
text stringlengths 454 608k | url stringlengths 17 896 | dump stringclasses 91
values | source stringclasses 1
value | word_count int64 101 114k | flesch_reading_ease float64 50 104 |
|---|---|---|---|---|---|
Microsoft offers great guidance on how to use OUIF with SPFx by taking an explicit dependency on the latest version of the OUIF React package. I also wrote about this previously in August of 2017. And to be crystal clear, the guidance IS THE BEST APPROACH!
You get an explicit dependency with npm i office-ui-fabric-react@latest --save (or any version you care to use), and also remember to remove the reference to @microsoft/sp-office-ui-fabric-core as mentioned in the guidance as the core styles are included in the main npm package.
A simple hello world sample will without using OUIF components be around 10KB in size, and when you add a button component with
import { Button } from 'office-ui-fabric-react/lib/Button';
the .js grows to 179KB. The size is not that bad in itself as it will be served compressed from a CDN, but it illustrates how much the bundle grows by just adding a simple OUIF component.
If you want the smallest bundle size possible and feel like living on the edge there is another option which I’ll outline below. But this approach comes with a huge caveat. Every time Microsoft release a new version of SPFx, you have to re-test and potentially rebuild and deploy your solutions as they can break if Microsoft have updated OUIF React with a breaking change.
Here’s how – stop reading if you want to play it safe!
Instead of adding a reference to office-ui-fabric-react, add a reference to @microsoft/office-ui-fabric-react-bundle instead. This is the internal version of OUIF React already bundled on each modern page.
As I’m on SPFx drop 1.4 I use:
npm i @microsoft/office-ui-fabric-react-bundle@1.4.0 --save
Be sure to use the bundle version matching your SPFx version.
Since this is a pre-bundled version of OUIF React components, you need to change from explicit static linking to dynamic linking for the components you use in your code.
import { Button } from '@microsoft/office-ui-fabric-react-bundle';
When you rebuild your web part, the size drops back down to 10kb even though the bundle file itself is 1.8MB. This is because this specific OUIF bundle is already included in the sp-pages-assembly .js file loaded automatically on a modern page. By using @microsoft/office-ui-fabric-react-bundle instead of office-ui-fabric-react we are now down to zero footprint.
If you are using the OUIF core CSS, remember to re-add @microsoft/sp-office-ui-fabric-core to your solution which adds around 1KB to the overall size.
History lesson
I raised an issue on github back in August of 2017 () where I point out that before SPFx v1.1.1 your solutions automagically took a dependency on the pre-loaded version of Office UI Fabric React. I discussed this a bit with Vesa Juvonen at Microsoft, and although this did work, OUIF React was not officially supported before the guidance came out which said to take an explicit dependency. If you have old solutions created pre v1.1.1, the recommendation is to upgrade those and add the explicit dependency. This will ensure your solutions will just keep on working and working and working on it :)
Summary
It is possible to get rid of the Office UI Fabric React footprint in your bundle size, but doing so requires that you have super control of your SPFx solutions and are ready to re-build and re-deploy them every time Microsoft release a new version of SPFx. So far the versions of OUIF have been backwards compatible, but we can be pretty sure that it won’t stay like this forever.
If you truly care about bundle sized, then think hard about which frameworks and components you use in your solution, and promote usage of the ones supporting static linking of the parts you use. | https://www.techmikael.com/2018/01/follow-up-discussion-on-bundle-sizes.html | CC-MAIN-2021-25 | refinedweb | 664 | 59.74 |
"Elasticsearch Client builder, complete with schema validation, and AWS boto-based authentication"
Project description
You may wonder why this even exists, as at first glance it doesn’t seem to make anything any easier than just using elasticsearch.Elasticsearch() to build a client connection. I needed to be able to reuse the more complex schema validation bits I was employing, namely:
- master_only detection
- AWS IAM credential collection via boto3.session.Session
- Elasticsearch version checking and validation, and the option to skip this.
- Configuration value validation, including file paths for SSL certificates, meaning:
- No unknown keys or unacceptable parameter values are accepted
- Acceptable values and ranges are established–and easy to amend, if necessary.
So, if you don’t need these, then this library probably isn’t what you’re looking for. If you want these features, then you’ve come to the right place.
Example Usage
from es_client import Builder config = { 'elasticsearch': { 'master_only': True, 'client': { 'hosts': '10.0.0.123', 'use_ssl': True, 'ca_certs': '/etc/elasticsearch/certs/ca.crt', 'username': 'joe_user', 'password': 'password', 'timeout': 60, } } } try: client = Builder(config).client except: # Do exception handling here...
Additionally, you can read from a YAML configuration file:
--- elasticsearch: master_only: true client: hosts: 10.0.0.123 use_ssl: true ca_certs: /etc/elasticsearch/certs/ca.crt username: joe_user password: password timeout: 60
from es_client import Builder from es_client.exceptions import ConfigurationError from es_client.helpers.utils import get_yaml try: client = Builder(get_yaml('/path/to/es_client.yml').client except: # Do exception handling here...
The same schema validations apply here as well.
Project details
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages. | https://pypi.org/project/es-client/1.1.1/ | CC-MAIN-2021-49 | refinedweb | 276 | 50.84 |
I face a really odd thing When rendering a scene the output AVI file is very different from the animation I see inside blender. The script is looping over a function which create the scene:
def main(self): for i in range(self.n_scenes): valid_scene = False while not valid_scene: self.clean_scene() valid_scene = self.create_scene() if len(os.listdir(self.output_path)): self.render_scene(f'{len(os.listdir(self.output_path))}.avi') else: self.render_scene('0.avi')
For example the initial position of the objects is really different from what I see in blender, in addition from the 2nd frame the locations are different from the first frame.
Before rendering I bake all the objects using
bpy.ops.ptcache.bake_all() and for cleaning the scene after each render using the following funciton:
def clean_scene(self): bpy.ops.object.select_by_type(type='MESH') bpy.ops.object.delete()
What am I doing wrong? Is there any why to reset the scene? why there is a difference between played animation over blender and the rendered one? | https://blenderartists.org/t/difference-between-played-and-rendered-animation/1184997 | CC-MAIN-2019-43 | refinedweb | 169 | 51.44 |
Class to manipulate a set of line segments. More...
#include <line_segment_set.h>
Class to manipulate a set of line segments.
Adds a line segment to this collection.
Draws this line segment set.
Draws the line segment on an image
returns the ith fitted line segment
Returns a vector containing the fitted line segments.
Randomly colors this line segment set on an image.
Draws the line segment set using a different random color for each segment
Reads this Edge_segment_set from an input stream.
Read an edge segment set from an input stream. The input edge_set is necessary to bind the fitted segments to the original detected edges
Implements kjb::Readable.
Reads this Edge_segment_set from an input file.
Reimplemented from kjb::Readable.
Returns the number of segments in this set.
Writes this Edge_segment_set to an output stream.
Implements kjb::Writeable.
Writes this Edge_segment_set to a file.
Reimplemented from kjb::Writeable. | http://kobus.ca/research/resources/doc/doxygen/classkjb_1_1Line__segment__set.html | CC-MAIN-2022-21 | refinedweb | 148 | 61.83 |
We're very excited to announce that - as of 5/16/2011 - BizTalk Terminator is an official Microsoft tool and is hosted at the Microsoft Download Center!
Go here to download it.
UPDATE: BizTalk Terminator is also available via the BizTalk Health Monitor tool which integrates MBV and Terminator functionality into an MMC Snap-In that you can run as a part of your BizTalk Admin Console. See here for more details on that.
Important info about Terminator:
- Terminator ClickOnce Deployment is no longer available now that we have moved to the Microsoft Download Center
- Terminator doesn’t care about the Windows version as long as the .NET framework is available
- Terminator requires a minimum of .NET 2.0
- Just because you’re logged in as a BTS Admin doesn’t mean all Terminator functionality will work for you. You need rights to read from registry on BTS box, make WMI calls, and make certain changes in BTS DBs that a BTS Admin can’t do. If you want to be sure you won’t run into any permissions issues, you may want to also be a local Admin on the BTS box and a SysAdmin within SQL.
- Terminator recognizes and has tasks for BTS2004, BTS2006, BTS2006 R2, BTS2009, BTS2010, BTS2013, and BTS2013 R2
- Terminator supports and has been tested with SQL2000, SQL2005, SQL2008, SQL2008 R2, SQL2012, and SQL2014
- If you try to run a task that uses WMI with Terminator remote to BTS when SQL is also remote to BTS, you’ll run into a double hop issue and get an error like the following: “WMIAccess::workOnInstances: Login failed for user ‘NT AUTHORITY\ANONYMOUS LOGON’.” This is a known issue and is due to WMI limitations and the fact that the BTS WMI namespace will only be installed on the BTS box. So if you plan on using a WMI task, you will need to run Terminator on the BTS box itself when SQL is remote to BTS. Also be sure to select the local BTS server in the BizTalkServer parameter dropdown.
- BTS2004 runs on .NET 1.1 and you need a minimum of BTS2004 SP2 to safely install .NET 2.0 on the box so most BTS2004 users run Terminator remotely (as mentioned above, the only caveat is the WMI tab that needs to be run on the BTS box if SQL is remote)
- To ensure that someone doesn’t download Terminator and continue to run the same version forever, the tool has a built-in timebomb that will disable the tool and ask the user to download the newer version. If you get the “Terminator is out of date. Please download a newer version” error when trying to run Terminator, simply go download the latest build and you’ll be back up and running. Normally, it’s not such a big deal to make sure you have the latest version of a tool but since Terminator does directly make changes to your BTS databases – potentially production DBs – we do place more stress on using the latest build of the tool.
- BE CAREFUL with this tool. If you are unsure about what a task does or if it’s right for your situation, thoroughly read the task documentation displayed when a task is selected. If you’re still unsure, don’t run it – contact MS support.
- If you want more info on how/when to use Terminator, take a look at
- If you are having problems with Terminator and have verified that you are running the latest build, please contact Microsoft Support and we will help troubleshoot your issue. Please have the BiztalkTerminator.log file (located at C:\temp) ready to provide the support engineer who assists you.
It's expired~~
We published the latest version just yesterday (11/30). Please try refreshing the Microsoft Download Center page. The new version you download should be 2.0.0.274 and expires on 2/28/2012. Post back if you're still having problems with it. – Thanks!
When running Terminator to fix and orphaned instance issue we are getting the following:
DataAccess::RunExecutionAsync: Login failed for user 'NT AUTHORITYANONYMOUS LOGON'.
We have the message box and tracking dbs on separate SQL instances. | https://blogs.msdn.microsoft.com/biztalkcpr/2009/09/30/biztalk-terminator-download-install-info/ | CC-MAIN-2017-34 | refinedweb | 703 | 58.72 |
Nivedita Singhvi wrote:
>
> "David S. Miller" wrote:
> > Where will sctp_statistics be defined? If it will be in net/sctp/*.c,
> > then you will need to ifdef this ipv4 procfs code on CONFIG_IP_SCTP
>
> Rats, yes, it is in net/sctp/protocol.c. I'll move it under the ifdef
> and make up a complete patch with the dependent code for review
> purposes and repost. Thanks for the catch!
My apologies for the latency in getting back on this (critical
interrupts from other directions)..
We're considering a modification to the original proposal, which
was to display SCTP SNMP stats in /proc/net/snmp along with the
other AF_INET protocols currently being displayed.
We're now considering simply displaying the sctp stats structures
(snmp and other extended) under the /proc/net/sctp/ subdirectory.
This is due to several reasons - one is that the CONFIG_IP_SCTP
def isnt enough. SCTP can also be compiled as a module, and may
or may not be loaded. We cant make assumptions in net/ipv4/proc.c
about whether the sctp_statistics structure is available or not..
Note #if defined (CONFIG_IP_SCTP) || defined (CONFIG_IP_SCTP_MODULE)
isnt enough. A clean way to do this would be to have an af_inet
top level registration process and have the sctp module register
when loaded, as is typical elsewhere. We really dont want to do
this at this point, and introduce too many dependencies on directories
outside of net/sctp at this time.
Secondly, the SCTP MIB is still being formed, and we're probably
going to need additions/changes to the spec. In the interim, (or
possibly, permanently) we're going to need extended sctp stats which
arent in the spec, much like the current linux mib struct which
defines a set of extended TCP counters.
It would be easier to manage this under the sctp subdirectory
altogether. i.e. We diplay the SCTP SNMP and other extended stats
as /proc/net/sctp/snmp and /proc/net/sctp/sctp_mib or some such
name (which would be somewhat dynamic short term). This would also
solve unnecessary duplication for AF_INET6 for us.
Any issues, thoughts, suggestions?
thanks,
Nivedita | http://oss.sgi.com/archives/netdev/2002-11/msg00250.html | CC-MAIN-2013-20 | refinedweb | 352 | 64.91 |
Success Party
A billionaire won a lottery but he is a big miser so to minimize the people he organizes a party but in a different style.
Each member attending a party is given a name and a single digit number (from 0 to 9). Now they all play a game.
The rules of the game are as follows:
If only one player is playing the game,then he will be the winner.
Otherwise, all the players add the numbers provided to them until they get a single digit number.
If the number obtained is available with any one of the player attending the party, then that player is declared as the winner.
Otherwise the game is declared as a draw.
Constraints
1 ≤ T ≤ 100
1 ≤ n ≤ 1000
Input
The first line contains T — the number of test cases.
Each test case contains a number n-the number of people attending the party.
Next n lines contains the name and the number separated by space.
Output
If the game is declared as a draw then print “NO”(without double quotes).
Otherwise print the name of the winners in each line and also display the total number of winners.
def sum_digits(n): s = 0 while n: s += n % 10 n //= 10 return s for x in range(int(input())): sum = 0 s = [] m = [] n = int(input()) for i in range(n): lis = [str(x) for x in input().split()] s.append(lis[0]) m.append(lis[1]) sum = sum + int(lis[1]) no = sum_digits(sum) while(no>=10): no = sum_digits(no) st = [] for y in range(len(m)): if int(m[y]) == no: st.append(s[y]) if len(st) == 0: print('NO') else: for z in st: print(z) print(len(st))
Competitive coder
Hackerearth coder
| https://coderinme.com/success-party-hackerearth-problem-coderinme/ | CC-MAIN-2019-47 | refinedweb | 296 | 70.63 |
A Rails Cloud Implementation Using CouchDB and Heroku
CouchDB is an interesting implementation of a schema-less data store. It supports client applications through HTTP and a REST-style API. I don't use CouchDB's support for replication, using it instead to store structured data. While I sometimes run CouchDB locally during development, I like to keep CouchDB running on a low-cost VPS instance that I access interactively and from client applications. (I will refer to data instances as "documents" in this article.)
When you have mastered how to use the Heroku platform to deploy and manage Rails web applications, you can choose CouchDB to use on the backend. Using a simple Rails app, Note Taker with Search (see the previous article in this series, "Deploying a Rails Application to Heroku"), I will demonstrate how to use CouchDB, based on my own use of this data storage and management tool. (The code download for this article contains all the examples in the directory note_taker_couchdb, and you should extract them and work along with me through every example.) I will use a combination of the APIs in the couchrest gem with direct REST-style calls using the simplehttp gem.
A particularly interesting CouchDB attribute is its versioning system. CouchDB never discards old versions after adding new data. Rather, it creates new versions of documents by reusing the ID of a document and updating the document's version number. Old versions are left intact. If you are concerned about wasted disk space, don't be: CouchDB also uses a lot of disk storage for indexes, and disk space is inexpensive.
You create indexes on documents by writing map/reduce functions in JavaScript and adding them to databases. The map/reduce functions that you write define what data can be searched for efficiently. The general topic of writing CouchDB map/reduce functions is beyond the scope of this article, but I will walk you through the function I defined for the next example. The database for this example is notes. I have only one type of data document in the notes database, and the document type is also called notes. In all further discussions, whenever I refer to notes I mean documents.
I write map/reduce functions for two types of views on the notes documents:
- words: used in note titles and content
- users: defined by user IDs in notes that specified who wrote the note
In this example, you are allowed to see only notes that have the same user ID as that set in a session when you login to this web application. CouchDB uses JSON to store data, so your notes documents will be stored internally as JSON. Map/reduce functions are also expressed as JSON with the JavaScript code in embedded strings. I don't much like this notation, but it is only a minor annoyance. Document IDs are specified by the hash key _id, and documents containing map/reduce JavaScript functions for defining views have ID names starting with _design; for example:
{ "_id": "_design/notes", "language": "javascript", "views": { "words": { "map": "function(doc) { var s = doc.title + doc.content;
var words = s.replace(/[0123456789!.,;]+/g,' ').toLowerCase().split(' ');
for (var word in words) { emit(words[word], doc._id); } }" } "users": { "map": "function(doc) { if (doc.user_id) { emit(doc.user_id, null); }}" } } }
Neither of these views required a reduce function. The function emit writes a key/value pair. It is fairly common to see null for either the key or value. In the view users, I only need all user IDs as keys because I specify a null value for each key/value pair; I only need the keys. Interestingly, the user IDs for the view are culled from the notes documents and there is no separate document type for users.
To help you understand the views created by these JavaScript functions, take a look at some examples of REST calls to access the two views I just created (note that %22 is a " (quotation mark) character in URL encoding):
- To get all words:
- To search for documents containing a specific word:
- To list the first 11 docs (including views):
- To get note docs by user ID = "1":
Numbers 2 and 4 are the most interesting, because they filter on specific key values. Also, notice in example number 3 that although the query would return all documents of type notes, I set a limit of returning 11 documents.
Author's Note: Using CouchDB seems natural to me because it is built with tools and concepts that I know, such as REST-style calls and JSON storage. I have been using CouchDB for almost a year, and unlike simpler key/value stores like memcached, Tokyo Cabinet, and Redis (which does offer some structure like lists and sets), document-oriented data stores like CouchDB are a more natural fit for most of my work. That said, I try to choose the best tools for each specific job and you obviously should too.
In all these examples, the returned data is in JSON format. CouchDB provides a web interface called Futon (see Figure 1 for a screenshot of me inspecting the document that defined the map/reduce functions for the two views I need in this example).
Figure 1. Using Futon to Inspect Two JavaScript Views: Here is a screenshot of me inspecting the document that defined the map/reduce functions for the two views.
At the bottom of the screenshot, I have nine versions of the implementations of these views. Futon makes it easy to go back and review changes in old versions. The screenshot in Figure 2 shows an edit view in Futon that allows you to modify a document and save it as a new version:
Figure 2. Using Futon to Edit One JavaScript View: Here is an edit view in Futon that allows you to modify a document and save it as a new version.
The screenshot in Figure 3 shows me using Futon to view a note. Notice that there are no data items for "words." Those are defined in an index and show themselves only when the user performs a search.
Figure 3. Inspecting a Note Document: Here is a screenshot of me using Futon to view a note.
I seldom use Futon for editing or creating documents, although I did use Futon to define my views. I write almost all of my CouchDB client code in Ruby.
Now you can look at the changes you need to make to the MongoDB-based web application (from the previous article in this series) to use CouchDB instead.
Require three gems in your environment.rb file:
config.gem 'postgres' config.gem 'couchrest' config.gem 'simplehttp'
Also set two global variables at the end on your environment.rb file:
# setup for CouchDB COUCHDB_HOST = ENV['COUCHDB_RUBY_DRIVER_HOST'] || 'localhost' COUCHDB_PORT = ENV['COUCHDB_RUBY_DRIVER_PORT'] || 5984
Most of the code changes are in the Notes model class. First, notice that this Notes class is not derived from ActiveRecord:
class Note attr_accessor :user_id, :title, :content def to_s "note: #{title} content: #{content[0..20]}..." end
Using mostly low-level, REST-style calls to CouchDB, I will manually implement the behavior in the ActiveRecord version from the PostgreSQL-backed example (Part I) and the MongoRecord::Base version from the MongoDB-backed example (Part II).
The next method is used to create a new note document. This code is simpler than the MongoDB article (where I had to create a document attribute that was a list of words in the document), but you pay for some of this simplicity by having to write the JavaScript view functions. Here, I use the higher-level save_doc API from the couchrest gem:
def Note.make user_id, title, content @db ||= CouchRest.database("{COUCHDB_HOST}:#{COUCHDB_PORT}/notes") @db.save_doc({'user_id' => user_id.to_s, 'title' => title, 'content' => content})['id'] end
The next method implements a search function. I tokenize the search string and for each token make a REST-style call to get all of the document IDs that contain the word. These results are stored in the hash table score_hash (keys are the document IDs, and the values are counts of how many times a search token is found in the corresponding document). I sort the hash table by value and return the documents in JSON hash table format in sort order:
def Note.search query @db ||= CouchRest.database("{COUCHDB_HOST}:#{COUCHDB_PORT}/notes") tokens = query.downcase.split score_hash = Hash.new(0) tokens.each {|token| uri = "{token}%22" JSON.parse(SimpleHttp.get(uri))['rows'].each {|row| score_hash[row['value']] += 1} } score_hash.sort {|a,b| a[1] <=> b[1]} score_hash.keys.collect {|key| @db.get(key)} end
Note: This implementation of method search would be very inefficient for search strings with many words, because a REST call would be made for each search word. Compare this to the MongoDB version of method search, where a single call is made and the entire query is performed on the server (in fast C++ code).
The next method returns all notes in the data store with a given user ID. I build a GET request URI and then use the simplehttp and json gems to get the documents as an array of JSON hash tables:
def Note.all user_id @db ||= CouchRest.database("{COUCHDB_HOST}:#{COUCHDB_PORT}/notes") uri = "{user_id}%22" JSON.parse(SimpleHttp.get(uri))['rows'].collect {|hash| @db.get(hash['id'])} end
The following method returns a note with a specific ID. In contrast to the last method, I use a low-level API from the couchrest gem instead of building a request URI and manually performing the REST call:
def Note.find id puts "** Note.find id=#{id}" @db ||= CouchRest.database("{COUCHDB_HOST}:#{COUCHDB_PORT}/notes") @db.get(id) end end
The controller code is almost identical to the first two Rails examples in this article. Calling the search method you just saw performs the search:
notes = Note.search(params[:search])
All notes with a specific user ID are found and passed to the scaffold view:
@notes = Note.all(session['user_id'])
Page 1 of 2
| http://www.developer.com/lang/rubyrails/article.php/3860651/A-Rails-Cloud-Implementation-Using-CouchDB-and-Heroku.htm | CC-MAIN-2015-18 | refinedweb | 1,669 | 62.48 |
Question:
How can I replace multiple spaces in a string with only one space in C#?
Example:
1 2 3 4 5
would be:
1 2 3 4 5
Solution:1
RegexOptions options = RegexOptions.None; Regex regex = new Regex("[ ]{2,}", options); tempo = regex.Replace(tempo, " ");
Solution:2
I like to use:
myString = Regex.Replace(myString, @"\s+", " ");
Since it will catch runs of any kind of whitespace (e.g. tabs, newlines, etc.) and replace them with a single space.
Solution:3
string xyz = "1 2 3 4 5"; xyz = string.Join( " ", xyz.Split( new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries ));
Solution:4
I think Matt's answer is the best, but I don't believe it's quite right. If you want to replace newlines, you must use:
myString = Regex.Replace(myString, @"\s+", " ", RegexOptions.Multiline);
Solution:5
Another approach which uses LINQ:
var list = str.Split(' ').Where(s => !string.IsNullOrWhiteSpace(s)); str = string.Join(" ", list);
Solution:6
It's much simpler than all that:
while(str.Contains(" ")) str = str.Replace(" ", " ");
Solution:7
Regex can be rather slow even with simple tasks. This creates an extension method that can be used off of any
string.
public static class StringExtension { public static String ReduceWhitespace(this String value) { var newString = new StringBuilder(); bool previousIsWhitespace = false; for (int i = 0; i < value.Length; i++) { if (Char.IsWhiteSpace(value[i])) { if (previousIsWhitespace) { continue; } previousIsWhitespace = true; } else { previousIsWhitespace = false; } newString.Append(value[i]); } return newString.ToString(); } }
It would be used as such:
string testValue = "This contains too much whitespace." testValue = testValue.ReduceWhitespace(); // testValue = "This contains too much whitespace."
Solution:8
myString = Regex.Replace(myString, " {2,}", " ");
Solution:9
For those, who don't like
Regex, here is a method that uses the
StringBuilder:
public static string FilterWhiteSpaces(string input) { if (input == null) return string.Empty; StringBuilder stringBuilder = new StringBuilder(input.Length); for (int i = 0; i < input.Length; i++) { char c = input[i]; if (i == 0 || c != ' ' || (c == ' ' && input[i - 1] != ' ')) stringBuilder.Append(c); } return stringBuilder.ToString(); }
In my tests, this method was 16 times faster on average with a very large set of small-to-medium sized strings, compared to a static compiled Regex. Compared to a non-compiled or non-static Regex, this should be even faster.
Keep in mind, that it does not remove leading or trailing spaces, only multiple occurrences of such.
Solution:10
You can simply do this in one line solution!
string s = "welcome to london"; s.Replace(" ", "()").Replace(")(", "").Replace("()", " ");
You can choose other brackets (or even other characters) if you like.
Solution:11
This is a shorter version, which should only be used if you are only doing this once, as it creates a new instance of the
Regex class every time it is called.
temp = new Regex(" {2,}").Replace(temp, " ");
If you are not too acquainted with regular expressions, here's a short explanation:
The
{2,} makes the regex search for the character preceding it, and finds substrings between 2 and unlimited times.
The
.Replace(temp, " ") replaces all matches in the string temp with a space.
If you want to use this multiple times, here is a better option, as it creates the regex IL at compile time:
Regex singleSpacify = new Regex(" {2,}", RegexOptions.Compiled); temp = singleSpacify.Replace(temp, " ");
Solution:12
no Regex, no Linq... removes leading and trailing spaces as well as reducing any embedded multiple space segments to one space
string myString = " 0 1 2 3 4 5 "; myString = string.Join(" ", myString.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries));
result:"0 1 2 3 4 5"
Solution:13
Consolodating other answers, per Joel, and hopefully improving slightly as I go:
You can do this with
Regex.Replace():
string s = Regex.Replace ( " 1 2 4 5", @"[ ]{2,}", " " );
Or with
String.Split():
static class StringExtensions { public static string Join(this IList<string> value, string separator) { return string.Join(separator, value.ToArray()); } } //... string s = " 1 2 4 5".Split ( " ".ToCharArray(), StringSplitOptions.RemoveEmptyEntries ).Join (" ");
Solution:14
I just wrote a new
Join that I like, so I thought I'd re-answer, with it:
public static string Join<T>(this IEnumerable<T> source, string separator) { return string.Join(separator, source.Select(e => e.ToString()).ToArray()); }
One of the cool things about this is that it work with collections that aren't strings, by calling ToString() on the elements. Usage is still the same:
//... string s = " 1 2 4 5".Split ( " ".ToCharArray(), StringSplitOptions.RemoveEmptyEntries ).Join (" ");
Solution:15
I know this is pretty old, but ran across this while trying to accomplish almost the same thing. Found this solution in RegEx Buddy. This pattern will replace all double spaces with single spaces and also trim leading and trailing spaces.
pattern: (?m:^ +| +$|( ){2,}) replacement: $1
Its a little difficult to read since we're dealing with empty space, so here it is again with the "spaces" replaced with a "_".
pattern: (?m:^_+|_+$|(_){2,}) <-- don't use this, just for illustration.
The "(?m:" construct enables the "multi-line" option. I generally like to include whatever options I can within the pattern itself so it is more self contained.
Solution:16
I can remove whitespaces with this
while word.contains(" ") //double space word = word.Replace(" "," "); //replace double space by single space. word = word.trim(); //to remove single whitespces from start & end.
Solution:17
Many answers are providing the right output but for those looking for the best performances, I did improve Nolanar's answer (which was the best answer for performance) by about 10%.
public static string MergeSpaces(this string str) { if (str == null) { return null; } else { StringBuilder stringBuilder = new StringBuilder(str.Length); int i = 0; foreach (char c in str) { if (c != ' ' || i == 0 || str[i - 1] != ' ') stringBuilder.Append(c); i++; } return stringBuilder.ToString(); } }
Solution:18
try this method
private string removeNestedWhitespaces(char[] st) { StringBuilder sb = new StringBuilder(); int indx = 0, length = st.Length; while (indx < length) { sb.Append(st[indx]); indx++; while (indx < length && st[indx] == ' ') indx++; if(sb.Length > 1 && sb[0] != ' ') sb.Append(' '); } return sb.ToString(); }
use it like this:
string test = removeNestedWhitespaces("1 2 3 4 5".toCharArray());
Solution:19
Old skool:
string oldText = " 1 2 3 4 5 "; string newText = oldText .Replace(" ", " " + (char)22 ) .Replace( (char)22 + " ", "" ) .Replace( (char)22 + "", "" ); Assert.That( newText, Is.EqualTo( " 1 2 3 4 5 " ) );
Solution:20
Without using regular expressions:
while (myString.IndexOf(" ", StringComparison.CurrentCulture) != -1) { myString = myString.Replace(" ", " "); }
OK to use on short strings, but will perform badly on long strings with lots of spaces.
Solution:21
Use the regex pattern
[ ]+ #only space var text = Regex.Replace(inputString, @"[ ]+", " ");
Solution:22
Mix of StringBuilder and Enumerable.Aggregate() as extension method for strings:
using System; using System.Linq; using System.Text; public static class StringExtension { public static string StripSpaces(this string s) { return s.Aggregate(new StringBuilder(), (acc, c) => { if (c != ' ' || acc.Length > 0 && acc[acc.Length-1] != ' ') acc.Append(c); return acc; }).ToString(); } public static void Main() { Console.WriteLine("\"" + StringExtension.StripSpaces("1 Hello World 2 ") + "\""); } }
Input:
"1 Hello World 2 "
Output:
"1 Hello World 2 "
Note:If u also have question or solution just comment us below or mail us on toontricks1994@gmail.com
EmoticonEmoticon | http://www.toontricks.com/2019/04/tutorial-how-do-i-replace-multiple.html | CC-MAIN-2019-18 | refinedweb | 1,178 | 60.51 |
Floating Bubbles
A Flutter Package for adding Floating bubbles in the Foreground to a widget.
Getting Started
In your flutter project(in pubspec.yaml) add the dependency:
dependencies: floating_bubbles: ^1.3.1
Import the package:
import 'package:floating_bubbles/floating_bubbles.dart';
Usage
Api Reached a Stable version. There won't be any changes to the existing features. Only new Features will be added. This message is for users who are using version v0.0.9 and below.
Here is an snippet on how to use Floating Bubbles to any Widget.
Creating FloatingBubbles() (this creates the animation and plays for amount of time you give as the duration.)
return Stack( children: [ Positioned.fill( child: Container( color: Colors.red, ), ), Positioned.fill( child: FloatingBubbles( noOfBubbles: 25, colorOfBubbles: Colors.green.withAlpha(30), sizeFactor: 0.16, duration: 120, //120 seconds. opacity: 70, paintingStyle: PaintingStyle.stroke, strokeWidth: 8, shape: BubbleShape.circle, //circle is the default. No need to explicitly mention if its a circle. ), );
Creating FloatingBubbles.alwaysRepeating() (Creates Floating Bubbles that always floats and doesn't stop.)
return Stack( children: [ Positioned.fill( child: Container( color: Colors.red, ), ), Positioned.fill( child: FloatingBubbles.alwaysRepeating( noOfBubbles: 25, colorOfBubbles: Colors.green.withAlpha(30), sizeFactor: 0.16, opacity: 70, paintingStyle: PaintingStyle.fill, shape: BubbleShape.square, ), );
Parameters:
For Creating FloatingBubbles()
For Creating FloatingBubbles.alwaysRepeating()
Example
The code for the Example shown below is here.
As the Gifs here are converted from mp4, there are some stutters. To see the MP4 format of these Gifs Click Here.
Stress Test
Stress Test has been done on this package. Below is the information(fps) on how the performance of the package when the animation was coupled with a heavy rive animation.
Average FPS of the UI when the package was stress tested on a low-end Android Phone
APP build in Debug Mode
APP build in Release Mode
Average FPS of the UI when the package was stress tested on a High-end Android Phone
APP build in Release Mode
Performance improvements will be made in the coming updates to make this package more suitable for low end devices. If you have any suggestions or ideas, just pull request :)
About Me
Support
Give a ⭐/👍 if you liked the work!! :) Suggestions are Welcome. Any issues just open an issue. I will reach you as soon as possible.
License
The Scripts and Documentation in this project are released under the MIT License
Libraries
- floating_bubbles
- Floating Bubbles Widget [...] | https://pub.dev/documentation/floating_bubbles/latest/ | CC-MAIN-2021-10 | refinedweb | 399 | 53.78 |
* Stefan Richter <stefanr@s5r6.in-berlin.de> wrote:> Ingo Molnar wrote:> > * Joe/> > How well do "git am", "quilt import" and friends cope with ever > changing directories?Once a driver is in a tree it's in Git and git mv is easy. People working with Linux better familiarize themselves with Git workflow - the sooner the better.If it's not in tree then it will adopt to whatever layout there is once it gets into Greg's tree. I dont see the problem.> How about using drivers/staging/this_driver/TODO and (or) its Kconfig > help text to leave a note about the plans for this driverThen tell me the same at a glance if you see patches for: +++ a/drivers/staging/wip/x.c +++ a/drivers/staging/bad/y.c> The worry that these will be ignored like > Documentation/feature-removal-schedule.txt is being ignored may apply > to the path name based solution too, I'm afraid.It wont be 'ignored', as it's in every patch, it's in every commit, it's in every substantial communication about that driver.The problem with feature-removal-schedule.txt is that it's too much out of sight and not part of the regular patch workflow. Same goes for any TODO file. Experience has shown that the actual _path_ were drivers end up does matter quite a bit, to general visibility and to mindset.That's one of the reasons why we have _half a thousand_ directories in drivers/ to begin with. The directory namespace is very powerful, and we use it to convey all sorts of information about the logical category a driver is in.Using it in drivers/staging/ instead of the current flat hierarchy would thus be pretty natural. Ingo | http://lkml.org/lkml/2009/10/14/359 | CC-MAIN-2016-30 | refinedweb | 293 | 64.81 |
What type of new control structures you would like to have in Perl? What would be your consideration for the design of control structures ? Would that make your task easier? Can you mimic them with current version (5.6+)?
I'm not sure how much perl6 will allow you to mess with the parser, but source-filters in perl5 suck.
As I understand it Perl 6 will give you pretty much complete access to the parser. The Perl 6 grammar will be represented with the new regexp system so you can tweak it to your hearts content.
Actually I think this might be a first for Perl. While other languages like Lisp and Pop-11 allow you to write your own syntax with macros, etc. I can't recall a language that has an explicit representation of the grammar that you can tweak directly at runtime. Nice.
A switch or case statment. Although after programming for a while with out them I seem to have lost the urge to use them and can't come up with a case where i needed them! ;)
A clearer control default values like my $var ||= $default without the 0 value gotcha.
Makeing elsif elseif...just because it continues to make me look twice at my code.
It is hard to streach outside the box though, I find my mind jumping to available solutions instead of wishing for changes.
The advantage to case statements is that each element is not mutually exclusive, as you have with a single if/elsif/else structure
So, in pseudocode, you might do something like:
switch (value) {
case 'needs_slight_cleaning':
&clean_up_values;
case 'good value':
&do_whatever_you_need_to;
break;
case 'totally unrelated';
&do_something_else;
break;
default:
&do_some_default_thing;
}
[download]
Note how there is no 'break' between the first two cases, so something that matches the first case will run '&clean_up_values' and '&do_whatever_you_need_to';
It's not an absolutely necessary control structure, but there are some times when it sure does come in handy. (most times when you have a giant if/elseif/else tree, where you're repeating large blocks of it).
Update: I forgot to answer the questions as they were asked:
The newest development versions of perl have a "defined-or" operator //, so the //= operator does that. There's even a patch you can apply to perl-5.8 to have that operator. The only sad part is that we'll have to wait a while until it's widely available for general use.
In my code I often find structures of the form
while ( 1 ) {
# yadda yadda
last if some_condition();
# yadda yadda
}
[download]
loop { # begin of enclosing block
# pre-test code
} while ( some_condition() ) {
# post-test code;
}
[download]
But Perl already gives a pretty close approximation for the attractive low price of an end-of-block redo:
{
# pre-code
last if some_condition();
# post-code
redo;
}
[download]
the lowliest monk
for(;
do {
# pre-test code
some_condition()
};
do {
post-code
}) {}
[download]
while (do {
# pre-test code
some_condition()
}) {
# post-code
}
[download]
Dijkstra aparently coined this: "looping n and a half times" (or the "loop and a half" as some people have shortened it) back in 1973. Knuth mentioned it as one of the main reasons for using goto in his 1974 "Structured Programming with go to Statements" (which does not seem to be available online unless you are an ACM member) ...
A: S;
if B then goto Z fi;
T;
goto A;
Z:
[download]
He mentions several alternatives that he finds inferor to the goto version for various reasons, and credits Ole-JOhan Dahl as proposing a syntax he really like -- which frankly I think kicks ass, and plan on writting as a P6 macro (I think macro is the right word)...
loop; S while !B: T; repeat;
[download]
loop {
S;
} while (!B) {
T;
}
[download]
{ S while !B; T; redo; }
[download]
On the off-chance that this does work, the code is so tricky you probably shouldn't even think about using it in real life.
I'm willing to accept the possibility that:
S while (!B): T;
[download]
is pronounced: "use T as the continue block for a while() loop that controls S."
If it doesn't, then it seems like the colon should be a semicolon, and you're looping over S until B returns TRUE, then calling T.. which a loop-and-a-half doesn't do.
I'm also willing to consider the possibility that the whole statement is somehow the conditional that controls the loop() statement, and could thus be written like so:
loop (; S while (!B): T ; repeat) {
}
[download]
but I'm damned if I can see how the conditional in the while() loop drops through to control the loop() statement, and I have no idea why you'd want to call repeat as the loop() statement's continuation routine.
The best way I know to express the loop-and-a-half is:
while (1) {
S; # make a calculation
last if (B); # drop out when the result is right
T; # adjust the parameters for another try
}
[download]
which is, at very least, easier to read.
The fact that expressing the idea requires a last statement goes right to the heart of the fight that made Dijkstra's Use of Go To Considered Harmful so infamous.
According to the key theory of structured programming (I don't reall who did the proof and don't have my references with me right now), you can write any program with nested function calls (where each function has a single entry point and a single exit point), while() loops, and if() statements.
The problem is that some forms of logic are extremely ugly when written using only those tools.
We've solved those aesthetic problems by adding things like the next, last and redo statements, continue blocks, else and elsif() statements, the capacity to exit a function from more than one place, and so on.
Technically, those tools exceed the 'minimal effective system' necessary to write programs, but they don't violate the spirit of structured programming, and they make the code a heck of a lot easier to read.
Really? Thats an interesting observation, I always found both forms useful for minimizing noise and making flow control clearer. I find unless in either form (block or modifier) somewhat more inclined to be difficult, but the modifier if, and even unless coupled with loop control statements like next and last to be very useful in enhancing readability.
When I see something like
next if $condition;
[download]
it allows me to think "condition is prohibited past this line", i dont have to worry that later on the block ends and !$condition is still possible. For instance in the following code if at a later I point I forget the importance of the next, or possible restructure code so it doesnt fire sometimes something bad could happen after the block and I might not even notice it until debugging. The statement form doesnt allow such complexity so it sort of red-flags itself as being "mess with this and the code below has to be completely reconsidered."
if ($condition) {
...
}
# !$condition stuff can happen here
[download]
You should stop looking at buggy code :)
Bah. If only I had the option :-/.
What type of new control structures you would like to have in Perl?
I would like to have the new control structures that are discussed in Synopsis 4.
What would be your consideration for the design of control structures ?
That would be Apocalypse 4.
Would that make your task easier?
Hmm, well, so far it seems to have made my task considerably harder... :-)
Can you mimic them with current version (5.6+)?
Yes, most of them can be emulated with Damian's various Perl6::* modules, but they'll work much better when they're built in.
I'm curious where you think the ideas for perl 6 came from? Any chance they might have picked up on the desires of the perl community and used those? Since perl 6 is no where near set in stone I would think now is the perfect time to voice opinions on what might be usefull in future versions of perl.
Modified language ever so slightly. Larry wall or not, just because there are plans for Perl6 doesn't mean that opening up discusion on control structures and what people would like changed is "amuzing." Maybe that statment wasn't meant as a slight (maybe i shouldn't respond in the middle of the night ;) ). Either way I think that Larry of all people should be supporting any type of community discussion on the matter even if its not in the "proper" channels mentioned in the following replies. Either way its just my two cents.
As Anonymous Monk said, largely too late.
The "loop-and-a-half" problem has already been mentioned, but I still haven't seen anything that looks really good (though the redo aproach may be the cleanest).
Something I've frequently found myself doing is wanting a three-way control structure for greater than, less than, and equal to. Sure there are ways to do it, but none of them really feel clean.
given fork {
case $_ < 0 {
#error
}
case $_ > 0 {
#parent
}
default {
#child
}
}
[download]
if ((my $pid = fork()) < 0){
#error
} elsif ($pid > 0) {
#parent
} else {
$child
}
[download]
if (get_the_boundary_x() < the_user_provided_x()){
draw_color("green");
elsif (get_the_boundary_x() == the_user_provided_x()){
draw_color("blue");
else {
draw_color("red");
}
[download]
merlyn's looking for a good idiom: return this if this is true shows another question without a (really good, or at least completely natural) answer. The suggested if (my $ret = thatroutine()){return $ret} feels ugly due to the synthetic variable $ret.
Second, as one odd way to solve your problem, you could execute one of a few code blocks:
(
sub { print "A is less than B" },
sub { print "A is equal to B" },
sub { print "A is greater than B"}
)[($a <=> $b) + 1)]->();
[download]
-- Randal L. Schwartz, Perl hacker
Be sure to read my standard disclaimer if this is a reply.
Well, speaking with tongue partially in cheek, I suppose Fredekin gates and generalized Toffoli gates would be nice.
The code versions of each look roughly like so:
sub fredekin {
my ($a,$b,$c) = @_;
return (($a) ? ($a,$c,$b) : ($a,$b,$c));
}
sub toffoli {
my @list = @_;
my $tail = pop @list;
my $state = 0;
for my $i (@list) {
$state++ if ($i);
}
if ($state == @list) {
$tail = ($tail) ? 0 : 1;
}
return ((@list, $tail));
}
[download]
The Fredekin gate takes a three-item list as input and returns a three-item list as output.
If the first item is FALSE, the return list is identical to the input list.
If the first item is TRUE, the last two items of the return list are swapped.
The Toffoli gate is more general, and does roughly the opposite.
It takes an N-item list as input, and returns an N-item list as output.
If any item from 0 to N-1 is FALSE, the output list is indentical to the input list.
If all the items from 0 to N-1 are TRUE, the logic value of the final item is flipped.. TRUE is replaced by FALSE, or FALSE is replaced by TRUE.
Both gates are universal, meaning you can build a complete Turing machine using nothing but arrays of either kind of gate.
The Fredekin gate also maintains perfect energy balance, meaning it never changes the number of TRUE or FALSE statements.
The Toffoli gate can change the number of TRUE and FALSE statements, which makes it slightly more powerful than the Fredekin gate (i.e.: you'll need fewer gates and scratch inputs to solve a problem with Toffoli gates), but as a consequence, the Toffoli gate runs 'hotter'.
Changing in the number of TRUE and FALSE statements involves energy transfer, and ultimately, that energy will be released as heat.
Both can serve as basic building blocks for quantum and/or reversible computation.
And as an aside, the Fredekin gate is actually kind of useful in everyday programming.
It's good for situations where you need to choose between two options based on the value of a third item.
And situations like that show up frequently when you try to arrange code for logical correctness.
Used as intended
The most useful key on my keyboard
Used only on CAPS LOCK DAY
Never used (intentionally)
Remapped
Pried off
I don't use a keyboard
Results (439 votes),
past polls | http://www.perlmonks.org/index.pl?node_id=455340 | CC-MAIN-2015-11 | refinedweb | 2,071 | 66.98 |
As we all know, iMovie is a great video editing tool on Mac OS. And it naturally supports MPEG-4, DV, MOV video formats. While M4V, MPEG-2, etc file formats are not included.
What If you want to edit those files with iMovie, you will find perfect solutions for these questions below:
import m4v into imovie
How to import a .m4v video file (handbrake rip file) into iMovie?
convert mpeg to imovie
Convert MPEG-2 to iMovie with the Best MPEG-2 to iMovie Converter
After taking time editing videos and make your amazing movie, you can easily burn imovie project to DVD.
How do I burn a DVD from iMovie without iDVD? | http://www.anddev.org/multimedia-problems-f28/how-to-convert-mxf-to-mov-with-mxf-to-mov-converter-for-mac-t2165436.html | CC-MAIN-2016-22 | refinedweb | 114 | 80.92 |
A module is a set of definitions that the module exports, as well as some actions (expressions evaluated for their side effect). The top-level forms in a Scheme source file compile a module; the source file is the module source. When Kawa compiles the module source, the result is the module class. Each exported definition is translated to a public field in the module class.
There are two kinds of module class: A static module is a class (or gets compiled to a class) all of whose public fields a static, and that does not have a public constructor. A JVM can only have a single global instance of a static module. An instance module has a public default constructor, and usually has at least one non-static public field. There can be multiple instances of an instance module; each instance is called a module instance. However, only a single instance of a module can be registered in an environment, so in most cases there is only a single instance of instance modules. Registering an instance in an environment means creating a binding mapping a magic name (derived from the class name) to the instance.
In fact, any Java class class that has the properties of either an instance module or a static module, is a module, and can be loaded or imported as such; the class need not have written using Scheme.
The definitions that a module exports are accessible to other modules.
These are the "public" definitions, to use Java terminology.
By default, all the identifiers declared at the top-level of a module
are exported, except those defined using
define-private.
However, a major purpose of using modules is to control the set of
names exported. One reason is to reduce the chance of accidental
name conflicts between separately developed modules. An even more
important reason is to enforce an interface: Client modules should
only use the names that are part of a documented interface, and should
not use internal implementation procedures (since those may change).
If there is a
module-export declaration in the module, then
only those names listed in a
module-export are exported.
There can be more than one
module-export, and they can be
anywhere in the Scheme file. As a matter of good style, I recommend
a single
module-export near the beginning of the file.
Syntax:
module-export
name
...
Make the definition for each
namebe exported. Note that it is an error if there is no definition for
namein the current module, or if it is defined using
define-private.
In this module,
fact is public and
worker is private:
(module-export fact) (define (worker x) ...) (define (fact x) ...)
Alternatively, you can write:
(define-private (worker x) ...) (define (fact x) ...)
In addition to
define (which can take an optional type specifier),
Kawa has some extra definition forms.
Syntax:
define-private
name [
::
type]
value
Syntax:
define-private (
name
formals)
body
Same as
define, except that
nameis not exported.
Syntax:
define-constant
name [
::
type]
value
Definites
nameto have the given
value. The value is readonly, and you cannot assign to it. (This is not fully enforced.) If the definition is at module level, then the compiler will create a
finalfield with the given name and type. The
valueis evaluated as normal; however, if it is a compile-time constant, it defaults to being static.
Syntax:
define-variable
name [
init]
If
initis specified and
namedoes not have a global variable binding, then
initis evaluated, and
namebound to the result. Otherwise, the value bound to
namedoes not change. (Note that
initis not evaluated if
namedoes have a global variable binding.)
Also, declares to the compiler that
namewill be looked up in the dynamic environment. This can be useful for shutting up warnings from
--warn-undefined-variable.
This is similar to the Common Lisp
defvarform. However, the Kawa version is (currently) only allowed at module level.
For
define-namespace and
define-private-namespace
see Namespaces and compound symbols.
If you want to just use a Scheme module as a module (i.e.
load
or
require it), you don't care how it gets translated
into a module class. However, Kawa gives you some control over how this
is done, and you can use a Scheme module to define a class which
you can use with other Java classes. This style of class definition
is an alternative to
define-class,
which lets you define classes and instances fairly conveniently.
The default name of the module class is the main part of the
filename of the Scheme source file (with directories and extensions
sripped off). That can be overridden by the
-T Kawa
command-line flag. The package-prefix specified by the
-P
flag is prepended to give the fully-qualified class name.
Syntax:
module-name
<name>
Sets the name of the generated class, overriding the default. If there is no ‘
.’ in the
name, the package-prefix (specified by the
-PKawa command-line flag) is prepended.
By default, the base class of the generated module class is unspecified;
you cannot count on it being more specific than
Object.
However, you can override it with
module-extends.
Syntax:
module-extends
<class>
Specifies that the class generated from the immediately surrounding module should extend (be a sub-class of) the class
<.
class>
Syntax:
module-implements
<interface>
...
Specifies that the class generated from the immediately surrounding module should implement the interfaces listed.
Note that the compiler does not currently check that all the abstract methods requires by the base class or implemented interfaces are actually provided, and have the correct signatures. This will hopefully be fixed, but for now, if you are forgot a method, you will probably get a verifier error
For each top-level exported definition the compiler creates a
corresponding public field with a similar (mangled) name.
By default, there is some indirection: The value of the Scheme variable
is not that of the field itself. Instead, the field is a
gnu.mapping.Symbol object, and the value Scheme variable is
defined to be the value stored in the
Symbol.
Howewer, if you specify an explicit type, then the field will
have the specified type, instead of being a
Symbol.
The indirection using
Symbol is also avoided if you use
define-constant.
If the Scheme definition defines a procedure (which is not re-assigned
in the module), then the compiler assumes the variable as bound as a
constant procedure. The compiler generates one or more methods
corresponding to the body of the Scheme procedure. It also generates
a public field with the same name; the value of the field is an
instance of a subclass of
<gnu.mapping.Procedure> which when
applied will execute the correct method (depending on the actual arguments).
The field is used when the procedure used as a value (such as being passed
as an argument to
map), but when the compiler is able to do so,
it will generate code to call the correct method directly.
You can control the signature of the generated method by declaring
the parameter types and the return type of the method. See the
applet (see Compiling to an applet) example for how this can be done.
If the procedures has optional parameters, then the compiler will
generate multiple methods, one for each argument list length.
(In rare cases the default expression may be such that this is
not possible, in which case an "variable argument list" method
is generated instead. This only happens when there is a nested
scope inside the default expression, which is very contrived.)
If there are
#!keyword or
#!rest arguments, the compiler
generate a "variable argument list" method. This is a method whose
last parameter is either an array or a
<list>, and whose
name has
$V appended to indicate the last parameter is a list.
Top-leval macros (defined using either
define-syntax
or
defmacro) create a field whose type is currently a sub-class of
kawa.lang.Syntax; this allows importing modules to detect
that the field is a macro and apply the macro at compile time.
Syntax:
module-static
name
...
Syntax:
module-static
'init-run
Control whether the generated fields and methods are static. If
#tor
'init-runis specified, then the module will be a static module, all definitions will be static. If
'init-runis specified, in addition the module body is evaluated in the class's static initializer. (Otherwise, it is run the first time it is
require'd.) Otherwise, the module is an instance module. However, the
names that are explicitly listed will be compiled to static fields and methods. If
#fis specified, then all exported names will be compiled to non-static (instance) fields and methods.
By default, if no
module-staticis specified:
-
If there is a
module-extendsor
module-implementsdeclaration, or one of the
--appletor
--servletcaommand-line flags was specified, then
(module-static #f)is implied.
-
If one of the command-line flags
--no-module-static,
--module-nonstatic,
--module-static, or
--module-static-runwas specified, the the default
#f,
#f,
#t, or
'init-run, respectively.
-
Otherwise the default is
(module-static #t). (It used to be
(module-static #f)in older Kawa versions.)
Note
(module-static #t)usually produces more efficient code, and is recommended if a module contains only procedure or macro definitions. (This may become the default.) However, a static module means that all environments in a JVM share the same bindings, which you may not want if you use multiple top-level environments.
Unfortuntely, the Java class verifier does not allow fields to have
arbitrary names. Therefore, the name of a field that represents a
Scheme variable is "mangled" (see Mapping Scheme names to Java names) into an acceptable Java name.
The implementation can recover the original name of a field
X
as
((gnu.mapping.Named) X).getName() because all the standard
compiler-generate field types implemented the
Named interface.
The top-level actions of a module will get compiled to a
run
method. If there is an explicit
method-extends, then the
module class will also automatically implement
java.lang.Runnable.
(Otherwise, the class does not implement
Runnable, since in that
case the
run method return an
Object rather than
void.
This will likely change.)
You can import a module into the current namespace with
require.
Syntax:
require
modulespec
The
modulespeccan be either a
<or a
classname>
'. In either case the names exported by the specified module (class) are added to the current set of visible names.
featurename
If
modulespecis
<where
classname>
classnameis an instance module (it has a public default constructor), and if no module instance for that class has been registered in the current environment, then a new instance is created and registered (using a "magic" identifier). If the module class either inherits from
gnu.expr.ModuleBodyor implements
java.lang.Runnablethen the corresponding
runmethod is executed. (This is done after the instance is registered so that cycles can be handled.) These actions (creating, registering, and running the module instance) are done both at compile time and at run time, if necessary.
All the public fields of the module class are then incorporated in the current set of local visible names in the current module. This is done at compile time - no new bindings are created at run-time (except for the magic binding used to register the module instance), and the imported bindings are private to the current module. References to the imported bindings will be compiled as field references, using the module instance (except for static fields).
If the
modulespecis
'then the
featurename
featurenameis looked up (at compile time) in the "feature table" which yields the implementing
<.
classname>
Syntax:
provide
'featurename
Declare that
'is available. A following
featurename
cond-expandin this scope will match
featurename.
Using
require and
provide with
featurenames is
similar to the same-named macros in SLib, Emacs, and Common Lisp.
However, in Kawa these are not functions, but instead they
are syntax forms that are processed at compile time. That is
why only quoted
featurenames are supported.
This is consistent with Kawa emphasis on compilation and
static binding.
For some examples, you may want to look in the
gnu/kawa/slib
directory. | http://www.gnu.org/software/kawa/Module-classes.html#id2600899 | crawl-003 | refinedweb | 2,029 | 55.34 |
ThreadCreate(), ThreadCreate_r()
Create a thread
Synopsis:
#include <sys/neutrino.h> int ThreadCreate( pid_t pid, void* (func)( void* ), void* arg, const struct _thread_attr* attr ); int ThreadCreate_r( pid_t pid, void* (func)( void* ), void* arg, const struct _thread_attr* attr );
Arguments:
- pid
- The ID of the process that you want to create the thread in, or 0 to create the thread in the current process.
- func
- A pointer to the function that you want the thread to execute. The arg argument that you pass to ThreadCreate() is passed to func() as its sole argument. If func() returns, it returns to the address defined in the exitfunc member of attr.
- arg
- A pointer to any data that you want to pass to func.
- attr
- A pointer to a _thread_attr structure that specifies the attributes for the new thread, or NULL if you want to use the default attributes.If you modify the attributes after creating the thread, the thread isn't affected.
For more information, see Thread attributes, below.
Library:
libc
Use the -l c option to qcc to link against this library. This library is usually included automatically.
Description:
These kernel calls create a new thread of execution, with attributes specified by attr, within the process specified by pid. If pid is zero, the current process is used.
The ThreadCreate() and ThreadCreate_r() functions are identical, except in the way they indicate errors. See the Returns section for details.
The new thread shares all resources of the process in which it's created. This includes memory, timers, channels and connections. The standard C library contains mutexes to make it thread-safe.
Thread attributes
The _thread_attr structure pointed to by attr contains at least the following members:
- int flags
- See below for a list of flags. The default flag is always zero.
- size_t stacksize
- The stack size of the thread stack defined in the stackaddr member. If stackaddr is NULL, then stacksize specifies the size of stack to dynamically allocate. If stacksize is zero, then 4096 bytes are assumed. The minimum allowed stacksize is defined by PTHREAD_STACK_MIN.
- void* stackaddr
- NULL, or the address of a stack that you want the thread to use. Set the stacksize member to the size of the stack.
If you provide a non-NULL stackaddr, it's your responsibility to release the stack when the thread dies. If stackaddr is NULL, then the kernel dynamically allocates a stack on thread creation and automatically releases it on the thread's death.
- void* (exitfunc)(void* status)
- The address to return to if the thread function returns.The thread returns to exitfunc. This means that the status variable isn't passed as a normal parameter. Instead, it appears in the return-value position dictated by the CPU's calling convention (e.g. EAX on an x86, R3 on PPC, V0 on MIPS, and so on).
The exitfunc function normally has to have compiler- and CPU-specific manipulation to access the status data (pulling it from the return register location to a proper local variable). Alternatively, you can write the exitfunc function in assembly language for each CPU.
- int policy
- The scheduling policy, as defined by the SchedSet() kernel call. This member is used only if you set the PTHREAD_EXPLICIT_SCHED flag. If you want the thread to inherit the policy, but you want to specify the scheduling parameters in the param member, set the PTHREAD_EXPLICIT_SCHED flag and set the policy member to SCHED_NOCHANGE.
- struct sched_param param
- A sched_param structure that specifies the scheduling parameters, as defined by the SchedSet() kernel call. This member is used only if you set the PTHREAD_EXPLICIT_SCHED flag.
You can set the attr argument's flags member to a combination of the following:
- PTHREAD_CREATE_JOINABLE (default)
- Put the thread into a zombie state when it terminates. It stays in this state until you retrieve its exit status or detach the thread.
- PTHREAD_CREATE_DETACHED
- Create the thread in the detached state; it doesn't become a zombie. You can't call ThreadJoin() for a detached thread.
- PTHREAD_INHERIT_SCHED (default)
- Use the scheduling attributes of the creating thread for the new thread.
- PTHREAD_EXPLICIT_SCHED
- Take the scheduling policy and parameters for the new thread from the policy and param members of attr.
- PTHREAD_SCOPE_SYSTEM (default)
- Schedule the thread against all threads in the system.
- PTHREAD_SCOPE_PROCESS
- Don't set this flag; the QNX Neutrino OS implements true microkernel threads that have only a system scope.
- PTHREAD_MULTISIG_ALLOW (default)
- If the thread dies because of an unblocked, uncaught signal, terminate all threads, and hence, the process.
- PTHREAD_MULTISIG_DISALLOW
- Terminate only this thread; all other threads in the process are unaffected.
- PTHREAD_CANCEL_DEFERRED (default)
- Cancellation occurs only at cancellation points as defined by ThreadCancel() .
- PTHREAD_CANCEL_ASYNCHRONOUS
- Every opcode executed by the thread is considered a cancellation point. The POSIX and C library aren't asynchronous-cancel safe.
Signal state
The signal state of the new thread is initialized as follows:
- The signal mask is inherited from the creating thread.
- The set of pending signals is empty.
- The cancel state and type are PTHREAD_CANCEL_ENABLE and PTHREAD_CANCEL_DEFERRED.
Local storage for private data
Each thread contains a thread local storage area for its private data. You can get a pointer to this area by calling __tls() (defined in <sys/storage.h>).
The thread local storage is defined by the structure _thread_local_storage, which contains at least the following members:
- void* (exitfunc)(void *)
- The exit function to call if the thread returns.
- void* arg
- The sole argument that was passed to the thread.
- int* errptr
- A pointer to a thread unique errno value. For the main thread, this points to the global variable errno . For all other threads, this points to the member errval in this structure.
- int errval
- A thread-unique errno that the thread uses if it isn't the main thread.
- int flags
- The thread flags used on thread creation in addition to runtime flags used for implementing thread cancellation.
- pid_t pid
- The ID of the process that contains the thread.
- int tid
- The thread's ID.
Blocking states
These calls don't block.
Returns:
The only difference between these functions is the way they indicate errors:
- ThreadCreate()
- The thread ID of the newly created thread. If an error occurs, the function returns -1 and sets errno .
- ThreadCreate_r()
- The thread ID of the newly created thread. This function does NOT set errno. If an error occurs, the function returns the negative of a value from the Errors section.
Errors:
- EAGAIN
- All kernel thread objects are in use.
- EFAULT
- A fault occurred when the kernel tried to access the buffers provided.
- EINVAL
- Invalid scheduling policy or priority specified.
- ENOTSUP
- PTHREAD_SCOPE_PROCESS was requested. All kernel threads are PTHREAD_SCOPE_SYSTEM.
- EPERM
- The calling thread doesn't have sufficient permission to create a thread in another process. Only a thread with a process ID of 1 can create threads in other processes.
- ESRCH
- The process indicated by pid doesn't exist.
Classification:
Caveats:
The QNX interpretation of PTHREAD_STACK_MIN is enough memory to run a thread that does nothing:
void nothingthread( void ) { return; } | https://developer.blackberry.com/playbook/native/reference/com.qnx.doc.neutrino.lib_ref/topic/t/threadcreate.html | CC-MAIN-2020-34 | refinedweb | 1,160 | 57.47 |
An Introduction to Cross-Platform, Cross-Browser WinJs
The Web Dev Zone is brought to you in partnership with Mendix. Discover how IT departments looking for ways to keep up with demand for business apps has caused a new breed of developers to surface - the Rapid Application. Times are changing! I copied the build over to a new directory and got to work on a very simple example I creatively named Jeremy’s Books. You can play with the example online or inline. You should be able to scroll and tap/touch your way through the list (tap on the link to open it). Be sure to refresh so you can see the animations.
There are really six things I’m showing here:
- How to scaffold a basic WinJS application
- Data-binding via templates
- Using the WinJS provided stylesheets
- Page entrance animations
- Tap animations
- The ListView control
For a more comprehensive walkthrough, you can check out all of the controls and experiment online at theTry WinJS site.
The basic pattern for wiring up the app looks like this (find it in the app.js source file)
WinJS.Application.onready = function () { WinJS.UI.processAll(); }; WinJS.Application.start();
The call to process all is what triggers parsing the declarative markup and instantiating the actual controls. After I’ve processed the controls, I trigger a page enter animation to animate the elements in from the right. When the animation finishes, I find the controls that were generated as the result of data-binding to wire in click handlers for a tap effect (tap on a book cover and you’ll see it respond).
WinJS.UI.Animation.enterPage(document.getElementById('mainDiv'), null).then(function () { var controls = document.getElementsByClassName("book"), i; for (i = 0; i < controls.length; i+=1) { addPointerDownHandlers(controls[i]); addPointerUpHandlers(controls[i]); } });
Each element gets multiple handlers for different types of input:
function addPointerUpHandlers(target) { target.addEventListener("pointerup", onPointerUp, false); target.addEventListener("touchend", onPointerUp, false); target.addEventListener("mouseup", onPointerUp, false); }
And the corresponding animation is triggered:
function onPointerUp(evt) { WinJS.UI.Animation.pointerUp(evt.target); evt.preventDefault(); }
For the list of books, I create a simple JSON array and then bind it to a list. I use the WinJS convention of assigning it to a namespace to make it easy to reference from markup:
WinJS.Namespace.define("Book.ListView", { data: new WinJS.Binding.List(books) });
Now that it’s wired up, let’s take a look at the HTML. The basic HTML simply includes the base for WinJS and the UI as well as several stylesheets. I’m using the “light” theme but you can swap that to the dark theme to see how it changes (I prefer dark but have grown accustomed to light themes for presenting). I use a specialdata-win-control attribute to define the item template:
<div id="bookTemplate" data- <div class="book"> <img src="#" data- <h4><a href="#" target="_blank" data-</a></h4> </div> </div>
Notice in the image tag that the attributes are not bound directly. Instead, the binding attribute is used to provide a list of attributes on the parent element and the properties to bind their values to (in this case, thesrc attribute is bound to the img property, and the alt attribute is bound to the title property of the data). Next, I declare the list view with options. I especially like that WinJS crunches whitespace so I can format my options across multiple lines. The options provide a template for the list view to use, indicate how to handle taps and swipes, provide the item template and also where the data is pulled from. Some may argue that is too much imperative code being squashed into a declarative attribute; however, the options may also be set up programmatically.
<div class="bookList" data-</div>
You should note that I passed plain JSON to the list binding option. I do not bind directly to the object, but instead bind to the exposed dataSource property. As you can see, it was very straightforward to wire up a fluid user experience with selection, animated feedback and scrolling. Although I’m optimistic about using this library in the future, right now the sheer size is a deal-breaker. The uncompressed JavaScript for the UI by itself is almost 3 megabytes in size, then add another megabyte for the base. In addition add the 150KB stylesheets and you’re looking at a lot to load in the browser. I am hoping in the future there will be options to build to specific controls and provide a trimmed-down version that only contains the bare necessities for what will be used in an app.
There’s obviously a ways to go, but the real promise is the ability to create experiences that can truly share both code and markup between multiple targets, whether they are platforms and browsers or native experiences such as Windows Store apps. I’ll be keeping a close eye on this framework as it evolves and look forward to sharing more in future posts.
Grab the source and see the demo. }} | https://dzone.com/articles/introduction-cross-platform | CC-MAIN-2015-48 | refinedweb | 846 | 52.8 |
Hello,
I have a basic setup and once starling.events.Event.ROOT_CREATED is fired I do this in the 'root' class:
_renderTexture = new RenderTexture(1024,1024);
_image = new Image(_renderTexture);
addChild(_image);
Which gives this error:
Exception fault: Error: Error #3605: Sampler 0 binds an invalid texture.
at flash.display3D::Context3D/drawTriangles()
at starling.display::QuadBatch/renderCustom()[starling\display\QuadBatch.as:236]
at starling.core::RenderSupport/finishQuadBatch() starling\core\RenderSupport.as:361]
I am setting it up wrong or is this a bug ?
Cheers.
I'm not familiarized with what exactly do ROOT_CREATED event and what enables you to do, why don't you just try the normal approach?, something more like this:
public class Start extends Sprite
{
private var starling:Starling;
public function Start()
{
stage.align = StageAlign.TOP_LEFT;
stage.scaleMode = StageScaleMode.NO_SCALE;
starling = new Starling(Test, stage);
starling.start();
}
}
and then in Test type what you have.
ROOT_CREATED = Event type that indicates that the root DisplayObject has been created
When the event is fired I do:
mStarling.start();
app.start(_fieldWidth,_fieldHeight);
In the app start the rendertexture gets' created and gives the error.
I guess it's a bug then.
Artemix: I tried 'your' way but getting the same error then.
Are you trying this on mobile or PC?
In your sample code you show creating an instance of RenderTexture and adding it to the stage with an image, but you don't draw into the RenderTexture first.
Usually one draws with the render texture before adding it to an image/stage. Have you tried delaying its addition to an image until after you have drawn for the first time? (not sure if this is an implied requirement but maybe worth a test)
Thanks Jeff ... "draw to the render texture before adding it to an image" ... In no sample code I have seen but that fixed it for me.
I am having this problem as well.
I've tried all the suggested fixes I've seen around.
Scout just doesn't display anything that is created with a render texture. I remember it used to, but now just throws the error:
Error #3605 in Context3D.drawTriangles()...
A sampler bings an invalid texture.
I also get a similar error when using Starling filters such as GlowFilter, in which case Scout just displays a black screen. Thoughts?
Is anyone experiencing the same issues on Scout? I've tried AIR 19 through 22, and every kind of Context3D profile!
The simple act of applying a filter or drawing a rendertexture will trigger the error in Scout.
var renderTexture:RenderTexture = new RenderTexture(1024, 1024);
renderTexture.draw(new Quad(200, 200));
addChild(new Image(renderTexture));
this is the exact Scout output, and I highlighted where the error occurs at drawTriangles. The error occurs when I add the Image to the stage (doesn't matter if I draw anything in the RenderTexture).
Definitely looks like a Scout problem to me; but I've got one idea:
could you try if activating double buffering makes a difference?
RenderTexture.useDoubleBuffering = true;
That's a static property on the RenderTexture class; call it before creating the first render texture.
I'm still on Starling 1.8 ! I'll submit a bug to Adobe. Thanks Daniel
Added a bug: please vote for it! Thanks
In Starling 1.8, the property is called optimizePersistentBuffers -- and works inverted. So set this to false and then try again. Thx!
Thanks for creating the bug report!
I tried both true and false with no luck unfortunately.
Plus this is a problem affecting filters as well, so I'm assuming it's a Scout issue.
I'm still having the same issue with RenderTexture, filters and MeshBatch...Does anyone know any way to fix this? I just couldn't profiling with Scout anyone.
I think this issue is related to the latest versions of AIR SDK (v29)... try v28 or v26 and see if it works
An old topic, but I'm seeing this same issue as well and it's the result of me using a RenderTexture. I do not see any issues at all in game, but when I visit Scout and view the "Stage3D Rendering" tab I am seeing the "Error #3605 in Context3D.drawTriangle() -A sampler binds an invalid texture".
Scout is unable to display any of my objects using that RenderTexture in game. Not really much of an issue since it only appears to be a problem viewing the Stage3D panel in Scout. I'm assuming this is a bug with Scout then?
Yes, I can not use Stage3D Panel in Scout as well. I tried both Windows and Mac and it crashes every time. | https://forum.starling-framework.org/d/4860-rendertexture-error-3605-sampler-0-binds-an-invalid-texture | CC-MAIN-2019-22 | refinedweb | 777 | 66.84 |
$37.50.
Premium members get this course for $159.20.
Premium members get this course for $389.00.
Premium members get this course for $62.50.
Premium members get this course for $12.50.
Premium members get this course for $99.99.
Computer101
EE Admin
Actually, I am a bit puzzled by your suggested solution since the examples in MSDN show that autoEvent.Set() is actually used to kill the timer :-
With monday.com’s project management tool, you can see what everyone on your team is working in a single glance. Its intuitive dashboards are customizable, so you can create systems that work for you.
You are quite correct:
timer.Enabled = true;
I would create the timer in the server contructor:
timer = new Timer();
timer.Interval = Convert.ToDouble(Configura
timer.Elapsed += new ElapsedEventHandler(OnTime
DebugLvl = ConfigurationSettings.AppS
and OnStart:
timer.Enabled = true;
I would also to some logging:
EventLog.WriteEntry("Servi
Hope this help
Sadly ... not a lot, except that you confirm that autoEvent.Set() is not the answer.
Which method do you mean by "server constructor" ? Also, you appear to be suggesting
a different sort of timer (is this one in Threading?) - where is the TimerCallback delegate?
I will have a try at some event logging, though. That might make facilitate debugging.
I was bite in a rush when I posted my previous reply.
The first thing I would do is change your timer and use the "using System.Timers;". The reason is that it is a server based timer with a smaller footprint.
You can also manipulate the timer externally if you declare the timer protected or public object of the service class and you pass the "components" variable to your working class.
I always set the oTimer.enabled = false; when the timer event fires and then do the required processing.
The server constructer - I mean service constructer:
public MDSWindowsService()
{
// This call is required by the Windows.Forms Component Designer.
InitializeComponent();
// TODO: Add any initialization after the InitComponent call
}
With regards to eventLogging - I can not live without event logging :)
I use a "layer base" event logging methodology e.g.
DebugLevel = "xxx" - DebugLevel = "999"
If the service object is my top object - the value of the first x will determine what logging I do on that object.
The service object call the worker object - the value of the 2nd x will determine what logging I do on that object.
The worker object call Business objects - the value of the 3rd x will determine what logging I do on that object.
You can create you own eventLogger which you keep on calling in your assemble and specify the value you assign to the method/exec/exception/prop
Hope this help
I will also look into your advice on event logging - thnx.
The console application is a single threaded application by definition and application execution and thus instance reference thread is 'hults' and kept while waiting for the timeout object 'process' the timeout.
The expert can write you an essay on this matter but that is basically the short and sweet of it.
Good luck
BTW, I do know that System.Threading.Timer sometimes craps out with certain OS versions after 1 to 100 iterations. Go to support.microsoft.com and search for System.Threading.Timer and see if your OS might be affected (check your service pack level, it's important); if you might be impacted, a new service pack might fix you.
Thread timer - based on callback. As a managed object, if you don't keep a reference to it, it goes away.
System timer - based on OS raised event.
Try explicitly defining Timer as System.Threading.Timer in both the declaration and the New invocation.
Also, try attaching to the service process using the Visual Studio debugger, set a breakpoint on Process(), and trace through it on the first invocation. Set your start delay (200 in your example) to 15000 to give you 15 seconds to attach to the process and set the breakpoint (set it larger if you are new to trying this). They way it works:
Load your service project into VS.NET
Start your service
go to the Debug menu and select Processes
find your service in the list of Processes
click the Attach button
Make sure ONLY Common Language Runtime is checked, then hit OK
Hit close
Set your breakpoint on the source line that begins the Process() routine (explicitly include the source in your project, if necessary)
Wait until the breakpoint is hit, then step through.
I believe this will give you some clue as to what is happening. Also, PLEASE invoke autoEvent.Set() at the end of Process().
BTW, did you check what version/service pack of your OS that you're using?
NOTES: System.Timer is not recommended by Microsoft for use in Windows Services - System.Threading.Timer is.\SimpleService.cs&font=3
this is a simple solution and is just what I needed
namespace MDSWindowsService
{
public class MDSWindowsService : System.ServiceProcess.Serv
{
/// <summary>
/// Required designer variable.
/// </summary>
protected Timer timer;
private System.ComponentModel.Cont
private PollDistributionHouses _pdh;
public MDSWindowsService()
{
// This call is required by the Windows.Forms Component Designer.
InitializeComponent();
// TODO: Add any initialization after the InitComponent call
timer = new Timer();
timer.Interval = double.Parse(Configuration
timer.Elapsed += new ElapsedEventHandler(OnTime
}
// The main entry point for the process
static void Main()
{
System.ServiceProcess.Serv
// More than one user Service may run within the same process. To add
// another service to this process, change the following line to
// create a second service object. For example,
//
// ServicesToRun = new System.ServiceProcess.Serv
//
ServicesToRun = new System.ServiceProcess.Serv
System.ServiceProcess.Serv
}
/// <summary>
/// Required method for Designer support - do not modify
/// the contents of this method with the code editor.
/// </summary>
private void InitializeComponent()
{
components = new System.ComponentModel.Cont
this.ServiceName = "MDSWindowsService";
}
protected void OnTimer(Object source, ElapsedEventArgs e)
{
string usrDir = null; //Directory where files will be
TimeSpan diffTSpan = new TimeSpan(1,0,0,0);
timer.Stop();
string strResult = _pdh.Process() ;
if (strResult.Length > 0)
{
strResult = "MDSWindowsService Failed on DHID "+strResult ;
BusinessLogic.NewEventLog (strResult, 27000) ;
}
timer.Start();
}
/// <summary>
/// Clean up any resources being used.
/// </summary>
protected override void Dispose( bool disposing )
{
if( disposing )
{
if (components != null)
{
components.Dispose();
}
}
base.Dispose( disposing );
}
/// <summary>
/// Set things in motion so your service can do its work.
/// </summary>
protected override void OnStart(string[] args)
{
// TODO: Add code here to start your service.
_pdh = new PollDistributionHouses() ;
OnContinue();
BusinessLogic.NewEventLog ("MDSWindowsService Started", 22001) ;
//EventLog.WriteEntry("MDS
}
/// <summary>
/// Stop this service.
/// </summary>
protected override void OnStop()
{
// TODO: Add code here to perform any tear-down necessary to stop your service.
OnPause();
_pdh = null ;
BusinessLogic.NewEventLog ("MDSWindowsService Started", 22002) ;
//EventLog.WriteEntry("MDS
}
protected override void OnPause()
{
timer.Enabled = false;
}
protected override void OnContinue()
{
timer.Enabled = true;
}
}
} | https://www.experts-exchange.com/questions/22069162/Re-Problem-with-Windows-Service-program-still.html | CC-MAIN-2018-13 | refinedweb | 1,124 | 50.84 |
django-twitter 0.1.0
An inobstrusive way to login with Twitter into your Django application.django-twitter allows your users to login into your application using Twitter in a easy way.
How To Use
==========
1. Add 'twitter' to your apps list
2. Include('twitter.urls') in your url app
3. Add in settings.py:
CONSUMER_KEY = "your_consumer_key"
CONSUMER_SECRET = "your_consumer_secret"
CALLBACK_URL = 'your_awesome_url'
CONSUMER_KEY: You can obtain it from your Twitter account.
CONSUMER_SECRET: You can obtain it from your Twitter account.
CALLBACK_URL: is the url inside your application that should be shown when the authentication process went ok. It must be same as Twitter callback url.
4. Connect with tokens_received signal:
from twitter import signals
def tokens_received(sender, request, screen_name, oauth_token, oauth_token_secret, **kwargs):
#Your stuff here
signals.tokens_received.connect(tokens_received)
How it works
============
To insert the link to Twitter, include this in your template : {% url twitter_begin_auth %} in a link.
When the user click on the link, is redirected to Twitter, and once logged in, it will redirect you to CALLBACK_URL in your application and tokens_received signal will be raised.
NOTE:
-----
Remember that your Twitter callback url must be the same as CALLBACK_URL
Dependencies
============
djano-twitter uses Django 1.3 and oauth2
References
==========
Some parts of Twython have been adapted to make possible this application. Thanks to Twython creator for share with us so amazing code.
Version 0.1.0
+ Initial release
- Downloads (All Versions):
- 5 downloads in the last day
- 25 downloads in the last week
- 103 downloads in the last month
- Author: Antonio Hinojo
- Keywords: twitter django login
- License:
Copyright (c) 2013 Antonio Hino: ahmontero
- DOAP record: django-twitter-0.1.0.xml | https://pypi.python.org/pypi/django-twitter | CC-MAIN-2015-48 | refinedweb | 272 | 56.45 |
Inheriting from DynamicObject is the way to go for 90% of applications. I implement most of my dynamic types that way, as Dino suggested. If you already have a base class though, implementing IDynamicMetaObjectProvider isn't all that difficult. But you should have good working knowledge of Expression Trees before you dive into that. Kevin On Thu, Jun 16, 2011 at 1:17 PM, Dino Viehland <dinov at microsoft.com> wrote: > You can implement IDynamicMetaObjectProvider on the object, then > implement a DynamicMetaObject which overrides GetMember and handles when > “Property” is accessed. You’ll need to produce an AST which represents how > to access the member. A simple way to do this would be if you had a “static > bool TryGetProperty(string name, Class1 class, out object res)” method then > you could generate an expression tree which just calls that method and if it > succeeds returns the result, otherwise you fallback to the binder that > called you. This would also have the result of making this work w/ C# > dynamic or other dynamic languages. **** > > ** ** > > An easier way to do this would be if you could make Class1 inherit from > .NET 4’s DynamicObject class. In that case you can just override > TryGetMember and return the value (rather than dealing w/ the ASTs and IDMOP > protocol).**** > > ** ** > > *From:* ironpython-users-bounces+dinov=microsoft.com at python.org [mailto: > ironpython-users-bounces+dinov=microsoft.com at python.org] *On Behalf Of * > zxpatric > *Sent:* Thursday, June 16, 2011 9:32 AM > *To:* ironpython-users at python.org > *Subject:* [Ironpython-users] (Resend after group email address changed): > Way to extend IronPython to application specific request without changing > its source code?**** > > ** ** > > Hi,**** > > **** > > I am looking to extend IronPython in the way that a script like following > can run:**** > > **** > > Class1 c1 = Class1()**** > > print c1.Property**** > > **** > > with Class1 defined in .NET module:**** > > **** > > public class Class1**** > > {**** > > private int a;**** > > public int A**** > > {**** > > get { return a;}**** > > set { a=value;}**** > > }**** > > };**** > > **** > > Property is not a .NET property of Class1 but there is an applicatin hard > "rule" for example that "Class1.Property" is equal to:**** > > **** > > public int Property**** > > {**** > > get { return A+1;}**** > > }**** > > **** > > How may I append this rule (as a .NET module to IronPython or > Microsoft.Scripting.dll?) without touching the IronPython source so that > print c1.Property could be correctly inteperated by IronPython?**** > > **** > > Thanks**** > > -Patrick.**** > > ** ** > > _______________________________________________ > Ironpython-users mailing list > Ironpython-users at python.org > > > -- Kevin Hazzard -------------- next part -------------- An HTML attachment was scrubbed... URL: <> | https://mail.python.org/pipermail/ironpython-users/2011-June/014937.html | CC-MAIN-2019-47 | refinedweb | 402 | 66.03 |
CAN with MCP2551
I try to use the new CAN support. The only tranciever I have access to is a couple of MCP2551. Since it is 5V I have added 2 resistors (the same way as in the drawing in the first post from "rudi ;-)" here:)
This is the code I am using:
from machine import CAN can = CAN(mode=CAN.NORMAL, baudrate=250000, pins=('P3', 'P4')) while True: can.send(id=2, data=bytes([1, 2, 3, 4, 5, 6, 7, 8])) print("send") print(can.recv()) time.sleep(1)
Nothing is received, but I can see some signals coming from the transciever with an oscilloscope.
The frame I try to send cannot be seen on the bus, but I can see that something is transmitted to the transceiver (with an oscilloscope).
I have tried this with a LoPy and a WiPy3 and two different MCP2551.
What can be wrong? I can read data from the bus with a CAN-interface to my computer in the same connector without problem.
I am no hardware expert, anything wrong with my connections?
Managed to send as well, awesome!
I received the SN65HVD230 tranciever today (a board called CJMCU-230). I can read from the bus now (will try to send later). Must have been something wrong with my connections. Thanks!
I´ve tried both 10kbps and 250kbps bus speed (on an isolated bus). I know for sure that the bus speed is 250k, I can read frames with a USB CAN interface. Have tried all modes. What I have found it should be ok to connect pin 8 (RS) to GND without resistor ().
Anyway, I gave up and ordered a couple of SN65HVD230, hopefully that will solve my problem.
- According to it should be 10k resistor between pin 8 and GND. Anyway, it's hard to trace connections from your photo to confirm that everything is OK. Also have in mind that recommended transceiver is the SN65HVD230, but MCP2551 also should work.
- Did you try with different speed 125000 or 500000? Devices on CAN bus have to talk at the same speed, sometimes for example in Mazda there are two speeds 125k and 500k on the CAN bus.
- Did you try with
mode=CAN.SILENT(for sniffing the bus) and
frame_format=CAN.FORMAT_BOTH(to catch 11bit (standard) and 29bit (extended) frames)? | https://forum.pycom.io/topic/2491/can-with-mcp2551 | CC-MAIN-2021-31 | refinedweb | 390 | 83.66 |
Does ejb Entity support blob insert (6 messages)
Can anybody post example of how to insert blob file using CMP or BMP bean.
- Posted by: Tim Allen MO
- Posted on: July 16 2003 01:14 EDT
Threaded Messages (6)
- Does ejb Entity support blob insert by Nagendra Prasad on July 16 2003 05:09 EDT
- Insert BLOB by Lofi Dewanto on July 16 2003 08:32 EDT
- using CMP 2.0 & Oracle 903/904 by Andy Stefancik on July 16 2003 08:51 EDT
- Thanx to Andy Stefancik and everyone by Tim Allen MO on July 16 2003 19:29 EDT
- Is there a size limit on blob when I use this approach? by Binesh Gummadi on June 14 2004 19:01 EDT
- Is there a size limit on blob when I use this approach? by Debu Panda on August 13 2004 12:17 EDT
Does ejb Entity support blob insert[ Go to top ]
No till Ejb 1.1 inserting of a blob is not supported.
- Posted by: Nagendra Prasad
- Posted on: July 16 2003 05:09 EDT
- in response to Tim Allen MO
You have to used it in the traditional jdbc way by inserting a byte array and then updating that with the blob reading byte by byte.
But you can retreive the blob with any finder method of the entity beans.
Hope this helps..
regards
Nagendra...
Insert BLOB[ Go to top ]
Sure you can use BLOB in EB 1.1 ;-)
- Posted by: Lofi Dewanto
- Posted on: July 16 2003 08:32 EDT
- in response to Nagendra Prasad
Just use a normal serializeable Java object. I'm using it in OpenUSS to handle attachment for my discussion forum EJB 1.1.
You can download the complete code (OpenUSS == Open Source) from
Hope this helps!
Lofi Dewanto
Example from OpenUSS ():
...
public class DiscussionFileBaseBean extends EntityAdapter
implements DiscussionFileBase {
public String id;
// Object state
public DiscussionFileObject file;
public DiscussionFileBasePK ejbCreate(String id, DiscussionFileObject file)
throws CreateException {
this.id = id;
this.file = file;
return null;
}
/**
* Gets the file of the discussion.
*
* @return the file of the discussion.
* @exception EJBException.
*/
public DiscussionFileObject getFile() {
return file;
}
/**
* Gets the file of the discussion.
*
* @param the file to be changed.
* @exception EJBException.
*/
public void setFile(DiscussionFileObject file) {
// Check first, if the param is null, don't update this!
// Let the old value survive!
if (!(file == null)) {
// Check the length of the file
if (file.getData().length != 0) {
// File is not empty
this.file = file;
// EJB container specific
setModified(true);
}
}
}
...
using CMP 2.0 & Oracle 903/904[ Go to top ]
Can anybody post example of how to insert blob file using CMP or BMP bean.
- Posted by: Andy Stefancik
- Posted on: July 16 2003 08:51 EDT
- in response to Tim Allen MO
Using the oracle.xml file in j2ee\home\config\database-schemas, I just mapped
a byte array to a blob in the db table, and used CMP. So in the Entity bean I
just work with a byte array, and the blob storage is transparent.
In oracle.xml
add this line
<type-mapping
In the Entity bean declare
public abstract byte [] getData_file();
public abstract void setData_file(byte [] newData_file);
In the create
public String ejbCreate(String newFwc,String newPart_no,String newMedia,
String newProd,String newTcode,String newSource,
String newCdate,String newCtime,String newLast_acc,
String newProg,String newRuntm,String newNdown,
byte [] newData_file,String newViewer,
String newDb)throws CreateException
{
.......
.......
setData_file(newData_file);
}
So I don't have to work with JDBC blob or BLOB handling, or database
stored procedures. I just call get or set. The container implements those
functions for me.
Thanx to Andy Stefancik and everyone[ Go to top ]
Hi Everyone
- Posted by: Tim Allen MO
- Posted on: July 16 2003 19:29 EDT
- in response to Andy Stefancik
Andy Stefancik your example did work and I was able to successfully upload a blob file of 95 kb. Once again thanx to everyone who replied....your help is deeply appericated :)
Example tried on system configuration ---> "JBoss 3.2.XXX and Mysql 4.0.3"
Have a nice week
Tim
Is there a size limit on blob when I use this approach?[ Go to top ]
Hi,
- Posted by: Binesh Gummadi
- Posted on: June 14 2004 19:01 EDT
- in response to Andy Stefancik
Thanks for your post and it works well. I guess there is a size limitation of 4k. I dont know if it is on the oracle database server or the appserver. We are using oracle application server(9IAS). I used a byte array to save the file into the database. It works like a charm when I upload the file less than 4k. Once you cross the limit of 4k its throwing erros.
Any Idea of how I can fix it?
I am reletively new to application servers.
Thanks
Binny
Is there a size limit on blob when I use this approach?[ Go to top ]
What version of OC4J are you using ? This works out of the box in 9.0.4
- Posted by: Debu Panda
- Posted on: August 13 2004 12:17 EDT
- in response to Binesh Gummadi
For 9.0.3, there is patch available
-Debu | http://www.theserverside.com/discussions/thread.tss?thread_id=20386 | CC-MAIN-2016-18 | refinedweb | 854 | 64.71 |
Creating Cellphone Game or Application
by Ralf Kistner
To create a game or application for your cellphone, you need the following:
To create a game or application for your cellphone, you need the following:
Note: This is not a tutorial to teach you Java. You should be confident with Java before reading this tutorial.
Step 1: In J2ME Wireless Toolkit, create a new project. Give the project any name you want. Make the class name Main. You don't need to change any of the settings.
Step 2: Create [J2ME home dir]\apps\[project name]\src\Main.java with the following code:
import javax.microedition.midlet.MIDlet;
import javax.microedition.lcdui.*;
public class Main extends MIDlet {
private Form mainForm;
public Main() {
//create a new Form with the specified title
mainForm = new Form("Hello World");
//append a String to the form
mainForm.append("Hello World!");
}
public void startApp () {
//show the Form in the display area
Display.getDisplay(this).setCurrent(mainForm);
}
public void destroyApp(boolean b) { }
public void pauseApp() { }
}
Step 3: In J2ME, build the project. If you don't get any errors, you can run your program. A frame with a picture of a cellphone should pop up. Click on the button under launch and you should see "Hello World!".
Congratulations! You've just created your own cellphone application!
Step 4: To get it on your cellphone, you'll have to create a package (Project-> Package-> Create Package).
See your cellphone's manual for futher instructions on how to put it on your cellphone.
<. | http://www.planet-source-code.com/vb/scripts/ShowCode.asp?txtCodeId=3066&lngWId=2 | CC-MAIN-2018-09 | refinedweb | 253 | 66.94 |
28 October 2010 10:43 [Source: ICIS news]
SINGAPORE (ICIS)--Borouge has achieved commercial production at its expanded polyolefins complex in Ruwais, ?xml:namespace>
“The company has begun to export small quantities of polypropylene (PP) and polyethylene (PE) from the expanded facility and will step up the volumes in the coming weeks,” the source added.
Following the start-up, Borouge has doubled its production of PE to 1.2m tonnes/year and begun to produce PP for the first time at its new 800,000 tonne/year plant at Ruwais.
“The mega-project Borouge 2, valued at an estimated US$5 billion (€3.65bn), triples the annual polyolefins production capacity of the plant to 2 million tonnes per year,” Borouge said in a separate statement.
