
File size: 16,156 Bytes
4b6d318 74d52fc a8eb7e8 74d52fc 68f5a70 a8eb7e8 74d52fc a8eb7e8 ce6509f 74d52fc df9ec78 cac3d06 df9ec78 cac3d06 0e73a31 df9ec78 cac3d06 0e73a31 df9ec78 cac3d06 ce6509f cac3d06 0e73a31 2914bb7 cac3d06 74d52fc df9ec78 0e73a31 a1982ff 74d52fc ce6509f 74d52fc b3e7744 1daec87 74d52fc 6acf99c 74d52fc 16fa660 74d52fc 5fec409 a8c23a5 5fec409 8065023 96e0345 8065023 4e2bb84 5fec409 f271614 4f2dfa7 74d52fc |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 |
# Standard Library Imports
import os
import uuid
import time
# Third-Party Libraries
import requests
import pandas as pd
from dotenv import load_dotenv
from tenacity import retry, stop_after_delay, wait_fixed, RetryError
import gradio as gr
# LangChain Imports
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import SpacyTextSplitter
from langchain.document_loaders import TextLoader
from langchain.memory import ConversationBufferMemory
from langchain.agents import initialize_agent, Tool
from langchain.agents.agent_types import AgentType
class AbbyyVantage:
"""
A client to interact with the ABBYY Vantage public API.
Handles authentication, skill listing, transaction initiation, and result retrieval.
"""
def __init__(self, client_id, client_secret, region="au"):
"""
Initializes the AbbyyVantageClient by authenticating using client credentials.
Args:
client_id (str): Your ABBYY Vantage client ID.
client_secret (str): Your ABBYY Vantage client secret.
region (str): ABBYY Vantage region ('eu', 'us', 'au', etc.). Defaults to 'au'.
Raises:
Exception: If authentication fails or access token is not returned.
"""
self.client_id = client_id
self.client_secret = client_secret
self.token_url = f"https://vantage-{region}.abbyy.com/auth2/connect/token"
self.api_base = f"https://vantage-{region}.abbyy.com/api/publicapi/v1"
try:
# Prepare data for token request using client credentials
data = {
'grant_type': 'client_credentials',
'client_id': self.client_id,
'client_secret': self.client_secret
}
# Request access token from ABBYY OAuth2 endpoint
res = requests.post(self.token_url, data=data)
res.raise_for_status()
# Extract access token from response
token = res.json().get('access_token')
if not token:
raise ValueError("No access token returned from ABBYY")
# Set authorization headers for future API calls
self._headers = {
"Authorization": f"Bearer {token}",
"accept": "application/json"
}
except Exception as e:
print(f"Error during authentication: {e}")
raise
def get_skills(self):
"""
Retrieves a list of available document processing skills from ABBYY Vantage.
Returns:
dict or None: A JSON object containing skill metadata or None if the request fails.
"""
try:
# Send GET request to fetch all available skills
res = requests.get(f'{self.api_base}/skills', headers=self._headers)
res.raise_for_status()
return res.json()
except Exception as e:
print(f"Failed to fetch skills: {e}")
return None
def process_document(self, file_path, skill_id):
"""
Starts a new transaction by uploading a file to be processed using a specific skill.
Args:
file_path (str): Path to the local PDF file to be uploaded.
skill_id (str): The ID of the skill to be used for processing.
Returns:
str or None: The transaction ID returned by the API or None if the request fails.
"""
try:
# Prepare API URL with query parameter for the skill ID
url = f"{self.api_base}/transactions/launch?skillId={skill_id}"
# Open the file in binary mode for upload
with open(file_path, "rb") as f:
files = {
"Files": (os.path.basename(file_path), f, "application/pdf")
}
# Post the file to ABBYY API to start a transaction
res = requests.post(url, headers=self._headers, files=files)
res.raise_for_status()
# Extract and return the transaction ID
return res.json().get('transactionId')
except Exception as e:
print(f"Failed to start transaction: {e}")
return None
def get_document_results(self, transaction_id, output_path="result_file.txt"):
"""
Checks the transaction status and downloads the result file if processing is complete.
Args:
transaction_id (str): The transaction ID to monitor.
output_path (str): Local file path to save the result file. Defaults to "result_file.txt".
Returns:
str or None: Path to the saved result file, or None if processing is incomplete or fails.
