
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
How to: Set Element Merge Directive Details
You use the DSL Details window together with the Domain-Specific Language Designer and DSL Explorer. The Element Merge Directive Details channel appears when you add or click an element merge directive in DSL Explorer as described in the following procedure.
To set element merge directive details for an element
In DSL Explorer, right-click the element, and click Add New Element Merge Directive.
The DSL Details window appears with the Element Merge Directive Details channel open.
In the Indexing class list, click the class on which to index the merge.
The tool window caption for this information also appears. For example, the caption might read “DSL Details – Merge Directive: ExampleModel accepts ExampleElement." From the caption, you can identify that ExampleModel is the class for which you are defining a merge directive and ExampleElement is the class that will be merged into the ExampleModel.
Click one of these options:
Forward merge to a different domain class. After you click this option, type the domain path of the new domain class in the box. This domain class will manage the merge as long as the domain class is in scope. For example, a domain path might be "ClassAReferenceClassB.ClassB", where ClassAReferenceClassB is a domain relationship and ClassB is the property name of the role upon which the indexing class interacts.
Process merge by creating links at paths. After you click this option, type a domain path in the box. This path instructs the Domain-Specific Language Designer on how to merge the incoming indexing class. For example, you can specify the location in which to create a link and the link, which connects the instance of the parent with the instance of the indexing class. To do this, you must define a merge directive for ClassA. ClassA participates in a domain relationship, which is named ClassAContainsClassB, and contains a collection of ClassB classes, if you specify the indexing class as ClassB. You can specify the link path as ClassAContainsClassB.Bs, where property Bs is the property name of the role that ClassA plays.
(Optional) Select the Uses custom accept check box to specify custom code.
If you select this check box, you can decide whether an instance of the indexing class should be accepted for merging into the parent class. For example, you have the ClassAContainsClassB domain relationship and you are defining a merge directive for ClassA with ClassB as the incoming indexing class. If you specify the custom accept to be true, and you transform all templates, a method call to CanMergeClassB appears in the method ClassA::CanMerge method. You will need to create this custom method ClassA::CanMergeClassB.
(Optional) Select the Uses custom merge check box to specify that you want to create custom code for the merge.
If you select this check box, you must merge the classes yourself. Paths are ignored. You can use the example in the previous step. If you select the Uses custom merge check box, you must implement ClassA::MergeRelateClassB and ClassA::MergeDisconnectClassB. For example, when ClassB is added to the ClassA’s collection, you will want to assign a unique value in the ClassB.Identification domain property. You can implement the expected methods as follows:
public class ClassA { private void MergeRelateClassB(DslModeling::ModelElement sourceElement, DslModeling::ElementGroup elementGroup) { ClassB classB = sourceElement as ClassB; if ( classB != null) { // add to the ClassA’s collection. this.Bs.Add( classB); // Here you can assign the Identification to ClassB classB.Identification = DateTime.Now.ToString(); } } private void MergeDisconnectClassB(DslModeling::ModelElement sourceElement) { ClassB classB = sourceElement as ClassB; if ( classB != null) { this.Bs.Add( classB); } } }
(Optional) Select the Applies to subclasses check box, which allows any subclasses of ClassB to be merged automatically with ClassA. | https://msdn.microsoft.com/en-us/library/bb126573(v=vs.80).aspx | CC-MAIN-2015-35 | refinedweb | 621 | 55.54 |
#include <Asynch_IO_Impl.h>
#include <Asynch_IO_Impl.h>
Inheritance diagram for ACE_Asynch_Write_Dgram_Impl:
[virtual]
[protected]
Do-nothing constructor.
[pure virtual]
This starts off an asynchronous send. Upto <message_block->total_length()> will be sent. <message_block>'s <rd_ptr> will be updated to reflect the sent bytes if the send operation is successful completed. Return code of 1 means immediate success and <number_of_bytes_sent> is updated to number of bytes sent. The <ACE_Handler::handle_write_dgram> method will still be called. Return code of 0 means the IO will complete proactively. Return code of -1 means there was an error, use errno to get the error code.
Scatter/gather is supported on WIN32 by using the <message_block->cont()> method. Up to ACE_IOV_MAX <message_block>'s are supported. Upto <message_block->length()> bytes will be sent from each <message block>=""> for a total of <message_block->total_length()> bytes. All <message_block>'s <rd_ptr>'s will be updated to reflect the bytes sent from each <message_block>.
Priority of the operation is specified by <priority>. On POSIX4-Unix, this is supported. Works like <nice> in Unix. Negative values are not allowed. 0 means priority of the operation same as the process priority. 1 means priority of the operation is one less than process. And so forth. On Win32, this argument is a no-op. <signal_number> is the POSIX4 real-time signal number to be used for the operation. <signal_number> ranges from ACE_SIGRTMIN to ACE_SIGRTMAX. This argument is a no-op on non-POSIX4 systems.
Implemented in ACE_POSIX_Asynch_Write_Dgram, and ACE_WIN32_Asynch_Write_Dgram. | http://www.theaceorb.com/1.4a/doxygen/ace/classACE__Asynch__Write__Dgram__Impl.html | CC-MAIN-2017-51 | refinedweb | 242 | 62.34 |
extract points within an image/volume mask More...
#include <vtkMaskPointsFilter.h>
extract points within an image/volume mask
vtkMaskPointsFilter extracts points that are inside an image mask. The image mask is a second input to the filter. Points that are inside a voxel marked "inside" are copied to the output. The image mask can be generated by vtkPointOccupancyFilter, with optional image processing steps performed on the mask. Thus vtkPointOccupancyFilter and vtkMaskPointsFilter are generally used together, with a pipeline of image processing algorithms in between the two filters.
Note also that this filter is a subclass of vtkPointCloudFilter which has the ability to produce an output mask indicating which points were selected for output. It also has an optional second output containing the points that were masked out (i.e., outliers) during processing.
Finally, the mask value indicating non-selection of points (i.e., the empty value) may be specified. The second input, masking image, is typically of type unsigned char so the empty value is of this type as well.
Definition at line 59 of file vtkMaskPointsFilter.h.
Definition at line 68 of file vtkMaskPointsFilter masking image.
It must be of type vtkImageData.
Specify the masking image.
It is vtkImageData output from an algorithm.
Set / get the values indicating whether a voxel is empty.
By default, an empty voxel is marked with a zero value. Any point inside a voxel marked empty is not selected for output. All other voxels with a value that is not equal to the empty value are selected for output.
Implements vtkPointCloudFilter..
Reimplemented from vtkPolyDataAlgorithm.
This is called by the superclass.
This is the method you should override.
Reimplemented from vtkPolyDataAlgorithm.
Definition at line 100 of file vtkMaskPointsFilter.h.
Definition at line 111 of file vtkMaskPointsFilter.h. | https://vtk.org/doc/nightly/html/classvtkMaskPointsFilter.html | CC-MAIN-2021-04 | refinedweb | 292 | 52.36 |
Adapters
Adapters allow you to interact with the Ethereum blockchain.
In this case, the adapter is the layer between Tailor and your connection to Ethereum network.
How to use adaptersHow to use adapters
Tailor currently only supports a web3.js adapter, with plans to support an ethers.js adapter and new adapters as they become available.
Web3 AdapterWeb3 Adapter
In order to configure the
Web3Adapter, all you need to do is create a
web3 instance, set a provider, and then pass the
web3 instance to the
.load method.
import Tailor from '@colony/tailor'; import Web3 from 'web3'; const web3 = new Web3('wss://mainnet.infura.io/ws'); const client = await Tailor.load({ ... adapter: { name: 'web3', options: { web3 } }, ... }); | https://docs.colony.io/tailor/docs-adapters/ | CC-MAIN-2019-13 | refinedweb | 116 | 67.86 |
A python library for persisting data within a script.
Project description
PyCaboose
Idea
Existing persistent storage solutions suck because they decouple your code from the data that it needs to run. Under current solutions you must either use a local file, a database, or some external service in order to store your data in between executions of your script. These solutions are bad because with any local storage you have to remember to copy your data over too when you want to use your script somewhere else while still retaining the stored data. External services require internet connections, and those can be unreliable, which is very bad. Another potential solution is to just have your script never terminate, thus it would have no need to persist data as it will retain it in memory. This is obviously stupid.
Enter PyCaboose, a Python library for persisting data within the script file itself.
Usage
Using PyCaboose is very easy. Consider the following example:
from pycaboose import Value a = Value(0) print(a.value) a.value += 1
The first time you run this script, it will print out
0. Then, the next time
you run the script, once the
Value object is instantiated, it will perform a
lookup for the most recent value, which is 1. So the
1 instead of
0.
How does it do this? Good question.
Mechanism
The secret sauce to PyCaboose is its in-script database. When the pycaboose module is imported, it opens your script file and scans it for a special marker that it places there the first time it is imported. Then, any time a PyCaboose Value is changed, it writes the new value to the script. So, using the above example, after running the script the first time, it will instead look like this:
from pycaboose import Value a = Value(0) print(a.value) a.value += 1 # pycaboose # # gANLA0sBhnEALg==
Breaking that down, it inserted a comment,
# pycaboose #, which indicates where
it will be storing data. This must be at the end of the file. Next, there is
another comment, but this time it is more involved.
There is a bunch of garbage. This garbage is a base64 encoded string. But what
does it encode? Another good question.
The b64 encoded string encodes a pickle. That pickle encodes a tuple
(line, value). The
line is how we know which variable we are talking about,
which is important if there is more than one Value in the script.
(Note this means that at the moment two Values cannot be declared
on the same line. Deal with it.)
In this case,
line will be
2, because we stored
a on line
2.
The
value is the stored value of the object, which in this case is
1
as that is the most recent value of the Value.
Now if we were to run the script again, upon instantiating the Value, PyCaboose will know that it has stored a value for that Value and loads that rather than using the value the user specified.
For writes, PyCaboose truncates the file, removing the line that stored the old value of the Value if it was previously stored. It then writes back any data it may have removed, and then writes the new data to the end of the file. In doing so it creates something of a LRU cache where accessing Values that haven't been accessed in a while is slower than accessing the Value that was most recently modified.
Disclaimer
Please note that this is more or less a joke and not really meant to be used. Please don't hold me responsible for data that is not persisted, or scripts that are completely mangled. For any import data you should have backups, backups of those backups, several GitHub repos containing the data, and the data should also be stored in DropBox, OneDrive, encoded and uploaded to YouTube, and should be stored on an insecure mongodb instance running on a raspberry pi in your closet.
Project details
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/pycaboose/1.1.0/ | CC-MAIN-2021-10 | refinedweb | 690 | 71.65 |
Images with all colors
Similar to the images on allrgb.com, make images where each pixel is a unique color (no color is used twice and no color is missing).
Give a program that generates such an image, along with a screenshot or file of the output (upload as PNG).
- Create the image purely algorithmically.
- Image must be 256×128 (or grid that can be screenshot and saved at 256×128)
- Use all 15-bit colors*
- No external input allowed (also no web queries, URLs or databases)
- No embedded images allowed (source code which is an image is fine, e.g. Piet)
- Dithering is allowed
- This is not a short code contest, although it might win you votes.
- If you're really up for a challenge, do 512×512, 2048×1024 or 4096×4096 (in increments of 3 bits).
Scoring is by vote. Vote for the most beautiful images made by the most elegant code and/or interesting algorithm.
Two-step algorithms, where you first generate a nice image and then fit all pixels to one of the available colors, are of course allowed, but won't win you elegance points.
* 15-bit colors are the 32768 colors that can be made by mixing 32 reds, 32 greens, and 32 blues, all in equidistant steps and equal ranges. Example: in 24 bits images (8 bit per channel), the range per channel is 0..255 (or 0..224), so divide it up into 32 equally spaced shades.
To be very clear, the array of image pixels should be a permutation, because all possible images have the same colors, just at different pixels locations. I'll give a trivial permutation here, which isn't beautiful at all:
Java 7
import java.awt.image.BufferedImage; import java.io.BufferedOutputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStream; import javax.imageio.ImageIO; public class FifteenBitColors { public static void main(String[] args) { BufferedImage img = new BufferedImage(256, 128, BufferedImage.TYPE_INT_RGB); // Generate algorithmically. for (int i = 0; i < 32768; i++) { int x = i & 255; int y = i / 256; int r = i << 3 & 0xF8; int g = i >> 2 & 0xF8; int b = i >> 7 & 0xF8; img.setRGB(x, y, (r << 8 | g) << 8 | b); } // Save. try (OutputStream out = new BufferedOutputStream(new FileOutputStream("RGB15.png"))) { ImageIO.write(img, "png", out); } catch (IOException e) { e.printStackTrace(); } } }
Winner
Because the 7 days are over, I'm declaring a winner
However, by no means, think this is over. I, and all readers, always welcome more awesome designs. Don't stop creating.
Winner: fejesjoco with 231 votes
It means you can place colors in a pattern, so when viewed with the eye, they blend into a different color. For example, see the image "clearly all RGB" on the allRGB page, and many others there.
Not dupe, but related:
small tip for verifying the output: sort the pixel array and check that all values are only 1 in difference as integer
I actually find your trivial permutation example to be quite pleasing to the eye.
@Zom-B Man, I freakin' love this post. Thanks!
Beautiful results/answers!
Not a valid answer, because it uses a source image, but I enjoyed working on a version of Las grupas de Sorolla.
I might actually work on making this an iOS app. This actually looks really cool.
You cannot make images with all possible colors because sRGB can only represent approx. 30% of all possible colors. Also the definition of "equidistant" implicitly depends on the characterisitcs of CRT because sRGB was made to emulate CRT-monitors.
Why I saw `creating` as `cheating`?
- 7 years ago
C#. After some editing, here is the current, somewhat optimized version (it even uses parallel processing!):
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using System.Drawing; using System.Drawing.Imaging; using System.Diagnostics; using System.IO; class Program { // algorithm settings, feel free to mess with it const bool AVERAGE = false; const int NUMCOLORS = 32; const int WIDTH = 256; const int HEIGHT = 128; const int STARTX = 128; const int STARTY = 64; // represent a coordinate struct XY { public int x, y; public XY(int x, int y) { this.x = x; this.y = y; } public override int GetHashCode() { return x ^ y; } public override bool Equals(object obj) { var that = (XY)obj; return this.x == that.x && this.y == that.y; } } // gets the difference between two colors static int coldiff(Color c1, Color c2) { var r = c1.R - c2.R; var g = c1.G - c2.G; var b = c1.B - c2.B; return r * r + g * g + b * b; } // gets the neighbors (3..8) of the given coordinate static List<XY> getneighbors(XY xy) { var ret = new List<XY>(8); for (var dy = -1; dy <= 1; dy++) { if (xy.y + dy == -1 || xy.y + dy == HEIGHT) continue; for (var dx = -1; dx <= 1; dx++) { if (xy.x + dx == -1 || xy.x + dx == WIDTH) continue; ret.Add(new XY(xy.x + dx, xy.y + dy)); } } return ret; } // calculates how well a color fits at the given coordinates static int calcdiff(Color[,] pixels, XY xy, Color c) { // get the diffs for each neighbor separately var diffs = new List<int>(8); foreach (var nxy in getneighbors(xy)) { var nc = pixels[nxy.y, nxy.x]; if (!nc.IsEmpty) diffs.Add(coldiff(nc, c)); } // average or minimum selection if (AVERAGE) return (int)diffs.Average(); else return diffs.Min(); } static void Main(string[] args) { // create every color once and randomize the order var colors = new List<Color>(); for (var r = 0; r < NUMCOLORS; r++) for (var g = 0; g < NUMCOLORS; g++) for (var b = 0; b < NUMCOLORS; b++) colors.Add(Color.FromArgb(r * 255 / (NUMCOLORS - 1), g * 255 / (NUMCOLORS - 1), b * 255 / (NUMCOLORS - 1))); var rnd = new Random(); colors.Sort(new Comparison<Color>((c1, c2) => rnd.Next(3) - 1)); // temporary place where we work (faster than all that many GetPixel calls) var pixels = new Color[HEIGHT, WIDTH]; Trace.Assert(pixels.Length == colors.Count); // constantly changing list of available coordinates (empty pixels which have non-empty neighbors) var available = new HashSet<XY>(); // calculate the checkpoints in advance var checkpoints = Enumerable.Range(1, 10).ToDictionary(i => i * colors.Count / 10 - 1, i => i - 1); // loop through all colors that we want to place for (var i = 0; i < colors.Count; i++) { if (i % 256 == 0) Console.WriteLine("{0:P}, queue size {1}", (double)i / WIDTH / HEIGHT, available.Count); XY bestxy; if (available.Count == 0) { // use the starting point bestxy = new XY(STARTX, STARTY); } else { // find the best place from the list of available coordinates // uses parallel processing, this is the most expensive step bestxy = available.AsParallel().OrderBy(xy => calcdiff(pixels, xy, colors[i])).First(); } // put the pixel where it belongs Trace.Assert(pixels[bestxy.y, bestxy.x].IsEmpty); pixels[bestxy.y, bestxy.x] = colors[i]; // adjust the available list available.Remove(bestxy); foreach (var nxy in getneighbors(bestxy)) if (pixels[nxy.y, nxy.x].IsEmpty) available.Add(nxy); // save a checkpoint int chkidx; if (checkpoints.TryGetValue(i, out chkidx)) { var img = new Bitmap(WIDTH, HEIGHT, PixelFormat.Format24bppRgb); for (var y = 0; y < HEIGHT; y++) { for (var x = 0; x < WIDTH; x++) { img.SetPixel(x, y, pixels[y, x]); } } img.Save("result" + chkidx + ".png"); } } Trace.Assert(available.Count == 0); } }
256x128 pixels, starting in the middle, minimum selection:
256x128 pixels, starting in the top left corner, minimum selection:
256x128 pixels, starting in the middle, average selection:
Here are two 10-frame animgifs that show how minimum and average selection works (kudos to the gif format for being able to display it with 256 colors only):
The mimimum selection mode grows with a small wavefront, like a blob, filling all pixels as it goes. In the average mode, however, when two different colored branches start growing next to each other, there will be a small black gap because nothing will be close enough to two different colors. Because of those gaps, the wavefront will be an order of magnitude larger, therefore the algorithm will be so much slower. But it's nice because it looks like a growing coral. If I would drop the average mode, it could be made a bit faster because each new color is compared to each existing pixel about 2-3 times. I see no other ways to optimize it, I think it's good enough as it is.
And the big attraction, here's an 512x512 pixels rendering, middle start, minimum selection:
I just can't stop playing with this! In the above code, the colors are sorted randomly. If we don't sort at all, or sort by hue (
(c1, c2) => c1.GetHue().CompareTo(c2.GetHue())), we get these, respectively (both middle start and minimum selection):
Another combination, where the coral form is kept until the end: hue ordered with average selection, with a 30-frame animgif:
UPDATE: IT IS READY!!!
You wanted hi-res, I wanted hi-res, you were impatient, I barely slept. Now I'm excited to announce that it's finally ready, production quality. And I am releasing it with a big bang, an awesome 1080p YouTube video! Click here for the video, let's make it viral to promote the geek style. I'm also posting stuff on my blog at, there will be a technical post about all the interesting details, the optimizations, how I made the video, etc. And finally, I am sharing the source code under GPL. It's become huge so a proper hosting is the best place for this, I will not edit the above part of my answer anymore. Be sure to compile in release mode! The program scales well to many CPU cores. A 4Kx4K render requires about 2-3 GB RAM.
I can now render huge images in 5-10 hours. I already have some 4Kx4K renders, I will post them later. The program has advanced a lot, there have been countless optimizations. I also made it user friendly so that anyone can easily use it, it has a nice command line. The program is also deterministically random, which means, you can use a random seed and it will generate the same image every time.
Here are some big renders.
My favorite 512:
The 2048's which appear in my video:
The first 4096 renders (TODO: they are being uploaded, and my website cannot handle the big traffic, so they are temporarily relocated):
Now this is cool!
Very nice :-D Now make some bigger ones!
@squeamishossifrage: it is O(N^2) with a big constant multiplier, it takes over a minute with 32K colors, so it would need optimization before I do that. How about I do that after 10 votes :).
@fejesjoco Start now; you'll get 10 votes; this is a really nice one! I have the same complexity issues with mine; 256x128 takes about 5 seconds but 4096x4096 takes over an hour, but optimizing is difficult because it's easier to play with stuff in unoptimized code.
You're a true artist! :)
OK I think I maxed it out, optimized, 512x512, animgifs, what else could I add? The 6-bit image looks just like the 5-bit one, so I'm not really interested in bigger sizes, I don't think it's worth the wait. But of course anyone can try :).
Keep a list with all the endpoints, just like a backtracking fill algorithm
I smell a winner! The animations are beautiful and the 512x512 really took it up a notch.
How much for a print?
^ I want one too!
I'm working on huge renders and an 1080p video. Gonna take hours or days. I hope someone will be able to create a print from a big render. Or even a t-shirt: code on one side, image on the other. Can anyone arrange that?
whats the code for the last one? wondering about that
@masterX244: It's the same code. Specific parameters plus a different comparator in the initial pixel sorting (the comparator will be parameterized in the next version).
@fejesjoco what parameters? maybe you could post the parameters below for usage
experimenting with some parameters atm to find one suitable for panorama print on 8kx2k size
I'm rewriting the whole thing to be faster because big renders take too much time. I'm also adding more parameterization options.
goin to abuse mah webserver as renderer for the panorama big one...
I'm seriously considering this as a live wallpaper for my phone (at an appropriate framerate). Any objections if I throw up a github/download link if I do? Attribution would obviously be present.
@Geobits I don't mind but I suggest to wait for the final version. Instead of linking to my SE profile, please check out my contact info on my SE profile and link to those.
Ooooh, final version. I like the sound of that. Will do.
rendering atm; 0,05 % on my lowend VPS and 1 % at my comp for a 8192x2048 in average mode with the hue sorting
@fejesjoco You could submit it to threadless; they make their shirts with spot process printing so the colors should be fine, although I don't know what their size and resolution limits are. Still, they'll handle all the printing, promo, and sales. You have to get community support to get threadless to actually accept the design though. You could also just search around for printers, e.g. this guy. Dunno where you live, but maybe you can find somebody local, although threadless is nice because it handles distribution.
@JasonC 4% atm on my render; cpu is nicely col at around 40 °C
It gets slower as it's progressing, it may take many days. I sped it up a lot already, I barely slept. I started running some renders for the night, some of them quit with out of memory exceptions, the others have barely progressed. I'm working hard on making it even faster, please hang tight.
yeah; i know that it may take days; but its no issue for me to let the comp run 24/7 for a while :P at least tis a nice stability test for the system
A simple 512x512 render took minutes with the above code, took 1m20s at midnight, and after the 3rd-4th total rewrite, it's now about 20s. Let me work on it a bit more, and let's hope I can make 4Kx4K renders in a couple of hours at most.
could you post the current versions, too?
another issue: program doesnt support larger amounts of checkpoints (tiied 50 and above: just getting a error) @fejesjoco
grrr; error... meant 500 checkpoints
Needs more parallelism! I want to see those cores *burn*! :D
@fejesjoco even that halfway optimized one would help to get that 4k one rendered cause anything is better than 2 weeks of rendertime :P
@masterX244 and everyone: Please be patient. A halfway optimized version will simply not get a 4K render. The algorithm is brutally exponential. The 4K image can take 1000x-10000x-100000x more time than the 512K image. I expect the queue size to go up to 1 million, and it is executed millions of times. One trick can mean the difference between hours and days. I am progressing very well and have many more ideas, it shouldn't take much longer. Please wait 1 or 2 days and you will get a 4K render a lot sooner than if you start now with the unfinished version.
Hmm... was this inspired by diffusion-limited aggregation?
It is readyyyyyyyyyyyyyyyyyy! See my last edit!
@Oberon I didn't know about it before. It does look like a similar concept.
2kx1k in the one mode after hue-sorting ran thru in approx 10 minutes: `All done! It took this long: 00:10:28.3399627` `artgen 128 2048 1024 1024 512 100 9263 11111111 hue-36 0 one` was the commandline used
btw @fejesjoco still having the seeds used for the video?
@masterX244: I think 12345, but not sure :). Maybe it should remain a mistery :). I also added a note: you should compile in release mode, it also speeds things up a lot. I have three 4K renders ready, the fourth may be ready today or tomorrow. I will post what I have soon.
yeah; immediately used release mode :) time to warm up my cpu, too :P
The program now scales very well to multiple CPU's. I'm running the last 4K render on 8 cores now.
rgb_2048_2.png is absolutely amazing!
I added the 4Kx4K renders. Some are still uploading, but the links will point to them when they arrive. So now this project is finished. Maybe I'll dream some new ideas in the coming days.
finally got a big render done, too.... rendered on 8192x2048 (needing wide ones for personal use);t=be95eee699d950f61cf7287b9f68e960
All your 16M images have exactly 16,703,545 colors for some reason. That's 73671 short of a win.
can ya tell which ones got nulled? @Zom-B
I think I've found why your code is so slow (Order O(n^4)), and I think I can fix it, if only I could port it to Java. I'm stuck at C# api things like OrderBy, ToDictionary and AsParallel
he already optimized :) read the latest edits after the 4k images @Zom-B :) 8kx2k took approx 6 hours with another old render runnign in paralell and other stuff running and eating cpu cycles. Currently writing a small compression utility to keep the imtermediate frames wthout hogging too much disk space up: already got a idea (using one image to track at which frame what pixel appeared)
Nice video! The music kinda cracks me up; it's so YouTube!
btw algorithm has one small issue which could give some more speedup if fixed (there are holes which you see as red spots in the hue-sort generated images after finishing -> those holes eat up space in the loop array and somehow get missed until the end when they are forcefilled) and thanks for keeping my CPU warm :)
@Zom-B: NOOOOOOOOO you're destroying my life!!! Seriously? How did you count? The program does count all colors after the render and I get 16777216, no repetitions!!! And now I checked again again and always get 16777216. I even checked with GIMP's colorcube analysis, same result. And why do you instantly accuse me of losing?
@masterX244: I know about the holes and, they are a side effect. There are just not enough similar colors to fill each branch. I doubt it can be changed. Or if you change it, it will be a different algorithm, different image. I do like it this way :).
@Zom-B: I'm open to suggestions about speeding up. I compare each new to pixel to all pixels placed already, it has its complexity. I'm doing that with as few instructions as possible. It may be changed more drastically, I could use a colorcube for searching (except in the average sqaure case, which is the slowest btw) or port it to C... I don't think it's worth any more of my or anyone's time, it's just good enough. If I spend more time with this, that will be on new algorithms.
Sorry for doubting you. It's Firefox that fscked up your images. I always copy/pasted images into paint shop pro and it always worked, except with your 4k images. Save As->Open in PSP and I count all colors with none missing.
Ok ZomB... It's just that I lived my life for this thing in the last 3 days, and you scared the hell out of me and I got very nervous. I'm alright now. I think I will submit a Firefox bugreport for that.
@masterX244 can I ask what you will do with these images? My wife wants to hang one on our wall :)
Please t-shirt with !
@fejesjoco some on my wall, too but others used as paper to fold nice looking boxes :) btw CPU still on full load :P and wide format fitted better on my wall, thats why i make those
@fejesjoco currently trying to port the simple version of your algo to java as part for my respone to another question but somehow the code says GAH! and doesnt work
Give him a medal :) awesome and neat.
@fejesjoco : seems that the big renders went 404 on your site
Yes, my site is struggling with the huge traffic, the video is going viral. I uploaded the big images to allrgb.com and my google drive (links can be found on my blog). I will re-upload them later when the traffic gets lower.
OK guys I fixed the links to point to my Google drive. I also added my fourth 4Kx4K render. It's similar to the 2nd, but look more closely!
Amazing. Well done. + 1
This really calls for a GPU implementation... It could work significantly faster :)
I got some tips here and elsewhere to submit my design to Threadless. So I did and I am waiting for approval. As it turns out, it's not as easy as submitting a rendered PNG, you have to make a complete design, survive several rounds of approval, and then get community votes. Of course I will send you a link when it's time to vote, but I doubt I have any chance next to those real pro designers there. Can anybody find a designer who can actually do something with these images? And not just mine of course, there are many awesome answers here.
The program is now featured on newscientist.com! I just want to thank you all guys, especially @Zom-B, for starting this thing and voting and giving ideas. It's also your success, codegolf's success, all geeks success :)
by the way: somehow those weird black "canyons" are generated only after the change; posting a comparison of a 8kx2k render in old and new algorithm in the next few days when it finished rendering
How awesome. Congratulations again, @fejesjoco
The allRGB website is now having capacity problems, ROFL
Some of you mentioned you would like a print. You can now get it here, I will add some more later (promo link with free shipping):
@MarkJeronimus They got CodeGolfed! It's great to see so many submissions from this thread on there!
@fejesjoco Got me an extra large one. Man you're really working the fame here; nice job! :D I'll keep an eye out for t-shirt printers too, but short-run high-quality photorealistic prints are kind of a specialty job (either the shop needs special equipment, or a screen printer has to be skilled with process prints).
You are in news !!. I created an account in this site just to tell you this :) I had seen this answer in this site couple of days ago and surprized to see it in news !!
by the way finished a 8kx2k render with the program out of the post aka the unoptimized version; took me 6 days to finish.... (wanted to see the differences added by the optimisations :)
You also made Gizmodo! I don't think I've ever seen the results of an of the CodeGolf challenges get this kinda of feeback. Really really really well done.
@fejesjoco Print arrived today; it's gorgeous -- society6 did a beautiful, high-quality job. Do you get decent kick-backs for sales with them?
In case anyone's still reading, here's an app for Android that I'm working on:
Whoa, this is great!
I have no words, it's just art.... Well done!
The output from this looks scarily similar to an image-generation program I've been working on for a while: (well, some of them do). For example, see this: (generated with properties set to [-.2,-.2,-.2,0,0,2] and seed properties set to [3,1,0,3]).
I put my own twist on your algorithm here:
These look like beautiful rainbow coral reefs.
For anyone who is having trouble deciding on a `NUMCOLORS` to use when they change the dimensions.. use `NUMCOLORS = (int)Math.Ceiling(Math.Pow(HEIGHT* WIDTH, (1.0 / 3.0)));`
After seeing this, I wrote a script to generate random images. They happen to look very similar to these.
Sorry, the file you have requested does not exist. :( ... the horrors of off-site hosting.
About to make this into an iOS app so people can generate their own images. :D
Umm the huge render links are dead.
This is beautiful.
The last 4 links point to a Google Drive location which no longer exists.
@fejesjoco it would appear that the source code hosted on google code is not available? I am getting an `401: Anonymous users does not have storage.objects.get access to object google-code-archive/v2/code.google.com/joco-tools/project.json.` or `The project joco-tools was not found.` error every time i attempt to access it :( would it be possible to share the source code via GitHub or otherwise?
What happened to the alternative code where the previews on the website got posted after the initial version?
@TaylorScott Had the source still floating around in a corner of my harddisks
20K CPU-hours in on a Ryzen processor on rendering one of those corals. 50% according to output but my estimate is 30%. Rendering it with 10K steps
I immediately thought this was a pretty neat idea when I saw it a couple years ago, but was kind of shocked at how slow it is. I have since implemented it in Python (renders in an hour or two), Java (renders in about 2-3 minutes) and most recently C++ (renders in about 20-25 seconds), all single threaded (w/ fully shuffled colors, the fastest). Most variants use CIELAB colorspace to look extra good; strict color orderings (non-shuffled colors, and similar) produce extremely wild outputs, sometimes deterministically. The variety is endless; I could be coaxed into posting examples and a repo.
@Mumbleskates make repo please!
@BenjaminUrquhart
@Mumbleskates thanks
@Mumbleskates Just FYI, my latest version runs in a couple of seconds. That's how it can also run in the Android app.
@fejesjoco Nice. I'm assuming the approach is similar, if that's the case; what size is it rendering? The only reason the one I made takes so long (30-40 minutes for some rendering modes, full 24 bit) is because it seeks exact best answers. Introducing stochastic inaccuracy could greatly speed it up, but I've found that for some of the coolest patterns this actually makes the end result less interesting.
The joco.name and source code links appear to be dead. Can these be updated?
rainbowsmoke.hu still works
Peter Taylor 7 years ago
When you say "Dithering is allowed", what do you mean? Is this an exception to the rule "each pixel is a unique color"? If not, what are you allowing which was otherwise forbidden? | https://libstdc.com/us/q/codegolf/22144 | CC-MAIN-2021-25 | refinedweb | 4,511 | 73.98 |
To understand this example, you should have the knowledge of following C++ programming topics:
#include <iostream> using namespace std; struct Distance{ int feet; float inch; }d1 , d2, sum; int main() { cout << "Enter 1st distance," << endl; cout << "Enter feet: "; cin >> d1.feet; cout << "Enter inch: "; cin >> d1.inch; cout << "\nEnter information for 2nd distance" << endl; cout << "Enter feet: "; cin >> d2.feet; cout << "Enter inch: "; cin >> d2.inch; sum.feet = d1.feet+d2.feet; sum.inch = d1.inch+d2.inch; // changing to feet if inch is greater than 12 if(sum.inch > 12) { ++ sum.feet; sum.inch -= 12; } cout << endl << "Sum of distances = " << sum.feet << " feet " << sum.inch << " inches"; return 0; }
Output
Enter 1st distance, Enter feet: 6 Enter inch: 3.4 Enter information for 2nd distance Enter feet: 5 Enter inch: 10.2 Sum of distances = 12 feet 1.6 inches
In this program, a structure
Distance containing two data members (inch and feet) is declared to store the distance in inch-feet system.
Here, two structure variables d1 and d2 are created to store the distance entered by the user. And, the sum variables stores the sum of the distances.
The
if..else statement is used to convert inches to feet if the value of inch of sum variable is greater than 12. | https://cdn.programiz.com/cpp-programming/examples/inch-feet-structure | CC-MAIN-2019-47 | refinedweb | 213 | 75.5 |
SQLite is a C library that provides a lightweight disk-based database that
doesn’t require a separate server process. Applications can use SQLite for
internal data storage. It’s also possible to prototype an application using
SQLite and then later port the application to a production database system.
SQLite databases are stored in a file on disk (usually with a “.db”
extension). If you attempt to connect to a database file that doesn’t exist,
SQLite with create a new database, assign it the name you passed to the
connect function and save it to your current working directory.
Typical sqlite setup and usage in Python is as follows:
- Create a connection object
- Initialize a database cursor
- Construct a query for the dataset of interest
- Pass the query string to the cursor’s
executemethod
- Iterate over the cursor’s result set
import sqlite3 db = sqlite3.connect(<filename>.db) cursor = db.cursor() SQL = "SELECT * FROM SAMPLE_TABLE" cursor.execute(SQL) # Iterate over cursor and print queried records. for record in cursor: print(record)
The result will be a list of tuples, so data elements can be accessed by row or selectively by referencing components by index offset.
Creating Datebases and Tables with
sqlite3
If the database file passed to the
sqlite3.connect method doesn’t exist, a
new database with the name specified will be created. The following example
creates a database consisting of 2 tables: The first table holds closing
stock prices, the second contains a mapping between ticker symbols and
company names (for more information on
SQLite datatypes and the resulting
affinity mappings of common datatypes for other RDBMS,
SQLite official documentation):
""" Creating a new database with two tables using sqlite3. ============================= Table 1 | ============================= TABLENAME: `CLOSING_PRICES` | | FIELDS : DATE TEXT | TICKER TEXT | CLOSE REAL | ============================= ============================= Table 2 | ============================= TABLENAME: `TICKER_MAPPING` | | FIELDS : TICKER TEXT| COMPANY NAME TEXT| ============================= """ import sqlite3 # Create new database `sample.db`. Notice `sample.db` is now # listed in your working directory. db = sqlite3.connect("sample.db") # Initiate cursor object. cursor = db.cursor() # Specify the DDL to create the two tables. tbl1_ddl = """CREATE TABLE CLOSING_PRICES ( DATE TEXT, TICKER TEXT, CLOSE REAL)""" tbl2_ddl = """CREATE TABLE TICKER_MAPPING ( TICKER TEXT, COMPANY_NAME TEXT)""" # Call the `cursor.execute` method, passing tbl1_ddl & tbl2_ddl as arguments. cursor.execute(tbl1_ddl) cursor.execute(tbl2_ddl) # IMPORTANT! Be sure to commit changes you want persisted. Without # commiting, changes will not be saved. db.commit() # Close connection to `sample.db`. db.close()
To verify that your tables have been created, run the following:
# Restablish connection to `sample.db`. db = sqlite3.connect('sample.db') cursor = db.cursor() cursor.execute("SELECT name FROM sqlite_master WHERE type='table'") print(cursor.fetchall()) db.close()
The following example demonstrates two methods of loading data into SQLite
tables. The first method assumes the data is already available within the
current Python session. The second method assumes data is being loaded from a
delimited data file. For the second example, refer to
ticker_data.csv,
which can be found here.
""" ========================================================== Method #1: Data already avialable in Python session | ========================================================== Insert four records into `CLOSING_PRICES` table based on the closing prices of AXP, GE, GS & UTX on 7.22.2016. """ # Reestablish connection to `sample.db` database. db = sqlite3.connect('sample.db') cursor = db.cursor() # Single records can be inserted using the `cursor.execute` method. cursor.execute("INSERT INTO TICKER_MAPPING VALUES ('AXP', 'American Express Company')") cursor.execute("INSERT INTO TICKER_MAPPING VALUES ('GE' , 'General Electric Company')") cursor.execute("INSERT INTO TICKER_MAPPING VALUES ('GS' , 'Goldman Sachs Group Inc')") cursor.execute("INSERT INTO TICKER_MAPPING VALUES ('UTX' , 'United Technologies Corporation')") # We can insert several records at once if we create a list of tuples of the # data to insert, then call `cursor.executemany`. closing_prices = [ ('20160722', 'AXP', 64.28), ('20160722', 'GE' , 32.06), ('20160722', 'GS' , 160.41), ('20160722', 'UTX', 105.13) ] cursor.executemany( "INSERT INTO CLOSING_PRICES VALUES (?,?,?)", closing_prices ) # Not forgetting to commit changes and close connection. db.commit() db.close()
The
(?,?,?) in
cursor.executemany serve as placeholders for columns in the
target table. There should be one
? for each column in the target table.
A more common scenario may be loading data from delimited data file into an SQLite database table. The syntax is similiar, with added file handling constructs:
""" ===================================== Method #2: Data read in from .csv | ===================================== Requires `ticker_data.csv` file. """ import sqlite3 import csv # Reestablish connection to `sample.db` database. db = sqlite3.connect('sample.db') cursor = db.cursor() # Open `ticker_data.csv`, and create a csv.reader instance. Then call # `executemany` on the records read from file to load into the database. with open('ticker_data.csv', 'r') as f: fcsv = csv.reader(f) # Read records from file into list. recs_to_load = [record for record in fcsv] # Load records into CLOSING_PROCES table. cursor.executemany("INSERT INTO CLOSING_PRICES VALUES (?,?,?)", recs_to_load) # Not forgetting to commit changes and close connection. db.commit() db.close()
Retrieving Table Data from SQLite Databases
To retrieve SQLite database records, an iterator in the form of a database cursor is returned, which is traversed to obtain to returned dataset elements:
import sqlite3 # Reestablish connection to `sample.db` database. db = sqlite3.connect('sample.db') cursor = db.cursor() #construct a query to retrieve data from `CLOSING_PRICES`. SQL = "SELECT * FROM CLOSING_PRICES" # call `cursor.execute` on query string. cursor.execute(SQL) # `cursor` can now be iterated over. for rec in cursor: print(rec) # Not forgetting to commit changes and close connection. db.commit() db.close()
Headers need to be extracted from the
cursor.description attribute:
# obtain reference to table headers. import sqlite3 # re-establish connection to `sample.db` database. db = sqlite3.connect('sample.db') cursor = db.cursor() # Construct query to retrieve data from CLOSING_PRICES table. SQL = "SELECT * FROM CLOSING_PRICES" # Call `cursor.execute` on SQL. cursor.execute(SQL) # Capture table headers into `headers` list. headers = [i[0] for i in cursor.description] # Not forgetting to commit changes and close connection. db.commit() db.close()
Using Bind Variables with SQLite
The following demonstrates the use of bind variables in SQLite for dynamic data retrieval:
import sqlite3 # Reestablish connection to `sample.db` database. db = sqlite3.connect('sample.db') cursor = db.cursor() # Bind variable key-value pairs. params = {'symbol':'GE','date':'20161125'} SQL = "SELECT * FROM CLOSING_PRICES WHERE TICKER=:symbol AND DATE!=:date" cursor.execute(SQL, params) # Get headers. headers = [i[0] for i in cursor.description] # Read records into list iterating over cursor. records = [record for record in cursor] # Not forgetting to commit changes and close connection. db.commit() db.close()
Final Note
At times, it can be useful to interact with SQLite databases from a graphical interface, especially as the number of database tables grows. One such tool is SQLiteStudio, a versatile SQLite IDE that includes the tools necessary to manage databases, schemas, tables and related objects. I encourage you to check it out. Until next time, happy coding! | http://www.jtrive.com/introduction-to-sqlite3.html | CC-MAIN-2020-16 | refinedweb | 1,112 | 51.75 |
I would like to Execute SPSS Statistics command syntax with SPSS Java Plugin.<br> I tried the demo which is described in the User Guide and it is not working for me:<br>
import com.ibm.statistics.plugin.*;
public class demo {public static void main(String[] args) {
try {
StatsUtil.start();
String[] command={"OMS",
"/DESTINATION FORMAT=HTML OUTFILE='/output/demo.html'.",
"DATA LIST FREE /salary (F).",
"BEGIN DATA",
"21450",
"30000",
"57000",
"END DATA.",
"DESCRIPTIVES salary.",
"OMSEND."};
StatsUtil.submit(command);
StatsUtil.stop();
} catch (StatsException e) {
e.printStackTrace();
}
}
}
Which steps do i have to take to get it working?
Or is there another possibility to run SPSS Statistics command syntax automatically.
The Production Mode (productionscript) or a Batch Job is not working because it's not a Server License.
Thanks for your support!
Answer by SystemAdmin (532) | Dec 05, 2012 at 04:42 PM
You didn't provide any clue about what happens when you run this, but perhaps your CLASSPATH is not set correctly.<br>
But you can run syntax without resorting to the Java plugin.
You can create a production mode job and then execute it by running Statistics with the -production command line switch. See the help on command line for details. This does not require a Server license unless you are trying to run the job remotely on SPSS Server.
HTH,
Jon Peck
Answer by SystemAdmin (532) | Dec 06, 2012 at 10:36 AM
Thanks a million!<br>
We're using the production command.
cd /d C:\Program Files\IBM\SPSS\Statistics\20 #*SPSS Statistics path
stats C:\job1.spj -production #*SPJ-job created in SPSS Statistics
This works perfectly for Version 20 and 21.
The Java solution is still not running.
The CLASSPATH should be set correctly.
The problem seems to have something to do with the main class.
German errors: Hauptklasse fehlt -> main class missing
We've already tried a workaround with a manifest-file and failed. :(
I've added a sceenshot of the cmd.
Even if we will probably stick to the production job, it would be good to know how to use the Java Plugin.
Thanks again,...
Kind Regards
Elvira
Answer by SystemAdmin (532) | Dec 06, 2012 at 05:35 PM
To compile the example, you need to specify both the classpath and the path to the source file. For example:<br>
javac -classpath c:\statistics\21\spssjavaplugin.jar demo.java
where 'c:\statistics\21' is the location where Statistics 21 is installed, and in this example the source file 'demo.java' is in the directory from which you're running javac.
Then, from that same directory, you would use the following to run the demo:
java -classpath .;c:\statistics\21\spssjavaplugin.jar demo
Also, you'll probably want to change the path in the example code from '/output/demo.html' to a valid location on your machine.
HTH
Answer by SystemAdmin (532) | Dec 12, 2012 at 08:42 AM
javac -classpath "C:\Program Files\IBM\SPSS\Statistics\21\spssjavaplugin.jar" demo.java<br> java -classpath .;"C:\Program Files\IBM\SPSS\Statistics\21\spssjavaplugin.jar" demo<br>
...works for me! Thanks!
45 | https://developer.ibm.com/answers/questions/221178/$%7Buser.profileUrl%7D/ | CC-MAIN-2020-10 | refinedweb | 517 | 58.89 |
Allows arbitrary number of commands to be strung together with each one feeding into the next ones input. Syntax is simple: x=pipe("cmd1", "cmd2", "cmd3").read() is equivalent to bash command x=
cmd1 | cmd2 | cmd3.
Works under python 2.4.2
Discussion
I wrote this because I wanted a convenient way to write bash like scripts in python. Occasionally there is some external command that needs to be invoked (such as 'jar' in my case) from within python. This makes it easier to handle and process these commands. Try the following:
import pipe
for i in pipe.pipe("cat /etc/passwd", "grep /bin/bash"): print i
to print all lines with '/bin/bash' from file '/etc/passwd'. I went a little further than just allowing strings to be issued as commands though. I thought wouldn't it be great if you could slot in python functions along the way to do processing in python? Simple:
import pipe import re
def grepper(fin, fout): ..for line in fin: ....if (re.search('/bin/bash', line)): ......fout.write(line)
for i in pipe.pipe("cat /etc/passwd", grepper): print i
To take it even further you could do the following:
import pipe import re
def grepper(fin, fout): ..for line in fin: ....if (re.search('/bin/bash', line)): ......fout.write(line)
def catter(fin, fout): ..f = file('/etc/passwd') ....for line in f: ......fout.write(line) ..f.close()
for i in pipe.pipe(catter, grepper): print i
You can intermix python functions with script utility software and apps that rely on communicating via standard io.
Pipe arguments are also very flexible, note that you can pass pipe a list of the already separated arguments for each command:
dirlist=pipe(["ls", "-al"])
is equivalent to:
dirlist=pipe("ls -al")
I've also included use of quotes in pipe so that:
dirlist=pipe("ls -al 'a funny name'")
will give the three arguments ["ls", "-al", "a funny name"]. You can also use backslash to quote a quote.
There are defects with the implementation. Currently the python functions commands do not behave as true processes in a pipe - they are all executed from the same python process. This means they have to be called during the building the building of the pipeline to evaluate whole stream that goes into the function. Perhaps a better way would be to use blocking threads.
A further convenience function could be written to build a callable object that encapsulates arguments for the pipe function:
def grepper2(fin, fout, args): ...
capture(grepper2, ["-v", "/bin/bash"]))
capture() returns a callable object which accepts fin and fout and has args stored as an instance.
more natural syntax for pipes:
I've seen that code before. The only problem is very time you need a to include a new utility you need to write the function for it.
stderr. I like the basic concept. Any idea how to trap stderr from all these? What if there are all subprocesses -- would that make trapping stderr any easier? | http://code.activestate.com/recipes/475171/ | crawl-002 | refinedweb | 503 | 74.39 |
I just had an interesting thought that I’d never seen published anywhere yet about jQuery. It’s real simple, nothing new, but I’d never thought about it before.
Normally, I’d do something like this:
var menu = $('.main-menu'),
items = menu.find('li'),
anchors = menu.find('a');
But down the line in my code, using items loses its connection with menu. I mean sure, I could have used variables like ‘menuItems’ and ‘menuAnchors’, but why do that when you could just do:
var menu = $('.main-menu');
menu.items = menu.find('li');
menu.anchors = menu.find('a');
// Later
menu.anchors.on('click', function() {}); // etc...
Of course you’re limited to using variable names that aren’t already in use by javascript and jQuery, but its convenience is nice to logically group objects together like that.
I mean, you could do the same with creating an empty object first, then storing the jQuery objects inside that, but it’s just one unnecessary step when you already have a perfectly good object to work with.
Just thought I’d share my “discovery” today, haha.
It’s a very messy way of working on things and you’re also giving some of your control away. You should be working within your own objects and your own namespace, not jQuery’s. You may be creating memory leaks all over the place, but you wouldn’t know since you (I’m assuming here) don’t actually know what jQuery is doing.
It does look pretty nice though, but I pretty much do something similar anyway.:
var menu = $('.main-menu');
menuItems = menu.find('li');
menuAnchors = menu.find('a');
// Later
menuAnchors.on('click', function() {}); // etc...
Or you could do this:
var menu = $('.main-menu');
menu_items = menu.find('li');
menu_anchors = menu.find('a');
// Later
menu_anchors.on('click', function() {}); // etc...
I just have some questions, if you wouldn’t mind explaining further. Thanks.
“It’s a very messy way of working on things and you’re also giving some of your control away.”
How so?
“You should be working within your own objects and your own namespace, not jQuery’s.”
Why?
“You may be creating memory leaks all over the place, but you wouldn’t know since you (I’m assuming here) don’t actually know what jQuery is doing.”
Do YOU know what it is doing?
Are you really trying to learn here or are you set on your way being “right”? I’m asking because the third quote there I begin with “You may” which actually answers your question, but cache your jQuery objects within jQuery objects if you want, I’m really not going to stop you – All I’m saying is that it’s a bad idea since you don’t control jQuery.
As for modular code and namespaces:
For small js scripts I guess it’s fine to work in jQuery’s namespace but once you start working on larger apps it becomes a problem and your own namespace becomes necessary. By default backboneboilerplate comes with all of this. It sets up modules for you and links all your scripts together with require.js.
I think you both made valid points. I don’t feel safe adding my properties and methods to an object created by another library, so i store jQuery elements like so:
var menu = {
$: $(‘#menu’),
prop: value
};
menu.$.addClass(‘super-special’);
Interestingly enough though I saw memory leaks mentioned somewhere and a quest to learn more lead me here. I’m fairly certain that none of the code above would cause memory leaks my my definition (a memory leak keeps growing IMO, not simple be maintained across the life of a page) some articles though, stated storing DOM objects to variables inside closers = the most common cause for leaks.
You must be logged in to reply to this topic. | http://css-tricks.com/forums/topic/cache-your-jquery-objects-in-a-jquery-object-itself/ | CC-MAIN-2015-06 | refinedweb | 639 | 73.78 |
04/23/2006: Getting Hibernate to Create Schema Creation SQL
I've seen some webpages that describe the SchemaExport Ant task. But it did not work when I tried to use it. The documentation for it was sparse. In any case, I traced through the underlying Hibernate code and found out that you can generate the schema creation SQL with just three lines of code:
package com.codebits; import java.io.File; import org.hibernate.cfg.Configuration; import org.hibernate.dialect.PostgreSQLDialect; public class Play { public static void main(String[] args) { Configuration cfg = new Configuration(); cfg.addDirectory(new File("config")); String[] lines = cfg.generateSchemaCreationScript(new PostgreSQLDialect()); for (int i = 0; i < lines.length; i++) { System.out.println(lines[i] + ";"); } } }
Place your .hbm.xml files into some directory (I called mine config) and then execute the above class. Your schema creation script will be displayed on the console. | https://medined.github.io/blog/page199/ | CC-MAIN-2022-27 | refinedweb | 147 | 54.08 |
The QListViewItemIterator class provides an iterator for collections of QListViewItems. More...
#include <qlistview.h>
List of all member functions.
Construct an instance of a QListViewItemIterator, with either a QListView* or a QListViewItem* as argument, to operate on the tree of QListViewItems, starting from the argument.
A QListViewItemIterator iterates over all the items from its starting point. This means that it always makes the first child of the current item the new current item. If there is no child, the next sibling becomes the new current item; and if there is no next sibling, the next sibling of the parent becomes current.
The following example creates a list of all the items that have been selected by the user, storing pointers to the items in a QPtrList:
QPtrList<QListViewItem> lst; QListViewItemIterator it( myListView ); while ( it.current() ) { if ( it.current()->isSelected() ) lst.append( it.current() ); ++it; }
An alternative approach is to use an IteratorFlag:
QPtrList<QListViewItem> lst; QListViewItemIterator it( myListView, QListViewItemIterator::Selected ); while ( it.current() ) { lst.append( it.current() ); ++it; }
A QListViewItemIterator provides a convenient and easy way to traverse a hierarchical QListView.
Multiple QListViewItemIterators can operate on the tree of QListViewItems. A QListView knows about all iterators operating on its QListViewItems. So when a QListViewItem gets removed all iterators that point to this item are updated and point to the following item if possible, otherwise to a valid item before the current one or to 0. Note however that deleting the parent item of an item that an iterator points to is not safe.
See also QListView, QListViewItem, and Advanced Widgets.-2007 Trolltech. All Rights Reserved. | http://idlebox.net/2007/apidocs/qt-x11-free-3.3.8.zip/qlistviewitemiterator.html | CC-MAIN-2014-15 | refinedweb | 265 | 63.9 |
09 December 2005 16:35 [Source: ICIS news]
TORONTO (ICIS news)--OxyVinyls said on Friday it will close its Fort Saskatchewan, Alberta polyvinyl chloride (PVC) resin plant at the end of January.?xml:namespace>
Jan Sieving, Los Angeles-based spokesperson for OxyVinyl parent Occidental Petroleum, said the closure comes because a raw material supplier is closing its Fort Saskatchewan vinyl chloride monomer (VCM) plant, which will leave the OxyVinyl unit without a feedstock supplier.
She said the closure will result in about 55 job losses. OxyVinyls will supply customers from its other plants in North America, she said, adding that OxyVinyls also has a PVC plant in Niagara Falls, Ontario.
Sieving could not immediately specify the Alberta plant’s capacity. According to a Chemical Market Reporter product profile, the unit’s capacity is 350,000 tonne/year. Industry sources here said the VCM supplier is Dow Chemical, which in 2002 announced plans to shutter its Fort Saskatchewan VCM facility. In light of Dow’s plans, OxyVinyl’s decision to close the PVC plant is not unexpected, the sources said, adding that Canada has no other local source of VCM and importing the product from the US is not a viable solution.
OxyVinyls, a 76:24 joint venture (jv) between Occidental’s OxyChem and Polyone, is described as North America’s largest PVC supplier. | http://www.icis.com/Articles/2005/12/09/1027494/oxyvinyls-to-shutter-alberta-pvc-plant-next-month.html | CC-MAIN-2014-41 | refinedweb | 223 | 56.39 |
using c++ libs with micropython
Hello there! :)
I have an 1602 rbg lcd from dfrobot (DFR0464) . This lcd only has c++ arduino library avaible, no micropython, or at least a i didn't find it yet. It shows up at I2C bus like three separate device: [62, 96, 112]
Can I use somehow c++ libs with micropython?
I figured it out eventually :)
I think the library was not working correct.
The hal_write_data and hal_write_command somehow got the blacklight I2C adress not the display it self.
that caused the issue. now works like charm.
I will post the code to other topic for this display.
@tttadam As far as I understand the driver, XX is for the LCD and YY for the backlight. You may check if in the process of rotating the parameters you assigned them wrong. The only places where the LCD is addressed is in the methods hal_write_command() and hal_write_data() with self.i2c_addr. All other calls should contain self.bl_i2c_address. (bl like backlight).
So it should be (i2c, 62, 2, 16, 96)
okay I made some more progress.
I can make only one part work, lcd or backlight...
I am not sure what would be the solution for that...
it depends how I init the lcd lcd = I2cLcd(i2c, XX, 2, 16, YY)
xx yy
62 96 - rgb ok / lcd fail
62 113 - init fail
96 62 - rgb fail /lcd ok
96 113 - init fail
113 62 - rgb fail / lcd ok
113 96 - rgb ok /lcd fail
@tttadam I found the issue. So I was using .writeto_mem in wrong parameter order.
Now works. exept the backlight. still no show any color....
@tttadam okay, I have some results! :)
I am able to init the display, but for lcd.putstr("hello") only got "@@@@@" signs on the LCD. (Still it's something)
lcd.clear() works
lcd.blink_cursor_on() works
lcd.blink_cursor_off() works, but leave an "" on the lcd, lcd.clear can't remove it, if I write on the display anything (right now anything is "@" signs) the "" will be the last caracter
lcd.backlight_rgb() or any backlight related command does nothing :( and it kills the lcd. (so after I use lcd.backlight() the caracters dissapear and the device doesn't react any of my commands until I reinit it.)
@robert-hh i am not sure how the arguments are rotated, I am getting an I2C bus error for this line (basically at the beginning :D, at line 75 )
"""Writes a command to the LCD."" self.i2c.writeto_mem(self.bl_i2c_addr, self.LCD_DDRAM, cmd)
I am using it the wrong way?
@robert-hh There is a driver here:
called pyb_i2c_grove_rgb_lcd.py. It seems to be for the right PCD, but the wrong board. But you have only to replace the calls to replace
from pyb import I2C, delay
with:
from machine import I2C
from utime import sleep_ms
and you have to replace calls to delay() with calls to sleep_ms(), and adapt the I2C api calls, which more or less replace:
i2c.mem_write(data, addr, memaddr, *, timeout=5000, addr_size=8)
into
i2c.writeto_mem(addr, memaddr, buf, *, addrsize=8)
Which just means, that the arguments are rotated.
i2c.mem_write()
@robert-hh Thanks for the tip, but I was unable to make any progress :(
I use this library for the LCD, this one worked fine with one of those i2c backpacks and an lcd.
This times runs without an error, but the display doesn't show anything, just all the pixels in the first row are on.
regarding the rgb led I found this library. This is written in python. but I tried out the writeto_mem() methods in command line, it also did nothing.
Also did a tons of googleing, with out any result
So if you could recommend me librarys it would be much appreciate :)
@tttadam It should be less complicated to combine a normal LCD1602 driver for the text and a PCA9633 driver for the background. For both, you find examples on the net. The address 96 and 112 would be the PCA9633 RGB led driver, 62 the LCD.
@tttadam Yes, you can include C++ libraries in the pycom repositories. You need to make a component in the pycom-esp-idf repository and then expose the functions / methods through the pycom-micropython-sigfox repo so that you can program your device in Python.
Please see the example here | https://forum.pycom.io/topic/5329/using-c-libs-with-micropython | CC-MAIN-2021-10 | refinedweb | 723 | 83.15 |
These are chat archives for rust-lang/rust
ndarray:
fn split<'a>( x: ArrayView1<'a, f64>, y: ArrayView1<'a, f64>, ) -> ( ArrayView1<'a, f64>, ArrayView1<'a, f64>, ArrayView1<'a, f64>, ArrayView1<'a, f64>, ) { let m = x.len() / 2; // `x` does not live long enough (borrowed value does not live long enough) (rust-cargo) // `y` does not live long enough (borrowed value does not live long enough) (rust-cargo) return ( x.slice(s![..m]), y.slice(s![..m]), x.slice(s![m..]), y.slice(s![m..]), ); }
@tsoernes You certainly could define the node as an enum, something like:
enum Node<T> { Value(T), Left(Box<Node<T>>), Right(Box<Node<T>>), Both(Box<Node<T>>, Box<Node<T>>), }
Not sure if it's not an overkill or if leaf/inner distinction with options for nodes would be easier to work with.
enum TreeNode { Leaf { value: f64, }, Node { feature_idx: usize, threshold: f64, left: Box<TreeNode>, right: Box<TreeNode>, }, }
Option<Box<TreeNode>>for the children (so there may be missing, if it is allowed)
Tthat, if not mentioned, defaults to
HeaderValue"
ArrayView::split_ator
ArrayView::reborrowplus
slice_move
split_atdid the trick for that example. Do you have any idea how to split the view with a filter, without copying?
X[np.where(X[:, i] < thresh)]; X[np.where(X[:, i] >= thresh)]which will create two views of a 2D array, 1 with rows where column
iis less than a threshold, and another view for the rest of the elements. It is possible to map the 2D array and generate two arrays of indecies --- one with rows of columns less than the threshold, and one with the rest --- and then use select, however that creates a copy of the array
/// Split `x` into two subviews: one with the rows where the value in the `feature_idx` column is below `threshold`, // and one where the value is equal or greater fn split2<'a>( x: ArrayView2<'a, f64>, feature_idx: usize, threshold: f64, ) -> (ArrayView2<'a, f64>, ArrayView2<'a, f64>) { // Any way to do both of these in 1 pass? let idxs_lt: Vec<usize> = x.outer_iter() .enumerate() .filter(|(i, e)| e[[feature_idx]] < threshold) .map(|(i, e)| i) .collect(); let idxs_gt: Vec<usize> = x.outer_iter() .enumerate() .filter(|(i, e)| e[[feature_idx]] >= threshold) .map(|(i, e)| i) .collect(); let xl = x.reborrow().select(Axis(0), &idxs_lt); let xr = x.reborrow().select(Axis(0), &idxs_gt); // mismatched types (expected struct `ndarray::ViewRepr`, found struct `ndarray::OwnedRepr`) (rust-cargo) // expected type `ndarray::ArrayBase<ndarray::ViewRepr<&'a f64>, _>` // found type `ndarray::ArrayBase<ndarray::OwnedRepr<f64>, _>` (rust-cargo) // I don't want to copy the values in x (xl, xr) }
.view()after the select, but that creates a copy which I do not want
x?
Vecs in a
for.
partition(for the first part):
u64value is within
0 .. usize::MAX?
value: u64
value <= usize::MAX as u64doesn't work as
usize::MAXare not guaranteed to fit into
u64
usizeis
u64no check if require either
#[cfg(target_pointer_width = "32")]May be all you need. The reference only implies 32 and 64 as valid values.
any(target_pointer_width = "16", target_pointer_width = "32")
target_pointer_width = "16"should be valid since it is used in std
numpythese create partial copies, not views. A view has certain structural requirements that do not hold for an arbitrary filter.
x == ((x as usize) as u64)should do the trick at runtime.
Any idea how to create a 2D
ndarray directly from a CSV file? This works:
let mut rdr = csv::Reader::from_path(file_path).unwrap(); let xx: Array1<Array1<f64>> = rdr.records() .map(|row| { row.unwrap() .into_iter() .map(|e| e.parse().unwrap()) .collect() }) .collect();
But using
let xx: Array2<f64> does not | https://gitter.im/rust-lang/rust/archives/2018/07/27 | CC-MAIN-2019-26 | refinedweb | 603 | 62.78 |
If you compile this simple program you will se what I am trying to get it to do. It all works fine other than the fact that if you get it win on you'r last try, it will say that you lost even though when it displays the numbers out, you see that you did not loose, you won. Although the computer doesn't see it that way. I don't know why it is doing this.
Thanks, August
(Script I was talking about is below.)
Code:#include <iostream> #include <conio.h> #include <math.h> #include <stdlib.h> #include <time.h> #include <fstream> using namespace std; int rand_0toN1(int n); int main(){ double lev_dif, lev_left, lev_play, lev_guess, lev_rand, goto_starter; srand(time(NULL)); // Set a seed for random-num. generation. souldnt_go: for(goto_starter=(99);goto_starter>50;){ clrscr(); cout<<"Choose level difficultey:"<<endl; cout<<endl; cout<<"1 - Super Hard"<<endl; cout<<"2 - Hard"<<endl; cout<<"3 - Medium"<<endl; cout<<"4 - Easy"<<endl; cout<<"5 - Super Easy"<<endl; cout<<"6 - Exit"<<endl; cout<<"\nOption: "; cin>>lev_dif; if(lev_dif == 6){ clrscr(); return 0; } else if(lev_dif < 1){ goto_starter = (99); } else if(lev_dif > 5){ goto_starter = (99); } else{ goto go_break; }} go_break: clrscr(); lev_play=(lev_dif + 2); lev_rand = rand_0toN1(99) + 1; cout<<"Guess a number bettween one and a hundred."<<endl; cout<<"Beginning Level "<<lev_dif; cout<<"\n"<<endl; for(lev_left = lev_play;lev_left > 0;lev_left = (lev_left - 1)){ cout<<"Guess "<<lev_left<<" of "<<lev_play<<": "; cin>>lev_guess; if(lev_guess > lev_rand){ cout<<"Wrong, guess lower."<<endl; } else if (lev_guess < lev_rand){ cout<<"Wrong, guess higher."<<endl; } else if (lev_guess == lev_rand){ cout<<"Right, you won!"<<endl; cout<<"The number was "<<lev_rand<<endl; getch( ); goto souldnt_go; } else{ clrscr(); return 0; }} cout<<"\nSorry, but you lost!"<<endl; cout<<"The right number was "<<lev_guess<<endl; getch( ); goto souldnt_go; } int rand_0toN1(int n) { return rand() % n; } | https://cboard.cprogramming.com/cplusplus-programming/64800-something-wrong-my-guessing-game.html | CC-MAIN-2017-43 | refinedweb | 298 | 64.91 |
Steve Juranich <sjuranic at condor.ee.washington.edu> writes: > I've read the docs on this, and it's still not entirely clear to me. In one > module, I've imported the re, os, and sys modules. Now in a parent module, > I will also need som funtionality from re, sys, and os. Does it severely > hinder performance to re-import the 3 system modules into the parent > namespace, or should I just resolve myself to getting at the functions by > tacking on an additional "name." construnction (e.g., > child.re.string.strip())? Just go ahead and import it in each module that uses it. The interpreter will really only load the module once, so any further imports are low overhead, just establishing a label for that module in the local namespace at the point of import. Currently loaded modules can be tracked in the sys.modules dictionary. -- -- David -- /-----------------------------------------------------------------------\ \ David Bolen \ E-mail: db3l at fitlinxx.com / | FitLinxx, Inc. \ Phone: (203) 708-5192 | / 860 Canal Street, Stamford, CT 06902 \ Fax: (203) 316-5150 \ \-----------------------------------------------------------------------/ | http://mail.python.org/pipermail/python-list/2000-September/036730.html | CC-MAIN-2013-20 | refinedweb | 173 | 65.42 |
See the attachment to this post for the full source code.
When I first started developing with SharePoint, I wanted to learn how to do the things that I did in ASP.NET. Many of those things easily transfer, thanks to Visual Studio 2010. For instance, it is very easy to use a WYSIWYG designer to create a web part using the new Visual Web Part template. It is also very easy to create an Application Page. What is not immediately evident is how to create a site page. In this post, we’ll see how to create and deploy a page template, instances of the template, and how to enable code-behind for a site page.
Using the most basic definition, a site page is customizable by an end user while an application page is not. That means that a user can pop open SharePoint Designer 2010 and make changes to a site page, but they cannot do this with an application page. So, what do we mean by “customizable”? When we open SharePoint Designer 2010 and make changes to a site page, those changes are stored in the database. The next time we request the page, the page is loaded from the database. There are more differences than this, but the key difference is really the ability to customize a page.
Coming from an ASP.NET background, we are much more used to coding application pages. We create a page, drag and drop some controls, write some backend code, hit F5, and see our page do something. One of the benefits of SharePoint is that we can create page templates that allow an end user to make changes to the page without requiring a developer. This means they can add web parts, add JavaScript, do neat things with jQuery and XSLT… all the kind of stuff you see on.
As a developer, you can do some pretty cool stuff to enable the end user with site page templates.
To start with, create an empty SharePoint 2010 project. I called mine “SampleToDeployAPage”. When prompted, choose to create this as a farm solution rather than a sandboxed solution. Once you have the project created, right-click and add a new Module called “CustomPages”. A folder is created called “CustomPages” with a file called “Sample.txt”. Rename Sample.txt to “MyPageTemplate.aspx”. Add the following markup to it:
1: <%@ Assembly Name="$SharePoint.Project.AssemblyFullName$" %>
2: <%@ Import Namespace="Microsoft.SharePoint.ApplicationPages" %>
3: <%@ Register Tagprefix="SharePoint"
4: Namespace="Microsoft.SharePoint.WebControls"
5: Assembly="Microsoft.SharePoint, Version=14.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c" %>
6: <%@ Register Tagprefix="Utilities"
7: Namespace="Microsoft.SharePoint.Utilities"
8: Assembly="Microsoft.SharePoint, Version=14.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c" %>
9: <%@ Register Tagprefix="asp"
10: Namespace="System.Web.UI"
11: Assembly="System.Web.Extensions, Version=3.5.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" %>
12: <%@ Import Namespace="Microsoft.SharePoint" %>
13: <%@ Assembly
14: Name="Microsoft.Web.CommandUI, Version=14.0.0.0, Culture=neutral, PublicKeyToken=71e9bce111e9429c" %>
15:
16: <%@ Page
17: Language="C#"
18: CodeBehind="MyPageTemplate.aspx.cs"
19: Inherits="SampleToDeployAPage.MyPageTemplate, $SharePoint.Project.AssemblyFullName$"
20: masterpagefile="~masterurl/default.master"
21: title="Testing This Page"
22: meta:progid="SharePoint.WebPartPage.Document" %>
23:
24: <asp:Content
25: <asp:Button
26: <asp:Label
27: <div></div>
28: <div></div>
29: For more information, visit
30: <a href="">
31: Chapter 3: Pages and Design (Part 1 of 2)</a>
32: </asp:Content>
It looks like a lot of code, but there’s really very little there. Line 1 defines the assembly, and Visual Studio 2010 will replace the token placeholder with the full 5-part name of our assembly. Lines 2 and 12 import a specific namespace (like a using statement in C#), and lines 3-11 register namespace prefixes. Line 19 references our assembly from the Global Assembly Cache so that SharePoint knows where to find the the class called SampleToDeployAPage.MyPageTemplate.
Now that you’ve created the markup, let’s create the code-behind. Right click the CustomPages folder and add a new Class called MyPageTemplate.aspx.cs. We’ll keep this one short:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using Microsoft.SharePoint.WebControls;
using Microsoft.SharePoint.WebPartPages;
using System.Web.UI.WebControls;
namespace SampleToDeployAPage
{
public class MyPageTemplate : WebPartPage
{
protected Button button1;
protected Label label1;
protected void Page_Load(object sender, EventArgs e)
{
}
protected void Button_Click(object sender, EventArgs e)
{
label1.Text = System.DateTime.Now.ToLongTimeString();
}
}
}
Looking at the two samples together, we are simply creating markup that references an assembly in the GAC. When we click a button, our Button_Click handler is called, and we can set the Text property of a label control in the markup. This is basic stuff to an ASP.NET developer. The result in our Solution Explorer pane should look kind of like the following:
See the attachment to this post for full source code.
Now that we’ve created our page, we need to deploy it to Visual Studio 2010. When we created our module called “CustomPages”, a file called “elements.xml” was created for us. That file tells SharePoint how to deploy our page to all of the web front end servers. We can even provision multiple instances of our template.
<?xml version="1.0" encoding="utf-8"?>
<Elements xmlns="">
<Module Name="CustomPages"
Url="SitePages"
Path="CustomPages">
<File Url="MyPageTemplate.aspx"
Name="SamplePage1.aspx"
Type="Ghostable"/>
<File Url="MyPageTemplate.aspx"
Name="SamplePage2.aspx"
Type="Ghostable"/>
<File Url="MyPageTemplate.aspx"
Name="SamplePage3.aspx"
Type="Ghostable"/>
</Module>
</Elements>
In this example, we are provisioning three instances of our page based on the single page template. We are provisioning this to the SitePages library for our site. If we deploy the solution as-is, we should see the following in SharePoint Designer 2010.
I highly recommend reading Understanding and Creating Customized and Uncustomized Files in Windows SharePoint Services 3.0 for deeper explanation of what is happening here.
At this point, we can right click the page and choose “Preview in Browser” to see the page. The URL on my box is, but this may be different for your environment. I wanted to add a few links to the Site Actions menu, and the easiest way to do this is to use the freely available Community Kit for SharePoint: Development Tools Edition. It includes a Custom Action project item that makes creating the following XML a snap, but you can simply cut and paste and add the following to the Elements.xml file (as a child of the Elements node) that we created previously.
<CustomAction Description="Custom action for page 1"
GroupId="SiteActions"
Id="MySiteAction1"
Location="Microsoft.SharePoint.StandardMenu"
Sequence="1000"
Title="MyCustomAction">
<UrlAction Url="{SiteUrl}/SitePages/SamplePage1.aspx" />
</CustomAction>
<CustomAction Description="Custom action for page 2"
GroupId="SiteActions"
Id="MySiteAction2"
Location="Microsoft.SharePoint.StandardMenu"
Sequence="1001"
Title="MyCustomAction">
<UrlAction Url="{SiteUrl}/SitePages/SamplePage2.aspx" />
</CustomAction>
<CustomAction Description="Custom action for page 3"
GroupId="SiteActions"
Id="MySiteAction3"
Location="Microsoft.SharePoint.StandardMenu"
Sequence="1002"
Title="MyCustomAction">
<UrlAction Url="{SiteUrl}/SitePages/SamplePage3.aspx" />
</CustomAction>
Notice the “SiteUrl” token in the Url attribute of the UrlAction elements that we defined. There are several token placeholders that you can use to avoid hardcoding paths in your solutions.
If we deployed everything right now, it would work. By default, a feature was created to deploy our module, and that feature is scoped to Web, meaning it is scoped to an individual site. And when we deploy our code and feature definitions, we will see links in the Site Actions menu as advertised, and the pages will render fine.
When we try to customize one of our new pages with SharePoint Designer 2010, we will get a series of errors.
For example, in SharePoint Designer 2010, go to the Site Pages node, right-click SamplePage3.aspx, and choose “Edit File in Advanced Mode”, you can edit the file, but when you save it you will get a series of errors. Save it as a new file called SamplePage4.aspx and try to preview it in the browser, you are met with the following error:
The base type 'SampleToDeployAPage.MyPageTemplate' is not allowed for this page. The type is not registered as safe.
The base type 'SampleToDeployAPage.MyPageTemplate' is not allowed for this page. The type is not registered as safe.
Remember that SharePoint is built upon ASP.NET. SharePoint is like ASP.NET with a healthy dose of Code Access Security layered on top. So, we need to do some security work to tell SharePoint that it’s OK for our page to use code behind.
Right-click the Package node in Visual Studio 2010’s Solution Explorer pane and choose View Template.
This lets us add a new configuration entry that marks our code as safe by adding a SafeControls entry to web.config.
<Assemblies>
<Assembly Location="SampleToDeployAPage.dll"
DeploymentTarget="GlobalAssemblyCache">
<SafeControls>
<SafeControl
Assembly="$SharePoint.Project.AssemblyFullName$"
Namespace="SampleToDeployAPage"
TypeName="MyPageTemplate" Safe="True"/>
</SafeControls>
</Assembly>
</Assemblies>
Yeah, that one’s a freebie :) This is a pretty cool trick on how to mark types in the current assembly as SafeControls.
Update: Waldek Mastykarz pointed out that there’s even an EASIER way to do add SafeControls. Click the CustomPages module and look at the properties window. There is a collection called “SafeControls”. Click that, and add a new SafeControl entry. I didn’t know this was there, thanks Waldek!
If we deployed everything right now, we’d still get another error if we tried to customize the page and preview it in a browser. This time, the error has to do with a security setting that enables certain pages to have code behind.
I blogged on this some time ago (see Code-blocks are not allowed within this file: Using Server-Side Code with SharePoint). The problem is that SharePoint has a setting that disallows server-side code with pages. This is a security feature that is good (you really don’t want end users to arbitrarily inject server-side code), but there may be cases where you are OK with some of your users having this capability. For instance, you can have a page that is only visible to a small team within your enterprise, and one of the team members is very technical and wants to provide some custom code for SharePoint. Party on, have fun with it, it saves my team from having to write that code.
To enable this scenario (and enable the Button_Click event handler in our code), we need to add an entry to web.config. Knowing that we can’t just go to every front-end web server and make the modifications (any admin worth his salt should slap you silly for even thinking about hand-modifying multiple web.config files in a production farm), we should provide this as part of our solution.
In the Solution Explorer, you will see a node called Features. Right-click this node and choose “Add Feature”. That will create a new feature called Feature2. Double-click this node to bring up the designer for the feature and change its scope to WebApplication.
After changing the scope to WebApplication, right-click the feature and choose “Add Event Receiver”. This will create a code file where you can handle events related to your feature. We will add code that will make modifications to web.config, adding a new entry to PageParserPaths when the feature is activated, and removing it when the feature is deactivated.
What we want to add is the following:
<SafeMode MaxControls="200" CallStack="false" DirectFileDependencies="10" TotalFileDependencies="50" AllowPageLevelTrace="false">
<PageParserPaths>
<PageParserPath VirtualPath="/SitePages/SamplePage3.aspx*" CompilationMode="Always" AllowServerSideScript="true" IncludeSubFolders="true" />
</PageParserPaths>
</SafeMode>
We want to add an entry into web.config that allows the path SitePages/SamplePage3.aspx as one of the pages that allows server-side scripting. Additionally, we don’t want to add this entry into web.config multiple times, and we want to remove this entry when our feature is deactivated. Below is the code that enables this.
using System;
using System.Runtime.InteropServices;
using System.Security.Permissions;
using Microsoft.SharePoint;
using Microsoft.SharePoint.Security;
using Microsoft.SharePoint.Administration;
using System.Collections.ObjectModel;
namespace SampleToDeployAPage.Features.Feature2
{
/// <summary>
/// This class handles events raised during feature activation, deactivation, installation, uninstallation, and upgrade.
/// </summary>
/// <remarks>
/// The GUID attached to this class may be used during packaging and should not be modified.
/// </remarks>
[Guid("122ec36d-8fbf-454b-a514-b0d9ef30af43")]
public class Feature2EventReceiver : SPFeatureReceiver
{
public override void FeatureActivated(SPFeatureReceiverProperties properties)
{
SPWebApplication webApplication = properties.Feature.Parent as SPWebApplication;
SPSecurity.RunWithElevatedPrivileges(delegate()
{
SPWebConfigModification mod = new SPWebConfigModification();
mod.Path = "configuration/SharePoint/SafeMode/PageParserPaths";
mod.Name = "PageParserPath[@VirtualPath='/SitePages/SamplePage3.aspx']";
mod.Owner = "SampleToDeployAPage";
mod.Sequence = 0;
mod.Type = SPWebConfigModification.SPWebConfigModificationType.EnsureChildNode;
mod.Value = "<PageParserPath VirtualPath='/SitePages/SamplePage3.aspx' CompilationMode='Always' AllowServerSideScript='true' />";
webApplication.WebConfigModifications.Add(mod);
webApplication.Farm.Services.GetValue<SPWebService>().ApplyWebConfigModifications();
webApplication.Update();
});
}
public override void FeatureDeactivating(SPFeatureReceiverProperties properties)
{
SPWebApplication webApplication = properties.Feature.Parent as SPWebApplication;
SPSecurity.RunWithElevatedPrivileges(delegate()
{
Collection<SPWebConfigModification> mods = webApplication.WebConfigModifications;
int initialModificationsCount = mods.Count;
for (int i = initialModificationsCount - 1; i >= 0; i--)
{
if (mods[i].Owner == "SampleToDeployAPage")
{
SPWebConfigModification modToRemove = mods[i];
mods.Remove(modToRemove);
}
}
if (initialModificationsCount > mods.Count)
{
webApplication.Farm.Services.GetValue<SPWebService>().ApplyWebConfigModifications();
webApplication.Update();
}
});
}
}
}
There is a bit of code to digest here, I am not going to explain it all (maybe in a future blog post). See the resources section below, I did a bit of research to make it finally work. Many thanks to Kirk Liehmon for his insight here.
That’s it… we’ve defined our page template, our elements.xml file to deploy the instances of the page template, a custom action so that the page shows up in the UI somewhere, we altered the solution manifest to include a SafeControls entry in web.config, and we event modified web.config to include a PageParserPaths entry for our page so that we could use code-behind. We now have a page that enables customization from within SharePoint Designer 2010.
For those wondering why this was so much work than ASP.NET, think about it: We create a page template that an end user can load into a tool and provide new widgets on the screen. In ASP.NET, we could have altered the master page or the page theme, but providing this level of end-user customization is just plain unheard of. This is a huge plus for using SharePoint as a foundation for ASP.NET application development. Even further, think about the security implications… we enabled a user to open a tool on a specific resource (thank goodness, not all resources) to provide server-side script for a page. This is simply awesome to think about how end users can gain a new level of productivity while freeing the developers from the mundane to focus on more strategic initiatives.
Pages and Design (Part 1 of 2) – An excerpt from Inside Microsoft Windows SharePoint Services 3.0 by Ted Pattison and Dan Larson. This is an excellent book, it is very highly recommended. All of the content still applies to learning SharePoint 2010.
Understanding and Creating Customized and Uncustomized Files in Windows SharePoint Services 3.0 – an excellent article by Andrew Connell that goes into depth on how page customization works with examples.
Community Kit for SharePoint: Development Tools Edition – a set of free add-ons to Visual Studio 2010 that make SharePoint development even easier.
Replaceable Parameters – list of replaceable token parameters in Visual Studio 2010 for SharePoint 2010 development.
UrlTokens of the CustomAction Feature – tokens that can be used with UrlAction for CustomActions
Force Visual Studio 2010 to Add a SafeControl Entry – This is a real gem, you have to bookmark this one. Given the current project in Visual Studio 2010, this shows how to add a SafeControl entry for a type in your project.
SharePoint CustomAction Identifiers – John Holliday did an awesome job listing the various CustomAction identifiers for SharePoint. This list is for SharePoint 2007, but highly applicable to SharePoint 2010.
I can’t thank Kirk Liehmon from ThreeWill enough for pointing out that the feature needed to be scoped to the application level instead of the Web level to deploy web.config modifications. Below is a chronological list of links that I followed while learning how to create a web.config modification in SharePoint. – this is where the lightbulb went off, I IM’d Kirk Liehmon, and it finally made sense.
Great tutorial, do you have information like this for SharePoint 2013 / VS2013?
I tried to follow along but got stuck at the first step "add a new Module called “CustomPages”. A folder is created called “CustomPages” with a file called “Sample.txt”. Rename Sample.txt to “MyPageTemplate.aspx”. Add the following markup to it"
When I add a module in VS2013, I don't get a folder with anything in it, just a class file, so I am not sure how to proceed.
Brian - I do not, I don't have a SharePoint installation available and configured to build full trust code against. Our recommendation would be to transition away from full trust code and to utilize the new SharePoint 2013 app model. Learn more at.
Great Article !! Had a lot of doubts with Site Pages earlier...But now everything is resolved!!
Cheers!! | http://blogs.msdn.com/b/kaevans/archive/2010/06/28/creating-a-sharepoint-site-page-with-code-behind-using-visual-studio-2010.aspx?wa=wsignin1.0 | CC-MAIN-2015-27 | refinedweb | 2,876 | 50.02 |
When upgrading some of my machines from FreeBSD 11 to FreeBSD 12, I found that some of them could not transfer data via Ethernet after the upgrade. ifconfig seemed to work normally, including showing "status: active", but that interface could neither send nor receive data packets, no matter what I tried. And a few minutes after booting my systems, they would silently hang, with no response whatsoever, even on a serial console.
I eventually narrowed down the problem to my machines with Intel 82547GI chips, which look like this in "pciconf -lv":
em0@pci0:1:1:0: class=0x020000 card=0x10758086 chip=0x10758086 rev=0x00 hdr=0x00
vendor = 'Intel Corporation'
device = '82547GI Gigabit Ethernet Controller'
class = network
subclass = ethernet
By comparing the FreeBSD 11 code (which I knew worked) with the FreeBSD 12 code which had the problem, I found the solution: the 82547 is an "edge" case which slipped through the cracks when the Intel em driver was modified for FreeBSD 12. Here is what I had to change in if_em.c to make the Intel 82547 Ethernet chips work:
root@prod:~ # svn diff /usr/src/sys/dev/e1000/if_em.c
Index: /usr/src/sys/dev/e1000/if_em.c
===================================================================
--- /usr/src/sys/dev/e1000/if_em.c (revision 344229)
+++ /usr/src/sys/dev/e1000/if_em.c (working copy)
@@ -31,13 +31,16 @@
#include <sys/sbuf.h>
#include <machine/_inttypes.h>
-#define em_mac_min e1000_82547
+// jagwas: #define em_mac_min e1000_82547
+#define em_mac_min e1000_82571 // jag; 25feb2019;
+ // so (adapter->hw.mac.type < em_mac_min)
+ // is true for 82547GI and below
#define igb_mac_min e1000_82575
/*********************************************************************
* Driver version:
*********************************************************************/
-char em_driver_version[] = "7.6.1-k";
+char em_driver_version[] = "7.6.1-k+jag3";
/*********************************************************************
* PCI Device ID Table
@@ -2476,6 +2479,24 @@
case e1000_i211:
pba = E1000_PBA_34K;
break;
+ // jag; 26feb2019 added this case section; adapted from
+ // FreeBSD 11 /usr/src/sys/dev/e1000/if_lem.c
+ case e1000_82547:
+ case e1000_82547_rev_2: /* 82547: Total Packet Buffer is 40K */
+ if (adapter->hw.mac.max_frame_size > 8192)
+ pba = E1000_PBA_22K; /* 22K for Rx, 18K for Tx */
+ else
+ pba = E1000_PBA_30K; /* 30K for Rx, 10K for Tx */
+
+ // jag; the following would be needed for plain 82547 (before GI)
+ // and would also require adding the elements set here to
+ // struct adapter in if_em.h:
+ // adapter->tx_fifo_head = 0;
+ // adapter->tx_head_addr = pba << EM_TX_HEAD_ADDR_SHIFT;
+ // adapter->tx_fifo_size =
+ // (E1000_PBA_40K - pba) << EM_PBA_BYTES_SHIFT;
+
+ break;
default:
if (adapter->hw.mac.max_frame_size > 8192)
pba = E1000_PBA_40K; /* 40K for Rx, 24K for Tx */
root@prod:~ #
With that change, my interfaces all now work fine, and my systems don't hang (I think the hanging problem was because the pre-change if_em.c was assigning more packet buffer space than the 82547GI actually has).
I believe this change will also help some of the other 82547 models to work, but I don't have any of those chips and so cannot test them. Those chips also seem to need some workarounds for special cases (like jumbo frames which cross buffer boundaries); those workarounds are implemented in FreeBSD 11 but not in FreeBSD 12, and I didn't implement them as part of this change because my 82547GI chip doesn't need them. (For example, see the lem_82547_fifo_workaround() function; search for "82547" in the /usr/src/sys/dev/e1000/if_lem.c file in FreeBSD 11 to see other workarounds).
This problem seems to exist on CURRENT, too (from looking at the code; I have not tested that). | https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=236119 | CC-MAIN-2020-05 | refinedweb | 551 | 60.14 |
Hi guys, I am downloading a historical data of several instruments and I find the surprise that the number exported to my csv file comes with many decimal places. I would like to know if my code is wrong or simply the API has a problem.
My code is this:
import eikon as ek
ek.set_app_id('XXXXXXXXXXXXXX')
df=ek.get_timeseries(['CARC.BA'], start_date='2016-01-01' , end_date='2018-01-01')
df.to_csv('CARC.BA_2016-01_2018-01-01.csv')
Then when i see my data i found numbers like this:
HIGH:1,45E+16 1,44E+16 1,4E+16 1,4E+16 1,42E+16 1,52E+16
this same problem with all my historical data.
I am unable to replicate the problem. This is data in csv file.
You can verify the data by setting raw_output to True.
df=ek.get_timeseries(['CARC.BA'], start_date='2016-01-01' , end_date='2018-01-01', raw_output=True) df
The output is raw JSON data.
{'timeseriesData': [{'dataPoints': [['2016-01-04T00:00:00Z', 2.0916375, 2.0916375, 2.0916375, 2.0916375, 4876.56202377324], ['2016-01-05T00:00:00Z', 2.0916375, 2.0916375, 2.0916375, 2.0916375, 768.0585187442853],
If you see your data well and compare it with the data from: you realize that it does not match, that on the one hand. On the other hand, the value 2.0916375 is impossible to be that.
@pablo
If I understand correctly what seems wrong to you is the number of decimal places in stock prices, right? Argentine stocks are quoted to 3 decimal places. When you see more decimals in the stock price history, this is very likely the effect of price history adjustment for capital change (and some dividend payment) events. If you look at the current price history for CARC.BA on Eikon you'll see that historical prices have a max of 3 decimals up to 2 Jan 2018 back. All earlier prices have more decimals. This is the result of the rights issue with ex date of 2 Jan 2018.
Due to this rights issue on 2 Jan 2018 all previous price history was adjusted by a factor of 0.82025.
If you'd like to further discuss any price history inconsistencies you see, I suggest you raise a case with Thomson Reuters Helpdesk by either calling the Helpdesk number in your country or by using Contact Us capability in your Eikon application. | https://community.developers.refinitiv.com/questions/28100/error-in-data.html | CC-MAIN-2021-43 | refinedweb | 402 | 73.58 |
Connect.
There are a couple ways to use I2C to connect an LCD to the Raspberry Pi. The simplest is to get an LCD with an I2C backpack. But the hardcore DIY way is to use a standard HD44780 LCD and connect it to the Pi via a chip called the PCF8574.
The PCF8574 converts the I2C signal sent from the Pi into a parallel signal that can be used by the LCD. Most I2C LCDs use the PCF8574 anyway. I’ll explain how to connect it both ways in a minute.
I’ll also show you how to program the LCD using Python, and, these tutorials will show you how to connect an LCD with the GPIO pins:
- How to Setup an LCD on the Raspberry Pi and Program it With C
- How to Setup an LCD on the Raspberry Pi and Program it With Python
Here’s the video version of this tutorial, where I go through the setup and show all of the programming examples below:
Connect backpack. Most LCDs can operate with 3.3V, but they’re meant to be run on 5V, so connect it to the 5V pin of the Pi if possible.
Connecting an LCD With a PCF8574
If you have an LCD without I2C and have a PCF8574 chip lying Ohms, but can be substituted with 1K to 3K Ohm resistors
In the diagram above, the blue wire connects to the Raspberry Pi’s SDA pin. The yellow wire connects to the Pi’s SCL pin.
Enable”:
Now arrow down and select “I2C Enable/Disable automatic loading”:
Choose “Yes” at the next prompt, exit the configuration menu, and reboot the Pi:
The I2C address of my LCD is 21. Take note of this number, we’ll need it later.
Programming the LCD
We’ll be using Python to program the LCD, so if this is your first time writing/running a Python program, you may want to check out How to Write and Run a Python Program on the Raspberry Pi before proceeding.:
# -*- coding: utf-8 -*- # Original code found at: # """ Compiled, mashed and generally mutilated 2014-2015 by Denis Pleic Made available under GNU GENERAL PUBLIC LICENSE # Modified Python I2C library for Raspberry Pi # as found on # Joined existing 'i2c_lib.py' and 'lc)) # write a character to lcd (or character rom) 0x09: backlight | RS=DR< # works! def lcd_write_char(self, charvalue, mode=1): self.lcd_write_four_bits(mode | (charvalue & 0xF0)) self.lcd_write_four_bits(mode | ((charvalue << 4) & 0xF0)) # put string function with optional char positioning def lcd_display_string(self, string, line=1, pos=0): if line == 1: pos_new = pos elif line == 2: pos_new = 0x40 + pos elif line == 3: pos_new = 0x14 + pos elif line == 4: pos_new = 0x54 + pos self.lcd_write(0x80 + pos_new) for char in string: self.lcd_write(ord(char), Rs) # clear lcd and set to home def lcd_clear(self): self.lcd_write(LCD_CLEARDISPLAY) self.lcd_write(LCD_RETURNHOME) # define backlight on/off (lcd.backlight(1); off= lcd.backlight(0) def backlight(self, state): # for state, 1 = on, 0 = off if state == 1: self.lcd_device.write_cmd(LCD_BACKLIGHT) elif state == 0: self.lcd_device.write_cmd(LCD_NOBACKLIGHT) # add custom characters (0 - 7) def lcd_load_custom_chars(self, fontdata): self.lcd_write(0x40); for char in fontdata: for line in char: self.lcd_write_char(line)
There are a couple things you may need to change in the code above, depending on your set up.’ll change line 22 to
ADDRESS = 0x21.
Write to the Display
The following is a bare minimum “Hello World!” program to demonstrate how to initialize the LCD:
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() mylcd.lcd_display_string("Hello World!", 1)
Position the Text
The function
mylcd.lcd_display_string() prints text to the screen and also lets you chose where to position it. The function is used as
mylcd.lcd_display_string("TEXT TO PRINT", ROW, COLUMN). For example, the following code prints “Hello World!” to row 2, column 3:
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() mylcd.lcd_display_string("Hello World!", 2, 3)
On a 16×2 LCD, the rows are numbered 1 – 2, while the columns are numbered 0 – 15. So to print “Hello World!” at the first column of the top row, you would use
mylcd.lcd_display_string("Hello World!", 1, 0).
Clear the Screen
The function
mylcd.lcd_clear() clears the screen:
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() mylcd.lcd_display_string("This is how you", 1) sleep(1) mylcd.lcd_clear() mylcd.lcd_display_string("clear the screen", 1) sleep(1) mylcd.lcd_clear()
Blinking Text
We can use a simple while loop with the
mylcd.lcd_display_string() and
mylcd.lcd_clear() functions to create a continuous blinking text effect:
import time import I2C_LCD_driver mylcd = I2C_LCD_driver.lcd() while True: mylcd.lcd_display_string(u"Hello world!") time.sleep(1) mylcd.lcd_clear() time.sleep(1)
You can use the
time.sleep() function on line 7 to change the time (in seconds) the text stays on. The time the text stays off can be changed in the
time.sleep() function on line 9. To end the program, press Ctrl-C.
Print the Date and Time
The following program prints the current date and time to the LCD:
import I2C_LCD_driver import time mylcd = I2C_LCD_driver.lcd() while True: mylcd.lcd_display_string("Time: %s" %time.strftime("%H:%M:%S"), 1) mylcd.lcd_display_string("Date: %s" %time.strftime("%m/%d/%Y"), 2)
Print Your IP Address
This code prints the IP address of your ethernet connection (eth0). To print the IP of your WiFi connection, change
eth0 to
wlan0 in line 18:)
Scroll Text Right to Left Continuously
This program will scroll a text string from the right side of the LCD to the left side and loop continuously:
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() str_pad = " " * 16 my_long_string = "This is a string that needs to scroll" my_long_string = str_pad + my_long_string while True: for i in range (0, len(my_long_string)): lcd_text = my_long_string[i:(i+16)] mylcd.lcd_display_string(lcd_text,1) sleep(0.4) mylcd.lcd_display_string(str_pad,1)
Scroll Text Right to Left Once
The following code slides text onto the screen from right to left once, then stops and leaves a cleared screen.
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() str_pad = " " * 16 my_long_string = "This is a string that needs to scroll" my_long_string = str_pad + my_long_string for i in range (0, len(my_long_string)): lcd_text = my_long_string[i:(i+16)] mylcd.lcd_display_string(lcd_text,1) sleep(0.4) mylcd.lcd_display_string(str_pad,1)
Scroll Text Left to Right Once
This program slides text onto the screen from left to right once, then stops and leaves the first 16 characters of the text string on the screen.
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() padding = " " * 16 my_long_string = "This is a string that needs to scroll" padded_string = my_long_string + padding for i in range (0, len(my_long_string)): lcd_text = padded_string[((len(my_long_string)-1)-i):-i] mylcd.lcd_display_string(lcd_text,1) sleep(0.4) mylcd.lcd_display_string(padding[(15+i):i], 1)
Custom Characters
You can create any pattern you want and print it to the display as a custom character. Each character is an array of 5 x 8 pixels. Up to 8 custom characters can be defined and stored in the LCD’s memory. This custom character generator will help you create the bit array needed to define the characters in the LCD memory.
Printing a Single Custom Character
The following code generates a “<” character:
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() fontdata1 = [ [ 0b00010, 0b00100, 0b01000, 0b10000, 0b01000, 0b00100, 0b00010, 0b00000 ], ] mylcd.lcd_load_custom_chars(fontdata1) mylcd.lcd_write(0x80) mylcd.lcd_write_char(0)
Printing Multiple Custom Characters
This program prints a large right pointing arrow (→) to the screen:
import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() fontdata1 = [ # char(0) - Upper-left character [ 0b00000, 0b00000, 0b00000, 0b00000, 0b00000, 0b00000, 0b11111, 0b11111 ], # char(1) - Upper-middle character [ 0b00000, 0b00000, 0b00100, 0b00110, 0b00111, 0b00111, 0b11111, 0b11111 ], # char(2) - Upper-right character [ 0b00000, 0b00000, 0b00000, 0b00000, 0b00000, 0b00000, 0b10000, 0b11000 ], # char(3) - Lower-left character [ 0b11111, 0b11111, 0b00000, 0b00000, 0b00000, 0b00000, 0b00000, 0b00000 ], # char(4) - Lower-middle character [ 0b11111, 0b11111, 0b00111, 0b00111, 0b00110, 0b00100, 0b00000, 0b00000 ], # char(5) - Lower-right character [ 0b11000, 0b10000, 0b00000, 0b00000, 0b00000, 0b00000, 0b00000, 0b00000 ], ] mylcd.lcd_load_custom_chars(fontdata1) mylcd.lcd_write(0x80) mylcd.lcd_write_char(0) mylcd.lcd_write_char(1) mylcd.lcd_write_char(2) mylcd.lcd_write(0xC0) mylcd.lcd_write_char(3) mylcd.lcd_write_char(4) mylcd.lcd_write_char(5)
Print Data from a Sensor
The code below will display data from is displayed on line 2:
import RPi.GPIO as GPIO import dht11 import I2C_LCD_driver from time import * mylcd = I2C_LCD_driver.lcd() GPIO.setwarnings(False) GPIO.setmode(GPIO.BCM) GPIO.cleanup() while True: instance = dht11.DHT11(pin = 4) result = instance.read() # Uncomment for Fahrenheit: # result.temperature = (result.temperature * 1.8) + 32 if result.is_valid(): mylcd.lcd_display_string("Temp: %d%s C" % (result.temperature, chr(223)), 1) mylcd.lcd_display_string("Humidity: %d %%" % result.humidity, 2)
For Fahrenheit, un-comment lines 18 and 19, and change the C to an F in line 22. You can also change the signal pin of the DHT11 input in line 15. interesting effects. For example, you can make some fun!
Thank you so much!! I’ve been playing with a couple of other bits of code all day trying to make them work, and all they would give me was seemingly random characters and behave differently at different times… Frustration levels now abating. Thanks again :)
Greate article! Helped me to connect chinese PCF8574 lcd backpack (blue one).
It doesn’t work on python 3. why do I make it to work on Python 3??
Did you change I2C bus 0 in line 20 of the driver to 1?
want to use Python3 , then change all unichr to chr in I2C_LCD_driver.py,
this is only a demo program now, the real driver is RPi_I2C_driver.py (line 34 has the i2c address)
import RPi_I2C_driver, time
mylcd = RPi_I2C_driver.lcd()
mylcd.lcd_display_string(“Python3 rocks…”,1)
time.sleep(3)
mylcd.lcd_clear()
mylcd.backlight(0)
Hi, I was wondering how to set the backlight off and then on? I tried different methods using the drivers, but none of them worked.
Try setting LCD_NOBACKLIGHT = 0x02 instead of 0x00
Great article. I’m a total novice to all this but managed to get my LCD display up and running without a glitch.
I would also like to figure out how to switch the backlight on and off. Any help would be greatly appreciated.
I figured it out. Kind of obvious, but it was late and had been a long day.
To turn the backlight on:
mylcd.backlight(1)
And to turn it off:
mylcd.backlight(0)
Awesome info. Will it hurt anything using the lcd without an i2c 3v to 5v converter? I have the sainsmart 20×4 which is made for Arduino i believe.
I have connected my HD44780 to RPi via I2C interface, downloaded smbus for python, copy&pasted python-code from this website and… nothing. I have 16 white rectangles on first line and nothing on second line (i have blue lcd with white digits). Good news is that LCD reacts with white rectangles when I run python code, if it is just connected to RPi there is only blue backlight.
Do you know what might be wrong? My LCD has 0x27 address from i2cdetect. I connected i2c to HD44780 with 16 wires, pin by pin (1–1, 2–2, 3–3, etc.)
Any ideas?
why 16 wires? if you use i2c you had to connect only ground,vcc,sda,scl on the i2c adapter of the screen..
By the way I had the same problem. White character, via python i’m able to turn on and off the backlight.
Hi kb06, What size resistors are you using for the contrast? It could be that the contrast resistor is too small, making the contrast too high. Also, does your LCD have an I2C backpack or are you using the PCF8574?
Us newbies that trawl the web looking for drivers etc really appreciate a well explained library that actually works. Like a pearl among the swill of junk code & bloatware, so lucid. Re a 3v3 Pi talking to a 5v PC8574: The iffy i2c signal here is when the Pi releases the lines for the various pullups to squabble over. According to the datasheet the 8574 min threshold for a rising edge is 70% or 3v5. The Pi has 1k8 internal pullups to 3v3 and the $1 ebay 8574 cards typically have 10k external pullups to 5v, the line therefore settle to ~3v6, enough to work without level shifters. And, if you’re squeamish about 0.1v headroom, surely you’d use a shottky diode in series with the plus side of the lcd supply rather than the inconvenience of level shifters?
How would the code be different when using a DHT22 sensor?
Great tutorial! but…
Does anybody know how to print a custom character at a certain location (column / row)?
Line 1 has addresses beginning 0x80
Line 2 addresses begin at 0xc0
Columns are numbered 0 to 15
The following code will scroll a character from left to right on line one
[code]
import RPi_I2C_driver
from time import *
mylcd = RPi_I2C_driver.lcd()
fontdata1 = [
[ 0b000000,
0b000000,
0b000000,
0b000000,
0b000000,
0b000000,
0b000000,
0b000000 ],
[ 0b00000,
0b00100,
0b01110,
0b11111,
0b01110,
0b00100,
0b00000,
0b00000 ]
]
mylcd.lcd_load_custom_chars(fontdata1)
for column in range(16):
addr=0x80
addr+=column
#print diamond symbol at line 1 column x
mylcd.lcd_write(addr)
mylcd.lcd_write_char(1)
sleep(0.5)
#blank it out
mylcd.lcd_write(addr)
mylcd.lcd_write_char(0)
[/code]
Here’s the mapping of a 2004 display. I guess it also applies for the 1602.×4-memory(b).gif
Actually these work for me:×4-lcd-cursor-address-table.bmp
Thank you, this has helped me greatly! Do you know how to alter the library to connect two I2C LCD displays?
import RPi_I2C_driver, time
mylcd0 = RPi_I2C_driver.lcd( ADDR = 0x27 )
mylcd0.lcd_display_string(“lcd on default address.”,1)
mylcd1 = RPi_I2C_driver.lcd( ADDR = 0x28 )
mylcd1.lcd_display_string(“lcd on custom address”, use i2cdetect to find i2c address of second lcd)
change
class lcd:
#initializes objects and lcd
def __init__(self):
self.lcd_device = i2c_device(ADDRESS)
TO
class lcd:
#initializes objects and lcd
def __init__(self,indirizzo=ADDRESS):
self.lcd_device = i2c_device(indirizzo)
and then when you initialize the lcd
mylcd = I2C_LCD_driver.lcd()
TO
mylcd = I2C_LCD_driver.lcd(0x3c)
or
mylcd = I2C_LCD_driver.lcd()
if you want to use the default address
Excellent, thanks for the quick response, I’ll give it a try.
It’s working? someone checked? I try but it’s fail.
it’s working? Anyone checked or have another idea how to connect two I2C LCD displays?
thanks a lot for tutorial, may I ask – does anyone know if there is a simple way to display info from volumio 2.0 over mpdlcd? LCD 16*2 is connected to RPi3 via i2c and functions…thank you…
Ask Volumio if they want to implement the functionality or if they had API for use on external program to query for status.
ok I understand, and thanks for your answer.
My LCD is up and running but I’m looking for a sample ‘Hello World’ sample code in PERL. Does anybody know a source?
take a look at.
From there you had to adapt the examples in python
Hello, i use mpd and output the information from mpc current to the display.
This is the command that i use it for output
title = os.popen(‘mpc current -f %title%’).read()
mylcd.lcd_display_string(title, 1)
it works fine but on the end of the string there is a bad character.
On the end of the string from titel there is a “\n” and this is the bad character on the lcd.
How i delete this sign in the output?
Sorry for my bad english
You can try title[:-1] or title.strip()
\n is the return carriage…strip will do the trick!
Thank you now it looks beautiful :-)
Glad I found this page, helpd me a lot with my internet radio. I have used the clock as the second line on my screen, but by haivng this clock running on there it makes the next and previous buttons unresponsive. Does anyone know how to solve this please?
We need the code! Perhaps you are inside a loop? try using threads or handlers for gpio.
Do I need to change or add something (lines 91-97 or anywhere else of the driver) for a 20×4 display?
It should work on a 20×4 LCD without any changes to the library code
Tested and works. Thanks.
Though I may need to insert a level converter, running the LCD from 3.3v on the Pi doesn’t give enough contrast straight-on, have to view from 20 degrees below straight-on to see it. Or should it be safe for the Pi to run the LCD from 5v without converting levels on SDA1/SCL1?
Oops, missed the comment in the article about connecting to “the 5V pin of the Pi if possible”, so I guess it is safe.
Beware, most other tutorials are clear on the fact that you should NOT plug 5v to raspberry GPIOs. So if LCD has its own 5v pullups, voltage adaptation is needed. Or a 3.3v LCD.
Would you please provide me with a solution?
copy your full code.
import I2C_LCD_driver
from time import *
mylcd = I2C_LCD_driver.lcd()
mylcd.lcd_display_string(“Hello World!”, 1)
——————————————————————
I need the File “/home/pi/I2C_LCD_driver.py” where the error is located…
# -*- coding: utf-8 -*-
# Original code found at:
#
“””
Compiled, mashed and generally mutilated 2014-2015 by Denis Pleic
Made available under GNU GENERAL PUBLIC LICENSE
# Modified Python I2C library for Raspberry Pi
# as found on
# Joined existing ‘i2c_lib.py’ and ‘lc):
…
I have just changed I2CBUS = 0 to I2CBUS = 1
Hi guys! Thanks for this tuto. How can I stop the date and time script with another script? No ctrl+c. I need to stop that scrip when another script starts but I don’t know how to doit
Check out this python module that extends the functionality of the HD44780 controller:
That looks really cool, thanks for posting it
LCD doesn’t display the DHT11 values part but displays others like the “hello world”. It just prints the value on the terminal. Why is that?
Is there a way to display more that 8 custom characters? I’m running into problems when trying to.
Thanks for your post!! Very helpful. Is there anyway I can use a 4×4 matrix keypad to display characters on the lcd. Thanks in advance :)
While the scrolling scripts are working on their own, when I try to incorporate scrolling into my own script, I get an error:
File “/home/pi/Documents/InternetRadio/I2C_LCD_driver.py”, line 160, in lcd_display_string
self.lcd_write(ord(char), Rs)
TypeError: ord() expected string of length 1, but int found
Why does it work okay in the above script but not in mine? Why is it expecting string length 1 from me? (excerpt):
for i in range (0, len(currentstream)):
lcd_text = currentstream[i:(i+20)] # displayed substring width, 4×20 LCD
mylcd.lcd_display_string(lcd_text,1)
sleep(0.2)
mylcd.lcd_display_string(str_pad,1)
got a problem with last python script
PRINT DATA FROM A SENSOR
when I try to run it i got this error message :
python temp.py
Traceback (most recent call last):
File “temp.py”, line 2, in
import dht11
ImportError: No module named dht11
can some one help me with this ?
Ran into same problem today.
git clone
Then copy dhy11.py to your directory where your files are from above. So dht11.py is in the same directory as I2C_LCD_driver.py For example,
cp /home/pi/project/DHT11_Python/dht11.py /home/project/dht11.py
Just thought I’d say this is a great tutorial, really covers all possible bases. 😁
hello
if I follow this steps, I can use this code in a lcd 20×4 ?
I use 20×4 LCD and work fine!
HI!
Work great!
Thankyou….
I try with two display , now i have I2C_LCD_driver.py and I2C_LCD_driver2.py with different address and in code
import I2C_LCD_driver
mylcd = I2C_LCD_driver.lcd()
import I2C_LCD_driver2
mylcd2 = I2C_LCD_driver2.lcd()
How can I add in I2C_LCD_driver.py two address for two display ?
I want to show display with 0x3f and 0x3D same information ?
import RPi_I2C_driver, time
text = “same information”
mylcd0 = RPi_I2C_driver.lcd( ADDR = 0x3f )
mylcd0.lcd_display_string(text,1)
mylcd1 = RPi_I2C_driver.lcd( ADDR = 0x3D )
mylcd1.lcd_display_string(text, check your indents)
Thank you , I hope I understand, I will try
I am having an issue with my LCD16x2 connected via an I2C module to the pi – the first time I run lcd_display_string and lcd_clear, the display will correctly display and remove the text, however the second (and any further times) I run the script, it does not clear the output, rather text gets added to the end of the last text.