Borouge is a joint venture between UAE’s stated-owned Abu Dhabi National Oil Company (ADNOC) | http://www.icis.com/Articles/2010/10/28/9405226/Borouge-achieves-commercial-ops-at-expanded-polyolefins.html | CC-MAIN-2014-42 | refinedweb | 141 | 52.9 |
Chatlog 2009-05-06
From SPARQL Working Group
See original RRSAgent log and preview nicely formatted version.
Please justify/explain all edits to this page, in your "edit summary" text.
<LeeF> Present: LeeF, ericP, ivanh, chimezie, pgearon, kasei, ywang4, axel, alex, LukeWM, steveh, andys, birte, bijan, SimonS, kendall, iv_an_ru, KjetilK, john-l 10:53:19 <RRSAgent> RRSAgent has joined #sparql 10:53:19 <RRSAgent> logging to 10:53:19 <ericP> Zakim, please dial MIT262 10:53:19 <Zakim> ok, ericP; the call is being made 10:53:20 <Zakim> SW_(SPRQL-F2F)6:30AM has now started 11:08:15 <LeeF> LeeF has joined #sparql 11:09:15 <LeeF> zakim, who's here? 11:09:15 <Zakim> On the phone I see Bristol, ivanh, MIT262, iv_an_ru 11:09:16 <Zakim> Bristol has SimonS, SteveH, Kjetil_, LukeWM, AndyS 11:09:17 <Zakim> On IRC I see LeeF, AndyS, bijan, RRSAgent, Kjetil_, Zakim, AlexPassant, SimonS, SteveH, LukeWM, AxelPolleres, ivanh, john-l, KjetilK, trackbot, iv_an_ru, kjetil, ericP 11:09:35 <LeeF> zakim, MIT262 has kasei, LeeF, ericP, pgearon 11:09:35 <Zakim> +kasei, LeeF, ericP, pgearon; got it 11:14:56 <AxelPolleres> Lee: goal, fix what we're gonna dfo the next 2 months and the next 15month 11:16:00 <pgearon> pgearon has joined #sparql 11:16:06 <ericP> scribenick: ericP 11:16:08 <kasei> kasei has joined #sparql 11:16:11 <LeeF> Day 1, slot 1 - ericP 11:16:48 <LeeF> day 1, slot 2- Simon 11:17:01 <LeeF> day 1, slot 3 - kasei 11:17:47 <LeeF> day 2 - slot 1 - paul 11:17:50 <LeeF> day 2 - slot 2 - alex 11:18:30 <LeeF> day 2 - slot 3 - kjetil 11:20:24 <ericP> topic: agenda 11:20:45 <ericP> LeeF: pre-lunch we will have a knock-down, drag-out feature fight 11:20:59 <ericP> ... after lunch: 11:21:03 <ericP> ... .. name of doc 11:21:07 <ericP> ... .. rdf:text 11:21:19 <ericP> ... .. template for editorial contributions 11:21:26 <ericP> ... .. tomorrow am: 11:21:43 <ericP> ... .. features (subqueries/aggregates) 11:21:47 <KjetilK> we lost your picture 11:22:09 <AxelPolleres> do you still see us? 11:22:17 <kasei> yes 11:22:18 <ericP> ... hope that alex and KjetilK 11:22:47 <ericP> ... ... will have everything they need <LeeF> topic: feature discussion 11:24:33 <ericP> subtopic: survey results 11:24:22 <AxelPolleres> 11:24:33 <AxelPolleres> 11:24:44 <SteveH> that's not the results 11:24:51 <LeeF> 11:25:21 <ericP> LeeF: when using results, i've been looking at top-ten 11:25:54 <ericP> ... been looking at the don't want column, noting that Clark and Parsia seem to use it as others used don't mind 11:26:14 <ericP> ... negation has ten votes in the top ten 11:26:49 <LeeF> LeeF has changed the topic to: F2F Agenda - 11:27:44 <ericP> LeeF: we agreed to updates, aggregates and subselects 11:28:06 <ericP> [reads through condorcet results] 11:28:28 <SteveH> q+ 11:28:33 <ivanh> zakim, mute me 11:28:33 <Zakim> ivanh should now be muted 11:28:44 <SteveH> 11:28:45 <LeeF> ack SteveH 11:29:20 <ericP> SteveH: produced another graph which ranks don't-want below don't-mind 11:29:34 <ericP> ... possibly a more fair representation 11:30:33 <ericP> [note that these two do not differ in the top ten] 11:31:14 <ericP> SteveH: we used don't-want to indicate things that we thought would impede the standards process 11:32:56 <ericP> ericP: so don't-want is a consensus issue where don't-mind is not 11:33:07 <LeeF> -> 11:33:12 <ericP> SteveH: yeah, though we didn't agree before hand so it's open to interpretation 11:34:24 <ericP> LeeF: service discription is not a magic bullet, it does give impls a way to supply features which didn't make the cut 11:34:46 <ericP> ... it's not trivial but i think it's well-worth the work 11:35:03 <ericP> ... DaRQ and SADL have been getting a bit of traction 11:35:20 <ericP> ... i was surprised that project expressions came out so low 11:36:10 <SteveH> +1 to nescessity of ProjectExpressions 11:36:35 <ericP> ... i called it a required feature, not because i wanted it, but because it seemed very strange to have aggregate projections but not scalar projections 11:36:56 <ericP> ... also, project appeared to have more consensus than the alternative assignment 11:37:25 <ericP> ... will amend this proposal with negation 11:37:44 <ericP> ... our deliverable should be "making negation less painful" 11:37:56 <ericP> ... Time Permitting: 11:38:24 <ericP> ... .. federated query, func lib, property paths 11:38:43 <ericP> ... skipped assignment as i don't see consensus around it 11:39:00 <ericP> ... left full-text out due to tech and political constraints 11:40:08 <AxelPolleres> eric: safer to leave full-text out. 11:40:10 <AndyS> q+ to ask EricP about IPR issues on full text 11:40:45 <ericP> ericP: full-text seems like it *could* have IPR so not worth including in charter if we're not likely to get to it 11:41:05 <ericP> AndyS, i don't know of any IPR, just that it seems marginally more dangerous than other spaces 11:41:13 <AndyS> ack 11:41:28 <AndyS> zakim, ack me 11:41:28 <Zakim> AndyS, you wanted to ask EricP about IPR issues on full text 11:41:29 <Zakim> I see no one on the speaker queue 11:41:56 <ericP> LeeF: added OWL 'cause i want SPARQL WG to tbe the first to use the extension mechanism 11:42:21 <ericP> LeeF: it's important that we don't go off and work on our pet features and expect a rubber stamp 11:42:44 <iv_an_ru> I'm afraid that we should say something about full text, at least as non-normative section that points to some full text query spec. 11:42:50 <AxelPolleres> "don't want"s in the top-12 plus SurfaceSyntax: Update 1 (Clark&Parsia), 11:42:50 <AxelPolleres> BasicFederatedQueries 1 (Clark&Parsia), 11:42:50 <AxelPolleres> FunctionLibrary 1 (Clark&Parsia), ProjectExpression 1 (Clark&Parsia), 11:42:50 <AxelPolleres> PropertyPaths 1 (RPI), FullText 1 (Clark&Parsia), 11:42:50 <AxelPolleres> Assignment 1 (Garlik), SPARQL/OWL 1 (OpenLink), SurfaceSyntax 1 (Clark&Parsia) 11:43:06 <ericP> ... OTOH, folks need to do the work. core features will require initiative 11:43:33 <ericP> ... i put SPARQL-OWL at the top of might-get-to list as i feel it will have energy 11:44:24 <ericP> ... property paths and basic fed query is likely to be the same players as other features 11:44:54 <AxelPolleres> birte arrived. 11:44:57 <kasei> i should say that i (rpi) used "don't want" more as a "rank below everything else", not as a "I have big problems with this" ... 11:45:05 <ericP> ... we should be conservative about surface syntax 11:45:07 <AxelPolleres> q? 11:46:11 <ericP> birte: [intro] interested in owl ontologies (thesis topic) 11:46:35 <ivanh> zakim, unmute me 11:46:35 <Zakim> ivanh should no longer be muted 11:46:59 <AndyS> zakim, who is on the phone? 11:46:59 <Zakim> On the phone I see Bristol, ivanh, MIT262, iv_an_ru 11:47:00 <Zakim> MIT262 has kasei, LeeF, ericP, pgearon 11:47:01 <Zakim> Bristol has SimonS, SteveH, Kjetil_, LukeWM, AndyS 11:47:27 <AxelPolleres> iv_an_ru, you wanted to say hi on the phone? do you hear us? 11:47:35 <iv_an_ru> Yes I hear you fine 11:48:31 <AxelPolleres> 11:48:49 <ericP> subtopic: Axel's Questions: 11:48:52 <KjetilK> q+ 11:49:51 <ericP> AxelPolleres: do we need a surface syntax, or just use subqueries? 11:49:57 <karl> karl has joined #sparql 11:50:16 <ericP> LeeF: is anyone uncomfortable with negation? 11:50:19 <KjetilK> q- 11:50:58 <ericP> AxelPolleres: i included objections in the question list 11:51:43 <ericP> ... if we need an intuitve expression, would they still want another syntax? 11:52:37 <ericP> AndyS: note that FILTERs do not have the expected scope so don't behave as folks expect 11:52:53 <ericP> ... so we should have negation as a separate features 11:53:41 <AxelPolleres> Steve: difference between empty result or empty binding set needs to be considered... example pending 11:53:57 <ericP> SteveH: share AndyS's concearn that FILTER negation may not behave as expected 11:54:21 <ericP> AxelPolleres: should we sub-divide service description? 11:54:30 <ericP> ... .. description of data set 11:54:39 <ericP> ... .. optimizer hints 11:54:42 <kasei> q+ to mention a fourth facet of service descriptions 11:54:48 <LukeWM> q+ 11:54:49 <SteveH> q+ to talk about scope 11:54:59 <ericP> ... .. entailment regimes 11:55:09 <LeeF> ack kasei 11:55:09 <Zakim> kasei, you wanted to mention a fourth facet of service descriptions 11:55:27 <LeeF> ack LukeWM 11:55:38 <LeeF> kasei: also supported extension functions & supported language extensions 11:55:54 <iv_an_ru> IMHO service descriptions consists of optional properties only, so there's no technical need to sub-divide. 11:56:18 <ericP> LukeWM: do we decide what you can put in the service description? i.e. schema? 11:56:27 <AxelPolleres> lee: a core would make sense 11:56:28 <iv_an_ru> yes 11:56:31 <ericP> LeeF: deciding on a core would encourage folks to impl and use it 11:56:32 <LeeF> ack SteveH 11:56:32 <Zakim> SteveH, you wanted to talk about scope 11:56:54 <ericP> SteveH: [echoing LukeWM more assertively] 11:57:00 <AxelPolleres> steve: promoting of certain vocabs is not in the spirit of RDF 11:57:10 <ericP> ... these schemas (e.g. DaRQ) evolve 11:57:12 <LeeF> q? 11:57:18 <AndyS> q+ 11:57:30 <iv_an_ru> 99% of service description issue is The Schema. 11:57:33 <ericP> ... we should just provide the dereferencing mechanism 11:57:43 <ivanh> q+ 11:58:01 <AndyS> I disagree with the "99%" comment. Finding the graph matters. 11:58:05 <LeeF> ack AndyS 11:58:17 <ericP> LeeF: is anyone's vote on service description conditional on any of these sub-features? 11:58:32 <iv_an_ru> AxelPolleres, we promote fn:, xsd: and some other namespaces anyway :) 11:58:37 <KjetilK> q+ 11:58:39 <ericP> AndyS: want to say "my dataset description is <there>" 11:58:45 <SimonS> q+ 11:58:45 <AxelPolleres> q+ 11:58:52 <kasei> +1 AndyS 11:58:59 <iv_an_ru> +1 AndyS 11:59:35 <LeeF> ack ivanh 11:59:41 <LeeF> q+ ericP to ask if anyone is opposed to standardizing the mechanism mainly/only & examples 11:59:49 <iv_an_ru> One should be able to read authoritative service description, but w/o any obligations. 12:00:12 <SimonS> q- 12:00:15 <ericP> ivanh: i don't disagree with AndyS and SteveH, but we should flush out features we enable 12:00:29 <LeeF> ack KjetilK 12:00:43 <ericP> KjetilK: can't we do dataset descriptions with queries? 12:00:54 <kasei> that could also be prohibitively expensive 12:00:57 <ericP> SteveH: doesn't give you the quantitative stuff 12:01:17 <ericP> AndyS: can put you in a loop. 12:01:23 <LeeF> q? 12:01:42 <ericP> ... might want to advertise the set of zip codes in the US 12:01:52 <iv_an_ru> I can't agree with dataset descriptions with queries, this will ban "select all' queries. 12:02:01 <LeeF> ack AxelPolleres 12:02:20 <ericP> SteveH: seems we need a tiny features like "i do <this>" 12:02:26 <Zakim> +??P9 12:02:31 <bijan> zakim, ??p9 is me 12:02:31 <Zakim> +bijan; got it 12:04:01 <LeeF> ack ericP 12:04:01 <Zakim> ericP, you wanted to ask if anyone is opposed to standardizing the mechanism mainly/only and to ask if anyone is opposed to standardizing the mechanism mainly/only & examples 12:04:19 <AxelPolleres> steve: small set of properties, e.g. sparql:supports 12:04:39 <AndyS> +1 12:04:42 <SteveH> +1 12:04:44 <LeeF> ericP: the impression I have is that if we provide the mechanism (e.g. DESCRIBE or something with endpoint URI) and some examples - we may flesh out some bits of a schema, but we don't want to decide on that /commit to that while deciding our feature set 12:04:48 <SimonS> +1 12:04:50 <LeeF> <general love for Eric> 12:04:51 <KjetilK> 0 12:04:55 <AlexPassant> +1 12:05:22 <ericP> bijan: [gargled "hi"] 12:05:38 <Zakim> -iv_an_ru <LeeF> subsubtopic: Full-text search 12:05:49 <ericP> AxelPolleres: [re: full text search] 12:06:18 <ericP> ... some debate whether regex handles a useful subset of full text 12:06:41 <ericP> ... i am now convinced that full-text is sufficiently different from regex 12:07:03 <LeeF> LARQ 12:07:11 <ericP> KjetilK: we have used LARQ and Viruoso 12:07:33 <Zakim> +iv_an_ru 12:07:38 <ericP> ... main cost of migration is the full-text 12:07:40 <AxelPolleres> Kjetil: LARC and Virtuoso provide very useful fulltext features, interoperability is low though and main cost of migration 12:07:46 <AndyS> LARQ -> 12:07:59 <ericP> ... our needs are a little bigger than regex 12:08:10 <iv_an_ru> full-text should be interoperable in its core. 12:08:15 <AxelPolleres> Kjetil: we haven't used scores so far. 12:08:36 <AndyS> q+ to comment on stemming 12:08:44 <ericP> SteveH: what proportion of the users are in your [expressivity] camp vs. those who need stemming and scoring 12:09:18 <ericP> KjetilK: writing regex is generally difficult 12:09:46 <ericP> ... our use cases are *possible* with regex + \p 12:09:47 <AxelPolleres> simon, can you put yourself on the q and explain your use case? 12:09:48 <iv_an_ru> regex is simply not for free text. Nothing to compare :) 12:10:17 <iv_an_ru> Scoring is an unavoidable. 12:10:55 <SimonS> +q 12:11:01 <AndyS> Agree - minimum is truncate results on score but returning score is nice 12:11:13 <AndyS> q- 12:11:23 <ericP> ... fear we are making SPARQL harder to deploy and adopt 12:11:31 <ericP> SteveH: matter of perspective 12:11:36 <bijan> I'm confused as to why specing entailment regimes makes it more expensive to deploy SPARQL in general. 12:11:39 <ericP> ... full-text is one of the harder things 12:11:55 <ericP> ... maybe 10-100 times harder than e.g. subselect 12:11:56 <iv_an_ru> AndyS, returning score is unavoidable, at least to find out the threshold value to use for truncating. 12:12:21 <AndyS> Alternative is to pass the score trunctae point into matching. 12:13:09 <iv_an_ru> ericP, we don't have to make the full-text mandatory part of every implementation, we just should specify that when implemented it should support some set of functions and some fixed syntax. 12:13:17 <ericP> KjetilK: every web site had a search box. need to be able to apt-get install and run 12:13:58 <ericP> AndyS: implementing Lucene may be more work than implementing SPARQL 12:14:13 <bijan> There are many lucene-esque toolkits as well 12:14:48 <AxelPolleres> iv_an_ru? kjetil asks whether you have something on your fulltext solution? 12:15:01 <KjetilK> iv_an_ru, what kind of solution have you built? 12:15:16 <KjetilK> iv_an_ru, and how expensive is it? 12:15:16 <iv_an_ru> We're using custom free-text, 12:15:27 <iv_an_ru> That was really expensive, but fast :) 12:16:32 <iv_an_ru> Others will probably implement a cheaper free-text, because our FT provides special indexing of tags of XML documents in order to accelerate XPath queries. 12:16:34 <AxelPolleres> Something like "?o contains <text condition> ?score . 12:16:39 <ericP> LeeF: who has something they would boot off the list in favor of full-text 12:16:51 <AxelPolleres> " doesn't look terribly compatible with triple patterns, does it? 12:17:03 <AndyS> (round table) 12:17:35 <iv_an_ru> AxelPollers, score etc should not be in triple patterns syntax, because options (score etc) can be numerous. 12:17:41 <LeeF> pgearon: we have it through lucene already 12:18:09 <iv_an_ru> ?o <contains> "text pattern" --- for simple cases, a FILTER with function call for complications. 12:18:16 <LeeF> kasei: I probably wouldn't implement it due to cost and lack of need, but would be happy for it to be an optional part of the language 12:18:49 <LeeF> ericP: w3c tries to make coherent set of technologies, might shoehorn us into xpath full text expression 12:19:03 <iv_an_ru> No doubt, FT should stay outside mandadory part of the language. 12:19:28 <LeeF> ericP: community could do outside of WG 12:19:51 <AxelPolleres> would custom functions in FILTERs and ORDER BY work? Is a new syntax really needed? 12:19:54 <ericP> LukeWM: don't *disagree* with SteveH 12:20:05 <ericP> ... can see the user motivations for it 12:20:32 <ericP> ... i wonder if we need to specify what happens behind the scenes 12:21:32 <LeeF> ericP: we've never had to specify how something is implemented, but we would be expected to write down what the functionality is 12:21:36 <AxelPolleres> luke: e.g. differences could be in whether stemming is done or only simple match 12:21:42 <LeeF> ericP: what a minimally conformant SPARQL implementation should do 12:21:43 <ericP> ... vs. just the syntax and leaving details to the service description 12:22:26 <ericP> pgearon: i don't see full-text as being essential 12:22:52 <ericP> SteveH: i can't back it 'cause we wouldn't implement it 12:23:15 <ericP> KjetilK: couldn't you just spec a syntax? 12:24:00 <ericP> LeeF: you have a cost porting between LARQ and Virtuoso 12:24:31 <ericP> ... what if you had consistent expressivity, but varying surface syntax? 12:24:35 <pgearon> If we do spec a syntax (which I don't mind) then this is why I'm +1 on service descriptions, so we can advertise whether or not this feature is available 12:24:37 <SteveH> it's bitten SQL badly 12:25:57 <ericP> KjetilK: if both systems meet our expressivity needs we can live with changing the surface syntax 12:26:07 <pgearon> SteveH, I see your argument, but DESCRIBE already set this precedent 12:26:13 <ericP> ... ori noted that regex are much slower 12:26:41 <AndyS> There are regex indexing schemes 12:26:50 <ericP> q+ to propose a "use xpath when possible" directive 12:27:13 <LeeF> ack SimonS 12:27:23 <ericP> q- 12:27:40 <ericP> AndyS: would be happy to see a syntax for free-text search 12:28:00 <ericP> ... the work investment goes up radically 12:28:24 <ericP> ... different engines have different features (e.g. scoring) 12:29:02 <pgearon> +1 12:29:03 <AxelPolleres> andy: worried about necessary effort 12:29:05 <ivanh> +1 12:29:15 <ericP> ... i don't think standards help beyond there 12:29:38 <ericP> KjetilK: happy with magic predicates or a fILTER function 12:29:47 <ericP> ... seems like a simple requirement 12:29:50 <bglimm> bglimm has joined #sparql 12:30:08 <AndyS> Property functions imply an exuection model we don't have so I pref explciit syntax for full text search 12:30:25 <ericP> SteveH: what user set is content with conjunctive word lists vs. stemming and ranking? 12:30:51 <ericP> ... web sites care about stemming and ranking, which would be ugly as magic predicates 12:31:06 <ericP> KjetilK: trying to give a good migration path to SPARQL 12:32:27 <ericP> SimonS: we need at least scoring 12:32:54 <ericP> ... faceted browsing is a compelling use case 12:33:05 <ericP> ... we need a ranked list as output 12:33:23 <ericP> ... predicate functions work for that 12:33:25 <AndyS> q+ to note that predicate functions can bite 12:33:52 <SteveH> wonders if were talking about implied ordering or ?x :fulltext [ result: ?res ; :rank ?rank ] 12:34:07 <ericP> AlexPassant: fine with current regex 12:34:13 <AlexPassant> uses regexps on doapstore.org search 12:34:14 <LeeF> ack AndyS 12:34:14 <Zakim> AndyS, you wanted to note that predicate functions can bite 12:34:24 <iv_an_ru> No implied ordering is possible. 12:34:59 <ericP> AndyS: predicate functions (graph patterns) can bite you as they require an undocumented order of execution 12:35:05 <iv_an_ru> I.e. it is possible but may cadd cost for no reason. 12:35:15 <ivanh> +1 to AndyS 12:35:19 <AxelPolleres> andy: example by orri for why fulltext is order dependent... we have to be cautious about that 12:35:36 <ericP> SimonS: true. it's not ugly, but it's not exactly what you want 12:35:59 <bijan> Here's my response to the "around the room": It seems that there is a community for which full text is must have, another community which doesn't need it at all (most of the stuff I work on and the people I work with have little text in the datasets), and maybe some who could take it or leave it. (<---so very unprofound!) So, optional. I would be surprised if I'd implement it in either the RDF or the OWL systems I work on right now. 12:36:18 <ericP> birte: we would implement SPARQL + OWL, and full-text would be low on the weekend list 12:37:26 <ericP> ivanh: am now convinced this can be a huge job 12:37:27 <LeeF> zakim, who's on the phone? 12:37:27 <Zakim> On the phone I see Bristol, ivanh, MIT262, bijan, iv_an_ru 12:37:28 <Zakim> MIT262 has kasei, LeeF, ericP, pgearon 12:37:29 <Zakim> Bristol has SimonS, SteveH, Kjetil_, LukeWM, AndyS 12:37:49 <bijan> Also, I have no expertise in this, so can't really help with the specification. 12:37:59 <LeeF> q? 12:38:09 <KjetilK> iv_an_ru: do you want to comment on fulltext? 12:38:10 <iv_an_ru> (I suspect I can only listen and type) 12:38:21 <iv_an_ru> I've printed all comments already. 12:38:38 <KjetilK> Zakim, unmute iv_an_ru 12:38:38 <Zakim> iv_an_ru was not muted, KjetilK 12:38:49 <bijan> (I don't even know what the different "levels" could be, i.e., what a "lite" version of the feature would be.) 12:39:10 <iv_an_ru> I've muted myself 'cause the connection is prohibitively noisy. 12:39:39 <AxelPolleres> axel: no objection, but if it affects execution order, i.e. doesn't fit into pred functionsd, it's a bit worrying me. 12:40:19 <AndyS> I don't see why we are forced to use XQ/FT -- is it even mappable? 12:40:37 <SteveH> mappable to what? 12:40:39 <AxelPolleres> eric: easiest way to handle it would be to handle to ask implementers to use existing XPath functions 12:40:55 <KjetilK> q+ 12:41:20 <bijan> My *prima facie* reaction is to wonder why we wouldn't use XPath full text 12:41:25 <AxelPolleres> ... Xquery WG will ask us why we don't reuse their mechanism. 12:41:30 <bijan> (As a naive to fulltext person.) 12:41:35 <SteveH> bijan, xpath fulltext is /very/ complex 12:41:43 <AxelPolleres> AndyS: I guess our user community would put it just the other way around. 12:41:45 <SteveH> and leans on XML heavily 12:41:58 <LeeF> ack KjetilK 12:42:15 <ericP> KjetilK: the stuff i advocate is much smaller than xpath full-text 12:42:21 <iv_an_ru> It's cheaper to extend XQ/FT with "RDF literal" type than to re-invent the whole bicycle. 12:42:25 <bijan> SteveH, Oh, I totally believe that. I'm just saying that it's a choice that needs explanation. That can go easy or that can go hard... :) 12:42:27 <AxelPolleres> Bijan, honestly, it seems just too cumbersome. 12:42:32 <ericP> ... would be happy with simple magic predicates 12:42:59 <ericP> ... and then say "if you want stemming et al, use xpath" 12:43:01 <ivanh> +1 to SteveH (although he was hardly audible) 12:43:08 <iv_an_ru> I don't like magic predicates, but customers do :| 12:43:16 <LeeF> q+ to talk about magic predicates 12:43:21 <ericP> SteveH: i don't think there is such thing as a simpel magic predicate 12:43:24 <AxelPolleres> Can someone point to an example where the execution order "kicks in"? 12:44:13 <ericP> ... magpreds in full-text arena imply execution ordering and update of the result set to be ordered 12:44:14 <iv_an_ru> Can someone point to an example where the execution order "kicks in"? --- ?text <contains> ?text-pattern ;) 12:44:29 <AndyS> Looking at 12:45:09 <ericP> KjetilK: how evil is a magic predicate compared to a filter function? 12:45:11 <AndyS> Example: want doc URLs back in relevance order 12:45:22 <iv_an_ru> IMHO, what's important is to keep "really" magic predicates (with side effects like new bindings) apart from plain "syntax sugar" for filtering functions. 12:45:37 <ericP> SteveH: i expect you're better off with regex 12:46:00 <iv_an_ru> Whatever requires the order, should be written as a subselect with ORDER BY. 12:46:04 <ericP> LeeF: we have avoided magic predicates to date 12:46:12 <SteveH> +1 to predicate functions being strange 12:46:23 <SimonS> +1 to ordering 12:46:32 <pgearon> LeeF, except "a" (for rdf:type) 12:46:33 <SteveH> we've deliberatly avoided predicate functions 12:46:34 <ericP> ... ½ happy with that 12:46:47 <SteveH> pgearon, a is in the syntax, not a function 12:46:52 <ericP> ... ½ of me notes that many impls add them anyways 12:46:55 <AndyS> They can be done right but there is scope for diviating from the declarative property paradigm 12:47:03 <pgearon> SteveH, that's fair 12:47:08 <ericP> ... we use it in anzo, but feel it's hideous 12:47:20 <ericP> ... would be happy if some group told us how to do us 12:47:42 <ericP> ... but as chair of the SPARQL WG, i fear that group should not be us 12:47:48 <SteveH> I have another issue with predicate functions, but I'll leave that 12:47:49 <pgearon> We deliberately expressed as much as we can with triples.... which brought us to predicate functions 12:48:03 <AxelPolleres> if we agree on we also implicitly standarize property functions also for other use cases? 12:48:22 <SteveH> AxelPolleres, it's a bit like a sanctioning 12:48:28 <AndyS> Axel, I am not proposing that - it assumes too much of the system. 12:48:32 <AxelPolleres> which would be ok, if we want that. 12:49:33 <ericP> [LeeF reads rest of Axel's list] 12:49:54 <iv_an_ru> Whether we need "magic" or not is question of taste, but the "magic" of the service must be 100% documented by service description. 12:50:08 <ericP> [ivanh would add questions on property paths] 12:50:27 <ericP> subsubtopic: property paths 12:50:54 <ericP> ivanh: with negation and property paths, we can properly express lists? 12:51:30 <ericP> LeeF: yes in the common case where you have a link the head of a list 12:53:21 <LeeF> ericP: if we use property paths we will be writing off some use cases that involve preventing people from injecting new items in closed lists 12:54:06 <ivanh> q+ 12:54:11 <AndyS> q+ to reply 12:54:41 <LeeF> q- leef 12:54:59 <bijan> It's not ensured in RDF or OWL Full 12:55:06 <LeeF> ericP: not sure how many use cases we're giving up if we don't have a mechanism to ensure a coherent list 12:55:40 <bijan> It's not really all that encouraged 12:55:47 <LeeF> q? 12:56:50 <LeeF> ack ivanh 12:57:13 <LeeF> ivanh: this (coherent lists) is true but not our job 12:57:17 <iv_an_ru> Does somebody use closed lists? 12:57:22 <AndyS> (is this "property paths" or "list access"?) 12:57:39 <bijan> q+ 12:57:54 <AxelPolleres> q+ to ask whether we talk about PropertyPaths or AccessingLists here 12:58:42 <AndyS> +1 to ivanh for the list access need in SPARQL point 12:58:46 <ericP> ivanh: the missing list access in SPARQL has a deleterious affect on SPARQL 12:58:52 <LeeF> ack AndyS 12:58:52 <Zakim> AndyS, you wanted to reply 12:59:14 <iv_an_ru> OTOH we don't have convenient features for selecting all items of a numbered list (?s ?p ?o filter (?p is of sort rdf:_N )) or for finding a position of ?o in a list ?s (i.e. to extract N from rdf:_N). 12:59:23 <pgearon> +1 to ivanh for the list access need in SPARQL point 12:59:26 <ericP> AndyS: you need to detect [list] cycles anyways 12:59:52 <bijan> +1 to killing rdf:list! 12:59:56 <KjetilK> +1 to scrapping it in RDF ;-) 12:59:56 <SteveH> +1!!! 13:00:01 <bijan> use XML Schema lists! 13:00:05 <LeeF> q? 13:00:20 <LeeF> ack bijan 13:00:38 <ericP> bijan: i didn't undstand ivanh's point about coherent lists 13:00:54 <ericP> ... if we define list access, we can define coherent list access 13:00:57 <SteveH> +1 to bijan 13:01:17 <ericP> ... i feel that lists in RDF are bad, so i don't mind their use being discouraged 13:01:18 <LeeF> ack AxelPolleres 13:01:19 <Zakim> AxelPolleres, you wanted to ask whether we talk about PropertyPaths or AccessingLists here 13:01:40 <ericP> AxelPolleres: we didn't start out with a priority of access lists 13:01:49 <bijan> q+ 13:01:59 <pgearon> I don't like lists, but they're used in OWL (eg. owl:intersectionOf) so they can't be avoided 13:02:00 <ericP> ... if we can get the common use case with property paths, then good 13:02:30 <ericP> ... lists (are|are not)? the only way of expressing order 13:02:33 <bijan> q- 13:02:58 <bijan> I'm fine with that 13:03:13 <AndyS> Steve+Andy: There is rdf:Seq 13:03:26 <AxelPolleres> Break! 13:03:40 <LeeF> +27min. 13:03:50 <Zakim> -ivanh 13:04:01 <Zakim> -iv_an_ru 13:35:07 <LeeF> we're re-starting 13:35:34 <LeeF> scribenick: SimonS <LeeF> subsubtopic: ProjectExpressions & Assignment 13:35:52 <SimonS> AxelPolleres: continue discussion of questions 13:35:52 <ivanh> zakim, dial ivanh-voip 13:35:52 <Zakim> ok, ivanh; the call is being made 13:35:54 <Zakim> +ivanh 13:36:03 <ivanh> zakim, mute me 13:36:03 <Zakim> ivanh should now be muted 13:36:05 <AxelPolleres> continue with 13:36:12 <SimonS> AxelPolleres: ProjectExpressions 13:36:37 <SimonS> there is redundancy between Assignment and ProjectExpressions 13:36:47 <SimonS> Questions: same expressiveness? 13:36:59 <SimonS> ...don't want, why? 13:37:10 <LeeF> Clark & Parsia stated a preference for assignment because ProjectExpressions may be too complex for their use cases (not sure what those use cases look like) 13:37:50 <ericP> q? 13:38:04 <SimonS> SteveH: should not be an expressivity difference, but as SPARQL similar to SQL, do it similarly. 13:38:08 <ericP> q+ to say that it's an tedium difference 13:38:52 <SimonS> AxelPolleres: also redundant for ScalarExpressionsIn* 13:38:57 <AndyS> Roughly: { pattern1 assign pattern 2 } is equiv to { { SELECT assign { pattern1 } pattern 2 } 13:39:22 <SimonS> AxelPolleres: Objection against syntax rather than assignment per se? 13:39:30 <AxelPolleres> q? 13:39:40 <SimonS> SteveH: true, due to background in relational databases. 13:39:46 <LeeF> zakim, who's on the phone? 13:39:46 <Zakim> On the phone I see Bristol, ivanh (muted), MIT262, bijan 13:39:47 <Zakim> MIT262 has kasei, LeeF, ericP, pgearon 13:39:49 <Zakim> Bristol has SimonS, SteveH, Kjetil_, LukeWM, AndyS 13:39:52 <ericP> ack me 13:39:52 <Zakim> ericP, you wanted to say that it's an tedium difference 13:40:36 <SimonS> ericP: sees extra select as noise, would like more crisp syntax using let. 13:40:42 <SimonS> q+ 13:40:42 <LeeF> q+ to note that assignment is not always more terse 13:41:12 <SimonS> SteveH: does not think assignment will be often used 13:42:24 <Zakim> +iv_an_ru 13:42:51 <SimonS> steveH: will happen in subqueries anyway and will be needed to project out, so directly do it in projection. 13:43:10 <SimonS> ericP: but if you do not have subquery, you will need additional subquery. 13:43:20 <iv_an_ru> I'd like to have LET in SQL, but not in SPARQL :) 13:43:31 <AndyS> --> from TopQuadrant 13:43:54 <SimonS> ericP: how many people do want to push their constraints down to the binding of the variable? 13:44:10 <AndyS> Works well with CONSTRUCT. 13:44:50 <SimonS> SteveH: Prefer having subqueries, LET would be abbreviation only, maybe not often used. 13:44:57 <LeeF> -> comparison of simple use of projection vs. aggregate 13:45:08 <kendall> kendall has joined #sparql 13:45:20 <SimonS> Axel: Don't see the difference, logically 13:45:26 <kendall> hi LeeF 13:46:02 <SimonS> AxelPolleres: mean LET ?X = SELECT... vs SELEXT .. as ?X 13:46:25 <SimonS> SteveH: refers to ?X=3 13:46:57 <SimonS> AndyS: various forms of assignments. Logical vs. relational algebra. Semantics are compatible. 13:47:15 <SimonS> SteveH: LET looks like assignment, but logically it can't be. 13:47:45 <SimonS> ...want to avoid misleading syntax 13:48:04 <LeeF> q? 13:48:12 <SimonS> AxelPolleres: Really everything subsumed by project expressions. 13:48:18 <SteveH> SELECT 3 as ?x => ?x := 3 13:48:24 <KjetilK> ack SimonS 13:48:29 <AndyS> Scoping issues? 13:49:21 <SimonS> SimonS: prefers LET syntax as crisper 13:49:26 <SimonS> ...and shorter 13:49:43 <LeeF> is LET { <var> := <expr> } (theoretically) identical to { SELECT <expr> AS <var> }? 13:49:50 <KjetilK> ack LeeF 13:49:50 <Zakim> LeeF, you wanted to note that assignment is not always more terse 13:49:53 <SimonS> SteveH: emphasizes misunderstandability of Assignment 13:50:10 <LeeF> 13:50:36 <SimonS> LeeF: Uses both in different cases. 13:50:48 <AxelPolleres> Zakim, who is on the phone? 13:50:48 <Zakim> On the phone I see Bristol, ivanh (muted), MIT262, bijan, iv_an_ru 13:50:49 <Zakim> MIT262 has kasei, LeeF, ericP, pgearon 13:50:50 <Zakim> Bristol has SimonS, SteveH, Kjetil_, LukeWM, AndyS 13:51:00 <AndyS> { pattern1 LET (?x := ?a+?b) pattern 2 } is equiv to { { SELECT (?a+?b AS ?x) { pattern1 } pattern 2 } - need to have patten1 under select. 13:51:04 <SimonS> ...thinks the language should be kept minimal, however. 13:51:06 <kendall> (oh, man, what a joy pastebin is in this context; no more crappy code pastes into IRC) 13:51:38 <LeeF> thanks, AndyS 13:52:03 <SimonS> SteveH: ProjectExpressions is Superset of Assignment. Or Maybe not? 13:52:10 <AndyS> 13:52:24 <AxelPolleres> Lee: Is there anybody who wants assignment, but not project expressions? 13:52:38 <KjetilK> Zakim, Bristol has SimonS, SteveH, KjetilK, LukeWM, AndyS, AxelPolleres, AlexPassant, bglimm 13:52:42 <Zakim> +KjetilK, AxelPolleres, AlexPassant, bglimm; got it 13:52:54 <SimonS> AndyS: example easier to use Assignment, if we assign something, then do something with it. 13:53:33 <SimonS> LeeF: Are we discussing whether to do both or one over the other? 13:54:00 <AxelPolleres> SimonS: I think we should have one of them 13:54:23 <AxelPolleres> Steve: We should have only projectExpressions 13:54:52 <iv_an_ru> Maybe "LET ?x is a shorthand for ?a+?b" ... do something with ?x 13:54:57 <SimonS> SteveH: ordering issues with Assigment 13:55:21 <iv_an_ru> No circular assignments in any case, so no ordering headache. 13:55:51 <SimonS> AndyS: agree, but we have control if it gets into the algebra. 13:56:03 <AxelPolleres> ordering issues with assignment would be nesting issues with projectExpressions/subqueries. 13:56:08 <SimonS> ...fine, if value-based, not reference based. 13:56:45 <SimonS> SteveH: thinks this is exactly the kind of misunderstandings he means. 13:57:01 <kendall> C&P prefers explicit LET syntax for assignment, fwiw 13:57:03 <SimonS> Axelpolleres: In the case of subselect you have the same problem with nesting 13:57:17 <kendall> But we won't object to project expressions (though I find them much harder to read FWIW) 13:57:39 <SimonS> AndyS: We will have to discuss this for aggregates as well 13:58:12 <SimonS> AxelPolleres: aggregate proposal means allow selects as expressions, but not require project expressions. 13:58:38 <SimonS> SteveH: then we loose some powerful subqueries 14:00:06 <SimonS> SimonS: Aren't subqueries possible without project? 14:00:12 <SimonS> SteveH: no 14:00:26 <SimonS> AndyS: not sure SteveH is right 14:01:12 <SimonS> pgearon: don't care which one is chosen. 14:01:45 <SimonS> LeeF: Think we need ProjectExpressions, would not object to Assignment in addition 14:02:17 <SimonS> LeeF: cost to do both seems non trivial, but not huge 14:02:27 <kendall> ivanh: I resemble that remark! 14:02:51 <SteveH> q+ 14:03:12 <SimonS> ericP: Thinks, it does not make sense to emulate SQL. 14:03:28 <ivanh> ack SteveH 14:03:38 <SimonS> SteveH: agrees, but wants to stay close to relational algebra. Take good bits of SQL, but not bad ones. 14:03:56 <SimonS> ericP: SQL does a lot in selects 14:04:00 <LeeF> SPARQL looks like SQL. When I teach SPARQL to new people, they have a strong expectation that it has other SQL-like capabilities - so there is an education cost to things that diverge from that 14:04:06 <SimonS> ... unkeen on emulating exactly that 14:04:21 <SimonS> ... e.g. subqueries don't share variable names etc. 14:04:29 <SimonS> ... Not so good to optimize 14:04:44 <SimonS> ... e.g. UNIONS would be n subselects in SQL 14:04:56 <iv_an_ru> We shouldn't try to share variable names either. 14:04:58 <kendall> -1 on emulating SQL; -10 for reasons of pedagogic utility (sorry, LeeF) 14:05:05 <iv_an_ru> (I meen between sub-selects) 14:05:06 <SimonS> ... what exactly of SQL do you want to reuse? 14:05:26 <SimonS> SteveH: makes sense to be similar to SQL, as people know it. 14:05:28 <iv_an_ru> I'd like to reuse the runtime ;) 14:05:37 <ivanh> +1 to kendall; sparql is not sql, and we should not take the relationships between the two too far 14:05:38 <SimonS> ... want to reuse composability from relational algebra 14:06:00 <SimonS> ... i.e. brackets around query, project out results 14:06:12 <kendall> competing with SQL, in any sense, is a game we will always lose IMO -- "they" have a massive lead in just about every sense 14:06:17 <SimonS> Axel: Don't we lose this with FILTER in OPTIONAL? 14:06:19 <iv_an_ru> SimonS, make sense to be identical to SQL or noticeable distinct, but not similar --- "Stroustrup's law". 14:06:36 <iv_an_ru> +1 14:06:55 <kendall> but how best do that is the question, of course 14:07:12 <SimonS> AndyS: reusability refers to idea of layered joins 14:07:49 <SimonS> SteveH: usually one starts with simpler logical units of a query to compose a more complicated one. Easy and natural. 14:08:47 <kendall> for my $$, we already are "enough like SQL" that we ought to play some distinguishing moves for this phase of SPARQL evolution; which is one non-self-interested reason to push stuff like svc descriptions, inference regimes, etc. 14:08:53 <SimonS> ericP: consents to go with the relational closure approach. 14:09:38 <SimonS> AxelPolleres: back to ProjectExpressions. Seem to be strongly wanted, no objections. Can do assignment, if time allows. 14:09:49 <SimonS> SteveH: Does not capture my concerns. 14:10:08 <LeeF> What I hear is: Steve feels strongly about not incluing assignment. Kendall feels strongly about having assignment 14:10:12 <SimonS> ... have to define Assignments in terms of projections. 14:10:24 <SimonS> Axel: Would somebody object to dropping Assignment? 14:10:44 <kendall> we might object if project expressions don't subsume assignment semantically 14:10:45 <iv_an_ru> I don't like assignment 14:10:46 <SimonS> Kendall: maybe 14:10:50 <kendall> if they do, then we wouldn't 14:11:17 <kendall> thanks, Simon! :) 14:11:27 <kendall> NP 14:11:51 <kendall> so, LeeF, if someone would write an email showing that PEs subsume assignment, I'd be happy to let "LET" go :) 14:12:06 <kendall> well, i mean, assuming that I find the email convincing :> <LeeF> subsubtopic: Basic federated queries 14:11:42 <SimonS> AxelPolleres: LimitPerResource 14:11:58 <SimonS> ...still OK to drop it, if subsumed by subselects? 14:12:11 <SteveH> q+ 14:12:14 <SimonS> ...remarks for basic federated queries? 14:12:32 <ericP> q+ to say that the Health Care and Life Sciences WG uses them a lot 14:13:10 <kendall> and we'll keep using them in Pellet-Jena, so it's not a big deal 14:13:33 <AndyS> q+ 14:14:23 <SimonS> SimonS: separate marking part of query to be evaluated at one EP from choosing the EP. 14:14:23 <kendall> (FWIW, I want LET because I think the queries are more explicitly clear with them than w/out them) 14:15:16 <SimonS> AndyS: coming back to kendall: do things that are not in SQL but are useful. e.g. simple federated query is just to get the connectivity going. 14:15:16 <LeeF> ACTION: SteveH to write up how/whether assignment is subsumed by projected expressions + subqueries (tentative, with LukeWM) 14:15:16 <trackbot> Created ACTION-13 - Write up how/whether assignment is subsumed by projected expressions + subqueries (tentative, with LukeWM) [on Steve Harris - due 2009-05-13]. 14:15:33 <SimonS> SteveH: feature is needed. 14:15:55 <SimonS> ... but: concerns about triggering remote requests from inside DMZ 14:16:15 <SimonS> ... hence, SPARQL without federation should be allowed. 14:16:21 <ericP> ack SteveH 14:16:26 <SimonS> Axel: same as FROM? 14:16:30 <AndyS> ack AndyS 14:16:32 <KjetilK> +1 to SteveH 14:16:49 <SimonS> SteveH: in FROM you do not have to dereference URIs. 14:17:09 <pgearon> FROM doesn't specify that URLs should be dereferenced. But I note that most implementations go and do just this 14:17:15 <SimonS> AndyS: Endpoint can reject any query, if it wants to. 14:17:44 <SimonS> SteveH: want to make sure SPARQL does not sound dangerous per se to security people. 14:18:18 <SimonS> ...if it is in core, then it should be switched off by default. or have separate language SPARQL+Federation. 14:18:35 <pgearon> Security is going to be much more important when we look at how this interacts with Updates 14:18:48 <ericP> ack me 14:18:48 <Zakim> ericP, you wanted to say that the Health Care and Life Sciences WG uses them a lot 14:18:52 <AxelPolleres> sounds to me that this is an issue, but doesn't impete working on the feature 14:19:22 <SimonS> LeeF: mark security as an issue, but may work on this feature. 14:19:33 <kendall> +1 re: security 14:19:42 <LeeF> ISSUE: How to specify BasicFederatedQuery in a way that acknowledges optional nature of feature & security issues 14:19:42 <trackbot> Created ISSUE-1 - How to specify BasicFederatedQuery in a way that acknowledges optional nature of feature & security issues ; please complete additional details at . 14:19:42 <SimonS> SteveH: have compliance to SPARQL and "SPARQL-F" 14:20:00 <SimonS> AndyS: you can reject any query today. 14:20:06 <iv_an_ru> I've implemented graph-level security recently and found it relatively cheap, so I don't worry too much. 14:20:25 <AxelPolleres> sounds like some of the candidate core features for service descriptions then? 14:20:41 <SimonS> Kjetil: useful to be able to refuse to evaluate query. 14:21:10 <kendall> I think federation should be non-standardized and an area of vendor "competitive advantage"...It's super use-case specific in our experience, to boot 14:21:34 <SimonS> LeeF: coformance is important, but we can postpone that. 14:22:02 <SimonS> I think if it is vendor specific, you can not use it on the semantic WEB 14:22:13 <iv_an_ru> competitive implenetaitons of non-standardized fedaration is Bad Thing. <LeeF> subsubtopic: LimitPerResource & Surface Syntax 14:22:14 <SimonS> AxelPolleres: LimitByResource 14:23:05 <SimonS> Kjetil: Without LimitByResource, working on multiple datasources becomes more difficult. 14:23:16 <KjetilK> - LimitClause ::= 'LIMIT' INTEGER 14:23:16 <KjetilK> + LimitClause ::= 'LIMIT' Var? INTEGER 14:23:17 <SimonS> SteveH: possible with SubSelects 14:23:23 <AxelPolleres> 14:23:37 <SimonS> Kjetil: can't be simpler than limit by resource. 14:23:58 <SimonS> SteveH: more complex requirements than covered by current proposal. 14:24:18 <AxelPolleres> limit is always "distinct", yes? (otherwise doesn't make sense, does it?) 14:24:20 <SimonS> Kjetil: then use subselects, but we want it simple. 14:24:39 <SimonS> AxelPolleres: Why not limit by variable list 14:24:43 <SimonS> ...? 14:24:47 <kendall> iv_an_ru: I obviously don't agree 14:24:50 <SimonS> video is gone. 14:25:04 <AxelPolleres> LIMIT ?x ?y INTEGER ? 14:25:10 <AxelPolleres> q? 14:25:12 <SimonS> SteveH: Seems to be redundant, so leave it 14:25:29 <SimonS> Kjetil: Want this one simple syntax for our use case. 14:26:53 <kendall> in fact, competitive implementations of non-standard federation can be a good thing if it clarifies the market such that standardization can happy in a subsequent phase; premature standardization can do the opposite: cloud & foreclose the market, etc 14:26:59 <SimonS> Kjetil: You only care e.g. about distinct subjects. For example only have 10 resources plus their descriptions 14:27:29 <iv_an_ru> Why not DESCRIBE with appropriate flags? 14:27:49 <SimonS> SteveH: does not see the difference. Use Aggregates? 14:28:13 <SimonS> Kjetil: perhaps possible. 14:28:27 <SimonS> Axel: If subselect have LIMIT + aggregates. 14:28:42 <SimonS> SteveH: think we need better examples than in the wiki. 14:29:00 <SimonS> Kjetil: Really need aggregate plus limit. 14:29:34 <SimonS> SteveH: also want things like "up to three eMail adresses" 14:29:38 <iv_an_ru> kendall, _cooperative_ implementations of non-standard federation can be a good thing. Like AndyS and I kept SPARUL syntax in sync even if started it independently. 14:30:01 <SimonS> agree, iv_an_ru 14:30:07 <kendall> eh...not convinced 14:30:11 <LeeF> q? 14:30:21 <kendall> that's only true if the market really wants one thing, and the cooperating parties are workin on that one thing 14:30:28 <kendall> which i don't believe in this case 14:30:32 <iv_an_ru> We've seen enough "browser wars", don't want "sparql web-service endpoint wars" even if I win. 14:30:35 <kendall> so, whatever, we don't have to agree about this :> 14:30:42 <SimonS> AlexPassant: Would prefer concentrating of subqueries plus aggregates 14:31:09 <SimonS> Axel: Anyone else arguing for extra syntax? 14:31:52 <SimonS> LeeF: Negation is an example, which is possible, but painful. 14:32:09 <SteveH> I don't think all cases of Negation can be done curretnly 14:32:09 <SimonS> ... If there is not a consensus for special syntax. 14:32:23 <SimonS> ... we can do it later, as for negation. 14:32:39 <LukeWM> q+ 14:33:15 <LeeF> SteveH, you're probably right, but Bob MacGregor made a habit of trying to find such cases and didn't yet succeed (on sparql-dev and dawg-comments) 14:33:51 <LeeF> ack LukeWM 14:34:03 <SteveH> ?x a :A UNSAID { ?x a :B } is at least hard, though not impossible 14:34:07 <SimonS> LukeWM: There is difference between adding surface syntax for old and new features. For old ones there are lots of use cases. 14:34:09 <AndyS> Try writing intersection using cross product and negation. It can be done (apparantly). But it is very hard to get right. 14:34:26 <LeeF> SteveH, AndyS, I agree re: very hard, that's not what i was saying :) 14:35:04 <SimonS> Kjetil: If time allows and subselects + aggregates are done, maybe come back? 14:35:31 <SimonS> SteveH: Object. Will not have user experience by then. 14:36:09 <SimonS> SteveH: use case means real users in the field 14:36:57 <SimonS> Axel: Objection to dropping? 14:37:01 <SimonS> Kjetil: no. 14:37:12 <SimonS> Axel: Next one is SurfaceSyntax 14:37:22 <SimonS> ... what is surface syntax? 14:37:24 <AxelPolleres> 14:38:35 <SimonS> ... disjunction in FILTER (IN or BETWEEN) 14:39:03 <SimonS> ... path operators for concatenation etc 14:39:12 <SimonS> ... needed anyway for property paths 14:39:22 <SimonS> ... allow commas in expression lists 14:39:30 <SimonS> ... oppinions? 14:39:46 <AndyS> q+ to worry about the feature overall 14:39:48 <AxelPolleres> q+ on IN 14:39:53 <SimonS> SteveH: like IN, rely on it as an optimization. 14:39:59 <SimonS> ... comma probably useful 14:40:28 <SimonS> ... regarding IN: possibly gives list access if specified right, if right hand side is a list. 14:40:48 <SimonS> Axel: but that is a different feature 14:41:13 <SimonS> AndyS: all things possible using dynamic dispatch 14:41:25 <SimonS> Axel: Also IN SELECT ...? 14:41:30 <KjetilK> DefaultDescribeResult is also doable as SurfaceSyntax 14:41:42 <SimonS> SteveH: means SQL style IN. 14:41:56 <Zakim> -iv_an_ru 14:41:58 <SimonS> Axel: with subselects it is no longer syntactic sugar. 14:42:44 <SteveH> SteveH: yes it is :) 14:42:48 <AxelPolleres> IN range, IN subselect, IN lists 14:43:15 <SimonS> Axel: three possibilities - IN range, IN subselect, IN list. 14:43:48 <SimonS> SteveH: depends on how range is expressed. Could be a list. 14:44:06 <kasei> i would support "IN range", but generally not any of the other 3 surface syntaxes 14:44:17 <SimonS> ... not advocating this, just pointing it out. 14:44:19 <LeeF> q? 14:44:58 <SimonS> AndyS: feature is surface syntax. Not comfortable with putting it under SurfaceSyntax. Discussion too open. 14:45:00 <ericP> q+ to propose a feature called "query language" 14:45:02 <ericP> q- 14:45:22 <AndyS> ack me 14:45:27 <SimonS> Axel: left are IN between, commas. 14:45:30 <Zakim> AndyS, you wanted to worry about the feature overall 14:45:35 <LeeF> FYI: I'm building as I listen to the conversation 14:45:55 <KjetilK> q+ to ask whether we have agreed on the definition of surface syntax? 14:46:17 <SimonS> SteveH: IN with constants on the right is easy. 14:46:35 <SimonS> LeeF: not have a generic SurfaceSyntax item 14:47:12 <SimonS> ... changing SurfaceSyntac to Commas and IN in FeatureProposal 14:47:56 <SimonS> AndyS: can drop commas, nobody would complain. 14:48:11 <SimonS> LeeF: do it, if time permits. 14:49:13 <SimonS> Axel: objections to Commas if time allowed? 14:49:41 <SimonS> SteveH: commas in select alone do not help, also need it in limit etc. <LeeF> subsubtopic: SPARQL/OWL 14:50:30 <SimonS> Axel: next one is SPARQL/OWL 14:50:43 <chimezie> chimezie has joined #sparql 14:51:03 <SimonS> LeeF: Important to have. Who objects and why? 14:51:28 <PovAddict> PovAddict has joined #sparql 14:51:44 <KjetilK> q- 14:51:54 <Zakim> +Chimezie_Ogbuji 14:51:54 <KjetilK> q+ to say something negative 14:52:07 <chimezie> Zakim, mute me 14:52:07 <Zakim> Chimezie_Ogbuji should now be muted 14:52:09 <SimonS> ... discuss other entailment regimes. 14:52:12 <SimonS> ... do one. 14:52:18 <AndyS> If the goal to prove the extension point, makes sense to me to look at a simpler one (first). SPARQL/OWL has value in itself - not a proof point. 14:52:24 <SimonS> ... if it goes well, maybe do another one or two. 14:52:31 <bglimm> q+ 14:52:43 <SteveH> q+ 14:52:53 <bijan> q+ to say my main goal is force commonality on existing implementations 14:52:59 <bijan> er...one of my main goals 14:53:03 <KjetilK> ack me 14:53:05 <Zakim> KjetilK, you wanted to say something negative 14:53:10 <Zakim> -Bristol 14:53:24 <KjetilK> do you hear us? 14:53:26 <AxelPolleres> we need to redial it seems 14:53:26 <LeeF> that will be a lesson to saying something negative about SPARQL/OWL 14:54:20 <SteveH> we have a dependency on AndyS's knowledge of the phone :) 14:55:22 <iv_an_ru> We've added optional commas to select list syntax because SQL people wrote them. 14:55:39 <Zakim> +??P0 14:55:47 <SteveH> iv_an_ru, any idea what it did to the class of your parser? 14:55:57 <SteveH> iv_an_ru, is it still in LL1? 14:56:01 <KjetilK> Zakim, ??P0 is Bristol 14:56:01 <Zakim> +Bristol; got it 14:56:01 <LeeF> zakim, ??P0 is Bristol 14:56:02 <Zakim> I already had ??P0 as Bristol, LeeF 14:56:06 <iv_an_ru> Yes of course. 14:56:36 <iv_an_ru> It's still LALR1 because commas are either optional delimiters of the list or nested in (...) 14:56:46 <bijan> There are OWL Profiles 14:56:55 <bijan> OWL RL is explicitly designed to work for forward chaining 14:56:57 <SimonS> Kjetil: Have OWL users, have some simple inferences, which take forever 14:57:08 <SimonS> SteveH: just specify results only. 14:57:24 <SimonS> Axel: purpose is being able to specify what it means to support OWL. 14:57:32 <LeeF> q? 14:57:37 <LeeF> ack bglimm 14:57:47 <iv_an_ru> Moreover, it may be convenient to "invert" the informal description of the grammar and say that commas are not required as soon as select list stays unambiguous. 14:57:59 <bijan> Kjetil, it's not clear to me that the inferences are "simple". 14:58:11 <SimonS> Birte: There needs to be some way of telling users that results will not only be subgraph matching. Have users how need that. 14:58:34 <AxelPolleres> q+ to speak about why we need more refined notions of entailment even. 14:58:37 <SimonS> Kjetil: Is it that important? 14:59:01 <bijan> I'll note that RacerPro has it's own query language, NRQL 14:59:10 <SimonS> Birte: There is no standardized OWL query language, so use SPARQL. 14:59:32 <ivanh> q+ 14:59:34 <SimonS> ...instead of inventing another one. 14:59:44 <iv_an_ru> +1, the best advantage of SPARQL is the very fact of being implemented. 15:00:09 <iv_an_ru> Implementation of something is more convenient than spec of everything. 15:00:11 <LeeF> iv_an_ru, +30 to that (i think lessons from SPARQL v1 prove that out nicely) 15:00:26 <SimonS> Axel: support having OWL entailment regime, but DERI wants something more fine grained. 15:00:46 <SimonS> ...want to be able to say, "we support subset A, but not subsetB" 15:00:53 <SimonS> ...also interested in RIF rules. 15:01:01 <AndyS> Liitle house example --> 15:01:23 <AndyS> q+ 15:01:30 <SimonS> ...sometimes one just does not want to have full OWL on the Web, as it results in nonsense results. 15:02:13 <SimonS> Kjetil: OWL is too slow today. 15:02:23 <SimonS> SteveH: not everybody needs to do OWL. 15:02:39 <bijan> I'd like to address the OWL's too slow issue 15:02:40 <SimonS> AndyS: The point is being able to layer algebra on top of OWL inferencing. 15:03:07 <LeeF> ack AxelPolleres 15:03:07 <Zakim> AxelPolleres, you wanted to comment on IN and to speak about why we need more refined notions of entailment even. 15:03:12 <LeeF> ack SteveH 15:03:13 <AxelPolleres> ack SteveH 15:03:30 <LeeF> ack bijan 15:03:30 <Zakim> bijan, you wanted to say my main goal is force commonality on existing implementations 15:03:34 <SimonS> SteveH: OWL is not a special case. Regime includes RDFS and others. 15:03:54 <SimonS> bijan: OWL fast for many users/datasets/reasoners. 15:04:09 <SimonS> ... number of OWL2 profiles, which improve that even more. 15:04:38 <SimonS> ... need to take care of inconsistencies in the dataset for such entailment regime. 15:05:06 <SimonS> ... main objective is make OWL query engines use SPARQL and become interoperable 15:05:34 <LeeF> q? 15:05:38 <LeeF> ack ivanh 15:06:08 <bijan> OWL Profiles: 15:06:29 <SimonS> ivanh: OWL is not only huge DL reasoning with hundrets of classes. There are smaller profiles and smaller features useful on their own 15:06:58 <SimonS> ... discussion at WWW with LOD community. 15:07:12 <SimonS> ... They are starting to consider OWL as adding value 15:07:39 <SimonS> ... Need RDFS as well, which can not correctly be descibed in SPARQL today. 15:07:54 <LeeF> ack AndyS 15:07:59 <SimonS> ... goal: describe SPARQL on top of OWL and RDFS reasoning 15:08:29 <SimonS> AndyS: bijan to give a brief sketch of what is needed; scoping? 15:08:45 <SimonS> bijan: inconsistencies 15:09:01 <SimonS> ... syntactically higher order variables, e.g. in predicate positions 15:09:28 <SimonS> ... BNodes 15:09:42 <SimonS> ... derive additional information from them? 15:09:43 <pgearon> +1 for not deriving new bnodes! 15:10:29 <SimonS> ... restrict range of variables in order to guarantee finite results 15:10:56 <SimonS> AndyS: summarize in email please 15:11:14 <LeeF> ACTION: bijan to send mail about issues in BGP matching that must be considered when specifying OWL in SPARQL semantics 15:11:14 <trackbot> Created ACTION-14 - Send mail about issues in BGP matching that must be considered when specifying OWL in SPARQL semantics [on Bijan Parsia - due 2009-05-13]. 15:11:53 <ivanh> q+ 15:12:12 <SimonS> Axel: Define Entailment regime for OWL, subregimes for OWL EL and the like time permits? 15:12:54 <SimonS> bijan: Issues should be the same for all, also for RIF. Describe abstractly. 15:13:27 <SimonS> ericP: include relationship of OWL to RDF? e.g. using graph API with DL 15:13:32 <SteveH> I wonder if we can call it SPARQL/Entailment instead? 15:13:46 <SteveH> /OWL is a little specific 15:14:03 <LeeF> SteveH, I already updated it :) 15:14:11 <LeeF> (not sure if the new wording is best) 15:14:16 <SteveH> :) 15:14:39 <SimonS> bijan: need that, e.g. for BNodes. 15:14:45 <bglimm> updated to what? 15:14:56 <LeeF> bglimm, see 15:15:02 <SteveH> LeeF, is unchanged 15:15:06 <bijan> SteveH, that could be reasonable. 15:15:09 <LeeF> SteveH, see 15:15:20 <LeeF> ack ivanh 15:15:39 <SimonS> ivanh: for subsets like RL the situation may be even simpler. 15:15:43 <bijan> Right, for simpler regimes it'll be simpler 15:15:58 <bijan> But then the regime would meet the criteria inherently 15:16:22 <AxelPolleres> q+ to ask (chair-hat-off) about SPARQL/RIF in/out of scope here, if we find volunteers? 15:16:37 <SimonS> ivanh: for the records - we need to allow to clearly define the capabilities of an endpoint. Needs service descriptions. 15:16:43 <LeeF> ack AxelPolleres 15:16:43 <Zakim> AxelPolleres, you wanted to ask (chair-hat-off) about SPARQL/RIF in/out of scope here, if we find volunteers? 15:16:58 <AndyS> q+ to note UC for multiple entailment in one query 15:17:01 <ivanh> q? 15:17:04 <ivanh> q+ 15:17:29 <SimonS> Axel: also extend to RIF? Seems closey related. Would that be in the scope of SPARQL/entailment, time allowed? 15:17:40 <AndyS> What would SPARQL/RIF involve? 15:17:40 <SimonS> LeeF: included in modified feature proposal. 15:18:40 <ericP> from a fashion perspective, we have a chance to develop more styles if we go madly off in all directions at once 15:18:40 <SimonS> AndyS: service descriptions do not cover multiple regimes in a single query. 15:19:01 <SimonS> ivanh: not sure this is useful. 15:19:11 <chimezie> I'm not even sure if that can be done in a sound way 15:19:12 <bijan> I think its' pretty clear that having multiple *is* useful. I think it's useful at least :) 15:19:24 <chimezie> i.e., specific entailment regimes for specific parts of the active graph 15:19:29 <SteveH> I have used multiple in one query 15:19:38 <SteveH> not sure how it realtes/comflicts with decriptions though 15:19:49 <bijan> chimezie, I thought it was for different BGPs 15:20:09 <bijan> Then it's just querying the *whole* graph under different semantics and combining the results under the algebra 15:20:17 <AndyS> One way - different graphs with different entailment in one datasets. (There may be other ways - just an example - but this is no syntax way) 15:20:18 <SimonS> ... reg. Axel's question: OWL is clearly described in RDF, hence also in SPARQL. For RIF, this does not hold. Hence, need additional syntax or protocol. 15:20:18 <bijan> Which will be sound 15:20:53 <AxelPolleres> 15:21:01 <chimezie> I interpreted that differently (i.e., I thought they were talking about parts of teh graph rather than parts of the query) 15:21:09 <bijan> Ah. 15:21:13 <SteveH> I agree with ericP 15:21:14 <SimonS> I like and have used multiple graphs as AndyS proposes. 15:21:25 <SteveH> (pre Garlik) 15:21:29 <AxelPolleres> q? 15:21:35 <AndyS> ack me 15:21:35 <Zakim> AndyS, you wanted to note UC for multiple entailment in one query 15:21:38 <LeeF> ack ivanh 15:22:04 <SimonS> Axel: in above link, semantics of RIF+RDF is specified, includes entailed RDF triples 15:22:10 <bijan> q+ 15:22:23 <SimonS> ivanh: does not include encoding RIF rules in RDF. 15:22:24 <chimezie> By reference to a RIF ruleset, ivanh 15:22:38 <SimonS> ... so how do I give endpoint the rules it needs. 15:22:55 <SimonS> AndyS: different issue - ParametrizedInference 15:23:38 <SimonS> SimonS: disagree 15:24:44 <chimezie> My impression is (as Bijan suggested) many of the issues that will need to be addressed on the path towards an OWL-DL entailment regime, will be re-usable for other regimes (including RIF+RDF). As long as we aren't explicitely ruling out the possiblity of investigating taking that further step once the details for SPARQL-DL are worked out 15:24:52 <SimonS> ... Today, many endpoints do inferencing without being parametrized. 15:25:20 <chimezie> +1 on explicitly excluding further regimes .. 15:25:23 <SimonS> Axel: Want do define what it means to evaluate a SPARQL query together with some RIF rules. Would not want to exclude it. 15:25:29 <ivanh> chimezie, I would not talk about SPARQL-DL but SPARQL-OWL 15:25:33 <bijan> q- 15:25:37 <LeeF> q? <LeeF> subtopic: Next steps after lunch break 15:25:59 <LeeF> 15:26:52 <bijan> I may be asleep this evening :) 15:26:56 <SimonS> LeeF: everybody have a look at the list during lunch break 15:27:26 <KjetilK> q+ to ask about ProjectExpression as required 15:27:45 <SimonS> ... and need to think about order 15:28:06 <bijan> It looks good to me 15:28:18 <bijan> q+ 15:28:29 <ivanh> :;-) 15:28:50 <SimonS> Kjetil: Should project expressions really be required? 15:29:04 <SimonS> SteveH: hardly possible to do aggregates and subqueires without. 15:29:11 <bijan> On queue! 15:29:15 <LeeF> q? 15:29:23 <KjetilK> ack me 15:29:24 <Zakim> KjetilK, you wanted to ask about ProjectExpression as required 15:29:28 <chimezie> We have a person on queue 15:29:36 <LeeF> ack bijan 15:30:17 <SimonS> bijan: What if we find out something is harder to do than expected? 15:30:23 <SimonS> ... do we have a strategy there? 15:30:43 <SimonS> LeeF: Use the usual W3C excuse... ;-) 15:31:05 <bijan> I love lead pipes! 15:31:24 <AndyS> We had the lead pipes at our house removed last month 15:31:49 <SimonS> LeeF: break. 15:36:38 <LeeF> chimezie, sorry, did not notice that you joined on the phone! 15:38:00 <AxelPolleres> chime, we are having the break for one hour, would be good if you checked as all the others and have objections/concenrs ready when we continue. 15:46:17 <chimezie> AxelPolleres�:� will do 15:46:34 <chimezie> LeeF�:� np :) 16:33:48 <LeeF> chimezie, bijan, iv_an_ru we're starting back up 16:33:54 <LeeF> please join if you can/intend to :) 16:34:59 <AxelPolleres> Extremely useful for people new to W3C telecons/IRC: (if you haven't been pointet at yet) 16:35:43 <kasei> scribenick: kasei <LeeF> subtopic: Feature decision <LeeF> summary: RESOLVED: To accept the set of required and time-permitting features as specified in and pending completion of the action listed therein 16:35:55 <LeeF> 16:36:59 <kasei> LeeF: regarding "in order" of time-permitting features, might extend timeline for required features, not for time-permitting 16:37:34 <kasei> ... assuming get through required features, need to decide which time-permitting features 16:38:27 <kasei> ... overlap of work for some features, not others (bgp entailment). makes sense to do some work in parallel. 16:39:08 <SteveH> +1 16:39:10 <AxelPolleres> +1 16:39:10 <KjetilK> +1 16:39:19 <kasei> ... inclinded to remove ordering, in charter note time permitting features, and punt on choosing until it comes up later 16:39:20 <AlexPassant> +1, fair enough 16:39:25 <SimonS> +1 16:40:11 <kasei> AndyS: may be contention of WG when coming together with features toward the end 16:41:51 <kasei> LeeF: should be default that things are rec track, but should be aware lots of ancillary work, chance we'll have to make some things WG notes 16:42:09 <AxelPolleres> q+ 16:42:14 <LeeF> ack AxelPolleres 16:42:56 <kasei> AxelPolleres: would it make sense to mention a point in time to decide rec track features? 16:43:46 <kasei> ... not sure has to be in charter 16:43:54 <bglimm> q+ 16:44:10 <LeeF> ack bglimm 16:44:13 <kasei> LeeF: don't want entailment work to come back to WG to get response "sorry, that'll be WG note" 16:45:26 <kasei> bglimm: people interested in entialment regimes won't contribute much to the other query language features 16:45:55 <kendall> There's an obvious denial of service strategy from a disinterested majority against the "time-permitting" work items that's bothersome 16:46:15 <kasei> LeeF: don't want to sacrifice required features for time-permitting ones, but don't want required features to be unnecessary obstacles to the time-permittings. 16:47:04 <kasei> ... open issues on required features shouldn't prevent discussion of time-permitting features 16:47:18 <bglimm> q+ 16:47:53 <ericP> +1 to deathmarch 16:47:59 <SteveH> -1 to deathmarch 16:48:10 <LeeF> ack bglimm 16:49:05 <kasei> bglimm: if people working on required parts can't spend time on coordination of time-permitting features, unlikely to work in the end... 16:50:00 <kasei> ... is it worth working on these features if unlikely to have time to review at the end 16:50:21 <kendall> fwiw, I don't think it's entirely true that inference people, say, won't work on required features, since implementations count as working on them. 16:50:45 <LeeF> kendall, I think that bglimm is mainly speaking for herself 16:51:38 <kasei> SteveH: tends to be contentious issues that take up most time 16:51:39 <kendall> as am I 16:52:07 <kasei> LeeF: don't mean to imply that people won't have time to review time-permitting features 16:52:13 <bglimm> I am mainly speaking for myself 16:52:26 <kasei> ... is acknowledgement that it's a worthwhile effort 16:52:47 <SteveH> +1 if I wasn't willing to read it, I wouldn't support it being a feature 16:53:00 <LeeF> q? 16:53:01 <kasei> LeeF: also, other source of feedback. imagine that there will be non-trivial feedback re: entialment from outside the WG 16:53:22 <kendall> steveh, thanks for saying that :) 16:55:17 <kasei> LeeF: asked everyone to look at current feature proposal to see if we're near consensus 16:55:44 <KjetilK> q+ 16:55:48 <kasei> AndyS: from pov of writing the charter, wondering if its as clear as we can make it 16:56:03 <kasei> ... established that there is quite a bit of connection between some features 16:56:31 <kasei> ... (subqueries, aggregation, proj. exprs.) 16:58:28 <kasei> LeeF: won't hash out charter text, but will need to be explicit abotu what will be in charter 16:59:44 <kasei> ... relatively happy with current list 17:01:05 <kasei> pgearon: happy, but note we haven't discussed update yet. 17:01:12 <AndyS> +1 -- update is underdiscussed 17:02:05 <kasei> SteveH: ambitious, but can't think of anything to remove 17:02:45 <kasei> AndyS: ambitious, but don't think it will push out all time-permitting features. also notes lack of update discussion. 17:03:18 <kasei> ... re: BasicFederatedQuery, would spend time working on it 17:04:16 <kasei> KjetilK: too bad full text didn't reach consensus (would like a vote as a time-permitting feature) 17:04:17 <KjetilK> Specify a simple, optional freetext query syntax and semantics. 17:04:18 <kendall> update being underdiscussed, particularly w/r/t security implications, worries me 17:04:29 <SteveH> +1 to kendall 17:04:42 <KjetilK> +1 17:04:44 <kasei> LeeF: poll on (possibly simple) full text feature 17:04:45 <pgearon> +1 17:04:48 <AlexPassant> 0 17:04:49 <LukeWM> 0 17:04:50 <kasei> 0 17:04:52 <SimonS> +1 17:04:53 <AxelPolleres> 0 17:04:53 <SteveH> -1 too complex 17:04:53 <bglimm> 0 17:04:58 <john-l> +1 17:04:58 <ericP> -1 17:05:01 <kendall> -1 17:05:07 <AndyS> +1 only as far as syntax, -1 for spec results or text QL 17:05:18 <SteveH> kendall, day 2 has a slot on update, FWIW, but I share your concerns 17:05:49 <LeeF> 0 17:06:17 <kendall> can't shake the thought of sparql injection attacks (and hard to see how we can implement, over http, the standard defense) 17:06:22 <kasei> ... based on previous criteria, doesn't seem to be enough consensus. 17:06:57 <AndyS> kendall, agreed - one reson I prefer 2 languages, not one mega language of QL+U 17:07:12 <pgearon> kendall, I share you concerns. OTOH, the most consistent complaint I hear about SPARQL is the lack of Update 17:07:13 <kasei> KjetilK: lack of consensus is clear. don't need to spend more time on it. 17:07:32 <kendall> but it doesn't have to be in the language 17:07:37 <kendall> it could be in the protocol 17:07:46 <kendall> or, as andy says, in something entirely separate 17:07:57 <kendall> (those may be isomorphic, in which case i don't care which) 17:08:36 <kasei> ... possible to have something about DefaultDescribeResults in a note? 17:09:09 <AndyS> q+ 17:09:15 <kasei> LeeF: would be willing to consider it, but don't want to publish a note that hasn't had enough WG review. 17:09:45 <kasei> AndyS: member submission would be a good route 17:09:50 <AndyS> ack me 17:09:58 <LeeF> ack KjetilK 17:09:58 <KjetilK> ack me 17:10:42 <kasei> AlexP: ok with required. for time-permittion, priority would be entailment extensions. 17:11:17 <kasei> SimonS: ambitious, but ok. if only time to do one time-permittion, want federated query. 17:11:41 <kendall> KjetilK: as long as we're all a little bit unhappy in roughly the same measure, then that's how we know we're making standards! :> 17:12:09 <kasei> bglimm: fine with the list. priority features is entailment. 17:12:28 <KjetilK> q+ to ask if we are in the same situation with FunctionLibrary as SurfaceSyntax with regards to IPR 17:12:53 <kasei> AxelPolleres: didn't talk much about function library. should we spend more time discussing? 17:13:37 <kasei> AndyS: nervous about things like restricting to xpath functions. 17:14:13 <kasei> AxelPolleres: should we scope to looking into only certain functions? 17:14:23 <kasei> AndyS: no 17:14:37 <LeeF> "Common functions dealing with core SPARQL types including IRIs, literals, numbers, and strings" ? 17:15:17 <kasei> Kjetil: if we leave it unscoped, would that be problematic for the charter? 17:15:46 <AndyS> q+ 17:15:52 <LeeF> ack KjetilK 17:15:52 <Zakim> KjetilK, you wanted to ask if we are in the same situation with FunctionLibrary as SurfaceSyntax with regards to IPR 17:16:03 <kasei> ericP: would make it challenging for IP issues. 17:16:40 <AxelPolleres> XPath + RIF DTB (has iri-string conversion which can be used for iri construction) 17:17:26 <kasei> ... motivation to make it easy for new groups to join the WG. 17:17:57 <AxelPolleres> ISSUE: scope of functions to be clarified further for the charter 17:17:58 <trackbot> Created ISSUE-2 - Scope of functions to be clarified further for the charter ; please complete additional details at . 17:18:47 <AxelPolleres> s/functions/function library/ 17:18:48 <kasei> LeeF: punt on IP issues until writing charter 17:19:16 <LeeF> chimezie, are you around? 17:19:20 <LeeF> john-l, are you around? 17:19:31 <chimezie> I'm here, on IRC at least 17:19:57 <LeeF> chimezie, are you happy (enough) with the proposal for WG features as it currently exists at ? 17:20:57 <LeeF> PROPOSED: To accept the set of required and time-permitting features as specified in and pending completion of the action listed therein 17:21:13 <chimezie> It doesn't include BNode reference (which is important for us), but time-constraints , etc.. 17:21:26 <SteveH> seconded 17:21:31 <AxelPolleres> +1 17:21:33 <chimezie> So, yes, looks good :) 17:21:33 <ericP> +1 17:21:37 <KjetilK> threeonded 17:21:37 <LeeF> thanks, chimezie 17:22:05 <bglimm> Leef, you could call OWL Flavors, OWL Profiles since this is what they are called in the OWL standard 17:22:05 <bijan> +1 (before going home) 17:22:13 <pgearon> +1 17:22:52 <bglimm> +1 17:23:03 <kasei> LeeF: does anyone abstain or object to propsal? 17:23:05 <AndyS> +1 17:23:09 <SimonS> +1 17:23:10 <LeeF> RESOLVED: To accept the set of required and time-permitting features as specified in and pending completion of the action listed therein 17:23:15 <LeeF> No abstentions or objections <LeeF> topic: Features & Rationale document <LeeF> summary: Aim for first draft of at end of first week of June 17:24:05 <kasei> LeeF: want to give time to KjetilK and Alex re: rationale document 17:24:30 <AlexPassant> Features doc currently at: 17:24:58 <kasei> KjetilK: start puting down description of features on wiki 17:25:28 <kasei> ... will use wiki for collab. environment. at some point will freeze page and put into a more formal document. 17:26:05 <AndyS> q+ 17:26:17 <kasei> AlexP: for each feature: motivation, description, proposed syntax, discussion 17:26:42 <kasei> Steve: we aren't chartered to discuss syntax (?) 17:27:06 <kasei> LeeF: intention is to do a more involved document later on. question is whether to discuss any syntax now. 17:27:32 <kasei> KjetilK: examples are important. useful, but maybe should be "examples" not "proposed syntax" 17:27:40 <LeeF> +1 to Andy - examples only based on existing implementations is a good idea 17:27:50 <kasei> AndyS: must be existing implementations, not just "examples". 17:28:12 <LeeF> ack AndyS 17:28:48 <kasei> ... would help to ask for particular things needed for the document. lots of existing wiki content. 17:30:02 <kasei> KjetilK: descriptions might belong before motivations. 17:31:00 <kasei> LeeF: next issue - naming. 17:31:29 <SimonS> SPARQL 2010 17:31:30 <kasei> ... "2.0" and "1.1". are there others? 17:31:54 <kasei> ... update may have another name, but what name for the core language? 17:32:09 <SteveH> also federated might have a different name... 17:32:55 <AxelPolleres> Axel: getting back to F+R Schedule 17:33:04 <kasei> ... would be great to have something in 4 weeks. 17:33:11 <AxelPolleres> LeeF: reasonable within 4 weeks? 17:33:31 <AxelPolleres> Kjetil&Alex agree. 17:33:45 <AlexPassant> +1 first week of june 17:34:11 <kasei> KjetilK: have one day a week. telecon + editing document. 17:34:40 <kasei> Alex: 1 day a week. 17:35:39 <kasei> LeeF: first draft doesn't need to be huge. touch on everything, but can then hear from the WG and from outside. 17:36:32 <kasei> AxelPolleres: don't have to write it all yourselves. ask for content, can discuss on telecon. <LeeF> topic: Naming and Modularity <LeeF> summary: RESOLVED: The whole megillah is called SPARQL, with pieces called SPARQL/Query and SPARQL/Update and possibly others and RESOLVED: (open world) The version of SPARQL worked on by this working group includes SPARQL/Query 1.1 and SPARQL/Update 1.0 17:36:52 <kasei> LeeF: back to naming. what do people prefer? 17:37:02 <kasei> ericP: don't care 17:37:09 <AxelPolleres> Axel: "feature champions" should be asked for help to put concrete text, where necessary, editor doesn't imply Alex and Kjetil write all by themselves. Use the wiki! 17:37:27 <kasei> pgearon: if update is in it, 2.0, otherwise 1.1. 17:37:38 <kasei> kasei: 1.1, not strong preference. 17:37:38 <AlexPassant> +1 for pgearon 17:38:06 <kasei> ericP: wondering about pgearon's opinion 17:38:19 <kasei> pgearon: update is a big feature. 2.0 signifies this. 17:38:27 <kasei> LeeF: 2.0 17:38:41 <kasei> LukeWM: don't care 17:39:06 <kasei> SteveH: feel strongly 1.1, update should be a different language (so should federated query) 17:39:24 <kendall> steveh: what marketing point do you want to make with "1.1" name? 17:39:31 <kasei> AndyS: agrees with SteveH. had strong input about calling things 2.0 (based on OWL) -- bad idea. 17:39:33 <kendall> (sorry i can't dial-in, feel free to ignore me!) 17:40:09 <kasei> ... keep query language 1.1, wouldn't expect compliance to involve implementing update. 17:40:19 <kendall> AndyS: calling sparql anything based on OWL is dumb -- +1 17:40:21 <kasei> KjetilK: 1.1. update as seperate. SPARQL/OWL seperate. 17:40:50 <kasei> AlexP: 2.0 with update, otherwise 1.1. 17:41:21 <kasei> SimonS: keep update seperate. meant "2010". even if many followup WGs, no problem. 17:41:53 <kasei> bglimm: no strong opinion. probably 1.1 with update/federated separate. (2.0 if all in one.) 17:42:22 <SteveH> q+ 17:42:31 <LeeF> ack SteveH 17:42:43 <kasei> AxelPolleres: 1.1 is good, would not keep federation separate, but update separate. 17:43:14 <kasei> SteveH: update should be separate. SQL got this wrong. 17:43:30 <kasei> LeeF: seems to be consensus on that. does anyone think otherwise? 17:43:50 <kendall> fwiw, i think "1.1" is a dumb name 17:43:57 <john-l> Leef, you prefer 2.0? 17:44:03 <LeeF> vastly 17:44:04 <AxelPolleres> Axel: SPARQL 2010 and keeping all in one would be along the lines of SQL 99. I personally like SPARQL1.1 and SPARQL/Update separate. 17:44:15 <LeeF> i'm happy with 2010 also fwiw :) 17:44:17 <LeeF> q+ yimin 17:44:20 <kasei> ericP: worries about what keeping update separate looks like. 17:44:26 <john-l> I prefer 2010. 17:44:47 <kendall> SPARQL 2010: The Sadistic Satyr 17:44:54 <kasei> ... issues with keeping grammar together or separate. 17:45:32 <kasei> ... trying to work out mechanics of what is meant by "separate language". one doc for query with section for update? 17:45:37 <AndyS> Much laughter over "The Speedy Squirrel" 17:45:47 <kasei> ... second document with only additions to grammar? 17:46:26 <kasei> ... care about distinction between sparql and update with protocol and also branding on products. 17:47:10 <kasei> SteveH: imagining two langs would share grammar. core sparql would error if you tried to use update. 17:48:05 <AndyS> q+ 17:48:12 <kasei> pgearon: was also expecting update to be a strict superset. insert-select, delete-select use the select we've already got. 17:48:44 <AndyS> ack me 17:48:46 <LeeF> ack yimin 17:49:15 <kasei> yimin: expereince with users having trouble with many different varieties of OWL (DL, ...). trouble differentiating. 17:49:54 <kasei> ... consideration for ease of users. would like to have update in the same language. 17:50:02 <kendall> (what users are these? i don't recognize 'yimin') 17:50:20 <kendall> AH 17:50:22 <pgearon> +q 17:50:22 <kendall> thanks, LeeF 17:50:30 <kasei> ericP: SQL has sublanguages, but users don't think of them. 17:50:39 <LeeF> ack pgearon 17:50:41 <kendall> I think that's a pretty awfula analogy 17:50:56 <ericP> thank you 17:51:23 <kasei> pgearon: if we didn't split the language into parts, select can't go through the http protocol with http GET. 17:51:35 <AndyS> I like "SPARQL" as the overall name and SPARQL/(sub-part) 17:51:51 <kasei> ... delete-select through "PUT"? would be nice through "DELETE", but tricky to resolve proper http methods. 17:52:10 <kendall> (i'm always amazed people deploy real systems where "users" are expected to write SPARQL by hand. This is cruel and unusual punishment!) 17:53:15 <AxelPolleres> (kendall, people write a lot of SQL, don't they?) 17:53:19 <kasei> ... can't put insert, delete through GET. need alignment with protocol. update touches on many things, frustrating that it's last on the schedule. 17:53:56 <kendall> Axel: no, they don't 17:54:04 <kendall> programmers don't even write that much SQL these days 17:54:33 <SteveH> I like Andy's proposal 17:54:41 <kasei> AxelPolleres: no particular preference. 17:55:13 <AndyS> (was not my proposal - I just liked it) 17:55:21 <kasei> SteveH: branding "SPARQL/Query", "SPARQL/Update", ... 17:55:29 <kendall> +1 17:55:32 <kasei> LeeF: do we need a specific name for the work this WG is doing? 17:55:51 <AxelPolleres> SteveH: SPARQL = SPARQL/Query SPARQL/Update 17:56:33 <AndyS> 17:56:45 <LeeF> PROPOSED: The whole megillah is called SPARQL, with pieces called SPARQL/Query and SPARQL/Update and possibly others 17:56:49 <SteveH> surely 17:56:58 <KjetilK> SPARQL 1.1 = SPARQL/Query 1.1 SPARQL/Update 1.0 etc 17:57:08 <ericP> +1 to megillah (SP?) proposal 17:57:12 <kendall> SPARQL/Inference (We can hope!!) 17:57:57 <SteveH> isn't this WG a megillah? 17:57:58 <AxelPolleres> rdf-sparql-query11/ , rdf-sparql-update/ rdf-sparql-entailments/, rdf-sparql-protocol11/ 17:58:07 <AndyS> .g seems to agree on spelling 17:58:15 <SteveH> federated also 17:58:20 <KjetilK> +1 17:58:20 <AndyS> +1 17:58:23 <LeeF> RESOLVED: The whole megillah is called SPARQL, with pieces called SPARQL/Query and SPARQL/Update and possibly others 17:58:29 <SteveH> +1, as long as federated is seperate 17:58:40 <AxelPolleres> +1 17:58:55 <bglimm> +1 17:59:10 <kasei> ericP: tempted not to number overall SPARQL. 17:59:11 <AndyS> Are we using Apache Ivy to import all the docs? 17:59:21 <kendall> +[1.1,2.0] 17:59:26 <kendall> hah 17:59:32 <kasei> LeeF: no number for everything, numbered components (update, query) 17:59:46 <LeeF> PROPOSED: The version of SPARQL query lanaguage worked on by this working group is called SPARQL/Query 1.1 18:00:00 <ericP> i second 18:00:02 <AndyS> +i 18:00:05 <KjetilK> +1 18:00:10 <kendall> why the 1.1 bit? 18:00:10 <pgearon> +1 18:00:26 <LeeF> PROPOSED: The version of SPARQL query lanaguage worked on by this working group are called SPARQL/Query 1.1 and SPARQL/Update 1.0 18:00:30 <kendall> previous version "SPARQL", this version "SPARQL/Query" 18:00:34 <ericP> i second 18:00:35 <SteveH> what about federated 18:01:25 <LeeF> PROPOSED: The version of SPARQL worked on by this working group includes SPARQL/Query 1.1 and SPARQL/Update 1.0 18:01:33 <ericP> i object 18:02:59 <kasei> ericP: regarding "safety" of implementation. safety means datastore isn't updated. doesn't execute remote queries. 18:03:37 <kasei> SteveH: importantly, doesn't make any GET requests. current standard doesn't force you to GET on a FROM<...>. 18:03:56 <kasei> ... no network requests from the endpoint. 18:03:59 <AndyS> q+ 18:04:26 <kasei> ... concern is around admins installing software and not having to worry about the server making requests. 18:04:59 <kasei> ericP: wouldn't that mean addressing FROM? 18:05:23 <kasei> SteveH: ideally, yes. but there are many stores that don't GET on a FROM. 18:06:10 <LeeF> ack AndyS 18:06:10 <kasei> ... want to implemented federated sparql, but also want to have a public endpoint that doesn't do that. 18:06:25 <kasei> AndyS: difference between what is in the spec and what compliance with the spec is. 18:06:40 <kasei> ... "if you implement feature X, this is what occurs" 18:07:55 <kasei> ericP: so you are seeking alignment between the branding name and the security policies? 18:08:36 <KjetilK> +q to say that we need a version number for the megillah to distinguish it from the previous version? 18:08:48 <kasei> SteveH: bet there are plenty of people who deploy SPARQL servers without realizing the implications 18:09:51 <AndyS> How about writing specific text in the future docs that says "This set of featurs is safe" +details 18:09:52 <kasei> ericP: if we have an identifier for a "safe" version of SPARQL, should address "FROM" at the same time. 18:10:45 <kasei> ... should safety be deeper than the branding name, with saddle and configuration options? 18:11:35 <kasei> ... if we identify network safe operations, people can implement/use the safe version. 18:11:51 <SimonS> +1 to AndyS' proposal of marking safe features 18:12:10 <kasei> SteveH: that you have to explicitly ban those features is a security problem. 18:13:03 <kasei> ericP: suggest SteveH lobby for text that deals with safe operations, a "SPARQL/Safe" name. 18:13:32 <LeeF> SPARQL/DangerDangerDanger 18:13:58 <AxelPolleres> would it make sense to define an "endpoint set" similar to "dataset"? would that help? 18:13:59 <kasei> ... what you want requires such detail that we can't address it now. 18:14:06 <KjetilK> +1 to not rule it out 18:14:14 <LeeF> q? 18:14:27 <LeeF> PROPOSED: (open world) The version of SPARQL worked on by this working group includes SPARQL/Query 1.1 and SPARQL/Update 1.0 18:14:50 <AxelPolleres> ... and systems have freedom how to treat that as they are free to fix the dataset. 18:15:22 <AndyS> Suggest: This WG acknowledges that there are security issues in federated query and the WG will continue to be careful about this. 18:15:41 <KjetilK> +1 18:15:49 <kasei> LeeF: any abstentions or objections? 18:15:49 <pgearon> +1 18:15:52 <AxelPolleres> +1 18:15:52 <LeeF> RESOLVED: (open world) The version of SPARQL worked on by this working group includes SPARQL/Query 1.1 and SPARQL/Update 1.0 18:16:02 <SteveH> can we have an issue along the lines of what AndyS wrote 18:16:03 <KjetilK> ack me 18:16:03 <Zakim> KjetilK, you wanted to say that we need a version number for the megillah to distinguish it from the previous version? 18:16:06 <bglimm> +1 18:16:52 <kasei> KjetilK: what should title of features document be? 18:17:34 <kasei> ... "yeah, I'm happy" 18:18:45 <ericP> topic: response to rdf:text <LeeF> summary: RESOLVED: Send the text on as SPARQL WG feedback to OWL WG and RIF WG regarding rdf:text Last call 18:18:30 <kasei> LeeF: next up, response to rdf:text 18:18:41 <kasei> ... tomorrow dive into features 18:19:09 <AxelPolleres> 18:19:09 <ywang4> ywang4 has joined #sparql 18:19:30 <AxelPolleres> 18:19:37 <kasei> AxelPolleres: current response, based on comments by AndyS. 18:19:48 <kasei> ... interop problems with SPARQL. 18:20:45 <kasei> ... rdf:text a datatype for plain/lang literals useful for OWL/RIF. 18:21:12 <kasei> ... with current defintion, too strong regarding semantic equivalence literals 18:22:10 <kasei> ... document proposes rdf graph serializations do not use rdf:text. AndyS observed also affects SPARQL. 18:22:34 <kasei> ... str/datatype/lang functions would also be affected 18:23:19 <kasei> ... point out problems with rdf:text. suggest to editors to add section mentioning interop issues with sparql. 18:23:52 <kasei> ... suggest clarify interactions with sparql. 18:24:12 <kasei> ... rdf:text should affect D-entailment 18:24:22 <ericP> q+ to check a use case 18:24:50 <kasei> LeeF: if not using D-entailment, datatype() would return rdf:text, no lang(), ... 18:25:15 <kasei> AxelPolleres: with D-entailment, rdf:text literals would entail the non-dt literal 18:25:21 <ericP> q- 18:25:36 <kasei> AndyS: no such thing as D-entailment. class of entailments. 18:25:39 <LeeF> q+ to ask about if rdf:text literals are allowed in SPARQL queries and if so what they mean when 18:25:54 <SteveH> q+ to ask meta-question 18:27:11 <kasei> ... literals have lang or dt, not both. code relies on this. 18:27:47 <kasei> AxelPolleres: want to say rdf:text is only syntactic. 18:28:20 <kasei> AndyS: you've introduced a new problem. haven't heard answers to previously brought up problems 18:30:33 <kasei> AxelPolleres: if your data doesn't have rdf:text in it, you won't get it out of the functions. 18:30:55 <bglimm> q+ 18:31:45 <kasei> AndyS: i can't sort out based on the current spec what a sparql processor should do 18:32:08 <kasei> LeeF: I keep thinking of rdf:text nodes int he graph 18:32:56 <kasei> ... would you need to prohibit literal constants in queries that are typed as rdf:text? 18:32:56 <LeeF> FILTER(lang("foo@en"^^rdf:text)) 18:33:30 <LeeF> INSERT { <a> <b> "foo@en"^^rdf:text } ... 18:33:36 <kasei> ericP: no reason somebody would assert such a query in RDF right now 18:34:02 <kasei> ... we can ignore it if there's no use case for writing some literal has datatype rdf:text. 18:34:55 <bglimm> q- 18:35:13 <LeeF> ack me 18:35:13 <Zakim> LeeF, you wanted to ask about if rdf:text literals are allowed in SPARQL queries and if so what they mean when 18:35:28 <kasei> AndyS: need to give guidance for tools that generate this (data, queries?) 18:36:28 <kasei> ... it's legal and generates confusion. 18:36:43 <kasei> ... rdf:text doc doesn't make it clear what to do. 18:36:52 <kasei> ... suggestions is to have a section for sparql issues. 18:37:13 <kasei> ericP: shouldn't be a "sparql" section 18:38:32 <kasei> ... what you can learn from SPARQL you can also find through a graph api 18:39:19 <kasei> AndyS: if you turned it into an RDF graph, you wouldn't see rdf:text 18:40:08 <kasei> ericP: what behaviour for an owl restriction for things with rdf:text datatype. does it have any members? 18:40:58 <kasei> AndyS: half the text in the spec tries to stop you from doing that. 18:41:39 <kasei> ... not a sparql-specific issue. 18:42:12 <kasei> ... other than new issues, where are we on current text? 18:42:36 <kasei> AxelPolleres: would not require a new section 18:43:43 <kasei> AndyS: removing the discussion of codepoints would be a good start 18:44:24 <AxelPolleres> EricP, are you talking about now? 18:44:49 <kasei> ericP: sparql went with IRI for allowable values. would like discussion on iri vs. uris. 18:45:09 <kasei> ... sparql made decision on intent of rdf core 18:45:53 <kasei> ... allowing iri resources (kanji, arabic in urls, etc.) 18:46:10 <kasei> ... draw text from sparql spec 18:46:22 <AndyS> q? 18:46:35 <kasei> AxelPolleres: would like concrete suggestion 18:46:42 <ericP> 18:47:20 <ericP> \ 18:47:58 <ericP> scribenick: ericP 18:48:03 <ericP> ack SteveH 18:48:03 <Zakim> SteveH, you wanted to ask meta-question 18:48:38 <ericP> SteveH: i didn't see how rdf:text solved the problem 18:49:10 <ericP> ... the right way to do this was to change RDF and attempt to isolate the other specs from those changes as best you can 18:49:38 <ericP> AxelPolleres: i think only the semantic equivalence is a problem 18:50:10 <ericP> ... we started with symbols spaces which were not the same as RDF's 18:50:21 <ericP> OWL was doing something similar 18:50:31 <ericP> AxelPolleres, OWL was doing something similar 18:51:23 <ericP> SteveH: as it stands, rdf:text changes RDF 18:51:40 <ericP> ... which means that those hundreds of RDF impls are technically incorrect 18:52:14 <ericP> AxelPolleres: the alternative serialization is only present in RIF 18:52:51 <ericP> ... there is a combined semantics of RIF and RDF graphs 18:55:12 <ericP> AndyS: by putting the language info into a lexical form, it's not behaving like other datatype [extensions] 18:56:02 <SteveH> q- 18:56:11 <ericP> what's FILTER ("@"^^rdf:text == false) ? 18:56:19 <ericP> or FILTER (""^^rdf:text == false) ? 18:57:42 <AndyS> 18:58:36 <AxelPolleres> ""^^rdf:text 18:59:50 <AxelPolleres> ""^^xs:integer 19:00:05 <AndyS> FILTER(""^^xs:string) 19:00:10 <AndyS> FILTER("false"^^xs:string) 19:00:23 <AxelPolleres> FILTER(""^^xs:integer) 19:00:46 <AxelPolleres> FILTER ("@"^^rdf:text == false) 19:03:32 <AndyS> 19:16:27 <AxelPolleres> eric, are you typing in ? 19:17:16 <AndyS> I hope that the replies from the OWL/RIF will include references to specific text 19:17:57 <ericP> 19:31:41 <LeeF> PROPOSED: Send the text on as SPARQL WG feedback to OWL WG and RIF WG regarding rdf:text Last call 19:31:56 <ericP> second 19:32:08 <AndyS> 19:34:55 <LeeF> PROPOSED: Send the text on as SPARQL WG feedback to OWL WG and RIF WG regarding rdf:text Last Call 19:44:24 <AxelPolleres> 19:44:30 <AndyS> 19:55:38 <kasei> scribenick: kasei 19:55:55 <kasei> LeeF: suggests sending comments without suggested text 19:56:47 <kasei> AndyS: text regarding rdf:text not appearing in sparql xml results should go along with similar text on rdf graph serializations. 20:00:27 <AxelPolleres> PROPOSED: Send the text on as SPARQL WG feedback to OWL WG and RIF WG regarding rdf:text Last call 20:01:10 <AndyS> 20:01:33 <LeeF> PROPOSED: Send the text on as SPARQL WG feedback to OWL WG and RIF WG regarding rdf:text Last call 20:01:48 <AxelPolleres> +1 20:01:52 <bglimm> +1 20:01:57 <pgearon> +1 20:02:11 <LeeF> RESOLVED: Send the text on as SPARQL WG feedback to OWL WG and RIF WG regarding rdf:text Last call 20:02:41 <kasei> LeeF: either AndyS or LeeF should send the comments 20:03:05 <LeeF> ACTION: LeeF to send SPARQL WG response to OWL WG and RIF WG re: rdf:text 20:03:05 <trackbot> Created ACTION-15 - Send SPARQL WG response to OWL WG and RIF WG re: rdf:text [on Lee Feigenbaum - due 2009-05-13]. <LeeF> Adjourned for the day. 20:04:01 <Zakim> -MIT262 20:04:07 <Zakim> -Bristol 20:04:08 <Zakim> SW_(SPRQL-F2F)6:30AM has ended 20:04:10 <Zakim> Attendees were kasei, ericP, LeeF, pgearon, yimin, KjetilK, AlexPassant, AndyS, AxelPolleres, SimonS, bglimm, LukeWM 20:05:28 <kasei> kasei has left #sparql 20:24:40 <LeeF> LeeF has joined #sparql 20:40:00 <LeeF__> LeeF__ has joined #sparql 21:26:28 <Zakim> Zakim has left #sparql 21:53:53 <pgearon> pgearon has joined #sparql 22:46:22 <bglimm> bglimm has joined #sparql 23:54:52 <LeeF> LeeF has joined #sparql # SPECIAL MARKER FOR CHATSYNC. DO NOT EDIT THIS LINE OR BELOW. SRCLINESUSED=00001415 | http://www.w3.org/2009/sparql/wiki/Chatlog_2009-05-06 | CC-MAIN-2014-41 | refinedweb | 16,590 | 69.72 |
?
