
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"langchain-ai",
"langchain"
] | I'm building a flow where I'm using both gpt-3.5 and gpt-4 based chains and I need to use different API keys for each (due to API access + external factors)
Both `ChatOpenAI` and `OpenAI` set `openai.api_key = openai_api_key` which is a global variable on the package.
This means that if I instantiate multiple ChatOpenAI instances, the last one's API key will override the other ones and that one will be used when calling the OpenAI endpoints.
Based on https://github.com/openai/openai-python/issues/233#issuecomment-1464732160 there's an undocumented feature where we can pass the api_key on each openai client call and that key will be used.
As a side note, I've also noticed `ChatOpenAI` and a few other classes take in an optional `openai_api_key` as part of initialisation which is correctly used over the env var but the docstring says that the `OPENAI_API_KEY` env var should be set, which doesn't seem to be case. Can we confirm if this env var is needed elsewhere or if it's possible to just pass in the values when instantiating the chat models.
Thanks! | Encapsulate API keys | https://api.github.com/repos/langchain-ai/langchain/issues/3446/comments | 4 | 2023-04-24T15:12:21Z | 2023-09-24T16:08:02Z | https://github.com/langchain-ai/langchain/issues/3446 | 1,681,513,674 | 3,446 |
[
"langchain-ai",
"langchain"
] | I wonder if this work: https://arxiv.org/abs/2304.11062
Could be integrated with LangChain | Possible Enhancement | https://api.github.com/repos/langchain-ai/langchain/issues/3445/comments | 1 | 2023-04-24T14:51:55Z | 2023-09-10T16:28:02Z | https://github.com/langchain-ai/langchain/issues/3445 | 1,681,468,911 | 3,445 |
[
"langchain-ai",
"langchain"
] | Hi, I'm trying to use the examples for Azure OpenAI with langchain, for example this notebook in https://python.langchain.com/en/harrison-docs-refactor-3-24/modules/models/llms/integrations/azure_openai_example.html , but I always find this error:
Exception has occurred: InvalidRequestError Resource not found
I have tried multiple combinations with the environment variables, but nothing works, I have also tested it in a python script with the same results.
Regards. | Azure OpenAI - Exception has occurred: InvalidRequestError Resource not found | https://api.github.com/repos/langchain-ai/langchain/issues/3444/comments | 8 | 2023-04-24T14:31:33Z | 2023-09-24T16:08:07Z | https://github.com/langchain-ai/langchain/issues/3444 | 1,681,415,525 | 3,444 |
[
"langchain-ai",
"langchain"
] | Hello, I came across a code snippet in the tutorial page on "Conversation Agent (for Chat Models)" that has left me a bit confused. The tutorial also mentioned a warning error like this:
`WARNING:root:Failed to default session, using empty session: HTTPConnectionPool(host='localhost', port=8000): Max retries exceeded with url: /sessions (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x10a1767c0>: Failed to establish a new connection: [Errno 61] Connection refused'))`
Then i found the line of code in question is:
`os.environ["LANGCHAIN_HANDLER"] = "langchain"`
When I remove this line from the code, the program still seems to work without any errors. So why is this line of code exists.
Thank you! | Question about setting LANGCHAIN_HANDLER environment variable | https://api.github.com/repos/langchain-ai/langchain/issues/3443/comments | 4 | 2023-04-24T14:08:05Z | 2024-01-06T18:09:31Z | https://github.com/langchain-ai/langchain/issues/3443 | 1,681,362,534 | 3,443 |
[
"langchain-ai",
"langchain"
] | Aim::
aim.Text(outputs_res["output"]), name="on_chain_end", context=resp
KeyError: 'output'
Wandb::
resp.update({"action": "on_chain_end", "outputs": outputs["output"]})
KeyError: 'output'
Has anyone dealt with this issue yet while building custom agents with LLMSingleActionAgent, thank you | LLMOps integration of Aim and Wandb breaks when trying to parse agent output into dashboard for experiment tracking... | https://api.github.com/repos/langchain-ai/langchain/issues/3441/comments | 1 | 2023-04-24T12:07:58Z | 2023-09-10T16:28:08Z | https://github.com/langchain-ai/langchain/issues/3441 | 1,681,126,941 | 3,441 |
[
"langchain-ai",
"langchain"
] | I think that among the actions that the agent can take, there may be actions without input. (e.g. return the current state in real time)
But in practice, LM often does that, but current MRKL parsers don't allow it. I'm a newbie so I don't know, but is there a special reason?
