
Recipe: Async On-Policy Knowledge Distillation Trainer
Authors: Brilliant Hanabi, furunding
Last updated: 2025-11-08
1. Background
On-policy knowledge distillation (KD) trains a student policy to imitate a stronger teacher using samples drawn from the student's current policy. For each on-policy rollout the teacher returns soft, top-k token distributions and the student is optimized with a token-wise sparse KL objective that focuses learning on the teacher's high-probability modes. Because training examples come from the student's own state distribution, KD reduces distributional mismatch relative to off-policy distillation or supervised fine-tuning (SFT), improving stability and sample efficiency. Compared with reinforcement learning, KD avoids high-variance reward-based optimization and complex reward design by providing dense, informative per-token targets, which typically yields faster convergence and simpler scaling. Recent empirical and implementation-focused writeups (e.g., ThinkingMachines' blog on on-policy distillation) also demonstrate that on-policy distillation can deliver high-quality behavior with substantially lower compute and data requirements than many alternative approaches.
Built on verl’s Ray-based single-controller components, we initially assembled a strictly on-policy KD pipeline where rollout generation, teacher knowledge acquisition, and policy optimization ran in lockstep. In practice, this synchronous design proved highly inefficient: the three stages had to wait for one another, creating pipeline bubbles and underutilized GPUs. To address this, we extend the asynchronous schedulers introduced by the One-Step-Off Policy pipeline to overlap these phases. This overlap preserves the same distillation objective while trading some strict on-policy guarantees for substantial gains in end-to-end throughput and hardware utilization.
2. Distillation Overview and Objective
This recipe centers on on-policy knowledge distillation: the student policy learns from a stronger teacher on samples generated by the current policy (on-policy). For each input prompt, the student (actor) generates responses; the teacher provides top-k token distributions, and the student is trained to match them token-wise.
Core components:
- Teacher signal: top-k log-probabilities and token indices per valid token position.
- Student objective: sparse, token-level KL divergence between student logits and teacher top-k distribution.
Objective: encourage student probabilities $Q$ to cover teacher modes $P$ using token-wise $\mathrm{KL}(P,|,Q)$ computed on the teacher's top-k support.
3. Efficient System Design
3.1 Schedulers (One-Step / Two-Step Off-Policy)
The native (serial) on-policy distillation process is shown in the figure below.
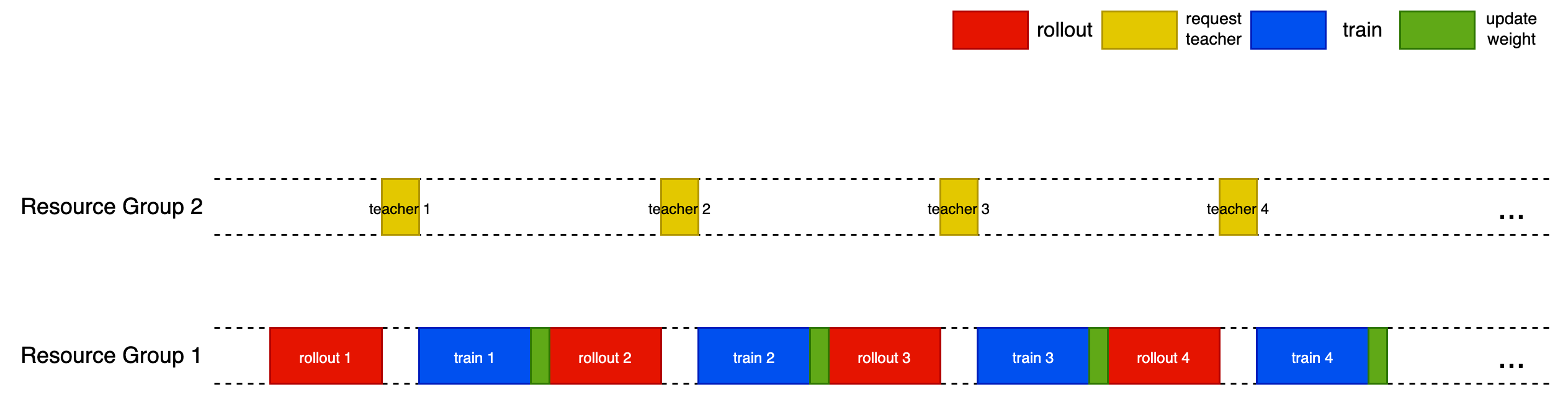
This recipe supports optional schedulers that overlap generation, teacher querying, and updates to improve throughput without changing the distillation objective.