Can .Net Provide a Vehicle for alternatives? (Score:5, Insightful)
Do the
That's the way I helped a Fortune 500 company start adopting Linux back in 1998... the friendly and subversive way!
As for the tasks VB are not suited for (again, I only know VB6, not VB.Net) the biggest glaring omission in my experience was the lack of decent Regular Expressions, or Hash Tables / "Dictionaries"--unless you link to the VBScript/IE6 library like everyone used to. On the other hand, there are IMOHO problems with languages like Perl that make them bad for a number of solutions, but that hasn't stopped nutty fanatics from treating them like "golden hammers".
While I'm writing disclaimers, there are a number of commercial applications out there written entirely in VB. In all cases I've observed, they "evolved" out of a simple and useful app and fell into being examples of the most counter-intuitive user interfaces and over all "kludginess".
Re:Can .Net Provide a Vehicle for alternatives? (Score:5, Informative)
.NET simply provides the programmer with the ability to program in the language they either know better or in a language that seems better suited to the job, without taking a performance hit, since they all compile to the same intermediate language.
.NET 2.0 takes this to even more extremes, in that, more toolbox items are available and virtually all of the components are data aware. Also, Visual Studio 2005 Pro includes a development IIS instance and SQL Server 2005 Express is included.
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Funny)
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Informative)
That is not always true. Unless you put the following line in your AssemblyInfo file your class library, it is likely the resulting byte code can not be used by other
[assembly: System.CLSCompliant(true)]
Visual Studio 2005 Pro includes a development IIS instance
It's actually Cassini. The only real nice thing about this is that Cassini is much lighte behi
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Informative)
By the way, in terms of speed
Re:Can .Net Provide a Vehicle for alternatives? (Score:4, Insightful)
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Insightful)
90% of laptop owners
80% of windows users
Even current integrated graphics won't cut it with Vista... And really, how many computers will have been purchased between now and Vista? I'm guessing that the amount of computers purchased that have adequate Video Cards to run Aero will be less than half, so this does little to really change the ratios.
You're right, computers without amazing video cards will be able to run Vista, but the whole point of this thread
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Insightful)
Re:Can .Net Provide a Vehicle for alternatives? (Score:5, Insightful)
Where the true advantage of the
Im a C# programmer at heart, but the existing codebase here is VB. I migrate it to vb.net as needed and all new stuf is coded that way.
vb.net is not the same old vb6 that you grew up with. It now has all the advantages of C#, but with the VB syntax. When your employer is clueless about
Re:Can .Net Provide a Vehicle for alternatives? (Score:5, Informative)
.NET languages are all pretty much interoperable, so long as you make sure to build your assembly as CLSCompliant [msmvps.com] (which may limit usage of some language features). The main problem is that VB.NET is quite a bit different from VB6. For someone who's only ever done VB code, it's easier to learn VB.NET than C#, but for everybody else you may as well start directly with C#. In the past, I'd have advocated building your UI with VB and calling C++ COM objects for any heavy lifting. Now, I'd recommend you go C# and do everything there.
You get regular expressions and collections with
.NET (though not as many different collections as in Java, unless you bring in the J# assemblies for your project). You also get generics, anonymous methods (anonymous delegates, lambda functions, closures, whatever you want to call them), and quite a bit more cool stuff, though I have no idea how well that's exposed through the VB.NET language. Even cooler than that, you could subversively write modules in a functional language like F# [microsoft.com] (a dialect of ML) and nobody'd know the difference from their VB.NET or C# environments. (yeah, you can do that with Java as well.)
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Insightful)
Any user interface, regardless of language, should be usability tested at every major release. A lot of developers are horrible at adding interface widgets because they're too wrapped up in the solution rather than the proble
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Funny)
Re:Can .Net Provide a Vehicle for alternatives? (Score:4, Informative)
Just FYI about
VB.NET directly supports dictionaries, even by using generics.
It also suports reasonably powerful regular expressions via the System.Text.RegularExpressions namespace.
VB's not that bad (Score:5, Informative)
I have one customer that specs VB.NET for all their apps. After getting comfortable with it there's just no reason for some of the comments here. VB isn't "easier" than C#, just different. If you're a bad VB programmer, switching to C# isn't going to make you a better one.
My opinion is that a lot of bias against VB stretches back to the day when it was not considered a "real" programming language. But it's grown up and turned into a capable language and if that's what the customer wants, there's no need to try to sell them on C#.
Re:Can .Net Provide a Vehicle for alternatives? (Score:3, Insightful)
I've written in both, the main advantage C# has is that it is less verbose but that doesn't make it better, it probably makes it more difficult for inexpierenced programm
Re:Got nothing better to do? Troll (Score:3, Insightful)
Yes, and my experience is that it takes them a long time learn, and they're not very good with it when they're done.
The reason VB developers wouldn't learn C# is probably a productivity issue, rather than not being able to learn the language
No, the reason VB programmers wouldn't learn C# is that they're generally not very good developers, and it takes them a long time to learn new languages.
C# is more like Jav
Re:Got nothing better to do? Troll (Score:5, Insightful)
"Every language does have it's place, but there are perceptions tha can raise and lower a language's value ON YOUR RESUME"
The perception itself does not raise or lower the actual value
Story:
Way back when, in the DARK days of DOS programming, and when most if not all of Microsoft's support was done on CompuServe, one of the forums was called "MSLANGS" - In there, among others, were the C form, and the PDS form (read that as Pro Compiled BASIC). Both generated OBJ files, for the identical linker (MASM used the same linker) - and in fact, if you wrote code that did NOT involve stings, and used the equivilent control structures, you got identical OBJ files. The big differences were pointers in C, and BSTRS in Basic. Now, as a LOT of business code then, as now, was string related, the string functions that were in basic allowed you to develop certain classes of application a LOT faster than the C guys. They would slag on us for "BASIC", and we'd smile, underbid them, and produce the work in less time. Yeah, the perceved value for a "BASIC" programmer was lower - but often the client didn't care what it was written in - only what the application did, how it performed, and how it was going to be maintained. So, which tool was more valuable? If I can underbid you by 10%, but do the job in 25% less time.... (hence, get more contracts...)
Languages are tools - pick the tool for the job.
Of course, sometimes part of the "Job" is your OWN personal development - then perceptions count for a lot
Back then, it was HARD for a BASIC programmer to get a job - VERY hard. It was niche - BIG time (IEEE-488 aka GPIB aka HPIB instrament control was one - the one I was in). Even if you had a CS degree, folks looked down at you. Then one day, Microsoft came out with VB 1.0. I ordered my copy that day. The world changed. Withing a year, the folks who KNEW BASIC (the old DOS stuff) were in demand, as we actually had a clue. I've never looked back. I've done some C, some light C++, enough MASM to have shipped a bunch of old DOS drivers to clients, and now C# and others.
My advise to anyone reading? Don't be a lanuage snob, but also, don't forget, there are language snobs out there, perceptions DO matter, and don't let yourself get boxed into a corner. Evolve or die
Which version of VB is it? (Score:5, Insightful)
Re:Which version of VB is it? (Score:5, Insightful)
This is the *huge* issue, that will make or break your decision.
If it's VB6, run for the hills. It's end-of-lifed.
VB.NET is a great place.
You'll be able to leverage all of the
You'll be able to mix-n-match C# code.
There is continuing investment in the language and tools. There's already a page dedicated to VB9 [microsoft.com] with some awesome features I wish were going to be in C#.
If you're betting on a Windows environment, VB.NET is a great place to be.
Your first choice should be "Are we going to bet on
If the answer is yes, VB.NET vs. C# vs. Managed C++ is a secondary call.
Re:Which version of VB is it? (Score:3, Insightful)
That has to be somewhere in the manual of permanent employment as one of the tricks of the trade... "introduce technology that no one else understands so that you're the only person who can maintain it". If the original poster's boss has any brain cells, he'll refuse to have any C# lying about unless he has more than 1 programmer capable of working with it.
Daniel:Which version of VB is it? (Score:5, Insightful)
This is a critical point, and bears on the way the boss is making the decision. Professional programmers don't like VB because, as a language, it is not very good. But that doesn't mean the boss is being stupid. No. He's actually making the decision using a fairly reliable algorithm: repeat what has worked in the past.
The problem with this algorithm is that it can fail when the future is sufficiently different from the past. As in the platform being not supported anymore.
VB is not so much a bad language as an obsolete (and mediocre) one. But it isn't just a language -- it's an IDE and an operating environment with widgets and libraries and so forth. And in the other aspects that VB is relatively strong for some kinds of tasks. Visual Basic is Visual -- it really encourages you to think and work in terms of concrete visual objects. For a professional programmer, this is higly limiting, because a lot of problems you deal with aren't visual. Limiting isn't necessarily bad if the problem you're working on falls squarely in the middle of them.
You just don't do complex programming in VB. It's perfectly adequate for simple form based clients to a client/server style database backed applications that lack demanding scalability or support requirements. Most VB programs consist mostly of short event handler scripts around form components. The tight coupling of business logic to UI code is anethema to systems programmers. Clearly it is bad architecture, but the purpose of architecture is to reduce the cost of development and maintenance. In these kinds of applications, being able to get the application working quick enough outweighs any architectural drawbacks.
I think the sweet spot for you would be C# and Visual Studio. The way you lay out forms and such is the same as in VB 6, and these days learning how the bits is the real work on the learning curve, not the language. Forms in C# hava a Java/Swingish kind of MVC pattern, but it's really only one new design pattern you need to deal with. Once he's got the hang of it the boss can pretty much see a one to one correspondence between bits in the old VB app and a new C# app. You could go with VB.NET, but really for the kind of cmdbtn_click scripts of a typical VB app, there is no reason a VB6 programmer couldn't look at, understand, and maintain the same script in C# without having to swallow the whole C# enchilada.
And C# is a modern, well designed language. This means that if you have a piece of work that is sufficiently complex to worry about reuse, maintainability, scalability or other advanced requirements, you can address them properly. Many of the best practices and frameworks from Java have their counterparts in C#, such as O-R mapping, unit testing and so forth.
IN any case, you're in for tough sledding Dealing with a guy who has built a business where he does everything is difficult. These guys seldom can make the leap to creating a company that is bigger than they can handle personally. Even if they understand change is necessary, and that they can't do it themselves; even if they hire people to create change, they usually end up fighting change tooth and nail. Often they undermine the efforts of anybody to do anthing independently, such as book keeping or filing. Everybody is running a three legged race with the boss, and since he only has two legs, there's a lot of waiting around for him to catch up so he can toss all your recent work into the crapper.
Underneath this behavior is fear and beneath fear is insecurity and ego protection. Probably against all expectations, this guy has made a reasonable success so far; he has customers who send him enough money that there's more work than he can do himself. And since he didn't get where he is by saying no, he hired more people. But he'd probably be happier if it was just him. He may not know how to supervise people or even run a bu
Pay the piper, call the tune (Score:3, Insightful)
For the boss dude, the company and its product is his life and he is stuck with what happens to it. He hired you because, well, you could be off doing your own business and your own software package in whatever language you desire, but you decided to work for The Man, and for all you know and all the boss dude knows, you could be a life-long partner in the business or you could be here toda
Re:Which version of VB is it? (Score:3, Insightful)
Stay the hell away from managed C++ if you can avoid it. There is precious little reason to use C++ unless you intend to do something unsafe such as call Win32 or other unmanaged code so managed C++ is something of a misnomer. The only reason to use it in my opinion is if you have some legacy C++ that you need to abstract behind an object and expose into
.NET land.
It's also worth pointing out that if ever the day arrives where Mono
Re:Which version of VB is it? (Score:4, Insightful)
In all fairness, this differs from the old VB runtime just how?
Currently there are 3 versions of the
.NET Framework. v1.0, 1.1 and 2.0. I would assume any newer Windows installation at least comes with v1.1 by default, which most current .NET-applications depend on. Oh noes! I have to click "Windows update" and wait 30 seconds! My, oh my.
As for "refusing to install it". How zelous can you get? Do you refuse to install Sun's JVM as well? Yes, I see you think java ain't a real platform as well. Do you refuse to install perl or php when you write web-applications as well?
Now let me tell you about the real world: If an application does useful stuff, and uses a framework that cut development time to a tenth, that is not just a real application, but anyone remotely interested in costs will find that framework great. So will probably most realworld developers who care about getting stuff done without wasting their time on rewriting the same generic code 50 times per project.
Since it sounds like this is a product that will be used outside of a controlled environment (ie withing a specific company, you know what you are running the app on), then you are asking for a technical support nightmare.
"Install the
.NET Framework version 2.0 available at Windows Update or download it from this link [microsoft.com].". Yeah, that was, like, you know, the worst of technical support nightmares.
I know this is slashdot, but I can't believe this zealous rubbish got mod'ed "Insightful" and not "Troll".
Give us a bone! (Score:5, Informative)
Picking the right tool really requires a better understanding of your project.
Beyond the general problem, what are your expectations for reliability/testability, schedule, maintainability, expandability, performance?
If the owner is the only one qualified to improve the product, Visual Basic might be a good choice.
I once worked for a company that had an extremely accurate satellite propagation program. The problem was it was written in GWBASIC and did not run in a text-only mode (EGA graphics required!). For fun, I tried to convert it to C, but gave up - pure spaghetti code. The author became the head of a 200-person engineering department -- best leave it in GWBASIC and let him support it.
Re:Give us a bone! (Score:5, Funny)
Re:Give us a bone! (Score:4, Funny)
Couldn't agree more! (Score:5, Funny)
And it's called hell.
Re:Couldn't agree more! (Score:4, Funny)
You can tell the difference?
Rethink your approach, perhaps (Score:5, Insightful)
There's a different point of view you need to seriously consider: who's signing your paycheck? It's not Microsoft, is it? I thought not.
Consider meeting your boss in the middle. It's possible your boss is set on VB6 because he can read it fluently. Perhaps you could convince him to port it to VB.net. VB.net might not be so different that it would scare him. The GUI isn't all that different. And the
.net framework would allow you to gradually expose him to other languages (C# or C++/CLI.) And it would allow you the opportunity to use a language with better libraries than VB6.
Have you dug a bit to find out why he's so pro-VB6? Maybe he's biased against
.net because it's an interpreted language (like Java)? Perhaps half of his client base is all still running Windows 95 on 90 MHz pentiums, and .net is not an option for them. Maybe he'd be OK with C or C++ compiled to native executables, as long as there are no .net requirements. Microsoft's latest version of C/C++ has a strong push towards safer coding with bounds-checked versions of all the standard library functions. That might be good enough for him.
Or maybe he just has only two or three long-term clients that are stuck on Windows 3.1, but they've been with him for 25 years so he feels he has to support them into the far future. Consider buying them a few cheapo PCs to run your software: $400 each for a few bottom-feeder Dells would go a long way with customer goodwill, and would allow the rest of you to move into the 21st century of tools. And a $1200 hardware investment is much less money than your time spent struggling with old tools.
If he built a successful business around a piece of software, the chances are good he's smart enough to listen to rational arguments. So don't be irrational by kicking in your heels and saying "no! no! no!" unless you really enjoy job hunting.
Re:Rethink your approach, perhaps (Score:2, Informative)
Just ignore most of the ad hominem remarks against VB6 here. I hate Microsoft as much as the next
Re:Rethink your approach, perhaps (Score:5, Insightful)
Better yet, given that he's built a succesful business by writing version 1 in VB and that you don't actually have any rational arguments, why not defer to his judgment? The worst that can happen is that the next time this question comes up, you'll have a useful opinion instead of just vague concern that VB isn't 1337 enough.
It does have it's place too (Score:5, Informative)
So General Motors, or at least some small division of it, hired their company to do a project and my roomate was assigned to it. He was kinda miffed though, because GM insisted it had to be done in VB. He talked to them and they acceded that the backend could be in PERL, but the client side UI had to be VB. Well he didn't really know anything about VB, he just disdained it as a "toy language"... That all changed on that project. He was amazed by it's flexability in doing Is and speed of development. He said that every time they totally changed the requirements of the client interface he could get a new one done in a couple hours.
In the end, he was certianly no VB-all-the-time convert, but he had a respect for the situations it was useful in.
Not knowing anyting about this project I can't say, but there are projects out there that something like VB is the best answer for.
Re:Rethink your approach, perhaps (Score:4, Interesting)
In summary: don't blame VB for shitty programs, blame the programmer. And if you'd rather write in something else, why should I care? I'll judge you on the results, not the language used to write it.
Re:Rethink your approach, perhaps (Score:4, Informative)
Aiiighghghghhhhh!!!! Why, why, why do people keep saying this?!
Java is a compiled language. The Java source you write gets turned into native machine code. It's just that the compilation happens at runtime, unlike with many other languages where it happens earlier. Same process, different time.
It's not like this is a new concept. For one thing, the documentation describing it has been up on the Java web site for years. For another thing, people on Slashdot have been saying it for years. And for another thing, LISP environments that do incremental compilation to machine code at runtime have been around for at least, what, 15 years? Some quick googling indicates that language environments that compile stuff to native machine code at runtime have been around since 1968.
And heck, it's not as if it's even all that high tech or complicated in certain ways. You don't need something as esoteric as the internals of a JVM to see machine code being generated at runtime. If you want to see it happen on something simple, go to your nearest Unix or Linux machine and type "tcpdump -d not port 53". Notice that it spits out machine code? Now try some different filter expressions like "not host 127.0.0.1" or "host 127.0.0.1 and tcp and port 25" and watch how the assembly code changes. Yes, that's right -- even tcpdump compiles code at runtime, at least it does so with the packet-matching code, which is where the speed is really needed.
So hopefully it's not too hard to comprehend now that modern JVMs do the same thing, and as far as I know, so does the
.NET virtual machine.
Re:Rethink your approach, perhaps (OT) (Score:3, Informative)
That's actually some sort of bytecode. I've been hacking x86 assembly for 10 years now, and there's no way x86 has a "ldxb" instruction.
Re:Rethink your approach, perhaps (Score:3, Informative)
While I agree with most of your post, that's not actually true—tcpdump compiles to bytecode, which it then interprets much like a non-optimised JVM. To see this, run the same commands on the same version of tcpdump on different CPU architectures (I tried SPARC and i386): you’ll see the same instructions being generated (you can even check that the compiled bytes are the same, if you use the -dd option).
Re:Rethink your approach, perhaps (Score:3, Informative)
Actually I would say you're both right and you're both wrong.
Java is neither 100% compiled or 100% interpreted. Java is compiled in the sense that what is executed is not the original source code. The Java compiler has taken the code and produced a bytecode file that is closer to machine code than the original source and as a result executes far more efficiently than a purely interpreted language. Also, because what is interpreted is not the original source cod
Re:Rethink your approach, perhaps (Score:5, Informative)
VB was my second language and VB6 does vastly improve the VB experience, but there are several large problems: it doesn't support inheritance (only polymorphism); it is very difficult to use advanced features of the Windows API, it is very hard to debug and profile, and finally, it can lead to extremely unstable code.
The VB6 language supports a feature where you can implement an interface, similar to Java or C# interfaces, or C++ pure virtual functions. It does not, however, support a method to inherit methods from another class. Thus, you often find yourself writing reams of code to delegate to another class that has a common implementation of various functions. Furthermore, if an interface changes, all the classes that inherit that interface must also be changed. That can lead to a rather large maintenance headache. Furthermore, changing the interface often plays havoc with the IDE's parser, so it can no longer tell which methods on the class are inherited in the Intellisense functions.
More advanced features of the Windows API require you to copy and paste large bits of function and constant declarations into your code, and you have to jump through all kinds of hoops just to properly use the registry, system tray, or message handlers. I.e. if you want to catch a certain message sent to a window, you have to use SetWindowLong to override the message procedure of the window (you pass in the address of another procedure, which you acquire by calling "Address Of"). There is also all kinds of problems with passing pointers to structs, since you can't get a pointer in VB6. I.e. often, many window procedures require a struct with a pointer to another struct. There are hacks to get that, such as allocating a new memory buffer (using the LocalAlloc API), using CopyMemory to copy the VB struct into the memory location, then passing the pointer you got from the LocalAlloc call in as a struct member, and then using CopyMemory after the call to put the data into the VB6 struct. There are also undocumented functions to retrieve the address of variables, but there is, of course, no way to dereference a pointer, short of copying the data into a VB struct, or doing some fancy copying to change what an object points to (but that plays havoc with the reference counting).
Next, you've got the instability issues. Using *any* of these features leads to instability. Under normal circumstances, things work alright, but if you try to run the application in the IDE while you've got a custom message handler set up for a window, then the moment you hit "Stop" to end execution, the whole IDE crashes. The reason for this is that the VB6 IDE runs the app inside the IDE's process, so if your app causes a GPF or similar, the whole IDE goes with it. It also makes it a real pain for debugging, since setting breakpoints inside the window procedure often causes crashes.
Finally, it's very difficult to debug a VB application. If you've ever looked at the assembly output of the compiler, it's absolutely horrendous. Trying to step through it in WinDebug or something similar is just about impossible. The only way to debug it is with source code and full symbols, but even that is rather difficult sometimes. For example, most of the magic happens within the VB6 runtime (just about every VB statement is implemented as a call to the runtime; even assignment), so it's very difficult to follow what is really going on underneath the hood.
Those are my main problems with it. I also don't like many other things. For example, VB is really slow. Slower than
No argument really. (Score:5, Insightful)
Depends on a lot of factors (Score:3, Informative)
On the other hand, it has trouble coping with large complex projects (One of my larger projects regularly crashes the VB IDE when I load it, for no particular reason, and sometimes the VB compiler spits out mysterious build failure errors for no particular reason), and it lacks a lot of important features you get out of better languages and tools. If performance is a concern, you'll also find that it has trouble scaling there (though it's at least tolerable, and if you're careful you can get pretty efficient code out of it). There are also some data models and algorithms that simply don't work well in VB due to the overhead and inefficiency of using COM IDispatch and reference counting for every object.
If you need to make a transition from VB, you might be able to manage to convert it over to VB.net, but I've never been able to do that successfully. I personally use C# for any project these days that I would have used VB6 for in the past. And if you don't really need to do much in the way of UI, C++ is a pretty solid option for almost anything else, even if it's tough for some VB coders to grasp.
One middle-ground option would be to rewrite chunks of the application using C++ or C# and wrap them in COM so that you can drop them into the existing VB application. I had pretty good success doing this with performance-critical parts of a few of my larger VB applications and didn't lose any of the benefits of doing my UI in VB in the process.
Re:Depends on a lot of factors (Score:4, Insightful)
what? (Score:5, Insightful)
The language is irrelevant to comp scientists (Score:4, Insightful)
Actually, the problem is whoever hires people who are qualified for task A to do task B.
This is a perfect example of the difference between a university-educated computer scientist, and a graduate of a 6-month "tech college" program. The community college drone has only been taught how to use one or two tools to perform common tasks, whereas the computer scientist is taught to truly understand the tools, as well as the thinking that went into them, how to use them to solve multiple abstract classes of problems (instead of just a few common, specific problems), and how to apply that knowledge to use tools they haven't seen yet.
A real computer scientist doesn't care what language they work in. A good employer should know that when they hire the 6-month grad at $18/hr, they're getting a code monkey that can do only what is explictly listed on their resume. They know that when they spend the extra money for a computer scientist with an actual degree, they expect that programmer to be much more capable, flexible, and adaptable. The fact that they've never programmed in VB before is nothing more than a minor roadblock. Send them to Borders/Indigo/Chapters with $50, tell them to pick up an O'Reilly or Knox book on VB, leave them alone for a couple days, and they should then be able to apply all their learning in the new language.
Re:The language is irrelevant to comp scientists (Score:3, Insightful)
I agree that a "real" computer scientist could easily learn a new language and it really might be just a minor roadblock. However, the language is certainly not irrelevant, and we really do care what language we work in. A craftsman needs the right tools. I wouldn't want to code in a language that
My biggest gripe... (Score:2)
Re:My biggest gripe... (Score:5, Informative)
I used to think so, too.
Try this. [microsoft.com]
Who's your buddy now?
:-)
Re:My biggest gripe... (Score:2)
If I could mod you up or transfer all my karma points to you I would. Thanks.
Re:My biggest gripe... (Score:3, Funny)
Wha? (Score:3, Insightful)
OK, just to get this out of the way, the owner of the company hired you to re-write his program in Visual Basic, and you don't know Visual Basic? I mean, it's not like he hired you to simply re-write it in any language, he wanted you to re-write it in VB. And he obviously knows VB since he wrote the software in the first place. So, uh, WTF?
First, I have to assume you mean VB 6, since VB.net bears more resemblance to C# than anything else. If you're talking VB.net, don't worry about it. The syntax might be annoying, but it's a decent language. Anyway, as for the merits of VB, well, it's appearantly good enough for a large project, since you're looking at one right now that was good enough to start a company that can support 5-9 people. This company's appearantly been around a while; I hope nobody's writing new stuff in VB. So don't worry about whether it's good enough or not, it is.
The issue I would have with it is, it's being killed by Microsoft. There's nothing you can do about it. It may not work on new versions of Windows. Old versions of Windows won't be supported anymore. You'll run into security holes that won't be fixed, or try to interoperate with software that needs a newer version of Windows. Basically, you're going to get screwed, it's just a question of when. If your company has the time and money to do a rewrite, do it in a language that's going to be around for a while.
Normally of course, I'd call you nuts for doing a complete rewrite unless it's a pile of crap that's falling apart at the seams and the basic architecture is shit, but it's written in VB. Which has its merits, and maybe I'm wrong here, but I consider it more of a prototyping language than anything else. Just don't rewrite it in VB 6. Seriously, quit first, it won't do shit for your resume to have VB 6 on there, and it'll just cost the company a crapload of money for no good reason.
Why the hell did he hire you? (Score:2)
But, in fairness, if you have serious doubts about the platform the owner insists upon using, then this isn't the place for you to be working.
You're either onboard, or you owe it to your boss to leave the company.
One of the best assessments I've seen (Score:5, Informative)
Really, reading his argument in the context of having a bunch of C++ coders build a nice Windows app in 2006, I think I'd probably conclude that C# was the way to go, as opposed to VB. But keep in mind that C#.NET and VB.NET are more alike than they are different. For most apps, the arguments for managed code (VB or other) are very potent.
My take: If you and every single developer on your team can't instantly see and explain the differences between the 4 arguments to this function:
void foo(std::string a, std::string * b, std::string & c, std::string *& d)
stop now and use managed code of some kind.
If you all can, think really hard about why you want to spend your talent managing memory instead of doing things that'll really make your application shine. (There are reasons. They don't apply to most apps.)
Re:One of the best assessments I've seen (Score:2)
Re:One of the best assessments I've seen (Score:2)
Using C# is a far call from using VB, even if it is VB.NET.
I'll give you that it's a far call from VB 6. But what makes it a far call from VB.NET in your opinion? I like C# much better because the syntax is much more familiar to me, but the appropriate uses for each as well as the capabilities of each seem largely similar to me. Performance is identical. So what does C# buy someone whose mind hasn't been molded by 15 years of C/C++, apart from mono's c# implementation being more mature than its VB.NET imple:VisualBasic = the devil (Score:5, Insightful)
this is seriously one of the funniest things I've read on slashdot in the last week. For the canonical car analogy, it's like saying sheet metal has no place in modern automobiles.
normally... (Score:2)
I'm not sure what type of app you're aiming at, but C++ and Java come to mind as solid choices.
Easy answer (Score:2)
Re:Easy answer (Score:5, Funny)
Cross Platform? (Score:5, Insightful)
To that end: Python and C++ are generally good choices. They each have their place. I really like my C++, but rapid development is somewhat of a joke. It takes years and years to master and even after using it for close to 8 years on a daily basis I'm still amazed at what I don't know sometimes. However, you can do anything with C++. If you can think of something, there is already probably a library out there to do it. I don't recommend it to novices or people who want rapid development, however if you want a rock solid well performing system it really can't be beat.
If you're doing GUI stuff, you would have to take a VERY serious look at the combination of Python and Qt. Qt is the de facto cross platform toolkit. It has everything from GUI libraries to network libraries to regular expressions, xml parsers, you name it. It's very good. It's also very good with C++.
I don't know much about C#, but with Mono you at least have the possibility of it being cross platform. I'm not a big Java fan. After being a C++ guy for so many years it just seems like crap. It lacks the good things from C++ with all of the syntax overhead, and it lacks the flexibility of Python.
If you didn't guess I write almost everything it Python or C++. They are my dual golden hammers.
I do a lot of Scheme too, but I'd be an idiot to recommend that to you!
Perl is glorified shell. I wouldn't touch it except for the smallest most throw away programs, if even for that anymore. Still I know people who swear by it, mostly sysadmin types.
I've played with Ruby a bit. It has some definite strengths, but the library support, or lack thereof is a big minus. Syntactically it reeks of Perl and IMHO lacks the elegance of Python. Still it's got some really cool unique stuff.
Overall I would recommend Python, but like another post mentioned, what are you trying to accomplish? You should fit the tool to the task not the task to the tool.
Re:Cross Platform? (Score:2)
However, the folks at RealSoftware got greedy and let the quality of their past products go to their heads. All current versions of the software are written and compiled using RB itself... a move that has
Re:This post was brought to you (Score:3, Funny)
VB isn't _that_ bad (Score:2)
VB.Net is fine too. The biggest problem is that simple languages attract simple people.
Not too bad overall.... (Score:2) 75871-4590326?v=glance&n=283155 [amazon.com]
and then learning the essential stuff from Charles Petzold 75871-4590326?v=glance [amazon.com]).
What is better? (Score:2)
For one thing... (Score:2)
In my opinion, if you are re-writing, I would say do it in Java - then it will work on Mac and Linux and everything. But if you are determined to be Gates' whipping boy, at least do it in C#.
VB6 has its place... (Score:5, Informative)
They vanished after they tried to compete in the
I got an internship with Microsoft after spending most of my interview defending VB as a language choice -- this was pre-C#/.Net.
Some "facts" from above annoyed me, so I'm responding:
1) VB is only interpreted.
VB6 can be compiled to P-code, and will run interpreted. However, by default it's compiled to executable code. The only "penalty" for using VB6 when it comes to speed is really the memory footprint of the VB6 runtime DLLs.
2) VB6 is not suited to large products.
I'm aware of at least one company that based an entire website off VB6 apps. I'm sure they would be ASP.Net now, but at the time (VB4), that wasn't yet an option. So the web engine was actually a series of VB apps that were invoked to process the web request as ReadLine and Print commands.
3) VB6 -> VB.Net
(The person in question did only propose this as an idea.)
I would argue against this. There are certain elements only possible in VB6, and the switch to managed code is unfortunately not as seamless as MS would have liked. Hence the uproar when MS EOL'd VB6. VB.Net is great for managed code, and even has some features that C# lacks. I personally prefer C#, but I come from enough of a mixed background that I can handle what VB.Net code comes my way. While rewriting the application in VB.Net may be the proper thing to do, it certainly does not provide much in the line of benefits above and beyond rewriting the application in C#.
VB does have certain benefits to use. As a RAD environment, it is (or was
While I can't know why your manager wants to use VB, it's not such a terrible order.
If your manager only wants to preserve the look-and-feel of previous versions, the previous proposal of writing COM components in C++ for the high-performance portions and using VB for the front-end is certainly a very viable option, and one that I've used previously. In this manner, the weaknesses of VB6 can be circumvented while still leveraging existing components and possibly even code. At the far end of the advancement spectrum, even managed components can be exposed to COM clients -- Adam Nathan's wonderful ".Net and COM: The Complete Interoperability Guide" is probably the most complete book on the subject. If appropriate, you can write new code in C#, and expose it back to VB6.
If your manager wants to preserve the code base in VB6, you might want to determine why he wants to rewrite the application -- it's possible a better solution is just to rewrite portions of the code, depending on the scope of the changes he desires. The right tool for the right job -- VB is the right tool for some jobs, but shouldn't be presupposed to be the right tool for every job.
That being said, there are few things you can't do in VB -- although some of the solutions are probably not as simple as they may be in other languages. Keep in mind, however, that it is even possible to get assembly code linked into a VB6 application, if necessary. It just takes a little bit of creativity.
Re:VB6 has its place... (Score:3, Informative)
Try this:
- Write a very simply object in VB with just a few properties that can be set.
- Write the same object interface in C++.
- Write a test harness which instantiates and then releases 1 million of each type
- Compare the results.
C++ allocates and deallocates COM objects an order of magnitude faster. If you're working with lots of insta
Depends! (Score:4, Informative)
Here's my two-cents, by language/environment:
VB6
---
If you're writing business applications, VB6 will get you through. Manipulating very large datasets can be a bit of a challenge, and you're always going to have problems with user experience (due in large part to a complete lack of multithreading). Applications can be made that are *functional*, although your resultant UI will always seem dated.
VB.NET
------
This is an entirely different beast. You've got a much more powerful langauge on your hands, with as much power and expressivity as Java - it is quite straightforward to produce a modern, performant application with little muss or fuss.
My suggestion, if VB is an absolute must, would be to insist (as best you can) on VB.NET. Now, that being said, VB is not a magic bullet - VB/VB.NET/C#/Java, they are all languages designed to allow a programmer to express their thoughts, and it's quite easy to produce unworkable software with any of them. Do not allow yourself to fall into the 'C# is better than VB.NET' arguments, simply because they are completely non-sensical; the power of any
I've worked professionally in VB, VB.NET, Java, Perl (alot of Perl, in fact), C#, and C/C++, and I must say IMO the most expressive langauge is C++, hands down. I love Perl, and you can do an amazing amount of things with it, but the power and flexibility of C++ is unmatched in the list above. VB.NET/C#, however, can be excellent choices for presentation-centric applications (Windows Forms applications or Web Forms). In the past, I've worked on projects that combined the two; a C# GUI that interfaced with a C++ server component. It worked great.
Any
Short Story: If you're writing a business-focused application with limited or no multithreading needs, VB works; If you need a modern GUI with all the latest bells and whistled VB.NET/C# should be examined; If you need high-performance, minimal runtime requirements, and low-level system interaction, look somewhere else. Real-time equipment monitoring, for instance, is a task best left to C++. The rest can be done in VB or a
Have fun!
Bryan
==
Myriad of problems (Score:3, Informative)
Some good things to point out though:
VB is not an open standard,
VB is platform specific
VB is generally quite time consuming to maintain for large apps
VB is much slower than C++ for certain CPU intensive apps.
Possibly: The people expected to maintain the code are less well-versed in VB
If this is a small-enough, simple-enough, Windows-centric enough application, there's probably no good reason to do a total rewrite in a different language.
If, on the other hand, this app might have a customer base on a non-Windows platform, and if the program is likely to dramatically increase in size in the future, it might be worthwhile to think about changing it to a different language.
This original poster scares me (Score:5, Insightful)
The crucial ingredient in any project is the people you end up working with, not the language. I'm not a fan of VB, but if this kid doesn't have the experience of successfully completing a project in the real world, he should consider following the owner's experience -- and only worry about changing the underlying language once he has a couple of releases under his belt.
Sticking to VB is asking for strange bugs (Score:3, Insightful)
And if you really have to stick with VB, you have to impose strict coding rules, like requiring "OPTION EXPLICIT" on ALL code, be strict about variable naming and so on.
Better be so strict about the rules that you actually end up with C#.
Why does the software need to be rewritten? (Score:3, Interesting)
Suggest not rewriting the software and simply going through and improving where needed..
Problems with VB6 (Score:5, Informative)
2) COM components in VB don't keep the same GUID from time to time (depending on what changes you're making). This causes build problems because when the component's GUIDs change, you have to change all the other projects that reference them. This can be a huge timesink in development.
3) VB6 is unsupported and is a black box, which means no one else can support it either
List of problems from my ex-employer (Score:5, Informative)
> against VB because I'm not familiar enough with it.
I, as system programmer, for three years did ported number of VB applications to C/C++. Funny job for system programmer, don't you think?
The list of problems of my employer was:
1. Run-time libraries conflicts. VB applications affected worse of all by "DLL-Hell" probles of Windows: lots of functionality resides in ActiveX components developped by third parties. People usually quote ActiveX support as VB first advantage, but from POV of deployment and support it is hell.
2. Run-time libraries dependencies. Since VB is all into ActiveX, you might start using some component you haven't explicitely installed. Then when you ship the application to your customers you might find yourself in silly situation: half of them report everything is Ok, half - scream that nothing is working. Apparently, first half have the similar set of applications installed - and VB application finds the library missing from its own installation.
3. Internationalization. That was huge problem for my employer. We have had quite number of customers in Japan. M$ did internationalizion of VB in straight way: it didn't. In other words, VB as we have it in Europe/US and VB in Asia are two different VBs. Absolutely different. Since Japanese love VB, most of our customers had it installed. The situation looked so: if customer installs our application - other and her/his own applications stop working; if s/he reinstalls VB anew - our application stop working. Interpreter is the same, but run time libraries are very very different.
4. Upgradability. VB applications are one hell to maintain. We have had lots of reports that installation of our application made with VB4 was breaking VB5/VB6 installations. According to M$, the cure was to upgrade everyone to VB6. But VB6 introduced some problems so our custormers were split - half used VB5 and other half VB6.
To conclude. One can write good application in VB. But M$ doesn't make that very easy. The whole ActiveX thing is one hell to deploy and maintain.
problems with VB (Score:4, Insightful)
-to me, the syntax is OK
-the API, compared to Java, is really bad (no jdbc, no generics,
-the GUI is easy
-writing maintainable code is difficult. VB(.NET) is hard to style because of its IDE. Eclipse is magnitudes better..
Coding defensively (Score:3, Insightful)
A quality program must be coded defensively, in other words it must assume that anything can fail at any time and that it must sensically deal with it. It must not make assumptions about external inputs. Unfortunately, few programs are coded to this level of quality, but they are the ones that you won't see security advisories about. Programs that are not coded defensively will, upon hitting a problem, exit with an error message that does not help you find out what that problem is, or continue doing something where it does not make sense to continue. Troubleshooting and maintaining defensively coded applications is simple - whereas with other applications a developer often just leaves the bug for eternity.
There is extremely little example code for VB that is coded defensively. If you disagree, please post a link to an example where code to open a file has a code path that is run specifically when the file can't be opened. In the meantime, google has 748000 hits for "80004005".
However, for your particular situation, this is largely moot. If you're already working with a specific developer, they will either code defensively or they won't, regardless of language..
Wait, let me get this straight... (Score:5, Insightful)
I don't.
If you're going to be working on rewriting it, it needs to be rewritten in a language you have significant experience writing in. Period. For instance, if *I* were going to be rewriting it, the logical languages to choose would be Perl or maybe lisp, because those are the languages I know well enough to write good code. If he wanted it rewritten in VB, he needed to hire someone with VB experience.
VB *is* reasonably good for certain things (mostly, pure GUI work, e.g., an application that facilitates data entry), but only if the programmer doing the work is familiar with VB. I've seen applications written in VB by someone who didn't know the language well, and they were universally terrible in every respect (_including_ the UI). This is true in any language. When somebody is just learning the language, they aren't going to be comfortable with the language's features or conventions, and so they're going to write execrable code for several months until they learn those things. During that time, you don't want them writing something mission-critical in that language. It's bad juju.
My take on it - can't believe no one else has said (Score:4, Insightful)
>in VisualBasic. This scares me, but I honestly can't make a good argument against VB because I'm
>not familiar enough with it.
So if you were hired to do this job, wasn't it made plain up front that it was to be done in VB? If this scares you now, didn't it scare you then? Why did you take the job? If you're not very familiar with VB, why would someone hire you to re-write a program using VB?
Steve.
Re:Umm (Score:3)
Re:Basically. . . (Score:2)
Re:Basically. . . (Score:2)
On the other hand, VB6 seems to get sluggish when you have more than 100,000 or so strings in memory. Nearing that boundary, I've gotten performance increases by storing strings in a file and just remembering their addresses, even when there's plenty of free ram, which is crazy.
Re:3 reasons from personal experience (Score:4, Informative)
That's actually the main feature of Classic VB -- that it's really just a user-friendly wrapper around Windows COM. If you want MS Office automation or anything that ties in closely with other Windows apps, VB6 is still a very good choice.
Although I agree strongly with your assessment of VB server apps.
Re:3 reasons from personal experience (Score:4, Insightful)
In other words, you're a Java bigot that looks down upon those that don't agree with your choice of tools. It used to be C bigots that irritated me the most (the "if you can't do it in C it isn't worth doing" mindset), but now it seems that most of them have moved to C# and have finally realized the benefits of a decent GUI development system. A friend of mine once put it this way: "Welcome to VB you pompous assholes." VB6 and VB.Net have their place, and calling people that use them bozos won't win you any points (although you'll probably garner some karma from like-minded mods.) But the biggest argument to me isn't that VB6 is a black box (from an empirical standpoint it's about as thoroughly understood as it's possible for a black box to be, and
Re:3 reasons from personal experience (Score:3, Insightful)
I work with Perl, Java, C# regularly. A crappy coder can use C, C++, JAVA or whatever , he will still produce crappy code. I use these languages because I'm more familiar with C related languages.
Assuming that the guy is working on VB
Instead of wasting your time on syntax matter, better to focus on the application architecture.
I'm sure that half of the negative comment came from the simple reason that VB means virtual "BASIC". Most of
Re:3 reasons from personal experience (Score:3, Insightful)
Re:3 reasons from personal experience (Score:5, Insightful)
Because it sucks .
It is a language designed so that a genius can write libraries designed for the merely smart to use. How many geniuses do you have in your workgroup? Me, I'm lucky. But I'd really rather they work on real design than trying to remember how copy constructors interact with template instantiation.
I don't know C++, and I know that I don't know it. Somewhere around here I have a list of interview questions for people who put C++ on their resume. They're mostly from me reading C++ code and going "what the heck does that imply?"
Unsurprisingly, most candidates fail that section of the interview. And they fail even trivial stuff like "what's a virtual pointer all about?" They may be aces at writing O(n^3) algorithms with CString, but they have no clue what's going on under the surface.
To be fair, I do know some true C++ experts. Most of them would rather be writing Haskell.
Re:3 reasons from personal experience (Score:3, Insightful)
Of course they fail that portion of your interview questions - 'virtual pointers' don't exist. Virtual methods exist, pure virtual methods exist, pointers to virtual methods exist, but there's no such thing as a 'virtual pointer'.
'CString' is a Windo
C++ is not for dummies (Score:4, Insightful)
Now don't get me wrong, I work with C++ every day and I love it because of the sheer power it gives me. You can basically abstract away any management chores using smart pointers and other objects. And you can write the most obscenely decoupled functionality using traits classes and such. But put this same stuff in the hands of a VB coder, and you'll get C++ code using VB idiom. And that's NOT GOOD. VB coding idiom is not exception safe AND does not deal with memory management, so you'll have memory leaks all over the place, and even if they bother to put in the deletes in the proper places, you're one exception away from leaking a whole bunch of stuff. Teach them to use smart pointers to fix this? In an average C++ project "done right", you'll have to write a lot of smart pointers/auto objects yourself, and people who are used to VB are _not_ capable of writing proper smart pointers in C++. That requires reading and understanding all of Scott Meyers' books, and they won't do that. They'll think they grasp the language when they have their first MFC-generated dialog on-screen. It'll only get worse from there. | https://slashdot.org/story/06/06/01/0223211/making-an-argument-against-using-visual-basic?sdsrc=prevbtmprev | CC-MAIN-2017-04 | refinedweb | 10,171 | 71.24 |
{ "device": "Lamp", "type": "Switch", "commands": [ { "name": "turn Lamp on", "command": "/api/Lamp/ON" }, { "name": "turn Lamp off", "command": "/api/Lamp/OFF" } ] }
I need to deserialize the JSON into a(n) C# object(s). I am having trouble though understanding how to format the C# code. I used json2csharp.com and came up with this:
public class Command { public string name { get; set; } public string command { get; set; } } public class RootObject { public string device { get; set; } public string type { get; set; } public List<Command> commands { get; set; } }
However, I do not fully understand the two different objects. This is the C# code that returns a null value for
command1:
HttpClient client = new HttpClient(); string url = ""; string json = await client.GetStringAsync(url); Commands command1 = JsonConvert.DeserializeObject<Commands>(json); TestOutput.Text = command1.command;
If someone could explain the classes and how they transfer over from the JSON, that would be really helpful. | http://www.howtobuildsoftware.com/index.php/how-do/gho/c-json-object-trouble-converting-from-json-to-c-objects-how-do-the-classes-work | CC-MAIN-2018-39 | refinedweb | 149 | 52.09 |
Crawl 0.5.4
Python tool for finding files in a set of paths. Based on the Hike ruby gem
Crawl is a port of the Ruby gem Hike to Python. Crawl will scan through a list of given folders for a requested file. You can also specify a list of possible extensions and aliases for those extensions.
Install
$ pip install crawl
Usage
import crawl trail = crawl.Crawl() trail.append_paths('lib','foo','bar') trail.append_extensions('js','py') trail.alias_extension('.coffee','.js') trail.find('blah')
Getting Involved
If you want to get involved and help make Crawl better then please feel free. Just fork and clone the repo and install any development requirements by running the following from the commmand line:
$ pip install -r dev_requirements.txt
Please write any necessary unit tests and check all tests still pass with your changes. If you want to discuss suggested changes then please raise an issue, that way other people can discuss them as well. When you’re happy everything is ready to go just submit a pull request and I’ll check it out.
Running Tests
Run the following from the command line to run all tests:
$ nosetests
Credits
Huge amounts of credit to Sam Stephenson(@sstephenson) and Josh Peek(@josh) for all their work on the original Hike gem. I have basically just rewritten their code and tests in python, tweaking where necessary to make things more ‘pythonic’ (I hope).
License
Crawl is licensed under the MIT License, please see the LICENSE file for more details.
- Downloads (All Versions):
- 32 downloads in the last day
- 149 downloads in the last week
- 172 downloads in the last month
- Author: Will McKenzie
- Download URL:
- License: MIT License
- Categories
- Package Index Owner: OiNutter
- DOAP record: Crawl-0.5.4.xml | https://pypi.python.org/pypi/Crawl/0.5.4 | CC-MAIN-2015-11 | refinedweb | 295 | 68.7 |
(LOOK AT THE FUNCTION ALL THE WAY AT THE BOTTOM OF THE CODE) i'm on giving my whole code, but just the class and the method. im having a problem with the last method printArray. My professor asked us to make it ask for no parameters. im having a problem with accessing a text file sent through int main. It was first sent to function readFromFile. I was wondering how to keep the filename in my ifstream infile. I'm trying to output the filename as an array in printArray, but it's not even reading any file!, its outputting correctly at 5 numbers per line, but the number is some weird number. I know how to fix it if i could use a parameter for my printArray function, but i was instructed not to have any parameters.
Code:#include <iostream> #include <iomanip> #include <fstream> const int maxValues = 100; ifstream infile; ofstream outfile; using namespace std; // The typedef for the Array class typedef double arrElem; // put your Array class here class Array { private: static const int arrElems = 100; // max values that array can hold arrElem arr[arrElems]; // the array itself int numberUsed; // value of positions used up in array public: void readFromFile(char fileName[arrElems]); void printArray(void); int getSize(); }; char fileName[maxValues]; void Array::readFromFile(char fileName[arrElems]) { static int filesize = 0; infile.open(fileName); if (infile.fail()) { cout << "Opening file " << fileName << " failed. Goodbye." << endl; exit(1); } infile >> ws; // to make sure it doesn't read last value twice while (infile.eof() == false) { filesize++; infile >> arr[arrElems]; infile >> ws; if (filesize > 100) { cout << "There are more values in the file than there are positions" << " in the array." << endl; } } numberUsed = filesize; } int Array::getSize() { return numberUsed; } void Array::printArray() // THIS FUNCTION'S NOT WORKING CORRECTLY { int i; static int perLine = 5; for (i = 0; i < numberUsed; i++) { infile >> arr[arrElems]; cout << arr[arrElems] << " "; if ((i+1) % perLine == 0) cout << endl; } } | https://cboard.cprogramming.com/cplusplus-programming/37091-problem-sending-files-class-method.html | CC-MAIN-2017-51 | refinedweb | 321 | 59.94 |
Whenever I put something within my try-catch blocks, I get this error "cannot find symbol" when I have already defined everything clearly for each try-catch blocks. None of the try catch blocks work, dunno why.
Printable View
Whenever I put something within my try-catch blocks, I get this error "cannot find symbol" when I have already defined everything clearly for each try-catch blocks. None of the try catch blocks work, dunno why.
Unless you show us the code and the full error message it's hard to say what is wrong other than maybe you haven't declared a variable/method you are using or you haven't added an import statement you need.
If this is a duplicate of your other thread then please close one of them or it's going to get really confusing.
And where's the full error message?
client1 is declared inside the try block and so is local to that block. You need to declare client1 outside the try block.
BTW I should point out you should be closing the socket in a finally block else if any of your code throws an exception the socket won't be closed.
And learn how to use code tags - read the blue text below this line to see how it is done.
I haven't looked - it's hard to read code that hasn't been formatted (hence we keep asking you to use code tags). And I don't have the time at the moment so you'll just have to run it and see if it works.
Good Luck.
Oh nvm tks, will get back 2 u if I face any more probs, tks 4 ur tym.
You are creating the TimeStamp objects but then not doing anything with them. What are you trying to achieve?You are creating the TimeStamp objects but then not doing anything with them. What are you trying to achieve?Quote:
My time-stampping doesn't give any output, dunno why
Oh ya, I din realise earlier, was so caught up in fixing my exceptions. Basically, I need time-stamps to check that curr time doesn differ from the time-stamp time by more than 1 min & if it does to retransmit data. I m not sure how to reestablish connection to retransmit data, do I create a new socket for connection re-establishment? Since m implementing a simplified Kerberos protocol, m not sure how to handle the creation of challenges either. Coding on Kerberos seems to be very little on the net, in fact I can hardly find exaamples. If u have knowledge on Kerberos pls share, tks.
Just a small point on exception handling Susan, that will make coding simpler and the finished code clearer...
The try...catch structure is designed to allow you to write the bulk of your code without worrying about the errors until the end of the method. So you should open a single 'try' block, write all the method code, then catch all the errors at the end, e.g..Code:
public void aMethod {
// declare variables that may need tidying up after errors
...
try {
// initialise variables
...
// put main body of method code here, ignoring exceptions
...
...
}
// now the main work has been done, handle any problems that may have occurred
catch (ExceptionA a) {
... // handle a
}
catch (ExceptionB b) {
... // handle b
}
finally {
... // tidy up variables, close handles, etc.
}
} // end of method
It's only a guideline, but it is Best Practice ;)
Most software today is very much like an Egyptian pyramid with millions of bricks piled on top of each other, with no structural integrity, but just done by brute force and thousands of slaves...
Alan Kay
I can do that but m trying to fix my socket connection now again, it says my client hasn't been intialized.
This is my errorneous code
Client:
Code:
Socket client1; //Defined outside
BufferedReader userInput; //Defined outside
DataOutputStream ServerOut; //Defined outside
BufferedReader ServerInfo; //Defined outside
try {
client1 = new Socket("127.0.0.1",9001);
} catch (UnknownHostException e) {
System.err.println(e);
System.exit(1);
} catch (IOException e) {
System.err.println(e);
System.exit(1);
}
Server:
Code:
Socket socket1; // Defined outside
BufferedReader ClientInfo; //Defined outside
ClientInfo =
new BufferedReader(new InputStreamReader(socket1.getInputStream()));
If you get an error, please post the full error message and stack trace, if present.
Incidentally, socket1 on the server has been declared but hasn't been initialised.
Optimism is an occupational hazard of programming; feedback is the treatment...
Kent Beck
Ok, I changed my code, now since m sending strings from client to server, I want to know how I can send multiple strings to server. Eg. If client types hello then server echoes hello, then client types world server should echo world & it sholuld continue until client stops so how to send multiple strings in java?
You need the server code to loop back to waiting for the client after it handles the client message, and the client to loop round and send a new message after every server acknowledgement.
I can't say more without seeing the relevant code.
Programs must be written for people to read, and only incidentally for machines to execute...
Abelson and Sussman
I will post now.
Server:
Code:
import java.io.*;
import java.net.*;
import java.util.*;
public class AS3{
public static void main(String[] args ){
int i = 1;
try{
ServerSocket s = new ServerSocket(9001);
for (;;){
Socket incoming = s.accept( );
System.out.println("Spawning " + i);
new RealEchoHandler(incoming, i).start();
i++;
}
} catch (Exception e){ System.out.println(e); }
}
}
class RealEchoHandler extends Thread{
DataInputStream in;
DataOutputStream out;
private Socket incoming;
private int counter;
public RealEchoHandler(Socket i, int c){
incoming = i;
counter = c;
}
public void run(){
try {
in = new DataInputStream(incoming.getInputStream());
out = new DataOutputStream(incoming.getOutputStream());
//boolean done = false;
String str="";
String [16] store;
out.writeUTF("Connected!\n");
out.flush();
int idx = 0;
while (idx != 17){
out.writeUTF(">");
out.flush();
str= in.readUTF();
System.out.println(in+":"+ str);
if (str != null)
{
store[idx] = str;
if(idx % 4 == 0)
{
out.writeUTF("Echo (" + counter + "): " + str+"\n");
out.flush();
}
}
idx++;
}
incoming.close();
} catch (Exception e){
System.out.println(e);
}
}
} | http://forums.codeguru.com/printthread.php?t=508255&pp=15&page=1 | CC-MAIN-2013-48 | refinedweb | 1,024 | 64.81 |
This is a Java Program to Find the Area of a Triangle Given Three Sides.
Semiperimeter = (a+b+c)/2
Area = sqrt(sp*(sp-a)*(sp-b)*(sp-c))
Semiperimeter = (a+b+c)/2
Area = sqrt(sp*(sp-a)*(sp-b)*(sp-c))
Enter the length of three sides of triangle. Now we use the Heron’s formula to get the area of triangle.
Here is the source code of the Java Program to Find the Area of a Triangle Given Three Sides. The Java program is successfully compiled and run on a Windows system. The program output is also shown below.
public class Triangle
{
public static void main(String args[])
{
double s1, s2, s3, s4, area;
Scanner s = new Scanner(System.in);
System.out.print("Enter the first side :");
s1 = s.nextDouble();
System.out.print("Enter the second side :");
s2 = s.nextDouble();
System.out.print("Enter the third side :");
s3 = s.nextDouble();
s4 = (s1 + s2 + s3 )/ 2 ;
area = Math.sqrt(s4 * (s4 - s1) * (s4 - s2) * (s4 - s3));
System.out.print("Area of Triangle is:"+area+" sq units");
}
}
Output:
$ javac Triangle.java $ java Triangle Enter the first side :3 Enter the second side :4 Enter the third side :5 Area of Triangle is:6.0 sq units
Sanfoundry Global Education & Learning Series – 1000 Java Programs.
Here’s the list of Best Reference Books in Java Programming, Data Structures and Algorithms.
» Next Page - Java Program to Calculate the Sum, Multiplication, Division and Subtraction of Two Numbers | http://www.sanfoundry.com/java-program-find-area-triangle-given-three-sides/ | CC-MAIN-2017-43 | refinedweb | 245 | 59.6 |
eli.carter@inet.com (Eli Carter) writes: > Enrico Scholz wrote: > [snip] > > An issue related to the `BuildRecommends'-tag is the behavior while > > upgrading a package. A package with all fulfilled recommendations > > (being called full-package now) should takes precedence over older > > packages (serial + version + release) or the same package with a > > missing recommendation (called half-package now). > > > > The critical case is the comparision of a half-package and an older > > full-package. I think the half-package should take precedence because > > it is being built by the user who knows his needs and can not take > > advantage of the extra-features of the full-package. > > What about upgrading a half-package to a half-package with a different > set of fullfilled buildrequirements? This is a difficult case where no answer can be found which satisfies everybody. I would use the following heuristic: - the package with the highest count of satisfied recommendations will take precedence. Therefore the additional variable mentioned in my proposal could be the (negative) count of missing recommendations. - if the same number of recommendations are fulfilled packages are assumed to be equal Most distributed RPMs should be full-packages or half-packages built within the standard environment of the used distribution. Additional features will be compiled in by the user; mostly by fulfilling a new recommendation without removing another one. If he does the latter, he is on his own and has to force an upgrade. > Example: > package P > buildrecommends0: A > buildrecommends1: B > buildrecommends2: C > > Currently installed: > P 1.2.3-4 with buildrecommends 0 + 1 > > rpm --upgrade of the following P's: > P 1.2.3-4 w/ 2 older package > P 1.2.3-4 w/ 1 + 2 "same" package (both are missing one recommendation) > P 1.2.3-5 w/ 0 newer package; upgrade Not comparable directly, because spec-file -5 can define other buildrecommends. Therefore normal election takes place. This case can be a problem with automatic upgrades; but I think a user who compiles his own packages can turn off the automatic upgrade of such packages. People distributing (half-)packages should take care not to release newer versions with lesser features, but this is a general problem... > P 1.2.3-5 w/ 0 + 2 newer package; upgrade > Suppose P 1.2.3-6 adds "buildrecommends3: D" > P 1.2.3-6 w/ 3 newer package; upgrade The new `buildrecommends3' is meaningless; because release changed, decision happens there. > Can the same thing be accomplished by having buildrequires that > apply to a specific sub-package? Can it be specified to omit a sub-package to build? If not it won't take any difference if the `BuildRecommends:' is in the main-package or in the subpackage; the warning appears in any case. > (With the ability to build specific sub-packages only, if that > functionality is not already available...) When using the %{BUILDRECOMMEND<nr>} extension, you could write: ------ foo.spec ------ BuildRecommend0: xemacs BuildRecommend1: emacs ... %if %{BUILDRECOMMEND0} %package xemacs ... %file xemacs ... %endif %if %{BUILDRECOMMEND1} %package emacs ... %file emacs ... %endif -------- Therefore you get foo-xemacs with installed xemacs, foo-emacs with installed emacs, foo-emacs and foo-xemacs with installed xemacs and emacs or nothing else. > With 3 buildrecommends, that would translate into 8 mutually > exclusive subpackages (and hence that many different variations > of the name...ewww). (2^nth I'm afraid...) I don't know exactly how powerful the %if statement in RPM is, but you can use the shell: | %define COND0 %(test %{BUILDRECOMMEND0} = 0 -a %{BUILDRECOMMEND0} = 0 && echo 1 || echo 0) | %define COND1 %(test %{BUILDRECOMMEND0} = 0 -a %{BUILDRECOMMEND0} = 1 && echo 1 || echo 0) | %define COND2 %(test %{BUILDRECOMMEND0} = 1 -a %{BUILDRECOMMEND0} = 0 && echo 1 || echo 0) | %define COND3 %(test %{BUILDRECOMMEND0} = 1 -a %{BUILDRECOMMEND0} = 1 && echo 1 || echo 0) These %{COND.} are mutually exclusive so you can apply them on the subpackages as shown above. (Extending the example above to 3 buildrecommends should be trivial; but 10 or more could be become a problem ;) ) Thanks Enrico | http://www.redhat.com/archives/rpm-list/2001-June/msg00201.html | CC-MAIN-2014-42 | refinedweb | 659 | 54.42 |
When the anomaly detection features of machine learning are enabled, you can create machine learning jobs to detect and inspect memory usage and network traffic anomalies for hosts and Kubernetes pods.
You can model system memory usage, along with inbound and outbound network traffic across hosts or pods. You can detect unusual increases in memory usage, and unusually high inbound or outbound traffic across hosts or pods.
Create a machine learning job to detect anomalous memory usage and network traffic automatically.
Once the machine learning jobs are created, these settings can not be changed. You can recreate these jobs later. However, any previously detected anomalies are removed.
- In the side navigation, click Observability > Metrics > Anomaly detection.
- You’ll be prompted to create a machine learning job for Hosts or Kubernetes Pods.
Choose a start date for the machine learning analysis.
Machine learning jobs analyze the last four weeks of data and continue to run indefinitely.
Select a partition field.
By default, the Kubernetes partition field
kubernetes.namespaceis selected.
Partitions allow you to create independent models for different groups of data that share similar behavior. For example, you may want to build separate models for machine type, or cloud availability zone, so that anomalies are not weighted equally across groups.
- Click Enable Jobs.
- You’re now ready to explore your metric anomalies. Click View anomalies to view the Anomaly Explorer in Machine Learning.
These pre-defined anomaly detection jobs use custom rules. To update the rules in the Anomaly Explorer, select actions > Configure rules. The changes only take effect for new results. If you want to apply the changes to existing results, clone and rerun the job.
On the Inventory page, click Show history to view the metric values within the selected time frame. Detected anomalies with an anomaly score equal to 50, or higher, are highlighted in red. To examine the detected anomalies, use the Anomaly Explorer.
| https://www.elastic.co/guide/en/observability/7.10/inspect-metric-anomalies.html | CC-MAIN-2021-17 | refinedweb | 317 | 50.33 |
We are given two strings, let's say str1 and str2 containing characters and the task is to calculate the common subsequences in both the strings. In the below program we are using dynamic programming and for that we need to know what dynamic programming is and at what problems it can be used.
Dynamic programming approach is similar to divide and conquer in breaking down the problem into smaller and yet smaller possible sub-problems. But unlike, divide and conquer, these subproblems are not solved independently. Rather, results of these smaller subproblems are remembered and used for similar or overlapping sub-problems.
Dynamic programming is used where we have problems, which can be divided into similar subproblems, so that their results can be reused. Mostly, these algorithms are used for optimization. Before solving the in-hand sub-problem, dynamic algorithms will try to examine the results of the previously solved sub-problems. The solutions of sub-problems are combined in order to achieve the best solution.
So we can say that −
Input − string str1 = “abc” String str2 = “ab” Output − count is 3
Explanation − From the given strings common subsequences formed are: {‘a’, ‘b’ , ‘ab’}.
Input − string str1 = “ajblqcpdz” String str2 = “aefcnbtdi” Output − count is 11
Common subsequences are − From the given strings common subsequences formed are: { “a”, “b”, “c”, “d”, “ab”, “bd”, “ad”, “ac”, “cd”, “abd”, “acd” }
Input the two strings let’s say str1 and str2.
Calculate the length of the given string using the length() function that will return an integer value as per the number of characters in a string and store it in len1 for str1 and in len2 for str2.
Create a 2-D array to implement dynamic programming let’s say arr[len1+1][len2+1]
Start loop for i to 0 till i less than len1
Inside loop, start another loop for j to 0 till j less than len2
Inside loop, check IF str1[i-1] = str2[j-1] then set arr[i][j] = 1 + arr[i][j-1] + arr[i-1][j]
Else, then set arr[i][j] = arr[i][j-1] + arr[i-1][j] = arr[i-1][j-1]
Return arr[len1][len2]
Print the result.
#include <iostream> using namespace std; // To count the number of subsequences in the string int countsequences(string str, string str2){ int n1 = str.length(); int n2 = str2.length(); int dp[n1+1][n2+1]; for (int i = 0; i <= n1; i++){ for (int j = 0; j <= n2; j++){ dp[i][j] = 0; } } // for each character of str for (int i = 1; i <= n1; i++){ // for each character in str2 for (int j = 1; j <= n2; j++){ // if character are same in both // the string if (str[i - 1] == str2[j - 1]){ dp[i][j] = 1 + dp[i][j - 1] + dp[i - 1][j]; } else{ dp[i][j] = dp[i][j - 1] + dp[i - 1][j] - dp[i - 1][j - 1]; } } } return dp[n1][n2]; } int main(){ string str = "abcdejkil"; string str2 = "bcdfkaoenlp"; cout <<"count is: "<<countsequences(str, str2) << endl; return 0; }
If we run the above code we will get the following output −
count is: 51 | https://www.tutorialspoint.com/count-common-subsequence-in-two-strings-in-cplusplus | CC-MAIN-2021-25 | refinedweb | 524 | 59.47 |
You need to sign in to do that
Don't have an account?
.
All Answers
"Just saving the SomeApexWrapper class again fixes the issue."
So making no changes to the code, but saving/rebuilding the class fixes the issue?
Thats right.
Have yo had this issue?
I have not, but it sounds either like something you might check with support to see if there's something odd. It might not be JSON related, but just a compile order/related classes issue.
You might try the "Compile All Classes" link on the Apex page - it seems to solve some of the odd issues sometimes.
I did try that. But, I can't do it everytime I make changes in other classes. I am going to log a case with support and see what they have to say..
Hmm, it's working for me either way. If you'd post more precise instructions for getting the error, I could see about fixing it.
Thanks,
I'd just like to say I have been encountering this error as well. It seems to be intermittent. It is happening with a custom class, that I have defined within the same class as the caller. I have tried the fix provided above, and that didn't seem to resolve it either. The line that seems to be causing the issue is when I attempt to parse some JSON received via a webservice call.
Like I said this is intermitent and it could be possible it is due to bad JSON being returned by the webservice. I am attempting to add some logging to track what is returned by the webservice in event of this error so I can see for sure. I don't expect you to be able to do much with just this information, but I just wanted to make a note and say this error is still hanging around. Even if it is based on bad data from the webservice call, the error could be more helpful
Fantastic explanation @aeben. I've been pulling my hair out since last night struggling with the same issue. I am getting JSON from a webservice call. The JSON has an Array which I am deserializing to Apex Type. The funny thing is that it would work for some time and then if I tried the same after say 30 minutes, it would give an error. I didn't realize that if I changed something in the code and tested again, it would work again. Logically explaining the symptoms was quite difficult to say the least. You have done a great job doing this. Thanks.
I have changed the class loading as per the instructions below to preload the wrapper using Type.forName(). The first test went well. Will have to wait for some time to test again to ensure that it works consistently.
@Kenji775, I was encoutering the same error as well and under the same conditions as well. The JSON was returned by a webservice and the error was intermittent. See @aeben's post above to preload the class type. This should help you fix the issue.
I can confirm now that the fix has solved the problem and I am getting consistent results. Thanks @aeben.
@Kenji775, The following lines works for me consistently. If you are using namespaces, make sure you are passing it as the first parameter to Type.forName. Good luck.
Type wrapperType = Type.forName('limeSurveyWebserviceObject');
limeSurveyWebserviceObject limeObject = (limeSurveyWebserviceObject) JSON.deserialize(JSONString, wrapperType);
Thank you! Thank you! Thank you! This was making me nuts. I had code that worked in developer sandboxes but then when I deployed it to production I got this error trying to deserialize JSON in an Account object. This tip seems to work for me.
Does anyone have consistent steps that cause this bug to happen? I.E.
1. change class that jsonparsing class is dependent on
2. change class that is dependent on jsonparsing class
3. run jsonparsing class
I tried the type.forname solution about a week ago but the bug was still intermittently occuring for me. I had to revert the production code to use the non-native parser because it worked when I deployed and then stopped working about 30 minutes later.
Now I can't reproduce the bug on sandbox but I can't deploy it to production either because I have no way to confirm that the bug is gone.
Sorry, no way to consistantly reproduce, but I'm hearing good things about making that wrapper class, then deserialzing to that. I'm gonna give it a shot and see what happens.
That's what I was afraid of. I tried some of these solutions before and they didn't actually fix the issue and since I have no way to make the bug happen I have no way to confirm that it has been fixed.
The error seems to be getting more prevelant and it's causing me more and more headaches. Attempting to create the wrapper class doesn't seem to help either. It seems to be random, but set at compile time. As in, sometimes when you save and reuplaod the class it works, other times it doesn't. Though it seems to be not working more than it is. Also, I'm not sure if it has to do with preloading the class, as putting the offending code in a loop with a try catch doesn't work either. It's maddeing because it tends to work in execute anonymous, but fails when in a class. It's like sometimes the main class doesn't load the custom classes defined within it. This is what my code looks like now.
Also, just for the record, the limeSurveyWebserviceObject class is defined in the same class as the code that is calling it (it's the only code that will use it, so I'm just keeping things clean).
Are you using namespaces? If so, try using a fully qualified name in Type.forName.
Nope, no namespaces.
Also, I'm trying your full solution
JSONParser parser = JSON.createParser('test');
Type wrapperType = Type.forName('limeSurveyWebserviceObject');
limeSurveyWebserviceObject aw = (limeSurveyWebserviceObject) parser.reasValueAs(wrapperType);
But getting the error
Save error: Method does not exist or incorrect signature: [JSONParser].reasValueAs(Type) scheduler.cls /FPI Sandbox/src/classes line 197 Force.com save problem
I am thinking I am maybe just not quite understanding how to use your solution. I have one main class that contains both the method that is erroring and the definiton for the type of object I am trying to deserialize to. The main class is called 'scheduler'. The method that is erroring is called 'scheduleContact' and of course the object type is called 'limeSurveyWebserviceObject'. Also, the method is a global static, that is @remoteAction annotated.
Wait, I might have got it. I'll post back in after my deploy.
That's a compile error. There's a typo in solution... it should be "readValueAs"
Nope, still epic fail. This is the current parsing setup
This is the JSON it is attempting to parse
Is it possible that the mapping to the fields is case sensitive? Meaning it can't map the JSON field "SURVEY" to the class field named "survey"? I know Apex is case insensitive, but perhaps the underlying reflection stuff that deals with the mapping of JSON fields to class fields is case sensitive? Just a wild guess.
good point @TLF. its worth a try.
Giving it a go now. Let ya know how it goes.
Nope, still no good. **bleep** this bug!
Sorry for the delay, this took us a great deal of effort to track down internally. The type token (foo.class or type.forname('foo')) is the first time apex has anything remotely looking like reflection, and there was an assertion being violated in our type caching algorithm under a certain set of conditions (e.g. inheritance or inner classes) which only manifested under a certain condition that was very difficult to reproduce consistently. Nasty one.
The bugfix should be rolled out in the next few days.
I hardly know what any of that means, but I saw the words 'fixed' and 'next few days' which means I love you XD Thank you so much, (both you and your team) for tracking this down and finding what will hopefully be a fix.
I've been running into the same issue deserializing the standard CampaignMember object. Do you think the fix will resolve that issue as well?
Also, did you know that deserializaiton fails for sObjects that contain custom date fields? (can't deserialize date format YYYY-MM-DD)
Dan
I'm REALLY curious because I spent quite a bit of time trying to reproduce this consistently (unsuccesfully). What was the certain condition?
Can you provide specific code samples that fail for you? I'll check into it.
It would be impossible to reproduce it consistently, as it has to do with the order things are evicted from the cache we use for apex class definitions. It's a two-level cache and the semantics are pretty complicated.
Here's some deserialization test code that fails - but not on every org!
Create a custom 'Date' field TestDateField on the CampaignMember object. Then run the following test class.
@istest
public class serializationtest
{
public static testmethod void testserialization()
{
Lead ld = new Lead(company='comp',lastname='last');
Campaign camp = new Campaign(Name='camp',IsActive=true);
insert ld;
insert camp;
CampaignMember cm = new CampaignMember(LeadID = ld.id, CampaignID = camp.id, Status='Responded');
cm.TestDateField__c = Date.Today();
insert cm;
String ser = json.serialize(cm);
System.debug(ser);
CampaignMember cmrestored = (CampaignMember)json.deserialize(ser, CampaignMember.class);
}
}
The exception you get is: System.JSONException: Cannot deserialize instance of date from VALUE_STRING value 2011-11-30 at [Source: java.io.StringReader@215a9da7; line: 1, column: 263]
It's case 06644992 on the partner portal (just opened yesterday before I found this thread). The support rep told me that it worked if you changed Date.Today() to DateTime.Now().Date() - and it did, on his org. But it still failed on mine - which he found quite surprising. I have two orgs that I know of where it fails.
There is a workaround - use regular expressions to replace the date string in the serialized data with the numeric Unix timestamp and it works.The problem does not occur with serialized APEX classes. I haven't tried it with SObjects other than CampaignMember.
Hopefully this is enough information for you to puzzle out the issue.
Enjoy :-)
Dan
Thanks, that reproduces the problem for me. I should be able to get this fix into the upcoming release.
Based on your previous note about the caching, it looks like if you re-save your Apex class with the @remoteAction that is misbehaving, it appears to correct the issue. Not a solution for anyone, I'm sure, but at least you can keep working.
Rich: when you say "upcoming release", is that Spring '12 or (hopefully) before that?
I mean Spring '12. It's checked into the Spring '12 code line now.
So, if Spring '12 is typically around Februrary, this suggests that Apex JSON and/or remoteActions are not production-ready until then?
Recompiling / redeploying an Apex class to clear it from the cache isn't going to be a viable option for production apps.
I share your frustration. We're in a change moratorium for production at the moment, there's nothing I can do.
This particular bug only appears to manifest when dealing with inheritance or inner classes. If you flatten out the class hierarchies that you're deserializing, you should be able to avoid it.
It's alright, at least I know there is a fix being worked on.
Being as I suck at programming in general, could you explain that workaround a little more, or give some sample code to explain what you mean? Do I just take my custom class and put in it's own file?
Thanks Rich - my issue is indeed occuring related to an inner class. I'm going to try to flatten it out and try again.
Did that fix your issue? I had 2 inner classes and I moved them into their own files and I thought I fixed it but the problem is back again.
However, I took out the Type.forName() code. Should that still be required?
I'm just wondering what I need to do to make my code work until Spring.
Thanks for getting an answer on this thread, helped us get our apex correct and functional with very little run around. Definately likes to act up upon remoting.
I removed my inner classes but am still getting the same error.
I'm glad I'm not the only person that's seeing this. I'm trying to deserialize into a instance of a class that contains an array of instances of another class. I'm only using Strings and Integers, and there is no class nesting.
The only difference between the sample code below and my real code is the # of strings and the variable and class names. The rest is pretty much verbatim.
This problem is a blocker for our release of a feature... we were planning on using the JSON API to facilitate communication with a web service.
==== file = "Inner.cls" =======
public class Inner {
public String s1;
public String s2;
public Inner(String s1, String s2) {
this.s1 = s1;
this.s2 = s2;
}
}
==== file = "Outer.cls" =======
public class Outer {
public Integer numResults;
public Inner[] results;
public Outer(Integer numResults, Inner[] results) {
this.numResults = numResults;
this.results = results;
}
public static testmethod void testDeserialize() {
// create JSON which represents
// Outer containing an array of two Inner instances
String jsonToParse = '{"numResults" : 2, "results" : [';
jsonToParse = jsonToParse + '{"s1": "a0550000008Wit0",';
jsonToParse = jsonToParse + '"s2": "something"},';
jsonToParse = jsonToParse + '{"s1": "a0550A0F008Zbd0",';
jsonToParse = jsonToParse + '"s2": "something else"}]}';
Outer response = (Outer) JSON.deserialize(jsonToParse, Outer.class);
}
}
Chris Merrill
Senior Software Engineer
Adconion Media Group
cmerrill@adconion.com
LearnerSF, what's your org id?
Is there a solid work around, or is this bug going to be patched before Spring 12? We change our class structure and it will start working, then it will stop again. Do I need to choose an alternative to deserializing until the Spring 12 release?
Well, until this is fixed you can always use the JSONParser class to read the instance variables instead of deserialize/readValueAs.
I've been wrestling with this the past few days. Some things I've noticed:
It's definitely a challenge for a current project I'm working on, as we are relying on serialization / deserialization to make parameter passing as abstract as possible. I guess parsing is an acceptable fallback, we just didn't factor that into the timing to write, test and deliver the app, and it introduces a lot of baggage.
I'm currently testing one last-ditch idea: if I have a VF page that uses my class as its controller and I somehow ping that VF page on a frequent interval (every 5 minutes), will that keep the class "alive" in the cache?
I am experiencing the exact same issue attempting ot deserialize CampaignMember objects.
I've also noticed that the odds of seeing a failure increase when the code that does the deserialization is invoked from a unit test class that contains multiple tests, and it's run under the Apex test runner.
But the problem is very intermittent.
I do know that when the failure occurs, the type information from CampaignMember.class is not value (displays as aot=null in a debug message).
Unfortunately, I have not been able to come up with sample code that reliably reproduces the error.
Okay, I'm pretty sure I've got a final solution to this, and it will be available in the upcoming major release (Spring '12). In the meantime, it appears to not be an issue in the new bytecode runtime. Not much solace to people developing packages for the appexchange, i know, but if you're running into this issue and you want to flip your org to the new runtime, please contact support.
Hey Rich,
I found this thread while searching for "Don't know the type of the Apex object to deserialize at", and it seems that I am encountering the same problem as the other folks here.
I have nested wrapper classes and I am trying to use JSON.deserialize to put a webservice's response into the classes. (The deserialization is done in a VF controller, for what it's worth.)
I'm getting basically the same behaviour as everyone else is describing - it works 80% of the time, then stops working and throwing the "Don't know the type" exception.
One thing I have not been able to do is resolve the problem by recompiling code. I have observed the following though: when I get the error on my VF page in Chrome, if I change to Firefox and load my VF page it works first time and works if I refresh the page in Chrome. (For the record, I do a bunch of refreshes, saving code, screaming and crying before I switch to Firefox.)
Does this make any sense in the context of the problem you are seeing? Does the request coming from a different browser cause the Apex wrapper classes to be reloaded, whereas repeated sending of the request from one browser does not?
Thanks in advance,
Trevor Ford.
I was doing the deserializing inside of a trigger - so I don't know that Visual Force would have any impact.
The server's behavior is identical in this regard irrespective of browser type. I think you're just seeing a correlation due to chance.
Thanks for confirming that Rich.
I haven't seen the error since the bytecode runtime was switched in our sandbox, thanks a lot for that tip!
Cheers,
Trevor. | https://developer.salesforce.com/forums/?id=906F0000000908DIAQ | CC-MAIN-2021-04 | refinedweb | 2,989 | 65.83 |
Odoo Help
This community is for beginners and experts willing to share their Odoo knowledge. It's not a forum to discuss ideas, but a knowledge base of questions and their answers.
How setting front-end or look and feel administration environmet.
Hello, I installed the server 9, and when I access through localhost: 8069, I see everything messed up as if I had not configured the CSS.
Thank you.
Javierl
Thank you Ermin. I will see it that you has explain. In other hand, when I try enter to the localhost:8069, I receive a message inform me that don't show because the page isn't sure or it haven't got permissions.
Regards.
Javier.
Part of log file.
2016-11-18 13:18:23,528 19808 INFO None werkzeug: 127.0.0.1 - - [18/Nov/2016 13:18:23] "POST /web/database/drop HTTP/1.1" 303 -2016-11-18 13:18:23,828 19808 INFO openerpdemo werkzeug: 127.0.0.1 - - [18/Nov/2016 13:18:23] "GET /web/database/manager HTTP/1.1" 200 -2016-11-18 13:19:06,760 19808 INFO openerpdemo werkzeug: 127.0.0.1 - - [18/Nov/2016 13:19:06] "POST /longpolling/poll HTTP/1.1" 200 -2016-11-18 13:19:06,760 19808 ERROR openerpdemo openerp.service.server: Exception happened during processing of request from ('127.0.0.1', 24044)Traceback (most recent call last):
File "SocketServer.pyc", line 599, in process_request_thread File "SocketServer.pyc", line 334, in finish_request File "SocketServer.pyc", line 657, in __init__ File "SocketServer.pyc", line 716, in finish File "socket.pyc", line 283, in close File "socket.pyc", line 307, in flusherror: [Errno 10053] Se ha anulado una conexión establecida por el software en su equipo.
Keep studying the problem and get to this message, which indicates that you are not loading several sheets of styles, did someone happen to you?
The style sheet was not loaded because its MIME type, "application / x-css", is not "text / css".
Thank you, Javier.
Thank you for your help, but I don't fix this error. I uninstalled the app and install newly but I continue see the same way.
Dear, I can fix the problem. I tell you how.