Does anyone know how to resolve this?
hallo im traying to use this scipt, whit an crius oled lcd display. but i dont get anything on the screen??
do i maybe mist something? does the module maybe have to paste into an specific folder, whit modules? or does the module have to be compiled first?
i only get this error!! ??
Traceback (most recent call last):
File “lcdtest2.py”, line 3, in
mylcd = I2C_LCD_driver.lcd()
File “/home/pi/lcd_test/I2C_LCD_driver.py”, line 111, in __init__
self.lcd_write(0x03)
File “/home/pi/lcd_test/I2C_LCD_driver.py”, line 136, in lcd_write
self.lcd_write_four_bits(mode | (cmd & 0xF0))
File “/home/pi/lcd_test/I2C_LCD_driver.py”, line 131, in lcd_write_four_bits
self.lcd_device.write_cmd(data | LCD_BACKLIGHT)
File “/home/pi/lcd_test/I2C_LCD_driver.py”, line 34, in write_cmd
self.bus.write_byte(self.addr, cmd)
IOError: [Errno 110] Connection timed out
thanks allready,. greetz,freedom
On the Raspberry Pi zero W in raspi-config Advanced settings I can’t find the I2C, SPI or Serial enables
Look under menu option 5 – Interfacing Options then you should see options P1 – P8. I2C is P5, SPI is P4, Serial is P6.
Shown above in the tutorial they’re in Advanced. Is this a difference on the Zero W or a change between Raspbian Jessie and Stretch? Either way it should be updated to mention both.
I’m still using jessie with most recent updates. It’s the same on my Zero W and Pi 2.
How do I implement my DHT22? What library is the best one to use?
hey guys, i tried to set up my i2c with my lcd but the problem is the string command doesn’t display on my lcd
i tried the backlight command and it works.
I had this problem. The i2c backpack has a variable resistor this adjusts the contrast. Write a program which displays a string on line one and immediately exits. Now with a small screw driver adjust that potentiometer. Hopefully the string is now on display.
Thanks very much for your work and Videos, its works a charm on Python 3
Can I use this library with 20*4 LCD display?
Very good tutorial!
Is it possible to write to the display with the backlight off?
If I use lcd_display_string(“String”), the backlight is always switched on, even if it was set to off before.
Any ideas?
Regards
Stefan
Another point: To switch the backlight of the display off, I use this snippet:
import I2C_LCD_driver
mylcd = I2C_LCD_driver.lcd()
mylcd.backlight(0)
The problem now is, if the display was illuminated, the backlight will be switched off as exspected, so far so good.
But, if it is already black, it gets switched on for one moment and gets switched off again. So during the instantiation of mylcd the light goes on. How can I prevent that?
Thank you very much. It all worked out perfectly.
Thanks very much you make very very happy this afternoon
I have followed this tutorial but still the i2c lcd does not work. I get an error that says it cant find the librabry. Which folder should it be saved to?
This excellent website definitely has all the info I
needed about this subject and didn’t know who to ask.
Hi, Fantastic tutorial, after reading so many this is the only one that i have understood and got working.
Having said that, how would I get text stings that are longer that 16 to scroll?
any help would be great.
Thanks
Hello, by turning on i2c in PI configuration, will it affect any other device connected to gpios?
Hi. Thanks for this! It help me a lot.
I want to know if maybe you have some tutorial for making a menu. Im searching in google, and not find anything yet.
I want to make a menu with this library and physicall buttons. (i know how to make the buttons.. but not the menu, how move trough the menu also.
Thanks!
I dont speak english.
I used this module to interface 2 displays using 1 Arduino Uno board to displaying LCD 16×2 , and graphical display interface the display but only one LCD was working is it possible using Arduino Uno board
Bonjour, comment adapter “PRINT DATA FROM A SENSOR” à un AM2302 branché sur un Pi GPIO#4 ? Merci.
Very clear tutorial. Thanks. Worked straight away, but the IP address script gives an error.
Line 15:
structpack(‘256s’, ifname[:15])
structerror: argument for ‘s’ must be a bytes object
Great article indeed. How to use the LCD with a multiplexer TCA9548A? How can I specify the multiplexer channel? Many thanks for your feedback.
Thank you I can finally turn backlight on / off :D
This was a great tutorial, thank you! I have my PI setup as a webserver just for experiments and was curios if you have any examples on how to display the server uptime on the LCD? Thank you in advance!
Great stuff.
Just my little contribution. About scrolling long lines: Here is some code to “rotate” instead of scrolling. The rotate left and right functions have been derived from the geeksforgeeks page ():
def rotate_str_left(input, d):
“””
return the input string rotated of d character to the left
“””
Lfirst = input[0: d]
Lsecond = input[d:]
return Lsecond + Lfirst
def rotate_str_right(input, d):
“””
return the input string rotated of d character to the right
“””
Rfirst = input[0: len(input) – d]
Rsecond = input[len(input) – d:]
return Rsecond + Rfirst
import lib.I2C_LCD_driver as I2C_LCD_driver
from time import sleep
my_lcd = I2C_LCD_driver.lcd()
str_pad = ” — ” # can be any other set of spaces and charcaters, just keep it as short as possible
long_string = “Logger listening @ 115200 baud on ttyUSB0”
long_string1 = long_string + str_pad
max_chars = 20 # I am using a 4 x 20 LCD
while True:
if len(long_string) <= max_chars:
line1_Text = long_string
my_lcd.lcd_display_string(line1_Text, 1)
else:
line1_Text = long_string1[:max_chars]
my_lcd.lcd_display_string(line1_Text, 1)
long_string1 = rotate_str_left(long_string1, 1)
it writes on line 1 of the LCD, long_string can be passed or read from a file. If long_string length stays within the 20 characters limit it'll be printed on the LCD as is, otherwise it will be rotated (instead of scrolled) left bound. The rotate_right can be used if you need to display in languages that read from right to left.
great tutorial, But I get an error when running the write to display script
In line 114 self.lcd_device.write_cmd(data l LCD_BACKLIGHT)
I get Attribute error: ‘lcd’ object has no attribute ‘lcd_device’
trace back are lines 119 and 139 | https://www.circuitbasics.com/raspberry-pi-i2c-lcd-set-up-and-programming/ | CC-MAIN-2021-39 | refinedweb | 4,526 | 75 |
Outline: Object Orientation
Programmers are creatures of habit, and we tend to stick with established language features unless we have some compelling reason to embrace new ones. Object-oriented (OO) features are a good example of this issue. PHP programmers consider PHP's OO features to be a good idea—but use them sparingly, if at all. The story is similar with many Python programmers, who prefer not to use Python's OO features.
Java sits at the other end of the language spectrum: It's an OO language, so there's no getting away from classes when you use Java. Despite Java's OO pedigree, however, a lot of Java code is still written in a procedural manner.
Why this bias against (or possible misuse of) OO? I think it boils down to a combination of personal inclination and engineering judgment. If a PHP or Python programmer has extensive experience with one of these languages and hasn't used the OO features often, the disinclination may be due to simple inertia. But certain development tasks might be better implemented in an OO context than in the familiar procedural/functional paradigm.
It's true that OO programming can result in issues such as heap fragmentation or other nondeterministic platform states, such as performance deterioration. Indeed, the issue of OO heap use was one reason why C++ took many years to replace C in embedded development projects. Back in the 1990s, disk, CPU, and memory were at such a premium that, at least in the minds of designers, they precluded the use of OO languages (which also precluded potential productivity gains from using these emerging languages).
I think it's still fair to say that many Python programmers avoid OO features unless no other option exists. In this article, I compare Python and Java to show how they stack up against each other in terms of complexity and speed. I hope this will allow for an objective assessment!
Let's take a look at some code, starting with Python.
A Python Class
As is the case with Python in general, the Python OO paradigm is pretty concise, as the simple class in Listing 1 illustrates.
Listing 1A Python class.
class Student: def __init__(self, name, age, major): self.name = name self.age = age self.major = major def is_old(self): return self.age > 100
The Student class has three data members: name, age, and major subject.
The __init__() method is the closest thing Python has to a constructor. Notice the use of self.name to initialize the state of the instance. Also included is the simple method is_old() to determine (in a slightly "ageist" manner) whether the underlying student is young or old (with "old" being over 100 years).
The code in Listing 1 illustrates one of the great merits of OO programming: Code and data reside in close proximity to each other. Data is of course the repository of state, so the use of OO brings code, data, and state together in a manner useful to programmers. Clearly, you can do all of this without OO code, but OO makes it a matter of rather beautiful simplicity.
Remember: Most source code on the planet exists to model some real-world entity or process. OO can be a very clear, minimum-impedance technique for such modeling. This might even be a compelling reason for using the OO approach at all costs!
An Equivalent Java Class
Not to be outdone by our Python coding effort, Listing 2 shows an equivalent Java class.
Listing 2A Java student class.
public class Student { String name; int age; String major; public Student() { // TODO Auto-generated constructor stub } public Student(String name, int age, String major) { this.name = name; this.age = age; this.major = major; } }
The Java code in Listing 2 is very similar to the Python code in Listing 1. Notice that the use of OO can produce quite readable code in either language. Listing 1 is not likely to baffle a Java programmer, even without a background in Python. Likewise, a Python programmer well versed in the Python OO features would easily understand the Java code in Listing 2.
So here's our first takeaway: Well-written OO code can help to promote inter-language comprehensibility.
Why is this important? In our multi-language era, such comprehensibility is a prize worth pursuing. (For more on this topic, interested readers can check out my blog and my most recent eBook.)
The modern era of software can be defined by the rapid adoption of application deployment on the Web and the concomitant use of browsers to access those applications. Users now routinely demand from web-hosted applications what used to be called "desktop features." Such usability generally can't be delivered using just one programming language. Programmers must increasingly be comfortable in numerous languages: Java, Scala, JavaScript, HTML, CSS, Python, SQL, and so on.
A Matter of Speed: Python Versus Java Code
Speed is always an issue. Let's modify Listing 1 so that we can get a feel for the speed of the underlying code.
Running the Python Code
Listing 3 illustrates a simple (toy) program that attempts to "stress" the platform a little.
Listing 3A timed program run.
import time class Student: def __init__(self, name, age, major): self.name = name self.age = age self.major = major def is_old(self): return self.age > 100 start = time.clock() for x in xrange(500000): s = Student('John', 23, 'Physics') print 'Student %s is %s years old and is studying %s' %(s.name, s.age, s.major) print 'Student is old? %d ' %(s.is_old()) stop = time.clock() print stop - start
Listing 3 is a slightly augmented version of Listing 1. This revised code does the following:
- Import the time module.
- Create a time snapshot at the beginning of the program.
- Instantiate a large number of Student objects.
- Access the data inside each object.
- Take a time snapshot and subtract the original time.
- Display the time required to run the program.
Admittedly, this is a pretty crude test. But let's see an example run that creates 500,000 objects. This is an excerpt from the full program run:
Student John is 23 years old and is studying Physics Student is old? 0 29.8887370933
We can think of this as a baseline test: It takes about 30 seconds for a program run of 500,000 objects. Now let's raise the number of objects created to 800,000:
Student John is 23 years old and is studying Physics Student is old? 0 48.2298926572
From this, we see that a program run of 800,000 objects takes about 48 seconds. Let's double the number of objects created, to 1,600,000:
Student John is 23 years old and is studying Physics Student is old? 0 97.3272409408
That's 97 seconds for 1,600,000 objects.
Now let's do a comparative run using Java.
Running the Java Code
Listing 4 illustrates a simple Java program that also attempts to stress the platform a little.
Listing 4The Java test program.
public class Student { String name; int age; String major; public Student() { // TODO Auto-generated constructor stub } public Student(String name, int age, String major) { this.name = name; this.age = age; this.major = major; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getMajor() { return major; } public void setMajor(String major) { this.major = major; } public static void main(String[] args) { long startTime = System.currentTimeMillis(); for (int i = 0; i < 500000; i++) { Student student = new Student("John", 23, "Physics"); System.out.println("Student " + student.getName() + " is "
+ student.getAge() + " years old and is studying " + student.getMajor()); } long estimatedTime = System.currentTimeMillis() - startTime; System.out.println("Time estimate: " + estimatedTime/1000); } }+ student.getAge() + " years old and is studying " + student.getMajor()); } long estimatedTime = System.currentTimeMillis() - startTime; System.out.println("Time estimate: " + estimatedTime/1000); } }
Notice in Listing 4 that I've included automatically generated getter and setter methods. Experienced Eclipse Java developers use this feature all the time; the getters and setters are automatically generated by Eclipse. The same is true for the two constructors. This type of productivity enhancement is really handy, and because such code is machine-generated, it's completely error-free.
Let's run the Java code with 500,000 objects, just as we did for the Python case:
Student John is 23 years old and is studying Physics Student is old: false Time estimate: 31
That's 31 seconds for 500,000 objects. Now we run it with 800,000 objects:
Student John is 23 years old and is studying Physics Student is old: false Time estimate: 50
That's 50 seconds for 800,000 objects. Now we run our final Java test with 1,600,000 objects:
Student John is 23 years old and is studying Physics Student is old: false Time estimate: 104
That's 104 seconds for 1,600,000 objects.
Let's tabulate the results for comparison.
Comparative Speed Test
The test results show that the Python code outperforms the Java code by a small margin. This is not unexpected. Java might be called a "heavyweight" mainstream language; it comes with a certain amount of baggage, including but not limited to the following:
- Portability. This simply means that Java bytecode will run on any platform with an appropriate Java virtual machine (JVM).
- Type safety. As the example illustrates, type safety is closely related to memory safety. This language feature helps to avoid situations in which an attempt is made to copy an invalid bit pattern into a given memory area.
- Built-in security. The Java security model is based on a sandbox in which code can run safely with minimal negative effects on the underlying platform.
As with any technology, this feature set comes at a cost; however, as the table shows, the cost in the current test context is not exactly exorbitant.
This is our second takeaway: OO does have a cost, but it's relatively cheap considering all the extra capabilities you get.
Extending the Test
The tests I ran for this example are pretty simple. A more realistic test might use objects that read and write to a database, or send and receive network traffic. If the data in such programs is derived from files, that would help in stressing the application with disk I/O.
Running the Code
Python can be run from the command line; more conveniently, you can run it from within an integrated development environment (IDE) such as Eclipse. I prefer to use an IDE because of the many productivity enhancements they offer: code generation, unit testing, package and module creation, and so on.
Getting started with Python and Eclipse is easy: Install Eclipse and then use the Eclipse Marketplace to install the PyDev plug-in. Create a Python (or PyDev) module, and you're all set to start creating your Python code.
Of course, it's even easier to run the Java code in Eclipse, because the default installation already includes support for Java. And let's not forget all the ancillary Java productivity enhancements: code completion, code generation (getters, setters, constructors, etc.), refactoring, and so on.
Regardless of your language choice or programming model (OO versus procedural or functional), there is no denying that the use of a modern IDE such as Eclipse is a major productivity enhancement. This type of tool facilitates agile development in the form of code generation, refactoring, and tool integration via plug-ins.
Final Thoughts
OO languages were the subject of a certain amount of mistrust back in the 1990s. In those days, many organizations preferred to stick with mainstream languages such as C, rather than adopting the new C++. Then along came Java, and I think it's fair to say that C++ was no longer the de facto OO language.
Nowadays, OO languages are used in embedded platforms pretty much as a matter of course. However, there is still some resistance to using the OO features in languages such as Python and PHP. The reasons for this resistance might have more to do with programmer preferences than with reality!
One interesting aspect of a comparison between OO code in different languages is the commonality between such languages. Python OO code is not vastly different from equivalent code in Java. This could be considered an advantage of using OO features in the multi-language era, helping programmers to produce good code. Simpler code is generally well received by maintenance programmers and production support staff.
The speed of such broadly equivalent Java and Python code is pretty similar, as I've illustrated here with simple tests, as well as comparable results in my article "Database Development: Comparing Python and Java ORM Performance."
OO offers many advantages in any language. The potential ease of understanding that OO provides could be a strong motivation for its use. Given this and the other advantages, OO seems to offer too many pluses right now, and potentially in the future, for smart programmers to keep avoiding it. | http://www.informit.com/articles/article.aspx?p=2436668 | CC-MAIN-2017-13 | refinedweb | 2,188 | 56.45 |
- Fix build against gcc:11
- Add missing
{,make}depends
Apply with `git am -s < <(curl -s)
{,make}depends
Apply with `git am -s < <(curl -s)
Thank you @rudism.Bro it worked!
Please update, current build doesn't work.
Tyvm @rudism! It worked like a charm!
I had to inject a missing header to get past the
uint32_t error. There may be a better way to do it, but adding this to the end of the
prepare() function in
PKGBUILD got it to work for me:
sed -i '1i\#include <cstdint>' $srcdir/anbox/src/anbox/input/manager.cpp
Edit: I also had to downgrade
lxc to get the
session-manager to work (which is a known issue)
sudo pacman -U
I have the same problem than diogovk.
I'm having the same output as Diogo's comment below. Probably bc gcc11
hmm, anyone else getting this error?
~/.cache/yay/anbox-git/src/anbox/src/anbox/input/manager.h:39:8: error: ‘uint32_t’ in namespace ‘std’ does not name a type; did you mean ‘wint_t’?
anbox: error while loading shared libraries: libprotobuf-lite.so.26: cannot open shared object file: No such file or directory
Can you add me as a co-maintainer?. | https://aur.tuna.tsinghua.edu.cn/packages/anbox-git/?O=50&PP=10 | CC-MAIN-2022-05 | refinedweb | 201 | 65.52 |
This page is likely outdated (last edited on 13 Sep 2009). Visit the new documentation for updated content.
MonoTouch Installation
MonoTouch is an SDK for developing applications for the iPhone using Mono. In addition to the Unix SDK, we are also releasing an optional alpha release of MonoDevelop 2.2 that contains support for iPhone application development.
Our MonoTouch_Beta page contains other useful information for developers getting started with MonoTouch on the iPhone Beta program, and instructions for signing up for the beta program.
The SDK can only be downloaded if you have received a beta invitation. Invitations are going out in waves to people who have filled out the beta signup form.
Basic Requirements
To try out MonoTouch, you will need to have Apple’s iPhone SDK 3.0 or higher, available from Apple’s iPhone Dev Center.
With the iPhone SDK you will be able to write applications and test them on the iPhone simulator. Additionally, if you want to deploy the resulting applications on the device for AppStore, Ad-Hoc or Enterprise distribution you will need to be part of the iPhone developer program.
Make sure that you can launch the iPhone simulator before continuing to the next step.
Mono Installation
Download and install the latest version of Mono 2.4 for OSX from the Mono downloads page.
MonoTouch SDK Installation
Do not bother performing this step until you have Mono 2.4 from the previous step done. If you do not install Mono 2.4, your install will not work.
Download and install the MonoTouch DMG file. This will give you access to the command line tools to develop applications with MonoTouch. The tutorials on this site will guide you through the steps of getting your sample applications running from the command line.
MonoDevelop Installation
To get you up and running in the shortest amount of time, you will want to install MonoDevelop on your system. Keep in mind that MonoDevelop for OSX is a preview of the upcoming MonoDevelop 2.2 and has a few rendering glitches.
To get MonoDevelop 2.2 up and running, you need:
- The MonoTouch-enabled version of MonoDevelop 2.2 Alpha for OSX.
Downloads
Documentation
In addition to the tutorials on this site, our web site at docs.go-mono.com contains the API documentation for the libraries shipped with MonoTouch. Look for the MonoTouch namespace.
The API design for the CIL/Objective-C binding is covered in our MonoTouch_API document.
Samples
We have ported some sample applications from CocoaTouch/Objective-C to MonoTouch, you can:
- Browse the Source Code on the web
- Use AnonSVN to download a copy to your machine using SVN.
- Download a tarball.
Most of the samples are built using the pure SDK and Unix makefiles. This is done to illustrate the process used.
There is one MonoDevelop for iPhone setup called
monocatalog-md which is identical to
monocatalog. The only difference is that this is a pre-made MonoDevelop solution file.
The samples require MonoTouch to be installed. | https://www.mono-project.com/archived/monotouch_installation/ | CC-MAIN-2020-50 | refinedweb | 503 | 58.89 |
- Prompt the user for a positive integer less than 100.- Convert the integer into its binary representation, you MUST hard code the solution with your own algorithm with loop NOT using the java buit-in method such as: Integer.toBinaryString(int ).- Display both the original integer and the binary output.
Here's the Java program that works. For a dollar you don't get much error checking or formatting. Please contact me if you need any additional help. Depending on what you want it could be free or cost a little $$.
import java.util.Scanner;public class Integer2Binary { private static Scanner kb = new Scanner(System.in); public static void main(String[] args) { System.out.println( "\nProgram to get postive integer < 100 and convert to binary\n"); int n; do { System.out.print("Enter an integer (0<n<100): "); n = kb.nextInt(); } while (!(0 < n && n < 100)); int nSav = n; // convert the int to binary: String binStr = ""; // since n<100, the largest power of 2 that fits will be 64 = 2^6 binStr += n / 64; n = n % 64; binStr += n / 32; n = n % 32; binStr += n / 16; n = n % 16; binStr += n / 8; n = n % 8; binStr += n / 4; n = n % 4; binStr += n / 2; n = n % 2; binStr += n; // convert string to numbers: int binNum = Integer.parseInt(binStr); System.out.println("" + "\nThe original decimal integer: " + nSav + "\nThis number's binary equivalent is: " + binNum); }}Integer2Binary.java
Secure Information
Content will be erased after question is completed.
Enter the email address associated with your account, and we will email you a link to reset your password.
Forgot your password? | https://www.studypool.com/discuss/22951/display-both-the-original-integer-and-the-binary-output?free | CC-MAIN-2017-13 | refinedweb | 267 | 56.35 |
tornado.queues – Queues for coroutines¶
New in version 4.2.
Asynchronous queues for coroutines. These classes are very similar to those provided in the standard library’s asyncio package.
Warning
Unlike the standard library’s
queue module, the classes defined here
are not thread-safe. To use these queues from another thread,
use
IOLoop.add_callback to transfer control to the
IOLoop thread
before calling any queue methods.
Classes¶
Queue¶
- class
tornado.queues.
Queue(maxsize: int = 0)[source]¶
Coordinate producer and consumer coroutines.
If maxsize is 0 (the default) the queue size is unbounded.
from tornado import gen from tornado.ioloop import IOLoop from tornado.queues import Queue q = Queue(maxsize=2) async def consumer(): async for item in q: try: print('Doing work on %s' % item) await gen.sleep(0.01) finally: q.task_done() async def producer(): for item in range(5): await q.put(item) print('Put %s' % item) async def main(): # Start consumer without waiting (since it never finishes). IOLoop.current().spawn_callback(consumer) await producer() # Wait for producer to put all tasks. await q.join() # Wait for consumer to finish all tasks. print('Done') IOLoop.current().run_sync(main)
Put 0 Put 1 Doing work on 0 Put 2 Doing work on 1 Put 3 Doing work on 2 Put 4 Doing work on 3 Doing work on 4 Done
In versions of Python without native coroutines (before 3.5),
consumer()could be written as:
@gen.coroutine def consumer(): while True: item = yield q.get() try: print('Doing work on %s' % item) yield gen.sleep(0.01) finally: q.task_done()
Changed in version 4.3: Added
async forsupport in Python 3.5.
put(item: _T, timeout: Union[float, datetime.timedelta] = None) → Future[None][source]¶
Put an item into the queue, perhaps waiting until there is room.
Returns a Future, which raises
tornado.util.TimeoutErrorafter a timeout.
timeoutmay be a number denoting a time (on the same scale as
tornado.ioloop.IOLoop.time, normally
time.time), or a
datetime.timedeltaobject for a deadline relative to the current time.
put_nowait(item: _T) → None[source]¶
Put an item into the queue without blocking.
If no free slot is immediately available, raise
QueueFull.
get(timeout: Union[float, datetime.timedelta] = None) → Awaitable[_T][source]¶
Remove and return an item from the queue.
Returns an awaitable which resolves once an item is available, or raises
tornado.util.TimeoutErrorafter a timeout.
timeoutmay be a number denoting a time (on the same scale as
tornado.ioloop.IOLoop.time, normally
time.time), or a
datetime.timedeltaobject for a deadline relative to the current time.
Note
The
timeoutargument of this method differs from that of the standard library’s
queue.Queue.get. That method interprets numeric values as relative timeouts; this one interprets them as absolute deadlines and requires
timedeltaobjects for relative timeouts (consistent with other timeouts in Tornado).
get_nowait() → _T[source]¶
Remove and return an item from the queue without blocking.
Return an item if one is immediately available, else raise
QueueEmpty.
task_done() → None[source]¶
Indicate that a formerly enqueued task is complete.
Used by queue consumers. For each
getused to fetch a task, a subsequent call to
task_donetells the queue that the processing on the task is complete.
If a
joinis blocking, it resumes when all items have been processed; that is, when every
putis matched by a
task_done.
Raises
ValueErrorif called more times than
put.
join(timeout: Union[float, datetime.timedelta] = None) → Awaitable[None][source]¶
Block until all items in the queue are processed.
Returns an awaitable, which raises
tornado.util.TimeoutErrorafter a timeout.
PriorityQueue¶
- class
tornado.queues.
PriorityQueue(maxsize: int = 0)[source]¶
A
Queuethat retrieves entries in priority order, lowest first.
Entries are typically tuples like
(priority number, data).
from tornado.queues import PriorityQueue q = PriorityQueue() q.put((1, 'medium-priority item')) q.put((0, 'high-priority item')) q.put((10, 'low-priority item')) print(q.get_nowait()) print(q.get_nowait()) print(q.get_nowait())
(0, 'high-priority item') (1, 'medium-priority item') (10, 'low-priority item')
Exceptions¶
QueueEmpty¶
- exception
tornado.queues.
QueueEmpty[source]¶
Raised by
Queue.get_nowaitwhen the queue has no items.
QueueFull¶
- exception
tornado.queues.
QueueFull[source]¶
Raised by
Queue.put_nowaitwhen a queue is at its maximum size. | https://www.tornadoweb.org/en/branch6.0/queues.html | CC-MAIN-2022-27 | refinedweb | 693 | 62.75 |
This interview appeared in the March 1995 issue of Dr. Dobb's Journal, and is reprinted with permission.
Tell us something about your long-term interest in generic programming.
I started thinking about generic programming in the late 70s when I observed that some algorithms depended not on some particular implementation of a data structure but only on a few fundamental semantic properties of the structure. I started going through many different algorithms, and I found that most algorithms can be abstracted away from a particular implementation in such a way that efficiency is not lost. Efficiency is a fundamental concern of mine. It is silly to abstract an algorithm in such a way that when you instantiate it back it becomes inefficient.
At that time I thought that the right way of doing this kind of research was to develop a programming language, which is what I started doing with two of my friends, Deepak Kapur, who at present is a professor at State University of New York, Albany, and David Musser, professor at Rensselaer Polytechnic Institute. At that time the three of us worked at the General Electric Research Center at Schenectady, NY. We started working on a language called Tecton, which would allow people to describe algorithms associated with what we called generic structures, which is just a collection of formal types and properties of these types. Sort of mathematical stuff. We realized that one can define an algebra of operations on these structures, you can refine them, you can enrich them, and do all sorts of things.
There were some interesting ideas, but the research didn't lead to practical results because Tecton was functional. We believed Backus's idea that we should liberate programming from the von Neumann style, and we didn't want to have side effects. That limited our ability to handle very many algorithms that require the notion of state and side effects.
The interesting thing about Tecton, which I realized sometime in the late 70s, was that there was a fundamental limitation in the accepted notion of an abstract data type. People usually viewed abstract data types as something which tells you only about the behavior of an object and the implementation is totally hidden. It was commonly assumed that the complexity of an operation is part of implementation and that abstraction ignores complexity. One of the things that is central to generic programming as I understand it now, is that complexity, or at least some general notion of complexity, has to be associated with an operation.
Let's take an example. Consider an abstract data type stack. It's not enough to have Push and Pop connected with the axiom wherein you push something onto the stack and after you pop the stack you get the same thing back. It is of paramount importance that pushing the stack is a constant time operation regardless of the size of the stack. If I implement the stack so that every time I push it becomes slower and slower, no one will want to use this stack.
We need to separate the implementation from the interface but not at the cost of totally ignoring complexity. Complexity has to be and is a part of the unwritten contract between the module and its user. The reason for introducing the notion of abstract data types was to allow interchangeable software modules. You cannot have interchangeable modules unless these modules share similar complexity behavior. If I replace one module with another module with the same functional behavior but with different complexity tradeoffs, the user of this code will be unpleasantly surprised. I could tell him anything I like about data abstraction, and he still would not want to use the code. Complexity assertions have to be part of the interface.
Around 1983 I moved from GE Research to the faculty of the Polytechnic University, formerly known as Brooklyn Polytechnic, in NY. I started working on graph algorithms. My principal collaborator was Aaron Kershenbaum, now at IBM Yorktown Heights. He was an expert in graph and network algorithms, and I convinced him that some of the ideas of high order and generic programming were applicable to graph algorithms. He had some grants and provided me with support to start working with him to apply these ideas to real network algorithms. He was interested in building a toolbox of high order generic components so that some of these algorithms could be implemented, because some of the network algorithms are so complex that while they are theoretically analyzed, but never implemented. I decided to use a dialect of Lisp called Scheme to build such a toolbox. Aaron and I developed a large library of components in Scheme demonstrating all kinds of programming techniques. Network algorithms were the primary target. Later Dave Musser, who was still at GE Research, joined us, and we developed even more components, a fairly large library. The library was used at the university by graduate students, but was never used commercially. I realized during this activity that side effects are important, because you cannot really do graph operations without side effects. You cannot replicate a graph every time you want to modify a vertex. Therefore, the insight at that time was that you can combine high order techniques when building generic algorithms with disciplined use of side effects. Side effects are not necessarily bad; they are bad only when they are misused.
In the summer of 1985 I was invited back to GE Research to teach a course on high order programming. I demonstrated how you can construct complex algorithms using this technique. One of the people who attended was Art Chen, then the manager of the Information Systems Laboratory. He was sufficiently impressed to ask me if I could produce an industrial strength library using these techniques in Ada, provided that I would get support. Being a poor assistant professor, I said yes, even though I didn't know any Ada at the time. I collaborated with Dave Musser in building this Ada library. It was an important undertaking, because switching from a dynamically typed language, such as Scheme, to a strongly typed language, such as Ada, allowed me to realize the importance of strong typing. Everybody realizes that strong typing helps in catching errors. I discovered that strong typing, in the context of Ada generics, was also an instrument of capturing designs. It was not just a tool to catch bugs. It was also a tool to think. That work led to the idea of orthogonal decomposition of a component space. I realized that software components belong to different categories. Object-oriented programming aficionados think that everything is an object. When I was working on the Ada generic library, I realized that this wasn't so. There are things that are objects. Things that have state and change their state are objects. And then there are things that are not objects. A binary search is not an object. It is an algorithm. Moreover, I realized that by decomposing the component space into several orthogonal dimensions, we can reduce the number of components, and, more importantly, we can provide a conceptual framework of how to design things.
Then I was offered a job at Bell Laboratories working in the C++ group on C++ libraries. They asked me whether I could do it in C++. Of course, I didn't know C++ and, of course, I said I could. But I couldn't do it in C++, because in 1987 C++ didn't have templates, which are essential for enabling this style of programming. Inheritance was the only mechanism to obtain genericity and it was not sufficient.
Even now C++ inheritance is not of much use for generic programming. Let's discuss why. Many people have attempted to use inheritance to implement data structures and container classes. As we know now, there were few if any successful attempts. C++ inheritance, and the programming style associated with it are dramatically limited. It is impossible to implement a design which includes as trivial a thing as equality using it. If you start with a base class X at the root of your hierarchy and define a virtual equality operator on this class which takes an argument of the type X, then derive class Y from class X. What is the interface of the equality? It has equality which compares Y with X. Using animals as an example (OO people love animals), define mammal and derive giraffe from mammal. Then define a member function mate, where animal mates with animal and returns an animal. Then you derive giraffe from animal and, of course, it has a function mate where giraffe mates with animal and returns an animal. It's definitely not what you want. While mating may not be very important for C++ programmers, equality is. I do not know a single algorithm where equality of some kind is not used.
You need templates to deal with such problems. You can have template class animal which has member function mate which takes animal and returns animal. When you instantiate giraffe, mate will do the right thing. The template is a more powerful mechanism in that respect.
However, I was able to build a rather large library of algorithms, which later became part of the Unix System Laboratory Standard Component Library. I learned a lot at Bell Labs by talking to people like Andy Koenig and Bjarne Stroustrup about programming. I realized that C/C++ is an important programming language with some fundamental paradigms that cannot be ignored. In particular I learned that pointers are very good. I don't mean dangling pointers. I don't mean pointers to the stack. But I mean that the general notion of pointer is a powerful tool. The notion of address is universally used. It is incorrectly believed that pointers make our thinking sequential. That is not so. Without some kind of address we cannot describe any parallel algorithm. If you attempt to describe an addition of n numbers in parallel, you cannot do it unless you can talk about the first number being added to the second number, while the third number is added to the fourth number. You need some kind of indexing. You need some kind of address to describe any kind of algorithm, sequential or parallel. The notion of an address or a location is fundamental in our conceptualizing computational processes---algorithms..
C++ is successful because instead of trying to come up with some machine model invented by just contemplating one's navel, Bjarne started with C and tried to evolve C further, allowing more general programming techniques but within the framework of this machine model. The machine model of C is very simple. You have the memory where things reside. You have pointers to the consecutive elements of the memory. It's very easy to understand. C++ keeps this model, but makes things that reside in the memory more extensive than in the C machine, because C has a limited set of data types. It has structures that allow a sort of an extensible type system, but it does not allow you to define operations on structures. This limits the extensibility of the type system. C++ moved C's machine model much further toward a truly extensible type system.
In 1988 I moved to HP Labs where I was hired to work on generic libraries. For several years, instead of doing that I worked on disk drives, which was exciting but was totally orthogonal to this area of research. I returned to generic library development in 1992 when Bill Worley, who was my lab director established an algorithms project with me being its manager. C++ had templates by then. I discovered that Bjarne had done a marvelous job at designing templates. I had participated in several discussions early on at Bell Labs about designing templates and argued rather violently with Bjarne that he should make C++ templates as close to Ada generics as possible. I think that I argued so violently that he decided against that. I realized the importance of having template functions in C++ and not just template classes, as some people believed. I thought, however, that template functions should work like Ada generics, that is, that they should be explicitly instantiated. Bjarne did not listen to me and he designed a template function mechanism where templates are instantiated implicitly using an overloading mechanism. This particular technique became crucial for my work because I discovered that it allowed me to do many things that were not possible in Ada. I view this particular design by Bjarne as a marvelous piece of work and I'm very happy that he didn't follow my advice.
When did you first conceive of the STL and what was its original purpose?...) We wrote a huge library, a lot of code with a lot of data structures and algorithms, function objects, adaptors, and so on. There was a lot of code, but no documentation. Our work was viewed as a research project with the goal of demonstrating that you can have algorithms defined as generically as possible and still extremely efficient. We spent a lot of time taking measurements, and we found that we can make these algorithms as generic as they can be, and still be as efficient as hand-written code. There is no performance penalty for this style of programming! The library was growing, but it wasn't clear where it was heading as a project. It took several fortunate events to lead it toward STL.
When and why did you decide to propose STL as part of the ANSI/ISO Standard C++ definition?
During the summer of 1993, Andy Koenig came to teach a C++ course at Stanford. I showed him some of our stuff, and I think he was genuinely excited about it. He arranged an invitation for me to give a talk at the November meeting of the ANSI/ISO C++ Standards Committee in San Jose. I gave a talk entitled "The Science of C++ Programming." The talk was rather theoretical. The main point was that there are fundamental laws connecting basic operations on elements of C++ which have to be obeyed. I showed a set of laws that connect very primitive operations such as constructors, assignment, and equality. C++ as a language does not impose any constraints. You can define your equality operator to do multiplication. But equality should be equality, and it should be a reflexive operation. A should be equal to A. It should be symmetric. If A is equal to B, then B should be equal to A. And it should be transitive. Standard mathematical axioms. Equality is essential for other operations. There are axioms that connect constructors and equality. If you construct an object with a copy constructor out of another object, the two objects should be equal. C++ does not mandate this, but this is one of the fundamental laws that we must obey. Assignment has to create equal objects. So I presented a bunch of axioms that connected these basic operations. I talked a little bit about axioms of iterators and showed some of the generic algorithms working on iterators. It was a two-hour talk and, I thought, rather dry. However, it was very well received. I didn't think at that time about using this thing as a part of the standard because it was commonly perceived that this was some kind of advanced programming technique which would not be used in the "real world". I thought there was no interest at all in any of this work by practical people.
I gave this talk in November, and I didn't think about ANSI at all until January. On January 6 I got a mail message from Andy Koenig, who is the project editor of the standard document, saying that if I wanted to make my library a part of the standard, I should submit a proposal by January 25. My answer was, "Andy, are you crazy?" to which he answered, "Well, yes I am crazy, but why not try it?"
At that point there was a lot of code but there was no documentation, much less a formal proposal. Meng and I spent 80-hour weeks to come up with a proposal in time for the mailing deadline. During that time the only person who knew it was coming was Andy. He was the only supporter and he did help a lot during this period. We sent the proposal out, and waited. While doing the proposal we defined a lot of things. When you write things down, especially when you propose them as a standard, you discover all kinds of flaws with your design. We had to re-implement every single piece of code in the library, several hundred components, between the January mailing and the next meeting in March in San Diego. Then we had to revise the proposal, because while writing the code, we discovered many flaws.
Can you characterize the discussions and debate in the committee following the proposal? Was there immediate support? Opposition?
We did not believe that anything would come out of it. I gave a talk, which was very well received. There were a lot of objections, most of which took this form: this is a huge proposal, it's way too late, a resolution had been passed at the previous meeting not to accept any major proposals, and here is this enormous thing, the largest proposal ever, with a lot of totally new things. The vote was taken, and, interestingly enough, an overwhelming majority voted to review the proposal at the next meeting and put it to a vote at the next meeting in Waterloo, Ontario.
Bjarne Stroustrup became a strong supporter of STL. A lot of people helped with suggestions, modifications, and revisions. Bjarne came here for a week to work with us. Andy helped constantly. C++ is a complex language, so it is not always clear what a given construct means. Almost daily I called Andy or Bjarne to ask whether such-and-such was doable in C++. I should give Andy special credit. He conceived of STL as part of the standard library. Bjarne became the main pusher of STL on the committee. There were other people who were helpful: Mike Vilot, the head of the library group, Nathan Myers of Rogue Wave, Larry Podmolik of Andersen Consulting. There were many others.
The STL as we proposed it in San Diego was written in present C++. We were asked to rewrite it using the new ANSI/ISO language features, some of which are not implemented. There was an enormous demand on Bjarne's and Andy's time trying to verify that we were using these non-implemented features correctly.
People wanted containers independent of the memory model, which was somewhat excessive because the language doesn't include memory models. People wanted the library to provide some mechanism for abstracting memory models. Earlier versions of STL assumed that the size of the container is expressible as an integer of type size_t and that the distance between two iterators is of type ptrdiff_t. And now we were told, why don't you abstract from that? It's a tall order because the language does not abstract from that; C and C++ arrays are not parameterized by these types. We invented a mechanism called "allocator," which encapsulates information about the memory model. That caused grave consequences for every component in the library. You might wonder what memory models have to do with algorithms or the container interfaces. If you cannot use things like size_t, you also cannot use things like T* because of different pointer types (T*, T huge *, etc.). Then you cannot use references because with different memory models you have different reference types. There were tremendous ramifications on the library.
The second major thing was to extend our original set of data structures with associative data structures. That was easier, but coming up with a standard is always hard because we needed something which people would use for years to come for their containers. STL has from the point of view of containers, a very clean dichotomy. It provides two fundamental kinds of container classes: sequences and associative containers. They are like regular memory and content-addressable memory. It has a clean semantics explaining what these containers do.
When I arrived at Waterloo, Bjarne spent a lot of time explaining to me that I shouldn't be concerned, that most likely it was going to fail, but that we did our best, we tried, and we should be brave. The level of expectation was low. We expected major opposition. There was some opposition but it was minor. When the vote was taken in Waterloo, it was totally surprising because it was maybe 80% in favor and 20% against. Everybody expected a battle, everybody expected controversy. There was a battle, but the vote was overwhelming.
What effect does STL have on the class libraries published in the ANSI/ISO February 1994 working paper?
STL was incorporated into the working paper in Waterloo. The STL document is split apart, and put in different places of the library parts of the working paper. Mile Vilot is responsible for doing that. I do not take active part in the editorial activities. I am not a member of the committee but every time an STL-related change is proposed, it is run by me. The committee is very considerate.
Several template changes have been accepted by the committee. Which ones have impact on STL?
Prior to the acceptance of STL there were two changes that were used by the revised STL. One is the ability to have template member functions. STL uses them extensively to allow you to construct any kind of a container from any other kind of a container. There is a single constructor that allows you to construct vectors out of lists or out of other containers. There is a templatized constructor which is templatized on the iterator, so if you give a pair of iterators to a container constructor, the container is constructed out of the elements which are specified by this range. A range is a set of elements specified by a pair of iterators, generalized pointers, or addresses. The second significant new feature used in STL was template arguments which are templates themselves, and that's how allocators, as originally proposed, were done.
Did the requirements of STL influence any of the proposed template changes?
In Valley Forge, Bjarne proposed a significant addition to templates called "partial specialization," which would allow many of the algorithms and classes to be much more efficient and which would address a problem of code size. I worked with Bjarne on the proposal and it was driven by the need of making STL even more efficient. Let me explain what partial specialization is. At present you can have a template function parameterized by class T called swap(T&, T&) and swaps them. This is the most generic possible swap. If you want to specialize swap and do something different for a particular type, you can have a function swap(int&, int&), and which does integer swapping in some different way. However it was not possible to have an intermediate partial specialization, that is, to provide a template function of the following form:
template <class T> void swap(vector<T>&, vector<T>&);This form provides a special way to swap vectors. This is an important problem from an efficiency point of view. If you swap vectors with the most generic swap, which uses three assignments, vectors are copied three times, which takes linear time. However, if we have this partial specialization of swap for vectors that swap two vectors, then you can have a fast, constant time operation, that moves a couple of pointers in the vector headers. That would allow sort, for example, to work on vectors of vectors much faster. With the present STL, without partial specialization, the only way to make it work faster is for any particular kind of vector, such as vector<int>, to define its own swap, which can be done but which puts a burden on the programmer. In very many cases, partial specialization would allow algorithms to be more effective on some generic classes. You can have the most generic swap, a less generic swap, an even less generic swap, and a totally specific swap. You can do partial specialization, and the compiler will find the closest match. Another example is copy. At present the copy algorithm just goes through a sequence of elements defined by iterators and copies them one by one. However, with partial specialization we can define a template function:
template <class T> T ** copy(T**,T**,T**);This will efficiently copy a range of pointers by using memcpy, because when we're copying pointers we don't have to worry about construction and destruction and we can just move bits with memcpy. That can be done once and for all in the library and the user doesn't need to be concerned. We can have particular specializations of algorithms for some of the types. That was a very important change, and as far as I know it was favorably received in Valley Forge and will be part of the Standard.
What kinds of applications beyond the standard class libraries are best served by STL ?
I have hopes that STL will introduce a style of programming called generic programming. I believe that this style is applicable to any kind of application, that is, trying to write algorithms and data structures in the most generic way. Specifying families or categories of such structures satisfying common semantic requirements is a universal paradigm applicable to anything. It will take a long time before the technology is understood and developed. STL is a starting point for this type of programming.
Eventually we will have standard catalogs of generic components with well-defined interfaces, with well-defined complexities. Programmers will stop programming at the micro level. You will never need to write a binary search routine again. Even now, STL provides several binary search algorithms written in the most generic way. Anything that is binary-searchable can be searched by those algorithms. The minimum requirements that the algorithm assumes are the only requirements that the code uses. I hope that the same thing will happen for all software components. We will have standard catalogs and people will stop writing these things.
That was Doug McIlroy's dream when he published a famous paper talking about component factories in 1969. STL is an example of the programming technology which will enable such component factories. Of course, a major effort is needed, not just research effort, but industrial effort to provide programmers with such catalogs, to have tools which will allow people to find the components they need, and to glue the components together, and to verify that their complexity assumptions are met.
STL does not implement a persistent object container model. The map and multimap containers are particularly good candidates for persistent storage containers as inverted indexes into persistent object databases. Have you done any work in that direction or can you comment an such implementations?
This point was noticed by many people. STL does not implement persistence for a good reason. STL is as large as was conceivable at that time. I don't think that any larger set of components would have passed through the standards committee. But persistence is something that several people thought about. During the design of STL and especially during the design of the allocator component, Bjarne observed that allocators, which encapsulate memory models, could be used to encapsulate a persistent memory model. The insight was Bjarne's, and it is an important and interesting insight. Several object database companies are looking at that. In October 1994 I attended a meeting of the Object Database Management Group. I gave a talk on STL, and there was strong interest there to make the containers within their emerging interface to conform to STL. They were not looking at the allocators as such. Some of the members of the Group are, however, investigating whether allocators can be used to implement persistency. I expect that there will be persistent object stores with STL-conforming interfaces fitting into the STL framework within the next year.
Set, multiset, map, and multimap are implemented with a red-black tree data structure. Have you experimented with other structures such as B*trees?
I don't think that would be quite right for in-memory data structures, but this is something that needs to be done. The same interfaces defined by STL need to be implemented with other data structures---skip lists, splay trees, half-balanced trees, and so on. It's a major research activity that needs to be done because STL provides us with a framework where we can compare the performance of these structures. The interface is fixed. The basic complexity requirements are fixed. Now we can have meaningful experiments comparing different data structures to each other. There were a lot of people from the data structure community coming up with all kinds of data structures for that kind of interface. I hope that they would implement them as generic data structures within the STL framework.
Are compiler vendors working with you to implement STL into their products?
Yes. I get a lot of calls from compiler vendors. Pete Becker of Borland was extremely helpful. He helped by writing some code so that we could implement allocators for all the memory models of Borland compilers. Symantec is going to release an STL implementation for their Macintosh compiler. Edison Design Group has been very helpful. We have had a lot of support from most compiler vendors.
STL includes templates that support memory models of 16-bit MS-DOS compilers. With the current emphasis on 32-bit, flat model compilers and operating systems, do you think that the memory-model orientation will continue to be valid?
Irrespective of Intel architecture, memory model is an object, which encapsulates the information about what is a pointer, what are the integer size and difference types associated with this pointer, what is the reference type associated with this pointer, and so on. Abstracting that is important if we introduce other kinds of memory such as persistent memory, shared memory, and so on. A nice feature of STL is that the only place that mentions the machine-related types in STL---something that refers to real pointer, real reference---is encapsulated within roughly 16 lines of code. Everything else, all the containers, all the algorithms, are built abstractly without mentioning anything which relates to the machine. From the point of view of portability, all the machine-specific things which relate to the notion of address, pointer, and so on, are encapsulated within a tiny, well-understood mechanism. Allocators, however, are not essential to STL, not as essential as the decomposition of fundamental data structures and algorithms.
The ANSI/ISO C Standards committee treated platform-specific issues such as memory models as implementation details and did not attempt to codify them. Will the C++ committee be taking a different view of these issues? If so, why?
I think that STL is ahead of the C++ standard from the point of view of memory models. But there is a significant difference between C and C++. C++ has constructors and operator new, which deal with memory model and which are part of the language. It might be important now to look at generalizing things like operator new to be able to take allocators the way STL containers take allocators. It is not as important now as it was before STL was accepted, because STL data structures will eliminate the majority of the needs for using new. Most people should not allocate arrays because STL does an effective job in doing so. I never need to use new in my code, and I pay great attention to efficiency. The code tends to be more efficient than if I were to use new. With the acceptance of STL, new will sort of fade away. STL also solves the problem of deleting because, for example, in the case of a vector, the destructor will destroy it on the exit from the block. You don't need to worry about releasing the storage as you do when you use new. STL can dramatically minimize the demand for garbage collection. Disciplined use of containers allows you to do whatever you need to do without automatic memory management. The STL constructors and destructors do allocation properly.
The C++ Standard Library subcommittee is defining standard namespaces and conventions for exception handling. Will STL classes have namespaces and throw exceptions?
Yes they will. Members of the committee are dealing with that, and they are doing a great job.
How different from the current STL definition will the eventual standard definition be? Will the committee influence changes or is the design under tighter control?
It seems to be a consensus that there should not be any major changes to STL.
How can programmers gain an early experience with STL in anticipation of it becoming a standard?
They can download the STL header files from butler.hpl.hp.com under /stl and use it with Borland or IBM compiler, or with any other compiler powerful enough to handle STL The only way to learn some style of programming is by programming. They need to look at examples and write programs in this style.
You are collaborating with P.J. (Bill) Plauger to write a book about STL. What will be the emphasis of the book and when is it scheduled to be published?
It is scheduled to be published in the summer of 1995 and is going to be an annotated STL implementation. It will be similar to Bill's books on the Standard C Library and the Draft Standard C++ Library. He is taking the lead on the book, which will serve as a standard reference document on the use of the STL. I hope to write a paper with Bjarne that will address language/library interactions in the context of C++/STL. It might lead to another book.
A lot more work needs to be done. For STL to become a success, people should do research experimenting with this style of programming. More books and articles need to be written explaining how to program in this style. Courses need to be developed. Tutorials need to be written. Tools need to be built which help people navigate through libraries. STL is a framework and it would be nice to have a tool with which to browse through this framework.
What is the relationship between generic programming and object-oriented programming?
In one sense, generic programming is a natural continuation of the fundamental ideas of object-oriented programming---separating the interface and implementation and polymorphic behavior of the components. However, there is a radical difference. Object-oriented programming emphasizes the syntax of linguistic elements of the program construction. You have to use inheritance, you have to use classes, you have to use objects, objects send messages. Generic programming does not start with the notion of whether you use inheritance or you don't use inheritance. It starts with an attempt to classify or produce a taxonomy of what kinds of things are there and how they behave. That is, what does it mean that two things are equal? What is the right way to define equality? Not just actions of equality. You can analyze equality deeper and discover that there is a generic notion of equality wherein two objects are equal if their parts, or at least their essential parts are equal. We can have a generic recipe for an equality operation. We can discuss what kinds of objects there are. There are sequences. There are operations on sequences. What are the semantics of these operations? What types of sequences from the point of view of complexity tradeoffs should we offer the user? What kinds of algorithms are there on sequences? What kind of different sorting functions do we need? And only after we develop that, after we have the conceptual taxonomy of the components, do we address the issue of how to implement them. Do we use templates? Do we use inheritance? Do we use macros? What kind of language technology do we use? The fundamental idea of generic programming is to classify abstract software components and their behavior and come up with a standard taxonomy. The starting point is with real, efficient algorithms and data structures and not with the language. Of course, it is always embodied in the language. You cannot have generic programming outside of a language. STL is done in C++. You could implement it in Ada. You could implement it in other languages. They would be slightly different, but there are some fundamental things that would be there. Binary search has to be everywhere. Sort has to be everywhere. That's what people do. There will be some modification on the semantics of the containers, slight modifications imposed by the language. In some languages you can use inheritance more, in some languages you have to use templates. But the fundamental difference is precisely that generic programming starts with semantics and semantic decomposition. For example, we decide that we need a component called swap. Then we figure out how this particular component will work in different languages. The emphasis is on the semantics and semantic classification, while object-orientedness, especially as it has evolved, places a much stronger emphasis, and, I think, too much of an emphasis, on precisely how to develop things, that is, using class hierarchies. OOP tells you how to build class hierarchies, but it doesn't tell you what should be inside those class hierarchies.
What do you see as the future of STL and generic programming?
I mentioned before the dream of programmers having standard repositories of abstract components with interfaces that are well understood and that conform to common paradigms. To do that there needs to be a lot more effort to develop the scientific underpinnings of this style of programming. STL starts it to some degree by classifying the semantics of some fundamental components. We need to work more on that. The goal is to transform software engineering from a craft to an engineering discipline. It needs a taxonomy of fundamental concepts and some laws that govern those concepts, which are well understood, which can be taught, which every programmer knows even if he cannot state them correctly. Many people know arithmetic even if they never heard of commutativity. Everybody who graduated from high school knows that 2+5 is equal to 5+2. Not all of them know that it is a commutative property of addition. I hope that most programmers will learn the fundamental semantic properties of fundamental operations. What does assignment mean? What does equality mean? How to construct data structures.
At present C++ is the best vehicle for this style of programming. I have tried different languages and I think that C++ allows this marvelous combination of abstractness and efficiency. However, I think that it is possible to design a language based on C and on many of the insights that C++ brought into the world, a language which is more suitable to this style of programming, which lacks some of the deficiencies of C++, in particular its enormous size. STL deals with things called concepts. What is an iterator? Not a class. Not a type. It is a concept. (Or, if we want to be more formal, it is what Bourbaki calls a structure type, what logicians call a theory, or what type theory people call a sort.) It is something which doesn't have a linguistic incarnation in C++. But it could. You could have a language where you could talk about concepts, refine them, and then finally form them in a very programmatic kind of way into classes. (There are, of course, languages that deal with sorts, but they are not of much use if you want to sort.) We could have a language where we could define something called forward iterator, which is just defined as a concept in STL---it doesn't have a C++ incarnation. Then we can refine forward iterator into bidirectional iterator. Then random iterator can be refined from that. It is possible to design a language which would enable even far greater ease for this style of programming. I am fully convinced that it has to be as efficient and as close to the machine as are C and C++. And I do believe that it is possible to construct a language that allows close approximation to the machine on the one hand and has the ability to deal with very abstract entities on the other hand. I think that abstractness can be even greater than it is in C++ without creating a gap between underlying machines. I think that generic programming can influence language research and that we will have practical languages, which are easy to use and are well suited for that style of programming. From that you can deduce what I am planning to work on next.Copyright © 1995 Dr. Dobb's Journal | http://idlebox.net/2006/apidocs/sgi-stl-v3.3.zip/drdobbs-interview.html | CC-MAIN-2013-48 | refinedweb | 6,917 | 64.1 |
C# Corner
The .NET Framework has full support for running multiple threads at once. In this article, Patrick Steele looks at how threads accomplish their task and why you need to be careful how you manage a WinForms application with multiple threads.
But this doesn't have to happen. The .NET Framework has full support for running multiple threads at once. In this article, we'll look at how threads accomplish their task and why you need to be careful how you manage a WinForms application with multiple threads.
Thread Basics
A thread is the basic unit of which an operating system uses to execute code. Every process that is started uses at least one thread. For .NET applications, the framework will spin up a couple of threads for housekeeping (garbage collection, finalization queue, etc...) and then one thread for the AppDomain. A .NET process can have multiple AppDomains and an AppDomain supports multiple threads. For this discussion, we're just concerned about the one thread that gets our application running.
Let's start with a simple console application:
using System;namespace HelloWorld{ class Program { static void Main(string[] args) { Console.WriteLine("Hello, Visual Studio Magazine!"); Console.ReadKey(); } }}
When running this application, the .NET Framework creates a new AppDomain with a single thread. That thread is then instructed to start running code at the "Main" method. The first thing it does is writes our "hello" message to the console. After that, it calls the ReadKey method. This waits for the user to press any key. This is called a "blocking operation" since the thread is blocked and can't do anything until a key is pressed. The blocking happens somewhere deep inside the call to ReadKey (because that's where our thread is running code). Once a key is pressed, the thread is done and the application exits.
Some Multithreading
Let's add a little bit of multithreading to our console application:
using System;using System.Threading;namespace HelloWorldMultiThreaded{ class Program { static void Main(string[] args) { Console.WriteLine("Start counting..."); StartCounting(); Console.WriteLine("Press any key to exit..."); Console.ReadKey(); Console.WriteLine("Exiting..."); } private static void StartCounting() { var thread = new Thread(() => { for(var x= 0 ; x < 10 ; x++) { Console.Write("{0}... ", x); Thread.Sleep(1000); } }); thread.Start(); } }
Let's take a step by step approach to see what is going on:
Run this code and play around with it. Note that if you press a key before the second thread is done counting to 9, you'll see the "Exiting..." message, but the numbers continue to print even though the Main method's thread has exited. That's because the second thread is a foreground thread.
All threads behave the same way and all threads are defined as either a foreground thread (the default) or a background thread. The only difference is how the .NET runtime treats them. A .NET application won't exit until all foreground threads have completed. In our example, the second thread is a foreground thread and therefore, the counting will continue even though the Main thread for the application has ended.
If you want to see the difference a background thread makes, we can mark the second thread as a background thread by calling:
thread.IsBackground = true;
Right before we start the thread at "thread.Start()". Now if you run the application, you'll notice that a key press during the second thread's counting will end the application. Since the first thread is the only foreground thread, the .NET Framework will end the application (and stop all background threads) as soon as the Main method exits.
WinForms and the Message Pump
Windows applications (either WinForms in .NET, or C/C++ applications) are driven by messages being sent to them from the operating system. The OS will tell you when:
How is all of this messaging coordinated in your application? The messages are placed in a FIFO (first in, first out) queue and your application pulls them out one by one and processes them. At the heart of almost every windows application is code that looks basically like this (simplified pseudo-code):
while(msg = get_next_message()){ dispatch_message(msg);}
This is called the message pump. What this code does is monitor the Windows message queue. When a message appears, it pulls the message and dispatches it to your application. Dispatching means it looks to see if you have an event handler set up for the particular message. When the user clicks on a button, the .NET Framework will determine which button was clicked and if you have an event handler subscribed for the "Click" event of the button. If so, the framework then calls your event handler and your code is executed.
This message pump handles messages for your entire application. Every control on all of your forms can have a message sent to it (a message to paint itself, a message to scroll, etc...). All of these messages get dispatched via this message pump.
If you look at a basic WinForms application in C#, you'll notice the Main() method found in Program.cs has the following code:
static void Main() { Application.EnableVisualStyles(); Application.SetCompatibleTextRenderingDefault(false); Application.Run(new Form1()); }
The very last line of code is a call to Application.Run(). This is a .NET Framework method and it encapsulates the Windows message pump I just described. The form passed to the method is considered the "main" form for your application. Once that form is closed, the message pump exits, the thread comes back to Main where there is nothing left to do and the program exits.
A Non-Responsive UI
Now that we know what is going on, let's revisit the situation that I described at the beginning of this article:
Why does your UI become unresponsive? Why does task manager display a "(Not Responding)" message next to your application? Let's look at what happens when an event handler contains something like this:
private void button1_Click(object sender, EventArgs e) { Thread.Sleep(20*1000); }
Obviously this is a contrived example of some code that takes 20 seconds to complete -- it's only a simulation.
If we consider that the .NET Framework started a single thread, executed the code in Main and is currently sitting inside the message pump processing messages from the operating system:
At this point, two things will happen. The user will be patient and eventually, your event handler finishes. The thread returns back to the message loop and all of those messages that have been backing up are processed. The app becomes responsive again and the user is happy, but annoyed. The other possibility is that the user, while in Task Manager, kills your app and starts over thinking your app just hung. This could cause a loss of work and loss of confidence in your application's stability.
Multithreading in WinForms
So let's do a similar multithreaded counter like we did in our console application. Instead of outputting the digits 0-9 to the console, we'll put them in a textbox. We'll start the counting when the user clicks on a button. Here's the "click" event which will start up a second thread and then allow the first thread to return to the message loop:
private void button1_Click(object sender, System.EventArgs e) { var thread = new Thread(StartCounting); thread.IsBackground = true; thread.Start(); } private void StartCounting() { for (var i = 0; i < 10; i++) { textBox1.Text = i.ToString(); Thread.Sleep(1000); } }
Notice that we made the thread a background thread. We don't want this thread to prevent the application from ending so we've changed it to a background thread.
Run the code and click on the button. What? You got an exception?
System.InvalidOperationException: Cross-thread operation not valid: Control 'textBox1' accessed from a thread other than the thread it was created on.
What is happening? The .NET Framework is helping you identify your mistake. The textbox was created on the "main" thread (the one that is running the message pump). At this point in the code, when we're trying to update the Textbox's Text property, we're running on a different thread. Updating WinForms controls from background threads is not allowed as it can cause many issues -- not the least of which is that the thread we're running on does not have a message pump running! Without the message pump, the update of the property (which happens via a Windows message), would never be processed in this thread. If you've written code like this before in .NET Framework 1.x, you didn't get this exception. It's a new exception introduced in 2.0 to help you identify this scenario of cross-thread operations.
So now we need to somehow get the textbox update to be performed on the main thread. WinForms helps us out by providing an "Invoke" method on all Control-derived classes which will take a delegate and will marshal that delegate to the main thread (where our message pump is).
Here's an update to our code for updating the textbox:
private delegate void DisplayCountDelegate(int i); private void StartCounting() { for (var i = 0; i < 10; i++) { textBox1.Invoke(new DisplayCountDelegate(DisplayCount), i); Thread.Sleep(1000); } } private void DisplayCount(int i) { textBox1.Text = i.ToString(); }
First, we define a separate delegate for displaying our count. The next change is inside the for loop. Instead of directly updating the Text property, we using TextBox1's Invoke method and give it a delegate. That delegate will be marshaled to the main thread and executed there via the message pump. Run this code and you'll see that we can move the form, resize it and do other things and the form stays responsive while the background thread runs. You'll also notice that if you close the form before the second thread has counted to 9, the application will exit.
Multithreaded Complexity
Another thing you might have noticed is that if you click the button multiple times, multiple threads are started and you'll get a mingling of updates in the textbox as each thread is running the for loop. We can prevent this by disabling the start button as soon as the second thread is started:
private void button1_Click(object sender, System.EventArgs e) { var thread = new Thread(StartCounting); thread.IsBackground = true; thread.Start(); button1.Enabled = false; }
This works. It prevents the user for spinning up a whole bunch of threads. But it introduces another problem -- how do we re-enable the button once the thread is complete? Your initial reaction might be to enable the button after the for loop as completed:
private void StartCounting() { for (var i = 0; i < 10; i++) { textBox1.Invoke(new DisplayCountDelegate(DisplayCount), i); Thread.Sleep(1000); } button1.Enabled = true; }
But remember, we can't manipulate controls from a background thread. We'd have to create another delegate and marshal it to the main thread using Invoke:
private delegate void EnableButtonDelegate(); private void StartCounting() { for (var i = 0; i < 10; i++) { textBox1.Invoke(new DisplayCountDelegate(DisplayCount), i); Thread.Sleep(1000); } button1.Invoke(new EnableButtonDelegate(EnableButton)); } private void EnableButton() { button1.Enabled = true; }
This works, but our code is starting to get a little messy. We've got delegates defined for marshalling calls back to the main thread. Those calls are executed via Invoke and any parameters are sent via an object[] (no strong typing). Because of this complexity, the .NET Framework introduced the BackgroundWorker.
The BackgroundWorker Component
The BackgroundWorker component is designed specifically for running code on a separate thread and reporting progress back to the main thread. The BackgroundWorker component supports two events for reporting progress. The big benefit of the BackgroundWorker is that these events are raised on the same thread that created the BackgroundWorker. Therefore, as long as you take care to create your BackgroundWorker on the main thread, the events will run on the main thread and you won't have to deal with delegate's and Invokes.
ProgressChanged event: This event is raised whenever the ReportProgress method is called. The ReportProgress event has two overloads. The first is a single integer argument. This usually represents the percentage of work completed (0 to 100). The second overload adds a "userState" argument of type object. This allows you some more flexibility in the type of data used to report progress in your background thread.
RunWorkerCompleted event: This event is raised once the BackgroundWorker has completed its processing.
Counting with the BackgroundWorker
Now let's look at a revised example using the BackgroundWorker to do the processing of the for loop.
public partial class Form1 : Form { private readonly BackgroundWorker worker; public Form1() { InitializeComponent(); worker = new BackgroundWorker(); worker.WorkerReportsProgress = true; worker.DoWork += StartCounting; worker.ProgressChanged += worker_ProgressChanged; worker.RunWorkerCompleted += worker_RunWorkerCompleted; } private void button1_Click(object sender, System.EventArgs e) { worker.RunWorkerAsync(); button1.Enabled = false; } private void StartCounting(object sender, DoWorkEventArgs e) { BackgroundWorker bgWorker = (BackgroundWorker) sender; for (var i = 0; i < 10; i++) { bgWorker.ReportProgress(i); Thread.Sleep(1000); } } private void worker_ProgressChanged(object sender,ProgressChangedEventArgs e) { textBox1.Text = e.ProgressPercentage.ToString(); } void worker_RunWorkerCompleted(object sender,RunWorkerCompletedEventArgs e) { button1.Enabled = true; } }
This is much simpler. In the form's constructor, we set up the BackgroundWorker. You must indicate that it will be reporting progress events by setting the WorkerReportsProgress property to true. Then we hook up the events that run the for loop, report the progress and finally, re-enable the button once the worker is completed. The StartCount method was updated to call the BackgroundWorter's ReportProgress method. That method will raise the ProgressChanged event on the main thread (no delegates or Invoke required!).
As you can see, the BackgroundWorker is the preferred way to perform long-running tasks in the background in a WinForms application. By using events that are fired on the main thread, it greatly simplifies the communications between your background task and the UI.
Conclusion
I hope this exploration into WinForms has helped you understand the complexities of multithreading. This is by no means an exhaustive guide on multithreading. My goal was to help you understand some of the lower level mechanics of windows and utilize that knowledge to make your UI's responsive as long-running operations take place.
Printable Format
> More TechLibrary
I agree to this site's Privacy Policy.
> More Webcasts | http://visualstudiomagazine.com/articles/2010/11/18/multithreading-in-winforms.aspx | CC-MAIN-2015-18 | refinedweb | 2,386 | 57.16 |
You can subscribe to this list here.
Showing
3
results of 3
Christian wrote:
> Did you try ObexFS? It's a FUSE-based filesystem for OBEX (actually a
> small wrapper on top of ObexFTP).
> If it doesn't work: what are the special cases needed for e.g. the
> "E:" base dir?
I don't know why, but in the obexfs mounted filesystem I'm not able to
create the directory (I'm using the debian/testing GNU/Linux).
That's why I had to write this script.
> You shouldn't need to use -"C" (create dir). The plain "-c" (change
> dir) should do.
>> cmd="obexftp -b your_mobile_bt_address_or_name -C E:"
In fact I could use "-c" for copying of the file. AFAIK "-C" is needed
for creating of a directory.
If the directory already exists, then "-c" is equivalent to "-C", so I
decided to use "-C" in both cases just for simplicity.
However I may be wrong.
--
regards,
Wojtek
Hi Wojtek,
Am 06.05.2008 um 13:42 schrieb Wojtek Zabolotny:
> sending ... tree of directories to my mobile via obexftp.
> with the following very simple script
Did you try ObexFS? It's a FUSE-based filesystem for OBEX (actually a
small wrapper on top of ObexFTP).
If it doesn't work: what are the special cases needed for e.g. the
"E:" base dir?
> cmd="obexftp -b your_mobile_bt_address_or_name -C E:"
You shouldn't need to use -"C" (create dir). The plain "-c" (change
dir) should do.
regards,
Christian
Hi All,
I had a problem with sending of multiple files (in fact of the whole
tree of directories) to my mobile via obexftp.
I've managed to solve it with the following very simple script (for
Python on Linux):
#!/usr/bin/python
import os
cmd="obexftp -b your_mobile_bt_address_or_name -C E:"
#The line above is customized for sending of the files to the SD/MMC
#card in my mobile. You may need to modify it!
for f in os.walk("."):
for d in f[1]:
#This is directory
cmd1=cmd+f[0][1:]+"/"+d
print cmd1
os.system(cmd1)
for fl in f[2]:
#This is a file
cmd1=cmd+f[0][1:]+" -p "+f[0]+"/"+fl
print cmd1
os.system(cmd1)
The script sends all the files and the directories down from the current
directory, and puts them into
the same directory structure on the SD/MMC card (E:) on the mobile.
Probably this script is not fully multiplatform ready, and maybe it is
not protected against "malicious" filenames (e.g. containing spaces or
special characters, which could disturb the operation of "os.system"
command), however it was very usefull for me, so I'd like to provide it
as a public domain contribution for other openobex users.
--
HTH & Regards,
Wojtek
wzab@... | http://sourceforge.net/p/openobex/mailman/openobex-users/?viewmonth=200805&viewday=6 | CC-MAIN-2015-27 | refinedweb | 462 | 76.01 |
ES6 its JS, ES6 is about the next generation of Javascript.
ES6 is so useful because all the ES6 features React, Angular and Vue apps typically use. In general, ES6 allows us to write clean and robust react apps and this help us to do more powerful things.
Content:
- Let and const
- Arrow functions
- Modules (Exports & Imports)
- Classes
- The threeDots ...
- Destructuring
Let and const
Let and const are different ways of creating variables.
We have var to create a variable in js but with ES6, There, two different keywords were introduced, let and const.
Var still works but you're highly encouraged to use let and const
Let is the new var, you use it for create a variable with value. But the most important point here is use let if you want to create a variable that really is variable.
Use const if you plan on creating a constant value, so something which you only assign once and never change.
In normal JS, We use var keyword to create a variable
var myName = 'Mohamed'; console.log(myName); myName = 'Khaled'; console.log(myName);
In ES6, We can use let keyword instead of var to create a variable
let myName = 'Mohamed'; console.log(myName); myName = 'Khaled'; console.log(myName);
Also we can use const to create a constant variable. That means we can't reassign this value
In the next example, We get an ERROR because we try to reassign a constant variable
const myName = 'Mohamed'; console.log(myName); myName = 'Khaled'; //ERROR console.log(myName);
Arrow functions.
Arrow functions is a different syntax for creating Javascript functions.
A normal javascript function of course looks like this.
function printName(name){ console.log(name); } printName(); //undefined printName('Mohamed'); //Mohamed
But Arrow functions:
const printName = (name) => { console.log(name); } printName(); printName('Mohamed');
There some alternatives to this syntax
If we have one argument
const printName = name => { console.log(name); } printName(); printName('Mohamed');
If we have a function which receives no arguments, we need to pass an empty pair of parentheses
const printName = () => { console.log('Mohamed'); } printName();
If we have a function which receives more than one argument, we need parentheses
const printName = (name1, name2, age) => { console.log(name1, name2, age); } printName('Mohamed', 'Khaled', 23); //Mohamed //Khaled //23
Also we can update our function body
const mul = (number) => { return number * 5; } console.log (mul(3)); //15
We can update this function and remove braces and retrun keyword
const mul = (number) => number * 5; console.log (mul(3));
We can update also
const mul = number => number * 5; console.log (mul(3)); //15
Modules (Exports & Imports)
We can split our code over multiple files, HOW?
We have to import them in the correct order in out html files, So we can import content from another file
Example, If we have person.js file that have an object
//Object const person = { name: 'Mohamed' } export default person
If we have another file utility.js, We can export multiple things
export const printMohamed = () => { console.log('Mohamed'); } export const mul = number => number * 5; export const baseData = 10;
We can import this somewhere else. For example this file app.js
//Notice: We can name person whatever we want because it's the default import person from './person.js' import prs from './person.js'
We should use curly braces to explicitly target specific things from that file
import {baseData} from './utility.js' import {mul} from './utility.js'
We can assign an alias with any name you choose after as keyword
import {mul as multiply} from './utility.js' import {printMohamed as mkhy} from './utility.js'
If we have multiple named exports in a file and we want to import all of them, We use special character * and then assign an alias
import * as bundled from './utility.js'
If we have more than once and we want to import special exports
import {baseData},{printMohamed} from './utility.js'
Classes
Classes are blueprints for objects, Class can have both properties and methods
Here's We created Person class that has name property and mul method. Then we created an object from this class
//Create class class Person{ name = 'Mohamed'; mul = number => number * 5; } //Use class, use new keyword const myPerson = new Person(); console.log(myPerson.name); //"Mohamed" console.log(myPerson.mul(3)); //15
Another example, We created class that has a constructor and print method. Then we created an object from this class
//Create class class Person{ //Default function method constructor(){ this.name = 'Mohamed'; } printMyName(){ console.log(this.name); } } //Create an instance or object const person = new Person(); person.printMyName(); //"Mohamed"
What if we want to make an inheritance? Here we use super keyword.
super keyword It's a keyword and it simply executes the parent constructor
//Create Human class class Human{ constructor(){ this.gender = 'male'; } printGender(){ console.log(this.gender); } } //Create Person class class Person extends Human{ constructor(){ super(); this.name = 'Mohamed'; } printMyName(){ console.log(this.name); } } //Create an instance or object const person = new Person(); person.printMyName(); //"Mohamed" person.printGender(); //"male"
Pay attention in the next important case:
Here our person class extends from Human class but person class has it's own properties and methods.
class Human{ //Default function method constructor(){ this.name = 'Mohamed'; this.gender = 'male'; this.age = 23; } printGender(){ console.log(this.gender); } printAge(){ console.log(this.age); } } class Person extends Human{ constructor(){ super(); this.name = 'Sarah'; this.gender = 'Female'; this.age = 35; } printMyName(){ console.log(this.name); } } const person = new Person(); person.printMyName(); //"Sarah" person.printGender(); //"Female" person.printAge(); //35
Important notes on Classes, Properties and Methods
ES7 offers a different syntax of initializing properties and methods
In ES6, Properties are like variables attached to classes or objects
constructor(){ this.myProperty = 'value'; this.name = 'Mohamed'; }
In ES7, We can assign a property directly inside our class so we skip the constructor function call.
In fact behind the scene this will still be transformed to use constructor functions
myProperty = 'value' name = 'Mohamed';
In ES6, As we discussed before, Methods are like functions attached to classes or objects
//myMethod () {...} printMyName(){ console.log(this.name); }
In ES7: We use an arrow function as a property value so you have got no problems with the this keyword
//myMethod = () => {...} printMyName = () => {console.log('Mohamed');} printGender = () => {this.gender);} printMyName = () => {this.name);}
In the next example, We can get rid of the constructor in the human class and get rid of the this keyword. Also we convert our methods to arrow functions. Finally, We no longer need to call super keyword.
Pay attention: If you run it on JSbin, You will get an error because doesn't recognize the syntax. So you actually need to choose ES6/Babel
class Human{ gender = 'female'; printGender = () => { console.log(this.gender); } } class Person extends Human{ name = 'Mohamed'; gender = 'male'; printMyName = () => { console.log(this.name); } } const person = new Person(); person.printMyName(); //"Mohamed" person.printGender(); //"male"
The threeDots ...
- The spread and the Rest operators called the threeDots
- The operator is just three dots ...
- The spread operator is used to split up array elements or object properties. In other words, To copy arrays or add properties to an object whilst safely copying that old object. The spread operator takes out all elements, all properties and distributors them in a new array or object or wherever you are using it
EX1 ... With array
const numbers = [1,2,3]; const newNumbers = [numbers,4,5]; console.log(newNumbers); //[[1, 2, 3], 4, 5] const spreadNumbers =[...numbers,4,5]; console.log(spreadNumbers); //[1, 2, 3, 4, 5]
EX2 .. With object
const oldPerson = { name : 'Mohamed' }; const newPerson = { ...oldPerson, age: 23 } console.log(newPerson);
Output
[object Object] {
age: 23,
name: "Mohamed"
}
- The rest operator is used to merge a list of function arguments into an array and we use it in a function argument list
const filterFunc1 = (...args) => { return args.filter(el => el === 1); } console.log(filterFunc1(1,2,7,1,3,8,9,1,2)); //[1, 1, 1]
EX3
const filterFunc2 = (...args) => { return args.filter(el => el === 1 || el ===2); } console.log(filterFunc2(1,2,7,1,3,8,9,1,2)); //[1, 2, 1, 1, 2]
Destructuring
- Destructuring allows you to easily extract array elements or object properties and store them in variables
- Destructuring is different than what spread operator do
- Destructuring allows you to pull out single element or properties and store them in varables for arrays and objects
Array example:
[a,b] = ['Mohamed','Khaled'] console.log(a); //Mohamed console.log(b); //Khaled
Object example:
myInfo1 = {name:'Mohamed'}; console.log(myInfo1.name); //Mohamed console.log(myInfo1.age); //undefined myInfo2 = {name:'Mohamed', age:23}; console.log(myInfo2.name); //Mohamed console.log(myInfo2.age); //23
EX1
const numbers = [1,2,3]; [num1,num2] = numbers; console.log(num1,num2); //1 //2
EX2
const numbers = [1,2,3]; [num1, ,num3] = numbers; console.log(num1,num3); //1 //3
EX3
const {name} = {name:'Mohamed', age:23} console.log(name); //Mohamed console.log(age); //undefined
EX4
const {name,age} = {name:'Mohamed', age:23} console.log(name); //Mohamed console.log(age); //23
Some reference:
Read more about let
Read more about const
Read more about ES6 Arrow Functions
Discussion (4)
I always recommend this site to practice ES6 knowledge, eskatas.org. It's a fun katas style site.
It's in this post
What are your favourite programming katas sites?
Nick Taylor
Feel free to add other katas 😉
Great Article
I think there is a typo error here
//Create class
class Person{
//Default function method
constructor(){
this.name = 'Mohamed';
}
}
//Create an instance or object
const person = new Person1();
person.printMyName(); //"Mohamed"
Great overview, thanks 😀
Great document
In the class inheritance example
small note:
class Person extends Human2
Should be :
class Person extends Human
inheritaning class Person from Human
Regards | https://practicaldev-herokuapp-com.global.ssl.fastly.net/mkhy19/do-you-know-es6---part-1-387m | CC-MAIN-2021-10 | refinedweb | 1,601 | 50.94 |
![endif]-->
Download and unzip the following file as YOUR_SKETCH_FOLDER/hardware. After re-launch your IDE, you can find Arduino Fio in the Board menu. You can also choose Arduino Pro or Pro Mini (8MHz) instead, as the settings are the same for both.
hardware_folder_for_fio.zip
The ATmega328P on the Arduino Fio comes preburned with a bootloader that allows you to upload new code to it without the use of an external hardware programmer. It communicates using the original STK500 protocol (reference, C header files).
There are two ways you can upload new sketches to the Arduino Fio: you can use an FTDI USB-to-serial cable, or USB-to-serial adaptor board; or you can program it wirelessly, over a pair of XBee radios. If you're new to the XBee radios, it's helpful to know a bit about them before attempting the wireless programming. This introduction may help.
You can also bypass the bootloader and program the ATmega328P with an external programmer; see these instructions for details.
LIke all Arduino boards, the Arduino Fio can be programmed with the Arduino software (download). If you're new to Arduino, see the Getting Started Guide , the reference and tutorials.
The FIo does not have a built-in USB-to-serial adaptor, so if you're going to program it over USB, you'll need an adapter.
To program the Fio using either FTDI cable or an adaptor with the same pin configuration, attach a row of male pin headers to the cable or adaptor like so:
Then connect the headers to the FTDI pins on the Fio:
If your headers don't fit snugly in the holes (and most won't), you should hold the connector firmly so that the metal of the pins touches the metal of the holes while you're programming.
When your cable is connected to the Fio, open the Arduino programming environment, choose Fio from the Tools-->Board menu. Then choose your serial port from the serial port menu, and you're ready to program If you're using the FTDI adaptor, you'll see the TX and RX lights flicker. You won't see any visible sign on the Fio, but you will see the following in the IDE when you've successfully uploaded code:
This tutorial borrows from Xbee Adapter - wireless Arduino programming by Limor Fried
In order to upload sketches wirelessly using XBee radios, you'll need the following:
On your USB-to-serial adaptor, solder in a tiny jumper between the RTS pin and D3 as shown here:
In order to program the Fio wirelessly, you need to configure two XBee radios, one for the Fio and one to connect to the programming computer serially. The latter will connect to your computer using the adapters mentioned in the last step. Once you've done that, you'll program the Fio using the radio link just like a normal Arduino USB-to-serial link.
The settings for the two radios are as follows:.
If you're running Windows, you have to make a slight change to the driver preferences. In the Device Manager, select the USB COM port. Then right click and select Properties. Click on the Port Settings tab, and click on Advanced..., then make Set RTS On Close is selected and click OK to apply settings.
You can configure your radios using a terminal application, or using X-CTU on Windows, or you can use the Fio XBee Config Tool. This is a modified version of Shigeru Kobayashi's XBeeConfigTool.
If you prefer to set your settings manually, you can set them using any Serial terminal application, such as CoolTerm. Connect the adapter to your computer, and open its serial port at 9600 bps using your favorite serial terminal application.
Set your terminal application's termination string to be a carriage return (ASCI 0x0D) only. Then open the port, and type:
+++
The XBee will respond:
OK
For the programmer radio, type:
ATRE,BD6,ID1234,MY0,DLFFFF,D33,IC8, RR3,RO10,WR
The XBee will respond:
OK OK OK OK OK OK OK OK OK
For the Fio radio, type:
ATRE,BD6,ID1234,MY1,DL0,D35,IU0,IAFFFF,RO10,WR
The XBee will respond:
OK OK OK OK OK OK OK OK OK OK
That's it! Now connect the Fio radio to your Fio, leave the programming radio in the XBee adapter, and you're ready to upload sketches to your Fio.
Uploading sketches to the Fio is similar to other Arduino boards.
As you upload, you should see the green RSSI light on the Fio light up. If you're using an XBee Explorer, you'll also see the TX and RX lights on it flicker as the sketch uploads.
If the Fio does not respond, here are the most common causes of error:
When in doubt, check the Fio by programming it over a wired connection as described above.
When your'e ready to start writing sketches for the Arduino Fio, here are some programming tips that will make your life easier. | http://arduino.cc/en/Main/ArduinoBoardFioProgramming2 | CC-MAIN-2014-10 | refinedweb | 844 | 66.17 |
For opportunity to create and post some cool effects for your LED strips. Maybe you can be your own Griswold (National Lampoon’s Christmas Vacation) with these!
You’ve got to check out the Fire effect with toilet paper – looks pretty cool!
Please read the article Arduino – Controlling a WS2812 LED first, as it will show you some of the basics.
Also note that you’re invited to post your own effects or ideas in the comment section or in the Arduino/WS2811/WS2812 – Share you lighting effects and patterns here … forum topic.
There are 960 comments. You can read them below.
You can post your own comments by using the form below, or reply to existing comments by using the "Reply" button.
Great tutorial! Thanks so much for sharing the examples and creating the videos!
Michael
Thanks Michael for taking the time to post a “Thank you” note! It’s very much appreciated!
hans
It’s nice and saved lots of time writing colour routines, thanks. Ported to ARM and wrote my own library to lit each pixel and set RGB colour.
seaworld
Hi.
Very good tutorial, but I think there is an error on the picture 2 “Arduino & WS2812 – Only running on external power supply”. I guess when you connect Arduino to external power supply in this case external +5V (DC) should be connected to Vin pin of the Arduino, but on your chart it is connected to +5V (that i theory should be used to supply detectors connected to Arduino).
Regards
Evghenii
Evghenii
Hi Evghenii,
I guess you’re right that usually Vin is being used, instead of +5V.
And even though the displayed setup works just fine (I’ve been using this setup for almost 2 years now on a daily basis), I should probably look into changing the picture to be really 100% correct.
The problem is that I’m traveling until next month, so I won’t be near my stuff in the next weeks to make the modifications …
hans
Actually the VIN pin is connected to the voltage regulator, which at least on the UNO is supposed to be fed with 7-16V. When using a (regulated?) 5V source the 5V terminal can be properly used as an input.
Kevin Z
Thank you for sharing your work !
bogdan
You’re welcome Bogdan, and thanks for taking the time to post a “Thank you”
hans
[…] códigos para programar los Leds fueron sacados de Tweaking4all.com para los que quieran practicar y aplicar otros diseños de Leds para reemplazar ornamenta […]
Hans,
Fantastic site! I just got a Arduino Uno starter kit from Amazon and waiting for a 1m strip of WS2812 lights to arrive as I have a project I am working on for a holistic friend of mine. I’m 50 and new to all of this, but from my research, using the Arduino and the light strip is my best way to go here, so I am learning as I go now.
I have to create a 7 led light strip that goes in the following order LED1 always red, number 2 always orange, 3=yellow, 4=green, 5=blue, 6=indigo and 7=violet.
What I need the sketch to do is run for about 10 minutes in a random format where 1 of the 7 led lights will light up for a second or two and other lights remain off and then the next random led lights up. Then after 10 minutes, I need the strip to then run a continuous simple chase format where LED1 lights up for a second or two (all other lights off), then goes off. Then LED 2 goes on (all others off) , then the pattern continues #3 thru #7 then start over again at #1.
I’ll be reading more of your posts, but any advice on how to proceed would be greatly appreciated!
Chuck
Hi Chuck,
Maybe (considering the potential code we’d be posting) it’s better to start a topic in our Arduino Forum. Any post in the forum, I read …
It does not sound like this would be a very complicated project, so I most certainly am willing to help you with this.
hans
Thanks Hans, I appreciate the help! I will start a topic in the Arduino Forum, thank you for pointing me the way! :-)
Chuck
I’ll be looking forward to your post
hans
Hello Hans,
I have been following this thread with interest.
I am a complete novice but have made some limited progress with some modifications as you will see from the attached code. I would be extremely grateful if you could point the way with the next stage as a variation on your Strobe code. I have so far modified it to produce the following: –
1. A second strobe function including and an additional integer that I have called BlackDelay which needs to have a different integer value to the FlashDelay.
2. Corresponding duplicate function and statement blocks for the second strobe function.
What I would like to do is make each Pixel individually addressable with a predetermined fixed colour/colour combination and strobe sequence. At the moment I am using 5 PL9823 addressable RGB LEDS for testing but will eventually require >100.
Not every one of the intended 100 or so Pixels will be unique, as in some Pixels may share the same colour/colour combination and strobe sequenceI and I am assuming that if there are say 80 variants, that these could be configured in setup and then called from a loop function for each Pixel?
My modified code is as follows:
If you could give me some idea as to the methodology for this more complicated variant of your original code I would be extremely grateful.
David
Hi David,
I’d recommend taking this to the forum.
On top of that: I’m traveling so I won’t be able to give you anything good until I get back home, which will be in a few days.
If you decide to move this to the forum;
– Post a link to the Forum post here would be great for others that might be interested
– I do see every post in the forum, so I won’t forget or miss it
Sorry for the delay …
hans
Hello Hans,
Thanks for your reply. Despite being logged on as dp34067 I am unable to create a new topic in the forum.
Am I barking up the wrong tree and should I just be replying to one of the existing topics?
dp34067
Hmm, you should be able to create a new topic.
– I just checked your user profile and it’s set to “participant”, so you should be able to create a new topic.
Can you try reloading the page and try again (if you haven’t done that already)?
If not then that would be a problem
I did notice however that the login dialog doesn’t always seem refresh the page as it should, after loggin in.
Please let me know if this issue persists. I’ll do some investigating on my end as well.
hans
Hello i have a question, first off thank you for all the code and great job, second I try to put the code into Arduino and compile it, it keeps saying ‘meteorrain’ was not declared in this scope any idea of how i could fix that?
Richard Amador
Hi Richard,
it’s a little hard to determine why you get this message without seeing the code.
Please do not post the full code here though, rather use the forum for that to avoid that the comment sections gets too long.
The most common reasons why you’d see that message:
1) You copied the code from this website and are one of the very unlucky users where the Arduino IDE is doing something goofy with it.
fix: Copy and Paste the sketch from the website into Notepad, Copy again from there and paste it in the Arduino IDE – this typically filters invisible characters causing issues.
2) You’ve typed the code and made a typo somewhere.
fix: Look around the “void meteorRain(…)” function definition. You may have missed a “}” or a “;” (quite common).
hans
Hello Hans,
I switched browsers from Firefox to Google Chrome and all seems well, but that may be a coincidence!
dp34067
I tested it here with a fake username in Chrome and Safari – it worked just fine unfortunately. So I’m guessing it was a caching issue.
I’ll keep an eye on it and take a better look once I get back home. Maybe one or the other thing is caching where it shouldn’t.
hans
Hello;
nice effects and thanks for writing such a informative tutorial.
But i am here with a stupid question :D
how to display a static color using arduino?
i want to make led strip (ws2812b) to show a static color lets say only red. So that when i start arduino my led strip would only display red color and continue to display it.
Adnan
Hi Adan,
There are no stupid question ….
Setting the entire strip in one color can be done (in this framework) with:
So for example for setting all LEDs to blue:
hans
thank you so much!
askfriends
You’re welcome.
p.s. I also posted some code in your forum topic.
hans
Just wanna thank you for this great tutorial with flexible codes and videos! Awesome!
Hadj
Thank you for taking the time to post a “Thank you” Hadj!
…
It’s much appreciated
hans
Running Arduino 1.6.3 with FastLED 3.0, Arduino Nano 3, 328 atmega, WS2812B leds. LEDs, when setup with RGB ordering, output green for red, and red for green. Blue is fine.Switching to GRB ordering, all the LEDs in my strip turn green, with hints of other colors (ie a flashing “red” LED will be a slightly pulsing fully lit green LED.The coloring of the strip does not occur in the RGB ordering – but obviously, the colors are backwards.Any thoughts?
matt.h
Hi Matt,
there are several ways of ordering the LED colors, not sure why some (often Chinese) manufacturers choose a different order. You’ve already tried RGB and GRB, if I understand you comment correctly. As far as I can see, these combinaties should be valid, and you’d have to test which one works for your strip:
RGB, RBG, GRB, GBR, BRG, and BGR.
Since I haven’t ran into this issue, I would not be able to predict which one would work for you.
Note: When you set all LEDs to WHITE then the color scheme should not matter, since all values (R, G and B) should be FF.
However ,… if you strip does not light up white, then there might be another problem.
hans
I am “newbie” with Ardunio and my English is not sooooo good (I read better than I write). So I have to use Google translator to help me to write to you.
But I hope you can help me.
I visited this site: //. I liked what I saw and tried out all the sketch on this site.
So my question is: Can I find a sketch/Framework that contains all the effect-sketch in the Framework?
I want to teach me the use of functions (I would think that I have to use functions to “connect” sketch together?), but still has a lot before I understand their use. Unless there is a sketch which shows that use of all smal sketch in the Framework.
I would be very grateful if you could write me the sketch to show me all the effect-sketch in use in Framework.
You can also post it on your site so that other people can use it. :)
I want to study how you put together all the sketch and run them together, and use off function to be beeter to write code. I want to make myself a great Christmas stuff! :)
I use Adafruit_NeoPixel library. I would be very happy for your help.
Nils-Johnny Friis
Hi Nils-Johnny,
you’re English is actually pretty good – with or without help from Google
I suppose theoretically, you could put all effects into one sketch. It might be however, that you run out of memory (depending on the Arduino model you’re using).
First you’d have to copy all the functions I have mentioned here into the same sketch – just keep adding them at the end each time.
Next you’ll have to look at the “loop()” function where we call these functions – this is where you have to be creative and see how you’d like to call them (what order etc).
Posting the entire code here would be a bit large, so I did post it in the forum … You’ll find the FastLED and NeoPixel versions in this post.
hans
OMG…you know how cool it is when you find EXACTLY what you are looking for on the magical interwebs? Thanks so much for sharing your knowledge on this…just got my first set of pixels to make a marquee sign, and have been trying to explore both of the libraries you use here on my own…this write-up pulled it all together for me! Now I have them doing exactly what I want, and have come up with some different ideas that I never would have thought of…
Thanks for sharing your knowledge!
Greg Wren
Thanks Greg!
It’s equally awesome to see a “Thank you” note like this one – it’s so much appreciated! Thanks!
(and yes; playing with these LED strips is awesome!
)
hans
Hi,
These LED routines are all great. I’m trying to combine a few of them into one program and have a variable chose which one to display. I’ve only tested a few so far, but I found that the Bouncing colored balls gets stuck and does not return to the loop. I added a line after showstrip; to break if the variable is not set to the value for that routine. I thought I’d mention this in case someone else is attempting to do the same thing.
mikewolf
Thanks Mikewolf
Glad you’re having fun with LED strips haha (so do I!).
I have not run into this issue before, but it makes sense since we keep the balls bouncing using “while(true)”.
You could of course add a timer or something and then modify the while to something that checks if it has been bouncing for a certain time.
A few other users have been toying with combining the effects, see this forum post and this one.
Not sure how helpful they will be of course for your project, just thought I should mention it …
If you have created a cool project, feel free to post it in the forum!
I’m sure others might enjoy it as well – but it’s totally optional of course …
hans
Hi ,
I added the Cylon and New Kitt to my Program and noticed every time these routine starts over, most of the leds briefly flash white. I cant see anything in the code that could be causing this. Any ideas?
mikewolf
I had the same issue with my 300 led strip.
It turns out that the control voltage needs to be in close match with the supply voltage.
I used a transistor, with the arduino connected to the base (with a 100k pulldown resistor) and the supply voltage on the collector, then connected the strip to the emitter and all the glitches went away.
Maybe you could just use a pulldown resistor on its own, thinking about it. The glitches do seem to be data rate associated.
flow in
I figured it out. I forgot to put a break in between one of my “switch case” statements. It was briefly going to a function that just called up all white leds.
mikewolf
Hi MikeWolf!
See; that’s what I like to see haha … I sleep, while the user finds a problem and resolves it. Awesome!
Glad to hear it works now!
hans
Once I get the NewKitt routine to change colors everytime the eyes hit the sides or each other, my life will be complete
mikewolf
Hi MikeWolf,
You could change color in the bounces in the NewKITT function. Just a dirty hack, but say you’d want to use only 2 colors (red and white):
Obviously, this can be done nicer, and I don’t know if only 2 colors would be OK for your purposes.
hans
Hi Hans,
I got it to do exactly what I wanted. I was already using the bouncing color ball routine, so I used the array to call up the different colors as it switches from left to right, outside to center, etc. I’m just started learning this arduino stuff. I’ve been programming pic micros in assembly language for the past 25 years. Using these addressable LEDs is a great way to learn a new language. FYI, I’m using a Teensy 3.2 as my processor.
mikewolf
Hi MikeWolf!
Glad to hear that!
Hey, for me, a lot of this stuff is new as well. I used to play with the BASICStamp (far from as advanced as using assembly) for a while, but the Arduino made things a lot easier. Also good to know that Teensy pulls this off!
hans
Does anyone know how to program these effects so that you can select a button for each or one button to scroll thru each with a random selector as well?
I built a crosley type jukebox with digital screen and Kodi with 4 pairs of WS2811 LED’s. 10 LED’s on 2 strings vertical and 9 LED’s on 2 strings horizontal.
I have tried piecing together Fastled Multiple string code with Fastled DEMO100 code but only the first effect lights up.
(Apologies: due to the length of the code, I had to move it to the forum: see this post)
imdr5534
Hi Imdr5534
….
I had to move the lengthy code to the forum. Apologies for that.
I’ll post an answer there.
hans
Utterly fantastic. Thank you so much for taking the time to create, write up, and share all of these fantastic light displays with us! You have a true gift and a generous heart.
Since your code has saved me at least a day’s worth of work, I would happily donate to your site for your time and effort, but I’d rather all of the funds go directly to you (instead of 90% through Flattr). Are there alternatives (like PayPal) or something similar? I’m US-based, if that makes a difference.
Thanks again! I really appreciate your work!
KTTJ
Hi KITJ!
Thank you for your kind compliments – that is always a motivator to keep going
.
You can donate through PayPal, although it’s not required yet very much appreciated.
Unfortunately, PayPal did not allow me to have a donate button but I do have a PayPal account. I’ll email you the details.
hans
Absolutely Amazing! You truly are the keymaster of NeoPixels. I absolutely love WS2812’s and have been playing with them for about 6 months now. This is by far the best use of them I have found. I was hoping you could point me to an example that uses your examples with a switch. I have been trying for a few days now to get your code with “all effects” to operate through a switch case instead of time delays. I have had no luck getting a switch to control even two shows. I must be missing something very simple like checking my switch at the wrong times. Hopefully there is something out there for me? Otherwise you have made a wonderful contribution to NeoPixels.
(int thanks, thanks++);
abarrelofmonkeys
Hi ABarrelOfMonkeys!
Thank you very much for the compliment.
As for using a switch, I recall another user asking for something like this as well (see this comment, this forum topic might get you started as well).
Unfortunately, I’m traveling for work, so I have little chance and time to help you on your way.
I should be back in about 2 weeks, which would clear my schedule a little more …
hans
For those interested in effects for Christmas, look at Spike’s project in this forum post.
hans
Hi Hans,
Thank you, I hope others find it useful.
As KITJ! asked above, would you also send me the details so that I can buy you a drink please?
Your preferred currency too if you would be so kind.
I’m still working on more stuff for Christmas, although the wife doesn’t think I should go overboard with the amount of LEDs. As if I would
spike
Thanks Spike,
I could use a drink right now haha (it’s super hot here right now).
….
You can donate through PayPal (email: hans at luijten dot net) … pick a subject like “drink” or “LEDs”. PayPal doesn’t allow me to place a Donate Now button on my website
Hahaha once you get the hang of it … you WILL go overboard with the LED strips … don’t forget to send pictures!!!!
It’s awesome stuff to play with …
hans
Hi Hans,
Indeed, it’s very hot here at the moment too.
Yes, I read your post about PP saying that you couldn’t use a link, it’s a real shame.
You’re quite right, LEDs are seriously addictive, I have been playing with them for a couple of years. This is one of my creations
But thanks to you, I am getting better at the coding side of it.
Is there a list of the NeoPixel or FastLED commands anywhere?
A drink should be in your inbox
Enjoy!
spike
You’re the best Spike!!!
Perfect timing for sending me a few drinks!
Oh wow! Love the YouTube video you posted – that’s so cool! I better start looking into an effect like that as well …
As for lists of available commands, I found this keyword list for NeoPixel, and this FastLED reference. The one for FastLED actually had a good explanation with it. Hope that helps …
hans
Hi, I’m new to all of this LED and Audrino stuff, I was wondering if it is at all possible to create a “Chase” effect or any of the effects posted here for that matter, using a single color LED strip with UV LED’s?
Anthony
Hi Anthony,
I would assume this is very well possible,… if you can find a LED strip with UV LED’s.
Then the next question would be finding a library that supports that particular LED strip.
Unfortunately, I have not yet seen a LED strip with just UV LEDs.
hans
First off, thank you Hans for writing back so quickly. I really do appreciate it and your your time. So yes to, there are lots of strip out there with UV LED’s but to my understanding they are all analog. I can’t seem to find a single color digital strip anywhere let alone one that is UV. This is basically for a computer build that I’m putting together. The other question I came up with is permanent placement of the arduino in side the computer. Is it possible/ok to, substitute the external 5v power supply you in your diagram with a molex connection to the 5v 30a DC rail on a ATX computer psu?
Again I really do appreciate your help!!!!!
Anthony
Hi Anthony,
you’re most welcome.
I think the problem with Analog strips is that you cannot address the LEDs individually, so making that work with an Arduino might not be possible. I did find this Arduino Forum Topic, which might be of interest.
As for powering the Arduino+LEDs with your computers PSU; that should work (5V 30A is definitely enough). Just make sure that you get a PSU with some extra watts available to power your PC (mainboard, disks, videocard, etc) and the LEDs. Placing the Arduino itself in the case would not be a problem though.
hans
And So Again, I’m calling on your expertise……..
So I went and got an Arduino UNO Starter kit, ordered a whole mess of led strips (waiting for them to be delivered). Downloaded the Arduino Software and the Fast LED Library. No matter what i do whether its open a file from the fast led library or just copy and past it from here. All I get are error messages. I have to say beyond the simple downloading and uploading of files or copying and pasting the code. I truly have no clue as to what I’m doing or looking at, or even what I’m doing wrong. Whatever help you can give would be greatly appreciated.
Anthony
Hi Anthony,
Could you post the exact steps and error message?
hans
Ok, so ill start from the beginning.
I downloaded the arduino ide, installed the drivers. All apears properly
In the arduino software I went to TOOLS>BOARD and made sure my UNO was selected, Same thing for the COM
All seems to be working properly, I even ran through the blink project in getting started everything functioned as it should.
I tried several ways to use the FASTLED library, Ill go over each one:
#1) Sketch>Include Library>Add .ZIP Library, When the window opens, Downloads> LEDEeffects_Sources.zip> Open
Then I get:
Arduino: 1.6.7 (Windows 10), Board: “Arduino/Genuino Uno”
Specified folder/zip file does not contain a valid library
This report would have more information with
“Show verbose output during compilation”
enabled in File > Preferences.
#2)Manuallly extrating the files to the arduino library: I followed the Instructions from here:
After restarting the IDE I get a window:
ignoring bad library name
The library “FastLED Examples” cannot be used.
Library Names can only contain basic letters and numbers.(ASCII only and no spaces, and it cannot start with a number)
GRRRRRRRRRRR You can See My fustration, and oviously just copy and pasting the code doesnt work.
Really Hans, thank you.
Anthony
Hi Anthony,
I can totally understand the frustration … it’s too bad that the Arduino IDE doesn’t handle GitHub ZIP’s all that well (see also here). You could try that older FastLED library and the Arduino IDE could automatically update it to the latest version.
So I quickly started up a Windows virtual machine to describe it for you., and installed the latest Arduino IDE (1.6.9).
After the application started, I went to the menu: Sketch -> Include Library -> Manage Libraries. This will open a window, which takes a bit to load everything it can find. But once it’s done, you can type “fastled” in the “Filter your search…” box.
FastLED should appear here. Click it and the button “install” will appear. Installation takes seconds. Once done, click “Close” and the FastLED library should be available.
hans
p.s. you’ll find the examples in File->Examples->FastLED
hans
Ok, so I was able to find the library and install it through the IDE like you said. Much to my delight, the effects that I want to use are not included…… sigh……The effects that I’m looking for are:
Newkitt, Strobe, RunningLights, Bouncing balls multi color
Also saw this one on you tube
My Project: I’m building a new High End Gaming Computer, with a custom liquid cooling system, of which the main focal point of the system will be the a custom built reservoir tank. Everything inside the case will be visible through large side panel windows. I plan on cutting the led strip down to length, to fit inside a sealed tube, inside the center of the reservoir and have the LED’s running the desired effects while the coolant is swirling around the reservoir.
So obviously I will have to change the led count from 60 to whatever it is that’s on the strip after I cut it. Correct? Hopefully……..
I ordered 2 strips of Waterproof WS2812 LEDS one with a 60 LED count, One with a 144 LED count. Again in theory either should work as long as I change the LED count in the sketch accordingly?
I also “get” the part in the code, on how to tweak the colors.
So simply put, where can I get the the code, for the examples I gave from beginning to end, simply copy and paste into a sketch, save it, use it, and works?
Anthony
Hi Anthony … good to hear you’ve got the library running now
Looks like you’re starting an interesting project (send pictures when you’re done!!).
Yes you’d have to reduce the LED count to make it fit the strip/LED count you’re actually using.
The examples can be found in the code here as well. There is pretty much no overhead in my code – I just made it so it can be used with both libraries.
As for combining effects, take a look in the Tweaking4All Arduino Forum (goor place to ask questions too). It’s not super extensive, but this topic for example discusses how to put multiple effects together. For most effects, it’s a matter of copy and paste, for a few others it takes a little bit more work … but it can be done!
hans
I don’t think I’m going as far as combining effects. Just switching them around as the mood suits me. I’ll definitely be posting up some pics soon as I get things up and running. Might even do a you tube videos on the build too.
Anthony
Awesome!
Feel free to post links here, or send me pictures (I can place pictures in the comments for you).
hans
For those interested:
Spike posted the code and such for how to make an awesome Christmas star with effects in this forum post.
A YouTube video demo can be found here.
hans
Hans, Can you please take a look at this and tell me what exactly is wrong with it?
When I try to verify I get “setAll” was not declared in this scope…..
#include “FastLED.h”
#define DATA_PIN 6
#define LED_TYPE WS2812B
#define COLOR_ORDER GRB
#define NUM_LEDS 144
CRGB leds[NUM_LEDS];);
}
Anthony
P.S.
It seems as though the set all error message comes up on every sketch I copy from here. So I’m sure it’s just me, missing something.
Anthony
Hi Anthony,
you forgot to copy the “framework” (link = see above).
In the framework code (depending which library you choose, in your case FastLED), you’ll need to replace the following code with the code for the effect:
hans
Thank You, Thank You, Thank You, Thank You…………. Finally its working just as it should.
Anthony
Awesome! Good to hear that!
hans
Hi Guys
Looking for major help, I have made an intinity mirror which is using 205 ws2812B what I would like to do is use the fire sketch (which i can of course) but what i cannot do or maybe its not possiable is to have 2 starting point with the flames using 100 leds.
starting point (1) leds 1 to 100
starting point (2) leds 205 to 105
The idea is that it looks like the flames are starting at the same point and lapping round the mirror
I really enjoy working with the arduino and leds but sometimes its so bloody frustating :)
If you think its not possiable let me know as i will then give up on that idea, on a postive note if it is any help would be much appreciated
Fantastic page by the way
Steve
Hi Steve,
thanks for the compliment
I wouldn’t think of it as impossible, would it be OK if both sets behave the same with the fire effect? Or should they be different?
p.s. it’s better to discuss this in our Arduino Forum, otherwise the comments in this topic become too much – I took the liberty to start this topic for you question.
hans
Hi Hans
Thank you for your reply, if they were the same for a start then I dont think that would matter if I like the effect , I was trying a sort of New Kitt with the flames instead of the chasing lights but you guessed I could get it to work
Steve
Hi Steve,
you’re most welcome!
I posted a code suggestion in this forum topic.
Give it a try – it should mimic what you’d like to see – but I’m unable to test this, since I don’t have my hardware with me.
hans
I couldnt get it to work (typo)
Steve
Im back on here as im unable to login on the forum username ap0ll0 password as been sent but unable to get logon
do you know i have been trying on and off for 3 weeks to do what you have just put on the forum yes its working the only problem is the start point for 0 to 99
is starting at 99
man i wish i could do what you have just done
ap0ll0
Hi Ap0ll0!
I just emailed you a new password – I have no idea why the forum acts up every now and then. Time to start looking for a new forum for WordPress I suppose.
I’ll add a comment to the forum topic again …
ap0ll0
As for being able to do this your self; practice … and believe me, I’m not a great coder either … it just takes a lot of playing with code to get a feel for it.
hans
Interested in cool effects and uses of effects, checkout App0ll0’s work in the forum … it looks awesome!
hans
hi how to do that was to be turned on and off by pressing button
chemix
Awesome guide and resource, many thanks and praise for all of the useful info, demos, and code! Can’t wait to fiddle with these-
Kent Caldwell
Hi Hans!
Could you help me, please?
I want to combine different effects in 1 sketch, but Bouncing Balls effect (that I rly like) is endless. What shall I change in code to limit number of Bouncing Balls cycles?
tidehunter
Hi TideHunter,
I’d start with playing with the while loop in line 26 (while (true) {), maybe change that to some like this:
Just a crude example of how we make the infinite look (while(true)) a finite loop.
ps. If you’d like to discuss the code, please consider starting a forum topic in the Arduino Forum. Just to avoid that the comments here become very long.
hans
Hello!
I’ve been trying to utilize your hint about random numbers in order to run different functions every time I switch on the arduino, but I keep getting error messages. I try to tie if and if else statements to different functions and numbers but I’ve been unsuccessful. Can you please let me know a better way to think about calling random functions?
jacchavez
Hi Jacchavez!
Please start a topic in the forum, so we can exchange code examples without making the comments here too lengthy – I’ll see what I can do to help
hans
That’s exactly what I’m looking for, for my Hot Tub Led light project… I can’t find the topic in the forum… has it been done?
kylegap
Hi Kylegap!
I found the forum topic you started (excellent!
) – for you and other, please continue discussion in this forum topic.
For reference, I’ll post the short fix for this here as well:
When using the code of the Led Effects All in one project, you could modify it to actually do this.Modify this part:
to this:
The entire EEPROM part has been removed and has been replaced by a random selection (0 to 18).
To improve the randomness, you can add the following line to the void setup() function;
Hope this helps
hans
Hi Hans! Just joining in the chorus of voices expressing gratitude for your tutorial and examples. Thank you for your time and energy. It certainly helps to add light to my day! Keep it up!
-j
Jesse
Hi Jesse!
Thank you so much for the compliments and taking the time to post it here. It’s so much appreciated and definitely a motivator to keep going!
Thanks
hans
HI,
A while back I posted about using an RS-422 ic to extend the wiring between and arduino and a strip of addressable LEDs to 1000 feet.
Since then I’ve added remote control using a Sony IR codes, a music interface, and made a high power LED pixel using a WS2811 IC and power Mosfets. I was thinking of making an arduino shield that would contain these features as well as a circuit board to make the high power pixel. I put a video on youtube that shows the music interface in action and the high power pixel thats made up of 3 watt red, green and blue LEDs.
