g = data['close'].pct_change(periods=1).groupby(['ticker'])
too_high=pd.Series(g.max()>1).values
too_small=pd.Series(g.min()<-1).values
is_outliner = too_high * too_small # is outliner? if too small or to high (boolean)
indexes=g.max().index
outliners = [k for k,v in zip(indexes, too_high) if v]
inliners=set(indexes)-set(outliners)
data = data.reset_index(level=0)
return data.drop(outliners).set_index('date', append=True)
data = drop_daily_outliners(data)
# + id="kT2g5P0JkHsk" colab={"base_uri": "https://localhost:8080/", "height": 494} cellView="form" outputId="2fa6f249-33c1-4203-d95c-fa97af0e5f8b"
#@title zscores
#@markdown Calculates the z-scores
daily_returns = most_traded_data.close - most_traded_data.open
daily_returns_by_ticker=daily_returns.groupby('ticker').sum()
zscores = np.abs(stats.zscore(daily_returns_by_ticker))
z_values=pd.DataFrame(zscores, daily_returns_by_ticker.index, columns=['z'])
display(z_values.nlargest(5, columns='z'))
sns.distplot(zscores, rug=True, hist=False)
# + id="6yd5OZm2kHsl" colab={"base_uri": "https://localhost:8080/", "height": 337} cellView="form" outputId="8dd71ee7-cc45-4c31-eb0f-67c68d142489"
#@markdown How would it look with out the top_k outliners based on their zscore
top_k = 30 #@param{type:'number'}
no_outliners=z_values.nsmallest(z_values.shape[0] - top_k, columns='z')
display(pd.concat([no_outliners.kurtosis(), no_outliners.skew()]))
sns.distplot(no_outliners, rug=True, hist=False, fit=stats.norm)
# + id="ybLcfUUAkHsl" colab={"base_uri": "https://localhost:8080/", "height": 246} cellView="form" outputId="ed968c9a-8e72-4200-e716-8e0ca073e578"
#@markdown Remove outliners based on their zscore
large_ticks=z_values.nlargest(top_k, columns='z').index
data.drop(large_ticks, level=0, inplace=True) # Drop the outliner ticks
display(data.shape)
# + [markdown] id="BGCjwbAFXuxK"
# ## Compute Returns
# - Daily
# - Weekly
# - Monthly
# - Yearly
# + cellView="form" id="LVDYpEdy-JU3"
#@title Class Compute
#@markdown class Compute > Returns
class Compute:
def __init__(self, data):
self.data = data
def timeline_column(self, company_name, column='close'):
company_indexes=self.data.index.get_level_values(0)
keep_idx=self.data.index.get_level_values(0)==company_name
values = self.data[keep_idx][column].droplevel(0,0)
return company_indexes[keep_idx], values
def set_company_data(self, company_name):
company_indexes=data.index.get_level_values(0)
keep_idx=data.index.get_level_values(0)==company_name
self.company_data = data[keep_idx]
class Returns(Compute):
def __init__(self, data):
super().__init__(data)
def monthly(self, company_name):
company_idx, close = self.timeline_column(company_name)
returns=pd.DataFrame({
'returns_M1':close.pct_change(1, freq = 'M'),
'returns_M2':close.pct_change(2, freq = 'M'),
'returns_M3':close.pct_change(3, freq = 'M'),
'returns_M6':close.pct_change(6, freq = 'M'),
'returns_Y1':close.pct_change(1, freq = 'Y')
}).set_index(company_idx, append=True)
return returns.swaplevel()
def weekly(self, company_name):
company_idx, close = self.timeline_column(company_name)
returns=pd.DataFrame(
{'returns_W1':close.pct_change(1, freq = 'W'),
'returns_W3':close.pct_change(2, freq = 'W'),
'returns_W5':close.pct_change(3, freq = 'W')}
).set_index(company_idx, append=True)
return returns.swaplevel()
def daily(self, company_name):
company_idx, close = self.timeline_column(company_name)
returns=pd.DataFrame(
{'returns_D1':close.pct_change(periods=1),
'returns_D3':close.pct_change(periods=3),
'returns_D5':close.pct_change(periods=5),
'returns_D10':close.pct_change(periods=10),
'returns_D21':close.pct_change(periods=21)}
).set_index(company_idx, append=True)
return returns.swaplevel()
def all_returns(self, company_name):
return pd.concat([self.daily(company_name),
self.weekly(company_name),
self.monthly(company_name)])
# + [markdown] id="LX_M11t9fDPk"
# # Calculate metrics
# + cellView="form" id="yb7skWbEzU2k"
#@title class Metrics
class Metrics(Compute):
"""
Calulates several metrics for a dataset with multiple indexes.
"""
def __init__(self, data):
super().__init__(data)
def momentum_indicators(self):
if company_name is not None:
self.set_company_data(company_name)
# Bollinger Bands
self.company_data['SMA'] = talib.SMA(self.company_data.close.values)
self.company_data['bb_upper'], self.company_data['bb_middle'], self.company_data['bb_lower'] = talib.BBANDS(self.company_data.close.values, matype=MA_Type.T3)
self.company_data['momentum'] = talib.MOM(self.company_data.close.values, timeperiod=14)
#Average Directional Movement Index (ADX)
self.company_data['ADX'] = talib.ADX(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values, timeperiod=14)
# Absolute Price Oscillator (APO)
self.company_data['APO'] = talib.APO(self.company_data.close.values)
# Percentage Price Oscillator (PPO)
self.company_data['PPO'] = talib.PPO(self.company_data.close.values)
# Aroon Oscillator
self.company_data['AROONOSC'] = talib.AROONOSC(self.company_data.high.values, self.company_data.low.values)
# Balance of Power (BOP) indicator
self.company_data['BOP'] = talib.BOP(self.company_data.open.values, self.company_data.high.values, self.company_data.low.values, self.company_data.close.values)
# Commodity Channel Index (CCI)
self.company_data['CCI'] = talib.CCI(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values)
# Moving Average Convergence Divergence (MACD),
self.company_data.macd_fast, self.company_data.macd_slow, self.company_data.signal_period = talib.MACD(self.company_data.close.values)
# Chande Momentum Oscillator (CMO)
self.company_data['CMO'] = talib.CMO(self.company_data.close.values)
# Flow Index (MFI)
self.company_data['MFI'] = talib.MFI(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values, self.company_data.volume.values, timeperiod=14)
# Relative Strength Index (RSI)
self.company_data['RSI'] = talib.RSI(self.company_data.close.values, timeperiod=14)
#Stochastic RSI (STOCHRSI)
self.company_data.fastk, self.company_data.fastd = talib.STOCHRSI(self.company_data.close.values)
#Stochastic (STOCH)
self.company_data.slowk, self.company_data.slowd = talib.STOCH(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values)
#Ultimate Oscillator (ULTOSC)
self.company_data['ULTOSC'] = talib.ULTOSC(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values)
#Williams' %R (WILLR)
self.company_data['WILLR'] = talib.WILLR(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values, timeperiod=14)
def volume_indicators(self):
if company_name is not None:
self.set_company_data(company_name)
# Chaikin A/D Line
self.company_data['AD'] = talib.AD(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values, self.company_data.volume.values)
#Chaikin A/D Oscillator (ADOSC)
self.company_data['ADOSC'] = talib.ADOSC(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values, self.company_data.volume.values)
#On Balance Volume (OBV)
self.company_data['OBV'] = talib.OBV(self.company_data.close.values, self.company_data.volume.values)
def volatility_indicators(self, company_name=None):
if company_name is not None:
self.set_company_data(company_name)
# ATR
self.company_data['ATR'] = talib.ATR(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values)
#NATR
self.company_data['NATR'] = talib.NATR(self.company_data.high.values, self.company_data.low.values, self.company_data.close.values)
def all_metrics(self, company_name):
self.set_company_data(company_name)
self.volume_indicators()
self.volatility_indicators()
self.momentum_indicators()
return self.company_data
m=Metrics(data)
# + cellView="form" id="cn-xiPpcyywE"
#@markdown def pretty_ploter
def pretty_ploter(data, metric):
plt.figure(figsize=(16.1, 10), dpi=80)
plt.plot(data[metric].values)
plt.title(f'{metric} change during time')
plt.xlabel('Timestamp')
plt.ylabel(f'{metric} value')
# + cellView="form" id="RZ945QFXvGx1"
#@title Calculate an example
#@markdown Set the example company
company_name = 'EXPD' #@param {type:'string'}
metrics = m.all_metrics(company_name)
# + [markdown] id="8eMCx6VrkHsn"
# ### Momentum Indicators
# + [markdown] id="2GqfQJJhkHsn"
# TA-Lib offers the following choices - feel free to experiment with as many as you like. [Here](https://mrjbq7.github.io/ta-lib/func_groups/momentum_indicators.html) the documentations.
# + [markdown] id="Y8XASJbtkHsn"
# |Function| Name|
# |:---|:---|
# |PLUS_DM| Plus Directional Movement|
# |MINUS_DM| Minus Directional Movement|
# |PLUS_DI| Plus Directional Indicator|
# |MINUS_DI| Minus Directional Indicator|
# |DX| Directional Movement Index|
# |ADX| Average Directional Movement Index|
# |ADXR| Average Directional Movement Index Rating|
# |APO| Absolute Price Oscillator|
# |PPO| Percentage Price Oscillator|
# |AROON| Aroon|
# |AROONOSC| Aroon Oscillator|
# |BOP| Balance Of Power|
# |CCI| Commodity Channel Index|
# |CMO| Chande Momentum Oscillator|
# |MACD| Moving Average Convergence/Divergence|
# |MACDEXT| MACD with controllable MA type|
# |MACDFIX| Moving Average Convergence/Divergence Fix 12/26|
# |MFI| Money Flow Index|
# |MOM| Momentum|
# |RSI| Relative Strength Index|
# |STOCH| Stochastic|
# |STOCHF| Stochastic Fast|
# |STOCHRSI| Stochastic Relative Strength Index|
# |TRIX| 1-day Rate-Of-Change (ROC) of a Triple Smooth EMA|
# |ULTOSC| Ultimate Oscillator|
# |WILLR| Williams' %R|
# + id="wfRbOPNCkHsn"
# pprint.pprint(talib.get_function_groups())
# + [markdown] id="C_LAApD1WIDR"
# #### Bollinger Bands
# + id="HnUDHX47kHsm" colab={"base_uri": "https://localhost:8080/", "height": 885} cellView="form" outputId="eea39310-2da4-4fb0-adac-03b7af8470f9"
#@markdown Bollinger Bands graphs
fig, axs = plt.subplots(2, figsize=(16.1, 10), dpi=80)
fig.suptitle(f'{CPNY_name} stock (2008-2014)')
# price
axs[0].plot(CPNY.momentum.values, alpha=.7, label='Momentum')
axs[0].set_title('Price (Close daily)')
axs[0].set_xlabel('Timestamp')
axs[0].set_ylabel('Momentum value')
# Momentum
axs[1].plot(CPNY.close.values, alpha=.7, label='Close')
axs[1].plot(CPNY.SMA.values, alpha=.7, label='SMA')
axs[1].set_title('Momentum (14 day period)')
axs[1].set_xlabel('Timestamp')
axs[1].set_ylabel('Close value')
# Display
plt.legend()
plt.show()
# + [markdown] id="iW5-6U3PkHsz"
# |Function| Name|
# |:---|:---|
# |TRANGE| True Range|
# |ATR| Average True Range|
# |NATR| Normalized Average True Range|
# + [markdown] id="b38nscJhkHso"
# #### Average Directional Movement Index (ADX)
# + id="bdPm1gcAkHso"
#Average Directional Movement Index (ADX)
#@markdown The ADX combines of two other indicators, namely the positive and directional indicators (PLUS_DI and MINUS_DI), which in turn build on the positive and directional movement (PLUS_DM and MINUS_DM). For additional details see [Wikipdia](https://en.wikipedia.org/wiki/Average_directional_movement_index) and [Investopedia](https://www.investopedia.com/articles/trading/07/adx-trend-indicator.asp).
pretty_ploter(CPNY,'ADX')
# + [markdown] id="WHb95DwckHso"
# #### Absolute Price Oscillator (APO)
# + [markdown] id="WBBFg28hkHsp"
# The absolute Price Oscillator (APO) is computed as the difference between two exponential moving averages (EMA) of price series, expressed as an absolute value. The EMA windows usually contain 26 and 12 data points, respectively.
# + id="oHjZWb14kHsp"
# Absolute Price Oscillator (APO)
pretty_ploter(CPNY,'APO')
# + [markdown] id="PzPMiqJIkHsp"
# #### Percentage Price Oscillator (PPO)
# + [markdown] id="PbeDUncxkHsp"
# The Percentage Price Oscillator (APO) is computed as the difference between two exponential moving averages (EMA) of price series, expressed as a percentage value and thus comparable across assets. The EMA windows usually contain 26 and 12 data points, respectively.
# + id="R7N3Pu6_kHsp"
# Percentage Price Oscillator (PPO)
pretty_ploter(CPNY,'PPO')
# + [markdown] id="kBkx-dIkkHsq"
# #### Aroon Oscillator (APO)
# + [markdown] id="_sjzXl48kHsq"
# #### Aroon Up/Down Indicator (PPO)
# + [markdown] id="2_VdhN7IkHsq"
# The indicator measures the time between highs and the time between lows over a time period. It computes an AROON_UP and an AROON_DWN indicator as follows:
#
# $$
# \begin{align*}
# \text{AROON_UP}&=\frac{T-\text{Periods since T period High}}{T}\times 100\\
# \text{AROON_DWN}&=\frac{T-\text{Periods since T period Low}}{T}\times 100
# \end{align*}
# $$
# + [markdown] id="EohxfpE_kHsq"
# #### Aroon Oscillator (AROONOSC
# + [markdown] id="jCRb2T4ykHsq"
# The Aroon Oscillator is simply the difference between the Aroon Up and Aroon Down indicators.
# + id="Z2D2z1QFkHsr"
# Aroon Oscillator (AROONOSC)
pretty_ploter(CPNY,'AROONOSC')
# + [markdown] id="f7WMF-w9kHsr"
# #### Balance Of Power (BOP)
# + [markdown] id="BXpqa_DxkHsr"
# The Balance of Power (BOP) intends to measure the strength of buyers relative to sellers in the market by assessing the ability of each side to drive prices. It is computer as the difference between the close and the open price, divided by the difference between the high and the low price:
#
# $$
# \text{BOP}_t= \frac{P_t^\text{Close}-P_t^\text{Open}}{P_t^\text{High}-P_t^\text{Low}}
# $$
# + id="hMUaK3E7kHsr"
# Balance of Power (BOP) indicator
pretty_ploter(CPNY, 'BOP')
# + [markdown] id="Jt_FDpVekHsr"
# #### Commodity Channel Index (CCI)
# + [markdown] id="XaJdgs4QkHss"
# The Commodity Channel Index (CCI) measures the difference between the current *typical* price, computed as the average of current low, high and close price and the historical average price. A positive (negative) CCI indicates that price is above (below) the historic average. When CCI is below zero, the price is below the hsitoric average. It is computed as:
#
# $$
# \begin{align*}
# \bar{P_t}&=\frac{P_t^H+P_t^L+P_t^C}{3}\\
# \text{CCI}_t & =\frac{\bar{P_t} - \text{SMA}(T)_t}{0.15\sum_{t=i}^T |\bar{P_t}-\text{SMA}(N)_t|/T}
# \end{align*}
# $$
# + id="pbMP3cBCkHss"
# Commodity Channel Index (CCI)
pretty_ploter(CPNY, 'CCI')
# + [markdown] id="gdyUtYFdkHss"
# #### Moving Average Convergence/Divergence (MACD)
# + [markdown] id="lrRaKjrhkHss"
# Moving Average Convergence Divergence (MACD) is a trend-following (lagging) momentum indicator that shows the relationship between two moving averages of a security’s price. It is calculated by subtracting the 26-period Exponential Moving Average (EMA) from the 12-period EMA.
#
# The TA-Lib implementation returns the MACD value and its signal line, which is the 9-day EMA of the MACD. In addition, the MACD-Histogram measures the distance between the indicator and its signal line.
# + id="ANHp5hLWkHst"
# Moving Average Convergence Divergence (MACD),
plt.figure(figsize=(16.1, 10), dpi=80)
plt.plot(CPNY.macd_fast, label = 'MACD fast')
plt.plot(CPNY.macd_slow, label = 'MACD slow')
plt.plot(CPNY.signal_period, label = 'Signal 9 periods')
plt.xlabel('time')
# Set the y axis label of the current axis.
plt.ylabel('MACD score')
# Set a title of the current axes.
plt.title('Moving average convergence/divergence score')
# show a legend on the plot
plt.legend()
# Display a figure.
plt.show()
# + [markdown] id="_wIB65szkHst"
# #### Chande Momentum Oscillator (CMO)
# + [markdown] id="fyRM3J_UkHst"
# The Chande Momentum Oscillator (CMO) intends to measure momentum on both up and down days. It is calculated as the difference between the sum of gains and losses over at time period T, divided by the sum of all price movement over the same period. It oscillates between +100 and -100.
# + id="tVgw3JU8kHst"
# Chande Momentum Oscillator (CMO)
pretty_ploter(CPNY,'CMO')
# + [markdown] id="35NfQTFpkHst"
# #### Money Flow Index
# + [markdown] id="gvek51eckHst"
# The Money Flow Index (MFI) incorporates price and volume information to identify overbought or oversold conditions. The indicator is typically calculated using 14 periods of data. An MFI reading above 80 is considered overbought and an MFI reading below 20 is considered oversold.
# + id="Pq2nBge2kHsu"
# Flow Index (MFI)
pretty_ploter(CPNY,'MFI')
# + [markdown] id="WtAESniQkHsu"
# #### Relative Strength Index
# + [markdown] id="Ry2_y5c-kHsu"
# RSI compares the magnitude of recent price changes across stocks to identify stocks as overbought or oversold. A high RSI (usually above 70) indicates overbought and a low RSI (typically below 30) indicates oversold. It first computes the average price change for a given number (often 14) of prior trading days with rising and falling prices, respectively as $\text{up}_t$ and $\text{down}_t$. Then, the RSI is computed as:
# $$
# \text{RSI}_t=100-\frac{100}{1+\frac{\text{up}_t}{\text{down}_t}}
# $$
#
#
# + id="fZvzE8pSkHsu"
# Relative Strength Index (RSI)
pretty_ploter(CPNY,'RSI')
# + [markdown] id="s9QhjqBhkHsu"
# #### Stochastic RSI (STOCHRSI)
# + [markdown] id="orYSqcBmkHsu"
# The Stochastic Relative Strength Index (STOCHRSI) is based on the RSI just described and intends to identify crossovers as well as overbought and oversold conditions. It compares the distance of the current RSI to the lowest RSI over a given time period T to the maximum range of values the RSI has assumed for this period. It is computed as follows:
#
# $$
# \text{STOCHRSI}_t= \frac{\text{RSI}_t-\text{RSI}_t^L(T)}{\text{RSI}_t^H(T)-\text{RSI}_t^L(T)}
# $$
#
# The TA-Lib implementation offers more flexibility than the original "Unsmoothed stochastic RSI" version by <NAME> Kroll (1993). To calculate the original indicator, keep the `timeperiod` and `fastk_period` equal.
#
# The return value `fastk` is the unsmoothed RSI. The `fastd_period` is used to compute a smoothed STOCHRSI, which is returned as `fastd`. If you do not care about STOCHRSI smoothing, just set `fastd_period` to 1 and ignore the `fastd` output.
#
# Reference: "Stochastic RSI and Dynamic Momentum Index" by <NAME> and <NAME> Stock&Commodities V.11:5 (189-199)
#
# + id="8GBmaCx4kHsv"
#Stochastic RSI (STOCHRSI)
plt.figure(figsize=(16.1, 10), dpi=80)
plt.plot(CPNY.fastk, alpha=0.50)
plt.plot(CPNY.fastd, alpha=0.50)
# + [markdown] id="G7A3mCQ1kHsv"
# #### Stochastic (STOCH)
# + [markdown] id="t686rHjjkHsv"
# A stochastic oscillator is a momentum indicator comparing a particular closing price of a security to a range of its prices over a certain period of time. Stochastic oscillators are based on the idea that closing prices should confirm the trend.
# + [markdown] id="wSsCrCsVkHsv"
# For stochastic (STOCH), there are four different lines: `FASTK`, `FASTD`, `SLOWK` and `SLOWD`. The `D` is the signal line usually drawn over its corresponding `K` function.
#
# $$
# \begin{align*}
# & K^\text{Fast}(T_K) & = &\frac{P_t-P_{T_K}^L}{P_{T_K}^H-P_{T_K}^L}* 100 \\
# & D^\text{Fast}(T_{\text{FastD}}) & = & \text{MA}(T_{\text{FastD}})[K^\text{Fast}]\\
# & K^\text{Slow}(T_{\text{SlowK}}) & = &\text{MA}(T_{\text{SlowK}})[K^\text{Fast}]\\
# & D^\text{Slow}(T_{\text{SlowD}}) & = &\text{MA}(T_{\text{SlowD}})[K^\text{Slow}]
# \end{align*}
# $$
#
#
# The $P_{T_K}^L$, $P_{T_K}^H$, and $P_{T_K}^L$ are the extreme values among the last $T_K$ period.
# $K^\text{Slow}$ and $D^\text{Fast}$ are equivalent when using the same period.
# + id="ETnOjC76kHsv"
#Stochastic (STOCH)
plt.figure(figsize=(16.1, 10), dpi=80)
plt.plot(CPNY.slowk, alpha=0.5)
plt.plot(CPNY.slowd, alpha=0.5)
# + [markdown] id="a-sFW83fkHsw"
# #### Ultimate Oscillator (ULTOSC)
# + [markdown] id="APO6CbdHkHsw"
# The Ultimate Oscillator (ULTOSC), developed by <NAME>, measures the average difference of the current close to the previous lowest price over three time frames (default: 7, 14, and 28) to avoid overreacting to short-term price changes and incorporat short, medium, and long-term market trends. It first computes the buying pressure, $\text{BP}_t$, then sums it over the three periods $T_1, T_2, T_3$, normalized by the True Range ($\text{TR}_t$.
# $$
# \begin{align*}
# \text{BP}_t & = P_t^\text{Close}-\min(P_{t-1}^\text{Close}, P_t^\text{Low})\\
# \text{TR}_t & = \max(P_{t-1}^\text{Close}, P_t^\text{High})-\min(P_{t-1}^\text{Close}, P_t^\text{Low})
# \end{align*}
# $$
#
# ULTOSC is then computed as a weighted average over the three periods as follows:
# $$
# \begin{align*}
# \text{Avg}_t(T) & = \frac{\sum_{i=0}^{T-1} \text{BP}_{t-i}}{\sum_{i=0}^{T-1} \text{TR}_{t-i}}\\
# \text{ULTOSC}_t & = 100*\frac{4\text{Avg}_t(7) + 2\text{Avg}_t(14) + \text{Avg}_t(28)}{4+2+1}
# \end{align*}
# $$
# + id="gO6JlexWkHsw"
#Ultimate Oscillator (ULTOSC)
pretty_ploter(CPNY,'ULTOSC')
# + [markdown] id="aQWUETJVkHsw"
# #### Williams' %R (WILLR)
# + [markdown] id="YJ_G5N72kHsw"
# Williams %R, also known as the Williams Percent Range, is a momentum indicator that moves between 0 and -100 and measures overbought and oversold levels to identify entry and exit points. It is similar to the Stochastic oscillator and compares the current closing price $P_t^\text{Close}$ to the range of highest ($P_T^\text{High}$) and lowest ($P_T^\text{Low}$) prices over the last T periods (typically 14). The indicators is computed as:
#
# $$
# \text{WILLR}_t = \frac{P_T^\text{High}-P_t^\text{Close}}{P_T^\text{High}-P_T^\text{Low}}
# $$
#
# + id="d6TW5PNJkHsw"
#Williams' %R (WILLR)
pretty_ploter(CPNY,'WILLR')
# + [markdown] id="lQ8-iSGzkHsx"
# ## Volume Indicators
# + [markdown] id="S-r3ZReXkHsx"
# |Function| Name|
# |:---|:---|
# |AD| Chaikin A/D Line|
# |ADOSC| Chaikin A/D Oscillator|
# |OBV| On Balance Volume|
# + [markdown] id="lJZvwXzEkHsx"
# #### Chaikin A/D Line
# + [markdown] id="gWsIUAMpkHsx"
# The Chaikin Advance/Decline or Accumulation/Distribution Line (AD) is a volume-based indicator designed to measure the cumulative flow of money into and out of an asset. The indicator assumes that the degree of buying or selling pressure can be determined by the location of the close, relative to the high and low for the period. There is buying (sellng) pressure when a stock closes in the upper (lower) half of a period's range. The intention is to signal a change in direction when the indicator diverges from the security price.
#
# The Accumulation/Distribution Line is a running total of each period's Money Flow Volume. It is calculated as follows:
#
# 1. The Money Flow Multiplier (MFI) is the relationship of the close to the high-low range:
# 2. The MFI is multiplied by the period's volume $V_t$ to come up with a Money Flow Volume (MFV).
# 3. A running total of the Money Flow Volume forms the Accumulation Distribution Line:
# $$
# \begin{align*}
# &\text{MFI}_t&=\frac{P_t^\text{Close}-P_t^\text{Low}}{P_t^\text{High}-P_t^\text{Low}}\\
# &\text{MFV}_t&=\text{MFI}_t \times V_t\\
# &\text{AD}_t&=\text{AD}_{t-1}+\text{MFV}_t
# \end{align*}
# $$
# + id="Zt1GA4enkHsx" colab={"base_uri": "https://localhost:8080/", "height": 189} outputId="b34723c8-970b-43b0-b622-c58d8980024d"
# Chaikin A/D Line
pretty_ploter(CPNY, 'AD')
# + [markdown] id="p9EHOWLpkHsx"
# #### Chaikin A/D Oscillator (ADOSC)
# + [markdown] id="g3ZEyZbOkHsy"
# The Chaikin A/D Oscillator (ADOSC) is the Moving Average Convergence Divergence indicator (MACD) applied to the Chaikin A/D Line. The Chaikin Oscillator intends to predict changes in the Accumulation/Distribution Line.
#
# It is computed as the difference between the 3-day exponential moving average and the 10-day exponential moving average of the Accumulation/Distribution Line.
# + id="_orvPvjhkHsy" colab={"base_uri": "https://localhost:8080/", "height": 189} outputId="cec9f029-d712-40b5-fe13-127ed9708c0f"
#Chaikin A/D Oscillator (ADOSC)
pretty_ploter(CPNY, 'ADOSC')
# + [markdown] id="8itqbzb9kHsy"
# #### On Balance Volume (OBV)
# + [markdown] id="AYIjyC1xkHsy"
# The On Balance Volume indicator (OBV) is a cumulative momentum indicator that relates volume to price change. It assumes that OBV changes precede price changes because smart money can be seen flowing into the security by a rising OBV. When the public then moves into the security, both the security and OBV will rise.
#
# The current OBV is computed by adding (subtracting) the current volume to the last OBV if the security closes higher (lower) than the previous close.
#
# $$
# \text{OBV}_t =
# \begin{cases}
# \text{OBV}_{t-1}+V_t & \text{if }P_t>P_{t-1}\\
# \text{OBV}_{t-1}-V_t & \text{if }P_t<P_{t-1}\\
# \text{OBV}_{t-1} & \text{otherwise}
# \end{cases}
# $$
# + id="-siFP5e_kHsy"
#On Balance Volume (OBV)
pretty_ploter(CPNY, 'OBV')
# + [markdown] id="I5gZxMAfkHsy"
# ## Volatility Indicators
# + [markdown] id="m8rhN7QukHsz"
# ### ATR
# + [markdown] id="oZFGZlS-kHsz"
# The Average True Range indicator (ATR) shows volatility of the market. It was introduced by <NAME> (1978) and has been used as a component of numerous other indicators since. It aims to anticipate changes in trend such that the higher its value, the higher the probability of a trend change; the lower the indicator’s value, the weaker the current trend.
#
# It is computed as the simple moving average for a period T of the True Range (TRANGE), which measures volatility as the absolute value of the largest recent trading range:
# $$
# \text{TRANGE}_t = \max\left[P_t^\text{High} - P_t^\text{low}, \left| P_t^\text{High} - P_{t-1}^\text{Close}\right|, \left| P_t^\text{low} - P_{t-1}^\text{Close}\right|\right]
# $$
# + id="_mTZ1P2lkHsz"
# ATR
pretty_ploter(CPNY, 'ATR')
# + [markdown] id="S90TJ9RokHsz"
# ### NATR
# + [markdown] id="N3lB4D5zkHsz"
# The Normalized Average True Range (NATR) is a normalized version of the ATR computed as follows:
#
# $$
# \text{NATR}_t = \frac{\text{ATR}_t(T)}{P_t^\text{Close}} * 100
# $$
#
# Normalization make the ATR function more relevant in the folllowing scenarios:
# - Long term analysis where the price changes drastically.
# - Cross-market or cross-security ATR comparison.
# + id="sfP7k7KvkHs0"
#NATR
pretty_ploter(CPNY, 'NATR')
# + [markdown] id="3hgLeBCNkHs0"
# ## Rolling Factor Betas
# + [markdown] id="iHvbcQQRkHs0"
# # Persist results
# + colab={"base_uri": "https://localhost:8080/", "height": 37} id="RUF05lMaq0nr" outputId="240f2708-fe21-4ebc-ebfd-67511f6e2a03"
r=Returns(data)
m=Metrics(data)
DATA_STORE = Path('..', 'data', 'stock_metrics.h5')
store = pd.HDFStore(DATA_STORE)
for company_name in progress_bar(set(data.index.get_level_values(0))):
returns = r.all_returns(company_name)
metrics = m.all_metrics(company_name)
store[f'data/{company_name}'] = returns.join(metrics)
store.close()
| ml-trading-strategy/notebooks/Milestone_2_Starter_Notebook.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# +
# Importar bibliotecas basicas
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn import datasets
# +
# Cargar Datasets
diabetes = datasets.load_diabetes()
# -
diabetes.feature_names
# +
# Preparar dataframes
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size=0.2)
# -
# Crear modelo
model = LinearRegression()
model.fit(x_train, y_train)
model.score(x_test, y_test)
model.coef_
y_pred = model.predict(x_test)
y_pred
# +
# Dibujar prediccion vs datos reales
plt.plot(y_test, y_pred, '.')
x = np.linspace(0, 330, 100)
y = x
plt.plot(x,y)
plt.show()
# -
| sesion41/Diabetes LR.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Classification - Adult Census using Vowpal Wabbit in MMLSpark
#
# In this example, we predict incomes from the *Adult Census* dataset using Vowpal Wabbit (VW) classifier in MMLSpark.
# First, we read the data and split it into train and test sets as in this [example](https://github.com/Azure/mmlspark/blob/master/notebooks/samples/Classification%20-%20Adult%20Census.ipynb
# ).
data = spark.read.parquet("wasbs://<EMAIL>/AdultCensusIncome.parquet")
data = data.select(["education", "marital-status", "hours-per-week", "income"])
train, test = data.randomSplit([0.75, 0.25], seed=123)
train.limit(10).toPandas()
# Next, we define a pipeline that includes feature engineering and training of a VW classifier. We use a featurizer provided by VW that hashes the feature names.
# Note that VW expects classification labels being -1 or 1. Thus, the income category is mapped to this space before feeding training data into the pipeline.
# +
from pyspark.sql.functions import when, col
from pyspark.ml import Pipeline
from mmlspark.vw import VowpalWabbitFeaturizer, VowpalWabbitClassifier
# Define classification label
train = train.withColumn("label", when(col("income").contains("<"), 0.0).otherwise(1.0))
# Specify featurizer
vw_featurizer = VowpalWabbitFeaturizer(inputCols=["education", "marital-status", "hours-per-week"], \
outputCol="features")
# Define VW classification model
args = "--loss_function=logistic --quiet --holdout_off"
vw_model = VowpalWabbitClassifier(featuresCol="features", \
labelCol="label", \
args=args, \
numPasses=10)
# Create a pipeline
vw_pipeline = Pipeline(stages=[vw_featurizer, vw_model])
# -
# Then, we are ready to train the model by fitting the pipeline with the training data.
# Train the model
vw_trained = vw_pipeline.fit(train)
# After the model is trained, we apply it to predict the income of each sample in the test set.
# Making predictions
test = test.withColumn("label", when(col("income").contains("<"), 0.0).otherwise(1.0))
prediction = vw_trained.transform(test)
prediction.limit(10).toPandas()
# Finally, we evaluate the model performance using `ComputeModelStatistics` function which will compute confusion matrix, accuracy, precision, recall, and AUC by default for classificaiton models.
from mmlspark.train import ComputeModelStatistics
metrics = ComputeModelStatistics(evaluationMetric="classification",
labelCol="label",
scoredLabelsCol="prediction").transform(prediction)
metrics.toPandas()
| notebooks/samples/Classification - Adult Census with Vowpal Wabbit.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="UbgapGliFILi" colab_type="text"
# ## License
# + [markdown] id="2l5ES4VuElhc" colab_type="text"
# Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# + [markdown] id="W7i1IleCdIEZ" colab_type="text"
# # Load test analysis
# + [markdown] id="6AZnmE2XGXrq" colab_type="text"
# ## Initialization
# + colab_type="code" id="XHUPlLRgNBgS" colab={}
from google.colab import auth
auth.authenticate_user()
project_id = '[your project id]'
# + [markdown] id="sexUkYLdGc0z" colab_type="text"
# ## Log Overview
# + colab_type="code" id="nFF9Wz1CAyVI" outputId="f9b72bc3-eeb6-420a-be46-7ef6401cea4c" colab={"base_uri": "https://localhost:8080/", "height": 34}
import pandas as pd
import datetime
today = datetime.datetime.utcnow().strftime("%Y%m%d")
df = pd.io.gbq.read_gbq('''
SELECT
count(*) as total
FROM
`web_instr_container.stdout_{}`
'''.format(today), project_id=project_id)
total = df.total[0]
print(f'Log records: {total}')
# + [markdown] id="gPGqwNuNEjMK" colab_type="text"
#
# + [markdown] id="YgkJ4CrhFToC" colab_type="text"
# ## Client Latency
# + id="hNHRDHQwFWLa" colab_type="code" outputId="7435344c-4286-4691-bd1c-993937bf8f26" colab={"base_uri": "https://localhost:8080/", "height": 296}
import pandas as pd
import datetime
today = datetime.datetime.utcnow().strftime("%Y%m%d")
df = pd.io.gbq.read_gbq('''
SELECT
EXTRACT(MINUTE FROM timestamp) AS Minute,
REGEXP_EXTRACT(textPayload, r"LoadTest: latency: ([0-9]+)\.") AS Latency
FROM
`web_instr_container.stdout_{}`
WHERE
EXTRACT(HOUR FROM timestamp) = 2
AND
EXTRACT(MINUTE FROM timestamp) > 0
AND
EXTRACT(MINUTE FROM timestamp) < 5
ORDER BY
Minute
'''.format(today), project_id=project_id)
df1 = df[pd.isnull(df['Latency']) == False]
df1 = df1.astype({'Minute': 'int64', 'Latency': 'int64'})
latency = df1.groupby('Minute').median()
ax = latency.plot()
ax.set_xlabel('Time (min)')
ax.set_ylabel('Median Client Latency (ms)')
# + [markdown] id="zVnd4pgzj0ze" colab_type="text"
# ## Scatter Plot
# + id="AwHu2e3zIUCh" colab_type="code" outputId="029cb0a4-a5fe-40a0-bd92-abdbddd94694" colab={"base_uri": "https://localhost:8080/", "height": 296}
import pandas as pd
import datetime
today = datetime.datetime.utcnow().strftime("%Y%m%d")
df = pd.io.gbq.read_gbq('''
SELECT
EXTRACT(SECOND FROM timestamp) AS Seconds,
REGEXP_EXTRACT(textPayload, r"LoadTest: latency: ([0-9]+)\.") AS Latency
FROM
`web_instr_container.stdout_{}`
WHERE
EXTRACT(HOUR FROM timestamp) = 2
AND
EXTRACT(MINUTE FROM timestamp) = 3
ORDER BY
Seconds
'''.format(today), project_id=project_id)
df1 = df[pd.isnull(df['Latency']) == False]
df1 = df1.astype({'Seconds': 'int64', 'Latency': 'int64'})
ax = df1.plot.scatter(x='Seconds', y='Latency', c='DarkBlue')
ax.set_xlabel('Time (s)')
ax.set_ylabel('Client Latency (ms)')
# + [markdown] id="Mi4EGHIwd4jK" colab_type="text"
# ## Responses
# + colab_type="code" id="y318gNmwU57S" outputId="2e40cff7-a5f3-4c37-ce8a-8a9447e4dd43" colab={"base_uri": "https://localhost:8080/", "height": 359}
import pandas as pd
import datetime
today = datetime.datetime.utcnow().strftime("%Y%m%d")
df = pd.io.gbq.read_gbq('''
SELECT
EXTRACT(MINUTE FROM timestamp) as Minute,
httpRequest.status AS Status
FROM
`web_instr_load_balancer.requests_{}`
GROUP BY
Minute, Status
ORDER BY Minute, Status
'''.format(today), project_id=project_id)
df.head(10)
# + id="qweYw59UL7In" colab_type="code" colab={}
| examples/web-instrumentation/load_test_analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Simple CPW Meander
#
# We'll be creating a 2D design and adding a meandered resonator QComponent.
# Will use component called OpenToGround for termination of resonators.
#
# Simple RouteMeander resonator object will be shown.
#
# RouteMeander: Implements a simple CPW, with a single meander.
# OpenToGround: A basic open to ground termination. Functions as a pin for auto drawing.
# For convenience, let's begin by enabling
# automatic reloading of modules when they change.
# %load_ext autoreload
# %autoreload 2
import qiskit_metal as metal
from qiskit_metal import designs, draw
from qiskit_metal import MetalGUI, Dict, Headings
# +
# Each time you create a new quantum circuit design,
# you start by instantiating a QDesign class.
# The design class `DesignPlanar` is best for 2D circuit designs.
design = designs.DesignPlanar()
gui = MetalGUI(design)
# -
from qiskit_metal.qlibrary.terminations.open_to_ground import OpenToGround
from qiskit_metal.qlibrary.tlines.meandered import RouteMeander
# Be aware of the default_options that can be overridden by user.
RouteMeander.get_template_options(design)
# Be aware of the default_options that can be overridden by user.
OpenToGround.get_template_options(design)
# To force overwrite a QComponent with an existing name.
# This is useful when re-running cells in a notebook.
design.overwrite_enabled = True
# A RouteMeander connector are shown. The terminations are open-to-ground.
#
# The pin_inputs is the default dictionary for passing pins into a component, **BUT** how the dictionary is structured is component dependent. Using the below structure (eg. start_pin, end_pin) is suggested for any 2 port type connection, but you should always check the documentation for the specific component you are wanting to use.