In python, in the file __init__.py, in my case in the folder C:\Python27\Tools\pynche, I added the follow lines:
import mimetypes
mimetypes.add_type("text/css", ".css", True)
Restart the PC, and the site worked OK.
Thank you for your help.
Javier. | https://www.odoo.com/forum/help-1/question/how-setting-front-end-or-look-and-feel-administration-environmet-110969 | CC-MAIN-2016-50 | refinedweb | 418 | 78.25 |
Introduction
If you have a program which executes from top to bottom, it would not be responsive and feasible to build complex Applications. Thus, .NET framework offers some classes to create complex Applications.
What is threading?
In short, thread is like a virtualized CPU, which helps to develop complex Applications.
Understanding threading
Suppose, you have a computer, which has only one CPU, which is capable of executing only one operation at a time and your Application has a complex operation. Thus, in this situation, your Application will take too much time. This means that the whole machine would freeze and appear unresponsive. Thus, your Application performance will decrease.
Thus, for this purpose, we will be using multithreading in C#.NET. Thus, we will divide our program into the different parts, using threading. You know, every Application runs its own process in Windows. Thus, every process will run in its own thread.
Thread Class
Thread class can be found in System.Threading namespace. Using this class, you can create a new thread and can manage your programs like property, status etc. of your thread.
Example
The following code shows how to create a thread in C#.NET
You may observe this. I create a new Local Variable thread of ThreadStart delegate and pass the loopTask as a parameter to execute it. This loopTask function has a loop. We create a new object myThread from Thread Class and pass Local Variable thread to the Thread Constructor. Start the thread, using myThread.Start(); and Thread.Sleep(2000); will pause the current for 2000 milliseconds.
Finally, the result will be: This code can also be written in a more simple way like:
In the code, given above, we are using lambda expression ( => ) for the initialization.
Passing Value as Parameter
The Thread constructor has another overload, which.
To stop the thread, what we use is Thread.Abort method. This method can be executed by other threads at any time. When Thread.Abort is executed, it throws an exception ThreadAbortException. | https://www.c-sharpcorner.com/blogs/multithreading-in-c-sharp-net | CC-MAIN-2018-13 | refinedweb | 334 | 68.16 |
Opened 5 years ago
Last modified 5 years ago
#17494 new defect
Memory leak for letterplace implementation of free algebras
Description
At #17435, I noticed the following:
sage: L.<x,y,z> = FreeAlgebra(GF(25,'t'), implementation='letterplace') sage: p = x^4+x*y*x*z+2*z^2*x*y sage: for i in range(20): ....: m = get_memory_usage() ....: for j in range(300): ....: z = p^7 ....: print get_memory_usage()-m ....: 2.0 2.0 2.0 2.0 0.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 2.0 0.0 2.0 2.0
This leak even pertains when #16958 is applied.
Change History (4)
comment:1 Changed 5 years ago by
- Report Upstream changed from Not yet reported upstream; Will do shortly. to Reported upstream. Developers acknowledge bug.
comment:2 Changed 5 years ago by
- Report Upstream changed from Reported upstream. Developers acknowledge bug. to Fixed upstream, in a later stable release.
If I understand correctly, the leak is fixed in a later version of singular. Hope it will be in Sage soon...
comment:3 follow-up: ↓ 4 Changed 5 years ago by
comment:4 in reply to: ↑ 3 Changed 5 years ago by
Maybe related:
I think that points to a more basic and hence more severe memory leak.
import gc, collections gc.collect() old=set( id(a) for a in gc.get_objects()) R.<x,y,z>=ZZ[] f=12^2*(x^4+y^4)-15^2*(x^2+y^2)*z^2+350*x^2*y^2+9^2*z^4 pt=[1,2,3] m=get_memory_usage() for i in xrange(10^5): temp=f(x=x+pt[0]*z,y=y+pt[1]*z,z=pt[2]*z) #This also uses a lot of memory. if (i% 100) == 0: print get_memory_usage()-m gc.collect() new=collections.Counter( str(type(a)) for a in gc.get_objects() if id(a) not in old) new
This code clearly shows leaking and it shows the leak is not in python reference counted objects. I would find it hard to believe that such a basic leak in normal polynomial arithmetic would go unnoticed in Singular, so I would expect the error is somewhere in the sage/singular interface.
Here is the corresponding computation in Singular (as shipped with Sage):
So, the leak is in Singular, not in the wrapper. | https://trac.sagemath.org/ticket/17494 | CC-MAIN-2020-16 | refinedweb | 404 | 65.62 |
PCs come with an amazingly powerful device: a graphics processing
unit (GPU). It is mostly underutilized, often doing little more than
rendering a desktop to the user. But computing on the GPU is
refreshingly fast compared to conventional CPU processing whenever
significant portions of your program can be run in parallel. The
applications are seemingly endless including: matrix computations,
signal transformations, random number generation, molecular modeling,
and password recovery. Why are GPUs are so effective? They have
hundreds, in some cases thousands, of cores available for parallel
processing. Compare this to the typical one to four CPU cores on
today's PCs. (For a more technical treatment see:
graphics.stanford.edu/~mhouston/public_talks/cs448-gpgpu.pdf
Here I present a way to use the power of NVidia's Cuda-enabled
GPUs for computing using Java with an Eclipse-based IDE. My platform
is Debian Wheezy (64 and 32 bit), but I have also reproduced the
process on Linux Mint 13, and it can be done on many other Linux
distributions. The approach can be adapted to a Windows install, a
process that is well documented elsewhere.
This is a September 2013 update of the original article. Since
writing this article, there are many new developments particularly in
regard to the process for installing the NVidia Development driver on
Linux. As distros evolve, it has become increasingly difficult to
disable the Nouveau driver, a requirement for installing the NVidia
driver. Also, occasionally the compiler (gcc) that ships with the
distro differs from the compiler used to compile the OS's kernel
itself. Finally, Linux systems using the NVidia Optimus technology
require additional gymnastics to configure the driver.
Easily accessing the power of the GPU for general purpose
computing requires a GPU programming utility that exposes a set of
high-level methods and does all of the granular, hardware-level work
for us. The popular choices are OpenGl and Cuda. Cuda works only with
NVidia GPUs. I prefer NVidia devices and this article presents a Cuda
solution.
Eclipse is my favorite IDE for programming in Java, C++, and PHP.
NVidia provides an Eclipse-based IDE called Nsight, which is
pre-configured for Cuda C++ development. Other features, like Java,
PHP, etc., can be added to your Nsight installation from compatible
Eclipse software repositories (e.g. Nsight 5.5 is compatible with the
Eclipse Juno repository).
Direct programming with Cuda requires using unmanaged C++ code. I
prefer programming with managed code. To do this I use a method for
wrapping the C++ functionality of Cuda in bindings that are
accessible to Java. In the past, on a Windows 7 platform, I wrote my own wrappers for use with C#.net code (see my CodeProject Article). With Java, this
is not necessary because open source wrappers are available. I use
JCuda.
There are four basic elements presented here:
Sometimes tutorials present steps that the writer followed on an
existing production machine that already had certain prerequisite
configurations in place. Consequently, when a reader follows the
steps, the procedure may fail. To avoid this, I tested the process
described below from fresh installs of Mint 13_64 bit, Linux Mint
13_32 bit, Debian Wheezy x32, and Debian Wheezy x64. For Mint, I
chose the Mate flavor in both cases. Here are the details of my
demonstration machines:
Stable, Long Term Service releases for distributions were
explicitly chosen for this project. Interim, releases frequently
change certain basic hardware configurations and filesystem
arrangements. After reviewing and contributing to several hundred
Linux forum posts, I am certain that you will experience fewer
headaches if you do the same.
On Linux systems there are configuration complications with
systems that use the NVidia Optimus technology. Simply stated, GPU
tasks that do not require the high-performance of the NVidia GPU are
delegated to a lower-performance, lower-power consumption GPU,
typically Intel devices. This process is currently not well
implemented on Linux machines. But, it can be made to work! If you
are lucky, your machine has a BIOs setting for disabling Optimus
integration, but many PC manufacturers do not bother to provide this
option. Enter Bumblebee, a program that allows you to specify the GPU
to use for a given application. Because I have not constructed a test
on an Optimus system, details for Optimus-enabled GPUs are not
provided here and you will have to research the Bumblebee gymnastics
independently. Later, when you configure eclipse for JCuda, my
understanding is that Eclipse (and Nsight) can be run with optirun
eclipse and the proper GPU will
be used for debugging your programs. Here are some promising resources:
(post # 7) and
Computationally intensive applications, e.g. Fourier
transforms, whether they are done on the CPU or the GPU, will give
your system a stress test. Start small and monitor system
temperatures when you have high computational overhead.
NVidia has an exhaustive list of Cuda-compatible GPUs on their
Developer Zone web site:. Check
to see if yours is listed. Also, determine whether your machine uses
the NVidia Optimus technology and, if it does, see the note above.
There are some prerequisites. From a terminal, run the following
commands to get them:
Download the latest Cuda release from:. (Note: The NVidia site
only shows Ubuntu releases for Debian forks like Mint. The Cuda
releases for Ubuntu work well with Mint LTS 13 and Debian Wheezy.)
Select the proper 32/64 choice and prefer the .run file over the .deb
file. My most recent download was cuda_5.5.22_linux_32.run (or
cuda_5.5.22_linux_64.run).Split the installer into its three
component installer scripts: toolkit, driver, and samples. This
fine-grained control is a great benefit if/when troubles occur. Here
is the syntax for splitting the installer.sh
cuda_5.5.22_linux_32.run -extract=<theCompletePathToYourDestination>
or
sh cuda_5.5.22_linux_64.run
-extract=<theCompletePathToYourDestination>
The following three files are
created:
We start by installing the NVidia developer driver. This step
creates the most trouble for Linux users because it varies
substantially from distro to distro. Before you do anything; print
this page, save your work, and be sure you are backed-up.
You cannot have an X server running when you install the developer
drivers. Do a preliminary test to make sure you can drop to a console
and stop your X server. Simultaneously press [ctrl][alt][f2]. If you
are lucky your desktop shows a console prompting you to login. If so,
login and stop the display manager:
You should now see the console. If you see a blank screen, do
[ctrl]+[alt]+[f2] again. Now you can either run sudo reboot or
startx to return to your desktop. If this test fails, then you
should install your package manager's NVidia non-free driver, then
try it again... even though in a subsequent step we will be removing
it.
Debian and it's siblings use a default driver called nouveau,
a wonderful, open-source solution for NVidia GPU's that is totally
incompatible with NVidia Cuda development. It must be disabled at
boot time. One way is to modify grub:
gksu gedit /etc/default/grub
Find the line that reads: “GRUB_CMDLINE_LINUX_DEFAULT=...” and
make it read:
GRUB_CMDLINE_LINUX_DEFAULT="quiet nouveau.modeset=0"
Save the file, close gedit, and run:
sudo update-grub
sudo reboot
Next, edit your blacklist configuration file (gksu gedit
/etc/modprobe.d/blacklist.conf) and add these lines to the end:
Then, remove everything
NVidia from the system with:
sudo apt-get remove --purge NVidia*
Drop to a console ([ctrl][alt][f2]), exit the X server (e.g. sudo
service mdm stop), and run the installer:
sudo
sh NVIDIA-Linux-x86-319.37.run (or sudo sh
NVIDIA-Linux-x64-319.37.run)
Your installer may fail. The most common errors are that a display
manager is in use or that there is a conflict (with nouveau).
Retracing the steps above will remedy these problems. But, sometimes
an error will occur if the distro's kernel was compiled with an
earlier version of gcc. (You'll see something like: The compiler
used to compile the kernel (gcc 4.6) does not exactly match the
current compiler (gcc 4.7).) Occasionally selecting to ignore
this will work, but again, don't count on it. You need to install the
gcc version used to compile the kernel (e.g. 4.6 in the example
above). Do this using your preferred package manager. Next, because
your machine now has two gcc versions, we need to create
alternatives. Using the example of gcc 4.6 and gcc 4.7 we run:
sudo update-alternatives --install /usr/bin/gcc gcc
/usr/bin/gcc-4.6 10sudo update-alternatives --install
/usr/bin/gcc gcc /usr/bin/gcc-4.7 20Now, when you run:sudo
update-alternatives --config gcc
You can pick gcc 4.6 as the active version. Later, after
the install, you can switch it back.
Whew! Now it gets easier. Next, we install the toolkit with:
sudo sh
cuda-linux-rel-5.5.22-16488124.run (or sudo sh
cuda-linux64-rel-5.5.22-16488124.run)
(If you see a gcc version error, see Your installer may fail
under Install the Developer Driver above.)
Your toolkit install console will present the following text when
it is complete:
* Please make sure your PATH includes
/usr/local/cuda-5.5/bin* Please make sure your LD_LIBRARY_PATH*
for 32-bit Linux distributions includes /usr/local/cuda-5.5/lib*
for 64-bit Linux distributions includes
/usr/local/cuda-5.5/lib64:/usr/local/cuda-5.5/lib* OR* for
32-bit Linux distributions add /usr/local/cuda-5.5/lib* for
64-bit Linux distributions add /usr/local/cuda-5.5/lib64 and
/usr/local/cuda-5.5/lib* to /etc/ld.so.conf and run
ldconfig as root
Set your additional paths persistently by editing (creating if
necessary) the .profile file in your home directory. Add
PATH=$PATH:/usr/local/cuda-5.5/bin to the end of the file,
save, then logout and login.
Use a persistent, modular approach for managing your
LD_LIBRARY_PATH. I never edit the /etc/ld.so.conf file.
Rather, my ld.so.conf file contains the line: include
/etc/ld.so.conf.d/*.conf. I create a new file in the
/etc/ld.so.conf.d folder named cuda.conf that has the
following line(s):
Then run sudo ldconfig.
Install the samples by running your third, split-out installer
script:
sudo sh cuda-samples-linux-5.5.22-16488124.run
Now let's run a test. From a terminal, change to the folder where
the deviceQuery sample is located (default is
/usr/local/cuda-5.5/samples/1_Utilities/deviceQuery). Make the
sample with the system compiler:
sudo make
(If you see a gcc version error when you run sudo make, see Your
installer may fail under Install the Developer Driver above.)
Then, run the sample with:
./deviceQuery
I see the following on my 64 bit test system:
/usr/local/cuda-5.5/samples/1_Utilities/deviceQuery $
./deviceQuery ./deviceQuery Starting...Cuda
Device Query (Runtime API) version (CudaRT static linking)Detected
1 Cuda Capable device(s)Device 0: "GeForce GTX 560
Ti"etc., etc., ...Runtime
Version = 5.5, NumDevs = 1, Device0 = GeForce GTX 560 T
Nsight is a fork of Eclipse that is pre-configured for C++ and
Cuda. It is included in your toolkit install (you already have it).
For now, run it from a terminal:
/usr/local/cuda-5.5/libnsight/nsight. (Do not double-click the
file from your file manager.) Later you can make a desktop launcher.
Go ahead and choose the default folder for projects that it
recommends.Let's test it.
My output in the console window is:
[Cuda Bandwidth Test] - Starting...Running on..Device
0:GeForce GTX 560 Ti.etc., ...
Nsight can be expanded through Help>Install New Software.
To add Java development, you need to add to your Available
Software Sites. (Note: the Kepler repository does not work as of
Nsight 5.5) Then, install Eclipse Java Development Tools.
Follow the install dialog and restart Nsight.
Download the zip for your platform from.
Extract it to a folder in your home directory. Then start Nsight.
Create a new Java Project (File > New > Java Project)
and name it JCudaHello. Right-click the JCudaHello
project in the project explorer and select Properties. Go to
the Java Build Path tree item and select the Libraries
tab. Click Add External Jars, navigate to the extracted folder
you created, and pick jCuda-0.5.5.jar.
With the Libraries tab still open, expand the tree for the
jCuda-0.5.5.jar you
added and click on Native library location (none). Then click
the Edit button. You will be asked for a location. Click
External Folder and again navigate to the extracted folder.
Click OK.
Now, right-click your src folder in the jcudaHello project from
the Project Explorer and select New > Class. Name the
class cudaTest and select the public static void main
method stub:
Click Finish. Delete the code that is pre-generated in cudaTest.java
from the editor pane and paste this in:
import jcuda.Pointer;
import jcuda.runtime.JCuda;
public class test {
public static
void main(String[] args) {
Pointer pointer = new Pointer();
JCuda.cudaMalloc(pointer, 4);
System.out.println("Pointer: " + pointer);
JCuda.cudaFree(pointer);
}
}
When you run it, you should see something like this:
Pointer: Pointer[nativePointer=0x800100000,byteOffset=0]
The project code is a zipped Eclipse workspace that does not
include any hidden meta-data folders or information files. When you
unzip it to your location of choice, you will see two
sub-directories: JCudaFftDemo and Notes.
First, we need to create an Nsight Java project from the existing
sources in the JCudaFftDemo folder. Start Nsight and choose
your extracted directory (parent directory for JCudaFftDemo) when it
asks you to select a workspace. Create a new Java Project from the
File menu and give it the exact name: JCudaFftDemo. Then,
click Finish. If you expand the trees for the project in the
Project Explorer you should see:
Next, you need to add the JCuda binaries to the Java Build Path.
Right-click the JCudaFftDemo project in the Project Explorer
and select Properties. Go to the Java Build Path tree
item and select the Libraries tab. Click Add External Jars,
navigate to the JCuda binaries you downloaded in Setup – Step 7,
and pick jCuda-0.5.5.jar,
jcublas-0.5.5.jar, and jcufft-0.5.5.jar.
With the Libraries tab still open, one at a time,
expand the trees for the jars you added and click on Native
library location (none). Click the Edit button and set the
location to match your JCuda binaries directory. (We are repeating
Step 7 in the above Setup section, this time for the new
project.)
Then, run it as a Java application. Here is the output console from
my Linux Mint 13, 32 bit laptop:
Creating sin wave input data: Frequency = 11.0, N = 1048576, dt =
5.0E-5 ... L2 Norm of original signal: 724.10583
Performing a 1D C2C FFT on GPU with JCufft... GPU FFT time:
0.121 seconds Performing a 1D C2C FFT on CPU...
CPU time: 3.698 seconds GPU FFT L2 Norm: 741484.3
CPU FFT L2 Norm: 741484.4 Index at maximum in GPU power
spectrum = 572, frequency = 10.910034 Index at maximum in CPU
power spectrum = 572, frequency = 10.910034
Performing 1D C2C IFFT(FFT) on GPU with JCufft... GPU time:
0.231 seconds Performing 1D C2C IFFT(FFT) on CPU...
CPU time: 3.992 seconds GPU FFT L2 Norm: 724.1056
CPU FFT L2 Norm: 724.10583
First, a word about complex data arrays; CUDA and JCuda can work
with data arrays that contain complex vectors of type float or double,
provided you construct the array as an interleaved, complex number
sequence. This is best demonstrated with an example. Let’s say we have
a complex vector of length 2: (1 + 2i, 3 + 4i). The corresponding
interleaved data array has a length of 4 and has the form: (1, 2, 3,
4). In the project code I use this format for all complex vectors that
are submitted to JCuda methods.
In contrast, for CPU coding simplicity, I use a ComplexFloat class
to represent complex numbers. When using this class to from a complex
vector, the vector x = (1 + 2i, 3 + 4i) has the form ComplexFloat[2] =
(x[0].Real = 1, x[0].Imaginary = 2, x[1].Real = 3, x[1].Imaginary =
4). The array, and the vector it represents, both have the same
length: 2.
ComplexFloat
Main.java is the entry point for the application. It creates a
sample signal and performs the demo. The signal produced is:
sin(2*pi*FREQ *t) sampled N times in increments of dT. The demo
computes forward and inverse Fourier transforms of the test signal
— both on the GPU and the CPU — and provides execution
times and signal characteristics for the results.
The CPU FFT part of the code (FftCpuFloat.java) purposely implements
the Cooley–Tukey algorithm in an awkward way that depends on instances
of the ComplexFloat.java class. Little attention is paid to memory
allocation and access. Also, although I have multi-core CPUs, my CPU
thread executes on only one core. Doing this makes the radix-2
procedure intuitive and simple, but there is an overhead cost that
will overstate the advantage of using the GPU.
You can adjust the constants (FREQ, N, and dT) for creating the test
signal from the Main.java class. Using a Linux 32 bit
installation on an older Dell laptop I found that, by varying the
length of the test signal (N), the CPU FFT outperformed the JCuda FFT
with signals that had fewer than 4096 complex elements. Thereafter,
the JCuda FFT speeds overwhelmed my CPU FFT. At N = 4194304, JCuda was
250 times faster than the CPU FFT (CPU = 23 seconds, GPU = 0.9
seconds). Beyond that, the laptop fans blaze during the CPU
computation loop (system temp: 90 C) and fear of thermal overload
prompted me to curtail testing. (My Linux 64 bit desktop, has a 6 core
AMD Phenom II on a Sabretooth mombo, 16 GiB of memory, a GeForce GTX
560 Ti graphics card, and some great fans. It can process FFTs (CPU or
GPU) all night provided I manage memory effectively.)
A fair amount of the speed advantage I observe is due to the
inefficiency of my poorly optimized CPU implementation. More rigorous
CPU/GPU evaluations using optimized CPU code suggest that gains are
roughly 10X. I'll take 10X over 1X, but the practical reality is; the
the power of CUDA's underlying implementation efficiency together with
the intrinsic GPU gain (whatever it really is), collectively gives me
an average 50X boost.
The Notes folder in the project download includes some tips on
how to run a deployed, runnable jar. Basically, you need to use the -Djava.libraries.path
switch to point to your JCuda binaries folder.
Getting setup and becoming acquainted with CUDA, JCuda, and Nsight
takes a fair amount of work. But it's worth it. General-purpose
computing on graphics processing units (GPGPU) is a very important
tool to have in your coding toolbox. I hope this article helps make
the process more accessible to other GPGPU novices like me. I wish you
success as a cutting-edge JCuda c. | https://www.codeproject.com/Articles/513265/GPU-Computing-Using-CUDA-Eclipse-and-Java-with-JCu?msg=5305501 | CC-MAIN-2020-29 | refinedweb | 3,236 | 58.89 |
mold for clay fruit from Japan
Mold for Clay Fruit
pink plastic mold for soft clay for making clay fruit
for strawberries, its stems and leaves (3 sizes), banana, watermelon and orange
by Padico
import from Japan
content: 1 mold with 12 shapes
size of the big strawberry: 2.3cm (0.9")
size of the mold: 9.4cm (W) x 7.4cm (H) x 1.3cm (D) (3.7"x 2.9"x0.5")
Use mold oil, Vaseline or Baby Lotion to grease the molds if you are using clay that tends to stick or has a stickier than usual texture
Dried clay can be lifted out of the mold with another piece of clay if necessary
very good quality
super cute design
perfect as a present or to make your miniature pastry etc. yourself
| http://www.modes4u.com/en/kawaii/p9274_mold-for-clay-fruit-from-Japan.html | CC-MAIN-2013-20 | refinedweb | 135 | 75.74 |
SwiftIO and MadBoard (id)
In the tutorial before, you try your first project. Maybe you noticed that the code begins with the two following statements. Actually, they are necessary for all of your projects later. Why? Let's find it out.
import SwiftIO
import MadBoard
As mentioned before, a pin can be used for different functionalities. And multiple pins can all support the same functionality. So at the beginning of your code, you need to tell the usage of the specified pin.
let led = DigitalOut(Id.D0)
SwiftIO
SwiftIO is in charge of all the basic hardware functionalities. With it, you don’t need to handle complicated low-level stuff. You will invoke related APIs that allow you to deal with different signals and communication protocols. You will learn more details in next section.
MadBoard (id)
After choosing the functionality provided by the
SwiftIO, you need to specify the pin. Or else the board doesn't know which pin you want🤔. The pins are distinguished by their ids. Each id consists of a prefix for its functionality (D for digital, A for analog...) and a number (from 0). They are all stored in
MadBoard.
The pinout below tells you the functionalities each pin supports. For example, P0 (pin 0) to P35 can all be served as digital pins, so the ids are D0 to D35. Besides, some of them can be analog pins (A0 to A13).
- The ids with the same prefix share the same functionality. So whether the pin D0 or D21 is used, their usage is the same.
- The ids with the same numbers refer to the same pin. So you cannot use A0 and D0 at the same time. | https://docs.madmachine.io/tutorials/swiftio-circuit-playgrounds/preparation/swiftio-madboard | CC-MAIN-2022-21 | refinedweb | 282 | 77.23 |
It all started because I had developed a PHP/MySQL application that worked in isolation. Then a requirement to submit data from an InfoPath form arose.
In all my searching on the internet, I couldn't for the life of me find anyone who had documented the process of developing a web service in PHP that could talk
to InfoPath - everyone seems to use ASP or C#. I tried using NuSOAP, however the documentation
was pretty light on, and I could only really get it to work with RPC encoding.
The problem is that InfoPath requires WSDL XML in Document/Literal.... and my knowledge of namespaces and schemas was terrible!
Enter this project...
This is very basic, and really only covers the Request/Response methods of WSDL. It assumes you already know how to code in PHP and create forms in InfoPath.
Note: Ensure that the PHP_SOAP extension is active in your PHP installation.
This is designed to be very easy to implement and very manageable for upgrades. There are two files that are of interest:
wsdl.php is the script that will generate the WSDL XML for you. This is the file that you aim your SOAP client (InfoPath in this example) towards.
soap-service.php is the SOAP server. It can be called whatever you want, provided it is linked correctly in the
wsdl.php function declaration.
Edit wsdl.php and replace the area below the comments. What we are doing here is naming our Web Service, and defining what functions we want available
for the Web Service. Our function is a simple survey to ask a user their name, their favourite colour, and their favourite number. The SOAP Server will save
these results to a plain text file. We are calling this function ChooseColour:
ChooseColour
$serviceName = "My Example Web Service Access Point";
$functions[] = array(
"funcName" => "ChooseColour",
"doc" => "Send a favourite colour and number to a text file.",
"inputParams" => array(array("name" => "Name", "type" => "string"),
array("name" => "FavColour", "type" => "string"),
array("name" => "FavNumber", "type" => "int")),
"outputParams" => array(array("name" => "Success", "type" => "boolean")),
"soapAddress" => ""
);
Hopefully it's pretty obvious, however:
serviceName
$functions
funcName
doc
inputParams
outputParams
soapAddress
There can be as many functions declared in this array as required. All functions are declared in the same manner.
That is all you need to do. You now have a functional WSDL generator!
Now! Let's test it out to make sure it's all working... Place the wsdl.php file on your web server, and point your browser to it. You should see the page listing
the name of your Web Service that you declared, and a list of all your functions that you declared. At the bottom in the grey box is the raw XML WSDL output that
the SOAP client will see. An example of this output is shown at the top of this article.
Speaking of SOAP clients: For them to get the XML WSDL output, you need to append "?WSDL" (without the quotes) to the end of the URL, otherwise they
will get the page you just saw. Below is what they will receive if you append "?WSDL":
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<wsdl:definitions
xmlns:soap=""
xmlns:wsdl=""
xmlns:s=""
targetNamespace=""
xmlns:
<wsdl:types>
<s:schema
<s:element
<s:complexType><s:sequence>
<s:element
<s:element
:documentation>Send a favourite colour and number to a text file.</wsdl:documentation>
</wsdl:operation>
</wsdl:binding>
<wsdl:service
<wsdl:port
<soap:address
</wsdl:port>
</wsdl:service>
</wsdl:definitions>
So, let's test it out in a SOAP client (InfoPath Designer). Fire up InfoPath Designer and create a Data Connection to it. Create a Blank Form, then click on the Data tab in the ribbon, then Data Connections. Then click Add, then Create a new connection to submit data and press Next. Then select To a Web Service and press Next. Now enter the URL to your
wsdl.php file... something along the lines of. Add "?WSDL" to the end of it to get the raw XML output (). InfoPath will add that for you anyway if you forget. Press Next to access the Web Service!
If everything worked, you should now see a list of your functions that you declared. Selecting a function and pressing next will then give you access to a list of all
of your input parameters and their data types. You can now select each of these parameters and choose a data field from your form that will bind to this.
OK, so we know our connection is available - let's build the form to test it.
From the Home ribbon, drag three TextBoxes (from the Controls section) on to your blank form. Then, drag a button onto your form. Right click on the third textbox, and click TextBox Properties. Select Whole Number (Integer) from the Data Type box. Select the Data Connection following the steps as per in Step 2, except now you can assign the data source fields to the fields you just created. Select the "tns:Name" parameter, then select the radio button "Field or Group". Then press the button to the right of the text box that looks like a series of nodes on a tree. Choose
field1 from myFields.
tns:Name
field1
myFields
Now select "tns:FavColour" and choose field2 for this.
tns:FavColour
Finally select "tns:FavNumber" and choose field3 - this is the field we specified as an integer. You will get a validation error upon submitting the form if you have a data type mismatch between the form's fields and the data connection's fields.
tns:FavNumber
Now press Next, and ensure "Set as the default submit connection" is ticked, and press Finish. Right click on the button, and click Button Properties. Click the Action box, and select Submit, then press OK. Now activate Full Trust on the form to allow this to run on the local machine: File -> Form Options -> Security and Trust -> Full Trust.
Finished! Feel free to pretty it up if you want.
Now edit our soap-service.php file to implement our ChooseColour() function that we want to call to create our survey results file:
ChooseColour()
<?php
ini_set("soap.wsdl_cache_enabled", "0"); // disabling WSDL cache
$server = new SoapServer(""); // WSDL file for function definitions
$server->addFunction("ChooseColour"); // Same func name as in our WSDL XML, and below
$server->handle();
function ChooseColour($formdata) {
$attempt = false; // File writing attempt successful or not
$formdata = get_object_vars($formdata); // Pull parameters from SOAP connection
// Sort out the parameters and grab their data
$myname = $formdata['Name'];
$mycolour = $formdata['FavColour'];
$mynumber = $formdata['FavNumber'];
$str = "Name: " . $myname . ", ";
$str .= "Colour: " . $mycolour . ", ";
$str .= "Number: " . $mynumber . "\r\n";
$filename = "./formdata.txt";
if (($fp = fopen($filename, "a")) == false) return array('Success' => false);
if (fwrite($fp, $str)) {
$attempt = true;
}
fclose($fp);
return array('Success' => $attempt);
}
?>
The parameters are automatically sorted from the XML by the SoapServer class' handle function! All we need to do is remember what the name of the parameters were. Easy!
SoapServer
And there you have it! You can now run your InfoPath form and communicate with your PHP projects!
Go back in to InfoPath Designer, and on the Home ribbon, press Preview. This will launch the form. Now enter your name in the first field, your favourite colour in the second field, and your favourite number in the last. Finally press Submit. The form will then close. Now navigate to the location of your folder, and there should be a formdata.txt file there with the information you just entered!
Hopefully I helped someone, as I nearly went postal trying to get this to work. The specific combination of technologies I needed to use hadn't been widely used/documented on the internet, so this is my contribution. Thanks for reading and good luck!
Source files converted to UTF-8 encoding, and addition of line below as suggested by W. Kleinschmit (thanks!):
header("Content-Type: application/soap+xml; charset=utf-8");
Initial article.
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
$results = array();
for ($i=0;$i<3;$i++) {
$results["Success" . $i] = $attempt . $i;
}
return $results;
$functions[] = array(
"funcName" => "ChooseColour",
"doc" => "Send a favourite colour and number to a text file",
"inputParams" => array(
array("name" => "Name", "type" => "string"),
array("name" => "FavColour", "type" => "string"),
array("name" => "FavNumber", "type" => "int")
),
"outputParams" => array(
array("name"=>"Success0","type"=>"string"),
array("name"=>"Success1","type"=>"string"),
array("name"=>"Success2","type"=>"string")
),
"soapAddress" => ""
);
$resultarr = array();
foreach ($myresults as $value) {
//<...Perform any work that needs to be done to the value,
// otherwise skip this foreach loop as you already have
// an array ready to implode ($myresults)...>
$resultarr[] = $value;
}
$delim = "-#|#-";
return implode($delim, $resultarr);
Error: Invalid XML: <?xml version="1.0" encoding="UTF-8"?>
<SOAP-ENV:Envelope xmlns:<SOAP-ENV:Body><ns1:ChooseColourResponse><ns1:Success>true</ns1:Success></ns1:ChooseColourResponse></SOAP-ENV:Body></SOAP-ENV:Envelop
General News Suggestion Question Bug Answer Joke Praise Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages. | https://www.codeproject.com/Articles/535009/PHP-Web-Service-WSDL-Generator-SOAP-Server-Documen?PageFlow=FixedWidth | CC-MAIN-2017-26 | refinedweb | 1,507 | 56.35 |
Are you sure?
This action might not be possible to undo. Are you sure you want to continue?
6109-1(d)(3)(ii) of the Procedure and Administration Regulations Notice 2004-1 SECTION 1. PURPOSE This notice addresses the requirements of section 301.6109-1(d)(3)(ii) of the regulations on Procedure and Administration, relating to applications for Individual Taxpayer Identification Numbers (ITINs). The Service has changed its ITIN application process. This notice confirms that taxpayers who comply with the new ITIN application process will be deemed to have satisfied the requirements in section 301.61091(d)(3)(ii) relating to the time for applying for an ITIN. This notice also solicits public comments regarding the changes to the ITIN application process. SECTION 2. BACKGROUND Section 6109(a)(1) generally provides that a person must furnish a taxpayer identifying number (TIN) on any return, statement, or other document required to be made under the Internal Revenue Code (Code). For taxpayers eligible to obtain a social security number (SSN), the SSN is the taxpayer’s TIN. See section 6109(d); section 301.6109-1(d)(4). Taxpayers who are required under the Code to furnish a TIN, but who are not eligible for a SSN, must obtain an ITIN from the Service. See Section 301.6109-1(d)(3)(ii). A taxpayer must apply for an ITIN on Form W-7, Application for the IRS Individual Taxpayer Identification Number.. SECTION 3. FORM W-7 AND ACCOMPANYING INSTRUCTIONS The Service has revised Form W-7 and the accompanying instructions. In general, a taxpayer who must obtain an ITIN from the Service is required to attach the taxpayer’s original, completed tax return for which the ITIN is needed, such as a Form 1040, to the Form W-7. There are, however, certain exceptions to the requirement that a completed return be filed with the Form W-7. These exceptions are described in detail in the instructions to the revised Form W-7. One of the exceptions applies to holders of financial accounts generating income subject to information reporting or
withholding requirements. In these cases, an applicant for an ITIN must provide the IRS with evidence that the applicant had opened the account with the financial institution and that the applicant had an ownership interest in the account. The Treasury Department and the IRS will consider changes to the requirements of this exception if necessary to ensure the timely issuance of ITINs to holders of these types of financial accounts. In addition, financial institutions may participate in the IRS' acceptance agent program. SECTION 4. CLARIFICATION OF REGULATORY REQUIREMENTS Section 301.6109-1(d)(3)(ii) provides that any taxpayer who is required to furnish an ITIN must apply for an ITIN on Form W-7. The regulation further states that the application must be made far enough in advance of the taxpayer’s first required use of the ITIN to permit the issuance of the ITIN in time for the taxpayer to comply with the required use (e.g., the timely filing of a tax return). This requirement was intended to prevent delays related to Code filing requirements. Under the Service’s new ITIN application process, applicants, in general, are required to submit the Form W-7 with (and not in advance of) the original, completed tax return for which the ITIN is needed. Accordingly, taxpayers who comply with the Service’s new ITIN application process will be deemed to have satisfied the requirements of section 301.6109-1(d)(3)(ii) with respect to the time for applying for an ITIN. The original, completed tax return and the Form W-7 must be filed with the IRS office specified in the instructions to the Form W-7 regardless of where the taxpayer might otherwise be required to file the tax return. The tax return will be processed in the same manner as if it were filed at the address specified in the tax return instructions. No separate filing of the tax return (e.g., a copy) with any other IRS office is requested or required. Taxpayers are responsible for filing the original, completed tax return, with the Form W-7, by the due date applicable to the tax return for which the ITIN is needed (generally, April 15 of the year following the calendar year covered by the tax return). If a taxpayer requires an ITIN for an amended or delinquent return, then the Form W-7 must be submitted together with the return to the IRS office specified in the instructions accompanying the Form W-7. SECTION 5. EFFECTIVE DATE This notice is effective December 17, 2003. SECTION 6. COMMENTS The Service is committed to maintaining a dialogue with stakeholders on the ITIN application process, including Form W-7. Comments in response to this notice will be considered carefully by the Service in future revisions to the ITIN application process
and Form W-7. The Service welcomes all comments and suggestions and is particularly interested in comments on the following matters: 1. How can Form W-7 and the instructions be simplified or clarified? 2. The instructions to Form W-7 provide four exceptions to the requirement that a completed tax return be attached to Form W-7. Should these exceptions be modified? Are additional exceptions needed? 3. ITIN applicants may submit a Form W-7 to an acceptance agent. The acceptance agent reviews the applicant's documentation and forwards the completed Form W-7 to the Service. What steps, if any, should the Service consider to improve the acceptance agent program? Comments must be submitted by June 15, 2004. Comments may be submitted electronically to notice.comments@irscounsel.treas.gov. Alternatively, comments may be sent to CC:PA:LPD:PR (Notice 2004-1), Room 5203, Internal Revenue Service, P.O. Box 7604, Ben Franklin Station, Washington, DC 20044. Submissions may be hand delivered Monday through Friday between the hours of 8 a.m. and 4 p.m. to: CC:PA:LPD:PR (Notice 2004-1), Courier’s Desk, Internal Revenue Service, 1111 Constitution Avenue, N.W., Washington, DC 20224. SECTION 7. CONTACT INFORMATION The principal author of this notice is Michael A. Skeen of the Office of Associate Chief Counsel (Procedure and Administration), Administrative Provisions and Judicial Practice Division. For further information regarding this notice, contact Michael A. Skeen on (202) 622-4910 (not a toll-free call). | https://www.scribd.com/document/536013/US-Internal-Revenue-Service-n-04-1 | CC-MAIN-2018-26 | refinedweb | 1,069 | 55.03 |
# Crime, Race and Lethal Force in the USA — Part 3

This is the concluding part of my article devoted to a statistical analysis of police shootings and criminality among the white and the black population of the United States. In the [first part](https://habr.com/ru/post/519154/), we talked about the research background, goals, assumptions, and source data; in the [second part](https://habr.com/ru/post/519484/), we investigated the national use-of-force and crime data and tracked their connection with race.
Let's recall the intermediate inferences that we were able to make from the available data for 2000 — 2018:
* White police victims outnumber black victims in absolute figures.
* Use of lethal force results in an average of 5.9 per one million Black deaths and 2.3 per one million White deaths (Black victim count is 2.6 greater in unit values).
* Year-to-year scatter in Black lethal force fatalities is nearly twice the scatter in White fatalities.
* White fatalities grow continuously from year to year (by 0.1 — 0.2 per million on average), while Black fatalities rolled back to their 2009 level after climaxing in 2011 — 2013.
* Whites commit twice as many offenses as Blacks in absolute numbers, but three times as fewer in per capita numbers (per 1 million population within that race).
* Criminality among Whites grows more or less steadily over the entire period of investigation (doubled over 19 years). Criminality among Blacks also grows, but by leaps and starts; over the entire period, however, the growth factor is also 2, like with Whites.
* Fatal encounters with law enforcement are connected with criminality (number of offenses committed). The correlation though differs between the two races: for Whites, it is almost perfect, for Blacks — far from perfect.
* Lethal force victims grow 'in reply to' criminality growth, generally with a few years' lag (this is more conspicuous in the Black data).
* White offenders tend to meet death from the police a little more frequently than Black offenders.
Today, as I promised, we'll be looking at the geographical distribution of these data across the states, which ought to either confirm or confute the previous conclusions.
However, before we take up geography, let's make a step back and see what happens if we analyze only the most violent offenses instead of 'All Offenses' as the source data for criminality. Many of my readers have pointed out in their comments that this would have been more proper, since 'All Offenses' incorporate those which should not (in practice) be associated with aggressive behavior provoking police shooting, such as petty larceny or selling drugs. I cannot whole-heartedly agree with this reasoning because, as I see it, any offense can arouse or heighten attention from the law enforcement, which in turn may wind up sadly… Still, let's just be curious enough to check!
Assault and Murder Instead of All Offenses
------------------------------------------
We just need to change one line of code where we form the crime dataset. Replace this line
```
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'] == 'All Offenses']
```
with this:
```
df_crimes1 = df_crimes1.loc[df_crimes1['Offense'].str.contains('Assault|Murder')]
```
Our new filter now lets through only offenses connected with assault (simple and aggravated) and murder / non-negligent homicide (negligent / justifiable homicide / manslaughter cases are not included).
We leave the rest of the code as it was.
The number of crimes per 1 million population within each race now looks as follows:
[](https://habrastorage.org/webt/kw/zc/3y/kwzc3y39sp6jahvr4lyxpit6z_e.jpeg)
We can see that, though the scale (Y-axis) is much lower, the shape of the curves is almost identical to the All Offenses ones we saw previously.
The criminality vs. lethal force victims curves for both races:
[](https://habrastorage.org/webt/kd/8d/40/kd8d40scxicdwq5dhsxvwbwlf-g.jpeg)
[](https://habrastorage.org/webt/hr/wt/5i/hrwt5ibvrhhhuroyrbrqjpu3ea4.jpeg)
And the correlation matrix:
| | White\_promln\_cr | White\_promln\_uof | Black\_promln\_cr | Black\_promln\_uof |
| --- | --- | --- | --- | --- |
| White\_promln\_cr | 1.000000 | 0.684757 | 0.986622 | 0.729674 |
| White\_promln\_uof | **0.684757** | 1.000000 | 0.614132 | 0.795486 |
| Black\_promln\_cr | 0.986622 | 0.614132 | 1.000000 | **0.680893** |
| Black\_promln\_uof | 0.729674 | 0.795486 | 0.680893 | 1.000000 |
The correlation between criminality and lethal force fatalities is worse this time (**0.68** against 0.88 and 0.72 for All Offenses). But the silver lining here is the fact that the correlation coefficients for Whites and Blacks are almost equal, which gives reason to say there is some *constant correlation* between crime and police shootings / victims (regardless of race).
Now for our 'DIY' index — the ratio of lethal force deaths to the number of crimes (both per capita):
[](https://habrastorage.org/webt/uc/ff/9m/ucff9mx3a0whuembgrqzqksqfzc.jpeg)
The difference here is even more apparent. The inference is the same: White criminals are more likely to get killed by the police than Black criminals.
The summary is that all our prior conclusions hold true.
Well, down to geography lessons now! :)
Source Data
-----------
To investigate criminality in individual states, I used different source endpoints in the FBI database:
* [State level UCR Estimated Crime Data Endpoint](https://crime-data-explorer.fr.cloud.gov/api#summary-controller) — without race classification (the resulting CSV can be downloaded [from here](https://yadi.sk/d/2rA1BR8pzT_Yyw))
* [State level Arrest Demographic Count By Offense Endpoint](https://crime-data-explorer.fr.cloud.gov/api#arrest-data-controller) — with race classification (the resulting CSV can be downloaded [from here](https://yadi.sk/d/J--y1RfgVYqQFA))
Unfortunately, I didn't manage to get complete data on committed offenses with the offense state, year and offender race, much as I tried. The returned results had large gaps, for example, some states were totally omitted. But the alternative data on arrests is quite sufficient for our humble research.
The first dataset contains crime counts for all the 51 states from 1991 to 2018, for the following offense categories:
1. **violent crime** (murder, rape, robbery and aggravated assault)
2. **homicide** (all types, including negligent / justifiable)
3. **rape legacy** (using outdated metrics — before 2013)
4. **rape revised** (using updated metrics — from 2013 on)
5. **robbery**
6. **aggravated assault**
7. **property crime**
8. **burglary**
9. **larceny**
10. **motor vehicle theft**
11. **arson**
For our purposes, we'll be using the 'violent crime' category, in keeping with the rest of the research.
The second dataset features the number of arrests for the 51 states from 2000 to 2018, with details on the arrested persons' race (refer to the [previous part](https://habr.com/ru/post/519484/) for the race categories). Since the arrest dataset uses a different offense classification and doesn't provide the combined 'violent crime' category, the requests and retrieved results are for the four constituent offenses — murder / non-negligent manslaughter, robbery, rape, and aggravated assault.
Crime Distribution (No Racial Factor)
-------------------------------------
First, we'll look at the distribution of violent crimes across the states regardless of the offenders' race:
```
import pandas as pd, numpy as np
CRIME_STATES_FILE = ROOT_FOLDER + '\\crimes_by_state.csv'
df_crime_states = pd.read_csv(CRIME_STATES_FILE, sep=';', header=0,
usecols=['year', 'state_abbr', 'population', 'violent_crime'])
```
The resulting dataset:
| | year | state\_abbr | population | violent\_crime |
| --- | --- | --- | --- | --- |
| 0 | 2016 | AL | 4860545 | 25878 |
| 1 | 1996 | AL | 4273000 | 24159 |
| 2 | 1997 | AL | 4319000 | 24379 |
| 3 | 1998 | AL | 4352000 | 22286 |
| 4 | 1999 | AL | 4369862 | 21421 |
| ... | ... | ... | ... | ... |
| 1423 | 2000 | DC | 572059 | 8626 |
| 1424 | 2001 | DC | 573822 | 9195 |
| 1425 | 2002 | DC | 569157 | 9322 |
| 1426 | 2003 | DC | 557620 | 9061 |
| 1427 | 2016 | DC | 684336 | 8236 |
1428 rows × 4 columns
Adding the full state names (the list of states we already used in our research — [CSV](https://yadi.sk/d/Fb5NOSiLiVXwDA)) and optimizing / sorting the data:
```
df_crime_states = df_crime_states.merge(df_state_names, on='state_abbr')
df_crime_states.dropna(inplace=True)
df_crime_states.sort_values(by=['year', 'state_abbr'], inplace=True)
```
Since the dataset already has population values, let's calculate the number of crimes per million people:
```
df_crime_states['crime_promln'] = df_crime_states['violent_crime'] * 1e6 /
df_crime_states['population']
```
Finally, we'll turn the data into a table spanning the 2000 — 2018 period transposing the state names and dropping the redundant columns:
```
df_crime_states_agg = df_crime_states.groupby(['state_name',
'year'])['violent_crime'].sum().unstack(level=1).T
df_crime_states_agg.fillna(0, inplace=True)
df_crime_states_agg = df_crime_states_agg.astype('uint32').loc[2000:2018, :]
```
The resulting table contains 19 rows (year observations from 2000 through 2018) and 51 columns (by the number of states).
Let's display the top 10 states for the average number of crimes:
```
df_crime_states_agg_top10 = df_crime_states_agg.describe().T.nlargest(10, 'mean').\
astype('uint32')
```
| | count | mean | std | min | 25% | 50% | 75% | max |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| state\_name | | | | | | | | |
| California | 19 | 181514 | 19425 | 153763 | 165508 | 178597 | 193022 | 212867 |
| Texas | 19 | 117614 | 6522 | 104734 | 113212 | 121091 | 122084 | 126018 |
| Florida | 19 | 110104 | 18542 | 81980 | 92809 | 113541 | 127488 | 131878 |
| New York | 19 | 81618 | 9548 | 68495 | 75549 | 77563 | 85376 | 105111 |
| Illinois | 19 | 62866 | 10445 | 47775 | 54039 | 64185 | 69937 | 81196 |
| Michigan | 19 | 49273 | 5029 | 41712 | 44900 | 49737 | 54035 | 56981 |
| Pennsylvania | 19 | 46941 | 5066 | 39192 | 41607 | 48188 | 51021 | 55028 |
| Tennessee | 19 | 41951 | 2432 | 38063 | 40321 | 41562 | 43358 | 46482 |
| Georgia | 19 | 40228 | 3327 | 34355 | 38283 | 39435 | 41495 | 47353 |
| North Carolina | 19 | 37936 | 3193 | 32718 | 34706 | 38243 | 40258 | 43125 |
We'll also make it more graphic with a box plot:
```
df_crime_states_top10 = df_crime_states_agg.loc[:, df_crime_states_agg_top10.index]
plt = df_crime_states_top10.plot.box(figsize=(12, 10))
plt.set_ylabel('Violent crime count (2000 - 2018)')
```
[](https://habrastorage.org/webt/ye/uh/8a/yeuh8aezvjefjayhy42mbtwulyu.jpeg)
The 'Hollywood' state easily and notoriously beats the rest 9. The 'prizewinners' are California, Texas and Florida, all three in the South, the regular settings for most Hollywood criminal blockbusters.
You can also see that criminality has changed considerably over the observed period in some states (California, Florida and Illinois), whereas in others (like Georgia) it has remained almost constant.
I tend to think the crime rates are in some way connected with population :) Let's see the top 10 states by population in 2018:
```
df_crime_states_2018 = df_crime_states.loc[df_crime_states['year'] == 2018]
plt = df_crime_states_2018.nlargest(10, 'population').\
sort_values(by='population').plot.barh(x='state_name',
y='population', legend=False, figsize=(10,5))
plt.set_xlabel('2018 Population')
plt.set_ylabel('')
```
[](https://habrastorage.org/webt/vs/l7/jw/vsl7jwzjq6exl7wvn9n7smg5ynm.jpeg)
Same old mugs here :) Let's check the correlation between crimes and population:
```
df_corr = df_crime_states[df_crime_states['year']>=2000].groupby(['state_name']).mean()
df_corr = df_corr.loc[:, ['population', 'violent_crime']]
df_corr.corr(method='pearson').at['population', 'violent_crime']
```
The calculated Pearson correlation coefficient is **0.98**. Q.E.D.
But the per capita crime counts give a staringly different picture:
```
plt = df_crime_states_2018.nlargest(10, 'crime_promln').\
sort_values(by='crime_promln').plot.barh(x='state_name',
y='crime_promln', legend=False, figsize=(10,5))
plt.set_xlabel('Number of violent crimes per 1 mln. population (2018)')
plt.set_ylabel('')
```
[](https://habrastorage.org/webt/mn/l6/ku/mnl6ku1mdhfx91aosskstutsbks.jpeg)
There's a pretty kettle of fish! The leaders by per capita crimes are the least populated states: District Columbia (with the US capital) and Alaska (both home to some 700+ thousand people as of 2018), as well as one medium-populated state — New Mexico, with 2 mln. people. Only one state from our previous toplist is featured here — Tennessee, which gives this state a less-than-desirable reputation.
We will then display these results on the US map. To do this, we need the [folium](https://python-visualization.github.io/folium/) library:
```
import folium
```
First, the 2018 absolute crime counts:
```
FOLIUM_URL = 'https://raw.githubusercontent.com/python-visualization/folium/master/examples/data'
FOLIUM_US_MAP = f'{FOLIUM_URL}/us-states.json'
m = folium.Map(location=[48, -102], zoom_start=3)
folium.Choropleth(
geo_data=FOLIUM_US_MAP,
name='choropleth',
data=df_crime_states_2018,
columns=['state_abbr', 'violent_crime'],
key_on='feature.id',
fill_color='YlOrRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Violent crimes in 2018',
bins=df_crime_states_2018['violent_crime'].quantile(
list(np.linspace(0.0, 1.0, 5))).to_list(),
reset=True
).add_to(m)
folium.LayerControl().add_to(m)
m
```
[](https://habrastorage.org/webt/pj/l3/31/pjl331up3rcdvw5ln4em3upeboy.jpeg)
The same in per capita values (per 1 million):
```
m = folium.Map(location=[48, -102], zoom_start=3)
folium.Choropleth(
geo_data=FOLIUM_US_MAP,
name='choropleth',
data=df_crime_states_2018,
columns=['state_abbr', 'crime_promln'],
key_on='feature.id',
fill_color='YlOrRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Violent crimes in 2018 (per 1 mln. population)',
bins=df_crime_states_2018['crime_promln'].quantile(
list(np.linspace(0.0, 1.0, 5))).to_list(),
reset=True
).add_to(m)
folium.LayerControl().add_to(m)
m
```
[](https://habrastorage.org/webt/zy/no/k6/zynok6rzyj0aakk_7-9j4k6nbju.jpeg)
In the first case, as we can see, crimes are more or less evenly distributed in the North to South direction. In the second case, it's mostly the Southern states plus DC and Alaska that make the trend.
Lethal Force Fatalities Across States (No Racial Factor)
--------------------------------------------------------
We are now going to look at lethal force used in individual states across the country.
To prepare the dataset, we'll complement the UOF (Use Of Force) data we used previously by the full state names, group the cases by states, and constrain the observations to years 2000 through 2018:
```
df_fenc_agg_states = df_fenc.merge(df_state_names, how='inner',
left_on='State', right_on='state_abbr')
df_fenc_agg_states.fillna(0, inplace=True)
df_fenc_agg_states = df_fenc_agg_states.rename(columns={'state_name_x': 'State Name'})
df_fenc_agg_states = df_fenc_agg_states.loc[:, ['Year', 'Race', 'State',
'State Name', 'Cause', 'UOF']]
df_fenc_agg_states = df_fenc_agg_states.\
groupby(['Year', 'State Name', 'State'])['UOF'].\
count().unstack(level=0)
df_fenc_agg_states.fillna(0, inplace=True)
df_fenc_agg_states = df_fenc_agg_states.astype('uint16').loc[:, :2018]
df_fenc_agg_states = df_fenc_agg_states.reset_index()
```
Top 10 states for police victims in 2018:
```
df_fenc_agg_states_2018 = df_fenc_agg_states.loc[:, ['State Name', 2018]]
plt = df_fenc_agg_states_2018.nlargest(10, 2018).sort_values(2018).plot.barh(
x='State Name', y=2018, legend=False, figsize=(10,5))
plt.set_xlabel('Number of UOF victims in 2018')
plt.set_ylabel('')
```
[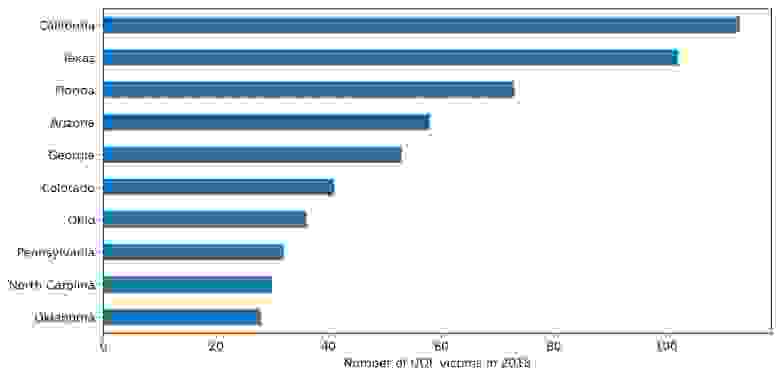](https://habrastorage.org/webt/mn/gf/ee/mngfeevxlnhmkifsvdv0aluhiru.jpeg)
Let's also review the data for the entire period as a box plot:
```
fenc_top10 = df_fenc_agg_states.loc[df_fenc_agg_states['State Name'].\
isin(df_fenc_agg_states_2018.nlargest(10, 2018)['State Name'])]
fenc_top10 = fenc_top10.T
fenc_top10.columns = fenc_top10.loc['State Name', :]
fenc_top10 = fenc_top10.reset_index().loc[2:, :].set_index('Year')
df_sorted = fenc_top10.mean().sort_values(ascending=False)
fenc_top10 = fenc_top10.loc[:, df_sorted.index]
plt = fenc_top10.plot.box(figsize=(12, 6))
plt.set_ylabel('Number of UOF victims (2000 - 2018)')
```
[](https://habrastorage.org/webt/fm/fp/xf/fmfpxfdvtg4ojgbqqijjbin1os4.jpeg)
Yep! The same 'unholy trio' of California, Texas and Florida, with their other two Southern sidekicks — Arizona and Georgia. The leaders again show large scatter indicative of year-to-year changes.
Connection Between Lethal Force Fatalities and Crimes
-----------------------------------------------------
As in the previous part of this research, we are investigating the possible connection between criminality and deaths at the hands of law enforcement. We'll start without the racial factor, to see if such a connection exists in principle and how it varies from state to state.
At first, we must merge the UOF and (violent) crime datasets, setting the observation period to 2000 — 2018:
```
# add full state names
df_fenc_crime_states = df_fenc.merge(df_state_names, how='inner',
left_on='State', right_on='state_abbr')
# rename some columns
df_fenc_crime_states = df_fenc_crime_states.rename(columns={'Year': 'year',
'state_name_x': 'state_name'})
# truncate period to 2000-2018
df_fenc_crime_states = df_fenc_crime_states[df_fenc_crime_states['year'].between(2000,
2018)]
# group by year and state
df_fenc_crime_states = df_fenc_crime_states.groupby(['year', 'state_name'])['UOF'].\
count().reset_index()
# join with crime data
df_fenc_crime_states = df_fenc_crime_states.merge(df_crime_states[df_crime_states['year'].\
between(2000, 2018)], how='outer', on=['year', 'state_name'])
# set missing data to zero
df_fenc_crime_states.fillna({'UOF': 0}, inplace=True)
# unify data types
df_fenc_crime_states = df_fenc_crime_states.astype({'year': 'uint16', 'UOF': 'uint16',
'population': 'uint32', 'violent_crime': 'uint32'})
# sort data
df_fenc_crime_states = df_fenc_crime_states.sort_values(by=['year', 'state_name'])
```
**Resulting dataset**
| | year | state\_name | UOF | state\_abbr | population | violent\_crime | crime\_promln |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 2000 | Alabama | 7 | AL | 4447100 | 21620 | 4861.595197 |
| 1 | 2000 | Alaska | 2 | AK | 626932 | 3554 | 5668.876369 |
| 2 | 2000 | Arizona | 11 | AZ | 5130632 | 27281 | 5317.278651 |
| 3 | 2000 | Arkansas | 4 | AR | 2673400 | 11904 | 4452.756789 |
| 4 | 2000 | California | 97 | CA | 33871648 | 210531 | 6215.552311 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 907 | 2018 | Virginia | 18 | VA | 8517685 | 17032 | 1999.604353 |
| 908 | 2018 | Washington | 24 | WA | 7535591 | 23472 | 3114.818732 |
| 909 | 2018 | West Virginia | 7 | WV | 1805832 | 5236 | 2899.494527 |
| 910 | 2018 | Wisconsin | 10 | WI | 5813568 | 17176 | 2954.467893 |
| 911 | 2018 | Wyoming | 4 | WY | 577737 | 1226 | 2122.072846 |
As you will remember, the **UOF** column contains the number of deaths from encounters with law enforcement officers (who I sometimes call here just 'the police', but who include, of course, other agencies such as the FBI) where lethal force was used intentionally.
We will also make a separate dataset with year-average values:
```
df_fenc_crime_states_agg = df_fenc_crime_states.groupby(['state_name']).\
mean().loc[:, ['UOF', 'violent_crime']]
```
Now let's look at the year averages for crimes and lethal force fatalities for all the 51 states on one plot:
```
plt = df_fenc_crime_states_agg['violent_crime'].plot.bar(legend=True, figsize=(15,5))
plt.set_ylabel('Number of violent crimes (year average)')
plt2 = df_fenc_crime_states_agg['UOF'].plot(secondary_y=True, style='g', legend=True)
plt2.set_ylabel('Number of UOF victims (year average)', rotation=90)
plt2.set_xlabel('')
plt.set_xlabel('')
plt.set_xticklabels(df_fenc_crime_states_agg.index, rotation='vertical')
```
[](https://habrastorage.org/webt/z2/vx/qt/z2vxqtqhcqt7v4wlskecjygwrww.jpeg)
Looking closely at this combined chart, one can see the following:
* the connection between crime and use of force is plainly trackable: the green UOF curve tends to repeat the shape of the crime bars
* the more criminal states (such as Florida, Illinois, Michigan, New York and Texas) evince proportionately less use of force compared to the less criminal states
Let's also make a scatterplot:
```
plt = df_fenc_crime_states_agg.plot.scatter(x='violent_crime', y='UOF')
plt.set_xlabel('Number of violent crimes (year average)')
plt.set_ylabel('Number of UOF victims (year average)')
```
[](https://habrastorage.org/webt/vs/mt/gc/vsmtgcguf4_e2x3cnspv8sxc1im.jpeg)
Here it becomes conspicuous that the ratio between crime and use of lethal force is affected by the crime rate. Speaking crudely, in states with the number of violent crimes below 75k the number of police victims grows more slowly; whereas in the states with the crime count above 75k this growth is quite steep. This latter group includes, as we can see, only four states. Let's look them 'in the face':
```
df_fenc_crime_states_agg[df_fenc_crime_states_agg['violent_crime'] > 75000]
```
| | UOF | violent\_crime |
| --- | --- | --- |
| state\_name | | |
| California | 133.263158 | 181514.578947 |
| Florida | 54.578947 | 110104.315789 |
| New York | 19.157895 | 81618.052632 |
| Texas | 64.368421 | 117614.631579 |
Will you be surprised? We've got the same 'four horsemen of the Apocalypse': California, Florida, Texas and New York.
Correspondingly, let's calculate the correlation coefficients between our data for three cases:
1. states with the year average crime count up to 75,000
2. states with the year average crime count above 75,000
3. all the states
For the first case:
```
df_fenc_crime_states_agg[df_fenc_crime_states_agg['violent_crime'] <= \
75000].corr(method='pearson').at['UOF', 'violent_crime']
```
— we obtain **0.839** as the correlation coefficient. This is a statistically valid value, although it doesn't reach 0.9 due to scatter across the 47 states.
For the first case:
```
df_fenc_crime_states_agg[df_fenc_crime_states_agg['violent_crime'] > \
75000].corr(method='pearson').at['UOF', 'violent_crime']
```
— we get **0.999** — an ideal correlation!
For the last case (all states):
```
df_fenc_crime_states_agg.corr(method='pearson').at['UOF', 'violent_crime']
```
— the correlation is estimated at **0.935**. This overall correlation may be considered very good.
Let's now look at the geographical distribution of our 'offender shootdown' index (the term is coined here for brevity). As before, we divide the number of lethal force fatalities by the number of crimes:
```
df_fenc_crime_states_agg['uof_by_crime'] = df_fenc_crime_states_agg['UOF'] /
df_fenc_crime_states_agg['violent_crime']
plt = df_fenc_crime_states_agg.loc[:, 'uof_by_crime'].sort_values(ascending=False).\
plot.bar(figsize=(15,5))
plt.set_xlabel('')
plt.set_ylabel('Ratio of UOF victims to number of violent crimes')
```
[](https://habrastorage.org/webt/vq/wq/bi/vqwqbiy5j991msrfzupq3ps7mew.jpeg)
It is interesting to observe that our erstwhile leaders have shifted toward the center or even the rightmost end of the chart, which must mean that the most criminal states don't have the most 'bloodthirsty' police (towards real or potential offenders).
**Intermediate conclusions:**
> 1. The number of violent crimes is directly proportionate to population (good call, Captain Obvious!)
> 2. The most populated states (California, Florida, Texas and New York) are also the most criminal, in absolute values.
> 3. In per capita values, Southern states are more criminal than Northern states, with the exception of Alaska and District Columbia.
> 4. Lethal force deaths are correlated to criminality with an average coefficient of 0.93 across all the states. This correlation reaches almost unity (strictly linear) for the most criminal states and only 0.84 for the rest.
>
>
>
>
Racial Factor in Criminality and Lethal Force Fatalities Across States
----------------------------------------------------------------------
Proving that crime rates do affect police victim rates, let's add the racial factor and see what it affects. As I explained above, we'll be using the arrest data for this purpose as being the most complete and covering the main offenses for all the states. There is, of course, no such state or country where one could equate the number of committed crimes to the number of arrests; yet these parameters are closely related. As such, we can do very well with arrest data for our statistical analysis. And, as we already agreed, only violent offenses (murder, rape, robbery, aggravated assault) will be taken into account.
Let's load the source data from the CSV file and routinely add the full state names:
```
ARRESTS_FILE = ROOT_FOLDER + '\\arrests_by_state_race.csv'
# arrests of Blacks and Whites only
df_arrests = pd.read_csv(ARRESTS_FILE, sep=';', header=0,
usecols=['data_year', 'state', 'white', 'black'])
# sum the four offenses and group by states
df_arrests = df_arrests.groupby(['data_year', 'state']).sum().reset_index()
# add state names
df_arrests = df_arrests.merge(df_state_names, left_on='state', right_on='state_abbr')
# rename / remove columns
df_arrests = df_arrests.rename(columns={'data_year': 'year'}).drop(columns='state_abbr')
# peek at the result
df_arrests.head()
```
| | year | state | black | white | state\_name |
| --- | --- | --- | --- | --- | --- |
| 0 | 2000 | AK | 140 | 613 | Alaska |
| 1 | 2001 | AK | 139 | 718 | Alaska |
| 2 | 2002 | AK | 143 | 677 | Alaska |
| 3 | 2003 | AK | 173 | 801 | Alaska |
| 4 | 2004 | AK | 163 | 765 | Alaska |
We'll also create a dataframe with year average values:
```
df_arrests_agg = df_arrests.groupby(['state_name']).mean().drop(columns='year')
```
**Arrests of Whites and Blacks in 51 states (year average counts)**
| | black | white |
| --- | --- | --- |
| state\_name | | |
| Alabama | 2805.842105 | 1757.315789 |
| Alaska | 221.894737 | 844.157895 |
| Arizona | 1378.368421 | 7007.157895 |
| Arkansas | 2387.894737 | 2303.789474 |
| California | 26668.368421 | 87252.315789 |
| Colorado | 1268.210526 | 5157.368421 |
| Connecticut | 2097.631579 | 2981.210526 |
| Delaware | 1356.894737 | 1048.578947 |
| District of Columbia | 111.111111 | 4.944444 |
| Florida | 12.000000 | 7.000000 |
| Georgia | 8262.842105 | 3502.894737 |
| Hawaii | 81.052632 | 368.736842 |
| Idaho | 44.000000 | 1362.263158 |
| Illinois | 5699.842105 | 1841.894737 |
| Indiana | 3553.368421 | 5192.263158 |
| Iowa | 1104.421053 | 3039.473684 |
| Kansas | 522.315789 | 1501.315789 |
| Kentucky | 1476.894737 | 1906.052632 |
| Louisiana | 5928.789474 | 3414.263158 |
| Maine | 63.736842 | 699.526316 |
| Maryland | 7189.105263 | 4010.684211 |
| Massachusetts | 3407.157895 | 7319.684211 |
| Michigan | 7628.157895 | 6304.157895 |
| Minnesota | 2231.210526 | 2645.736842 |
| Mississippi | 1462.210526 | 474.368421 |
| Missouri | 5777.473684 | 5703.368421 |
| Montana | 27.684211 | 673.684211 |
| Nebraska | 591.421053 | 1058.526316 |
| Nevada | 1956.421053 | 3817.210526 |
| New Hampshire | 68.368421 | 640.789474 |
| New Jersey | 6424.157895 | 6043.789474 |
| New Mexico | 234.421053 | 2809.368421 |
| New York | 8394.526316 | 8734.947368 |
| North Carolina | 10527.947368 | 7412.947368 |
| North Dakota | 61.263158 | 277.052632 |
| Ohio | 4063.947368 | 4071.368421 |
| Oklahoma | 1625.105263 | 3353.000000 |
| Oregon | 445.105263 | 3373.368421 |
| Pennsylvania | 11974.157895 | 11039.473684 |
| Rhode Island | 275.684211 | 699.210526 |
| South Carolina | 5578.526316 | 3615.421053 |
| South Dakota | 67.105263 | 349.368421 |
| Tennessee | 6799.894737 | 8462.526316 |
| Texas | 10547.631579 | 22062.684211 |
| Utah | 167.105263 | 1748.894737 |
| Vermont | 43.526316 | 439.210526 |
| Virginia | 4100.421053 | 3060.263158 |
| Washington | 1688.947368 | 6012.105263 |
| West Virginia | 271.263158 | 1528.315789 |
| Wisconsin | 3440.055556 | 4107.722222 |
| Wyoming | 27.263158 | 506.947368 |
Looking at this table, one can't overlook some oddities. In some states the arrest counts reach hundreds and thousands, while in others — only dozens or fewer. That's the case with Florida, one of the most populated states: it counts only 19 arrests per year (12 Blacks and 7 Whites). Surely, some data is missing here; let's check:
```
df_arrests[df_arrests['state'] == 'FL']
```
And indeed we see that data for Florida is available only for 2017. Well, we'll have to put up with this, I suppose. All the other states have complete data. But the ten / hundred-fold difference should be accounted for by population. Let's add population-by-race data and have a look.
The population data was taken from the US Census Bureau website (which is for some reason not accessible in Russia). You can download the prepared CSV file with 2010 — 2019 data [from here](https://yadi.sk/d/5b3mbIvLP83boQ).
Unfortunately, no state population data exist for prior periods (2000 — 2009). We have therefore to narrow down our observation period to 9 years (from 2010 through 2018) for this part of the research.
```
POP_STATES_FILES = ROOT_FOLDER + '\\us_pop_states_race_2010-2019.csv'
df_pop_states = pd.read_csv(POP_STATES_FILES, sep=';', header=0)
# the source CSV has a specific format, so some trickery is required :)
df_pop_states = df_pop_states.melt('state_name', var_name='r_year', value_name='pop')
df_pop_states['race'] = df_pop_states['r_year'].str[0]
df_pop_states['year'] = df_pop_states['r_year'].str[2:].astype('uint16')
df_pop_states.drop(columns='r_year', inplace=True)
df_pop_states = df_pop_states[df_pop_states['year'].between(2000, 2018)]
df_pop_states = df_pop_states.groupby(['state_name', 'year', 'race']).sum().\
unstack().reset_index()
df_pop_states.columns = ['state_name', 'year', 'black_pop', 'white_pop']
```
**White and Black population across states**
| | year | black\_pop | white\_pop |
| --- | --- | --- | --- |
| state\_name | | | |
| Alabama | 2010 | 5044936 | 13462236 |
| Alabama | 2011 | 5067912 | 13477008 |
| Alabama | 2012 | 5102512 | 13484256 |
| Alabama | 2013 | 5137360 | 13488812 |
| Alabama | 2014 | 5162316 | 13493432 |
| ... | ... | ... | ... |
| Wyoming | 2014 | 31392 | 2167008 |
| Wyoming | 2015 | 29568 | 2177740 |
| Wyoming | 2016 | 29304 | 2170700 |
| Wyoming | 2017 | 29444 | 2148128 |
| Wyoming | 2018 | 29604 | 2139896 |
Merging this data with the arrests dataset, we can calculate the per-million arrest counts:
```
df_arrests_2010_2018 = df_arrests.merge(df_pop_states, how='inner',
on=['year', 'state_name'])
df_arrests_2010_2018['white_arrests_promln'] = df_arrests_2010_2018['white'] * 1e6 /
df_arrests_2010_2018['white_pop']
df_arrests_2010_2018['black_arrests_promln'] = df_arrests_2010_2018['black'] * 1e6 /
df_arrests_2010_2018['black_pop']
```
And again let's calculate the year averages:
```
df_arrests_2010_2018_agg = df_arrests_2010_2018.groupby(
['state_name', 'state']).mean().drop(columns='year').reset_index()
df_arrests_2010_2018_agg = df_arrests_2010_2018_agg.set_index('state_name')
```
**Combined arrest dataset with absolute and per-million counts**
| | state | black | white | black\_pop | white\_pop | white\_arrests\_promln | black\_arrests\_promln |
| --- | --- | --- | --- | --- | --- | --- | --- |
| state\_name | | | | | | | |
| Alabama | AL | 1682.000000 | 1342.000000 | 5.152399e+06 | 1.349158e+07 | 99.424741 | 324.055203 |
| Alaska | AK | 255.000000 | 870.555556 | 1.069489e+05 | 1.957445e+06 | 445.199704 | 2390.243876 |
| Arizona | AZ | 1635.555556 | 6852.000000 | 1.279172e+06 | 2.260403e+07 | 302.923002 | 1267.000192 |
| Arkansas | AR | 1960.666667 | 2466.000000 | 1.855574e+06 | 9.465137e+06 | 260.459917 | 1055.854934 |
| California | CA | 24381.666667 | 79477.000000 | 1.007921e+07 | 1.128020e+08 | 704.731408 | 2419.234376 |
| Colorado | CO | 1377.222222 | 5171.555556 | 9.508173e+05 | 1.882940e+07 | 274.209456 | 1439.257054 |
| Connecticut | CT | 1823.777778 | 2295.333333 | 1.643690e+06 | 1.165681e+07 | 196.712775 | 1114.811569 |
| Delaware | DE | 1318.000000 | 914.111111 | 8.354622e+05 | 2.635794e+06 | 347.374980 | 1582.395733 |
| District of Columbia | DC | 139.222222 | 4.777778 | 1.288488e+06 | 1.154416e+06 | 4.112547 | 108.101938 |
| Florida | FL | 12.000000 | 7.000000 | 1.415383e+07 | 6.498292e+07 | 0.107721 | 0.847827 |
| Georgia | GA | 8137.222222 | 4271.444444 | 1.279378e+07 | 2.500293e+07 | 170.939250 | 639.869143 |
| Hawaii | HI | 81.333333 | 383.777778 | 1.124298e+05 | 1.453712e+06 | 264.353469 | 725.477589 |
| Idaho | ID | 51.888889 | 1373.777778 | 5.288222e+04 | 6.154316e+06 | 223.151878 | 978.205026 |
| Illinois | IL | 4216.000000 | 1284.222222 | 7.554687e+06 | 3.980927e+07 | 32.199075 | 557.493894 |
| Indiana | IN | 2924.444444 | 5186.111111 | 2.522917e+06 | 2.267508e+07 | 228.699515 | 1155.168768 |
| Iowa | IA | 1181.000000 | 2999.222222 | 4.305640e+05 | 1.141794e+07 | 262.666753 | 2760.038539 |
| Kansas | KS | 539.555556 | 1512.111111 | 7.116182e+05 | 1.006714e+07 | 150.232160 | 758.851182 |
| Kentucky | KY | 1443.888889 | 2173.666667 | 1.442174e+06 | 1.558094e+07 | 139.526970 | 1001.433470 |
| Louisiana | LA | 5917.000000 | 3255.333333 | 6.021228e+06 | 1.174245e+07 | 277.277874 | 981.334817 |
| Maine | ME | 78.000000 | 678.000000 | 7.667733e+04 | 5.059062e+06 | 134.024032 | 1019.061684 |
| Maryland | MD | 6460.444444 | 3325.444444 | 7.229037e+06 | 1.426036e+07 | 233.317775 | 893.942720 |
| Massachusetts | MA | 3349.555556 | 6895.111111 | 2.249232e+06 | 2.226671e+07 | 309.745910 | 1505.096888 |
| Michigan | MI | 6302.444444 | 5647.444444 | 5.645176e+06 | 3.170670e+07 | 178.111684 | 1116.364030 |
| Minnesota | MN | 2570.000000 | 2686.777778 | 1.311818e+06 | 1.867259e+07 | 143.902882 | 1986.464052 |
| Mississippi | MS | 1251.000000 | 418.777778 | 4.478208e+06 | 7.122651e+06 | 58.753686 | 279.574565 |
| Missouri | MO | 4588.333333 | 5146.111111 | 2.854060e+06 | 2.023871e+07 | 254.292323 | 1608.303611 |
| Montana | MT | 34.222222 | 788.333333 | 2.210444e+04 | 3.660813e+06 | 214.944902 | 1525.795754 |
| Nebraska | NE | 618.888889 | 1154.888889 | 3.701520e+05 | 6.709768e+06 | 172.269972 | 1687.725359 |
| Nevada | NV | 2450.000000 | 4480.333333 | 1.052192e+06 | 8.647157e+06 | 517.401564 | 2316.374085 |
| New Hampshire | NH | 89.777778 | 784.777778 | 7.873600e+04 | 5.012056e+06 | 156.580888 | 1141.127571 |
| New Jersey | NJ | 5429.555556 | 4971.888889 | 5.241910e+06 | 2.595141e+07 | 191.427955 | 1037.217679 |
| New Mexico | NM | 260.111111 | 3136.000000 | 2.053876e+05 | 6.905377e+06 | 454.129135 | 1268.115549 |
| New York | NY | 6035.777778 | 6600.222222 | 1.373077e+07 | 5.534157e+07 | 119.253616 | 439.581451 |
| North Carolina | NC | 9549.000000 | 6759.333333 | 8.804027e+06 | 2.844145e+07 | 238.320077 | 1088.968561 |
| North Dakota | ND | 100.666667 | 386.222222 | 6.583289e+04 | 2.583206e+06 | 149.190455 | 1536.987272 |
| Ohio | OH | 3632.888889 | 3733.333333 | 5.879375e+06 | 3.844592e+07 | 97.107129 | 617.699379 |
| Oklahoma | OK | 1577.333333 | 3049.000000 | 1.189604e+06 | 1.160567e+07 | 262.904593 | 1326.463864 |
| Oregon | OR | 375.444444 | 3125.000000 | 3.292284e+05 | 1.402225e+07 | 222.819615 | 1148.158169 |
| Pennsylvania | PA | 11227.000000 | 10652.111111 | 5.945100e+06 | 4.232445e+07 | 251.598838 | 1893.415475 |
| Rhode Island | RI | 274.888889 | 595.000000 | 3.275551e+05 | 3.592825e+06 | 165.605635 | 837.932682 |
| South Carolina | SC | 4703.222222 | 3094.111111 | 5.365012e+06 | 1.324712e+07 | 234.287821 | 877.892998 |
| South Dakota | SD | 103.777778 | 448.333333 | 6.154533e+04 | 2.903489e+06 | 153.995184 | 1641.137012 |
| Tennessee | TN | 7603.000000 | 9068.666667 | 4.460808e+06 | 2.070126e+07 | 438.486812 | 1708.022356 |
| Texas | TX | 10821.666667 | 21122.111111 | 1.345661e+07 | 8.628389e+07 | 245.051258 | 803.917061 |
| Utah | UT | 193.222222 | 1797.333333 | 1.558876e+05 | 1.079659e+07 | 166.431266 | 1240.117890 |
| Vermont | VT | 54.222222 | 520.555556 | 3.017111e+04 | 2.376143e+06 | 219.129918 | 1785.111547 |
| Virginia | VA | 4059.555556 | 3071.222222 | 6.544598e+06 | 2.340732e+07 | 131.178648 | 620.504151 |
| Washington | WA | 1791.777778 | 5870.444444 | 1.147000e+06 | 2.289368e+07 | 256.632241 | 1566.862244 |
| West Virginia | WV | 294.111111 | 1648.666667 | 2.597649e+05 | 6.908718e+06 | 238.517207 | 1132.059057 |
| Wisconsin | WI | 3525.333333 | 4046.222222 | 1.516534e+06 | 2.018658e+07 | 200.441064 | 2325.622492 |
| Wyoming | WY | 28.777778 | 464.555556 | 2.856356e+04 | 2.151349e+06 | 216.004646 | 1005.725503 |
Let's visualize this stuff.
1. Absolute arrest counts
```
plt = df_arrests_2010_2018_agg[['white', 'black']].sort_index(ascending=False).\
plot.barh(color=['g', 'olive'], figsize=(10, 20))
plt.set_ylabel('')
plt.set_xlabel('Year-average arrest count (2010-2018)')
```
**Tall image**
[](https://habrastorage.org/webt/lm/_c/ew/lm_cewe38-iadr9wo1l2ojwvz1a.jpeg)
2. Arrest counts per million population (for each race)
```
plt = df_arrests_2010_2018_agg[['white_arrests_promln', 'black_arrests_promln']].\
sort_index(ascending=False).plot.barh(color=['g', 'olive'], figsize=(10, 20))
plt.set_ylabel('')
plt.set_xlabel('Year-average arrest count per 1 mln. within race (2010-2018)')
```
**Another tall image**
[](https://habrastorage.org/webt/pt/hi/6u/pthi6upbqowkkq3ipkbh9vr6ln4.jpeg)
What can we infer from this data?
First of all, we see that the number of arrests is affected by population — this is observed for both races.
Secondly, Whites get busted *somewhat* more often than Blacks in absolute figures. The 'somewhat' — because this rule isn't universal for all the states (exclusions are North Carolina, Georgia, Louisiana, etc.); at the same time, the difference is but slight in most states, except a few (like California, Texas, Colorado, Massachusetts and a few others).
Last but not least, Blacks get arrested *much* more often *in all the states* in per capita values.
Let's back these observations by numbers.
Difference between the average White and Black arrest counts:
```
df_arrests_2010_2018['white'].mean() / df_arrests_2010_2018['black'].mean()
```
— we get **1.56**. That is, the observed 9 years saw on average **one and a half times more Whites being arrested** than Blacks.
Then in per capita values:
```
df_arrests_2010_2018['white_arrests_promln'].mean() /
df_arrests_2010_2018['black_arrests_promln'].mean()
```
— the ratio is **0.183**. That is, **a Black person is on average 5.5 times more likely to get arrested** than a White person.
Thus, the previous conclusion of higher criminality among Blacks (compared to Whites) is confirmed by the arrest data for all the states of the USA.
To understand how race and criminality are connected with lethal force victims, let's merge the two datasets.
First, we prepare the use-of-force data with the victims' race details:
```
df_fenc_agg_states1 = df_fenc.merge(df_state_names, how='inner',
left_on='State', right_on='state_abbr')
df_fenc_agg_states1.fillna(0, inplace=True)
df_fenc_agg_states1 = df_fenc_agg_states1.rename(columns={
'state_name_x': 'state_name', 'Year': 'year'})
df_fenc_agg_states1 = df_fenc_agg_states1.loc[df_fenc_agg_states1['year'].\
between(2000, 2018), ['year', 'Race', 'state_name', 'UOF']]
df_fenc_agg_states1 = df_fenc_agg_states1.groupby(['year', 'state_name', 'Race'])['UOF'].\
count().unstack().reset_index()
df_fenc_agg_states1 = df_fenc_agg_states1.rename(columns={
'Black': 'black_uof', 'White': 'white_uof'})
df_fenc_agg_states1 = df_fenc_agg_states1.fillna(0).astype({
'black_uof': 'uint32', 'white_uof': 'uint32'})
```
**Resulting UOF dataset**
| Race | year | state\_name | black\_uof | white\_uof |
| --- | --- | --- | --- | --- |
| 0 | 2000 | Alabama | 4 | 3 |
| 1 | 2000 | Alaska | 0 | 2 |
| 2 | 2000 | Arizona | 0 | 11 |
| 3 | 2000 | Arkansas | 1 | 3 |
| 4 | 2000 | California | 19 | 78 |
| ... | ... | ... | ... | ... |
| 907 | 2018 | Virginia | 11 | 7 |
| 908 | 2018 | Washington | 0 | 24 |
| 909 | 2018 | West Virginia | 2 | 5 |
| 910 | 2018 | Wisconsin | 3 | 7 |
| 911 | 2018 | Wyoming | 0 | 4 |
Then we're merging it with the arrest data:
```
df_arrests_fenc = df_arrests.merge(df_fenc_agg_states1,
on=['state_name', 'year'])
df_arrests_fenc = df_arrests_fenc.rename(columns={
'white': 'white_arrests', 'black': 'black_arrests'})
```
**Example data for 2017**
| | year | state | black\_arrests | white\_arrests | state\_name | black\_uof | white\_uof |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 15 | 2017 | AK | 266 | 859 | Alaska | 2 | 3 |
| 34 | 2017 | AL | 3098 | 2509 | Alabama | 7 | 17 |
| 53 | 2017 | AR | 2092 | 2674 | Arkansas | 6 | 7 |
| 72 | 2017 | AZ | 2431 | 7829 | Arizona | 6 | 43 |
| 91 | 2017 | CA | 24937 | 80367 | California | 25 | 137 |
| 110 | 2017 | CO | 1781 | 6079 | Colorado | 2 | 27 |
| 127 | 2017 | CT | 1687 | 2114 | Connecticut | 1 | 5 |
| 140 | 2017 | DE | 1198 | 782 | Delaware | 4 | 3 |
| 159 | 2017 | GA | 7747 | 4171 | Georgia | 15 | 21 |
| 173 | 2017 | HI | 88 | 419 | Hawaii | 0 | 1 |
| 192 | 2017 | IA | 1400 | 3524 | Iowa | 1 | 5 |
| 210 | 2017 | ID | 61 | 1423 | Idaho | 0 | 6 |
| 229 | 2017 | IL | 2847 | 947 | Illinois | 13 | 11 |
| 248 | 2017 | IN | 3565 | 4300 | Indiana | 9 | 13 |
| 267 | 2017 | KS | 585 | 1651 | Kansas | 3 | 10 |
| 286 | 2017 | KY | 1481 | 2035 | Kentucky | 1 | 18 |
| 305 | 2017 | LA | 5875 | 2284 | Louisiana | 13 | 5 |
| 324 | 2017 | MA | 2953 | 6089 | Massachusetts | 1 | 4 |
| 343 | 2017 | MD | 6662 | 3371 | Maryland | 8 | 5 |
| 361 | 2017 | ME | 89 | 675 | Maine | 1 | 8 |
| 380 | 2017 | MI | 6149 | 5459 | Michigan | 6 | 7 |
| 399 | 2017 | MN | 2513 | 2681 | Minnesota | 1 | 7 |
| 418 | 2017 | MO | 4571 | 5007 | Missouri | 13 | 20 |
| 437 | 2017 | MS | 1266 | 409 | Mississippi | 7 | 10 |
| 455 | 2017 | MT | 50 | 915 | Montana | 0 | 3 |
| 474 | 2017 | NC | 8177 | 5576 | North Carolina | 9 | 14 |
| 501 | 2017 | NE | 80 | 578 | Nebraska | 0 | 1 |
| 516 | 2017 | NH | 113 | 817 | New Hampshire | 0 | 3 |
| 535 | 2017 | NJ | 4859 | 4136 | New Jersey | 9 | 6 |
| 554 | 2017 | NM | 205 | 2094 | New Mexico | 0 | 20 |
| 573 | 2017 | NV | 2695 | 4657 | Nevada | 3 | 12 |
| 592 | 2017 | NY | 5923 | 6633 | New York | 7 | 9 |
| 611 | 2017 | OH | 4472 | 3882 | Ohio | 11 | 23 |
| 630 | 2017 | OK | 1638 | 2872 | Oklahoma | 3 | 20 |
| 649 | 2017 | OR | 453 | 3222 | Oregon | 2 | 9 |
| 668 | 2017 | PA | 10123 | 10191 | Pennsylvania | 7 | 17 |
| 681 | 2017 | RI | 315 | 633 | Rhode Island | 0 | 1 |
| 700 | 2017 | SC | 4645 | 2964 | South Carolina | 3 | 10 |
| 712 | 2017 | SD | 124 | 537 | South Dakota | 0 | 2 |
| 731 | 2017 | TN | 6654 | 8496 | Tennessee | 4 | 24 |
| 750 | 2017 | TX | 11493 | 20911 | Texas | 18 | 56 |
| 769 | 2017 | UT | 199 | 1964 | Utah | 1 | 5 |
| 788 | 2017 | VA | 4283 | 3247 | Virginia | 8 | 17 |
| 804 | 2017 | VT | 75 | 626 | Vermont | 0 | 1 |
| 823 | 2017 | WA | 1890 | 5804 | Washington | 8 | 27 |
| 842 | 2017 | WV | 350 | 1705 | West Virginia | 1 | 10 |
| 856 | 2017 | WY | 36 | 549 | Wyoming | 0 | 1 |
| 872 | 2017 | DC | 135 | 8 | District of Columbia | 1 | 1 |
| 890 | 2017 | WI | 3604 | 4106 | Wisconsin | 6 | 15 |
| 892 | 2017 | FL | 12 | 7 | Florida | 19 | 43 |
OK, time to calculate the correlation coefficients between arrests and lethal force fatalities, as we did before:
```
df_corr = df_arrests_fenc.loc[:, ['white_arrests', 'black_arrests',
'white_uof', 'black_uof']].corr(method='pearson').iloc[:2, 2:]
df_corr.style.background_gradient(cmap='PuBu')
```
| | white\_uof | black\_uof |
| --- | --- | --- |
| white\_arrests | **0.872766** | 0.622167 |
| black\_arrests | 0.702350 | **0.766852** |
Again we've produced quite good correlations: **0.87** for Whites and **0.77** for Blacks. It's curious that these values are very close to those we obtained for All Offenses in the previous part of the article (**0.88** for Whites and **0.72** for Blacks).
What about our 'offender shootdown' index? Let's check:
```
df_arrests_fenc['white_uof_by_arr'] = df_arrests_fenc['white_uof'] /
df_arrests_fenc['white_arrests']
df_arrests_fenc['black_uof_by_arr'] = df_arrests_fenc['black_uof'] /
df_arrests_fenc['black_arrests']
df_arrests_fenc.replace([np.inf, -np.inf], np.nan, inplace=True)
df_arrests_fenc.fillna({'white_uof_by_arr': 0, 'black_uof_by_arr': 0}, inplace=True)
```
To see how this index is distributed geographically, let's take the 2018 data point:
```
plt = df_arrests_fenc.loc[df_arrests_fenc['year'] == 2018,
['state_name', 'white_uof_by_arr', 'black_uof_by_arr']].\
sort_values(by='state_name', ascending=False).\
plot.barh(x='state_name', color=['g', 'olive'], figsize=(10, 20))
plt.set_ylabel('')
plt.set_xlabel('Ratio of UOF victims to violent crimes (2018)')
```
**Tall image again**
[](https://habrastorage.org/webt/vn/jw/5a/vnjw5agwbt7mq1u_thhpq1yisje.jpeg)
The index for Whites is greater in most states, with some exclusions (Utah, West Virginia, Kansas, Idaho, and District Columbia).