IR remote LEDs
mikewolf
Hi there!
i appreciate you taking the time to upload this, alot of it looks cool, but… i am very much a beginner to this and it looks very unfriendly to me, i have tried with both NeoPixel and FastLED library, and get the same errors no matter what, yet, virtually no explanation on how to fix it :( i get either, NUM_LED not defined or SetAll not defined, and it is frustrating me :(
i have a strong of 50 WS2811 12mm LEDs i want to make use of for christmas :(
can you please help me ? D:
mikeb1479
Hi Mikeb1479,
I can understand that this might be challenging for beginners, but no worries – I’ll try to help get you started.
First of all, the general idea was to have a few functions available which are defined in this part (FastLED as an example).
Paste this in the Arduino IDE editor.
Now select this section in this code:
and replace it with the function you found with the effect you’d like to use, for example for the FadeInOut effect:
I hope this makes more sense now … please feel free to ask though!
hans
wow!
thanks so much friend :D
it worked very well and much easier that you explained it simply to me :), i now have a few cool effects to choose from for christmas tree lighting :D
i made sure to save them also!
thanks so very much for your time and your help, it is much appreciated! :D
mikeb1479
Awesome Mike!
Glad I could help … have fun with the LED strips (I know I do!).
hans
i have been, theyre now being used as xmas lights :D
mikeb1479
hey,
sorry to bother you again, but, other night i had a thought, that maybe you would like
i was thinking of, sound activated WS2811 lighting, using an UNO, microphone and my WS2811 led’s, but, cannot find a decent sketch anyway :|
was surprised you didnt have one also :o or did it not interest you ? :)
many htnaks :D
mikeb1479
Here is a link, which shows driving 7 LED’s, but one could change the solid LED’s to WS2811/12 and define a color or color mix.
gbonsack
Nice!
hans
Hi Mike,
yes, ginormous LED VU meters is something on my to-do list … unfortunately, all the little projects I’m working on plus and my fulltime job do conflict constantly. I actually prefer working on projects here over my actual job, but … my actual job pays the bills
hans
Hey,
I’ve been playing around with the Fire code, i’ve been running into problems getting it to start and end within a pixel range.
Any idea what I need to change to achieve this?
Thanks for all of this has been really helpful!!
xena2000
Hi Xena2000,
sorry for the late reply.
In essence you’d need to change the “for” loops in fire() function. For example (untested):
You can call Fire() the same way as usual, I just added 2 additional parameters (First and Last LED).
I have not tested this, since I do not have my gear near me. But give it a try (I hope I didn’t overlook anything).
hans
I created an Android application to control it via Bluetooth:
Thiago
Hi Thiago,
very nice!!! Thanks for sharing!
hans
Hi Thiango, Thanks for sharing, I would love to try this out and incorporate it into my Christmas lights next year.
Can you give me more info on how it is implemented please;
What BT modules does it support? Assuming it would connect to an Arduino etc
I guess I’m really asking for an idiots guide, including how to install your app to an Android device as there doesn’t appear to be an APK.
Spike
I’m using an HC-05 Bluetooth Module connected on an Arduino Uno, but the Android application should work with any Bluetooth module.
The Android APK can be found here:
Thiago
Thats awesome, thank you.
Which sketch should be uploaded to the Arduino? I’m assuming it should be ‘lightita.ino’ ?
What is the ‘effects.ino’ sketch for?
Sorry for all the questions but I appreciate your support.
Thank you
spike
You should open the lightita.ino on the Arduino IDE and the effects.ino should be opened automatically on another tab inside the IDE. The effects.ino file contains all the effects, I separated on two different files to keep things organized.
Thiago
Thanks a lot!!!!
have a nice days!!
Aldo
Thanks! You too Aldo!
hans
Although a very cool and fantastically laid out article, I find a lot of the code needlessly complex. To me, the big no no’s in an animation that may have button or other controls include:
My other big issue is counting pixels up and down and I’ll use the cylon as an example. Why have all that code to count up and down, when you could just use some basic high school math and use sine waves instead? You could use it to go back and forth, you could use phase shifting and have waves, you could clip it and so on. In addition, with FastLED’s beatsin8() function, you don’t even need delays at all.
Andrew
Hi Andrew,
thank you very much for your input, and you’re right about the ability to optimize this much more. If I’d be writing this just for me, things would look very different. However … the intend is that everybody (as far as possible) can follow all this just fine, or at least with minimal effort. And yes, there is always room for improvements, and I’m very open to that, so please feel free to post modified sources that have been optimized. I’m confident that certain users will definitely be interested.
Also keep in mind; I’m trying to target everybody and I have found that explaining a sinus to my 11 year old nephew proved challenging, not to mention that quite a few users have no programming background.
I would like to invite you though to post optimized alternatives here – It would be welcome for sure.
hans
Marvelous amount of information – thanks. I’ve bookmarked your site for additional reading.
I am into light painting photography, using tri-color LEDs for years, with a bank of logic switches to control color. Just read a magazine article about Arduino’s and have gone crazy looking for new light patterns and codes. I have a two part question:
First, I want to build several light painting props, where I can turn on a “GO” switch and then select one of the switch positions of a 4 or 5 position switch. Should I go with the “HIGH/LOW” logic or put resistors between the 5 positions and push 0, 1.25, 2.5, 3.75 or 5 volts to the input and do voltage logic?
In either case, what would the: if, then else logic look like, directing the Arduino to run program1 … program5?
I went to the forum and read imdr5534 logic, but that was for a system generated number and not a selected input.
Thank you in advance.
gbonsack
Hello Gbonsack!
Thank you for the compliment, and … Wow, I had never heard about light painting photography – that looks great!
I’d probably go for using several pins and maybe a rotary switch. You’ll need a wire from GND with a resistor to a pin or several pins (see basic diagram here – you’ll find some basic code there as well on how to read a switch/button state), then a wire for each pin to a switch which shorts to +5V. I’d probably consider using a rotary switch so we do not switch multiple switches at the same time.
Then in code it could look something like this:
It could be done more elegant of course, but this would probably be an easy start.
hans
Thanks, That’s the way I was leaning, but with only a few weeks of coding, my first test loop was only working for switch position 1 and 2 and not 3, 4 and 5. It may have been a bread board or jumper wire issue too, now that I think of it. Adafruit has an article on using pixel strips, to paint with, search for: Jabberwock.
gbonsack
I’d go with what feels right for you, especially when you’re just starting with the Arduino.
You can always try to find more elegant solutions once you get more experienced with Arduino coding – at least that’s how it works for me. This way I get a better feel for what I’m doing as well …
I’ll take a looksy and see what Jabberwock stuff I can find (some links I found so far: Overview, and this one).
So far I like it
hans
That’s it. Happy Holiday’s
gbonsack
Merry Christmas and a Happy New Year to you too
hans
Hi Hans! Could you help me please?
I want to combine 10 effects in one sketch, but Effect Bouncing Balls is infinite … ..i don’t know how limit the number of cycles Bouncing Balls?
merry chirstmas and
happy new year!!!!!!!!
Aldo
Hi Aldo,
several users have been working on combining the effects in one sketch (see also our Arduino Forum).
The trick for the bouncing balls is found in modifying like #26;
This keeps going forever of course. You could modify this to a loop, or a time count.
Hope this helps
hans
thanks a lot!!! bye.. Hans!!!
rompipelotas
Hi, Hans,
You helped me a few years ago with a sketch and now I’m back for more.
. I’m making a cloud lamp and I’d like to have a lightning effect inside. I have an Arduino Mega and a short strip of WS2812B NeoPixels. I want the effect to be random, like real lightning. For example, three quick flashes, dark for several seconds, then a slower flash fading up; that kind of thing. I thought I could edit the strobe sketch or the Halloween eyes, but I don’t understand how to use the random function. Would love some help!
Thanks,
Claire
Claire Tompkins
Hi Claire!
Welcome back
…
Maybe this will be helpful;
The function is called as such:
Where the first 3 parameters define the color (0xff),
The 4th parameter sets the number of flashes (10 flashes),
The 5th parameter sets the delay between flashes (50 ms),
and finally the 6th parameter determines how long we’d like to wait after the flashes have been done (1000 ms).
So this function is responsible for a one time effect.
In the example: 10 white flashes with 50ms pause between each flash, and once done a 1 second delay (1,000 ms = 1 second).
Now, since it’s placed in the “void loop() { … }” this function will be called over and over again, with the same parameters. So just a rinse and repeat of the same effect. To add randomness to this we could modify the function call and use the Arduino “random()” function.
An illustration how we we could use this (can be done much more compact – but this way it’s easier to read and understand):
In the beginning of the sketch, just before the “void setup {” line, define the following variables:
… and change the “void loop() {” to something like this:
Note: the Arduino doesn’t really do random numbers very well, since it always starts with the same “seed”. We can however change the seed by a more random number whenever the sketch starts by adding the “randomSeed()” function to the “void setup() { … }”.
Just an idea to add more randomness to the whole thing: make the color brightness intensity random as well:
You might notice that I introduced two things here. First of all “random(x);” produces a random number between zero and x. “random(x,y);” generates a random number between x and y. You might want to use that in the other variables as well, to make sure that a minimum delay is observed.
The other thing I did is set the color to “red, red, red” – I’m packing a random number between 30 and 255 for the variable red. Since you might want to keep a “white” like color, we would need to have red, green and blue to be the same number. So I’m just recycling the variable for green and blue as well – I hope that doesn’t make it too confusing.
Hope this helps
hans
Thanks! But I need some more hand holding, I’m afraid. Are you suggesting editing the Strobe sketch? I added the six suggested lines to the top of the sketch and replaced the void loop section as you wrote. But I don’t know what to do with the other two sections of code, void setup and void loop.
Claire
Claire Tompkins
Hi Claire,
maybe it’s better to start a forum topic – so we can post full size code and such without disrupting the comment section here.
I already started a topic here …
hans
FYI, I pulled the code from the Forum page and pasted into the Arduino editing program, made a the changes for NUM_LEDS and PIN and tried to compile it – got a couple of error messages (240 and 300?). Did a re-type of code and still the same error messages and then I stated to look at the “error lines” and found several referenced lines as blank lines, more online searches and found copy/paste can add hidden code. So if the error referenced line 15, I did a control L and enter 15, moved the cursor to the stated of line 16 and hit back space until the cursor was at the last character in line 14, then “enter”, “enter” and that error line disappeared. After doing this several times, the Forum code worked beautifully, so I started to tweak the code for my “Light Painting” sticks.
Could find a place to comment on the Forum page, so I’m doing it here.
Thanks
gbonsack
Hi Gbonsack,
You’ll have to register (free) to be able to post comments in the forum.
It’s a little inconvenient, I know, but unfortunately a fully open forum invites spammer and script-kiddies to come pollute the forum with none-sense, trolling, advertising, misleading information, etc. — my sincere apologies that I made it that users need to sign up …
Anyhoo; you did indeed catch the issue with the error codes.
As mentioned below; copy the code, paste it into Notepad, copy all from Notepad, paste it into your Arduino IDE – this should strip all excessive characters.
Under what operating system did you see this happen and with which browser?
(can’t reproduce it with Google Chrome on MacOS)
hans
Hello, i am a beginner with WS2812B LED strips with an Arduino nano and I would like to use the KITT effect. I try to use it but I get an error. Are you able to help me please, thank you. The error message is:Arduino: 1.8.1 (Windows 10), Board: “Arduino Nano, ATmega328”
sketch_jan14c:8: error: stray ‘\302’ in program
 FastLED.addLeds<WS2811, PIN, GRB>(leds, NUM_LEDS).setCorrection( TypicalLEDStrip );
^
sketch_jan14c:8: error: stray ‘\240’ in program
sketch_jan14c:12: error: stray ‘\302’ in program
 TwinkleRandom(20, 100, false);
^
— LINES DELETED —
Peter Bohus
Hi Peter,
first off the friendly request to post large source codes, logs, or other lengthy outputs in the forum
Coming back to your issue:
I suspect you might have copied and pasted the code into the Arduino IDE?
The “stray ‘\240′” and “stray ‘302’” refer to characters in your code that may not be visible, but do interfere with the code.
I tried finding some reference for you: this is one at Stack Exchange.
Now, what I usually do (I assume you’re working under Windows) is copy code, then paste it into Notepad, select everything in Notepad and copy it again. Now excessive characters are gone … now paste it into your code editor and try again …
Hope this helps.
hans
Thanks, it all works now!
Thanks again!:)
Peter Bohus
Awesome!
hans
Hello,
I would like to ask you if it is possible (how) to change the colour of the moving strip from red to another colour on the cyclon effect. Also how can I do it so the strips start moving from both sides and bounce like this one but from both sides not just one. So it would look like this:
——–> <——–
<——————>
——–> <——–
Explained:
From both ends the leds will move towards the other side passing each other in the centre (not bouncing apart) then at the ends they bounce back and pas each other again etc.
Thanks, I hope you can help me as that would be amazing (I’m only a beginner so need to learn these codes)
:)
Thanks Peter
Peter Bohus
Hi Peter,
Changing the color of the running LED is easy. You can pass it to the function in the “void()” section.
For example:
Red:
Green:
Blue:
The first 3 parameters are hex RGB (red green blue) colors (see also the color picker in this article).
As for your second question; this is kind-a what the New KITT effect does, just a little more elaborate.
You’d have to modify this a little bit for the NewKITT() function (so copy the NEW Kitt code and replace the “void NewKITT(…)” function with thsi):
I have not tested any of these, but I’m confident this will do the trick …
hans
That is kind of what I wanted, but I wanted it to not bounce apart in the middle. Like the Cylon but from both sides so it will start on left and right and go to the opposite sides and then bounce at the end of the strip and bounce back again to the opposite sides instead of bouncing in the middle.
Thanks Peter
Peter Bohus
Hi Peter!
I think I know what you might mean haha … so we have 2 “runners”, one starts on the left and bounce on the right, back the to left where it bounces again to the right etc. In the meanwhile the other one does the exact opposite?
We could tweak one or the other function together for that;
I have not been able to test this though … but it might get you started.
You’d call it in the void loop.
Hope this helps …
hans
Hi, i need some help. I’m clueless when it comes to programming so I’m kinda lost. I have an issue, whatever is meant to fade out and then in to change, is blinking and changing instead. Is my strip faulty, or am i doing something wrong. Using arduino nano clone and ws2812b 5050 led tape (60 led),
Arduino nano, ATmega328
Drax
Hi Drax,
I’d first see if the LED strand test works, just to make sure Arduino, LEDs and powersupply play nice.
I have only played with the Uno, and I tend to stay away from clones since they can create all kinds of issues.
hans
Made a video showing what is wrong here. I that an LED tape issue, arduino issue or power supply issue ?
Drax
Hi Drax,
ehm, the link to the video is somehow pointing to this page again … could you repost the link please?
Sorry for the inconvenience …
hans
Hans, Windows 10 and Microsoft Edge gave me the 302 and 240 error messages. As for the Forum, I thought I was logged in, as it showed my IP address, login name.
gbonsack
Oh boy, yeah … I really cannot recommend Microsoft browsers for any purpose. Rather use something like Google Chrome, Apple Safar, FireFox or Opera.
Thanks for posting this though, since others might run into the same issue!
As for the forum; maybe this is browser related as well – I have not tested Microsoft Edge with my website yet.
Would you mind checking again? When logged in, you should see (at the bottom of a topic) a text editor to post replies.
hans
Hello Hans,
).
First, thank you very much for this superb page. (The best on the web
Difficult to find information on the implementation of “NeoPixel” (Adafruit).
I am a beginner in programming (Arduino IDE) and I realized an e-textile project (ATtiny85 + 1x LED RGB WS2812B) with one of your script (NeoPixel) that works well.
The base comes from: “Blinking Halloween Eyes”. (My script not posted as requested).
But I would like to work with 2-3 colors like: “Fade In and Fade Out Your own Color(s)”.
Since “Blinking Halloween Eyes”, so I would like to add 2-3 colors and a Fade-in. (Existing Fade-out).
Currently I come back with another color with function: [setAll(0,0,0);].
I want to keep the random side for the whole !
I tried to mix these two scripts unsuccessfully. Can you help me ? Thank you in advance – I would be so happy.
(If it’s simpler with the “FastLED” Framework. I can also try).
Greetings from Switzerland
PS: My current project uses only one LED RGB, but in the future why not 2-3 LEDs – which would have a different sequence.
Guy-Laurent
Hello Guy-Laurent!
First off: thank you for the very nice compliment – that’s always appreciated and definitely a motivator!
Thank you so much for observing the code posting request, if you’d like, you can post the code in our Arduino forum.
I’m not sure I understand what you’d like to accomplish though (sorry – it’s early in the morning here so I probably need more coffee)
…
I guess I’m getting a little confused; do you want a each “eyes” to appear in different colors?
Or a different color to fade in/out? And you’re using only one LED? or one LED Strip?
Since I’m sure I can help, I did start this forum topic so we can chat about code and how to implement it. (you’d have to register, but it’s free)
hans
Hello Hans,
Thank you for the message – and your link.
I am now registered on the forum – but I can not log in !
Tested with Chrome (clear cache) & I.E.11 – Win7Ux64
Do you have to validate my registration ?
If there is no more coffee, I will go to sleep
See you soon,
Guy-Laurent
BravoZulu
Hi Guy-Laurent,
I registered yesterday and had the same issue you have. Seems that admins must approve your account before you can post on the forum.
I could not create a topic right after registering but this morning it was ok.
Try again a bit later
cam
Hi Cam,
I’m sorry to hear you’re running into issues with the forum (I’m getting pretty fed up with the forum software
).
Admins do not need to approve your account, but I did notice that on rare occasions a page needs to be reloaded for the text box to appear so you can add or reply to a post.
Please let me know if you run into more issues with the forum – I’m already looking for a replacement forum.
hans
Hi Guy
Yes, coffee is always good
…
I noticed that sometimes the forum is acting up, so I’m already looking into replacing it with another forum.
Occasionally the user has to reload the page to be able to post a new topic or reply to a topic. It’s quite aggravating since I can’t seem to find a fix for it.
Would you mind trying to login again?
hans
Hello Hans,
After many tests yesterday – I’m now logged
(Yesterday by selecting a link in the history of the browser, I was logged – but only on this page of course – Then by clicking on the link of the other subject I was losing the log-in).
The problem: when you do the log-in, the Menu at the top right is always as if you were not logged in. (You do not see the user – [User Menu]).
It seems that at this moment, by making a refresh of page one becomes logged !
Then I repeatedly got the message (Top of Chrome): “WebGL encountered a problem” – [Ignore] [Refresh].
(Never seen this message before with other sites).
To be continued…
So, I will continue on the page: blinking-halloween-eyes-with-different-colors
Guy-Laurent
BravoZulu
« Houston, we have a problem »
After log-in according to the trick: refresh the page, I have posted 3 times without success !
The image I wanted to attach was too big !? (Max 4MB).
I went from 3.6MB to 1.5MB then 960KB – Every time with the error message (Chrome):
I attempted to send the image alone (960KB) with the same error.
My Post is now Online – but no picture
To be continued…
Guy-Laurent
BravoZulu
Bingo !
With an image (alone) of 86KB.
BravoZulu
Hi Guy!
Oh wow, I better check my settings then … I did set it to 4Mb max, so the images should have worked, and I have never seen this error message before.
Just verified the settings, both PHP and bbPress are set to 4Mb per file max, and max 4 files per post. I’ll try uploading something myself and see what that does …
Again apologies for the problems you’re running into and thanks for sticking around
hans
OK, tested it as admin and as a participant (forum roles) and both were able to upload a 2Mb picture.
I’m running Google Chrome on macOS Sierra.
I did change some settings in bbPress, maybe this helps. Would you mind trying again?
(I’ll continue this conversation there haha)
hans
Hello Hans,
I think you saw, I was able to download 2 images (2.7MB and 450KB) without problems. (Chrome Win7Ux64).
Your changes seem to be conclusive
PS: I can now read: “Your account has the ability to upload any attachment regardless of size and type.”
BravoZulu
I got the comment window this AM??? System re-booted over night??? Flip-A-Coin
gbonsack
Hi Gbonsack …
ehm, you mean your system rebooted? Not sure what you’re referring to
)
(I need more coffee – that’s for sure
hans
Hi,
I wanted to thank you for all these examples, it made me want to have fun with those LEDs. I actually had a DAC project ongoing and I’m using these ideas (and the way they’re coded since I’m in uncharted territory here).
I actually have a problem but since I modified the code to fit my plans I’m going post my code on the forum so anyone can help me understand what’s wrong :D
Thanks again for the ideas and the very well explained code there is on this page, it is very educational.
cam
I registered but couldn’t create topic so I’ll explain my problem here, code is there.
It seems that dutch people inspired me on this project since my DAC board is based on Doede Douma DDDAC with differences on components (all SMD to gain size). an output buffer has been added as well as a FIFO buffer followed by a reclock board.
First, context. I’m making myself a DAC and I was looking into VHDL and PWM for a little while but as I expected, last time I used VHDL was in school more than 10 years ago and I suck a lot at it! I have a bit better knowledge of C.
Back to subject of interest. I found this article which made me hopeful (almost a better man!). My idea of the result goes through phases (I used switch/case
).
1st phase: Start-up lighting to actually signify to user it started. I used fade in/out code, I only modified the brightness increasing with sine wave instead of linear.
).
2nd phase: RaspberryPi starts and look for a connection to my NAS. I used twinkle effect.
3rd phase: When NAS is found, the RaspberryPi updates its output and my arduino goes back to almost the same fade in/out as in phase 1 except it doesn’t go back to LEDs off but stays to 50% (I don’t want too much light and I like how it looks to go high and a little back down
4th phase: Steady lighting at defined brightness. If connection to NAS is lost, it goes back to phase 2.
Seems nice but it only half works. phase 1 and 2 works perfectly fine but when I connect my wire to simulate the input from the RaspberryPi it goes crazy. It’s like the switch/case is broken and I have all code executed at the same time and it looks bad
I could make a video to clear things up if required. I’ve got to mention I don’t arduino but a smaller Adafruit Pro Trinket with 10 LEDs.
cam
I actually could open a new topic on the forum. Follow up there.
cam
You have saved me so much time….Tons of love.
Warren Richardson
Hi Warren!
Thanks for taking the time to post a “Thank you” … glad to hear you’ve enjoyed this article!
hans
I just uploaded, to the Forum, my modified Button Cycle .ino, where every time I press a normally open switch, the sketch jumps to the next loop (case) segment and does a different light pattern sequence. The problem is if I am doing a photography workshop and the people want loop #5 repeated, I have to power down and restart at loop #1, pressing the button time and again until I get to loop #5 (each loop creates a 35 second light show). I have tried to modify that sketch to take a keypad input of 5 to jump to that case (Keypad_Test), but I have two (2) lines that keep giving me error messages. I have re-typed those lines and many other lines above and below the error lines, plus lines in the define section and have cleared many other error messages (I’m using Windows 10) and from previous posts see where I should have possibly saved the code to Notepad and then copied it into IDE. If that is the answer, then so be it, but if I am doing something stupid, then tell me – thanks.
gbonsack
I just replied with a suggestion the forum.
Others; please feel free to join the conversation with better and/or smarted solutions!
hans
I solved the issue, with the 2 lines of code that were giving me error messages, it seems that “Fat Fingers” had creeped in and I had an extra character in the define line. I now have a working 3 X 4 matrix keypad., where I can press any one of the 12 keys and that case/loop runs. A sample video has been posted on YouTube and I’ll post the full code on the Forum page
Hans, thanks for the comments, to get me thinking correctly.
gbonsack
Awesome! Very nice effects! Love the stills as well!
hans
Sorry. I now to coding and i am zero. Of course i have a long road to go and for now i m just trying to het the logic. I just want to ask this ; i see j and k and i integers. I didnt get what are these because i dont see that we define these letters as integer names in void setup. Are they predefined in library or what? Thanks. Sorry for my english. I m not native talker. So i guess u also understand why its hard to understand that kind of articles for me.
Stan
Hi Stan,
these variables are defined on the fly. For example:
This says: start a loop where we count 0-256, by using the integer variable k. See the “int” in front of it? Here we define “k” as an integer (see also the for-loop section of my mine course).
The definition of variables is done based their scope.
So for example, a variable that needs to be available everywhere, is defined way at the beginning of your code.
If the variable is only needed in for example the “setup()” function, then we define it only there, ideally in the beginning of the code.
If however, the variable is only need briefly, for example for counting in a loop, then we can choose to define it right there (as seen in the example).
hans
Yes Hans i see int goes for integer but i disnt know we Define k in here. I was thinking we Want k to do something in ur code. So its a Define code, not a Do code. Umm okay. Thanks for ur very fast reply that was so nice of u. I will dig on that in my mind. I m a newbee. Thanks again. I guess i need another article that teachea Coding from zero and the logics of it.
Stan
No worries, we all had to start at some point in time …
This might be helpful to get started: Arduino Programming for Beginners.
I wrote it for those with no programming experience, so maybe it’s helpful for you as well.
Enjoy! And feel free to ask question if you have any (either under the related article or in the forum).
hans
Wow. This cant be real. I email and wrote so messages on some websites and i wait for days long but was no reply. And you show me road to start and tell me to feel free to ask if i have some to. My friend i would like to give a handshake to u. I m so happy to hear this friensly sentences from u. I do thank you. Now i have more energy to sit and learn this. (I am web&graphic designer and in love with electronics from childhood times and i want to combine them in my interior design lighting projects). Peace..
Stan
Hi Stan,
I got my Arduino unit mid-November and beat my head against the wall too. My best advise is think of coding as a good book – Introduction, Table of Content and the individual chapter or chapters.
What I wanted to do was create a “Light Painting Stick” for photography, where I could press one of the keys, on a 3 X 4 keypad and have that sub-loop/sketch run. With a few comments from Hans, it all came together for me and if you read the above Feb. 5 post, there is a link to the finished code – enjoy this site.
gbonsack
Thanks Gronsack. . I ve seen a lot on light paintings and its a realy awesome type of usage of leds. I will definitely check that post and the code
Stan
You’re most welcome – I try to answer as fast as I can … sometimes that’s right away, sometimes it’s a day later (timezone difference and of course sometimes my daytime job interferes
).
I’m always happy to help!
hans
hello,
i want to make a rainbow code of the color wipe. i mean that the color stable to show out like a rainbow in 16 LED lights. i dont want to make a rainbow run. can u suggest for me? thank you very much.
candy
candy
Sorry i dont understand what is color wipe
Stan
candy,
If I understand correctly, you want LED ‘0’ (first LED) to be red and the last LED to be violet? If so consider defining each of the 16 LED’s like this (you need to enter color code as desired). This is copied from another program, so verbiage may have to be changed to suit. Have to run for an appointment, but will check later today.
//
};
gbonsack
Awesome guys – thanks for chiming in!
If we indeed mean a static rainbow, then that code would work, and I’m sure there would be a smart calculation for it as well but using array like that is easier to understand.
hans
thank you very much
yes, i want LED ‘0’ (first LED) to be red and the last LED to be violet which show out at the same time in 16 LED’s. But the colors are not run in the 16 LED
But the above code, where can i put it?
Otherwise, i want to adjust the code. when i load the program to my arduino, my other function I2C display can not show out out and detect sensor must delay to read the data, can you give me some suggest?
candy
I just wrote this:
#include <Adafruit_NeoPixel.h>
#define PIN 6
Adafruit_NeoPixel strip = Adafruit_NeoPixel(8, PIN, NEO_GRB + NEO_KHZ800);
// I wrote this using just an 8 LED strip, so change 8 above to 16 and double the lines below
void setup() {
strip.begin();
strip.show();
// Initialize all pixels to ‘off’
}
void loop ()
{
strip.setPixelColor(0,125, 0, 0);
strip.setPixelColor(1, 80, 45, 0);
strip.setPixelColor(2, 64, 64, 0);
strip.setPixelColor(3, 0, 125, 0);
strip.setPixelColor(4, 0, 64, 64);
strip.setPixelColor(5, 0, 0, 125);
strip.setPixelColor(6, 50, 0, 75);
strip.setPixelColor(7, 40, 40, 40);
// (led position, amount red, green, blue) I use lower numbers to reduce brightness
strip.show();
}
gbonsack
thank you very much, Gbonsack
candy
i try it that is good result for me. thank you for your time. thank you very much….
candy
That would work very well of course! Thanks Gbonsack!
Candy; you’ll just have to expand this to 16 LEDs – you can use the color picker and split the hexadecimal number into 3 sections. For example B5FF8A would become (the first parameter – 1 – is the LED number):
So B5FF8A becomes: B5, FF, and 8A. to let the Arduino know this is not a normal number, but a hexadecimal number, add “0x” (zero-X) in front of each of the numbers (this would save you from having to think too much about hexadecimal number and convert them).
hans
thank you Hans
BUt i have another problem to come out.. plz help.
candy
Hi Candy,
I’m sorry that I had to remove all the code you posted, but this became a little too much for the comment section.
Could you place your question in our Arduino forum please?
I’d be happy to take a look and see where I can help. But with long codes being posted here, other users would have to scrolls for days to find something.
hans
Hi Candy,
I do not have my Arduino stuff nearby, but you could try this modified code:
Not sure if the colors will appears as desired …
The code would replace this section:
Your next question is to combine the code with controlling a display and reading sensors. This makes things a little bit more complicated and we’d need to see the code for those peripherals.
Since this might become a rather longer topic, I recommend starting a topic in our Arduino Forum.
hans
thank you very much, Hans.
candy
Hello Hans
I tried myself at the rainbowcycle code.
In the video it looks great.
But I don’t get it….
I’m receiving always the error message:
21: error: ‘setPixel’ was not declared in this scope
setPixel(i, *c, *(c+1), *(c+2));
^
23: error: ‘showStrip’ was not declared in this scope
showStrip();
^
exit status 1
‘setPixel’ was not declared in this scope
This report would have more information with
“Show verbose output during compilation”
option enabled in File -> Preferences.
I’m an apprentince and I tried to do an LED Matrix as a project with the arduino Nano.
I’m trying to get a few programms on my arduino and switch between those with some switches.
I really like the rainbow effect so I decided to do the rainbowcycle too
as I said and mentioned I’m getting the same error message again and again…
Do u have some extra files where u declared respective defined these functions?
Thanks already
Trollo_meo
Hi Trollo_meo,
since I do not see the entire sketch you’re using (and pretty please do not post it here – the forum is the place to post large pieces of code), I can only guess that you didn’t copy the framework.
See this section: FastLED Framework.
The idea was to have a framework depending on the library you’d like to use – FastLED (recommended) or NeoPixel.
The “framework” is the base for all sketches, and where indicated you have to paste the effect code into this framework code.
Hope this helps,
Hans
hans
Here is a link to my latest Arduino driven Light Stick video:
I find cutting the output of the LED’s to 25 to 50% gives me better color saturation and doesn’t burn out the video colors.
I now have the 121 keypad code working, as well as the multiple position and pushbutton advance switch code. Thanks again to you Hans, for your direction and tips.
gbonsack
That’s just awesome! I probably should dig into this topic as well – looks really great!
Thanks for sharing!
hans
Hi there, I’m very new to all of this. I have completed the strand test and uploaded a couple effects. My question is: if I want to make a standalone strip that cycles through effects with the push of a button, where would I begin? As in, I want to give the whole assembly a power cord, and just use a button to cycle through effects, how would I do so?
Ben Linsenmeyer
Hi Ben,
cycling through effects has been requested a few times (which makes me want to write an article about it, but simple do not seem to get to actually finding time to do it). A few users have been working on the same question in the Arduino Forum – that would be a great starting point.
Feel free to join a conversation there or post your own question.
hans
Ben, thanks to a few comments from Hans, I have created several different light painting sticks, using the Arduino Uno Board and either a 12 button keypad, a 5 position switch or a normally open push button (9 sub-sketches). Sample video’s can be seem on my YouTube page “Gerald Bonsack”. I have found that as the 9V battery gets weak, the Arduino wants to do it own thing and not follow my written code. I have posted one or two of the .ino files, on the Forum page and will post others, if requested. For the 5 position switch, I have the 10k resistor between the ground and the common connection between the 5V supply and the switch – output from the switch goes to INPUT PINS, on the board. Since I started playing with the Arduino only a couple of months ago, my code my not be pretty, but it works.
gbonsack
Hello! I am trying out these sketches using an Adafruit Trinket as my microcontroller. For some reason, no matter if I try the Neopixel library, or the Fast LED library, all I am getting when I upload any sketch, say the Fire sketch, is just all white LEDs. The Neopixel sketches from Adafruit work fine. Any ideas?
Marc Johnston
Hi Marc,
ehm, I’m not familiar with the AdaFruit Trinket. As far as I can read from the specs, there is a 3V and a 5V version – so it might be related to that, since the LEDs might expect 5V for their data, then again, you said that the NeoPixel examples do work.
The next thing might be in the initialization – verify that with the ones used in the NeoPixel examples:
Also make sure you use the same NeoPixel library (but you probably already do this).
Since NeoPixel is the only one you want to use (for testing), you could narrow down the code to:
hans
Hans,
Thanks for the reply. I will say upfront, that I am a Arduino newbie. However, using the code you posted gave me the white LEDs again. I compared that code to a working Neo Pixel sketch, and noticed some differences that pertain to the Trinket. I modified the code with those bits, and now when I run it, all the LEDs go black. Here is the modified code:
Marc Johnston
Hi Marc,
no worries, we all had to start at some point right?
Hey! You caught the same difference I did!
This code would indeed not do much since you didn’t include an effect, but I think you’re getting closer!
Replace this code with the effect you’d like to use (unless you already did that):
For example with:
hans
And also, here is a working sketch from Adafruit:
Marc Johnston
Hi Marc,
the only exceptional things I see in this working code is:
I’d assume you have to bring that over to the demo code from this article as well, which would make it like so (note: your code says PIN 0!):
(I hope I got all the differences, and this would be the “base” code of course – just didn’t want to post very lengthy code, that would be better in the forum, if we want to continue the topic)
Hope this helps
hans
Thanks for all the help Hans. I’ll look back into it once I get another Trinket in.
My original intent was to use the Neopixels to fix the lighting in a friends jukebox. Most of the lighting effects on it were made by using fluorescent tubes, and color wheels. The color wheels have long since quit working, and are expensive to replace. I like the fire effect example here, but as I wasn’t able to get it working (yet), so we went with another fire effect I found @ Adafruit. Anyways, the end result looks much better than I anticipated. We ended up using two of the Neopixel rings for the “ends” of the top of the jukeboxe, a strip behind the “compact disc” area, and two strips going verticle up the leg areas (that’s where the fire is). I still think the fire example here will look better, and once I figure it out, I can easily upload it.
Here is a short video we made:
Marc Johnston
Very nice results mate, the Jukebox looks great.
I usually use the nano for my small lighting projects, though I also relied on a lot of great help from Hans.
Here’s Christmas decoration I 3D printed and lit up with a nano and some ws2812’s
Spike
Awesome Spike!
What brand/model 3D printer do you use?
hans
That is very nice! I think I may order me a Nano instead of a Trinket. It seems to be a bit more powerful, and not much bigger.
Marc Johnston
Hi Marc!
Thanks for the video – that looks awesome!
The fire effect would indeed be very cool for this purpose!
hans
Hi Hans, Thank you, but it’s all down to your help, it wouldn’t be so good without it.
That was printed on a version of the i3 that I built myself. I now have an Original Prusa i3 MK2.
Spike
Hi Marc, Thank you, I got mine from a UK ebay seller who was very quick to dispatch and with comms.
The nano has served me well for a lot of LED projects, including a 30×15 matrix
Spike
Oh Wow! I like the matrix! Very cool!
Yeah I dabbled for a bit with 3D printers, and have to say that I’m probably not patient/accurate enough to work with 3D printers (LeapFrog) just yet haha …
Maybe one of these days I’ll pick it up again.
hans
Well, I ordered a bunch of Nanos, and have been playing around with them. All the sketches work fine in them, so I think I’ll use the Trinket for something else. I appreciate everyone’s help!
Marc Johnston
You’re very welcome mate. Glad they are working well for you.
Spike
I just wanted to thank you for the code examples!
Bret
Thanks Bret for taking the time and effort to post a Thank-You — it’s much appreciated!
hans
Thank you for sharing the code and beautiful videos with clear details!!!
Prasanna K
Hi Prasanna!
Thank you very much for the compliment and for taking the time to post a “Thank you” – it’s very much appreciated!
hans
Trying to figure out how to reverse the direction of the running lights code. Any help is appreciated!
Steve Doll
If you like to have the LEDs run into the opposite direction, just:
Is this what you’re looking for?
hans
Doesnt seem to change the direction
Steve Doll
Doh, I modified the wrong for-loop … I should drink more coffee before replying hahah …
I’m sorry – I do not have my Arduino and LEDs anywhere near me, so I cannot test …
hans
Appreciate the help, unfortunately that makes the LEDs not work at all
Steve Doll
I guess I’ll have to find an Arduino + LED strip to do some testing …
hans
One last tweak needed to get the lights to run in reverse, setting the Position to the end and decreasing it:
Gizmo Props
Thanks for chiming in Gizmo Props! Awesome!
Hans
Hi! The “Compile” didn´t pass because the “SIN” function doesn´t exist on my project.
Supposed this SIN function is included in the NEOPIXEL Library?
Thanks for your support!!
Sebastian Krupnik
Hi Sebastian,
the sin() function is a standard function that comes with the Arduino IDE (link).
Since the code looks OK, my first guess would be to update your Arduino IDE to the latest version (link).
hans
Hi Hans, mi interface is for coding is (using a PHOTON). Not sure how to upgrade this interface. Have you know what to do?
Thank you!!
Sebastian Krupnik
Hi Sebastian,
I have never worked with that tool, and unfortunately it seems required that one has to signs up.
Maybe other users/visitors are familiar with this tool and can assist?
hans
hi im new to coding on Arduino but iv been trying to do the KITT effect (Cylon) for ages and just found this site yesterday iv managed to get it working but not liking the look of the KITT effect when i slow it down, iv set the speed to about “70” as i want it to look like the real KITT car but i can see the LED’s are not fading into the red as its going along.. it looks as if its just turning the led’s on from 0% brightness to 100% also the faded sides of the eye that I’m guessing jumps from 0% to 50% brightness.. so my question is can i make the effect better by fading the LED’s in as they go along.. for example each LED will not jump straight to 100 instead 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% brightness.. any help il be much appreciated.
chris
Hi Chris,
that would most certainly be possible, maybe we should try to find a video that displays the 100% correct effect.
I did play a little with fading (happened to be for a bouncing ball project), and selecting 10, 20,…,90, 100% is a little tricky since brightness does not behave in a linear way with LEDs.
We can start a forum topic if you’d like.
hans
Sure anything that would help me would be great also this is helping me learn to code
Chris
Hello there Hans, and thank you very very much for this guide!
I just started learning how to use the arduino, my idea was to have custom led configs on my pc case for fun, and I found out learning arduino with 2812b leds is a much better way to do this than lets say buying a retail product like NZXT Hue+.
I have a question, I got it all working, but I need a way to either update the arduino data to change effects.
Is there a way to have many effects on the memory and by an USB command change between it? Or perhaps a way to double click a shortcut and it will directly upload a sketch to it?
I used this program () and got it to control the lighting via the COM port in real time, works great based on the music, is there a way to do it to change effects??
Once again, thank you very much for the hard work!!
Moreno Antunes
Hi Moreno,
glad to hear you’re having fun with these LEDs as well.
In our Arduino forum, you’ll find a few topics covering the combining of all effects in one sketch.
I’m planning on writing a dedicated article for that, but just simply haven’t gotten to it yet.
So, it’s very well possible, just might take some work to get it going …
hans
candy
This page is awesome. I’m trying to combine your fade code, with another “code” i found.
–
I basically want my Neopixel strip to beat like the program attached throughout the whole strip but with your fading script.
Any thoughts???
Jeffrey T Pruitt
Hi Jeffrey,
thanks for the compliment!
As for the heartbeat code you found, this can be modified to:
This code should replace the following lines in the base code of this article:
Please note that I did not have the opportunity to test this code, please let us know how well this does (or does not) work.
Also note that I changed the variable names to make it more readable, and … keep in mind that I might have made typos …
Also keep in mind that the original code only uses 3 LEDs (see comments in the loop() section).
hans
Thank you thank you thank you!!!!This did exactly what I was looking for, I’m just starting with Arduino, neopixel etc, so I’m still trying to figure out coding things so this is a HUGE help.
Thanks again!
Jeffrey T Pruitt
You’re most welcome
…
Did it work as expected?
hans
[…] Arduino – LEDStrip effects for NeoPixel and FastLED […]
hi there is anyone can tell me that these codes will work on RGB led strip as well thx
lucky kang
Hi Lucky,
it depends on what RGB strips you’re using. The WS2811 and WS2812 are RGB LED strips running on 5V (typically). There are some cheap knock offs that use a different color order (GRB for example), but in essence that works just the same.
Do you have any specifications?
hans
is these code on these RGB strips thx
lucky kang
Hi Lucky,
I can’t guarantee that. It states it’s RGB, but since sellers post whatever they like, there is no guarantee – one thing I noticed is that these LEDs are 12V, so I would not recommend using them.
hans
can u recommend and good RGB led strips thx
lucky kang
I just ordered some strips from AliExpress – I had ordered from this seller before and they work very well.
They are also very affordable. See this link.
I always pick the 5 Meter strand with 60 LEDs per meter, with black PCB and IP65 (5M 60 IP65).
The LEDs are waterproof and casted in some kind of solid transparent silicone, which makes it very well protected against dust, water, bugs etc etc. It also makes it look really nice with the black “PCB”. It’s $22.73 for a 5 meter strand – different sizes are available – at the time of this writing.
hans
hi i order ws2811 from ebay and the all three colour work except white why is that anyone help thx
jony
Hi Jony,
if each color works, then white would be when all colors are ON.
this should work for all types of LED strands. Now if the strand is not really a WS2811, it might become tricky to control the LED colors. Quite a lot of sellers advertise wrong or misleading information. Did you try some test code from the “Controlling LEDs with Arduino” article?
hans
ok
lucky kang
so can you tell me how can i do that please thx
jony
Hi Jony,
did you run the test sketches?
Normally, to get white, one would set the color to 0xff, 0xff, 0xff (all 3 colors to max).
hans
Hi tweaking4all.com. My English translator level is Google, I apologize for the mistakes.
– I googled a lot about LED on WS2812b, and came across your magic site, which helped me a lot in mastering. But I have a few questions, tell or send me to the desired section of your forum.
I
downloaded “AllLEDEffects-FastLED” unlocked ALL effects, but in the
case of “Bouncing Balls Multi Color” and just Bouncing Balls it stays on
this effect and that’s it. In the case of “Fire” if something is unlocked in addition to this effect, then “Fire” simply does not play.
Questions:
1. How to remove these shortcomings?
2. How to make a random effect switching time, or every 10 minutes?
3. In the “Bouncing Balls Multi Color” effect, do random colors?
prof
Hi Prof,
well, I’d start with making those 2 effects work properly.
You can create the code from scratch by copying the initial framework, for the library you want to use, and then paste in the effect code.
As for multiple effects in one sketch, consult our Arduino Forum, there are a few topics on this, for example this one, that should help get you started.
hans
hi guys is anyone can help me i jst wanna add two pir sensor with these codes top and bottom im bit confuse with wiring and coding is anyone knows how to do it thx
lucky kang
Hi Lucky,
It is best to start a forum topic in our Arduino forum for this. I monitor this daily, and it would keep off-topic and long source codes away from these comment sections.
Do however feel free to post the link to the forum topic here to grab the attention of others.
hans
anyone knows how to add pir sensor click the link for the topic forum thx
luckykang
The project i m working on is stair project one PIR sensor bottom stair and one top so when bottom sensor activate the light start from bottom to top when top sensor activate the light start top to bottom and also how to do the wiring also thx
Similar to this video
John
None of the videos are working. I’d love to see the examples though, is it easy enough to fix them?
Or are they working for other people?
Wrybread
Hi Wrybread,
Could you let me know which Operating System and which browser versions you’re using?
I have seen the videos causing issues with old Android devices, but with Windows and Mac I have not seen any issues yet.
If you have an older OS, consider trying Google Chrome.
hans
Hello friends! I
have very little knowledge on the subject but, I would like to join
several of these codes mentioned in several strips of Led, say, 8; Therefore, how can the code be assembled in this way?
Thank you all
Daniel
Hi Daniel!
I’m not sure what you mean? Are you thinking of running 8 strips in parallel?
hans
Hi,
I’m a complete novice with Arduino and Neopixels, and by novice I mean I’ve never coded anything before! I’ve picked up some bits and pieces but I’ve found that most tutorials jump through stages without actually explaining the basics, pretty much just copy and paste code which isn’t great for learning! I’ve been attempting the Rainbow Cycle sketch but I get an error message saying the the number of LEDs has not been declared, where do I put this value in the code?
I’m also hoping to loop 5 rainbow cycles and then run a colour wipe through every colour on my RGBW Neopixels before returning to the rainbow cycle, is this possible to run on the Arduino as one sketch?
Thanks in advance!
Dan
Hi Dan,
you’re probably right about the lack of detailed info, since most assume some basic knowledge.
Maybe this little intro course is useful, in case you want to dig a little deeper.
As for the number of defined LEDs, the line
defines the number of LEDs in your strand. You’ll see it in both examples (NeoPixel and FastLED).
Doing 5x rainbow, and then a colour wipe for several colors is most certainly possible.
You’d need something like this
As you might see; I combined the code of both effects, and call them in the loop().
It does the 5xrainbow, wipe for Red, wipe for Green, wipe for Blue.
After it completed that, it will do the loop again, so effectively do 5xRainbow, and 3x wipe.
Keep in mind that the code needs to be pasted in the framework, replacing the text between the lines (maybe you forgot that earlier):
and
If you want to add more colors, you can add a line like this for each color you’d want:
If you want a ton of colors for the colour wipe, then consider using for-loops (see also the little course).
For example:
This example would go through all colors (16 million), so you might want to narrow that down haha.
Hope this is helpful.
hans
Thanks Hans, this is great! I’ll get stuck into all of that, plenty of material to get me started!
Thanks again
Dan
Cool! Well, feel free to ask if you run into issue or have questions …
hans
I’ve been messing about with all of this and I seem to be getting a warning message saying that I have created a compound expression list after dealing with a declaration problem, will this cause any problems with the neopixels? See below;
Users/Daniel/Documents/Arduino/RainbowCycle/RainbowCycle.ino: In function ‘void rainbowCycle(int)’:
/Users/Daniel/Documents/Arduino/RainbowCycle/RainbowCycle.ino:35:40: warning: expression list treated as compound expression in initializer [-fpermissive]
int setPixel(i, *c, *(c+1), *(c+2));
^
/Users/Daniel/Documents/Arduino/RainbowCycle/RainbowCycle.ino: In function ‘void colorWipe(byte, byte, byte, int)’:
/Users/Daniel/Documents/Arduino/RainbowCycle/RainbowCycle.ino:65:38: warning: expression list treated as compound expression in initializer [-fpermissive]
int setPixel(i, red, green, blue);
^
Dan
Hi Dan,
it is a warning which most likely will not stop your program from running. It does point to something not being 100% perfect though.
I haven’t ran into this problem before so, just a guess here; look for this line in your code (defining the function SetPixel):
and replace that line with:
But there could be other reasons – Maybe you can post your code in our Arduino Forum so I can look at it (without making this treat super long) …
hans
[…] Tweaking4All’s also really nice Fire neopixel sketch. Same comments as with John’s work. THANK YOU. […]
First off, thank you so much for this resource!! So great!
Question: Using the “Fire” code to create a flame inside an outdoor lamp post w/diffuser to simulate a flame. I’d like to change the flame colors to have more orange and less red. Also would like less white and more yellow? Could you recommend changes to the Fire code to modify the output as such?
Thanks in advance.
Tony
Hi Tony,
I have not tested this, but in the last procedure used by the fire code (setPixelHeatColor()), you could play a little with the “Red” value when the pixel colors are calculated, worse thing that can happen is that the colors will be off
hans
Thank you for the reply. I actually modified the code on my own in a similar manner.
Tony
[…] […]
Dear All,
I am new to this project.I don’t have any idea about coding but i want to run all this code on a neopixel stripe. How to combine all these codes to run in one single sketch.
Dhiraj Kumar
Ha!
JaquesHaas
I would like to repeat the Dhiraj Kumar’s question!
Daniel Fernandes
Hi Daniel (and Dhiraj),
there have been a few requests for this and some of the users have worked on it in the forum – however, it will take some work and reading to get this done, which might not be the easiest for a beginner.
If users could tell me how they would like to see then, then I’ll try to create code to include all effects.
Do we prefer toggling effects with a push button? Or based on a predefined pattern?
hans
It is really refreshing to find someone such as yourself who has the knowledge, and is willing to share it – without a demeaning / snarky attitude.
Thank you!
John
John
Hi John,
thank you for the very nice compliment. It’s very much appreciated and definitely a motivator to keep working on more articles.
And the relaxed attitude is what I’m going for. I like to show folks how things can be done, in a fun way. The more folks that participate with the same mindset, the more fun it will be for all of us …
hans
Thanks, great stuff.
For the Particle.io I needed to add one line after including the FastLED library:
#include <FastLED.h>
FASTLED_USING_NAMESPACE
Unlike Arduino, the Particle.io uses namespace and so requires this single line to compile correctly. More about it here.
Brian
Awesome!
Thanks for the info Brian!
hans
[…] ici est LEDStrip Effect – Snow Sparkle, mais a cette adresse on peux trouver plein d’autres […]
Thank you for sharing your fantastic work. I arrived here after searching or neopixel fire. I wanted to bring a big picture of a rocket to life on my sons wall. I plan on using a shorter strip, so I think with a few little tweaks your code will be work great for me.
I love the other effects too, so I’m going to have to think of where I can use them.
Ian
Hi Ian,
Thank you for taking the time to post a thank-you – it’s very much appreciated. Glad to hear you’re having fun!
I guess I should have placed a warning, the darn LED strips can be very addicting!
hans
Thank you very much for this great site and nice examples
Henrik Lauridsen
Hi Hendrik!
Thank you so much for taking the time to post a thank-you note. It’s very much appreciated.
Glad to hear that you enjoy the website!
hans
Hi, and thank you for your examples they really have made it easier for me to get some good effects as I start getting my christmas led displays ready (it’s my first year doing my own). And in response to Daniel and Dhiraj’s question, I have created a single sketch that includes all your examples as their own functions and then call them in the order I prefer in the loop section, I now have my pro-mini running my first example string with hours of different effects before they get repeated. These have saved me a huge amount of time and I can’t praise you enough. Thank You. :)
Dai
Hi Dai!
That’s awesome and thanks for sharing!
Feel free to post the sketch if you’re comfortable doing that – once I get the time to play with that, I’ll try to write an article on how to do that and your input would be very welcome.
hans
Here is my sketch that I have been using to get the timings sorted out (Sorry if it is too long), I have had to make a few adjustments to your demos to prevent infinite loop in BouncingBalls and BouncingColoredBalls , which is now simply a for loop which runs the amount of times specified in the extra parameter “timesToRun”. Also there are some short routines that would need a for loop in the main loop to make them run a certain amount of times (like I have done for the Fire function). I also added a colorWipeReverse function which as the name suggests simply goes the other way.
You will notice I have a couple of Serial.print(millis());, one at the beginning of the main loop and one at the end, this is to tell me the timing of each loop as I change settings. I am doing that so that I can set each effect to last X amount of time.
There are a couple of other changes you may find from your examples although I did not make note of what I was changing but I’m sure you will spot them.
I hope this is of some use to others as it is just the beginning of setting my own strings, so not perfect, but usable.
And just a note about hardware, I am using Arduino Uno for testing (as it is easer) and then a pro-mini in the actual project. The led string I am using with these have 3 leds from each ws2811 IC so the 14 pixels listed are actually 42 on the test string, this may make the timings I have used a little more understandable.
Dai
Hi Dai,
thank you so much for taking the time to post the code – I’m sure others will love it (as do I).
Well done!
hans
Hi Dai,
I would like to add my appreciation too. You have done an awesome job and I plan to give it a try, as soon as I can get the time.
Thank you for sharing your code.
Spike
Thank you Spike, I’m glad you like it, but the thanks should go to Hans as it is 99% his code, I just copy/pasted it all into one sketch ( with a couple of very minor tweaks.
)
Dai
It’s all about team work! And LED strips are fun to play with hahah
hans
Thanks for your examples! These were a great inspiration to me.
So now, I want to show a rainbow, but not cycling from right to left or left to right. All 150 LEDs should show the same color value and change the rainbow colors.
How can I do this?
astro0302
Hi Astro0302!
The modification for that shouldn’t be too hard.
Try something like this:
You see the two for loops? The first one cycles colors (j), and the second one addresses each LED (i).
Instead of doing a color change for each LED, I moved the color selection out of that loop (i).
So it selects a color and then applies it to all LEDs.
Now, I did not test this (I’m traveling) so it might need a little tweaking, but it will get you started.
If you have a working sketch, then please feel free to post it here.
hans
Hi Hans! Thanks for your fast reply. Works great!
Now my ledstripe has the right WAF.
Andreas
astro0302
Awesome!
hans
I have this sketch that is part of a sequence I am testing at the moment, not a finished one but might be useful to you. Obviously you will need to change the settings for your own pixel type and quantity but it works on my test strip. You can change the colour sequence in the sketch in each “colorStep” using RGB values.
Dai
Sorry, posted around the same time as Hans, and his solution is far more elegant than mine.
Dai
Nice work, Dai.
I see you have used the ws2811 in your sketch, and I’m fairly new at this, so please bear with me.
I’ve been running various test sketches using WS2812 and a 144 pixel strip. Fascinating what can be done with one data wire!
If you have a couple of minutes, could you comment on my question, below?
If I were to change “#define NUM_LEDS 14” to “#define NUM_LEDS 144”, and “LEDS.addLeds<WS2811,DATA_PIN,BRG>(leds,NUM_LEDS);” to the specification line for the WS2812, could I expect the sketch to work?
Thanks.
John
John
Hi John,
It will work just fine with the 2812 as well.
You are right though that some of the settings need to be modified to match the 2812 and the LED count you’d like to use.
The “addLeds” line might not need to be changed, since i seem to have used that as well even though I have a 2812 strip hahah …
hans
Yes, and one thing you might need to change would be the “BRG” in the “addLeds” line, some are GRB and some RGB, I had to adjust it to suit my pixels.
Dai
Got the sketch working just fine. Now comes the fun of tweaking it!
A question on the lines below:
Why do some lines use Hex color designation, and some use the RGB color names? Are they interchangeable, or are there coding reasons why one or the other is used?
Thanks.John
circuitdriver
Hi John,
Very good question … I guess that is my sloppiness ie. not always working consistently, especially when a project takes several days and effects have been written on different days.
Anyhoo … Decimal numbers and hex numbers are indeed interchangeable.
hans
Just to add that if you copied my sketch there would be some that I have changed as I have got used to using decimals for the brightness level and have changed some of them to make it easier for me to understand.
Dai
That’s a good plan!
I like hex numbers because they look more consistent (always 0x plus 2 characters), but I agree that decimal numbers are easier to read for us humans
hans
Multi Color Bouncing Balls
Hi !Could show me in the code of “Multi Color Bouncing Balls” how to invert the show. For easy wiring of my strip led , I want that the first led is the number 15 ” Starting led is 15 instead of 0″
Please explain me !
thank a lot !fred
fred49
Hi
Inverting the order should not be too hard.
Try the following code (I have not had a chance to test this, but I’m confident that it will work OK):
Only one line did get changed, where we simply flip the LED order by subtracting the original position from the total number of LEDs.
So position 0 becomes 15-0=15, position 1 becomes 15-1=14, position 2 becomes 15-2=13, etc.
The “-1” is added since we count 15 LEDs, but we humans start counting with “1” where as the LED array starts counting with “0”.
So the 15th LED actually is position 14 in the LED array in the code.
Hope this helps!
hans
Hi Hans
You are too strong in programming, it works perfectly with my 3 colors. Thanks again and again.
You facilitate the wiring of my garland.
I am ready for chrismast
thank you
fred49
Thanks Fred49!
Glad to hear it worked out for you. Just in case you post a YouTube video or something like that; then please feel free to share the link here as well. Always cool to see what other people do!
A little early, but Merry Christmas for you guys!
hans
Hi !
This is my video of my project :
Is it possible to desynchronize my three ramps relative to each other ?
thanks
Have a good day
FRED49
Wow that looks cool!
I’m not sure about the code you’ve used, but per strand you could change one of these variables;
I’d play with them and see what the effect is.
I’m not quite sure what you mean with desynchronize but I assume you mean: so they don’t look too much alike.
You could modify the calculation for “Dampening[i]” … say change 0.90 to 0.50 or 1.0.
Either way I have not tested, but you should be able to mimic or trigger different behavior.
Of course the values have to be different per strand, so I’d probably start with testing which gives you the desired effect and the use the value used for that as a parameter to pass to the function.
hans
Hi !
Thanks for all
in fact , this is my program i use :
I have 3 exit for my annimation.
And I would like it to have a start shifting in time.
To not see the balls all go up at the same time.
No worries if you can not look at this for me, I’m doing tests for the moment to add annimation.
thanks again
have a good day
fred
fred49
What you could do is make the gravity value a random value – not too much different from the original of course:
to
This way the “gravity” will be slightly different each time the function will be called.
I have not tested this, but this is what I’d play with – maybe the notation of the random float can be done better. It basically adds 9 + “a random number between 0…99 divided by 100” (so we get a fraction of “1”) and after that make it a negative number, so that -9.81 is a possible outcome. Or better set -9 … -9.99 is a possible outcome.
See also the Arduino random function and the randomSeed function.
hans
I am new to Arduino. I want to add multiple sketch in one . How can I do this. As a Arduino can run only one sketch at a time. If I want to run multiple led function in one sketch then what is the solution for it?
Dhiraj Kumar
Hi Dhiraj,
apologies for the late reply.
You can only run one sketch on your Arduino at a time.
To get the multiple sketches to work, you’ll have to rewrite the code so all of it is in one single sketch.
In this case (LED effects) you’ll have to combine them, like for example in this post.
hans
First off, thanks for the really well written and highly nutritive tutorial.
I’m using the FadeInOut code broken up into two chunks like below. Curious as to how I can change the speed the leds fade up and down. Very new to Arduino and coding so my attempts experimenting with different values have resulted in undesired results. –E
void FadeIn(byte red, byte green, byte blue){ float r, g, b; for(int k = 0; k < 256; k=k+1) { r = (k/256.0)*red; g = (k/256.0)*green; b = (k/256.0)*blue; setAll(r,g,b); showStrip(); }}
void FadeOut(byte red, byte green, byte blue){ float r, g, b; for(int k = 255; k >= 0; k=k-2) { r = (k/256.0)*red; g = (k/256.0)*green; b = (k/256.0)*blue; setAll(r,g,b); showStrip(); }}
Eric
Hi Eric,
first off: thank you very much for the compliment, it’s much appreciated!
As for changing speed, the procedure you use is pretty much at the max of it’s speed.
We can delay it though by adding delays in the loops, for example by using the delay() function. Of course it would be nice to be able to pass the “delay” value in the function, so I modified the functions a little bit to accommodate that. The delayvalue is expressed in milliseconds (1 second = 1,000 milliseconds).
So basically when a color changes, we apply (setAll) and show (ShowStrip) it, and right after that we wait an x number of milliseconds.
Is this what you’re looking for?
hans
If I’m understanding correctly that would add a delay between the fade up and fade down. What I would like to do is slow down the time it takes for the Led to go from black to the desired brightness level and correspondingly light to dark. I’m using the code in a motion activated light sensing night light. So, fading on and off slowly is what I’m after.
Cheers!
eric
Hi Eric,
No this would add a delay between each color “step”, effectively making the transition slower. So FadeIn and FadeOut would be slower, depending on the value you pass for “delayvalue”. Give it a try. DelayValue-0 is the same as the original speed. DelayValue=1000 will make it that the fade will take about 255 seconds (dee the “for” loop).
hans
Tried adding DelayValue=x and got errors. Mind showing how you would use it and why it causes the speed change. Thanks Hans!!
Code below where I’m calling FadeIn
eric
Hi Eric,
what error messages did you get? Did you use the code I gave?
if so, calling FadeIn or FadeOut would be something like this:
or
hans
Thanks Hans, that led me to the solution after a little experimenting which is better than being given the answer! Now it fades as slowly as I like.
What I ended up changing:(in Bold)
1) adding a delay value to the RGB values where I’m calling FadeIn and FadeOut
2) adding “uint8_t wait” to method header
3) and finally “delay(wait);” after strip.show() which finally pushes the change to the strip
eric
Well done Eric! Thanks for posting it here!
And yes; the best way to learn is to play with it yourself, but sometimes a nudge in the right direction helps right?
hans
Thanks for your easy to follow no-nonsense explanations, very straightforward to follow.
I want to build some hanging outdoor Christmas decoration with my children (to get them interested in electronics and coding), using either Adafruit DotStar LED strip APA102 144LEDs/m or Adafruit NeoPixel RGBW 144LEDs/m and a 5V DC Trinket Pro (small size, easy to waterproof). I want to drive three two-metre strips independently (same effect, but different velocity/randomness). Does this mean I need three 5V DC PSUs and three Adafruit Trinkets? Or is there an alternative solution to drive three strips independently but from a single larger/more capable microcontroller?
On another note – what is the limit of the length of cable if one wants to keep the microcontroller and the LED strips at a distance, say, four metres?
Thanks in advance for some hints!
Systembolaget
Hi Systembolaget,
Thanks for the compliment – it’s much appreciated.
Well, the easiest would indeed be with 3 Trinkets yet.
Two major challenges might be, when using just one, are:
1) Addressing the LEDs in 3 blocks, but with some coding tricks that might not be the hardest part.
2) Having the effects on the 3 “strips” behave indecently. Arduino’s are usually not use in a multi-task setup, so they usually do things in sequence. Again, with so code skills you could consider using interrupts, but I’m sure that would make it difficult and possible undermine the enthusiasm of your kids.
As for the length, I assume you mean the wires between Arduino and strip; 4 meters might work just fine. It will be a matter of testing, but I wouldn’t expect any issues.
Hope this helps!
hans
Ok, thanks for your input! I bought:
The PSU and Trinket will go in the enclosure to withstand the winter weather. We can’t wait for the parts to arrive. With the help of your forum here, we hope to get the coding just right.
Systembolaget
Looking at the latest FastLED git, it seems that one can drive multiple strips doing different things
However, I will stick to three independent setups to not overload the kids.
Systembolaget
Sounds like you’re ready for a cool project – your kids will love it!
And you’re right, don’t want to make it too complicated, otherwise they’ll loose interest and that would be a shame.
Keep us posted on the progress!
hans
Hi again,
I found this page while googling other led animation stuff led animations and thought it would be useful to others to know a way to have their arduino’s use a non-blocking method to display animations. I am using this to allow a button press to change animations (in progress) and so far it looks very promising. I haven’t had time to convert any of your animations yet (but I’m sure to try soon) but I do think it would work with a little tweaking.
Here is a code snippet example showing both ways to code the same display, I’m not sure if either are the best way to do this but it’s code I am trying at the moment.
NON-BLOCKING METHOD
NORMAL METHOD (using delay)
Both of these move a trail of pixels from outside edge to the middle, but the non-blocking method allows the arduino to do other stuff in between (like checking sensors, reading button presses etc).
Anyway I hope it is useful to someone else and thanks again for the inspiration gained from this site.
Dai
Thanks Dia!
Your info is much appreciated – great tip! – and I’m sure users will have benefit from it! Awesome, thanks!
hans
Hi,
thanks for your great examples.
I went a different route in my project by using the strip as receiver and define the content on a different machine.
The controller opens an UDP port and accepts commands in a json format as input.
Your effects should be fairly easy to be added to this structure so you can trigger them over Wifi.
I hope you enjoy it and I helps others to come up with some ideas.
Cheers
Trinitor
That’s a pretty cool project, I’ve bookmarked it for when I get my ESP8266! I’m currently using arduino pro minis for my strings as they are cheap and can control around 600 (ish) pixels depending on the code, but I think the ESP8266 has more possibilities. I might try adjusting your code to see if I can get an Arduino Mega with ethernet board working with it. I like to code in python and think if I get this working it would mean I could use some scripting to get all the effects I could possibly need (for now anyway :) ) Thanks for posting this.
Dai
Thanks – I’ve listed this for my ESP8266 future projects as well
hans
Be advised that the fastPixel library has problems with the 8266, but the neo seems fine.
Mike Garber
Thanks Mike for the heads up!
Others will most definitely benefit from it!
I still have to get started with the ESP8266, hopefully by then FastLED will be updated
hans
I’ve been playing around with some different effects for a few strings of NEOPIXELS running on an Arduino Pro Mini and have found that theatreChaseRainbow function will prevent any further effects being displayed. I have adjusted my effects to put this one last and it works for now but I must put it last in the list and have also noticed that the millis() count is reset to Zero after this effect finishes. I don’t know if this is possibly a memory limit reached causing a reset or something like that but thought I would post in case somebody had noticed (and maybe fixed) it.
The code I am using for this strip is :-
And the Serial output I get is :-
If I comment out the theatreChaseRainbow effect then the millis() count is normal (keeps adding after each cycle). Any body have any ideas?
Also what I haven’t shown here is if you put the theatreChaseRainbow in the middle of the list it will display the effects before it but then resets after it and the following effects do not show (it starts from the beginning again without completing the main loop)
Dai
Hi Dai,
I couldn’t find anything weird that might trigger these issues.
millis() will not reset until it has run for about 50 days (according to the documentation).
Resetting the clock used by millis() isn’t even that easy (see this post).
So now I’m left guess, and what might do the trick is where you use “NUM_LEDS”, and use “NUM_LEDS-1” instead, so try the theaterChaseRainbow with this code (I changed 2 lines):
Maybe not exactly the correct programmers way to do this, but worth a test.
hans
Thank you Hans, that has worked on a small test with only three effects, but when i put the full script in place it seems to go back to previous behaviour (resetting the millis count and starting from the beginning…) I am guessing at this point that there would be a memory full error which might cause a reset because it is not happening when I use less effects, but thank you for trying and I might have to reduce the number of effects for these strings or I might use another method to get similar effect.
Dai
Erratic behavior could indeed be caused by out-of-memory (see this document).
This still happens when you change the order of the effect (ie. start with theaterChaseRainbow() and run the other effects after that)?
hans
Yes, I think it is a simple out of memory error, and thanks to your link I may be able to fix it using PROGMEM for some fixed variables, although I will have to come back to it when I’ve finished a few other bits .
I did try with theaterChase Rainbow at the beginning and the results are the same, that is, if I only have one (or maybe two) other effects it works as expected, but if I have more effects (and the associated Serial.print statements that I’m using for tests) then theaterChaseRainbow will trigger a restart (not directly but because of the memory issue). So I’m sure that it can be overcome with a little coding change on my part.
Thanks for the great help and advice, it is much appreciated
Dai
I thought I had better post the solution to my particular problem in case it might be of use to others with a similar issue, I decided to try and “shorten” or “shrinkify” the theaterChaseRainbow sketch and this is what I ended up with :-
This makes use of the fadeall function I am using in another sketch to turn off the lights after they have been displayed, it can be set differently to have the lights go off almost immediately to make the pattern more like the original one you (Hans) posted.
Anyway, everything is working as it should and I am again a happy bunny
Thanks again for your advise/inspiration.
Dai
Hi Dai!
Great to hear you’re happy with the result and thanks for posting your function!
hans
We got our setup (Pro Trinket 5V and APA102C 144 LEDs/m strip) working and are now wondering how we could achieve something along the monochromatic/polychromatic “twinkle” or “sparkle” effects shown above, but more subtle and continuous, also taking into account that the brightness of LEDs should fade in/out sinusoidal or, rather, logarithmic (human brightness perception)?
Here’s one code-less example of “random twinkling” that shows what we’re after… do you have some ideas how that could be done?
Thanks for some hints!
Systembolaget
Hi Systembolaget,
that’s good news!
As for the desired effect; I like the idea, but I have not code readily available to do this.
i’d have to sit down and set everything up to do some testing to see what works best.
Unfortunately, I do not have my gear readily available so it would take quite some time before I’d have code available …
hans
Hi Systembolaget,
You could try this sketch I think it goes some way towards what you want, it uses the TwinkleRandom sketch with some minor modifications, you can enter the fade speed using the extra parameter I added. You will probably need a longer fade value for longer strings as I have only been using this on a 14 pixel string at the moment. Also this doesn’t fade pixels in but does fade them out. Hope this helps towards finding something useful.
Dai
Hej Hans,
after going through the FastLED 3.1 codebase on Github, I found a good solution, which is nicely twinkling, glittering or sparkling; maybe useful for others, too.
Systembolaget
Awesome! Thanks Systembolaget for posting this!!
hans
This subtle change allows for hue, saturation and brightness control. Randomised or clamped to a range. Enjoy!
Systembolaget
Nice! You’re having fun with the LED strips, aren’t you? (me too!)
Thanks again for posting your code!
hans
Hello, and thank you very much for this very impressive Effects!
Never found a site with this much of exaples!
I want to use all effects by calling them in the main loop(), all is working ok but the effect:
“Bouncing Balls” is running and never ends :-(
In that effect there is this codepart:
while WHAT is true ?
So please can someone tell me how i can stopp the effect after one time running?
I want to change the Ballcolor after each run, so i want to call the function this way:
Daniel
Hi Daniel,
thank you for the compliment!
As for the “while(true)” – this keeps the loop going until the end of time (unless power gets disrupted of course.
I did this to avoid having to look for an elegant exit.
To change that you’d have to change the while-loop.
to (for example – i don’t think this is very elegant):
This will make the balls do 100 “steps”.
To make it more elegant, untested though, you could try to make the balls stop once they do not bounce beyond a certain height;
The idea being; if one of the balls has passed a position higher than LED #4 then we set “started” to true (meaning; we can now start looking for when a ball goes below LED #3). “canstop” will become true when “started” is true AND we found a ball below LED #3.
Again the numbers 3 and 4 are arbitrary chosen, you’ll have to play with that to see what value works for you.
Hope this will get you started – feel free to ask questions and/or share your findings.
hans
Hello Hans and first of all Vrolijk Kerstfeest to you and your family!
I really try your second implementation but it is not working here with my 60 led strip.
It stars with red ball, red i flying to top, after red goes to 0, green starts to top and after
reaching 0, the blue ball stops – so there is only one jumping per ball!
I have a idee: when the Ball is about to die, he stays a longer time on StripLED 0 for around 1 second, so i try
to stop the function at this position, but i’m really not good in programming inside a arduino loop().
Daniel
Hi Daniel,
sorry that it didn’t work as hoped – I’m a little limited since I cannot test as my hardware is nowhere near me.
Your timer approach could work, but I do tend to write if statements with more brackets to make sure it does what is expected. So you line
I’d write as:
Another thing we could do is use a counter that increase with each bounce and when a certain number has been reached; we exit.
Something in the line of:
Hope this helps … and Merry Christmas
hans
Hello Hans, i try all the ideas but nothing works really good.
But then i checked again your code “BouncingBalls” and i found a 100% perfect
solution :-)
I replace only one code line from the script with this one!
It works perfekt and stopps wenn Balljumping in lower then 0.1
But this woes not work with the multi bouncing balls “BouncingColoredBalls”
because in this line
you can not check witch of the 3 balls in in the stopping-phase….and also it looks like
the balls are touching each other and amplify or break the jumping Gravity formula :-(
But for now its ok with one Ball bouncing…..
By the way your idee:
is working but the >6 must be in my case around >210 for one ball because on each jump
and fall the ball is passing 2 times the Index 0.
But i will try to use this code for the 3 ball bouncing, by increesing the value >600.
I will post here for others if i got success.
Have a nice eavening Hans, great site.!
Daniel
Awesome fix Daniel – can’t believe I totally overlooked that one.
Yeah with multiple balls you’ll have a challenge.
Maybe it would be good (with 3 balls) that a ball stops bouncing once it’s done with it’s bounce(s), until all balls are done.
Since ImpactVelocity will never be below 0, we could abuse that – set it to -1 when the bounce is done.
Not sure what the impact will be of not setting the ball … but I figured it may remain “at the bottom”?
Again; untested, but maybe it’s helpful …
hans
Good morning! Thanks a lot for this awesome and helpful site. The toilet paper hack is my favourite
I used your code for my attiny85 with a WS2812 strip. A motion sensor turns the effect on and off after a short delay. Now here comes my question and it would be great if you could help me, because I want to use this for an infinity mirror as a christmas present!
Question: Do you have an idea how to go through all effects instead of repeating only one? So, whenever the sensor detects a new motion, he does not show the previous effect but a new one. Do you think this is possible?
Best regards from Germany
Maike
Hi Maike!
Thanks for the compliment and I have to agree that the toilet paper hack looks great and is kind-a funny at the same time
.
In the forum, and some posts here, show some examples on how to use multiple effects in one sketch. See for example this comment or this forum topic.
I hope to find time soon to work on questions like this – unfortunately at this time regular work leaves me very little time to do fun projects.
hans
Thank you very much for your answer! It worked out and my parents-in-law were very happy about their present. I used it for an infinity mirror with a motion sensor and two magnetic key holders. It was fun doing the project, so thanks for your help and sharing for knowledge
Enjoy Christmas!
maike
Hi Maike!
Merry Christmas to you too!
Glad to hear your project worked out … actually sounds like an interesting project!
hans
If you want to take a look at it:
The next one will be better, but this was very good to learn all the differents tasks from cutting ikea mirrors to coding the neopixels! Thanks to your great descriptions, videos and explanations
maike
Oh wow! that looks nice! Well done!
I’ll have to look into that some more as well … I like it!
hans
Hi Hans,
Could you show an meteor rain example. Thank you in advance,
Henrik
Henrik Lauridsen
Hi Hendrik,
well, ehm … that depends on what a meteor shower looks like.
Do you have an example? For example a YouTube video that shows this effect?
Merry Christmas and a happy New Year to you too
hans
Hi Hans,
Thank you for your reply and wishes.
Something like :
Meteor rain
Meteor rain 2
I would like to be able to change color and speed of the meteor rain.
By the way I always comes back to this site. Great site. Thank you,
Henrik
Henrik Lauridsen
Hi Henrik!
Thanks for the YouTube links,… and thanks for keeping traffic on my website going, it’s very much appreciated.
As for the code for the meteor rain; I’ll have to do some tinkering – mostly finding my Arduino and LED strips.
It doesn’t look like this would be super complicated though.
I’ll try to make some time this week to write some code for this, and maybe combine that with some extras to cycle through all the effects mentioned in this post.
Might take a little though,…
hans
Hi Hans,
Thank you for your time.
I am looking forward to your solution with excitement.
Henrik Lauridsen
Hi Hendrik,
I hope you like this one; it’s currently only for one strip though.
The function meteorRain takes 6 parameters:
For the color of the meteor: red, green, blue
– meteorSize: size of the meteor (including trail)
– meteorIntensity: intensity of the trail, or how fast the trail fades (1=fast fade, 10=slow fade)
– speedDelay: how fast the meteor moves by setting a delay value (so higher value = slower)
I have the meteor fade all the way, so even if the meteor is out of sight (past the end of the strip) then the trail will keep going until it’s totally gone.
Give it a shot an see what you think. I’m sure there is room for improvement (for example; dividing colors to mimic a fade is OK but can be done better).
I did try this with a 60 LED strip and looked pretty good. Then again; I never payed much attention to the meteor rain effect in the past.
Let me know what you think, and if it’s worthy I’ll add it to the list above – if not, then we’ll do some tweaking …
hans
Hi Hans,
Thank you very much for your time and solution. Its looking good and in my opinion absolutely worthy to join the list above.
Of course it would be great with an option to support more strip syncron or asyncron and a wait state before the meteor started all over.
Again thank you and please keep up the good work,
Henrik
Henrik Lauridsen
Hej,
here’s one with a sparkling and adjustable length trail. Colour can be fixed or change, too. Happy Easter!
Systembolaget
Thanks Hendrik!
Glad you liked it. As for your suggestion; Hey, it wouldn’t be fun if we couldn’t improve this right?
The option to add more strips would of course be great, but that would no longer fit this “generic” approach I’m afraid.
hans
Since I love playing with LED strips, a variant that might be better;
This one only works with FastLED since NeoPixel has no function to fade LEDs (by my knowledge).
I’ve added a few options like the size of the meteor (excl. tail), how fast the tail decays, if the tail LEDs should decay at random (leaving little pieces that decay less fast). Play a little with the values and to add randomness – play with random values as well.
As for a random start when using multiple Arduino’s and/or strands;
you could do a “delay(random(12345));” before the meteorRain() call. You’d probably need to set randomSeed() in the setup function, for example:
If anyone knows of a trick to make LEDs fade in NeoPixel, then I’d love to hear that so we can add this to the list.
Happy New Year!
hans
Got it to work for NeoPixel as well … so I’ll add it to the article;
hans
Thanks to you Systembolaget!
Very clean and compact – I like it. I’ll have to test it and see if we can squeeze it in this article as well!
hans
Looks really good! Just had a chance to test it.
Unfortunately, it would not fit in the “generic” approach of this article, but for those who are looking for this effect: highly recommend trying this one!
Happy New Year!
hans
Happy New Year to you guys!
hans
Thank you and a happy New Year to you.
Henrik Lauridsen
Hi again,
I forgot to wish you a merry Christmas and a happy new year
Henrik Lauridsen
Thanks a lot.
Really great job !
See you !
Lephilelec
Thanks Lephilelec for taking the time to post a Thank-You note!
It’s very much appreciated!
Happy New Year!
hans
UPDATE:
Added a new Effect (thanks Hendrik for pointing me to a cool new effect): Meteor Rain.
hans
HI THERE
I want to integrate the meteor rain effect with a ultrasonic sensor .Could you point me in the direction of how exactly to go about it.
p.s- I am a newbie at arduino :)
arav kumar
Hi Arav,
I have yet to play with an ultrasonic sensor. Not sure if it passes a value or an on/off state.
Either way, you could setup a loop that checks the sensor. Once the sensor “triggers”, call the meteor effect?
hans
UPDATE:
Finally found the time to combine all sketches into one single sketch.
I’ve created it such a way that you can toggle effect (fast!) with a single button.
See: Arduino – All LEDStrip effects in one (NeoPixel and FastLED)
hans
Hi Hans. I am incredibly grateful for the code and help you’ve added with this post. So very much appreciated. Is there any way to learn the language you’ve used to program these sketches?
Gary Kester
Thanks Gary!
I very much appreciate your post!
To get started, at some point I wrote a course for my nephews. Maybe this is a good starting point to get familiar with the language.
Here is the link of the overview page: Arduino Programming for Beginners.
Don’t be afraid to ask if you have questions … we are all beginners at some point, and I’m 100% sure there are better programmers than me out there that can teach me a few things as well.
hans
We can always do what we do better ;). I’m learning from the bottom up and your tutorial is gold for that. I’m also trying to implement the lighting effects into some of my projects at the same time. e.g.
Have you ever done a sketch that results in 2 different effects to two different sets of neopixels (of different lengths) at the same time?
I’d like to have the core pulse randomly separate to the circle that I want a superfast spinning effect on.
Gary Kester
Hi Gary!
That’s a cool project, which initially (since I forgot to read the “Iron man” text) made me think of a LED ring around a speaker responding to music. Anyhoo – both fun projects!
I have not played with multiple strips yet – I’ve always used math to set the LEDs so it looks like 2 strands. FastLED however does support multiple strands, but I can imagine it to be challenging to have 2 or more effects to run in parallel. I’m thinking about timing issues and such.
I guess I would start using 2 Arduino’s for that – to get max speed as well.
Then again, if you’d make one procedure handling the spinning – just 1 step, and another one doing just one step of the other effect, and then call them in a certain sequence in loop(); might work.
hans
Hi Hans,
I have a question regarding powering more LED strips.
I need to power 300 WS2812b LEDs or more, but my PSU can’t handle that much (300 x 60 mA)
Can I do the following?
5 LED strips and 5 PSU’s
Every PSU with common ground including Arduino ground.
Every strip + connected to VCC on its own PSU
All strips data pin connected to Arduino data pin 6
Thank you.
Henrik
Henrik Lauridsen
Hi Hendrik,
in my practical experience, 300 x 20mA would work or is at least worth a test. This works since not all LEDs are on and at max brightness all the time for a long period of time. Which would suggest a 6A power supply could pull this off.
If you’d like to use individual PSU’s, then your approach looks good; common GND, Vcc for each strip.
However if all strips have a common data pin 6, then they most likely all will display the exact same effect. Not sure if that’s what you had in mind..
hans
Hi Hans,
Thank you for your reply..
This was what I meant, but formulated it wrong.
Thank you again,
Henrik
Henrik Lauridsen
I guess we are talking about the same approach then
hans
Hi Guys,
Just adding my contribution. The enclosed sketch is based on the Hero Powerplant sketch done my Tony Sherwood for Adafruit Industries.
I modified it to allow for 2 sets of Neopixels (1 for the circle – RGBW and another for the core RGB) with different colors running off different pins.
Video of the effect on Youtube
//fades all pixels subtly
//code by Tony Sherwood for Adafruit Industries
//modified by Gary Kester for Make It Real (Australia)
#include <Adafruit_NeoPixel.h>
#define PIN1 1
#define PIN2 2
// Parameter 1 = number of pixels in circle
// Parameter 2 = pin number (most are valid)
// Parameter 3 = pixel type flags, add together as needed:
// circle = Adafruit_NeoPixel(10, PIN1, NEO_GRBW + NEO_KHZ800);
Adafruit_NeoPixel core = Adafruit_NeoPixel(6, PIN2, NEO_GRB + NEO_KHZ800);
int alpha; // Current value of the pixels
int dir = 1; // Direction of the pixels… 1 = getting brighter, 0 = getting dimmer
int flip; // Randomly flip the direction every once in a while
int minAlpha = 25; // Min value of brightness
int maxAlpha = 100; // Max value of brightness
int alphaDelta = 5; // Delta of brightness between times through the loop
void setup() {
circle.begin();
core.begin();
circle.show(); // Initialize all pixels to ‘off’
core.show(); // Initialize all pixels to ‘off’
}
void loop() {
flip = random(32);
if(flip > 20) {
dir = 1 – dir;
}
// Some example procedures showing how to display to the pixels:
if (dir == 1) {
alpha += alphaDelta;
}
if (dir == 0) {
alpha -= alphaDelta;
}
if (alpha < minAlpha) {
alpha = minAlpha;
dir = 1;
}
if (alpha > maxAlpha) {
alpha = maxAlpha;
dir = 0;
}
// Change the line below to alter the color of the lights
// The numbers represent the Red, Green, and Blue values
// of the lights, as a value between 0(off) and 1(max brightness)
//
// EX:
colorWipe(circle.Color(alpha, 0, alpha/2)); // Pink
// colorWipe(circle.Color(0, 0, alpha)); // Blue
colorWipe2(core.Color(alpha, alpha, alpha)); // Blue
}
// Fill the dots one after the other with a color
void colorWipe(uint32_t c) {
for(uint16_t i=0; i<circle.numPixels(); i++) {
circle.setPixelColor(i, c);
circle.show();
;
}
}
// Fill the dots one after the other with a color
void colorWipe2(uint32_t c) {
for(uint16_t i=0; i<core.numPixels(); i++) {
core.setPixelColor(i, c);
core.show();
;
}
}
Gary Kester
With a link this time
Gary Kester
Hi Gary,
Thats fantastic, thanks for sharing your work.
I’m planning to build some more Christmas lights and I’ve been pondering on a way to use more than one strip/string on individual pins.
This will help a lot.
Spike
Thanks Gary! Awesome!
hans
Thank you for this fast and cool library!
Umberto Giacobbi
Hi Umberto!
Thanks you very much for the compliment! Glad you’re having fun with it as well!
hans
Hello! You have a great website, very fascinating stuff on here! I am an art student looking to do a sculpture project involving light, and I am stuck because I am using Adadfruit’s drum sound sensor code. Of course, all it is is a sound reactive digital 30 Neopixel light using GEMMA MO and Electret Microphone amplifier. I am using varying pixels because they will be wrapped around trees like belts, and whenever someone speaks, it should light up. Problem is I do not want simple bars and rainbow lighting as the code is given, I want something like your last demo the Meteor light or something simpler like a trail of light across the strip. Could you help me customize this code? The project is due next Wednesday (Valentine’s day).
you can read their code from this link
or
Here is the code:
* LED “Color Organ” for Adafruit Trinket and NeoPixel LEDs.
Hardware requirements:
– Adafruit Trinket or Gemma mini microcontroller (ATTiny85).
– Adafruit Electret Microphone Amplifier (ID: 1063)
– Several Neopixels, you can mix and match
o Adafruit Flora RGB Smart Pixels (ID: 1260)
o Adafruit NeoPixel Digital LED strip (ID: 1138)
o Adafruit Neopixel Ring (ID: 1463)
Software requirements:
– Adafruit NeoPixel library
Connections:
– 5 V to mic amp +
– GND to mic amp –
– Analog pinto microphone output (configurable below)
– Digital pin to LED data input (configurable below)
Written by Adafruit Industries. Distributed under the BSD license.
This paragraph must be included in any redistribution.
*/
#include <Adafruit_NeoPixel.h>
#define N_PIXELS 27 // Number of pixels you are using
#define MIC_PIN A1 // Microphone is attached to Trinket GPIO #2/Gemma D2 (A1)
#define LED_PIN 0 // NeoPixel LED strand is connected to GPIO #0 / D0
#define DC_OFFSET 0 // DC offset in mic signal – if unusure, leave 0
#define NOISE 100 // Noise/hum/interference in mic signal
#define SAMPLES 60 // Length of buffer for dynamic level adjustment
#define TOP (N_PIXELS +1) // Allow dot to go slightly off scale
// Comment out the next line if you do not want brightness control or have a Gemma
//#define POT_PIN 3 // if defined, a potentiometer is on GPIO #3 (A3, Trinket only)() {
//memset(vol, 0, sizeof(vol));
memset(vol,0,sizeof(int)*SAMPLES);//Thanks Neil! ‘peak’ dot at top
// if POT_PIN is defined, we have a potentiometer on GPIO #3 on a Trinket
// (Gemma doesn’t have this pin)
uint8_t bright = 255;
#ifdef POT_PIN
bright = analogRead(POT_PIN); // Read pin (0-255) (adjust potentiometer
// to give 0 to Vcc volts
#endif
strip.setBrightness(bright); // Set LED brightness (if POT_PIN at top
// define commented out, will be full)
// Color pixels based on rainbow gradient
for(i=0; i<N_PIXELS; i++) {
if(i >= height)
strip.setPixelColor(i, 0, 0, 0);
else
strip.setPixelColor(i,Wheel(map(i,0,strip.numPixels()-1,30,150)));
}
strip.show(); // Update strip
vol[volCount] = n; // Save sample for dynamic leveling
if(++volCount >= SAMPLES) volCount = 0; // Advance/rollover sample counter
// Get volume range of prior frames
minLvl = maxLvl = vol[0];
for(i=1; i<SAMPLES; i++) {
if(vol[i] < minLvl) minLvl = vol[i];
else if(vol ‘jumpy’);
}
}
Sharon Noordermeer
Thank you so much for putting this lot together an incredible resource. I am trying to work out how to run three of these effects from three different pins. I am building a brain storming hat for a party that has a Cloud which i would like to have the Multi colour sparkle. Then two Tubes with LEDs in that will run the Meteor sequence down to two 16 pixel rings that will Cycle up in colour showing the “charge” in the helmet. I was hoping to add sound and some Other lights in the cloud to strobe to signify Lightning ( but time is not on my side)
. Any help or directions to Previous topics that might help would be greatly appreciated thank you all very much.
Dan Rutter
Hi Dan,
I’d recommend using 3 Arduino’s instead of trying to run 3 different effects on one Arduino.
The code would become quite challenging.
Since you’d want to use something small; check out the Arduino Nano, and if you’re more experienced the ESP8266.
hans
I’m learning about arduino for pixels in trying to build a home theater marquee. I’ve used your code example and got a basic marquee chase working but I’m confused one a couple things. I’m not understanding how to set the speed delay. My brain just isn’t processing the code for it.
I’m also trying to figure out how to use multiple pixels as one, like 2 or 3 pixels count as 1 unit with the units chasing.
Lastly, I’ve seen a video on YouTube with someone doing a similar project and he was able to run 4 or 5 different versions of a chase off 1 board, all switched with a simple button press. Any idea how that might work?
Thanks for any advice you can offer!
Tim
Hi Tim,
apologies for the late response … (I’m in the middle of a move from the US to Europe)
The speed delay basically is the time “consumed” between each step.
See it as: LED1 on, wait x milliseconds, LED1 off, LED2 on, wait x milliseconds, LED2 off, LED3 on, wait x milliseconds, etc.
The higher the number, the slower the chase will be.
I don’t have my equipment near me (it’s in a big container somewhere on the ocean hahah), but I’d look in this part of the code:
I’ve marked the 5th line, in this for-loop you will have to do some coding to make a single LED become “bigger”.
While thinking about this, there maybe a more elegant way to do this … I’d probably make a virtual LED array, populate it as done in this code (so instead of “setPixel”). Then call my own procedure that “translates” the virtual LED to a set of 3 LEDs. This does require some extra work of course.
I have yet to experiment with multiple strands on one board. Libraries like FastLED so support this though, but your loop will become a little more complex since you want to effects to work independently. If they do not need to run independently and you’re OK with all strips doing exactly the same thing, then things become more simple: you can connect all LED strips in parallel (so the Din wire of all strips tied together and connected to the same pin on the Arduino).
hans
I appreciate the response.
I may not have been clear in my first post. I understand what a delay is, just not how to read it within this code. The language is very Greek to me. Not trying to become an expert either but tinkering a bit for a couple projects.
I think what I’m trying to achieve is one block of code with 3-5 different chase-style patterns/colors that can easily be changed with the press of an auxiliary button. I do have some chasing EL wire that I need to control as well and if 1 arduino nano can handle both that would be perfect but if I have to use a second controller it’s not a huge deal.
I will tinker some more and ask if I have anymore questions.
Thank you and safe travels!
Tim
Hi Tim!
Thanks for the safe travels wish! I’ve made it to Europe – now wait another month before my belongings get here. Yikes!
Which of the two theatre chase examples were you looking at?
I don’t mind helping to “un-Greek” the code
hans
Wow! You’re moving to Europe eh Hans … UK by any chance?
Spike
Yeah … I’m moving to The Netherlands … sorry, not the UK. I’d stop by for a beer otherwise
hans
Hello Hans,
Just digging into the project again after having to shelf it for a bit.
I’ve found your posting on combining multiple effects into one string that can then be changed with a SPST switch. Got that working but now Im tweeking the theater chase modes. I’m doing different light timings but still not sure how to adjust the speed delay.
Is it also possible to reverse the direction?
lastly, and maybe this requires all new coding but can the chase be set so all lights are on at a “dim” level and the chase lights are just turned up brighter”.
Any help is appreciated. I unfortunately don’t have the time to invest in learning as much code as possible right now but would like to put some cool lights to good use!
Cheers!
Tim
Hi Tim,
you’ve got quite a few questions there
…
To reverse the TheatreChase, you’ll have to reverse the for-loop, for example, like so:
(I have not tested this, but it seemed the easiest fix)
To have the strand have dimmed lights instead of OFF, you could do this:
I have not tested this one either (play with the value of ChaseBaseBrightness, and you may have to so a “setAll(ChaseBaseBrigthness,ChaseBaseBrigthness,ChaseBaseBrigthness)” before calling the function.
In the second for-loop you could define a color instead as well (instead of 2xChaseBaseBrigthness). If the dimmed color has to match the red,green,blue, then you may have to do a calculation to determine the dimmer value for red, green and blue.
Hope this is what you’re looking for.
hans
Hello again Hans,
About ready to put your awesome code into action and your below help got the “always” on function for the theater chase working.
However I’ve not been able to figure out how to possibly reverse the direction of the theater chase. I compared the code you posted to what I had but didn’t see any differences that changed the actions.
I’m actually working with your full sketch of all functions and picking out the ones that work best for my set-up. I have the button working to change functions but I’m curious if a second button can be added to go backwards through the list?
And I am also hoping to be able to reverse the direction of the RunningLights as until my project is fully built I’m not sure what will look best and currently the Theater Chase runs one direction and the Running Lights go the other!
Thanks for any help as always!
Cheers!
Tim
Hi Tim,
Sorry for the late reply; it took me a little bit to catch up again
Basically what you’d want to do, is have the for-loop count in the opposite direction.
Either by reversing the loop, or by calculating the LED pixel at ShowPixel().
Maybe I’m not awake enough yet … let me try again – I do not have any hardware near by to test.
For RunningLights you could try this;
Apologies if this doesn’t work out right away – after doing so much work on ApplePi-Baker (one of my projects) I’m experiencing a little brain-fog
hans
Hello Hans,
As always, thanks for taking the time to look into this. I will give your code examples a shot.
I was hoping to be able to program the Arduino with a few functions, firstly controlling the LEDs but secondly to control an IR LED performing a few functions of a TV remote. Basically upon powering on, having the Arduino send a Power On signal to the TV and possibly upon main losing power having enough charge built up in a capacitor to fire off a Power Off signal to the TV. I wanted to integrate a 3×4 Matrix keypad in to be able to select the lighting sequences and use a few other commands for the TV like volume and input. I’ve tried asking for some help elsewhere but it seems there’s a lot of expectation for people to learn full programming languages when they only want to figure out a few small things so I very much appreciate that you took the time to write your code and tutorials and continue to provide support to us who keep asking for help.
Keep being awesome!
Tim
Thanks Tim!
Sounds like an interesting project you’re working on!
Sending IR to your TV at startup should not be a big problem (I’ve never done it though). Sending a signal on power loss could be a little more challenging, since the Arduino would need to somehow detect the power loss. I can come up with a few solutions to consider, but I would need to know more about the setup. For example, you could add a relay to the power source of whichever power source you want to monitor. If powered, the relay switches ON, and on power loss it would switch OFF. Your Arduino would be able to detect that. But that’s running ahead of what you’re working with I suppose
hans
Thanks for the great tutorial. Helps a lot when you get started with led stuff.
I would like to run a NeoPixel LED matrix (8×64 pixel) and NeoPixel LED strip (144 LEDs) at the same time off one Arduino.
I can upload the program for running either one just fine. What the best way (code wise) to run both in parallel in a loop? Or do I need a second Arduino?
Cheers,
Rolf
Rolf
Hi Rolf,
thank you for the nice compliment and thank-you note – it’s much appreciated!
As for running two strips at the same time; I know the FastLED library (works with NeoPixel strips/matrix as well) can handle more than one strip at a time. The problem however is to program things in such a way that both are handled in parallel (or very fast in sequence). This may become a little tricky – but it’s not impossible.
I guess it also depends on the complexity of what you’re trying to do and how fast it needs to “move”.
Since Arduino’s get cheaper and cheaper, you may want to consider using 2 instead.
hans
[…]. […]
[…] for everything from simple single color fades and classic Cylon eyes to effects that look like meteors falling from the sky. Seriously! Check out the video after the break. Those chasing lights you see around theater signs? […]
[…]. […]
Thanks so much for this article! I have used it to get started with 2812 LEDs. So much good information.
I have tried to modify the Fire sketch to split a strip in half and make it look like the fire starts in the center and flows out to the ends. My programming skills are not up to the task. Any help would be appreciated!
Thanks!
Barn
Barn Blanken
Hi Barn,
thank you very much for the compliment!
In your case, you could connect the strands in parallel.
For example if each strand is 30 LEDs, then set the LED count to 30.
Connect the 3 wires of both strands together to the Arduino.
Both strands should now give the exact same effect.
Hope this helps.
hans
Thanks for the quick reply!
Yes I considered using two strings but I want to use this as one setting on a string of lights that will be on my Hexacopter. I build a lot of multirotors and airplanes for night flying and I want to add 2812 LEDs to my tool box. Woodie Copter Thread
The plan is for the LED strip to wrap around the craft with the center of the strip on the nose of the craft and the two ends at the back. This will allow for different color patterns and I think the fire would look good coming from the center and down each side. I could even pass it a speed parameter so the flames grew longer as the airspeed increased.
Barn
Barn Blanken
Hi Barn,
That looks like an awesome project!
A hexacopter – Nice!! I just sold my DJO Vision (only quad copter, I know) since I wasn’t using it for a few years now. But; it’s awesome gear to play with (if you’re allowed to use it in your area haha).
Did you want the “2” flames to behave differently? Or is it OK that they behave identical. If identical is OK, then you could place 2 strands (or more) in parallel. If they should behave differently, then coding may become a challenge and using 2 ESP’s or Arduino’s maybe much easier (although I’m aware that it will add unwanted weight).
Keep us posted, I love these kind of projects!
hans | https://www.tweaking4all.com/hardware/arduino/adruino-led-strip-effects/ | CC-MAIN-2021-04 | refinedweb | 27,576 | 78.38 |
08-10-2010 06:13 AM
Hello,
I wonder whether the garbage collector handles cyclic references, or whether I should always be using WeakReferences. For example, would the following code create a cyclic reference?
public class MyClass { private Runnable runnable; public void init() { this.runnable = new Runnable() { public void run() { MyClass.this.doSomething(); } } } void doSomething() {} }
If this code is problematic, how can I fix it?
Thank you.
08-10-2010 08:04 AM
> ... whether the garbage collector handles cyclic references ...
Modern garbage collectors handle cyclic references just fine. And I believe that RIM implementation is pretty good - their Java VM needs to work for days in embeded environment with limited resources.
> would the following code create a cyclic reference?
No.
Once doSomething() is done, runnable object won't have any references to the outer class.
If doSomething() does not exit - well it is not GC question any more
08-11-2010 05:32 AM
@Plato: Do you have any references that document this property? I am not sure, and the `WeakReference` class is still there and not deprecated, which could indicate otherwise.
As for my code, it does maintain a cyclic reference. The runnable object has a reference to the object of the outer class, and the outer class is maintaing a reference to it in the "runnable" variable. This creates a cyclic reference. Think of this runnable as a MenuItem instead, and my point should be clarified.
08-11-2010 08:20 AM
Weak References are very useful, for example for references to things that 'belong' to other people, by using a Weak Reference you don't stop the other person freeing the Object. The fact that they are present is not related to your question about circular references.
I have never seen detailed documentation on the garbage collector, however I would, as Plato suggested, assume that something as obvious as a cyclic reference is catered for by it.
In your case, the Runnable object runnable, is not going to be a candidate for garbage collection until the instance of MyClass is de-referenced, so the fact that there is possible circular reference is irrelevant.
Running <myclass>.init() would result in a new Runnable being created, which because of the cyclic reference, might appear to cause a memory leak. I'm pretty sure that is not the case however, because the runnable in MyClass, only points to the most current Runnable, so the previous one would be a candidate for garbage collection. | http://supportforums.blackberry.com/t5/Java-Development/Does-the-BlackBerry-Garbage-Collector-handle-cyclic-references/m-p/564990 | crawl-003 | refinedweb | 413 | 62.58 |
A convenient command line wrapper around bjoern web server
Project description
bjoern-cli
bjoern-cli is a command line wrapper to serve a Python WSGI app with bjoern server. It exists because the only way to serve an app with bjoern is to import it in your code and configure the entrypoint to launch the server. This way to serve bjoern ties your application code to a webserver implementation and upgrading or changing the server becomes a change in application code.
With
bjoern-cli you can configure your application to expose the WSGI app object and serve it from command line. It also provides a convenient wrappers to selectively use features that are compiled in bjoern and ignore those that aren't.
Installation
If you ship your app in a docker container then the recommended way is to install
bjoern-cli in the container context separate from the application. This makes it easier to upgrade the server or simply swap it out for something inferior.
Alternatively you can also use it as an app dependency. If that is what you want to do — and you really shouldn't be doing it like this — add
bjoern-cli in your
setup.py or
requirements.txt file. If you are using the pathetically slow, pain in the ass tool then put it in
Pipenv file.
pip install bjoern-cli
Usage
Assuming that your application
api is exposed by module
my_app.web, you can start the server with
bjoern-cli --module my_app.web --app api
Following command line parameters are available:
--host host Host name or the IP address to bind with (default: 0.0.0.0) --port port Port number to bind with (default: 8787) --module module Importable python module that exposes the WSGI app (default: None) --app app Name of the app as exposed by the module (default: app) --statsd-enable Expose metrics to statsd (default: False) --statsd-host host Address of the Statsd collector (default: 127.0.0.1) --statsd-port port Port of the Statsd collector (default: 8125) --statsd-ns namespace Statsd metrics namespace (default: bjoern) --statsd-tags tags Comma separated list of tags to expose with metrics (default: [])
Features than can be selectively compiled into bjoern are appropriately indicated in the argument description. If a feature is not available its parameter description is followed by
"Ignored since bjoern is not compiled with this feature".
Caveat
Note that bjoern-cli fetches bjoern from github instead of PyPI. This is necessary at this time because the version of bjoern with Statsd support is not tagged and pulling from github remains the only way to install it.
This also means that bjoern will be compiled when you install
bjoern-cli and you are expected to setup proper feature flags in the installation environment.
If you are installing bjoern-cli in a docker container then adding the following snippet to the Dockerfile should enable statsd and tags support.
ENV BJOERN_WANT_STATSD=true BJOERN_WANT_STATSD_TAGS=true
If you are in a shell then simply run
BJOERN_WANT_STATSD=true BJOERN_WANT_STATSD_TAGS=true pip install bjoern-cli
You can consult setup.py to know the version of bjoern that will be installed.
Project details
Release history Release notifications | RSS feed
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/bjoern-cli/ | CC-MAIN-2021-21 | refinedweb | 551 | 50.46 |
Johns Hopkins University
Analysis of an
Electronic Voting System
By
Tadayoshi Kohno
Information Security Institute
Johns Hopkins University
Yoshi @cs.jhu.edu
Adam
Stubblefield
Information Security Institute
Johns Hopkins University
Astubble @cs.jhu.edu
Aviel D.
Rubin
Information Security Institute
Johns Hopkins University
Rubin @cs.jhu.edu
Dan S.
Wallach
Department of Computer Science
Rice University
Dwallach @cs.rice.edu
July 23, 2003
CONTENTS
Abstract
1 Introduction
1.1 Electronic voting systems
1.2 “Certified” DRE systems
1.3 Summary of results
2 System
overview
Table 1: This table summarizes some of the more important attacks on the system.
IMAGE…
2.1 Details
3
Smartcards
3.1 Homebrew smartcards
3.1.1 Multiple voting
3.1.2 Administrator and ender cards
3.2 Unprotected PINs
3.3 Terminal-to-card authentication
4 Data storage
4.1 Data storage overview
4.2 System configuration
4.3 Ballot definition
4.4 Votes and audit logs
5 Communicating
with the outside world
5.1 Tampering with ballot definitions
5.2 Preventing the start of an election
5.3 Tampering with election results
5.4 Attacking the voting terminals directly
6
Software engineering
6.1 Code Legacy
6.2 Coding style
6.3 Coding process
6.4 Code completeness and correctness
7
Conclusions
Acknowledgments
References
SCOOP EDITOR'S NOTE - THIS PAGE IS AN HTML VERSION OF:
Check the original for correct formatting of code sections..[1].
[1 ]
-6&item_id=433030
1 Introduction
The essence of democracy is that everyone accepts the results of elections, even when they lose them.
Elections allow the populace to choose their representatives and express their preferences for how they will be governed. Naturally, the integrity of the election process is fundamental to the integrity of democracy itself. And, unsurprisingly, history is littered with examples of elections being manipulated in order to influence their outcome.
The design of a “good” voting system, whether electronic or using traditional paper ballots or mechanical devices, must be robust against a wide variety of potentially fraudulent behavior.. Another important consideration, as shown by the so-called “butterfly ballots” in the Florida 2000 presidential election, is the importance of human factors. A voting system must be comprehensible to and usable by the entire voting population, regardless of age, infirmity, or disability. Providing accessibility to such a diverse population is an important engineering problem and one where, if other security is done well, electronic voting could be a great improvement over current paper systems. Flaws in any of these aspects of a voting system, however, can lead to indecisive or incorrect election results.
1.1 Electronic voting systems
There have been several studies on using computer technologies to improve elections [Cal01, Cal00, Mer00, Nat01, Rub02]. These studies caution about the risks of moving too quickly to adopt electronic voting machines because of the software engineering challenges, insider threats, network vulnerabilities, and the challenges of auditing.
As a result of the Florida 2000 presidential election, the inadequacies of widely-used punch card voting systems have become well understood by the general population. or a smartcard or some other token that allows them to approach a voting terminal, enter the PIN or smartcard,.
The most fundamental problem with such a voting system is that the entire election hinges on the correctness, robustness, and security of the software within the voting terminal. Should that code have securityrelevant flaws, they might be exploitable either by unscrupulous voters or by malevolent.
The only known solution to this problem is to introduce a “voter-verifiable audit trail.” [DMNW03].
Most commonly, this is achieved by adding a printer to the voting terminal. When the voter finishes selecting candidates, a ballot is printed on paper and presented to the voter. If the printed ballot reflects the voter’s intent, the ballot is saved for future reference. If not, the ballot is mechanically destroyed. Using this “Mercuri method,” [Mer00] the tally of the paper ballots takes precedence over any electronic tallies. As
-->PAGE 2
a result, the correctness of the voting terminal software no longer matters; either a voting terminal prints correct ballots or it is taken out of service.
1.2 “Certified” DRE systems
Many government entities have adopted paperless DRE systems without appearing to have critically questioned the security claims made by the systems’ vendors. Until recently, such systems have been dubiously “certified” for use without any public release of the analyses behind these certifications, much less any release of the source code that might allow independent third parties to perform their own analyses. Some vendors have claimed “security through obscurity” as a defense, despite the security community’s universally held belief in the inadequacy of obscurity to provide meaningful protection.
“Security through obscurity” is a long-rejected theory that systems can be made more secure by simply hiding the security mechanisms from public view. While this theory has some validity in situations where the need for security is not great — hiding a spare key to a liquor cabinet just out of sight of small children — the theory has been soundly rejected as a means of serious security [Ker83]. This is because it has the twin faults of not providing serious security from real attackers, who can easily overcome minimal security measures, and of limiting public and general security oversight of the system, which has proven to be the best method for creating and maintaining a truly secure system [Sch00].
Indeed, source code that appears to correspond to a version of Diebold’s voting system appeared recently on the Internet. This appearance, announced by Bev Harris and discussed in her book, Black Box Voting [Har03], gives us a unique opportunity to analyze a widely used, paperless DRE system and evaluate the manufacturer’s security claims.
To the best of our knowledge, the code (hereafter referred to as the “Diebold code”) was discovered by others on a publicly available Diebold ftp site in January, 2003. It has since been copied to other sites around the world and its release has been the subject of numerous press reports. To the authors’ knowledge, Diebold has raised no objection to the broad publication and republication of the code to date. Jones discusses the origins of this code in extensive detail [Jon03].
The security of Diebold’s voting system is of growing concern as on July 21, 2003, the company finalized an agreement for up to $55.6 million to deliver touch-screen voting technology to the state of Maryland. The contract includes about 11,000 Diebold touch-screen voting systems. Diebold voting systems were also used in state-wide elections in Georgia in 2002.
We only inspected unencrypted source code that we believe was used in Diebold’s AccuVote-TS voting terminal [Die03] (the “AVTSCE” tree in the CVS archive). We have not independently verified the current or past use of the code by Diebold or that the code we analyzed is actually Diebold code, although as explained further in Section 6.1, the copyright notices and code legacy information in the code itself are consistent with publicly available systems offered by Diebold and a company it acquired in 2001, Global Election Systems.
Also, the code itself built and worked as an election system consistent with Diebold’s public descriptions of its system. We concluded that even if it turned out that the code was not part of a current or past Diebold voting system, analysis of it would be useful to the broader public debate around electronic voting systems security and assist election officials and members of the public in their consideration of not only Diebold systems, but other electronic voting systems currently being marketed nationwide and around the world. We did not have source code to Diebold’s GEMS back-end election management system.