# +
open_start_options = Dict(pos_x='1000um',
pos_y='0um',
orientation = '-90')
open_start_meander = OpenToGround(design,'Open_meander_start',options=open_start_options)
open_end_options = Dict(pos_x='1000um',
pos_y='1500um',
orientation='90',
termination_gap='10um')
open_end_meander = OpenToGround(design,'Open_meander_end',options=open_end_options)
# +
meander_options = Dict(pin_inputs=Dict(start_pin=Dict(
component='Open_meander_start',
pin='open'),
end_pin=Dict(
component='Open_meander_end',
pin='open')
),
total_length='9mm',
fillet='99.99um')
testMeander = RouteMeander(design,'meanderTest',options=meander_options)
gui.rebuild()
gui.autoscale()
gui.zoom_on_components([testMeander.name, open_start_meander.name, open_end_meander.name])
# -
#Let's see what the testMeander object looks like
testMeander #print meanderTest information
#Let's see what the open_start_meander object looks like
open_start_meander #print Open_meander_start information
# We can also see what active connections there are from the netlist. Pins that share the same net_id indicate they are connected. Pins that are not on the net list are currently open.
design.net_info
# Save screenshot as a .png formatted file.
gui.screenshot()
# + tags=["nbsphinx-thumbnail"]
# Screenshot the canvas only as a .png formatted file.
gui.figure.savefig('shot.png')
from IPython.display import Image, display
_disp_ops = dict(width=500)
display(Image('shot.png', **_disp_ops))
# -
# Closing the Qiskit Metal GUI
gui.main_window.close()
| tutorials/Appendix C Circuit examples/B. Resonators/11-Resonator_Meander.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
#hide
from lnscrape import LNScrape
# # lnscrape
#
# > Scraper for Lexis-Nexis. Only academic use.
# This file will become your README and also the index of your documentation.
# ## Install
# `pip install lnscrape`
# ## How to use
# Initialize the LNScrape module with your Boolean search query, sources and log-in details. This will open a browser instance. Wait until the set up is finished before continuing.
lns = LNScrape.LNScrape(query="(climate AND (change OR disaster))",
sources = ['USA Today'],
username= "username",
password = 'password')
# Then run the following command to initialize the automated selection and downloading process.
lns.scrape(start_page=1)
| index.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] toc="true"
# # Table of Contents
# <p><div class="lev1 toc-item"><a href="#Oraux-CentraleSupélec-PSI---Juin-2018" data-toc-modified-id="Oraux-CentraleSupélec-PSI---Juin-2018-1"><span class="toc-item-num">1 </span>Oraux CentraleSupélec PSI - Juin 2018</a></div><div class="lev2 toc-item"><a href="#Remarques-préliminaires" data-toc-modified-id="Remarques-préliminaires-11"><span class="toc-item-num">1.1 </span>Remarques préliminaires</a></div><div class="lev2 toc-item"><a href="#Planche-160" data-toc-modified-id="Planche-160-12"><span class="toc-item-num">1.2 </span>Planche 160</a></div><div class="lev2 toc-item"><a href="#Planche-162" data-toc-modified-id="Planche-162-13"><span class="toc-item-num">1.3 </span>Planche 162</a></div><div class="lev2 toc-item"><a href="#Planche-166" data-toc-modified-id="Planche-166-14"><span class="toc-item-num">1.4 </span>Planche 166</a></div><div class="lev2 toc-item"><a href="#Planche-168" data-toc-modified-id="Planche-168-15"><span class="toc-item-num">1.5 </span>Planche 168</a></div><div class="lev2 toc-item"><a href="#Planche-170" data-toc-modified-id="Planche-170-16"><span class="toc-item-num">1.6 </span>Planche 170</a></div><div class="lev2 toc-item"><a href="#Planche-172" data-toc-modified-id="Planche-172-17"><span class="toc-item-num">1.7 </span>Planche 172</a></div><div class="lev2 toc-item"><a href="#Planche-177" data-toc-modified-id="Planche-177-18"><span class="toc-item-num">1.8 </span>Planche 177</a></div><div class="lev1 toc-item"><a href="#À-voir-aussi" data-toc-modified-id="À-voir-aussi-2"><span class="toc-item-num">2 </span>À voir aussi</a></div><div class="lev2 toc-item"><a href="#Les-oraux---(exercices-de-maths-avec-Python)" data-toc-modified-id="Les-oraux---(exercices-de-maths-avec-Python)-21"><span class="toc-item-num">2.1 </span><a href="http://perso.crans.org/besson/infoMP/oraux/solutions/" target="_blank">Les oraux</a> <em>(exercices de maths avec Python)</em></a></div><div class="lev2 toc-item"><a href="#Fiches-de-révisions-pour-les-oraux" data-toc-modified-id="Fiches-de-révisions-pour-les-oraux-22"><span class="toc-item-num">2.2 </span>Fiches de révisions <em>pour les oraux</em></a></div><div class="lev2 toc-item"><a href="#Quelques-exemples-de-sujets-d'oraux-corrigés" data-toc-modified-id="Quelques-exemples-de-sujets-d'oraux-corrigés-23"><span class="toc-item-num">2.3 </span>Quelques exemples de sujets <em>d'oraux</em> corrigés</a></div><div class="lev2 toc-item"><a href="#D'autres-notebooks-?" data-toc-modified-id="D'autres-notebooks-?-24"><span class="toc-item-num">2.4 </span>D'autres notebooks ?</a></div>
# -
# # Oraux CentraleSupélec PSI - Juin 2018
#
# - Ce [notebook Jupyter](https://www.jupyter.org) est une proposition de correction, en [Python 3](https://www.python.org/), d'exercices d'annales de l'épreuve "maths-info" du [concours CentraleSupélec](http://www.concours-centrale-supelec.fr/), filière PSI.
# - Les exercices viennent de l'[Officiel de la Taupe](http://odlt.fr/), [2017](http://www.odlt.fr/Oraux_2018.pdf) (planches 162 à 177, page 23).
# - Ce document a été écrit par [<NAME>](http://perso.crans.org/besson/), et est disponible en ligne [sur mon site](https://perso.crans.org/besson/publis/notebooks/Oraux_CentraleSupelec_PSI__Juin_2018.html).
# ## Remarques préliminaires
# - Les exercices sans Python ne sont pas traités.
# - Les exercices avec Python utilisent Python 3, [numpy](http://numpy.org), [matplotlib](http://matplotlib.org), [scipy](http://scipy.org) et [sympy](http://sympy.org), et essaient d'être résolus le plus simplement et le plus rapidement possible. L'efficacité (algorithmique, en terme de mémoire et de temps de calcul), n'est *pas* une priorité. La concision et simplicité de la solution proposée est prioritaire.
import numpy as np
import matplotlib.pyplot as plt
from scipy import integrate
import numpy.random as rd
# ----
# ## Planche 160
# - $I_n := \int_0^1 \frac{1}{(1+t)^n \sqrt{1-t}} \mathrm{d}t$ et $I_n := \int_0^1 \frac{1/2}{(1+t)^n \sqrt{1-t}} \mathrm{d}t$ sont définies pour tout $n$ car leur intégrande est continue et bien définie sur $]0,1[$ et intégrable en $1$ parce qu'on sait (par intégrale de Riemann) que $\frac{1}{\sqrt{u}}$ est intégrable en $0^+$ (et changement de variable $u = 1-t$).
# - On les calcule très simplement :
def I(n):
def f(t):
return 1 / ((1+t)**n * np.sqrt(1-t))
i, err = integrate.quad(f, 0, 1)
return i
def J(n):
def f(t):
return 1 / ((1+t)**n * np.sqrt(1-t))
i, err = integrate.quad(f, 0, 0.5)
return i
# +
valeurs_n = np.arange(1, 50)
valeurs_In = np.array([I(n) for n in valeurs_n])
plt.figure()
plt.plot(valeurs_n, valeurs_In, 'ro')
plt.title("Valeurs de $I_n$")
plt.show()
# -
# - On conjecture que $I_n$ est décroissante. C'est évident puisque si on note $f_n(t)$ son intégrande, on observe que $f_{n+1}(t) \leq f_n(t)$ pour tout $t$, et donc par monotonie de l'intégrale, $I_{n+1} \leq I_n$.
# - On conjecture que $I_n \to 0$. Cela se montre très facilement avec le théorème de convergence dominée.
plt.figure()
plt.plot(np.log(valeurs_n), np.log(valeurs_In), 'go')
plt.title(r"Valeurs de $\ln(I_n)$ en fonction de $\ln(n)$")
plt.show()
# - Ce qu'on observe permet de conjecturer que $\alpha=1$ est l'unique entier tel que $n^{\alpha} I_n$ converge vers une limite non nulle.
# +
valeurs_Jn = np.array([J(n) for n in valeurs_n])
alpha = 1
plt.figure()
plt.plot(valeurs_n, valeurs_n**alpha * valeurs_In, 'r+', label=r'$n^{\alpha} I_n$')
plt.plot(valeurs_n, valeurs_n**alpha * valeurs_Jn, 'b+', label=r'$n^{\alpha} J_n$')
plt.legend()
plt.title(r"Valeurs de $n^{\alpha} I_n$ et $n^{\alpha} J_n$")
plt.show()
# -
# - On en déduit qu'il en est de même pour $J_n$, on a $n^{\alpha} J_n \to l$ la même limite que $n^{\alpha} I_n$.
# - Pour finir, on montre mathématiquement que $n^{\alpha} (I_n - J_n)$ tend vers $0$.
plt.figure()
plt.plot(valeurs_n, valeurs_n**alpha * (valeurs_In - valeurs_Jn), 'g+', label=r'$n^{\alpha} (I_n - J_n)$')
plt.legend()
plt.title(r"Valeurs de $n^{\alpha} (I_n - J_n)$")
plt.show()
# - Puis rapidement, on montre que $\forall x \geq 0, \ln(1 + x) \geq \frac{x}{1+x}$. Ca peut se prouver de plein de façons différentes, mais par exemple on écrit $f(x) = (x+1) \log(x+1) - x$ qui est de classe $\mathcal{C}^1$, et on la dérive. $f'(x) = \log(x+1) + 1 - 1 > 0$ donc $f$ est croissante, et $f(0) = 0$ donc $f(x) \geq f(0) = 0$ pour tout $x \geq 0$.
X = np.linspace(0, 100, 10000)
plt.plot(X, np.log(1 + X), 'r-', label=r'$\log(1+x)$')
plt.plot(X, X / (1 + X), 'b-', label=r'$\frac{x}{1+x}$')
plt.legend()
plt.title("Comparaison entre deux fonctions")
plt.show()
# ---
# ## Planche 162
# On commence par définir la fonction, en utilisant `numpy.cos` et pas `math.cos` (les fonctions de `numpy` peuvent travailler sur des tableaux, c'est plus pratique).
# +
def f(x):
return x * (1 - x) * (1 + np.cos(5 * np.pi * x))
Xs = np.linspace(0, 1, 2000)
Ys = f(Xs)
# -
# Pas besoin de lire le maximum sur un graphique :
M = max_de_f = max(Ys)
print("Sur [0, 1], avec 2000 points, M =", M)
# On affiche la fonction, comme demandé, avec un titre :
plt.figure()
plt.plot(Xs, Ys)
plt.title("Fonction $f(x)$ sur $[0,1]$")
plt.show()
# Pour calculer l'intégrale, on utilise `scipy.integrate.quad` :
# +
def In(x, n):
def fn(x):
return f(x) ** n
return integrate.quad(fn, 0, 1)[0]
def Sn(x):
return np.sum([In(Xs, n) * x**n for n in range(0, n+1)], axis=0)
# -
# On vérifie avant de se lancer dans l'affichage :
for n in range(10):
print("In(x,", n, ") =", In(Xs, n))
# +
a = 1/M + 0.1
X2s = np.linspace(-a, a, 2000)
plt.figure()
for n in [10, 20, 30, 40, 50]:
plt.plot(X2s, Sn(X2s), label="n =" + str(n))
plt.legend()
plt.show()
# -
# $S_n(x)$ semble diverger pour $x\to2^-$ quand $n\to\infty$.
# Le rayon de convergence de la série $\sum In x^n$ **semble** être $2$.
def un(n):
return In(Xs, n + 1) / In(Xs, n)
for n in range(10):
print("un =", un(n), "pour n =", n)
# Ici, `un` ne peut pas être utilisé comme une fonction "numpy" qui travaille sur un tableau, on stocke donc les valeurs "plus manuellement" :
def affiche_termes_un(N):
valeurs_un = [0] * N
for n in range(N):
valeurs_un[n] = un(n)
plt.figure()
plt.plot(valeurs_un, 'o-')
plt.title("Suite $u_n$")
plt.grid()
plt.show()
affiche_termes_un(30)
# La suite $u_n$ semble être croissante (on peut le prouver), toujours plus petite que $1$ (se prouve facilement aussi, $I_{n+1} < I_n$), et semble converger.
# Peut-être vers $1/2$, il faut aller regarder plus loin ?
affiche_termes_un(100)
# Pour conclure, on peut prouver que la suite est monotone et bornée, donc elle converge.
# Il est plus dur de calculer sa limite, et cela sort de l'exercice.
# ---
# ## Planche 166
case_max = 12
univers = list(range(case_max))
def prochaine_case(case):
return (case + rd.randint(1, 6+1)) % case_max
def Yn(duree, depart=0):
case = depart
for coup in range(duree):
case = prochaine_case(case)
return case
# Avant de s'en servir pour simuler plein de trajectoirs, on peut vérifier :
#
# - en un coup, on avance pas plus de 6 cases :
[Yn(1) for _ in range(10)]
# - En 100 coups, on commence à ne plus voir de tendance :
[Yn(100) for _ in range(10)]
# Pour l'histogramme, on triche un peu en utilisant `numpy.bincount`. Mais on peut le faire à la main très simplement !
np.bincount(_, minlength=case_max)
def histogramme(duree, repetitions=5000):
cases = [Yn(duree) for _ in range(repetitions)]
frequences = np.bincount(cases, minlength=case_max)
# aussi a la main si besoin
frequences = [0] * case_max
for case in cases:
frequences[case] += 1
return frequences / np.sum(frequences)
histogramme(50)
def voir_histogramme(valeurs_n):
for n in valeurs_n:
plt.figure()
plt.bar(np.arange(case_max), histogramme(n))
plt.title("Histogramme de cases visitées en " + str(n) + " coups")
plt.show()
voir_histogramme([1, 2, 3, 50, 100, 200])
# On s'approche d'une distribution uniforme !
# On a tout simplement l'expression suivante :
# $$\forall n \geq 0, \mathbb{P}(Y_{n+1} = k) = \frac{1}{6} \sum_{\delta = 1}^{6} \mathbb{P}(Y_n = k - \delta \mod 12).$$
# Avec $k - 1 \mod 12 = 11$ si $k = 0$ par exemple.
# On a donc la matrice suivante pour exprimer $U_n = (\mathbb{P}(Y_n = k))_{0\leq k \leq 11}$ en fonction de $U_{n-1}$ :
#
# $$ P = \frac{1}{6} \begin{bmatrix}
# 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 & 1 \\
# 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1\\
# 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1\\
# 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1\\
# 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1\\
# 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1\\
# 1 & 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 \\
# 0 & 1 & 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 & 0 \\
# 0 & 0 & 1 & 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 & 0 \\
# 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 & 1 & 0 & 0 & 0 \\
# 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 & 1 & 0 & 0 \\
# 0 & 0 & 0 & 0 & 0 & 1 & 1 & 1 & 1 & 1 & 1 & 0 \\
# \end{bmatrix}$$
# On va la définir rapidement en Python, et calculer ses valeurs propres notamment.
P = np.zeros((case_max, case_max))
for k in range(case_max):
for i in range(k - 6, k):
P[k, i] = 1
P
import numpy.linalg as LA
spectre, vecteur_propres = LA.eig(P)
# On a besoin d'éliminer les erreurs d'arrondis, mais on voit que $6$ est valeur propre, associée au vecteur $[0,\dots,1,\dots,0]$ avec un $1$ seulement à la 8ème composante.
np.round(spectre)
np.round(vecteur_propres[0])
# $P$ n'est pas diagonalisable, **à prouver** au tableau si l'examinateur le demande.
# ----
# ## Planche 168
# - Soit $f(x) = \frac{1}{2 - \exp(x)}$, et $a(n) = \frac{f^{(n)}(0)}{n!}$.
#
def f(x):
return 1 / (2 - np.exp(x))
# - Soit $g(x) = 2 - \exp(x)$, telle que $g(x) f(x) = 1$. En dérivant $n > 0$ fois cette identité et en utilisant la formule de Leibniz, on trouve :
# $$ (g(x)f(x))^{(n)} = 0 = \sum_{k=0}^n {n \choose k} g^{(k)}(x) f^{(n-k)}(x).$$
# Donc en $x=0$, on utilise que $g^{(k)}(x) = - \exp(x)$, qui donne que $g^{(k)}(0) = 1$ si $k=0$ ou $-1$ sinon, pour trouver que $\sum_{k=0}^n {n \choose k} f^{(k)}(0) = f^{(n)}(0)$. En écrivant ${n \choose k} = \frac{k! (n-k)!}{n!}$ et avec la formule définissant $a(n)$, cela donne directement la somme recherchée : $$ a(n) = \sum_{k=1}^n \frac{a(n-k)}{k!}.$$
# - Pour calculer $a(n)$ avec Python, on utilise cette formule comme une formule récursive, et on triche un peu en utilisant `math.factorial` pour calculer $k!$. Il nous faut aussi $a(0) = f(0) = 1$ :
# +
from math import factorial
def a_0an(nMax):
valeurs_a = np.zeros(nMax+1)
valeurs_a[0] = 1.0
for n in range(1, nMax+1):
valeurs_a[n] = sum(valeurs_a[n-k] / factorial(k) for k in range(1, n+1))
return valeurs_a
# +
nMax = 10
valeurs_n = np.arange(0, nMax + 1)
valeurs_a = a_0an(nMax)
for n in valeurs_n:
print("Pour n =", n, "on a a(n) =", valeurs_a[n])
# -
plt.figure()
plt.plot(valeurs_n, valeurs_a, 'ro', label=r'$a(n)$')
plt.plot(valeurs_n, 1 / np.log(2)**valeurs_n, 'g+', label=r'$1/\log(2)^n$')
plt.plot(valeurs_n, 1 / (2 * np.log(2)**valeurs_n), 'bd', label=r'$1/(2\log(2)^n)$')
plt.title("$a(n)$ et deux autres suites")
plt.legend()
plt.show()
# - On observe que $a(n)$ est comprise entre $\frac{1}{2(\log(2))^n}$ et $\frac{1}{\log(2)^n}$, donc le rayon de convergence de $S(x) = \sum a(n) x^n$ est $\log(2)$.
# - On va calculer les sommes partielles $S_n(x)$ de la série $S(x)$ :
def Sn(x, n):
valeurs_a = a_0an(n)
return sum(valeurs_a[k] * x**k for k in range(0, n + 1))
# On peut vérifie que notre fonction marche :
x = 0.5
for n in range(0, 6 + 1):
print("Pour n =", n, "S_n(x) =", Sn(x, n))
valeurs_x = np.linspace(0, 0.5, 1000)
valeurs_f = f(valeurs_x)
# <span style="color:red;">Je pense que l'énoncé comporte une typo sur l'intervale ! Vu le rayon de convergence, on ne voit rien si on affiche sur $[0,10]$ !</span>
plt.figure()
for n in range(0, 6 + 1):
valeurs_Sn = []
for x in valeurs_x:
valeurs_Sn.append(Sn(x, n))
plt.plot(valeurs_x, valeurs_Sn, ':', label='$S_' + str(n) + '(x)$')
plt.plot(valeurs_x, valeurs_f, '-', label='$f(x)$')
plt.title("$f(x)$ et $S_n(x)$ pour $n = 0$ à $n = 6$")
plt.legend()
plt.show()
# ## Planche 170
def u(n):
return np.arctan(n+1) - np.arctan(n)
# +
valeurs_n = np.arange(50)
valeurs_u = u(valeurs_n)
plt.figure()
plt.plot(valeurs_n, valeurs_u, "o-")
plt.title("Premières valeurs de $u_n$")
# -
# On peut vérifier le prognostic quand à la somme de la série $\sum u_n$ :
pi/2
sum(valeurs_u)
somme_serie = pi/2
somme_partielle = sum(valeurs_u)
erreur_relative = abs(somme_partielle - somme_serie) / somme_serie
erreur_relative
# Avec seulement $50$ termes, on a moins de $1.5%$ d'erreur relative, c'est déjà pas mal !
# $(u_n)_n$ semble être décroisante, et tendre vers $0$. On peut prouver ça mathématiquement.
# On sait aussi que $\forall x\neq0, \arctan(x) + \arctan(1/x) = \frac{\pi}{2}$, et que $\arctan(x) \sim x$, donc on obtient que $u_n \sim \frac{1}{n} - \frac{1}{n+1} = \frac{1}{n(n+1)}$.
# On peut le vérifier :
# +
valeurs_n = np.arange(10, 1000)
valeurs_u = u(valeurs_n)
valeurs_equivalents = 1 / (valeurs_n * (valeurs_n + 1))
plt.figure()
plt.plot(valeurs_n, valeurs_u / valeurs_equivalents, "-")
plt.title(r"Valeurs de $u_n / \frac{1}{n(n+1)}$")
# -
# - Pour $e = (e_n)_{n\in\mathbb{N}}$ une suite de nombres égaux à $0$ ou $1$ (*i.e.*, $\forall n, e_n \in \{0,1\}$, $S_n(e) = \sum{i=0}^n e_i u_i$ est bornée entre $0$ et $\sum_{i=0}^n u_i$. Et $u_n \sim \frac{1}{n(n+1)}$ qui est le terme général d'une série convergente (par critère de Cauchy, par exemple, avec $\alpha=2$). Donc la série $\sum u_n$ converge et donc par encadrement, $S_n(e)$ converge pour $n\to\infty$, *i.e.*, $S(e)$ converge. Ces justifications donnent aussi que $$0 \leq S(e) \leq \sum_{n\geq0} u_n = \lim_{n\to\infty} \arctan(n) - \arctan(0) = \frac{\pi}{2}.$$
# - Pour $e = (0, 1, 0, 1, \ldots)$, $S(e)$ peut être calculée avec Python. Pour trouver une valeur approchée à $\delta = 10^{-5}$ près, il faut borner le **reste** de la série, $R_n(e) = \sum_{i \geq n + 1} e_i u_i$. Ici, $R_{2n+1}(e) \leq u_{2n+2}$ or $u_i \leq \frac{1}{i(i+1)}$, donc $R_{2n+1}(e) \leq \frac{1}{(2n+1)(2n+2)}$. $\frac{1}{(2n+1)(2n+2)} \leq \delta$ dès que $2n+1 \geq \sqrt{\delta}$, *i.e.*, $n \geq \frac{\sqrt{\delta}+1}{2}$. Calculons ça :
from math import ceil, sqrt, pi
def Se(e, delta=1e-5, borne_sur_n_0=10000):
borne_sur_n_1 = int(ceil(1 + sqrt(delta)/2.0))
borne_sur_n = max(borne_sur_n_0, borne_sur_n_1)
somme_partielle = 0
for n in range(0, borne_sur_n + 1):
somme_partielle += e(n) * u(n)
return somme_partielle
def e010101(n):
return 1 if n % 2 == 0 else 0
delta = 1e-5
Se010101 = Se(e010101, delta)
print("Pour delta =", delta, "on a Se010101(delta) ~=", round(Se010101, 5))
# - Pour inverser la fonction, et trouver la suite $e$ telle que $S(e) = x$ pour un $x$ donné, il faut réfléchir un peu plus.
def inverse_Se(x, n):
assert 0 < x < pi/2.0, "Erreur : x doit être entre 0 et pi/2 strictement."
print("Je vous laisse chercher.")
raise NotImplementedError
# Ca suffit pour la partie Python.
# ----
# ## Planche 172
# +
from random import random
def pile(proba):
""" True si pile, False si face (false, face, facile à retenir)."""
return random() < proba
# -
# - D'abord, on écrit une fonction pour **simuler** l'événement aléatoire :
def En(n, p):
lance = pile(p)
for i in range(n - 1):
nouveau_lance = pile(p)
if lance and nouveau_lance:
return False
nouveau_lance = lance
return True
import numpy as np
lances = [ En(2, 0.5) for _ in range(100) ]
np.bincount(lances)
def pn(n, p, nbSimulations=100000):
return np.mean([ En(n, p) for _ in range(nbSimulations) ])
# - Par exemple, pour seulement $2$ lancés, on a $1 - p_n = p^2$ car $\overline{E_n}$ est l'événement d'obtenir $2$ piles qui est de probabilité $p^2$.
pn(2, 0.5)
# - Avec $4$ lancés, on a $p_n$ bien plus petit.
pn(4, 0.5)
# - On vérifie que $p_n(n, p)$ est décroissante en $p$, à $n$ fixé :
pn(4, 0.1)
pn(4, 0.9)
# - On vérifie que $p_n(n, p)$ est décroissante en $n$, à $p$ fixé :
pn(6, 0.2)
pn(20, 0.2)
pn(100, 0.2)
# - Notons que la suite semble converger ? Ou alors elle décroit de moins en moins rapidement.
# - Par récurrence et en considérant les possibles valeurs des deux derniers lancés numérotés $n+2$ et $n+1$, on peut montrer que
# $$\forall n, p_{n+2} = (1-p) p_{n+1} + p(1-p) p_n$$
# - Si $p_n$ converge, on trouve sa limite $l$ comme point fixe de l'équation précédente. $l = (1-p) l + p(1-p) l$ ssi $1 = 1-p + p(1-p)$ ou $l=0$, donc si $p\neq0$, $l=0$. Ainsi l'événement "on obtient deux piles d'affilé sur un nombre infini de lancers$ est bien presque sûr.
# - Je vous laisse terminer pour calculer $T$ et les dernières questions.
# ----
# ## Planche 177
#
# - Le domaine de définition de $f(x) = \sum_{n \geq 1} \frac{x^n}{n^2}$ est $[-1, 1]$ car $\sum \frac{x^n}{n^k}$ converge si $\sum x^n$ converge (par $k$ dérivations successives), qui converge ssi $|x| < 1$. Et en $-1$ et $1$, on utilise $\sum \frac{1}{n^2} = \frac{\pi^2}{6}$.
#
# - Pour calculer $f(x)$ à $10^{-5}$ près, il faut calculer sa somme partielle $S_n(x) := \sum_{i=1}^n \frac{x^i}{i^2}$ en bornant son reste $S_n(x) := \sum_{i \geq n+1} \frac{x^i}{i^2}$ par (au moins) $10^{-5}$. Une inégalité montre rapidement que $R_n(x) \leq |x|^{n+1}\sum_{i\geq n+1} \frac{1}{i^2} $, et donc $R_n(x) \leq \delta$ dès que $|x|^{n+1} \leq \frac{\pi^2}{6} \delta$, puisque $\sum_{i\geq n+1} \frac{1}{i^2} \leq \sum_{i=0}^{+\infty} \frac{1}{i^2} = \frac{\pi^2}{6}$. En inversant pour trouver $n$, cela donne que le reste est contrôlé par $\delta$ dès que $n \leq \log_{|x|}\left( \frac{6}{\pi^2} \delta \right) - 1$ (si $x\neq 0$, et par $n \geq 0$ sinon).
from math import floor, log, pi
# +
delta = 1e-5
def f(x):
if x == 0: return 0
borne_sur_n = int(floor(log((6/pi**2 * delta), abs(x)) - 1))
somme_partielle = 0
for n in range(1, borne_sur_n + 1):
somme_partielle += x**n / n**2
return somme_partielle
# -
for x in [-0.75, -0.5, 0.25, 0, 0.25, 0.5, 0.75]:
print("Pour x =", x, "\tf(x) =", round(f(x), 5))
# - L'intégrale $g(t) = \int_0^x \frac{\ln(1 - t)}{t} \mathrm{d}t$ est bien défine sur $D = [-1, 1]$ puisque son intégrande existe, est continue et bien intégrable sur tout interval de la forme $]a, 0[$ ou $]0, b[$ pour $-1 < a < 0$ ou $0 < b < 1$. Le seul point qui peut déranger l'intégrabilité est en $0$, mais $\ln(1-t) \sim t$ quand $t\to0$ donc l'intégrande est $\sim 1$ en $0^-$ et $0^+$ et donc est bien intégrable. De plus, comme "intégrale de la borne supérieure" d'une fonction continue, $g$ est dérivable sur l'intérieur de son domaine, *i.e.*, sur $]-1, 1[$.
#
# - Pour la calculer numériquement, on utilise **évidemment** le module `scipy.integrate` et sa fonction `integrale, erreur = quad(f, a, b)`, qui donne une approximation de la valeur d'une intégrale en dimension 1 et une *borne* sur son erreur :
from scipy import integrate
def g(x):
def h(t):
return log(1 - t) / t
integrale, erreur = integrate.quad(h, 0, x)
return integrale
# - On visualise les deux fonctions $f$ et $g$ sur le domaine $D$ :
import numpy as np
import matplotlib.pyplot as plt
# +
domaine = np.linspace(-0.99, 0.99, 1000)
valeurs_f = [f(x) for x in domaine]
valeurs_g = [g(x) for x in domaine]
plt.figure()
plt.plot(domaine, valeurs_f, label="$f(x)$")
plt.plot(domaine, valeurs_g, label="$g(x)$")
plt.legend()
plt.grid()
plt.title("Représentation de $f(x)$ et $g(x)$")
plt.show()
# -
# - On conjecture que $g(x) = - f(x)$.
#
# La suite des questions est à faire au brouillon et sans Python :
#
# - On trouve que $f'(x) = \sum_{n\geq 1} \frac{n x^{n-1}}{n^2} = \frac{1}{x} \sum_{n\geq 1} \frac{x^n}{n}$ si $x\neq0$. Or on sait que $\log(1 + x) = \sum_{n\geq 1} \frac{x^n}{n}$ et donc cela montre bien que $g(x) = \int_0^x - f'(t) \mathrm{d}t = f(0) - f(x) = f(x)$ comme observé.
#
# - On trouve que $g(1) = - f(1) = - \frac{\pi^2}{6}$.
#
# - Par ailleurs, un changement de variable $u=1-x$ donne $g(1-x) = \int_x^1 \frac{\ln(u)}{1-u} \mathrm{d} u$, et une intégration par partie avec $a(u) = \ln(u)$ et $b'(u) = \frac{1}{1-u}$ donne $g(1-x) = [\ln(u)\ln(1-u)]_x^1 + \int_x^1 \frac{\ln(1-u)}{u} \mathrm{d}u$ et donc on reconnaît que $$g(1-x) = \ln(x)\ln(1-x) + g(1) - g(x).$$
#
# - Je vous laisse la fin comme exercice !
# ----
# # À voir aussi
#
# ## [Les oraux](http://perso.crans.org/besson/infoMP/oraux/solutions/) *(exercices de maths avec Python)*
#
# Se préparer aux oraux de ["maths avec Python" (maths 2)](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/#oMat2) du concours Centrale Supélec peut être utile.
#
# Après les écrits et la fin de l'année, pour ceux qui seront admissibles à Centrale-Supélec, ils vous restera <b>les oraux</b> (le concours Centrale-Supélec a un <a title="Quelques exemples d'exercices sur le site du concours Centrale-Supélec" href="http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/#oMat2">oral d'informatique</a>, et un peu d'algorithmique et de Python peuvent en théorie être demandés à chaque oral de maths et de SI).
#
# Je vous invite à lire [cette page avec attention](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/#oMat2), et à jeter un œil aux documents mis à disposition :
#
# ## Fiches de révisions *pour les oraux*
#
# 1. [Calcul matriciel](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/Python-matrices.pdf), avec [numpy](https://docs.scipy.org/doc/numpy/) et [numpy.linalg](http://docs.scipy.org/doc/numpy/reference/routines.linalg.html),
# 2. [Réalisation de tracés](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/Python-plot.pdf), avec [matplotlib](http://matplotlib.org/users/beginner.html),
# 3. [Analyse numérique](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/Python-AN.pdf), avec [numpy](https://docs.scipy.org/doc/numpy/) et [scipy](http://docs.scipy.org/doc/scipy/reference/tutorial/index.html). Voir par exemple [scipy.integrate](http://docs.scipy.org/doc/scipy/reference/tutorial/integrate.html) avec les fonctions [scipy.integrate.quad](http://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.quad.html) (intégrale numérique) et [scipy.integrate.odeint](http://docs.scipy.org/doc/scipy/reference/generated/scipy.integrate.odeint.html) (résolution numérique d'une équation différentielle),
# 4. [Polynômes](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/Python-polynomes.pdf) : avec [numpy.polynomials](https://docs.scipy.org/doc/numpy/reference/routines.polynomials.package.html), [ce tutoriel peut aider](https://docs.scipy.org/doc/numpy/reference/routines.polynomials.classes.html),
# 5. [Probabilités](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/Python-random.pdf), avec [numpy](https://docs.scipy.org/doc/numpy/) et [random](https://docs.python.org/3/library/random.html).
#
# Pour réviser : voir [ce tutoriel Matplotlib (en anglais)](http://www.labri.fr/perso/nrougier/teaching/matplotlib/), [ce tutoriel Numpy (en anglais)](http://www.labri.fr/perso/nrougier/teaching/numpy/numpy.html).
# Ainsi que tous les [TP](http://perso.crans.org/besson/infoMP/TPs/solutions/), [TD](http://perso.crans.org/besson/infoMP/TDs/solutions/) et [DS](http://perso.crans.org/besson/infoMP/DSs/solutions/) en Python que j'ai donné et corrigé au Lycée Lakanal (Sceaux, 92) en 2015-2016 !
#
# ## Quelques exemples de sujets *d'oraux* corrigés
# > Ces 5 sujets sont corrigés, et nous les avons tous traité en classe durant les deux TP de révisions pour les oraux (10 et 11 juin).
#
# - PC : [sujet #1](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/PC-Mat2-2015-27.pdf) ([correction PC #1](http://perso.crans.org/besson/infoMP/oraux/solutions/PC_Mat2_2015_27.html)), [sujet #2](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/PC-Mat2-2015-28.pdf) ([correction PC #2](http://perso.crans.org/besson/infoMP/oraux/solutions/PC_Mat2_2015_28.html)).
# - PSI : [sujet #1](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/PSI-Mat2-2015-24.pdf) ([correction PSI #1](http://perso.crans.org/besson/infoMP/oraux/solutions/PSI_Mat2_2015_24.html)), [sujet #2](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/PSI-Mat2-2015-25.pdf) ([correction PSI #2](http://perso.crans.org/besson/infoMP/oraux/solutions/PSI_Mat2_2015_25.html)), [sujet #3](http://www.concours-centrale-supelec.fr/CentraleSupelec/MultiY/C2015/PSI-Mat2-2015-26.pdf) ([correction PSI #3](http://perso.crans.org/besson/infoMP/oraux/solutions/PSI_Mat2_2015_26.html)).
# - MP : pas de sujet mis à disposition, mais le programme est le même que pour les PC et PSI (pour cette épreuve).
# ----
# ## D'autres notebooks ?
#
# > Ce document est distribué [sous licence libre (MIT)](https://lbesson.mit-license.org/), comme [les autres notebooks](https://GitHub.com/Naereen/notebooks/) que j'ai écrit depuis 2015.
| Oraux_CentraleSupelec_PSI__Juin_2018.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Useful Links
# [PipelineAI Home](http://pipeline.ai)
#
# [PipelineAI Docs](http://pipeline.ai/docs)
# ## DO NOT UPLOAD SENSITIVE DATA
# PipelineAI Community Edition is shared by many 1000's of users. Assume everyone can see everything including your notebooks and data.
# ## Want to Self-Host PipelineAI?
# You can upgrade to the self-hosted PipelineAI [Standalone or Enterprise](http://pipeline.ai/products) Editions by contacting [<EMAIL>](mailto:<EMAIL>).
# ## GPU support is Here!
#
# We do not allow long-running (> 1 min) jobs in PipelineAI Community Edition.
#
# **Reminder that we will block users who take advantage of this free community offering.**
# ## Enjoy PipelineAI Community Edition!
| README_FIRST.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Mean Average Precision
# +
# %matplotlib inline
plt.rcParams['figure.figsize'] = (15.0, 5.0) # Setting default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['font.family'] = 'Times New Roman'
fig = plt.figure()
plt.plot([0, 0.2, 0.2, 0.4, 0.6, 0.6, 0.8, 1, 1, 1, 1],
[1, 1, 0.5, 0.67, 0.75, 0.6, 0.67, 0.71, 0.62, 0.56, 0.5],'-o', linewidth=3.0, color='blue', markersize=10.0)
plt.xlabel('Recall', fontsize=20)
plt.ylabel('Precision', fontsize=20)
plt.tick_params(labelsize=18)
plt.title('Recall and Precision zig-zag curve', fontsize=22)
# Showing the plot
plt.show()
plt.plot([0, 0.2, 0.2, 0.4, 0.6, 0.6, 0.8, 1, 1, 1, 1],
[1, 1, 0.5, 0.67, 0.75, 0.6, 0.67, 0.71, 0.62, 0.56, 0.5],'-o', linewidth=1.0, color='blue', markersize=7.0)
plt.plot([0, 0.2, 0.2, 0.4, 0.6, 0.6, 0.8, 1, 1, 1, 1],
[1, 1, 0.75, 0.75, 0.75, 0.71, 0.71, 0.71, 0.62, 0.56, 0.5],'-o', linewidth=3.0, color='green', markersize=7.0)
plt.plot([0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1],
[1, 1, 1, 0.75, 0.75, 0.75, 0.75, 0.71, 0.71, 0.71, 0.71], 'ro', markersize=10.0, markerfacecolor='white', markeredgewidth=4.0)
plt.xlabel('Recall', fontsize=20)
plt.ylabel('Precision', fontsize=20)
plt.tick_params(labelsize=18)
plt.title('Interpolated Recall and Precision zig-zag curve', fontsize=22)
# Showing the plot
plt.show()
| mean-average-precision.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Combine Catalogs
# There's a LOT of EB catalogs in the literature, and some very good ones not yet published as well... In total we'll easily have a sample of many thousands of EBs to consider if we combine them
#
# Here we'll combine catalogs to make a super-sample, and produce an easier to use file for the rest of the project.
#
# Read in:
# - ASAS-SN EBs
# - Catalina EBs
# - Kepler EBs (Villanova)
# - CEV
# - <NAME>'s TESS Sample (X-match to Gaia)
# +
# %matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from astropy.table import Table
from scipy.optimize import curve_fit
from matplotlib.colors import LogNorm
from glob import glob
# +
import matplotlib
matplotlib.rcParams.update({'font.size':18})
# matplotlib.rcParams.update({'font.family':'serif'})
# for the TESS Science Online 48hr sprint, we'll be using Cyberpunk for the graphics!
# https://github.com/dhaitz/mplcyberpunk
import mplcyberpunk
plt.style.use("cyberpunk")
# -
# ## Read in every catalog
#
# some need cleaning up, apply (roughly) uniform quality cuts where possible
# +
# KEPLER
# already x-matched the Villanova EBs to Gaia DR2 & the Bailer-Jones catalogs
file = '../data/1543957677477A.csv'
df = pd.read_csv(file)
# df.columns
ok = np.where(np.isfinite(df['parallax']) & # this is basically the same as the TGAS file...
(df['parallax_error'] < 0.1) &
(df['ModFlag'] == 1) &
(df['ResFlag'] == 1) &
np.isfinite(df['bp_rp']) &
(df['phot_bp_mean_flux_error']/df['phot_bp_mean_flux'] < 0.02) &
(df['phot_rp_mean_flux_error']/df['phot_rp_mean_flux'] < 0.02) &
(df['phot_g_mean_flux_error']/df['phot_g_mean_flux'] < 0.02) &
(df['angDist'] < 0.5) & (df['angDist.1'] < 0.5))[0]
print(df.shape, ok.shape)
# +
# CATALINA
# i can't recall which catalog this came from originally, but it has been xmatched to Gaia DR2 & BailerJones
file = '../data/1540942562357A.csv'
df2 = pd.read_csv(file)
# df2.columns
ok2 = np.where(np.isfinite(df2['parallax']) & # this is basically the same as the TGAS file...