Let's compare the values for Whites and Blacks averaged for all the states:
```
plt = df_arrests_fenc.loc[:, ['white_uof_by_arr', 'black_uof_by_arr']].\
mean().plot.bar(color=['g', 'olive'])
plt.set_ylabel('Ratio of UOF victims to violent crimes (2018)')
plt.set_xticklabels(['White', 'Black'], rotation=0)
```
[](https://habrastorage.org/webt/qt/9z/gj/qt9zgjagyh_dghmvfhvesu37dp4.jpeg)
The index is **2.5 times greater** for Whites than for Blacks. If this index really says something, it means that a White criminal is on average 2.5 times more likely to meet death from the police than a Black criminal. Of course, this index varies much from state to state: for example, in Idaho a Black criminal is twice as likely to become a law enforcement victim, whereas in Mississippi — four times less likely.
Well, that's it really. Time to summarize our research.
Conclusions
-----------
1. In the US, criminality is a function of population. The most 'criminal' states that we are used to watching movies or read about are simply the most populated. When analyzing per capita crime rates, the top positions are taken by some quite unexpected states like Alaska, District Columbia (with Washington City) and New Mexico.
2. Southern states are on average more criminal than Northern states (in per capita crime values).
3. Per capita crimes and arrests are unevenly distributed among the US white and black populations: black persons commit 3 times more crimes and are 5 times more often arrested than white persons.
4. A black person is on average 2.5 times more likely to get killed in an encounter with law enforcement than a white person.
5. Lethal force fatalities correlate well with criminality: the higher the crime rate, the more people get killed by the police. This correlation holds true for most states and for both races, although it is somewhat more pronounced among the white population. This is also confirmed by the difference in the victim-to-crime ratio between the races: white criminals are more likely to get killed by the police.
As a final word, I'd like to say thanks to my readers for their valuable comments and advice.
**P.S.** In a future (separate) article I am planning to continue analyzing crime and its connection with race in the US. We can first look into hate crimes and then discuss the law enforcement / offender interfaces from a reversed point of view, investigating line-of-duty fatalities among US police officers. I'd appreciate if you let me know in the comments if this subject is of interest. | https://habr.com/ru/post/519640/ | null | null | 6,861 | 50.53 |
- Defining a Process
- Process Attributes
- Process Information
- Process Primitives
- Simple Children
- Sessions and Process Groups
- Introduction to ladsh
- Creating Clones
10.6 Sessions and Process Groups
In Linux, as in other Unix systems, users normally interact with groups of related processes. Although they initially log in to a single terminal and use a single process (their shell, which provides a command-line interface), users end up running many processes as a result of actions such as
- Running noninteractive tasks in the background
- Switching among interactive tasks via job control, which is discussed more fully in Chapter 15
- Starting multiple processes that work together through pipes
- Running a windowing system, such as the X Window System, which allows multiple terminal windows to be opened
In order to manage all of these processes, the kernel needs to group the processes in ways more complicated than the simple parent-child relationship we have already discussed. These groupings are called sessions and process groups. Figure 10.1 shows the relationship among sessions, process groups, and processes.
Figure 10.1 Sessions, Process Groups, and Processes
10.6.1 Sessions.
#include <unistd.h> pid_t setsid(void);
10.6.2 Controlling Terminal (see Chapter 16 for information on pseudo terminal devices). The terminal to which a session is related is called the controlling terminal (or controlling tty) of the session. A terminal can be the controlling terminal for only one session at a time.
Although the controlling terminal for a session can be changed, this is usually done only by processes that manage a user's initial logging in to a system. Information on how to change a session's controlling tty appears in Chapter 16, on pages 338-339.
10.6.3 Process Groups
One of the original design goals of Unix was to construct a set of simple tools that could be used together in complex ways (through mechanisms like pipes). Most Linux users have done something like the following, which is a practical example of this philosophy:
ls | grep "^[aA].*\.gz" | more
Another popular feature added to Unix fairly early was job control. Job control allows users to suspend the current task (known as the foreground task) while they go and do something else on their terminals. When the suspended task is a sequence of processes working together, the system needs to keep track of which processes should be suspended when the user wants to suspend "the" foreground task. Process groups allow the system to keep track of which processes are working together and hence should be managed together via job control.
Processes are added to a process group through setpgid().
int setpgid(pid_t pid, pid_t pgid);
pid is the process that is being placed in a new process group (0 may be used to indicate the current process). pgid is the process group ID the process pid should belong to, or 0 if the process should be in a new process group whose pgid is the same as that process's pid. Like sessions, a process group leader is the process whose pid is the same as its process group ID (or pgid).
The rules for how setpgid() may be used are a bit complicated.
- A process may set the process group of itself or one of its children. It may not change the process group for any other process on the system, even if the process calling setpgid() has root privileges.
- A session leader may not change its process group.
- A process may not be moved into a process group whose leader is in a different session from itself. In other words, all the processes in a process group must belong to the same session.
setpgid() call places the calling process into its own process group and its own session. This is necessary to ensure that two sessions do not contain processes in the same process group.
A full example of process groups is given when we discuss job control in Chapter 15.
When the connection to a terminal is lost, the kernel sends a signal (SIGHUP; see Chapter 12 for more information on signals) to the leader of the session containing the terminal's foreground process group, which is usually a shell. This allows the shell to terminate the user's processes unconditionally, notify the processes that the user has logged out (usually, through a SIGHUP), or take some other action (or inaction). Although this setup may seem complicated, it lets the session group leader decide how closed terminals should be handled rather than putting that decision in the kernel. This allows system administrators flexibile control over account policies.
Determining the process group is easily done through the getpgid() and getpgrp() functions.
pid_t getpgid(pid_t pid)
Returns the pgid of process pid. If pid is 0, the pgid of the current process is returned. No special permissions are needed to use this call; any process may determine the process group to which any other process belongs.
pid_t getpgrp(void)
Returns the pgid of the current process (equivalent to getpgid(0)).
10.6.4 Orphaned Process Groups
The mechanism for how processes are terminated (or allowed to continue) when their session disappears is quite complicated. Imagine a session with multiple process groups in it (Figure 10.1 may help you visualize this). The session is being run on a terminal, and a normal system shell is the session leader.
When the session leader (the shell) exits, the process groups are left in a difficult situation. If they are actively running, they can no longer use stdin or stdout as the terminal has been closed. If they have been suspended, they will probably never run again as the user of that terminal cannot easily restart them, but never running means they will not terminate either.
In this situation, each process group is called an orphaned process group. POSIX defines this as a process group whose parent is also a member of that process group, or is not a member of that group's session. This is another way of saying that a process group is not orphaned as long as a process in that group has a parent in the same session but a different group.
While both definitions are complicated, the concept is pretty simple. If a process group is suspended and there is not a process around that can tell it to continue, the process group is orphaned. [18]
When the shell exits, any of its child programs become children of init, but stay in their original session. Assuming that every program in the session is a descendant of the shell, all of the process groups in that session become orphaned. [19] When a process group is orphaned, every process in that process group is sent a SIGHUP, which normally terminates the program. Programs that have chosen not to terminate on SIGHUP are sent a SIGCONT, which resumes any suspended processes. This sequence terminates most processes and makes sure that any processes that are left are able to run (are not suspended). [20]
Once a process has been orphaned, it is forcibly disassociated from its controlling terminal (to allow a new user to make use of that terminal). If programs that continue running try to access that terminal, those attempts result in errors, with errno set to EIO. The processes remain in the same session, and the session ID is not used for a new process ID until every program in that session has exited. | https://www.informit.com/articles/article.aspx?p=397655&seqNum=6 | CC-MAIN-2020-29 | refinedweb | 1,244 | 67.79 |
Notice: On April 23, 2014, Statalist moved from an email list to a forum, based at statalist.org.
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Re: st: weights
--- On Wed, 27/10/10, Chiara Mussida wrote:
> thanks Maarten, by using sum <snip> How to get a total sum,
> not only for the householdin the sample, but representative
> for all household (=weight)?
di r(sum)
If you want to store it I would do so in a scalar. A variable
would be inefficient as it usses too much memory and a local
is not so precise. The latter can be important as now you
are dealing with an extremely large number, which is where
precision can become an issue. Generally I would first
create a tempname and use that tempname for the scalar to
avoid any problems due to the fact that scalars and variables
share the same namespace:
tempname sum
scalar `sum' = r(sum)
Hope this helps,
Maarten
--------------------------
Maarten L. Buis
Institut fuer Soziologie
Universitaet Tuebingen
Wilhelmstrasse 36
72074 Tuebingen
Germany
--------------------------
*
* For searches and help try:
*
*
* | https://www.stata.com/statalist/archive/2010-10/msg01098.html | CC-MAIN-2022-05 | refinedweb | 181 | 63.63 |
I am working on a simple project in which a tab delimited text file is read into a program.
My problem:
When reading the text file there are regularly empty data spaces. This lack of data is causing an unexpected output. For lines that do not have data in the token[4] position all data read is ignored and "4" is displayed when I run a System.out.println(Just a test that the data is being read properly). When I incorporate a value in the token[4] position the data reads fine. It is not acceptable that I input a value in the token[4] position. See below for file and code.
2014 Employee Edward Rodrigo 6500
2014 Salesman Patricia Capola 5600 5000000
2014 Executive Suzy Allen 10000 55
2015 Executive James McHale 12500 49
2015 Employee Bernie Johnson 5500
2014 Salesman David Branch 6700 2000000
2015 Salesman Jonathan Stein 4600 300000
2014 Executive Michael Largo 17000 50
2015 Employee Kevin Bolden 9200
2015 Employee Thomas Sullivan 6250
// Imports are here
import java.io.*;
import java.util.*;
public class EmployeeData {
public static void main(String[] args) throws IOException {
// Initialize variables
String FILE = "employees.txt"; // Constant for file name to be read
ArrayList<Employee> emp2014; // Array list for 2014 employees
ArrayList<Employee> emp2015; // Array list for 2015 employees
Scanner scan;
// Try statement for error handling
try {
scan = new Scanner(new BufferedReader(new FileReader(FILE)));
emp2014 = new ArrayList();
emp2015 = new ArrayList();
// While loop to read FILE
while (scan.hasNextLine()) {
String l = scan.nextLine();
String[] token = l.split("\t");
try {
String year = token[0];
String type = token[1];
String name = token[2];
String monthly = token[3];
String bonus = token[4];
System.out.println(year + " " + type + " " + name + " " + monthly + " " + bonus);
} catch (Exception a) {
System.out.println(a.getMessage());
}
}
} catch(Exception b) {
System.out.println(b.getMessage());
}
}
}
run:
4
2014 Salesman Patricia Capola 5600 5000000
2014 Executive Suzy Allen 10000 55
2015 Executive James McHale 12500 49
4
2014 Salesman David Branch 6700 2000000
2015 Salesman Jonathan Stein 4600 300000
2014 Executive Michael Largo 17000 50
4
4
BUILD SUCCESSFUL (total time: 0 seconds)
This is happening because you are actually getting an
ArrayOutOfBoundsException and the message for that is '4'. Because the index of 4 is greater than the length of the array. You should put in your catch statement
b.printStackTrace() as this will give you greater details when ever the caught exception occurs.
You can get around this by adding the following:
String bonus = ""; if(token.length > 4) bonus = token[4]; | https://codedump.io/share/frYBVeTzczxu/1/read-tab-delimited-file-and-ignore-empty-space | CC-MAIN-2017-34 | refinedweb | 419 | 54.02 |
By Shivprasad koirala.
IntroductionQuestion 1 :-What are Special Collections?Question 2:-How do we do security in WCF?Question 3:-How do you do Self-Hosting?Question 4:-What is WSDL?Question 5:-What is Cross Join and in which scenario do we use Cross Join?Question 6:-How does index makes search faster?Question 7:-What coding standards did you followed your projects ?Question 8:-Why is stringbuilder concatenation more efficient than simple string concatenation?Question 9 :-How do we write a HttpHandler ?Question 10:- What is the difference between render and prender event ?Question 11:-What is SOAP?Question 12:-What are different types of Validators?Question 13:-Why do we need Sessions?Question 14:-How to cache an ASP.NET page?Question 15:-What are the diferences between INNER JOIN, LEFT JOIN and RIGHT JOIN in SQL Server?Question 16:-Who is faster hashtable or dictionary ?Question 17:-What role did your play in your current project?Question 18:-If A class inherits from multiple interfaces and the interfaces have same method names. How can we provide different implementation?.
Lets continue with the 3rd part of 18 .NET interview question series. If you want to see the past 2 articles you can visit for part 1 at and for part 2 at
In this part we will see some important questions on SQL , WCF and ASP.NET
Do view my 500 videos on .NET , C# , WCF , Silverlight , design patterns , ASP.NET , UML by click on .NET interview questions
If you want to have a overview of what kind of questions are asked in .NET interviews do click on this link where i have discussed from overall view of different questions asked during .NET and C# interviews,
If you want to understand the physcology of how .NET interviewer conducts interviewer click on this link
Hashtable ObjHash = CollectionsUtil.CreateCaseInsensitiveHashtable();
ObjHash.Add("feroz","he is a developer");
string str = (string) ObjHash["FEROZ"];
MessageBox.Show(str);
2. ListCollection:-Good for Collections that typically contain less number of elements.
Example:-
ListDictionary ObjDic = new ListDictionary();
ObjDic.Add("feroz", "he is a developer");
ObjDic.Add("moosa", "he is a developer");
HybridDictionary ObjHybrid = new HybridDictionary();
ObjHybrid.Add("feroz", "he is a developer");
ObjDic.Add("Wasim", "he is a network administrator");
ObjDic.Add("moosa", "he is a hardware engineer");
Transport Security:Message level security is implemented with message data itself. Due to this it is independent of the protocol. Some of the common ways of implementing message level security is by encrypting data using some standard encryption algorithm.
Below Diagram illustrate the concept of security in WCF.
Step1: //Create a URI to serve as the base address // Address as well binding
Uri httpUrl = new Uri("");
Step2: //Create ServiceHost
ServiceHost host = new ServiceHost(typeof(ClassLibrary1.HelloWorldService),httpUrl);
Step3: //Add a service endpoint
host.AddServiceEndpoint(typeof(ClassLibrary1.IHelloWorldService) , new WSHttpBinding(), "");
Step4: //Enable metadata exchange
ServiceMetadataBehavior smb = new ServiceMetadataBehavior();
smb.HttpGetEnabled = true;
host.Description.Behaviors.Add(smb);
Step5: //Start the Service
host.Open();
Step6:
Console.WriteLine("Service is host at " + DateTime.Now.ToString());
Console.WriteLine("Host is running... Press key to stop");
Console.ReadLine();
To see how WSDL look like, just go to Visual Studio create a webservice and run .asmx file you will see the output like below diagram and when you click on service description then the WSDL will be seen.
-"
xmlns:tm=""
xmlns:soapenc=""
xmlns:mime=""
xmlns:tns="" xmlns:s=""
xmlns:soap12=""
xmlns:http=""
targetNamespace=""
xmlns:
-
-">
-
-
-
-
+
-
-
For Example:- We have following two tables.
Look at the "Product" table:
Note that the "P_Id" column is the primary key in the "Product" table.
Next, we have the "SubProduct" table:
Note that the "Sub_Id" column is the primary key in the "SubProduct" table.
There are lots of scenarios where we use the cross join(permutation and combination), below are the example of hotel where customer's gets the detail of combined product and its total cost, So that it is easy to select their respective choice.
Query:- select Product.ProductName,SubProduct.SubProductName,(Product.Cost+SubProduct.Cost)as TotalCost from Product cross join SubProduct
The output look like below:For obejct.string str = "shiv";
/* The below line of code creates three copies of string object one for the concatenation at right hand side and the other for new value at the left hand side. The first old allocated memory is sent for garbage collection.*/str = str + "shiv";("shiv");.
First create a class which implements Ihttphandler
public class clsHttpHandler : IHttpHandler{
public bool IsReusable { get { return true; } }
public void ProcessRequest(HttpContext context) { // Put implementation here. }}
Step 2 make a entry in the web.config file.
1- First the ASP.NET UI objects are saved in to view state. 2- loaded viewstate is assembled to create the final HTML.
The first step is pre-render event and the second step is the render event.
Prerender
This is the event in which the objects will be saved to viewstate.This makes the PreRender event the right place for changing properties of controls or changing Control structure.Once the PreRender phase is done those changes to objects are locked in and the viewstate can not be changed. The PreRender step can be overridden using OnPreRender event.
Render.
Render event assembles the HTML so that it can be sent to the browser.In Render event developers can write custom HTML and override any HTML which is created till now.The Render method takes an HtmlTextWriter object as a parameter and uses that to output HTML to be streamed to the browser. Changes can still be made at this point, but they are reflected to the client only i.e. the end browser.
The below diagram dipicts an simple request and response using SOAP.
IN ASP.NET there are six different types of Validators.
Required Field Validator.Regular Expression Validator.Compare Validator.Range Validator.CustomValidator.Validation Summary
RequiredFieldValidator:-Ensure that the control has a value to assign in it or user does not skip an entry.
For Example:-
RegularExpressionValidator:-Ensure that the value of the control matches the expression of validator that is specified.This type of validation enables you to check for sequence of character, such as e-mail address,telephone number,postal code and so on.
// for internet E-Mail.
CompareValidator:-Ensure that the value of one control should be equal to value of another control.which is commonly used in password,less than,greater than or equal to.
For Example:-
RangeValidator:-Ensures that the value of the control is in specified lower and upper boundaries or specified range. You can check ranges within pairs of numbers, alphabetic characters.
>
CustomValidator:-This control is used to perform user defined validations.
ValidationSummary:-This validator is used to displays a detailed summary on the validation errors that currently exist.
Answer:.Below is the diagram to understand in better manner.In the above example, when the user request the IIS server for the Page1.aspx then the request is broadcasted to the user/client browser and the connection is broken, Now when the same user request the IIS server for the Page2.aspx then again the request is broadcasted to the user/client browser but this time again the same user is treated as a new user as the connection was broken by IIS server after displaying the Page1.aspx page.Note:-So every single time a new request is made the same user is treated as a new one, so in order to maintain this we need Sessions..
Create a new table as"Customers":
Note that the "Cust_Id" column is the primary key in the "Customers" table.This means that no two rows can have the same Cust_Id.The Cust_Id distinguishes two persons even if they have the same name.Next, we have the "Orders" table:
Note that the "Order_Id" column is the primary key in the "Orders" table and that the "Cust_Id" column refers to the persons in the "Customers" table without using their names.
Notice that the relationship between the two tables above is the "Cust_Id" column.
LEFT JOIN: Return all rows from the left table, even if there are no matches in the right table.For Example:- The Following is the example for LEFT JOIN:
Considering the above two tables:
Query:- Select * from Customers left join Orders on Customers.Cust_Id = Orders.Cust_Id
The output will look like following:
RIGHT JOIN: Return all rows from the right table, even if there are no matches in the left table.For Example:- The Following is the example for RIGHT JOIN:
Query:- Select * from Customers right join Orders on Customers.Cust_Id = Orders.Cust_Id
INNER JOIN: The INNER JOIN keyword return rows when there is at least one match in both tables.For Example:- The Following is the example for RIGHT JOIN:Considering the above two tables:
Query:- Select * from Customers inner join Orders on Customers.Cust_Id = Orders.Cust_Id
Below goes the same code for hashtable and dictionary.
Hashtable hashtable = new Hashtable();hashtable[1] = "One";hashtable[2] = "Two";hashtable[13] = "Thirteen";
var dictionary = new Dictionary();dictionary.Add(i.ToString("00000"), 10);dictionary.Add(i.ToString("00000"), 11);
In todays world people expect professionals who can do multitasking. The best way to approach the answer is by explaining what things did you do in the complete SDLC cycle. Below goes my version of the answer , you can tailor the same as per your needs.
My main role in the project was coding , unit testing and bug fixing. Said and done that i was involved in all phases of the project. I worked with the business analyst in the requirement phase to gather requirements and was a active member in writing use cases. I also assisted the technical architect in design phase. In design phase i helped the architect in proof of concept and putting down the technical design document.My main role was in coding phase where i executed project with proper unit testing.In system integration test and UAT i was actively involved in bug fixing.
Other than the project i help COE team for any kind of RND and POC work.
In case you are doing some extra activities in the company like helping COE , presales team or any other initative do speak about the same."); } }
Hall of Fame Twitter Terms of Service Privacy Policy Contact Us Archives Tell A Friend | http://www.dotnetspark.com/kb/4165-18-most-asked-net--c-sharp--interview-questions.aspx | CC-MAIN-2017-09 | refinedweb | 1,712 | 58.48 |
Video Recording is too fast
Please note I am duplicating this questions because I did not get the answer I am seeking for.
Please have a look at the following code.
#include <iostream> #include <opencv2/core/core.hpp> #include <string> #include <opencv2/imgproc/imgproc.hpp> #include <opencv2/highgui/highgui.hpp> #include <opencv2/imgproc/imgproc.hpp> #include <opencv2/video/background_segm.hpp> using namespace std; using namespace cv; double getMSE(const Mat& I1, const Mat& I2); int main() { Mat current; VideoCapture cam1; VideoWriter *writer = new VideoWriter(); cam1.open(0); namedWindow("Normal"); if(!cam1.isOpened()) { cout << "Cam not found" << endl; return -1; } cam1>>current; Size *s = new Size((int)current.cols,current.rows); writer->open("D:/OpenCV Final Year/OpenCV Video/MyVideo.avi",CV_FOURCC('D','I','V','X'),10,*s,true); while(true) { //Take the input cam1 >> current; *writer << current; imshow("Normal",current); if(waitKey(30)>=0) { break; } } }
This code runs fine, no issue. But, when I run the recorded video, it is super fast! Like it is fast forwarded. I really do not understand why. Please help.
In the previous question I was advised to use
usleep() and I coudn't find it so I used
Sleep(). But I got the same results! Anyway this is a real time application, so video should be displayed to the user real time. Using such methods disturb how the video is shown because video also displayed to the user after the specified number of milliseconds. you know, it is like watching a movie which gets stuck always.
Please help. | http://answers.opencv.org/question/16522/video-recording-is-too-fast/ | CC-MAIN-2019-13 | refinedweb | 254 | 69.48 |
Dave Love <address@hidden> writes: >>>>>> "KH" ==. As I'm not Autoconf expert, I don't know the difference. It seems that HPUX 10.20 supplies two sets of X (X11R5 and X11R6). In addition, for Xaw and Xmu, it has these files. /usr/contrib/X11R6/lib/Xaw.a, /usr/contrib/X11R6/lib/Xmu.a, /usr/lib/X11R6/llib-lXaw.ln, /usr/lib/X11R4/libXaw.sl, /usr/lib/X11R6/llib-lXmu.ln, /usr/lib/X11R4/libXmu.sl, (I have no idea about HPUX's file name convertion). And, it seems that the definition of C_SWITCH_X_SYSTEM and LD_SWITCH_X_DEFAULT in hpux10.h was a workaround for a bug in configure. But, I think fixing configure at this moment is very dangerous, and it seems better to fix the workaround works for HPUX 10.20 (and also for HPUX 11) is better. By the way, I found another problem in hpux9.h and configure. It has this code: #ifndef HAVE_LIBXMU /* HP-UX doesn't supply Xmu. */ #define LIBXMU #endif But, (1) configure doesn't define HAVE_LIBXMU, (2) HPUX10.20 surely supplies Xmu. So, if I configure emacs with --without-gcc --with-x-toolkit=athena (we need this argument because the current configure can't find Athena support on HPUX), compilation fails as below: /usr/ccs/bin/ld: (Warning) At least one PA 2.0 object file (dispnew.o) was detected. The linked output may not run on a PA 1.x system. /usr/ccs/bin/ld: Unsatisfied symbols: XmuConvertStandardSelection (code) _XA_LENGTH (data) XmuRegisterExternalAgent (code) XmuCvtStringToShapeStyle (code) _XEditResCheckMessages (code) XmuCvtStringToCursor (code) [...] ... because, src/Makefile.in has this line: #ifndef LIBXMU #define LIBXMU -lXmu #endif and as LIBXMU is already defined as NULL, ld doesn't get -lXmu arg. I could compile Emacs by adding this workaround in hpux10.h. #ifndef HAVE_LIBXMU #ifdef LIBXMU #undef LIBXMU #endif #endif My conclusion is that the current configuration for HPUX is severely broken. :-( All I can do is to try Emacs on HPUX 10.20 in a very adhoc way as above. I think we must find someone who knows HPUX 9, 10, and 11 well and can test Emacs on them. > Do other autoconf'ed programs which use X get this right > on HP-UX? Do you have any recomended X program to test? --- Ken'ichi HANDA address@hidden | http://lists.gnu.org/archive/html/emacs-devel/2000-11/msg00181.html | CC-MAIN-2014-15 | refinedweb | 381 | 60.31 |
would be very interested in Matlab wrapping as well. Please post to the
list any information you discover.
-dan
On 7/13/11 8:19 AM, "Joel Andersson" <joel.andersson@...>
wrote:
>
--
Daniel Blezek, PhD
Medical Imaging Informatics Innovation Center
P 127 or (77) 8 8886
T 507 538 8886
E blezek.daniel@...
Mayo Clinic
200 First St. S.W.
Harwick SL-44
Rochester, MN 55905
mayoclinic.org
"It is more complicated than you think." -- RFC 1925
Hi all,
I have some C++ code that implements a data messaging system between
processes, and from which I am generating a python wrapper using swig.
90% of the time this is all working fine. In two instances though I
have seen a problem where a variable passed into python contains
garbage values, rather than the expected vector of zeros. The
weirdness is that if I, in python, convert the data into a numpy array
AND print that array, then I get the values I expect. I've tried this
with only one of either using np.asarray or the print, but the "fix"
only works with both. Obviously I'd like to not have to depend on a
print statement to get my values out.
Here's a little code python code snippet to show what I mean:
################
import numpy as np
# this is just data format declarations
import RTMA_config as rc
# these are the swig-wrapped messaging interface
from PyRTMA import RTMA_Module, CMessage, copy_from_msg
def setup_RTMA(server):
mod = RTMA_Module(rc.MID, 0)
mod.ConnectToMMM(server)
mod.Subscribe(rc.MT_DATA)
mod.SendModuleReady()
print "Connected to RTMA at", server
return mod
def run(mod):
while True:
msg = CMessage()
rcv = mod.ReadMessage(msg, 0.1)
if rcv == 1:
process_message(msg)
def process_message(msg):
if msg.GetHeader().msg_type == rc.MT_DATA:
data = rc.MDF_DATA()
copy_from_msg(data, msg)
#print "A", np.asarray(data.dof_vals[:]) # this is the
critical line -> put this in and the next line works
print "B", data.dof_vals[:] # shows
garbage values without previous line, or 0s with it
server = 'localhost:7111'
mod = setup_RTMA(server)
run(mod)
################
copy_to_msg is defined in PyRTMA.i as:
%pythoncode %{
from ctypes import memmove, addressof, sizeof
def copy_from_msg(data, cmsg):
memmove(addressof(data), cmsg.data, sizeof(data))
%}
Does anyone have any idea what might be causing my particular issue,
or how I should go about debugging it?
Thanks,
Angus.
--
AJC McMorland
Post-doctoral research fellow
Neurobiology, University of Pittsburgh
On Wed, 13 Jul 2011 15:19:40 +0200 Joel Andersson <joel.andersson@...> wrote:
JA> Is there some way to use SWIG to generate a C interface to C++ code?
There is a branch with the C backend in SWIG svn (called gsoc2008-maciekd)
but I don't know what is its state. I'm curious myself about it but just
didn't have time to test it yet.
Concerning Matlab, we allowed using our C++ library from it via its
support for COM. Of course, we also had a tool for generating COM wrappers
for C++ code while SWIG can't do it directly, the only possibility (and one
that I'm going to test soon) is to use C# backend and then COM Interop.
But then, again, there is a branch in SWIG svn containing code for COM
backend (gsoc2008-jezabek). Unfortunately I don't know about its state
neither.
Please let us know about your experience if you test either of these
branches.
Thanks,
VZ
--
Joel Andersson, PhD Student
Electrical Engineering Department (ESAT-SCD), Room 05.11,
K.U.Leuven, Kasteelpark Arenberg 10 - bus 2446, 3001 Heverlee, Belgium
Phone: +32-16-321819
Mobile: +32-486-672874 (Belgium) / +34-63-4452111 (Spain) / +46-727-365878
(Sweden)
Private address: Weidestraat 5, 3000 Leuven, Belgium
On 07/07/11 22:29, Joris Gillis wrote:
>> From: William Fulton
>>> (A): How long would it take for such a patch to make it into SWIG?
>> Would it be backported to SWIG 1.3 too? Would a patched version reach
>> the ubuntu repositories of Natty? What about Lucid LTS?
>>>
>> As long as it takes Xavier to look at it and commit it to trunk. We
>> normally release a new version every few weeks. However, when the
>> distributions take new releases from us is entirely up to them. Ubuntu
>> usually take from Debian so best to get Debian to upgrade. However, I
>> havn't ever noticed Ubuntu patch SWIG in their distributed versions in
>> the past. You'll need to persuade them.
>>
>
>
>> If you copy octrun.swg into the directory that your interface file is
>> in
>> or into a subdirectory called swig_lib and modify, then SWIG will use
>> that version instead of the distributed one. Using swig -v shows the
>> order in which the include paths are searched. You can add in -I too of
>> course.
>>
>> Your problem then becomes one of making sure your version of octrun.swg
>> works with whichever version of SWIG your users have installed. You
>> could ship different versions and use the SWIGVERSION macro for version
>> specific code. You can add the following (possibly inside the
>> SWIGVERSION macro) into your version of octrun.swg to load the default
>> one:
>>
>> %include "octave/octrun.swg"
>
> Thank you very much sir,
>
> Your pointer to SWIG's notion of search paths is invaluable. This will be a short-term solution for us.
>
> Now to come up with some mechanism to do a 'swig -co' and applying a patch live in the build system.
> Our software is LGPL, while SWIG is GPL, so just including a verbatim copy of whole of octrun.swg is probably no option, right?
Please read the license page -. There is
a disconnect between the SWIG source and the code you feed into SWIG.
octrun.swg is part of the SWIG library code and is permissively licensed.
I suggest you put your patch into the SourceForge patch system when you
are happy with it.
William
On 07/07/11 03:06, Aubrey Barnard wrote:
> Greetings Swig users,
>
> It appears that the Python distutils does not install the Python module
> generated by Swig. Does anybody know a correct solution or a workaround?
>
> Here is the scenario. Imagine I have foo.c and foo.i. A setup.py would
> be like the following:
> ----------------------------------------
> from distutils.core import setup, Extension
> setup(name='foo',
> py_modules=['foo'],
> ext_modules=[
> Extension(
> name='_foo',
> sources=[
> 'foo.i',
> 'foo.c',
> ),
> ],
> )
> ----------------------------------------
>
> Running "python setup.py install --user" produces:
> $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
> running install
> running build
> running build_py
> file foo.py (for module foo) not found
> file foo.py (for module foo) not found
> running build_ext
> building '_foo' extension
> swigging foo.i to foo_wrap.c
> swig -python -o foo_wrap.c foo.i
> creating build
> creating build/temp.linux-x86_64-2.7
> creating build/src
> gcc ...
> running install_lib
> copying build/lib.linux-x86_64-2.7/_foo.so ->
> ~/.local/lib/python2.7/site-packages
> running install_egg_info
> Writing ~/.local/lib/python2.7/site-packages/foo-0.1-py2.7.egg-info
> $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
>
> Distutils is trying to install foo.py before Swig generates it.
>
> Running the above command again produces:
> $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
> running install
> running build
> running build_py
> copying foo.py -> build/lib.linux-x86_64-2.7
> running build_ext
> running install_lib
> copying build/lib.linux-x86_64-2.7/_foo.so ->
> ~/.local/lib/python2.7/site-packages
> copying build/lib.linux-x86_64-2.7/foo.py ->
> ~/.local/lib/python2.7/site-packages
> byte-compiling ~/.local/lib/python2.7/site-packages/foo.py to foo.pyc
> running install_egg_info
> Removing ~/.local/lib/python2.7/site-packages/foo-0.1-py2.7.egg-info
> Writing ~/.local/lib/python2.7/site-packages/foo-0.1-py2.7.egg-info
> $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
>
> Can the same build/installation results be accomplished without running
> Distutils twice? (I would feel really silly putting instructions to that
> effect into the README.) The larger concern is that Distutils copies the
> old foo.py when rebuilding which is simply the wrong behavior for this
> scenario.
>
> I've tried listing foo.py as a data file, but it won't install alongside
> _foo.so without me specifying the exact path which is not general enough
> for arbitrary installs.
>
> Extra information:
> Swig 2.0.1
> Python 2.7
>
> I can take this issue to the Distutils list if needed, but I figured
> this list has more Distutils-Swig expertise and that somebody here has
> run across this issue before.
This looks like it is entirely a distutils problem and although people
here may use distutils, you will probably get more luck approaching a
distutils specific list.
William | https://sourceforge.net/p/swig/mailman/swig-user/?viewmonth=201107&viewday=13 | CC-MAIN-2018-22 | refinedweb | 1,397 | 59.09 |
Howdy! Last week I had the pleasure of increasing my curliness by a 3x factor thanks to the moist Orlando weather, which I visited for delivering a session on what’s new with WIF in the .NET framework 4.5. I also took advantage of the occasion for having detailed conversations with many of you guys, which is always a fantastic balsam to counter the filter bubble that enshrouds me when I spend too long in Redmond. Thank you!
Giving the talk was great fun, and a source of great satisfaction. If you follow this blog since the first days, you know that I’ve been (literally
) preaching this claims-based identity religion for many many years, and seeing how deep it is being wedged in the platform and how mainstream it became… well, it’s an incredible feeling.
I was also impressed by the turnover: despite it being awfully, awfully early in the morning (8:30am in Orlando time is 5:30am in Redmond time) you guys showed up on time, filled the room, gave me your attention (yes, I can see you even if they shoot a lot of MegaLumens straight in my face) and followed up with great questions. Thank you!!!
Well, as you already guessed from the title of the post, I am writing this because the recording of the talk is now up and available on channel9 for your viewing pleasure (if you can stomach my Italian-Genovese-English accent, that is). The deck is not up yet (as usual I turned it in AFTER the talk
) but should be shortly.
Here there’s a quick summary of the topics touched:
- WIF1.0 vs. WIF in .NET 4.5
- ClaimsIdentity’s role in the .NET classes hierarchy
- Improvements in accessing claims
- Class movements across namespaces
- Config elements movements across sections
- Web Farms and sessions
- Win8 claims
- Misc improvements
- The new tools: design & capabilities
- New samples
- Using WIF to SSO from Windows Azure Active Directory to your own web applications
If that sounds like a tasty menu, dive right in! Also note, this morning we released the refresh of the WIF tools for Visual Studio 2012 RC hence you can experience firsthand all the things you’ll see in the video.
Alrighty. Next week I will show up for a short 2 days at TechEd EU in Amsterdam: if you are around and you want to have a chat, please come find me. As usual, have fun!
Hi Vittorio,
Last year Microsoft released a CTP of SAML-P 2.0 support for WIF. Is it planned to be supported in WIF 4.5 ?
Kind regards,
oblabla | https://blogs.msdn.microsoft.com/vbertocci/2012/06/19/the-recording-of-whats-new-in-wif-4-5-from-teched-usa-is-live/ | CC-MAIN-2016-40 | refinedweb | 440 | 64.54 |
Zuul v3 Migration Guide¶
This is a temporary section of the Infra Manual to assist in the conversion to Zuul v3. Some of the content herein will only be relevant before and shortly after we move from Zuul v2 to v3.
What is Zuul v3?¶
Zuul v3 is the third major version of the project gating system developed for use by the OpenStack project as part of its software development process. It includes several major new features and backwards incompatible changes from previous versions.
It was first described in the Zuul v3 spec.
In short, the major new features of interest to OpenStack developers are:
In-repo configuration
Native support for multi-node jobs
Ansible job content
Integration with more systems
We’re pretty excited about Zuul v3, and we think it’s going to improve the development process for all OpenStack developers. But we also know that not everyone needs to know everything about Zuul v3 in order for this to work. The sections below provide increasing amounts of information about Zuul v3. Please at least read the first section, and then continue reading as long as subsequent sections remain relevant to the way you work.
What’s the Minimum I Need to Know?¶
You have stuff to do, and most of it doesn’t involve the CI system, so this will be short.
The name of the CI system will be changing¶
For varied historical reasons, the name OpenStack’s CI system used to report to Gerrit has been Jenkins, even 5 years after it actually became Zuul doing the reporting and 1 year after we stopped using Jenkins altogether. We’re finally changing it to Zuul. If you see a comment from Jenkins, it’s Zuul v2. If you see a comment from Zuul, it’s Zuul v3.
Job names will be changing¶
In Zuul v2, almost every project has a unique
python27 job. For
example,
gate-nova-python27. In v3, we will have a single python27
job that can be used for every project. So when Zuul reports on your
changes, the job name will now be
openstack-py27 rather than
gate-project-python27.
For details about job names, see Consistent Naming for Jobs with Zuul v3.
All existing jobs will be migrated automatically¶
Jobs covered by the Consistent Testing Interface will all be migrated automatically to newly written v3 native jobs and you should not need to do anything special.
The rest of the jobs will be migrated to new auto-generated jobs. As the content of these is auto-generated from JJB template transformation, these jobs will need post-migration attention.
If you have custom jobs for your project, you or someone from your project should keep reading this document, and see Legacy Job Migration Details.
Web-based log streaming¶
Zuul v3 restores a feature lost in Zuul v2.5: web-based console log
streaming. If you click on the name of a running job on the status
page, a live stream of the job’s console log will appear and
automatically update. It is also possible to access streaming logs
from the terminal using a
finger client (so you may watch a job’s
progress from the terminal, or pipe it through
grep), though the
command to do so is not yet incorporated into the status page; expect
that to be added soon.
My Project Has Customized Jobs, Tell Me More¶
If you’ve read this far, you may have a passing familiarity with the project-config repo and you have created some jobs of your own, or customized how jobs are run on your project.
As mentioned earlier, we’re going to try to automatically migrate all of the jobs from v2 to v3. However, some jobs may benefit from further manual tweaks. This section and the one following should give you the information needed to understand how to make those.
How Jobs Are Defined in Zuul v3¶
In Zuul v2, jobs were defined in Jenkins and Zuul merely instructed
Jenkins to run them. This split between job definition and execution
produced the often confusing dual configuration in the project-config
repository, where we were required to define a job in
jenkins/jobs
and then separately tell Zuul to run it in
zuul/layout.yaml.
Zuul v3 is responsible for choosing when to run which jobs, and running them; jobs only need to be added to one system.
All aspects of Zuul relating to jobs are configured with YAML files similar to the Zuul v2 layout. See the Zuul User Guide for more information on how jobs are configured.
Where Jobs Are Defined in Zuul v3¶
Zuul v3 loads its configuration directly from git repos. This lets us accomplish a number of things we have long desired: instantaneous reconfiguration and in-repo configuration.
Zuul starts by loading the configuration in the project-config zuul.d
directory in the project-config repository.
This contains all of the pipeline definitions and some very basic job
definitions. Zuul looks for its configuration in files named
zuul.yaml or
.zuul.yaml, or in directories named
zuul.d or
.zuul.d. Then it loads configuration from the zuul-jobs zuul.yaml
file in the zuul-jobs repository. This
repository contains job definitions intended to be used by any Zuul
installation, including, but not limited to, OpenStack’s Zuul. Then
it loads jobs from the openstack-zuul-jobs zuul.d directory in the
openstack-zuul-jobs repository which is where we keep most of
the OpenStack-specific jobs. Finally,
it loads jobs defined in all of the repositories in the system. This
means that any repo can define its own jobs. And in most cases,
changes to those jobs will be self-testing, as Zuul will dynamically
change its configuration in response to proposed changes.
This is very powerful, but there are some limitations. See the sections of the Zuul User Guide about Security Contexts and Configuration Loading for more details.
Note that all OpenStack projects share a single namespace for job names, so we have established some guidelines detailed in Consistent Naming for Jobs with Zuul v3 for how to name jobs. Adhere to these so that we may avoid collisions between jobs defined in various repositories.
Zuul jobs are documented in their own repositories. Here are links to the documentation for the repositories mentioned above:
How Jobs Are Selected to Run in Zuul v3¶
How Zuul v3 determines which jobs are run (and with which parameters) is, to put it mildly, different than Zuul v2.
In Zuul v2, we accomplished most of this with 2,500 lines of incomprehensible regular expressions. They are gone in v3. Instead we have a number of simple concepts that work together to allow us to express when a job should run in a human-friendly manner.
Job definitions may appear more than once in the Zuul configuration.
We call these multiple definitions variants. Job definitions have
several fields, such as
branches and
files, which act as
matchers to determine whether the job is applicable to a change.
When Zuul runs a job, it builds up a new job definition with all of
the matching variants applied. Later variants can override settings
on earlier definitions, but any settings not overridden will be
present as well.
For example, consider this simple job definition for a job named
fedstack:
- job: name: fedstack nodeset: fedora-26 vars: neutron: true
This may then be supplemented with a job variant:
- job: name: fedstack branches: stable/pike nodeset: fedora-25
This variant indicates that, while by default, the fedstack job runs
on fedora-26 nodes, any changes to the stable/pike branch should run
on fedora-25 nodes instead. In both cases, the
neutron variable
will be set to
true.
Such job variants apply to any project that uses the job, so they are appropriate when you know how the job should behave in all circumstances. Sometimes you want to make a change to how a job runs, but only in the context of a specific project. Enhancements to the project definition help with that. A project definition looks like this:
- project: name: openstack/cloudycloud check: jobs: - fedstack
We call the highlighted portion the
project-pipeline definition.
That says “run the fedstack job on changes to the cloudycloud project
in the check pipeline”. A change to the master branch of cloudycloud
will run the job described in the first definition above. A change on
the stable/pike branch will combine both variants and use the new
merged definition when running the job.
If we want to change how the job is run only for the cloudycloud project, we can alter the project-pipeline definition to specify a project-local variant. It behaves (almost) just like a regular job variant, but it only applies to the project in question. To specify that fedstack jobs are non-voting on cloudycloud, we would do the following:
- project: name: openstack/cloudycloud check: jobs: - fedstack: voting: false
This variant is combined with all other matching variants to indicate that all fedstack jobs run on cloudycloud are non-voting, and additionally, stable/pike jobs run on fedora-25 instead of fedora-26.
As long as at least one variant matches a change, the job will run; a variant can’t be used to “undo” an earlier matching variant.
One final note about variants: in some cases Zuul attaches an implied branch matcher to job definitions. The rules are tricky, but in general, jobs defined in a multi-branch project get an implied branch matcher of their current branch. This makes it so that we can branch a project from master along with all of its job definitions, and jobs will continue to work as expected.
I Write Jobs, How Does Zuul v3 Actually Work?¶
We previously covered some things you need to know if you simply want already-existing jobs to be run on your project. If you want to create or alter the behavior of jobs, you’ll want to read this section. Zuul v3 has a number of facilities to promote code re-use, so as a job author, your work may range in complexity from a simple variable tweak, to stacking some existing roles together, and on to creating new Ansible roles.
Job Inheritance¶
We discussed job variance earlier – it’s a method for making small changes to jobs in specific contexts, such as on a certain branch or a certain project. That allows us to avoid creating many nearly identical jobs just to handle such situations. Another method of job reuse is inheritance. Just as in object-oriented programming, inheritance in Zuul allows us to build on an existing job.
Every job in Zuul has a parent, except for jobs which we call base
jobs. A base job is intended to handle fundamental tasks like
setting up git repositories and archiving logs. You probably won’t be
creating base jobs; we expect to have very few of them, and they can
only be created in the
project-config repository. Instead, all
other jobs inherit from, at the very least, one of the base jobs.
A job in Zuul has three execution phases: pre-run, run, and post-run.
Each of these correspond to an Ansible playbook, but we’ll discuss
that in more detail later. The main action of the job – the part
that is intended to succeed or fail based on the content of the change
– happens in the run phase. Actions which should always succeed,
such as preparing the environment or collecting results, happen in the
pre-run and post-run phases respectively. These have a special
behavior when inheritance comes into play: child jobs “nest” inside of
parent jobs. Take for example a job named
tox-py27 which inherits
from
tox which inherits from
unittests which inherits from
base (this example is not contrived – this is actually how the
tox-py27 job is implemented). The pre- and post-run execution
phases from all of those jobs come in to play; however, only the run
phase of the terminal job is executed. The sequence, indented for
visual clarity, looks like this:
base pre-run unittests pre-run tox pre-run tox-py27 pre-run tox-py27 run tox-py27 post-run tox post-run unittests post-run base post-run
The base pre- and post-run playbooks handle setting up repositories and archiving logs. The unittests pre- and post-run playbooks run bindep and collect testr output. The tox pre- and post-run playbooks install tox and collect tox debugging logs. Finally, the tox-py27 run playbook actually runs tox.
A Simple Shell Job¶
Zuul v3 uses Ansible to run jobs, and that gives us a lot of power and flexibility, especially in constructing multi-node jobs. But it can also get out of the way if all you want to do is run a shell script.
See HOWTO: Add an in-repo job below for a walkthrough describing how to set up a simple shell-based job.
Ansible Playbooks¶
Every job runs several playbooks in succession. At the very least, it will run the pre-run playbook from the base job, the playbook for the job itself, and the post-run playbook from the base job. Most jobs will run even more.
In Zuul v2 with jenkins-job-builder, we often combined the job content – that is, the executable code – with the job description, putting large shell snippets inside the JJB yaml, or including them into the yaml, or, if scripts got especially large, writing a small amount of shell in JJB to run a larger script found elsewhere.
In Zuul v3, the job content should always be separate from the job
description. Rather than embedding shell scripts into Zuul yaml
configuration, the content takes the form of Ansible playbooks (which
might perform all of the job actions, or they might delegate to a
shell script). Either way, a given job’s playbook is always located
in the same repository as the job definition. That means a job
defined in
project-config will find its playbook in
project-config as well. And a job defined in an OpenStack project
repo will find its playbook in the project repo.
A job with pre- or post-run playbooks must specify the path to those playbooks explicitly. The path is relative to the root of the repository. For example:
- job: name: test-job pre-run: playbooks/test-job-pre.yaml post-run: playbooks/test-job-post.yaml
However, the main playbook for the job may either be explicitly
specified (with the
run: attribute) or if that is omitted, an
implied value of
playbooks/<jobname> is used. In the above
example, Zuul would look for the main playbook in
playbooks/test-job.yaml.
Ansible Roles¶
Roles are the main unit of code reuse in Ansible. We’re building a
significant library of useful roles in the
zuul-jobs,
openstack-zuul-jobs, and
project-config projects. In many
cases, these roles correspond to jenkins-job-builder macros that we
used in Zuul v2. That allows us to build up playbooks using lists of
roles in the same way that we built jobs from list of builder macros
in Zuul v2.
Ansible roles must be installed in the environment where Ansible is
run. That means a role used by a Zuul job must be installed before
the job starts running. Zuul has special support for roles to
accomodate this. A job may use the
roles: attribute to specify
that another project in the system must be installed because that job
uses roles that are defined there. For instance, if your job uses a
role from
zuul-jobs, you should add the following to your job
configuration:
- job: name: test-job roles: - zuul: zuul/zuul-jobs
The project where the job is defined is always added as an implicit source for roles.
Note
If a project implements a single role, Zuul expects the root of
that project to be the root of the role (i.e., the project root
directory should have a
tasks/ subdirectory or similar). If
the project contains more than one role, the roles should be
located in subdirectories of the
roles/ directory (e.g.,
roles/myrole/tasks/).
Ansible Variables¶
In Zuul v2, a number of variables with information about Zuul and the
change being tested were available as environment variables, generally
prefixed with
ZUUL_. In Zuul v3, these have been replaced with
Ansible variables which provide much more information as well as much
richer structured data. See the Job Content
section of the Zuul User Guide for a full list.
Secret Variables¶
A new feature in Zuul v3 is the ability to provide secrets which can be used to perform tasks with jobs run in post and release pipelines, like authenticating a job to a remote service or generating cryptographic signatures automatically. These secrets are asymmetrically encrypted for inclusion in job definitions using per-project public keys served from a Zuul API, and are presented in their decrypted form as Ansible variables the jobs can use.
Note
Credentials and similar secrets encrypted for the per-project keys Zuul uses cannot be decrypted except by Zuul and (by extension) the root sysadmins operating the Zuul service and maintaining the job nodes where those secrets are utilized. By policy, these sysadmins will not deliberately decrypt secrets or access decrypted secrets, aside from non-production test vectors used to ensure the feature is working correctly. They will not under any circumstances be able to provide decrypted copies of your project’s secrets on request, and so you cannot consider the encrypted copy as a backup but should instead find ways to safely maintain (and if necessary share) your own backup copies if you’re unable to easily revoke/replace them when lost.
If you want to encrypt a secret, you can use the
tools/encrypt_secret.py script from project
zuul/zuul. For example, to encrypt file
file_with_secret for project
openstack/kolla use:
$ tools/encrypt_secret.py --infile file_with_secret \ --tenant openstack openstack/kolla
Periodic Jobs¶
In Zuul v3 periodic jobs are just like regular jobs. So instead of
putting
periodic-foo-master and
periodic-foo-pike on a
project, you just put
foo in the periodic pipeline. Zuul will then
emit trigger events for every project-branch combination.
So if you add a periodic job to a project it will run on all of that project’s branches. If you only want it to run on a subset of branches, just use branch matchers in the project-pipeline in the regular way.
The following will run
tox-py35 on all branches in the project:
- project: name: openstack/<projectname> periodic: jobs: - tox-py35
This example runs
tox-py35 only on
master and
stable/queens branches:
- project: name: openstack/<projectname> periodic: jobs: - tox-py35: branches: - master - stable/queens
Changes to OpenStack tox jobs¶
One of the most common job types in OpenStack are tox-based tests. With the Zuul v3 rollout there are new and shiny versions of the tox jobs.
There are a few important things to know about them.
tox vs. tox-py27 vs. vs. openstack-tox vs. openstack-tox-py27¶
There is a base
tox job and a set of jobs like
tox-py27 and
tox-py35. There is also a base
openstack-tox job and a set of jobs like
openstack-tox-py27,
openstack-tox-py35.
The
tox base job is what it sounds like - it’s a base job. It knows how to
run tox and fetch logs and results. It has parameters you can set to control its
behavior, see the description in zuul-jobs for details.
tox-py27 is a job that uses the
tox base job and sets
tox_envlist
to
py27. We’ve made jobs for each of the common tox environments.
Those are jobs that just run tox. As Zuul v3 is designed to have directly shareable job definitions that can be used across Zuul deployments, these jobs do not contain OpenStack specific logic. OpenStack projects should not use them, but non-OpenStack projects using OpenStack’s Zuul may want to.
openstack-tox is a base job that builds on the
tox base job and adds
behaviors specific to OpenStack. Specifically, it adds
openstack/requirements to the
required-projects list and sets the
tox_constraints_file variable to point to
src/opendev.org/openstack/requirements/upper-constraints.txt.
openstack-tox-py27 is like
tox-py27 but uses
openstack-tox as a
base job.
OpenStack projects with custom tox environments should base them on
openstack-tox, not
tox:
- job: name: tooz-tox-py35-etcd3 parent: openstack-tox vars: tox_envlist: py35-etcd3
Installation of ‘sibling’ requirements¶
One of Zuul’s strengths is doing multi-repo testing. We obviously all use the heck out of that for integration tests, but for tox things it has historically been a bit harder to manage.
In Zuul v3, we’ve added functionality to the base
tox job that will look
to see if there are other git repos in the
required-projects list. If there
are, it will look at the virtualenv that tox creates, get the list of installed
packages, see if any of the git repos present provides that package, and if so
will update the virtualenv with an installation of that project from its git
repository.
Long story short, if you wanted to make a job for awesome-project that did tox-level testing against patches to keystoneauth, you’d do this:
- job: name: awesome-project-tox-py27-keystoneauth parent: openstack-tox-py27 required-projects: - openstack/keystoneauth
Then put that job into your project pipelines. If you do that, that job will inject master of keystoneauth (or a speculative master state if there are any Depends-On lines involved) into tox’s py27 virtualenv before running tests.
If you want to disable this behavior, it’s controlled by a variable
tox_install_siblings.
HOWTO: Add an in-repo job¶
This is a simple guide that shows how to add a Zuul v3 job to your OpenStack project.
Create a
.zuul.yamlfile in your project. This is where you will configure your project and define its jobs.
In your
.zuul.yaml, define your project. You will need to define which pipelines will run jobs, and the names of the jobs to run in each pipeline. Below is an example project which adds two jobs to the
checkpipeline:
- project: check: jobs: - <projectname>-functional - tox-py35
In
.zuul.yaml, you will also define custom jobs, if any. If you define your own jobs, note that job names should be prefixed with the project name to avoid accidentally conflicting with a similarly named job, as discussed in Consistent Naming for Jobs with Zuul v3.
For our example project, our custom job is defined as:
- job: name: <projectname>-functional
The actual magic behind the
<projectname>-functionaljob is found in the Ansible playbook that implements it. See the next step below.
Zuul v3 comes with many pre-defined jobs that you may use. The non-OpenStack specific jobs, such as
tox-py27,
tox-py35,
tox-pep8, and
tox-docsare defined in the zuul-jobs zuul.yaml file.
The predefined OpenStack-specific jobs, such as
openstack-doc-buildand
tox-py35-constraintsare defined in the openstack-zuul-jobs jobs.yaml file.
Write any Ansible playbooks for your custom jobs. By default, these are placed in the
playbooksdirectory of your project. Our
<projectname>-functionaljob playbook will be placed in the file
playbooks/<projectname>-functional.yaml. Below are the contents:
- hosts: all tasks: - name: Run functional test script command: run-functional-tests.sh args: chdir: "{{ zuul.project.src_dir }}"
This playbook will execute on our host named
ubuntu-xenial, which we get for free from the Zuul base job. If you need more nodes, or a node of a different type, you will need to define these in your
.zuul.yamlfile.
Note that some playbook actions are restricted in the Zuul environment. Also multiple roles are available for your use in the zuul-jobs roles and openstack-zuul-jobs roles directories.
For more detailed information on jobs, playbooks, or any of the topics discussed in this guide, see the complete Zuul v3 documentation.
Legacy Job Migration Details¶.
Migrated Job Locations¶
Automigrated jobs have their job definitions in openstack-zuul-jobs in the files zuul.d/zuul-legacy-jobs.yaml, project templates in zuul.d/zuul-legacy-project-templates.yaml and the playbooks containing the job content itself in playbooks/legacy.
The
project-pipeline definitions for automigrated jobs are in
project-config in the zuul.d/projects.yaml file.
Migrated Job Naming¶
Jobs which correspond to newly-written v3 jobs were mapping to the appropriate new v3 job.
If an old job did not yet have a corresponding v3 job, the following rules apply for the name of the new auto-generated job:
project names are removed from jobs
the
gate-prefix is removed, if one exists
the
legacy-prefix is added
the string
ubuntu-xenialis removed from the name if it exists
the
-nvsuffix used to indicate non-voting jobs is removed and the job is marked as non-voting directly
Migrated Job and Project Matchers¶
In v2 there was a huge section of regexes at the top of the layout file that filtered when a job was run. In v3, that content has been moved to matchers and variants on the jobs themselves. In some cases this means that jobs defined in a project-template for a project have to be expanded and applied to the project individually so that the appropriate matchers and variants can be applied. As jobs are reworked from converted legacy jobs to new and shiny v3 native jobs, some of these matches can be added to the job definition rather than at the project-pipeline definition and can be re-added to project-templates.
HOWTO: Update Legacy Jobs¶
All of the auto-converted jobs prefixed with
legacy- should be replaced.
They are using old interfaces and not making good use of the new system.
Some of the
legacy- jobs are legitimate central shared jobs we just
haven’t gotten around to making new central versions of. Don’t worry about
those. (
releasenotes and
api-ref jobs are good examples here)
Both are discussed below.
Moving Legacy Jobs to Projects¶
At your earliest convenience, for every job specific to your project:
Copy the job definition into your
.zuul.yamlfile in your repo. You must rename the job as part of the step. Replacing the
legacy-prefix with your project name is a good way to ensure jobs don’t conflict.
Add the new jobs to your project pipeline definition in your
.zuul.yamlfile. This will cause both the new and old
legacy-copies to run.
Submit patches to project-config and openstack-zuul-jobs with Depends-On and Needed-By pointing to each other so that reviewers can verify both patches. The openstack-zuul-jobs patch should Depends-On the project-config patch. Specifically, these patches should contain:
A patch to project-config to remove the legacy jobs from your project’s pipeline definition in
zuul.d/projects.yamlwhich is Needed-By the next patch. (See what_not_to_convert for information about which jobs should stay.)
A patch to openstack-zuul-jobs removing the jobs from
zuul.d/zuul-legacy-jobs.yamland their corresponding playbooks from
playbooks/legacy. It should Depends-On the project-config patch.
The openstack-zuul-jobs patch will give a config error because the project-config patch removing use of the jobs hasn’t landed. That’s ok. We’ll recheck it once the project-config patch lands.
Stable Branches¶
If your project has stable branches, you should also add a
.zuul.yaml file (with job and project definitions – just as on
master) and any playbooks to each stable branch. Zuul will
automatically add branch matchers for the current branch to any jobs
defined on a multi-branch project. Jobs defined in a stable branch
will therefore only apply to changes on the stable branch, and
likewise master. Backporting these changes is a little more work now
during the transition from Zuul v2 to v3, but when we make the next
stable branch from master, no extra would should be required – the
new branch will already contain all the right content, and
configuration on both the master and stable branches will be able to
diverge naturally.
Reworking Legacy Jobs to be v3 Native¶
Once the jobs are under your control you should rework them to no longer use
a base job prefixed with
legacy- or any of the legacy v2 interfaces.
See if you can just replace them with something existing¶
We didn’t try to auto-convert non-standard tox jobs to use the openstack-tox base job as there was too much unknown for us to do it automatically. For you, just switching to using that’s likely the easiest thing to do.
For instance, the job
legacy-tooz-tox-py35-etcd3 can just become:
- job: name: tooz-tox-py35-etcd3 parent: openstack-tox vars: tox_envlist: py35-etcd3
and you can just delete
playbooks/legacy/tooz-tox-py35-etcd3/.
Converting Custom dsvm jobs¶
If your job is a custom dsvm job - try to migrate it to use the new
devstack or
devstack-tempest base jobs.
Note
There may be a couple of edge cases they can’t handle yet.
You can see for an example of just about everything you might want to do using the new devstack base job.
Converting Other Legacy Changes¶
If those don’t apply, this will mean the following changes:
Add the repos you need to the job’s
required-projectslist. This will make sure that zuul clones what you need into
src/.
Stop using zuul-cloner. The repos are on disk in
src/. Just reference them.
Stop using
ZUUL_env vars, the
/etc/nodepooldirectory, and the
WORKSPACEand
BUILD_TIMEOUTenvironment variables. Zuul and nodepool info is available in the zuul and nodepool ansible vars. Timeout information is in
zuul.timeout. WORKSPACE isn’t really a thing in v3. Tasks all start in
/home/zuul, and the source code for the project that triggered the change is in
src/{{ zuul.project.canonical_name }}.
We added a
mkdir /home/zuul/workspaceto each generated playbook, but that’s not really a thing, it’s just for transition and is not needed in new jobs.
Remove
environment: '{{ zuul | zuul_legacy_vars }}'from tasks once they don’t need the legacy environment variables.
Rework log collection. The synchronize commands in the generated
post.yamlare very non-ideal.
Stop using nodesets prefixed with
legacy-. Each of them should have an equivalent non-legacy nodeset.
What to Convert?¶
Some jobs should not be migrated and should always stay in project-config. Refer to Central Config Exceptions for up to date info on which jobs should remain in centralized config.
Outside of these jobs, most jobs can be migrated to a project repository. If a job is used by a single project then migration is simple: you should move the job to that project’s repository. If a job is used by multiple projects then things get a little trickier. In this scenario, you should move the job to the project that is mostly testing and where the developers are best placed to maintain the job. For example, a job that validates interaction between nova and os-vif might be run for both of these projects. However, the job is mostly focused on os-vif and it’s likely that os-vif developers would be best placed to resolve issues that may arise. As a result, the job should live in os-vif. More information is provided below.
Where Should Jobs And Templates Live?¶
We have a global namespace for jobs and project-templates, you can easily define a job or a template in one project and use it in others. Thus, do not blindly convert jobs but consider how to group and use them. Some recommendations and examples:
Some projects like devstack, tempest, and rally, should define a common set of jobs that others can reuse directly or via inheritance.
If your project consists of a server and a client project where you have common tests, define one place for these common tests. We recommend to use the server project for this.
The puppet team is defining a common set of jobs and templates in
openstack/puppet-openstack-integration.
The requirements team has the
check-requirementsjob in the
openstack/requirementsproject so that other projects can use it.
The documentation team defines common jobs and templates in
openstack/openstack-manualsprojects and other projects like
openstack/security-guidereuse these easily.
Options for Restricting When Jobs are Triggered¶
Zuul v3 allows to specify when jobs are triggered to run based on
changed files. You can define for a job either a list of
irrelevant-files or a list of
files. Do not use both together.
See the Zuul User Guide for more information on how jobs are configured. | https://docs.openstack.org/infra/manual/zuulv3.html | CC-MAIN-2019-43 | refinedweb | 5,492 | 61.56 |
’ll tell you something more interesting.
Literally, none of the candidates know what
private?
I think you the stuff you lie is about default access.
So in the case of no modifier (default), whether the subclass can see it’s superclass’s methods/fields depends on the location of the subclass . If the subclass is in another package, then the answer is it can’t. If the subclass is in the same package then it CAN access the superclass methods/fields.
One example:
package myarea;
public class MyHome{
private int frontDoorLock;
public int myAddress;
int defaultWifiPaswd;
}
package myarea;
public class MyBedroom{
public static void main(String[] args) {
MyHome a = new MyHome();
int v1 = a.myAddress; // works
int v2 = a.defaultWifiPaswd; // works
int v3 = a.frontDoorLock; // doesn’t work
}
}
package neighbourArea;
import myarea.MyHome;
public class NeighbourHome{
public static void main(String[] args) {
MyHome a = new MyHome();
int v1 = a.myAddress; // works
int v2 = a.defaultWifiPwd; // doesn’t work
int v3 = a.privateVar; // doesn’t work
}
Thanks
Sankalp
My post is in response to your question ”Bonus question: why did I say I was lying?
Dear Sankalp,
your example is a very good example how package private fields and methods work, where they are accessible from and where and when are they unreachable. The actual lie is somewhere else. If you consider the statement:
The statement
“package private is the protection of a method or a field when you do not write any access modifier in front of it”
is a bit vague. Not precise. Think of interfaces!
Exactly Peter!
Actually Interface’s thought came to my mind, because all fields defined in interface are always public (and even static +final). Am I missing some more you hinted ? :)
Thanks
Sankalp | https://www.javacodegeeks.com/2014/08/java-private-protected-public-and-default.html/comment-page-1/ | CC-MAIN-2017-26 | refinedweb | 289 | 66.13 |
jGuru Forums
Posted By:
Anonymous
Posted On:
Tuesday, December 30, 2003 06:32 AM
I am running out into this silly problem and I am finding tricky to find what is going wrong!It may have have to do woth Class/Local variable issue also but nor so sure!!
I have a List which is a public class variable .
I store retrevied values into it in a method using 'this'
keyword so that I can access retreived list anywhere in my class.
public class aClass{
public List retreivedList ;
public List syncretreivedList ;
private void amethod(String s){
List alist = null;
this.retreivedList = someobject.getRetrevedValues();
//Then perform follwoing things:
alist = this.retreivedList ;
debug("BEFORE ::SIZE = alist.size()= " + alist.size() );
this.syncretreivedList = Collections.synchronizedList(alist);
/*retreve a portion of buffer size where iBufferSize has some int value*/
this.syncretreivedList.subList(iBufferSize, this.syncretreivedList.size()).clear();
debug("AFTER manipulation :SIZE = alist.size() = " + alist.size() + " and this.retreivedList.size() = " + this.retreivedList.size());
And it prints same sublit size values for both alist.size() as well as this.retreivedList.size() while I want this.retreivedList.size() to print the original value [not after sublist] size.
I have not defined retreivedList as local in my method.
Any help?
Please use html tags to format code blocks.
Re: List as Class Variable and Local Variable
Posted By:
Anin_Mathen
Posted On:
Friday, January 2, 2004 11:55 AM | http://www.jguru.com/forums/view.jsp?EID=1136278 | CC-MAIN-2015-22 | refinedweb | 229 | 51.24 |
Please meet IntelliJ IDEA 2016.3, the third massive IDE update planned for this year. Two years ago we used to have one major release per year. Now we have three and all feature-rich – not to mention tons of minor bugfix releases.
Read below to see the highlights of press Alt+Enter inside a non-trivial for-loop, the IDE will prompt you to replace it with an chain of stream API calls. The quick-fix will leverage count, sum, flatMap, map, mapToInt, collect, filter, anyMatch, findFirst, toArray, and other APIs if necessary. Also, when appropriate, the IDE will prompt you to replace certain code with Map.computeIfAbsent, Collections.removeIf or ThreadLocal.withInitial. (Note: a similar quick-fix is now available for Kotlin as well.)
Scala
- Scala.js. The Scala plugin now provides code completion and quick navigation for js.Dynamic–based on fields and methods defined in JavaScript libraries or project files.
- Scala Meta. Another major plugin improvement is support for scala.meta. IntelliJ IDEA supports new-style macro annotations and provides coding assistance for scala.meta quasiquotes.. If needed, the plugin is also capable of tracking stacktraces for chosen classes.
User Interface
- Parameter Hints. This new feature, enabled by default, shows the names of method parameters for passed values that are literals or nulls. These hints make code more readable. If you find hints redundant for certain methods, you can tell the IDE to hide hints for these methods.
-.
- Flat file Icons. We’ve also reworked file icons for a more flat design. While the new icons may look unusual, we believe they feel more sharp and less noisy.
Build Tools
- Delegate IDE build/run actions to Gradle. Allows you to delegate the native IntelliJ IDEA Build, Build Artifacts (both WAR and EAR) and Run actions to Gradle. When this option is enabled, all these actions are performed via the corresponding Gradle tasks. The Runaction is delegated to the dynamic Gradle JavaExec task configured according to the run configuration. To enable this option, check Settings → Build, Execution, Deployment → Build Tools → Gradle → Runner → Delegate IDE build/run actions to Gradle.
- Gradle Composite Builds. New powerful option that lets you substitute any of your Gradle dependencies with another project. This feature requires Gradle 3.1 or higher.
- Polyglot Maven. A set of Maven extensions that allows the POM file to be written in Groovy, Scala, Ruby and other languages. While project import works for any language, coding assistance within POM files is available only for Groovy.
VCS
- Git/Mercurial Log. The Log viewer has been reworked some more, this time mainly to improve its ergonomics and speed. Commit details have moved to the right, giving you more screen space. Commit messages in the table are now aligned and thus more readable. Labels have been moved to the right and are now displayed in a more elegant way. Filter values now persist between IDE restarts. For Git, searching via the Text, Author and Path filters is now much faster.
- Merge and Diff. The Merge dialog now show a Resolve icon on the left side of the Editor when the IDE is capable of resolving the conflict automatically. We’ve added line markers to the dialog to indicate actual changes to the base revision. Last but not least, both Diff and Merge now provide full syntax highlighting for non-local revisions.
- Managing Remotes. Now, the IDE provides an interface for managing Git remotes for every repo in the project.
JavaScript
- ECMAScript 6. IntelliJ IDEA now reports all var declarations and helps replace them with let or const declarations, depending on recognized value semantics. For all require() calls, the IDE now provides a quick-fix that replaces them with import statements. For function calls and prototype chains, the IDE provides a quick-fix that replaces them with class statements. Other improvements include better support for destructuring assignments, and default exports.
- TypeScript. TypeScript gets a more accurate rename refactoring for overridden methods, and a quick-fix to shorten import statements.
- Flow. Now, when you set the JavaScript version to Flow, the IDE reports problems in the files annotated with “// @flow” on the fly.
Application Servers
- TomEE 7. The support for TomEE has been updated to its major version.
- Liberty. Loose applications are now supported and can be run from the IDE. To run a loose application, open the Deployment tab of your WebSphere Run configuration and select the loose application XML file–instead of an artifact.
React Native
- Debugger. Now you can run and debug React Native apps without leaving IntelliJ IDEA.
Android
- Blueprint. A new mode in the Designer that hides all of the visuals from views and shows only their outlines. You can choose to have it side by side with the Designer.
- Constraint Layout. This is a new layout manager which allows you to create large and complex layouts with a flat view hierarchy. It’s similar to Relative Layout in that all views are laid out according to relationships between sibling views and the parent layout, but it’s more flexible and easier to use.
- Instant Run. The update has brought many stability and reliability improvements to Instant Run. If you have previously disabled it, the Android team encourages you to re-enable it.
- APK Analyzer. It lets you drill into your APK to help you reduce your APK size, debug 64K method limit issues, view contents of Dex files and more.
Databases
- Editing Multiple Cells. Now you can edit several similar cells at once. Select several cells and start typing a value.
- Bulk Submit. Now changes made in the Table Editor are stored locally and submitted in bulk, via Ctrl+Enter (Cmd+Enter for OS X). Changes not yet submitted can be canceled via Undo.
- Finding Usages. Now you can find usages of database objects inside the source code of other objects. For instance, you can find which stored procedures, functions or views use a given table.
Clouds
- Google Cloud Tools. Google has introduced their own IDE plugin for deploying to Google App Engine. Eventually this plugin will replace the Google App Engine plugin provided with us.
- OpenShift Origin (V3). The updated integration lets create OpenShift 3 applications and manage their resources such as projects, services and pods.
Toolbox App
- Toolbox App is a new desktop application that lets you install and update all JetBrains IDEs with ease. Learn more.
For more details and screenshots about the new features, check out the What’s New page. All impatient, proceed directly to the Download page.
Note, if you have an IntelliJ IDEA license purchased before November 2015, you can purchase a new subscription at 40% off. This offer to be redeemed no later than Jan 1, 2017.
Is this update available via the incremental updater, ala Android Studio, or do I have to instead download, uninstall, reinstall it all again?
Just use this one
Still no incremental updater?
I have only seen that for point releases (16.2.1 -> 16.2.2 but not 16.1.x -> 16.2)
Is there a way to remove the old folder icons? on the bright layout they are really akward..
After updating via Toolbox, I get “error invoking main method” on launch.
Rolling back and re-updating produced the same result.
It looks like the ability to attach Gradle tasks to execute during certain events (before/after sync, before/after rebuild) is no longer working. I can setup these actions but Gradle is never invoked.
It seems only before/after *rebuild* was affected, I’ve created the issue at
Also before/after build/rebuild task activation doesn’t work if “delegation to Gradle” is enabled. But I think the feature is useless for that mode and “before/after build/rebuild” should be unavailable for setup.
Is there a way to turn on parameter hints for all parameters? I’ve turned it off fully since it seems strange on just some params and not all of them.
Awesome as always. Thank you Jetbrains for making our lives easier!
I changed my javascript code to use ECMAScript 6. The editor tells me that ‘var’ used instead of ‘let’ or ‘const’. That’s good. When I change my ‘var’ to a ‘let’, the ‘let’ is properly syntax colored in a JS file, but NOT in a JSP file inside the script tags. The var was syntax colored in both JSP and JS files, just the new ‘let’ is not. ‘const’ is properly syntax colored in either case, though.
It’s impossible to analyze code in Android projects:
It seems there’s a small problem with JSON(B) fields in the table view. I got Postgres 9.5 and can’t insert/edit fields via the editor. I tried the “latest” offical driver “postgresql-9.4-1201.jdbc4” and the current one from the website “postgresql-9.4-1212”. With both errors I get
[42804] ERROR: column “fields_json” is of type json but expression is of type character varying Hinweis: You will need to rewrite or cast the expression. Position: 85
PS: Not sure but “Hinweis” may come from my german system settings..
I’m also having this same problem with the latest version of phpStorm 2017.1.2
Ditto
Wondering the same as Kevin in How can I enable parameter hints for all parameters?
Typescript:
Cannot resolve file in import statement.
Ex:
the folder contains: abc.ts, abc.d.ts
import * as ABC from “../../abc/abc”; gives an error.
I think this is due to the same file name, but in 2016.2 works without errors.
Sorry guys but is there a way to used old icons but these icon set is super ugly.
One suggestion for default “Parameter Name Hints Blacklist”:
*.has*(*)
for example, hamcrest uses hasSize(int size)
Time for ‘./build-package -f IC -p debian -v 2016.3’
Three updates to ide a year is not very impressive when others gets multiple updates a month.. And eery time new features. Intellij is starting to be dinosaur which can’t move fast enough in the modern world.
Totally borked my Android build. Gradle is trying to use the the wrong jre. I believe it’s the one in the included jre, rather than the project sdk but I’m still trying to figure it out.
Sounds as it is related to
Yeah, I also was affected by this issue. @JoeHz, see my comment to the item that Andrey referred to.
I have disabled Parameter Hints for particular method. Is it possible to enable it again for that method? I could not find setting to do revert it.
Settings | Editor | General | Appearance | Show parameter hints | Configure
I hate flat design and I am very disappointed with your new flat icons. Can I have the old icons back?
I found it really slow on my Office PC, was faster 16.2.x
For me it is slow as well.
The grails view + groovy editors are unusably slow. I’ve seen keystrokes that take 15+ seconds to appear in the editor. Tweaked memory settings to no avail.
Could you please attach CPU snapshot? This would greatly help us have it fixed earlier. More details on how to capture/submit snapshots:
IDEA-165479 submitted. Thanks
on mac 10.11.6 , it is slow ,and always die, I have to restart it,why?
If you share more details, you’ll help us a lot to figure out what happens. Please submit an issue to our tracker with logs if possible. If you have performance problems, a CPU snapshot may also greatly help us get it fixed sooner. More details on how to take a snapshot:
Stop changing UI. IDEA is not modern web resource. It is not playground for UX. It is professional tool!
Great job as always, but the subscription payment wasn’t very smooth. My billing date was Dec 1, and I paid with PayPal. The day before I checked that the subscription was active. On Dec 2 I got a message from IDE that you subscription has expired and you may no longer use the product. The funny part was that I could actually continue using it. But as a loyal customer, I logged into my JetBrains account and paid the subscription fee manually. Not a big deal, just was surprised that I wasn’t billed automatically.
Is there a way to make parameter hints respect line character limit? We have a weird 100 characters per line limit, and because of parameter hints, I can’t really see if the line is within the limit or not.
A big regression with debugging gradle plugins
In 2016.3 debugging doesn’t work anymore.
while it worked in every version from IDEA 14 till now (didn’t use gradle plugins in IDEA 13 dunno)
Is there a way to get the old icons back? Those flat icons are hardly recognizable – actually its more stressful for your eyes…
also interesting in the way to change icons back, please help us, and stop changing style each major release ! (its ur UX designers A/B testing us or what ?)
thank you | https://blog.jetbrains.com/idea/2016/11/intellij-idea-2016-3-ga-java-8-and-es6-debugger-and-ui-improvements-and-a-ton-more/?replytocom=395126 | CC-MAIN-2020-10 | refinedweb | 2,181 | 67.04 |
Hope the learning series is quite easy to understand. Please reach out to me in case of any queries, will try to solve the queries at the earliest.
In Sitecore CMS, every web page is split into multiple pieces/blocks and each of these blocks is rendered/presented by different components (a piece of functionality) separately. Every component is defined with a specific purpose and functionality.
For example a basic web page can have a header, a footer and page body. In this case, we might have a header component, footer component, page body component
Now, each of these components requires some logic to present the right content in each of these sections dynamically. This logic which could generate a piece of html dynamically is nothing but a rendering in Sitecore. Once all the renderings are rendered in page, the complete html of the page is generated and could display the web page as required.
In Sitecore MVC, each rendering is nothing but a controller action or even it could be a simple view.
Before jumping to how to create a rendering, let us discuss how it can be rendered and which the commonly used renderings are. To answer this, we use 2 types of renderings commonly – View Rendering and Controller Rendering.
View Rendering is used when we don’t have much business logic to be executed. Controller rendering is used when we have business logic to be executed.
The renderings can be assigned to a layout statically or dynamically. We can statically bind the components/renderings to the layout when we are sure that its place will not change at any given time ex. Header and Footer. When we are not sure about the placing of the components ex. Main body components then we go for dynamic bindings also known as Placeholders.
So to create a View rendering in Sitecore
- Create a partial view in a Visual Studio.
- Add any HTML which can make you understand that the view rendering is rendered on Front end.
- Publish this View.
- Go to Content Editor and navigate to Renderings (/sitecore/layout/Renderings).
- Right Click >> Insert >> View Rendering.
- Name it View rendering and add the Path of the View which we created (/Views/ViewRendering.cshtml).
- Publish this rendering and note it’s ID.
- Let’s statically bind this View Rendering in the Layout we created earlier.
- Add code ‘@Sitecore().Rendering(“{275115AB-C60F-4FC8-ADC5-A5D5F381BF5D}”)’ in Main.cshtml – the Layout.
- Publish this view and Browse
- This means our View rendering is rendered successfully on the Layout. So we learnt about creating a View rendering and statically binding it to the layout. Now let’s learn about Controller rendering and dynamically binding it to the layout.
To create a Controller rendering in Sitecore
- Let’ create a Controller in Visual Studio and write one Action method.
- If you remember we have one Fruits folder in Sitecore, so we will create a Controller rendering to display all the fruits on the page.
- Click on Controller Folder and Click on Add >> Controller.
- MVC 5 Controller – Empty.
- Name it “ControllerRendering”.
- The body of the Controller looks something like this.
- Now let’s add the Sitecore namespaces and code to fetch the Fruits folder in the business logic.
- Now we need to create a View for this controller.
- Hover over the method and right Click >> Add View.
- Let the name be Index and it be partial View. Click Add.
- The body of the View should be to read the list of Fruit and display them.
- Now let’s publish the whole solution as the code behind in involved. Right Click on Solution >> Publish.
- Once the publish task is completed. Reload the Sitecore and go to the Content Editor.
- Navigate to the Renderings ((/sitecore/layout/Renderings).
- Right Click >> Insert >> Controller rendering.
- Let the name be Controller rendering.
- Enter the value for Controller and Action Fields.
- Publish the Rendering.
- Let’s dynamically bind this rendering to the Main Layout.
- Add this code ‘@Sitecore().Placeholder(“main”)’ in Main Layout.
- Publish the Main.cshtml
- Go to the Test Item in Sitecore (/sitecore/content/Home/Test Item)
- Click on Presentation tab >> Details.
- Click on Edit link the pop up.
- Click on the Controls tab in the left.
- Click on Add button in the right.
- Select the ‘Controller rendering’ which we created and in Add to Placeholder textbox, write ‘main’ as we have set ‘main’ as key in our Main layout – ‘@Sitecore().Placeholder(“main”)’
- Click Select >> Click OK >> Click OK.
- Save the Changes and Publish the Test Item.
- Now Browse
So we learnt about View Rendering and Controller rendering and how to assign them to Layout based on statically and dynamically bindings. For statically binding we need the ID of the Rendering we create and For dynamically binding we use the placeholder keys.
In the next blog, we will learn about the placeholders and placeholder settings.
Thank you.. Keep Learning.. Keep Sitecoring.. 🙂
One thought on “What are Renderings? Which ones we frequently use?”
Pingback: Creating a Layout – Part I | Sitecore Dairies | https://sitecorediaries.org/2019/12/06/what-are-renderings-which-ones-we-frequently-use/ | CC-MAIN-2021-25 | refinedweb | 836 | 68.06 |
From sjl’s utilities (thanks so much for the nice docstrings). The goal here is to read some code and learn about (hidden) gems.
The following snippets should be copy-pastable. They are the ones I find most interesting, I left some behind.
To reduce the dependency load, Alexandria or Quickutil functions can be imported one by one with Quickutil.
Table of Contents
Higher order functions
See also and How to do functional programming in CL.
(defun juxt (&rest functions) "Return a function that will juxtapose the results of `functions`. This is like Clojure's `juxt`. Given functions `(f0 f1 ... fn)`, this will return a new function which, when called with some arguments, will return `(list (f0 ...args...) (f1 ...args...) ... (fn ...args...))`. Example: (funcall (juxt #'list #'+ #'- #'*) 1 2) => ((1 2) 3 -1 2) " (lambda (&rest args) (mapcar (alexandria:rcurry #'apply args) functions)))
(defun nullary (function &optional result) "Return a new function that acts as a nullary-patched version of `function`. The new function will return `result` when called with zero arguments, and delegate to `function` otherwise. Examples: (max 1 10 2) ; => 10 (max) ; => invalid number of arguments (funcall (nullary #'max)) ; => nil (funcall (nullary #'max 0)) ; => 0 (funcall (nullary #'max 0) 1 10 2) ; => 10 (reduce #'max nil) ; => invalid number of arguments (reduce (nullary #'max) nil) ; => nil (reduce (nullary #'max :empty) nil) ; => :empty (reduce (nullary #'max) '(1 10 2)) ; => 10 " (lambda (&rest args) (if (null args) result (apply function args))))
(defmacro gathering (&body body) ;; "Run `body` to gather some things and return a fresh list of them. `body` will be executed with the symbol `gather` bound to a function of one argument. Once `body` has finished, a list of everything `gather` was called on will be returned. It's handy for pulling results out of code that executes procedurally and doesn't return anything, like `maphash` or Alexandria's `map-permutations`. The `gather` function can be passed to other functions, but should not be retained once the `gathering` form has returned (it would be useless to do so anyway). Examples: (gathering (dotimes (i 5) (gather i)) => (0 1 2 3 4) (gathering (mapc #'gather '(1 2 3)) (mapc #'gather '(a b))) => (1 2 3 a b) " (with-gensyms (result) `(let ((,result (make-queue))) (flet ((gather (item) (enqueue item ,result))) (declare (dynamic-extent #'gather)) ,@body) (queue-contents ,result))))
Here we need the
queue struct.
(defstruct (queue (:constructor make-queue)) (contents nil :type list) (last nil :type list) (size 0 :type fixnum)) ;; real code is richer, with inline and inlinable function declarations. (defun make-queue () "Allocate and return a fresh queue." (make-queue%)) (defun queue-empty-p (queue) "Return whether `queue` is empty." (zerop (queue-size queue))) (defun enqueue (item queue) "Enqueue `item` in `queue`, returning the new size of the queue." (let ((cell (cons item nil))) (if (queue-empty-p queue) (setf (queue-contents queue) cell) (setf (cdr (queue-last queue)) cell)) (setf (queue-last queue) cell)) (incf (queue-size queue))) (defun dequeue (queue) "Dequeue an item from `queue` and return it." (when (zerop (decf (queue-size queue))) (setf (queue-last queue) nil)) (pop (queue-contents queue))) (defun queue-append (queue list) "Enqueue each element of `list` in `queue` and return the queue's final size." (loop :for item :in list :for size = (enqueue item queue) :finally (return size)))
Sequences
(defun frequencies (sequence &key (test 'eql)) ;; "Return a hash table containing the frequencies of the items in `sequence`. Uses `test` for the `:test` of the hash table. Example: (frequencies '(foo foo bar)) => {foo 2 bar 1} " (iterate (with result = (make-hash-table :test test)) (for i :in-whatever sequence) (incf (gethash i result 0)) (finally (return result))))
(defun proportions (sequence &key (test 'eql) (float t)) "Return a hash table containing the proportions of the items in `sequence`. Uses `test` for the `:test` of the hash table. If `float` is `t` the hash table values will be coerced to floats, otherwise they will be left as rationals. Example: (proportions '(foo foo bar)) => {foo 0.66666 bar 0.33333} (proportions '(foo foo bar) :float nil) => {foo 2/3 bar 1/3} " (let* ((freqs (frequencies sequence :test test)) (total (reduce #'+ (hash-table-values freqs) :initial-value (if float 1.0 1)))) (mutate-hash-values (lambda (v) (/ v total)) freqs)))
(defun group-by (function sequence &key (test #'eql) (key #'identity)) "Return a hash table of the elements of `sequence` grouped by `function`. This function groups the elements of `sequence` into buckets. The bucket for an element is determined by calling `function` on it. The result is a hash table (with test `test`) whose keys are the bucket identifiers and whose values are lists of the elements in each bucket. The order of these lists is unspecified. If `key` is given it will be called on each element before passing it to `function` to produce the bucket identifier. This does not effect what is stored in the lists. Examples: (defparameter *items* '((1 foo) (1 bar) (2 cats) (3 cats))) (group-by #'first *items*) ; => { 1 ((1 foo) (1 bar)) ; 2 ((2 cats)) ; 3 ((3 cats)) } (group-by #'second *items*) ; => { foo ((1 foo)) ; bar ((1 bar)) ; cats ((2 cats) (3 cats)) } (group-by #'evenp *items* :key #'first) ; => { t ((2 cats)) ; nil ((1 foo) (1 bar) (3 cats)) } " (iterate (with result = (make-hash-table :test test)) (for i :in-whatever sequence) (push i (gethash (funcall function (funcall key i)) result)) (finally (return result)))) (defun take-list (n list) (iterate (declare (iterate:declare-variables)) (repeat n) (for item :in list) (collect item))) (defun take-seq (n seq) (subseq seq 0 (min n (length seq))))
(defmacro do-repeat (n &body body) "Perform `body` `n` times." `(dotimes (,(gensym) ,n) ,@body))
(defmacro do-range (ranges &body body) "Perform `body` on the given `ranges`. Each range in `ranges` should be of the form `(variable from below)`. During iteration `body` will be executed with `variable` bound to successive values in the range [`from`, `below`). If multiple ranges are given they will be iterated in a nested fashion. Example: (do-range ((x 0 3) (y 10 12)) (pr x y)) ; => ; 0 10 ; 0 11 ; 1 10 ; 1 11 ; 2 10 ; 2 11 " (if (null ranges) `(progn ,@body) (destructuring-bind (var from below) (first ranges) `(loop :for ,var :from ,from :below ,below :do (do-range ,(rest ranges) ,@body)))))
(defun enumerate (sequence &key (start 0) (step 1) key) "Return an alist of `(n . element)` for each element of `sequence`. `start` and `step` control the values generated for `n`, NOT which elements of the sequence are enumerated. Examples: (enumerate '(a b c)) ; => ((0 . A) (1 . B) (2 . C)) (enumerate '(a b c) :start 1) ; => ((1 . A) (2 . B) (3 . C)) (enumerate '(a b c) :key #'ensure-keyword) ; => ((0 . :A) (1 . :B) (2 . :C)) " (iterate (for el :in-whatever sequence) (for n :from start :by step) (collect (cons n (if key (funcall key el) el)))))
uses
iterate, on Quicklisp (see also Shinmera’s For).
The following
take is taken from Serapeum (also available in CL21).
The original helpers (take-list, etc) are originally inlined for optimal performance with a custom “defun-inline”.
