
code stringlengths 38 801k | repo_path stringlengths 6 263 |
|---|---|
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# # Appropriate figure sizes
# +
import matplotlib.pyplot as plt
from tueplots import figsizes
# Increase the resolution of all the plots below
plt.rcParams.update({"figure.dpi": 150})
# -
# Figure sizes are tuples. They describe the figure sizes in `inches`, just like what matplotlib expects.
#
# Outputs of `figsize` functions are dictionaries that match `rcParams`.
#
icml_size = figsizes.icml2022_full()
icml_size
# We can use them to make differently sized figures. The height-to-width ratio is (loosely) based on the golden ratio.
fig, ax = plt.subplots()
ax.plot([1.0, 2.0], [3.0, 4.0])
plt.show()
plt.rcParams.update(figsizes.icml2022_half(nrows=3))
fig, ax = plt.subplots()
ax.plot([1.0, 2.0], [3.0, 4.0])
plt.show()
# +
plt.rcParams.update(figsizes.neurips2021())
fig, ax = plt.subplots()
ax.plot([1.0, 2.0], [3.0, 4.0])
plt.show()
# +
plt.rcParams.update(figsizes.aistats2022_full())
fig, ax = plt.subplots()
ax.plot([1.0, 2.0], [3.0, 4.0])
plt.show()
# +
plt.rcParams.update(figsizes.neurips2021(nrows=2, ncols=3))
fig, axes = plt.subplots(nrows=2, ncols=3, sharex=True, sharey=True)
for ax in axes.flatten():
ax.plot([1.0, 2.0], [3.0, 4.0])
plt.show()
# +
plt.rcParams.update(figsizes.icml2022_half(nrows=2, ncols=2))
fig, axes = plt.subplots(nrows=2, ncols=2, sharex=True, sharey=True)
for ax in axes.flatten():
ax.plot([1.0, 2.0], [3.0, 4.0])
plt.show()
# +
plt.rcParams.update(figsizes.icml2022_half(nrows=2, ncols=2, height_to_width_ratio=1.0))
fig, axes = plt.subplots(nrows=2, ncols=2, sharex=True, sharey=True)
for ax in axes.flatten():
ax.plot([1.0, 2.0], [3.0, 4.0])
plt.show()
# -
| docs/source/example_notebooks/figsizes.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Libraries
# Import relevant libraries
# +
import pandas as pd
import numpy as np
import datetime as dt
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
# %matplotlib inline
# -
# ### Data Import
# Import data to visualize.
# +
solar_logan = pd.read_csv('Exports/Solar_Logan.csv')
solar_saltlake = pd.read_csv('Exports/Solar_SaltLake.csv')
ppf_logan = pd.read_csv('Exports/PPF & Weather_Logan.csv')
ppf_saltlake = pd.read_csv('Exports/PPF & Weather_SaltLake.csv')
ppf_daily_logan = pd.read_csv('Exports/PPF_Logan_DailyAve.csv')
ppf_daily_saltlake = pd.read_csv('Exports/PPF_SaltLake_DailyAve.csv')
ppf_monthly_logan = pd.read_csv('Exports/PPF_Logan_MonthlyAve.csv')
ppf_monthly_saltlake = pd.read_csv('Exports/PPF_SaltLake_MonthlyAve.csv')
ppf_daily_logan_max = pd.read_csv('Exports/PPF_Logan_DailyMax.csv')
ppf_daily_saltlake_max = pd.read_csv('Exports/PPF_SaltLake_DailyMax.csv')
# -
# Add datetime formatting to date column.
# +
solar_logan['Date'] = pd.to_datetime(solar_logan['Date'], format='%Y-%m-%d')
solar_saltlake['Date'] = pd.to_datetime(solar_saltlake['Date'], format='%Y-%m-%d')
ppf_logan['Date'] = pd.to_datetime(ppf_logan['Date'], format='%Y-%m-%d %H:%M:%S')
ppf_saltlake['Date'] = pd.to_datetime(ppf_saltlake['Date'], format='%Y-%m-%d %H:%M:%S')
ppf_daily_logan['Date'] = pd.to_datetime(ppf_daily_logan['Date'], format='%Y-%m-%d')
ppf_daily_saltlake['Date'] = pd.to_datetime(ppf_daily_saltlake['Date'], format='%Y-%m-%d')
ppf_monthly_logan['Date'] = pd.to_datetime(ppf_monthly_logan['Date'], format='%Y-%m-%d')
ppf_monthly_saltlake['Date'] = pd.to_datetime(ppf_monthly_saltlake['Date'], format='%Y-%m-%d')
ppf_daily_logan_max['Date'] = pd.to_datetime(ppf_daily_logan_max['Date'], format='%Y-%m-%d')
ppf_daily_saltlake_max['Date'] = pd.to_datetime(ppf_daily_saltlake_max['Date'], format='%Y-%m-%d')
# -
# ### Visualizations
# Visualize the data that has been imported.
# #### Photoperiods
# +
plt.style.use('seaborn')
# Convert light duration to hours
df = solar_logan
df['Light(hours)'] = df['Sunlight_Duration(min)']/60
df['Dark(hours)'] = df['Dark_Duration(min)']/60
# Set x and y values
x = df['Date']
y1 = df['Light(hours)']
y2 = df['Dark(hours)']
# Create a color palette
pal = ["#0141CF", "#FD7F00"]
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.stackplot(x,y1,y2, labels=['Light (hours)','Dark (hours)'], colors=pal, alpha=0.4)
plt.legend(loc='upper right', frameon=1)
# set ticks every month
ax.xaxis.set_major_locator(mdates.MonthLocator())
# set major ticks format
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b'))
# Set axis limits
ax.set_xlim([dt.date(2021, 1, 1), dt.date(2021, 12, 31)])
ax.set_ylim([0,24])
# Add axis labels and title
plt.title('Annual Light/Dark Duration in Logan, UT')
plt.xlabel('Month')
plt.ylabel('Duration(hours)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/LoganPhotoperiods.png', dpi=300)
# +
plt.style.use('seaborn')
# Convert light duration to hours
df = solar_saltlake
df['Light(hours)'] = df['Sunlight_Duration(min)']/60
df['Dark(hours)'] = df['Dark_Duration(min)']/60
# Set x and y values
x = df['Date']
y1 = df['Light(hours)']
y2 = df['Dark(hours)']
# Create a color palette
pal = ["#0141CF", "#FD7F00"]
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.stackplot(x,y1,y2, labels=['Light (hours)','Dark (hours)'], colors=pal, alpha=0.4)
plt.legend(loc='upper right', frameon=1)
# set ticks every month
ax.xaxis.set_major_locator(mdates.MonthLocator())
# set major ticks format
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b'))
# Set axis limits
ax.set_xlim([dt.date(2021, 1, 1), dt.date(2021, 12, 31)])
ax.set_ylim([0,24])
# Add axis labels and title
plt.title('Annual Light/Dark Duration in Salt Lake City, UT')
plt.xlabel('Month')
plt.ylabel('Duration(hours)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/SaltLakePhotoperiods.png', dpi=300)
# -
# #### Average PAR Intensity
# This averages all non-zero PAR values for each day.
# +
plt.style.use('seaborn')
# Convert light duration to hours
df = ppf_daily_logan
# Set x and y values
x = df['Date']
y1 = df['Estimated_PPF(umol/m^2*s^1)']
# y2 = df['Dark(hours)']
# Create a color palette
pal = ["#0141CF"]
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.stackplot(x,y1, labels=['Estimated Average PPF for Logan, UT'], colors=pal, alpha=0.4)
# plt.legend(loc='upper right', frameon=1)
# set ticks every month
ax.xaxis.set_major_locator(mdates.MonthLocator())
# set major ticks format
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b'))
# Set axis limits
ax.set_xlim([dt.date(2021, 1, 1), dt.date(2021, 12, 31)])
# ax.set_ylim([0,24])
# Add axis labels and title
plt.title('Estimated Average PPF for Logan, UT')
plt.xlabel('Month')
plt.ylabel('Photosynthetic Photon Flux (µmol m-2 s-1)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/LoganPPF_average.png', dpi=300)
# +
plt.style.use('seaborn')
# Convert light duration to hours
df = ppf_daily_saltlake
# Set x and y values
x = df['Date']
y1 = df['Estimated_PPF(umol/m^2*s^1)']
# y2 = df['Dark(hours)']
# Create a color palette
pal = ["#0141CF"]
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.stackplot(x,y1, labels=['Estimated Average PPF for Salt Lake City, UT'], colors=pal, alpha=0.4)
# plt.legend(loc='upper right', frameon=1)
# set ticks every month
ax.xaxis.set_major_locator(mdates.MonthLocator())
# set major ticks format
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b'))
# Set axis limits
ax.set_xlim([dt.date(2021, 1, 1), dt.date(2021, 12, 31)])
# ax.set_ylim([0,24])
# Add axis labels and title
plt.title('Estimated Average PPF for Salt Lake City, UT')
plt.xlabel('Month')
plt.ylabel('Photosynthetic Photon Flux (µmol m-2 s-1)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/SaltLakePPF_average.png', dpi=300)
# -
# #### Maximum Daily PAR
# +
plt.style.use('seaborn')
# Convert light duration to hours
df = ppf_daily_logan_max
# Set x and y values
x = df['Date']
y1 = df['Estimated_PPF(umol/m^2*s^1)']
# y2 = df['Dark(hours)']
# Create a color palette
pal = ["#0141CF"]
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.stackplot(x,y1, labels=['Estimated Average PPF for Logan, UT'], colors=pal, alpha=0.4)
# plt.legend(loc='upper right', frameon=1)
# set ticks every month
ax.xaxis.set_major_locator(mdates.MonthLocator())
# set major ticks format
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b'))
# Set axis limits
ax.set_xlim([dt.date(2021, 1, 1), dt.date(2021, 12, 31)])
# ax.set_ylim([0,24])
# Add axis labels and title
plt.title('Estimated Maximum PPF for Logan, UT')
plt.xlabel('Month')
plt.ylabel('Photosynthetic Photon Flux (µmol m-2 s-1)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/LoganPPF_max.png', dpi=300)
# +
plt.style.use('seaborn')
# Convert light duration to hours
df = ppf_daily_saltlake_max
# Set x and y values
x = df['Date']
y1 = df['Estimated_PPF(umol/m^2*s^1)']
# y2 = df['Dark(hours)']
# Create a color palette
pal = ["#0141CF"]
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.stackplot(x,y1, labels=['Estimated Average PPF for Salt Lake City, UT'], colors=pal, alpha=0.4)
# plt.legend(loc='upper right', frameon=1)
# set ticks every month
ax.xaxis.set_major_locator(mdates.MonthLocator())
# set major ticks format
ax.xaxis.set_major_formatter(mdates.DateFormatter('%b'))
# Set axis limits
ax.set_xlim([dt.date(2021, 1, 1), dt.date(2021, 12, 31)])
# ax.set_ylim([0,24])
# Add axis labels and title
plt.title('Estimated Maximum PPF for Logan, UT')
plt.xlabel('Month')
plt.ylabel('Photosynthetic Photon Flux (µmol m-2 s-1)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/SaltLakePPF_max.png', dpi=300)
# -
# #### Example of Daily PAR
# Example of sunlight duration and intensity during key days in the year (solstices and equinoxes).
# +
plt.style.use('seaborn')
# Create a copy of the dataframe
df = ppf_logan
# Set x and y values
x = df[(df['Date'] >= '2021-03-20') & (df['Date'] < '2021-03-21')]['Date']
y1 = df[(df['Date'] >= '2021-03-20') & (df['Date'] < '2021-03-21')]['Estimated_PPF(umol/m^2*s^1)']
y2 = df[(df['Date'] >= '2021-06-20') & (df['Date'] < '2021-06-21')]['Estimated_PPF(umol/m^2*s^1)']
y3 = df[(df['Date'] >= '2021-09-22') & (df['Date'] < '2021-09-23')]['Estimated_PPF(umol/m^2*s^1)']
y4 = df[(df['Date'] >= '2021-12-21') & (df['Date'] < '2021-12-22')]['Estimated_PPF(umol/m^2*s^1)']
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.plot(x,y1, label='March Equinox')
ax.plot(x,y2, label='June Solstice')
ax.plot(x,y3, label='September Equinox')
ax.plot(x,y4, label='December Solstice')
plt.legend(loc='upper left', frameon=1)
# Set x axis tick labels
hours = mdates.HourLocator(interval = 1)
h_fmt = mdates.DateFormatter('%H')
ax.xaxis.set_major_locator(hours)
ax.xaxis.set_major_formatter(h_fmt)
plt.xticks(rotation = -45)
# Add axis labels and title
plt.title('Estimated Daily PPF for Logan, UT')
plt.xlabel('Hour')
plt.ylabel('Photosynthetic Photon Flux (µmol m-2 s-1)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/LoganPPF.png', dpi=300)
# +
plt.style.use('seaborn')
# Create a copy of the dataframe
df = ppf_saltlake
# Set x and y values
x = df[(df['Date'] >= '2021-03-20') & (df['Date'] < '2021-03-21')]['Date']
y1 = df[(df['Date'] >= '2021-03-20') & (df['Date'] < '2021-03-21')]['Estimated_PPF(umol/m^2*s^1)']
y2 = df[(df['Date'] >= '2021-06-20') & (df['Date'] < '2021-06-21')]['Estimated_PPF(umol/m^2*s^1)']
y3 = df[(df['Date'] >= '2021-09-22') & (df['Date'] < '2021-09-23')]['Estimated_PPF(umol/m^2*s^1)']
y4 = df[(df['Date'] >= '2021-12-21') & (df['Date'] < '2021-12-22')]['Estimated_PPF(umol/m^2*s^1)']
# Plot data
fig, ax = plt.subplots(figsize=(6.5,4))
ax.plot(x,y1, label='March Equinox')
ax.plot(x,y2, label='June Solstice')
ax.plot(x,y3, label='September Equinox')
ax.plot(x,y4, label='December Solstice')
plt.legend(loc='upper left', frameon=1)
# Set x axis tick labels
hours = mdates.HourLocator(interval = 1)
h_fmt = mdates.DateFormatter('%H')
ax.xaxis.set_major_locator(hours)
ax.xaxis.set_major_formatter(h_fmt)
plt.xticks(rotation = -45)
# Add axis labels and title
plt.title('Estimated Daily PPF for Salt Lake City, UT')
plt.xlabel('Hour')
plt.ylabel('Photosynthetic Photon Flux (µmol m-2 s-1)')
# Ensure proper layout
fig.tight_layout()
# Save plot
plt.savefig('Exports/SaltLakePPF.png', dpi=300)
# -
| Solar & Weather Calculator - Visualizations.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Billboard: Hot 100
import requests
from bs4 import BeautifulSoup
import pandas as pd
response = requests.get("https://www.billboard.com/charts/hot-100")
doc = BeautifulSoup(response.text)
ranks = doc.find_all(class_='chart-list-item__rank')
for rank in ranks:
print(rank.text.strip())
artist_names = doc.find_all(class_='chart-list-item__artist')
for artist in artist_names:
print(artist.text.strip())
titles = doc.find_all(class_='chart-list-item__title-text')
for title in titles:
print(title.text.strip())
full_chart = doc.find_all(class_='chart-list-item__first-row')
full_chart = doc.find_all(class_='chart-list-item__first-row')
for text in full_chart:
row = {}
row['Rank'] = text.find(class_='chart-list-item__rank').text.strip()
row['Artist'] = text.find(class_='chart-list-item__artist').text.strip()
row['Song'] = text.find(class_='chart-list-item__title-text').text.strip()
print(row)
# +
full_chart = doc.find_all(class_='chart-list-item__first-row')
rows = []
for text in full_chart:
row = {}
row['Rank'] = text.find(class_='chart-list-item__rank').text.strip()
row['Artist'] = text.find(class_='chart-list-item__artist').text.strip()
row['Song'] = text.find(class_='chart-list-item__title-text').text.strip()
rows.append(row)
rows
df = pd.DataFrame(rows)
df
# -
df.to_csv('billboard', index=False)
| 09-homework/billboard.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernel_info:
# name: python3
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # <NAME>ump Stock Portfolio
# During Trump Presidental, he did not support climate change. Stocks relate to climate change it did not go up much or it went down. Pesidental can affect the stock market or particular stocks.
#
#
# https://en.wikipedia.org/wiki/Political_positions_of_Donald_Trump
# + outputHidden=false inputHidden=false
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import math
import warnings
warnings.filterwarnings("ignore")
# fix_yahoo_finance is used to fetch data
import fix_yahoo_finance as yf
yf.pdr_override()
# + outputHidden=false inputHidden=false
# input
symbols = ['GE','JCI','ALSMY','VWDRY','OC']
start = '2017-01-01'
end = '2019-01-01'
# Read data
df = yf.download(symbols,start,end)['Adj Close']
# View Columns
df.head()
# + outputHidden=false inputHidden=false
df.tail()
# + outputHidden=false inputHidden=false
from datetime import datetime
from dateutil import relativedelta
d1 = datetime.strptime(start, "%Y-%m-%d")
d2 = datetime.strptime(end, "%Y-%m-%d")
delta = relativedelta.relativedelta(d2,d1)
print('How many years of investing?')
print('%s years' % delta.years)
# + outputHidden=false inputHidden=false
from datetime import datetime
def calculate_years(start, end):
date_format = "%Y-%m-%d"
a = datetime.strptime(start, date_format).year
b = datetime.strptime(end, date_format).year
years = b - a
return years
# + outputHidden=false inputHidden=false
print(calculate_years(start, end), 'years')
# + outputHidden=false inputHidden=false
Cash = 100000
print('Percentage of invest:')
percent_invest = [0.20, 0.20, 0.20, 0.20, 0.20]
for i, x in zip(df.columns, percent_invest):
cost = x * Cash
print('{}: {}'.format(i, cost))
# + outputHidden=false inputHidden=false
print('Number of Shares:')
percent_invest = [0.20, 0.20, 0.20, 0.20, 0.20]
for i, x, y in zip(df.columns, percent_invest, df.iloc[0]):
cost = x * Cash
shares = int(cost/y)
print('{}: {}'.format(i, shares))
# + outputHidden=false inputHidden=false
print('Beginning Value:')
percent_invest = [0.20, 0.20, 0.20, 0.20, 0.20]
for i, x, y in zip(df.columns, percent_invest, df.iloc[0]):
cost = x * Cash
shares = int(cost/y)
Begin_Value = round(shares * y, 2)
print('{}: ${}'.format(i, Begin_Value))
# + outputHidden=false inputHidden=false
print('Current Value:')
percent_invest = [0.20, 0.20, 0.20, 0.20, 0.20]
for i, x, y, z in zip(df.columns, percent_invest, df.iloc[0], df.iloc[-1]):
cost = x * Cash
shares = int(cost/y)
Current_Value = round(shares * z, 2)
print('{}: ${}'.format(i, Current_Value))
# + outputHidden=false inputHidden=false
result = []
percent_invest = [0.20, 0.20, 0.20, 0.20, 0.20]
for i, x, y, z in zip(df.columns, percent_invest, df.iloc[0], df.iloc[-1]):
cost = x * Cash
shares = int(cost/y)
Current_Value = round(shares * z, 2)
result.append(Current_Value)
print('Total Value: $%s' % round(sum(result),2))
# + outputHidden=false inputHidden=false
for s in symbols:
df[s].plot(label = s, figsize = (15,10))
plt.legend()
# + outputHidden=false inputHidden=false
df.min()
# + outputHidden=false inputHidden=false
for s in symbols:
print(s + ":", df[s].max())
# + outputHidden=false inputHidden=false
# Creating a Return Data Frame for all individual banks stocks:
returns = pd.DataFrame()
for s in symbols:
returns[s + " Return"] = df[s].pct_change().dropna()
returns.head(4)
# + outputHidden=false inputHidden=false
sns.pairplot(returns[1:] )
# + outputHidden=false inputHidden=false
# dates each bank stock had the best and worst single day returns.
print(returns.idxmax())
# + outputHidden=false inputHidden=false
# dates each bank stock had the best and worst single day returns.
print(returns.idxmin())
# + outputHidden=false inputHidden=false
returns.corr()
# + outputHidden=false inputHidden=false
# Heatmap for return of all the stocks
plt.figure(figsize=(15,10))
sns.heatmap(returns.corr(), cmap="Blues",linewidths=.1, annot= True)
sns.clustermap(returns.corr(), cmap="binary",linewidths=.1, annot= True)
# + outputHidden=false inputHidden=false
# heatmap for Adj. Close prices for all the stock
plt.figure(figsize = (17,8))
sns.heatmap(df.corr(), cmap="autumn",linewidths=.1, annot= True)
sns.clustermap(df.corr(), cmap="winter",linewidths=.1, annot= True)
| Python_Stock/Portfolio_Strategies/Trump_Stock_Portfolio.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + colab={"base_uri": "https://localhost:8080/"} id="D7wgmJW7-H45" executionInfo={"status": "ok", "timestamp": 1631698095080, "user_tz": -180, "elapsed": 27021, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="6d95294a-c963-4cc0-a3f1-c90a213ea192"
from google.colab import drive
drive.mount('/content/drive')
# + id="XyawWW80QN8u" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1631698100084, "user_tz": -180, "elapsed": 5010, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="d6ebc148-0a16-458e-d781-3af17272900c"
# !pip install -q tensorflow_text
# + id="AaY_Oz0IQyIn" executionInfo={"status": "ok", "timestamp": 1631698118537, "user_tz": -180, "elapsed": 3515, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
import numpy as np
import typing
from typing import Any, Tuple
import tensorflow as tf
from tensorflow.keras.layers.experimental import preprocessing
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from sklearn.model_selection import train_test_split
# + id="9ZXfz3P3RIfk" executionInfo={"status": "ok", "timestamp": 1631698134083, "user_tz": -180, "elapsed": 399, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
use_builtins = True
# + [markdown] id="ndWV0v46D_aC"
# # The data
# + [markdown] id="fJiG3ExNWPfe"
# ## Download and prepare the dataset
# + id="z0N3JoJMRjlP" executionInfo={"status": "ok", "timestamp": 1631698147370, "user_tz": -180, "elapsed": 287, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
# /content/drive/MyDrive/MasterThesis/paraphrasing/Parapgrasing-Masking.tsv
# Download the file
import pathlib
# path_to_zip = tf.keras.utils.get_file(
# 'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
# extract=True)
# path_to_file = pathlib.Path(path_to_zip).parent/'spa-eng/spa.txt'
# path_to_file = pathlib.Path('/content/drive/MyDrive/MasterThesis/paraphrasing/Parapgrasing - Masking2.tsv')
# path_to_file = pathlib.Path('/content/drive/MyDrive/MasterThesis/paraphrasing/Parapgrasing-Masking-3.tsv')
# path_to_file = pathlib.Path('/content/drive/MyDrive/Master thesis/paraphrasing/ParapgrasingMask/Parapgrasing - Masking - maskWithWords.tsv')
path_to_file = pathlib.Path('/content/drive/MyDrive/MasterThesis/paraphrasing/ParapgrasingMask/ParaphrasingHSWithNotHS.tsv')
# + id="jR1HhhGtUvIw" executionInfo={"status": "ok", "timestamp": 1631698151075, "user_tz": -180, "elapsed": 1341, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
def load_data(path):
text = path.read_text(encoding='utf-8')
lines = text.splitlines()
pairs = [line.split('\t') for line in lines]
# inp = [inp for targ, inp in pairs]
# targ = [targ for targ, inp in pairs]
targ = [inp for targ, inp in pairs]
inp = [targ for targ, inp in pairs]
return targ, inp
# + colab={"base_uri": "https://localhost:8080/"} id="8VxLZ2wYVB3e" executionInfo={"status": "ok", "timestamp": 1631698153692, "user_tz": -180, "elapsed": 987, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="deb398d3-3017-47a0-fab6-86854a3bd550"
targ, inp = load_data(path_to_file)
print(inp[3])
# + colab={"base_uri": "https://localhost:8080/"} id="_v8AyFv6VDu7" executionInfo={"status": "ok", "timestamp": 1631698156692, "user_tz": -180, "elapsed": 30, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="2344d7e0-7e30-4194-c3de-59e6e5854d76"
print(targ[3])
# + [markdown] id="ZIczuMYPWRUd"
# ## Create a tf.data dataset
# + id="tYsJHFUUVPLu" executionInfo={"status": "ok", "timestamp": 1631698167459, "user_tz": -180, "elapsed": 5846, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
BUFFER_SIZE = len(inp)
BATCH_SIZE = 64
dataset = tf.data.Dataset.from_tensor_slices((inp, targ)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
# dataset
# + id="7cVHg2NCJq70"
# train_size=1190
# val_size=400
# val_ds = dataset.take(val_size)
# train_ds = dataset.skip(val_size).take(train_size)
# + id="fPJ-tLWmJS6T" executionInfo={"status": "ok", "timestamp": 1631698169482, "user_tz": -180, "elapsed": 5, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
def get_dataset_partitions_tf(ds, ds_size, train_split=0.8, val_split=0.2, shuffle=True, shuffle_size=1000):
assert (train_split + val_split) == 1
if shuffle:
# Specify seed to always have the same split distribution between runs
ds = ds.shuffle(shuffle_size, seed=12)
train_size = int(train_split * ds_size)
val_size = int(val_split * ds_size)
train_ds = ds.take(train_size)
val_ds = ds.skip(train_size).take(val_size)
# test_ds = ds.skip(train_size).skip(val_size)
return train_ds, val_ds
# + colab={"base_uri": "https://localhost:8080/"} id="q7UJYGyRLkQj" executionInfo={"status": "ok", "timestamp": 1631698173390, "user_tz": -180, "elapsed": 387, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="06e35a1e-35d5-4335-8309-05e0218d7a01"
get_dataset_partitions_tf(dataset,1592,0.8,0.2,True,1000)
# + id="-iouu6T3oKN3"
# val_dataset = dataset.enumerate() \
# .filter(lambda x,y: x % 5 == 0) \
# .map(lambda x,y: y)
# train_dataset = dataset.enumerate() \
# .filter(lambda x,y: x % 5 != 0) \
# .map(lambda x,y: y)
# tf.split(dataset, [train_dataset,val_dataset], axis=0, num=None, name="split")
# for i in val_dataset:
# print(i)
# print()
# for i in train_dataset:
# print(i)
# + colab={"base_uri": "https://localhost:8080/"} id="kV-TMe8fEeJ-" executionInfo={"status": "ok", "timestamp": 1631698176926, "user_tz": -180, "elapsed": 24, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="e26ad986-4815-4444-d567-80f3738dcf2a"
for exam_input_batch, exam_target_batch in dataset.take(1):
for i in range(5):
print(exam_input_batch.numpy()[i].decode('utf-8'))
# print()
print(exam_target_batch.numpy()[i].decode('utf-8'))
print()
break
# + id="59WLqrOlWXpB"
# for example_input_batch, example_target_batch in dataset.take(1):
# for i in range(5):
# print(example_input_batch.numpy()[i].decode('utf-8'))
# # print()
# print(example_target_batch.numpy()[i].decode('utf-8'))
# print()
# break
# + [markdown] id="6GHIFeWxX5rJ"
# ## Text preprocessing
# + colab={"base_uri": "https://localhost:8080/"} id="2vP5z8aEiaXt" executionInfo={"status": "ok", "timestamp": 1631698252232, "user_tz": -180, "elapsed": 714, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="41d85e82-d058-4b08-88f8-474945f85010"
example_text = tf.constant('#إغلاق_حسابات_البدون_في_البنوك الحل على إ رصاصة سلاإأم يا فيك يا فيه نقطه اخر السطر .')
print(example_text.numpy())
# print(tf_text.normalize_utf8(example_text, 'NFKD').numpy())
# + id="S3f9ofLViGwg"
# example_text = tf.constant('يا حيوان يا متخلف هو قال لو للزمالك هقول جول بس طالما ل حسنيه اغادير هقول فيها شك و التصوير مش واضح دي تسميه ايه يا قذر يا حثاله')
# print(example_text.numpy().decode('utf-8'))
# print(tf_text.normalize_utf8(example_text, 'NFKD').numpy().decode('utf-8'))
# + id="T6CHu2ymZFbX"
# example_text = tf.constant('علي شحم يا طاقية يا عنصري القم بس')
# print(example_text.numpy().decode('utf-8'))
# print(tf_text.normalize_utf8(example_text, 'NFKD').numpy().decode('utf-8'))
# + id="jy05RexWWa7_" executionInfo={"status": "ok", "timestamp": 1631698199861, "user_tz": -180, "elapsed": 675, "user": {"displayName": "Do salam", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
import re
text_cleaning_re = "[a-zA-Z]|\d+|[٠١٢٣٤٥٦٧٨٩]|[.#،<>@,\\-_”“٪ًَ]"
def tf_lower_and_split_punct(text):
text = tf.strings.regex_replace(text, '[إأآا]', 'ا')
# Split accecented characters.
text = tf_text.normalize_utf8(text, 'NFKD')
# text = tf.strings.lower(text)
# Keep space, a to z, and select punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿]', '')
# Add spaces around punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿_#]', r' \0 ')
# Strip whitespace.
# text = tf.strings.strip(text)
# text = re.sub(text_cleaning_re, ' ', str(text).lower()).strip()
# text = tf.strings.regex_replace(text, r'(.)\1+', r'\1\1')
text = tf.strings.regex_replace(text,text_cleaning_re, '')
text = tf.strings.regex_replace(text, 'ى', 'ي')
text = tf.strings.regex_replace(text, "ة", "ه")
text = tf.strings.regex_replace(text, '[إأآا]', 'ا')
# text = re.sub(r'(.)\1+', r'\1\1', str(text))
# text = re.sub("[إأآا]", "ا", str(text))
# text = re.sub("ى", "ي", str(text))
text = tf.strings.join(['[START]', text, '[END]'], separator=' ')
return text
# + colab={"base_uri": "https://localhost:8080/"} id="B-Ii1y-IYH5Y" executionInfo={"status": "ok", "timestamp": 1631698203053, "user_tz": -180, "elapsed": 403, "user": {"displayName": "Do salam", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="77a18f08-67a3-4895-d0e4-891f477ed406"
print(example_text.numpy().decode())
print(tf_lower_and_split_punct(example_text).numpy().decode())
# + [markdown] id="yscyfTX7dJTw"
# ## Text Vectorization
# + colab={"base_uri": "https://localhost:8080/"} id="tcjpOnpMYP60" executionInfo={"status": "ok", "timestamp": 1631698207239, "user_tz": -180, "elapsed": 812, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="a61b6daf-a964-4f78-8927-4bc4ee869db8"
max_vocab_size = 5000
####TextVectorization Before paraphrasing
input_text_processor = preprocessing.TextVectorization(
standardize=tf_lower_and_split_punct,
# output_mode="int",
max_tokens=max_vocab_size
)
input_text_processor.adapt(inp)
# Here are the first 10 words from the vocabulary:
input_text_processor.get_vocabulary()[:20]
# + colab={"base_uri": "https://localhost:8080/"} id="WxlkTXVzdQPy" executionInfo={"status": "ok", "timestamp": 1631698213196, "user_tz": -180, "elapsed": 910, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="2f59cb92-b3c0-4a88-e5ac-a7d498f84244"
#TextVectorization after paraphrasing(masking)
output_text_processor = preprocessing.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
output_text_processor.adapt(targ)
output_text_processor.get_vocabulary()[:20]
# + id="uxOgjkanjPp-" executionInfo={"status": "ok", "timestamp": 1631698291489, "user_tz": -180, "elapsed": 403, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
#Now these layers can convert a batch of strings into a batch of token IDs:
# example_tokens = input_text_processor(example_input_batch)
# example_tokens[:3, :10]
# + id="3x--N155jrL8" executionInfo={"status": "ok", "timestamp": 1631698298380, "user_tz": -180, "elapsed": 447, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
#The get_vocabulary method can be used to convert token IDs back to text:
input_vocab = np.array(input_text_processor.get_vocabulary())
# tokens = input_vocab[example_tokens[0].numpy()]
# ' '.join(tokens)
# + colab={"base_uri": "https://localhost:8080/", "height": 299} id="qAAO8j10jwT8" executionInfo={"status": "ok", "timestamp": 1628541919590, "user_tz": -180, "elapsed": 12, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="7f28774c-cb34-46f4-d83f-86961a5bd382"
#The returned token IDs are zero-padded. This can easily be turned into a mask:
plt.subplot(1, 2, 1)
plt.pcolormesh(example_tokens)
plt.title('Token IDs')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
# + [markdown] id="21DcO-u-kOKy"
# #The encoder/decoder model
# + id="cC-7kyiWkKQd" executionInfo={"status": "ok", "timestamp": 1631698306204, "user_tz": -180, "elapsed": 439, "user": {"displayName": "Do salam", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
embedding_dim = 256
units = 1024
# + [markdown] id="-3GvVd7ak2qY"
# ##The encoder
# + id="kJGZ93d0ktOW" executionInfo={"status": "ok", "timestamp": 1631698307786, "user_tz": -180, "elapsed": 8, "user": {"displayName": "Do salam", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
class ShapeChecker():
def __init__(self):
# Keep a cache of every axis-name seen
self.shapes = {}
def __call__(self, tensor, names, broadcast=False):
if not tf.executing_eagerly():
return
if isinstance(names, str):
names = (names,)
shape = tf.shape(tensor)
rank = tf.rank(tensor)
if rank != len(names):
raise ValueError(f'Rank mismatch:\n'
f' found {rank}: {shape.numpy()}\n'
f' expected {len(names)}: {names}\n')
for i, name in enumerate(names):
if isinstance(name, int):
old_dim = name
else:
old_dim = self.shapes.get(name, None)
new_dim = shape[i]
if (broadcast and new_dim == 1):
continue
if old_dim is None:
# If the axis name is new, add its length to the cache.
self.shapes[name] = new_dim
continue
if new_dim != old_dim:
raise ValueError(f"Shape mismatch for dimension: '{name}'\n"
f" found: {new_dim}\n"
f" expected: {old_dim}\n")
# + id="2SvHKwdikRQU" executionInfo={"status": "ok", "timestamp": 1631698311895, "user_tz": -180, "elapsed": 417, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
class Encoder(tf.keras.layers.Layer):
def __init__(self, input_vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.enc_units = enc_units
self.input_vocab_size = input_vocab_size
# The embedding layer converts tokens to vectors
self.embedding = tf.keras.layers.Embedding(self.input_vocab_size,
embedding_dim)
# The GRU RNN layer processes those vectors sequentially.
self.gru = tf.keras.layers.GRU(self.enc_units,
# Return the sequence and state
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, tokens, state=None):
shape_checker = ShapeChecker()
shape_checker(tokens, ('batch', 's'))
# 2. The embedding layer looks up the embedding for each token.
vectors = self.embedding(tokens)
shape_checker(vectors, ('batch', 's', 'embed_dim'))
# 3. The GRU processes the embedding sequence.
# output shape: (batch, s, enc_units)
# state shape: (batch, enc_units)
output, state = self.gru(vectors, initial_state=state)
shape_checker(output, ('batch', 's', 'enc_units'))
shape_checker(state, ('batch', 'enc_units'))
# 4. Returns the new sequence and its state.
return output, state
# + id="0xGoMKf1kaFJ" executionInfo={"status": "ok", "timestamp": 1631698330936, "user_tz": -180, "elapsed": 442, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
# Convert the input text to tokens.
# example_tokens = input_text_processor(example_input_batch)
# Encode the input sequence.
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
# example_enc_output, example_enc_state = encoder(example_tokens)
# print(f'Input batch, shape (batch): {example_input_batch.shape}')
# print(f'Input batch tokens, shape (batch, s): {example_tokens.shape}')
# print(f'Encoder output, shape (batch, s, units): {example_enc_output.shape}')
# print(f'Encoder state, shape (batch, units): {example_enc_state.shape}')
# + [markdown] id="n5z40aMNk-cZ"
# ##The attention head
# + id="z1xJw7Soka7s" executionInfo={"status": "ok", "timestamp": 1631698333956, "user_tz": -180, "elapsed": 406, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
# For Eqn. (4), the Bahdanau attention
self.W1 = tf.keras.layers.Dense(units, use_bias=False)
self.W2 = tf.keras.layers.Dense(units, use_bias=False)
self.attention = tf.keras.layers.AdditiveAttention()
def call(self, query, value, mask):
shape_checker = ShapeChecker()
shape_checker(query, ('batch', 't', 'query_units'))
shape_checker(value, ('batch', 's', 'value_units'))
shape_checker(mask, ('batch', 's'))
# From Eqn. (4), `W1@ht`.
w1_query = self.W1(query)
shape_checker(w1_query, ('batch', 't', 'attn_units'))
# From Eqn. (4), `W2@hs`.
w2_key = self.W2(value)
shape_checker(w2_key, ('batch', 's', 'attn_units'))
query_mask = tf.ones(tf.shape(query)[:-1], dtype=bool)
value_mask = mask
context_vector, attention_weights = self.attention(
inputs = [w1_query, value, w2_key],
mask=[query_mask, value_mask],
return_attention_scores = True,
)
shape_checker(context_vector, ('batch', 't', 'value_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
return context_vector, attention_weights
# + [markdown] id="_n85ybwYBuE7"
# ##Test the Attention layer
# + id="F7EBnNj6lBRp" executionInfo={"status": "ok", "timestamp": 1631698337083, "user_tz": -180, "elapsed": 723, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
attention_layer = BahdanauAttention(units)
# + id="kA2MKSwalM3W" executionInfo={"status": "ok", "timestamp": 1631698353685, "user_tz": -180, "elapsed": 387, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
# (example_tokens != 0).shape
# + colab={"base_uri": "https://localhost:8080/", "height": 231} id="H2kk0ri0lHwu" executionInfo={"status": "error", "timestamp": 1631698369473, "user_tz": -180, "elapsed": 9, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="f3cc2056-67ca-41cc-b1cb-a4ab9a4b25da"
# Later, the decoder will generate this attention query
# example_attention_query = tf.random.normal(shape=[len(example_tokens), 2, 10])
# Attend to the encoded tokens
context_vector, attention_weights = attention_layer(
query=example_attention_query,
value=example_enc_output,
mask=(example_tokens != 0))
print(f'Attention result shape: (batch_size, query_seq_length, units): {context_vector.shape}')
print(f'Attention weights shape: (batch_size, query_seq_length, value_seq_length): {attention_weights.shape}')
# + colab={"base_uri": "https://localhost:8080/", "height": 299} id="_FLfQbmxlISS" executionInfo={"status": "ok", "timestamp": 1628541925735, "user_tz": -180, "elapsed": 422, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="8bce2213-420f-4c37-e284-e30aba63404c"
plt.subplot(1, 2, 1)
plt.pcolormesh(attention_weights[:, 0, :])
plt.title('Attention weights')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
# + colab={"base_uri": "https://localhost:8080/"} id="rNq63wbqlQ5G" executionInfo={"status": "ok", "timestamp": 1628541925735, "user_tz": -180, "elapsed": 15, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="913436a5-16ed-443d-adaa-d6ce47c130a0"
attention_weights.shape
# + id="0hptn2SIlT0x"
attention_slice = attention_weights[0, 0].numpy()
attention_slice = attention_slice[attention_slice != 0]
# + colab={"base_uri": "https://localhost:8080/", "height": 424} id="w75xGyexlWxU" executionInfo={"status": "ok", "timestamp": 1628541927192, "user_tz": -180, "elapsed": 1466, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="8418de3e-3efb-44b1-e269-6c597f51ec19"
plt.suptitle('Attention weights for one sequence')
plt.figure(figsize=(12, 6))
a1 = plt.subplot(1, 2, 1)
plt.bar(range(len(attention_slice)), attention_slice)
# freeze the xlim
plt.xlim(plt.xlim())
plt.xlabel('Attention weights')
a2 = plt.subplot(1, 2, 2)
plt.bar(range(len(attention_slice)), attention_slice)
plt.xlabel('Attention weights, zoomed')
# zoom in
top = max(a1.get_ylim())
zoom = 0.85*top
a2.set_ylim([0.90*top, top])
a1.plot(a1.get_xlim(), [zoom, zoom], color='k')
# + [markdown] id="AaPKcbh1lblf"
# ##The decoder
# + id="Edn0eFOGlYQG" executionInfo={"status": "ok", "timestamp": 1631698386950, "user_tz": -180, "elapsed": 6, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
class Decoder(tf.keras.layers.Layer):
def __init__(self, output_vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.dec_units = dec_units
self.output_vocab_size = output_vocab_size
self.embedding_dim = embedding_dim
# For Step 1. The embedding layer convets token IDs to vectors
self.embedding = tf.keras.layers.Embedding(self.output_vocab_size,
embedding_dim)
# For Step 2. The RNN keeps track of what's been generated so far.
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
# For step 3. The RNN output will be the query for the attention layer.
self.attention = BahdanauAttention(self.dec_units)
# For step 4. Eqn. (3): converting `ct` to `at`
self.Wc = tf.keras.layers.Dense(dec_units, activation=tf.math.tanh,
use_bias=False)
# For step 5. This fully connected layer produces the logits for each
# output token.
self.fc = tf.keras.layers.Dense(self.output_vocab_size)
# + id="Nttj7G3fleC0" executionInfo={"status": "ok", "timestamp": 1631698391245, "user_tz": -180, "elapsed": 367, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
class DecoderInput(typing.NamedTuple):
new_tokens: Any
enc_output: Any
mask: Any
class DecoderOutput(typing.NamedTuple):
logits: Any
attention_weights: Any
# + id="LLyv-oOZlgRs" executionInfo={"status": "ok", "timestamp": 1631698391791, "user_tz": -180, "elapsed": 6, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
def call(self,
inputs: DecoderInput,
state=None) -> Tuple[DecoderOutput, tf.Tensor]:
shape_checker = ShapeChecker()
shape_checker(inputs.new_tokens, ('batch', 't'))
shape_checker(inputs.enc_output, ('batch', 's', 'enc_units'))
shape_checker(inputs.mask, ('batch', 's'))
if state is not None:
shape_checker(state, ('batch', 'dec_units'))
# Step 1. Lookup the embeddings
vectors = self.embedding(inputs.new_tokens)
shape_checker(vectors, ('batch', 't', 'embedding_dim'))
# Step 2. Process one step with the RNN
rnn_output, state = self.gru(vectors, initial_state=state)
shape_checker(rnn_output, ('batch', 't', 'dec_units'))
shape_checker(state, ('batch', 'dec_units'))
# Step 3. Use the RNN output as the query for the attention over the
# encoder output.
context_vector, attention_weights = self.attention(
query=rnn_output, value=inputs.enc_output, mask=inputs.mask)
shape_checker(context_vector, ('batch', 't', 'dec_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
# Step 4. Eqn. (3): Join the context_vector and rnn_output
# [ct; ht] shape: (batch t, value_units + query_units)
context_and_rnn_output = tf.concat([context_vector, rnn_output], axis=-1)
# Step 4. Eqn. (3): `at = tanh(Wc@[ct; ht])`
attention_vector = self.Wc(context_and_rnn_output)
shape_checker(attention_vector, ('batch', 't', 'dec_units'))
# Step 5. Generate logit predictions:
logits = self.fc(attention_vector)
shape_checker(logits, ('batch', 't', 'output_vocab_size'))
return DecoderOutput(logits, attention_weights), state
# + id="_n43Inr-libv" executionInfo={"status": "ok", "timestamp": 1631698393773, "user_tz": -180, "elapsed": 2, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
Decoder.call = call
# + id="1OWYS8A9lj33" executionInfo={"status": "ok", "timestamp": 1631698394439, "user_tz": -180, "elapsed": 12, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}}
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
# + id="Y-Vpdpodllvv" colab={"base_uri": "https://localhost:8080/", "height": 357} executionInfo={"status": "error", "timestamp": 1631698398672, "user_tz": -180, "elapsed": 10, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14GgP0GyFxHH-3NAPSZ_ethp4uMqaN8pUWhOxcO0NDw=s64", "userId": "03587359084159229589"}} outputId="b9cb8eba-1eb2-48e9-8632-09c609520000"
# Convert the target sequence, and collect the "[START]" tokens
example_output_tokens = output_text_processor(example_target_batch)
start_index = output_text_processor._index_lookup_layer('[START]').numpy()
first_token = tf.constant([[start_index]] * example_output_tokens.shape[0])
# + colab={"base_uri": "https://localhost:8080/"} id="504mgOlVlncu" executionInfo={"status": "ok", "timestamp": 1628541927194, "user_tz": -180, "elapsed": 38, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="58b7a2d9-1beb-4fd9-c72a-4583935ef25e"
# Run the decoder
dec_result, dec_state = decoder(
inputs = DecoderInput(new_tokens=first_token,
enc_output=example_enc_output,
mask=(example_tokens != 0)),
state = example_enc_state
)
print(f'logits shape: (batch_size, t, output_vocab_size) {dec_result.logits.shape}')
print(f'state shape: (batch_size, dec_units) {dec_state.shape}')
# + id="2N1-81R4lpE7"
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
# + colab={"base_uri": "https://localhost:8080/"} id="Dcq0_bdqlrn9" executionInfo={"status": "ok", "timestamp": 1628541927195, "user_tz": -180, "elapsed": 27, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="a5f9179d-cf36-42c7-a3b3-3adacc7380e9"
vocab = np.array(output_text_processor.get_vocabulary())
first_word = vocab[sampled_token.numpy()]
first_word[:5]
# + id="1UDw_FWGltet"
dec_result, dec_state = decoder(
DecoderInput(sampled_token,
example_enc_output,
mask=(example_tokens != 0)),
state=dec_state)
# + colab={"base_uri": "https://localhost:8080/"} id="ErxSLE8Rlwnh" executionInfo={"status": "ok", "timestamp": 1628541927195, "user_tz": -180, "elapsed": 16, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="5aa82e60-f59c-4e79-a630-cfba65b48e1e"
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
first_word = vocab[sampled_token.numpy()]
first_word[:5]
# + [markdown] id="FZYqCCMBmBPF"
# #Training
# + [markdown] id="k9MnQklHDKTP"
# ## Define the loss function
# + id="uU7SaL2Fly5r"
class MaskedLoss(tf.keras.losses.Loss):
def __init__(self):
self.name = 'masked_loss'
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def __call__(self, y_true, y_pred):
shape_checker = ShapeChecker()
shape_checker(y_true, ('batch', 't'))
shape_checker(y_pred, ('batch', 't', 'logits'))
# Calculate the loss for each item in the batch.
loss = self.loss(y_true, y_pred)
shape_checker(loss, ('batch', 't'))
# Mask off the losses on padding.
mask = tf.cast(y_true != 0, tf.float32)
shape_checker(mask, ('batch', 't'))
loss *= mask
# Return the total.
return tf.reduce_sum(loss)
# + [markdown] id="fQoZAibJDN1D"
# ## Implement the training step
# + id="MMjdwhELmGvo"
#Implement the training step
class TrainTranslator(tf.keras.Model):
def __init__(self, embedding_dim, units,
input_text_processor,
output_text_processor,
use_tf_function=True):
super().__init__()
# Build the encoder and decoder
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.use_tf_function = use_tf_function
self.shape_checker = ShapeChecker()
def train_step(self, inputs):
self.shape_checker = ShapeChecker()
if self.use_tf_function:
return self._tf_train_step(inputs)
else:
return self._train_step(inputs)
# + id="5u7nApk7mLXc"
def _preprocess(self, input_text, target_text):
self.shape_checker(input_text, ('batch',))
self.shape_checker(target_text, ('batch',))
# Convert the text to token IDs
input_tokens = self.input_text_processor(input_text)
target_tokens = self.output_text_processor(target_text)
self.shape_checker(input_tokens, ('batch', 's'))
self.shape_checker(target_tokens, ('batch', 't'))
# Convert IDs to masks.
input_mask = input_tokens != 0
self.shape_checker(input_mask, ('batch', 's'))
target_mask = target_tokens != 0
self.shape_checker(target_mask, ('batch', 't'))
return input_tokens, input_mask, target_tokens, target_mask
# + id="CD5pPKOemM-2"
TrainTranslator._preprocess = _preprocess
# + id="BFv9BM7ZmOwH"
def _train_step(self, inputs):
input_text, target_text = inputs
(input_tokens, input_mask,
target_tokens, target_mask) = self._preprocess(input_text, target_text)
max_target_length = tf.shape(target_tokens)[1]
with tf.GradientTape() as tape:
# Encode the input
enc_output, enc_state = self.encoder(input_tokens)
self.shape_checker(enc_output, ('batch', 's', 'enc_units'))
self.shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder's state to the encoder's final state.
# This only works if the encoder and decoder have the same number of
# units.
dec_state = enc_state
loss = tf.constant(0.0)
for t in tf.range(max_target_length-1):
# Pass in two tokens from the target sequence:
# 1. The current input to the decoder.
# 2. The target the target for the decoder's next prediction.
new_tokens = target_tokens[:, t:t+2]
step_loss, dec_state = self._loop_step(new_tokens, input_mask,
enc_output, dec_state)
loss = loss + step_loss
# Average the loss over all non padding tokens.
average_loss = loss / tf.reduce_sum(tf.cast(target_mask, tf.float32))
# Apply an optimization step
variables = self.trainable_variables
gradients = tape.gradient(average_loss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# Return a dict mapping metric names to current value
return {'batch_loss': average_loss}
# + id="mEhp3pq-mQXg"
TrainTranslator._train_step = _train_step
# + id="0mtZvbsNmSS0"
def _loop_step(self, new_tokens, input_mask, enc_output, dec_state):
input_token, target_token = new_tokens[:, 0:1], new_tokens[:, 1:2]
# Run the decoder one step.
decoder_input = DecoderInput(new_tokens=input_token,
enc_output=enc_output,
mask=input_mask)
dec_result, dec_state = self.decoder(decoder_input, state=dec_state)
self.shape_checker(dec_result.logits, ('batch', 't1', 'logits'))
self.shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
self.shape_checker(dec_state, ('batch', 'dec_units'))
# `self.loss` returns the total for non-padded tokens
y = target_token
y_pred = dec_result.logits
step_loss = self.loss(y, y_pred)
return step_loss, dec_state
# + id="GSTnBASXmUBU"
TrainTranslator._loop_step = _loop_step
# + [markdown] id="C9X290LiDguC"
# ## Test the training step
# + id="h2gQJLSSmVOx"
#Test the training step
translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
use_tf_function=False)
# Configure the loss and optimizer
translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
metrics=["accuracy"]
)
# + colab={"base_uri": "https://localhost:8080/"} id="5m01xokNmYyL" executionInfo={"status": "ok", "timestamp": 1628541927714, "user_tz": -180, "elapsed": 13, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="40f2c312-7dc9-4de5-e88c-108fc46e0d71"
np.log(output_text_processor.vocabulary_size())
# + colab={"base_uri": "https://localhost:8080/"} id="galSRTeSmaR3" executionInfo={"status": "ok", "timestamp": 1628541945462, "user_tz": -180, "elapsed": 17758, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="0876c88d-b4e4-4bbe-87e2-664cdbcadf72"
# %%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
# + id="niZzANjVmhf6"
@tf.function(input_signature=[[tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])]])
def _tf_train_step(self, inputs):
return self._train_step(inputs)
# + id="I4ZVo8qJmmpb"
TrainTranslator._tf_train_step = _tf_train_step
# + id="OwQ66_LEmnJ6"
translator.use_tf_function = True
# + colab={"base_uri": "https://localhost:8080/"} id="1vI2AzXfmo2U" executionInfo={"status": "ok", "timestamp": 1628541950529, "user_tz": -180, "elapsed": 5080, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="486f6b83-3ffa-4512-b972-0c002c7c98cd"
translator.train_step([example_input_batch, example_target_batch])
# + colab={"base_uri": "https://localhost:8080/"} id="xZZRQfE-mqap" executionInfo={"status": "ok", "timestamp": 1628541959581, "user_tz": -180, "elapsed": 9068, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="c7e5e69e-503a-4986-86e5-a95e190a93ed"
# %%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
# + colab={"base_uri": "https://localhost:8080/", "height": 301} id="LjGp440ymsSH" executionInfo={"status": "ok", "timestamp": 1628542049897, "user_tz": -180, "elapsed": 90344, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="68dea898-b87b-457f-d2cf-581ea49da81b"
losses = []
for n in range(100):
print('.', end='')
logs = translator.train_step([example_input_batch, example_target_batch])
losses.append(logs['batch_loss'].numpy())
print()
plt.plot(losses)
# + id="aUInL1GsmxkD"
train_translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor)
# Configure the loss and optimizer
train_translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
metrics=["accuracy"]
)
# + [markdown] id="k3cL6T4Tm2EV"
# ## Train the model
# + id="NgjJU-tNm4Xk"
class BatchLogs(tf.keras.callbacks.Callback):
def __init__(self, key):
self.key = key
self.logs = []
def on_train_batch_end(self, n, logs):
self.logs.append(logs[self.key])
batch_loss = BatchLogs('batch_loss')
# + id="sln5WccxIb8W"
from keras.callbacks import EarlyStopping
my_callbacks = [
tf.keras.callbacks.EarlyStopping(monitor='batch_loss',patience=5),
# tf.keras.callbacks.ReduceLROnPlateau(factor=0.1,
# min_lr = 0.01,
# monitor = 'val_loss',
# verbose = 1)
# batch_loss = BatchLogs('batch_loss')
]
# + colab={"base_uri": "https://localhost:8080/"} id="B7ieq2elm71Y" executionInfo={"status": "ok", "timestamp": 1628543416566, "user_tz": -180, "elapsed": 1366309, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="24560501-4955-49eb-90dd-03e3867bfa19"
train_translator.fit(dataset, epochs=50,callbacks=my_callbacks)
# + colab={"base_uri": "https://localhost:8080/"} id="QYOXHm1Fm9ar" executionInfo={"status": "ok", "timestamp": 1628543416567, "user_tz": -180, "elapsed": 23, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="28659793-afe4-<PASSWORD>"
plt.plot(batch_loss.logs)
plt.ylim([0, 100])
plt.xlabel('Batch #')
plt.ylabel('CE/token')
# + [markdown] id="_EDWeKyGnExQ"
# #Translate
# + id="LbrRu0eam_Za"
class Translator(tf.Module):
def __init__(self, encoder, decoder, input_text_processor,
output_text_processor):
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.output_token_string_from_index = (
tf.keras.layers.experimental.preprocessing.StringLookup(
vocabulary=output_text_processor.get_vocabulary(),
mask_token='',
invert=True))
# The output should never generate padding, unknown, or start.
index_from_string = tf.keras.layers.experimental.preprocessing.StringLookup(
vocabulary=output_text_processor.get_vocabulary(), mask_token='')
token_mask_ids = index_from_string(['', '[UNK]', '[START]']).numpy()
token_mask = np.zeros([index_from_string.vocabulary_size()], dtype=np.bool)
token_mask[np.array(token_mask_ids)] = True
self.token_mask = token_mask
self.start_token = index_from_string('[START]')
self.end_token = index_from_string('[END]')
# + id="RzYJ_inQnVku"
translator = Translator(
encoder=train_translator.encoder,
decoder=train_translator.decoder,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
)
# + [markdown] id="4_D7ID0DCXK-"
# ##Convert token IDs to text
# + id="qPKIIhIYnWTf"
#Convert token IDs to text
def tokens_to_text(self, result_tokens):
shape_checker = ShapeChecker()
shape_checker(result_tokens, ('batch', 't'))
result_text_tokens = self.output_token_string_from_index(result_tokens)
shape_checker(result_text_tokens, ('batch', 't'))
result_text = tf.strings.reduce_join(result_text_tokens,
axis=1, separator=' ')
shape_checker(result_text, ('batch'))
result_text = tf.strings.strip(result_text)
shape_checker(result_text, ('batch',))
return result_text
# + id="2fiykfvTndg2"
Translator.tokens_to_text = tokens_to_text
# + colab={"base_uri": "https://localhost:8080/"} id="OQerZ5vSndzm" executionInfo={"status": "ok", "timestamp": 1628543417050, "user_tz": -180, "elapsed": 30, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="f1c955a7-640d-4206-dd77-12c574505566"
example_output_tokens = tf.random.uniform(
shape=[5, 2], minval=0, dtype=tf.int64,
maxval=output_text_processor.vocabulary_size())
translator.tokens_to_text(example_output_tokens).numpy()
# + [markdown] id="BdC2aAtQCcHw"
# ## Sample from the decoder's predictions
# + id="9QE1GMVHnf2M"
#Sample from the decoder's predictions
def sample(self, logits, temperature):
shape_checker = ShapeChecker()
# 't' is usually 1 here.
shape_checker(logits, ('batch', 't', 'vocab'))
shape_checker(self.token_mask, ('vocab',))
token_mask = self.token_mask[tf.newaxis, tf.newaxis, :]
shape_checker(token_mask, ('batch', 't', 'vocab'), broadcast=True)
# Set the logits for all masked tokens to -inf, so they are never chosen.
logits = tf.where(self.token_mask, -np.inf, logits)
if temperature == 0.0:
new_tokens = tf.argmax(logits, axis=-1)
else:
logits = tf.squeeze(logits, axis=1)
new_tokens = tf.random.categorical(logits/temperature,
num_samples=1)
shape_checker(new_tokens, ('batch', 't'))
return new_tokens
# + id="lQqz8N5onlPA"
Translator.sample = sample
# + colab={"base_uri": "https://localhost:8080/"} id="zaB9gxKhnnIo" executionInfo={"status": "ok", "timestamp": 1628543417051, "user_tz": -180, "elapsed": 20, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="05f0a3ed-4e39-4549-c69e-a9fb11d4a37d"
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
# + colab={"base_uri": "https://localhost:8080/"} id="iISJujhknouG" executionInfo={"status": "ok", "timestamp": 1628543417051, "user_tz": -180, "elapsed": 12, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="cc019c87-a452-43bf-b0d8-75438056a71c"
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
# + [markdown] id="9x84X4ndCjEs"
# ## Implement the translation loop
# + id="BzU_z3QWnqP6"
#Implement the translation loop
def translate_unrolled(self,
input_text, *,
max_length=50,
return_attention=True,
temperature=1.0):
batch_size = tf.shape(input_text)[0]
input_tokens = self.input_text_processor(input_text)
enc_output, enc_state = self.encoder(input_tokens)
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
result_tokens = []
attention = []
done = tf.zeros([batch_size, 1], dtype=tf.bool)
for _ in range(max_length):
dec_input = DecoderInput(new_tokens=new_tokens,
enc_output=enc_output,
mask=(input_tokens!=0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
attention.append(dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens.append(new_tokens)
if tf.executing_eagerly() and tf.reduce_all(done):
break
# Convert the list of generates token ids to a list of strings.
result_tokens = tf.concat(result_tokens, axis=-1)
result_text = self.tokens_to_text(result_tokens)
if return_attention:
attention_stack = tf.concat(attention, axis=1)
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
# + id="85ub2TtpnuKU"
Translator.translate = translate_unrolled
# + colab={"base_uri": "https://localhost:8080/"} id="2OfJ09sBn0P9" executionInfo={"status": "ok", "timestamp": 1628543417307, "user_tz": -180, "elapsed": 263, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="b0650799-d0dd-4ae3-96e4-c22430ca9343"
# %%time
input_text = tf.constant([
'بكري يا معرص يا عار الصعيد ملعون ضهر ابوك يا عرص', # "It's really cold here."
'تبا لكم ولأشكالكم', # "This is my life.""
])
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
# + id="0Ss7K3-coG_G"
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
# + colab={"base_uri": "https://localhost:8080/"} id="OKtQmQfJofI8" executionInfo={"status": "ok", "timestamp": 1628543434063, "user_tz": -180, "elapsed": 16758, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="31b06e18-3130-4c0d-a08b-711fe8c280bd"
# %%time
result = translator.tf_translate(
input_text = input_text)
# + colab={"base_uri": "https://localhost:8080/"} id="WLlXsnUKog8e" executionInfo={"status": "ok", "timestamp": 1628543434064, "user_tz": -180, "elapsed": 40, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="be608118-6dd1-4836-de36-d4289ad5cfc9"
# %%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
# + [markdown] id="7omXkyUjCrsl"
# ## Visualize the process
# + colab={"base_uri": "https://localhost:8080/"} id="uw0i5Yxbut55" executionInfo={"status": "ok", "timestamp": 1628543434064, "user_tz": -180, "elapsed": 22, "user": {"displayName": "salam thabit", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="51a54170-16ac-4c6c-a488-f09fdb5d860d"
a = result['attention'][0]
print(np.sum(a, axis=-1))
# + colab={"base_uri": "https://localhost:8080/"} id="TWf6Gfs3u0Hj" executionInfo={"status": "ok", "timestamp": 1628543434568, "user_tz": -180, "elapsed": 517, "user": {"displayName": "salam thabit", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="456e7570-f4be-492c-8053-e33b4bf18042"
_ = plt.bar(range(len(a[0, :])), a[0, :])
# + colab={"base_uri": "https://localhost:8080/", "height": 285} id="-BZyZG0Pu2eL" executionInfo={"status": "ok", "timestamp": 1628543434569, "user_tz": -180, "elapsed": 27, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="cb96201c-7161-48b4-d1d7-924a5a122a57"
plt.imshow(np.array(a), vmin=0.0)
# + id="SBFtpVOuu4QO"
def plot_attention(attention, sentence, predicted_sentence):
sentence = tf_lower_and_split_punct(sentence).numpy().decode().split()
predicted_sentence = predicted_sentence.numpy().decode().split() + ['[END]']
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
attention = attention[:len(predicted_sentence), :len(sentence)]
ax.matshow(attention, cmap='viridis', vmin=0.0)
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xlabel('Input text')
ax.set_ylabel('Output text')
plt.suptitle('Attention weights')
# + [markdown] id="JBLEv87QCzuP"
# ## Labeled attention plots
# + colab={"base_uri": "https://localhost:8080/"} id="RHq8Ps2Zu7wp" executionInfo={"status": "ok", "timestamp": 1628543434905, "user_tz": -180, "elapsed": 345, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="b6281d36-ffb3-4ec1-81e5-6cd882a9ed12"
i=0
plot_attention(result['attention'][i], input_text[i], result['text'][i])
# + colab={"base_uri": "https://localhost:8080/"} id="CMEIazsuu-EA" executionInfo={"status": "ok", "timestamp": 1628543434906, "user_tz": -180, "elapsed": 22, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="f894902c-ef31-418c-d53b-4a6886275f8b"
# %%time
three_input_text = tf.constant([
# This is my life.
'يا راس هرم الفساد ف مصر معلش انت مش عارف تشغلهم',
# Are they still home?
'برجل ولا يوصف بك كرجل ولا من اتباع الرجال انت أنت حثالة ومن أتباع الحثالة يا خسيس',
# Try to find out.'
'كسمك يا بكاري يا جساما يا ابن المنايك',
'فين يا ابن القحبه يا معرص السودان مش هيعملوا اَي شي من مخططكم هاهاهاهاها و لسه يا خونه',
'يا حقير يا واطي يا داعر يا روكي لوليتش قاعد يلعب مصارعة 5 كورة يضرب فيها وما ياخذ عليها كرت ولا حتى فاول !!!!!!!!!!!!!!!!!!!!!'
])
result = translator.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
# + colab={"base_uri": "https://localhost:8080/", "height": 53} id="9bwmT-1gvL_1" executionInfo={"status": "ok", "timestamp": 1628543434907, "user_tz": -180, "elapsed": 9, "user": {"displayName": "salam thabit", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="9fa7e7e3-d5fb-457f-9b1f-0a10d8a2d89b"
result['text'][1].numpy().decode()
# + colab={"base_uri": "https://localhost:8080/", "height": 660} id="-76ImO2FvZtL" executionInfo={"status": "ok", "timestamp": 1628543435241, "user_tz": -180, "elapsed": 342, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="48d4a7d5-1403-454e-b2c2-a7e60aa2d3c3"
i = 0
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
# + colab={"base_uri": "https://localhost:8080/"} id="Zc9CaXtovzPy" executionInfo={"status": "ok", "timestamp": 1628543435647, "user_tz": -180, "elapsed": 409, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="b90888ed-62d3-4961-b00c-eeb176c8afb2"
i = 1
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
# + colab={"base_uri": "https://localhost:8080/", "height": 660} id="SfeB3WrWv2P8" executionInfo={"status": "ok", "timestamp": 1628543435648, "user_tz": -180, "elapsed": 19, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="24346865-27bc-471a-ccd1-5aae7f32c1f2"
i = 2
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
# + colab={"base_uri": "https://localhost:8080/"} id="rOuVZASrv7KK" executionInfo={"status": "ok", "timestamp": 1628543435648, "user_tz": -180, "elapsed": 16, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="1f9e996f-ccde-4a2c-ac35-16e6fd878716"
long_input_text = tf.constant([inp[-1]])
import textwrap
print('Expected output:\n', '\n'.join(textwrap.wrap(targ[-1])))
# + colab={"base_uri": "https://localhost:8080/"} id="hHfoKvcHv9uH" executionInfo={"status": "ok", "timestamp": 1628543436035, "user_tz": -180, "elapsed": 5, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="415c848a-06e0-4428-8ef9-196adcbc23fc"
result = translator.tf_translate(long_input_text)
i = 0
plot_attention(result['attention'][i], long_input_text[i], result['text'][i])
_ = plt.suptitle('This never works')
# + [markdown] id="2Tt8Qu2ms_b7"
# #Blue score
# + colab={"base_uri": "https://localhost:8080/"} id="shqDFxbywCIW" executionInfo={"status": "ok", "timestamp": 1628543436306, "user_tz": -180, "elapsed": 275, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="cfacc26b-f029-48e0-fe11-32fc4ec5e77c"
# n-gram individual BLEU
from nltk.translate.bleu_score import sentence_bleu
# reference = [['@USER @USER كسمك يا ابن العرص يا اللي امك زانيه اهلي ميين اللي مستواه كده واهلي ميين اللي الخكام بتسانده يا ابن المره الفاجره']]
reference = str('@USER @USER كسمك يا ابن العرص يا اللي امك زانيه اهلي ميين اللي مستواه كده واهلي ميين اللي الخكام بتسانده يا ابن المره الفاجره').split()
candidate = str('@USER @USER **** يا ابن ***** يا اللي امك ***** اهلي ميين اللي مستواه كده واهلي ميين اللي الخكام بتسانده يا ابن المره *******').split()
print('Individual 1-gram: %f' % sentence_bleu([reference], candidate, weights=(1, 0, 0, 0)))
print('Individual 2-gram: %f' % sentence_bleu([reference], candidate, weights=(0, 1, 0, 0)))
print('Individual 3-gram: %f' % sentence_bleu([reference], candidate, weights=(0, 0, 1, 0)))
print('Individual 4-gram: %f' % sentence_bleu([reference], candidate, weights=(0, 0, 0, 1)))
# + id="x_WwCy44tCJy"
test_file = pathlib.Path('/content/drive/MyDrive/Master thesis/paraphrasing/paraphrasingTest.tsv')
targ_test, inp_test = load_data(test_file)
test_dataset = tf.data.Dataset.from_tensor_slices((inp_test, targ_test)).shuffle(BUFFER_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
# + colab={"base_uri": "https://localhost:8080/"} id="h_E6XkwBcbo-" executionInfo={"status": "ok", "timestamp": 1628543437131, "user_tz": -180, "elapsed": 38, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="06219b5f-1604-4270-c0a8-4d57d0395776"
for example_input_batch, example_target_batch in test_dataset.take(1):
for i in range(5):
print(example_input_batch.numpy()[i].decode('utf-8'))
# print()
print(example_target_batch.numpy()[i].decode('utf-8'))
print()
break
# + colab={"base_uri": "https://localhost:8080/"} id="7ES7Gm7fcdNl" executionInfo={"status": "ok", "timestamp": 1628543437133, "user_tz": -180, "elapsed": 29, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="20544648-5ac1-473a-ff1d-57e4aa14da26"
print(inp_test[2:3])
# + colab={"base_uri": "https://localhost:8080/"} id="F0GqYRuFcf0f" executionInfo={"status": "ok", "timestamp": 1628543438749, "user_tz": -180, "elapsed": 1623, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="d8cd3500-0bb2-4d9f-b55b-729b7f24f003"
test_input_text = tf.constant(inp_test[:402])
test_result = translator.tf_translate(test_input_text)
for tr in test_result['text']:
print(tr.numpy().decode())
# list(tr.split("\n"))
print()
# + colab={"base_uri": "https://localhost:8080/", "height": 412} id="eBjsaXtCchgP" executionInfo={"status": "error", "timestamp": 1628543971237, "user_tz": -180, "elapsed": 532491, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AOh14Gj0cMvIp1hk0qzr3By0zUCW2LL_Ph1mCJDW10TRJTU=s64", "userId": "10444042167236672835"}} outputId="81e5ba1e-d744-4e06-bf09-ff87f367d01c"
from nltk.translate.bleu_score import corpus_bleu
def bleu_score():
predicted = []
for tr in range(len(inp_test)):
# for tr in range(5):
test_input_text = tf.constant(inp_test)
# print('salam1',test_input_text)
# test_input_text = tf.constant(inp_test[:5])
test_result = translator.tf_translate(test_input_text)
# print('salam 2',test_result)
# test_result = translator.tf_translate(test_input_text[:5])
test_result= test_result['text'][tr].numpy().decode()
# print('salam3',test_result)
predicted_list = list(test_result.split("\n"))
# print('salam4',predicted_list)
predicted.append(predicted_list)
# print('Predicted List',predicted)
bleu_dic = {}
# bleu_dic['1-grams'] = corpus_bleu(targ_test[:5], predicted, weights=(1.0, 0, 0, 0))
# bleu_dic['1-2-grams'] = corpus_bleu(targ_test[:5], predicted, weights=(0.5, 0.5, 0, 0))
# bleu_dic['1-3-grams'] = corpus_bleu(targ_test[:5], predicted, weights=(0.3, 0.3, 0.3, 0))
# bleu_dic['1-4-grams'] = corpus_bleu(targ_test[:5], predicted, weights=(0.25, 0.25, 0.25, 0.25))
# predicted = str('اما انت تقعد طول عمرك لا مبدا ولا راي ثابت يا ***** . اقسم بربي ماتجي حاجة يا ***** يا **** الانكليز . راس مالك كلام بس . عقاب **** . معمر سيد وحفتر راح يركب عليك . ')
# targ_test = str('اما انت تقعد طول عمرك لا مبدا ولا راي ثابت يا ***** . اقسم بربي ماتجي حاجة يا ***** يا **** الانكليز . راس مالك كلام بس . عقاب **** . معمر سيد وحفتر راح يركب عليك . ')
# predicted = ['']
bleu_dic['1-grams'] = corpus_bleu([targ_test], predicted, weights=(1.0, 0, 0, 0))
bleu_dic['1-2-grams'] = corpus_bleu([targ_test], predicted, weights=(0.5, 0.5, 0, 0))
bleu_dic['1-3-grams'] = corpus_bleu([targ_test], predicted, weights=(0.3, 0.3, 0.3, 0))
bleu_dic['1-4-grams'] = corpus_bleu([targ_test], predicted, weights=(0.25, 0.25, 0.25, 0.25))
res = "\n\n\n".join("Input: {} \nActual: {} \nPredicted: {}".format(x, y,z) for x, y, z in zip(inp_test, targ_test, predicted))
# print(" \n-------------\n BLUE SCORE : \n-------------\n ",bleu_dic, "\n\n\n-------------\n")
print(res , "\n\n\n-------------\n")
return bleu_dic
bleu_test = bleu_score()
bleu_test
# + id="AOjGCF6sck7a"
plt.bar(x = bleu_test.keys(), height = bleu_test.values())
plt.title("BLEU Score with the test set")
plt.ylim((0,1))
plt.show()
# + id="5VcNYB_vcmiG"
| Experiments/HateSpeechMaskingModels/otherExperiments/tensorflow/MT - Paraphrasing - with words.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# ---
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "c00ebae7-6946-4549-aa4b-d8f5c64a0b3c", "showTitle": false, "title": ""}
# # Try running clustering using just the first recorder name
#
# See: https://github.com/pensoft/BiCIKL/issues/28
#
# Building the markov chain model for team parsing in this environment took some time (training step)
# Loaded a datafile built externally to test the process, overwriting the recordedby value with the extracted forst team member.
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "eac391ec-61f4-4f25-9e53-bd9c0b3a24e3", "showTitle": false, "title": ""}
do_setup = False
if do_setup:
recordedby_first_team_member = 'dbfs:/FileStore/tables/agents_first_tm_csv.gz'
sparkDF = spark.read.csv(recordedby_first_team_member, sep='\t', header="true", inferSchema="true")
# Save as table
sparkDF.write.mode('overwrite').saveAsTable('nickyn.occurrence_first_tm')
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "20852b5c-2709-4436-aefd-5d846eb88053", "showTitle": false, "title": ""}
# %sql
USE nickyn;
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "6ed6d8e5-a2d3-4e72-be8b-fe891f033f57", "showTitle": false, "title": ""}
# %sql
DROP TABLE IF EXISTS occurrence;
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "6768a9eb-0c9a-4b3e-950a-cc608ab996ef", "showTitle": false, "title": ""}
# Add an occurrence table with an extra column holding the first team member name (`first_tm`).
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "91b3a30a-8139-4f2e-968c-e1dba4fe2889", "showTitle": false, "title": ""}
# %sql
CREATE TABLE occurrence
AS
SELECT *
FROM gbif.occurrence;
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "00120cb6-8ac7-41fe-b4f4-42bd87676cec", "showTitle": false, "title": ""}
# Run original clustering, storing results in hash, candidates and relationships
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "fb71099c-24d7-4343-8dcf-026be548b4de", "showTitle": false, "title": ""}
# %sql
DROP TABLE IF EXISTS hash;
DROP TABLE IF EXISTS candidates;
DROP TABLE IF EXISTS relationships;
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "4fd38cee-27ab-4942-9b69-3efa0d084d0a", "showTitle": false, "title": ""}
# %scala
import org.gbif.pipelines.clustering.Cluster
val args = Array("--hive-db", "nickyn", "--hive-table-hashed", "hash", "--hive-table-candidates", "candidates", "--hive-table-relationships", "relationships")
Cluster.main(args)
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "949b85d6-4950-41f7-82d2-5bcf200d22b6", "showTitle": false, "title": ""}
# How many relationships were created?
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "6cb1ee72-b5e6-40f2-9052-986a78fd1466", "showTitle": false, "title": ""}
# %sql
SELECT count(DISTINCT id1), count(*) FROM relationships
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "ab240be0-f958-4b1d-94e4-ede1181ff6f9", "showTitle": false, "title": ""}
# %sql
SELECT count(DISTINCT id1), count(*)
FROM relationships
WHERE reasons LIKE '%SAME_RECORDER_NAME%'
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "5ff13c7e-5334-4a84-a767-4f77ff0ef106", "showTitle": false, "title": ""}
# %sql
SELECT occ1.gbifid, occ1.recordedby, occ2.gbifid, occ2.recordedby
FROM occurrence occ1 INNER JOIN relationships rel ON occ1.gbifid = rel.id1
INNER JOIN occurrence occ2 on rel.id2 = occ2.gbifid
WHERE occ1.recordedby != occ2.recordedby
AND rel.REASONS LIKE '%SAME_RECORDER_NAME%'
LIMIT 50
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "9523560c-1dbe-4824-807d-206fd6c3ba36", "showTitle": false, "title": ""}
# ## Use the first team member instead of the full recordedby value
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "17daa06d-00b4-4542-b829-feaf5c40bc73", "showTitle": false, "title": ""}
# How many `recordedby` values exist?
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "34f27fd3-9487-4e29-ac2b-866b4d49b104", "showTitle": false, "title": ""}
# %sql
SELECT COUNT(DISTINCT first_tm)
FROM occurrence_first_tm
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "0235bc2d-ca71-48b1-b316-fa549b548b32", "showTitle": false, "title": ""}
# Update recordedby with first team member values
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "5c60036a-e352-4059-b197-e9293444613b", "showTitle": false, "title": ""}
# %sql
MERGE INTO occurrence occ
USING occurrence_first_tm occftm
ON occ.gbifid = occftm.gbifIDsRecordedBy
WHEN MATCHED AND occftm.first_tm IS NOT NULL THEN
UPDATE SET occ.recordedby = occftm.first_tm
# + [markdown] application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "7ce59e0c-b848-4458-a3d2-f69809884faa", "showTitle": false, "title": ""}
# Run clustering, storing results in hash_rb, candidates_rb and relationships_rb
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "fa05d8c5-1d9d-4800-8900-b7fc9d046af0", "showTitle": false, "title": ""}
# %sql
DROP TABLE IF EXISTS hash_rb;
DROP TABLE IF EXISTS candidates_rb;
DROP TABLE IF EXISTS relationships_rb;
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "8c98eb93-1e7a-42c3-9808-252a3042d668", "showTitle": false, "title": ""}
# %scala
import org.gbif.pipelines.clustering.Cluster
val args = Array("--hive-db", "nickyn", "--hive-table-hashed", "hash_rb", "--hive-table-candidates", "candidates_rb", "--hive-table-relationships", "relationships_rb")
Cluster.main(args)
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "feab91d8-f27c-41bb-aabc-28d0c0213d2a", "showTitle": false, "title": ""}
# %sql
SELECT count(DISTINCT id1), count(*)
FROM relationships_rb;
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "603d1e44-7c1f-47ba-946d-cee5bc4a4ad8", "showTitle": false, "title": ""}
# %sql
SELECT count(DISTINCT id1), count(*)
FROM relationships_rb
WHERE reasons LIKE '%SAME_RECORDER_NAME%'
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "0d4ed1a7-7f23-4d19-ab9b-82fa13400196", "showTitle": false, "title": ""}
# %sql
SELECT occ1.gbifid, occ1.recordedby, occ2.gbifid, occ2.recordedby
FROM gbif.occurrence occ1 INNER JOIN relationships_rb rel ON occ1.gbifid = rel.id1
INNER JOIN gbif.occurrence occ2 on rel.id2 = occ2.gbifid
WHERE occ1.recordedby != occ2.recordedby
AND rel.REASONS LIKE '%SAME_RECORDER_NAME%'
LIMIT 50
# + application/vnd.databricks.v1+cell={"inputWidgets": {}, "nuid": "0fdaf0d9-e3f0-4eed-a95c-8451db01fb7f", "showTitle": false, "title": ""}
| Topic 3 Enhance the GBIF clustering algorithms/results/recordedby_first_team_member.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
import pandas as pd
population_EHPAD = pd.read_excel(
'FRA/EHPA_residents.xlsx',
usecols="A:F",
skiprows=range(0,5),
nrows=11,
sheet_name="T1"
)
population_EHPAD.rename(columns={
population_EHPAD.columns[0]: "age",
population_EHPAD.columns[-1]: "Total"
}, inplace = True)
population_EHPAD
EHPAD_age_map = {
"60-69": [0, 1], # Assumes that no one one in the below 65 cat is below 60
"70-79": [2, 3],
"80+": [4, 5, 6, 7],
}
import french_population as fp
# +
EHPAD_age_table = fp.new_age_table(index=["EHPAD"])
for age in EHPAD_age_map:
for row in EHPAD_age_map[age]:
EHPAD_age_table.loc["EHPAD",age] += \
population_EHPAD.loc[row, "Total"]
EHPAD_age_table["total"] = EHPAD_age_table.sum(axis=1)
EHPAD_age_table["name"] = "EHPAD"
EHPAD_age_table["fra_code"] = "EHPAD"
# -
EHPAD_age_table
import extract_opencovidfr_2_ICL as o2i
o2i.data_dir = o2i.Path("./")
o2i.pop_per_region = o2i.read_pop_region(o2i.data_dir + 'FRA/french_population_age_regional.csv')
# +
fic = "FRA/opencovid19-fr-chiffres-cles.csv"
reg = "REG"
src = o2i.pd.read_csv(fic)
active_regions = o2i.find_active_regions(src, reg)
srcReg = o2i.clean_region_data(src, active_regions)
print(reg + " : " + str(srcReg.shape[0]) + " lignes")
dst = o2i.convert_opencovidfr_to_ICL_model(srcReg, o2i.pop_per_region)
# -
def calculate_daily_change(df, region_id, cumulated_field, field):
reg_logicind = df["geoId"] == region_id
reg_deaths = np.array(df.loc[reg_logicind, cumulated_field])
for i, deaths in enumerate(reg_deaths):
if i>0 and deaths < reg_deaths[i-1]:
reg_deaths[i] = reg_deaths[i-1]
reg_deaths = reg_deaths-[0, *reg_deaths[:-1]]
df.loc[reg_logicind, field] = reg_deaths
dst.sort_values("t", inplace=True)
active_regions = dst["geoId"].unique()
dst["deaths"] = 0
for region in active_regions:
calculate_daily_change(dst, region, "cumulated_deaths", "deaths")
calculate_daily_change(dst, region, "cumulated_cases", "cases")
import numpy as np
reg_logicind = dst["geoId"] == "REG-84"
reg_deaths = np.array(dst.loc[reg_logicind, "cumulated_deaths"])
for i, deaths in enumerate(reg_deaths):
if i>0 and deaths < reg_deaths[i-1]:
reg_deaths[i] = reg_deaths[i-1]
reg_deaths = reg_deaths-[0, *reg_deaths[:-1]]
dst.loc[reg_logicind, "deaths"] = reg_deaths
dst
| data/data_test.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
from scipy import stats
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
# get_ipython().run_line_magic('matplotlib', 'qt5')
def time_to_maturity(t0, T, y=252):
t0 = np.datetime64(t0)
T = np.datetime64(T)
return (np.busday_count(t0, T) / y)
ttm = time_to_maturity('2019-03-29', '2019-04-10')
print(ttm)
# +
def bsm_price(option_type, sigma, s, k, r, ttm, q):
# calculate the bsm price of European call and put options
sigma = float(sigma)
d1 = (np.log(s / k) + (r - q + sigma ** 2 * 0.5) * ttm) / (sigma * np.sqrt(ttm))
d2 = d1 - sigma * np.sqrt(ttm)
if option_type == 'c':
price = np.exp(-r*ttm) * (s * np.exp((r - q)*ttm) * stats.norm.cdf(d1) - k * stats.norm.cdf(d2))
return price
elif option_type == 'p':
price = np.exp(-r*ttm) * (k * stats.norm.cdf(-d2) - s * np.exp((r - q)*ttm) * stats.norm.cdf(-d1))
return price
else:
print('No such option type %s') %option_type
def implied_volatility(option_type, option_price, s, k, r, ttm, q):
if np.isnan(option_price):
return np.nan
else :
upper_vol = 1
lower_vol = 0.00001
mid_vol = (upper_vol + lower_vol)/2.0
tol = 0.0001
# Bisection method
while upper_vol-lower_vol >= tol :
fa = option_price - bsm_price(option_type, lower_vol, s, k, r, ttm, q)
fc = option_price - bsm_price(option_type, mid_vol, s, k, r, ttm, q)
if fa*fc <= 0:
upper_vol = mid_vol
lower_vol = lower_vol
else:
lower_vol = mid_vol
upper_vol = upper_vol
mid_vol = (upper_vol + lower_vol)/2.0
return mid_vol
# -
# ## Operation test
import time
startTime = time.time()
iv = implied_volatility(option_type='c',option_price=0.3, s = 3, k = 3, r = 0.017, ttm=30.0/252, q=0.01)
endTime = time.time() - startTime
print('Implied volatility : ', iv)
print('Opration time : ', endTime)
# Data is obtained from KRX webpage
df = pd.read_csv('190329put.csv', index_col = 'date')
df.head()
# ## Preparing index & splitting df by index
# +
# sort_of_date : literally sort of date without overlap
# sorting_by_date : a list including dfs splited by sort of dates.
sorting_by_date = []
sort_of_date = df.index.drop_duplicates()
# split dfs along date
for date in sort_of_date:
sorting_by_date.append(df.loc[date].drop('type', axis=1))
# -
# ex) '2019-04-11' data
sorting_by_date[0].head()
#len(sorting_by_date[10])
# search the highest length, minimum strike, maximum strike df for grid
# +
tmp_len_list = []
tmp_mink_list = []
tmp_maxk_list = []
for i in range(len(sorting_by_date)):
length = len(sorting_by_date[i])
tmp_len_list.append(length)
min_k = min(sorting_by_date[i]['strike'])
tmp_mink_list.append(min_k)
max_k = max(sorting_by_date[i]['strike'])
tmp_maxk_list.append(max_k)
print(tmp_len_list)
print('min strike: ', min(tmp_mink_list))
print('max strike: ', max(tmp_maxk_list))
# -
global_min_strike = min(tmp_mink_list)
global_max_strike = max(tmp_maxk_list)
# ## Inter&extrapolation on data for smoothed surface
# +
from scipy.optimize import curve_fit
def func(x, a, b, c): # extrapolation function
return a * (x ** 2) + b * x + c
interpolated_strike = np.arange(global_min_strike, global_max_strike+2.5, 2.5) # 2.5 is delta_k
nan_value = np.empty_like(interpolated_strike)
nan_value.fill(np.nan) # ready for mv interpolation
expanded_df = pd.DataFrame(np.concatenate([interpolated_strike.reshape(-1,1), nan_value.reshape(-1,1)], axis=1),
columns=['strike', 'mv'])
interpolated_df_list=[]
for i in range(len(sorting_by_date)):
merged_df = pd.merge_ordered(sorting_by_date[i],expanded_df, on='strike').drop('mv_y', axis=1).rename(columns={'mv_x': 'mv'})
## interpolation first for stability of extrapolated values
merged_df.mv.interpolate(method='polynomial', order=2, inplace=True) # interpolation!
## then, extrapolation process start
# Initial parameter guess, just to kick off the optimization
guess = (0.5, 0.5, 0.5)
# Create copy of data to remove NaNs for curve fitting
fit_df = merged_df.dropna()
# Place to store function parameters for each column
col_params = {}
# Get x & y
x = fit_df['strike'].values
y = fit_df['mv'].values
# Curve fit column and get curve parameters
params = curve_fit(func, x, y, guess)
# Store optimized parameters
col_params['mv'] = params[0]
# Extrapolate
ix = merged_df[pd.isnull(merged_df['mv'])].index
x = merged_df[pd.isnull(merged_df['mv'])]['strike'].values
# Extrapolate those points with the fitted function
merged_df['mv'].loc[ix] = func(x, *col_params['mv'])
expanded_date=np.empty_like(interpolated_strike, dtype='object') # dtype='object' is important for arbitrary length of str!
expanded_date.fill(sort_of_date[i])
merged_df.index = expanded_date # index setting to datetime
interpolated_df_list.append(merged_df)
# -
# ## Drawing surface
# +
s = 276.48 # 2019.03.28 KOSPI200 close price
r = 0.017 # reference : return of Korea Treasury Bond 3yr
# preparation for grid
ttm_list=[]
for date in sort_of_date:
ttm_list.append(time_to_maturity('2019-03-29', date))
strike_list = interpolated_strike
mv_list=[]
for df in interpolated_df_list:
mv_list.append(df.mv.values)
mv_mat = np.array(mv_list) # (11, 83)
# Making 3d grid value
'''
x_axis = time to maturity
y_axis = strike price
z_axis = implied volatility
'''
ttm, k = np.meshgrid(ttm_list, strike_list) # (83, 11)
im_vol_matrix = np.zeros_like(ttm)
for i in range(len(ttm_list)): # along with TTM (11)
ttm_ = ttm_list[i]
for j in range(len(strike_list)): # along with Strike Price (83)
k_ = strike_list[j]
mv_ = mv_mat[i][j]
im_vol_matrix[j][i] = implied_volatility(option_type='p', option_price=mv_, s = s, k = k_, r = r, ttm=ttm_, q=0.0)
# +
plt.rcParams['figure.figsize'] = [30, 15]
plt.rcParams.update({'font.size': 20})
plt.rc('axes', labelsize = 25)
plt.rc('figure', titlesize = 30)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
surf = ax.plot_surface(ttm, k , im_vol_matrix, cmap='viridis',
linewidth=0.5, antialiased=False, alpha=0.4)
wire = ax.plot_wireframe(ttm, k, im_vol_matrix, color='r',linewidth=0.2)
ax.set_xlabel('Time to Maturity(day/year)')
ax.set_ylabel('Strike')
ax.set_zlabel('Implied volatility')
ax.set_title('Volatility surface')
fig.colorbar(surf, shrink=0.5, aspect=5)
fig.tight_layout()
| Basic/5. Volatility Surface.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import queue
class Intcode:
def __init__(self, intcode=None, inputs=None, outputs=None, manual=True):
if intcode == None:
self.intcode = [99]
self.inputs = inputs
if inputs == None:
self.inputs = queue.Queue()
if type(inputs) == list:
q = inputs
self.inputs = queue.Queue()
[self.inputs.put(i) for i in q]
self.outputs = outputs
if outputs == None:
self.outputs = queue.Queue()
if type(outputs) == list:
q = outputs
self.outputs = queue.Queue()
[self.outputs.put(i) for i in q]
self.base = 0
self.pc = 0
self.mem = intcode.copy()
self.manual = manual
def __mem(self, p, v=None):
if p >= len(self.mem):
self.mem += [0] * (1 + p - len(self.mem))
if not v == None:
self.mem[p] = v
return self.mem[p]
def __get(self, var, mode):
tar = self.pc + ['A', 'B', 'C'].index(var) + 1
if mode == 0:
return self.__mem(self.__mem(tar))
elif mode == 1:
return self.__mem(tar)
elif mode == 2:
return self.__mem(self.base + self.__mem(tar))
return None
def __set(self, var, mode, value):
tar = self.pc + ['A', 'B', 'C'].index(var) + 1
if mode == 0:
return self.__mem(self.__mem(tar), value)
elif mode == 1:
return self.__mem(tar, value)
elif mode == 2:
return self.__mem(self.base + self.__mem(tar), value)
return None
def run(self):
while not (self.__mem(self.pc) % 100 == 99):
op = self.__mem(self.pc) % 100
modes = []
for i in range(3):
modes += [int(self.__mem(self.pc) / 100 / 10**i) % 10]
l = 4
if op == 1:
A = self.__get('A', modes[0])
B = self.__get('B', modes[1])
self.__set('C', modes[2], A + B)
elif op == 2:
A = self.__get('A', modes[0])
B = self.__get('B', modes[1])
self.__set('C', modes[2], A * B)
elif op == 3:
if self.manual:
inp = input('Gief pls: ')
if inp == 'abort':
return "Aborted"
self.inputs.put(int(inp))
self.__set('A', modes[0], self.inputs.get())
self.inputs.task_done()
l = 2
elif op == 4:
A = self.__get('A', modes[0])
if self.manual:
print('Take pls:', A)
self.outputs.put(A)
l = 2
elif op == 5:
A = self.__get('A', modes[0])
B = self.__get('B', modes[1])
if A:
self.pc = B
l = 0
else:
l = 3
elif op == 6:
A = self.__get('A', modes[0])
B = self.__get('B', modes[1])
if not A:
self.pc = B
l = 0
else:
l = 3
elif op == 7:
A = self.__get('A', modes[0])
B = self.__get('B', modes[1])
if A < B:
self.__set('C', modes[2], 1)
else:
self.__set('C', modes[2], 0)
elif op == 8:
A = self.__get('A', modes[0])
B = self.__get('B', modes[1])
if A == B:
self.__set('C', modes[2], 1)
else:
self.__set('C', modes[2], 0)
elif op == 9:
A = self.__get('A', modes[0])
self.base += A
l = 2
else:
return "Something went wrong."
self.pc += l
return self.mem, list(self.outputs.queue)
def process_Intcode_test(params, output, message):
prg = Intcode(*params)
if not prg.run() == output:
print(message)
return False
return True
process_Intcode_test([[1,9,10,3,2,3,11,0,99,30,40,50]],
([3500,9,10,70,2,3,11,0,99,30,40,50], []), "FAIL: process_Intcode_test 01")
process_Intcode_test([[1,0,0,0,99]], ([2,0,0,0,99], []), "FAIL: process_Intcode_test 02")
process_Intcode_test([[2,3,0,3,99]], ([2,3,0,6,99], []), "FAIL: process_Intcode_test 03")
process_Intcode_test([[2,4,4,5,99,0]], ([2,4,4,5,99,9801], []), "FAIL: process_Intcode_test 04")
process_Intcode_test([[1,1,1,4,99,5,6,0,99]], ([30,1,1,4,2,5,6,0,99], []), "FAIL: process_Intcode_test 05")
process_Intcode_test([[1002,4,3,4,33]], ([1002,4,3,4,99], []), "FAIL: process_Intcode_test 07")
process_Intcode_test([[1101,100,-1,4,0]], ([1101,100,-1,4,99], []), "FAIL: process_Intcode_test 08")
#testing with inputs
process_Intcode_test([[3,0,4,0,99], [456], [], False], ([456,0,4,0,99], [456]), "FAIL: process_Intcode_test 06")
process_Intcode_test([[3,9,8,9,10,9,4,9,99,-1,8], [8], [], False], ([3,9,8,9,10,9,4,9,99,1,8], [1]), "FAIL: process_Intcode_test 09")
process_Intcode_test([[3,9,8,9,10,9,4,9,99,-1,8], [5], [], False], ([3,9,8,9,10,9,4,9,99,0,8], [0]), "FAIL: process_Intcode_test 10")
process_Intcode_test([[3,9,7,9,10,9,4,9,99,-1,8], [5], [], False], ([3,9,7,9,10,9,4,9,99,1,8], [1]), "FAIL: process_Intcode_test 11")
process_Intcode_test([[3,9,7,9,10,9,4,9,99,-1,8], [8], [], False], ([3,9,7,9,10,9,4,9,99,0,8], [0]), "FAIL: process_Intcode_test 12")
process_Intcode_test([[3,3,1108,-1,8,3,4,3,99], [8], [], False], ([3,3,1108,1,8,3,4,3,99], [1]), "FAIL: process_Intcode_test 13")
process_Intcode_test([[3,3,1108,-1,8,3,4,3,99], [5], [], False], ([3,3,1108,0,8,3,4,3,99], [0]), "FAIL: process_Intcode_test 14")
process_Intcode_test([[3,3,1107,-1,8,3,4,3,99], [5], [], False], ([3,3,1107,1,8,3,4,3,99], [1]), "FAIL: process_Intcode_test 15")
process_Intcode_test([[3,3,1107,-1,8,3,4,3,99], [8], [], False], ([3,3,1107,0,8,3,4,3,99], [0]), "FAIL: process_Intcode_test 16")
#day 9 tests
process_Intcode_test([[109,1,204,-1,1001,100,1,100,1008,100,16,101,1006,101,0,99], [], [], False], ([109, 1, 204, -1, 1001, 100, 1, 100, 1008, 100, 16, 101, 1006, 101, 0, 99, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 16, 1], [109,1,204,-1,1001,100,1,100,1008,100,16,101,1006,101,0,99]), "FAIL: process_Intcode_test 17")
process_Intcode_test([[1102,34915192,34915192,7,4,7,99,0], [], [], False], ([1102, 34915192, 34915192, 7, 4, 7, 99, 1219070632396864], [1219070632396864]), "FAIL: process_Intcode_test 18")
process_Intcode_test([[104,1125899906842624,99], [], [], False], ([104, 1125899906842624, 99], [1125899906842624]), "FAIL: process_Intcode_test 18")
# +
def turn(p, d, r):
dx, dy = d
if r:
dx, dy = dy, -dx
else:
dx, dy = -dy, dx
px, py = p
return (px + dx, py + dy), (dx, dy)
import threading
with open("input11.txt") as infile:
intcode = [int(i) for i in infile.readlines()[0].split(',')]
inp = queue.Queue()
out = queue.Queue()
prg = Intcode(intcode, inputs=inp, outputs=out, manual=False)
position = (0,0)
direction = (0,1)
panels = dict()
t = threading.Thread(target=Intcode.run, name='paintbot', args=(prg,))
t.start()
while t.is_alive():
inp.put(panels.get(position, 0))
panels[position] = out.get()
position, direction = turn(position, direction, out.get())
len(panels)
# +
def turn(p, d, r):
dx, dy = d
if r:
dx, dy = dy, -dx
else:
dx, dy = -dy, dx
px, py = p
return (px + dx, py + dy), (dx, dy)
import threading
with open("input11.txt") as infile:
intcode = [int(i) for i in infile.readlines()[0].split(',')]
inp = queue.Queue()
out = queue.Queue()
prg = Intcode(intcode, inputs=inp, outputs=out, manual=False)
position = (0,0)
direction = (0,1)
panels = dict()
t = threading.Thread(target=Intcode.run, name='paintbot', args=(prg,))
t.start()
xmin, xmax, ymin, ymax = 0, 0, 0, 0
inp.put(1)
panels[position] = out.get()
position, direction = turn(position, direction, out.get())
while t.is_alive():
x, y = position
xmin = min(xmin, x)
ymin = min(ymin, y)
xmax = max(xmax, x)
ymax = max(ymax, y)
inp.put(panels.get(position, 0))
panels[position] = out.get()
position, direction = turn(position, direction, out.get())
for y in range(ymax, ymin-1, -1):
line = ''
for x in range(xmin, xmax+1, 1):
line += '#' if panels.get((x,y), 0) else ' '
print(line)
| 11/11.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # PLAN
#
# - [x] Acquisition
# - [x] Select what list of repos to scrape.
# - [x] Get requests from the site.
# - [x] Save responses to variables.
# - [ ] Cleanup
# - [ ] Prepare the data for delivery.
# - [ ] Delivery
# - [ ] Github repo
# - [ ] This notebook.
# - [ ] Documentation within the notebook.
# - [ ] README file in the repo.
# - [ ] Python scripts if applicable.
# - [ ] Website Demo
# # ENVIRONMENT
from requests import get
from bs4 import BeautifulSoup
SEARCH_PHRASE = 'Moon Phases'
# ## TEACHERS PAY TEACHERS
tpt_url = "https://www.teacherspayteachers.com/Browse/Search:" + SEARCH_PHRASE.replace(" ","%20") + "/Order:Relevance/Grade-Level/Second/Price-Range/Free"
tpt_url
def get_tpt_results(url):
"""
This function takes a url and returns a dictionary that
contains the metadata of the results of the query.
"""
response = get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = []
for result in soup.find_all('div', class_='SearchProductRowLayout'):
d = dict()
d['result_title'] = result.find('div', class_='ProductRowTitleBespoke').text
d['result_href'] = 'https://www.teacherspayteachers.com'+result.a['href']
d['result_desc'] = result.find('div', class_='TruncatedTextBox').text.strip().encode("utf-8")
results.append(d)
return results
tpt = get_tpt_results(tpt_url)
# ## EDUCATION.COM
ec_url = "https://www.education.com/resources/second-grade/" + SEARCH_PHRASE.replace(" ","%20")
ec_url
def get_ec_results(url):
"""
This function takes a url and returns a dictionary that
contains the metadata of the results of the query.