(df2['parallax_error']/df2['parallax'] < 0.1) &
(df2['ModFlag'] == 1) &
(df2['ResFlag'] == 1) &
np.isfinite(df2['bp_rp']) &
(df2['phot_bp_mean_flux_error']/df2['phot_bp_mean_flux'] < 0.02) &
(df2['phot_rp_mean_flux_error']/df2['phot_rp_mean_flux'] < 0.02) &
(df2['phot_g_mean_flux_error']/df2['phot_g_mean_flux'] < 0.02) &
(df2['angDist'] < 0.5) &
np.isfinite(df2['Per']))[0]
print(df2.shape, ok2.shape)
# +
# #ASAS-SN
# asas = pd.read_csv('../data/asassn-catalog.csv')
# asas.columns
# okA = np.where((asas['Mean VMag'] < 16) &
# (asas['Jmag'] - asas['Kmag'] > -0.5) &
# (asas['Jmag'] - asas['Kmag'] < 2) &
# (asas['Classification Probability'] > 0.9) &
# (asas['Type'] == 'EA') | (asas['Type'] == 'EB') | (asas['Type'] == 'EW'))[0]
# AokA = np.where((asas['Parallax Error'][okA]/asas['Parallax'][okA] < 0.1) &
# np.isfinite(asas['Jmag'][okA]) &
# np.isfinite(asas['Kmag'][okA]) &
# (asas['Jmag'][okA] - asas['Kmag'][okA] > -0.5) &
# (asas['Jmag'][okA] - asas['Kmag'][okA] < 2) &
# (asas['Parallax'][okA] > 0) &
# np.isfinite(asas['Parallax'][okA]))[0]
# print(asas.shape, okA.shape, AokA.shape)
# -
#ASAS-SN
asassn = pd.read_csv('../data/2020-09-08-17_38_28.csv')
asassn.columns
plt.hexbin(asassn['I'], asassn['b'], norm=LogNorm())
# +
# drop W Uma's for now?
EBs = np.where(((asassn['Type'] == 'EA') | (asassn['Type'] == 'EB')) & # (asassn['Type'] == 'EW') |
(asassn['Class_Probability'] > 0.99) &
(asassn['parallax_over_error'] > 10) &
(asassn['parallax'] > 0) &
np.isfinite(asassn['parallax']) &
(asassn['e_Gmag'] < 0.01)
)[0]
print(asassn.shape, EBs.shape)
# +
# note: (I,b) is acutally Galactic coordinates (l,b), a typo in ASAS-SN
# asassn[['ID', 'I','b', 'Amplitude', 'Period', 'Gmag', 'BPmag',
# 'RPmag', 'dist', 'Jmag', 'Kmag', 'W1mag']].loc[EBs].to_csv('asassn_ebs_36k.csv')
# +
# Catalog of Eclipsing Variables
# http://vizier.u-strasbg.fr/viz-bin/VizieR?-source=J/A+A/446/785
# xmatched to Gaia DR2
cev = pd.read_csv('../data/CEV-Gaia-2arcsec.csv')
# cev.columns
okC = np.where(np.isfinite(cev['parallax']) &
(cev['parallax_error']/cev['parallax'] < 0.1) &
np.isfinite(cev['bp_rp']) &
(cev['phot_bp_mean_flux_error']/cev['phot_bp_mean_flux'] < 0.02) &
(cev['phot_rp_mean_flux_error']/cev['phot_rp_mean_flux'] < 0.02) &
(cev['phot_g_mean_flux_error']/cev['phot_g_mean_flux'] < 0.02) &
np.isfinite(cev['Per']))[0]
print(cev.shape, okC.shape)
# -
# +
# add Erin's catalog, use TIC to join with Trevor's Gaia-xmatch
elh0 = pd.read_csv('../data/ehoward.txt')
elh = pd.read_csv('../data/IDs.csv')
print(elh0.shape, elh.shape)
# KIC-to-TIC conversion, if needed?
KICTIC = pd.read_csv('/Users/james/Dropbox/research_projects/kic2tic/KIC2TIC.csv')
# the TESS-Gaia xmatch from Trevor
gdir = '/Users/james/Dropbox/research_projects/TESS-Gaia/'
gfiles = glob(gdir+'*1arsec-result.csv')
gaia0 = pd.concat((pd.read_csv(f) for f in gfiles), ignore_index=True, sort=False)
EHow = pd.merge(elh, gaia0, left_on='TIC', right_on='ticid', how='inner').drop_duplicates(subset=['TIC'])
Eok = np.where(np.isfinite(EHow['parallax']) &
(EHow['parallax_error']/EHow['parallax'] < 0.1) &
np.isfinite(EHow['bp_rp']) &
(EHow['phot_bp_mean_flux_error']/EHow['phot_bp_mean_flux'] < 0.02) &
(EHow['phot_rp_mean_flux_error']/EHow['phot_rp_mean_flux'] < 0.02) &
(EHow['phot_g_mean_flux_error']/EHow['phot_g_mean_flux'] < 0.02)
)[0]
print(EHow.shape, Eok.shape)
# -
EHow.iloc[Eok][['source_id', 'ra', 'dec', 'bp_rp', 'parallax',
'phot_g_mean_mag', 'teff_val', 'lum_val']].to_csv('Ehow.csv')
# +
gaia = gaia0.drop_duplicates(subset=['source_id'])
gok = np.where(np.isfinite(gaia['parallax']) &
(gaia['parallax_error']/gaia['parallax'] < 0.1) &
np.isfinite(gaia['bp_rp']) &
(gaia['phot_bp_mean_flux_error']/gaia['phot_bp_mean_flux'] < 0.02) &
(gaia['phot_rp_mean_flux_error']/gaia['phot_rp_mean_flux'] < 0.02) &
(gaia['phot_g_mean_flux_error']/gaia['phot_g_mean_flux'] < 0.02)
)[0]
print(gaia.shape, gok.size)
# -
_ = plt.hist2d(gaia['ra'].values[gok], gaia['dec'].values[gok], bins=100, cmap=plt.cm.coolwarm, norm=LogNorm())
# +
# Malkov 2020, http://vizier.u-strasbg.fr/viz-bin/VizieR?-source=J%2FMNRAS%2F491%2F5489%2Ftablea1
m20 = pd.read_csv('../data/1599574064401A.csv')
okM = np.where(np.isfinite(m20['parallax']) &
(m20['parallax_error']/cev['parallax'] < 0.1) &
np.isfinite(m20['bp_rp']) &
(m20['phot_bp_mean_flux_error']/m20['phot_bp_mean_flux'] < 0.02) &
(m20['phot_rp_mean_flux_error']/m20['phot_rp_mean_flux'] < 0.02) &
(m20['phot_g_mean_flux_error']/m20['phot_g_mean_flux'] < 0.02) &
np.isfinite(m20['Per']))[0]
print(m20.shape, okM.shape)
# +
# any other catalogs?
# -
# ## Combine
#
# Make a single big Pandas dataframe
# +
# columns to grab:
# make the CMD: distance, bp_rp color, Gmag
# def want to save Periods - they available for all catalogs?
# prob want to save Gaia "source_id" so we can unique the list
# +
save_cols = ['source_id', 'ra', 'dec', 'bp_rp', 'parallax', 'phot_g_mean_mag', 'Per']
# Kepler
# df[save_cols].loc[ok]
# Catalina
# df2[save_cols].loc[ok2]
# Catalog of Eclipsing Variables
# cev[save_cols].loc[okC]
# Malkov'20
# m20[save_cols].loc[okM]
# ASAS-SN
asassn.rename(columns={'GDR2_ID':'source_id', 'BP-RP':'bp_rp','Gmag':'phot_g_mean_mag',
'Period':'Per', 'RAJ2000':'ra', 'DEJ2000':'dec'},
inplace=True)
# asassn[save_cols].loc[EBs]
BigCat = pd.concat((df[save_cols].loc[ok],
df2[save_cols].loc[ok2],
cev[save_cols].loc[okC],
m20[save_cols].loc[okM],
asassn[save_cols].loc[EBs]),
ignore_index=True, sort=False)
# -
print(len(df[save_cols].loc[ok]), # kepler
len(df2[save_cols].loc[ok2]), # catalina
len(cev[save_cols].loc[okC]), # CEV
len(m20[save_cols].loc[okM]), # M20
len(asassn[save_cols].loc[EBs]), len(BigCat.csvCat))
2346 +8863 +1252 +59
print(BigCat.shape, BigCat['source_id'].unique().size)
BigCat.to_csv('BigCat.csv')
_ = plt.hist( np.log10(BigCat['Per'].astype('float')) )
longP = (BigCat['Per'].astype('float') > 10)
sum(longP)
# +
plt.figure(figsize=(7,7))
plt.hexbin(BigCat['bp_rp'][longP],
BigCat['phot_g_mean_mag'][longP] - 5. * np.log10(1000./BigCat['parallax'][longP]) + 5,
norm=LogNorm(), cmap=plt.cm.cool)
plt.gca().invert_yaxis()
plt.xlabel('$G_{BP} - G_{RP}$ (mag)')
plt.ylabel('$M_G$ (mag)')
# -
# +
plt.figure(figsize=(9,5))
Hbins = np.linspace(-1.5, 3.1, num=75)
hist,be = np.histogram(np.log10(df['Per'][ok]), bins=Hbins)
plt.plot((be[1:]+be[:-1])/2, hist, '-o', label='Kepler EBs')
hist,be = np.histogram(np.log10(df2['Per'][ok2]), bins=Hbins)
plt.plot((be[1:]+be[:-1])/2, hist, '-o', label='Catalina EBs')
hist,be = np.histogram(np.log10(asassn['Per'][EBs].astype('float')), bins=Hbins)
plt.plot((be[1:]+be[:-1])/2, hist, '-o', label='ASAS-SN EBs')
hist,be = np.histogram(np.log10(cev['Per'][okC]), bins=Hbins)
plt.plot((be[1:]+be[:-1])/2, hist, '-o', label='CEV EBs')
plt.xlabel('log$_{10}$ ($P_{orb}$ / days)')
plt.yscale('log')
plt.ylabel('# of EBs')
plt.legend(fontsize=13)
# alas, these don't work w/ histograms... yet!
mplcyberpunk.add_glow_effects()
# plt.savefig('.png', dpi=300, bbox_inches='tight', pad_inches=0.25)
# +
# save the TESS-Gaia xmatch, cleaned up and only saving same columns as the "BigCat"
gaia[save_cols[0:-1]].iloc[gok].to_csv('gaia_tess2min.csv')
# -
# are these interesting?
#
# Brian Powell's first-pass look at the 48k EB's found these to be "interesting".
#
# - which catalog are they from?
# - what else can we say about them?
# interesting Brian Powell
intBP = [19, 262, 297, 736, 742, 767, 2371, 2413, 2490, 2643, 2913, 3026, 3066,
3101, 3167, 3191, 3205, 3208, 3225, 3537, 3573, 3688, 3844, 3898, 3957,
4107, 4136, 4216, 4286, 4363, 4467, 4760, 4878, 5217, 5248, 5346, 5375,
5447, 5448, 5477, 5535, 5547, 5587, 5623, 5671, 5684, 5864, 5897, 5904,
6152, 6177, 6204, 6262, 6266, 6311, 6361, 6376, 6406, 6424, 6553, 6559,
6599, 6628, 6706, 6707, 6746, 6748, 6756, 6829, 6850, 6856, 6861, 6871,
6895, 6965, 6966, 6984, 7058, 7075, 7108, 7121, 7131, 7134, 7137, 7143,
7152, 7156, 7262, 7269, 7271, 7307, 7342, 7369, 7378, 7407, 7412, 7413,
7431, 7473, 7497, 7500, 7603, 7612, 7630, 7633, 7654, 7667, 7678, 7722,
7776, 7832, 7967, 8060, 8103, 8114, 8147, 8172, 8192, 8284, 8423, 8432,
8448, 8451, 8454, 8505, 8531, 8546, 8573, 8611, 8690, 8738, 8746, 8794,
8814, 8853, 8899, 8955, 9014, 9019, 9051, 9062, 9073, 9161, 9219, 9243,
9400, 9535, 9543, 9698, 9715, 9724, 9739, 9778, 9805, 9812, 9869, 9876,
9886, 9978, 10035, 10044, 10117, 10322, 10449, 10666, 10784, 10863, 10876,
10916, 10938, 10988, 11006, 11149, 11203, 37788, 40000]
BigCat.iloc[intBP]['Per'].astype('float').values
| notebooks/combine_catalogs.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="uaUs9qD2nkxo"
# **Load Google Drive**
# + id="r5IElWi7KoxJ" colab={"base_uri": "https://localhost:8080/"} outputId="0dcb1f10-29ee-4c2b-9e9d-02c120e03047"
from google.colab import drive
drive.mount('/content/drive')
# %cd /content/drive/MyDrive/
# + [markdown] id="QmeO_6ZQn5tR"
# Download the repository (if not already done)
# + id="FvbZmQGNJHpt"
# #%%shell
#git clone https://github.com/FrancesCOde/YOLOX.git
# + [markdown] id="ImvtBgjEoDL0"
# **Install the requirements**
# + id="RzGoGAraLM5i"
# %%shell
# cd YOLOX
pip3 install -U pip && pip3 install -r requirements.txt
# + id="MQwvYikOLkmx"
# %%shell
# cd YOLOX
pip3 install -v -e .
pip3 install cython; pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
# + [markdown] id="XzLJJkZkoXBG"
# **Train the YOLOX-nano model**
# + colab={"base_uri": "https://localhost:8080/"} id="t8jLHDhm_R1m" outputId="647097cd-0b66-40e0-e348-50ba5a85914a"
# %%shell
# cd YOLOX
python tools/train.py -f exps/example/custom/nano.py -d 1 -b 16 --fp16 -c yolox_nano.pth
# + [markdown] id="_0sT9eGbpTPw"
# **Calculate performance on the test set**
# + colab={"base_uri": "https://localhost:8080/"} id="DLG67CvMnNUy" outputId="c287144c-3b24-4e11-c99d-0972fff94b88"
# %%shell
# cd YOLOX
python tools/eval.py -n yolox-nano -c YOLOX_outputs/nano/latest_ckpt.pth -b 1 -d 1 --conf 0.001 --fp16 --fuse
# + [markdown] id="ngnsVqXqpIrA"
# **Video Test and FPS calculation**
# + colab={"base_uri": "https://localhost:8080/"} id="xMpg31UQsGtH" outputId="70d82933-9042-47d7-e203-366b29ef5071"
# %%shell
# cd YOLOX
python tools/demo.py video -n yolox-nano -c YOLOX_outputs/nano/latest_ckpt.pth --path /content/drive/MyDrive/open-images-v4/test_veges.mp4 --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu
| YoloXnano_test.ipynb |
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 1.1.0
# language: julia
# name: julia-1.1
# ---
# # 7 Solution Methods to Solve the Growth Model with Julia
#
# This notebook is part of a computational appendix that accompanies the paper
#
# > MATLAB, Python, Julia: What to Choose in Economics?
# > > Coleman, Lyon, Maliar, and Maliar (2017)
#
# In order to run the codes in this notebook you will need to install and configure a few Julia packages. We recommend following the instructions on [quantecon.org](https://lectures.quantecon.org/jl/getting_started.html).
#
# Once your Julia installation is up and running, there are a few additional packages you will need in order to run the code here. To do this uncomment the lines in the cell below (by deleting the `#` and space at the beginning of each line) and run the cell:
using Pkg
pkg"add InstantiateFromURL"
using InstantiateFromURL: activate_github_path
activate_github_path("sglyon/CLMMJuliaPythonMatlab", path="Growth/julia", activate=true, force=true)
# +
using Printf, Random, LinearAlgebra
using BasisMatrices, Optim, QuantEcon, Parameters
using BasisMatrices: Degree, Derivative
# -
# ## Model
#
# This section gives a short description of the commonly used stochastic Neoclassical growth model.
#
# There is a single infinitely-lived representative agent who consumes and saves using capital. The consumer discounts the future with factor $\beta$ and derives utility from only consumption. Additionally, saved capital will depreciate at $\delta$.
#
# The consumer has access to a Cobb-Douglas technology which uses capital saved from the previous period to produce and is subject to stochastic productivity shocks.
#
# Productivity shocks follow an AR(1) in logs.
#
# The agent's problem can be written recursively using the following Bellman equation
#
# \begin{align}
# V(k_t, z_t) &= \max_{k_{t+1}} u(c_t) + \beta E \left[ V(k_{t+1}, z_{t+1}) \right] \\
# &\text{subject to } \\
# c_t &= z_t f(k_t) + (1 - \delta) k_t - k_{t+1} \\
# \log z_{t+1} &= \rho \log z_t + \sigma \varepsilon
# \end{align}
# ## Julia Code
#
# We begin by defining a type that describes our model. It will hold the three things
#
# 1. Parameters of the growth model
# 2. Grids used for approximating the solution
# 3. Nodes and weights used to approximate integration
#
# Note the `@with_kw` comes from the `Parameters` package -- It allows one to specify default arguments for the parameters when building a type (for more information refer to their [documentation](http://parametersjl.readthedocs.io/en/latest/)). One of the benefits of using the `Parameters` package is their code allows us to do things like, `@unpack a, b, c = Params` which takes elements from inside the type `Params` and "unpacks" them... i.e. it automates code of the form `a, b, c = Params.a, Params.b, Params.c`
"""
The stochastic Neoclassical growth model type contains parameters
which define the model
* α: Capital share in output
* β: Discount factor
* δ: Depreciation rate
* γ: Risk aversion
* ρ: Persistence of the log of the productivity level
* σ: Standard deviation of shocks to log productivity level
* A: Coefficient on C-D production function
* kgrid: Grid over capital
* zgrid: Grid over productivity
* grid: Grid of (k, z) pairs
* eps_nodes: Nodes used to integrate
* weights: Weights used to integrate
* z1: A grid of the possible z1s tomorrow given eps_nodes and zgrid
"""
@with_kw struct NeoclassicalGrowth
# Parameters
α::Float64 = 0.36
β::Float64 = 0.99
δ::Float64 = 0.02
γ::Float64 = 2.0
ρ::Float64 = 0.95
σ::Float64 = 0.01
A::Float64 = (1.0/β - (1 - δ)) / α
# Grids
kgrid::Vector{Float64} = collect(range(0.9, stop=1.1, length=10))
zgrid::Vector{Float64} = collect(range(0.9, stop=1.1, length=10))
grid::Matrix{Float64} = gridmake(kgrid, zgrid)
eps_nodes::Vector{Float64} = qnwnorm(5, 0.0, σ^2)[1]
weights::Vector{Float64} = qnwnorm(5, 0.0, σ^2)[2]
z1::Matrix{Float64} = (zgrid.^(ρ))' .* exp.(eps_nodes)
end
# We also define some useful functions so that we [don't repeat ourselves](https://lectures.quantecon.org/py/writing_good_code.html#don-t-repeat-yourself) later in the code.
# +
# Helper functions
f(ncgm::NeoclassicalGrowth, k, z) = @. z * (ncgm.A * k^ncgm.α)
df(ncgm::NeoclassicalGrowth, k, z) = @. ncgm.α * z * (ncgm.A * k^(ncgm.α - 1.0))
u(ncgm::NeoclassicalGrowth, c) = c > 1e-10 ? @.(c^(1-ncgm.γ)-1)/(1-ncgm.γ) : -1e10
du(ncgm::NeoclassicalGrowth, c) = c > 1e-10 ? c.^(-ncgm.γ) : 1e10
duinv(ncgm::NeoclassicalGrowth, u) = u .^ (-1 / ncgm.γ)
expendables_t(ncgm::NeoclassicalGrowth, k, z) = (1-ncgm.δ)*k + f(ncgm, k, z)
# -
# ## Solution Methods
#
# In this notebook, we describe the following solution methods:
#
# * Conventional Value Function Iteration
# * Envelope Condition Value Function Iteration
# * Envelope Condition Derivative Value Function Iteration
# * Endogenous Grid Value Function Iteration
# * Conventional Policy Function Iteration
# * Envelope Condition Policy Function Iteration
# * Euler Equation Method
#
# Each of these solution methods will have a very similar structure that follows a few basic steps:
#
# 1. Guess a function (either value function or policy function).
# 2. Using this function, update our guess of both the value and policy functions.
# 3. Check whether the function we guessed and what it was updated to are similar enough. If so, proceed. If not, return to step 2 using the newly updated functions.
# 4. Output the policy and value functions.
#
# In order to reduce the amount of repeated code and keep the exposition as clean as possible (the notebook is plenty long as is...), we will define multiple solution types that will have a more general (abstract) type called `SolutionMethod`. A solution can then be characterized by a concrete type `ValueCoeffs` (a special case for each solution method) which consists of an approximation degree, coefficients for the value function, and coefficients for the policy function. The rest of the functions below that are just more helper methods. We will then define a general solve method that applies steps 1, 3, and 4 from the algorithm above. Finally, we will implement a special method to do step 2 for each of the algorithms.
#
# These implementation may seem a bit confusing at first (though hopefully the idea itself feels intuitive) -- The implementation takes advantage of a powerful type system in Julia.
# +
# Types for solution methods
abstract type SolutionMethod end
struct IterateOnPolicy <: SolutionMethod end
struct VFI_ECM <: SolutionMethod end
struct VFI_EGM <: SolutionMethod end
struct VFI <: SolutionMethod end
struct PFI_ECM <: SolutionMethod end
struct PFI <: SolutionMethod end
struct dVFI_ECM <: SolutionMethod end
struct EulEq <: SolutionMethod end
#
# Type for Approximating Value and Policy
#
mutable struct ValueCoeffs{T <: SolutionMethod,D <: Degree}
d::D
v_coeffs::Vector{Float64}
k_coeffs::Vector{Float64}
end
function ValueCoeffs(::Type{Val{d}}, method::T) where T <: SolutionMethod where d
# Initialize two vectors of zeros
deg = Degree{d}()
n = n_complete(2, deg)
v_coeffs = zeros(n)
k_coeffs = zeros(n)
return ValueCoeffs{T,Degree{d}}(deg, v_coeffs, k_coeffs)
end
function ValueCoeffs(
ncgm::NeoclassicalGrowth, ::Type{Val{d}}, method::T
) where T <: SolutionMethod where d
# Initialize with vector of zeros
deg = Degree{d}()
n = n_complete(2, deg)
v_coeffs = zeros(n)
# Policy guesses based on k and z
k, z = ncgm.grid[:, 1], ncgm.grid[:, 2]
css = ncgm.A - ncgm.δ
yss = ncgm.A
c_pol = f(ncgm, k, z) * (css/yss)
# Figure out what kp is
k_pol = expendables_t(ncgm, k, z) - c_pol
k_coeffs = complete_polynomial(ncgm.grid, d) \ k_pol
return ValueCoeffs{T,Degree{d}}(deg, v_coeffs, k_coeffs)
end
solutionmethod(::ValueCoeffs{T}) where T <:SolutionMethod = T
# A few copy methods to make life easier
Base.copy(vp::ValueCoeffs{T,D}) where T where D =
ValueCoeffs{T,D}(vp.d, vp.v_coeffs, vp.k_coeffs)
function Base.copy(vp::ValueCoeffs{T1,D}, ::T2) where T1 where D where T2 <: SolutionMethod
ValueCoeffs{T2,D}(vp.d, vp.v_coeffs, vp.k_coeffs)
end
function Base.copy(
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{T}, ::Type{Val{new_degree}}
) where T where new_degree
# Build Value and policy matrix
deg = Degree{new_degree}()
V = build_V(ncgm, vp)
k = build_k(ncgm, vp)
# Build new Phi
Phi = complete_polynomial(ncgm.grid, deg)
v_coeffs = Phi \ V
k_coeffs = Phi \ k
return ValueCoeffs{T,Degree{new_degree}}(deg, v_coeffs, k_coeffs)
end
# -
# We will need to repeatedly update coefficients, build $V$ (or $dV$ depending on the solution method), and be able to compute expected values, so we define some additional helper functions below.
# +
"""
Updates the coefficients for the value function inplace in `vp`
"""
function update_v!(vp::ValueCoeffs, new_coeffs::Vector{Float64}, dampen::Float64)
vp.v_coeffs = (1-dampen)*vp.v_coeffs + dampen*new_coeffs
end
"""
Updates the coefficients for the policy function inplace in `vp`
"""
function update_k!(vp::ValueCoeffs, new_coeffs::Vector{Float64}, dampen::Float64)
vp.k_coeffs = (1-dampen)*vp.k_coeffs + dampen*new_coeffs
end
"""
Builds either V or dV depending on the solution method that is given. If it
is a solution method that iterates on the derivative of the value function
then it will return derivative of the value function, otherwise the
value function itself
"""
build_V_or_dV(ncgm::NeoclassicalGrowth, vp::ValueCoeffs) =
build_V_or_dV(ncgm, vp, solutionmethod(vp)())
build_V_or_dV(ncgm, vp::ValueCoeffs, ::SolutionMethod) = build_V(ncgm, vp)
build_V_or_dV(ncgm, vp::ValueCoeffs, T::dVFI_ECM) = build_dV(ncgm, vp)
function build_dV(ncgm::NeoclassicalGrowth, vp::ValueCoeffs)
Φ = complete_polynomial(ncgm.grid, vp.d, Derivative{1}())
Φ*vp.v_coeffs
end
function build_V(ncgm::NeoclassicalGrowth, vp::ValueCoeffs)
Φ = complete_polynomial(ncgm.grid, vp.d)
Φ*vp.v_coeffs
end
function build_k(ncgm::NeoclassicalGrowth, vp::ValueCoeffs)
Φ = complete_polynomial(ncgm.grid, vp.d)
Φ*vp.k_coeffs
end
# -
# Additionally, in order to evaluate the value function, we will need to be able to take expectations.
#
# These functions evaluates expectations by taking the policy $k_{t+1}$ and the current productivity state $z_t$ as inputs. They then integrates over the possible $z_{t+1}$s.
# +
function compute_EV!(cp_kpzp::Vector{Float64}, ncgm::NeoclassicalGrowth,
vp::ValueCoeffs, kp, iz)
# Pull out information from types
z1, weightsz = ncgm.z1, ncgm.weights
# Get number nodes
nzp = length(weightsz)
EV = 0.0
for izp in 1:nzp
zp = z1[izp, iz]
complete_polynomial!(cp_kpzp, [kp, zp], vp.d)
EV += weightsz[izp] * dot(vp.v_coeffs, cp_kpzp)
end
return EV
end
function compute_EV(ncgm::NeoclassicalGrowth, vp::ValueCoeffs, kp, iz)
cp_kpzp = Array{Float64}(undef, n_complete(2, vp.d))
return compute_EV!(cp_kpzp, ncgm, vp, kp, iz)
end
function compute_EV(ncgm::NeoclassicalGrowth, vp::ValueCoeffs)
# Get length of k and z grids
kgrid, zgrid = ncgm.kgrid, ncgm.zgrid
nk, nz = length(kgrid), length(zgrid)
temp = Array{Float64}(undef, n_complete(2, vp.d))
# Allocate space to store EV
EV = Array{Float64}(undef, nk*nz)
_inds = LinearIndices((nk, nz))
for ik in 1:nk, iz in 1:nz
# Pull out states
k = kgrid[ik]
z = zgrid[iz]
ikiz_index = _inds[ik, iz]
# Pass to scalar EV
complete_polynomial!(temp, [k, z], vp.d)
kp = dot(vp.k_coeffs, temp)
EV[ikiz_index] = compute_EV!(temp, ncgm, vp, kp, iz)
end
return EV
end
function compute_dEV!(cp_dkpzp::Vector, ncgm::NeoclassicalGrowth,
vp::ValueCoeffs, kp, iz)
# Pull out information from types
z1, weightsz = ncgm.z1, ncgm.weights
# Get number nodes
nzp = length(weightsz)
dEV = 0.0
for izp in 1:nzp
zp = z1[izp, iz]
complete_polynomial!(cp_dkpzp, [kp, zp], vp.d, Derivative{1}())
dEV += weightsz[izp] * dot(vp.v_coeffs, cp_dkpzp)
end
return dEV
end
function compute_dEV(ncgm::NeoclassicalGrowth, vp::ValueCoeffs, kp, iz)
compute_dEV!(Array{Float64}(undef, n_complete(2, vp.d)), ncgm, vp, kp, iz)
end
# -
# ### General Solution Method
#
# As promised, below is some code that "generally" applies the algorithm that we described -- Notice that it is implemented for a type `ValueCoeffs{SolutionMethod}` which is our abstract type. We will define a special version of `update` for each solution method and then we will only need this one `solve` method and won't repeat the more tedious portions of our code.
function solve(
ncgm::NeoclassicalGrowth, vp::ValueCoeffs;
tol::Float64=1e-6, maxiter::Int=5000, dampen::Float64=1.0,
nskipprint::Int=1, verbose::Bool=true
)
# Get number of k and z on grid
nk, nz = length(ncgm.kgrid), length(ncgm.zgrid)
# Build basis matrix and value function
dPhi = complete_polynomial(ncgm.grid, vp.d, Derivative{1}())
Phi = complete_polynomial(ncgm.grid, vp.d)
V = build_V_or_dV(ncgm, vp)
k = build_k(ncgm, vp)
Vnew = copy(V)
knew = copy(k)
# Print column names
if verbose
@printf("| Iteration | Distance V | Distance K |\n")
end
# Iterate to convergence
dist, iter = 10.0, 0
while (tol < dist) & (iter < maxiter)
# Update the value function using appropriate update methods
update!(Vnew, knew, ncgm, vp, Phi, dPhi)
# Compute distance and update all relevant elements
iter += 1
dist_v = maximum(abs, 1.0 .- Vnew./V)
dist_k = maximum(abs, 1.0 .- knew./k)
copy!(V, Vnew)
copy!(k, knew)
# If we are iterating on a policy, use the difference of values
# otherwise use the distance on policy
dist = ifelse(solutionmethod(vp) == IterateOnPolicy, dist_v, dist_k)
# Print status update
if verbose && (iter%nskipprint == 0)
@printf("|%-11d|%-12e|%-12e|\n", iter, dist_v, dist_k)
end
end
# Update value and policy functions one last time as long as the
# solution method isn't IterateOnPolicy
if ~(solutionmethod(vp) == IterateOnPolicy)
# Update capital policy after finished
kp = env_condition_kp(ncgm, vp)
update_k!(vp, complete_polynomial(ncgm.grid, vp.d) \ kp, 1.0)
# Update value function according to specified policy
vp_igp = copy(vp, IterateOnPolicy())
solve(ncgm, vp_igp; tol=1e-10, maxiter=5000, verbose=false)
update_v!(vp, vp_igp.v_coeffs, 1.0)
end
return vp
end
# ### Iterating to Convergence (given policy)
#
# This isn't one of the methods described above, but it is used as an element of a few of our methods (and also as a way to get a first guess at the value function). This method takes an initial policy function, $\bar{k}(k_t, z_t)$, as given, and then, without changing the policy, iterates until the value function has converged.
#
# Thus the "update section" of the algorithm in this instance would be:
#
# * Leave policy function unchanged
# * At each point of grid, $(k_t, z_t)$, compute $\hat{V}(k_t, z_t) = u(c(\bar{k}(k_t, z_t))) + \beta E \left[ V(\bar{k}(k_t, z_t), z_{t+1}) \right]$
function update!(V::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{IterateOnPolicy},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Get sizes and allocate for complete_polynomial
kgrid = ncgm.kgrid; zgrid = ncgm.zgrid;
nk, nz = length(kgrid), length(zgrid)
_inds = LinearIndices((nk, nz))
# Iterate over all states
for ik in 1:nk, iz in 1:nz
# Pull out states
k = kgrid[ik]
z = zgrid[iz]
# Pull out policy and evaluate consumption
ikiz_index = _inds[ik, iz]
k1 = kpol[ikiz_index]
c = expendables_t(ncgm, k, z) - k1
# New value
EV = compute_EV(ncgm, vp, k1, iz)
V[ikiz_index] = u(ncgm, c) + ncgm.β*EV
end
# Update coefficients
update_v!(vp, Φ \ V, 1.0)
update_k!(vp, Φ \ kpol, 1.0)
return V
end
# ### Conventional Value Function Iteration
#
# This is one of the first solution methods for macroeconomics a graduate student in economics typically learns.
#
# In this solution method, one takes as given a value function, $V(k_t, z_t)$, and then solves for the optimal policy given the value function.
#
# The update section takes the form:
#
# * For each point, $(k_t, z_t)$, numerically solve for $c^*(k_t, z_t)$ to satisfy the first order condition $u'(c^*) = \beta E \left[ V_1((1 - \delta) k_t + z_t f(k_t) - c^*, z_{t+1}) \right]$
# * Define $k^*(k_t, z_t) = (1 - \delta) k_t + z_t f(k_t) - c^*(k_t, z_t)$
# * Update value function according to $\hat{V}(k_t, z_t) = u(c^*(k_t, z_t)) + \beta E \left[ V(k^*(k_t, z_t), z_{t+1}) \right]$
function update!(V::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{VFI},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Get sizes and allocate for complete_polynomial
kgrid = ncgm.kgrid; zgrid = ncgm.zgrid
nk, nz = length(kgrid), length(zgrid)
# Iterate over all states
temp = Array{Float64}(undef, n_complete(2, vp.d))
_inds = LinearIndices((nk, nz))
for iz=1:nz, ik=1:nk
k = kgrid[ik]; z = zgrid[iz]
# Define an objective function (negative for minimization)
y = expendables_t(ncgm, k, z)
solme(kp) = du(ncgm, y - kp) - ncgm.β*compute_dEV!(temp, ncgm, vp, kp, iz)
# Find sol to foc
kp = brent(solme, 1e-8, y-1e-8; rtol=1e-12)
c = expendables_t(ncgm, k, z) - kp
# New value
ikiz_index = _inds[ik, iz]
EV = compute_EV!(temp, ncgm, vp, kp, iz)
V[ikiz_index] = u(ncgm, c) + ncgm.β*EV
kpol[ikiz_index] = kp
end
# Update coefficients
update_v!(vp, Φ \ V, 1.0)
update_k!(vp, Φ \ kpol, 1.0)
return V
end
# ### Endogenous Grid Value Function Iteration
#
# Method introduced by <NAME>. The key to this method is that the grid of points being used to approximate is over $(k_{t+1}, z_{t})$ instead of $(k_t, z_t)$. The insightful piece of this algorithm is that the transformation allows one to write a closed form for the consumption function, $c^*(k_{t+1}, z_t) = u'^{-1} \left( V_1(k_{t+1}, z_{t+1}) \right]$.
#
# Then for a given $(k_{t+1}, z_{t})$ the update section would be
#
# * Define $c^*(k_{t+1}, z_t) = u'^{-1} \left( \beta E \left[ V_1(k_{t+1}, z_{t+1}) \right] \right)$
# * Find $k_t$ such that $k_t = (1 - \delta) k_t + z_t f(k_t) - k_{t+1}$
# * Update value function according to $\hat{V}(k_t, z_t) = u(c^*(k_{t+1}, z_t)) + \beta E \left[ V(k_{t+1}, z_{t+1}) \right]$
#
function update!(V::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{VFI_EGM},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Get sizes and allocate for complete_polynomial
kgrid = ncgm.kgrid; zgrid = ncgm.zgrid; grid = ncgm.grid;
nk, nz = length(kgrid), length(zgrid)
# Iterate
temp = Array{Float64}(undef, n_complete(2, vp.d))
_inds = LinearIndices((nk, nz))
for iz=1:nz, ik=1:nk
# In EGM we use the grid points as if they were our
# policy for yesterday and find implied kt
ikiz_index = _inds[ik, iz]
k1 = kgrid[ik];z = zgrid[iz];
# Compute the derivative of expected values
dEV = compute_dEV!(temp, ncgm, vp, k1, iz)
# Compute optimal consumption
c = duinv(ncgm, ncgm.β*dEV)
# Need to find corresponding kt for optimal c
obj(kt) = expendables_t(ncgm, kt, z) - c - k1
kt_star = brent(obj, 0.0, 2.0, xtol=1e-10)
# New value
EV = compute_EV!(temp, ncgm, vp, k1, iz)
V[ikiz_index] = u(ncgm, c) + ncgm.β*EV
kpol[ikiz_index] = kt_star
end
# New Φ (has our new "kt_star" and z points)
Φ_egm = complete_polynomial([kpol grid[:, 2]], vp.d)
# Update coefficients
update_v!(vp, Φ_egm \ V, 1.0)
update_k!(vp, Φ_egm \ grid[:, 1], 1.0)
# Update V and kpol to be value and policy corresponding
# to our grid again
copy!(V, Φ*vp.v_coeffs)
copy!(kpol, Φ*vp.k_coeffs)
return V
end
# ### Envelope Condition Value Function Iteration
#
# Very similar to the previous method. The insight of this algorithm is that since we are already approximating the value function and can evaluate its derivative, we can skip the numerical optimization piece of the update method and compute directly the policy using the envelope condition (hence the name).
#
# The envelope condition says:
#
# $$c^*(k_t, z_t) = u'^{-1} \left( \frac{\partial V(k_t, z_t)}{\partial k_t} (1 - \delta + r)^{-1} \right)$$
#
# so
#
# $$k^*(k_t, z_t) = z_t f(k_t) + (1-\delta)k_t - c^*(k_t, z_t)$$
#
# The functions below compute the policy using the envelope condition.
# +
function env_condition_kp!(cp_out::Vector{Float64}, ncgm::NeoclassicalGrowth,
vp::ValueCoeffs, k::Float64, z::Float64)
# Compute derivative of VF
dV = dot(vp.v_coeffs, complete_polynomial!(cp_out, [k, z], vp.d, Derivative{1}()))
# Consumption is then computed as
c = duinv(ncgm, dV / (1 - ncgm.δ .+ df(ncgm, k, z)))
return expendables_t(ncgm, k, z) - c
end
function env_condition_kp(ncgm::NeoclassicalGrowth, vp::ValueCoeffs,
k::Float64, z::Float64)
cp_out = Array{Float64}(undef, n_complete(2, vp.d))
env_condition_kp!(cp_out, ncgm, vp, k, z)
end
function env_condition_kp(ncgm::NeoclassicalGrowth, vp::ValueCoeffs)
# Pull out k and z from grid
k = ncgm.grid[:, 1]
z = ncgm.grid[:, 2]
# Create basis matrix for entire grid
dPhi = complete_polynomial(ncgm.grid, vp.d, Derivative{1}())
# Compute consumption
c = duinv(ncgm, (dPhi*vp.v_coeffs) ./ (1-ncgm.δ.+df(ncgm, k, z)))
return expendables_t(ncgm, k, z) .- c
end
# -
# The update method is then very similar to other value iteration style methods, but avoids the numerical solver.
#
# * For each point, $(k_t, z_t)$ get $c^*(k_t, z_t)$ from the envelope condition
# * Define $k^*(k_t, z_t) = (1 - \delta) k_t + z_t f(k_t) - c^*(k_t, z_t)$
# * Update value function according to $\hat{V}(k_t, z_t) = u(c^*(k_t, z_t)) + \beta E \left[ V(k^*(k_t, z_t), z_{t+1}) \right]$
# +
function update!(V::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{VFI_ECM},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Get sizes and allocate for complete_polynomial
kgrid = ncgm.kgrid; zgrid = ncgm.zgrid;
nk, nz = length(kgrid), length(zgrid)
# Iterate over all states
temp = Array{Float64}(undef, n_complete(2, vp.d))
_inds = LinearIndices((nk, nz))
for ik in 1:nk, iz in 1:nz
ikiz_index = _inds[ik, iz]
k = kgrid[ik]
z = zgrid[iz]
# Policy from envelope condition
kp = env_condition_kp!(temp, ncgm, vp, k, z)
c = expendables_t(ncgm, k, z) - kp
kpol[ikiz_index] = kp
# New value
EV = compute_EV!(temp, ncgm, vp, kp, iz)
V[ikiz_index] = u(ncgm, c) + ncgm.β*EV
end
# Update coefficients
update_v!(vp, Φ \ V, 1.0)
update_k!(vp, Φ \ kpol, 1.0)
return V
end
# -
# ### Conventional Policy Function Iteration
#
# Policy function iteration is different than value function iteration in that it starts with a policy function, then updates the value function, and finally finds the new optimal policy function. Given a policy $c(k_t, z_t)$ and for each pair $(k_t, z_t)$
#
# * Define $k(k_t, z_t) = (1 - \delta) k_t + z_t f(k_t) - c(k_t, z_t)$
# * Find fixed point of $V(k_t, z_t) = u(c(k_t, z_t)) + \beta E \left[ V(k(k_t, z_t), z_t) \right]$ (Iterate to convergence given policy)
# * Given $V(k_t, z_t)$, numerically solve for new policy $c^*(k_t, z_t)$ -- Stop when $c(k_t, z_t) \approx c^*(k_t, z_t)$
function update!(V::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{PFI},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Get sizes and allocate for complete_polynomial
kgrid = ncgm.kgrid; zgrid = ncgm.zgrid; grid = ncgm.grid;
nk, nz = length(kgrid), length(zgrid)
# Copy valuecoeffs object and use to iterate to
# convergence given a policy
vp_igp = copy(vp, IterateOnPolicy())
solve(ncgm, vp_igp; nskipprint=1000, maxiter=5000, verbose=false)
# Update the policy and values
temp = Array{Float64}(undef, n_complete(2, vp.d))
_inds = LinearIndices((nk, nz))
for ik in 1:nk, iz in 1:nz
k = kgrid[ik]; z = zgrid[iz];
# Define an objective function (negative for minimization)
y = expendables_t(ncgm, k, z)
solme(kp) = du(ncgm, y - kp) - ncgm.β*compute_dEV!(temp, ncgm, vp, kp, iz)
# Find minimum of objective
kp = brent(solme, 1e-8, y-1e-8; rtol=1e-12)
# Update policy function
ikiz_index = _inds[ik, iz]
kpol[ikiz_index] = kp
end
# Get new coeffs
update_k!(vp, Φ \ kpol, 1.0)
update_v!(vp, vp_igp.v_coeffs, 1.0)
# Update all elements of value
copy!(V, Φ*vp.v_coeffs)
return V
end
# ### Envelope Condition Policy Function Iteration
#
# Similar to policy function iteration, but, rather than numerically solve for new policies, it uses the envelope condition to directly compute them. Given a starting policy $c(k_t, z_t)$ and for each pair $(k_t, z_t)$
#
# * Define $k(k_t, z_t) = (1 - \delta) k_t + z_t f(k_t) - c(k_t, z_t)$
# * Find fixed point of $V(k_t, z_t) = u(c(k_t, z_t)) + \beta E \left[ V(k(k_t, z_t), z_t) \right]$ (Iterate to convergence given policy)
# * Given $V(k_t, z_t)$ find $c^*(k_t, z_t)$ using envelope condition -- Stop when $c(k_t, z_t) \approx c^*(k_t, z_t)$
function update!(V::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{PFI_ECM},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Copy valuecoeffs object and use to iterate to
# convergence given a policy
vp_igp = copy(vp, IterateOnPolicy())
solve(ncgm, vp_igp; nskipprint=1000, maxiter=5000, verbose=false)
# Update the policy and values
kp = env_condition_kp(ncgm, vp)
update_k!(vp, Φ \ kp, 1.0)
update_v!(vp, vp_igp.v_coeffs, 1.0)
# Update all elements of value
copy!(V, Φ*vp.v_coeffs)
copy!(kpol, kp)
return V
end
# ### Euler Equation Method
#
# Euler equation methods operate directly on the Euler equation: $u'(c_t) = \beta E \left[ u'(c_{t+1}) (1 - \delta + z_t f'(k_t)) \right]$.