"""
try:
# Get transaction status and metadata
url = f"{self.api_base}/transactions/{transaction_id}"
res = requests.get(url, headers=self._headers)
res.raise_for_status()
data = res.json()
except Exception as e:
print(f"Failed to fetch transaction details: {e}")
return None
# Extract processing status
status = data.get('status')
print(f"Transaction status: {status}")
# Handle status outcomes
if status == 'Processing':
print("File is still being processed. Try again later.")
return 'Processing'
elif status != 'Processed':
print(f"Unexpected status: {status}")
return f"Unexpected status: {status}"
try:
# Navigate to the result file ID in the JSON structure
file_id = data['documents'][0]['resultFiles'][0]['fileId']
# Build the download URL using transaction ID and file ID
download_url = f"{self.api_base}/transactions/{transaction_id}/files/{file_id}/download"
# Download the result file
res = requests.get(download_url, headers=self._headers)
res.raise_for_status()
# Save the file to the specified path
with open(output_path, 'wb') as f:
f.write(res.content)
print(f"File downloaded and saved to: {output_path}")
return 'Processed'
except (KeyError, IndexError) as e:
print(f"Error accessing file ID in response JSON: {e}")
except Exception as e:
print(f"Failed to download or save file: {e}")
# df = pd.DataFrame(client.get_skills())
# df
# ----------- Process OCR & Setup Retrieval Agent -------------
def process_pdf_ocr(file):
print('process_pdf_ocr', file)
client = AbbyyVantage(client_id=os.getenv("ABBY_CLIENT_ID"),
client_secret=os.getenv("ABBY_CLIENT_SECRET"),
region="au" # or "us", "au", etc.
)
skill_id = '1681402d-2931-41cb-9717-bb7612bc09aa'
trans_id = client.process_document(file_path=file, skill_id=skill_id)
@retry(stop=stop_after_delay(60), wait=wait_fixed(3))
def wait_for_processing():
status = client.get_document_results(trans_id, output_path="/tmp/result_file.txt")
print(f"Status: {status}")
if status == 'Processed':
print("|-- Processed")
return status
raise Exception("Still Processing")
try:
status = wait_for_processing()
print("|--OCR Successful")
setup_agent("/tmp/result_file.txt")
print("|--Chatbot is ready")
return "OCR Successful. Chatbot is ready"
except RetryError:
print("|--OCR Failed or Timed Out")
return "OCR Failed or Timed Out"
# Global state
retrieval_chain = None
agent_executor = None
# ----------- Setup LangChain Retrieval Agent -------------
def setup_agent(file):
global retrieval_chain, agent_executor
if not os.path.exists(file):
return "Please process a PDF first."
loader = TextLoader(file)
documents = loader.load()
splitter = SpacyTextSplitter()
chunks = splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(chunks, embedding=embeddings, collection_name=f"temp_collection_{uuid.uuid4().hex}")
retriever = vectordb.as_retriever(search_kwargs={"k": 10})
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
retrieval_chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(model="gpt-3.5-turbo"),
retriever=retriever,
memory=memory,
return_source_documents=False
)
tools = [
Tool(
name="PolicyRetrievalRAG",
func=retrieval_chain.run,
description="Use this tool to retrieve the most relevant clauses from the insurance policy based on the user's question."
)
]
agent_executor = initialize_agent(
tools=tools,
llm=ChatOpenAI(model="gpt-4o"),
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
handle_parsing_errors=True,
verbose=True
)
print("|--Agent setup complete")
return "Agent is ready."
# ----------- Chat Interface Handler -------------
def ask_question(message, history):
if agent_executor is None:
return "❗ Chatbot not ready. Please upload and process a PDF first."