Furthermore, we only analyzed source code that could be directly observed and copied from the CVS software archive without further effort. A large amount of the other data made publicly available was protected by very weak compression/encryption software known as PKZip, which requires a password for
-->PAGE 3
access to the underlying work. PKZip passwords are relatively easy to avoid, and programs for locating passwords for PKZip files are readily available online. Moreover, passwords that others have located for these files have been freely available online for some time. Nonetheless, we decided to limit our research to only the files that were publicly available without any further effort, in part due to concerns about possible liability under the anti-circumvention provisions of the Digital Millennium Copyright Act.
Even with this restricted view of the source code, we discovered significant and wide-reaching security vulnerabilities in the AccuVote-TS voting terminal. Most notably, voters can easily program their own smartcards to simulate the behavior of valid smartcards used in the election. With such homebrew cards, a voter can cast multiple ballots without leaving any trace. A voter can also perform actions that normally require administrative privileges, including viewing partial results and terminating the election early. Similar undesirable modifications could be made by malevolent poll workers (or even maintenance staff) with access to the voting terminals before the start of an election..
As part of our analysis, we considered both the specific ways that the code uses cryptographic techniques and the general software engineering quality of its construction. Neither provides us with any confidence of the system’s correctness. Cryptography, when used at all, is used incorrectly. In many places where cryptography would seem obvious and necessary, none is used. More generally, we see no evidence of rigorous software engineering discipline. Comments in the code and the revision change logs indicate the engineers were aware of areas in the system that needed improvement, though these comments only address specific problems with the code and not with the design itself. We also saw no evidence of any changecontrol process that might restrict a developer’s ability to insert arbitrary patches to the code. Absent such processes, a malevolent developer could easily make changes to the code that would create vulnerabilities to be later exploited on Election Day. We also note that the software is written entirely in C++. When programming in an unsafe language like C++, programmers must exercise tight discipline to prevent their programs from being vulnerable to buffer overflow attacks and other weaknesses. Indeed, buffer overflows caused real problems for AccuVote-TS systems in real elections.[2]
2 System overview
Although the Diebold code is designed to run on a DRE device (an example of which is shown in Figure 1), one can run it on a regular Microsoft Windows computer (during our experiments we compiled and ran the code on a Windows 2000 PC).
In the following we describe the process for setting up and running an election using the Diebold system.
Although we know exactly how the code works from our analysis, we must still make some assumptions about the external processes at election sites. In all such cases, our assumptions are based on the way the Diebold code works, and we believe that our assumptions are reasonable. There may, however, be additional administrative procedures in place that are not indicated by the source code. We first describe the architecture at a very high level, and then, in Section 2.1 we present an overview of the code. Since the Diebold code can be run both on DRE devices and PCs, we shall refer to a device running the vote collection software as a voting terminal.
SETTING UP. Before an election takes place, one of the first things the election officials must do is specify the political offices and issues to be decided by the voters along with the candidates and their party affiliations.
[2] (page 48)
-->PAGE 4
Table 1: This table summarizes some of the more important attacks on the system.
( See PDF File for formatting of this table…)
Voter Poll Worker Poll Worker Internet Provider OS Voting Section
(with forged (with access to (with access to (with access to Developer Device
smartcard) storage media) network traffic) to network traffic) Developer
Vote multiple times 3.1.1
Vote multiple times ² ² ² 3.1.1
using forged smartcard
Access administrative functions ² ² ² ² 3.1.2
or close polling station
Modify system configuration ² ² ² 4.2
Impersonate legitimate voting ² ² ² ² ² 4.3
machine to tallying authority
Modify ballot definition ² ² ² ² ² 4.3 and 5.1
(e.g., party affiliation)
Cause votes to be miscounted ² ² ² ² ² 4.3 and 5.1
by tampering with configuration
Tamper with audit logs ² ² ² 4.4
Create, delete, and modify votes ² ² ² 4.4
on device
Link votes to voters ² ² ² 4.4
Delay the start of an election ² ² ² ² ² 5.2
Tamper with election results ² ² ² ² ² 5.2
Insert backdoors into code ² ² 6.3
Table 1: This table summarizes some of the more important attacks on the system.
-->PAGE 5
IMAGE NOT INCLUDED IN THIS FILE… SEE PDF VERSION
Figure 1: A Diebold DRE Voting Machine (photo from). Note the smartcard reader in the lower-right hand corner.
(Scoop Editor's Note.. a
Diebold machine can also be seen here....)
Variations on the ballot can be presented to voters based on their party affiliations. We call this data a ballot definition. In the Diebold system, a ballot definition is encoded as the file election.edb and stored on a back-end server.
Shortly prior to the election, the voting terminals must be installed at each voting location. In common usage, we believe the voting terminals will be distributed without a ballot definition pre-installed. Instead, a governmental entity using Diebold voting terminals has a variety of choices in how to distribute the ballot definitions. They may be distributed using removable media, such as floppy disks or storage cards. They may also be transmitted over the Internet or a dial-up connection. This provides additional flexibility to the election administrator in the event of last-minute changes to the ballot.
THE ELECTION. Once the voting terminal is initialized with the ballot definitions, and the election begins, voters are allowed to cast their votes. To get started, however, the voter must have a voter card. The voter card is a memory card or smartcard; i.e., it is a credit-card sized plastic card with a computer chip on it that can store data and, in the case of the smartcard, perform computation. We do not know exactly how the voter gets his voter card. It could be sent in the mail with information about where to vote, or it could be given out at the voting site on the day of the election. To understand the voting software itself, however, we do not need to know what process is used to distribute the cards to voters.
The voter takes the voter card and inserts it into a smartcard reader attached to the voting terminal. The terminal checks that the smartcard in its reader is a voter card and, if it is, presents a ballot to the voter on the terminal screen. The actual ballot the voter sees may depend on the voter’s political party, which is encoded on the voter card. If a ballot cannot be found for the voter’s party, the voter is given a nonpartisan ballot.
At this point, the voter interacts with the voting terminal, touching the appropriate boxes on the screen for his or her desired candidates. Headphones are available for visually-impaired voters to privately interact with the terminal. Before the ballots are committed to storage in the terminal, the voter is given a final chance to review his or her selections. If the voter confirms this, the vote is recorded on the voting terminal and the voter card is “canceled.” This latter step is intended to prevent the voter from voting again with the same card. After the voter finishes voting, the terminal is ready for another voter to use.
REPORTING THE RESULTS. A poll worker ends the election process by inserting an administrator card or an ender card (a special card that can only be used to end the election) into the voting terminal. Upon detecting the presence of such a card (and, in the case of the administrator card, checking a PIN entered by the card user), the poll worker is asked to confirm that the election is finished. If the poll worker agrees, then the voting terminal enters the post-election stage and can transmit its results to the back-end server.
As we have only analyzed the code for the Diebold voting terminal, we do not know exactly how the back-end server tabulates the final results it gathers from the individual terminals. Obviously, it collects all the votes from the various voting terminals. We are unable to verify that there are checks to ensure, for example, that there are no more votes collected than people who are registered at or have entered any given polling location.
We now describe the Diebold system in more detail, making explicit references to the relevant portions of the code. The voting terminal is implemented in the directory BallotStation/, but uses libraries in the supporting directories Ballot/, DES/, DiagMode/, Shared/, TSElection/, Utilities/, and VoterCard/.
The method CBallotStationApp::DoRun() is the main loop for the voting terminal software.
The DoRun() method begins by invoking CBallotStationApp::LoadRegistry(), which loads information about the voting terminal from the registry (the registry keys are stored under HKEY_LOCAL_ 7 MACHINE\Software\GlobalElectionSystems\AccuVote-TS4) . If the program fails to load the registry information, it believes that it is uninitialized and therefore creates a new instance of the CTSRegistryDlg class that asks the administrator to set up the machine for the first time. The administrator chooses, among other things, the COM port to use with the smartcard reader, the directory locations to store files, and the polling location identifier. The CBallotStationApp::DoRun() method then checks for the presence of a smartcard reader and, if none found, gives the administrator the option to interact with the CTSRegistryDlg again.
The DoRun() method then enters a while loop that iterates until the software is shut down. The first thing DoRun() does in this loop is check for the presence of some removable media on which to store election results and ballot configurations (a floppy under Windows or a removable storage card on a Windows CE device). It then tries to open the election configuration file election.edb. If it fails to open the configuration file, the program enters the CTSElectionDoc::ES_NOELECTION state and invokes CBallotStationApp::Download(), which creates an instance of CTransferElecDlg to download the configuration file. To do the download, the terminal connects to a back-end server using either the Internet or a dial-up connection. The program then enters the CTSElectionDoc::ES_PREELECT state, invokes the CBallotStationApp::PreElect() method, which in turn creates an instance of CPreElectDlg. The administrator can then decide to start the election, in which case the method CPreElectDlg::OnSetForElection() sets the state of the terminal to CTSElectionDoc::ES_ ELECTION.
Returning to the while loop in CBallotStationApp::DoRun(), now that the machine is in the state CTSElectionDoc::ES_ELECTION, the DoRun() method invokes CBallotStationApp:: Election(), which creates an instance of CVoteDlg. When a card in inserted into the reader, the reader checks to see if the card is a voter card, administrator card, or ender card. If it is an ender card, or if it is an administrator card and if the user enters the correct PIN, the CVoteDlg ends and the user is asked whether he wishes to terminate the election and, if so, the state of the terminal is set to CTSElectionDoc:: ES_POSTELECT. If the user entered a voter card, then DoVote() is invoked (here DoVote() is an actual function; it does not belong to any class). The DoVote() function finds the appropriate ballot for the user’s voter group or, if none exists, opens the nonpartisan ballot (recall that the system is designed to allow voters to vote by group or party). It then creates an instance of CBallotDlg to display the ballot and collect the votes.
We recall that if, during the election process, someone inserted an administrator or ender card into the terminal and choses to end the election, the system would enter the CTSElectionDoc::ES_POSTELECT state. At this point the voting terminal would offer the ability to upload the election results to some back-end server for final tabulation. The actual transfer of results is handled by the CTransferResultsDlg:: OnTransfer() method.
We will present more details about the Diebold system in the following sections.
While it is true that one can design secure systems around the use of smartcards, simply the use of smartcards in a system does not imply that the system is secure. The system must use the smartcards in an intelligent and security-conscious way. Unfortunately, the Diebold system’s use of smartcards provides very little (if any) additional security and, in fact, opens the system to several attacks.
-->PAGE 8
Upon reviewing the Diebold code, we observed that the smartcards do not perform any cryptographic operations.
3 For example, authentication of the terminal to the smartcard is done “the old-fashioned way:” the terminal sends a cleartext (i.e., unencrypted) 8-byte password to the card and, if the password is correct, the card believes that it is talking to a legitimate voting terminal. Unfortunately, this method of authentication is insecure: an attacker can easily learn the 8-byte password used to authenticate the terminal to the card (see Section 3.3), and thereby communicate with a legitimate smartcard using his own smartcard reader.
Furthermore, there is no authentication of the smartcard to the device. This means that nothing prevents an attacker from using his own homebrew smartcard in a voting terminal. One might naturally wonder how easy it would be for an attacker to make such a homebrew smartcard. First, we note that many smartcard vendors sell cards that can be programmed by the user. An attacker who knows the protocol spoken by the voting terminal to the legitimate smartcard could easily implement a homebrew card that speaks the same protocol. Even if the attacker does not a priori know the protocol, an attacker could easily learn enough about the protocol to create new voter cards by attaching a “wiretap” device between the voting terminal and a legitimate smartcard and observing the communicated messages. The parts for building such a device are readily available and, given the privacy of voting booths, might be unlikely to be noticed by poll workers.
An attacker might not even need to use a wiretap to see the protocol in use. Smartcards generally use the ISO 7816 standard smartcard message formats. Likewise, the important data on the legitimate voting card is stored as a file (named 0x3D40 — smartcard files have numbers instead of textual file name) that can be easily read by a portable smartcard reader. Again, given the privacy of voting booths, an attacker using such a card reader would be unlikely to be noticed. Given the ease with which an attacker can interact with legitimate smartcards, plus the weak password-based authentication scheme (see Section 3.3), an attacker could quickly gain enough insight to create homebrew voting cards, perhaps quickly enough to be able to use such homebrew cards during the same election day.
The only impediment to the mass production of homebrew smartcards is that each voting terminal will make sure that the smartcard has encoded in it the correct m_ElectionKey, m_VCenter, and m_DLVersion (see DoVote() in BallotStation/Vote.cpp). The m_ElectionKey and m_ DLVersion are likely the same for all locations and, furthermore, for backward-compatibility purposes it is possible to use a card with m_ElectionKey and m_DLVersion undefined. The m_VCenter value could be learned on a per-location-basis by interacting with legitimate smartcards, from an insider, or from inferences based on the m_VCenter values observed at other polling locations.
It is worth pointing out that both the smartcards and readers supported by the code are available commercially over the Internet in small quantities. The smartcards, model number CLXSU004KC0, are available from CardLogix4, where $33.50 buys ten cards. General purpose CyberFlex JavaCards from Schlumberger cost $110 for five cards5. Smartcard reader/writers are available in a variety of models for under $100 from many vendors.
In the following two subsections we illustrate what an attacker could accomplish using homebrew smartcards in voting terminals running the Diebold code.
[3] This, in an of itself, is an immediate red-flag. One of the biggest advantages of smartcards over classic magnetic-stripe cards is the smartcard’s ability to perform cryptographic operations internally with physically protected keys. Since the smartcards in the Diebold system do not perform any cryptographic operations, they effectively provide no more security than traditional magneticstripe cards.
[4 ]
[5]
-->PAGE 9
In the Diebold system, a voter begins the voting process by inserting a smartcard into the voting terminal.
Upon checking that the card is “active,” the voting terminal collects the user’s vote and then deactivates the user’s card (the deactivation actually occurs by changing the card’s type, which is stored as an 8-bit byte on the card, from VOTER_CARD (0x01) to CANCELED_CARD (0x08)). Since an adversary can make perfectly valid smartcards, the adversary could bring a stack of active cards to the voting booth. Doing so gives the adversary the ability to vote multiple times. More simply, instead of bringing multiple cards to the voting booth, the adversary could program a smartcard to ignore the voting terminal’s deactivation command. Such an adversary could use one card to vote multiple times.
Will the adversary’s multiple-votes be detected by the voting system? To answer this question, we must first consider what information is encoded on the voter cards on a per-voter basis. The only per-voter information is a “voter serial number” (m_VoterSN in the CVoterInfo class). Because of the way the Diebold system works, m_VoterSN is only recorded by the voting terminal if the voter decides not to place a vote (as noted in the comments in TSElection/Results.cpp, this field is recorded for uncounted votes for backward compatibility reasons). It is important to note that if a voter decides to cancel his or her vote, the voter will have the opportunity to vote again using that same card (and, after the vote has been cast, m_VoterSN will not be recorded).
Can the back-end tabulation system detect multiple-vote casting? If we assume the number of collected votes becomes greater than the number of people who showed up to vote, and if the polling locations keep accurate counts of the number of people who show up to vote, then the back-end system, if designed properly, should be able to detect the existence of counterfeit votes. However, because m_VoterSN is only stored for those who did not vote, there will be no way for the tabulating system to count the true number of voters or distinguish the real votes from the counterfeit votes. This would cast serious doubt on the validity of the election results. We point out, however, that we only analyzed the voting terminal’s code; we do not know whether such checks are performed in the actual back-end tabulating system.
3.1.2 Administrator and ender cards
As noted in Section 2, in addition to the voter cards that users use when they vote, there are also administrator cards and ender cards. These cards have special purposes in this system. Namely, the administrator cards give the possessor the ability to access administrative functionality (namely, the administrative dialog BallotStation/AdminDlg.cpp), and both types of cards allow the possessor to end the election (hence the term “ender card”).
Just as an adversary can manufacture his or her own voter cards, an adversary can manufacture his or her own administrator and ender cards (administrator cards have an easily-circumventable PIN, which we will discuss in Section 3.2). This attack is easiest if the attacker has knowledge of the Diebold code or can interact with a legitimate administrator or ender card. However, an attacker without knowledge of the innerworkings of the Diebold system and without the ability to interact directly with a legitimate administrator or ender card may have a difficult time producing a homebrew administrator or ender card since the attacker would not know what distinguishes an administrator or ender card from a normal voter card. (The distinction is that, for a voter card m_CardType is set to 0x01, for an ender card m_CardType is set to 0x02, and for an administrator card m_CardType is set to 0x04.) As one might expect, an adversary in possession of such illicit cards has further attack options against the Diebold system. Using a homebrew administrator card, a poll worker, who might not otherwise have access to the administrator functions of the Diebold system but who does have access to the voting machines before and after the elections, could gain access to the administrator controls. If a malicious voter entered an administrator or ender card into the voting device instead of the normal voter card, then the voter would be
-->PAGE 10
able to terminate the election and, if the card is an administrator card, gain access to additional administrative controls.
The use of administrator or ender cards prior to the completion of the actual election represents an interesting denial-of-service attack. Once “ended,” the voting terminal will no longer accept new voters (see CVoteDlg::OnCardIn()) until the terminal is somehow reset. Such an attack, if mounted simultaneously by multiple people, could shut down a polling place. If a polling place is in a precinct considered to favor one candidate over another, attacking that specific polling place could benefit the less-favored candidate.
Even if the poll workers were later able to resurrect the systems, the attack might succeed in deterring a large number of potential voters from voting (e.g., if the attack was performed over the lunch hour). If such an attack was mounted, one might think the attackers would be identified and caught. We note that many governmental entities do not require identification to be presented by a voter, instead allowing for “provisional” ballots to be cast. By the time the poll workers realize that one of their voting terminals has been disabled, the perpetrator may have long-since left the scene.
When a user enters an administrator card into a voting terminal, the voting terminal asks the user to enter a 4-digit PIN. If the correct PIN is entered, the user is given access to the administrative controls.
Upon looking more closely at this administrator authentication process, however, we see that there is a flaw with the way the PINs are verified. When the terminal and the smartcard first begin communicating, the PIN value stored on the card is sent in cleartext from the card to the voting terminal. Then, when the user enters the PIN into the terminal, it is compared with the PIN that the smartcard sent (CPinDlg::OnOK()).
If these values are equal, the system accepts the PIN. Herein lies the flaw with this design: any person with a smartcard reader can easily extract the PIN from an administrator card. The adversary doesn’t even need to fully understand the protocol between the terminal and the device: if the response from the card is n bytes long, the attacker who correctly guesses that the PIN is sent in the clear would only have to try n¡3 possible PINs, rather than 10,000. This means that the PINs are easily circumventable. Of course, if the adversary knows the protocol between the card and the device, an adversary could just make his own administrator card, using any desired PIN (Section 3.1.2).
3.3 Terminal-to-card authentication
Let us now consider how the terminal authenticates to the card in more detail (note that this is different from the Administrator PIN; here the terminal is being authenticated rather than the user). The relevant code from VoterCard/CLXSmartCard.cpp is listed below. The code is slightly modified for illustrative purposes, but the developers’ comments have been left intact.
SMC_ERROR CCLXSmartCard::Open(CCardReader* pReader)
{
... [removed code] ...
// Now initiate access to the card
// If failed to access the file then have unknown card
if (SelectFile(0x3d40) != SMC_OK)
st = SMC_UNKNOWNCARD;
// Else if our password works then all done
else if (Verify(0x80, 8, {0xed, 0x0a, 0xed, 0x0a, 0xed, 0x0a, 0xed, 0x0a})
== SMC_OK)
st = SMC_OK;
// Else if manufactures password works then try to change password
else if(Verify(0x80, 8, {0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08})
-->PAGE 11
== SMC_OK) {
st = ChangeCode(8, {0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08},
8, {0xed, 0x0a, 0xed, 0x0a, 0xed, 0x0a, 0xed, 0x0a});
// Else have a bad card
} else
st = SMC_BADCARD;
return st;
}
In the above code, the SelectFile(0x3d40) command sends the bytes 0x00, 0xA4, 0x00, 0x00, 0x02, 0x3D, 0x40, 0x00 to the smartcard in cleartext; this is the ISO 7816 smartcard command for selecting a file on the card (0x3D40 in this case). If passwd is a sequence of 8 bytes, the Verify(0x80, 8,passwd) command sends the bytes 0x00, 0x20 0x00, 0x80, 0x08, passwd[0], passwd[1], . . . , passwd[7], 0x00 to the smartcard in cleartext.
There are several issues with the above code. First, hard-coding passwords in C++ files is generally a poor design choice. We will discuss coding practices in more detail in Section 6, but we summarize some issues here. Hard-coding passwords into C++ files suggests a lack of key and password management. Furthermore, even if the developers assumed that the passwords would be manually changed and the software recompiled on a per-election basis, it would be very easy for someone to forget to change the constants in VoterCard/CLXSmartCard.cpp. (Recompiling on a per-election basis may also be a concern, since good software engineering practices would dictate additional testing and certification if the code were to be recompiled for each election.) The above issues would only be a concern if the authentication method were otherwise secure. Unfortunately, it is not. Since the password is sent in the clear from the terminal to the card, an attacker who puts a fake card into the terminal and records the command from the terminal will be able to learn the password (and file name) and then re-use that password with real cards. An adversary with knowledge of this password could then create counterfeit voting cards. As we have already discussed (see Section 3.1.1), this can allow the adversary to cast multiple votes, among other attacks. Hence, the authentication of the voting terminal to the smartcards is insecure. We find this particularly surprising because modern smartcard designs allow cryptographic operations to be performed directly on the smartcard, making it possible to create systems that are not as easily vulnerable to security breaches.
Furthermore, note the control flow in the above code-snippet. If the password chosen by the designers of the system (“\xED\x0A\xED\x0A\xED\x0A\xED\x0A”) does not work, then CCLXSmartCard:: Open() uses the smartcard manufacturer’s default password6 of “\x00\x01\x02\x03\x04\x05\ x06\x07.” One issue with this is that it implies that sometimes the system is used with un-initialized smartcards. This means that an attacker might not even need to figure out the system’s password in order to be able to authenticate to the cards. As we noted in Section 3.1, some smartcards allow a user to get a listing of all the files on a card. If the system uses such a card and also uses the manufacturer’s default password of \x00\x01\x02\x03\x04\x05\x06\x07, then an attacker, even without any knowledge of the source code and without the ability to intercept the connection between a legitimate card and a voting terminal, but with access to a legitimate voter card, will still be able to learn enough about the smartcards to be able to create counterfeit voter cards.7
[6]Many smartcards are shipped with default passwords.
[7] Making homebrew cards this way is somewhat risky, as the attacker must make assumptions about the system. In particular, the attacker is assuming that his or her counterfeit cards would not be detected by the voting terminals. Without access to the source code, the attacker would never know, without testing, whether it was truly safe to attack a voting terminal.
-->PAGE 12
4 Data storage
While the data stored internally on each voting terminal is not as accessible to an attacker as the voting system’s smartcards, exploiting such information presents a powerful attack vector, especially for an election insider. In this section we outline the data storage available to each terminal and then detail how each distinct type of data is stored.
4.1 Data storage overview
Each voting terminal has two distinct types of internal data storage. A main (or system) storage area contains the terminal’s operating system, program executables, static data files such as fonts, and system configuration information, as well as backup copies of dynamic data files such as the voting records and audit logs.
Each terminal also contains a removable storage device that is used to store the primary copies of these dynamic data files. When the terminal is running a standard copy of Windows (e.g., Windows 2000) the removable storage area is the first floppy drive; when the terminal is running Windows CE the removable storage area is a removable storage card. Storing the dynamic data on two distinct devices is advantageous for both reliability and security: if either of the two storage mediums fails, data can still be recovered from the copy.
Unfortunately, under Windows CE, which we believe is used in commercial Diebold voting terminals, the existence of the removable storage device is not enforced properly. Unlike other versions of Windows, removable storage cards are mounted as subdirectories under CE. When the voting software wants to know if a storage card is inserted, it simply checks to see if the Storage Card subdirectory exists in the filesystem’s root directory. While this is the default name for a mounted storage device, it is also a perfectly legitimate directory name for a directory in the main storage area. Thus, if such a directory exists, the terminal can be fooled into using the same storage device for all of the data.8 This would reduce the amount of redundancy in the voting system and would increase the chances that a hardware fault could cause recorded votes to be lost.
The majority of the system configuration information for each terminal is stored in the Windows registry under HKEY_LOCAL_MACHINE\Software\GlobalElectionSystems\AccuVote-TS4 . This includes both identification information such as the terminal’s serial number and more traditional configuration information such as the COM port that the smartcard reader is attached to. All of the configuration information is stored in the clear, without any form of integrity protection. Thus, all an adversary must do is modify the system registry to trick a given voting terminal into effectively impersonating any other voting terminal. It is unclear how the tallying authority would deal with results from two different voting terminals with the same voting ID — at the very least human intervention to resolve the conflict would probably be required.
The Federal Election Commission draft standard9 requires each terminal to keep track of the total number of votes that have ever been cast on it — the “Protective Counter.” This counter is used to provide yet another method for ensuring that the number of votes cast on each terminal is correct. However, as the following code from Utilities/machine.cpp shows, the counter is simply stored as an integer in the file system.bin in the terminal’s system directory (error handling code has been removed for clarity):
[8]This situation can be easily corrected by checking for the FILE ATTRIBUTE TEMPORARY attribute on the directory as described in
[9]
-->PAGE 13
long GetProtectedCounter()
{
DWORD protectedCounter = 0;
CString filename = ::GetSysDir();
filename += _T("system.bin");
CFile file;
file.Open(filename, CFile::modeRead | CFile::modeCreate |
CFile::modeNoTruncate);
file.Read(&protectedCounter, sizeof(protectedCounter));
file.Close();
return protectedCounter;
}
By modifying this counter, an adversary could cast doubt on an election by creating a discrepancy between the number of votes cast on a given terminal and the number of votes that are tallied in the election. While the current method of implementing the counter is totally insecure, even a cryptographic checksum would not be enough to protect the counter; an adversary with the ability to modify and view the counter would still be able to roll it back to a previous state. In fact, the only solution that would work would be to implement the protective counter in a tamper-resistant hardware token, requiring modifications to the physical voting terminal hardware.
The “ballot definition” for each election contains everything from the background color of the screen to the PPP username and password to use when reporting the results. This data is not encrypted or checksummed (cryptographically or otherwise) and so can be easily modified by any attacker with physical access to the file. While many attacks, such as changing the party affiliation of a candidate, would be noticed by some voters, many more subtle attacks are possible. By simply changing the order of the candidates as they appear in the ballot definition, the results file will change accordingly. However, the candidate information itself is not stored in the results file. The file merely tracks that candidate 1 got so many votes and candidate 2 got so many other votes. If an attacker reordered the candidates on the ballot definition, voters would unwittingly cast their ballots for the wrong candidate. As with denial-of-service attacks (see Section 3.1.2), ballot reordering attacks would be particularly effective in polling locations known to be heavily partisan.
Even without modifying the ballot definition, an attacker can gain almost enough information to impersonate the voting terminal to the back-end server. The terminal’s voting center ID, PPP dial-in number, username, password and the IP address of the back-end server are all available in the clear (these are parsed into a CElectionHeaderItem in TSElection\TSElectionObj.cpp). Assuming an attacker is able to guess or create a voting terminal ID, he would be able to transmit fraudulent vote reports to the backend server by dialing in from his own computer. While both the paper trail and data stored on legitimate terminals could be used to compensate for this attack after the fact, it could, at the very least, delay the election results. (The PPP number, username, password, and IP address of the back-end server are also stored in the registry HKEY_LOCAL_MACHINE\Software\GlobalElectionSystems\AccuVote-TS4\ TransferParams. Since the ballot definition may be transported on portable memory cards or floppy disks, the ballot definition may perhaps be easier to obtain from this distribution media rather than from the voting terminal’s internal data storage.) We will return to some of these points in Section 5.1, where we show that modifying and viewing ballot definition files does not always require physical access to the terminals on which they are stored.
-->PAGE 14
Unlike the other data stored on the voting terminal, both the vote records and the audit logs are encrypted and checksummed before being written to the storage device. Unfortunately, neither the encrypting nor the checksumming is done securely.
All of the data on a storage device is encrypted using a single, hardcoded DES [NBS77] key: #define DESKEY ((des_key*)"F2654hD4") Note that this value is not a hex representation of a key. Instead, the bytes in the string “F2654hD4” are fed directly into the DES key scheduler. If the same binary is used on every voting terminal, an attacker with access to the source code, or even to a single binary image, could learn the key, and thus read and modify voting and auditing records. Even if proper key management were to be implemented, many problems would still remain. First, DES keys can be recovered by brute force in a very short time period [Gil98]. DES should be replaced with either triple-DES [Sch96] or, preferably, AES [DJ02]. Second, DES is being used in CBC mode which requires an initialization vector to ensure its security. The implementation here always uses zero for its IV. This is illustrated by the call to DesCBCEncrypt in TSElection/RecordFile.cpp; since the second to last argument is NULL, DesCBCEncrypt will use the all-zero IV.
DesCBCEncrypt((des_c_block*)tmp, (des_c_block*)record.m_Data, totalSize, DESKEY, NULL, DES_ENCRYPT); This allows an attacker to mount a variety of cryptanalytic attacks on the data. To correctly implement CBC mode, a source of “strong” random numbers must be used to generate a fresh IV for each encryption [BDJR97]. Suitably strong random numbers can be derived from many different sources, ranging from custom hardware through observation of user behavior. (Jones reports that the vendor may have been aware of this design flaw in their code for several years [Jon01, Jon03]. We see no evidence that this design flaw was ever addressed.) Before being encrypted, a 16-bit cyclic redundancy check (CRC) of the plaintext data is computed.
This CRC is then stored along with the ciphertext in the file and verified whenever the data is decrypted and read. This process in handled by the ReadRecord and WriteRecord functions in TSElection/ RecordFile.cpp. Since the CRC is an unkeyed, public function, it does not provide any real integrity for the data. In fact, by storing it in an unencrypted form, the purpose of encrypting the data in the first place (leaking no information about the contents of the plaintext) is undermined. A much more secure design would be to first encrypt the data to be stored and then to compute a keyed cryptographic checksum (such as HMAC-SHA1 [BCK96]) of the ciphertext. This cryptographic checksum could then be used to detect any tampering with the plaintexts. Note also that each entry has a timestamp, which will prevent the re-ordering, though not deletion, of records.
Each entry in a plaintext audit log is simply a timestamped, informational text string. At the time that the logging occurs, the log can also be printed to an attached printer. If the printer is unplugged, off, or malfunctioning, however, no record will be stored elsewhere to indicate that the failure occurred. The following code from TSElection/Audit.cpp demonstrates that the designers failed to consider these issues:
if (m_Print && print) {
CPrinter printer;
// If failed to open printer then just return.
CString name = ::GetPrinterPort();
if (name.Find(_T("\\")) != -1)
name = GetParentDir(name) + _T("audit.log");
if (!printer.Open(name, ::GetPrintReverse(), FALSE))
::TSMessageBox(_T("Failed to open printer for logging"));
} else {
-->PAGE 15
Do the printing: : :
}
If the cable attaching the printer to the terminal is exposed, an attacker could create discrepancies between the printed log and the log stored on the terminal by unplugging the printer (or, by simply cutting the cable).
An attacker’s most likely target will be the voting records, themselves. Each voter’s votes are stored as a bit array based on the ordering in the ballot definition file along with other information such as the precinct the voter was in, although no information that can be linked to a voter’s identity is included. If the voter has chosen a write-in candidate, this information is also included as an ASCII string. An attacker given access to this file would be able to generate as many fake votes as he or she pleased, and such votes would be indistinguishable from the true votes cast on the terminal.
While the voter’s identity is not stored with the votes, each vote is given a serial number. These serial numbers are generated by a linear congruential random number generator (LCG), seeded with static information about the election and voting terminal. No dynamic information, such as the current time, is used.
// LCG - Linear Conguential Generator - used to generate ballot serial numbers
// A psuedo-random-sequence generator
// (per Applied Cryptography, by Bruce Schneier, Wiley, 1996)
#define LCG_MULTIPLIER 1366
#define LCG_INCREMENTOR 150889
#define LCG_PERIOD 714025
static inline int lcgGenerator(int lastSN)
{
return ::mod(((lastSN * LCG_MULTIPLIER) + LCG_INCREMENTOR), LCG_PERIOD);
}
While the code’s authors apparently decided to use an LCG because it appeared in Applied Cryptography [Sch96], LCG’s are far from secure. However, attacking this random number generator is unnecessary for determining the order in which votes were cast: each vote is written to the file sequentially. Thus, if an attacker is able to determine the order in which voters cast their ballots, the results file has a nice list, in the order in which voters used the terminal. A malevolent poll worker, for example, could surreptitiously track the order in which voters use the voting terminals. Later, in collaboration with other attackers who might intercept the poorly encrypted voting records, the exact voting record of each voter could be reconstructed.
Physical access to the voting results may not even be necessary to acquire the voting records, if they are transmitted across the Internet.
5 Communicating with the outside world
The Diebold voting machines cannot work in isolation. They must be able to both receive a ballot definition file as input and report voting results as output. As described in Section 2, there are essentially two ways to load a voting terminal with an initial election configuration: via some removable media, such as a floppy disk, or over the Internet. In the latter case, the voting terminal could either be plugged directly into the Internet or could use a dial-up connection (the dial-up connection could be to a local ISP, or directly to the election authority’s modem banks). After the election is over, election results are sent to a back-end post-processing server over the network (again, possibly through a dial-up connection).
Unfortunately, there are a number of attacks against this system that exploit the system’s reliance on and communication with the outside world.
-->PAGE 16
5.1 Tampering with ballot definitions
We first note that it is possible for an adversary to tamper with the voting terminals’ ballot definition file (election.edb). If the voting terminals load the ballot definition from a floppy or removable storage card, then an adversary, such as a poll worker, could tamper with the contents of the floppy before inserting it into the voting terminal. On a potentially much larger scale, if the voting terminals download the ballot definition from the Internet, then an adversary could tamper with the ballot definition file en-route from the back-end server to the voting terminal. With respect to the latter, we point out that the adversary need not be an election insider; the adversary could, for example, be someone working at the local ISP. If a wireless network is used, anybody within radio range becomes a potential adversary. With high-gain antennas, the adversary can be sufficiently distant to have little risk of detection. ASCII text.10 Let us now consider some example attacks that make use of modifying the ballot definition file. Because no cryptographic techniques are in place to guard the integrity of the ballot definition file, an attacker could add, remove, or change issues on the ballot, and thereby confuse the result of the election.
In the system, different voters can be presented with different ballots depending on their party affiliations (see CBallotRelSet::Open(), which adds different issues to the ballot depending on the voter’s m_ VGroup1 and m_VGroup2 CVoterInfo fields). If an attacker changes the party affiliations of the candidates, then he may succeed in forcing the voters to view and vote on erroneous ballots. Even in municipalities that use the same ballot for all voters, a common option in voting systems is to allow a voter to select all the candidates from a given political party. Voters may not notice if candidates have incorrect party affiliations listed next to their names, and by choosing to vote a straight ticket, would end up casting ballots for undesirable candidates.
As an example of what might happen if the party affiliations were listed incorrectly, we note that, according to a news story11, in the 2000 New Mexico presidential election, over 65,000 votes were incorrectly counted because a worker accidentally had the party affiliations wrong. (We are not claiming, however, that those affiliations were maliciously assigned incorrectly. Nor are we implying that this had an effect on the results of the election.) Likewise, an attacker who can change the ballot definition could also change the ordering of the candidates running for a particular office. Since, at the end of the election, the results are uploaded to the server in the order that they appear in the the ballot definition file, and since the server will believe that the results appear in their original order, this attack could also succeed in swapping the votes between parties in a predominantly partisan precinct. This ballot reordering attack is also discussed in more detail in Section 4.3.
5.2 Preventing the start of an election
Suppose that the election officials are planning to download the configuration files over the Internet and that they are running late and do not have much time before the election starts to distribute ballot definitions manually (i.e., they might not have enough time to distribute physical media with the ballot definition files from central office to every voting precinct). In such a situation, an adversary could mount a traditional
[10] The relevant sections of code are as follows: CTransferElecDlg::OnTransfer() invokes CTSElectionDoc:: CreateEDB(), which reads the data from a CDL2Archive. The way the code works, CDL2Archive reads and writes to a CBufferedSocketFile. Returning to CTSElectionDoc::CreateEDB(), we see that it invokes CTSElectionDB:: Create(), which subsequently invokes CTSElectionFile::Save(). The functions called in CTSElectionFile:: Save() read data, such as strings, from the CDL2Archive.
[11]
-->PAGE 17
Internet denial-of-service attack against the election management’s server and thereby prevent the voting terminals from acquiring their ballot definitions before the start of the election. To mount such an attack effectively, the adversary would ideally need to know the topology of the system’s network, and the name of the server(s) supplying the ballot definition file.12 If a fair number of people from a certain demographic plan to vote early in the morning, then this could impact the results of the election.
Of course, we acknowledge that there are other ways to postpone the start of an election at a voting location that do not depend on the use of this system (e.g., flat tires for all poll workers for a given precinct).
Unlike such traditional attacks, however, the network-based attack (1) is relatively easy for anyone with knowledge of the election system’s network topology to accomplish; (2) this attack can be performed on a very large scale, as the central distribution point(s) for ballot definitions becomes an effective single point of failure; and (3) the attacker can be physically located anywhere in the Internet-connected world, complicating efforts to apprehend the attacker. Such attacks could prevent or delay the start of an election at all voting locations in a state. We note that this attack is not restricted to the system we analyzed; it is applicable to any system that downloads its ballot definition files using the Internet.
5.3 Tampering with election results
Just as it is possible for an adversary to tamper with the downloading of the ballot definition file (Section 5.1), it is also possible for an adversary to tamper with the uploading of the election results. To make this task even easier for the adversary, we note that although the election results are stored “encrypted” on the voting devices (Section 4.4), the results are sent from the voting devices to the back-end server over an unauthenticated and unencrypted channel. In particular, CTransferResultsDlg::OnTransfer() writes ballot results to an instance of CDL2Archive, which then writes the votes in cleartext to a socket without any cryptographic checksum.
Sending election results in this way over the Internet is a bad idea. Nothing prevents an attacker with access to the network traffic, such as workers at a local ISP, from modifying the data in transit. Such an attacker could, for example, decrease one candidates vote count by n and increase the another candidate’s count by n. Of course, to introduce controlled changes to the votes, the attacker would require some knowledge of the structure of the messages sent from the voting terminals to the back-end server. If the voting terminals use a modem connection directly to the tabulating authority’s network, rather than the Internet, then the risk of such an attack is less, although still not inconsequential. A sophisticated adversary (or employee of the local phone company) could tap the phone line and intercept the communication. All of these adversaries could be easily defeated by properly using standard encryption suites like SSL/TLS, used throughout the World Wide Web for e-commerce security. We are puzzled why such a widely accepted and studied technology is not used by the voting terminals to safely communicate across potentially hostile networks.
5.4 Attacking the voting terminals directly
In some configurations, where the voting terminals are directly connected to the Internet, it may be possible for an adversary to attack them directly, perhaps using an operating system exploit or buffer overflow attack of some kind. Ideally the voting devices and their associated firewalls would be configured to accept no incoming connections [CBR03]. This concern would apply to any voting terminal, from any vendor, with a direct Internet connection.
[12] Knowledge of the specific servers
is unnecessary for a large scale distributed denial of
service attack. An attacker simply needs to correctly guess
that the ballot definition’s file server is on a specific
network (e.g., at the voting system’s vendor or in the
municipality’s government).
-->PAGE 18
6 Software engineering
When creating a secure system, getting the design right is only part of the battle. The design must then be securely implemented. We now examine the coding practices and implementation style used to create the voting device. This type of analysis can offer insights into future versions of the code. For example, if a current implementation has followed good implementation practices but is simply incomplete, one would be more inclined to believe that future, more complete versions of the code would be of a similar high quality.
Of course, the opposite is also true, perhaps even more so: it is very difficult to produce a secure system by building on an insecure foundation.
Of course, reading the source code to a product gives only an incomplete view into the actions and intentions of the developers who created that code. Regardless, we can see the overall software design, we can read the comments in the code, and thanks to the CVS repository, we can even look at earlier versions of the code and read the developers’ commentary as they committed their changes to the archive.
Inside cvs.tar we found multiple CVS archives. Two of the archives, AccuTouch and AVTSCE implement full voting terminals. The AccuTouch code dates to around 2000 and is copyrighted by “Global Election Systems, Inc.” while the AVTSCE code dates to mid-2002 and is copyrighted by “Diebold Election Systems, Inc.” (The CVS logs show that the copyright notice was updated on February 26, 2002.) Many files are nearly identical between the two systems and the overall design appears very similar. Indeed, Diebold acquired Global Election Systems in September, 2001.13 Some of the code, such as the functions to compute CRCs and DES, dates back to 1996, when Global Election Systems was called “I-Mark Systems.” This legacy is apparent in the code itself as there are portions of the AVTSCE code, including entire classes, that are either simply not used or removed through the use of #ifdef statements. Many of these functions are either incomplete or, worse, do not perform the function that they imply as is the case with
CompareFiles in Utilities/FileUtil.cpp:
BOOL CompareFiles(const CString& file1, const CString& file2)
{
/* XXX use a CRC or something similar */
BOOL exists1, exists2;
HANDLE hFind;
WIN32_FIND_DATA fd1, fd2;
exists1 = ((hFind = ::FindFirstFile(file1, &fd1)) != INVALID_HANDLE_VALUE);
::FindClose(hFind);
exists2 = ((hFind = ::FindFirstFile(file2, &fd2)) != INVALID_HANDLE_VALUE);
::FindClose(hFind);
return (exists1 && exists2 && fd1.nFileSizeLow == fd2.nFileSizeLow);
}
Currently the code will declare any two files to be the same that have the same size. The author’s comment to use a CRC doesn’t make much sense, as a byte-by-byte comparison would be more efficient. If this code were ever used, its inaccuracies could lead to wide variety of subsequent errors.
While most of the preprocessor directives that remove code correctly use #if 0 as their condition, some use #ifdef XXX. There is no reason that a later programmer should realize that defining XXX will cause blocks of code to be reincluded in the system (causing unpredictable results, at best). We also noticed
[13]
-->PAGE 19
#ifdef LOUISIANA in the code. Prudent software engineering would recommend a single implementation of the voting software, where individual states or municipalities could have their desired custom features expressed in configuration files.
While the system is implemented in an unsafe language (C++), the code reflects an awareness of avoiding such common hazards as buffer overflows. Most string operations already use their safe equivalents, and there are comments reminding the developers to change others (e.g., should really use snprintf).
While we are not prepared to claim that there are no buffer overflows in the current code, there are at the very least no glaringly obvious ones. Of course, a better solution would have been to write the entire system in a safe language, such as Java or C#.
The core concepts of object oriented programming such as encapsulation are well represented, though in some places C++’s non-typesafe nature is exploited with casts that could conceivably fail. This could cause problems in the future as these locations are not well documented.
Overall, the code is rather unevenly commented. While most files have a description of their overall function, the meanings of individual functions, their arguments, and the algorithms within are more often than not undocumented. An extreme example of a complex but completely undocumented function is the
CBallotRelSet::Open function from TSElection/TSElectionSet.cpp:
void CBallotRelSet::Open(const CDistrict* district, const CBaseunit* baseunit,
const CVGroup* vgroup1, const CVGroup* vgroup2)
{
ASSERT(m_pDB != NULL);
ASSERT(m_pDB->IsOpen());
ASSERT(GetSize() == 0);
ASSERT(district != NULL);
ASSERT(baseunit != NULL);();
for (int i = 0; i < count; i++) { const CBaseunit& curBaseunit = baseunitTable.GetAt(i); if (baseunit->KeyId() == -1 || *baseunit == curBaseunit) {
const CBallotRelationshipItem* pBalRelItem = NULL;
while ((pBalRelItem = m_pDB->FindNextBalRel(curBaseunit, pBalRelItem))){
if (!vgroup1 || vgroup1->KeyId() == -1 ||
(*vgroup1 == pBalRelItem->m_VGroup1 && !vgroup2) ||
(vgroup2 && *vgroup2 == pBalRelItem->m_VGroup2 &&
*vgroup1 == pBalRelItem->m_VGroup1))
Add(pBalRelItem);
}
}
}
m_CurIndex = 0;
m_Open = TRUE;
}
}
}
-->PAGE 20
Nothing about this code makes its purpose readily apparent. Certainly, it has two nested loops and is doing all kinds of comparisons. Beyond that, most readers of the code would need to invest significant time to learn the meaning of the various names shown here.
An important point to consider is how code is added to the system. From the CVS logs, we can see that most code updates are in response to specific bugs that needed to be fixed. There are numerous authors who have committed changes to the CVS tree, and the only evidence that we have found that the code undergoes any sort of review process comes from a single log comment: “Modify code to avoid multiple exit points to meet Wyle requirements.” This could refer to Wyle Laboratories whose website claims that they provide all manner of testing services.14 There are also pieces of the voting system that come from third parties. Most obviously is the operating system, either Windows 2000 or Windows CE. Both of these OSes have had numerous security vulnerabilities and their source code is not available for examination to help rule out the possibility of future attacks.
Besides the operating system, an audio library called “fmod” is used.15 While the source to fmod is available with commercial licenses, unless the code is fully audited there is no proof that fmod itself does not contain a backdoor.
Due to the lack of comments, the legacy nature of the code, and the use of third-party code and operating systems, we believe that any sort of comprehensive, top-to-bottom code review would be nearly impossible.
Not only does this increase the chances that bugs exist in the code, but it also implies that any of the coders could insert a malicious backdoor into the system. The current design deficiencies provide enough other attack vectors that such an explicit backdoor is not required to successfully attack the system. Regardless, even if the design problems are eventually rectified, the problems with the coding process may well remain intact.
6.4 Code completeness and correctness
While the code we studied implements a full system, the implementors have included extensive comments on the changes that would be necessary before the system should be considered complete. It is unclear whether the programmers actually intended to go back and remedy all of these issues as many of the comments existed, unchanged, for months, while other modifications took place around them. It is also unclear whether later version of AVTSCE were subsequently created. (Modification dates and locations are easily visible from the CVS logs.) These comments come in a number of varieties. For illustrative purposes, we have chosen to show a few such comments from the subsystem that plays audio prompts to visually-impaired voters.
² Notes on code reorganization:
/* Okay, I don’t like this one bit. Its really tough to tell where m AudioPlayer should live. [...] A reorganization might be in order here. */
² Notes on parts of code that need cleaning up:
/* This is a bit of a hack for now. [...] Calling from the timer message appears to work. Solution is to always do a 1ms wait between audio clips. */
[14]
[15]
-->PAGE 21
² Notes on bugs that need fixing:
/* need to work on exception *caused by audio*. I think they will currently result in double-fault. */
There are, however, no comments that would suggest that the design will radically change from a security perspective. None of the security issues that have been discussed in this paper are pointed out or marked for correction. In fact, the only evidence at all that a redesign might at one point have been considered comes from outside the code: the Crypto++ library16 is included in another CVS archive in cvs.tar.
However, the library was added in September 2000 and was never used or updated. We infer that one of the developers may have thought that improving the cryptography would be useful, but then got distracted with other business.
7 Conclusions
Using publicly available source code, we performed an analysis of a voting machine. This code was apparently developed by a company that sells to states and other municipalities that use them in real elections.
We found significant security flaws: voters can trivially cast multiple ballots with no built-in traceability, administrative functions can be performed by regular voters, and the threats posed by insiders such as poll workers, software developers, and even janitors, is even greater. Based on our analysis of the development environment, including change logs and comments, we believe that an appropriate level of programming discipline for a project such as this was not maintained. In fact, there appears to have been little quality control in the process. binaries running in the machine correspond to the source code and that the compilers used on the source code are non-malicious.
However, open source is a good start.) Such open design processes have proven successful in projects ranging from very focused efforts, such as specifying the Advanced Encryption Standard (AES) [NBB+00], through very large and complex systems such as maintaining the Linux operating system.
Alternatively, security models such as the voter-verified audit trail allow for electronic voting systems that produce a paper trail that can be seen and verified by a voter. In such a system, the correctness burden on the voting terminal’s code is less extreme because voters can see and verify a physical object that embodies their vote. Even if, for whatever reason, the machines cannot name the winner of an election, then the paper ballots can be recounted, either mechanically or manually, to gain progressively more accurate election results..
[16]˜weidai/cryptlib.html
-->PAGE 22
We thank Cindy Cohn, David Dill, Badri Natarajan, Jason Schultz, David Wagner, and Richard Wiebe for their suggestions and advice.
[BCK96] M. Bellare, R. Canetti, and H. Krawczyk. Keying hash functions for message authentication.
In Advances in Cryptology: Proceedings of CRYPTO ’96, pages 1–15. Springer-Verlag, 1996.
[BDJR97] M. Bellare, A. Desai, E. Jokipii, and P. Rogaway. A concrete security treatment of symmetric encryption. In Proceedings of the 38th Annual Symposium on Foundations of Computer Science, pages 394–403. IEEE Computer Society Press, 1997.
[Cal00] California Internet Voting Task Force. A report on the feasiblility of Internet voting, January 2000..
[Cal01] Voting: What Is; What Could be, July 2001. Reports/.
[CBR03] W. R. Cheswick, S. M. Bellovin, and A. D. Rubin. Firewalls and Internet Security; Repelling the Wily Hacker. Addison-Wesley, Reading, MA, 2003.
[Die03] Diebold Election Systems. AVTSCE/ source tree, 2003. Available in.
[DJ02] J. Daemen and V. Jijmen. The Design of Rijndael: AES–The Advanced Encryption Standard.Springer, 2002.
[DMNW03] D. L. Dill, R. Mercuri, P. G. Neumann, and D. S. Wallach. Frequently Asked Questions about DRE Voting Systems, February 2003..
[Gil98] J. Gilmore, editor. Cracking DES: Secrets of Encryption Research, Wiretap Politics & Chip Design. O’Reilly, July 1998.
[Har03] B. Harris. Black Box Voting: Vote Tampering in the 21st Century. Elon House/Plan Nine, July 2003.
[Jon01] D. W. Jones. Problems with Voting Systems and the Applicable Standards, May 2001. Testimony before the U.S. House of Representatives’ Committee on Science,.
[Jon03] D. W. Jones. The Case of the Diebold FTP Site, July 2003..
[Ker83] A. Kerckhoffs. La Cryptographie Militaire. Libraire Militaire de L. Baudoin & Cie, Paris, 1883.
[Mer00] R. Mercuri. Electronic Vote Tabulation Checks and Balances. PhD thesis, University of Pennsylvania, Philadelphia, PA, October 2000.
-->PAGE 23
[Nat01] National Science Foundation. Report on the National Workshop on Internet Voting: Issues and Research AGenda, March 2001..
[NBB+00] J. Nechvatal, E. Barker, L. Bassham, W. Burr, M. Dworkin, J. Foti, and E. Roback. Report on the Development of the Advanced Encryption Standard (AES), October 2000.
[NBS77] NBS. Data encryption standard, January 1977. Federal Information Processing Standards Publication 46.
[Rub02] A. D. Rubin. Security considerations for remote electronic voting. Communications of the ACM, 45(12):39–44, December 2002..
[Sch96] B. Schneier. Applied Cryptography: Protocols, Algorithms, and Source Code in C. JohnWiley & Sons, New York, second edition, 1996.
[Sch00] B. Schneier. Secrets and Lies. John Wiley & Sons, New York, 2000.
--> PAGE 24
Check the original for correct formatting of code sections. | http://www.scoop.co.nz/stories/HL0307/S00196.htm | crawl-003 | refinedweb | 11,933 | 51.38 |
Filing your income tax return (ITR) is a routine affair if your income is above the taxable limit. However, have you considered a situation where your income is below the taxable limit for the year? Do you still need to file your income tax return?
If you have been wondering about this, here is a look at reasons why you should consider filing your ITR even if your income is below the taxable limit.
Know your exemption limits
In most financial years, the Finance Ministry updates the limits to which income is exempted from tax. Keep a check on whether your income qualifies for exemption.
Exemption limit for Assessment Year 2016-17
You are exempted from income tax if your income does not exceed Rs 2.5 lakh. However, this exemption is only for individuals under 60 years of age.
If you are between ages 60 and 80, you are exempted from income tax with an income of up to Rs 3 lakh.
For individuals aged 80 years and above, the limit is enhanced to Rs 5 Lakh.
Should you file your returns?.
The author is CEO, BankBazaar.com | http://www.financialexpress.com/industry/banking-finance/why-you-should-file-income-tax-returns-even-if-your-income-is-below-taxable-limit/288879/ | CC-MAIN-2017-43 | refinedweb | 189 | 72.66 |
Subject: Re: [boost] [multiprecision] Are these types suitable asnumerictypes for unit tests?
From: Christopher Kormanyos (e_float_at_[hidden])
Date: 2013-06-10 16:59:41
>>I've filed a bug report:
>>Can we just use the separately compiled boost.test in the mean time?
>>John.
>Hi John,
>I did
a local edit of my multiprecision directory in trunk.
>I qualified both enable_if and disable_if with the boost
>namespace. I still need to run all tests and the like.
>But it's looking good so far.
>After things quiet down after 1.54, I can can commit the changes
>with your approval if you like. Or if you've got a batch of
>other things to do, you may prefer to do the search and replace?
>Anyway, it is a simple modification however and whenever
>we end up doing it.
>Sincerely, Chris.
Or are you trying to say we should play the long game and
get the *using* directives out of Boost.Test?
Sorry if I missed that one (clear in your bug report,
but I glossed over it).
Sincerely, Chris.
Boost list run by bdawes at acm.org, gregod at cs.rpi.edu, cpdaniel at pacbell.net, john at johnmaddock.co.uk | https://lists.boost.org/Archives/boost/2013/06/204546.php | CC-MAIN-2021-43 | refinedweb | 201 | 77.43 |
How to Make a GSM Location Tracker With the AdaFruit FONA and Arduino
Introduction: How to Make a GSM Location Tracker With the AdaFruit FONA and Arduino
Introduction
In this tutorial we are going to make a web connected location logger using the Adafruit FONA Board, an Arduino, and the Sparkfun Data Service. It will get its location using triangulation and post it to an online database with a GET request over a cellular (GPRS) connection.
We will be using CoolTerm to communicate with the FONA, so please install it here. There is a link to a Sparkfun Tutorial on how to use it in Resources.
We will also be using the Sparkfun Data Service for the online database portion of this tutorial. Any "internet of things" service should work, however, with some modification to the code.
Resources
- Adafruit FONA page. Great resource for pinouts/SIM card info, etc
- The Datasheets for the GSM module, These are a good reference for commands and more technical info.
Parts List
- Adafruit FONA board
- I have the uFL antenna connector version for its small size, but either version should work fine
- GSM Antenna
- I have a uFL antenna, but any antenna of the right frequency that fits should be ok. Look at the Adafruit documentation and be sure to get the right one
- Lipo Battery
- Arduino Uno
- A breadboard
- The Internet
- SIM Card
- Hookup Wire
Step 1: Hookup the Fona
You will need your Lipo Battery, the Arduino, the FONA + Antennae, a breadboard, your SIM card, and some hookup wire. I like to attach my breadboards and Arduino’s together like in the picture, it makes for a more reliable connection and less troubles trying to keep the two in close proximity while prototyping. I just used a piece of blue corrugated plastic and some hot glue, but a piece of cardboard will work just as well.
- Insert your SIM Card into the SIM Slot on the back of the Board
- Attach the Antenna
Make the following Connections
Arduino to Breadboard
- Arduino GND -> breadboard Ground
- Arduino 5v -> breadboard Power
FONA to Breadboard
- Solder on the header pins if you haven’t already
- Plug the FONA like in the picture, with the Bat PIN in ROW 1
- FONA Vio -> Power Bus (This is VERY important. Communication won’t work without this)
- FONA GND -> Ground Bus
FONA to Arduino
- FONA RX -> PIN 3
- FONA TX -> PIN 4
- FONA PS -> PIN 6 (‘Power State’ pin. It is HIGH when the FONA is on, and LOW with the FONA is off)
- FONA KEY -> PIN 7 (Pull this pin low for 2 seconds and the FONA will turn off/on)
Your setup should look somewhat like it does in the picture.
- Double check all of the connections
- Plug the Battery into the Connector on the FONA
The FONA is powered from the battery it is attached to. It will not work without that battery there. The USB connector on the FONA charges the Battery, that is all. The FONA will not work with just the USB plugged in, as the power comes from the Battery, NOT the USB connection. If you want to charge the Battery from an external 5v source, there is a hole next to the USB port labeled ‘5v’. I have a green wire soldered into it, so I can charge the battery from the Arduino. This is useful for embedding but not needed for prototyping.
Step 2: Test the FONA
Upload the following code to test the FONA - Arduino Connection:
#include <SoftwareSerial.h><softwareserial.h><br></softwareserial.h>
#define FONA_RX 3 //comms #define FONA_TX 4 //comms #define FONA_KEY 6 //powers board down #define FONA_PS 7 //status pin. Is the board on or not?
SoftwareSerial fonaSS = SoftwareSerial(FONA_TX, FONA_RX); //initialize software serial char inChar = 0;
void setup() { pinMode(FONA_PS, INPUT); pinMode(FONA_KEY,OUTPUT); digitalWrite(FONA_KEY, HIGH); Serial.begin(9600); Serial.println("Serial Ready"); fonaSS.begin(9600); Serial.println("Software Serial Ready"); }
void loop() { if (fonaSS.available()){ inChar = fonaSS.read(); Serial.write(inChar); delay(20); } if (Serial.available()>0){ fonaSS.write(Serial.read()); } }
Turn on FONA
- to turn on the the FONA press and hold the button by the Battery Connector for 2 seconds and release.
- The blue power light should turn on and if the SIM connects, a red light will start to blink slowly.
- To turn off the board press and hold the same button
Connect Coolterm
Once the code is uploaded, connect to the Arduino Serial Port using Coolterm.
- Select the correct Serial Port
- Baud Rate is set to 9600
- Under Terminal on the left make sure Line Mode is selected
- Click OK and then Connect
- Then in the command bar type: AT and press Enter. It is not case sensitive.
- If the FONA module is active and listening it will respond with OK
If everything has gone OK up to here, Congrats!
Step 3: The AT Commands
Working with these GSM modules is basically just sending them commands over the Serial Port and parsing the responses. These modules have quite a bit of smarts built into them, which makes this process easier.
To send a command, type it into the command line in Coolterm and press Enter.
Command Syntax
-.
- Try out all of these commands. It’s pretty cool! Try making a phone call or sending a text!
- For a compendium of all the commands the datasheet is here.
Get your Location!
Type in the following commands to get your (approximate) location
- AT+CMGF=1
- response: OK
- AT+CGATT=1
- response: OK
- AT+SAPBR=3,1,"CONTYPE","GPRS"
- response: OK
- AT+SAPBR=3,1,"APN","your apn here"
- response: OK
- AT+SAPBR=1,1 -> note: the red light should start blinking faster
- response: OK
- AT+CIPGSMLOC=1,1
- response: +CIPGSMLOC:
- followed by: OK
Make a GET Request!
To make a GET request, it’s a similar process at the beginning. You should type all of these out and make sure your SIM card connects and does a GET request manually before you continue. It is actually very important in these complicated systems to check functionality at each step so if it stops working you know exactly at which point it stopped working. It makes the debugging process much easier.
- First we setup the GPRS:
-
Step 4: Set Up a Sparkfun Data Stream
The next step is to create a place for us to send the location data we just received. We are going to use a service that Sparkfun provides for free: data.sparkfun.com. There is a nice set of tutorials that they have put together for it, so I won't be redundant.
For the included code to work right there needs to be 4 columns labeled:
- latitude
- longitude
- time
- date
Once that is done, make sure you have the Private and Public keys and move on to the next step.
Step 5: Putting It Into Code
We have learned what commands we need to get our location, to send a get request, and we have created an online database to send our data to. The next step is creating code to automate the process of getting our location and sending up to the database.
- Download the attached: FONA_Location.ino
- Copy your APN, Public, and Private keys into the correct spots at the top of the code
- Upload
- Connect with CoolTerm and watch the Serial Monitor for any Errors. It should look like the attached image.
- Make sure the HTTPACTION responds with a 200
- Check your Sparkfun Datastream to see if the data appears.
- I tried to make the code as legible as possible, there are lots of comments.
At this point you should have the GSM module autonomously getting location and posting it to Sparkfun every 5 minutes, which means we are successful. You can now power your arduino with a battery and take it for a walk and see if it works!
Step 6: Epilogue
The other aspect we haven't talked about here is power consumption. It would be safe to assume that if you are building a cellular tracker, you will want to put it on something that moves, which will mean it will need to stray from the power outlet/usb ports of our world. This means battery power, which means measuring power consumption and calculating battery life, etc.
Cellular stuff has a reputation for being pretty power hungry. Adafruit says this module can draw up to 2 Amps (!!) in short bursts. However, the way we are using it, it spends most of its time power off, consuming very little.
I measured the power consumption from the Battery during normal use.
- Powered on: ~ 25mA
- Get Request: Peaks at 150-200mA for short durations
- One full cycle of requesting location and sending a GET request consumes ~ 7.47 joules
- avg of 53.4 mA for 35 Seconds
- Powered off: ~150µA quiescent power consumption
If we were using a battery with a capacity of 1000mAH, we could get send locations for ~ 10 days at 15 minute intervals before the battery gave out. (in theory, and not considering the power consumption of the Arduino)
Note:
I did notice some strange behavior when the battery was connected to the FONA and the Arduino was unplugged. There was between 20-100mA flowing out of the battery for no reason. I'm not sure why this is, but I would be cautious about leaving batteries plugged in to the FONA without it being controlled by a microcontroller.
I have assembled this project with a 2G sim card. It keeps hanging up on Disabled echo:
Any ideas why?
I'm going to have a go at this project but instead of using the sparkfun web data server I'm going to use my own website which conveniently runs PHP and MYSQL. Please wish me luck!
GOOD LUCK
Thanks! I have just got the FONA 3G working properly with Coolterm - had to give it 3ms delay between the characters to get it to ping google etc.
Now to get your code working. I have every faith in your work ....
I´m wondering if you can give me the code? I´m struggling a bit.
The 3G fona is very tricky/dysfunctional. I went to 2G with great success. Let me know if you need more info on 2G solutions.
Hi Kinasmith,
Will this work with the 3G version of the Fona?
This is my first Arduino project...
According to Adafruit http on the 3G fona is "not natively supported":
Did you have any luck getting the code to work?
I ended up using the ideas in this code to create my own code. I did try this code but unfortunately I think that the GSM part of my FONA 800L is broken.
I checked my board with cool term and no luck!
I never actually really wanted to make a GSM tracker anyway - I wanted to build a weather station and the HTTP GET principle works very well on the 2G board. I did not use the sparkfun database as I needed much more in the way of data sorting facilities so used a database on my own website.
Can you please send me the code to get this project working with 3g? I'm kinda struggling at the moment
Kieran - you will struggle with the Fona 3G, but it does work. I think one other person got it to work over at the adafruit discussion forum. Go to the forum and search 'FONA 3G'. Also, try petitioning adafruit to develop the FONA library for the 3G version. They seem to think the 3G is not able to handle HTTP commands, but I think they are wrong - There's a big mistake/omission in the SIM6320 manual which leaves out all the HTTP commands.
Let me know how you get on as I'd like to use it myself one day - I'm too lazy to actually write the code myself.
Would it work with Sparkfun web data server?
hi kina,
can we replaced adafruit FONA board with using GSM shield sim 800?...are coding will working with different board?...tq
Dear Sir, thank for that code.
I would like to understand why you used the command
AT+CMGF=1
That command is to set SMS system to text mode.
Why is it useful to use that command in that context (Activating brearer profile to get gsm location)?
Okay,
To make this work for my FONA 808 Shield I had to modify the original sketch quite a bit. The PIN Out had to be changed a little and there is not need to turn the FONA on and off with the shield so I got rid of a lot of that. Added a few commands in the GPRS setup. I added a few delays to get the serial output to be clean. Also I had to add a 10sec delay to the getLocation function otherwise it would return an error. Runs like a champ for me now.
One thing to note. In the getLocation sub routine. The data is broken down into substrings but char position. I had to change this for my area. The Lat and Lon results will vary depending on location. It could start with 3 digits, or a - sign.
for example Kina's location was:
+CIPGSMLOC: 0,-73.974037,40.646976,2015/02/16,21:05:11
mine was
+CIPGSMLOC: 0,34.403347,-103.33228,2016/04/26,03:45:54
so our longitudes started at different locations in the string. Kina's Lat has 10 chars, mine has 10. Kina's Lon has 9 Chars mine has 10.
I think a better way to do this would be to break the string down where the commas are. I'm new to this and will try to figure it out.
Also, the cell towers in my current location are few and far between. I'm going to see if I can get a more accurate fix using the GPS location instead.
Thanks for the nice piece of code Kina!
Nice work! I'm glad you could get it to work with different hardware and happy my code helped a little in that process.
I use Black Wireless. They have pretty cheap prepaid plans and I use them for my phone plan too, so it makes it easy.
Awesome work! Also thank you Kina!
What data plan are you using? And who is your provided? I tried adding delays like you mentioned and I also followed all the changes you mentioned but I am getting server time out. +CIPGSMLOC: 408
I feel like it might be due to only using the $3 dollar a month talk and text via T-mobile. That plan doesn't include data.
I was using a prepaid plan which included data. You will need data access to the network. Talk/Text only plans won't work.?
The edited sketch
I am get 408 as a response anyone seen that? I believe it means server busy, is anyone else trying just the talk and text plan via T-Mobile?
I am get 408 as a response anyone seen that? I believe it means server busy, is anyone else trying just the talk and text plan via T-Mobile?
Getting Location...: Get Location ERROR:
HELLO, THANKS SO MUCH FOR YOUR WORK..
i tried to implement this using sim808 lonet module.. although i removed all things gprs.. since i only want the gps detaild printed out only,, but i keep getting this error on the serial monitor
I got this to work with the GPS. I added a sub routine to turn on the GPS and changed the getLocation sub routine to retrieve location data from the GPS. Its very accurate. It can take about 30mins for the GPS to get a good lock. Mine usually locks in less than 5. I also edited the getLocation to break the content string down by commas. Now if the tag travels from say Canada to the tip of South America, the lat and lon fields will always be correct even with the shifting length of those strings. Sketch is included below.
Thanks again Kina! Never would have done this without your original code.
mat is
In step three I had to use a few more commands to set up the GPRS.
AT+CIPSHUT //deactivates GPRS PDP content
SHUT OK
AT+CGATT=1
OK
AT+SAPBR=3,1,"CONTYPE","GPRS"
OK
AT+SAPBR=3,1,"APN","FONAnet"
OK
AT+CSTT="FONAnet" //starts task and sets APN
OK
AT+SAPBR=1,1
OK
AT+CIICR //brings up wireless connection with GPRS
OK
Moving on but this may require editing the original sketch. I'm guessing these new protocals were implemented after the original sketch was written but I'm not sure
I tried each and every step and it worked but the last and the final step gave me the following reports. My sim is unlocked too, so is there anything that I should do to get this working.
.......OKERRORERROR
Set to TEXT Mode:
Attach GPRS: OK
Set Connection Type To GPRS:
Set APN: OK.
GPRS Already on
ERROR: OK
FONA Already On, Did Nothing
Initializing: please wait 10 s
According to Adafruit http on the 3G fona is "not natively supported":
Thanks mate, this helped, at first I had putted coordinates as in reverse hehe...
Hi kinasmith
first of all thanks for sharing this with us =)
i went through each step and they worked fine with no errors, except for the final step where the following output appears in the Serial Monitor :
............OKOK
Set to TEXT Mode:
Attach GPRS: OK
Set Connection Type To GPRS:
Set APN: OK.
GPRS Already on
ERROR: OK
FONA Already On, Did Nothing
Initializing: please wait 10 sec...
Disable echo: OKOKERROR
Set to TEXT Mode:
Attach GPRS: OK
Set Connection Type To GPRS:
Set APN: OK
GPRS Already on
ERROR: OK
I can't tell too much from the Serial print output. Did you try inputing each command in Cool-Term like I described above? Does each one work? Make sure your APN is correct. And make sure your service provider isn't blocking your device from connecting to the network, some carriers don't like unapproved devices on their networks.
Yes i did input each command in cool-term and no errors has appeared to me except the last step. and the carrier is not blocking my device. so what do you think the problem is ?
Which step is the "last step"? Which command is giving you an error? what is the error? Have you looked it up in the Application Notes? What cellular service are you using? Are you using the FONA board? What revision of it? What country are you in? Have you tried other commands or capabilities of the FONA? Can you send/receive SMS? Can you make a GET request? What is your signal strength?
What i mean by the last step is the fifth step of your instructable .. All the commands in the first , second and third step worked fine with me i got all the responses Ok and the GPS long and lat. I am from Kuwait and using Ooredoo GPRS service (APN is action.ooredoo.com) with FONA 808 board and have tried making a phone call and send/receive sms messages and it worked like a charm i also tried establishing a UDP connection using the tcp applications command sheet and it also worked ! Well i had a problem when making a GET request after intitating the http and entering the command at+httppara"cid",1 it used to respond with at+httpara=b instead of OK i tried setting the url first ! then the http parameters and i think it worked since at+httppara"cid",1 responded with OK after that. Then i had and error in the serial monitor after uploading Fona_location.ino file to the Arduino. What should i do to make it work and send the location to the sparkfun data stream that I created ? I really appreciate that you're trying to help me Thank you so much !
That all seems right. Can you make the post to the sparkfun database using cool-term? If yes, try checking the code to make sure there are no typos or anything and make sure all the commands are right. Make sure all the commands work in Cool-Term, then double check that each command works with the FONA in code. Beyond that, I'm not sure how much I can help. Cellular stuff is a pain to work with. Happy debugging!
please advise and thank you
Hi I get "+CME ERROR: operation not allowed" after I key in AT+SAPBR=1,1. What do I do?
Hi. How to make a vehicle tracker system by using lonet sin808 and arduino uno? Can u help me?
Sorry. Lonet sim808.
What’s the accuracy for the location? I’ve read something about ±200m using cell phone estimation only.
If accuracy was important, I would use a real GPS.
Yes of course, but GPS doesn’t work in buildings and requires additional hard- and software. So I’m wondering how the SIM800 estimates position and how accurate it is. What are your experiences? Are we talking about a few hundred meters or kilometers?
My impression is that this command I'm using above gives you the GPS location of the cell tower you are connected to, not your "actual" location. Which would make accuracy contingent on the density of cell towers in the area. I have not done extensive testing on this.
got a signal and i got internet access tuned out it was the mobile provider they don't allow data over anything apart from phones. anyway after a lot of complaining. i managed to get them to allow data on my arduino device. im nearly there but i cant get the getLocation() to work. it just returns an Error 0. and i know it has a GPS location as i tried the (sendATCommand("AT+CIPGSMLOC=1,1")).... is there any way of capturing the string returned from that command straight from the sendATcommand as your way dont seem to work on the LoNet
See Step #3. You should be doing all of this through a Serial Terminal to make sure everything works, read the errors, etc. before you try to implement it in code. In the Serial Terminal, send the command, you'll see the response. Again, reference step #3. | http://www.instructables.com/id/How-to-make-a-Mobile-Cellular-Location-Logger-with/ | CC-MAIN-2017-43 | refinedweb | 3,755 | 72.66 |
Java program to add two numbers :- Given below is the code of java program that adds two numbers which are entered by the user.
Java programming source code
import java.util.Scanner; class AddNumbers { public static void main(String args[]) { int x, y, z; System.out.println("Enter two integers to calculate their sum "); Scanner in = new Scanner(System.in); x = in.nextInt(); y = in.nextInt(); z = x + y; System.out.println("Sum of entered integers = "+z); } }
Download Add numbers program class file.
Output of program:
Above code can add only numbers in range of integers(4 bytes), if you wish to add very large numbers then you can use BigInteger class. Code to add very large numbers:
import java.util.Scanner; import java.math.BigInteger; class AddingLargeNumbers { public static void main(String[] args) { String number1, number2; Scanner in = new Scanner(System.in); System.out.println("Enter first large number"); number1 = in.nextLine(); System.out.println("Enter second large number"); number2 = in.nextLine(); BigInteger first = new BigInteger(number1); BigInteger second = new BigInteger(number2); BigInteger sum; sum = first.add(second); System.out.println("Result of addition = " + sum); } }
In our code we create two objects of BigInteger class in java.math package. Input should be digit strings otherwise an exception will be raised, also you cannot simply use '+' operator to add objects of BigInteger class, you have to use add method for addition of two objects.
Output of program:
Enter first large number 11111111111111 Enter second large number 99999999999999 Result of addition = 111111111111110
Download Adding Large numbers program class file. | http://www.programmingsimplified.com/java/source-code/java-program-add-two-numbers | CC-MAIN-2017-09 | refinedweb | 258 | 50.53 |
How to create a range image from a point cloud
This tutorial demonstrates how to create a range image from a point cloud and a given sensor position. The code creates an example point cloud of a rectangle floating in front of the observer.
The code
First, create a file called, let’s say,
range_image_creation.cpp in your favorite
editor, and place the following code inside it:
Explanation
Lets look at this in parts:
#include <pcl/range_image/range_image.h> int main (int argc, char** argv) { pcl::PointCloud<pcl::PointXYZ> pointCloud; // Generate the data for (float y=-0.5f; y<=0.5f; y+=0.01f) { for (float z=-0.5f; z<=0.5f; z+=0.01f) { pcl::PointXYZ point; point.x = 2.0f - y; point.y = y; point.z = z; pointCloud.points.push_back(point); } } pointCloud.width = (uint32_t) pointCloud.points.size(); pointCloud.height = 1;
This includes the necessary range image header, starts the main and generates a point cloud that represents a rectangle.
float angularResolution = (float) ( 1.0f * (M_PI/180.0f)); // 1.0 degree in radians float maxAngleWidth = (float) (360.0f * (M_PI/180.0f)); // 360.0 degree in radians float maxAngleHeight = (float) (180.0f * (M_PI/180.0f)); // 180.0 degree in radians Eigen::Affine3f sensorPose = (Eigen::Affine3f)Eigen::Translation3f(0.0f, 0.0f, 0.0f); pcl::RangeImage::CoordinateFrame coordinate_frame = pcl::RangeImage::CAMERA_FRAME; float noiseLevel=0.00; float minRange = 0.0f; int borderSize = 1;
This part defines the parameters for the range image we want to create.
The angular resolution is supposed to be 1 degree, meaning the beams represented by neighboring pixels differ by one degree.
maxAngleWidth=360 and maxAngleHeight=180 mean that the range sensor we are simulating has a complete 360 degree view of the surrounding. You can always use this setting, since the range image will be cropped to only the areas where something was observed automatically. Yet you can save some computation by reducing the values. E.g. for a laser scanner with a 180 degree view facing forward, where no points behind the sensor can be observed, maxAngleWidth=180 is enough.
sensorPose defines the 6DOF position of the virtual sensor as the origin with roll=pitch=yaw=0.
coordinate_frame=CAMERA_FRAME tells the system that x is facing right, y downwards and the z axis is forward. An alternative would be LASER_FRAME, with x facing forward, y to the left and z upwards.
For noiseLevel=0 the range image is created using a normal z-buffer. Yet if you want to average over points falling in the same cell you can use a higher value. 0.05 would mean, that all point with a maximum distance of 5cm to the closest point are used to calculate the range.
If minRange is greater 0 all points that are closer will be ignored.
borderSize greater 0 will leave a border of unobserved points around the image when cropping it.
pcl::RangeImage rangeImage; rangeImage.createFromPointCloud(pointCloud, angularResolution, maxAngleWidth, maxAngleHeight, sensorPose, coordinate_frame, noiseLevel, minRange, borderSize); std::cout << rangeImage << "\n";
The remaining code creates the range image from the point cloud with the given parameters and outputs some information on the terminal.
The range image is derived from the PointCloud class and its points have the members x,y,z and range. There are three kinds of points. Valid points have a real range greater zero. Unobserved points have x=y=z=NAN and range=-INFINITY. Far range points have x=y=z=NAN and range=INFINITY.
Compiling and running the program
Add the following lines to your CMakeLists.txt file:
After you have made the executable, you can run it. Simply do:
$ ./range_image_creation
You should see the following:
range image of size 42x36 with angular resolution 1deg/pixel and 1512 points | http://pointclouds.org/documentation/tutorials/range_image_creation.php | CC-MAIN-2018-17 | refinedweb | 619 | 58.58 |
![if !(IE 9)]> <![endif]>
This article was initially meant as a review of bugs found in the FreeCAD open-source project but eventually took a bit different direction. It happened because a considerable portion of the warnings had been generated for the third-party libraries employed by the project. Extensive use of third-party libraries in software development is highly beneficial, especially in the open-source software domain. And bugs found in these libraries are no good reason to reject them. But we still should keep in mind that third-party code we use in our projects may contain bugs, so we must be prepared to meet and, if possible, fix them, thus improving the libraries.
FreeCAD is a free and open-source general purpose parametric 3D CAD modeler allowing creating 3D models and drawing their projections. FreeCAD's developer Juergen Riegel, working at DaimlerChrysler corporation, positions his program as the first free mechanical engineering and design tool. There is a well-known issue in a number of related areas that deals with the lack of a full-fledged open-source CAD application, and the FreeCAD project is just aiming to become one. So let's check its source code with PVS-Studio to help this open-source project become a bit better. I bet you encounter "glitches" in various modelers every now and then when you can't hit a certain point or align a line which is constantly shifting one pixel away from the desired position. All of that may be just a result of some typos in the source code.
The FreeCAD project is cross-platform and there is a very good collection of documents on building it available at their site. It wasn't difficult to get project files for Visual Studio Community 2013 for further analysis by the PVS-Studio plugin installed on my computer. But for some reason, the check wouldn't go well at first...
As I found out, the cause of the analyzer's internal error had been the presence of a binary sequence in the preprocessed text *.i file. The analyzer can sort out issues like that but it was something unfamiliar this time. The trouble was with one of the lines in the source-file compilation parameters.
/FI"Drawing.dir/Debug//Drawing_d.pch"
The /FI (Name Forced Include File) compilation switch, just like the #include directive, serves for including text header files. But in this case, the programmers are trying to include a file with binary data. It even manages to compile somehow - I guess Visual C++ simply ignores it.
But if we try to preprocess those files, instead of compiling them, Visual C++ will display an error message. However, the Clang compiler, used in PVS-Studio by default, included the binary file into the *.i file without much thinking. PVS-Studio never expected such a trap and went crazy.
To make it clearer, here's a fragment of the file preprocessed by Clang:
I carefully checked the project without that switch but the authors ought to know that they have an error there.
The first bug samples to be discussed result from a very well-known issue.
V501 There are identical sub-expressions 'surfaceTwo->IsVRational()' to the left and to the right of the '!=' operator. modelrefine.cpp 780
bool FaceTypedBSpline::isEqual(const TopoDS_Face &faceOne, const TopoDS_Face &faceTwo) const { .... if (surfaceOne->IsURational() != surfaceTwo->IsURational()) return false; if (surfaceTwo->IsVRational() != surfaceTwo->IsVRational())// <= return false; if (surfaceOne->IsUPeriodic() != surfaceTwo->IsUPeriodic()) return false; if (surfaceOne->IsVPeriodic() != surfaceTwo->IsVPeriodic()) return false; if (surfaceOne->IsUClosed() != surfaceTwo->IsUClosed()) return false; if (surfaceOne->IsVClosed() != surfaceTwo->IsVClosed()) return false; if (surfaceOne->UDegree() != surfaceTwo->UDegree()) return false; if (surfaceOne->VDegree() != surfaceTwo->VDegree()) return false; .... }
Because of a tiny typo, there is the wrong variable "surfaceTwo" instead of "surfaceOne" found to the left of the inequality operator. I can just recommend to copy-paste larger text blocks next time, though we will speak of such samples a bit later, too =).
V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 162, 164. taskpanelview.cpp 162
/// @cond DOXERR void TaskPanelView::OnChange(....) { std::string temp; if (Reason.Type == SelectionChanges::AddSelection) { } else if (Reason.Type == SelectionChanges::ClrSelection) { } else if (Reason.Type == SelectionChanges::RmvSelection) { } else if (Reason.Type == SelectionChanges::RmvSelection) { } }
Why are we discussing an incomplete function? Because this code will most likely face the same troubles as in the next two samples.
V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 1465, 1467. application.cpp 1465
pair<string, string> customSyntax(const string& s) { #if defined(FC_OS_MACOSX) if (s.find("-psn_") == 0) return make_pair(string("psn"), s.substr(5)); #endif if (s.find("-display") == 0) return make_pair(string("display"), string("null")); else if (s.find("-style") == 0) return make_pair(string("style"), string("null")); .... else if (s.find("-button") == 0) // <= return make_pair(string("button"), string("null")); // <= else if (s.find("-button") == 0) // <= return make_pair(string("button"), string("null")); // <= else if (s.find("-btn") == 0) return make_pair(string("btn"), string("null")); .... }
Hopefully, the author forgot to fix only one copy-pasted line but still managed to fully implement the code searching for all the necessary lines.
V517 The use of 'if (A) {...} else if (A) {...}' pattern was detected. There is a probability of logical error presence. Check lines: 191, 199. blendernavigationstyle.cpp 191
SbBool BlenderNavigationStyle::processSoEvent(....) { .... else if (!press && (this->currentmode == NavigationStyle::DRAGGING)) { // <= SbTime tmp = (ev->getTime() - this->centerTime); float dci = (float)QApplication::....; if (tmp.getValue() < dci) { newmode = NavigationStyle::ZOOMING; } processed = TRUE; } else if (!press && (this->currentmode == NavigationStyle::DRAGGING)) { // <= this->setViewing(false); processed = TRUE; } .... }
And now there is what I suppose to be quite a serious bug for such an application. In modeling, a large bulk of work has to be done through mouse navigation, but we've got a problem with that: the source code under the last condition never gets control because the first condition is the same and is executed first.
V523 The 'then' statement is equivalent to the 'else' statement. viewproviderfemmesh.cpp 695
inline void insEdgeVec(std::map<int,std::set<int> > &map, int n1, int n2) { if(n1<n2) map[n2].insert(n1); else map[n2].insert(n1); };
Regardless of the condition, there is always only one branch to be executed. I guess what the programmer really intended was the following:
inline void insEdgeVec(std::map<int,std::set<int> > &map, int n1, int n2) { if(n1<n2) map[n2].insert(n1); else map[n1].insert(n2); };
Why is it exactly the last line that I have fixed? Well, probably you will like the following article on this subject: The Last Line Effect. But it is also possible that the first line should be fixed instead - I'm not sure :).
V570 The 'this->quat[3]' variable is assigned to itself. rotation.cpp 260
Rotation & Rotation::invert(void) { this->quat[0] = -this->quat[0]; this->quat[1] = -this->quat[1]; this->quat[2] = -this->quat[2]; this->quat[3] = this->quat[3]; // <= return *this; }
A bit more of "the last line effect" errors. What the analyzer didn't like about this code is the missing minus sign in the last line. But I can't say for sure if it is a bug or not in this particular case; it may be that the programmer, when implementing this conversion, just wanted to specifically emphasize that the fourth component doesn't get changed.
V576 Incorrect format. A different number of actual arguments is expected while calling 'fprintf' function. Expected: 2. Present: 3. memdebug.cpp 222
int __cdecl MemDebug::sAllocHook(....) { .... if ( pvData != NULL ) fprintf( logFile, " at %p\n", pvData ); else fprintf( logFile, "\n", pvData ); // <= .... }
This code doesn't make sense. If the pointer is null, you can simply print the character of the new string without passing unused parameters to the function.
V596 The object was created but it is not being used. The 'throw' keyword could be missing: throw Exception(FOO); waypointpyimp.cpp 231
void WaypointPy::setTool(Py::Int arg) { if((int)arg.operator long() > 0) getWaypointPtr()->Tool = (int)arg.operator long(); else Base::Exception("negativ tool not allowed!"); }
An exception-type object is created in this code but not used. I guess the keyword "throw" is missing here:
void WaypointPy::setTool(Py::Int arg) { if((int)arg.operator long() > 0) getWaypointPtr()->Tool = (int)arg.operator long(); else throw Base::Exception("negativ tool not allowed!"); }
A few more issues of this kind:
V599 The virtual destructor is not present, although the 'Curve' class contains virtual functions. constraints.cpp 1442
class Curve { //a base class for all curve-based //objects (line, circle/arc, ellipse/arc) // <= public: virtual DeriVector2 CalculateNormal(....) = 0; virtual int PushOwnParams(VEC_pD &pvec) = 0; virtual void ReconstructOnNewPvec (....) = 0; virtual Curve* Copy() = 0; }; class Line: public Curve // <= { public: Line(){} Point p1; Point p2; DeriVector2 CalculateNormal(Point &p, double* derivparam = 0); virtual int PushOwnParams(VEC_pD &pvec); virtual void ReconstructOnNewPvec (VEC_pD &pvec, int &cnt); virtual Line* Copy(); };
The use:
class ConstraintAngleViaPoint : public Constraint { private: inline double* angle() { return pvec[0]; }; Curve* crv1; // <= Curve* crv2; // <= .... }; ConstraintAngleViaPoint::~ConstraintAngleViaPoint() { delete crv1; crv1 = 0; // <= delete crv2; crv2 = 0; // <= }
In the base class "Curve", virtual functions are declared but the destructor to be created as default is not. And of course, it won't be virtual! It means that all the objects derived from this class won't be fully clear if used when a pointer to the child class is saved into a pointer to the base class. As the comment suggests, the base class has a lot of child ones, for example the "Line" class in the example above.
V655 The strings were concatenated but are not utilized. Consider inspecting the expression. propertyitem.cpp 1013
void PropertyVectorDistanceItem::setValue(const QVariant& variant) { if (!variant.canConvert<Base::Vector3d>()) return; const Base::Vector3d& value = variant.value<Base::Vector3d>(); Base::Quantity q = Base::Quantity(value.x, Base::Unit::Length); QString unit = QString::fromLatin1("('%1 %2'").arg(....; q = Base::Quantity(value.y, Base::Unit::Length); unit + QString::fromLatin1("'%1 %2'").arg(....; // <= setPropertyValue(unit); }
The analyzer has detected a meaningless string summation. If you look close, you will notice that the programmer probably wanted to use the '+=' operator instead of simple addition. If so, this code would make sense.
V595 The 'root' pointer was utilized before it was verified against nullptr. Check lines: 293, 294. view3dinventorexamples.cpp 293
void LightManip(SoSeparator * root) { SoInput in; in.setBuffer((void *)scenegraph, std::strlen(scenegraph)); SoSeparator * _root = SoDB::readAll( &in ); root->addChild(_root); // <= if ( root == NULL ) return; // <= root->ref(); .... }
One example of a pointer check in a wrong place, and all the rest issues are found in the following files:
V519 The 'myIndex[1]' variable is assigned values twice successively. Perhaps this is a mistake. Check lines: 60, 61. brepmesh_pairofindex.hxx 61
//! Prepends index to the pair. inline void Prepend(const Standard_Integer theIndex) { if (myIndex[1] >= 0) Standard_OutOfRange::Raise ("BRepMesh_PairOfIndex...."); myIndex[1] = myIndex[0]; myIndex[1] = theIndex; }
In this sample, the programmer overwrites the value of the 'myIndex' array's item having index 1. I think the code was actually meant to look like this:
myIndex[1] = myIndex[0]; myIndex[0] = theIndex;
V501 There are identical sub-expressions '0 <= theParamsHint.Y()' to the left and to the right of the '&&' operator. smesh_block.cpp 661
bool SMESH_Block::ComputeParameters(const gp_Pnt& thePoint, gp_XYZ& theParams, const int theShapeID, const gp_XYZ& theParamsHint) { .... bool hasHint = ( 0 <= theParamsHint.X() && theParamsHint.X() <= 1 && 0 <= theParamsHint.Y() && theParamsHint.Y() <= 1 && 0 <= theParamsHint.Y() && theParamsHint.Y() <= 1 ); // <= .... }
A check with .Z() is obviously missing here. And there is such a function in the class indeed: the class itself is even named "gp_XYZ".
V503 This is a nonsensical comparison: pointer < 0. driverdat_r_smds_mesh.cpp 55
Driver_Mesh::Status DriverDAT_R_SMDS_Mesh::Perform() { .... FILE* aFileId = fopen(file2Read, "r"); if (aFileId < 0) { fprintf(stderr, "....", file2Read); return DRS_FAIL; } .... }
A pointer can't be less than zero. Even in the plainest examples with the fopen() function, that you can find in books and on the Internet, operators == or != are used to compare a function value to NULL.
I was wondering at how code like that could have appeared at all but my co-worker Andrey Karpov told me that such things often happen when refactoring code where the open() function was previously used. This function returns -1 in this case, so the comparison <0 is quite legal. In the course of program refactoring or porting, programmers replace this function with fopen() but forget to fix the check.
Another issue of this kind:
V562 It's odd to compare a bool type value with a value of 12: !myType == SMESHDS_MoveNode. smeshds_command.cpp 75
class SMESHDS_EXPORT SMESHDS_Command { .... private: SMESHDS_CommandType myType; .... }; enum SMESHDS_CommandType { SMESHDS_AddNode, SMESHDS_AddEdge, SMESHDS_AddTriangle, SMESHDS_AddQuadrangle, .... }; void SMESHDS_Command::MoveNode(....) { if (!myType == SMESHDS_MoveNode) // <= { MESSAGE("SMESHDS_Command::MoveNode : Bad Type"); return; } .... }
Here we have an enumeration named "SMESHDS_CommandType" containing a lot of constants. The analyzer has detected an incorrect check: a variable of this type is compared to a named constant, but what for is the negation symbol?? I bet the check should actually look like this:
if (myType != SMESHDS_MoveNode) // <= { MESSAGE("SMESHDS_Command::MoveNode : Bad Type"); return; }
Unfortunately, this check with message printing was copied to 20 other fragments. See the full list: FreeCAD_V562.txt.
V567 Undefined behavior. The order of argument evaluation is not defined for 'splice' function. The 'outerBndPos' variable is modified while being used twice between sequence points. smesh_pattern.cpp 4260
void SMESH_Pattern::arrangeBoundaries (....) { .... if ( outerBndPos != boundaryList.begin() ) boundaryList.splice( boundaryList.begin(), boundaryList, outerBndPos, // <= ++outerBndPos ); // <= }
The analyzer is actually not quite correct about this code. There's no undefined behavior here, but there is an error, so the warning was displayed not in vain. The C++ standard doesn't put any restrictions on the evaluation order of a function's actual arguments. So it is unknown which values will be passed into the function.
Let me clarify on it by a simple example:
int a = 5; printf("%i, %i", a, ++a);
This code may print both "5, 6" and "6, 6", which depends on the compiler and its settings.
V663 Infinite loop is possible. The 'cin.eof()' condition is insufficient to break from the loop. Consider adding the 'cin.fail()' function call to the conditional expression. unv_utilities.hxx 63
inline bool beginning_of_dataset(....) { .... while( ((olds != "-1") || (news == "-1") ) && !in_file.eof() ){ olds = news; in_file >> news; } .... }
When working with the 'std::istream' class, it's not enough to call the function 'eof()' to terminate the loop. If a failure occurs when reading the data, calling the 'eof()' function will always return 'false'. To terminate the loop in this case, we need an additional check for the value returned by the function 'fail()'.
V595 The 'anElem' pointer was utilized before it was verified against nullptr. Check lines: 1950, 1951. smesh_controls.cpp 1950
bool ElemGeomType::IsSatisfy( long theId ) { if (!myMesh) return false; const SMDS_MeshElement* anElem = myMesh->FindElement( theId ); const SMDSAbs_ElementType anElemType = anElem->GetType(); if (!anElem || (myType != SMDSAbs_All && anElemType != myType)) return false; const int aNbNode = anElem->NbNodes(); .... }
The "anElem" pointer is dereferenced one line earlier than being checked for being valid.
Here are a few other similar issues in this project:
V567 Undefined behavior. The 'this->n_' variable is modified while being used twice between sequence points. regex_token_iterator.hpp 63
template<typename BidiIter> struct regex_token_iterator_impl : counted_base<regex_token_iterator_impl<BidiIter> > { .... if(0 != (++this->n_ %= (int)this->subs_.size()) || .... { .... } .... }
It is unknown which of the operands of the %= operator will be evaluated first. Therefore, the expression being correct or incorrect depends on pure chance.
Try and integrate static analyzers into the development process to run regular analysis of your projects and third-party libraries they use. It will help you save plenty of time when writing new code and maintaining old ... | https://www.viva64.com/en/b/0322/ | CC-MAIN-2018-17 | refinedweb | 2,608 | 50.94 |
# Recursion
Recursion is a strategy that algorithms use to solve specific problems. A recursive algorithm is an algorithm that solves the main problem by using the solution of a simpler sub-problem of the same type. Recursion is a particular way of solving a problem by having a function calling itself repeatedly. It is always applied to a function only. By using recursion, we can reduce the size of the program or source code. In recursion, a function invokes itself. And the function that invokes itself is referred to as a recursive function.
Suppose we have a user-defined function named ‘recursion’, and it will be written in the main function. The compiler will execute the recursion function automatically, and it will search for a particular function definition. This function definition will be executed, and control will go back to the main function. If we call the same function inside the function definition, then the compiler will move on to function definition first. When the compiler executes the recursion function, we will be calling the same function.
```
function main(){
function recursion() {
// function code
recursion();
// function code
}
recursion();
}
main();
```
This recursion process will be executed infinitely until we apply the exit condition. A recursion should have two things:
1. ‘Base’ or ‘Exit’ condition.
2. Recursive function call.
Without base condition, the program will not stop. The base condition helps us to prevent infinite recursions of a function. We can call a function directly or indirectly in recursion.
**Working**
In recursion, the main problem can be solved by using a simpler subproblem of the same type. This can be done until the problem becomes so simple that a declarative answer can be provided. Once a definite answer is provided through step-by-step substitution, the main problem can be solved. This how recursion works.
Suppose we need to compute the factorial of 5. So, we will call the function factorial of 5.Factorial of 5 is equal to :
We can also write a factorial of 5 as:
It is easy to ascertain that for any value of ‘n’ , its factorial will be n into n minus 1 factorial.
For calculating the factorial of 5, if we break it down into a simpler subproblem and use that solution. Then we can say that factorial of 5 is equal to:
We call the function factorial and ask it to find the factorial of 5. That called function will say OK, and it will calculate the factorial of 5, but it will need a factorial of 4.Because the factorial of 5 is equal to 5 into factorial of 4. At this point, the function will make a call to itself. And we are calling the same function within the function. Now, the function will run again to find the factorial of 4, which will be equal to 4, into a factorial of 3.
Within the function, the function will call itself again. Now function for factorial of 3 will be run. Factorial of 3 will be equal to 3 into factorial of 2.
It can be seen that problem size is going to be reduced. Similarly, we will have functions of factorial of 2 and 1.
So the problem size given to the function will keep on reducing at a point the problem will become so simple that we don’t need computations to solve it. So we have reduced the above function until the point where we have to find the factorial of zero. So, we have reduced the problem to such a state where it has become so simple that we have a defined answer. And there is no computation for that particular case.
As the factorial of 0 is equal to 1, we can put it previous function where the factorial of 1 will become 1.Using this, we can arrive at the factorial of 2 and substitute 1 in it. Similarly, we will keep on substituting the factorial function in its previous function. It can be seen that we have solved the main problem by using the solution of simpler sub-problems. At each time, we are finding the solution to the problem by using the subproblem solution.
**Types of Recursion**
A recursion has the following major categories:
1. Direct Recursion
2. Indirect Recursion
3. Tail Recursion
4. Non-Tail Recursion
***Direct Recursion***
In a direct function, we call the same function directly in its main body. It can be seen below that we have the function ‘recursion’, and it is called with the same name in its main body. So, this is direct recursion.
```
function recursion() {
// function code
recursion();
// function code
}
}
```
***Indirect Recursion***
In an indirect recursion, a function indirectly calls the original function through some other function. It can be seen below, there is a function ‘recursion1’, and we call another function ‘recursion2’ in its main body. Then we call the ‘recursion1’ in the definition of ‘recursion2’. So, the recursion occurs here indirectly.
```
recursion1(){
recursion2();
}
recursion2(){
recursion1();
}
```
***Tail Recursion***
In a tail-recursion, a recursive call is a final thing done by the function. Thus, there is no need to keep a record of the previous state.
If we see the following code, there is a function defined with the name ‘recursion’. So it can be seen that the last operation performed in this is ‘recursion’. So recursive statement is executing at the end, and no function will be performed after that. And there is no need to keep the record in the stack because there will be no record use in the stack, and it will be useless.
```
function recursion(n){
if(n == 0){
return;
}else{
console.log(n);
return recursion(n - 1);
}
}
```
Now we write the main program as shown below and pass 3 in it.
```
function main(){
recursion(3);
return 0;
}
```
Let us comprehend this along with the help of a stack. Suppose we make a stack. The program will start from the main in this stack, and an activation record will be formed of the main function. Activation record tells that for how much time the record will remain active. Then recursion(3) will be called. In the main function, as 3 is not equal to 0 so it will print 3 and will return recursion(2). Now, 2 is also not equal to 0, so it will print 2 and return recursion(1). And activation record recursion(1) will be created in the stack. Then 1 is not equal to 0, so 1 will be printed. Now 0 will be returned.
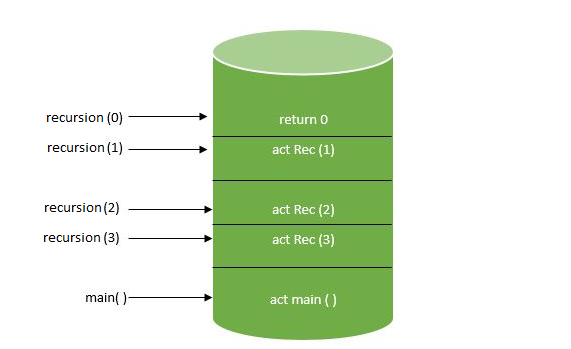***Non-Tail Recursion***
A recursion function is called non-tail recursive if recursion is the not last thing done by the function. There is a need to keep a record of the previous state.
Let us take the previous example in which we have defined the function ‘recursion’. As compare to tail recursion, now operation will not end after function ‘recursion’, and some other operation will also be performed after the recursion function call. We will remove the print statement after if condition and write ‘recursion(n-1)’.And we write the print statement. Recursive function ‘fun’ is not calling at the last but the is print statement after that.
```
function recursion(n){
if(n == 0){
return;
recursion(n - 1);
console.log(n);
return recursion(n - 1);
}
}
```
Its main program will be similar to the tail recursion main program and pass 3 in it.
```
function main(){
recursion(3);
return 0;
}
```
Now let us see it's working in the activation record. The program will start from the main, and an activation record will be formed of the main function. Then recursion(3) will be called. As 3 is not equal to 0, so again recursive will be called, and control will not go to print statement. After calling recursive, 2 will be created in the activation record. Condition ‘if’ will be failed, and recursive will be called again. And 1 will be created in the activation record. And finally, it will be returned for 0.
**Pseudo Code of Recursion**
To understand the pseudo for recursion, let us take an example of a factorial number. We have named a factorial function as ‘fa’ and take some input as input parameter for which we want to find factorial. An integer will be returned because we want to find the factorial of a number. The factorial of any number in the solution will be n into the factorial of n minus 1. We will keep on returning the solution until this problem becomes so simple that we directly answer without making another function call. The condition will be that if the n is equivalent to zero, then the solution will be 1. So when we have to calculate 0 factorial, we said that solution was 1. So off course, we want to return the solution.
```
function factorial(n) {
if (n === 0) {
return 1;
}
else {
return n * factorial(n - 1);
}
}
```
**Fibonacci Series Implementation Using Recursion**
The Fibonacci series is usually denoted by:
In this series, the next value is the total of the previous two values. We can represent this series in the form of the array as:
 There are a total of 7 indexes from 0 to 6. In this array, Fibonacci at index 3 is equal to the Fibonacci of index 2 plus Fibonacci of index 1. Similarly, Fibonacci at index 2 is equal to Fibonacci of index 1 plus Fibonacci of index 0.
In a generalized form, it will be:
Now in case of its recursive function,if the value of ‘n’ is greater than 1 then Fibonacci sequence will be equal to ‘fib (n-1)’ plus ‘fib (n-2)’. And if the ‘n’ is less than or equal to 1 then Fibonacci sequence will be equal to ‘n’.
In recursion, firstly, we will call the Fibonacci function ‘f(n)’.Lets assume that the n is 5. As the n is greater than 1, so fib(5) will be equal to fib(4) and fib(3). Now we will completely solve fib(4) and then fib(3). When we call fib(4), then it will call fib(3) and fib(2). Then fib(3) will call fib (2) and fib(1). Now fib(2) will call fib(1) and fib(0).
```
function fib(n){
if(n < 2) {
return n;
}
else {
return fib(n - 1) + fib(n - 2);
}
}
```
**Advantages and Disadvantages of Recursion**
***Advantages***
It has the following benefits:
1. It is easy to write. It means that we have to write small code for a recursive function.
2. It reduces time complexity.
3. We have to write a lesser number of lines as an iterative technique, so the size of code decreases in it.
4. It adds clearness and decreases the time required to write and debug code.
***Disadvantages***
It has the following disadvantages:
1. It consumes more storage space due to the use of the stack. To solve the recursive function, the stack is used, so it requires more storage space than the iterative technique.
2. A computer may run out of memory if the terminating condition is written wrong.
3. It is not efficient in terms of speed and time.
**Applications of Recursion**
It has the following applications:
1. Recursion is used in different types of data structures like linked lists and trees.
2. It is used to implement sorting techniques such as merge sort and quick sort because their implementation becomes different with iterative approaches.
3. Recursion is used to find all files in a folder and subfolder in the hierarchy.
4. It is also used in elevator programming. | https://habr.com/ru/post/559982/ | null | null | 2,187 | 58.28 |
How to C# Socket programming
C# simplifies the network programming through its namespaces like System.Net and System.Net.Sockets . A Socket is an End-Point of To and From (Bidirectional) communication link between two programs (Server Program and Client Program ) running on the same network . We need two programs for communicating a socket application in C#. A Server Socket Program ( Server ) and a Client Socket Program ( Client ) . resides and the Port Number assign for listening for client's request .
Once the connection is established between Server and Client , they can communicate (read or write ) through their own sockets.
There are two types of communication protocol uses for Socket Programming in C# , they are TCP/IP ( Transmission Control Protocol/Internet protocol ) Communication and UDP/IP ( User Datagram Protocol/Internet protocol ) Communication .
In the following section we are going to communicate a C# Server Socket Program and C# Client Socket Program using TCP/IP Communication Protocol.
The above picture shows a Server and Client communication interfaces in C#.
C# Server Socket Program:
The Server Socket Program is done through a C# Console based application . Here the Server is listening for the Client's request , and when the C# Server gets a request from Client socket , the Server sends a response to the Client . Click the following link to see in detail of a C# Server Socket Program.
C# Client Socket Program:
The C# Client Socket Program is a windows based application . When the C# Client program execute , it will establish a connection to the C# Server program and send request to the Server , at the same time it also receive the response from C# Server . Click the following link to see in detail of C# Client Socket Program.
How to run this program ?
The C# Socket Program
- C# Server Socket program
- C# Client Socket program
- C# Multi threaded socket programming
- C# Multi threaded Server Socket programming
- C# Multi threaded Client Socket programming
- How to C# Chat server programming
- How to C# Chat Server
- How to C# Chat Client
- How to web browser in C#
| http://csharp.net-informations.com/communications/csharp-socket-programming.htm | CC-MAIN-2014-15 | refinedweb | 343 | 52.8 |
KPMG IN country.
The industry is at a cross roads today, where it can leverage opportunities created by
global shifts in sugar trade as well as the emergence of sugarcane as a source of
renewable energy, through ethanol and cogeneration. While some of these
opportunities have been well researched in the past, there was a need to assess the
potential for India and to develop a comprehensive and actionable roadmap that
could enable the Indian industry to take its rightful place as a food and energy
producer for one of the world's leading economies.
Indian Sugar Exim Corporation (ISEC), an apex body with both Indian Sugar Mills
Association (ISMA) and National Federation of Cooperative Sugar Factories (NFCSF)
as its constituents, has sponsored KPMG for developing this roadmap. Over last
few months, KPMG had extensive discussions with stakeholders across the value
chain – farmers, millers, international traders and policy makers. These were
supported with data collation from various sources, a comprehensive consumer
study and expert views from international sugar research agencies. This report is the
culmination of all these efforts and insights.
The report identifies imperatives for industry stakeholders, both from business and
regulatory perspectives.The impact of these imperatives will enable greater prosperity
for millions of farmers and drive future growth of the industry in domestic and
international markets, while contributing towards food and energy security for India.
We appreciate the contribution of the KPMG team in developing this roadmap and
the industry stakeholders and policy makers now need to work together to enable
its successful implementation.
© 2007 KPMG, an Indian partnership and a member firm of the KPMG network of independent member
firms affiliated with KPMG International, a Swiss cooperative. All rights reserved.
Foreword
removal of EU subsidies have provided new horizons for the sector.The sector today
has transformational opportunities that would enable it not only to continue to
service the domestic markets but also emerge as a significant carbon credit and
power producer and support an ethanol blending programme of E10 and beyond.
However the sugar regulations would have to evolve to facilitate the transformation
of the sector. We believe in the potential of the sector and have therefore partnered
with ISEC in conceptualizing the sector roadmap 2017.
In the past, while there have been major studies conducted on the regulatory
aspects of the sector, there have been none which have provided a comprehensive
roadmap incorporating both the business and regulatory perspectives. This study
aims at providing that comprehensive roadmap.
It has been a challenging task, but we've received tremendous support from the
industry in developing this study. We are confident of the potential of the
transformation opportunities and if the sector were to traverse the recommended
roadmap, it would move towards the shared vision.
We are grateful to ISEC for giving us the opportunity and to all stakeholders who
contributed to this study.
Arvind Mahajan
Executive Director, KPMG Advisory Services Pvt. Ltd.
© 2007 KPMG, an Indian partnership and a member firm of the KPMG network of independent member
firms affiliated with KPMG International, a Swiss cooperative. All rights reserved.
Contents
1 Executive Summary 1
3 Shared Vision 24
Abbreviations 199
References 202
This Document is CONFIDENTIAL and its circulation and use are RESTRICTED. ©2007 KPMG, the Indian
member firm of KPMG International, a Swiss cooperative. All rights reserved. KPMG and the KPMG logo are
registered trademarks of KPMG International, a Swiss cooperative. Printed in India
Executive Summary
In an era where there is a need for inclusive growth, the sugar industry is amongst
the few industries that have successfully contributed to the rural economy. It has
done so by commercially utilizing the rural resources to meet the large domestic
demand for sugar and by generating surplus energy to meet the increasing energy
needs of India. In addition to this, the industry has become the mainstay of the
alcohol industry. The sector supports over 50 million farmers and their families, and
delivers value addition at the farm side1. In general, sugarcane price accounts for
approximately 70 percent of the ex-mill sugar price2.
The sector also has a significant standing in the global sugar space. The Indian
domestic sugar market is one of the largest markets in the world, in volume terms.
India is also the second largest sugar producing geography. India remains a key
growth driver for world sugar, growing above the Asian and world consumption
growth average.
Globally, in most of the key geographies like Brazil and Thailand, regulations have a
significant influence on the sugar sector. Perishable nature of cane, small farm
landholdings and the need to influence domestic prices; all have been the drivers for
regulations. In India, too, sugar is highly regulated. Since 1993, the regulatory
environment has considerably eased, but sugar still continues to be an essential
commodity under the Essential Commodity Act. There are regulations across the
entire value chain land demarcation, sugarcane price, sugarcane procurement,
sugar production and sale of sugar by mills in domestic and international markets.
1
Source: ISMA Indian sugar year book 2005-06
2
Source: KPMG Analysis
3
Source: AC Nielsen, KPMG Analysis
5.51
14
30.0%
12
10
5.26
8 12.8%
6 25.8% 2.24
4
4.51
2
0
Low incom e High incom e Industrial Sm all Business
household household
Madras School of Economics (MSE) has also raised the need to reassess the
weightage of sugar in the wholesale price index (WPI). As per MSE, the share of
expenditure within a basket of consumption and investment goods can be used as
an indicator for assessing the suitability of WPI weights.While the current weight for
sugar and Gur is 3.68 percent, MSE suggests that the appropriate weight for sugar
should be 2.02 percent as per the current basis of WPI calculation that excludes
services. MSE further suggests that services should be included in the WPI
calculation, and in that case the appropriate weight for sugar would be 1.04 percent5.