"""
response = get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = []
for result in soup.find_all('div', class_='result'):
d = dict()
d['result_title'] = result.find('div', class_='title').text
d['result_href'] = 'https://www.education.com'+result.a['href']
d['result_desc'] = result.find('div', class_='description').text.strip().encode("utf-8")
results.append(d)
return results
ec = get_ec_results(ec_url)
# ## CLEAN-UP
# _Let's clean up the encoding later..._
# +
# def clean_text(text):
# cleaned = original.replace('\n',' ')
# cleaned = cleaned.replace('\t',' ')
# return cleaned
# clean_text(tpt_text)
# -
for result in tpt:
print(result['result_title'])
print(result['result_desc'])
print(result['result_href'])
print('\n')
for result in ec:
print(result['result_title'])
print(result['result_desc'])
print(result['result_href'])
print('\n')
| v0.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from my_commonfunctions import *
def get_index_of_max_area_contour(contours):
i = 0
i_max = 0
area_max = 0
for c in contours:
area = cv2.contourArea(c)
if area > area_max:
area_max = area
i_max = i
i += 1
return i_max
def derotate_and_crop(img_gray):
# Derotate
angle = get_rotation_angle(img_gray)
gray_rotated = rotate_bound(img_gray, angle)
# Adaptive thresh & canny
thresh = cv2.adaptiveThreshold(gray_rotated, 256, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 11)
if img_gray.shape[0] * img_gray.shape[1] > 900000:
thresh = cv2.medianBlur(thresh, 3)
edges = cv2.Canny(thresh, 100, 200)
# Distance between staves & staff thickness
distance_between_staves, staff_thickness = get_distance_between_staves_and_staff_thickness(thresh)
# Musical score mask
kernel_size = distance_between_staves * 3
k = np.ones((kernel_size, kernel_size))
k2 = np.ones((int(kernel_size*1.5), int(kernel_size*1.5)))
k3 = np.ones((kernel_size*6, kernel_size))
dilated = cv2.dilate(edges, k)
dilated_eroded = cv2.erode(dilated, k2)
dilated_eroded_dilated = cv2.dilate(dilated_eroded, k3)
# my_show_images([thresh, edges, dilated, dilated_eroded, dilated_eroded_dilated], row_max=2)
# Bounding rectangle of the max area contour
image, contours, hierarchy = cv2.findContours(dilated_eroded_dilated, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
i_max = get_index_of_max_area_contour(contours)
x, y, w, h = cv2.boundingRect(contours[i_max])
return gray_rotated[y:y+h, x:x+w], distance_between_staves, staff_thickness
def find_4_points(img):
pts = np.transpose((np.nonzero(img)[1], np.nonzero(img)[0]))
#pts = np.non(pts)
rect = np.zeros((4, 2), dtype="float32")
# the top-left point will have the smallest sum, whereas
# the bottom-right point will have the largest sum
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# now, compute the difference between the points, the
# top-right point will have the smallest difference,
# whereas the bottom-left will have the largest difference
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def deskew(img, musical_lines_points, kernel_size):
points = find_4_points(musical_lines_points)
diameter1 = math.sqrt((points[0][0]-points[2][0])**2+(points[0][1]-points[2][1])**2)
diameter2 = math.sqrt((points[1][0]-points[3][0])**2+(points[1][1]-points[3][1])**2)
direction1 = points[2]-points[0]
direction2 = points[3]-points[1]
points[0] = points[0] - 0.07 * direction1
points[2] = points[2] + 0.07 * direction1
points[1] = points[1] - 0.07 * direction2
points[3] = points[3] + 0.07 * direction2
points[0][1] = points[0][1] - kernel_size * 3.5
points[2][1] = points[2][1] + kernel_size * 3.5
points[1][1] = points[1][1] - kernel_size * 3.5
points[3][1] = points[3][1] + kernel_size * 3.5
diameter1 = math.sqrt((points[0][0]-points[2][0])**2+(points[0][1]-points[2][1])**2)
diameter2 = math.sqrt((points[1][0]-points[3][0])**2+(points[1][1]-points[3][1])**2)
direction1 = points[2]-points[0]
direction2 = points[3]-points[1]
d = max(diameter1,diameter2)
unit_direction1 = direction1 / np.linalg.norm(direction1)
unit_direction2 = direction2 / np.linalg.norm(direction2)
dot_product = np.dot(unit_direction1, unit_direction2)
angle_between = np.arccos(dot_product)
angle = (math.pi-angle_between)/2
maxWidth = round( d * math.cos(angle))
maxHeight = round(d * math.sin(angle))
# print(maxWidth)
# print(maxHeight)
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# compute the perspective transform matrix and then apply it
M = cv2.getPerspectiveTransform(points, dst)
warped = cv2.warpPerspective(img, M, (maxWidth, maxHeight),borderValue=(255,255,255))
# return the warped image
return warped
img_gray = my_imread_gray('02.PNG')
derotated_croped_gray, distance_between_staves, staff_thickness = derotate_and_crop(img_gray)
print(distance_between_staves, staff_thickness)
my_show_images([img_gray, derotated_croped_gray], row_max=2)
# +
edges = canny(derotated_croped_gray, 2, 1, 25)
height = derotated_croped_gray.shape[0]
width = derotated_croped_gray.shape[1]
lines = probabilistic_hough_line(edges, threshold=10, line_length=5, line_gap=3, theta=np.arange(np.pi/4, np.pi*3/4, np.pi/90))
lines_img = np.zeros(edges.shape)
for l in lines:
x1 = l[0][0]
y1 = l[0][1]
x2 = l[1][0]
y2 = l[1][1]
#print(l)
#print(x1, y1, x2, y2)
cv2.line(lines_img, (x1,y1), (x2,y2), (255,255,255), 2)
my_show_images([edges, lines_img], dpi=200, row_max=2)
# -
lines_img.shape
# +
kernel_size = int(distance_between_staves*1.5)
k = np.ones((kernel_size, kernel_size))
k2_multiplier = 3 if np.cbrt(kernel_size) > 3 else np.cbrt(kernel_size) > 3
k2 = np.ones((int(kernel_size*k2_multiplier), int(kernel_size*k2_multiplier)))
print(distance_between_staves)
print(k2_multiplier)
musical_lines_mask = cv2.erode(cv2.dilate(lines_img, k), k2)
my_show_images([musical_lines_mask])
# -
image, contours, hierarchy = cv2.findContours((musical_lines_mask*255).astype(np.uint8), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# +
musical_lines_mask_width = musical_lines_mask.shape[1]
contours_filtered = []
for c in contours:
c = cv2.convexHull(c)
# epsilon = 0.05*cv2.arcLength(c,True)
# c = cv2.approxPolyDP(c,epsilon,True)
x_points = c.T[0]
#print(x_points)
c_min_x = np.min(x_points)
c_max_x = np.max(x_points)
c_width = c_max_x - c_min_x
#print(c_min_x, c_max_x, c_width)
if c_width / musical_lines_mask_width >= .75:
contours_filtered.append(c)
len(contours_filtered)
# -
musical_lines_mask_contours_drawn = rgb2gray(cv2.drawContours(gray2rgb((musical_lines_mask*255).astype(np.uint8)), contours_filtered, -1, (255,255,255), 3))
my_show_images([musical_lines_mask, musical_lines_mask_contours_drawn], row_max=2)
# +
rows,cols = musical_lines_mask.shape[:2]
musical_lines_mask_contours_lines_drawn = np.zeros((rows, cols, 3))
for c in contours_filtered:
[vx,vy,x,y] = cv2.fitLine(c, cv2.DIST_L2,0,0.01,0.01)
lefty = int((-x*vy/vx) + y)
righty = int(((cols-x)*vy/vx)+y)
cv2.line(musical_lines_mask_contours_lines_drawn, (cols-1,righty), (0,lefty), (255,255,255),2)
musical_lines_mask_contours_lines_drawn = rgb2gray(musical_lines_mask_contours_lines_drawn)
musical_lines_points = (musical_lines_mask_contours_lines_drawn > 0.5) & (musical_lines_mask_contours_drawn > 0.5)
my_show_images([musical_lines_mask_contours_lines_drawn > 0.5, (musical_lines_mask_contours_lines_drawn > 0.5) | (musical_lines_mask_contours_drawn > 0.5)], row_max=2)
# -
if len(contours_filtered) > 1:
deskewed = deskew(derotated_croped_gray, musical_lines_points, kernel_size)
else:
deskewed = deskew(derotated_croped_gray, musical_lines_mask_contours_drawn, kernel_size)
my_show_images([deskewed])
# +
# io.imsave('deskewed_derotated.png', deskewed)
# -
| Junk/Yamani/Deskew Dev.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %matplotlib inline
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# +
def plotData(x, y, h):
plt.subplots()
plt.plot(X, h)
plt.scatter(x, y, c='red')
plt.grid(color='gray', linestyle='--', linewidth=.6, axis='both', which='both', alpha=.4)
plt.show()
def calcR2(actual_y,predicted_y,avg_y):
return np.square(predicted_y - avg_y).sum()/np.square(actual_y - avg_y).sum()
def calcSlope(x,y,mean_x,mean_y):
numerator = np.sum((x - mean_x) * (y - mean_y))
denominator = np.sum(np.square(x - mean_x))
return numerator/denominator
# -
X = np.array([1,2,3,4,5])
Y = np.array([3,4,2,4, 5])
# 
# 
# 
# +
mean_x = np.mean(X)
mean_y = np.mean(Y)
slope_m = calcSlope(X,Y, mean_x, mean_y)
intercept_c = mean_y - mean_x * slope_m
m = len(X)
H=[]
for i in range(0,m):
H.append(slope_m * X[i] + intercept_c)
print("Slope : {}, Y Intercept : {}, Prediction Accuracy (R2 Error) : {}".format(slope_m,intercept_c,calcR2(Y,H,mean_y)))
# -
plotData(X,Y,H)
| notebooks/01-simple-linear-regression.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Inspect data
# #### List of tasks accomplished in this Jupyter Notebook:
# - Remove dead larvae and experiments that were accidentally begun before the larval daylight cycle.
# - Convert experiment start time to number of minutes elapsed since light cycle ON time
# - Save cleaned dataset in a new `CSV` file.
# - Check that the number of fed and starved animals in each experiment adds up to the total number of animals.
# - Output the number of animals in each experiment (total) and the number of fed and starved animals for each experiment as a TXT file
# - Check that each experiment larva has one video HDF5 file and one folder
import numpy as np
import pandas as pd
import glob, os
# - Remove dead larvae and experiments that were accidentally begun before the larval daylight cycle.
# - Convert experiment start time to number of minutes elapsed since light cycle ON time
# - Save cleaned dataset in a new `CSV` file.
# +
df = pd.read_csv('./data/experiment_IDs/static_data_naive.csv')
print(len(df), "total larvae experiments")
no_dead = df[df['dead'] == 'no'].copy()
print(len(no_dead), "larvae after removing dead larvae")
no_dead["start_hour"] = pd.DatetimeIndex(no_dead['acclimate_start']).hour
no_dead["start_min"] = pd.DatetimeIndex(no_dead['acclimate_start']).minute
# Remove experiments starting before 9am
times = no_dead[no_dead["start_hour"] >= 9]
# Remove experiments starting after
times = times[(times["start_hour"] <= 9+11) | \
((times["start_hour"] <= 9+12) & (times["start_min"] <= 45))]
print(len(times), "larvae after removing experiments not during daylight")
times["minutes_past_L"] = pd.to_datetime("2018-01-01"+times["experiment_start"], format="%Y-%m-%d%H:%M")
times["minutes_past_L"] = times["minutes_past_L"] - pd.to_datetime("2018-01-01-09:00:00")
times["minutes_past_L"] = pd.DatetimeIndex(times["minutes_past_L"]).hour * 60 + \
pd.DatetimeIndex(times["minutes_past_L"]).minute
times.to_csv("./data/experiment_IDs/cleaned_static_data.csv", index=None)
print("--- Data cleaned and saved to file ---")
# -
# - Check that the number of fed and starved animals in each experiment adds up to the total number of animals.
# - Output the number of animals in each experiment (total) and the number of fed and starved animals for each experiment as a TXT file
# +
# READ IN CLEANED DATASET
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
textfile = [str(len(df))+" Total larvae in entire dataset"]
num_s = len(df[df["starved"] == '1day'])
num_f = len(df[df["starved"] == 'no'])
textfile.append(str(num_s)+" Starved larvae in entire dataset")
textfile.append(str(num_f)+" Fed larvae in entire dataset")
textfile.append('---')
# Check that number of fed and starved animals adds up to the total
assert len(df) == num_s + num_f
experiments = df["treatment_odor"].unique()
for experiment in experiments:
temp = df[df["treatment_odor"] == experiment]
temp_starved = temp[temp["starved"] == '1day']
temp_fed = temp[temp["starved"] == 'no']
# Check that number of fed and starved animals adds up to the total
assert len(temp) == len(temp_fed) + len(temp_starved)
textfile.append(experiment.upper())
textfile.append(str(len(temp))+" Total larvae")
textfile.append(str(len(temp_starved))+" Starved larvae")
textfile.append(str(len(temp_fed))+" Fed larvae")
textfile.append('---')
text_df = pd.DataFrame(textfile)
text_df.to_csv("./data/experiment_IDs/n_values.csv", header=None, index=None)
print("--- Data summary values saved to file ---")
# -
# - Check that each experiment larva has one video HDF5 file and one folder
# +
# READ IN CLEANED DATASET
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
animals = df["animal_ID"].values
# Create folder names for each animal ID to use in checking
df["acc_filenames"] = "./data/trajectories/video_csvs/"+df["animal_ID"]+"-acclimate.csv"
df["exp_filenames"] = "./data/trajectories/video_csvs/"+df["animal_ID"]+"-experiment.csv"
acc_fnames = df["acc_filenames"].values
exp_fnames = df["exp_filenames"].values
# Check that every animal ID is unique
assert len(set(acc_fnames)) == len(acc_fnames)
assert len(set(exp_fnames)) == len(exp_fnames)
# Check that each animal has 1 and only 1 file associated with the animal
accs = glob.glob('./data/trajectories/video_csvs/*-acclimate.csv')
exps = glob.glob('./data/trajectories/video_csvs/*-experiment.csv')
assert sorted(acc_fnames) == sorted(accs)
assert sorted(exp_fnames) == sorted(exps)
# CHECK THAT MANUALLY ANNOTATED FILES ALL EXIST AND ARE SPELLED CORRECTLY
df = pd.read_csv("./data/trajectories/manually_checked_beginning_pause.csv")
for name in df["filename"].values:
fname = "./data/trajectories/video_csvs/"+name+".csv"
if not os.path.isfile(fname):
print(fname)
print("--- All checks passed ---")
# +
# READ IN CLEANED DATASET AND TEST THAT ALL FILES EXIST FOR DATA DRYAD UPLOAD
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
print(len(df), 'cleaned animal IDs to analyze\n---')
# Print out the files in the video folders that are not necessary
# These belong to dead larvae or those pupated before the end of the experiment
# 2018
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
df = df[df['animal_ID'].str.startswith('18')]
df["acc_filenames"] = "/home/eleanor/Downloads/videos/"+df["animal_ID"]+"-acclimate.avi"
df["exp_filenames"] = "/home/eleanor/Downloads/videos/"+df["animal_ID"]+"-experiment.avi"
acc_fnames = df["acc_filenames"].values
exp_fnames = df["exp_filenames"].values
acc_fs = glob.glob('/home/eleanor/Downloads/videos/18*-acclimate.avi')
exp_fs = glob.glob('/home/eleanor/Downloads/videos/18*-experiment.avi')
a_missing = [x for x in acc_fs if x not in acc_fnames]
e_missing = [x for x in exp_fs if x not in exp_fnames]
print(len(a_missing), 'acclimate and', len(e_missing), 'experiment videos included that are not valid larvae (2018).')
for a in sorted(a_missing):
print(a)
a_missing = [x for x in acc_fnames if x not in acc_fs]
e_missing = [x for x in exp_fnames if x not in exp_fs]
print(len(a_missing), 'acclimate and', len(e_missing), 'missing videos (2018).\n---')
for a in sorted(a_missing):
print(a)
# 2017
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
df = df[df['animal_ID'].str.startswith('17')]
df["acc_filenames"] = "/home/eleanor/Downloads/videos/"+df["animal_ID"]+"-acclimate.avi"
df["exp_filenames"] = "/home/eleanor/Downloads/videos/"+df["animal_ID"]+"-experiment.avi"
acc_fnames = df["acc_filenames"].values
exp_fnames = df["exp_filenames"].values
acc_fs = glob.glob('/home/eleanor/Downloads/videos/17*-acclimate.avi')
exp_fs = glob.glob('/home/eleanor/Downloads/videos/17*-experiment.avi')
a_missing = [x for x in acc_fs if x not in acc_fnames]
e_missing = [x for x in exp_fs if x not in exp_fnames]
print(len(a_missing), 'acclimate and', len(e_missing), 'experiment videos included that are not valid larvae (2017).')
for a in sorted(e_missing):
print(a)
a_missing = [x for x in acc_fnames if x not in acc_fs]
e_missing = [x for x in exp_fnames if x not in exp_fs]
print(len(a_missing), 'acclimate and', len(e_missing), 'missing videos (2017).\n---')
for a in sorted(a_missing):
print(a)
# 2019
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
df = df[df['animal_ID'].str.startswith('19')]
df['dat'] = df['animal_ID'].str[0:6]
df['num'] = df['animal_ID'].str[7:9]
df['pos'] = df['animal_ID'].str[10:]
df["acc_filenames"] = "/home/eleanor/Downloads/videos/"+df['dat']+'-'+df['num']+'-'+"A"+'-'+df['pos']+'.avi'
df["exp_filenames"] = "/home/eleanor/Downloads/videos/"+df['dat']+'-'+df['num']+'-'+"E"+'-'+df['pos']+'.avi'
acc_fnames = df["acc_filenames"].values
exp_fnames = df["exp_filenames"].values
acc_fs = glob.glob('/home/eleanor/Downloads/videos/19*A*.avi')
exp_fs = glob.glob('/home/eleanor/Downloads/videos/19*E*.avi')
a_missing = [x for x in acc_fs if x not in acc_fnames]
e_missing = [x for x in exp_fs if x not in exp_fnames]
print(len(a_missing), 'acclimate and', len(e_missing), 'experiment videos included that are not valid larvae (2019).')
for a in sorted(a_missing):
print(a)
a_missing = [x for x in acc_fnames if x not in acc_fs]
e_missing = [x for x in exp_fnames if x not in exp_fs]
print(len(a_missing), 'acclimate and', len(e_missing), 'missing videos (2019).\n---')
for a in sorted(a_missing):
print(a)
# +
# READ IN CLEANED DATASET AND TEST THAT ALL FILES EXIST FOR DATA DRYAD UPLOAD
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
print(len(df), 'cleaned animal IDs to analyze\n---')
# Print out the files in the video folders that are not necessary
# These belong to dead larvae or those pupated before the end of the experiment
# 2018
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
df = df[df['animal_ID'].str.startswith('18')]
df["acc_filenames"] = "/home/eleanor/Downloads/analysis_files_reviewed/"+df["animal_ID"]+"-acclimate"
df["exp_filenames"] = "/home/eleanor/Downloads/analysis_files_reviewed/"+df["animal_ID"]+"-experiment"
acc_fnames = df["acc_filenames"].values
exp_fnames = df["exp_filenames"].values
acc_fs = glob.glob('/home/eleanor/Downloads/analysis_files_reviewed/18*-acclimate')
exp_fs = glob.glob('/home/eleanor/Downloads/analysis_files_reviewed/18*-experiment')
a_missing = [x for x in acc_fs if x not in acc_fnames]
e_missing = [x for x in exp_fs if x not in exp_fnames]
print(len(a_missing), 'acclimate and', len(e_missing), 'experiment files included that are not valid larvae (2018).')
for a in sorted(a_missing):
print(a)
a_missing = [x for x in acc_fnames if x not in acc_fs]
e_missing = [x for x in exp_fnames if x not in exp_fs]
print(len(a_missing), 'acclimate and', len(e_missing), 'missing files (2018).\n---')
for a in sorted(a_missing):
print(a)
# 2017
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
df = df[df['animal_ID'].str.startswith('17')]
df["acc_filenames"] = "/home/eleanor/Downloads/analysis_files_reviewed/"+df["animal_ID"]+"-acclimate"
df["exp_filenames"] = "/home/eleanor/Downloads/analysis_files_reviewed/"+df["animal_ID"]+"-experiment"
acc_fnames = df["acc_filenames"].values
exp_fnames = df["exp_filenames"].values
acc_fs = glob.glob('/home/eleanor/Downloads/analysis_files_reviewed/17*-acclimate')
exp_fs = glob.glob('/home/eleanor/Downloads/analysis_files_reviewed/17*-experiment')
a_missing = [x for x in acc_fs if x not in acc_fnames]
e_missing = [x for x in exp_fs if x not in exp_fnames]
print(len(a_missing), 'acclimate and', len(e_missing), 'experiment files included that are not valid larvae (2017).')
for a in sorted(e_missing):
print(a)
a_missing = [x for x in acc_fnames if x not in acc_fs]
e_missing = [x for x in exp_fnames if x not in exp_fs]
print(len(a_missing), 'acclimate and', len(e_missing), 'missing files (2017).\n---')
for a in sorted(a_missing):
print(a)
# 2019
df = pd.read_csv("./data/experiment_IDs/cleaned_static_data.csv")
df = df[df['animal_ID'].str.startswith('19')]
df['dat'] = df['animal_ID'].str[0:6]
df['num'] = df['animal_ID'].str[7:9]
df['pos'] = df['animal_ID'].str[10:]
df["acc_filenames"] = "/home/eleanor/Downloads/analysis_files_reviewed/"+df['dat']+'-'+df['num']+'-'+"A"+'-'+df['pos']
df["exp_filenames"] = "/home/eleanor/Downloads/analysis_files_reviewed/"+df['dat']+'-'+df['num']+'-'+"E"+'-'+df['pos']
acc_fnames = df["acc_filenames"].values
exp_fnames = df["exp_filenames"].values
acc_fs = glob.glob('/home/eleanor/Downloads/analysis_files_reviewed/19*A*')
exp_fs = glob.glob('/home/eleanor/Downloads/analysis_files_reviewed/19*E*')
a_missing = [x for x in acc_fs if x not in acc_fnames]
e_missing = [x for x in exp_fs if x not in exp_fnames]
print(len(a_missing), 'acclimate and', len(e_missing), 'experiment files included that are not valid larvae (2019).')
for a in sorted(e_missing):
print(a)
a_missing = [x for x in acc_fnames if x not in acc_fs]
e_missing = [x for x in exp_fnames if x not in exp_fs]
print(len(a_missing), 'acclimate and', len(e_missing), 'missing files (2019).\n---')
for a in sorted(a_missing):
print(a)
# -
| 0_inspect_data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + colab={"base_uri": "https://localhost:8080/"} id="CCS93v8ehrPJ" executionInfo={"status": "ok", "timestamp": 1611679091512, "user_tz": -330, "elapsed": 26425, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="95806e7c-479a-400f-93c2-59b6f2070962"
from google.colab import drive
drive.mount('/content/drive')
# + id="VMwhFHlkhCjj" executionInfo={"status": "ok", "timestamp": 1611679369472, "user_tz": -330, "elapsed": 1366, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
import numpy as np
import os
import matplotlib.pyplot as plt
from imutils import paths
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.layers import AveragePooling2D
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import tensorflow as tf
# + id="7IvujwUJhCj1" executionInfo={"status": "ok", "timestamp": 1611679118274, "user_tz": -330, "elapsed": 16393, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
dataset=r'/content/drive/MyDrive/Projects/mask_dataset/Dataset'
imagePaths=list(paths.list_images(dataset))
# + id="juWirjMchCj3"
imagePaths
# + id="ypGFOHIVhCj4" executionInfo={"status": "ok", "timestamp": 1611679334369, "user_tz": -330, "elapsed": 207157, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
data=[]
labels=[]
for i in imagePaths:
label=i.split(os.path.sep)[-2]
labels.append(label)
image=load_img(i,target_size=(224,224))
image=img_to_array(image)
image=preprocess_input(image)
data.append(image)
# + colab={"base_uri": "https://localhost:8080/"} id="XQAka39AkAq6" executionInfo={"status": "ok", "timestamp": 1611679376134, "user_tz": -330, "elapsed": 1129, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="f709ca33-0098-4004-c760-54872ed0cdb9"
# cd /content/drive/MyDrive/Projects/mask_dataset
# + id="gO_Q0BYVhCj4"
data
# + id="M_xjEyV2hCj5"
labels
# + id="GoQ--yH8hCj6"
# + id="cshzuEhyhCj7" executionInfo={"status": "ok", "timestamp": 1611679694996, "user_tz": -330, "elapsed": 1766, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
data=np.array(data,dtype='float32')
labels=np.array(labels)
# + colab={"base_uri": "https://localhost:8080/"} id="cCxKIo8KhCkB" executionInfo={"status": "ok", "timestamp": 1611679698050, "user_tz": -330, "elapsed": 1991, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="ae1e3827-f177-473f-a359-172f2db24718"
data.shape
# + id="xqZwQCuqhCkC"
labels
# + id="CxjVoi63hCkC" executionInfo={"status": "ok", "timestamp": 1611679704020, "user_tz": -330, "elapsed": 1692, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
lb=LabelBinarizer()
labels=lb.fit_transform(labels)
labels=to_categorical(labels)
# + id="lf_ugAkMhCkD"
labels
# + id="ee3FhaWHhCkD" executionInfo={"status": "ok", "timestamp": 1611679710858, "user_tz": -330, "elapsed": 1891, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
# + id="1Zr6t8CEhCkE" executionInfo={"status": "ok", "timestamp": 1611679711459, "user_tz": -330, "elapsed": 1336, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
train_X,test_X,train_Y,test_Y=train_test_split(data,labels,test_size=0.20,stratify=labels,random_state=10)
# + colab={"base_uri": "https://localhost:8080/"} id="ZDQFIYGshCkF" executionInfo={"status": "ok", "timestamp": 1611679715262, "user_tz": -330, "elapsed": 1169, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="4016c9da-dcd7-4276-9373-d80489772f73"
train_X.shape
# + colab={"base_uri": "https://localhost:8080/"} id="JlvihbzhhCkF" executionInfo={"status": "ok", "timestamp": 1611679717035, "user_tz": -330, "elapsed": 1171, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="88f62c27-7adc-49c8-9533-10577fc1040c"
train_Y.shape
# + colab={"base_uri": "https://localhost:8080/"} id="hNGfroXmhCkG" executionInfo={"status": "ok", "timestamp": 1611679718829, "user_tz": -330, "elapsed": 1245, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="aa5432d9-8713-4bdf-86d1-0e83d4fcf98f"
test_X.shape
# + colab={"base_uri": "https://localhost:8080/"} id="A5QhhYNnhCkG" executionInfo={"status": "ok", "timestamp": 1611679720661, "user_tz": -330, "elapsed": 1139, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="e28fb030-8a73-4a27-bc27-106fc486a47c"
test_Y.shape
# + id="qovTGYDmhCkH" executionInfo={"status": "ok", "timestamp": 1611679722055, "user_tz": -330, "elapsed": 1170, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
# + id="L-qHSd2zhCkH" executionInfo={"status": "ok", "timestamp": 1611679724127, "user_tz": -330, "elapsed": 1246, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
aug=ImageDataGenerator(rotation_range=20,zoom_range=0.15,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.15,horizontal_flip=True,vertical_flip=True,fill_mode='nearest')
# + colab={"base_uri": "https://localhost:8080/"} id="_6SC6_nThCkI" executionInfo={"status": "ok", "timestamp": 1611679732784, "user_tz": -330, "elapsed": 7816, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}} outputId="3f7957ca-da04-42df-e043-106488a79a6a"
baseModel=MobileNetV2(weights='imagenet',include_top=False,input_tensor=Input(shape=(224,224,3)))
# + id="sdHdVSA5hCkI"
baseModel.summary()
# + id="Cy-8a3RThCkI" executionInfo={"status": "ok", "timestamp": 1611679749061, "user_tz": -330, "elapsed": 1935, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
headModel=baseModel.output
headModel=AveragePooling2D(pool_size=(7,7))(headModel)
headModel=Flatten(name='Flatten')(headModel)
headModel=Dense(128,activation='relu')(headModel)
headModel=Dropout(0.5)(headModel)
headModel=Dense(2,activation='softmax')(headModel)
model=Model(inputs=baseModel.input,outputs=headModel)
# + id="oeAd2tTuhCkJ" executionInfo={"status": "ok", "timestamp": 1611679751858, "user_tz": -330, "elapsed": 1158, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
for layer in baseModel.layers:
layer.trainable=False
# + id="<KEY>"
model.summary()
# + id="6yCjtgfwhCkK"
# + id="Uh8LbMjMhCkK"
# + id="253uHWl3hCkL"
learning_rate=0.001
Epochs=20
BS=12
opt=Adam(lr=learning_rate,decay=learning_rate/Epochs)
model.compile(loss='binary_crossentropy',optimizer=opt,metrics=['accuracy'])
H=model.fit(
aug.flow(train_X,train_Y,batch_size=BS),
steps_per_epoch=len(train_X)//BS,
validation_data=(test_X,test_Y),
validation_steps=len(test_X)//BS,
epochs=Epochs
)
saved_model_dir = '' #means current directory
tf.saved_model.save(model, saved_model_dir)
# + id="0Nc2gRk7kgVb" executionInfo={"status": "ok", "timestamp": 1611679958055, "user_tz": -330, "elapsed": 9242, "user": {"displayName": "<NAME> (RA1811005010009)", "photoUrl": "", "userId": "00802928257337283334"}}
#saves to the current directory
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
tflite_model = converter.convert() #converts our model into a .tflite model which flutter uses for ondevice machine learning
with open('model.tflite', 'wb') as f: #to write the converted model into a file, written as binary so add 'wb' instead of 'w'
f.write(tflite_model)
# + id="yMlpjpEDhCkL"
predict=model.predict(test_X,batch_size=BS)
predict=np.argmax(predict,axis=1)
print(classification_report(test_Y.argmax(axis=1),predict,target_names=lb.classes_))
# + id="Yu1r90HvhCkM"
# plot the training loss and accuracy
N = Epochs
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["accuracy"], label="val_accuracy")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(r'E:\Mask-Detection-and-Recognition-using-Deep-Learning-Keras\plot_v2.png')
| Mask Training.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import re, math, random # regexes, math functions, random numbers
import matplotlib.pyplot as plt # pyplot
from collections import defaultdict, Counter
from functools import partial, reduce
# +
#
# functions for working with vectors
#
def vector_add(v, w):
"""adds two vectors componentwise"""
return [v_i + w_i for v_i, w_i in zip(v,w)]
def vector_subtract(v, w):
"""subtracts two vectors componentwise"""
return [v_i - w_i for v_i, w_i in zip(v,w)]
def vector_sum(vectors):
return reduce(vector_add, vectors)
def scalar_multiply(c, v):
return [c * v_i for v_i in v]
def vector_mean(vectors):
"""compute the vector whose i-th element is the mean of the
i-th elements of the input vectors"""
n = len(vectors)
return scalar_multiply(1/n, vector_sum(vectors))
def dot(v, w):
"""v_1 * w_1 + ... + v_n * w_n"""
return sum(v_i * w_i for v_i, w_i in zip(v, w))
def sum_of_squares(v):
"""v_1 * v_1 + ... + v_n * v_n"""
return dot(v, v)
def magnitude(v):
return math.sqrt(sum_of_squares(v))
def squared_distance(v, w):
return sum_of_squares(vector_subtract(v, w))
def distance(v, w):
return math.sqrt(squared_distance(v, w))
# -
# If we picked a number k like 3 or 5, then we want to classify new data by finding k nearest labeled points and the neighboring data points vote on the new output on how to classify that new data point.
#
#
# Write a function to do this:
def raw_majority_vote(labels):
votes = Counter(labels)
winner, _ = votes.most_common(1)[0]
return winner
cities = [(-86.75,33.5666666666667,'Python'),(-88.25,30.6833333333333,'Python'),(-112.016666666667,33.4333333333333,'Java'),(-110.933333333333,32.1166666666667,'Java'),(-92.2333333333333,34.7333333333333,'R'),(-121.95,37.7,'R'),(-118.15,33.8166666666667,'Python'),(-118.233333333333,34.05,'Java'),(-122.316666666667,37.8166666666667,'R'),(-117.6,34.05,'Python'),(-116.533333333333,33.8166666666667,'Python'),(-121.5,38.5166666666667,'R'),(-117.166666666667,32.7333333333333,'R'),(-122.383333333333,37.6166666666667,'R'),(-121.933333333333,37.3666666666667,'R'),(-122.016666666667,36.9833333333333,'Python'),(-104.716666666667,38.8166666666667,'Python'),(-104.866666666667,39.75,'Python'),(-72.65,41.7333333333333,'R'),(-75.6,39.6666666666667,'Python'),(-77.0333333333333,38.85,'Python'),(-80.2666666666667,25.8,'Java'),(-81.3833333333333,28.55,'Java'),(-82.5333333333333,27.9666666666667,'Java'),(-84.4333333333333,33.65,'Python'),(-116.216666666667,43.5666666666667,'Python'),(-87.75,41.7833333333333,'Java'),(-86.2833333333333,39.7333333333333,'Java'),(-93.65,41.5333333333333,'Java'),(-97.4166666666667,37.65,'Java'),(-85.7333333333333,38.1833333333333,'Python'),(-90.25,29.9833333333333,'Java'),(-70.3166666666667,43.65,'R'),(-76.6666666666667,39.1833333333333,'R'),(-71.0333333333333,42.3666666666667,'R'),(-72.5333333333333,42.2,'R'),(-83.0166666666667,42.4166666666667,'Python'),(-84.6,42.7833333333333,'Python'),(-93.2166666666667,44.8833333333333,'Python'),(-90.0833333333333,32.3166666666667,'Java'),(-94.5833333333333,39.1166666666667,'Java'),(-90.3833333333333,38.75,'Python'),(-108.533333333333,45.8,'Python'),(-95.9,41.3,'Python'),(-115.166666666667,36.0833333333333,'Java'),(-71.4333333333333,42.9333333333333,'R'),(-74.1666666666667,40.7,'R'),(-106.616666666667,35.05,'Python'),(-78.7333333333333,42.9333333333333,'R'),(-73.9666666666667,40.7833333333333,'R'),(-80.9333333333333,35.2166666666667,'Python'),(-78.7833333333333,35.8666666666667,'Python'),(-100.75,46.7666666666667,'Java'),(-84.5166666666667,39.15,'Java'),(-81.85,41.4,'Java'),(-82.8833333333333,40,'Java'),(-97.6,35.4,'Python'),(-122.666666666667,45.5333333333333,'Python'),(-75.25,39.8833333333333,'Python'),(-80.2166666666667,40.5,'Python'),(-71.4333333333333,41.7333333333333,'R'),(-81.1166666666667,33.95,'R'),(-96.7333333333333,43.5666666666667,'Python'),(-90,35.05,'R'),(-86.6833333333333,36.1166666666667,'R'),(-97.7,30.3,'Python'),(-96.85,32.85,'Java'),(-95.35,29.9666666666667,'Java'),(-98.4666666666667,29.5333333333333,'Java'),(-111.966666666667,40.7666666666667,'Python'),(-73.15,44.4666666666667,'R'),(-77.3333333333333,37.5,'Python'),(-122.3,47.5333333333333,'Python'),(-89.3333333333333,43.1333333333333,'R'),(-104.816666666667,41.15,'Java')]
raw_majority_vote(cities)
votes = Counter(cities)
votes.most_common(1)[0]
# We have different optinos on how to do "voting"
# - pick a winner at random
# - weight the votes by distance and pick the weighted winner
# - reduce k until we find a unique winner (**THIS is the one we will implement below**)
winner, winner_count = votes.most_common(1)[0]
winner
winner_count
votes.values()
num_winners = len([count for count in votes.values() if count == winner_count])
num_winners
def majority_vote(labels):
"""assumes that labels are ordered from nearest to farthest"""
vote_counts = Counter(labels)
winner, winner_count = vote_counts.most_common(1)[0]
# list comprehension is looking at vote_count values
# then taking a tally of the number of winners where the values of the vote_count
# matches the winner_count (which is the number of times a given label appeared the MOST)
num_winners = len([count
for count in vote_counts.values()
if count == winner_count])
if num_winners == 1:
return winner # unique winner, so return it
else:
return majority_vote(labels[:-1]) # try again without the farthest
majority_vote(cities)
# Now with the my_majority_vote function, we're able to create the knn function
cities = [([longitude, latitude], language) for longitude, latitude, language in cities]
cities[:5]
by_distance = sorted(cities, key=lambda city: distance(city[0], [34.0522, 118.2437]))
by_distance[:5]
def knn_classify(k, labeled_points, new_point):
"""each labeled point should be a pair (point, label)"""
# order the labeled points from nearest to farthest
by_distance = sorted(labeled_points, key=lambda point_label: distance(point_label[0], new_point))
# find the labels for the k closest
k_nearest_labels = [label for _, label in by_distance[:k]]
# and let them vote
return majority_vote(k_nearest_labels)
# In practice: let's test on "Favorite Languages"
for k in [1, 3, 5, 7]:
num_correct = 0
for city in cities:
# unpack the tuple city ([lat, long], city)
location, actual_language = city
# create a list of all other cities except for the one in question
other_cities = [other_city for other_city in cities if other_city != city]
predicted_language = knn_classify(k, other_cities, location)
if predicted_language == actual_language:
num_correct += 1
print(k, "neighbors[s]:", num_correct, "correct out of", len(cities))
| ipynb/Chapter_12-k_Nearest_Neighbors.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# get_ipython().magic('matplotlib notebook')
get_ipython().magic('matplotlib inline')
get_ipython().magic('load_ext autoreload')
get_ipython().magic('autoreload 2')
#___________________________________________________________________________________________________________________
import os
import tripyview as tpv
import numpy as np
# + tags=["parameters"]
# Parameters
mesh_path ='/work/ollie/projects/clidyn/FESOM2/meshes/core2/'
save_path = None #'~/figures/test_papermill/'
save_fname = None
#_____________________________________________________________________________________
which_cycl = 1
which_mode = 'variable'
#_____________________________________________________________________________________
input_paths= list()
input_paths.append('/home/ollie/pscholz/results/trr181_tke_ctrl_ck0.1/')
input_paths.append('/home/ollie/pscholz/results/trr181_tke_ctrl_ck0.3/')
input_paths.append('/home/ollie/pscholz/results/trr181_tke+idemix_orig_ck0.1/')
input_paths.append('/home/ollie/pscholz/results/trr181_tke+idemix_jayne09_ck0.1/')
input_paths.append('/home/ollie/pscholz/results/old_trr181_tke+idemix_nycander05_ck0.1/')
input_paths.append('/home/ollie/pscholz/results/old_trr181_tke+idemix_stormtide2_ck0.1/')
input_paths.append('/home/ollie/pscholz/results/trr181_tke+idemix_jayne09_ck0.3/')
input_paths.append('/home/ollie/pscholz/results/old_trr181_tke+idemix_nycander05_ck0.3/')
input_paths.append('/home/ollie/pscholz/results/old_trr181_tke+idemix_stormtide2_ck0.3/')
input_names= list()
input_names.append('TKE, ck=0.1')
input_names.append('TKE, ck=0.3')
input_names.append('TKE+IDEMIX, ck=0.1, jayne (old param)')
input_names.append('TKE+IDEMIX, ck=0.1, jayne (new param)')
input_names.append('TKE+IDEMIX, ck=0.1, nycander (new param)')
input_names.append('TKE+IDEMIX, ck=0.1, stormtide (new param)')
input_names.append('TKE+IDEMIX, ck=0.3, jayne (new param)')
input_names.append('TKE+IDEMIX, ck=0.3, nycander (new param)')
input_names.append('TKE+IDEMIX, ck=0.3, stormtide (new param)')
vname = 'temp'
year = [1979,2019]
mon, day, record, box, depth = None, None, None, None, 100
#_____________________________________________________________________________________
# do anomaly plots in case ref_path is not None
ref_path = None #'/home/ollie/pscholz/results/trr181_tke_ctrl_ck0.1/' # None
ref_name = None #'TKE, ck=0.1' # None
ref_year = None # [2009,2019]
ref_mon, ref_day, ref_record = None, None, None
#_____________________________________________________________________________________
which_clim = 'phc3'
clim_path = '/work/ollie/pscholz/INIT_HYDRO/phc3.0/phc3.0_annual.nc'
#_____________________________________________________________________________________
cstr = 'blue2red'
cnum = 20
cref = 0
crange, cmin, cmax, cfac, climit = None, None, None, None, None
#_____________________________________________________________________________________
ncolumn = 3
do_rescale = None
which_dpi = 300
proj = 'pc'
# +
#___LOAD FESOM2 MESH___________________________________________________________________________________
mesh=tpv.load_mesh_fesom2(mesh_path, do_rot='None', focus=0, do_info=True, do_pickle=True,
do_earea=True, do_narea=True, do_eresol=[True,'mean'], do_nresol=[True,'eresol'])
#______________________________________________________________________________________________________
if which_cycl is not None:
for ii,ipath in enumerate(input_paths):
input_paths[ii] = os.path.join(ipath,'{:d}/'.format(which_cycl))
print(ii, ipath, input_paths[ii])
if ref_path is not None:
ref_path = os.path.join(ref_path,'{:d}/'.format(which_cycl))
print('R', ref_path)
#______________________________________________________________________________________________________
cinfo=dict({'cstr':cstr, 'cnum':cnum})
if crange is not None: cinfo['crange']=crange
if cmin is not None: cinfo['cmin' ]=cmin
if cmax is not None: cinfo['cmax' ]=cmax
if cref is not None: cinfo['cref' ]=cref
if cfac is not None: cinfo['cfac' ]=cfac
if climit is not None: cinfo['climit']=climit
if ref_path is not None: cinfo['cref' ]=0.0
#______________________________________________________________________________________________________
# in case of diff plots
if ref_path is not None:
if ref_year is None: ref_year = year
if ref_mon is None: ref_mon = mon
if ref_record is None: ref_record = record
# +
#___LOAD Climatology DATA______________________________________________________________________________
clim_vname = vname
if (vname in ['temp', 'salt', 'pdens'] or 'sigma' in vname) and (depth is not 'bottom'):
if vname=='temp' and which_clim.lower()=='woa18': clim_vname = 't00an1'
elif vname=='salt' and which_clim.lower()=='woa18': clim_vname = 's00an1'
clim = tpv.load_climatology(mesh, clim_path, clim_vname, depth=depth)
else: raise ValueError('climatology not supported for choosen vname')
#___LOAD FESOM2 REFERENCE DATA________________________________________________________________________
data_list = list()
if ref_path is not None:
print(ref_path)
data_ref = tpv.load_data_fesom2(mesh, ref_path, vname=vname, year=ref_year, mon=ref_mon, day=ref_day, record=ref_record,
depth=depth, descript=ref_name, do_info=False)
data_list.append(tpv.do_anomaly(data_ref, clim))
del data_ref
#___LOAD FESOM2 DATA___________________________________________________________________________________
for datapath,descript in zip(input_paths, input_names):
print(datapath)
data = tpv.load_data_fesom2(mesh, datapath, vname=vname, year=year, mon=mon, day=day, record=record,
depth=depth, descript=descript, do_info=False)
data_list.append(tpv.do_anomaly(data, clim))
del data
# +
#___PLOT FESOM2 DATA___________________________________________________________________________________
spath = save_path
sname = vname
slabel = data_list[0][sname].attrs['str_lsave']
if spath is not None: spath = os.path.join(spath,'{}_{}_{}.png'.format(which_mode, sname, slabel))
nrow = np.ceil(len(data_list)/ncolumn).astype('int')
if save_fname is not None: spath = save_fname
# pos_gap = [0.005, 0.01]
pos_gap = [0.005, 0.04]
if proj in ['nps, sps']:pos_gap = [0.005, 0.035]
fig, ax, cbar = tpv.plot_hslice(mesh, data_list, cinfo=cinfo, box=box, n_rc=[nrow, ncolumn],
figsize=[ncolumn*7, nrow*3.5], proj = proj,
do_lsmask='fesom', do_rescale=do_rescale, title='descript',
pos_gap=pos_gap, pos_extend=[0.03, 0.03, 0.905, 0.975],
do_save=spath, save_dpi=which_dpi)
| templates_notebooks/template_hslice_clim.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# <center>
# <img src="../../img/ods_stickers.jpg" />
#
# ## [mlcourse.ai](https://mlcourse.ai) – Open Machine Learning Course
#
# Author: [<NAME>](http://arseny.info/pages/about-me.html). Translated and edited by [<NAME>](https://www.linkedin.com/in/christinabutsko/), [<NAME>](https://yorko.github.io/), [<NAME>](https://www.linkedin.com/in/egor-polusmak/), [<NAME>](https://www.linkedin.com/in/anastasiamanokhina/), [<NAME>](https://www.linkedin.com/in/anna-larionova-74434689/), [<NAME>](https://www.linkedin.com/in/evgenysushko/) and [<NAME>](https://www.linkedin.com/in/yuanyuanpao/). This material is subject to the terms and conditions of the [Creative Commons CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license. Free use is permitted for any non-commercial purpose.
# # <center> Topic 6. Feature Engineering and Feature Selection</center>
# In this course, we have already seen several key machine learning algorithms. However, before moving on to the more fancy ones, we’d like to take a small detour and talk about data preparation. The well-known concept of “garbage in — garbage out” applies 100% to any task in machine learning. Any experienced professional can recall numerous times when a simple model trained on high-quality data was proven to be better than a complicated multi-model ensemble built on data that wasn’t clean.
#
# To start, I wanted to review three similar but different tasks:
# * **feature extraction** and **feature engineering**: transformation of raw data into features suitable for modeling;
# * **feature transformation**: transformation of data to improve the accuracy of the algorithm;
# * **feature selection**: removing unnecessary features.
#
# This article will contain almost no math, but there will be a fair amount of code. Some examples will use the dataset from Renthop company, which is used in the [Two Sigma Connect: Rental Listing Inquiries Kaggle competition](https://www.kaggle.com/c/two-sigma-connect-rental-listing-inquiries). The file `train.json` is also kept [here](https://drive.google.com/open?id=1_lqydkMrmyNAgG4vU4wVmp6-j7tV0XI8) as `renthop_train.json.gz` (so do unpack it first). In this task, you need to predict the popularity of a new rental listing, i.e. classify the listing into three classes: `['low', 'medium' , 'high']`. To evaluate the solutions, we will use the log loss metric (the smaller, the better). Those who do not have a Kaggle account, will have to register; you will also need to accept the rules of the competition in order to download the data.
# +
# preload dataset automatically, if not already in place.
import os
import requests
url = "https://drive.google.com/uc?export=download&id=1_lqydkMrmyNAgG4vU4wVmp6-j7tV0XI8"
file_name = "../../data/renthop_train.json.gz"
def load_renthop_dataset(url, target, overwrite=False):
# check if exists already
if os.path.isfile(target) and not overwrite:
print("Dataset is already in place")
return
print("Will download the dataset from", url)
response = requests.get(url)
open(target, "wb").write(response.content)
load_renthop_dataset(url, file_name)
# +
import numpy as np
import pandas as pd
df = pd.read_json(file_name, compression="gzip")
# -
# ## Article outline
#
# 1. Feature Extraction
# 1. Texts
# 2. Images
# 3. Geospatial data
# 4. Date and time
# 5. Time series, web, etc.
#
# 2. Feature transformations
# 1. Normalization and changing distribution
# 2. Interactions
# 3. Filling in the missing values
#
# 3. Feature selection
# 1. Statistical approaches
# 2. Selection by modeling
# 3. Grid search
# ## Feature Extraction
#
# In practice, data rarely comes in the form of ready-to-use matrices. That's why every task begins with feature extraction. Sometimes, it can be enough to read the csv file and convert it into `numpy.array`, but this is a rare exception. Let's look at some of the popular types of data from which features can be extracted.
# ### Texts
#
# Text is a type of data that can come in different formats; there are so many text processing methods that cannot fit in a single article. Nevertheless, we will review the most popular ones.
#
# Before working with text, one must tokenize it. Tokenization implies splitting the text into units (hence, tokens). Most simply, tokens are just the words. But splitting by word can lose some of the meaning -- "Santa Barbara" is one token, not two, but "rock'n'roll" should not be split into two tokens. There are ready-to-use tokenizers that take into account peculiarities of the language, but they make mistakes as well, especially when you work with specific sources of text (newspapers, slang, misspellings, typos).
#
# After tokenization, you will normalize the data. For text, this is about stemming and/or lemmatization; these are similar processes used to process different forms of a word. One can read about the difference between them [here](http://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html).
#
# So, now that we have turned the document into a sequence of words, we can represent it with vectors. The easiest approach is called Bag of Words: we create a vector with the length of the vocabulary, compute the number of occurrences of each word in the text, and place that number of occurrences in the appropriate position in the vector. The process described looks simpler in code:
# +
texts = ["i have a cat", "you have a dog", "you and i have a cat and a dog"]
vocabulary = list(
enumerate(set([word for sentence in texts for word in sentence.split()]))
)
print("Vocabulary:", vocabulary)
def vectorize(text):
vector = np.zeros(len(vocabulary))
for i, word in vocabulary:
num = 0
for w in text:
if w == word:
num += 1
if num:
vector[i] = num
return vector
print("Vectors:")
for sentence in texts:
print(vectorize(sentence.split()))
# -
# Here is an illustration of the process:
#
# <img src='../../img/bag_of_words.png' width=50%>
#
# This is an extremely naive implementation. In practice, you need to consider stop words, the maximum length of the vocabulary, more efficient data structures (usually text data is converted to a sparse vector), etc.
#
# When using algorithms like Bag of Words, we lose the order of the words in the text, which means that the texts "i have no cows" and "no, i have cows" will appear identical after vectorization when, in fact, they have the opposite meaning. To avoid this problem, we can revisit our tokenization step and use N-grams (the *sequence* of N consecutive tokens) instead.
# +
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer(ngram_range=(1, 1))
vect.fit_transform(["no i have cows", "i have no cows"]).toarray()
# -
vect.vocabulary_
vect = CountVectorizer(ngram_range=(1, 2))
vect.fit_transform(["no i have cows", "i have no cows"]).toarray()
vect.vocabulary_
# Also note that one does not have to use only words. In some cases, it is possible to generate N-grams of characters. This approach would be able to account for similarity of related words or handle typos.
# +
from scipy.spatial.distance import euclidean
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer(ngram_range=(3, 3), analyzer="char_wb")
n1, n2, n3, n4 = vect.fit_transform(
["andersen", "petersen", "petrov", "smith"]
).toarray()
euclidean(n1, n2), euclidean(n2, n3), euclidean(n3, n4)
# -
# Adding onto the Bag of Words idea: words that are rarely found in the corpus (in all the documents of this dataset) but are present in this particular document might be more important. Then it makes sense to increase the weight of more domain-specific words to separate them out from common words. This approach is called TF-IDF (term frequency-inverse document frequency), which cannot be written in a few lines, so you should look into the details in references such as [this wiki](https://en.wikipedia.org/wiki/Tf%E2%80%93idf). The default option is as follows:
#
# $$ \large idf(t,D) = \log\frac{\mid D\mid}{df(d,t)+1} $$
#
# $$ \large tfidf(t,d,D) = tf(t,d) \times idf(t,D) $$
#
# Ideas similar to Bag of Words can also be found outside of text problems e.g. bag of sites in the [Catch Me If You Can competition](https://inclass.kaggle.com/c/catch-me-if-you-can-intruder-detection-through-webpage-session-tracking), [bag of apps](https://www.kaggle.com/xiaoml/talkingdata-mobile-user-demographics/bag-of-app-id-python-2-27392), [bag of events](http://www.interdigital.com/download/58540a46e3b9659c9f000372), etc.
#
# 
#
# Using these algorithms, it is possible to obtain a working solution for a simple problem, which can serve as a baseline. However, for those who do not like the classics, there are new approaches. The most popular method in the new wave is [Word2Vec](https://arxiv.org/pdf/1310.4546.pdf), but there are a few alternatives as well ([GloVe](https://nlp.stanford.edu/pubs/glove.pdf), [Fasttext](https://arxiv.org/abs/1607.01759), etc.).
#
# Word2Vec is a special case of the word embedding algorithms. Using Word2Vec and similar models, we can not only vectorize words in a high-dimensional space (typically a few hundred dimensions) but also compare their semantic similarity. This is a classic example of operations that can be performed on vectorized concepts: king - man + woman = queen.
#
# 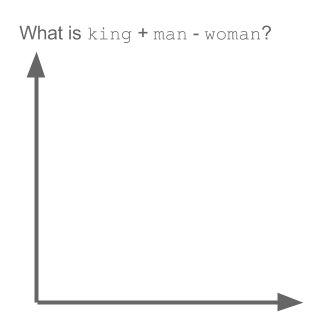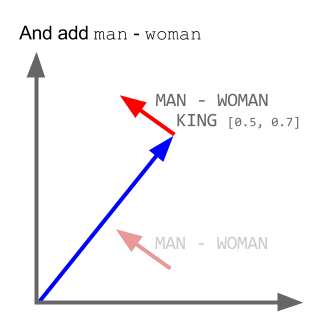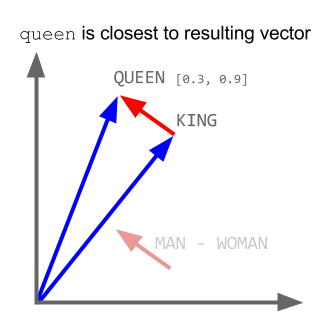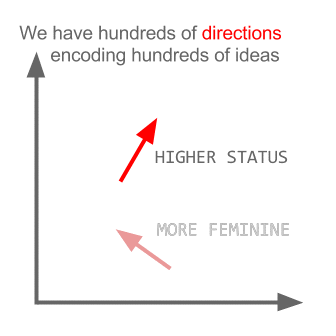
#
# It is worth noting that this model does not comprehend the meaning of the words but simply tries to position the vectors such that words used in common context are close to each other. If this is not taken into account, a lot of fun examples will come up.
#
# Such models need to be trained on very large datasets in order for the vector coordinates to capture the semantics. A pretrained model for your own tasks can be downloaded [here](https://github.com/3Top/word2vec-api#where-to-get-a-pretrained-models).
#
# Similar methods are applied in other areas such as bioinformatics. An unexpected application is [food2vec](https://jaan.io/food2vec-augmented-cooking-machine-intelligence/). You can probably think of a few other fresh ideas; the concept is universal enough.
# ### Images
#
# Working with images is easier and harder at the same time. It is easier because it is possible to just use one of the popular pretrained networks without much thinking but harder because, if you need to dig into the details, you may end up going really deep. Let's start from the beginning.
#
# In a time when GPUs were weaker and the "renaissance of neural networks" had not happened yet, feature generation from images was its own complex field. One had to work at a low level, determining corners, borders of regions, color distributions statistics, and so on. Experienced specialists in computer vision could draw a lot of parallels between older approaches and neural networks; in particular, convolutional layers in today's networks are similar to [Haar cascades](https://en.wikipedia.org/wiki/Haar-like_feature). If you are interested in reading more, here are a couple of links to some interesting libraries: [skimage](http://scikit-image.org/docs/stable/api/skimage.feature.html) and [SimpleCV](http://simplecv.readthedocs.io/en/latest/SimpleCV.Features.html).
#
# Often for problems associated with images, a convolutional neural network is used. You do not have to come up with the architecture and train a network from scratch. Instead, download a pretrained state-of-the-art network with the weights from public sources. Data scientists often do so-called fine-tuning to adapt these networks to their needs by "detaching" the last fully connected layers of the network, adding new layers chosen for a specific task, and then training the network on new data. If your task is to just vectorize the image (for example, to use some non-network classifier), you only need to remove the last layers and use the output from the previous layers:
# +
# doesn't work with Python 3.7
# # Install Keras and tensorflow (https://keras.io/)
# from keras.applications.resnet50 import ResNet50, preprocess_input
# from keras.preprocessing import image
# from scipy.misc import face
# import numpy as np
# resnet_settings = {'include_top': False, 'weights': 'imagenet'}
# resnet = ResNet50(**resnet_settings)
# # What a cute raccoon!
# img = image.array_to_img(face())
# img
# +
# # In real life, you may need to pay more attention to resizing
# img = img.resize((224, 224))
# x = image.img_to_array(img)
# x = np.expand_dims(x, axis=0)
# x = preprocess_input(x)
# # Need an extra dimension because model is designed to work with an array
# # of images - i.e. tensor shaped (batch_size, width, height, n_channels)
# features = resnet.predict(x)
# -
# <img src='https://cdn-images-1.medium.com/max/800/1*Iw_cKFwLkTVO2SPrOZU2rQ.png' width=60%>
#
# *Here's a classifier trained on one dataset and adapted for a different one by "detaching" the last layer and adding a new one instead.*
#
# Nevertheless, we should not focus too much on neural network techniques. Features generated by hand are still very useful: for example, for predicting the popularity of a rental listing, we can assume that bright apartments attract more attention and create a feature such as "the average value of the pixel". You can find some inspiring examples in the documentation of [relevant libraries](http://pillow.readthedocs.io/en/3.1.x/reference/ImageStat.html).
#
# If there is text on the image, you can read it without unraveling a complicated neural network. For example, check out [pytesseract](https://github.com/madmaze/pytesseract).
# ```python
# import pytesseract
# from PIL import Image
# import requests
# from io import BytesIO
#
# ##### Just a random picture from search
# img = 'http://ohscurrent.org/wp-content/uploads/2015/09/domus-01-google.jpg'
#
# img = requests.get(img)
# img = Image.open(BytesIO(img.content))
# text = pytesseract.image_to_string(img)
#
# text
#
# Out: 'Google'
# ```
# One must understand that `pytesseract` is not a solution for everything.
# ```python
# ##### This time we take a picture from Renthop
# img = requests.get('https://photos.renthop.com/2/8393298_6acaf11f030217d05f3a5604b9a2f70f.jpg')
# img = Image.open(BytesIO(img.content))
# pytesseract.image_to_string(img)
#
# Out: 'Cunveztible to 4}»'
# ```
# Another case where neural networks cannot help is extracting features from meta-information. For images, EXIF stores many useful meta-information: manufacturer and camera model, resolution, use of the flash, geographic coordinates of shooting, software used to process image and more.
# ### Geospatial data
#
# Geographic data is not so often found in problems, but it is still useful to master the basic techniques for working with it, especially since there are quite a number of ready-to-use solutions in this field.
#
# Geospatial data is often presented in the form of addresses or coordinates of (Latitude, Longitude). Depending on the task, you may need two mutually-inverse operations: geocoding (recovering a point from an address) and reverse geocoding (recovering an address from a point). Both operations are accessible in practice via external APIs from Google Maps or OpenStreetMap. Different geocoders have their own characteristics, and the quality varies from region to region. Fortunately, there are universal libraries like [geopy](https://github.com/geopy/geopy) that act as wrappers for these external services.
#
# If you have a lot of data, you will quickly reach the limits of external API. Besides, it is not always the fastest to receive information via HTTP. Therefore, it is necessary to consider using a local version of OpenStreetMap.
#
# If you have a small amount of data, enough time, and no desire to extract fancy features, you can use `reverse_geocoder` in lieu of OpenStreetMap:
# ```python
# import reverse_geocoder as revgc
#
# revgc.search((df.latitude, df.longitude))
# Loading formatted geocoded file...
#
# Out: [OrderedDict([('lat', '40.74482'),
# ('lon', '-73.94875'),
# ('name', 'Long Island City'),
# ('admin1', 'New York'),
# ('admin2', 'Queens County'),
# ('cc', 'US')])]
# ```
# When working with geoсoding, we must not forget that addresses may contain typos, which makes the data cleaning step necessary. Coordinates contain fewer misprints, but its position can be incorrect due to GPS noise or bad accuracy in places like tunnels, downtown areas, etc. If the data source is a mobile device, the geolocation may not be determined by GPS but by WiFi networks in the area, which leads to holes in space and teleportation. While traveling along in Manhattan, there can suddenly be a WiFi location from Chicago.
#
# > WiFi location tracking is based on the combination of SSID and MAC-addresses, which may correspond to different points e.g. federal provider standardizes the firmware of routers up to MAC-address and places them in different cities. Even a company's move to another office with its routers can cause issues.
#
# The point is usually located among infrastructure. Here, you can really unleash your imagination and invent features based on your life experience and domain knowledge: the proximity of a point to the subway, the number of stories in the building, the distance to the nearest store, the number of ATMs around, etc. For any task, you can easily come up with dozens of features and extract them from various external sources. For problems outside an urban environment, you may consider features from more specific sources e.g. the height above sea level.
#
# If two or more points are interconnected, it may be worthwhile to extract features from the route between them. In that case, distances (great circle distance and road distance calculated by the routing graph), number of turns with the ratio of left to right turns, number of traffic lights, junctions, and bridges will be useful. In one of my own tasks, I generated a feature called "the complexity of the road", which computed the graph-calculated distance divided by the GCD.
# ### Date and time
#
# You would think that date and time are standardized because of their prevalence, but, nevertheless, some pitfalls remain.
#
# Let's start with the day of the week, which are easy to turn into 7 dummy variables using one-hot encoding. In addition, we will also create a separate binary feature for the weekend called `is_weekend`.
# ```python
# df['dow'] = df['created'].apply(lambda x: x.date().weekday())
# df['is_weekend'] = df['created'].apply(lambda x: 1 if x.date().weekday() in (5, 6) else 0)
# ```
# Some tasks may require additional calendar features. For example, cash withdrawals can be linked to a pay day; the purchase of a metro card, to the beginning of the month. In general, when working with time series data, it is a good idea to have a calendar with public holidays, abnormal weather conditions, and other important events.
#
# > Q: What do Chinese New Year, the New York marathon, and the Trump inauguration have in common?
#
# > A: They all need to be put on the calendar of potential anomalies.
#
# Dealing with hour (minute, day of the month ...) is not as simple as it seems. If you use the hour as a real variable, we slightly contradict the nature of data: `0<23` while `0:00:00 02.01> 01.01 23:00:00`. For some problems, this can be critical. At the same time, if you encode them as categorical variables, you'll breed a large numbers of features and lose information about proximity -- the difference between 22 and 23 will be the same as the difference between 22 and 7.
#
# There also exist some more esoteric approaches to such data like projecting the time onto a circle and using the two coordinates.
def make_harmonic_features(value, period=24):
value *= 2 * np.pi / period
return np.cos(value), np.sin(value)
# This transformation preserves the distance between points, which is important for algorithms that estimate distance (kNN, SVM, k-means ...)
# +
from scipy.spatial import distance
euclidean(make_harmonic_features(23), make_harmonic_features(1))
# -
euclidean(make_harmonic_features(9), make_harmonic_features(11))
euclidean(make_harmonic_features(9), make_harmonic_features(21))
# However, the difference between such coding methods is down to the third decimal place in the metric.
# ### Time series, web, etc.
#
# Regarding time series — we will not go into too much detail here (mostly due to my personal lack of experience), but I will point you to a [useful library that automatically generates features for time series](https://github.com/blue-yonder/tsfresh).
#
# If you are working with web data, then you usually have information about the user's User Agent. It is a wealth of information. First, one needs to extract the operating system from it. Secondly, make a feature `is_mobile`. Third, look at the browser.
# +
# Install pyyaml ua-parser user-agents
import user_agents
ua = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/56.0.2924.76 Chrome/56.0.2924.76 Safari/537.36"
ua = user_agents.parse(ua)
print("Is a bot? ", ua.is_bot)
print("Is mobile? ", ua.is_mobile)
print("Is PC? ", ua.is_pc)
print("OS Family: ", ua.os.family)
print("OS Version: ", ua.os.version)
print("Browser Family: ", ua.browser.family)
print("Browser Version: ", ua.browser.version)
# -
# > As in other domains, you can come up with your own features based on intuition about the nature of the data. At the time of this writing, Chromium 56 was new, but, after some time, only users who haven't rebooted their browser for a long time will have this version. In this case, why not introduce a feature called "lag behind the latest version of the browser"?
#
# In addition to the operating system and browser, you can look at the referrer (not always available), [http_accept_language](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Accept-Language), and other meta information.
#
# The next useful piece of information is the IP-address, from which you can extract the country and possibly the city, provider, and connection type (mobile/stationary). You need to understand that there is a variety of proxy and outdated databases, so this feature can contain noise. Network administration gurus may try to extract even fancier features like suggestions for [using VPN](https://habrahabr.ru/post/216295/). By the way, the data from the IP-address is well combined with `http_accept_language`: if the user is sitting at the Chilean proxies and browser locale is `ru_RU`, something is unclean and worth a look in the corresponding column in the table (`is_traveler_or_proxy_user`).
#
# Any given area has so many specifics that it is too much for an individual to absorb completely. Therefore, I invite everyone to share their experiences and discuss feature extraction and generation in the comments section.
# ## Feature transformations
#
# ### Normalization and changing distribution
#
# Monotonic feature transformation is critical for some algorithms and has no effect on others. This is one of the reasons for the increased popularity of decision trees and all its derivative algorithms (random forest, gradient boosting). Not everyone can or want to tinker with transformations, and these algorithms are robust to unusual distributions.
#
# There are also purely engineering reasons: `np.log` is a way of dealing with large numbers that do not fit in `np.float64`. This is an exception rather than a rule; often it's driven by the desire to adapt the dataset to the requirements of the algorithm. Parametric methods usually require a minimum of symmetric and unimodal distribution of data, which is not always given in real data. There may be more stringent requirements; recall [our earlier article about linear models](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-4-linear-classification-and-regression-44a41b9b5220).
#
# However, data requirements are imposed not only by parametric methods; [K nearest neighbors](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-3-classification-decision-trees-and-k-nearest-neighbors-8613c6b6d2cd) will predict complete nonsense if features are not normalized e.g. when one distribution is located in the vicinity of zero and does not go beyond (-1, 1) while the other’s range is on the order of hundreds of thousands.
#
# A simple example: suppose that the task is to predict the cost of an apartment from two variables — the distance from city center and the number of rooms. The number of rooms rarely exceeds 5 whereas the distance from city center can easily be in the thousands of meters.
#
# The simplest transformation is Standard Scaling (or Z-score normalization):
#
# $$ \large z= \frac{x-\mu}{\sigma} $$
#
# Note that Standard Scaling does not make the distribution normal in the strict sense.
# +
import numpy as np
from scipy.stats import beta, shapiro
from sklearn.preprocessing import StandardScaler
data = beta(1, 10).rvs(1000).reshape(-1, 1)
shapiro(data)
# +
# Value of the statistic, p-value
shapiro(StandardScaler().fit_transform(data))
# With such p-value we'd have to reject the null hypothesis of normality of the data
# -
# But, to some extent, it protects against outliers:
data = np.array([1, 1, 0, -1, 2, 1, 2, 3, -2, 4, 100]).reshape(-1, 1).astype(np.float64)
StandardScaler().fit_transform(data)
(data - data.mean()) / data.std()
# Another fairly popular option is MinMax Scaling, which brings all the points within a predetermined interval (typically (0, 1)).
#
# $$ \large X_{norm}=\frac{X-X_{min}}{X_{max}-X_{min}} $$
# +
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler().fit_transform(data)
# -
(data - data.min()) / (data.max() - data.min())
# StandardScaling and MinMax Scaling have similar applications and are often more or less interchangeable. However, if the algorithm involves the calculation of distances between points or vectors, the default choice is StandardScaling. But MinMax Scaling is useful for visualization by bringing features within the interval (0, 255).
#
# If we assume that some data is not normally distributed but is described by the [log-normal distribution](https://en.wikipedia.org/wiki/Log-normal_distribution), it can easily be transformed to a normal distribution:
# +
from scipy.stats import lognorm
data = lognorm(s=1).rvs(1000)
shapiro(data)
# -
shapiro(np.log(data))
# The lognormal distribution is suitable for describing salaries, price of securities, urban population, number of comments on articles on the internet, etc. However, to apply this procedure, the underlying distribution does not necessarily have to be lognormal; you can try to apply this transformation to any distribution with a heavy right tail. Furthermore, one can try to use other similar transformations, formulating their own hypotheses on how to approximate the available distribution to a normal. Examples of such transformations are [Box-Cox transformation](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.boxcox.html) (logarithm is a special case of the Box-Cox transformation) or [Yeo-Johnson transformation](https://gist.github.com/mesgarpour/f24769cd186e2db853957b10ff6b7a95) (extends the range of applicability to negative numbers). In addition, you can also try adding a constant to the feature — `np.log (x + const)`.
#
# In the examples above, we have worked with synthetic data and strictly tested normality using the Shapiro-Wilk test. Let’s try to look at some real data and test for normality using a less formal method — [Q-Q plot](https://en.wikipedia.org/wiki/Q%E2%80%93Q_plot). For a normal distribution, it will look like a smooth diagonal line, and visual anomalies should be intuitively understandable.
#
# 
# Q-Q plot for lognormal distribution
#
# 
# Q-Q plot for the same distribution after taking the logarithm
# +
# Let's draw plots!
import statsmodels.api as sm
# Let's take the price feature from Renthop dataset and filter by hands the most extreme values for clarity
price = df.price[(df.price <= 20000) & (df.price > 500)]
price_log = np.log(price)
# A lot of gestures so that sklearn didn't shower us with warnings
price_mm = (
MinMaxScaler()
.fit_transform(price.values.reshape(-1, 1).astype(np.float64))
.flatten()
)
price_z = (
StandardScaler()
.fit_transform(price.values.reshape(-1, 1).astype(np.float64))
.flatten()
)
# -
# Q-Q plot of the initial feature
sm.qqplot(price, loc=price.mean(), scale=price.std())
# Q-Q plot after StandardScaler. Shape doesn’t change
sm.qqplot(price_z, loc=price_z.mean(), scale=price_z.std())
# Q-Q plot after MinMaxScaler. Shape doesn’t change
sm.qqplot(price_mm, loc=price_mm.mean(), scale=price_mm.std())
# Q-Q plot after taking the logarithm. Things are getting better!
sm.qqplot(price_log, loc=price_log.mean(), scale=price_log.std())
# Let’s see whether transformations can somehow help the real model. There is no silver bullet here.
# ### Interactions
#
# If previous transformations seemed rather math-driven, this part is more about the nature of the data; it can be attributed to both feature transformations and feature creation.
#
# Let’s come back again to the Two Sigma Connect: Rental Listing Inquiries problem. Among the features in this problem are the number of rooms and the price. Logic suggests that the cost per single room is more indicative than the total cost, so we can generate such a feature.
rooms = df["bedrooms"].apply(lambda x: max(x, 0.5))
# Avoid division by zero; .5 is chosen more or less arbitrarily
df["price_per_bedroom"] = df["price"] / rooms
# You should limit yourself in this process. If there are a limited number of features, it is possible to generate all the possible interactions and then weed out the unnecessary ones using the techniques described in the next section. In addition, not all interactions between features must have a physical meaning; for example, polynomial features (see [sklearn.preprocessing.PolynomialFeatures](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PolynomialFeatures.html)) are often used in linear models and are almost impossible to interpret.
# ### Filling in the missing values
#
# Not many algorithms can work with missing values, and the real world often provides data with gaps. Fortunately, this is one of the tasks for which one doesn’t need any creativity. Both key python libraries for data analysis provide easy-to-use solutions: [pandas.DataFrame.fillna](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.fillna.html) and [sklearn.preprocessing.Imputer](http://scikit-learn.org/stable/modules/preprocessing.html#imputation).
#
# These solutions do not have any magic happening behind the scenes. Approaches to handling missing values are pretty straightforward:
#
# * encode missing values with a separate blank value like `"n/a"` (for categorical variables);
# * use the most probable value of the feature (mean or median for the numerical variables, the most common value for categorical variables);
# * or, conversely, encode with some extreme value (good for decision-tree models since it allows the model to make a partition between the missing and non-missing values);
# * for ordered data (e.g. time series), take the adjacent value — next or previous.
#
# 
#
# Easy-to-use library solutions sometimes suggest sticking to something like `df = df.fillna(0)` and not sweat the gaps. But this is not the best solution: data preparation takes more time than building models, so thoughtless gap-filling may hide a bug in processing and damage the model.
# ## Feature selection
#
# Why would it even be necessary to select features? To some, this idea may seem counterintuitive, but there are at least two important reasons to get rid of unimportant features. The first is clear to every engineer: the more data, the higher the computational complexity. As long as we work with toy datasets, the size of the data is not a problem, but, for real loaded production systems, hundreds of extra features will be quite tangible. The second reason is that some algorithms take noise (non-informative features) as a signal and overfit.
#
# ### Statistical approaches
#
# The most obvious candidate for removal is a feature whose value remains unchanged, i.e., it contains no information at all. If we build on this thought, it is reasonable to say that features with low variance are worse than those with high variance. So, one can consider cutting features with variance below a certain threshold.
# +
from sklearn.datasets import make_classification
from sklearn.feature_selection import VarianceThreshold
x_data_generated, y_data_generated = make_classification()
x_data_generated.shape
# -
VarianceThreshold(0.7).fit_transform(x_data_generated).shape
VarianceThreshold(0.8).fit_transform(x_data_generated).shape
VarianceThreshold(0.9).fit_transform(x_data_generated).shape
# There are other ways that are also [based on classical statistics](http://scikit-learn.org/stable/modules/feature_selection.html#univariate-feature-selection).
# +
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
x_data_kbest = SelectKBest(f_classif, k=5).fit_transform(
x_data_generated, y_data_generated
)
x_data_varth = VarianceThreshold(0.9).fit_transform(x_data_generated)
# -
logit = LogisticRegression(solver="lbfgs", random_state=17)
cross_val_score(
logit, x_data_generated, y_data_generated, scoring="neg_log_loss", cv=5
).mean()
cross_val_score(
logit, x_data_kbest, y_data_generated, scoring="neg_log_loss", cv=5
).mean()
cross_val_score(
logit, x_data_varth, y_data_generated, scoring="neg_log_loss", cv=5
).mean()
# We can see that our selected features have improved the quality of the classifier. Of course, this example is purely artificial; however, it is worth using for real problems.
# ### Selection by modeling
#
# Another approach is to use some baseline model for feature evaluation because the model will clearly show the importance of the features. Two types of models are usually used: some “wooden” composition such as [Random Forest](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-5-ensembles-of-algorithms-and-random-forest-8e05246cbba7) or a linear model with Lasso regularization so that it is prone to nullify weights of weak features. The logic is intuitive: if features are clearly useless in a simple model, there is no need to drag them to a more complex one.
# +
# Synthetic example
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
x_data_generated, y_data_generated = make_classification()
rf = RandomForestClassifier(n_estimators=10, random_state=17)
pipe = make_pipeline(SelectFromModel(estimator=rf), logit)
print(
cross_val_score(
logit, x_data_generated, y_data_generated, scoring="neg_log_loss", cv=5
).mean()
)
print(
cross_val_score(
rf, x_data_generated, y_data_generated, scoring="neg_log_loss", cv=5
).mean()
)
print(
cross_val_score(
pipe, x_data_generated, y_data_generated, scoring="neg_log_loss", cv=5
).mean()
)
# -
# We must not forget that this is not a silver bullet again - it can make the performance worse.
# +
# x_data, y_data = get_data()
x_data = x_data_generated
y_data = y_data_generated
pipe1 = make_pipeline(StandardScaler(), SelectFromModel(estimator=rf), logit)
pipe2 = make_pipeline(StandardScaler(), logit)
print(
"LR + selection: ",
cross_val_score(pipe1, x_data, y_data, scoring="neg_log_loss", cv=5).mean(),
)
print(
"LR: ", cross_val_score(pipe2, x_data, y_data, scoring="neg_log_loss", cv=5).mean()
)
print("RF: ", cross_val_score(rf, x_data, y_data, scoring="neg_log_loss", cv=5).mean())
# -
# ### Grid search
# Finally, we get to the most reliable method, which is also the most computationally complex: trivial grid search. Train a model on a subset of features, store results, repeat for different subsets, and compare the quality of models to identify the best feature set. This approach is called [Exhaustive Feature Selection](http://rasbt.github.io/mlxtend/user_guide/feature_selection/ExhaustiveFeatureSelector/).
#
# Searching all combinations usually takes too long, so you can try to reduce the search space. Fix a small number N, iterate through all combinations of N features, choose the best combination, and then iterate through the combinations of (N + 1) features so that the previous best combination of features is fixed and only a single new feature is considered. It is possible to iterate until we hit a maximum number of characteristics or until the quality of the model ceases to increase significantly. This algorithm is called [Sequential Feature Selection](http://rasbt.github.io/mlxtend/user_guide/feature_selection/SequentialFeatureSelector/).
#
# This algorithm can be reversed: start with the complete feature space and remove features one by one until it does not impair the quality of the model or until the desired number of features is reached.
# +
# Install mlxtend
from mlxtend.feature_selection import SequentialFeatureSelector
selector = SequentialFeatureSelector(
logit, scoring="neg_log_loss", verbose=2, k_features=3, forward=False, n_jobs=-1
)
selector.fit(x_data, y_data)
# -
# Take a look how this approach was done in one [simple yet elegant Kaggle kernel](https://www.kaggle.com/arsenyinfo/easy-feature-selection-pipeline-0-55-at-lb).
| jupyter_english/topic06_features_regression/topic6_feature_engineering_feature_selection.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] pycharm={"name": "#%% md\n"}
# # Problem 55
# ## Lychrel numbers
#
# If we take $47$, reverse and add, $47 + 74 = 121$, which is palindromic.
#
# Not all numbers produce palindromes so quickly. For example,
#
# $$349 + 943 = 1292$$
#
# $$1292 + 2921 = 4213$$
#
# $$4213 + 3124 = 7337$$
#
# That is, $349$ took three iterations to arrive at a palindrome.
#
# Although no one has proved it yet, it is thought that some numbers, like $196$, never produce a palindrome. A number that never forms a palindrome through the reverse and add process is called a Lychrel number. Due to the theoretical nature of these numbers, and for the purpose of this problem, we shall assume that a number is Lychrel until proven otherwise. In addition you are given that for every number below ten-thousand, it will either (i) become a palindrome in less than fifty iterations, or, (ii) no one, with all the computing power that exists, has managed so far to map it to a palindrome. In fact, $10677$ is the first number to be shown to require over fifty iterations before producing a palindrome: $4668731596684224866951378664$ ($53$ iterations, $28$-digits).
#
# Surprisingly, there are palindromic numbers that are themselves Lychrel numbers; the first example is $4994$.
#
# How many Lychrel numbers are there below ten-thousand?
#
# NOTE: Wording was modified slightly on $24$ April $2007$ to emphasise the theoretical nature of Lychrel numbers.
#
# OEIS Sequence: [A306481](https://oeis.org/A306481)
#
# ## Solution
# + pycharm={"name": "#%%\n"}
from euler.big_int import BigInt
from euler.numbers import is_palindrome
# + pycharm={"name": "#%%\n"}
def compute(n: int) -> int:
result = 0
for i in range(1, n + 1):
number = BigInt(i)
number += BigInt(number.str[::-1])
j = 1
while j <= 50 and not is_palindrome(number):
number += BigInt(number.str[::-1])
j += 1
if j > 50:
result += 1
return result
# + pycharm={"name": "#%%\n"}
compute(10_000)
# + pycharm={"name": "#%%\n"}
# %timeit -n 100 -r 1 -p 6 compute(10_000)
| problems/0055/solution.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .jl
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 1.4.2
# language: julia
# name: julia-1.4
# ---
using StochasticDiffEq, DiffEqProblemLibrary, Random
using DiffEqProblemLibrary.SDEProblemLibrary: importsdeproblems; importsdeproblems()
prob = DiffEqProblemLibrary.SDEProblemLibrary.oval2ModelExample(largeFluctuations=true,useBigs=false)
Random.seed!(250)
prob = remake(prob,tspan = (0.0,500.0))
sol = solve(prob,SRIW1(),dt=(1/2)^(18),progress=true,qmax=1.125,
saveat=0.1,abstol=1e-5,reltol=1e-3,maxiters=1e7);
Random.seed!(250)
prob = remake(prob,tspan = (0.0,500.0))
@time sol = solve(prob,SRIW1(),dt=(1/2)^(18),progress=true,qmax=1.125,
saveat=0.1,abstol=1e-5,reltol=1e-3,maxiters=1e7);
println(maximum(sol[:,2]))
using Plots; gr()
lw = 2
lw2 = 3
p1 = plot(sol,vars=(0,16),
title="(A) Timeseries of Ecad Concentration",xguide="Time (s)",
yguide="Concentration",guidefont=font(16),tickfont=font(16),
linewidth=lw,leg=false)
p2 = plot(sol,vars=(0,17),
title="(B) Timeseries of Vim Concentration",xguide="Time (s)",
yguide="Concentration",guidefont=font(16),
tickfont=font(16),linewidth=lw,leg=false)
# +
prob = remake(prob,tspan = (0.0,1.0))
## Little Run
sol = solve(prob,EM(),dt=(1/2)^(20),
progressbar=true,saveat=0.1)
println("EM")
@time sol = solve(prob,EM(),dt=(1/2)^(20),
progressbar=true,saveat=0.1)
sol = solve(prob,SRI(),dt=(1/2)^(18),adaptive=false,
progressbar=true,save_everystep=false)
println("SRI")
@time sol = solve(prob,SRI(),dt=(1/2)^(18),adaptive=false,
progressbar=true,save_everystep=false)
sol = solve(prob,SRIW1(),dt=(1/2)^(18),adaptive=false,
adaptivealg=:RSwM3,progressbar=false,qmax=4,saveat=0.1)
println("SRIW1")
@time sol = solve(prob,SRIW1(),dt=(1/2)^(18),adaptive=false,
adaptivealg=:RSwM3,progressbar=false,qmax=4,saveat=0.1)
sol = solve(prob,SRI(),dt=(1/2)^(18),
adaptivealg=:RSwM3,progressbar=false,qmax=1.125,
saveat=0.1,abstol=1e-6,reltol=1e-4)
println("SRI Adaptive")
@time sol = solve(prob,SRI(),dt=(1/2)^(18),
adaptivealg=:RSwM3,progressbar=false,qmax=1.125,
saveat=0.1,abstol=1e-6,reltol=1e-4)
@show length(sol.t)
sol = solve(prob,SRIW1(),dt=(1/2)^(18),
adaptivealg=:RSwM3,progressbar=false,qmax=1.125,
saveat=0.1,abstol=1e-6,reltol=1e-4)
println("SRIW1 Adaptive")
@time sol = solve(prob,SRIW1(),dt=(1/2)^(18),
adaptivealg=:RSwM3,progressbar=false,qmax=1.125,
saveat=0.1,abstol=1e-6,reltol=1e-4)
@show length(sol.t)
# -
using DiffEqBenchmarks
DiffEqBenchmarks.bench_footer(WEAVE_ARGS[:folder],WEAVE_ARGS[:file])
| notebook/StiffSDE/Oval2LongRun.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from time import sleep
# +
c=('\033[m',
'\033[0;30;41m',
'\033[0;30;42m',
'\033[0;30;43m',
'\033[0;30;44m',
'\033[0;30;45m',
'\033[7;30m')
def ajuda(com):
titulo(f'Acessando o manual do comando \'{com}\'', 4)
print(c[6], end='')
help(com)
print(c[0], end='')
sleep(2)
def titulo(msg, cor=0):
tam = len(msg) + 4
print(c[cor], end='')
print('~'*tam)
print(f' {msg}')
print('~' * tam)
print(c[0], end='')
sleep(1)
comando = " "
while True:
titulo('Sitema de Ajuda Python', 2)
comando = str(input('Função ou Biblioteca >'))
if comando.upper() == 'FIM':
break
else:
ajuda(comando)
titulo('Até Logo', 1)
# -
| .ipynb_checkpoints/EX106 - Sistema interativo de ajuda em Python-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Timing Functions in Python
#
# <code>time</code> library [link to docs](https://docs.python.org/2/library/time.html) <br>
# <code>timeit</code> library [link to docs](https://docs.python.org/2/library/timeit.html) <br>
import time
import timeit
# ### UTC and local time
#
# <code>time</code> has methods which return the UTC time and local time in a somewhat useless structure format. <br>
# <code>time.gmtime()</code> returns the structure with the current gm or UTC time. <br>
# <code>time.localtime()</code> returns a structure with the current local time <br>
currentTime = time.gmtime()
print(currentTime)
# As you can see, the returned values are not very interesting or useful themselves. Lets parse structure into more useful forms. <br>
# <br>
# First, lets parse it into a __human-readable form__. This is useful for printing the time to the console, but generally would be used with a secondary form that is easier for a computer to read.
time.strftime("%a, %d %b %Y %H:%M:%S +0000", currentTime)
# Now lets parse it into a __computer-friendly form__. To start with, we should understand what type of structure <code>currentTime</code> is.
type(currentTime)
# As we can see, <code>currentTime</code> is an instance of a class, <code>struct_time</code> as is defined in the <code>time</code> library.
# The string that was returned when we ran <code>print(currentTime)</code> showed us the values associated with several of the class variables. We can access these class variables by using the dot "<code>.</code>" notation.
currentTime.tm_hour
# With this knowledge, it becomes trivial to parse this data into a more usable format.
def parseTime(timeObj):
'''parseTime:
takes time.struct_time instances
:return time displayed as string - year month day hour min sec'''
return (str(timeObj.tm_year) + str(timeObj.tm_mon) + str(timeObj.tm_mday) +
str(timeObj.tm_hour) + str(timeObj.tm_min) + str(timeObj.tm_sec))
parseTime(currentTime)
| Guides/python/timing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: radiopadre
# language: python
# name: radiopadre
# ---
# # Radiopadre Tutorial
# <NAME> <<EMAIL>>, January 2018
#
# Radiopadre is a framework, built on the Jupyter notebook, for browsing and visualizing data reduction products. It is particularly useful for visualizing data products on remote servers, where connection latencies and/or lack of software etc. limits the usual visualization options. It includes integration with the JS9 browser-based FITS viewer (with CARTA integration coming soon).
#
# The general use case for Radiopadre is "here I am sitting with a slow ssh connection into a remote cluster node, my pipeline has produced 500 plots/logs/FITS images, how do I make sense of this mess?" More specifically, there are three (somewhat overlapping) scenarios that Radiopadre is designed for:
#
# * Just browsing: interactively exploring the aforementioned 500 files using a notebook.
#
# * Automated reporting: customized Radiopadre notebooks that automatically generate a report composed of a pipeline's outputs and intermediate products. Since your pipeline's output is (hopefully!) structured, i.e. in terms of filename conventions etc., you can write a notebook to exploit that structure and make a corresponding report automatically.
#
# * Sharing notebooks: fiddle with a notebook until everything is visualized just right, insert explanatory text in mardkdown cells in between, voila, you have an instant report you can share with colleagues.
# ## Installing Radiopadre
# Refer to README.md on the github repository: https://github.com/ratt-ru/radiopadre
#
# ## Running this tutorial
#
# Data files for this tutorial are available here: https://www.dropbox.com/sh/be4pc23rsavj67s/AAB2Ejv8cLsVT8wj60DiqS8Ya?dl=0
#
# Download the tutorial and untar itsomewhere. Then run Radiopadre (locally or remotely, if you unpacked the tutorial on a remote node) in the resulting directory. A Jupyter console will pop up in your browser. Click on ``radiopadre-tutorial.ipynb`` to open it in a separate window, then click the "Run all" button on the toolbar (or use "Cell|Run all" in the menu, which is the same thing.) Wait for the notebook to run through and render, then carry on reading.
#
# ## Every Radiopadre notebook starts with this
from radiopadre import ls, settings
dd = ls() # calls radiopadre.ls() to get a directory listing, assigns this to dd
dd # standard notebook feature: the result of the last expression on the cell is rendered in HTML
dd.show()
print("Calling .show() on an object renders it in HTML anyway, same as if it was the last statement in the cell")
# ## Most objects knows how to show() themselves
# So what can you see from the above? ``dd`` is a directory object than can render itself -- you get a directory listing. Clearly, Radiopadre can recognize certain types of files -- you can see an ``images/`` subdirectory above, a measurement set, a couple of FITS files, some PNG images, etc. Clicking on a file will either download it or display it in a new tab (this works well for PNG or text files -- don't click on FITS files unless you mean to download a whole copy!) FITS files have a "JS9" button next to them that invokes the JS9 viewer either below the cell, or in a new browser tab. Try it!
#
# Now let's get some objects from the directory listing and get them to render.
images_subdir = dd[0]
demo_ms = dd[1]
fits_image = dd[2]
log_file = dd[-1] # last file in directory... consistent with Python list syntax
images_subdir.show()
demo_ms.show(_=(32,0)) # _ selects channels/correlations... more detail later
fits_image.show()
log_file.show()
# be prepared for a lot of output below... scroll through it
# ## Most things are list-like
# What you see above is that different object types know how to show themselves intelligently. You also see that a directory object acts like a Python list -- ``dd[n]`` gets the n-th object from the directory. What about a slice?
images_subdir[5:10]
# Since a directory is a list of files, it makes sence that the Python slice syntax ``[5:10]`` returns an object that is also a list of files. There are other list-like objects in radiopadre. For example, an MS can be considered a list of rows. So...
#
#
type(demo_ms[5:10])
sub_ms = demo_ms[5:10] # gives us a table containing rows 5 through 9 of the MS
sub_ms.show(_=(32,0)) # _ selects channels/correlations... more detail later
# And a text file is really just a list of lines, so:
log_file[-10:] # extract last ten lines and show them
# NB: FITS images and PNG images are not lists in any sense, so this syntax doesn't work on them. (In the future I'll consider supporting numpy-like slicing, e.g. ``[100:200,100:200]``, to transparently extract subsections of images, but for now this is not implemented.)
# ## And list-like things can be searched with ()
# Radiopadre's list-like objects (directories/file lists, text files, CASA tables) also support a "search" function, invoked by calling them like a function. This returns an object that is subset of the original object. Three examples:
png_files = dd("*.png") # on directories, () works like a shell pattern
png_files
log_file("Gain plots") # on text files, () works like grep
demo_ms("ANTENNA1==1").show(_=(32,0)) # on tables, () does a TaQL query
# ## Other useful things to do with directories/lists of files
# If you have a list of image or FITS files, you can ask for thumbnails by calling ``.thumbs()``.
png_files.thumbs() # for PNG images, these are nice and clickable!
# And calling ``.images`` on a directory returns a list of images. For which we can, of course, render thumbnails:
images_subdir.images.thumbs()
# Other such "list of files by type" attributes are ``.fits``, ``.tables``, and ``.dirs``:
dd.fits.show()
dd.tables.show()
dd.dirs.show()
dd.fits.thumbs(vmin=-1e-4, vmax=0.01) # and FITS files also know how to make themselves a thumbnail
# note that thumbs() takes optional arguments just like show()
# And the ``show_all()`` method will call ``show()`` on every file object in the list. This is useful if you want to render a bunch of objects with the same parameters:
# note the difference: dd.fits selects all files of type FITS, dd("*fits") selects all files matching "*fits".
# In our case this happens to be one and the same thing, but it doesn't have to be
dd("*fits").show_all(vmin=0, vmax=1e-2, colormap='hot')
# show_all() passes all its arguments to the show() method of each file.
# ## Accessing a single file by name
# The ``(pattern)`` operation applied to a directory always returns a filelist (possibly an empty one), even if the pattern is not really a pattern and selects only one file:
dirties = dd("j0839-5417_2-MFS-dirty.fits")
print("This is a list:", type(dirties), len(dirties)) # this is a list even though we only specified one file
print("This is a single file:", type(dirties[0])) # so we have to use [0] to get at the FITS file itself
# Note that the summary attribute returns a short summary of any radiopadre object (as text or HTML).
# You can show() or print it
print("This is a summary of the list:",dirties.summary)
print("And now in HTML:")
dirties.summary.show()
print("This is a summary of the file:",dirties[0].summary)
print("And now in HTML:")
dirties[0].summary.show()
# If you want to get at one specific file, using ``dd(name_or_pattern)[0]`` becomes a hassle. Filelists therefore support a direct ``[name_or_pattern]`` operation which always returns a single file object. If ``name_or_pattern`` matches multiple files, only the first one is returned (but radiopadre will show you a transient warning message).
dirty_image = dd["*fits"] # matches 2 files. if you re-execute this with Ctrl+Enter, you'll see a warning
print(type(dirty_image))
dirty_image = dd["*dirty*fits"] # this will match just the one file
dirty_image.show()
# ## Working with text files
# By default, radiopadre renders the beginning and end of a text file. But you can also explicitly render just the head, or just the tail, or the full file.
log_file
log_file.head(5) # same as log_file.show(head=5). Number is optional -- default is 10
log_file.tail(5) # same as log_file.show(tail=5)
log_file.full() # same as log_file.show(full=True). Use the scrollbar next to the cell output.
log_file("Gain") # same as log_file.grep("Gain") or log_file.show(grep="Gain")
# and of course all objects are just "lists of lines", so the normal list slicing syntax works
log_file("Gain")[10:20].show()
log_file("Gain")[-1]
# ## "Watching" text files
# If you're still running a reduction and want to keep an eye on a log file that's being updated, use the ``.watch()`` method. This works exactly like ``.show()`` and takes the same arguments, but adds a "refresh" button at the top right corner of the cell, which re-executes the cell every time you click it.
log_file.watch(head=0, tail=10)
# ## Running shell commands
# Use ``.sh("command")`` on a directory object to quickly run a shell command in that directory. The result is output as a list-of-lines, so all the usual display tricks work.
dd.sh("df -h")
dd.sh("df -h")("/boot")
# ## Working with FITS files
# As you saw above, FITS files can be rendered with ``show()``, or viewed via the JS9 buttons. There's also an explicit ``.js9()`` method which invokes the viewer in a cell:
dirty_image.summary.show()
dirty_image.js9()
# With multiple FITS files, it's possible to load all of them into JS9, and use the "<" and ">" keys to switch between images. Use the "JS9 all" button to do this:
dd("*fits")
# There's a shortcut for doing this directly -- just call ``.js9()`` on a list of FITS files (note that "collective" functions such as ``.thumbs()`` and ``.js9()`` will only work on *homogenuous* filelists, i.e. lists of FITS files. Don't try calling them on a list contaning a mix of files -- it won't work!)
# If you're wondering how to tell JS9 to start with specific scale settings, use the "with settings" trick
# shown here. It will be explained below...
with settings.fits(vmin=-1e-4, vmax=0.01):
dd("*fits")[0].js9()
# The ``.header`` attribute of a FITS file object returns the FITS header, in the same kind of object (list-of-lines) as a text file. So all the tricks we did on text files above still apply:
dirty_image.header
dirty_image.header("CDELT*")
dirty_image.header.full()
# If you want to read in data from the FITS file, the ``.fitsobj`` attribute returns a ``PrimaryHDU`` object, just like ``astropy.io.fits.open(filename)`` would:
dirty_image.fitsobj
# ## Working with CASA tables
# As you saw above, a CASA table object knows how to render itself as a table. Default is to render rows 0 to 100. With array columns, the default display becomes a little unwieldy:
demo_ms
# With optional arguments to ``.show()``, you can render just a subset of rows (given as start_row, nrows), and a subset of columns, taking a slice through an array column. The below tells radiopadre to render the first 10 rows, taking the column TIME in its entirety, and taking a ``[32:34,:]`` slice through the DATA column.
demo_ms.show(0,10,TIME=(),DATA=(slice(32,34),None))
# If you want to render *all* columns with a common slice, use the optional ``_`` argument (we saw this above). The given slice will be applied to all columns as much as possible (or at least to those that match the shape):
demo_ms.show(0, 10, _=(32,0)) # selects channel 32, correlation 0 from all 2D array columns. Doesn't apply to
# other types of columns
# The ``.table`` attribute returns a casacore table object with which you can do all the normal casacore table operations:
print(type(demo_ms.table))
# But if you want to quickly read data from a table, radiopadre provides some fancier methods. For example, subtables of the table are available as a ``.SUBTABLE_NAME`` attribute. This gives another table object, with all the functions above available:
demo_ms.ANTENNA
## and .subtables gives you a list of all the subtables
for subtable in demo_ms.subtables:
subtable.show()
# ### Accessing table columns
# Columns of the table can be read via a ``.COLUMN`` attribute. You can either use it a-la ``getcol()``:
data = demo_ms.DATA(0,5)
print(data.shape)
data
# ...or else apply a numpy-style array index with ``[]``:
demo_ms.DATA[0:10,:,0] # read rows 0~9, corrrelation 0
# Another useful feature is creating a masked array from a combination of a column and FLAG/FLAG_ROW. Append ``_F`` to the column name to get a masked array:
import pylab
pylab.plot(demo_ms.DATA[32,:,0].real, '+b')
pylab.plot(demo_ms.DATA_F[32,:,0].real, 'xr')
# of course all of these things work together
demo_ms("ANTENNA1==1 && ANTENNA2==3").DATA_F[:20,32:64,:].shape
demo_ms.UVW()
# So combining the above, here's how to compute the UVW in wavelengths of all baselines to antenna 1, and make a uv-coverage plot of that subset of baselines:
import numpy as np
freqs = demo_ms.SPECTRAL_WINDOW.CHAN_FREQ(0, 1) # read frequencies for spw 0
print(freqs)
subset = demo_ms("ANTENNA1 == 1")
uvw_lambda = subset.UVW()[np.newaxis,:,:]*3e+8/freqs[0,:,np.newaxis,np.newaxis]
print(uvw_lambda.shape)
pylab.plot(uvw_lambda[:,:,0].flatten(), uvw_lambda[:,:,1].flatten(), '.')
# ## The ls() function
# ...is where it all begins. As you saw, ``ls()`` gives you the current directory. You can also use ``ls`` with filename patterns, and also specify a sort order:
ls("*txt -rt") # give *txt files in reverse order of modification time
logs = ls("*txt -rt") # of course this just returns a list-of-files object
logs
# You can also use the "R" switch for a recursive directory listing:
ls("*png -R")
# Or give a filename to get an object representing that one file:
image = ls("1525170187-1_meqtrees-gjones_plots-chan.png")
image
# Om the same principle, give a subdirectory name to get a directory object:
images_dir = ls("images")
images_dir
# One thing to note is that ``ls()`` (i.e. with no patterns) doesn't necessarily list **all** files. The files included by default are governed by radiopadre settings. Below we'll see how to change those.
# ## Using and changing settings
# The ``settings`` object we imported above can be used to set various defaults of Radiopadre. Like most other objects, it knows how to render itself:
settings # same as settings.show(), if it's the last expression in the cell
# and the various sections will also render themselves
settings.files
# changing settings is as easy as
settings.files.include = "*png"
# the new settings apply from that point onwards, so you probably want to do this at the top of a notebook
ls()
# from now on, only "*png" files will be listed. Unless you override this by an explicit pattern to ls(),
# e.g. in this case "*" overrides settings.files.include:
ls("*")
# ### Using "with" to change settings temporarily
# Python's ``with`` statement works with radiopadre settings to change settings temporarily. For example, the default FITS rendering settings look like this:
#
settings.fits
# Here's how we can render FITS images with different settings, *without* changing the global settings. Whatever we set in ``with`` only applies in the body of the ``with`` statement. In this case it is particularly useful, as it will also apply to the JS9 displays by default:
with settings.fits(vmin=1e-6, vmax=1, colormap='hot', scale='log'):
ls("*fits").show() # this shows a list of FITS files
ls("*fits").show_all() # and this calls show() on every FITS file
# observe that the global settings haven't changed:
settings.fits
| radiopadre/notebooks/radiopadre-tutorial.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python (herschelhelp_internal)
# language: python
# name: helpint
# ---
# # EGS master catalogue
# ## Preparation of Canada France Hawaii Telescope Lensing Survey (CFHTLenS) data
#
# CFHTLenS catalogue: the catalogue comes from `dmu0_CFHTLenS`.
#
# In the catalogue, we keep:
#
# - The identifier (it's unique in the catalogue);
# - The position;
# - The stellarity;
# - The kron magnitude, there doesn't appear to be aperture magnitudes. This may mean the survey is unusable.
#
# We use the publication year 2012 for the epoch.
from herschelhelp_internal import git_version
print("This notebook was run with herschelhelp_internal version: \n{}".format(git_version()))
import datetime
print("This notebook was executed on: \n{}".format(datetime.datetime.now()))
# +
# %matplotlib inline
# #%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
plt.rc('figure', figsize=(10, 6))
from collections import OrderedDict
import os
from astropy import units as u
from astropy.coordinates import SkyCoord
from astropy.table import Column, Table
import numpy as np
from herschelhelp_internal.flagging import gaia_flag_column
from herschelhelp_internal.masterlist import nb_astcor_diag_plot, remove_duplicates
from herschelhelp_internal.utils import astrometric_correction, mag_to_flux
# +
OUT_DIR = os.environ.get('TMP_DIR', "./data_tmp")
try:
os.makedirs(OUT_DIR)
except FileExistsError:
pass
RA_COL = "cfhtlens_ra"
DEC_COL = "cfhtlens_dec"
# -
# ## I - Column selection
# +
imported_columns = OrderedDict({
'id': "cfhtlens_id",
'ALPHA_J2000': "cfhtlens_ra",
'DELTA_J2000': "cfhtlens_dec",
'CLASS_STAR': "cfhtlens_stellarity",
'MAG_u': "m_cfhtlens_u",
'MAGERR_u': "merr_cfhtlens_u",
'MAG_g': "m_cfhtlens_g",
'MAGERR_g': "merr_cfhtlens_g",
'MAG_r': "m_cfhtlens_r",
'MAGERR_r': "merr_cfhtlens_r",
'MAG_i': "m_cfhtlens_i",
'MAGERR_i': "merr_cfhtlens_i",
'MAG_z': "m_cfhtlens_z",
'MAGERR_z': "merr_cfhtlens_z",
})
catalogue = Table.read("../../dmu0/dmu0_CFHTLenS/data/CFHTLenS_EGS.fits")[list(imported_columns)]
for column in imported_columns:
catalogue[column].name = imported_columns[column]
epoch = 2012 #Year of publication
# Clean table metadata
catalogue.meta = None
# +
# Adding flux and band-flag columns
for col in catalogue.colnames:
if col.startswith('m_'):
errcol = "merr{}".format(col[1:])
catalogue[col][catalogue[col] <= 0] = np.nan
catalogue[errcol][catalogue[errcol] <= 0] = np.nan
catalogue[col][catalogue[col] > 90.] = np.nan
catalogue[errcol][catalogue[errcol] > 90.] = np.nan
flux, error = mag_to_flux(np.array(catalogue[col]), np.array(catalogue[errcol]))
# Fluxes are added in µJy
catalogue.add_column(Column(flux * 1.e6, name="f{}".format(col[1:])))
catalogue.add_column(Column(error * 1.e6, name="ferr{}".format(col[1:])))
# We add nan filled aperture photometry for consistency
catalogue.add_column(Column(np.full(len(catalogue), np.nan), name="m_ap{}".format(col[1:])))
catalogue.add_column(Column(np.full(len(catalogue), np.nan), name="merr_ap{}".format(col[1:])))
catalogue.add_column(Column(np.full(len(catalogue), np.nan), name="f_ap{}".format(col[1:])))
catalogue.add_column(Column(np.full(len(catalogue), np.nan), name="ferr_ap{}".format(col[1:])))
# Band-flag column
if "ap" not in col:
catalogue.add_column(Column(np.zeros(len(catalogue), dtype=bool), name="flag{}".format(col[1:])))
# TODO: Set to True the flag columns for fluxes that should not be used for SED fitting.
# -
catalogue[:10].show_in_notebook()
# ## II - Removal of duplicated sources
# We remove duplicated objects from the input catalogues.
# +
SORT_COLS = ['merr_cfhtlens_u',
'merr_cfhtlens_g',
'merr_cfhtlens_r',
'merr_cfhtlens_i',
'merr_cfhtlens_z']
FLAG_NAME = 'cfhtlens_flag_cleaned'
nb_orig_sources = len(catalogue)
catalogue = remove_duplicates(catalogue, RA_COL, DEC_COL, sort_col=SORT_COLS,flag_name=FLAG_NAME)
nb_sources = len(catalogue)
print("The initial catalogue had {} sources.".format(nb_orig_sources))
print("The cleaned catalogue has {} sources ({} removed).".format(nb_sources, nb_orig_sources - nb_sources))
print("The cleaned catalogue has {} sources flagged as having been cleaned".format(np.sum(catalogue[FLAG_NAME])))
# -
# ## III - Astrometry correction
#
# We match the astrometry to the Gaia one. We limit the Gaia catalogue to sources with a g band flux between the 30th and the 70th percentile. Some quick tests show that this give the lower dispersion in the results.
gaia = Table.read("../../dmu0/dmu0_GAIA/data/GAIA_EGS.fits")
gaia_coords = SkyCoord(gaia['ra'], gaia['dec'])
nb_astcor_diag_plot(catalogue[RA_COL], catalogue[DEC_COL],
gaia_coords.ra, gaia_coords.dec)
# +
delta_ra, delta_dec = astrometric_correction(
SkyCoord(catalogue[RA_COL], catalogue[DEC_COL]),
gaia_coords
)
print("RA correction: {}".format(delta_ra))
print("Dec correction: {}".format(delta_dec))
# -
catalogue[RA_COL] += delta_ra.to(u.deg)
catalogue[DEC_COL] += delta_dec.to(u.deg)
nb_astcor_diag_plot(catalogue[RA_COL], catalogue[DEC_COL],
gaia_coords.ra, gaia_coords.dec)
# ## IV - Flagging Gaia objects
catalogue.add_column(
gaia_flag_column(SkyCoord(catalogue[RA_COL], catalogue[DEC_COL]), epoch, gaia)
)
# +
GAIA_FLAG_NAME = "cfhtlens_flag_gaia"
catalogue['flag_gaia'].name = GAIA_FLAG_NAME
print("{} sources flagged.".format(np.sum(catalogue[GAIA_FLAG_NAME] > 0)))
# -
# ## V - Flagging objects near bright stars
# # VI - Saving to disk
catalogue.write("{}/CFHTLENS.fits".format(OUT_DIR), overwrite=True)
| dmu1/dmu1_ml_EGS/1.5_CFHTLenS.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Homework 2: Problems (due 7 October 2020 before class)
# ### PHYS 440/540, Fall 2020
# https://github.com/gtrichards/PHYS_440_540/
#
#
# ## Problem 1
# Follow the example from the Central Limit Theorem cells in BasicStats2.ipynb and simulate the distribution of 1,000,000 draws of a (very) non-Gaussian distribution (for example chi-square with low $k$). Demonstrate that the result confirms the central limit theorem by showing that the mean of the draws becomes Gaussian with large `N`.
#
# Note that you'll need functions to both generate the true distribution and also to take random draws from it.
#
# See below for code starter.
#
#
# ## Problem 2
#
# On Data Camp:
#
# Do Chapters 1 and 2 of "Exploratory Data Analysis in Python" to get some practice with CDF.
#
# Chapter 2 is actually the only one that I care about, but it makes sense to do chapter 1 to give you some context. Chapter 1 introduces some Pandas tools. I'm not planning on assigning the "Data Manipulation with Pandas" course, but you might find that useful as well.
#
# Note this lesson talks about PMFs. A PMF is a PDF for a discrete distribution. For the sake of comparing this assignment to class you can think of PMFs and PDFs as the same thing.
# +
import numpy as np
from matplotlib import pyplot as plt
from scipy.stats import norm
from scipy import stats
N=2 # Number of draws. Show both small and large values
xgrid = np.linspace(____,____,____) # Array to sample the space
dist = stats.____(____) # Complete
plt.plot(xgrid,____.pdf(____)) # Complete
#Rug plot of N random draws
x = np.random.____(____) # N random draws
plt.plot(x, 0*x, '|', markersize=50) #Rug plot of random draws
plt.xlabel('x')
plt.ylabel('pdf')
plt.xlim(____,____) #Limit the x-axis range to make things easier to see
# Repeat that 1,000,000 times, averaging the N draws each time
yy = []
for i in np.arange(____): # Complete
xx = np.random.____(_____) # N random draws
yy.append(xx.mean()) # Append average of those random draws to the end of the array
#Plot the histogram with Scott or Freedman bins
_ = plt.hist(yy,____,____,histtype="stepfilled",alpha=0.5)
#Overplot a Gaussian at the appropriate location
distG = stats.norm(loc=____,scale=np.sqrt(2*np.pi/N)) # Complete
plt.plot(____,____.____(____)) # Complete
# -
# ### Some useful definitions and functions
import numpy as np
from matplotlib import pyplot as plt
from scipy import stats
from astroML.plotting import setup_text_plots
from astroML.stats import sigmaG
from astroML.plotting import hist as fancyhist
setup_text_plots(fontsize=14, usetex=True)
# %matplotlib inline
# This astroML function adjusts matplotlib settings for a uniform feel in the
# textbook. Note that with `usetex=True`, fonts are rendered with $\LaTeX$. This
# may result in an error if $\LaTeX$ is not installed on your system. In that
# case, you can set usetex to `False`.
| homeworks/PHYS_440_540_F20_HW2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="b1UL_3e218jK"
# # Final Assignment
# <NAME> <br>
# GitHub: <a href="https://github.com/mateusvictor">mateusvictor</a>
#
# + id="I8fxscLrRoWy"
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# + [markdown] id="L3fhTRFtRHSs"
# ## 1
# + colab={"base_uri": "https://localhost:8080/", "height": 227} id="oZUOPSHF2eIj" outputId="24daee13-a742-48ff-8d71-7f91369276a5"
df_interests =pd.read_csv('https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DV0101EN-SkillsNetwork/labs/FinalModule_Coursera/data/Topic_Survey_Assignment.csv')
df_interests
# + id="AJG3Qips2mTU" colab={"base_uri": "https://localhost:8080/", "height": 674} outputId="cb2c42ee-0c35-4aab-d30f-e9c55f91a9f1"
df_interests.sort_values('Very interested', ascending=False, inplace=True)
df_interests = (df_interests / 2333).round(2)
ax =df_interests.plot(kind='bar', figsize=(20,8), width = 0.8, color = ['#5cb85c', '#5bc0de', '#d9534F', '#FFFFFF'])
plt.legend(labels=df_interests.columns,fontsize= 14)
plt.title("Percentage of Respondents' Interest in Data Science Areas",fontsize= 16)
plt.xticks(fontsize=14)
for spine in plt.gca().spines.values():
spine.set_visible(False)
plt.yticks([])
for p in ax.patches:
width = p.get_width()
height = p.get_height()
x, y = p.get_xy()
ax.annotate(f'{height:.0%}', (x + width/2, y + height*1.02), ha='center')
plt.savefig("1.png")
plt.show()
# + id="omaz1Jbk-eUe"
# + id="ioW12aHIDspa"
# + [markdown] id="844RqIZiRJDR"
# ## 2
# + colab={"base_uri": "https://localhost:8080/", "height": 347} id="lLUa_2JzTQFK" outputId="898bd666-f066-40ac-cb45-8c50c6703aa7"
df_crimes = pd.read_csv('Police_Department_Incidents_-_Previous_Year__2016_.csv')
df_new = df_crimes['PdDistrict'].value_counts().to_frame()
df_new.reset_index(inplace=True)
df_new.columns = ['Neighborhood', 'Count']
df_new
# + colab={"base_uri": "https://localhost:8080/", "height": 853} id="-B72kZsJ3-Oy" outputId="8004c931-f2a7-419b-cff3-4464846f817b"
import folium
latitude = 37.77
longitude = -122.42
# !wget --quiet https://cocl.us/sanfran_geojson -O world_countries.json
sanfran_geo = r'world_countries.json' # geojson file
sanfran_map = folium.Map(location=[37.77,-122.42], zoom_start=12)
sanfran_map.choropleth(
geo_data=sanfran_geo,
data=df_new,
columns=['Neighborhood', 'Count'],
key_on='feature.properties.DISTRICT',
fill_color='YlOrRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Crime Rate in San Francisco'
)
sanfran_map
| Data_Vizualization/DT_Vizualization_Final_Assignment.ipynb |
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .r
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: R
# name: ir
# ---
# + [markdown] id="d3hUeY1Ng7NZ"
# # 7장 시계열을 위한 상태공간 모델
#
# > 시계열을 위한 상태공간 모델 중 칼만필터에 대한 소스코드 입니다.
# - author: "<NAME>"
# - toc: false
# - comments: false
# - categories: [state space model, kalman filter, R]
# - permalink: /chapter7-kalman-filter/
# - badges: true
# - hide_github_badge: true
# + id="Tj8MQeauYZ8I"
ts.length <- 100
# + colab={"base_uri": "https://localhost:8080/", "height": 34} id="CjPprEOyYk03" outputId="9bc55ff4-d3b9-45d7-ea72-4e2c6718acb1"
ts
# + id="1wM3yfGWYdzZ"
a <- rep(0.5, ts.length)
# + colab={"base_uri": "https://localhost:8080/"} id="dQL4lhRnYmBr" outputId="85a9c11f-817d-479a-ac80-03a4eaba7678"
print(length(a))
print(a)
# + id="h57qI7-3YiNV"
x <- rep(0, ts.length)
v <- rep(0, ts.length)
for (ts in 2:ts.length) { # 2 에서 100 까지 (ts - 1의 수행 때문)
x[ts] <- v[ts - 1] * 2 + x[ts - 1] + 1/2 * a[ts-1] ^ 2
x[ts] <- x[ts] + rnorm(1, sd = 20)
v[ts] <- v[ts - 1] + 2 * a[ts-1]
}
# + colab={"base_uri": "https://localhost:8080/", "height": 437} id="kIFGSflvY69U" outputId="f6dc58e8-497e-48ca-e0ac-2f3c1dd67723"
par(mfrow = c(3, 1))
plot(x, main = "Position", type = 'l')
plot(v, main = "Velocity", type = 'l')
plot(a, main = "Acceleration", type = 'l')
# + colab={"base_uri": "https://localhost:8080/", "height": 437} id="O4ZtZy7aZCl0" outputId="2d1aee54-a888-418a-bd16-8d395a089d1c"
z <- x + rnorm(ts.length, sd = 300)
plot (x, ylim = range(c(x, z)))
lines(z)
# + id="GZpz-FzNZrEq"
kalman.motion <- function(z, Q, R, A, H) {
dimState = dim(Q)[1]
xhatminus <- array(rep(0, ts.length * dimState),
c(ts.length, dimState))
xhat <- array(rep(0, ts.length * dimState),
c(ts.length, dimState))
Pminus <- array(rep(0, ts.length * dimState * dimState),
c(ts.length, dimState, dimState))
P <- array(rep(0, ts.length * dimState * dimState),
c(ts.length, dimState, dimState))
K <- array(rep(0, ts.length * dimState),
c(ts.length, dimState)) # Kalman gain # 칼만이득
# intial guesses = starting at 0 for all metrics
# 초기 추측 = 모든 지표는 0으로 시작합니다
xhat[1, ] <- rep(0, dimState)
P[1, , ] <- diag(dimState)
for (k in 2:ts.length) {
# 시간의 갱신
xhatminus[k, ] <- A %*% matrix(xhat[k-1, ])
Pminus[k, , ] <- A %*% P[k-1, , ] %*% t(A) + Q
K[k, ] <- Pminus[k, , ] %*% H %*%
solve( t(H) %*% Pminus[k, , ] %*% H + R )
xhat[k, ] <- xhatminus[k, ] + K[k, ] %*%
(z[k]- t(H) %*% xhatminus[k, ])
P[k, , ] <- (diag(dimState)-K[k,] %*% t(H)) %*% Pminus[k, , ]
}
## we return both the forecast and the smoothed value
## 예측과 평활화된 값 모두를 반환합니다
return(list(xhat = xhat, xhatminus = xhatminus))
}
# + id="a92192VTZure"
R <- 10^2 ## measurement variance - this value should be set
## according to known physical limits of measuring tool
## we set it consistent with the noise we added to x
## to produce x in the data generation above
## 측정 분산 - 이 값은 측정 도구에 대하여 알려진,
## 물리적인 한계에 따라서 설정되어야만 합니다.
## x에 더해진 노이즈와 일관성있게 설정합니다.
Q <- 10 ## process variance - usually regarded as hyperparameter
## to be tuned to maximize performance
## 과정의 분산 - 일반적으로, 성능의 최대화를 위해서
## 조정되어야 하는 하이퍼파라미터로서 취급됩니다
## dynamical parameters
## 동적 파라미터
A <- matrix(1) ## x_t = A * x_t-1 (how prior x affects later x) (사전의 x가 나중의 x에 얼마나 영향을 미치는지)
H <- matrix(1) ## y_t = H * x_t (translating state to measurement) (상태를 측정으로 변환)
## run the data through the Kalman filtering method
## 칼만필터 방법으로 데이터를 넣고 돌립니다
xhat <- kalman.motion(z, diag(1) * Q, R, A, H)[[1]]
# + id="2n07QLDL4ZJm"
result = kalman.motion(z, diag(1) * Q, R, A, H)
xhat = result[[1]]
xhatminus = result[[2]]
# + colab={"base_uri": "https://localhost:8080/", "height": 437} id="wa7hWUzNZwxP" outputId="75d2c158-e653-4f12-fb95-134f9c1af783"
z <- x + rnorm(ts.length, sd = 300)
plot (x, type="l", lty=2, ylim = range(c(x, z)))
lines(z, lty=1)
lines(xhat, lty=3)
lines(xhatminus, lty=4)
# + id="lchWQvwJ5IFi"
| _notebooks/2020-12-22-chapter7-kalman-filter.ipynb |
# +
# Copyright 2010 <NAME> <EMAIL>
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Global constraint regular in Google CP Solver.
This is a translation of MiniZinc's regular constraint (defined in
lib/zinc/globals.mzn). All comments are from the MiniZinc code.
'''
The sequence of values in array 'x' (which must all be in the range 1..S)
is accepted by the DFA of 'Q' states with input 1..S and transition
function 'd' (which maps (1..Q, 1..S) -> 0..Q)) and initial state 'q0'
(which must be in 1..Q) and accepting states 'F' (which all must be in
1..Q). We reserve state 0 to be an always failing state.
'''
It is, however, translated from the Comet model:
* Comet: http://www.hakank.org/comet/regular.co
Here we test with the following regular expression:
0*1{3}0+1{2}0+1{1}0*
using an array of size 10.