3.1.1 One-Step-Off-Policy
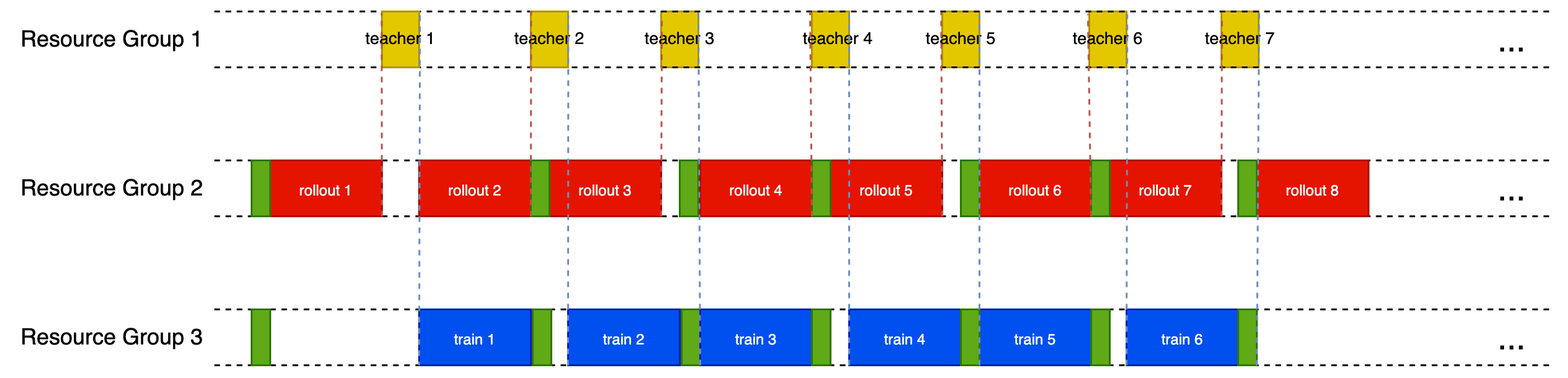
- Warm-up: 2 steps.
- Overlap pattern: rollout while actor update; weight sync while teacher retrieving.
- Timing keys:
sync_rollout_weights,wait_prev_gen,wait_prev_teacher.
3.1.2 Two-Step-Off-Policy
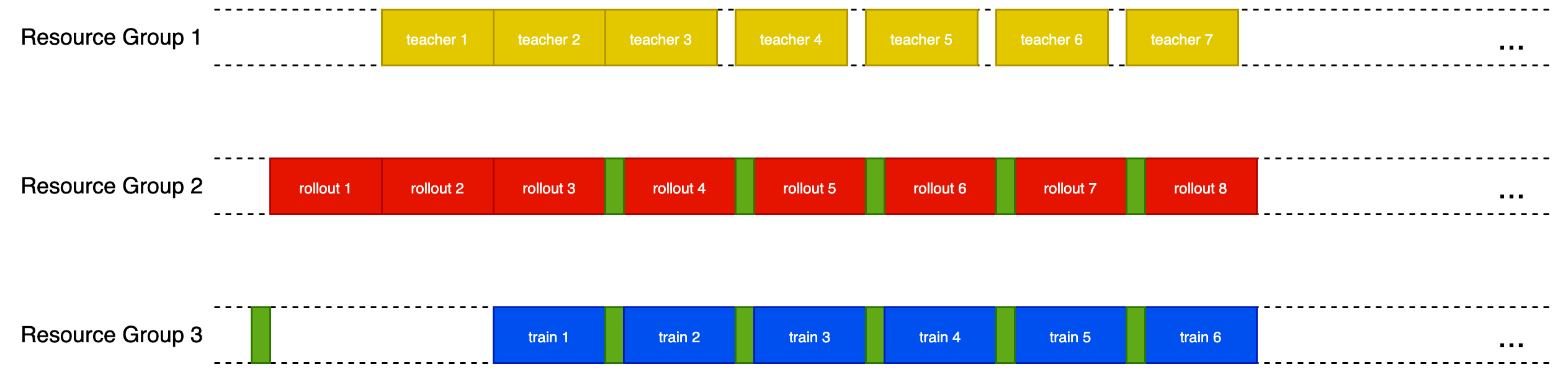
- Warm-up: 3 steps.
- Overlap pattern: rollout, actor update while teacher retrieving; interleave weight sync.
- Timing keys:
sync_rollout_weights,max(wait_prev_gen, wait_prev_prev_teacher).
Tip: Use two_step_off when teacher takes much more time than sync; one_step_off for simpler overlapping.