While the sector grows in stature and continues to play a key role in the economy, it
is expected to face some significant challenges.There is lack of alignment between
sugarcane and sugar prices. As a result, it leads to cane payment arrears and
induces cyclicality. The arrears typically result in the eventual need for government
support packages, while the pronounced cyclicality destabilizes the sector
revenues. The average sugarcane yields have also, at best, stagnated, and the
average recovery is amongst the lowest in comparison with key sugar producing
nations. Large sugar inventory exposure and sugar price volatility also results in high
sugar price risk for the sector. In the past ten years, on an average basis, even the
large listed sugar firms have struggled to generate Return on Invested Capital
(ROIC) over and above their cost of capital. This is primarily due to high mandated
fixed cane prices and volatile sugar prices6.
4
Source:Household sugar consumption and income segments as per AC Nielsen survey. Monthly
household income less than INR 5000 considered as low income household. Total non levy sugar
consumption estimated at 17.52 million MT annually
5
Source:Madras School of Economics
6
Source:Prowess, KPMG Analysis
Sector roadmap 2017 addresses all these issues. The sector roadmap comprises
business and regulatory roadmap that lay out the respective perspectives. The key
features of the sector roadmap are discussed below.
Shared
Vision
Self sufficiency in
meeting domestic demand
High economic profit Fulfilling consumer
Social welfare of stakeholders driven growth needs
Enhanced contribution to
nation’s energy Risk minimization
requirement
Collaboration between
farmer and miller
Policy makers Consumers
HIGH
Product Cyclicality
management *
High impact
innovation opportunities
Sugar price which are largely
risk mgmt. By products - untapped
Ethanol, Cogen
Extent of International
potential trade Productivity
improvements
currently
untapped
High impact
opportunities which
Domestic
demand have been
traditionally tapped
LOW
LOW Impact -Level of criticality, HIGH
value of opportunity
7
Cyclicality management refers to cane and sugar price alignment
Thus, ensuring the alignment between sugarcane and sugar prices would be the
key policy imperative for managing cyclicality.
8
Note: All references to years are for sugar year (October to September) unless otherwise specified
9
Source: ISMA
Low High
Sri Lanka
East Africa
White sugar import potential as
percent of total import potential
High
Iran Bangladesh
Indonesia
Pakistan
Saudi Arabia
Low
UAE
Freight advantage
The target markets are estimated to import 10 million MT of sugar by 201712. India
would be able to leverage this opportunity through productivity improvements and
alignment of cane and sugar prices in the domestic market. India's competitiveness
can also be increased by enhancing export infrastructure like loading rates and draft
in Indian ports. Since the current cost structure of the Indian industry is uncompetitive
for exports, in case of a large sugar surplus, the government could consider using WTO
compliant subsidies to enable exports while creating stability in the domestic market.
The industry could also explore ways of collectively sharing losses due to exports, if
any, since exports would enable lower stocks in the domestic market, thus benefiting
both mills and farmers through higher sugar realization.
10
Source: Centre for International Economics
11
Bubble size represents the estimated sugar imports in 2017 in MT
12
Source: KPMG Analysis
The sector has the potential to improve sugarcane yields by 10 percent and also
improve the recovery by 50 basis points by 2017. This would enable the sector to
produce additional 4.1 million MT of sugar. Assuming constant drawal, to meet the
targeted demand, the area under cane would need to increase by 0.2 million
hectares. This would be possible by better utilization of existing cane demarcated
areas. This would also ensure minimal impact on other crops. A higher drawal or
greater increase in farm productivity will also enable the target demand to be met,
without any increase in cane acreage. In order to crush the additional cane, the
13
crushing capacity would need to increase by 0.23 million TCD by 2017 . This can be
met through expansion of the existing units rather than new mills being established.
Water management would be a key focus area since sugarcane is a water intensive
crop. The adoption of advanced techniques like drip irrigation would help achieve
sustainable growth for the sector.
Encouraging efficiency at the mill side, quality improvement at the farm side and
strengthening the farmer-miller relationship would be the key policy imperatives.
Greater investments in research and development of seed varieties and adoption of
improved farm practices will be key imperatives for improving farm productivity.
By-products opportunity
Fuel ethanol and surplus power production through cogeneration provide the two
key by-products' related opportunities.
Globally energy security and environmental concerns are driving the adoption of fuel
ethanol across countries. Leading countries including Brazil, U.S., Europe, Australia,
Canada and Japan have established fuel ethanol programmes. In the future, global
fuel ethanol demand is likely to grow exponentially. Global ethanol exports, currently
14
at 6.5 billion litres are expected to increase to 50 to 200 billion litres by 2020 . This
increase would largely depend on world crude prices and regulatory evolution.
13
Source: KPMG Analysis
14
Source: McKinsey Quarterly
7000
6000
Alcohol demand (Million litres)
965
The regulatory environment will need to facilitate the transition to higher blending
programme through necessary changes that would be made to the Sugarcane
Control Order. Higher levels of blending will also need mills having the flexibility to
shift from sugar to ethanol, based on market dynamics.
For the cogeneration opportunity, in 2017, there is a total exportable power potential
of approximately 9,700 MW. This can fulfil almost 6 percent of the additional power
requirement of 128 GW by 2017. The sector can also generate 48 million carbon
credits through cogeneration16.
15
KPMG Analysis
16
KPMG Analysis
10000
2570
8000
Power (MW)
6000
9688
4000 6271
2000
847
0
Present Additional Additional Total exportable
exportable power exportable exportable potential in 2017
potential in 2007 potential in 2017
Consistent policies for cogeneration at the central and state levels would be the key
policy imperative.
A viable commodity exchange for sugar would be essential for effective hedging and
price risk management.
17
KPMG Analysis
Summary of opportunities
By products
! 3,000 mllion litres of ethanol
! 9,700 MW of exportable Sugar price risk management
power ! Use of hedging for
! 48 million carbon credits managing VaR of INR
! Energy security through 3,000 crores
green sources ! Greater use of commodity
! Investment - 320 crores to exchanges
Sugar is regulated at the central and state levels. Hence, it is also subject to conflicts
that arise from diverse perspectives at the two governance levels. Some of these
conflicts relate to announcement of the Statutory Minimum Price (SMP) and State
Advised Price (SAP), incentive schemes, molasses control and cogeneration (MNES
Act). For establishing a level playing field and for removal of regulatory distortions,
such conflicts need to be resolved.
For the key sugar regulations, modifications have been suggested. The suggested
modifications are broadly in line with the Mahajan committee recommendations.
The modifications are also broadly in line with the views of LMC, an international
agency focusing on sugar. The regulatory modifications are evolutionary in nature.
Regulations, with recommended changes are:
Cane pricing
! Formula-based pricing – Cane price linked to prices of sugar and primary
byproducts (molasses and surplus bagasse) and to average recovery
! Prices to be determined using a fixed formula based on region specific
variations
! Incentives to be given for varieties with high sucrose content and for early and
late maturing varieties
! Minimum support prices to be announced to protect farmers from
subsistence risk
International trade
! Removal of non-tariff trade restrictions
Levy sugar
! Levy sugar to be discontinued
! Sugar for PDS requirements to be sourced from the free market
Currently the sugar industry is passing through a phase of surplus production and
there is an expected surplus of 7.8 million MT of sugar. This has been largely due to
the remunerative sugar cane prices that are prevalent for the last two years as well
as the inability of the sugar industry to export sugar when the world prices were
viable last year. As a result, the sugar stocks in India are at an all time high which has
depressed the domestic sugar prices making it difficult for the mills to pay the
farmers. A host of factors, including a coincidental surplus in the international
market, has intensified the seriousness of the situation.
While this report has discussed several long term proposals for the growth and
development of the industry, there is a need for immediate measures to help keep
the industry viable. These could include -
! Exports can be used to reduce the domestic stock to manageable levels. India
is not competitive in white or raw sugar exports as seen earlier. Also, the
markets for white plantation sugar have decreased, while the markets for
refined 45 ICUMSA and raw sugar have increased. India has the capability to
produce raw sugar, while its competitiveness is low. The government needs
to extend full support to the industry for enabling exports through appropriate
subsidies and policy measures. Hence the government can consider
extending the WTO compliant support to reduce stocks so that sugar prices
recover in the domestic market
! The government can create strategic stock which will help in reducing the
stocks in the market. Reduced stocks will lead to price recovery and enable
payment of cane prices to farmers.The industry will thus maintain its viability
for subsequent years.
!
The Indian government's policies would need to support the sugar industry,
considering its massive impact on the agro economy and associated social
objectives encompassing large masses.
Both central government as well as the state government regulate and legislate
cane pricing, sometimes causing avoidable aberrations through conflicting laws. A
consensus between central and state governments on cane pricing is therefore an
essential prerequisite for successful implementation of the roadmap.18.
18
Ch. Tikaramji & others vs. state of Uttar Pradesh & others, 1956
The central government could also explore making suitable modifications to the
Essential Commodities Act in order to implement the cane pricing regulatory
modifications by defining a fair price for cane in addition to a minimum price. In case
of monthly release mechanism, the key pre-requisites would be creation of a
strategic stock and definition of a sustainable price band for sugar.
Going forward, the sector would also need to periodically review the roadmap and
realign it with the changing business dynamics. The key trends that could
necessitate realignment include
! Future growth of Brazil and its influence on the global sugar trade
! Future evolution of WTO regulations for sugar
! Growth of ethanol and emergence of alternative ethanol production
techniques like cellulosic ethanol
! Development of cane quality measurement systems
! Growth of alternate sweeteners as sugar substitutes
! Emergence and success of contract farming within India
! Impact of biotechnology
However, the entire value chain of the sector farm side, mill side and market side is
confronted by significant business and regulatory challenges. Many of these
challenges not only impact the sugar business but also impair the high potential by-
products' businesses. The sector, thus, requires a comprehensive sector road map
to guide it towards achieving its potential.
The study aims at drafting such a sector road map, which will identify requisite
business and regulatory initiatives for unlocking the sector's potential over the next
ten years. The sector road map 2017 will comprise business and regulatory
roadmaps.
Business roadmap 2017 is guided by the sector's shared vision. It aims at evaluating
transformation opportunities, identifying business imperatives for realizing the
opportunities, incorporating learnings from other industries that have undergone
similar transformation and visualizing the appropriate policy environment.
! Sector analysis KPMG tools and analysis frameworks were utilized for the
analysis.The key frameworks included vision articulation, sector performance
analysis, value chain analysis, opportunity evaluation and projections and
industries' transformation analysis.
! Regulatory analysis The key KPMG tools and analysis frameworks that
were used included regulatory transition analysis, risk evaluation, scenario
analysis and implementation plan formulation.
To synthesize the aspirations, extensive primary interactions were held with various
stakeholders' representatives. The interactions were primarily held with farmer
associations, farmer representatives, miller associations, private and cooperative
millers, international traders and key policy makers.The study was also supported by
a nationwide consumer survey.
Farmers aspire for increasing yields, higher cane prices and timely payment of cane
prices to drive higher economic profit at the farm side. For minimizing crop risks,
farmers aspire for effective extension services, crop off take assurance, accessibility of
timely finances and improved harvesting and transport infrastructure.
Millers aspire for increasing economic profit through higher availability of cane,
better sucrose content in sugarcane, better sugar realizations in domestic market,
flexibility to export sugar, higher value addition from by-products including alcohol
and removal of competition distorting policy interventions. At the same time, millers
in general are looking to reduce sugar price risk through hedging. Overall, millers
aspire for ease of regulations and greater influence over business levers.
The government or specifically sugar sector policy makers aspire that the sector
continues to be self sufficient in meeting domestic demand, assumes a bigger role
in meeting the growing energy needs of India, continues to address the social
needs of stakeholders including farmers, millers and consumers and that the sector
increase its contribution to the exchequer.
18
Economic profit is being defined as returns from operating assets over and above capital costs
Consumers' aspirations provide another component of the shared vision in the form
of fulfilling consumer needs.
Shared
Vision
Self sufficiency in
meeting domestic demand
High economic profit Fulfilling consumer
Social welfare of stakeholders driven growth needs
Enhanced contribution to
nation’s energy Risk minimization
requirement
Collaboration between
farmer and miller
Policy makers Consumers
Sugarcane is primarily grown in nine states of India: Andhra Pradesh, Bihar, Gujarat,
Haryana, Karnataka, Maharashtra, Punjab, Uttar Pradesh and Tamil Nadu. More than
50 million farmers and their families are dependent on sugarcane for their livelihood.
The sugar industry caters to an estimated 12 percent of rural population in these
nine states through direct and indirect employment. Effectively, each farmer
contributes to the production of 2.9 MT of sugar every year19.
19
Average rural household size of 5.37 is assumed. Source: AC Nielsen, Business World Marketing White
book 2006. Sugar production for the year 2007 has been estimated to be 27 million MT. Source: ISMA
20
Cane purchase tax, sugar excise duty, molasses excise duty and cess on sugar have been considered.
Source: ISMA Indian Sugar Year book 2005-06.
Punjab 1.8%
Haryana 2.1%
Bihar 2.2%
Gujarat 6.1%
Maharashtra 27.1%
Karnataka 10.2%
Andhra Pradesh 6.4%
21
Map not to scale and illustrative
30
Sugar production (million MT)
20
15
10
05
0 2001
2005
1977
1961
1973
1981
1997
1965
1969
1985
1989
1993
Private Mills have increased their share of production while the share of
cooperative mills has reduced
The Indian sugar sector is composed of three distinct categories - public mills,
private mills and cooperative mills. Public mills account for around 6 percent of the
total mills in operation while the private mills account for approximately 40 percent
and the cooperative mills account for approximately 53 percent. In the recent past,
the number of operational private mills has been increasing as a percentage of the
total number of mills.
22
Sugar production for the year 2007 has been estimated to be 27 million MT. Source: ISMA.
450
400
350
259 251 269 235 284 240
Number of mills
30 0 (59.4%) (53.0%)
250
200
37 37 29 29 30 29
150 (8.5%) (6.4%)
100
140 145 155 159 166 184
(32.1%) (40.6%)
50
0
2001 2002 2003 2004 2005 2006
Private Public Cooperative
Also, the share of sugar production by private mills has been increasing. At present,
the sugar production from the private mills accounts for more than 54 percent of the
total production while the share of production from the cooperative mills has come
down to 43 percent from 57 percent in 2001. This is due to the fact that the number
of operational private mills has been steadily increasing since 2001, while the
number of cooperative mills has remained stagnant. Also, the states of
Maharashtra, Karnataka and Tamil Nadu, which have a high concentration of
cooperative mills, were affected by woolly aphid pest attacks in 2003-04 apart from
the drought that affected almost all cane producing states.
20
Sugar production (million MT)
8.27
10.50 10.16 (42.9 %)
15 9.43
(56.7%)
0.49
6.02 4.65 (2.5%)
10 0.70
0.79 0.78
0.51 0.46
(4.2%)
5 9.28
7.23 8.32 10.51
7.03 7.58 (54.5%)
(39.0%)
0
2001 2002 2003 2004 2005 2006
Private Public Cooperative
Figure 14: Sector wise production (2001 - 2006)
Source: ISMA, KPMG analysis
The key characteristic of cane production in India is the small landholding size
Sugarcane is the primary raw material for sugar production and adequate sugarcane
availability is a prerequisite for mill viability. The sugarcane production in India is
unique in various aspects. One such aspect is the land holding size.The landholding
size of 4 hectares or more is present in only 25 percent of the area under sugarcane
cultivation. The bulk of the land under sugarcane is between 1 and 4 hectare. This
land holding structure is a key structural feature of the sugar industry in India.
There are more than 50 million farmers and families involved in the sugarcane
cultivation and these farmers supply sugarcane to almost 500 mills in various parts
of the nine sugar producing states23. Therefore, on an average, each mill procures
cane from 18000 farmers24 which is one of the highest in the world. This increases
the complexity of managing cane procurement, quality control and cane
development.
The small landholdings also limit the extent of mechanization and reduce the ability
of the farmer to invest in farm productivity. The ability of a farmer to sustain himself
in the event of a crop failure or lack of crop off take or non-payment of dues is also
limited by the size of the land holding.
23
Source: ISMA Indian Sugar Year book 2005-06
24
Average rural household size of 5.37 is assumed. Source: AC Nielsen, Business World Marketing White
book 2006
0.5 - 1 ha (12%)
4 - 10 ha (25%)
1- 2 ha (24%)
2 - 4 ha (28%)
Figure 15: Distribution of area under sugarcane for different size of landholding
Source: ICRA sector analysis “The Indian Sugar Industry” July 2006, AC Nielson, KPMG analysis
4.2 Consumption.
20 3.5
18
3.0
16
GDP at factor cost (INR million crore)
Sugar consumption (million MT)
14 2.5
12
2.0
10
1.5
8
6 1.0
4
0.5
2
0 00
2000
2002
2003
2004
2005
2006
1996
1997
1998
1999
2001
In 2006, the drawal rate (which indicates the use of sugarcane for sugar production
as a percent of total sugarcane production) was 68 percent which was an all time
high.This has been a reversal in trend from the 1960's, when the drawal rate was at
30 percent. The percentage of cane used for chewing and other purposes has
remained largely constant over the years.
350 100%
90%
300
Sugarcane used (million MT)
80%
68 68
250 62 % %
60 61 70%
Drawal (percent)
% 60
54 % % % 56
53 54
% 53
49
51 % % % 60%
200 % 45
47 46
%
% %
42 % 43 %
% % 50%
150 48
% 40%
100 30%
20%
50
10%
0 0%
1991
2001
1992
2002
1997
1993
2003
1990
1995
2000
2005
1996
2006
1988
1989
1998
1999
1994
2004
25
For 2005 and 2006, the percentage of cane used for seed, feed and chewing has been assumed to be
11.9 percent based on historical average and the percentage of cane used for Gur and Khandsari has
been calculated based on the same.
6
10.77
4
6.75
2
0
Household (Non Levy) Indirect (Industrial&
Small business)
Figure 18: All India non levy sugar consumption (2006-07)
Source: AC Nielsen survey conducted in March 2007, KPMG analysis
The low income households, with a monthly income of less than INR 5,000, account
for an estimated 4.51 million MT every year, contributing to 25.8 percent of total
non-levy sugar consumption. The high income households, with a monthly income
of more than INR 5,000, account for an estimated 2.24 million MT of consumption
every year with a share of 12.8 percent of non-levy sugar consumption.
20
18
Total estimated non levy sugar
16 consumption = 17.52 million MT
5.51
14
Consumption (million MT)
12
10
5.26
8
6 2.24
4
4.51
2
0
Low incom e High incom e Industrial Sm all Business
household household
26
Figure 19: All India non levy sugar consumption by segments (2006-07)
Source: AC Nielsen survey conducted in March 2007, KPMG analysis
26
Household sugar consumption and income segments are as per AC Nielsen survey. Households with
monthly income less than INR 5,000 are considered as low income households.
6 100
Monthly hous ehold consumption (kg)
88.5
5.11 5.11
Figure 20: All India non-levy household monthly sugar consumption by income levels (2006-07) 27
Source: AC Nielsen survey conducted in March 2007, KPMG analysis
The per capita sugar consumption increases with rise in income. At the lowest
income levels, the average household sugar consumption is at 2.2 kg per month,
while at the highest income levels the average household sugar consumption is at
5.11 kg per month.
Even for low income households, a 10 percent increase in sugar price results in
less than 1 percent increase in the monthly food expense
The impact of sugar price variation is minimal on the monthly household expense, in
case of direct consumption. At the lowest income level, a 10 percent increase in
sugar price increases the household expense by approximately INR 4 per month. At
the highest income level, a 10 percent increase in sugar price increases the
household expense by approximately INR 10 per month. This translates to less than
1 percent increase in the monthly food expense for any segment.
27
Household sugar consumption and income segments as per AC Nielsen survey
0.90% 0.86%
Change in monthly food expense (percent)
0.80% Urban
Rural
0.70% 0.64%
0.60%
0.50%
0.20%
0.20% 0.15%
0.12%
0.09% 0.09%
0.10% 0.07% 0.05%
0.04%
0.00%
<2500 2501-5000 5001-10000 10001- 20001- 30001- > 40000
20000 30000 40000
Figure 21: Impact of 10 percent increase in sugar price on monthly household expense (2006-07) 28
Source: AC Nielsen survey conducted in March 2007, KPMG analysis
28
Total household expense estimated using savings rate for different income segments Source: IMRB.
Food expense for urban segments assumed at 42.5 percent and for rural segments at 55.05 percent
of total expense. Source: NSSO. The sugar retail price assumed to be INR 18 per kg. Household sugar
consumption and income segments as per AC Nielsen survey.
0.8
1.27 1.32
0.6
1.04
0.4 0.84 0.79
0.2
0
Dairy Confectionary Bakery Carbonated Others*
Processing Beverages
Sweet meat vendors are the largest consumers of sugar amongst small
businesses
Sweet meat vendors account for an estimated 58 percent of the total sugar
consumption, amongst small business. Restaurants and tea/coffee shops account
for an estimated 22 percent and 17 percent of the sugar consumption, with the rest
being accounted for by juice centres, candy shops and similar establishments.
60%
50%
Share of consumption (percent)
30% 58.4%
20%
22.5%
10% 17.8%
1.1% 0.4%
0%
Sweetmeat Restaurants, Tea/coffee Juice centres, Others(Ic e
(large, medium, office canteen, (shop + road side juice candy/
small, roadside) caterers roadside) /lasiwala,dairy/ kulfiwala etc)
milk shop etc.
29
Others include ice cream, fruit juices, fruit drinks, fruit nectars, squashes, health drinks, beer, wine,
pharmaceuticals, chyawanprash, ketchup/sauces, jams and star hotels
30
Map not to scale and illustrative
EU
Pakistan
Indonesia
Sri Lanka
Somalia
Brazil
Australia
South Africa
31
Map not to scale and illustrative
25000
Stakeholder earnings per MT of sugar :
! Farmer earnings - INR 5170 1000 21189
! Normative miller earnings - INR 1000 200
875 19589 400
20000 ! Government taxes - INR 1090 1000
4000
Value per MT of sugar (INR)
Minimum ex
15000 215 264 13978 mill price
5170
needed
10000
7951 378
Resultant
retail price
5000
0
xe -
ic x-
ns ne
ar e
co ne
ar ve
ar e
st ion
st ion
e
m ty
rt
pr t
ar il
on
es d
rt
il an
Ta ne
m an
m rad
od n
pr t e
m et a
o
n
v i an
n
m cie
po
r m ati
tra Ca
Ca
pr Ca
e
gi
n
s
co uct
co ers
sp
gi
st
si
gi
ta lt
Ca
C
ic
gi
ill an
T
e
ille m
re esu
R
is
le s
co So
an
ie
nv
m ult
m Nor
ut
Tr
R
Co
s
D
Re
Figure 26: Value chain for sugar (Illustrative) - Production in West UP, retail sale in Delhi (2007) 32
Source: ISMA, SBI Capital Markets Limited report on sugar sector August 2006, Industry sources, KPMG
analysis
The cost of cane procurement accounts for 70 percent of the ex-mill sugar price and
is the largest cost component of sugar. Thus, given the different taxes across the
value chain, in case of western UP, the government earns approximately INR 1,100
per MT of sugar sold, while millers' margins are typically in the range of INR 1,000
per MT of sugar. In case of western UP, due to a high SAP, farmer margins are
approximately INR 5,200 per MT of sugar. The retail sugar price needed to sustain
the current price in western UP would be approximately INR 21 per kg.
32
Average cost of cane cultivation assumed to be INR 73.63 per quintal.Transportation cost of INR 3.50 per
quintal is assumed based on industry interactions. Average western UP recovery of 9.26 percent used to
estimate cane cost per MT of sugar. Cane margin calculated is based on Western UP SAP in 2006 at INR
1250 per MT of cane.
4000
Minimum ex
15000
699 11989 mill price
2553 needed
1344
10000 7394
Resultant
retail price
5000
0
xe -
ic x-
ns ne
ar e
co ne
ar ve
ar e
st ion
st ion
e
pr t
ar il
es d
rt
or
il an
Ta ne
m an
m rad
od n
pr t e
m eta
n
vi an
n
po
r m ati
tra Ca
Ca
pr Ca
e
gi
n
s
co uct
co ers
sp
gi
st
gi
ta lt
Ca
C
ic
gi
ill an
T
e
ille m
re su
R
le s
an
ie
nv
m lt
m Nor
Re
su
ut
Tr
Co
Re
Figure 27: Value chain for sugar (Illustrative) - Production in Tamil Nadu, retail sale in Chennai (2007) 33
Source: ISMA, SBI Capital Markets Limited report on sugar sector August 2006, Industry sources, KPMG
analysis
In case of Tamil Nadu, the government earns approximately INR 1,574 per MT of
sugar sold due to higher cane taxes, while millers' margins are typically in the range
of INR 1,000 per MT of sugar. Due to a lower cane price, farmer margins are
approximately INR 3,000 per MT of sugar. The retail sugar price needed to sustain
the current price in Tamil Nadu would be approximately INR 19.5 per kg.
The distribution of sugar is typically done through various channels and the cost
differential between ex-mill price and retail price could vary widely based on the
market being addressed and the channel being utilized.
33
Average cost of cane cultivation assumed to be INR 73.63 per quintal. Transportation cost of INR 8.12 per
quintal of cane is assumed based on industry interactions. Average western UP recovery of 9.26 percent
used to estimate cane cost per MT of sugar. Cane margin calculated is based on Western UP SAP in 2006.
Excise duty on molasses INR 750 per MT & 3 INR 645 crores
percent cess
Duty on levy sugar INR 525.3 per tonne INR 101 crores
Duty on free sale sugar INR 875 per tonne INR 1512 crores
The sugar produced by the mills attracts an excise duty and a cess. The total duty is
INR 523.3 per MT on levy sugar and INR 875 per MT on free sale sugar including the
sugar cess. In 2006, this amounted to more than INR 1610 crores.
The mills also pay an excise duty on molasses. This excise duty amounts to INR 750
per MT in addition to a 3 percent cess. In 2006, the total duty paid by the mills
amounted to more than INR 645 crores.
In addition to the various taxes discussed above, the industry also pays direct taxes
to the government. Additional taxes also accrue from other value added products
like alcohol, chemicals, paper boards, and so on.
Haryana 15 INR 15
Sugarcane
Juice
Exportable
Bio Fertilizer
Power
Rectified Spirit Biogas
Primary by prodrcts
Industrial Potable
Fuel Ethanol
Alcohol Alcohol Emerging businesses
Ethanol and cogeneration have emerged as key by products for the sugar
industry in India
Bagasse based cogeneration for exportable power is an emerging trend in the sugar
industry. Bagasse generated by a sugar mill enables the mill to export power after
meeting its captive power and steam requirements..
Karnataka Uttar
25% Pradesh
27%
Punjab
1%
Andhra
Tamil Nadu Pradesh
29% 18%
100%
80%
142 114 37 39 36 17
60%
40%
20%
55 8
21 8
5 5
0%
Maharashtra Uttar Andhra Karnataka Tamil Nadu Gujarat
Pradesh Pradesh
Ethanol manufacturing units Mills without distilleries
Revitalization
package
E-5 blending
Controls on program
distribution 2004
Future 2003
Levy removed
trading
Delicensing quota allowed 2002
of sugar reduced
Sugar
Sugar
exports
industry 2001 Tuteja
imports
decanalised
2000 E-5 blending Committee
included 1998 program in 9 report on
Molasses
in OGL 1997 Removal of states and 4 revitalization
Decontrol
requirement union of industry.
1994 Three of licensing territories
1993 Revitalization
Levy sale exchanges and
announced. package
Mahajan quota permitted to restrictions
Implementa announced
Sugar export Committee reduced conduct on storage tion under for the sugar
Sugar promotion report. from 40 futures and way. industry.
Molasses imports act repealed Sugar percent to trading in movement
and sugar companies 30 percent. sugar. of sugar.
sector placed
exports were Levy quota Levy quota
decontrolled. under
Some state Open decanalised. allowed to reduced 30 reduced
set up new percent to from 15
govts General capacities or 15 percent. percent to
continue License. expand 10 percent.
to restrict
existing
utilisation,
capacities
sale and
without a
movement.
license.
The by-products of sugar are regulated as well. There are state specific restrictions
on the movement and sale of molasses, while realizations from by-product value
additions are partially dependent on the government influenced prices.
! Only certain
Free Sugar
types of sugar
can be produced ! Monthly release quota for
! Sugar has to be free sale
packed in jute ! Export order required for
bags exports
! Excise duty on sugar
! Sugar cess levied
! Import duty
Sugar is regulated both at the central and state levels, and is exposed to conflicts in
terms of policies and government regulations. This also leads to distortion of the
level playing field across states.
While sugar has grown at a fast pace, its average margin is below the peer industry
average. Its growth is comparable to dairy and coffee. However. in the past, tea and
coffee have had better margins than sugar. In fact sugar's margin is comparable to
paper, which has traditionally been a low margin industry. Therefore while large
sugar firms and to some extent, the industry as a whole have grown in line with
demand and new capacities have continously been added, the growth has not been
as profitable as some of the other industries.
22%
Tea
Coffee
10 Year Average Margin 1998-2007 TTM
17%
Peer Industry average = 15 percent
Sugar
12% Paper
7% Dairy
34
Margin = EBITA/ Revenue. EBITA does not include other revenue and revenue is net of excise. TTM is
twelve month trailing ending Dec' 2006. Tea comprises Tata tea and Jayshree tea. Paper comprises BILT,
TNN, Star, Sirupur, Seshasayee, AP, West Coast and JK. Dairy comprises Heritage, Vadilal, Milkfood,
Modern Dairies. Coffee comprises Tata, CCL. Sugar comprises Balrampur, Bajaj, Dhampur, EID, Shakti,
Bannari and Oudh.
Only the top listed companies have been considered for this analysis. The
cooperative sector and smaller sugar mills account for a significant proportion of the
total sugar production. Their ROIC is typically lower than that of the large listed
companies.
25%
20%
10%
Minimum of large listed companies
5%
0%
1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 TTM
2007
35
EP = IC*(ROIC-WACC).
IC = Equity + Debt + Deferred tax liability.WACC assumed to be 13 percent
ROIC = EBITA*(1-marginal tax rate @ 33 percent)/ IC
Best of large listed companies reflects the yearly maximum ROIC from the set of companies considered.
The minimum of large listed companies reflects the minimum ROIC from the set of companies considered
Globally, India is a key sugar geography, since it is the largest consumer and
the second largest producer. The global landscape is highly influenced by
Brazil, given that it is the least cost producer and the largest exporter of
sugar. Ethanol has had a significant influence on the global sugar market.
Worldwide, the sugar industry is regulated. This is because of the
perishable nature of cane, the need to influence domestic prices and the
landholding structure; though the instruments of regulation vary across
geographies.
5.1 Production
The world sugar production has been increasing steadily at a CAGR of 1.5 percent.
Currently the total world sugar production stands at 150 million MT of sugar. Brazil,
India, China and U.S.A are the major sugar producing countries accounting for 45
percent of the total sugar production. EU collectively produces around 14 percent of
the total sugar production. Brazil is the largest producer of sugar and has increased
its production by 5.7 percent CAGR over the last 7 years since deregulation in 1999-
2000. India is the second largest producer and its sugar production has increased
consistently except in years which were drought affected.
Others
Drought Australia
100
in India Mexico
80
U.S.A.
60 4% -1.9%
Deregulation 6% -0.2% China
in Brazil
40 14% 2.9% India
20 Brazil
21% 5.7%
Total
0
1999 2000 2001 2002 2003 2004 2005 2006 CAGR
! Availability of fertile land Brazil has the ability to expand cane acreage by
farming unutilized fertile land, without adversely impacting other crops. The
increasing acreage resulted in increasing cultivation of cane. The cane
acreage grew at 10 percent CAGR from 1996-2005.
6 30
Sugar production (million MT)
Acreage (million hectares)
5 25
4 20
3 15
2 10
1 5
0 0
1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006
Acreage SugarProduction
Indonesia
120
Pakistan
50% 1.7%
100
Mexico
80 Russian Fed
USA
60
6% 0.3% Brazil
40 7% 2.7%
China
8% 4.4%
20 India
14% 3.4%
Total
0
1999 2000 2001 2002 2003 2004 2005 2006 CAGR
The total world consumption is at.
Asia 3.05%
Africa 3.01%
Oceania 1.48%
Europe 0.62%
Australia 72%
Brazil 56%
Thailand 35%
EU 20%
India 4%
The major producers of sugar in the world are also the leading exporters, and are
highly dependent on the world trade. Australia exports around 72 percent of its
production, while Brazil exports 56 percent of its production. India is however
unique, as it has the world's largest consumption market. India's dependence on
the world trade is marginal and therefore, it is largely insulated from the global price
variations. In case of a global surplus though, domestic prices tend to get influenced
by low global prices since exports from India are less viable. Historically, India has
used the world trade to manage its surplus and deficit, as it is typically self sufficient
in sugar. At no point in the last 7 years has India imported or exported more than 2
percent of the total world sugar trade.
30
3
25
Trade (million MT)
2
1.5
1.0 1.1 1.1 20
1
15
0
-0.3 -0.2
-1 10
-1.0
-2 5
-2.1
-3 1999 2000 2001 2002 2003 2004 2005 2006 0
Total global trade India’s exports Trade as percent of Production
The world sugar trade accounts for around 36 percent of the global sugar
production. India is a marginal player in the world sugar trade market. The average
volume of preferential trade is around 10 million MT of sugar annually. The world
sugar trade is dominated by Brazil and EU. Australia and Thailand are the other major
sugar exporting countries.
Australia
Others 7%
Brazil
27%
34%
South Africa
2%
Colombia
2%
Guatemela
2% Thailand
3% India EU
2% 21%
600
Sugar price (USD per MT)
500
400
300
200
100
0
Dec-04
Dec-05
Dec-06
Aug-05
Aug-06
Feb-05
Feb-06
Feb-07
Oct-05
Oct-06
Jun-05
Jun-06
Apr-05
Apr-06
White Raw
Thus, given the high influence of Brazil, large sugar exporters typically generate
higher margins from domestic sales as compared to the exports. Government
intervention and regulations are used to maintain high domestic prices in these
countries, when compared with the current world sugar price. This is a key feature of
the sugar trade worldwide. India is unique in this respect, due to its low reliance on
exports, and has one of the lowest retail prices of sugar amongst the key
geographies.
India 405
Thailand 535
Brazil 558
Australia 781
36
USD to INR conversion assumed to be INR 44.5 per USD
37
Source: Future production modelled by Brazil's Ministry of Agriculture, Livestock and Supply (MAPA),
Sugarcane and Aeroenergy Department and as quoted by Sugar Industry Oversight Group, Australia
38
Source: CLSA Indian agribusiness sector outlook May 2006
Australia72%
Saudi Arabia
South Africa 1%
Others
1%
8%
Russia
2% Brazil
India 36%
5%
EU
6%
China
9%
USA
32%
39
Map not to scale and illustrative
600 80
70
500
White Sugar Price (USD per MT)
300 40
30
200
20
100
10
0 0
May-02
May-04
May- 03
Sep -02
Sep- 04
Jan - 03
Sep- 03
Sep- 05
Sep- 06
Jan -02
Jan- 05
Jan- 06
Jan- 04
May-
May-
LDP Crude oil
Figure 49: Linkage between sugar and crude oil prices (1998 - 2006)
Source: U.S. Department of Energy, Energy Information Administration
Germany
USA France S.Korea
China
Spain Japan
Mexico Thailand
Guatemala Costa Rica Nigeria India
Philippines
Colombia Singapore
Brazil
Peru Indonesia
Australia
Established South
Africa
Emerging Argentina
Planned
!Consumer
protection
International !Domestic
trade industry
protection
!Consumer
protection
40
Cane pricing in Australia is done through free market pricing though a formula is available for reference
to mills and farmers
The sugar sector has evolved over the years, and India is the second largest
producer and largest consumer of sugar in the world. In order to fulfil the stakeholder's
aspirations, there is still a long way to go. Thus, going forward, the stakeholders
would need to influence their business drivers so that the sector can move towards
its shared vision. The sector would also need to identify and exploit opportunities
that would enable this future growth, while benefiting all stakeholders.
Figure 52 outlines some of the major business drivers for farmers and millers that
have a direct impact on their individual aspirations.
Cost of cultivation
Payment of Farmer
dues risk
Farm productivity
Farmer
Miller
Farmer Economic Profits
Relationship
Domestic price
Mill Economic Profits
Miller
Byproducts Realization
Inventory cost
Cane
Availability Risk Mill Risk Price Risk
For mills, the drivers for economic profits are the sugar prices in domestic and
international markets and by-product realizations. The inventory cost has a negative
impact, and also influences the extent of price risk. The mill efficiency influences the
milling costs, hence the overall economic profit. The risk of cane availability is
significant for mills, and is influenced by the farmer-miller relationship.
There are interdependencies between farmer and miller business drivers. A high
cane price benefits farmers, but leads to lower profits for mills, for a given sugar
price. Cane price and mill realization, if misaligned, can lead to arrears, that would
negatively impact both the mills and farmers. Higher mill efficiency on the other
hand leads to better recovery, with the benefits being shared by both farmers and
millers. As discussed, the farmer-miller relationship is a key mitigating factor for both
millers and farmers.
Figure 53 outlines some of the major business drivers for consumers and the
government that have a direct impact on their individual aspirations. Some of these
also have a strong linkage with farmer and miller aspirations.
World price
Food Security
Government
Social Welfare
Cane Price
Movement in opposite direction Movement in same direction
For the government, food security is the key aspiration. It is influenced by domestic
production as well as India's linkages with international trade. Energy security is
driven by the extent of investments that mills have made in byproduct capacities.
Fiscal revenue for the government is directly related to the mill realizations.
The social objectives of the government highlight a key conflict area. From a social
perspective, the cane price should be high, so that it benefits the farmer. For the
benefit of the consumers, the price of sugar should be low. In case both of these
events occur together, as was seen earlier, they would lead to arrears leading to
default of payments to farmers and reduced availability for consumers in the
subsequent years.
Therefore, the critical business drivers that can be leveraged by the sector to move
towards the shared vision are:
! Domestic demand
! International trade
! Byproducts value addition
! Productivity improvement
! Cyclicality management
! Cane and sugar pricing
! Sugar price risk management
! Product innovation
These business drivers need to be leveraged in such a way that the sector is able to
fulfil its aspirations, without diluting its social objectives. Each of these drivers also
translates into an opportunity that could become the enabler for future growth.
These enablers are discussed in the subsequent sections.
If the sugar sector is able to leverage these opportunities, it will be able to move
towards its shared vision. From the current state of being a large producer and
consumer, with low participation in international trade and a low return on invested
capital for most years, the sector could become a significant food and energy
producer, with strong linkages with global trade. This can be achieved through self
sufficiency in sugar and through investments in ethanol and cogen. The sector could
also benefit from lower cyclicality and more sustained revenues.
20
19.2
15
10
0
2007 2017
Given the range of growth rates (1.9 to 5.5 percent) the estimated sugar
consumption in 2017 is expected to be between 22.8 million MT and 33.3 million MT
of sugar. The drivers for consumption are growth in the GDP and population growth.
GDP growth is expected to be high, while the population growth is expected to stay
at the current levels. Given the high variability in estimates for consumption,
historical CAGR growth has been used as an indicator and a CAGR of 4 percent has
been assumed for projecting future demand.
Using the assumed growth rate of 4 percent, the projected domestic sugar
consumption is estimated to be at 28.5 million MT in 2017.This sugar demand can be
met either through increase in domestic sugar production or through sugar imports.
Figure 56: Feasibility of raw sugar imports from Brazil and Thailand (2007)41
Source: ISMA Hand book of sugar statistics Sep 2006, Cris Infac sugar sector report November 2006,
KPMG analysis
However, even at the current low international prices, landed cost of imports is
higher than the typical ex-mill price range for sugar, which is produced domestically.
With the EU subsidized sugar easing out of the world market, the average world
prices were expected to increase and CIE estimated the increase to be in the range
of USD 50 to USD 100 per MT. Thus, sugar imports are expected to be a costlier
option than the locally produced sugar. In case of white imports, the freight rates are
also expected to increase, thus further increasing the cost of imported sugar.
Given the large domestic market and the changing international landscape, food
security is a key concern. Hence, the domestic sugar consumption will have to be
met primarily through domestic production.
41
Illustrative
3 3.3
2 2.3
2.1
1.7 1.3
1
0.3 18
0.7
0
-0.9
-1 16
-1.9
-2
14
-3 -3.3
-4
12
-5
-5.8
-6 10
1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006
Surplus/ Deficit Production Consumption
In the past, domestic sugar deficit has typically not been more than 1.5 months of
consumption Given the cyclicality in sugarcane production, from a long term
capacity planning perspective, India would need to target an excess production
equivalent to approximately 1.5 months of consumption; i.e. an additional 3.5 million
MT of sugar by 2017. This would ensure that domestic demand is met in most
scenarios. In case of exigencies, if there is a deficit in production, it can then be
addressed through raw sugar imports. At the same time, surplus may need to be
handled through exports or through structural mechanisms like a strategic stock.
Producing the required quantity of sugar would need adequate capacity expansion
at the farm and mill side.
Apart from cyclicality in production, a sugar surplus could also occur if the future
economic attractiveness of ethanol or cogen leads to excess cane cultivation. In
such a scenario, international trade will enable India to manage the surplus
production with relatively lower impact on the domestic market.
Iran
(0.7) Pakistan
(0.9)
Saudi Arabia UAE
(1.2) (1.8)
Bangladesh
(0.8)
Sri Lanka
(0.6)
East Africa
(0.6) Indonesia
(1.3).
42
Map illustrative and not to scale
1.8 0.1
0.1
1.6
Sugar imports (million MT)
1.4 0.6
Others
1.2 1.1
0.2 Thailand
1.0 0.6
SouthAfrica
0.8
EU
0.3 0.3
0.6 0.2 0.2 Brazil
1.1 0.8 0.4
0.4 0.2 0.1 Australia
0.3
0.5 0.5 0.1
0.2 0.4 0.4
0.2 0.2
0.1
0.0
an
n
ka
ia
ia
a
E
ric
es
Ira
rab
es
UA
an
t
kis
Af
lad
on
iL
iA
Pa
st
ng
Ind
Sr
ud
Ea
Ba
Sa
Countries like Bangladesh and Sri Lanka primarily import white sugar while
countries like UAE, Saudi Arabia and Indonesia are major importers of raw sugar due
to the presence of destination refineries in these countries.
2.0
Sugar imports (million MT)
1.8
0.3 Whit e
1.6
0.9 Raw
1.4
1.2
0.3
0.7
1.0
1.5
0.8
43
44
With EU vacating 4.5 million MT of exports from the world market, the export
opportunity for India has increased
In 2005, EU exported sugar to more than 100 countries across the world including
1.5 million MT to countries in Asia and East Africa including Pakistan, Bangladesh,
Indonesia, UAE, Kenya and Sri Lanka. The reduction in EU exports, which started in
mid 2006 as a result of a WTO ruling, is scheduled to continue till 2010. It is expected
to lead to redistribution of global trade and players like India could benefit.
Iran Pakistan
Saudi Arabia (0.02) (0.19)
(0.02) Bangladesh
UAE (0.03)
(0.58)
Sri Lanka
East Africa (0.33)
(0.07) Indonesia
(0.28)
45
Map illustrative and not to scale
30 (0.9) Raw 29
Saudi Arabia UAE
50 (1.2) 25
(1.8)
45 Bangladesh Thailand India Brazil
Raw
25 (0.8)
30
Thailand India Brazil Sri Lanka
East Africa (0.6)
(0.6)
Indonesia
( ) Import value Freight charges to Sri Lanka (1.3)
in million MT
Freight charges 85
in USD per MT White 15
of sugar 35
Thailand India Brazil
Increasing competitveness
Figure 62: Major Indian Ocean importers of sugar along with freight rates from major exporters (2006)46
Source: Industry sources, KPMG research
At present, Thailand has the most competitive freight rates for Indonesia and near by
countries, while India is competitive in case of neighbouring markets like Pakistan
and Sri Lanka as well as in the Middle East and East Africa markets. The freight
advantage can be further enhanced by improving the port infrastructure through
improvements in the loading rates and draft. Some ports in India have already
initiated dredging projects to enable the same, but given the large investments
needed, the government may need to play a larger role in the future.
46
Map illustrative and not to scale. Raw sugar shipped in bulk, white sugar shipped in PP bags.
UAE
Bangladesh
Indonesia of 45 ICUMSA will increase going forward,
India would need to develop the capability to produce these varieties in order to
leverage the export opportunity.
47
Map illustrative and not to scale
500
London white sugar prices (USD per MT)
450
350 Indian white exports on variable basis are viable above USD 335
300
250
200
150
100
Feb-07
Feb-05
Apr-05
Jun-05
Aug-05
Oct-05
Dec-05
Feb-06
Apr-06
Jun-06
Aug-06
Oct-06
Dec-06
Dec-04
Given the current cost structure, the Indian white sugar exports are typically viable
above USD 375 per MT on a total cost basis and USD 335 per MT on a variable cost
basis.The world prices have stayed above this level for a considerable period of time
only in case of global deficit production. In the past, the long term sugar price was
around USD 270 per MT and it is expected to increase with the reduction in EU
exports. At this price the Indian sugar exports on a variable cost basis could become
relatively more competitive.
In case of a surplus that cannot be managed in the domestic market, Indian mills can
consider exporting at variable price basis, since their profitability is primarily
dependent on the large domestic market and exports account for a small part of
revenues. In case of a surplus, if the mills have to export at a loss, then the industry
could consider developing a mechanism whereby the loss is shared by the industry
as a whole since the benefits of higher prices in the domestic market would accrue
to all mills and farmers.
500
London white sugar prices (USD per MT)
450
400
Indian raw exports are viable above USD 350
350
Indian raw exports on variable basis are viable above USD 310
300
250
200
150
100
Feb-07
Apr-05
Apr-06
Jun-05
Jun-06
Dec-04
Feb-05
Feb-06
Aug-05
Aug-06
Dec-05
Dec-06
Oct-05
Oct-06
Figure 65: London raw sugar prices (2004 2007) 48
Source: Industry sources, Bloomberg, KPMG analysis
At the current cost of production and world raw sugar prices, the Indian exports of
raw sugar looks unviable. However, the reduced cost of production and a
sustainable cane price can improve India's competitiveness for global trade.
48
Cost of raw sugar production in India is assumed to be USD 25 per MT of sugar lesser than cost of white
sugar production. Source: Industry interactions
Low High
Sri Lanka
East Africa
percent of total import potential
White sugar import potential as
High
Iran Bangladesh
Indonesia
Pakistan
Saudi Arabia
Low
UAE
Freight advantage
India's export potential for the target markets is dependent on two key parameters -
! India's relative freight advantage for the target countries A higher freight
advantage would imply greater competitiveness for Indian exports as
compared to Thailand and Brazil, its major competitors in the target markets.
49
The bubble size represents the estimated sugar imports in 2017.
50
Due to the divergent data available on imports and consumption for Bangladesh, Sri Lanka, Iran and Saudi
Arabia, the average consumption growth rate for Asia has been assumed to be the growth rate for imports
for these markets. Since these markets are structural importers, it is assumed that the growth rate of
imports would be at least equal to the growth rate of consumption. It is assumed that UAE imports would
be dependent on the consumption growth rate of countries that import white sugar from the UAE based
refineries. Therefore, the average consumption growth rate for Asia has been assumed to be the growth
rate for imports for UAE. For Indonesia, imports as a percentage of consumption have been consistently
reducing over the last few years and hence no future growth has been assumed for Indonesia imports. For
East Africa, divergent data is available on imports over the last few years and hence the average
consumption growth rate for Africa has been assumed to be the growth rate for imports. Pakistan is an
occasional importer and has also been a net exporter in the past. The proportion of raw and white sugar in
imports for these countries is assumed to remain the same in 2017.
The target markets are expected to import 10 million MT of sugar per annum by 2017.
The key imperatives for India to be able to leverage this opportunity would be
productivity improvements in the long term, investments for producing raw sugar
and white sugar of international standards and a policy environment which
encourages international trade with minimal non-tariff restrictions. Given the
strategic role that exports can play for maintaining stability in the domestic market,
the government could also consider extending WTO compliant support to the
industry for exporting sugar, in case of a surplus that cannot be managed in the
domestic market. As a developing country, India has been allowed under WTO
norms to extend these subsidies till 2013. Further extensions may also be
considered as part of subsequent rounds of WTO negotiations.
Area under
cane Research and
Development
Mill efficiency
Mill side
Increase in
capacities
Figure 68: Drivers for mill and farm side capacity expansion 51
Source: KPMG analysis
51
Infrastructure includes cultivation, harvesting and transportation infrastructure
The farm side capacity expansion can be driven by increasing the area under cane as
well as farm productivity improvements.The farm productivity improvements would
be enabled through increased yields, as well as increased sucrose content of cane.
Both of these would be driven by research and development, which will focus on
developing seed varieties, advanced farm practices and improved infrastructure for
cultivation, harvesting and transportation.
The mill side capacity expansion will by driven by improved mill efficiency as well as
necessary increase in mill capacities.
India's yields compare favourably with global yields but there is high
variability across regions
There is a high variability in yields across regions in India, due to climactic conditions
and variability in farm practices. Tropical areas have higher yields as compared to sub
tropical areas. Tamil Nadu has the maximum yield in India, and is in fact higher than
all the other major sugar geographies. On the other hand, India's minimum yield is in
Bihar, which is amongst the lowest in the world.
52
Sugar production for 2007 assumed to be 27 million MT. Source: ISMA. Projected domestic sugar demand
for 2017 is 28.5 million MT and India would target producing an additional 3.5 million MT equivalent to 1.5
months of consumption from a food security perspective.
70 65.6
60
50
40
30
20
10% 14% 15% 12% -3%
10
0
1956 1961 1966 1971 1976 1981 1986 1991 1996 2001 2006
Growth rates for the specified ten year period
At a state level,Tamil Nadu has increased its yield by more than 10 percent during the
last decade. However, yields in other states have not seen similar improvements.
Given the historical trend in yield improvement, India can aspire to increase the yield by
10 percent over the next ten years to an average all India yield of 72.2 MT per hectare.
120
110.6
110
100
Yield (MT per hectare)
90
77.9
80
76
74
70
66.4
64.4
60
58.2
57.8
50
40 42.6
30
1997 1998 1999 2000 2001 2002 2003 2004 2005 2006
Andhra Pradesh Gujarat Karnataka
Maharashtra T.N. Uttar Pradesh
Bihar Punjab Haryana
Brazil 14.6
Australia 13.5
Mexico 12.2
Thailand 11.3
India 10.1
Percentage
11 10.95
10.82
10.5
10.05
10
9.78
9.5 9.49
9.30
9.16
9
8.5
8
1997 1998 1999 2000 2001 2002 2003 2004 2005 2006
Figure 73: Recovery of sugar from sugarcane in the states (1997 2006)
Source: ISMA Handbook of Sugar Statistics Sep 2006
Mill efficiency has high variation across states and adoption of best practices for
sugar production can lead to lower losses. Again, Tamil Nadu has the lowest mill
losses; while Bihar has the highest. Mill losses are a function of the technology and
processes used for sugar production. Therefore, it is not impacted by climatic
variations across states.
Punjab 2.00
Maharashtra 2.02
Haryana 2.04
Gujarat 2.10
Karnataka 2.15
Bihar 2.22
Total losses in percentage
During cultivation, inter cropping pattern and inter row planting are critical variables.
Adoption of best practices for integrated nutrient management and insect control
has been proven to improve yields.
Sugarcane is a water intensive crop, and therefore water management plays a key
role. Across most of the country, irrigation is currently being done through traditional
means, leading to a significant wastage of water.The availability of subsidized water
and power for agriculture, also leads to distortion of economic incentives for
conservation of water in some cases. Increase in sugarcane cultivation, therefore, is
perceived as being detrimental to the availability of water in a given region.
The adoption of advanced techniques like drip irrigation can address this constraint.
Drip irrigation offers the potential to enable water conservation while increasing
farm productivity. Drip irrigation can reduce water consumption for cane cultivation
by 20 to 50 percent53. Since establishing the drip irrigation infrastructure would
require investments, policies would need to encourage these through the farmer-
miller relationship and through government financing.
Over the longer term, productivity can also be significantly increased through better
ratoon management. Again, sharing and adoption of best practices across states
can contribute to this effort.
53
Source: Irrigation management in sugarcane with special emphasis on drip irrigation by Dr. C Kailasam,
Principal Scientist, Sugarcane Breeding Institute, Coimbatore.
One of the key outputs of R&D, cane variety development, has reduced over
the last 16 years
35
30
Number of co canes developed
25
20
15
10
0
2000
2002
2003
2004
2005
2001
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
In the recent past, the number of seed varieties being developed by the research
institutes has been decreasing. This is further compounded by the fact that the
current role of the Indian sugar industry is limited to encouraging adoption of
varieties developed by these institutes. There is no direct linkage between the
research institutes and industry, unlike the leading producers.
54
Co-canes are seed varieties developed by Sugar Breeding Institute, Coimbatore
In Brazil, Ridesa (Inter-university Network for the Development of the Sugar and
Ethanol Sector) is a national programme for seed research, which involves the
government, industry and universities. Ridesa has successfully been able to
produce varieties in 6 to 7 years, as against a typical duration of 10 to 12 years. Brazil
also provides good illustration of direct involvement of industry in research.
Copersucar, a large sugar producer, has been responsible for innovations through its
research arm, Copersucar Technological Centre, in the past56.
100 2.50
2.2 2.2
90 2.1
Share of investments (percent)
80 2.00
as percent of GDP
70
50
40 1.00
30
20 0.50
0 0.00
1999-00 2000-01 2001-02 2002-03 2003-04 2004-05 2005-06
Public Private (P)
55
Source: KPMG Research, Industry interactions
56
Source: KPMG Research, Industry interactions
Going forward, the sugar industry would have to play a greater role in funding
research initiatives for cane, and work closely with research institutes for setting the
research agenda. It will also have to identify relevant future research opportunities.
Also, the government's share of investment in agriculture in the areas of irrigation
technologies, pest and disease management and seed variety development needs
to increase.
Figure 77: Application of funds of SDF (From 1983-84 till Oct 2005)57
Source: ISMA, KPMG research
35
Demand for sugar (MillionMT)
30 3.5
25
20
15 28.5
10
0
Domestic Requirement for
demand enabling food
security
Figure 78: Demand for sugar (2017)58
Source: ISMA, KPMG analysis
57
Total loans from SDF towards research and cane development is INR 541.07 crores since 1983-84
58
Domestic consumption growth rate assumed at 4 percent CAGR.
35
0.9
1.4
2.7
30
27.0
25
Sugar (millionMT)
20
15
10
0
Expected 10 percent yield 50 basis points Un met demand
production 2007 improvement recovery
improvement
The increased demand for sugar can be largely met through vertical improvements,
including yield and recovery improvements. Assuming a 10 percent yield
improvement and a 50 basis points improvement in recovery, the total sugar
production in India will reach an estimated 31.1 million MT in 2017. This would leave
an unmet demand of an estimated 0.9 million MT of sugar.
An additional acreage of 0.2 million hectares60 will address the unmet demand. This
would be a marginal increase in current area under cane and can be enabled by
better utilization of the existing cane demarcated areas, thus minimizing any
adverse impact on other crops. The unmet demand can also be addressed through
further increasing the farm productivity and increasing drawal.
59
Total sugar production in 2007 assumed to be 27 million MT. Base yield and recovery rates for 2007
assumed to be same as 2006 figures. Drawal assumed constant at 2006 levels.
60
Base yield and recovery rates for 2007 assumed to be same as 2006 figures. Drawal assumed constant at
2006 levels
Apart from all of these, the relationship would incentivize the mill for investing in
rural development, over and above the cane related investments.
Assuming an average of INR 130 crores investment for a 5,000 TCD standalone
sugar mill63, estimated investment of INR 6,000 crore would be required. Currently,
the milling capacity in India is adequate for production of 27 million MT of sugar and
further capacity expansion is already in progress. It can be assumed that the
additional capacity requirement of 0.23 million TCD would be fulfilled through
capacity utilization balancing and expansions by existing mills. Given that the
average mill size in India is low, this would also enable existing mills to attain a viable
economic scale, which has been estimated at 5000 TCD for India64 in case of stand
alone sugar mills. The viable economic scale is expected to be much lower in case of
integrated mills.
61
Weighted average crushing period. Source: ISMA Handbook of Sugar Statistics November 2006.
62
Recovery for 2007 assumed to be at 2006 levels (10.24 percent). Recovery for 2007 assumed to be 10.74
percent. Sugar production in 2007 assumed to be 27 million MT. Source: ISMA. Sugar production in 2017
assumed to be 32 million MT as per demand projections.
63
Source: Industry sources, KPMG Research
64
Source: Tuteja Committee
Mill side
Increase in
capacities
0.23 million
TCD
Figure 80: Drivers for mill and farm side capacity expansion65
Source: KPMG analysis
6.5 Byproducts
In most scenarios, mills can improve their profitability by adopting an
integrated model.
30%
Return on capital employed (percent)
24%
25% 23%
22% 21%
20%
17% 17%
15 % 13% 14%
11%
10 %
10 %
5% 4%
1%
0%
Normal Up cycle Down cycle
Sugar Molasses Bagasse Sugar Molasses Power Sugar Ethanol Bagasse Sugar Ethanol Power
65
Infrastructure includes cultivation, harvesting and transportation infrastructure
66
ROCE = PBIT/Capital Employed. Assumption: Plant capacity - 5000 TCD; Days of operation - 182 days at
90 percent capacity utilization; Process 50 percent of molasses into alcohol/ethanol and 75 percent of
bagasse into power. Ethanol and cogen prices are not cyclical
30% 27%
26%
25% 22%
20%
15%
14%
15%
11%
10%
5%
0%
Normal Up cycle Down cycle
Sugar Ethanol Bagasse Sugar Molasses Power Sugar Ethanol Power
It can also be seen that the incremental investment in the integrated mills also
provides a higher return during the various scenarios. Thus, investing in ethanol and
cogeneration can provide higher profitability and greater stability under various
scenarios of the sugar cycle.
Assuming that mills adopt the integrated model, ethanol has the potential to
substitute up to 10 percent of the current fuel demand, at the current level of
resources and efficiencies
67
ROICE = Incremental PBIT/ Incremental Capital Employed. Assumption: Plant capacity - 5000 TCD; Days
of operation - 182 days at 90 percent capacity utilization; Process 50 percent of molasses into
alcohol/ethanol and 75 percent of bagasse into power. Ethanol and cogen prices are not cyclical
2500
Alcohol (million litres) 593
2000
593
1500
2662
711
1000
500
765
0
Potable Industrial E-5 Additional Total alcohol
alcohol for E -10 available
Figure 83: Alcohol potential and molasses based surplus and deficit (2007)68
Source:Planning Commission, Government of India, Report of the committee on Development of Bio fuels, 2003
At present, the total sugarcane produced in India can be used to support the E10
requirements of the country using the molasses route. The current distillery
capacity is 2,900 million litres of alcohol, of which 1,300 million litres are attached to
the sugar industry. Thus, given the adequate availability of molasses and viable
economic returns, the present distillery capacity attached to the sugar industry is
adequate for meeting the estimated (current) E10 demand.
4500
4000
Alcohol demand (Million litres)
965
3500
17
3000
965
2500
2000
1003 3013
1500
1000
500 1028
0
Potable Industrial E-5 Total alcohol Surplus Additional
available alcohol for E -10
Figure 84: Alcohol potential and molasses based surplus and deficit (2017)69
Source: Planning Commission, Government of India, Report of the committee on Development of Bio-fuel,
2003, KPMG analysis
68
Total sugar produced in 2007 assumed to be 27 million MT. Cane crushed for sugar assumed to be 263 million MT
in 2007. Source: ISMA. Molasses conversion assumed at 4.5 percent of cane crushed. Ethanol conversion
assumed at 225 litres per MT of molasses. The demand for ethanol, potable and industrial alcohol and distillery
capacity as given by the Planning Commission
69
Total cane crushed for sugar in 2017 assumed to be 298 million MT assuming recovery at 10.74 percent. Molasses
conversion assumed at 4.5 percent of cane crushed. Ethanol conversion assumed at 225 litres per MT of
molasses.The demand for ethanol, potable and industrial alcohol as given by the Planning Commission
Brazil Proalcool programme: In 1975, the first Proalcool programme was launched
in response to the 1974 oil price rise. At that time, Brazil was the third most
dependent country on oil imports. In 1996, the Brazil government announced
Proalcool II, which was aimed at deregulating the markets for alcohol. Over the
period from 1975 to 2002, fuel ethanol was used to help replace 55 billion gallons of
gasoline saving the country around USD 52 billion. Brazil uses an ethanol blend of 18
to 26 percent depending on crude and sugar prices. Brazil has also pioneered the
use of flex fuel vehicles that can run on any blend of ethanol and gasoline.
US ethanol program: In the U.S., security concerns for U.S. energy supplies during
world oil crises of 1973 and 1979 marked the beginning of ethanol's use as a
gasoline extender in 'gasohol'. At
present, the U.S. uses a 10 percent blend for ethanol and 2003 consumption was 10
billion litres. Environmental concerns and the need to add oxygenates to fuel have
also driven the demand for ethanol. Ethanol produced from corn accounts for 90
percent of the production in the U.S., and is incentivized by federal tax exemptions.
Individual states offer additional incentives for ethanol production. In 2003, new
markets like California encouraged the production of ethanol by banning MTBE, the
most widely used oxygenate.
70
Assuming that reduction of 1 MT of sugar production will lead to production of 600 litres of alcohol using
the B molasses route.Source: ISMA
71
Source: McKinsey Quarterly
72
Source: ISMA, FO LichtWorld Ethanol Markets Outlook to 2012
The key drivers for ethanol adoption across these geographies have been the
environmental concerns and increasing need for energy. The reduction in
dependence on crude imports has been another major driver. The success of the
ethanol programme across geographies has typically been driven by government
mandate for adoption of appropriate blending levels. Another feature has been
continued government support for these programmes through subsidies or other
incentives for adoption.
India faces similar concerns as its energy needs increase and India needs to
consider adoption of ethanol for higher blending levels.
7000
6000
965
Alcoholdemand(Millionlitres)
Figure 85: Alcohol potential and molasses based surplus and deficit (2017)
Source: Planning Commission, Government of India, Report of the committee on Development of Bio-fuel,
2003, KPMG analysis
The regulatory environment will need to facilitate this transition through necessary
changes to the sugarcane control order and a consistent policy on blending. Higher
levels of blending will need to be supported through increased cane acreage and
direct production of ethanol from cane juice. For this, mills would require the
flexibility to shift from sugar to ethanol, based on the market dynamics. The increase
in the blending ratio would need to be done in a consultative manner between the
government, the sugar industry and the automotive industry.
Higher levels of blending beyond E-5 would need to be initiated once the
blending program has stabilized
The potential of higher levels of blending would be indicated by the success of the
current E 5 blending programme and its ability to scale up. The rationalization of tax
and duty structures across states to enable easy movement of ethanol and
molasses would be needed. Since molasses is also controlled by the state
governments in some cases, a consensus will need to be reached between the
central and state governments. This would also include addressing the commercial
impact on the state revenues due to possible diversion of molasses from potable
alcohol. A clear, consistent and milestone based policy both at the centre and state
levels on blending to encourage investments in distilleries would be critical and a
consultative approach would be required with the automotive industry for
technology support. Distribution and storage networks will need to be established
between the sugar mills and oil marketing companies.
73
Total cane crushed for sugar in 2017 assumed to be 298 million MT. Recovery assumed to be at 10.74
percent in 2017. No diversion of cane assumed for the additional acreage. Molasses conversion is
assumed at 4.5 percent of cane crushed. Ethanol conversion assumed at 225 litres per MT of molasses.
Demand for ethanol, potable and industrial alcohol as given by Planning Commission
12000
10000
2570
8000
Power (MW)
6000
9688
4000 6271
2000
847
0
Present Additional Additional Total exportable
exportable power exportable exportable potential in 2017
potential in 2007 potential in 2017
At present, the total installed power capacity in India is 128 GW, and the
requirement is expected to increase to 306 GW in 2016-1776. Presently, the bagasse
based exportable power is 847 MW, but this could increase to approximately 9,700
MW by 2017. The bagasse based cogeneration is currently less than 0.6 percent of
the installed capacity, but can fulfil 6 percent of the additional future requirement.
74
For a 80 KLPD distillery, an investment of INR 80 crore is assumed including zero pollution systems. 300
day operations assumed for the distillery.
75
Total cane crushed for sugar in 2007 assumed to be 263 million MT. Drawal and recovery assumed at 2006
levels. Drawal is assumed to be 67.7 percent and recovery at 10.24 percent. Total cane crushed for sugar in
2017 assumed at 298 million MT with a recovery of 10.74 percent. Bagasse conversion from cane assumed
at 30 percent of cane crushed. 87 atm pressure boiler is assumed. 2.4 MT of steam assumed to be
produced from 1 MT of bagasse. 1MWhr assumed to be produced from 4.7 MT of steam. Potential in 2017
based on 280 million MT of cane crushed. 150 days of operation assumed. 36 units of power per MT of
cane are assumed to be used for captive consumption.
76
Source: KPMG India Energy Outlook
! For existing standalone mills, if high pressure cogen is used, the investments
in boilers and turbines would benefit the sugar mill as well
! In case of new integrated mills, the total investment would be lower as
compared to stand alone sugar mill and cogen plant
77
Carbon credit potential of 5000 credits each year for every MW of generation capacity at US$10/credit.
USD/INR exchange rate assumed at 44.50
78
For each MW of cogen, an investment of INR 4.5 crore is assumed. Days of operation assumed to be 150.
Arrears trigger the decline in sugar production and have an amplifying effect on
cyclicality. Minimizing arrears can reduce the induced cyclicality for sugar
In case of SMP, the cane price is fixed after taking into consideration the expected
sugar price. Hence, the arrears are lower as compared to SAP.
SAP states
Yearly balance cane price payable as percent of total payable
30
25 24.1
20
15.5 16.0
15 Cooperative
dominated states
9.9
10
7.6
6.7
5 3.5
0
Pradesh
Pradesh
Tamil Nadu
Karnataka
Maharashtra
Haryana
Punjab
Gujarat
Andhra
Uttar
Arrears have been relatively low in cooperative cane pricing states like Maharashtra
and Gujarat while it has been high in SAP states like UP, Haryana and Punjab.
Indi a 2.60
Pulses
405 0.60
Condiments 2.46
China
600 &spices 0.6 6
2.32
Sri Lanka Wheat
675 1.38
2.76
Bangladesh Fruits
1.46
1000
1.80
Vegetables
USA 1.46
1000
2.34
Eggs, meat
UK & fish 2.21
1100
1.82
Rice
Japan 2.45
2000
1.52
Sugar
3.62
Figure 90: Sugar prices USD/MT (2006) 79,Weights in wholesale price index (Base: 1994-95) (2007)
Source: ISMA, Office of the Economic Adviser, Ministry of Commerce and Industry, Government of India,
CMIE Database
India has the lowest sugar prices amongst the major sugar consuming countries. At
the same time, it also has high WPI weightage for sugar. These reflect the need to
protect consumer interests. However, the sugar price multiple hasn't moved as
much as the other products in WPI, including essential commodities like rice and
wheat since 1993-94.
Figure 91: Share of expenditure for sugar in a commodity basket of consumption and investment goods
(2004-05)
Source: Madras School of Economics
79
Sugar prices at Rs 18/kg & USD/INR of 44.50 assumed
25000
20000
INR p er tonne of sugar
15000
10000
5000
0
1999 2000 2001 2002 2003 2004 2005 2006
Cane cost at SMP Cane cost at SAP Delhi M-30 Sugar price
Whenever the difference between the cane prices and the sugar prices reduces, the
cane arrears rise. Arrears are created since mills with a low realization due to low
sugar price are unable to pay high cane prices, which is typically 70 percent of the ex-
mill realization. An additional impact of high cane prices is the fact that excess cane
is produced at the expense of other crops.
80
Assumption: Cane costs at SMP and SAP are calculated using the recovery rates of Western U.P. to arrive at
cane cost per MT of sugar. Computation based on 2006 data.
Figure 93 shows how the cane and sugar prices have moved in the past few years.
The cane prices have been plotted on per MT of sugar basis. Cane prices have
consistently increased though sugar prices have been volatile. When cane price and
sugar price have moved in tandem, the arrears have been low. However, whenever
the margin between cane and sugar price is reduced, the total arrears have shot up
drastically.
Hence there is a need for a policy to create a link between cane and sugar price to
maintain their alignment. This would ensure that arrears are minimized and possibly
eliminated, thus reducing the induced cyclicality in the sugar sector.
Linkage of cane price with sugar price would link the farmer and consumer
social objectives
81
Assumption Ex factory price assumed to be equal to wholesale price less duties and levies, margins and
transport cost. Cane costs at SMP and SAP are calculated using the recovery rates of Western U.P. to
arrive at cane cost per MT of sugar. Computation based on 2006 data.
The floor price would protect the interests of the mills and farmers to ensure that the
cane price can be realized from the sugar price and adequate returns are available for
farmers and mills, irrespective of the demand and supply situation. Ceiling price
would protect the interests of the consumers to ensure that adequate availability is
maintained in line with the consumption pattern. Government policy would
therefore need to balance both the farmer and consumer interests.
Aligning the cane and sugar price can lead to significant gains for the sector
Total Losses suffered
Aligning cane and sugar prices will improve the financial viability of mills and reduce
the need for government support. In the past, government support was required to
address high cane arrears in the form of rehabilitation packages, both at the central
and state levels. Also, in surplus years, there has been a high inventory build up,
leading to high inventory holding costs for the sector. During the deficit years, India
imported sugar to address domestic demand. This led to opportunity cost in terms
of lost sales for farmers and mills, while negatively impacting government revenues
through import duty reductions.
In additional to the losses described above, the sustainability of the sector has also
been at risk. This is primarily due to the high amount of arrears and the involvement
of a large number of farmers and mills.
4.5 14
Sugar Production, Consumption (million MT)
4.0
12
3.5
10
2.5 8
2.0 6
1.5
4
1.0
2
0.5
0.0 0
Oct Nov Dec Jan Feb Mar Apr May Jun Jul Aug Sep
Value at Risk (VaR) is one of the tools that estimate the potential risk of loss due to
the price risk. VaR helps assess the monetary value of the worst expected loss, on a
portfolio over a given time period with a given confidence level.
In case of sugar, the production timing is not aligned with consumption timing that
leads to high inventory. While the production is seasonal, the consumption is almost
evenly spread throughout the year. Thus, the sector needs to maintain high
inventories that peak towards the end of the crushing season.
The market prices for sugar are volatile, and therefore there is a price risk for the
inventory. In the absence of any risk management techniques, mills can potentially
lose significant amount of value through erosion of inventory value.
VaR is calculated as the average value of stock which is held over the specified
duration multiplied by the volatility to which the stock is exposed.
In case of sugar, VaR is estimated at INR 3140 crores at a sector level for a year82.The
VaR is estimated at a 95 percent confidence level.
82
VaR = INR 375590 Crores Days (average inventory*average price*no. of days) * 0.51 percent (std.
deviation) * 1.64 (95 percent confidence interval) = INR 3140 crores
= INR 1000
3 Months
The risk protection offered by hedging depends on the hedge ratio, i.e. the proportion
of the inventory that is being hedged. Hedging does not enable speculation. It is a
mechanism for managing risk that can protect the inventory value from being eroded.
Hedging is possible for sugar since sugar contracts are being actively traded
on the commodity exchanges
21
Pepper
24
Mustard seed
38
Wheat
39
Soy Oil
40
Sugar 67
ge
Soy bean Perc enta
Figure 98: Hedgers as a percentage of total traders on the exchange: Share of end-users in business (2007)
Source: NCDEX
30 40%
15%
10
6.07 6.05 10%
8%
5
0.98 5%
0 0%
2004-05 2005-06 2006-07
NCDEX Volumes Sugar Production
Ratio of NCDEX volume to sugar production
Figure 99: NCDEX Volumes vs. Sugar production in India (FY 2005 - FY 2007)
Source: NCDEX, ISMA Hand book of Indian Sugar Statistics Sep 2006
The ratio of volumes that are traded on the exchange to sugar production has been
increasing, indicating increasing depth of the market.Though this indicator has been
increasing, it is still low as compared to the total volume of sugar produced in India
and there is significant room for greater participation. Higher participation from
stakeholders across the value chain would enable greater depth in the market, thus
increasing the hedging capability for the sector and ensuring greater confidence in
market operations.
1400
2-Jan-07
2-Feb-07
2-Mar-07
2-Jan-06
2-Feb-06
2-Mar-06
2-Apr-06
2-May-06
2-Jun-06
2-Jul-06
2-Aug-06
2-Sep-06
2-Oct-06
2-Nov-06
2-Dec-06
Spot Price M+1 future price Spot+Holding cost
Exchanges have adopted various checks and controls to ensure a fair market
In order to enable greater participation on the commodity exchanges, fair market
operations would be the key factor and the exchanges are working towards ensuring
the same though various checks and control83.These include -
83
Source: NCDEX
Going forward, several initiatives are planned for increasing the participation and for
further strengthening the market. The key to the future growth of the exchanges
would be greater participation by stakeholders and higher confidence in market
operations. In order to achieve the same, several initiatives are being undertaken84 -
! Awareness and training programmes with mills, buyers and corporate across
the country for enabling greater participation
! Greater promotion of use of hedging by participants under the hedging policy
! Long term futures contracts in sugar 18 month sugar contract is being
evaluated and can provide an alternative price discovery mechanism for
farmers and mills
! Higher position limits as current limits do not suffice in providing complete
coverage for the sugar production of mills
! Opening futures trading to foreign participation focus on SAARC nations and
south east Asia
84
Source: NCDEX
In case of industrial consumers, sugar is used in the form of liquid sugar and
concentrates, apart from white sugar. Similarly, household consumers are also
starting to use various sugar varieties like demerrera and icing sugar. For the export
markets, India will need to start producing raw sugar as well as white sugar of 45
ICUMSA varieties.
While opportunities exist to tap the industrial and household markets, the potential
is expected to be limited since these are currently emerging niche segments. For
export markets, the potential will be dependent on India's ability to be a cost
competitive exporter.
By products
! 3,000 mllion litres of ethanol
! 9,700 MW of exportable Sugar price risk management
power ! Use of hedging for
! 48 million carbon credits managing VaR of INR 3,000
! Energy security through crores
green sources ! Greater use of commodity
! Investment - INR 320 crores exchanges
to
The above discussed opportunities have the potential to enable the sector to move
towards its shared vision. These opportunities could have varying degrees of impact
on the sector due to their criticality towards achieving the vision and the value of the
opportunity. While some of these opportunities are currently being tapped, some of
them are largely untapped and offer significant potential in the future.
Extent of International
potential trade Productivity
improvements
currently
untapped
High impact
opportunities which
Domestic
demand have been
traditionally tapped
LOW
LOW Impact -Level of criticality, HIGH
value of opportunity
! Cyclicality management
! Byproducts
! Productivity improvements
! Sugar price risk management
! International trade
While the domestic demand is critical and offers large opportunity, it is currently
being addressed by the sugar industry. Similarly, while product innovation is largely
untapped, it is expected to be a relatively small opportunity since it is expected to be
targeted at specific segments.
The future policy environment would need to enable the sector to leverage these
opportunities. The regulatory roadmap would define the regulatory modifications
needed for creating the appropriate policy environment.
85
Note: Cyclicality management refers to cane and sugar price alignment.
State Control/ Monopoly phase is marked by limited competition and high extent of
state control on firms. The next phase in the evolution journey is Reforms Emerge,
where the regulatory regime is initiated and competition intensifies. The third phase
is that of State of flux, which is a high growth phase for the sector, where the
traditional assumptions are challenged and state influence dwindles, hostile
competitors emerge, significant investments are made and the culture is
characterized by a 'beat the regulator' approach.The fourth phase is that of Refocus,
where the industry settles and consolidates, customer segmentation is of
importance, core competencies are refocused, impact of regulation further
subsides and culture is 'beat the competition'. The fifth and the final leg of the overall
evolution journey is Dynamic competition, where regulatory influence is largely
limited to natural monopoly, complex partnerships and alliances are forged,
customers and markets are highly segmented and businesses challenge the
'efficient frontier'.
Globally, one can see instances of industries being at various stages of evolution. In
the 2000s, the oil industry in Bulgaria and Czech Republic were at the state of flux,
while the Australian oil industry seemed to have reached dynamic competition
phase. In United Kingdom, water, electricity and gas were at state of flux, while
telecom seems to be in the dynamic competition phase. In United State of America,
gas, telecom and railways also seem to have achieved the dynamic competition
phase.
Insurance
Fertilizer
Telecom
Power
Textile
Cement
In each of the industries under consideration, like sugar there were transformation
objectives. The fulfilment of the same brought in investments, ushered in
improvement in sector performance, provided opportunities to both public and
private players and addressed social objectives.
As is evident from the industries' transformation case studies, the key imperative
was the evolution of regulations that facilitated the successful transition.
Sugar also has similar transformational opportunities and can seize the same
through appropriate business and regulatory initiatives.
86
For all industries, initiation of state control/ monopoly phase is abridged. All other phases are chronicled
as per actual years
during 2001-06
! 6 million MT - Middle East,
Sri Lanka and Nepal
Social Impact
State ! Greater domestic availability
control/ Reforms State of
Monopoly Emerge flux
State
control/ Reforms State of
Monopoly Emerge flux
around 20 percent
Entry of private players- REL,
Tata Energy
Social Impact
State ! AP - Increase customer
control/ Reforms State of service levels; implement
Monopoly Emerge flux standards of performance
Pre 1991 1991-2003 Post 2003
State
control/ Reforms State of
Monopoly Emerge flux
CO2
Social Impact
! No change in farm gate price
of Urea since 2003
State ! Contribution in increasing
control/ Reforms State of fertilizer application
Monopoly Emerge flux
! The transformation of the industry has led to new opportunities for both
private and public players. In sectors like telecom, insurance and power, state
owned companies have evolved and are successfully competing with private
players.
! Evolution of regulations has led to greater social benefits for all stakeholders.
In case of sectors like telecom, insurance, power and fertilizer, evolution of
regulations has led to greater degrees of freedom for the firms and the
benefits have accrued to investors, consumers and producers.
! The sustainable growth of the firms was made possible by aligning the
market forces for supply of raw materials and sale of end products. In case of
textiles, government intervention for cotton has been limited to declaration of
a support price while there is no intervention in the price of cotton textiles. In
case of power, most large power projects are based on power price being
indexed to the key raw material price e.g. coal and natural gas. In case of the
fertilizer industry, the pricing policy has been structured to enable firms to
earn a minimum return on invested capital, while government subsidies
enable the availability of fertilizers at an affordable price to farmers.
The sugar industry also has the opportunity to evolve along this path supported by a
rationalized policy environment that will protect stakeholder interests, while
enabling sustainable growth for the industry.
In India, currently the regulations are prevalent across the sugar value chain. While
the command area enables legal enforcement of supply of cane within the mill's
allocated catchment area, it also restricts new mills from being set up within 15 km
of existing mills. While the cane price is mandated by the central government, there
are few states that also declare state specific cane prices. Mills also need to deliver
a maximum of 10 percent of sugar produced to the government for distribution
through the Public distribution system (PDS), at a price that is often lower than cost
of production. For the remaining sugar produced, the sale is usually as per the
release orders given by the Central government, unless exemptions are allowed
through legal intervention. Also, international trade is regulated through import
tariffs and through non-tariff restrictions on exports that may also include temporary
export bans.
Assuming the absence of any regulations, all stakeholders would have the
freedom to take business decisions, in line with their respective aspirations.
Farmer
Farmers would be able to sell cane to the highest bidder and not necessarily be
restricted to sell to any particular mill. Besides the cane price offered, millers'
investments in farm productivity and in other facets of farmer - miller relationships
would also influence the farmers' choice of miller for selling the produce. Further the
cane price would be driven primarily by the demand and supply of cane on a year-to-
year basis.
Miller
Mills would be free to buy cane from any farmer and the cane price offered by a
particular mill would depend on
The mill capacity would not be restricted by the availability of cane within the
allocated command area, but would also depend on the ability to procure cane from
longer distances. Mills would typically weigh the cost of procuring cane from longer
distances against the benefits of economies of scale. The cost benefit analysis
would include:
! Benefits of scale - Procuring more cane from longer distances would support
bigger capacities and would lead to lower fixed costs per unit
! Additional cost of cane procurement - Procurement of additional cane from
longer distances would imply a greater transportation cost
! Additional cost due to inversion loss - Procurement of cane from longer
distances would lead to longer transit times and greater inversion losses
! Duration of campaign - Higher capacities may enable mills to reduce crushing
periods for a given cane availability. While this may increase average recovery,
the capacity utilization may be adversely impacted
Also, the sale of sugar by mills would be driven by the mill's view on future and
current prices, both in the domestic and international markets. It also depends on
the inventory holding cost, which is likely to be incurred by the mill.
Consumer
For the consumer, the lack of regulation would imply that the sugar price and
availability would be driven by demand and supply conditions both in the domestic
and international markets. There would be no assured availability at affordable
prices.
The typical factors that drive the need for classifying an agro commodity as an
essential commodity are: need for consumer protection and risk of availability.
Consumer protection is needed:
The risk of availability is high if there is high dependence on imports. Therefore, there
is a risk of low availability in case of high world prices.
In case of sugar, the relevance of these factors has progressively decreased over
the years. Levy sugar ensures availability at a reasonable price for households that
are below poverty line while 75 percent of non-levy consumption is either for
industrial or for high income households. Even for low income households that are
not covered under PDS, a 10 percent increase in sugar prices has an impact of less
than 1 percent on monthly food expense. Therefore, the need for ensuring
availability at low prices is limited for sugar.
Also, given the growth in production, India is expected to remain self sufficient in
sugar in the years to come. The increased attractiveness of sugarcane due to
emergence of ethanol and cogeneration will further enable greater sugar availability.
In the past, even in years of deficit production, the availability gap has not been more
than 1.5 months of consumption. This has been effectively bridged through the
import of raw sugar. The cumulative sugar imports in the past 10 years account for
less than 3 percent of the total domestic sugar consumption. Given the adequate
availability of refining capacity in India, raw sugar imports can be used in the future
as well, if domestic production is less than consumption.
The policy environment for the future would need to consider the reduced need for
sugar to be considered an essential commodity, thus enabling greater degrees of
freedom for the industry, while protecting stakeholder interests, to a reasonable
extent.
In order to implement the business roadmap outlined above, the key objectives for
the regulatory environment would be to facilitate
! Level playing field - The regulatory environment should enable all firms
within the sector to compete effectively without any distortions either in cane
supply or in sugar marketing. The distortions may be due to state level policy
variations or due to conflicts between the regulatory provisions at the central
and state levels. These could be because of policies related to cane pricing,
incentive schemes for capacity addition or restrictions on movement of
byproducts like molasses, amongst others. Distortions may also be present
in the form of restrictive barriers to entry or exit for players.
! Efficient use of resources - The regulatory environment would need to
incentivize efficiency both at the farm and mill side. Given that agricultural
land is a scarce commodity, as far as possible, the future growth of the sector
would need to rely on productivity and efficiency improvements. Similarly,
efficiency improvements at the mill side will enable greater production
without added pressure on scarce resources.
! Strengthen the farmer-miller relationship - The farmer-miller relationship
would be a key driver for the future growth of the sector and the regulatory
environment would need to protect and incentivize this relationship. Given
the small landholdings in India, this relationship would need to be the basis for
inclusive growth for farmers and millers.
! Reduce cyclicality and ensure better management of downturns - As
discussed above, the cyclicality in the sugar industry is partly natural and
partly induced. The regulatory environment would need to minimize the
induced cyclicality and promote mechanisms that would enable better
management of the downturn.
! Better sugar price risk management - Given the seasonal production and
resultant large inventories, the regulatory environment would need to enable
and promote the adoption of risk management mechanisms, including
commodity exchanges.
! Linkage with international markets - International markets have a high
strategic value for India for managing the surplus and deficits that cannot be
managed in the domestic market.The regulatory environment would need to
enable and incentivize greater participation in international trade by the Indian
industry.
The current regulatory environment in India for sugar is composed of five major
regulations. Further modifications to these would need to be evaluated for
developing the regulatory roadmap. These regulations are -
Apart from these regulations, policy imperatives identified as part of the business
roadmap, such as byproducts policy and resolution of central and state policy
conflicts would also need to be addressed.
! Access to funds - The cooperative sugar mills are not allowed to access
capital markets. They are also not allowed to build reserves for future
expansion, since all the profits are distributed amongst shareholders in the
form of cane price. This constraint has been partially relaxed under the Multi
State Act. Cooperatives covered under this act can allocate not less than 10
percent of profits as reserves.This is over and above 25 percent of profits that
these cooperatives need to transfer to a statutory reserves fund.
Shareholders for cooperatives comprise farmers with small landholdings,
thus constraining access to additional equity for the mills. Access to bank
Going forward, these constraints will have to be addressed. There is a need for a
supportive policy environment for the cooperatives to enable them to strengthen
their competitiveness. Enabling cooperatives to raise funds from cheaper sources
like External Commercial Borrowings (ECB), Initial Public Offerings (IPO) and other
market borrowings can allow the mills to modernise and expand. As cooperatives
are a state subject, the state governments need to enable investments in the sector.
National Cooperative Development Corporation (NCDC) can also play a key role in
facilitating access to funds.
A high powered committee led by Shri Shivaji Rao Patil is currently examining these
constraints for the cooperative sector in India and is expected to recommend
appropriate modifications.
Identification of instruments of
regulation
Inter linkages between
regulations
Identification of
macroeconomic factors
Identification of end state
Scenario generation
Pre requisites for regulatory
modification
Scenario evaluation
Implementation roadmap
Identification of optimal
scenarios
The command area allocates a specific area to a mill for cane procurement. Farmers
within the allocated area have the option of registering with the mill for cane supply.
In case the farmer registers a specific quantity or acreage of cane, the farmer is
legally bound to deliver that quantity, or cane from the registered acreage, to the mill
post harvesting. If the farmer does not register, then the farmer is free to sell the
cane to any buyer. However, in some parts of India, this may need the permission of
the Cane Commissioner, based on a No Objection Certificate from the mill, in
whose command area the cane has been produced. The mill cannot register cane
from outside the allocated area. The command area is allocated on a permanent
basis though the government may reallocate the area, if required.
Regulatory levers
Government Govt. mandated By mutual National level Regional level Does not
mandated with periodic consent definition definition exist
reviews
Figure 113: Scenario definition for reservation of cane area
Source: KPMG Analysis
The regulatory modification options that have been considered for command area
are -
The command area impacts the cane supply as well as the long term relationship
between farmers and millers, while restricting their choice of buyer and seller
respectively.The relevant evaluation criteria that have been considered are:
! Mill efficiency
! Investments in farm productivity
! Timely payments to farmers
! Additional availability of cane since the time allocation of area was done
! Additional demand for cane by new and existing mills including any capacity
expansion in progress
! Changes in farming patterns that may have occurred since the time allocation
of area was done e.g. emergence of more profitable crops across the region
A review for all mills in every review cycle may not be feasible, but a review can be
done on an exception basis for areas where surplus cane is available, or if the mill
performance has consistently been below the benchmark.
The efficiency of the review mechanism would depend on the ability to objectively
set feasible and measurable benchmarks by collating data across mills in a given
area. The process for reallocation could be as per the process defined by the
Mahajan Committee that involves discussions with the affected mills and provides
for a legal recourse for all parties.
By mutual consent
Farmers would be free to sell cane either on an opportunistic basis to the highest
bidder or farmers and millers could enter into mutually acceptable contracts. If the
mutually acceptable contract is legally enforceable, it would enable assured offtake
for farmers and assured supply for mills for the contract duration. At the end of the
contract duration, both mills and farmers would be free to evaluate other options for
cane supply. It can be assumed that the contract duration would be long enough for
mills to recover the benefits of investments that they would make in farm
productivity and in the relationship with farmers. Contract renewal would be
dependent on the farmer's and miller's perception of the cane price offered and the
benefits of the relationship. The entry barriers for new capacities would be lower
since farmers would be able to switch to different mills at the end of the contract
durations and there would be no need for the government to allocate area.
If the contracts do not have adequate legal remedies for immediate enforcement,
then implementation would be a concern area for both mills and farmers. Further,
sustained violations would reduce the stakeholder's confidence in the system,
leading to increase in opportunistic sales rather than long term contracts. There
would also be a significant risk of creation of intermediaries, since it will not be
feasible for mills to negotiate individually with thousands of farmers and there will
be a need for collective bargaining. This has in fact been a major cause of failure of
command area removal in Pakistan. Farmers will continue to be free to sell cane
without contracts with the associated risks of offtake and low bargaining power post
harvesting.
Govt. Mandated
Govt. mandated,
periodic reviews
By mutual consent
Based on the relative benefits and drawbacks of the above scenarios, the
government mandated command area with reviews enables efficient use of
resources and facilitates a level playing field, while addressing the social objectives
of farmer sustainability and mill viability. However the risks related to
implementation will need to be mitigated. These risks and possible mitigations are:
! The role of the middleman took birth. The middlemen purchases cane from
growers before harvest at a price lower than the one at which he eventually
sells to the mill. While the role of the middleman is frowned upon by the
millers, growers as well as the government, without a suitable alternative this
practice persists.
According to the Pakistan Sugar Mills Association, the freedom of such sale and
negotiation may bring short term benefits at the cost of potential technical and
financial support extended to growers by the local mills. The help, thus extended to
growers who agree to supply their cane in the mill in their locality, could include
financing seed, new varieties, fertilizer, pesticides, machinery and expertise
services.
Source: ISMA
Case study – Use of captive farms and large landholdings in Brazil and
Australia
In Brazil and Australia, cane farming is typically done on large sized plantations.
Average landholding sizes are much larger than in India. In Australia, approximately
5,800 independent growers supply bulk of the cane for the entire sugar industry. In
Brazil, only 25 percent of the cane is sourced through independent growers, with
mills sourcing the remaining cane from plantations owned by them. In both cases,
the large size of the farms enables them to effectively bargain with the mills and the
capacity of the farmers to sustain risks of crop offtake and crop failure is much
higher. The growers are also not entirely dependent on the mills for investments in
farm productivity. In both these cases, mutual contracts are established between
mills and farmers for cane supply through collective or individual negotiations. The
need for regulatory intervention for cane supply is limited, unlike in India, since
Indian farmers have low bargaining power and low ability to sustain risks, due to
small landholdings.
Since distance restriction between mills impacts the sustainability of the mill
through availability of cane, relevant evaluation criteria that have been considered
are:
Low
National definition
Regional definition
Based on relative benefits and drawbacks of the above scenarios, the distance
separation between mills needs to continue with benchmarks defined at a regional
level.This would enable the social objective of mill sustainability. However, the risks
related to implementation will need to be mitigated. These risks and possible
mitigations are:
Figure 116: Comparison with previous studies for reservation of cane area
Source: KPMG Analysis
The cane pricing mechanism determines the cane price that the farmer receives. At
present, the cane pricing models in India vary by state as discussed in the section on
the Sector Snapshot. Some states follow the SMP model with farmers entitled to a
share of mill realization at the end of the year. Some states follow the SAP model
with a fixed price mandated by the state government, which is typically more than
the cane price, as determined using the SMP model. In case of cooperatives, the
mill profits are distributed as cane price amongst farmer members.
The payment schedule is a critical aspect of the cane pricing model, since the timing
and relative quantum of payment determines the price signalling effectiveness of
the cane price.
Regulatory levers
Free market pricing Formula based Mandated Single stage Multiple stage
pricing fixed price
The macroeconomic factors that have been considered for generation and
evaluation of scenarios for cane pricing are:
Since the cane pricing mechanism impacts the incentives for both farmers and
millers to improve efficiencies and also determines the sustainability of farmers and
mills, the evaluation criteria for cane pricing are:
The free price system would need negotiations between the mills and large number
of farmers, thereby enabling the creation of intermediaries. Given the perishable
nature of cane, the farmer's bargaining power post harvesting would be very low. In
case a single mill is present in a given area, the farmer may also face a monopsony
risk. In years of surplus cane production, cane prices may be very low, causing a
subsistence risk for farmers.
At times when the cane supply is greater than the demand, and the output prices
are low, formula based cane price may even be lower than the cost of cane
production.This would lead to subsistence risk for farmers.
Formula based
Fixed mandated
Based on the relative benefits and drawbacks of the above scenarios, the formula
based pricing model enables efficient use of resources, reduces cyclicality and
provides for a level playing field. However sustenance risk for farmers need to be
mitigated and issues related to implementation need to be addressed. These risks
and possible mitigations are:
Figure 119: Scenario evaluation for cane pricing linkage with quality
Source: KPMG Analysis
Based on the benefits and drawbacks of the options considered, the cane price
should be linked to quality of cane for an individual farmer. Given the lack of
technologies at the current time for enabling such a system, cane price can currently
be linked to recovery and as and when the sucrose measurement techniques
become available, they can be adopted.
Linked to sugar,
primary and
secondary byproduct
Figure 120: Scenario evaluation for cane pricing linkage to output prices
Source: KPMG Analysis
Based on the benefits and drawbacks of the options considered, the cane price
should be linked to sugar and primary by-products price (molasses and surplus
bagasse). This would enable reduction in cyclicality, while addressing the social
objectives of mill and farmer sustainability. It is also relatively easy to implement. In
this case, the low output prices may create a sustenance risk for farmers. The
mitigation for the same through mandated support prices has been discussed
earlier as part of the discussion on cane price linkage to quality.
The minimum sugar price needed to sustain the support price of cane would need
to be determined when the support prices are declared. This can be the basis for
determining the lower end of the sustainable price band.
Fixed formula
Both farmers and millers have a lower incentive for improving the quality since the
incremental benefits would need to be shared in the predetermined ratio. The
system is easy to administer since there is no need for collation of data across mills
and for benchmark setting. However, the consensus between stakeholders would
need to be established for defining the sharing ratios.
Variable formula
Both farmers and millers have a higher incentive for improving the quality since the
incremental benefits would not be shared. While the sharing ratio for output price
would be fixed, the quality and efficiency ratios would be based on benchmarks.The
cane price would depend on performance relative to the benchmark. The system is
complex to administer since there is a need for collation of data across mills and for
benchmark setting. Further, the consensus between stakeholders would need to be
established for defining the sharing ratios as well as for setting benchmarks.
Fixed formula
Variable formula
Figure 121: Scenario definition for cane pricing fixed vs. variable formula
Source: KPMG Analysis
Though fixed formula provides lower incentives for efficient use of resources, given
the large number of mills and farmers in India, it would be more feasible to
implement as compared to the variable formula.
The formula definition for the formula based pricing could be done either at a
national or a regional level. Both these options have been considered:
! National formula - The formula sharing ratios are defined at the national level
and are applicable across the country
! Regional pricing - The formula sharing ratios are defined at the regional level
and account for regional variations
National formula
Since the formula sharing ratios would not account for regional external variations
like soil conditions, climate and infrastructure availability, farmers in regions with
lower productivity would be disadvantaged. The farmers in regions with higher
productivity would have a lower incentive for improving productivity.
Efficient use of
High
resources – Incentivize
mill efficiency, cane
Medium
quality
Low
Regional formula
National formula
Figure 122: Scenario evaluation for cane pricing national vs. regional formula
Source: KPMG Analysis
The payment made to the farmer just before the start of sowing for the next season
has the maximum impact and is the most relevant price signal. The farmers receive
two payments at this time. The first one is the advance payment, which the farmer
receives for the cane delivered for the current season. The other is the final payment
that the farmer receives for cane delivered in the previous season. The advance
payment for the current season is the more relevant price signal, since it is based on
the expected prices in the coming year, whereas the payment received for last
year's delivery has a distorting impact. This is because it is based on the past prices.
An attempt, therefore, needs to be made to increase the relative value of the
advance payment for the current season as compared to final payment for the last
season. Even then, a one year lag is inevitable in the price signal since ideally, the
cane acreage should be determined by expected prices in the season for which the
cane is currently being sown.
! One time payment - The entire cane price is paid to the farmer within a
stipulated time after cane delivery.
! Multi-stage payment - The cane payments are structured in multiple stages.
An advance price is paid at the time of cane delivery and subsequent
payments may be made during the season with the final instalment being
paid immediately after the end of the season. The advance price would be
based on expected sugar prices. The subsequent payments would be used to
adjust for the difference between expected and actual sugar price and factor
in the impact of relevant performance parameters.
Since the cane payment schedule impacts the price signal and is critical for the
farmer to meet the working capital needs for the ensuing season, the criteria for
evaluation are:
The cane cost accounts for almost 70 percent of the ex mill price of sugar, making it
difficult for the mills to pay the entire price at the beginning of the season. Also,
since the cane price would be paid before the end of the season, it cannot be linked
to actual sugar price and would have to be based on expected sugar price only. In
case the actual sugar price is much lower, it may lead to margin pressures for mills
and in extreme cases may also lead to arrears.
Low
! If final price for cane as per the formula is lower than the advance price paid to
farmers at the time of cane delivery:The difference between the price paid to
farmers and the actual price would need to be borne by the government. In
such a case, interventions would be needed through the independent
regulator to ensure that the sugar price is adequate to meet the cane price.
The interventions would be triggered by the sugar price dropping below the
floor price of a defined sustainable price band.
The cane pricing system would therefore need to be a formula based system that is
linked to sugar and primary by-products prices (molasses and surplus bagasse), mill
recovery and takes into account regional variations in climate, soil conditions and
infrastructure availability. The payments would be made in a multi-stage payment
schedule with the final payment being made immediately after the end of the
season. The magnitude of the first payment would need to be high, relative to
subsequent payments. An independent regulator would be needed for the
definition of the formula and for determining cane price on an annual basis. Support
prices would be needed for protecting farmers against subsistence risk and would
need to be based on cost of production of cane only. The independent regulator
would need to intervene in case the sugar price drops to a level that cannot support
the minimum support price for cane.
Also, as per LMC, an international agency focusing on the sugar industry, the key
regulatory imperatives for India would be:
Profit ! Mill profits ! Cane price to be linked to ! Cane price to be linked ! Regulator to
sharing and over and average recovery and to average recovery, replace the
factors to be above the sugar price sugar price and primary Sugarcane
considered support byproducts Pricing Board –
price to be ! To be linked to sucrose Role of
Regional shared content over long term ! To be linked to sucrose regulator not
variations equally content over long term restricted to
! Share of farmers to be
between cane pricing
Role of the based on 10 year average ! Share of farmers to be
farmers and
government cost of cane determined by regulator ! Profit share for
millers
! Premium for varieties ! Premium for varieties farmers in
primary by -
! Final price to be ! Final price to be products
announced by end of announced by end of
season season
The cane price is linked to cane quality as measured by sucrose content of cane,
where the quality and sweetness is measured by CCS (Commercial Cane Sugar).
The CCS index prices sugarcane following a combination of weight (40 percent) and
sugar content (60 percent) and its calculation involves measurements of Pol, Brix
and Fiber in cane.
90
Overall sucrose recovery (%)
85
80
75
70
65
1972/73 1976/77 1980/81 1984/85 1988/89 1992/93 1996/97 2000/01 2004/05
Thailand also has a quota system that enables it to regulate the domestic price and
ensure mill viability as well as farmer viability through guaranteed cane and sugar
prices. In case of price changes in the international market, the government
intervenes to address the shortfall between the guaranteed cane price and the
actual sugar realizations.
Case study – Free market pricing in Australia with a variable formula linked to
sugar for reference
At present, the cane pricing in Australia is completely deregulated, while the
Queensland pricing formula is still used as a reference by mills and farmers. The
formula was used for payment for cane in Queensland, Australia's largest sugar
producing region, prior to the deregulation in 2004. The pricing is structured
according to a formula, which was originally designed to allocate net proceeds from
sugar sales between millers and growers, so that profits were shared roughly
according to the ratio of their assets. The recovery is defined in terms of 'commercial
cane sugar' (CCS). The formula is based on the assumption that at base levels of
efficiency, the proceeds should be split in the ratio of two-thirds to farmers and one-
third to the miller for standard production. The formula is an illustration of a variable
pricing formula and is defined as :
Pc = Ps*(90/100)*(CCS-4)/100 + 0.578
Pc refers to cane price, Ps refers to sugar price and CCS refers to quality of cane.
Under the formula, growers share income only from the resulting raw sugar stream
of the mill. Other outputs such as molasses and bagasse are treated as the property
of the mill. The growers' share of revenue has varied between 62 to 67 percent over
the past decade.
Case study – Variable formula based pricing in Brazil linked to sugar and
ethanol pricing
Brazil's cane payment system is based on both the quality of cane and the prices of
sugar, anhydrous ethanol and hydrous ethanol since 1998-99. The cane quality is
assessed in terms of recoverable sugar, measured as kilograms of total reducing
sugar (TRS) per MT of cane. This is calculated by measuring both juice Brix and juice
Pol; then the weight of wet bagasse is also measured (inversely related to the
amount of fiber in cane).
The price of TRS per kilogram is obtained from a formula, which takes into account
the price of white sugar in the international and domestic markets, the price of VHP
sugar in the international market, the price of hydrous and anhydrous ethanol in the
domestic and international markets. These prices are provided by the Centro de
Estudos Avancados em Economia Aplicada (CEPEA). One interesting element in the
pricing of TRS to growers is that the formula takes into account how costly it is to
make each of the products from the same amount of cane. On an average the
grower's revenue share amounts to 56 to 61 percent.
Brazil is the only country where farmers have a share in ethanol profits as well, due
to its unique dynamic management of product mix, where the mills utilize cane to
produce both sugar and ethanol directly. The Brazilian system is an illustration of
variable pricing formula.
Since the growers in Brazil are paid on the basis of cane quality and there is no
relative payment scheme, independent growers concentrate their deliveries in
those months, when cane sucrose and juice purity are at their highest. The
independent growers have tended to concentrate deliveries in the months of
highest sucrose content and juice purity, and millers process their own cane on
either side of the sucrose peak. In India, given the large number of farmers, the
implementation of a relative quality based payment system would be difficult, but
the variety specific incentives can be used to encourage adoption of high sucrose
varieties.
On an inter-seasonal basis, beet and cane prices are loosely correlated with the
domestic price of sugar. This means that when beet and cane prices are set during
pre-season negotiations, the processors, growers and the government
representatives take into account the various market conditions. Significantly, the
provincial governments have allowed the prices of beet and cane to fall as well as
rise, reflecting changes in market conditions.
Source: LMC
The regulatory modification options that have been considered for monthly release
mechanism are:
Since monthly release mechanism influences the domestic prices and restricts the
ability of mills to manage the price risk, the evaluation criteria that have been
considered are:
Removal of release mechanism would also lead to a risk of high prices for
consumers and risk of low prices for mills and farmers, since the government
intervention would be limited. The risk of manipulation of future prices on the
commodity exchanges would also need to be addressed.
The removal of monthly release mechanism would enable better price risk
management and help create a level playing field while addressing the social
objectives of consumer protection and mill and farmer sustainability. The risks that
would need to be mitigated are:
! Risk of high prices for consumers - This risk can be mitigated through
government intervention using a strategic stock.The strategic stock would be
a market based mechanism rather than a regulatory mechanism for
influencing the price and availability. The risk could be further mitigated by an
appropriate international trade tariff policy, which would enable the
management of deficits and surplus in production, through imports and
exports.
The strategic stock would need to ensure that mills make adequate returns after
accounting for cane price, taxes and cost of conversion.This would enable sustained
growth for the sector and also lead to minimization of arrears.The strategic stock will
also enable lower volatility in prices, thus strengthening the financial position of the
sector.
Given the change in the consumer profile, as indicated by the consumer survey, and
the need for re-evaluation of sugar to be a part of the Essential Commodities Act,
definition of a sustainable price band will not adversely impact the consumer
interests.
The strategic stock can be implemented in multiple ways. The key determinant
would be the title ownership of the stock.
The operational management of the strategic stock in line with the defined price
band could be done by an independent body, considering the large number of
stakeholder groups that would be impacted. While the sustainable price band could
be defined by the government and the industry, the independent body would be
responsible for day to day operations.The independent body could be funded jointly
or individually by the industry and the government. The funding could also be done
through a Special Purpose Vehicle (SPV). Existing mechanisms, like the SDF, could
be partially utilized for setting up the strategic stock and for sharing the losses, if any,
due to its operations. The independent body could hold the title of the stock and its
operational management would need to be done in a neutral and independent
manner. Sector objectives would need to be fulfilled without preference being given
to any individual stakeholder group.
The strategic stock can effectively replace the monthly release mechanism and
provide significant benefits for all stakeholders.
! The need for government intervention and control would be reduced and the
industry would have the opportunity to become self reliant.
! The interests of the farmers would be protected since the cane price will be
recovered from the sugar price, thus minimizing arrears.
! Industry attractiveness would increase since margins would be protected
due to the sustainable price band.
! The induced cyclicality would reduce leading to greater stability in earnings
for both millers and farmers.
Previous studies like the Tuteja Committee recommended the removal of monthly
release mechanism.The Mahajan Committee recommended that monthly releases
be continued and the releases should be decided in consultation with the industry. It
also recommended the use of buffer stock, export restrictions and monthly release
mechanism to control the domestic prices in a sustainable band.
Also, as per LMC, an international agency focusing on the sugar industry, the key
regulatory imperatives for India would be
Figure 130: Comparison with previous studies for monthly release mechanism
Source: KPMG Analysis
The release of the central government stocks was successfully used to control the
sugar prices in the domestic market in 2004 and 2005.The government usually sells
through auctions to address the domestic demand in case of spurt in domestic
prices. To bolster the state reserves, the country typically imports Cuban sugar
through preferential agreements.
The buffer stock system in China is self sustaining and the cost of managing the
system is recovered through the profits generated by the sale of sugar in times of
high prices.The buffer stock model adopted by China is completely owned and
managed by the government. In case of India, this model can be suitably modified to
enable even greater efficiencies. The mills could partner with the government for
either storage or ownership of the buffer stock.
Case study – Other commodities like rice and wheat in India Absence of
monthly release mechanism and FCI operated buffer stock
In India, there are a number of agro commodities which are part of the Essential
Commodities Act. In addition, many of these commodities like rice and wheat are
produced only during certain months, but are consumed throughout the year. Also,
these agro commodities are produced only in certain states.
To procure the food grains, the ministry uses a Minimum Support Price (MSP). The
Food Corporation of India (FCI) maintains the central pool and supplies food grains to
the various states. Also, FCI intervenes when the producer prices fall below MSP, or
in case of the regional shortages. Apart from FCI, which is the main agency for
procurement and distribution, state government agencies also play a vital role in the
distribution of these food grains.
In August 1978, the monthly release mechanism was removed. Due to huge stocks,
mills started selling sugar under cut throat competition and prices crashed. As a
result, the industry suffered heavy losses. To remedy the situation, the industry
resumed a period of voluntary release mechanism in March 1979. By June 1979, the
government resumed the monthly release mechanism.
Again, the government decided in February 2002 to dispense with the release
mechanism by March 2003, after futures/forward trading in sugar was established.
Fearing drastic fall in sugar prices following the removal of monthly release, a
number of factories approached the courts in 2002 for release orders for sale of free
sale sugar. Courts held that the government had no authority to enforce restrictions
on the sale of free sale sugar and allowed the sale of sugar leading to fall in sugar
prices. The sugar industry simultaneously urged the Government to continue with
the release mechanism. Thus, the release mechanism was extended up to
September, 2005, with another review scheduled for taking a decision.
Regulatory levers
The trade restrictions influence India's ability to participate and leverage global trade
and also influence domestic prices. Hence, the evaluation criteria that have been
considered are:
Based on the benefits and drawbacks discussed above, the removal of non-tariff
restrictions will enable sugar price risk management and enhance linkages with the
international trade. This will be done along with addressing the social objectives of
consumer protection and mill and farmer sustainability.The risks that would need to
be mitigated are:
! High world prices and attractive export realizations may lead to high prices in
the domestic market Historically, domestic prices have been higher than the
world prices for sugar. As discussed in the section 'Business roadmap', major
sugar producers export at competitive world prices while maintaining high
domestic prices. The risk of exports leading to small domestic supply is
therefore low.The risk can be mitigated through the use of strategic stock for
augmenting the domestic supply and by the import tariff policy.