#
# Given an initial policy $c(k_t, z_t)$ for each grid point $(k_t, z_t)$
#
# * Find $k(k_t, z_t) = (1-\delta)k_t + z_t f(k_t) - c(k_t, z_t)$
# * Let $c_{t+1} = c(k(k_t, z_t), z_t)$
# * Numerically solve for a $c^*$ that satisfies the Euler equation i.e. $u'(c^*) = \beta E \left[ u'(c_{t+1}) (1 - \delta + z_t f'(k_t)) \right]$
# * Stop when $c^*(k_t, z_t) \approx c(k_t, z_t)$
# Conventional Euler equation method
function update!(V::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{EulEq},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Get sizes and allocate for complete_polynomial
@unpack kgrid, zgrid, weights, z1 = ncgm
nz1, nz = size(z1)
nk = length(kgrid)
# Iterate over all states
temp = Array{Float64}(undef, n_complete(2, vp.d))
_inds = LinearIndices((nk, nz))
for iz in 1:nz, ik in 1:nk
k = kgrid[ik]; z = zgrid[iz];
# Create current polynomial
complete_polynomial!(temp, [k, z], vp.d)
# Compute what capital will be tomorrow according to policy
kp = dot(temp, vp.k_coeffs)
# Compute RHS of EE
rhs_ee = 0.0
for iz1 in 1:nz1
# Possible z in t+1
zp = z1[iz1, iz]
# Policy for k_{t+2}
complete_polynomial!(temp, [kp, zp], vp.d)
kpp = dot(temp, vp.k_coeffs)
# Implied t+1 consumption
cp = expendables_t(ncgm, kp, zp) - kpp
# Add to running expectation
rhs_ee += ncgm.β*weights[iz1]*du(ncgm, cp)*(1-ncgm.δ+df(ncgm, kp, zp))
end
# The rhs of EE implies consumption and investment in t
c = duinv(ncgm, rhs_ee)
kp_star = expendables_t(ncgm, k, z) - c
# New value
ikiz_index = _inds[ik, iz]
EV = compute_EV!(temp, ncgm, vp, kp_star, iz)
V[ikiz_index] = u(ncgm, c) + ncgm.β*EV
kpol[ikiz_index] = kp_star
end
# Update coefficients
update_v!(vp, Φ \ V, 1.0)
update_k!(vp, Φ \ kpol, 1.0)
return V
end
# ### Envelope Condition Derivative Value Function Iteration
#
# This method uses the same insight of the "Envelope Condition Value Function Iteration," but, rather than iterate directly on the value function, it iterates on the derivative of the value function. The update steps are
#
# * For each point, $(k_t, z_t)$ get $c^*(k_t, z_t)$ from the envelope condition (which only depends on the derivative of the value function!)
# * Define $k^*(k_t, z_t) = (1 - \delta) k_t + z_t f(k_t) - c^*(k_t, z_t)$
# * Update value function according to $\hat{V}_1(k_t, z_t) = \beta (1 - \delta + z_t f'(k_t)) E \left[ V_1(k^*(k_t, z_t), z_{t+1}) \right]$
#
# Once it has converged, you use the implied policy rule and iterate to convergence using the "iterate to convergence (given policy)" method.
function update!(dV::Vector{Float64}, kpol::Vector{Float64},
ncgm::NeoclassicalGrowth, vp::ValueCoeffs{dVFI_ECM},
Φ::Matrix{Float64}, dΦ::Matrix{Float64})
# Get sizes and allocate for complete_polynomial
kgrid = ncgm.kgrid; zgrid = ncgm.zgrid; grid = ncgm.grid;
nk, nz, ns = length(kgrid), length(zgrid), size(grid, 1)
# Iterate over all states
temp = Array{Float64}(undef, n_complete(2, vp.d))
_inds = LinearIndices((nk, nz))
for iz=1:nz, ik=1:nk
k = kgrid[ik]; z = zgrid[iz];
# Envelope condition implies optimal kp
kp = env_condition_kp!(temp, ncgm, vp, k, z)
c = expendables_t(ncgm, k, z) - kp
# New value
ikiz_index = _inds[ik, iz]
dEV = compute_dEV!(temp, ncgm, vp, kp, iz)
dV[ikiz_index] = (1-ncgm.δ+df(ncgm, k, z))*ncgm.β*dEV
kpol[ikiz_index] = kp
end
# Get new coeffs
update_k!(vp, Φ \ kpol, 1.0)
update_v!(vp, dΦ \ dV, 1.0)
return dV
end
# ### Simulation and Euler Error Methods
#
# The following functions to simulate and compute Euler errors are easily defined given our model type and the solution type.
# +
"""
Simulates the neoclassical growth model for a given set of solution
coefficients. It simulates for `capT` periods and discards first
`nburn` observations.
"""
function simulate(ncgm::NeoclassicalGrowth, vp::ValueCoeffs,
shocks::Vector{Float64}; capT::Int=10_000,
nburn::Int=200)
# Unpack parameters
kp = 0.0 # Policy holder
temp = Array{Float64}(undef, n_complete(2, vp.d))
# Allocate space for k and z
ksim = Array{Float64}(undef, capT+nburn)
zsim = Array{Float64}(undef, capT+nburn)
# Initialize both k and z at 1
ksim[1] = 1.0
zsim[1] = 1.0
# Simulate
temp = Array{Float64}(undef, n_complete(2, vp.d))
for t in 2:capT+nburn
# Evaluate k_t given yesterday's (k_{t-1}, z_{t-1})
kp = env_condition_kp!(temp, ncgm, vp, ksim[t-1], zsim[t-1])
# Draw new z and update k using policy above
zsim[t] = zsim[t-1]^ncgm.ρ * exp(ncgm.σ*shocks[t])
ksim[t] = kp
end
return ksim[nburn+1:end], zsim[nburn+1:end]
end
function simulate(ncgm::NeoclassicalGrowth, vp::ValueCoeffs;
capT::Int=10_000, nburn::Int=200, seed=42)
Random.seed!(seed) # Set specific seed
shocks = randn(capT + nburn)
return simulate(ncgm, vp, shocks; capT=capT, nburn=nburn)
end
"""
This function evaluates the Euler Equation residual for a single point (k, z)
"""
function EulerEquation!(out::Vector{Float64}, ncgm::NeoclassicalGrowth,
vp::ValueCoeffs, k::Float64, z::Float64,
nodes::Vector{Float64}, weights::Vector{Float64})
# Evaluate consumption today
k1 = env_condition_kp!(out, ncgm, vp, k, z)
c = expendables_t(ncgm, k, z) - k1
LHS = du(ncgm, c)
# For each of realizations tomorrow, evaluate expectation on RHS
RHS = 0.0
for (eps, w) in zip(nodes, weights)
# Compute ztp1
z1 = z^ncgm.ρ * exp(eps)
# Evaluate the ktp2
ktp2 = env_condition_kp!(out, ncgm, vp, k1, z1)
# Get c1
c1 = expendables_t(ncgm, k1, z1) - ktp2
# Update RHS of equation
RHS = RHS + w*du(ncgm, c1)*(1 - ncgm.δ + df(ncgm, k1, z1))
end
return abs(ncgm.β*RHS/LHS - 1.0)
end
"""
Given simulations for k and z, it computes the euler equation residuals
along the entire simulation. It reports the mean and max values in
log10.
"""
function ee_residuals(ncgm::NeoclassicalGrowth, vp::ValueCoeffs,
ksim::Vector{Float64}, zsim::Vector{Float64}; Qn::Int=10)
# Figure out how many periods we simulated for and make sure k and z
# are same length
capT = length(ksim)
@assert length(zsim) == capT
# Finer integration nodes
eps_nodes, weight_nodes = qnwnorm(Qn, 0.0, ncgm.σ^2)
temp = Array{Float64}(undef, n_complete(2, vp.d))
# Compute EE for each period
EE_resid = Array{Float64}(undef, capT)
for t=1:capT
# Pull out current state
k, z = ksim[t], zsim[t]
# Compute residual of Euler Equation
EE_resid[t] = EulerEquation!(temp, ncgm, vp, k, z, eps_nodes, weight_nodes)
end
return EE_resid
end
function ee_residuals(ncgm::NeoclassicalGrowth, vp::ValueCoeffs; Qn::Int=10)
# Simulate and then call other ee_residuals method
ksim, zsim = simulate(ncgm, vp)
return ee_residuals(ncgm, vp, ksim, zsim; Qn=Qn)
end
# -
# ## A Horse Race
#
# We can now run a horse race to compare the methods in terms of both accuracy and speed.
function main(sm::SolutionMethod, nd::Int=5, shocks=randn(capT+nburn);
capT=10_000, nburn=200, tol=1e-9, maxiter=2500,
nskipprint=25, verbose=true)
# Create model
ncgm = NeoclassicalGrowth()
# Create initial quadratic guess
vp = ValueCoeffs(ncgm, Val{2}, IterateOnPolicy())
solve(ncgm, vp; tol=1e-6, verbose=false)
# Allocate memory for timings
times = Array{Float64}(undef, nd-1)
sols = Array{ValueCoeffs}(undef, nd-1)
mean_ees = Array{Float64}(undef, nd-1)
max_ees = Array{Float64}(undef, nd-1)
# Solve using the solution method for degree 2 to 5
vp = copy(vp, sm)
for d in 2:nd
# Change degree of solution method
vp = copy(ncgm, vp, Val{d})
# Time the current method
start_time = time()
solve(ncgm, vp; tol=tol, maxiter=maxiter, nskipprint=nskipprint,
verbose=verbose)
end_time = time()
# Save the time and solution
times[d-1] = end_time - start_time
sols[d-1] = vp
# Simulate and compute EE
ks, zs = simulate(ncgm, vp, shocks; capT=capT, nburn=nburn)
resids = ee_residuals(ncgm, vp, ks, zs; Qn=10)
mean_ees[d-1] = log10.(mean(abs.(resids)))
max_ees[d-1] = log10.(maximum(abs, resids))
end
return sols, times, mean_ees, max_ees
end
# +
Random.seed!(52)
shocks = randn(10200)
for sol_method in [VFI(), VFI_EGM(), VFI_ECM(), dVFI_ECM(),
PFI(), PFI_ECM(), EulEq()]
# Make sure everything is compiled
main(sol_method, 5, shocks; maxiter=2, verbose=false)
# Run for real
s_sm, t_sm, mean_eem, max_eem = main(sol_method, 5, shocks;
tol=1e-8, verbose=false)
println("Solution Method: $sol_method")
for (d, t) in zip([2, 3, 4, 5], t_sm)
println("\tDegree $d took time $t")
println("\tMean & Max EE are" *
"$(round(mean_eem[d-1], digits=3)) & $(round(max_eem[d-1], digits=3))")
end
end
# -
| Growth/notebooks/GrowthModelSolutionMethods_jl.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
import numpy as np
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
# +
clusternames = ["adj_ERPositive", "adj_PRPositive", "adj_HER2Positive", "adj_Triple Neg"]
gsea_frames = {}
for cluster in clusternames:
df = pd.read_csv(f"GSEA_/{cluster}/gseapy.gsea.gene_set.report.csv", index_col=0).iloc[:,:-3]
indexlist = []
for i in df.index:
new_i = i.rstrip(" ")
indexlist.append(new_i)
df.index = indexlist
print(df.index)
df['fdr'] = df.apply(lambda row: 5.0 if (row['fdr'] == 0.0) else -np.log10(row['fdr']), axis=1)
df = df.loc[~df.index.duplicated(keep='first')]
gsea_frames[cluster] = df
gsea_df = pd.DataFrame(index= gsea_frames['adj_ERPositive'].index)
for i in gsea_frames:
gsea_df[i] = gsea_frames[i][f'fdr']
# -
gsea_df.columns = ["ER", "PR", "HER2", "Triple Neg"]
gsea_df
wall_hormones = pd.read_csv('../exp/adjusted_distributions_receptors.csv', index_col = 0)
wall_hormones.columns = ["ER", "PR", "HER2", "Triple Neg"]
wall_hormones
def read_reactome(file_name, gene_name_start = "ENSG0"):
df = pd.read_csv(file_name, sep='\t', header=None)
if gene_name_start == None:
sub_df = df
else:
subset_vec = df[0].str.startswith(gene_name_start)
sub_df = df.loc[subset_vec]
genes_df = sub_df.groupby(1)[0].apply(list)
names_df = sub_df.groupby(1)[3].max()
out_df = pd.concat([genes_df,names_df], axis=1)
out_df.columns = ['genes', 'pathway_name']
out_df.index = out_df.pathway_name
return out_df
reactome_ngenes = read_reactome("../data/Ensembl2Reactome_All_Levels.txt.gz")
length_dict = {}
for i in wall_hormones.index:
if i in reactome_ngenes.index:
nr_genes = len(reactome_ngenes.loc[i, "genes"])
else:
print(f'{i} not found')
length_dict[i] = nr_genes
wall_hormones["ngenes"] = wall_hormones.index.map(length_dict)
gsea_df["ngenes"] = gsea_df.index.map(length_dict)
wall_hormones
gsea_df
# +
comparison_df_index = [x for x in wall_hormones.columns if x != "ngenes"]
print(comparison_df_index)
comparison_df = pd.DataFrame(index=comparison_df_index)
anova_mean = []
gsea_mean = []
anova_median = []
gsea_median = []
no_anova_genes = []
no_gsea_genes = []
for i in wall_hormones.columns:
if i != "ngenes":
anova_mean.append(wall_hormones[wall_hormones[i] > 3]['ngenes'].mean(axis=0))
no_anova_genes.append(wall_hormones[wall_hormones[i] > 3]["ngenes"].shape[0])
gsea_mean.append(gsea_df[gsea_df[i] > 3]["ngenes"].mean(axis=0))
no_gsea_genes.append(gsea_df[gsea_df[i] > 3]["ngenes"].shape[0])
anova_median.append(wall_hormones[wall_hormones[i] > 3]['ngenes'].median(axis=0))
gsea_median.append(gsea_df[gsea_df[i] > 3]["ngenes"].median(axis=0))
comparison_df["ANOVA pathways"] = no_anova_genes
comparison_df["GSEA pathways"] = no_gsea_genes
comparison_df["ANOVA median"] = anova_median
comparison_df["GSEA median"] = gsea_median
comparison_df["Fold change"] = comparison_df["GSEA median"] / comparison_df["ANOVA median"]
comparison_df
# -
| metabric/src/anova_gsea_fdr_pathwaysize_hormones.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + colab={} colab_type="code" id="e-YsQrBjzNdX"
# ! pip install -U pip
# ! pip install -U torch==1.5.0
# ! pip install -U torchaudio==0.5.0
# ! pip install -U torchvision==0.6.0
# ! pip install -U matplotlib==3.2.1
# ! pip install -U trains==0.15.0
# ! pip install -U pandas==1.0.4
# ! pip install -U numpy==1.18.4
# ! pip install -U tensorboard==2.2.1
# + colab={} colab_type="code" id="T7T0Rf26zNdm"
import PIL
import io
import pandas as pd
import numpy as np
from pathlib2 import Path
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
import torchaudio
from torchvision.transforms import ToTensor
from trains import Task
# %matplotlib inline
# -
task = Task.init(project_name='Audio Example', task_name='audio classifier')
configuration_dict = {'number_of_epochs': 10, 'batch_size': 4, 'dropout': 0.25, 'base_lr': 0.001}
configuration_dict = task.connect(configuration_dict) # enabling configuration override by trains
print(configuration_dict) # printing actual configuration (after override in remote mode)
# + colab={} colab_type="code" id="msiz7QdvzNeA"
# Download UrbanSound8K dataset (https://urbansounddataset.weebly.com/urbansound8k.html)
path_to_UrbanSound8K = './data/UrbanSound8K'
# + colab={} colab_type="code" id="wXtmZe7yzNeS"
class UrbanSoundDataset(Dataset):
#rapper for the UrbanSound8K dataset
def __init__(self, csv_path, file_path, folderList):
self.file_path = file_path
self.file_names = []
self.labels = []
self.folders = []
#loop through the csv entries and only add entries from folders in the folder list
csvData = pd.read_csv(csv_path)
for i in range(0,len(csvData)):
if csvData.iloc[i, 5] in folderList:
self.file_names.append(csvData.iloc[i, 0])
self.labels.append(csvData.iloc[i, 6])
self.folders.append(csvData.iloc[i, 5])
def __getitem__(self, index):
#format the file path and load the file
path = self.file_path / ("fold" + str(self.folders[index])) / self.file_names[index]
sound, sample_rate = torchaudio.load(path, out = None, normalization = True)
# UrbanSound8K uses two channels, this will convert them to one
soundData = torch.mean(sound, dim=0, keepdim=True)
#Make sure all files are the same size
if soundData.numel() < 160000:
fixedsize_data = torch.nn.functional.pad(soundData, (0, 160000 - soundData.numel()))
else:
fixedsize_data = soundData[0,:160000].reshape(1,160000)
#downsample the audio
downsample_data = fixedsize_data[::5]
melspectogram_transform = torchaudio.transforms.MelSpectrogram(sample_rate=sample_rate)
melspectogram = melspectogram_transform(downsample_data)
melspectogram_db = torchaudio.transforms.AmplitudeToDB()(melspectogram)
return fixedsize_data, sample_rate, melspectogram_db, self.labels[index]
def __len__(self):
return len(self.file_names)
csv_path = Path(path_to_UrbanSound8K) / 'metadata' / 'UrbanSound8K.csv'
file_path = Path(path_to_UrbanSound8K) / 'audio'
train_set = UrbanSoundDataset(csv_path, file_path, range(1,10))
test_set = UrbanSoundDataset(csv_path, file_path, [10])
print("Train set size: " + str(len(train_set)))
print("Test set size: " + str(len(test_set)))
train_loader = torch.utils.data.DataLoader(train_set, batch_size = configuration_dict.get('batch_size', 4),
shuffle = True, pin_memory=True, num_workers=1)
test_loader = torch.utils.data.DataLoader(test_set, batch_size = configuration_dict.get('batch_size', 4),
shuffle = False, pin_memory=True, num_workers=1)
classes = ('air_conditioner', 'car_horn', 'children_playing', 'dog_bark', 'drilling', 'engine_idling',
'gun_shot', 'jackhammer', 'siren', 'street_music')
# + colab={} colab_type="code" id="ylblw-k1zNeZ"
class Net(nn.Module):
def __init__(self, num_classes, dropout_value):
super(Net,self).__init__()
self.num_classes = num_classes
self.dropout_value = dropout_value
self.C1 = nn.Conv2d(1,16,3)
self.C2 = nn.Conv2d(16,32,3)
self.C3 = nn.Conv2d(32,64,3)
self.C4 = nn.Conv2d(64,128,3)
self.maxpool1 = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(128*29*197,128)
self.fc2 = nn.Linear(128,self.num_classes)
self.dropout = nn.Dropout(self.dropout_value)
def forward(self,x):
# add sequence of convolutional and max pooling layers
x = F.relu(self.C1(x))
x = self.maxpool1(F.relu(self.C2(x)))
x = F.relu(self.C3(x))
x = self.maxpool1(F.relu(self.C4(x)))
# flatten image input
x = x.view(-1,128*29*197)
x = F.relu(self.fc1(self.dropout(x)))
x = self.fc2(self.dropout(x))
return x
model = Net(len(classes), configuration_dict.get('dropout', 0.25))
# + colab={} colab_type="code" id="3yKYru14zNef"
optimizer = optim.SGD(model.parameters(), lr = configuration_dict.get('base_lr', 0.001), momentum = 0.9)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size = 3, gamma = 0.1)
criterion = nn.CrossEntropyLoss()
# -
device = torch.cuda.current_device() if torch.cuda.is_available() else torch.device('cpu')
print('Device to use: {}'.format(device))
model.to(device)
tensorboard_writer = SummaryWriter('./tensorboard_logs')
def plot_signal(signal, title, cmap=None):
fig = plt.figure()
if signal.ndim == 1:
plt.plot(signal)
else:
plt.imshow(signal, cmap=cmap)
plt.title(title)
plot_buf = io.BytesIO()
plt.savefig(plot_buf, format='jpeg')
plot_buf.seek(0)
plt.close(fig)
return ToTensor()(PIL.Image.open(plot_buf))
# + colab={} colab_type="code" id="Vdthqz3JzNem"
def train(model, epoch):
model.train()
for batch_idx, (sounds, sample_rate, inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
iteration = epoch * len(train_loader) + batch_idx
if batch_idx % log_interval == 0: #print training stats
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'
.format(epoch, batch_idx * len(inputs), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss))
tensorboard_writer.add_scalar('training loss/loss', loss, iteration)
tensorboard_writer.add_scalar('learning rate/lr', optimizer.param_groups[0]['lr'], iteration)
if batch_idx % debug_interval == 0: # report debug image every 500 mini-batches
for n, (inp, pred, label) in enumerate(zip(inputs, predicted, labels)):
series = 'label_{}_pred_{}'.format(classes[label.cpu()], classes[pred.cpu()])
tensorboard_writer.add_image('Train MelSpectrogram samples/{}'.format(n),
plot_signal(inp.cpu().numpy().squeeze(), series, 'hot'), iteration)
# + colab={} colab_type="code" id="LBWoj7u5zNes"
def test(model, epoch):
model.eval()
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for idx, (sounds, sample_rate, inputs, labels) in enumerate(test_loader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels)
for i in range(len(inputs)):
label = labels[i].item()
class_correct[label] += c[i].item()
class_total[label] += 1
iteration = (epoch + 1) * len(train_loader)
if idx % debug_interval == 0: # report debug image every 100 mini-batches
for n, (sound, inp, pred, label) in enumerate(zip(sounds, inputs, predicted, labels)):
series = 'label_{}_pred_{}'.format(classes[label.cpu()], classes[pred.cpu()])
tensorboard_writer.add_audio('Test audio samples/{}'.format(n),
sound, iteration, int(sample_rate[n]))
tensorboard_writer.add_image('Test MelSpectrogram samples/{}_{}'.format(idx, n),
plot_signal(inp.cpu().numpy().squeeze(), series, 'hot'), iteration)
total_accuracy = 100 * sum(class_correct)/sum(class_total)
print('[Iteration {}] Accuracy on the {} test images: {}%\n'.format(epoch, sum(class_total), total_accuracy))
tensorboard_writer.add_scalar('accuracy/total', total_accuracy, iteration)
# + colab={} colab_type="code" id="X5lx3g_5zNey"
log_interval = 100
debug_interval = 200
for epoch in range(configuration_dict.get('number_of_epochs', 10)):
train(model, epoch)
test(model, epoch)
scheduler.step()
| examples/frameworks/pytorch/notebooks/audio/audio_classifier_UrbanSound8K.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
from sklearn.neighbors import NearestNeighbors
from scipy import ndarray
filename='preprocessed_majority.csv'
datapd_0=pd.read_csv(filename, index_col=0)
filename='preprocessed_minority.csv'
datapd_1=pd.read_csv(filename, index_col=0 )
print('Majority class dataframe shape:', datapd_0.shape)
print('Minority class dataframe shape:', datapd_1.shape)
n_feat=datapd_0.shape[1]
print('Imbalance Ratio:', datapd_0.shape[0]/datapd_1.shape[0])
features_0=np.asarray(datapd_0)
features_1=np.asarray(datapd_1)
s=93
features_1=np.take(features_1,np.random.RandomState(seed=s).permutation(features_1.shape[0]),axis=0,out=features_1)
features_0=np.take(features_0,np.random.RandomState(seed=s).permutation(features_0.shape[0]),axis=0,out=features_0)
a=len(features_1)//3
b=len(features_0)//3
fold_1_min=features_1[0:a]
fold_1_maj=features_0[0:b]
fold_1_tst=np.concatenate((fold_1_min,fold_1_maj))
lab_1_tst=np.concatenate((np.zeros(len(fold_1_min))+1, np.zeros(len(fold_1_maj))))
fold_2_min=features_1[a:2*a]
fold_2_maj=features_0[b:2*b]
fold_2_tst=np.concatenate((fold_2_min,fold_2_maj))
lab_2_tst=np.concatenate((np.zeros(len(fold_1_min))+1, np.zeros(len(fold_1_maj))))
fold_3_min=features_1[2*a:]
fold_3_maj=features_0[2*b:]
fold_3_tst=np.concatenate((fold_3_min,fold_3_maj))
lab_3_tst=np.concatenate((np.zeros(len(fold_3_min))+1, np.zeros(len(fold_3_maj))))
fold_1_trn=np.concatenate((fold_2_min,fold_3_min,fold_2_maj,fold_3_maj))
lab_1_trn=np.concatenate((np.zeros(a+len(fold_3_min))+1,np.zeros(b+len(fold_3_maj))))
fold_2_trn=np.concatenate((fold_1_min,fold_3_min,fold_1_maj,fold_3_maj))
lab_2_trn=np.concatenate((np.zeros(a+len(fold_3_min))+1,np.zeros(b+len(fold_3_maj))))
fold_3_trn=np.concatenate((fold_2_min,fold_1_min,fold_2_maj,fold_1_maj))
lab_3_trn=np.concatenate((np.zeros(2*a)+1,np.zeros(2*b)))
training_folds_feats=[fold_1_trn,fold_2_trn,fold_3_trn]
testing_folds_feats=[fold_1_tst,fold_2_tst,fold_3_tst]
training_folds_labels=[lab_1_trn,lab_2_trn,lab_3_trn]
testing_folds_labels=[lab_1_tst,lab_2_tst,lab_3_tst]
def lr(X_train,y_train,X_test,y_test):
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import balanced_accuracy_score
logreg = LogisticRegression(C=1e5, solver='lbfgs', multi_class='multinomial', class_weight={0: 1, 1: 1})
logreg.fit(X_train, y_train)
y_pred= logreg.predict(X_test)
con_mat=confusion_matrix(y_test,y_pred)
bal_acc=balanced_accuracy_score(y_test,y_pred)
tn, fp, fn, tp = con_mat.ravel()
print('tn, fp, fn, tp:', tn, fp, fn, tp)
f1 = f1_score(y_test, y_pred)
precision=precision_score(y_test, y_pred)
recall=recall_score(y_test, y_pred)
print('balanced accuracy_LR:', bal_acc)
print('f1 score_LR:', f1)
print('confusion matrix_LR',con_mat)
return(f1, bal_acc, precision, recall, con_mat)
def svm(X_train,y_train,X_test,y_test):
from sklearn import preprocessing
from sklearn import metrics
#from sklearn import svm
from sklearn.svm import LinearSVC
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import balanced_accuracy_score
X_train = preprocessing.scale(X_train)
X_test = preprocessing.scale(X_test)
#svm= svm.SVC(kernel='linear', decision_function_shape='ovo', class_weight={0: 1., 1: 1.},probability=True)
svm= LinearSVC(random_state=0, tol=1e-5)
svm.fit(X_train, y_train)
y_pred= svm.predict(X_test)
con_mat=confusion_matrix(y_test,y_pred)
bal_acc=balanced_accuracy_score(y_test,y_pred)
tn, fp, fn, tp = con_mat.ravel()
print('tn, fp, fn, tp:', tn, fp, fn, tp)
f1 = f1_score(y_test, y_pred)
precision=precision_score(y_test, y_pred)
recall=recall_score(y_test, y_pred)
print('balanced accuracy_SVM:', bal_acc)
print('f1 score_SVM:', f1)
print('confusion matrix_SVM',con_mat)
return( f1, bal_acc, precision, recall, con_mat)
def knn(X_train,y_train,X_test,y_test):
from sklearn import metrics
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import balanced_accuracy_score
knn = KNeighborsClassifier(n_neighbors=10)
knn.fit(X_train, y_train)
y_pred= knn.predict(X_test)
con_mat=confusion_matrix(y_test,y_pred)
bal_acc=balanced_accuracy_score(y_test,y_pred)
tn, fp, fn, tp = con_mat.ravel()
print('tn, fp, fn, tp:', tn, fp, fn, tp)
print('balanced accuracy_KNN:', bal_acc)
f1 = f1_score(y_test, y_pred)
precision=precision_score(y_test, y_pred)
recall=recall_score(y_test, y_pred)
print('f1 score_KNN:', f1)
print('confusion matrix_KNN',con_mat)
return(f1, bal_acc, precision, recall, con_mat)
# +
def Neb_grps(data,near_neb):
nbrs = NearestNeighbors(n_neighbors=near_neb, algorithm='ball_tree').fit(data)
distances, indices = nbrs.kneighbors(data)
neb_class=[]
for i in (indices):
neb_class.append(i)
return(np.asarray(neb_class))
def LoRAS(data,num_samples,shadow,sigma,num_RACOS,num_afcomb):
np.random.seed(42)
data_shadow=([])
for i in range (num_samples):
c=0
while c<shadow:
data_shadow.append(data[i]+np.random.normal(0,sigma))
c=c+1
data_shadow==np.asarray(data_shadow)
data_shadow_lc=([])
for i in range(num_RACOS):
idx = np.random.randint(shadow*num_samples, size=num_afcomb)
w=np.random.randint(100, size=len(idx))
aff_w=np.asarray(w/sum(w))
data_tsl=np.array(data_shadow)[idx,:]
data_tsl_=np.dot(aff_w, data_tsl)
data_shadow_lc.append(data_tsl_)
return(np.asarray(data_shadow_lc))
def LoRAS_gen(num_samples,shadow,sigma,num_RACOS,num_afcomb):
RACOS_set=[]
for i in range (len(nb_list)):
RACOS_i= LoRAS(features_1_trn[nb_list[i]],num_samples,shadow,sigma,num_RACOS,num_afcomb)
RACOS_set.append(RACOS_i)
LoRAS_set=np.asarray(RACOS_set)
LoRAS_1=np.reshape(LoRAS_set,(len(features_1_trn)*num_RACOS,n_feat))
return(np.concatenate((LoRAS_1,features_1_trn)))
# -
def OVS(training_data,training_labels,neb):
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=62, k_neighbors=neb, kind='regular',ratio=1)
SMOTE_feat, SMOTE_labels = sm.fit_resample(training_data,training_labels)
smbl1 = SMOTE(random_state=62, k_neighbors=neb, kind='borderline1',ratio=1)
SMOTE_feat_bl1, SMOTE_labels_bl1 = smbl1.fit_resample(training_data,training_labels)
smbl2 = SMOTE(random_state=62, k_neighbors=neb, kind='borderline2',ratio=1)
SMOTE_feat_bl2, SMOTE_labels_bl2 = smbl2.fit_resample(training_data,training_labels)
smsvm = SMOTE(random_state=62, k_neighbors=neb, kind='svm',ratio=1)
SMOTE_feat_svm, SMOTE_labels_svm = smsvm.fit_resample(training_data,training_labels)
from imblearn.over_sampling import ADASYN
ad = ADASYN(random_state=62,n_neighbors=neb, ratio=1)
ADASYN_feat, ADASYN_labels = ad.fit_resample(training_data,training_labels)
return(SMOTE_feat, SMOTE_labels,SMOTE_feat_bl1, SMOTE_labels_bl1, SMOTE_feat_bl2, SMOTE_labels_bl2,SMOTE_feat_svm, SMOTE_labels_svm,ADASYN_feat, ADASYN_labels)
# +
LR=[]
SVM=[]
KNN=[]
LR_SM=[]
SVM_SM=[]
KNN_SM=[]
LR_SMBL1=[]
SVM_SMBL1=[]
KNN_SMBL1=[]
LR_SMBL2=[]
SVM_SMBL2=[]
KNN_SMBL2=[]
LR_SMSVM=[]
SVM_SMSVM=[]
KNN_SMSVM=[]
LR_ADA=[]
SVM_ADA=[]
KNN_ADA=[]
i=0
while i<3:
SMOTE_feat, SMOTE_labels,SMOTE_feat_bl1, SMOTE_labels_bl1, SMOTE_feat_bl2, SMOTE_labels_bl2,SMOTE_feat_svm, SMOTE_labels_svm,ADASYN_feat, ADASYN_labels=OVS(training_folds_feats[i],training_folds_labels[i],30)
f1_lr, bal_acc_lr, precision_lr, recall_lr, mat_lr=lr(training_folds_feats[i],training_folds_labels[i],testing_folds_feats[i],testing_folds_labels[i])
LR.append([f1_lr, bal_acc_lr, precision_lr, recall_lr])
f1_svm,bal_acc_svm,precision_svm, recall_svm,mat_svm=svm(training_folds_feats[i],training_folds_labels[i],testing_folds_feats[i],testing_folds_labels[i])
SVM.append([f1_svm,bal_acc_svm,precision_svm, recall_svm])
f1_knn,bal_acc_knn,precision_knn, recall_knn,mat_knn=knn(training_folds_feats[i],training_folds_labels[i],testing_folds_feats[i],testing_folds_labels[i])
KNN.append([f1_knn,bal_acc_knn,precision_knn, recall_knn])
f1_lr_SMOTE,bal_acc_lr_SMOTE,precision_lr_SMOTE, recall_lr_SMOTE,mat_lr_SMOTE=lr(SMOTE_feat,SMOTE_labels,testing_folds_feats[i],testing_folds_labels[i])
LR_SM.append([f1_lr_SMOTE,bal_acc_lr_SMOTE,precision_lr_SMOTE, recall_lr_SMOTE])
f1_svm_SMOTE,bal_acc_svm_SMOTE,precision_svm_SMOTE, recall_svm_SMOTE,mat_svm_SMOTE=svm(SMOTE_feat,SMOTE_labels,testing_folds_feats[i],testing_folds_labels[i])
SVM_SM.append([f1_svm_SMOTE,bal_acc_svm_SMOTE,precision_svm_SMOTE, recall_svm_SMOTE])
f1_knn_SMOTE,bal_acc_knn_SMOTE,precision_knn_SMOTE, recall_knn_SMOTE,mat_knn_SMOTE=knn(SMOTE_feat,SMOTE_labels,testing_folds_feats[i],testing_folds_labels[i])
KNN_SM.append([f1_knn_SMOTE,bal_acc_knn_SMOTE,precision_knn_SMOTE, recall_knn_SMOTE])
f1_lr_SMOTE_bl1,bal_acc_lr_SMOTE_bl1,precision_lr_SMOTE_bl1, recall_lr_SMOTE_bl1,mat_lr_SMOTE_bl1=lr(SMOTE_feat_bl1,SMOTE_labels_bl1,testing_folds_feats[i],testing_folds_labels[i])
LR_SMBL1.append([f1_lr_SMOTE_bl1,bal_acc_lr_SMOTE_bl1,precision_lr_SMOTE_bl1, recall_lr_SMOTE_bl1])
f1_svm_SMOTE_bl1,bal_acc_svm_SMOTE_bl1,precision_svm_SMOTE_bl1, recall_svm_SMOTE_bl1,mat_svm_SMOTE_bl1=svm(SMOTE_feat_bl1,SMOTE_labels_bl1,testing_folds_feats[i],testing_folds_labels[i])
SVM_SMBL1.append([f1_svm_SMOTE_bl1,bal_acc_svm_SMOTE_bl1,precision_svm_SMOTE_bl1, recall_svm_SMOTE_bl1])
f1_knn_SMOTE_bl1,bal_acc_knn_SMOTE_bl1,precision_knn_SMOTE_bl1, recall_knn_SMOTE_bl1,mat_knn_SMOTE_bl1=knn(SMOTE_feat_bl1,SMOTE_labels_bl1,testing_folds_feats[i],testing_folds_labels[i])
KNN_SMBL1.append([f1_knn_SMOTE_bl1,bal_acc_knn_SMOTE_bl1,precision_knn_SMOTE_bl1, recall_knn_SMOTE_bl1])
f1_lr_SMOTE_bl2,bal_acc_lr_SMOTE_bl2,precision_lr_SMOTE_bl2, recall_lr_SMOTE_bl2,mat_lr_SMOTE_bl2=lr(SMOTE_feat_bl2,SMOTE_labels_bl2,testing_folds_feats[i],testing_folds_labels[i])
LR_SMBL2.append([f1_lr_SMOTE_bl2,bal_acc_lr_SMOTE_bl2,precision_lr_SMOTE_bl2, recall_lr_SMOTE_bl2])
f1_svm_SMOTE_bl2,bal_acc_svm_SMOTE_bl2,precision_svm_SMOTE_bl2, recall_svm_SMOTE_bl2,mat_svm_SMOTE_bl2=svm(SMOTE_feat_bl1,SMOTE_labels_bl1,testing_folds_feats[i],testing_folds_labels[i])
SVM_SMBL2.append([f1_svm_SMOTE_bl2,bal_acc_svm_SMOTE_bl2,precision_svm_SMOTE_bl2, recall_svm_SMOTE_bl2])
f1_knn_SMOTE_bl2,bal_acc_knn_SMOTE_bl2,precision_knn_SMOTE_bl2, recall_knn_SMOTE_bl2,mat_knn_SMOTE_bl2=knn(SMOTE_feat_bl2,SMOTE_labels_bl2,testing_folds_feats[i],testing_folds_labels[i])
KNN_SMBL2.append([f1_knn_SMOTE_bl2,bal_acc_knn_SMOTE_bl2,precision_knn_SMOTE_bl2, recall_knn_SMOTE_bl2])
f1_lr_SMOTE_svm,bal_acc_lr_SMOTE_svm,precision_lr_SMOTE_svm, recall_lr_SMOTE_svm,mat_lr_SMOTE_svm=lr(SMOTE_feat_svm,SMOTE_labels_svm,testing_folds_feats[i],testing_folds_labels[i])
LR_SMSVM.append([f1_lr_SMOTE_svm,bal_acc_lr_SMOTE_svm,precision_lr_SMOTE_svm, recall_lr_SMOTE_svm])
f1_svm_SMOTE_svm,bal_acc_svm_SMOTE_svm,precision_svm_SMOTE_svm, recall_svm_SMOTE_svm,mat_svm_SMOTE_svm=svm(SMOTE_feat_svm,SMOTE_labels_svm,testing_folds_feats[i],testing_folds_labels[i])
SVM_SMSVM.append([f1_svm_SMOTE_svm,bal_acc_svm_SMOTE_svm,precision_svm_SMOTE_svm, recall_svm_SMOTE_svm])
f1_knn_SMOTE_svm,bal_acc_knn_SMOTE_svm,precision_knn_SMOTE_svm, recall_knn_SMOTE_svm,mat_knn_SMOTE_svm=knn(SMOTE_feat_svm,SMOTE_labels_svm,testing_folds_feats[i],testing_folds_labels[i])
KNN_SMSVM.append([f1_knn_SMOTE_svm,bal_acc_knn_SMOTE_svm,precision_knn_SMOTE_svm, recall_knn_SMOTE_svm])
f1_lr_ADASYN,bal_acc_lr_ADASYN,precision_lr_ADASYN, recall_lr_ADASYN,mat_lr_ADASYN=lr(ADASYN_feat,ADASYN_labels,testing_folds_feats[i],testing_folds_labels[i])
LR_ADA.append([f1_lr_ADASYN,bal_acc_lr_ADASYN,precision_lr_ADASYN, recall_lr_ADASYN])
f1_svm_ADASYN,bal_acc_svm_ADASYN,precision_svm_ADASYN, recall_svm_ADASYN,mat_svm_ADASYN=svm(ADASYN_feat,ADASYN_labels,testing_folds_feats[i],testing_folds_labels[i])
SVM_ADA.append([f1_svm_ADASYN,bal_acc_svm_ADASYN,precision_svm_ADASYN, recall_svm_ADASYN])
f1_knn_ADASYN,bal_acc_knn_ADASYN,precision_knn_ADASYN, recall_knn_ADASYN,mat_knn_ADASYN=knn(ADASYN_feat,ADASYN_labels,testing_folds_feats[i],testing_folds_labels[i])
KNN_ADA.append([f1_knn_ADASYN,bal_acc_knn_ADASYN,precision_knn_ADASYN, recall_knn_ADASYN])
i=i+1
# -
LR_LoRAS=[]
SVM_LoRAS=[]
KNN_LoRAS=[]
for i in range(3):
features = training_folds_feats[i]
labels= training_folds_labels[i]
label_1=np.where(labels == 1)[0]
label_1=list(label_1)
features_1_trn=features[label_1]
label_0=np.where(labels == 0)[0]
label_0=list(label_0)
features_0_trn=features[label_0]
num_samples=30
shadow=100
sigma=.005
num_RACOS=(len(features_0_trn)-len(features_1_trn))//len(features_1_trn)
num_afcomb=50
nb_list=Neb_grps(features_1_trn, num_samples)
LoRAS_1=LoRAS_gen(num_samples,shadow,sigma,num_RACOS,num_afcomb)
LoRAS_train=np.concatenate((LoRAS_1,features_0_trn))
LoRAS_labels=np.concatenate((np.zeros(len(LoRAS_1))+1, np.zeros(len(features_0_trn))))
f1_lr_LoRAS,bal_acc_lr_LoRAS,precision_lr_LoRAS, recall_lr_LoRAS,mat_lr_LoRAS=lr(LoRAS_train,LoRAS_labels,testing_folds_feats[i],testing_folds_labels[i])
LR_LoRAS.append([f1_lr_LoRAS,bal_acc_lr_LoRAS,precision_lr_LoRAS, recall_lr_LoRAS])
f1_svm_LoRAS,bal_acc_svm_LoRAS,precision_svm_LoRAS, recall_svm_LoRAS,mat_svm_LoRAS=svm(LoRAS_train,LoRAS_labels,testing_folds_feats[i],testing_folds_labels[i])
SVM_LoRAS.append([f1_svm_LoRAS,bal_acc_svm_LoRAS,precision_svm_LoRAS, recall_svm_LoRAS])
f1_knn_LoRAS,bal_acc_knn_LoRAS,precision_knn_LoRAS, recall_knn_LoRAS,mat_knn_LoRAS=knn(LoRAS_train,LoRAS_labels,testing_folds_feats[i],testing_folds_labels[i])
KNN_LoRAS.append([f1_knn_LoRAS,bal_acc_knn_LoRAS,precision_knn_LoRAS, recall_knn_LoRAS])
LR_tLoRAS=[]
SVM_tLoRAS=[]
KNN_tLoRAS=[]
from sklearn.manifold import TSNE
for i in range(3):
features = training_folds_feats[i]
labels= training_folds_labels[i]
label_1=np.where(labels == 1)[0]
label_1=list(label_1)
features_1_trn=features[label_1]
label_0=np.where(labels == 0)[0]
label_0=list(label_0)
features_0_trn=features[label_0]
data_embedded_min = TSNE().fit_transform(features_1_trn)
result_min= pd.DataFrame(data = data_embedded_min, columns = ['t-SNE0', 't-SNE1'])
min_t=np.asmatrix(result_min)
min_t=min_t[0:len(features_1_trn)]
min_t=min_t[:, [0,1]]
num_samples=30
shadow=100
sigma=.005
num_RACOS=(len(features_0_trn)-len(features_1_trn))//len(features_1_trn)
num_afcomb=50
nb_list=Neb_grps(min_t, num_samples)
LoRAS_1=LoRAS_gen(num_samples,shadow,sigma,num_RACOS,num_afcomb)
LoRAS_train=np.concatenate((LoRAS_1,features_0_trn))
LoRAS_labels=np.concatenate((np.zeros(len(LoRAS_1))+1, np.zeros(len(features_0_trn))))
f1_lr_LoRAS,bal_acc_lr_LoRAS,precision_lr_LoRAS, recall_lr_LoRAS,mat_lr_LoRAS=lr(LoRAS_train,LoRAS_labels,testing_folds_feats[i],testing_folds_labels[i])
LR_tLoRAS.append([f1_lr_LoRAS,bal_acc_lr_LoRAS,precision_lr_LoRAS, recall_lr_LoRAS])
f1_svm_LoRAS,bal_acc_svm_LoRAS,precision_svm_LoRAS, recall_svm_LoRAS,mat_svm_LoRAS=svm(LoRAS_train,LoRAS_labels,testing_folds_feats[i],testing_folds_labels[i])
SVM_tLoRAS.append([f1_svm_LoRAS,bal_acc_svm_LoRAS,precision_svm_LoRAS, recall_svm_LoRAS])
f1_knn_LoRAS,bal_acc_knn_LoRAS,precision_knn_LoRAS, recall_knn_LoRAS,mat_knn_LoRAS=knn(LoRAS_train,LoRAS_labels,testing_folds_feats[i],testing_folds_labels[i])
KNN_tLoRAS.append([f1_knn_LoRAS,bal_acc_knn_LoRAS,precision_knn_LoRAS, recall_knn_LoRAS])
def stats(arr):
x=np.mean(np.asarray(arr), axis = 0)
y=np.std(np.asarray(arr), axis = 0)
return(x,y)
# +
print('F1|Balanced Accuracy|precision|recall :: mean|sd')
print('Without Oversampling')
LR_m, LR_sd=stats(LR)
print('lr:',LR_m, LR_sd)
SVM_m, SVM_sd=stats(SVM)
print('svm:',SVM_m, SVM_sd)
KNN_m, KNN_sd= stats(KNN)
print('knn:',KNN_m, KNN_sd)
print('SMOTE Oversampling')
LR_SM_m, LR_SM_sd=stats(LR_SM)
print('lr:',LR_SM_m, LR_SM_sd)
SVM_SM_m, SVM_SM_sd=stats(SVM_SM)
print('svm:',SVM_SM_m, SVM_SM_sd)
KNN_SM_m, KNN_SM_sd=stats(KNN_SM)
print('knn:',KNN_SM_m, KNN_SM_sd)
print('SMOTE-Bl1 Oversampling')
LR_SMBL1_m, LR_SMBL1_sd=stats(LR_SMBL1)
print('lr:',LR_SMBL1_m, LR_SMBL1_sd)
SVM_SMBL1_m,SVM_SMBL1_sd=stats(SVM_SMBL1)
print('svm:',SVM_SMBL1_m,SVM_SMBL1_sd)
KNN_SMBL1_m, KNN_SMBL1_sd= stats(KNN_SMBL1)
print('knn:',KNN_SMBL1_m, KNN_SMBL1_sd)
print('SMOTE-Bl2 Oversampling')
LR_SMBL2_m, LR_SMBL2_sd=stats(LR_SMBL2)
print('lr:',LR_SMBL2_m, LR_SMBL2_sd)
SVM_SMBL2_m, SVM_SMBL2_sd=stats(SVM_SMBL2)
print('svm:',SVM_SMBL2_m, SVM_SMBL2_sd)
KNN_SMBL2_m, KNN_SMBL2_sd= stats(KNN_SMBL2)
print('knn:',KNN_SMBL2_m, KNN_SMBL2_sd)
print('SMOTE-SVM Oversampling')
LR_SMSVM_m, LR_SMSVM_sd=stats(LR_SMSVM)
print('lr:',LR_SMSVM_m, LR_SMSVM_sd)
SVM_SMSVM_m, SVM_SMSVM_sd=stats(SVM_SMSVM)
print('svm:',SVM_SMSVM_m, SVM_SMSVM_sd)
KNN_SMSVM_m, KNN_SMSVM_sd= stats(KNN_SMSVM)
print('knn:',KNN_SMSVM_m, KNN_SMSVM_sd)
print('ADASYN Oversampling')
LR_ADA_m, LR_ADA_sd=stats(LR_ADA)
print('lr:',LR_ADA_m, LR_ADA_sd)
SVM_ADA_m, SVM_ADA_sd=stats(SVM_ADA)
print('svm:',SVM_ADA_m, SVM_ADA_sd)
KNN_ADA_m, KNN_ADA_sd=stats(KNN_ADA)
print('knn:',KNN_ADA_m, KNN_ADA_sd)
print('LoRAS Oversampling')
LR_LoRAS_m, LR_LoRAS_sd=stats(LR_LoRAS)
print('lr:',LR_LoRAS_m, LR_LoRAS_sd)
SVM_LoRAS_m, SVM_LoRAS_sd=stats(SVM_LoRAS)
print('svm:',SVM_LoRAS_m, SVM_LoRAS_sd)
KNN_LoRAS_m, KNN_LoRAS_sd=stats(KNN_LoRAS)
print('knn:',KNN_LoRAS_m, KNN_LoRAS_sd)
print('tLoRAS Oversampling')
LR_tLoRAS_m, LR_tLoRAS_sd=stats(LR_tLoRAS)
print('lr:',LR_tLoRAS_m, LR_tLoRAS_sd)
SVM_tLoRAS_m, SVM_tLoRAS_sd=stats(SVM_tLoRAS)
print('svm:',SVM_tLoRAS_m, SVM_tLoRAS_sd)
KNN_tLoRAS_m, KNN_tLoRAS_sd=stats(KNN_tLoRAS)
print('knn:',KNN_tLoRAS_m, KNN_tLoRAS_sd)
# -
| Proliferative_cardiomyocytes/CV_cluster11_100.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/julianyraiol/ml-deploy/blob/main/Trab_Final_Previs%C3%A3o_emprestimo.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="2KzIJ4bxV0YU"
#
# * <NAME> - <EMAIL>
# * <NAME> - <EMAIL>
# * <NAME> - <EMAIL>
#
# + [markdown] id="q2SuDsdUQ5Ed"
#
#
# [Dataset](https://www.kaggle.com/ninzaami/loan-predication)
#
#
# + [markdown] id="tFQcO9krRjbt"
# # Introdução
#
# - A empresa procura automatizar (em tempo real) o processo de qualificação do crédito com base nas informações prestadas pelos clientes durante o preenchimento de um formulário de candidatura online. Espera-se com o desenvolvimento de modelos de ML que possam ajudar a empresa a prever a aprovação de empréstimos na aceleração do processo de tomada de decisão para determinar se um solicitante é elegível para um empréstimo ou não.