Practical details:
- Inputs per batch:
teacher_topk_logps,teacher_topk_indices,attention_mask(to select valid token positions). - Loss injection: last pipeline stage computes KL via a logits processor; earlier stages remain unchanged.
- Optional dynamic micro-batching groups sequences by density to reduce padding overhead.
The pipeline:
- Actor parameters are synchronized to a rollout worker group (nccl broadcast) with a little bit latency.
- Rollout workers (vLLM-backed) generate sequences asynchronously (
async_generate_sequences). - Teacher client service (ZeroMQ based) returns top-k log-probabilities + token indices for each sequence (batched micro-requests), enabling KL-based guidance.
- Megatron actor performs a KL divergence computation between student logits and teacher top-k distributions (custom TP-aware kernel in
megatron_kl_loss.py). - Scheduling strategies (
one_step_off_scheduler,two_step_off_scheduler) can overlap phases (optional for throughput):
3.2 Weights sync between actor and rollout
We initially followed the weight synchronization path from the One-Step-Off-Policy recipe (Ray collective broadcast across all actor and rollout ranks, plus Megatron-side allgather of parameter shards). In practice this became the dominant bottleneck, so we made three changes:
- Batch-and-bulk load on the rollout side: instead of streaming tensors one-by-one (in one-step-off-policy recipe), we stage a bundle of parameter tensors and issue a single batched load into the rollout engine. In our setup this reduced the weight-loading time by roughly 3×.
- Batch-and-bulk broadcast between the actor and rollout: instead of streaming tensors one-by-one (in one-step-off-policy recipe), we stage a bundle of parameter tensors and issue a single batched broadcast between the actor and rollout workers.
- Replace allgather with gather-to-root in Megatron: parameter shards are gathered to actor rank 0 (rather than allgathered to everyone), and that root then serves as the single source for broadcasting to rollout ranks. On top of the previous change, 2 and 3 changes delivered an additional ~4× speedup in the synchronization phase.
4. High-Level Data & Control Flow
Driver (TaskRunner)
├─ Initialize Ray, tokenizer, datasets, worker groups
├─ Build ResourcePoolManager (actor vs rollout GPU layouts)
├─ Trainer.fit()
├─ init_workers(): build actor + rollout groups, broadcast weight metadata, create nccl collective group
├─ continuous_iterator(): epochs → batches
├─ scheduler (see Section 6)
• _async_gen_next_batch(): optional weight sync + non-blocking rollout
• _async_get_teacher_knowledge(): submit teacher requests, store future
├─ For each step:
• Sync rollout weights
• Retrieve (batch, gen_output, teacher_output) from futures
• Merge gen + teacher outputs → DataProto
• Compute metrics (response length stats, timing, throughput)
• Update actor (forward_backward_batch + KL loss + optimizer step)
• (Optional) save checkpoint
Note: Schedulers are optional and explained later; the distillation objective is independent of how phases are overlapped.
5. Key Components
5.1 OnPolicyDistillTrainer (ray_trainer.py)
- Creates
GenerationBatchFutureobjects holding rollout and (later) teacher futures. - Adds scheduling + teacher integration + modified metric emission (KL, timing, MFU).
5.2 Actor Worker (Megatron)
OnPolicyDistillActor.update_policy()orchestrates micro-batch forward/backward.- KL Loss injection via
logits_processorduring forward on pipeline last stage.
5.3 Rollout Worker (vLLM / SGLang)
- Pure inference mode (
init_modelbuilds model; no optimizer). async_generate_sequencesreturns a Ray future for overlapping.
5.4 Teacher Service (teacher/)
- Proxy + worker architecture (ZMQ REQ/REP) for batched top-k retrieval.
TeacherClient.submit()returns aFuture; aggregator composes micro-batches.- Configurable temperature, max tokens, only-response mode.
5.5 KL Loss (megatron_kl_loss.py)
- Performs normalization & stable per-token probability construction across TP shards.
- Gradient is (student_probs - teacher_sparse_probs) scaled by upstream grad.
6. Configuration Highlights (on_policy_distill_trainer.yaml)
| Section | Purpose | Notable Keys |
|---|---|---|
| actor_rollout_ref.teacher | Teacher server | server_ip, server_port, n_server_workers |
| trainer | Global training control | total_epochs, save_freq, scheduler (one_step_off |
| rollout | Resource split for rollout | n_gpus_per_node, nnodes |
Remember to set trainer.n_gpus_per_node, trainer.nnodes, rollout.n_gpus_per_node and rollout.nnodes to allocate GPU resources.