advisory_prompt = (
"Use the PolicyRetrievalRAG tool to extract the most relevant clauses from the policy document. "
"Always base your response strictly on the actual policy content — do not fabricate or assume.\n\n"
"Respond strictly in this structured format using **Markdown** with **emojis**, and wrap everything inside a `Final Answer:` block for compatibility:\n\n"
"Final Answer:\n"
"### 📄 Policy Details\n"
"- Quote or paraphrase the most relevant clauses from the policy.\n\n"
"### 💡 Advisor’s Practical Tip\n"
"- Give actionable tips to help the user get the most from their policy.\n\n"
"### ⚠️ Caveats and Exclusions\n"
"- Mention any exclusions, limitations, or waiting periods.\n\n"
"Your tone should be empathetic and clear — like a smart, helpful insurance advisor.\n"
"Always include **all four** sections.\n\n"
"---\n"
"### Example Response:\n"
"Final Answer:\n"
"### 📄 Policy Details\n"
"- The policy includes a 24-month waiting period for pre-existing conditions.\n\n"
"### 💡 Advisor’s Practical Tip\n"
"- Explore top-up plans that might waive or reduce the waiting period.\n\n"
"### ⚠️ Caveats and Exclusions\n"
"- Conditions like diabetes and hypertension are counted as pre-existing, so they'll be excluded during the waiting period.\n"
)
prompt = f"{advisory_prompt}\nQuestion: {message}"
try:
response = agent_executor.run(prompt)
return response
except Exception as e:
return f"❌ Error: {str(e)}"
# ----------- Gradio UI -------------
with gr.Blocks(theme='shivi/calm_seafoam', title="📄 Insurance Policy AIdvisor") as demo:
gr.Markdown("# Insurance Policy AIdvisor App")
gr.Markdown("### Upload policy and converse")
with gr.Tab("📄 Upload PDF"):
gr.Markdown("### Upload a PDF. And Intellignet Document Processing will automatically process it using ABBYY Vantage, Agent Factory, ChromaDB and LangChain")
pdf_file = gr.File(label="📤 Upload a PDF", file_types=[".pdf"])
ocr_status = gr.Textbox(label="Processing Status", interactive=False)
pdf_file.change(process_pdf_ocr, inputs=[pdf_file], outputs=[ocr_status])
gr.Examples(
examples=[["Shri Health Suraksha Insurance Policy.pdf"]], #,["small-insudoc.pdf"],["Principal-Sample-Life-Insurance-Policy.pdf"]],
inputs=[pdf_file],
label="Example PDFs"
)
with gr.Tab("💬 Chatbot"):
