
File size: 8,795 Bytes
f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 93ee587 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 8ae5504 5435fd3 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 5435fd3 f471fb4 5b673bc f471fb4 5435fd3 f471fb4 5435fd3 1e07cbe 5435fd3 1e07cbe 5435fd3 cfb8cb0 93ee587 cfb8cb0 3b428b1 5435fd3 3b428b1 5435fd3 93ee587 5435fd3 f471fb4 5435fd3 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 | ---
license: apache-2.0
library_name: transformers
pipeline_tag: zero-shot-image-classification
language:
- zh
- en
datasets:
- BM-6B
- ImageNet
- ImageNet-CN
- Flickr30K
- Flickr30K-CN
- COCO-CN
tags:
- onnx
- feature-extraction
- multimodal
- image-text-retrieval
- zero-shot-image-classification
- bilingual
- chinese
- english
- vision-language
- custom-code
model-index:
- name: M2-Encoder-0.4B
results:
- task:
type: zero-shot-image-classification
name: Zero-Shot Image Classification
dataset:
name: ImageNet
type: ImageNet
metrics:
- type: accuracy
value: 78.5
name: Top-1 Accuracy
- task:
type: zero-shot-image-classification
name: Zero-Shot Image Classification
dataset:
name: ImageNet-CN
type: ImageNet-CN
metrics:
- type: accuracy
value: 69.1
name: Top-1 Accuracy
- task:
type: image-text-retrieval
name: Zero-Shot Image-Text Retrieval
dataset:
name: Flickr30K
type: Flickr30K
metrics:
- type: mean_recall
value: 94.5
name: MR
- task:
type: image-text-retrieval
name: Zero-Shot Image-Text Retrieval
dataset:
name: COCO
type: COCO
metrics:
- type: mean_recall
value: 75.2
name: MR
- task:
type: image-text-retrieval
name: Zero-Shot Image-Text Retrieval
dataset:
name: Flickr30K-CN
type: Flickr30K-CN
metrics:
- type: mean_recall
value: 91.2
name: MR
- task:
type: image-text-retrieval
name: Zero-Shot Image-Text Retrieval
dataset:
name: COCO-CN
type: COCO-CN
metrics:
- type: mean_recall
value: 87.8
name: MR
---
# M2-Encoder-0.4B
`M2-Encoder-0.4B` is a Hugging Face export of the bilingual vision-language foundation model from the paper [M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining](https://arxiv.org/abs/2401.15896).
It supports Chinese-English image-text retrieval, zero-shot image classification, `transformers` remote-code loading, ONNXRuntime inference, and Hugging Face Inference Endpoints via the bundled `handler.py`.
This is the smallest published M2-Encoder variant and is the best starting point for CPU demos, Spaces, and lightweight retrieval services.
## Links
- Paper: https://arxiv.org/abs/2401.15896
- Official code: https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/M2_Encoder
- ModelScope source model: `M2Cognition/M2-Encoder`
- Hugging Face repo: `malusama/M2-Encoder-0.4B`
- Hugging Face Space demo: https://huggingface.co/spaces/malusama/M2-Encoder-0.4B-Space
## At A Glance
| Item | Value |
| --- | --- |
| Variant | `M2-Encoder-0.4B` |
| Languages | Chinese, English |
| Embedding dimension | `768` |
| Image size | `224` |
| Main tasks | Image-text retrieval, zero-shot image classification, bilingual feature extraction |
| Weight format | `safetensors` |
| ONNX export | `onnx/text_encoder.onnx`, `onnx/image_encoder.onnx` |
## Files In This Repo
- `m2_encoder_0.4B.safetensors`: main `transformers` weight file
- `onnx/text_encoder.onnx`: text embedding encoder
- `onnx/image_encoder.onnx`: image embedding encoder
- `examples/run_onnx_inference.py`: runnable ONNX example
- `handler.py`: custom handler for Hugging Face Inference Endpoints
## Transformers Usage
### ModelScope-equivalent scoring
The original ModelScope sample computes probabilities from raw normalized embedding dot products:
```python
from transformers import AutoModel, AutoProcessor
repo_id = "malusama/M2-Encoder-0.4B"
model = AutoModel.from_pretrained(repo_id, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(repo_id, trust_remote_code=True)
text_inputs = processor(
text=["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"],
return_tensors="pt",
)
image_inputs = processor(images="pokemon.jpeg", return_tensors="pt")
text_outputs = model(**text_inputs)
image_outputs = model(**image_inputs)
probs = (image_outputs.image_embeds @ text_outputs.text_embeds.t()).softmax(dim=-1)
print(probs)
```
### CLIP-style logits
`model(**inputs)` also returns `logits_per_image` and `logits_per_text`, which use the model's learned `logit_scale`.