! Low cost imports may lead to low domestic prices impacting the mill and
farmer sustainability The risk can be mitigated through modifications to
import tariffs. India's current import tariff of 60 percent is much lower than
the WTO bound rate of 150 percent and therefore the risk of low cost imports
is low. Given the social objectives of farmer and mill sustainability, India
would need to maintain a high bound rate even in the future to ensure that
subsidized sugar from other geographies does not hamper the sustainability
of the Indian industry.
Also, as per LMC, an international agency focusing on the sugar industry, the key
regulatory imperatives for India would be
Each mill may sell only a specified amount of sugar on the domestic market (quota
A); the remainder of its output (quotas B and C) is exported.
! Quota A - Quota A is the Cane and Sugar Board's policy instrument for
ensuring that the domestic market is adequately supplied with sugar at stable
prices. The domestic marketing of sugar is controlled via a system of weekly
sales quotas, and the government fixes the domestic sugar prices. This
ensures price transparency in the domestic market.
! Quota B - The purpose of quota B is to establish a representative price for all
sugar exports, and is used to calculate industry revenue for the purpose of
revenue sharing between millers and growers. As such, it is the basis for price
transparency for export sugar.
! Quota C -This quota represents the balance of sugar output. This sugar must
be exported, although millers are under no obligation to export this sugar in
the same crop year. However, for the purpose of revenue sharing, it is
assumed that quota C sugar is sold at the quota B price, during the marketing
year in which it was produced.
The quota system enables Thailand to regulate the domestic price and ensure mill
viability as well as farmer viability through the guaranteed prices. In case of price
changes in the international market, the government intervenes to address the
shortfall between the guaranteed price and the actual realizations.
Source: LMC
The mills in Australia can export any quantity of sugar at international prices. The
cane price is linked to realizations from the export markets as well as the domestic
market.They are also free to import sugar at international prices. Thus, the domestic
sugar prices are always at import parity. Further, the domestic sugar prices as well as
domestic sugar production are directly linked to the international sugar prices and
trade, due to the free regulation regime in Australia.
Given the presence of large farmers and the low domestic consumption, the need
for influencing domestic price in Australia is low. Consequently, absence of tariff
policies does not have a major impact on the stakeholders, unlike in India.
The implementation of a price band system has helped Colombia to stabilise its
domestic price. In particular, the system has successfully insulated the domestic
producers from the world market in times of very depressed prices, while offering
little or no support when world sugar prices have been high.
In order to prevent prices from falling to export parity levels, Colombia operates a
market clearing mechanism to ensure that the country's exportable surplus does
not enter the domestic market. For a country that is a net exporter, such a
mechanism is essential for a price band system to work effectively.
The price band system is WTO compatible as long as the total value of a fixed tariff
plus a variable tariff/duty stays within the bound rate agreed by a country.
Given India's low reliance on imports, this may not be a relevant system for India due
to high implementation complexity. In case of India, import tariffs can be fixed within
theWTO bound rates and depending on the domestic surplus or deficit situation, the
same can be varied.
Levy sugar enables the government to supply sugar through the PDS to Below
Poverty Line (BPL) households and ensure the availability of sugar at affordable
prices. In the analysis, it has been assumed that the current 10 percent levy quota is
adequate to meet the consumption needs of the target segment. It is also assumed
that the sugar would continue to be part of the PDS in the future as well.
The current subsidy for levy sugar is made up of various components and is shared
between the mills and the government.
The difference between the levy price and the free market price is borne by the mills.
The levy price is supposed to be fixed based on the actual cost of production. Though
some states in India follow the SAP cane pricing model and cane price in these
states is typically higher than the SMP, the levy price is fixed assuming cane price to
be equal to SMP. Also, the levy price was last fixed in 2003, though the cost of sugar
production has increased since then.
Regulatory levers
The regulatory modification options that have been considered for levy sugar are-
Since levy sugar is targeted at consumer protection and lower levy price impacts the
mills and farmers, the evaluation criteria that have been considered are:
Medium
Low
Based on the above discussion of benefits and drawbacks, removal of levy sugar
would increase the economic profits of the sector, while addressing the social
objectives of consumer protection and mill and farmer sustainability by shifting the
subsidy cost from mills and farmers to the government.
Levy sugar ! Levy sugar to be ! Levy sugar ! Levy sugar to be ! Subsidy to shift
discontinued in a phased to be discontinued and sugar from farmers
manner over two years maintained for PDS to be procured and mills to the
at 10 through the free market government
! If sugar is maintained as percent
part of PDS, it should be
procured through open ! If levy sugar
tenders or at a fixed is not lifted
price from the mills, within three
linked to the free market months of
price the levy
release, it
! Levy price to be based would
on actual cane price paid revert to
by the mills free sale
sugar
! Levy price to be
announced before the
start of the season
8.11 Summary
Complete absence of all regulations would not be the optimal scenario for the sugar
industry and there is a need for developing an appropriate regulatory environment.
This environment would need to enable the industry to leverage the transformation
opportunities. Farmer interests would need to be protected and sector
attractiveness would need to be enhanced. Protection for consumer interests
would need to be aligned with the consumption pattern. There is a need to re-
evaluate the inclusion of sugar in the Essential Commodity Act. The weightage of
sugar in the WPI also needs to be re-assessed.
The regulatory modifications suggested are evolutionary in nature. Given the large
number of stakeholders involved and the strategic importance of the sugar industry,
these modifications would gradually enable the industry to align itself with the
emerging opportunities. The summary of recommendations that have been made
for regulatory modifications to enable the sector to successfully implement the
business roadmap is:
As the regulatory modifications are implemented, they may have short term
impacts, which would adversely impact the stakeholders during the transition
period. The stakeholders have varying abilities to manage these impacts and
therefore certain pre requisites would need to be fulfilled before the regulatory
modifications are implemented. The modifications themselves would need to be
implemented in a phased manner to ensure that there is minimum disruption to the
sector during the transition.
Identification of instruments of
regulation
Inter linkages between
regulations
Identification of
macroeconomic factors
Identification of end state
Scenario generation
Pre requisites for regulatory
modification
Scenario evaluation
Implementation roadmap
Identification of optimal
scenarios
The issue of low recovery would be addressed by mills that are looking at long term
growth, since consistently lower cane price offered due to low recovery may lead to
farmers shifting to alternate crops or shifting to alternate buyers through reduction
in supply of cane to the mill. Also, if the mill recovery is consistently lower than other
mills, the regulator may need to reallocate cane area during the review to other
efficient mills.
To mitigate this risk, appropriate monthly release modification process would need
to be followed. Adequate mitigating mechanisms including creation of a strategic
stock and definition of a sustainable price band, which will link sugar and cane
prices, will be key pre-requisites for removal of monthly release mechanism.
Supply side
The modifications to cane pricing would need to be done before the start of sowing
so that the farmers can form a view on expected prices and can dedicate acreage to
cane accordingly. The modifications in reservation of cane area would not be
impacted by the macroeconomic environment; since reviews would happen only
over the long term and on an exception basis as per the pre-defined criteria.
From the farmer's and miller's point of view, the modifications should be done when
there is a deficit of sugar in the domestic market and when the international prices
are high. In this scenario, the domestic sugar prices would also be high. In case
there is a drop in prices, due to flow of excess supply post changes to the regulation,
farmers and mills would be more capable of sustaining the impact.
From the consumer's point of view, the modifications should be done when there is
surplus of sugar in the domestic market and when international prices are low. In
this scenario, the domestic sugar prices would also be low and even if there is an
increase in prices, due to reduction in supply post changes to the regulation,
consumers would be more capable of sustaining the impact.
Given the consumption pattern for sugar, the market side regulatory modifications
would need to be done at a time when farmer and miller risks can be minimized.This
would imply sustainable high domestic sugar prices and preferably high
international prices.
As has been observed in the past, monthly release removal has led to sharp increase
in supply and drop in sugar prices. Consequently, the monthly release removal
should be done towards the end of the sugar season, when stocks are at their
lowest level relative to the rest of the year. Due to low stocks, the impact of drop in
prices is expected to be limited and the markets would stabilize faster.
In April 2000, the government also establishedTDSAT, a separate authority from the
TRAI, to handle disputes in the telecom sector.
TRAI was established as an independent statutory authority under the TRAI Act in
1997.The functions and responsibilities of TRAI include:
! The strategic stock has been created and can be used for intervening to
stabilize the sugar price
! The commodity exchange is used by the mills to protect themselves against
price risk
! Greater access to international markets is available and therefore in the short
term, the reduction in sugar prices is constrained by export parity prices
The supply side modifications should be implemented before the start of the
sowing season. The suggested timelines for the regulatory modifications are
detailed below.
Once the environment is conducive for regulatory modifications, the supply side
modifications can be initiated. The government and the regulator would need to
develop and communicate the detailed policies for supply side changes. Both the
command area policy and the cane pricing policy would need to be covered.
Currently there are no non tariff restrictions on export since the export ban was lifted
earlier this year and the same can be continued for the future. In addition levy sugar
can be removed at this time. Since the strategic stock creation and sustainable price
band definition would be done by this time, the monthly release mechanism can
also be removed.
The supply side modifications would be done before the beginning of the sowing
season and the support price for cane as well as the expected advance price can be
announced so that farmers can dedicate acreage for cane accordingly. At the same
time, benchmark definition for command area and cane pricing and definition of
review cycle for command area can be completed.
By the beginning of the sugar season the regulator would need to announce the
advance price for cane and the percentage payable within a stipulated time of
delivery.This would also mark the beginning of the linkage between sugar and cane
prices since the advance price would be based on the expected sugar price.
However the first payment of preceding year would continue to influence the
farmers' sowing decisions. As a result, a complete impact of the linkage between
cane and sugar prices would be observed with a year's lag, i.e. in the subsequent
sugar season.
The process would then enter the steady state phase where the policies defined by
the government with the regulator and the stakeholders would be implemented on
an ongoing basis by the regulator.These would include:
Till the steady state is achieved the government could consider a mitigation
approach whereby, the existing regulations are not completely removed, but kept in
abeyance. Based on the experience of the stakeholders and their ability to manage
the changes in the business environment, the government could temporarily invoke
some of the existing regulations. This would enable the regulator to have an
alternate option available in case the suggested mitigation mechanisms fail to
stabilize the sector. Once the steady state is achieved, all the modifications can be
made permanent in nature.
While this report has discussed several long term proposals for the growth and
development of the industry, there is a need for immediate measures to help keep
the industry viable.
The government, in conjunction with the industry, can consider implementing the
following steps immediately to help the industry and the farmers in the current
situation
! The government can create strategic stock which will help in reducing the
stocks in the market. Reduced stocks will lead to price recovery and enable
payment of cane prices to farmers.The industry will thus maintain its viability
for subsequent years.
! Reduced sugar availability does not imply reduced cane availability. The
industry and the government can explore ways of processing sugarcane into
products other than sugar. One major product which can be produced in this
manner is ethanol. The government can also explore the feasibility of using
surplus cane to produce ethanol directly from cane or through the B
molasses route thus allowing sugar prices to recover to sustainable levels.
!87.
Sugarcane is covered under the Essential Commodities Act due to its perishable
nature and the need for regulation on cane supply and pricing. Given the large
number of farmers with small landholdings involved in farming cane, sugarcane
needs to be regulated. Cane is also increasingly being viewed as a strategic crop due
to the emergence of ethanol and cogeneration. Since cane is produced primarily in
nine states but cane based products are consumed across the country, it needs to
be regulated in a unified manner. Moreover, for a sustainable price band to be
effective across the country, it is necessary that can pricing be done consistently
across states.The independent regulator could play this role in the future.
In case the cane pricing modifications are not implemented, the policy imperatives
that may get impacted are:
! Level playing field - Different models of cane pricing across states would
lead to distortions in incentives for cane cultivation and sugar production
across regions. New investments needed for addressing the transformation
opportunities may therefore, be concentrated in specific regions leading to
inequitable growth across the country
87
Ch. Tikaramji & others vs. state of Uttar Pradesh & others, 1956
If a consensus is not reached between the central and state governments and
suitable modifications to the Essential Commodities Act are not feasible, then the
adverse impact can be partially addressed through additional mitigation steps
discussed below.
The business and regulatory roadmaps outlined in this report have the
potential to transform the sector and move towards its stated vision. It
needs to be recognized though, that globally, the sugar sector is fast
evolving and the impact of some of these emerging trends may require re-
evaluating the future direction of the sector.
Going forward, the changes in the global and domestic sugar industry may
necessitate that the sector vision and roadmap be realigned with changing business
dynamics. Some trends that may have a significant impact in the future are:
AP Andhra Pradesh
ARPU Average Revenue
Cogen Cogeneration
EU European Union
GW GigaWatt
HA Hectare
IC Investment Capital
KG Kilogram
MT MetricTon
MW MegaWatt
UP Uttar Pradesh
Bloomberg ()
Report of the High Powered Committee for the sugar industry - Mahajan
committee report on sugar industry, 1998
NCDEX ()
Prowess
Report of the Commission for Agricultural Costs and Prices on Price policy
for sugarcane for the 2006-2007 season, August 2005
Delhi
4B, DLF Corporate Park
DLF City, Phase III
Gurgaon 122 002
Telephone: +91 124 3074000
Bangalore
Maruthi Info-Tech Centre
11-12/1, Inner Ring Road
Koramangala, Bangalore – 560 071
Phone: +91 80 39806000
Chennai
Wescare Towers
16 Cenotaph Road,Teynampet
Chennai 600 018
Telephone: +91 44 39844900
Hyderabad
II Floor, Merchant Towers
Road No. 4, Banjara Hills
Hyderabad 500 034
Telephone: +91 40 39847000
Kolkata
Park Plaza, Block F, Floor 6
71 Park Street
Kolkata 700 016
Telephone: +91 33 39823210
Pune
703, Godrej Castlemaine
Bund Garden
Pune - 411 001
Telephone: +91 20 30585764
The information contained here in is of a general nature and is not intended to address the © 2007 KPMG, an Indian partnership and a
circumstances of any particular individual or entity. Although we endeavor to provide accurate and member firm of the KPMG network of independent
timely in formation, there can be no guarantee that such information is accurate as of the date it is member firms affiliated with KPMG International, a
received or that it will continue to be accurate in the future. No one should acton such information Swiss cooperative. All rights reserved.
without appropriate professional advice after a thorough examination of the particular situation. KPMG and the KPMG logo are registered
trademarks of KPMG International, a Swiss
cooperative. Printed in India. | https://www.scribd.com/document/49089616/Sugar-Industry-Report-VV-IMP | CC-MAIN-2019-35 | refinedweb | 25,400 | 51.89 |
On Tue, 19 Apr 2005, Matt Benson <gudnabrsam@yahoo.com> wrote:
> I think we already have 1. and 2. if we want to use
> antlibs,
except we don't have the descriptors, yet.
> and assuming we can place additional resources where we like.
We can.
>> Something where loading of the descriptor gets triggered by the
>> namespace URI, but this is optional, at least for me.
>
> If we have consent to add resources,
did anybody object?
> then yes, the above is optional, but for me only barely so.
I understand that, and have no problem with adding a new ant* protocol
to shorten this. It doesn't have to be ant: and it doesn't have to be
antlib:, but even for antlib we could easily make it work by adding a
subprotocol if needed.
> It almost seems integral that if we are going to essentially bundle
> antlibs in the core, then those should be distinguished by a custom
> means of access, and that as terse as possible.
Yes, I agree, but it is no show-stopper to me.
Stefan
---------------------------------------------------------------------
To unsubscribe, e-mail: dev-unsubscribe@ant.apache.org
For additional commands, e-mail: dev-help@ant.apache.org | http://mail-archives.apache.org/mod_mbox/ant-dev/200504.mbox/%3Cm3y8be3h6i.fsf@bodewig.bost.de%3E | CC-MAIN-2014-10 | refinedweb | 198 | 74.19 |
In the first part of this article I discussed how to implement a SiteMapProvider for an MCMS website.
ASP.NET 2.0 ships with three new controls that can be used for site navigation:
- TreeView
Problems with the TreeView control
SiteMapPath and the Menu control can easily be used on a MCMS website but the TreeView control is implemented in a way which causes problems with MCMS. The reason for these problems are the fact that the TreeView control is able to populate nodes on demand. What does this mean?
Populate on demand is highly useful especially for large sites! If this feature would not be available then the treeview would always be prepopulated with the whole tree structure - means with all nodes in the tree which can be the whole channel structure in MCMS. Enumerating the whole channel structure - which would be required without populate on demand - can take a very long time and can bring the overall server performance down quickly.
Have a look at the following picture:
Here the TreeView control shows only the Root Level and one level below. The Control only enumerated the root channel and the first level of included channels and the SiteMapProvider was also only called for these 4 nodes.
If a user now clicks on one of the "+" signs (e.g. for the Development channel) the tree view control needs to get the additional data for the nodes inside the Development channel. To do this the TreeView control does a postback to the server to request the additional nodes and after the postback the result will then look as follows:
In the last beta I worked with this postback was a normal http postback as you will know it from your own web forms. The caveat with this approach is that the whole screen gets refreshed rather than only the piece inside the Development node.
So for the final release the design was changed and now a new technique included in ASP.NET 2.0.
A second problem coming up with these AJAX postbacks is that they raise the "Are you sure you want to navigate away from this page?" message when clicking on one of the nodes to expand or collapse the treeview while being in edit mode.
Solution
So how can we address these problems?
The first problem can be addressed if we can modify the action property of the form tag before the user clicks on the node to populate the content of the next level. Code like the following will do this:
<script>
if (typeof (__CMS_CurrentUrl) != "undefined")
{
__CMS_PostbackForm.action = __CMS_CurrentUrl;
}
</script>
The second problem is a little bit more complicated. I earlier outlined a method to address this problem for the ASP.NET 1.1 controls but unfortunatelly this method fails - again due to the fact that AJAX is used to modify the html content on the client side. So we need to use a method which executes the content of the href attribute without actually executing the href itself.
Looking into the browser event model there is a solution for this: the onclick event is fired before the content of the href attribute is accessed. So if we manage to execute the javascript code in the href attribute from inside the onclick event and if we manage to prevent the execution of the href attribute the problem will not show up.
To execute the javascript code stored in the href we can use the eval javascript function. And to prevent the href attribute from being executed we need to return "false" from the onclick event handler as this will cancel the user action.
Introducing the MCMSTreeView control
As an implementation that addresses both problems I decided to implement a custom TreeView control which is derived from the ASP.NET 2.0 TreeView control. This control will run fine on normal ASP.NET pages and on MCMS templates and channel rendering scripts:
using System.Collections.Generic;
using System.Text;
using System.Web;
using System.IO;
using System.Web.UI;
using System.Text.RegularExpressions;
using System.Web.UI.WebControls;
namespace StefanG.ServerControls
{
public class MCMSTreeView : TreeView
{
protected override void Render(System.Web.UI.HtmlTextWriter output)
{
// catch the output of the original HtmlPlaceholderControl
TextWriter tempWriter = new StringWriter();
base.Render(new System.Web.UI.HtmlTextWriter(tempWriter));
string orightml = tempWriter.ToString();
//;\"");
output.Write(newhtml);
// as a final stepForTreeView", script);
}
}
}
I found that the GetChildNodes method was being called for an extra level down in addition to what you mentioned?
Has anyone created a treeview navigation using SiteMapProvider which does not rely on javascript? The EnableClientScript setting on the treeview control just turns off the AJAX functionality, javascript is required for the full postback mode.
For accessibility reasons it is necessary to be able to provide navigation with javascript turned off.
I have posted a solution for this problem a subsection of this article but it someone just looking on…
Now after MCMS 2002 SP2 has been released I would like to point you again to an article series I have…
Does this issue also exist with the menu control?
Hi Chandy,
usually the menu control does not do any postbacks to populate the items.
Cheers,
Stefan
Hi Stefan
Thanks for the nice article. I used the MCMSTreeView class to generate Sitemap. Now it is live.
But m facing weired issue with it. Some time the treeview shows javascript error "Object required" and also that time not allow to expand any node with another javascript error “expandState is null or not an object”.
After some analysis and research, we got that this is related to the javascript generated for Treeview control. There is an http handler called WebResources.axd in .net 2.0, which generates javascript functions required by particular page. The problem is with how these .axd extensions are mapped in IIS.
Then we were able to reproduce it on dev machine by checking the “Verify that file exists” check box of the site’s IIS Configuration setting against .axd application extension.
But we check all loadbalanced Server’s “Verify that file exists” check box on production, it was already unchecked.
At last that solution didn’t work.
Can you please help me???
Hi Niki,
sorry I have never seen this. But if it is a problem with the AXD references, then it is an ASP.NET issue and not a MCMS issue.
So you might want to follow up with an ASP.NET expert.
Cheers,
Stefan
Hi, I am creating a navigation for MCMS based multilingual website using asp.net menu but I am confused about how to bind the Menu, I can use three options which are mentioned below also I have to allow the user to sort those menus as well:
1)Using a hardcoded XML file with Multi Language Menu in Nodes.
2)Using a hardcoded resource file with multiplie languages.
3)At run time using the MCMS Channel names and creating one Navigation Channel and binding it back to the ASP.NET menu.
Which would be the best Option to bind such a navigational Menu.
Regards
Ankit Srivastava
ankit.sri@hotmail.com
Hi Ankit,
you should use a custom SiteMapProvider as discussed in the first part of this article series.
Cheers,
Stefan
Hi,
I used the code you provided, but it only fixes the problem for the top-level node. I believe that for the other nodes, you need to do the same trick in the GetCallbackResult method.
To do so, add the following code:
protected override string GetCallbackResult()
{
string orightml = base.GetCallbackResult();
//;"");
return newhtml;
}
Regards | https://blogs.technet.microsoft.com/stefan_gossner/2005/12/15/asp-net-2-0-and-mcms-site-navigation-part-2/ | CC-MAIN-2018-13 | refinedweb | 1,260 | 64 |
SQLAlchemy 0.9 Documentation
SQLAlchemy 0.9 Documentation
legacy version
Dialects
- Drizzle
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
-
- Sybase
Project Versions
SQLite¶
Support for the SQLite database..
The other axis along which SQLite’s transactional locking is impacted is
via the nature of the
BEGIN statement used. The three varieties
are “deferred”, “immediate”, and “exclusive”, as described at
BEGIN TRANSACTION. A straight
BEGIN statement uses the “deferred” mode, where the transction()
See also
SQLite Foreign Key Support - on the SQLite web site.
Events - SQLAlchemy event API..
Note.execute("create table x (a integer, b integer)") conn.execute("insert into x (a, b) values (1, 1)") conn.execute("insert into x (a, b) values (2, 2)") result = conn.execute("select x.a, x.b from x") assert result.keys() == ["a", "b"] result = conn.execute(''':
Driver¶
When using Python 2.5 and above, the built in
sqlite3 driver is
already installed and no additional installation is needed. Otherwise,
the
pysqlite2 driver needs to be present. This is the same driver as
sqlite3, just with a different name.
The
pysqlite2 driver will be loaded first, and if not found,
sqlite3
is loaded. This allows an explicitly installed pysqlite driver to take
precedence over the built in one. As with all dialects, a specific
DBAPI module may be provided to
create_engine() to control
this explicitly:
from sqlite3 import dbapi2 as sqlite e = create_engine('sqlite+pysqlite:///file.db', module=sqlite).
Changed in version 0.7: Default selection of
NullPoolfor SQLite file-based databases. Previous versions select
SingletonThreadPoolby default for all SQLite databases....execute("BEGIN").
New in version 0.9.9.
DBAPI¶
Documentation and download information (if applicable) for pysqlcipher is available at:
Driver¶
The driver here is the pysqlcipher driver, which makes. | https://docs.sqlalchemy.org/en/rel_0_9/dialects/sqlite.html | CC-MAIN-2018-51 | refinedweb | 288 | 51.55 |
Common Compiler-Supported C++ Variable Types
In most of the examples thus far, you have defined variables of type int—that is, integers. However, C++ programmers can choose from a variety of fundamental variable types supported directly by the compiler. Choosing the right variable type is as important as choosing the right tools for the job! A Phillips screwdriver won’t work well with a regular screw head just like an unsigned integer can’t be used to store values that are negative! Table 3.1 enlists the various variable types and the nature of data they can contain.
TABLE 3.1 Variable Types
The following sections explain the important types in greater detail.
Using Type bool to Store Boolean Values
C++ provides a type that is specially created for containing Boolean values true or false, both of which are reserved C++ keywords. This type is particularly useful in storing settings and flags that can be ON or OFF, present or absent, available or unavailable, and the like.
A sample declaration of an initialized Boolean variable is
bool alwaysOnTop = false;
An expression that evaluates to a Boolean type is
bool deleteFile = (userSelection == "yes"); // evaluates to true if userSelection contains "yes", else to false
Conditional expressions are explained in Lesson 5, “Working with Expressions, Statements, and Operators.”
Using Type char to Store Character Values
Use type char to store a single character. A sample declaration is
char userInput = 'Y'; // initialized char to 'Y'
Note that memory is comprised of bits and bytes. Bits can be either 0 or 1, and bytes can contain numeric representation using these bits. So, working or assigning character data as shown in the example, the compiler converts the character into a numeric representation that can be placed into memory. The numeric representation of Latin characters A–Z, a–z, numbers 0–9, some special keystrokes (for example, DEL), and special characters (such as backspace) has been standardized by the American Standard Code for Information Interchange, also called ASCII.
You can look up the table in Appendix D, “ASCII Codes,” to see that the character Y assigned to variable userInput has the ASCII value 89 in decimal. Thus, what the compiler does is store 89 in the memory space allocated for userInput.
The Concept of Signed and Unsigned Integers
Sign implies positive or negative. All numbers you work with using a computer are stored in the memory in the form of bits and bytes. A memory location that is 1 byte large contains 8 bits. Each bit can either be a 0 or 1 (that is, carry one of these two values at best). Thus, a memory location that is 1 byte large can contain a maximum of 2 to the power 8 values—that is, 256 unique values. Similarly, a memory location that is 16 bits large can contain 2 to the power 16 values—that is, 65,536 unique values.
If these values were to be unsigned—assumed to be only positive—then one byte could contain integer values ranging from 0 through 255 and two bytes would contain values ranging from 0 through 65,535, respectively. Look at Table 3.1 and note that the unsigned short is the type that supports this range, as it is contained in 16 bits of memory. Thus, it is quite easy to model positive values in bits and bytes (see Figure 3.1).
FIGURE 3.1 Organization of bits in a 16-bit unsigned short integer.
How to model negative numbers in this space? One way is to “sacrifice” a bit as the sign-bit that would indicate if the values contained in the other bits are positive or negative (see Figure 3.2). The sign-bit needs to be the most-significant-bit (MSB) as the least-significant-one would be required to model odd numbers. So, when the MSB contains sign-information, it is assumed that 0 would be positive and 1 would mean negative, and the other bytes contain the absolute value.
FIGURE 3.2 Organization of bits in a 16-bit signed short integer.
Thus, a signed number that occupies 8 bits can contain values ranging from –128 through 127, and one that occupies 16 bits can contain values ranging from –32,768 through 32,767. If you look at Table 3.1 again, note that the (signed) short is the type that supports positive and negative integer values in a 16-bit space.
Signed Integer Types short, int, long, and long long
These types differ in their sizes and thereby differ in the range of values they can contain. int is possibly the most used type and is 32 bits wide on most compilers. Use the right type depending on your projection of the maximum value that particular variable would be expected to hold.
Declaring a variable of a signed type is simple:
short int gradesInMath = -5; // not your best score int moneyInBank = -70000; // overdraft long populationChange = -85000; // reducing population long long countryGDPChange = -70000000000;
Unsigned Integer Types unsigned short, unsigned int, unsigned long, and unsigned long long
Unlike their signed counterparts, unsigned integer variable types cannot contain sign information, and hence they can actually support twice as many positive values.
Declaring a variable of an unsigned type is as simple as this:
unsigned short int numColorsInRainbow = 7; unsigned int numEggsInBasket = 24; // will always be positive unsigned long numCarsInNewYork = 700000; unsigned long long countryMedicareExpense = 70000000000;
Avoid Overflow Errors by Selecting Correct Data Types
Data types such as short, int, long, unsigned short, unsigned int, unsigned long, and the like have a finite capacity for containing numbers. When you exceed the limit imposed by the type chosen in an arithmetic operation, you create an overflow.
Take unsigned short for an example. Data type short consumes 16 bits and can hence contain values from 0 through 65,535. When you add 1 to 65,535 in an unsigned short, the value overflows to 0. It’s like the odometer of a car that suffers a mechanical overflow when it can support only five digits and the car has done 99,999 kilometers (or miles).
In this case, unsigned short was never the right type for such a counter. The programmer was better off using unsigned int to support numbers higher than 65,535.
In the case of a signed short integer, which has a range of –32,768 through 32,767, adding 1 to 32,767 may result in the signed integer taking the highest negative value. This behavior is compiler dependent.
Listing 3.4 demonstrates the overflow errors that you can inadvertently introduce via arithmetic operations.
LISTING 3.4 Demonstrating the Ill-Effects of Signed and Unsigned Integer Overflow Errors
0: #include <iostream> 1: using namespace std; 2: 3: int main() 4: { 5: unsigned short uShortValue = 65535; 6: cout << "Incrementing unsigned short " << uShortValue << " gives: "; 7: cout << ++uShortValue << endl; 8: 9: short signedShort = 32767; 10: cout << "Incrementing signed short " << signedShort << " gives: "; 11: cout << ++signedShort << endl; 12: 13: return 0; 14: }
Output
Incrementing unsigned short 65535 gives: 0 Incrementing signed short 32767 gives: -32768
Analysis
The output indicates that unintentional overflow situations result in unpredictable and unintuitive behavior for the application. Lines 7 and 11 increment an unsigned short and a signed short that have previously been initialized to their maximum supported values –65,535 and 32,767, respectively. The output demonstrates the value they hold after the increment operation, namely an overflow of 65,535 to zero in the unsigned short and an overflow of 32,767 to –32,768 in the signed short. One wouldn’t expect the result of an increment operation to reduce the value in question, but that is exactly what happens when an integer type overflows. If you were using the values in question to allocate memory, then with the unsigned short, you can reach a point where you request zero bytes when your actual need is 65536 bytes.
Floating-Point Types float and double
Floating-point numbers are what you might have learned in school as real numbers. These are numbers that can be positive or negative. They can contain decimal values. So, if you want to store the value of pi (22 / 7 or 3.14) in a variable in C++, you would use a floating-point type.
Declaring variables of these types follows exactly the same pattern as the int in Listing 3.1. So, a float that allows you to store decimal values would be declared as the following:
float pi = 3.14;
And a double precision float (called simply a double) is defined as
double morePrecisePi = 22.0 / 7; | http://www.informit.com/articles/article.aspx?p=2755729&seqNum=2 | CC-MAIN-2018-47 | refinedweb | 1,434 | 57.71 |
Mercurial > dropbear
view libtommath/bn_mp_mul_2.c @ 475:52a644e7b8e1 pubkey-options
* Patch from Frédéric Moulins adding options to authorized_keys. Needs review.
line source
#include <tommath.h> #ifdef BN_MP_MUL*2 */ int mp_mul_2(mp_int * a, mp_int * b) { int x, res, oldused; /* grow to accomodate result */ if (b->alloc < a->used + 1) { if ((res = mp_grow (b, a->used + 1)) != MP_OKAY) { return res; } } oldused = b->used; b->used = a->used; { register mp_digit r, rr, *tmpa, *tmpb; /* alias for source */ tmpa = a->dp; /* alias for dest */ tmpb = b->dp; /* carry */ r = 0; for (x = 0; x < a->used; x++) { /* get what will be the *next* carry bit from the * MSB of the current digit */ rr = *tmpa >> ((mp_digit)(DIGIT_BIT - 1)); /* now shift up this digit, add in the carry [from the previous] */ *tmpb++ = ((*tmpa++ << ((mp_digit)1)) | r) & MP_MASK; /* copy the carry that would be from the source * digit into the next iteration */ r = rr; } /* new leading digit? */ if (r != 0) { /* add a MSB which is always 1 at this point */ *tmpb = 1; ++(b->used); } /* now zero any excess digits on the destination * that we didn't write to */ tmpb = b->dp + b->used; for (x = b->used; x < oldused; x++) { *tmpb++ = 0; } } b->sign = a->sign; return MP_OKAY; } #endif /* $Source: /cvs/libtom/libtommath/bn_mp_mul_2.c,v $ */ /* $Revision: 1.3 $ */ /* $Date: 2006/03/31 14:18:44 $ */ | https://hg.ucc.asn.au/dropbear/file/52a644e7b8e1/libtommath/bn_mp_mul_2.c | CC-MAIN-2022-21 | refinedweb | 219 | 65.05 |
Floating Point Support
You may ask yourself "Why should an RTOS care about floating point?" Indeed, the Nut/OS kernel doesn't use any floating point operations. And as long as the supported CPUs don't provide any floating point hardware, the kernel is not involved. However, Nut/OS is more than just a kernel and offers a rich set of standard I/O routines. Applications may want to use these routines to read floating point values from a TCP socket or display them on an LCD.
Be aware that dealing with floating point values will significantly blow up your code. When programming for tiny embedded devices it is recommended to avoid them. Thus, floating point support in Nut/OS is disabled by default. You have to start the Configurator, enable it, re-create the build tree and re-build the system.
Enabling Floating Point Support
Start the Nut/OS Configurator and load the configuration of your board. Make sure that all settings are OK (press Crtl+T) and that the right compiler is selected in the Tools section of the component tree. If unsure, consult the Nut/OS Software Manual.
To enable floating point I/O, check the option Floating Point below C Runtime (Target Specific) -> File Streams in the module tree on the left side of the Configurator's main window.
After selecting Generate Build Tree from the build menu, the Configurator will create or re-write a header file named crt.h in the subdirectory include/cfg of your build tree.
#ifndef _INCLUDE_CFG_CRT_H_ #define _INCLUDE_CFG_CRT_H_ /* * Do not edit! Automatically generated on Mon May 09 19:34:19 2005 */ #ifndef STDIO_FLOATING_POINT #define STDIO_FLOATING_POINT #endif #endif
When rebuilding Nut/OS by selecting Build Nut/OS from the build menu, then this header file will be used instead of the original one in the source tree.
If you prefer to build Nut/OS on the command line within the source tree, then you need to edit the original file before running make install.
Sample Application
The sample code in app/uart, which is included in the Ethernut distribution, demonstrates floating point output, if floating point support had been enabled in the Configurator. The following code fragments show the relevant parts:
#include <cfg/crt.h> #include <stdio.h> ... #ifdef STDIO_FLOATING_POINT double dval = 0.0; #endif ... int main(void) { ... for (;;) { ... #ifdef STDIO_FLOATING_POINT dval += 1.0125; fprintf(uart, "FP %f\n", dval); #endif ... } }
Floating Point Internals
Nut/OS supports floating point input and output, which means, that it is able to convert ASCII representations of floating point values to their binary representations for input and vice versa for output. In other words, the Nut/OS standard I/O functions can read ASCII digits to store them in floating point variables or they can be used to print out the values of floating point numbers in ASCII digits.
Nut/OS does not provide floating point routines by itself, but depends on external floating point libraries. The ImageCraft AVR Compiler comes with build in libraries, while avrlibc provides this support for GCCAVR. Just recently (June 2008), floating point support had been added for ARM targets using newlib.
Reading floating point values is done inside the internal function
int _getf(int _getb(int, void *, size_t), int fd, CONST char *fmt, va_list ap)
Printing floating point values is a different story. It is actually done in function
int _putf(int _putb(int, CONST void *, size_t), int fd, CONST char *fmt, va_list ap)
The newlib library, used for building Nut/OS applications running on ARM CPUs, offers the function _dtoa_r to convert the binary representation to ASCII strings. However, things are more complicated here, because the fuction uses unique internal routines to allocate heap memory. These routines are not provided by Nut/OS and, even worse, the newlib memory management conficts with the one provided by Nut/OS. TO solve this issue, a new function _sbrk had been added to the Nut/OS libraries, which is used by newlib to request heap space. This way, a part of the Nut/OS heap is assigned to the newlib memory management. Since newlib calls _sbrk every time it wants to increase its heap space and because it expects a continous memory area for the total heap memory, a hard coded number of bytes will be allocated by Nut/OS on the first call. This value is specified in crt/sbrk.c:
#ifndef LIB_HEAPSIZE #define LIB_HEAPSIZE 16384 #endif
Currently you can't change this value in the Configurator. Instead you may add the following line to the file UserConf.mk in the build tree prior to building the Nut/OS libraries:
HWDEF += -DLIB_HEAPSIZE=8192
Note, that floating point I/O for ARM targets is still experimental and may not work as expected.
Not much additional code is added by Nut/OS, but the amount of code added by the external libraries will be significant. If you are using the GNU compiler, do not forget to add -lm to the LIBS= entry in your application's Makefile.
Runtime Libraries and stdio
Today's C libraries for embedded systems are distributed with a rich set of stdio function, which partly may be more advanced than those provided by Nut/OS. Typically they offer full floating point support. So why not use them?
The main reason is, that they are less well connected to the hardware. Typically they pass output or expect input on a character by character base, which is slow. Further, they are not fully compatible among each other, which transfers the burden of porting from one platform to another to the application programmer. In opposite to desktop computers, embedded systems do not come with predefined standard devices. C libraries for embedded systems handle this in different ways. Another problem is network support. Some libraries even provide rich file system access, but not much is offered when it comes to networking. On the other hand, Nut/OS provides almost all stdio functions on all platforms for almost all I/O devices including TCP streams in a consistent way.
Both, Nut/OS and the C runtime library, offer a large number of stdio functions with equal names. Sometimes this results in conflicts while linking application codes, or worse, while the application code is running. If an application with stdio calls acts strange, you should inspect the cross reference list in the linker map file first. Make sure, that all stdio calls are linked to Nut/OS libraries.
The following extract from a GCC linker map file shows, that fprintf is located in the Nut/OS library libnutcrt.a and referenced in the application object file uart.o.
Cross Reference Table Symbol File fprintf ../../nutbld-enut30d-gcc/lib\libnutcrt.a(fprintf.o) uart.o
When removing -lnutcrt from the LIBS entry in the application's Makefile, the linker will take fprintf from C library instead. In this specific case, using newlib for ARM, it will additionally result in several linker errors.
Cross Reference Table Symbol File fprintf c:/programme/yagarto/bin/../lib/gcc/arm-elf/4.2.2/../../../../arm-elf/lib\libc.a uart.o
If you are using YAGARTO, which includes newlib, another problem appears. Actually the same problem exists with all libraries, which had been build with syscall support. You will end up with a number of undefined references.
To remove the syscalls module from YAGARTO's newlib, change to arm-elf/lib within the YAGARTO installation directory and run
arm-elf-ar -d libc.a lib_a-syscalls.o
This had been tested with newlib 1.16 in YAGARTO 20080408. For previous releases try
arm-elf-ar -d libc.a syscalls.o
Some History
In early releases Nut/OS simply ignored floating point values. Until today the author never needed it and is almost sure, that he will never need it. Unless you have to handle very large ranges, everything can be done with integers. Keep in mind, that floating point calculations are slow, consume a lot of CPU power and worse, they may result in significant rounding errors.
Anyway, it had been added. Early releases of Nut/OS offered two libraries, nutcrtf and nutcrt. The first one included floating point I/O while the latter didn't. These libraries were build by compiling either getff.c and putff.c for the floating point version or getf.c and putf.c for the library without floating point support. Internally the first two simply include the latter two source files after defining STDIO_FLOATING_POINT. What a crap! :-)
If an application required floating point I/O, the default library nutcrt had been replaced by nutcrtf in the list of libraries to be linked to the application code. This way the user wasn't forced to change any original source code. After the introduction of the Configurator, customizing and rebuilding Nut/OS became much more simple. Furthermore, by separating the build directory from the source tree, several differently configured systems can easily coexist. Thus, there is no specific floating point version of any library required any more.
Floating point I/O for ARM targets is available in Nut/OS version 4.5.5 and above.
Harald Kipp
Castrop-Rauxel, June 28th, 2008. | http://www.ethernut.de/en/documents/ntn-4_floats.html | CC-MAIN-2022-21 | refinedweb | 1,526 | 55.95 |
hey im now starting prog in c++ n im being honest- im REALLY flustered
i have to create a program to get information from a user, put the info to a file, create another program to read from that file, calculate total scores of x amount of students n grade and output to the screen.
i have the parts about getting the info from the user and putting it into a file down...kinda ( there is no space between the variables, and its the loop is not working). i do not know how to ready diff types of data on one line (str, int and double) from the file and into the other prog. im so lost!
here's what i have so far:-
#include <iostream> #include <fstream> #include <string> using namespace std; main () { ofStream outFile; outFile.open ('records.dat'); string firstName, lastName; int count, sc1, sc2, sc3, sc4, sc5 = 0; while (count <= 5); { cout << "\nEnter student's first name: "\n"; cin >> firstName; outFile << firstName; cout << "Enter student's last name: "\n"; cin >> lastName; outFile << lastName; cout << "Enter 5 scores (of 10 or less) with spaces: \n"; cin >> sc1 >>sc2 >>sc3 >> sc4 >> sc5; count ++; } return 0 }
(wondering if an array would have worked?)
this is just the first program (decided that i probably should work on 1 at a time)
Edited by WaltP: Added CODE tags -- with all the help about them, how could you miss using them???? | https://www.daniweb.com/programming/software-development/threads/256125/help-needed | CC-MAIN-2017-39 | refinedweb | 238 | 67.42 |
Improve the Performance of your React Forms
Forms can get slow pretty fast. Let's explore how state colocation can keep our React forms fast.
Forms can get slow pretty fast. Let's explore how state colocation can keep our React forms fast.
If you use a ref in your effect callback, shouldn't it be included in the dependencies? Why refs are a special exception to the rule!
Why can't React just magically know what to do without a key?
Excellent TypeScript definitions for your React forms
How to improve your custom hook APIs with a simple pattern
Testing React.useEffect is much simpler than you think it is.
The sneaky, surreptitious bug that React saved us from by using closures
How and why I import react using a namespace (
import * as React from 'react')
A basic introduction memoization and how React memoization features work.
How and why you should use CSS variables (custom properties) for theming instead of React context.
Epic React is your learning spotlight so you can ship harder, better, faster, stronger
Simplify and speed up your app development using React composition
Some common mistakes I see people make with useEffect and how to avoid them.
Speed up your app's loading of code/data/assets with "render as you fetch" with and without React Suspense for Data Fetching
It wasn't a library. It was the way I was thinking about and defining state.
Is your app as fast as you think it is for your users?
When was the last time you saw an error and had no idea what it meant (and therefore no idea what to do about it)? Today? Yeah, you're not alone... Let's talk about how to fix that..
I still remember when I first heard about React. It was January 2014. I was listening to a podcast. Pete Hunt and Jordan Walke were on talking about this framework they created at Facebook that. | https://epicreact.dev/articles/ | CC-MAIN-2021-43 | refinedweb | 327 | 73.78 |
Kotlin does a lot for us in the way of reducing boilerplate. But what is it really doing? We will be inspecting some decompiled Kotlin to discover how it does its job.
Introduction
My name is Victoria Gonda, and I am a software developer at Collective Idea. We are a consulting company in Holland, Michigan. We provide custom software solutions for our clients.
One of the things that interested me the most when I started programming was learning about all the different programming languages. When I found out about Kotlin, I was super excited to get going at it. I didn’t have many expectations of what it was like. Now, I would take working with Kotlin over Java any day.
What is Kotlin
What is Kotlin? Kotlin is a statically typed programming language for the JVM, Android, and the browser. Let’s dig in a little bit more to what this means.
It’s statically typed, so we have the same type safety that we do in Java. This means that we get great auto complete. Because it’s statically typed, this can inform the IDE about what’s possible.
Compared to Java, types can also be inferred. We don’t have to specify if something is a string if it’s clear. In Java, this has to be done: we have to say
String name = "Victoria"; whereas in Kotlin we can merely do
name = "Victoria" because it’s clear it’s a string. Semi-colons are unnecessary, and the keyword
val acts as a final declaration in Java.
Null safety is built into the type system. As such, we always know when and if something can be null, and the compiler will force us to check for it. This means we can say goodbye to NullPointerExceptions.
I also enjoy Kotlin’s boilerplate production and its functional language features. Kotlin is much more concise than Java, but in a good way. It’s not terse the way some other languages can be, making it so short that it becomes unreadable.
Kotlin is also interoperable with Java, and it compiles down to byte code for the JVM to run.
Examples
A simple class was the first thing I tried decompiling. Here, there is a user with a first and last name that are strings where the first name is immutable and cannot be null.
class User( var firstName: String, var lastName: String? )
The question mark after string for lastname makes it nullable.
Let’s put the class through the decompiler so that we can see the result:; } }
Notice is that the class is final by default, so you can’t extend it. Immutability can be a great tool for making classes simpler and thread safe.
The fields are private by default.
Firstname is immutable, so it’s marked as final. There are also the nullable and nonnull annotations. In the constructor, in the first line in the body, the check parameter is not null. Nullability is built into the type system, so you’re usually safe.
If you call Kotlin code from Java, Kotlin does a check for us here just in case.
public static void checkParameterIsNotNull( Object value, String paramName) { if (value == null) { // prints error with stack trace throwParameterIsNullException(paramName); } }
Get more development news like this
It explicitly points us to exactly what and where something was null when it wasn’t supposed to be.
Caused by: java.lang.IllegalStateException: firstName must not be null at com.project.User.<init>(User.kt:8)
We can make this class into a data class. This is done simply by adding the keyword data at the beginning of the class declaration.
data class User( val firstName: String, val lastName: String? )
This is what the Java code looks like:; } @NotNull public final String component1() { return this.firstName; } @Nullable public final String component2() { return this.lastName; } @NotNull public final User copy(@NotNull String firstName, @Nullable String lastName) { Intrinsics.checkParameterIsNotNull(firstName, "firstName"); return new User(firstName, lastName); } // $FF: synthetic method // $FF: bridge method @NotNull public static User copy$default(User var0, String var1, String var2, int var3, Object var4) { if((var3 & 1) != 0) { var1 = var0.firstName; } if((var3 & 2) != 0) { var2 = var0.lastName; } return var0.copy(var1, var2); } public String toString() { return "User(firstName=" + this.firstName + ", lastName=" + this.lastName + ")"; } public int hashCode() { return (this.firstName != null?this.firstName.hashCode():0) * 31 + (this.lastName != null?this.lastName.hashCode() had the same things before with some other additions. There are components that are used for de-structuring and class declarations.
There’s a copy method. Copy methods can be really useful when working with immutable types. For copy, there’s also a synthetic bridge method. This gets into how the JVM handles classes and such.
There’s a
toString, which clearly prints out all the variables and what they are, additionally, hashCode and equal methods.
One more thing before moving on is that we can declare default values.
data class User( val firstName: String = "Victoria", var lastName: String? )
Here, if a first name is not provided, just use the string Victoria. We can pair default values with named parameters to get a substitution for builders. Here’s an example where we are clearly creating an object, but we’re only providing what we care about.
val user = User( lastName = "Gonda" )
Notice that firstname is left off. You can exclude any of the variables that either have a default value or can be null.
Null Safety
One of the biggest things that we hear about Kotlin is this null safety. You notate that a variable is nullable with a question mark.
// Wont compile var maybeString: String? = "Hello" maybeString.length
Here we have the string and then question mark. If there’s a question mark, it’s nullable. Otherwise, you’re safe; you don’t have to worry about it. It’s similar to Swift’s optional if you’re familiar with that.
If you don’t check a nullable value for null before you call something on it, it won’t compile.
This uses the Safe Call Operator. That’s the question mark after maybeString and before .length.
val maybeString: String? = “Hello" maybeString?.length
This calls .length on the object if it’s not null and returns null otherwise.
Here is the result in Java.
String maybeString = "Hello"; maybeString.length();
But, there are no null checks. Let’s see what happened if that variable is null. Will we get that null pointer exception?
If we set maybeString to null, let’s see what we get.
String maybeString = this.getString(); if(maybeString != null) { maybeString.length(); }
It is adding that null check in there. The compiler just knew that it couldn’t possibly be null. We were assigning a string to an immutable value because we used val, so it removed all the extra code for us.
By using the double bang or double exclamation point, you can get around compiler errors.
val maybeString: String? = getString() maybeString!!.length
Having those two exclamation points after maybeString before you call length, it will call that method on that variable and not make you do the checks. Here it is in Java:
String maybeString = this.getString(); if(maybeString == null) { Intrinsics.throwNpe(); } maybeString.length();
This will result in the NullPointerException.
Kotlin has a couple other null safety options. We can combine the Null Safety Operator with let to create null safe scoping.
val maybeString: String? = getString() return maybeString?.let { string -> string.length }
Here, we named a variable string within the block. If maybeString is not null, it will execute everything in the block. Otherwise, it will just return null. If we did not specify that inside the block we wanted it to be called string, it would default to a variable named it.
It’s a bit unimpressive for this small little code chunk, but it can be super handy for multiple lines of code. You can almost think of it as a map but for a single value. Here it is in Java:
String maybeString = (String) null; if(maybeString != null) { String string = (String)maybeString; string.length(); }
It checks for null, assigns the value to a variable named string, and then performs any operation that you include in the lambda. Had we allowed it to default, that variable name would be it instead of string.
One last null check thing that we’ll look at today is the Elvis Operator. If you turned your head on your side, you might see a familiar face in it.
val maybeString: String? = getString() return maybeString?.length ?: 0
With this, we can give an optional value if a variable is null. It’s much like an is not null ternary operator. This will return the length of a string if maybeString is not null, and zero otherwise.
String maybeString = this.getString(); return maybeString != null ? maybeString.length() : 0;
Delegation
Null safety and data classes are two of the biggest wins for me with Kotlin; but there are other things I enjoy.
Delegation can be a good replacement for inheritance. By using composition over inheritance, we can get out of some of the sticky situations that we get into with inheritance. Delegation is a form of composition. With it, we can cut down on some of our cognitive overhead and the number of things to keep track of when we’re reading and following code around.
Here’s the copy printer example in Kotlin.
class CopyPrinter(copier: Copy, printer: Print) : Copy by copier, Print by printer interface Copy { fun copy(page: Page): Page } interface Print { fun print(page: Page) }
The most interesting part of this copy printer is the class declaration. It says it copies by copy and prints by print, right there. Afterwards, we just have our interfaces for copy and print. It’s really clear and pretty simple. Here’s the Java.
public final class CopyPrinter implements Copy, Print { // $FF: synthetic field private final Copy $$delegate_0; // $FF: synthetic field private final Print $$delegate_1; public CopyPrinter(@NotNull Copy copier, @NotNull Print printer) { Intrinsics.checkParameterIsNotNull(copier, "copier"); Intrinsics.checkParameterIsNotNull(printer, "printer"); super(); this.$$delegate_0 = copier; this.$$delegate_1 = printer; } @NotNull public Page copy(@NotNull Page page) { Intrinsics.checkParameterIsNotNull(page, "page"); return this.$$delegate_0.copy(page); } public void print(@NotNull Page page) { Intrinsics.checkParameterIsNotNull(page, "page"); this.$$delegate_1.print(page); } } public interface Copy { @NotNull Page copy(@NotNull Page var1); } public interface Print { void print(@NotNull Page var1); }
It is many more lines of code, but we can pretty clearly see what’s going on. There is a class, and it implements copy and print. Then we have fields to store the copy and print objects.
It then takes a copy and print in the constructor and assigns them to those fields. From there, it forwards the copy and print methods to those copy and print objects that were passed in in the constructor.
Finally, there are interfaces for copy and print, which look as you might expect.
Static Utility Classes
Some of the methods that we put in these can be application specific. Others are pretty consistent and almost feel like they should just be on the class themselves.
Kotlin has a pretty smooth way of handling this with extensions. It allows us to access these methods from an instance of a class. From Kotlin, it up looks like we’re modifying that class, even if it’s a final class like String.
TextUtils.isEmpty("hello");
One place that I found it helpful in the past is when I was doing a lot of math with time. With this, I added an extension function to date time, and I could easily and quickly set boundaries around a time.
Let’s look at an example of extending the string class. Remember that String is final, which means it can’t be inherited. We’ll just add a function that doubles the string, meaning it takes a string and puts it next to each other. This is what it looks like in Kotlin.
// StringExt.kt fun String.double(): String() { return this + this }
It really looks like we’re modifying the class. To declare it, we take the class name and then dot it with the function name. Here we’re doing String.double.
Then when we call it, it looks like we’re calling a method that has just always been on String.
"hello".double()
This may not be unexpected from an interpreted language, but it’s a lot different from what we’re used to in Java. Here’s the Java that comes from it.
public final class StringExtKt { @NotNull public static final String double( @NotNull String $receiver) { Intrinsics .checkParameterIsNotNull($receiver, "$receiver"); return $receiver + $reveiver; }
This does what we manually do with a util class (making it a
Final class). When you call it, it just calls that static method on the class. In fact, this is how we would call it if we had written our extension in Kotlin and then called it from Java in another part of our code.
StringExtKt.double("hello");
Functional Language Properties
Let’s look at an example. Let’s take creating a list of the first N squares. In Java, you might have a counter and a loop and add the square to the list and end the loop whenever you reach N. How might this look in Kotlin?
fun firstNSquares(n: Int): Array<Int> = Array(n, { i -> i * i })
Here, the lambda is passed into the array list constructor - this is in the closure. In it is an input variable,
i, and then the operation we want to perform,
i times
i.
It looped through the numbers, zero through
n, performs that operation, and adds it to the list.
What this looks like in Java:
@NotNull public static final Integer[] firstNSquares(int n) { Integer[] result$iv = new Integer[n]; int i$iv = 0; int var3 = n - 1; if(i$iv <= var3) { while(true) { Integer var9 = Integer.valueOf(i$iv * i$iv); result$iv[i$iv] = var9; if(i$iv == var3) { break; } ++i$iv; } } return (Integer[])((Object[])result$iv); }
Here is the same code with some of the variables renamed, and casting removed so we can understand it better.
@NotNull public static Integer[] firstNSquares(int n) { Integer[] resultArray = new Integer[n]; int i = 0; int max = n - 1; if(i <= max) { while(true) { Integer square = i * i; resultArray[i] = square; if(i == max) { break; } ++i; } } return resultArray; }
It’s creating the list, looping through all of the numbers, performing the operation, adding it to the list, and then breaking when it reaches N. It’s the same concept that we might do if we were writing it in Java. We might use a different loop or put conditionals in a different place, but it’s the same idea.
We could easily also include a function in that lambda.
fun firstNSquares(n: Int): Array<Int> = Array(n, { i -> square(i + 1) })
Here, we square with
i + 1, correctly making a list of the first N squares. The only thing here that changed is that method inside the lambda. In the Java example, the only line that changed, is the line to call that method.
Integer square = square(i+1);
The examples of functions that we’ve looked at so far have all been inlined. Here’s the let declaration, and you can notice the inline keyword in the signature.
public inline fun <T, R> T.let(block: (T) -> R): R = block(this)
This means that the compiler generates the code to insert into the body of the function where it’s being used.
inline fun beforeAndAfter( startString: String, function: (string: String) -> String ) { print("Before: $startString") val after = function(startString) print("After: $after") }
Here’s the Java. see that the function takes a string and Function1 as parameters. Here’s the interface for Function1.
public interface Function1<in P1, out R> : Function<R> { public operator fun invoke(p1: P1): R }
The one corresponds to the number of parameters. If we had had two parameters, it would’ve been Function2. It has one method,
invoke. The first thing inside of the body is those null checks. We’ve seen those before. Then we’re concatenating the string to print out.
Next is the interesting part.’re calling invoke on the function that was passed in. That’s how it performs the lambda passed into the function. After that, we concatenate the results string and print that out.
fun example() { beforeAndAfter("hello", { string -> string + " world" }) }
Passing in the string part is really easy. The lambda passed in is contained in curly braces. Then the arrow indicates the operation we want to perform. In Java:
public final void example() { String startString$iv = "hello"; String after$iv = "Before: " + startString$iv; System.out.print(after$iv); String string = (String)startString$iv; after$iv = (String)(string + " world"); string = "After: " + after$iv; System.out.print(string); }
Here are a couple of other ways we could call the before and after function.
beforeAndAfter("hello", { string -> string + " world" }) beforeAndAfter("hello", { it + " world" }) beforeAndAfter("hello") { it + " world" }
The first line is what we’ve seen before. If we don’t name the variable, it will default to “it”. which is shown in the second line. If a lambda is the last parameter of a function, you can put it outside of the parentheses.
Let’s see what it looks like if we do not have the function inlined.
fun beforeAndAfter( startString: String, function: (string: String) -> String ) { print("Before: $startString") val after = function(startString) print("After: $after") }
Let’s decompile this and see what we get.
public final void example() { this.beforeAndAfter("hello", (Function1)null.INSTANCE); }
We have null.INSTANCE. What is that? Upon inspection of the byte code we get this:
And in pseudocode:
// Pseudocode for bytecode final class BytecodeClass extends Lambda implements Function1 { public void invoke(String string) { StringBuilder sb = new StringBuilder("hello"); sb.append(" world"); returnValue = sb.toString(); } static Function1 INSTANCE = new BytecodeClass(); }
It’s creating a class that extends the lambda and implements
Function1. Then, as we might expect, it implements the invoke method. It creates a string builder and concatenates the given string with the string World. It then stores the result wherever it puts returned values.
Conclusion
We’ve looked at data classes, null safety, delegation, class extensions, and lambdas. Some additional language features to note are:
- Companion objects and smart casting
- Collection functions
- Control flow structures
- Operator overloading.
Android Studio offers an easy way to convert Java into Kotlin. To do this, go to the Java file that you want to convert, and go to the menu>Code>Convert Java File to Kotlin File.
After spending quite a bit of time with Kotlin and then working with Java, Java feels like a long construction detour that I was not expecting. I can still get to where I’m going, but it takes a lot longer and it’s much more annoying.
Interestingly enough, I’ve noticed that Kotlin has made me a better programmer in general.
You can find me on Twitter, @TTGonda.
Questions
When Apple released Swift 3, there was a lot of changes that caused issues for developers who were using Swift 2 in doing the migration. Do you think it’s going to be the same in Kotlin if we migrate to the next versions of Kotlin?
I know that they’re very focused on making the different versions of Kotlin as backward compatible as possible. I think we’ll have much less of an issue with that.
Have you faced any problems while working on Kotlin and trying to integrate libraries?
I’ve had almost no problems with this. Some libraries are starting to have Kotlin counterparts. In others, because it is completely interoperable with Java, there hasn’t been too much issue with that at all.
Do you have any tips for moving from writing a lot of Java code to writing a bit less Kotlin code after having written a lot of Java code in the past?
One thing is taking the Java code and converting it into Kotlin. That has been really helpful. We have a project that was entirely written in Java, and we’re slowly converting some of the files. Any new files that we make, we write in Kotlin, and because it’s so seamlessly interoperable, this is super easy to do.
Have you found that Kotlin is more for data classes and models and stuff like that, or do you do a lot of Android stuff with it also?
I just started working on an Android app that’s 100% Kotlin. It works for data classes, and everything else.
If you had to a put a number on it, how much faster do you think it’s been for you to write in Kotlin as opposed to Java?
I probably write at least a third faster.
Have you found that the final by default class structure from Kotlin has given you any issues?
Not too much. There’s some libraries, but it depends on them being extendable.
How is debugging in Kotlin?
It’s been pretty much just as easy as debugging in Java.
About the content
This talk was delivered live in April 2017 at Droidcon Boston. The video was recorded, produced, and transcribed by Realm, and is published here with the permission of the conference organizers. | https://academy.realm.io/posts/kotlin-does-java-droidcon-boston-2017-gonda/ | CC-MAIN-2018-47 | refinedweb | 3,547 | 66.94 |
The 1999 C99 standard introduces several new language features.
These new features include:
Some features similar to extensions to C90 offered in the GNU compiler, for example, macros with a variable number of arguments.
Some features available in C++, such as
to mix declarations and statements.
Some entirely new features, for example complex numbers, restricted pointers and designated initializers.
New keywords and identifiers.
Extended syntax for the existing C90 language.
A selection of new features in C99 that might be of interest to developers using them for the first time are documented.
Some examples of special cases where the language specified by the C90 standard is not a
subset of C++ include support for
and structure tag namespaces. For example, in C90 the following code expands to
x =
a / b - c; because
/* hello world */ is deleted, but in C++ and
C99 it expands to
x = a - c; because everything from
// to
the end of the first line is deleted:
x = a //* hello world */ b - c;
The following code demonstrates how typedef and the structure tag are treated differently between C (90 and 99) and C++ because of their merged namespaces:
typedef int a; { struct a { int x, y; }; printf("%d\n", sizeof(a)); }
In C 90 and C99, this code defines two types with separate names whereby
a
is a typedef for
int and
struct a is a structure type
containing two integer data types.
sizeof(a) evaluates to
sizeof(int).
In C++, a structure type can be addressed using only its tag. This means that when the
definition of
struct a is in scope, the name
a used on its
own refers to the structure type rather than the typedef, so in C++
sizeof(a) is greater than
sizeof(int). | http://infocenter.arm.com/help/topic/com.arm.doc.dui0472m/chr1359124237277.html | CC-MAIN-2017-17 | refinedweb | 291 | 55.88 |
.
In this article I’ll cover two cases. Getting all the contents of a single tag and converting non-nested tags to a dictionary. My language of choice is Python, specifically version 3. Regular expressions are part of the standard library.
Retrieving the contents of a single tag
If you know the tag you are looking for, creating a regular expression to find it is pretty easy.
I wrote the following Python function to get the contents of a single tag.
import re def xmlfind(text, tag, attributes=None): """Isolate the content of a tag from XML text. Arguments: text: The text to look in. tag: The tag to look for. In '<lat>23.7</lat>' the tag is 'lat'. attributes: A dict of attributes info that is part of the start tag. E.g. the dict {"unit": "degrees"} would produce '<lat unit="degrees">'. Returns: A list containing the data in the requested tag. """ if attributes: xs = ' '.join(['{}="{}"'.format(k, v) for k, v in attributes.items()]) rx = '<{0} {1}>(.*?)</{0}>'.format(tag, xs) else: rx = '<{0}>(.*?)</{0}>'.format(tag) return re.findall(rx, text, re.DOTALL)
The last line basically does all the work. The rest is for dealing with attributes in the start tag.
In the case without attributes, and with the tag lat, the regular expression would look like <lat>(.*?)</lat>. It has three parts. Translated into English they mean:
- Match the string <lat>.
- Match a group of 0 or more characters, but as little as possible.
- Match the string </lat>.
The findall function returns all the found groups. Let’s use the XML weather report on this page as a sample.
In the example below, the text from the weather report is stored as data and the xmlfind function is defined as above. We will use it to extract the information in the image tag.
In [8]: xmlfind(data, 'image') Out[8]: ["\n <url></url>\n"\ " <title>NOAA's National Weather Service</title>\n"\ " <link></link>\n"]
Note that this is a list which contains one string. (The string is re-formatted to fit this page better.) If the tag occurs multiple times in the given text, you will get multiple matches.
Closing remarks
The purpose of this article is not to convince you that an XML parser is unnecessary. If you need to read a whole XML file or a deeply nested one the solutions presented here will not be sufficient.
But in special cases they can be quite useful. | http://rsmith.home.xs4all.nl/programming/extracting-data-from-xml-with-regular-expressions.html | CC-MAIN-2017-30 | refinedweb | 415 | 77.64 |
We are about to switch to a new forum software. Until then we have removed the registration on this forum.
I would delete this post but it appears there isn’t a way to do that.
The original post:
I am trying to make a function that determines whether two line segments intersect. (I’m creating a program that involves figuring out whether a given point is inside a polygon.) The function is a method of the
LineSegment class that inputs another
LineSegment l, (that’s a lowercase L, not a 1) and figures out whether they intersect. It outputs
0 or
1 instead of
False or
True for reasons that are unimportant here. Here it is:
def intersects( self, l ): lx1 = l.get_x1() # The x-coordinate of the first endpoint of l lx2 = l.get_x2() # The x-coordinate of the second endpoint of l ly1 = l.get_y1() # The y-coordinate of the first endpoint of l ly2 = l.get_y2() # The y-coordinate of the second endpoint of l lm = l.get_m() # The slope of l lb = l.get_b() # The y-intercept of l '''self.m is the slope of this line, self.b is the y-intercept of this line, self.x1 is the x-coordinate of the first endpoint of this line, etc. if self.m == lm: # If the slopes are the same — i.e. the lines are parallel — they don’t intersect return 0 else: # If the lines aren’t parallel: ix = iy = 0 # ix will be the x coordinate of the intersection point; iy will be the y coordinate if self.m == 'vertical': # If this line (self) is vertical (we need this condition because slope-intercept form doesn’t work with vertical lines) ix = self.x1 # The x-coordinate of the intersection point is just the x coordinate of this line, because it’s vertical iy = lm * ix + lb # Plug that into the other equation to find the y coordinate elif lm == 'vertical': # The reverse — if l is vertical ix = lx1 iy = self.m * ix + self.b else: # Otherwise, solve for the intersection point ix = ( lb - self.b ) / ( self.m - lm ) iy = self.m * ix + self.b # I have tested this and everything up to here works — it always finds the correct intersection point. However, we still have to make sure the intersection point isn’t outside either segment. We do this by seeing whether the x-coordinate of the intersection, ix, is between self.x1 and self.x2 and also between lx1 and lx2, and whether the y-coordinate of the intersection, iy, is between self.y1 and self.y2 and also between ly1 and ly2. ): return 1 else: return 0
This works. However, I then realized that I wanted to go into more detail — I want method to output 0 if they don’t intersect and 1 if they do, but if the intersection point lies on the endpoint of one (or both) of the segments — i.e. they intersect in a T or L shape — it should output 0.5. I thought I would go about this by first testing whether they “strictly intersect” — i.e. they intersect in an X, not a T or an L — and if they do, output 1; if they don’t, then proceed from there. Here’s how I thought to test for “strict intersection” — just make all the inequalities strict: ): ...
For some reason, this is never true — I’ve tested this by putting something like
print( 'hi' ) after this
if statement and the program prints nothing (even when the intersection point is obviously not an endpoint of a line). Why is this? | https://forum.processing.org/two/discussion/16395/program-doesn-t-know-when-two-line-segments-intersect-solved | CC-MAIN-2019-43 | refinedweb | 606 | 74.29 |
Simple serial transceiver – Aurel RTX-MID
October 24, 2011 12 Comments
I’ve been looking for a simple and cheap wireless serial data solution for quite a while now…
No specific usage, but things like every time you integrate your Arduino into a project and then 2 days later you want to update the code and you have to dismount everything, or simply remote control a project or more generally just getting tired of “all the wires”…
There are of course plenty of solutions out there, but I wanted something cheap and simple to use !
The WiFly solution that I’ve already used here, is “ok” simplicity wise but far too expensive !
Then you have RF link devices like this one, which are really cheap indeed … but as simple as they might be to install, they get a fair amount of noise so you get added complexity in the code to filter out some of that noise and do some error checks…
Anyhow, I’m sure I could go on forever like this, again one of the reasons I haven’t gotten anything until now, it’s that I couldn’t decide what to go with !
Finally, I got 2 of these TRX-MID Aurel boards from Farnell (quite reliable guys, I use them whenever I can, it’s a shame they seem to be more oriented towards professionals than hobbyists…) :
- they are 2-3 times more expensive than the really basic ones (12£ here in the UK, probably ~ 15$ in the US)
- they are transceivers, which means you can have bi-directional communication
- they seem to be slightly higher specs, so I hope for less noise / more reliable communication
Before I insert them into any project, I need to do some testing / benchmarking to get a feeling for how good / bad they really are.
The simplest setup would have been to connect both of them to the PC through 2 USB to serial adapters, BUT given that I have only 1 3.3Volts cable, I had to use something else…
The next “simplest” solution was for me to use the IOIO board, connected to an Android phone. I know, it doesn’t sound very simple, but it’s a 3V3 board and it’s really quick to write a few lines of Java to make it send some serial data periodically:
- TX
- the Android phone and the IOIO are there simply to periodically send some serial data
- GND and VCC come directly from the IOIO board
- pin 6 / Enable is connected to VCC through a 10k resitor
- pin 5 / TX/RX is connected to VCC, telling the transceiver that it’s in TX mode
- pin 4 / Input Data is connected to pin 5 of the IOIO
- RX
- the FTDI USB – Serial cable connecting the transceiver directly to the PC, on which I used Tera Term
- GND and VCC come directly from the FTDI cable
- pin 6 / Enable is connected to VCC through a 10k resistor
- pin 5 / TX/RX is not connected, telling the transceiver it’s in RX mode (same as if I had connected it to GND, I think it has an internal pull down resistor connected to it)
- pin 9 / Data Out is connected to the RX pin of the cable
All in all, it’s a fairly simple connectivity, it literally took me 10minutes to set all this up, and then it worked from the 1st try !
Now it’s time for a quick test, which consisted of simply seeing the “Hello World” sent by the IOIO board display in the serial terminal on the PC, and then take the board in another room (~5meters and 2 walls apart).
Everything worked well (at 9600bps), but when I took the transmitter to the other room, I would get some spurious characters at the end of each transmission. I haven’t fully investigated this, but it seems that without an external antenna, the range is really 5-10 meters, no more. One can obviously add some error checking in the software or lower the bps to extend that.
- I like
- the fact that you can start into RX / TX mode by simply pulling a pin down / up (as oposed to the user manual where they describe a fairly complicated sequence (“From powerdown mode (pin 4-5-6 low), drive high pin 6 (ENABLE), then after 20us drive high pin 5 (RX/TX) 200us, hold on 40us and then drive down 20us pin 6 (ENABLE).“) which I’m sure it’s necessary in some more complex use cases
- don’t have to set the speed
- I dislike
- you need an extra wire to set TX/RX, it’s not full duplex (can’t send / receive at the same time) – that’s really not problem for connecting remote sensors for example, but it makes it virtually impossible to use these boards to make an Arduino fully wireless
- limited at 9600bps, again ok for some sensors, not really enough to replace wires (most of the applications expect at tleast 115200bps)
- the range – this can be mediated by adding an antenna, but that makes things more complex
package org.trandi.helloioio; import ioio.lib.api.DigitalOutput; import ioio.lib.api.Uart; import ioio.lib.api.exception.ConnectionLostException; import ioio.lib.util.AbstractIOIOActivity; import java.io.OutputStream; import java.lang.Thread.UncaughtExceptionHandler; import android.os.Bundle; import android.util.Log; import android.widget.TextView; public class Main); _msg = (TextView) findViewById(R.id.textViewMsg); } /** * MyIOIOThread extends AbstractIOIOActivity.IOIOThread { private DigitalOutput _onboardLED; // The on-board LED private Uart _uart; private OutputStream _dataOS; private long _count = 0; /** *); _dataOS = _uart.getOutput { onboardLED(true); final String msg = "HelloWorld " + _count++ + "\n"; runOnUiThread(new Runnable(){ @Override public void run() { _msg.setText(msg); } }); _dataOS.write(msg.getBytes()); onboardLED(false); Thread.sleep(1000); } catch (Exception e) { msg("Can't write; } }
Pingback: RC Car Electronics | Robotics / Electronics / Physical Computing
I understand that these are old message long ago ….. now it has made great strides Technology ….. Ever tried ESP8266 ??? It costs about $ 3 and can send and receive wireless full duplex and anche ….. and can Marshalling sue outputs via the Internet by the world Any Where there COVER WiFi ( search on Google ESP8266 ) . However, even with RF modules you can do impossible things for WiFi , as send messages to kilometers away via Air and without any internet connection … we just want a good antenna … look at this too …
Max
Thanks Max I knew about the ESP modules , but as you said this is a pretty old post…:)
No chance I would bother with these for a new project….
Hi, I have 2 RTX-MID-5V in the drawer closed for some time, perhaps ready for trial use Arduino or other. I have in the past been dealing with RF module, especially those Aurel and advice I can give you to increase the flow rate is put on pin 1 a piece of copper wire 0.8-1mm diameter along 17-18 cm (the wire must have a correct length given for 433 MHz … see google …) this is in the form of transmission and receipt and you’ll see that the capacity will increase by much. Indeed these modules, as you can see they have the printed antenna on PCB and if you don’t put an external antenna might also fail. If you want to bring long you keep RTX-MID-3V as receiving and use the transmitter model Aurel TXBOOST-433, this module has data input to 5v, but is powered at 12v and unleash a transmit power of 400mw (around 400-500 meters), but if you power for short periods to 18v you have 800mw trasmission ranging from 1 km to 1.5 Km. Only thing is that you can’t use a baud rate of 9600, but maximum 4 kHz modulation, so you can use it with COM terminal to 1200-2400 bps.
Sorry for my poor English language, but it is not my original language. Ciao from Italy, I hope this help …
Max
Hi Max,
Wow… ! That’s some very precise and useful info, thanks a ton !
I haven’t played with those for a while, but I’ll keep this advice in mind the next time I put them in a new project…
Dan
That’s super nice
But would you have an idea how to connect several emitters (simple on/off switches) to one receiver connected to the pc in usb so that the pc is able to identify emitters with an id ?
Salut,
Sorry for the late reply.
I don’t think this is possible as this are quite simple devices that area paired with each other.
You might be better of using the cheap Bluetooth boards, similar to what I’ve used for my SPOKA project, where not only you can have plenty of them, but they can connect directly to the PC which is admittedly much nicer than having to connect an extra board.
Hope this helps,
Dan
For a little more, I’ve used these:
Good wireless range, plus you also get USB and a fairly powerful microcontroller.
they look nice !
Pingback: SPOKA Night Light controlled from and Android Phone « Robotics / Electronics / Physical Computing
Haha, soon with IOIO over bluetooth you can cut the middle-man 😀
Nice build!
Yes, indeed ! 🙂 More seriously now, it’s “crazy” how easy it was to use the IOIO for testing, while the only reason I chose it was the right voltage 🙂
I haven’t followed the latest IOIO developments, but what’s the status on the bluetooth ? Will it be a new board, or some addon that you simply plug into a “good old” IOIO ?
Actually, the cheap bluetooth devices we were talking about on the IOIO forum make these transceivers pointless ! Beyond the range (I haven’t tested it properly on either side, but I have a feeling these simple transceivers, with an antenna, would fare better !) everything else is in favour of the bluetooth: – cheaper – size is similar – can have full duplex – bps muuuch higher – can connect directly to a phone / PC – etc. …
Dan | https://trandi.wordpress.com/2011/10/24/simple-serial-transceiver/ | CC-MAIN-2017-26 | refinedweb | 1,679 | 58.76 |
25 March 2011 22:48 [Source: ICIS news]
HOUSTON (ICIS)--?xml:namespace>
One producer led with a nomination of plus 21 cents/lb ($463/tonne, €329/tonne), which would place April contracts at $1.25/lb. The March contract settled at $1.04/lb.
Meanwhile, the other three producers nominated plus 17 cents/lb, which would put their April contracts at $1.21/lb.
One producer said such large monthly increases could continue in the months ahead, as supply is expected to remain tight with a series of industry turnarounds scheduled to begin in April.
In addition, crude prices are still increasing and two
Historically, BD has settled at the lowest nomination. However, a split settlement was considered likely for April, extending a trend from recent months.
One producer questioned whether it might be better to do away with the nominating process altogether, assuming settlements continue to be split.
US BD producers include ExxonMobil, INEOS, LyondellBasell, Shell and TPC Group.
Additional reporting by Ben DuBose
($1 = €0.71) | http://www.icis.com/Articles/2011/03/25/9447409/us-april-bd-proposed-up-to-20-higher-on-rising-crude-tight-supply.html | CC-MAIN-2014-52 | refinedweb | 168 | 55.84 |
Django cookie law
This is a Django application that makes it easy to implement cookies compliant with Dutch law, as far as I am able to tell. I'm not a lawyer, so use at your own risk.
Requirements
- jQuery
Usage
- Add the cookie_law app to your INSTALLED_APPS.
- Add 'url(r'^cookies/', include('apps.cookie_law.urls')),' to your main urls.py, without the ''.
- Run the cookie_law migrations or syncdb if you don't use South.
- Load the cookie_bar template tags and include {% show_cookie_bar %} under the <body> tag in your base template.
- Make a cookie bar in the admin.
- Surround your cookies with {% if request.COOKIES.allow_cookies == '1' %} <cookie> {% endif %} | https://bitbucket.org/kcleong/lib_django_cookie_law/src | CC-MAIN-2015-32 | refinedweb | 109 | 70.8 |
On 14 Jul 2008, at 16:58, Henning Thielemann wrote: > >'. Ok, I read your articles. While I must say the terminology is a bit confusing, I agree with the overall distinction. However, for an API, using 'error' should be done very seldom, preferably never. Thus I probably should reconsider the use case and think about how to restructure the API in a way that this error never occurs. Oleg and Chung-chieh's "Lightweight Static Capabilites"[1] show some interesting and simple ideas how one could do that. [1]: >> Note that we have to wrap IO exceptions and propagate them >> separately in the Ghc monad.(**) > > That's a good thing. All (IO) exceptions should be handled this way. > (See the extensible exception thread on this list.) > > >>. > >. Ah sorry. This is an existing function, that tries to find a module in the set of installed packages (or only within a specified package). I think it can reasonably be expected to fail. For example, the package could be hidden or the module is not part of an existing package. Well, actually, the original type was findModule :: Session -> ModuleName -> Maybe PackageId -> IO Module and throwing an exception was used as error the reporting mechanism. I think Simon's Extensible Exception paper actually mentions that they are sometimes used as error reporting mechanism "for convenience". Of course, we can and should normalise this behaviour at the API-level, so I will study your list of articles and the mailing list thread (I was hoping I could avoid reading the whole thread ;) ) > >> (*)? > It performs less matching on constructors. Consider the monad instance of the Either variant: instance Monad Ghc where return x = Ghc $ \_ -> return (Right x) m >>= k = Ghc $ \s -> do rslt <- runGhc m s case rslt of Left err -> return (Left err) Right a -> runGhc (k a) s Here, every >>= immediately deconstructs the value constructed by the monad. If an error is thrown, all >>= calls will merely deconstruct the value of the previous call, and reconstruct it immediately. The CPS variant looks like this: instance Monad Ghc where return x = Ghc $ \s fk k -> k x m >>= f = Ghc $ \s fk k -> runGhc' m s fk (\a -> runGhc' (f a) s fk k) This simply adjusts the continuation and the failure continuation is just passed through and is called directly in case of an error throw err = Ghc $ \_ fk _ -> fk err i.e., the CPS immediately jumps to the error handler and aborts the current continuation. / Thomas -- Once upon a time is now. -------------- next part -------------- A non-text attachment was scrubbed... Name: PGP.sig Type: application/pgp-signature Size: 194 bytes Desc: This is a digitally signed message part Url : | http://www.haskell.org/pipermail/libraries/2008-July/010205.html | CC-MAIN-2014-15 | refinedweb | 449 | 61.46 |
Each module has its own configuration section named after the module name. The
configuration section will be "
[::module_filename_prefix
]"
where module_filename_prefix is the filename of the module with the
.p4m extension removed. For example, the
init_exp.p4m module has a
configuration section of
[::init_exp].
Each module is loaded into its own namespace, also named after the module in
the same manner. Thus in the above example the Initialise Experiment Files
module uses the namespace
::init_exp. This means that all local
variables within that module will be within that name space and will not clash
with identical named variables in other modules. When pregap4 reads the
configuration file any configuration section starting in double colon is taken
to be a name space and the following configuration is executed in that
namespace. So the following example enables the Initialise Experiment Files
module, but disables the Estimate Base Accuracies module.
[::init_exp] set enabled 1 [::eba] set enabled 0
In the following sections the variables, inputs and outputs of each module are
listed. Every module has an
enabled local variable. This may be either
0 for disabled or
1 for enabled. Disabled modules are still
listed in the configuration panel, although they will not be executed.
The tables in each section below list the module filename, the local variables
and a very brief description of their valid values, the files used or produced
by this module, the possible sequence specific errors that can be produced
(which will be written to the failure file as the reason for failure), and the
format of any
SEQ lines in the module report. Other information may
also be reported, but the
SEQ lines are easily recognisable to
facilitate easy parsing of results. | http://staden.sourceforge.net/manual/pregap4_unix_61.html | CC-MAIN-2016-26 | refinedweb | 283 | 53.61 |
Welcome to PresentationWindows! PresentationWindows is a window class library like no other, and introduces three window classes:
WndProcWindow, which derives from Window,
WndProcWindow
Window
AeroWindow, which derives from WndProcWindow,
AeroWindow
and MagnifyWindow, which derives from AeroWindow.
MagnifyWindow
WndProcWindow is like a regular window, but simply adds a WndProc() function for easy interop. This is the least feature rich class in this library.
WndProc()
AeroWindow is like a regular window, but has a WndProc function AND lets you set the glass frame extension with simple dependency properties. It also lets you specify the resize border extension, and optionally put controls in the title bar area of the window (like firefox, IE and opera).
WndProc
MagnifyWindow includes all of the features of the previous two window classes, but adds yet another feature. It provides automatic support for magnification, providing a "magnifying glass" on the window that follows your cursor, magnifying everything it touches. this takes advantage of the high-quality vector graphics in wpf to scale the content without loss of quality. The magnifier automatically shows and hides itself when you set the MagnifyAmount property to your desired magnification factor.
MagnifyAmount
Here's the magnifier in action:
This works on any windows version XP and above, and the following screenshots showcase many different visual styles:
It's a simple task: you want to make your application look nicer by extending the aero glass frame. You might have tried it in Windows Forms, but the text is unreadable on the controls, and it requires a lot of tricks to make it work. You then might try WPF, which would work nicely because this is the kind of thing that WPF is cut out for.
Now you have a choice: You can PInvoke the raw API to extend the glass frame, or you can use the WindowChrome class provided with the WPF ribbon. The API works, but (hopefully sooner rather than later) you might find out that it doesn't take differences in DPI into account, meaning that the glass won't be extended all the way if your DPI is higher than the default.
WindowChrome
WindowChrome takes the DPI into account, but by using it, you forfeit all of the title bar stuff that the OS normally provides. Then there is the issue of the basic and classic themes, which need their own implementation to work because desktop composition is disabled in those scenarios.
There are tutorials on how to overcome these problems yourself manually, but they are difficult and time consuming. I have looked, but there doesn't seem to be any library that wraps all that functionality into a professional library that you can initiate in XAML. Until now, that is.
Using the code is really simple. The only things you need to do are:
1: Add a reference to the class library
2: Add a XAML namespace reference in your MainWindow.xaml file (see below) and tell the XAML to create an instance of one of the PresentationWindows classes instead of a regular Window.
3: Change your MainWindow class in MainWindow.xaml.cs (or .vb) to derive from one of the PresentationWindows classes.
MainWindow
The following example shows how to set up a MagnifyWindow, with the magnification factor set to 2.
<presentation:MagnifyWindow
xmlns=""
xmlns:x=""
xmlns:presentation="clr-namespace:PresentationWindows;assembly=PresentationWindows"
xmlns:
<Grid>
</Grid>
</presentation:MagnifyWindow>
The AeroWindow class has a number of new properties, including the following:
FrameExtension (default="0,0,0,0") - This is a special property of type "WindowFrameThickness", and specifies the amount to further extend the window frame on each respective side. The type "WindowFrameThickness" works like a regular Thickness, but also has a definition for "Full" extension (Which extends the window frame completely, like the gadgets window), and allows to have some sides of the window to have no frame at all (e.g., FrameExtension="*,0,*,15" leaves only the window chrome for the top and bottom). This is property is the most important new property in this library.
WindowFrameThickness
CaptionHeight (default="Default") - This is another special property of type
CaptionHeight. This should be set to the desired height of the title bar, or "Default".
CaptionHeight
ResizeBorderExtension (default="Full") - This is also of type
WindowFrameThickness, and works like the FrameExtensionProperty, but is for how far the "Resize Border" (Defined as the area on the window where the user can drag to resize the window) is extended.
ResizeBorderExtension
FrameExtensionProperty
AlwaysShowBasicFrame (default="False") - Set to "true" to force the window to act as if Desktop Composition (Windows aero) is always disabled. What it actually does is use the basic version of the window frame instead of the aero border.
AlwaysShowBasicFrame
TitleBarContent (Default=null) - This is a special property that specifies what should be shown in the title bar of the window. The actual content will only be shown if a different template is specified, as the default template doesn't show this content.
TitleBarContent
The
MagnifyWindow type also adds a new property:
MagnifyAmount (Default=1) - This property specifies how much the "magnifying glass" magnifies the content. When this property is set to 1, no glass is shown. But when it is set to a different value, a magnifying glass is shown on the window (see screenshot above). This glass follows the mouse, magnifying everything in its path. The window chrome in the background is not magnified, and when the aero border is used, the basic caption buttons are turned on so they are usable.
Also, you may have noticed that to use
TitleBarContent, you need to specify a different template. I have included a static class named "Templates" that you can get these from. There are four templates here:
AeroWindowNormalTemplate
AeroWindowTitleBarContentTemplate
MagnifyWindowNormalTemplate
MagnifyWindowTitleBarContentTemplate
These should be self-explanatory. You can set these in XAML by adding the following property in the window definition:
Template="{x:Static presentation:Templates.MagnifyWindowTitleBarContentTemplate}"
In the traditional Window class, you wouldn't really set the Template property, because WPF handles that for you, and you wouldn't just style a window the same way you would style a button.
AeroWindow (and all its derived types) is different. You can XAML out a template for the window that affects its appearance, and use binding and parts to make it properly work with the basic and classic theme, and use correct system sizes.
While doing this, I have learned how to write templates in code. All of the four default templates are actually written with code.
Traditionally, windows visual styles are not a part of WPF, as the buttons are vector styled, and are separate from the windows visual style system. If I tried that here, keeping the correct window styles would be a nightmare, so I got a little hacky. The basic window borders are drawn with visual styles in mind, by using the Windows Forms visual style classes. It's about perfect, but the one downside is that you don't get the high quality vector scaling, since this is stored as a bitmap in Windows.
Also, in Windows 8, people might be telling you that Aero is gone. That is simply not true, and in fact, there's no way to turn it off! The only thing about aero that are gone are the transparent windows and flip 3d. The window frame still works the same way. Thus, this works in Windows 8, and adds a nice touch of your favorite color to your window (see screenshot).
November 2, 2012 - Added screenshots.
November 3, 2012 - Added more instructions.
I really enjoyed making this library and this article. Please give me some feedback! Thank you.
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL) | https://www.codeproject.com/Articles/483614/Introducing-PresentationWindows | CC-MAIN-2019-30 | refinedweb | 1,284 | 52.09 |
In MessageTag.java:
- Remove unused:
import java.util.Locale;
- Add in release():
_bundleRef = null;
_args = null;
_debug = false;
_messageFormat = null;
_arguments = null;
- Replace in doStartTag():
EVAL_BODY_TAG with EVAL_BODY_BUFFERED
In BundleTag.java:
- Remove unused:
import javax.naming.InitialContext;
import javax.naming.NamingException;
Please supply patches created using 'cvs diff -u'. That makes it much simpler
for us to apply them. Thanks.
Patrick,
Please provided the patch as Martin indicated, but also have in mind that the
taglib requirement is JSP 1.1, not 1.2, so we cannot change the return to
EVAL_BODY_BUFFERED.
Regards,
Felipe
OK, will try to find some time to do the diff.
Right now, I don't have any CVS soft. I guess
I have to learn this stuff.
Give me some time..
Or.. is there a quicker way via a cvs web interface?
CVS might be a little bit intimidating at first, but once you get used to it,
it's a breeze.
Regarding the web, yes, there is a cvsweb interface, but it won't work for patches.
Created attachment 11727 [details]
MessageTag patch
Created attachment 11728 [details]
BundleTag patch
Applied changes to CVS, thanks for the patch. | https://bz.apache.org/bugzilla/show_bug.cgi?id=28252 | CC-MAIN-2020-45 | refinedweb | 193 | 69.18 |
1 Reply
Latest reply
on Feb 6, 2012 9:35 PM by 855728
JAX-WS Dispatch client deployed in weblogic 10.3.0 sends empty namespace
855728
Feb 3, 2012 4:04 AM
We have a weird issue.
Currently in the production environment we have the below application deployed
1. WebService1.war
2. WebApp1.war
3. WebApp2.war
Webapp1.war and WebApp2.war invokes WebService1.war and there is no issue in production.
We have another new webservice2.war component that is going to production soon is deployed in dev and QA environment. After deploying WebService2.war in dev and QA, WebApp1.war started sending empty namespace in the request to Webservice1.war but WebApp2.war which also uses the same web webservice method is sending the proper request. This is how request from WebApp1.war looks like (For security reason I have not given the entire request):
<env:Envelope xmlns:<env:Header/><env:Body><GetDetails xmlns="Test"><Info xmlns=""></Info></GetDetails></env:Body></env:Envelope>
In the above request xmlns is empty and that is an issue because at the service layer the Info object is null and it is throwing NullPointerException.
Additional Details:
1.All the above mentioned applications are deployed in Weblogic 10.3.0. WebService1.war was implemented using JAX-WS and created in Bottom Up fashion. WebService2.war is also implemented using JAX-WS and created using wsdl (Top Down webservice).
WebApp1.war uses JAX-WS dispatch client. And there is no issue when the client is tested as a standalone client from our local machine even when WebService2.war is deployed. WebApp2.war uses stubs created using com.sun.tools.ws.ant.WsImport to invoke the webservice. And there is no issue no matter WebService2.war is deployed or not.
We dont know how the new webservice2 component can cause webapp1 to send empty namespace in the request to webservice1
Please let me know if you need any other details. And I would really appreciate your inputs.
Edited by: user8115570 on Feb 2, 2012 8:01 PM
I have the same question
Show 0 Likes
(0)
This content has been marked as final.
Show 1 reply
1.
Re: JAX-WS Dispatch client deployed in weblogic 10.3.0 sends empty namespace
855728
Feb 6, 2012 9:35 PM
(
in response to
855728
)
Child element should be added like this at the client side.
SOAPElement message = payload.addChildElement("Info","",targetNameSpace);
Actions | https://community.oracle.com/message/10132709 | CC-MAIN-2017-22 | refinedweb | 406 | 60.72 |
On November 1, 2016, I started a year-long project, challenging myself to master one expert-level skill every month. For the first eleven months, I succeeded at each of the challenges:
I landed a standing backflip, learned to draw realistic portraits, solved a Rubik’s Cube in 17 seconds, played a five-minute improvisational blues guitar solo, held a 30-minute conversation in a foreign language, built the software part of a self-driving car, developed musical perfect pitch, solved a Saturday New York Times crossword puzzle, memorized the order of a deck of cards in less than two minutes (the threshold to be considered a grandmaster of memory), completed one set of 40 pull-ups, and continuously freestyle rapped for 3 minutes.
Then, through a sequence of random events, I was offered the chance to sit down with the world chess champion Magnus Carlsen in Hamburg, Germany for an in-person chess game.
I accepted. How could I not?
And so, this became my twelfth and final challenge: With a little over one month of preparations, could I defeat world champion Magnus Carlsen at a game of chess?
Unlike my previous challenges, this one was near impossible.
I had selected all of my other challenges to be aggressively ambitious, but also optimistically feasible in a 30-day timespan. I set the challenges with the hope that I would succeed at 75% of them (I just wasn’t sure which 75%).
On the other hand, even if I had unlimited time, this challenge would still be dangerously difficult: The second best chess player in the world has a hard time defeating Magnus, and he’s devoted his entire life to the game. How could I possibly expect to have even a remote chance?
Truthfully, I didn’t. At least, I didn’t if I planned to learn chess like everybody else in the history of chess has.
But, this offered an interesting opportunity: Unlike my other challenges, where success was ambitiously in reach, could I take on a completely impossible challenge, and see if I could come up with a radical approach, rendering the challenge a little less impossible?
I wasn’t sure if I could, or not. But, I thought it would be fun to try.
I documented my entire process from start to finish through a series of daily blog posts, which are compiled here into a single narrative. In this article, you can relive my month of insights, frustrations, learning hacks, triumphs, and failures as I attempt the impossible.
At the end of this post, I share the video of the actual game against Magnus.
But first, let me walk you through how I prepared for the game, starting on October 1, 2017, when I had absolutely no plan. Just the desire to try.
Note: I was asked not to reveal the details of the actual game until after it happened and it was written about in the Wall Street Journal (the article is also linked at the end of this post). Thus, in order to document my journey via daily blog posts, without spoiling the game, I used the Play Magnus app for a bit of misdirection while framing up the narrative. However, I tried to write the posts so that, after the game happened and readers have knowledge of the match, the posts would still read naturally and normally.
Today, I begin the final month and challenge of my M2M project: Can I defeat world champion Magnus Carlsen at a game of chess?
How am I going to do this?
The most immediate question is “How will you actually be able to play Magnus Carlsen, #1-rated chess player in the world, at a game of chess?”
Well, Magnus and his team have released an app called Play Magnus, which features a chess computer that is meant to simulate Magnus as an opponent. In fact, Magnus and team have digitally reconstructed Magnus’s playing style at every age from Age 5 until Age 26 (Magnus’s current age) by using records of his past games.
I will use the Play Magnus app to train, with the goal of defeating Magnus at his current age of 26. Specifically, I hope to do this while playing with the white pieces (which means I get to move first).
My starting point
My dad taught me the rules of chess when I was a kid, and we probably played a game or two per year when I was growing up.
Three years ago, during my senior year at Brown, I first downloaded the Play Magnus app and occasionally played against the computer with limited success.
In the past year, I’ve played a handful of casual games with equally-amateurish friends.
In other words, I’ve played chess before, but I’m definitely not a competitive player, nor do I have any idea what my chess rating would be (chess players are given numeric ratings based on their performance against other players).
This morning, I played five games against the Play Magnus app, winning against Magnus Age 7, winning and losing against Magnus Age 7.5, and winning and losing against Magnus Age 8.
Then, tonight, I filmed a few more games, winning against Magnus 7, Magnus 7.5, and Magnus 8 in a row, and then losing to Magnus 9. (There’s no 8.5 level).
It seems that my current level is somewhere around Magnus Age 8 or Age 9, which is clearly quite far from Magnus 26.
As reference, Magnus became a grandmaster at Age 13.
An extra week
While every challenge of my M2M project has lasted for exactly a month, this challenge is going to be slightly different — although not by much. Rather than ending on October 31, I will be ending this challenge on November 9 (Updated to November 17).
I’d prefer to keep this challenge strictly contained within the month of October, but I think it’s going to be worth bending the format slightly.
Later in the month, I’ll explain why I’ve decided to adjust the format. For now, I can’t say much more.
If anything, I can use the extra training time, especially since this challenge is likely my most ambitious.
Anyway, tomorrow, I’ll start trying to figure out how I’m going to pull this off.
Yesterday, to test my current chess abilities, I played a few games against the Play Magnus app at different age levels (from Age 7 to Age 9).
While these games gave me a rough sense of my starting point, they don’t give me a clear, quantitative way to track my day-over-day progress. Thus, today, I decided to try and compute my numeric chess rating.
As I mentioned yesterday, chess players are given numeric ratings based on their performance against other players. The idea is that, given two players with known ratings, the outcome of a match should be probabilistically predictable.
For example, using the most popular rating system, called Elo, a player whose rating is 100 points greater than their opponent’s is expected to win 64% of their matches. If the difference is 200 points, then the stronger player is expected to win 76% of matches.
With each win or loss in a match, a player’s rating is updated, based on the following (semi-arbitrary, but agreed upon) Elo equation:
More interestingly, here’s how particular ratings correspond to categories of players (according to Wikipedia). Notably, a grandmaster has a rating around 2500 and a novice is below 1200.
Additionally, according to the United States Chess Federation, a beginner is usually around 800, a mid-level player is around 1600, and a professional, around 2400.
Magnus is currently rated at 2826, and has achieved the highest rating ever at 2882 in May 2014.
My current rating is somewhere around 1100, putting me squarely in the novice category. To determine this rating, I played a number of games today on Chess.com, which maintains and computes ratings for all the players on the site.
Chess.com is actually really cool: At the click of a button, you are instantly matched with another chess player of similar skill level from anywhere in the world.
Chess.com doesn’t use the Elo rating system, but, according to the forums, my Chess.com rating should be roughly equal to my Elo rating. In other words, I’m definitely an amateur.
So, over the next month, I just need to figure out how to boost my rating from 1100 to 2700–2800.
I’m still not sure exactly how to do this, or if it’s even possible (I’m almost certain no one has even made this kind of jump even in the span of five years), but I’m going to give it my best shot.
The good news about starting in amateur territory is there’s really only one direction to go…
Doesn’t this seem like a bad way to finish your project?” says most of my friends when discussing this month’s challenge. “It seems like it’s effectively impossible. Isn’t it anticlimactic if you fail on the last challenge, especially after eleven months of only successes?”
These friend do have a point: This month’s challenge (defeating Magnus Carlsen at a game of chess) is dancing on the boundary between what’s possible and what’s not.
However, for this exact reason, I see this month as the best possible way to finish off this project. Let me explain…
There are two ways you can live your life: 1. Always succeeding by playing exclusively in your comfort zone and shying away from the boundary of your personal limits, or 2. Aggressively pursuing and finding your personal limits by hitting them head on, resulting in what may be perceived as “failure”.
In fact, failure is the best possible signal, as it is the only way to truly identify your limits. So, if you want to become the best version of yourself, you should want to hit the point of failure.
Thus, my hope with this project was to pick ambitious goals that rubbed right up against this failure point, pushing me to grow and discover the outer limits of my abilities.
In this way, I failed: My “successful” track record means that I didn’t pick ambitious enough goals, and that I left some amount of personal growth on the table.
In fact, most of the time, when I completed my goal for the month, I was weirdly disappointed. For example, here’s a video where I land my very first backflip and then try to convince my coach that it doesn’t count.
In other words, my drug of choice is the constant, day-over-day pursuit of mastery, not the discrete moment in time when a particular goal is reached. As a result, I can maximize the amount of this drug I get to enjoy by taking my pursuits all the way to the boundary of my abilities and to the point of failure.
Therefore, while this month’s challenge is a bit far-fetched, it’s the realest embodiment of what this project is all about. By attempting to defeat Magnus as my last challenge, I hope to fully embrace the idea that failure is the purest signal of personal growth.
Now, with that said, I’m going to do everything I possibly can to beat Magnus. I’m not planning for failure. I’m playing for the win.
But, I do understand what I’m up against: Even the second best chess player in the world struggles to win against Magnus.
So for me, it isn’t about winning or losing, but instead, it’s about the pursuit of the win. It’s about the fight.
The outcome doesn’t dictate success. The quality of the fight does.
And this month, I’m set up for the best and biggest fight of the entire year.
In the past few days, I’ve played many games of chess on Chess.com and spent a lot of time researching the game, approaches to learning, etc. The hope is that I can find some new insight that will enable me to greatly accelerate my learning speed.
So far, I’ve yet to find this insight.
Chess is a particularly hard game “to fake” because, in almost all cases, the better player is simply the one who has more information.
In fact, in a famous study by Adriaan de Groot, it was shown that expert chess players and weaker players look forward or compute lines approximately the same number of moves ahead, and that these players evaluate different positions, to a similar depth of moves, in roughly similar speeds.
In other words, via this finding, de Groot suggests that an expert’s advantage does not come from her ability to perform brute force calculations, but instead, from her body of chess knowledge. (While it has since been shown that some of de Groot’s claims aren’t as strong as originally thought, this general conclusion has held up).
In this way, chess expertise is mostly a function of the expert’s ability to identify, often at a glance, a huge corpus of chess positions and recall or derive the best move in each of these positions.
Thus, if I choose to train in traditional way, I would essentially need to find some magical way to learn and internalize as many chess positions as Magnus has in his over 20 years of playing chess. And this is why this month’s challenge seems a bit far-fetched.
But, what if I didn’t rely on a large knowledge base? What if I instead tried to create a set of heuristics that I could use to evaluate theoretically any chess position?
After all, this is how computers play chess (via positional computation), and they are much better than humans.
Could I invent a system that let’s me compute like a computer, but that can work with the processing speeds of my human brain?
There’s a 0% chance that I’m the first person to consider this kind of approach, so maybe not. But, there’s a lot of data out there (i.e. I have downloaded records of every competitive chess match Magnus has ever played), so perhaps something can be worked out.
Clearly, I can’t play by the normal chess rules if I want any shot of competing at the level of Magnus. (By “normal chess rules” I mean the normal way people learn chess. If I could just bend the actual rules of the game, i.e. cheating, then this challenge would definitely be easier…).
I’m skeptical that some magical analytical chess method exists, but it’s worth thinking about it for a few days, and seeing if I can make any progress.
Hopefully, soon, I’ll be able to formulate an actual training approach for this month. Right now, I’m still floating around in the discovery phase.
As soon as I have an interesting training idea, I’ll be sure to share it.
Yesterday, I wondered if I could sidestep the traditional approach to learning chess, and instead, develop a chessboard evaluation algorithm that I could perform in my head, effectively transforming me into a slow chess computer.
Today, I’ve thought through how I might do this, and will use this post as the first of a few posts to explore these ideas:
Method 1: The extreme memory challenge
Chess has a finite number of states, which means that the 32 chess pieces can only be arranged on the 64 squares in so many different ways.
Not only that, but for each of these states, there exists an associated best move.
Therefore, theoretically, I can become the best chess player in the world entirely through brute force, simply memorizing all possible pairs of chessboard configurations and associated best moves.
In fact, I already have an advantage: Back in November 2016, I became a grandmaster of memory, memorizing a shuffled deck of playing cards in one minute and 47 seconds. I can simply use the same mnemonic techniques to memorize all chessboard configurations.
If I wanted to be smart about it, I could even rank chessboard configurations by popularity (based on records of chess matches) or likelihood (based on the number of ways the configuration can be reached). By doing so, I can start by memorizing all the most popular chessboard configurations, and then, proceed toward the least likely ones.
This way, if I run out of time, at least I’ll have memorized the most useful pairs of configurations and best moves.
But, this “running out of time” problem turns out to be a very big problem…
It’s estimated that there are on the order of 10⁴³ possible chessboard configurations. So, even if I could memorize one configuration every second, it would still take me slightly less than one trillion trillion trillion years (3.17 × 10³⁵ years) to memorize all possible configurations.
I’m trying to contain this challenge to about a month, so this is pushing it a bit.
Also, if I had one trillion trillion trillion years to spare, I might as well learn chess the traditional way. It would be much faster.
Method 2: Do it like a computer
Even computers don’t have the horsepower to use the brute force approach. Instead, they need to use a set of algorithms that attempt to approximate the brute force approach, but in much less time.
Here’s generally how a chess computer works…
For any given chessboard configuration, the chess computer will play every possible legal move, resulting in a number of new configurations. Then, for each of these new configurations, the computer will play every legal move again, and so on, branching into all the possible future states of the chessboard.
At some point, the computer will stop branching and will evaluate each of the resulting chessboards. During this evaluation, the computer uses an algorithm to compute the relative winning chances of white compared to black based on the particular board configuration.
Then, the computer takes all of these results back up the tree, and determines which first order move produced the most future states with strong relative winning chances.
Finally, the computer plays this best move in the actual game.
In other words, the computer’s strength is based on 1. How deep the computer travels in the tree, and 2. How accurate the computer’s evaluation algorithm is.
Interestingly, essentially all chess computers optimize for depth, and not evaluation. In particular, the makers of chess computers will try to design evaluation algorithms that are “good enough”, but really fast.
By having an extremely fast evaluation algorithm, the chess program can handle many more chess configurations, and thus, can explore many more levels of the tree, which grows exponentially in size level by level.
So, if I wanted to exactly replicate a chess computer, but in my brain, I would need to be able to extrapolate out to, remember, and quickly evaluate thousands of chessboard configurations every time I wanted to make a move.
Because, for these kinds of calculations, I’m much slower than a computer, I again would simply run out of time. Not in the game. Not in the month. But in my lifetime many times over.
Thus, unlike computers, I can’t rely on depth — which leaves only one option: Learn to compute evaluation algorithms in my head.
In other words, can I learn to perform an evaluation algorithm in my head, and, if I can, can this algorithm be effective without going past the first level of the tree?
The answer to the second question is yes: Recently, using deep learning, researchers have built effective chess computers that only evaluate one level deep and perform just as well as the best chess computers in the world (although they are about 10x slower).
Perhaps, I can figure out how to convert this evaluation algorithm into something that I can computational perform in my head a la some kind of elaborate mental math trick.
I have some ideas about how to do this, but I need to experiment a bit further before sharing. Hopefully, by tomorrow, I’ll have something to share.
Yesterday, I determined that my best chance of defeating Magnus is learning how to numerical compute chessboard evaluations in my head. Today, I will begin to describe how I plan to do this.
How a deep learning-based chess computer works
It’s probably useful to understand how a computer uses deep learning to evaluate chess positions, so let’s start here…
Bitboard representation
The first step is to convert the physical chessboard position into to a numerical representation that can be mathematically manipulated.
In every academic paper I’ve read, the chessboard is converted into its bitboard representation, which is a binary string of size 773. In other words, the chessboard is represented as a string of 773 1’s and 0's.
Why 773?
Well, there are 64 squares on a chessboard. For each square, we want to encode which chess piece, if any, is on that square. There are 6 different chess piece types of 2 different colors. Therefore, we need 64 x 6 x 2 = 768 bits to represent the entire chess board. We then use five more bits to represent the side to move (one bit, representing White or Black) and the castling rights (four bits for White’s kingside, White’s queenside, Black’s kingside, and Black’s queenside).
Thus, we need 773 binary bits to represent a chessboard.
The simple evaluation algorithm
Once the chessboard is converted into its numerical form (which we will denote as the vector x), we want to perform some function on x, called f(x), so that we get a scalar (single number) output y that best approximates the winning chances of white (i.e. the evaluation of the board). Of course, y can be a negative number, signifying that the position is better for black.
The simplest version of this function y = f(x) would be y = wx, where w is a vector of 773 weights that, when multiplied with the bitboard vector, results in a single number (which is effectively some weighted average of each of the bitboard bits).
This may be a bit confusing, so let’s understand what this function means for actual chess pieces on an actual chessboard…
This function is basically saying “If a white queen is on square d4 of a chessboard, then add or subtract some corresponding amount from the total evaluation score. If a black king is on square c2, then add or subtract some other corresponding amount from the total evaluation score” and so on for all permutations of piece types of both colors and squares on the chessboard.
By the way, I haven’t mentioned it yet, so now is a good time to do so: On an actual chessboard, each square can be referred to by a letter from a to h and a number from 1 to 8. This is called algebraic chess notation. It’s not super important to fully understand how this notation is used right now, but this is what I mean by “d4” and “c2” above.
Anyway, this evaluation function, as described above, is clearly too crude to correctly approximate the true evaluation function (The true evaluation function is the just the functional form of the brute force approach. Yesterday, we determined this approach to be impossible for both computers and humans).
So, we need something a little bit more sophisticated.
The deep learning approach
Our function from above mapped the input bits from the bitboard representation directly to a final evaluation, which ends up being too simple.
But, we can create a more sophisticated function by adding a hidden layer in between the input x and the output y. Let’s call this hidden layer h.
So now, we have two functions: One function, f¹(x) = h, that maps the input bitboard representation to an intermediate vector called h (which can theoretically be of any size), and a second function, f²(h) = y, that maps the vector h to the output evaluation y.
If this is not sophisticated enough, we can keep adding more intermediate vectors, h¹, h², h³, etc., and the functions that map from intermediate step to intermediate step, until it is. Each intermediate step is called a layer and, the more layers we have, the deeper our neural network is. This is where the term “deep learning” comes from.
In some of the papers I read, the evaluation functions only had three layers, and in other papers, the evaluation function had nine layers.
Obviously, the more layers, the more computations, but also, the more accurate the evaluation (theoretically).
Number of mathematical operations.
Interestingly, even though these evaluation functions are sophisticated, the underlying mathematical operations are very simple, only requiring addition and multiplication. These are both operations that I can perform in my head, at scale, which I’ll discuss in much greater depth in the next couple of days.
However, even if the operations themselves are simple, I would still need to perform thousands of operations to execute these evaluation functions in my brain, which could still take a lot of time.
Let’s figure just how many operations I would need to perform, and just how long that would take me.
Again, suspend your disbelief about my ability to perform and keep track of all these operations. I’ll explain how I plan to do this soon.
How much computation is required?