# + [markdown] id="AGtQfRryRoL1"
# # Objetivo
#
# 👉 Este caderno tem como objetivo:
#
# Analise os dados do cliente fornecidos no conjunto de dados (EDA)
# Construir vários modelos de ML que podem prever a aprovação de empréstimos
# 👨💻 Os modelos de aprendizado de máquina usados neste projeto são:
#
# - Regressão Logística
# - K-vizinho mais próximo (KNN)
# - Máquina de vetor de suporte (SVM)
# - Baías ingénuas
# - Árvore de Decisão
# - Floresta Aleatória
# - Gradient Boost
# + [markdown] id="MApwoqrRSGpU"
# # Descrição do conjunto de dados 🧾¶
# 👉 Existem 13 variáveis neste conjunto de dados:
#
# - 8 variáveis categóricas,
# - 4 variáveis contínuas, e
# - 1 variável para acomodar o ID do empréstimo.
# + [markdown] id="TYoWVISCTL58"
# # Importando bibliotecas e os dados
# + id="978229b5"
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# %matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report,confusion_matrix,f1_score
from sklearn.preprocessing import LabelEncoder
# + id="82bbd3f8"
df = pd.read_csv('train_loan.csv')
# + colab={"base_uri": "https://localhost:8080/", "height": 206} id="a5e4c45e" outputId="a2b6cbe4-373c-4cfa-d643-653daf8886fe"
df.head()
# + colab={"base_uri": "https://localhost:8080/"} id="hbPCVULRV6HJ" outputId="876889ed-b9dd-46c9-a8cf-5076e04454ed"
df.info()
# + colab={"base_uri": "https://localhost:8080/"} id="j1lA6FfpeyDp" outputId="81c58442-c66d-47c9-9854-fd01634c8dd7"
df.Loan_Status.value_counts()
# + [markdown] id="j9zOHidgS2Vs"
# # Explorando as variáveis categóricas
# + colab={"base_uri": "https://localhost:8080/"} id="eba170ec" outputId="1789f093-d360-4132-845a-4619bea8c887"
df.Loan_ID.value_counts(dropna=False)
# + colab={"base_uri": "https://localhost:8080/"} id="87ce98bd" outputId="ff116bcf-38e9-44dd-c1bf-79325df9d368"
df.Gender.value_counts(dropna=False)
# + colab={"base_uri": "https://localhost:8080/"} id="700a1dc2" outputId="51697baf-03a6-4fac-9b4e-bad22665fb23"
df.Gender.value_counts()
# + colab={"base_uri": "https://localhost:8080/", "height": 285} id="f7e86df1" outputId="5f6a09b3-b9d8-487c-f75d-471f6d245e7f"
sns.countplot(x="Gender", data=df, palette="hls")
plt.show()
# + colab={"base_uri": "https://localhost:8080/"} id="2b5be5cd" outputId="576f93cc-43a0-4b3d-e765-1b6e49cf810c"
countMale = len(df[df.Gender == 'Male'])
countFemale = len(df[df.Gender == 'Female'])
countNull = len(df[df.Gender.isnull()])
print("Porcentagem de candidatos do sexo masculino: {:.2f}%".format((countMale / (len(df.Gender))*100)))
print("Porcentagem de candidatos do sexo feminino: {:.2f}%".format((countFemale / (len(df.Gender))*100)))
print("Porcentagem de valores ausentes: {:.2f}%".format((countNull / (len(df.Gender))*100)))
# + id="2a1d735b"
# casado
# + colab={"base_uri": "https://localhost:8080/"} id="2b0f65e3" outputId="38d7e7cf-a1f4-49d9-cb45-f14fbc5d7a79"
df.Married.value_counts(dropna=False)
# + colab={"base_uri": "https://localhost:8080/", "height": 302} id="fce94b5e" outputId="a3e2161c-15e9-4f7b-f371-ee7a7840dfa8"
sns.countplot(x='Married', data=df, palette = 'Paired')
# + colab={"base_uri": "https://localhost:8080/"} id="4811948a" outputId="897b2b17-4dd3-4393-ad4e-ebb609ef20c0"
countMarried = len(df[df.Married == 'Yes'])
countNotMarried = len(df[df.Married == 'No'])
countNull = len(df[df.Married.isnull()])
print("% de casados: {:.2f}%".format((countMarried / (len(df.Married))*100)))
print("% de nao casados: {:.2f}%".format((countNotMarried / (len(df.Married))*100)))
print("% de valores ausentes: {:.2f}%".format((countNull / (len(df.Married))*100)))
# + colab={"base_uri": "https://localhost:8080/"} id="054271e6" outputId="c2021f44-2184-42a1-bec9-5622fbaa6caf"
df.Education.value_counts(dropna=False)
# + colab={"base_uri": "https://localhost:8080/", "height": 287} id="1863b871" outputId="0055676b-c1d3-4ece-89e8-81f2e9958707"
sns.countplot(x="Education", data=df, palette="rocket")
plt.show()
# + colab={"base_uri": "https://localhost:8080/"} id="b1405145" outputId="c27ad758-a329-4fce-b206-f2ff01b15241"
countGraduate = len(df[df.Education == 'Graduate'])
countNotGraduate = len(df[df.Education == 'Not Graduate'])
countNull = len(df[df.Education.isnull()])
print("% de graduados: {:.2f}%".format((countGraduate / (len(df.Education))*100)))
print("% nao graduados: {:.2f}%".format((countNotGraduate / (len(df.Education))*100)))
print("% valores faltantes: {:.2f}%".format((countNull / (len(df.Education))*100)))
# + colab={"base_uri": "https://localhost:8080/"} id="bb9b88e8" outputId="71e11352-fbdd-4fa1-85f0-63321ef08c14"
df.Self_Employed.value_counts(dropna=False)
# + colab={"base_uri": "https://localhost:8080/", "height": 285} id="3607189a" outputId="006b74e4-7b51-4eac-b3af-aed08282fe47"
sns.countplot(x="Self_Employed", data=df, palette="crest")
plt.show()
# + colab={"base_uri": "https://localhost:8080/"} id="c717eb6e" outputId="d9ccab27-2893-4139-9147-ebb62f6094bb"
countNo = len(df[df.Self_Employed == 'No'])
countYes = len(df[df.Self_Employed == 'Yes'])
countNull = len(df[df.Self_Employed.isnull()])
print("% trabalhadores por conta própria: {:.2f}%".format((countNo / (len(df.Self_Employed))*100)))
print("% autônomos: {:.2f}%".format((countYes / (len(df.Self_Employed))*100)))
print("% valores faltantes: {:.2f}%".format((countNull / (len(df.Self_Employed))*100)))
# + [markdown] id="vzj4b7TAS_KM"
# # Explorando as variáveis númericas
# + colab={"base_uri": "https://localhost:8080/"} id="2a4eacac" outputId="1dfb4dd8-6465-448e-9b1d-7075686eec4e"
df[['ApplicantIncome','CoapplicantIncome','LoanAmount']].describe()
# + colab={"base_uri": "https://localhost:8080/"} id="a9337157" outputId="1f5567e0-2688-40fd-f7a5-cb607cf2ca04"
sns.set(style="darkgrid")
fig, axs = plt.subplots(2, 2, figsize=(10, 8))
sns.histplot(data=df, x="ApplicantIncome", kde=True, ax=axs[0, 0], color='green')
sns.histplot(data=df, x="CoapplicantIncome", kde=True, ax=axs[0, 1], color='skyblue')
sns.histplot(data=df, x="LoanAmount", kde=True, ax=axs[1, 0], color='orange')
# + colab={"base_uri": "https://localhost:8080/"} id="db6bb401" outputId="57972072-b08b-45f1-ac0a-acb93eda79dd"
plt.figure(figsize=(10,7))
sns.heatmap(df.corr(), annot=True, cmap='inferno')
# + colab={"base_uri": "https://localhost:8080/"} id="4f47cc26" outputId="aa39f3be-6ed3-444d-874e-cc6345993aa3"
pd.crosstab(df.Gender,df.Married).plot(kind="bar", stacked=True, figsize=(5,5), color=['#f64f59','#12c2e9'])
plt.title('Gender vs Married')
plt.xlabel('Gender')
plt.ylabel('Frequency')
plt.xticks(rotation=0)
plt.show()
# + colab={"base_uri": "https://localhost:8080/"} id="953c1e70" outputId="64076d90-18c2-4871-954b-8f32cd51d067"
pd.crosstab(df.Self_Employed,df.Credit_History).plot(kind="bar", stacked=True, figsize=(5,5), color=['#544a7d','#ffd452'])
plt.title('Self Employed vs Credit History')
plt.xlabel('Self Employed')
plt.ylabel('Frequency')
plt.legend(["Bad Credit", "Good Credit"])
plt.xticks(rotation=0)
plt.show()
# + colab={"base_uri": "https://localhost:8080/"} id="9400a8fa" outputId="f13d39b1-987a-4de5-c39e-5082044e2edb"
from pandas.plotting import scatter_matrix
attributes = ["ApplicantIncome", "CoapplicantIncome", "LoanAmount", "Loan_Amount_Term", "Credit_History", "Loan_Status"]
scatter_matrix(df, figsize=(12, 8))
# + [markdown] id="6VFv9T1MK39_"
# # 5. Pré-processamento de dados
# + [markdown] id="5DE13bCBK_wd"
# #### 5.1 Eliminar variáveis desnecessárias
# + id="ggAwxwRFK_SV"
#df = df.drop(['Loan_ID','CoapplicantIncome','Loan_Amount_Term','Credit_History','Property_Area'], axis = 1)
df = df.drop(['Loan_ID'], axis=1)
# + [markdown] id="OYe7S4DcLOjV"
# #### 5.2 Tratando valores nulos (Missing Values)
#
# * Dependents: Assumindo o valor majoritário da coluna.
#
# * Self_Employed: Assumindo o valor majoritário da coluna.
#
# * Loan_Amount_Term: Preenchendo com valor médio da coluna.
#
# * Credit_History: assumindo o valor marjoritário da coluna.
#
# * Married: Assumindo o valor majoritário da coluna.
#
# * Gender: Assumindo o valor majoritário da coluna.
# + colab={"base_uri": "https://localhost:8080/"} id="1dhZzWjmhxeR" outputId="97ffaaad-902b-42f7-88b2-8f6236b0bf00"
df.isnull().sum()
# + id="bBeHr92DLQnN"
# Categóricas
df['Gender'].fillna(df['Gender'].mode()[0],inplace=True)
df['Married'].fillna(df['Married'].mode()[0],inplace=True)
df['Dependents'].fillna(df['Dependents'].mode()[0],inplace=True)
df['Self_Employed'].fillna(df['Self_Employed'].mode()[0],inplace=True)
df['Credit_History'].fillna(df['Credit_History'].mode()[0],inplace=True)
df['Loan_Amount_Term'].fillna(df['Loan_Amount_Term'].mode()[0],inplace=True)
# + id="DS2BPjckLkIM"
#numérica
df['LoanAmount'].fillna(df['LoanAmount'].mean(),inplace=True)
# + colab={"base_uri": "https://localhost:8080/"} id="mLIOjubdhuP5" outputId="a9391283-b1a3-47e3-f164-25606587de6b"
df.isnull().sum()
# + [markdown] id="8-gwI4ozLwxV"
# #### 5.3 One-hot (codificação)
# - Nesta seção, transformarei variáveis categóricas em uma forma que poderia ser fornecida por algoritmos de ML para fazer uma previsão melhor
# + colab={"base_uri": "https://localhost:8080/"} id="vRymY9zxilzo" outputId="08a6858b-356a-4564-951d-eac2ebbddabc"
df.info()
# + colab={"base_uri": "https://localhost:8080/", "height": 143} id="4OvbtcLbo9Vw" outputId="33408334-cec1-48d8-8751-bd3698485ff2"
df.head(3)
# + id="pLC3HEGPojJ4"
gender_values = {'Female': 0, 'Male':1}
married_values = {'No': 0, 'Yes': 1}
education_values = {'Graduate': 0, 'Not Graduate': 1}
employed_values = {'No': 0, 'Yes': 1}
dependent_values = {'3+': 3, '0':0, '2':2, '1':1}
loan_values = {'Y': 1, 'N':0}
property_area = {'Rural': 0, 'Semiurban': 1, 'Urban': 2}
df.replace({'Gender': gender_values,
'Married': married_values,
'Education': education_values,
'Self_Employed': employed_values,
'Dependents': dependent_values,
'Loan_Status': loan_values,
'Property_Area': property_area }, inplace=True)
# + colab={"base_uri": "https://localhost:8080/", "height": 143} id="XPkZe046ybrx" outputId="b6ff3d2d-5cee-4fa2-c4ed-bb22f832ffd0"
df.head(3)
# + colab={"base_uri": "https://localhost:8080/"} id="C5dI2qLJy0cA" outputId="348f85df-05a6-4896-9a15-7153c82d4824"
df.Dependents.value_counts()
# + [markdown] id="TkIxqf7fMyTS"
# #### 5.5 Criando X e Y
#
# Os recursos dependentes (status do empréstimo) serão separados dos recursos independentes.
# + id="lBnYJysFM_MM"
X = df.drop(["Loan_Status"], axis=1)
y = df["Loan_Status"]
# + [markdown] id="HZP0wDBHNEbu"
# #### 5.6 Técnica SMOTE
# - Na exploração anterior, pode-se ver que o número entre empréstimos aprovados e rejeitados está desequilibrado. Nesta seção, a técnica de sobreamostragem será usada para evitar sobreajuste
# + id="drpEMnIANbs8"
import missingno as mso
import seaborn as sns
import warnings
import os
import scipy
from scipy import stats
from scipy.stats import pearsonr
from scipy.stats import ttest_ind
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import CategoricalNB
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
# + colab={"base_uri": "https://localhost:8080/", "height": 143} id="yVk9YdtLm5ZC" outputId="ef737cf4-af19-4626-aba0-c580df8bdb99"
df.head(3)
# + id="ERqRSPEgNG3s"
X, y = SMOTE().fit_resample(X, y)
# + colab={"base_uri": "https://localhost:8080/", "height": 285} id="Su2JdMLJNkDt" outputId="6d94d779-0d5f-4882-d4be-19177314bed0"
sns.set_theme(style="darkgrid")
sns.countplot(y=y, data=df, palette="coolwarm")
plt.ylabel('Loan Status')
plt.xlabel('Total')
plt.show()
# + [markdown] id="bWTU-sDyNweM"
# #### 5.7 Data Normalization
# Nesta seção, a normalização de dados será realizada para normalizar o intervalo de variáveis independentes ou recursos de dados
# + id="zBrYvHZsN5Gk"
X = MinMaxScaler().fit_transform(X)
# + [markdown] id="F5uQhnELOG5M"
# #### 5.8 Dividindo o conjunto de dados
#
# O conjunto de dados será dividido em 80% de trem e 20% de teste.
# + id="JHvumvVyOBoU"
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# + [markdown] id="uf_IINRZOKqz"
# # Modelo
#
#
# + [markdown] id="Rpq6vXvOOb47"
# #### 6.1 Logistic Regression
# + colab={"base_uri": "https://localhost:8080/"} id="rx22c8EFOQH1" outputId="dffb90e8-7ad2-4a35-9982-0fa09fa3edc8"
LRclassifier = LogisticRegression(solver='saga', max_iter=500, random_state=1)
LRclassifier.fit(X_train, y_train)
y_pred = LRclassifier.predict(X_test)
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
from sklearn.metrics import accuracy_score
LRAcc = accuracy_score(y_pred,y_test)
print('LR accuracy: {:.2f}%'.format(LRAcc*100))
# + [markdown] id="PwCDmNPsOWiM"
# #### 6.2 K-Nearest Neighbour (KNN)
# + colab={"base_uri": "https://localhost:8080/", "height": 302} id="AvA5W_0kOV5c" outputId="67dd1645-f20a-49b9-d7b2-2e59d38811fd"
scoreListknn = []
for i in range(1,21):
KNclassifier = KNeighborsClassifier(n_neighbors = i)
KNclassifier.fit(X_train, y_train)
scoreListknn.append(KNclassifier.score(X_test, y_test))
plt.plot(range(1,21), scoreListknn)
plt.xticks(np.arange(1,21,1))
plt.xlabel("K value")
plt.ylabel("Score")
plt.show()
KNAcc = max(scoreListknn)
print("KNN best accuracy: {:.2f}%".format(KNAcc*100))
# + [markdown] id="aLUFXVZZOo4k"
# #### 6.3 Support Vector Machine (SVM)
# + colab={"base_uri": "https://localhost:8080/"} id="E4kVkaMEOqYM" outputId="32e0aa52-cc62-41a8-d578-d5e9e3c46012"
SVCclassifier = SVC(kernel='rbf', max_iter=500)
SVCclassifier.fit(X_train, y_train)
y_pred = SVCclassifier.predict(X_test)
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
from sklearn.metrics import accuracy_score
SVCAcc = accuracy_score(y_pred,y_test)
print('SVC accuracy: {:.2f}%'.format(SVCAcc*100))
# + [markdown] id="SDznQ-CsOw7l"
# #### 6.4 Naive Bayes
# + colab={"base_uri": "https://localhost:8080/"} id="PaESAw5ROwas" outputId="01ad87f6-1e52-4b74-cfe5-2f0176d43bd8"
NBclassifier1 = CategoricalNB()
NBclassifier1.fit(X_train, y_train)
y_pred = NBclassifier1.predict(X_test)
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
from sklearn.metrics import accuracy_score
NBAcc1 = accuracy_score(y_pred,y_test)
print('Categorical Naive Bayes accuracy: {:.2f}%'.format(NBAcc1*100))
# + [markdown] id="Bee6EGdHO38l"
# #### 6.4.2 Gaussian NB
# + colab={"base_uri": "https://localhost:8080/"} id="VNp76AvIO5Us" outputId="685a2391-a5c5-4e82-e7b5-2991e314d3d5"
NBclassifier2 = GaussianNB()
NBclassifier2.fit(X_train, y_train)
y_pred = NBclassifier2.predict(X_test)
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
from sklearn.metrics import accuracy_score
NBAcc2 = accuracy_score(y_pred,y_test)
print('Gaussian Naive Bayes accuracy: {:.2f}%'.format(NBAcc2*100))
# + [markdown] id="P2iXwspHO-FU"
# #### 6.5 Decision Tree
# + colab={"base_uri": "https://localhost:8080/", "height": 302} id="s7RKFVbPPAHF" outputId="2cb37af0-a330-4d13-817e-4cb9e80bba01"
scoreListDT = []
for i in range(2,21):
DTclassifier = DecisionTreeClassifier(max_leaf_nodes=i)
DTclassifier.fit(X_train, y_train)
scoreListDT.append(DTclassifier.score(X_test, y_test))
plt.plot(range(2,21), scoreListDT)
plt.xticks(np.arange(2,21,1))
plt.xlabel("Leaf")
plt.ylabel("Score")
plt.show()
DTAcc = max(scoreListDT)
print("Decision Tree Accuracy: {:.2f}%".format(DTAcc*100))
# + [markdown] id="uMpOPOEyPFhz"
# #### 6.6 Random Forest
# + colab={"base_uri": "https://localhost:8080/", "height": 302} id="uJMFZ4qMPHN8" outputId="0f8caea7-cc1b-4dfc-cc13-8c71eb734957"
scoreListRF = []
for i in range(2,25):
RFclassifier = RandomForestClassifier(n_estimators = 1000, random_state = 1, max_leaf_nodes=i)
RFclassifier.fit(X_train, y_train)
scoreListRF.append(RFclassifier.score(X_test, y_test))
plt.plot(range(2,25), scoreListRF)
plt.xticks(np.arange(2,25,1))
plt.xlabel("RF Value")
plt.ylabel("Score")
plt.show()
RFAcc = max(scoreListRF)
print("Random Forest Accuracy: {:.2f}%".format(RFAcc*100))
# + [markdown] id="9Q9Cz1qJPLuj"
# #### 6.7 Gradient Boosting
# + id="3wMKcX-pPM97"
paramsGB={'n_estimators':[100,200,300,400,500],
'max_depth':[1,2,3,4,5],
'subsample':[0.5,1],
'max_leaf_nodes':[2,5,10,20,30,40,50]}
# + colab={"base_uri": "https://localhost:8080/"} id="wUpNmjSmPRCk" outputId="2616e2ee-e932-4762-a9c3-1cae5cd7a638"
GB = RandomizedSearchCV(GradientBoostingClassifier(), paramsGB, cv=20)
GB.fit(X_train, y_train)
# + colab={"base_uri": "https://localhost:8080/"} id="S7lSxO5nPTFT" outputId="79047110-9f79-487c-f972-8a7da4b176eb"
print(GB.best_estimator_)
print(GB.best_score_)
print(GB.best_params_)
print(GB.best_index_)
# + colab={"base_uri": "https://localhost:8080/"} id="mwE35YjkPXPU" outputId="e56711ac-49fc-46cf-9d65-c4ce41612a23"
GBclassifier = GradientBoostingClassifier(subsample=1, n_estimators=400, max_depth=5, max_leaf_nodes=20)
GBclassifier.fit(X_train, y_train)
y_pred = GBclassifier.predict(X_test)
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
from sklearn.metrics import accuracy_score
GBAcc = accuracy_score(y_pred,y_test)
print('Gradient Boosting accuracy: {:.2f}%'.format(GBAcc*100))
# + [markdown] id="y0nZtHagPaEW"
# # 7. Comparação de modelo
# + colab={"base_uri": "https://localhost:8080/", "height": 300} id="s9vMaI-uPeTc" outputId="5762b1c7-bd4f-4961-a614-bde1efea9da3"
compare = pd.DataFrame({'Model': ['Logistic Regression', 'K Neighbors',
'SVM', 'Categorical NB',
'Gaussian NB', 'Decision Tree',
'Random Forest', 'Gradient Boost'],
'Accuracy': [LRAcc*100, KNAcc*100, SVCAcc*100,
NBAcc1*100, NBAcc2*100, DTAcc*100,
RFAcc*100, GBAcc*100]})
compare.sort_values(by='Accuracy', ascending=False)
# + [markdown] id="ObPS-Y_cPomE"
# * Em geral, pode-se ver que todo o modelo pode atingir até 73% de acurácia, exceto KNN.
# * Como pode ser visto, Random Forest podem atingir até 81,06% de acurácia.
#
# + [markdown] id="9q4AFPMxTsD4"
# #### Teste de Classificação
# + id="aOFpo0O7Tqeb"
teste = np.array([[1,1,3,0,0,9504,275.0]])
DTclassifier.predict(teste)
# + [markdown] id="HM-vJc-s1veo"
# # 8. Métricas de avaliação do melhor modelo
# + id="oQVj2fAh2Ara"
clf_rf = RFclassifier
# + colab={"base_uri": "https://localhost:8080/"} id="uflWSJws11Ss" outputId="9e9e5c50-8f83-433c-da03-bb99b922129d"
print(pd.crosstab(y_test,clf_rf.predict(X_test), rownames = ['Real'], colnames=['Predito'], margins=True))
# + id="qdkkum7P2xnh"
from sklearn.model_selection import train_test_split
from sklearn import metrics
# + colab={"base_uri": "https://localhost:8080/"} id="hi6D6uqh2hjJ" outputId="04876458-13dc-48f3-df29-b1029972e617"
print(metrics.classification_report(y_test, clf_rf.predict(X_test)))
# + [markdown] id="1JNjrgQOS3DC"
# # Persistindo o melhor modelo em disco
# + colab={"base_uri": "https://localhost:8080/"} id="1TuqRrZd1PEw" outputId="352bb95e-bc3c-47e1-89ea-b3f11cc5c986"
RFclassifier.fit(X_train,y_train)
# + id="w5FGU3hW5vKA"
import joblib
# + [markdown] id="q_zUQNIS592t"
# #### Persistindo o melhor modelo em disco
# + colab={"base_uri": "https://localhost:8080/"} id="kKjkp3TB4lSn" outputId="76719cb9-da09-43d8-b1d1-d8bad2a393e3"
joblib.dump(clf_rf, 'model.pkl')
# + colab={"base_uri": "https://localhost:8080/"} id="e2Ly-DTQSryL" outputId="bcdba887-6e8a-4bf3-e2c1-e7bdd7507a25"
#Listando os arquivos em disco
# !ls
# + id="T92_TcDpTMSq"
#Carregando o modelo a partir do disco para a memória
model = joblib.load('model.pkl')
# + colab={"base_uri": "https://localhost:8080/"} id="o-9RX3ByTWEZ" outputId="febc1364-e10d-47f2-fba6-0b0d92d8090f"
# Verificando atributos do modelo
print("Atributos do Modelo:\n\nClasses:{}\n\nEstimators:{}\n\nParametros:{}".format(model.classes_,model.n_estimators,model.base_estimator))
# + [markdown] id="c40hRx0u73DA"
# Teste de Classificação
# + id="5qH5SYS_7vjD"
teste = np.array([[1,1,3,0,0,9504,275.0]])
model.predict(teste)
# + [markdown] id="ty5JOCm_76yn"
# Probabilidades de Classes
# + id="bacP8tMf77mH"
model.predict_proba(teste)
# + [markdown] id="cGxSY2sA8FqH"
# agora iremos pegar esse modelo e construir uma Web API para disponibilizar esse modelo para outras aplicações.
# + [markdown] id="eCW0_cH98WXG"
# # Código da Web API
# + [markdown] id="p1T7v5LSFVyA"
# [Repositório](https://github.com/julianyraiol/ml-deploy)
| notebooks/Trab_Final_Previsao_emprestimo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/Thiviyaa/Foundations-of-AI/blob/main/2021_11_28_Thiviyaa_S_AT_CapstoneProject8_Dictionary_QuestionCopy_v1_2.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="UYmMpXkNw9I6"
# # Capstone Project 8: The Horizon Bank - Python Dictionaries
# + [markdown] id="PaanjkTewd2U"
# ---
# + [markdown] id="x9vfVAsbslya"
# ### Context
#
# Decades before, most of the banks used to maintain the details of their customers in a record book or in an excel sheet in a computer. This is not so reliable as compared to today’s revolutionary growth of technology in almost all of the fields.
#
# There is also a negative side in today’s growth of technology i.e. the increasing cyber crimes all over the world.
#
# Do you know, in earlier days we need to stand in a long queue for hours in banks to deposit (a sum of money paid into a bank account) or withdraw (a sum of money withdrawn from a bank account) or to create a new bank account?
# But nowadays with the growth of technology, users can create and maintain their bank account or pay their electric bills, phone bills by sitting in their homes. All they need is a smartphone and internet.
#
# Now, a new bank called Horizon Bank decides to update their banking model from old excel sheets to the latest technology and require a sample project of a bank model. Let us help them in creating this bank application.
# + [markdown] id="G9pdov_M0nzo"
# ---
# + [markdown] id="2i36Yv3-MPY5"
# ### Problem Statement
#
# In this project, you have to write a computer program to create an interactive bank application for the Horizon Bank. The application must have two simple functionalities:
#
# 1. Allow a customer to create a new bank account with their following personal details:
#
# - Full name
#
# - Permanent residential address
#
# - Personal or residential phone number
#
# - Valid government-issued identification
#
# - Amount to be deposited to the account
#
# 2. Allow an existing customer of the bank to
#
# - Check their bank balance
#
# - Withdraw some amount from their account provided that the withdrawal amount is less than the available bank balance
#
# - Deposit some amount to their account
#
# + [markdown] id="Y9JYGh67SE1-"
# ---
# + [markdown] id="x9vH6k9ySGFi"
# #### Getting Started
#
# Follow the steps described below to solve the project:
#
# 1. Click on the link provided below to open the Colab file for this project.
#
# https://colab.research.google.com/drive/18fHQRfI8wgvNq-JGnDLttG75HStcSZJ3
#
# 2. Create the duplicate copy of the Colab file. Here are the steps to create the duplicate copy:
#
# - Click on the **File** menu. A new drop-down list will appear.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/0_file_menu.png' width=500>
#
# - Click on the **Save a copy in Drive** option. A duplicate copy will get created. It will open up in the new tab on your web browser.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/1_create_colab_duplicate_copy.png' width=500>
#
# - After creating the duplicate copy of the notebook, please rename it in the **YYYY-MM-DD_StudentName_CapstoneProject8** format.
#
# 3. Now, write your code in the prescribed code cells.
# + [markdown] id="d55HBFcBpENK"
# ---
# + [markdown] id="toeLx5LJpIV-"
# ### Project Requirements
#
# 1. Create an empty dictionary and store it in the `cust_data` variable. Also, create a list holding the attributes to be filled by a customer. Store the list in the `new_user_attributes` variable.
#
# 2. Create a function to add a new user to the 'cust_data' dictionary. Name the function as `new_user()`.
#
# 3. Create a function to get the account details of an existing user from the `cust_data` dictionary. Name the function as `existing_user()`.