This model was created by <NAME> (<EMAIL>)
Also see my other Google CP Solver models:
http://www.hakank.org/google_or_tools/
"""
from __future__ import print_function
from ortools.constraint_solver import pywrapcp
#
# Global constraint regular
#
# This is a translation of MiniZinc's regular constraint (defined in
# lib/zinc/globals.mzn), via the Comet code refered above.
# All comments are from the MiniZinc code.
# '''
# The sequence of values in array 'x' (which must all be in the range 1..S)
# is accepted by the DFA of 'Q' states with input 1..S and transition
# function 'd' (which maps (1..Q, 1..S) -> 0..Q)) and initial state 'q0'
# (which must be in 1..Q) and accepting states 'F' (which all must be in
# 1..Q). We reserve state 0 to be an always failing state.
# '''
#
# x : IntVar array
# Q : number of states
# S : input_max
# d : transition matrix
# q0: initial state
# F : accepting states
def regular(x, Q, S, d, q0, F):
solver = x[0].solver()
assert Q > 0, 'regular: "Q" must be greater than zero'
assert S > 0, 'regular: "S" must be greater than zero'
# d2 is the same as d, except we add one extra transition for
# each possible input; each extra transition is from state zero
# to state zero. This allows us to continue even if we hit a
# non-accepted input.
d2 = []
for i in range(Q + 1):
for j in range(1, S + 1):
if i == 0:
d2.append((0, j, 0))
else:
d2.append((i, j, d[i - 1][j - 1]))
solver.Add(solver.TransitionConstraint(x, d2, q0, F))
#
# Make a transition (automaton) matrix from a
# single pattern, e.g. [3,2,1]
#
def make_transition_matrix(pattern):
p_len = len(pattern)
print('p_len:', p_len)
num_states = p_len + sum(pattern)
print('num_states:', num_states)
t_matrix = []
for i in range(num_states):
row = []
for j in range(2):
row.append(0)
t_matrix.append(row)
# convert pattern to a 0/1 pattern for easy handling of
# the states
tmp = [0 for i in range(num_states)]
c = 0
tmp[c] = 0
for i in range(p_len):
for j in range(pattern[i]):
c += 1
tmp[c] = 1
if c < num_states - 1:
c += 1
tmp[c] = 0
print('tmp:', tmp)
t_matrix[num_states - 1][0] = num_states
t_matrix[num_states - 1][1] = 0
for i in range(num_states):
if tmp[i] == 0:
t_matrix[i][0] = i + 1
t_matrix[i][1] = i + 2
else:
if i < num_states - 1:
if tmp[i + 1] == 1:
t_matrix[i][0] = 0
t_matrix[i][1] = i + 2
else:
t_matrix[i][0] = i + 2
t_matrix[i][1] = 0
print('The states:')
for i in range(num_states):
for j in range(2):
print(t_matrix[i][j], end=' ')
print()
print()
return t_matrix
# Create the solver.
solver = pywrapcp.Solver('Regular test')
#
# data
#
this_len = 10
pp = [3, 2, 1]
transition_fn = make_transition_matrix(pp)
n_states = len(transition_fn)
input_max = 2
# Note: we use '1' and '2' (rather than 0 and 1)
# since 0 represents the failing state.
initial_state = 1
accepting_states = [n_states]
# declare variables
reg_input = [
solver.IntVar(1, input_max, 'reg_input[%i]' % i) for i in range(this_len)
]
#
# constraints
#
regular(reg_input, n_states, input_max, transition_fn, initial_state,
accepting_states)
#
# solution and search
#
db = solver.Phase(reg_input, solver.CHOOSE_MIN_SIZE_HIGHEST_MAX,
solver.ASSIGN_MIN_VALUE)
solver.NewSearch(db)
num_solutions = 0
while solver.NextSolution():
print('reg_input:', [reg_input[i].Value() - 1 for i in range(this_len)])
num_solutions += 1
solver.EndSearch()
print()
print('num_solutions:', num_solutions)
print('failures:', solver.Failures())
print('branches:', solver.Branches())
print('WallTime:', solver.WallTime(), 'ms')
| examples/notebook/contrib/regular_table2.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Running optimizations in Optimistic has some processing overhead over leaner libraries like scipy.optimize, used for things like checking that parameters are safely within defined bounds or storing data in human-readable formats. In this notebook, we compare the overhead to pure Python implementations.
# +
import numpy as np
from parametric import Parameter
from optimistic import experiment, GridSearch, GradientDescent
import time
x = Parameter('x', 0.5)
@experiment
def gaussian():
return np.exp(-x**2)
# -
# %%time
grid = GridSearch(gaussian, steps=1000, show_progress=False, record_data=False).add_parameter(x, bounds=(-1, 1))
grid.run()
# %%time
results = np.array([])
for x0 in np.linspace(-1, 1, 1000):
results = np.append(results, gaussian(x=x0))
# gaussian(x=x0)
| tutorials/Benchmarking.ipynb |
# -*- coding: utf-8 -*-
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Julia 1.5.2
# language: julia
# name: julia-1.5
# ---
# # Show the experimental results
# import Packages
using JLD
using Statistics
using Plots, StatsPlots
default(:bglegend, plot_color(default(:bg), 0.8))
default(:fglegend, plot_color(ifelse(isdark(plot_color(default(:bg))), :white, :black), 0.6));
# # Forward SFS
# ## False Positive Rate (FPR)
# load results
FPR_homotopy, FPR_homotopy_H, FPR_homotopy_S, FPR_polytope, FPR_DS = jldopen("result/ex_FPR.jld", "r") do f
read(f["FPR_A"]), read(f["FPR_Ao"]), read(f["FPR_As"]), read(f["FPR_Aso"]), read(f["FPR_DS"])
end;
Ns = [50, 100, 150, 200]
zero_num = size(FPR_homotopy, 1)
FPR_homotopy_mean = reshape(mean(FPR_homotopy, dims=2), zero_num, length(Ns))
FPR_homotopy_H_mean = reshape(mean(FPR_homotopy_H, dims=2), zero_num, length(Ns))
FPR_homotopy_S_mean = reshape(mean(FPR_homotopy_S, dims=2), zero_num, length(Ns))
FPR_polytope_mean = reshape(mean(FPR_polytope, dims=2), zero_num, length(Ns))
FPR_DS_mean = reshape(mean(FPR_DS, dims=2), zero_num, length(Ns));
Cs = [:red, :orange, :green, :blue, :purple]
p = Array{typeof(plot())}(undef, zero_num)
for j in 1:zero_num
plot()
plot!(1:length(Ns), FPR_homotopy_mean[j,:], label="Homotopy", color=Cs[1], markershape=:circle)
plot!(1:length(Ns), FPR_homotopy_H_mean[j,:], label="Homotopy-H", color=Cs[2], markershape=:circle)
plot!(1:length(Ns), FPR_homotopy_S_mean[j,:], label="Homotopy-S", color=Cs[3], markershape=:circle)
plot!(1:length(Ns), FPR_polytope_mean[j,:], label="Polytope", color=Cs[4], markershape=:circle)
plot!(1:length(Ns), FPR_DS_mean[j,:], label="DS", color=Cs[5], markershape=:circle)
# plot setting
plot!(; ylims=(0, 0.3))
plot!(; xlabel="Sample size", ylabel="False Positive Rate (FPR)")
plot!(; legend=:topright)
plot!(; guidefontsize=16, legendfontsize=12, tickfontsize=10)
p[j] = plot!(; xticks=(1:length(Ns), Ns))
end
p[1]
# ## True Positive Rate (TPR)
# load results
TPR_homotopy, TPR_homotopy_H, TPR_homotopy_S, TPR_polytope, TPR_DS = jldopen("result/ex_TPR.jld", "r") do f
read(f["TPR_A"]), read(f["TPR_Ao"]), read(f["TPR_As"]), read(f["TPR_Aso"]), read(f["TPR_DS"])
end;
# +
Ns = [50, 100, 150, 200]
nonzero_num = size(TPR_homotopy, 1)
iter_size = size(TPR_homotopy, 2)
TPR_homotopy_mean = reshape(mean(TPR_homotopy, dims=2), nonzero_num, length(Ns))
TPR_homotopy_SE = reshape(std(TPR_homotopy, dims=2) ./ √iter_size, nonzero_num, length(Ns))
TPR_homotopy_H_mean = reshape(mean(TPR_homotopy_H, dims=2), nonzero_num, length(Ns))
TPR_homotopy_H_SE = reshape(std(TPR_homotopy_H, dims=2) ./ √iter_size, nonzero_num, length(Ns))
TPR_homotopy_S_mean = reshape(mean(TPR_homotopy_S, dims=2), nonzero_num, length(Ns))
TPR_homotopy_S_SE = reshape(std(TPR_homotopy_S, dims=2) ./ √iter_size, nonzero_num, length(Ns))
TPR_polytope_mean = reshape(mean(TPR_polytope, dims=2), nonzero_num, length(Ns))
TPR_polytope_SE = reshape(std(TPR_polytope, dims=2) ./ √iter_size, nonzero_num, length(Ns))
TPR_DS_mean = reshape(mean(TPR_DS, dims=2), nonzero_num, length(Ns))
TPR_DS_SE = reshape(std(TPR_DS, dims=2) ./ √iter_size, nonzero_num, length(Ns));
# -
Cs = [:red, :orange, :green, :blue, :purple]
p = Array{typeof(plot())}(undef, nonzero_num)
for j in 1:nonzero_num
p[j] = plot()
# Homotopy
plot!(p[j], 1:length(Ns), (TPR_homotopy_mean - TPR_homotopy_SE)[j,:]; fillrange=(TPR_homotopy_mean + TPR_homotopy_SE)[j,:], fillalpha=0.2, α=0, label=nothing, color=Cs[1])
plot!(p[j], 1:length(Ns), TPR_homotopy_mean[j,:], label="Homotopy", color=Cs[1], markershape=:circle)
# Homotopy-H
plot!(p[j], 1:length(Ns), (TPR_homotopy_H_mean - TPR_homotopy_H_SE)[j,:]; fillrange=(TPR_homotopy_H_mean + TPR_homotopy_H_SE)[j,:], fillalpha=0.2, α=0, label=nothing, color=Cs[2])
plot!(p[j], 1:length(Ns), TPR_homotopy_H_mean[j,:], label="Homotopy-H", color=Cs[2], markershape=:circle)
# Homotopy-S
plot!(p[j], 1:length(Ns), (TPR_homotopy_S_mean - TPR_homotopy_S_SE)[j,:]; fillrange=(TPR_homotopy_S_mean + TPR_homotopy_S_SE)[j,:], fillalpha=0.2, α=0, label=nothing, color=Cs[3])
plot!(p[j], 1:length(Ns), TPR_homotopy_S_mean[j,:], label="Homotopy-S", color=Cs[3], markershape=:circle)
# Polytope
plot!(p[j], 1:length(Ns), (TPR_polytope_mean - TPR_homotopy_SE)[j,:]; fillrange=(TPR_polytope_mean + TPR_homotopy_SE)[j,:], fillalpha=0.2, α=0, label=nothing, color=Cs[4])
plot!(p[j], 1:length(Ns), TPR_polytope_mean[j,:], label="Polytope", color=Cs[4], markershape=:circle)
# DS
plot!(p[j], 1:length(Ns), (TPR_DS_mean - TPR_DS_SE)[j,:]; fillrange=(TPR_DS_mean + TPR_DS_SE)[j,:], fillalpha=0.2, α=0, label=nothing, color=Cs[5])
plot!(p[j], 1:length(Ns), TPR_DS_mean[j,:], label="DS", color=Cs[5], markershape=:circle)
# plot setting
plot!(p[j]; ylims=(0, 1))
plot!(p[j]; legend=:topleft)
plot!(p[j]; xlabel="Sample size", ylabel="True Positive Rate (TPR)")
plot!(p[j]; guidefontsize=16, legendfontsize=12, tickfontsize=10)
end
p[1]
# ## Lengths of CIs
# load results
results = jldopen(relpath("result/ex_CI_length.jld"), "r") do f
read(f["result"])
end
tmp = results[2]
results[2] = results[3]
results[3] = tmp;
Cs = [:red3, :orange3, :green3, :blue3, :purple3]
p = plot()
for i in eachindex(results)
violin!(p, fill(i, length(results[i])), results[i]; c=Cs[i], label=nothing)
end
plot!(p; xticks=(1:length(results), ["Homotopy", "Homotopy-H", "Homotopy-S", "Polytope", "DS"]))
plot!(p; xlabel="method", ylabel="length of confidence interval")
# scatter!(p, 1:length(results), median.(results); c=:magenta, label=nothing)
plot!(p; guidefontsize=16, legendfontsize=12, tickfontsize=10)
plot!(p; ylims=(0, 7))
# # Forward-Backward SFS
# ## FPR
# load results
FPR, FPR_OC = jldopen("result/stepwise/ex_FPR_FB.jld", "r") do f
read(f["FPR"]), read(f["FPR_OC"])
end;
FPR_mean = reshape(mean(FPR, dims=1), size(FPR, 2), size(FPR, 3))
FPR_OC_mean = reshape(mean(FPR_OC, dims=1), size(FPR_OC, 2), size(FPR_OC, 3));
Ns = (50, 100, 150)
ps = (10, 20, 50)
h_cs = (:red2, :violetred2, :darkred)
o_cs = (:blue2, :skyblue, :navyblue)
p = plot()
for j = 1:size(FPR, 3) # σ
plot!(p, 1:length(Ns), FPR_mean[:,j], label="Homotopy, p=$(ps[j])", color=h_cs[j], markershape=:circle)
plot!(p, 1:length(Ns), FPR_OC_mean[:,j], label="Quadratic, p=$(ps[j])", color=o_cs[j], markershape=:rect)
end
# plot setting
plot!(p; ylims=(0, 0.3))
plot!(p; xlabel="Sample size", ylabel="False Positive Rate (FPR)")
plot!(p; legend=:topright)
plot!(p; guidefontsize=16, legendfontsize=12, tickfontsize=10)
plot!(p; xticks=(1:length(Ns), Ns))
# ## TPR
# load results
TPR, TPR_OC = jldopen("result/stepwise/ex_TPR_FB.jld", "r") do f
read(f["TPR"]), read(f["TPR_OC"])
end;
TPR_mean = reshape(mean(TPR, dims=1), size(TPR, 2), size(TPR, 3), size(TPR, 4))
TPR_SE = reshape(std(TPR, dims=1) ./ √size(TPR, 1), size(TPR, 2), size(TPR, 3), size(TPR, 4))
TPR_OC_mean = reshape(mean(TPR_OC, dims=1), size(TPR_OC, 2), size(TPR_OC, 3), size(TPR_OC, 4))
TPR_OC_SE = reshape(std(TPR_OC, dims=1) ./ √size(TPR_OC, 1), size(TPR_OC, 2), size(TPR_OC, 3), size(TPR_OC, 4));
Ns = (50, 100, 150)
ps = (10, 20, 50)
βs = (0.01, 0.25, 0.5, 1.)
p = Array{typeof(plot())}(undef, length(βs))
h_cs = (:red2, :violetred2, :darkred)
o_cs = (:blue2, :skyblue, :darkblue)
for k = eachindex(βs)
p[k] = plot()
for j = eachindex(ps) # p
# Homotopy
plot!(p[k], 1:length(Ns), (TPR_mean - TPR_SE)[:,j,k]; fillrange=(TPR_mean + TPR_SE)[:,j,k], fillalpha=0.2, α=0, label=nothing, color=h_cs[j])
plot!(p[k], 1:length(Ns), TPR_mean[:,j,k], label="Homotopy, p=$(ps[j])", color=h_cs[j], markershape=:circle)
# Quadratic
plot!(p[k], 1:length(Ns), (TPR_OC_mean - TPR_OC_SE)[:,j,k]; fillrange=(TPR_OC_mean + TPR_OC_SE)[:,j,k], fillalpha=0.2, α=0, label=nothing, color=o_cs[j])
plot!(p[k], 1:length(Ns), TPR_OC_mean[:,j,k], label="Quadratic, p=$(ps[j])", color=o_cs[j], markershape=:rect)
end
# plot setting
plot!(p[k]; ylims=(0, 1))
plot!(p[k]; legend=:best)
plot!(p[k]; xlabel="Sample size", ylabel="True Positive Rate (TPR)")
plot!(p[k]; guidefontsize=14, legendfontsize=9, tickfontsize=9)
plot!(p[k]; xticks=(1:length(Ns), Ns))
plot!(p[k]; title="signal:$(βs[k])")
filename = string("TPR_signal_", βs[k], ".pdf")
end
plot(p..., layout=(1, 4), titlefontsize=16, size=(900, 900))
# ## Lengths of CIs
# load results
CI_lengths, CI_lengths_OC = jldopen("result/stepwise/ex_CI_length.jld", "r") do f
read(f["CI_lengths"]), read(f["CI_lengths_OC"])
end;
p = plot()
violin!(p, fill(1, length(CI_lengths)), CI_lengths; c=:red2, label=nothing)
violin!(p, fill(2, length(CI_lengths_OC)), CI_lengths_OC; c=:blue2, label=nothing)
plot!(p; xticks=(1:2, ["homotopy", "over-conditioning"]))
plot!(p; yscale=:log10)
plot!(p; xlabel="method", ylabel="length of confidence interval")
plot!(p; guidefontsize=16, legendfontsize=12, tickfontsize=10)
| ex1_reproduce_plots.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: py35
# language: python
# name: py35
# ---
# +
# Dependencies and Setup
import matplotlib.pyplot as plt
import pandas as pd
import scipy.stats as st
import numpy as np
# Study data files
mouse_metadata_path = "data/Mouse_metadata.csv"
study_results_path = "data/Study_results.csv"
# Read the mouse data and the study results
mouse_metadata = pd.read_csv(mouse_metadata_path)
study_results = pd.read_csv(study_results_path)
# Combine the data into a single dataset
combined_data= pd.merge(mouse_metadata,study_results,on = 'Mouse ID')
combined_data.head()
# -
# Check the number of Mice count
Mice_count = len(combined_data['Mouse ID'].unique())
Mice_count
# Check the count of Mouse ID
combined_data['Mouse ID'].value_counts()
# Sort combined data by Tumor Volume to get the median values
sorted_data = combined_data.sort_values(["Tumor Volume (mm3)"])
sorted_data .head()
# +
# Generate a summary statistics table consisting of the mean, median, variance, standard deviation,
#and SEM of the tumor volume for each drug regimen.
# create a groupby for the Drug Regimen and Tumor volume
grouped_sorted_data = sorted_data.groupby(['Drug Regimen'])
grouped_sorted_data
mean = grouped_sorted_data['Tumor Volume (mm3)'].mean()
median = grouped_sorted_data['Tumor Volume (mm3)'].median()
variance = grouped_sorted_data['Tumor Volume (mm3)'].var()
stdv = grouped_sorted_data['Tumor Volume (mm3)'].std()
SEM = grouped_sorted_data['Tumor Volume (mm3)'].sem()
summary_stat = pd.DataFrame({'Mean': mean , 'Median': median , 'Variance': variance
,'Standard Deviation': stdv , 'SEM':SEM})
summary_stat
# +
# Generate a bar plot showing the number of mice per time point for each treatment throughout the course of the study using pandas.
#create a groupby for drug regimen with mouse ID for the Bar charts
bar_data = combined_data.groupby(['Drug Regimen']).count()['Mouse ID']
bar_data
# -
# Set a Title and labels
bar_data.plot(kind= 'bar' ,facecolor= 'blue')
plt.xlabel('Drug Regimen')
plt.ylabel('Number Data points')
plt.show()
plt.tight_layout()
# +
# Generate a bar plot showing the number of mice per time point for each treatment throughout the course of the study using pyplot.
# create a list for the drug regimen
drug = [230,178,178,188,186,181,161,228,181,182]
drug_regimen = ['Capomulin','Ceftamin','Infubinol','Ketapril','Naftisol','Placebo','Propriva','Ramicane','Stelasyn','Zoniferol']
# Create a bar chart based upon the above data
x_axis = np.arange(len(bar_data))
plt.bar(x_axis, drug, color='b', align='center')
# Create the ticks for our bar chart's x axis
tick_locations = [value for value in x_axis]
plt.xticks(tick_locations, drug_regimen ,rotation = 'vertical')
# Set the limits of the x axis
plt.xlim(-0.75, len(x_axis)-0.25)
# Set the limits of the y axis
plt.ylim(0, max(drug)+10)
# Give the chart x label, and y label
plt.xlabel('Drug Regimen')
plt.ylabel('Number Data points')
# +
# Generate a pie plot showing the distribution of female versus male mice using pandas
# To find the distribution of female or male mice in the study, we need to groupby the Mouse ID and Sex
gender = combined_data.groupby(['Mouse ID' , 'Sex']).count()
gender
# -
# seperate the male count from the female count
mice_gender = pd.DataFrame(gender.groupby(['Sex']).count())
mice_gender
gender_percent = ((mice_gender/mice_gender.sum())*100)
gender_percent
# +
# The colors of each section of the pie chart (pyplot)
colors = ['blue' , 'orange']
# Tells matplotlib to seperate the "Humans" section from the others
explode = (0.1, 0,)
labels = ('Female','Male')
Sizes = [49.8 , 50.2]
plt.pie(Sizes, explode=explode, labels=labels, colors=colors,
autopct="%1.1f%%", shadow=True, startangle=140)
plt.axis("equal")
plt.show()
# +
# Pandas pie plot
explode = (0.1, 0,)
colors = ['blue' , 'orange']
explode = (0.1, 0,)
plot = gender_percent.plot.pie( figsize = (5,5),colors =colors,autopct="%1.1f%%", shadow=True,
startangle=140,explode=explode ,subplots=True)
# +
#Calculate the final tumor volume of each mouse across four of the most promising treatment regimens:
#Capomulin, Ramicane, Infubinol, and Ceftamin. Calculate the quartiles and IQR and quantitatively
#determine if there are any potential outliers across all four treatment regimens.
# Calculate the final tumor volume of each mouse across four of the most promising treatment regimens.
#Calculate the IQR and quantitatively determine if there are any potential outliers.
treatment = combined_data[combined_data['Drug Regimen'].isin(['Capomulin','Ramicane','Infubinol','Ceftamin'])]
treatment = treatment.sort_values(['Timepoint'])
treatment
# -
#Generate a line plot of time point versus tumor volume for a single mouse treated with Capomulin.
time_tumor = combined_data[combined_data['Mouse ID'].isin(['j119'])]
time_tumor
time_tumor_analsysis = time_tumor[['Mouse ID','Timepoint','Tumor Volume (mm3)']]
time_tumor_analsysis
line_plot = time_tumor_analsysis.plot.line()
#Generate a scatter plot of mouse weight versus average tumor volume for the Capomulin treatment regimen.
Capomulin= combined_data[combined_data['Drug Regimen'].isin(['Capomulin'])]
Capomulin
Capomulin_analysis = treatment[['Mouse ID','Weight (g)','Tumor Volume (mm3)']]
Capomulin_analysis
avrg_volume = Capomulin_analysis.groupby('Weight (g)')['Tumor Volume (mm3)'].mean()
avrg_volume
# +
x_axis = np.arange(0, 10, 0.1)
avrg_volume = []
for x in x_axis:
avrg_volume.append(x * x + np.random.randint(0, np.ceil(max(x_axis))))
plt.xlabel('Weight (g)')
plt.ylabel('Tumor Volume (mm3)')
plt.scatter(x_axis, avrg_volume, marker="o", color="red")
plt.show()
# -
| Pymaceuticals/Pymaceuticals.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pandas as pd
from models import *
from keras.utils import to_categorical
train_df = pd.read_csv("../data/train_gamcompare/csv/big_bow_df.csv")
y_train = to_categorical(train_df['correct'].values)
X_train = train_df.drop(['correct','aligner', 'read', 'mq'], axis=1).values
X_train.shape
model = bow_model()
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='SGD', metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=256, epochs=1, verbose=1, shuffle=True, validation_split=0.2)
model.save()
| notebooks/bow_all_size.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %run ../prelude.py --style=uncompressed --animation=spacetime
# ## Initialize Sliders & default parameters
# +
# Initial values
# Most cells below are modified from spMspM_pruned
M = 4
N = 4
K = 4
density = [1.0, 1.0]
cutoff = 2 #reuse cutoff value for K rank budget in sampling methods
magnitude_thres = 1
interval = 5
seed = 10
sample_rate = 0.4 # dictates sample threshold for portion of A
def set_params(rank_M, rank_N, rank_K, tensor_density, thres_cutoff, mag_thres, uniform_sample_rate, max_value, rand_seed):
global M
global N
global K
global density
global seed
global cutoff
global magnitude_thres
global sample_rate
global interval
M = rank_M
N = rank_N
K = rank_K
density = tensor_density[::-1]
seed = rand_seed
cutoff = thres_cutoff
magnitude_thres = mag_thres
sample_rate = uniform_sample_rate
interval = max_value
w = interactive(set_params,
rank_M=widgets.IntSlider(min=2, max=10, step=1, value=M),
rank_N=widgets.IntSlider(min=2, max=10, step=1, value=N),
rank_K=widgets.IntSlider(min=2, max=10, step=1, value=K),
tensor_density=widgets.FloatRangeSlider(min=0.1, max=1.0, step=0.05, value=density),
thres_cutoff=widgets.IntSlider(min=0, max=10, step=1, value=cutoff),
mag_thres=widgets.IntSlider(min=0, max=10, step=1, value=magnitude_thres),
uniform_sample_rate=widgets.FloatSlider(min=0, max=1.0, step=0.05, value=sample_rate),
max_value=widgets.IntSlider(min=0, max=20, step=1, value=interval),
rand_seed=widgets.IntSlider(min=0, max=100, step=1, value=seed))
display(w)
# -
# ## Input Tensors
# +
a = Tensor.fromRandom(["M", "K"], [M, K], density, interval, seed=seed)
a.setColor("blue")
displayTensor(a)
# Create swapped rank version of a
a_swapped = a.swapRanks()
displayTensor(a_swapped)
b = Tensor.fromRandom(["N", "K"], [N, K], density, interval, seed=2*seed)
b.setColor("green")
displayTensor(b)
# Create swapped rank version of b
b_swapped = b.swapRanks()
displayTensor(b_swapped)
# -
# ## Reference Output
# +
z_validate = Tensor(rank_ids=["M", "N"], shape=[M, N])
a_m = a.getRoot()
b_n = b.getRoot()
z_m = z_validate.getRoot()
for m, (z_n, a_k) in z_m << a_m:
for n, (z_ref, b_k) in z_n << b_n:
for k, (a_val, b_val) in a_k & b_k:
z_ref += a_val * b_val
displayTensor(z_validate)
def compareZ(z):
n = 0
total = 0
z1 = z_validate.getRoot()
z2 = z.getRoot()
for m, (ab_n, z1_n, z2_n) in z1 | z2:
for n, (ab_val, z1_val, z2_val) in z1_n | z2_n:
# Unpack the values to use abs (arggh)
z1_val = Payload.get(z1_val)
z2_val = Payload.get(z2_val)
n += 1
total += abs(z1_val-z2_val)
return total/n
# -
# ## Prune Functions and helper functions
# +
# Threshold (number of elements > cutoff) prune
class ThresholdPrune():
def __init__(self, threshold=2):
self.threshold = threshold
def __call__(self, n, c, p):
size = p.countValues()
result = size > self.threshold
print(f"Preserve = {result}")
return result
# MCMM uniform random sampling
class UniformRandomPrune():
def __init__(self, sample_rate=0.5):
self.sample_rate = sample_rate
def __call__(self, n, c, p):
sample = random.uniform(0,1)
result = (sample < self.sample_rate)
print(f"Preserve = {result}")
return result
# MCMM sample against number of elements
class RandomSizePrune():
def __init__(self, max_size=4):
self.max_size = max_size
def __call__(self, n, c, p):
size = p.countValues()
sample = random.uniform(0, 1)
result = (sample < (size / self.max_size))
print(f"Preserve = {result}")
return result
# a cute recursive helper for getting total absolute magnitude of Fiber of arbitrary rank
# this is modeled after countValues(), but I haven't tested it super thoroughly
# is this a helpful thing to add as a Fiber method? useful for computing matrix norms and stuff
def get_magnitude(p):
mag = 0
if not (Payload.contains(p, Fiber)):
return p.v()
for el in p.payloads:
if Payload.contains(el, Fiber):
mag += get_magnitude(el)
else:
mag += np.absolute(el.v()) if not Payload.isEmpty(el) else 0
return mag
#not a sampling method, just aggregate value-based pruning of arbitrary rank
class ValueMagnitudePrune():
def __init__(self, mag_thres=1):
self.mag_thres = mag_thres
def __call__(self, n, c, p):
#This will prune by individual element or aggregate absolute magnitude
if Payload.contains(p, Fiber):
magnitude = get_magnitude(p)
else:
magnitude = p.v()
result = (magnitude > self.mag_thres)
return result
# Uniform sampling with a budget that can be dynamically updated
class UniformBudgetPrune():
def __init__(self, n_sampled=0, max_n_sampled=5, sample_rate=0.5):
self.n_sampled = n_sampled
self.max_n_sampled = max_n_sampled
self.sample_rate = sample_rate
def __call__(self, n, c, p):
if self.n_sampled < self.max_n_sampled:
sample = random.uniform(0,1)
result = (sample < self.sample_rate)
if result == True:
self.n_sampled += 1
print(f"Preserve = {result}")
return result
else:
print("Preserve = False")
return False
# N-element-weighted sampling with a budget that gets dynamically updated
class OccupancyBudgetPrune():
def __init__(self, n_sampled=0, max_n_sampled=5, max_size=6):
self.n_sampled = n_sampled
self.max_n_sampled = max_n_sampled
self.max_size = max_size
def __call__(self, n, c, p):
if self.n_sampled < self.max_n_sampled:
size = p.countValues()
sample = random.uniform(0, 1)
result = (sample < (size / self.max_size))
if result == True:
self.n_sampled += 1
print(f"Preserve = {result}")
return result
else:
print("Preserve = False")
return False
# Random Sampling with dynamic sample threshold and budget
class DynamicUniformPrune():
def __init__(self, counter=0, budget=5, sample_rate=0.5):
self.counter = counter
self.budget = budget
self.sample_rate = sample_rate
def update(self, idx):
if idx > 1: #DEBUG; placeholder for a fancier update, for now, just force rest to be kept
self.budget = 1000
self.sample_rate = 1.0
def __call__(self, n, c, p):
if self.counter < self.budget:
sample = random.uniform(0, 1)
result = (sample < self.sample_rate)
if result == True:
self.counter += 1
print(f"Preserve = {result}")
return result
else:
print("Preserve = False")
return False
# Update budget AND magnitude thres dynamically
class DynamicOccupancyMCMM():
def __init__(self, counter=0, budget=5, threshold=1):
self.counter = counter
self.budget = budget
self.threshold = threshold
def __call__(self, n, c, p):
if self.counter < self.budget:
size = p.countValues()
#dynamic update of threshold
if size > self.threshold:
self.threshold = size
sample = random.uniform(0, 1)
result = (sample < (size / self.threshold))
if result == True:
self.counter += 1
print(f"Preserve = {result}")
return result
else:
print("Preserve = False")
return False
# Update budget AND magnitude thres dynamically
class DynamicMagnitudePrune():
def __init__(self, counter=0, budget=5, threshold=0):
self.counter = counter
self.budget = budget
self.threshold = threshold
def __call__(self, n, c, p):
if self.counter < self.budget:
val = get_magnitude(p)
result = (val > self.threshold)
if result == True:
self.counter += 1
print(f"Preserve = {result}")
return result
else:
print("Preserve = False")
return False
# -
# ## Tiling A&B (offline)
# +
#FIXME add sliders for tile params (also to-do: online tiling)
K0=int(K/2)
M0=int(M/2)
N0=int(N/2)
a_tiled = Tensor(rank_ids=["K1", "M1", "K0", "M0"])
a_tiled.setColor("blue")
b_tiled = Tensor(rank_ids=["K1", "N1", "K0", "N0"])
b_tiled.setColor("green")
#first, fill out versions tiled along K
a_m = a.getRoot()
a_tiled_k1 = a_tiled.getRoot()
for (m, a_k) in a_m:
for (k, value) in a_k:
k1 = k // K0
k0 = k % K0
m1 = m // M0
m0 = m % M0
a_tiled_m0 = a_tiled_k1.getPayloadRef(k1, m1, k0, m0)
a_tiled_m0 <<= value
b_n = b.getRoot()
b_tiled_k1 = b_tiled.getRoot()
for (n, b_k) in b_n:
for (k, value) in b_k:
k1 = k // K0
k0 = k % K0
n1 = n // N0
n0 = n % N0
b_tiled_n0 = b_tiled_k1.getPayloadRef(k1, n1, k0, n0)
b_tiled_n0 <<= value
displayTensor(a_tiled)
displayTensor(b_tiled)
# -
# ## Simple Tiled Execution
# +
z_tiled = Tensor(rank_ids=["M1", "N1", "M0", "N0"])
a_tiled_k1 = a_tiled.getRoot()
b_tiled_k1 = b_tiled.getRoot()
z_tiled_m1 = z_tiled.getRoot()
canvas = createCanvas(a_swapped, b_swapped)
for k1, (a_m1, b_n1) in a_tiled_k1 & b_tiled_k1:
for m1, (z_n1, a_k0) in z_tiled_m1 << a_m1:
for n1, (z_m0, b_k0) in z_n1 << b_n1:
for k0, (a_m0, b_n0) in a_k0 & b_k0:
for m0, (z_n0, a_val) in z_m0 << a_m0:
for n0, (z_ref, b_val) in z_n0 << b_n0:
z_ref += a_val * b_val
canvas.addFrame(((k1*K0)+k0, (m1*M0)+m0), ((k1*K0)+k0, (n1*N0)+n0))
displayTensor(z_tiled)
displayCanvas(canvas)
# -
# ## Prune entire tiles
# +
z_tiled = Tensor(rank_ids=["M1", "N1", "M0", "N0"])
a_tiled_k1 = a_tiled.getRoot()
b_tiled_k1 = b_tiled.getRoot()
z_tiled_m1 = z_tiled.getRoot()
canvas = createCanvas(a_swapped, b_swapped)
tile_budget = 1 #subsample tiles according to aggregate magnitude
sample_tensor = DynamicMagnitudePrune(0, tile_budget, 11)
for k1, (a_m1, b_n1) in a_tiled_k1 & b_tiled_k1:
for m1, (z_n1, a_k0) in z_tiled_m1 << a_m1.prune(sample_tensor):
for n1, (z_m0, b_k0) in z_n1 << b_n1:
for k0, (a_m0, b_n0) in a_k0 & b_k0:
for m0, (z_n0, a_val) in z_m0 << a_m0:
for n0, (z_ref, b_val) in z_n0 << b_n0:
z_ref += a_val * b_val
canvas.addFrame(((k1*K0)+k0, (m1*M0)+m0), ((k1*K0)+k0, (n1*N0)+n0))
# Sample feedback mechanism; set a per-col budget; increase thres if we aren't reaching budget
if sample_tensor.counter < tile_budget:
sample_tensor.threshold -= 1
print(f"Updated Threshold: {sample_tensor.threshold}")
sample_tensor.counter = 0 #reset per A M1 fiber
displayTensor(z_tiled)
displayCanvas(canvas)
# -
# ## Prune to budget within tile (dynamically force balanced load)
# +
z_tiled = Tensor(rank_ids=["M1", "N1", "M0", "N0"])
a_tiled_k1 = a_tiled.getRoot()
b_tiled_k1 = b_tiled.getRoot()
z_tiled_m1 = z_tiled.getRoot()
canvas = createCanvas(a_swapped, b_swapped)
per_tile_budget = 1 #subsample within tiles according to magnitude
sample_tensor = DynamicMagnitudePrune(0, per_tile_budget, 3)
for k1, (a_m1, b_n1) in a_tiled_k1 & b_tiled_k1:
for m1, (z_n1, a_k0) in z_tiled_m1 << a_m1:
for n1, (z_m0, b_k0) in z_n1 << b_n1:
for k0, (a_m0, b_n0) in a_k0 & b_k0:
for m0, (z_n0, a_val) in z_m0 << a_m0.prune(sample_tensor):
for n0, (z_ref, b_val) in z_n0 << b_n0:
z_ref += a_val * b_val
canvas.addFrame(((k1*K0)+k0, (m1*M0)+m0), ((k1*K0)+k0, (n1*N0)+n0))
# Sample feedback mechanism; set a per-col budget; increase thres if we aren't reaching budget
if sample_tensor.counter < per_tile_budget:
sample_tensor.threshold -= 1
print(f"Updated Threshold: {sample_tensor.threshold}")
sample_tensor.counter = 0 #reset per A tile
displayTensor(z_tiled)
displayCanvas(canvas)
# -
# ## MCMM per tile
# +
z_tiled = Tensor(rank_ids=["M1", "N1", "M0", "N0"])
a_tiled_k1 = a_tiled.getRoot()
b_tiled_k1 = b_tiled.getRoot()
z_tiled_m1 = z_tiled.getRoot()
canvas = createCanvas(a_swapped, b_swapped)
per_tile_budget=4
sample_tensor = UniformBudgetPrune(0, per_tile_budget, sample_rate)
for k1, (a_m1, b_n1) in a_tiled_k1 & b_tiled_k1:
for m1, (z_n1, a_k0) in z_tiled_m1 << a_m1:
for n1, (z_m0, b_k0) in z_n1 << b_n1:
for k0, (a_m0, b_n0) in a_k0.prune(sample_tensor) & b_k0:
for m0, (z_n0, a_val) in z_m0 << a_m0:
for n0, (z_ref, b_val) in z_n0 << b_n0:
z_ref += a_val * b_val
canvas.addFrame(((k1*K0)+k0, (m1*M0)+m0), ((k1*K0)+k0, (n1*N0)+n0))
sample_tensor.n_sampled = 0 #reset per A tile
displayTensor(z_tiled)
displayCanvas(canvas)
# -
| notebooks/sparse-gemm/MCMM-tiling.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:python_3]
# language: python
# name: conda-env-python_3-py
# ---
from openfermion.hamiltonians import MolecularData
from openfermion.transforms import get_fermion_operator, get_sparse_operator, jordan_wigner,bravyi_kitaev
from openfermion.utils import get_ground_state,eigenspectrum,count_qubits
import numpy as np
import scipy
import scipy.linalg
from openfermionpyscf import run_pyscf
# +
element_names = ['H', 'Li']
basis = 'sto-6g'
charge = 0
multiplicity = 1
# Single point at equilibrium for testing
spacings = [1.6]
# Add points for a full dissociation curve from 0.1 to 3.0 angstroms
#spacings += [0.2 * r for r in range(1, 11)]
# Set run options
run_scf = 1
run_mp2 = 1
run_cisd = 1
run_ccsd = 1
run_fci = 1
verbose = 1
# Run Diatomic Curve
for spacing in spacings:
description = "{}".format(spacing)
geometry = [[element_names[0], [0, 0, 0]],
[element_names[1], [0, 0, spacing]]]
molecule = MolecularData(geometry,
basis,
multiplicity,
charge,
description)
molecule = run_pyscf(molecule,
run_scf=run_scf,
run_mp2=run_mp2,
run_cisd=run_cisd,
run_ccsd=run_ccsd,
run_fci=run_fci,
verbose=verbose)
molecule.save()
# -
# # the total Hamiltonian. Require 12 qubits
molecular_hamiltonian = molecule.get_molecular_hamiltonian()
# + jupyter={"outputs_hidden": true}
molecular_hamiltonian
# -
# Map operator to fermions and qubits.
fermion_hamiltonian = get_fermion_operator(molecular_hamiltonian)
# + jupyter={"outputs_hidden": true}
fermion_hamiltonian
# + jupyter={"outputs_hidden": true}
qubit_hamiltonian = bravyi_kitaev(fermion_hamiltonian)
qubit_hamiltonian.compress()
print('The bravyi_kitaev Hamiltonian in canonical basis follows:\n{}'.format(qubit_hamiltonian))
# -
# # active space on 1,2,3 orbits. Only 6 qubits required (considering spin degree of freedom)
# +
active_space_start = 1
active_space_stop = 4
molecular_hamiltonian = molecule.get_molecular_hamiltonian(
occupied_indices=[0],
active_indices=range(active_space_start, active_space_stop))
# + jupyter={"outputs_hidden": true}
# Map operator to fermions and qubits.
fermion_hamiltonian = get_fermion_operator(molecular_hamiltonian)
qubit_hamiltonian = bravyi_kitaev(fermion_hamiltonian)
qubit_hamiltonian.compress()
print('The bravyi_kitaev Hamiltonian in canonical basis follows:\n{}'.format(qubit_hamiltonian))
# -
# # Construct effective Hamiltonian on qubits 0,2,4, by average on |1> for qubit 1,3,5
#
# > using method in “Quantum chemistry calculations on a trapped-ion quantum simulator” ,Physical Review X 8, 031022 (2018)
terms_dict=qubit_hamiltonian.terms
# the first qubit is
def partial_average(key,drop_qubits=[1,3,5],avg_dict={'X':0,'Y':0,'Z':1},init_fock=0):
key=list(key)
factor=1
new_key=[]
for k in key:
if k[0] not in drop_qubits:
new_key.append(k)
if k[0] in drop_qubits:
if k[0]==0:
factor*=avg_dict[k[1]]
else:
factor*=avg_dict[k[1]]
#print(key)
new_key=tuple(new_key)
{new_key:factor}
return (new_key,factor)
reduced_terms=[]
for key in terms_dict.keys():
rt=partial_average(key)
reduced_terms.append(rt)
reduced_terms
# ## combining all same terms in sim_dict
# +
import numpy as np
ham_terms=np.array([f[0] for f in reduced_terms])
factors=np.array([f[1] for f in reduced_terms])
cs=np.array([c for c in qubit_hamiltonian.terms.values()])
cs_rescale=np.multiply(factors,cs)
reduced_terms_rescale=[]
for i in range(len(reduced_terms)):
if cs_rescale[i] !=0:
reduced_terms_rescale.append((reduced_terms[i][0],cs_rescale[i]))
reduced_terms_rescale
# -
sim_dict={}
for term in reduced_terms_rescale:
if term not in sim_dict.keys():
sim_dict[term[0]]=term[1]
else:
sim_dict[term[0]]+=term[1]
[sim_dict.values()]
| OpenFermion_tutorial.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib inline
import pandas as pd
n_features = 10
n_dense_neurons = 3
x = tf.placeholder(tf.float32,(None,n_features))
b = tf.Variable(tf.zeros([n_dense_neurons]))
W = tf.Variable(tf.random_normal([n_features, n_dense_neurons]))
xW = tf.matmul(x,W)
z = tf.add(xW,b)
a = tf.sigmoid(z)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
layer_out = sess.run(a, feed_dict={x : np.random.random([1, n_features])})
print(layer_out)
x_data = np.linspace(0,10,10) + np.random.uniform(-1.5,1.5,10)
y_label = np.linspace(0,10,10) + np.random.uniform(-1.5,1.5,10)
plt.plot(x_data,y_label,'*')
params = np.random.rand(2)
print(params)
m, b = [tf.Variable(p) for p in params]
# +
error = 0
for x,y in zip(x_data,y_label):
y_hat = m*x + b
error += (y-y_hat)**2
# -
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train = optimizer.minimize(error)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(100):
sess.run(train)
final_slope , final_intercept = sess.run([m,b])
# +
x_test = np.linspace(-1,11,10)
y_pred_plot = final_slope*x_test + final_intercept
plt.plot(x_test,y_pred_plot,'r')
plt.plot(x_data,y_label,'*')
# -
x_data = np.linspace(0.0, 10.0, 1000000)
noise = np.random.randn(len(x_data))
b = 5
y_true = (0.5 * x_data ) + 5 + noise
data = pd.concat([pd.DataFrame(data=x_data, columns=['X Data']), pd.DataFrame(data=y_true, columns=['Y'])], axis=1)
data.head()
data.sample(n=250).plot(kind='scatter', x='X Data', y='Y')
batch_size = 8
m = tf.Variable(0.5)
b = tf.Variable(0.5)
xph = tf.placeholder(tf.float32,[batch_size])
yph = tf.placeholder(tf.float32,[batch_size])
y_model = m*xph + b
error = tf.reduce_sum(tf.square(yph-y_model))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001)
train = optimizer.minimize(error)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
rand_ind = np.random.randint(len(x_data), size=batch_size)
feed = {xph: x_data[rand_ind], yph: y_true[rand_ind]}
sess.run(train, feed_dict=feed)
model_m, model_b = sess.run([m,b])
y_hat = x_data * model_m + model_b
data.sample(n=250).plot(kind='scatter',x='X Data',y='Y')
plt.plot(x_data,y_hat,'r')
from sklearn.model_selection import train_test_split
x_train, x_eval, y_train, y_eval = train_test_split(x_data, y_true, test_size=0.3, random_state = 101)
# +
print(x_train.shape)
print(y_train.shape)
print(x_eval.shape)
print(y_eval.shape)
# -
| course/general/code/frameworks_basics/tensorflow/tensorflow_nn_example.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + id="FIKGeHwxduea"
# default_exp mdprop
# + [markdown] id="_jLE_5-I9HzS"
# # Mdprop_Permits_Fore_Vac/Vio Intake and Operations
#
# > This notebook uses Mdprop_Permits_Fore_Vac/Vio data to generate a portion of BNIA's Vital Signs report.
# + [markdown] id="SDr38WxKc7hp"
# ### 43 baltvac - O
#
#
# + id="CI8ig0LPczpp"
NO Query Found
Waiting on City Housing
Completed by Cheyrl
# + [markdown] id="XfwOgcYTs90R"
# Todo:
# - Wrap as Function
# + [markdown] id="re1mKu02JABB"
# #### __Columns Used__
#
#
# - ✅ 32 - __ownroc__ - (MdProp) Owner Occupied
#
# - ✅ 34 - __vacants__ - (MdProp[totalres], Vacants) number of demolition permits per 1000 residential properties
#
# - ✅ xxx - __baltvac__ - (Vacants)
#
# - ✅ 35 - __vio__ - (Violations, MdProp[totalres]) Number of of new constructio permits per 1000 residential properties
#
# - ✅ 37 - __Totalres__ - (Mdprop) The total number of residential properties located within an area as identified by Maryland Property View.
#
# - ✅ 36 - __resrehab__ - (MdProp[totalres], Permits) Percentage of properties with rehabilitation permits exceeding $5k
#
# - ✅ 33 - __fore__ - ( MdProp[totalres], Close_Crawl )
#
# - ✅ 41 - __demper__ - (MdProp[totalres], Permits) number of demolition permits per 1000 residential properties
#
# - ✅ 42 - __constper__ - (MdProp[totalres], Permits) Number of of new constructio permits per 1000 residential properties
#
# - ✅ 141 - __comprop__ - (MdProp) Percentage of properties with rehabilitation permits exceeding $5k
#
# - ✅ 142 - __crehab__ - (MdProp[comprop], Permits) Percentage of properties with rehabilitation permits exceeding $5k
# + [markdown] id="cCvsPP8AJRJA"
# #### __Datasets Used__
#
#
# - ✅ foreclosures.foreclosures_201X __(33-fore-> 2018/ 2019 Close-Crawler)__
#
# - ✅✔️ housing.vacants_201X __(34-vacant -> datenotice, dateabate, datecancle)__
#
# - ✅ housing.permits_201X __(36-resrehab, 41-demper, 42-constper -> field22, casetype, propuse, existingus, cost)__
#
# - ✅✔️ housing.mdprop_201X - [totalres](https://bniajfi.org/indicators/Housing%20And%20Community%20Development/totalres) __( 33-fore, 34-vacant, 35-vio, 36-resrehab, 40-taxlien, 41-demper, 42-constper, __ ownroc __)__
#
# + [markdown] id="qNdhjWoXzv0o"
# ❌ = no data for
#
# ✔️ = Geocoded
#
# ✅ = Processed (starting from 2019)
# + [markdown] id="iSNOAJoTlQr0"
# This colab and more can be found at https://github.com/BNIA/vitalSigns.
#
# + [markdown] id="OJoF8Gs1HPTi"
# General Outline
# 1. Import and merge CSA/ BCity Esri boundary files
# 2.
# + id="1bxzHfOPxdzu"
year = '20'
# + [markdown] id="ukxt0JZCsaxc"
# ## About this Tutorial:
# + [markdown] id="Z9Oix1S6gvm4"
# ### Whats Inside?
# + [markdown] id="lEdBnKIqli8m"
# #### __The Tutorial__
#
# This lab is split into two sections.
# + [markdown] id="-1RKv4DiMVwo"
# # Guided Walkthrough
# + [markdown] id="e8-mgsByhrxG"
# ## SETUP:
# + [markdown] id="0hHCW-qPMeH6"
# ### Import Modules
# + id="WUvcamATFo4G"
# %%capture
# ! pip install -U -q PyDrive
# ! pip install geopy
# ! pip install geopandas
# ! pip install geoplot
# + id="p6ueNkdkJX6B"
# !apt install libspatialindex-dev
# !pip install rtree
# + id="4a0sk8EFZTZu"
# %%capture
# !pip install dataplay
# + id="nNOByHFKFo4m"
# %%capture
# These imports will handle everything
import os
import sys
import csv
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import geopandas as gpd
from geopandas import GeoDataFrame
import psycopg2
import pyproj
from pyproj import Proj, transform
# conda install -c conda-forge proj4
from shapely.geometry import Point
from shapely import wkb
from shapely.wkt import loads
# https://pypi.org/project/geopy/
from geopy.geocoders import Nominatim
# In case file is KML, enable support
import fiona
fiona.drvsupport.supported_drivers['kml'] = 'rw'
fiona.drvsupport.supported_drivers['KML'] = 'rw'
# + id="evj9GJLdSlxF"
from IPython.display import clear_output
clear_output(wait=True)
# + id="uTcb3bD84mSA"
import ipywidgets as widgets
from ipywidgets import interact, interact_manual
# + [markdown] id="q8tLzJzcMh74"
# ### Configure Enviornment
# + id="OuH4mBeYCUqU"
# This will just beautify the output
pd.set_option('display.expand_frame_repr', False)
pd.set_option('display.precision', 2)
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
# pd.set_option('display.expand_frame_repr', False)
# pd.set_option('display.precision', 2)
# pd.reset_option('max_colwidth')
pd.set_option('max_colwidth', 20)
# pd.reset_option('max_colwidth')
# + [markdown] id="P8jxi_B1I46s"
#
# + [markdown] id="U8OnGX6rp5MD"
# ### TPOP CSA and Baltimore
# + [markdown] id="tlQvkkbaB0ZI"
# Get Baltimore
# + id="-xeV9WHdOhBv"
#collapse_output
#collapse_input
csa = "https://services1.arcgis.com/mVFRs7NF4iFitgbY/ArcGIS/rest/services/Tpop/FeatureServer/0/query?where=1%3D1&outFields=*&returnGeometry=true&f=pgeojson"
csa = gpd.read_file(csa);
csa.head(1)
# + [markdown] id="QyBS5PlHB1db"
# Get CSA
# + id="-Jq4w-l3p5MI"
url2 = "https://services1.arcgis.com/mVFRs7NF4iFitgbY/ArcGIS/rest/services/Tpop/FeatureServer/1/query?where=1%3D1&outFields=*&returnGeometry=true&f=pgeojson"
csa2 = gpd.read_file(url2);
csa2['CSA2010'] = csa2['City_1']
csa2['OBJECTID'] = 56
csa2 = csa2.drop(columns=['City_1'])
csa2.head()
# + [markdown] id="s_as946Yp5MI"
# Append do no append Bcity. We put it on the Bottom of the df because when performing the ponp it returns only the last matching columns CSA Label.
# + id="RWZigszHUWm5"
# csa = pd.concat([csa2, csa], ignore_index=True)
csa = csa.append(csa2).reset_index(drop=True)
# + id="0YyzBRuKp5MJ"
csa.head(3)
# + id="WLpXYhJHB_rt"
csa.tail(3)
# + id="wpZDcRVkk9SJ"
csa.head()
# + id="wG_g3sp2J2pq"
csa.drop(columns=['Shape__Area', 'Shape__Length', 'OBJECTID'], axis=1).to_file("BCity_and_CSA.geojson", driver='GeoJSON')
# + [markdown] id="vOMcCRrmqd6i"
# # MDProp
# + id="R5hUOLsEqe2B"
import pandas as pd
import geopandas
original = gpd.read_file('MDPropertyView_2021_CSACity.shp')
original.columns
pd.set_option('display.max_columns', None)
# + id="BU6pFWqJr3c3"
original.rename(columns={ 'CSA':'CSA2010', 'BaltCity':'InBaltimore'}, inplace=True)
df = original[ original['CSA2010'].notnull() | original['InBaltimore'].notnull() ]
# + id="FLPrW6FAr8rR"
print('After filtering records where a CSA or Baltimore geo-code match Exists')
print( 'All rows Before Filter: ', original.shape[0] ) # rows, columns
print( '# w BCity.isnull: ', df.InBaltimore.isnull().sum() ); bmorow = df[ df.CSA2010.isnull() ].shape[0]
print( '# w CSA2010.isnull: ', bmorow ); csarow = df[ df.CSA2010.notnull() ].shape[0]
print( '# w CSA2010.notnull: ', csarow );
print( '# rows After Filter: ', df.shape[0],'==',csarow,'+',bmorow,'==', csarow + bmorow);
# + id="G4TqFcJlsBkw"
# add baltimore city
df.CSA2010 = df.CSA2010.fillna('Baltimore City')
# + id="kajA73-cqnQI"
mdprop = df.copy()
mdprop.head(1)
# + [markdown] id="PF7NoFzRLshU"
# # Permits - OLD PointsInPolygons
# + [markdown] id="P3WNvZGQOTxw"
# ## Import
# + id="NozF5A2AL03d"
permits = gpd.read_file("Permits_2019_CSACity.shp");
permits.head()
# + id="WrE9nT8qVWlW"
permits.columns
permits.crs
permits.head(5)
# + id="ekA3msZtM9Az"
# Convert to EPSG:4326
permits = permits.to_crs(epsg=4326)
permits.crs
# + id="gJlWDqDaNDja"
# Convert Geom to Coords
permits['x'] = permits.geometry.x
permits['y'] = permits.geometry.y
permits.head(5)
# + id="ht5jj0laT2e3"
permits = permits[ permits.geometry.y > 38 ]
# + id="VHYcyhxeUMDS"
# Reference: All Points
base = csa.plot(color='white', edgecolor='black')
permits.plot(ax=base, marker='o', color='green', markersize=5);
# + id="X1cUfBhYVKXA"
permits.columns
# + id="jYNkI1nvhKDM"
# + id="Gn6WcQWykoQr"
csa.tail()
# + id="xY1mXy0A9CA_"
from dataplay import geoms
# Get CSA Labels for all Points.
# permitsCsa = geoms.getPolygonOnPoints(permits, csa, 'geometry', 'geometry', 'CSA2010' )
permitsCsa = geoms.workWithGeometryData(method='ponp', df=permits, polys=csa, ptsCoordCol='geometry', polygonsCoordCol='geometry', polyColorCol=False, polygonsLabel='CSA2010', pntsClr='red', polysClr='white')
# permitsCsa = permitsCsa.drop('geometry',axis=1)
# + id="oK-gG3AXkgz6"
permitsCsa.head(10)
# + [markdown] id="J6_DjC2wT4Nl"
# ## Processing
# + [markdown] id="yIOlaXsSOh78"
# All
# + id="nwUuhSiyOj40"
permitsAll = permits
# + id="muxJghsFOj5J"
# Reference: All Points
base = csa.plot(color='white', edgecolor='black')
permitsAll.plot(ax=base, marker='o', color='green', markersize=5);
# + id="Dk16SK99Nqk9"
permits = permitsAll
# + id="BnzmHoZEOOJz"
# y < 0
permitsLessThanZero = permits[ permits.geometry.y < 0 ]
print('Y<0: ', permitsLessThanZero.size, '\n')
# + id="tV9v5r63M9Av"
# y > 0
permitsGreaterThanZero = permits[ permits.geometry.y > 0 ]
print('Y>0: ', permitsGreaterThanZero.size, '\n')
permitsGreaterThanZero.plot();
# + id="05pzlYn0ROpV"
# 0 < y < 38
permitsOver38 = permits[ permits.geometry.y < 38 ]
permitsOver38 = permitsOver38[ permitsOver38.geometry.y > 0 ]
print('0 < y < 38: ', permitsOver38.size, '\n')
# + id="m6fJQNAHRVzY"
# y > 38
permitsUnder38 = permits[ permits.geometry.y > 38 ]
print('Y>38 Less than Zero: ', permitsUnder38.size, '\n')
permitsUnder38.plot();
# + [markdown] id="4wOWg8j6rJtp"
# # Permits
# + id="JNRLZHHh6KHN"
import pandas as pd
import geopandas
original = gpd.read_file("Permits_20"+year+"_CSACity.shp", geometry='geometry');
original.columns
# + id="Qiw4TZ8Msppg"
original.rename(columns={ 'CSA':'CSA2010', 'BaltCity':'InBaltimore'}, inplace=True)
df = original[ original['CSA2010'].notnull() | original['InBaltimore'].notnull() ]
# + id="lVYhbJ5dsq0w"
print('After filtering records where a CSA or Baltimore geo-code match Exists')
print( 'All rows Before Filter: ', original.shape[0] ) # rows, columns
print( '# w BCity.isnull: ', df.InBaltimore.isnull().sum() ); bmorow = df[ df.CSA2010.isnull() ].shape[0]
print( '# w CSA2010.isnull: ', bmorow ); csarow = df[ df.CSA2010.notnull() ].shape[0]
print( '# w CSA2010.notnull: ', csarow );
print( '# rows After Filter: ', df.shape[0],'==',csarow,'+',bmorow,'==', csarow + bmorow);
# + id="-MjNhXd2sviB"
# add baltimore city
df.CSA2010 = df.CSA2010.fillna('Baltimore City')
# + id="7hkvEAYFsxdQ"
permitsCsa = df.copy()
permitsCsa.head(1)
# + [markdown] id="ZlEVV_MPJYdL"
# # Vacants
# + id="Jliq7cU0J1Tw"
import pandas as pd
import geopandas
original = gpd.read_file("Vacants_20"+year+"_CSACity.shp", geometry='geometry');
original.columns
# + id="aQc11qNjJ1T2"
original.rename(columns={ 'CSA':'CSA2010', 'BaltCity':'InBaltimore'}, inplace=True)
df = original[ original['CSA2010'].notnull() | original['InBaltimore'].notnull() ]
# + id="0PR5-7WUJ1T2"
print('After filtering records where a CSA or Baltimore geo-code match Exists')
print( 'All rows Before Filter: ', original.shape[0] ) # rows, columns
print( '# w BCity.isnull: ', df.InBaltimore.isnull().sum() ); bmorow = df[ df.CSA2010.isnull() ].shape[0]
print( '# w CSA2010.isnull: ', bmorow ); csarow = df[ df.CSA2010.notnull() ].shape[0]
print( '# w CSA2010.notnull: ', csarow );
print( '# rows After Filter: ', df.shape[0],'==',csarow,'+',bmorow,'==', csarow + bmorow);
# + id="vFY3Ha3wJ1T3"
# add baltimore city
df.CSA2010 = df.CSA2010.fillna('Baltimore City')
# + id="Jvq0qmjSJ1T3"
vacants = df.copy()
vacants.head(1)
# + [markdown] id="EWLsineDJaqq"
# # Vio
# + id="tYjKJWELKDPH"
import pandas as pd
import geopandas
original = gpd.read_file("Violations_20"+year+"_CSACity.shp", geometry='geometry');
original.columns
# + id="mTsGphfZKDPK"
original.rename(columns={ 'CSA':'CSA2010', 'BaltCity':'InBaltimore'}, inplace=True)
df = original[ original['CSA2010'].notnull() | original['InBaltimore'].notnull() ]
# + id="0jXJBdmfKDPK"
print('After filtering records where a CSA or Baltimore geo-code match Exists')
print( 'All rows Before Filter: ', original.shape[0] ) # rows, columns
print( '# w BCity.isnull: ', df.InBaltimore.isnull().sum() ); bmorow = df[ df.CSA2010.isnull() ].shape[0]
print( '# w CSA2010.isnull: ', bmorow ); csarow = df[ df.CSA2010.notnull() ].shape[0]
print( '# w CSA2010.notnull: ', csarow );
print( '# rows After Filter: ', df.shape[0],'==',csarow,'+',bmorow,'==', csarow + bmorow);
# + id="ohpqE47KKDPL"
# add baltimore city
df.CSA2010 = df.CSA2010.fillna('Baltimore City')
# + id="EqPh_McAKDPL"
violations = df.copy()
violations.head(1)
# + [markdown] id="_qt24vyvLvui"
# # Foreclosures_2019_CSACity
# + id="VQpxkb7ULxu1"
import pandas as pd
import geopandas
original = gpd.read_file("Foreclosures_20192020_CSACity.shp", geometry='geometry');
original.columns
# + id="Ws4auvPKLxu-"
original.rename(columns={ 'CSA':'CSA2010', 'BaltCity':'InBaltimore'}, inplace=True)
df = original[ original['CSA2010'].notnull() | original['InBaltimore'].notnull() ]
# + id="vkQzisoQLxu-"
print('After filtering records where a CSA or Baltimore geo-code match Exists')
print( 'All rows Before Filter: ', original.shape[0] ) # rows, columns
print( '# w BCity.isnull: ', df.InBaltimore.isnull().sum() ); bmorow = df[ df.CSA2010.isnull() ].shape[0]
print( '# w CSA2010.isnull: ', bmorow ); csarow = df[ df.CSA2010.notnull() ].shape[0]
print( '# w CSA2010.notnull: ', csarow );
print( '# rows After Filter: ', df.shape[0],'==',csarow,'+',bmorow,'==', csarow + bmorow);
# + id="twsGY0seLxu_"
# add baltimore city
df.CSA2010 = df.CSA2010.fillna('Baltimore City')
# + id="tfyKtBiCLxu_"
foreclosures = df.copy()
foreclosures.head(1)
# + id="R7zGwptw4-OF"
foreclosures19 = foreclosures[foreclosures['Case_Numbe'].str.contains("24O19")]
foreclosures20 = foreclosures[foreclosures['Case_Numbe'].str.contains("24O20")]
if (year=='19'): forclosure = foreclosures19.copy()
else: forclosure = foreclosures20.copy()
# + id="dzp9Nco75dET"
forclosure.head()
# + [markdown] id="G9JpYDIngTfd"
# # Create Indicators
# + [markdown] id="vYcquREdhCk2"
# ### [Totalres 37](https://bniajfi.org/indicators/Housing%20And%20Community%20Development/totalres) - (Mdprop) - Complete
# + id="LogPFQrc-TyD"
mdprop.head(1)
# + id="teK29cuFLKeE"
#export
totalres = mdprop.copy()
totalres['totalres'+year] = 1
totalres = totalres[ totalres['DESCLU'].isin(['Apartments', 'Residential', 'Residential Commercial', 'Residential Condominium']) ]
totalres = totalres[ totalres['ADDRESS'].notna() ]
print(totalres.ADDRESS.unique() )
totalres = totalres[['CSA2010','totalres'+year]]
totalres = totalres.groupby('CSA2010').sum(numeric_only=True)
# Make sure ALL csas and BaltimoreCity are included. among other things
totalres = csa[ ['CSA2010','tpop10'] ].merge( totalres, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Update the baltimore CSA.
totalres.at[55,'totalres'+year] = totalres['totalres'+year].sum()
# Create the Indicator
totalres.to_csv('37-totalres-'+year+'.csv', index=False)
totalres.head(58)
# + [markdown] id="UmMtPyVkb5WY"
# old_notes="""
# 2016 uses dataset housing.mdprop_2017
# 2017 uses dataset housing.mdprop_2017v2
# 2016s dataset was collected in January of 2017
# 2017s dataset was collected in Novermber of 2017
# """
# + [markdown] id="bMFZ2dapGAJf"
# ### OwnRoc 32 - ( MdProp[totalres] ) - Complete
# + id="MmYUD_wZGe1Q"
original = """ with numerator AS (
select (sum(
case
when (ooi like 'H') AND (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1
else 0
end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa
),
denominator AS (
select (sum(
case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1
else NULL
end)::numeric
) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop
),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
)
update vital_signs.data
set ownroc = result from tbl where data.csa = tbl.csa and data_year = '2016';
"""
ownroc_translation = """
Numerator = sum vacants_2017 when
(ooi like 'H') AND
(address != $$NULL$$) AND
(desclu = $$Apartments$$ OR
desclu = $$Residential$$ OR
desclu = $$Residential Commercial$$ OR
desclu = $$Residential Condominium$$
Denominator = mdprop_2017.totalres
return = (numerator / denominator )* 100
"""
# + id="ytYn510qbh8a"
oldNotes = """ 2016 uses dataset housing.mdprop_2017
2017 uses dataset housing.mdprop_2017v2
2016s dataset was collected in January of 2017
2017s dataset was collected in Novermber of 2017
"""
# + id="SiDypHIJLcPO"
#export
import datetime
ownroc = mdprop.copy()
ownroc = ownroc[ ownroc['OOI']=='H']
ownroc = ownroc.dropna( subset=['ADDRESS'] )
ownroc = ownroc[ ownroc['DESCLU'].isin(['Apartments', 'Residential', 'Residential Commercial', 'Residential Condominium']) ]
ownroc.to_csv('ownroc'+str(year)+'_Filtered_Records.csv', index=False)
print( 'Records Matching Query: ', ownroc.size / len(ownroc.columns) )
# Aggregate Numeric Values by Sum
ownroc['ownrocCount'] = 1
ownroc = ownroc.groupby('CSA2010').sum(numeric_only=True)
ownroc = csa[ ['CSA2010'] ].merge( ownroc, left_on='CSA2010', right_on='CSA2010', how='outer' )
ownroc = csa.merge( ownroc, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Create the Indicator
ownroc['ownroc'] = ownroc['ownrocCount'] * 100 / totalres['totalres'+year]
ownroc.at[55,'ownrocCount'] = ownroc['ownrocCount'].sum()
ownroc.at[55,'ownroc'] = ownroc['ownrocCount'].sum() * 100/ totalres['totalres'+year].sum()
ownroc = ownroc[ ['CSA2010', 'ownrocCount', 'ownroc'] ]
ownroc.to_csv('32-ownroc'+year+'.csv', index=False)
ownroc.tail(60)
# + [markdown] id="5IId52zH3dS8"
# ### Vacant 34 - (MdProp[totalres], Vacants) - Complete
# + id="i0hElbGuQaSY"
totalres = pd.read_csv('37-totalres-'+year+'.csv')
# + id="PVnHNEAJf37z"
# 34- vacant - percentage of residential properties that are vacant and abandoned
# https://services1.arcgis.com/mVFRs7NF4iFitgbY/arcgis/rest/services/vacant/FeatureServer/layers
# Numerator: housing.vacants_201X
# Denominator: housing.mdprop_201X
long_Description: """
The percentage of residential properties that have been classified as being vacant and abandoned by the Baltimore City Department
of Housing out of all properties. Properties are classified as being vacant and abandoned if: the property is not habitable and
appears boarded up or open to the elements; the property was designated as being vacant prior to the current year and still
remains vacant; and the property is a multi-family structure where all units are considered to be vacant.
"""
vacant_SQL = """
2016
with numerator AS (
select (sum( case
when (datenotice between '2004-01-01' and '2016-12-31') AND (dateabate is NULL OR dateabate >= '2016-12-31') AND
(datecancel is NULL OR datecancel > '2016-12-31') then 1 else NULL end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.vacants_2016', 'gid', 'the_geom') a
left join housing.vacants_2016 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum(
case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1
else NULL
end)::numeric
) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop
),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
)
update vital_signs.data
set vacant = result from tbl where data.csa = tbl.csa and data_year = '2016';"
2017
with numerator AS (
select (sum( case
when (datenotice between '2004-01-01' and '2017-12-31') AND (dateabate is NULL OR dateabate >= '2017-12-31') AND (datecancel is NULL OR datecancel > '2017-12-31') then 1 else NULL end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.vacants_2017', 'gid', 'the_geom') a
left join housing.vacants_2017 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum( case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1 else NULL end)::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017vs', 'gid', 'the_geom') a
left join housing.mdprop_2017vs b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
)
select * from tbl order by csa asc"
column "dateabate" does not exist
"""
vacant_translation = """
Numerator = sum vacants_2017 when
(datenotice between '2004-01-01' and '2017-12-31')
AND (dateabate is NULL OR dateabate >= '2017-12-31')
AND (datecancel is NULL OR datecancel > '2017-12-31')
Denominator = mdprop_2017.totalres
return = (numerator / denominator )* 100
"""
# + id="7yS-Ux2JdbEv"
te = """
with numerator AS (
select (sum(
case
when (datenotice between '2004-01-01' and '2017-12-31') AND (dateabate is NULL OR dateabate >= '2017-12-31') AND (datecancel is NULL OR datecancel > '2017-12-31')
then 1
else NULL
end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.vacants_2017', 'gid', 'the_geom') a
left join housing.vacants_2017 b on a.gid = b.gid
group by csa
),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
)
select * from tbl order by csa asc
"""
# + id="G14fABYHnuoq"
vacants.head(1)
# + id="-GIdcA_NQc5W"
#export
import datetime
vacantsCsa = vacants.copy()
# (datenotice between '2004-01-01' and '2016-12-31') AND
# (dateabate is NULL OR dateabate >= '2016-12-31') AND
# (datecancel is NULL OR datecancel > '2016-12-31')
vacantsCsa['DateNotice2'] = pd.to_datetime(vacantsCsa['DateNotice'],infer_datetime_format=True)
vacantsCsa = vacantsCsa[
( vacantsCsa['DateNotice2']>=pd.Timestamp(2000+int(year)-13,1,1) ) &
( vacantsCsa['DateNotice2']<=pd.Timestamp(2000+int(year),12,31) )
]
vacantsCsa.to_csv('vacants_Filtered_Records.csv', index=False)
print( 'Records Matching Query: ', vacantsCsa.size / len(vacantsCsa.columns) )
# Aggregate Numeric Values by Sum
vacantsCsa['vacantsCount'] = 1
vacantsCsa = vacantsCsa.groupby('CSA2010').sum(numeric_only=True)
vacantsCsa = totalres[ ['CSA2010', 'totalres'+year] ].merge( vacantsCsa, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Create the Indicator
vacantsCsa['vacants'+year] = vacantsCsa['vacantsCount'] * 100 / totalres['totalres'+year]
vacantsCsa.at[55,'vacantsCount'] = vacantsCsa['vacantsCount'].sum()
vacantsCsa.at[55,'vacants'+year] = vacantsCsa['vacantsCount'].sum() * 100 / totalres['totalres'+year].sum()
vacantsCsa = vacantsCsa[ ['CSA2010', 'vacantsCount', 'vacants'+year, 'totalres'+year ] ]
vacantsCsa.to_csv('34-vacants'+year+'.csv', index=False)
vacantsCsa.tail(60)
# + [markdown] id="QuBJlaPqQc5V"
# ### BaltVac 43 - (Vacants) - Complete
# + id="G0l-K_XcQDK0"
vacants.OwnerAbbr.unique()
# + id="X5y1s7ElvFxf"
#export
import datetime
baltvac = vacants.copy()
baltvac = baltvac[ (baltvac['OwnerAbbr'].str.contains('DHCD|HABC|HUD|MCC|USA', regex=True, na=False) ) ]
baltvac['DateNotice2'] = pd.to_datetime(baltvac['DateNotice'],infer_datetime_format=True)
baltvac = baltvac[
( baltvac['DateNotice2']>=pd.Timestamp(2000+int(year)-13,1,1) ) &
( baltvac['DateNotice2']<=pd.Timestamp(2000+int(year),12,31) )
]
baltvac.to_csv('baltvac_Filtered_Records.csv', index=False)
print( 'Records Matching Query: ', baltvac.size / len(baltvac.columns) )
# Aggregate Numeric Values by Sum
baltvac['baltvacCount'] = 1
baltvac = baltvac.groupby('CSA2010').sum(numeric_only=True)
baltvac = vacantsCsa[ ['CSA2010', 'vacants'+year] ].merge( baltvac, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Create the Indicator
baltvac['baltvac'+year] = baltvac['baltvacCount'] / vacantsCsa['vacantsCount'] * 100
baltvac.at[55,'baltvacCount'] = baltvac['baltvacCount'].sum()
baltvac.at[55,'baltvac'+year] = baltvac['baltvacCount'].sum() * 100 / vacantsCsa['vacantsCount'].sum()
baltvac = baltvac[ ['CSA2010', 'baltvacCount', 'baltvac'+year, 'vacants'+year ] ]
baltvac.to_csv('43-baltvac'+year+'.csv', index=False)
baltvac.tail(60)
# + [markdown] id="PMzIRtVn3aaC"
# ### Vio 35 - (MdProp[totalres], Violations) - Complete
# + id="I7tu2xr0cWeg"
a2016_query = """
with numerator AS (
select (sum(
case
when (datenotice between '2016-01-01' and '2016-12-31') AND (dateabate is NULL OR dateabate >= '2016-12-31') AND (datecancel is NULL OR datecancel > '2016-12-31')
then 1
else NULL
end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.violations_thru2016', 'gid', 'the_geom') a
left join housing.violations_thru2016 b on a.gid = b.gid
group by csa
),
denominator AS (
select (sum(
case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1
else NULL
end)::numeric
) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop
),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
)
update vital_signs.data
set vio = result from tbl where data.csa = tbl.csa and data_year = '2016';
(datenotice between '2016-01-01' and '2016-12-31') AND (dateabate is NULL OR dateabate >= '2016-12-31') AND (datecancel is NULL OR datecancel > '2016-12-31')
"""
a2017_query = """
with numerator AS (
select (sum(
case
when (datenotice between '2017-01-01' and '2017-12-31') AND (dateabate is NULL OR dateabate >= '2017-12-31') AND (datecancel is NULL OR datecancel > '2017-12-31')
then 1
else NULL
end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.violations_2017', 'gid', 'the_geom') a
left join housing.violations_2017 b on a.gid = b.gid
group by csa
),
denominator AS (
select (sum(
case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1
else NULL
end)::numeric
) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017v2', 'gid', 'the_geom') a
left join housing.mdprop_2017v2 b on a.gid = b.gid
group by csa, the_pop
),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
)
select * from tbl where 1 = 1 ORDER BY csa ASC;
"""
# + id="Jrumg2YhHQzQ"
#export
# Numerator
vio = violations.copy()
# drop null
vio['DateCancel'] = pd.to_datetime(vio['DateCancel'])
vio['DateAbate'] = pd.to_datetime(vio['DateAbate'])
vio['DateNotice'] = pd.to_datetime(vio['DateNotice'], errors='coerce')
# Numerator
vio = vio[['DateNotice', 'DateAbate', 'DateCancel','CSA2010']]
vio.head(1)
start_date = '20'+year+'-01-01'
end_date = '20'+year+'-12-31'
mask = vio[ ( vio['DateNotice'] > start_date ) & ( vio['DateNotice'] <= end_date) ]
mask1 = mask[ ( pd.isnull( mask['DateAbate'] ) ) | ( mask['DateAbate'] >= end_date ) ]
mask2 = mask1[ pd.isnull( mask1['DateCancel'] ) | ( mask1['DateCancel'] > end_date ) ]
vio = mask2.copy()
vio.to_csv('vio_Filtered_Records.csv', index=False)
# + id="e06URS6ZQ3Rh"
#export
# Aggregate Numeric Values by Sum
vio['vioCount'] = 1
vio = vio.groupby('CSA2010').sum(numeric_only=True)
vio = totalres[ ['CSA2010', 'totalres'+year] ].merge( vio, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Create the Indicator
vio['vio'] = vio['vioCount'] * 100 / totalres['totalres'+year]
# Create Baltimore's Record.
vio.at[55,'vioCount'] = vio['vioCount'].sum()
vio.at[55,'vio'] = vio['vioCount'].sum() * 100 / totalres['totalres'+year].sum()
vio.to_csv('35-violations'+year+'.csv', index=False)
vio.tail()
# + [markdown] id="qvrpq23i3fAm"
# ### Fore 33 - (MdProp[totalres], Close Crawl) - Complete
# + [markdown] id="ERgOMXd8LIhh"
# - case crawl should have a dramatic reduction in 2020. no foreclosures were permited after march 2020 because covid.
# + id="Nte9-qonf85D"
# 33 - fore - percent of properties under mortgage foreclosure
# https://services1.arcgis.com/mVFRs7NF4iFitgbY/arcgis/rest/services/Constper/FeatureServer/layers
# https://bniajfi.org/indicators/Housing%20And%20Community%20Development/fore
# Numerator: foreclosures.foreclosures_201X
# Denominator: housing.mdprop_201X
# run the 2018 and 2019 crawler first!
long_Description: """
The percentage of properties where the lending company or loan servicer has filed a foreclosure proceeding with the
altimore City Circuit Court out of all residential properties within an area. This is not a measure of actual foreclosures
since not every property that receives a filing results in a property dispossession.
"""
fore_SQL = """
2016
with numerator AS (
select (sum( case when csa_present then 1 else NULL end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('foreclosures.foreclosures_2016', 'gid', 'the_geom') a
left join foreclosures.foreclosures_2016 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum( case when (address != $$NULL$$)
AND (desclu = $$Apartments$$
OR desclu = $$Residential$$
OR desclu = $$Residential Commercial$$
OR desclu = $$Residential Condominium$$) then 1 else NULL end)::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa )
update vital_signs.data
set fore = result from tbl where data.csa = tbl.csa and data_year = '2016';
--/* <fore_16 number> */
select(sum( case when csa_present then 1 else NULL end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('foreclosures.foreclosures_2016', 'gid', 'the_geom') a
left join foreclosures.foreclosures_2016 b on a.gid = b.gid
group by csa order by csa = 'Baltimore City', csa
WHERE (ooi like 'H')
AND (address != $$NULL$$)
AND (desclu = $$Apartments$$
OR desclu = $$Residential$$
OR desclu = $$Residential Commercial$$
OR desclu = $$Residential Condominium$$
"""
fore_translation = "( count of closecrawl records per CSA / mdprop_2017.totalres )* 100"
# + id="EGzmAAkj9BNR"
#export
# Aggregate Numeric Values by Sum
forclosure['foreCount'] = 1
fore = forclosure.groupby('CSA2010').sum(numeric_only=True)
# Make sure ALL csas and BaltimoreCity are included. among other things
fore = totalres[ ['CSA2010', 'totalres'+year] ].merge( fore, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Create the Indicator
fore['fore'] = fore['foreCount'] * 100 / fore['totalres'+year]
fore.at[55,'foreCount'] = fore['foreCount'].sum()
fore.at[55,'fore'] = fore['foreCount'].sum() * 100 / fore['totalres'+year].sum()
fore = fore[['CSA2010', 'foreCount', 'fore', 'totalres'+year ]]
fore.to_csv('33-fore'+year+'.csv', index=False)
fore.tail(60)
# + [markdown] id="sfkW3QrQ3YSf"
# ### Resrehab 36 - (MdProp[totalres], Permits) - Complete
# + id="rUFXbmjtfvnk"
# 36- resrehab - Percentage of properties with rehabilitation permits exceeding $5k
# https://services1.arcgis.com/mVFRs7NF4iFitgbY/arcgis/rest/services/resrehab/FeatureServer/layers
# Numerator: housing.permits_201X
# Denominator: housing.mdprop_201X
long_Description: """
The percent of residential properties that have applied for and received a permit to renovate the interior and/or exterior
of a property where the cost of renovation will exceed $5,000. The threshold of $5,000 is used to differentiate a minor
and more significant renovation project.
"""
resrehab_SQL = """
2016
with numerator AS (
select sum( case
when (exis = $$SF$$ OR exis = $$MF$$ ) AND (type1 = $$AA$$ OR type1 = $$ADD$$ OR type1 = $$ALT$$) AND (costts >=5000)
then 1 else 0 end)::numeric as result, csa from vital_signs.match_csas_and_bc_by_geom('housing.permits_2016', 'gid', 'the_geom') a
left join housing.permits_2016 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum( case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1 else NULL end)::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa )
update vital_signs.data
set resrehab = result from tbl where data.csa = tbl.csa and data_year = '2016';"
2017
with numerator AS (
select sum(case
when (existingus = $$SF$$
OR propuse = $$SF$$
OR existingus = $$MF$$
OR propuse = $$MF$$
OR existingus = $$DFAM$$
OR propuse = $$DFAM$$
OR existingus like '%1-%'
OR propuse like '%1-%'
)
AND casetype LIKE any (ARRAY['COM'])
AND (field22 = $$AA$$ OR field22 = $$ADD$$ OR field22 = $$ALT$$)
AND (cost >=5000) then 1 else 0 end )::numeric as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.permits_2017', 'gid', 'the_geom') a
left join housing.permits_2017 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum( case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$) then 1 else NULL end )::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017v2', 'gid', 'the_geom') a
left join housing.mdprop_2017v2 b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa )
select * from tbl where 1 = 1 ORDER BY csa ASC;"
INVALID COLUMN NAMES
"/* FIELD22: NEW ALT OTH DEM AA ADD */
2016 - > exis, prop, type1, cossts
2017 -> existingus, propuse, field22, cost
"""
resrehab_translation = """
Numerator = sum permits_2017 when (
existingus = $$SF$$ OR existingus = $$MF$$ OR existingus = $$DFAM$$ OR existingus like '%1-%'
OR propuse = $$SF$$ OR propuse = $$MF$$ OR propuse = $$DFAM$$ OR propuse like '%1-%'
)
AND casetype LIKE any (ARRAY['COM'])
AND (field22 = $$AA$$ OR field22 = $$ADD$$ OR field22 = $$ALT$$)
AND (cost >=5000) then 1 else 0 end )
Denominator = mdprop.totalres
return = (numerator / denominator )* 100
"""
# + [markdown] id="2oY6vn2NdaeA"
# INVALID COLUMN NAMES
# 2016 - > exis, prop, type1, cossts
# 2017 -> existingus, propuse, field22, cost
# + id="g8hBCeeB0bOx"
#export
resrehab = permitsCsa
resrehab['Field22'] = resrehab['typework']
use = ".SF.|.MF.|.DFAM.|.1-.|SF|MF|DFAM|1-.|.1-"
resrehab = resrehab[
( permitsCsa['existingus'].str.contains(use, regex=True, na=False) ) &
( permitsCsa['propuse'].str.contains(use, regex=True, na=False) ) &
( permitsCsa['casetype'].str.contains('.COM.|COM', regex=True, na=False) ) &
( permitsCsa['Field22'].str.contains('.AA.|.ADD.|.ALT.|AA|ADD|ALT|ADD', regex=True, na=False) ) &
( permitsCsa['cost'] >=5000 )
]
resrehab.to_csv('resrehab'+year+'_Filtered_Records.csv', index=False)
print( 'Records Matching Query: ', resrehab.size / len(resrehab.columns) )
# Aggregate Numeric Values by Sum
resrehab['resrehabCount'] = 1
resrehab = resrehab.groupby('CSA2010').sum(numeric_only=True)
# Make sure ALL csas and BaltimoreCity are included. among other things
resrehab = totalres[ ['CSA2010','totalres'+year] ].merge( resrehab, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Update the baltimore CSA.
resrehab.at[55,'resrehabCount'] = resrehab['resrehabCount'].sum()
# Create the Indicator
resrehab['resrehab'+year] = resrehab['resrehabCount'] * 100 / totalres['totalres'+year]
resrehab = resrehab[ ['CSA2010', 'resrehabCount', 'resrehab'+year, 'totalres'+year ] ]
resrehab.to_csv('36-resrehab'+year+'.csv', index=False)
resrehab.head()
resrehab.tail()
# + [markdown] id="473Wzgfs3PkE"
# ### Demper 41 - (MdProp[totalres], Permits) - Complete
# + [markdown] id="RRlNs1zJd9wA"
# INVALID COLUMN NAMES 2016 - > exis, prop, type1, cossts 2017 -> existingus, propuse, field22, cost
# + id="7zwVjcRjfgkp"
# 41- demper - number of demolition permits per 1000 residential properties
# https://services1.arcgis.com/mVFRs7NF4iFitgbY/arcgis/rest/services/demper/FeatureServer/layers
# Numerator: housing.dempermits_201X
# Denominator: housing.mdprop_201X
long_Description: """
The number of permits issued for the demolition of residential buildings per 1,000 existing residential properties.
The permits are analyzed by date of issue and not date of actual demolition.
"""
demper_SQL = """
2016
with numerator AS (
select (sum( case
when csa_present then 1 else 0 end)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.dempermits_2016', 'gid', 'the_geom') a
left join housing.dempermits_2016 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum(
case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1
else NULL
end)::numeric
) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(1000::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa )
update vital_signs.data
set demper = result from tbl where data.csa = tbl.csa and data_year = '2016'; "
2017
with numerator AS (
select (sum(
case
when csa_present AND casetype LIKE any ( ARRAY['DEM'] ) AND planaddres != ''
then 1 else 0
end
)::numeric) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.permits_2017', 'gid', 'the_geom') a
left join housing.permits_2017 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum( case
when (address != $$NULL$$) AND
(desclu = $$Apartments$$
OR desclu = $$Residential$$
OR desclu = $$Residential Commercial$$
OR desclu = $$Residential Condominium$$
) then 1 else NULL end )::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017v2', 'gid', 'the_geom') a
left join housing.mdprop_2017v2 b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(1000::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
select * from tbl where 1 = 1 ORDER BY csa ASC;"
INVALID COLUMN NAMES
2016 - > exis, prop, type1, cossts
2017 -> existingus, propuse, field22, cost
"""
demper_translation = """ ( sum permits_2017 when csa_present AND casetype LIKE any ( ARRAY['DEM'] ) AND planaddres != '' / mdprop.totalres )* 1000 """
# + id="MFqw42ic0RT2"
#export
demper = permitsCsa[
( permitsCsa['casetype'].str.contains('DEM|.DEM.|DEM.|.DEM', regex=True, na=False) )
]
filter = demper["PLANADDRES"] != ""
demper = demper[filter]
demper.to_csv('demper'+year+'_Filtered_Records.csv', index=False)
print( 'Records Matching Query: ', demper.size / len(demper.columns) )
# Aggregate Numeric Values by Sum
demper['demperCount'] = 1
demper = demper.groupby('CSA2010').sum(numeric_only=True)
# Make sure ALL csas and BaltimoreCity are included. among other things
demper = totalres[ ['CSA2010','totalres'+year] ].merge( demper, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Update the baltimore CSA.
demper.at[55,'demperCount'] = demper['demperCount'].sum()
# Create the Indicator
demper['demper'+year] = demper['demperCount'] * 100 / totalres['totalres'+year]
# Create the Indicator
demper['demper'+year] = demper['demperCount'] * 1000 / totalres['totalres'+year]
demper = demper[['CSA2010', 'demperCount', 'demper'+year, 'totalres'+year ]]
demper.to_csv('41-demper'+year+'.csv', index=False)
demper.head(60)
# + [markdown] id="YLNNLLgW3MLH"
# ### Constper 42 - (MdProp[totalres], Permits) - Complete
# + [markdown] id="KTBzN_rYeGww"
# INVALID COLUMN NAMES 2016 - > exis, prop, type1, cossts 2017 -> existingus, propuse, field22, cost
# + id="NTrhWh4tfTsH"
# 42- constper - Number of of new constructio permits per 1000 residential properties
# https://services1.arcgis.com/mVFRs7NF4iFitgbY/arcgis/rest/services/constper/FeatureServer/layers
# Numerator: housing.permits_201X
# Denominator: housing.mdprop_201X
long_Description: """
The number of permits issued for new residential buildings per 1,000 existing residential properties within a community.
The permits are analyzed by date of issue and not date of completion.
"""
constper_SQL = """
2016
with numerator as (
select sum( case
when (prop = $$SF$$ OR prop = $$MF$$) AND (type1 = $$NEW$$) then 1 else 0 end)::numeric as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.permits_2016', 'gid', 'the_geom') a
left join housing.permits_2016 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum( case
when (address != $$NULL$$) AND (desclu = $$Apartments$$ OR desclu = $$Residential$$ OR desclu = $$Residential Commercial$$ OR desclu = $$Residential Condominium$$)
then 1 else NULL end)::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(1000::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa )
update vital_signs.data
set constper = result from tbl where data.csa = tbl.csa and data_year = '2016'; "
2017
with numerator as (
select sum(
case
when (existingus = $$SF$$
OR propuse = $$SF$$
OR existingus = $$MF$$
OR propuse = $$MF$$
OR existingus = $$DFAM$$
OR propuse = $$DFAM$$
OR existingus like '%1-%'
OR propuse like '%1-%'
) AND (field22 = $$NEW$$)
AND casetype LIKE any ( ARRAY['COM'] )
then 1 else 0 end )::numeric as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.permits_2017', 'gid', 'the_geom') a
left join housing.permits_2017 b on a.gid = b.gid
group by csa ),
denominator AS (
select (sum( case
when (address != $$NULL$$)
AND (desclu = $$Apartments$$
OR desclu = $$Residential$$
OR desclu = $$Residential Commercial$$
OR desclu = $$Residential Condominium$$
) then 1 else NULL end )::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017v2', 'gid', 'the_geom') a
left join housing.mdprop_2017v2 b on a.gid = b.gid
group by csa, the_pop ),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(1000::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa )
select * from tbl where 1 = 1 ORDER BY csa ASC;"
INVALID COLUMN NAMES
2016 - > exis, prop, type1, cossts
2017 -> existingus, propuse, field22, cost
"""
constper_translation = """
Numerator = sum permits_2017 when (existingus = $$SF$$
OR existingus = $$DFAM$$ OR existingus = $$MF$$ OR existingus like '%1-%'
OR propuse = $$SF$$ OR propuse = $$MF$$ OR propuse = $$DFAM$$ OR propuse like '%1-%'
)
AND (field22 = $$NEW$$)
AND casetype LIKE any ( ARRAY['COM'] )
Denominator = mdprop.totalres
return = (numerator / Denominator )* 1000
"""
# + id="iYy6zHbXUpDc"
permitsCsa.casetype.unique()
# + id="-sgEc6gK3WBo"
#export
# 2018 and 2017 is not working with the new datasets given (CSA LABELS)
use = "SF|MF|.SF.|.MF.|.SF|.MF|SF.|MF."
constper = permitsCsa
constper['Field22'] = constper['typework']
constper = constper[
#(
# permitsCsa['existingus'].str.contains(use, regex=True, na=False) |
# permitsCsa['propuse'].str.contains(use, regex=True, na=False)
#) &
#( permitsCsa['casetype'].str.contains('COM|.COM.|COM.|.COM', regex=True, na=False) ) &
( constper['Field22'].str.contains('NEW|.NEW.|NEW.|.NEW', regex=True, na=False) )
]
constper = constper[constper["PLANADDRES"] != ""]
constper = constper[['CSA2010','existingus','propuse','casetype','Field22','PLANADDRES' ]]
constper.to_csv('constper'+year+'_Filtered_Records.csv', index=False)
print( 'Records Matching Query: ', constper.size / len(constper.columns) )
# Aggregate Numeric Values by Sum
constper['constperCount'] = 1
constper = constper.groupby('CSA2010').sum(numeric_only=True)
# Make sure ALL csas and BaltimoreCity are included. among other things
constper = totalres[ ['CSA2010','totalres'+year] ].merge( constper, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Update the baltimore CSA.
constper.at[55,'constperCount'] = constper['constperCount'].sum()
# Create the Indicator
constper['42-constper'+year] = constper['constperCount'] * 1000 / totalres['totalres'+year]
constper.to_csv('42-constper'+year+'.csv', index=False)
constper.head(80)
# + [markdown] id="8Gn00GaKyPS5"
# ### Comprop 141 - (MdProp) - Complete
# + id="ctd-m8SJeY02"
"""
2016 uses dataset housing.mdprop_2017
2017 uses dataset housing.mdprop_2017v2
2016s dataset was collected in January of 2017
2017s dataset was collected in Novermber of 2017
"""
# + id="Vem-Zk_vYf_w"
"""
<comprop>* Indicator Number 141/
with tbl AS (
select (sum(
case
when (lu like 'C' OR lu LIKE 'EC' OR lu LIKE 'I')
then 1
else 0
end)::numeric
) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa, the_pop
)
update vital_signs.data
set comprop = result from tbl where data.csa = tbl.csa and data_year = '2016';
"""
# + id="QHtYkLSf7Ggn"
#export
# sum( case when (lu like 'C' OR lu LIKE 'EC' OR lu LIKE 'I')
comprop = mdprop.copy()
comprop['comprop'+year] = 1
# mdprop = csa[['CSA','comprop19']]
comprop = comprop[ comprop['LU'].isin( ['C','EC','I'] ) ]
comprop = comprop.groupby('CSA2010').sum(numeric_only=True)
# Make sure ALL csas and BaltimoreCity are included. among other things
comprop = csa[ ['CSA2010','tpop10'] ].merge( comprop, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Update the baltimore CSA.
comprop.at[55,'comprop'+year] = comprop['comprop'+year].sum()
comprop = comprop[['comprop'+year, 'CSA2010']]
comprop.head(58)
# Create the Indicator
comprop.to_csv('141-comprop'+year+'.csv', index=False)
# + [markdown] id="YNWVUTsSyQSw"
# ### Crehab 142 - (Permits, MdProp[comprop]) - Complete
# + [markdown] id="TZMteAKJypoY"
# This is the original SQL query
# + [markdown] id="icza8EjUETns"
# It Uses Comprop 141.
# + [markdown] id="OFAraE9WepPY"
# 2016 - > exis, prop, type1, cossts 2017 -> existingus, propuse, field22, cost Column Errors NO COLUMN exis NO COLUMN prop
# + id="0gH-6Rfj38qU"
originalQuery = """ <crehab_16> * Indicator Number 142/
with numerator AS (
select sum(
case
when (
exis LIKE any (ARRAY['COM','IND','BUS','AIR','ANIM','BAR','BEAU','DELI','FAC','ASM','ALV%','DOTH','DWC','EDU','FOOD','HCF','HIH','HOS','MIXC','INS','MER','LIB','MNTL','MOB','PUB','STO','UT','VAC','VAL','DFAM'])
AND
prop LIKE any (ARRAY['COM','IND','BUS','AIR','ANIM','BAR','BEAU','DELI','FAC','ASM','ALV%','DOTH','DWC','EDU','FOOD','HCF','HIH','HOS','MIXC','INS','MER','LIB','MNTL','MOB','PUB','STO','UT','DFAM'])
AND
type1 = ANY (ARRAY['AA','ALT','ADD','NEW'])
and costts >=5000
)
then 1
else 0
end)::numeric as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.permits_2016', 'gid', 'the_geom') a
left join housing.permits_2016 b on a.gid = b.gid
group by csa
),
denominator AS (
select (sum(
case
when (lu like 'C' OR lu LIKE 'EC' OR lu LIKE 'I')
then 1
else 0
end)::numeric
) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017', 'gid', 'the_geom') a
left join housing.mdprop_2017 b on a.gid = b.gid
group by csa
),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator left join denominator on numerator.csa = denominator.csa
)
update vital_signs.data
set crehab = result from tbl where data.csa = tbl.csa and data_year = '2016';"""
original17Query = """
NEW SQL 17 QUERY Version 1
/* FIELD22: NEW ALT OTH DEM AA ADD */
with numerator AS (
select sum(
case
when (
(
existingus LIKE any (ARRAY['2-%','3-%','4-%','5-%','6-%','7-%', 'COM','IND','BUS','AIR','ANIM','BAR','BEAU','DELI','FAC','ASM','ALV%','DOTH','DWC','EDU','FOOD','HCF','HIH','HOS','MIXC','INS','MER','LIB','MNTL','MOB','PUB','STO','UT','VAC','VAL','DFAM'])
)
and casetype LIKE any (ARRAY['COM'])
AND field22 = ANY (ARRAY['AA','ALT','ADD', 'NEW'])
AND cost >=5000
)
then 1 else 0 end
)::numeric as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.permits_2017', 'gid', 'the_geom') a
left join housing.permits_2017 b on a.gid = b.gid
group by csa
),
denominator AS (
select (sum(
case
when (lu like 'C' OR lu LIKE 'EC' OR lu LIKE 'I')
then 1 else 0
end
)::numeric ) as result, csa
from vital_signs.match_csas_and_bc_by_geom('housing.mdprop_2017v2', 'gid', 'the_geom') a
left join housing.mdprop_2017v2 b on a.gid = b.gid
group by csa
),
tbl AS (
select denominator.csa,(numerator.result / denominator.result)*(100::numeric) as result
from numerator
left join denominator
on numerator.csa = denominator.csa
)
select * from tbl where 1 = 1 ORDER BY csa ASC;
"""
# + [markdown] id="BBaGjUsPJ1BC"
# The above query is outdated because we shouldnt filter for new in the type1 column.
#
# Also. NO FILTERING ON PROP!
# + id="lNEasrBEEXlY"
permitsCsa.head(1)
# + id="bQrs6d_mMbcI"
# '2-%','3-%','4-%','5-%','6-%','7-%', 'COM','IND','BUS','AIR','ANIM','BAR','BEAU','DELI','FAC','ASM','ALV%','DOTH','DWC','EDU','FOOD','HCF','HIH','HOS','MIXC','INS','MER','LIB','MNTL','MOB','PUB','STO','UT','VAC','VAL','DFAM'
# crehab.loc[crehab['existingus'].str.contains('2-|3-|4-|5-|6-|7-|COM|IND|BUS|AIR|ANIM|BAR|BEAU|DELI|FAC|ASM|ALV|DOTH|DWC|EDU|FOOD|HCF|HIH|HOS|MIXC|INS|MER|LIB|MNTL|MOB|PUB|STO|UT|VAC|VAL|DFAM') == True]
# + id="prww38bVFC4f"
#export
# get the permits file
crehab = permitsCsa.copy()
# Our Column to Sum on
crehab['crehab'+year] = 1
# Filter 1
print('No Filter:', crehab.shape[0])
print('Filter Cost:', crehab[crehab['cost'] >=5000].cost.shape[0])
print('Filter ExistingUse:', crehab.loc[crehab['existingus'].str.contains('2-|3-|4-|5-|6-|7-|COM|IND|BUS|AIR|ANIM|BAR|BEAU|DELI|FAC|ASM|ALV|DOTH|DWC|EDU|FOOD|HCF|HIH|HOS|MIXC|INS|MER|LIB|MNTL|MOB|PUB|STO|UT|VAC|VAL|DFAM') == True].shape[0])
# print('Filter Propuse:', crehab.loc[ crehab['propuse'].str.contains('COM|IND|BUS|AIR|ANIM|BAR|BEAU|DELI|FAC|ASM|ALV|DOTH|DWC|EDU|FOOD|HCF|HIH|HOS|MIXC|INS|MER|LIB|MNTL|MOB|PUB|STO|UT|DFAM') == True].shape[0])
print('Filter typework:', crehab[ crehab['typework'].isin( ['AA','ALT','ADD'] ) ].shape[0])
crehab.loc[ crehab['propuse'].str.contains('COM|IND|BUS|AIR|ANIM|BAR|BEAU|DELI|FAC|ASM|ALV|DOTH|DWC|EDU|FOOD|HCF|HIH|HOS|MIXC|INS|MER|LIB|MNTL|MOB|PUB|STO|UT|DFAM') == True].propuse.unique()
crehab = crehab.loc[crehab['existingus'].str.contains('2-|3-|4-|5-|6-|7-|COM|IND|BUS|AIR|ANIM|BAR|BEAU|DELI|FAC|ASM|ALV|DOTH|DWC|EDU|FOOD|HCF|HIH|HOS|MIXC|INS|MER|LIB|MNTL|MOB|PUB|STO|UT|VAC|VAL|DFAM') == True]
# crehab = crehab.loc[ crehab['propuse'].str.contains('COM|IND|BUS|AIR|ANIM|BAR|BEAU|DELI|FAC|ASM|ALV|DOTH|DWC|EDU|FOOD|HCF|HIH|HOS|MIXC|INS|MER|LIB|MNTL|MOB|PUB|STO|UT|DFAM') == True]
crehab = crehab[ crehab['cost'] >=5000 ]
crehab = crehab[ crehab['typework'].isin( ['AA','ALT','ADD'] ) ]
crehab.head(1)
# + id="FavO7zR7PW2m"
#export
crehab = crehab.groupby('CSA2010').sum(numeric_only=True)
# Make sure ALL csas and BaltimoreCity are included. among other things
crehab = csa[ ['CSA2010','tpop10'] ].merge( crehab, left_on='CSA2010', right_on='CSA2010', how='outer' )
# Update the baltimore CSA.
crehab.at[55,'crehab'+year] = crehab['crehab'+year].sum()
crehab = crehab[['crehab'+year, 'CSA2010']]
crehab['crehab'+year] = crehab['crehab'+year] *100 / comprop['comprop'+year]
crehab.head(58)
# Create the Indicator
crehab.to_csv('142-crehab'+year+'.csv', index=False)
# + id="r7o9pVtj51L9"
| notebooks/Mdprop_Permits_Fore_Vac Vio.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + slideshow={"slide_type": "skip"}
from notebook.services.config import ConfigManager
cm = ConfigManager()
cm.update('livereveal', {'scroll': True,})
# %load_ext autoreload
# %autoreload 2
import os
import sys
sys.path.append(os.path.abspath("."))
from viewer import ThreeJsViewer
# + [markdown] slideshow={"slide_type": "slide"}
# # Frame and Transformation
# + [markdown] slideshow={"slide_type": "slide"}
# <img src="https://gramaziokohler.github.io/compas_fab/latest/_images/02_coordinate_frames.jpg" />
# + [markdown] slideshow={"slide_type": "slide"}
# ## Frame
# + [markdown] cell_style="center" slideshow={"slide_type": "-"}
# A frame is defined by a base point and two orthonormal base vectors (xaxis, yaxis), which specify the normal (zaxis).
# It describes location and orientation in a (right-handed) cartesian coordinate system.
#
# <div align="middle"><img src='images/frame.svg' style='height:350px' /></div>
# + cell_style="center" slideshow={"slide_type": "slide"}
"""There are several ways to construct a `Frame`.
"""
from compas.geometry import Point
from compas.geometry import Vector
from compas.geometry import Frame
from compas.geometry import Plane
# Frame autocorrects axes to be orthonormal
F = Frame(Point(1, 0, 0), Vector(-0.45, 0.1, 0.3), Vector(1, 0, 0))
print(F)
F = Frame([1, 0, 0], [-0.45, 0.1, 0.3], [1, 0, 0])
F = Frame.from_points([1, 1, 1], [2, 3, 6], [6, 3, 0])
F = Frame.from_plane(Plane([0, 0, 0], [0.5, 0.2, 0.1]))
F = Frame.from_euler_angles([0.5, 1., 0.2])
F = Frame.worldXY()
print(F)
# + [markdown] cell_style="center" slideshow={"slide_type": "slide"}
# ### Frame as a cartesian coordinate system
# + [markdown] cell_style="split" slideshow={"slide_type": "-"}
# <img src='images/point_in_frame.svg' style='height:350px' />
# + cell_style="split" slideshow={"slide_type": "fragment"}
"""Example: 'point in frame'
"""
point = Point(146.00, 150.00, 161.50)
xaxis = Vector(0.9767, 0.0010, -0.214)
yaxis = Vector(0.1002, 0.8818, 0.4609)
# coordinate system F
F = Frame(point, xaxis, yaxis)
# point in F (local coordinates)
P = Point(35., 35., 35.)
# point in global (world) coordinates
P_ = F.to_world_coords(P)
print(P_)
# check
P2 = F.to_local_coords(P_)
print(P2)
# + [markdown] slideshow={"slide_type": "notes"}
# The simple example above shows how to use a frame as a coordinate system: Starting from a point `P` in the local (user-defined, relative) coordinate system of frame `F`, i.e. its position is relative to the origin and orientation of `F`, we want to get the position `P_` of `P` in the global (world, absolute) coordinate system.
# + [markdown] slideshow={"slide_type": "slide"}
# ### Frame in frame
# + [markdown] cell_style="split" slideshow={"slide_type": "-"}
# <img src='images/frame_in_frame_point.svg' style='height:450px' />
# + cell_style="split" slideshow={"slide_type": "fragment"}
"""Example: 'frame in frame'
# TODO update graphic!
"""
from compas.geometry import *
# coordinate system F0
point = Point(146.00, 150.00, 161.50)
xaxis = Vector(0.9767, 0.0010, -0.214)
yaxis = Vector(0.1002, 0.8818, 0.4609)
F0 = Frame(point, xaxis, yaxis)
# frame F in F0 (local coordinates)
point = Point(35., 35., 35.)
xaxis = Vector(0.604, 0.430, 0.671)
yaxis = Vector(-0.631, 0.772, 0.074)
F = Frame(point, xaxis, yaxis)
# frame in global (world) coordinate system
F_wcf = F0.to_world_coords(F)
print(F_wcf)
# check
F2 = F0.to_local_coords(F_wcf)
print(F2)
print(F == F2)
# + [markdown] slideshow={"slide_type": "skip"}
# ### Example
#
# Bring a box from the world coordinate system into another coordinate system.
# + slideshow={"slide_type": "slide"}
"""Example: Bring a box from the world coordinate system into another coordinate system.
"""
from compas.geometry import Frame
from compas.geometry import Box
# Box in the world coordinate system
frame = Frame([1, 0, 0], [-0.45, 0.1, 0.3], [1, 0, 0])
width, length, height = 1, 1, 1
box = Box(frame, width, length, height)
# Frame F representing a coordinate system
F = Frame([2, 2, 2], [0.978, 0.010, -0.210], [0.090, 0.882, 0.463])
# Represent box frame in frame F and construct new box
box_frame_transformed = F.to_world_coords(box.frame)
box_transformed = Box(box_frame_transformed, width, length, height)
print("Box frame transformed:", box_transformed.frame)
# + slideshow={"slide_type": "slide"}
from viewer import ThreeJsViewer
viewer = ThreeJsViewer()
viewer.draw_frame(Frame.worldXY(), line_width=2)
viewer.draw_box(box)
viewer.draw_frame(F, line_width=2)
viewer.draw_box(box_transformed, color='#3FB59D')
camera_position=[5.0, -5.0, 2.0]
viewer.show(camera_position)
# + [markdown] slideshow={"slide_type": "notes"}
# ### Further information
#
# * https://en.wikipedia.org/wiki/Frame_of_reference
# * https://en.wikipedia.org/wiki/Cartesian_coordinate_system
# + [markdown] slideshow={"slide_type": "slide"}
# ## Transformation
# + [markdown] slideshow={"slide_type": "fragment"}
# Transformations refer to operations such as moving, rotating, and scaling objects. They are stored using 4x4 transformation matrices.
#
# Most transformations preserve the parallel relationship among the parts of the geometry. For example collinear points
# remain collinear after the transformation. Also points on one plane stay coplanar after transformation. This type of
# transformation is called an *affine transformation* and concerns transformations such as `Rotation`, `Translation`,
# `Scale`, `Reflection`, `Shear` and orthogonal and parallel `Projection`. Only perspective `Projection` is not *affine*.