Those logits are useful, but they are not the same computation as the raw dot product used in the original ModelScope demo.
## ONNXRuntime Usage
This repo also includes two ONNX exports:
- `onnx/text_encoder.onnx`
- `onnx/image_encoder.onnx`
Minimal example:
```python
import importlib
import json
import os
import sys
import onnxruntime as ort
from huggingface_hub import snapshot_download
from PIL import Image
repo_id = "malusama/M2-Encoder-0.4B"
model_dir = snapshot_download(repo_id=repo_id)
sys.path.insert(0, model_dir)
tokenizer_config = json.load(open(os.path.join(model_dir, "tokenizer_config.json"), "r", encoding="utf-8"))
GLMChineseTokenizer = importlib.import_module("tokenization_glm").GLMChineseTokenizer
M2EncoderImageProcessor = importlib.import_module("image_processing_m2_encoder").M2EncoderImageProcessor
tokenizer = GLMChineseTokenizer(
vocab_file=os.path.join(model_dir, "sp.model"),
eos_token=tokenizer_config.get("eos_token"),
pad_token=tokenizer_config.get("pad_token"),
cls_token=tokenizer_config.get("cls_token"),
mask_token=tokenizer_config.get("mask_token"),
unk_token=tokenizer_config.get("unk_token"),
)
image_processor = M2EncoderImageProcessor.from_pretrained(model_dir)
text_inputs = tokenizer(
["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"],
padding="max_length",
truncation=True,
max_length=52,
return_special_tokens_mask=True,
return_tensors="np",
)
image_inputs = image_processor(Image.open("pokemon.jpeg").convert("RGB"), return_tensors="np")
text_session = ort.InferenceSession(
os.path.join(model_dir, "onnx", "text_encoder.onnx"),
providers=["CPUExecutionProvider"],
)
image_session = ort.InferenceSession(
os.path.join(model_dir, "onnx", "image_encoder.onnx"),
providers=["CPUExecutionProvider"],
)
text_embeds = text_session.run(
None,
{
"input_ids": text_inputs["input_ids"],
"attention_mask": text_inputs["attention_mask"],
},
)[0]
image_embeds = image_session.run(
None,
{"pixel_values": image_inputs["pixel_values"]},
)[0]
```
Runnable script:
```bash