#
# 4. Finally, create an infinite `while` loop to run the application.
#
# + [markdown] id="5JRlGIBRqCGl"
# ---
# + [markdown] id="UCusTfW0tcxe"
# #### 1. Customer Data
#
# The data of all the customers needs to be stored in a Python dictionary. Let's call it `cust_data`.
#
# The key of the `cust_data` dictionary should be an account number of a customer. Its corresponding value should be another dictionary holding the personal details of a customer such as `name`, `address, email id` etc. as shown below.
#
# ```
# cust_data = {10011 : {'name': karthik,
# 'address': 'C42, MG Complex, Sector-14, Vashi',
# 'phone num': '9876543210',
# 'govt id': 'C12345Z',
# 'amount': 15999}}
# ```
#
# Here, `10011` is the account number for Karthik's saving account. It acts as a key to the dictionary containing his details.
#
# To add the personal details of another customer to the `cust_data` dictionary, you need to append it with existing data in the dictionary as shown below.
#
# ```
# cust_data = {10011 : {'name': karthik,
# 'address': 'C42, MG Complex, Sector-14, Vashi',
# 'phone num': '9876543210',
# 'govt id': 'C12345Z',
# 'amount': 15999},
# 100012 : {'name' : Hrithik,
# 'address': B-910, Mandapeshwar Kripa, Borivalli,
# 'phone num' : '9876543210',
# 'govt id': 'QL44345',
# 'amount': 13999}}
# ```
#
# Next, you need to create a list holding the personal attributes of a customer, i.e.,
#
# `['name', 'address', 'phone num', 'govt id', 'amount']`.
# + id="6RL71w3ntzcH"
# Creating the empty 'cust_data' dictionary and the 'new_user_attributes' list.
cust_data = {}
new_user_attributes = ['name', 'address', 'phone num', 'govt id', 'amount']
# + [markdown] id="RETr5Tv1JBls"
# ---
# + [markdown] id="0_OEabQbGQcP"
# #### 2. Add New User
#
# Create a function to add a new user to the `cust_data` dictionary. Name the function as `new_user()`. To do this, follow the steps described below.
#
# **Step 1**: Create a random five-digit account number (ranging between 10000 to 99999) for a new customer using the `random` module. Make sure that it doesn't already exist in the `cust_data` dictionary.
#
# **Step 2**: Create an empty list and store it in the `new_user_input` variable. This list is used to store the details of the user that is given in the `new_user_attribues` list.
#
# **Step 3**: Prompt the user to enter all of their required details one-by-one and add them to the list `new_user_input`. Make sure that the amount added to the list is an integer data-type.
#
# **Step 4**: Create a dictionary for the new user and add it to the `cust_data` dictionary.
#
# **Step 5**: Display the following message to the user.
#
# ```
# Your details are added successfully.
# Your account number is ABCDE
# Please don't lose it.
# ```
# where `ABCDE` is some randomly generated 5-digit account number (ranging between 10000 to 99999) for the new user.
#
#
# + [markdown] id="X6kTBtzgQAip"
# **Note**: Write your code wherever you see the `Write your code here` comment.
# + id="mROhcvIy0ML6" colab={"base_uri": "https://localhost:8080/"} outputId="38535d58-0674-4619-d0a2-d8b0cdea546f"
# The 'new_user()' function to add a new user to the 'cust_data' dictionary.
from random import randint
def new_user():
# Step 1: Create a random five-digit account number and store it in 'acc_num' variable
acc_num = str(randint(10000,99999)) # Write your code here
# Step 2: Create an empty list and store it in the 'new_user_inputs' variable.
# Write your code here
new_user_inputs = []
# Step 3: Prompting the user to enter all of their required details one-by-one and add them to the list new_user_input.
for i in range(len(new_user_attributes)):
user_input = input("Enter " + new_user_attributes[i] + ":\n")
if new_user_attributes[i] == 'amount':
new_user_inputs.append(int(user_input))
else:
new_user_inputs.append(user_input)
# Step 4: Creating a dictionary for the new user and add it to the cust_data dictionary.
cust_data[acc_num] = dict(zip(new_user_attributes, new_user_inputs))
# Step 5: Display the message on successfull account creation to the user.
# Write your code here
print("User Account created successfully")
new_user()
cust_data
# + [markdown] id="aJJT0ojPGPcd"
# ---
# + [markdown] id="rZsDogK8LaOW"
# #### 3. Existing User
#
# The function to get the account details of an existing user from the `cust_data` dictionary. Name the function as `existing_user()`. To do this, follow the steps described below.
#
# **Step 1**: Prompt the user to enter their account number. Keep prompting until they enter their correct account number. For each invalid account number, print the following message to the user.
#
# ```
# Not found. Please enter your correct account number:
# ```
#
# **Step 2**: Once the user has entered the correct account number, print the following message to the user.
#
# ```
# Welcome, user_name !
# Enter 1 to check your balance.
# Enter 2 to withdraw an amount.
# Enter 3 to deposit an amount.
# ```
# where `user_name` is the name of the existing user who entered his account number correctly in the first step.
#
# **Step 3**: Prompt the user to enter either `1, 2` or `3`. Keep prompting until the user enters the valid input. For each invalid input, print the following message to the user.
#
# ```
# Invalid input!
# Enter 1 to check your balance.
# Enter 2 to withdraw an amount.
# Enter 3 to deposit an amount.
# ```
#
# **Step 4**: In the case of valid input:
#
# - If the user enters `1`, then display their available account balance.
#
# - Else if the user enters `2`, then prompt the user to enter the withdrawal amount by displaying the `Enter the amount to be withdrawn:` message.
#
# - If the withdrawal amount is greater than the available balance, then display the following message.
#
# ```
# Insufficient balance.
# Available balance: X
# ```
#
# where `X` is the available balance in the user's account.
#
# - Else, subtract the withdrawal amount from the available balance and replace the existing available amount with the updated amount in the `cust_data` dictionary. Also, print the following message.
#
# ```
# Withdrawal successful.
# Available Balance: Y
# ```
#
# where `Y` is the updated amount.
#
# - Else if the user enters `3`, then prompt them to enter the amount to be deposited to their account by displaying the `Enter the amount to be deposited:` message. Add the deposit amount to the available balance and update the new deposit amount in the `cust_data` dictionary. Also, display the following message.
#
# ```
# Deposit successful.
# Available Balance: Z
# ```
#
# where `Z` is the updated deposit amount.
#
# + id="8HV3cY6O9LeE" colab={"base_uri": "https://localhost:8080/"} outputId="b2dd4c0e-4150-46ad-c6a8-b895f934b94d"
# The 'existing_user()' function to get the account details of an existing user from the 'cust_data' dictionary.
def existing_user():
# Step 1: Ask the user to enter the existing account number and store it as an integer.
acc_num = input("Enter your account number: ") # Write your code here
while acc_num not in cust_data:
acc_num = int(input("Not found. Please enter your correct account number:\n"))
# Step 2: Print the welcome message to the user.
# Write your code here
print("Welcome")
# Step 3: Asking the user to select a valid choice.
print("Enter 1 to check your balance.\nEnter 2 to withdraw an amount.\nEnter 3 to deposit an amount.")
user_choice = input()
while user_choice not in ['1','2','3']:
print("\nInvalid input!")
print("Enter 1 to check your balance.\nEnter 2 to withdraw an amount.\nEnter 3 to deposit an amount.")
user_choice = input()
# Step 4:
# If 'user_choice == 1' then display the account balance i.e. 'cust_data[acc_num]['amount']'
if user_choice == '1':
# Write your code here
print("Your account Balance is ", cust_data[acc_num]['amount'])
# Else if 'user_choice == 2' then subtract the withdrawal amount from the available balance.
elif user_choice == '2':
amt = int(input("\nEnter the amount to be withdrawn:\n"))
if amt > cust_data[acc_num]['amount']:
print("\nInsufficient balance.\nAvailable balance:", cust_data[acc_num]['amount'])
else:
new_amt = int(cust_data[acc_num]['amount']) - amt
cust_data[acc_num]['amount'] = new_amt
print("\nWithdrawal successful.\nAvailable Balance:", cust_data[acc_num]['amount'])
# Else if 'user_choice == 3' then add the deposit amount to the available balance.
elif user_choice == '3':
amt = int(input("\nEnter the amount to be deposited:\n"))
new_amt = int(cust_data[acc_num]['amount']) + amt
cust_data[acc_num]['amount'] = new_amt
print("\nDeposit successful.\nAvailable Balance:", cust_data[acc_num]['amount'])
existing_user()
# + [markdown] id="gdgW4-R6LVB3"
# ---
# + [markdown] id="NyHSsEwEoEvH"
# #### 4. Infinite `while` Loop
#
# Finally, create an infinite `while` loop to run the application. Inside the loop:
#
# 1. Create a list of valid inputs, i.e., `'1', '2', '3'`
#
# 2. Prompt the user to enter either `1, 2,` or `3` by displaying the following message.
#
# ```
# Welcome to the Horizon Bank!
#
# Enter 1 if you are a new customer.
# Enter 2 if you are an existing customer.
# Enter 3 to terminate the application.
# ```
#
# Keep prompting until the user enters the valid input. For each invalid input, print the following message to the user.
#
# ```
# Invalid input!
# Enter 1 if you are a new customer.
# Enter 2 if you are an existing customer.
# Enter 3 to terminate the application.
# ```
#
# 3. If the user enters `1`, then create a new account for the user and get their personal details. After creating the account, terminate the application with the `Thank you, for banking with us!` message.
#
# 4. Else if the user enters 2, then display their account balance, reduce their balance or increase their balance depending on their further input. Afterwards, terminate the application with the `Thank you, for banking with us!` message.
#
# 5. Else if the user enters 3, then terminate the application with the `Thank you, for banking with us!` message.
# + id="-QAIIkM1qCNr" colab={"base_uri": "https://localhost:8080/", "height": 623} outputId="b01cf1fc-6810-4127-ff37-95b7ba34af8b"
# Create an infinite while loop to run the application.
while True:
valid_inputs = ['1','2','3']
print("Welcome to the Horizon Bank!")
print("\nEnter 1 if you are a new customer.\nEnter 2 if you are an existing customer.\nEnter 3 to terminate the application.")
user_choice = input()
while user_choice not in ['1','2','3']:
print("Invalid input!")
print("Enter 1 if you are a new customer.\nEnter 2 if you are an existing customer.\nEnter 3 to terminate the application.\n")
user_choice = input()
# If the user enters 1, then call the 'new_user()' function (to create a new account for the user and get their personal details).
# Write your code here
if user_choice == '1':
new_user()
break
# Else If the user enters 2, then call the 'existing_user()' function.
# Write your code here
elif user_choice == '2':
existing_user()
break
# Else If the user enters 3, then terminate the application with the 'Thank you, for banking with us!' message.
# Write your code here
elif user_choice == '3':
print("Thank you, for banking with us!")
existing_user()
# + [markdown] id="G3WtFv0Ah3nx"
# **Hints**:
#
# - If the user enters `1` i.e. *New customer*, then invoke the `new_user()` function and break the infinite loop using the `break` keyword after displaying the thank you message (`'Thank you, for banking with us!'`).
#
# - Else if the user enters `2` i.e. *Existing customer*, then invoke the `existing_user()` function and break the infinite loop using the `break` keyword after displaying the thank you message (`'Thank you, for banking with us!'`).
#
# - Else if the user enters `3` i.e. *Quit application*, then display the thank you message (`‘Thank you, for banking with us!’`) and break the infinite loop using the `break` keyword.
# + [markdown] id="4qIsQMIj-Is3"
# ---
# + [markdown] id="XQoHiNqUCr2L"
# ### Submitting the Project
#
# Follow the steps described below to submit the project.
#
# 1. After finishing the project, click on the **Share** button on the top right corner of the notebook. A new dialog box will appear.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/2_share_button.png' width=500>
#
# 2. In the dialog box, click on the **Copy link** button.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/3_copy_link.png' width=500>
#
#
# 3. The link of the duplicate copy (named as **YYYY-MM-DD_StudentName_CapstoneProject8**) of the notebook will get copied
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/4_copy_link_confirmation.png' width=500>
#
# 4. Go to your dashboard and click on the **My Projects** option.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/5_student_dashboard.png' width=800>
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/6_my_projects.png' width=800>
#
# 5. Click on the **View Project** button for the project you want to submit.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/7_view_project.png' width=800>
#
# 6. Click on the **Submit Project Here** button.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/8_submit_project.png' width=800>
#
# 7. Paste the link to the project file named as **YYYY-MM-DD_StudentName_CapstoneProject8** in the URL box and then click on the **Submit** button.
#
# <img src='https://student-datasets-bucket.s3.ap-south-1.amazonaws.com/images/project-share-images/9_enter_project_url.png' width=800>
#
# + [markdown] id="fZV1ZSS5CuTq"
# ---
| 2021_11_28_Thiviyaa_S_AT_CapstoneProject8_Dictionary_QuestionCopy_v1_2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import tensorflow as tf
# 常量操作
a = tf.constant(2)
b = tf.constant(3)
# 创建会话,并执行计算操作
with tf.Session() as sess:
print("a: %i" % sess.run(a))
print("b: %i" % sess.run(b))
print("Addition with constants: %i" % sess.run(a + b))
print("Multiplication with constants: %i" % sess.run(a * b))
# 占位符操作
# x = tf.placeholder(dtype, shape, name)
x = tf.placeholder(tf.int16, shape=(), name='x')
y = tf.placeholder(tf.int16, shape=(), name='y')
# 计算操作
add = tf.add(x, y)
mul = tf.multiply(x, y)
# 加载默认数据流图
with tf.Session() as sess:
# 不填充数据,直接执行操作,报错
print("Addition with variables: %i" % sess.run(add))
print("Multiplication with variables: %i" % sess.run(mul))
# 加载默认数据流图
with tf.Session() as sess:
# 填充数据,执行操作
print("Addition with variables: %i" % sess.run(add, feed_dict={x: 10, y: 3}))
print("Multiplication with variables: %i" % sess.run(add, feed_dict={x: 2, y: 5}))
| operation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] deletable=true editable=true
# # MNIST Image Classification with TensorFlow
#
# This notebook demonstrates how to implement a simple linear image models on MNIST using Estimator.
# <hr/>
# This <a href="mnist_models.ipynb">companion notebook</a> extends the basic harness of this notebook to a variety of models including DNN, CNN, dropout, pooling etc.
# + deletable=true editable=true
import numpy as np
import shutil
import os
import tensorflow as tf
print(tf.__version__)
# + [markdown] deletable=true editable=true
# ## Exploring the data
#
# Let's download MNIST data and examine the shape. We will need these numbers ...
# + deletable=true editable=true
HEIGHT = 28
WIDTH = 28
NCLASSES = 10
# +
# Get mnist data
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Scale our features between 0 and 1
x_train, x_test = x_train / 255.0, x_test / 255.0
# Convert labels to categorical one-hot encoding
y_train = tf.keras.utils.to_categorical(y = y_train, num_classes = NCLASSES)
y_test = tf.keras.utils.to_categorical(y = y_test, num_classes = NCLASSES)
print("x_train.shape = {}".format(x_train.shape))
print("y_train.shape = {}".format(y_train.shape))
print("x_test.shape = {}".format(x_test.shape))
print("y_test.shape = {}".format(y_test.shape))
# + deletable=true editable=true
import matplotlib.pyplot as plt
IMGNO = 12
plt.imshow(x_test[IMGNO].reshape(HEIGHT, WIDTH));
# + [markdown] deletable=true editable=true
# ## Define the model.
# Let's start with a very simple linear classifier. All our models will have this basic interface -- they will take an image and return probabilities.
# + deletable=true editable=true
# Build Keras Model Using Keras Sequential API
def linear_model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape = [HEIGHT, WIDTH], name = "image"))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(units = NCLASSES, activation = tf.nn.softmax, name = "probabilities"))
return model
# -
def dnn_model():
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape = [HEIGHT, WIDTH], name = "image"))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation="relu"))
model.add(tf.keras.layers.Dense(64, activation="relu"))
model.add(tf.keras.layers.Dropout(rate=0.1))
model.add(tf.keras.layers.Dense(units = NCLASSES, activation = tf.nn.softmax, name = "probabilities"))
return model
# + [markdown] deletable=true editable=true
# ## Write Input Functions
#
# As usual, we need to specify input functions for training, evaluation, and predicition.
# + deletable=true editable=true
# Create training input function
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x = {"image": x_train},
y = y_train,
batch_size = 100,
num_epochs = None,
shuffle = True,
queue_capacity = 5000
)
# Create evaluation input function
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x = {"image": x_test},
y = y_test,
batch_size = 100,
num_epochs = 1,
shuffle = False,
queue_capacity = 5000
)
# Create serving input function for inference
def serving_input_fn():
placeholders = {"image": tf.placeholder(dtype = tf.float32, shape = [None, HEIGHT, WIDTH])}
features = placeholders # as-is
return tf.estimator.export.ServingInputReceiver(features = features, receiver_tensors = placeholders)
# + [markdown] deletable=true editable=true
# ## Create train_and_evaluate function
# + [markdown] deletable=true editable=true
# tf.estimator.train_and_evaluate does distributed training.
# + deletable=true editable=true
def train_and_evaluate(output_dir, hparams):
# Build Keras model
model = linear_model()
# Compile Keras model with optimizer, loss function, and eval metrics
model.compile(
optimizer = "adam",
loss = "categorical_crossentropy",
metrics = ["accuracy"])
# Convert Keras model to an Estimator
estimator = tf.keras.estimator.model_to_estimator(
keras_model = model,
model_dir = output_dir)
# Set estimator's train_spec to use train_input_fn and train for so many steps
train_spec = tf.estimator.TrainSpec(
input_fn = train_input_fn,
max_steps = hparams["train_steps"])
# Create exporter that uses serving_input_fn to create saved_model for serving
exporter = tf.estimator.LatestExporter(
name = "exporter",
serving_input_receiver_fn = serving_input_fn)
# Set estimator's eval_spec to use eval_input_fn and export saved_model
eval_spec = tf.estimator.EvalSpec(
input_fn = eval_input_fn,
steps = None,
exporters = exporter)
# Run train_and_evaluate loop
tf.estimator.train_and_evaluate(
estimator = estimator,
train_spec = train_spec,
eval_spec = eval_spec)
# + editable=true
def train_and_evaluate_dnn(output_dir, hparams):
# Build Keras model
model = dnn_model()
# Compile Keras model with optimizer, loss function, and eval metrics
model.compile(
optimizer = "adam",
loss = "categorical_crossentropy",
metrics = ["accuracy"])
# Convert Keras model to an Estimator
estimator = tf.keras.estimator.model_to_estimator(
keras_model = model,
model_dir = output_dir)
# Set estimator's train_spec to use train_input_fn and train for so many steps
train_spec = tf.estimator.TrainSpec(
input_fn = train_input_fn,
max_steps = hparams["train_steps"])
# Create exporter that uses serving_input_fn to create saved_model for serving
exporter = tf.estimator.LatestExporter(
name = "exporter",
serving_input_receiver_fn = serving_input_fn)
# Set estimator's eval_spec to use eval_input_fn and export saved_model
eval_spec = tf.estimator.EvalSpec(
input_fn = eval_input_fn,
steps = None,
exporters = exporter)
# Run train_and_evaluate loop
tf.estimator.train_and_evaluate(
estimator = estimator,
train_spec = train_spec,
eval_spec = eval_spec)
preds = model.predict_classes(x_test)
actuals = y_test
return (preds, actuals)
# -
def plain_keras():
model = dnn_model()
# Compile Keras model with optimizer, loss function, and eval metrics
model.compile(
optimizer = "adam",
loss = "categorical_crossentropy",
metrics = ["accuracy"])
model.fit(x_train, y_train)
y_pred = model.predict_classes(x_test)
return(y_test, y_pred)
(yt, yp) = plain_keras()
yt[:5]
y_true = [np.argmax(yy) for yy in yt]
with tf.Session() as sess:
with sess.as_default():
cm = tf.confusion_matrix(yp, y_true).eval()
cm
# + [markdown] deletable=true editable=true
# This is the main() function
# + deletable=true editable=true
OUTDIR = "mnist/learned"
shutil.rmtree(OUTDIR, ignore_errors = True) # start fresh each time
hparams = {"train_steps": 1000, "learning_rate": 0.01}
train_and_evaluate(OUTDIR, hparams)
# -
# I got:
#
# `Saving dict for global step 1000: categorical_accuracy = 0.9112, global_step = 1000, loss = 0.32516304`
#
# In other words, we achieved 91.12% accuracy with the simple linear model!
# Saving dict for global step 1000: categorical_accuracy = 0.9131, global_step = 1000, loss = 0.32085687
# +
OUTDIR = "mnist/learned"
shutil.rmtree(OUTDIR, ignore_errors = True) # start fresh each time
hparams = {"train_steps": 2000, "learning_rate": 0.01}
(preds, actuals) = train_and_evaluate_dnn(OUTDIR, hparams)
# +
OUTDIR = "mnist/learned"
shutil.rmtree(OUTDIR, ignore_errors = True) # start fresh each time
hparams = {"train_steps": 2000, "learning_rate": 0.01}
(x_test, yhat, y) = train_and_evaluate_dnn(OUTDIR, hparams)
# -
yhat
y
xt1 == xt2.all()
yhat.shape
y.shape
yhat[1]
np.argmax(yhat[1])
y_preds = [np.argmax(yh) for yh in yhat]
# +
y_preds[:5]
# 6, 9, 4, 5, 9
# 8, 3, 3, 9, 9
# 2, 8, 6, 6, 8
# -
yhat[:5]
y[:5]
y_true = [np.argmax(yy) for yy in y]
# +
y_true[:5]
# 7, 2, 1, 0, 4
# 7, 2, 1, 0, 4
# 7, 2, 1, 0, 4
# -
with tf.Session() as sess:
with sess.as_default():
cm = tf.confusion_matrix(y_preds, y_true).eval()
cm
from sklearn.metrics import confusion_matrix as skcm
skcm(y_preds, y_true)
# +
# First pass: Saving dict for global step 1000: categorical_accuracy = 0.9489, global_step = 1000, loss = 0.17488453
# added one dense layer, 64 units
# Second pass (another layer of 32 units):
# Saving dict for global step 1000: categorical_accuracy = 0.9516, global_step = 1000, loss = 0.16565359
# Third pass: dropout layer with probability 0.5:
# Saving dict for global step 1000: categorical_accuracy = 0.9437, global_step = 1000, loss = 0.1882948
# Fourth pass: dropout layer with probability 0.1:
# Saving dict for global step 1000: categorical_accuracy = 0.9528, global_step = 1000, loss = 0.15361284
# Fifth pass: Upped second layer to 64 units:
# Saving dict for global step 1000: categorical_accuracy = 0.9539, global_step = 1000, loss = 0.14908159
# Sixth pass: Upped first layer to 128 units:
# Saving dict for global step 1000: categorical_accuracy = 0.9649, global_step = 1000, loss = 0.11287299
# 7th pass: Upped train steps to 2000:
# Saving dict for global step 2000: categorical_accuracy = 0.9707, global_step = 2000, loss = 0.094434
# + [markdown] deletable=true editable=true
# <pre>
# # Copyright 2017 Google Inc. All Rights Reserved.
# #
# # Licensed under the Apache License, Version 2.0 (the "License");
# # you may not use this file except in compliance with the License.
# # You may obtain a copy of the License at
# #
# # http://www.apache.org/licenses/LICENSE-2.0
# #
# # Unless required by applicable law or agreed to in writing, software
# # distributed under the License is distributed on an "AS IS" BASIS,
# # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# # See the License for the specific language governing permissions and
# # limitations under the License.
# </pre>
| courses/machine_learning/deepdive/08_image_keras/mnist_linear.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Disasters Risk Assessment in California
# Here we have some EDA with visualizations that are aid in risk assment due to wildfires, earthquakes, COVID-19, along with the combined risk in the state of California. All analyses are done at the county level.
# 1. [Wildfires Risk](#wildfire)
# 2. [Earthquakes Risk](#earthquake)
# 3. [COVID-19 Risk](#covid)
# 4. [Combined Risk](#combo)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
disasters = pd.read_csv('../data/covid_fire_earthquake_summary.csv')
pd.set_option('display.max_columns', 500)
disasters.head()
# #### change all per capita columns to per 10,000
disasters['covid_death_per_capita'] = disasters['covid_death_per_capita'] * 10000
disasters['covid_confirmed_per_capita'] = disasters['covid_confirmed_per_capita'] * 10000
disasters['covid_active_cases_per_capita'] = disasters['covid_active_cases_per_capita'] * 10000
# rename columns to reflect the change
col_names = {'covid_death_per_capita': 'covid_death_per_10000', 'covid_confirmed_per_capita': 'covid_confirmed_per_10000', 'covid_active_cases_per_10000': 'covid_active_cases_per_10000'}
disasters.rename(columns=col_names, inplace=True)
# <a id = wildfire> </a>
# ### 1. Wildfire Risk
# look at the distribution of number of fires per county
plt.hist(disasters['fires_per_county_in_2020'])
plt.title('Distribution of Number of Fires Per County in 2020')
plt.ylabel('Frequency')
plt.xlabel('Number of Fires Per County in 2020');
# Most counties have had 5 or less fires this year (including currently active ones).
# top 10 counties with the most fires in 2020
fire_number = disasters.sort_values('fires_per_county_in_2020', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='fires_per_county_in_2020',x='county', data=fire_number, palette='coolwarm_r');
plt.title('Top 10 Counties with the Most Number of Fires in 2020')
plt.xticks(rotation=45)
plt.xlabel('County')
plt.ylabel('Number of Fires in 2020');
fire_risk = disasters.sort_values('fire_score', ascending=False)[:10]
# lets look at the fire score
sns.barplot(y='fire_score',x='county', data=fire_risk, palette='coolwarm_r');
plt.title('Top 10 CA counties with the Highest Fire Risk')
plt.xlabel('County')
plt.ylabel('Fire Risk')
plt.xticks(rotation=45)
plt.yticks([])
plt.savefig('../figures/fire_index_county', bbox_inches='tight');
# Riverside county leads in the number of fires and fire risk this year.
# <a id = earthquake> </a>
# ### Earthquake Risk
# distribution of number of earthquakes per county in 2020
plt.hist(disasters['earthquakes_per_county_in_2020'])
plt.title('Distribution of the Number of Earthquakes Per County in 2020')
plt.xlabel('Number of Earthquakes Per County')
plt.ylabel('Frequency');
# Most counties have had zero earthquakes this year.
#let's look at the 10 counties which had the more earthquakes in 2020
earthquake_number = disasters.sort_values(by='earthquakes_per_county_in_2020', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='earthquakes_per_county_in_2020',x='county', data=earthquake_number, palette='cividis');
plt.title('Top 10 Counties the Highest Number of Earthquakes in 2020')
plt.xlabel('County')
plt.ylabel('Number of Earthquakes in 2020')
plt.xticks(rotation=45);
earthquake_risk = disasters.sort_values(by='earthquakes_score', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='earthquakes_score',x='county', data=earthquake_risk, palette='cividis');
plt.title('Top 10 Counties the Highest Earthquakes Risk')
plt.xlabel('County')
plt.ylabel('Earthquake Risk')
plt.xticks(rotation=45)
plt.yticks([])
plt.savefig('../figures/earthquake_index_county', bbox_inches='tight');
# Imperial county leads in the number of earthquakes and earthquake risk this year
# <a id = covid> </a>
# ### COVID-19 Risk
# distribution of number of covid cases per capita per county in 2020
plt.hist(disasters['covid_confirmed_per_10000'], color='skyblue')
plt.title('Distribution of the Number of COVID-19 Cases Per 10,000 Due to COVID-10')
plt.xlabel('Number of COVID-19 Cases Per 10,000 Per County')
plt.ylabel('Frequency')
plt.savefig('../figures/covid_confirmed_capita_dist', bbox_inches='tight');
# total number of confirmed covid cases in california
sum(disasters['covid_confirmed'])/sum(disasters['county_population']) * 10000
# distribution of number of deaths per capita per county in 2020
plt.hist(disasters['covid_death_per_10000'], color='skyblue')
plt.title('Distribution of the Number of Death Per 10,000 Due to COVID-10')
plt.xlabel('Number of Death Per 10,000 Per County')
plt.ylabel('Frequency')
plt.savefig('../figures/covid_death_capita_dist', bbox_inches='tight');
# Most counties have less than % COVID-19 death per 10,000 capita.
# +
#let's look at the 10 counties which had the most covid deaths per capita
covid_death_capita = disasters.sort_values(by='covid_death_per_10000', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='covid_death_per_10000',x='county', data=covid_death_capita, palette='afmhot');
plt.title('Top 10 Counties the Highest Number of Death Due to COVID-19')
plt.xlabel('County')
plt.ylabel('Death Per 10,000 Capita')
plt.xticks(rotation=45)
plt.savefig('../figures/covid_death_capita', bbox_inches='tight');
# +
#let's look at the 10 counties which had the most covid confirmed cases per capita
confirmed_capita = disasters.sort_values(by='covid_confirmed_per_10000', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='covid_confirmed_per_10000',x='county', data=confirmed_capita, palette='afmhot');
plt.title('Top 10 Counties the Highest Number of COVID-19 Cases Per 10,000')
plt.xlabel('County')
plt.ylabel('Number of Confirmed Cases')
plt.xticks(rotation=45)
plt.savefig('../figures/covid_confirmed_capita', bbox_inches='tight');
# -
# Imperial county is leading in the number of deaths due to COVID-19
# distribution of fatality rate
plt.hist(disasters['covid_case_fatality_ratio'], color='skyblue')
plt.title('Distribution of COVID-19 Fatality Rate')
plt.xlabel('Fatality Rate')
plt.ylabel('Frequency');
# Most counties have relatively low fatality rate
# +
#let's look at the 10 counties which had the highest case fatality rate
fatality_rate = disasters.sort_values(by='covid_case_fatality_ratio', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='covid_case_fatality_ratio',x='county', data=fatality_rate, palette='afmhot');
plt.title('Top 10 Counties the Highest COVID-19 Case Fatality')
plt.xlabel('County')
plt.ylabel('Fatality Rate')
plt.xticks(rotation=45);
# -
# calculate the per capita fatality rate
disasters['fatality_rate_per_10000'] = disasters['covid_case_fatality_ratio']/disasters['county_population'] *10000
# distribution of fatality rate per capita
plt.hist(disasters['fatality_rate_per_10000'])
plt.title('Distribution of COVID-19 Fatality Rate Per 10,000')
plt.xlabel('Fatality Rate Per Capita')
plt.ylabel('Frequency');
# Again, most counties have low fatality rate
# +
#top 10 counties with the highest case fatality rate per capita
fatality_rate_capita = disasters.sort_values(by='fatality_rate_per_10000', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='fatality_rate_per_10000',x='county', data=fatality_rate_capita, palette='afmhot');
plt.title('Top 10 Counties the Highest COVID-19 Fatality Per Case Per 10,000')
plt.xlabel('County')
plt.ylabel('Fatality Per Case Per 10,000 Capita')
plt.xticks(rotation=45)
plt.savefig('../figures/covid_case_death_capita', bbox_inches='tight');
# -
# In terms of fatality rate, Inyo has the highest fatality rate. Imperial county is no longer in the top 10 suggesting that the interventions are leading to recoveries rather than deaths.
# <a id = combo> </a>
# ### Combined metric
# For a combined risk score, we are simply adding the scaled covid confirmed cases per capita, fire score, and earthquake score. This would allow that all the metrics to contribute equally to the final combined risk index.
# first scaled each metric by standardization
covid_ss = (disasters['covid_confirmed_per_10000'] - np.mean(disasters['covid_confirmed_per_10000'])) / np.std(disasters['covid_confirmed_per_10000'])
fire_ss = (disasters['fire_score'] - np.mean(disasters['fire_score'])) / np.std(disasters['fire_score'])
earthquake_ss = (disasters['earthquakes_score'] - np.mean(disasters['earthquakes_score'])) / np.std(disasters['earthquakes_score'])
# add the scaled metrics together
disasters['combined_risk'] = round((covid_ss + fire_ss + earthquake_ss), 0)
# +
#top 10 counties with the highest combined risk index
fatality_rate_capita = disasters.sort_values(by='combined_risk', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='combined_risk',x='county', data=fatality_rate_capita, palette='YlOrRd_r');
plt.title('Top 10 Counties the Highest Combined COVID-19/Wildfire/Earthquake Risk')
plt.xlabel('County')
plt.ylabel('Risk Index')
plt.xticks(rotation=45);
# -
# using a different covid metric
covid_ss2 = (disasters['fatality_rate_per_10000'] - np.mean(disasters['fatality_rate_per_10000'])) / np.std(disasters['fatality_rate_per_10000'])
# calculating the combined risk
disasters['combined_risk_2'] = round((covid_ss2 + fire_ss + earthquake_ss), 0)
# +
#top 10 counties with the highest combined risk index 2
fatality_rate_capita = disasters.sort_values(by='combined_risk_2', ascending=False)[:10]
f, ax=plt.subplots(figsize=(10,5))
sns.barplot(y='combined_risk_2',x='county', data=fatality_rate_capita, palette='YlOrRd_r');
plt.title('Top 10 Counties the Highest Combined COVID-19/Wildfire/Earthquake Risk 2')
plt.xlabel('County')
plt.ylabel('Risk Index')
plt.xticks(rotation=45);
# -
disasters.to_csv('../data/combined_risk_added.csv')
| code/more_eda_emiko.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.utils import np_utils
# -
# Exception: URL fetch failure on https://s3.amazonaws.com/img-datasets/mnist.pkl.gz : None -- [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1076)
#
# # cd "/Applications/Python 3.6/"
# sudo "./Install Certificates.command"
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print("X_train:", X_train.shape, "y_train:", y_train.shape)
print("X_test :", X_test.shape, "y_test :", y_test.shape)
# +
num_rows = 28
num_cols = 28
num_channels = 1
num_classes = 10
X_train = X_train.reshape(X_train.shape[0], num_rows, num_cols, num_channels).astype(np.float32) / 255
X_test = X_test.reshape(X_test.shape[0], num_rows, num_cols, num_channels).astype(np.float32) / 255
print("X_train:", X_train.shape, "X_test:", X_test.shape)
# +
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
print("y_train:", y_train.shape, "y_test:", y_test.shape)
# +
im = X_train[1001,:,:,0]
plt.imshow(im,cmap='gray')
plt.show()
print('Label:',np.nonzero(y_train[1001,:])[0][0])
# +
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(28, 28, 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (1, 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# -
model.summary()
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# Remove Dropout for inference
for k in model.layers:
if type(k) is keras.layers.Dropout:
model.layers.remove(k)
model.summary()
# Save the model
model.save('mnistCNN.h5')
# +
import coremltools
output_labels = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
scale = 1/255.
coreml_model = coremltools.converters.keras.convert('./mnistCNN.h5',
input_names='image',
image_input_names='image',
output_names='output',
class_labels=output_labels,
image_scale=scale)
coreml_model.author = '<NAME>'
coreml_model.license = 'MIT'
coreml_model.short_description = 'Model to classify hand written digit'
coreml_model.input_description['image'] = 'Grayscale image of hand written digit'
coreml_model.output_description['output'] = 'Predicted digit'
coreml_model.save('mnistCNN.mlmodel')
# -
| MNISTHandwrittingRecognition/MNISTCNN/MNISTCNN.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: roadnetwork
# language: python
# name: roadnetwork
# ---
# # Real City Case
#
# ※Warning: Real data is not uploaded. Only few example data is uploaded. Just see how simulation goes.
#
# This notebook gives a brief overview on how to run simulation on real city's road network.
import warnings
warnings.filterwarnings('ignore')
# %load_ext autoreload
# %autoreload 2
import sys
sys.path.append("../")
import osmnx as ox
import torch as th
import networkx as nx
import dgl
DATA_FOLDER='../data_example/'
# First load simplified road network graph G and visualize it.
G_simplified =ox.load_graphml(DATA_FOLDER+'seoul_rectangular_drive_network_simplified_with_speed.graphml')
ox.plot_graph(G_simplified, fig_height=15)
for edge in G_simplified.edges(data=True):
# add two node id of edge
u, v, data = edge
data['u'] = u
data['v'] = v
# Now load speed information and for convenience, convert speed data road name to speed data road index.
from speed_info import SpeedInfo
speed_info = SpeedInfo(DATA_FOLDER+'road_speed_seoul_20181023.csv')
for edge in G_simplified.edges(data=True):
u, v, data = edge
# convert road name to road index
data['speed_info_closest_road_index'] = speed_info.road_names_dict[data['speed_info_closest_road']]
# Now load following data.
# * initial driver distribution
# * call data
# * total driver number at each time
# +
from driver_initializer import *
from call_generator import *
driver_initializer = BootstrapDriverInitializer(DATA_FOLDER+'seoul_idle_driver_initial_distribution_20181023.csv')
call_generator = BootstrapCallGenerator(DATA_FOLDER+'seoul_call_data_20181023.csv')
total_driver_number_per_time = TotalDriverCount(DATA_FOLDER+'seoul_total_driver_per_time_20181023.csv')
# -
# Because above graph G is networkx Graph object, we need to convert it to dgl(deep graph library) Graph object. After conversion, let's transform the graph into its line graph.
g = dgl.DGLGraph()
g.from_networkx(G_simplified, edge_attrs=['length', 'u', 'v', 'speed_info_closest_road_index'])
g_line = g.line_graph(shared=True)
# ## Training
# This is a code for training GCN-DQN and GAT-DQN. Rule-based strategies do not need training. First generate environment(city) and DQNAgent with different model(GAT, GCN).