(defun take (n seq) "Return a fresh sequence of the first `n` elements of `seq`. The result will be of the same type as `seq`. If `seq` is shorter than `n` a shorter result will be returned. Example: (take 2 '(a b c)) => (a b) (take 4 #(1)) => #(1) From Serapeum. " (check-type n array-index) (ctypecase seq (list (take-list n seq)) (sequence (take-seq n seq)))) (defun take-list (n list) (iterate (declare (iterate:declare-variables)) (repeat n) (for item :in list) (collect item))) (defun take-seq (n seq) (subseq seq 0 (min n (length seq))))
(defun take-while-list (predicate list) (iterate (for item :in list) (while (funcall predicate item)) (collect item))) (defun take-while-seq (predicate seq) (subseq seq 0 (position-if-not predicate seq))) (defun take-while (predicate seq) "Take elements from `seq` as long as `predicate` remains true. The result will be a fresh sequence of the same type as `seq`. Example: (take-while #'evenp '(2 4 5 6 7 8)) ; => (2 4) (take-while #'evenp #(1)) ; => #() " (ctypecase seq (list (take-while-list predicate seq)) (sequence (take-while-seq predicate seq))))
(defun drop-list (n list) (copy-list (nthcdr n list))) (defun drop-seq (n seq) (subseq seq (min n (length seq)))) (defun drop (n seq) "Return a fresh copy of the `seq` without the first `n` elements. The result will be of the same type as `seq`. If `seq` is shorter than `n` an empty sequence will be returned. Example: (drop 2 '(a b c)) => (c) (drop 4 #(1)) => #() From Serapeum. " (check-type n array-index) (ctypecase seq (list (drop-list n seq)) (sequence (drop-seq n seq))))
(defun drop-while-list (predicate list) (iterate (for tail :on list) (while (funcall predicate (first tail))) (finally (return (copy-list tail))))) (defun drop-while-seq (predicate seq) (let ((start (position-if-not predicate seq))) (if start (subseq seq start) (subseq seq 0 0)))) (defun drop-while (predicate seq) "Drop elements from `seq` as long as `predicate` remains true. The result will be a fresh sequence of the same type as `seq`. Example: (drop-while #'evenp '(2 4 5 6 7 8)) ; => (5 6 7 8) (drop-while #'evenp #(2)) ; => #(2) " (ctypecase seq (list (drop-while-list predicate seq)) (sequence (drop-while-seq predicate seq))))
(defun extrema (predicate sequence) "Return the smallest and largest elements of `sequence` according to `predicate`. `predicate` should be a strict ordering predicate (e.g. `<`). Returns the smallest and largest elements in the sequence as two values, respectively. " (iterate (with min = (elt sequence 0)) (with max = (elt sequence 0)) (for el :in-whatever sequence) (when (funcall predicate el min) (setf min el)) (when (funcall predicate max el) (setf max el)) (finally (return (values min max)))))
(defun summation (sequence &key key) "Return the sum of all elements of `sequence`. If `key` is given, it will be called on each element to compute the addend. This function's ugly name was chosen so it wouldn't clash with iterate's `sum` symbol. Sorry. Examples: (sum #(1 2 3)) ; => 6 (sum '(\"1\" \"2\" \"3\") :key #'parse-integer) ; => 6 (sum '(\"1\" \"2\" \"3\") :key #'length) ; => 3 " (if key (iterate (for n :in-whatever sequence) (sum (funcall key n))) (iterate (for n :in-whatever sequence) (sum n))))
(defun product (sequence &key key) ;; "Return the product of all elements of `sequence`. If `key` is given, it will be called on each element to compute the multiplicand. Examples: (product #(1 2 3)) ; => 6 (product '(\"1\" \"2\" \"3\") :key #'parse-integer) ; => 6 (product '(\"1\" \"2\" \"3\") :key #'length) ; => 1 " (if key (iterate (for n :in-whatever sequence) (multiplying (funcall key n))) (iterate (for n :in-whatever sequence) (multiplying n))))
Debugging and logging
(defun pr (&rest args) "Print `args` readably, separated by spaces and followed by a newline. Returns the first argument, so you can just wrap it around a form without interfering with the rest of the program. This is what `print` should have been. " (format t "~{~S~^ ~}~%" args) (finish-output) (first args))
(defmacro prl (&rest args) "Print `args` labeled and readably. Each argument form will be printed, then evaluated and the result printed. One final newline will be printed after everything. Returns the last result. Examples: (let ((i 1) (l (list 1 2 3))) (prl i (second l))) ; => i 1 (second l) 2 " `(prog1 (progn ,@(mapcar (lambda (arg) `(pr ',arg ,arg)) args)) (terpri) (finish-output)))
(defmacro shut-up (&body body) "Run `body` with stdout and stderr redirected to the void." `(let ((*standard-output* (make-broadcast-stream)) (*error-output* (make-broadcast-stream))) ,@body))
(defmacro comment (&body body) "Do nothing with a bunch of forms. Handy for block-commenting multiple expressions. " (declare (ignore body)) nil)
Pretty-print a table.
Didn’t test.
See also
(defun print-table (rows) ;; "Print `rows` as a nicely-formatted table. Each row should have the same number of colums. Columns will be justified properly to fit the longest item in each one. Example: (print-table '((1 :red something) (2 :green more))) => 1 | RED | SOMETHING 2 | GREEN | MORE " (when rows (iterate (with column-sizes = (reduce (alexandria:curry #'mapcar #'max) (mapcar (alexandria:curry #'mapcar (compose #'length #'aesthetic-string)) rows))) ; lol (for row :in rows) (format t "~{~vA~^ | ~}~%" (weave column-sizes row)))) (values)) ;; from Quickutil. (defun ensure-function (function-designator) "Returns the function designated by `function-designator`: if `function-designator` is a function, it is returned, otherwise it must be a function name and its `fdefinition` is returned." (if (functionp function-designator) function-designator (fdefinition function-designator))) ;; from Quickutil. (defun compose (function &rest more-functions) "Returns a function composed of `function` and `more-functions` that applies its ; arguments to to each in turn, starting from the rightmost of `more-functions`, and then calling the next one with the primary value of the last." (declare (optimize (speed 3) (safety 1) (debug 1))) (reduce (lambda (f g) (let ((f (ensure-function f)) (g (ensure-function g))) (lambda (&rest arguments) (declare (dynamic-extent arguments)) (funcall f (apply g arguments))))) more-functions :initial-value function)) (defun make-gensym-list (length &optional (x "G")) "Returns a list of `length` gensyms, each generated as if with a call to `make-gensym`, using the second (optional, defaulting to `\"G\"`) argument." (let ((g (if (typep x '(integer 0)) x (string x)))) (loop repeat length collect (gensym g)))) (define-compiler-macro compose (function &rest more-functions) (labels ((compose-1 (funs) (if (cdr funs) `(funcall ,(car funs) ,(compose-1 (cdr funs))) `(apply ,(car funs) arguments)))) (let* ((args (cons function more-functions)) (funs (make-gensym-list (length args) "COMPOSE"))) `(let ,(loop for f in funs for arg in args collect `(,f (ensure-function ,arg))) (declare (optimize (speed 3) (safety 1) (debug 1))) (lambda (&rest arguments) (declare (dynamic-extent arguments)) ,(compose-1 funs)))))) ;; from Quickutil. (defun weave (&rest lists) "Return a list whose elements alternate between each of the lists `lists`. Weaving stops when any of the lists has been exhausted." (apply #'mapcan #'list lists)) (defun aesthetic-string (thing) "Return the string used to represent `thing` when printing aesthetically." (format nil "~A" thing))
Pretty print a hash-table:
(defun print-hash-table (hash-table &optional (stream t)) "Print a pretty representation of `hash-table` to `stream.` Respects `*print-length*` when printing the elements. " (let* ((keys (alexandria:hash-table-keys hash-table)) (vals (alexandria:hash-table-values hash-table)) (count (hash-table-count hash-table)) (key-width (-<> keys (mapcar (alexandria:compose #'length #'prin1-to-string) <>) (reduce #'max <> :initial-value 0) (clamp 0 20 <>)))) (print-unreadable-object (hash-table stream :type t) (princ ;; Something shits the bed and output gets jumbled (in SBCL at least) if ;; we try to print to `stream` directly in the format statement inside ;; `print-unreadable-object`, so instead we can just render to a string ;; and `princ` that. (format nil ":test ~A :count ~D {~%~{~{ ~vs ~s~}~%~}}" (hash-table-test hash-table) count (loop :with limit = (or *print-length* 40) :for key :in keys :for val :in vals :for i :from 0 :to limit :collect (if (= i limit) (list key-width :too-many-items (list (- count i) :more)) (list key-width key val)))) stream))) (terpri stream) (values)) (defun pht (hash-table &optional (stream t)) "Synonym for `print-hash-table` for less typing at the REPL." (print-hash-table hash-table stream)) (defun print-hash-table-concisely (hash-table &optional (stream t)) "Print a concise representation of `hash-table` to `stream.` Should respect `*print-length*` when printing the elements. " (print-unreadable-object (hash-table stream :type t) (prin1 (hash-table-test hash-table)) (write-char #\space stream) (prin1 (hash-table-contents hash-table) stream))) ;; needed: (defun clamp (from to value) "Clamp `value` between `from` and `to`." (let ((max (max from to)) (min (min from to))) (cond ((> value max) max) ((< value min) min) (t value)))) ;; see (defmacro -<> (expr &rest forms) "Thread the given forms, with `<>` as a placeholder." ;; I am going to lose my fucking mind if I have to program lisp without ;; a threading macro, but I don't want to add another dep to this library, so ;; here we are. `(let* ((<> ,expr) ,@(mapcar (lambda (form) (if (symbolp form) `(<> (,form <>)) `(<> ,form))) forms)) <>))
For the
-<> threading macro, see cl-arrows and arrow-macros.
Profiling (with SBCL)
#+sbcl (defun dump-profile (filename) (with-open-file (*standard-output* filename :direction :output :if-exists :supersede) (sb-sprof:report :type :graph :sort-by :cumulative-samples :sort-order :ascending) (sb-sprof:report :type :flat :min-percent 0.5))) #+sbcl (defun start-profiling (&key call-count-packages (mode :cpu)) "Start profiling performance. SBCL only. `call-count-packages` should be a list of package designators. Functions in these packages will have their call counts recorded via `sb-sprof::profile-call-counts`. " (sb-sprof::reset) (-<> call-count-packages (mapcar #'mkstr <>) (mapcar #'string-upcase <>) (mapc #'sb-sprof::profile-call-counts <>)) (sb-sprof::start-profiling :max-samples 50000 :mode mode ; :mode :time :sample-interval 0.01 :threads :all)) #+sbcl (defun stop-profiling (&optional (filename "lisp.prof")) "Stop profiling performance and dump a report to `filename`. SBCL only." (sb-sprof::stop-profiling) (dump-profile filename)) #+sbcl (defmacro profile (&body body) "Profile `body` and dump the report to `lisp.prof`." `(progn (start-profiling) (unwind-protect (time (progn ,@body)) (stop-profiling)))) | https://lisp-journey.gitlab.io/blog/snippets-functional-style-more/ | CC-MAIN-2022-40 | refinedweb | 2,848 | 57.2 |
How Does a SysAdmin Can Apply
a Python Skills To His Daily Work? (Part1)
“The system administrator needs to be able to program” – this phrase often provokes objections from many professionals.
- What for? Hands it is more reliable.
- But you can automate typical operations.
- And break a bunch of devices if something goes wrong?
- But you still can break them even with your hands.
You have listened to the summary of typical discussions on this issue. Most admins stop editing the previously copied pieces of the config in the text editor and copying them to the console. Or preparing typical configuration files, but adding them to the equipment by hand through the console.
If you look towards the manufacturers of network equipment,
it turns out that the same Cisco has long offered a variety of options for automating work with network equipment: from TCL on iOS to Python on NX-OS and IOS-XR. This is called network automation or network programmability, and Cisco has courses in this direction.
And Cisco is not alone here: Juniper c PyEZ, HP, Huawei and so on.
Many tools – Netconf, Restconf, Ansible, Puppet and Python, Python. The analysis of specific tools will be postponed for a later time, let’s move on to a concrete example.
- The second question, which sometimes causes heated discussions, usually leads to a complete misunderstanding of each other: “Does a system administrator really need network devices in DNS?”.
Let’s leave a detailed analysis of the participants’ positions for later, formulating the task that led to Python and SNMP. And it all started with a traceroute.
Despite the presence of a variety of monitoring systems that watch and see a lot, MPLS-TE, which deploys traffic in a bizarre way, the correct ICMP and traceroute and ping utilities in many cases are able to give the right information quickly and now. But traceroute output only as IP addresses in a large network will require additional efforts to understand exactly where the packets came from. For example, we see that forward and reverse traffic from the user goes through different routers, but for which ones? The solution is obviously to enter the router’s addresses in the DNS. And for corporate networks where you rarely use unnumbered, placing separate addresses on connectors, if you enter the interface addresses in DNS, you can quickly understand what interface the ICMP packet came from the router.
- However, manually running the DNS database on a large network requires a very large amount of labor not of the most difficult work. But the interface domain name will consist of the interface name, interface description, router’s hostname and domain name. All this router carries in its configuration. The main thing is to collect and properly glue and bind to the right address.
So this task should be automated.
The first thought, the analysis of configurations, quickly faded, the network is large, multi-vendor, and even equipment from different generations, so the idea of parsing configs quickly became unpopular.
The second thought is to use what gives the right answers to universal requests for equipment from different vendors. The answer was obvious – SNMP. It, for all its features, is implemented in the software of any vendor.
Let’s get started
First, we need to install a Python:
sudo apt-get install python3
We need modules to work with SNMP, IP addresses, over time. But for their installation, it is necessary to put pip. True, it is now bundled with python.
sudo apt install python3-pip
And now we put the modules.
pip3 install pysnmp
pip3 install datetime
pip3 install ipaddress
Let’s try to get its hostname from the router. SNMP uses for requests to the host OID. On the OID, the host returns information corresponding to this OID. We want to get a hostname – we need to query 1.3.6.1.2.1.1.5.0.
And so the first script that requests only the hostname.
# import section from pysnmp.hlapi import * from ipaddress import * from datetime import datetime # var section #snmp community_string = 'derfnutfo' # From file ip_address_host = '192.168.88.1' # From file port_snmp = 161 OID_sysName = '1.3.6.1.2.1.1.5.0' # From SNMPv2-MIB hostname/sysname # function section def snmp_getcmd(community, ip, port, OID): return (getCmd(SnmpEngine(), CommunityData(community), UdpTransportTarget((ip, port)), ContextData(), ObjectType(ObjectIdentity(OID)))) def snmp_get_next(community, ip, port, OID): errorIndication, errorStatus, errorIndex, varBinds = next(snmp_getcmd(community, ip, port, OID)) for name, val in varBinds: return (val.prettyPrint()) #code section sysname = (snmp_get_next(community_string, ip_address_host, port_snmp, OID_sysName)) print('hostname= ' + sysname)
Run and get:
hostname = MikroTik
Let’s take a look at the script in more detail:
First, we import the necessary modules:
- pysnmp – allows the script to work with the host via SNMP
- ipaddress – provides work with addresses. Checking addresses for correctness, checking for occurrences of addresses to the network address, etc.
- datetime – get the current time. In this task, you need to organize logs.
Then we start four variables:
- community
- Host address
- SNMP port
- OID value
Two functions:
1. snmp_getcmd
2. snmp_get_next
- The first function sends a GET request to the specified host, at the specified port, with the specified community and OID.
- The second function is the snmp_getcmd generator. Probably split into two functions was not entirely correct, but it turned out so.
This script lacks some things:
1. In the script, you need to load the ip addresses of the hosts. For example, from a text file. At loading it is necessary to check up the loaded address for correctness, differently pysnmp can very strongly be surprised and the script will stop with a traceback. It is not important where you will get the addresses from the file from the database, but you must be sure that the addresses that you received are correct. And so, the source of the addresses is a text file, one line is one address in decimal form.
2. The network equipment can be turned off at the time of polling, it can be incorrectly configured, as a result pysnmp will in this case not at all what we are waiting for and after further processing of the received information we get a stop of the script with a traceback. We need an error handler for our SNMP interaction.
3. A log file is needed, in which the processed errors will be recorded.
Load the addresses and create a log file
- Enter the variable for the file name.
- We write a function check_ip to verify the correctness of the address.
- We write the function get_from_file of address loading, which checks each address for correctness and if it is not so, writes a message about it to the log.
- We implement the loading of data into the list.
filename_of_ip = 'ip.txt' # name of the file with IP addresses #log filename_log = 'zone_gen.log' # def check_ip(ip): # ip address verification correctness try: ip_address(ip) except ValueError: return False else: return True def get_from_file(file, filelog): # selects ip addresses from the file. one line - one address in decimal form fd = open(file,'r') list_ip = [] for line in fd: line=line.rstrip('\n') if check_ip(line): list_ip.append(line) else: filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ': Error Garbage at source ip addresses ' + line) print('Error Garbage at source ip addresses ' + line) fd.close() return list_ip #code section # open the log file filed = open(filename_log,'w') # write down the current time filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + '\n') ip_from_file = get_from_file(filename_of_ip, filed) for ip_address_host in ip_from_file: sysname = (snmp_get_next(community_string, ip_address_host, port_snmp, OID_sysName)) print('hostname= ' + sysname) filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + '\n') filed.close()
Create the file ip.txt
192.168.88.1
172.1.1.1
12.43.dsds.f4
192.168.88.1
The second address in this list does not respond to SNMP. Run the script and verify that you need an error handler for SNMP.
Error ip 12.43.dsds.f4
hostname = MikroTik
Traceback (most recent last call last):
File “/snmp/snmp_read3.py”, line 77, in print (‘hostname =’ + sysname)
TypeError: Can not convert ‘NoneType’ object to str implicitly
Process finished with exit code 1
It is impossible to understand the contents of traceback that the reason for the failure was an inaccessible host. Let’s try to intercept possible reasons for stopping the script and write all the information to the log.
Creating an error handler for pysnmp
The snmp_get_next function already has errorIndication, errorStatus, errorIndex, varmints. In varBinds, the received data is unloaded, in variables beginning with error, error information is unloaded. It only needs to be handled correctly. Since in the future there will be several more functions in the script for working with SNMP, it makes sense to process the errors in a separate function.
def errors(errorIndication, errorStatus, errorIndex, ip, file): # error handling In case of errors, we return False and write to the file if errorIndication: print(errorIndication, 'ip address ', ip) file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + str(errorIndication) + ' = ip address = ' + ip + '\n') return False elif errorStatus: print(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + '%s at %s' % (errorStatus.prettyPrint(), errorIndex and varBinds[int(errorIndex) - 1][0] or '?')) file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + '%s at %s' % (errorStatus.prettyPrint(), errorIndex and varBinds[int(errorIndex) - 1][0] or '?' + '\n')) return False else: return True
And now we add error handling to the snmp_get_next function and write to the log file. The function should now return not only data but also a message about whether there were errors.
def snmp_get_next(community, ip, port, OID, file): errorIndication, errorStatus, errorIndex, varBinds = next(snmp_getcmd(community, ip, port, OID)) if errors(errorIndication, errorStatus, errorIndex, ip, file): for name, val in varBinds: return (val.prettyPrint(), True) else: file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : Error snmp_get_next ip = ' + ip + ' OID = ' + OID + '\n') return ('Error', False)
Now you need to rewrite the code section a bit, taking into account that now there are messages about the success of the request.
In addition, we add a few checks:
1. Sysname is less than three characters long. We will write the file to the log so that we can look at it more closely.
2. Discover that some Huawei and Catos give only a hostname to the request. Since we do not really want to look for OIDs separately (not the fact that it exists at all, maybe it’s a software error), we’ll add this domain manually to such hosts.
3. We find that hosts with incorrect community behave differently, most initiate an error handler, and some for some reason answer that the script perceives as a normal situation.
4. We add at the time of debugging a different level of logging so that later we do not pick out unnecessary messages throughout the script.
for ip_address_host in ip_from_file: # get sysname hostname + domainname, error flag sysname, flag_snmp_get = (snmp_get_next(community_string, ip_address_host, port_snmp, OID_sysName, filed)) if flag_snmp_get: # It's OK, the host responded to snmp if sysname == 'No Such Object currently exists at this OID': # and the community is invalid. it is necessary to skip the host, otherwise we catch traceback. And you just can not catch that problem in the community, so you should always ask for the hostname, which gives all the devices print('ERROR community', sysname, ' ', ip_address_host) filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + 'ERROR community sysname = ' + sysname + ' ip = ' + ip_address_host + '\n') else: if log_level == 'debug': filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + ' sysname ' + sysname + ' type ' + str(type(sysname)) + ' len ' + str(len(sysname)) + ' ip ' + ip_address_host + '\n') if len(sysname) &lt; 3 if log_level == 'debug' or log_level == 'normal': filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + 'Error sysname 3 = ' + sysname + ' ip = ' + ip_address_host + '\n') if sysname.find(domain) == -1: # something gave up a hostname without a domain, for example, Huawei or Catos sysname = sysname + '.' + domain if log_level == 'debug' or log_level == 'normal': filed.write("check domain : " + sysname + " " + ip_address_host + " " + "\n") print('hostname= ' + sysname)
Let’s check this script on the same file ip.txt
Error The garbage in the source of ip addresses 12.43.dsds.f4
hostname = MikroTik.mydomain.com
No SNMP response received before timeout ip address 172.1.1.1
hostname = MikroTik.mydomain.com
Everything worked out regularly, we caught all the errors, the script missed the hosts with errors. Now, with this script, you can build a hostname from all the devices that respond to SNMP.
- Now it remains to collect the names of interfaces, description of interfaces, interface addresses and correctly decompose into configuration files bind. But about this in the second part.
PS: We note that in a good way log messages should be formed in a different way to the principle.
For example time special symbol error code special character description_objects special character additional_information. This will then help configure the automatic processing of the log.
UPD: error correction. | https://www.smartspate.com/how-does-a-sysadmin-can-apply-a-python-skills-to-his-daily-work/ | CC-MAIN-2019-30 | refinedweb | 2,177 | 55.44 |
Search: Search took 0.02 seconds.
- 10 Jan 2011 6:09 PM
I suppose your enterprise project will meet lots of troubles in theming, for which sencha has little docs~
And it is a bit of challenge for all members to understand the concept of SASS and...
- 10 Jan 2011 6:03 PM
you are right~
the demo was made in spare time when I was playing with Sencha Touch~
Sencha touch is lacking docs, esp. those you will need even if you read the code.
Controller is such case....
- 13 Dec 2010 7:02 PM
- Replies
- 0
- Views
- 665
seems no variables that have connections with font-size?
font-size in default themes are measured by relative units; the only way to adjust font-size is to change the value one by one?
- 10 Dec 2010 7:25 PM
- Replies
- 10
- Views
- 5,183
thx~i read the guide first.
hope you will release more docs about theming~
- 10 Dec 2010 2:28 AM
- Replies
- 10
- Views
- 5,183
⋯⋯up
- 9 Dec 2010 10:24 PM
- Replies
- 10
- Views
- 5,183
i am going to implement a customized theme using sass. It's completely different look&feel, so i cannot simply modify some variables, e.g. the $base_color. Is there any info about the theme...
- 5 Dec 2010 7:37 PM
- Replies
- 2
- Views
- 816
do you mean i can fix the problem by: ?
- 5 Dec 2010 7:26 PM
- Replies
- 2
- Views
- 816
console output:
seems screen resize handler throws some exceptions.
all my code:
any suggestion?
- 30 Nov 2010 5:17 AM
Jump to post Thread: Dose Sencha Touch have DataGrid? by RobinQu
- Replies
- 3
- Views
- 3,047
i can't find data grid in API.
Should i implement a customized Ext.DataView to serve as data grid?
- 29 Nov 2010 7:13 PM
- Replies
- 1
- Views
- 785
.......helps....!
- 29 Nov 2010 12:08 AM
- Replies
- 1
- Views
- 785
page seems to be scaled on android~
HTC G7 claims to be 480*800, but it looks completed different compared to the browser window of the same size on desktop
i added
<meta name="viewport"...
- 28 Nov 2010 6:59 PM
Ext.Application instance will create the namespace itself:
- 27 Nov 2010 8:45 PM
the model is sth like this
Cm.Contact = SC.Record.extend(
/** @scope Cm.Contact.prototype */ {
name: SC.Record.attr(String),
tel: SC.Record.attr(String),
avatar: SC.Record.attr(String, {...
- 27 Nov 2010 8:38 PM
I've been play around with Sencha Touch recently, and I made a Contacts Manager demo using MVC pattern.
I hope my demo helps:
- 27 Nov 2010 8:27 PM
thx, that's what i needed~
and i recommend you try out Sproutcore~
it's a completely different kind of frameworks compared to Sencha or YUI.
- 27 Nov 2010 8:24 PM
- Replies
- 4
- Views
- 2,943
Ext.dispatch() and Ext.ControllerManager.get() sometimes helps~
and some views have "scope" and "handler" property can help you to hook up with a controller
but it's a truth that MVC in Sencha...
- 27 Nov 2010 5:47 AM
I've been evaluating frameworks for a mobile project.
Sproutcore is powerful and it perfectly appeals to me. However, the mobile edition of sproutcore is remote and apps using Sproutcore desktop...
Results 1 to 17 of 17 | https://www.sencha.com/forum/search.php?s=0ba42c300bdee434c217355a624c053c&searchid=11502965 | CC-MAIN-2015-22 | refinedweb | 557 | 82.34 |
2017-09-26 Meeting Notes
Andrew Paprocki (API), Brian Terlson (BT), Chip Morningstar (CM), Claude Pache (CPE), Godfrey Chan (GCN), Jordan Harband (JHD), Leo Balter (LBR), Maggie Pint (MPT), Michael Ficarra (MF), Michael Saboff (MLS), Patrick Soquet (PST), Peter Hoddie (PHE), Rex Jaeschke (RJE), Rob Palmer (RPR), Ron Buckton (RBN), Sam Goto (SGO), Sebastian Markbåge (SM), Shu-yu Guo (SYG), Waldemar Horwat (WH), Yehuda Katz (YK), Mathias Bynens (MB), Justin Ridgewell (JRL), Kyle Verrier (KVR), Keith Cirkel (KCL), Till Schneidereit (TST), Aki Rose (AKI), Daniel Ehrenberg (DE), Valerie Young (VYG), Rick Waldron (RW), Dave Herman (DH), Henry Zhu (HZU), Tim Disney (TD),
Remote: István Sebestyén (IS), Ben Newman (BN), Caridy Patiño (CP), Keith Miller (KM), Gabriel Isenberg (GI), Zibi Braniecki (ZB)
Opening, welcome and roll call
Adoption of Agenda
Conclusion/Resolution
- Adopted
Approval of previous meeting minutes
There were no issues with the minutes of the July 2017 meeting (Ecma/TC39/2017/034).
Conclusion/Resolution
- Approved without change
5. Report from ECMA Secretariat
There were no objections to the proposed changes to Ecma/TC39/2017/038, 2nd draft ECMA-404 2nd edition (Rev. 1)
Status of reporting to Japanese comments on fast track?
- Adopt all but one Japanese comments; provide rationale for not being able to adopt the one comment
There were no objections to Ecma/TC39/2017/040, 1st draft ECMA-414 3rd edition (with JISC comments) (Rev. 1), or to Ecma/TC39/2017/041, Disposition of comments regarding ISO/IEC DIS 22275 completed by Ecma (Rev. 1).
Conclusion/Resolution
- RJE to resolve language issues in the 414 suite
6. Meeting Schedule
DE: Dan set up list of proposed locations & times. Proposed 2 East Coast meetings, 3 west coast meetings, 1 Europe.
Schedule postponed to Thursday with hope of Bay Area hosting of January meeting
Conclusion/Resolution
- Revisit first thing Thursday to confirm contentious meeting hosts/areas
7. ECMA-262 Status Updates
(Brian Terlson)
BT: Many items stage 3; deadline for November meeting for Stage 4 proposals to be ready for inclusion in ES2018. 5 or so proposals in stage 3 before this meeting, doubtful they'll make it into ES2018.
YK: Making stage 4 still needs 2 implementations in browsers.
BT: Stage 3 is a big list, we have to be careful for getting these into ES2018. Need to figure out timing beyond November. Talk to me if you need help; assume November is cuttoff for Stage 4 into ES2018.
BT: Normative bug fixes added to spec; Missing toNumber coercion that became security issue in Chrome, Project Zero reproduced this.
MB: The security issue was in ChakraCore / Edge.
BT: Working on unifying conventions, using standard set of conventions for looping, get/set values, parameters, concatting strings. Spec is getting a lot better factories & uniform conventions. Hoping to support polymorphic references so one can see a list of all parts of spec that use a polymorphic reference. Changed grammar params, supporting better tooling in ES code. I promise Ron's work will blow us away
RBN: I can't promise that.
BT: I can.
BT: If anyone has any questions I'm happy to answer them around the state of 262
Conclusion/Resolution
- On track for publication
8. ECMA-402 Status Updates
(Daniel Ehrenberg)
DE: Lots of editorial/non-normative updates
DE: One other change: make all the
Intl.* objects ES6-style classes where the prototype is not an instance of the class. Many minor editorial PRs and minor normative PRs. Please help with reviews.
Conclusion/Resolution
- On track
9. ECMA-404 Status Updates
(Chip Morningstar)
CM: Been finalised for a while; we're in the process of running through JTC1 fast track. Need to update spec to reflect new RFC numbers; but through finalisation+specification we have to formally bless as a change. Patrick emailed this - the same ECMA-404 spec but with new RFC reference.
YK: I saw there was a proposal to make this JSON a proper subset of ECMA-262; is this a change to 404 or 262?
CM: 262 only
10. Test262 Status Updates
(Leo Balter)
LBR: Have updates on test 262. We have more comtributors since last meeting. We've been working with contributors from Igalia, partnership with Bloomberg. At Bocoup we have partnership with Facebook on Test262 - thankful for these. Valerie Young joining us for Test262 with interesting work, really appreciate. Test runners added that we're incorporating with, allow us to integrate with projects that want to use Test262. We're going beyond browser implementations and making sure Test262 is useful for other projects - brings us more feedback, more contributors & improvements. Really appreciate work so far. Rick & I are doing mentorship for contributors. Almost 60,000 tests right now in Test262. Thankyou
BT: Related projects are eshost-cli and eshost... It's used in the Test262 harness to run scripts uniformly across node, browsers. Gotten a lot better recently. If you're testing scripts in different engines,
eshost is going to help a lot. Check it out!
Conclusion/Resolution
- New contributors
- On track
11.ii.a Pipeline Operator
(Daniel Ehrenberg)
DE: Evolution of bind operator. Frequently requested feature from community; I wanted to give it a chance at TC39.
(Presenting slides)
BT: To give context, pipeline operator is coming up over bind operator (which is a popular proposal with babel plugin usage)
DE: To clarify Brian and Ron are doing a lot towards both of these proposals
BT: These two proposals are about 50/50 split as to which they prefer. Setting expectations around bind operator though, it may not be right choice. Point being we're trying to get use-cases from bind operator into pipeline, let's be careful about that.
JHD: Does advancing this prevent the bind operator proposal? Worried about Array.prototype.slice.call, etc. Also worried about imperative nature; bind operator lets me bind ahead of time, this looks to not. Does this proposal obstruct bind usecases later?
RBN: Partial application can solve most issues around bind.
Array.prototype.slice(?)
JHD: Want to delete Function.prototype.call and things still work
BT: Why?
JHD: Because then I'm not relying on the
.call API. It's not super common to be robust against things like this, but that doesnt mean its not a good goal. We need to allow users to harden their code and prevent edge cases like this.
BT: (example of removing matchAll)
JHD: Defense model here is that you run code in an environment you trust, but after that anything could happen. I use
Function.bind.call to protect against this.
BT: It's reasonable to have a syntax for method extraction, but the pipeline operator does not hit this mark.
JHD: Yes - I love this operator, but it needs to not prevent these use cases.
BT: We don't want
:: being used alongside pipeline (
|>), what I'm envisioning is pipeline operator, plus partial application syntax, plus a hypothetical new syntax for method extraction.
YK: I really like this proposal. Some concerns with previous proposal that are addressed here. I do prefer pipeline to not refer to
this because it confuses the model. This is addressed with the partial application syntax (
?). The two aren't coupled necessarily but we should try to think of both.
WH: My fear is we end up with too many independent features and lose sight of overall simplicity of language. If this gets accepted we're pretty much required to do partial application which has some serious problems to the extent that I wouldn't want it in the language - this proposal depends on that. Also this doesn't address the method extraction use cases we just discussed (referencing the
:: discussion above).
TST: How does this work for async functions? Async function calls will become more and more common and this may cause friction.
DE: Only supported in as much as async functions return Promises. We've discussed implicit awaits for Async Generators; coupled with yield. We've been careful about adding points where the function pauses without having explicit syntax — this is problematic. Should we add explicit await support?
TST: My preference would be a combinating operator for async function calls.
TST: This is introducing a new way of calling functions, and not having that do something useful for async functions would be bad.
YK: At minimum it seems that
x |> await fn doesn't work.
DE: In particular, even if you put parens in the right places, you'd be awaiting
fn, not
x.
CM: A concern I have around the cognitive burden of the overall language. What problem does this solve? Rather than this would be nice?
DE: People monkey patch methods to do this right now, there are functions frameworks to this now.
CM: I don't understand what this has to do with monkey patching?
DE: The difference is that rather than writing decomposed pipelines, people will monkey-patch existing classes to add functionality to a type. Some users find the pipeline syntax preferable. It solves a composability problem.
MPT: We've been using fluent apis in JavaScript forever. People love that. jQuery for example. It resonates, people understand it. Pushing data through a series of operations.
CM: Do people monkey patch though? That's the concern.
MTP: I have.
YK: The biggest motivation for this is that libs and frameworks want to use a more functional style of programming. People want to use more functional composition these days, left-to-right composition is the big missing thing. Alternative to monkey patching is wrapper class, but it's complicated, not a good way to make a functional pattern. This is.
DH: Without operator any method you want you have to think of in advance, but with operator you can decentralise what functions can partake in composition chain. There is a popular jquery framework for doing this with classes, but you have to specify up-front which methods are included, so it does not work as well.
DE: Stage 1?
WH: I do want us to see coherent version of this with partial application. I want to see a general solution for this syntax area rather than accepting ad-hoc proposals one by one.
DE: Can we work on a general story for Stage 2?
JHD: That follows the process document
MF: Same concerns, want to see alternative or exploration around bound method extraction
BT: Strawman would be keep
:: as prefix operator.
DE: We can explore syntactic versions of that. Should we be Stage 1 or 0 then? Any objections to Stage 1?
(No objections)
Conclusion/Resolution
- Stage 1 acceptance
- Before Stage 2: investigate strawman for method extraction, which may simply be prefix form of
::
Code of Conduct update
tc39.github.io/code-of-conduct
LBR: Since last meeting we have Code of Conduct approved. We expect everyone to act accordingly. Document is a single page document, one can get it printed. It will be sent to ECMA. We need to assemble an enforcement team; we're looking for volunteers to enforce this. Any volunteers? Please reach out to me if you wish to volunteer for the Code of Conduct Enforcement Committee.
Conclusion/Resolution
- Leo is finding more volunteers for the enforcement committee
- The chair group should add a formal summary of the Code of Conduct for the next agenda templates.
- We already have an email for reporting. It currently goes to the chair group (Rex, Dan, Leo) and the Editor (Brian Terlson).
11.ii.b How should ECMA-402 proceed in light of "ICU standardization" concerns
- https//github.com/tc39/ecma402/pull/172
(Daniel Ehrenberg)
DE: 3 browsers use ICU, 1 uses its own. ECMA-402 tries to be as specific as possible about what the algorithms mean without reference to ICU, but compatibility issues arise none-the-less
- https//github.com/tc39/ecma402/pull/172
Proposing to add text to ECMA-402 to specify goals as we evolve. Not complete solution but attempts to address concerns before, involving Intl standards.
BT: ChakraCore is most likely to be using ICU, we'll be closing all of our Intl bugs per compatibility with other browsers. The added paragraph is good. We won't be hearing differences in spec though; as we'll be using the same API.
RW: We previously discussed normatively specifying ICU correct?
DE: Yes, we discussed but it doesn't seem a good idea as we need to specify the actual data; the locale database JS implementations have. But we cannot because this data changes over time:
- data improves over time (e.g., geopolitcal changes)
- All vendors upstreaming data via CLDR, so things are moving towards convergence
- Each vendor tailors it to their distribution
- Differences of opinion
- Regional legalities (representing some things differently per region, lawyers won't accept restrictions on this).
RW: I just wanted to ensure we're not codifying this. Even though implementations will use the same data?
DE: The underlying locale data is even tailored to different vendors. No one ships the exact contents of CLDR, so it's not reasonable to require using it.
MB: The added paragraph makes sense as it matches reality, but how does this affect Test262 tests?
DE: Test262 will not be able to assert on string output of these methods.
BT: A bunch of tests do this.
DE: New ones won't be able to. These should be moved to a separate area.
BT: These are good tests. The spec says you can return empty string if you want to though, so I guess they're all invalid?
DE: Spec allows more variation.
BT: Total freedom to pick whatever pattern to return though right?
DE: There are minimal requirements though, for example for dates you need to have an hour-minutes pattern. There is a minimum list with minimum requirements.
YK: Question for Node are you planning to implement this?
PST: Nope
DE: It's up to implementers, there is no requirements for this. (Added clarification later: Node already ships V8's Intl support by default; there's nothing for Node to do here. However, V8 currently exposes a compile-time flag which some users switch off to disable ECMA-402, which RW is using.)
RW: We're already shipping Node without
Intl support
YK: So you can not ship Intl, but is there possibility of shipping a different Intl to what's specced?
MB: When working on implementations, Unicode property escapes proposal depends on various documents; Unicode Standard, Emoji spec published by Unicode. ICU has its version.
DE: In particular, ICU ships a subset of these properties, and sometimes lags in the Unicode data version.
MB: The main Unicode standard is ratified every summer.
DE: All converging to same thing though.
MB: Mostly a problem of timelines. Emoji drafts have own timelines. ICU has its own release cycle. Which do we follow? When do we decide to update the spec/proposals? When one of the drafts is updated? When one of the specs is formally updated? When ICU updates?
DE: Looking for consensus for interoperability. Any objections?
Conclusion/Resolution
- Consensus we've addressed the concerns as best as we can, but accept that it's not perfect.
11.ii.c Extensible literals
(Daniel Ehrenberg)
DE: Shame Brendan (Eich) wasn't here, this is his wish list.
(Presenting)
BT: Brendan presented suffixes as a general value types framework. Noticed examples has IEEE 754 decimal values. Does this take into account things like operator overloading?
DE: Good question, decomposition for value types is many fold; literals, operator overloading. In this case we call a function and whatever the function returns is given. The CSS Typed Object Model was specified before this.
DH: Brendan had thought about introducing a staging system, which has downsides. The benefit is that this is a bunch of pre-computation that you could pull out. No sound way to precompute this way. User land compilers can do unsound pre-computation to compile away suffixes, which is good enough for us. The particular path for this design precludes that kind of staging.
DE: Good point. Template literals have facility for caching but might be too heavyweight.
DH: Hard for any solution to meet reasonable requirements.
MLS: Concerns this is creating a bigger problem that this is solving. Automagic calling of some constructor to get some object - with a literal what works and what doesn't? It's a pandoras box of overloading operators. If this was a reservation of syntax for future extensions I'd be comfortable with this. Makes sense to reserve syntax for integers, decimal. As Dave says some of this is unsolvable arbitrarily.
WH: The syntax is already reserved. You don't need the proposal for that.
DE: Currently the syntax is invalid.
MLS: Sure, but we could reserve the syntax space as a forbidden extension. I could go with that. The automagic calling of functions is my concern.
DE: This was a specific request from Brendan, that if we add specific literals such as BigInt then the mechanism should be open for user-defined literals as well. As far as Operator Overloading it is much more complicated at runtime. May or may not be something we ever want to add. On extensibility, I don't think we would ever want JS to have a pixel value type; but web platform would, so I'm not sure if you would want to support only built-in things.
MLS: So what even happens when you return +?
DE: In this proposal, return an object. However, seems like for some people extensible literals only make sense in conjunction with operator overloading, is that right?
MLS: Which is a much harder problem to solve. So maybe we should just reserve the syntax?
DE: Interesting proposal. Should this be a needs-consensus PR to reserve syntax ahead of time?
YK: In what sense is it not reserved?
DE: It's not reserved, a syntax error. Section 16 reserves for extensions beyond spec.
BT: Yes technically implementations are allowed to extend past spec. Reserving syntax communicates we plan to reserve syntax for something. I don't think this needs a needs-consensus PR.
DE: We can achieve consensus now.
WH: First comment was the same as Dave Hermans. Order of evaluation, having to parse string every time.
WH: Second comment: not all identifiers are allowed here.
DE: Yes we couldn't allow
x0 for example.
WH: I saw that in the proposal. But you missed
e and
_. This is a case of where we allow some identifiers and not others. That's fine.
WH: Third comment: we will not be able to introduce new builtins because of compatibility reasons. Will prevent us from introducing things analogous to decimals, bignums in the future.
WH: Fourth comment: other languages let us customise strings, thoughts on that?
DE: No, but we thought about customising object literals.
WH: Yes we shouldn't do that, objects aren't literals they are expressions. This could explode the grammar as well, causing problems for contextual keywords. Doing just for numbers doesn't have same impact.
MPT: if we go down road of literals, date literals would be major usecase.
WH: If we had extensible string literals we could use them for dates.
MPT: Yes we could. Dates are very close to CSS types.
YK: Once we approve this we wont be able to have any more builtins. Secondly, in order for specs to be experimented on then we need to use tools like Babel. Reserving syntax means Babel cannot experiment. Reservation is difficult for this.
MF: What is the relationship to tagged templates? I don't see the advantage.
DE: Usability; it would be awkward for example to wrap all bigints in backticks. This is a story to generalise use-cases like this.
DE: So, stage 1 or stage 0?
WH: I'm happy with stage 1.
RW: So stage 1 but with no additions in Section 16?
DE: No, we'll leave things as they are.
(No restrictions will be added to Section 16)
Conclusion/Resolution
- Stage 1 acceptance
12.i.a Intl.NumberFormat.prototype.formatToParts for Stage 4
(Daniel Ehrenberg)
DE: (presenting slides)
DE: Intl.NumberFormat.prototype.formatToParts ready for stage 4?
DE: It is already shipped in Chrome Canary and behind a flag Firefox.
Everyone: Applause
Conclusion/Resolution
- Stage 4 acceptance
12.i.b Intl.Segmenter for Stage 3
DE: (presenting slides)
E: Intl.Segmenter ready for stage 3?
Everyone: Signs of approval
Conclusion/Resolution
- Stage 3 acceptance
Secretariat
(István Sebestyén)
IS: (briefing on ECMA-262, 402, 404)
Conclusion/Resolution
- On track
11.iv.a First Class Protocols
(Michael Ficarra)
MF: This was originally in last meeting as Interfaces, now called First-Class Protocols.
MF: (Presenting Slides)
WH: Will extending existing classes work in Mark's world when native prototypes are sealed?
MF: No, it will not be usable in that way.
SGO: Will protocols inherit pre-written methods or do I need to copy over?
MF: You do not need to manually copy over all methods; any written in the protocol will be copied onto the implementee.
JHD: What does the
implements keyword (following class name in class declaration/expression) do?
MF: As shown in an earlier slide; it checks for complete implementation of required symbols and copies methods over.
JHD: Is the return of a Protocol a constructor at runtime?
MF: No, it is an object who's prototype is null.
MF: Any more questions? I'm looking for stage 1.
BT: Is the
implements operator the right verb?
MF: I'm open to change. It was designed to be close to
instanceof
YK: A few comments. There are existing supersets which use
implements keyword - TypeScript for example. Should TypeScript migrate? Could we have a nominal check for
implements?
MF: It would require magic - we'd need to record that a protocol has been implemented rather than do a simple
in check.
YK: A few more comments; at design time a class can implement but what happens with the dynamic API? Also what happens with duplicate definitions?
MF: Depends on your definition of, for example
Foldable, there are different symbols and so two (or more) implementations would all have a different lexical definition of
Foldable.
YK: What restrictions are we putting in place for this?
MF: Key part of the proposal is for ad-hoc extension. I dont see this as a problem.
YK: Doesn't it have the same problem as monkey-patching in general?
MF: No, each implementation gets what they want out of it.
WH: I have concerns on fragility and complexity. You cannot extend frozen classes, so they become second class citizen. Makes the problem much worse by encouraging monkey patching existing classes. This will lead to interface hell the likes of which you might find in Java.
WH: Suppose you have an interface that defines several concepts. Say, for example, we want to create a protocol which shares only 1 method from an existing protocol
MF: I don't see the use. If you have a set of methods you can have for free why not have them?
WH: I don't want them.
MF: Then I don't see why you'd want to use that example protocol.
WH: Let's say we have a protocol for fields that defines addition, multiplication, commutativity, etc. I want my protocol to only define addition, not multiplication.
MF: Well you cannot use a subset of the protocol; if the protocol defines both you need to implement both.
WH: This is the interface hell which ecmascript has avoided so far.
MF: In Haskell, a typeclass is idiomatically only meant to provide one thing. Some Haskell users are very vocal about typeclasses that ask to implement more than one thing. Hopefully we'll have the same thing here. Many people have their own implementation of functions built on top of reduce, I'd like to get to the point where we can share that information.
BT: What was the issue with frozen classes?
WH: This asks users to monkey patch classes, so frozen classes will not work.
BT: Isnt that the point of frozen classes? You're locking them for extension.
WH: No, frozen classes are useful in other ways, for defensive programming.
MF: It's fair to say that frozen classes don't get to extend to protocols post-frozen. They have expressed their intent to not extend this.
JHD: Why would you want to freeze a class and still have it mutable later?
WH: No, protocols are not changing the behaviour of the class; so they are useful even with frozen classes.
MF: You can create a sealed class as long as the protocol definition exists before declaring the class. I'm confident this wont be an issue.
WH: I'm confident it is.
MF: Okay, Array.prototype has a string property called
'map'. If we want to implement a Functor on Array, a Functor.map protocol's Symbol could only be implemented at definition time. You don't have access to the Symbol before the protocol exists.
WH: You're letting implementation drive behaviour - it's the wrong thing to do.
JHD: Could this be made to handle array-likes or string property protocols like "thenables". Could your proposal handle existing string-based protocols; for example thenable? It could then retroactively implement, for example thenable, without access to the Protocol. People are generally familiar with duck-typing, like thenables, so this would make more sense.
CM: I have a meta question; will this make sense who hasn't written Functional Programming? As in, 98% of JavaScript programmers.
MF: I didn't mean to give the impression that this was a functional programming proposal.
CM: This is too many layers of abstraction. It's a smart idea but I'm having trouble with it. I know lots of people will have trouble with it. What is it you're trying to accomplish?
MF: I would point to you the iteration protocol which is something we do with this. We don't expect people to define iteration protocols, but they reap the benefits of iterators.
CM: Right, so these is generalising protocols for userland?
MF: Yes.
MPT: Something that defines a contract; these are very helpful with Dependency Injection, but with generic types, abstract classes we end up with a huge mess of what I'd call "inheritance". I personally advice my younger developers from inheritance, its an untestable mess. Contracts are the part I like, subscribing to an implementation. Is this a can of worms to open?
MF: Conceptually this doesn't mash together objects. There are no namespace conflicts.
MPT: Not worried about namespace conflicts, worried about smashed together behaviours.
CM: Yes - too many orthogonal regions of distinction for people to detect.
MF: Do you have recommendations for changes? How can we change this?
SGO: I would appreciate more examples; how does this reflect web development?
DH: A few reactions. I'm not sure I share aversion to inheritance - this is about fitting in with object mechanisms we have. The cowpath of existing mixin pattern is an important signal. Primary concerns though: the convenience of
thing.map over
thing[SomeProtocol.map].
MF: Were the examples in slides not convenient enough?
DH: It's hard to beat
thing.map. My other concern is wanting to allow separate pieces of code to allow implementations of interfaces independently. Show us an example protocol, the ways in which instance coherence blows up and what this does to resolve that. How do you solve the "instance coherence" problem (which has been extensively studied in the industry)?
MF: Thanks that's great feedback.
YK: I'm worried that multiple pieces of code implement the exact same protocol. The "who got there first" problem isn't solved for laws about types.
MF: Yes, you can implement the same laws but with different performance characteristics.
YK: Yes, so in Rust you either implement your protocol for a foreign type or a foreign protocol for your type. This isnt the case here?
DH: This is out there - but it has come up before that we need way to talk about "packages" in general. When people write JavaScript there is a set of implicit semantics that strongly defines a "package". For example Rust brings in the notion of crates as a first class piece of the language.
SYG: Dave and Yehuda talked before about doing this in userland. What do you lose by doing this only in userland?
MF: You lose the syntax, which is a large part of the ergonomics.
SYG: Sure, Im concerned if its just sugar. Do you lose guarantees if its just in userland?
MF: Yes, this could also be done as a userland package. It requires group buy-in to this pattern though, promoting that with the language is the best way to accomplish that.
SYG: So... would we start wholesale moving to protocols?
MF: Hopefully; it would be great to see built in Protocols, it would be great to look into. Assuming this gets in I would love to extract these concepts, like those in the built-in collections. I will be looking into what can be extracted as protocols if this reaches stage 1.
DE: Is this what we want? There are some implicit protocols in ecmascript but incoherent; Symbol.iterator, thenables. Is the goal here to reify this?
MF: I would love this to be the case. How would we go about representing the concept of some of these, like Array likes? I would like to work with someone who has more knowledge of the HTML concepts.
DE: CustomElements looked into using Symbols but it wasn't ergonomic enough. Do we add new methods to reify them in protocols?
MF: Yes
KVR: My question; if I'm writing a function that I want to adhere to a protocol, how can I make assurances about types? Seems an uphill battle without a type system? Maybe it makes sense to push this into TypeScript or Flow?
MF: Yes type system would help with automatic resolution. Without types we can use same techniques we do today. Runtime checks on parameters, etc.
MPT: It'd be nice to implement things like comparability - in different use cases, for example I might want two dates to be comparable by timezone where others do not.
WH: What happens if you want to use someone else's code with a different notion of comparability?
MPT: We cry
MF: No need to cry, you can represent two different notions of comparability.
WH: Now you have two notions of comparability.
MF: This is okay.
WH: No it's not, now everyone will have to choose one or the other even if they don't directly care about the distinction between them, and their decisions might later turn out to be the wrong ones.
-- Out of time --
MF: Any objections to Stage 1? Do we want to look into these problems more?
WH: I won't block stage 1 but the negatives outweigh the positives right now.
- concerns about complexity of language and breaking existing usage patterns such as freezing
- ok with exploring for stage 1
MF: Please express your concerns about freezing in the issue tracker so we can resolve this.
YK: I feel the same, I have concerns about even the rough shape of this solution. I'd like to explore other options along this line.
BT: Are you hoping to subsume use-cases like mixins?
MF: This would hope to eliminate the need for the mixin pattern.
BT: Then this would clearly be stage 1. There are two proposals - traits and mixins, that are on the wiki that these subsumes.
DH: As long as we note that this does not stop us seeking other proposals.
Conclusion/Resolution
- Stage 1 acceptance
12.i.b Class fields status update
(Daniel Ehrenberg)
DE: (presenting slides)
(On ASI/semicolons, in private class fields)
WH: Annoying that
async behaves differently from
get,
set, and
static with respect to line breaks.
WH: Not having ASI inside classes would simplify a lot of things.
YK: If you are a person who doesn't write semicolons, of which ASI is a shifting landscape then you need to keep a strong linter. Is it that we want to enable people who want to avoid writing semicolon to rely on lints?
JHD: Short of web compatibility changes, we either have to enforce
; for private class fields - adding to the list of rules you need to keep for ASI, or ban ASI which people may get angry over.
SM: Two use cases are people who refuse to work with semicolons, but also those who are hit by accidental ASI - we should focus on that use case more.
DE: If we ban ASI for now, we can add it later.
WH: If we allow ASI for now, we're stuck with it forever. Disallowing now means we can revisit.
KCL: What we're saying is that to use private class fields we have to use semicolons? Right now we have workarounds for ASI through changing code, but this would be the first feature where to opt-in we need to use semicolons.
LBR: Semicolons are already there. We cannot get rid of them. ASI Issues are inevitable. I had a proposal for comma, but ASI is inevitable.
WH: I think it is harmful to allow ASI. Class syntax is evolving rapidly. ASI will mandate no-line-terminator-here restrictions in weird places, which are hard to remember — they're in some places but not other. Let's bite the bullet and disallow ASI for now.
LBR: We already have semicolons in class bodies, we already have ASI within method definitions, etc. The semicolon is already a ClassElement, ASI comes with it, I don't think adding limitations between new class fields will be a good thing. (The current proposal seems just fine as it is).
SM: (an example of class fields assigned with arrow function)
DE: It does not seem we're at consensus on this topic. As a default, I think we should stick with ASI.
Conclusion/Resolution
- Proposal holds status quo
Update: Will revisit at the November meeting, due to further concerns raised afterwards by committee members. This remains an unsettled topic.
12.i.g Atomics.waitAsync for stage 2
(Shu-yu Guo)
SYG: (presenting slides)
YK: Expected semantics for this that blocking waits would execute first due to the task queue.
SYG: I dont think it is currently specced this way.
WH: I've reviewed the proposal. Happy with it except for one detail: I'm worried about the proposed line cutting semantics — you can get starvation from this behavior. (Provides exemplar details):
- Agent 1 does async wait
- Agent 2 does async wait
- Agent 1 does sync wait; gets inserted first in waiting queue (right before Agent 1's async wait)
- Agent 2 does sync wait; gets inserted third in waiting queue (right before Agent 2's async wait)
-
- ...
Problem: Agent 2 gets starved out.
SYG: I understand the concerns here. I'll open an issue on the tracker. To recap, we have consensus for stage 2, we will raise the issue Waldemar has raised.
Conclusion/Resolution
- Stage 2 acceptance
12.i.g Intl.PluralRules for Stage 4
(Daniel Ehrenberg)
MB: Intl.PluralRules also has the capability to figure out plurals but also ordinals. Should we split into two methods, since ordinals have nothing to do with pluralization?
DE: It has shipped in Chrome Canary - do you want to unship it there?
CP: Need a way to format ordinal
DE: CLDR does not have the data for formatting ordinals - too much data, too complex.
MB: What I'm saying is that plurals and ordinals could have their own API method instead of everything being part of Intl.PluralRules
DE: But they have the same API shape
MB: Yes - but that doesn't mean they are the same. I'm not looking to block this, just raising the point.
DE: We could unship this from Chrome to resolve this, but is this just a superficial change?
ZB: Looking through CLDR data I see Filipino, Welsh and Irish language the sentence structure changes for ordinal changes.
DE: Yes we need to differentiate ordinal and cardinal
ZB: We need to translate the whole sentence depending on the ordinal category
DE: So what to Mathias' point - should we have separate classes?
ZB: Ordinal is rare enough to not validate a separate class. Very rarely you will need an ordinal type.
MB: I'm not suggesting we should completely reinvent the API, just to separate into separate classes
DE: How would we do that without changing the API?
MB: Well it would be the same class, just separated into two e.g. Intl.PluralRules & Intl.Ordinals, and without the need for the options object. Still returns the same results.
DE: Options are useful for future extensions
MB: We can always add an options object later
ZB: I support moving forward with Intl.PluralForms handling the two types.
DE: Ordinal and cardinal? No separate constructors?
ZB: Correct.
Conclusion/Resolution
- Stage 4 acceptance
12.i.c Intl.RelativeTimeFormat for Stage 3
(Daniel Ehrenberg)
DE: Some pushback to making changes for singular vs plural. Temporal proposal uses plural, RelativeTimeFormat uses singular. ECMA working group says stick with singular. Other contention is style name; short medium & long? These CLDR names are well founded as well as in other formatting libraries - we would want to stick with these conventions.
MPT: The values differ depending on the use case. Are we talking duration of time or unit of time?
DE: The ECMA-402 working group encouraged singular for consistency; we have to have a break somewhere given the mismatch between Temporal and Intl.DateTimeFormat
MPT: But the careful convention is, singular for date, plural for duration. This is like a duration.
DE: Oh, I see your point.
DE: For style, we are sticking with the CLDR convention, following feedback from the ECMA-402 working group.
MLS: Medium seems to be used in Date formatters for macOS and Windows APIs.
DE: What about for duration formatters?
MLS: Not sure...
DE: Can anyone sign up to review this for stage 3?
MPT: I'll be a reviewer.
MB: Me too
Conclusion/Resolution
- Singular or Plural? Plural
- Medium size? Do more research
- Stage 3 Reviewers:
- Maggie Pint
- Mathias Bynens
12.i.f flatMap for stage 2
(Michael Ficarra)
MF: Current issue is what do we consider "flattenable"? Candidates are Iterable - but unexpected behaviour with Strings; or another Symbol. For Stage 2 we've stuck with
isConcatSpreadable Symbol.
YK: I'm fine with isConcatSpreadable. I think Domenic's position is that a lot of things pretend to be arrays, the platform can't continue to pretend things are arrays.
isConcatSpreadable is - for better or worse - what we can use to continue pretending "thing" is an array. Or we could look at a "new thing".
BT: Is there a concrete proposal for new thing?
YK: Not really no.
MF: Do we have a consensus on Stage 2?
LBR: Can we take the time to make this stage 3? I'd be up for it.
BT: The spec has not changed for a year, the one big issue was around
isConcatSpreadable - which has been addressed. Personally I have no problems with Stage 3.
MF: Has anyone given it a full review?
BT: We're missing one more reviewer for Stage 3.
RW: I can commit to reviewing to Stage 3 for tomorrow.
JHD: Me too.
Conclusion/Resolution
- Stage 2 acceptance
- Will address it again in this meeting for Stage 3
- Reviewers for Stage 3:
- Rick Waldron, co-reviewing with Valerie Young
- Jordan Harband
12.i.i Early Errors for RegExp literals
(Andre Bargull, Daniel Ehrenberg)
DE: (Presenting Explainer)
Conclusion/Resolution
- Consensus Achieved
12.i.j Timezone tweak
(Daniel Ehrenberg for Jungshik Shin)
DE: (Presenting Explainer)
Conclusion/Resolution
- Consensus Achieved
12.i.k Sloppy function hoisting web reality tweak
(Daniel Ehrenberg)
DE: (Presenting Explainer)
DE: Let's defer this.
Conclusion/Resolution
- Consensus
12.i.l export-ns-from
(Ben Newman, John-David Dalton)
BN: (Presenting Explainer)
BN: Consensus?
BT: So the spec text hasn't changed from the proposal. Its just a PR, if you read it before nothing has changed.
YK: Does this include
export from
BT: Lets keep them separate.
Conclusion/Resolution
- Consensus on spec text; will add tests before next meeting to remove needs-tests tag and permit merge.
12.i.m Iteration protocol change
(Michael Saboff for Keith Miller in abstentia)
MLS: (Presenting Explainer)
SYG: I'm onboard but this is shipped. What is the issue with webcompat?
BT: Was this considered before?
MLS: We had no answer as to why it was originally done this way.
YK: I feel confident we did not discuss this before.
DE: I would suggest it ended up being a cleaner spec by writing it this way.
DE: (Quotes Reference) from Allen Wirfs-Brock "So I did the obvious optimizations at the spec. levels. I probably didn't do it for next because it would have required inlining two levels of iterator-related abstract operations which would have generally obscured what was going on."
TS: A similar thing came up in WHATWG Streams, where an options object is passed in. It would be good to establish a precedent that configuration arguments for iteration are evaluated eagerly.
MLS: Consensus, and also that we will continue to do this kind of optimisation within the spec?
YK: It's not an optimisation in as much as it is semantic change that allows for optimisation.
DE: We have agreement on this particular case, right?
Conclusion/Resolution
- Consensus
- Consider spec changes that use cached Get()s in similar cases on a case per case basis
12.ii.a Introducing Intl.Locale for Stage 2
(Daniel Ehrenberg)
DE: (presenting slides)
BT: It seems as though if I just add a garbage string then it wouldn't error, but wouldn't provide anything useful.
DE: Valid concern, we need to discuss further.
ZB: On garbage strings: we are validating that they are valid locale strings (RFC5646).
BT: It seems wrong to give an invalid locale and it not tell me about it; e.g.
xx-xx - is this valid?
ZB: No.
DE: Let's revisit this once we reach stage 2
ZB: To clarify: Brian you're asking two questions: Does it support garbage, which I would say no. Second is does it accept invalid locales? Its a negotiation of which locales you want and what you want from them- not to verify browser has all data for this locale.
CP: We're focusing on the wrong part of the proposal. We're bringing to the table how we can extract this information.
ZB: The algorithms already exist here, they're just hidden. We just want to expose it so libraries can use it
?: Is normalisation like upper or lowercase specifiied by ICU?
DE: If you pass a locale into Intl.DateTimeFormat, for example, and read it back out it should comeback normalised. The input format is case insensitive but output is normalised.
DE: So are we ready for Stage 2?
MLS: Is it stage 0 right now? Should it go to stage 1 first? There's no rush right?
DE: Stage 2 doesn't need all of the details right
ZB: This has been evaluated for over a year.
YK: The question is: does it satisfy everything for stage 2
DE: I can go back to experts to get more reviews and clarify things
YK: This seems like a process for stage 2. Stage 2 is draft level of quality.
MLS: This wont make it for ES2018 so why rush through stages?
DE: Stage 1 or Stage 2 doesn't change anything.
BT: Let's push it to stage 1.
Conclusion/Resolution
- Stage1 proposal
- Point of further research: What should be the behavior when an unknown locale is passed in--throw an exception or parse it anyway? | https://esdiscuss.org/notes/2017-09-26 | CC-MAIN-2020-50 | refinedweb | 7,325 | 67.15 |
... Java Util Examples List - Util Tutorials
Java Jar File
.
Read more at:
http:/
http:/
...
Java Jar File
Java Util Zip. Zip files/folders inside a folder, without zipping the original source folder.
Java Util Zip. Zip files/folders inside a folder, without zipping the original... the method a very static scenario. I want to take the files inside the folder... this code works wonderful, its another example from a different website. The only
java-jar file creation - Java Beginners
://
Thanks
RoseIndia Team...java-jar file creation how to create a jar file?i have a folder
quqtion on jar files
quqtion on jar files give me realtime examples on .jar class files
A Jar file combines several classes into a single archive file. Basically,library classes are stored in the jar file.
For more information,please go
regarding java files genarated by jsp
regarding java files genarated by jsp Hi,...
I'm running a project...: 233 in the generated java file
Syntax error, insert "}" to complete Block"
Where to find the genarated java file???
Thank u in advance
Java JAR Files
Java JAR Files
...
In computing, a JAR file (or Java ARchive) is used for aggregating
many files... XML files, java classes and
other objects including JAR, WAR and RAR Java
java jar file - Java Beginners
java jar file How to create jar Executable File.Give me simple steps to create jar files Hi Friend,
Try the following code:
import... int buffer = 10240;
protected void createJarArchive(File jarFile, File
regarding
util packages in java
util packages in java write a java program to display present date and after 25days what will be the date?
import java.util.*;
import java.text.*;
class FindDate{
public static void main(String[] args
Doubts regarding Hashtable - Java Beginners
information,
Thanks...Doubts regarding Hashtable Hi,
I am new to hashtable.Is... then a constructor is no return any value. so your example is occuring a null pointer exception
Creating JAR File - Java Beginners
Creating JAR File Respected Sir,
I would like you to please help me, in letting me know, as to how to create JAR file from my JAVA source or class files. And what is this manifest file, and what changes needs to be done
Doubt regarding charts and jsp
java application output to an jsp page?
thanks in advance
Put the jar...Doubt regarding charts and jsp Hi,
I successfully executed the bar chart in normal java application.
But I want the Bar Chart to be executed
How to create a jar file
a single executable jar of it... so pls tell me how it will b possible for me???
The given code creates a jar file using java.
import java.io.*;
import...How to create a jar file Hello!!!!
I have a project which has
JAR FILE
JAR FILE WHAT IS JAR FILE,EXPLAIN IN DETAIL?
A JAR file is a collection of class files and auxiliary resources associated with applets and applications.
The Java Archive (JAR) file format enables to bundle multiple
Creating JAR File - Java Beginners
Creating JAR File Respected Sir,
Thankyou very much for your..., which says, Failed to load Main-Class manifest attribute from H:\Stuff\NIIT\Java... (NIITInteracts folder) which contains some .class files along with subpackages (some
How to Unjar a Jar file in Java
A JAR file is a collection of Java class files that contains images, methods.... x and f indicates the you're extraction files from the archive. Example: jar xf....
JAR file in Java simplifies distribution and makes it available across
quotion on .jar
quotion on .jar in realtime where we use .jar class files.
A Jar file combines several classes into a single archive file. Basically,library classes are stored in the jar file.
For more information,please go through
Java FTP jar
Java FTP jar Which Java FTP jar should be used in Java program for uploading files on FTP server?
Thanks
Hi,
You should use commons-net-3.2.jar in your java project.
Read more at FTP File Upload in Java
jar file - Java Beginners
options in jar file. What is Jar File? JAR files are packaged in the zip format What is Jar File?JAR files are packaged in the zip format making..., it is downloaded fast from internet and can used on the fly.The JAR or Java Archive
Listing the Main Attributes in a JAR File Manifest
Listing the Main Attributes in a JAR File Manifest
Jar Manifest: Jar Manifest file is the main
section of a jar file. This file contains the detailed information util package Examples
How to use JAR file in Java
JAR which stands for Java ARchive allows a programmer to archive or collect... in JAR files, then you just need to download one single file and Run it.
When you....
JAR files also add portability as this file can be downloaded anywhere and run
regarding applets - Java Beginners
/java/example/java/awt/
Thanks.
Amardeep...regarding applets sir can you please tell how one applet can send request to another say i want to send some information Hi friend
Java Util Package - Utility Package of Java
Java Util Package - Utility Package of Java
Java Utility package is one of the most commonly used packages in the java
program. The Utility Package of Java consist
Changes in Jar and Zip
;
In Java SE 6 there are two changes in jar command
behavior:
Before Java SE 6, the timestamps (date
and time) of extracted files by jar... in Java SE 6, they do a change
in jar command behavior that is the date
files
.
Please visit the following link:
files
files write a java program to calculate the time taken to read a given number of files. file names should be given at command line.
Hello Friend,
Try the following code:
import java.io.*;
import java.util.*;
class
What is a JAR file in Java
files in a JAR file. JAR stands for the Java Archive. This file format is
used... What is a JAR file in Java
...
java application in it. The jar file can execute from the javaw (Java Web
Start
Viewing contents of a JAR File
the jar file operation through
the given example.
Program Result:
This program...
Viewing contents of a JAR File
This section shows you how you can read the content of
jar file
Create JAR file - Java Beginners
to make my .class files to get converted into .jar file.
More knowledge...; javac *.java
4. Then type the following :-
C:\Answers\Examples>jar -cf...Create JAR file Respected Sir,
I got the answer from your side
regarding... args[]) throws IOException {
System.out.println("Example of value comparing
How to Create Jar File using Java
How to Create Jar File using Java Programming Language
A Jar file combines... called this method and specify the folder 'Examples' whose java files... is the code for Java Jar File Function:
import java.io.*;
import
java files - Java Beginners
java files Hi!
How to create files (not temporary) when i got exception in my java program.
I want to write the complete exception in file...://
Thanks
Java files - Java Beginners
Java files i want to get an example on how to develop a Java OO application which reads, analyses, sorts, and displays student project marks.... The input files are structured as follows:
one student record per line
jar file
jar file how to create a jar file in java
Java Execute Jar file
JAR stands for Java ARchive and is platform independent. By making all... operating system or platform.
To execute a JAR file, one must have Java... step is to make the JAR file executable. All class files of the application
Reading files in Java
.
Please provide me the example code for reading big text file in Java. What do you suggest for Reading files in Java?
Thanks...Reading files in Java I have to make a program in my project
regarding rev
regarding rev write a prog. in java that display all the arguments passed at the command line in reverse order
regarding jdbc - JDBC
regarding jdbc how to connect mysql with java
example you have provided is having some error and i am not able to remove that error
please provide me detail explanation Hi friend,
Please give the full source
change jar file icon - Java Beginners
change jar file icon How to create or change jar file icon Hi friend,
The basic format of the command for creating a JAR file is:
jar cf jar-file input-file(s)
* The c option indicates that you want
Copy Files - Java Beginners
Copy Files I saw the post on copying multiple files () and I have something... a list of JPEG files that my boss gave me, and I was planning on putting them
Creating a JAR file in Java
Creating a JAR file in Java
...
through the java source code by using the jar tool command which is provided by
the JDK (Java Development Kit). Here, you can learn how to use the jar command
java util date - Time Zone throwing illegal argument exception
java util date - Time Zone throwing illegal argument exception Sample Code
String timestamp1 = "Wed Mar 02 00:00:54 PST 2011";
Date d = new Date...());
The date object is not getting created for IST time zone. Java
Fat Jar Eclipse Plug-In
deploys an Eclipse java-project into one executable jar.
It adds the Entry "Build... contains all needed classes and can be executed directly with "java -jar... Tuffs ( ) which handles jar-files inside a jar
how can create a jar file - Java Beginners
or more files that you want to include in your JAR file. The input-file(s) argument...how can create a jar file plz any one help me which file can i create the jar file plz give exact command Hi
The basic format
Regarding Project
Regarding Project sir,
i am doing a project in java.
my project is CITY GUIDE it is an web application.
please give me documentation of my project
regarding object references - Java Interview Questions
regarding object references How can we find the number of instances created to an object in java? Write a program for this? Hi Friend,
Try the following code:
class Example
{
static int ob = 0;
public Example
Only change jar file icon - Java Beginners
or more files that you want to include in your JAR file. The input-file(s) argument...Only change jar file icon Dear Friend
I know that how to create a jar file but i don't know How to change jar file Icon.
I can change .exe file
save and open jmenu item How to create a save and open jmenu item in java desktop application.
Here is a simple JMenuItem example in java swing through which you can perform open and save operations on File
Regarding GUI Applications
open jmenu item in java How to create a save and open jmenu item in java desktop application.
Here is a simple JMenuItem example in java swing through which you can perform open and save operations on File.
import
Regarding GUI Applications
GUI Applications How to create a save and open jmenu item in java desktop application.
Here is a simple JMenuItem example in java swing...);
}
}
If you want the simple one, then here is another example of JMenuItem
jar file
jar file how to run a java file by making it a desktop icon i need complete procedur ..through cmd
regarding j2me - Java Beginners
regarding j2me sir but i have to use the drawString u tell me how can i display two too long strings
Java Jar File - Java Beginners
Java Jar File What is a Java JAR file ..and how can i open a .jar file in Java? Just create a Jar file and Double click on it, it will automatically runs main method in that Jar : to create Project as JAR
Jar file creation - Swing AWT
beans IDE..i am also using 3 rd party JAR files...
my application is a serail port... files or is it rioght way to store in lib of JDK
In diiff sysytem jar files show reference problem where to place jar files so that when i run proj
regarding interview in java
regarding interview in java why java doesnot suppor muliple inheritance
Java does not support multiple inheritance directly... it will take.It creates complexity.Therefore java does not support it directly
Concatenate two pdf files
.
In this example we need iText.jar file, without this jar file we...Concatenate two pdf files
In this program we are going to concatenate two pdf files
requesting for a jar file - Development process
After extracting, put the following jar files in the lib folder of your apache...requesting for a jar file Sir Please send me a jar file of this sir , i need this package jar file org.apache.poi.hssf.usermodel for Excel reading
Structs jar files
Structs jar files please Post required jar files for structs.
Thanks,
L.Mahesh Kumar
creating a jar file - JSP-Servlet
. where to place the html or jsp files
2. how to create a jar file and how can...creating a jar file Can you give me detail answer
1. i am having.../introductiontoconfigrationservlet.shtml
Regarding Exception - Java Beginners
Regarding Exception 1.Where and when can we use IllegalArgumentException?
2.What is the difference between fillInStackTrace and printStackTrace ? In which cases they can be used? Hi friend,
public class
Regarding Gantt chart generation - Java Beginners
Regarding Gantt chart generation how to generate a jdbc gantt chart using jfreechart api in netbeans simple java application? Hi Friend... Example", // chart Heading
"Task", // X-axis label
Read the Key-Value of Properties Files in Java
Read the Key-Value of Properties Files in Java
... to read the
key-value of properties files in Java. This section
provides you an example for illustration how to read key and it's regarding
values from.
regarding jdbc - JDBC
regarding jdbc how i can configure java with ms access
util
Filter Files in Java
Filter Files in Java
Introduction
The Filter File Java example code provides the following functionalities:
Filtering the files depending on the file... have downloaded two files jar files and placed them in lib folder to work
a problem during add jar file javax.annotation.Resource
library C:\Program Files (x86)\Java\jre7\lib\rt.jar...a problem during add jar file javax.annotation.Resource when i use this jar file in my application i got this problem pls tell me about it
Access
Regarding GUI Applications
Regarding GUI Applications How to create a save and open jmenu item in java desktop application
Java util date
Java util date
The class Date in "java.util" package represents... to
string and string to date.
Read more at:
http:/
Regarding project - Applet
Regarding project hi friend ,
iam doing project in Visual cryptography in Java so i need the Help regarding how to make a share of a original imahe into shares
anu
Associate a value with an object
with an object in Java util.
Here, you
will know how to associate the value for the separate code. Values regarding to
the separate code are maintained... of the several extentions
to the java programming language i.e. the "
How to delete files in Java?
, we use the delete() function to delete the file.
Given below example will give you a clear idea :
Example :
import java.io.*;
public class DeleteFile
Regarding Documentation of Packages
Regarding Documentation of Packages Hello
How to get java packages ie documentation of classes ,Interfaces and methods
from windows command prompt.In the sense Java.lang,java.awt,java.math etc
Could not able to load jar file - WebSevices
paths of the jar files. when I run that batch it is giving me error like...Could not able to load jar file Hi,
I tried to parse the xml file to a java object. I followed the procedure that you have mentioned | http://www.roseindia.net/tutorialhelp/comment/66529 | CC-MAIN-2014-52 | refinedweb | 2,663 | 64.2 |
Creating a Bar Chart Web Component with Stencil
There are a number of very robust charting libraries on the market. Some are commercial. Some are free. You should use them. Every once in a while though, you need to roll your own. Not to worry! With a splash of SVG and helping hand from Stencil, you can create a chart as a web component for all to use.
The Array of Data
Most chart libraries can get pretty complex. Most of that has to do with abstracting how data is represented. Those abstractions are what make the library so useful in so many cases. In this case however, we are not building a library for all the cases, we are building a bar chart to meet our specific case. This can simplify our work dramatically.
According to Wikipedia, in a bar chart “One axis of the chart shows the specific categories being compared, and the other axis represents a measured value.” According to me, a bar chart is an array of numbers. Let us start there, with some SVG and an array of numbers.
import { Component, h, Prop } from '@stencil/core'; @Component( { tag: 'ionx-chart', styleUrl: 'chart.css', shadow: true } ) export class Chart { render() { return ( <svg width="320" height="240"></svg> ); } // Values to use in the chart @Prop() data: Array<number> = []; }
Each
number in the
Array is going to take up the same amount of space along one of the axes. For this example, we will use the horizontal axis. The horizontal axis is
320 pixels across. If we get ten (10) values in the
Array, each bar will take up
32 pixels.
The Maximum Ratio
Believe it or not, we are almost there. The last piece of information we need to know before we can render the chart is the largest (maximum) value (number) in the
Array. We need to know the maximum because we are looking to establish a ratio. We want the maximum value in the
Array to equal the available number of pixels we have along the vertical axis.
private ratio: number = 1;
For example, if the values in the array are all larger than the
240 pixels we have along the vertical axis, how do we render the bar? Let us say the maximum value in the
Array is
1,000. The available space we have
240 divided by the maximum value of
1,000 gives us a ratio of
240:1,000 or
0.24. Now we can multiply any
number in the
Array by
0.24, and we will know the height of the bar and that bar will fit in our viewable area.
Do not believe me? Let us say that the next
numberin the
Arrayis
500. The value of
500is half of
1,000. If
1,000equals all our vertical pixels (
240), then
500should equal half our vertical pixels, or
120. Ready for this?
500 * 0.24 = 120
The Will Render
Before we render the
data we will need a place to figure out that maximum value and corresponding ratio. The best place for that from a Stencil perspective is in
componentWillRender(), which is called before each render.
componentWillRender() { let maximum: number = 0; // Find the largest value for( let d: number = 0; d < this.data.length; d++ ) maximum = Math.max( maximum, this.data[d] ); // Round up to nearest whole number // Assign the ratio maximum.= Math.ceil( maximum ); this.ratio = 240 / maximum; }
It should become pretty clear, pretty quickly, that the limiting factor of our chart, and indeed any chart, is the amount of data to render. Not because rendering takes a long time, but because figuring out the edges of our data does. This is why supercomputers have to be used for weather maps, when all you see is some colored splotches.
A bar chart however, is not a weather map. We can do all this processing (and a considerable amount more) right here in the browser.
The Render
Now we have all the pertinent pieces of information, we need to put those bars on the screen! A bar in SVG is a
rect. The
rect needs to know where it is positioned (
x,
y) and its dimensions (
width,
height).
The
height we already know will be the value (number) in this iteration of the
data multiplied by the
ratio we calculated earlier. We also talked about how the
width of each bar is the amount of space we have along the horizontal axis (
320) divided by the number of values in the
data. We do not know how many values that will be, so we calculate it inline.
The
x position is almost identical, except we multiply the
width by the
index of the iteration. If the
width is
50 pixels, the first iteration (
index === 0) will result in
x being zero (0). Yes, please! The next iteration (
index === 1) multiplied by a
width of
50 places
x at
50. Exactly!
render() { return ( <svg width="320" height="240"> {this.data.map( ( value: number, index: number ) => <rect fill={`rgb( ${Math.floor( Math.random() * 255)}, ${Math.floor( Math.random() * 255)}, ${Math.floor( Math.random() * 255)} )`} x={( 320 / this.data.length ) * index} y={240 - ( value * this.ratio )} width={320 / this.data.length} height={value * this.ratio} /> ) } </svg> ); }
The only one that is a little tricky in SVG-land is the
y position. When we think of the Web, we generally think of the top-left of the screen as being (
0, 0) on the coordinate system. In the case of SVG however (
0, 0) is at the bottom left.
This means that if we placed
y at
240 and then said the
height of the
rect was
100, the resulting
rect would actually be drawn off the SVG viewport (from
240 to
340). In order to offset this, we subtract the calculated
height using our
ratio, from the
height of the viewable area of the SVG.
In order to see each bar, the
fill is a randomly generated CSS
rgb() value. This kind of begs the question “Maybe the bar should be abstracted into a class that includes fill color?” Yup! And congratulations on coming full circle – that is exactly what the charting libraries do; abstract all the things. How far you go with it is up to you.
✋ But What About …
There are two examples included in the running demonstration, and the GitHub repository. One example is the chart that we have just created. The other example is a chart that includes many of the typical considerations you might find in a chart.
- Chart title
- Axis labels
- Value labels
- Dynamic fill
- Rounded corners
- Flexible sizing
- CSS properties
The code is not abstracted to the point of a library, but it should give you a starting place to consider more sophisticated rendering situations for your own chart component.
Next Steps: Building more web components with Stencil
All of these options definitely add complexity to the math and rendering, but it all follows the same pattern. First, figure out the structure of the data. Second, figure out the edges of the data. Third, consider any information you might need to calculate for layout. Finally, iterate over the data to render your output.
Now the next time you need a custom chart, you will know where to start – with Stencil and a web component.
github repository not available.
Join the discussion on the Ionic Forum | https://ionicframework.com/blog/building-with-stencil-bar-chart/ | CC-MAIN-2021-43 | refinedweb | 1,230 | 74.08 |
We value your feedback.
Take our survey and automatically be enter to win anyone of the following:
Yeti Cooler, Amazon eGift Card, and Movie eGift Card!
//the movieclip declaration public var score:Score; //the currentScore, used to keep track of the score, declaration public var currentScore; //the timer event in the same class as the above declarations public function onTick(event:TimerEvent):void { currentScore = currentScore + 1; score.scoreText.text = String(currentScore); //other unrelated code } //the Score class. package { import flash.display.MovieClip; import flash.text.TextField; public class Score extends MovieClip { public function Score() { } } } //the linked Score MovieClip in my library has a dynamic text field in it wth the instance name //scoreText
Add your voice to the tech community where 5M+ people just like you are talking about what matters.
score = new Score() score.x = 350; score.y = 50; addChild(score);
If you are experiencing a similar issue, please ask a related question
Join the community of 500,000 technology professionals and ask your questions. | https://www.experts-exchange.com/questions/24423404/as3-movieclip-disappears.html | CC-MAIN-2017-43 | refinedweb | 166 | 56.15 |
The Samba-Bugzilla – Bug 1679
Printing problems with Samba 3.0 under Sun Solaris
Last modified: 2005-08-24 10:20:25 UTC
When printing with samba 3.0.6 under solaris 9 on a sun server the jobs are
printed and removed from the job queue as they should when finished, but the
jobs are still shown as documents being printed on the Windows clients. The
samba package was successfully compiled locally with gcc version 3.3.1. The
install was done as an upgrade to a running version of samba.2.2.8a. I would
really have liked somebody to compile a binary 3.0 version that was proven to
work properly under sun solaris.
Are the documents showing as "Spooling" in the windows print monitor ?
Created attachment 630 [details]
workaround parsing bug in print change notify code
do you use netbios aliases and include files to define printers ?
If so, please try tyhis second patch as a temporary workaround.
Created attachment 637 [details]
test case -- disable the backgroup print queue update daemon
In version 3.0.7 containing the proposed patch (id=630) the problem now seems
to have been resolved. However, the configure script gave warnings about not
being able to compile net/if.h, netinet/ip.h and security/pam_modules.h
(because being dependant on sys/socket.h, netinet/in.h and security/pam_appl.h
respectively). I don't know if this has any impact, but to be sure I made a
workaround for this by adding lines like
#ifndef _PAM_APPL_H
#include <security/pam_appl.h>
#endif
in the failing include files. This should of course be handled more
appropriately in the samba source suite. When compiling 3.0.6 those warnings
were ignored by me.
(In reply to comment #5)
> In version 3.0.7 containing the proposed patch (id=630) the problem now seems
> to have been resolved.
The problem still occurs on a debian woody (x86) machine with deb packages
version 3.0.7-1 from samba.org installed.
I'm afraid the problem is not fully resolved yet. Suddenly the document lists
again appeared to become not exhausted after jobs were printed. Most probably
this behaviour started when one of the printers failed for a period.
Temporarely resolved by clearing the lists manually and then restating smbd.
The queue update bug is fixed by
(which also fixes bug 1519). Suggest you test 3.0.7 after applying
that patch.
sorry for the same, cleaning up the database to prevent unecessary reopens of bugs. | https://bugzilla.samba.org/show_bug.cgi?id=1679 | CC-MAIN-2016-50 | refinedweb | 421 | 68.36 |
This example Groovy source code file (UnicodeEscapes1.groovy) is included in the DevDaily.com
"Java Source Code
Warehouse" project. The intent of this project is to help you "Learn Java by Example" TM.
This example Groovy source code file (UnicodeEscapes1.groovy) is included in the DevDaily.com
"Java Source Code
Warehouse" project. The intent of this project is to help you "Learn Java by Example" TM.
groovytestcase, groovytestcase, unicodeescapes1, unicodeescapes1
groovytestcase, groovytestcase, unicodeescapes1, unicodeescapes1
package gls.ch03.s03
/**
* GLS 3.3:
* Implementations first recognize Unicode escapes in their input, translating
* the ASCII characters backslash and 'u' followed by four hexadecimal digits
* to the Unicode character with the indicated hexadecimal value, and passing
* all other characters unchanged.
*
* @author Alan Green
* @author Jeremy Rayner
*/
class UnicodeEscapes1 extends GroovyTestCase {
void testAllHexDigits() {
// All hex digits work (char def0 is a special codepoint)
def s = "\u1234\u5678\u9abc\u0fed\u9ABC\u0FEC"
assert s.charAt(0) == 0x1234
assert s.charAt(1) == 0x5678
assert s.charAt(2) == 0x9abc
assert s.charAt(3) == 0x0fed
assert s.charAt(4) == 0x9abc
assert s.charAt(5) == 0x0fec
}
// There can be 1 or more u's after the backslash
void testMultipleUs() {
assert "\uu0061" == "a"
assert "\uuu0061" == "a"
assert "\uuuuu0061" == "a"
}
void testOtherVariations() {
// Capital 'U' not allowed
// assert "\U0061" == "a" // @fail:parse
}
// todo: Implementations should use the \ uxxxx notation as an output format to
// display Unicode characters when a suitable font is not available.
// (to be tested as part of the standard library)
// todo: Representing supplementary characters requires two consecutive Unicode
// escapes.
// (not sure how to test)
// see: gls.ch03.s01.Unicode2.testUTF16SupplementaryCharacters()
// todo: test unicode escapes last in file
// and invalid escapes at end of file
}
Here is a short list of links related to this Groovy UnicodeEscapes1.groovy source code file: | http://alvinalexander.com/java/jwarehouse/groovy/src/tck/test/gls/ch03/s03/UnicodeEscapes1.groovy.shtml | CC-MAIN-2015-06 | refinedweb | 290 | 59.5 |
Hi,
This is starting to drive me totally crazy :0. I bought an Bluetooth Mate Silver (Sparkfun) to use with my Arduino Duemilanove. I use NewSoftSerial beta 11 to communicate with the RN-42 (- beware the class is called SoftwareSerial in the NewSoftSerial beta 11!). I also use the Arduino (usb) serial port to relay input from the Arduino serial monitor to the RN-42. Also, I have a bluetooth device in my PC so I can connect to the RN-42.
The sketch I’m using makes it possible to send data (in both directions): Arduino serial monitor->Arduino Duemilanove->RN-42->TeraTerm (PC bluetooth terminal program). This works.
Writing $$$ in both TeraTerm and Arduino serial monitor I can make the RN-42 go into command mode. BUT when I do it from the Ardunio serial monitor I only get rubbish echoed back and not CMD as expected! I have spent days trying to figure out what’s wrong but I just can’t get it to work. My mission is to make the sketch change baud rate from 115200 to 9600. Any help appreciated extremly much!
This is my sketch
#include <icrmacros.h> #include <SoftwareSerial.h> /* Bluetooth Mate Echo by: Jim Lindblom - jim at sparkfun.com date: 3/15/11 license: CC-SA v3.0 - Use this code however you'd like, for any purpose. If you happen to find it useful, or make it better, let us know! This code allows you to send any of the RN-42 commands to the Bluetooth Mate via the Arduino Serial monitor. Characters sent over USB-Serial to the Arduino are relayed to the Mate, and vice-versa. Here are the connections necessary: Bluetooth Mate-----------------Arduino CTS-I (not connected) VCC------------------------5V or 3.3V (supplied from pin A0) GND--------------------------GND TX-O-------------------------D2 RX-I-------------------------D3 RTS-O (not connected) How to use: You can use the serial monitor to send any commands listed in the RN-42 Advanced User Manual ( to the Bluetooth Mate. Open up the serial monitor to 9600bps, and make sure the pull-down menu next to the baud rate selection is initially set to "No line ending". Now enter the configuration command $$ in the serial monitor and click Send. The Bluetooth mate should respond with "CMD". The RN-42 module expects a newline character after every command. So, once you're in command mode, change the "No line ending" drop down selection to "Newline". To test, send a simple command. For instance, try looking for other bluetooth devices by sending the I command. Type I and click Send. The Bluetooth Mate should respond with "Inquiry, COD", follwed by any bluetooth devices it may have found. To exit command mode, either connect to another device, or send ---. The newline and no line ending selections are very important! If you don't get any response, make sure you've set that menu correctly. */ // We'll use the newsoftserial library to communicate with the Mate //#include <NewSoftSerial.h> int bluetoothTx = 2; // TX-O pin of bluetooth mate, Arduino D2 int bluetoothRx = 3; // RX-I pin of bluetooth mate, Arduino D3 //NewSoftSerial bluetooth(bluetoothTx, bluetoothRx); SoftwareSerial bluetooth(bluetoothTx, bluetoothRx); void setup() { pinMode(A0, OUTPUT); // Use analog pin 0 to power on/off the bluetooth on pinMode(A1, OUTPUT); // Use analog pin 1 to reset the bluetooth on PIO6. Serial.begin(9600); // Begin the serial monitor at 9600bps btReboot(); // Reboot/reset the RN-42 bluetooth to defaults. }! } // Switch off, on and reset the bluetooth to factory defaults. Start serial. void btReboot() { int dt = 20; digitalWrite(A0, LOW); // Switch off delay(dt); digitalWrite(A1, HIGH); // Set PIO6 high to reset delay(dt); digitalWrite(A0, HIGH); // Switch on delay(dt); digitalWrite(A1, LOW); // Toggle PIO6 3 times to reset digitalWrite(A1, HIGH); delay(dt); digitalWrite(A1, LOW); digitalWrite(A1, HIGH); delay(dt); digitalWrite(A1, LOW); digitalWrite(A1, HIGH); Serial.println("Starting..."); bluetooth.begin(115200); // The Bluetooth Mate defaults to 115200bps /* // Can't get this to work!! :( bluetooth.print("$$"); // Enter command mode delay(250); // Short delay, wait for the Mate to send back CMD Serial.println((char)bluetooth.read()); bluetooth.println("U,9600,N"); // Temporarily Change the baudrate to 9600, no parity // 115200 can be too fast at times for NewSoftSerial to relay the data reliably bluetooth.begin(9600); // Start bluetooth serial at 9600 */ }
Cheers | https://forum.arduino.cc/t/bluetooth-rn-42-command-mode-problem-solved/73840 | CC-MAIN-2022-21 | refinedweb | 723 | 55.95 |
With monday.com’s project management tool, you can see what everyone on your team is working in a single glance. Its intuitive dashboards are customizable, so you can create systems that work for you.
I would start with base class "Item"
Fields:
Item name (IrishSpring)
Item type (BodySoap)
Price (Example: 2.25)
Quantity (3)
Constructors:
No-arg constructor
3-arg constructor (Default quantity 1)
4-arg constructor
Methods:
getInvoice() Computes the total cost. Does not print anything.
Display() displays all the values of the item. Calls getInvoice() method
Store each class in a file named for the class, so Item.java in this case.
The values in the paranthesis above are example values that you don't necessary need to use in code for definition of Item class. You would probably want to set those as the values in your test class that will have the main method described in last step of assignment.
Open in new window
price = 2.25;
Price 2.25 won't compile.
public class NuseryItem extends Item
Once you have built the three different classes, you just need to build a main class something similar to this:
Open in new window
Open in new window | https://www.experts-exchange.com/questions/24439246/Learning-Java.html | CC-MAIN-2018-13 | refinedweb | 201 | 74.59 |
Care”?
Further Reading on SmashingMag:
- Rebuilding An HTML5 Game In Unity
- What Web Designers Can Learn From Video Games
- Finger-Friendly Design: Ideal Mobile Touchscreen Target Sizes
Getting Started
Before you start sketching the next Temple Run or Angry Birds, you should be aware of a few things that could dampen your excitement:
- Performance. Mobile browsers are not traditionally known for their blazing JavaScript engines. With iOS 6 and Chrome beta for Android, though, things are improving fast.
- Resolution. A veritable cornucopia of Android devices sport a wide range of resolutions. Not to mention the increased resolution and pixel density of the iPhone 4 and iPad 3.