#
# <img src='images/transformations2D.svg' style='width:800px' />
# + [markdown] slideshow={"slide_type": "slide"}
# A transformation matrix looks like this:
#
# \begin{equation*}
# \mathbf{T} = \begin{bmatrix}
# a_{11} & a_{12} & a_{13} & a_{14}\\
# a_{21} & a_{22} & a_{23} & a_{24}\\
# a_{31} & a_{32} & a_{33} & a_{34}\\
# a_{41} & a_{42} & a_{43} & a_{44}\\
# \end{bmatrix}
# \end{equation*}
# + [markdown] slideshow={"slide_type": "slide"}
# But for different transformations, different coefficients are used:
#
# The `Rotation` just uses the upper left 3x3 coefficients,
#
# \begin{equation*}
# \mathbf{T} = \begin{bmatrix}
# a_{11} & a_{12} & a_{13} & 0\\
# a_{21} & a_{22} & a_{23} & 0\\
# a_{31} & a_{32} & a_{33} & 0\\
# 0 & 0 & 0 & 1\\
# \end{bmatrix}
# \end{equation*}
# + [markdown] slideshow={"slide_type": "slide"}
# the `Translation` just uses the first 3 coefficients of the 4th column,
#
# \begin{equation*}
# \mathbf{T} = \begin{bmatrix}
# 1 & 0 & 0 & a_{14}\\
# 0 & 1 & 0 & a_{24}\\
# 0 & 0 & 1 & a_{34}\\
# 0 & 0 & 0 & 1\\
# \end{bmatrix}
# \end{equation*}
# + [markdown] slideshow={"slide_type": "slide"}
# and `Scale` uses only the first 3 values of the diagonal.
#
# \begin{equation*}
# \mathbf{T} = \begin{bmatrix}
# a_{11} & 0 & 0 & 0\\
# 0 & a_{22} & 0 & 0\\
# 0 & 0 & a_{33} & 0\\
# 0 & 0 & 0 & 1\\
# \end{bmatrix}
# \end{equation*}
# + slideshow={"slide_type": "skip"}
from compas.geometry import *
axis, angle = [0.2, 0.4, 0.1], 0.3
R = Rotation.from_axis_and_angle(axis, angle)
print("Rotation:\n", R)
translation_vector = [5, 3, 1]
T = Translation(translation_vector)
print("Translation:\n", T)
scale_factors = [0.1, 0.3, 0.4]
S = Scale(scale_factors)
print("Scale:\n", S)
point, normal = [0.3, 0.2, 1], [0.3, 0.1, 1]
R = Reflection(point, normal) # TODO: should take a plane!!
print("Reflection:\n", R)
point, normal = [0, 0, 0], [0, 0, 1]
perspective = [1, 1, 0]
P = Projection.perspective(point, normal, perspective)
print("Perspective projection:\n", R)
angle, direction = 0.1, [0.1, 0.2, 0.3]
point, normal = [4, 3, 1], [-0.11, 0.31, -0.17]
S = Shear(angle, direction, point, normal)
print("Shear:\n", S)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Inverse transformation
#
# The inverse transformation $T^{-1}$ is calculated through inverting the transformation matrix $T$.
#
# $T \times T^{-1} = I$, with $I$ as identity matrix.
# + slideshow={"slide_type": "slide"}
"""Example: Transform a point and invert the transformation
"""
from compas.geometry import *
from math import pi
p = Point(3, 4, 5)
T = Rotation.from_axis_and_angle([2, 2, 2], pi/4)
# transform Point p with T
p.transform(T)
print(p) # transformed point
# create inverse Transformation to T
Tinv = T.inverse()
# transform Point p with inverse Transformation
p.transform(Tinv)
# check if p has the same values as in the beginning
print(p) # == (3, 4, 5)
# what is the result of multiplying T with Tinv?
print(T * Tinv)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Concatenation
#
# The concatenation of several `Transformations` are simple matrix multiplications.
# But matrices are not commutative ($\mathbf{A}\times\mathbf{B} \neq \mathbf{B}\times\mathbf{A}$),
# so it is important to consider the order of multiplication.
#
# There are 2 ways to concatenate transformation matrices:
#
# <table style="font-size:100%">
# <tr style="background: none;">
# <td style="text-align: right">
# Pre-multiplication:<br/>
# Post-multiplication:<br/>
# </td>
# <td style="text-align: left">
# $\mathbf{C}=\mathbf{B}\times\mathbf{A}$<br/>
# $\mathbf{C}=\mathbf{A}\times\mathbf{B}$<br/>
# </td>
# <td style="text-align: left">
# (apply $\mathbf{B}$ to the left of $\mathbf{A}$)<br/>
# (apply $\mathbf{B}$ to the right of $\mathbf{A}$)<br/>
# </td>
# </tr>
# </table>
#
# Which one you choose depends on what you want to do...
# + [markdown] slideshow={"slide_type": "slide"}
# ### Pre-multiplication
#
# Think of transformations with respect to the global (world) coordinate system.
#
# <div align="center"><img src="images/pre-multiplication.svg" width="800" /></div>
# + [markdown] cell_style="center" slideshow={"slide_type": "slide"}
# ## Pre-multiplication
#
# If you transform an object first with transformation $\mathbf{A}$, then with transformation $\mathbf{B}$,
# followed by transformation $\mathbf{C}$, you get the same result as transforming the object with only
# one transformation $\mathbf{M}$ which is calculated by $\mathbf{M}=\mathbf{C}\times\mathbf{B}\times\mathbf{A}$.
# (Transformations applied from right to left.)
# + cell_style="center" slideshow={"slide_type": "fragment"}
"""Example: Pre-multiply transformations
"""
from compas.geometry import *
p = Point(1, 1, 1)
translation = [1, 2, 3]
A = Translation(translation) # create Translation
axis, angle = [-0.8, 0.35, 0.5], 2.2
B = Rotation.from_axis_and_angle(axis, angle) # create Rotation
scale_factors = [0.1, 0.3, 0.4]
C = Scale(scale_factors) # create Scale
# Transform one by one
p1 = p.transformed(A)
p1.transform(B)
p1.transform(C)
# Transform with only one concatenated matrix
p2 = p.transformed(C * B * A)
print(p1)
print(p2)
allclose(p1, p2)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Post-multiplication
#
# Think of transformations as transforming the local coordinate frame.
#
# <div align="center"><img src="images/post-multiplication.svg" width="800" /></div>
# + cell_style="split" slideshow={"slide_type": "skip"}
"""Example: pre-multiplication"""
import math
R = Rotation.from_axis_and_angle([0, 0, 1], math.radians(30))
T = Translation([2, 0, 0])
S = Scale([0.5] * 3)
C = S * T * R
C
# + cell_style="split" slideshow={"slide_type": "skip"}
"""Example: post-multiplication"""
import math
R = Rotation.from_axis_and_angle([0, 0, 1], math.radians(30))
T = Translation([2, 0, 0])
S = Scale([0.5] * 3)
C = R * T * S
C
# + slideshow={"slide_type": "slide"}
"""Example: Decompose transformations
"""
from compas.geometry import *
scale_factors = [0.1, 0.3, 0.4]
A = Scale(scale_factors) # create Scale
axis, angle = [-0.8, 0.35, 0.5], 2.2
B = Rotation.from_axis_and_angle(axis, angle) # create Rotation
translation = [1, 2, 3]
C = Translation(translation) # create Translation
# Concatenate transformations
M = C * B * A
# A matrix can also be decomposed into it's components of Scale,
# Shear, Rotation, Translation and Perspective
Sc, Sh, R, T, P = M.decomposed()
# Check
print(A == Sc)
print(B == R)
print(C == T)
print(P * T * R * Sh * Sc == M)
# + [markdown] slideshow={"slide_type": "skip"}
# ### Question
#
# To transform a point, you simply multiply the point with the transformation matrix. But a transformation matrix is 4x4
# and vectors and points are 3x1, so how can they be multiplied?
# + [markdown] slideshow={"slide_type": "skip"}
# ### Matrix multiplication
#
# If $\mathbf{A}$ is an $m \times n$ matrix and $\mathbf{B}$ is an $n \times p$ matrix, the matrix product $\mathbf{C} = \mathbf{A}\mathbf{B}$ is defined to be a $m \times p$ matrix.
# + [markdown] slideshow={"slide_type": "skip"}
# <table style="font-size: 100%;">
# <tr style="background: none;">
# <td style="text-align: left;">
# \begin{equation*}
# {\overset {4\times 2{\text{ matrix}}}{\begin{bmatrix}a_{11}&a_{12}\\a_{21}&a_{22}\\a_{31}&a_{32}\\a_{41}&a_{42}\\\end{bmatrix}}}
# {\overset {2\times 3{\text{ matrix}}}{\begin{bmatrix}b_{11}&b_{12}&b_{13}\\b_{21}&b_{22}&b_{23}\\\end{bmatrix}}}=
# {\overset {4\times 3{\text{ matrix}}}{\begin{bmatrix}x_{11}&x_{12}&x_{13}\\x_{21}&x_{22}&x_{23}\\x_{31}&x_{32}&x_{33}\\x_{41}&x_{42}&x_{43}\\\end{bmatrix}}}
# \end{equation*}
# <br />
# <br />
# $x_{12}=a_{11}b_{12}+a_{12}b_{22}\\
# x_{33}=a_{31}b_{13}+a_{32}b_{23}$
# </td>
# <td>
# <img width="300" src="https://upload.wikimedia.org/wikipedia/commons/thumb/e/eb/Matrix_multiplication_diagram_2.svg/470px-Matrix_multiplication_diagram_2.svg.png" />
# </td>
# </tr>
# </table>
#
# https://en.wikipedia.org/wiki/Matrix_multiplication
# + [markdown] slideshow={"slide_type": "skip"}
# ### Homogenisation
#
# To transform points and vectors, i.e. multiply them with the transformation matrix, we need to homogenize them first.
# This means representing a 3-vector (x, y, z) as a 4-vector (x, y, z, 1) for points, or (x, y, z, 0) for vectors.
#
# Points:
# \begin{equation*}
# \begin{bmatrix}x'\\y'\\z'\\1\end{bmatrix} =
# \begin{bmatrix}
# a_{11} & a_{12} & a_{13} & a_{14}\\
# a_{21} & a_{22} & a_{23} & a_{24}\\
# a_{31} & a_{32} & a_{33} & a_{34}\\
# a_{41} & a_{42} & a_{43} & a_{44}\\
# \end{bmatrix}
# \times
# \begin{bmatrix}x\\y\\z\\1\end{bmatrix}
# \end{equation*}
#
# Vectors:
# \begin{equation*}
# \begin{bmatrix}x'\\y'\\z'\\0\end{bmatrix} =
# \begin{bmatrix}
# a_{11} & a_{12} & a_{13} & a_{14}\\
# a_{21} & a_{22} & a_{23} & a_{24}\\
# a_{31} & a_{32} & a_{33} & a_{34}\\
# a_{41} & a_{42} & a_{43} & a_{44}\\
# \end{bmatrix}
# \times
# \begin{bmatrix}x\\y\\z\\0\end{bmatrix}
# \end{equation*}
# + [markdown] slideshow={"slide_type": "skip"}
# **NOTE**:
# <p style="background-color: yellow;">
# That is one of the reasons for distinguishing between points and vectors!
# </p>
# + slideshow={"slide_type": "slide"}
"""Example: transform point and vector
"""
# create Transformation
R = Rotation.from_axis_and_angle([-0.248, -0.786, -0.566], 2.78, point=[1.0, 0.0, 0.0])
# apply Transformation to Point
p = Point(1, 1, 1)
p.transform(T)
# apply Transformation to Vector
v = Vector(1, 1, 1)
v.transform(T)
# print them both
print(p)
print(v)
# + [markdown] slideshow={"slide_type": "slide"}
# ## Transformation of multiple points
#
# If you need to transform multiple points it is better to do this with the methods `transform_points` or `transform_points_numpy`
# than applying the transformation on each point. (likewise `transform_vectors` or `transform_vectors_numpy`)
# + slideshow={"slide_type": "slide"}
import time
import compas
from compas.datastructures import Mesh
from compas.geometry import transform_points
from compas.geometry import transform_points_numpy
# load mesh
mesh = Mesh.from_ply(compas.get('bunny.ply'))
v, f = mesh.to_vertices_and_faces()
print("The mesh has {} vertices.".format(len(v)))
# create Transformation
T = Rotation.from_axis_and_angle([-0.248, -0.786, -0.566], 2.78, point=[1.0, 0.0, 0.0])
# transform points with transform_points
t0 = time.time()
transform_points(v, T)
print("transfrom_points takes {:.4f} seconds.".format(time.time() - t0))
# transform points with transform_points_numpy
t0 = time.time()
transform_points_numpy(v, T)
print("transfrom_points_numpy takes {:.4f} seconds.".format(time.time() - t0))
# + [markdown] slideshow={"slide_type": "notes"}
# **NOTE**:
# <p style="background-color: yellow;">
# If you want to apply several transformations on a big mesh, it is faster to multiply transformations first
# and then apply only one transformation to mesh.
# </p>
# + [markdown] slideshow={"slide_type": "slide"}
# ## Frame and Transformation
#
# <img src='images/frame_transformation.svg' style='height:450px' />
# + [markdown] slideshow={"slide_type": "slide"}
# ### Difference between change-basis transformation and transformation between frames.
#
# `Transformation.change_basis(f1, f2)` and `Transformation.from_frame_to_frame(f1, f2)`
#
# A change-basis transformation allows to remap geometry of one coordinate system in another, i.e. represent the same coordinates in 2 different frames,
# whereas the Transformation between 2 frames allows to transform geometry from one coordinate system into the other one.
# + cell_style="center" slideshow={"slide_type": "slide"}
"""This example computes a transformation between two frames F1 and F2.
"""
from compas.geometry import Frame
from compas.geometry import Transformation
F1 = Frame([2, 2, 2], [0.12, 0.58, 0.81], [-0.80, 0.53, -0.26])
F2 = Frame([1, 1, 1], [0.68, 0.68, 0.27], [-0.67, 0.73, -0.15])
T = Transformation.from_frame_to_frame(F1, F2)
print(T)
# now transform F1 with T
F2 == F1.transformed(T)
# + cell_style="center" slideshow={"slide_type": "slide"}
"""This example computes a change-basis transformation between two frames F1 and F2.
"""
from compas.geometry import Frame
from compas.geometry import Transformation
F1 = Frame([2, 2, 2], [0.12, 0.58, 0.81], [-0.80, 0.53, -0.26])
F2 = Frame([1, 1, 1], [0.68, 0.68, 0.27], [-0.67, 0.73, -0.15])
T = Transformation.change_basis(F1, F2)
print(T)
# F1 local = worldXY F1 in F2
Point(0, 0, 0).transformed(T) == F2.to_local_coords(F1.point)
# + slideshow={"slide_type": "skip"}
"""Example: Bring a box from the world coordinate system into another coordinate system.
"""
from compas.geometry import Frame
from compas.geometry import Transformation
from compas.geometry import Box
# Box in the world coordinate system
frame = Frame([1, 0, 0], [-0.45, 0.1, 0.3], [1, 0, 0])
width, length, height = 1, 1, 1
box = Box(frame, width, length, height)
# Frame F representing a coordinate system
F = Frame([2, 2, 2], [0.978, 0.010, -0.210], [0.090, 0.882, 0.463])
# Get transformation between frames and apply transformation on box.
T = Transformation.from_frame_to_frame(Frame.worldXY(), F)
box_transformed = box.transformed(T)
print("Box frame transformed", box_transformed.frame)
# + slideshow={"slide_type": "skip"}
viewer = ThreeJsViewer()
viewer.draw_frame(Frame.worldXY())
viewer.draw_box(box)
viewer.draw_frame(F)
viewer.draw_box(box_transformed, color="#00aaff")
camera_position=[5.0, -5.0, 2.0]
viewer.show(camera_position)
# + [markdown] slideshow={"slide_type": "skip"}
# ### Difference between `transform()` and `transformed()`
#
#
# * Make a copy of box and transform it (don't change box):
# box_transformed = box.transformed(T)
# * Transform box (returns `None`):
# box.transform(T)
# + [markdown] slideshow={"slide_type": "skip"}
# **NOTE**:
# <p style="background-color: yellow;">
# Depending on the size of the object, copying takes time. So consider carefully if you really need a copy.
# </p>
# + [markdown] cell_style="center" slideshow={"slide_type": "slide"}
# ## Rotation and orientation
#
# A `Rotation` is a circular movement of an object around a point of rotation. A three-dimensional object can always be rotated around an infinite number of imaginary lines called rotation axes.
#
# + cell_style="center" slideshow={"slide_type": "fragment"}
"""There are several ways to construct a `Rotation`.
"""
import math
from compas.geometry import Rotation
R = Rotation.from_axis_and_angle([1, 0, 0], math.radians(30))
R = Rotation.from_axis_and_angle([1, 0, 0], math.radians(30), point=[1, 0, 0])
R = Rotation.from_basis_vectors([0.68, 0.68, 0.27], [-0.67, 0.73, -0.15])
R = Rotation.from_frame(Frame([1, 1, 1], [0.68, 0.68, 0.27], [-0.67, 0.73, -0.15]))
R = Rotation.from_axis_angle_vector([-0.043, -0.254, 0.617])
R = Rotation.from_quaternion([0.945, -0.021, -0.125, 0.303])
R = Rotation.from_euler_angles([1.4, 0.5, 2.3], static=True, axes='xyz')
print(R)
# + cell_style="center" slideshow={"slide_type": "skip"}
import math
from compas.geometry import Sphere
viewer = ThreeJsViewer()
sphere = viewer.draw_sphere(Sphere((0,2,0), 0.5))
times = []
transformations = []
for i in range(0, 360, 1):
transformations.append(Rotation.from_axis_and_angle([0,0,1], math.radians(i)))
times.append(i * 0.01)
sphere_action = viewer.create_action(sphere, transformations, times)
# + cell_style="center" slideshow={"slide_type": "skip"}
camera_position=[0.0, 0.0, 10.0]
viewer.show(camera_position=camera_position, action=sphere_action)
# + [markdown] cell_style="split" slideshow={"slide_type": "slide"}
# ### Euler angles
#
# The Euler angles are three angles introduced by <NAME>uler to describe the orientation of a rigid body with respect
# to a fixed coordinate system.
#
# The three elemental rotations may be
# * extrinsic (`static=True`, rotations about the axes xyz of the original coordinate system, which is assumed to remain motionless), or
# * intrinsic (`static=False`, rotations about the axes of the rotating coordinate system XYZ, solidary with the moving body, which changes its orientation after each elemental rotation).
#
# Euler angles are typically denoted as α, β, γ. Different authors use different sets of rotation axes to
# define Euler angles (`axes='xyz'`,`axes='xyx'`, ...) or different names for the same angles.
# In flight dynamics, the principal rotations described with Euler angles are known as *pitch*, *roll* and *yaw*.
# + [markdown] cell_style="split" slideshow={"slide_type": "-"}
# <img src='https://upload.wikimedia.org/wikipedia/commons/thumb/8/82/Euler.png/543px-Euler.png' style='height:450px' />
# + cell_style="center" slideshow={"slide_type": "skip"}
from compas.geometry import *
box = Box(Frame([0,0,0], [1,0,0], [0,1,0]), 1., 1., 1.)
alpha, beta, gamma = 0.3, 0.5, 0.7
xaxis, yaxis, zaxis = [1, 0, 0], [0, 1, 0], [0, 0, 1]
Rx = Rotation.from_axis_and_angle(xaxis, alpha)
Ry = Rotation.from_axis_and_angle(yaxis, beta)
Rz = Rotation.from_axis_and_angle(zaxis, gamma)
# + slideshow={"slide_type": "skip"}
viewer = ThreeJsViewer()
jbox = viewer.draw_box(box)
frame = viewer.draw_frame(box.frame)
times = [0, 3, 5, 8, 10, 13, 17]
transformations = [Transformation()]
transformations += [Rx] * 2
transformations += [Rx * Ry] * 2
transformations += [Rx * Ry * Rz] * 2
box_action = viewer.create_action(jbox, transformations, times)
frame_action = viewer.create_action(frame, transformations, times)
# + slideshow={"slide_type": "skip"}
viewer.show()
# + cell_style="split" slideshow={"slide_type": "skip"}
box_action
# + cell_style="split" slideshow={"slide_type": "skip"}
frame_action
# + slideshow={"slide_type": "slide"}
"""Example: Rotations from euler angles, rotate an object based on 3 euler angles.
"""
import compas
from compas.geometry import Frame
from compas.geometry import Rotation
from compas.datastructures import Mesh
from compas.datastructures import mesh_transform
# euler angles
alpha, beta, gamma = -0.156, -0.274, 0.785
static, axes = True, 'xyz'
# Version 1: Create Rotation from angles
R1 = Rotation.from_euler_angles([alpha, beta, gamma], static, axes)
# Version 2: Concatenate 3 Rotations
xaxis, yaxis, zaxis = [1, 0, 0], [0, 1, 0], [0, 0, 1]
Rx = Rotation.from_axis_and_angle(xaxis, alpha)
Ry = Rotation.from_axis_and_angle(yaxis, beta)
Rz = Rotation.from_axis_and_angle(zaxis, gamma)
if static: # check difference between pre- and post-concatenation!
R2 = Rz * Ry * Rx
else:
R2 = Rx * Ry * Rz
# Check
print(R1 == R2)
# + [markdown] cell_style="split" slideshow={"slide_type": "slide"}
# ### Axis-angle representation
#
# The axis–angle representation of a rotation parameterizes a rotation in a three-dimensional Euclidean space by two
# quantities: a unit vector $\mathbf{e}$ indicating the direction of an axis of rotation, and an angle $θ$ describing
# the magnitude of the rotation about the axis.
# + [markdown] cell_style="split"
# <img src='https://upload.wikimedia.org/wikipedia/commons/thumb/7/7b/Angle_axis_vector.svg/300px-Angle_axis_vector.svg.png' style='height:250px' />
# + slideshow={"slide_type": "slide"}
"""Example: Create a rotation from and axis and an angle.
"""
from compas.geometry import *
aav = Vector(-0.043, -0.254, 0.617)
angle, axis = aav.unitized(), aav.length
print(angle, axis)
R = Rotation.from_axis_angle_vector(aav)
axis, angle = R.axis_and_angle
print(axis, angle)
# + [markdown] slideshow={"slide_type": "slide"}
# ### Unit Quaternion
#
# In mathematics, the quaternions are a number system that extends the complex numbers.
#
# Quaternions are generally represented in the form:
#
# ${\displaystyle a+b\ \mathbf{i} +c\ \mathbf{j} +d\ \mathbf{k} }$
#
# where $a$, $b$, $c$, and $d$ are real numbers, and $\mathbf{i}$, $\mathbf{j}$, and $\mathbf{k}$ are the fundamental quaternion units.
#
# Unit quaternions, also known as versors, provide a convenient mathematical notation for representing orientations and
# rotations of objects in three dimensions. Compared to Euler angles they are simpler to compose and compared to
# rotation matrices they are more compact, more numerically stable, and more efficient.
#
# + slideshow={"slide_type": "slide"}
from compas.geometry import Rotation
from compas.geometry import Quaternion
q = Quaternion(0.918958, -0.020197, -0.151477, 0.363544)
print(q.is_unit)
R = Rotation.from_quaternion(q)
print(R.quaternion == q)
# + slideshow={"slide_type": "slide"}
"""Example: Different Robot vendors use different conventions to describe TCP orientation."""
from compas.geometry import Point
from compas.geometry import Vector
from compas.geometry import Frame
point = Point(0.0, 0.0, 63.0)
xaxis = Vector(0.68, 0.68, 0.27)
yaxis = Vector(-0.67, 0.73, -0.15)
F = Frame(point, xaxis, yaxis)
print(F.quaternion) # ABB
print(F.euler_angles(static=False, axes='xyz')) # Staubli
print(F.euler_angles(static=False, axes='zyx')) # KUKA
print(F.axis_angle_vector) # UR
# + [markdown] slideshow={"slide_type": "slide"}
# ### Assignment Task 1
#
# Project the box corner coordinates of a (rotated and translated) box onto the xy-plane. You can use either
# orthogonal, parallel or perspective Projection. In the end visualize the edges of the projected box corners
# (tip: Mesh will help you there).
#
#
# <div align="center"><br><img src="images/assignment1_1.jpg" width="600" /></div>
# + [markdown] slideshow={"slide_type": "slide"}
# ### Further information
#
# * https://en.wikipedia.org/wiki/Transformation_matrix
# * https://en.wikipedia.org/wiki/Euler_angles
# * https://en.wikipedia.org/wiki/Axis%E2%80%93angle_representation
# * https://en.wikipedia.org/wiki/Quaternions_and_spatial_rotation
| modules/module2/Frame and Transformation.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/dldudgns73/BERTem/blob/master/transE.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + [markdown] id="fknHs0U8q2Bj"
# # **개체 (Entity)**
#
# 정의 : 인간의 개념 또는 정보의 세계에서 의미있는 하나의 정보 단위
#
# EX) 위키피디아의 페이지
# [거미(가수)](https://https://ko.wikipedia.org/wiki/%EA%B1%B0%EB%AF%B8_(%EA%B0%80%EC%88%98))
#
# [그림]
#
# 이러한 개체들의 관계를 이용하여 Triple, 그래프의 형태로 표현이 가능
#
# **<개체 1, 관계, 개체 2>**
#
# **<Subject, Relation, Object>**
#
# **<Head, Predicate, Tail>**
#
# **EX)**
#
# **<거미, 성별, 여자>**
#
# **<거미, 직업, 가수>**
#
# **<거미, 배우자, 조정석>**
#
# **...**
#
# [그림]
#
# # **TransE**
#
# 그래프 임베딩의 한 방법 (Translation-based)
#
# 모든 개체와 관계에 대해서 Subject + Relation = Object가 되도록 모델을 학습
#
# [수식]
#
# [그림]
#
# ##Negative Sampling
#
# TransE 모델을 학습하기 위한 방법
#
# 정답(Positive) Triple과 오답(Negative) Triple의 거리가 멀어지도록 학습
#
# [그림]
#
# # **Link Prediction**
#
# <Subject, Relation, X> 혹은 <X, Relation, Object>가 주어졌을 때, X에 해당하는 개체를 찾는 문제
#
| transE.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] deletable=true editable=true
# ### Dependencies
# - keras - obviously
# - h5py - for model checkpointing
# - keras-tqdm - because my [Jupyter notebooks freezes on the default Keras progbar](https://github.com/fchollet/keras/issues/4880). Also, it's awesome
# + deletable=true editable=true
# %matplotlib inline
import matplotlib.pyplot as plt
# + deletable=true editable=true
'''Trains a memory network on the bAbI dataset.
References:
- <NAME>, <NAME>, <NAME>, <NAME>, <NAME>,
"Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks",
http://arxiv.org/abs/1502.05698
- <NAME>, <NAME>, <NAME>, <NAME>,
"End-To-End Memory Networks",
http://arxiv.org/abs/1503.08895
Reaches 98.6% accuracy on task 'single_supporting_fact_10k' after 120 epochs.
Time per epoch: 3s on CPU (core i7).
'''
# compat
from __future__ import print_function
# python
from imp import reload
from functools import reduce
import tarfile
import numpy as np
import re
# ML
from keras.models import Sequential, Model
from keras.layers.embeddings import Embedding
from keras.layers import Input, Activation, Dense, Permute, Dropout, add, dot, concatenate
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from keras.callbacks import ModelCheckpoint
from keras_tqdm import TQDMNotebookCallback
# local libs
import preprocess
import models
reload(preprocess)
# + deletable=true editable=true
try:
path = get_file('babi-tasks-v1-2.tar.gz', origin='https://s3.amazonaws.com/text-datasets/babi_tasks_1-20_v1-2.tar.gz')
except:
print('Error downloading dataset, please download it manually:\n'
'$ wget http://www.thespermwhale.com/jaseweston/babi/tasks_1-20_v1-2.tar.gz\n'
'$ mv tasks_1-20_v1-2.tar.gz ~/.keras/datasets/babi-tasks-v1-2.tar.gz')
raise
tar = tarfile.open(path)
challenges = {
# QA1 with 10,000 samples
'single_supporting_fact_10k': 'tasks_1-20_v1-2/en-10k/qa1_single-supporting-fact_{}.txt',
# QA2 with 10,000 samples
'two_supporting_facts_10k': 'tasks_1-20_v1-2/en-10k/qa2_two-supporting-facts_{}.txt',
}
challenge_type = 'two_supporting_facts_10k' #'single_supporting_fact_10k'
challenge = challenges[challenge_type]
# + deletable=true editable=true
print('Extracting stories for the challenge:', challenge_type)
train_stories = preprocess.get_stories(tar.extractfile(challenge.format('train')))
test_stories = preprocess.get_stories(tar.extractfile(challenge.format('test')))
vocab = set()
for story, q, answer in train_stories + test_stories:
vocab |= set(story + q + [answer])
vocab = sorted(vocab)
# -
vocab
# + deletable=true editable=true
train_stories[0]
# + [markdown] deletable=true editable=true
# Our vocab is pretty simple, and consists of the adverb 'where', people, places, prepositions, verbs, objects, definite article 'the', and two punctuation marks.
#
# Our single adverb: ['Where']
#
# People: ['Daniel', 'John', 'Mary', 'Sandra']
#
# Places: ['bathroom', 'bedroom', 'garden', 'hallway','kitchen','office']
#
# Prepositions: ['back', 'to']
#
# Verbs: ['is', 'journeyed', 'moved', 'travelled', 'went']
#
# Articles: ['the']
#
# Punctuanion: ['.', '?',]
# + deletable=true editable=true
# Reserve 0 for masking via pad_sequences
vocab_size = len(vocab) + 1
story_maxlen = max(map(len, (x for x, _, _ in train_stories + test_stories)))
query_maxlen = max(map(len, (x for _, x, _ in train_stories + test_stories)))
print('-')
print('Vocab size:', vocab_size, 'unique words')
print('Story max length:', story_maxlen, 'words')
print('Query max length:', query_maxlen, 'words')
print('Number of training stories:', len(train_stories))
print('Number of test stories:', len(test_stories))
print('-')
print('Here\'s what a "story" tuple looks like (input, query, answer):')
print(train_stories[0])
print('-')
print('Vectorizing the word sequences...')
word_idx = dict((c, i + 1) for i, c in enumerate(vocab))
idx_to_word = {value: key for (key, value) in word_idx.items()} # reverse lookup
idx_to_word.update({0: '~'})
# + deletable=true editable=true
reload(preprocess)
ve = preprocess.BabiVectorizer()
inputs_train, queries_train, answers_train = ve.vectorize_all('train')
inputs_test, queries_test, answers_test = ve.vectorize_all('test')
# + deletable=true editable=true
print('-')
print('inputs: integer tensor of shape (samples, max_length)')
print('inputs_train shape:', inputs_train.shape)
print('inputs_test shape:', inputs_test.shape)
print('-')
print('queries: integer tensor of shape (samples, max_length)')
print('queries_train shape:', queries_train.shape)
print('queries_test shape:', queries_test.shape)
print('-')
print('answers: binary (1 or 0) tensor of shape (samples, vocab_size)')
print('answers_train shape:', answers_train.shape)
print('answers_test shape:', answers_test.shape)
print('-')
# + deletable=true editable=true
class DeepMemNet:
def __init__(self, vocab_size=22, story_maxlen=68, query_maxlen=4):
# placeholders
input_sequence = Input((story_maxlen,))
question = Input((query_maxlen,))
# encoders
# embed the input sequence into a sequence of vectors
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_size,
output_dim=64))
input_encoder_m.add(Dropout(0.3))
# output: (samples, story_maxlen, embedding_dim)
# embed the input into a sequence of vectors of size query_maxlen
input_encoder_c = Sequential()
input_encoder_c.add(Embedding(input_dim=vocab_size,
output_dim=query_maxlen))
input_encoder_c.add(Dropout(0.3))
# output: (samples, story_maxlen, query_maxlen)
# embed the question into a sequence of vectors
question_encoder = Sequential()
question_encoder.add(Embedding(input_dim=vocab_size,
output_dim=64,
input_length=query_maxlen))
question_encoder.add(Dropout(0.3))
# output: (samples, query_maxlen, embedding_dim)
# encode input sequence and questions (which are indices)
# to sequences of dense vectors
input_encoded_m = input_encoder_m(input_sequence)
input_encoded_c = input_encoder_c(input_sequence)
question_encoded = question_encoder(question)
# compute a 'match' between the first input vector sequence
# and the question vector sequence
# shape: `(samples, story_maxlen, query_maxlen)`
match = dot([input_encoded_m, question_encoded], axes=(2, 2))
match = Activation('softmax')(match)
# add the match matrix with the second input vector sequence
response = add([match, input_encoded_c]) # (samples, story_maxlen, query_maxlen)
response = Permute((2, 1))(response) # (samples, query_maxlen, story_maxlen)
# concatenate the match matrix with the question vector sequence
answer = concatenate([response, question_encoded])
# the original paper uses a matrix multiplication for this reduction step.
# we choose to use a RNN instead.
answer = LSTM(32)(answer) # (samples, 32)
# one regularization layer -- more would probably be needed.
answer = Dropout(0.3)(answer)
answer = Dense(vocab_size)(answer) # (samples, vocab_size)
# we output a probability distribution over the vocabulary
answer = Activation('softmax')(answer)
# build the final model
model = Model([input_sequence, question], answer)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy',
metrics=['accuracy'])
self.model = model
# + deletable=true editable=true
filepath = 'dmn{:02}.hdf5'.format(0)
checkpointer = ModelCheckpoint(monitor='val_acc', filepath=filepath, verbose=1, save_best_only=False)
# + deletable=true editable=true
dmn = DeepMemNet(vocab_size=ve.vocab_size, story_maxlen=ve.story_maxlen, query_maxlen=ve.query_maxlen)
dmn.model.summary()
# + deletable=true editable=true
# train
dmn.model.fit([inputs_train, queries_train], answers_train,
batch_size=32,
epochs=120,
validation_data=([inputs_test, queries_test], answers_test),
verbose=0, callbacks=[checkpointer, TQDMNotebookCallback()])
# + deletable=true editable=true
ans = dmn.model.predict([inputs_test, queries_test])
# + deletable=true editable=true
plt.plot(ans[0])
# + deletable=true editable=true
i = 0
sentence = ve.deindex_sentence(inputs_test[i])
print(sentence)
query = ve.deindex_sentence(queries_test[i])
print(query)
print(ve.devectorize_ans(ans[i]))
| training.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Deep Learning Toolkit for Splunk - Notebook for PyTorch
# ## Logistic Regression in PyTorch
# This notebook contains an example for a simple logistic regression in PyTorch.<br>By default every time you save this notebook the cells are exported into a python module which is then used for executing your custom model invoked by Splunk MLTK Container App.
# ## Stage 0 - import libraries
# At stage 0 we define all imports necessary to run our subsequent code depending on various libraries.
# + deletable=false name="mltkc_import"
# this definition exposes all python module imports that should be available in all subsequent commands
import json
import datetime
import numpy as np
import scipy as sp
import pandas as pd
import torch
# global constants
MODEL_DIRECTORY = "/srv/app/model/data/"
# -
# THIS CELL IS NOT EXPORTED - free notebook cell for testing purposes
print("numpy version: " + np.__version__)
print("scipy version: " + sp.__version__)
print("pandas version: " + pd.__version__)
print("PyTorch: " + torch.__version__)
if torch.cuda.is_available():
print(f"There are {torch.cuda.device_count()} CUDA devices available")
for i in range(0,torch.cuda.device_count()):
print(f"Device {i:0}: {torch.cuda.get_device_name(i)} ")
else:
print("No GPU found")
# ## Stage 1 - get a data sample from Splunk
# In Splunk run a search to pipe a prepared sample dataset into this environment.
# | inputlookup iris.csv <br>
# | fit MLTKContainer mode=stage algo=pytorch_nn epochs=10 species from petal_length petal_width sepal_length sepal_width into app:PyTorch_iris_model_nn
# After you run this search your data set sample is available as a csv inside the container to develop your model. The name is taken from the into keyword ("PyTorch_iris_model" in the example above) or set to "default" if no into keyword is present. This step is intended to work with a subset of your data to create your custom model.
# + deletable=false name="mltkc_stage"
# this cell is not executed from MLTK and should only be used for staging data into the notebook environment
def stage(name):
with open("data/"+name+".csv", 'r') as f:
df = pd.read_csv(f)
with open("data/"+name+".json", 'r') as f:
param = json.load(f)
return df, param
# -
# THIS CELL IS NOT EXPORTED - free notebook cell for testing purposes
df, param = stage("PyTorch_iris_model_nn")
#print(param)
print(df.describe)
# ## Stage 2 - create and initialize a model
# + deletable=false name="mltkc_init"
def init(df,param):
X = df[param['feature_variables']]
Y = df[param['target_variables']]
input_size = int(X.shape[1])
num_classes = len(np.unique(Y.to_numpy()))
learning_rate = 0.001
mapping = { key: value for value,key in enumerate(np.unique(Y.to_numpy().reshape(-1))) }
print("FIT build neural network model with input shape " + str(X.shape))
print("FIT build model with target classes " + str(num_classes))
model = {
"input_size": input_size,
"num_classes": num_classes,
"learning_rate": learning_rate,
"mapping": mapping,
"num_epochs": 10000,
"batch_size": 100,
"hidden_layers" : 10,
}
device = None
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
model['device'] = device
if 'options' in param:
if 'params' in param['options']:
if 'epochs' in param['options']['params']:
model['num_epochs'] = int(param['options']['params']['epochs'])
if 'batch_size' in param['options']['params']:
model['batch_size'] = int(param['options']['params']['batch_size'])
if 'hidden_layers' in param['options']['params']:
model['hidden_layers'] = int(param['options']['params']['hidden_layers'])
# Simple neural network model
model['model'] = torch.nn.Sequential(
torch.nn.Linear(model['input_size'], model['hidden_layers']),
torch.nn.ReLU(),
torch.nn.Linear(model['hidden_layers'], model['num_classes']),
).to(model['device'])
# Define loss and optimizer
model['criterion'] = torch.nn.CrossEntropyLoss()
model['optimizer'] = torch.optim.SGD(model['model'].parameters(), lr=learning_rate)
return model
# -
model = init(df,param)
print(model)
# ## Stage 3 - fit the model
# + deletable=false name="mltkc_fit"
def fit(model,df,param):
returns = {}
X = df[param['feature_variables']].astype('float32').to_numpy()
Y = df[param['target_variables']].to_numpy().reshape(-1)
mapping = { key: value for value,key in enumerate(np.unique(Y)) }
Y = df[param['target_variables']].replace( {param['target_variables'][0]:mapping } ).to_numpy().reshape(-1)
if 'options' in param:
if 'params' in param['options']:
if 'epochs' in param['options']['params']:
model['num_epochs'] = int(param['options']['params']['epochs'])
if 'batch_size' in param['options']['params']:
model['batch_size'] = int(param['options']['params']['batch_size'])
print(model['num_epochs'])
inputs = torch.from_numpy(X).to(model['device'])
targets = torch.from_numpy(Y).to(model['device'])
for epoch in range(model['num_epochs']):
outputs = model['model'](inputs)
loss = model['criterion'](outputs, targets)
model['optimizer'].zero_grad()
loss.backward()
model['optimizer'].step()
if (epoch+1) % (model['num_epochs']/100) == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, model['num_epochs'], loss.item()))
# memorize parameters
returns['model_epochs'] = model['num_epochs']
returns['model_batch_size'] = model['batch_size']
returns['model_loss_acc'] = loss.item()
return returns
# -
returns = fit(model,df,param)
print(returns['model_loss_acc'])
# ## Stage 4 - apply the model
# + deletable=false name="mltkc_apply"
def apply(model,df,param):
X = df[param['feature_variables']].astype('float32').to_numpy()
classes = {v: k for k, v in model['mapping'].items()}
with torch.no_grad():
input = torch.from_numpy(X).to(model['device'])
output = model['model'](input)
y_hat = output.data
_, predicted = torch.max(output.data, 1)
predicted = predicted.cpu()
prediction = [classes[key] for key in predicted.numpy()]
return prediction
# -
y_hat = apply(model,df,param)
y_hat
# ## Stage 5 - save the model
# + deletable=false name="mltkc_save"
# save model to name in expected convention "<algo_name>_<model_name>.h5"
def save(model,name):
torch.save(model, MODEL_DIRECTORY + name + ".pt")
return model
# -
# ## Stage 6 - load the model
# + deletable=false name="mltkc_load"
# load model from name in expected convention "<algo_name>_<model_name>.h5"
def load(name):
model = torch.load(MODEL_DIRECTORY + name + ".pt")
return model
# -
# ## Stage 7 - provide a summary of the model
# + deletable=false name="mltkc_summary"
# return model summary
def summary(model=None):
returns = {"version": {"pytorch": torch.__version__} }
if model is not None:
if 'model' in model:
returns["summary"] = str(model)
return returns
# -
# ## End of Stages
# All subsequent cells are not tagged and can be used for further freeform code
| notebooks/pytorch_nn.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ### Notebook to compile the facs data table from the FlowJo output (+IndexSort plugin).
# .fcs files were gated in FlowJo and well location was preserved using the IndexSort plugin. Bi-exponential transform was applied and the FACS data was exported as the transformed 'channel' tables. To preserve the well location, also the un-transformed 'scale' tables were exported. These tables are beeing merged in this notebook.
import pandas as pd
import os
# +
plates = ['8227_INX_celltype_P1_003',
'8227_INX_celltype_P2_004',
'8227_INX_celltype_P3_005']
path = '../data/facs_data/'
# +
# get all csv files in channel and scale folder
files = [f for f in os.listdir(path+'channel/') if f.endswith(".csv")]
fcs = ['_'.join(x.split('_')[1:-1]) for x in files]
data = pd.DataFrame({'file': files, 'fcs': fcs, 'plate': [plates.index(p) for p in fcs]}).set_index('file')
dfs_channel = [pd.DataFrame() for i in range(len(plates))]
for f in files:
fj = pd.read_csv(path+'channel/{}'.format(f))
dfs_channel[data.loc[f, 'plate']] = dfs_channel[data.loc[f, 'plate']].append(fj)
dfs_scale = [pd.DataFrame() for i in range(len(plates))]
for f in files:
fj = pd.read_csv(path+'scale/{}'.format(f))
dfs_scale[data.loc[f, 'plate']] = dfs_scale[data.loc[f, 'plate']].append(fj)
# replace the index columns with the non-transformed values from scale
for i in range(len(dfs_channel)):
dfs_channel[i].loc[:, ['IdxCol', 'IdxRow', 'Time']] = dfs_scale[i].loc[:, ['IdxCol', 'IdxRow', 'Time']]
# transform row index in letter and make Well column. Somehow, the IdxRow index from FJ is reversed
for i in range(len(dfs_channel)):
dfs_channel[i]["IdxRow"] = dfs_channel[i]["IdxRow"].apply(
lambda x: [
"A",
"B",
"C",
"D",
"E",
"F",
"G",
"H",
"I",
"J",
"K",
"L",
"M",
"N",
"O",
"P",
][-x]
)
dfs_channel[i]["Well"] = dfs_channel[i]["IdxRow"] + dfs_channel[i]["IdxCol"].astype(str)
dfs_channel[i] = dfs_channel[i].rename(columns={'IdxRow': 'Row', 'IdxCol': 'Column'})
# save one table for each plate
[dfs_channel[i].to_csv(path+'facs_data_P{}.txt'.format(i+1), sep='\t', index=False) for i in range(len(dfs_channel))]
# -
| code/compile_facs_data.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# %matplotlib inline
#
# # Clipping images with patches
#
#
# Demo of image that's been clipped by a circular patch.
#
# +
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import matplotlib.cbook as cbook
with cbook.get_sample_data('grace_hopper.png') as image_file:
image = plt.imread(image_file)
fig, ax = plt.subplots()
im = ax.imshow(image)
patch = patches.Circle((260, 200), radius=200, transform=ax.transData)
im.set_clip_path(patch)
ax.axis('off')
plt.show()
# -
# ------------
#
# References
# """"""""""
#
# The use of the following functions and methods is shown
# in this example:
#
#
import matplotlib
matplotlib.axes.Axes.imshow
matplotlib.pyplot.imshow
matplotlib.artist.Artist.set_clip_path
| matplotlib/gallery_jupyter/images_contours_and_fields/image_clip_path.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/Shakestick/HelloWorld/blob/main/Happy_Halloween.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + colab={"base_uri": "https://localhost:8080/"} id="j6H_5Bcd-vR_" outputId="cacd3ef8-ab88-411b-e061-3e7111ecf170"
pip install pyfiglet
# + colab={"base_uri": "https://localhost:8080/"} id="JxMy79Ko-1TB" outputId="3a80b24a-85e0-4fb4-c7d4-0fde1b039113"
import pyfiglet
import sys,time,random
halloween = pyfiglet.figlet_format("H appy Halloween")
typing_speed = 50 #wpm
def slow_type(halloween):
for x in halloween :
sys.stdout.write(x)
sys.stdout.flush()
time.sleep(random.random()*49.0/typing_speed)
slow_type(halloween)
| Happy_Halloween.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/ummeamunira/datavisualization/blob/master/Matplotlib.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="E1wVnmvdc4NQ" colab_type="code" colab={}
# %matplotlib inline
# + [markdown] id="KiVoZFuyc4NT" colab_type="text"
#
# ***********
# Usage Guide
# ***********
#
# This tutorial covers some basic usage patterns and best-practices to
# help you get started with Matplotlib.
#
# + id="jWQAJpsDc4NU" colab_type="code" colab={}
# sphinx_gallery_thumbnail_number = 3
import matplotlib.pyplot as plt
import numpy as np
# + [markdown] id="iTSJG_gGc4NW" colab_type="text"
# A simple example
# ================
#
# Matplotlib graphs your data on `~.figure.Figure`\s (i.e., windows, Jupyter
# widgets, etc.), each of which can contain one or more `~.axes.Axes` (i.e., an
# area where points can be specified in terms of x-y coordinates (or theta-r
# in a polar plot, or x-y-z in a 3D plot, etc.). The most simple way of
# creating a figure with an axes is using `.pyplot.subplots`. We can then use
# `.Axes.plot` to draw some data on the axes:
#
#
# + id="6gpr2MAsc4NX" colab_type="code" colab={}
fig, ax = plt.subplots() # Create a figure containing a single axes.
ax.plot([1, 2, 3, 4], [1, 4, 2, 3]) # Plot some data on the axes.
# + [markdown] id="9-HrV7MCc4Na" colab_type="text"
# Many other plotting libraries or languages do not require you to explicitly
# create an axes. For example, in MATLAB, one can just do
#
# .. code-block:: matlab
#
# plot([1, 2, 3, 4], [1, 4, 2, 3]) % MATLAB plot.
#
# and get the desired graph.
#
# In fact, you can do the same in Matplotlib: for each `~.axes.Axes` graphing
# method, there is a corresponding function in the :mod:`matplotlib.pyplot`
# module that performs that plot on the "current" axes, creating that axes (and
# its parent figure) if they don't exist yet. So the previous example can be
# written more shortly as
#
#
# + id="-buoMViRc4Nb" colab_type="code" colab={}
plt.plot([1, 2, 3, 4], [1, 4, 2, 3]) # Matplotlib plot.
# + [markdown] id="NUwVJNnRc4Nd" colab_type="text"
#
# Parts of a Figure
# =================
#
# Now, let's have a deeper look at the components of a Matplotlib figure.
#
# 
#
#
# :class:`~matplotlib.figure.Figure`
# ----------------------------------
#
# The **whole** figure. The figure keeps
# track of all the child :class:`~matplotlib.axes.Axes`, a smattering of
# 'special' artists (titles, figure legends, etc), and the **canvas**.
# (Don't worry too much about the canvas, it is crucial as it is the
# object that actually does the drawing to get you your plot, but as the
# user it is more-or-less invisible to you). A figure can contain any
# number of :class:`~matplotlib.axes.Axes`, but will typically have
# at least one.
#
# The easiest way to create a new figure is with pyplot::
#
# fig = plt.figure() # an empty figure with no Axes
# fig, ax = plt.subplots() # a figure with a single Axes
# fig, axs = plt.subplots(2, 2) # a figure with a 2x2 grid of Axes
#
# It's convenient to create the axes together with the figure, but you can
# also add axes later on, allowing for more complex axes layouts.
#
# :class:`~matplotlib.axes.Axes`
# ------------------------------
#
# This is what you think of as 'a plot', it is the region of the image
# with the data space. A given figure
# can contain many Axes, but a given :class:`~matplotlib.axes.Axes`
# object can only be in one :class:`~matplotlib.figure.Figure`. The
# Axes contains two (or three in the case of 3D)
# :class:`~matplotlib.axis.Axis` objects (be aware of the difference
# between **Axes** and **Axis**) which take care of the data limits (the
# data limits can also be controlled via the :meth:`.axes.Axes.set_xlim` and
# :meth:`.axes.Axes.set_ylim` methods). Each :class:`~.axes.Axes` has a title
# (set via :meth:`~matplotlib.axes.Axes.set_title`), an x-label (set via
# :meth:`~matplotlib.axes.Axes.set_xlabel`), and a y-label set via
# :meth:`~matplotlib.axes.Axes.set_ylabel`).
#
# The :class:`~.axes.Axes` class and its member functions are the primary entry
# point to working with the OO interface.
#
# :class:`~matplotlib.axis.Axis`
# ------------------------------
#
# These are the number-line-like objects. They take
# care of setting the graph limits and generating the ticks (the marks
# on the axis) and ticklabels (strings labeling the ticks). The location of
# the ticks is determined by a `~matplotlib.ticker.Locator` object and the
# ticklabel strings are formatted by a `~matplotlib.ticker.Formatter`. The
# combination of the correct `.Locator` and `.Formatter` gives very fine
# control over the tick locations and labels.
#
# :class:`~matplotlib.artist.Artist`
# ----------------------------------
#
# Basically everything you can see on the figure is an artist (even the
# `.Figure`, `Axes <.axes.Axes>`, and `~.axis.Axis` objects). This includes
# `.Text` objects, `.Line2D` objects, :mod:`.collections` objects, `.Patch`
# objects ... (you get the idea). When the figure is rendered, all of the
# artists are drawn to the **canvas**. Most Artists are tied to an Axes; such
# an Artist cannot be shared by multiple Axes, or moved from one to another.
#
#
# Types of inputs to plotting functions
# =====================================
#
# All of plotting functions expect `numpy.array` or `numpy.ma.masked_array` as
# input. Classes that are 'array-like' such as `pandas` data objects
# and `numpy.matrix` may or may not work as intended. It is best to
# convert these to `numpy.array` objects prior to plotting.
#
# For example, to convert a `pandas.DataFrame` ::
#
# a = pandas.DataFrame(np.random.rand(4,5), columns = list('abcde'))
# a_asarray = a.values
#
# and to convert a `numpy.matrix` ::
#
# b = np.matrix([[1, 2], [3, 4]])
# b_asarray = np.asarray(b)
#
#
# The object-oriented interface and the pyplot interface
# ======================================================
#
# As noted above, there are essentially two ways to use Matplotlib:
#
# - Explicitly create figures and axes, and call methods on them (the
# "object-oriented (OO) style").
# - Rely on pyplot to automatically create and manage the figures and axes, and
# use pyplot functions for plotting.
#
# So one can do (OO-style)
#
#
# + id="e37HLNN3c4Nd" colab_type="code" colab={}
x = np.linspace(0, 2, 100)
# Note that even in the OO-style, we use `.pyplot.figure` to create the figure.
fig, ax = plt.subplots() # Create a figure and an axes.
ax.plot(x, x, label='linear') # Plot some data on the axes.
ax.plot(x, x**2, label='quadratic') # Plot more data on the axes...
ax.plot(x, x**3, label='cubic') # ... and some more.
ax.set_xlabel('x label') # Add an x-label to the axes.
ax.set_ylabel('y label') # Add a y-label to the axes.
ax.set_title("Simple Plot") # Add a title to the axes.
ax.legend() # Add a legend.
# + [markdown] id="9VeUlGOcc4Nf" colab_type="text"
# or (pyplot-style)
#
#
# + id="8W8P1Lytc4Ng" colab_type="code" colab={}
x = np.linspace(0, 2, 100)
plt.plot(x, x, label='linear') # Plot some data on the (implicit) axes.
plt.plot(x, x**2, label='quadratic') # etc.
plt.plot(x, x**3, label='cubic')
plt.xlabel('x label')
plt.ylabel('y label')
plt.title("Simple Plot")
plt.legend()
# + [markdown] id="_QedY9Nac4Ni" colab_type="text"
# Actually there is a third approach, for the case where you are embedding
# Matplotlib in a GUI application, which completely drops pyplot, even for
# figure creation. We won't discuss it here; see the corresponding section in
# the gallery for more info (`user_interfaces`).
#
# Matplotlib's documentation and examples use both the OO and the pyplot
# approaches (which are equally powerful), and you should feel free to use
# either (however, it is preferable pick one of them and stick to it, instead
# of mixing them). In general, we suggest to restrict pyplot to interactive
# plotting (e.g., in a Jupyter notebook), and to prefer the OO-style for
# non-interactive plotting (in functions and scripts that are intended to be
# reused as part of a larger project).
#
# <div class="alert alert-info"><h4>Note</h4><p>In older examples, you may find examples that instead used the so-called
# ``pylab`` interface, via ``from pylab import *``. This star-import
# imports everything both from pyplot and from :mod:`numpy`, so that one
# could do ::
#
# x = linspace(0, 2, 100)
# plot(x, x, label='linear')
# ...
#
# for an even more MATLAB-like style. This approach is strongly discouraged
# nowadays and deprecated; it is only mentioned here because you may still
# encounter it in the wild.</p></div>
#
# Typically one finds oneself making the same plots over and over
# again, but with different data sets, which leads to needing to write
# specialized functions to do the plotting. The recommended function
# signature is something like:
#
#
# + id="BgngWNQyc4Nj" colab_type="code" colab={}
def my_plotter(ax, data1, data2, param_dict):
"""
A helper function to make a graph
Parameters
----------
ax : Axes
The axes to draw to
data1 : array
The x data
data2 : array
The y data
param_dict : dict
Dictionary of kwargs to pass to ax.plot
Returns
-------
out : list
list of artists added
"""
out = ax.plot(data1, data2, **param_dict)
return out
# + [markdown] id="bN1Ks1VLc4Nl" colab_type="text"
# which you would then use as:
#
#
# + id="3D-PxTJ8c4Nl" colab_type="code" colab={}
data1, data2, data3, data4 = np.random.randn(4, 100)
fig, ax = plt.subplots(1, 1)
my_plotter(ax, data1, data2, {'marker': 'x'})
# + [markdown] id="znKhQqHEc4Nn" colab_type="text"
# or if you wanted to have 2 sub-plots:
#
#
# + id="bbMUru10c4No" colab_type="code" colab={}
fig, (ax1, ax2) = plt.subplots(1, 2)
my_plotter(ax1, data1, data2, {'marker': 'x'})
my_plotter(ax2, data3, data4, {'marker': 'o'})
# + [markdown] id="58lPsb9tc4Np" colab_type="text"
# For these simple examples this style seems like overkill, however
# once the graphs get slightly more complex it pays off.
#
#
#
# Backends
# ========
#
#
# What is a backend?
# ------------------
#
# A lot of documentation on the website and in the mailing lists refers
# to the "backend" and many new users are confused by this term.
# matplotlib targets many different use cases and output formats. Some
# people use matplotlib interactively from the python shell and have
# plotting windows pop up when they type commands. Some people run
# `Jupyter <https://jupyter.org>`_ notebooks and draw inline plots for
# quick data analysis. Others embed matplotlib into graphical user
# interfaces like wxpython or pygtk to build rich applications. Some
# people use matplotlib in batch scripts to generate postscript images
# from numerical simulations, and still others run web application
# servers to dynamically serve up graphs.
#
# To support all of these use cases, matplotlib can target different
# outputs, and each of these capabilities is called a backend; the
# "frontend" is the user facing code, i.e., the plotting code, whereas the
# "backend" does all the hard work behind-the-scenes to make the figure.
# There are two types of backends: user interface backends (for use in
# pygtk, wxpython, tkinter, qt4, or macosx; also referred to as
# "interactive backends") and hardcopy backends to make image files
# (PNG, SVG, PDF, PS; also referred to as "non-interactive backends").
#
# Selecting a backend
# -------------------
#
# There are three ways to configure your backend:
#
# 1. The :rc:`backend` parameter in your ``matplotlibrc`` file
# 2. The :envvar:`MPLBACKEND` environment variable
# 3. The function :func:`matplotlib.use`
#
# A more detailed description is given below.
#
# If multiple of these are configurations are present, the last one from the
# list takes precedence; e.g. calling :func:`matplotlib.use()` will override
# the setting in your ``matplotlibrc``.
#
# If no backend is explicitly set, Matplotlib automatically detects a usable
# backend based on what is available on your system and on whether a GUI event
# loop is already running. On Linux, if the environment variable
# :envvar:`DISPLAY` is unset, the "event loop" is identified as "headless",
# which causes a fallback to a noninteractive backend (agg).
#
# Here is a detailed description of the configuration methods:
#
# #. Setting :rc:`backend` in your ``matplotlibrc`` file::
#
# backend : qt5agg # use pyqt5 with antigrain (agg) rendering
#
# See also :doc:`/tutorials/introductory/customizing`.
#
# #. Setting the :envvar:`MPLBACKEND` environment variable:
#
# You can set the environment variable either for your current shell or for
# a single script.
#
# On Unix::
#
# > export MPLBACKEND=qt5agg
# > python simple_plot.py
#
# > MPLBACKEND=qt5agg python simple_plot.py
#
# On Windows, only the former is possible::
#
# > set MPLBACKEND=qt5agg
# > python simple_plot.py
#
# Setting this environment variable will override the ``backend`` parameter
# in *any* ``matplotlibrc``, even if there is a ``matplotlibrc`` in your
# current working directory. Therefore, setting :envvar:`MPLBACKEND`
# globally, e.g. in your ``.bashrc`` or ``.profile``, is discouraged as it
# might lead to counter-intuitive behavior.
#
# #. If your script depends on a specific backend you can use the function
# :func:`matplotlib.use`::
#
# import matplotlib
# matplotlib.use('qt5agg')
#
# This should be done before any figure is created; otherwise Matplotlib may
# fail to switch the backend and raise an ImportError.
#
# Using `~matplotlib.use` will require changes in your code if users want to
# use a different backend. Therefore, you should avoid explicitly calling
# `~matplotlib.use` unless absolutely necessary.
#
#
# The builtin backends
# --------------------
#
# By default, Matplotlib should automatically select a default backend which
# allows both interactive work and plotting from scripts, with output to the
# screen and/or to a file, so at least initially you will not need to worry
# about the backend. The most common exception is if your Python distribution
# comes without :mod:`tkinter` and you have no other GUI toolkit installed;
# this happens on certain Linux distributions, where you need to install a
# Linux package named ``python-tk`` (or similar).
#
# If, however, you want to write graphical user interfaces, or a web
# application server (`howto-webapp`), or need a better
# understanding of what is going on, read on. To make things a little
# more customizable for graphical user interfaces, matplotlib separates
# the concept of the renderer (the thing that actually does the drawing)
# from the canvas (the place where the drawing goes). The canonical
# renderer for user interfaces is ``Agg`` which uses the `Anti-Grain
# Geometry`_ C++ library to make a raster (pixel) image of the figure; it
# is used by the ``Qt5Agg``, ``Qt4Agg``, ``GTK3Agg``, ``wxAgg``, ``TkAgg``, and
# ``macosx`` backends. An alternative renderer is based on the Cairo library,
# used by ``Qt5Cairo``, ``Qt4Cairo``, etc.
#
# For the rendering engines, one can also distinguish between `vector
# <https://en.wikipedia.org/wiki/Vector_graphics>`_ or `raster
# <https://en.wikipedia.org/wiki/Raster_graphics>`_ renderers. Vector
# graphics languages issue drawing commands like "draw a line from this
# point to this point" and hence are scale free, and raster backends
# generate a pixel representation of the line whose accuracy depends on a
# DPI setting.
#
# Here is a summary of the matplotlib renderers (there is an eponymous
# backend for each; these are *non-interactive backends*, capable of
# writing to a file):
#
# ======== ========= =======================================================
# Renderer Filetypes Description
# ======== ========= =======================================================
# AGG png raster_ graphics -- high quality images using the
# `Anti-Grain Geometry`_ engine
# PS ps, vector_ graphics -- Postscript_ output
# eps
# PDF pdf vector_ graphics -- `Portable Document Format`_
# SVG svg vector_ graphics -- `Scalable Vector Graphics`_
# Cairo png, ps, raster_ or vector_ graphics -- using the Cairo_ library
# pdf, svg
# ======== ========= =======================================================
#
# To save plots using the non-interactive backends, use the
# ``matplotlib.pyplot.savefig('filename')`` method.
#
# To save plots using the non-interactive backends, use the
# ``matplotlib.pyplot.savefig('filename')`` method.
#
# And here are the user interfaces and renderer combinations supported;
# these are *interactive backends*, capable of displaying to the screen
# and of using appropriate renderers from the table above to write to
# a file:
#
# ========= ================================================================
# Backend Description
# ========= ================================================================
# Qt5Agg Agg rendering in a :term:`Qt5` canvas (requires PyQt5_). This
# backend can be activated in IPython with ``%matplotlib qt5``.
# ipympl Agg rendering embedded in a Jupyter widget. (requires ipympl).
# This backend can be enabled in a Jupyter notebook with
# ``%matplotlib ipympl``.
# GTK3Agg Agg rendering to a :term:`GTK` 3.x canvas (requires PyGObject_,
# and pycairo_ or cairocffi_). This backend can be activated in
# IPython with ``%matplotlib gtk3``.
# macosx Agg rendering into a Cocoa canvas in OSX. This backend can be
# activated in IPython with ``%matplotlib osx``.
# TkAgg Agg rendering to a :term:`Tk` canvas (requires TkInter_). This
# backend can be activated in IPython with ``%matplotlib tk``.
# nbAgg Embed an interactive figure in a Jupyter classic notebook. This
# backend can be enabled in Jupyter notebooks via
# ``%matplotlib notebook``.
# WebAgg On ``show()`` will start a tornado server with an interactive
# figure.
# GTK3Cairo Cairo rendering to a :term:`GTK` 3.x canvas (requires PyGObject_,
# and pycairo_ or cairocffi_).
# Qt4Agg Agg rendering to a :term:`Qt4` canvas (requires PyQt4_ or
# ``pyside``). This backend can be activated in IPython with
# ``%matplotlib qt4``.
# wxAgg Agg rendering to a :term:`wxWidgets` canvas (requires wxPython_ 4).
# This backend can be activated in IPython with ``%matplotlib wx``.
# ========= ================================================================
#
# <div class="alert alert-info"><h4>Note</h4><p>The names of builtin backends case-insensitive; e.g., 'Qt5Agg' and
# 'qt5agg' are equivalent.</p></div>
#
#
# ipympl
# ^^^^^^
#
# The Jupyter widget ecosystem is moving too fast to support directly in
# Matplotlib. To install ipympl
#
# .. code-block:: bash
#
# pip install ipympl
# jupyter nbextension enable --py --sys-prefix ipympl
#
# or
#
# .. code-block:: bash
#
# conda install ipympl -c conda-forge
#
# See `jupyter-matplotlib <https://github.com/matplotlib/jupyter-matplotlib>`__
# for more details.
#
# GTK and Cairo
# ^^^^^^^^^^^^^
#
# ``GTK3`` backends (*both* ``GTK3Agg`` and ``GTK3Cairo``) depend on Cairo
# (pycairo>=1.11.0 or cairocffi).
#
#
# How do I select PyQt4 or PySide?
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
#
# The :envvar:`QT_API` environment variable can be set to either ``pyqt`` or
# ``pyside`` to use ``PyQt4`` or ``PySide``, respectively.
#
# Since the default value for the bindings to be used is ``PyQt4``, Matplotlib
# first tries to import it, if the import fails, it tries to import ``PySide``.
#
# Using non-builtin backends
# --------------------------
# More generally, any importable backend can be selected by using any of the
# methods above. If ``name.of.the.backend`` is the module containing the
# backend, use ``module://name.of.the.backend`` as the backend name, e.g.
# ``matplotlib.use('module://name.of.the.backend')``.
#
#
#
# What is interactive mode?
# =========================
#
# Use of an interactive backend (see `what-is-a-backend`)
# permits--but does not by itself require or ensure--plotting
# to the screen. Whether and when plotting to the screen occurs,
# and whether a script or shell session continues after a plot
# is drawn on the screen, depends on the functions and methods
# that are called, and on a state variable that determines whether
# matplotlib is in "interactive mode". The default Boolean value is set
# by the :file:`matplotlibrc` file, and may be customized like any other
# configuration parameter (see :doc:`/tutorials/introductory/customizing`). It
# may also be set via :func:`matplotlib.interactive`, and its
# value may be queried via :func:`matplotlib.is_interactive`. Turning
# interactive mode on and off in the middle of a stream of plotting
# commands, whether in a script or in a shell, is rarely needed
# and potentially confusing, so in the following we will assume all
# plotting is done with interactive mode either on or off.
#
# <div class="alert alert-info"><h4>Note</h4><p>Major changes related to interactivity, and in particular the
# role and behavior of :func:`~matplotlib.pyplot.show`, were made in the
# transition to matplotlib version 1.0, and bugs were fixed in
# 1.0.1. Here we describe the version 1.0.1 behavior for the
# primary interactive backends, with the partial exception of
# *macosx*.</p></div>
#
# Interactive mode may also be turned on via :func:`matplotlib.pyplot.ion`,
# and turned off via :func:`matplotlib.pyplot.ioff`.
#
# <div class="alert alert-info"><h4>Note</h4><p>Interactive mode works with suitable backends in ipython and in
# the ordinary python shell, but it does *not* work in the IDLE IDE.
# If the default backend does not support interactivity, an interactive
# backend can be explicitly activated using any of the methods discussed
# in `What is a backend?`_.</p></div>
#
#
# Interactive example
# --------------------
#
# From an ordinary python prompt, or after invoking ipython with no options,
# try this::
#
# import matplotlib.pyplot as plt
# plt.ion()
# plt.plot([1.6, 2.7])
#
# This will pop up a plot window. Your terminal prompt will remain active, so
# that you can type additional commands such as::
#
# plt.title("interactive test")
# plt.xlabel("index")
#
# On most interactive backends, the figure window will also be updated if you
# change it via the object-oriented interface. E.g. get a reference to the
# `~matplotlib.axes.Axes` instance, and call a method of that instance::
#
# ax = plt.gca()
# ax.plot([3.1, 2.2])
#
# If you are using certain backends (like ``macosx``), or an older version
# of matplotlib, you may not see the new line added to the plot immediately.
# In this case, you need to explicitly call :func:`~matplotlib.pyplot.draw`
# in order to update the plot::
#
# plt.draw()
#
#
# Non-interactive example
# -----------------------
#
# Start a fresh session as in the previous example, but now
# turn interactive mode off::
#
# import matplotlib.pyplot as plt
# plt.ioff()
# plt.plot([1.6, 2.7])
#
# Nothing happened--or at least nothing has shown up on the
# screen (unless you are using *macosx* backend, which is
# anomalous). To make the plot appear, you need to do this::
#
# plt.show()
#
# Now you see the plot, but your terminal command line is
# unresponsive; the :func:`.pyplot.show()` command *blocks* the input
# of additional commands until you manually kill the plot
# window.
#
# What good is this--being forced to use a blocking function?
# Suppose you need a script that plots the contents of a file
# to the screen. You want to look at that plot, and then end
# the script. Without some blocking command such as ``show()``, the
# script would flash up the plot and then end immediately,
# leaving nothing on the screen.
#
# In addition, non-interactive mode delays all drawing until
# ``show()`` is called; this is more efficient than redrawing
# the plot each time a line in the script adds a new feature.
#
# Prior to version 1.0, ``show()`` generally could not be called
# more than once in a single script (although sometimes one
# could get away with it); for version 1.0.1 and above, this
# restriction is lifted, so one can write a script like this::
#
# import numpy as np
# import matplotlib.pyplot as plt
#
# plt.ioff()
# for i in range(3):
# plt.plot(np.random.rand(10))
# plt.show()
#
# which makes three plots, one at a time. I.e. the second plot will show up,
# once the first plot is closed.
#
# Summary
# -------
#
# In interactive mode, pyplot functions automatically draw
# to the screen.
#
# When plotting interactively, if using
# object method calls in addition to pyplot functions, then
# call :func:`~matplotlib.pyplot.draw` whenever you want to
# refresh the plot.
#
# Use non-interactive mode in scripts in which you want to
# generate one or more figures and display them before ending
# or generating a new set of figures. In that case, use
# :func:`~matplotlib.pyplot.show` to display the figure(s) and
# to block execution until you have manually destroyed them.
#
#
# Performance
# ===========
#
# Whether exploring data in interactive mode or programmatically
# saving lots of plots, rendering performance can be a painful
# bottleneck in your pipeline. Matplotlib provides a couple
# ways to greatly reduce rendering time at the cost of a slight
# change (to a settable tolerance) in your plot's appearance.
# The methods available to reduce rendering time depend on the
# type of plot that is being created.
#
# Line segment simplification
# ---------------------------
#
# For plots that have line segments (e.g. typical line plots,
# outlines of polygons, etc.), rendering performance can be
# controlled by the ``path.simplify`` and
# ``path.simplify_threshold`` parameters in your
# ``matplotlibrc`` file (see
# :doc:`/tutorials/introductory/customizing` for
# more information about the ``matplotlibrc`` file).
# The ``path.simplify`` parameter is a boolean indicating whether
# or not line segments are simplified at all. The
# ``path.simplify_threshold`` parameter controls how much line
# segments are simplified; higher thresholds result in quicker
# rendering.
#
# The following script will first display the data without any
# simplification, and then display the same data with simplification.
# Try interacting with both of them::
#
# import numpy as np
# import matplotlib.pyplot as plt
# import matplotlib as mpl
#
# # Setup, and create the data to plot
# y = np.random.rand(100000)
# y[50000:] *= 2
# y[np.logspace(1, np.log10(50000), 400).astype(int)] = -1
# mpl.rcParams['path.simplify'] = True
#
# mpl.rcParams['path.simplify_threshold'] = 0.0
# plt.plot(y)
# plt.show()
#
# mpl.rcParams['path.simplify_threshold'] = 1.0
# plt.plot(y)
# plt.show()
#
# Matplotlib currently defaults to a conservative simplification
# threshold of ``1/9``. If you want to change your default settings
# to use a different value, you can change your ``matplotlibrc``
# file. Alternatively, you could create a new style for
# interactive plotting (with maximal simplification) and another
# style for publication quality plotting (with minimal
# simplification) and activate them as necessary. See
# :doc:`/tutorials/introductory/customizing` for
# instructions on how to perform these actions.
#
# The simplification works by iteratively merging line segments
# into a single vector until the next line segment's perpendicular
# distance to the vector (measured in display-coordinate space)
# is greater than the ``path.simplify_threshold`` parameter.
#
# <div class="alert alert-info"><h4>Note</h4><p>Changes related to how line segments are simplified were made
# in version 2.1. Rendering time will still be improved by these
# parameters prior to 2.1, but rendering time for some kinds of
# data will be vastly improved in versions 2.1 and greater.</p></div>
#
# Marker simplification
# ---------------------
#
# Markers can also be simplified, albeit less robustly than
# line segments. Marker simplification is only available
# to :class:`~matplotlib.lines.Line2D` objects (through the
# ``markevery`` property). Wherever
# :class:`~matplotlib.lines.Line2D` construction parameters
# are passed through, such as
# :func:`matplotlib.pyplot.plot` and
# :meth:`matplotlib.axes.Axes.plot`, the ``markevery``
# parameter can be used::
#
# plt.plot(x, y, markevery=10)
#
# The markevery argument allows for naive subsampling, or an
# attempt at evenly spaced (along the *x* axis) sampling. See the
# :doc:`/gallery/lines_bars_and_markers/markevery_demo`
# for more information.
#
# Splitting lines into smaller chunks
# -----------------------------------
#
# If you are using the Agg backend (see `what-is-a-backend`),
# then you can make use of the ``agg.path.chunksize`` rc parameter.
# This allows you to specify a chunk size, and any lines with
# greater than that many vertices will be split into multiple
# lines, each of which has no more than ``agg.path.chunksize``
# many vertices. (Unless ``agg.path.chunksize`` is zero, in
# which case there is no chunking.) For some kind of data,
# chunking the line up into reasonable sizes can greatly
# decrease rendering time.
#
# The following script will first display the data without any
# chunk size restriction, and then display the same data with
# a chunk size of 10,000. The difference can best be seen when
# the figures are large, try maximizing the GUI and then
# interacting with them::
#
# import numpy as np
# import matplotlib.pyplot as plt
# import matplotlib as mpl
# mpl.rcParams['path.simplify_threshold'] = 1.0
#
# # Setup, and create the data to plot
# y = np.random.rand(100000)
# y[50000:] *= 2
# y[np.logspace(1, np.log10(50000), 400).astype(int)] = -1
# mpl.rcParams['path.simplify'] = True
#
# mpl.rcParams['agg.path.chunksize'] = 0
# plt.plot(y)
# plt.show()
#
# mpl.rcParams['agg.path.chunksize'] = 10000
# plt.plot(y)
# plt.show()
#
# Legends
# -------
#
# The default legend behavior for axes attempts to find the location
# that covers the fewest data points (``loc='best'``). This can be a
# very expensive computation if there are lots of data points. In
# this case, you may want to provide a specific location.
#
# Using the *fast* style
# ----------------------
#
# The *fast* style can be used to automatically set
# simplification and chunking parameters to reasonable
# settings to speed up plotting large amounts of data.
# It can be used simply by running::
#
# import matplotlib.style as mplstyle
# mplstyle.use('fast')
#
# It is very light weight, so it plays nicely with other
# styles, just make sure the fast style is applied last
# so that other styles do not overwrite the settings::
#
# mplstyle.use(['dark_background', 'ggplot', 'fast'])
#
#
| Matplotlib.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
def quick_sort(list): #extra-place
s = []
b = []
k = []
if len(list) <= 1:
return list
else:
key = list[0] #第一個數為key值
for i in list:
if i < key: #比key值小的數
s.append(i)
elif i > key: #比key值大的數
b.append(i)
else:
k.append(i)
s = quick_sort(s)
b = quick_sort(b)
return s + k + b
mylist = [3,16,22,11,2,37,57,55,21]
print("result:",quick_sort(mylist))
| HW1/quicksort.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: env_melusine37
# language: python
# name: env_melusine37
# ---
# # Comparison of the various model architectures tutorial
# In the NeuralModel class, we propose several standard neural architectures for text classification. In particular, we include the well known `bert` architecture that usually allows for a significant improvement in NLP tasks.
#
# * `RNN` are widely used for text processing.
# * `CNN` or Convolutional Neural Networks are usually used for image classification tasks but give excellent results, comparable to the `RNN`, in our case.
# * `Attentive` Neural Networks emerged recently for text processing and shows extremely promissing results. We therefore decided to include such models as part of Melusine and ease their used for email processing. We propose both an original attentive-based classifier as well as a wrap-up for a standard `Bert classifier`.
#
# All our architectures follow the same general pattern: the email and header texts are embedded using one of the encoder listed above. The text vector is concatenated with a vector built using the email meta data (hour, email domain, email attachement ...)
#
# In this tutorial we compare the different models' characteristics such as inference & training time, precision and architecture.
# ## Dataset preparation
#
# The dataset preparation is developped in **tutorial 07: models**.
# +
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID";
# The GPU id to use, usually either "0" or "1", or "" to use CPU;
os.environ["CUDA_VISIBLE_DEVICES"]="";
# +
# load inputs
import numpy as np
import pandas as pd
from copy import deepcopy
from sklearn.preprocessing import LabelEncoder
from melusine import load_email_data
# Text input
df_emails_preprocessed = load_email_data(type="preprocessed")
df_emails_preprocessed['clean_text'] = df_emails_preprocessed['clean_header'] + " " + df_emails_preprocessed['clean_body']
# Metadata input
df_meta = pd.read_csv('/home/78169t/melusine/melusine/data/metadata.csv', encoding='utf-8', sep=';')
# Dataset
X = pd.concat([df_emails_preprocessed['clean_text'],df_meta],axis=1)
y = df_emails_preprocessed['label']
le = LabelEncoder()
y = le.fit_transform(y)
# +
from melusine.nlp_tools.embedding import Embedding
pretrained_embedding = Embedding(
tokens_column='tokens',
workers=1,
min_count=5
)
pretrained_embedding.train(df_emails_preprocessed)
# -
# ## Models
# +
import tensorflow.keras.backend as K
import time
from melusine.models.train import NeuralModel
from melusine.models.neural_architectures import cnn_model, rnn_model, transformers_model, bert_model
from sklearn.metrics import accuracy_score, classification_report
# -
# #!pip install psutil
import psutil
def get_available_memory():
return psutil.virtual_memory()._asdict()['available']
# ### RNN
#
# `RNN` are traditionally used with textual data as they are specifically designed to handle sequentially structured data. Inputs are sequentially computed given a cell operation, generally a `LSTM` or `GRU` cell. At each step, the current input as well as the output from the previous step are used to compute the next hidden state. The proposed architecture includes a 2-layers bidirectional `GRU` network. The network last hidden state is used as the final sentence embedding.
#
# <img src="./images/rnn-model.png" style="width:500px">
memory_start = get_available_memory()
RNN_model = NeuralModel(architecture_function=rnn_model,
pretrained_embedding=pretrained_embedding,
text_input_column="clean_text",
meta_input_list=['extension', 'dayofweek', 'hour', 'min','attachment_type'],
n_epochs=1)
training_start = time.time()
RNN_model.fit(X, y)
training_end = time.time()
RNN_memory = memory_start - get_available_memory()
RNN_memory = round(RNN_memory / 1e9 * 1024 , 1)
print('RNN is using {} Mb memory (RAM).'.format(str(RNN_memory)))
RNN_N_trainable_parameters = int(np.sum([K.count_params(p) for p in RNN_model.model.trainable_weights]))
RNN_N_non_trainable_parameters = int(np.sum([K.count_params(p) for p in RNN_model.model.non_trainable_weights]))
RNN_training_time = round(training_end - training_start, 2)
RNN_N_trainable_parameters, RNN_N_non_trainable_parameters, RNN_training_time
y_res = []
inference_start = time.time()
for i in range(X.shape[0]):
X_copy = deepcopy(X.loc[i:i, :])
y_res.append(RNN_model.predict(X_copy))
y_res = le.inverse_transform(np.ravel(y_res))
inference_end = time.time()
RNN_inference_time = round((inference_end - inference_start)/len(y_res) * 1000, 2)
RNN_accuracy = accuracy_score(y_res, le.inverse_transform(y))
RNN_cls_report = classification_report(le.inverse_transform(y), y_res, output_dict=True, zero_division=0)
# ### CNN
#
# `CNN` uses multiple filters to discriminate patterns in data. Such filters are assembled across the hidden layers to build more complex patterns and structures. The last layer should therefore capture a global and generic representation of the data. In our architecture, we use a two hidden layers `CNN` with respectively 200 filters for each hidden layer. The last hidden states are aggregated using a max pooling operation.
#
# <img src="./images/cnn-model.png" style="width:500px">
memory_start = get_available_memory()
CNN_model = NeuralModel(architecture_function=cnn_model,
pretrained_embedding=pretrained_embedding,
text_input_column="clean_text",
meta_input_list=['extension', 'dayofweek', 'hour', 'min', 'attachment_type'],
n_epochs=1)
training_start = time.time()
CNN_model.fit(X, y)
training_end = time.time()
CNN_memory = memory_start - get_available_memory()
CNN_memory = round(CNN_memory / 1e9 * 1024 , 1)
print('CNN is using {} Mb memory (RAM).'.format(str(CNN_memory)))
CNN_N_trainable_parameters = int(np.sum([K.count_params(p) for p in CNN_model.model.trainable_weights]))
CNN_N_non_trainable_parameters = int(np.sum([K.count_params(p) for p in CNN_model.model.non_trainable_weights]))
CNN_training_time = round(training_end - training_start, 2)
CNN_N_trainable_parameters, CNN_N_non_trainable_parameters, CNN_training_time
y_res = []
inference_start = time.time()
for i in range(X.shape[0]):
X_copy = deepcopy(X.loc[i:i, :])
y_res.append(CNN_model.predict(X_copy))
y_res = le.inverse_transform(np.ravel(y_res))
inference_end = time.time()
CNN_inference_time = round((inference_end - inference_start)/len(y_res) * 1000, 2)
CNN_accuracy = accuracy_score(y_res, le.inverse_transform(y))
CNN_cls_report = classification_report(le.inverse_transform(y), y_res, output_dict=True, zero_division=0)
# ### Transformer
#
# #### Multi-heads Attention Classifier
#
# Attentive-based neural networks are fairly new in the NLP community but results are extremely promising. They rely on the self-attention operation which computes hidden states as a weighted sum from the inputs. As the multiple filters in the `CNN` architecture, the multi-branch attention aggregate multiple attention operation to capture various properties from the input. Such operation is easily perform on GPU infrastructure. We propose an architecture inspired from previously introduced RNN and CNN architecture with a two layers multi-branch attention module follow by a max pooling operation.
#
# <img src="./images/transformer-model.png" style="width:500px">
memory_start = get_available_memory()
Transformer_model = NeuralModel(architecture_function=transformers_model,
pretrained_embedding=pretrained_embedding,
text_input_column="clean_text",
meta_input_list=['extension', 'dayofweek', 'hour', 'min', 'attachment_type'],
n_epochs=1)
training_start = time.time()
Transformer_model.fit(X, y)
training_end = time.time()
Transformer_memory = memory_start - get_available_memory()
Transformer_memory = round(Transformer_memory / 1e9 * 1024 , 1)
print('Transformer is using {} Mb memory (RAM).'.format(str(Transformer_memory)))
Transformer_N_trainable_parameters = int(np.sum([K.count_params(p) for p in Transformer_model.model.trainable_weights]))
Transformer_N_non_trainable_parameters = int(np.sum([K.count_params(p) for p in Transformer_model.model.non_trainable_weights]))
Transformer_training_time = round(training_end - training_start, 2)
Transformer_N_trainable_parameters, Transformer_N_non_trainable_parameters, Transformer_training_time
y_res = []
inference_start = time.time()
for i in range(X.shape[0]):
X_copy = deepcopy(X.loc[i:i, :])
y_res.append(Transformer_model.predict(X_copy))
y_res = le.inverse_transform(np.ravel(y_res))
inference_end = time.time()
Transformer_inference_time = round((inference_end - inference_start)/len(y_res) * 1000, 2)
Transformer_accuracy = accuracy_score(y_res, le.inverse_transform(y))
Transformer_cls_report = classification_report(le.inverse_transform(y), y_res, output_dict=True, zero_division=0)
# #### Bert Model
#
# We also propose a wrap-up for the popular pre-trained `bert` architecture. `bert` architecture encodes every sentence tokens with a contextualized embeddings: each words embeddings depends from all words in the sentence. However, we only use the first sentence embedding, usually called the **classification token** in our classifier model.
#
# <img src="./images/bert-model.png" style="width:500px">
#
#
# Bert tokenizers and models can be downloaded here: https://huggingface.co/transformers/pretrained_models.html
#
# Only Camembert and Flaubert are available now in Melusine.
# ### Camembert
memory_start = get_available_memory()
CamemBert_model = NeuralModel(architecture_function=bert_model,
pretrained_embedding=None,
text_input_column="clean_text",
meta_input_list=['extension', 'dayofweek', 'hour', 'min', 'attachment_type'],
n_epochs=1,
bert_tokenizer='jplu/tf-camembert-base',
bert_model='jplu/tf-camembert-base')
training_start = time.time()
CamemBert_model.fit(X, y)
training_end = time.time()
CamemBert_memory = memory_start - get_available_memory()
CamemBert_memory = round(CamemBert_memory / 1e9 * 1024 , 1)
print('CamemBert is using {} Mb memory (RAM).'.format(str(CamemBert_memory)))
CamemBert_N_trainable_parameters = int(np.sum([K.count_params(p) for p in CamemBert_model.model.trainable_weights]))
CamemBert_N_non_trainable_parameters = int(np.sum([K.count_params(p) for p in CamemBert_model.model.non_trainable_weights]))
CamemBert_training_time = round(training_end - training_start, 2)
CamemBert_N_trainable_parameters, CamemBert_N_non_trainable_parameters, CamemBert_training_time
y_res = []
inference_start = time.time()
for i in range(X.shape[0]):
X_copy = deepcopy(X.loc[i:i, :])
y_res.append(CamemBert_model.predict(X_copy))
y_res = le.inverse_transform(np.ravel(y_res))
inference_end = time.time()
CamemBert_inference_time = round((inference_end - inference_start)/len(y_res) * 1000, 2)
CamemBert_accuracy = accuracy_score(y_res, le.inverse_transform(y))
CamemBert_cls_report = classification_report(le.inverse_transform(y), y_res, output_dict=True, zero_division=0)
# ### Flaubert
memory_start = get_available_memory()
FlauBert_model = NeuralModel(architecture_function=bert_model,
pretrained_embedding=None,
text_input_column="clean_text",
meta_input_list=['extension', 'dayofweek', 'hour', 'min', 'attachment_type'],
n_epochs=1,
bert_tokenizer='jplu/tf-flaubert-base-cased',
bert_model='jplu/tf-flaubert-base-cased')
training_start = time.time()
FlauBert_model.fit(X, y)
training_end = time.time()
FlauBert_memory = memory_start - get_available_memory()
FlauBert_memory = round(FlauBert_memory / 1e9 * 1024 , 1)
print('FlauBert is using {} Mb memory (RAM).'.format(str(FlauBert_memory)))
FlauBert_N_trainable_parameters = int(np.sum([K.count_params(p) for p in FlauBert_model.model.trainable_weights]))
FlauBert_N_non_trainable_parameters = int(np.sum([K.count_params(p) for p in FlauBert_model.model.non_trainable_weights]))
FlauBert_training_time = round(training_end - training_start, 2)
FlauBert_N_trainable_parameters, FlauBert_N_non_trainable_parameters, FlauBert_training_time
y_res = []
inference_start = time.time()
for i in range(X.shape[0]):
X_copy = deepcopy(X.loc[i:i, :])
y_res.append(FlauBert_model.predict(X_copy))
y_res = le.inverse_transform(np.ravel(y_res))
inference_end = time.time()
FlauBert_inference_time = round((inference_end - inference_start)/len(y_res) * 1000, 2)
FlauBert_accuracy = accuracy_score(y_res, le.inverse_transform(y))
FlauBert_cls_report = classification_report(le.inverse_transform(y), y_res, output_dict=True, zero_division=0)
# # Comparison of the model characteristics
# +
parameters_list = ["Number of Parameters", "Memory Usage (Mb)", "Training time (s./epoch)",
"Inference time (ms./sample)", "Accuracy (%)"]
models_names = ['RNN', 'CNN', 'Transformers', 'CamemBert', 'FlauBert']
N_trainable_parameters = [RNN_N_trainable_parameters, CNN_N_trainable_parameters,
Transformer_N_trainable_parameters, CamemBert_N_trainable_parameters, FlauBert_N_trainable_parameters]
memory_usage = [RNN_memory, CNN_memory,
Transformer_memory, CamemBert_memory, FlauBert_memory]
training_time = [RNN_training_time, CNN_training_time,
Transformer_training_time, CamemBert_training_time, FlauBert_training_time]
inference_time = [RNN_inference_time, CNN_inference_time,
Transformer_inference_time, CamemBert_inference_time, FlauBert_inference_time]
accuracy = [RNN_accuracy, CNN_accuracy,
Transformer_accuracy, CamemBert_accuracy, FlauBert_accuracy]
data = [N_trainable_parameters, memory_usage, training_time, inference_time, accuracy]
# -
def format_table(data, columns_header, row_header):
row_format = "{:>15}|" * (len(row_header))
row_format = "{:>30}|" + row_format
space = ['']*len(row_header)
space_format = "{:->15}+" * (len(row_header))
space_format = "{:->30}+" + space_format
print(row_format.format("", *row_header))
for col, row in zip(columns_header, data):
print(space_format.format("", *space))
print(row_format.format(col, *row))
format_table(data, parameters_list, models_names)
# ⚠️⚠️ **The metrics above are computed on a very small sample and may therefore be misleading. Please use your own dataset to compare extensively the models and their performances** ⚠️⚠️
# # Classification Report
# Please install plotly to plot the following graphs
#
# ``!pip install --upgrade plotly``
import plotly.graph_objs as go
import plotly as plotly
import plotly.express as px
def cls_report_2_df(cls_report, model_name):
cls_report_df = pd.DataFrame.from_dict(cls_report)
cls_report_df.drop(['accuracy', 'macro avg', 'weighted avg'], axis=1, inplace=True)
cls_report_df = cls_report_df.T
cls_report_df['class'] = cls_report_df.index
cls_report_df['model'] = model_name
return cls_report_df
models = ['RNN', 'CNN', 'Transformers', 'CamemBert', 'FlauBert']
cls_reports = [RNN_cls_report, CNN_cls_report, Transformer_cls_report, FlauBert_cls_report, CamemBert_cls_report]
ALL_cls_report_df = [cls_report_2_df(c, m) for (c, m) in zip(cls_reports, models)]
ALL_cls_report_df = pd.concat(ALL_cls_report_df)
px.scatter(ALL_cls_report_df,
x="precision",
y="recall",
size='support',
color='model',
hover_data=['class'],
title="Precision and Recall given classes and models")
# ⚠️⚠️ **The metrics above are computed on a very small sample and may therefore be misleading. Please use your own dataset to compare extensively the models and their performances** ⚠️⚠️
| tutorial/tutorial13_attention_models.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import mcsim.monte_carlo as mc
help(mcsim.monte_carlo.run_simulation)
# +
#set simulation parameters
reduced_temp = 1.5
num_steps = 5000
cutoff = 3
freq = 1000
coordinates, box_length = mc.read_xyz('../lj_sample_configurations/lj_sample_config_periodic1.txt')
# -
final_coordinates = mc.run_simulation(coordinates, box_length, cutoff, reduced_temp, num_steps)
| mc-package/Untitled.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="view-in-github" colab_type="text"
# <a href="https://colab.research.google.com/github/Finyasy/NLP/blob/main/NLP.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# + id="IYZlFvQLX2z7"
import tensorflow as tf
import tensorflow as keras
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# + colab={"base_uri": "https://localhost:8080/"} id="KCuTLdO7X3oc" outputId="646f81cf-6de5-4b0b-d212-cba179022c5a"
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer=Tokenizer(num_words=100,oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index=tokenizer.word_index
print(word_index)
# + colab={"base_uri": "https://localhost:8080/"} id="moLsMwHJZANd" outputId="c8dc545e-44a7-404e-9ff7-3f60157d62bb"
sequences=tokenizer.texts_to_sequences(sentences)
print(word_index)
print(sequences)
# + colab={"base_uri": "https://localhost:8080/"} id="C5t1B1KXn2JU" outputId="ea6aa4b4-d8fc-4bed-e027-6ec984b84ce2"
padded=pad_sequences(sequences,maxlen=7)
print("\nWord Index=",word_index)
print("\nSequences=",sequences)
print("\nPadded Sequences:")
print(padded)
# + colab={"base_uri": "https://localhost:8080/"} id="V7yEf6YEgUR0" outputId="b242492f-dece-43d3-f736-58183abf8593"
test_data=[
'i really love my dog',
'My dog love meat'
]
test_seq=tokenizer.texts_to_sequences(test_data)
print("\nTest Sequence:",test_seq)
# + colab={"base_uri": "https://localhost:8080/"} id="XzNc2SG_jDAc" outputId="67c1d82d-2d99-49fb-ea46-59cb0eadda50"
padded=pad_sequences(test_seq,maxlen=10)
print("\nPadded Sequence:",padded)
# + id="Qzjvyu0hqTJW"
# + colab={"base_uri": "https://localhost:8080/"} id="exQm46C_qiS8" outputId="59039e45-87e3-492e-e6a7-7e11884d3aa0"
padded=pad_sequences(test_seq,padding='post',maxlen=10)
print("\nPadded Sequence:",padded)
# + colab={"base_uri": "https://localhost:8080/"} id="WmpY2xQrqtnm" outputId="4bb86735-280a-4ba1-d0f0-2c964e7bc7e1"
padded=pad_sequences(test_seq,padding='pre',truncating='post',maxlen=10)
print("\nPadded Sequence:",padded)
# + id="tqYGGTaOq4xN"
# Run this to ensure TensorFlow 2.x is used
try:
# # %tensorflow_version only exists in Colab.
# %tensorflow_version 2.x
except Exception:
pass
# + id="bQ_jmf2gXNku"
import json
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# + id="eIfyWakjYPTc"
vocab_size=1000
embedding_dim=16
max_length=100
trunc_type='post'
padding_type='post'
oov_tok="<OOV>"
training_size=2000
# + colab={"base_uri": "https://localhost:8080/"} id="hLrTyff3Y_7N" outputId="ff785ffd-3a0e-453a-e2aa-726d92e114fc"
# !wget --no-check-certificate \
# https://storage.googleapis.com/laurencemoroney-blog.appspot.com/sarcasm.json \
# -O /tmp/sarcasm.json
# + id="heZKJjxuZGH1"
with open("/tmp/sarcasm.json",mode='r') as f:
datastore=json.load(f)
sentences=[]
labels=[]
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
# + id="-I1m4W6Qahsk"
training_sentences=sentences[0:training_size]
testing_sentences=sentences[training_size:]
training_labels=labels[0:training_size]
testing_labels=labels[training_size:]
# + id="Znk-4qWqbk-E"
tokenizer=Tokenizer(num_words=vocab_size,oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index=tokenizer.word_index
training_sequences=tokenizer.texts_to_sequences(training_sentences)
training_padded=pad_sequences(training_sequences,maxlen=max_length,padding=padding_type,truncating=trunc_type)
testing_sequences=tokenizer.texts_to_sequences(testing_sentences)
testing_padded=pad_sequences(testing_sequences,maxlen=max_length,padding=padding_type,truncating=trunc_type)
# + id="-iAVsNXwcJIe"
import numpy as np
training_padded=np.array(training_padded)
training_labels=np.array(training_labels)
testing_padded=np.array(testing_padded)
testing_labels=np.array(testing_labels)
# + id="P5EpK_pLenog"
model=tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size,embedding_dim,input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24,activation='relu'),
tf.keras.layers.Dense(1,activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# + colab={"base_uri": "https://localhost:8080/"} id="xAlR8Y55gBv_" outputId="5947beaa-59a7-45a5-a32f-73c09399369e"
model.summary()
# + colab={"base_uri": "https://localhost:8080/"} id="nsMWqS2lgMkA" outputId="92b1da81-98f1-426f-ebce-936b45439b2d"
num_epochs=30
history=model.fit(training_padded,training_labels,epochs=num_epochs,validation_data=(testing_padded,testing_labels),verbose=2)
# + colab={"base_uri": "https://localhost:8080/", "height": 541} id="htCf6rfag2Un" outputId="e2045a52-c635-4984-df16-1f3ec964c9c7"
import matplotlib.pyplot as plt
def plot_graphs(history,string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string,'val_'+string])
plt.show()
plot_graphs(history,"accuracy")
plot_graphs(history,"loss")
# + colab={"base_uri": "https://localhost:8080/"} id="TncNUjc9ibjf" outputId="0538545d-94b0-4e38-97ac-4d70a3ae8f7e"
reverse_word_index=dict([(value,key) for (key,value) in word_index.items()])
def decode_sentence(text):
return ' '.join([reverse_word_index.get(i,'?') for i in text])
print(decode_sentence(training_padded[0]))
print(training_sentences[2])
print(labels[2])
# + colab={"base_uri": "https://localhost:8080/"} id="YPJB1NqoljNH" outputId="9943ccec-a84f-4cb7-82e1-49fc157a4596"
e=model.layers[0]
weights=e.get_weights()[0]
print(weights.shape) #shape:(vocab_size,embeddibg_dim)
# + id="oV8kbZNZmZYb"
# + id="LoBXVffknldU"
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
# + colab={"base_uri": "https://localhost:8080/", "height": 17} id="eNQPAGoam43y" outputId="5ad3790d-da62-4c86-b06d-bbcd20ff54aa"
try:
from google.colab import files
except ImportError:
pass
else:
#files.download('vecs.tsv')
files.download('meta.tsv')
# + colab={"base_uri": "https://localhost:8080/"} id="aYap1p4zm_7V" outputId="9e71d9ed-6d55-48ff-8913-66bae74b5934"
sentence = ["I'm feeling sick", "Happy merry christmas"]
sequences = tokenizer.texts_to_sequences(sentence)
padded = pad_sequences(sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
print(model.predict(padded))
# + colab={"base_uri": "https://localhost:8080/", "height": 136} id="G29JmFqqoCsg" outputId="df20c59f-e670-45af-fc57-13a2a19e02e9"
# Load the TensorBoard notebook ex
\tensorboard --logdir logs/hparam_tuning
# + id="84zcpkR5igjW"
| NLP.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Data modeling notebook
#
#
# ## Summary
#
# In this notebook I will first preprocess the dataset that was cleaned in data wrangling notebook. For preprocessing I will use sklearn's OneHotEncoder and LabelEncoder. Speciffically, OneHotEncoder for columns that contain nominal values and LabelEncoder for those that contain ordinal values. I made sure that nominal values have small cardinality in the data_wrangling notebook.
#
# ## Steps
# ### 1. Setting thing up
# * Import libraries
# * Read in cleaned data
#
# ### 2. Preprocessing
# * Label encode ordinal values
# * One-hot encode nominal values
#
# ### 3. Building a model
# * Beayesian hyperparameter optimization
# * Feature importance
# * Recursive feature selection
# * Spearman rank correlation
#
# ### 4. Model interpretation
# * Partial depandence plots
# * Statistical tests
#
#
# ### 1. Setting things up
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.feature_selection import RFE
from eli5.sklearn import PermutationImportance
from eli5 import show_weights
import matplotlib.pyplot as plt
import scipy.stats as st
from scipy.cluster import hierarchy as hc
import scipy
import seaborn as sns
from pdpbox import pdp
import xgboost as xgb
from skopt import BayesSearchCV
df = pd.read_csv("./cleaned_loans.csv")
pd.set_option("display.max_rows", 150)
df.head().T
# *Let's see how much is the data imbalanced:*
frac_1 = df[df.loan_status == 1].shape[0] / df.shape[0]
frac_0 = df[df.loan_status == 0].shape[0] / df.shape[0]
print(f'fraction of fully paid: {frac_1}\n\nfraction of charged off: {frac_0}')
# ## 2. Preprocessing
# Lebel enocode "grade" column:
def f(x):
if x == 'A':
return 6
elif x == 'B':
return 5
elif x == 'C':
return 4
elif x == 'D':
return 3
elif x == 'E':
return 2
elif x == 'F':
return 1
else:
return 0
df["grade"] = df.grade.apply(f)
# Label encode "emp_length" column:
def f(x):
if x == '10+ years':
return 10
elif x == '9 years':
return 9
elif x == '8 years':
return 8
elif x == '7 years':
return 7
elif x == '6 years':
return 6
elif x == '5 years':
return 5
elif x == '4 years':
return 4
elif x == '3 years':
return 3
elif x == '2 years':
return 2
elif x == '1 year':
return 1
else:
return 0
df["emp_length"] = df.emp_length.apply(f)
# Get the feature names for preprocessing:
cat_cols_onehot = ["addr_state",
"purpose",
"verification_status",
"home_ownership"
]
cat_col_label = ["term"]
# One-hot encode:
onehot_enc = OneHotEncoder(sparse=False)
onehot_encode_cols = pd.DataFrame(onehot_enc.fit_transform(df[cat_cols_onehot]),
#PermutationImportance() throws an error if type of a column name is int
#instead of string so set the column names to categories of onehot encoder
columns=np.concatenate(onehot_enc.categories_, axis=0)
)
onehot_encode_cols.index = df.index
# Label incode "term":
label_enc = LabelEncoder()
label_enc_cols = pd.DataFrame()
for col in cat_col_label:
label_enc_cols[col] = label_enc.fit_transform(df[col])
label_enc_cols.index = df.index
# Concatinate all the features back together:
df_preprocessed = pd.concat([onehot_encode_cols,
label_enc_cols,
df.drop(cat_col_label + cat_cols_onehot, axis=1)
],
axis=1
)
df_preprocessed.shape
df_preprocessed.describe().T
df_preprocessed.head().T
# Split the data for training and validating:
X_train, X_valid, y_train, y_valid = train_test_split(df_preprocessed.drop(["loan_status"], axis=1),
df_preprocessed.loan_status,
test_size=0.1,
random_state=22
)
eval_set = [(X_train, y_train), (X_valid, y_valid)]
eval_metric="auc"
# ### 3. Building a model
# Run a Bayes search to tune hyperparameters:
bayes_cv_tuner = BayesSearchCV(
estimator=xgb.XGBRegressor(
n_jobs=-1,
objective='binary:logistic',
eval_metric='auc',
tree_method='approx'
),
search_spaces={
'learning_rate': (1e-2, 3, 'log-uniform'),
'min_child_weight': (0, 10),
'max_depth': (0, 7),
'subsample': (0.1, 1.0),
'colsample_bytree': (0.1, 1.0, 'log-uniform'),
'gamma': (0.1, 3, 'log-uniform'),
'n_estimators': (50, 250),
'scale_pos_weight': (1e-6, 20, 'log-uniform')
},
scoring='roc_auc',
cv=StratifiedKFold(
n_splits=3,
shuffle=True,
random_state=42
),
n_jobs=2,
n_iter=10,
verbose=0,
refit=True,
random_state=42
)
def status_print(optim_result):
all_models = pd.DataFrame(bayes_cv_tuner.cv_results_)
best_params = pd.Series(bayes_cv_tuner.best_params_)
print(f'Model #{len(all_models)}\nBest ROC-AUC: {np.round(bayes_cv_tuner.best_score_, 4)}\nBest params: {bayes_cv_tuner.best_params_}\n')
result = bayes_cv_tuner.fit(X_train.values, y_train.values, callback=status_print)
# Train an xgboost model:
m = xgb.XGBRegressor(objective="binary:logistic",
learning_rate=0.0775,
n_estimators=169,
min_child_weight=6,
max_depth=6,
sub_sample=0.4799,
colsample_bytree=0.4141,
gamma=1.3974,
nthread=-1,
scale_pos_weight=0.0545,
eval_set=eval_set,
)
m.fit(X_train, y_train, eval_set=eval_set, eval_metric=eval_metric, verbose=True)
# Plot the traing and validation scores vs number of trees:
result = m.evals_result()
epochs = len(result['validation_0']['auc'])
x_axis = range(0, epochs)
fig, ax = plt.subplots()
ax.plot(x_axis, result["validation_0"]["auc"], label="Train")
ax.plot(x_axis, result["validation_1"]["auc"], label="Validation")
ax.legend()
plt.ylabel("auc score")
plt.show()
# The mode is obviously overfitting. I'm going to use skpot's feature importance to reduce the number of features and combat overfitting.
prm_imp = PermutationImportance(m, random_state=22).fit(X_valid, y_valid)
show_weights(prm_imp, feature_names=X_train.columns.to_list())
# Use sklearn's Recursive Feature Elimination to drop half of the features:
rfe = RFE(m, n_features_to_select=20)
rfe.fit(X_valid, y_valid)
columns = X_valid.columns[rfe.support_].to_list()
X_train_imp = X_train[columns]
X_valid_imp = X_valid[columns]
# Train xgboost model on the new dataset:
eval_set = [(X_train_imp, y_train), (X_valid_imp, y_valid)]
eval_metric="auc"
m.fit(X_train_imp, y_train, eval_set=eval_set, eval_metric=eval_metric, verbose=True)
# Check the feature importance again:
prm_imp = PermutationImportance(m, random_state=22).fit(X_valid_imp, y_valid)
show_weights(prm_imp, feature_names=X_train_imp.columns.to_list())
# Use Spearman rank corralation to find features that contain the same information so the set size can be further reduced. Plot dendogram of correlations:
corr = np.round(scipy.stats.spearmanr(X_train_imp).correlation, 4)
corr_condensed = hc.distance.squareform(1-corr)
z = hc.linkage(corr_condensed, method='average')
fig = plt.figure(figsize=(16, 10))
dendogram = hc.dendrogram(z, labels=X_train_imp.columns, orientation='left', leaf_font_size=16)
plt.show()
# Dendogram clearly shows high rank correlation between "installment" and "loan_amnt". That is actually intuitive
# since the loan amount will tipicaly be equaly spread over term into instalments. So high positive correlation makes sense. Let's train the model and check if it hurts the score:
eval_set = [(X_train_imp.drop(["loan_amnt"], axis=1), y_train), (X_valid_imp.drop("loan_amnt", axis=1), y_valid)]
m.fit(X_train_imp.drop(["loan_amnt"], axis=1), y_train, eval_set=eval_set, eval_metric=eval_metric, verbose=True)
# Since removing loan_amnt doesn't hurt the score I will remove it from the dataset:
X_train_imp.drop(["loan_amnt"], axis=1, inplace=True)
X_valid_imp.drop(["loan_amnt"], axis=1, inplace=True)
# ### 4. Model interpretation
prm_imp = PermutationImportance(m, random_state=22).fit(X_valid_imp, y_valid)
show_weights(prm_imp, feature_names=X_train_imp.columns.to_list())
# It looks like the "annual_inc" is the most informative feature. Let's plot it's partial depandence plot
pdp_annual_inc = pdp.pdp_isolate(model=m, dataset=X_valid_imp,
model_features=X_train_imp.columns.to_list(),
feature="annual_inc",
num_grid_points=20
)
pdp.pdp_plot(pdp_annual_inc, "annual_inc", cluster=True, n_cluster_centers=5)
plt.show()
# It looks like there is a postive correlation between the amount money a borrower makes and the probability it will not default. Let's run a two-tailed t-test with 1% significance to check the hypothesis:
# * Under null hypothesis there is no difference in annual income between borrowers how defaulted and those who didn't
# * Under alternative hypothesis there is difference either positive or negative
ai_1 = X_train_imp.annual_inc[y_train == 1]
ai_0 = X_train_imp.annual_inc[y_train == 0]
print(f'ai_1 size: {ai_1.shape[0]}\nai_0 size: {ai_0.shape[0]}')
# I'm assuming that observations within each set are independent as well as the two sets are independent from each other.
# Sizes need to be similar, so I'm going to randomly sample 5088 observations from ai_1
ai_1 = ai_1.sample(n=5088, axis=0, random_state=44)
ai_1.size
# *Let's check the normality of the two sets:*
fig = plt.figure(figsize=(20,4))
title = fig.suptitle("Annual income distributions", fontsize=14)
fig.subplots_adjust(top=0.85, wspace=0.1)
ax1 = fig.add_subplot(1,2,1)
ax1.set_title("Default-YES")
ax1.set_xlabel("Annual icome")
ax1.set_ylabel("Density")
sns.kdeplot(ai_0, ax=ax1, shade=True, color='r')
ax2 = fig.add_subplot(1,2,2)
ax2.set_title("Default-NO")
ax2.set_xlabel("Annual icome")
ax2.set_ylabel("Density")
sns.kdeplot(ai_1, ax=ax2, shade=True, color='r')
st.ttest_ind(ai_1, ai_0)
# The conclusion is that there is in fact a significant difference in annual income between the borrowers who had defaulted and those who had not.
pdp_annual_inc = pdp.pdp_isolate(model=m, dataset=X_valid_imp,
model_features=X_train_imp.columns.to_list(),
feature="age_cr_line",
num_grid_points=20
)
pdp.pdp_plot(pdp_annual_inc, "age_cr_line", cluster=True, n_cluster_centers=5)
plt.show()
# From the age_cr_line partial depandence plot we can see that there is a cluster of borrowers who have lower default rate despite general trend older the credit line the more likely default is.
# +
features_to_plot = ['age_cr_line', 'annual_inc']
inter1 = pdp.pdp_interact(model=m,
dataset=X_train_imp,
model_features=X_train_imp.columns.to_list(),
features=features_to_plot
)
pdp.pdp_interact_plot(pdp_interact_out=inter1, feature_names=features_to_plot, plot_type='contour', plot_pdp=True)
plt.show()
# -
# From this 2D partial dependence plot we can see that for a fixed annual income that is higher than average, riskier borrowers are those with realy young age of credit line and those with realy old age of credit line. Borrowers with lower than average income are risky regardless of their age credit line.
# It would be interesting to group borrowers based on their income and age credit line and see whether that imporves the model score.
pdp_annual_inc = pdp.pdp_isolate(model=m, dataset=X_valid_imp,
model_features=X_train_imp.columns.to_list(),
feature="int_rate",
num_grid_points=20
)
pdp.pdp_plot(pdp_annual_inc, "int_rate", cluster=True, n_cluster_centers=5)
plt.show()
# +
features_to_plot = ['int_rate', 'annual_inc']
inter1 = pdp.pdp_interact(model=m,
dataset=X_train_imp,
model_features=X_train_imp.columns.to_list(),
features=features_to_plot
)
pdp.pdp_interact_plot(pdp_interact_out=inter1, feature_names=features_to_plot, plot_type='contour', plot_pdp=True)
plt.show()
# -
# We can see that for a fixed income higher interest rate greatly increases the default chances.
pdp_annual_inc = pdp.pdp_isolate(model=m, dataset=X_valid_imp,
model_features=X_train_imp.columns.to_list(),
feature="small_business",
num_grid_points=20
)
pdp.pdp_plot(pdp_annual_inc, "small_business", cluster=True, n_cluster_centers=5)
plt.show()
print(f'size of y=1: {X_train_imp.small_business[y_train == 1].shape[0]}\nsize of y=0: {X_train_imp.small_business[y_train == 0].shape[0]}')
subsample = X_train_imp.small_business[y_train == 1].sample(5088, axis=0, random_state=22)
sb_1 = subsample.sum() / subsample.shape[0]
sb_0 = X_train_imp.small_business[y_train == 0].sum() / X_train_imp.small_business[y_train == 0].shape[0]
print(f'fraction of small business loans in non-defaulters: {sb_1}\nfraction of small business loans in defaulters: {sb_0}')
# Since the observations are independent and sample sizes are bigger than 10 I can run a test on the difference:
st.ttest_ind(subsample, X_train_imp.small_business[y_train == 0])
# We can safely claim that on average borrowers who had applied for a small business loan have defaulted on their loan more often than those who applied for a loan for a different purpose.
| data_modeling.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Day 9 - Relative mode and unlimited memory
#
# * https://adventofcode.com/2019/day/9
#
# Today's puzzle requires updates to the [`intcode` module](./incode.py):
#
# - Added a `ParameterMode.set` hook; so far I had hard-coded mode 0 (positional) setting in `BoundInstruction`.
# - Support relative mode and the `9` opcode:
# - I've added support for *registers*, in general, containing a single register named *relative base*
# - I've updated the `ParameterMode.get` hooks to accept a `registers` keyword argument, so we can base parameters off of registers.