python examples/run_onnx_inference.py --image pokemon.jpeg --text 杰尼龟 妙蛙种子 小火龙 皮卡丘
```
## Inference Endpoints
This repo includes a `handler.py` for Hugging Face Inference Endpoints custom deployments.
Example request body:
```json
{
"inputs": {
"text": ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"],
"image": "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
},
"parameters": {
"return_probs": true,
"return_logits": false
}
}
```
Example response fields:
- `text_embedding`
- `image_embedding`
- `scores`
- `probs`
- `logits_per_image` when `return_logits=true`
## Evaluation Summary
According to the official project README and paper, the M2-Encoder series is trained on the bilingual BM-6B corpus and evaluated on:
- ImageNet
- ImageNet-CN
- Flickr30K
- Flickr30K-CN
- COCO-CN
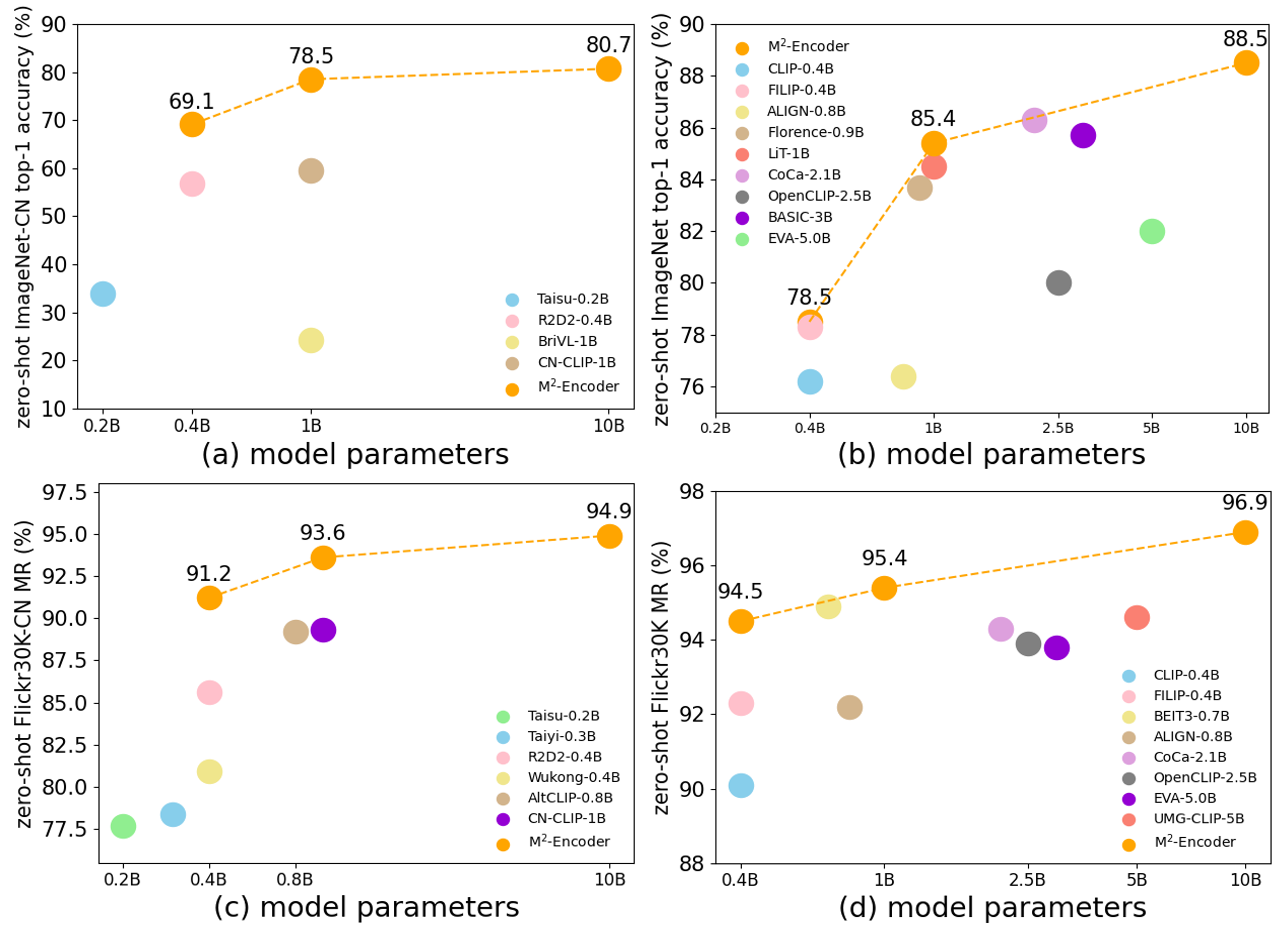
The official project reports that the M2-Encoder family sets strong bilingual retrieval and zero-shot classification results, and that the 10B variant reaches 88.5 top-1 on ImageNet and 80.7 top-1 on ImageNet-CN in the zero-shot setting. See the paper for exact cross-variant comparisons.
The structured `model-index` metadata in this card is taken from the official paper tables for this released variant. On the Hugging Face page, those results should surface in the evaluation panel once the metadata is parsed.

## Notes
- This is a Hugging Face remote-code adapter, not a native `transformers` implementation merged upstream.
- `trust_remote_code=True` is required for `AutoModel` and `AutoProcessor`.
- This repo is intended for retrieval, classification, and embedding use cases, not text generation.
- The Hub export has been numerically checked against the official implementation for the published demo workflow.
## Citation
```bibtex
@misc{guo2024m2encoder,
title={M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining},
author={Qingpei Guo and Furong Xu and Hanxiao Zhang and Wang Ren and Ziping Ma and Lin Ju and Jian Wang and Jingdong Chen and Ming Yang},
year={2024},
url={https://arxiv.org/abs/2401.15896}
}
```
|