Dynamic Batch Size
Enable by:
actor_rollout_ref.actor.use_dynamic_bsz=True
actor_rollout_ref.actor.max_token_len=6000 # cap post-group token length
Improves utilization under variable sequence lengths.
Resource Guidelines
- Actor pool:
trainer.nnodes * trainer.n_gpus_per_nodeGPUs. - Rollout pool:
rollout.nnodes * rollout.n_gpus_per_nodeGPUs. - Ensure teacher server capacity ≈
n_server_workersto avoid stalls (monitorwait_prev_teacher).
7. Usage Examples
7.1 Launch Teacher Server
Before training process, you should have a teacher server to provide logp information.
We provide a toy teacher server example with vLLM. It needs telnet to check proxy status, and python command to run. So if you have not installed telnet, you can just delete these code in start_server.sh. And some OS use python3 rather than python, so you also need to modify it. Also you can change the port of teacher if you meet port conflict.
There are 3 arguments can be set for vllm backend --tp-size, --n-logprobs and --ckpt-path in start_server.sh / worker.py. You should set before you start server.
We also provide a toy multi-node teacher server. You can start the main node using start_server.sh and start the slave nodes using join_server.sh. Still remember to set args in join_server.sh, especially the $PROXY_IP and $PROXY_BACKEND_PORT of main node.
When training, student will automatically use the teacher's topk (n-logprobs) to set its own topk argument at line 83 of recipe/gkd/megatron_kl_loss.py, so you don't need to set student's topk argument.
cd recipe/gkd/teacher
bash start_server.sh
# Exports ports and launches proxy + worker (default vLLM backend)
Verify with:
telnet localhost 15555
7.2 Minimal Local (Megatron + vLLM) Run
python3 -m recipe.gkd.main_gkd \
--config-path=recipe/gkd/config \
--config-name=on_policy_distill_trainer \
actor_rollout_ref.model.path=/path/to/MODEL \
data.train_files=/path/to/train.parquet \
trainer.total_epochs=2 \
trainer.n_gpus_per_node=4 rollout.n_gpus_per_node=2 \
actor_rollout_ref.teacher.server_ip=127.0.0.1 \
actor_rollout_ref.teacher.server_port=15555 \
trainer.scheduler=one_step_off
(Requires a running teacher server).
7.3 Ray Job Submission (Distilled 16B Example)
See run_moonlight_dsv3_training.sh for a full script including:
- Dist ckpt path setup (
dist_checkpointing_path) - Expert parallel sizing (EP / ETP)
- Dynamic batch sizing
- Two-step-off scheduling for deeper overlap.
Submit (after adjusting paths):
bash recipe/gkd/run_moonlight_dsv3_training.sh
8. Metrics & Monitoring
Emitted metrics include (prefixes may vary):
- Timing:
timing/wait_prev_gen,timing/sync_rollout_weights,timing/get_teacher_knowledge,timing/update_actor. - Sequence stats:
response_seq_len/*(avg, max, min, counts). - Performance:
perf/mfu/actor,perf/max_memory_allocated_gb,perf/cpu_memory_used_gb. - Distillation:
actor/kl_loss,actor/grad_norm,actor/lr.
Interpretation Tips:
- High
wait_prev_teacher→ scalen_server_workersand allocate more teacher GPUs or reduce per-request batch size, or just usetwo_step_off. - High
wait_prev_genwith uniform lengths → allocate more rollout GPUs. - High
sync_rollout_weights→ check NCCL env / network congestion and try to modifyactor_rollout_ref.rollout.update_weights_bucket_megabytes.
9. Extensibility Notes
- Add new schedulers by following interface returning
(epoch, batch, gen_output, teacher_output, timing_dict). - Integrate different distillation signals (e.g., hidden states, intermediate reasoning tokens) by extending
teacher_utils.get_teacher_knowledgeand modifyinglogits_processor.
10. Functional Support Summary
| Category | Supported |
|---|---|
| Train engine | Megatron |
| Rollout engine | vLLM |
| Distillation signal | Teacher top-k logprobs & indices |
| Scheduling | one_step_off, two_step_off |
11. Quick Checklist Before Running
- Teacher server reachable (
telnet <ip> <port>). actor_rollout_ref.model.pathcontains the correct Megatron/HF config artifacts.train_filespoints to a parquet dataset compatible with this recipe's dataset loader.- NCCL environment vars set (see
config/runtime_env.yaml).
Feel free to open issues or PRs to extend scheduler variants, add new distillation objectives, or broaden engine support, and more improvement.