# - I've added a `relative` mode to `PamaterMode`, which returns the memory value relative to the *relative base* register, or sets memory values using the same rules.
# - I've added a `registers` keyword argument to the `Instruction.__call__()` method so instructions can update
# register values.
# - Support unlimited memory addressing
# - I've added a new Memory class that handles this. For now I'm going to assume that memory addressing is not
# going to address wildly large values and so just `.extend()` the list with zeros to grow the memory.
# We could use a sparse implementation instead if that ever proves to be incorrect. I've put in an assertion
# to catch memory addresses greater than 16 bits.
#
# See the [diff on GitHub](https://github.com/mjpieters/adventofcode/commit/3d69f28) for details on the opcode and memory code changes.
#
# With these changes, parts 1 and 2 where a breeze to run (with part 2 taking about 3 seconds).
import aocd
data = aocd.get_data(day=9, year=2019)
memory = list(map(int, data.split(',')))
# +
from intcode import CPU, base_opcodes, ioset
output, intset = ioset(1)
CPU(intset).reset(memory).execute()
print("Part 1:", output[0])
# -
output, intset = ioset(2)
CPU(intset).reset(memory).execute()
print("Part 2:", output[0])
| 2019/Day 09.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:plda]
# language: python
# name: conda-env-plda-py
# ---
import os
import sys
sys.path.insert(0, os.path.join(os.getcwd(), '..', '..'))
import plda
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib inline
# # Load Data.
# To minimize the size of this repository, I only provide 200 training and 100 testing images.
training_data = np.load('mnist_data/mnist_train_images.npy')
training_labels = np.load('mnist_data/mnist_train_labels.npy')
testing_data = np.load('mnist_data/mnist_test_images.npy')
testing_labels = np.load('mnist_data/mnist_test_labels.npy')
print(training_data.shape, training_labels.shape)
print(testing_data.shape, testing_labels.shape)
# +
n_examples = 5
fig, ax_arr = plt.subplots(1, n_examples, figsize=(10, 2))
for x in range(n_examples):
ax_arr[x].imshow(training_data[x].reshape(28, 28), cmap='gray')
ax_arr[x].set_xticks([])
ax_arr[x].set_yticks([])
plt.show()
# -
# # Optional control over Preprocessing with Principal Components Analysis
# +
classifier = plda.Classifier()
# Use the 5 top principal components to reduce overfitting.
# This will preprocess training data from shape (200, 784) to (200, 5).
classifier.fit_model(training_data, training_labels, n_principal_components=5)
predictions, log_p_predictions = classifier.predict(testing_data)
# -
print('Accuracy: {}'.format((testing_labels == predictions).mean()))
# +
n_examples = 10
fig, ax_arr = plt.subplots(1, n_examples, figsize=(20, 2))
for x in range(n_examples):
ax_arr[x].imshow(testing_data[x].reshape(28, 28), cmap='gray')
ax_arr[x].set_xticks([])
ax_arr[x].set_yticks([])
title = 'Prediction: {}'
xlabel = 'Truth: {}'
ax_arr[x].set_title(title.format(predictions[x]))
ax_arr[x].set_xlabel(xlabel.format(testing_labels[x]))
plt.show()
# -
# # Default setting uses as many Principal Components as possible.
# +
classifier = plda.Classifier()
# Use as many principal components as possible.
classifier.fit_model(training_data, training_labels)
predictions, log_p_predictions = classifier.predict(testing_data)
# -
# Overfit due to curse of dimensionality:
# ratio of avg. sample size to data dimension is very small
# (about ~20 / 200 = ~.2).
print('Accuracy: {}'.format((testing_labels == predictions).mean()))
# +
n_examples = 10
fig, ax_arr = plt.subplots(1, n_examples, figsize=(20, 2))
for x in range(n_examples):
ax_arr[x].imshow(testing_data[x].reshape(28, 28), cmap='gray')
ax_arr[x].set_xticks([])
ax_arr[x].set_yticks([])
title = 'Prediction: {}'
xlabel = 'Truth: {}'
ax_arr[x].set_title(title.format(predictions[x]))
ax_arr[x].set_xlabel(xlabel.format(testing_labels[x]))
plt.show()
# -
# # Getting PCA Preprocessing information
type(classifier.model.pca)
classifier.model.pca
classifier.model.pca.n_features_ # Original dimensionality.
classifier.model.pca.n_components # Preprocessed dimensionality
# # Parameters fitted via Maximum Likelihood of the Data
# +
Psi = classifier.model.Psi
A = classifier.model.A
inv_A = classifier.model.inv_A
m = classifier.model.m
# Indices of the subspace used for classification.
relevant_U_dims = classifier.model.relevant_U_dims
# -
# # Prior Gaussian Parameters
classifier.model.prior_params.keys()
# # Posterior Gaussian Parameters
# Categories in the training data.
classifier.model.posterior_params.keys()
# Parameters for a category.
classifier.model.posterior_params[0].keys()
# # Posterior Predictive Gaussian Parameters
# Categories in the training data.
classifier.model.posterior_predictive_params.keys()
# Parameters for a category.
classifier.model.posterior_predictive_params[0].keys()
# # Transforming Data to PLDA Space
# There are 4 "spaces" that result from the transformations the model performs:
# 1. Data space ('D'),
# 2. Preprocessed data space ('X'),
# 3. Latent space ('U'), and
# 4. The "effective" subspace of the latent space ('U_model'),
# which is essentially the set of dimensions the model actually uses for prediction.
#
# You can transform data between these spaces using the `classifier.model.transform()` function.
# +
U_model = classifier.model.transform(training_data, from_space='D', to_space='U_model')
print(training_data.shape)
print(U_model.shape)
# +
D = classifier.model.transform(U_model, from_space='U_model', to_space='D')
print(U_model.shape)
print(D.shape)
| plda_bkp/mnist_demo/mnist_demo.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Volume Mesh
#
# Mesh is an object which displays triangles in 3d.
# An scalar can be displayed on the mesh using color map.
# +
import vtk
import k3d
import numpy as np
import math
import ipywidgets as widgets
from vtk.util import numpy_support
from k3d.helpers import quad, download
filename = download('https://vedo.embl.es/examples/data/embryo.slc')
reader = vtk.vtkSLCReader()
reader.SetFileName(filename)
reader.Update()
vti = reader.GetOutput()
x, y, z = vti.GetDimensions()
volume_data = numpy_support.vtk_to_numpy(vti.GetPointData().GetArray(0)).reshape(-1, y, x).astype(np.float32)
# -
basic_color_maps = [(attr, getattr(k3d.basic_color_maps, attr)) for attr in dir(k3d.basic_color_maps) if not attr.startswith('__')]
paraview_color_maps = [(attr, getattr(k3d.paraview_color_maps, attr)) for attr in dir(k3d.paraview_color_maps) if not attr.startswith('__')]
matplotlib_color_maps = [(attr, getattr(k3d.matplotlib_color_maps, attr)) for attr in dir(k3d.matplotlib_color_maps) if not attr.startswith('__')]
colormaps = basic_color_maps + paraview_color_maps + matplotlib_color_maps
# +
vertices, indices = quad(20.0, 20.0)
plot = k3d.plot()
obj = k3d.mesh(vertices, indices, volume=volume_data, side='double', volume_bounds=[-10, 10, -10, 10, -10, 10])
model_matrix = {}
for t in np.linspace(0, 2* np.pi, 100):
obj.transform.rotation = [t, math.sin(t), math.cos(t), 1]
model_matrix[str(t)] = obj.model_matrix
obj.model_matrix = model_matrix
plot += obj
plot.display()
# +
tf_editor = k3d.transfer_function_editor()
@widgets.interact(x=widgets.Dropdown(options=colormaps, description='ColorMap:'))
def g(x):
tf_editor.color_map = np.array(x, dtype=np.float32)
_ = widgets.link((tf_editor, 'color_map'), (obj, 'color_map'))
_ = widgets.link((tf_editor, 'opacity_function'), (obj, 'opacity_function'))
tf_editor.display()
# -
tf_editor.opacity_function = np.array([
0, 0,
0.04, 0,
0.1, 1,
1,1
], dtype=np.float32)
plot.start_auto_play()
plot.stop_auto_play()
f = open('./volume.html', 'w', encoding='UTF-8')
f.write(plot.get_snapshot(9, 'K3DInstance.startAutoPlay();'))
f.close()
| examples/mesh_volume_texture.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="0JJ2NQ3Nx4W4" colab_type="text"
# # Using LightFM for Recommendations
#
# Check out [LightFM here](https://lyst.github.io/lightfm/docs/index.html) and view it's [documentation here](http://lyst.github.io/lightfm/docs/home.html)
#
# LightFM is a Python implementation of a number of popular recommendation algorithms for both implicit and explicit feedback.
#
# It also makes it possible to incorporate both item and user metadata into the traditional matrix factorization algorithms. It represents each user and item as the sum of the latent representations of their features, thus allowing recommendations to generalise to new items (via item features) and to new users (via user features).
#
# The details of the approach are described in the LightFM paper, available on [arXiv](http://arxiv.org/abs/1507.08439).
#
# + id="oP7obkGAvyTO" colab_type="code" outputId="16efafcd-8414-48fd-c0bd-49f7dcbbac7e" executionInfo={"status": "ok", "timestamp": 1575679094553, "user_tz": 240, "elapsed": 14782, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}} colab={"base_uri": "https://localhost:8080/", "height": 312}
# Install lightFM, takes around 15 seconds
# !pip install lightfm
# + [markdown] id="mObVypUdyFfz" colab_type="text"
# The first step is to get the Movielens data. This is a classic small recommender dataset, consisting of around 950 users, 1700 movies, and 100,000 ratings. The ratings are on a scale from 1 to 5, but we’ll all treat them as implicit positive feedback in this example.
#
# Fortunately, this is one of the functions provided by LightFM itself.
# + id="7A2Fptc1vy37" colab_type="code" colab={}
# Import our modules
import numpy as np
from lightfm.datasets import fetch_movielens
from lightfm import LightFM
# + id="8kEEE1vsv4Dp" colab_type="code" outputId="c4e69f46-857a-4841-beed-1febcb2d35c5" executionInfo={"status": "ok", "timestamp": 1575679124313, "user_tz": 240, "elapsed": 2939, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}} colab={"base_uri": "https://localhost:8080/", "height": 225}
# Use one of LightFM's inbuild datasets, setting the minimum rating to return at over 4.0
data = fetch_movielens(min_rating = 4.0)
data
# + id="Q7eXzwwIyAaZ" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 104} outputId="25d245e0-10b9-4ea1-a2cd-b1c0252a45bb" executionInfo={"status": "ok", "timestamp": 1575679124317, "user_tz": 240, "elapsed": 2565, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}}
# Get our key and value from our dataset
# By printing it, we see it's comprised of a data segments containing test, train, item_features, item_feature_labels & item_labels
for key, value in data.items():
print(key, type(value), value.shape)
# + id="slPJ4hn_yNOj" colab_type="code" outputId="cc3f09cc-88bc-4d84-8942-6759ccaf30b0" executionInfo={"status": "ok", "timestamp": 1575679210431, "user_tz": 240, "elapsed": 940, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}} colab={"base_uri": "https://localhost:8080/", "height": 35}
# What type of data are we working with? coo_matrix
type(data['train'])
# + id="tqBntxy9zHaF" colab_type="code" outputId="5d08cfb2-51e2-40b1-b18d-58bfeb379b47" executionInfo={"status": "ok", "timestamp": 1575679213260, "user_tz": 240, "elapsed": 552, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}} colab={"base_uri": "https://localhost:8080/", "height": 52}
# Each row represents a user, and each column an item.
# We use .tocsr() to view it as a Compressed Sparse Row format, it's an inbuilt function in the coo_matrix object
m1 = data['train'].tocsr()
print(m1[0,0])
print(m1[0,1])
# + [markdown] id="ZcE4UE4Bytto" colab_type="text"
# **coo_matrix - A sparse matrix in COOrdinate format - Intended Usage:**
#
# - COO is a fast format for constructing sparse matrices
# - Once a matrix has been constructed, convert to CSR or CSC format for fast arithmetic and matrix vector operations
# - By default when converting to CSR or CSC format, duplicate (i,j) entries will be summed together. This facilitates efficient construction of finite element matrices and the like. (see example)
# + id="L-ygYGxIv4O8" colab_type="code" outputId="22a9487e-5ef8-4371-ae04-cb9943826568" executionInfo={"status": "ok", "timestamp": 1575679432546, "user_tz": 240, "elapsed": 562, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}} colab={"base_uri": "https://localhost:8080/", "height": 87}
print(repr(data['train'])) # rept() is used in debugging to get a string representation of object
print(repr(data['test']))
# + [markdown] id="FoGJfN120J5Q" colab_type="text"
# # Let's now create and train our model
# + [markdown] id="HYbDfvRM8I5f" colab_type="text"
# **Four loss functions are available:**
#
# - **logistic**: useful when both positive (1) and negative (-1) interactions are present.
# - **BPR**: Bayesian Personalised Ranking pairwise loss. Maximises the prediction difference between a positive example and a randomly chosen negative example. Useful when only positive interactions are present and optimising ROC AUC is desired.
# - **WARP**: Weighted Approximate-Rank Pairwise loss. Maximises the rank of positive examples by repeatedly sampling negative examples until rank violating one is found. Useful when only positive interactions are present and optimising the top of the recommendation list (precision@k) is desired.
# - **k-OS WARP**: k-th order statistic loss. A modification of WARP that uses the k-th positive example for any given user as a basis for pairwise updates.
#
# **Two learning rate schedules are available:**
# - adagrad
# - adadelta
# + id="5_wQ4_WEv5VB" colab_type="code" colab={}
# Creat our model object from LightFM
# We specify the loss type to be WARP (Weighted Approximate-Rank Pairwise )
model = LightFM(loss = 'warp')
# + id="pJV2VOCav9zS" colab_type="code" colab={}
# Extract our training and test datasets
train = data['train']
test = data['test']
# + id="jemcXW9g9kne" colab_type="code" colab={"base_uri": "https://localhost:8080/", "height": 35} outputId="3fc0c8af-3469-4128-903d-0c5ccfff1bf7" executionInfo={"status": "ok", "timestamp": 1575681954903, "user_tz": 240, "elapsed": 805, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}}
# Fit our model over 10 epochs
model.fit(train, epochs=10)
# + [markdown] id="spfITtcp-By2" colab_type="text"
# # Performance Evaluation
#
# We use Precision and AUC to avaluate our model performance.
#
# **The ROC AUC metric for a model**: the probability that a randomly chosen positive example has a higher score than a randomly chosen negative example. A perfect score is 1.0.
#
# **The precision at k metric for a model**: the fraction of known positives in the first k positions of the ranked list of results. A perfect score is 1.0.
# + id="DcD9wDSzzbCQ" colab_type="code" outputId="10d18094-2a12-42ba-e839-148dac44fcd5" executionInfo={"status": "ok", "timestamp": 1575681963768, "user_tz": 240, "elapsed": 869, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}} colab={"base_uri": "https://localhost:8080/", "height": 52}
# Evaluate it's performance
from lightfm.evaluation import precision_at_k
from lightfm.evaluation import auc_score
train_precision = precision_at_k(model, train, k=10).mean()
test_precision = precision_at_k(model, test, k=10).mean()
train_auc = auc_score(model, train).mean()
test_auc = auc_score(model, test).mean()
print('Precision: train %.2f, test %.2f.' % (train_precision, test_precision))
print('AUC: train %.2f, test %.2f.' % (train_auc, test_auc))
# + [markdown] id="aRXeCHXG03GU" colab_type="text"
# We got
# # Let's see what movies are recommended for some users
# + id="uvC-B4rIv_Ka" colab_type="code" colab={}
# Function credit goes to <NAME>
# Let's test it out and see how well it works
# https://towardsdatascience.com/how-to-build-a-movie-recommender-system-in-python-using-lightfm-8fa49d7cbe3b
def sample_recommendation(model, data, user_ids):
'''uses model, data and a list of users ideas and outputs the recommended movies along with known positives for each user'''
n_users, n_items = data['train'].shape
for user_id in user_ids:
known_positives = data['item_labels'][data['train'].tocsr()[user_id].indices]
scores = model.predict(user_id, np.arange(n_items))
top_items = data['item_labels'][np.argsort(-scores)]
print("User %s" % user_id)
print("Known positives:")
# Print the first 3 known positives
for x in known_positives[:3]:
print("%s" % x)
# Print the first 3 recommended movies
print("Recommended:")
for x in top_items[:3]:
print("%s" % x)
print("\n")
# + id="IasvcwZ9wbUf" colab_type="code" outputId="c4e51ecb-43a7-48e2-dcc8-e9aecc3a8072" executionInfo={"status": "ok", "timestamp": 1575684162783, "user_tz": 240, "elapsed": 535, "user": {"displayName": "<NAME>", "photoUrl": "https://lh3.googleusercontent.com/a-/AAuE7mCGo6aIm0tOcd5EhqWlYb0rime9sBvHS9YMpx0D2w=s64", "userId": "08597265227091462140"}} colab={"base_uri": "https://localhost:8080/", "height": 589}
# Testing on users 6, 125 and 336
sample_recommendation(model, data, [6, 125, 336])
# + [markdown] id="Cpao0Fmi0TcX" colab_type="text"
# ### Learn to build and create your own datasets for LightFM here
#
# https://lyst.github.io/lightfm/docs/examples/dataset.html
| notebooks/26.0 Case Study 14 - LightFM Recommendation Engine.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
import pandas as pd
import os
from os import listdir
from os.path import isfile, join, getsize, dirname
from collections import Counter, OrderedDict
from sklearn.preprocessing import LabelEncoder
import shutil
import warnings
import hickle
import h5py
import pickle
import random
import gc
import time
import feather
import matplotlib.pyplot as plt
warnings.filterwarnings('ignore')
path = "../../../../../../zion/OpenSNP/people"
meta = "../../../../../../zion/OpenSNP/meta"
beacons = "../../../../../zion/OpenSNP/beacon"
main_path = join(beacons, "Main")
with open(join(beacons, "RMAF_3034.pickle"), 'rb') as handle:
maf = pickle.load(handle)
# +
ind = np.arange(500,3001,500)
for i in ind:
data = feather.read_dataframe(join(beacons, "fBeacon_"+str(i)+".ftr"))
data.set_index("rs_id", inplace=True)
print("Read in: ", data.shape)
gc.collect()
data = maf.join(data, how="left")
gc.collect()
del data["chr"]
del data["count"]
gc.collect()
data.fillna("NN", inplace=True)
gc.collect()
print("Writing in: ", data.shape)
data.to_feather(join(beacons, "RBeacon_"+str(i)+".ftr"))
# +
ind = np.arange(1000,3001,500)
beacon = feather.read_dataframe(join(beacons, "fBeacon_"+str(500)+".ftr"))
beacon.set_index("rs_id", inplace=True)
gc.collect()
for i in ind:
data = feather.read_dataframe(join(beacons, "fBeacon_"+str(i)+".ftr"))
data.set_index("rs_id", inplace=True)
print("Read in: ", data.shape)
gc.collect()
beacon = pd.concat([beacon, data], axis=1)
gc.collect()
print("Writing in: ", data.shape)
beacon.reset_index(inplace=True)
beacon.to_feather(join(beacons, "Beacon.ftr"))
# +
######################################################################################################################
# -
beacon = feather.read_dataframe(join(beacons, "Beacon.ftr"))
beacon.set_index("rs_id", inplace=True)
print(beacon.shape)
print(maf.shape)
maf["major"] = "-"
maf["major_freq"] = 0
maf["minor"] = "-"
maf["minor_freq"] = 0
# +
# %%time
def calculate(item):
line = ''.join(item).replace("N","")
return line
res = np.apply_along_axis(calculate, 1, beacon.values)
def foo(item):
return list(map(lambda c2: c2, item[0]))
res = res.reshape(res.shape[0],1)
res = [foo(res[i]) for i in range(len(res))]
result = [list(Counter(e).items()) for e in res]
result = np.array(result)
result.shape
# +
# %%time
maf["major"] = [i[0][0] if i else "-" for i in result ]
maf["major_freq"] = [i[0][1] if i else 0 for i in result ]
maf["minor"] = [i[1][0] if len(i) > 1 else "-" for i in result ]
maf["minor_freq"] = [i[1][1] if len(i) > 1 else 0 for i in result ]
t = maf["major_freq"] + maf["minor_freq"]
maf["major_freq"] = maf["major_freq"] / t
maf["minor_freq"] = maf["minor_freq"] / t
maf = maf.fillna(0)
maf
# +
# Create Reference
def getReference(maf):
greater = maf.loc[maf['major_freq'] > maf['minor_freq']]
equal = maf.loc[maf['major_freq'] == maf['minor_freq']]
smaller = maf.loc[maf['major_freq'] < maf['minor_freq']]
greater["normal"] = greater['major'] + "" + greater['major']
equal["normal"] = equal['major'] + "" + equal['major'] #TODO
smaller["normal"] = smaller['minor'] + "" + smaller['minor']
x = pd.concat([greater,equal,smaller], axis=0)
x = x.sort_values(by=['rs_id'])
reference = x["normal"].values
reference = np.expand_dims(reference, axis=1)
return reference
reference = getReference(maf)
# -
maf.to_pickle(join(beacons, "MAF.pickle"))
with open(join(beacons, "Reference.pickle"), 'wb') as handle:
pickle.dump(reference, handle, protocol=pickle.HIGHEST_PROTOCOL)
# +
######################################################################################################################
# +
def findUserIndex(fileName):
fileName = fileName[4:]
return int(fileName.split("_")[0])
def findFileIndex(fileName):
return int(fileName.split("_")[1][4:])
def findSkipCount(fileName):
filePath = join(path, fileName)
with open(filePath, "r") as f:
i = 0
for line in f:
if line[0] == "#" or line[0] == " ":
i += 1
else:
if line[0:6] == "rs-id":
i += 1
break
return i
def readClean(data):
# Remove X,Y,MT chromosomes
no_x_y = np.logical_and(data["chromosome"] != "X",data["chromosome"] != "Y")
data = data[np.logical_and(no_x_y, data["chromosome"] != "MT")]
data = data.fillna("NN")
data[data == "II"] = "NN"
data[data == "--"] = "NN"
data[data == "DD"] = "NN"
data[data == "DI"] = "NN"
return data.iloc[np.where(data.iloc[:,[1]] != "NN")[0]]
def readDf(file, rowSkip):
data = pd.read_csv(join(path, file), sep="\t", header=None, skiprows=rowSkip)
data.columns = ['rs_id', 'chromosome', 'position', 'allele']
del data['position']
data = data.set_index('rs_id')
data = data.rename(columns={"allele": findUserIndex(file)})
return data
def readFileComplete(fileName):
rowSkip = findSkipCount(fileName)
beacon = readDf(fileName, rowSkip)
beacon = readClean(beacon)
return beacon
def mergeClean(beacon):
beacon = beacon.loc[~beacon.index.duplicated(keep='first')]
beacon = beacon[pd.to_numeric(beacon['chr'], errors='coerce').notnull()]
beacon["chr"] = pd.to_numeric(beacon["chr"])
beacon = beacon.sort_values(by=['chr'])
beacon = beacon.fillna("NN")
maf = beacon[['chr']]
beacon = beacon.drop(['chr'], axis=1)
t = np.where(np.sum(beacon.values != "NN", axis=1) > 1)[0]
beacon = beacon.iloc[t]
ind = []
for j in range(len(beacon.index)):
if beacon.index[j][0] == "r":
ind.append(j)
ind = np.array(ind)
beacon = beacon.iloc[ind]
beacon.columns = beacon.columns.astype(int)
return beacon, maf
# +
################################################################################################################################
# +
# Trim except .23andme and small genome files
files = np.array([f for f in listdir(path) if isfile(join(path, f))], dtype=str)
types = []
sizes = []
for f in files:
types.append(f.split(".")[-2])
sizes.append(getsize(join(path,f)))
types = np.array(types)
sizes = np.array(sizes)
Counter(types)
ind = np.logical_and(types == "23andme", sizes > 15 * 1000000)
files = files[ind]
# Deal with multiple file people, select newest one
user_filename = {}
for f in files:
user_filename.setdefault(int(findUserIndex(f)),[]).append(f)
multiple_files = {k:v for (k,v) in user_filename.items() if len(v) > 1}
for m in multiple_files:
f_names = multiple_files.get(m)
selected = [findFileIndex(item) for item in f_names]
selected = selected.index(max(selected))
for i in range(len(f_names)):
if i != selected:
index = np.argwhere(files==f_names[i])
files = np.delete(files, index)
user_filename = {}
for f in files:
user_filename[int(findUserIndex(f))] = f
user_ind = np.array(list(user_filename.keys()))
# +
################################################################################################################################
# +
# Read phenotype file
with open(join(beacons, "OpenSNP_Phenotype.pickle"), 'rb') as handle:
pheno = pickle.load(handle)
print(pheno.shape)
# Trim people have less phenotypes than threshold
people_thres = 0
x = np.sum(pheno != "-", axis=1)
pheno = pheno.loc[x >= people_thres]
pheno.shape
files = [v for (k,v) in user_filename.items() if k in pheno.index.values]
len(files)
# -
# Build Beacon
print("Started main beacon build.")
beacon = readFileComplete(files[0])
beacon = beacon.rename(columns={"chromosome": "chr"})
i = 1
while i < len(files):
start = time.time()
try:
data = readFileComplete(files[i])
beacon = pd.merge(beacon, data, left_index=True, right_index=True, how='outer')
beacon["chr"].fillna(beacon["chromosome"], inplace=True)
beacon = beacon.drop("chromosome", axis=1)
except:
print("File " + files[i] + " is skipped.\n")
end = time.time()
print(str(i) + ". step is completed in " + str(end - start) + " seconds.")
if i % 100 == 0 or i == len(files) - 1:
print("Cleaning main beacon started.")
beacon, maf = mergeClean(beacon)
print("Cleaned main beacon.")
# SAVE
beacon.to_pickle(join(main_path, "tBeacon_main_"+str(i)+".pickle"))
maf.to_pickle(join(main_path, "tMAF_main_"+str(i)+".pickle"))
if i != len(files) - 1:
i+=1
print("\n" + str(i) + " has started")
beacon = readFileComplete(files[i])
beacon = beacon.rename(columns={"chromosome": "chr"})
i+=1
print("Ended main beacon build.\n")
print([item for item, count in Counter(beacon.index.values).items() if count > 1])
# +
################################################################################################################################
# -
# Join MAF's
with open(join(main_path, "tMAF_main_"+str(3033)+".pickle"), 'rb') as handle:
maf = pickle.load(handle)
ind = np.arange(100,3001,100)
for i in ind:
with open(join(main_path, "tMAF_main_"+str(i)+".pickle"), 'rb') as handle:
data = pickle.load(handle)
data = data.rename(columns={"chr": "chromosome"})
maf = pd.merge(maf, data, left_index=True, right_index=True, how='outer')
maf["chr"] = maf['chr'].fillna(maf['chromosome'])
del maf["chromosome"]
print(i, " is completed.")
ind = []
for j in range(len(maf.index)):
if maf.index[j][0] == "r":
ind.append(j)
maf = maf.iloc[ind]
ii = np.logical_and(maf["chr"] != 0, maf["chr"] != 25)
ii = np.logical_and(maf["chr"] != 26, ii)
maf = maf[ii]
maf.to_pickle(join(beacons, "OMAF_3031.pickle"))
# Join Beacons
j = 0
block_size = 5
ind = np.arange(500, 3001, 100)
for i in ind:
if j % block_size == 0:
j += 1
with open(join(main_path, "tBeacon_main_" + str(i) + ".pickle"), 'rb') as handle:
beacon = pickle.load(handle)
print(" NEW START ", i, " is started --> ", beacon.shape)
continue
start = time.time()
print("", i, " is started --> ", beacon.shape)
with open(join(main_path, "tBeacon_main_" + str(i) + ".pickle"), 'rb') as handle:
data = pickle.load(handle)
cp1 = time.time()
print("Data is loaded in ", cp1 - start, " seconds")
beacon = pd.merge(beacon, data, left_index=True, right_index=True, how="outer")
cp2 = time.time()
print("Merge is done in ", cp2 - cp1, " seconds")
j += 1
if j % block_size == 0:
print("SAVING MERGINGS ", i)
beacon.values[beacon.isnull().values] = "NN"
cp3 = time.time()
print("Filling NN is done in ", cp3 - cp2, " seconds")
#beacon.to_pickle(join(beacons, "kBeacon_" + str(i) + ".pickle"))
beacon.to_parquet(join(beacons, "kBeacon_" + str(i) + ".parquet"), engine='fastparquet')
print()
# %%time
beacon_1400 = pd.read_parquet(join(beacons, "kBeacon_"+str(1400)+".parquet"), engine='fastparquet')
# %%time
beacon_1900 = pd.read_parquet(join(beacons, "kBeacon_"+str(1900)+".parquet"), engine='fastparquet')
beacon = pd.merge(beacon, data, left_index=True, right_index=True, how="outer")
beacon.values[beacon.isnull().values] = "NN"
beacon.to_parquet(join(beacons, "kBeacon_" + str(i) + ".parquet"), engine='fastparquet')
import gc
gc.collect()
beacon_1400.shape
# Save to a file
beacon.to_pickle(join(beacons, "Beacon_3031.pickle"))
hickle.dump(beacon, join(beacons, "Beacon_3031.pickle"), mode='w')
maf.to_pickle(join(beacons, "OpenSNP_MAF_3031.pickle"))
ratios2 = np.sum(beacon == "NN", axis=1)
ratios2 = (ratios2 / (beacon.shape[1]/100)).values
plt.figure()
_ = plt.hist(100-ratios, bins=np.arange(0,105,5), alpha=0.5, label='OpenSNP')
plt.title("OpenSNP")
plt.xticks(np.arange(0,105,5))
plt.xlabel("Percentage of Sequenced People")
plt.ylabel("Number of SNP's")
plt.legend(loc="upper left")
plt.show()
plt.figure()
_ = plt.hist(100-ratios2, bins=np.arange(0,105,5), alpha=0.5, label='OpenSNP')
plt.title("OpenSNP")
plt.xticks(np.arange(0,105,5))
plt.xlabel("Percentage of Sequenced People")
plt.ylabel("Number of SNP's")
plt.legend(loc="upper left")
plt.show()
# +
################################################################################################################################
# -
'''
%%time
ind = np.arange(100,3001,100)
for i in ind:
with open(join(main_path, "tBeacon_main_"+str(i)+".pickle"), 'rb') as handle:
data = pickle.load(handle)
print("Loaded data.")
data = maf.join(data, how='left')
data.fillna("NN", inplace=True)
print("NN filled.")
del data["chr"]
print("Dropped chr.")
data.to_pickle(join(beacons, "aBeacon_main"+str(i)+".pickle"))
print(i, " is dumped, DONE.\n")
break
'''
'''
with open(join(beacons, "MAF_3034.pickle"), 'rb') as handle:
maf = pickle.load(handle)
print(maf.shape)
maf["count"] = 0
%%time
data2 = feather.read_dataframe(join(beacons, "fBeacon_3000.ftr"))
data2.set_index("rs_id", inplace=True)
print(data2.shape)
sums = np.sum(data2.values != "NN", axis=1)
temp = np.where(maf.index.isin(data2.index))
col = np.zeros(maf.shape[0])
col[temp] = sums
maf["current"] = col
maf["count"] += maf["current"]
gc.collect()
del maf["current"]
with open(join(beacons, "MAF_3034.pickle"), 'wb') as handle:
pickle.dump(maf, handle)
maf2 = maf[maf["count"] >= 8]
with open(join(beacons, "RMAF_3034.pickle"), 'wb') as handle:
pickle.dump(maf2, handle)
'''
| src/data_process/beacon_builder.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Linear Regression
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# ## Get the training data
# +
dfx = pd.read_csv('../Datasets/linearX.csv')
dfy = pd.read_csv('../Datasets/linearY.csv')
x = dfx.values
y = dfy.values
x = x.reshape((-1,))
y = y.reshape((-1,))
print(x.shape)
print(y.shape)
# -
# ## Visualise and Preprocess
plt.scatter(x,y)
X = (x-x.mean())/x.std()
Y = y
plt.scatter(X,Y)
plt.show()
plt.scatter(X,Y)
plt.show()
# ## Gradient Descent Algorithm
# - Start with a random theta
# - Repeat until converge
# - Update Theta according to the rule
#
#
# +
def hypothesis(x,theta):
return theta[0] + theta[1]*x
def error(X,Y,theta):
m = X.shape[0]
error = 0
for i in range(m):
hx = hypothesis(X[i],theta)
error += (hx-Y[i])**2
return error
def gradient(X,Y,theta):
grad = np.zeros((2,))
m = X.shape[0]
for i in range(m):
hx = hypothesis(X[i],theta)
grad[0] += (hx-Y[i])
grad[1] += (hx-Y[i])*X[i]
return grad
#Algorithm
def gradientDescent(X,Y,learning_rate=0.001):
theta = np.array([-2.0,0.0])
itr = 0
max_itr = 100
error_list = []
theta_list = []
while(itr<=max_itr):
grad = gradient(X,Y,theta)
e = error(X,Y,theta)
error_list.append(e)
theta_list.append((theta[0],theta[1]))
theta[0] = theta[0] - learning_rate*grad[0]
theta[1] = theta[1] - learning_rate*grad[1]
itr += 1
return theta,error_list,theta_list
# -
final_theta, error_list,theta_list = gradientDescent(X,Y)
plt.plot(error_list)
plt.show()
print(final_theta)
# +
### Plot the line for testing data
xtest = np.linspace(-2,6,10)
print(xtest)
# -
plt.scatter(X,Y,label='Training Data')
plt.scatter(xtest,hypothesis(xtest,final_theta),color='orange',label="Prediction")
plt.legend()
plt.show()
# ### Visualising Gradient Descent
# - Plotting Error Surface and Contours
# +
# 3D Loss Plot
from mpl_toolkits.mplot3d import Axes3D
#ax = fig.add_subplot(111,project='3d')
T0 = np.arange(-2,3,0.01)
T1 = np.arange(-2,3,0.01)
T0,T1 = np.meshgrid(T0,T1)
J = np.zeros(T0.shape)
m = T0.shape[0]
n = T0.shape[1]
for i in range(m):
for j in range(n):
J[i,j] = np.sum((Y - T1[i,j]*X - T0[i,j])**2)
fig = plt.figure()
axes = fig.gca(projection='3d')
theta_list = np.array(theta_list)
axes.scatter(theta_list[:,0],theta_list[:,1],error_list,c='k')
axes.plot_surface(T0,T1,J,cmap='rainbow',alpha=.5)
plt.show()
# -
fig = plt.figure()
axes = fig.gca(projection='3d')
axes.contour(T0,T1,J,cmap='rainbow')
axes.set_xlim([-2,2])
axes.set_ylim([-2,2])
axes.scatter(theta_list[:,0],theta_list[:,1],error_list,c='k',marker='^')
plt.title("3D Contour")
plt.show()
plt.contour(T0,T1,J)
plt.title("2D Contour")
th = np.array(theta_list)
plt.scatter(th[:,0],th[:,1],marker='>',label='Trajectory')
plt.legend()
plt.show()
| 9. Linear Regression/Linear Regression (Extra Topic)/linear-regression-complete.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: graco
# language: python
# name: graco
# ---
# +
from itertools import islice, combinations, product
from pyclustering.cluster.kmedoids import kmedoids
from collections import defaultdict
from scipy.stats import hypergeom
from goatools import obo_parser
from collections import Counter
from functools import partial
import os
import time
import graco
import numpy as np
import pandas as pd
import networkx as nx
# +
pd.set_option("display.max_columns", 50)
DATA_DIRECTORY = "/home/clusterduck123/Desktop/git/supplements/data"
CPP_DIRECTORY = "/home/clusterduck123/Desktop/git/graco/graco/cpp"
RAW_DATA_DIRECTORY = f"{DATA_DIRECTORY}/raw_data"
PPI_DIRECTORY = f"{DATA_DIRECTORY}/PPI"
ANNOTATIONS_DIRECTORY = f"{DATA_DIRECTORY}/annotations"
MATRIX_DIRECTORY = f"{DATA_DIRECTORY}/matrix"
CLUSTERS_DIRECTORY = f"{DATA_DIRECTORY}/clusters"
# -
# # Enrichment
# #### Set parameters
namespace = 'CC'
lb_GO = 5
ub_GO = 500
min_lvl = 0
max_lvl = 100
# #### Load and parse data
# +
PPI = nx.read_edgelist(f"{PPI_DIRECTORY}/BioGRID_sc.txt")
annotation_df = all_CC_annotations_df = pd.read_csv(f"{ANNOTATIONS_DIRECTORY}/BioGRID-SGD_{namespace}_sc.csv")
go_dag = obo_parser.GODag(f"{RAW_DATA_DIRECTORY}/go-basic.obo")
gene_population = set(PPI.nodes())
GO_population = {go_id for go_id in set(annotation_df.GO_ID)
if (lb_GO <= len(annotation_df[annotation_df.GO_ID == go_id]) <= ub_GO and
min_lvl <= go_dag[go_id].level <= max_lvl)}
annotation_df = annotation_df[annotation_df.GO_ID.isin(GO_population)]
# -
# #### Define dictionaries
# +
# Conversion dictionaries
int2GO = dict(enumerate(GO_population))
GO2int = dict(zip(int2GO.values(), int2GO.keys()))
GO2gene = {go_id:set(annotation_df.Systematic_ID[annotation_df.GO_ID == go_id])
for go_id in GO_population}
gene2GO = {gene :set(annotation_df.GO_ID[annotation_df.Systematic_ID == gene])
for gene in PPI}
global_GO_counter = Counter(GO_term for GO_terms in map(gene2GO.get,gene_population) for GO_term in GO_terms)
# -
# # Here we GO
# #### Functions
# +
def hypergeometric_test(cluster):
n = len(cluster)
k,K = zip(*((count, global_GO_counter[go_term]) for go_term,count in count_GO_terms(cluster).items()))
return 1-hypergeom.cdf(k=np.array(k)-1, M=N, N=n, n=np.array(K))
def count_GO_terms(cluster):
GO_terms_in_cluster = map(gene2GO.get,cluster)
return Counter(GO_term for GO_terms in GO_terms_in_cluster for GO_term in GO_terms)
def gene_enriched_in_cluster(gene, cluster, enrichment):
return bool(gene2GO[gene] & set(GO_index[enrichment[cluster]]))
def get_enrichment_df(alpha, p_values):
m = p_values.size
c = np.log(m) + np.euler_gamma + 1/(2*m)
sorted_p_values = np.sort(p_values.values.flatten())
for k,P_k in enumerate(sorted_p_values,1):
if P_k > k/(m*c) * alpha:
break
threshold = sorted_p_values[k-2]
return p_values_df < threshold
def get_number_of_max_runs(GV, distance, n_clusters):
runs = max(int(run) for run,species,db,ncluster_txt in
map(partial(str.split, sep='_'), os.listdir(f"{CLUSTERS_DIRECTORY}/{GV}/{distance}"))
if int(ncluster_txt.split('.')[0]) == n_clusters)
return runs
# -
# #### Parameters
# +
alpha = 0.05
MIN_CLUSTERS = 2
MAX_CLUSTERS = 100
MAX_RUNS = 20
cluster_coverages = defaultdict(pd.DataFrame)
GO_coverages = defaultdict(pd.DataFrame)
gene_coverages = defaultdict(pd.DataFrame)
# +
N = len(gene_population)
for method in ['GDV_similarity']:
if not os.path.exists(f"{DATA_DIRECTORY}/enrichments/{namespace}/{method}"):
os.makedirs(f"{DATA_DIRECTORY}/enrichments/{namespace}/{method}")
GV, distance = method.split('_')
runs = min(get_number_of_max_runs(GV, distance, MAX_CLUSTERS-1), MAX_RUNS)
for run in range(runs+1):
t1 = time.time()
print(f"{GV}-{distance} {run}")
cluster_coverages[method][run] = pd.Series(np.nan, index=range(MIN_CLUSTERS, MAX_CLUSTERS))
GO_coverages[method][run] = pd.Series(np.nan, index=range(MIN_CLUSTERS, MAX_CLUSTERS))
gene_coverages[method][run] = pd.Series(np.nan, index=range(MIN_CLUSTERS, MAX_CLUSTERS))
for nb_clusters in range(MIN_CLUSTERS, MAX_CLUSTERS):
with open(f"{CLUSTERS_DIRECTORY}/{GV}/{distance}/{run}_sc_BioGRID_{nb_clusters}.txt", 'r') as f:
clusters = [line.split() for line in f]
p_values = {cluster_nr: hypergeometric_test(cluster)
for cluster_nr,cluster in enumerate(clusters)}
GO_index = p_values_df.index
m = sum(map(len, p_values.values()))
enrichment = get_enrichment(alpha,p_values_df)
cluster_coverages[method][run][nb_clusters] = sum(enrichment_df.any()) /nb_clusters
GO_coverages[method][run][nb_clusters] = sum(enrichment_df.any(axis=1))/len(GO_population)
gene_coverages[method][run][nb_clusters] = sum(1 for cluster in clusters for gene in clusters[cluster]
if gene_enriched_in_cluster(gene, cluster, enrichment_df))/N
t2 = time.time()
print(f'{nb_clusters}: {t2-t1:.2f}sec', end='\r')
cluster_coverages[method].to_csv(f"{DATA_DIRECTORY}/enrichments/{namespace}/{method}/cluster_coverage.txt")
GO_coverages[method].to_csv(f"{DATA_DIRECTORY}/enrichments/{namespace}/{method}/GO_coverage.txt")
gene_coverages[method].to_csv(f"{DATA_DIRECTORY}/enrichments/{namespace}/{method}/gene_coverage.txt")
print()
# -
p_values = {cluster_nr: hypergeometric_test(cluster)
for cluster_nr,cluster in enumerate(clusters)}
sum(map(len, p_values.values()))
list(cluster_nr2GO_counter)
| new_beginning/.ipynb_checkpoints/Lets_GO3-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# pre-processing data
from sklearn.datasets import load_wine
import pandas as pd
import numpy as np
# standardize the Data
from sklearn.preprocessing import StandardScaler
# PCA
from sklearn.decomposition import PCA
# draw graph
import matplotlib.pyplot as plt
# %matplotlib inline
# ## LOAD DATA
# - https://medium.com/jameslearningnote/%E8%B3%87%E6%96%99%E5%88%86%E6%9E%90-%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92-%E7%AC%AC2-1%E8%AC%9B-%E5%A6%82%E4%BD%95%E7%8D%B2%E5%8F%96%E8%B3%87%E6%96%99-sklearn%E5%85%A7%E5%BB%BA%E8%B3%87%E6%96%99%E9%9B%86-baa8f027ed7b
# load the wine data and get the dictionary key
wine = load_wine()
wine.keys()
print(wine['target_names'])
print(wine['target'])
print(wine['data'])
print(wine['feature_names'])
# see the wine data information
print(wine['DESCR'])
# get the variables and data
variables = wine['feature_names']
datas = wine['data']
# build the dataframe
wine_df = pd.DataFrame(datas, columns = variables )
wine_df.head()
# get our target y
target = wine['target']
y = pd.DataFrame(target, columns = ['target_names'] )
y.head()
# ## Standardize the Data
# ##### 13 Variables' in chinese.
# - 酒精、蘋果酸、灰燼、灰燼的鹼度、鎂、總酚、黃烷類、Nonflavanoid酚、前花青素、顏色強度、顏色、OD280/OD315被稀釋的酒、脯氨酸
# Standardizing the features
std_wine = StandardScaler().fit_transform(wine_df)
std_wine_df = pd.DataFrame(std_wine, columns = variables )
std_wine_df.head()
# ## PCA Projection to 2D
# ##### In general, we do the scree plot first to choose the number of components in PCA.
# ##### To visualize the PCA , just choose 2 components in this demo, so the students can easily get the point.
# - https://towardsdatascience.com/pca-using-python-scikit-learn-e653f8989e60
# - The original data has 13 columns.
# - In this section, the code projects the original data which is 13 dimensional into 2 dimensions.
# - I should note that after dimensionality reduction, there usually isn’t a particular meaning assigned to each principal component. The new components are just the two main dimensions of variation.
pca = PCA(n_components = 2)
principalComponents = pca.fit_transform(std_wine)
principal_df = pd.DataFrame(data = principalComponents
, columns = ['principal component 1', 'principal component 2'])
principal_df.head()
final_df = pd.concat([principal_df, y], axis = 1)
final_df.head()
# ## Visualize 2D Projection
# - This section is just plotting 2 dimensional data. Notice on the graph below that the classes seem well separated from each other.
fig = plt.figure(figsize = (8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 15)
ax.set_ylabel('Principal Component 2', fontsize = 15)
targets = [0,1,2]
colors = ['r', 'g', 'b']
for target, color in zip(targets,colors):
indicesToKeep = final_df['target_names'] == target
ax.scatter(final_df.loc[indicesToKeep, 'principal component 1'],
final_df.loc[indicesToKeep, 'principal component 2'],
c = color,
s = 50)
ax.legend(list(wine.target_names))
ax.grid()
pca.explained_variance_ratio_
# ## Remark:Scree Plot
# - https://etav.github.io/python/scikit_pca.html
# ##### Step 1: Standardize the Dataset
# - We had do it at the top.
# ##### Step 2: Create a Covariance Matrix
#we have 13 features
covar_matrix = PCA(n_components = 13)
# ##### Step 3: Calculate Eigenvalues
#calculate variance ratios
covar_matrix.fit(std_wine)
variance = covar_matrix.explained_variance_ratio_
variance
#cumulative sum of variance explained with [n] features
var = np.cumsum(np.round(covar_matrix.explained_variance_ratio_, decimals=3)*100)
var
# - Step 4, 5 & 6: Sort & Select
# +
plt.ylabel('% Variance Explained')
plt.xlabel('# of Features')
plt.title('PCA Analysis')
plt.ylim(30,100.5)
plt.style.context('seaborn-whitegrid')
plt.grid()
plt.plot(var)
# -
| Exploratory_Data_Analysis/wine.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.8 64-bit (''base'': conda)'
# name: python3
# ---
# + colab={"base_uri": "https://localhost:8080/"} id="Ne5fZvGSRMx2" outputId="7df0f987-e41d-4321-be90-ceaaeccc5c0a"
# Download CBDB sqlite
# !git clone https://github.com/cbdb-project/cbdb_sqlite.git
# + colab={"base_uri": "https://localhost:8080/"} id="sTdiMTi2SDtD" outputId="4a466ade-d6a2-46cc-cbf9-3fbf3cf9f17a"
# import glob
import os
latest_file = "./cbdb_sqlite/latest.7z"
latest_db = latest_file.split("/")[2].split(".")[0] + ".db"
print(latest_db)
if os.path.isfile(latest_db):
os.remove(latest_db)
# + colab={"base_uri": "https://localhost:8080/"} id="JiWn2I7NS3gw" outputId="dd2bce89-37aa-4d97-8eca-49607e55e2d8"
# Explode latest database file
# !pip install pyunpack
# !pip install patool
from pyunpack import Archive
Archive(latest_file).extractall(".")
# + id="wgk0n6IjTC66"
# Create connection to database
import sqlite3
import pandas as pd
global CONN
database_file = os.path.basename(latest_file).split(".")[0]+".db"
CONN = sqlite3.connect(database_file)
# + id="6L7vHwL3TUnw"
fullenames_df = pd.read_sql_query("SELECT c_name_chn FROM BIOG_MAIN", CONN).drop_duplicates().dropna()
# exclude c_alt_name_type_code = 7 (birth-order name / 行第, e.g. 第二十三)
givennames_df = pd.read_sql_query("SELECT c_alt_name_chn FROM ALTNAME_DATA where c_alt_name_type_code <> 7", CONN).drop_duplicates().dropna()
# + id="POEJnpbyTVTA"
def names_massage(df, column):
# remove content in brackets
df[column] = df[column].str.replace("[\((].*[\))]", "", regex=True)
# remove single-character name
df = df[df[column].apply(lambda x: len(x)>1)]
# filter out weird characters
df = df[df[column].str.contains('\?|?|#|!|!|【|。|、.|,|,|\*|、|\[|□|�|{|「')==False]
df = df[df[column].str.contains('.*[a-zA-Z]+.*')==False]
df = df[df[column].str.contains('\d')==False]
df.drop_duplicates().dropna()
return df
# + id="4JAgPmpt5MKp"
filtered_fullnames = names_massage(fullenames_df, 'c_name_chn')
filtered_givennames = names_massage(givennames_df, 'c_alt_name_chn')
# + colab={"base_uri": "https://localhost:8080/", "height": 507} id="hSr5zMZ8CXOr" outputId="ecfd9323-1a0b-4e63-984b-1c6434331e34"
filtered_fullnames
# + colab={"base_uri": "https://localhost:8080/", "height": 419} id="fyO9rqkfCYM_" outputId="2688470c-2881-4821-f940-217ab340bf1f"
filtered_givennames
# + id="UPTc9Qt9CgKw"
# combine df
final_df = pd.concat([filtered_fullnames, filtered_givennames], axis=1).stack().reset_index(drop=True).drop_duplicates().dropna().to_frame(name='name')
# + colab={"base_uri": "https://localhost:8080/", "height": 419} id="i6kWrl4Uh1gx" outputId="2a42a1d4-f9b4-4e64-83db-9d83732e4353"
final_df
# + colab={"base_uri": "https://localhost:8080/", "height": 419} id="Wd3TNKbObLJl" outputId="c049b492-f89b-4e3a-fc54-64d87d38147c"
# Sort by descending order of the length
final_df = final_df.sort_values(by="name", key=lambda x: -x.str.len())
final_df
# + id="DvIGLM4LDV2q"
final_df.to_csv('cbdb_entity_names.csv', index=False)
# + id="xFKENa-da6Br"
# close the db
CONN.close()
# + id="DWpDBAAUbSAc"
| scripts/generate_CBDB_name_entities.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
from keras.layers import Bidirectional, Dense, Embedding, Input, Lambda, LSTM, RepeatVector, TimeDistributed, Layer, Activation, Dropout
from keras.preprocessing.sequence import pad_sequences
from keras.layers.advanced_activations import ELU
from keras.preprocessing.text import Tokenizer
from keras.callbacks import ModelCheckpoint
from keras.optimizers import Adam
from keras import backend as K
from keras.models import Model
from scipy import spatial
import tensorflow as tf
import pandas as pd
import numpy as np
import codecs
import csv
import os
# ### Directories and text loading
# Initially we will set the main directories and some variables regarding the characteristics of our texts.
# We set the maximum sequence length to 15, the maximun number of words in our vocabulary to 12000 and we will use 50-dimensional embeddings. Finally we load our texts from a csv. The text file is the train file of the Quora Kaggle challenge containing around 808000 sentences.
# +
BASE_DIR = 'C:/Users/gianc/Desktop/PhD/Progetti/vae/'
TRAIN_DATA_FILE = BASE_DIR + 'train.csv'#'train_micro.csv'
GLOVE_EMBEDDING = BASE_DIR + 'glove.6B.50d.txt'
VALIDATION_SPLIT = 0.2
MAX_SEQUENCE_LENGTH = 15
MAX_NB_WORDS = 12000
EMBEDDING_DIM = 50
texts = []
with codecs.open(TRAIN_DATA_FILE, encoding='utf-8') as f:
reader = csv.reader(f, delimiter=',')
header = next(reader)
for values in reader:
texts.append(values[3])
texts.append(values[4])
print('Found %s texts in train.csv' % len(texts))
# -
# ### Text Preprocessing
# To preprocess the text we will use the tokenizer and the text_to_sequences function from Keras
#
tokenizer = Tokenizer(MAX_NB_WORDS)
tokenizer.fit_on_texts(texts)
word_index = tokenizer.word_index #the dict values start from 1 so this is fine with zeropadding
index2word = {v: k for k, v in word_index.items()}
print('Found %s unique tokens' % len(word_index))
sequences = tokenizer.texts_to_sequences(texts)
data_1 = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
print('Shape of data tensor:', data_1.shape)
NB_WORDS = (min(tokenizer.num_words, len(word_index)) + 1 ) #+1 for zero padding
data_1_val = data_1[801000:807000] #select 6000 sentences as validation data
# ### Sentence generator
# In order to reduce the memory requirements we will gradually read our sentences from the csv through Pandas as we feed them to the model
def sent_generator(TRAIN_DATA_FILE, chunksize):
reader = pd.read_csv(TRAIN_DATA_FILE, chunksize=chunksize, iterator=True)
for df in reader:
#print(df.shape)
#df=pd.read_csv(TRAIN_DATA_FILE, iterator=False)
val3 = df.iloc[:,3:4].values.tolist()
val4 = df.iloc[:,4:5].values.tolist()
flat3 = [item for sublist in val3 for item in sublist]
flat4 = [str(item) for sublist in val4 for item in sublist]
texts = []
texts.extend(flat3[:])
texts.extend(flat4[:])
sequences = tokenizer.texts_to_sequences(texts)
data_train = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
yield [data_train, data_train]
# ### Word embeddings
# We will use pretrained Glove word embeddings as embeddings for our network. We create a matrix with one embedding for every word in our vocabulary and then we will pass this matrix as weights to the keras embedding layer of our model
# +
embeddings_index = {}
f = open(GLOVE_EMBEDDING, encoding='utf8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
glove_embedding_matrix = np.zeros((NB_WORDS, EMBEDDING_DIM))
for word, i in word_index.items():
if i < NB_WORDS:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be the word embedding of 'unk'.
glove_embedding_matrix[i] = embedding_vector
else:
glove_embedding_matrix[i] = embeddings_index.get('unk')
print('Null word embeddings: %d' % np.sum(np.sum(glove_embedding_matrix, axis=1) == 0))
# -
# ### VAE model
# Our model is based on a seq2seq architecture with a bidirectional LSTM encoder and an LSTM decoder and ELU activations.
# We feed the latent representation at every timestep as input to the decoder through "RepeatVector(max_len)".
# To avoid the one-hot representation of labels we use the "tf.contrib.seq2seq.sequence_loss" that requires as labels only the word indexes (the same that go in input to the embedding matrix) and calculates internally the final softmax (so the model ends with a dense layer with linear activation). Optionally the "sequence_loss" allows to use the sampled softmax which helps when dealing with large vocabularies (for example with a 50k words vocabulary) but in this I didn't use it.
# Moreover, due to the pandas iterator that reads the csv both the train size and validation size must be divisible by the batch_size.
# +
batch_size = 100
max_len = MAX_SEQUENCE_LENGTH
emb_dim = EMBEDDING_DIM
latent_dim = 32
intermediate_dim = 96
epsilon_std = 1.0
num_sampled=500
act = ELU()
#y = Input(batch_shape=(None, max_len, NB_WORDS))
x = Input(batch_shape=(None, max_len))
x_embed = Embedding(NB_WORDS, emb_dim, weights=[glove_embedding_matrix],
input_length=max_len, trainable=False)(x)
h = Bidirectional(LSTM(intermediate_dim, return_sequences=False, recurrent_dropout=0.2), merge_mode='concat')(x_embed)
#h = Bidirectional(LSTM(intermediate_dim, return_sequences=False), merge_mode='concat')(h)
h = Dropout(0.2)(h)
h = Dense(intermediate_dim, activation='linear')(h)
h = act(h)
h = Dropout(0.2)(h)
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0.,
stddev=epsilon_std)
return z_mean + K.exp(z_log_var / 2) * epsilon
# note that "output_shape" isn't necessary with the TensorFlow backend
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
# we instantiate these layers separately so as to reuse them later
repeated_context = RepeatVector(max_len)
decoder_h = LSTM(intermediate_dim, return_sequences=True, recurrent_dropout=0.2)
decoder_mean = TimeDistributed(Dense(NB_WORDS, activation='linear'))#softmax is applied in the seq2seqloss by tf
h_decoded = decoder_h(repeated_context(z))
x_decoded_mean = decoder_mean(h_decoded)
# placeholder loss
def zero_loss(y_true, y_pred):
return K.zeros_like(y_pred)
#=========================== Necessary only if you want to use Sampled Softmax =======================#
#Sampled softmax
logits = tf.constant(np.random.randn(batch_size, max_len, NB_WORDS), tf.float32)
targets = tf.constant(np.random.randint(NB_WORDS, size=(batch_size, max_len)), tf.int32)
proj_w = tf.constant(np.random.randn(NB_WORDS, NB_WORDS), tf.float32)
proj_b = tf.constant(np.zeros(NB_WORDS), tf.float32)
def _sampled_loss(labels, logits):
labels = tf.cast(labels, tf.int64)
labels = tf.reshape(labels, [-1, 1])
logits = tf.cast(logits, tf.float32)
return tf.cast(
tf.nn.sampled_softmax_loss(
proj_w,
proj_b,
labels,
logits,
num_sampled=num_sampled,
num_classes=NB_WORDS),
tf.float32)
softmax_loss_f = _sampled_loss
#====================================================================================================#
# Custom VAE loss layer
class CustomVariationalLayer(Layer):
def __init__(self, **kwargs):
self.is_placeholder = True
super(CustomVariationalLayer, self).__init__(**kwargs)
self.target_weights = tf.constant(np.ones((batch_size, max_len)), tf.float32)
def vae_loss(self, x, x_decoded_mean):
#xent_loss = K.sum(metrics.categorical_crossentropy(x, x_decoded_mean), axis=-1)
labels = tf.cast(x, tf.int32)
xent_loss = K.sum(tf.contrib.seq2seq.sequence_loss(x_decoded_mean, labels,
weights=self.target_weights,
average_across_timesteps=False,
average_across_batch=False), axis=-1)
#softmax_loss_function=softmax_loss_f), axis=-1)#, uncomment for sampled doftmax
kl_loss = - 0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
return K.mean(xent_loss + kl_loss)
def call(self, inputs):
x = inputs[0]
x_decoded_mean = inputs[1]
print(x.shape, x_decoded_mean.shape)
loss = self.vae_loss(x, x_decoded_mean)
self.add_loss(loss, inputs=inputs)
# we don't use this output, but it has to have the correct shape:
return K.ones_like(x)
loss_layer = CustomVariationalLayer()([x, x_decoded_mean])
vae = Model(x, [loss_layer])
opt = Adam(lr=0.01) #SGD(lr=1e-2, decay=1e-6, momentum=0.9, nesterov=True)
vae.compile(optimizer='adam', loss=[zero_loss])
vae.summary()
# -
# ### Model training
# We train our model for 100 epochs through keras ".fit_generator". The number of steps per epoch is equal to the number of sentences that we have in the train set (800000) divided by the batch size; the additional /2 is due to the fact that our csv has two sentnces per line so in the end we have to read with our generator only 400000 lines per epoch.
# For validation data we pass the same array twice since input and labels of this model are the same.
# If we didn't use the "tf.contrib.seq2seq.sequence_loss" (or another similar function) we would have had to pass as labels the sequence of word one-hot encodings with dimension (batch_size, seq_len, vocab_size) consuming a lot of memory.
# +
def create_model_checkpoint(dir, model_name):
filepath = dir + '/' + model_name + ".h5" #-{epoch:02d}-{decoded_mean:.2f}
directory = os.path.dirname(filepath)
try:
os.stat(directory)
except:
os.mkdir(directory)
checkpointer = ModelCheckpoint(filepath=filepath, verbose=1, save_best_only=False)
return checkpointer
checkpointer = create_model_checkpoint('models', 'vae_seq2seq')
nb_epoch=100
n_steps = (800000/2)/batch_size #we use the first 800000
for counter in range(nb_epoch):
print('-------epoch: ',counter,'--------')
vae.fit_generator(sent_generator(TRAIN_DATA_FILE, batch_size/2),
steps_per_epoch=n_steps, epochs=1, callbacks=[checkpointer],
validation_data=(data_1_val, data_1_val))
vae.save('models/vae_lstm800k32dim96hid.h5')
# -
# ### Project and sample sentences from the latent space
# Now we build an encoder model model that takes a sentence and projects it on the latent space and a decoder model that goes from the latent space back to the text representation
# +
# build a model to project sentences on the latent space
encoder = Model(x, z_mean)
# build a generator that can sample sentences from the learned distribution
decoder_input = Input(shape=(latent_dim,))
_h_decoded = decoder_h(repeated_context(decoder_input))
_x_decoded_mean = decoder_mean(_h_decoded)
_x_decoded_mean = Activation('softmax')(_x_decoded_mean)
generator = Model(decoder_input, _x_decoded_mean)
# -
# ### Test on validation sentences
# +
index2word = {v: k for k, v in word_index.items()}
sent_encoded = encoder.predict(data_1_val, batch_size = 16)
x_test_reconstructed = generator.predict(sent_encoded)
sent_idx = 672
reconstructed_indexes = np.apply_along_axis(np.argmax, 1, x_test_reconstructed[sent_idx])
#np.apply_along_axis(np.max, 1, x_test_reconstructed[sent_idx])
#np.max(np.apply_along_axis(np.max, 1, x_test_reconstructed[sent_idx]))
word_list = list(np.vectorize(index2word.get)(reconstructed_indexes))
word_list
original_sent = list(np.vectorize(index2word.get)(data_1_val[sent_idx]))
original_sent
# -
# ### Sentence processing and interpolation
# +
# function to parse a sentence
def sent_parse(sentence, mat_shape):
sequence = tokenizer.texts_to_sequences(sentence)
padded_sent = pad_sequences(sequence, maxlen=MAX_SEQUENCE_LENGTH)
return padded_sent#[padded_sent, sent_one_hot]
# input: encoded sentence vector
# output: encoded sentence vector in dataset with highest cosine similarity
def find_similar_encoding(sent_vect):
all_cosine = []
for sent in sent_encoded:
result = 1 - spatial.distance.cosine(sent_vect, sent)
all_cosine.append(result)
data_array = np.array(all_cosine)
maximum = data_array.argsort()[-3:][::-1][1]
new_vec = sent_encoded[maximum]
return new_vec
# input: two points, integer n
# output: n equidistant points on the line between the input points (inclusive)
def shortest_homology(point_one, point_two, num):
dist_vec = point_two - point_one
sample = np.linspace(0, 1, num, endpoint = True)
hom_sample = []
for s in sample:
hom_sample.append(point_one + s * dist_vec)
return hom_sample
# input: original dimension sentence vector
# output: sentence text
def print_latent_sentence(sent_vect):
sent_vect = np.reshape(sent_vect,[1,latent_dim])
sent_reconstructed = generator.predict(sent_vect)
sent_reconstructed = np.reshape(sent_reconstructed,[max_len,NB_WORDS])
reconstructed_indexes = np.apply_along_axis(np.argmax, 1, sent_reconstructed)
np.apply_along_axis(np.max, 1, x_test_reconstructed[sent_idx])
np.max(np.apply_along_axis(np.max, 1, x_test_reconstructed[sent_idx]))
word_list = list(np.vectorize(index2word.get)(reconstructed_indexes))
w_list = [w for w in word_list if w]
print(' '.join(w_list))
#print(word_list)
def new_sents_interp(sent1, sent2, n):
tok_sent1 = sent_parse(sent1, [15])
tok_sent2 = sent_parse(sent2, [15])
enc_sent1 = encoder.predict(tok_sent1, batch_size = 16)
enc_sent2 = encoder.predict(tok_sent2, batch_size = 16)
test_hom = shortest_homology(enc_sent1, enc_sent2, n)
for point in test_hom:
print_latent_sentence(point)
# -
# ### Example
# Now we can try to parse two sentences and interpolate between them generating new sentences
# +
sentence1=['where can i find a book on machine learning']
mysent = sent_parse(sentence1, [15])
mysent_encoded = encoder.predict(mysent, batch_size = 16)
print_latent_sentence(mysent_encoded)
print_latent_sentence(find_similar_encoding(mysent_encoded))
sentence2=['how can i become a successful entrepreneur']
mysent2 = sent_parse(sentence2, [15])
mysent_encoded2 = encoder.predict(mysent2, batch_size = 16)
print_latent_sentence(mysent_encoded2)
print_latent_sentence(find_similar_encoding(mysent_encoded2))
print('-----------------')
new_sents_interp(sentence1, sentence2, 6)
# -
# ### Results
# After training with these parameters for 100 epochs I got these results from interpolating between these two sentences:
#
# sentence1=['where can i find a book on machine learning']
# sentence2=['how can i become a successful entrepreneur']
#
# Generated sentences:
# - ------------------------------------------- -
# - where can i find a book on machine learning
# - where can i find a a machine book
# - how can i write a a machine book
# - how can i become a successful architect
# - how can i become a successful architect
# - how can i become a successful entrepreneur
# - ------------------------------------------- -
#
# As we can see the results are not yet completely satisfying because not all the sentences are grammatically correct and in the interpolation the same sentence has been generated multiple times but anyway the model, even in this preliminary version seems to start working.
# There are certainly many improvements that could be done like:
# - removing all the sentences longer than 15 instead of just truncating them
# - introduce the equivalent of word dropout used in the original paper for this decoder architecture
# - parameter tuning (this model trains in few hours on a GTX950M with 2GB memory so it's definitely possible to try larger nets)
# - Using word embeddings with higher dimensionality
# - train on a more general dataset (Quora sentences are all questions)
#
# Stay tuned for future refinings of the model!
| VAE_cn/text_vae.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] id="SKAX5C8gAJxT"
# # Intro
#
# This notebook contains code to prepare any additional data that I used during the competition. For each dataset, I performed some preprocessing and then transformed the data to sentence embeddings.
# + [markdown] id="fre87Ny_AJxW"
# # Setup
# + id="ma5qUjE0AJxX"
# Install dependencies
# !pip install pandas
# !pip install numpy
# !pip install matplotlib
# !pip install seaborn
# !pip install h5py
# !pip install torch
# !pip install scipy
# !pip install sacremoses
# !pip install sentencepiece
# !pip install jieba
# !pip install numpy
# !pip install nltk
# !pip install sentence-transformers
# !pip install datasets
# + id="76RWMJbeAJxY"
# Import dependencies
import gzip
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
plt.style.use('ggplot')
import seaborn as sns
import re
import math
import torch
from scipy.stats import truncnorm
from tqdm import tqdm
from sentence_transformers import SentenceTransformer, util
from pathlib import Path
from datasets import load_dataset, concatenate_datasets
import gc
gc.enable()
# + id="rZWvodEntfD8"
from google.colab import drive
drive.mount('gdrive')
# + [markdown] id="cdrg0ARyAJxY"
# # Constants
# + id="EKydXLEiAJxZ"
BASE_INPUT = 'gdrive/MyDrive/Lit/Lit_Submission'
BASE_OUTPUT = 'gdrive/MyDrive/Lit/Lit_Submission'
# + [markdown] id="R8L-nIaeAJxZ"
# # Functions
# + id="XNcrpinYAJxZ"
def create_dir_if_not_exist(out_dir):
output_dir = Path(out_dir)
output_dir.mkdir(parents=True, exist_ok=True)
return output_dir
# + id="zAUsYdcbAJxa"
# a utility function to save a pandas dataframe to csv
# it will create directories if they don't exist
def df_to_csv(df, out_dir, out_file):
output_dir = create_dir_if_not_exist(os.path.join(BASE_OUTPUT, out_dir))
df.to_csv(output_dir / out_file)
# + id="7zsIY-0EAJxb"
def encode_and_save(sentences, out_dir, data_name, scores=None, model_name='paraphrase-TinyBERT-L6-v2'):
model = SentenceTransformer(model_name)
encoded = model.encode(sentences, convert_to_tensor=True)
output_dir = create_dir_if_not_exist(os.path.join(BASE_OUTPUT, out_dir))
out_file = os.path.join(output_dir, 'encoded-' + data_name + '-' + model_name + '.pt')
pairs = []
for idx, sent in enumerate(sentences):
pair = [sent, encoded[idx]]
if scores:
pair.append(score[idx])
with open(out_file, 'wb') as f:
torch.save(encoded, f)
# + id="htB1uaTVAJxc"
def get_simple_wiki():
simplewiki_path = os.path.join(BASE_OUTPUT, 'data/external/simplewiki-2020-11-01.jsonl.gz')
if not os.path.exists(simplewiki_path):
util.http_get('https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/datasets/simplewiki-2020-11-01.jsonl.gz', simplewiki_path)
passages = []
with gzip.open(simplewiki_path, 'rt', encoding='utf8') as fIn:
for line in fIn:
data = json.loads(line.strip())
passages.extend(data['paragraphs'])
return passages
# + id="PD7meGCVAJxc"
def truncated_normal(mean=180, sd=17, low=135, high=205):
"""
Return a number that belong to a normal distribution
Parameters:
-----------
mean: (int/float)
Mean of the distribution
sd: (int/float)
Standard deviation of the distribution
low: (int/float)
Lowest number fo the distribution
high: (int/float)
"""
return truncnorm( (low - mean) / sd, (high - mean) / sd, loc=mean, scale=sd ).rvs()
# + id="bXL2yFzEAJxd"
def chunks(lst, n):
"""Yield successive n-sized chunks from lst."""
for i in range(0, len(lst), n):
yield lst[i:i + n]
# + id="D5eeAXN1AJxd"
def get_trainset_word_distribution(text):
words = text.split()
cut = math.floor(truncated_normal())
chunked = chunks(words, cut)
texts = [' '.join(c) for c in chunked]
return texts
# + id="q1qwwUtQAJxd"
def clean_file(file):
attribution = ''
texts = []
attribution_start = False
current_text = ''
max_len = truncated_normal()
for ln in file:
line = ln.strip()
if line != '':
if re.search('free to download', line) or attribution_start:
attribution = attribution + ' ' + line
attribution_start = True
else:
if len(current_text) < max_len:
current_text = current_text + ' ' + line
else:
texts.append(current_text)
current_text = line
max_len = truncated_normal()
attributions = [attribution for _ in texts]
return texts, attributions
# + id="lYe582JUAJxe"
def get_cb_corpus():
in_dir = os.path.join(BASE_INPUT, 'data/external/cb_corpus.txt')
chapters = []
current_chapter = []
with open(in_dir, 'r') as f:
for line in tqdm(f):
ln = line.strip()
if ln[:7] == 'CHAPTER':
chapters.append(current_chapter)
current_chapter = []
elif not re.match(r'_BOOK_TITLE_|-LCB-|-RCB-', ln) and ln != '':
rand_div = truncated_normal()
curr_len = len(' '.join(current_chapter).split(' '))
if curr_len < rand_div:
current_chapter.append(ln)
else:
chapters.append(current_chapter)
current_chapter = []
return chapters
# + id="-m803VNuAJxf"
# + [markdown] id="n55xb-TkAJxf"
# # Wikipedia data
#
# This data contains text snippets from Wikipedia. It was downloaded from https://huggingface.co/datasets/wikitext and some preprocessing was applied.
# + id="qkKIHyRKAJxg"
# download the dataset
wikitext_dataset = load_dataset('wikitext', 'wikitext-103-v1')
# apply some preprocessing
wikitext_train = wikitext_dataset['train']
wikitext_train = wikitext_train.filter(lambda example: len(example['text'])>100)
def replace_n(example):
example['text'] = example['text'].replace('\n', ' ')
return example
wikitext_train = wikitext_train.map(replace_n)
# we only want samples between 600 and 1100 characters
wikitext_train = wikitext_train.filter(lambda example: len(example['text']) < 1100 and len(example['text']) > 600)
# convert the dataset to a dataframe and save it
wikitext_train_pd = wikitext_train.to_pandas()
df_to_csv(df=wikitext_train_pd, out_dir='data/preprocessed', out_file='wiki_snippets.csv')
# convert the dataset to sentence embeddings and save the result
wiki_snippets = wikitext_train_pd.text.tolist()
encode_and_save(sentences=wiki_snippets, out_dir='embeddings', data_name='wiki_snippets')
gc.collect()
# + [markdown] id="0UZQ-LFEAJxh"
# # SimpleWiki data
#
# This data contains snippets from Simple Wiki. It was downloaded from https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/datasets/simplewiki-2020-11-01.jsonl.gz
# + id="evHHrlLAAJxh"
simplewiki_snippets = get_simple_wiki()
# filter out snippets which are too long
simplewiki_filtered = [p for p in simplewiki_snippets if len(p) < 1200]
# convert the dataset to a dataframe and save it
simple_df = pd.DataFrame(simplewiki_filtered, columns=['text'])
df_to_csv(df=simple_df, out_dir='data/preprocessed', out_file='simplewiki.csv')
# convert the dataset to sentence embeddings and save the result
encode_and_save(sentences=simplewiki_filtered, out_dir='embeddings', data_name='simplewiki')
# + [markdown] id="tiqi73kKAJxi"
# # Bookcorpus data
# This data contains part of the book corpus. It was downloaded from https://huggingface.co/datasets/bookcorpusopen
#
# **Please note:**
#
# Due to processing resource limitations, only 20% of the bookcorpus dataset were selected. I made the selection randomly. The code can still be used to see how I preprocessed the data, but the resulting selection may produce different results during model training.
# + id="Kzh-uWzZAJxi"
# load the dataset
bookcorpus = load_dataset('bookcorpusopen')
# apply some preprocessing
bookcorpus = bookcorpus['train'].remove_columns('title')
def process_batch(batch):
out = []
for text in batch['text']:
out.extend(get_trainset_word_distribution(text))
return {'text': out}
bookcorpus_chunked = bookcorpus.map(process_batch, batched=True)
bookcorpus_chunked = bookcorpus_chunked.filter(lambda example: len(example['text']) < 1200)
# convert to pandas, select 20% and save
bookcorpus_df = bookcorpus_chunked.to_pandas()
msk = np.random.rand(len(bookcorpus)) < 0.2
bookcorpus_02 = bookcorpus[msk]
df_to_csv(df=bookcorpus_02, out_dir='data/preprocessed', out_file='bookcorpus.csv')
# convert the dataset to sentence embeddings and save the result
bookcorpus_texts = bookcorpus_02.text.tolist()
encode_and_save(sentences=bookcorpus_texts, out_dir='embeddings', data_name='bookcorpus')
gc.collect()
# + [markdown] id="gDd4xEIuAJxi"
# # African Storybooks data
#
# This data was downloaded manually from https://www.africanstorybook.org/ .
# I downloaded all books starting from letter A up to and including letter D.
# The downloaded books were converted from .epub to .txt using Calibre (`ebook-convert input.epub output.txt`).
#
# The full bash script used to convert the books:
# ```
# # # #!/bin/bash
# for filename in *.epub; do
# ebook-convert $filename "$filename.txt"
# done
# ```
#
# + id="ga6UklouAJxj"
# read in the data and clean the texts
in_dir = os.path.join(BASE_INPUT, 'data/external/a_d_txt')
all_texts = []
all_attributions = []
for file in os.listdir(in_dir):
with open(os.path.join(in_dir, file), 'r') as f:
txt, attr = clean_file(f)
if txt != '' and attr != '':
all_texts.extend(txt)
all_attributions.extend(attr)
# create and save as pandas dataframe
asb_df = pd.DataFrame.from_dict({'text': all_texts, 'attribution': all_attributions})
df_to_csv(df=asb_df, out_dir='data/preprocessed', out_file='asb.csv')
# convert the dataset to sentence embeddings and save the result
asb_sents = asb_df.text.tolist()
encode_and_save(sentences=asb_sents, out_dir='embeddings', data_name='asb')
gc.collect()
# + [markdown] id="sbhS_InuAJxj"
# # Scraped data
# This dataset contains scraped data from wikipedia, wikibooks, simplewiki and kids.frontiersin.org. It was taken from https://www.kaggle.com/teeyee314/readability-url-scrape.
# + id="5vEk46ZmAJxk"
in_dir = os.path.join(BASE_INPUT, 'data/external/external_df.csv')
scraped_data = pd.read_csv(in_dir)
txts = []
for txt in scraped_data.usable_external.values:
txts.extend(get_trainset_word_distribution(txt))
scraped_df = pd.DataFrame(txts, columns=['text'])
df_to_csv(df=scraped_df, out_dir='data/preprocessed', out_file='kaggle_scraped.csv')
scraped_sents = scraped_df.text.tolist()
encode_and_save(sentences=scraped_sents, out_dir='embeddings', data_name='kaggle_scraped')
gc.collect()
# + [markdown] id="biCYWNXQAJxk"
# # Onestop Corpus data
# This dataset was downloaded from https://huggingface.co/datasets/onestop_english
# + id="_NNxfhHGAJxl"
onestop_data = load_dataset('onestop_english')
onestop_data = onestop_data['train']
onestop_df = onestop_data.to_pandas()
df_to_csv(df=onestop_df, out_dir='data/preprocessed', out_file='onestop.csv')
onestop_sents = onestop_df.text.tolist()
encode_and_save(sentences=onestop_sents, out_dir='embeddings', data_name='onestop')
gc.collect()
# + [markdown] id="Hl-rPWnuAJxl"
# # CC News data
# This dataset was downloaded from https://huggingface.co/datasets/cc_news
# + id="6gfXRfNUAJxl"
news_data = load_dataset('cc_news')
news_data = news_data['train']
news_data = news_data.filter(lambda example: len(example['text']) < 1200)
news_df = pd.DataFrame(news_data['text'], columns=['text'])
df_to_csv(df=news_df, out_dir='data/preprocessed', out_file='news.csv')
news_sents = news_df.text.tolist()
encode_and_save(sentences=news_sents, out_dir='embeddings', data_name='news')
gc.collect()
# + [markdown] id="pfD6GfmIAJxm"
# # Children's book corpus data
# This dataset was downloaded from https://research.fb.com/downloads/babi/
# + id="l2gSUV5vAJxm"
cb_corpus = get_cb_corpus()
cb_corpus = [' '.join(c) for c in cb_corpus]
cb_corpus = pd.DataFrame(cb_corpus, columns=['text'])
cb_corpus.drop([0])
df_to_csv(df=cb_corpus, out_dir='data/preprocessed', out_file='cb_corpus.csv')
cb_sents = cb_corpus.text.tolist()
encode_and_save(sentences=cb_sents, out_dir='embeddings', data_name='cb_corpus')
gc.collect()
| notebooks/02_clrp_external_data_prep.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Numerical estimating the SCGF for 1D diffusion in a quadratic potential
# $$dX_t = -X^3_t dt + \sqrt{2\epsilon}dW_t $$
# We consider the following dynamical observable:
# $$A_T = \frac{1}{T}\int_0^T X_t(X_t+1)dt$$
# +
import numpy as np
import torch
import time
import os
import sys
import torchsde
from torch import nn
import matplotlib.pyplot as plt
from tqdm import trange
from matplotlib import rc
plt.rc('text', usetex=True)
plt.rc('font', family='serif')
rc('xtick', labelsize=14)
rc('ytick', labelsize=14)
# -
# ## Defining the neural network
# defining a DeepRitz block: $L_i(s) = \phi[W_{i2}\cdot\phi(W_{i1}\cdot s +b_{i1}) + b_{i2}] + s$
class DeepRitz_block(nn.Module):
def __init__(self, h_size):
super(DeepRitz_block, self).__init__()
self.dim_h = h_size
self.activation_function = nn.Tanh()
block = [nn.Linear(self.dim_h, self.dim_h),
self.activation_function,
nn.Linear(self.dim_h, self.dim_h),
self.activation_function]
self._block = nn.Sequential(*block)
def forward(self, x):
return self._block(x) + x
# defining the neural network constructed by DeepRitz blocks: $\delta u_\theta(X, \lambda) = W\cdot L_n \otimes \dots \otimes L_1(X, \lambda)$
class Neural_Network(nn.Module):
def __init__(self, in_size, h_size = 10, block_size = 1, dev="cpu"):
super(Neural_Network, self).__init__()
self.num_blocks = block_size
self.dim_x = in_size
self.dim_h = h_size
self.dev = dev
self.dim_input = self.dim_x + 1
# assemble the neural network with DeepRitz blocks
self._block = DeepRitz_block(self.dim_h)
if self.dim_h > self.dim_input:
model = [nn.ConstantPad1d((0, self.dim_h - self.dim_input), 0)]
else:
model = [nn.Linear(self.dim_input, self.dim_h)]
for _ in range(self.num_blocks):
model.append(self._block)
model.append(nn.Linear(self.dim_h, self.dim_x))
self._model = nn.Sequential(*model)
def forward(self, x, k):
return self._model( torch.cat([x, k*torch.ones([*x.shape[:-1], 1]).to(self.dev)], -1) )
# ## defining the system of interest
# $dX_t = [b(X_t) + \delta u_\theta(X_t, \lambda)]dt + \sqrt{2\epsilon}dW_t$
# +
class ODE(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return -x**3
class SDE(nn.Module):
# sde_type = 'stratonovich'
sde_type = 'ito'
noise_type = 'general'
def __init__(self, Drift, Diffusion, h_size = 10, blocks_size = 1, unit_size=10., dev = "cpu"):
super(SDE, self).__init__()
self.dim_x = Diffusion.size(1)
self._drift_0 = Drift.to(dev)
# const diffusion matrix D:
self._diffusion = Diffusion
# the trial driven force u(x)
def drift(self, t, x):
return neural_network(x, lambdas) + self._drift_0(x)
# the diffusion matrix
def diffusion(self, t, x):
return self._diffusion.expand(x.size(0), self.dim_x, self.dim_x)
# the drift b(x)
def drift_0(self, t, x):
return self._drift_0(x)
# -
# ## Learning SCGF
# (Here we set the hidden layer demension to be 20 for demonstration purpose, more accurate estimation requires larger size, e.g., 50, or more training steps)
# +
dim_x, dim_h, num_blocks = 1, 20, 2
dev = "cuda:0" if torch.cuda.is_available() else "cpu"
print(dev)
neural_network = Neural_Network(dim_x, dim_h, num_blocks, dev).to(dev)
Psi = []
A_T = []
K_T = []
epsilon = 0.01
D = 2 * epsilon
diffusion = torch.tensor( np.sqrt(D) * np.eye(dim_x)).float().to(dev)
ode = ODE()
sde = SDE(ode, diffusion, dim_h, num_blocks, dev).to(dev)
sde_method = 'euler' if sde.sde_type == 'ito' else 'modpoint'
# +
Bias = 1./epsilon * torch.linspace(-1,1,11) # 11 lambda from -1 to 1
batch_size = 50 # batch size for each lambda
batch_size_tot = batch_size * Bias.shape[0]
dt = 1e-3 # time step
T = 5. # duration of sampled trajectories
LR =5e-3 # learning rate
x_init = torch.zeros([batch_size_tot, dim_x]).to(dev)
lambdas = Bias.repeat(batch_size,1).t().reshape([-1,1]).to(dev)
optimizer = torch.optim.Adagrad(neural_network.parameters(), lr = LR)
# -
ts = torch.arange(0, T+dt, dt).to(dev)
step = 0
while step < 500:
start_time = time.time()
optimizer.zero_grad()
# generate trajectories according to the controlled process
bm = torchsde.BrownianInterval(t0=ts[0], t1=ts[-1], size=(batch_size_tot, 1),device=dev)
traj = torchsde.sdeint(sde, x_init.to(dev), ts, dt = dt, bm=bm,
method=sde_method, names={'drift': 'drift', 'diffusion': 'diffusion'})
# compute the loss function
delta_u = neural_network(traj, lambdas.expand([*traj.shape[:-1],1]))[:-1]
K = 1/2 * 1/D * torch.sum(delta_u**2, (0,-1)) *dt/T
A = torch.sum(traj*(traj+1), (0,-1)) * dt/T
loss_batch = (K - lambdas.squeeze() * A)
loss = loss_batch.mean()
assert not torch.isnan(loss), "We've got a NaN"
loss.backward()
resample = False
for p in neural_network.parameters():
if p.grad.max() > 1e6:
resample = True
print("We need to re-sample", p.grad.max())
break
if resample == False:
Psi.append(loss_batch.cpu().detach().numpy())
K_T.append(K.cpu().detach().numpy())
A_T.append(A.cpu().detach().numpy())
step += 1
x_init = traj[-1].detach()
optimizer.step()
# (Optional) Replica Exchange:
# with torch.no_grad():
# swap = np.random.choice(batch_size_tot, 2)
# M_T = ((traj[:-1,swap[0]] - (F+F0)[:,swap[0]])**2).sum() * dt
# - ((traj[:-1,swap[1]] - (F+F0)[:,swap[1]])**2).sum()* dt
# if np.random.rand() < torch.exp(M_T /4):
# x_init[[swap[0],swap[1]]] = x_init[[swap[1],swap[0]]]
t_simul = time.time()
print('step %i - time: %.2f sec - loss: %.4f - k * %.4f = %.4f'
% (step, float(t_simul-start_time),
np.mean(K_T[-1]), np.mean(A_T[-1]), np.mean(Psi[-1])*epsilon))
# ## Plotting the time evolution of the estimator with each $\lambda$
# Note: $K_T = \frac{1}{2T}\int_0^T\delta u_\theta D^{-1} \delta u_\theta (X_t, \lambda)dt$ is the Girsanov weight, equivalent to a path integral version of level 2.5 rate function
# +
SCGF = -epsilon * np.array(Psi).reshape([len(Psi),Bias.size(0),-1]).mean(-1)
K = np.array(K_T).reshape([len(K_T),Bias.size(0),-1]).mean(-1)
A = np.array(A_T).reshape([len(A_T),Bias.size(0),-1]).mean(-1)
plt.figure(figsize=(18,3))
plt.subplot(1,3,1)
plt.plot(SCGF)
plt.grid()
plt.ylabel('SCGF',fontsize=16)
plt.xlabel('training steps',fontsize=16)
plt.subplot(1,3,2)
plt.plot(K)
plt.grid()
plt.ylabel(r'$K_T$',fontsize=16)
plt.xlabel('training steps',fontsize=16)
plt.subplot(1,3,3)
plt.plot(A)
plt.grid()
plt.ylabel(r'$A_T$',fontsize=16)
plt.xlabel('training steps',fontsize=16)
plt.show()
# -
# ## Comparing to the the exact solution at zero-noise limit
# <NAME> _et al._ has shown that in the limit $\epsilon\rightarrow0$, the SCGF can be solved analytically:
# $$\psi_{\epsilon\rightarrow0}(\lambda) = \max_q\{ -\frac{1}{4} q^6 + \lambda(q^2+q) \}$$
# +
h = np.linspace(-1,1,1000)[None]
x = np.linspace(-10,10,1000)[None].T
G = np.max(-1/4*x**6 + (x**2 + x) @ h, 0)
fig, ax = plt.subplots()
ax.plot(Bias * epsilon, SCGF[-10:].mean(0),'o', label=r'numerical results at $\epsilon=0.01$')
ax.plot(h.squeeze(),G,'--',color='grey', label=r'analytical results at $\epsilon\rightarrow0$')
ax.set_xlabel(r'$\lambda$',fontsize=16)
ax.set_ylabel(r'$\hat{\psi}_{\epsilon}(\lambda)$',fontsize=16)
ax.grid()
plt.legend(fontsize=14)
plt.show()
# -
| 1D_Diffusion_Quadratic_Potential.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# Import the important packages
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', None)
# -
def create_lag(df, p, sortList, partList, lagList):
"""
Cette fonction prend comme intrant un df, une liste de variables pour lesquelles il faut
creer des valeurs retardees, le nombre de retard, les variables sur lesquelles il faut sort,
les variables de partition et la liste de varibles pour lesquelles on veut des valeurs retardees.
La fonction retourne un df augmente des variables retardees
"""
df = df.sort_values(by=sortList)
for feature in lagList:
for i in range(p):
df['{}.L{}'.format(feature,i+1)] = df.groupby(partList)[feature].shift(i+1)
return df
# Load the raw data
gamesdf = pd.read_csv('../../data/games.csv')
# #### Inspect the data
gamesdf.head()
gamesdf.describe(include='all')
gamesdf.columns
# +
# List des features
features5L = ['away.teamStats.teamSkaterStats.blocked','away.teamStats.teamSkaterStats.faceOffWinPercentage',
'away.teamStats.teamSkaterStats.giveaways','away.teamStats.teamSkaterStats.goals',
'away.teamStats.teamSkaterStats.hits','away.teamStats.teamSkaterStats.pim',
'away.teamStats.teamSkaterStats.powerPlayGoals','away.teamStats.teamSkaterStats.powerPlayOpportunities',
'away.teamStats.teamSkaterStats.powerPlayPercentage','away.teamStats.teamSkaterStats.shots',
'away.teamStats.teamSkaterStats.takeaways','home.teamStats.teamSkaterStats.blocked',
'home.teamStats.teamSkaterStats.faceOffWinPercentage','home.teamStats.teamSkaterStats.giveaways',
'home.teamStats.teamSkaterStats.goals','home.teamStats.teamSkaterStats.hits',
'home.teamStats.teamSkaterStats.pim','home.teamStats.teamSkaterStats.powerPlayGoals',
'home.teamStats.teamSkaterStats.powerPlayOpportunities','home.teamStats.teamSkaterStats.powerPlayPercentage',
'home.teamStats.teamSkaterStats.shots','home.teamStats.teamSkaterStats.takeaways']
features1L = ['teams.away.leagueRecord.losses','teams.away.leagueRecord.ot',
'teams.away.leagueRecord.wins','teams.home.leagueRecord.losses',
'teams.home.leagueRecord.ot','teams.home.leagueRecord.wins']
#Variables date, saisons et equipes
state_time = ['teams.home.team.name', 'season', 'gamePk']
# -
# #### Create columns
# +
# home win
gamesdf['game.homewin'] = (gamesdf['teams.home.score'] - gamesdf['teams.away.score']> 0).astype('int')
# Keep relevent features and game.homewin
gamesdf['teams.home.leagueRecord.gameplayed'] = gamesdf['teams.home.leagueRecord.losses'] + gamesdf['teams.home.leagueRecord.wins'] + gamesdf['teams.home.leagueRecord.ot']
gamesdf['teams.away.leagueRecord.gameplayed'] = gamesdf['teams.away.leagueRecord.losses'] + gamesdf['teams.away.leagueRecord.wins'] + gamesdf['teams.away.leagueRecord.ot']
gamesdf = gamesdf[['game.homewin','teams.away.team.name','teams.home.leagueRecord.gameplayed','gameType','teams.away.leagueRecord.gameplayed'] + features5L + features1L + state_time]
# Create lags for features with only 1 lag
gamesdf = create_lag(df=gamesdf,
p=1,
sortList=['teams.home.team.name', 'season', 'gamePk'],
partList=['teams.home.team.name', 'season'],
lagList=features1L)
# Create lags for features with 5 lags
gamesdf = create_lag(df=gamesdf,
p=10,
sortList=['teams.home.team.name', 'season', 'gamePk'],
partList=['teams.home.team.name', 'season'],
lagList=features5L)
# Drop features that are not lagged
gamesdf = gamesdf.drop(columns=['gamePk'] + features1L + features5L)
# team away
gamesdf['teams.away.leagueRecord.gameplayed.L1'] = gamesdf['teams.away.leagueRecord.losses.L1'] + gamesdf['teams.away.leagueRecord.wins.L1'] + gamesdf['teams.away.leagueRecord.ot.L1']
# team home
gamesdf['teams.home.leagueRecord.gameplayed.L1'] = gamesdf['teams.home.leagueRecord.losses.L1'] + gamesdf['teams.home.leagueRecord.wins.L1'] + gamesdf['teams.home.leagueRecord.ot.L1']
# Nombre de points = ot + wins * 2
# team away
gamesdf['teams.away.leagueRecord.points.L1'] = (gamesdf['teams.away.leagueRecord.wins.L1'] * 2 ) + gamesdf['teams.away.leagueRecord.ot.L1']
# team home
gamesdf['teams.home.leagueRecord.points.L1'] = (gamesdf['teams.home.leagueRecord.wins.L1'] * 2 ) + gamesdf['teams.home.leagueRecord.ot.L1']
# Points Per Game = points / gp
# team away
gamesdf['teams.away.leagueRecord.ppg.L1'] = gamesdf['teams.away.leagueRecord.points.L1'] / gamesdf['teams.away.leagueRecord.gameplayed.L1']
# team home
gamesdf['teams.home.leagueRecord.ppg.L1'] = gamesdf['teams.home.leagueRecord.points.L1'] / gamesdf['teams.home.leagueRecord.gameplayed.L1']
# Difference PPG entre Home vs Away = home PPG - away PPG
gamesdf['game.ppgdiff_home.L1'] = gamesdf['teams.home.leagueRecord.ppg.L1'] - gamesdf['teams.away.leagueRecord.ppg.L1']
# -
# #### Clean data
# +
# only Regular season matches ('A'= Allstar , 'P' = PostSeason, 'PR' = PreSeason)
gamesdf = gamesdf[gamesdf['gameType'] == 'R']
# there are some games with no data
#gamesdf.dropna(subset = ['game.ppgdiff_home'], inplace = True)
# only take games between the 15th and the 70 th game of the seasion
# Should we do the same thing for the away team ?
gamesdf = gamesdf[gamesdf['teams.home.leagueRecord.gameplayed'].between(15,70)]
# -
gamesdf.head()
gamesdf = gamesdf.dropna(axis=1)
# Save the data
gamesdf.to_csv('../../data/model_input.csv')
| notebooks/z_old_02_data_manip.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import matplotlib.pyplot as plt
from os.path import expanduser, join, isfile
import gzip
import pickle
import article_analysis.parse as aap
import article_analysis.ngram_tools as aan
import numpy as np
# %load_ext autoreload
# %autoreload 1
# %aimport article_analysis.parse
# %aimport article_analysis.ngram_tools
# %matplotlib inline
# -
fpath = expanduser('~/data/jstor/latest/')
ii = 0
chunk = aap.get_chunk(fpath, 'ngrams_dict', ii)
kk = list(chunk.keys())
kk[:5]
ex1 = chunk[kk[0]]
# +
# list(ex1.items())[:5]
# +
def positions2counts(article):
ngrams_dict = {}
for k, item in article.items():
ngrams_dict[k] = {kk: len(v) for kk, v in item.items()}
return ngrams_dict
def chunk_positions2counts(chunk):
chunk_new = {k: positions2counts(v) for k, v in chunk.items()}
return chunk_new
# -
ex1_tr = positions2counts(ex1)
chunk_tr = chunk_positions2counts(chunk)
list(chunk_tr['10.2307/255571'][1].items())[:5]
ex_article = chunk_tr['10.2307/255571']
sample_counts = [chunk[k][1] for k in kk[:5]]
sample_ngdicts = [chunk[k] for k in kk[:5]]
len(sample_ngdicts[0])
aac = aan.AlphabetAccumulator()
for c in sample_counts:
aac.update_with_counts(c)
ngram_dist = aac.yield_distribution()
len(ngram_dist), [len(x) for x in sample_counts], len(set([x for sublist in sample_counts for x in sublist.keys()]))
ns = [v[-1] + v[-2] for k, v in ngram_dist.items()]
np.mean(ns), np.std(ns)
aanag = aan.NgramAggregator(list(range(1,6)))
aanag.update_with_ngram_dicts(sample_ngdicts)
ngram_dist = aanag.yield_distribution()
len(ngram_dist[1]), [len(x) for x in sample_counts], len(set([x for sublist in sample_counts for x in sublist.keys()]))
ng_tmp = ngram_dist[1]
kk2 = list(ng_tmp.keys())
{k: ng_tmp[k] for k in kk2[:10]}
| notebooks/dev_stats.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Nearest neighbor for handwritten digit recognition
#
# In this notebook we will build a classifier that takes an image of a handwritten digit and outputs a label 0-9. We will look at a particularly simple strategy for this problem known as the **nearest neighbor classifier**.
#
# To run this notebook you should have the following Python packages installed:
# * `numpy`
# * `matplotlib`
# * `sklearn`
# ## 1. The MNIST dataset
#
# `MNIST` is a classic dataset in machine learning, consisting of 28x28 gray-scale images handwritten digits. The original training set contains 60,000 examples and the test set contains 10,000 examples. In this notebook we will be working with a subset of this data: a training set of 7,500 examples and a test set of 1,000 examples.
# +
# %matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import time
## Load the training set
train_data = np.load('MNIST/train_data.npy')
train_labels = np.load('MNIST/train_labels.npy')
## Load the testing set
test_data = np.load('MNIST/test_data.npy')
test_labels = np.load('MNIST/test_labels.npy')
# -
## Print out their dimensions
print("Training dataset dimensions: ", np.shape(train_data))
print("Number of training labels: ", len(train_labels))
print("Testing dataset dimensions: ", np.shape(test_data))
print("Number of testing labels: ", len(test_labels))
# +
## Compute the number of examples of each digit
train_digits, train_counts = np.unique(train_labels, return_counts=True)
print("Training set distribution:")
print(dict(zip(train_digits, train_counts)))
test_digits, test_counts = np.unique(test_labels, return_counts=True)
print("Test set distribution:")
print(dict(zip(test_digits, test_counts)))
# -
# ## 2. Visualizing the data
# Each data point is stored as 784-dimensional vector. To visualize a data point, we first reshape it to a 28x28 image.
# +
## Define a function that displays a digit given its vector representation
def show_digit(x):
plt.axis('off')
plt.imshow(x.reshape((28,28)), cmap=plt.cm.gray)
plt.show()
return
## Define a function that takes an index into a particular data set ("train" or "test") and displays that image.
def vis_image(index, dataset="train"):
if(dataset=="train"):
show_digit(train_data[index,])
label = train_labels[index]
else:
show_digit(test_data[index,])
label = test_labels[index]
print("Label " + str(label))
return
## View the first data point in the training set
vis_image(0, "train")
## Now view the first data point in the test set
vis_image(0, "test")
# -
# ## 3. Squared Euclidean distance
#
# To compute nearest neighbors in our data set, we need to first be able to compute distances between data points. A natural distance function is _Euclidean distance_: for two vectors $x, y \in \mathbb{R}^d$, their Euclidean distance is defined as
# $$\|x - y\| = \sqrt{\sum_{i=1}^d (x_i - y_i)^2}.$$
# Often we omit the square root, and simply compute _squared Euclidean distance_:
# $$\|x - y\|^2 = \sum_{i=1}^d (x_i - y_i)^2.$$
# For the purposes of nearest neighbor computations, the two are equivalent: for three vectors $x, y, z \in \mathbb{R}^d$, we have $\|x - y\| \leq \|x - z\|$ if and only if $\|x - y\|^2 \leq \|x - z\|^2$.
#
# Now we just need to be able to compute squared Euclidean distance. The following function does so.
# +
## Computes squared Euclidean distance between two vectors.
def squared_dist(x,y):
return np.sum(np.square(x-y))
## Compute distance between a seven and a one in our training set.
print("Distance from 7 to 1: ", squared_dist(train_data[4,],train_data[5,]))
## Compute distance between a seven and a two in our training set.
print("Distance from 7 to 2: ", squared_dist(train_data[4,],train_data[1,]))
## Compute distance between two seven's in our training set.
print("Distance from 7 to 7: ", squared_dist(train_data[4,],train_data[7,]))
# -
# ## 4. Computing nearest neighbors
#
# Now that we have a distance function defined, we can now turn to nearest neighbor classification.
# +
## Takes a vector x and returns the index of its nearest neighbor in train_data
def find_NN(x):
# Compute distances from x to every row in train_data
distances = [squared_dist(x,train_data[i,]) for i in range(len(train_labels))]
# Get the index of the smallest distance
return np.argmin(distances)
## Takes a vector x and returns the class of its nearest neighbor in train_data
def NN_classifier(x):
# Get the index of the the nearest neighbor
index = find_NN(x)
# Return its class
return train_labels[index]
# -
## A success case:
print("A success case:")
print("NN classification: ", NN_classifier(test_data[0,]))
print("True label: ", test_labels[0])
print("The test image:")
vis_image(0, "test")
print("The corresponding nearest neighbor image:")
vis_image(find_NN(test_data[0,]), "train")
## A failure case:
print("A failure case:")
print("NN classification: ", NN_classifier(test_data[39,]))
print("True label: ", test_labels[39])
print("The test image:")
vis_image(39, "test")
print("The corresponding nearest neighbor image:")
vis_image(find_NN(test_data[39,]), "train")
# ## 5. For you to try
# The above two examples show the results of the NN classifier on test points number 0 and 39.
#
# Now try test point number 100.
# * What is the index of its nearest neighbor in the training set? _Record the answer: you will enter it as part of this week's assignment._
# * Display both the test point and its nearest neighbor.
# * What label is predicted? Is this the correct label?
print("NN index: ", find_NN(test_data[100,]))
print("The test image:")
vis_image(100, "test")
print("The corresponding nearest neighbor image:")
vis_image(find_NN(test_data[100,]), "train")
# ## 6. Processing the full test set
#
# Now let's apply our nearest neighbor classifier over the full data set.
#
# Note that to classify each test point, our code takes a full pass over each of the 7500 training examples. Thus we should not expect testing to be very fast. The following code takes about 100-150 seconds on 2.6 GHz Intel Core i5.
# +
## Predict on each test data point (and time it!)
t_before = time.time()
test_predictions = [NN_classifier(test_data[i,]) for i in range(len(test_labels))]
t_after = time.time()
## Compute the error
err_positions = np.not_equal(test_predictions, test_labels)
error = float(np.sum(err_positions))/len(test_labels)
print("Error of nearest neighbor classifier: ", error)
print("Classification time (seconds): ", t_after - t_before)
# -
# ## 7. Faster nearest neighbor methods
#
# Performing nearest neighbor classification in the way we have presented requires a full pass through the training set in order to classify a single point. If there are $N$ training points in $\mathbb{R}^d$, this takes $O(N d)$ time.
#
# Fortunately, there are faster methods to perform nearest neighbor look up if we are willing to spend some time preprocessing the training set. `scikit-learn` has fast implementations of two useful nearest neighbor data structures: the _ball tree_ and the _k-d tree_.
# +
from sklearn.neighbors import BallTree
## Build nearest neighbor structure on training data
t_before = time.time()
ball_tree = BallTree(train_data)
t_after = time.time()
## Compute training time
t_training = t_after - t_before
print("Time to build data structure (seconds): ", t_training)
## Get nearest neighbor predictions on testing data
t_before = time.time()
test_neighbors = np.squeeze(ball_tree.query(test_data, k=1, return_distance=False))
ball_tree_predictions = train_labels[test_neighbors]
t_after = time.time()
## Compute testing time
t_testing = t_after - t_before
print("Time to classify test set (seconds): ", t_testing)
## Verify that the predictions are the same
print("Ball tree produces same predictions as above? ", np.array_equal(test_predictions, ball_tree_predictions))
# +
from sklearn.neighbors import KDTree
## Build nearest neighbor structure on training data
t_before = time.time()
kd_tree = KDTree(train_data)
t_after = time.time()
## Compute training time
t_training = t_after - t_before
print("Time to build data structure (seconds): ", t_training)
## Get nearest neighbor predictions on testing data
t_before = time.time()
test_neighbors = np.squeeze(kd_tree.query(test_data, k=1, return_distance=False))
kd_tree_predictions = train_labels[test_neighbors]
t_after = time.time()
## Compute testing time
t_testing = t_after - t_before
print("Time to classify test set (seconds): ", t_testing)
## Verify that the predictions are the same
print("KD tree produces same predictions as above? ", np.array_equal(test_predictions, kd_tree_predictions))
# -
| Assignement 1/NN_MNIST/Nearest_neighbor_MNIST.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
__author__ = "<NAME>"
__copyright__ = "Copyright 2018, <NAME>"
__credits__ = ["<NAME>"]
__license__ = "MIT"
__version__ = "0.0.1"
__maintainer__ = "<NAME>"
__email__ = "<EMAIL>"
__status__ = "Development"
import pandas as pd
import numpy as np
import scipy.special
import statistics
import scipy.stats
import seaborn as sns
import matplotlib.pyplot as plt
from bokeh.plotting import figure, show, output_file
data = pd.read_csv('../data/Life Cycle/example/LC_export_4-4-2018.csv')
data.columns = ['Start_Date_UTC', 'End_Date_UTC','Start_Time_Local','End_time_Local','Duration','Name','Location']
data_sleep = data[data.Name == " Sleep"]
#1hour = 3600 seconds
sleep_hours =( data_sleep.Duration / 3600)
# -
sleep_hours.describe()
median = statistics.median(sleep_hours)
print ('Median =', median)
IQR = scipy.stats.iqr(sleep_hours)
print("Interquartile Range (IQR)=",IQR)
p1 = figure(title = "Histogram")
hist, edges = np.histogram(sleep_hours, density=True, bins=100)
p1.quad(top=hist, bottom=0, left=edges[:-1], right=edges[1:],
fill_color="#036564", line_color="#033649")
#p1.legend.background_fill_color = "darkgrey"
p1.xaxis.axis_label = 'Sleep time (Hours)'
p1.yaxis.axis_label = 'Relative frequency'
output_file('descriptive_statistics.html', title="Sleep time")
show(p1)
plt.show()
sns.set_style("whitegrid")
ax = sns.boxplot(data=pd.Series.to_frame(sleep_hours))
ax = sns.swarmplot(data=pd.Series.to_frame(sleep_hours),color="black")
| QS-AD/Descriptive_statistics.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Bagging using SVM for IMDB movie ratings
#
# The dataset is obtained from https://www.kaggle.com/karrrimba/movie-metadatacsv/home
# Importing libraries
from random import seed
from random import randrange
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import statistics as stat
from sklearn import svm
from sklearn.metrics import accuracy_score
# Load a CSV file
df = pd.read_csv("movie_metadata.csv")
print(df.shape)
print(len(df[round(df['imdb_score'])==1.0]))
print(len(df[round(df['imdb_score'])==2.0]))
print(len(df[round(df['imdb_score'])==3.0]))
print(len(df[round(df['imdb_score'])==9.0]))
df=df[round(df['imdb_score'])!=1.0]
df=df[round(df['imdb_score'])!=2.0]
df=df[round(df['imdb_score'])!=3.0]
df=df[round(df['imdb_score'])!=9.0]
df.shape
df.columns
df = df.drop(['movie_title','actor_3_name','content_rating','director_name','genres','language','country','title_year','actor_2_name','actor_1_name','plot_keywords','movie_imdb_link'], axis = 1)
df.head()
df =df.dropna()
print(df.shape)
columnsToEncode = list(df.select_dtypes(include=['category','object']))
le = LabelEncoder()
for feature in columnsToEncode:
try:
df[feature] = le.fit_transform(df[feature])
except:
print('Error encoding ' + feature)
df.head()
# +
X=df
y=round(X['imdb_score'])
#y.apply(np.round)
X = X.drop(['imdb_score'], axis = 1)
scaler=StandardScaler()
X = scaler.fit_transform(X)
y = np.array(y).astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state =1)
# +
clf = svm.SVC()
clf.fit(X_train, y_train)
clf.predict(X_test)
prediction = clf.predict(X_test)
print(accuracy_score(y_test,prediction))
# +
# Create a random subsample from the dataset with replacement
def subsample(X_train,y_train,ratio):
X_sample = list()
y_sample = list()
n_sample = round(len(X_train) * ratio)
while len(X_sample) < n_sample:
index = randrange(len(X_train))
X_sample.append(X_train[index])
y_sample.append(y_train[index])
X_sample_np = np.asarray(X_sample)
y_sample_np = np.asarray(y_sample)
return (X_sample_np,y_sample_np)
# Make a prediction with a list of bagged trees
def bagging_predict_soft_voting(models, row):
#Lets find out what each model predicts
pred = list()
for i in range(len(models)):
pred.append(models[i].predict_proba(row.reshape(1,-1)))
finalprob=np.zeros((5,))
for i in range(len(pred)):
finalprob=finalprob+pred[i][0]
final_class = finalprob.argmax(axis=-1)
return final_class
# Bootstrap Aggregation Algorithm
def bagging(X_train,y_train,X_test,sample_size,n_estimators):
models = list()
for i in range(n_estimators):
X_sample_np,y_sample_np = subsample(X_train,y_train,sample_size)
model = svm.SVC(probability=True)
model.fit(X_sample_np, y_sample_np)
models.append(model)
predictions = [bagging_predict_soft_voting(models, row) for row in X_test]
return(predictions)
# +
predictions=bagging(X_train,y_train,X_test,0.7,1)
total=np.sum([y_test[i]==(predictions[i]+4) for i in range(len(predictions))])
print("Accuracy:",total,"/",len(predictions),"* 100 =","{0:.3f}".format(total/len(predictions)*100),"%")
# +
predictions=bagging(X_train,y_train,X_test,0.7,2)
total=np.sum([y_test[i]==(predictions[i]+4) for i in range(len(predictions))])
print("Accuracy:",total,"/",len(predictions),"* 100 =","{0:.3f}".format(total/len(predictions)*100),"%")
# +
predictions=bagging(X_train,y_train,X_test,0.7,5)
total=np.sum([y_test[i]==(predictions[i]+4) for i in range(len(predictions))])
print("Accuracy:",total,"/",len(predictions),"* 100 =","{0:.3f}".format(total/len(predictions)*100),"%")
# +
predictions=bagging(X_train,y_train,X_test,0.7,10)
total=np.sum([y_test[i]==(predictions[i]+4) for i in range(len(predictions))])
print("Accuracy:",total,"/",len(predictions),"* 100 =","{0:.3f}".format(total/len(predictions)*100),"%")
# +
predictions=bagging(X_train,y_train,X_test,0.7,15)
total=np.sum([y_test[i]==(predictions[i]+4) for i in range(len(predictions))])
print("Accuracy:",total,"/",len(predictions),"* 100 =","{0:.3f}".format(total/len(predictions)*100),"%")
# -
from sklearn.ensemble import BaggingClassifier
model = BaggingClassifier(svm.SVC(),n_estimators=20,random_state=1)
model.fit(X_train, y_train)
model.score(X_test,y_test)
| Ensembling methods/Bagging using SVM for IMDB movie ratings.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # The Spinning Effective One-Body Initial Condition Solver
#
# ## Author: <NAME>
#
# ## This module documents the reduced spinning effective one-body initial condition solver as numerically implemented in LALSuite's SEOBNRv3 gravitational waveform approximant. That is, we follow Section IV A of [Buonanno, Chen, and Damour (2006)](https://arxiv.org/abs/gr-qc/0508067).
