
Upload README.md with huggingface_hub
Browse files
README.md
CHANGED
|
@@ -38,44 +38,40 @@ Inspired by [DAC](https://arxiv.org/abs/2306.06546) (Descript Audio Codec). Stri
|
|
| 38 |
|
| 39 |
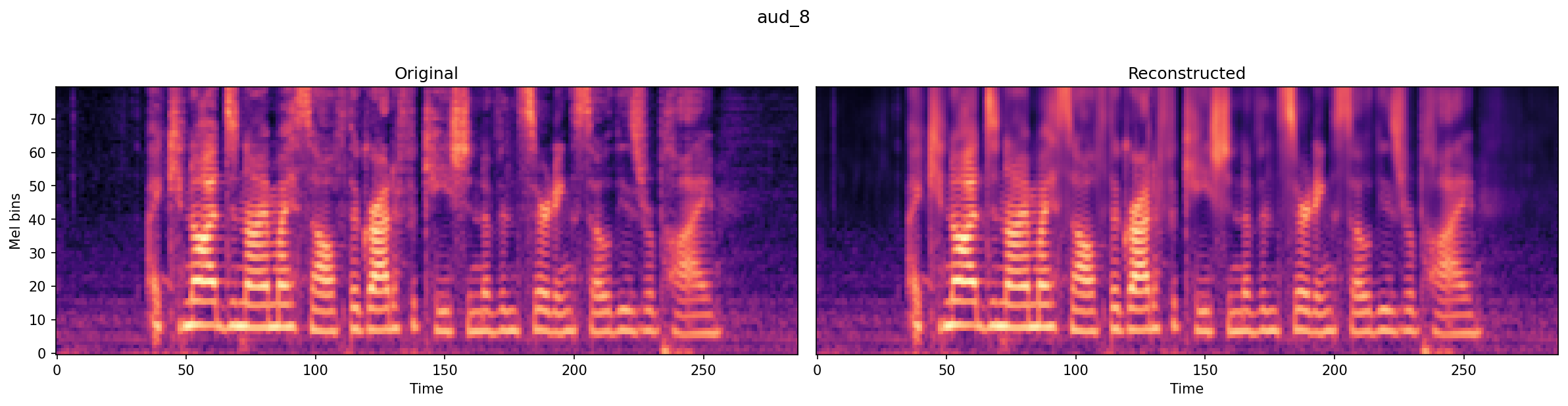
|
| 40 |
|
| 41 |
-
##
|
| 42 |
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
uv sync
|
| 48 |
-
```
|
| 49 |
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
python inference.py --input audio.wav --output reconstructed.wav
|
| 54 |
-
```
|
| 55 |
-
Downloads model weights from HuggingFace on first run. Resamples to 16kHz if needed.
|
| 56 |
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
-
|
|
|
|
| 65 |
|
|
|
|
| 66 |
```
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
│ ├── model.py # RVQCodec, VQ, RVQ, encoder/decoder
|
| 72 |
-
│ ├── loss.py # Multi-scale spectral losses
|
| 73 |
-
│ ├── loader.py # Dataset loading (in-memory + streaming)
|
| 74 |
-
│ ├── train.py # Training loop
|
| 75 |
-
│ ├── inference.py # Reconstruct audio from trained model
|
| 76 |
-
│ ├── prepare_data.py # Preprocess LibriSpeech into chunks
|
| 77 |
-
│ └── utils.py # Checkpointing, logging, profiling
|
| 78 |
-
└── assets/ # Audio samples, images
|
| 79 |
```
|
| 80 |
|
| 81 |
## 📚 References
|
|
|
|
| 38 |
|
| 39 |

|
| 40 |
|
| 41 |
+
## Usage
|
| 42 |
|
| 43 |
+
```python
|
| 44 |
+
from huggingface_hub import hf_hub_download
|
| 45 |
+
import torch, yaml, soundfile as sf, torchaudio
|
| 46 |
+
from model import RVQCodec
|
|
|
|
|
|
|
| 47 |
|
| 48 |
+
# load model
|
| 49 |
+
model_path = hf_hub_download("taresh18/nano-codec", "model.pt")
|
| 50 |
+
config_path = hf_hub_download("taresh18/nano-codec", "config.yaml")
|
|
|
|
|
|
|
|
|
|
| 51 |
|
| 52 |
+
with open(config_path) as f:
|
| 53 |
+
cfg = yaml.safe_load(f)
|
| 54 |
+
|
| 55 |
+
model = RVQCodec(in_ch=1, latent_ch=cfg['latent_dim'], K=cfg['codebook_size'],
|
| 56 |
+
num_rvq_levels=cfg['num_rvq_levels'], codebook_dim=cfg.get('codebook_dim', 8))
|
| 57 |
+
model.load_state_dict(torch.load(model_path, map_location="cpu", weights_only=True))
|
| 58 |
+
model.eval()
|
| 59 |
+
|
| 60 |
+
# reconstruct audio
|
| 61 |
+
audio, sr = sf.read("input.wav", dtype="float32")
|
| 62 |
+
waveform = torch.from_numpy(audio).unsqueeze(0).unsqueeze(0) # [1, 1, T]
|
| 63 |
+
if sr != 16000:
|
| 64 |
+
waveform = torchaudio.functional.resample(waveform, sr, 16000)
|
| 65 |
|
| 66 |
+
with torch.no_grad():
|
| 67 |
+
recon, _, _, _ = model(waveform)
|
| 68 |
|
| 69 |
+
sf.write("reconstructed.wav", recon[0, 0].numpy(), 16000)
|
| 70 |
```
|
| 71 |
+
|
| 72 |
+
Or use the inference script from the [GitHub repo](https://github.com/taresh18/nano-codec):
|
| 73 |
+
```bash
|
| 74 |
+
python inference.py --input audio.wav --output reconstructed.wav
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 75 |
```
|
| 76 |
|
| 77 |
## 📚 References
|