Counting the operations
Let’s say that I have an evaluation function that contains only one hidden layer, which has a width of 2048. This means that the function from inputs x to the internal vector h, f¹(x) = h, converts a 773-digit vector into a 2048-digit vector, by multiply x by a matrix of size 773 x 2048. Let’s call this matrix W¹. (By the way, I picked this setup because the chess computer, Deep Pink, uses intermediate layers of size 2048).
To execute f¹ in this way requires 773 x 2048 = 1,583,104 multiplications and (773–1) x 2048 = 1,581,056 additions, totaling to 3,164,160 operations.
Then, f² converts h to the output scalar y, by multiplying h by a 2048-digit vector, called w², which requires 2048 multiplications and 2047 additions, or 4095 total operations.
Thus, this evaluation function would require that I perform 3,168,255 total operations.
Counting the memory capacity required
To perform this mental calculation, not only will I need to execute these operations, but I’ll also need to have enough memory capacity.
In particular, I’ll have needed to pre-memorize all the values of matrix W¹, which is 1,583,104 numbers, and vector w², which is 2048 numbers. I would also need to remember h while computing f¹, so I can use the result to compute f², which requires that I remember another 2048 numbers.
Let’s now convert this memorization effort to specific memory operations.
For the 1,583,104 weights of W¹ and the 2048 weights of w², I would only require a read operation from my memory for each (during game-time computation).
For the 2048 digits of h, I would require both a write operation and a read operation for each.
Thus, I would require 1,587,200 read operations and 2048 write operations, or 1,589,248 in total.
How long would this take?
We now know that I would need to execute 3,168,255 mathematical operations and 1,589,248 memory operations to evaluation a given chess position. How long exactly would this take?
This of course depends on the size of the multiplication and divisions, and the sizes of the numbers being stored in memory. I’ll talk more about this sizing soon, but for now, I’ll just provide my estimates.
I estimate that I could perform one mathematical operation in 3 seconds and one memory operation in 1 second. Thus, I could evaluate one chess position in 11,094,013 seconds or a little over four months.
Clearly, this is a long time (and doesn’t factor in the fact that I can’t, as a human, process continuously for 4 months), but we’re getting closer.
Of course, in a given chess game, I would need to make more than one evaluation. Since I’m a pretty novice player, I estimate that I would need to evaluate ~10–15 options per move.
Since the average chess game is estimated to be 40 moves, this would be about 500 evaluations per game.
Therefore, to play an entire chess game using this method, I would need 2,000 months or 167 years to play the game.
Of course, this is still problematic, but way less problematic than yesterday’s conclusion of one trillion trillion trillion years. In fact, I’m getting closer to an approach that I could actually execute in my lifetime (let’s say I have 75 years left to live).
The next step
I’ve made two assumptions above, one of which is good news for me and one of which is bad news for me.
First, the bad news: It would take me 167 years to play one chess game, assuming that my one-level deep evaluation function was sufficiently good. I suspect that one level isn’t enough, and that at least two or three levels would be needed, if not more.
The good news is that I’m not a computer, which means there is no reason I need to use bitboard representation as my starting point, potentially allowing me to reduce the size of the problem substantially.
Computers like 1’s and 0’s, and don’t care too much about “big numbers” like 773, which is why bitboard representation is optimal for computers.
But, for me, I can deal with any two- or three-digit number just as well as I can deal with a 1 or 0 from a memory perspective and almost as well as I can from a computational perspective.
I think I could squash my chessboard representation to under 40 digits, which would significantly reduce the number of operations necessary (although, may slightly increase the operation time).
In the next few days, I’ll discuss how I plan to reduce the size of the problem and optimize the evaluation function for my human brain, so that I can perform all the necessary evaluations in a reasonable timeframe.
Last night, I climbed into bed, ready to go to sleep. As soon as I closed my eyes, I realized that I made a major mistake in my calculations from yesterday.
Well, technically I didn’t make a mistake. The chessboard evaluation algorithm I described yesterday does require 3,168,255 math operations and 1,589,248 memory operations. However, I failed to recognize that most of these operations are irrelevant.
Let me explain…
If you haven’t yet read yesterday’s post, it would be very helpful for you to read that first. Read it here.
Addressing my mistake
Yesterday, I introduced bitboard representation, which is a way to completely describe the state of a chessboard via 773 1’s and 0’s. Bitboard representation is the input vector to my evaluation function.
When calculating the number of math operations this evaluation function would require, I overlooked the fact that only a maximum of 37 digits out of the 773 in bitboard representation can be 1’s, and the rest are 0’s.
This is important for two reason:
- The function, f¹(x), that converts the input bitboard representation x into the hidden vector h, doesn’t actually require any multiplication operations, since either I’m multiplying by 0 (in which case, the term can be completely ignored), or I’m multiplying by 1 (in which case, the original term can be used unchanged). In this way, all 1,583,104 multiplication operations that I estimated yesterday are no longer necessary.
- f¹(x) only requires addition operations between all the 1’s in the bitboard representation, which we’ve now correctly capped at 37. Therefore, instead of 1,581,056 addition operation as estimated yesterday, the algorithm only requires 36 x 2048 = 73,728 operations.
f² still requires the same 4095 operations, which means that, in total, the evaluation algorithm only requires 77,823 math operations.
This is a 40x improvement from yesterday.
Additionally, the memory operations scale down in the same way: For f¹, I only need (37 x 2048) + 2048 =77,824 read operations, and 2048 write operations, totaling to 79,872 memory operations.
Therefore, in total, the evaluation algorithm described yesterday actually only requires 157,695 total operations.
Computing the new time requirements
If I again assume that I can perform one mathematical operation in 3 seconds and one memory operation in 1 second, I would be able to evaluate one chess position in 313,341 seconds or 3.6 days, which is down considerably from yesterday’s four months.
Still, if we assume that I would need to execute 500 evaluations per game, I would need 3.6 days x 500 evaluations = 5 years to play one game.
5 years is still too long, but at least now I can complete one game of (computationally beautiful) chess in my lifetime.
But, I think I can do better…
Using “Threshold Search”
Yesterday, I assumed that I would need to evaluate 10–15 options per move in order to find the optimal option. In other words, I would perform 15 evaluations, determine which move led to the greatest evaluation score, and then play that move in the game.
However, what if it’s unnecessary to find the absolute best move? What if it’s only necessary to find a move with an evaluation above a certain threshold?
Then, for a given move, I can stop evaluating once I find the first board position that surpasses this threshold. Theoretically, I could pick this board position on my first try (although, I wouldn’t be able to do this consistently. Otherwise, I would just be the world’s greatest chess player).
Though, I estimate I could find a threshold-passing move in 2.5 evaluations on average.
Therefore, if I’m able to implement this thresholding into my evaluation algorithm, I can reduce the number of evaluations from 500 to 100.
But, I can still do better…
Playing the opening
On Chess.com, I’m able to run my games through a real chess computer that analyzes each of my moves. The computer categorizes the moves into “Excellent” (for when I play the absolute best move), “Good” (for when I play a move above the threshold, but not the best move), and “Inaccuracy”, “Mistake”, and “Blunder” (for when I screw up).
You’ll notice that 8 out of my 49 moves were below the threshold (I was playing White).
Interestingly though, going through all of my games, I seem to play moves exclusively in the Excellent and Good categories until about move 12–15, at which point, the game becomes too complex and I’m in trouble.
I’ve also found that towards the end of the game, I make very few below-threshold moves.
Based on this data, let’s say that I only need to perform my mental evaluations for 24 out of the 40 moves found in an average game.
Thus, in one game, I’d only require 60 total evaluations, and at 3.6 days per evaluation, I could complete a full game in 7 months.
This is getting closer, but I can still do better…
Finding reductions via “Update Operations”
Right now, every time I’m doing an evaluation, I’m starting the computation over from scratch, which isn’t actually necessary, and far from most efficient.
Particularly, the hidden layer h, the output of f¹ (which is the most computationally costly step of the algorithm), is nearly identical to the previous h computed in the previous evaluation.
In fact, if the new evaluation is the first for a particular move, then h only differs by the move the opposing color made, and the move under consideration. (Keep in mind, because I’m using the thresholding approach, the move corresponding to the last evaluation I computed, and thus, the last h I computed, was actually executed in the game, so I have an accurate starting point in my working memory.)
Thus, in this case, each of the 2048 values of h need to be updated with four operations: One corresponding to the move made by the opposition, one to cancel out where the opposition’s piece was prior to the move, one corresponding to the move under consideration, and one to cancel out where this piece was prior to consideration.
Thus, to update h, only 4 x 2048 = 8192 math operations (additions) are necessary.
If I prepare a certain opening as White, and Magnus responds with the theoretically determined moves, I can come into the game having pre-memorized the first h vector I’ll need, thus only ever having to perform updates.
Of course, if the game veers off script, I’ll need to execute a full evaluation for the first move, but never after that.
Thus, in total, since 4095 operations are still required to convert h to the output y, 8192 + 4095 = 12,287 math operations are needed for an update evaluation.
The memory capacity required also scales down with this update approach, so that only 8192 x 2 + 4096 = 20,480 memory operations are needed per evaluation.
If the evaluation is the second, third, etc. for a particular move, then h only differs by the move previously under consideration and the move currently under consideration. Thus, again, each of the 2048 values of h need to be updated with four operations.
So, this kind of update also requires 12,287 math operations and 20,480 memory operations.
Again, assuming that I can perform one mathematical operation in 3 seconds and one memory operation in 1 second, using this updating approach, I would be able to evaluate one chess position in 57, 341 seconds or 16 hours.
This means that I could complete one full game of chess in 16 hours x 60 evaluations = 40 days.
Clearly, more optimizations are still required, but things are looking better.
In fact, we are starting to get into the range where I could do a David Blaine-style stunt, where I spend 40 days in a jail cell computing chess moves for a one-game extended exhibition.
I think I’d prefer to continue optimizing my algorithm instead, but I’d likely have a price if a very generous sponsor came along. After all, it would be a pretty fascinating human experiment.
Still, tomorrow, I’ll continue to look for ways to improve my computation time.
Hopefully, in the next two days, I can finish all the theoretical planning, have a clear plan in mind, and begin the computer work necessary to generate the actual algorithm.
Yesterday, through some further optimizations, I was able to decrease the run time of my chess evaluation algorithm to 16 hours per evaluation, thus requiring about 40 days for an entire game.
While I’m excited about where this is headed, there’s a problem: Even if this algorithm can be executed in a reasonable time, learning it would be nearly impossible, requiring that I pre-memorize about 1.6 million algorithm parameters (i.e. random numbers) before I even complete my first evaluation.
That’s just too many parameters to try to memorize.
The good news is that it’s probably not necessary to have so many parameters. In fact, the self-driving car algorithm that I built during May, which was based on NVIDIA’s Autopilot model, only required 250,000 parameters.
With this in mind, I suspect that a good chess algorithm only requires about 20,000–25,000 parameters — an order of magnitude less than the self-driving car, given that a self-driving car needs to make sense of much less structured and much less contained data.
Assuming this is sufficient, I’m completely prepared to pre-memorize 20,000 parameters.
To put this in perspective, in October 2015, Suresh Kumar Sharma memorized and recited 70,030 digits of the number pi.
Thus, memorizing 20,000 random numbers is fully in the possible human range. (I will be truncating the parameters, which span from values of 0 to 1, at two digits, which should maintain the integrity of the function, while also capping the number of digits I need to memorize to 40,000).
Reducing the required number of parameters
In my algorithm from yesterday, most of the parameters came from the multiplication of the 773 digits of bitboard representation with the 2048 rows of the hidden vector h.
Thus, in order to reduce the number of necessary parameters, I can either condense bitboard representation, or choose a smaller width for the hidden layer.
At first, my instinct was to condense bitboard representation down to 37 digits, where the positions in the vector corresponded to particular chess pieces and the numbers at each of these spots corresponded to the particular squares on the board. For example, the first spot in the vector could correspond to the White king, and the value in this spot could span from 1 to 64.
I think an idea like this is worth experimenting with (in the future), but my instinct is that this particular representation is creating too many dependencies/correlations between variables, resulting in a much less accurate evaluation function.
Thus, my best option is to reduce the width of the hidden layer.
I’ve been using 2048 as the width of the hidden layer, which I realized from the beginning is quite large, but I tried to carry it through for as long as possible as a way to force myself to find other large optimizations.
I hypothesize I can create a chess algorithm that is good enough with two hidden layers of width 16, which would require that I memorize 12,640 parameters.
Of course, I need to practically validate this hypothesis by creating and running the algorithm, but, for now, let’s assume this algorithm will work. Even if it works, it may not be time effective, in which case it’s not worth actually building.
So, let’s validate this first…
The new hypothesized algorithm
Unlike the algorithm from the past two days, my hypothesized algorithm has not one, but two hidden layers, which should provide our model with one extra level of abstraction to work with.
This algorithm takes in the 773 digits of the bitboard representation, converts these 773 digits into 16 digits (tuned by 12,368 parameters), converts these 16 digits into another set of 16 digits (tuned by 256 parameters), and outputs an evaluation (tuned by 16 parameters).
This algorithm would require (36 x 16) + (16 x 16) + (15 x 16)+ 16 + 15 = 1103 math operations, (36 x 16) + (16 x 16) + 16 = 848 memory read operations, and 16 + 16 = 32 memory write operations.
Thus, still assuming a 3-second execution time per math operation and a 1-second execution time per memory operation, one evaluation would require (3 x 1,103) + 880 = 4,189 seconds = 1.2 hours to execute.
Of course, as explained yesterday, most evaluations would only be updates on previous evaluations. Using this new algorithm, an update evaluation would require (4 x 16) + (16 x 16) + (15 x 16) + (16 + 15) = 591 math operations, 16 + (4 x 16) + 16 + (16 x 16) + 16 = 368 memory read operations, and 16 + 16 = 32 memory write operations.
Therefore, an update evaluation would require (3 x 591) + 400= 2,173 seconds = 36 minutes to execute.
So, a full game can be played in 36 minutes x 60 evaluation = 36 hours = 1.5 days.
This is still a little long for complete use during a standard chess match, but I could imagine a chess grandmaster using one or two evaluations of this type during a game to calculate a particularly challenging position.
This new algorithm has an execution time of 1.5 days per game, which is almost acceptable, and requires memorizing 12,640 parameters, which is very much in the human range.
In other words, with a few more optimizations, this algorithm is actually playable, assuming that the structure has enough built-in connections to properly evaluation chess positions.
If it does, I might have a chance. If not, I’m likely in trouble.
Time to start testing this assumption…
For the past four days, I’ve been working on a new way to master chess: Constructing and learning a chess algorithm that can be mentally executed (like a computer) to numerically evaluate chess positions.
I still have a lot more work to do on this and a lot more to share.
But, today, I took a break from this work to play some normal games of chess on Chess.com. After all, the better I can evaluate positions without the algorithm, the more effective I will be at using it.
Despite my break, I’m fully committed to my algorithmic approach to chess mastery, as it is the clearest path to rapid chess improvement.
Nevertheless, in the past few days, some of my friends have questioned whether or not I’m actually “learning chess”. And in the traditional sense, I’m not.
But, that’s only in the traditional sense.
The goal, at the end of the day, is to play a competitive game of chess. The path there shouldn’t and doesn’t matter.
Just because everyone else takes one particular path doesn’t mean that this path is the only path or the best path. Sometimes, it’s worth questioning why the standard path is standard and if it’s the only way to a particular destination.
Of course, it’s still unclear whether or not my algorithmic approach will work, but it’s definitely the path most worth exploring.
Tomorrow, I’ll continue working on and writing about this new approach to learning chess. I’m excited to see how far I can take it…
Today, based on analysis from the past few days, I started building my chess algorithm. The hope is that I can build an algorithm that is both effective (i.e. plays at a grandmaster level), but also learnable, so that I can execute it in my brain.
As I started working, I realized very quickly that I first need to work out exactly how I plan to perform all of my mental calculations. This mental process will inform how I structure the data in my deep learning model.
Therefore, I’ve used this post as a way to think through and document exactly this process. In particular, I’m going to walk through how I plan to mentally convert any given chessboard into a numerical evaluation of the position.
The mental mechanics of my algorithm
First, I look down at the board:
Starting in the a column, I find the first piece. In this case, it’s on a1, and is a Rook. This Rook has a corresponding algorithmic parameter (i.e. a number between -1 and 1, rounded to two places after the decimal point) that I add to the running total of the first sub-calculation. Since this is the first piece on the board, the Rook’s value is added to zero.
The algorithmic parameter for the Rook can be found in my memory, using the following mental structure:
In my memory, I have eight mind palaces that correspond to each of the lettered columns from a to h. A mind palace, as explained during November’s card memorization challenge, is a fixed, visualizable location to which I can attach memories or information. For example, one such location could be my childhood house.
In each mind palace, there are nines rooms, one corresponding to each row from 1 to 8, and an extra room to store the data associated with castling rights. For example, one such room could be my bedroom in my childhood house.
In the first eight rooms, there are six landmarks. For example, one such landmark could be the desk in my bedroom in my childhood house. In the ninth room, there are only four landmarks.
Attached to each landmark are two 2-digit numbers that represent the relevant algorithmic parameters.
The first three landmarks correspond to the White pieces and the second three landmarks correspond to the Black pieces. The first landmark (of each set of three) is used for the algorithm parameters associated with the King and Queen, the second landmark is used for the Rook and Bishop, and the third landmark is used for the Knight and Pawns.
So, when looking at the board above, I start by mentally traveling to the first mind palace (column a), to the first room (row 1), to the second landmark (for the White Rook and Bishop), and to the first 2-digit number (for the White Rook).
I take this 2-digit number and add it to the running total.
Next, I move up the column until I hit the next piece. In this case, there is a White pawn on a2. So, staying in the a mind palace, I mentally navigate to third landmark in the second room, and select the second 2-digit number, which I then add to the running total.
I next move on to the Black pawn on a6, and so on, until I’ve worked my way through the entire board. Then, I enter the ninth room, which provides the 2-digit algorithmic parameters associated with castling rights.
At this point, I take the summed total and store it in my separate 16-landmark mind palace, which holds the values for the first internal output (i.e. the values for the h¹ vector of the first hidden layer).
This completes the first pass of the chessboard, outputting the first of 16 values for h¹. Thus, I still need to complete fifteen more passes, which repeat the process, but each using a completely new set of mind palaces.
In other words, I actually need 16 distinct mind universes, in which each universe has eight mind palaces of eight rooms of six landmarks and one room of four landmarks.
After completing the process 16 times, and storing each outputted value in the h¹ mind palace, I can move onto the second hidden layer, converting h¹ into h² by passing the values of h¹ through a matrix of 256 algorithmic parameters.
These parameters are stored in a single mind palace of 16 rooms. Each room has eight landmarks and each landmark holds two 2-digit parameters.
Unlike the conversion from the chessboard to h¹, for the conversion of h¹ to h², I almost certainly need to use all 256 parameters in row (unless I implement some kind of squashing function between h¹ and h², reducing some of the h¹values to zero… I’ll explore this option later).
Thus, I start by taking the first value of h¹ and multiplying it (via mental math cross multiplication) by the first value in the first room of the h² mind palace. Then, I take the second value of h², multiply it to the second value in the first room, and add the result to the previous result. I continue in this way until I finish multiplying and adding all the terms in the first room, at which point I store the total as the first value of h².
I proceed with the rest of the room, until all the values of h² are computed.
Finally, I need to convert h² to a single number that represents the numerical evaluation of the given chess position.
To do this, I access one final room in the h² mind palace, which has eight landmarks each holding two 2-digit numbers. I multiply the first number in this mind palace with the first value of h², the second number with the second value of h², and so on, adding the results along the way.
In the end, I’m left with a single sum, which should closely approximate the true evaluation of the chess position.
If this number is greater than the determined threshold value, then I should play the move corresponding to this calculation. If not, then I need to start all over with a different potential move in mind.
Some notes:
- I still need to work out how I plan to store negative numbers in my visual memory.
- Currently, I’ve only created one mind universe, so, assuming I can computationally validate my algorithmic approach, I’ll need to create 15 more universes. I’ll also need to create a higher level naming scheme or mnemonic system for the universes that I can use to keep them straight in my brain.
- There is a potential chance that I will need more layers, fewer layers, or different sized layers in my deep learning model. In any of these cases, I’ll need to repeat or remove the procedures, as described above, accordingly.
With the details of my mental evaluation algorithm worked out, I have everything I need to been the computational part of the process.
Today, I started writing a few lines of code, which will be used to generate my chess algorithm. While doing so, I started daydreaming about how this algorithmic approach could change the game of chess if it actually works.
In particular, I tried to answer the question: “If this works, what’s the ideal outcome?”.
There are two parts to this answer…
1. Execution speed
The first part has to do with the execution speed of this method, which I believe can be reduced to less than 10 minutes per evaluation with the appropriate practice.
As a comparable, Alex Mullen, the #1-rated memory athlete in the world, memorized 520 random digits in five minutes. While, one full chess evaluation requires manipulating 816 digits if all the pieces are on the board and 560 digits if half the pieces are on the board.
While these tasks aren’t exactly the same, in my experience, writing numbers to memory takes just about the same times as reading numbers from memory and subsequently adding them.
To be conservative though, I’ve padded Alex’s five minute time, predicting that an expert practitioner at mental chess calculations could execute one chess evaluation in 10 minutes.
At 60 evaluations per game (which is what I predict for myself), an entire game could be completed in 10 hours, which, at least in my eyes, is completely reasonable. Many of the games in this World Chess Championship last for six, seven, or eight hours.
Of course, if a more experienced player can more intelligently implement the algorithm, I suspect she can cut down the number of evaluations per game to around 30, shortening the game to a fairly standard five hours for a classical game.
2. Widespread adoption
I’m not sure if this computational approach to chess will ever catch on as the exclusive strategy of elite players (although, I guess it’s possible), but I can imagine elite players augmenting their games with the occasionally mental algorithmic calculation.
In fact, I wonder if a strong player (2200–2600), who augments her game with this approach, could become a serious threat to the top players in the world.
I’d like to think that, if this works, it’s causes a bit of a stir in the chess world.
It might seem that this approach tarnishes the sanctity of the game, but chess players have been using machine computation for years as part of their training approach. (Chess players use computers to work out the best theoretical lines in certain positions, and then memorize these lines in a rote or intuitive fashion).
Anyway, if this approach to chess does catch on, I might as well give it a catchy name…
At first, I was thinking about something boring like “Human Computational Chess”, but I’m just going to commit to the more self-serving approach:
Introducing Max Chess: A style of chess play that uses a combination of intuitive moves and mental algorithmic computation. These mental computations are known as Max Calculations.
It’s probably cooler if someone else names a particular technique after you, but I think the cool ship has already sailed, so I’m just going to go with it.
Now, assuming Max Chess even works, let’s see if it catches on…
Today, to accelerate my progress, I thought it might be a good idea to solicit some outside help from someone with a bit more chess AI experience.
So, I shot out a bunch of emails this morning, and surprisingly, received back many replies very quickly. Unfortunately, though, all the replies took the same form…
In other words, no one was interested in collaborating on this project — or, at least no one was interested in collaborating on this project starting immediately and at full-intensity.
This is understandable.
If I knew that I was going down this algorithmic path at the beginning of the month, and really wanted a collaborator, I should have planned much further in advance.
But, in a way, I’m glad I was rejected. Because now, I have no excuse but to figure out everything on my own.
Ultimately, the purpose of this project is to use time constraints and ambitious goals as motivation to level up my skills, so that’s exactly what I’ll do. Since there’s going to be a little bit of an extra learning curve (given that I’ve never played around with chess data or chess AI previously), this challenge is definitely going to come down to the wire.
But, this time pressure is what makes the project exciting, so here I go… Time to become a master of chess AI.
Side note: To completely negate everything I’ve said above, if you do think you have the relevant experience and are interested in helping out, leave a comment and we’ll figure something out. Always happy to learn from someone else when an option. (And of course always happy to figure it out on my own when it’s not).
Yesterday, after a failed attempt to recruit some help, I realized that I need to proceed on my own. In particular, I need to figure out how to actually produce my (currently) mythical, only theoretical evaluation algorithm via some sort of computer wizardry.
Well, actually, it’s not wizardry — it just seems that way because I haven’t formalized a tangible approach yet. So, let’s do that in this post.
There are four steps to creating the ultimate Max Chess algorithm:
Step 1: Creating the dataset
In order to train a deep learning model (i.e. have my computer generate an evaluation algorithm), I need a large dataset from which my computer can learn. Specifically, this dataset needs to contain pairs of bitboard representations of chess positions as inputs and the numerical evaluations that correspond to these positions as outputs.
In other words, the dataset contains both the inputs and the outputs, and I’m asking my computer to best approximate the function that maps these inputs to outputs.
There seems to be plenty of chess games online that I can download, including 2,600 games that Magnus has played on the record.
The challenge for this part of the process will be A. Converting the data into my modified bitboard representation (so the data maps one-to-one with my mental process) and B. Generating evaluations for each of the bitboard representations using the open-source chess engine Stockfish (which has a chess rating of around 3100).
Step 2: Creating the model
The next step is to create the deep learning model. Basically, this is the framework for the algorithm to built around.
The model is meant to describe the form that a function (between inputs and outputs in the dataset) should take. However, before training the model, the specifics of the function are unknown. The model simply lays out the functional form.
Theoretical, this model shouldn’t have to deviate too far from already well-studied deep learning models.
I should be able to implement the model in Tensorflow (Google’s library for machine learning) without too much difficulty.
Step 3: Training the model on the dataset
Once the model is built, I need to feed it the entire dataset and let my computer go to work trying to generate the algorithm. This algorithm will map inputs to outputs within the framework of the model, and will be tuned with the algorithm parameters that I’ll need to memorize.
The actual training process should be fairly hands off. The hard part is usually getting the model and the dataset to play nicely with each other, which is honestly where I spent 70% of time during May’s self-driving car challenge.
Step 4: Testing the model and iterating
Once the algorithm is generated, I should test to see at what level it can play chess.
If the algorithm plays at a level far above Magnus, I can simplify and retrain my model, creating a more easily learned and executed evaluation algorithm.
If the algorithm plays at a level below Magnus, I’ll need to create a more sophisticated model, within the limits of what I’ll be able to learn and execute as a human.
During this step, I’ll finally find out if Max Chess has any merit whatsoever.
Now that I have a clear plan laid out, I’ll get started on Step 1 tomorrow.
Yesterday, I laid out my four-step plan for building a human-executable chess algorithm.
Today, I started working on the first step: Creating the dataset.
In particular, I need to take the large corpus of chess games in Portable Game Notation (PGN) and programmatically analyze them and convert them into the correct form, featuring a modified bitboard input and a numerical evaluation output.
Luckily, there’s an amazing library on Github called Python Chess that makes this a lot easier.
As explained on Github, Python Chess is “a pure Python chess library with move generation and validation, PGN parsing and writing, Polyglot opening book reading, Gaviota tablebase probing, Syzygy tablebase probing and UCI engine communication”.
The parts I’m particular interested in are…
- PGN parsing, which allows my Python program to read any chess game in the PGN format.
- UCI (Universal Chess Interface) engine communication, which lets me directly interface with and leverage the power of the Stockfish chess engine for analysis purposes.
The documentation for Python Chess is also extremely good and filled with plenty of examples.
Today, using the Python Chess library, I was able to write a small program that can 1. Parse a PGN chess game, 2. Numerically evaluate each position, and 3. Print out each move, a visualization of the board after each move, and the evaluation (in centipawns) corresponding to each board position.
import chess
import chess.pgn
import chess.uciboard = chess.Board()
pgn = open("data/game1.pgn")
game = chess.pgn.read_game(pgn)engine = chess.uci.popen_engine("stockfish")
engine.uci()
info_handler = chess.uci.InfoHandler()
engine.info_handlers.append(info_handler)for move in game.main_line():engine.position(board)
engine.go(movetime=2000)
evaluation = info_handler.info["score"][1].cpif not board.turn:
evaluation *= -1
print move
print evaluation
board.push_uci(move.uci())
print board
Now, I just need to convert this data into the correct form, so it can be used by my deep learning model (that I’ve yet to build) for the purposes of training / generating the algorithm.
I’m making progress…
Today, I didn’t have time to write any more chess code. So, for today’s post, I figured I’d share the other part of my preparations: The actually games.
Of course, my approach this month has a mostly all or nothing flavor (either I can effectively execute a very strong chess algorithm in my brain, or I can’t), but I’m still playing real chess games on the side to improve my ability to implement this algorithm.
In particular, I’ve been practicing 1. Picking the right moves to evaluate and 2. Playing the right moves without the algorithm when I’m 100% confident.
Recently though, I’ve also been practicing my attacking abilities. In other words, I’ve been trying to aggressively checkmate my opponent’s King during the middle game (compared to my typical approach of exchanging pieces and trying to win in the end game).
Here are three games from today or yesterday that demonstrate my newly aggressive approach. To watch the sped-up playback of the games, click on the picture of the chessboard of the game you want to watch and then click the play button.
Game 1 — I play White and get Black’s Queen on move 15.
Game 2 — I play Black and checkmate White in 12 moves
Game 3 — I play White and checkmate Black in 26 moves
These games aren’t perfect. I still make a few major mistakes per game, and so do my opponents.
In fact, this is one of the biggest challenges with Chess.com: I’m only matched with real people of a similar skill level, which isn’t optimally conducive to improving.
But, I’m still able to test out my new ideas in this environment, while relying on the algorithmic part of my approach for the larger-scale improvements.
Tomorrow, I should hopefully have some time to make more algorithmic progress…ciboard =for move in test_game.main_line():print moveengine.position(board)
engine.go(movetime=2000)
evaluation = info_handler.info["score"][1].cpif board.turn:
if prev_eval - evaluation > 0.3:
print "bad move"
else:
print "good move"
if not board.turn:
evaluation *= -1
if evaluation - prev_eval > 0.3:
print "bad move"
else:
print "good move"
prev_eval = evaluation
board.push_uci(move.uci())
print board
Yesterday, on the plane, I had a really interesting idea: Could a room full of completely amateur chess players defeat the world’s best chess player after less than one hour of collective training?
I think the answer is yes, and, in fact, they could use a distributed version of my human algorithmic approach (i.e. Max Chess) to do so.
In other words, rather than just me learning and computing ever single chess evaluation on my own, instead, each amateur chess player could be in charge of a single mathematical operation, which they could each learn in a few minutes.
By computing mostly in parallel, the entire room of amateur players could evaluate an entire chess board in theoretically a few minutes, letting them not only play at a high level, but also make moves in a reasonable amount of time.
There have been past attempts of Wisdom of the Crowds-style chess games, where thousands of chess players are pitted against a single grandmaster. In these games, each member of the crowd recommends a move and the most popular move is played, while the grandmaster plays as normal.
In the most popular of these games, Garry Kasparov, the grandmaster, defeated a crowd of over 50,000. In other words, the crowd wasn’t so wise.
However, using the distributed algorithmic approach, the crowd would collectively play at the level of an incredible power chess computer. In fact, unlike in my case, the evaluation algorithm can remain reasonably sophisticated, since the computations aren’t restricted by the limits of a single human brain.
Using this approach, we (the amateur chess players of the world) could potentially stage the first crowd vs. grandmaster game where the crowd convincingly defeats a grandmaster, and in style.
To be clear, this doesn’t mean that I’m giving up on my one-man-band approach. I’m still trying to do this completely on my own.
However, I do think this method would scale wonderfully to a larger crowd of people, and if done, the chess game could be played at a speed that may actually be interesting to outside spectators (where as, in my game, I’ll be staring into space for dozens of minutes at a time, mentally calculating).
Maybe, after I complete this month’s challenge, I’ll try to organize a crowd-style algorithmically-inspired chess match.
Today, I went into Manhattan, and, while I was there, I stopped by Bryant Park to play a few games against the chess hustlers.
I wanted to test out my chess skills in the wild, especially since I need more practice playing over an actual chess board.
Apparently, according to chess forums, etc., many players who practice exclusively online (on a digital board) struggle to play as effectively in the real-world (on a physical board). This mostly has to do with how the boards are visualized:
A digital board looks like this…
While a physical board looks like this…
I’m definitely getting used to the digital board, so today’s games in the park were a nice change.
I played three games against three different opponents, with 5 minutes on the clock for each. In all three cases, I was beaten handily. These guys were good.
After the games, now with extra motivation to improve my chess skills, I found a cafe and spent a few minutes working more on my chess algorithm.
In particular, I quickly wrote up the functions needed to convert the PGN chessboard representations into the desired bitboard representation.
def convertLetterToNumber(letter):
if letter == 'K':
return '100000000000'
if letter == 'Q':
return '010000000000'
if letter == 'R':
return '001000000000'
if letter == 'B':
return '000100000000'
if letter == 'N':
return '000010000000'
if letter == 'P':
return '000001000000'
if letter == 'k':
return '000000100000'
if letter == 'q':
return '000000010000'
if letter == 'r':
return '000000001000'
if letter == 'b':
return '000000000100'
if letter == 'n':
return '000000000010'
if letter == 'p':
return '000000000001'
if letter == '1':
return '000000000000'
if letter == '2':
return '000000000000000000000000'
if letter == '3':
return '000000000000000000000000000000000000'
if letter == '4':
return '000000000000000000000000000000000000000000000000'
if letter == '5':
return '000000000000000000000000000000000000000000000000000000000000'
if letter == '6':
return '000000000000000000000000000000000000000000000000000000000000000000000000'
if letter == '7':
return '000000000000000000000000000000000000000000000000000000000000000000000000000000000000'
if letter == '8':
return '000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000'
if letter == '/':
return ''def convertToBB(board):
bitBoard = ''
board = str(board.fen()).split(' ')[0]
for letter in board:
bitBoard = bitBoard + convertLetterToNumber(letter)
return bitBoardprint convertToBB(board)
While I’m making some progress on the algorithm, since I’ve been in New York, I haven’t made quite as much progress as I hoped, only spending a few minutes here and there on it.
Let’s see if I can set aside a reasonable chunk of time tomorrow to make some substantial progress…
Today, I turned a corner in my chess development: I’m finally starting to appreciate the beauty in the game, which is fueling my desire to improve my chess game in the traditional way, in addition to the algorithmic way.
Before starting this month’s challenge, I was a bit concerned about studying chess. In particular, I imagined that learning chess was just memorizing predetermined sequences of moves, and was worried that, by simply converting chess to memorized patterns, the game would lose some of its interest to me.
In the past, while playing chess with friends, I’ve enjoyed my reliance on real-time cleverness and intuition, not pattern recognition. I feared I would lose this part of my game, as I learned more theory and began to play more like a well-trained computer.
Ironically, this fear came true, but not in the way that I expected. After all, my main training approach this month (my algorithmic approach) effectively removes all of the cleverness and intuition from the gameplay, and instead, treats chess like one big, boring computation.
This computational approach is still thrilling to me though, not because it makes the actual game more fun, but because it represents an entirely new method of playing chess.
Interestingly though, adding to my chess knowledge in the normal way hasn’t reduced my intellectual pleasure in the game as I expected. In fact, it has increased it.
The more I see and understand, the more I can appreciate the beauty of particular chess lines or combinations of moves.
Sure, there are certain parts of my game that are now more mechanical, but this allows me to explore new intellectual curiosities and combinations at higher levels. It seems there is always a higher level to explore (especially since my chess rating is around 1200, while Magnus is at 2822 and computers are at around 3100).
The more normal chess I’ve learned this month, the more I’m drawn to pursuing the traditional approach. There is just something intellectually beautiful about the game and the potential to make ever-continuing progress, and I’d love to explore this world further.
With that said, this isn’t a world that can fully be explored in one month, so I’m happily continuing with primary focus on my algorithmic approach.
To be clear, I’m not pitting the algorithmic approach against the traditional approach. Instead, I’m saying: “Early in this month, I fell in love with the mathematical beauty of and the potential to break new ground with the algorithmic approach. Just today, I’ve finally found a similar beauty in the way that chess is traditionally played and learned, and also want to explore this further”.
In other words, this month, I’m developing two new fascinations that I can enjoy, appreciate, and explore for the rest of my life.
This is the great thing about the M2M project: It has continually exposed me to new, personally-satisfying pursuits that I can continue to enjoy forever, even once the particular month ends.
Today, my brain suddenly identified traditional chess as one of these lifelong pursuits.
If I had this appreciation for traditional chess at the beginning of the month, I wonder if I would have so easily and quickly resorted to the algorithmic approach, or if I would have been held back by my romanticism for the “normal way”.
Luckily, this wasn’t the case, and now I get to explore both in parallel.
Today, I finished writing the small Python script that converts chess games downloaded from the internet into properly formatted data needed to train my machine learning model.
Thus, today, it was time to start building out the machine learning model itself.
Rather than starting from scratch, I instead looked for an already coded-up model on Github. In particular, I needed to find a model that analogizes reasonably well to chess.
I didn’t have to look very hard: The machine learning version of “Hello World” is called MNIST, and it works perfectly for my purposes.
MNIST is a dataset that consists of 28 x 28px images of handwritten digits like these:
The dataset also includes ten labels, indicating which digit is represented in each image (i.e. the labels for the above images would be 5, 0, 4, 1).
The objective is to craft a model that, given a collection of 28 x 28=784 values, can accurately predict the correct numerical digit.
In a very similar way, the objective of my chess model, given a collection of 8 x 8 = 64 values (where each value is represented using 12-digit one-hot encoding), is to accurately predict whether the chess move is a good move or a bad move.
So, all I need to do is download some example code from Github, modify it for my purposes, and let it run. Of course, there are still complexities with this approach (i.e. getting the data in the right format, optimizing the model for my purposes, etc.), but I should be able to use already-existing code as a solid foundation.
Here’s the code I found:)
Tomorrow, I’ll take a crack at modifying this code, and see if I can get anything working.
Parkinson’s Law states that “work expands so as to fill the time available for its completion”, and I’m definitely experiencing this phenomenon during this final M2M challenge.
In particular, at the beginning of the month, I decided to extend this challenge into early November, rather than keeping it contained within a single month. I did this for a good reason, which I’ll explain soon, but this extra time isn’t exactly helping me.
Instead, I’ve simply adjusted my pace as to fit the work to the extended timeline.
As a result, in the past week, especially since I’m currently visiting family, I’ve found it challenging to make focused progress for more than a few minutes each day.
So, in order to combat this slowing pace and start building momentum, I’ve decided to set an interim deadline: By Sunday, October 29, I must finish creating my chess algorithm and shift my focus fully to learning and practicing the algorithm.
This gives me one week to 1. Build the machine learning model, 2. Finish creating the full dataset, 3. Testing the trained model, 4. Making further optimizations, 5. Testing the strength of the chess algorithm, and, in general, 6. Validating or invalidating the approach.
Hopefully, with this interim deadline in place, I feel a greater sense of urgency and can overcome the friction of Parkinson’s Law.
Two days ago, I found some code on Github that I should be able to modify to create my chess algorithm. Today, I will dissect the code line by line to ensure I fully understand it, preparing me to create the best plan for moving forward.
Again, the code that I found is designed to take in an input image (of size 28 x 28 pixels, as shown below) and output a prediction of the numerical digit handwritten in the image.
Here’s the code in its entirety:)
Part 1: Importing the necessary libraries and helper functions
The first seven lines of code are used to important the necessarily libraries and helper functions required to build the machine learning model.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionimport argparse
import sysfrom tensorflow.examples.tutorials.mnist import input_dataimport tensorflow as tf
Most importantly, line 6 (“from tensorflow.examples.tutorials.mnist import input_data”) is used to import the dataset, and line 7 (“import tensorflow as tf”) is used to import the TensorFlow machine learning framework.
I can keep these seven lines as is, except for line 6, which will depend on the format of my chess data.
Part 2: Reading the dataset
The next four lines are used to read the dataset. In other words, these lines convert the data into a format that can be used within the rest of the program.
FLAGS = Nonedef main(_):
# Import data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
This is the part of the code that is most intimidating to me, but I have a few ideas.
Firstly, based on the documentation that accompanies the Github code, it seems that the data is prepared in a fairly straightforward way, contained within two matrices:
- The first matrix has dimensions of 784 by 55,000, where 784 represents the number of pixel in the image and 55,000 represents the number of images in the dataset.
- The second matrix has dimensions of 10 by 55,000, where 10 represents the labels (i.e. digit names) for each image, and again 55,000 represents the number of images.
I should be able to prepare two similar matrices for my chess data, even if I don’t do it in a particularly fancy way. In fact, I might construct these matrices in a Python format and then just copy and paste them into the same file as the rest of the code, so I don’t have to worry about actually reading the data into the program, etc.
This sounds a little hacky, but should do the trick.
In fact, to confirm the shape of the data, I modified the program, asking it simply to print out the the array representing the first image:)
print(mnist.test.images[0]))
And here’s what it printed:
It looks like each of these image arrays are then nested inside of another, larger array. In particular, here’s the output if I ask the program to print all of the image arrays:
In other words, I need to prepare my data in a set of 773-digit arrays (one array for each chessboard configuration) nested inside of a larger array.
For the labels, in my case “good move” and “bad move”, I need to nest 2-digit arrays (one array for each chessboard label), inside of a larger array.
In this case, [1, 0] = good move and [0,1] = bad move. This kind of structure matches the “one_hot=True” structure of the original program.
The original program likely separates all of the labels out in this way, rather than using binary notation, to indicate that the labels aren’t correlated to each other.
In the chess case, the goodness or badness of a move is technically correlated, but I’ll stick with the one hot structure for now.
Part 3: Create the model
The next five lines of code are used to define the shape of the model.
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + b
In this case, there are no hidden layers. The function is simply mapping inputs directly to outputs, with no intermediate steps.
In the above example, 784 represents the size of an image and 10 represents the number of possible labels.
In the same way, for my chess program, 773 represents the size of a chessboard representation, and 2 represents the number of possible labels.
So, I can update the code, for my purposes, in the following way:
# Create the model
x = tf.placeholder(tf.float32, [None, 773])
W = tf.Variable(tf.zeros([773, 2]))
b = tf.Variable(tf.zeros([2]))
y = tf.matmul(x, W) + b
Of course, I’m skeptical that a model this simplistic will play chess at a sufficiently high level. So, I can modify the code to support my more sophisticated model, which has two hidden layers, first mapping the 773 bits of the chessboard to 16 interim values, which are then mapped to another 16 interim values, which are then finally mapped to the output array.
# Create the model
x = tf.placeholder(tf.float32, [None, 773])
W1 = tf.Variable(tf.zeros([773, 16]))
b1 = tf.Variable(tf.zeros([16]))
h1 = tf.matmul(x, W1) + b1
W2 = tf.Variable(tf.zeros([16, 16]))
b2 = tf.Variable(tf.zeros([16]))
h2 = tf.matmul(h1, W2) + b2
W3 = tf.Variable(tf.zeros([16, 2]))
b3 = tf.Variable(tf.zeros([2]))
y = tf.matmul(h2, W3) + b3
Part 4: Training the model
Now that we have the framework for our model setup, we need to actually train it.
In other words, we need to tell the program how to recognize if a model is good or bad. A good model does a good job approximating the function that correctly maps chess positions to evaluations, while a bad model does)
For our purposes, we define a function called the Cross Entropy, which basically outputs how bad the model’s predictions are compared to the true values, which we use to test the quality of our model during training. For as long as the model is still bad, we use a mathematical technique called Gradient Descent to minimize the Cross Entropy until it’s below an acceptably small amount.
For implementation purposes, it’s not important to understand the math underlying either Cross Entropy or Gradient Descent. For my purposes this is both good and bad: It’s bad because I’m much stronger on the theoretical, mathematical side of machine learning versus the implementation side. It’s good because I’m forced to improve my abilities on the implementation side.
Part 5: Test the trained model
Once the model is trained, we want to test how well the model actually performs by comparing what the model predicts against the true labels in the dataset.
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
When the model outputs a prediction, it outputs a 10-digit array, where each digit of the array is a number between 0 and 1. Then, this array is fed into the function tf.argmax(y, 1), which outputs the label corresponding to the position in the array with the value closest to 1.
Part 6. Run the program
Finally, there’s some code that’s needed to make the program actually run:)
Now that I’ve digested the entire program and convinced myself that I understand what’s going on, I’ll start playing around with it tomorrow and see if I can output any initial results.
Yesterday, I deconstructed, line by line, the code that I’m using to generate my chess algorithm. Today, I explored this code a little bit further.
In particular, I wanted to answer two questions today:
Question 1
Once I fully train the machine learning model, how do I output the resulting algorithmic parameters in a readable format (so that I can then proceed to memorize them)?
In my code, the variable W represents the matrix that holds all of the algorithm parameters, so I figured that I could just run the command print(W).
However, unlike normal Python code, Tensorflow does not allow for this kind of syntax.
After a little playing around, I discovered I need to run a Tensorflow Interaction Session in order to extract the values of W.
This isn’t anything theoretically fancy. It’s simply the syntax that Tensorflow requires…
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()for i in range(0,784):
for j in range(0,10):
param = sess.run(W)[i][j]
print(round(param,2))
And here’s the output — a list of all 7840 parameters contained in W:
You’ll notice that I’m using the round function to round all of the parameters to two digits after the decimal point, as this is the limit for what my human brain can handle.
I still need to figure out how to update these values within W, and then validate that the model still works reasonably well with this level of detail. (If it doesn’t, then my algorithmic approach is in big trouble).
Question 2
Does my more sophisticated model actually produce better results? And if it does, are the results better by enough to justify the extra complexity?
If I just run the sample code as it (where the code is trying to identify handwritten numerical digits in input images), the model predicts the correct digit 92% of the time, which isn’t too bad.
If I make the model in the sample code more sophisticated, by adding two hidden layers, and then retesting its predictions, it only correctly identifies digits 11% of the time (i.e. essentially no better than a random guess).
I’m not sure if I simply don’t have enough data to train this more sophisticated model, or if there’s a gap in my understand in regards to building more sophisticated models.
If it’s a data problem, I can resolve that. If it’s a gap in my understand, I can resolve that too, but it may uncover some potential obstacles for my algorithm chess approach.
Hopefully, I can find a way forward. Hopefully, there’s even a way forward.
Today, I had a good idea. In fact, after some brainstorming with a friend, I figured out a surefire way to complete this month’s challenge.
It’s important to mention that this idea was heavily inspired by Nathan Fielder of Comedy Central’s Nathan for You, which is currently the only TV show I’m watching. While the humor of the show probably isn’t for everyone, I find the show brilliant and immensely satisfying.
Anyway, here’s the idea:
As I defined this month’s challenge, I need to defeat world champion Magnus Carlsen at a game of chess.
It turns out that, based on this definition of success, there actually is one minor loophole: I didn’t specify that Magnus Carlsen needs to be the World Chess Champion. Rather, I just specified that he need to be a world champion.
In other words, I don’t need to defeat the Magnus Carlsen at a game of chess. I just need to defeat a Magnus Carlsen at a game of chess, as long as this Magnus Carlsen is the world champion at anything.
Firstly, after a quick search on Facebook, I found dozens of other Magnus Carlsens who would be perfect candidates for my chess match. I guess Magnus Carlsen is a reasonably popular nordic name.
Even if I couldn’t convince any of these other Magnus Carlsens to participate, I can alway find someone who’d be willing to change their name if properly compensated. (In Nathan’s show, in one of the episodes, he pays a guy from Craigslist $1,001 to change his name).
Once I have a willing Magnus Carlsen, I’ll need to ensure that he is the world champion at something.
This is an incredibly flexible constraint…
I could even ask Magnus Carlsen #2 to invent a new board game that only he knows the rules for, guaranteeing that he is the world champion. Of course, I would stage a world championship event just to be sure.
Then, assuming Magnus Carlsen #2 isn’t a very good chess player, we’d play a game of chess and I’d easily defeat him, thereby allowing me to officially defeat world champion Magnus Carlsen at a game of chess.
Clearly, the point of my M2M project isn’t to bend semantics, but I did find this idea amusing. And, not only that, but it is technically legitimately.
Anyway, the purpose of sharing this, other than perhaps amusing one other person, is to say that there are always many creative ways to reach you goals. Sometimes, you just need to think a little differently.
My flight from New York to San Francisco just landed, which means that I’ll be back to my regular routine tomorrow. As part of this “regular routine”, I plan to greatly accelerate my chess efforts.
For the past eight days, I was in New York, primarily for a family function that lasted through the weekend (Friday through Sunday). During the six weekdays that I was in New York, staying at my parent’s house, I was still working full time. This wasn’t a vacation.
As a result, I needed to make a decision about how I wanted to use my extracurricular time in the evenings.
Typically, I mainly use this time for my M2M project and related activities, but, given that I haven’t seen my parents, sisters, or extend family for months, and don’t see them very often, I wanted to allocate a lot of this time to spend with them.
As a result, truthfully, in the past eight days, I probably spent a total of two hours working directly on my chess preparations, which isn’t very much at all.
But this was largely by design: I decided that I would prioritize time with my family over doing work (in all the forms that takes), and that I would find extra work time in the coming weeks, now that I’m back in San Francisco, to balance things out.
It’s often challenging to prioritize time with friends, family, etc., and similarly challenging to prioritize time to relax, play, and think, since these activities don’t have any timelines, deadlines, or ways to measure productivity or progress. It’s especially challenging to prioritize these activities when there are other available activities that do offer a greater sense of progress, productivity, or urgency.
We, as humans, want to feel important and often use progress or productivity (or even unnecessary busyness) as a way to prove to ourselves that we are important.
But, we can also be important just by enjoying the love we share with others (by spending time with friends and family) and by enjoying the love we have for ourselves (by relaxing, playing, exploring, etc.).
In fact, when I reflect on my life, my strongest memories are either of the times I spent with people I love or of the times I explored new places or things (traveling, learning new things, etc.).
Of course, when I was in New York, there was the option to lock myself in my bedroom and pound out chess code for hours. In fact, if I took this approach, I’d likely be in a better place with my preparations right at this moment.
However, I very happily sacrificed some of this preparation time for a lot of great time with my family. And, the truth is… I didn’t sacrifice this time at all. I simply decided to reallocate it to this upcoming week.
Often, in our lives, we create a fake sense of urgency around things that, when we zoom out, aren’t so urgent or grand after all. It’s very easy to chase these “urgent things” our entire lives, preventing us from enjoying much of what life has to offer.
I’m not perfect at resisting this temptation, but this past week was good practice in doing so and reaping the benefits.
With that said, now that I’m back in San Francisco, I’m going to reestablish this massive, largely artificial sense of importance and urgency that surrounds this month’s challenge.
So, here I go…
Today, I finally got back to working on my chess algorithm, which I’m hoping to finish by Sunday night.
I started by throwing out all of the code I previously had, which I just couldn’t make work.
After watching a few Tensorflow tutorials on YouTube, I was able to write a new program that works with CSV datasets. I was even able to get it to run on a tiny, test dataset:
Now that I had figured out how to import a dataset into a Python program, and then subsequently run it through a machine learning model, I needed to expand my data processing program from a few days ago, so that I could convert chess games in PGN format into rows in my CSV file.
Here’s what those changes look like:
import chess
import chess.pgn
import chess.uciboard = chess.Board()
pgn = open("data/caruana_carlsen_2017.pgn")
test_game = chess.pgn.read_game(pgn)engine = chess.uci.popen_engine("stockfish")
engine.uci()
info_handler = chess.uci.InfoHandler()
engine.info_handlers.append(info_handler)prev_eval = 0
diff = 0
output_data_string = ''def convertLetterToNumber(letter):
if letter == 'K':
return '1,0,0,0,0,0,0,0,0,0,0,0,'
if letter == 'Q':
return '0,1,0,0,0,0,0,0,0,0,0,0,'
if letter == 'R':
return '0,0,1,0,0,0,0,0,0,0,0,0,'
if letter == 'B':
return '0,0,0,1,0,0,0,0,0,0,0,0,'
if letter == 'N':
return '0,0,0,0,1,0,0,0,0,0,0,0,'
if letter == 'P':
return '0,0,0,0,0,1,0,0,0,0,0,0,'
if letter == 'k':
return '0,0,0,0,0,0,1,0,0,0,0,0,'
if letter == 'q':
return '0,0,0,0,0,0,0,1,0,0,0,0,'
if letter == 'r':
return '0,0,0,0,0,0,0,0,1,0,0,0,'
if letter == 'b':
return '0,0,0,0,0,0,0,0,0,1,0,0,'
if letter == 'n':
return '0,0,0,0,0,0,0,0,0,0,1,0,'
if letter == 'p':
return '0,0,0,0,0,0,0,0,0,0,0,1,'
if letter == '1':
return '0,0,0,0,0,0,0,0,0,0,0,0,'
if letter == '2':
return '0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,'
if letter == '3':
return '0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,'
if letter == '4':
return == == == == '8': == '/':
return ''def convertToBB(board):
bitBoard = ''
board = str(board.fen()).split(' ')[0]
for letter in board:
bitBoard = bitBoard + convertLetterToNumber(letter)
bitBoard = bitBoard[1:-1]
return bitBoardfor move in test_game.main_line():
engine.position(board)
engine.go(movetime=2000)
evaluation = info_handler.info["score"][1].cp
evaluation_label = ""if board.turn:
if prev_eval - evaluation > 0.3:
evaluation_label = "B" #badmove
else:
evaluation_label = "G" #goodmove
if not board.turn:
evaluation *= -1
if evaluation - prev_eval > 0.3:
evaluation_label = "B" #badmove
else:
evaluation_label = "G" #goodmove
prev_eval = evaluation
board.push_uci(move.uci())
out_board = convertToBB(board)
output_data_string = output_data_string + out_board + ',' + evaluation_label + '\n'
f = open('chessdata.csv','w')
f.write(output_data_string)
f.close()
And, here’s the output… (Each row has 768 columns of 1’s and 0’s corresponding to a bitboard representation of a chess position, and the 769th column is either a G or a B, labeling the chess position as “good” or “bad” accordingly. I haven’t yet encoded castling rights. I’ll do that once I can get my current setup to work.)
With this done, I had the two pieces I needed: 1. A way to convert chess positions into CSV files, and 2. A way to read CSV files into a machine learning model.
However, when I tried to put them together, the program wouldn’t run. Instead, I just got errors like this one…
pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 8, saw 5
…suggesting that my dataset was “dirty” in some capacity.
And this one…
ValueError: Cannot feed value of shape (43, 1) for Tensor u’Placeholder_1:0', which has shape ‘(?, 2)’
…suggesting that my data wasn’t conforming to the machine learning model, which is also likely a result of “dirty” data.
I tried to clean up the data by hand, but continued getting error messages.
Eventually, I discovered that I was generating a CSV file that sometimes contained two commas in a row (see below), which was causing my problems.
I found the bug in my data processing program, and then tried to run my machine learning model on the dataset again.
Finally, it worked (in the sense that it was running), but it was failing to calculate the “cost function”, which is one of the most important ingredients to the machine learning training process.
I was able to reduce the dataset down, and get it to train normally (with a calculated cost, etc.), but, for some reason, when scaling it up to the full dataset, something is breaking down.
Tomorrow, I’ll try to diagnose the problem.
Nevertheless, I made a ton of progress today, and nearly have everything working together. Once everything’s working, I suspect I will need to spend some time optimizing the model (i.e. finding the optimal balance between maximum chess performance and maximum learnability).
Yesterday, after a focused, 90-minute coding session, I was nearly able to get my program to read a CSV representation of a chess position, and then, use it to train a machine learning model.
Today, I was able to identify and fix the bug in yesterday’s code, letting me successfully run the program and train my model.
I then wrote some code that takes the parameters of the outputted model and writes them to a CSV file like this:
With this done, I’ve officially completed the full chess algorithm pipeline.
Here’s what the pipeline can do:
- Takes a chess game downloaded from the internet and converts it into a correctly formatted CSV. The CSV file contains the bitboard (i.e. 1’s and 0’s) representation of the chess position, and labels each chess position as either “good” or “bad”, using the Stockfish chess engine to compute all the evaluations.
- Reads the CSV file into a machine learning program, randomizes the order of the data, divides the data into a training dataset and a testing dataset, trains a machine learning model on the training dataset, and tests the model’s performance on the testing dataset.
- Once the model is tuned so that it can properly determine “good” and “bad” chess positions, it outputs the algorithmic parameters to another, properly-organized CSV file. Soon, I’ll use this file to memorize all of the algorithmic parameters, effectively transforming my brain into a chess computer.
Almost all of this code was written in the past two days (over the span of two hours), which is pretty amazing considering I’ve made very incremental progress for the past two weeks.
Clearly, a fully focused and committed approach goes a long way.
Yesterday, I finished building my chess algorithm pipeline, which can take chess games downloaded from the internet, convert them into a machine learning-friendly format, and then use them to train a machine learning model. At the end of the pipeline, the program outputs a list of algorithmic parameters that I can memorize and eventually use to compute chess evaluations in my brain.
This was great progress, but, as of yesterday, there was still a problem: The part of my program that is meant to label each chess position with either “good” or “bad” (so that the machine learning model knows how to properly evaluation the position) didn’t actually work at all…
In other words, the program outputted “good” and “bad” labels nearly at random, not actually tied to the true evaluation of the chess position.
Clearly, if my data is poorly labeled, even if I can build an incredibly accurate machine learning model, the resulting chess algorithm will still be just as ineffective as the data is bad.
So, today, I worked on addressing this problem.
In particular, I continuously tweaked my program until its outputs matched the “true” evaluations of the positions.
As my source of truth, I used the website lichess.org, which allows users to import and analyze chess games, explicitly identifying all the bad moves (inaccuracies, mistakes, and blunders) in the given game:
After about 30 minutes of work, I was able to get my program to exactly mirror the evaluations of lichess across every chess game that I tested.
So, I was finally ready to generate my correctly-label dataset.
As of yesterday, the program in my pipeline that converts chess games into CSV files could only handle one game at a time. Thus, today, I augmented the program so that it can cycle through millions of games on its own.
I’m using the chess database from lichess.org (which contains over 200 million chess games) to generate my properly label dataset.
Right now, I’m running all of the September 2017 games (which is about 12 million games) through my program.
Because the program needs to deeply evaluate each position, using the Stockfish chess engine with a depth of 22, the program is taking a long time to run. It looks like it will only be able to crunch through about 150 games every 24 hours, or approximately 6,000 chess positions, if I continue to run it just on my local computer.
Also, I can only use half of these chess positions for my training dataset, given that I’m currently only training my model to play with the White pieces.
I’m not sure how many chess positions I’ll need in order to train a decently functional model, but I’m guessing somewhere between 25,000–50,000 should be enough, which will take about a week to generate at the high end.
With that said, the program is iteratively writing each evaluated chess position to the CSV file in real-time, so I can start playing around with the data that’s already processed as the other games are still processing.
Yesterday, I predicted that I would be able to process 150 chess games every 24 hours. It’s been 24 hours since that prediction, and, in reality, I’m processing more like 350 games every 24 hours.
In fact, so far, I’ve evaluated 10,000 chess positions (as either good or bad) and have written these evaluations to my training_dataset CSV file, ready for consumption by my machine learning model.
Although I still need a lot more data, today, at around 2pm, I started training my model on what data I had, just to see what would happen.
In the beginning, the accuracy of the model, as measured on the training data, was only slightly more than 50% (i.e. a completely random evaluation, good or bad, of the chess positions).
Eight hours later, after 10,000 iterations through the 7,000 chess positions (3,000 chess positions have processed since then), the model’s accuracy on the training data leveled off at around 99%.
At first, I didn’t realize that this accuracy was based on the training data, so I thought this was unbelievably good. In other words, I thought this accuracy number represented how the model performed on data it had never seen before (while in reality the model was optimizing itself around this exact data).
When I tested the model on genuine test data (i.e. data the model truly had never seen before), it was only able to correctly evaluate the position about 70% of the time, which is not great.
I’m hoping I can improve this performance with a lot more data, but I may also need to add sophistication to the model.
Of course, the more data, the longer the model is going to take to run, which means the slower I’ll be able to iterate on my approach.
I could really use some special hardware right about now to speed things up… I may need to look into cloud compute engines to give me a little extra boost.
I’m still making progress, but a 70% performance is a bit of a letdown after I waited nearly eight hours to see the results.
Yesterday, after eight hours of processing, I was able to test the first version of my chess algorithm.
Sadly, it was only able to correctly evaluate chess positions as good or bad 70% of the time, which isn’t very good for my purposes.
Of course, this algorithm was created only based on 300 chess games, while I have access to over 200 million games. So, hopefully the algorithm will become more accurate as I feed it significantly more data.
Even if I can create an algorithm that is 99% accurate though, it’s still unclear how well this algorithm can be used to play chess at a high level.
In other words, even if I can identify and play “good” chess moves with 99% accuracy, is this enough to defeat the world’s best chess player?
In order to find out, I built a program today that let’s me test out my algorithm within actual gameplay. Here’s how it works:
- Since I’m playing with the White pieces, I make the first move. To do so, I suggest a move to the program.
- The program then runs this move through my algorithm and decides whether the move is good or bad.
- If it’s good, the program automatically plays the move. If not, it asks me to suggest another move until I find a good move.
- Then, my opponent responds with the Black pieces. I enter Black’s move into the program.
- After Black’s move is recorded, I suggest my next move, which is again played if the move is evaluated to be good.
- And so, until the game is over.
Here’s what the program looks like running in my Terminal:
In this way, I can test out different chess algorithms to see how they perform against chess computers of different strengths.
If I can find an algorithm that, when used in this way, allows me to defeat Magnus Age 26, within the Play Magnus app, then I can proceed to learn the algorithm, so I can execute it fully in my brain.
Right now, since the algorithm only has an accuracy of 70%, it’s still very bad at chess. I played a game, blindly using the algorithm, against Magnus Age 7 within the Play Magnus app, and I was very quickly defeated.
Still, it’s an exciting milestone: I finally have all the pieces I need to actually play algorithmic chess (i.e. Max Chess). Now, I just need to improve the algorithm itself…
Today is the 365th day of my M2M project and this is the 365th consecutive blog post. In other words, I’ve been M2Ming for exactly a year now, which is a crazy thing to think about.
In fact, it’s hard to remember what life was like pre-M2M, when I didn’t need to write a blog post every day. This blogging thing has just become a natural, expected part of my daily routine.
At the outset of this project, today was supposed to be the last day. Tomorrow, I’d wake up and the project would be over.
But, that’s not quite what’s happening…
As explained on October 1, I’ve extended this month’s challenge into November for reasons that I’m excited to share very soon.
Originally, I said that I would finish on November 9, but it’s looking like I may continue blogging until November 17 or so.
As I previously mentioned, I’d prefer not to deviate from the strict, one-month timeline (and just complete the project today), but these extra couple of weeks will be worth it.
I still can’t say too much more about why these extra couple weeks will be special, but it will all become clear soon.
A few days ago, after waiting eight hours for my personal computer to run my chess program, I found out that I would need more computing power to have any chance of creating a usable chess algorithm.
In particular, I can’t use my personal computer to process the amount of data I need to build my chess algorithm within a reasonable timespan. I need a much much faster, more powerful computer.
Luckily, cloud computing exists, where I just upload my code to someone else’s computer (Amazon’s, Google’s, etc.) through the internet, and then let their specially optimized machines go to town.
If only it were that simple though…
I spent some time trying to get my code running on Amazon Web Services, with limited success. After the basic setup, I struggled to get my massive dataset into Amazon storage to be accessed at code runtime.
But then, while researching my options, I came across a tool called Floyd, and it’s pure magic.
Floyd is a layer that sits on top of AWS and lets me deploy my code super easily:
- I open Terminal, and navigate to my chess-ai folder on my local computer
- I run two special Floyd commands
- My code is uploaded to Floyd’s servers and instantly starts running on their GPU-optimized computers.
There are few additional things I needed to figure out like separately uploading and “mounting” my dataset, downloading output files off of Floyd’s servers, etc.
But, overall, I got things up and running very quickly.
As a result, here’s my model running now…
The Floyd computers seem about 3x faster than my personal computer, and I can run multiple jobs in parallel, so it’s definitely helping. Floyd runs at about 75% of the speed of AWS, but the ease of use more than makes up for this. It’s also only $99/mo for the biggest plan, which I’ll happily pay for something this good.
It’s always great to find a new tool that I can add to my arsenal.
Now, whenever I need to do any kind of data science or machine learning project in the future, I’ll know where and how to deploy it in only a few minutes.
This is why learning compounds over time… Today, I did a lot of upfront work to discover the best tool and learn how to use it. Now, I can continue reaping the rewards forever.
I might have a problem…
Yesterday, I excitingly found an easy way to get my chess code running on faster computers in the cloud. The hope was that, if I can process a lot more data and then train my model on this larger dataset, for more iterations, I should be able to greatly improve the performance of my chess algorithm.
As of a few days ago, I could only get my algorithm to correctly label a chess position as “good” or “bad” 70% of the time. I figured I could get this up to around 98–99% just by scaling up my operation.
However, after running the beefier version of my program overnight, I woke up to find that the algorithm is still stuck at the 70% accuracy level.
Not only that, but after it reached this point, the model continued to slowly improve its accuracy on the training data, but started to perform worse on the testing data.
In other words, after my algorithm reached the 70% mark, any attempt it made to improve actually caused it to get worse…
For example, after 6,600 iterations, the test accuracy was 68.1%:
After 9,900 iterations, the test accuracy was down to 67.6%:
So, it seems that my model, as it’s currently constructed, is maxing out at 70%, which isn’t great. In fact, I’d bet the reason it plateaus here is fairly simple: 70% of the data in the dataset is labeled as “good” and the rest is labeled as “bad”.
In other words, my model performs best simply by guessing that every single chess position is “good”, thereby automatically achieving 70% accuracy.
I haven’t confirmed this explanation, but I suspect it’s something like this.
So, now what?
Well, I was really hoping that I could use the most operationally-basic machine learning model, at a large enough scale, to pull this off. But, either the model isn’t sophisticated enough or my labelling scheme for the data is just nonsensical.
In either case, I have some ideas for how to move forward from here, which I’ll discuss tomorrow.
Yesterday, I ran into a bit of a problem: My chess program, as it currently exists, won’t be able to help me become a grandmaster. Instead, it will only help me correctly identify chess moves as “good” or “bad” 70% of the time, which is worse than I can do as an amateur human chess player.
So, if I want to have any shot of defeating Magnus, I need to try something else. In particular, I can either continue searching for an effective algorithm or I can try to find a completely new approach.
Before trying something new, I think it’s certainly worth continuing down the algorithmic path. After all, the failure of this one particular algorithm doesn’t imply that the entire general approach is hopeless.
In fact, I would have been extraordinarily lucky (or clever…?) if the first algorithm (or class of algorithms) I tried was a functional one. Most often, when trying to create new technical solutions, it takes a few iterations, or more, to land at a workable solution.
Of course, these aren’t random iterations. I still need to be smart about what I try next…
So, what should I try next?
Within the algorithmic space, there are only two possible paths I can go down, and they aren’t exactly mutually exclusive:
1. Build a better model
Use the same dataset, but build a more robust model using Convolutional Neural Nets. Start with a highly sophisticated model, even if it’s not reasonable for human execution, just to see if a high-performance algorithm can even be made. If it can, then slowly reduce the sophistication of the model until it performs just at the level of Magnus Carlsen, and hope that this (or some optimized version of this) is learnable and executable by a human. If it can’t, then it means that my dataset is crappy, and I need to try option #2
2. Build a better dataset
Create a new dataset, constructed and labelled based on some new principle. In particular, try to use the fact that I’m human to my advantage. Maybe, construct the dataset based on a set of heuristics (i.e. for each piece: the number of other pieces directly attacking it, the number of other pieces able to attack it within one move, the number of possible moves it can make, the relative value of the piece compared to the other pieces on the board, etc.). Develop a long list of possible heuristics, and then use the computer to help find which ones are useful and in what combination (this is effectively what the convolutional neural net, from #1, should do, but it will likely be impossible to unravel what heuristics it’s actually using). Alternatively, use the same kind of board input, but label the outputs differently. Perhaps, for example, only try to output which piece is the best to move in each position.
Here’s my plan for moving forward:
- Construct a Convolutional Neural Net, and run my current dataset through it.
- In this way, either validate or invalidate the goodness of my dataset.
- Assuming (very strongly so) that the problem is with my dataset, construct a new dataset, and run it through the Convolutional Neural Net.
- Continue this process until I find a dataset that is good.
- Then, start stripping back the model (i.e. the Convolutional Neural Net) while trying to maintain the performance.
- If the model can be reduced, so that it can be performed by a human, without overly compromising the performance, ride off into the sunset (and by that I mean… spend a ridiculous amount of time and brainpower learning and practicing the resulting algorithm).
- If the model cannot be reduced without sacrificing performance, try to find another good dataset.
Honestly, this whole process is quite thrilling. In a different life, maybe I would turn this into a Ph.D. thesis, where I try to algorithmically solve chess and then generalize these findings to other domains (i.e. How to develop computer-created, human-executable decision-making algorithms).
But, for now, the Ph.D. will have to wait, and instead, I’ll see what I can accomplish in an hour per day over the next few days.
I have good news and bad news…
The good news is that I’m much more proficient at building, training, and deploying machine learning models. Today, in only 30 minutes, I was able to construct a brand new, more sophisticated machine learning model (a convolutional neural network) based around my chess data, upload the dataset and model to a cloud computer (via Floyd), and begin training the model on machine learning-optimized GPUs.
The bad new is that it doesn’t seem like this model is going to perform any better than my previous one. In other words, as anticipated, the problem with my chess algorithm is a function of how I’ve constructed my dataset.
The new model is still training, so I could wake up to a surprise, but I’m not counting on it.
With that said, it is interesting how much more quickly I’m able to build and deploy new machine learning code. In fact, everything I’ve done for this month’s challenge I could now likely complete in one day.
That’s the amazing and crazy thing about learning… By fighting through the unknown and the occasional frustration, something that previously took me 30 days now will only take me a few hours.
Even if I don’t succeed at defeating Magnus at a game of chess in the next few weeks, I’ve definitely leveled up my data science skills in a big way, which will serve me very well in the future on a number of project.
This entire month’s challenge has hinged on a single question:
If I have a big set of chess positions labelled as either “good” or “bad”, can I create a function that correctly maps the numerical representations of these chess positions to the appropriate label with a very high degree of accuracy?
I think the answer to this question is yes, but it assumes that the original dataset is properly labelled. In other words, if I’ve incorrectly labelled some chess positions as “good” when they are actually “bad” and some as “bad” when they are actually “good”, my function won’t be able to find and correctly extrapolate patterns.
I’m almost certain that this is the current problem I’m facing and that I’ve mislabelled much of my dataset.
Let me explain where I went wrong (and then share how I’m going to fix it)…
Labelling my dataset v1
The dataset I’ve been using was labelled in the following way:
- For a given chess position, compute its evaluation.
- Then, for this given position, compute the evaluation of the position that came immediately before it.
- Find the difference between the evaluations (i.e. the current evaluation minus the previous evaluation).
- If this difference is greater than a certain threshold value, label the position as “good”. If the difference is less than the same threshold value, label the position as “bad”.
This method assumes that if the most recent move you made reduced the evaluation of the position, it was a bad move. Therefore, if you are evaluating this position, you should consider it bad because the move that got you there was also bad. (The same logic applies for good positions).
But, there is a problem here… There are multiple ways to reach any given position. And, the moves that immediately lead to this position don’t necessarily need to be all “good” or “bad”.
For example, in one case, I can play a sequence of all good moves, followed by one bad move, and end up in the “bad” position. In another case, I can start the game by making bad moves, followed by a series of good moves (in an attempt to work out of the mess I created), and still end up in the same position.
In other words, it’s highly likely that, in my dataset, there are multiple copies of the same chess position with different labels.
If this is the case, it’s no surprise that I couldn’t find a reasonable function to describe the data.
Originally, I overlooked this problem via the following justification:
Sure, there might be multiple ways to get to a single chess position, but because I’m going to be using the algorithm for every move of the game, I will only be making a sequence of “good” moves prior to the final move in the sequence. Thus, the evaluation of a given chess position will only be based on this final move — where if the move is “good”, then the chess position is naturally good and if the move is “bad”, then the chess position itself is bad.
Even though this is how I would implement my chess algorithm in practice, my dataset was still created with all possible paths to a given chess position, not just the one path that I would take during game time.
And so, I essentially created a crappy dataset, resulting in a crappy machine learning model and an ineffective chess algorithm.
Labelling my dataset v2
An hour ago, I came up with a much better (and computationally faster) way to label my dataset. Here’s how it works:
- Load a bunch of chess games.
- For each game, determine if White won or lost.
- For each chess position in each game, label all the positions as either +1 if White won the game and -1 if White lost the game (and 0 if it’s a tie).
- Process millions of games in this way, and keep a running tally for each distinct position (i.e. If the position has never been seen before, add it to the list. If the position has already been seen, increment the totalassociated with the position by either +1 or -1).
- Once all the games are processed, go through each of the distinct positions, and label the position as “good” if its tally is greater than or equal to zero, and “bad” if its tally is less than zero.
In this way, every chess position has a unique label. And each label should be highly accurate based on the following two thoughts: “Over millions of games, this chess position led to more wins than losses, so it’s almost certainly a good chess position” and “Over millions of games, this chess position led to more losses than wins, so it’s almost certainly a bad chess position”.
Additionally, because I don’t need to use the Stockfish engine to evaluate any of the moves, my new create_data program runs about 10000x faster than my previous program, so I’ll be able to prepare much more data (It processes 1,000 chess games, or about 40,000 chess positions, every 15 seconds).
Right now, I have it set up to process 2 million games or about 80 million chess positions overnight.
It’s been running for 30 minutes now and has already processed 193,658 games.
Honestly, this morning I wasn’t sure how or if I was going to make forward progress, but I feel really optimistic about this new approach.
In fact, I can’t see how this data wouldn’t be clean (so if you have any ideas, leave a comment and let me know).
Assuming this data is clean though, I should be able to generate a workable chess algorithm. Whether or not this chess algorithm will be human-learnable is another story. But, I’m going to take this one step at a time…
Last night, I left my computer running while it processed chess games using my new labelling method from yesterday.
As a reminder, this new method labels all chess positions from a winning game as +1 and all chess positions from a losing game as -1. Then, each time the program sees the same chess position, it continues to add together these +1 and -1 labels until a final total is reached. The higher the number, the more definitively “good” the move is, and the lower the number, the move definitively “bad” the move is.
After waking up this morning, I saw that my program had crashed after processing around 700,000 chess games. Simply, my computer ran out of usable memory.
Sadly, as a result, none of the output was saved.
Thus, I restarted the program, setting the cutoff to around 700,000 games.
Once the dataset was successfully created, I uploaded it to Floyd (the cloud computing platform I use), mounted it to my train_model program, and started training my machine learning model.
However, very quickly Floyd (which is just built on top of AWS) also ran out of memory and threw an error message. I tried to max out the specs on Floyd and rerun the program, but only to run out of memory again.
So, I scaled things back and created a dataset based on 100,000 chess games… This still broke Floyd.
I scaled back to 25,000 chess games, and finally Floyd had enough memory capacity to handle the training.
I’ve been running the training program for about four hours now and the accuracy of the program has been steadily climbing, but it still has a long way to go:
It started at around 45.5% accuracy on the test data (worse than randomly guessing, assuming good and bad positions are about equal).
And, after four hours, reached about 54.4% accuracy on the test data (slightly better than randomly guessing)…
Hopefully, if I let this program run through the night, it will continue to steadily march up towards 99%. (The program is only cycling through ~400 iterations per hour, so this could take a long time).
To hedge, I’m preparing a few other datasets that I also want to use for training purposes in parallel. In particular, I’m worried that, because I had to shrink down my dataset to get the program to run on Floyd, there may be many chess positions in my dataset that were only processed once, effectively labelled randomly (rather than being properly labelled by the aggregate view).
Thus, I’m creating a few datasets where I’m processing significantly more chess games, but only accepting chess positions into my labelled dataset that have been seen multiple times and demonstrate a definitive label (i.e. the chess position has a tally that is >25, or >50, or >100).
In this way, I can likely eliminate any one-off positions and create a dataset that has a cleaner divide between “good” positions and “bad” positions.
I also always have the option of introducing a third label called “neutral” that is assigned to these less definitive chess positions, but an additional label will add significantly more complexity — so it’s only worth it if it greatly increase the effectiveness of the algorithm.
Anyway, today has been a lot of waiting around, running out of memory, and crunching data. Hopefully, tomorrow, I’ll have some indication whether or not I’m headed in the right direction.
Honestly, this is starting to seem like a job for Google’s Alpha Go or IBM Watson as far as infrastructure and optimization are concerned. Is it too late in the game to pursue some kind of sponsorship/collaboration…?
In a few hours, I get on a plane to Germany. I’ll be there until the 10th, and then will be in Denmark through the 12th.
In other words, I’ll mostly be traveling for the rest of this challenge.
I could of course stay in my hotel room and continue working on my chess code, but exploring these new countries is a much better use of my time.
So, let’s take stock of where I currently am…
Last night, I started running a new program that looked promising. However, almost immediately after publishing yesterday’s post, and after 4.5 hours of processing, the program failed: File sizes once again got too big, and this time, it seems like it had nothing to do with my infrastructure configuration, and instead, had to do with the limits of Python and Tensorflow.
Clearly, there’s some kind of optimization I’m overlooking.
This morning, I set up a bunch of other experiments, slicing and dicing the dataset in all sorts of ways.
I’m starting to get quite proficient at setting up new machine learning experiments (and also just conceptualizing new, useful experiments to run). However, even though I’ve made major progress on the software front, my hardware skills are still very raw, and I have a lot to learn about setting up the infrastructure necessary to successfully use large datasets and models.
I’m not sure I’ll have the time in Europe to address these hardware skill deficiencies.
Nevertheless, while my trip to Europe may slow down my chess code progress, it is still a continuation of this challenge’s narrative. I’ll explain soon…
I got to Germany today at around 6pm, so most of my day was spent attempting to sleep on an airplane.
However, while in the air, one of my machine learning models continued to train.
Yesterday, at 10am, when the model started running, it could correctly identify chess positions as “good” or “bad” with 68% accuracy:
As of a few minutes ago, the model is now at 75% accuracy:
While there is still a long way to go, this is the most promising training session I’ve run to date: With each set of 100 iterations, the model’s accuracy is getting better and better with no sign of tapering off.
The progress is gradual, but steady.
This model might just go all the way…
I’m heading to bed now, but am eager to see its progress when I wake up.
Today, my computer was still chugging along, slowly training my machine learning model, which will ultimately, if successful, output my human chess algorithm.
This iteration of my model is still looking optimistic (as it did yesterday), but I couldn’t do much today other than wait for it to finish.
So, I figured today would be a good day to try to take on Magnus, Age 26, and see if I can win a chess game the old-fashioned way.
Of course, I haven’t exactly practiced much normal chess — given that I committed heavily to my algorithmic approach — but still, today, I gave a normal game my best go.
I started off playing solid for the first dozen moves or so, but eventually Magnus got an advantage…
Soon after, he leveraged this advantage and checkmated my King….
Clearly, without an algorithm to lean on, Magnus is still dominant.
But, it’s not over yet… I still have a little time to get my algorithm up and running. I’ll let my computer keep chugging away, and hope it finishes up soon.
I’m typically very good at estimating how long doing anything will take me. Whether it’s writing a Medium post, or launching an app, or running errands, or practically anything else, I can usually guess the exact amount of time required plus or minus very little.
However, there are cases, particularly when I have limited experience in the relevant domain, when my time estimation skills fail me.
This month’s challenge is one of those cases…
I severely underestimated how much time I would need to allocate to training machine learning models. I expected (especially when using high-powered GPUs) that I could train any model in under a day.
However, this was a bad assumption: Currently, the model that I’m training (which is so far my most promising) has been running for over 80 hours and I suspect it will need at least another 80, if not even more, to finish.
In other words, the iteration cycle for something like this isn’t measured in hours, but rather weeks.
Typically, my learning method is to try something as fast as I can, see the result, react to the outcome, and iterate. But, this is a much more challenging approach to take when each iteration takes dozens of hours.
Coming into this challenge, I was fairly comfortable with the mathematical and theoretical parts of data science, but had limited practical experience.
During my self-driving car challenge, I became more comfortable with some of the basic tools, but didn’t actually have to do much real data science: For my self-driving car, I used an already-prepared dataset on an already-prepared machine learning model on an already-solved problem (more or less).
On the other hand, with this chess challenge, I needed to envision a new solution (to a new problem), prepare a new and useful dataset, and then build a new machine learning model specifically optimized for this dataset and my envisioned solution.
In other words, this time around, I needed to do everything from scratch, and, given that this was my very first experience with end-to-end data science, I had no reference point for how much time this would actually take.
Additionally, during the self-driving car month, I was able to run everything on my personal computer, not needing to learn about deployment in the cloud, as I did this time around.
Of course, when I started this chess challenge, I also didn’t anticipate that I would be leaning so heavily on data science in general, so I was really just hoping that “whatever I come up with, it will be achievable in a month”.
Now that I feel more comfortable with practical, end-to-end data science, I could probably pull off the machine learning part of this challenge in a month or so, but it would still be really tough and I would need to get a little lucky (i.e. I still wouldn’t have time for many iterations).
And, even if I was able to complete the machine learning and data science parts of my algorithmic chess approach, I would still need to memorize and learn the algorithm in the remaining days of the month, which would also be quite tough: Learning this kind of algorithm would be similar to my card memorization challenge, but about 10x more involved.
In other words, I greatly underestimated how much time it would take to defeat the world chess champion. It turns out, not so surprisingly, that this is a pretty ambitious feat after all.
I’d say, more realistically, this challenge could be completed in about 3–6 months, starting from where I had started, working full-time at it.
Still, defeating the world’s best chess player after six months of preparations would be incredibly unprecedented and fascinating, so it still may be worth giving it a go.
The best part about incorrectly estimating the time required for anything is that you’re forced to reflect and recalibrate your time estimation abilities.
I’d say I have a much better sense of “data science time” now, which I’m sure is something that will serve me well in the future.
Anyways, my model is still training, and I’m hoping that I can start playing around with the output by Monday or so.
Today, I spent most of the day exploring Copenhagen by foot. Although it was quite cold, it was a sunny day and I really enjoyed the city.
However, things didn’t go quite as planned…
I left the hotel this morning with a fully charged phone, but, for some reason, perhaps the cold, my phone immediately died after stepping outside.
Rather than heading back to the hotel, I figured I’d continue on without the crutch of Google Maps. I decided to just wander without a specific plan or direction, and then, at the end of my day, just try to find my way back.
I trusted that I’d figure it out.
There was something freeing about forging my own path and not relying on technology to guide me around. It forced me to be more present and to more fully observe my surroundings.
Interesting, this feeling of forging my own path is very similar to the one I experienced during this month’s chess challenge: I headed off into the unknown without a plan or a guide to follow, and found pleasure in the process of pioneering forward.
I eventually found my way back to the hotel, which I hope is a signal of what’s to come in these last few days of my chess challenge.
I just got off a twelve hour flight from Copenhagen back to San Francisco, so I’m going to keep this post pretty short…
While on the plane, since I had nothing better to do, I played around with my chess algorithm, trying to find ways to optimize it and ultimately finding a way to increase its efficiency by 10x.
In other words, my sloppy code was a large contributor to the slow training process over the past couple of days.
Anyway, with the boost in speed, my model is effectively done training now, and I’ve been using it to analyze and play chess games with promising results.
I’ll share more tomorrow…
Today, I finished the first version of my chess algorithm, allowing me to play a solid game of chess as a human chess computer. The algorithm is ~94% accurate, which may be sufficient.
Here’s a ten-minute video, where I explain the algorithm and use it to analyze a chess game on Chess.com that I recently played:
(Update: This is the game I played against Magnus, which I later revealed)
I’m excited that it works, and curious to see how much farther I can take it.
The next steps would be to determine the chess rating of the algorithm, play some assisted games with it to see how I do, and then, assuming it’s working as expected, see if I can optimize it further (to minimize the amount of required memorization).
It’s looking like Max Chess may actually become a reality…
Yesterday, I finally was able to test my chess algorithm on a recent game I played, and it worked quite well. You can watch the 10-minute video demonstration here.
Today, I dug a little bit deeper into the performance of the algorithm, and the results were still good, although not perfect.
For the first 25 moves or so of any chess game, the algorithm performs more or less perfectly. It identifies good moves as good and bad moves as bad — comfortable carrying its user through the chess game’s opening and some of the middle game.
The algorithm performs less well in the late middle game and end game. In particular, during this part of the game, the algorithm’s threshold for good moves is too low: It recognizes too many inaccurate moves as good.
The algorithm does find the best line in the end games (consistently calculating these moves as good), but there is too much surrounding noise for me, as the user of the algorithm, to find this best line.
I’m not particular surprised by this outcome: This iteration of the model was only trained on 1,500 games and about 50,000 chess positions (I used this reduced dataset so that version 1 of my model could at least finish training before the challenge ended).
The problem with such a small dataset is that it likely doesn’t have enough duplicates of later-stage chess positions to produce accurate labels for these positions.
I just took a quick look at the dataset, and there are many later-stage chess positions that only appear once in the entire dataset. In fact, most of the later-stage chess positions only appear once, which distorts this part of the dataset.
On the other hand, the earlier chess positions are seen enough times that the true natures of these positions were correctly revealed when the dataset was created (Hence the nearly perfect results during openings and early middle games).
This problem can likely be remedied though: I just need to process many more games to create a fully undistorted dataset.
Of course, training a model on this dataset may take much longer, but the result, theoretically, should be significantly better for performance on all parts of the chess game.
Thus, today, I started training the same model, but this time on a dataset of 100,000 games. I’m also processing more games, hoping to build a dataset of around ten million games.
Based on what I’ve seen so far, I suspect these models, with the input of much more data, will be nearly perfect in their performance. After all, the current model is incredibly accurate, and it’s only basing its performance on 1,500 games.
If anything, yesterday’s result proved to me that algorithmic chess is a legitimate and functional approach (that already works reasonably well).
What is still unclear is whether or not “perfect performance” at identifying good moves and bad moves leads to Magnus-level gameplay. This is still to be determined…
Two days ago, I showed that my algorithmic chess approach is actually workable. It’s still not quite finished, but it does and can work, which is quite exciting.
Right now, my computer is working away on V2 of the algorithm and it’s looking like the performance of this version is going to be better.
I’m going to officially end this challenge and the entire project on Friday, so I’m not sure I’ll be defeating Magnus at chess before then.
Even if I don’t complete this challenge in the next two days, the past six weeks have been particularly exciting for me:
- I pioneered a new way to learn and play chess (and validated that it has potential), hopefully impacting the future of chess in some capacity.
- I developed a much stronger practical understanding of the end-to-end data science and machine learning process, which will serve me very well moving forward.
- I discovered a much deeper appreciation for the game of chess and for the ongoing dedication of the world’s top players to the game. I finally understand the beauty of the game, and will certainly continue playing chess the normal, non-algorithmic way reasonably regularly.
- I made some interesting friends in the chess community, which I’ll talk more about on Friday.
Overall, a very successful “unsuccessful” challenge.
In other words, while I might not succeed at reaching my particular goal (of defeating Magnus), I was successful in using this goal to propel myself into a new space, to find a new source of intellectual joy, and to flex my creative and technical muscles in pursuit of the goal.
This point is important: Don’t measure the quality of your life by the outcomes, but by the pursuit of those outcomes.
If you optimize for and value the pursuit, favorable outcomes will follow anyway, even if they aren’t the outcomes you planned for.
If you only value the outcomes, you will miss out on most of the pleasures of your life — since we spend most (all) of our life in pursuit.
Like with all of my past challenges, today I decided to tally up the total amount of time I spent on this final chess challenge.
Since this challenge was effectively 50% longer than previous challenges, it’s no surprise that I spent a bit longer on it. In particular, over the past six weeks, I committed 34 hours to the pursuit of defeating Magnus.
It turns out that 34 hours isn’t quite enough, but, knowing what I know now, I don’t think it’s too far off.
I’d estimate that it would take between 500–1,000 hours to become a human chess computer capable of defeating the world champion (assuming that an algorithmic approach at this level of gameplay is possible… the verdict is still out).
While this is considerably more time than the 34 hours I spent, it’s completely dwarfed by the tens of thousands of hours that Magnus has spent playing chess.
Of course, this estimate only matters if I can actually demonstrate the result.
For now, I’m going to take a little break from my chess preparations, but, if inspiration strikes, I’m may proceed forward.
1,000 hours really isn’t so crazy. It’s about six months of a standard 9-to-5 job.
I suspect that I’ll be circling back some time in the future, putting in these 1,000 hours, and, assuming everything goes to plan, playing a competitive game against Magnus (in what will still likely be a very lengthy game).
Until then, Magnus can continue enjoying his spot at the top…
Today is the very last day of my M2M project, and I’m excited to finally share one of the most unexpected parts of this month’s challenge (and the entire project): I had the opportunity to play a game of chess, over the board, with the real Magnus Carlsen last week (November 9) in Hamburg, Germany.
It was an incredibly energizing and enjoyable experience, and I’m really grateful that I had the opportunity.
To celebrate the completion of the project, The Wall Street Journal wrote a story covering the match, and produced a video to go along with it:
FAQ 1: How did you set up a game with Magnus?
I didn’t. The game was offered to me (via a collaboration between Magnus’s team and the Wall Street Journal), and I accepted. This didn’t seem like something I should turn down.
FAQ 2: Did you actually think you were going to win?
I never thought I was going to win. In fact, this was the entire premise of this challenge: How could I take what is an impossible challenge (i.e. if I trained using a traditional chess approach, I would have an effectively 0% chance of victory), and approach it from a new angle. Perhaps, I wouldn’t completely crack the impossibility of the challenge, but maybe I could poke a few holes in it, making some fascinating headway and introducing some unconventional ideas along the way. This was more an exploration of how you approach the impossible than anything else.
While I made decent and interesting progress towards this alternative approach, it wasn’t quite ready by the time that I sat down for the game with Magnus. So, barely having learned normal chess, I sat down to play the game as a complete amateur.
Anyway, this year has been a ton of fun, and I’m sure M2M Season 2 is somewhere in my future.
Until then, thanks to everyone who has been following along, providing input, and supporting the project over the past twelve months. It has meant (and continues to mean) a lot to me. | https://medium.com/@maxdeutsch/my-month-long-quest-to-become-a-chess-master-from-scratch-51ff8003d3f2 | CC-MAIN-2021-25 | refinedweb | 25,135 | 58.42 |
On 05/08/2012 08:36 AM, Nick Coghlan wrote: > No, the idea is to make the two activities (identifying package > portions and deciding whether or not to continue scanning sys.path) > *independent*. I'm all for this. > Suppose I want to implement a loader where the main path entry is > actually just a reference to a separately configured path definition > (e.g. to an application configuration file with an extra set of paths > to check for Python modules). With a callback API, I can implement > that directly, since I would be able to just pass the received > "portion_found" callback down while scanning the subpath with the > usual sys.path_hooks entries. It doesn't matter if that callback is > called zero, one or many times - it will still do the right thing. > > Even if the subscan finds several portions before discovering a > loader, it will *still* do the right thing - the fact we end up > returning return a loader instead of None would override the fact that > we previously called "portion_found". > > With the current implementation, there's no option to return > *multiple* path segments - loaders are restricted to returning at most > one portion to add to the namespace package. So have it return a list of strings instead of a single string. > I think Antoine's right - having to introspect the return type from > the method call is a major code smell, and I think it's a sign we're > asking one return value to serve too many different purposes. I don't disagree with this. But we've got a function that we're asking to return one of 2 things, as you say. How is this normally handled? I would not use a callback. I'd return a tuple with the two things: (loader, list_of_portions). That seems way more straightforward. Eric. | https://mail.python.org/pipermail/import-sig/2012-May/000586.html | CC-MAIN-2016-50 | refinedweb | 304 | 61.67 |
We can capture the screenshot of a particular section of the page like the logo of the website in Selenium. For doing so we need to import a PIL imaging library. It may or may not be a part of the standard libraries. However if it is unavailable, it can be installed with pip install Pillow command.
For capturing the screenshot, get_screenshot_as_png() method is available. This method gives a binary data which is present in the memory. Then the image can be modified and finally saved.
There is no built-in method to capture the logo of the web site separately. To achieve this we have to crop the image of the full page to the size of the image logo.
driver.get_screenshot_as_png('screenshot_t.png')
In the arguments, we have to provide the screenshot file name along with the extension of .png. If anything else is used as extension, a warning message will be thrown and the image cannot be viewed.
The screenshot gets saved in the same path of the program.
Finally we need to crop the image with the help of location and size methods in Webdriver.
Every element has a unique location measured by the (x, y) co-ordinates. The location method gives two values – x and y coordinates.
Every element has a dimension defined by its height and width. These values are obtained by size method, which gives two values - height and width.
Now for cropping the image.
# to get the axes l = location['x']; t = location['y']; r = location['x']+size['width']; b = location['y']+size['height']; # to compute the cropped image dimension cropImage = Image.open('screenshot_t.png') cropImage = cropImage.crop(l, t, r, b)) cropImage.save('cropImage.png')
Code Implementation for capturing a section of a page.
from selenium import webdriver from PIL import Image from io import BytesIO logo to capture the screenshot s= driver.find_element_by_xpath("//img[@class='top-logo']") # to get the element location location = s.location # to get the dimension the element size = s.size #to save the screenshot of complete page p = driver.get_screenshot_as_png("logo_tutorialspoint.png") #to get the x axis l = location['x'] #to get the y axis t = location['y'] # to get the length the element b = location['y']+size['height'] # to get the width the element r = location['x']+size['width'] # to open the captured image with PIL imgOpen = Image.open(BytesIO(p)) # to crop the captured image to size of the logo imgLogo = imgLogo.crop(l, t, r, b) # to save the cropped image imgLogo.save("logo_tutorialspoint.png") #to close the browser driver.close() | https://www.tutorialspoint.com/how-to-get-the-screenshot-of-a-particular-section-of-the-page-like-the-logo-of-a-website-in-selenium-with-python | CC-MAIN-2021-39 | refinedweb | 428 | 58.58 |
Using Mapping-Lookups is a powerful tool to gather data within an integration scenario. But is it possible to perform Mapping-Lookups using ABAP Proxies?
Help content does not provide any information about it, so we gave it a shot. Within a B2B customer order scenario, we want to look up order details out of several SAP ERP clients using ABAP Proxies.
SAP Help content about Lookups…
Good news first, it is possible. You can use a SOAP channel with message protocol XI 3.0 (available since PI 7.11), within your java mapping. Details on how to program the java mapping can be found here.
The important part for Proxy-Lookups is these 2 LOC:
// 4. Set the operation name and namespace; optional step, // only necessary if the used adapter needs these parameters. accessor.setOperationName(“myInterfaceName”);
accessor.setOperationNamespace(“myInterfaceNS”);
These are needed to call the proxy, otherwise the XI header does not provide the information about the interface and operation to call, which is needed by the local integration engine.
During runtime, ABAP proxy lookup calls, can be identified within the local MONIS (SXMB_MONI) by sender component name “Mapping” and the receiver component name is the name of the system which the integrations calls later on. This is the receiver determined within the routing. Afaik, it is not possible to override these header informations. But imho, it’s nice to know, where the journey is going to, after the Lookup has been performed.
Thanks for sharing the information.
Hi Markus
It is also possible to perform SOAP lookup on the ABAP proxies via the Web Service Runtime of the ERP system.
On the consumer side, it can be achieve with a Java UDF as described by the following blog
SOAP Lookup from UDF
On the provider side, the ABAP proxy can be exposed as a web service via SOAMANAGER by creating a binding for it.
With this approach, you can use the SOAP channel with the default SOAP 1.1 protocol. It is also no longer necessary to set the operation name and namespace as this does not go through the local integration engine on the ERP system.
Hi Eng,
nice comment. But i still prefer the proxy solution. Using the web service runtime makes it more complicated and decreases the performance. Imho, it’s the preferred way for PI/PO consultants…
Hi Markus,
Just curious – do you have any article/documentation stating the performance of the web service runtime against the proxy runtime? Would be interesting to see how they stack against one another in order to make a better judgment when choosing such a solution in the future.
Rgds
Eng Swee | https://blogs.sap.com/2014/04/04/mapping-lookup-to-abap-proxy/ | CC-MAIN-2017-43 | refinedweb | 444 | 63.8 |
CFD Online Discussion Forums
(
)
-
CFD-Wiki
(
)
- -
book issue
(
)
zxaar
September 14, 2005 17:45
book issue
Currently we have one book related to CFD, there are few other possible topics like Combustion, multiphase flows etc. We shall also keep in mind to provide books related to them too, so that if some user wish to add to these topics, he or / she shall do it there and not in main CFD text book
Jonas Larsson
September 15, 2005 05:09
Re: book issue
I'm not really sure what you mean with "one book related to CFD", everything in the Wiki as it is now, belongs to the same namespace and is interlinked (or can be interlinked). A wiki is just a large number of independent articles which are interlinked. The structure is determined by how we link between articles. Links can always be changed and added later. The Wiki does not have a buildt-in tree structure. But we can of course create a tree-like structure by the links and the article/topic structure we build.
Perhaps we should have two new "trees" that - one for special topics, like the ones you mention ("Combusition", "Multi-Phase", ...) and one for special application areas ("Aerospace", "Automotive", "Turbomachinery", ...).
zxaar
September 15, 2005 17:30
Re: book issue
Yes this is what i meant, we have to create more tree roots or links at top level.
Jonas Larsson
September 16, 2005 05:54
Re: book issue
Okay, I have created two new links from the main page to "Application areas" and "Special topics". That will give new editors more "entry points" into the Wiki. I think one of the main problem with getting people to contribute is that they don't know where to start.
We should also think about using categories to inter-link and collect articles that have a common subject... I have for example made a couple of categories for "Dimensionless parameters" and "Famous persons" to give you an example for how categories can be used. Here are the links to them:
All times are GMT -4. The time now is
11:21
. | http://www.cfd-online.com/Forums/cfd-wiki/57058-book-issue-print.html | CC-MAIN-2016-36 | refinedweb | 354 | 67.99 |
I am currently working on the coin_flip function for the ‘Games of Chance’ project, I am curious about why I am getting a response of ‘none,’ in addition to what I expect…
def coin_flip(call, bet): print("Thank you for playing, you have bet " + str(bet) + ' dollars on ' + str(call) + '!') num = random.randint(1, 2) # If the coin flip is heads if num == 1 and call == "Heads": if call == "Heads": return print("You win " + str(bet) + ", You made the correct call, Heads") return print("Heads!") # If the coin flip is tails if num == 2 and call == "Tails": if call == "Tails": return print("You win " + str(bet) + ", You made the correct call, Tails") else: return print("Tails!") # If you lose the game else: print("I'm sorry, you lost " + str(bet) +" by betting on " + str(call)) print(coin_flip("Tails", 15)) print (money)
I’ve tried to work through and isolate what about the code is causing that to return, but I am stumped.
Thanks in advance for the help! | https://discuss.codecademy.com/t/coin-flip-help/449499 | CC-MAIN-2022-21 | refinedweb | 168 | 66.61 |
The Storage Team Blog about file services and storage features in Windows Server, Windows XP, Windows Vista and Windows 7.
This is a common topic in the DFS_FRS newsgroup. Customers will describe how some users are unexpectedly denied access to targets in the namespace whereas other users can access the targets without problems. Customers also ask whether there are DFS permissions somewhere that must be adjusted. The answer is that DFS clients will respect the combination of NTFS and share permissions set on the particular target the client is trying to access. Inconsistent access is often caused by the following configurations:
So if your users have unexpected access problems, check the share and NTFS permissions for all targets as described above. Also, when setting NTFS permissions, always use the path of the physical folder (\\servername\sharename) instead of navigating through the DFS namespace to set permissions. This is especially important when you have multiple folder targets for a given folder. Setting permissions on a folder by using its DFS path can cause the folder to inherit permissions from its parent folder in the namespace. In addition, if there are multiple folder targets, only one of them gets its permissions updated when you use the DFS path. KB article 842604 also covers this recommendation.
And finally, for any admins out there whose users are using Office 2000 against a domain-based namespace, I recently helped a newsgroup reader solve a problem that we thought was permissions-related due to the inconsistent access problems, but in fact the problem was something else entirely. See articles 272230 and 294687 for details.
--Jill | http://blogs.technet.com/b/filecab/archive/2006/08/09/444825.aspx | CC-MAIN-2013-20 | refinedweb | 269 | 50.67 |
Revision: 3.00
Date: October 1, 2001
By: Lofton Henderson
This document is intended as a permanent reference document and user manual for designers and contributers to the SVG Conformance Test Suite. It is the repository for currently agreed methods, templates, procedures, and techniques. This is the third public release of the document, and correlates with the public release of the completed BE test suite, subsequent to REC SVG publication. The first release (mid-2000) corresponded to an earlier public release of a subset (slightly over half) of the full BE suite. The second public release (early 2001) was a full BE suite, and corresponded to public CR draft of SVG.
Some parts of this document remain incomplete. In particular, the synopses of technical content of other conformance projects, in the chapter "Related Conformance Work", have not yet been detailed. In addition, some procedures and methods documented in the first public release have now been superseded or deprecated. potential differences include:
While the formality and rigor of a certification suite might not be needed, the SVG conformance suite will (eventually) embody "traceability" (see below) -- what specification in the standard justifies a given test?
The SVG WG agreed to two milestones:
At the time of release of this document, the BE suite is complete and the SVG 1.0 REC has been published. Some initial work has been done on DT tests, but it has not yet been integrated into the test suite structure, nor in this current (REC) test suite public release.
For those interested in a quick user guide for test construction, you can skip directly to "How to Write Tests". The rest of this document provides background, detailed explanation, and motivation for the methods used.
The material in Section 2, especially the brief synopsis of the nature and content of each existing suite, remains incomplete.
Section 3 is substantially complete.
The material in section 4 is complete for Static Rendering, but Dynamic has not been addressed. A couple of topics like overall test-suite linking structure are still incomplete (e.g., when substantial DT tests are generated and added) .
Section 5 -- How to Write Tests -- is substantially complete for Static Rendering "how-to", including incorporation of experience from a couple years' work on the BE test suite.
Section 6, Test Review Guidelines, is complete.
Section 7, Glossary, contains a useful subset of key terms used in this document..
Note. Since the initial release of this document (4/2000) to this release (10/2001), there has also been substantial test suite work on XSLT, XSL-FO, DOM Java binding, etc. These could be researched and include in a future version of this document section.
See [5] and [3].
The applicability of CGM test suite experience to at least the static rendering subset of SVG is obvious.
CGM and SVG differ in other ways:
Note. As of this date (10/2001), work is substantially complete and a public release is pending for a test suite for REC WebCGM..
Note. Current release (10/2001) is about 2,000 tests. Level of effort has surely increased significantly, by an amount tbd. (now finished), and a drill-down (DT) release subsequent to that.
A major natural division in the specification is:
Static rendering got first priority for development and release of BE tests, although work on dynamic proceeded in parallel, and followed closely on the static tests. Prioritization (if any) for future DT work is tbd.
Functionality will be ordered in the suite, for purposes of execution and navigation through the suite, from most basic to most complex -- implementations should encounter the simplest and most basic tests first, before being subjected to progressively more complex and advanced functionality. This mirrors the organization of the REC SVG document.
Given our intent to make progressive releases of test suite modules, it made sense to generally follow this ordering for the building of the materials, at least for the completion of the DT and ER tests.
The SVG WG agreed at Cupertino (11/1999) to divide up the functionality by chapter. For static rendering, the following chapters are addressed in BE testing:
Building and executing tests in chapter order does not appear to always lead to a basic-to-complex ordering.
From most basic (or fundamental -- basic does not necessarily mean simple), to most advanced, a rough functional ordering might be:
The issue of test suite ordering and organization was resolved for the completed BE suite -- chapter order. The issue is still open for future DT work.
The decision was implicitly made for the dynamic parts of the BE suite -- chapter order, first priority assigned equally to the tests in a breadth first set touching on each of the dynamic functionalities.
Each Test Case (TC) in the static rendering module contains three principle components:
The operator script comprises a few sentences describing what is being tested, what the results should be, verdict criteria for pass/fail, allowable deviations from the reference image, etc.
#1, #2, and #3 are file instances, one for each Test Case. #3 includes navigation information, and is the source for generating are generated for each test case:
Note. The traceability links were postponed until the SVG spec stabilized. Now that REC has been published, this should be added to the test suite..
See below, section [4.4.2] and [4.4.4], for futher details about the test harnesses.
Most of the SR materials are applicable to most dynamic tests. However, there may be cases (e.g., some DOM) which do not have graphical output, and there will be some which could (but need not necessarily) have animated graphical "reference images".
For the BE suite, the dynamic materials are the same as for static tests. This material may be further refined as more of the dynamic functionalities' tests are developed (looking forward to DT development).
Four generic test categories have been decided. These are equally applicable to static rendering and dynamic test modules:
Note. As of the date of this document (10/2001), only BE and DT tests have gotten any implementation attention. is necessarily a part of the process, and test purposes initially decided on a two-window approach, for standard release harnesses:
So in any case, a browser would have to be available for convenient viewing of all of the materials, but it is not necessary that a viewer-under-test be a browser plug-in.
Since the initial determination, additional harnesses have been added to the public release:
A strong naming convention for the materials is useful, both with the management of the test suite repository, as well as with requirement #2 above.
Test names aare primary test harness (static rendering, at least), is an HTML page which identifies the test, invokes the PNG reference image, and presents the operator script. The plug-in variant also presents the SVG beside the PNG.
Navigation buttons an early WG decision (11/1999) and subsequent discussions, the principal HTML harness presented the operator script and the PNG reference image, but did not assume a browser-invokable SVG viewer -- the test administrator had to get the SVG image into another window, or onto a printer, or whatever was appropriate. There was a companion SVG-only harness to assist this (with exactly parallel navigation capabilities to the PNG-plus-Operator Script harness.)
With the current method for producing harness(es) -- XSLT stylesheet applied to instances of a simple XML grammar which describes each test case -- it is not difficult to produce multiple harness versions, including variants such as PNG plus rendered SVG plus operator script, for browser-plugin SVG viewers. These have now been included in the public release.
The first generation design of simple XML grammar for describing tests, and the XSLT stylesheet for producing the HTML page, have been released. A "manual" SVG template has been released as well -- see next chapter for details.
Work was completed on a "second generation" of harness and template tools:
This evolved into a test suite editor's tool, for performing major upgrades that involve modifying the standard template in a uniform manner. Because so many exceptions arose, which had to get manual or special processing, this line of tools has been largely abandoned in favor of simpler generic methods -- 'sed' scripts and the like.
Originally planned for the second generation tools:
After some working group experience with the BE suite and processes, it was decided that this sort of "make" overhead was undesirable.
Each test , at least for the static rendering module, is put into a standard template. As just discussed, this was originally a manual process -- the test writer puts the test body content into the template, and sets the routine information items in the template. The second generation tools mentioned in the previous section relieved this requirement somewhat, as long as the content was written in the appropriate coordinate range, etc.
Features of the standard template include:
#1, #3, #5, and #7 are the most critical. The template-generating tools do carry these parts forward, and generate the other parts anew at each upgrade run. An initial TC submission which has these parts can be input to the tools, to generate a fully conformant SVG test case instance (the latter is a management process for the "test suite editor", whoever that is).. Originally this was a manual process. It has been replaced with the Revision keyword of CVS (the suite is now maintained in a CVS repository).
The overall linking structure is: TOC, WG tentatively decided the latter (the structure of the suite is not likely to be regular enough to make the former widely practical).
An index of all files would be a useful addition, in some future release of the test suite.
Processes and procedures still need to be designed, and a test suite editor assigned, for:
Previously, the test suite editor was the repository, and all of these items were ensured by the editor. The repository is now in CVS. An introduction to it can be found in the document "CVS Repository for SVG Test Suite" (presently only accessible to the WG). All WG members now interact directly with the CVS repository. Experience has shown that there are varying degrees of completeness, correctness, and integrity in the results with all-WG direct access.
Once a test case was submitted, it is "owned" by the repository. All WG and public releases are from the repository, and all maintenance changes to test cases must be applied to the latest repository version.
If the second generation tools (for automatic SVG template generation) had been made operational, adherence of test cases to the exact formatting (as opposed to functional) details of the template conventions could have been somewhat automated. However test contributors would have still had to adher to certain minimum requirements in structuring the initial contribution (see previous section, plus later sections about using the templates). And, as indicated earlier, there were too many exception cases in which the automated procedures couldn't be applied. for BE suite completion.
To be done: inventory what is available within the WG (for further DT development -- BE is done).