#
#
# **Notebook Status:** <font color='red'><b> In progress </b></font>
#
# **Validation Notes:** This module is under active development -- do ***not*** use the resulting code for scientific applications. In the future, this module will be validated against the LALSuite [SEOBNRv3/SEOBNRv3_opt code]( https://git.ligo.org/lscsoft/lalsuite.) that was reviewed and approved for LIGO parameter estimation by the LIGO Scientific Collaboration.
#
#
# ## Introduction
# ### The Physical System of Interest
#
# Consider two compact objects (e.g. black holes or neutron stars) with masses $m_{1}$, $m_{2}$ (in solar masses) and spin angular momenta ${\bf S}_{1}$, ${\bf S}_{2}$ in a binary system. The spinning effective one-body ("SEOB") Hamiltonian $H_{\rm real}$ (see [BB2010](https://arxiv.org/abs/0912.3517) Equation (5.69)) describes the dynamics of this system. We seek initial conditions for nonadiabatic evolutions of such a system, and follow [BCD2006](https://arxiv.org/abs/gr-qc/0508067) Section IV A.
#
# To compute the initial conditions, we begin with the following system parameters:
# 1. the mass of each compact object, denoted $m_{1}$, $m_{2}$,
# 1. the spin vector of each compact object, denoted ${\bf S}_{1}$, ${\bf S}_{2}$, and
# 1. initial orbital frequency $f$.
#
# We choose a right-handed spatial coordinate basis $\left\{ {\bf e}_{0}, {\bf e}_{1}, {\bf e}_{2} \right\}$ so that the initial separation vector ${\bf r}$ between the compact objects lies along the ${\bf e}_{0}$-axis and the orbital plane coincides with the ${\bf e}_{0}$, ${\bf e}_{1}$-plane. Assume that ${\bf S}_{1}$, ${\bf S}_{2}$ are written in this basis. Our goal is to produce initial dynamical variables
# 1. ${\bf x} = \left( x, y, z \right)$, and
# 1. ${\bf p} = \left( p_{x}, p_{y}, p_{z} \right)$.
#
# We include below the physical parameters necessary to compute the initial conditions. Besides the physical parameters, we also need the [Euler–Mascheroni constant](https://en.wikipedia.org/wiki/Euler%E2%80%93Mascheroni_constant) $\gamma$ and the [geomtrized](https://en.wikipedia.org/wiki/Geometrized_unit_system) solar mass $\mathcal{M}_{\odot}$, both hard-coded in LALSuite with the significant digits shown below. (The following links point directly to the appropriate LALSuite documentation: [$\gamma$](https://lscsoft.docs.ligo.org/lalsuite/lal/group___l_a_l_constants__h.html#gac6af32574ff8acaeeafe8bf422281e98) and [$\mathcal{M}_{\odot}$](https://lscsoft.docs.ligo.org/lalsuite/lal/group___l_a_l_constants__h.html#gab83f8c705dda3fd0bb2d5f2470bb9cdd).)
#
# Please note that throughout this notebook we adpot the following conventions:
# 1. $c = G = 1$ where $c$ is the speed of light in a vacuum and $G$ is Newton's gravitational constant,
# 1. $m_{1} \ge m_{2}$,
# 1. hatted vectors (e.g. $\hat{\bf L}_{N}$) usually denote scaled or unit vectors, and
# 1. the initial inclination angle $\iota$ of the system relative to some observer is chosen to be zero.
#
# <font color='red'>Please note that in [BCD2006](https://arxiv.org/abs/gr-qc/0508067) the initial conditions are solved for given an initial separation; here we use a given initial frequency instead. The difference is in our approach to solving Equation (4.8). Our approach also differs from that found in LALSuite's SEOBNRv3 code XLALSimIMRSpinEOBInitialConditionsPrec() function (file: LALSimIMRSpinEOBInitialConditionsPrec.c) because we choose our intial coordinate system so that the inclination angle $\iota$ is zero and $m_{1} \ge m_{2}$.</font>
#
# ### Citations
# Throughout this module, we refer to
# * [Buonanno, Chen, and Damour (2006)](https://arxiv.org/abs/gr-qc/0508067) as BCD2006,
# * [Barausse and Buonanno (2010)](https://arxiv.org/abs/0912.3517) as BB2010,
# * [Taracchini, et. al. (2012)](https://arxiv.org/abs/1202.0790) as T2012,
# * [Damour, et. al. (2009)](https://arxiv.org/abs/0811.2069) as DIN2009, and
# * [Pan, et. al. (2014)](https://arxiv.org/abs/1307.6232) as P2014.
#
# LALSuite line numbers are taken from Git commit bba40f2 (see [LALSuite's GitLab page](https://git.ligo.org/lscsoft/lalsuite)).
# +
# Initial condition solver for the spinning effective one-body formulation
# See https://arxiv.org/abs/gr-qc/0508067 Section IV A, which we refer to as BCD2006
# Import necessary NumPy, SymPy, and SEOBNR modules
import numpy as np
import os.path
from scipy.optimize import root
from scipy.interpolate import interp1d, interp2d
from numpy.linalg import norm
import SEOBNR.NQC_corrections as nqc
import SEOBNR.nqc_interp as nqi
# For testing, remove numpy and sympy expression files
# For now, do NOT regenerate CSE expressions
import shutil, os
import sys#TylerK: Add sys to get cmdline_helper from NRPy top directory; remove this line and next when debugged
sys.path.append('/home/tyler/nrpytutorial')
# #!rm -r SEOBNR_Playground_Pycodes#TylerK: for testing
outdir = os.path.join("SEOBNR_Playground_Pycodes/")
import cmdline_helper as cmd
cmd.mkdir(outdir)
with open(outdir+"__init__.py", "w") as file:
file.write("")
# Input variables: will eventually structure this module as a function with the following input parameters
# m1, m2 given in solar masses, f in Hz, and spin in
m1 = 23.
m2 = 10.
f = 20.
S1 = np.array([0.01, 0.02, -0.03])
S2 = np.array([0.04, -0.05, 0.06])
# Initial condtions are computed with tortoise = 0; we later convert momentum if necessary
# See LALSuite's LALSimIMRSpinEOBInitialConditionsPrec.c Line 775 and the discussion
# preceeding Equation (14) of Taracchini, et. al. 2012 (https://arxiv.org/abs/1202.0790)
tortoise = 0.0
# The values of the following constants are from LALSuite (see LALSuite documentation at
# https://lscsoft.docs.ligo.org/lalsuite/lal/group___l_a_l_constants__h.html).
# Euler–Mascheroni constant $\gamma$
EMgamma = 0.577215664901532860606512090082402431
# Geomtrized solar mass $\mathcal{M}_{\odot}$
Msol = 4.925491025543575903411922162094833998e-6
# Solar mass in kg
#MsolSI = 1.98892e30
#Convert the spins to dimensionless quantities
S1 *= m1*m1
S2 *= m2*m2
# -
# <a id='toc'></a>
#
# # Table of Contents
# $$\label{toc}$$
#
# This notebook is organized as follows, matching the "steps" listed in [BCD2006](https://arxiv.org/abs/gr-qc/0508067):
#
# 1. [Step 1:](#step1) Initial Coordinate Choice
# * [Step 1.a:](#massterms) Mass terms
# * [Step 1.b:](#spinterms) Spin terms
# * [Step 1.c:](#ln) Normalized Orbital Angular Momenutm $\hat{\bf L}_{N}$
# * [Step 1.d:](#rhat) Normalized Position $\hat{\bf r}$
# * [Step 1.e:](#vhat) Normalized Velocity $\hat{\bf v}$
# * [Note](#step1note)
# 1. [Step 2:](#step2) Compute ${\bf r}$, ${\bf p}_{r}$, ${\bf p}_{\theta}$, and ${\bf p}_{\phi}$
# * [Step 2.a:](#omega) $\omega$
# * [Step 2.b:](#velocity) Initial Velocity $v$
# * [Step 2.c:](#skerr) ${\bf S}_{\rm Kerr}$
# * [Step 2.d:](#rootfinding) Root finding
# 1. [Step 3:](#step3) Rotate $\hat{\bf L} \to {\bf e}_{z}$
# * [Note](#step3not3)
# * [Step 3.a:](#phat) Normalize ${\bf q}$ and ${\bf p}$
# * [Step 3.b:](#lhat) $\hat{\bf L}$
# * [Step 3.c:](#rotate) Rotation matrix
# * [Step 3.d:](#rotaterhat) Rotate $\hat{\bf r}$
# * [Step 3.e:](#rotatevhat) Rotate $\hat{\bf v}$
# * [Step 3.f:](#rotatelnhat) Rotate $\hat{\bf L}_{N}$
# * [Step 3.g:](#rotates1) Rotate ${\bf S}_{1}$
# * [Step 3.h:](#rotates2) Rotate ${\bf S}_{2}$
# * [Step 3.i:](#rotateshat1) Rotate $\hat{\bf S}_{1}$
# * [Step 3.j:](#rotateshat2) Rotate $\hat{\bf S}_{2}$
# * [Step 3.k:](#rotateq) Rotate ${\bf q}$
# * [Step 3.l:](#rotatep) Rotate ${\bf p}$
# 1. [Step 4:](#step4) Compute $\dot{\bf r}$
# * [Step 4.a:](#carttosph) Convert from Cartesian to Spherical Coordinates
# * [Step 4.b:](#secondderiv) Second derivatives of $H_{\rm real}$
# * [Stop 4.c:](#dedr) $\frac{ \partial E }{ \partial r }$
# * [Step 4.e:](#sigmastar) $\boldsymbol{\sigma}^{*}$
# * [Step 4.f:](#hreal) $H_{\rm real}$
# 1. [Step 5:](#step5) Invert the rotation of Step 3
# 1. [Output](#latex_pdf_output): Output this notebook to $\LaTeX$-formatted PDF file
# 1. [Validation](#validation): Perform validation checks against LALSuite's SEOBNRv3 code (commit bba40f2)
# <a id='step1'></a>
#
# # Step 1: Initial Coordinate Choice \[Back to [top](#toc)\]
# $$\label{step1}$$
# <a id='massterms'></a>
#
# ## Step 1.a: Mass terms \[Back to [top](#toc)\]
# $$\label{massterms}$$
#
# Following the notation preceeding [BCD2006](https://arxiv.org/abs/gr-qc/0508067) Equation (2.2), we define the total mass of the system $M$ and the symmetric mass ratio $\eta$:
#
# \begin{align*}
# M &= m_{1} + m_{2} \\
# \eta &= \frac{ m_{1} m_{2} }{ M^{2} }
# \end{align*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Lines 762--763.
# +
# Binary system total mass $M$
M = m1 + m2
# Inverse mass terms used repeatedly when computing initial conditions
Minv = 1/M
Msqinv = Minv*Minv
# Symmetric mass ratio $\eta$
eta = m1*m2*Msqinv
#print("eta = %.15e\n" % eta) #TYLERK: agrees with LALSuite!
# -
# <a id='spinterms'></a>
#
# ## Step 1.b: Spin terms \[Back to [top](#toc)\]
# $$\label{spinterms}$$
#
# Since we assumed $G = c = 1$, we normalize and make the spin angular momenta dimensionless via:
#
# \begin{align*}
# \hat{\bf S}_{1} &= \frac{ 1 }{ M^{2} } {\bf S}_{1} \\
# \hat{\bf S}_{2} &= \frac{ 1 }{ M^{2} } {\bf S}_{2}
# \end{align*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Lines 768--771.
# +
# Normalized, dimensionless spin vectors
S1hat = Msqinv*S1
S2hat = Msqinv*S2
#print("Normed spin1: %.15e, %.15e, %.15e\n" % (S1hat[0], S1hat[1], S1hat[2]))#TYLERK: agrees with LALSuite!
#print("Normed spin2: %.15e, %.15e, %.15e\n" % (S2hat[0], S2hat[1], S2hat[2]))
# -
# <a id='ln'></a>
#
# ## Step 1.c: Normalized Orbital Angular Momenutm $\hat{\bf L}_{N}$ \[Back to [top](#toc)\]
# $$\label{ln}$$
#
# Since we assume that the initial separation vector ${\bf r}$ between $m_{1}$ and $m_{2}$ lies along the ${\bf e}_{0}$-axis and the initial orbital plane coincides with the ${\bf e}_{0},{\bf e}_{1}$-plane, the normalized inital orbital angular momentum vector $\hat{\bf L}_{N}$ is given by
#
# \begin{equation*}
# \hat{\bf L}_{N} = \begin{bmatrix} 0 \\ 0 \\ 1 \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Lines 787--789.
# Normalized orbital angular momentum
LNhat = np.array([0., 0., 1.])
#TYLERK: agrees with LALSuite!
# <a id='rhat'></a>
#
# ## Step 1.d: Normalized Position $\hat{\bf r}$ \[Back to [top](#toc)\]
# $$\label{rhat}$$
#
# We assumed that the initial separation vector ${\bf r}$ lies along the ${\bf e}_{0}$-axis, so the normalized initial separation vector $\hat{\bf r}$ is given by
#
# \begin{equation*}
# \hat{\bf r} = \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix}.
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Lines 801--803.
# Normalized position vector
rhat = np.array([1., 0., 0.])
#TYLERK: agrees with LALSuite
# <a id='vhat'></a>
#
# ## Step 1.e: Normalized Velocity $\hat{\bf v}$ \[Back to [top](#toc)\]
# $$\label{vhat}$$
#
# Given normalized orbital angular momentum ($\hat{\bf L}_{N}$) and normalized position ($\hat{\bf r}$), the normalized velocity vector ($\hat{\bf v}$) is given by
#
# \begin{equation*}
# \hat{\bf v} = \frac{ \hat{\bf L}_{N} \times \hat{\bf r} }{ \left\lvert \hat{\bf L}_{N} \times \hat{\bf r} \right\rvert }.
# \end{equation*}
#
# Given $\hat{\bf L}_{N} = \begin{bmatrix} 0 \\ 0 \\ 1 \end{bmatrix}$ and $\hat{\bf r} = \begin{bmatrix} 1 \\ 0 \\ 0 \end{bmatrix}$ it is clear that $\hat{\bf v} = \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix}$.
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Lines 807--811.
# Normalized velocity vector
vhat = np.array([0., 1., 0.])
#TYLERK: agrees with LALSuite
# <a id='step1note'></a>
#
# ## Note \[Back to [top](#toc)\]
# $$\label{step1note}$$
#
# Since we began assuming $\iota = 0$, we do not need to rotate $\hat{\bf r}$, $\hat{\bf v}$, $\hat{\bf L}_{N}$, ${\bf S}_{1}$, ${\bf S}_{2}$, $\hat{\bf S}_{1}$, or $\hat{\bf S}_{2}$ as is done at LALSimIMRSpinEOBInitialConditionsPrec.c Lines 840-847 (Step 1 of [BCD2006](https://arxiv.org/abs/gr-qc/0508067) Section IV A). In particular, the rotation matrix in this case is the $3\times3$ identity matrix.
# <a id='step2'></a>
#
# # Step 2: Compute ${\bf r}$ and ${\bf p}$ in spherical coordinates \[Back to [top](#toc)\]
# $$\label{step2}$$
#
# We seek postion vector ${\bf r}$ and ${\bf p}$ assuming a spherical orbit without radiation reaction.
# <a id='omega'></a>
#
# ## Step 2.a: Initial orbital frequency $\omega$ \[Back to [top](#toc)\]
# $$\label{omega}$$
#
# Noting that the plane of the polarization of the gravitational wave "rotates at twice the orbital rate" (see the "Effects of passing" section of [this Wikipedia article](https://en.wikipedia.org/wiki/Gravitational_wave#Effects_of_passing)), the initial orbital frequency is
#
# \begin{equation*}
# \omega = M \mathcal{M}_{\odot} \pi f.
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 893.
# Omega: initial orbital angular frequency
omega = M*Msol*np.pi*f
#print("omega = %.15e\n" % omega)#TYLERK: agrees with LALSuite
# <a id='velocity'></a>
#
# ## Step 2.b: Initial Velocity $v$ \[Back to [top](#toc)\]
# $$\label{velocity}$$
#
# <font color='red'>Is there a paper reference for this formula? Zach suggested Kepler's Laws, but a cursory look didn't reveal a convincing link.</font>
#
# \begin{equation*}
# v = \sqrt[3]{ \omega }.
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 894.
# v: initial velocity and velocity squared, since we use that quantity often
v = np.cbrt(omega)
vsq = v*v
# GOOD NEWS: WE'RE FINDING THE SAME VALUE FOR V THAT LALSUITE COMPUTES!
# <a id='skerr'></a>
#
# ## Step 2.c: ${\bf S}_{\rm Kerr}$ \[Back to [top](#toc)\]
# $$\label{skerr}$$
#
# <font color='red'>This cell may be unecessary because we compute a in the derivatives (and spins depned on time so $a$ is time-dependent!).</font>
#
# From [BB2010](https://arxiv.org/abs/0912.3517) Equations (5.2), (5.64), and (5.67) we have
#
# \begin{equation*}
# {\bf S}_{\rm Kerr} = {\bf S}_{1} + {\bf S}_{2}.
# \end{equation*}
#
# Taking the square of [BB2010](https://arxiv.org/abs/0912.3517) Equation (4.9),
#
# \begin{equation*}
# a^{2} = \frac{ {\bf S}_{\rm Kerr} \cdot {\bf S}_{\rm Kerr} }{ M^{2} }
# \end{equation*}
#
# so that
#
# \begin{equation*}
# a = \sqrt{ a^{2} }.
# \end{equation*}
# +
# Compute S_Kerr, the spin of the deformed Kerr background
# See https://arxiv.org/abs/0912.3517 Equations (5.2), (5.64), and (5.67)
SKerr = np.add(S1, S2)
# Normalize S_Kerr by total mass
SKerr *= Msqinv
# Compute a, which is a parameter in metric potentials of a Kerr spacetime
# See https://arxiv.org/abs/0912.3517 Equation (4.9)
asq = np.dot(SKerr,SKerr)
a = np.sqrt(asq)
#print("a = %.15e\n" % a)#TYLERK: agrees with LALSuite!
# -
# <a id='rootfinding'></a>
#
# ## Step 2.d: Root-finding \[Back to [top](#toc)\]
# $$\label{rootfinding}$$
#
# We will write components of the momentum vector ${\bf p}$ in spherical coordinates with components ${\bf p}_{r}$, ${\bf p}_{\theta}$, and ${\bf p}_{\phi}$. In the special case in which we find ourselves, we have (see [BCD2006](https://arxiv.org/abs/gr-qc/0508067) Equations (4.7) and (4.9)):
#
# \begin{align*}
# {\bf r}^{\theta} &= \frac{ \pi }{ 2 } \\
# {\bf r}^{\phi} &= 0 \\
# {\bf p}_{r} &= 0.
# \end{align*}
#
# From [BCD2006](https://arxiv.org/abs/gr-qc/0508067) Equations (4.8)--(4.9), we seek to solve
#
# \begin{equation*}
# \begin{bmatrix} \frac{ \partial H }{ \partial {\bf r}^{r} } \\ \frac{ \partial H }{ \partial {\bf p}^{\theta} } \\ \frac{ \partial H }{ \partial {\bf p}^{\phi} } - \omega \end{bmatrix} = \begin{bmatrix} 0 \\ 0 \\ 0 \end{bmatrix}.
# \end{equation*}
#
# As the Hamiltonian is given in Cartesian coordinates, this requires computing $\frac{ \partial H }{ \partial {\bf r}^{0} }$, $\frac{ \partial H }{ \partial {\bf p}^{1} }$, and $\frac{ \partial H }{ \partial {\bf p}^{2} }$ and then converting to spherical coordinates. That is, using the chain rule and recalling $\phi = 0$ and $\theta = \frac{ \pi }{ 2 }$, we find
#
# \begin{align*}
# \frac{\partial H}{\partial {\bf r}^{r}} &= \frac{\partial H}{\partial {\bf r}^{0}} - \frac{\frac{\partial H}{\partial {\bf p}^{1}}{\bf p}^{\phi}}{\left({\bf r}^{r}\right)^{2}} + \frac{\frac{\partial H}{\partial {\bf p}^{2}}{\bf p}^{\theta}}{\left({\bf r}^{r}\right)^{2}} \\
# \frac{\partial H}{\partial {\bf p}^{\theta}} &= -\frac{\frac{\partial H}{\partial {\bf p}^{2}}}{{\bf r}^{r}} \\
# \frac{\partial H}{\partial {\bf p}^{\phi}} &= \frac{\frac{\partial H}{\partial {\bf p}^{1}}}{{\bf r}^{r}}.
# \end{align*}
#
# <font color='red'>The quantities above should be re-derived and double-checked. Note that in LALSuite, the root-finding routine sets ${\bf p}^{\theta} = -r {\bf p}^{2}$ and ${\bf p}^{\phi} = r {\bf p}^{1}$ (see LALSimIMRSpinEOBInitialConditionsPrec.c Lines 409--411). In case we want to note this later, LALSuite uses the following initial guesses for the root-finding routine:
#
# \begin{align*}
# {\bf r}^{r} &= \frac{ 1 }{ v^{2} } \\
# {\bf p}^{\phi} &= v \\
# {\bf p}^{\theta} &= 0.2.
# \end{align*}
#
# Note: LALSuite scales the initial guesses given to the root-finding routine; see LALSimIMRSpinEOBInitialConditionsPrec.c Line 899. In the end, we should have a cartesian postition vector ${\bf q}$ and momentum vector ${\bf p}$.</font>
#
# <font color='red'>IMPORTANT NOTE: WE REWROTE THE TERMS RHO2INV, LAMBDAINV, AND XI2INV AS COMPARED TO V3_OPT IN LALSUITE TO AVOID A CATESTROPHIC CANCELLATION.</font>
#
# +
# Check if a file of partial derivative expressions has already been generated.
# If not, generate them!
#if not os.path.isfile("SEOBNR_Playground_Pycodes/numpy_expressions.py"):
if not os.path.isfile("SEOBNR_Playground_Pycodes/numpy_Hreal_expressions.py"):
# import SEOBNR.Hamiltonian_and_derivs as Had
import SEOBNR.Hamiltonian_and_derivs_playground as Had #TylerK:rename!
Had.output_H_and_derivs()
import SEOBNR_Playground_Pycodes.sympy_expression as se
se.sympy_cse()
from SEOBNR_Playground_Pycodes.new_dHdx import new_compute_dHdx # For testing
from SEOBNR_Playground_Pycodes.new_dHdpy import new_compute_dHdpy # For testing
from SEOBNR_Playground_Pycodes.new_dHdpz import new_compute_dHdpz # For testing
from SEOBNR.constant_coeffs import compute_const_coeffs
KK, k0, k1, k2, k3, k4, k5, k5l, dSO, dSS = compute_const_coeffs(eta,EMgamma,a)
#The coefficients do agree with LALSuite!
# Inital root guess
root_guess = [1/(v*v), v*2, 0.001*200]
# print(root_guess) # This is the same initial guess given to GSL in LALSuite, but you won't know it unless you're
# careful about their scale factors (which are done and undone and done and undone...)
# Define the function of which we want to find the roots
def root_func(F):
#Recompute Hamiltonian derivatives using latest minimization guess
dHdx = new_compute_dHdx(m1, m2, eta, F[0], 0.0, 0.0, 0.0, F[1], F[2], S1hat[0], S1hat[1], S1hat[2], S2hat[0],
S2hat[1], S2hat[2], KK, k0, k1, dSO, dSS, 2, EMgamma)
dHdpy = new_compute_dHdpy(m1, m2, eta, F[0], 0.0, 0.0, 0.0, F[1], F[2], S1hat[0], S1hat[1], S1hat[2], S2hat[0],
S2hat[1], S2hat[2], KK, k0, k1, dSO, dSS, 1, EMgamma)
dHdpz = new_compute_dHdpz(m1, m2, eta, F[0], 0.0, 0.0, 0.0, F[1], F[2], S1hat[0], S1hat[1], S1hat[2], S2hat[0],
S2hat[1], S2hat[2], KK, k0, k1, dSO, dSS, 1, EMgamma)
return [ dHdx[0]/eta + (-dHdpz[0]*F[2]/eta - dHdpy[0]*F[1]/eta)/F[0], -dHdpz[0]/F[0]/eta, dHdpy[0]/F[0]/eta - omega ]
# Find the roots of root_func
soln = root(root_func, root_guess, args=(), method='hybr', jac=None, tol=None, callback=None)
print(soln.success)
print(soln.message)
# Populate separation (q) and momentum (p) vectors with the results of root()
q = np.array([soln.x[0], 0., 0.])
p = np.array([0., soln.x[1], soln.x[2]])
print(q[0])
print(p[1])
print(p[2])
# -
# <a id='step3'></a>
#
# # Step 3: Rotate $\hat{\bf L} \to {\bf e}_{z}$ \[Back to [top](#toc)\]
# $$\label{step3}$$
# <a id='step3note'></a>
# ## Note \[Back to [top](#toc)\]
# $$\label{step3note}$$
#
# At this point, LALSimIMRSpinEOBInitialConditionsPrec.c normalizes the Cartesian separation and momentum vectors constructed in [Step 2](#step2). We already have a normalized separation vector $\hat{\bf r}$, so we skip that step.
# <a id='phat'></a>
#
# ## Step 3.a: Normalize ${\bf q}$ and ${\bf p}$ \[Back to [top](#toc)\]
# $$\label{phat}$$
#
# Next we normalize the separation vector ${\bf q}$ and the position vector ${\bf p}$ we found in [Step 2](#step2):
#
# \begin{align*}
# \hat{\bf q} &= \frac{ {\bf q} }{ \left\lvert {\bf q} \right\rvert} \\
# \hat{\bf p} &= \frac{ {\bf p} }{ \left\lvert {\bf p} \right\rvert}.
# \end{align*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1101.
# Normalize the separation and momentum vectors
qhat = q/norm(q)
phat = p/norm(p)
# <a id='lhat'></a>
#
# ## Step 3.b: $\hat{\bf L}$ \[Back to [top](#toc)\]
# $$\label{lhat}$$
#
# We compute the normalized relativistic angular momentum vector $\hat{\bf L}$:
#
# \begin{equation*}
# \hat{\bf L} = \frac{ \hat{\bf r} \times \hat{\bf p} }{ \left\lvert \hat{\bf r} \times \hat{\bf p} \right\rvert }.
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Lines 1098--1100.
# Normalize the relativistic angular momentum vector
Lhat = np.cross(rhat,phat)
Lhat /= norm(Lhat)
# <a id='rotate'></a>
#
# ## Step 3.c: Rotation matrix \[Back to [top](#toc)\]
# $$\label{rotate}$$
#
# The rotation matrix from the $\left\{ \hat{\bf r}, {\bf v}, \hat{\bf L}_{N} \right\}$ frame to the $\left\{ \hat{\bf r}, {\bf p}, \hat{\bf L} \right\}$ frame is given by
#
# \begin{equation*}
# \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}.
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1107.
# Rotation matrix
rotate = np.array([rhat, phat, Lhat])
# <a id='rotaterhat'></a>
#
# ## Step 3.d: Rotate $\hat{\bf r}$ \[Back to [top](#toc)\]
# $$\label{rotatesrhat}$$
#
# We now rotate $\hat{\bf r}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# \hat{\bf r}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} \hat{\bf r}^{0} \\ \hat{\bf r}^{1} \\ \hat{\bf r}^{2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1112.
# Rotate the normalized separation vector
rhatprm = np.dot(rotate,rhat)
# <a id='rotatevhat'></a>
#
# ## Step 3.e: Rotate $\hat{\bf v}$ \[Back to [top](#toc)\]
# $$\label{rotatevhat}$$
#
# We rotate $\hat{\bf v}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# \hat{\bf v}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} \hat{\bf v}^{0} \\ \hat{\bf v}^{1} \\ \hat{\bf v}^{2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1113.
# Rotate the normalized velocity vector
vhatprm = np.dot(rotate, vhat)
# <a id='rotatelnhat'></a>
#
# ## Step 3.f: Rotate $\hat{\bf L}_{N}$ \[Back to [top](#toc)\]
# $$\label{rotatelnhat}$$
#
# We rotate $\hat{\bf L}_{N}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# \hat{\bf L}_{N}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} \hat{\bf L}_{N}^{0} \\ \hat{\bf L}_{N}^{1} \\ \hat{\bf L}_{N}^{2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1114.
# Rotate the normalized angular momentum vector
LNhatprm = np.dot(rotate, LNhat)
# <a id='rotates1'></a>
#
# ## Step 3.g: Rotate ${\bf S}_{1}$ \[Back to [top](#toc)\]
# $$\label{rotates1}$$
#
# We rotate ${\bf S}_{1}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# {\bf S}_{1}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} {\bf S}_{1}^{0} \\ {\bf S}_{1}^{1} \\ {\bf S}_{1}^{2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1115.
# Rotate the S1 vector
S1prm = np.dot(rotate, S1)
# <a id='rotates2'></a>
#
# ## Step 3.h: Rotate ${\bf S}_{2}$ \[Back to [top](#toc)\]
# $$\label{rotates2}$$
#
# We rotate ${\bf S}_{2}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# {\bf S}_{2}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} {\bf S}_{2}^{0} \\ {\bf S}_{2}^{1} \\ {\bf S}_{2}^{z} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1116.
# Rotate the S2 vector
S2prm = np.dot(rotate, S2)
# <a id='rotates1hat'></a>
#
# ## Step 3.i: Rotate $\hat{\bf S}_{1}$ \[Back to [top](#toc)\]
# $$\label{rotates1hat}$$
#
# We rotate $\hat{\bf S}_{1}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# \hat{\bf S}_{1}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} \hat{\bf S}_{1}^{0} \\ \hat{\bf S}_{1}^{1} \\ \hat{\bf S}_{1}^{1} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1117.
# Rotate the normalized S1 vector
S1hatprm = np.dot(rotate, S1hat)
# <a id='rotates2hat'></a>
#
# ## Step 3.j: Rotate $\hat{\bf S}_{2}$ \[Back to [top](#toc)\]
# $$\label{rotates2hat\hat}$$
#
# We rotate $\hat{\bf S}_{2}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# \hat{\bf S}_{2}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} \hat{\bf S}_{2}^{0} \\ \hat{\bf S}_{2}^{1} \\ \hat{\bf S}_{2}^{2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1118.
# Rotate the normalized S2 vector
S2hatprm = np.dot(rotate, S2hat)
# <a id='rotateq'></a>
#
# ## Step 3.k: Rotate ${\bf q}$ \[Back to [top](#toc)\]
# $$\label{rotateq}$$
#
# We rotate ${\bf q}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# {\bf r}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} {\bf q}^{0} \\ {\bf q}^{1} \\ {\bf q}^{2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1119.
# Rotate the separation vector
rprm = np.dot(rotate,q)
# <a id='rotatep'></a>
#
# ## Step 3.l: Rotate ${\bf p}$ \[Back to [top](#toc)\]
# $$\label{rotatep}$$
#
# We rotate ${\bf p}$. We'll use primes to denote the rotated vector.
#
# \begin{equation*}
# {\bf p}^{\prime} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf r}^{1} & \hat{\bf r}^{2} \\
# \hat{\bf p}^{0} & \hat{\bf p}^{1} & \hat{\bf p}^{2} \\
# \hat{\bf L}^{0} & \hat{\bf L}^{1} & \hat{\bf L}^{2}\end{bmatrix}
# \begin{bmatrix} {\bf p}^{0} \\ {\bf p}^{1} \\ {\bf p}^{2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1120.
# Rotate the momentum vector
pprm = np.dot(rotate, p)
# <a id='step4'></a>
#
# # Step 4: Compute $\dot{\bf r}$ \[Back to [top](#toc)\]
# $$\label{step4}$$
# <a id='carttosph'></a>
#
# ## Step 4.a: Convert from Cartesian to Spherical Coordinates \[Back to [top](#toc)\]
# $$\label{carttosph}$$
#
# We convert position and momentum into spherical coordinates. In the special case where $\theta = \frac{ \pi }{ 2 }$ and $\phi = 0$, the spherical position vector ${\bf r} = \left( {\bf r}^{r}, {\bf r}^{\theta}, {\bf r}^{\phi} \right)$ is given by
#
# \begin{align*}
# {\bf r}^{r} &= {\bf r}^{0} \\
# {\bf r}^{\theta} &= \frac{ \pi }{ 2 } \\
# {\bf r}^{\phi} &= 0
# \end{align*}
#
# and the spherical momentum vector ${\bf p} = \left( {\bf p}^{r}, {\bf p}^{\theta}, {\bf p}^{\phi} \right)$ is given by
#
# \begin{align*}
# {\bf p}^{r} &= {\bf p}^{0} \\
# {\bf p}^{\theta} &= - {\bf r}^{0}{\bf p}^{2} \\
# {\bf p}^{\phi} &= {\bf r}^{0}{\bf p}^{1} \\
# \end{align*}
#
# LALSuite calls a Cartesian to spherical routine at LALSimIMRSpinEOBInitialConditionsPrec.c Line 1139, and the function itself is defined on Lines 243--285.
# Convert the separation vector from Cartesian to spherical coordinates
r = np.array([rprm[0], np.pi/2., 0.])
psph = np.array([pprm[0], -rprm[0]*pprm[2], rprm[0]*pprm[1]])
# <a id='secondderiv'></a>
#
# ## Step 4.b: Second derivatives of $H_{\rm real}$ \[Back to [top](#toc)\]
# $$\label{seconderiv}$$
#
# We need to compute $\frac{ \partial H }{ \partial {\bf p}^{\phi} }$, $\frac{ \partial^{2} H_{\rm real} }{ \partial r^{2} }$, and $\frac{ \partial^{2} H_{\rm real} }{ \partial r \partial {\bf p}^{\phi} }$ (<font color='red'>in another module</font>).
#
# <font color='red'>Note: be sure that, following this, we use normalized spins.</font>
# +
# Import second derivatives of H from another function/routine
#dHdpphi = dHdpx/r[0] - omega
#TylerK: Hard-code temporarily so that we can get to validation
dHdpphi = 0.1
d2Hdr2 = 0.2
d2Hdrdpphi = 0.3
# -
# <a id='dedr'></a>
#
# ## Stop 4.c: $\frac{ \partial E }{ \partial r }$ \[Back to [top](#toc)\]
# $$\label{dedr}$$
#
# We seek to compute $\frac{ \partial H }{\partial r}$, and [BCD2006](https://arxiv.org/abs/gr-qc/0508067) uses the convention $H \equiv E$. (see [BCD2006](https://arxiv.org/abs/gr-qc/0508067) Equation (3.7)). From [BCD2006](https://arxiv.org/abs/gr-qc/0508067) Equation Equation (4.14) (noting that this equation applies in spherical coordinates when ${\bf r}$ is directed along the ${\bf e}_{0}$ axis),
#
# \begin{equation*}
# \frac{ \partial E }{ \partial r } = -\frac{ \frac{ \partial H }{ \partial {\bf p}^{\phi} } \frac{ \partial^{2} H }{ \left(\partial {\bf r}^{r} \right)^{2} } }{ \frac{ \partial^{2} H }{ \partial {\bf r}^{r} \partial {\bf p}^{\phi} } }.
# \end{equation*}
# Time derivative of Hamiltonain with respect to separation magnitude r
dEdr = -dHdpphi*d2Hdr2/d2Hdrdpphi
# <a id='sigmastar'></a>
#
# ## Step 4.e: $\boldsymbol{\sigma}^{*}$ \[Back to [top](#toc)\]
# $$\label{sigmastar}$$
#
# From [BB2010](https://arxiv.org/abs/0912.3517) Equation (5.3),
#
# \begin{equation*}
# \boldsymbol{\sigma}^{*} = \frac{ m_{2} }{ m_{1} } {\bf S}_{1} + \frac{ m_{1} }{ m_{2} }{\bf S}_{2}.
# \end{equation*}
# Spin combination sigmastar
sigmastar = np.add(m2/m1*S1, m1/m2*S2)
# <a id='hreal'></a>
#
# ## Step 4.f: $H_{\rm real}$ \[Back to [top](#toc)\]
# $$\label{hreal}$$
#
# We now compute $H_{\rm real}$ (LALSimIMRSpinEOBInitialConditionsPrec.c Line 1217). To do so, we need to restructure the output of Tutorial-SEOBNR_Documentation by first making sure each expression is on a single line and then reversing the lines.
# +
# Compute the value of the Hamiltonian, Hreal
# Hreal is computed in another function, written in SymPy so we can take advantage of CSE
# This other function writes the terms in the reverse order needed for numerical computation
# Open the output file
with open('SEOBNR/Hamiltonian-Hreal_one_line_expressions.txt', 'w') as output:
count = 0
# Read output of Tutorial-SEOBNR_Documentation
for line in list(open("SEOBNR/Hamiltonian-Hreal_on_top.txt")):
# Read the first line
if count == 0:
prevline=line
#Check if prevline is a complete expression
elif "=" in prevline and "=" in line:
output.write("%s\n" % prevline.strip('\n'))
prevline=line
# Check if line needs to be adjoined to prevline
elif "=" in prevline and not "=" in line:
prevline = prevline.strip('\n')
prevline = (prevline+line).replace(" ","")
# Be sure to print the last line.
if count == len(list(open("SEOBNR/Hamiltonian-Hreal_on_top.txt")))-1:
if not "=" in line:
print("ERROR. Algorithm not robust if there is no equals sign on the final line. Sorry.")
sys.exit(1)
else:
output.write("%s\n" % line)
count = count + 1
# Now reverse the expressions
with open('SEOBNR_Playground_Pycodes/Hreal_on_bottom.py', 'w') as output:
# output.write("import numpy as np\ndef compute_Hreal(m1, m2, gamma, tortoise, dSO, dSS, x, y, z, p1, p2, p3, S1x, S1y, S1z, S2x, S2y, S2z):")
output.write("import numpy as np\ndef compute_Hreal(m1=23., m2=10., gamma=0.577215664901532860606512090082402431, tortoise=1, dSO=-7.966696593617955e+01, dSS=1.261873764525631e+01, x=2.129681018601393e+01, y=0.000000000000000e+00, z=0.000000000000000e+00, p1=0.000000000000000e+00, p2=2.335391115580442e-01, p3=-4.235164736271502e-22, S1x=4.857667584940312e-03, S1y=9.715161660389764e-03, S1z=-1.457311842632286e-02, S2x=3.673094582185491e-03, S2y=-4.591302628615413e-03, S2z=5.509696538546906e-03):")
for line in reversed(list(open("SEOBNR/Hamiltonian-Hreal_one_line_expressions.txt"))):
output.write("\t%s\n" % line.rstrip().replace("sp.sqrt", "np.sqrt").replace("sp.Rational",
"np.divide").replace("sp.abs", "np.abs").replace("sp.log",
"np.log").replace("sp.sign", "np.sign").replace("sp.pi",
"np.pi"))
output.write("\treturn Hreal")
import SEOBNR_Playground_Pycodes.Hreal_on_bottom as Ham
#All inputs agree with LALSuite
#eta, KK, tortoise, and dSO all agree with LALSuite to 16 significant digits
#Hard-code other inputs so we know they agree exactly with LALSuite
#LALSuite command used: ./lalsimulation/src/lalsim-inspiral -a SEOBNRv3 -M 23 -m 10 -f 20 -X 0.01 -Y 0.02 -Z -0.03 -x 0.04 -y -0.05 -z 0.06
Hreal = Ham.compute_Hreal(m1=m1, m2=m2, gamma=EMgamma, tortoise=1, dSO=dSO, dSS=dSS,
x=rprm[0], y=rprm[1], z=rprm[2], p1=pprm[0], p2=pprm[1], p3=pprm[2],
S1x=S1hatprm[0], S1y=S1hatprm[1], S1z=S1hatprm[2],
S2x=S2hatprm[0], S2y=S2hatprm[1], S2z=S2hatprm[2])
print(Hreal)#TylerK
#Hreal = Ham.compute_Hreal(m1, m2, EMgamma, 1, dSO, dSS,
# 2.129681018601393e+01, 0.000000000000000e+00, 0.000000000000000e+00,
# 0.000000000000000e+00, 2.335391115580442e-01, -4.235164736271502e-22,
# 4.857667584940312e-03, 9.715161660389764e-03, -1.457311842632286e-02,
# 3.673094582185491e-03, -4.591302628615413e-03, 5.509696538546906e-03)
# -
#Temporary validation code block: all hard-coded values from LALSuite!
Hreal_valid = Ham.compute_Hreal(m1=23., m2=10., gamma=EMgamma, tortoise=1,
dSO=-7.966696593617955e+01, dSS=1.261873764525631e+01,
x=2.129681018601393e+01, y=0.000000000000000e+00, z=0.000000000000000e+00,
p1=0.000000000000000e+00, p2=2.335391115580442e-01, p3=-4.235164736271502e-22,
S1x=4.857667584940312e-03, S1y=9.715161660389764e-03, S1z=-1.457311842632286e-02,
S2x=3.673094582185491e-03, S2y=-4.591302628615413e-03, S2z=5.509696538546906e-03)
print(Hreal_valid)#TylerK
Hreal_valid = Ham.compute_Hreal()
print(Hreal_valid)#TylerK
if(np.abs(Hreal_valid-9.952429072947245e-01)>1e-14):
print("ERROR. You have broken the Hamiltonian computation!")
sys.exit(1)
# <a id='polardata'></a>
#
# ## Polar data \[Back to [top](#toc)\]
# $$\label{polardata}$$
#
# At LALSimIMRSpinEOBInitialConditionsPrec.c Lines 1234--1238, we set the following polar data ${\bf P}$:
#
# \begin{align*}
# {\bf P}^{0} &= {\bf r}^{r} \\
# {\bf P}^{1} &= 0 \\
# {\bf P}^{2} &= {\bf p}^{r} \\
# {\bf P}^{3} &= {\bf p}^{\phi}
# \end{align*}
# Populate a vector of polar coordinate values
polar = np.array([r[0], 0., psph[0], psph[1]])
# <a id='vphikepler'></a>
#
# ## vPhiKepler \[Back to [top](#toc)\]
# $$\label{vphikepler}$$
#
# From [T2012](https://arxiv.org/abs/1202.0790) Equation (A2),
#
# \begin{equation*}
# {\rm vPhiKepler} = \frac{ 1 }{ \omega^{2} \left( {\bf r}^{r} \right)^{3} }.
# \end{equation*}
#
# See LALSimIMRSpinEOBFactorizedWaveformPrec_v3opt.c Lines 113 and 1271--1315. <font color='red'>Note that SEOBNRv3_opt recalculates $\omega$, but I think the $\omega$ above is based on a circular orbit and therefore the recalcuation is unnecessary.</font>
# Keplarian velocity
vPhiKepler = 1./(omega*omega*r[0]*r[0]*r[0])
# <a id='rcrossp'></a>
#
# ## ${\bf r} \times {\bf p}$ \[Back to [top](#toc)\]
# $$\label{rcrossp}$$
#
# We'll use the notation
#
# \begin{equation*}
# {\rm rcrossp} = {\bf r}^{\prime} \times {\bf p}^{\prime}.
# \end{equation*}
#
# See LALSimIMRSpinEOBFactorizedWaveformPrec_v3opt.c Lines 170--172.
# r cross p
rcrossp = np.cross(rprm,pprm)
# <a id='vphi'></a>
#
# ## vPhi \[Back to [top](#toc)\]
# $$\label{vphi}$$
#
# We'll use the notation (<font color='red'> paper reference?</font>)
#
# \begin{equation*}
# {\rm vPhi} = \omega {\bf r}^{r} \sqrt[3]{\rm vPhiKepler}.
# \end{equation*}
#
# See LALSimIMRSpinEOBFactorizedWaveformPrec_v3opt.c Lines 185 and 190.
# Keplarian velocity
vPhi = omega*r[0]*np.cbrt(vPhiKepler)
# <a id='sidot'></a>
#
# ## ${\bf S}_{i} \cdot \hat{\bf L}$ \[Back to [top](#toc)\]
# $$\label{sidotl}$$
#
# We compute ${\bf S}_{1} \cdot \hat{\bf L}$ and ${\bf S}_{2} \cdot \hat{\bf L}$.
#
# See LALSimIMRSpinEOBFactorizedFluxPrec_v3opt.c lines 131--134.
# S dot L
s1dotL = np.dot(S1,Lhat)
s2dotL = np.dot(S2,Lhat)
# <a id='chii'></a>
# ## $\boldsymbol{\chi}_{\rm S}$, $\boldsymbol{\chi}_{\rm A}$ \[Back to [top](#toc)\]
# $$\label{chii}$$
#
# From [P2014](https://arxiv.org/abs/1307.6232) Equation 17, we have
#
# \begin{align*}
# \chi_{\rm S} = \frac{1}{2} \left( {\bf S}_{1} + {\bf S}_{2} \right) \cdot \hat{\bf L} \\
# \chi_{\rm A} = \frac{1}{2} \left( {\bf S}_{1} - {\bf S}_{2} \right) \cdot \hat{\bf L}
# \end{align*}
# Spin combinations chiS and chiA
chiS = 0.5*(s1dotL + s2dotL)
chiA = 0.5*(s1dotL - s2dotL)
# <a id='mihat'></a>
# ## $\hat{m}_{i}$ \[Back to [top](#toc)\]
# $$\label{mihat}$$
#
# We scale the masses $m_{1}$, $m_{2}$ by total mass. See LALSimIMREOBNewtonianMultipole.c Lines 540--541.
#
# \begin{align*}
# \hat{m}_{1} = \frac{ m_{1} }{ M } \\
# \hat{m}_{2} = \frac{ m_{2} }{ M } \\
# \end{align*}
# Normalized mass
mhat1 = m1*Minv
mhat2 = m2*Minv
# <a id='newtonianmultipole'></a>
#
# ## Newtonian multipole \[Back to [top](#toc)\]
# $$\label{newtonianmultipole}$$
#
# The Newtonian multipolar waveform is given in [DIN2009](https://arxiv.org/abs/0811.2069) Equation (4). For a given $(\ell, m)$ we define
#
# \begin{align*}
# \epsilon &= \left( \ell + m \right) {\rm mod } 2 \\
# n &= \left( i m \right)^{\ell} \frac{ 8 \pi }{ \left( 2 \ell + 1 \right)!! } \sqrt{ \frac{ \left( \ell + 1 \right) \left( \ell + 2 \right) }{ \ell \left( \ell - 1 \right) } }
# \end{align*}
#
# along with the associated Legendre function evaluated at zero. See LALSimIMRSpinEOBFactorizedWaveformPrec_v3opt.c Line 206 and LALSimIMREOBNewtonianMultipole.c Lines 205, 210, 290, and 309--506.
# +
# Compute Newtonian multipole
# Compute the associated Legendre function of degree l and order m at x=0
def AssociatedLegendre(l,m):
if l==1:
if m==1:
return -1.
else:
print("You used a bad (l,m)")
if l==2:
if m==2:
return 3.
elif m==1:
return 0.
else:
print("You used a bad (l,m)")
if l==3:
if m==3:
return 15.
elif m==2:
return 0.
elif m==1:
return 1.5
else:
print("You used a bad (l,m)")
if l==4:
if m==4:
return 105.
elif m==3:
return 0.
elif m==2:
return -7.5
elif m==1:
return 0.
else:
print("You used a bad (l,m)")
if l==5:
if m==5:
return -945.
elif m==4:
return 0.
elif m==3:
return 52.5
elif m==2:
return 0.
elif m==1:
return -1.875
else:
print("You used a bad (l,m)")
if l==6:
if m==6:
return 10395.
elif m==5:
return 0.
elif m==4:
return -472.5
elif m==3:
return 0.
elif m==2:
return 13.125
elif m==1:
return 0.
else:
print("You used a bad (l,m)")
if l==7:
if m==7:
return -135135.
elif m==6:
return 0.
elif m==5:
return 5197.5
elif m==4:
return 0.
elif m==3:
return -118.125
elif m==2:
return 0.
elif m==1:
return 2.1875
else:
print("You used a bad (l,m)")
if l==8:
if m==8:
return 2027025.
elif m==7:
return 0.
elif m==6:
return -67567.5
elif m==5:
return 0.
elif m==4:
return 1299.375
elif m==3:
return 0.
elif m==2:
return -19.6875
elif m==1:
return 0.
else:
print("You used a bad (l,m)")
# Compute the prefix for the Newtonian multipole
def NewtonianPrefix(m1,m2,l,m,epsilon,eta):
Mtot = m1 + m2
m1hat = m1/Mtot
m2hat = m2/Mtot
if (m%2)==0:
sign = 1
else:
sign = -1
lpepm1 = l + epsilon - 1
if (m1!=m2) or sign==1:
c = np.power(m2hat,lpepm1) + sign*np.power(m1hat,lpepm1)
else:
if l==2 or l==3:
c = -1.
elif l==4 or l==5:
c = -0.5
else:
c = 0.
n = np.power(complex(0,m), l)
doubfact = doublefactorial(2*l+1)
if epsilon==0:
n *= 8.*np.pi/doubfact
n *= np.sqrt((l+1)*(l+2)/(l*(l-1)))
elif epsilon==1:
n = -n
n *= 16.j*np.pi/doubfact
n *= np.sqrt(((2*l+1)* (l+2) * (l*l - m*m))/((2*l - 1) * (l+1) * l * (l-1)))
else:
print("Epsilon must be 0 or 1")
exit()
return n*eta*c
# Function to compute a double factorial; see https://en.wikipedia.org/wiki/Double_factorial
def doublefactorial(n):
if n <= 0:
return 1
else:
return n * doublefactorial(n-2)
# -
# <a id='hlmtab'></a>
#
# ## hLMTab \[Back to [top](#toc)\]
# $$\label{hlmtab}$$
#
# In order to compute flux, we need to build the matrix "hLMTab". See [T2012](https://arxiv.org/abs/1202.0790) Equation (17) and the Appendix, along with [this private LIGO doc](https://dcc.ligo.org/T1400476).
# +
# The following populates a matrix T_{lm} of resummed leading-order logarithms of tail effects
deltam = (m1 - m2)/(m1 + m2)
flux = 0.
fa1 = interp1d(nqi.domain, nqi.a1Range, kind='cubic')
fa2 = interp1d(nqi.domain, nqi.a2Range, kind='cubic')
fa3 = interp1d(nqi.domain, nqi.a3Range, kind='cubic')
fb1 = interp1d(nqi.domain, nqi.b1Range, kind='cubic')
fb2 = interp1d(nqi.domain, nqi.b2Range, kind='cubic')
a1 = fa1(eta)
a2 = fa2(eta)
a3 = fa3(eta)
b1 = -fb1(eta)
b2 = -fb2(eta)
fa3sAmax = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amaxa3sVal, kind='cubic')
fa4Amax = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amaxa4Val, kind='cubic')
fa5Amax = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amaxa5Val, kind='cubic')
fb3Amax = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amaxb3Val, kind='cubic')
fb4Amax = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amaxb4Val, kind='cubic')
fa3sAmed = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Ameda3sVal, kind='cubic')
fa4Amed = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Ameda4Val, kind='cubic')
fa5Amed = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Ameda5Val, kind='cubic')
fb3Amed = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amedb3Val, kind='cubic')
fb4Amed = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amedb4Val, kind='cubic')
fa3sAmin = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amina3sVal, kind='cubic')
fa4Amin = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amina4Val, kind='cubic')
fa5Amin = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Amina5Val, kind='cubic')
fb3Amin = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Aminb3Val, kind='cubic')
fb4Amin = interp2d(nqi.aDomain, nqi.etaDomain, nqi.Aminb4Val, kind='cubic')
chiAmaxCoeffs = [fa3sAmax(a,eta), fa4Amax(a,eta), fa5Amax(a,eta), fb3Amax(a,eta), fb4Amax(a,eta)]
chiAmedCoeffs = [fa3sAmed(a,eta), fa4Amed(a,eta), fa5Amed(a,eta), fb3Amed(a,eta), fb4Amed(a,eta)]
chiAminCoeffs = [fa3sAmin(a,eta), fa4Amin(a,eta), fa5Amin(a,eta), fb3Amin(a,eta), fb4Amin(a,eta)]
chi = a/(1. - 2.*eta)
if eta < 1.0e-15:
chiAmax = (chi + 1.)/2.
chiAmin = (chi - 1.)/2.
else:
if chi <= 0:
chiAmax = (1. + chi)*(1. - 2.*eta)/(1.+ deltam - 2.*eta)
if (1. + deltam - 2.*eta + 2.*chi*(1. - 2.*eta))/(1. - deltam - 2.*eta) < 1.:
chiAmin = -(1. + chi)*(1. - 2.*eta)/(1. - deltam - 2.*eta)
else:
chiAmin = -(1. - chi)*(1. - 2.*eta)/(1. + deltam - 2.*eta)
else:
chiAmin = -(1. - chi)*(1. - 2.*eta)/(1. + deltam - 2.*eta)
if -(1. + deltam - 2.*eta - 2.*chi*(1. - 2.*eta))/(1. - deltam - 2.*eta) > -1.:
chiAmax = (1. - chi)*(1. - 2.*eta)/(1. - deltam - 2.*eta)
else:
chiAmax = (1. + chi)*(1. - 2.*eta)/(1. + deltam - 2.*eta)
chiAmed = (chiAmax + chiAmin)/2.
if chiAmax < 1.0e-15:
cmax = 1.0
cmed = 0.0
cmin = 0.0
else:
cmax = (chiA - chiAmed)*(chiA - chiAmin)/(chiAmax - chiAmed)/(chiAmax - chiAmin)
cmed = -(chiA - chiAmax)*(chiA - chiAmin)/(chiAmax - chiAmed)/(chiAmed - chiAmin)
cmin = (chiA - chiAmax)*(chiA - chiAmed)/(chiAmax - chiAmin)/(chiAmed - chiAmin)
nqcmax = chiAmaxCoeffs[0]
nqcmed = chiAmedCoeffs[0]
nqcmin = chiAminCoeffs[0]
a3S = cmax*nqcmax + cmed*nqcmed + cmin*nqcmin
nqcmax = chiAmaxCoeffs[1]
nqcmed = chiAmedCoeffs[1]
nqcmin = chiAminCoeffs[1]
a4 = cmax*nqcmax + cmed*nqcmed + cmin*nqcmin
nqcmax = chiAmaxCoeffs[2]
nqcmed = chiAmedCoeffs[2]
nqcmin = chiAminCoeffs[2]
a5 = cmax*nqcmax + cmed*nqcmed + cmin*nqcmin
nqcmax = chiAmaxCoeffs[3]
nqcmed = chiAmedCoeffs[3]
nqcmin = chiAminCoeffs[3]
b3 = cmax*nqcmax + cmed*nqcmed + cmin*nqcmin
nqcmax = chiAmaxCoeffs[4]
nqcmed = chiAmedCoeffs[4]
nqcmin = chiAminCoeffs[4]
b4 = cmax*nqcmax + cmed*nqcmed + cmin*nqcmin
rsq = polar[0]*polar[0]
sqrtr = np.sqrt(polar[0])
prsq = polar[2]*polar[2]
mag = 1. + (prsq/(rsq*omega*omega))*(a1 + a2/polar[0] + (a3 + a3S)/(polar[0]*sqrtr) + a4/rsq + a5/(rsq*sqrtr))
phase = b1*polar[2]/(polar[0]*omega) + prsq*polar[2]/(polar[0]*omega)*(b2 + b3/sqrtr + b4/polar[0])
nqc = complex(mag*np.cos(phase),0)
nqc += complex(0,mag*np.sin(phase))
import factorized_modes as fm
for l in range(2, 9):
for m in range(1, l+1):
epsilon = (l + m) % 2
legendre = AssociatedLegendre(l-epsilon,m)*np.sqrt(2*l+1*np.math.factorial(l-m)/4*np.pi*np.math.factorial(l+m))
#Note that LALSimIMREOBNewtonianMultipole.c Line 74 atrributes the
#Newtonian prefix calculations to https://arxiv.org/abs/1106.1021v2
prefix = NewtonianPrefix(m1,m2,l,m,epsilon,eta)
multipole = prefix*legendre*np.power(vPhi*vPhi,(l+epsilon)/2.)
if ((l+m)%2)==0:
Slm = (Hreal*Hreal - 1.)/(2.*eta) + 1.
else:
Slm = v*psph[2]
eulerlog = EMgamma + np.log(2.*m*v)
k = m*omega
Hrealk = Hreal * k
Hrealksq4 = 4. * Hrealk*Hrealk
Hrealk4pi = 4. * np.pi *Hrealk
Tlmprefac = np.sqrt(Hrealk4pi/(1.-np.exp(-Hrealk4pi)))/np.math.factorial(l)
Tlmprodfac = 1.
for i in range(1,l+1):
Tlmprodfac *= Hrealksq4 + (i*i)
Tlm = Tlmprefac*np.sqrt(Tlmprodfac)
auxflm = 0.
if l==2:
if m==2:
rholm = 1 + vsq * (fm.rho22v2 + v*(fm.rho22v3 + v*(fm.rho22v4 + v*(fm.rho22v5 + v*(fm.rho22v6
+ fm.rho22v6l*eulerlog + v*(fm.rho22v7 + v*(fm.rho22v8 + fm.rho22v8l*eulerlog
+ (fm.rho22v10 + fm.rho22v10l*eulerlog)*vsq)))))))
elif m==1:
rholm = 1. + v * (fm.rho21v1 + v*(fm.rho21v2 + v*(fm.rho21v3 + v*(fm.rho21v4 + v*(fm.rho21v5
+ v*(fm.rho21v6 + fm.rho21v6l*eulerlog + v*(fm.rho21v7 + fm.rho21v7l*eulerlog
+ v*(fm.rho21v8 + fm.rho21v8l*eulerlog + (fm.rho21v10 + fm.rho21v10l*eulerlog)*vsq))))))))
auxflm = v*fm.f21v1 + vsq*v*fm.f21v3
else:
print("You used a bad (l,m)")
elif l==3:
if m==3:
rholm = 1. + vsq*(fm.rho33v2 + v*(fm.rho33v3 + v*(fm.rho33v4 + v*(fm.rho33v5 + v*(fm.rho33v6
+ fm.rho33v6l*eulerlog + v*(fm.rho33v7 + (fm.rho33v8 + fm.rho33v8l*eulerlog)*v))))))
auxflm = v*vsq*fm.f33v3;
elif m==2:
rholm = 1. + v*(fm.rho32v + v*(fm.rho32v2 + v*(fm.rho32v3 + v*(fm.rho32v4 + v*(fm.rho32v5
+ v*(fm.rho32v6 + fm.rho32v6l*eulerlog + (fm.rho32v8 + fm.rho32v8l*eulerlog)*vsq))))))
elif m==1:
rholm = 1. + vsq*(fm.rho31v2 + v*(fm.rho31v3 + v*(fm.rho31v4 + v*(fm.rho31v5 + v*(fm.rho31v6
+ fm.rho31v6l*eulerlog + v*(fm.rho31v7 + (fm.rho31v8 + fm.rho31v8l*eulerlog)*v))))))
auxflm = v*vsq*fm.f31v3
else:
print("You used a bad (l,m)")
elif l==4:
if m==4:
rholm = 1. + vsq*(fm.rho44v2 + v*(fm.rho44v3 + v*(fm.rho44v4 + v*(fm.rho44v5 + (fm.rho44v6
+ fm.rho44v6l*eulerlog)*v))))
elif m==3:
rholm = 1. + v*(fm.rho43v + v*(fm.rho43v2 + vsq*(fm.rho43v4 + v*(fm.rho43v5 + (fm.rho43v6
+ fm.rho43v6l*eulerlog)*v))))
auxflm = v*fm.f43v
elif m==2:
rholm = 1. + vsq*(fm.rho42v2 + v*(fm.rho42v3 + v*(fm.rho42v4 + v*(fm.rho42v5 + (fm.rho42v6
+ fm.rho42v6l*eulerlog)*v))))
elif m==1:
rholm = 1. + v*(fm.rho41v + v*(fm.rho41v2 + vsq*(fm.rho41v4 + v*(fm.rho41v5 + (fm.rho41v6
+ fm.rho41v6l*eulerlog)*v))))
auxflm = v*fm.f41v
else:
print("You used a bad (l,m)")
elif l==5:
if m==5:
rholm = 1. + vsq*(fm.rho55v2 + v*(fm.rho55v3 + v*(fm.rho55v4 + v*(fm.rho55v5 + fm.rho55v6*v))))
elif m==4:
rholm = 1. + vsq*(fm.rho54v2 + v*(fm.rho54v3 + fm.rho54v4*v))
elif m==3:
rholm = 1. + vsq*(fm.rho53v2 + v*(fm.rho53v3 + v*(fm.rho53v4 + fm.rho53v5*v)))
elif m==2:
rholm = 1. + vsq*(fm.rho52v2 + v*(fm.rho52v3 + fm.rho52v4*v))
elif m==1:
rholm = 1. + vsq*(fm.rho51v2 + v*(fm.rho51v3 + v*(fm.rho51v4 + fm.rho51v5*v)))
else:
print("You used a bad (l,m)")
elif l==6:
if m==6:
rholm = 1. + vsq*(fm.rho66v2 + v*(fm.rho66v3 + fm.rho66v4*v))
elif m==5:
rholm = 1. + vsq*(fm.rho65v2 + fm.rho65v3*v)
elif m==4:
rholm = 1. + vsq*(fm.rho64v2 + v*(fm.rho64v3 + fm.rho64v4*v))
elif m==3:
rholm = 1. + vsq*(fm.rho63v2 + fm.rho63v3*v)
elif m==2:
rholm = 1. + vsq*(fm.rho62v2 + v*(fm.rho62v3 + fm.rho62v4*v))
elif m==1:
rholm = 1. + vsq*(fm.rho61v2 + fm.rho61v3*v)
else:
print("You used a bad (l,m)")
elif l==7:
if m==7:
rholm = 1. + vsq*(fm.rho77v2 + fm.rho77v3*v)
elif m==6:
rholm = 1. + fm.rho76v2*vsq
elif m==5:
rholm = 1. + vsq*(fm.rho75v2 + fm.rho75v3*v)
elif m==4:
rholm = 1. + fm.rho74v2*vsq
elif m==3:
rholm = 1. + vsq*(fm.rho73v2 + fm.rho73v3*v)
elif m==2:
rholm = 1. + fm.rho72v2*vsq
elif m==1:
rholm = 1. + vsq*(fm.rho71v2 + fm.rho71v3*v)
else:
print("You used a bad (l,m)")
elif l==8:
if m==8:
rholm = 1. + fm.rho88v2*vsq
elif m==7:
rholm = 1. + fm.rho87v2*vsq
elif m==6:
rholm = 1. + fm.rho86v2*vsq
elif m==5:
rholm = 1. + fm.rho85v2*vsq
elif m==4:
rholm = 1. + fm.rho84v2*vsq
elif m==3:
rholm = 1. + fm.rho83v2*vsq
elif m==2:
rholm = 1. + fm.rho82v2*vsq
elif m==1:
rholm = 1. + fm.rho81v2*vsq
else:
print("You used a bad (l,m)")
else:
print("You used a bad (l,m)")
rholmPowl = np.power(rholm,l)
if eta==0.25 and (m % 2):
rholmPowl = auxflm
else:
rholmPowl += auxflm
hlm = Tlm*Slm*rholmPowl*multipole
if (m*m*omega*omega*hlm*hlm) > 5.:
hlm *= nqc
flux += m*m*omega*omega*hlm*hlm
if omega*omega > 1 or flux > 5:
flux = 0.
flux *= 8./np.pi
flux /= eta
rdot = -flux/dEdr
pr = rdot/(dHdpr/px)
# -
# <a id='step5'></a>
#
# # Step 5: Invert the rotation of Step 3 \[Back to [top](#toc)\]
# $$\label{step5}$$
# <a id='invrotationmatrix'></a>
#
# ## Inverse Rotation Matrix \[Back to [top](#toc)\]
# $$\label{invrotationmatrix}$$
#
# The matrix to invert the rotation applied in [Step 3](#step3) is:
#
# \begin{equation*}
# \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf p}^{0} & \hat{\bf L}^{0} \\
# \hat{\bf r}^{1} & \hat{\bf p}^{1} & \hat{\bf L}^{1} \\
# \hat{\bf r}^{2} & \hat{\bf p}^{2} & \hat{\bf L}^{2}\end{bmatrix}.
# \end{equation*}
#
# To see that this is indeed the correct matrix inverse, note that by construction $\hat{\bf q}$, $\hat{\bf p}$, and $\hat{\bf L}$ are all unit vectors orthogonal to one another. See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1107.
invert00 = rhat0
invert01 = phat0
invert02 = Lhat0
invert10 = rhat1
invert11 = phat1
invert12 = Lhat1
invert20 = rhat2
invert21 = phat2
invert22 = Lhat2
# <a id='invrotaterhat'></a>
#
# ## Rotate $\hat{\bf r}^{\prime}$ \[Back to [top](#toc)\]
# $$\label{invrotaterhat}$$
#
# We rotate $\hat{\bf r}^{\prime}$ and call the new separation vector ${\bf r}$.
#
# \begin{equation*}
# \hat{\bf r} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf p}^{0} & \hat{\bf L}^{0} \\
# \hat{\bf r}^{1} & \hat{\bf p}^{1} & \hat{\bf L}^{1} \\
# \hat{\bf r}^{2} & \hat{\bf p}^{2} & \hat{\bf L}^{2} \end{bmatrix}
# \begin{bmatrix} \hat{\bf r}^{\prime 0} \\ \hat{\bf r}^{\prime 1} \\ \hat{\bf r}^{\prime 2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1315.
rhat0 = rhat0*rhatprm0 + phat0*rhatprm1 + Lhat0*rhatprm2
rhat1 = rhat1*rhatprm0 + phat1*rhatprm1 + Lhat1*rhatprm2
rhat0 = rhat2*rhatprm0 + phat2*rhatprm1 + Lhat2*rhatprm2
# <a id='invrotatevhat'></a>
#
# ## Rotate $\hat{\bf v}^{\prime}$ \[Back to [top](#toc)\]
# $$\label{invrotatevhat}$$
#
# We rotate $\hat{\bf v}^{\prime}$ and call the new separation vector ${\bf v}$.
#
# \begin{equation*}
# \hat{\bf v} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf p}^{0} & \hat{\bf L}^{0} \\
# \hat{\bf r}^{1} & \hat{\bf p}^{1} & \hat{\bf L}^{1} \\
# \hat{\bf r}^{2} & \hat{\bf p}^{2} & \hat{\bf L}^{2} \end{bmatrix}
# \begin{bmatrix} \hat{\bf v}^{\prime 0} \\ \hat{\bf v}^{\prime 1} \\ \hat{\bf v}^{\prime 2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1316.
vhat0 = rhat0*vhatprm0 + phat0*vhatprm1 + Lhat0*vhatprm2
vhat1 = rhat1*vhatprm0 + phat1*vhatprm1 + Lhat1*vhatprm2
vhat2 = rhat2*vhatprm0 + phat2*vhatprm1 + Lhat2*vhatprm2
# <a id='invrotatelnhat'></a>
#
# ## Rotate $\hat{\bf L}_{N}^{\prime}$ \[Back to [top](#toc)\]
# $$\label{invrotatelnhat}$$
#
# We rotate $\hat{\bf L}_{N}^{\prime}$ and call the new separation vector ${\bf L}_{N}$.
#
# \begin{equation*}
# \hat{\bf L}_{N} = \begin{bmatrix} \hat{\bf r}^{0} & \hat{\bf p}^{0} & \hat{\bf L}^{0} \\
# \hat{\bf r}^{1} & \hat{\bf p}^{1} & \hat{\bf L}^{1} \\
# \hat{\bf r}^{2} & \hat{\bf p}^{2} & \hat{\bf L}^{2} \end{bmatrix}
# \begin{bmatrix} \hat{\bf L}_{N}^{\prime 0} \\ \hat{\bf L}_{N}^{\prime 1} \\ \hat{\bf L}_{N}^{\prime 2} \end{bmatrix}
# \end{equation*}
#
# See LALSimIMRSpinEOBInitialConditionsPrec.c Line 1317.
LNhat0 = rhat0*LNhatprm0 + phat0*LNhatprm1 + Lhat0*LNhatprm2
LNhat1 = rhat1*LNhatprm0 + phat1*LNhatprm1 + Lhat1*LNhatprm2
LNhat2 = rhat2*LNhatprm0 + phat2*LNhatprm1 + Lhat2*LNhatprm2
# <a id='tortoise_matrix'></a>
#
# # Tortoise Conversion Matrix \[Back to [top](#toc)\]
# $$\label{tortoise_matrix}$$
#
# <font color='red'>We're now back to LALSpinPrecHcapRvecDerivative_v3opt.c, Lines 92--96.</font>
#
# From [Pan, Buonanno, Buchman, et. al. (2010)](https://arxiv.org/abs/0912.3466v2) Equation (A3) the matrix for the coordinate conversion to tortoise coordinates is
#
# \begin{align*}
# \begin{pmatrix} 1 + \frac{ x^{2} }{ r^{2} } \left( \xi - 1 \right) & \frac{ x y }{ r^{2} } \left( \xi - 1 \right) & \frac{ x z }{ r^{2} } \left( \xi - 1 \right) \\
# \frac{ x y }{ r^{2} } \left( \xi - 1 \right) & 1 + \frac{ y^{2} }{ r^{2} } \left( \xi - 1 \right) & \frac{ y z }{ r^{2} } \left( \xi - 1 \right) \\
# \frac{ x z }{ r^{2} } \left( \xi - 1 \right) & \frac{ y z }{ r^{2} } \left( \xi - 1 \right) & 1 + \frac{ z^{2} }{ r^{2} } \left( \xi - 1 \right) \end{pmatrix}
# \end{align*}
ximinus1 = xi - 1
toTort = sp.Array([[1 + x*x*ximinus1/(r*r), x*y*ximinus1/(r*r), x*z*ximinus1/(r*r)],
[x*y*ximinus1/(r*r), 1 + y*y*ximinus1/(r*r), y*z*ximinus1/(r*r)],
[x*z*ximinus1/(r*r), y*z*ximinus1/(r*r), 1 + z*z*ximinus1/(r*r)]])
# <a id='latex_pdf_output'></a>
#
# # Output: Output this notebook to $\LaTeX$-formatted PDF file \[Back to [top](#toc)\]
# $$\label{latex_pdf_output}$$
# !jupyter nbconvert --to latex --template latex_nrpy_style.tplx --log-level='WARN' Tutorial-SEOBNR_Initial_Conditions.ipynb
# !pdflatex -interaction=batchmode Tutorial-SEOBNR_Initial_Conditions.tex
# !pdflatex -interaction=batchmode Tutorial-SEOBNR_Initial_Conditions.tex
# !pdflatex -interaction=batchmode Tutorial-SEOBNR_Initial_Conditions.tex
# !rm -f Tut*.out Tut*.aux Tut*.log
# <a id='validation'></a>
#
# # Validation: Perform validation checks against LALSuite's SEOBNRv3 code (commit bba40f2) \[Back to [top](#toc)\]
# $$\label{validation}$$
# +
#Validation Cell
#Here we perform a validation check by comparing the derivative values to hard-coded values produced by SEOBNRv3
#in LALSuite. If this check fails, y'all done sump'tin wrong!
derivative_list = [dHdx,dHdy,dHdz,dHdpx,dHdpy,dHdpz,dHds1x,dHds1y,dHds1z,dHds2x,dHds2y,dHds2z]
for q in derivative list:
from SEOBNR_Playground_Pycodes.new_q import new_compute_q
from SEOBNR.constant_coeffs import compute_const_coeffs
KK, k0, k1, k2, k3, k4, k5, k5l, dSO, dSS = compute_const_coeffs(eta,EMgamma,a)
#The coefficients do agree with LALSuite!
tortoise = 1 #Only for testing
Hreal = compute_Hreal(m1, m2, eta, 10.0, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, tortoise, EMgamma)
Hreal_pert = compute_Hreal(m1, m2, eta, 10.0*(1.+1e-15), 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, tortoise, EMgamma)
termbyterm_dHdx = new_compute_dHdx(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 2, EMgamma)
termbyterm_dHdy = new_compute_dHdy(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 2, EMgamma)
termbyterm_dHdz = new_compute_dHdz(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 2, EMgamma)
termbyterm_dHdpx = new_compute_dHdpx(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHdpy = new_compute_dHdpy(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHdpz = new_compute_dHdpz(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHds1x = new_compute_dHds1x(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHds1y = new_compute_dHds1y(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHds1z = new_compute_dHds1z(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHds2x = new_compute_dHds2x(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHds2y = new_compute_dHds2y(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
termbyterm_dHds2z = new_compute_dHds2z(m1, m2, eta, 10, 11.0, 12.0,
0.01, 0.02, 0.03,
0.004, 0.005, -0.006,
0.007, -0.008, 0.009,
KK, k0, k1, dSO, dSS, 1, EMgamma)
print("exact Hreal = %.15e" % Hreal)
print("pertd Hreal = %.15e" % Hreal_pert)
print("relative diff in Hreal = %.15e\n" % (np.abs(Hreal - Hreal_pert)/np.abs(Hreal)))
print("new term-by-term computation of dHdx = %.15e\n" % (termbyterm_dHdx[0]))
print("new term-by-term computation of dHdy = %.15e\n" % termbyterm_dHdy[0])
print("new term-by-term computation of dHdz = %.15e\n" % termbyterm_dHdz[0])
print("new term-by-term computation of dHdpx = %.15e\n" % termbyterm_dHdpx[0])
print("new term-by-term computation of dHdpy = %.15e\n" % termbyterm_dHdpy[0])
print("new term-by-term computation of dHdpz = %.15e\n" % termbyterm_dHdpz[0])
print("new term-by-term computation of dHds1x = %.15e\n" % termbyterm_dHds1x[0])
print("new term-by-term computation of dHds1y = %.15e\n" % termbyterm_dHds1y[0])
print("new term-by-term computation of dHds1z = %.15e\n" % termbyterm_dHds1z[0])
print("new term-by-term computation of dHds2x = %.15e\n" % termbyterm_dHds2x[0])
print("new term-by-term computation of dHds2y = %.15e\n" % termbyterm_dHds2y[0])
print("new term-by-term computation of dHds2z = %.15e\n" % termbyterm_dHds2z[0])
| in_progress/Tutorial-SEOBNR_Initial_Conditions.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# 
#
# <a href="https://hub.callysto.ca/jupyter/hub/user-redirect/git-pull?repo=https%3A%2F%2Fgithub.com%2Fcallysto%2Fcurriculum-notebooks&branch=master&subPath=Mathematics/FibonacciNumbers/fibonacci-numbers.ipynb&depth=1" target="_parent"><img src="https://raw.githubusercontent.com/callysto/curriculum-notebooks/master/open-in-callysto-button.svg?sanitize=true" width="123" height="24" alt="Open in Callysto"/></a>
# # Fibonacci Numbers
# The **Fibonacci** sequence is the set of numbers that starts out like this:
#
# $$0,1,1,2,3,5,8,13,\ldots.$$
#
# It's easy to recognize the pattern here. Each number is the sum of the previous two numbers in the sequence. Except, of course, the first two number, 0 and 1, which we put in there to get things started.
#
# This sequence, or pattern of numbers, goes on forever.
# These numbers are most commonly known as the **Fibonacci numbers**, after the Italian mathematician **L. Fibonacci** (c. 1200 C.E.). However, these numbers were actually first described hundreds of years before, by Indian mathematicians. The first such mathematician for whom we have written records was **Virahanka** (c. 700 C.E.).
#
# It is difficult to overcome the usage of a name adopted hundreds of years ago, and so in what follows we will refer to the Virahanka-Fibonacci numbers as the "Fibonacci numbers."
# **Exercise 1:** Check out the following article about the "so-called Fibonacci" numbers in ancient India: https://www.sciencedirect.com/science/article/pii/0315086085900217
# For an excellent exposition about the motivation, poetry, and linguistics of these early mathematicians, and to learn about some fascinating properties of these numbers, check out the following video:
from IPython.display import YouTubeVideo
YouTubeVideo('LP253wHIoO8', start=2633)
# It's convenient to label these numbers, so we write $F_0 = 0$, $F_1 = 1$ $F_2 = 2$ and so on. The list of numbers is thus defined **recursively** by the formula
# $$ \qquad$$
# $$ F_n = F_{n-1} + F_{n-2}.$$
#
# We can check the few numbers in the Fibonacci sequence are obtained by that formula, by computing:
# $$\begin{eqnarray*}
# F_{2} &=&F_{1}+F_{0}=1+0=1 \\
# F_{3} &=&F_{2}+F_{1}=1+1=2 \\
# F_{4} &=&F_{3}+F_{2}=2+1=3 \\
# F_{5} &=&F_{4}+F_{3}=3+2=5 \\
# F_{6} &=&F_{5}+F_{4}=5+3=8 \\
# F_{7} &=&F_{6}+F_{5}=8+5=13 \\
# &&\vdots
# \end{eqnarray*}
# $$
# Here is a list of the first 40 Fibonacci numbers:
# $$
# \begin{array}{rrrrrrrrrrrrrrr}
# 0 & & 1 & & 1 & & 2 & & 3 & & 5 & & 8 & & 13 \\
# & & & & & & & & & & & & & & \\
# 21 & & 34 & & 55 & & 89 & & 144 & & 233 & & 377 & & 610 \\
# & & & & & & & & & & & & & & \\
# 987 & & 1597 & & 2584 & & 4181 & & 6765 & & 10946 & & 17711 & & 28657
# \\
# & & & & & & & & & & & & & & \\
# 46368 & & 75025 & & 121393 & & 196418 & & 317811 & & 614229 & & 832040
# & & 1346269 \\
# & & & & & & & & & & & & & & \\
# 2178309 & & 3524578 & & 5702887 & & 9227465 & & 14930352 & & 24157817 &
# & 39088169 & & 63245986%
# \end{array}$$
#
# **Exercise 2:** Write a code that computes the first N Fibonacci numbers, saves them into an array, and displays them on the screen.
# **WAIT** -- before you read the next cell, try to do Exercise 2!
# +
N = 20 # Set the size of the list we will compute
F=[0,1] # The first two numbers in the list
for i in range(2, N):
F.append(F[i-1]+F[i-2]) # append the next item on the list
print('First',N,'Fibonacci numbers:',F)
# -
# **For fun,** we can make a little widget to control how many numbers to print out.
# +
from ipywidgets import interact
def printFib(N=10):
F=[0,1] # The first two numbers in the list
for i in range(2, N):
F.append(F[i-1]+F[i-2]) # append the next item on the list
print(F)
interact(printFib, N=(10,100,10));
# -
# By moving the slider above, print out the first 100 Fibonacci numbers
#
# As we can see, this sequence grows pretty fast. The Fibonacci numbers seem
# to have one more digit after about every five terms in the sequence.
# ## How fast does it grow?
#
# One of the ways to study the growth of a sequence is to look at ratios between consecutive terms. We look at ratios of pairs of numbers in the Fibonacci sequence.
#
# The first few values are
# \begin{eqnarray}
# F_2/F_1 &=& 1 \\
# F_3/F_2 &=& 2/1 = 2 \\
# F_4/F_3 &=& 3/2 = 1.5 \\
# F_5/F_4 &=& 5/3 = 1.666... \\
# F_6/F_5 &=& 8/5 = 1.6 \\
# F_7/F_6 &=& 13/8 = 1.625
# \end{eqnarray}
#
# So the ratios are levelling out somewhere around 1.6. We observe that $1.6^5 \approx 10$, which is why after every five terms in the Fibonacci sequence, we get another digit. This tells us we have roughly **exponential growth,** where $F_n$ grows about as quickly as the exponential function $(1.6)^n$.
#
# We can check this computation in Python. We use $ ** $ to take a power, as in the following cell.
(1.6)**5
# ## The Golden Ratio
#
# We can print out a bunch of these ratios, and plot them, just to see that they do. The easiest way to do this is with a bit of Python code. Perhaps you can try this yourself.
#
# **Exercise 3** Write some code that computes the first N ratios $F_{n+1}/F_n$, save them it into an array, and displays them on the screen.
# **WAIT!** Don't read any further until you try the exercises.
# +
# %matplotlib inline
from matplotlib.pyplot import *
N = 20
F = [0,1]
R = []
for i in range(2, N):
F.append(F[i-1]+F[i-2]) # append the next item on the list
R.append(F[i]/F[i-1])
figure(figsize=(10,6));
plot(R,'o')
title('The first '+str(N-2)+' Ratios $F_{n+1}/F_n$')
xlabel('$n$')
ylabel('$Ratio$');
print('The first', N-2, 'ratios are:',R)
# -
# We see the numbers are levelling out at the value 1.6108034... This number may be familiar to you. It is called the **Golden Ratio.**
#
# We can compute the exact value by observing the ratios satisfy a nice algebraic equation:
# $$
# \frac{F_{n+2}}{F_{n+1}}=\frac{F_{n+1}+F_{n}}{F_{n+1}}=1+\frac{F_{n}}{F_{n+1}}=1+\frac{1}{\frac{F_{n+1}}{F_{n}}},
# $$
# or more simply
# $$\frac{F_{n+2}}{F_{n+1}}=1+\frac{1}{\frac{F_{n+1}}{F_{n}}}.$$
#
# As $n$ gets larger and larger, the ratios $F_{n+2}/F_{n+1}$ and $F_{n+1}/F_{n}$ tend toward a final value, say $x$. This value must then solve the equation
# $$x=1+\frac{1}{x}.$$
#
# We rewrite this as a quadratic equation
# $$x^2=x+1$$
# which we solve from the quadratic formula
# $$ x= \frac{1 \pm \sqrt{1+4}}{2} = \frac{1 \pm \sqrt{5}}{2}.$$
# It is the positive solution $x= \frac{1 + \sqrt{5}}{2} = 1.6108034...$ which is called the Golden Ratio.
#
#
# The **Golden ratio** comes up in art, geometry, and Greek mythology as a perfect ratio that is pleasing to the eye (and to the gods).
#
# For instance, the rectangle shown below is said to have the dimensions of the Golden ratio, because the big rectangle has the same shape as the smaller rectangle inside. Mathematically, we have the ratios of lengths
# $$ \frac{a+b}{a} = \frac{a}{b}.$$
#
# 
#
# Writing $x = \frac{a}{b}$, the above equation simplifies to
# $$ 1 + \frac{1}{x} = x,$$
# which is the same quadratic equation we saw for the limit of ratios of Fibonacci numbers.
# For more information about the Golden ratio see
# https://en.wikipedia.org/wiki/Golden_ratio
# ## A Formula for the Fibonacci Sequence $F_n$
# Let's give the Golden ratio a special name. In honour of the ancient Greeks who used it so much, we call it `phi:'
# $$ \varphi = \frac{1 + \sqrt{5}}{2}. $$
# We'll call the other quadratic root 'psi:'
# $$ \psi = \frac{1 - \sqrt{5}}{2}. $$
# This number $\psi$ is called the **conjugate** of $\varphi$ because it looks the same, except for the negative sign in front of the $\sqrt{5}$.
#
# Here's something **amazing.** It turns out that we have a remarkable formula for the Fibonnaci numbers, in terms of these two Greek numbers. The formula says
# $$F_n = \frac{\varphi^n - \psi^n}{\sqrt{5}}.$$
#
# #### Wow!
#
# Seems amazing. And it is handy because now we can compute, say, the thousandth term in the sequence, $F_{1000}$ directly, without having to compute all the other terms that come before.
#
# But, whenever someone gives you a formula, you should check it!
#
# **Exercise 4:** Write a piece of code to show that the formula above, with $\varphi,\psi$ does produce, say, the first 20 Fibonnaci numbers.
#
# **WAIT!** Don't go on until you try writing a program yourself, to compute the Fibonacci numbers using only powers of $\varphi, \psi$.
# +
## SOLUTION (don't peak!)
from numpy import * ## We need this to define square roots
phi = (1 + sqrt(5))/2
psi = (1 - sqrt(5))/2
for n in range(20):
print( (phi**n - psi**n)/sqrt(5) )
# -
# Looking at that computer output, it does seem to give Fibonacci numbers, with a bit of numerical error.
#
# ## Checking the Math
#
# Doing math, though, we like exact answers and we want to know why. So WHY does this formula $(\phi^n - \psi^n)/\sqrt{5}$ give Fibonacci numbers?
#
# Well, we can check, step by step.
#
# For $n=0$, the formula gives
# $$\frac{\varphi^0 - \psi^0}{\sqrt{5}} = \frac{1-1}{\sqrt{5}} = 0,$$ which is $F[0]$, the first Fibonacci number.
#
# For $n=1$, the formula gives
# $$\frac{\varphi^1 - \psi^1}{\sqrt{5}} =
# \frac{\frac{1 + \sqrt{5}}{2} - \frac{1 -\sqrt{5}}{2} }{\sqrt{5}} = \frac{\sqrt{5}}{\sqrt{5}} = 1,$$ which is $F[1]$, the next Fibonacci number.
#
# For $n=2$, it looks harder because we get the squares $\varphi^2, \psi^2$ in the formula. But then remember that both $\varphi$ and $\psi$ solve the quadratic $x^2 = x+1$, so we know $\varphi^2 = \phi +1$ and $\psi^2 = \psi +1$. So we can write
# $$\frac{\phi^2 - \psi^2}{\sqrt{5}} = \frac{\phi + 1 - \psi -1}{\sqrt{5}} = \frac{\phi - \psi }{\sqrt{5}} = 1,$$
# since we already calculated this in the $n=1$ step. So this really is $F[2]=1$.
#
# For $n=3,4,5,\ldots$ again it might seem like it will be hard because of the higher powers. But multiplying the formulas $\varphi^2 = \varphi +1$ and $\psi^2 = \psi +1$ by powers of $\phi$ and $\psi$, we get
#
# $$\begin{eqnarray*}
# \varphi^2 &=& \varphi +1,\quad \varphi^3 = \varphi^2+\varphi
# ,\quad \varphi^4=\varphi^3+\varphi^2,\qquad \dots \qquad %
# \varphi^{n+2}=\varphi^{n+1}+{\varphi}^n,\quad \text{and} \\
# \psi^2 &=&\psi +1,\quad \psi^3=\psi^2+\psi ,\quad \psi^4=\psi^3+\psi^2,\qquad
# \dots \qquad \psi^{n+2}=\psi^{n+1}+\psi^n.
# \end{eqnarray*}$$
#
# So, assuming we know the generating formula already for $n$ and $n+1$ we can write the next term as
# $$\frac{\varphi^{n+2} - \psi^{n+2}}{\sqrt{5}} = \frac{\varphi^{n+1} +\varphi^n - \psi^{n+1} - \psi^n}{\sqrt{5}}
# = \frac{\varphi^{n+1} - \psi^{n+1}}{\sqrt{5}} + \frac{\varphi^{n} - \psi^{n}}{\sqrt{5}} = F[n+1] + F[n] = F[n+2].$$
#
# So we do get $\frac{\varphi^{n+2} - \psi^{n+2}}{\sqrt{5}} = F[n+2]$, and the formula holds for all numbers n.
#
# This method of verifying the formula for all n, based on previous values of n, is an example of **mathematical induction.**
# ## Why did this work?
#
# Well, from the Golden ratio, we have the formula $\varphi^2 = \varphi + 1$, which then gives the formula $\varphi^{n+2} = \varphi^{n+1} + \varphi^n$. This looks a lot like the Fibonacci formula $$F[n+2] = F[n+1] + F[n].$$ Same powers of $\psi$.
#
# If we take ANY linear combination of powers of $\varphi, \psi$, such as
# $$f(n) = 3\varphi^n + 4\psi^n,$$
# we will get a sequence that behaves like the Fibonacci sequence, with $f(n+2) = f(n+1) + f(n).$ To get the 'right' Fibonacci sequence, we just have to replace the 3 and 4 with the right coefficients.
# ## From sequences to functions
#
# Wouldn't it be fun to extend Fibonacci numbers to a function, defined for all numbers $x$?
#
# The problems is the function
# $$F[x] = \frac{\varphi^x - \psi^x}{\sqrt{5}}$$
# is not defined for values of $x$ other than integers.
#
# The issue is the term $\psi^{x}=\left( \frac{1-\sqrt{5}}{2}\right) ^{x}$, which is the power of a negative number.
# We don't really know how to define that. For instance, what is the square root of a negative number?
#
# To
# overcome this technical difficulty, we write
#
# $$\psi ^{x}=\left( -\left( -\psi \right) \right) ^{x}=\left( -\left( \frac{%
# \sqrt{5}-1}{2}\right) \right) ^{x}=\left( -1\right) ^{x}\left( \frac{\sqrt{5}%
# -1}{2}\right) ^{x}. $$
#
# Now the factor $\left( \frac{\sqrt{5}-1}{2} \right) ^{x}$ make sense since
# the number inside the brackets is positive. We have localized the problem into the powers of $-1$ for the term $\left(
# -1\right) ^{x}$. We would like to replace this term by a
# continuous function $m(x)$ such that it takes the values $\pm1$ on the integers. That is,
#
# $$m(n) =1\quad \text{if }n\text{ is even }\quad\text{and}\quad m(n) =-1\quad \text{if }n\text{ is odd.} $$
#
# The cosine function works. That is
#
# $$m\left( x\right) =\cos \left( \pi x\right) \qquad \text{does the job.} $$
# That is:
# $$\cos \left( n\pi \right) =1\quad \text{if }n\text{ is even}\quad\text{ and}\quad %
# \cos \left( n\pi \right) =-1\quad \text{if }n\text{ is odd.}$$
#
# Why this is a **good** choice would lead us to complex numbers and more!
# Hence, we obtain the following closed formula for our function $F[x]:$
#
# $$\begin{eqnarray*}
# F[x] &=&\frac{{\varphi }^{x}-\left( -1\right) ^{x}\left( -\psi
# \right) ^{x}}{{\varphi -\psi }}=\frac{1}{\sqrt{5}}\left( {\varphi }%
# ^{x}-\left( -1\right) ^{x}\left( -\psi \right) ^{x}\right) \\
# &=&\frac{1}{\sqrt{5}}\left( \left( \frac{1+\sqrt{5}}{2}\right) ^{x}-\cos
# \left( \pi x\right) \left( \frac{\sqrt{5}-1}{2}\right) ^{x}\right) .
# \end{eqnarray*}$$
#
# Let's plot this function, and the Fibonacci sequence.
#
# ## A plot of the continuous Fibonacci function
# +
# %matplotlib inline
from numpy import *
from matplotlib.pyplot import *
phi=(1+5**(1/2))/2
psi=(5**(1/2)-1)/2
x = arange(0,10)
y = (pow(phi,x) - cos(pi*x)*pow(psi,x))/sqrt(5)
xx = linspace(0,10)
yy = (pow(phi,xx) - cos(pi*xx)*pow(psi,xx))/sqrt(5)
figure(figsize=(10,6));
plot(x,y,'o',xx,yy);
title('The continuous Fibonacci function')
xlabel('$x$')
ylabel('$Fib(x)$');
# -
# ## A plot with negative values
#
# Well, with this general definition, we can even include negative numbers for $x$ in the function.
#
# Let's plot this too.
# +
# %matplotlib inline
from numpy import *
from matplotlib.pyplot import *
phi=(1+5**(1/2))/2
psi=(5**(1/2)-1)/2
x = arange(-10,10)
y = (pow(phi,x) - cos(pi*x)*pow(psi,x))/sqrt(5)
xx = linspace(-10,10,200)
yy = (pow(phi,xx) - cos(pi*xx)*pow(psi,xx))/sqrt(5)
figure(figsize=(10,6));
plot(x,y,'o',xx,yy);
title('The Fibonacci function, extended to negative values')
xlabel('$x$')
ylabel('$Fib(x)$');
# -
# So we see we can even get negative Fibonacci numbers!
# ## The Golden Ratio and Continued Fractions
# We have found that the Golden ratio ${\varphi =}\frac{{1+}\sqrt{5}}{2}$
# satisfies the identity
#
# $$
# {\varphi =1+}\frac{1}{{\varphi }}.
# $$
#
# Substituting for ${\varphi }$ on the denominator in the right, we obtain
#
# $$
# {\varphi =1+}\frac{1}{{1+}\frac{1}{{\varphi }}}.
# $$
#
# Substituting again for ${\varphi }$ on the denominator in the right, we
# obtain
#
# $$
# {\varphi =1+}\frac{1}{{1+}\dfrac{1}{{1+}\frac{1}{{\varphi }}}}.
# $$
#
# Repeating this again,
#
# $$
# {\varphi =1+}\frac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\frac{1}{{\varphi }}}}}%
# .$$
#
# And again,
#
# $$
# {\varphi =1+}\frac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\frac{1}{%
# {\varphi }}}}}}.
# $$
#
# And again,
#
# $$
# {\varphi =1+}\frac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\dfrac{1%
# }{{1+}\frac{1}{{\varphi }}}}}}}.
# $$
#
# We see that this process can be $\textit{continued indefinitely}$. This results
# in an $\textit{infinite expansion of a fraction}$. These type of expressions are known as
# $\textbf{continued fractions}$:
#
# $$
# {\varphi =1+}\frac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\dfrac{1%
# }{{1+}\dfrac{1}{{1+}\dfrac{1}{1+\dfrac{1}{{\vdots }}}}}}}}}.
# $$
#
# We can approximate continued fractions with the finite fractions obtained by
# stopping the development at some point. In our case, we obtain the
# approximates
#
# $$
# 1,~1+1,~1+\frac{1}{1+1},~1+\frac{1}{1+\dfrac{1}{1+1}},~1+\frac{1}{1+\dfrac{1%
# }{1+\dfrac{1}{1+1}}},~1+\frac{1}{1+\dfrac{1}{1+\dfrac{1}{1+\dfrac{1}{1+1}}}}%
# ,\dots
# $$
#
# Explicitly, these approximates are
#
# $$
# 1,~2,~\frac{3}{2},~\frac{5}{3},~\frac{8}{5},~\frac{13}{8},\dots
# $$
#
# This looks like it is just the sequence of ratios $F_{n+1}/F_n$ we saw above! How can we prove this is the case for all $n$?
#
# We know that the sequence $R_{n} = F_{n+1}/F_n$ satisfies the recursive relation.
#
# $$
# R_{n}=\frac{F_{n+1}}{F_{n}}=1+\frac{F_{n-1}}{F_{n}}=1+\frac{1}{R_{n-1}}%
# ,\qquad \text{with}\qquad R_{1}=1.
# $$
#
# Then, we can generate all the terms in the sequence $R_{n}$ by staring with $%
# R_{1}=1$, and then using the relation $R_{n+1}=1+\frac{1}{R_{n}}:$
#
# $$
# \begin{eqnarray*}
# R_{1} &=&1 \\
# R_{2} &=&1+\frac{1}{R_{1}}=1+\frac{1}{1}=2 \\
# R_{3} &=&1+\frac{1}{R_{2}}=1+\frac{1}{1+R_{1}}=1+\frac{1}{1+1} \\
# R_{4} &=&1+\frac{1}{R_{3}}=1+\frac{1}{1+\frac{1}{1+1}} \\
# R_{5} &=&1+\frac{1}{R_{4}}=1+\frac{1}{1+\frac{1}{1+\frac{1}{1+1}}} \\
# &&\vdots
# \end{eqnarray*}
# $$
#
# This confirms that both the sequence of rations $R_{n}$ and the sequence of
# approximations to the continuous fraction of ${\varphi }$ are the same
# sequence. $\square $
#
# In general, continued fractions are expressions of the form
#
# $$
# a_{0}+\frac{1}{a_{1}+\dfrac{1}{a_{2}+\dfrac{1}{a_{3}+\dots }}}
# $$
#
# where $a_{0}$ is an integer and $a_{1},a_{2},a_{3},\dots $ are positive
# integers. These type of fractions are abbreviated by the notation
#
# $$
# \left[ a_{0};a_{1},a_{2},a_{3},\dots \right] =a_{0}+\frac{1}{a_{1}+\dfrac{1}{%
# a_{2}+\dfrac{1}{a_{3}+\dots }}}.
# $$
#
# For example
#
# $$
# \begin{eqnarray*}
# \left[ 1;1,1,2\right] &=&1+\frac{1}{1+\dfrac{1}{1+\dfrac{1}{1+1}}}=\frac{8}{%
# 5} \\
# && \\
# \left[ 1;1,1,1,1,\dots \right] &=&{1+}\frac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{%
# {1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{{1+}\dfrac{1}{1+\dfrac{1}{{\vdots }%
# }}}}}}}}={\varphi }
# \end{eqnarray*}
# $$
#
# For more information of continued fractions, see
# https://en.wikipedia.org/wiki/Continued_fraction
#
#
# ## Conclusion
#
# ### What have we learned?
#
# - a **sequence** is an ordered list of numbers, which may go on forever.
# - the **Fibonacci sequence** 0,1,1,2,3,5,8,13,... is a famous list of numbers, well-studied since antiquity.
# - each number in this sequence is the sum of the two coming before it in the sequence.
# - the sequence grows fast, increasing by a **factor** of about **10** for every **five** terms.
# - the **ratio** of pairs of Fibonacci numbers converges to the **Golden ratio,** known since the ancient Greeks as the number
# $$\varphi = \frac{1 + \sqrt{5}}{2} \approx 1.6108.$$
# - the Fibonacci numbers can be computed directly as the difference of powers of $\varphi$ and its **conjugate,** $\psi = \frac{1 - \sqrt{5}}{2}.$ This is sometimes faster than computing the whole list of Fibonnaci numbers.
# - this formula with powers of $\varphi, \psi$ is verified using **induction.**
# - The Fibonacci numbers can be **extended** to a **continuous function** $Fib(x)$, defined for all real numbers $x$ (including negatives). It **oscillates** (wiggles) on the negative x-axis.
# - The **Golden Ratio** can also be expressed a **continued fraction,** which is an infinite expansion of fractions with sub-fraction terms. Many interesting numbers come from interesting continued fraction forms.