- Audio. Hope you enjoy the sound of silence. Audio support in mobile browsers is poor, to say the least. Lag is a major problem, as is the fact that most devices offer only a single channel. iOS won’t even load a sound until the user initiates the action. My advice is to hold tight and wait for browser vendors to sort this out.
Now, as a Web developer you’re used to dealing with the quirks of certain browsers and degrading gracefully and dealing with fragmented platforms. So, a few technical challenges won’t put you off, right? What’s more, all of these performance and audio problems are temporary. The mobile browser landscape is changing so quickly that these concerns will soon be a distant memory.
In this tutorial, we’ll make a relatively simple game that takes you through the basics and steers you away from pitfalls. The result will look like this:
- Play the demo.
- Download the demo (ZIP).
It’s a fairly simple game, in which the user bursts floating bubbles before they reach the top of the screen. Imaginatively, I’ve titled our little endeavour Pop.
We’ll develop this in a number of distinct stages:
- Cater to the multitude of viewports and optimize for mobile;
- Look briefly at using the canvas API to draw to the screen;
- Capture touch events;
- Make a basic game loop;
- Introduce sprites, or game “entities”;
- Add collision detection and some simple maths to spice things up;
- Add a bit of polish and some basic particle effects.
1. Setting The Stage
Enough of the background story. Fire up your favorite text editor, pour a strong brew of coffee, and let’s get our hands dirty.
As mentioned, there is a plethora of resolution sizes and pixel densities across devices. This means we’ll have to scale our canvas to fit the viewport. This could come at the price of a loss in quality, but one clever trick is to make the canvas small and then scale up, which provides a performance boost.
Let’s kick off with a basic HTML shim:
<!DOCTYPE HTML> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1, maximum-scale=1, user-scalable=0" /> <meta name="apple-mobile-web-app-capable" content="yes" /> <meta name="apple-mobile-web-app-status-bar-style" content="black-translucent" /> <style type="text/css"> body { margin: 0; padding: 0; background: #000;} canvas { display: block; margin: 0 auto; background: #fff; } </style> </head> <body> <canvas> </canvas> <script> // all the code goes here </script> </body> </html>
The
meta viewport tag tells mobile browsers to disable user scaling and to render at full size rather than shrink the page down. The subsequent
apple- prefixed meta tags allow the game to be bookmarked. On the iPhone, bookmarked apps do not display the toolbar at the bottom of the page, thus freeing up valuable real estate.
Take a look at the following:
// namespace our game var POP = { // set up some initial values WIDTH: 320, HEIGHT: 480, // we'll set the rest of these // in the init function RATIO: null, currentWidth: null, currentHeight: null, canvas: null, ctx: null, init: function() { // the proportion of width to height POP.RATIO = POP.WIDTH / POP.HEIGHT; // these will change when the screen is resized POP.currentWidth = POP.WIDTH; POP.currentHeight = POP.HEIGHT; // this is our canvas element POP.canvas = document.getElementsByTagName('canvas')[0]; // setting this is important // otherwise the browser will // default to 320 x 200 POP.canvas.width = POP.WIDTH; POP.canvas.height = POP.HEIGHT; // the canvas context enables us to // interact with the canvas api POP.ctx = POP.canvas.getContext('2d'); // we're ready to resize POP.resize(); }, resize: function() { POP.currentHeight = window.innerHeight; // resize the width in proportion // to the new height POP.currentWidth = POP.currentHeight * POP.RATIO; // this will create some extra space on the // page, allowing us to scroll past // the address bar, thus hiding it. if (POP.android || POP.ios) { document.body.style.height = (window.innerHeight + 50) + 'px'; } // set the new canvas style width and height // note: our canvas is still 320 x 480, but // we're essentially scaling it with CSS POP.canvas.style.width = POP.currentWidth + 'px'; POP.canvas.style.height = POP.currentHeight + 'px'; // we use a timeout here because some mobile // browsers don't fire if there is not // a short delay window.setTimeout(function() { window.scrollTo(0,1); }, 1); } }; window.addEventListener('load', POP.init, false); window.addEventListener('resize', POP.resize, false);
First, we create the
POP namespace for our game. Being good developers, we don’t want to pollute the global namespace. In keeping good practice, we will declare all variables at the start of the program. Most of them are obvious:
canvas refers to the
canvas element in the HTML, and
ctx enables us to access it via the JavaScript canvas API.
In
POP.init, we grab a reference to our canvas element, get its context and adjust the canvas element’s dimensions to 480 × 320. The
resize function, which is fired on resize and load events, adjusts the canvas’
style attribute for width and height accordingly while maintaining the ratio. Effectively, the canvas is still the same dimensions but has been scaled up using CSS. Try resizing your browser and you’ll see the canvas scale to fit.
If you tried that on your phone, you’ll notice that the address bar is still visible. Ugh! We can fix this by adding a few extra pixels to the document and then scrolling down to hide the address bar, like so:
// we need to sniff out Android and iOS // so that we can hide the address bar in // our resize function POP.ua = navigator.userAgent.toLowerCase(); POP.android = POP.ua.indexOf('android') > -1 ? true : false; POP.ios = ( POP.ua.indexOf('iphone') > -1 || POP.ua.indexOf('ipad') > -1 ) ? true : false;
The code above sniffs out the user agent, flagging for Android and iOS if present. Add it at the end of
POP.init, before the call to
POP.resize().
Then, in the
resize function, if
android or
ios is
true, we add another 50 pixels to the document’s height — i.e. enough extra space to be able to scroll down past the address bar.
// this will create some extra space on the // page, enabling us to scroll past // the address bar, thus hiding it. if (POP.android || POP.ios) { document.body.style.height = (window.innerHeight + 50) + 'px'; }
Notice that we do this only for Android and iOS devices; otherwise, nasty scroll bars will appear. Also, we need to delay the firing of
scrollTo to make sure it doesn’t get ignored on mobile Safari.
2. A Blank Canvas
Now that we’ve scaled our canvas snuggly to the viewport, let’s add the ability to draw some shapes.
Note: In this tutorial, we’re going to stick with basic geometric shapes. iOS 5 and Chrome beta for Android can handle a lot of image sprites at a high frame rate. Try that on Android 3.2 or lower and the frame rate will drop exponentially. Luckily, there is not much overhead when drawing circles, so we can have a lot of bubbles in our game without hampering performance on older devices.
Below, we’ve added a basic
Draw object that allows us to clear the screen, draw a rectangle and circle, and add some text. Nothing mind-blowing yet. Mozilla Developers Network has excellent resources as always, replete with examples for drawing to the canvas.
// abstracts various canvas operations into // standalone functions POP.Draw = { clear: function() { POP.ctx.clearRect(0, 0, POP.WIDTH, POP.HEIGHT); }, rect: function(x, y, w, h, col) { POP.ctx.fillStyle = col; POP.ctx.fillRect(x, y, w, h); }, circle: function(x, y, r, col) { POP.ctx.fillStyle = col; POP.ctx.beginPath(); POP.ctx.arc(x + 5, y + 5, r, 0, Math.PI * 2, true); POP.ctx.closePath(); POP.ctx.fill(); }, text: function(string, x, y, size, col) { POP.ctx.font = 'bold '+size+'px Monospace'; POP.ctx.fillStyle = col; POP.ctx.fillText(string, x, y); } };
Our
Draw object has methods for clearing the screen and drawing rectangles, circles and text. The benefit of abstracting these operations is that we don’t have to remember the exact canvas API calls, and we can now draw a circle with one line of code, rather than five.
Let’s put it to the test:
// include this at the end of POP.init function POP.Draw.clear(); POP.Draw.rect(120,120,150,150, 'green'); POP.Draw.circle(100, 100, 50, 'rgba(255,0,0,0.5)'); POP.Draw.text('Hello World', 100, 100, 10, '#000');
Include the code above at the end of the
POP.init function, and you should see a couple of shapes drawn to the canvas.
3. The Magic Touch
Just as we have the
click event, mobile browsers provide methods for catching touch events.
The interesting parts of the code below are the
touchstart,
touchmove and
touchend events. With the standard
click event, we can get the coordinates from
e.pageX and
e.pageY. Touch events are slightly different. They contain a
touches array, each element of which contains touch coordinates and other data. We only want the first touch, and we access it like so:
e.touches[0].
Note: Android provides JavaScript access to multi-touch actions only since version 4.
We also call
e.preventDefault(); when each event is fired to disable scrolling, zooming and any other action that would interrupt the flow of the game.
Add the following code to the
POP.init function.
// listen for clicks window.addEventListener('click', function(e) { e.preventDefault(); POP.Input.set(e); }, false); // listen for touches window.addEventListener('touchstart', function(e) { e.preventDefault(); // the event object has an array // named touches; we just want // the first touch POP.Input.set(e.touches[0]); }, false); window.addEventListener('touchmove', function(e) { // we're not interested in this, // but prevent default behaviour // so the screen doesn't scroll // or zoom e.preventDefault(); }, false); window.addEventListener('touchend', function(e) { // as above e.preventDefault(); }, false);
You probably noticed that the code above passes the event data to an
Input object, which we’ve yet to define. Let’s do that now:
// + add this at the bottom of your code, // before the window.addEventListeners POP.Input = { x: 0, y: 0, tapped :false, set: function(data) { this.x = data.pageX; this.y = data.pageY; this.tapped = true; POP.Draw.circle(this.x, this.y, 10, 'red'); } };
Now, try it out. Hmm, the circles are not appearing. A quick scratch of the head and a lightbulb moment! Because we’ve scaled the canvas, we need to account for this when mapping the touch to the screen’s position.
First, we need to subtract the offset from the coordinates.
var offsetTop = POP.canvas.offsetTop, offsetLeft = POP.canvas.offsetLeft; this.x = data.pageX - offsetLeft; this.y = data.pageY - offsetTop;
Then, we need to take into account the factor by which the canvas has been scaled so that we can plot to the actual canvas (which is still 320 × 480).
var offsetTop = POP.canvas.offsetTop, offsetLeft = POP.canvas.offsetLeft; scale = POP.currentWidth / POP.WIDTH; this.x = ( data.pageX - offsetLeft ) / scale; this.y = ( data.pageY - offsetTop ) / scale;
If your head is starting to hurt, a practical example should provide some relief. Imagine the player taps the 500 × 750 canvas above at
400,400. We need to translate that to 480 × 320 because, as far as the JavaScript is concerned, those are the dimensions of the canvas. So, the actual
x coordinate is 400 divided by the scale; in this case, 400 ÷ 1.56 = 320.5.
Rather than calculating this on each touch event, we can calculate them after resizing. Add the following code to the start of the program, along with the other variable declarations:
// let's keep track of scale // along with all initial declarations // at the start of the program scale: 1, // the position of the canvas // in relation to the screen offset = {top: 0, left: 0},
In our resize function, after adjusting the canvas’ width and height, we make note of the current scale and offset:
// add this to the resize function. POP.scale = POP.currentWidth / POP.WIDTH; POP.offset.top = POP.canvas.offsetTop; POP.offset.left = POP.canvas.offsetLeft;
Now, we can use them in the
set method of our
POP.Input class:
this.x = (data.pageX - POP.offset.left) / POP.scale; this.y = (data.pageY - POP.offset.top) / POP.scale;
4. In The Loop
A typical game loop goes something like this:
- Poll user input,
- Update characters and process collisions,
- Render characters on the screen,
- Repeat.
We could, of course, use
setInterval, but there’s a shiny new toy in town named
requestAnimationFrame. It promises smoother animation and is more battery-efficient. The bad news is that it’s not supported consistently across browsers. But Paul Irish has come to the rescue with a handy shim.
Let’s go ahead and add the shim to the start of our current code base.
// // shim layer with setTimeout fallback window.requestAnimFrame = (function(){ return window.requestAnimationFrame || window.webkitRequestAnimationFrame || window.mozRequestAnimationFrame || window.oRequestAnimationFrame || window.msRequestAnimationFrame || function( callback ){ window.setTimeout(callback, 1000 / 60); }; })();
And let’s create a rudimentary game loop:
// Add this at the end of POP.init; // it will then repeat continuously POP.loop(); // Add the following functions after POP.init: // this is where all entities will be moved // and checked for collisions, etc. update: function() { }, // this is where we draw all the entities render: function() { POP.Draw.clear(); }, // the actual loop // requests animation frame, // then proceeds to update // and render loop: function() { requestAnimFrame( POP.loop ); POP.update(); POP.render(); }
We call the loop at the end of
POP.init. The
POP.loop function in turn calls our
POP.update and
POP.render methods.
requestAnimFrame ensures that the loop is called again, preferably at 60 frames per second. Note that we don’t have to worry about checking for input in our loop because we’re already listening for touch and click events, which is accessible through our
POP.Input class.
The problem now is that our touches from the last step are immediately wiped off the screen. We need a better approach to remember what was drawn to the screen and where.
5. Spritely Will Do It
First, we add an entity array to keep track of all entities. This array will hold a reference to all touches, bubbles, particles and any other dynamic thing we want to add to the game.
// put this at start of program entities: [],
Let’s create a
Touch class that draws a circle at the point of contact, fades it out and then removes it.
POP.Touch = function(x, y) { this.type = 'touch'; // we'll need this later this.x = x; // the x coordinate this.y = y; // the y coordinate this.r = 5; // the radius this.opacity = 1; // initial opacity; the dot will fade out this.fade = 0.05; // amount by which to fade on each game tick this.remove = false; // flag for removing this entity. POP.update // will take care of this this.update = function() { // reduce the opacity accordingly this.opacity -= this.fade; // if opacity if 0 or less, flag for removal this.remove = (this.opacity < 0) ? true : false; }; this.render = function() { POP.Draw.circle(this.x, this.y, this.r, 'rgba(255,0,0,'+this.opacity+')'); }; };
The
Touch class sets a number of properties when initiated. The x and y coordinates are passed as arguments, and we set the radius
this.r to 5 pixels. We also set an initial opacity to 1 and the rate by which the touch fades to 0.05. There is also a
remove flag that tells the main game loop whether to remove this from the entities array.
Crucially, the class has two main methods:
update and
render. We will call these from the corresponding part of our game loop.
We can then spawn a new instance of
Touch in the game loop, and then move them via the update method:
// POP.update function update: function() { var i; // spawn a new instance of Touch // if the user has tapped the screen if (POP.Input.tapped) { POP.entities.push(new POP.Touch(POP.Input.x, POP.Input.y)); // set tapped back to false // to avoid spawning a new touch // in the next cycle POP.Input.tapped = false; } // cycle through all entities and update as necessary for (i = 0; i < POP.entities.length; i += 1) { POP.entities[i].update(); // delete from array if remove property // flag is set to true if (POP.entities[i].remove) { POP.entities.splice(i, 1); } } },
Basically, if
POP.Input.tapped is
true, then we add a new instance of
POP.Touch to our entities array. We then cycle through the entities array, calling the
update method for each entity. Finally, if the entity is flagged for removal, we delete it from the array.
Next, we render them in the
POP.render function.
// POP.render function render: function() { var i; POP.Draw.rect(0, 0, POP.WIDTH, POP.HEIGHT, '#036'); // cycle through all entities and render to canvas for (i = 0; i < POP.entities.length; i += 1) { POP.entities[i].render(); } },
Similar to our update function, we cycle through the entities and call their
render method to draw them to the screen.
So far, so good. Now we’ll add a
Bubble class that will create a bubble that floats up for the user to pop.
POP.Bubble = function() { this.type = 'bubble'; this.x = 100; this.r = 5; // the radius of the bubble this.y = POP.HEIGHT + 100; // make sure it starts off screen this.remove = false; this.update = function() { // move up the screen by 1 pixel this.y -= 1; // if off screen, flag for removal if (this.y < -10) { this.remove = true; } }; this.render = function() { POP.Draw.circle(this.x, this.y, this.r, 'rgba(255,255,255,1)'); }; };
The
POP.Bubble class is very similar to the
Touch class, the main differences being that it doesn’t fade but moves upwards. The motion is achieved by updating the
y position,
this.y, in the update function. Here, we also check whether the bubble is off screen; if so, we flag it for removal.
Note: We could have created a base
Entity class that both
Touch and
Bubble inherit from. But, I’d rather not open another can of worms about JavaScript prototypical inheritance versus classic at this point.
// Add at the start of the program // the amount of game ticks until // we spawn a bubble nextBubble: 100, // at the start of POP.update // decrease our nextBubble counter POP.nextBubble -= 1; // if the counter is less than zero if (POP.nextBubble < 0) { // put a new instance of bubble into our entities array POP.entities.push(new POP.Bubble()); // reset the counter with a random value POP.nextBubble = ( Math.random() * 100 ) + 100; }
Above, we have added a random timer to our game loop that will spawn an instance of
Bubble at a random position. At the start of the game, we set
nextBubble with a value of 100. This is subtracted on each game tick and, when it reaches 0, we spawn a bubble and reset the
nextBubble counter.
6. Putting It Together
First of all, there is not yet any notion of collision detection. We can add that with a simple function. The math behind this is basic geometry, which you can brush up on at Wolfram MathWorld.
// this function checks if two circles overlap POP.collides = function(a, b) { var distance_squared = ( ((a.x - b.x) * (a.x - b.x)) + ((a.y - b.y) * (a.y - b.y))); var radii_squared = (a.r + b.r) * (a.r + b.r); if (distance_squared < radii_squared) { return true; } else { return false; } }; // at the start of POP.update, we set a flag for checking collisions var i, checkCollision = false; // we only need to check for a collision // if the user tapped on this game tick // and then incorporate into the main logic if (POP.Input.tapped) { POP.entities.push(new POP.Touch(POP.Input.x, POP.Input.y)); // set tapped back to false // to avoid spawning a new touch // in the next cycle POP.Input.tapped = false; checkCollision = true; } // cycle through all entities and update as necessary for (i = 0; i < POP.entities.length; i += 1) { POP.entities[i].update(); if (POP.entities[i].type === 'bubble' && checkCollision) { hit = POP.collides(POP.entities[i], {x: POP.Input.x, y: POP.Input.y, r: 7}); POP.entities[i].remove = hit; } // delete from array if remove property // is set to true if (POP.entities[i].remove) { POP.entities.splice(i, 1); } }
The bubbles are rather boring; they all travel at the same speed on a very predictable trajectory. Making the bubbles travel at random speeds is a simple task:
POP.Bubble = function() { this.type = 'bubble'; this.r = (Math.random() * 20) + 10; this.speed = (Math.random() * 3) + 1; this.x = (Math.random() * (POP.WIDTH) - this.r); this.y = POP.HEIGHT + (Math.random() * 100) + 100; this.remove = false; this.update = function() { this.y -= this.speed; // the rest of the class is unchanged
And let’s make them oscillate from side to side, so that they are harder to hit:
// the amount by which the bubble // will move from side to side this.waveSize = 5 + this.r; // we need to remember the original // x position for our sine wave calculation this.xConstant = this.x; this.remove = false; this.update = function() { // a sine wave is commonly a function of time var time = new Date().getTime() * 0.002; this.y -= this.speed; // the x coordinate to follow a sine wave this.x = this.waveSize * Math.sin(time) + this.xConstant; // the rest of the class is unchanged
Again, we’re using some basic geometry to achieve this effect; in this case, a sine wave. While you don’t need to be a math whiz to make games, basic understanding goes a long way. The article “A Quick Look Into the Math of Animations With JavaScript” should get you started.
Let’s also show some statistics on screen. To do this, we will need to track various actions throughout the game.
Put the following code, along with all of the other variable declarations, at the beginning of the program.
// this goes at the start of the program // to track players's progress POP.score = { taps: 0, hit: 0, escaped: 0, accuracy: 0 },
Now, in the
Bubble class we can keep track of
POP.score.escaped when a bubble goes off screen.
// in the bubble class, when a bubble makes it to // the top of the screen if (this.y < -10) { POP.score.escaped += 1; // update score this.remove = true; }
In the main update loop, we increase
POP.score.hit accordingly:
// in the update loop if (POP.entities[i].type === 'bubble' && checkCollision) { hit = POP.collides(POP.entities[i], {x: POP.Input.x, y: POP.Input.y, r: 7}); if (hit) { POP.score.hit += 1; } POP.entities[i].remove = hit; }
In order for the statistics to be accurate, we need to record all of the taps the user makes:
// and record all taps if (POP.Input.tapped) { // keep track of taps; needed to // calculate accuracy POP.score.taps += 1;
Accuracy is obtained by dividing the number of hits by the number of taps, multiplied by 100, which gives us a nice percentage. Note that
~~(POP.score.accuracy) is a quick way (i.e. a hack) to round floats down to integers.
// Add at the end of the update loop // to calculate accuracy POP.score.accuracy = (POP.score.hit / POP.score.taps) * 100; POP.score.accuracy = isNaN(POP.score.accuracy) ? 0 : ~~(POP.score.accuracy); // a handy way to round floats
Lastly, we use our
POP.Draw.text to display the scores in the main update function.
// and finally in the draw function POP.Draw.text('Hit: ' + POP.score.hit, 20, 30, 14, '#fff'); POP.Draw.text('Escaped: ' + POP.score.escaped, 20, 50, 14, '#fff'); POP.Draw.text('Accuracy: ' + POP.score.accuracy + '%', 20, 70, 14, '#fff');
7. Spit And Polish
There’s a common understanding that a playable demo can be made in a couple of hours, but a polished game takes days, week, months or even years!
We can do a few things to improve the visual appeal of the game.
Particle Effects
Most games boast some form of particle effects, which are great for explosions. What if we made a bubble explode into many tiny bubbles when it is popped, rather than disappear instantly?
Take a look at our
Particle class:
POP.Particle = function(x, y,r, col) { this.x = x; this.y = y; this.r = r; this.col = col; // determines whether particle will // travel to the right of left // 50% chance of either happening this.dir = (Math.random() * 2 > 1) ? 1 : -1; // random values so particles do not // travel at the same speeds this.vx = ~~(Math.random() * 4) * this.dir; this.vy = ~~(Math.random() * 7); this.remove = false; this.update = function() { // update coordinates this.x += this.vx; this.y += this.vy; // increase velocity so particle // accelerates off screen this.vx *= 0.99; this.vy *= 0.99; // adding this negative amount to the // y velocity exerts an upward pull on // the particle, as if drawn to the // surface this.vy -= 0.25; // off screen if (this.y < 0) { this.remove = true; } }; this.render = function() { POP.Draw.circle(this.x, this.y, this.r, this.col); }; };
It’s fairly obvious what is going on here. Using some basic acceleration so that the particles speed up as the reach the surface is a nice touch. Again, this math and physics are beyond the scope of this article, but for those interested, Skookum Digital Works explains it in depth.
To create the particle effect, we push several particles into our
entities array whenever a bubble is hit:
// modify the main update function like so: if (hit) { // spawn an explosion for (var n = 0; n < 5; n +=1 ) { POP.entities.push(new POP.Particle( POP.entities[i].x, POP.entities[i].y, 2, // random opacity to spice it up a bit 'rgba(255,255,255,'+Math.random()*1+')' )); } POP.score.hit += 1; }
Waves
Given the underwater theme of the game, adding a wave effect to the top of the screen would be a nice touch. We can do this by drawing a number of overlapping circles to give the illusion of waves:
// set up our wave effect; // basically, a series of overlapping circles // across the top of screen POP.wave = { x: -25, // x coordinate of first circle y: -40, // y coordinate of first circle r: 50, // circle radius time: 0, // we'll use this in calculating the sine wave offset: 0 // this will be the sine wave offset }; // calculate how many circles we need to // cover the screen's width POP.wave.total = Math.ceil(POP.WIDTH / POP.wave.r) + 1;
Add the code above to the
POP.init function.
POP.wave has a number of values that we’ll need to draw the waves.
Add the following to the main update function. It uses a sine wave to adjust the position of the waves and give the illusion of movement.
// update wave offset // feel free to play with these values for // either slower or faster waves POP.wave.time = new Date().getTime() * 0.002; POP.wave.offset = Math.sin(POP.wave.time * 0.8) * 5;
All that’s left to be done is to draw the waves, which goes into the render function.
// display snazzy wave effect for (i = 0; i < POP.wave.total; i++) { POP.Draw.circle( POP.wave.x + POP.wave.offset + (i * POP.wave.r), POP.wave.y, POP.wave.r, '#fff'); }
Here, we’ve reused our sine wave solution for the bubbles to make the waves move gently to and fro. Feeling seasick yet?
Final Thoughts
Phew! That was fun. Hope you enjoyed this short forage into tricks and techniques for making an HTML5 game. We’ve managed to create a very simple game that works on most smartphones as well as modern browsers. Here are some things you could consider doing:
- Store high scores using local storage.
- Add a splash screen and a “Game over” screen.
- Enable power-ups.
- Add audio. Contrary to what I said at the beginning of this article, this isn’t impossible, just a bit of a headache. One technique is to use audio sprites (kind of like CSS image sprites); Remy Sharp breaks it down.
- Let your imagination run wild!
If you are interested in further exploring the possibilities of mobile HTML5 games, I recommend test-driving a couple of frameworks to see what works for you. Juho Vepsäläinen offers a useful summary of most game engines. If you’re willing to invest a little cash, then Impact is a great starting point, with thorough documentation and lively helpful forums. And the impressive X-Type demonstrates what is possible. Not bad, eh?
(al) (jc) | https://www.smashingmagazine.com/2012/10/design-your-own-mobile-game/ | CC-MAIN-2018-17 | refinedweb | 4,934 | 67.55 |
Parameter-we can pass two type of parameter to the method.
There are two type of parameter
I have full explained these two concept through programming which is given below.There are some steps please follow it
Step 1 - First open your visual studio->File->New->Project->console Application->OK->write the program which is below:
see it
- Input parameter
- Out parameter
- Input parameter- This kind of parameter is specify to give the same input to method for calling it.
- Call by value -> In this case when we call the method of any class (which takes some parameter) from main method using object.Then value of parameter in main method will directly copy to the class method to parameter values respectively. In this case if some changes occurs in values within the method that change not occurs in actual variable .I have full describe this concept through programming which is given below.
- Call by reference -> In this case when we call the method,the reference address of variable is passed to the method.If some changes occurs in values within the method that changes occurs in actual variable.To specify this parameter we use 'ref' Keyword at the time of parameter declaration as well as the calling method.
Step 1 - First open your visual studio->File->New->Project->console Application->OK->write the program which is below:
see it
using System; namespace callbyvalue { class Program { public class employee { public void display(int a, String b) { Console.WriteLine("Integer value is"+" " +a); Console.WriteLine(" String value is" + " " + b); Console.ReadLine(); } } public class student { public void show(ref String str) { Console.WriteLine("Enter the value"); string s = Console.ReadLine(); str = str + s; Console.WriteLine("value in str variable is"+" "+str); Console.ReadLine(); } } //all class member is called through main method. static void Main(string[] args) { //creating the object of employee class first and implementing the call by value concept. String m = "sunil"; employee emp = new employee(); emp.display(200,m); Console.WriteLine("value in variable m is" +" "+m); Console.ReadLine(); //creating the object of employee class first and implementing the call by Reference concept string msg="Hello"; student st = new student(); st.show(ref msg); Console.WriteLine("value in msg is" +" "+msg);//value at address msg will be print,because here address is copy not value thatswhy at same address value will be print Console.ReadLine(); } } }
Step 2 - Now Run the program(press F5).
Output:
Description:-There are some steps to describe the whole program.
- First i have created a employee class ,In employee class i have taken a display method which takes two parameter.Ex display(int a, String b).On this class i have implemented call by value concept.
- After that i have created a student class .In student class i have taken a show method which takes one parameter with ref keyword.This class is used for implementing the call by reference concept in c#.
- After that i have created object of employee class in main method,here i have define a variable m which holds the sunil value .after that i called display method using object.EX. emp.display(200,m), these value directly pass to the display method. see it. a <--200, b <--m<--sunil and display method will print a and b values,if we print m value then sunil will print because here value is copy not reference address.
- After that i have created object of student class in main method and called student class method by the object.Ex st.show(ref msg);here reference address of msg will copy to the str variable.If we print msg value in main method then different value will print which is calculated by the show method in student class.
- In call value actual value is copy to the method but In call by reference reference address of value is copy to the method.
There are following difference between value type and reference type on the basis of storage.
- Value type store within stack memory and reference type store within heap memory.
- Structure,all primitive data type except string,enum are the example of value type.Class,string,array,delegate,interface is the example of reference type.
- Value type directly store values within stack but reference type contains reference object of value which store in heap.
- when value type is copy to another value type then actual value is copy,but when reference type is copy to another reference type then reference address of value is copy .
- Value type can be initialize with zero(0) and reference type initialize with NULL.
Note:- Output parameter concept i will discuss next tutorial
For more...
For more...
- How to host asp.net website on server free
- How to host asp.net application on IIS server
- String and string builder in c#
- Delegate in c#
- File Handling Real application
- How to add controls at run time in .NET Application
- How to implement Form based authentication in asp.net
- How to use web services in asp.net application
- How to send mail from asp.net website free
- How to implement cookies in asp.net application
- How to make composite custom controls in .NET
- How to create captcha image without dll file
- How to handle date in sql server
- How to implement Reflection concepts
I hope this helpful for you.if any problem please comment it, i will improve it as soon as possible.
To Get the Latest Free Updates Subscribe
To Get the Latest Free Updates Subscribe
Click below to download whole application.
awesome. i didn't see this much of explain before.
awesome.....for reading this explain clear my concept ..........
thanks keep it up
thanks yaar
awesome explanation
Really simple and good explanation. :)
Thanks a lot sir for this awesome explanation :D
Very helpfull | https://www.msdotnet.co.in/2013/04/call-by-value-and-call-by-reference-in-c.html?showComment=1392862824059 | CC-MAIN-2021-17 | refinedweb | 963 | 57.27 |
React State Array Get Length Example
In this quick tip article, we'll see how to get the length of an array or state array in React.
React is a JavaScript library for rendering user interfaces therefore it simply deals with the UI and doesn't provide its own utilities for handling arrays or similar tasks. As a result, you simply need to use the built-in JavaScript methods and APIs.
JavaScript' Array Length by Example in React
In this example, we'll see how to get the length of an array in React and JavaScript.
JavaScript already provides many built-in methods for getting the length of an array, let's see how to use in a React example.
The length property of an object which is an instance of type Array sets or returns the number of elements in that array. The value is an unsigned, 32-bit integer that is always numerically greater than the highest index in the array. Source
Create an
index.js file and add the following code:
import React from 'react' class App extends React.Component { render(){ const array = ["React","is", "awesome", "!"]; const length = array.length; return( <div> <p>Array length is { length }.</p> </div> ) } } ReactDOM.render(<App />, document.getElementById("root"));
In the
render() method, we simply define a JavaScript array then we get the length of the array using the
Array.length method. Finally we return a JSX markup to didplay the length of the array.
You should import React and ReactDOM in your project and use ReactDOM to mount the component in the DOM:
<script src=""></script> <script src=""></script> <div id="root"></div>
In the same way, you can get the length of the array in React state as follows:
class App extends React.Component { state = { array: ["Hello", "React"] }; render() { return ( <div> <p>React State Array Length: {this.state.array.length}</p> </div> ); } } ReactDOM.render(<App />, document.getElementById("root"));
Conclusion
In this quick example, we've seen how to use the
Array.length method to get the length of a local array or state array and render the result in the DOM. | https://www.techiediaries.com/react-state-array-get-length-example/ | CC-MAIN-2021-39 | refinedweb | 352 | 63.7 |
Hi all,
I'm trying to determine the best way to toggle between my test and live dbs, and I've hit a bit of a wall. I'm using MySQL 5.0.22 and SQLObject 0.7, and since I'm in a corporate environment, neither of those is likely to change any time soon.
My setup is as follows:
I've got two dbs, which I'll call app and app_dev, living on different hosts and accessed by different users. My connection is set up is in my model as follows:
password_map={"app":{'username': passwords.LIVE_USERNAME,
'passwd': passwords.LIVE_PASSWORD,
'host': 'app'},
"app_dev":{'username': passwords.DEV_USERNAME,
'passwd': passwords.DEV_PASSWORD,
'host': 'app_dev"}}
_connection = connectionForURI(
"mysql://%(username)s:%(passwd)s@%(host)s/%(db)s" %
{'username': password_map[Config.DB_NAME]['username'],
'passwd': password_map[Config.DB_NAME]['passwd'],
'db': Config.DB_NAME,
'host': password_map[Config.DB_NAME]['host']})
I set up my unit tests like this:
from <package> import Config
Config.DB_NAME = app_dev
from <package> import model
This isn't an especially good practice, and I'm trying to figure out how to change my connection after I import my model.
My original thought was to set up a class method to toggle back and forth:
@classmethod
def changeDatabase(cls, database):
"""Toggles between live and dev databases.
database: string, one of ("app", "live", "app-dev", "dev").
"""
if database in ["app", "live"]:
cls._connection = connectionForURI(cls.live_connection_string)
elif database in ["app-dev", "dev"]:
cls._connection = connectionForURI(cls.dev_connection_string)
else:
raise ValueError("database must be one of ('app', 'live', "
"'app-dev', 'dev')")
However, this method results in a lost connection to the second DB. Is there a better way to switch between different connections? Would a hub help, or is that only for managing multiple connections to the same db across threads?
Thanks,
Molly | http://sourceforge.net/p/sqlobject/mailman/attachment/d4031e50807101125w6d754ecej1df7738fee0d51e9%40mail.gmail.com/1/ | CC-MAIN-2015-27 | refinedweb | 295 | 51.65 |
Omnipytent 1.3.0: Async Tasks and Selection UIs
Idan Arye
・1 min read
If you don't know what Omnipytent is, read this first:
Version 1.3.0 of Omnipytent introduces a new concept - async tasks. In this post I'll try to explain what are async tasks and what are they good for.
The problem: single-threaded, event loop based UI
(you can skip this section if you already understand why we need async tasks)
Vim has a single-threaded architecture. When you perform an operation (by typing a key, running a run-mode command, using
:autocmd etc.) that operation takes over the thread, and nothing else can get updated. The operation may receive input from the user (e.g. with
input() or
getchar()) or update the TUI (e.g. with
:echo or by running a shell command with
:!) but Vim's event loop itself is stuck until the operation is finished. You can't run other commands, which means that there is nothing to update the TUI, but even the jobs and terminals can't read anything from their streams while that operation is running.
Your everyday Vim operations are quick and "atomic" enough for this to not be a problem. Vim can't do anything else when you type
w twe needo jump to the next word, but this happens so fast that it doesn't matter, and you don't need Vim do do anything else during. If you are running shell commands, on the other end, they can take quite long and you'd have to patiently wait for them to finish. Luckily, Neovim and Vim8 have jobs and terminals, so you can just launch it and it runs in the background.
But what if you need the "result" of the command you ran in the terminal? fzf, for example, is running
fzf in a terminal, and use the result to open the chosen file. This can't be done in a single Vim function invocation - it needs in one function to start the terminal, then yield executing back to the event loop, and once
fzf exist run another function to deal with the result. If it was done in the same function that launched the terminal, Vim would be unable to update the terminal buffer and the user wouldn't be able to use it.
And it's not just shell commands - sometimes you just need to user to use Vim's UI itself. A good example is fugitive.vim's
:Gcommit command. It opens a new buffer for the user to type the commit message in, and when they save and close that buffer the plugin creates a new Git commit with that commit message. Until the function called by
:Gcommit finishes it hogs the event loop and the user can't write the commit message nor can they save and close the window, so
:Gcommit must terminate before that and another function must be called when the window is close to finish the process.
Plugins like fugitive or the one bundled with fzf are registering callbacks to implement that behavior. It's not that hard to do, but it is quite cumbersome (even more than in JS!) and requires some familiarity with Vimscript and Vim's architecture. Omnipytent tasks are supposed to be simple and streamlines, so this callback registration is too much - we need something simpler. And that's where async tasks come in.
The idea: generator based async tasks
(you can skip this section if you don't care how they work, and go directly to the next sections for examples on how to use them)
A generator function in Python is a function that has at least one
yield expression. If you want to learn more about it read the Python docs - for our purpose it's enough to mention that the
yield yields both a value and the execution itself - so if a callee
yields, the execution goes back to the caller which can chose, at a later point, to resume the callee from where it
yielded.
This was used for async IO before the
async and
await keywords were introduced in Python 3.5, and since Omnipytent wants to support older versions it uses
yield for its async tasks.
An async task looks something like this:
@task def my_async_task(ctx): do_something() result = yield ASYNC_COMMAND() followup(result)
When the task
yields,
ASYNC_COMMAND() does three things:
- It prepares of the command (e.g. open a window or start a terminal)
- It registers itself in Omnipytent.
- It registers a callback/
:autocmdin Vim to resume itself once done.
After that -
:OP my_async_task terminates and control goes back to Vim's event loop. But
my_async_task itself is not terminated yet - at some point it will be resumed and the task will continue and do the followup.
And of course - you can
yield another async command later in the task.
Omnipytent comes bundled in with some useful async commands. If you need to create your own - refer to
:help omnipytent-creating-AsyncCommand.
INPUT_BUFFER - basic async user input
For the example, I'll use the same example project from the first post - Spring's example pet clinic web application. Lets say we want a task for adding animal owners. The API is simple - a POST request with the details - but how will we prompt the user (which is us) to enter the fields?
Up until now, we'd have to use
input() to allow the user to enter that data. With async tasks, we can do better:
import requests, yaml OWNER_FIELDS = ('firstName', 'lastName', 'address', 'city', 'telephone') @task def add_owner(ctx): empty_form = '\n'.join('%s: ' % field for field in OWNER_FIELDS) filled_form = yield INPUT_BUFFER(text=empty_form, filetype='yaml') parsed_form = yaml.load('\n'.join(filled_form)) requests.post('', data=parsed_form)
The important line is the second line of the task function - the one where we do the
yield.
INPUT_BUFFER is one of the async commands bundled with Omnipytent, and it opens a new window with a buffer for the user to edit. We set the original text - a YAMLish form with blank fields for the user to fill - and also set the file type to YAML to get some nice coloring. Then we
yield this command object - and the execution control returns to Vim's event loop. Now the user can fill the form, and when they close it Omnipytent kicks back in and the task resumes - with
filled_form set to the lines of the buffer the user filled.
This is how it looks in action:
CHOOSE - the power of selection UIs
The primary motivation behind async tasks was to support selection UIs. These are usually fuzzy matchers like fzf or Unite, but I use the term Selection UIs because this mechanism is not limited to tools that allow fuzzy search - any tool that provides a TUI for selecting from a list can fit.
Tests can accept arguments, but it's not always convenient to type the arguments. When the arguments are long, or complex, or hard to remember, and when there is an easy way to programmatically generate the list of possibilities, it is far more convenient for the user to filter and pick what they want with a selection UI.
For my next trick I'll need to add a missing method to the example project:
// src/main/java/org/springframework/samples/petclinic/owner/OwnerController.java @GetMapping("/owners.json") public @ResponseBody List<Map<String, Object>> showResourcesVetList() { return this.owners.findByLastName("").stream().map(owner -> { Map<String, Object> entry = new HashMap<>(); entry.put("id", owner.getId()); entry.put("firstName", owner.getFirstName()); entry.put("lastName", owner.getLastName()); entry.put("address", owner.getAddress()); entry.put("city", owner.getCity()); entry.put("telephone", owner.getTelephone()); return entry; }).collect(Collectors.toList()); }
All it does is add a new path -
/owners.json - that generates a JSON of all the owners. Nothing fancy, but the orig example project only supported getting them as an HTML page, which is harder to parse (unless you use a regex)
We want to write an Omnipytent task that reads that list with a GET request, lets the user pick one of the owners, edit it, and update it with a POST request. To do the selection, we are going to use another async command -
CHOOSE:
import json @task def edit_owner(ctx): entries = json.loads(requests.get('').text) entry = yield CHOOSE( entries, fmt='{firstName} {lastName}'.format_map, preview=lambda entry: yaml.dump(entry, default_flow_style=False)) owner_id = entry.pop('id') orig_form = yaml.dump(entry, default_flow_style=False) edited_form = yield INPUT_BUFFER(text=orig_form, filetype='yaml') parsed_form = yaml.load('\n'.join(edited_form)) edit_url = '' % owner_id requests.post(edit_url, data=parsed_form)
CHOOSE runs whatever selection UI installed in your Vim. It first checks for fzf, then Denite, Unite, CtrlP, and finally - if none of the above is available, it uses an
inputlist() based selection UI. Or - if you have other preferences - you can set the selection UI with
g:omnipytent_selectionUI.
Other than the list of options, we pass two more arguments to
CHOOSE:
fmt: The options are
dicts but the selection UIs pick from lines. This argument is a function that formats each option into a line.
preview: fzf, Denite and Unite support a preview of the items, and this argument is a function for rendering that preview.
After we yield
CHOOSE, we get back the picked option and use it to display an
INPUT_BUFFER - which I already explained earlier.
Let's see it at work:
Multi selection and generator options tasks - an actually motivational example
The previous examples were a nice way to show the power of async tasks, but they are not really something you'd write Omnipytent tasks for. If you want to actually add and edit owners you'd use the web application, and if you need a quick way to run these while developing to test your code, editing the text buffer each and every time is a bit cumbersome.
So how about something you actually want to create a task for? How about... running tests?
Running tests is a great use case for
CHOOSE. When I work on a piece of code I often want to run a test that checks it. I don't want to run all the tests, because it'll take too long and will generate too much output. I want to run just this specific test and see just its output - which will reflect the changes I did to the code.
Test names are often long - they need to encode the name of the class/module that contains the test, the name of the test function itself, and sometimes the parametrization. Writing the full name each time is cumbersome. Writing that name inside the test makes it easier to run, but now we have to edit the tasks file when we want another test - and figure the name of that test. Not that hard, but can now do better - we now have
CHOOSE!
Decent project management tools usually have a command for listing all the tests, but this is Maven so we'll have to parse the files ourselves:
import re @task def run_tests(ctx): pattern = re.compile(r'@Test\n\s*public void (\w+)\(') test_names = [] for path in local.path('src/test').walk(lambda p: p.basename.endswith('.java')): for match in pattern.finditer(path.read('utf8')): test_names.append('#'.join((path.stem, match.group(1)))) chosen_tests = yield CHOOSE(test_names, multi=True) cmd = local['mvn']['test'] cmd = cmd['-Dtest=' + ','.join(chosen_tests), 'test'] cmd & TERMINAL_PANEL
Note that there is a new argument to
CHOOSE:
multi=True. As you may have guessed from the name, it allows the user to select multiple options. Only fzf, Denite and Unite support this, but even with CtrlP and
inputlist() it'll still return a list to keep some uniformity in the task.
We then join the chosen tests, and voila!
But... we still need to pick the test we want to run each time. Picking it with fzf is definitely better than typing it, but since we usually want to run the same test(s) many times when we work on the same area of the code, it could be nice if Omnipytent could remember our last choice.
Well - it can. Omnipytent already had
@task.options that remembers the user's choice, but you could only pick one option and the option keys had to be hard-coded as local variables. Omnipytent 1.3.0 solves both these problems:
@task.optionsis now based on
CHOOSE- so it can use more elaborate selection UIs. A new variant -
@task.options_multi- allows you to pick multiple options. If you are using CtrlP or
inputlist()and still want multiple choices you'll have to pass them as arguments. Or just upgrade to fzf/Denite/Unite.
- If the task function is a generator, instead of using the local variables as options it uses the
yielded values as options.
This means we can split our
run_tests into two tasks:
pick_tests and
run_tests.
pick_tests will always prompt us to choose the tests, but
run_tests will remember our last choice:
@task.options_multi def pick_tests(ctx): ctx.key(str) pattern = re.compile(r'@Test\n\s*public void (\w+)\(') for path in local.path('src/test').walk(lambda p: p.basename.endswith('.java')): for match in pattern.finditer(path.read('utf8')): yield '#'.join((path.stem, match.group(1))) @task(pick_tests) def run_tests(ctx): cmd = local['mvn']['test'] cmd = cmd['-Dtest=' + ','.join(ctx.dep.pick_tests), 'test'] cmd & TERMINAL_PANEL
Note the first line of
pick_tests:
ctx.key(str). Because the
yielded options can be objects, we need a string keys of them, and
ctx.key sets the function for picking these keys. The key must be deterministic, because these keys will be used to cache the choice. There is also
ctx.preview for setting a preview function, but we don't need one here.
And here is how it works:
Conclusion
Omnipytent's goal was to allow micro-automation of simple project tasks. Async tasks allow you to add better UI to that automation, farther enhancing the power at your fingertips.
Know Not Only Your Weaknesses, But Strengths as Well
Most people want to develop self-awareness. Whether we are managers, entrepreneurs, or aspiring software engineers, the more knowledge we have of our strength and weaknesses, the easier life becomes.
| https://dev.to/idanarye/omnipytent-130-async-tasks-and-selection-uis-2e0o | CC-MAIN-2020-16 | refinedweb | 2,379 | 62.68 |
Settings
#include <settings.h>
Detailed Description
This class contains global kirigami settings about the current device setup It is exposed to QML as the singleton "Settings".
Definition at line 16 of file settings.h.
Property Documentation
- Returns
- application window icon, basically ::windowIcon()
- Since
- 5.62
- org.kde.kirigami 2.10
Definition at line 73 of file settings.h.
True if the user in this moment is interacting with the app with the touch screen.
Definition at line 45 of file settings.h.
- Returns
- runtime information about the libraries in use
- Since
- 5.52
- org.kde.kirigami 2.6
Definition at line 65 of file settings.h.
True if we are running on a small mobile device such as a mobile phone This is used when we want to do specific adaptations to our UI for small screen form factors, such as having bigger touch areas.
Definition at line 32 of file settings.h.
How many lines of text the mouse wheel should scroll.
Definition at line 57 of file settings.h.
name of the QtQuickControls2 style we are using, for instance org.kde.desktop, Plasma, Material, Universal etc
Definition at line 51 of file settings.h.
True if the device we are running on is behaving like a tablet: Note that this doesn't mean exactly a tablet form factor, but that the preferred input mode for the device is the touch screen and that pointer and keyboard are either secondary or not available.
Definition at line 40 of file settings.h.
True if the system can dynamically enter in tablet mode (or the device is actually a tablet).
such as transformable laptops that support keyboard detachment
Definition at line 25 of file settings.h.
The documentation for this class was generated from the following files:
Documentation copyright © 1996-2021 The KDE developers.
Generated on Fri Apr 9 2021 22:38:02 by doxygen 1.8.11 written by Dimitri van Heesch, © 1997-2006
KDE's Doxygen guidelines are available online. | https://api.kde.org/frameworks/kirigami/html/classSettings.html | CC-MAIN-2021-17 | refinedweb | 331 | 57.47 |
Sql question
Sql question How to display duplicate values in Sql?
Hi Friend,
Please visit the following link:
Thanks
Database Sql question? - WebSevices
Database Sql question? Given relation r (a, b,c), show how to use the exstended SQL features to generate a histogram of c versus a, dividing a into 20 equal-sized partions (that is where each partition contains 5 percent
hai this is sql question
hai this is sql question what are tables in home appliances web application
question
question Dear Sir,
could you please send me a simple example of java and database connectivity with java and sql
Please visit the following link:
JDBC Tutorials
question
question good afternoon,
how to get user name and password according to current date,using mysql and jsp.please give me the code immediately.
hi ,
i think it is easy on executeQuery();
sql query is select uname
sql command question
sql command question I have three tables as below:
Table 1: options
fields: optionsID, optionsCatID, name
Table 2: optionCat
fields: optionsCatID... this design is. Anyways I need to find out the sql command which can first see
sql - SQL
sql i have fields as qno,subid,que,op1,op2,op3,op4,ans; and i am having 90 rows in that table .question is am willing to arragnge all the entries... the Query :
"select * from question order by qno Asc"
For more information
SQL Error - SQL
SQL Error Invalid character value for cast specification on column number 5 (Designation)
Whats this error about this if the field i specified in programming error.
ie DB fields in above question
jsp - SQL
jsp hi..
How to get more than 10 numbers using the integet,get me the query for that Hi Friend,
Please clarify your question.
Thanks Please describe your question clearly
database - SQL
the particular question corresponding date.
4.If current date not found the select question randomly by rand() function
query : "select * from tablename order... question.
5.This way to display Question corrsponding Date.
Thanks
database - SQL
am doing project in JSP Question & Answers. In my home page i have to display everyday 1 question as "Question of the day" from database. It should not change till the end of the day. Next day it should display another question. i am using
Important Question
the UserNames in the Account table from SQL Database should come Automatically
Java Question
Java Question how can we increment the value of database SQL by using the java servlet program ? plz help me
Hi Friend,
Try the following code:
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.
database - SQL
database For ex:
Suppose there is 1000 questions (records) in my database. In my home page i want to display everyday 1 question as day of the question.It should not get change until date change...
Hi friend
DBMs - SQL
in question 2, create a physical database design
6.Implement the database
Inserting Data into mysql - SQL
Inserting Data into mysql My sincere apologize for this post. I noticed there is no category for php. However am hoping my question will fit into the SQL category though under php.
I need help with reading from a csv file
question
question sir plz tell me what should i give in title box. just i want java program for the question typed in this area
Question
Question When there is an exception in my program how java runtime system handles
sql
difference between sql and oracle what is the difference between sql and oracle
sql
sql how to get first row in sql with using where condition in sql?
how to get last row in sql with using where condition in sql
jdbc interview question
do you handle sql exception?
Type 1 Drivers
Bridge drivers... the SQL calls to the database and also often rely on native code... machine.
Advantages and Disadvantages of all Drivers
Handling SQL Exceptions
question
question dear sir/madam
my question is how to compare two text format in java..we are java beginners..so we need the complete source code for above mentioned question...we have to compare each and every
question Dear sir
i had some typing mistake at previous question
so its my humble request to let me know the steps to start the tomcat6 under the tomcat directory
jdbc interview question
?
how do you handle sql exception?
Please visit the following links
jdbc interview question
; Stored Procedure: A stored procedure is a named group of SQL statements... the PreparedStatement because the SQL statement that is sent gets pre-compiled (i.e.... to safely provide values to the SQL parameters, through a range of setter methods
sql
sql I want interview sql questions
Please visit the following link:
SQL Tutorials
Jtable Question - Java Beginners
:access");
String sql = "Select * from data";
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery( sql );
ResultSetMetaData md
Need SQL Statement
Need SQL Statement QUESTION IS CAPITALIZED AT THE BOTTOM...
There is a table Employee, with three columns: Name (varchar), Department (varchar... IS THE SQL STATEMENT NEEDED TO ACHIEVE THESE RESULTS
search query - SQL
and tell me... Hi Friend,
Please clarify your question.
Thanks
SQL
SQL In my computer i have microsoft sql 2008.how can i set that in the cmd.i want to use that in cmd.what is the default username and password
question
Question
A question
QUESTION
Ask Questions?
If you are facing any programming issue, such as compilation errors or not able to find the code you are looking for.
Ask your questions, our development team will try to give answers to your questions. | http://www.roseindia.net/tutorialhelp/comment/74423 | CC-MAIN-2013-20 | refinedweb | 932 | 62.38 |
Multi-Threading a Neo4j Traversal
Today, we are going to take a look at how to take a Neo4j traversal and split it up into lots of smaller traversals. I promise it will be electrifying.
Join the DZone community and get the full member experience.Join For Free
What would you think if I ran out of time,
Would you stand up and walk out on me?
Lend me your eyes and I’ll write you a post
And I’ll try not to run out of memory.
Oh, I get by with a little help from my threads
Mm, I get high with a little help from my threads
Mm, gonna try with a little help from my threads
Today, we are going to take a look at how to take a Neo4j traversal and split it up into lots of smaller traversals. I promise it will be electrifying.
We were faced with the problem of figuring out which parts of a power grid were electrified. Our traversal would start at a power supplier that produced electricity for the grid at an initial voltage. Electricity on the grid goes from high voltage to low voltage. As we traversed, if we ran into equipment at a higher voltage than we had before, then we stopped that branch of the traversal. If we ran into off-switches at either end of the connections between equipment, we had to stop that branch of the traversal. This traversal would continue until it couldn’t branch anymore and we’d captured our objective of finding all the equipment that is energized by a power supplier.
To make things interesting, we needed to handle a test graph of 20 million pieces of equipment in under 15 minutes, and another test graph of 200 million pieces of equipment in under 30 minutes. The real graph would end up with about 500 million pieces of equipment. We went about trying to model this in different ways and ultimately settled on a very simple model optimized for this purpose.
Every piece of equipment is just a node, and it is connected to other pieces of equipment by a single relationship with two boolean properties. If either one of these is false, then the traversal cannot continue down this branch. If they are both true, then we check the voltage on the second node and allow it if it is the same or lower.
Let’s take a look at how we would write this traversal using the Traversal API. First, we would get all the starting equipment nodes (yes, there could be multiple). For each, we would start a traversal by getting the voltage of our initial node and using that as our initial branch state with a custom expander and evaluator (I’ll talk about these in a second). Then for every path, we look at the last node and if we haven’t seen it globally (across the multiple traversals, remember we can have many starting points), then we add it to the result set.
Set<Node> startingEquipment = new HashSet<>(); Set results = new HashSet<>(); ArrayList<Long> skip = new ArrayList<>(); try (Transaction tx = db.beginTx()) { ((Collection) input.get("ids")).forEach( (id) -> startingEquipment.add(db.findNode(Labels.Equipment, "equipment_id", id))); if (startingEquipment.isEmpty()) { throw Exceptions.equipmentNotFound; } startingEquipment.forEach(bus -> { InitialBranchState.State<Double> ibs; ibs = new InitialBranchState.State<>((Double) bus.getProperty("voltage", 999.0), 0.0); TraversalDescription td = db.traversalDescription() .depthFirst() .expand(expander, ibs) .uniqueness(Uniqueness.NODE_GLOBAL) .evaluator(evaluator); for (org.neo4j.graphdb.Path position : td.traverse(bus)) { Node endNode = position.endNode(); if (!skip.contains(endNode.getId())) { results.add(position.endNode().getProperty("equipment_id")); skip.add(endNode.getId()); } endNode.setProperty("Energized", true); } }); tx.success(); } return Response.ok().entity(objectMapper.writeValueAsString(results)).build();
Now, let’s talk about the custom expander. It needs to check the voltage of where we just arrived and make sure we can continue by comparing the voltage and updating the branch state. Then it must continue with any relationships that have both our switch states to on. Like this:
public class EnergizationExpander implements PathExpander<Double> { @Override public Iterable<Relationship> expand(Path path, BranchState<Double> branchState) { ArrayList<Relationship> rels = new ArrayList<>(); Node endNode = path.endNode(); Double voltage = (Double) endNode.getProperty("voltage", 999.0); if (voltage <= branchState.getState()) { // Set the new voltage branchState.setState(voltage); endNode.getRelationships(Direction.OUTGOING, RelationshipTypes.CONNECTED).forEach(rel -> { if ((Boolean)rel.getProperty("incoming_switch_on", false) && (Boolean)rel.getProperty("outgoing_switch_on", false)) { rels.add(rel); } }); } return rels; }
Finally, the custom evaluator must check the last node and confirm that the voltage is lower or equal to the previous voltage in order to be included.
public class EnergizationEvaluator implements PathEvaluator<Double> { @Override public Evaluation evaluate(Path path, BranchState<Double> branchState) { // Path with just the single node, ignore it and continue if (path.length() == 0 ) { return Evaluation.INCLUDE_AND_CONTINUE; } // Make sure last Equipment voltage is equal to or lower than previous voltage Double voltage = (Double) path.endNode().getProperty("voltage", 999.0); if (voltage <= branchState.getState()) { return Evaluation.INCLUDE_AND_CONTINUE; } else { return Evaluation.EXCLUDE_AND_PRUNE; } }
That’s it. It’s not terribly complicated, but the problem is performance. It was taking hours on the 20 million equipment dataset and we needed it to be under 15 minutes. So what do we do? Well, one of the things we can do is go to a lower level API… even to the super secret low-level SPI. I tried that, and it was much better — but not good enough. One error we see all the time when people build their own Neo4j extensions is that they hold the result set in memory and then release it all at the end of the traversal. That increases memory pressure and generally slows you down. It’s better to stream out the results right away. So I did that and it was under 15 minutes (finally) but we could do better. We had to in order to deal with the large test data set, anyway.
I’m gonna multi-thread this sucka. But how? My first attempt using Futures resulted in worse times than before and I traced the culprit to each future having to start its own transaction in order to interact with the graph. So what we really need is long running threads that start a single transaction and do all their work there. In addition, as the work is produced it needs to be streamed out. OK, so how did I do this? …well, in not the most elegant way that’s for sure. We start by creating two Queues. One queue will contain our work, and the second will have our results.
BlockingQueue<Work> queue = new LinkedBlockingQueue<>(); BlockingQueue<String> results = new LinkedBlockingQueue <>();
We’ll start one worker per core, passing in both queues when we create them.
public static final int CPUS = Runtime.getRuntime().availableProcessors(); for (int i = 0; i < CPUS; ++i) { service.execute(new Worker(queue, results)); }
We will get all the starting points like before, and add them to our work queue. The Work object just holds the node id and the voltage of that node id. We are keeping “branch state” manually.
for (String equipmentId : (Collection<String>) input.get("ids")) { Cursor<NodeItem> nodes = ops.nodeCursorGetFromUniqueIndexSeek(descriptor, equipmentId); if (nodes.next()) { long equipmentNodeId = nodes.get().id(); energized2.add((int) equipmentNodeId); jg.writeString(equipmentId); queue.add(new Work(equipmentNodeId, (Double)ops.nodeGetProperty(equipmentNodeId, propertyVoltage))); } nodes.close(); }
Before we take a look at the work being done, let’s talk about the results. I need a way to kill these threads and close things down. So what I decided to do is to have the results queue poll in a loop for up to 1 second. If there is a value there then great, we stream it out. If not we end our traversal. Remember that results are being added to the queue as work is being done, so if a whole second passes with no new results, it’s pretty much done. Neo4j can traverse millions of relationships per second per core, so I think my assumption is good. Worst case, we can up this a bit.
JsonGenerator jg = objectMapper.getJsonFactory().createJsonGenerator(os, JsonEncoding.UTF8); jg.writeStartArray(); String result; do { result = null; try { result = results.poll(1, TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); } if (result == null) { break; } jg.writeString(result); } while (true); jg.writeEndArray(); jg.flush(); jg.close(); service.shutdown(); service.awaitTermination(5, TimeUnit.SECONDS);
Alright, let’s look at the Worker now. In the Worker
run method, we are looping taking from the work queue. The
take() method blocks, so if there is nothing to do it will wait until something appears.
try (Transaction tx = Energization.dbapi.beginTx()) { ThreadToStatementContextBridge ctx = Energization.dbapi.getDependencyResolver().resolveDependency(ThreadToStatementContextBridge.class); ReadOperations ops = ctx.get().readOperations(); do { Work item = this.processQueue.take(); this.processEntry(item, ops); count++; } while (true);
The
processEntry method does the real work. Just like before we check the relationship properties before continuing and if they are both set to true, we verify the voltage is less than or equal to our current voltage. If it all looks good, it adds the new equipment to the results queue, and creates a new work item with the new equipment and the new voltage as properties:
private void processEntry(Work work, ReadOperations ops) throws EntityNotFoundException, InterruptedException, IOException { relationshipIterator = ops.nodeGetRelationships(work.getNodeId(), org.neo4j.graphdb.Direction.BOTH); while (relationshipIterator.hasNext()) { c = ops.relationshipCursor(relationshipIterator.next()); if (c.next() && (boolean) c.get().getProperty( Energization.propertyIncomingSwitchOn) && (boolean) c.get().getProperty( Energization.propertyOutgoingSwitchOn)) { long otherNodeId = c.get().otherNode(work.getNodeId()); if (!energized2.contains((int) otherNodeId)) { double newVoltage = (double) ops.nodeGetProperty(otherNodeId, Energization.propertyVoltage); if (newVoltage <= (double) work.getVoltage()) { if(energized2.checkedAdd((int) otherNodeId)) { results.add((String) ops.nodeGetProperty(otherNodeId, Energization.propertyEquipmentId)); processQueue.put(new Work(otherNodeId, newVoltage)); } } } } } }
So what was the final verdict? On my 4 core desktop, the 20 million equipment dataset returns in under a minute, and the 200 million equipment dataset in 15 minutes — well, under our requirements. On a proper 32 or 64 core server, this will be lightning fast. As always, the source code is on GitHub. Traversal multi-threading. When you absolutely, positively got to kill every core in the server, accept no substitutes.
Now if that looks way too complicated… no worries. I hear we might see this fellow below learn some new tricks.
Published at DZone with permission of Max De Marzi, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own. | https://dzone.com/articles/multi-threading-a-neo4j-traversal | CC-MAIN-2022-21 | refinedweb | 1,738 | 50.73 |
The wiringPi LCD devLib allows you to drive most of the popular 1, 2 and 4-line LCD displays that are based on the Hitachi HD44780U or compatible controllers.
It allows you to connect multiple displays to a single Raspberry Pi. The displays can be connected directly to the Pi’s on-board GPIO or via the many GPIO expander chips supported by wiringPi – e.g. the MCP23017 I2C GPIO expander (e.g. as used on some of the Adafruit boards)
Top: standard 16×2 LCD display connected directly to a Raspberry Pi and (below) an Adafruit RGB back-lit LCD plate with control buttons. See this page for more details of the Adafruit display setup using wiringPi
The following Fritzing diagrams describe how to connect the displays directly to the on-board GPIO of a Raspberry Pi in both 8 and 4-bit modes:
LCD Connected to a Pi in 4-bit pode
LCD connected to a Pi in 8-bit mode.
When using a 5v display, make sure you always connect the R/W pin on the display to ground to force the display to be read-only to the host. If not, the display can potentially present 5v back to the Pi which is potentially damaging.
Initialisation and Usage
To use the LCD library, you’ll need this at the start of your program:
#include <wiringPi.h> #include <lcd.h>
First, you need to initialise wiringPi in the way you want to. The LCD library will call pinMode functions as required.
-) ;
Functions
- lcdHome (int handle)
- lcdClear (int handle)
These home the cursor and clear the screen respectively.
- lcdDisplay (int fd, int state) ;
- lcdCursor (int fd, int state) ;
- lcdCursorBlink (int fd, int state) ;
These turn the display on or off, turn the cursor on or off and the cursor blink on or off. The state parameter is True or False. The initial settings are display on, cursor off and cursor blink off.
- lcdPosition (int handle, int x, int y) ;
Set the position of the cursor for subsequent text entry. x is the column and 0 is the left-most edge. y is the line and 0 is the top line.
- lcdCharDef (int handle, int index, unsigned char data [8]) ;
This allows you to re-define one of the 8 user-definable chanracters in the display. The data array is 8 bytes which represent the character from the top-line to the bottom line. Note that the characters are actually 5×8, so only the lower 5 bits are used. The index is from 0 to 7 and you can subsequently print the character defined using the lcdPutchar() call.
- lcdPutchar (int handle, unsigned char data) ;
- lcdPuts (int handle, const char *string) ;
- lcdPrintf (int handle, const char *message, …) ;
These output a single ASCII character, a string or a formatted string using the usual printf formatting commands.
At the moment, there is no clever scrolling of the screen, but long lines will wrap to the next line, if necessary.
Do see the example program lcd.c.
When using a 5v display, make sure you always connect the R/W pin on the display to ground to force the display to be read-only to the host. If not, the display can potentially present 5v back to the Pi which is potentially damaging.
You refer to the diagram of the edge connector on the LCD and use that to hook up the pins on the GPIO connector. Use the diagram here to help you keep track of the GPIO pins you are using.
For a 2nd (or 3rd, etc.) display, you wire the displays in parallel, connecting up all the same pins with the exception of the E pin. Each display needs its own unique E pin connected back to a different GPIO pin. | http://wiringpi.com/dev-lib/lcd-library/ | CC-MAIN-2018-17 | refinedweb | 632 | 69.72 |
E
August 13, 2010
We begin with a function
f to count the random numbers required to reach a sum greater than one:
(define (f)
(do ((i 0 (+ i 1))
(s 0.0 (+ s (rand))))
((< 1 s) i)))
Now we run the simulation n times:
(define (e n)
(do ((i 0 (+ i 1))
(s 0.0 (+ s (f))))
((= i n) (/ s i))))
And the answer is:
> (e #e1e6)
2.718844
Run
f enough times, and the surprising average is the transcendental number e. A good explanation of the math involved is given by John Walker. Mathematically, this puzzle is known as the uniform sum distribution.
We used
rand from the Standard Prelude. You can run the program at.
[…] Praxis – E By Remco Niemeijer In today’s Programming Praxis exercise our task is to determine how many random numbers between 0 and 1 we […]
My Haskell solution (see for a version with comments):
A couple of improvements could be made. I left the j variable in accidently, it is unused. In C++, the scope of the sum value could be confined to the for loop in which it appears. A do { } while loop would mean that I didnt have two different increments of the ttrial variable.
Here’s my solution in Clojure:
PLT “racket”:
#! /bin/sh
#| Hey Emacs, this is -*-scheme-*- code!
#$Id$
exec mzscheme -l errortrace –require “$0″ –main — ${1+”$@”}
|#
#lang scheme
;;
(define (trial)
(let loop ([number-of-numbers 0]
[sum 0])
(if (inexact
(/ (apply + outcomes)
(length outcomes)))))
(provide main)
/me tips his hat to Mark VandeWettering, Oregon ’86 or thereabouts
Gaah. Stupid wordpad.
Here’s a Python implementation:
import random
import sys
random.seed()
numIterations = int(sys.argv[1])
count = 0.0
sum = 0.0
for i in range(numIterations):
sum += random.random()
if sum > 1.0:
count += 1.0
sum = 0.0
print numIterations/count
A naive ruby implementation
Here’s a Java solution:
The output, as expected, is 2.72197.
(* OCaml *)
let test () =
let acc = ref 0. and cpt = ref 0 in
while !acc < 1. do
incr cpt;
acc := !acc +. (Random.float 1.);
done;
!cpt;;
let mean n =
let rec aux n =
if n = 0
then 0
else test () + aux (n-1)
in
(float_of_int (aux n)) /. (float_of_int n);;
print_string ((string_of_float (mean 10000))^”\n”);;
(* Purely functional looks even better (well, as in “no references”…) *)
let rec test acc cpt =
if acc < 1.
then test (acc +. (Random.float 1.)) (cpt + 1)
else cpt
let mean n =
let rec aux n =
if n = 0
then 0
else test 0. 0 + aux (n-1)
in (float_of_int (aux n)) /. (float_of_int n);;
print_string ((string_of_float (mean 10000))^”\n”);;
[…] about computing Euler’s Number, e, using Clojure. It wasn’t until I saw the idea on Programming Praxis, though, that I decided to just do […]
//quick and dirty javascript
var getRandomCount = function(ctr,buf){
while(buf < 1){
var nbr = Math.random();
ctr = ctr + 1;
buf = buf + nbr;
}
return ctr;
}
var getAverageNumberOfTimes = function(iter){
var total = 0;
for(i=0;i<iter;i++){
total = total + getRandomCount(0,0);
}
return total;
}
alert(getAverageNumberOfTimes(1000)/1000);
C#
Random randNum = new Random();
int trials = 1000000;
long totalTrials = 0;
double i = 0;
for (int runs = 0; runs < trials; i = 0, runs++)
for (totalTrials++ ; (i += randNum.NextDouble()) < 1.0; totalTrials++) ;
Console.WriteLine((float)totalTrials / trials);
Console.ReadLine();
Here is a FORTH version, without floating point.
A random 32 bit number is treated as binary random between 0-1. When overflow occurs (requires 33 bits), it is interpreted as exceeding 1.0.
And here is session with SwiftForth :- | https://programmingpraxis.com/2010/08/13/e/2/ | CC-MAIN-2016-50 | refinedweb | 586 | 66.74 |
On Fri, Mar 24, 2006 at 12:54:01PM +0200, Kari Pahula wrote: > I'm packaging libggtl (ITP #358659), which uses libsl (ITP #358657). > The latter is rather unfortunately named. The namespace of two letter > acronyms is rather crowded and there is already a /usr/lib/libsl0 in > libsl0-heimdal. To be precise, it is a file collision, not a directory: libsl0-heimdal: usr/lib/libsl.so.0 libsl0-heimdal: usr/lib/libsl.so.0.1.2 > What would be a sane way to handle this situation? I'm thinking of > just copying libsl into the package and linking statically to it and > to not package libsl at all. The obvious disadvantage to this is that the source package will be nonpristine (well, unless you use an embedded-style source package, which is like borderline-pristine or something). > Most of the uses of libsl are internal in libggtl, but some parts of > its API return libsl derived data structures. There would be some > need to have libsl at hand for users... Otherwise I would just take > the easy road and not bother packaging libsl at all. Perhaps you could install include files, including any from libsl, to /usr/include/ggtl/ (rather than cause more 2 letter collisions), and rename the library file to libggtl-sl? (And update the soname too of course). This means that some binaries won't run on different distributions, but there's no way around that anyway, right? Justin | https://lists.debian.org/debian-mentors/2006/03/msg00359.html | CC-MAIN-2016-50 | refinedweb | 243 | 64.2 |
When the user taps a book in
ContentView we’re going to present a detail view with some more information – the genre of the book, their brief review, and more. We’re also going to reuse our new
RatingView, and even customize it so you can see just how flexible SwiftUI is.
To make this screen more interesting, we’re going to add some artwork that represents each category in our app. I’ve picked out some artwork already from Unsplash, and placed it into the project11-files folder for this book – if you haven’t downloaded them, please do so now and then drag them into your asset catalog.
Unsplash has a license that allows us to use pictures commercially or non-commercially, with or without attribution, although attribution is appreciated. The pictures I’ve added are by Ryan Wallace, Eugene Triguba, Jamie Street, Alvaro Serrano, Joao Silas, David Dilbert, and Casey Horner – you can get the originals from if you want.
Next, create a new SwiftUI view called “DetailView”. This only needs one property, which is the book it should show, so please add that now:
let book: Book
Even just having that property is enough to break the preview code at the bottom of DetailView.swift. Previously this was easy to fix because we just sent in an example object, but with Core Data involved things are messier: creating a new book also means having a managed object context to create it inside.
To fix this, we can update our preview code to create a temporary managed object context, then use that to create our book. Once that’s done we can pass in some example data to make our preview look good, then use the test book to create a detail view preview.
Creating a managed object context means we need to start by importing Core Data. Add this line near the top of DetailView.swift, next to the existing
import:
import CoreData
As for the previews code itself, replace whatever you have now with this:
struct DetailView_Previews: PreviewProvider { static let moc = NSManagedObjectContext(concurrencyType: .mainQueueConcurrencyType) static var previews: some View { let book = Book(context: moc) book.title = "Test book" book.author = "Test author" book.genre = "Fantasy" book.rating = 4 book.review = "This was a great book; I really enjoyed it." return NavigationView { DetailView(book: book) } } }
As you can see, creating a managed object context involves telling the system what concurrency type we want to use. This is another way of saying “which thread do you plan to access your data using?” For our example, using the main queue – that’s the one the app was launched using – is perfectly fine.
With that done we can turn our attention to more interesting problems, namely designing the view itself. To start with, we’re going to place the category image and genre inside a
ZStack, so we can put one on top of the other nicely. This in turn means going inside a
GeometryReader, so we can make sure the image doesn’t take up too much space. I’ve picked out some styling that I think looks good, but you’re welcome to experiment with the styling all you want.
Replace the current
body property with this:
GeometryReader { geometry in VStack { ZStack(alignment: .bottomTrailing) { Image(self.book.genre ?? "Fantasy") .frame(maxWidth: geometry.size.width) Text(self.book.genre?.uppercased() ?? "FANTASY") .font(.caption) .fontWeight(.black) .padding(8) .foregroundColor(.white) .background(Color.black.opacity(0.75)) .clipShape(Capsule()) .offset(x: -5, y: -5) } } } .navigationBarTitle(Text(book.title ?? "Unknown Book"), displayMode: .inline)
That places the genre name in the bottom-right corner of the
ZStack, with a background color, bold font, and a little padding to help it stand out.
Below that
Stack we’re going to add the author, review, and rating, plus a spacer so that everything gets pushed to the top of the view. We don’t want users to be able to adjust the rating here, so instead we can use another constant binding to turn this into a simple read-only view. Even better, because we used SF Symbols to create the rating image, we can scale them up seamlessly with a simple
font() modifier, to make better use of all the space we have.
So, add these views directly below the previous
ZStack:
Text(self.book.author ?? "Unknown author") .font(.title) .foregroundColor(.secondary) Text(self.book.review ?? "No review") .padding() RatingView(rating: .constant(Int(self.book.rating))) .font(.largeTitle) Spacer()
That completes
DetailView, so we can head back to ContentView.swift to change the navigation link so it points to the correct thing:
NavigationLink(destination: DetailView(book: book)) {
Now run the app again, because you should be able to tap any of the books you’ve entered to show them in our new detail. | https://www.hackingwithswift.com/books/ios-swiftui/showing-book-details | CC-MAIN-2021-31 | refinedweb | 800 | 51.48 |
11 April 2011 10:37 [Source: ICIS news]
By Serena Seng and Tahir Ikram
?xml:namespace>
"We’re looking at early 2014 to have anywhere between one to three [commercial plants], lets’ say small-to-medium sized commercial plants in operation," the company’s executive chairman Roger Stroud told ICIS in an interview.
He said the small-to-medium commercial plants, or photo bioreactors, will have between 250 to 500 shipping containers growing algae in an enclosed environment to capture carbon dioxide and produce biofuels.
Algae, a second generation biofuel, is considered a better option by some environmentalists because it does not directly compete with food cultivation.
Each container can grow up to 250 tonnes of dry algae a year, Stroud added.
As an illustration of the kind of business the company could do, Stroud said hypothetically the company could have 100,000 containers in the
“That, in broad terms, would capture 50m tonnes of carbon dioxide. Which is a lot, and would create a fuel feed – based on the numbers we’ve already discussed – about 25m tonnes.
“I mention that as an example of where this could go over that period of time. We’ll call it a hypothetical example at this stage, or, sorry, we’ll call it a target. A robust target but it’s achievable,” he added.
Algae.Tec, which was listed on the Australian Securities Exchange in January this year and on the Frankfurt Stock Exchange a month later in February, is hoping to start listing its American Depositary Receipts (ADRs) in the
He said the company had chosen six species of algae out of the 60 it had studied to use to produce biofuels and biomass.
Currently, Algae.Tec is manufacturing demonstration modules of its algae-based bioreactors in
Preliminary discussions are being held this week with a German company that is looking into introducing Algae.Tec’s alternative source of energy to the southern part of
According to Stroud
“We don’t want to say that we’re going to change the world in 5 minutes – maybe in 20 years we will, but what we believe we do, we’ll continue to punch above our weight,” Stroud said.
“We’re a small company, but... there’s no reason why we can’t move and contribute to this ever-changing | http://www.icis.com/Articles/2011/04/11/9451358/australias-algae.tec-plans-biofuel-commercial-ops-by-14.html | CC-MAIN-2013-48 | refinedweb | 386 | 55.47 |
On Thursday 23 September 2004 7:56 pm, Steve Izma wrote: > Hmmm. I now realize I didn't think this through completely before > replying last time, so it's now more apparent to me what Keith > was doing. > > I like python's facility for this, but one reason, I think, that > it works so well is because of how easy it is in python to step > through a list, so that you can set up a "while" loop and step > through each option and write the appropriate code for each one, > if it's present. I would prefer to avoid calling outside macros to > process the options and instead just be able to set flags and > variables. Indeed. My sample macro code -- which was derived from actual working code -- was designed to simulate the behaviour of a 'switch' within a 'while' loop in C code, (which is how option parsing is C is traditionally handled with the getopt() function), and my option handler macros providing the 'case' implementations. I don't know Python, but I assume its getopt module operates in a similar fashion. > How about having getopt set local variables based on the option > names, both the long or the short ones (one could choose between > readability and conciseness). Flags would always > be numeric (essentially boolean) and options with values would > always return a string, which if numeric would require a unit > designator [...] Thinking about this, I believe it should be feasible, and may indeed offer a better and more robust implementation than requiring the user to provide call back macros. Using macros certainly offers greater flexibility; however it also places an additional burden of initialisation on the user. By stipulating that flags are always returned in registers, and option arguments are always placed in strings, we can handle the initialisation in a consistent manner, and the user is assured a consistent API to the .getopt request. For initialisation, I would suggest that all possible flag registers are defined with zero value, and all possible option argument strings are either guaranteed to be undefined, or, perhaps preferably, are defined with zero length, prior to parsing the argument list. I do believe that the user should be required to provide two call back macros -- one to handle the case of parsing an undefined option, since IMHO the user *needs* to be able to choose the appropriate action, and the second to process the arguments which remain, after the options have been stripped. I think this second used supplied macro should also be required to perform *all* of the user defined processing which requires access to the flags and strings set by .getopt, thus allowing .getopt to take the responsibility for removing these flags and strings from their respective namespaces, on completion. As a final observation, if both long and short options are declared to control the same function within the user's call back code, then the user must explicitly take responsibility for interpreting both forms equivalently. I can see no reliable way of handling this implicitly, within any .getopt implementation. Best regards, Keith. | http://lists.gnu.org/archive/html/groff/2004-09/msg00060.html | CC-MAIN-2014-35 | refinedweb | 514 | 52.83 |
Solution for
Programming Exercise 5.4
THIS PAGE DISCUSSES ONE POSSIBLE SOLUTION to the following exercise from this on-line Java textbook.
Exercise 5.4: The BlackjackHand class from Section 5.5 is an extension of the Hand class from Section 5.3. The instance methods in the Hand class are discussed in Section 5.3. In addition to those methods, BlackjackHand includes an instance method, getBlackjackValue(), that returns the value of the hand for the game of Blackjack. For this exercise, you will also need the Deck and Card classes from Section 5, your program will depend on Card.java, Deck.java, Hand.java, and BlackjackHand.java.
Discussion
This problem is mostly a warm-up for the next one. It uses objects of three different types, Card, Deck, and BlackjackHand. The Hand class is used indirectly, as the superclass of BlackjackHand. To use these objects, you need to know what methods are available in each class, so you should review the information that you have about the classes before beginning the program.
An algorithm for the program isCreate a deck repeat while user wants to continue: Shuffle the deck Create a new BlackjackHand Decide the number of cards in the hand Deal cards from the deck into the hand, and print them out Display the value of the hand
Some variation is possible. You could use just one BlackjackHand object, and remove all the cards from it between hands. The Hand class includes an instance method, clear(), that could be used for this purpose. Similarly, you could create a new Deck object each time through the loop. Or, you might want to use one deck and shuffle it only when the number of cards in the deck gets too small. You could say: "if (deck.cardsLeft() < 6) deck.shuffle()".
Since we always want to do at least one hand, we can use a do..while statement for the loop. Putting in some variable names, we can refine the algorithm todeck = new Deck(); do: deck.shuffle(); hand = new BlackjackHand(); cardsInHand = a random number between 2 and 6 Deal cards from deck into hand, and print them out. Display hand.getBlackjackValue() Ask if use wants to go again while user wants to go again
The number of cards in the hand is supposed to be a random number between 2 and 6. There are five possible values. The expression "(int)(Math.random()*5)" has one of the 5 possible values 0, 1, 2, 3, or 4. Adding 2 to the result gives one of the values 2, 3, 4, 5, or 6. So, the number of cards can be computed as "2 + (int)(Math.random()*5)".
Once we know the number of cards, we can use a for loop to deal cards into the hand, one at a time. The function call deck.dealCard() gets a card from the deck. Once we have a card, we can add it to the hand with the subroutine call hand.addCard(card). This allows us to refine the algorithm todeck = new Deck(); do: deck.shuffle(); hand = new BlackjackHand(); cardsInHand = 2 + (int)(Math.random()*5) for i = 0 to cardsInHand: card = deck.dealCard() hand.addCard(card) Display the card Display hand.getBlackjackValue() Ask if use wants to go again while user wants to go again
This algorithm can be translated pretty directly into the main() routine of the program, which is shown below.
The Solution
/* Creates random blackjack hands, with 2 to 6 cards, and prints out the blackjack value of each hand. The user decides when to stop. */ public class TestBlackjackHand { public static void main(String[] args) { Deck deck; // A deck of cards. Card card; // A card dealt from the deck. BlackjackHand hand; // A hand of from two to six cards. int cardsInHand; // Number or cards in the hand. boolean again; // Set to true if user wants to continue. deck = new Deck(); // Create the deck. do { deck.shuffle(); hand = new BlackjackHand(); cardsInHand = 2 + (int)(Math.random()*5); TextIO.putln(); TextIO.putln(); TextIO.putln("Hand contains:"); for ( int i = 1; i <= cardsInHand; i++ ) { // Get a card from the deck, print it out, // and add it to the hand. card = deck.dealCard(); hand.addCard(card); TextIO.putln(" " + card); } TextIO.putln("Value of hand is " + hand.getBlackjackValue()); TextIO.putln(); TextIO.put("Again? "); again = TextIO.getlnBoolean(); } while (again == true); } } // end class TestBlackjackHand
[ Exercises | Chapter Index | Main Index ] | http://math.hws.edu/eck/cs124/javanotes3/c5/ex-5-4-answer.html | crawl-002 | refinedweb | 729 | 74.9 |
Setting Up a Development Environment¶
This.
Testing Neutron¶
Why Should You Care¶
There’s two ways to approach testing:
- Write unit tests because they’re required to get your patch merged. This typically involves mock heavy tests that assert that your code is as written.
- Putting as much thought in to your testing strategy as you do to the rest of your code. Use different layers of testing as appropriate to provide high quality coverage. Are you touching an agent? Test it against an actual system! Are you adding a new API? Test it for race conditions against a real database! Are you adding a new cross-cutting feature? Test that it does what it’s supposed to do when run on a real cloud!
Do you feel the need to verify your change manually? If so, the next few sections attempt to guide you through Neutron’s different test infrastructures to help you make intelligent decisions and best exploit Neutron’s test offerings.
Definitions¶
We will talk about three classes of tests: unit, functional and integration. Each respective category typically targets a larger scope of code. Other than that broad categorization, here are a few more characteristic:
- Unit tests - Should be able to run on your laptop, directly following a ‘git clone’ of the project. The underlying system must not be mutated, mocks can be used to achieve this. A unit test typically targets a function or class.
- Functional tests - Run against a pre-configured environment (tools/configure_for_func_testing.sh). Typically test a component such as an agent using no mocks.
- Integration tests - Run against a running cloud, often target the API level, but also ‘scenarios’ or ‘user stories’. You may find such tests under tests/tempest/api, tests/tempest/scenario, tests/fullstack, and in the Tempest and Rally projects.
Tests in the Neutron tree are typically organized by the testing infrastructure used, and not by the scope of the test. For example, many tests under the ‘unit’ directory invoke an API call and assert that the expected output was received. The scope of such a test is the entire Neutron server stack, and clearly not a specific function such as in a typical unit test.
Testing Frameworks¶
The different frameworks are listed below. The intent is to list the capabilities of each testing framework as to help the reader understand when should each tool be used. Remember that when adding code that touches many areas of Neutron, each area should be tested with the appropriate framework. Overlap between different test layers is often desirable and encouraged.
Unit Tests¶
Unit tests (neutron/tests.
At the start of each test run:
- RPC listeners are mocked away.
- The fake Oslo messaging driver is used.
At the end of each test run:
- Mocks are automatically reverted.
- The in-memory database is cleared of content, but its schema is maintained.
- The global Oslo configuration object is reset.
The unit testing framework can be used to effectively test database interaction, for example, distributed routers allocate a MAC address for every host running an OVS agent. One of DVR’s DB mixins implements a method that lists all host MAC addresses. Its test looks like this:
def test_get_dvr_mac_address_list(self): self._create_dvr_mac_entry('host_1', 'mac_1') self._create_dvr_mac_entry('host_2', 'mac_2') mac_list = self.mixin.get_dvr_mac_address_list(self.ctx) self.assertEqual(2, len(mac_list))
It inserts two new host MAC address, invokes the method under test and asserts its output. The test has many things going for it:
- It targets the method under test correctly, not taking on a larger scope than is necessary.
- It does not use mocks to assert that methods were called, it simply invokes the method and asserts its output (In this case, that the list method returns two records).
This is allowed by the fact that the method was built to be testable - The method has clear input and output with no side effects.
You can get oslo.db to generate a file-based sqlite database by setting OS_TEST_DBAPI_ADMIN_CONNECTION to a file based URL as described in this mailing list post. This file will be created but (confusingly) won’t be the actual file used for the database. To find the actual file, set a break point in your test method and inspect self.engine.url.
$ OS_TEST_DBAPI_ADMIN_CONNECTION=sqlite:///sqlite.db .tox/py27/bin/python -m \ testtools.run neutron.tests.unit... ... (Pdb) self.engine.url sqlite:////tmp/iwbgvhbshp.db
Now, you can inspect this file using sqlite3.
$ sqlite3 /tmp/iwbgvhbshp.db
Functional Tests¶. Note that when run at the gate, the functional tests compile OVS from source. Check out neutron/tests/contrib/gate_hook.sh. Other jobs presently use OVS from packages.
Let’s examine the benefits of the functional testing framework. Neutron offers a library called ‘ip_lib’ that wraps around the ‘ip’ binary. One of its methods is called ‘device_exists’ which accepts a device name and a namespace and returns True if the device exists in the given namespace. It’s easy building a test that targets the method directly, and such a test would be considered a ‘unit’ test. However, what framework should such a test use? A test using the unit tests framework could not mutate state on the system, and so could not actually create a device and assert that it now exists. Such a test would look roughly like this:
- It would mock ‘execute’, a method that executes shell commands against the system to return an IP device named ‘foo’.
- It would then assert that when ‘device_exists’ is called with ‘foo’, it returns True, but when called with a different device name it returns False.
- It would most likely assert that ‘execute’ was called using something like: ‘ip link show foo’.
The value of such a test is arguable. Remember that new tests are not free, they need to be maintained. Code is often refactored, reimplemented and optimized.
- There are other ways to find out if a device exists (Such as by looking at ‘/sys/class/net’), and in such a case the test would have to be updated.
- Methods are mocked using their name. When methods are renamed, moved or removed, their mocks must be updated. This slows down development for avoidable reasons.
- Most importantly, the test does not assert the behavior of the method. It merely asserts that the code is as written.
When adding a functional test for ‘device_exists’, several framework level methods were added. These methods may now be used by other tests as well. One such method creates a virtual device in a namespace, and ensures that both the namespace and the device are cleaned up at the end of the test run regardless of success or failure using the ‘addCleanup’ method. The test generates details for a temporary device, asserts that a device by that name does not exist, create that device, asserts that it now exists, deletes it, and asserts that it no longer exists. Such a test avoids all three issues mentioned above if it were written using the unit testing framework.
Functional tests are also used to target larger scope, such as agents. Many good examples exist: See the OVS, L3 and DHCP agents functional tests. Such tests target a top level agent method and assert that the system interaction that was supposed to be perform was indeed performed. For example, to test the DHCP agent’s top level method that accepts network attributes and configures dnsmasq for that network, the test:
- Instantiates an instance of the DHCP agent class (But does not start its process).
- Calls its top level function with prepared data.
- Creates a temporary namespace and device, and calls ‘dhclient’ from that namespace.
- Assert that the device successfully obtained the expected IP address.
Fullstack Tests¶
Why?¶
The idea behind “fullstack” testing is to fill a gap between unit + functional tests and Tempest. Tempest tests are expensive to run, and target black box API tests exclusively. Tempest requires an OpenStack deployment to be run against, which can be difficult to configure and setup. Full stack testing addresses these issues by taking care of the deployment itself, according to the topology that the test requires. Developers further benefit from full stack testing as it can sufficiently simulate a real environment and provide a rapidly reproducible way to verify code while you’re still writing it.
How?¶
Full stack tests set up their own Neutron processes (Server & agents). They assume a working Rabbit and MySQL server before the run starts. Instructions on how to run fullstack tests on a VM are available below.
Each test defines its own topology (What and how many servers and agents should be running).
Since the test runs on the machine itself, full stack testing enables “white box” testing. This means that you can, for example, create a router through the API and then assert that a namespace was created for it.
Full stack tests run in the Neutron tree with Neutron resources alone. You may use the Neutron API (The Neutron server is set to NOAUTH so that Keystone is out of the picture). VMs may be simulated with a container-like class: neutron.tests.fullstack.resources.machine.FakeFullstackMachine. An example of its usage may be found at: neutron/tests/fullstack/test_connectivity.py.
Full stack testing can simulate multi node testing by starting an agent multiple times. Specifically, each node would have its own copy of the OVS/LinuxBridge/DHCP/L3 agents, all configured with the same “host” value. Each OVS agent is connected to its own pair of br-int/br-ex, and those bridges are then interconnected. For LinuxBridge agent each agent is started in its own namespace, called “host-<some_random_value>”. Such namespaces are connected with OVS “central” bridge to each other.
Segmentation at the database layer is guaranteed by creating a database per test. The messaging layer achieves segmentation by utilizing a RabbitMQ feature called ‘vhosts’. In short, just like a MySQL server serve multiple databases, so can a RabbitMQ server serve multiple messaging domains. Exchanges and queues in one ‘vhost’ are segmented from those in another ‘vhost’.
Please note that if the change you would like to test using fullstack tests involves a change to python-neutronclient as well as neutron, then you should make sure your fullstack tests are in a separate third change that depends on the python-neutronclient change using the ‘Depends-On’ tag in the commit message. You will need to wait for the next release of python-neutronclient, and a minimum version bump for python-neutronclient in the global requirements, before your fullstack tests will work in the gate. This is because tox uses the version of python-neutronclient listed in the upper-constraints.txt file in the openstack/requirements repository.