# +
from main import *
city = City(g_line, call_generator, driver_initializer, total_driver_number_per_time=total_driver_number_per_time,
speed_info = speed_info, name='real_city_with_speed', driver_coefficient=0.5, consider_speed = True,
verbose=True)
# +
# Policy can be four types. Refer the paper for the details.
# POLICY_ARGMAX = 0
# POLICY_POW = 1
# POLICY_EXP = 2
# POLICY_ENTROPY = 3
dqn_agent_gcn = DQNAgent(city, model_type='gcn', policy_pow=1.5, strategy=POLICY_POW)
dqn_agent_gat = DQNAgent(city, model_type='gat', policy_pow=1.5, strategy=POLICY_POW)
# -
TRAIN_EPOCH = 5
TRAIN_TIME_STEPS = 1440
log_save_folder = 'train_logs'
model_save_folder = 'model_data'
if not os.path.exists(log_save_folder):
os.makedirs(log_save_folder)
error_file = open('%s/error_log.txt'% log_save_folder, 'w')
try:
train(city, dqn_agent_gat, epochs = TRAIN_EPOCH, time_steps=TRAIN_TIME_STEPS, write_log=True, save_model=True, log_save_folder=log_save_folder, model_save_folder=model_save_folder)
train(city, dqn_agent_gcn, epochs = TRAIN_EPOCH, time_steps=TRAIN_TIME_STEPS, write_log=True, save_model=True, log_save_folder=log_save_folder, model_save_folder=model_save_folder)
except Exception as e:
error_file.write(str(e))
error_file.flush()
# ## Evaluation
# This is a code for evaluation of different models.
TEST_EPOCH = 2
TEST_TIME_STEPS = 1440
save_folder = 'test_result'
import os
def test_all_for_city(city, save_folder):
if not os.path.exists(save_folder):
os.mkdir(save_folder)
dqn_agent_gcn = DQNAgent(city, model_type='gcn', policy_pow=1.5, strategy=POLICY_POW)
dqn_agent_gat = DQNAgent(city, model_type='gat', policy_pow=1.5, strategy=POLICY_POW)
# (1) Random Agent
evaluate(city, RandomAgent(), epochs = TEST_EPOCH, time_steps=TEST_TIME_STEPS, save_folder=save_folder)
# (2) Proportional Agent
evaluate(city, ProportionalAgent(city, proportional='order', policy_pow=1.5), epochs = TEST_EPOCH, time_steps=TEST_TIME_STEPS, save_folder=save_folder)
# (3) GCN_DQN, GAT_DQN Agent
error_file = open('%s/error_log.txt'% save_folder, 'w')
try:
with torch.no_grad():
evaluate(city, dqn_agent_gcn, epochs = TEST_EPOCH, time_steps=TEST_TIME_STEPS, load_model='model_data/dqn_gcn_1.5',save_folder=save_folder)
evaluate(city, dqn_agent_gat, epochs = TEST_EPOCH, time_steps=TEST_TIME_STEPS, load_model='model_data/dqn_gat_1.5',save_folder=save_folder)
except Exception as e:
error_file.write(str(e))
error_file.flush()
# +
# test on different driver number
driver_coefficients = [0.1, 0.25, 0.5]
for d in driver_coefficients:
city = City(g_line, call_generator, driver_initializer, total_driver_number_per_time=total_driver_number_per_time,
speed_info = speed_info, name='real_city_with_speed', driver_coefficient=d, consider_speed = True)
test_all_for_city(city, "real_city_with_driver_%.2f" % d)
| notebook/Tutorial_RealCity.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Dependencies:
# +
# %matplotlib inline
import pandas as pd
import numpy as np
import datetime
import pylab
import matplotlib.pyplot as plt, mpld3
import matplotlib.ticker as mtick
import matplotlib.ticker as ticker
import matplotlib.mlab as mlab
import matplotlib.gridspec as gridspec
import matplotlib.lines as mlines
import matplotlib.transforms as mtransforms
from termcolor import colored
from scipy import stats
import seaborn as sns
plt.style.use('seaborn-whitegrid')
# Hide warning messages in notebook
import warnings
warnings.filterwarnings("ignore")
# -
# ## Import CSV files
# ### Tsunamis Dataset
# +
# Import Historical_Tsunami_Event_Locations file
tsunami_historical_df = pd.read_csv('../csv-files/Historical_Tsunami_Event_Locations.csv',
error_bad_lines=False)
tsunami_historical_df.head()
# Review data
print (" ")
print ("Tsunami data: ")
display(tsunami_historical_df.head(2))
# -
# ### Volcanoes Dataset
# Import volcanoes file
volcanos_event = pd.read_csv('../csv-files/volcanoes.csv', error_bad_lines=False)
volcanos_event.head(3)
# ### Earthquakes Dataset
# Import earthquakes file
earthquakes_df = pd.read_csv('../csv-files/earthquakes.csv', error_bad_lines=False)
earthquakes_df.head(3)
# ### Global Land Temperature Dataset
# Import GlobalLandTemperatures_ByCountry file
GlobalLand_data = pd.read_csv('../csv-files/GlobalLandTemperatures_ByCountry.csv', error_bad_lines=False)
GlobalLand_data.head(3)
# <tr>
# ## Cleaning Datasets
# #### Clean Global Land Temperature Data:
# Filter by year (1960-2013)
Global_T_data = GlobalLand_data[(GlobalLand_data['dt'] > '1959-12-31')]
Global_T_data['Year'] = pd.DatetimeIndex(Global_T_data['dt']).year
Global_T_data.reset_index(inplace = True)
Global_T_data.head(3)
# +
# Rename column index to something else to be able drop that column
Global_data_df = Global_T_data.rename(columns={"index": "index_la",
"AverageTemperature": "avr_temp",
"Country": "country",
"Year": "year"})
# Drop colums
global_land_temp1 = Global_data_df.drop(["AverageTemperatureUncertainty",
"index_la", "dt"], axis=1)
# Show unique values in 'country' column
global_land_temp1["country"].unique()
global_land_temp1["year"].unique()
# Grab DataFrame rows where column has certain values
country_list = ["Azerbaijan", "Colombia", "United States", "Italy", "France",
"Cuba", "Iran", "Egypt", "China", "Turkey", "India", "Russia",
'Georgia', 'Bulgaria', 'Afghanistan', 'Pakistan', 'Serbia',
"Mexico", "Japan", "Georgia", "Thailand",
"Puerto Rico", "Norway", "Indonesia"]
countries_df1 = global_land_temp1[global_land_temp1.country.isin(country_list)]
# Change temperature from celcius to farenheit in avr_temp column
def f(x):
x = x * 1.8 + 32
return float(x)
countries_df1['avr_temp'] = countries_df1['avr_temp'].apply(f)
# Group by year to find avr tem per year
countries_grouped1 = countries_df1.groupby(['year']).mean()
countries_grouped1.reset_index(inplace=True)
countries_grouped1.head()
# -
# Filter by year (1990-2013)
temp_from_1990 = GlobalLand_data[(GlobalLand_data['dt'] > '1989-12-31')]
temp_from_1990['Year'] = pd.DatetimeIndex(temp_from_1990['dt']).year
temp_from_1990.reset_index(inplace = True)
temp_from_1990.head(3)
# +
# Rename column index to something else to be able drop that column
GlobalLand_clean = temp_from_1990.rename(columns={"index": "index_la",
"AverageTemperature": "avr_temp",
"Country": "country",
"Year": "year"})
# Drop colums
global_land_temp = GlobalLand_clean.drop(["AverageTemperatureUncertainty",
"index_la", "dt"], axis=1)
# Show unique values in 'country' column
global_land_temp["country"].unique()
global_land_temp["year"].unique()
# Grab DataFrame rows where column has certain values
country_list = ["Azerbaijan", "Colombia", "United States", "Italy", "France",
"Cuba", "Iran", "Egypt", "China", "Turkey", "India", "Russia",
'Georgia', 'Bulgaria', 'Afghanistan', 'Pakistan', 'Serbia',
"Mexico", "Japan", "Georgia", "Thailand",
"Puerto Rico", "Norway", "Indonesia"]
countries_df = global_land_temp[global_land_temp.country.isin(country_list)]
# Change temperature from celcius to farenheit in avr_temp column
def f(x):
x = x * 1.8 + 32
return float(x)
countries_df['avr_temp'] = countries_df['avr_temp'].apply(f)
# Group by year to find avr tem per year
countries_grouped = countries_df.groupby(['year']).mean()
countries_grouped.reset_index(inplace=True)
countries_grouped.head()
# -
# #### Clean Tsunami Data:
# +
# Drop colums from tsunami_historical_df
tsunami_historical = tsunami_historical_df.drop(['X', 'Y', 'DATE_STRIN',
'REGION_COD', 'LOCATION_N',
'AREA', 'REGION_COD',
'EVENT_RE_1', 'LONGITUDE',
'LATITUDE', 'TSEVENT_ID'], axis=1)
# Rename columns
tsunami_historic = tsunami_historical.rename(columns={"YEAR": "year",
"COUNTRY": "country"})
# Drop rows with missing values
tsunami_event_dff = tsunami_historic.dropna(subset = ["year", "country"])
# Drop all rows which contains year 2014
tsunami_event_df = tsunami_event_dff[tsunami_event_dff.year != 2014]
# Change upper caps to capitalize in country column
tsunami_event_df['country'] = tsunami_event_df['country'].str.capitalize()
# Drop missing rows from country column
tsunami_clean = tsunami_event_df.dropna(subset = ['country'])
# Drop duplicates
tsunami_clean = tsunami_event_df.drop_duplicates()
# Group by year to find how many events happend per year
tsun_event = tsunami_clean.groupby('year').count()
tsun_event.reset_index(inplace=True)
tsun_event.head()
# -
# #### Clean Volcanoes Data:
# +
# Drop colums
volcanos_event_drop = volcanos_event.drop(["Month", "Day", "Associated Tsunami",
"Associated Earthquake", "Location",
"Elevation", "Type", "Status", "Time",
"Volcano Explosivity Index (VEI)",
"Latitude","Longitude", "Name"], axis=1)
# Rename columns
volcano_event = volcanos_event_drop.rename(columns={"Year": "year",
"Country": "country"})
# Because in Global Temp data we have years bellow 2014,
# we want to keep the same year in volcanoes data to do analyses
volcanos_df = volcano_event[volcano_event.year != 2014]
# Drop rows with missing values
volcanoes_data = volcanos_df.dropna(subset = ["year", "country"])
# Drop duplicates
volcano_clean = volcanoes_data.drop_duplicates()
# Group by year to find count how many events happend per year
volcano_event = volcano_clean.groupby('year').count()
volcano_event.reset_index(inplace=True)
volcano_event.head()
# -
# <tr>
# #### Clean Earthquakes Data:
# Here we are going to display earthquakes from year (2000 to 2014) with min magnitude 5.5
# Data specifically chosen from year 2000 to 2014 - because there to many earthquakes happenning everyday and we won't be able to display them all. For the same reason chosen magnitude (min 5.5), and also we will be able to see most strongest earthquakes.
# +
# Create new column called 'year'
earthquakes_df['year'] = pd.DatetimeIndex(earthquakes_df['date']).year
# Drop columns
earthquakes_df_data = earthquakes_df.drop(["date", "depth", "net", "latitude", "longitude",
"updated", "place", "depthError", "mag"], axis=1)
# Because in Global Temp data we have years bellow 2014,
# we want to keep the same year in earthquakes data to do analyses
earthquakes_df_dr = earthquakes_df_data[earthquakes_df_data.year != 2014]
# Drop rows with missing values
earthquakes_data = earthquakes_df_dr.dropna(subset = ["year", "country"])
# Drop duplicates
earthquakes_clean = earthquakes_data.drop_duplicates()
# Group by year to find count how many events happend per year
earthquakes_event = earthquakes_clean.groupby('year').count()
earthquakes_event.reset_index(inplace=True)
earthquakes_event.head()
# -
# <tr>
# ## Create Graphs
# **Colors for plots in used:**
# <br>
#
# <font color='#C10505'>TrendLine color      #C10505 - red</font><br>
# <font color='#049A18'>Temp. Change      #049A18 - green</font><br>
# <font color='#0066cc'>Tsunami         #0066cc - blue</font><br>
# <font color='#8E4B0F'>Volcano       #8E4B0F - burgundy</font><br>
# <font color='#FFA335'>Earthquakes      #FFA335 - orange</font><br>
# ### Global Land Temperature Graph:
# Display **-Land Temperture Changes per Year-** graph
# (This graph created to show that if we will look intro temperature changes from 1960, we will see big differents between temperatures) <br>
# Show on the Plot Global Land Temperature changed from year 1960 to 2013:
# +
#__________________________________GLOBAL TEMP CHANGE 1960-2013_____________________________________
# Assigning columns
x = countries_grouped1["year"]
y = countries_grouped1["avr_temp"]
# Creating plot
fig = plt.figure(figsize = (14, 5))
ax1 = fig.add_subplot(111)
ax1.set_xticks(np.arange(1961, 1993, 2013))
#ax1.set_xticks(np.arange(y))
ax1.plot(y, color="#049A18", label="high_wage", linewidth=2.5, marker='o')
ax1.set_xticklabels(x)
# Creating line plot
line = mlines.Line2D([0, 1], [0, 1], color='#C10505')
transform = ax1.transAxes
line.set_transform(transform)
ax1.add_line(line)
# Giving parameters to the ticks
ax1.tick_params(axis="x", labelsize=12.5, color="black")
ax1.tick_params(axis="y", labelsize=12.5, color="black")
# Adding % sign to the yaxis ticks
fmt = '{x:,.0f}°F'
tick = mtick.StrMethodFormatter(fmt)
ax1.yaxis.set_major_formatter(tick)
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Creating title and labels
fig.suptitle("Land Temperture Change over Years", fontsize=14, fontweight="bold")
plt.ylabel("Average Temperature",fontsize=12)
plt.xlabel("Years " + str()+'\n 1960 - 2013 '+str(), fontsize=12, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Global_Temp_Change_1960_2013.png")
plt.show()
# -
# On this graph we will cut amount of year because of our other datas that we will be compairing Global Temperature Change. <br>
# Show on the Plot Global Land Temperature changed from year 1990 to 2013:
# +
#__________________________________GLOBAL TEMP CHANGE 1990 to 2013_____________________________________
# Assigning columns
x = countries_grouped["year"]
y = countries_grouped["avr_temp"]
# Creating plot
fig = plt.figure(figsize = (14, 5))
ax1 = fig.add_subplot(111)
ax1.set_xticks(np.arange(len(x)))
ax1.plot(y, color="#049A18", linewidth=2.5, marker='o', ls = "-")
ax1.set_xticklabels(x)
# Creating line plot
line = mlines.Line2D([0, 1], [0, 1], color='#C10505')
transform = ax1.transAxes
line.set_transform(transform)
ax1.add_line(line)
# Giving parameters to the ticks
ax1.tick_params(axis="x", labelsize=12.5, color="black")
ax1.tick_params(axis="y", labelsize=12.5, color="black")
# Adding % sign to the yaxis ticks
fmt = '{x:,.0f}°F'
tick = mtick.StrMethodFormatter(fmt)
ax1.yaxis.set_major_formatter(tick)
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Creating title and labels
fig.suptitle("Land Temperture Change over Years", fontsize=16, fontweight="bold")
plt.ylabel("Average Temperature",fontsize=13, fontweight="bold")
plt.xlabel("Years", fontsize=13, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Global_Temp_Change_1990_2013.png")
plt.show()
# -
# <tr>
# ### Tsunamis Graph:
# Display **-Number of Tsunamis per Year-** graph
# +
#_________________________________________TSUNAMI_____________________________________
# Assigning columns
x_x = tsun_event["year"]
y_y = tsun_event["country"]
# Creating plot
fig = plt.figure(figsize = (14, 5))
ax1 = fig.add_subplot(111)
ax1.set_xticks(np.arange(len(x_x)))
#ax1.set_xticks(np.arange(y_y))
ax1.plot(y_y, color="#0066cc", label="", linewidth=2.5, marker='o')
ax1.set_xticklabels(x_x)
# Creating line plot
line = mlines.Line2D([0, 1], [0, 1], color='#C10505')
transform = ax1.transAxes
line.set_transform(transform)
ax1.add_line(line)
# Giving parameters to the ticks
ax1.tick_params(axis="x", labelsize=12.5, color="black")
ax1.tick_params(axis="y", labelsize=12.5, color="black")
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Creating title and labels
fig.suptitle("Number of Tsunamis over Years", fontsize=16, fontweight="bold")
plt.ylabel("Number of Tsunamis", fontsize=13, fontweight="bold")
plt.xlabel("Years", fontsize=13, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Tsunamis_over_Years.png")
plt.show()
# +
#_________________________________________VOLCANO_____________________________________
# Assigning columns
xx_x = volcano_event["year"]
yy_y = volcano_event["country"]
# Creating plot
fig = plt.figure(figsize = (14, 5))
ax1 = fig.add_subplot(111)
ax1.set_xticks(np.arange(len(xx_x)))
ax1.plot(yy_y, color="#8E4B0F", label="", linewidth=2.5, marker='o')
ax1.set_xticklabels(xx_x)
# Creating line plot
line = mlines.Line2D([0, 1], [0, 1], color='#C10505')
transform = ax1.transAxes
line.set_transform(transform)
ax1.add_line(line)
# Giving parameters to the ticks
ax1.tick_params(axis="x", labelsize=12.5, color="black")
ax1.tick_params(axis="y", labelsize=12.5, color="black")
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Creating title and labels
fig.suptitle("Number of Volcano Eruptions over Years", fontsize=16, fontweight="bold")
plt.ylabel("Number of Volcano Eruptions", fontsize=13, fontweight="bold")
plt.xlabel("Years", fontsize=13, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Volcanoes_over_Years.png")
plt.show()
# +
#_________________________________________Earthquakes_____________________________________
# Assigning columns
xx_xx = earthquakes_event["year"]
yy_yy = earthquakes_event["country"]
# Create plot
fig = plt.figure(figsize = (14, 5))
ax1 = fig.add_subplot(111)
ax1.set_xticks(np.arange(len(xx_xx)))
#ax1.set_xticks(np.arange(y_y))
ax1.plot(yy_yy, color="#FFA335", label="", linewidth=2.5, marker='o')
ax1.set_xticklabels(xx_xx)
# Creating line plot
line = mlines.Line2D([0, 1], [0, 1], color='#C10505')
transform = ax1.transAxes
line.set_transform(transform)
ax1.add_line(line)
# Giving parameters to the ticks
ax1.tick_params(axis="x", labelsize=12.5, color="black")
ax1.tick_params(axis="y", labelsize=12.5, color="black")
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Creating title and labels
fig.suptitle("Number of Earthquakes over Years" + str()+'\n(min magn. of 5.5) '+str(),
fontsize=15, fontweight="bold")
plt.ylabel("Number of Earthquakes", fontsize=13, fontweight="bold")
plt.xlabel("Years", fontsize=13, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Earthquakes_over_Years.png")
plt.show()
# -
# <tr>
# **Show on the graph how Global Land Temperature Change reacted for numbers of Tsunamies over the years.** <br>
# To fit yaxis and ylabels on the graph, we will move yaxis to the right side.
# +
#__________________________________GLOBAL TEMP CHANGE_____________________________________
fig = plt.figure(figsize = (14, 6))
ax1 = fig.add_subplot(211)
ax1.plot(x, y, color="#049A18", linewidth=1.8, marker='o', ls='-')
ax1.yaxis.tick_right()
# Adding % sign to the yaxis ticks
fmt = '{x:,.0f}°F'
tick = mtick.StrMethodFormatter(fmt)
ax1.yaxis.set_major_formatter(tick)
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Add TrendLine
z = np.polyfit(x, y, 1)
p = np.poly1d(z)
pylab.plot(x,p(x),"r-", color="#C10505")
# Creating title and labels
fig.suptitle("Global Temperature vs. Number of Tsunamis over the Years", fontsize=15, fontweight="bold")
plt.ylabel("Avg Temperature over Years", fontsize=10, fontweight="bold")
#___________________________________TSUNAMI over the years______________________________________
ax2 = plt.subplot(212)
ax2.plot(x, y_y, color="#0066cc", linewidth=1.8, marker='o', ls='-')
ax2.yaxis.tick_right()
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Add TrendLine
z = np.polyfit(x_x, y_y, 1)
p = np.poly1d(z)
pylab.plot(x_x,p(x_x),"r-", color="#C10505")
# Creating title and labels
plt.ylabel("Tsunamis over Years", fontsize=10, fontweight="bold")
plt.xlabel("Years", fontsize=10, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Temp_Change_vs_Tsunamis_over_Year.png")
plt.show()
# -
# <tr>
# **Show on the graph how Global Land Temperature Change reacted for numbers of Volcanoes over the years.** <br>
# To fit yaxis and ylabels on the graph, we will move yaxis to the right side.
# +
#__________________________________GLOBAL TEMP CHANGE_____________________________________
fig = plt.figure(figsize = (14, 6))
ax1 = fig.add_subplot(211)
ax1.plot(x, y, color="#049A18", linewidth=1.8, marker='o', ls='-')
ax1.yaxis.tick_right()
# Adding % sign to the yaxis ticks
fmt = '{x:,.0f}°F'
tick = mtick.StrMethodFormatter(fmt)
ax1.yaxis.set_major_formatter(tick)
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Add TrendLine
z = np.polyfit(x, y, 1)
p = np.poly1d(z)
pylab.plot(x,p(x),"r-", color="#C10505")
# Creating title and labels
fig.suptitle("Global Temperature vs. Number of Volcanoes over the Years", fontsize=15, fontweight="bold")
plt.ylabel("Avg Temperature over Years", fontsize=10, fontweight="bold")
#_________________________________________Volcanoes over the years_____________________________________
ax2 = plt.subplot(212)
#ax2.set_xticks(np.arange(len(x_x)))
ax2.plot(x, yy_y, color="#8E4B0F", linewidth=1.8, marker='o', ls='-')
ax2.yaxis.tick_right()
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Add TrendLine
z = np.polyfit(xx_x, yy_y, 1)
p = np.poly1d(z)
pylab.plot(xx_x,p(xx_x),"r-", color="#C10505")
# Creating labels
plt.ylabel("Volcanoes over Years", fontsize=10, fontweight="bold")
plt.xlabel("Years", fontsize=10, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Temp_Change_vs_Volcanoes_over_Year.png")
plt.show()
# -
# <tr>
# Now that we will be comparing Earthquakes with Global Temperature Change we need to create one more DataFrame for Global Temperature with the same amount of year that in Earthquakes data, to be able to see changes just for those years.
# <br>
# **Show on the graph how Global Land Temperature Change reacted for numbers of Earthquakes with 5.5 mag and higher. <br>
# From years 2000 to 2013.** <br>
# To fit yaxis and ylabels on the graph, we will move yaxis to the right side.
# +
# Filter data to have values in year column only from 2000 to 2013
global_temp_vol = countries_grouped[countries_grouped.year > 1999]
global_temp_vol.reset_index(inplace = True)
global_temp_vol
# Rename columns
clean_years = global_temp_vol.rename(columns={"index": "indexx"})
# Drop colums
glob_temp = clean_years.drop(["indexx"], axis=1)
glob_temp.head(2)
# +
# Assigning columns
xy = glob_temp["year"]
yx = glob_temp["avr_temp"]
#__________________________________GLOBAL TEMP CHANGE_____________________________________
fig = plt.figure(figsize = (14, 6))
ax1 = fig.add_subplot(211)
ax1.plot(xy, yx, color="#049A18", linewidth=1.8, marker='o', ls='-')
ax1.yaxis.tick_right()
# Adding % sign to the yaxis ticks
fmt = '{x:,.0f}°F'
tick = mtick.StrMethodFormatter(fmt)
ax1.yaxis.set_major_formatter(tick)
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Add TrendLine
z = np.polyfit(xy, yx, 1)
p = np.poly1d(z)
pylab.plot(xy,p(xy),"r-", color="#C10505")
# Creating title and labels
fig.suptitle("Global Temperature vs. Number of Earthquakes from (5.5 mag) over the Years",
fontsize=15, fontweight="bold")
plt.ylabel("Avg Temperature over Years", fontsize=10, fontweight="bold")
#_________________________________________Earthquakes over the years_____________________________________
ax2 = plt.subplot(212)
ax2.plot(xy, yy_yy, color="#FFA335", linewidth=1.8, marker='o', ls='-')
ax2.yaxis.tick_right()
# Set up grid
plt.grid(True, which='major', lw=0.2)
# Add TrendLine
z = np.polyfit(xx_xx, yy_yy, 1)
p = np.poly1d(z)
pylab.plot(xx_xx,p(xx_xx),"r-", color="#C10505")
# Creating labels
plt.ylabel("Earthquakes over Years", fontsize=10, fontweight="bold")
plt.xlabel("Years", fontsize=10, fontweight="bold")
# Save our graph and show the grap
plt.savefig("../Images/Temp_Change_vs_Earthquakes_over_Year.png")
plt.show()
# -
# Save DataFrames to CSV file
countries_grouped.to_csv(r'../csv-files/output_data/avr_temp_from_1990_df.csv')
countries_grouped1.to_csv(r'../csv-files/output_data/avr_temp_from_1960_df.csv')
glob_temp.to_csv(r'../csv-files/output_data/avr_temp_from_2000_df.csv')
tsun_event.to_csv(r'../csv-files/output_data/tsunami_df.csv')
volcano_event.to_csv(r'../csv-files/output_data/volcanoes_df.csv')
earthquakes_event.to_csv(r'../csv-files/output_data/earthquakes_df.csv')
| JupyterNotebook/Natural_Disasters_Analysis.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/crazylazylife/A-to-Z-Resources-for-Students/blob/master/LFQA_CoQA.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + colab={"base_uri": "https://localhost:8080/"} id="pa10ntuvf85G" outputId="12d45853-8730-4680-b8cb-21b993cdaf08"
# !pip install elasticsearch
# !pip install faiss_gpu
# !pip install nlp
# !pip install transformers==3.0.2
# + id="hPMhdU3dy0_D"
from lfqa_utils import *
# + colab={"base_uri": "https://localhost:8080/"} id="Oy4uyAtSghgc" outputId="4e27fc5d-6d92-4a7c-b5b6-4cb1f0e84b28"
import nlp
data = nlp.load_dataset("coqa")
# + id="qmWJ8x67iUpF"
data["train"][0]
# + id="cBHV42FstAQe"
data['validation'][0]
# + id="EAYorzXOic8E"
s2s_train_dset = CoQADatasetS2S(data['train'], document_cache={})
s2s_valid_dset = CoQADatasetS2S(data['validation'], document_cache = {}, training=False)
# + colab={"base_uri": "https://localhost:8080/", "height": 267, "referenced_widgets": ["b49a1a34f7af4986a88ad4b5a5991342", "57d2267107c1481f8224617ebb2e92cc", "9892769f85f14c498c0174878a6eae3d", "60e4346a12ba49e4b16e5e98f5c84c86", "<KEY>", "<KEY>", "<KEY>", "<KEY>", "2bec526e92dc47c28c37209aa2add6b9", "d15095a6a90d40ebbaae45e57da94445", "e062cfffda1641f0b26ffeb973a54d4c", "<KEY>", "604dca98cf8e41ff9dce621ae032dd02", "a801b50e48f74d27a7b4dc76a6d8b056", "63fdcc3641ad447bbf5393ed72b12347", "e7da0792cce44ce09c6ffe5472f1ffc7", "<KEY>", "<KEY>", "<KEY>", "<KEY>", "<KEY>", "4cea2e7a0ffb4431ac3b36dcef1f75d2", "<KEY>", "3ff790cc14cc49a7ab4ea10cab38ac9a", "21abfff5078843ec8a5cc62206e4e165", "<KEY>", "<KEY>", "<KEY>", "4443fb6ef79447d3baccbd3c506e065e", "828e7391dec34a3ba50a8be43b1d4267", "<KEY>", "839989e6f6394de59f606c64489ec29b"]} id="f3I1Ro21tlUK" outputId="0126e902-5573-414f-813e-efed2834bcb4"
qa_s2s_tokenizer, pre_model = make_qa_s2s_model(
model_name="facebook/bart-large",
from_file=None,
device="cuda:0"
)
qa_s2s_model = torch.nn.DataParallel(pre_model)
# + id="Xj7nP3-8_Vhx"
class ArgumentsS2S():
def __init__(self):
self.batch_size = 4
self.backward_freq = 16
self.max_length = 256
self.print_freq = 100
self.model_save_name = "seq2seq_models/coqa_bart_model"
self.learning_rate = 2e-4
self.num_epochs = 3
s2s_args = ArgumentsS2S()
# + colab={"base_uri": "https://localhost:8080/", "height": 394} id="iUTJhxjqtplk" outputId="e2840191-daec-44f6-8da9-500b1472d7a5"
train_qa_s2s(qa_s2s_model, qa_s2s_tokenizer, s2s_train_dset, s2s_valid_dset, s2s_args)
# + id="LpZ8HSzg-0sW"
| LFQA_CoQA.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# **Chapter 16 – Natural Language Processing with RNNs and Attention**
# _This notebook contains all the sample code in chapter 16._
# <table align="left">
# <td>
# <a target="_blank" href="https://colab.research.google.com/github/ageron/handson-ml2/blob/master/16_nlp_with_rnns_and_attention.ipynb"><img src="https://www.tensorflow.org/images/colab_logo_32px.png" />Run in Google Colab</a>
# </td>
# </table>
# # Setup
# First, let's import a few common modules, ensure MatplotLib plots figures inline and prepare a function to save the figures. We also check that Python 3.5 or later is installed (although Python 2.x may work, it is deprecated so we strongly recommend you use Python 3 instead), as well as Scikit-Learn ≥0.20 and TensorFlow ≥2.0.
# +
# Python ≥3.5 is required
import sys
assert sys.version_info >= (3, 5)
# Scikit-Learn ≥0.20 is required
import sklearn
assert sklearn.__version__ >= "0.20"
try:
# # %tensorflow_version only exists in Colab.
# %tensorflow_version 2.x
# !pip install -q -U tensorflow-addons
# !pip install -q -U transformers
IS_COLAB = True
except Exception:
IS_COLAB = False
# TensorFlow ≥2.0 is required
import tensorflow as tf
from tensorflow import keras
assert tf.__version__ >= "2.0"
if not tf.config.list_physical_devices('GPU'):
print("No GPU was detected. LSTMs and CNNs can be very slow without a GPU.")
if IS_COLAB:
print("Go to Runtime > Change runtime and select a GPU hardware accelerator.")
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
tf.random.set_seed(42)
# To plot pretty figures
# %matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "nlp"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
# -
# # Char-RNN
# ## Splitting a sequence into batches of shuffled windows
# For example, let's split the sequence 0 to 14 into windows of length 5, each shifted by 2 (e.g.,`[0, 1, 2, 3, 4]`, `[2, 3, 4, 5, 6]`, etc.), then shuffle them, and split them into inputs (the first 4 steps) and targets (the last 4 steps) (e.g., `[2, 3, 4, 5, 6]` would be split into `[[2, 3, 4, 5], [3, 4, 5, 6]]`), then create batches of 3 such input/target pairs:
# +
np.random.seed(42)
tf.random.set_seed(42)
n_steps = 5
dataset = tf.data.Dataset.from_tensor_slices(tf.range(15))
dataset = dataset.window(n_steps, shift=2, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(n_steps))
dataset = dataset.shuffle(10).map(lambda window: (window[:-1], window[1:]))
dataset = dataset.batch(3).prefetch(1)
for index, (X_batch, Y_batch) in enumerate(dataset):
print("_" * 20, "Batch", index, "\nX_batch")
print(X_batch.numpy())
print("=" * 5, "\nY_batch")
print(Y_batch.numpy())
# -
# ## Loading the Data and Preparing the Dataset
shakespeare_url = "https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt"
filepath = keras.utils.get_file("shakespeare.txt", shakespeare_url)
with open(filepath) as f:
shakespeare_text = f.read()
print(shakespeare_text[:148])
"".join(sorted(set(shakespeare_text.lower())))
tokenizer = keras.preprocessing.text.Tokenizer(char_level=True)
tokenizer.fit_on_texts(shakespeare_text)
tokenizer.texts_to_sequences(["First"])
tokenizer.sequences_to_texts([[20, 6, 9, 8, 3]])
max_id = len(tokenizer.word_index) # number of distinct characters
dataset_size = tokenizer.document_count # total number of characters
[encoded] = np.array(tokenizer.texts_to_sequences([shakespeare_text])) - 1
train_size = dataset_size * 90 // 100
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
n_steps = 100
window_length = n_steps + 1 # target = input shifted 1 character ahead
dataset = dataset.repeat().window(window_length, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
np.random.seed(42)
tf.random.set_seed(42)
batch_size = 32
dataset = dataset.shuffle(10000).batch(batch_size)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)
for X_batch, Y_batch in dataset.take(1):
print(X_batch.shape, Y_batch.shape)
# ## Creating and Training the Model
# **Warning**: the following code may take up to 24 hours to run, depending on your hardware. If you use a GPU, it may take just 1 or 2 hours, or less.
# **Note**: the `GRU` class will only use the GPU (if you have one) when using the default values for the following arguments: `activation`, `recurrent_activation`, `recurrent_dropout`, `unroll`, `use_bias` and `reset_after`. This is why I commented out `recurrent_dropout=0.2` (compared to the book).
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, input_shape=[None, max_id],
#dropout=0.2, recurrent_dropout=0.2),
dropout=0.2),
keras.layers.GRU(128, return_sequences=True,
#dropout=0.2, recurrent_dropout=0.2),
dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id,
activation="softmax"))
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam")
history = model.fit(dataset, steps_per_epoch=train_size // batch_size,
epochs=10)
# ## Using the Model to Generate Text
def preprocess(texts):
X = np.array(tokenizer.texts_to_sequences(texts)) - 1
return tf.one_hot(X, max_id)
# **Warning**: the `predict_classes()` method is deprecated. Instead, we must use `np.argmax(model(X_new), axis=-1)`.
X_new = preprocess(["How are yo"])
#Y_pred = model.predict_classes(X_new)
Y_pred = np.argmax(model(X_new), axis=-1)
tokenizer.sequences_to_texts(Y_pred + 1)[0][-1] # 1st sentence, last char
# +
tf.random.set_seed(42)
tf.random.categorical([[np.log(0.5), np.log(0.4), np.log(0.1)]], num_samples=40).numpy()
# -
def next_char(text, temperature=1):
X_new = preprocess([text])
y_proba = model(X_new)[0, -1:, :]
rescaled_logits = tf.math.log(y_proba) / temperature
char_id = tf.random.categorical(rescaled_logits, num_samples=1) + 1
return tokenizer.sequences_to_texts(char_id.numpy())[0]
# +
tf.random.set_seed(42)
next_char("How are yo", temperature=1)
# -
def complete_text(text, n_chars=50, temperature=1):
for _ in range(n_chars):
text += next_char(text, temperature)
return text
# +
tf.random.set_seed(42)
print(complete_text("t", temperature=0.2))
# -
print(complete_text("t", temperature=1))
print(complete_text("t", temperature=2))
# ## Stateful RNN
tf.random.set_seed(42)
dataset = tf.data.Dataset.from_tensor_slices(encoded[:train_size])
dataset = dataset.window(window_length, shift=n_steps, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
dataset = dataset.repeat().batch(1)
dataset = dataset.map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)
batch_size = 32
encoded_parts = np.array_split(encoded[:train_size], batch_size)
datasets = []
for encoded_part in encoded_parts:
dataset = tf.data.Dataset.from_tensor_slices(encoded_part)
dataset = dataset.window(window_length, shift=n_steps, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_length))
datasets.append(dataset)
dataset = tf.data.Dataset.zip(tuple(datasets)).map(lambda *windows: tf.stack(windows))
dataset = dataset.repeat().map(lambda windows: (windows[:, :-1], windows[:, 1:]))
dataset = dataset.map(
lambda X_batch, Y_batch: (tf.one_hot(X_batch, depth=max_id), Y_batch))
dataset = dataset.prefetch(1)
# **Note**: once again, I commented out `recurrent_dropout=0.2` (compared to the book) so you can get GPU acceleration (if you have one).
model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, stateful=True,
#dropout=0.2, recurrent_dropout=0.2,
dropout=0.2,
batch_input_shape=[batch_size, None, max_id]),
keras.layers.GRU(128, return_sequences=True, stateful=True,
#dropout=0.2, recurrent_dropout=0.2),
dropout=0.2),
keras.layers.TimeDistributed(keras.layers.Dense(max_id,
activation="softmax"))
])
class ResetStatesCallback(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs):
self.model.reset_states()
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam")
steps_per_epoch = train_size // batch_size // n_steps
history = model.fit(dataset, steps_per_epoch=steps_per_epoch, epochs=50,
callbacks=[ResetStatesCallback()])
# To use the model with different batch sizes, we need to create a stateless copy. We can get rid of dropout since it is only used during training:
stateless_model = keras.models.Sequential([
keras.layers.GRU(128, return_sequences=True, input_shape=[None, max_id]),
keras.layers.GRU(128, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(max_id,
activation="softmax"))
])
# To set the weights, we first need to build the model (so the weights get created):
stateless_model.build(tf.TensorShape([None, None, max_id]))
stateless_model.set_weights(model.get_weights())
model = stateless_model
# +
tf.random.set_seed(42)
print(complete_text("t"))
# -
# # Sentiment Analysis
tf.random.set_seed(42)
# You can load the IMDB dataset easily:
(X_train, y_train), (X_test, y_test) = keras.datasets.imdb.load_data()
X_train[0][:10]
word_index = keras.datasets.imdb.get_word_index()
id_to_word = {id_ + 3: word for word, id_ in word_index.items()}
for id_, token in enumerate(("<pad>", "<sos>", "<unk>")):
id_to_word[id_] = token
" ".join([id_to_word[id_] for id_ in X_train[0][:10]])
# +
import tensorflow_datasets as tfds
datasets, info = tfds.load("imdb_reviews", as_supervised=True, with_info=True)
# -
datasets.keys()
train_size = info.splits["train"].num_examples
test_size = info.splits["test"].num_examples
train_size, test_size
for X_batch, y_batch in datasets["train"].batch(2).take(1):
for review, label in zip(X_batch.numpy(), y_batch.numpy()):
print("Review:", review.decode("utf-8")[:200], "...")
print("Label:", label, "= Positive" if label else "= Negative")
print()
def preprocess(X_batch, y_batch):
X_batch = tf.strings.substr(X_batch, 0, 300)
X_batch = tf.strings.regex_replace(X_batch, rb"<br\s*/?>", b" ")
X_batch = tf.strings.regex_replace(X_batch, b"[^a-zA-Z']", b" ")
X_batch = tf.strings.split(X_batch)
return X_batch.to_tensor(default_value=b"<pad>"), y_batch
preprocess(X_batch, y_batch)
# +
from collections import Counter
vocabulary = Counter()
for X_batch, y_batch in datasets["train"].batch(32).map(preprocess):
for review in X_batch:
vocabulary.update(list(review.numpy()))
# -
vocabulary.most_common()[:3]
len(vocabulary)
vocab_size = 10000
truncated_vocabulary = [
word for word, count in vocabulary.most_common()[:vocab_size]]
word_to_id = {word: index for index, word in enumerate(truncated_vocabulary)}
for word in b"This movie was faaaaaantastic".split():
print(word_to_id.get(word) or vocab_size)
words = tf.constant(truncated_vocabulary)
word_ids = tf.range(len(truncated_vocabulary), dtype=tf.int64)
vocab_init = tf.lookup.KeyValueTensorInitializer(words, word_ids)
num_oov_buckets = 1000
table = tf.lookup.StaticVocabularyTable(vocab_init, num_oov_buckets)
table.lookup(tf.constant([b"This movie was faaaaaantastic".split()]))
# +
def encode_words(X_batch, y_batch):
return table.lookup(X_batch), y_batch
train_set = datasets["train"].repeat().batch(32).map(preprocess)
train_set = train_set.map(encode_words).prefetch(1)
# -
for X_batch, y_batch in train_set.take(1):
print(X_batch)
print(y_batch)
embed_size = 128
model = keras.models.Sequential([
keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size,
mask_zero=True, # not shown in the book
input_shape=[None]),
keras.layers.GRU(128, return_sequences=True),
keras.layers.GRU(128),
keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
history = model.fit(train_set, steps_per_epoch=train_size // 32, epochs=5)
# Or using manual masking:
K = keras.backend
embed_size = 128
inputs = keras.layers.Input(shape=[None])
mask = keras.layers.Lambda(lambda inputs: K.not_equal(inputs, 0))(inputs)
z = keras.layers.Embedding(vocab_size + num_oov_buckets, embed_size)(inputs)
z = keras.layers.GRU(128, return_sequences=True)(z, mask=mask)
z = keras.layers.GRU(128)(z, mask=mask)
outputs = keras.layers.Dense(1, activation="sigmoid")(z)
model = keras.models.Model(inputs=[inputs], outputs=[outputs])
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
history = model.fit(train_set, steps_per_epoch=train_size // 32, epochs=5)
# ## Reusing Pretrained Embeddings
tf.random.set_seed(42)
TFHUB_CACHE_DIR = os.path.join(os.curdir, "my_tfhub_cache")
os.environ["TFHUB_CACHE_DIR"] = TFHUB_CACHE_DIR
# +
import tensorflow_hub as hub
model = keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/tf2-preview/nnlm-en-dim50/1",
dtype=tf.string, input_shape=[], output_shape=[50]),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="adam",
metrics=["accuracy"])
# -
for dirpath, dirnames, filenames in os.walk(TFHUB_CACHE_DIR):
for filename in filenames:
print(os.path.join(dirpath, filename))
# +
import tensorflow_datasets as tfds
datasets, info = tfds.load("imdb_reviews", as_supervised=True, with_info=True)
train_size = info.splits["train"].num_examples
batch_size = 32
train_set = datasets["train"].repeat().batch(batch_size).prefetch(1)
history = model.fit(train_set, steps_per_epoch=train_size // batch_size, epochs=5)
# -
# ## Automatic Translation
tf.random.set_seed(42)
vocab_size = 100
embed_size = 10
# +
import tensorflow_addons as tfa
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
sequence_lengths = keras.layers.Input(shape=[], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
encoder = keras.layers.LSTM(512, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_embeddings)
encoder_state = [state_h, state_c]
sampler = tfa.seq2seq.sampler.TrainingSampler()
decoder_cell = keras.layers.LSTMCell(512)
output_layer = keras.layers.Dense(vocab_size)
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell, sampler,
output_layer=output_layer)
final_outputs, final_state, final_sequence_lengths = decoder(
decoder_embeddings, initial_state=encoder_state,
sequence_length=sequence_lengths)
Y_proba = tf.nn.softmax(final_outputs.rnn_output)
model = keras.models.Model(
inputs=[encoder_inputs, decoder_inputs, sequence_lengths],
outputs=[Y_proba])
# -
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam")
# +
X = np.random.randint(100, size=10*1000).reshape(1000, 10)
Y = np.random.randint(100, size=15*1000).reshape(1000, 15)
X_decoder = np.c_[np.zeros((1000, 1)), Y[:, :-1]]
seq_lengths = np.full([1000], 15)
history = model.fit([X, X_decoder, seq_lengths], Y, epochs=2)
# -
# ### Bidirectional Recurrent Layers
# +
model = keras.models.Sequential([
keras.layers.GRU(10, return_sequences=True, input_shape=[None, 10]),
keras.layers.Bidirectional(keras.layers.GRU(10, return_sequences=True))
])
model.summary()
# -
# ### Positional Encoding
class PositionalEncoding(keras.layers.Layer):
def __init__(self, max_steps, max_dims, dtype=tf.float32, **kwargs):
super().__init__(dtype=dtype, **kwargs)
if max_dims % 2 == 1: max_dims += 1 # max_dims must be even
p, i = np.meshgrid(np.arange(max_steps), np.arange(max_dims // 2))
pos_emb = np.empty((1, max_steps, max_dims))
pos_emb[0, :, ::2] = np.sin(p / 10000**(2 * i / max_dims)).T
pos_emb[0, :, 1::2] = np.cos(p / 10000**(2 * i / max_dims)).T
self.positional_embedding = tf.constant(pos_emb.astype(self.dtype))
def call(self, inputs):
shape = tf.shape(inputs)
return inputs + self.positional_embedding[:, :shape[-2], :shape[-1]]
max_steps = 201
max_dims = 512
pos_emb = PositionalEncoding(max_steps, max_dims)
PE = pos_emb(np.zeros((1, max_steps, max_dims), np.float32))[0].numpy()
i1, i2, crop_i = 100, 101, 150
p1, p2, p3 = 22, 60, 35
fig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, sharex=True, figsize=(9, 5))
ax1.plot([p1, p1], [-1, 1], "k--", label="$p = {}$".format(p1))
ax1.plot([p2, p2], [-1, 1], "k--", label="$p = {}$".format(p2), alpha=0.5)
ax1.plot(p3, PE[p3, i1], "bx", label="$p = {}$".format(p3))
ax1.plot(PE[:,i1], "b-", label="$i = {}$".format(i1))
ax1.plot(PE[:,i2], "r-", label="$i = {}$".format(i2))
ax1.plot([p1, p2], [PE[p1, i1], PE[p2, i1]], "bo")
ax1.plot([p1, p2], [PE[p1, i2], PE[p2, i2]], "ro")
ax1.legend(loc="center right", fontsize=14, framealpha=0.95)
ax1.set_ylabel("$P_{(p,i)}$", rotation=0, fontsize=16)
ax1.grid(True, alpha=0.3)
ax1.hlines(0, 0, max_steps - 1, color="k", linewidth=1, alpha=0.3)
ax1.axis([0, max_steps - 1, -1, 1])
ax2.imshow(PE.T[:crop_i], cmap="gray", interpolation="bilinear", aspect="auto")
ax2.hlines(i1, 0, max_steps - 1, color="b")
cheat = 2 # need to raise the red line a bit, or else it hides the blue one
ax2.hlines(i2+cheat, 0, max_steps - 1, color="r")
ax2.plot([p1, p1], [0, crop_i], "k--")
ax2.plot([p2, p2], [0, crop_i], "k--", alpha=0.5)
ax2.plot([p1, p2], [i2+cheat, i2+cheat], "ro")
ax2.plot([p1, p2], [i1, i1], "bo")
ax2.axis([0, max_steps - 1, 0, crop_i])
ax2.set_xlabel("$p$", fontsize=16)
ax2.set_ylabel("$i$", rotation=0, fontsize=16)
save_fig("positional_embedding_plot")
plt.show()
embed_size = 512; max_steps = 500; vocab_size = 10000
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
embeddings = keras.layers.Embedding(vocab_size, embed_size)
encoder_embeddings = embeddings(encoder_inputs)
decoder_embeddings = embeddings(decoder_inputs)
positional_encoding = PositionalEncoding(max_steps, max_dims=embed_size)
encoder_in = positional_encoding(encoder_embeddings)
decoder_in = positional_encoding(decoder_embeddings)
# Here is a (very) simplified Transformer (the actual architecture has skip connections, layer norm, dense nets, and most importantly it uses Multi-Head Attention instead of regular Attention):
# +
Z = encoder_in
for N in range(6):
Z = keras.layers.Attention(use_scale=True)([Z, Z])
encoder_outputs = Z
Z = decoder_in
for N in range(6):
Z = keras.layers.Attention(use_scale=True, causal=True)([Z, Z])
Z = keras.layers.Attention(use_scale=True)([Z, encoder_outputs])
outputs = keras.layers.TimeDistributed(
keras.layers.Dense(vocab_size, activation="softmax"))(Z)
# -
# Here's a basic implementation of the `MultiHeadAttention` layer. One will likely be added to `keras.layers` in the near future. Note that `Conv1D` layers with `kernel_size=1` (and the default `padding="valid"` and `strides=1`) is equivalent to a `TimeDistributed(Dense(...))` layer.