# [](https://github.com/callysto/curriculum-notebooks/blob/master/LICENSE.md)
| _build/html/_sources/curriculum-notebooks/Mathematics/FibonacciNumbers/fibonacci-numbers.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# Sign Language MNIST dataset Kaggle Data Source:
# https://www.kaggle.com/datamunge/sign-language-mnist
#
# Source Code/Inspiration: PacktPublishing © 2019 , Trilogy Education Services © 2019
#
# Image Source: https://www.kaggle.com/datamunge/sign-language-mnist
#
# 
# +
# Import dependencies
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# -
# # Load Data
# +
train_raw_data = pd.read_csv('sign_mnist_train/sign_mnist_train.csv')
train_raw_data.head()
# +
test_raw_data = pd.read_csv('sign_mnist_test/sign_mnist_test.csv')
test_raw_data.head()
# -
# # Explore Data
# +
# View label column
# Get our training labels
labels = train_raw_data['label'].values
# Get our testing labels
test_labels = test_raw_data['label'].values
# View the unique labels, 24 in total (no 9)
unique_labels = np.array(labels)
np.unique(unique_labels)
# +
# View how many instances of each label in the training data
# Source code for annotating label count: https://datavizpyr.com/how-to-annotate-bars-in-barplot-with-matplotlib-in-python
# Plot the quantities in each class
plt.figure(figsize = (18,8))
cplot = sns.countplot(x =labels, palette='crest')
for p in cplot.patches:
cplot.annotate(format(p.get_height(), '.0f'),
(p.get_x() + p.get_width() / 2., p.get_height()),
ha = 'center', va = 'center',
xytext = (0, 9),
textcoords = 'offset points')
plt.xlabel("Labels", size=14)
plt.ylabel("Count", size=14)
# -
# # Preparing dataset for training
# +
# Drop label column to keep pixel data for training data
train_raw_data.drop('label', axis = 1, inplace = True)
# Drop label column to keep pixel data for testing data
test_raw_data.drop('label', axis = 1, inplace = True)
# +
# Extract the image data from each row
pxl_img = train_raw_data.values
pxl_img = np.array([np.reshape(i, (28, 28)) for i in pxl_img])
pxl_img = np.array([i.flatten() for i in pxl_img])
test_images = test_raw_data.values
test_images = np.array([np.reshape(i, (28, 28)) for i in test_images])
test_images = np.array([i.flatten() for i in test_images])
# +
# One-hot encoding
from keras.utils import to_categorical
one_hot_label = to_categorical(labels)
one_hot_label
test_labels = to_categorical(test_labels)
# -
# Inspect an image
index = 0
print(one_hot_label[index])
plt.imshow(pxl_img[index].reshape(28,28), cmap='gray')
# Inspect an image
index = 3
print(one_hot_label[index])
plt.imshow(pxl_img[index].reshape(28,28),cmap='gray')
# Inspect an image
index = 10
print(one_hot_label[index])
plt.imshow(pxl_img[index].reshape(28,28),cmap='gray')
# +
# Split data into x_train, x_test, y_train and y_test
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(pxl_img, one_hot_label, test_size = 0.3, random_state = 101)
# -
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# +
# Scale images
from sklearn.preprocessing import MinMaxScaler
scale_normalize = MinMaxScaler().fit(x_train)
x_train = scale_normalize.transform(x_train)
x_test = scale_normalize.transform(x_test)
print("Training Shape:", x_train.shape)
print("Testing Shape:", x_test.shape)
# +
# Reshape images into the size required by TF and Keras
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# -
# Show image to check
plt.imshow(x_train[0].reshape(28,28),cmap='gray')
# +
# Reshape images into the size required by TF and Keras - test
index = 10
print(test_labels[index])
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1)
print(test_images.shape)
plt.imshow(pxl_img[index].reshape(28,28),cmap='gray')
# -
# # Create Model
# +
# Create CNN Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import Adam
num_classes = 25
model = Sequential()
# Add the first layer
model.add(Conv2D(64, kernel_size=(3,3), activation = 'relu', input_shape=(28, 28 ,1) ))
model.add(MaxPooling2D(pool_size = (2, 2)))
# Add a second hidden layer
model.add(Conv2D(64, kernel_size = (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
# Add a third hidden layer
model.add(Conv2D(64, kernel_size = (3, 3), activation = 'relu'))
model.add(MaxPooling2D(pool_size = (2, 2)))
# Add a fourth hidden layer
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.20))
# Add final output layer
model.add(Dense(num_classes, activation = 'softmax'))
# -
# # Compile Model
# +
# Compile Model
model.compile(loss = 'categorical_crossentropy',
optimizer= Adam(),
metrics=['accuracy'])
# -
# # Model Summary
print(model.summary())
# # Train Model
# +
batch_size = 128
epochs = 10
history = model.fit(x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_data = (x_test, y_test))
# Accuracy score
score = model.evaluate(x_test, y_test, verbose=0)
print('Train loss:', score[0])
print('Train accuracy:', score[1])
# -
# # Plotting Loss and Accuracy Charts
# +
# Plotting loss chart
# Loading model performance results
history_dict = history.history
# Extract the loss and validation losses
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
# Get the number of epochs and create an array up to that number using range()
epochs = range(1, len(loss_values) + 1)
# Plot line charts for both Validation and Training Loss
line1 = plt.plot(epochs, val_loss_values, label='Validation/Test Loss')
line2 = plt.plot(epochs, loss_values, label='Training Loss')
plt.setp(line1, linewidth=2.0, marker = '+', markersize=10.0)
plt.setp(line2, linewidth=2.0, marker = '4', markersize=10.0)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training data Loss chart')
plt.grid(True)
plt.legend()
plt.show()
# +
# Plotting accuracy chart
# Loading model performance results
history_dict = history.history
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
epochs = range(1, len(loss_values) + 1)
line1 = plt.plot(epochs, val_acc_values, label='Validation/Test Accuracy')
line2 = plt.plot(epochs, acc_values, label='Training Accuracy')
plt.setp(line1, linewidth=2.0, marker = '+', markersize=10.0)
plt.setp(line2, linewidth=2.0, marker = '4', markersize=10.0)
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.title('Training Accuracy chart')
plt.grid(True)
plt.legend()
plt.show()
# +
# Getting accuracy score for test data
from sklearn.metrics import accuracy_score
y_pred = model.predict(test_images)
# Accuracy score
score = accuracy_score(test_labels, y_pred.round())
print('Test accuracy:', score)
# -
# # Save Model
# Save Model
model.save("sign_mnist_cnn.h5")
# +
# Relabel number to letter
def relabel_to_letter(result):
letter_labels = { 0: 'A',
1: 'B',
2: 'C',
3: 'D',
4: 'E',
5: 'F',
6: 'G',
7: 'H',
8: 'I',
9: 'K',
10: 'L',
11: 'M',
12: 'N',
13: 'O',
14: 'P',
15: 'Q',
16: 'R',
17: 'S',
18: 'T',
19: 'U',
20: 'V',
21: 'W',
22: 'X',
23: 'Y'}
try:
res = int(result)
return letter_labels[res]
except:
return "Error"
# -
# # Test Model with Webcam Input
# +
# Source code: https://github.com/PacktPublishing/
# # !pip install opencv-python
import cv2
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
##############################
frame=cv2.flip(frame, 1)
#define region of interest
roi = frame[100:400, 320:620]
cv2.imshow('roi', roi)
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
roi = cv2.resize(roi, (28, 28), interpolation = cv2.INTER_AREA)
cv2.imshow('roi sacled and gray', roi)
copy = frame.copy()
cv2.rectangle(copy, (320, 100), (620, 400), (255,0,0), 5)
roi = roi.reshape(1,28,28,1)
result = str(model.predict_classes(roi, 1, verbose = 0)[0])
cv2.putText(copy, relabel_to_letter(result), (300 , 100), cv2.FONT_HERSHEY_COMPLEX, 2, (0, 255, 0), 2)
cv2.imshow('frame', copy)
if cv2.waitKey(1) == 13: #13 is the Enter Key
break
cap.release()
cv2.destroyAllWindows()
# -
| CNN-MNIST-Sign-Language/CNN-MNIST-Sign-Language.ipynb |
/ ---
/ jupyter:
/ jupytext:
/ text_representation:
/ extension: .q
/ format_name: light
/ format_version: '1.5'
/ jupytext_version: 1.14.4
/ kernelspec:
/ display_name: SQL
/ language: sql
/ name: SQL
/ ---
/ + [markdown] azdata_cell_guid="71e98025-9dc5-4c95-bcc3-4b1d6d37fa80"
/ Cleanup
/ + azdata_cell_guid="202df3d5-ed5c-407c-a56f-bc73b6c27f0b"
USE [SSDTWithtSQLt];
GO
DROP PROC IF EXISTS [TestUnitTesting].[test Procedure Vessel_Create - Create Vessel without VesselCode should return error Expect success]
GO
/ + [markdown] azdata_cell_guid="384e722e-a43d-4f22-b288-cc5216656f73"
/ Create the test
/ + azdata_cell_guid="4eefadcc-b71d-4b76-8c5f-b63ec6c67ee2"
USE [SSDTWithtSQLt];
GO
DROP PROC IF EXISTS [TestUnitTesting].[test Procedure Vessel_Create - Create Vessel without VesselCode should return error Expect success]
GO
CREATE PROC [TestUnitTesting].[test Procedure Vessel_Create - Create Vessel without VesselCode should return error Expect success]
AS
/*
<documentation>
<author>ABM040</author>
<summary>Test the procedure Vessel_Create</summary>
<returns>nothing</returns>
</documentation>
Changes:
Date Who Notes
---------- --- --------------------------------------------------------------
20210714 ABM040 Creation
*/
SET NOCOUNT ON;
----- ASSEMBLE -----------------------------------------------
-- Declare the variables
DECLARE @actual INT;
EXEC tSQLt.FakeTable @TableName = N'[dbo].[Vessel]',
@Identity = 1,
@ComputedColumns = 1,
@Defaults = 1;
-- Get the expected value
EXEC tSQLt.ExpectException @ExpectedMessage = 'Invalid parameter: @VesselCode cannot be NULL!',
@ExpectedSeverity = NULL,
@ExpectedState = NULL;
----- ACT ----------------------------------------------------
-- Execute the procedure
EXEC dbo.Vessel_Create @VesselID = @actual OUTPUT, -- int
--@VesselCode = '$$$', -- char(3)
@VesselName = '<NAME>', -- varchar(50)
@TEU = 10000, -- int
@Plug = 50, -- int
@OperatorID = null -- int
----- ASSERT -------------------------------------------------
--Not neccessary
/ + [markdown] azdata_cell_guid="22e13ea1-23d0-458c-841a-b6b5ff665c15"
/ Run the test
/ + azdata_cell_guid="eb535ac8-492c-4c80-8faf-315eff6f0db5"
USE [SSDTWithtSQLt]
GO
EXEC tSQLt.Run @TestName = N'[TestUnitTesting].[test Procedure Vessel_Create - Create Vessel without VesselCode should return error Expect success]';
/ + [markdown] azdata_cell_guid="88e21bd4-ab83-49b0-afc9-3c19da08b668"
/ Run all the tests
/ + azdata_cell_guid="e96e878a-6c56-4d5c-9d02-613fdbc09a00"
USE [SSDTWithtSQLt]
GO
EXEC tSQLt.RunAll;
| tSQLt_In_15min/Demo/tSQLt/008_CreateTest-TestingForFailure.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import os
import numpy as np
import numpy.ma as ma
import numpy.testing as npt
import diff_classifier.msd as msd
import diff_classifier.features as ft
import diff_classifier.heatmaps as hm
# +
prefix = 'test'
msd_file = 'msd_{}.csv'.format(prefix)
ft_file = 'features_{}.csv'.format(prefix)
dataf = msd.random_traj_dataset(nparts=30, ndist=(1, 1), seed=3)
msds = msd.all_msds2(dataf, frames=100)
msds.to_csv(msd_file)
feat = ft.calculate_features(msds)
feat.to_csv(ft_file)
dataset = feat.drop(['frames', 'Track_ID'], axis=1)
# -
hm.plot_particles_in_frame(prefix, x_range=100, y_range=20, upload=False)
assert os.path.isfile('in_frame_{}.png'.format(prefix))
hm.plot_heatmap(prefix, resolution=400, rows=1, cols=2, figsize=(6,5), upload=False)
assert os.path.isfile('hm_asymmetry1_{}.png'.format(prefix))
hm.plot_scatterplot(prefix, resolution=400, rows=1, cols=1, dotsize=120, upload=False)
assert os.path.isfile('scatter_asymmetry1_{}.png'.format(prefix))
hm.plot_trajectories(prefix, resolution=520, rows=1, cols=1, upload=False)
assert os.path.isfile('traj_{}.png'.format(prefix))
hm.plot_histogram(prefix, fps=1, umppx=1, frames=100, frame_interval=5, frame_range=5, y_range=10, upload=False)
geomean, gSEM = hm.plot_individual_msds(prefix, umppx=1, fps=1, y_range=400, alpha=0.3, upload=False)
npt.assert_equal(332.8, np.round(np.sum(geomean), 1))
np.sum(gSEM)
# +
merged_ft = pd.read_csv('features_{}.csv'.format(prefix))
string = feature
leveler = merged_ft[string]
t_min = vmin
t_max = vmax
ires = resolution
# Building points and color schemes
# ----------
zs = ma.masked_invalid(merged_ft[string])
zs = ma.masked_where(zs <= t_min, zs)
zs = ma.masked_where(zs >= t_max, zs)
to_mask = ma.getmask(zs)
zs = ma.compressed(zs)
xs = ma.compressed(ma.masked_where(to_mask, merged_ft['X'].astype(int)))
ys = ma.compressed(ma.masked_where(to_mask, merged_ft['Y'].astype(int)))
points = np.zeros((xs.shape[0], 2))
points[:, 0] = xs
points[:, 1] = ys
vor = Voronoi(points)
# Plot
# ----------
fig = plt.figure(figsize=figsize, dpi=dpi)
regions, vertices = voronoi_finite_polygons_2d(vor)
# +
from scipy.spatial import Voronoi
prefix = 'test'
msd_file = 'msd_{}.csv'.format(prefix)
ft_file = 'features_{}.csv'.format(prefix)
dataf = msd.random_traj_dataset(nparts=30, ndist=(1, 1), seed=3)
msds = msd.all_msds2(dataf, frames=100)
msds.to_csv(msd_file)
feat = ft.calculate_features(msds)
feat.to_csv(ft_file)
xs = feat['X'].astype(int)
ys = feat['Y'].astype(int)
points = np.zeros((xs.shape[0], 2))
points[:, 0] = xs
points[:, 1] = ys
vor = Voronoi(points)
regions, vertices = hm.voronoi_finite_polygons_2d(vor)
# -
regions
np.mean(vertices)
| notebooks/development/08_20_18_hm_plot_testing.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import time
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\BABI\chromedriver_win32\chromedriver.exe')
driver.get("https://accounts.google.com/signin/oauth/identifier?client_id=216296035834-k1k6qe060s2tp2a2jam4ljdcms00sttg.apps.googleusercontent.com&as=z0f1UfXuc05E1_a9Dn0Yfw&destination=https%3A%2F%2Fmedium.com&approval_state=!ChRPRlI4YjJMWU52eTFqb2dJdWpnaBIfWXpndHB6cnMyeUFWOEhuU1JuY2dubW91MWdGZkZCYw%E2%88%99AF-3PDcAAAAAXooBqMqrm_45DL_VERlxdtG6CxrEgGLS&oauthgdpr=1&xsrfsig=ChkAeAh8TxptgCP9Uhupakf_s6y6I2GlcWO9Eg5hcHByb3ZhbF9zdGF0ZRILZGVzdGluYXRpb24SBXNvYWN1Eg9vYXV0aHJpc2t5c2NvcGU&flowName=GeneralOAuthFlow")
driver.find_element_by_name('identifier').send_keys('your<PASSWORD>')
driver.find_element_by_xpath('//*[@id="identifierNext"]/span/span').click()
driver.implicitly_wait(4)
driver.find_element_by_name('password').send_keys('<PASSWORD>')
driver.find_element_by_xpath('//*[@id="passwordNext"]/span/span').click()
driver.implicitly_wait(8)
titles = []
temp = []
all_links = []
SCROLL_PAUSE_TIME = 0.5
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down to bottom
temp.append(driver.find_elements_by_xpath("//h2[@class='ui-h2 ui-xs-h4 ui-clamp3']"))
#all_links.append(driver.find_elements_by_xpath("//a[@class='ds-link ds-link--stylePointer u-width100pct']"))
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if len(temp) > 200:
titles.append(driver.find_elements_by_xpath("//h2[@class='ui-h2 ui-xs-h4 ui-clamp3']"))
all_links.append(driver.find_elements_by_xpath("//a[@class='ds-link ds-link--stylePointer u-width100pct']"))
break
last_height = new_height
all_titles = [title.text for title in titles[0]]
all_links = [link.get_attribute('href') for link in all_links[0]]
links_all = all_links[5:]
links_all[0]
import time
from selenium import webdriver
driver = webdriver.Chrome(r'C:\Users\BABI\chromedriver_win32\chromedriver.exe')
documents = []
for link in links_all:
driver = webdriver.Chrome(r'C:\Users\BABI\chromedriver_win32\chromedriver.exe')
driver.get(str(link))
doc = []
description_p = driver.find_elements_by_tag_name('p')
for para in description_p:
doc.append(para.text)
documents.append(''.join(doc))
driver.close()
dataset = pa.DataFrame({'Title':all_titles,'Links':links_all,'Description':documents})
dataset.to_csv('medium_final.csv')
# -
| Web Scrapers/medium_scrapper.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# name: python3
# ---
# + [markdown] id="I93eS3Lyl-3y"
# d : 폴더, - : 파일
# list명령어 상세 출력결과 라인별 첫 단어 의미
#
# + colab={"base_uri": "https://localhost:8080/"} id="8Zt0MigiffSE" outputId="e257f22b-8139-4422-cb4d-70ab5bbb24a0"
# !ls
# + colab={"base_uri": "https://localhost:8080/"} id="ezZpxsrTfjK9" outputId="f24d3858-c887-4901-d8b0-dab551c8eb78"
# !ls -l
# + colab={"base_uri": "https://localhost:8080/"} id="bwpSpJdzfjTH" outputId="e0159f11-db1a-4cf2-e3e0-aa81d27a342c"
# !pwd
# + colab={"base_uri": "https://localhost:8080/"} id="zW2piJLtgyAt" outputId="55498f80-11cf-4cd0-ab1b-a7e9f3ee6dc1"
# !ls -l ./sample_data
# + colab={"base_uri": "https://localhost:8080/"} id="Y4SiLyQJgyE4" outputId="f1e3a095-42f9-498a-f770-f0c9d372db82"
# !ls -l ./Wholesale_customers_data.csv
# + colab={"base_uri": "https://localhost:8080/"} id="CxW4QzrFipAR" outputId="c6bafff3-fa3e-4a0a-899f-c33b9e8f5ffd"
import pandas as pd
df = pd.read_csv('Wholesale_customers_data.csv')
df.info()
# + colab={"base_uri": "https://localhost:8080/", "height": 142} id="pWeEIB54ipMs" outputId="47f02431-e23b-4f57-ad22-8cdc6f9f4803"
mydict = [{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000 }]
df = pd.DataFrame(mydict)
df
# + colab={"base_uri": "https://localhost:8080/"} id="tv7cpt1pipPg" outputId="95d4499b-3b33-4b8a-cb84-e206d66ce411"
df.iloc[0]
# + colab={"base_uri": "https://localhost:8080/"} id="Vd527ku_ipS_" outputId="499828d6-c5fe-4766-dcb5-48c6d5380125"
df.iloc[0,1]
# + colab={"base_uri": "https://localhost:8080/"} id="OpSiJA0HnXHN" outputId="401fef1e-542e-4f5d-a3e9-7b084da65b3e"
df.iloc[1,2]
# + colab={"base_uri": "https://localhost:8080/", "height": 110} id="moZewhcQoo4w" outputId="dc81391f-9fdd-439e-8042-95f443323903"
df.iloc[1:3,2:5] # range(1,6) → 1~5
# + colab={"base_uri": "https://localhost:8080/", "height": 142} id="8zpeaxG5o168" outputId="919e7018-366e-456a-bb62-aa8364fd5698"
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
df
# + colab={"base_uri": "https://localhost:8080/"} id="DykljhmVqJzT" outputId="d8ee62d9-5338-4087-856a-24884cd59bb9"
df.loc['cobra','shield']
# + colab={"base_uri": "https://localhost:8080/", "height": 110} id="C_EXhgPirB_c" outputId="faf37f49-063b-4789-ce29-1d731658bd00"
df.loc['cobra':'viper','max_speed':'shield']
| iloc_pandas.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + id="H0yuMa58fYGE" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1618367804027, "user_tz": -480, "elapsed": 1726, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}} outputId="1f7c8dfd-7229-4d04-e9dc-5353e40968c4"
# 连接Google Drive
from google.colab import drive
drive.mount('/content/drive')
# + id="TvzEx6RQBeQd" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1618367805990, "user_tz": -480, "elapsed": 3679, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}} outputId="21e2ed16-b541-4e53-b9d1-63cd2000a3a6"
import math, copy, time
import torch
import torch.nn.functional as F
from torch.nn.parameter import Parameter
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.optim as optim
import torch.sparse as sparse
from torch import linalg as LA
from sklearn.preprocessing import normalize
import numpy as np
import pandas as pd
import os
import sys
from tqdm import tqdm
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
from scipy.sparse import coo_matrix
# # %matplotlib inline
# Device and random seed settings.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
SEED = 996
np.random.seed(SEED)
torch.manual_seed(SEED)
if device=="cuda":
torch.cuda.manual_seed(SEED)
# + id="b2ZJ7gphBeQj" executionInfo={"status": "ok", "timestamp": 1618367805991, "user_tz": -480, "elapsed": 3675, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
# # hyper-parameters
# LR = 1e-3
# NODE_FEATURES = 10
# EMB_DIM = 128
# GCN_HIDDEN = 16
# GCN_DROP = 0
# WEIGHT_DECAY = 5e-4
EPOCHS = 100
# ngf = 16 # 这个再调吧
n_blocks = 3
side_len = 32 # 不可以动,接近算力极限
seq_len = 24 # 不建议动,要与数据一致
batch_size = 4
testing_set_rate = 0.3
heads = 8
d_model = 64
ngf = d_model // 4
drive_prefix = "/content/drive/My Drive/"
corr_path_prefix = "/content/drive/My Drive/UrbanTrans/fine-gain-data/c_"
speed_path_prefix = "/content/drive/My Drive/UrbanTrans/fine-gain-data/s_"
nodes_features_path = "/content/drive/My Drive/UrbanTrans/fine-gain-data/nodes_features.npy"
model_out_path = drive_prefix + "UrbanTrans/Model/ours_"
data_date = 20121100
# + id="EDClfSvCbm5c" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1618367836902, "user_tz": -480, "elapsed": 34581, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}} outputId="93d0b5da-77e5-490e-bced-4cb87d06c4c0"
# Data loading...
print("Data loading...")
corr_mat_seqs = []
speed_mat_seqs = []
for i in tqdm(range(1, 31)):
corr_path = corr_path_prefix + str(data_date + i) + '.npy'
speed_path = speed_path_prefix + str(data_date + i) + '.npy'
corr_mat_seqs.append(np.load(corr_path))
speed_mat_seqs.append(np.load(speed_path))
corr_mat_seqs = np.concatenate(corr_mat_seqs)
speed_mat_seqs = np.concatenate(speed_mat_seqs)
# 坏掉的全0的数据
# corr_mat_seqs = np.delete(corr_mat_seqs, 575, 0)
# speed_mat_seqs = np.delete(speed_mat_seqs, 575, 0)
# 规范化阈值
speed_mat_seqs[speed_mat_seqs>70] = 70
speed_mat_seqs[speed_mat_seqs==0] = 70
nodes_features = np.load(nodes_features_path)
print("corr shape:", corr_mat_seqs.shape, "speed shape:", speed_mat_seqs.shape, \
"nodes features shape:", nodes_features.shape)
print("corr size:", corr_mat_seqs.nbytes, "speed size:", speed_mat_seqs.nbytes, \
"nodes features size:", nodes_features.nbytes)
# 归一化
nodes_features = normalize(nodes_features, axis=0, norm='max')
corr_mat_seqs = corr_mat_seqs / corr_mat_seqs.max()
speed_mat_seqs = speed_mat_seqs / speed_mat_seqs.max()
# + id="UU_yzptUS7wG" executionInfo={"status": "ok", "timestamp": 1618367836904, "user_tz": -480, "elapsed": 34578, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
class UrbanDataset(Dataset):
"""Urban dataset"""
def __init__(self, corr_mat, speed_mat):
"""
Construct a model from hyperparameters.
Parameters:
corr_mat - (np.array) (seq_len, side_len**2, side_len**2)
speed_mat - (np.array) (seq_len, side_len, side_len)
Returns:
Urban dataset.
Raises:
None, todo
"""
self.corr_mat = torch.from_numpy(corr_mat)
self.speed_mat = torch.from_numpy(speed_mat)
def __len__(self):
return len(self.corr_mat) - 24
def __getitem__(self, idx):
corr_seq = self.corr_mat[idx : idx+24]
speed_seq = self.speed_mat[idx : idx+24]
return corr_seq, speed_seq
class UrbanSparseDataset(Dataset):
"""
Urban sparse dataset
"""
training_set_size = int(len(corr_mat_seqs) * (1 - testing_set_rate))
testing_set_size = len(corr_mat_seqs) - training_set_size
urban_training_set = UrbanDataset(corr_mat_seqs[:training_set_size], speed_mat_seqs[:training_set_size])
urban_testing_set = UrbanDataset(corr_mat_seqs[training_set_size:], speed_mat_seqs[training_set_size:])
train_dataloader = DataLoader(urban_training_set, batch_size=batch_size, shuffle=True, num_workers=0, drop_last=True)
test_dataloader = DataLoader(urban_testing_set, batch_size=1, shuffle=False, num_workers=0, drop_last=True)
# + id="kPk_g6mKBeQj" executionInfo={"status": "ok", "timestamp": 1618367836905, "user_tz": -480, "elapsed": 34576, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
# Hinton的论文
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
# + id="VkJDmqKyqlVd" executionInfo={"status": "ok", "timestamp": 1618367836905, "user_tz": -480, "elapsed": 34571, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
# GAT for weights shared batch training
class GATConv(nn.Module):
"""
Simple PyTorch Implementation of the Graph Attention layer.
"""
# https://dsgiitr.com/blogs/gat/
def __init__(self, in_features, out_features, heads, alpha=0.2, dropout=0.6 ,batch_size=4, seq_len=24, concat=True):
super(GATConv, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.concat = concat # conacat = True for all layers except the output layer.
self.heads = heads
self.batch_size = batch_size
self.seq_len = seq_len
# Xavier Initialization of Weights
# Alternatively use weights_init to apply weights of choice
self.W = nn.Parameter(torch.Tensor(in_features, heads * out_features))
# nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.a = nn.ParameterList([nn.Parameter(torch.Tensor(2 * out_features, 1)) for _ in range(heads)])
# nn.init.xavier_uniform_(self.a.data, gain=1.414)
# LeakyReLU
self.leakyrelu = nn.LeakyReLU(alpha)
self.softmax = nn.Softmax(dim=-1)
self.elu = nn.ELU()
self.dropout = nn.Dropout(dropout) # drop prob = 0.6
def forward(self, input, adj):
print("input size:", input.size(), "adj size:", adj.size(), "W size", self.W.size())
# (nodes_num, feature_dim), (batch_size, seq_len, side_len**2, side_len**2)
# Linear Transformation
N = input.size(1) # node_num = side_len**2
x = torch.matmul(input, self.W) # => (batch_size x nodes_num x out_features*heads)
print("1",x.size())
x = x.view(-1, N, self.heads, self.out_features) # => (batch_size x nodes_num x self.heads x out_features)
print("2",x.size())
x = x.permute(2, 0, 1, 3) # => (heads x batch_size x nodes_num x out_features)
print("3",x.size())
# Attention Mechanism
attn = []
zero_vec = -9e15 * torch.ones(N, N).to(device)
for i, a in zip(x, self.a):
for idx, j in enumerate(i):
print(idx)
attn_r = torch.cat([j.view(N,1,self.out_features).expand(N,N,self.out_features).reshape(N*N, self.out_features),
j.view(1,N,self.out_features).expand(N,N,self.out_features).reshape(N*N, self.out_features)],
dim=-1).view(N,N,2*self.out_features)
# attn_in = torch.cat([j.expand(-1, self.out_features*N).view(N*N, self.out_features), j.expand(N*N,1)], dim=-1).view(N,N,2*self.out_features)
# => (N x N x 2*out_dim)
attn_r = self.leakyrelu(torch.matmul(attn_r, a)).squeeze()
# => (N x N)
attn_r = torch.where(adj[idx] > 0, attn_r, zero_vec)
attn_r = self.softmax(attn_r)
attn_r = self.dropout(attn_r)
attn.append(torch.matmul(attn_r, i)) # => (N, out_dim)
del attn_r
x = torch.cat(attn, 0).reshape(self.heads, -1, N, self.out_features)
# Average attention score
x = torch.mean(x, 0)
print("8", x.size())
# => (batch_size x nodes_num x out_dim)
if self.concat:
return self.elu(x)
else:
return x
class GAT(nn.Module):
def __init__(self, nfeat, nhid, nemb, dropout=0.6, batch_size=4, seq_len=24, heads=6):
super(GAT, self).__init__()
self.conv1 = GATConv(nfeat, nhid, heads=heads)
self.conv2 = GATConv(nhid, nemb, heads=heads)
self.dropout = nn.Dropout(dropout)
self.elu = nn.ELU()
def forward(self, x, adj):
# Dropout before the GAT layer is used to avoid overfitting in small datasets like Cora.
# One can skip them if the dataset is sufficiently large.
# Transform x and adj to batch
print("begin GAT")
node_num = x.size(-2)
feature_dim = x.size(-1)
batch_size = adj.size(0)
seq_len = adj.size(1)
adj = adj.view(batch_size*seq_len, node_num, node_num) # => (batch_size x node_num x node_num)
x = x.view(-1, node_num, feature_dim).expand(batch_size*seq_len, node_num, feature_dim) # => (batch_size (or 1) x node_num x feature_dim)
print("x size",x.size(), "adj size", adj.size())
x = self.dropout(x)
x = self.elu(self.conv1(x, adj))
x = self.dropout(x)
x = self.conv1(x, adj)
x = torch.reshape(x, (batch_size, seq_len, node_num, nemb))
print("out size", x.size())
return x
# + id="bNcWLjT_BeQk" executionInfo={"status": "ok", "timestamp": 1618367837945, "user_tz": -480, "elapsed": 35607, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
# GCN for multi-view embedding
class GraphConvolution(nn.Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
support = torch.matmul(input, self.weight)
output = torch.matmul(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nemb, dropout, seq_len):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(nfeat, nhid)
self.gc2 = GraphConvolution(nhid, nemb)
self.dropout = dropout
def forward(self, x, adj):
x = F.relu(self.gc1(x, adj))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj)
return x
# 这个就先不用了
# class MultiViewEmbed(nn.Module):
# def __init__(self, nemb, side_len, embeds, n_view): # N views
# super(MultiViewEmbed, self).__init__()
# # embed = GCN(nfeat, nhid, nemb, dropout, seq_len)
# self.embeds = embeds
# self.fc1 = nn.Linear(n_view*nemb, nemb)
# self.fc2 = nn.Linear((side_len**2)*nemb, nemb)
# self.relu = nn.ReLU(True)
# def forward(self, input):
# x, adjs = input[0], input[1]
# embeddings = [emb(x, adj) for emb, adj in zip(self.embeds, adjs)]
# embeddings = torch.cat(embeddings,dim=-1)
# embeddings = self.relu(self.fc1(embeddings))
# embeddings = embeddings.contiguous().view(embeddings.size(0), embeddings.size(1), -1)
# embeddings = self.relu(self.fc2(embeddings))
# return embeddings
# 暂时使用这个
class SingleViewEmbed(nn.Module):
def __init__(self, nemb, side_len, embed):
super(SingleViewEmbed, self).__init__()
self.embed = embed
self.fc = nn.Linear((side_len**2)*nemb, nemb)
self.relu = nn.ReLU(True)
def forward(self, input):
x, adj = input[0], input[1]
embedding = self.embed(x, adj)
# -> (batch_size, seq_len, nodes(side_len*side_len), emb_dim)
embedding = embedding.contiguous().view(embedding.size(0), embedding.size(1), -1)
# -> (batch_size, seq_len, nodes*emb_dim)
embedding = self.relu(self.fc(embedding))
# -> (batch_size, seq_len, emb_dim)
# 这一步将向量的维度压缩的太厉害了,是否可以考虑改进一下(CNN)
return embedding
# + id="XfzIw3c-ef3B" executionInfo={"status": "ok", "timestamp": 1618367837945, "user_tz": -480, "elapsed": 35604, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
class SingleViewEmbedCNN(nn.Module):
def __init__(self, nemb, side_len, embed):
super(SingleViewEmbedCNN, self).__init__()
self.embed = embed
# 这个地方的channels维度是可以调的
self.conv1 = nn.Conv2d(in_channels=nemb, out_channels=nemb, kernel_size=4, stride=2, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=nemb, out_channels=nemb, kernel_size=4, stride=2, padding=1, bias=False)
self.conv3 = nn.Conv2d(in_channels=nemb, out_channels=nemb, kernel_size=4, stride=2, padding=1, bias=False)
self.conv4 = nn.Conv2d(in_channels=nemb, out_channels=nemb, kernel_size=4, stride=1, padding=0)
# self.bn1 = nn.BatchNorm2d(nemb)
self.bn1 = nn.BatchNorm2d(nemb)
self.bn2 = nn.BatchNorm2d(nemb)
self.bn3 = nn.BatchNorm2d(nemb)
self.relu = nn.ReLU(True)
self.sigmoid = nn.Sigmoid()
self.side_len = side_len
def forward(self, input):
x, adj = input[0], input[1]
embedding = self.embed(x, adj)
batch_size = embedding.size(0)
seq_len = embedding.size(1)
# -> (batch_size, seq_len, nodes(side_len*side_len), emb_dim)
embedding = embedding.contiguous().view(batch_size*seq_len, self.side_len, self.side_len, -1)
embedding = embedding.permute(0, 3, 1, 2)
embedding = self.relu(self.conv1(embedding))
# (batch_size*seq_len)
# -> (nemb) x 16 x 16
embedding = self.relu(self.bn1(self.conv2(embedding)))
# -> (nemb) x 8 x 8
embedding = self.relu(self.bn2(self.conv3(embedding)))
# -> (nemb) x 4 x 4
embedding = self.sigmoid(self.bn3(self.conv4(embedding)))
# -> (nemb) x 1 x 1
embedding = embedding.squeeze()
# -> (batch_size*seq_len, nemb)
embedding = embedding.view(batch_size, seq_len, -1)
# -> (batch_size, seq_len, nemb)
return embedding
# + id="1N6R-hOLBeQk" executionInfo={"status": "ok", "timestamp": 1618367837946, "user_tz": -480, "elapsed": 35601, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
# Upsampling for output target
class UpSampling(nn.Module):
def __init__(self, nz, ngf):
super(UpSampling, self).__init__()
self.relu = nn.ReLU(True)
self.sigmoid = nn.Sigmoid()
self.convt1 = nn.ConvTranspose2d(in_channels=nz, out_channels=ngf*4, kernel_size=4, stride=1, padding=0, bias=False)
self.convt2 = nn.ConvTranspose2d(in_channels=ngf*4, out_channels=ngf*2, kernel_size=4, stride=2, padding=1, bias=False)
self.convt3 = nn.ConvTranspose2d(in_channels=ngf*2, out_channels=ngf, kernel_size=4, stride=2, padding=1, bias=False)
self.convt4 = nn.ConvTranspose2d(in_channels=ngf, out_channels=1, kernel_size=4, stride=2, padding=1)
self.bn1 = nn.BatchNorm2d(ngf*4)
self.bn2 = nn.BatchNorm2d(ngf*2)
self.bn3 = nn.BatchNorm2d(ngf)
def forward(self, input):
x = input.contiguous().view(input.size(0)*input.size(1), -1, 1, 1)
# input nz
x = self.relu(self.bn1(self.convt1(x)))
# -> (ngf x 4) x 4 x 4
x = self.relu(self.bn2(self.convt2(x)))
# -> (ngf x 2) x 8 x 8
x = self.relu(self.bn3(self.convt3(x)))
# -> (ngf) x 16 x 16
x = self.sigmoid(self.convt4(x))
# -> (1) x 32 x 32
return x
# Output => embedding
# 这部分讲道理也是应该要用卷积来做的
class OutputEmbed(nn.Module):
def __init__(self,in_dim,hidden,out_dim):
super(OutputEmbed, self).__init__()
self.relu = nn.ReLU(True)
self.fc1 = nn.Linear(in_dim, hidden)
self.fc2 = nn.Linear(hidden, out_dim)
def forward(self, x):
x=x.contiguous().view(x.size(0), x.size(1), -1)
return self.fc2(self.relu(self.fc1(x)))
# + id="1eWu_Inr8F8D" executionInfo={"status": "ok", "timestamp": 1618367837946, "user_tz": -480, "elapsed": 35598, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
class OutputEmbedCNN(nn.Module):
def __init__(self,ngf):
super(OutputEmbedCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=ngf//2, kernel_size=4, stride=2, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=ngf//2, out_channels=ngf, kernel_size=4, stride=2, padding=1, bias=False)
self.conv3 = nn.Conv2d(in_channels=ngf, out_channels=ngf*2, kernel_size=4, stride=2, padding=1, bias=False)
self.conv4 = nn.Conv2d(in_channels=ngf*2, out_channels=ngf*4, kernel_size=4, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(ngf)
self.bn2 = nn.BatchNorm2d(ngf*2)
self.bn3 = nn.BatchNorm2d(ngf*4)
self.relu = nn.ReLU(True)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
batch_size = x.size(0)
seq_len = x.size(1)
x = x.contiguous().view(x.size(0) * x.size(1), 1, side_len, side_len)
x = self.relu(self.conv1(x))
# # -> (ngf / 2) x 16 x 16
x = self.relu(self.bn1(self.conv2(x)))
# # -> (ngf) x 8 x 8
x = self.relu(self.bn2(self.conv3(x)))
# # -> (ngf x 2) x 4 x 4
x = self.sigmoid(self.bn3(self.conv4(x)))
# # -> (ngf x 4) x 1 x 1
x = x.squeeze()
x = x.contiguous().view(batch_size, seq_len, -1)
return x
# # -> (ngf / 2) x 16 x 16
# x = self.relu(self.bn1(self.conv2(x)))
# -> (ngf) x 8 x 8
# x = self.relu(self.bn2(self.conv3(x)))
# -> (ngf x 2) x 4 x 4
# + id="VQe5e3JQBeQl" executionInfo={"status": "ok", "timestamp": 1618367837947, "user_tz": -480, "elapsed": 35595, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
# Transformer for learning time dependent
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, tgt_mask, src_mask=None,):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
x = self.src_embed(src)
return self.encoder(x, src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
# 残差连接
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
# "Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
def attention(query, key, value, mask=None, dropout=None):
"Compute Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
# Connect each layer in encoder or decoder
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
# Encoding the time position and add to embedding
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
# + id="Op8ARveUBeQp" executionInfo={"status": "ok", "timestamp": 1618367837948, "user_tz": -480, "elapsed": 35592, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
def make_model(n_features=32, side_len=16, hidden=512, n_blocks=2, seq_len=24, \
d_model=128, d_ff=512, ngf=32, heads=8, dropout=0.1, views=1):
"""
Construct a model from hyperparameters.
Parameters:
seq_len - (int) the length of sequence in the task (including start symbol)
side_len - (int) The city is divided into grids with sides side_len
n_features - (int) the dim of node features
hidden - (int) GCN hidden dim
d_model - (int) embedding dim at each time position
d_ff - (int) hidden dim of position-wise feed forward network
n_blocks - (int) number of block repeats in Encode and Decode
heads - (int) number of attention heads
dropout - (float) dropout rate
Returns:
Full model.
Raises:
None, todo
"""
c = copy.deepcopy
attn = MultiHeadedAttention(heads, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
if views > 1:
embeds = nn.ModuleList([GCN(n_features, hidden, d_model, dropout, seq_len) for _ in range(views)])
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), n_blocks),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), n_blocks),
nn.Sequential(MultiViewEmbed(d_model, side_len, embeds, views), c(position)),
nn.Sequential(OutputEmbed(side_len**2,hidden, d_model),c(position)),
UpSampling(d_model, ngf)
)
else:
embed = GCN(n_features, hidden, d_model, dropout, seq_len)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), n_blocks),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), n_blocks),
nn.Sequential(SingleViewEmbed(d_model, side_len, embed), c(position)),
# nn.Sequential(SingleViewEmbedCNN(d_model, side_len, embed), c(position)),
# nn.Sequential(OutputEmbed(side_len**2,hidden, d_model),c(position)),
nn.Sequential(OutputEmbedCNN(ngf),c(position)),
UpSampling(d_model, ngf)
)
# todo GCN params
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
# 上面的代码会修改GCN的初始化,后续看看能不能修改
# 先不管
return model.to(device)
# + id="huCSak-tBeQs" executionInfo={"status": "ok", "timestamp": 1618367837948, "user_tz": -480, "elapsed": 35589, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
def loss_fn(X,Y):
Xs = X.split(1, dim=0)
Ys = Y.split(1, dim=0)
F_norm = 0
for x, y in zip(Xs, Ys):
F_norm += LA.norm(x-y)
# F_norm += (x-y).sum()
# return F_norm
return F_norm / len(Xs)
mse = nn.MSELoss()
def RMSE(x, y):
return torch.sqrt(mse(x, y))
def MAPE(x, y):
return torch.abs((x - y) / y).mean() * 100
# class LossCompute:
# "A simple loss compute and train function."
# def __init__(self, generator, criterion, opt=None):
# self.generator = generator
# self.criterion = criterion
# self.opt = opt
# def __call__(self, x, y, norm=24*16):
# x = self.generator(x)
# # loss = self.criterion(x.contiguous().view(-1, x.size(-1)),
# # y.contiguous().view(-1)) / norm
# loss = self.criterion(x, y) / norm
# loss.backward()
# if self.opt is not None:
# self.opt.step()
# self.opt.optimizer.zero_grad()
# return loss.item() * norm
# + id="O_3SPWBLBeQs" executionInfo={"status": "ok", "timestamp": 1618367837948, "user_tz": -480, "elapsed": 35586, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
# 修改multi-view
class Batch:
"Object for holding a batch of data with mask during training."
def __init__(self, srcs, trg=None):
self.srcs = srcs
self.src_mask = None
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg)
self.ntokens = int(self.trg_y.size(0) * self.trg_y.size(1))
@staticmethod
def make_std_mask(tgt):
"Create a mask to hide future words."
batch, seq_len = tgt.size(0),tgt.size(1)
tgt_mask = torch.ones(batch, seq_len).unsqueeze(-2)
tgt_mask = tgt_mask == 1
tgt_mask = tgt_mask & Variable(
subsequent_mask(seq_len).type_as(tgt_mask.data))
return tgt_mask
# + id="FXmAeiSTBeQt" executionInfo={"status": "ok", "timestamp": 1618367837949, "user_tz": -480, "elapsed": 35583, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
def batch_gen(X, dataloader, start_symbol=-1e9):
"""
Generate random data for a urban status prediction task.
Parameters:
batch - (int) the size of batch
nbatches - (int) the num of total batch
seq_len - (int) the length of sequence in the task (including start symbol)
side_len - (int) The city is divided into grids with sides side_len
n_features - (int) the dim of node features
start_symbol - (float) represents the beginning of a sequence
Returns:
A data iterator, create one batch each time
Raises:
None, todo
"""
X = Variable(torch.from_numpy(X), requires_grad=False).float()
for i_batch, (corr, speed) in enumerate(dataloader):
corr[:, 0] = start_symbol
speed[:, 0] = start_symbol
src = Variable(corr, requires_grad=False).float()
tgt = Variable(speed, requires_grad=False).float()
yield copy.deepcopy(X), Batch(src, tgt)
# + id="gswf9JbXBeQt" colab={"base_uri": "https://localhost:8080/"} executionInfo={"status": "ok", "timestamp": 1618367838299, "user_tz": -480, "elapsed": 35929, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}} outputId="60cebe24-c0eb-4a4d-c153-daab063dd9b0"
# 这里是必须要修改的
# model = MultiViewEmbed(nfeat=32, nhid=512, nemb=128, dropout=0.1, seq_len=24, side_len=16, N=2)
model = make_model(n_features=148, side_len=32, n_blocks=n_blocks, heads=heads, d_model=d_model, hidden=2*d_model,ngf=ngf)
optimizer = optim.Adam(model.parameters(), lr=1e-3, betas=(0.9, 0.98), eps=1e-9)
print(model)
def run_epoch(epoch):
start = time.time()
data_iter = batch_gen(nodes_features, train_dataloader)
test_iter = batch_gen(nodes_features, test_dataloader)
train_losses = []
for i, (x,batch) in enumerate(data_iter):
model.train()
optimizer.zero_grad()
x = x.to(device)
# print("batch ",i)
adjs = batch.srcs.to(device)
src = (x, adjs)
out = model(src=src, tgt=batch.trg.to(device), tgt_mask=batch.trg_mask.to(device))
y_pred = model.generator(out)
y_pred = y_pred.view(batch_size, seq_len-1, side_len, side_len)
# print(y_pred.size(), batch.trg_y.size())
loss = loss_fn(y_pred, batch.trg_y.to(device))
train_losses.append(loss.item())
loss.backward()
optimizer.step()
train_end = time.time()
print("train loss ", np.mean(train_losses), "time ", train_end - start, "s")
# model evaluation
test_losses = []
rmse_losses = []
mape_losses = []
for x, batch in test_iter:
model.eval()
x = x.to(device)
adjs = batch.srcs.to(device)
src = (x, adjs)
out = model(src=src, tgt=batch.trg.to(device), tgt_mask=batch.trg_mask.to(device))
y_pred = model.generator(out)
y_pred = y_pred.view(1, seq_len-1, side_len, side_len)
loss = loss_fn(y_pred, batch.trg_y.to(device))
rmse_loss = RMSE(y_pred, batch.trg_y.to(device))
mape_loss = MAPE(y_pred, batch.trg_y.to(device))
test_losses.append(loss.item())
rmse_losses.append(rmse_loss.item())
mape_losses.append(mape_loss.item())
test_end = time.time()
print("test loss ", np.mean(test_losses), "time ", test_end - train_end, "s")
print("RMSE:", rmse_loss.item(), "MAPE:", mape_loss.item())
if rmse_loss.item() < 0.12 and mape_loss.item() < 16.5:
torch.save(model.state_dict(), model_out_path + str(epoch) + '.pkl')
# visualization
y = batch.trg_y[0,0,:,:].squeeze().cpu() * 70
y_hat = y_pred[0,0,:,:].squeeze().detach().cpu() * 70
plt.figure()
fig, ax =plt.subplots(1,2,figsize=(16,6))
sns.heatmap(y_hat, ax=ax[0], vmin=0, vmax=70)
sns.heatmap(y, ax=ax[1], vmin=0, vmax=70)
plt.show()
def main():
for i in range(EPOCHS):
print("epoch ",i)
run_epoch(i)
# + id="aC6phnUaBeQu" colab={"base_uri": "https://localhost:8080/", "height": 1000, "output_embedded_package_id": "1BfyQBTm_Ieg1q4gP0fFxS7PeO8sfxsKd"} executionInfo={"status": "ok", "timestamp": 1618372359760, "user_tz": -480, "elapsed": 4557384, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}} outputId="fe8bfcc9-cdf0-4c9d-dce8-fcd01a6aa505"
main()
# + id="G56lux0iIJVA" executionInfo={"status": "ok", "timestamp": 1618372359761, "user_tz": -480, "elapsed": 4557378, "user": {"displayName": "<NAME>", "photoUrl": "", "userId": "14670160567213968619"}}
| UTest.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.8.10 64-bit
# name: python3
# ---
import numpy as np
import pandas as pd
"""
1. I need SVM class
2. I need __init__ function with learning rate and #iteration parameter
3. I need train function with X,y parameter
4. I need predict function
"""
# +
class SVM:
"""
This is a binary classification algorithm with linear kernals.
"""
def __init__(self, learning_rate, iteration):
"""
:param learning_rate: A samll value needed for gradient decent, default value id 0.1.
:param iteration: Number of training iteration, default value is 10,000.
"""
self.lr = learning_rate
self.it = iteration
def cost_function(self, y, y_pred):
"""
:param y: Original target value.
:param y_pred: predicted target value.
"""
return
def train(self, X, y):
"""
:param X: training data feature values ---> N Dimentional vector.
:param y: training data target value -----> 1 Dimentional array.
"""
# Target value should be in the shape of (n, 1) not (n, ).
# So, this will check that and change the shape to (n, 1), if not.
try:
y.shape[1]
except IndexError as e:
# we need to change it to the 1 D array, not a list.
print("ERROR: Target array should be a one dimentional array not a list"
"----> here the target value not in the shape of (n,1). \nShape ({shape_y_0},1) and {shape_y} not match"
.format(shape_y_0 = y.shape[0] , shape_y = y.shape))
return
# m is number of training samples.
self.m = X.shape[0]
# n is number of features/columns/dependant variables.
self.n = X.shape[1]
# Set the initial weight.
self.w = np.zeros((self.n , 1))
# bias.
self.b = 0
for it in range(1, self.it+1):
# 1. Find the predicted value.
# 2. Find the Cost function.
# 3. Find the derivation of weights and bias.
# 4. Apply Gradient Decent.
y_pred = self.sigmoid(np.dot(X, self.w) + self.b)
cost = self.cost_function(y, y_pred)
# Derivation of w and b.
dw = ""
db = ""
# Chnage the parameter value/ apply Gradient decent.
self.w = self.w - (self.lr * dw)
self.b = self.b - (self.lr * db)
if it % 1000 == 0:
print("The Cost function for the iteration {}----->{} :)".format(it, cost))
def predict(self, test_X):
y_pred = ""
return y_pred
# -
| SVM/support_vector_machine_binary_classifier.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: 'Python 3.8.8 (''_virtual_env'': venv)'
# name: python388jvsc74a57bd069e1671651cf2522b1166c0ccf34a767d835e77568d9bde8c7492b49cf3fcd39
# ---
# ## Initialization
# + tags=[]
import os, sys
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from Coinbase_API.encryption import Coinbase_cryption
DRIVER_PATH = os.path.join(os.getcwd(),"chromedriver.exe")
options = Options()
options.headless = False
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(DRIVER_PATH, options=options)
# Go to site
coinbase_site = "https://www.coinbase.com/dashboard"
driver.get(coinbase_site)
time.sleep(2)
# # Get Email+Password
email = '<EMAIL>'
coinbase_enc = Coinbase_cryption()
grid_email = driver.find_element_by_id("email").send_keys(email)
grid_password = driver.find_element_by_id("password").send_keys(coinbase_enc.decrypt_pswd())
grid_stay = driver.find_element_by_id("stay_signed_in").click()
grid_connect = driver.find_element_by_id("signin_button").click()
# -
# ### SAVE Cookie for the initialization after manual OAuth2
# +
import pickle
# Save cookies
file_cookie = os.getenv('COINBASE_PATH')+'COOKIE.pkl'
def save_cookies(file):
cookies = driver.get_cookies()
with open(file, 'wb') as f:
pickle.dump(cookies, f)
save_cookies(file_cookie)
# print(cookies)
# -
# ### Reopen using Cookie
# +
import pickle
import os, sys
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common import exceptions
from Coinbase_API.encryption import Coinbase_cryption
DRIVER_PATH = os.path.join(os.getcwd(),"chromedriver.exe")
options = Options()
options.headless = False
options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(DRIVER_PATH, options=options)
def load_cookies(file):
with open(file, 'rb') as f:
cookies = pickle.load(f)
for c in cookies:
if isinstance(c.get("expiry"), float):
c["expiry"] = int(c["expiry"])
driver.add_cookie(c)
# N=input('Pause')
# Go to site
coinbase_site = "https://www.coinbase.com/dashboard"
driver.get(coinbase_site)
time.sleep(2)
## Add cookies
file_cookie = os.getenv('COINBASE_PATH')+'COOKIE.pkl'
load_cookies(file_cookie)
# # Get Email+Password
email = '<EMAIL>'
coinbase_enc = Coinbase_cryption()
grid_email = driver.find_element_by_id("email").send_keys(email)
grid_password = driver.find_element_by_id("password").send_keys(coinbase_enc.decrypt_pswd())
grid_stay = driver.find_element_by_id("stay_signed_in").click()
grid_connect = driver.find_element_by_id("signin_button").click()
# -
| Python_Bot/coinbase_api/Examples/proto_Scrapping_transfer.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:the-lig]
# language: python
# name: conda-env-the-lig-py
# ---
# +
import warnings
warnings.filterwarnings('ignore')
import json
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
from sklearn.metrics import mean_squared_error
element_symbol = {
6: 'C',
7: 'N',
8: 'O',
9: 'F',
15: 'P',
16: 'S',
17: 'Cl',
35: 'Br',
53: 'I'
}
# +
# %matplotlib inline
plt.style.use('fivethirtyeight')
plt.rcParams['axes.facecolor']='w'
#plt.rcParams['axes.linewidth']=1
plt.rcParams['axes.edgecolor']='w'
plt.rcParams['figure.facecolor']='w'
plt.rcParams['savefig.facecolor']='w'
#plt.rcParams['grid.color']='white'
# +
rdkit_features = pd.read_csv('../data/pdbbind_2018_general_rdkit_features_clean.csv', index_col=0)
rfscore_features = pd.read_csv('../data/pdbbind_2018_general_rfscore_features_clean.csv', index_col=0)
nnscore_features = pd.read_csv('../data/pdbbind_2018_general_binana_features_clean.csv', index_col=0)
binding_data = pd.read_csv('../data/pdbbind_2018_general_binding_data_clean.csv', index_col=0, squeeze=True)
binding_data = binding_data.rename('pK')
# re-label RF-Score features to use element symbol instead of atomic number
rfscore_features = rfscore_features.rename(mapper = lambda f: element_symbol[int(f.split('.')[0])] + '-' + element_symbol[int(f.split('.')[1])], axis='columns')
all_features = pd.concat([rdkit_features, rfscore_features, nnscore_features], axis='columns')
feature_sets = {
'Vina': pd.Index(['vina_gauss1', 'vina_gauss2', 'vina_hydrogen', 'vina_hydrophobic', 'vina_repulsion', 'num_rotors']),
'RDKit': rdkit_features.columns,
'RF-Score': rfscore_features.columns,
'NNScore 2.0': nnscore_features.columns,
}
feature_sets['RF-Score v3'] = feature_sets['RF-Score'].union(feature_sets['Vina'])
for f in ['Vina', 'RF-Score', 'RF-Score v3', 'NNScore 2.0']:
feature_sets[f'{f} + RDKit'] = feature_sets[f].union(feature_sets['RDKit'])
# Vina, and hence anything that includes its terms, already uses the number of rotatable bonds, so we drop the RDKit version
if f != 'RF-Score':
feature_sets[f'{f} + RDKit'] = feature_sets[f'{f} + RDKit'].drop(['NumRotatableBonds'])
core_sets = {}
for year in ['2007', '2013', '2016']:
with open(f'../data/pdbbind_{year}_core_pdbs.txt') as f:
core_sets[year] = sorted([l.strip() for l in f])
core_sets['all'] = [pdb for pdb in core_sets['2007']]
core_sets['all'] = core_sets['all'] + [pdb for pdb in core_sets['2013'] if pdb not in core_sets['all']]
core_sets['all'] = core_sets['all'] + [pdb for pdb in core_sets['2016'] if pdb not in core_sets['all']]
with open('../data/pdbbind_2018_refined_pdbs.txt') as f:
refined_2018 = pd.Index([l.strip() for l in f])
# -
for c in core_sets:
core_sets[c] = pd.Index(core_sets[c])
core_sets[c] = core_sets[c].intersection(all_features.index)
# +
test_sets = {c: pd.Index(core_sets[c], name=c).intersection(all_features.index) for c in core_sets}
test = pd.Index(core_sets['all'])
train = all_features.index.difference(test)
# -
features = all_features.loc[train, feature_sets['RF-Score v3']]
targets = binding_data.loc[train]
binned = targets.apply(lambda x: int(x))
# +
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import ElasticNetCV
from sklearn.linear_model import LinearRegression
from sklearn.neural_network import MLPRegressor
from sklearn.svm import SVR
from xgboost import XGBRegressor
# -
print('CV score: ', enet_estimator.best_score_**0.5)
for core_set in core_sets:
idx = pd.Index(core_sets[core_set])
X_test = all_features.loc[idx, feature_sets['RF-Score v3']]
y_test = binding_data.loc[idx]
pred = enet_estimator.predict(X_test)
print(core_set, pearsonr(y_test, pred))
# +
nn_params = {
'nn__hidden_layer_sizes': [(n,) for n in np.arange(5, 100, 5)],
'nn__activation': ['tanh'],
'nn__alpha': 10.0 ** -np.arange(1, 7),
'nn__max_iter': [500, 1000],
}
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42).split(features, binned)
pipe = Pipeline([('scaler', StandardScaler()), ('nn', MLPRegressor())])
nn_estimator = RandomizedSearchCV(pipe, param_distributions=nn_params, cv=cv, refit=True, n_iter=100, n_jobs=32, verbose=10, random_state=42).fit(features, targets)
# -
nn_estimator.best_params_
# +
estimators = {
#'enet': ElasticNet(),
'rf': RandomForestRegressor(),
'svr': SVR(),
'nn': MLPRegressor(),
'ab': AdaBoostRegressor(),
'gb': GradientBoostingRegressor(),
'xgb': XGBRegressor()
}
params = {
'enet': {
'enet__l1_ratio': [.1, .5, .7, .9, .95, .99, 1],
'enet__alpha': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
},
'rf': {
'rf__n_estimators': np.arange(50, 1050, 50),
'rf__max_features': np.arange(0.1, 1.0, 0.1)
},
'svr': {
'svr__kernel': ['linear', 'rbf'],
'svr__C': 10.0 ** -np.arange(-3, 3),
'svr__gamma': 10.0 ** -np.arange(-3, 3)
},
'nn': {
'nn__hidden_layer_sizes': [(n,) for n in np.arange(5, 200, 5)],
'nn__activation': ['tanh'],
'nn__alpha': 10.0 ** -np.arange(1, 7),
'nn__max_iter': [500, 1000]
},
'ab': {
'ab__learning_rate': [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5],
'ab__n_estimators': np.arange(50, 550, 50),
},
'gb': {
'gb__learning_rate': [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5],
'gb__max_depth': np.arange(1, 11, 2),
'gb__n_estimators': np.arange(50, 550, 50),
'gb__subsample': [0.5, 1]
},
'xgb': {
'xgb__learning_rate': [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5],
'xgb__max_depth': np.arange(1, 11, 2),
'xgb__n_estimators': np.arange(50, 550, 50),
'xgb__subsample': [0.5, 1]
}
}
# +
best_params = {}
cv_scores = {}
test_score = {}
for f in feature_sets:
print(f'Using {f} features...')
features = all_features.loc[train, feature_sets[f]]
best_params[f] = {}
cv_scores[f] = {}
test_score[f] = {}
for e in estimators:
# sweep SVM separately due to O(d^3) complexity
if e == 'svr':
continue
print(f'\tRandom search optimisation for {e} estimator...')
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42).split(features, binned)
pipe = Pipeline([('scaler', StandardScaler()), (e, estimators[e])])
model = RandomizedSearchCV(pipe, param_distributions=params[e], cv=cv, refit=True, iid='False', n_iter=100, n_jobs=64, verbose=0, random_state=42).fit(features, targets)
#cv_score[e] = model.best_score_
# get pearson correlation for each cv fold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42).split(features, binned)
scores = cross_val_score(model.best_estimator_, features, targets, cv=cv)
cv_scores[f][e] = [s**0.5 for s in scores] # convert r-squared to pearsonr
best_params[f][e] = model.best_params_
test_score[f][e] = {}
for core_set in core_sets:
idx = pd.Index(core_sets[core_set])
X_test = all_features.loc[idx, feature_sets[f]]
y_test = binding_data.loc[idx]
pred = model.predict(X_test)
rp = pearsonr(y_test, pred)
test_score[f][e][core_set] = rp
# -
# JSON encoder for np.int64
def default(o):
if isinstance(o, np.integer):
return int(o)
raise TypeError
# +
with open('../results/random_search_best_params.json', 'w') as f:
json.dump(best_params, f, default=default)
with open('../results/random_search_best_cv_scores.json', 'w') as f:
json.dump(cv_scores, f, default=default)
# -
with open('../results/random_search_best_cv_scores.json') as f:
cv_scores = json.load(f)
mean_cv_score = {f: {e: np.mean(cv_scores[f][e]) for e in cv_scores[f]} for f in cv_scores}
# +
row_order = ['RDKit', 'Vina', 'Vina + RDKit', 'RF-Score', 'RF-Score + RDKit', 'RF-Score v3', 'RF-Score v3 + RDKit', 'NNScore 2.0', 'NNScore 2.0 + RDKit']
column_order = ['Linear', 'Neural Network', 'AdaBoost', 'Gradient Boosting', 'XGBoost', 'Random Forest']
mapper = {
'enet': 'Linear',
'ab': 'AdaBoost',
'gb': 'Gradient Boosting',
'xgb': 'XGBoost',
'rf': 'Random Forest',
'nn': 'Neural Network',
}
df = pd.DataFrame(mean_cv_score).T
df = df.rename(mapper=mapper, axis='columns')
df = df.loc[row_order, column_order]
df = df.drop('Gradient Boosting', axis='columns')
fig, ax = plt.subplots(1,1,figsize=(6,6))
sns.heatmap(df, annot=True, cmap='viridis', cbar_kws={'label': r"Mean Pearson Correlation Coefficient"}, ax=ax)
ax.set_xlabel('Algorithm')
ax.set_ylabel('Features Used')
ax.hlines([1, 3, 5, 7], *ax.get_xlim(), linestyle=':', linewidth=2)
fig.savefig('../figures/algorithm_comparison.jpg', dpi=350, bbox_inches='tight')
# -
test_dfs = {}
for c in core_sets:
results = {f: {e: np.mean(test_score[f][e][c]) for e in test_score[f]} for f in test_score}
df = pd.DataFrame(mean_cv_score).T
df = df.rename(mapper=mapper, axis='columns')
df = df.loc[row_order, column_order]
test_dfs[c] = df
# +
rf_oob_n_estimators = {}
rf_val_n_estimators = {}
features = all_features.loc[train]
targets = binding_data.loc[train]
binned = targets.apply(lambda x: int(x/2))
# 80-20 train-validation split with stratifiication on binned pK values
features_train, features_test, y_train, y_test = train_test_split(features, targets, train_size=0.8, stratify=binned)
for f in feature_sets:
X_train = features_train.loc[:,feature_sets[f]]
X_test = features_test.loc[:, feature_sets[f]]
oob = []
val = []
for n in np.arange(50, 1050, 50):
rf = RandomForestRegressor(n_estimators=n, max_features=0.33, random_state=42, n_jobs=64, oob_score=True)
rf.fit(X_train, y_train)
oob.append(rf.oob_score_**0.5)
val.append(stats.pearsonr(y_test, rf.predict(X_test))[0])
rf_oob_n_estimators[f] = pd.Series(data=oob, index=np.arange(50, 1050, 50))
rf_val_n_estimators[f] = pd.Series(data=val, index=np.arange(50, 1050, 50))
# +
rf_oob_max_features = {}
rf_val_max_features = {}
features = all_features.loc[train]
targets = binding_data.loc[train]
binned = targets.apply(lambda x: int(x/2))
# 80-20 train-validation split with stratifiication on binned pK values
features_train, features_test, y_train, y_test = train_test_split(features, targets, train_size=0.8, stratify=binned)
for f in feature_sets:
X_train = features_train.loc[:,feature_sets[f]]
X_test = features_test.loc[:, feature_sets[f]]
oob = []
val = []
for n in np.arange(0.05, 1.05, 0.05):
rf = RandomForestRegressor(n_estimators=500, max_features=n, random_state=42, n_jobs=64, oob_score=True)
rf.fit(X_train, y_train)
oob.append(rf.oob_score_**0.5)
val.append(stats.pearsonr(y_test, rf.predict(X_test))[0])
rf_oob_max_features[f] = pd.Series(data=oob, index=np.arange(0.05, 1.05, 0.05))
rf_val_max_features[f] = pd.Series(data=val, index=np.arange(0.05, 1.05, 0.05))
# +
fig, ax = plt.subplots(1,2,figsize=(12,6))#, sharex=True, sharey=True)
colours = iter(plt.rcParams['axes.prop_cycle'].by_key()['color'][:5])
for f in ['Vina', 'RF-Score', 'RF-Score v3', 'NNScore 2.0']:
colour = next(colours)
rf_oob_n_estimators[f'{f} + RDKit'].plot(ax=ax[0], color=colour, alpha=0.5, label=f'{f} + RDKit')
rf_oob_n_estimators[f].plot(ax=ax[0], color=colour, label=f, alpha=0.5, linestyle=':')
colour = next(colours)
rf_oob_n_estimators['RDKit'].plot(ax=ax[0], color=colour, alpha=0.5, label='RDKit')
ax[0].set_xlabel('n_estimators')
ax[0].set_ylabel('Pearson correlation coefficient')
ax[0].set_title('Out-of-bag validation')
colours = iter(plt.rcParams['axes.prop_cycle'].by_key()['color'][:5])
for f in ['Vina', 'RF-Score', 'RF-Score v3', 'NNScore 2.0']:
colour = next(colours)
rf_val_n_estimators[f'{f} + RDKit'].plot(ax=ax[1], color=colour, alpha=0.5, label=f'{f} + RDKit')
rf_val_n_estimators[f].plot(ax=ax[1], color=colour, label=f, alpha=0.5, linestyle=':')
colour = next(colours)
rf_oob_n_estimators['RDKit'].plot(ax=ax[1], color=colour, alpha=0.5, label='RDKit', linestyle=':')
ax[1].set_xlabel('n_estimators')
ax[1].set_ylabel('Pearson correlation coefficient')
ax[1].set_title('Held-out validation')
fig.tight_layout()
ax[0].legend(loc='upper left', bbox_to_anchor=(-0.2, 1.35),ncol=5, title='Features used')
fig.savefig('../figures/pdbbind_2018_refined_validation_n_estimators.jpg', dpi=350, bbox_inches='tight')
# +
fig, ax = plt.subplots(1,2,figsize=(12,6))
colours = iter(plt.rcParams['axes.prop_cycle'].by_key()['color'][:5])
for f in ['Vina', 'RF-Score', 'RF-Score v3', 'NNScore 2.0']:
colour = next(colours)
rf_oob_max_features[f'{f} + RDKit'].plot(ax=ax[0], color=colour, alpha=0.5, label=f'{f} + RDKit')
rf_oob_max_features[f].plot(ax=ax[0], color=colour, label=f, alpha=0.5, linestyle=':')
colour = next(colours)
rf_oob_max_features['RDKit'].plot(ax=ax[0], color=colour, alpha=0.5, label='RDKit')
ax[0].set_xlabel('max_features')
ax[0].set_ylabel('Pearson correlation coefficient')
ax[0].set_title('Out-of-bag validation')
colours = iter(plt.rcParams['axes.prop_cycle'].by_key()['color'][:5])
for f in ['Vina', 'RF-Score', 'RF-Score v3', 'NNScore 2.0']:
colour = next(colours)
rf_val_max_features[f'{f} + RDKit'].plot(ax=ax[1], color=colour, alpha=0.5, label=f'{f} + RDKit')
rf_val_max_features[f].plot(ax=ax[1], color=colour, label=f, alpha=0.5, linestyle=':')
colour = next(colours)
rf_oob_max_features['RDKit'].plot(ax=ax[1], color=colour, alpha=0.5, label='RDKit')
ax[1].set_xlabel('max_features')
ax[1].set_ylabel('Pearson correlation coefficient')
ax[1].set_title('Held-out validation')
fig.tight_layout()
ax[0].legend(loc='upper left', bbox_to_anchor=(-0.2, 1.35),ncol=5, title='Features used')
fig.savefig('../figures/pdbbind_2018_refined_validation_max_features.jpg', dpi=350, bbox_inches='tight')
# -
best_params['NNScore 2.0 + RDKit']['xgb']
# +
xgb_params = {
'xgb__learning_rate': [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3, 0.4, 0.5],
'xgb__max_depth': np.arange(1, 8, 1),
'xgb__n_estimators': np.arange(50, 550, 50),
'xgb__subsample': [0.5, 1],
'xgb__reg_alpha': [0.0001, 0.001, 0.01, 0.1, 1, 5],
'xgb__reg_lambda': [0.01, 0.1, 1, 5, 10, 50]
}
xgb_best_params = {}
xgb_cv_scores = {}
for f in feature_sets:
print(f'Using {f} features...')
features = all_features.loc[train, feature_sets[f]]
xgb_best_params[f] = {}
xgb_cv_scores[f] = {}
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42).split(features, binned)
pipe = Pipeline([('scaler', StandardScaler()), ('xgb', XGBRegressor())])
model = RandomizedSearchCV(pipe, param_distributions=params[e], cv=cv, refit=True, iid='False', n_iter=500, n_jobs=64, verbose=1, random_state=42).fit(features, targets)
#cv_score[e] = model.best_score_
# get pearson correlation for each cv fold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42).split(features, binned)
scores = cross_val_score(model.best_estimator_, features, targets, cv=cv)
xgb_cv_scores[f] = [s**0.5 for s in scores] # convert r-squared to pearsonr
xgb_best_params[f][e] = model.best_params_
# +
xgb_params = {'subsample': 0.5, 'n_estimators': 500, 'max_depth': 7, 'learning_rate': 0.01}
xgb_test_scores = {}
xgb_cv_scores = {}
for f in feature_sets:
print(f'Using {f} features...')
xgb_test_scores[f] = {}
X_train = all_features.loc[train, feature_sets[f]]
y_train = binding_data.loc[train]
binned = y_train.apply(lambda x: int(x))
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42).split(X_train, binned)
xgb = XGBRegressor(**xgb_params, n_jobs=64, random_state=42)
scores = cross_val_score(xgb, X_train, y_train, cv=cv)
xgb_cv_scores[f] = [s**0.5 for s in scores] # convert r-squared to pearsonr
xgb.fit(X_train, y_train)
for t in test_sets:
X_test = all_features.loc[test_sets[t], feature_sets[f]]
y_test = binding_data.loc[test_sets[t]]
pred = xgb.predict(X_test)
rp = stats.pearsonr(y_test, pred)[0]
xgb_test_scores[f][t] = rp
# +
row_order = ['RDKit', 'Vina', 'Vina + RDKit', 'RF-Score', 'RF-Score + RDKit', 'RF-Score v3', 'RF-Score v3 + RDKit', 'NNScore 2.0', 'NNScore 2.0 + RDKit']
column_order = ['Cross. Val.', '2007 Core', '2013 Core', '2016 Core', 'Combined Core']
mapper = {
'2007': '2007 Core',
'2013': '2013 Core',
'2016': '2016 Core',
'all': 'Combined Core',
}
df = pd.DataFrame(xgb_test_scores).T
df = df.rename(mapper=mapper, axis='columns')
xgb_mean_cv_score = {f: np.mean(xgb_cv_scores[f]) for f in xgb_cv_scores}
xgb_mean_cv_score = pd.Series(xgb_mean_cv_score)
df['Cross. Val.'] = xgb_mean_cv_score.loc[df.index]
df = df.loc[row_order, column_order]
fig, ax = plt.subplots(1,1,figsize=(7, 6))
sns.heatmap(df, cmap='viridis', annot=True, fmt='.3f', vmin=0.6, vmax=0.85, ax=ax, cbar_kws={'label': 'Pearson correlation coefficient'})
ax.hlines([1, 3, 5, 7], *ax.get_xlim(), linestyle=':', linewidth=2)
ax.set_xlabel('Test Set')
ax.set_ylabel('Features Used')
ax.set_title('XGBoost')
fig.savefig('../figures/xgboost_performance_summary.jpg', dpi=350, bbox_inches='tight')
# +
rf_params = {'n_estimators': 500, 'max_features': 0.33}
rf_cv_scores = {}
rf_test_scores = {}
for f in feature_sets:
print(f'Using {f} features...')
rf_test_scores[f] = {}
X_train = all_features.loc[train, feature_sets[f]]
y_train = binding_data.loc[train]
binned = y_train.apply(lambda x: int(x))
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42).split(X_train, binned)
rf = RandomForestRegressor(**rf_params, n_jobs=64, random_state=42)
scores = cross_val_score(rf, X_train, y_train, cv=cv)
rf_cv_scores[f] = [s**0.5 for s in scores] # convert r-squared to pearsonr
rf.fit(X_train, y_train)
for t in test_sets:
X_test = all_features.loc[test_sets[t], feature_sets[f]]
y_test = binding_data.loc[test_sets[t]]
pred = rf.predict(X_test)
rp = stats.pearsonr(y_test, pred)[0]
rf_test_scores[f][t] = rp
# +
row_order = ['RDKit', 'Vina', 'Vina + RDKit', 'RF-Score', 'RF-Score + RDKit', 'RF-Score v3', 'RF-Score v3 + RDKit', 'NNScore 2.0', 'NNScore 2.0 + RDKit']
column_order = ['Cross. Val.', '2007 Core', '2013 Core', '2016 Core', 'Combined Core']
mapper = {
'2007': '2007 Core',
'2013': '2013 Core',
'2016': '2016 Core',
'all': 'Combined Core',
}
df = pd.DataFrame(rf_test_scores).T
df = df.rename(mapper=mapper, axis='columns')
rf_mean_cv_score = {f: np.mean(rf_cv_scores[f]) for f in rf_cv_scores}
rf_mean_cv_score = pd.Series(rf_mean_cv_score)
df['Cross. Val.'] = rf_mean_cv_score.loc[df.index]
df = df.loc[row_order, column_order]
fig, ax = plt.subplots(1,1,figsize=(7, 6))
sns.heatmap(df, cmap='viridis', annot=True, fmt='.3f', vmin=0.6, vmax=0.85, ax=ax, cbar_kws={'label': 'Pearson correlation coefficient'})
ax.hlines([1, 3, 5, 7], *ax.get_xlim(), linestyle=':', linewidth=2)
ax.set_xlabel('Test Set')
ax.set_ylabel('Features Used')
ax.set_title('Random Forest')
fig.savefig('../figures/rf_performance_summary.jpg', dpi=350, bbox_inches='tight')
# +
# run data through smina --score-only
# -
| notebooks/.ipynb_checkpoints/algorithm-selection-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn import metrics
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# %matplotlib inline
# -
data=pd.read_csv('Population living below national poverty line_Cleaned.csv')
data.head(5)
# +
#removing columns which wont be that vital
data=data.drop('Other' ,axis=1)
# -
data=data.drop('Year.2', axis=1)
# +
#new data
data.head()
# -
data=data.dropna()
data.info()
# +
#new data
data.head()
# -
data=data.rename(columns={'WorldBank[7]':'WorldBank',
'CIA[8]':'CIA',})
# +
data.head()
# +
#removing the %
data["WorldBank"]=data["WorldBank"].astype(str).str.replace("%", "")
# -
data["CIA"]=data["CIA"].astype(str).str.replace("%", "")
# +
#converting it to numeric data
data["WorldBank"] = data["WorldBank"].apply(pd.to_numeric, errors='coerce').astype('float64')
# -
data["CIA"] = data["CIA"].apply(pd.to_numeric, errors='coerce').astype('float64')
data.info()
# +
#data corr is a function to analyze the relation between various numeric datas
#here we can see that the data of World Bank and CIA have 88% co relation
#indicating that both presented similar data values
data.corr()
# -
data.head()
len(data)
# +
#percentage people worldwide
#around 30.87 people worldwide live in poor conditions
wb_num=((data['WorldBank'].sum())/129)
wb_num
# -
| People lacking in basic needs data/Population living below national poverty line.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: hcad_pred
# language: python
# name: hcad_pred
# ---
# + [markdown] papermill={"duration": 0.023867, "end_time": "2020-07-22T04:25:13.918965", "exception": false, "start_time": "2020-07-22T04:25:13.895098", "status": "completed"} tags=[]
# # Find the comparables: real_acc.txt
#
# The file `real_acc.txt` contains important property information like number total appraised value (the target on this exercise), neighborhood, school district, economic group, land value, and more. Let's load this file and grab a subset with the important columns to continue our study.
# + papermill={"duration": 0.02521, "end_time": "2020-07-22T04:25:13.961186", "exception": false, "start_time": "2020-07-22T04:25:13.935976", "status": "completed"} tags=[]
# %load_ext autoreload
# %autoreload 2
# + papermill={"duration": 0.579656, "end_time": "2020-07-22T04:25:14.548123", "exception": false, "start_time": "2020-07-22T04:25:13.968467", "status": "completed"} tags=[]
from pathlib import Path
import pickle
import pandas as pd
from src.definitions import ROOT_DIR
from src.data.utils import Table, save_pickle
# + papermill={"duration": 0.035254, "end_time": "2020-07-22T04:25:14.590827", "exception": false, "start_time": "2020-07-22T04:25:14.555573", "status": "completed"} tags=[]
real_acct_fn = ROOT_DIR / 'data/external/2016/Real_acct_owner/real_acct.txt'
assert real_acct_fn.exists()
# + papermill={"duration": 0.036585, "end_time": "2020-07-22T04:25:14.642693", "exception": false, "start_time": "2020-07-22T04:25:14.606108", "status": "completed"} tags=[]
real_acct = Table(real_acct_fn, '2016')
# + papermill={"duration": 0.03006, "end_time": "2020-07-22T04:25:14.680047", "exception": false, "start_time": "2020-07-22T04:25:14.649987", "status": "completed"} tags=[]
real_acct.get_header()
# + [markdown] papermill={"duration": 0.007887, "end_time": "2020-07-22T04:25:14.695819", "exception": false, "start_time": "2020-07-22T04:25:14.687932", "status": "completed"} tags=[]
# # Load accounts and columns of interest
# Let's remove the account numbers that don't meet free-standing single-family home criteria that we found while processing the `building_res.txt` file.
#
# Also, the columns above show a lot of value information along property groups that might come in handy when predicting the appraised value. Now let's get a slice of some of the important columns.
# + papermill={"duration": 9.151563, "end_time": "2020-07-22T04:25:23.855555", "exception": false, "start_time": "2020-07-22T04:25:14.703992", "status": "completed"} tags=[]
skiprows = real_acct.get_skiprows()
# + papermill={"duration": 0.022728, "end_time": "2020-07-22T04:25:23.886122", "exception": false, "start_time": "2020-07-22T04:25:23.863394", "status": "completed"} tags=[]
cols = [
'acct',
'site_addr_3', # Zip
'school_dist',
'Neighborhood_Code',
'Market_Area_1_Dscr',
'Market_Area_2_Dscr',
'center_code',
'bld_ar',
'land_ar',
'acreage',
'land_val',
'tot_appr_val', # Target
'prior_land_val',
'prior_tot_appr_val',
'new_own_dt', # New owner date
]
# + papermill={"duration": 7.785614, "end_time": "2020-07-22T04:25:31.680434", "exception": false, "start_time": "2020-07-22T04:25:23.894820", "status": "completed"} tags=[]
real_acct_df = real_acct.get_df(skiprows=skiprows, usecols=cols)
# + papermill={"duration": 0.038279, "end_time": "2020-07-22T04:25:31.726594", "exception": false, "start_time": "2020-07-22T04:25:31.688315", "status": "completed"} tags=[]
real_acct_df.head()
# + [markdown] papermill={"duration": 0.009327, "end_time": "2020-07-22T04:25:31.744503", "exception": false, "start_time": "2020-07-22T04:25:31.735176", "status": "completed"} tags=[]
# Double check if the there is only one account number per row
# + papermill={"duration": 0.114296, "end_time": "2020-07-22T04:25:31.867621", "exception": false, "start_time": "2020-07-22T04:25:31.753325", "status": "completed"} tags=[]
assert real_acct_df['acct'].is_unique
# + [markdown] papermill={"duration": 0.008699, "end_time": "2020-07-22T04:25:31.884949", "exception": false, "start_time": "2020-07-22T04:25:31.876250", "status": "completed"} tags=[]
# # Export real_acct
# + papermill={"duration": 0.392284, "end_time": "2020-07-22T04:25:32.286052", "exception": false, "start_time": "2020-07-22T04:25:31.893768", "status": "completed"} tags=[]
save_fn = ROOT_DIR / 'data/raw/2016/real_acct_comps.pickle'
save_pickle(real_acct_df, save_fn)
| notebooks/01_Exploratory/output/1.2-rp-hcad-data-view-real-acct_20200721.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Tutorial 15: Vision Transformers
#
# 
#
# **Filled notebook:**
# [](https://github.com/phlippe/uvadlc_notebooks/blob/master/docs/tutorial_notebooks/tutorial15/Vision_Transformer.ipynb)
# [](https://colab.research.google.com/github/phlippe/uvadlc_notebooks/blob/master/docs/tutorial_notebooks/tutorial15/Vision_Transformer.ipynb)
# **Pre-trained models:**
# [](https://github.com/phlippe/saved_models/tree/main/tutorial15)
# [](https://drive.google.com/drive/folders/1BmisSPs5BXQKpolyHp5X4klSAhpDx479?usp=sharing)
# In this tutorial, we will take a closer look at a recent new trend: Transformers for Computer Vision. Since [<NAME> et al.](https://openreview.net/pdf?id=YicbFdNTTy) successfully applied a Transformer on a variety of imagine recognition benchmarks, there have been an incredible amount of follow-up works showing that CNNs might not be optimal architecture for Computer Vision anymore. But how do Vision Transformers work exactly, and what benefits and drawbacks do they offer in contrast to CNNs? We will answer these questions by implementing a Vision Transformer ourselves, and train it on the popular, small dataset CIFAR10. We will compare these results to the convolutional architectures of [Tutorial 5](https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial5/Inception_ResNet_DenseNet.html).
#
# If you are not familiar with Transformers yet, take a look at [Tutorial 6](https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial6/Transformers_and_MHAttention.html) where we discuss the fundamentals of Multi-Head Attention and Transformers. As in many previous tutorials, we will use [PyTorch Lightning](https://www.pytorchlightning.ai/) again (introduced in [Tutorial 5](https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial5/Inception_ResNet_DenseNet.html)). Let's start with importing our standard set of libraries.
# +
## Standard libraries
import os
import numpy as np
import random
import math
import json
from functools import partial
from PIL import Image
## Imports for plotting
import matplotlib.pyplot as plt
plt.set_cmap('cividis')
# %matplotlib inline
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('svg', 'pdf') # For export
from matplotlib.colors import to_rgb
import matplotlib
matplotlib.rcParams['lines.linewidth'] = 2.0
import seaborn as sns
sns.reset_orig()
## tqdm for loading bars
from tqdm.notebook import tqdm
## PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
## Torchvision
import torchvision
from torchvision.datasets import CIFAR10
from torchvision import transforms
# PyTorch Lightning
try:
import pytorch_lightning as pl
except ModuleNotFoundError: # Google Colab does not have PyTorch Lightning installed by default. Hence, we do it here if necessary
# !pip install pytorch-lightning==1.3.4
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
# Import tensorboard
# %load_ext tensorboard
# Path to the folder where the datasets are/should be downloaded (e.g. CIFAR10)
DATASET_PATH = "../data"
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = "../saved_models/tutorial15"
# Setting the seed
pl.seed_everything(42)
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.determinstic = True
torch.backends.cudnn.benchmark = False
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print("Device:", device)
# -
# We provide a pre-trained Vision Transformer which we download in the next cell. However, Vision Transformers can be relatively quickly trained on CIFAR10 with an overall training time of less than an hour on an NVIDIA TitanRTX. Feel free to experiment with training your own Transformer once you went through the whole notebook.
# +
import urllib.request
from urllib.error import HTTPError
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/"
# Files to download
pretrained_files = ["tutorial15/ViT.ckpt", "tutorial15/tensorboards/ViT/events.out.tfevents.ViT",
"tutorial5/tensorboards/ResNet/events.out.tfevents.resnet"]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:
file_path = os.path.join(CHECKPOINT_PATH, file_name.split("/",1)[1])
if "/" in file_name.split("/",1)[1]:
os.makedirs(file_path.rsplit("/",1)[0], exist_ok=True)
if not os.path.isfile(file_path):
file_url = base_url + file_name
print("Downloading %s..." % file_url)
try:
urllib.request.urlretrieve(file_url, file_path)
except HTTPError as e:
print("Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n", e)
# -
# We load the CIFAR10 dataset below. We use the same setup of the datasets and data augmentations as for the CNNs in Tutorial 5 to keep a fair comparison. The constants in the `transforms.Normalize` correspond to the values that scale and shift the data to a zero mean and standard deviation of one.
# +
test_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.49139968, 0.48215841, 0.44653091], [0.24703223, 0.24348513, 0.26158784])
])
# For training, we add some augmentation. Networks are too powerful and would overfit.
train_transform = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop((32,32),scale=(0.8,1.0),ratio=(0.9,1.1)),
transforms.ToTensor(),
transforms.Normalize([0.49139968, 0.48215841, 0.44653091], [0.24703223, 0.24348513, 0.26158784])
])
# Loading the training dataset. We need to split it into a training and validation part
# We need to do a little trick because the validation set should not use the augmentation.
train_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=train_transform, download=True)
val_dataset = CIFAR10(root=DATASET_PATH, train=True, transform=test_transform, download=True)
pl.seed_everything(42)
train_set, _ = torch.utils.data.random_split(train_dataset, [45000, 5000])
pl.seed_everything(42)
_, val_set = torch.utils.data.random_split(val_dataset, [45000, 5000])
# Loading the test set
test_set = CIFAR10(root=DATASET_PATH, train=False, transform=test_transform, download=True)
# We define a set of data loaders that we can use for various purposes later.
train_loader = data.DataLoader(train_set, batch_size=128, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
val_loader = data.DataLoader(val_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
test_loader = data.DataLoader(test_set, batch_size=128, shuffle=False, drop_last=False, num_workers=4)
# Visualize some examples
NUM_IMAGES = 4
CIFAR_images = torch.stack([val_set[idx][0] for idx in range(NUM_IMAGES)], dim=0)
img_grid = torchvision.utils.make_grid(CIFAR_images, nrow=4, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(8,8))
plt.title("Image examples of the CIFAR10 dataset")
plt.imshow(img_grid)
plt.axis('off')
plt.show()
plt.close()
# -
# ## Transformers for image classification
#
# Transformers have been originally proposed to process sets since it is a permutation-equivariant architecture, i.e., producing the same output permuted if the input is permuted. To apply Transformers to sequences, we have simply added a positional encoding to the input feature vectors, and the model learned by itself what to do with it. So, why not do the same thing on images? This is exactly what [<NAME> et al.](https://openreview.net/pdf?id=YicbFdNTTy) proposed in their paper "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale". Specifically, the Vision Transformer is a model for image classification that views images as sequences of smaller patches. As a preprocessing step, we split an image of, for example, $48\times 48$ pixels into 9 $16\times 16$ patches. Each of those patches is considered to be a "word"/"token", and projected to a feature space. With adding positional encodings and a token for classification on top, we can apply a Transformer as usual to this sequence and start training it for our task. A nice GIF visualization of the architecture is shown below (figure credit - [<NAME>](https://github.com/lucidrains/vit-pytorch/blob/main/images/vit.gif)):
#
# <center width="100%"><img src="vit.gif" width="600px"></center>
#
# We will walk step by step through the Vision Transformer, and implement all parts by ourselves. First, let's implement the image preprocessing: an image of size $N\times N$ has to be split into $(N/M)^2$ patches of size $M\times M$. These represent the input words to the Transformer.
def img_to_patch(x, patch_size, flatten_channels=True):
"""
Inputs:
x - torch.Tensor representing the image of shape [B, C, H, W]
patch_size - Number of pixels per dimension of the patches (integer)
flatten_channels - If True, the patches will be returned in a flattened format
as a feature vector instead of a image grid.
"""
B, C, H, W = x.shape
x = x.reshape(B, C, H//patch_size, patch_size, W//patch_size, patch_size)
x = x.permute(0, 2, 4, 1, 3, 5) # [B, H', W', C, p_H, p_W]
x = x.flatten(1,2) # [B, H'*W', C, p_H, p_W]
if flatten_channels:
x = x.flatten(2,4) # [B, H'*W', C*p_H*p_W]
return x
# Let's take a look at how that works for our CIFAR examples above. For our images of size $32\times 32$, we choose a patch size of 4. Hence, we obtain sequences of 64 patches of size $4\times 4$. We visualize them below:
# +
img_patches = img_to_patch(CIFAR_images, patch_size=4, flatten_channels=False)
fig, ax = plt.subplots(CIFAR_images.shape[0], 1, figsize=(14,3))
fig.suptitle("Images as input sequences of patches")
for i in range(CIFAR_images.shape[0]):
img_grid = torchvision.utils.make_grid(img_patches[i], nrow=64, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
ax[i].imshow(img_grid)
ax[i].axis('off')
plt.show()
plt.close()
# -
# Compared to the original images, it is much harder to recognize the objects from those patch lists now. Still, this is the input we provide to the Transformer for classifying the images. The model has to learn itself how it has to combine the patches to recognize the objects. The inductive bias in CNNs that an image is grid of pixels, is lost in this input format.
#
# After we have looked at the preprocessing, we can now start building the Transformer model. Since we have discussed the fundamentals of Multi-Head Attention in [Tutorial 6](https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial6/Transformers_and_MHAttention.html), we will use the PyTorch module `nn.MultiheadAttention` ([docs](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html?highlight=multihead#torch.nn.MultiheadAttention)) here. Further, we use the Pre-Layer Normalization version of the Transformer blocks proposed by [<NAME> et al.](http://proceedings.mlr.press/v119/xiong20b/xiong20b.pdf) in 2020. The idea is to apply Layer Normalization not in between residual blocks, but instead as a first layer in the residual blocks. This reorganization of the layers supports better gradient flow and removes the necessity of a warm-up stage. A visualization of the difference between the standard Post-LN and the Pre-LN version is shown below.
#
# <center width="100%"><img src="pre_layer_norm.svg" width="400px"></center>
#
# The implementation of the Pre-LN attention block looks as follows:
class AttentionBlock(nn.Module):
def __init__(self, embed_dim, hidden_dim, num_heads, dropout=0.0):
"""
Inputs:
embed_dim - Dimensionality of input and attention feature vectors
hidden_dim - Dimensionality of hidden layer in feed-forward network
(usually 2-4x larger than embed_dim)
num_heads - Number of heads to use in the Multi-Head Attention block
dropout - Amount of dropout to apply in the feed-forward network
"""
super().__init__()
self.layer_norm_1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads)
self.layer_norm_2 = nn.LayerNorm(embed_dim)
self.linear = nn.Sequential(
nn.Linear(embed_dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
inp_x = self.layer_norm_1(x)
x = x + self.attn(inp_x, inp_x, inp_x)[0]
x = x + self.linear(self.layer_norm_2(x))
return x
# Now we have all modules ready to build our own Vision Transformer. Besides the Transformer encoder, we need the following modules:
#
# * A **linear projection** layer that maps the input patches to a feature vector of larger size. It is implemented by a simple linear layer that takes each $M\times M$ patch independently as input.
# * A **classification token** that is added to the input sequence. We will use the output feature vector of the classification token (CLS token in short) for determining the classification prediction.
# * Learnable **positional encodings** that are added to the tokens before being processed by the Transformer. Those are needed to learn position-dependent information, and convert the set to a sequence. Since we usually work with a fixed resolution, we can learn the positional encodings instead of having the pattern of sine and cosine functions.
# * A **MLP head** that takes the output feature vector of the CLS token, and maps it to a classification prediction. This is usually implemented by a small feed-forward network or even a single linear layer.
#
# With those components in mind, let's implement the full Vision Transformer below:
class VisionTransformer(nn.Module):
def __init__(self, embed_dim, hidden_dim, num_channels, num_heads, num_layers, num_classes, patch_size, num_patches, dropout=0.0):
"""
Inputs:
embed_dim - Dimensionality of the input feature vectors to the Transformer
hidden_dim - Dimensionality of the hidden layer in the feed-forward networks
within the Transformer
num_channels - Number of channels of the input (3 for RGB)
num_heads - Number of heads to use in the Multi-Head Attention block
num_layers - Number of layers to use in the Transformer
num_classes - Number of classes to predict
patch_size - Number of pixels that the patches have per dimension
num_patches - Maximum number of patches an image can have
dropout - Amount of dropout to apply in the feed-forward network and
on the input encoding
"""
super().__init__()
self.patch_size = patch_size
# Layers/Networks
self.input_layer = nn.Linear(num_channels*(patch_size**2), embed_dim)
self.transformer = nn.Sequential(*[AttentionBlock(embed_dim, hidden_dim, num_heads, dropout=dropout) for _ in range(num_layers)])
self.mlp_head = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(embed_dim, num_classes)
)
self.dropout = nn.Dropout(dropout)
# Parameters/Embeddings
self.cls_token = nn.Parameter(torch.randn(1,1,embed_dim))
self.pos_embedding = nn.Parameter(torch.randn(1,1+num_patches,embed_dim))
def forward(self, x):
# Preprocess input
x = img_to_patch(x, self.patch_size)
B, T, _ = x.shape
x = self.input_layer(x)
# Add CLS token and positional encoding
cls_token = self.cls_token.repeat(B, 1, 1)
x = torch.cat([cls_token, x], dim=1)
x = x + self.pos_embedding[:,:T+1]
# Apply Transforrmer
x = self.dropout(x)
x = x.transpose(0, 1)
x = self.transformer(x)
# Perform classification prediction
cls = x[0]
out = self.mlp_head(cls)
return out
# Finally, we can put everything into a PyTorch Lightning Module as usual. We use `torch.optim.AdamW` as the optimizer, which is Adam with a corrected weight decay implementation. Since we use the Pre-LN Transformer version, we do not need to use a learning rate warmup stage anymore. Instead, we use the same learning rate scheduler as the CNNs in our previous tutorial on image classification.
class ViT(pl.LightningModule):
def __init__(self, model_kwargs, lr):
super().__init__()
self.save_hyperparameters()
self.model = VisionTransformer(**model_kwargs)
self.example_input_array = next(iter(train_loader))[0]
def forward(self, x):
return self.model(x)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(), lr=self.hparams.lr)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100,150], gamma=0.1)
return [optimizer], [lr_scheduler]
def _calculate_loss(self, batch, mode="train"):
imgs, labels = batch
preds = self.model(imgs)
loss = F.cross_entropy(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log('%s_loss' % mode, loss)
self.log('%s_acc' % mode, acc)
return loss
def training_step(self, batch, batch_idx):
loss = self._calculate_loss(batch, mode="train")
return loss
def validation_step(self, batch, batch_idx):
self._calculate_loss(batch, mode="val")
def test_step(self, batch, batch_idx):
self._calculate_loss(batch, mode="test")
# ## Experiments
#
# Commonly, Vision Transformers are applied to large-scale image classification benchmarks such as ImageNet to leverage their full potential. However, here we take a step back and ask: can Vision Transformer also succeed on classical, small benchmarks such as CIFAR10? To find this out, we train a Vision Transformer from scratch on the CIFAR10 dataset. Let's first create a training function for our PyTorch Lightning module which also loads the pre-trained model if you have downloaded it above.
def train_model(**kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "ViT"),
gpus=1 if str(device)=="cuda:0" else 0,
max_epochs=180,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc"),
LearningRateMonitor("epoch")],
progress_bar_refresh_rate=1)
trainer.logger._log_graph = True # If True, we plot the computation graph in tensorboard
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, "ViT.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model at %s, loading..." % pretrained_filename)
model = ViT.load_from_checkpoint(pretrained_filename) # Automatically loads the model with the saved hyperparameters
else:
pl.seed_everything(42) # To be reproducable
model = ViT(**kwargs)
trainer.fit(model, train_loader, val_loader)
model = ViT.load_from_checkpoint(trainer.checkpoint_callback.best_model_path) # Load best checkpoint after training
# Test best model on validation and test set
val_result = trainer.test(model, test_dataloaders=val_loader, verbose=False)
test_result = trainer.test(model, test_dataloaders=test_loader, verbose=False)
result = {"test": test_result[0]["test_acc"], "val": val_result[0]["test_acc"]}
return model, result
# Now, we can already start training our model. As seen in our implementation, we have couple of hyperparameter that we have to choose. When creating this notebook, we have performed a small grid search over hyperparameters and listed the best hyperparameters in the cell below. Nevertheless, it is worth to discuss the influence that each hyperparameter has, and what intuition we have for choosing its value.
#
# First, let's consider the patch size. The smaller we make the patches, the longer the input sequences to the Transformer become. While in general, this allows the Transformer to model more complex functions, it requires a longer computation time due to its quadratic memory usage in the attention layer. Furthermore, small patches can make the task more difficult since the Transformer has to learn which patches are close-by, and which are far away. We experimented with patch sizes of 2, 4 and 8 which gives us the input sequence lengths of 256, 64, and 16 respectively. We found 4 to result in the best performance, and hence pick it below.
#
# Next, the embedding and hidden dimensionality have a similar impact to a Transformer as to an MLP. The larger the sizes, the more complex the model becomes, and the longer it takes to train. In Transformer however, we have one more aspect to consider: the query-key sizes in the Multi-Head Attention layers. Each key has the feature dimensionality of `embed_dim/num_heads`. Considering that we have an input sequence length of 64, a minimum reasonable size for the key vectors is 16 or 32. Lower dimensionalities can restrain the possible attention maps too much. We observed that more than 8 heads are not necessary for the Transformer, and therefore pick a embedding dimensionality of `256`. The hidden dimensionality in the feed-forward networks is usually 2-4x larger than the embedding dimensionality, and thus we pick `512`.
#
# Finally, the learning rate for Transformers is usually relatively small, and in papers, a common value to use is 3e-5. However, since we work with a smaller dataset and have a potentially easier task, we found that we are able to increase the learning rate to 3e-4 without any problems. To reduce overfitting, we use a dropout value of 0.2. Remember that we also use small image augmentations as regularization during training.
#
# Feel free to explore the hyperparameters yourself by changing the values below. In general, the Vision Transformer did not show to be too sensitive to the hyperparameter choices on the CIFAR10 dataset.
model, results = train_model(model_kwargs={
'embed_dim': 256,
'hidden_dim': 512,
'num_heads': 8,
'num_layers': 6,
'patch_size': 4,
'num_channels': 3,
'num_patches': 64,
'num_classes': 10,
'dropout': 0.2
},
lr=3e-4)
print("ViT results", results)
# The Vision Transformer achieves a validation and test performance of about 75%. In comparison, almost all CNN architectures that we have tested in [Tutorial 5](https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial5/Inception_ResNet_DenseNet.html) obtained a classification performance of around 90%. This is a considerable gap and shows that although Vision Transformers perform strongly on ImageNet with potential pretraining, they cannot come close to simple CNNs on CIFAR10 when being trained from scratch. The differences between a CNN and Transformer can be well observed in the training curves. Let's look at them in a tensorboard below:
# Opens tensorboard in notebook. Adjust the path to your CHECKPOINT_PATH!
# %tensorboard --logdir ../saved_models/tutorial15/tensorboards/
# <center><img src="tensorboard_screenshot.png" width="100%"/></center>
# The tensorboard compares the Vision Transformer to a ResNet trained on CIFAR10. When looking at the training losses, we see that the ResNet learns much more quickly in the first iterations. While the learning rate might have an influence on the initial learning speed, we see the same trend in the validation accuracy. The ResNet achieves the best performance of the Vision Transformer after just 5 epochs (2000 iterations). Further, while the ResNet training loss and validation accuracy have a similar trend, the validation performance of the Vision Transformers only marginally changes after 10k iterations while the training loss has almost just started going down. Yet, the Vision Transformer is also able to achieve a close-to 100% accuracy on the training set.
#
# All those observed phenomenons can be explained with a concept that we have visited before: inductive biases. Convolutional Neural Networks have been designed with the assumption that images are translation invariant. Hence, we apply convolutions with shared filters across the image. Furthermore, a CNN architecture integrates the concept of distance in an image: two pixels that are close to each other are more related than two distant pixels. Local patterns are combined into larger patterns, until we perform our classification prediction. All those aspects are inductive biases of a CNN. In contrast, a Vision Transformer does not know which two pixels are close to each other, and which are far apart. It has to learn this information solely from the sparse learning signal of the classification task. This is a huge disadvantage when we have a small dataset since such information is crucial for generalizing to an unseen test dataset. With large enough datasets and/or good pre-training, a Transformer can learn this information without the need of inductive biases, and instead is more flexible than a CNN. Especially long-distance relations between local patterns can be difficult to process in CNNs, while in Transformers, all patches have the distance of one. This is why Vision Transformers are so strong on large-scale datasets such as ImageNet, but underperform a lot when being applied to a small dataset such as CIFAR10.
# ## Conclusion
#
# In this tutorial, we have implemented our own Vision Transformer from scratch and applied it on the task of image classification. Vision Transformers work by splitting an image into a sequence of smaller patches, use those as input to a standard Transformer encoder. While Vision Transformers achieved outstanding results on large-scale image recognition benchmarks such as ImageNet, they considerably underperform when being trained from scratch on small-scale datasets like CIFAR10. The reason is that in contrast to CNNs, Transformers do not have the inductive biases of translation invariance and the feature hierachy (i.e. larger patterns consist of many smaller patterns). However, these aspects can be learned when enough data is provided, or the model has been pre-trained on other large-scale tasks. Considering that Vision Transformers have just been proposed end of 2020, there is likely a lot more to come on Transformers for Computer Vision.
#
#
# ### References
#
# Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." International Conference on Representation Learning (2021). [link](https://arxiv.org/pdf/2010.11929.pdf)
#
# <NAME>, et al. "When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations." arXiv preprint arXiv:2106.01548 (2021). [link](https://arxiv.org/abs/2106.01548)
#
# Tolstikhin, Ilya, et al. "MLP-mixer: An all-MLP Architecture for Vision." arXiv preprint arXiv:2105.01601 (2021). [link](https://arxiv.org/abs/2105.01601)
#
# Xiong, Ruibin, et al. "On layer normalization in the transformer architecture." International Conference on Machine Learning. PMLR, 2020. [link](http://proceedings.mlr.press/v119/xiong20b/xiong20b.pdf)
| docs/tutorial_notebooks/tutorial15/Vision_Transformer.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# + [markdown] tags=[]
# # # !pip install sodapy
# -
import pandas as pd
from sodapy import Socrata
client = Socrata("data.lacounty.gov", None)
client.timeout = 1000
results = client.get("9trm-uz8i", limit=limit, offset=offset)
main_df = pd.DataFrame.from_records(results)
offset = 0
limit = 1000
frames = []
# +
while True:
results = client.get("9trm-uz8i", limit=limit, offset=offset)
res_df = pd.DataFrame.from_records(results)
if res_df.empty == True:
break
frames.append(res_df)
offset += limit
main_df = pd.concat(frames)
# -
new_df = results_df.query('istaxableparcel == "Y" & usecodedescchar1 == "Commercial"')
| data/pullData.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [conda env:recommend]
# language: python
# name: conda-env-recommend-py
# ---
# + tags=[]
# Data manipulation
import numpy as np
import pandas as pd
pd.options.display.max_rows = 100
# Modeling
from matrix_factorization import BaselineModel, KernelMF, train_update_test_split
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# Other
import os
import random
import sys
# Reload imported code
# %load_ext autoreload
# %autoreload 2
# Print all output
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
rand_seed = 2
np.random.seed(rand_seed)
random.seed(rand_seed)
# -
# # Load data
# **Movie data found here https://grouplens.org/datasets/movielens/**
# +
cols = ['user_id', 'item_id', 'rating', 'timestamp']
# movie_data = pd.read_csv('../data/ml-1m/ratings.dat', names = cols, sep = '::', usecols=[0, 1, 2], engine='python')
movie_data = pd.read_csv('../data/ml-100k/u.data', names = cols, sep = '\t', usecols=[0, 1, 2], engine='python')
X = movie_data[['user_id', 'item_id']]
y = movie_data['rating']
# Prepare data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Prepare data for online learning
X_train_initial, y_train_initial, X_train_update, y_train_update, X_test_update, y_test_update = train_update_test_split(movie_data, frac_new_users=0.2)
movie_data.head(10)
# -
# # Simple model with global mean
# This is similar to just the global standard deviation
# + tags=[]
global_mean = y_train.mean()
pred = [global_mean for _ in range(y_test.shape[0])]
rmse = mean_squared_error(y_test, pred, squared = False)
print(f'\nTest RMSE: {rmse:4f}')
# -
# # Baseline Model with biases
# ## SGD
# +
# %%time
baseline_model = BaselineModel(method='sgd', n_epochs = 20, reg = 0.005, lr = 0.01, verbose=1)
baseline_model.fit(X_train, y_train)
pred = baseline_model.predict(X_test)
rmse = mean_squared_error(y_test, pred, squared = False)
print(f'\nTest RMSE: {rmse:.4f}')
# -
baseline_model.recommend(user=200)
# ## ALS
# +
# %%time
baseline_model = BaselineModel(method='als', n_epochs = 20, reg = 0.5, verbose=1)
baseline_model.fit(X_train, y_train)
pred = baseline_model.predict(X_test)
rmse = mean_squared_error(y_test, pred, squared = False)
print(f'\nTest RMSE: {rmse:.4f}')
# -
# ## Updating with new users
# + tags=[]
baseline_model = BaselineModel(method='sgd', n_epochs = 20, lr=0.01, reg = 0.05, verbose=1)
baseline_model.fit(X_train_initial, y_train_initial)
# + tags=[]
# %%time
baseline_model.update_users(X_train_update, y_train_update, n_epochs=20, lr=0.001, verbose=1)
pred = baseline_model.predict(X_test_update)
rmse = mean_squared_error(y_test_update, pred, squared = False)
print(f'\nTest RMSE: {rmse:.4f}')
# -
# # Matrix Factorization
# ## Linear Kernel
# +
# %%time
matrix_fact = KernelMF(n_epochs = 20, n_factors = 100, verbose = 1, lr = 0.001, reg = 0.005)
matrix_fact.fit(X_train, y_train)
pred = matrix_fact.predict(X_test)
rmse = mean_squared_error(y_test, pred, squared = False)
print(f'\nTest RMSE: {rmse:.4f}')
# -
# ## Getting list of recommendations for a user
user = 200
items_known = X_train.query('user_id == @user')['item_id']
matrix_fact.recommend(user=user, items_known=items_known)
# ## Updating with new users
matrix_fact = KernelMF(n_epochs = 20, n_factors = 100, verbose = 1, lr = 0.001, reg = 0.005)
matrix_fact.fit(X_train_initial, y_train_initial)
# +
# %%time
# Update model with new users
matrix_fact.update_users(X_train_update, y_train_update, lr=0.001, n_epochs=20, verbose=1)
pred = matrix_fact.predict(X_test_update)
rmse = mean_squared_error(y_test_update, pred, squared = False)
print(f'\nTest RMSE: {rmse:.4f}')
# -
# ## Sigmoid kernel
# +
# %%time
matrix_fact = KernelMF(n_epochs = 20, n_factors = 100, verbose = 1, lr = 0.01, reg = 0.005, kernel='sigmoid')
matrix_fact.fit(X_train, y_train)
pred = matrix_fact.predict(X_test)
rmse = mean_squared_error(y_test, pred, squared = False)
print(f'\nTest RMSE: {rmse:.4f}')
# -
# ## RBF Kernel
# +
# %%time
matrix_fact = KernelMF(n_epochs = 20, n_factors = 100, verbose = 1, lr = 0.5, reg = 0.005, kernel='rbf')
matrix_fact.fit(X_train, y_train)
pred = matrix_fact.predict(X_test)
rmse = mean_squared_error(y_test, pred, squared = False)
print(f'\nTest RMSE: {rmse:.4f}')
# -
# # Scikit-learn compatability
# +
from sklearn.model_selection import GridSearchCV, ParameterGrid
param_grid = {
'kernel': ['linear', 'sigmoid', 'rbf'],
'n_factors': [10, 20, 50],
'n_epochs': [10, 20, 50],
'reg': [0, 0.005, 0.1]
}
grid_search = GridSearchCV(KernelMF(verbose=0), scoring = 'neg_root_mean_squared_error', param_grid=param_grid, n_jobs=-1, cv=5, verbose=1)
grid_search.fit(X_train, y_train)
# -
grid_search.best_score_
grid_search.best_params_
| examples/recommender-system.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Installation
# H2O offers an R package that can be installed from CRAN and a python package that can be installed from PyPI.Also you may want to look at the [documentation](http://docs.h2o.ai/h2o/latest-stable/h2o-docs/downloading.html) for complete details.
# ### Pre-requisites
# * Python
# * Java 7 or later, which you can get at the [Java download page](https://www.oracle.com/technetwork/java/javase/downloads/index.html).To build H2O or run H2O tests, the 64-bit JDK is required. To run the H2O binary using either the command line, R or Python packages, only 64-bit JRE is required.
# ### Dependencies
#
"""
pip install requests
pip install tabulate
pip install "colorama>=0.3.8"
pip install future
"""
# #### Finally Installing on the system with pip
# +
#pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o
# -
# #### or Conda
# +
# conda install -c h2oai h2o=3.22.1.2
# -
# Note: When installing H2O from pip in OS X El Capitan, users must include the --user flag. For example -
#
# ```
# pip install -f http://h2o-release.s3.amazonaws.com/h2o/latest_stable_Py.html h2o --user
#
# ```
#
# ## Testing installation
import h2o
h2o.init()
# ## Importing Data with H2O in Python
#
# The data belongs to the white variants of the Portuguese "Vinho Verde" wine.
# * Source: https://archive.ics.uci.edu/ml/datasets/Wine+Quality
# * CSV FIle : (https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv)
wine_data = h2o.import_file("winequality-white.csv")
wine_data.head(5)# The default head() command displays the first 10 rows.
# ## EDA
wine_data.describe()
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10,10))
corr = wine_data.cor().as_data_frame()
corr.index = wine_data.columns
sns.heatmap(corr, annot = True, cmap='RdYlGn', vmin=-1, vmax=1)
plt.title("Correlation Heatmap", fontsize=16)
plt.show()
# ## Modeling with H2O
# Let us now build a regression model to predict the Quality of the wine. There a lot of [Algorithms](http://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science.html) available in the H2O module both for Classification as well as Regression problems.
# ### Splitting data into Test and Training sets
wine_split = wine_data.split_frame(ratios = [0.8], seed = 1234)
wine_train = wine_split[0] # using 80% for training
wine_test = wine_split[1] #rest 20% for testing
print(wine_train.shape, wine_test.shape)
# ### Defining Predictor Variables
#
predictors = list(wine_data.columns)
predictors.remove('quality') # Since we need to predict quality
predictors
# ## Generalized Linear Model
# We shall build a Generalized Linear Model (GLM) with default settings. Generalized Linear Models (GLM) estimate regression models for outcomes following exponential distributions. In addition to the Gaussian (i.e. normal) distribution, these include Poisson, binomial, and gamma distributions. You can read more about GLM in the [documentation](http://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/glm.html).
# Import the function for GLM
from h2o.estimators.glm import H2OGeneralizedLinearEstimator
# Set up GLM for regression
glm = H2OGeneralizedLinearEstimator(family = 'gaussian', model_id = 'glm_default')
# Use .train() to build the model
glm.train(x = predictors,
y = 'quality',
training_frame = wine_train)
print(glm)
# Now, let's check the model's performance on the test dataset
glm.model_performance(wine_test)
# ### Making Predictions
predictions = glm.predict(wine_test)
predictions.head(5)
# ### Export GLM model as MOJO
glm.download_mojo('./wine_mojo.zip')
| h2o_python.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import pyodbc
import pandas as pd
# +
conn = pyodbc.connect('Driver={SQL Server Native Client 11.0};'
'Server=DESKTOP-4TA4DJ5;'
'Database=Project;'
'Trusted_Connection=yes;')
cursor=conn.cursor()
#Run Instructions
#select_method[6]()
print("Job Application - Views")
print("MENU")
print("Below is the list of Functions")
print("Press 1 to execute : vw_GetJobPosition")
print("Press 2 to execute : vw_GetTwitterData")
print("Press 3 to execute : VW_GetTweetdatawithUser")
print("Press 4 to execute : VW_GetInstaPostData")
print("Press 5 to execute : VW_GetUserwiseTweetCount")
print("Press 6 to execute : VW_GetCollegewiseTweetCount")
def vw_GetJobPosition():
cursor.execute('select * from vw_GetJobPosition')
for row in cursor:
print(row)
def vw_GetTwitterData():
cursor.execute('select * from vw_GetTwitterData')
for row in cursor:
print(row)
def VW_GetTweetdatawithUser():
cursor.execute('SELECT * from VW_GetTweetdatawithUser')
for row in cursor:
print(row)
def VW_GetInstaPostData():
cursor.execute('select * from VW_GetInstaPostData')
for row in cursor:
print(row)
def VW_GetUserwiseTweetCount():
cursor.execute('select * from VW_GetUserwiseTweetCount')
for row in cursor:
print(row)
def VW_GetCollegewiseTweetCount():
cursor.execute('select * from VW_GetCollegewiseTweetCount')
for row in cursor:
print(row)
# -
select_method = {1 : vw_GetJobPosition,
2 : vw_GetTwitterData,
3 : VW_GetTweetdatawithUser,
4 : VW_GetInstaPostData,
5 : VW_GetUserwiseTweetCount,
6 : VW_GetCollegewiseTweetCount
}
| IPYNB Files/SwitchCase for Views.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [default]
# language: python
# name: python3
# ---
# ### Testing Hypotheses ###
#
# Data scientists are often faced with yes-no questions about the world. You have seen some examples of such questions in this course:
#
# - Is chocolate good for you?
# - Did water from the Broad Street pump cause cholera?
# - Have the demographics in California changed over the past decade?
#
# Whether we answer questions like these depends on the data we have. Census data about California can settle questions about demographics with hardly any uncertainty about the answer. We know that Broad Street pump water was contaminated by waste from cholera victims, so we can make a pretty good guess about whether it caused cholera.
#
# Whether chocolate or any other treatment is good for you will almost certainly have to be decided by medical experts, but an initial step consists of using data science to analyze data from studies and randomized experiments.