When?¶
- You’d like to test the interaction between Neutron components (Server and agents) and have already tested each component in isolation via unit or functional tests. You should have many unit tests, fewer tests to test a component and even fewer to test their interaction. Edge cases should not be tested with full stack testing.
- You’d like to increase coverage by testing features that require multi node testing such as l2pop, L3 HA and DVR.
- You’d like to test agent restarts. We’ve found bugs in the OVS, DHCP and L3 agents and haven’t found an effective way to test these scenarios. Full stack testing can help here as the full stack infrastructure can restart an agent during the test.
Example¶
Neutron offers a Quality of Service API, initially offering bandwidth capping at the port level. In the reference implementation, it does this by utilizing an OVS feature. neutron.tests.fullstack.test_qos.TestQoSWithOvsAgent.test_qos_policy_rule_lifecycle is a positive example of how the fullstack testing infrastructure should be used. It creates a network, subnet, QoS policy & rule and a port utilizing that policy. It then asserts that the expected bandwidth limitation is present on the OVS bridge connected to that port. The test is a true integration test, in the sense that it invokes the API and then asserts that Neutron interacted with the hypervisor appropriately.
API Tests¶
API tests (neutron/tests/tempest.
The neutron/tests/tempest/api directory was copied from the Tempest project around the Kilo timeframe. At the time, there was an overlap of tests between the Tempest and Neutron repositories. This overlap was then eliminated by carving out a subset of resources that belong to Tempest, with the rest in Neutron.
API tests that belong to Tempest deal with a subset of Neutron’s resources:
- Port
- Network
- Subnet
- Security Group
- Router
- Floating IP
These resources were chosen for their ubiquity. They are found in most Neutron deployments regardless of plugin, and are directly involved in the networking and security of an instance. Together, they form the bare minimum needed by Neutron.
This is excluding extensions to these resources (For example: Extra DHCP options to subnets, or snat_gateway mode to routers) that are not mandatory in the majority of cases.
Tests for other resources should be contributed to the Neutron repository. Scenario tests should be similarly split up between Tempest and Neutron according to the API they’re targeting.
Scenario Tests¶
Scenario tests (neutron/tests/tempest/scenario), like API tests, use the Tempest test infrastructure and have the same requirements. Guidelines for writing a good scenario test may be found at the Tempest developer guide:
Scenario tests, like API tests, are split between the Tempest and Neutron repositories according to the Neutron API the test is targeting.
Rally Tests¶
Rally tests (rally-jobs/plugins) use the rally infrastructure to exercise a neutron deployment. Guidelines for writing a good rally test can be found in the rally plugin documentation. There are also some examples in tree; the process for adding rally plugins to neutron requires three steps: 1) write a plugin and place it under rally-jobs/plugins/. This is your rally scenario; 2) (optional) add a setup file under rally-jobs/extra/. This is any devstack configuration required to make sure your environment can successfully process your scenario requests; 3) edit neutron-neutron.yaml. This is your scenario ‘contract’ or SLA.
Development Process¶
It is expected that any new changes that are proposed for merge come with tests for that feature or code area. Any bugs fixes that are submitted must also have tests to prove that they stay fixed! In addition, before proposing for merge, all of the current tests should be passing.
Structure of the Unit Test Tree¶.
Note
At no time should the production code import anything from testing subtree (neutron.tests). There are distributions that split out neutron.tests modules in a separate package that is not installed by default, making any code that relies on presence of the modules to fail. For example, RDO is one of those distributions.
Running Tests¶
Before submitting a patch for review you should always ensure all tests pass; a tox run is triggered by the jenkins gate executed on gerrit for each patch pushed for review.:
PEP8 and Unit Tests¶
Functional Tests¶.
Fullstack Tests¶ /opt/stack/logs/dsvm-fullstack-logs (for example, a test named “test_example” will produce logs to /opt/stack/logs/dsvm-fullstack-logs/test_example/), so that will be a good place to look if your test is failing. Logging from the test infrastructure itself is placed in: /opt/stack/logs/dsvm-fullstack-logs/test_example.log. Fullstack test suite assumes 240.0.0.0/4 (Class E) range in root namespace of the test machine is available for its usage.
API & Scenario Tests¶
To run the api or scenario tests, deploy Tempest and Neutron with DevStack and then run the following command, from the tempest directory:
tox -e all-plugin
If you want to limit the amount of tests that you would like to run, you can do, for instance:
export DEVSTACK_GATE_TEMPEST_REGEX="<you-regex>" # e.g. "neutron" tox -e all-plugin $DEVSTACK_GATE_TEMPEST_REGEX
Running Individual Tests¶
For running individual test modules, cases or tests, you just need to pass the dot-separated path you want as an argument to it.
For example, the following would run only a single test or test case:
$ tox -e py27 neutron.tests.unit.test_manager $ tox -e py27 neutron.tests.unit.test_manager.NeutronManagerTestCase $ tox -e py27 neutron.tests.unit.test_manager.NeutronManagerTestCase.test_service_plugin_is_loaded
- If you want to pass other arguments to ostestr, you can do the following::
- $ tox -e -epy27 – –regex neutron.tests.unit.test_manager –serial
Coverage¶
Neutron has a fast growing code base and there are plenty of areas that need better coverage.
To get a grasp of the areas where tests are needed, you can check current unit tests coverage by running:
$ tox -ecover
Since the coverage command can only show unit test coverage, a coverage document is maintained that shows test coverage per area of code in: doc/source/devref/testing_coverage.rst. You could also rely on Zuul logs, that are generated post-merge (not every project builds coverage results). To access them, do the following:
- Go to:<first-2-digits-of-sha1>/<sha1>/post/neutron-coverage/.
- Spec is a work in progress to provide a better landing page.
Debugging¶
By default, calls to pdb.set_trace() will be ignored when tests are run. For pdb statements to work, invoke tox as follows:
$. | http://docs.openstack.org/developer/neutron/devref/development.environment.html | CC-MAIN-2017-04 | refinedweb | 2,867 | 64 |
BLE device name?
adv = bt.get_adv() get a ble device
but bt.resolve_adv_data(adv.data, bt.ADV_NAME_CMPL) always returns a 'None'
This is what I add into my lopy so they get a name:
bluetooth.set_advertisement(name="lopy", manufacturer_data="lopy_v1")
and when I look for the lopy I do this:
from network import Bluetooth
#import time - Dont need this part for this
bt = Bluetooth()
bt.start_scan(-1)
while True:
adv = bt.get_adv()
if adv and bt.resolve_adv_data(adv.data, Bluetooth.ADV_NAME_CMPL) == 'lopy':
try:
conn = bt.connect(adv.mac)
@daniel @Ralph Thank you for your explain,another questin ,when i set my LoPy ble device to scanning state,my iPhone can't search it too.
from network import Bluetooth
bluetooth = Bluetooth()
bluetooth.start_scan(-1)
@DongYin BLE advertisements can only carry a certain amount of data (up to 31 bytes) and the device advertising chooses what to send. Many devices do not advertise the name.
- Ralph Global Moderator last edited by
@DongYin I'm not the bluetooth expert, but I think not all devices return their name. I also get None for most devices I find in our office building, but when I test it with this BLE Peripheral simulator app, I do get the name. Maybe @daniel can confirm.
@duffo64 said in BLE device name?:
What happens if you try to use ADV_NAME_SHORT instead of ADV_NAME_CMPL ?
ADV_NAME_SHORT returns 'None' too.
if i use ADV_MANUFACTURER_DATA returns " b'L\x00\x10\x02\n\x00' "
others Address type all return 'None' | https://forum.pycom.io/topic/477/ble-device-name/4 | CC-MAIN-2019-35 | refinedweb | 247 | 59.3 |
Package errors
Overview ▹
Overview ▾
Package errors is a Google Stackdriver Error Reporting library.
This package is still experimental and subject to change.
See for more information.
To initialize a client, use the NewClient function. Generally you will want to do this on program initialization. The NewClient function takes as arguments a context, the project name, a service name, and a version string. The service name and version string identify the running program, and are included in error reports. The version string can be left empty. NewClient also takes a bool that indicates whether to report errors using Stackdriver Logging, which will result in errors appearing in both the logs and the error dashboard. This is useful if you are already a user of Stackdriver Logging.
import "cloud.google.com/go/errors" ... errorsClient, err = errors.NewClient(ctx, projectID, "myservice", "v1.0", true)
The client can recover panics in your program and report them as errors. To use this functionality, defer its Catch method, as you would any other function for recovering panics.
func foo(ctx context.Context, ...) { defer errorsClient.Catch(ctx) ... }
Catch writes an error report containing the recovered value and a stack trace to Stackdriver Error Reporting.
There are various options you can add to the call to Catch that modify how panics are handled.
WithMessage and WithMessagef add a custom message after the recovered value, using fmt.Sprint and fmt.Sprintf respectively.
defer errorsClient.Catch(ctx, errors.WithMessagef("x=%d", x))
WithRequest fills in various fields in the error report with information about an http.Request that's being handled.
defer errorsClient.Catch(ctx, errors.WithRequest(httpReq))
By default, after recovering a panic, Catch will panic again with the recovered value. You can turn off this behavior with the Repanic option.
defer errorsClient.Catch(ctx, errors.Repanic(false))
You can also change the default behavior for the client by changing the RepanicDefault field.
errorsClient.RepanicDefault = false
It is also possible to write an error report directly without recovering a panic, using Report or Reportf.
if err != nil { errorsClient.Reportf(ctx, r, "unexpected error %v", err) }
If you try to write an error report with a nil client, or if the client fails to write the report to the server, the error report is logged using log.Println.
type Client struct { // RepanicDefault determines whether Catch will re-panic after recovering a // panic. This behavior can be overridden for an individual call to Catch using // the Repanic option. RepanicDefault bool // contains filtered or unexported fields }
func NewClient ¶
func NewClient(ctx context.Context, projectID, serviceName, serviceVersion string, useLogging bool, opts ...option.ClientOption) (*Client, error)
func (*Client) Catch ¶
func (c *Client) Catch(ctx context.Context, opt ...Option)
Catch tries to recover a panic; if it succeeds, it writes an error report. It should be called by deferring it, like any other function for recovering panics.
Catch can be called concurrently with other calls to Catch, Report or Reportf.
func (*Client) Close ¶
func (c *Client) Close() error
Close closes any resources held by the client. Close should be called when the client is no longer needed. It need not be called at program exit.
func (*Client) Report ¶
func (c *Client) Report(ctx context.Context, r *http.Request, v ...interface{})
Report writes an error report unconditionally, instead of only when a panic occurs. If r is non-nil, information from the Request is included in the error report.
Report can be called concurrently with other calls to Catch, Report or Reportf.
func (*Client) Reportf ¶
func (c *Client) Reportf(ctx context.Context, r *http.Request, format string, v ...interface{})
Reportf writes an error report unconditionally, instead of only when a panic occurs. If r is non-nil, information from the Request is included in the error report.
Reportf can be called concurrently with other calls to Catch, Report or Reportf.
type Option ¶
An Option is an optional argument to Catch.
type Option interface { // contains filtered or unexported methods }
func PanicFlag ¶
func PanicFlag(p *bool) Option
PanicFlag returns an Option that can inform Catch that a panic has occurred. If *p is true when Catch is called, an error report is made even if recover returns nil. This allows Catch to report an error for panic(nil). If p is nil, the option is ignored.
Here is an example of how to use PanicFlag:
func foo(ctx context.Context, ...) { hasPanicked := true defer errorsClient.Catch(ctx, errors.PanicFlag(&hasPanicked)) ... ... // We have reached the end of the function, so we're not panicking. hasPanicked = false }
func Repanic ¶
func Repanic(r bool) Option
Repanic returns an Option that determines whether Catch will re-panic after it reports an error. This overrides the default in the client.
func WithMessage ¶
func WithMessage(v ...interface{}) Option
WithMessage returns an Option that sets a message to be included in the error report, if one is made. v is converted to a string with fmt.Sprint.
func WithMessagef ¶
func WithMessagef(format string, v ...interface{}) Option
WithMessagef returns an Option that sets a message to be included in the error report, if one is made. format and v are converted to a string with fmt.Sprintf.
func WithRequest ¶
func WithRequest(r *http.Request) Option
WithRequest returns an Option that informs Catch or Report of an http.Request that is being handled. Information from the Request is included in the error report, if one is made. | http://docs.activestate.com/activego/1.8/pkg/cloud.google.com/go/errors/ | CC-MAIN-2019-04 | refinedweb | 889 | 59.19 |
⚖️ A tool for transpiling C to Go.
A tool for converting C to Go.
The goals of this project are:
c2gorequires Go 1.9 or newer.
go get -u github.com/elliotchance/c2go
c2go transpile myfile.c
The
c2goprogram processes a single C file and outputs the translated code in Go. Let's use an included example, prime.c:
#include
int main() { int n, c;
printf("Enter a number\n"); scanf("%d", &n);
if ( n == 2 ) printf("Prime number.\n"); else { for ( c = 2 ; c <= n - 1 ; c++ ) { if ( n % c == 0 ) break; } if ( c != n ) printf("Not prime.\n"); else printf("Prime number.\n"); } return 0; } </stdio.h>
c2go transpile prime.c go run prime.go
Enter a number 23 Prime number.
prime.golooks like:
package main
import "unsafe"
import "github.com/elliotchance/c2go/noarch"
// ... lots of system types in Go removed for brevity.
var stdin *noarch.File var stdout *noarch.File var stderr *noarch.File
func main() { __init() var n int var c int noarch.Printf([]byte("Enter a number\n\x00")) noarch.Scanf([]byte("%d\x00"), (*[1]int)(unsafe.Pointer(&n))[:]) if n == 2 { noarch.Printf([]byte("Prime number.\n\x00")) } else { for c = 2; c <= n-1; func() int { c += 1 return c }() { if n%c == 0 { break } } if c != n { noarch.Printf([]byte("Not prime.\n\x00")) } else { noarch.Printf([]byte("Prime number.\n\x00")) } } return }
func __init() { stdin = noarch.Stdin stdout = noarch.Stdout stderr = noarch.Stderr } in a semi-intelligent way and producing Go. Easy, right!?
By default only unit tests are run with
go test. You can also include the integration tests:
go test -tags=integration ./...
Integration tests in the form of complete C programs that can be found in the tests directory.
Integration tests work like this:
Contributing is done with pull requests. There is no help that is too small! :)
If you're looking for where to start I can suggest finding a simple C program (like the other examples) that does not successfully translate into Go.
Or, if you don't want to do that you can submit it as an issue so that it can be picked up by someone else. | https://xscode.com/elliotchance/c2go | CC-MAIN-2021-17 | refinedweb | 362 | 80.17 |
In previous article, we have mentioned HTML to PDF in C# MVC using Rotativa or iTextSharp and read pdf in C#, now in this article demonstrates the conversion of HTML file to PDF using IronPDF library in C#. It is designed for people having zero knowledge about C# programming. You just need to follow the steps and get the task done.
There are many occasions when you need to convert HTML to PDF. It can be a difficult task to create PDF from HTML. To overcome all the difficulties regarding PDF, IronPDF provides a smart solution to all your problems. Besides creating PDF documents, IronPDF provides much more support for PDF documents, which helps in making the task much easier than writing a whole lot of complex code and managing dependencies along with it. In the IronPDF library, HTML to PDF conversion supports:
- HTML 4 and HTML 5 rendering
- CSS 3
- JavaScript
- Image assets & SVG assets
- Icon Fonts
- Responsive layouts
- External stylesheets
- Static and multithreaded rendering
IronPDF also supports creating the pdf from a website URL of a specific HTML webpage. However, here our main concern is to convert an HTML file to PDF file.
So, in this tutorial, we will learn how to create a PDF from a given HTML file in C#.
Requirements:
- Visual Studio 2019
- IronPDF Library
- HTML File to convert
First, you need to download and install Visual Studio 2019 from the Microsoft website. If you haven’t, please download it from this link. Once downloaded and installed, open Visual Studio 2019 and create a new project. When the project is created, install the IronPDF library from NuGet Packages. Copy the given code below and your HTML file is converted to PDF. Let's have a practical demonstration to understand it clearly.
After downloading and installing Visual Studio 2019 (not covered in this article), follow the steps.
Step 1: Create a new project
Click on create a new project.
Select Console App and click next.
Name to project to HTMLFILETOPDF and click create. You can simply name anything you want.
Step 2: Install IronPDF from Manage NuGet Packages
Right-click on the project in solution explorer and click Manage NuGet Packages. If solution explorer is not found on main screen please select it from the view tab on the top.
NuGet Window will appear. Now, click on browse and search for IronPDF.
Click Install as shown below and wait for the installation to complete. It will take a few minutes and later save you a lot of time while working with it.
Once the installation is completed, the readme file is open giving information about IronPDF and code examples. Close readme.txt and NuGet to get started with code.
Step 3: Place HTML file in the directory of the project
If you have an HTML file then simply place it inside your project folder which will be in this path: C:\Users\yourusername\source\repos\HTMLFILETOPDF\HTMLFILETOPDF.
If you do not have and HTML file or don’t know how to create, don’t worry I’ll show you how to do it.
Right click the project name in solution explorer and click on “Open folder in file explorer”. Once the file explorer is open, right click again and create a new text file. Name it to index and open.
Paste the following code in index.txt file.
<html> <head> <title>Html to PDF</title> </head> <body> <p>This is a HTML file and you are learning how to convert HTML file to PDF document using IronPDF library in C#.</p> </body> </html>
Now, save the file as HTML as shown in figure below.
You have successfully created an HTML file. Now we are good to go with the rest of the code.
Note: You can save the HTML file at any other location.
Step 4: Add the backend code for Creating PDF file from HTML file
Now here comes the technical part. You might be thinking about a complex code to create pdf document from an HTML file, but its totally opposite. A person with no background of programming can also understand the code. Thanks to IronPDF library. The code is very easy and simple to use.
Firstly, add the following IronPDF library to the start of the code.
using IronPdf;
Write the following code in the main function.
var Renderer = new IronPdf.HtmlToPdf(); var PDF = Renderer.RenderHTMLFileAsPdf("C:/Users/Zeeshan/source/repos/HTMLFILETOPDF/HTMLFILETOPDF/index.html"); var OutputPath ="C:/Users/Zeeshan/source/repos/HTMLFILETOPDF/HTMLFILETOPDF/index.pdf"; PDF.SaveAs(OutputPath); Console.WriteLine("PDF created successfully");
Note: Replace the username with yours in the path, if you are saving it the location of visual studio project folder. Don’t forget to change the path in the code, if the input file is in different location. You can also change the output path.
Step 5: Run the project
After successful build and run, PDF will be created as seen in solution explorer.
Output file:
All is done and HTML file is converted to PDF file as shown in the above steps.
I hope this was easy to understand and follow. You can also visit IronPDF FAQ to create PDF in C#.
IronPDf is a lifesaver. No need to worry about the technical aspects as the library manages most of it. You just need to copy the code from IronPDF website related to your task.
With this absolute beginner's guide, you are good to go with other stuff. If you still have any confusion, please ask in the comment section below. | https://qawithexperts.com/article/c-sharp/creating-a-pdf-file-from-html-file-in-c-using-ironpdf/365 | CC-MAIN-2021-39 | refinedweb | 925 | 73.98 |
In scenarios where the data will have some latency from the server and we don’t want.
It’s always the same thing: Go over to File >> New Project and give it a name.
And now select Web Application from the templates and your framework as ASP.NET Core 2.1,
Once you’re done with it you should have your project in the solution folder.
We’ll start writing our Hubs now.
Unlike normal signalR methods, the stream methods will be different as they have to stream the content over time when the chunks of data are available.
Create a C# file in the project with the name StreamHub or whatever you like. It is better to add it in a Folder though.
Derive that from Hub class and add a namespace in the file.
This is to add the signalR js on the client side.
Launch Package Manager Console (PMC) from the Visual Studio and navigate to project folder with the following command.
cd CodeRethinked.SignalRStreaming
Run npm init to create a package.json file
npm init -y
Ignore the warnings. Install the signalR client library.
npm install @aspnet/signalr
The npm install downloads the signalR client library to a subfolder under the node_modules folder.
Copy the signalr.js file from the <project_folder>.
Once you’ve saved libman.json our signalr.js will be available in the SignalR folder in lib.
Copy the following HTML into Index.chtml. For the purposes of the article, I’m removing the existing HTML in Index.cshtml and adding the following.
Notice we have signalrstream.js at the end. Let’s add the js file to stream the content.
Create a new signalrstream.js file in wwwroot\js folder. Add the following code into the js file.
ASP.NET SignalR now uses ES 6 features and not all browsers support ES 6 features. So, in order for it to work in all browsers, it is recommended to use transpilers such as babel.
Unlike traditional signalR, we now have different syntax for creating a connection.
And for regular signalR connections, we’ll add listeners with .on method but this is streamed so we have a stream method that accepts two arguments.
connection.stream will have to use subscribe method to subscribe to events. We’ll wire up for next, complete and error events and display messages in the messagesList element.
The code before/after the stream connection is related to async and start a connection as soon as we hit the js file.
Here is the output of the stream,
See it in action,
I’ve modified the StreamHub class to have the count up to 10 in the above gif image so that it won’t take any longer.
Notice the delay from items for streaming instead of sending the data all at once.
In the source code, I’ve removed the npm_modules from the solution to make it lightweight so install the npm modules with the following command and start the solution.
npm install
Streaming the content is not new but it is in signalR now and a great feature. Streaming will keep the.
View All | https://www.c-sharpcorner.com/article/streaming-in-asp-net-core-signalr2/ | CC-MAIN-2019-13 | refinedweb | 525 | 76.62 |
Description
Pipelines is a language and runtime for crafting massively parallel pipelines. Unlike other languages for defining data flow, the Pipeline language requires implementation of components to be defined seperately in the Python scripting language. This allows the details of implementations to be separated from the structure of the pipeline, while providing access to thousands of active libraries for machine learning, data analysis and processing.
pipelines alternatives and similar packages
Based on the "Concurrency and Parallelism" category.
Alternatively, view pipelines alternatives based on common mentions on social networks and blogs.
Ray9.5 10.0 pipelines VS RayAn open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
gevent8.6 8.5 L4 pipelines VS geventCoroutine-based concurrency library for Python
Faust8.4 2.4 pipelines VS FaustPython Stream Processing
Tomorrow5.6 0.0 L5 pipelines VS TomorrowMagic decorator syntax for asynchronous code in Python
Wallaroo5.5 2.1 pipelines VS WallarooDistributed Stream Processing
deco5.4 2.9 L5 pipelines VS decoDecorated Concurrency
eventlet5.4 6.5 L3 pipelines VS eventletConcurrent networking library for Python
SCOOP (Scalable COncurrent Operations in Python)SCOOP (Scalable COncurrent Operations in Python)
Thespian Actor LibraryPython Actor concurrency library
aiochan1.9 0.0 pipelines VS aiochanCSP-style concurrency for Python
pyeventbus0.9 0.0 pipelines pipelines or a related project?
README
<!-- --> <!----> <!--- or) ---> <!--- --->.
An example
As an introductory example, a simple pipeline for Fizz Buzz on even numbers could be written as follows -
from fizzbuzz import numbers from fizzbuzz import even from fizzbuzz import fizzbuzz from fizzbuzz import printer numbers /> even |> fizzbuzz where (number=*, fizz="Fizz", buzz="Buzz") |> printer
Meanwhile, the implementation of the components would be written in Python -
def numbers(): for number in range(1, 100): yield number def even(number): return number % 2 == 0 def fizzbuzz(number, fizz, buzz): if number % 15 == 0: return fizz + buzz elif number % 3 == 0: return fizz elif number % 5 == 0: return buzz else: return number def printer(number): print(number)
Running the Pipeline document would safely execute each component of the pipeline in parallel and output the expected result.
The imports
Components are scripted in Python and linked into a pipeline using imports. The syntax for an import has 3 parts - (1) the path to the module, (2) the name of the function, and (3) the alias for the component. Here's an example -
from parser import parse_fasta as parse
That's really all there is to imports. Once a component is imported it can be referenced anywhere in the document with the alias.
The stream
Every pipeline is operated on a stream of data. The stream of data is created by a Python generator. The following is an example of a generator that generates a stream of numbers from 0 to 1000.
def numbers(): for number in range(0, 1000): yield number
Here's a generator that reads entries from a file
def customers(): for line in open("customers.csv", 'r'): yield line
The first component in a pipeline is always the generator. The generator is run in parallel with all other components and each element of data is passed through the other components.
from utils import customers as customers # a generator function in the utils module from utils import parse_row as parser from utils import get_recommendations as recommender from utils import print_recommendations as printer customers |> parser |> recommender |> printer
The pipes
Pipes are what connect components together to form a pipeline. As of now, there are 2 types of pipes in the Pipeline language - (1) transformer pipes, and (2) filter pipes. Transformer pipes are used when input is to be passed through a component. For example, a function can be defined to determine the potential of a particle and a function can be defined to print the potential.
particles |> get_potential |> printer
The above pipeline code would pass data from the stream generated by
particles through
get_potential and then the output of
get_potential through
printer. Filter pipes work similarly except they use the following component to filter data. For example, a function can be defined to determine if a person is over 50 and then print their names to a file.
population /> over_50 |> printer
This would use the function referenced by
over_50 to filter out data from the stream generated by
population and then pass output to
printer.
The
where keyword
The
where keyword lets you pass in multiple parameters to a component as opposed to just what the output from the previous component was. For example, a function can be defined to print to a file the names of all applicants under a certain age.
applicants |> printer where (person=*, age_limit=21)
This could be done using a filter as well.
applicants /> age_limit where (person=*, age=21) |> printer
In this case, the function for
age_limit could look something like this -
def age_limit(person, age): return person.age <= age
Note that this function still has just one return value - the boolean expression that is used to determine wether input to the component is passed on as output.
The
to keyword
The
to keyword is for when you want the previous component has multiple return values and you want to specify which ones to pass on to the next component. As an example, if you had a function for calculating the electronegativity and electron affinity of an atom, you could use it in a pipeline as follows -
atoms |> calculator to (electronegativity, electron_affinity) |> printer where (line=electronegativity)
Here's an example using a filter.
atoms /> below where (atom=*, limit=2) to (is_below, electronegativity, electron_affinity) with is_below |> printer where (line=electronegativity)
Note the use of the
with keyword here. This is necessary for filters to specify which return value of the function is used to filter out elements in the stream.
Getting started
All you need to get started is the Pipelines compiler. You can install it by downloading the executable from Releases.
If you have the Nimble package manager installed and
~/.nimble/binpermanantly added to your PATH environment variable (look this up > if you don't know how to do this), you can also install by running the following command.
nimble install pipelines
Pipelines' only dependency is the Python interpreter being installed on your system. At the moment, most versions 2.7 and earlier are supported and support for Python 3 is in the works. Once Pipelines is installed and added to your PATH, you can create a
.pipelinefile, run or compile anywhere on your system -
$ pipelines the .pipeline compiler (v:0.1.0)
usage: pipelines Show this pipelines Compile .pipeline file pipelines Compile all .pipeline files in folder pipelines run Run .pipeline file pipelines clean Remove all compiled .py files from folder
for more info, go to github.com/calebwin/pipelines
### Some next steps There are several things I'm hoping to implement in the future for this project. I'm hoping to implement some sort of `and` operator for piping data from the stream into multiple components in parallel with the output ending up in the stream in a nondeterministic order. Further down the line, I plan on porting the whole thing to C and putting in a complete error handling system <!--- - String imports - Control allocation of processes with Pool - Use Pipe instead of multiple Queue - Only have num_cpus running at one time ---> | https://python.libhunt.com/pipelines-alternatives | CC-MAIN-2021-31 | refinedweb | 1,223 | 52.29 |
>
Hi,
I have a DLL written in C++. It also contains a .NET API written in C++/CLI, and these are linked together in a single DLL. The C++ code uses some Win32-specific calls, so I'm happy to be restricted to Windows platforms for now.
From any regular C# project in Visual Studio, I can just add it as a reference and use the .NET API to seamlessly interact with the library - no need for P/Invoke, DllImport or writing a C API.
DllImport
However, when I import it as an asset into a Unity project, it's recognized as a native plugin, and I can't use the C# API from any scripts in the project - they all behave as if the DLL doesn't exist. The C++/CLI code is compiled against .Net Framework 4.0, so I've set the Scripting Runtime Version to '.NET 4.x Equivalent', and the Api Compatibility Level to '.NET 4.x'.
I tried working around this by writing a C# library in Visual Studio that references the mixed C++/.Net library, and then importing both this C# library and the mixed library into the Unity project. When I do that the scripts in the Unity project compile, but the entire editor crashes when I press play.
Are mixed assemblies just not supported in Unity? If so, I couldn't find this documented anywhere. If they are, how can I figure out why Unity is treating my mixed assembly DLL as a native plugin rather than a managed plugin?
Answer by AP-IGD
·
Jun 20 at 12:53 PM
Same problem here, even after a year of having so many followers and no answers....
Hi everyone, no solution but some debugging insights.
I've tried the same thing (Unity 19.3.0a5 x64, Visual Studio 2017) and got the same result. As recommended by MS I've written a CLR (mixed) assembly to wrap my native c++11 lib. To be fully C# compliant, I've written the intermediate C# assembly, basically wrapping only the needed mixed classes/methods. All C# applications I've created/tested, don't cause any problems. Even with multi-threading, hardware controlers etc. no warnings, errors or crashes...
Try, debugging in Editor: Calling the C# lib from a Unity script crashes the editor... I've debugged the whole thing (attached VS debugger to Unity Editor using my libs compiled in debug) and the crash occurs immediatly when my C# lib calls the mixed library (actually its code is never reached...). To be more precise: during some dynamic class generation magic in the mono libs seemingly an error occurs, an exception message is generated and a log-file-write is called. Then good old c-style 'abort()' is called, not very -Stroustrup-...
Try, generating VS solution and debug only my part in pure C. Unfortunatly, 'File'->'Build setting...'->'Build' generation fails with the message
"...But the dll is not allowed to be included or could not be found." (the mixed one is meant here)
Since I've copied the lib to nearly all directories included in path and the project folders, I don't think it's not found. Remaining question:
Why is the library not allowed to be included?
I can only guess, that there's some kind of versioning conflict. .Net, C system libs orororor. I've not found any documentation on that.
This leaves me with to questions to the comunity:
: Does someone here has any info on the exact versions fot .Net, C-std... used by Unity?
: (Most likely answer is NO) Any guess how to wrap native C++ to Unity WITHOUT using global C functions, void pointer and all these unsafe (defined name by MS) methods?
I've quite some experience with tracking down bugs, versioning problems and all that. But, the long work and the complete absence of an error message makes me think, that I've found my master-of.
Texture2D manipulation in c++ dll Plugin
0
Answers
Unity iOS - "Assertion at reflection.c:6869" only in Development Build
0
Answers
The type or namespace name... again
0
Answers
C++ native plugin Failed with error '%1 is not a valid Win32 application
0
Answers
How can I get the Native Plugin example to work on Unity 5?
0
Answers | https://answers.unity.com/questions/1544167/does-unity-support-mixed-assemblies-with-both-nati.html | CC-MAIN-2019-30 | refinedweb | 720 | 65.32 |
I am getting an 'AttributeError: 'ADC' object has no attribute 'vref_to_pin()'' error when I try to use the ADC library in micropython on a lopy4
I am working with a lopy4 module for a contest I am entering. I use the machine.ADC library for getting data from an analog sensor.
I can use basic functions like ADC.init(), but as you know, before getting data from an ADC pin, you need to calibrate the voltage reference of the used pin.
As documented on the pycom docs, the process of calibration is based on the ADC.vref_to_pin() attribute. However, when I try to call ADC.vref_to_pin(), it returns an 'AttributeError: 'ADC' object has no attribute 'vref_to_pin'. The same happens when I try to use ADC.vref().
I must add that the machine library works fine, as I am using the machine.I2C library just fine.
Here is the basic code I am trying to run:
import pycom import machine adc = machine.ADC() voltage = adc.vref_to_pin('P22') print (voltage)
i think the function does not return any thing. it just connects the internal 1,1 V to a pin
so voltage does not become anything.
what software version are you running. if i run
adc.vref_to_pin('P22')
i get nothing
if i run
voltage = adc.vref_to_pin('P22') print (voltage)
i get None | https://forum.pycom.io/topic/4608/i-am-getting-an-attributeerror-adc-object-has-no-attribute-vref_to_pin-error-when-i-try-to-use-the-adc-library-in-micropython-on-a-lopy4 | CC-MAIN-2021-43 | refinedweb | 221 | 68.87 |
Generate wsdl from JSR 181 POJODan Smith Feb 12, 2007 11:38 AM
Is it possible to generate the WSDL file from a JSR-181 POJO endpoint using wstools or some other tool?
I was able to do this using Suns wsgen tool, but when I use the client based on that generated WSDL I get a org.jboss.ws.jaxb.UnmarshalException thrown from the server.
1. Re: Generate wsdl from JSR 181 POJOmonowai Feb 14, 2007 10:32 PM (in response to Dan Smith)
I too am now strugling with this. Seems to be that the Axis project bundled one - Java2WSDL - but JBoss is no longer supporting that release (ws4?) in the jboss-ws version shipping since AS 4.0.4.
It would be nice if the creation of WSDL files, or lack there of, were a little more clearly documented in what's offered. Even if it was just a simple NO! it would save a bit of searching :)
Seems to be nothing in the Wiki FAQ. my search continues....
2. Re: Generate wsdl from JSR 181 POJOmonowai Feb 14, 2007 10:44 PM (in response to Dan Smith)
Having just posted that, checkout, it may help you on the way.
3. Re: Generate wsdl from JSR 181 POJOmonowai Feb 15, 2007 7:45 PM (in response to Dan Smith)
I assume by the deafening silence on this, that this is either a really stupid question, or we're the only suckers doing this ¯\(°_o)/¯
Here's how it works for me. Create a file called wstools-java-to-wsdl.xml based upon wstools-config.xml but have it include the <java-wsdl> tags. Here is an example based on the 181ejb example:
<java-wsdl> <service name="TestService" style="rpc" endpoint="org.jboss.test.ws.jaxws.samples.jsr181ejb.EndpointInterface"/> <namespaces target- <mapping file="jaxrpc-mapping.xml"/> <webservices servlet- </java-wsdl>
Then, run the wstools with the following arguments:
-cp [FULL_PATH_TO_CLASS_FILE] -config ./resources/wstools-config.xml -dest ./resources/META-INF
My paths are relative to the folder jbossws-samples-1.0.4.GA\jaxws\jsr181ejb folder.
When run, it will create the META-INF/wsdl/TestServices.wsdl file.
It seems that wstools is not selective in what it creates. If you specify <java-wsdl> in your main wstools-config file, and you run the JBOSS sample ANT build files, then the WSDL will be recreated each time, overwriting your <soap:address location=.../> tag, which is not what you probably want to happen. I haven't looked in to how this works yet.
Likewise if the .wsdl file doesn't exist, then when you run your java2wsdl command, it will error complaining that it "can't load wsdl file" if your config contains the <wsdl-java> tags; Bit of a circular refrence going on there!
hth
4. Re: Generate wsdl from JSR 181 POJODavid Win Feb 15, 2007 9:52 PM (in response to Dan Smith)
To make it easier, you guys may want to consider using SOAPUI
if you use eclipse, you simply right click on the POJO and generate the webservice from it.
5. Re: Generate wsdl from JSR 181 POJOmonowai Feb 16, 2007 3:50 PM (in response to Dan Smith)
Indeed. Still it's nice to know what's going on behind the scenes, and a good UI is not really a substitute for clear doco.
I'm an Intellij user and with these IDE's being the memory hogs they are, running eclipse simply to maintain a few XML files is a bit of a pain; Soap's IntelliJ support is pretty basic, so I'll continue with the full UI I guess.
On the side, having just checked out the source for SOAPUI - and most of the jboss projects - it really feels like stepping back in time using ANT over Maven; All that configuration in your IDE, it's Like going from an automatic car to a manual. Geeze I've lost track of how many commons-collections and jaxb jars I've got lying around for all these o/s projects. Maven's on demand centralized repository structure is pure magic.
Oh well. The fun continues.
6. Re: Generate wsdl from JSR 181 POJOSammy Stag Feb 26, 2007 6:22 AM (in response to Dan Smith)
Hi,
I've been looking at this too over the last few days. The easiest way I can find is to do the following:
1) Compile your annotated JSR 181 pojo
2) Create a war file containing just the pojo class and web.xml
3) Deploy the war file and use your browser to get the WSDL by browsing to, for example,
4) Save the WSDL and use this to generate the endpoint interface, JAX-RPC mapping, etc as per the example in the JBossWS user guide.
If you look at the war file created by the JSR181 POJO example, you will see that it doesn't include the supplied WSDL file. The WSDL file is provided just for use by wstools, and is basically identical to the one you will get from your browser.
jar tvf output/libs/jaxws-samples-jsr181pojo.war META-INF/ META-INF/MANIFEST.MF WEB-INF/ WEB-INF/web.xml/samples/ WEB-INF/classes/org/jboss/test/ws/jaxws/samples/jsr181pojo/ WEB-INF/classes/org/jboss/test/ws/jaxws/samples/jsr181pojo/JSEBean01.class
It ought to be possible to get hold of the WSDL some other way, but I haven't figured it out yet. A bit of a shortcoming in the example I think.
7. Re: Generate wsdl from JSR 181 POJOSammy Stag Feb 26, 2007 9:49 AM (in response to Dan Smith)
Two more comments to make about this:
1) In wstools-config.xml, "location" can be a URL, so you don't need to save the WSDL to a file.
2) In wstools-config.xml, you might need to substitute "location" for "file" depending on your version of jbossws-client.jar. The version supplied with JBoss 4.0.5 GA expects "file". The version (in the "thirdparty" directory) which the example compiles against expects "location".
8. Re: Generate wsdl from JSR 181 POJOThomas Diesler Mar 1, 2007 10:20 AM (in response to Dan Smith)
This should be fixed in jbossws-1.2.0
9. Re: Generate wsdl from JSR 181 POJOmonowai Mar 7, 2007 12:46 AM (in response to Dan Smith)
"thomas.diesler@jboss.com" wrote:
This should be fixed in jbossws-1.2.0
Having moved to 1.2, things seem a lot smoother. thanks for all the effort Thomas, I can only imagine what goes in to getting this right.
wsproduce and wsconsume seem to do a fine job and the reduced level of annotations to get things right is a real boon.
Allan's suggestions were also valuable. Obtaining the wsdl straight from the server makes a lot of sense, and the fact you don't need to generate this to deploy your webservices is v. useful
cheers all | https://developer.jboss.org/thread/101743 | CC-MAIN-2018-17 | refinedweb | 1,166 | 63.09 |
Pokemon Go is awesome and we all want to show off when we catch rare Pokemon. Let’s build a quick hack using Python and Twilio MMS that will allow you to trick your friends into thinking that you’ve encountered legendary Pokemon.
You can continue reading to find out how to build this, or try it out now by texting an image and the name of a legendary Pokemon to:
(646) 760-3289
Getting started
Before diving into the code, you’ll first need to make sure you have the following:
- Python and pip installed on your machine
- A free Twilio account – sign up here
- The images we will need to use including screenshots of models of the legendary Pokemon and the overlay for the Pokemon encounter screen. Create a new folder called
pokemon-go-imagesin the directory where you want your project to live and save them there.
The dependencies we are going to use will be:
- The Twilio Python library for generating TwiML to respond to incoming messages
- Pillow for image manipulation
- Flask as the web framework for our web application
- Requests for downloading images from text messages
Open your terminal and enter these commands, preferably in the safety of a virtual environment:
pip install twilio==5.4.0 Flask==0.11.1 requests==2.10.0 Pillow==3.3.0
Overlaying images on top of each other
Let’s write some code to take the image we want to manipulate and overlay the Pokemon catching screen over it. We will use the Image module from PIL.
We need a function that takes a path to an image and the name of a Pokemon. Our function will resize the images to be compatible with each other, paste the overlay over the background image, paste the selected Pokemon on the image and then overwrite the original image with the new image.
Open a file called
overlay.py and add the following code (comments are included in-line to explain what is happening):
from PIL import Image def overlay(original_image_path, pokemon): overlay_image = Image.open('pokemon-go-images/overlay.png') # This is the image the user sends through text. background = Image.open(original_image_path) # Resizes the image received so that the height is always 512px. base_height = 512.0 height_percent = base_height / background.size[1] width = int(background.size[0] * height_percent) background = background.resize((width, int(base_height)), Image.BILINEAR) # Resize the overlay. overlay_image = overlay_image.resize(background.size, Image.BILINEAR) # Specify which pokemon sprite is used. pokemon_img = Image.open('pokemon-go-images/{}.png'.format(pokemon)) # Convert images to RGBA format. background = background.convert('RGBA') overlay_image = overlay_image.convert('RGBA') pokemon_img = pokemon_img.convert('RGBA') new_img = background new_img.paste(overlay_image, (0, 0), overlay_image) # Place the pokemon sprite centered on the background + overlay image. new_img.paste(pokemon_img, (int(width / 4), int(base_height / 4)), pokemon_img) # Save the new image. new_img.save(original_image_path,'PNG')
Try running it on your own image. This works best with images taken on phones, but let’s just see if it works for now. Open up your Python shell in the same directory as the file you just created and enter the following two lines:
from overlay import overlay overlay('path/to/image', 'mewtwo')
Now open the new image and see if you are catching a Mewtwo on a train like I am:
Responding to picture text messages
We need a Twilio phone number before we can respond to messages. You can buy a Twilio phone number here.
Now that we have the image manipulation taken care of, make a Flask app that receives picture messages and responds to them with a Pokemon being captured in that picture.
Open a file called
app.py in the same directory as before and add the following code:
import requests from flask import Flask, request, send_from_directory from twilio import twiml from overlay import overlay UPLOAD_FOLDER = '/Path/to/your/code/directory' legendary_pokemon = ['articuno', 'zapdos', 'moltres', 'mewtwo', 'mew'] app = Flask(__name__) @app.route('/sms', methods=['POST', 'GET']) def sms(): # Generate TwiML to respond to the message. response = twiml.Response() response.message("Please wait while we try to catch your Pokemon") if request.form['NumMedia'] != '0': # Default to Mew if no Pokemon is selected. if request.form['Body']: # Take the first word they sent, and convert it to lowercase. pokemon = request.form['Body'].split()[0].lower() if not pokemon in legendary_pokemon: pokemon = 'mew' else: pokemon = 'mew' # Save the image to a new file. filename = request.form['MessageSid'] + '.png' with open('{}/{}'.format(UPLOAD_FOLDER, filename), 'wb') as f: image_url = request.form['MediaUrl0'] f.write(requests.get(image_url).content) # Manipulate the image. overlay('{}/{}'.format(UPLOAD_FOLDER, filename), pokemon) # Respond to the text message. with response.message() as message: message.body = "{0}".format("Congrats on the sweet catch.") message.media('http://{your_ngrok_url}/uploads/{}'.format(filename)) else: response.message("Send me an image that you want to catch a Pokemon on!") return str(response) @app.route('/uploads/', the program opens the file to write the content of Twilio’s image to the file.
The second route,
/uploads/ handles the delivery of the
message.media TwiML using that URL to retrieve the new image.
Your Flask 5000
This provides us with a publicly accessible URL to the Flask app. Configure your phone number as seen in this image:
Before testing this out, make sure that you’ve changed the file paths and the URL to reflect your own.
Now try texting an image and the name of a legendary Pokemon to your newly configured Twilio number. Looks like we found a Zapdos in the Twilio New York office!
Time to catch ’em all!
Now that you can send messages to make it look like you are catching legendary Pokemon in any arbitrary picture, your quest to making your friends think you are a Pokemon master can truly begin.
The code for this project also lives on this GitHub repository.
For more Pokemon Go-related awesomeness, check out this post that will walk you through setting up SMS alerts when rare Pokemon are nearby.
Feel free to reach out if you have any questions or comments or just want to show off the cool stuff you’ve built.
- Twitter: @Sagnewshreds
- Github: Sagnew
- Twitch (streaming live code): Sagnewshreds
Thanks to my good friend Shahan Akhter for helping out with image manipulation and tweaking the Python code to make the images look better. | https://www.twilio.com/blog/2016/08/pokemon-faux-create-fake-pokemon-go-screenshots-with-python-flask-and-twilio-mms.html | CC-MAIN-2019-51 | refinedweb | 1,052 | 55.54 |
z.
It was hilarous. Toasts never made me laugh. Beause of you, everytime I see toast now, I'm beginning to see it dancing... O.o Okay, Let just say it was funny and pretty okay.
Rated 2.5 / 5 stars
wiu
The animation itself wasnt that great.. it wasnt bad either..
The sets of pics didnt help much, I wish it was more animated.
But tbh you had me laughing at the dancing bread throught the animation :p
Rated 2 / 5 stars
...
Well, that's a pretty damn old song, but in the past, every time i listen to it, it still sounded funny. Now, i dunno. It's just not as good now. Besides, you're a prick, i was gonna do pretty much just that. Well. It was still ok. 4/10 for you. It would have been 5/10 if you had ACTUALLY CREDITED Bob&Tom in the submission settings, so those people who hadn't heard it could go to their website or something, all you did was say that they made it, not actually give them anything in return (ie. more views on their website)
Rated 0 / 5 stars
failure
dude, all you did was take a song that had been on the bob and tom show for years, and put together a crappy slideshow to it. you fail, hard.
Rated 3 / 5 stars
WTF?
Funny as hell, but what's with the obsession with toast? | http://www.newgrounds.com/portal/view/375705 | CC-MAIN-2015-32 | refinedweb | 242 | 84.47 |
At my XLinq PDC2005 talk and in the XLinq Overview Document one of the differences I mentioned between XLinq and DOM is the treatment of XML Names in XLinq. XLinq's abstraction for XML Names is a class called XName which is the only way an XML Name shows up anywhere in the API. You seldom have to construct an XName since there is an implicit conversion from string. For example to construct an XElement with a local name Foo that has a namespace of you could do the following:
XElement foo = new XElement("{}Foo", ... any value or children of Foo ...);
So what is that string there with the curly braces in the constructor you ask? XLinq calls it the Expanded Name. This idea is very much inspired by James Clark's paper on XML Namespaces in which he talks about Universal Names defined as a local name and a qualifying URI. In his article he shows that XML Names are fundamentally these Universal Names (or what XLinq calls Expanded Names) and prefixes/default namespaces are simply shorthand for representing this full name (in a way that would work with XML 1.0 since XML was initially defined without XML Namespaces). He gives example in his paper of how default namespaces and prefixes map into Universal Names.
This is essentially what XLinq does in its API. When the XML is loaded into memory the default namespaces and prefixes are resolved to their corresponding Expanded Names and that is they way you deal with them in the API, via XNames. Namespace declarations (xmlns attributes) are retained as attributes in the in-memory tree and on output are used to associate prefixes with namespaces all over again. In other words from XLinq's perspective default namespace declarations and prefix declarations are purely serialization options. If you want to associate a prefix with a namespace in your output, say when creating a document from scratch, then you add an xmlns attribute right where you want the prefix defined. There are helper methods in XLinq planned (CreateNamespacePrefix, CreateDefaultNamespaceDecl - or something) but I put some notes at the end of the XLinq overview doc on how to do that manually if needed. The only trick is knowing the namespace of the xmlns attribute (). For example to declare the prefix ns and associate it with you could add the following attribute where you want it defined.
new XAttribute("{}ns",),
Anyway, I think James Clarks article on XML Namespaces is one of the better explanations on the subject and understanding that XML Names are really namespace+local name simplifies working with names in XLinq. I find that the XML code that I write, which pretty much always has namespaces involved, is quite a bit clearer and cleaner than the equivalent DOM code.
This is an area we are looking for feedback. Lemme know what you think.
cya,rem | http://blogs.msdn.com/b/daveremy/archive/2005/09/22/473126.aspx | CC-MAIN-2013-20 | refinedweb | 481 | 67.59 |
All the programs you've looked at so far perform synchronous I/O, meaning that while your program is reading or writing, all other activity is stopped. It can take a long time (relatively speaking) to read data to or from the backing store, especially if the backing store is a slow disk or (horrors!) a slow network.
With large files, or when reading or writing across the network, you'll want asynchronous I/O, which allows you to begin a read and then turn your attention to other matters while the Common Language Runtime (CLR) fulfills your request. The .NET Framework provides asynchronous I/O through the BeginRead( ) and BeginWrite( ) methods of Stream.
The sequence is to call BeginRead( ) on your file and then to go on to other, unrelated work while the read progresses in another thread. When the read completes, you are notified via a callback method. You can then process the data that was read, kick off another read, and then go back to your other work.
In addition to the three parameters you've used in the binary read (the buffer, the offset, and how many bytes to read), BeginRead( ) asks for a delegate and a state object.
The delegate is an optional callback method, which, if provided, is called when the data is read. The state object is also optional. In this example, pass in null for the state object. The state of the object is kept in the member variables of the test class.
You are free to put any object you like in the state parameter, and you can retrieve it when you are called back. Typically (as you might guess from the name), you stash away state values that you'll need on retrieval. The state parameter can be used by the developer to hold the state of the call (paused, pending, running, etc.). the BeginRead( ) method of Stream expects.
An AsyncCallBack delegate is declared in the System namespace as follows:
public delegate void AsyncCallback (IAsyncResult ar);
Thus this delegate can be associated with any method that returns void and that takes an IAsyncResult interface as a parameter. The CLR will pass in the IAsyncResult interface object at runtime when the method is called. You only have to declare the method:
void OnCompletedRead(IAsyncResult asyncResult)
and then hook up the delegate in the constructor:
AsynchIOTester( ) { //... myCallBack = new AsyncCallback(this.OnCompletedRead); }
Here's how it works, step by step. In Main( ), create an instance of the class and tell it to run:
public static void Main( ) { AsynchIOTester theApp = new AsynchIOTester( ); theApp.Run( ); }
The call to new invokes the constructor. In the constructor, open a file and get a Stream object back. Then allocate space in the buffer and hook up the callback mechanism:
AsynchIOTester( ) { inputStream = File.OpenRead(@"C:\test\source\AskTim.txt"); buffer = new byte[BufferSize]; myCallBack = new AsyncCallback(this.OnCompletedRead); }
In the Run( ) method, call BeginRead( ), which will cause an asynchronous read of the file:
inputStream.BeginRead( buffer, // where to put the results 0, // offset buffer.Length, // BufferSize myCallBack, // call back delegate null); // local state object
Then go on to do other work. In this case, simulate useful work by counting up to 500,000, displaying your progress every 1,000:
for (long i = 0; i < 500000; i++) { if (i%1000 == 0) { Console.WriteLine("i: {0}", i); } }
When the read completes, the CLR will call your callback method:
void OnCompletedRead(IAsyncResult asyncResult) {
The first thing to do when notified that the read has completed is find out how many bytes were actually read. Do so by calling the EndRead( ) method of the Stream object, passing in the IAsyncResult interface object passed in by the CLR:
int bytesRead = inputStream.EndRead(asyncResult);
EndRead( ) returns the number of bytes read. If the number is greater than zero, you'll convert the buffer into a string and write it to the console, and then call BeginRead( ) again, for another asynchronous read:
if (bytesRead > 0) { String s = Encoding.ASCII.GetString (buffer, 0, bytesRead); Console.WriteLine(s); inputStream.BeginRead( buffer, 0, buffer.Length, myCallBack, null); }
The effect is that you can do other work while the reads are taking place, but you can handle the read data (in this case, by outputting it to the console) each time a buffer-ful is ready. Example 21-7 provides the complete program.
namespace Programming_CSharp { using System; using System.IO; using System.Threading; using System.Text; public class AsynchIOTester { private Stream inputStream; // delegated method private AsyncCallback myCallBack; // buffer to hold the read data private byte[] buffer; // the size of the buffer const int BufferSize = 256; // constructor AsynchIOTester( ) { // open the input stream inputStream = File.OpenRead( @"C:\test\source\AskTim.txt"); // allocate a buffer buffer = new byte[BufferSize]; // assign the call back myCallBack = new AsyncCallback(this.OnCompletedRead); } public static void Main( ) { // create an instance of AsynchIOTester // which invokes the constructor AsynchIOTester theApp = new AsynchIOTester( ); // call the instance method theApp.Run( ); } void Run( ) { inputStream.BeginRead( buffer, // holds the results 0, // offset buffer.Length, // (BufferSize) myCallBack, // call back delegate null); // local state object // do some work while data is read for (long i = 0; i < 500000; i++) { if (i%1000 == 0) { Console.WriteLine("i: {0}", i); } } } // call back method void OnCompletedRead(IAsyncResult asyncResult) { int bytesRead = inputStream.EndRead(asyncResult); // if we got bytes, make them a string // and display them, then start up again. // Otherwise, we're done. if (bytesRead > 0) { String s = Encoding.ASCII.GetString(buffer, 0, bytesRead); Console.WriteLine(s); inputStream.BeginRead( buffer, 0, buffer.Length, myCallBack, null); } } } } Output (excerpt): i: 47000 i: 48000 i: 49000 Date: January 2001 From: Dave Heisler To: Ask Tim Subject: Questions About O'Reilly Dear Tim, I've been a programmer for about ten years. I had heard of O'Reilly books,then... Dave, You might be amazed at how many requests for help with school projects I get; i: 50000 i: 51000 i: 52000
The output reveals that the program is working on the two threads concurrently. The reads are done in the background while the other thread is counting and printing out every thousand. As the reads complete, they are printed to the console, and then you go back to counting. (I've shortened the listings to illustrate the output.)
In a real-world application, you might process user requests or compute values while the asynchronous I/O is busy retrieving or storing to a file or database. | https://etutorials.org/Programming/Programming+C.Sharp/Part+III+The+CLR+and+the+.NET+Framework/Chapter+21.+Streams/21.3+Asynchronous+IO/ | CC-MAIN-2022-21 | refinedweb | 1,063 | 63.49 |
New Features in Python 3.8 and 3.9
Python 3.8 and 3.9 comes with some useful features. Some are listed here
- Merging Dictionaries
The old style of merging Python dictionaries is using ** eg {**d1, **d2} which is not intuitively. The new way of merging dictionaries is using | as shown the in the example of new dictionaries merging code below:
Output:Output:
import cv2 as cv a = {'France':'Paris','Thailand':'Bangkok'} b = {'Germany':'Berlin','UK':'London'} print(a|b)
{‘France’: ‘Paris’, ‘Thailand’: ‘Bangkok’, ‘Germany’: ‘Berlin’, ‘UK’: ‘London’}
2. f-Strings Literal
f-strings, also called “formatted string literal”, ere string literals that have an
f at the beginning and curly braces containing expressions that will be replaced with their values. They replace the old clumsy style %-format and str-format syntax. See the example of using f-strings formatting below:
Output:Output:
country = 'France' capital = 'Paris' print(f'The capital of {country} is {capital}')
The capital of France is Paris
References:
- Python 3’s f-Strings: An Improved String Formatting Syntax (Guide)
- What’s New In Python 3.9
- What’s New In Python 3.8
Relevant Courses
April 15, 2021 | https://www.tertiaryinfotech.com/new-features-in-python-3-8-and-3-9/ | CC-MAIN-2022-21 | refinedweb | 193 | 57.37 |
This article is just written for my knowledge and understanding of the coolest part in Vue: the reactivity system.
Background
As we know, Vue.js team is working on 3.0 for a while. Recently it released the first Beta version. That means the core tech design is stable enough. Now I think it's time to walk through something inside Vue 3.0. That's one of my most favorite parts: the reactivity system.
What's reactivity?
For short, reactivity means, the result of calculations, which depends on some certain data, will be automatically updated, when the data changes.
In modern web development, we always need to render some data-related or state-related views. So obviously, making data reactive could give us lots of benefits. In Vue, the reactivity system always exists from its very early version till now. And I think that's one of the biggest reasons why Vue is so popular.
Let's have a look at the reactivity system in the early version of Vue first.
Reactivity in Vue from 0.x to 1.x
The first time I touched Vue is about 2014, I guess it was Vue 0.10. At that time, you could just pass a plain JavaScript object into a Vue component through
data option. Then you could use them in a piece of document fragment as its template with reactivity. Once the
data changes, the view would be automatically updated. Also you could use
computed and
watch options to benefit yourself from the reactivity system in more flexible ways. Same to the later Vue 1.x.
new Vue({ el: '#app', template: '<div @{{x}} + {{y}} = {{z}}</div>', data() { return { x: 1, y: 2 } }, computed: { z() { return this.x + this.y } }, watch: { x(newValue, oldValue) { console.log(`x is changed from ${oldValue} to ${newValue}`) } } })
You may found these APIs didn't change too much so far. Because they work the same totally.
So how does it work? How to make a plain JavaScript object reactive automatically?
Fortunately, in JavaScript we have an API
Object.defineProperty() which could overwrite the getter/setter of an object property. So to make them reactive, there could be 3 steps:
- Use
Object.defineProperty()to overwrite getters/setters of all the properties inside a data object recursively. Besides behaving normally, it additionally injects a trigger inside all setters, and a tracker inside all getters. Also it will create a small
Depinstance inside each time to record all the calculations which depend on this property.
- Every time we set a value into a property, it will call the setter, which will re-evaluate those related calculations inside the
Depinstance. Then you may ask how could we record all the related calculations. The fact is when each time we define a calculation like a
watchfunction or a DOM update function, it would run once first - sometimes it runs as the initialization, sometimes it's just a dry-run. And during that running, it will touch every tracker inside the getters it depends on. Each tracker will push the current calculation function into the corresponding
Depinstance.
- So next time when some data changes, it will find out all related calculations inside the corresponding
Depinstance, and then run them again. So the effect of these calculations will be updated automatically.
A simple implementation to observe data using
Object.defineProperty is like:
// data const data = { x: 1, y: 2 } // real data and deps behind let realX = data.x let realY = data.y const realDepsX = [] const realDepsY = [] // make it reactive Object.defineProperty(data, 'x', { get() { trackX() return realX }, set(v) { realX = v triggerX() } }) Object.defineProperty(data, 'y', { get() { trackY() return realY }, set(v) { realY = v triggerY() } }) // track and trigger a property const trackX = () => { if (isDryRun && currentDep) { realDepsX.push(currentDep) } } const trackY = () => { if (isDryRun && currentDep) { realDepsY.push(currentDep) } } const triggerX = () => { realDepsX.forEach(dep => dep()) } const triggerY = () => { realDepsY.forEach(dep => dep()) } // observe a function let isDryRun = false let currentDep = null const observe = fn => { isDryRun = true currentDep = fn fn() currentDep = null isDryRun = false } // define 3 functions const depA = () => console.log(`x = ${data.x}`) const depB = () => console.log(`y = ${data.y}`) const depC = () => console.log(`x + y = ${data.x + data.y}`) // dry-run all dependents observe(depA) observe(depB) observe(depC) // output: x = 1, y = 2, x + y = 3 // mutate data data.x = 3 // output: x = 3, x + y = 5 data.y = 4 // output: y = 4, x + y = 7
Inside Vue 2.x and earlier, the mechanism roughly like this above, but much better abstracted, designed, and implemented.
For supporting more complex cases like arrays, nested properties, or mutating more than 2 properties at the same time, there are more implementation and optimization details inside Vue, but basically, the same mechanism to we mentioned before.
Reactivity in Vue 2.x
From 1.x to 2.x, it was a total rewrite. And it introduced some really cool features like virtual DOM, server-side rendering, low-level render functions, etc. But the interesting thing is the reactivity system didn't change too much, however, the usage above was totally different:
- From 0.x to 1.x, the rendering logic depends on maintaining a document fragment. Inside that document fragment, there are some DOM update functions for each dynamic element, attribute, and text content. So the reactivity system mostly works between the data object and these DOM update functions. Since the functions all real DOM functions so the performance is not quite good. In Vue 2.x, this rendering logic of a Vue component became a whole pure JavaScript render function. So it would firstly return virtual nodes instead of real DOM nodes. Then it would update the real DOM based on the result of a fast mutation diff algorithm for the virtual DOM nodes. It was faster than before.
- In Vue 2.6, it introduced a standalone API
Vue.observalue(obj)to generate reactive plain JavaScript objects. So you could use them inside a
renderfunction or a
computedproperty. It was more flexible to use.
At the same time, there are some discussions in Vue community about abstracting the reactivity system into an independent package for wider usage. However it didn't happen at that time.
Limitation of the reactivity system before 3.0
So far, Vue didn't change the reactivity mechanism. But it doesn't mean the current solution is ideally perfect. As I personally understand, there are some caveats:
- Because of the limitation of
Object.definePropertywe couldn't observe some data changes like:
- Setting array items by assigning value to a certain index. (e.g.
arr[0] = value)
- Setting the length of an array. (e.g.
arr.length = 0)
- Adding a new property to an object. (e.g.
obj.newKey = value) So it needs some complementary APIs like
Vue.$set(obj, newKey, value).
- Because of the limitation of plain JavaScript data structure, for each reactive object there would be an unenumerable property named
__ob__, which might lead to conflict in some extreme cases.
- It didn't support more data types like
Mapand
Set. Neither other non-plain JavaScript objects.
- The performance is an issue. When the data is large, making it reactive when the initialization would cost visible time. There are some tips to flatten the initial cost but a little bit tricky.
Reactivity system in Vue 3.0
For short, in Vue 3.0, the reactivity system was totally rewritten with a new mechanism and new abstraction, as an independent package. And it also supports more modern JavaScript data types.
You may be familiar with it, maybe not. No worry. Let's quickly take a look at it first by creating a Vue 3.0 project.
Create a Vue 3.0 project
Until now, there is no stable full-featured project generator, since it's still in Beta. We could try Vue 3.0 through an experimental project named "vite":
V
Vite is now in 2.0 beta. Check out the Migration Guide if you are upgrading from 1.x.
Packages…
Just run these commands below:
$ npx create-vite-app hello-world $ cd hello-world $ npm install $ npm run dev
Then you could access your Vue 3.0 app through.
You could see there is already a Vue component
App.vue:
<template> <p> <span>Count is: {{ count }}</span> <button @increment</button> is positive: {{ isPositive }} </p> </template> <script> export default { data: () => ({ count: 0 }), computed: { isPositive() { return this.count > 0 } } } </script>
There is a reactive property
count and it's displayed in the
<template>. When users click the "increment" button, the property
count would be incremented, the computed property
isPositive would be re-calculated too, and the UI would be updated automatically.
It seems nothing different to the former version so far.
Now let's try something impossible in early versions of Vue.
1. Adding new property
As we mentioned, in Vue 2.x and earlier, we couldn't observe newly added property automatically. For example:
<template> <p> <span>My name is {{ name.given }} {{ name.family }}</span> <button @update name</button> </p> </template> <script> export default { data: () => ({ name: { given: 'Jinjiang' } }), methods: { update() { this.name.family = 'Zhao' } } } </script>
The
update method couldn't work properly because the new property
family couldn't be observed. So when adding this new property, the render function won't be re-calculated. If you want this work, you should manually use another complementary API as
Vue.$set(this.name, 'family', 'Zhao').
But in Vue 3.0, it already works as well. You don't need
Vue.$set anymore.
2. Assigning items to an array by index
Now let's try to set a value into an index of an array:
<template> <ul> <li v- {{ item }} <button @edit</button> </li> </ul> </template> <script> export default { data() { return { list: [ 'Client meeting', 'Plan webinar', 'Email newsletter' ] } }, methods: { edit(index) { const newItem = prompt('Input a new item') if (newItem) { this.list[index] = newItem } } } } </script>
In Vue 2.x and earlier, when you click one of the "edit" buttons in the list item and input a new piece of a text string, the view won't be changed, because setting item with an index like
this.list[index] = newItem couldn't be tracked. You should write
Vue.$set(this.list, index, newItem) instead. But in Vue 3.0, it works, too.
3. Setting the length property of an array
Also if we add another button to the example above to clean all items:
<template> <ul>...</ul> <!-- btw Vue 3.0 supports multi-root template like this --> <button @clean</button> </template> <script> export default { data: ..., methods: { ..., clean() { this.list.length = 0 } } } </script>
it won't work in Vue 2.x and earlier, because setting the length of an array like
this.list.length = 0 couldn't be tracked. So you have to use other methods like
this.list = []. But in Vue 3.0, all the ways above works.
4. Using ES Set/Map
Let's see a similar example with ES Set:
<template> <div> <ul> <li v- {{ item }} <button @remove</button> </li> </ul> <button @add</button> <button @clean</button> </div> </template> <script> export default { data: () => ({ list: new Set([ 'Client meeting', 'Plan webinar', 'Email newsletter' ]) }), created() { console.log(this.list) }, methods: { remove(item) { this.list.delete(item) }, add() { const newItem = prompt('Input a new item') if (newItem) { this.list.add(newItem) } }, clean() { this.list.clear() } } } </script>
Now we use a
Set instead of an array. In Vue 2.x and earlier, fortunately it could be rendered properly for the first time. But when you remove, add, or clear, the view won't be updated, because they are not tracked. So usually we don't use
Set or
Map in Vue 2.x and earlier. In Vue 3.0, the same code would work as you like, because it totally supports them.
5. Using non-reactive properties
If we have some one-time consuming heavy data in a Vue component, probably it doesn't need to be reactive, because once initialized, it won't change. But in Vue 2.x and earlier, whatever you use them again, all the properties inside will be tracked. So sometimes it costs visible time. Practically, we have some other ways to walk-around but it's a little bit tricky.
In Vue 3.0, it provides a dedicated API to do this -
markRaw:
<template> <div> Hello {{ test.name }} <button @should not update</button> </div> </template> <script> import { markRaw } from 'vue' export default { data: () => ({ test: markRaw({ name: 'Vue' }) }), methods: { update(){ this.test.name = 'Jinjiang' console.log(this.test) } } } </script>
In this case, we use
markRaw to tell the reactivity system, the property test and its descendants properties don't need to be tracked. So the tracking process would be skipped. At the same time, any further update on them won't trigger a re-render.
Additionally, there is another "twin" API -
readonly. This API could prevent data to be mutated. For example:
import { readonly } from 'vue' export default { data: () => ({ test: readonly({ name: 'Vue' }) }), methods: { update(){ this.test.name = 'Jinjiang' } } }
Then the mutation to
this.test would be failed.
So far we see the power and magic of the reactivity system in Vue 3.0. Actually there are more powerful ways to use it. But we won't move on immediately, because before mastering them, it's also great to know how it works behind Vue 3.0.
How it works
For short, the reactivity system in Vue 3.0 suits up with ES2015!
First part: simple data observer
Since ES2015, there are a pair of APIs -
Proxy and
Reflect. They are born to reactivity systems! Vue 3.0 reactivity system just be built based on that.
With
Proxy you could set a "trap" to observe any operation on a certain JavaScript object.
const data = { x: 1, y: 2 } // all behaviors of a proxy by operation types const handlers = { get(data, propName, proxy) { console.log(`Get ${propName}: ${data[propName]}!`) return data[propName] }, has(data, propName) { ... }, set(data, propName, value, proxy) { ... }, deleteProperty(data, propName) { ... }, // ... } // create a proxy object for the data const proxy = new Proxy(data, handlers) // print: 'Get x: 1' and return `1` proxy.x
With
Reflect you could behave the same as the original object.
const data = { x: 1, y: 2 } // all behaviors of a proxy by operation types const handlers = { get(data, propName, proxy) { console.log(`Get ${propName}: ${data[propName]}!`) // same behavior as before return Reflect.get(data, propName, proxy) }, has(...args) { return Reflect.set(...args) }, set(...args) { return Reflect.set(...args) }, deleteProperty(...args) { return Reflect.set(...args) }, // ... } // create a proxy object for the data const proxy = new Proxy(data, handlers) // print: 'Get x: 1' and return `1` proxy.x
So with
Proxy +
Reflect together, we could easily make a JavaScript object observable, and then, reactive.
const track = (...args) => console.log('track', ...args) const trigger = (...args) => console.log('trigger', ...args) // all behaviors of a proxy by operation types const handlers = { get(...args) { track('get', ...args); return Reflect.get(...args) }, has(...args) { track('has', ...args); return Reflect.set(...args) }, set(...args) { Reflect.set(...args); trigger('set', ...args) }, deleteProperty(...args) { Reflect.set(...args); trigger('delete', ...args) }, // ... } // create a proxy object for the data const data = { x: 1, y: 2 } const proxy = new Proxy(data, handlers) // will call `trigger()` in `set()` proxy.z = 3 // create a proxy object for an array const arr = [1,2,3] const arrProxy = new Proxy(arr, handlers) // will call `track()` & `trigger()` when get/set by index arrProxy[0] arrProxy[1] = 4 // will call `trigger()` when set `length` arrProxy.length = 0
So this observer is better than Object.defineProperty because it could observe every former dead angle. Also the observer just needs to set up a "trap" to an object. So less cost during the initialization.
And it's not all the implementation, because in
Proxy it could handle ALL kinds of behaviors with different purposes. So the completed code of handlers in Vue 3.0 is more complex.
For example if we run
arrProxy.push(10), the proxy would trigger a
set handler with
3 as its
propName and
10 as its
value. But we don't literally know whether or not it's a new index. So if we would like to track
arrProxy.length, we should do more precise determination about whether a set or a
deleteProperty operation would change the length.
Also this
Proxy +
Reflect mechanism supports you to track and trigger mutations in a
Set or a
Map. That means operations like:
const map = new Map() map.has('x') map.get('x') map.set('x', 1) map.delete('x')
would also be observable.
Second: more reactivity APIs
In Vue 3.0, we also provide some other APIs like
readonly and
markRaw. For
readonly what you need is just change the handlers like
set and
deleteProperty to avoid mutations. Probably like:
const track = (...args) => console.log('track', ...args) const trigger = (...args) => console.log('trigger', ...args) // all behaviors of a proxy by operation types const handlers = { get(...args) { track('get', ...args); return Reflect.get(...args) }, has(...args) { track('has', ...args); return Reflect.set(...args) }, set(...args) { console.warn('This is a readonly proxy, you couldn\'t modify it.') }, deleteProperty(...args) { console.warn('This is a readonly proxy, you couldn\'t modify it.') }, // ... } // create a proxy object for the data const data = { x: 1, y: 2 } const readonly = new Proxy(data, handlers) // will warn that you couldn't modify it readonly.z = 3 // will warn that you couldn't modify it delete readonly.x
For
markRaw, in Vue 3.0 it would set a unenumerable flag property named
__v_skip. So when we are creating a proxy for data, if there is a
__v_skip flag property, then it would be skipped. Probably like:
// track, trigger, reactive handlers const track = (...args) => console.log('track', ...args) const trigger = (...args) => console.log('trigger', ...args) const reactiveHandlers = { ... } // set an invisible skip flag to raw data const markRaw = data => Object.defineProperty( data, '__v_skip', { value: true } ) // create a proxy only when there is no skip flag on the data const reactive = data => { if (data.__v_skip) { return data } return new Proxy(data, reactiveHandlers) } // create a proxy object for the data const data = { x: 1, y: 2 } const rawData = markRaw(data) const reactiveData = readonly(data) console.log(rawData === data) // true console.log(reactiveData === data) // true
Additionally, a trial of using WeakMap to record deps and flags
Although it's not implemented in Vue 3.0 finally. But there was another try to record deps and flags using new data structures in ES2015.
With
Set and
Map, we could maintain the relationship out of the data itself. So we don't need flag properties like
__v_skip inside data any more - actually there are some other flag properties like
__v_isReactive and
__v_isReadonly in Vue 3.0. For example:
// a Map to record dependets const dependentMap = new Map() // track and trigger a property const track = (type, data, propName) => { if (isDryRun && currentFn) { if (!dependentMap.has(data)) { dependentMap.set(data, new Map()) } if (!dependentMap.get(data).has(propName)) { dependentMap.get(data).set(propName, new Set()) } dependentMap.get(data).get(propName).add(currentFn) } } const trigger = (type, data, propName) => { dependentMap.get(data).get(propName).forEach(fn => fn()) } // observe let isDryRun = false let currentFn = null const observe = fn => { isDryRun = true currentFn = fn fn() currentFn = null isDryRun = false }
Then with
Proxy/
Reflect together, we could track data mutation and trigger dependent functions:
// … handlers // … observe // make data and arr reactive const data = { x: 1, y: 2 } const proxy = new Proxy(data, handlers) const arr = [1, 2, 3] const arrProxy = new Proxy(arr, handlers) // observe functions const depA = () => console.log(`x = ${proxy.x}`) const depB = () => console.log(`y = ${proxy.y}`) const depC = () => console.log(`x + y = ${proxy.x + proxy.y}`) const depD = () => { let sum = 0 for (let i = 0; i < arrProxy.length; i++) { sum += arrProxy[i] } console.log(`sum = ${sum}`) } // dry-run all dependents observe(depA) observe(depB) observe(depC) observe(depD) // output: x = 1, y = 2, x + y = 3, sum = 6 // mutate data proxy.x = 3 // output: x = 3, x + y = 5 arrProxy[1] = 4 // output: sum = 8
Actually in early beta version of Vue 3.0, it uses
WeakMap instead of
Map so there won't be any memory leak to be worried about. But unfortunately, the performance is not good when data goes large. So later it changed back to flag properties.
Btw, there is also a trial of using
Symbols as the flag property names. With
Symbols the extreme cases could also be relieved a lot. But the same, the performance is still not good as normal string property names.
Although these experiments are not preserved finally, I think it's a good choice if you would like to make a pure (but maybe not quite performant) data observer on your own. So just mention this a little bit here.
Quick summary
Anyway we make data reactive first, and observe functions to track all the data they depend on. Then when we mutate the reactive data, relevant functions would be triggered to run again.
All the features and their further issues above have already been completed in Vue 3.0, with the power of ES2015 features.
If you would like to see all the live version of the code sample about explaining main mechanism of reactivity system in Vue from 0.x to 3.0. You could check out this CodePen and see its "Console" panel:
Now we have already known the basic usage of it - that's passing something into the
data option into a Vue component, and then using it into other options like
computed,
watch, or the
template. But this time, in Vue 3.0, it provides more util APIs, like
markRaw we mentioned before. So let's take a look at these util APIs.
Encapsulation
1. Proxy for objects
1.1 Basic:
reactive(data),
readonly(data),
markRaw(data)
First let me introduce
reactive(data). Just as the name, this API would create a reactive proxy for the data. But here maybe you don't need to use this directly, because the data object you return from the
data option will be set up with this API automatically.
Then if you just would like:
- Some pieces of data immutable, then you could use
readonly(data).
- Some pieces of data not reactive, then you could use
markRaw(data).
For example:
import { reactive, readonly, markRaw } from 'vue' const ComponentFoo = { data() { return { reactiveX: { x: 1 }, reactiveXInAnotherWay: reactive({ x: 1 }), immutableY: readonly({ y: 2 }), needntChangeReactivelyZ: markRaw({ z: 3 }) } }, // ... }
In this case:
- If the properties in
reactiveXor
reactiveXInAnotherWaychanged, the view using them in the template will be re-rendered automatically.
- If you modify the properties in
immutableY, there would be an error thrown. At the same time the view won't be re-rendered.
- If you modify the properties in
needntChangeReactivelyZ, the view won't be re-rendered.
Also for marking as raw data, you could mark the data, and then use it anywhere else:
const { markRaw } from 'vue' const obj = { x: 1 } const result = markRaw(obj) console.log(obj === result) // true const ComponentFoo = { data() { return { obj, result } }, // ... }
Here the properties in
this.obj and
this.result are both non-reactive.
1.2 Utils:
isReactive(data),
isReadonly(data),
isProxy(data),
toRaw(data)
Then you may need some util APIs to help you do the job better.
- For the reactive data proxy, then both
isProxy(data)and
isReactive(data)would be
true.
- For the readonly data proxy, then both
isProxy(data)and
isReadonly(data)would be
true.
- For the original data, whether or not it is marked as raw, then all the
isProxy(data)and
isReactive(data)and
isReadonly(data)would be
false.
- For the reactive or readonly data proxy, you could use
toRaw(data)to get the raw data back.
1.3 Advanced:
shallowReactive(data),
shallowReadonly(data)
With these 2 APIs, you could create a "shallow" data proxy, which means they won't setting traps deeply. Only the first-layer properties in these data proxies would be reactive or readonly. For example:
import { shallowReactive, shallowReadonly } from 'vue' const ComponentFoo = { data() { return { x: shallowReactive({ a: { b: 1 } }), y: shallowReadonly({ a: { b: 1 } }) } } }
In this case,
this.x.a is reactive, but
this.x.a.b is not;
this.y.a is readonly, but
this.y.a.b is not.
If you only consume reactive data inside its own component, I think these APIs above are totally enough. But when things come to the real world, sometimes we would like to share states between components, or just abstract state out of a component for better maintenance. So we need more APIs below.
2. Ref for primitive values
A ref could help you to hold a reference for a reactive value. Mostly it's used for a primitive value. For example, somehow we have a number variable named
counter in an ES module, but the code below doesn't work:
// store.js // This won't work. export const counter = 0; // This won't works neither. // import { reactive } from 'vue' // export const counter = reactive(0)
<!-- foo.vue --> <template> <div> {{ counter }} </div> </template> <script> import { counter } from './store.js' export { data() { return { counter } } } </script>
<!-- bar.vue --> <template> <button @increment</button> </template> <script> import { counter } from './store.js' export { data() { return { counter } } } </script>
… because primitive values are immutable. When importing and exporting primitive values, we lose the track. To do this, we could use a ref instead.
2.1 Basic:
ref(data)
To support the previous example, let's introduce
ref(data):
// store.js import { ref } from 'vue' export const counter = ref(0)
Then it would work properly.
There is one thing to notice: if you would like to access the value of refs out of a template, you should access its
value property instead. For example, if we'd like to modify
bar.vue to avoid
data option, we could add an
increment method to do this, with
counter.value:
<!-- bar.vue --> <template> <button @increment</button> </template> <script> import { counter } from './store.js' export { methods: { increment() { counter.value++ } } } </script>
For more caveats, we could do some quick tests later.
2.2 Utils:
isRef(data),
unref(data)
I think these 2 util APIs are easy to understand:
isRef(data): check a value is a ref or not.
unref(data): return the value of a ref.
2.3 Proxy to ref:
toRef(data, key),
toRefs(data)
These 2 util APIs are used for get refs from proxy data:
import { reactive, toRef, toRefs } from 'vue' const proxy = reactive({ x: 1, y: 2 }) const refX = toRef(proxy, 'x') proxy.x = 3 console.log(refX.value) // 3 const refs = toRefs(proxy) proxy.y = 4 console.log(refs.x.value) // 3 console.log(refs.y.value) // 4
As the example above, the typical usage of these APIs is spreading a reactive object into several sub variables and keep the reactivity at the same time.
2.4 Advanced:
shallowRef(data)
Only trigger update when the
ref.value is assigned by another value. For example:
import { shallowRef } from 'vue' const data = { x: 1, y: 2 } const ref = shallowRef(data) // won't trigger update ref.value.x = 3 // will trigger update ref.value = { x: 3, y: 2 }
Case:
computed(…)
Similar idea to
computed option inside a Vue component. But if you would like to share a computed state out of a component, I suggest you try this API:
// store.js import { ref, computed } from 'vue' export const firstName = ref('Jinjiang') export const lastName = ref('Zhao') // getter only version export const fullName = computed(() => `${firstName.value} ${lastName.value}`) // getter + setter version export const fullName2 = computed({ get: () => `${firstName.value} ${lastName.value}`, set: (v) => { const names = v.split(' ') if (names.length > 0) { firstName.value = names[0] } if (names.length > 1) { lastName.value = names[names.length - 1] } } })
// another-file.js import { firstName, lastName, fullName, fullName2 } from './store.js' console.log(fullName.value) // Jinjiang Zhao firstName.value = 'Evan' lastName.value = 'You' console.log(fullName.value) // Evan You fullName2.value = 'Jinjiang Zhao' console.log(firstName.value) // Jinjiang console.log(lastName.value) // Zhao
Case:
customRef(…)
This API is my best favorite API in Vue 3.0. Because with this API, you could define how and when to track/trigger your data, during getting or setting the value, that's totally mind-blowing!
For example:
<template> <input v- </template> <script> import { customRef } from 'vue' import { validate } from 'isemail' export default { data() { return { email: customRef((track, trigger) => { const value = '' return { get() { track() return value }, set(v) { if (validate(v)) { value = v trigger() } } } }) } } } </script>
That makes real-world user input much easier to handle.
3. Watch for effects
watchEffect(function),
watch(deps, callback)
In a Vue component, we could watch data mutations by
watch option or
vm.$watch() instance API. But the same question: what about watching data mutations out of a Vue component?
Similar to
computed reactivity API vs.
computed option, we have 2 reactivity APIs:
watchEffect and
watch.
// store.js import { ref, watch, watchEffect } from 'vue' export const counter = ref(0) // Will print the counter every time it's mutated. watchEffect(() => console.log(`The counter is ${counter.value}`)) // Do the similar thing with more options watch(counter, (newValue, oldValue) => console.log(`The counter: from ${oldValue} to ${newValue}`) )
4. Standalone package & usage
Also in Vue 3.0, we have a standalone package for these. That is
@vue/reactivity. You could also import most of the APIs we mentioned above, from this package. So the code is almost the same to above:
import { reactive, computed, effect } from '@vue/reactivity' const data = { x: 1, y: 2 } const proxy = reactive(data) const z = computed(() => proxy.x + proxy.y) // print 'sum: 3' effect(() => console.log(`sum: ${z.value}`)) console.log(proxy.x, proxy.y, z.value) // 1, 2, 3 proxy.x = 11 // print 'sum: 13' console.log(proxy.x, proxy.y, z.value) // 11, 2, 13
The only difference is there is no
watch and
watchEffect. Instead there is another low-level API named
effect. Its basic usage is just similar to
watchEffect but more flexible and powerful.
For more details, I suggest you to read the source code directly:
So you could even use these APIs in non-Vue related projects as you like.
From now on, you could think about it: with reactivity APIs, what else amazing stuff could you make? 😉
Benefit & caveats
So far we know how reactivity APIs work in Vue 3.0. Comparing to 2.x and earlier version, it:
- Fully covers all kinds of mutations of data, like adding a new property to an object, setting a value to an
indexof an array, etc.
- Fully support all new data structures, like
Mapand
Set.
- Has better performance.
- It could be used as a standalone package.
So if you really need or love any of the above, maybe it's time to try.
At the same time, there are some caveats for you:
- It only works on ES2015+
- DO use refs for primitive values for keeping the reactivity.
- The reactive proxy doesn't equal to the original data in JavaScript.
For more details, I prepared a cheat sheet on Gist below:
Also there are 2 more casual Codesandbox projects I test for myself previously. Maybe it's somehow a little bit useful:
- for
reactive,
readonly, and
markRaw:
- for
refand
computed:
Further use cases
So far we know a lot of things about the reactivity system in Vue, from the early version to 3.0. Now it's time to show some use cases based on that.
Composition API
The first thing is definitely the Vue Composition API, which is new in 3.0. With reactivity APIs, we could organize our code logic more flexibly.
import { ref, reactive, readonly, markRaw, computed, toRefs } from 'vue' export default { setup(props) { const counter = ref(0) const increment = () => counter.value++ const proxy = reactive({ x: 1, y: 2 }) const frozen = readonly({ x: 1, y: 2 }) const oneTimeLargeData = markRaw({ ... }) const isZero = computed(() => counter.value === 0) const propRefs = toRefs(props) // could use a,b,c,d,e,f in template and `this` return { a: counter, b: increment, c: proxy, d: frozen, e: oneTimeLargeData, f: isZero, ...propRefs } } }
I don't wanna show more demos about that because they are already everywhere. But IMO, for a further benefit few people talking about is, previously in Vue 2.x and earlier, we are used to putting everything on
this, when we:
- Create reactive data for a component instance.
- Access data/functions in the template.
- Access data/functions outside the component instance, mostly it happens when we set a template ref on a sub Vue component.
All 3 things always happen together. That means maybe we just:
- Would like to access something in the template, but don't need reactivity.
- Would like to create reactive data, but don't use that in the template.
Vue Composition API elegantly decouples them out by 2 steps:
- create reactive data;
- decide what the template needs.
Btw, for public instance members, I think the potential problem is still there. However, it's not a big matter so far.
Also, there are some other benefits, including but not limited to:
- Maintain reusable code without worrying about the naming conflict.
- Gathering logically related code together, rather than gathering instance members together with the same option type.
- Better and easier TypeScript support.
Also in Composition API, there are more APIs like
provide()/
inject(), lifecycle hooks, template refs, etc. For more about Composition API, please check out this URL:.
Cross-component state sharing
When sharing data between components. Reactivity APIs is also a good choice. We could even use them out of any Vue component, and finally use them into a Vue app, for example, with the composition APIs
provide and
inject:
// store.js import { ref } from 'vue' // use Symbol to avoid naming conflict export const key = Symbol() // create the store export const createStore = () => { const counter = ref(0) const increment = () => counter.value++ return { counter, increment } }
// App.vue import { provide } from 'vue' import { key, createStore } from './store' export default { setup() { // provide data first provide(key, createStore()) } }
// Foo.vue import { inject } from 'vue' import { key } from './store' export default { setup() { // you could inject state with the key // and rename it before you pass it into the template const { counter } = inject(key) return { x: counter } } }
// Bar.vue import { inject } from 'vue' import { key } from './store' export default { setup() { // you could inject state with the key // and rename it before you pass it into the template const { increment } = inject(key) return { y: increment } } }
So once user call y() in Bar.vue, the x in Foo.vue would be updated as well. You don't even need any more state management library to do that. That's quite easy to use.
Remember vue-hooks?
It's not an active project anymore. But I remember after React Hooks first time announced, Evan, the creator of Vue, just gave a POC under Vue in 1 day with less than 100 lines of code.
Here is the live demo in Codesandbox:
Why it could be done so easily with Vue. I think mostly because of the reactivity system in Vue. It already helps you done most of the job. What we need to do is just encapsulate them into a new pattern or more friendly APIs.
Writing React with Vue reactivity system
So let's try one more step POC. How about using Reactivity APIs in React to create React components?
import * as React from "react"; import { effect, reactive } from "@vue/reactivity"; const Vue = ({ setup, render }) => { const Comp = props => { const [renderResult, setRenderResult] = React.useState(null); const [reactiveProps] = React.useState(reactive({})); Object.assign(reactiveProps, props); React.useEffect(() => { const data = { ...setup(reactiveProps) }; effect(() => setRenderResult(render(data))); }, []); return renderResult; }; return Comp; }; const Foo = Vue({ setup: () => { const counter = ref(0); const increment = () => { counter.value++; }; return { x: counter, y: increment }; }, render: ({ x, y }) => <h1 onClick={y}>Hello World {x.value}</h1> });
I did a little test like above, it's not a full implementation. But somehow we could maintain a basic React component with 2 parts:
- Pure data logic with reactivity.
- Any data update would be observed and trigger component re-render.
Those correspond to
setup and
render functions as a Vue component does.
And there is no way to worry about whether or not I write a React hook outside a React component or inside a conditional block. Just code it as you like and make it happen as you imagine.
Final final conclusions
So that's all about the reactivity system in Vue, from early version to the latest 3.0 Beta. I'm still learning a lot of new stuff like programming languages, paradigms, frameworks, and ideas. They are all great and shining. But the reactivity system is always a powerful and elegant tool to help me solve all kinds of problems. And it's still keeping evolved.
With ES2015+, the new Reactivity APIs and its independent package, Composition APIs, Vue 3.0, and more amazing stuff in the ecosystem and community. Hope you could use them or get inspired from them, to build more great things much easier.
Hope you could know Vue and its reactivity system better through this article.
All the code samples in this article:
Discussion (6)
Really impressive post! Thanks!
I must login in Devto to like and comment this post! It's .... I don't know :v I will share with my colleagues about this post. You deserves more than this, bro.
is 'Dep' short for 'dependence'? why call it 'Dep'? it just looks like a subscribers collection.
Yes short for dependence. And it just comes from the source code. github.com/vuejs/vue/blob/dev/src/...
Thanks so much bz this article!
This is a MASSIVE post! Wow! Still haven't read all of it, but will definitely use it as a first step when learning Vue 3. Thanks! | https://practicaldev-herokuapp-com.global.ssl.fastly.net/jinjiang/understanding-reactivity-in-vue-3-0-1jni | CC-MAIN-2021-10 | refinedweb | 6,253 | 59.4 |
Starting from this version, Py++ provides complete support for the multi-module development and Unicode. It also adds one more strategy to split the generated code to files. This release contains many small usability features and documentation improvements.
This release adds support for GCC-XML 0.9, which is based on the GCC 4.2 parser. It also includes a few new features, several bugfixes, updated documentation, and a GCC-XML 0.7 to 0.9 upgrade guide.
Py++ is an object-oriented framework for creating a code generator for Boost.Python library.
User feedback functionality was improved.
Support for Boost.Python indexing suite version 2 was implemented.
Support for huge classes was added.
pygccxml is a simple framework to navigaet C++
classes from Python.
pygccxml has been ported to Mac OS.
New type traits have been added.
Logging functionality was improved.
pydsc is a simple and easy to use Python
documentation strings and comments spell checker.
import pydsc
#every module you import after it will be checked
#for errors
pyboost is a Python package that contains Python
bindings for few boost( ) libraries:
date_time
random
crc
rational
For usage example, please download relevant file
and take a look at "unittests" folder. | http://sourceforge.net/p/pygccxml/news/?source=navbar | CC-MAIN-2014-23 | refinedweb | 201 | 61.22 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.