# +
K = keras.backend
class MultiHeadAttention(keras.layers.Layer):
def __init__(self, n_heads, causal=False, use_scale=False, **kwargs):
self.n_heads = n_heads
self.causal = causal
self.use_scale = use_scale
super().__init__(**kwargs)
def build(self, batch_input_shape):
self.dims = batch_input_shape[0][-1]
self.q_dims, self.v_dims, self.k_dims = [self.dims // self.n_heads] * 3 # could be hyperparameters instead
self.q_linear = keras.layers.Conv1D(self.n_heads * self.q_dims, kernel_size=1, use_bias=False)
self.v_linear = keras.layers.Conv1D(self.n_heads * self.v_dims, kernel_size=1, use_bias=False)
self.k_linear = keras.layers.Conv1D(self.n_heads * self.k_dims, kernel_size=1, use_bias=False)
self.attention = keras.layers.Attention(causal=self.causal, use_scale=self.use_scale)
self.out_linear = keras.layers.Conv1D(self.dims, kernel_size=1, use_bias=False)
super().build(batch_input_shape)
def _multi_head_linear(self, inputs, linear):
shape = K.concatenate([K.shape(inputs)[:-1], [self.n_heads, -1]])
projected = K.reshape(linear(inputs), shape)
perm = K.permute_dimensions(projected, [0, 2, 1, 3])
return K.reshape(perm, [shape[0] * self.n_heads, shape[1], -1])
def call(self, inputs):
q = inputs[0]
v = inputs[1]
k = inputs[2] if len(inputs) > 2 else v
shape = K.shape(q)
q_proj = self._multi_head_linear(q, self.q_linear)
v_proj = self._multi_head_linear(v, self.v_linear)
k_proj = self._multi_head_linear(k, self.k_linear)
multi_attended = self.attention([q_proj, v_proj, k_proj])
shape_attended = K.shape(multi_attended)
reshaped_attended = K.reshape(multi_attended, [shape[0], self.n_heads, shape_attended[1], shape_attended[2]])
perm = K.permute_dimensions(reshaped_attended, [0, 2, 1, 3])
concat = K.reshape(perm, [shape[0], shape_attended[1], -1])
return self.out_linear(concat)
# -
Q = np.random.rand(2, 50, 512)
V = np.random.rand(2, 80, 512)
multi_attn = MultiHeadAttention(8)
multi_attn([Q, V]).shape
# # Exercise solutions
# ## 1. to 7.
# See Appendix A.
# ## 8.
# _Exercise:_ Embedded Reber grammars _were used by Hochreiter and Schmidhuber in [their paper](https://homl.info/93) about LSTMs. They are artificial grammars that produce strings such as "BPBTSXXVPSEPE." Check out Jenny Orr's [nice introduction](https://homl.info/108) to this topic. Choose a particular embedded Reber grammar (such as the one represented on Jenny Orr's page), then train an RNN to identify whether a string respects that grammar or not. You will first need to write a function capable of generating a training batch containing about 50% strings that respect the grammar, and 50% that don't._
# First we need to build a function that generates strings based on a grammar. The grammar will be represented as a list of possible transitions for each state. A transition specifies the string to output (or a grammar to generate it) and the next state.
# +
default_reber_grammar = [
[("B", 1)], # (state 0) =B=>(state 1)
[("T", 2), ("P", 3)], # (state 1) =T=>(state 2) or =P=>(state 3)
[("S", 2), ("X", 4)], # (state 2) =S=>(state 2) or =X=>(state 4)
[("T", 3), ("V", 5)], # and so on...
[("X", 3), ("S", 6)],
[("P", 4), ("V", 6)],
[("E", None)]] # (state 6) =E=>(terminal state)
embedded_reber_grammar = [
[("B", 1)],
[("T", 2), ("P", 3)],
[(default_reber_grammar, 4)],
[(default_reber_grammar, 5)],
[("T", 6)],
[("P", 6)],
[("E", None)]]
def generate_string(grammar):
state = 0
output = []
while state is not None:
index = np.random.randint(len(grammar[state]))
production, state = grammar[state][index]
if isinstance(production, list):
production = generate_string(grammar=production)
output.append(production)
return "".join(output)
# -
# Let's generate a few strings based on the default Reber grammar:
# +
np.random.seed(42)
for _ in range(25):
print(generate_string(default_reber_grammar), end=" ")
# -
# Looks good. Now let's generate a few strings based on the embedded Reber grammar:
# +
np.random.seed(42)
for _ in range(25):
print(generate_string(embedded_reber_grammar), end=" ")
# -
# Okay, now we need a function to generate strings that do not respect the grammar. We could generate a random string, but the task would be a bit too easy, so instead we will generate a string that respects the grammar, and we will corrupt it by changing just one character:
# +
POSSIBLE_CHARS = "BEPSTVX"
def generate_corrupted_string(grammar, chars=POSSIBLE_CHARS):
good_string = generate_string(grammar)
index = np.random.randint(len(good_string))
good_char = good_string[index]
bad_char = np.random.choice(sorted(set(chars) - set(good_char)))
return good_string[:index] + bad_char + good_string[index + 1:]
# -
# Let's look at a few corrupted strings:
# +
np.random.seed(42)
for _ in range(25):
print(generate_corrupted_string(embedded_reber_grammar), end=" ")
# -
# We cannot feed strings directly to an RNN, so we need to encode them somehow. One option would be to one-hot encode each character. Another option is to use embeddings. Let's go for the second option (but since there are just a handful of characters, one-hot encoding would probably be a good option as well). For embeddings to work, we need to convert each string into a sequence of character IDs. Let's write a function for that, using each character's index in the string of possible characters "BEPSTVX":
def string_to_ids(s, chars=POSSIBLE_CHARS):
return [chars.index(c) for c in s]
string_to_ids("BTTTXXVVETE")
# We can now generate the dataset, with 50% good strings, and 50% bad strings:
def generate_dataset(size):
good_strings = [string_to_ids(generate_string(embedded_reber_grammar))
for _ in range(size // 2)]
bad_strings = [string_to_ids(generate_corrupted_string(embedded_reber_grammar))
for _ in range(size - size // 2)]
all_strings = good_strings + bad_strings
X = tf.ragged.constant(all_strings, ragged_rank=1)
y = np.array([[1.] for _ in range(len(good_strings))] +
[[0.] for _ in range(len(bad_strings))])
return X, y
# +
np.random.seed(42)
X_train, y_train = generate_dataset(10000)
X_valid, y_valid = generate_dataset(2000)
# -
# Let's take a look at the first training sequence:
X_train[0]
# What class does it belong to?
y_train[0]
# Perfect! We are ready to create the RNN to identify good strings. We build a simple sequence binary classifier:
# +
np.random.seed(42)
tf.random.set_seed(42)
embedding_size = 5
model = keras.models.Sequential([
keras.layers.InputLayer(input_shape=[None], dtype=tf.int32, ragged=True),
keras.layers.Embedding(input_dim=len(POSSIBLE_CHARS), output_dim=embedding_size),
keras.layers.GRU(30),
keras.layers.Dense(1, activation="sigmoid")
])
optimizer = keras.optimizers.SGD(lr=0.02, momentum = 0.95, nesterov=True)
model.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
# -
# Now let's test our RNN on two tricky strings: the first one is bad while the second one is good. They only differ by the second to last character. If the RNN gets this right, it shows that it managed to notice the pattern that the second letter should always be equal to the second to last letter. That requires a fairly long short-term memory (which is the reason why we used a GRU cell).
# +
test_strings = ["BPBTSSSSSSSXXTTVPXVPXTTTTTVVETE",
"BPBTSSSSSSSXXTTVPXVPXTTTTTVVEPE"]
X_test = tf.ragged.constant([string_to_ids(s) for s in test_strings], ragged_rank=1)
y_proba = model.predict(X_test)
print()
print("Estimated probability that these are Reber strings:")
for index, string in enumerate(test_strings):
print("{}: {:.2f}%".format(string, 100 * y_proba[index][0]))
# -
# Ta-da! It worked fine. The RNN found the correct answers with very high confidence. :)
# ## 9.
# _Exercise: Train an Encoder–Decoder model that can convert a date string from one format to another (e.g., from "April 22, 2019" to "2019-04-22")._
# Let's start by creating the dataset. We will use random days between 1000-01-01 and 9999-12-31:
# +
from datetime import date
# cannot use strftime()'s %B format since it depends on the locale
MONTHS = ["January", "February", "March", "April", "May", "June",
"July", "August", "September", "October", "November", "December"]
def random_dates(n_dates):
min_date = date(1000, 1, 1).toordinal()
max_date = date(9999, 12, 31).toordinal()
ordinals = np.random.randint(max_date - min_date, size=n_dates) + min_date
dates = [date.fromordinal(ordinal) for ordinal in ordinals]
x = [MONTHS[dt.month - 1] + " " + dt.strftime("%d, %Y") for dt in dates]
y = [dt.isoformat() for dt in dates]
return x, y
# -
# Here are a few random dates, displayed in both the input format and the target format:
# +
np.random.seed(42)
n_dates = 3
x_example, y_example = random_dates(n_dates)
print("{:25s}{:25s}".format("Input", "Target"))
print("-" * 50)
for idx in range(n_dates):
print("{:25s}{:25s}".format(x_example[idx], y_example[idx]))
# -
# Let's get the list of all possible characters in the inputs:
INPUT_CHARS = "".join(sorted(set("".join(MONTHS) + "0123456789, ")))
INPUT_CHARS
# And here's the list of possible characters in the outputs:
OUTPUT_CHARS = "0123456789-"
# Let's write a function to convert a string to a list of character IDs, as we did in the previous exercise:
def date_str_to_ids(date_str, chars=INPUT_CHARS):
return [chars.index(c) for c in date_str]
date_str_to_ids(x_example[0], INPUT_CHARS)
date_str_to_ids(y_example[0], OUTPUT_CHARS)
# +
def prepare_date_strs(date_strs, chars=INPUT_CHARS):
X_ids = [date_str_to_ids(dt, chars) for dt in date_strs]
X = tf.ragged.constant(X_ids, ragged_rank=1)
return (X + 1).to_tensor() # using 0 as the padding token ID
def create_dataset(n_dates):
x, y = random_dates(n_dates)
return prepare_date_strs(x, INPUT_CHARS), prepare_date_strs(y, OUTPUT_CHARS)
# +
np.random.seed(42)
X_train, Y_train = create_dataset(10000)
X_valid, Y_valid = create_dataset(2000)
X_test, Y_test = create_dataset(2000)
# -
Y_train[0]
# ### First version: a very basic seq2seq model
# Let's first try the simplest possible model: we feed in the input sequence, which first goes through the encoder (an embedding layer followed by a single LSTM layer), which outputs a vector, then it goes through a decoder (a single LSTM layer, followed by a dense output layer), which outputs a sequence of vectors, each representing the estimated probabilities for all possible output character.
#
# Since the decoder expects a sequence as input, we repeat the vector (which is output by the decoder) as many times as the longest possible output sequence.
# +
embedding_size = 32
max_output_length = Y_train.shape[1]
np.random.seed(42)
tf.random.set_seed(42)
encoder = keras.models.Sequential([
keras.layers.Embedding(input_dim=len(INPUT_CHARS) + 1,
output_dim=embedding_size,
input_shape=[None]),
keras.layers.LSTM(128)
])
decoder = keras.models.Sequential([
keras.layers.LSTM(128, return_sequences=True),
keras.layers.Dense(len(OUTPUT_CHARS) + 1, activation="softmax")
])
model = keras.models.Sequential([
encoder,
keras.layers.RepeatVector(max_output_length),
decoder
])
optimizer = keras.optimizers.Nadam()
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))
# -
# Looks great, we reach 100% validation accuracy! Let's use the model to make some predictions. We will need to be able to convert a sequence of character IDs to a readable string:
def ids_to_date_strs(ids, chars=OUTPUT_CHARS):
return ["".join([("?" + chars)[index] for index in sequence])
for sequence in ids]
# Now we can use the model to convert some dates
X_new = prepare_date_strs(["September 17, 2009", "July 14, 1789"])
#ids = model.predict_classes(X_new)
ids = np.argmax(model.predict(X_new), axis=-1)
for date_str in ids_to_date_strs(ids):
print(date_str)
# Perfect! :)
# However, since the model was only trained on input strings of length 18 (which is the length of the longest date), it does not perform well if we try to use it to make predictions on shorter sequences:
X_new = prepare_date_strs(["May 02, 2020", "July 14, 1789"])
#ids = model.predict_classes(X_new)
ids = np.argmax(model.predict(X_new), axis=-1)
for date_str in ids_to_date_strs(ids):
print(date_str)
# Oops! We need to ensure that we always pass sequences of the same length as during training, using padding if necessary. Let's write a little helper function for that:
# +
max_input_length = X_train.shape[1]
def prepare_date_strs_padded(date_strs):
X = prepare_date_strs(date_strs)
if X.shape[1] < max_input_length:
X = tf.pad(X, [[0, 0], [0, max_input_length - X.shape[1]]])
return X
def convert_date_strs(date_strs):
X = prepare_date_strs_padded(date_strs)
#ids = model.predict_classes(X)
ids = np.argmax(model.predict(X), axis=-1)
return ids_to_date_strs(ids)
# -
convert_date_strs(["May 02, 2020", "July 14, 1789"])
# Cool! Granted, there are certainly much easier ways to write a date conversion tool (e.g., using regular expressions or even basic string manipulation), but you have to admit that using neural networks is way cooler. ;-)
# However, real-life sequence-to-sequence problems will usually be harder, so for the sake of completeness, let's build a more powerful model.
# ### Second version: feeding the shifted targets to the decoder (teacher forcing)
# Instead of feeding the decoder a simple repetition of the encoder's output vector, we can feed it the target sequence, shifted by one time step to the right. This way, at each time step the decoder will know what the previous target character was. This should help is tackle more complex sequence-to-sequence problems.
#
# Since the first output character of each target sequence has no previous character, we will need a new token to represent the start-of-sequence (sos).
#
# During inference, we won't know the target, so what will we feed the decoder? We can just predict one character at a time, starting with an sos token, then feeding the decoder all the characters that were predicted so far (we will look at this in more details later in this notebook).
#
# But if the decoder's LSTM expects to get the previous target as input at each step, how shall we pass it it the vector output by the encoder? Well, one option is to ignore the output vector, and instead use the encoder's LSTM state as the initial state of the decoder's LSTM (which requires that encoder's LSTM must have the same number of units as the decoder's LSTM).
#
# Now let's create the decoder's inputs (for training, validation and testing). The sos token will be represented using the last possible output character's ID + 1.
# +
sos_id = len(OUTPUT_CHARS) + 1
def shifted_output_sequences(Y):
sos_tokens = tf.fill(dims=(len(Y), 1), value=sos_id)
return tf.concat([sos_tokens, Y[:, :-1]], axis=1)
X_train_decoder = shifted_output_sequences(Y_train)
X_valid_decoder = shifted_output_sequences(Y_valid)
X_test_decoder = shifted_output_sequences(Y_test)
# -
# Let's take a look at the decoder's training inputs:
X_train_decoder
# Now let's build the model. It's not a simple sequential model anymore, so let's use the functional API:
# +
encoder_embedding_size = 32
decoder_embedding_size = 32
lstm_units = 128
np.random.seed(42)
tf.random.set_seed(42)
encoder_input = keras.layers.Input(shape=[None], dtype=tf.int32)
encoder_embedding = keras.layers.Embedding(
input_dim=len(INPUT_CHARS) + 1,
output_dim=encoder_embedding_size)(encoder_input)
_, encoder_state_h, encoder_state_c = keras.layers.LSTM(
lstm_units, return_state=True)(encoder_embedding)
encoder_state = [encoder_state_h, encoder_state_c]
decoder_input = keras.layers.Input(shape=[None], dtype=tf.int32)
decoder_embedding = keras.layers.Embedding(
input_dim=len(OUTPUT_CHARS) + 2,
output_dim=decoder_embedding_size)(decoder_input)
decoder_lstm_output = keras.layers.LSTM(lstm_units, return_sequences=True)(
decoder_embedding, initial_state=encoder_state)
decoder_output = keras.layers.Dense(len(OUTPUT_CHARS) + 1,
activation="softmax")(decoder_lstm_output)
model = keras.models.Model(inputs=[encoder_input, decoder_input],
outputs=[decoder_output])
optimizer = keras.optimizers.Nadam()
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit([X_train, X_train_decoder], Y_train, epochs=10,
validation_data=([X_valid, X_valid_decoder], Y_valid))
# -
# This model also reaches 100% validation accuracy, but it does so even faster.
# Let's once again use the model to make some predictions. This time we need to predict characters one by one.
# +
sos_id = len(OUTPUT_CHARS) + 1
def predict_date_strs(date_strs):
X = prepare_date_strs_padded(date_strs)
Y_pred = tf.fill(dims=(len(X), 1), value=sos_id)
for index in range(max_output_length):
pad_size = max_output_length - Y_pred.shape[1]
X_decoder = tf.pad(Y_pred, [[0, 0], [0, pad_size]])
Y_probas_next = model.predict([X, X_decoder])[:, index:index+1]
Y_pred_next = tf.argmax(Y_probas_next, axis=-1, output_type=tf.int32)
Y_pred = tf.concat([Y_pred, Y_pred_next], axis=1)
return ids_to_date_strs(Y_pred[:, 1:])
# -
predict_date_strs(["July 14, 1789", "May 01, 2020"])
# Works fine! :)
# ### Third version: using TF-Addons's seq2seq implementation
# Let's build exactly the same model, but using TF-Addon's seq2seq API. The implementation below is almost very similar to the TFA example higher in this notebook, except without the model input to specify the output sequence length, for simplicity (but you can easily add it back in if you need it for your projects, when the output sequences have very different lengths).
# +
import tensorflow_addons as tfa
np.random.seed(42)
tf.random.set_seed(42)
encoder_embedding_size = 32
decoder_embedding_size = 32
units = 128
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
sequence_lengths = keras.layers.Input(shape=[], dtype=np.int32)
encoder_embeddings = keras.layers.Embedding(
len(INPUT_CHARS) + 1, encoder_embedding_size)(encoder_inputs)
decoder_embedding_layer = keras.layers.Embedding(
len(OUTPUT_CHARS) + 2, decoder_embedding_size)
decoder_embeddings = decoder_embedding_layer(decoder_inputs)
encoder = keras.layers.LSTM(units, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_embeddings)
encoder_state = [state_h, state_c]
sampler = tfa.seq2seq.sampler.TrainingSampler()
decoder_cell = keras.layers.LSTMCell(units)
output_layer = keras.layers.Dense(len(OUTPUT_CHARS) + 1)
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell,
sampler,
output_layer=output_layer)
final_outputs, final_state, final_sequence_lengths = decoder(
decoder_embeddings,
initial_state=encoder_state)
Y_proba = keras.layers.Activation("softmax")(final_outputs.rnn_output)
model = keras.models.Model(inputs=[encoder_inputs, decoder_inputs],
outputs=[Y_proba])
optimizer = keras.optimizers.Nadam()
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit([X_train, X_train_decoder], Y_train, epochs=15,
validation_data=([X_valid, X_valid_decoder], Y_valid))
# -
# And once again, 100% validation accuracy! To use the model, we can just reuse the `predict_date_strs()` function:
predict_date_strs(["July 14, 1789", "May 01, 2020"])
# However, there's a much more efficient way to perform inference. Until now, during inference, we've run the model once for each new character. Instead, we can create a new decoder, based on the previously trained layers, but using a `GreedyEmbeddingSampler` instead of a `TrainingSampler`.
#
# At each time step, the `GreedyEmbeddingSampler` will compute the argmax of the decoder's outputs, and run the resulting token IDs through the decoder's embedding layer. Then it will feed the resulting embeddings to the decoder's LSTM cell at the next time step. This way, we only need to run the decoder once to get the full prediction.
# +
inference_sampler = tfa.seq2seq.sampler.GreedyEmbeddingSampler(
embedding_fn=decoder_embedding_layer)
inference_decoder = tfa.seq2seq.basic_decoder.BasicDecoder(
decoder_cell, inference_sampler, output_layer=output_layer,
maximum_iterations=max_output_length)
batch_size = tf.shape(encoder_inputs)[:1]
start_tokens = tf.fill(dims=batch_size, value=sos_id)
final_outputs, final_state, final_sequence_lengths = inference_decoder(
start_tokens,
initial_state=encoder_state,
start_tokens=start_tokens,
end_token=0)
inference_model = keras.models.Model(inputs=[encoder_inputs],
outputs=[final_outputs.sample_id])
# -
# A few notes:
# * The `GreedyEmbeddingSampler` needs the `start_tokens` (a vector containing the start-of-sequence ID for each decoder sequence), and the `end_token` (the decoder will stop decoding a sequence once the model outputs this token).
# * We must set `maximum_iterations` when creating the `BasicDecoder`, or else it may run into an infinite loop (if the model never outputs the end token for at least one of the sequences). This would force you would to restart the Jupyter kernel.
# * The decoder inputs are not needed anymore, since all the decoder inputs are generated dynamically based on the outputs from the previous time step.
# * The model's outputs are `final_outputs.sample_id` instead of the softmax of `final_outputs.rnn_outputs`. This allows us to directly get the argmax of the model's outputs. If you prefer to have access to the logits, you can replace `final_outputs.sample_id` with `final_outputs.rnn_outputs`.
# Now we can write a simple function that uses the model to perform the date format conversion:
def fast_predict_date_strs(date_strs):
X = prepare_date_strs_padded(date_strs)
Y_pred = inference_model.predict(X)
return ids_to_date_strs(Y_pred)
fast_predict_date_strs(["July 14, 1789", "May 01, 2020"])
# Let's check that it really is faster:
# %timeit predict_date_strs(["July 14, 1789", "May 01, 2020"])
# %timeit fast_predict_date_strs(["July 14, 1789", "May 01, 2020"])
# That's more than a 10x speedup! And it would be even more if we were handling longer sequences.
# ### Fourth version: using TF-Addons's seq2seq implementation with a scheduled sampler
# **Warning**: due to a TF bug, this version only works using TensorFlow 2.2 or above.
# When we trained the previous model, at each time step _t_ we gave the model the target token for time step _t_ - 1. However, at inference time, the model did not get the previous target at each time step. Instead, it got the previous prediction. So there is a discrepancy between training and inference, which may lead to disappointing performance. To alleviate this, we can gradually replace the targets with the predictions, during training. For this, we just need to replace the `TrainingSampler` with a `ScheduledEmbeddingTrainingSampler`, and use a Keras callback to gradually increase the `sampling_probability` (i.e., the probability that the decoder will use the prediction from the previous time step rather than the target for the previous time step).
# +
import tensorflow_addons as tfa
np.random.seed(42)
tf.random.set_seed(42)
n_epochs = 20
encoder_embedding_size = 32
decoder_embedding_size = 32
units = 128
encoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
decoder_inputs = keras.layers.Input(shape=[None], dtype=np.int32)
sequence_lengths = keras.layers.Input(shape=[], dtype=np.int32)
encoder_embeddings = keras.layers.Embedding(
len(INPUT_CHARS) + 1, encoder_embedding_size)(encoder_inputs)
decoder_embedding_layer = keras.layers.Embedding(
len(OUTPUT_CHARS) + 2, decoder_embedding_size)
decoder_embeddings = decoder_embedding_layer(decoder_inputs)
encoder = keras.layers.LSTM(units, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_embeddings)
encoder_state = [state_h, state_c]
sampler = tfa.seq2seq.sampler.ScheduledEmbeddingTrainingSampler(
sampling_probability=0.,
embedding_fn=decoder_embedding_layer)
# we must set the sampling_probability after creating the sampler
# (see https://github.com/tensorflow/addons/pull/1714)
sampler.sampling_probability = tf.Variable(0.)
decoder_cell = keras.layers.LSTMCell(units)
output_layer = keras.layers.Dense(len(OUTPUT_CHARS) + 1)
decoder = tfa.seq2seq.basic_decoder.BasicDecoder(decoder_cell,
sampler,
output_layer=output_layer)
final_outputs, final_state, final_sequence_lengths = decoder(
decoder_embeddings,
initial_state=encoder_state)
Y_proba = keras.layers.Activation("softmax")(final_outputs.rnn_output)
model = keras.models.Model(inputs=[encoder_inputs, decoder_inputs],
outputs=[Y_proba])
optimizer = keras.optimizers.Nadam()
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
def update_sampling_probability(epoch, logs):
proba = min(1.0, epoch / (n_epochs - 10))
sampler.sampling_probability.assign(proba)
sampling_probability_cb = keras.callbacks.LambdaCallback(
on_epoch_begin=update_sampling_probability)
history = model.fit([X_train, X_train_decoder], Y_train, epochs=n_epochs,
validation_data=([X_valid, X_valid_decoder], Y_valid),
callbacks=[sampling_probability_cb])
# -
# Not quite 100% validation accuracy, but close enough!
# For inference, we could do the exact same thing as earlier, using a `GreedyEmbeddingSampler`. However, just for the sake of completeness, let's use a `SampleEmbeddingSampler` instead. It's almost the same thing, except that instead of using the argmax of the model's output to find the token ID, it treats the outputs as logits and uses them to sample a token ID randomly. This can be useful when you want to generate text. The `softmax_temperature` argument serves the
# same purpose as when we generated Shakespeare-like text (the higher this argument, the more random the generated text will be).
# +
softmax_temperature = tf.Variable(1.)
inference_sampler = tfa.seq2seq.sampler.SampleEmbeddingSampler(
embedding_fn=decoder_embedding_layer,
softmax_temperature=softmax_temperature)
inference_decoder = tfa.seq2seq.basic_decoder.BasicDecoder(
decoder_cell, inference_sampler, output_layer=output_layer,
maximum_iterations=max_output_length)
batch_size = tf.shape(encoder_inputs)[:1]
start_tokens = tf.fill(dims=batch_size, value=sos_id)
final_outputs, final_state, final_sequence_lengths = inference_decoder(
start_tokens,
initial_state=encoder_state,
start_tokens=start_tokens,
end_token=0)
inference_model = keras.models.Model(inputs=[encoder_inputs],
outputs=[final_outputs.sample_id])
# -
def creative_predict_date_strs(date_strs, temperature=1.0):
softmax_temperature.assign(temperature)
X = prepare_date_strs_padded(date_strs)
Y_pred = inference_model.predict(X)
return ids_to_date_strs(Y_pred)
# +
tf.random.set_seed(42)
creative_predict_date_strs(["July 14, 1789", "May 01, 2020"])
# -
# Dates look good at room temperature. Now let's heat things up a bit:
# +
tf.random.set_seed(42)
creative_predict_date_strs(["July 14, 1789", "May 01, 2020"],
temperature=5.)
# -
# Oops, the dates are overcooked, now. Let's call them "creative" dates.
# ### Fifth version: using TFA seq2seq, the Keras subclassing API and attention mechanisms
# The sequences in this problem are pretty short, but if we wanted to tackle longer sequences, we would probably have to use attention mechanisms. While it's possible to code our own implementation, it's simpler and more efficient to use TF-Addons's implementation instead. Let's do that now, this time using Keras' subclassing API.
#
# **Warning**: due to a TensorFlow bug (see [this issue](https://github.com/tensorflow/addons/issues/1153) for details), the `get_initial_state()` method fails in eager mode, so for now we have to use the subclassing API, as Keras automatically calls `tf.function()` on the `call()` method (so it runs in graph mode).
# In this implementation, we've reverted back to using the `TrainingSampler`, for simplicity (but you can easily tweak it to use a `ScheduledEmbeddingTrainingSampler` instead). We also use a `GreedyEmbeddingSampler` during inference, so this class is pretty easy to use:
class DateTranslation(keras.models.Model):
def __init__(self, units=128, encoder_embedding_size=32,
decoder_embedding_size=32, **kwargs):
super().__init__(**kwargs)
self.encoder_embedding = keras.layers.Embedding(
input_dim=len(INPUT_CHARS) + 1,
output_dim=encoder_embedding_size)
self.encoder = keras.layers.LSTM(units,
return_sequences=True,
return_state=True)
self.decoder_embedding = keras.layers.Embedding(
input_dim=len(OUTPUT_CHARS) + 2,
output_dim=decoder_embedding_size)
self.attention = tfa.seq2seq.LuongAttention(units)
decoder_inner_cell = keras.layers.LSTMCell(units)
self.decoder_cell = tfa.seq2seq.AttentionWrapper(
cell=decoder_inner_cell,
attention_mechanism=self.attention)
output_layer = keras.layers.Dense(len(OUTPUT_CHARS) + 1)
self.decoder = tfa.seq2seq.BasicDecoder(
cell=self.decoder_cell,
sampler=tfa.seq2seq.sampler.TrainingSampler(),
output_layer=output_layer)
self.inference_decoder = tfa.seq2seq.BasicDecoder(
cell=self.decoder_cell,
sampler=tfa.seq2seq.sampler.GreedyEmbeddingSampler(
embedding_fn=self.decoder_embedding),
output_layer=output_layer,
maximum_iterations=max_output_length)
def call(self, inputs, training=None):
encoder_input, decoder_input = inputs
encoder_embeddings = self.encoder_embedding(encoder_input)
encoder_outputs, encoder_state_h, encoder_state_c = self.encoder(
encoder_embeddings,
training=training)
encoder_state = [encoder_state_h, encoder_state_c]
self.attention(encoder_outputs,
setup_memory=True)
decoder_embeddings = self.decoder_embedding(decoder_input)
decoder_initial_state = self.decoder_cell.get_initial_state(
decoder_embeddings)
decoder_initial_state = decoder_initial_state.clone(
cell_state=encoder_state)
if training:
decoder_outputs, _, _ = self.decoder(
decoder_embeddings,
initial_state=decoder_initial_state,
training=training)
else:
start_tokens = tf.zeros_like(encoder_input[:, 0]) + sos_id
decoder_outputs, _, _ = self.inference_decoder(
decoder_embeddings,
initial_state=decoder_initial_state,
start_tokens=start_tokens,
end_token=0)
return tf.nn.softmax(decoder_outputs.rnn_output)
# +
np.random.seed(42)
tf.random.set_seed(42)
model = DateTranslation()
optimizer = keras.optimizers.Nadam()
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit([X_train, X_train_decoder], Y_train, epochs=25,
validation_data=([X_valid, X_valid_decoder], Y_valid))
# -
# Not quite 100% validation accuracy, but close. It took a bit longer to converge this time, but there were also more parameters and more computations per iteration. And we did not use a scheduled sampler.
#
# To use the model, we can write yet another little function:
def fast_predict_date_strs_v2(date_strs):
X = prepare_date_strs_padded(date_strs)
X_decoder = tf.zeros(shape=(len(X), max_output_length), dtype=tf.int32)
Y_probas = model.predict([X, X_decoder])
Y_pred = tf.argmax(Y_probas, axis=-1)
return ids_to_date_strs(Y_pred)
fast_predict_date_strs_v2(["July 14, 1789", "May 01, 2020"])
# There are still a few interesting features from TF-Addons that you may want to look at:
# * Using a `BeamSearchDecoder` rather than a `BasicDecoder` for inference. Instead of outputing the character with the highest probability, this decoder keeps track of the several candidates, and keeps only the most likely sequences of candidates (see chapter 16 in the book for more details).
# * Setting masks or specifying `sequence_length` if the input or target sequences may have very different lengths.
# * Using a `ScheduledOutputTrainingSampler`, which gives you more flexibility than the `ScheduledEmbeddingTrainingSampler` to decide how to feed the output at time _t_ to the cell at time _t_+1. By default it feeds the outputs directly to cell, without computing the argmax ID and passing it through an embedding layer. Alternatively, you specify a `next_inputs_fn` function that will be used to convert the cell outputs to inputs at the next step.
# ## 10.
# _Exercise: Go through TensorFlow's [Neural Machine Translation with Attention tutorial](https://homl.info/nmttuto)._
# Simply open the Colab and follow its instructions. Alternatively, if you want a simpler example of using TF-Addons's seq2seq implementation for Neural Machine Translation (NMT), look at the solution to the previous question. The last model implementation will give you a simpler example of using TF-Addons to build an NMT model using attention mechanisms.
# ## 11.
# _Exercise: Use one of the recent language models (e.g., GPT) to generate more convincing Shakespearean text._
# The simplest way to use recent language models is to use the excellent [transformers library](https://huggingface.co/transformers/), open sourced by Hugging Face. It provides many modern neural net architectures (including BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet and more) for Natural Language Processing (NLP), including many pretrained models. It relies on either TensorFlow or PyTorch. Best of all: it's amazingly simple to use.
# First, let's load a pretrained model. In this example, we will use OpenAI's GPT model, with an additional Language Model on top (just a linear layer with weights tied to the input embeddings). Let's import it and load the pretrained weights (this will download about 445MB of data to `~/.cache/torch/transformers`):
# +
from transformers import TFOpenAIGPTLMHeadModel
model = TFOpenAIGPTLMHeadModel.from_pretrained("openai-gpt")
# -
# Next we will need a specialized tokenizer for this model. This one will try to use the [spaCy](https://spacy.io/) and [ftfy](https://pypi.org/project/ftfy/) libraries if they are installed, or else it will fall back to BERT's `BasicTokenizer` followed by Byte-Pair Encoding (which should be fine for most use cases).
# +
from transformers import OpenAIGPTTokenizer
tokenizer = OpenAIGPTTokenizer.from_pretrained("openai-gpt")
# -
# Now let's use the tokenizer to tokenize and encode the prompt text:
prompt_text = "This royal throne of kings, this sceptred isle"
encoded_prompt = tokenizer.encode(prompt_text,
add_special_tokens=False,
return_tensors="tf")
encoded_prompt
# Easy! Next, let's use the model to generate text after the prompt. We will generate 5 different sentences, each starting with the prompt text, followed by 40 additional tokens. For an explanation of what all the hyperparameters do, make sure to check out this great [blog post](https://huggingface.co/blog/how-to-generate) by <NAME> (from Hugging Face). You can play around with the hyperparameters to try to obtain better results.
# +
num_sequences = 5
length = 40
generated_sequences = model.generate(
input_ids=encoded_prompt,
do_sample=True,
max_length=length + len(encoded_prompt[0]),
temperature=1.0,
top_k=0,
top_p=0.9,
repetition_penalty=1.0,
num_return_sequences=num_sequences,
)
generated_sequences
# -
# Now let's decode the generated sequences and print them:
for sequence in generated_sequences:
text = tokenizer.decode(sequence, clean_up_tokenization_spaces=True)
print(text)
print("-" * 80)
# You can try more recent (and larger) models, such as GPT-2, CTRL, Transformer-XL or XLNet, which are all available as pretrained models in the transformers library, including variants with Language Models on top. The preprocessing steps vary slightly between models, so make sure to check out this [generation example](https://github.com/huggingface/transformers/blob/master/examples/run_generation.py) from the transformers documentation (this example uses PyTorch, but it will work with very little tweaks, such as adding `TF` at the beginning of the model class name, removing the `.to()` method calls, and using `return_tensors="tf"` instead of `"pt"`.
# Hope you enjoyed this chapter! :)
| 16_nlp_with_rnns_and_attention.ipynb |