#
# In this chapter, we will try to answer such yes-no questions, basing our conclusions on random samples and empirical distributions.
| notebooks/11/Testing_Hypotheses.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
import numpy as np
# +
M = ((-1, -1), (-1, 0), (-1, 1), (0, -1), (0, 1), (1, -1), (1, 0), (1, 1))
def calc_neighs(field, i, j):
"""
Calculate number of neighbors alive (assuming square field)
"""
neighs = 0
n = len(field)
for m in M:
row_idx = m[0] + i
col_idx = m[1] + j
if 0 <= row_idx < n and 0 <= col_idx < n:
if field[row_idx][col_idx]:
neighs += 1
return neighs
def make_move(field, moves=1):
"""
Make a move forward according to Game of Life rules
"""
n = len(field)
cur_field = field
for _ in range(moves):
new_field = np.zeros((n, n), dtype='uint8')
for i in range(n):
for j in range(n):
neighs = calc_neighs(cur_field, i, j)
if cur_field[i][j] and neighs == 2:
new_field[i][j] = 1
if neighs == 3:
new_field[i][j] = 1
cur_field = new_field
return cur_field
# -
def generate_population(size, random_state=-1):
"""
Generating initial population of individual solutions
:return: initial population as a list of 20x20 arrays
"""
if random_state != -1:
np.random.seed(random_state)
initial_states = np.split(np.random.binomial(1, 0.5, (20 * size, 20)).astype('uint8'), size)
return [make_move(state, 5) for state in initial_states]
np.random.seed(42)
population = generate_population(10)
import matplotlib.pyplot as plt
fig, ax = plt.subplots(ncols=3, figsize=(15, 5))
fig.tight_layout()
ax[0].set_xticks([], [])
ax[1].set_xticks([], [])
ax[2].set_xticks([], [])
ax[0].set_yticks([], [])
ax[1].set_yticks([], [])
ax[2].set_yticks([], []);
ax[0].imshow(population[0], cmap=plt.cm.Greys)
ax[1].imshow(population[1], cmap=plt.cm.Greys)
ax[2].imshow(population[2], cmap=plt.cm.Greys);
# fig.savefig('population_example.png', dpi=100, bbox_inches = 'tight', pad_inches = 0)
def show_field(field):
fig, ax = plt.subplots(figsize=(5, 5))
fig.tight_layout()
ax.set_xticks([], [])
ax.set_yticks([], [])
ax.imshow(field, cmap=plt.cm.Greys)
return fig
def generate_problem():
""" Generates example problem """
np.random.seed(42)
board = np.random.binomial(1, 0.01, (20, 20)).astype('uint8')
# toad
board[2, 3:6] = 1
board[3, 2:5] = 1
# glider 1
board[9, 5:8] = 1
board[8, 7] = 1
board[7, 6] = 1
# glider 2
board[16, 3:6] = 1
board[15, 5] = 1
board[14, 4] = 1
# beacon 1
board[2:4, 14:16]=1
board[4:6, 16:18]=1
# beacon 2
board[14:16, 14:16]=1
board[16:18, 16:18]=1
return board, make_move(board, 3)
X, Y = generate_problem()
fig, ax = plt.subplots(ncols=2, figsize=(10, 5))
fig.tight_layout()
ax[0].set_xticks([], [])
ax[0].set_yticks([], [])
ax[1].set_xticks([], [])
ax[1].set_yticks([], [])
ax[0].imshow(X, cmap=plt.cm.Greys)
ax[0].set_title("Start board")
ax[1].imshow(Y, cmap=plt.cm.Greys)
ax[1].set_title("End board (delta=3)");
fig.savefig('problem_example.png', dpi=100, bbox_inches = 'tight', pad_inches = 0)
# +
def fitness(start_field, end_field, delta):
"""
Calculate fitness for particular candidate (start configuration of the field)
:param start_field: candidate (start configuration)
:param end_field: target (stop configuration)
:param delta: number of steps to proceed before comparing to stop configuration
:return: value in range [0, 1] that indicates fractions of cells that match their state
"""
candidate = make_move(start_field, moves=delta)
return (candidate == end_field).sum() / 400
def score_population(population, target, delta):
"""
Apply fitness function for each gene in a population
:param population: list of candidate solutions
:param target: 20x20 array that represents field in stopping condition
:param delta: number of steps to revert
:return: list of scores for each solution
"""
return [fitness(gene, target, delta) for gene in population]
# -
score_population(population, Y, 3)
def selection(population, scores, retain_frac=0.8, retain_random=0.05):
"""
Apply selection operator to the population
:param population: list of candidate solutions
:param scores: list of score associated with each individual
:param retain_frac: percent of top individuals to retain
:param retain_random: chance of retaining sub-optimal individuals in the population
"""
retain_len = int(len(scores) * retain_frac)
sorted_indices = np.argsort(scores)[::-1]
population = [population[idx] for idx in sorted_indices]
selected = population[:retain_len]
leftovers = population[retain_len:]
for gene in leftovers:
if np.random.rand() < retain_random:
selected.append(gene)
return selected
score_population(selection(population, score_population(population, Y, 3)), Y, 3)
def mutate(field, switch_frac=0.1):
""" Inplace mutation of the provided field """
a = np.random.binomial(1, switch_frac, size=(20, 20)).astype('bool')
field[a] += 1
field[a] %= 2
return field
gene = np.copy(population[1])
gene_copy = np.copy(gene)
mutate(gene, 0.05)
fig, ax = plt.subplots(ncols=2, figsize=(10, 5))
fig.tight_layout()
ax[0].set_xticks([], [])
ax[0].set_yticks([], [])
ax[1].set_xticks([], [])
ax[1].set_yticks([], [])
ax[0].imshow(gene_copy, cmap=plt.cm.Greys)
ax[0].set_title("Original individual")
ax[1].imshow(gene, cmap=plt.cm.Greys)
ax[1].set_title("Mutated individual");
fig.savefig('mutation_example.png', dpi=100, bbox_inches = 'tight', pad_inches = 0)
def crossover(mom, dad):
""" Take two parents, return two children, interchanging half of the allels of each parent randomly """
select_mask = np.random.binomial(1, 0.5, size=(20, 20)).astype('bool')
child1, child2 = np.copy(mom), np.copy(dad)
child1[select_mask] = dad[select_mask]
child2[select_mask] = mom[select_mask]
return child1, child2
mom, dad = population[1], population[2]
child1, child2 = crossover(mom, dad)
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(10, 10))
fig.tight_layout()
ax[0, 0].set_xticks([], [])
ax[0, 0].set_yticks([], [])
ax[0, 1].set_xticks([], [])
ax[0, 1].set_yticks([], [])
ax[1, 0].set_xticks([], [])
ax[1, 0].set_yticks([], [])
ax[1, 1].set_xticks([], [])
ax[1, 1].set_yticks([], [])
ax[0, 0].imshow(mom, cmap=plt.cm.Greys)
ax[0, 0].set_title("Mother")
ax[0, 1].imshow(dad, cmap=plt.cm.Greys)
ax[0, 1].set_title("Father");
ax[1, 0].imshow(child1, cmap=plt.cm.Greys)
ax[1, 0].set_title("Child 1")
ax[1, 1].imshow(child2, cmap=plt.cm.Greys)
ax[1, 1].set_title('Child 2');
fig.savefig('crossover_example.png', dpi=100, bbox_inches = 'tight', pad_inches = 0)
def evolve(population, target, delta, retain_frac=0.8, retain_random=0.05, mutate_chance=0.05):
"""
Evolution step
:param Y: 20x20 array that represents field in stopping condition
:param delta: number of steps to revert
:return: new generation of the same size
"""
scores = score_population(population, target, delta)
next_population = selection(population, scores, retain_frac=retain_frac, retain_random=retain_random)
# mutate everyone expecting for the best candidate
for gene in next_population[1:]:
if np.random.rand() < mutate_chance:
mutate(gene)
places_left = len(population) - len(next_population)
children = []
parent_max_idx = len(next_population) - 1
while len(children) < places_left:
mom_idx, dad_idx = np.random.randint(0, parent_max_idx, 2)
if mom_idx != dad_idx:
child1, child2 = crossover(next_population[mom_idx], next_population[dad_idx])
children.append(child1)
if len(children) < places_left:
children.append(child2)
next_population.extend(children)
return next_population
next_gen = evolve(population, Y, 3)
def solve(target, delta, population_size=200, n_generations=300):
"""
:param target: 20x20 array that represents field in stopping condition
:param delta: number of steps to revert
:param n_generations: number of evolution generations. Overrides initialization value if specified
:return: 20x20 array that represents the best start field found and associated fitness value
"""
population = generate_population(population_size)
for generation in range(n_generations):
population = evolve(population, target, delta)
if generation == 0:
print("Generation #: best score")
elif generation % 50 == 0:
print("Generation ", generation, ": ", fitness(population[0], target, delta))
return population[0]
result = solve(Y, 3, n_generations=1000)
from MPGeneticSolver import MPGeneticSolver
mpgs = MPGeneticSolver(verbosity=1, early_stopping=False, n_generations=3000)
solution = mpgs.solve(Y, 3, False)
show_field(make_move(solution[0], 3));
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(10, 10))
fig.tight_layout()
ax[0, 0].set_xticks([], [])
ax[0, 0].set_yticks([], [])
ax[0, 1].set_xticks([], [])
ax[0, 1].set_yticks([], [])
ax[1, 0].set_xticks([], [])
ax[1, 0].set_yticks([], [])
ax[1, 1].set_xticks([], [])
ax[1, 1].set_yticks([], [])
ax[0, 0].imshow(X, cmap=plt.cm.Greys)
ax[0, 0].set_title("Target start field")
ax[0, 1].imshow(Y, cmap=plt.cm.Greys)
ax[0, 1].set_title("Target end field");
ax[1, 0].imshow(solution[0], cmap=plt.cm.Greys)
ax[1, 0].set_title("GA solution start field")
ax[1, 1].imshow(make_move(solution[0], 3), cmap=plt.cm.Greys)
ax[1, 1].set_title('GA solution end field');
fig.savefig('solution_example.png', dpi=100, bbox_inches = 'tight', pad_inches = 0)
| ga_tutorial.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# ## Gradient Descent Implementation
# In this Python notebook we will go through an example of implementing **Gradient Descent** in simple and multiple linear regression, for this we will be using housing dataset.
#Importing the dataset
import pandas as pd
housing = pd.read_csv('Housing.csv')
housing.head()
# Converting Yes to 1 and No to 0
housing['mainroad'] = housing['mainroad'].map({'yes': 1, 'no': 0})
housing['guestroom'] = housing['guestroom'].map({'yes': 1, 'no': 0})
housing['basement'] = housing['basement'].map({'yes': 1, 'no': 0})
housing['hotwaterheating'] = housing['hotwaterheating'].map({'yes': 1, 'no': 0})
housing['airconditioning'] = housing['airconditioning'].map({'yes': 1, 'no': 0})
housing['prefarea'] = housing['prefarea'].map({'yes': 1, 'no': 0})
#Converting furnishingstatus column to binary column using get_dummies
status = pd.get_dummies(housing['furnishingstatus'],drop_first=True)
housing = pd.concat([housing,status],axis=1)
housing.drop(['furnishingstatus'],axis=1,inplace=True)
housing.head()
# Normalisisng the data
housing = (housing - housing.mean())/housing.std()
housing.head()
# +
# Simple linear regression
# Assign feature variable X
X = housing['area']
# Assign response variable to y
y = housing['price']
# +
# Conventional way to import seaborn
import seaborn as sns
# To visualise in the notebook
# %matplotlib inline
# -
# Visualise the relationship between the features and the response using scatterplots
sns.pairplot(housing, x_vars='area', y_vars='price',size=7, aspect=0.7, kind='scatter')
# **For linear regression we use a cost function known as the mean squared error or MSE.**
# <img src="gd1.png"/>
# Now we will apply partial derivative with respect to m and c and will equate it to zero to find the least value of m and c for which our cost function get the lowest value as possible.
# <img src="gd2.png"/>
# Now to apply gradient descent from scratch we need our X and y variables as numpy arrays, Let's convert them.
import numpy as np
X = np.array(X)
y = np.array(y)
# +
# Implement gradient descent function
# Takes in X, y, current m and c (both initialised to 0), num_iterations, learning rate
# returns gradient at current m and c for each pair of m and c
def gradient(X, y, m_current=0, c_current=0, iters=1000, learning_rate=0.01):
N = float(len(y))
gd_df = pd.DataFrame( columns = ['m_current', 'c_current','cost'])
for i in range(iters):
y_current = (m_current * X) + c_current
cost = sum([data**2 for data in (y-y_current)]) / N
m_gradient = -(2/N) * sum(X * (y - y_current))
c_gradient = -(2/N) * sum(y - y_current)
m_current = m_current - (learning_rate * m_gradient)
c_current = c_current - (learning_rate * c_gradient)
gd_df.loc[i] = [m_current,c_current,cost]
return(gd_df)
# -
# print gradients at multiple (m, c) pairs
# notice that gradient decreased gradually towards 0
# we have used 1000 iterations, can use more if needed
gradients = gradient(X,y)
gradients
# plotting cost against num_iterations
gradients.reset_index().plot.line(x='index', y=['cost'])
# ### Multiple Regression: Applying Gradient Descent for Multiple (>1) Features
# +
# Assigning feature variable X
X = housing[['area','bedrooms']]
# Assigning response variable y
y = housing['price']
# +
# Add a columns of 1s as an intercept to X.
# The intercept column is needed for convenient matrix representation of cost function
X['intercept'] = 1
X = X.reindex_axis(['intercept','area','bedrooms'], axis=1)
X.head()
# -
# Convert X and y to arrays
import numpy as np
X = np.array(X)
y = np.array(y)
# Theta is the vector representing coefficients (intercept, area, bedrooms)
theta = np.matrix(np.array([0,0,0]))
alpha = 0.01
iterations = 1000
# +
# define cost function
# takes in theta (current values of coefficients b0, b1, b2), X and y
# returns total cost at current b0, b1, b2
def compute_cost(X, y, theta):
return np.sum(np.square(np.matmul(X, theta) - y)) / (2 * len(y))
# -
# More on [Numpy Matmul](https://docs.scipy.org/doc/numpy/reference/generated/numpy.matmul.html)
# <img src="gd.png"/>
# +
# gradient descent
# takes in current X, y, learning rate alpha, num_iters
# returns cost (notice it uses the cost function defined above)
def gradient_descent_multi(X, y, theta, alpha, iterations):
theta = np.zeros(X.shape[1])
m = len(X)
gdm_df = pd.DataFrame( columns = ['Bets','cost'])
for i in range(iterations):
gradient = (1/m) * np.matmul(X.T, np.matmul(X, theta) - y)
theta = theta - alpha * gradient
cost = compute_cost(X, y, theta)
gdm_df.loc[i] = [theta,cost]
return gdm_df
# -
# print costs with various values of coefficients b0, b1, b2
gradient_descent_multi(X, y, theta, alpha, iterations)
# print cost
gradient_descent_multi(X, y, theta, alpha, iterations).reset_index().plot.line(x='index', y=['cost'])
| Section 4/Gradient-Descent-Updated/Gradient_Descent_Updatd.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # Create an exclusion mask
#
# ## Introduction
#
# ### Prerequisites
#
# - Understanding of basic analyses in 1D or 3D.
# - Usage of `~regions` and catalogs, see the [catalog notebook](catalog.ipynb).
#
# ### Context
#
# Background templates stored in the DL3 IRF are often not reliable enough to be used without some corrections. A set of common techniques to perform background or normalisation from the data is implemented in gammapy: reflected regions for 1D spectrum analysis, field-of-view (FoV) background or ring background for 2D and 3D analyses.
#
# To avoid contamination of the background estimate from gamma-ray bright regions these methods require to exclude those regions from the data used for the estimation. To do so, we use exclusion masks. They are maps containing boolean values where excluded pixels are stored as False.
#
# **Objective: Build an exclusion mask around the Crab nebula excluding gamma-ray sources in the region.**
#
# ### Proposed approach
#
# Here we have to build a `Map` object, we must first define its geometry and then we can determine which pixels to exclude.
#
# We can rely on known sources positions and properties to build a list of regions (here `~regions.SkyRegions`) enclosing most of the signal that our detector would see from these objects. We show below how to build this list manually or from an existing catalog.
#
# Finally, we show how to build the mask from a `MapDataset`, finding pixels which contain statistically significant signal. To do so, we use the `ExcessMapEstimator`
#
# ## Setup
# %matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from astropy.coordinates import SkyCoord, Angle
from regions import CircleSkyRegion
from gammapy.maps import Map, WcsGeom
from gammapy.utils.regions import make_region
from gammapy.catalog import CATALOG_REGISTRY
from gammapy.datasets import Datasets
from gammapy.estimators import ExcessMapEstimator
from gammapy.modeling.models import FoVBackgroundModel
# ## Create the mask from a list of regions
#
# One can build an exclusion mask from regions. We show here how to proceed.
# ### Define the geometry
#
# Exclusions masks are stored in `Map` objects. One has therefore to define the geometry to use. Here we consider a region at the Galactic anticentre around the crab nebula.
position = SkyCoord(83.633083, 22.0145, unit="deg", frame="icrs")
geom = WcsGeom.create(
skydir=position, width="5 deg", binsz=0.02, frame="galactic"
)
# ### Create the list of regions
#
# A useful function to create region objects is `~gammapy.utils.regions.make_region`. It can take strings defining regions following the "ds9" format and convert them to `regions`.
#
# Here we use a region enclosing the Crab nebula with 0.3 degrees. The actual region size should depend on the expected PSF of the data used. We also add another region with a different shape as en example.
some_region = make_region("galactic;box(185,-4,1.0,0.5, 45)")
crab_region = make_region("icrs;circle(83.633083, 22.0145, 0.3)")
regions = [some_region, crab_region]
print(regions)
# Equivalently the regions can be read from a ds9 file, this time using `regions.read_ds9`.
# +
# regions = read_ds9('ds9.reg')
# -
# ### Create the mask map
#
# We can now create the map. We use the `WcsGeom.region_mask` method putting all pixels inside the regions to False.
mask_map = geom.region_mask(regions, inside=False)
mask_map.plot()
# ## Create the mask from a catalog of sources
#
# We can also build our list of regions from a list of catalog sources. Here we use the Fermi 4FGL catalog which we read using `~gammapy.catalog.SourceCatalog`.
fgl = CATALOG_REGISTRY.get_cls("4fgl")()
# We now select sources that are contained in the region we are interested in.
inside_geom = geom.contains(fgl.positions)
idx = np.where(inside_geom)[0]
# We now create the list of regions using our 0.3 degree radius a priori value. If the sources were extended, one would have to adapt the sizes to account for the larger size.
exclusion_radius = Angle("0.3 deg")
regions = [CircleSkyRegion(fgl[i].position, exclusion_radius) for i in idx]
# Now we can build the mask map the same way as above.
mask_map_catalog = geom.region_mask(regions, inside=False)
mask_map_catalog.plot()
# ### Combining masks
#
# If two masks share the same geometry it is easy to combine them with `Map` arithmetics.
# + nbsphinx-thumbnail={"tooltip": "Build an exclusion mask around the Crab nebula excluding gamma-ray sources in the region."}
mask_map *= mask_map_catalog
mask_map.plot()
# -
# ## Create the mask from statistically significant pixels in a dataset
#
# Here we want to determine an exclusion from the data directly. We will estimate the significance of the data and exclude all pixels above a given threshold.
#
# Here we use a dataset taken from Fermi data used in the 3FHL catalog. The dataset is already in the form of a `Datasets` object. We read it from disk.
filename = "$GAMMAPY_DATA/fermi-3fhl-crab/Fermi-LAT-3FHL_datasets.yaml"
datasets = Datasets.read(filename=filename)
datasets.models = [FoVBackgroundModel(dataset_name="Fermi-LAT")]
# We now apply a significance estimation. We integrate the counts using a correlation radius of 0.4 degree and apply regular significance estimate.
estimator = ExcessMapEstimator("0.4 deg", selection_optional=[])
result = estimator.run(datasets["Fermi-LAT"])
# Finally, we create the mask map by applying a threshold of 5 sigma to remove pixels.
mask_map_significance = result["sqrt_ts"] < 5.0
# Because the `ExcessMapEstimator` returns NaN for masked pixels, we need to put the NaN values to `True` to avoid incorrectly excluding them.
invalid_pixels = np.isnan(result["sqrt_ts"].data)
mask_map_significance.data[invalid_pixels] = True
mask_map_significance.sum_over_axes().plot();
# This method frequently yields isolated pixels or weakly significant features if one places the threshold too low.
#
# To overcome this issue, one can use `~skimage.filters.apply_hysteresis_threshold` . This filter allows to define two thresholds and mask only the pixels between the low and high thresholds if they are not continuously connected to a pixel above the high threshold. This allows to better preserve the structure of the excesses.
#
# Note that scikit-image is not a required dependency of gammapy, you might need to install it.
#
# ## Reading and writing exclusion masks
#
# `gammapy.maps` cannot directly read/write maps with boolean content. Thus, for serialisation of exclusion masks, it is necessary to do an explicit type casting between boolean and int, as we show here.
# To save masks to disk
mask_map_int = mask_map.copy()
mask_map_int.data = mask_map_int.data.astype(int)
mask_map_int.write("exclusion_mask.fits", overwrite="True")
# To read maps from disk
mask_map = Map.read("exclusion_mask.fits")
mask_map.data = mask_map.data.astype(bool)
| docs/tutorials/exclusion_mask.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # O que é Python?
#
# Python é uma linguagem de programação de alto nível, orientada a objetos, moderna e de propósito geral.
#
# #### Características gerais de Python:
#
# * **linguagem simples e limpa**: código intuitivo e fácil de ler, sintaxe minimalista de fácil aprendizado, capacidade de manutenção escalável bem com o tamanho dos projetos.
# * **linguagem expressiva**: Menos linhas de código, menos bugs, mais fáceis de manter.
#
# #### Detalhes técnicos:
#
# * **Digitado dinamicamente**: Não há necessidade de definir o tipo de variáveis, argumentos de função ou tipos de retorno.
# * **Gerenciamento automático de memória**: Não é necessário alocar e desalocar explicitamente a memória para variáveis e matrizes de dados. Não há vazamentos de memória (memory leak bugs).
# * **interpretado**: Não há necessidade de compilar o código. O interpretador Python lê e executa o código python diretamente.
#
# #### Vantagens:
#
# * A principal vantagem é a facilidade de programação, minimizando o tempo necessário para desenvolver, *debugar* (procurar por erros no programa) e manter o código.
# * Linguagem bem projetada que incentiva muitas boas práticas de programação:
# * Programação modular e orientada a objetos, bom sistema para empacotamento e reutilização de código. Isso geralmente resulta em código mais transparente, sustentável e livre de bugs.
# * Documentação totalmente integrada com o código.
# * Uma grande biblioteca padrão e uma grande coleção de pacotes complementares.
# * Muita documentação disponível!
#
# #### Desvantagens:
#
# * Como o Python é uma linguagem de programação interpretada e dinamicamente digitada, a execução do código python pode ser lenta em comparação com as linguagens de programação compiladas estaticamente, como C e Fortran.
import antigravity
# # Por que Python?
#
# ## Popularidade de Python no mundo
# últimos cinco anos (set. 2018)
# 
#
# **Python foi a linguagem de programação que mais cresceu no mundo nos últimos 5 anos (14,5%) e php foi a que mais decresceu (-6,5%)**
#
# http://pypl.github.io/PYPL.html
# # A linguagem de programação Python
#
# * Python é um exemplo de uma linguagem de programação de **alto nível**;
#
#
# * Exemplos de outras linguagens de alto nível: C, C ++, Perl e Java.
#
#
# * Linguagens de programação de **baixo nível**: "linguagens de máquina" ou "linguagens de montagem" (assembly language).
# * Posto de forma não muito rígida, os computadores só podem executar programas escritos em linguagens de baixo nível.
# * Os programas escritos em uma linguagem de alto nível precisam ser *processados* antes de poderem ser *executados*.
# * Esse processamento extra leva algum tempo, o que é uma pequena desvantagem das linguagens de alto nível.
#
# #### As vantagens de um programa de alto nível:
#
# * É muito mais fácil de programar.
#
#
# * Demora menos tempo para ser escrito, é mais curto e fácil de ler, além de ter maior probabilidade de estar correto.
#
#
# * É **portátil**: pode ser executado em diferentes tipos de computadores com poucas ou nenhuma modificação.
#
#
# * Programas de **baixo nível** podem ser executados em apenas **um tipo de computador** e precisam ser reescritos para serem executados em outro.
#
#
# * Por conta dessas vantagens quase todos os programas são escritos em linguagem de alto nível, a não ser aplicações específicas que necessitam linguagem de baixo nível.
# ### Interpretadores e compiladores
#
# São dois tipos de programas que processam linguagem de alto nível em linguagem de baixo nível.
#
# #### Interpretador:
#
# * Lê um programa de alto nível e o executa: faz o que o programa comanda.
#
#
# * Processa o programa um pouco por vez, lendo linhas e realizando cálculos alternadamente.
#
# <img src="pics/python_interpretor.png" style="max-width:40%; width: 40%">
# #### Compilador:
#
# * Lê o programa por completo e traduz antes de executar.
#
#
# * O programa de alto nível é chamado de **código-fonte** e o programa traduzido é chamado de **código-objeto** ou **executável**.
#
#
# * Depois que um programa é compilado, você pode executá-lo repetidamente sem mais traduções.
#
# <img src="pics/python_compiler.png" style="max-width:50%; width: 50%">
# # Python: uma linguagem interpretada
#
# #### Interpretador de Python
#
# * modo imediato (prompt)
# * modo script
#
# ### Interpretador de Python Modo Prompt
#
# * abrir um terminal de Linux (com Python previamente instalado)
# * python
# * para sair: ctrl + D
# * Para Windows, você pode usar o PyScripter para acessar o prompt ou rodar um script.
#
# <img src="pics/terminal.png" style="max-width:50%; width: 50%">
3*(7+2)
# + [markdown] slideshow={"slide_type": "slide"}
# # Rodando Python -- Rodando programas
#
# * execute seu programa:
# <img src="pythonProgram.png" alt="" style="width: 400px;"/>
#
# * ou torne seu programa executável adicionando a seguinte linha no topo do seu programa (altamente dependende de plataforma): ** #!/usr/bin/env **
# + [markdown] slideshow={"slide_type": "slide"}
# # Um exemplo de código
#
#
# +
x = 34 - 23 # comentário
y = "Hello" # outro comentário
z = 3.45
if z == 3.45 or y == "Hello":
x = x + 1
y = y + " World!" # concatenação de string
print (x)
print ('Podemos imprimir a frase: "%s"' % y) #formatação de string
# + [markdown] slideshow={"slide_type": "slide"}
#
# * **atribuição de valores** com **'='** e comparações com **'=='**
# * para números, o uso dos operadores **'+ - * / %'** é como o esperado
# * uso especial do operador **'+'** para concatenação de string
# * uso especial de **'%'** para formatação de string
# * **operadores lógicos** são palavras (**and**, **or**, **not** ) e não símbolos
# * comando básico para imprimir na tela é a função **<font color='red'>print</font>**
# * tipagem **dinâmica**: uma variável é criada em sua primeira atribuição
# * os tipos das variáveis não precisam ser declarados
# * o Python reconhece sozinho o tipo de cada variável
#
# + [markdown] slideshow={"slide_type": "slide"}
# # Tipos de dados simples em Python
#
# * **Inteiros**
# + slideshow={"slide_type": "fragment"}
z = 5/2 # divisão de número inteiro em Python 3
t = int(5/2)
print (z, t)
# + [markdown] slideshow={"slide_type": "fragment"}
# * **Floats**
# x = 3.456
# + [markdown] slideshow={"slide_type": "fragment"}
# * **Strings**
# + slideshow={"slide_type": "fragment"}
s = 'abc'
st = "abc"
stri = """abc"""
print ('%s, %s, %s' % (s, st, stri))
# + [markdown] slideshow={"slide_type": "slide"}
# **Tratamento de nomenclatura das variáveis em Python**
# -
# ## Objetos e referências
#
# Se executarmos os seguintes comandos:
a = "objeto"
b = "objeto"
# Sabemos que ***a*** e ***b*** se referirão a uma ***string*** mas não sabemos se eles apontam para o mesmo objeto de Python.
#
# O interpretador pode organizar sua memória de duas maneiras:
#
# * referir ***a*** e ***b*** a dois objetos distintos com os mesmos valores
# * referir ***a*** e ***b*** ao mesmo objeto
#
# 
#
# Podemos testar se duas variáveis se referem ao mesmo objeto:
a is b
# Nesse caso, ***a*** e ***b*** têm o mesmo valor mas não se referem ao mesmo objeto.
#
# 
#
# ## Alias
#
# Podemos forçar ***a*** e ***b*** a se referirem ao mesmo objeto. Com isso, criamos um **alias** (apelido).
a = [4, 5, 6]
b = [4, 5, 6]
a is b
a = b
a is b
a.append(88)
print('a = ', a, ', b = ', b)
# ### O que aconteceu???
#
# 
# 
#
#
# ### Recomendações em relação a **aliases**:
# Em geral, é mais seguro evitar fazer um **alias** de objetos **mutáveis**, como listas. Para objetos **imutáveis**, como strings, não há restrições de se fazer **aliases**.
#
# ## Clonagem de listas
#
# Se quisermos modificar uma lista e ao mesmo tempo mantermos uma cópia inalterada dessa lista, devemos **cloná-la**:
lista = [1, 2, 3]
clone_lista = lista[:]
clone_lista
# Podemos então criar uma nova lista ao tomar uma **fatia** de **toda a lista**.
#
# 
#
#
# E agora, como cada uma das listas é uma referência a um objeto diferente, podemos modificar uma variável, sem modificar a outra:
# +
a = [1, 2, 3]
b = a[:]
a.append(88)
print ('a: ', a, ', b: ', b)
b[2] = 199
print ('a: ', a, ', b: ', b)
# + [markdown] slideshow={"slide_type": "slide"}
# # Tipos de Sequências: Tuplas, Listas e Strings
# + [markdown] slideshow={"slide_type": "slide"}
# * <font color=red> Tupla </font>
# * Uma sequência simples e imutável de ítens.
# * Ítens podem ser de tipos mistos, incluindo sequências de tipos
# + [markdown] slideshow={"slide_type": "fragment"}
# * <font color=red> Strings </font>
# * Imutável
# * conceitualmente muito parecida com uma Tupla
# + [markdown] slideshow={"slide_type": "fragment"}
# * <font color=red> Lista </font>
# * Mutável, uma sequência ordenada de tipos mistos
# + [markdown] slideshow={"slide_type": "slide"}
# * Todos os três tipos de sequência compartilham bastante da mesma sintaxe e funcionalidade
#
#
# * Diferenças mais importantes:
# * tuplas e strings são imutáveis
# * listas são mutáveis
#
#
# * Os exemplos que mostraremos podem ser aplicados a todos os tipos de sequência
# + [markdown] slideshow={"slide_type": "slide"}
# # Tipos de Sequências: Definições
#
# * Tuplas são definidas usando parênteses (e vírgulas).
# + slideshow={"slide_type": "fragment"}
tupla = (3, 'abc', 4.56, (2, 23), 'k')
# + [markdown] slideshow={"slide_type": "fragment"}
# * Listas são definidas usando colchete (e vírgulas).
# + slideshow={"slide_type": "fragment"}
lista = ['abc', 34, 3.1415, 23]
# + [markdown] slideshow={"slide_type": "fragment"}
# * Strings são definidas usando aspas
# + slideshow={"slide_type": "fragment"}
st = 'Hello'
st = "Hello"
st = """Hello"""
# + [markdown] slideshow={"slide_type": "slide"}
# # Tipos de Sequências: acessando membros
#
# * Membros individuais de uma **tupla**, **lista** ou **string** podem ser acessados usando uma notação de colchete.
# * Os tipos de sequências são todos baseados no 0 (zero), os índices são contados a partir do 0.
# + slideshow={"slide_type": "fragment"}
tupla = (3, 'abc', 4.56, (2, 23), 'k')
print (tupla[1])
# + slideshow={"slide_type": "fragment"}
lista = ['abc', 34, 3.1415, 23]
print (lista[1])
# + slideshow={"slide_type": "fragment"}
st = 'Hello'
print (st[1])
# + [markdown] slideshow={"slide_type": "slide"}
# # Tipos de Sequências: índices negativos
#
# * índice positivo: contar da esquerda para a direita, começando do zero
# * índice negativo: contar da direita para a esquerda, começando do -1.
# + slideshow={"slide_type": "fragment"}
tupla = (3, 'abc', 4.56, (2, 23), 'k')
print (tupla[1])
# + slideshow={"slide_type": "fragment"}
print (tupla[-1])
# + [markdown] slideshow={"slide_type": "slide"}
# # Tipos de Sequências: fatiamento ("slicing")
#
# * Você pode retornar uma cópia do container (lista, tupla, string, ...) com um sub-conjunto dos membros originais, usando uma notação de cólon (dois pontos).
# + slideshow={"slide_type": "fragment"}
tupla = (3, 'abc', 4.56, (2, 23), 'k')
print (tupla[1:4])
# + slideshow={"slide_type": "fragment"}
print (tupla[1:-1])
# + [markdown] slideshow={"slide_type": "slide"}
# # Tuplas Vs. Listas
#
# * **Listas** são mais lentas, porém mais poderosas do que as **tuplas**
# * As **listas** podem ser modificadas e têm várias operações úteis que podemos fazer com elas (_reverse, sort, count, remove, index, insert_, ...)
# * As **tuplas** são imutáveis e têm menos funcionalidades.
#
#
# * Podemos converter listas e tuplas com as funções **_list()_** e **_tuple()_**
# + slideshow={"slide_type": "fragment"}
list(tupla)
# + [markdown] slideshow={"slide_type": "slide"}
# # Mais um tipo de dados: dicionários
#
# * Dicionários são containers que armazenam um **mapeamento** entre um conjunto de **_chaves_** (keys) e um conjunto de **_valores_**
# * Chaves podem ser qualquer tipo **imutável**.
# * Valores podem ser qualquer tipo.
# * Um único dicionário pode guardar valores de tipos diferentes.
#
#
# * O usuário pode modificar, ver, procurar e deletar o par chave-valor no dicionário.
# + [markdown] slideshow={"slide_type": "slide"}
# # Exemplos de dicionários
# + slideshow={"slide_type": "fragment"}
d = {'user': 'bozo', 'pwd': <PASSWORD>} # criação de um dicionário
d['user']
# + slideshow={"slide_type": "fragment"}
d['pwd']
# + slideshow={"slide_type": "fragment"}
d['bozo']
# + slideshow={"slide_type": "fragment"}
print (d)
# + slideshow={"slide_type": "slide"}
d['user'] = 'clown'
d
# + slideshow={"slide_type": "fragment"}
d['id'] = 45
d
# + slideshow={"slide_type": "fragment"}
del d['user'] # remover um ítem do dicionário
d
# + slideshow={"slide_type": "fragment"}
d.clear() # remover todos os ítens do dicionário
d
# + slideshow={"slide_type": "slide"}
d = {'user': {'bozo': 0}, 'p': 1234, 'i': 34}
d.keys() # lista das chaves do dicionário
# + slideshow={"slide_type": "fragment"}
d.values() # lista dos valores
# + slideshow={"slide_type": "fragment"}
d.items() # lista dos ítens
# + [markdown] slideshow={"slide_type": "slide"}
# # Espaço
#
# * O espaço em branco é significativo em Python: especialmente indentação e colocação de novas linhas
# * Use uma nova linha para terminar uma linha de código
# * Não se usa chaves {} para blocos de código!
# * Usa-se **indentação** para blocos de código
# + slideshow={"slide_type": "subslide"}
import time
saudacoes = {'quem': 'alunos e alunas', 'que': 'bem-vindos', 'aonde': 'ao curso de python', 'quando': time.strftime("%H:%M:%S")}
for key in saudacoes.keys():
if (key == 'quem'):
print (saudacoes[key])
if key == 'que':
print (saudacoes[key])
if (key == 'aonde'):
print (saudacoes[key])
if (key == 'quando'):
print ('Hoje às ' + saudacoes[key])
# + [markdown] slideshow={"slide_type": "slide"}
# # Funções
#
# * **'def'** cria uma função e atribui um nome
# * **'return'** envia um resultado de volta ao chamador da função
# * argumentos são passados por designação
# * os tipos dos argumentos e do retorno da função não são declarados
#
# def __nome_da_função__(arg1, arg2, ...argN):
#
# **_declarações_**
#
# return **_valor_a_retornar_**
#
# + slideshow={"slide_type": "subslide"}
def produto(x, y):
return x*y
# + slideshow={"slide_type": "fragment"}
produto(2,5)
# + [markdown] slideshow={"slide_type": "slide"}
# # Passagem de argumento para funções
#
# * Argumentos são passados por designação
# * Argumentos que são passados são designados como nomes locais
# * Designação de nomes de argumentos não afeta o chamador.
# * Designação de objetos mutáveis pode afetar o chamador.
# + slideshow={"slide_type": "subslide"}
x = 8
y = [1, 2]
print (x)
print (y[0])
# + slideshow={"slide_type": "fragment"}
def modificador(x, y):
x = 2 # modifica somente o valor local de x
y[0] = 'hi' # modifica o objeto compartilhado
modificador(x, y) # chamada da função
print ('x = %i' % x)
# + slideshow={"slide_type": "fragment"}
print ('y[0] =', y[0])
# + [markdown] slideshow={"slide_type": "slide"}
# # Pegadinhas de funções
#
#
# <font size="2.5">
# <ul>
# <li> Todas as funções em Python retornam um valor!
# <li> Funções sem retorno especificado, retornam o valor especial 'None'
# <li> Não existe sobrecarga de função (_function overloading_) em Python.
# <ul>
# <li> Duas funções diferentes não podem ter o mesmo nome, mesmo com argumentos diferentes.
# </ul>
#
# <li> Funções podem ser usadas como qualquer outro tipo. Elas podem ser:
# <ul>
# <li> argumentos de outras funções
# <li> valores de retorno de funções
# <li> designadas a variáveis
# <li> partes de listas, tuplas, etc.
# </ul>
# </ul>
# + [markdown] slideshow={"slide_type": "slide"}
# # Se divertindo com funções
# + slideshow={"slide_type": "fragment"}
def f(x, y):
return x + y
def g(x, y):
return x*y
def h(x, y):
if y == 0:
return 0
else:
return x/y
lista_de_funcoes = [f, g, h]
a = 23
b = 9
for function in lista_de_funcoes:
#print (function)
print (function(a, b))
# -
# # Listas e loops ***for***
#
# Suponha que temos duas listas. Se elas forem de tamanhos iguais, queremos imprimir seus valores em um único loop.
# +
lista1 = [1,3,5,7,9,11,13,15]
lista2 = [2,4,6,8,10,12,14,16]
# as listas têm o mesmo tamanho?
len(lista1) == len(lista2)
# -
# se as listas têm o mesmo número de elementos, imprima todos os elementos de cada uma das listas
if (len(lista1) == len(lista2)):
print(range(len(lista1)))
for i in range(len(lista1)):
print(lista1[i])
print(lista2[i])
# +
alunos = ['Ana', 'Luiz', 'Maria', 'Joana']
idades = [16, 18, 17, 19]
if (len(alunos)==len(idades)):
for (i, valor) in enumerate(alunos):
print(valor, ' tem ', idades[i], ' anos')
# -
# # List Comprehension
#
# A compreensão de listas fornece uma maneira concisa de criar listas.
# Aplicações comuns são fazer novas listas onde cada elemento é o resultado de algumas operações aplicadas a cada membro de outra seqüência ou iterável, ou criar uma subsequência daqueles elementos que satisfazem uma determinada condição.
# +
squares = []
for x in range(10):
squares.append(x**2)
squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# -
squares2 = [x**2 for x in range(10)]
print(squares2)
[(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
from math import pi
[str(round(pi, i)) for i in range(1, 6)]
# + [markdown] slideshow={"slide_type": "slide"}
# # Python em Física
# Python é certo para mim?
# 
# + [markdown] slideshow={"slide_type": "slide"}
# # Preciso...manipular grandes estruturas de dados
#
# * Talvez você queira dar uma olha em Pandas. 
# * Uma biblioteca de software escrita para Python para manipulação e anaálise de dados.<img src="table.png" alt="" style="width: 400px;"/>
# * alinhamento de dados
# * funcionalidade de séries temporais
# * agrupamento por, giro
# + [markdown] slideshow={"slide_type": "slide"}
# # Preciso...lidar com grandes 'arrays', matrizes
# <img src="numPy.png" alt="" style="width: 100px;"/>
# * NumPy é uma extensão escrita para adicionar suporte a arrays e matrizes grandes e multi-dimensionais, junto com uma grande biblioteca de funções matemáticas de alto nível para manipular esses arrays.
# * Exemplo: multiplicação de elementos de grandes arrays
# <table>
# <tr>
# <td>
# <font size="4">
# <b>Python</b>
# <img src='pics/pyEx.png'>
# Slow
# </td>
# <td>
# <font size="4">
# <b>NumPy</b>
# <img src='pics/numPyEx.png'>
# Fast (C)
# </td>
# </tr>
# </table>
# + [markdown] slideshow={"slide_type": "slide"}
# # Preciso...fazer computação científica
# <img src="pics/sciPy.png" alt="" style="width: 200px;"/>
# <table>
# <tr>
# <td>
# <li>SciPy vem com suporte para:
# <li>otimização
# <li>álgebra linear
# <li>integração
# <li>interpolação
# <li>funções especiais
# <li>FFT
# <li>equações diferenciais ordinárias
# <li>ajuste de funções
# <li>...
# </td>
# <td>
# <img src='pics/sciPy2.png'>
# </td>
# </tr>
# </table>
# + [markdown] slideshow={"slide_type": "slide"}
# # Preciso...de ROOT
# 
# * **Rootpy** é uma camada "pythonica" em cima de ***Pyroot*** (que é uma interface de Python para ROOT)
# * Não tem a intenção de recriar ROOT ou alterar o comportamento padrão de ROOT
# * Não é um "framework" de análise, mas uma biblioteca para ser usada pelo framework de análise de alguém
# * Fornece interface para os pacotes de Python científico (Pandas, NumPy, SciPy, ...)
#
#
# * **uproot** é um "desenpacotador" de ROOT en Python: https://github.com/scikit-hep/uproot
# -
# # Machine Learning!
#
# Python é a ferramenta mais usada para a implementação de aprendizado de máquina.
#
# Nesse curso, veremos:
#
# * scikit-learn
# * Keras
# * Tensor Flow
# * PyTorch
# + [markdown] slideshow={"slide_type": "slide"}
# # E tem mais...
# * QuTiP: simulação da dinâmica de sistemas quânticos abertos (open quantum system)
# * SymPy: biblioteca para matemática simbólica
# * scikit-learn: aprendizado de máquinas (machine learning) em Python
# * astropy: pacote para astronomia
# * cosmocalc: versão de Python do "Cosmology Calculator"
# * ALPS: algoritmos e bibliotecas para simulações em física
# * SunPy: física solar
# -
# ## Referências
#
# 1. http://github.com/jrjohansson/scientific-python-lectures
# 1. http://greenteapress.com/thinkpython/html/index.html
# 1. http://python.org/
| PythonIntro/python_intro.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
# %matplotlib inline
import numpy as np
from scipy.io import loadmat, savemat
from fooof import FOOOF
# +
# Load the mat file
data = loadmat('PSD.mat')
# Unpack data from dictioanry, and squeeze numpy arrays
freqs = np.squeeze(data['f'])
psd = np.squeeze(data['PSD_all'])
# -
i = 0
# Initialize FOOOF object
fm = FOOOF()
# Fit the FOOOF model, and report
fm.report(freqs, psd[:,i], [1, 15])
| Analysis/3.0 Edition/.ipynb_checkpoints/Untitled-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + [markdown] slideshow={"slide_type": "slide"}
# # hana-ml Tutorial - Classification
#
# **Author: TI HDA DB HANA Core CN**
#
# In this tutorial, we will show you how to use functions in hana-ml to preprocess data and train a classification model with a public Diabetes dataset. We also display many useful functions of model storage, dataset & model report and model explainations.
#
# ## Import necessary libraries and functions
# + slideshow={"slide_type": "slide"}
from hana_ml import dataframe
from hana_ml.dataframe import ConnectionContext
from hana_ml.algorithms.pal.utility import DataSets, Settings
from hana_ml.algorithms.pal.partition import train_test_val_split
from hana_ml.algorithms.pal.unified_classification import UnifiedClassification
from hana_ml.algorithms.pal.model_selection import GridSearchCV
from hana_ml.model_storage import ModelStorage
from IPython.core.display import HTML
from hana_ml.visualizers.shap import ShapleyExplainer
from hana_ml.visualizers.unified_report import UnifiedReport
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import time
import json
# %matplotlib inline
# -
# ## Create a connection to a SAP HANA instance
#
# First, you need to create a connetion to a SAP HANA instance. In the following cell, we use a config file, config/e2edata.ini to control the connection parameters.
#
# In your case, please update the following url, port, user, pwd with your HANA instance information for setting up the connection.
# + slideshow={"slide_type": "slide"}
# Please replace url, port, user, pwd with your HANA instance information
connection_context = ConnectionContext(url, port, user, pwd)
# + [markdown] slideshow={"slide_type": "slide"}
# ## Load the dataset
#
# Diabetes dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective is to predict based on diagnostic measurements whether a patient has diabetes. The meaning of each column is below:
#
# 1. **PREGNANCIES**: Number of times pregnant
# 2. **GLUCOSE**: Plasma glucose concentration a 2 hours in an oral glucose tolerance test
# 3. **BLOODPRESSURE**: Diastolic blood pressure (mm Hg)
# 4. **SKINTHICKNESS**: Triceps skin fold thickness (mm)
# 5. **INSULIN**: 2-Hour serum insulin (mu U/ml)
# 6. **BMI**: Body mass index (weight in kg/(height in m)^2)
# 7. **PEDIGREE**: Diabetes pedigree function
# 8. **AGE**: Age (years)
# 9. **CLASS**: Class variable (0 or 1), **target varaible**.
#
# In hana-ml, we provide a class called DataSets which contains several public datasets. You could use load_diabetes_data to load the diabetes dataset.
# -
# **Load the data**
# + slideshow={"slide_type": "slide"}
diabetes_dataset, _, _, _ = DataSets.load_diabetes_data(connection_context)
# number of rows and number of columns
print("Shape of diabetes datset: {}".format(diabetes_dataset.shape))
# columns
print(diabetes_dataset.columns)
# types of each column
print(diabetes_dataset.dtypes())
# -
# **Generate a Dataset Report**
UnifiedReport(diabetes_dataset).build().display()
# **Split the dataset**
# + slideshow={"slide_type": "slide"}
df_diabetes_train, df_diabetes_test, _ = train_test_val_split(data=diabetes_dataset,
random_seed=2,
training_percentage=0.8,
testing_percentage=0.2,
validation_percentage=0,
id_column='ID',
partition_method='stratified',
stratified_column='CLASS')
print("Number of training samples: {}".format(df_diabetes_train.count()))
print("Number of test samples: {}".format(df_diabetes_test.count()))
df_diabetes_test = df_diabetes_test.deselect('CLASS')
# -
# **Look at the first three row of data**
# + slideshow={"slide_type": "slide"}
print(df_diabetes_train.head(3).collect())
print(df_diabetes_test.head(3).collect())
# -
# ## Model training with CV
#
# UnifiedClassification offers a varity of classfication algorithm and we select HybridGradientBoostingTree for training.
# Other options are:
#
# - 'DecisionTree'
# - 'HybridGradientBoostingTree'
# - 'LogisticRegression'
# - 'MLP'
# - 'NaiveBayes'
# - 'RandomDecisionTree'
# - 'SVM'
# + slideshow={"slide_type": "slide"}
uc_hgbt = UnifiedClassification(func='HybridGradientBoostingTree')
gscv = GridSearchCV(estimator=uc_hgbt,
param_grid={'learning_rate': [0.001, 0.01, 0.1],
'n_estimators': [5, 10, 20, 50],
'split_threshold': [0.1, 0.5, 1]},
train_control=dict(fold_num=3,
resampling_method='cv',
random_state=1,
ref_metric=['auc']),
scoring='error_rate')
gscv.fit(data=df_diabetes_train,
key= 'ID',
label='CLASS',
partition_method='stratified',
partition_random_state=1,
stratified_column='CLASS',
build_report=False)
# -
# **Look at the model**
# Model table
print(gscv.estimator.model_[0].head(5).collect())
# Statistic
print(gscv.estimator.model_[1].collect())
# **Generate a model report**
# + slideshow={"slide_type": "slide"}
UnifiedReport(gscv.estimator).build().display()
# -
# **Save the model**
# +
model_storage = ModelStorage(connection_context=connection_context)
model_storage.clean_up()
# Saves the model for the first time
uc_hgbt.name = 'HGBT model' # The model name is mandatory
uc_hgbt.version = 1
model_storage.save_model(model=uc_hgbt)
# Lists models
model_storage.list_models()
# -
# ## Model prediction
# + slideshow={"slide_type": "slide"}
# Prediction with explaining of model
features = df_diabetes_test.columns
features.remove('ID')
pred_res = gscv.predict(data=df_diabetes_test,
attribution_method='tree-shap',
key='ID',
features=features)
pred_res.head(10).collect()
# + slideshow={"slide_type": "slide"}
# Look at the detail of first test instance
rc = pred_res.head(1).select("ID", "SCORE", "REASON_CODE").head(1).collect()
HTML(rc.to_html())
# -
# ## Model Explainability
# + slideshow={"slide_type": "slide"}
shapley_explainer = ShapleyExplainer(feature_data=df_diabetes_test.select(features),
reason_code_data=pred_res.select('REASON_CODE'))
shapley_explainer.summary_plot()
# -
# ## Close the connection
connection_context.close()
# + [markdown] slideshow={"slide_type": "slide"}
# ## Thank you!
| Python-API/pal/notebooks/tutorials/.ipynb_checkpoints/hana-ml_Tutorial_Classification-checkpoint.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# ## Redes Convolucionales
# #### Ejemplo clasificación de perros y gatos para CAPTCHA
#
# Este notebook utiliza datos de la [competición de Kaggle Dogs vs. Cats](https://www.kaggle.com/c/dogs-vs-cats/overview). En esta competicion se utiliza Asirra (Animal Species Image Recognition for Restricting Access), CAPTCHA que sirve para diferenciar entre una persona o una máquina accediendo a una página web. Este tipo de "pruebas" se utilizan para evitar emails de spam, y ataques por fuerza bruta contra servidores.
#
# En este notebook vamos a probar que hay técnicas de clasificado automáticas de imágenes mediante redes neuronales, que con las que se intenta saltar CAPTCHA
# + [markdown] _uuid="fe76d1d1ded592430e7548feacfa38dc42f085d9"
# # Import Library
# + _cell_guid="b1076dfc-b9ad-4769-8c92-a6c4dae69d19" _uuid="8f2839f25d086af736a60e9eeb907d3b93b6e0e5"
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator, load_img
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import random
import os
# -
# # Define Constants
# Tendremos una serie de constantes como las dimensiones de las imágenes, que serán fijas a lo largo de todo el notebook
# +
IMAGE_WIDTH=32
IMAGE_HEIGHT=32
IMAGE_CHANNELS=3
IMAGE_SIZE=(IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS)
BATCH_SIZE = 10
EPOCHS = 5
ROOT_PATH = "cats_dogs/"
TRAIN_PATH_TOT = ROOT_PATH + "train\\train\\"
TEST_PATH_TOT = ROOT_PATH + "test\\test\\"
MINI_TRAIN_PATH = ROOT_PATH + "mini_train\\train\\"
MINI_TEST_PATH = ROOT_PATH + "mini_test\\test1\\"
TRAIN_PATH = TRAIN_PATH_TOT
TEST_PATH = TEST_PATH_TOT
#########
TRAIN_PATH = "cats_dogs_img/train/train/"
TEST_PATH = "cats_dogs_img/test1/test1/"
# + [markdown] _uuid="7335a579cc0268fba5d34d6f7558f33c187eedb3"
# # Prepare Training Data
# 1. Descárgate el dataset de train de [la competición de Kaggle](https://www.kaggle.com/c/dogs-vs-cats/overview).
# 2. Descomprime el dataset y guardalo en la ruta que quieras del ordenador. Por supuesto, NO en la carpeta donde esté el repositorio
# 3. En este punto vamos guardar en una lista las etiquetas de cada foto.
# + _cell_guid="79c7e3d0-c299-4dcb-8224-4455121ee9b0" _uuid="d629ff2d2480ee46fbb7e2d37f6b5fab8052498a"
filenames = os.listdir(TRAIN_PATH)
categories = []
for filename in filenames:
category = filename.split('.')[0]
if category == 'dog':
categories.append(1)
else:
categories.append(0)
df = pd.DataFrame({
'filename': filenames,
'category': categories
})
# + _uuid="915bb9ba7063ab4d5c07c542419ae119003a5f98"
df
# + [markdown] _uuid="a999484fc35b73373fafe2253ae9db7ff46fdb90"
# ### See Total In count
# + _uuid="fa26f0bc7a6d835a24989790b20f3c6f32946f45"
df['category'].value_counts().plot.bar();
# + [markdown] _uuid="400a293df3c8499059d9175f3915187074efd971"
# # See sample image
# +
from skimage.io import imread
import cv2
#pip install opencv-python
sample = random.choice(filenames)
image = imread(TRAIN_PATH + sample)
print(image.shape)
print(np.max(image))
plt.imshow(image)
# -
# Una imagen no es mas que un array de HxWxC píxeles, siendo H(Height) y W(Width) las dimensiones de resolución de la imagen, y C el número de canales. Habrá tres valores por píxel.
image
# # Resize image
# Cargar todas las imágenes a la vez es un problema ya que son un total de 25000 (unos 500MB la carpeta de train). Este proceso require mucha memoria, por lo que tendremos que aplicarle un resize a cada imagen para bajarlas de resolución. Esto también nos sirve para solventar el problema de tener imágenes con distintas resoluciones.
# +
plt.figure(figsize=(12, 12))
sample = random.choice(filenames)
image = imread(TRAIN_PATH + sample)
imagesmall = cv2.resize(image, (IMAGE_WIDTH, IMAGE_HEIGHT))
print("Tamaño imagen original:", image.shape)
print("Tamaño imagen reshape:", imagesmall.shape)
print("Maximo valor por pixel:", np.max(imagesmall))
# Original image
plt.subplot(1, 2, 1)
plt.imshow(image)
# Resized image
plt.subplot(1, 2, 2)
plt.imshow(imagesmall);
# -
# # Color
# Podríamos cargar las imágenes como blanco y negro, de esta forma se reduciría el espacio de features considerablemente al contar con un único canal
# +
sample = random.choice(filenames)
##### CODE #####
# -
# # Load data
# Llega el momento de cargar los datos. Ya no estan sencillo como cuando teníamos datasets en CSVs puesto que ahora hay que cargar miles de archivos en memoria en este notebook. Para ello necesitaremos un programa iterativo que vaya recorriendo los archivos de la carpeta, cargarlos como array de numpy y almacenarlos en un objeto.
# +
def read_data(path, im_size):
X = []
Y = []
##### CODE #####
return np.array(X), np.array(Y)
X_train, y_train = read_data(TRAIN_PATH, IMAGE_SIZE)
X_test, y_test = read_data(TEST_PATH, IMAGE_SIZE)
print(X_train.shape)
print(X_test.shape)
# -
print(X_train[0].shape)
plt.imshow(X_train[0]);
X_train[0]
# # Normalized data
# Normalizar los datos hará que entrene mucho mejor la red, al estar todos los pixeles en la misma escala.
print("Min:", np.min(X_train))
print("Max:", np.max(X_train))
# +
X_train = X_train / 255.0
X_test = X_test / 255.0
print("Min:", np.min(X_train))
print("Max:", np.max(X_train))
# -
# # Shuffle data
# Como hemos cargado los datos de manera ordenada (primero gatos y luego perros), tendremos que desordenarlos para asegurarnos de que no haya ningún sesgo en el entrenamiento ni en la selección de datos de validación.
# +
##### CODE #####
# -
# # Save data
# Podemos guardar los arrays de numpy en un archivo `.npz`, de tal manera que luego sea más rápido importarlo
# +
##### CODE #####
# -
# Para cargar
# +
##### CODE #####
# + [markdown] _uuid="b244e6b7715a04fc6df92dd6dfa3d35c473ca600"
# # Build Model
#
# <img src="https://i.imgur.com/ebkMGGu.jpg" width="100%"/>
# -
# * **Conv Layer**: extraerá diferentes features de las imagenes
# * **Pooling Layer**: Reduce las dimensiones de las imágenes tras una capa convolucional
# * **Fully Connected Layer**: Tras las capas convolucionales, aplanamos las features y las introducimos como entrada de una red neuronal normal.
# * **Output Layer**: Las predicciones de la red
#
# Para el loss y la metrica, se puede usar un binary_crossentropy, al ser un target binario. O
# +
from tensorflow import keras
##### CODE #####
# + [markdown] _uuid="bd496f6c65888a969be3703135b0b03a8a1190c8"
# # Callbacks
# #### Early Stopping
# + _uuid="9aa032f0f6da539d23918890d2d131cc3aac8c7a"
from keras.callbacks import EarlyStopping
earlystop = EarlyStopping(patience=10)
# -
# # Fit the model
# +
##### CODE #####
# -
# # Evaluate
# Probemos los datos en el conjunto de test.
# +
##### CODE #####
# -
plt.imshow(X_test[0]);
# +
##### CODE #####
# -
# # Image data generator
# +
df["category"] = df["category"].replace({0: 'cat', 1: 'dog'})
print("Categorias:", df['category'].unique())
df.head()
# + _uuid="4252cce168ab65f88e44a8ebc2672607bc852af4"
##### CODE #####
# + _uuid="23d923dba747f8b47dc75569244cecc6f70df321"
plt.figure(figsize=(12, 12))
for i in range(0, 15):
plt.subplot(5, 3, i+1)
for X_batch, Y_batch in example_generator:
image = X_batch[0]
plt.imshow(image)
break
plt.tight_layout()
plt.show()
# + _uuid="4eeb7af8dcf02c4ef5ca744c8305c51a2f5cedef"
train_df, validate_df = train_test_split(df,
test_size=0.20,
random_state=42)
train_df = train_df.reset_index(drop=True)
validate_df = validate_df.reset_index(drop=True)
# + _uuid="ae3dec0361f0443132d0309d3b883ee80070cf9f"
total_train = train_df.shape[0]
total_validate = validate_df.shape[0]
print("Shape train", total_train)
print("Shape validation", total_validate)
validate_df.head()
# -
train_df.head()
# + [markdown] _uuid="ff760be9104f7d9492467b8d9d3405011aa77d11"
# # Training Generator
# + _uuid="4d1c7818703a8a4bac5c036fdea45972aa9e5e9e"
train_generator = train_datagen.flow_from_dataframe(
train_df,
TRAIN_PATH,
x_col='filename',
y_col='category',
target_size=(IMAGE_HEIGHT, IMAGE_WIDTH),
class_mode='binary',
batch_size=BATCH_SIZE
)
# + [markdown] _uuid="859c7b2857939c19fd2e3bb32839c9f7deb5aa3f"
# ### Validation Generator
# + _uuid="7925e16bcacc89f4484fb6fe47e54d6420af732e"
validation_datagen = ImageDataGenerator(rescale=1./255)
validation_generator = validation_datagen.flow_from_dataframe(
train_df,
TRAIN_PATH,
x_col='filename',
y_col='category',
target_size=(IMAGE_HEIGHT, IMAGE_WIDTH),
class_mode='binary',
batch_size=BATCH_SIZE
)
# + [markdown] _uuid="5cd8df64e794ed17de326b613a9819e7da977a0e"
# # Fit Model
# + _uuid="0836a4cc8aa0abf603e0f96573c0c4ff383ad56b"
##### CODE #####
# +
##### CODE #####
# -
results = model.evaluate(X_test, y_test)
print("test loss, test acc:", results)
# + [markdown] _uuid="1b76c0a9040bc0babf0a453e567e41e22f8a1e0e"
# # Virtualize Training
# + _uuid="79055f2dc3e2abb47bea758e0464c86ca42ab431"
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 12))
ax1.plot(history.history['loss'], color='b', label="Training loss")
ax1.plot(history.history['val_loss'], color='r', label="validation loss")
ax1.set_xticks(np.arange(1, EPOCHS, 1))
ax1.set_yticks(np.arange(0, 1, 0.1))
ax2.plot(history.history['accuracy'], color='b', label="Training accuracy")
ax2.plot(history.history['val_accuracy'], color='r',label="Validation accuracy")
ax2.set_xticks(np.arange(1, EPOCHS, 1))
legend = plt.legend(loc='best', shadow=True)
plt.tight_layout()
plt.show()
| 4-Machine_Learning/3-Deep Learning/2-Redes Neuronales Convolucionales/Dogs&Cats.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.8.3 ('base')
# language: python
# name: python3
# ---
from collections import Counter
import heapq
class Solution:
def topKFrequent(self, nums, k):
if len(nums) == k:
return nums
else:
x = Counter(nums)
heapq.heapify(nums)
return heapq.nlargest(k, x.keys(), key = x.get)
nums = [1,1,1,2,2,3]
k = 2
Solution().topKFrequent(nums,k)
nums = [1]
k = 1
Solution().topKFrequent(nums,k)
| 347topKelements.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.10.4 64-bit
# language: python
# name: python3
# ---
import os
import pathlib
import numpy as np
import cv2
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
# # Import the data
# checking directory as well counting content
L = 0
for dirpath, dirnames, filenames in os.walk("./Dataset_A"):
print(f"There are {len(dirnames)} directories and {len(filenames)} images in '{dirpath}'")
L = L + len(filenames)
data_dir = pathlib.Path("./Dataset_A/")
class_names = np.array(sorted([item.name for item in data_dir.glob('*')]))
print(class_names)
# # Functions for Preprocessing
EXAMPLE_IMG_PATH = "./Dataset_A/Covid/2edb88df42cab5e5fbc18b3965e0bd_jumbo.jpeg"
img1 = cv2.imread(EXAMPLE_IMG_PATH)
print(f"Image example shape: {img1.shape}")
plt.imshow(img1)
plt.title("Example image")
plt.axis("off")
plt.show()
# Grayscale
def rgb2gray(rgb_img):
output_img = cv2.cvtColor(rgb_img, cv2.COLOR_BGR2GRAY)
return output_img
# Scale to 0 to 1
def scale(image):
return image / 255
#resize
def resize_img(image, rows=224, cols=224):
return cv2.resize(image, dsize=(rows, cols), interpolation=cv2.INTER_CUBIC)
# resize the shape
def reshape(image, axis):
return np.expand_dims(image.mean(axis=axis), axis=1)
# Function to call other Preprocessing Functions
def preprocessed_img(input_img):
output_img = rgb2gray(input_img)
output_img = scale(output_img)
output_img = resize_img(output_img)
output_img = reshape(output_img, 1)
return output_img
# Image converted in array
preprocessed_img(img1)
# # Processing the whole dataset
# matrix containing L vectors of shape (224, 1)
mean_vector_matrix = np.zeros(shape=(L, 224, 1))
# Target vector containing the classes for L images
target_vector = np.zeros(shape=(L, 1))
# fill the matrix with normal class images. Class "1"
n = 0
for root, dirnames, filenames in os.walk("./Dataset_A/Normal"):
n_total = len(filenames)
for filename in filenames:
file_path = os.path.join(root, filename)
img = cv2.imread(file_path)
img = preprocessed_img(img)
mean_vector_matrix[n] = img
target_vector[n] = 1
if n % 20 == 0:
print(f"File {n} {filename}")
n = n + 1
# fill the matrix with covid class images. Class "0"
for root, dirnames, filenames in os.walk("./Dataset_A/Covid"):
n_total = len(filenames)
for filename in filenames:
file_path = os.path.join(root, filename)
img = cv2.imread(file_path)
img = preprocessed_img(img)
mean_vector_matrix[n] = img
target_vector[n] = 0
if n % 20 == 0:
print(f"File {n} {filename}")
n = n + 1
# # Train Test split
SEED = 0
x_train, x_test, y_train, y_test = train_test_split(mean_vector_matrix, target_vector, test_size=0.2, random_state=SEED)
tf.random.set_seed(SEED)
np.random.seed(SEED)
input_shape = x_train.shape
input_shape
#
#
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=64, activation='softmax', input_shape = input_shape),
tf.keras.layers.Dense(units=64, activation='softmax', input_shape = input_shape),
tf.keras.layers.Dense(units=64, activation='softmax', input_shape = input_shape),
tf.keras.layers.Dense(units=2, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer = 'adam',
metrics = ['accuracy']
)
history = model.fit(
x = x_train,
y = y_train,
epochs = 100
)
# +
plt.plot(history.history['accuracy'], label='accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
| covid_x-ray_by_rounak.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python [default]
# language: python
# name: python3
# ---
# %matplotlib inline
import os
files = os.listdir('/bigdata/all_trips.parquet/')
import fastparquet
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
len(files)
for f in files:
d = fastparquet.ParquetFile(os.path.join('/bigdata/all_trips.parquet/', f))
df = d.to_pandas(columns=['pickup_taxizone_id', 'pickup_datetime'])
df = df[df.pickup_datetime < '2016-07-01']
print("{} {}".format(f, df.shape[0]))
if 'alldf' in locals():
alldf = alldf.merge(df.groupby('pickup_taxizone_id').count()[['pickup_datetime']],
left_index=True, right_index=True, how='outer'
)
else:
alldf = df.groupby('pickup_taxizone_id').count()[['pickup_datetime']]
zz = pd.DataFrame(index=alldf.index,)
zz['N'] = np.nansum(alldf.values, axis=1)
zz['logN'] = np.log10(zz['N'])
import seaborn
seaborn.distplot(zz.logN.fillna(0), bins=np.arange(0, 7., 0.5), norm_hist=True)
# plt.xticks(np.linspace(0, 8, 17));
# plt.xlabel("Log10(Taxi Trips)")
# plt.ylabel("Frequency")
# plt.gcf().set_size_inches(8, 4)
import geopandas as gpd
import matplotlib.pyplot as plt
tz = gpd.read_file('../shapefiles/taxi_zones.shp')
tz = tz.merge(zz, left_on='LocationID', right_index=True)
tz.N.sum()
tz.plot(column='logN', cmap=plt.cm.viridis, linewidth=0.5, vmin=2, vmax=6.5)
plt.gcf().set_size_inches(12, 9)
z = tz
z = z[(z.borough != 'Staten Island')]
z = z[(z.borough != 'EWR')]
z.plot(column='logN', cmap=plt.cm.viridis, linewidth=0.5, vmin=2, vmax=6.5)
plt.gcf().set_size_inches(12, 9)
plt.tight_layout()
| 15_dataframe_analysis/attic/taxi_exploratory_chloropleth.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3 (ipykernel)
# language: python
# name: python3
# ---
# + [markdown] colab_type="text" id="ZL_6GK8qX35J"
#
#
# # Week 1: Multiple Output Models using the Keras Functional API
#
# Welcome to the first programming assignment of the course! Your task will be to use the Keras functional API to train a model to predict two outputs. For this lab, you will use the **[Wine Quality Dataset](https://archive.ics.uci.edu/ml/datasets/Wine+Quality)** from the **UCI machine learning repository**. It has separate datasets for red wine and white wine.
#
# Normally, the wines are classified into one of the quality ratings specified in the attributes. In this exercise, you will combine the two datasets to predict the wine quality and whether the wine is red or white solely from the attributes.
#
# You will model wine quality estimations as a regression problem and wine type detection as a binary classification problem.
#
# #### Please complete sections that are marked **(TODO)**
# + [markdown] colab_type="text" id="obdcD6urYBY9"
# ## Imports
# + colab={} colab_type="code" id="t8N3pcTQ5oQI"
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import itertools
import utils
# + [markdown] colab_type="text" id="gQMERzWQYpgm"
# ## Load Dataset
#
#
# You will now load the dataset from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/index.php) which are already saved in your workspace.
#
# ### Pre-process the white wine dataset (TODO)
# You will add a new column named `is_red` in your dataframe to indicate if the wine is white or red.
# - In the white wine dataset, you will fill the column `is_red` with zeros (0).
# + colab={} colab_type="code" deletable=false id="2qYAjKXCd4RH" nbgrader={"cell_type": "code", "checksum": "325ea195519b7035934c95bb529a062c", "grade": false, "grade_id": "cell-e5bfa0f152d9a21f", "locked": false, "schema_version": 3, "solution": true, "task": false}
## Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
## You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
# URL of the white wine dataset
URI = './winequality-white.csv'
# load the dataset from the URL
white_df = pd.read_csv(URI, sep=";")
# fill the `is_red` column with zeros.
white_df["is_red"] = 0
# keep only the first of duplicate items
white_df = white_df.drop_duplicates(keep='first')
# -
white_df.head()
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "defe38d6ec58fd31cd67b89e46c4373f", "grade": true, "grade_id": "cell-30575e713b55fc51", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
# You can click `File -> Open` in the menu above and open the `utils.py` file
# in case you want to inspect the unit tests being used for each graded function.
utils.test_white_df(white_df)
# + colab={} colab_type="code" id="OQHK0ohBQRCk"
print(white_df.alcohol[0])
print(white_df.alcohol[100])
# EXPECTED OUTPUT
# 8.8
# 9.1
# -
# ### Pre-process the red wine dataset (TODO)
# - In the red wine dataset, you will fill in the column `is_red` with ones (1).
# + colab={} colab_type="code" deletable=false id="8y3QxKwBed8v" nbgrader={"cell_type": "code", "checksum": "12e0963d15be33b01b4e6ebc8945e51e", "grade": false, "grade_id": "cell-e47a40f306593274", "locked": false, "schema_version": 3, "solution": true, "task": false}
## Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
## You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
# URL of the red wine dataset
URI = './winequality-red.csv'
# load the dataset from the URL
red_df = pd.read_csv(URI, sep=";")
# fill the `is_red` column with ones.
red_df["is_red"] = 1
# keep only the first of duplicate items
red_df = red_df.drop_duplicates(keep='first')
# -
red_df.head()
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "d8e0c91b0fd668b63ba74a8f2f958b59", "grade": true, "grade_id": "cell-2a75937adcc0c25b", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_red_df(red_df)
# + colab={} colab_type="code" id="zsB3LUzNQpo_"
print(red_df.alcohol[0])
print(red_df.alcohol[100])
# EXPECTED OUTPUT
# 9.4
# 10.2
# + [markdown] colab_type="text" id="2G8B-NYuM6-f"
# ### Concatenate the datasets
#
# Next, concatenate the red and white wine dataframes.
# + colab={} colab_type="code" id="YpQrOjJbfN3m"
df = pd.concat([red_df, white_df], ignore_index=True)
# + colab={} colab_type="code" id="Se2dTmThQyjb"
print(df.alcohol[0])
print(df.alcohol[100])
# EXPECTED OUTPUT
# 9.4
# 9.5
# -
# In a real-world scenario, you should shuffle the data. For this assignment however, **you are not** going to do that because the grader needs to test with deterministic data. If you want the code to do it **after** you've gotten your grade for this notebook, we left the commented line below for reference
# + colab={} colab_type="code" id="wx6y3rPpQv4k"
#df = df.iloc[np.random.permutation(len(df))]
# + [markdown] colab_type="text" id="-EqIcbg5M_n1"
# This will chart the quality of the wines.
# + colab={} colab_type="code" id="IsvK0-Sgy17C"
df['quality'].hist(bins=20);
# + [markdown] colab_type="text" id="Nut1rmYLzf-p"
# ### Imbalanced data (TODO)
# You can see from the plot above that the wine quality dataset is imbalanced.
# - Since there are very few observations with quality equal to 3, 4, 8 and 9, you can drop these observations from your dataset.
# - You can do this by removing data belonging to all classes except those > 4 and < 8.
# + colab={} colab_type="code" deletable=false id="doH9_-gnf3sz" nbgrader={"cell_type": "code", "checksum": "d9ba9fc3a3ca02ccc567be33652b80fe", "grade": false, "grade_id": "cell-6a3e9db696f6827b", "locked": false, "schema_version": 3, "solution": true, "task": false}
## Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
## You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
# get data with wine quality greater than 4 and less than 8
df = df[(df['quality'] > 4) & (df['quality'] < 8 )]
# reset index and drop the old one
df = df.reset_index(drop=True)
# -
df.head()
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "281e1d86a4803560ed5892cd7eda4c01", "grade": true, "grade_id": "cell-aed3da719d4682c7", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_df_drop(df)
# + colab={} colab_type="code" id="xNR1iAlMRPXO"
print(df.alcohol[0])
print(df.alcohol[100])
# EXPECTED OUTPUT
# 9.4
# 10.9
# + [markdown] colab_type="text" id="cwhuRpnVRTzG"
# You can plot again to see the new range of data and quality
# + colab={} colab_type="code" id="857ygzZiLgGg"
df['quality'].hist(bins=20);
# + [markdown] colab_type="text" id="n3k0vqSsp84t"
# ### Train Test Split (TODO)
#
# Next, you can split the datasets into training, test and validation datasets.
# - The data frame should be split 80:20 into `train` and `test` sets.
# - The resulting `train` should then be split 80:20 into `train` and `val` sets.
# - The `train_test_split` parameter `test_size` takes a float value that ranges between 0. and 1, and represents the proportion of the dataset that is allocated to the test set. The rest of the data is allocated to the training set.
# + colab={} colab_type="code" deletable=false id="PAVIf2-fgRVY" nbgrader={"cell_type": "code", "checksum": "7f5738f4fb51d65adc9a8acbdf2b9970", "grade": false, "grade_id": "cell-91946cadf745206b", "locked": false, "schema_version": 3, "solution": true, "task": false}
## Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
## You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
# Please do not change the random_state parameter. This is needed for grading.
# split df into 80:20 train and test sets
train, test = train_test_split(df, test_size=0.2, random_state = 1)
# split train into 80:20 train and val sets
train, val = train_test_split(train, test_size=0.2, random_state = 1)
# -
len(train), len(val), len(test)
# + colab={} colab_type="code" deletable=false editable=false id="57h9LcEzRWpk" nbgrader={"cell_type": "code", "checksum": "42adbe9e66efac7c7a5f8cd73ac92f22", "grade": true, "grade_id": "cell-64b8b38cd0b965f6", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_data_sizes(train.size, test.size, val.size)
# + [markdown] colab_type="text" id="RwTNu4KFqG-K"
# Here's where you can explore the training stats. You can pop the labels 'is_red' and 'quality' from the data as these will be used as the labels
#
# + colab={} colab_type="code" id="Y_afyhhHM6WQ"
train_stats = train.describe()
train_stats.pop('is_red')
train_stats.pop('quality')
train_stats = train_stats.transpose()
# + [markdown] colab_type="text" id="ahvbYm4fNqSt"
# Explore the training stats!
# + colab={} colab_type="code" id="n_gAtPjZ0otF"
train_stats
# + [markdown] colab_type="text" id="bGPvt9jir_HC"
# ### Get the labels (TODO)
#
# The features and labels are currently in the same dataframe.
# - You will want to store the label columns `is_red` and `quality` separately from the feature columns.
# - The following function, `format_output`, gets these two columns from the dataframe (it's given to you).
# - `format_output` also formats the data into numpy arrays.
# - Please use the `format_output` and apply it to the `train`, `val` and `test` sets to get dataframes for the labels.
# + colab={} colab_type="code" id="Z_fs14XQqZVP"
def format_output(data):
is_red = data.pop('is_red')
is_red = np.array(is_red)
quality = data.pop('quality')
quality = np.array(quality)
return (quality, is_red)
# + colab={} colab_type="code" deletable=false id="8L3ZZe1fQicm" nbgrader={"cell_type": "code", "checksum": "7a86809e54895a816434c48dc903f55d", "grade": false, "grade_id": "cell-5c30fa2c2a354b0f", "locked": false, "schema_version": 3, "solution": true, "task": false}
## Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
## You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
# format the output of the train set
train_Y = format_output(train)
# format the output of the val set
val_Y = format_output(val)
# format the output of the test set
test_Y = format_output(test)
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "359cabbafaed14ec9bbc1e57a7b6f32c", "grade": true, "grade_id": "cell-4977d8befb80f56b", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_format_output(df, train_Y, val_Y, test_Y)
# -
# Notice that after you get the labels, the `train`, `val` and `test` dataframes no longer contain the label columns, and contain just the feature columns.
# - This is because you used `.pop` in the `format_output` function.
train.head()
# + [markdown] colab_type="text" id="hEdbrruAsN1D"
# ### Normalize the data (TODO)
#
# Next, you can normalize the data, x, using the formula:
# $$x_{norm} = \frac{x - \mu}{\sigma}$$
# - The `norm` function is defined for you.
# - Please apply the `norm` function to normalize the dataframes that contains the feature columns of `train`, `val` and `test` sets.
# + colab={} colab_type="code" id="WWiZPAHCLjUs"
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
# + colab={} colab_type="code" deletable=false id="JEaOi2I2Lk69" nbgrader={"cell_type": "code", "checksum": "6bc0cdcb563d192f271067aa3373ff32", "grade": false, "grade_id": "cell-d8416d975c371095", "locked": false, "schema_version": 3, "solution": true, "task": false}
# Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
# You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
# normalize the train set
norm_train_X = norm(train)
# normalize the val set
norm_val_X = norm(val)
# normalize the test set
norm_test_X = norm(test)
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "4f567db45bf40191601780379cc100b8", "grade": true, "grade_id": "cell-97fad979d157529b", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_norm(norm_train_X, norm_val_X, norm_test_X, train, val, test)
# + [markdown] colab_type="text" id="hzykDwQhsaPO"
# ## Define the Model (TODO)
#
# Define the model using the functional API. The base model will be 2 `Dense` layers of 128 neurons each, and have the `'relu'` activation.
# - Check out the documentation for [tf.keras.layers.Dense](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Dense)
# + colab={} colab_type="code" deletable=false id="Rhcns3oTFkM6" nbgrader={"cell_type": "code", "checksum": "74b031247e569526552bf13a034a1c07", "grade": false, "grade_id": "cell-73fceedad1fe351c", "locked": false, "schema_version": 3, "solution": true, "task": false}
## Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
## You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
def base_model(inputs):
# connect a Dense layer with 128 neurons and a relu activation
x = Dense(units=128, activation='relu')(inputs)
# connect another Dense layer with 128 neurons and a relu activation
x = Dense(units=128, activation='relu')(x)
return x
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "9255924b3def80f679616e4c851a43e1", "grade": true, "grade_id": "cell-54f742a133353d75", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_base_model(base_model)
# + [markdown] colab_type="text" id="xem_fcVws6Kz"
# # Define output layers of the model (TODO)
#
# You will add output layers to the base model.
# - The model will need two outputs.
#
# One output layer will predict wine quality, which is a numeric value.
# - Define a `Dense` layer with 1 neuron.
# - Since this is a regression output, the activation can be left as its default value `None`.
#
# The other output layer will predict the wine type, which is either red `1` or not red `0` (white).
# - Define a `Dense` layer with 1 neuron.
# - Since there are two possible categories, you can use a sigmoid activation for binary classification.
#
# Define the `Model`
# - Define the `Model` object, and set the following parameters:
# - `inputs`: pass in the inputs to the model as a list.
# - `outputs`: pass in a list of the outputs that you just defined: wine quality, then wine type.
# - **Note**: please list the wine quality before wine type in the outputs, as this will affect the calculated loss if you choose the other order.
# + colab={} colab_type="code" deletable=false id="n5UGF8PMVLPt" nbgrader={"cell_type": "code", "checksum": "76d35b90d20cdcbb22986cd8211057de", "grade": false, "grade_id": "cell-19e285f482f021fb", "locked": false, "schema_version": 3, "solution": true, "task": false}
## Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
## You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
def final_model(inputs):
# get the base model
x = base_model(inputs)
# connect the output Dense layer for regression
wine_quality = Dense(units='1', name='wine_quality')(x)
# connect the output Dense layer for classification. this will use a sigmoid activation.
wine_type = Dense(units='1', activation='sigmoid', name='wine_type')(x)
# define the model using the input and output layers
model = Model(inputs=inputs, outputs=[wine_quality, wine_type])
return model
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "89cbf89d8ab5e2e59ecf7f63f517520a", "grade": true, "grade_id": "cell-40d050f855c817d1", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_final_model(final_model)
# + [markdown] colab_type="text" id="5R0BMTsltZyu"
# ## Compiling the Model
#
# Next, compile the model. When setting the loss parameter of `model.compile`, you're setting the loss for each of the two outputs (wine quality and wine type).
#
# To set more than one loss, use a dictionary of key-value pairs.
# - You can look at the docs for the losses [here](https://www.tensorflow.org/api_docs/python/tf/keras/losses#functions).
# - **Note**: For the desired spelling, please look at the "Functions" section of the documentation and not the "classes" section on that same page.
# - wine_type: Since you will be performing binary classification on wine type, you should use the binary crossentropy loss function for it. Please pass this in as a string.
# - **Hint**, this should be all lowercase. In the documentation, you'll see this under the "Functions" section, not the "Classes" section.
# - wine_quality: since this is a regression output, use the mean squared error. Please pass it in as a string, all lowercase.
# - **Hint**: You may notice that there are two aliases for mean squared error. Please use the shorter name.
#
#
# You will also set the metric for each of the two outputs. Again, to set metrics for two or more outputs, use a dictionary with key value pairs.
# - The metrics documentation is linked [here](https://www.tensorflow.org/api_docs/python/tf/keras/metrics).
# - For the wine type, please set it to accuracy as a string, all lowercase.
# - For wine quality, please use the root mean squared error. Instead of a string, you'll set it to an instance of the class [RootMeanSquaredError](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/RootMeanSquaredError), which belongs to the tf.keras.metrics module.
#
# **Note**: If you see the error message
# >Exception: wine quality loss function is incorrect.
#
# - Please also check your other losses and metrics, as the error may be caused by the other three key-value pairs and not the wine quality loss.
# + colab={} colab_type="code" deletable=false id="LK11duUbUjmh" nbgrader={"cell_type": "code", "checksum": "22f45067ca69eb2ccadb43874dbcc27b", "grade": false, "grade_id": "cell-81afdc4dcca51d5e", "locked": false, "schema_version": 3, "solution": true, "task": false}
# Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
# You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
inputs = tf.keras.layers.Input(shape=(11,))
rms = tf.keras.optimizers.RMSprop(lr=0.0001)
model = final_model(inputs)
model.compile(optimizer=rms,
loss = {'wine_type' : 'binary_crossentropy',
'wine_quality' : 'mse'
},
metrics = {'wine_type' : 'accuracy',
'wine_quality': tf.keras.metrics.RootMeanSquaredError()
}
)
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "88e02238ea5e456ff65e835cc8158054", "grade": true, "grade_id": "cell-2eeeba02391c4632", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_model_compile(model)
# + [markdown] colab_type="text" id="90MpAMpWuKm-"
# ## Training the Model
#
# Fit the model to the training inputs and outputs.
# - Check the documentation for [model.fit](https://www.tensorflow.org/api_docs/python/tf/keras/Model#fit).
# - Remember to use the normalized training set as inputs.
# - For the validation data, please use the normalized validation set.
# + colab={} colab_type="code" deletable=false id="_eiZkle4XwiY" nbgrader={"cell_type": "code", "checksum": "2ca7664be03bfd6fd3651ae44d17b793", "grade": false, "grade_id": "cell-0bb56262896f6680", "locked": false, "schema_version": 3, "solution": true, "task": false}
# Please uncomment all lines in this cell and replace those marked with `# YOUR CODE HERE`.
# You can select all lines in this code cell with Ctrl+A (Windows/Linux) or Cmd+A (Mac), then press Ctrl+/ (Windows/Linux) or Cmd+/ (Mac) to uncomment.
history = model.fit(norm_train_X, train_Y,
epochs = 180, validation_data=(norm_val_X, val_Y))
# + deletable=false editable=false nbgrader={"cell_type": "code", "checksum": "fadad8896eda9c8c2115970724b15508", "grade": true, "grade_id": "cell-eb4d5b41bef8f0ab", "locked": true, "points": 1, "schema_version": 3, "solution": false, "task": false}
utils.test_history(history)
# -
history.history.keys()
# + colab={} colab_type="code" id="CubF2J2gSf6q"
# Gather the training metrics
loss, wine_quality_loss, wine_type_loss, wine_quality_rmse, wine_type_accuracy = model.evaluate(x=norm_val_X, y=val_Y)
print()
print(f'loss: {loss}')
print(f'wine_quality_loss: {wine_quality_loss}')
print(f'wine_type_loss: {wine_type_loss}')
print(f'wine_quality_rmse: {wine_quality_rmse}')
print(f'wine_type_accuracy: {wine_type_accuracy}')
# EXPECTED VALUES
# ~ 0.30 - 0.38
# ~ 0.30 - 0.38
# ~ 0.018 - 0.030
# ~ 0.50 - 0.62
# ~ 0.97 - 1.0
# Example:
#0.3657050132751465
#0.3463745415210724
#0.019330406561493874
#0.5885359048843384
#0.9974651336669922
# + [markdown] colab_type="text" id="gPtTGAP4usnm"
# ## Analyze the Model Performance
#
# Note that the model has two outputs. The output at index 0 is quality and index 1 is wine type
#
# So, round the quality predictions to the nearest integer.
# + colab={} colab_type="code" id="tBq9PEeAaW-Y"
predictions = model.predict(norm_test_X)
quality_pred = predictions[0]
type_pred = predictions[1]
# + colab={} colab_type="code" id="YLhgTR4xTIxj"
print(quality_pred[0])
# EXPECTED OUTPUT
# 5.6 - 6.0
# + colab={} colab_type="code" id="MPi-eYfGTUXi"
print(type_pred[0])
print(type_pred[944])
# EXPECTED OUTPUT
# A number close to zero
# A number close to or equal to 1
# + [markdown] colab_type="text" id="Kohk-9C6vt_s"
# ### Plot Utilities
#
# We define a few utilities to visualize the model performance.
# + colab={} colab_type="code" id="62gEOFUhn6aQ"
def plot_metrics(metric_name, title, ylim=5):
plt.title(title)
plt.ylim(0,ylim)
plt.plot(history.history[metric_name],color='blue',label=metric_name)
plt.plot(history.history['val_' + metric_name],color='green',label='val_' + metric_name)
# + colab={} colab_type="code" id="6rfgSx7uz5dj"
def plot_confusion_matrix(y_true, y_pred, title='', labels=[0,1]):
cm = confusion_matrix(y_true, y_pred)
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm)
plt.title('Confusion matrix of the classifier')
fig.colorbar(cax)
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
fmt = 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="black" if cm[i, j] > thresh else "white")
plt.show()
# + colab={} colab_type="code" id="dfVLIqi017Vf"
def plot_diff(y_true, y_pred, title = '' ):
plt.scatter(y_true, y_pred)
plt.title(title)
plt.xlabel('True Values')
plt.ylabel('Predictions')
plt.axis('equal')
plt.axis('square')
plt.plot([-100, 100], [-100, 100])
return plt
# + [markdown] colab_type="text" id="8sd1jdFbwE0I"
# ### Plots for Metrics
# + colab={} colab_type="code" id="f3MwZ5J1pOfj"
plot_metrics('wine_quality_root_mean_squared_error', 'RMSE', ylim=2)
# + colab={} colab_type="code" id="QIAxEezCppnd"
plot_metrics('wine_type_loss', 'Wine Type Loss', ylim=0.2)
# + [markdown] colab_type="text" id="uYV9AOAMwI9p"
# ### Plots for Confusion Matrix
#
# Plot the confusion matrices for wine type. You can see that the model performs well for prediction of wine type from the confusion matrix and the loss metrics.
# + colab={} colab_type="code" id="C3hvTYxIaf3n"
plot_confusion_matrix(test_Y[1], np.round(type_pred), title='Wine Type', labels = [0, 1])
# + colab={} colab_type="code" id="GW91ym8P2I5y"
scatter_plot = plot_diff(test_Y[0], quality_pred, title='Type')
| Course-1 Custom Models, Layers and Loss Functions/Week-1/C1W1_Assignment.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# # BrainAge Project
import pandas as pd
import numpy as np
import nibabel as nib
from sklearn.model_selection import KFold
from sklearn.svm import SVR
svr = SVR(kernel='rbf')
from sklearn.feature_selection import VarianceThreshold, SelectKBest, f_regression
# +
# Load age
df = pd.read_csv('participants.tsv', sep='\t')
# Load IQ
y_age = []
for i in subj:
a = df.loc[df['participant_id'] == 'sub-'+i] #whole row
y.append(int(a.age))
y_
# -
df
# +
subj = ['10159', '10171', '10189', '10193']
# -
d = {}
for i in range(len(subj)):
img = nib.load('sub-'+subj[i]+'_anat_sub-'+subj[i]+'_T1w.nii.gz').get_fdata()
d[subj[i]] = img
d.keys()
d.get('10159').shape
# +
X = []
for i in d.values():
flattened = i.flatten()
X.append(flattened)
X = np.array(X)
# +
# from sklearn.model_selection import train_test_split
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# -
# ## Models
# * Support vector regressor
# * Linear Regression
#
# ## Feature selection
# * ANOVA
# *
# +
svr = SVR(kernel='linear')
# Remove features with too low between-subject variance
variance_threshold = VarianceThreshold(threshold=.01)
# Here we use a classical univariate feature selection based on F-test,
# namely Anova.
feature_selection = SelectKBest(f_regression, k=2000)
# We have our predictor (SVR), our feature selection (SelectKBest), and now,
# we can plug them together in a *pipeline* that performs the two operations
# successively:
from sklearn.pipeline import Pipeline
anova_svr = Pipeline([
('variance_threshold', variance_threshold),
('anova', feature_selection),
('svr', svr)])
### Fit and predict
kf = KFold(n_splits=5)
kf.get_n_splits(X)
for train_index, test_index in kf.split(X):
# print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
anova_svr.fit(X_train, y_train)
# -
age_pred = anova_svr.predict(X_test)
ytest
X[:2000]
| validation_models.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 2
# language: python
# name: python2
# ---
# +
# %load_ext autoreload
# %autoreload
import sys
from os import path
sys.path.append(path.dirname(path.dirname(sys.path[1])))
from arch.MnistConvNet import MnistConvNet
from arch.sensitivity.GDNet import GDNet, AdditiveGDNet
from arch.sensitivity.BDNet import BDNet
from exp.loaddata_utils import load_mnist_one_image
import torch
from torch.autograd import Variable
import exp.utils_visualise as utils_visualise
import os
import numpy as np
import torch.nn.functional as F
import matplotlib.pyplot as plt
import mnist_compare_utils
# +
# # %load parse_args_mnist
import argparse
import torch
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--dropout', type=str, default='gauss',
help='choose from ["gauss", "bern", "add_gauss"]')
parser.add_argument('--batch-size', type=int, default=256, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--estop_num', type=int, default=-1,
help='early stopping at which number of alpha. Default as None')
parser.add_argument('--clip_max', type=int, default=100,
help='Clip at which number')
parser.add_argument('--vis_method', type=str, default='log_alpha',
help='By loss or log_alpha')
parser.add_argument('--epochs', type=int, default=1000, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--ard_init', type=float, default=-6.,
help='ARD initialization')
parser.add_argument('--reg-coef', type=float, default=0.01,
help='regularization coefficient')
parser.add_argument('--no-cuda', action='store_false', default=True,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--epoch-print', type=int, default=10,
help='how many epochs to wait before logging training status')
parser.add_argument('--edge', type=int, default=4,
help='Output edge*edge grid of images samples')
parser.add_argument('--save-dir', type=str, default='figs/',
help='Save directory')
parser.add_argument('--save-tag', type=str, default='0721-gauss',
help='Unique tag for output images')
args, _ = parser.parse_known_args()
torch.manual_seed(args.seed)
args.cuda = not args.no_cuda and torch.cuda.is_available()
print 'cuda:', args.cuda
# -
# ## Test Gaussian dropout and get aupr
# +
input_size = (28, 28)
trained_classifier = torch.load('../../arch/pretrained/mnist.model')
net = GDNet(input_size, trained_classifier, ard_init=args.ard_init,
lr=args.lr, reg_coef=args.reg_coef, rw_max=30, cuda_enabled=args.cuda,
estop_num=args.estop_num, clip_max=args.clip_max,
)
# -
img_loader = load_mnist_one_image(img_index=None, batch_size=args.batch_size, cuda=args.cuda)
net.fit(img_loader, epochs=args.epochs, epoch_print=args.epoch_print)
# +
rank = net.get_param().data
images, labels = iter(img_loader).next()
def plot_the_img(img, cmap='gray'):
im = plt.imshow(img, cmap=cmap, interpolation='nearest')
plt.colorbar(im)
plt.show()
plot_the_img(rank.numpy())
plot_the_img(images[0, 0, ...].numpy(), cmap='gray')
# +
reload(mnist_compare_utils)
# Take out one mnist image and unnormalize it
logodds = mnist_compare_utils.calculate_logodds_diff_by_flipping(
trained_classifier, images[0, ...], labels[0], rank, flip_val=(-0.1307 / 0.3081))
# -
logodds
def plot_results(img1, img2, img1_title, img2_title):
fig = plt.figure()
ax1 = fig.add_subplot(121)
im = ax1.imshow(img1, cmap='gray', interpolation='nearest')
plt.colorbar(im)
plt.title(img1_title)
ax2 = fig.add_subplot(122)
im2 = ax2.imshow(img2, cmap='gray', interpolation='nearest')
plt.colorbar(im2)
plt.title(img2_title)
# filename = '%s/%s_debug.png' % (args.save_dir, args.save_tag)
plt.show()
# plt.savefig(filename, dpi=300)
# plt.close()
# +
orig_img = images[0, 0, ...].numpy()
plot_results(orig_img, flip_img, str(orig_log_odd), str(flip_log_odd))
# -
| exp/mnist-compare/notebooks/0725 - Remove pixels in mnist for GD.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.6.9 64-bit
# metadata:
# interpreter:
# hash: 767d51c1340bd893661ea55ea3124f6de3c7a262a8b4abca0554b478b1e2ff90
# name: python3
# ---
# # Calculate and plot the number of exchanged messages over time
# + tags=[]
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# -
# ## Global variables
# +
pd.set_option("display.precision", 5)
pd.set_option('display.max_rows', 500)
timeframe_upper_limit = 60 # Seconds after startup that you want to look at
# -
# ### Add path to the dict, use number of nodes as key
# It will:
# - collect all runs
# - use the key as groupby-column
# +
paths = {
# "111": "../../logs/maintenance/25-03-2021",
"73": "../../logs/maintenance/29-03-2021"
}
exclude_paths = ["faulty"]
num_nodes = 73
height = 2
degree = 8
num_runs = {
73: 3,
111: 5
}
# + tags=[]
# m_xxx = maintenance_xxx
# d_xxx = data_xxx
m_stamps = []
m_topologies = []
m_node_ids = []
m_runs = []
d_stamps = []
d_topologies = []
d_node_ids = []
d_runs = []
d_latencies = []
startup_times = {}
for path in paths :
#print(path)
for root, dirs, files in os.walk(paths[path]) :
dirs[:] = [directory for directory in dirs if directory not in exclude_paths]
# print(root)
# print(dirs)
# print(files)
run = root.split('_')[-1]
for file in files :
with open( os.path.join(root, file) ) as log :
node_id = file.split('_')[0][4:]
for line in log :
if "DATA RECEIVED" in line:
# data messages
elem = line.split( )
d_node_ids.append(int(node_id))
d_stamps.append( int(elem[8]) ) # unix timestamp
d_topologies.append( int(path) )
d_runs.append(int(run))
d_latencies.append(int(1000000*float(elem[-1])))
elif "STARTUP TIME" in line:
elem = line.split( )
startup_times[int(run)] = int(elem[-1])
d_data = pd.DataFrame(np.column_stack([d_topologies, d_runs, d_node_ids, d_latencies, d_stamps]),
columns=['topology', 'run', 'node_id', 'latency_micros','timestamp'])
# print(startup_time)
d_data
# + tags=[]
d_data['timestamp'] = d_data.apply(lambda row: row.timestamp - startup_times[row.run], axis=1)
d_data['timestamp_sec'] = d_data['timestamp'].apply(lambda x: x // 1000000000)
d_data
# -
# # Reduce timeframe
d_data = d_data[d_data.timestamp_sec <= timeframe_upper_limit]
d_data
# # Try to find outliers
d_outliers = d_data.groupby(['topology', 'run', 'node_id', 'timestamp_sec']).size().reset_index(name='number of messages').sort_values(by=['number of messages'], ascending=False, axis=0)
# d_outliers
# # Compute results
d_grouped = d_data.groupby(['topology', 'timestamp_sec']).size().reset_index(name='number of messages')
d_grouped['number of messages'] = d_grouped.apply(lambda row: row['number of messages'] / num_runs[row['topology']], axis=1)
d_grouped['number of messages per node'] = d_grouped.apply(lambda row: row['number of messages'] / row['topology'], axis=1)
d_grouped.head()
d_grouped = d_grouped[d_grouped['timestamp_sec'] >= 0]
# # Throughput
# +
ax = plt.gca()
d_grouped.plot(kind='line',x='timestamp_sec',y='number of messages',ax=ax)
plt.xlabel("[s] since startup")
plt.ylabel("Throughput at root per [s]")
plt.legend([str(num_nodes) +' nodes, ' + str(num_runs[num_nodes]) + ' runs, h=' + str(height) + ', d=' + str(degree)], loc=1)
stepsize=10
ax.xaxis.set_ticks(np.arange(0, timeframe_upper_limit + 1, stepsize))
plt.savefig('throughput-paper.pdf')
# +
first_30 = d_grouped[d_grouped['timestamp_sec'] <= 10]['number of messages'].sum()
first_60 = d_grouped[d_grouped['timestamp_sec'] <= 50]['number of messages'].sum()
f_30_55 = d_grouped[(d_grouped['timestamp_sec'] >= 35) & (d_grouped['timestamp_sec'] <= 55)]['number of messages'].sum()
print('Overall exchanged data within first 10s: ' + str(first_30))
print('Overall exchanged data within first 55s: ' + str(first_60))
print('Overall exchanged data between 10s and 55s: ' + str(f_30_55))
print('Exchanged data between 10s and 55s per second per node: ' + str(f_30_55 / (21*(100))))
print('\nOverall exchanged data messages during first 10 per node: ' + str(first_30 / num_nodes))
# -
# # Latency
d_latency = d_data.groupby(['topology', 'timestamp_sec'], as_index=False)['latency_micros'].mean()
d_latency['latency_micros'] = d_latency['latency_micros'] / 1000
d_latency.rename(columns = {'latency_micros':'latency_millis'}, inplace=True)
d_latency.head()
d_latency = d_latency[d_latency['timestamp_sec'] >= 0]
# +
ax = plt.gca()
d_latency.plot(kind='line',x='timestamp_sec',y='latency_millis',ax=ax)
plt.xlabel("[s] since startup")
plt.ylabel("Mean source-to-sink latency in [ms]")
plt.legend([str(num_nodes) +' nodes, ' + str(num_runs[num_nodes]) + ' runs, h=' + str(height) + ', d=' + str(degree)], loc=1)
stepsize=5
ax.xaxis.set_ticks(np.arange(0, timeframe_upper_limit + 1, stepsize))
plt.savefig('latency-paper.pdf')
# -
| benchmarks/notebooks/throughput+latency/throughput_latency-paper.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3.9.2 64-bit
# metadata:
# interpreter:
# hash: 8a9165a38afef2ca63a793efc4b24bbf7f99f4e695b0f158539651a5958eadc2
# name: python3
# ---
# # Calling in Parallel Vua Shell
#
# By <NAME>
# 3/13/2022
#
# ## Description:
# You may find yourself wanting to run a process in parallel (i.e. multiple processes running simultaneously) via the native shell (or zshell) native to your computational environment. This snippet provides an example of how to do so without the use of any non-generic packages or functions. This can enable you to make full use of the compute resources available without the additional overhead of installing other tools. The process can be divided into 3 main steps: 1) establishing the resource pool available to use, 2) defining a function to run in parallel if there are multiple components of a process that need to be run for each iteration, and 3) calling the function in parallel. This snippet will go through each process with an example which callas a python script using variables in nested for loops.
#
# ## Notes and Qualifiers:
# This code has been written and tested in BASH on native linux installations (OpenSUSE) and on Ubuntu for Windows (20.04.2 using WSL 2).
#
# ## 1) Evaluate Resource Pool
# Before you run anyting in parallel, you should first establish how many CPU threads ara avialble for use. The following command will give you details about the CPUs on the current machine. In this case, 12 is the nu,ber we are looking for (line 5):
# +
lscpu
#1 Architecture: x86_64
#2 CPU op-mode(s): 32-bit, 64-bit
#3 Byte Order: Little Endian
#4 Address sizes: 48 bits physical, 48 bits virtual
#5 CPU(s): 12
# On-line CPU(s) list: 0-11
# Thread(s) per core: 2
# Core(s) per socket: 6
# Socket(s): 1
# Vendor ID: AuthenticAMD
# CPU family: 23
# Model: 8
# Model name: AMD Ryzen 5 2600X Six-Core Processor
# Stepping: 2
# CPU MHz: 3600.265
# BogoMIPS: 7200.53
# Hypervisor vendor: Microsoft
# Virtualization type: full
# L1d cache: 192 KiB
# L1i cache: 384 KiB
# L2 cache: 3 MiB
# L3 cache: 8 MiB
# Vulnerability Itlb multihit: Not affected
# Vulnerability L1tf: Not affected
# Vulnerability Mds: Not affected
# Vulnerability Meltdown: Not affected
# Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
# Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
# Vulnerability Spectre v2: Mitigation; Full generic retpoline, IBPB conditional, STIBP disabled, RSB filling
# Vulnerability Srbds: Not affected
# Vulnerability Tsx async abort: Not affected
# Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxs
# r sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm rep_good nopl cpuid extd_api
# cid pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand h
# ypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw topoex
# t ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsav
# eopt xsavec xgetbv1 xsaves clzero xsaveerptr virt_ssbd arat
# -
# Always make sure you will not cause problems for other users by checking to see if anyone else is currenlty using the same machine. You can do this and learn more about the current memory and thread availability using either of the following commands. This will give you an active diplay of the processes currently running on the machine, including CPU and memory usage and runtime. Use q to exit the top display.
top
# or
htop
# ## 2) Defining your function
# Now that you know what you have to work with, you need to set up a function to run in parallel. The following function takes three arguements (subject, time, and run, in that order). It then uses these arguements to call a python function (nifty2numpy_parcellation.py). First, lets start by instantiating some global constant variables.
OUTDIR2=/mnt/usb1/HCP_1200_ICA-AROMA
TIME=tfMRI_MOTOR
# We need a list of subjects to iterate through. The following command creates a list out of each folder in the directory we assigned to OUTDIR2
SUBLIST=$(ls $OUTDIR2)
# Now assign the number of threads to use as a variable, leaving some for other processes.
N=10
# The following script creates a function. This function will take assign the first argument after the function call and assign it to the *subject* variable fot that function run. The *time* and *run* variables are assigned on a per-run basis in the same way using arguments *2* and *3*.
parcellate(){
# Use $ fllowed by a number to take an arguement passed to the function and assign it to a variable
local subject=$1
local time=$2
local run=$3
# This prints the target path to the terminal so we know which image we are targetting. In the event that re run into an error, we can check this against the true path as a way to check if the path is correct
echo ${OUTDIR2}/${subject}/MNINonLinear/Results/${time}_${run}/${time}_${run}-AROMA-denoised-nonsmoothed.nii.gz
python3 nifty2numpy_parcellation.py \
-input ${OUTDIR2}/${subject}/MNINonLinear/Results/${time}_${run}/${time}_${run}-AROMA-denoised-nonsmoothed.nii.gz \
-atlas Schaefer2018_200Parcels_7Networks_order_FSLMNI152_2mm \
--metadata /mnt/usb1/Code/MSC_HCP/
}
# ## 3) Calling in parallel
# Then, we can iterate through the subjects in *SUBLIST* and the runs within each subject using nested for loops.
for SUBJECT in $SUBLIST; do
for RUN in RL LR; do
# First we call the function for a SUBJECT, RUN to start one process.
parcellate "$SUBJECT" "$TIME" "$RUN" &
# Then we check to see if the number of processes we have running matches the $N value that we set
if [[ $(jobs -r -p | wc -l) -ge $N ]]; then
# If we are at our allotted ammount, then we will wait until one of our jobs is complete before starting another
wait -n
fi
done
done
# Note that you can keep 'htop' running in a second window to track your use of resources in real time. This is a good way to keep track of how far along you are, as well as what bottlenecks you have when running N threads at a time. For instance, you may find that you can only run 4 at a time, even through you have 12 threads because of a memory constraint.
| Snippets/Running in Parallel/calling_in_parallel_shell.ipynb |
# ---
# jupyter:
# jupytext:
# text_representation:
# extension: .py
# format_name: light
# format_version: '1.5'
# jupytext_version: 1.14.4
# kernelspec:
# display_name: Python 3
# language: python
# name: python3
# ---
# +
from pytorch_tabnet.tab_model import TabNetClassifier
import torch
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import roc_auc_score
import pandas as pd
import numpy as np
np.random.seed(0)
import os
import wget
from pathlib import Path
from matplotlib import pyplot as plt
# %matplotlib inline
# -
# # Download census-income dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
dataset_name = 'census-income'
out = Path(os.getcwd()+'/data/'+dataset_name+'.csv')
out.parent.mkdir(parents=True, exist_ok=True)
if out.exists():
print("File already exists.")
else:
print("Downloading file...")
wget.download(url, out.as_posix())
# # Load data and split
# +
train = pd.read_csv(out)
target = ' <=50K'
if "Set" not in train.columns:
train["Set"] = np.random.choice(["train", "valid", "test"], p =[.8, .1, .1], size=(train.shape[0],))
train_indices = train[train.Set=="train"].index
valid_indices = train[train.Set=="valid"].index
test_indices = train[train.Set=="test"].index
# -
# # Simple preprocessing
#
# Label encode categorical features and fill empty cells.
# +
nunique = train.nunique()
types = train.dtypes
categorical_columns = []
categorical_dims = {}
for col in train.columns:
if types[col] == 'object' or nunique[col] < 200:
print(col, train[col].nunique())
l_enc = LabelEncoder()
train[col] = train[col].fillna("VV_likely")
train[col] = l_enc.fit_transform(train[col].values)
categorical_columns.append(col)
categorical_dims[col] = len(l_enc.classes_)
else:
train.fillna(train.loc[train_indices, col].mean(), inplace=True)
# -
# check that pipeline accepts strings
train.loc[train[target]==0, target] = "wealthy"
train.loc[train[target]==1, target] = "not_wealthy"
# # Define categorical features for categorical embeddings
# +
unused_feat = ['Set']
features = [ col for col in train.columns if col not in unused_feat+[target]]
cat_idxs = [ i for i, f in enumerate(features) if f in categorical_columns]
cat_dims = [ categorical_dims[f] for i, f in enumerate(features) if f in categorical_columns]
# -
# # Network parameters
# +
tabnet_params = {"cat_idxs":cat_idxs,
"cat_dims":cat_dims,
"cat_emb_dim":1,
"optimizer_fn":torch.optim.Adam,
"optimizer_params":dict(lr=2e-2),
"scheduler_params":{"step_size":50, # how to use learning rate scheduler
"gamma":0.9},
"scheduler_fn":torch.optim.lr_scheduler.StepLR,
"mask_type":'entmax' # "sparsemax"
}
clf = TabNetClassifier(**tabnet_params
)
# -
# # Training
# +
X_train = train[features].values[train_indices]
y_train = train[target].values[train_indices]
X_valid = train[features].values[valid_indices]
y_valid = train[target].values[valid_indices]
X_test = train[features].values[test_indices]
y_test = train[target].values[test_indices]
# -
max_epochs = 100 if not os.getenv("CI", False) else 2
from pytorch_tabnet.augmentations import ClassificationSMOTE
aug = ClassificationSMOTE(p=0.2)
# +
# This illustrates the warm_start=False behaviour
save_history = []
for _ in range(2):
clf.fit(
X_train=X_train, y_train=y_train,
eval_set=[(X_train, y_train), (X_valid, y_valid)],
eval_name=['train', 'valid'],
eval_metric=['auc'],
max_epochs=max_epochs , patience=20,
batch_size=1024, virtual_batch_size=128,
num_workers=0,
weights=1,
drop_last=False,
augmentations=aug, #aug, None
)
save_history.append(clf.history["valid_auc"])
assert(np.all(np.array(save_history[0]==np.array(save_history[1]))))
# -
# plot losses
plt.plot(clf.history['loss'])
# plot auc
plt.plot(clf.history['train_auc'])
plt.plot(clf.history['valid_auc'])
# plot learning rates
plt.plot(clf.history['lr'])
# ## Predictions
# +
preds = clf.predict_proba(X_test)
test_auc = roc_auc_score(y_score=preds[:,1], y_true=y_test)
preds_valid = clf.predict_proba(X_valid)
valid_auc = roc_auc_score(y_score=preds_valid[:,1], y_true=y_valid)
print(f"BEST VALID SCORE FOR {dataset_name} : {clf.best_cost}")
print(f"FINAL TEST SCORE FOR {dataset_name} : {test_auc}")
# -
# check that best weights are used
assert np.isclose(valid_auc, np.max(clf.history['valid_auc']), atol=1e-6)
clf.predict(X_test)
# # Save and load Model
# save tabnet model
saving_path_name = "./tabnet_model_test_1"
saved_filepath = clf.save_model(saving_path_name)
# define new model with basic parameters and load state dict weights
loaded_clf = TabNetClassifier()
loaded_clf.load_model(saved_filepath)
# +
loaded_preds = loaded_clf.predict_proba(X_test)
loaded_test_auc = roc_auc_score(y_score=loaded_preds[:,1], y_true=y_test)
print(f"FINAL TEST SCORE FOR {dataset_name} : {loaded_test_auc}")
# -
assert(test_auc == loaded_test_auc)
loaded_clf.predict(X_test)
# # Global explainability : feat importance summing to 1
clf.feature_importances_
# # Local explainability and masks
explain_matrix, masks = clf.explain(X_test)
# +
fig, axs = plt.subplots(1, 3, figsize=(20,20))
for i in range(3):
axs[i].imshow(masks[i][:50])
axs[i].set_title(f"mask {i}")
# -
# # XGB
# +
from xgboost import XGBClassifier
clf_xgb = XGBClassifier(max_depth=8,
learning_rate=0.1,
n_estimators=1000,
verbosity=0,
silent=None,
objective='binary:logistic',
booster='gbtree',
n_jobs=-1,
nthread=None,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.7,
colsample_bytree=1,
colsample_bylevel=1,
colsample_bynode=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
base_score=0.5,
random_state=0,
seed=None,)
clf_xgb.fit(X_train, y_train,
eval_set=[(X_valid, y_valid)],
early_stopping_rounds=40,
verbose=10)
# +
preds = np.array(clf_xgb.predict_proba(X_valid))
valid_auc = roc_auc_score(y_score=preds[:,1], y_true=y_valid)
print(valid_auc)
preds = np.array(clf_xgb.predict_proba(X_test))
test_auc = roc_auc_score(y_score=preds[:,1], y_true=y_test)
print(test_auc)
| census_example.ipynb |