Note. The OASIS XSLT/Xpath conformance committee has pioneered and is now (10/2001) ready for public release of tools and procedures for accepting and integrating collections of externally authored test cases. These should be investigated for any future DT test suite construction..
Note. This potential source has never been exploited, but could be potentially useful for generating some DT tests.
Contributions from outside of the WG may some day be solicited. Miniminal processing for contributions should include:
There is only one way to assure, it should be possible to leverage methodology, or tests, or both, from such resources as the DOM test suite, [6]. CSS, [7], should be applicable as well (for future DT test generation).
This is meant to be a cookbook for writing the test cases for a functional module. Functional modules have generally corresponded: gradPatt,]).
See the next chapter, "Test Review Guidelines", for a concise summary of other details which you should pay attention to, when you design and write a test case.
Note.Traceability data currently are not integrated into the completed (REC SVG) BE suite. This will have to be done (as links into the SVG spec) in a future test suite release. sort of process, (pseudo-Xpointer) interpreter correctly handles of a simple XML grammar for describing tests, and the XSLT stylesheet for producing the HTML page, featured:
These were the extent of the "first generation" production tools. If you process the XML instances with CreateHTMLHarness.xslt (#2), you will get HTML pages which pull together and presents the PNG reference images, the operator scripts, and navigation buttons for the suite. Various batch commands have been supplied as well, to assist in making one or more of the harness types for one or a list of test cases.
Subsequent to the initial release of these tools, #2 - #4 have been rewritten, factored to improve maintainability, and augmented with another harness -- all-SVG which presents SVG and PNG side-by-side (but with no OS).
These tools are all in the CVS repository, in the tools subdirectory.
If you process the XML instances with CreateSVGHarness.xslt (#3), you will get a parallel set of SVG pages with SVG elements for navigation buttons, and inclusion by reference of the test case SVG instances themselves.
If you process the XML instances three times respectively through the three XSLT stylesheets of #4, you will get a set of three HTML files which generate frame-based pages. PNG is displayed side-by-side with SVG (the latter via a plugin), and the Operator Script is displayed below, in the bottom frame.
Initially I used only the XT tool of James Clark (get it from his Web site). You can use whatever tool you prefer, but a caveat -- different XSLT processor may give inconsistent results. Since the rewriting and revision of the stylesheets, and addition of the 4th harness (all-SVG), I use Apache/xalan for the two all-SVG harnesses (to avoid an anomoly involving appearance of unneeded namespace declarations).
A set of DOS batch command files exists, to facilitate generation of the harnesses. These are documented elsewhere (TBD).
A "manual" SVG template has been released as well.
The scheme has now been developed to the point that automatic generation of the SVG skeleton file, with some of the details filled in (see next section), is now possible. A set of advanced stylesheet tools was designed to do this from a slightly expanded XML grammar (featuring things like 'desc' strings, elements for author and creation date, etc). The final second-generation tools, however, stayed with the simple initial grammar and don't automate all of the required information. Therefore the static-output-template.svg is still the place to start if you are writing a new test case.
Starting with the static-output-template.svg and:
Note about #5: this is critical. All critical content should be inside of the "test-body-content" group. The second generation tools and maintenance processes rely on it --most of the stuff outside of this group is automatically generated, and it wouldd be lost if you put anything important there (the 'desc', and comment preamble will be preserved). Though these (2nd gen) tools are not in production, it would be wise to keep the option open.
Note about #2. That the test should be self-documenting implies that the picture should have a <text> element equivalent to the <desc> (across the very top is a good location, in most cases). (now superseded with CVS's Revision keyword).
See the next chapter, "Test Review Guidelines", for a concise summary of other details which you should pay attention to, when you design and write a test case.
The key feature of the XML instance is the Operator Script. Note when you fill in your XML instance, you will also define the name (per convention documented herein), and navigation links. The latter define the next and previous TCs in the sequence for link navigation through the suite.
Be sure that your TC's XML instance links correctly to its TC neighbors, and vice-versa! This is probably the most common mistake amongst contributors -- failure to adjust the links of neighbors when a new test case is added (or a test case is removed). (This is sufficiently annoying that an automated verification or even correction tool is on "the queue", for some future development.)).
Note. The following describes first-generation methods for getting the PNG reference images. New tools are available from several sources, e.g., Adobe, CSIRO, and the Apache/batik project, which allowed direct generation of correct PNG files for all test cases in the second public release, i.e., the complete BE suite.. Sometimes, especially in the early days of viewer implementation development, this is not possible -- no SVG viewer handles wasulated,.
Three.
Avoidance of color artifacts is not yet completely understood. However, be aware that color management systems on your computer may lead to incorrect colors in the PNG reference image. One commonly seen example is a faint pink tinge to areas that should be white. These color management artifacts can sometimes be detected by using tools in raster editors (such as Adobe ImageReady 2.0, Corel Photopaint, Macromedia Fireworks.). Previously, the serial number was manually maintained and updated, which proved to be something of an annoyance. Nevertheless, the version control benefits warranted the inconvenience. Originally, the serial number was identical to a version number -- 1, 2, 3, ... Its maintenance was solely the responsibility of the test suite editor, which somewhat alleviated the error-prone manual aspects.
Now, the serial number text string (in the Legend of test cases and templates) has been replaced with the Revision keyword of the CVS system. Every 'commit' of a changed SVG file, no matter how trivial the change, automatically updates the serial number. It is identical to the revision number in CVS.
Note: a very few .SVG files need to be treated as binary instead of text (e.g., ones with wide range UTF-16 character codes). Presently (10/2001), there are only two such test cases (still true?). Keyword substitution is suppressed for these. Therefore the serial number must be manually typed into the Legend after the rest of the test case production, and should match the current CVS revision number.:
In addition, evaluate the correctness of the navigation links:
Evaluate at least these criteria for the PNG reference image:.
See Test Requirement.
See Test Requirement.. | http://www.w3.org/Graphics/SVG/Test/svgTest-manual.htm | CC-MAIN-2018-13 | refinedweb | 3,095 | 52.9 |
-01-2016 06:35 AM
Hello,
I am trying to use the async and wait #pragmas but the SDSOC 2016.1 tool reports that async cannot be used with non-void return function call.
So I removed the returns from the function call since I did not really need them.
But now the tool says that one of ports being used in the function is axi_mm master and it needs a return parameter or at least and output scalar argument.
I tried to add a dummy output scalar to the function but the message remains.
The examples available from Xilinx so how to use the return which I cannot use to be able to use async/wait so I wonder if anyone has an example of how to use the output scalar instead of return.
Thanks,
08-01-2016 10:16 AM - edited 08-01-2016 10:16 AM
Hi eejlny,
I have tested the following code in both 2016.1 and 2016.2 SDSoC and it runs correctly on the ZC702 board (with add() function marked for hardware):
#include <stdio.h> #include "sds_lib.h" #pragma SDS data zero_copy(a); void add(int *a, int b, int &c) { c = *a + b; } int main() { int *a, b=2, c=0; a = (int*)sds_alloc(sizeof(int)); *a = 3; #pragma SDS async(0) add(a,b,c); #pragma SDS wait(0) printf("results is: %d\n\r",c); sds_free(a); return 0; }
If you continue to have problems, please post some code snippets relevant to your problems.
Sam
08-03-2016 01:49 AM
Thanks for the example. It works now.
I was not passing the scalar as a reference correctly but now I can use async with the void return.
Best Regards | https://forums.xilinx.com/t5/SDSoC-Environment-and-reVISION/async-and-non-void-return-function/td-p/712917 | CC-MAIN-2019-30 | refinedweb | 290 | 78.38 |
If you have a large and complicated solution with hundreds of projects, you probably need a way to see dependencies within the solution. You can use this information to improve the architecture of your application.
ReSharper provides two search features with related functionality:
- Find Code Dependent on Module lets you find all code symbols from the selected project or assembly reference that are used in the current project.
- Find Symbols External to Scope lets you find any outgoing references encountered within a certain scope which can be as narrow as a method or as large as a project.
- In Solution Explorer window, select a project or assembly reference.
- Do one of the following:
- On the main menu, choose ReSharper | Find | Find Code Dependent on Module.
- Right-click the selected item, then click Find Code Dependent on Module on the context menu.
You can investigate dependencies step by step or you can use the Optimize Reference feature to see all dependencies for all references at once. For more information, see Optimizing References.
- Select a file, folder or project.
- Do one of the following:
- On the main menu, choose ReSharper | Find | Find Symbols External to Scope.
- Right-click the selected item, then click Find Symbols External to Scope on the context menu.
- Place the caret at a container such as method, class, namespace, etc.
- Press Ctrl+Shift+GAlt+~ to display the Navigate to drop-down list.
- In the Navigate to drop-down list, click Referenced Code.
Search results for both features are displayed in the Find Results
window.
If a single usage is found, the caret moves to the corresponding location.
See Also
Procedures:
Reference: | http://www.jetbrains.com/resharper/webhelp/Navigation_and_Search__Finding_Usages__Finding_Dependencies_and_Referenced_Code.html | CC-MAIN-2014-49 | refinedweb | 273 | 56.45 |
The PCA9536 is an 8-pin CMOS device that provides 4 bits of General Purpose parallel Input/Output (GPIO) expansion for I2C-bus/SMBus applications. It consists of a 4-bit Configuration register to serve the purpose of input or output selection, 4-bit Input Port register, 4-bit Output Port register and a 4-bit Polarity Inversion register active HIGH or active LOW operation. Here is its demonstration with the raspberry pi using python code.
Step 1: What You Need..!!
1. Raspberry Pi
2. PCA9536 PCA9536 sensor and the other end to the I2C shield.
Also connect the Ethernet cable to the pi or you can use a WiFi module.
Connections are shown in the picture above.
Step 3: Code:
The python code for PCA9536 can be downloaded from our github repository- ControlEverythingCommunity
Here is the link for the same :...
The datasheet of PCA9536.
# PCA9536
# This code is designed to work with the PCA9536_I2CIO I2C Mini Module available from ControlEverything.com.
#...
import smbus
import time
# Get I2C bus
bus = smbus.SMBus(1)
# PCA9536 address, 0x41(65)
# Select configuration register, 0x03(03)
# 0xFF(255) All pins configured as inputs
bus.write_byte_data(0x41, 0x03, 0xFF)
# Output to screen
print "All Pins State are HIGH"
time.sleep(0.5)
# PCA9536 address, 0x41(65)
# Read data back from 0x00(00), 1 byte
data = bus.read_byte_data(0x41, 0x00)
# Convert the data to 4-bits
data = (data & 0x0F)
for i in range(0, 4) :
if (data & (2 ** i)) == 0 :
print "I/O Pin %d State is LOW" %i
else :
print "I/O Pin %d State is HIGH" %i
time.sleep(0.5)
Step 4: Applications:
PCA9536 can be employed as an I/O expander. It provides a simple solution when additional input/output is required. Usually it is employed in systems which require expansion for ACPI power switches, sensors, push buttons, LEDs, fans, etc.
Discussions | https://www.instructables.com/id/Raspberry-Pi-PCA9536-Inputoutput-Expander-Python-T/ | CC-MAIN-2019-18 | refinedweb | 310 | 65.12 |
Details
- Type:
Bug
- Status: Closed
- Priority:
Major
- Resolution: Fixed
- Affects Version/s: Nightly Builds
-
- Labels:None
- Environment:
Operating System: Windows XP
Platform: PC
Description
The parse() method returns a previously calculated root variable even after a
clear() operation.
Activity
Created an attachment (id=11780)
A patch file that fixes the bug.
The Digester class currently maintains a reference to the root object on the
stack via a member variable named "root." However, it doesn't properly keep
this in sync upon a clear() operation (see attached, simplified test case).
IMHO, the variable should be removed completely. You're (or I guess we're in
the open source world) just asking for problems when trying to keep these
values in sync. The patch (also attached) completely removes the root
variable and re-implements the getRoot() method to use the stack API to
reference the root element (peek using size - 1) instead. In order to remove
the variable, I had to modify the SetRootRule class also as it directly
referenced the root variable (bad idea). I changed it to use the getRoot()
method instead. I also added some checks in the test case
DigesterTestCase.testStackMethods() to exercise the code that I modified and
to illustrate the bug that was there.
Hi James,
After looking at the clear method, I'm not sure what the original intention of
the method was. It may be that it was never intended to be a public method at
all. I will ask on the email lists and see if anyone knows; digester arrived in
commons from the Tomcat project with this method already present and declared
public.
It may be possible to perform repeated parses with the same Digester object
under some circumstances, but I wouldn't bet on it. If this is what you are
trying to achieve, I suggest you change your code to create a new Digester
object for each input document instead.
The root variable can't just be reset to null from within the clear method,
because clear() is called automatically at the end of the parse() method. This
leads me to think that maybe it is just intended to free up any memory and is
not meant to be used directly [ie shouldn't be public]. And while it could be
reset from the start of the parse method, there are heaps of other variables
that would also need to be reset in order to safely perform a second parse with
the same Digester object, eg namespaces and matches.
I have therefore added a javadoc comment to the clear method saying it shouldn't
be used. I think it might even be a good idea to deprecate it so it can be
removed in the release-after-next.
I don't believe your proposed patch for removing the root member entirely will
work correctly, unfortunately. The digester's parse method can be called without
any object present on the stack at start. In this case, the digester stack is
empty when the parse method returns. Your new getRoot method will therefore fail
to return the "first created object". See the "Catalog" example in CVS for an
app that would fail with this patch.
I'd like to leave this bug open as a reminder to think about the clear method a
bit more before the next release.
James, please add any comments you have to this bug entry.
And by the way, the attached patch file is all screwed up, due to windows/unix
line feed differences....
My implementation of the getRoot() method takes the empty stack into account.
Here's the method...
public Object getRoot(){ return stack.isEmpty() ? null : stack.peek( stack.size() - 1 ); }
Why would we deprecate the clear() method rather than make it work properly if
we can? The intention of the getRoot() method is to return the first object
on the stack or null if the stack is empty, right? That's what it does, now.
I don't see the harm in removing the root variable and replacing the
references with a call to getRoot() instead (which is what I did). I would
strongly suggest you add this patch regardless of what you do to the clear()
method. This implementation is far less prone for errors.
Re-using a Digester is desirable because it can take quite some time to set up
a Digester object for parsing. The desire to re-use a Digester object came
from a post on the user list (-
user@jakarta.apache.org/msg06397.html).
BTW, your implementation of testGetRoot() causes an error because the
ObjectCreateRule automatically calls pop() during the end() method, so there
will be nothing on the stack.
Ahhhh. I see what you mean about the "first object created" stuff. The
Catalog example would fail. However, the documentation isn't really clear on
how the stack is supposed to work. The idea that the first thing created by
the rules will be returned isn't exactly obvious. In my mind, I don't imagine
anything to be on the stack at the end of parsing unless I push something on
there to begin with, using most of the default rules. So, when I use
Digester, I usually push my "root" object onto the stack prior to parsing. I
didn't realize that the first object pushed onto the stack is what's supposed
to be returned from parse(). That's not clear from the documentation. Or,
maybe that was just my misunderstanding. I don't really like that little
twist, though. It doesn't seem as clean, if you ask me. But, there's a LOT
of code out there using it the way it is now, so we'd better not break it.
And, you're right, my implementation WILL break a LOT of stuff. Oops!
i'm happy that clear does what it should do: it cleans the stacks. i'd probably favour a separate reset()
method rather than breaking the contact for clear().
it is possible (in some cases) for a single digester instance to parse multiple input documents in
sequence. it's just that the typical use case is to create a new digester instance in each case and so
multiple sequential usage has never really been supported.
in terms of, i'm a
little sceptical about the performance of pooled digester instances verses creating new instances each
time (at least in modern JVMs). depending on the level of concurrency and the number of digester rules,
the cost of the synchronization required by the pool may outweigh the construction cost. i would be
interested to see some actual timings.
anyway, i suspect that it'd be possible to add a reset method that would work for most rulesets (those
that clean up after themselves in finish). i'd prefer for any implementation to wait until after the 1.6.0
release branch is taken.
Robert
Re the purpose of the "getRoot" method: Stacks don't have roots. Trees have
roots. Digester's main purpose is to parse xml and generate a corresponding tree
of java objects. And the getRoot method returns the object which is the root of
the generated tree. Now that object might have been pushed onto the stack
before parsing began (in which case it will still be on the stack when parsing
finishes), or it may have been created by the first ObjectCreateRule to fire (in
which case it will not be on the stack when parsing finishes).
I guess this could be better explained; I will think about adding some javadoc
to the getRoot method.
Robert: I still am not sure that a user of Digester would ever have a reason to
call clear, nor that there is a reason a Rule class would ever want to. The only
reason I can see for this method to have ever existed is to provide "reset-like"
behaviour. But it doesn't, and that behaviour is rather nasty to provide
correctly [as I found out when I tried]. Can you suggest any situation in which
calling clear would have a useful effect other than as preparation for calling
parse a second time?
I think that "pooling" digester instances is a really bad idea. And not
necessary; if a "poolable" RuleSet is created to hold a reusable set of rules,
and a "poolable" parser object is created, then the Digester object itself is
pretty light-weight to create and configure for each document parsed.
Maybe what is needed is a way to "compile" or preprocess a set of rules. I
don't think the curren RuleSet provides that type of functionality, but that's
really what takes so long is the rule construction for a digester. If the
rules could be "plugged in" to a Digester and then have it parse something
that would eliminate the need for the Digester to be pooled.
Hmm..RuleSetBase is abstract. I'm surprised that there isn't a concrete
implementation of it, except in the xmlrules package.
But it should also be safe to create a Rules object, and add the rules to it.
You should be able to then reuse this Rules object in multiple different
Digester objects.
eg
Rules myRules = new RulesBase();
myRules.addRule("foo/bar", new ObjectCreateRule(String.class));
Then
digester = new Digester();
digester.setRules(myRules);
The RulesBase class doesn't have any state that changes during a parse as far as
I can see (unlike the Digester class). So there's no need to "reset" it between
parses. And this is likely to hold true for all the Rules implementations, I think.
I suspect that creating the xml parser object will also be moderately costly, so
suggest that is created once and passed to the Digester (or even more cleanly
have the Digester instance set as the parser's content handler).
I'm not so worried about the Rules implementations themselves having any
state. I'm more concerned with the individual Rule objects INSIDE the Rules
object. I would imagine that a lot of Rule implementations are NOT thread-
safe, so we would not be able to use a single Rules instance containing
multiple Rule instances across threads. Correct?
None of the Digester classes are "thread-safe" in the sense of being able to be
used concurrently by multiple threads. This is already documented.
But I expect that almost all Rule classes are "poolable", in the sense that they
can be reused without their behaviour being affected by what happened the last
time they were used. Because Rule objects are permitted (and expected) to be
invoked recursively, they normally cannot keep any kind of context information
using their own member variables; those that do are almost certainly broken in
other ways.
I had a quick peek at the standard Rule classes:
- FactoryCreateRule may have problems when the ignoreCreateRule option is used
[but that's pretty rare]. This could be fixed by modifying it to use the new
"named stacks" feature of the Digester - and should be; it probably fails when
invoked recursively.
- NodeCreateRule may have problems if the previous parse terminated with an
error because it doesn't reset the depth member on begin().
These are pretty unusual "corner cases". I couldn't see any other issues with
reusing instances of the standard Rule classes [NB: my opinion only].
And I expect these problem cases will occur only when a parse fails, so simply
ensuring that on parse failure the Rules object is removed from the pool and
replaced by a new one should resolve these.
On the use of clear()...
I'm not sure that clear() is very useful but it's there in the API and i see no reason to deprecate it or to
patch it since is works pretty much as advertised. I'd much prefer a new reset() method which could do
other things (such as nulling the root)
On pooling Digester instances...
I'm not against pooling Digester instances but I am a little sceptical about the performance gains in
most common use cases. It isn't an itch of mine. So, i'm unlikely to actively work towards being able to
safely pool Digester though i wouldn't object to backwards compatible changes to assist pooling.
On reusing Rule instances...
In general, people can create Rule implementations that cannot be used safely more than once. But I
agree with Simon's analysis that most of the common Rule implementation can be reused safely.
On compilation...
This would be very cool but a lot of work. Not an itch for me.
Hello,
I've recently made some changes to digester to make it thread safe for a
project here at ebay. We use digester for a long running batch like process
where pooling wasn't really an optimal solution for us as the parse times are
quite long (of the number of rules we have - hence filling up the pool when
there is a large spike might be problematic) and the volume is uneven, peaking
fairly high with a restrictive SLA for the system.
I've written some unit tests (still need to write more) for the changes and am
currently looking for optimization and clean up opportunities. Would a patch
be of any interest to anyone?
I will also send this message in an email to the commons-dev mail list.
Thanks.
-Eric Lucas
Hi Eric,
I'm definitely interested in viewing your patches to make digester
"thread-safe". If you could get permission to attach these to this bug entry, it
would be appreciated.
NB: Please ensure you have appropriate permission from your employer before
posting any code. If commons dev does like the changes, we may need to get some
official release before incorporating the code; I guess we can deal with that if
there is interest in merging your changes.
Re James Carman's proposal:
I've added a resetRoot() method to the Digester class which makes it possible
to reset this variable before parsing a second document using the same Digester
instance. This does not mean that using a Digester instance in this way is
supported, and this is noted in the javadoc.
Re Eric Lucas' proposal:
As there has been no followup to this since 17 June I think it reasonable to
consider this dead.
(Fixing JIRA import error)
Created an attachment (id=11779)
A test case that illustrates the bug. | https://issues.apache.org/jira/browse/DIGESTER-48 | CC-MAIN-2014-23 | refinedweb | 2,402 | 69.92 |
.
I will be speaking about remote pair programming at the Pivotal NYC office on 08/2012 at 12:45. Please join us or join the []()
August 2, 2012 at 6:42 am
I solved the copy/paste from `tmux` sessions over `SSH` by using X as a transport, and the [`xsel`]() command to put the `tmux` buffer into the X clipboard.
Please note that you need `X11Forwarding on` in your `~/.ssh/config` file, X11 open on your Mac, Pasteboard Syncing enabled in the X11.app preferences and the following shortcut into your `~/.tmux.conf`:
# Copy into the X clipboard
bind-key C-c run ‘tmux show-buffer | xsel -pbi’
After you select text in the tmux window, it is automatically copied in the tmux buffer, then when you’ll hit `C-b C-c` it gets copied in the X buffer by xsel, that gets forwarded over `SSH` to X11 on your mac, and synched in your OSX Pasteboard by X11.app.
The same can be accomplished in Vim, thanks to [this tip](), that boils down to these lines in your `~/.vimrc`:
“Copy and paste from X clipboard -
,
w !xsel -i -b
com -range Cz :silent :
ca cz Cz
Then you select in visual mode in Vim, hit `:cz` and the code goes through the same SSH/X11 pipe as described above :-).
This is mostly useful when you use vertical split panes, and when you don’t want to copy Vim generated source line numbers :-).
July 18, 2012 at 3:12 am
Marcello — Thanks! We’ll set that up and try it out.
July 18, 2012 at 6:00 am
Mental note: Never work at PivotalLabs.
July 18, 2012 at 7:04 am
Hello,
Thanks for great article. Unfortunately topic was not covered, hope to get more information how to setup tmux for remote programming in next article.
July 18, 2012 at 9:19 am
Checkout vimux for even more awesomeness between vim and tmux ()
July 18, 2012 at 10:50 am
In case you didn’t know, you don’t have to explicitly enter scroll mode. `ctrl+b, PageUp` (or `PageDown`) enters scroll mode and scrolls in that direction. E.g. `Enter` or `ctrl+c` exits scroll mode.
The opt+select trick is neat. I’ve had mouse mode off because of the selection issue, but maybe I’ll try turning it on again. Though most of the time I copy within Vim using Vim, which of course stays within the current tmux pane. I use [reattach-to-user-namespace]() to map the tmux clipboard to the OS X clipboard, then use `,y` and `,p` [like so]().
July 18, 2012 at 10:58 am
Oh, and I [blogged about Vimux]()) (that Evan Light mentioned) just the other day. If you use Vim in tmux, it’s very nice for running tests and other things.
July 18, 2012 at 11:01 am
Henrik — Thank you! We’ll definitely check out your links, especially Vimux.
July 18, 2012 at 1:25 pm
Are you really using the default ctrl-b?
I have mapped caps-lock to ctrl, and ctrl-a as the tmux prefix, as I’m sure many others have.
It makes it very easy to type tmux commands, because you can just use a single gesture; hit caps-lock and ‘a’ at the same time with the appropriate fingers “locked” together.
On a different level, facilities like panes and tabs should really be provided at the OS window-manager level. This would give a consistent set of commands for navigating and manipulating panes and tabs across apps, and even allow you to break-out panes into tabs or seperate windows, and vice-versa, at the window manager level.
It’s a sign that the OS window managers aren’t good enough when each application has to implement the functionality within itself, leading to multiple incompatible layers.
July 18, 2012 at 5:12 pm
Hi everyone. Our tmux-vim automatic saving Vim plugin is available here: [](). We’ve also integrated it into our vim-config configuration here: []().
July 18, 2012 at 5:26 pm
This is what I use for autosave (.vimrc):
” Autosave
set updatetime=1000
autocmd BufLeave * update
autocmd CursorHold * update
autocmd InsertLeave * update
July 19, 2012 at 7:02 am
I’m ViMUXing right now as we speak.
#FTW ;-)
July 19, 2012 at 5:13 pm
#SeeWhatIJustDid? July 19, 2012 at 5:15 pm
Snuggs!
July 20, 2012 at 5:25 am
Ivan — We have that, also, and it works great in MacVim, but do those setting trigger an autowrite when jumping from a Vim pane to another tmux pane? It doen’t for us. If it works for you maybe you could your .vimrc?
July 20, 2012 at 5:28 am
There is a [lively discussion on Hacker News]() about this post in addition to the comments below.
July 20, 2012 at 7:11 am
You can also prevent tmux from using the alternate scrollback, therefore allowing you to use the native OS X scrolling in Terminal (inc. via mouse wheel) without needing to enter scroll mode.
set -g terminal-overrides ‘xterm-256color:smcup@:rmcup@’
Also, to prevent the terminal from resizing when the other client is NOT active (i.e. keeping your terminal as large as you prefer, more often):
setw -g aggressive-resize on
July 20, 2012 at 8:51 am
I use [reattach-to-user-namespace]() plus `pbcopy` to get the tmux buffer onto the OSX clipboard.
bind y run-shell “reattach-to-user-namespace -l /bin/zsh -c ‘tmux show-buffer | pbcopy’”
It doesn’t solve the remote problem, but it works well locally.
You can also hit `v` while in tmux copy-mode to get visual block highlighting, ala using `C-v` in vim.
July 21, 2012 at 7:32 am
Here’s link to the image of the tmux highlighting since the one in my comment above didn’t seem to work.
[tmux visual block mode]()
July 21, 2012 at 7:38 am | http://pivotallabs.com/how-we-use-tmux-for-remote-pair-programming-/?tag=sf-tug | CC-MAIN-2014-10 | refinedweb | 1,002 | 70.13 |
i want rpogramming code for --> acceptive value from user and find out square of the no. in c++
i want help in programming coding in c++
@rohya, what do you mean by “acceptive”?
i think you want to accept a number from user and print square of that number isn’t it? What difficulty are you facing? please elaborate so that you get better help
But for now here’s the c++ code:
#include<iostream> using namespace std; int main() { int a; cout<<"enter the number"; cin>>a; int square= a*a; cout<< "The square is: " << square; return 0; }
this code will work in software borland c++?
and yes it’s accept not acceptive… typing error.
please just let me know is this code will work in software borland c++?
Ok, so since you asked i just installed Borland c++(version 3.1) for the first time.
important points to be noted:
- In Borland while using header files you must use .h extension. while, coding for online environments like codehcef or spoj never use .h extensions.
- You can not use "using namespace std" in Borland( I think)
and here is your answer, working code for finding square in borland with ouput:
![alt text][1]
Hope this helps!
thank you so much bro…
will you be help me out with this
question is : Accept number from user and find out cube of the number.
this also i want to be run in borland … plz try if you can…
In the above code:
Replace:
int square= a * a;
with:
int cube= a * a * a;
everything else remains the same.
ya image one only used in borland but showing thi error
#include<iostream> void main() { int a; cout<<"enter the number"<<end1; cin>>a; int cube; cube=a*a*a; cout<<"The cube of the number is: " << cube; }
output:
Line 2: error: ‘::main’ must return ‘int’
@rohya well, now you can follow the code in the image. i’m sure it wont be difficult to make out that cube of number = aaa so you just need to add multiply the square one more time with “a” and you have the cube! | https://discuss.codechef.com/t/i-want-help-in-programming-coding-in-c/2488 | CC-MAIN-2019-18 | refinedweb | 358 | 76.66 |
The Delivery Barrier
Introduction.
The Obvious: “No. Nonononono.”
Okay, that’s not a serious alternative. You could, if you were so inclined, manually copy your solution over to each and every customer system. Don’t. Even. Think. About. It.
The Automated Obvious: “No.”:
- It’s free, which is always good, right?
- It’s comparatively easy to learn – no complex concepts, just export to XML and reimport. Anyone can learn that fast.
- It’s extensible – if it doesn’t support what you need, just add the missing pieces yourself.
However, when using it as a delivery tool, there are some serious issues.
- It is most definitely not supported by SAP. Some of the import/export implementations available might not even use supported APIs to extract and insert development objects – probably because there are none. While this might not be huge deal for in-house use of SAPlink, the situation changes when you’re an external solution provider. You’ll be providing components for mission-critical enterprise systems – better make sure you’re covered when it comes to maintenance issues.
- There are virtually no integrity checks during either the export or the import process. A lot of things can go wrong when packaging software, and SAPlink is simply not designed to handle any of these issues.
- There is no support for object deletion. This happens frequently in product maintenance – you no longer need a class, so you delete it. SAPlink might be able to deliver the class, but it can’t deliver the deletion.
- There’s no dependency resolution during import. Imagine a class that uses a structure that contains a data element that in turn refers to an interface. You might need to import some of these objects in the right order because it largely depends on the object type import/export plugin whether you can import inactive objects that refer to other objects that don’t yet exist. Sometimes you can’t, and then you have to keep tabs on the dependencies manually. Not cool.
- Speaking of the plugins, the support for certain objects heavily relies on the plugins working correctly. Since the plugins come from a handful of loosely connected volunteers, they will naturally vary in quality, so YMMV.
- One of the most important points might be that on the target side, SAPlink actually does little less than automate the object creation. You can create a class using SAPlink just like you could manually – and vice versa, you can’t (legally, and most of the time technically as well) create a class that you couldn’t create manually as well. That means that you have to develop and deliver your solution in a namespace that is fully writeable by your prospective customer. Either you use Y or Z and risk conflicts with existing customer objects (besides demonstrating that you probably shouldn’t be delivering a product just yet), or you give the customer full access (production key) to a registered namespace, essentially rendering its protective character useless. Welcome to maintenance hell – oh and don’t forget that some of the object type plugins don’t (yet) support objects in registered namespaces.
Compared to the Copy&Paste approach, SAPlink certainly is a huge step – but for professional software delivery, a huge step in an entirely wrong direction.
The Slightly Less Obvious: “Not A Good Idea.” anumber of advantages:
- It is supported by SAP. Perhaps not exactly for the use case of delivering software to customers, but it is somehow covered by the standard maintenance.
- Not only is it officially supported, but it is also widely tested, and it is guaranteed to be implemented in every system landscape you might want to deliver software to – simply because everyone needs it.
- There is support for all relevant object types – obviously, since you need that capability within a customer system landscape anyway.
- It does a really great job of handling stuff like import-level ordering, inactive import and mass activation and import post-processing. There is a huge amount of complexity involved that is cleverly hidden underneath a tool that every ABAP developer uses without even thinking about it. I’d highly recommend the course ADM325 to every ABAP developer to get a deeper knowledge about the inner workings of the system.:
- Transport identifiers are generated automatically using the system ID (SID) of the exporting system (<sid>K9<nnnnn>). Not considering some special values, there is no telling what SIDs you might encounter in a customer system landscape. If the SID of your delivery system exists in a target landscape, transport identifiers will collide sooner or later, with very unpleasant effects. That means trouble, and there is no easy way to solve this.
- Only an extremely limited consistency checking is performed before exporting a transport. Basically, if it’s a valid and mostly consistent object, you can export it. That includes Z-Objects, Test stubs, Modifications and a few other things that might easily slip into delivery transport unnoticed. You can implement checks for this using CTS extension points, but you have to be aware of the danger and prepare for it.
- There is no support for modification adjustments, no SPAU/SPDD upgrade assistance. Your customer can modify your delivered objects (provided that you supply the modification key of the namespace, which you should), but then what? With the next delivery of that object, the customer has to backup his modifications (manually), have your transport overwrite it and re-implement the modifications (again, manually).
- There is no integrated dependency management. The CTS/TMS is supposed to be used in a system landscape that has a homogeneous arrangement of software versions, so whatever you can safely export from the development box, you’ll probably can import safely into the other boxes, right. If the transport originates from a system where HR happens to be installed and maybe you used some HR data elements or function modules just because they seemed convenient, you can export the transport easily. If the customer doesn’t have HR installed, you won’t land on the moon today – and you have no way of ensuring this beforehand, you’ll just notice during the import. The same pattern applies if you want to supply multiple add-ons that rely on each other – you can’t ensure that your customer will import these in the right order and only using matching versions.
- Speaking of versions – there is no version management to speak of, you’ll have to store the version number and patch level manually if you want to and build your own display function. Not a big deal, but cumbersome none the less.
- The import order of individual transports is not governed in any way. This not only affects dependencies (as discussed above), it also allows for mishaps like partial downgrades, import of patches in the wrong order and numerous other issues that will keep your support staff unnecessarily busy. Even worse, unintended downgrading of database tables might lead to data loss.
- One rather subtle problem lies hidden in the area of object deletion and skipped transports. With CTS/TMS transports, it’s easily possible to export a deletion record for an object that will cause the object to be deleted in the target system as well. Let’s assume you export that deletion record with version 5. The customer decides (consciously or by accident) to skip version 5 and upgrade directly from 4 to 6. In that case, the deletion record is not imported and the object stays in the system. In most cases, that won’t be a problem, but if you think of class hierarchies, interface implementations and other heavily interconnected objects, you might end up with leftovers of the unpleasant sort. This isn’t easy to solve, either: It’s not trivially possible to add a deletion record to the transport of version 6 because the TADIR entry of the object was deleted when exporting version 5, and you can’t add the deleted object to the transport of version 6 without creating the TADIR entry first. It’s possible, but not trivial – BTDT.
- There’s a procedural trapdoor that might lead to unexpected results as well. Since you’re essentially using the normal change management software logistics system of the customer system landscape, your software upgrades might be imported by the TMS along with regular in-landscape transports (that they technically are!) inadvertently. If that happens at the wrong time – especially when importing into the production system – bad things might occur. Avoid if possible.
- As a last hidden obstacle: There’s no support for a clean upgrade path between releases. Your software will inevitably use some components of the NetWeaver Basis, ECC, CRM or any other SAP product – I’ll simply call this “the foundation” from now on. For different releases of the foundation your product relies upon, you will frequently have to deliver slightly different product versions. This means that during a major upgrade, objects may have to be deleted while others might have to be added or changed. You have to figure out a way to support this manually – there’s nothing in the CTS/TMS that will help you with.
Pricey Professional Product Preparation:
- Supported by SAP, used by SAP. What better reference could you wish for?
- There’s extensive documentation available – online reference, 130 pages PDF, even SAP Tutor introductory videos when I last had the chance to use it. In addition, you’ll be assigned a personal contact, and at least for the people I’ve had the pleasure to work with, their competence and professionalism leaves nothing to be desired.
- The import tools, namely transactions SAINT and SPAM, are known to most basis admins. In contrast to the common TMS transport operations, they are designed for imports of large software packages and deal with all kinds of issues.
- If you ever wondered where the strange software component names come from – with the AAK, you get your shot at creating your own software component. The name of the software component is based on a registered namespace and therefore guaranteed to be unique; the delivery object lists contain the software component identifier and are therefore unique as well. The final EPS delivery files contain the system ID and installation number, which in this combination are unique as well (at least unique enough for all intents and purposes). Collisions with customer system IDs are thus avoided.
- There are extensive consistency checks during the packaging and export process that can even be extended by customer checks. For instance, as an i.s.h.med developer, you may want to stop some generated function groups from being delivered because they need to be generated on the customer system. Writing a custom check for this is rather straightforward.
- As the import uses the well-known SAINT/SPAM route, you’ll get full SPDD/SPAU modification support, including modification adjustment transports that can be used to automatically adjust the modifications on QA and production systems.
- There’s an integrated dependency management system that allows you to specify which software components have to be present or may not be present in which versions. These dependencies are checked early during the import process – if a dependency is not met, the entire import won’t happen.
- The AAK provides support for various upgrade or cross-grade scenarios, including release upgrades. You can build special Add-On Exchange Upgrade packages that allow you to cleanly remove objects that are no longer required in the new release and import whatever new objects are needed. This is fully integrated into the upgrade process itself.
- Hardly worth mentioning, but of course there is full support for deleting objects. With the rather recently released version 5.0, there’s even support for deletable add-ons.
- Compared with transports, a lot of additional checks take place during the installation process, including version checks (e. g. a downgrade protection) and collision checks with other application components.
- Since an entirely different set of tools is used for import, AAK Add-Ons can’t be mixed up with regular transports.
- Aside from regular versions (“Releases”), the AAK provides support for patches. The patch import process enforces the correct order of patches, thus ensuring a consistent software state on the customer system.
- Your software will be listed in the component version list via System > Status, which is something that every software developer should aspire.
- Finally, the certification process will get you a check by SAP and a certification logo, as well as a listing in the partner directory..
- The certification isn’t exactly cheap. One of the articles mentioned above has the figures – 15k€ for the first year and 10k€ for every subsequent year.
- An extensive system landscape is required or at least strongly recommended for the packaging and testing process. The usual rule of thumb is three systems per foundation release supported – depending on your requirements, this number might change in either direction, but it’s a good estimate for starters.
- The delivery process looks huge at first. It can be cut down once you get to know the system better and once the scenario is well-defined – there are many special cases that might not apply in your scenario, but you’ll have to think about them and decide whether to handle them consciously..
The Steep Incline.
You covered the topic to the point. Helped a lot to get the big picture at a glance. Thanks in advanced.
I just built a support package using the AAK and you blogged about it a day later, what a coincidence! 🙂
My 2 cents:
If you think AAK is hard, try WiX for comparison - without the fancy GUIs that hide 80% of the options available... 🙂
You wouldn't want a total beginner to deliver software to a mission-critical ERP-system, right?
I have to disagree: Knowledge is the key. One always has to be careful when assembling a delivery package, that's not an exclusive feature of the AAK. I don't concur with your assessment "any small mistake and you may have to redo the whole process again". If you missed a transport, that's a clear indication that you might have to re-think the way you collect the transports in the first place. I'd recommend using CTS projects, but YMMV. Manual collection is almost always a bad idea. Anyway, that's what import checks are for - noticing these mistakes BEFORE the software is delivered. If I had a Euro for every transport sent to me by a highly-paid consultancy company that was missing one object or the other, I could easily blog for a living...
Hi Volker,
do you have any resources which explains the organisation of CTS projects? At the moment, we organize the transport request order etc. in stupid little text fields using our local bug tracking system. It feels like the 80's.
I wonder if I can at a request to the CTS project and transport all request at once in given order.
As i type, TPTB are discussing on this. As-of-now, the relevant TRs are maintained in an excel & more-or-less collected manually which is IMO dangerous. My suggestion was to use our ticketing system to list the TRs, but after reading Daniel Sonnabend's comment i will be watching this blog.
Sounds good to me.
I agree. Relying on people (especially developers) to maintain stuff in two places is a recipe for desaster. Trust me on this, I'm a developer myself...
Hi Volker,
Thanks a lot for sharing your knowledge and experience of developing/delivering ABAP add-ons.
As Jason Scott mentioned on twitter: I'm pretty sure SAP will point everyone who wants to develop add-ons to saphcp, now that it is available and also with the planned (by SAP 🙂 ) transition to S4HANA.
However: most of the current S4HANA customers intend to stay on premise (at least for the time being), and it makes sense for some add-ons to be developed close to the data. Or the data might be so sensitive that the development of an add-on in the cloud is not an option.
Besides, there still remain tons of customers not (yet) moving to S4HANA. They might also be interested in an add-on.
So, all in all reason enough IMO to take this to SAP and let them come up with a better solution.
Fred
The difficulties for creating a Solution and packaing it using the AAK was never the barrier, its the price.
How can partners really help populate the SAP Store if you only have 2 or 3 small products that want to showcase?, The Apple Store and the Google Play market are overflowing with offers because its easy and cheap to put up products there.
A company that runs SAP does not want to download and install something just to "try it", they want software that is certified, and that will certainly not break their production system.....but i would bet my yearly salary that they also wish to have small "quality of life" add-ons that solve daily issues.
Thats why so far, business seek partners and hire programmers, analysts and consultants on a time basis just to build the things they want and need.
But if the SAP store was a first stop to look for solutions, then perhaps the ecosystem would be much richer and the barrier to entry much lower.
Alejandro,
I think you have a valid point there. ...
Volker
I totally agree with you. And in Addition: If the entrance to the ecosystem is easy, many in-house solution may become a part of it. With this in mind, any in-house developer may carfelully design their in-house solution from the bottom up.
Today I see many custom codings using fixed configurations in code where a customizing table may be more approbiated.
Volker
I would love to see something like that.
With AAK 5, I added the un-install option to an existing add-on via Attribute Change Package. This feature is really nice to have. | https://blogs.sap.com/2015/10/29/the-delivery-barrier/ | CC-MAIN-2022-27 | refinedweb | 3,018 | 61.56 |
In part 1, I gave an overview of a pattern we use in the UI development of Max. In this post, I plan to talk about DataModels. In part 1, I wrote:.
I want to talk a bit about the threading model. Making all public APIs single threaded on a DataModel may seem like overkill. It's certainly possible to make some methods thread safe. And, you might know that WPF data binding will actually handle property changed events from other threads. But, in my experience, making the APIs of DataModel single thread significantly simplifies the models and eliminates many possible bugs. The rules become very simple. Of course, DataModels usually need to do operations on background threads, but they can use the Dispatcher to dispatch the results back to the UI thread.
Let's go through a possible DataModel base class. I will use it in the sample moving forward.
First, the defition and constructor:
public class DataModel : INotifyPropertyChanged
{
public DataModel()
{
_dispatcher = Dispatcher.CurrentDispatcher;
}
We grab the current Dispatcher in the constructor. We now have it available for any background operations that need to be dispatch results to the UI thread.
Now, here's the definition of the possible states of the model:
public enum ModelState
Fectching, // The model is fetching data
Invalid, // The model is in an invalid state
Active // The model has fetched its data
I think these are pretty self explanatory. Basically, the model will be in a fetching state if it's fetching data asynchronously. Otherwise, it will be in the invalid or activate state. The state is made available through the following property:
public ModelState State
get
{
VerifyCalledOnUIThread();
return _state;
}
set
if (value != _state)
{
_state = value;
SendPropertyChanged("State");
}
This is the basic pattern we'll use for most model properties. When getting the value, we verify that we're on the UI thread and just return the cached value. When setting the property, we also verify that we're on the UI thread. And, if the value changed, we send the event that it changed. Let me fill in a couple of the utility functions now. The first is VerifyCalledOnUIThread():
[Conditional("Debug")]
protected void VerifyCalledOnUIThread()
Debug.Assert(Dispatcher.CurrentDispatcher == this.Dispatcher,
"Call must be made on UI thread.");
Basically, we make sure that we're on the right thread by checking the current dispatcher. The Conditional attribute makes it so this code isn't executed in retail bits. Sprinkling asserts in the code like this makes it easy to catch these violations early. Otherwise, you might end up tracing down hard to reproduce race conditions.
Next, here's our NotifyPropertyChanged event. We define our own add/remove handlers so we can verify that things are called on the UI thread. If handlers were added/removed from another thread, we'd run into threading issues.
public event PropertyChangedEventHandler PropertyChanged
add
_propertyChangedEvent += value;
remove
_propertyChangedEvent -= value;
And, SendPropertyChanged is a helper function that notifies listeners that the named property changed:
protected void SendPropertyChanged(string propertyName)
VerifyCalledOnUIThread();
if (_propertyChangedEvent != null)
_propertyChangedEvent(this, new PropertyChangedEventArgs(propertyName));
That just leaves the fields:
private ModelState _state;
private Dispatcher _dispatcher;
private PropertyChangedEventHandler _propertyChangedEvent;
}
I'll be using this base class in my sample moving forward. If anyone's interested, I could make the source code available, but it's all here and I plan to make the full version with comments available when I get further along in the sample.
This class is missing one major feature that I plan to talk more about later. But, I think I need a disclaimer here in case anyone starts any of their own code based on this. As mentioned above, one of the roles of a DataModel is to keep its data "live". This can lead to memory leaks. To keep data live, the model will need to register for change notifications from some other source, or maybe set up a timer. This will keep the DataModel object alive. If there's a DataTemplate pointing to the DataModel with data binding set up, it will have registered for property changed notifications from the DataModel, so the DataModel will be keeping the UI in the DataTemplate alive, even after it's been unloaded from the UI. The solution we use is to have a reference counted activate/deactivate pattern in our DataModel classes where a model is only live while active. We activate the model when the UI pointing to it is Loaded, and deactivate when Unloaded. I'll blog about this more in the future... | http://blogs.msdn.com/b/dancre/archive/2006/07/23/datamodel-view-viewmodel-pattern-2.aspx?Redirected=true | CC-MAIN-2015-27 | refinedweb | 752 | 55.54 |
Visual FoxPro enhances its existing XML features and its compatibility with XML DiffGram and .NET Framework ADO.NET DataSet formats by providing the XMLAdapter, XMLTable, and XMLField classes. With these classes, Visual FoxPro supports hierarchically formatted XML for the following:
- XML files that have associated schema, either inline or external, as implemented by ADO.NET DataSets based on the .NET Framework. For more information, see ADO.NET DataSets.
- Microsoft XML Data Reduced Schema (XDR) as used by Microsoft SQL XML
- ADO Recordset schemas that are produced when an ADO Recordset is saved as XML to a file or stream
Visual FoxPro can factor an XML file representing a collection of different and possibly related tables, such as an ADO.NET DataSet object, into separate Visual FoxPro cursors. Usually, this file contains data from a database management system (DBMS) with the structure of Parent > Child > Child. The XML can also have a nested format such as Parent > Child, Parent > Child, or a serial format such as Parent-Parent, Child-Child.
When you have hierarchical XML that represents a single table resulting from a multiple-table SQL JOIN command, Visual FoxPro creates only one cursor.
ADO.NET DataSets
In the .NET Framework, ADO.NET is a set of classes that expose data access services to the programmer. ADO.NET provides consistent access to data sources such as Microsoft SQL Server and other data sources exposed through OLE DB and XML.
The ADO.NET DataSet is used as the primary class for manipulating data and encapsulates data as XML. An ADO.NET DataSet object can produce XML in several ways:
- By returning the entire ADO.NET DataSet to the calling application.
This method returns all rows in the original query in XML DiffGram format with inline schema and update, insert, and delete operations as indicated. Rows that remain unchanged do not have the diffgr:hasChanges attribute.
When a DataSet object returns to the calling application from a method in an application that uses the .NET Framework and returns ADO.NET DataSet objects, it is always serialized, or converted, into XML. Visual FoxPro can convert this XML into cursors, which you can then manipulate in a Visual FoxPro application.
- By returning only changes to the ADO.NET DataSet to the .NET-based application.
This method returns only those rows, in XML DiffGram format, that were modified, added, or deleted.
If the ADO.NET DataSet object contains changes, they are marked with the attributes, DiffGram:hasChanges="modified" or DiffGram:hasChanges="inserted". For those records marked as "modified", the previous values appear in the section, diffgr:before. Records that are deleted appear only in the diffgr:before section and not in the main section of the DiffGram.
- By using the ADO.NET DataSet GetXml and GetXMLSchema methods to return XML as a .CLR stream or string type.
- By using the ADO.NET DataSet WriteXml and WriteXmlSchema methods to write the ADO.NET DataSet as XML to a file with inline schema, without schema, or separate schema.
For more information about XML DiffGram and ADO.NET DataSet formats, see the .NET Framework SDK on the MSDN Library Web site at .
Support for Schemas Generated by ADO.NET DataSets
XML that has external or inline XML Schema Definition (XSD) schema as generated by ADO.NET DataSets might contain elements not supported by Visual FoxPro, which disregards those elements. For example, these elements might include the following:
- xs:unique name
- xs:annotation
- Additional processing instructions and attributes such as the following:
- Schema prefix support, such as msdata:Prefix, that defines the scope of a group of elements
- XML prefix support, such as the vfpx attribute, that scopes the prefix to root elements
- msprop attribute and other attributes that use this namespace
- Other msdata attributes that reference items not supported by Visual FoxPro, such as msdata:Locale or msdata:Comment | http://www.yaldex.com/fox_pro_tutorial/html/eb5f9e49-00fe-4827-8608-dfe12e3f6d5e.htm | CC-MAIN-2017-04 | refinedweb | 640 | 57.47 |
This is the tenth lesson in a series introducing 10-year-olds to programming through Minecraft. Learn more here.
Note: These instructions are only guaranteed valid for Minecraft 1.6.2 (with no mods installed) and Forge 9.10.0.804. They also assume you already have the most recent JDK installed. Fingers crossed the real API is released soon and the state of modding Minecraft will be less in flux.
Installing Forge
Instructions for installing Forge are also available at at
Determine JDK version
Open a new Windows Explorer window and navigate to
C:\Program Files\Java\
You will have a directory in there called
jdk1.7.0_xx (depending on when exactly you installed the JDK). Double-click on it and then double-click on
bin. We are going to add the full path from the explorer address bar (e.g.
C:\Program Files\Java\jdk1.7.0_xx\bin) to our PATH environment variable. Leave this window open so we can copy the path later.
Add the JDK path to our PATH environment variable
- Right-click on "Computer" and choose Properties or Windows + X and choose 'System' or open Control Panel > System and Security > System
- Choose 'Advanced System Settings' (Windows 7: click on the 'Advanced' tab)
- Click the 'Environment variables' button at the bottom of the tab.
- In the "User variables for xxx" section at the top, you will see a variable called PATH.
- Click on it and then click the Edit button.
- Click in the "variable value" text box and then press End. The cursor should now be sitting at the end of the line, most likely after a semicolon. If there is not a semicolon at the end of the line, type one in.
- Copy (or type in) the full path from the Explorer window we used in the first step (e.g.
C:\Program Files\Java\jdk1.7.0_21\bin)
- Press OK (and close whatever other windows we opened for this step)
Installing Minecraft Forge
- Download the most recommended 'src' build from
- Extract the zip to a new directory (e.g.
C:\eclipse-workspace\)
- Open an explorer window to wherever you extracted it, double-click on
forge, and then double-click on
install.cmd.
Base Mod and Eclipse setup
These are a simplified version of the instructions found at at. I would suggest making a copy of the entire
forge directory just in case things get messy later...
- Make sure your workspace points to
/forge/mcp/eclipse(e.g.
c:\eclipse-workspace\forge\mcp\eclipse)
- Close Task list and Outline
Note that you've already got 7 warnings (we just ignore them)
Right-click on "src", New > Package. Name =
mc.{initials}.first
Right-click on the new package, New > Class. Name =
CommonProxy. Superclass = blank. Add an empty
voidmethod to it named
registerRenderers.
Right-click on "src", New > Package. Name =
mc.{initials}.first.client
Right-click on the new package, New > Class. Name =
ClientProxy. Superclass =
CommonProxy. Change the
importstatement to
mc.{initials}.first.CommonProxy. Add an override for
registerRenderers.
Right-click on the original package again, New > Class. Name =
Generic. Superclass = blank. Replace with the code below:
(Note - update
SidedProxy with the appropriate package names)
import cpw.mods.fml.common.Mod; import cpw.mods.fml.common.Mod.EventHandler; import cpw.mods.fml.common.Mod.Instance;; @Mod(modid="Generic", name="Generic", version="0.0.0") @NetworkMod(clientSideRequired=true, serverSideRequired=false) public class Generic { // The instance of your mod that Forge uses. @Instance("Generic") public static Generic instance; // Says where client and server 'proxy' code is loaded. @SidedProxy(clientSide= "mc.jb.first.client.ClientProxy", serverSide="mc.jb.first.CommonProxy") public static CommonProxy proxy; @EventHandler public void preInit(FMLPreInitializationEvent event) { } @EventHandler public void load(FMLInitializationEvent event) { proxy.registerRenderers(); } @EventHandler public void postInit(FMLPostInitializationEvent event) { } }
- You should be able to press the green play button (or Ctrl+F11) and have Minecraft launch with your new mod available. | https://www.jedidja.ca/minecraft-forge-setup/ | CC-MAIN-2020-40 | refinedweb | 646 | 57.47 |
* Last updated May 27th, 2013 *
Python is a general purpose scripting language that can be used for statistical analysis, numeric work, machine learning, etc. With packages like SciPy, matplotlib, CUDAmat/gnumpy, Theano, and Scikit, it’s a worthy, free competitor to Matlab.
Of course, Matlab is more than its scripting language; it’s an integrated development environment (IDE) which combines editing, execution, plotting, debugging, etc. Here I evaluate 4 IDEs for scientific Python on my Ubuntu 11.10 PC to see how they stack up to Matlab:
- IEP 3.2
- Spyder 2.2
- PyDev 2.7 + ipython
- Enthought Canopy 1.0 (commercial)
Generally, these IDEs combine a text editor, an integrated python shell (python or ipython), support for interactive plotting via matplotlib as well as several other features to tie everything together.
Criteria for evaluation
Python has support for many features of the Matlab IDE at the language level. The interactive Python shell has support for interactive execution and integrated help (simply type
help(object)). Profiling can easily be done via the cProfile module:
import cProfile as profile profile.run('myfun()')
Variables can be listed via
dir() or
locals() and inspected via the shell. Python also has support for creating GUI interfaces – for instance, via QT or GTK – which put GUIDE to shame.
Given this, the most important features for a Python IDE geared toward science are:
- A kick-ass text editor with introspection, autocomplete and so forth
- Seamless integration of Python shell and text editor
- Interactive plotting via matplotlib
- Seamless debugging
- An undefinable quality of well-thought out programs that causes a zen-like experience; for lack of a better term, smoothness
IEP
IEP, the interactive editor for Python, is
a cross-platform Python IDE focused on interactivity and introspection, which makes it very suitable for scientific computing.
The most notable feature of the user interface is its support for various Run commands which mimic those of Matlab. F5 will execute the currently edited Python file, F9 the current selection, while Ctrl+Enter will execute the current cell. Cells are defined via ##, equivalent to Matlab’s %%. This is a very neat feature.
An aside on dynamic loading and execution
To work comfortably with the interface, it’s important to understand how Python loads modules and functions compared to Matlab. In Matlab, if you have changed a function and save the file, on your next call Matlab will use the new definition.
In Python, it’s different. If I have a file
testcmd.py which I import via
import testcmd, if I then change
testcmd.py, neither executing
testcmd.py nor running
import again will load the updated definition.
reload(testcmd) must be called for the definition to be updated.
That means that IEP’s various interactive run modes work best when the function to be tested and the code executing it belong in the same file. While in Matlab a script file cannot contain function definitions, in Python script files can contain functions, classes, and procedural code, so this is not as limiting as it may appear at first.
It should also be noted that when a class is redefined in Python, any objects created before then will still use the old definition. For instance:
class Bob(object): def __init__(self): self.myvar = 1 def print_bob(self): print "Old myvar is:" print self.myvar bob = Bob() bob.print_bob() class Bob(object): def __init__(self): self.myvar = 2 def print_bob(self): print "New myvar is:" print self.myvar bob.print_bob() bob2 = Bob() bob2.print_bob() #rebind bob.__class__ = Bob bob.print_bob()
Results in:
Old myvar is: 1 Old myvar is: 1 New myvar is: 2 New myvar is: 1
Note that binding to the new class is accomplished via setting the
__class__ property of the old object. I wish that this information was included in the IEP tour, because it’s very important to understand these things in order to take advantage of the interactive execution.
Back to IEP
IEP has post-mortem debugging (checking the state of things when the last uncaught exception occured) via a Debug button – limited, but serviceable.
The editor is pretty good – it has auto-completion, live introspection (it knows that
bob2 has a
print_bob function), function signature hints, and it shows a tree of class/function definitions.
matplotlib is supported via the following settings in
.matplotlib/matplotlibrc:
interactive : True backend : Qt4Agg
Then setting the GUI to Qt in the shell configuration in IEP.
What IEP lacks in features, it makes up for in smoothness. Although the features are limited, they’re well thought out, and polished.
So:
- Editor: 3/5
- Interpreter integration: 4.5/5
- Plotting: 2/5
- Debugging: 2.5/5
- Smooth: 4/5
Overall score: 3.5/5
Spyder
a powerful interactive development environment for the Python language with advanced editing, interactive testing, debugging and introspection features
Perhaps the most notable feature of Spyder is that it uses ipython as its default command line environment – see here for an in-depth review of ipython and ipython Notebook. As such, it has built-in support for Matplotlib. Using ipython also alleviates some of the issues with editing modules, since ipython supports auto-reloading modules, via typing at the interpreter:
import ipy_autoreload %autoreload 2
Spyder supports running a selection (F9) and a file (F5) from within the editor, but no Ctrl+Enter for cell mode-like execution.
Spyder’s editor is excellent. It offers deep introspection, highlights errors, gives warnings, and opens up the docstring information upon calling a function. Errors and warnings are shown on the left hand side of the line number and can be inspected via clicking and holding over the error and warning icons – unintuitive, but workable. Upon highlighting a word, it automatically highlights all other instances of the word in the editor – handy for tracking variables.
The editor can find the file/line where a function was defined by holding the Ctrl button and clicking the function name – similar to the Ctrl+D – Open definition feature in Matlab.
It has support for setting breakpoints within the interface, and feeds that information to the pdb debugger.
pdb can then be manipulated via its command line interface inside ipython: c to continue, u to go up a level, q to quit, etc. New in 2.2, GUI equivalents for the debugger have been added.
It would be an ideal package were it not for its lack of polish. The project explorer – there is also an unrelated, but largely overlapping file explorer – is deeply confusing and annoying. The interface used to be messy and confusing, with toolbars for buttons you will never use – but this has been significantly improved in version 2.2, in part in response to the previous review in this very blog – kudos to the developer! I also found installation on Windows to be annoying.
To sum up:
- Editor: 4/5
- Interpretor integration: 4/5
- Plotting: 4/5
- Debugging: 4/5
- Smooth: 3/5 (up from 2/5 for version 2.0)
Total: 3.8/5
PyDev + ipython
PyDev is a Python IDE for Eclipse. Eclipse is kind of a meta-IDE for a bunch of languages. I wouldn’t call it smooth – it’s built like a tank. While it has a fantastic editor with deep introspection, support for refactoring and a gorgeous graphical debugger, it doesn’t play well with matplotlib. Specifically, it hangs when calling
draw.
Thus, you have to keep a separate ipython window open. A file may be run in ipython via the command:
run myfile.py
It’s a workable, if inelegant solution. I would recommend PyDev to those doing hardcore development in Python – for more casual users, look elsewhere.
- Editor: 5/5
- Interpretor integration: 2/5
- Plotting: 0/5
- Debugging: 5/5
- Smooth: 2/5
Overall score: 2.5/5
Enthought Canopy
Finally, we have a commercial editor from Enthought called Canopy, which, according to them
is a comprehensive Python analysis environment with easy installation & updates of the proven Enthought Python distribution
I installed the academic version, which required acquiring a license via my mail.mcgill.ca address. It wouldn’t open. In the command line, I get the error:
/home/patrick/Canopy/appdata/canopy-1.0.0.1160.rh5-x86_64/bin/python: symbol lookup error: /usr/lib/x86_64-linux-gnu/libgdk-x11-2.0.so.0: undefined symbol: g_source_set_name
I tried every trick in the book to get it running, but couldn’t figure it out. I figured I would try support, but Enthought redirects users to ask questions on StackOverflow, which is basically a way of saying to free users: you’re shit out of luck.
But I’m a good sport, so I decided to install it on another computer (Ubuntu 12.04LTS) to see if it would work. Here I got a different error:
QGtkStyle could not resolve GTK. Make sure you have installed the proper libraries.
And then Google wasn’t helpful, so I gave up. Easy installation, eh?
Score: minus eleventy
Canopy turned out to install fine on Windows, and I review it here.
39 thoughts on “Evaluating IDEs for scientific Python”. | http://xcorr.net/2013/04/17/evaluating-ides-for-scientific-python/ | CC-MAIN-2014-41 | refinedweb | 1,515 | 56.05 |
John purchased 100 shares of Black Forest Inc. stock at a price of $158.37 three months ago. He sold all stocks today for $157.23. During this period the stock paid dividends of $5.23 per share. What is John’s annualized holding period return (annual percentage rate)?
Professor came up with 10.33%. I just want to know how she came up with this answer. Thanks
Thank you for the opportunity to help you with your question!
the gain is dividend plus the difference in the prices
so the gain is (157.23-158.37+5.23) = 4.09
the return is 4.09/158.37*(12/3) = 10.33%
12 is for12 month a year.
Secure Information
Content will be erased after question is completed.
Enter the email address associated with your account, and we will email you a link to reset your password.
Forgot your password? | https://www.studypool.com/discuss/1177209/hpr-annual-percentage-rate-1?free | CC-MAIN-2017-09 | refinedweb | 150 | 79.97 |
> -----Original Message-----
> From: Brian M Dube [mailto:bdube@apache.org]
> Sent: Sunday, 20 July 2008 7:19 AM
> To: dev@forrest.apache.org
> Subject: Re: XInclude
>
> Ross Gardler wrote:
> > Brian M Dube wrote:
> >> Gavin wrote:
> >>> Well this seemed to pass my tests locally, its late I'll look in the
> >>> morning
> >>> and either fix it or revert.
> >>
> >> I committed r678217 to suppress validation on samples-b/xinclude.xml.
> >
> > -1
> >
> > Obscuring a bad commit is not good practice. We should revert the
> > offending commit or fix the problem it introduced.
>
> The problem does not appear to be trivial. The Document DTD would need
> to allow for XInclude almost everywhere. Is this practical? What is the
> alternative?
Well, bad day for me, I 'assumed' we had xinclude support for our
document-v20, so thanks for reverting.
In another thread I'm talking about removing the todo list, one of the items
on that list says :-
18. - [code] Migrate to a decent schema language, primarily so that we can
use namespaces in XML docs, allowing things like XInclude, in-line metadata,
in-line SVG, Jelly snippets, or anything else users can make a Transformer
for. → open
So it seems that is not done. I don't know the best way forward on this, we
can add it to our DTD, create a new one and add it to our schema, point to
something better existing or .. ??
The patch itself seems flawless in its application, matching the W3C
examples [1] pretty closely, so I don’t have a problem with the way they
have been applied as such, just need to work out the best approach to
approve the method and get it validated against our tests.
[1] -
Gav...
>
> Brian
>
>
> --
> Internal Virus Database is out-of-date.
> Checked by AVG.
> Version: 7.5.524 / Virus Database: 270.4.7 - Release Date: 7/8/2008 12:00
> AM | http://mail-archives.apache.org/mod_mbox/forrest-dev/200807.mbox/%3C011201c8ea32$c9c674f0$0200a8c0@developer%3E | CC-MAIN-2014-15 | refinedweb | 313 | 73.78 |
Downloads a file from the internet using the HTTP, HTTPS or FTP protocol.
InetRead ( "URL" [, options = 0] )
Internet Explorer 3 or greater must be installed for this function to work.
The URL parameter should be in the form "" - just like an address you would type into your web browser.
To use a username and password when connecting simply prefix the servername with "username:password@", e.g.
""
The returned data is in binary format. The BinaryToString() function can be used to convert the data to a string.
By default AutoIt forces a connection before starting a download. For dial-up users this will prompt to go online or dial the modem (depending on how the system is configured). The options value $INET_FORCEBYPASS (16) disables this behavior. Disabling the behavior can be useful for persistent connects (Broadband, LAN). However, it is also required to work around certain issues in Windows Vista and Windows 7.
FtpSetProxy, HttpSetProxy, HttpSetUserAgent, InetGet, InetGetSize
#include <MsgBoxConstants.au3> Example() Func Example() ; Read the file without downloading to a folder. The option of 'get the file from the local cache' has been selected. Local $dData = InetRead("") ; The number of bytes read is returned using the @extended macro. Local $iBytesRead = @extended ; Convert the ANSI compatible binary string back into a string. Local $sData = BinaryToString($dData) ; Display the results. MsgBox($MB_SYSTEMMODAL, "", "The number of bytes read: " & $iBytesRead & @CRLF & @CRLF & $sData) EndFunc ;==>Example | https://www.autoitscript.com/autoit3/docs/functions/InetRead.htm | CC-MAIN-2015-48 | refinedweb | 231 | 50.33 |
Ok, so i was looking around on google about how to incorporate DLL's written in C with VB .NET GUI's because its stupidly simple to create one in VB and C is faster. So I want to learn how to mix the two and i found a page of an example thats supposed to do just this (here: ). But when I execute the code, I always get this error:VB Code:VB Code:Quote:
An unhandled exception of type 'System.EntryPointNotFoundException' occurred in Call_C_dll.exe
Additional information: Unable to find an entry point named ReturnInParam in DLL vcdll.dll.
C Code:C Code:Code:
Public Class Form1
Inherits System.Windows.Forms.Form
_
| Windows Form Designer Generated Code |
-
<DllImport("vcdll = "Hey"
ReturnInParam(Num, Message)
MessageBox.Show(Message)
End Sub
End Class
the name and path of the dll is correct :( so whats wrong? thanksthe name and path of the dll is correct :( so whats wrong? thanksCode:
#include <WINDOWS.H>
LPCSTR DisplayStringByVal(LPCSTR pszString)
{
return "How's it goin? ";
}
void ReturnInParam(int* pnStan, char** pMsg)
{
long *buffer;
char text[7] = );
} | https://cboard.cprogramming.com/windows-programming/64130-dll-error-vbulletin-net-program-printable-thread.html | CC-MAIN-2017-22 | refinedweb | 181 | 67.55 |
Create an Abstract Class in Java parameter list but not providing an actual implementation of the method.
You can’t instantiate an abstract class. However, you can create a subclass that extends an abstract class and provides an implementation of the abstract methods defined by the abstract class. You can instantiate the subclass.
To create an abstract method, you specify the modifier abstract and replace the method body with a semicolon:
public abstract return-type method-name(parameter-list);
Here’s an example:
public abstract int hit(int batSpeed);
To create an abstract class, you use the abstract on the class declaration and include at least one abstract method. For example:
public abstract class Ball { public abstract int hit(int batSpeed); }
You can create a subclass from an abstract class like this:
public class BaseBall extends Ball { public int hit(int batSpeed) { // code that implements the hit method goes here } }
When you subclass an abstract class, the subclass must provide an implementation for each abstract method in the abstract class. In other words, it must override each abstract method.
Abstract classes are useful when you want to create a generic type that is used as the superclass for two or more subclasses, but the superclass itself doesn’t represent an actual object. If all employees are either salaried or hourly, for example, it makes sense to create an abstract Employee class and then use it as the base class for the SalariedEmployee and HourlyEmployee subclasses.
Here are a few additional details regarding abstract classes:
Not all the methods in an abstract class have to be abstract. A class can provide an implementation for some of its methods but not others. In fact, even if a class doesn’t have any abstract methods, you can still declare it as abstract. (In that case, though, the class can’t be instantiated.)
A private method can’t be abstract. All abstract methods must be public.
A class can’t be both abstract and final. | http://www.dummies.com/how-to/content/create-an-abstract-class-in-java.html | CC-MAIN-2014-41 | refinedweb | 331 | 59.84 |
/* BFD library -- caching of file descriptors. Copyright 1990, 1991, 1992, 1993, 1994, 1996, 2000, 2001, 2002, 2003, 2004, 2005 Free Software Foundation, Inc. Hacked by Steve Chamberlain of Cygnus Support (steve File caching The file caching mechanism is embedded within BFD and allows the application to open as many BFDs as it wants without regard to the underlying operating system's file descriptor limit (often as low as 20 open files). The module in <<cache.c>> maintains a least recently used list of <<BFD_CACHE_MAX_OPEN>> files, and exports the name <<bfd_cache_lookup>>, which runs around and makes sure that the required BFD is open. If not, then it chooses a file to close, closes it and opens the one wanted, returning its file handle. SUBSECTION Caching functions */ #include "bfd.h" #include "sysdep.h" #include "libbfd.h" #include "libiberty.h" /* In some cases we can optimize cache operation when reopening files. For instance, a flush is entirely unnecessary if the file is already closed, so a flush would use CACHE_NO_OPEN. Similarly, a seek using SEEK_SET or SEEK_END need not first seek to the current position. For stat we ignore seek errors, just in case the file has changed while we weren't looking. If it has, then it's possible that the file is shorter and we don't want a seek error to prevent us doing the stat. */ enum cache_flag { CACHE_NORMAL = 0, CACHE_NO_OPEN = 1, CACHE_NO_SEEK = 2, CACHE_NO_SEEK_ERROR = 4 }; /* The maximum number of files which the cache will keep open at one time. */ #define BFD_CACHE_MAX_OPEN 10 /* The number of BFD files we have open. */ static int open_files; /* Zero, or a pointer to the topmost BFD on the chain. This is used by the <<bfd_cache_lookup>> macro in @file{libbfd.h} to determine when it can avoid a function call. */ static bfd *bfd_last_cache = NULL; /* Insert a BFD into the cache. */ static void insert (bfd *abfd) {; } } /* Close a BFD and remove it from the cache. */ static bfd_boolean bfd_cache_delete (bfd *abfd) { bfd_boolean ret; if (fclose ((FILE *) abfd->iostream) == 0) ret = TRUE; else { ret = FALSE; bfd_set_error (bfd_error_system_call); } snip (abfd); abfd->iostream = NULL; --open_files; return ret; } /* We need to open a new file, and the cache is full. Find the least recently used cacheable BFD and close it. */ static bfd_boolean close_one (void) { register bfd *kill; if (bfd_last_cache == NULL) kill = NULL; else { for (kill = bfd_last_cache->lru_prev; ! kill->cacheable; kill = kill->lru_prev) { if (kill == bfd_last_cache) { kill = NULL; break; } } } if (kill == NULL) { /* There are no open cacheable BFD's. */ return TRUE; } kill->where = real_ftell ((FILE *) kill->iostream); /* Save the file st_mtime. This is a hack so that gdb can detect when an executable has been deleted and recreated. The only thing that makes this reasonable is that st_mtime doesn't change when a file is unlinked, so saving st_mtime makes BFD's file cache operation a little more transparent for this particular usage pattern. If we hadn't closed the file then we would not have lost the original contents, st_mtime etc. Of course, if something is writing to an existing file, then this is the wrong thing to do. FIXME: gdb should save these times itself on first opening a file, and this hack be removed. */ if (kill->direction == no_direction || kill->direction == read_direction) { bfd_get_mtime (kill); kill->mtime_set = TRUE; } return bfd_cache_delete (kill); } /* Check to see if the required BFD is the same as the last one looked up. If so, then it can use the stream in the BFD with impunity, since it can't have changed since the last lookup; otherwise, it has to perform the complicated lookup function. */ #define bfd_cache_lookup(x, flag) \ ((x) == bfd_last_cache \ ? (FILE *) (bfd_last_cache->iostream) \ : bfd_cache_lookup_worker (x, flag)) /* return NULL if it is unable to (re)open the @var{abfd}. */ static FILE * bfd_cache_lookup_worker (bfd *abfd, enum cache_flag flag) { bfd *orig_bfd = abfd; if ((abfd->flags & BFD_IN_MEMORY) != 0) abort (); if (abfd->my_archive) abfd = abfd->my_archive; if (abfd->iostream != NULL) { /* Move the file to the start of the cache. */ if (abfd != bfd_last_cache) { snip (abfd); insert (abfd); } return (FILE *) abfd->iostream; } if (flag & CACHE_NO_OPEN) return NULL; if (bfd_open_file (abfd) == NULL) ; else if (!(flag & CACHE_NO_SEEK) && real_fseek ((FILE *) abfd->iostream, abfd->where, SEEK_SET) != 0 && !(flag & CACHE_NO_SEEK_ERROR)) bfd_set_error (bfd_error_system_call); else return (FILE *) abfd->iostream; (*_bfd_error_handler) (_("reopening %B: %s\n"), orig_bfd, bfd_errmsg (bfd_get_error ())); return NULL; } static file_ptr cache_btell (struct bfd *abfd) { FILE *f = bfd_cache_lookup (abfd, CACHE_NO_OPEN); if (f == NULL) return abfd->where; return real_ftell (f); } static int cache_bseek (struct bfd *abfd, file_ptr offset, int whence) { FILE *f = bfd_cache_lookup (abfd, whence != SEEK_CUR ? CACHE_NO_SEEK : 0); if (f == NULL) return -1; return real_fseek (f, *f;; f = bfd_cache_lookup (abfd, 0); if (f == NULL) return 0; #if defined (__VAX) && defined (VMS) /* Apparently fread on Vax VMS does not keep the record length information. */ nread = read (fileno (f),, f); /* Set bfd_error if we did not read as much data as we expected. If the read failed due to an error set the bfd_error_system_call, else set bfd_error_file_truncated. */ if (nread < nbytes && ferror (f)) { bfd_set_error (bfd_error_system_call); return -1; } #endif return nread; } static file_ptr cache_bwrite (struct bfd *abfd, const void *where, file_ptr nbytes) { file_ptr nwrite; FILE *f = bfd_cache_lookup (abfd, 0); if (f == NULL) return 0; nwrite = fwrite (where, 1, nbytes, f); if (nwrite < nbytes && ferror (f)) { bfd_set_error (bfd_error_system_call); return -1; } return nwrite; } static int cache_bclose (struct bfd *abfd) { return bfd_cache_close (abfd); } static int cache_bflush (struct bfd *abfd) { int sts; FILE *f = bfd_cache_lookup (abfd, CACHE_NO_OPEN); if (f == NULL) return 0; sts = fflush (f); if (sts < 0) bfd_set_error (bfd_error_system_call); return sts; } static int cache_bstat (struct bfd *abfd, struct stat *sb) { int sts; FILE *f = bfd_cache_lookup (abfd, CACHE_NO_SEEK_ERROR); if (f == NULL) return -1; sts = fstat (fileno (f),_init SYNOPSIS bfd_boolean bfd_cache_init (bfd *abfd); DESCRIPTION Add a newly opened BFD to the cache. */ bfd_boolean bfd_cache_init (bfd *abfd) { BFD_ASSERT (abfd->iostream != NULL); if bfd_cache_close_all SYNOPSIS bfd_boolean bfd_cache_close_all (void); DESCRIPTION Remove all BFDs from the cache. If the attached file is open, then close it too. RETURNS <<FALSE>> is returned if closing one of the file fails, <<TRUE>> is returned if all is well. */ bfd{abfd}. Return the <<FILE *>> (possibly <<NULL>>) that results from this operation. Set up the BFD so that future accesses know the file is open. If the <<FILE *>> returned is <<NULL>>, then it won't have been put in the cache, so it won't have to be removed from it. */ FILE * bfd_open_file (bfd *abfd) { abfd->cacheable = TRUE; /* Allow it to be closed later. */ if (open_files >= BFD_CACHE_MAX_OPEN) { if (! close_one ()) return NULL; } switch (abfd->direction) { case read_direction: case no_direction: abfd->iostream = (PTR) real_fopen (abfd->filename, FOPEN_RB); break; case both_direction: case write_direction: if (abfd->opened_once) { abfd->iostream = (PTR) real_fopen (abfd->filename, FOPEN_RUB); if (abfd->iostream == NULL) abfd->iostream = (PTR) real) real_fopen (abfd->filename, FOPEN_WUB); abfd->opened_once = TRUE; } break; } if (abfd->iostream == NULL) bfd_set_error (bfd_error_system_call); else { if (! bfd_cache_init (abfd)) return NULL; } return (FILE *) abfd->iostream; } | http://opensource.apple.com/source/cxxfilt/cxxfilt-9/cxxfilt/bfd/cache.c | CC-MAIN-2014-52 | refinedweb | 1,115 | 69.62 |
Hi, On Mon, 2009-04-27 at 09:40 -0400, Valdis Kletnieks vt edu wrote: > On Thu, 23 Apr 2009 10:16:54 BST, Steven Whitehouse said: > > Finds the first set bit in a 64 bit word. This is required in order > > to fix a bug in GFS2, but I think it should be a generic function > > in case of future users. > > Seems like a sane idea.. > > > +static inline unsigned long __ffs64(u64 word) > > +{ > > +#if BITS_PER_LONG == 32 > > + if (((u32)word) == 0UL) > > + return __ffs((u32)(word >> 32)) + 32; > > +#elif BITS_PER_LONG != 64 > > +#error BITS_PER_LONG not 32 or 64 > > +#endif > > + return __ffs((unsigned long)word); > > +} > > + > > Does this have endian-ness issues (is that (u32)word the "high" or "low" > part)? Or is this intended only for looking at bitmaps and the like, and we > don't really care? The intent was that it would operate on native endian u64 words so that it shouldn't be affected by the endianess. In the GFS2 code where it is used, the byte ordering is converted to native order before this function is applied, Steve. | https://www.redhat.com/archives/cluster-devel/2009-April/msg00060.html | CC-MAIN-2014-10 | refinedweb | 179 | 67.59 |
Listed below are a number of common issues users face with the various parts of the C++ API.
C++ Extensions¶
Undefined symbol errors from PyTorch/ATen¶
Problem: You import your extension and get an
ImportError stating that
some C++ symbol from PyTorch or ATen is undefined. For example:
>>> import extension Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: /home/user/.pyenv/versions/3.7.1/lib/python3.7/site-packages/extension.cpython-37m-x86_64-linux-gnu.so: undefined symbol: _ZN2at19UndefinedTensorImpl10_singletonE
Fix: The fix is to
import torch before you import your extension. This will make
the symbols from the PyTorch dynamic (shared) library that your extension
depends on available, allowing them to be resolved once you import your extension.
I created a tensor using a function from
at:: and get errors¶
Problem: You created a tensor using e.g.
at::ones or
at::randn or
any other tensor factory from the
at:: namespace and are getting errors.
Fix: Replace
at:: with
torch:: for factory function calls. You
should never use factory functions from the
at:: namespace, as they will
create tensors. The corresponding
torch:: functions will create variables,
and you should only ever deal with variables in your code. | https://pytorch.org/cppdocs/notes/faq.html | CC-MAIN-2021-39 | refinedweb | 203 | 53.1 |
How to run two or more program?
Just like stash, it's can run N time same time.
Who can write a deom to show how to run two program same?
Stash uses Threads, plus much of stash is ui based, which allows callbacks to run seperate from the console.
As a simple example: this code will simply babble on, while you can do other work. set abort=True to cancel.
import threading import time abort=False def ping(): while not abort: print('I am thread number 1') time.sleep(5) def pong(): while not abort: print('I am thread number 2') time.sleep(5) threading.Thread(target=ping).start() threading.Thread(target=pong).start()
Thanks.
stash uses ui based ,not just threads.
run this demo,need using stop to stop program. and you cant't running other program.
The examle does not prevent you from running another program -- notice the play button is immediately available again.... though in this example i did not retain the required globals so pressing play in another script clears a variable needed by the threads.
There are a few aspects to your question, i think:
- How to show two ui's. you use present('panel') to show the ui in a tab
- to prevent global clearing of custom imported modules, there are a few strategies...the easiest is that any imports should be built ins or based in site-packages, as these will not be cleared. Note that means when you are developing, you should develop outside of site-packages or your module does not get reloaded when you make changes. or you would use
import mymodule reload(mymodule)
to ensure your changes get reflected. you can also modify the
__file__attribute so it does not start with './' or the abspath of the documents directory (for instance, set it to the abspath, but replace Documents with a '/./Documents', that currently is enough to fool the preflight script.)
3) global variables, should live inside such a saved module. for instance, stash uses a launcher script where it imports a module, then runs main on the imported module, so any globals are only global within the module, and not truly the global scope. this can make it harder to debug. you can also import and add any globals you want to save to the pythonista_startup module.
import pythonista_startup pythonista_startup.myglobalvariable = myglobalvariable
You can also prepend two underscores, which lets them survive the global clearing.
Of course, with any of these approaches, if you run the same script twice, you have to kake sure you don.'t delete your saved globals, otherwise your ui's will be looking for variables that don't exist
Thanks.
Just using a simply method.
so you can run more then one program same time. | https://forum.omz-software.com/topic/3103/how-to-run-two-or-more-program | CC-MAIN-2017-26 | refinedweb | 462 | 74.19 |
I need to read a whole file into memory and place it in a C++
std::string
char[]
std::ifstream t;
int length;
t.open("file.txt"); // open input file
t.seekg(0, std::ios::end); // go to the end
length = t.tellg(); // report location (this is the length)
t.seekg(0, std::ios::beg); // go back to the beginning
buffer = new char[length]; // allocate memory for a buffer of appropriate dimension
t.read(buffer, length); // read the whole file into the buffer
t.close(); // close file handle
// ... Do stuff with buffer here ...
std::string
char[]
std::ifstream t;
t.open("file.txt");
std::string buffer;
std::string line;
while(t){
std::getline(t, line);
// ... Append line to buffer and go on
}
t.close()
Update: Turns out that this method, while following STL idioms well, is actually surprisingly inefficient! Don't do this with large files. (See:)
You can make a streambuf iterator out of the file and initialize the string with it:
#include <string> #include <fstream> #include <streambuf> std::ifstream t("file.txt"); std::string str((std::istreambuf_iterator<char>(t)), std::istreambuf_iterator<char>());
Not sure where you're getting the
t.open("file.txt", "r") syntax from. As far as I know that's not a method that
std::ifstream has. It looks like you've confused it with C's
fopen.
Edit: Also note the extra parentheses around the first argument to the string constructor. These are essential. They prevent the problem known as the "most vexing parse", which in this case won't actually give you a compile error like it usually does, but will give you interesting (read: wrong) results.
Following KeithB's point in the comments, here's a way to do it that allocates all the memory up front (rather than relying on the string class's automatic reallocation):
#include <string> #include <fstream> #include <streambuf> std::ifstream t("file.txt"); std::string str; t.seekg(0, std::ios::end); str.reserve(t.tellg()); t.seekg(0, std::ios::beg); str.assign((std::istreambuf_iterator<char>(t)), std::istreambuf_iterator<char>()); | https://codedump.io/share/xjOOu5qUtN1p/1/read-whole-ascii-file-into-c-stdstring | CC-MAIN-2018-22 | refinedweb | 344 | 60.51 |
-------------------------------------------------------------------------------- Fedora Update Notification FEDORA-2009-6613 2009-06-18 11:01:08 -------------------------------------------------------------------------------- Name : perl-MooseX-Types Product : Fedora 10 Version : 0.12 Release : 1.fc10 URL : Summary : Organise your Moose types in libraries Description : The types provided with the Moose manpage. -------------------------------------------------------------------------------- Update Information: Mass Moose update. -------------------------------------------------------------------------------- ChangeLog: * Tue Jun 16 2009 Chris Weyl <cweyl alumni drew edu> 0.12-1 - auto-update to 0.12 (by cpan-spec-update 0.01) - added a new req on perl(Carp) (version 0) - added a new req on perl(Carp::Clan) (version 6.00) - added a new req on perl(Moose) (version 0.61) - added a new req on perl(Scalar::Util) (version 1.19) - added a new req on perl(Sub::Install) (version 0.924) - added a new req on perl(Sub::Name) (version 0) - added a new req on perl(namespace::clean) (version 0.08) * Tue Jun 2 2009 Chris Weyl <cweyl alumni drew edu> 0.11-2 - add br on CPAN for bundled version of M::I * Mon May 25 2009 Chris Weyl <cweyl alumni drew edu> 0.11-1 - auto-update to 0.11 (by cpan-spec-update 0.01) - altered br on perl(ExtUtils::MakeMaker) (0 => 6.42) - altered br on perl(Carp::Clan) (0 => 6.00) - added a new br on perl(Scalar::Util) (version 1.19) - added a new br on perl(Sub::Name) (version 0) - altered br on perl(Test::More) (0.62 => 0.80) * Thu Apr 2 2009 Chris Weyl <cweyl alumni drew edu> 0.10-1 - update to 0.10 * Thu Feb 26 2009 Fedora Release Engineering <rel-eng lists fedoraproject org> - 0.08-3 - Rebuilt for * Tue Dec 30 2008 Chris Weyl <cweyl alumni drew edu> 0.08-2 - add br on Test::Exception * Tue Dec 30 2008 Chris Weyl <cweyl alumni drew edu> 0.08-1 - update to 0.08 * Mon Nov 10 2008 Chris Weyl <cweyl alumni drew edu> 0.07-1 - update to 0.07, adjust BR accordingly. Note especially dep on Moose >= 0.61 -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- | https://www.redhat.com/archives/fedora-package-announce/2009-June/msg01491.html | CC-MAIN-2014-23 | refinedweb | 336 | 79.56 |
Strategy Library
Volatility Risk Premium Effect
Introduction
Long volatility means that the value of your portfolio increases when the volatility goes up. Short volatility means that you make money when the volatility goes down. The simplest example of volatility selling involves the sale of put and call contracts. Traders often long volatility by holding the long position of put or call options for hedging purpose. In contrast, the short volatility strategy expects to earn the systematic risk premium by selling options. This algorithm will explore the risk premium effect in volatility selling.
Method
This short volatility algorithm first prescreens the option contracts by the expiry and the strike. To include the weekly contract, we use the universe function
def Initialize(self): option.SetFilter(self.UniverseFunc) def UniverseFunc(self, universe): return universe.IncludeWeeklys().Strikes(-20, 20).Expiration(timedelta(25), timedelta(35))
The algorithm selects contracts with one month until maturity so we choose a small range for expiration.
In
OnData(), we divide the option chain into put and call options. Then we create two lists
expiries and
strikes to save all available expiration dates and stike prices to facilitate
sorting and filtering.
The algorithm needs three option contracts with one month to the maturity: one ATM call, one ATM put to contruct the ATM straddle,
one 15% OTM put. As it's difficult to find the contract with the specified days to maturity and strikes,
we use
min() to find the most closest contract.
expiries = [i.Expiry for i in puts] # determine expiration date nearly 30 days expiry = min(expiries, key=lambda x: abs((x.date()-self.Time.date()).days-30)) strikes = [i.Strike for i in puts] # determine at-the-money strike strike = min(strikes, key=lambda x: abs(x-underlying_price)) # determine 15% out-of-the-money strike otm_strike = min(strikes, key = lambda x:abs(x-Decimal(0.85)*underlying_price))
From the above expiration date and strike price, we pick three option contracts
self.atm_call = [i for i in calls if i.Expiry == expiry and i.Strike == strike] self.atm_put = [i for i in puts if i.Expiry == expiry and i.Strike == strike] self.otm_put = [i for i in puts if i.Expiry == expiry and i.Strike == otm_strike]
In trading, we sell the ATM straddle by selling one ATM call and one ATM put. Then we buy an OTM put option as insurance against a market crash. Then we wait until the expiration and sell the underlying positions after option exercise and assignment. The portfolio is rebalanced once a month.
You can also see our Documentation and Videos. You can also get in touch with us via Chat.
Did you find this page helpful? | https://www.quantconnect.com/tutorials/strategy-library/volatility-risk-premium-effect | CC-MAIN-2020-05 | refinedweb | 444 | 59.3 |
following.
Basically this is my dimensional array project
i need to take my userNumber and add it to the array?
while looping i want to check the arrays with arrays[i] not sure if i did it right?
how to properly use a boolean searchArray?
import javax.swing.*; import java.awt.event.*; import java.awt.*; import java.util.Scanner; //import public class DimensionalArrays { // instance variables - replace the example below with your own int[] userNumber = new int[5]; Scanner scan = new Scanner(System.in); your add method should do ONLY 1 thing add a number you can call that method many times BUT, you do not always want to add it to the array //add method ** gets a number as a parameter and adds to array public void add(int num) { int i = 0; while (i < 5) { num = num[i]; answers[i] = num; System.out.println(answers[i]); i = i +1; } } //for loop to search the array ** for (int i=0; i< array.length; i++){} then while looping over you gotta check the array with array[i] public static void main(String args[]){ //for loop to ask person to add digit to array for (int index = 0; index < userNumber.length; index++){ userNumbers[index]= i; //store number as value in array } | http://www.dreamincode.net/forums/topic/271016-java-one-dimensional-array-help/ | CC-MAIN-2017-43 | refinedweb | 209 | 56.29 |
It's not the same without you
Join the community to find out what other Atlassian users are discussing, debating and creating.
We are using a patched version of ehcache-2.7.5 in JIRA 7.1.9 to address
We noticed in the 7.2.3 update that jar is replaced by an Atlassian fork. What is in this fork? Is the source code available so we can apply our patch?
The reason for the modifications and the patch that was applied to fix it are both available here:
To the best of my knowledge, yes.
That said, you should keep in mind that if Atlassian is not shipping that version yet, then we have not tested with it. Using a version other than the one we supply may make it more difficult for the support team to help out if there are other changes included in that version that cause problems.
Thanks. We'll give it a shot.
If that doesn't work how do we see the patch from that terracotta ticket? Seems to be eluding me. Is it available in diff format somehow?
It isn't stated directly, just described. it is replacing the final call to "getQuietly" with the block of text at the end. The point is that this returns the loaded value directly instead of trying to retrieve it from the cache again.
I was able to hunt down the repo and extract a formal patch for you:
diff --git a/ehcache-core/src/main/java/net/sf/ehcache/Cache.java b/ehcache-core/src/main/java/net/sf/ehcache/Cache.java index af1592e..cdd6043 100644 --- a/ehcache-core/src/main/java/net/sf/ehcache/Cache.java +++ b/ehcache-core/src/main/java/net/sf/ehcache/Cache.java @@ -1859,7 +1859,9 @@ public class Cache implements InternalEhcache, StoreListener { value = loadValueUsingLoader(key, loader, loaderArgument); } if (value != null) { - put(new Element(key, value), false); + final Element newElement = new Element(key, value); + put(newElement, false); + return newElement; } } catch (TimeoutException e) { throw new LoaderTimeoutException("Timeout on load for key " + key,. | https://community.atlassian.com/t5/Jira-questions/What-modifications-are-in-ehcache-2-10-2-atlassian-4-jar/qaq-p/451822 | CC-MAIN-2018-30 | refinedweb | 343 | 58.38 |
.
Recently the creator of Behat, Konstantin Kudryashov (a.k.a. everzet), wrote a really great article called Introducing Modelling by Example. The workflow we are going to use, when we build our feature, is highly inspired by the one presented by everzet.
In short, we are going to use the same
.feature.
In our case we will have our functional context, which will, for now, also serve as our acceptance layer, and our integration context, which will cover our domain. We will start by building the domain and then add the UI and framework-specific things afterwards.
Small Refactorings
In order to use the "shared feature, multiple contexts" approach, we have to do a few refactorings of our existing setup.
First, we are going to delete the welcome feature we did in the first part, since we do not really need it and it does not really follow the generic style we need in order to use multiple contexts.
$ git rm features/functional/welcome.feature
Second, we are going to have our features in the root of the
features folder, so we can go ahead and remove the
path attribute from our
behat.yml file. We are also going to rename the
LaravelFeatureContext to
FunctionalFeatureContext (remember to change the class name as well):
default: suites: functional: contexts: [ FunctionalFeatureContext ]
Finally, just to clean things up a bit, I think we should move all Laravel-related stuff into its own trait:
#'; } }
In the
FunctionalFeatureContext we can then use the trait and delete the things we just moved:
/** * Behat context class. */ class FunctionalFeatureContext implements SnippetAcceptingContext { use LaravelTrait; /** * Initializes context. * * Every scenario gets its own context object. * You can also pass arbitrary arguments to the context constructor through behat.yml. */ public function __construct() { }
Traits are a great way to clean up your contexts.
Sharing a Feature
As presented in part one, we are going to build a small application for time tracking. The first feature is going to be about tracking time and generating a time sheet from the tracked entries. Here is the feature:
Remember that this is only an example. I find it easier to define features in real life, since you have an actual problem you need to solve and often get the chance to discuss the feature with colleagues, clients, or other stakeholders.
Okay, let us have Behat generate the scenario steps for us:
$ vendor/bin/behat --dry-run --append-snippets
We need to tweak the generated steps just a tiny bit. We only need four steps to cover the scenario. The end result should look something like this:
/** * (); }
Our functional context is all ready to go now, but we also need a context for our integration suite. First, we will add the suite to the
behat.yml file:
default: suites: functional: contexts: [ FunctionalFeatureContext ] integration: contexts: [ IntegrationFeatureContext ]
Next, we can just copy the default
FeatureContext:
$ cp features/bootstrap/FeatureContext.php features/bootstrap/IntegrationFeatureContext.php
Remember to change the class name to
IntegrationFeatureContext and also to copy the use statement for the
PendingException.
Finally, since we are sharing the feature, we can just copy the four step definitions from the functional context. If you run Behat, you will see that the feature is run twice: once for each context.
Designing the Domain
At this point, we are ready to start filling out the pending steps in our integration context in order to design the core domain of our application. The first step is
Given I have the following time entries, followed by a table with time entry records. Keeping it simple, let us just loop over the rows of the table, try to instantiate a time entry for each of them, and add them to an entries array on the context:; } }
Running Behat will cause a fatal error, since the
TimeTracker\TimeEntry class does not yet exist. This is where PhpSpec enters the stage. In the end,
TimeEntry
TimeEntry class:
$ vendor/bin/phpspec desc "TimeTracker\TimeEntry" $ vendor/bin/phpspec run Do you want me to create `TimeTracker\TimeEntry` for you? y
After the class is generated, we need to update the autoload section of our
composer.json file:
"autoload": { "classmap": [ "app/commands", "app/controllers", "app/models", "app/database/migrations", "app/database/seeds" ], "psr-4": { "TimeTracker\\": "src/TimeTracker" } },
And of course run
composer dump-autoload.
Running PhpSpec gives us green. Running Behat gives us green as well. What a great start!
Letting Behat guide our way, how about we just move along to the next step,
When I generate the time sheet, right away?
The keyword here is "generate", which looks like a term from our domain. In a programmer's world, translating "generate the timesheet" to code could just mean instantiating a
TimeSheet class with a bunch of time entries. It is important to try and stick to the language from the domain when we design our code. That way, our code will help describe the intended behavior of our application.
I identify the term
generate as important for the domain, which is why I think we should have a static generate method on a
TimeSheet class that serves as an alias for the constructor. This method should take a collection of time entries and store them on the time sheet.
Instead of just using an array, I think it will make sense to use the
Illuminate\Support\Collection class that comes with Laravel. Since
TimeEntry will be an Eloquent model, when we query the database for time entries, we will get one of these Laravel collections anyway. How about something like this:
use Illuminate\Support\Collection; use TimeTracker\TimeSheet; use TimeTracker\TimeEntry; ... /** * @When I generate the time sheet */ public function iGenerateTheTimeSheet() { $this->sheet = TimeSheet::generate(Collection::make($this->entries)); }
By the way, TimeSheet is not going to be an Eloquent class. At least for now, we only need to make the time entries persist, and then the time sheets will just be generated from the entries.
Running Behat will, once again, cause a fatal error, because
TimeSheet does not exist. PhpSpec can help us solve that:
$()
We still get a fatal error after creating the class, because the static
generate() method still does not exist. Since this is a really simple static method, I do not think there is a need for a spec. It is nothing more than a wrapper for the constructor:
<?php namespace TimeTracker; use Illuminate\Support\Collection; class TimeSheet { protected $entries; public function __construct(Collection $entries) { $this->entries = $entries; } public static function generate(Collection $entries) { return new static($entries); } }
This will get Behat back to green, but PhpSpec is now squeaking at us, saying:
Argument 1 passed to TimeTracker\TimeSheet::__construct() must be an instance of Illuminate\Support\Collection, none given. We can solve this by writing a simple
let() function that will be called before each spec:
<'); } }
This will get us back to green all over the line. The function makes sure that the time sheet is always constructed with a mock of the Collection class.
We can now safely move on to the
Then my total time spent on... step. We need a method that takes a task name and return the accumulated duration of all entries with this task name. Directly translated from gherkin to code, this could be something like
totalTimeSpentOn($task):
/** * ); }
The method does not exist, so running Behat will give us
Call to undefined method TimeTracker\TimeSheet::totalTimeSpentOn().
In order to spec out the method, we will write a spec that looks somehow similar to what we already have in our scenario:); }
Note that we do not use mocks for the
TimeEntry and
Collection.
Moving along:
$ vendor/bin/phpspec run Do you want me to create `TimeTracker\TimeSheet::totalTimeSpentOn()` for you? y $ vendor/bin/phpspec run 25 ✘ it should calculate total time spent on task expected [integer:240], but got null.
In order to filter the entries, we can use the
filter() method on the
Collection class. A simple solution that gets us to green:
public function totalTimeSpentOn($task) { $entries = $this->entries->filter(function($entry) use ($task) { return $entry->task === $task; }); $duration = 0; foreach ($entries as $entry) { $duration += $entry->duration; } return $duration; }
Our spec is green, but I feel that we could benefit from some refactoring here. The method seems to do two different things: filter entries and accumulate the duration. Let us extract the latter to its own method:
public function totalTimeSpentOn($task) { $entries = $this->entries->filter(function($entry) use ($task) { return $entry->task === $task; }); return $this->sumDuration($entries); } protected function sumDuration($entries) { $duration = 0; foreach ($entries as $entry) { $duration += $entry->duration; } return $duration; }
PhpSpec is still green and we now have three green steps in Behat. The last step should be easy to implement, since it is somewhat similar to the one we just did.
/** * @Then my total time spent should be :expectedDuration minutes */ public function myTotalTimeSpentShouldBeMinutes($expectedDuration) { $actualDuration = $this->sheet->totalTimeSpent(); PHPUnit::assertEquals($expectedDuration, $actualDuration); }
Running Behat will give us
Call to undefined method TimeTracker\TimeSheet::totalTimeSpent(). Instead of doing a separate example in our spec for this method, how about we just add it to the one we already have? It might not be completely in line with what is "right" to do, but let us be a little pragmatic:
... $this->beConstructedWith($collection); $this->totalTimeSpentOn('sleeping')->shouldBe(240); $this->totalTimeSpentOn('eating')->shouldBe(60); $this->totalTimeSpent()->shouldBe(300);
Let PhpSpec generate the method:
$ vendor/bin/phpspec run Do you want me to create `TimeTracker\TimeSheet::totalTimeSpent()` for you? y $ vendor/bin/phpspec run 25 ✘ it should calculate total time spent on task expected [integer:300], but got null.
Getting to green is easy now that we have the
sumDuration() method:
public function totalTimeSpent() { return $this->sumDuration($this->entries); }
And now we have a green feature. Our domain is slowly evolving!
Designing the User Interface
Now, we are moving to our functional suite. We are going to design the user interface and deal with all the Laravel-specific stuff that is not the concern of our domain.
While working in the functional suite, we can add the
-s flag to instruct Behat to only run our features through the
FunctionalFeatureContext:
$ vendor/bin/behat -s functional
The first step is going to look similar to the first one of the integration context. Instead of just making the entries persist on the context in an array, we need to actually make them persist in a database so that they can be retrieved later:(); } }
Running Behat will give us fatal error
Call to undefined method TimeTracker\TimeEntry::save(), since
TimeEntry still is not an Eloquent model. That is easy to fix:
namespace TimeTracker; class TimeEntry extends \Eloquent { }
If we run Behat again, Laravel will complain that it cannot connect to the database. We can fix this by adding a
database.php file to the
app/config/testing:
<?php return array( 'default' => 'sqlite', 'connections' => array( 'sqlite' => array( 'driver' => 'sqlite', 'database' => ':memory:', 'prefix' => '', ), ), );
Now if we run Behat, it will tell us that there is no
time_entries table. In order to fix this, we need to make a migration:
$ php artisan migrate:make createTimeEntriesTable --create="time_entries"
Schema::create('time_entries', function(Blueprint $table) { $table->increments('id'); $table->string('task'); $table->integer('duration'); $table->timestamps(); });
We are still not green, since we need a way to instruct Behat to run our migrations before every scenario, so we have a clean slate every time. By using Behat's annotations, we can add these two methods to the
LaravelTrait trait:
/** * @BeforeScenario */ public function setupDatabase() { $this->app['artisan']->call('migrate'); } /** * @AfterScenario */ public function cleanDatabase() { $this->app['artisan']->call('migrate:reset'); }
This is pretty neat and gets our first step to green.
Next up is the
When I generate the time sheet step. The way I see it, generating the time sheet is the equivalent of visiting the
index action of the time entry resource, since the time sheet is the collection of all the time entries. So the time sheet object is like a container for all the time entries and gives us a nice way to handle entries. Instead of going to
/time-entries, in order to see the time sheet, I think the employee should go to
/time-sheet. We should put that in our step definition:
/** * @When I generate the time sheet */ public function iGenerateTheTimeSheet() { $this->call('GET', '/time-sheet'); $this->crawler = new Crawler($this->client->getResponse()->getContent(), url('/')); }
This will cause a
NotFoundHttpException, since the route is not defined yet. As I just explained, I think this URL should map to the
index action on the time entry resource:
Route::get('time-sheet', ['as' => 'time_sheet', 'uses' => 'TimeEntriesController@index']);
In order to get to green, we need to generate the controller:
$ php artisan controller:make TimeEntriesController $ composer dump-autoload
And there we); }
The crawler is looking for a
<td> node with an id of
[task_name]TotalDuration or
totalDuration in the last example.
Since we still do not have a view, the crawler will tell us that
The current node list is empty.
In order to fix this, let us build the
index action. First, we fetch the collection of time entries. Second, we generate a time sheet from the entries and send it along to the (still non-existing) view.
use TimeTracker\TimeSheet; use TimeTracker\TimeEntry; class TimeEntriesController extends \BaseController { /** * Display a listing of the resource. * * @return Response */ public function index() { $entries = TimeEntry::all(); $sheet = TimeSheet::generate($entries); return View::make('time_entries.index', compact('sheet')); } ...
The view, for now, is just going to consist of a simple table with the summarised duration values:
!
Conclusion
If you run
vendor/bin/behat in order to run both Behat suites, you will see that both of them are green now. If you run PhpSpec though, unfortunately, you will see that our specs are broken. We get a fatal error
Class 'Eloquent' not found in .... This is because Eloquent is an alias. If you take a look in
app/config/app.php under aliases, you will see that
Eloquent is actually an alias for
Illuminate\Database\Eloquent\Model. In order to get PhpSpec back to green, we need to import this class:
namespace TimeTracker; use Illuminate\Database\Eloquent\Model as Eloquent; class TimeEntry extends Eloquent { }
If you run these two commands:
$ vendor/bin/phpspec run; vendor/bin/behat
You will see that we are back to green, both with Behat and PhpSpec. Y.
In the next article, we are going to do a lot of refactoring in order to avoid too much logic on our Eloquent models, since these are more difficult to test in isolation and are tightly coupled to Laravel. Stay tuned!
Envato Tuts+ tutorials are translated into other languages by our community members—you can be involved too!Translate this post
| https://code.tutsplus.com/tutorials/laravel-bdd-and-you-the-first-feature--cms-22486 | CC-MAIN-2017-51 | refinedweb | 2,445 | 50.06 |
GridSearch is Not Enough: Part Six
I write a lot of blogposts on why you need more than grid-search to properly judge a machine learning model. In this blogpost I want to demonstrate yet another reason; labels often seem to be wrong.
It turns out that bad labels are a huge problem in many popular benchmark datasets. To get an impression of the scale of the issue, just go to labelerrors.com. It’s an impressive project that shows problems with many popular datasets; CIFAR, MNIST, Amazon Reviews, IMDB, Quickdraw and Newsgroups just to name a few. It’s part of a research paper that tries to quantify how big of a problem these bad labels are.
Figure 1: The table from the paper gives a nice summary. It’s a huge problem.? Or are we creating a model that is better able to overfit on the bad labels?
The results from the paper didn’t surprise me much, but it did get me wondering how easy it might be for me to find bad labels in a dataset myself. After a bit of searching I discovered the Google Emotions dataset. This dataset contains text from Reddit (so expect profanity) with emotion tags attached. There are 28 different tags and a single text can belong to more than one emotion
The dataset also has an paper about it which explains how the dataset came to be. It explains what steps have been taken to make the dataset robust.
All of this amounts to quite a lot of effort indeed. So how hard would it be to find bad examples here?
Here’s a quick trick seems worthwhile. Let’s say that we train a model that is very general. That means high bias, low variance. You may have a lower capacity model this way, but it will be less prone to overfit on details.
After training such a model, it’d be interesting to see where the model disagrees with the training data. These would be valid candidates to check, but it might result in list that’s a bit too long for comfort. So to save time you can can sort the data based on the
predict_proba()-value. When the model gets it wrong, that’s interesting, but when it also associates a very low confidence to the correct class, that’s an example worth double checking.
So I figured I would try this trick on the Google emotions dataset to see what would happen. I tried predicting a few tags chosen at random and tried using this sorting trick to to see how easy it was to find bad labels. For each tag, I would apply my sorting to see if I could find bad labels in the top 20 results.
Here’s some of the results:
I don’t know about you, but many of these examples seem wrong.
Before pointing a finger, it’d be good to admit that interpreting emotion isn’t a straightforward task. At all. There’s context and all sorts of cultural interpretation to consider. It’s a tricky task to define well.
The paper also added a disclaimer to the paper to make people aware of potential flaws in the dataset. Here’s a part of it: labeling, precision, and recall for a trained model.
Adding this disclaimer is fair. That said. It really feels just a bit too weird that it was that easy for me to find examples that really seem so clearly wrongly labeled. I didn’t run through the whole dataset, so I don’t have a number on the amount of bad labels but I’m certainly worried now. Given the kind of label errors, I can certainly imagine that my grid-search results are skewed.
The abstract of the paper certainly paints a clear picture of what this exercise means for state-of-the-art models:
We find that lower capacity models may be practically more useful than higher capacity models in real-world datasets with high proportions of erroneously labeled data. For example, on ImageNet with corrected labels: ResNet-18 outperforms ResNet-50 if the prevalence of originally mislabeled test examples increases by just 6%. On CIFAR-10 with corrected labels: VGG-11 outperforms VGG-19 if the prevalence of originally mislabeled test examples increases by 5%. Traditionally, ML practitioners choose which model to deploy based on test accuracy – our findings advise caution here, proposing that judging models over correctly labeled test sets may be more useful, especially for noisy real-world datasets.
More people should do check their labels more frequently. Anybody is free to try out any trick that they like, but if you’re looking for a simple place to start, check out the cleanlab project. It’s made by the same authors of the labelerrors-paper and is meant to help you find bad labels. I’ve used it a bunch of times and I can confirm that it’s able to return relevant examples to double-check.
Here’s the standard snippet that you’d need:
from cleanlab.pruning import get_noise_indices # Find label indices = get_noise_indices( ordered_label_errors =numpy_array_of_noisy_labels, s=numpy_array_of_predicted_probabilities, psx='normalized_margin', # Orders label errors sorted_index_method ) # Use indices to subset dataframe examples_df.iloc[ordered_label_errors]
It’s not a lot of effort and it feels like such an obvious thing to check going forward. The disclaimer on the Google Emotions paper checks a lot of boxes, but imagine that in the future they’d add “we checked out labels with cleanlab before releasing it”. For a dataset that’s meant to become a public benchmark, it’d sure be a step worth adding.
For everyone; maybe we should spend a less time tuning parameters and instead spend it trying to get a more meaningful dataset. If working at Rasa is teaching me anything, it’s that this would be time well spent.
I read a few articles about bad labels which I summarised into TILs.
For attribution, please cite this work as
Warmerdam (2021, Sept. 2). koaning.io: Bad Labels. Retrieved from
BibTeX citation
@misc{warmerdam2021bad, author = {Warmerdam, Vincent}, title = {koaning.io: Bad Labels}, url = {}, year = {2021} } | https://koaning.io/posts/labels/?utm_source=pocket_mylist | CC-MAIN-2021-49 | refinedweb | 1,027 | 71.04 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.