chat = gr.ChatInterface(fn=ask_question,
title = "🤖 AIdvisor",
chatbot=gr.Chatbot(
avatar_images=(
"https://em-content.zobj.net/source/twitter/141/parrot_1f99c.png", # User
"https://em-content.zobj.net/source/twitter/141/robot-face_1f916.png" # Bot
)
)
)
gr.Examples(
examples=[
"Is there any bonus on this policy?",
"Will policy pay for the full room rent?",
"Is Cosmetic surgery covered in this policy?",
"Will this policy cover my cataract treatment?",
"Is ICU fully covered in this policy?",
"Is correction of eye sight covered? Are there any limits?",
# "In what forms are the certificate avalaible?",
# "How many employees should enroll if the member is to not contribute premium?",
# "Can insurer contest this policy?",
# "when can insurer make changes to the policy?",
# "I gave incorrect age in the policy, what to do now?",
# "Can the data I filled in the application form to get the insurance policy be used against me?",
],
inputs=chat.textbox
)
with gr.Tab("System Design"):
gr.Image(value="AIdvisor_devcon.png")
with gr.Tab("UML-System Diagram"):
gr.Markdown("[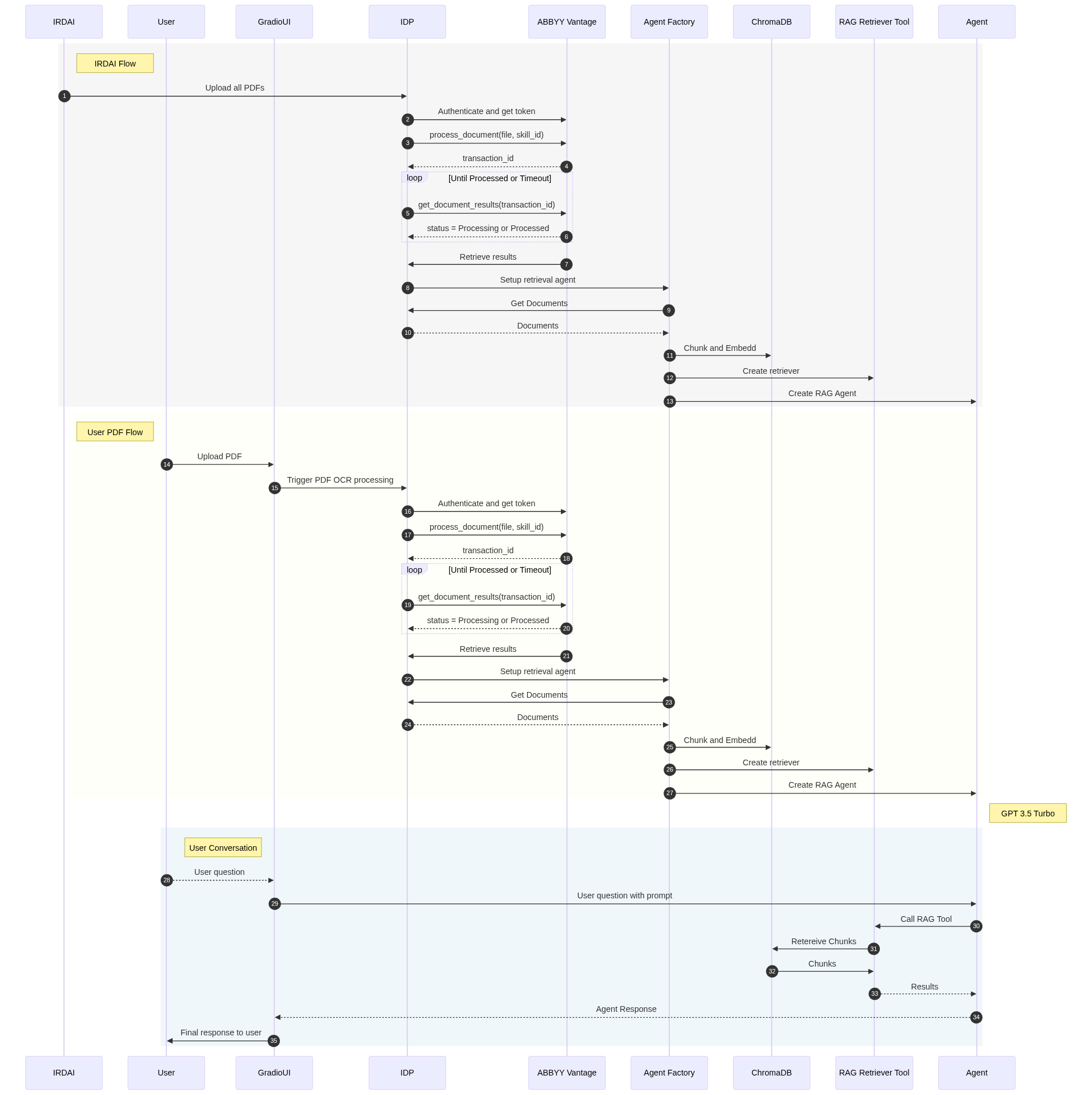](https://mermaid.live/edit#pako:eNrtVl1v2jAU_SuWn1qJIkIIhUirRGEgHrZVDCZ1QkImMcFqYme2s41V_e-7jhOapKnW91VIwbHP_b7HuY84ECHFPlb0R0Z5QGeMRJIkW45QSqRmAUsJ12i5mk3WiKh8sWyebhSV5tD8N88WkoRMbJbmvFw3MakUAVVql4aHnQhyVcvZXRM12e9Pp2-wIhE1kMnt7f09KjaaYEV1lu7gANYGmy_mJNBCnprY6VGKhMxuDbBcNzErqiWjP22cq8misrEWIn7ha83wlptzkmnBs2RvcyRpoJGM9hd9x-mg50ev27805wh9FpqimB40Eoc8tb7NPprH4peF2LJc3dw0U-ijTRoLEiISx-huNlcW30y0kaym1UeTTB_BYxYQME54iCKqkRYPlL9VQ4kIRZAloOriwGLaQeqBxfGOhUVwtWJetUagJeEKKsYEBzkrFguRog34B1FZPA2RgBqwhIpMW9BbvISwzh7uJFVZrNVF3eJlqe0NvipNdKbQh9IrxiPj1tlHq4rysC36NoVle6HCt9ezX-l0H301LyCTC5MYEdt-RrbKiFaTC6j0rEjJa_ZeGGwINI2UdPJhlfGHvKM-AgXCsB1_ZhUISGp6UJY77QIT60YBNsSclCEX2X4mmucBx_JHf_APouU3GvCmwrV8y5gsb7EzxwBnIee7rjW_a8miqFD7ZboqAdAq7-R8J-f_Sc6cesCLY869Ar-4WyO366F1JveiRmHn2jWfySE83N6rFK4Q1HB2Kjh4qIjpnCqVG1w2ezADqWdYjc6FbzUY-sX00dQhSYs6TlqTZT7CJvpyUkCV6aFeCNinkjJorbwkReHOA0pTcQVT0Vhxd1Vt0MK5etx2E3Cp4Iq2BG4vxDnj0LGygMGlg7Ji2MsraX64gyPJQuxrmdEOTqhMiHnFjwa2xXB3JXSLfViG9EDAry3e8icQg5HpuxBJKSlFFh2xfyCxgrcsDaF7irn0DAGrVE5FxjX2R6NcBfYf8W_sX426o6HrjLzr_nDoek5v3MEn2HaHTtfz-uOB43g9Z-iNnzr4T27V6Q561-7A7Q9H7ngwuO71O5iGDEbFT3Y4zmfkp7_uT8Ws)")
demo.launch(debug=True) |