Will there be a problem if I change it in the following way?
https://github.com/hwchase17/langchain/blob/0cf934ce7d8150dddf4a2514d6e7729a16d55b0f/langchain/agents/mrkl/output_parser.py#L21
```
regex = r"Action\s*\d*\s*:(.*?)(?:$|(?:\nAction\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)))"
```
https://github.com/hwchase17/langchain/blob/0cf934ce7d8150dddf4a2514d6e7729a16d55b0f/langchain/agents/mrkl/output_parser.py#L27
```
return AgentAction(action, action_input.strip(" ").strip('"') if action_input is not None else {}, text)
```
Thanks for reading. | [mrkl/output_parser.py] Behavior when there is no action input? | https://api.github.com/repos/langchain-ai/langchain/issues/3438/comments | 1 | 2023-04-24T10:19:03Z | 2023-09-10T16:28:13Z | https://github.com/langchain-ai/langchain/issues/3438 | 1,680,927,591 | 3,438 |
[
"langchain-ai",
"langchain"
] | Just an early idea of an agent i wanted to share:
The cognitive interview is a police interviewing technique used to gather information from witnesses of specific events. It is based on the idea that witnesses may not remember everything they saw, but their memory can be improved by certain psychological techniques.
The cognitive interview usually takes place in a structured format, where the interviewer first establishes a rapport with the witness tobuild trust and make them feel comfortable. The interviewer then encourages the witness to provide a detailed account of events by using open-ended questions and allowing the witness to speak freely. The interviewer may also ask the witness to recall specific details, such as the color of a car or the facial features of a suspect.
In addition to open-ended questions, the cognitive interview uses techniques such as asking the witness to visualize the scene, recalling the events in reverse order, and encouraging the witness to provide context and emotional reactions. These techniques aim to help the witness remember more details and give a more accurate account of what happened.
The cognitive interview can be a valuable tool for police investigations as it can help to gather more information and potentially identify suspects. However, it is important for the interviewer to be trained in using this technique to ensure that it is conducted properly and ethically. Additionally, it is important to note that not all witnesses may be suitable for a cognitive interview, especially those who may have experienced trauma or have cognitive disabilities.
tldr, steps:
1. Establish rapport with the witness
2. Encourage the witness to provide a detailed and open-ended account of events
3. Ask the witness to recall specific details
4. Use techniques such as visualization and recalling events in reverse order to aid memory
5. Ensure the interviewer is trained to conduct the technique properly and ethically.
Pseudo code that would implement this strategy in large language model prompting:
```
llm_system = """To implement the cognitive interview in police interviews of witnesses, follow these steps:
1. Begin by establishing a rapport with the witness to build trust and comfort.
2. Use open-ended questions and encourage the witness to provide a detailed account of events.
3. Ask the witness to recall specific details, such as the color of a car or the suspect's facial features.
4. Use techniques such as visualization and recalling events in reverse order to aid memory.
5. Remember to conduct the interview properly and ethically, and consider whether the technique is appropriate for all witnesses, especially those who may have experienced trauma or have cognitive disabilities."""
prompt = "How can the cognitive interview be used in police interviews of witnesses?"
generated_text = llm_system + prompt
print(generated_text)
```
Read more at:
https://www.perplexity.ai/?s=e&uuid=086ab031-cb02-41e6-976d-347ecc62ffc0 | Cognitive interview agent | https://api.github.com/repos/langchain-ai/langchain/issues/3436/comments | 1 | 2023-04-24T10:07:20Z | 2023-09-10T16:28:18Z | https://github.com/langchain-ai/langchain/issues/3436 | 1,680,907,446 | 3,436 |
[
"langchain-ai",
"langchain"
] | I am building an agent toolkit for APITable, a SaaS product, with the ultimate goal of enabling natural language API calls. I want to know if I can dynamically import a tool?
My idea is to create a `tool_prompt.txt` file with contents like this:
```
Get Spaces
Mode: get_spaces
Description: This tool is useful when you need to fetch all the spaces the user has access to,
find out how many spaces there are, or as an intermediary step that involv searching by spaces.
there is no input to this tool.
Get Nodes
Mode: get_nodes
Description: This tool uses APITable's node API to help you search for datasheets, mirrors, dashboards, folders, and forms.
These are all types of nodes in APITable.
The input to this tool is a space id.
You should only respond in JSON format like this:
{{"space_id": "spcjXzqVrjaP3"}}
Do not make up a space_id if you're not sure about it, use the get_spaces tool to retrieve all available space_ids.
Get Fields
Mode: get_fields
Description: This tool helps you search for fields in a datasheet using APITable's field API.
To use this tool, input a datasheet id.
If the user query includes terms like "latest", "oldest", or a specific field name,
please use this tool first to get the field name as field key
You should only respond in JSON format like this:
{{"datasheet_id": "dstlRNFl8L2mufwT5t"}}
Do not make up a datasheet_id if you're not sure about it, use the get_nodes tool to retrieve all available datasheet_ids.
```
Then, I want to create vectors and save them to a vector database like this:
```python
embeddings = OpenAIEmbeddings()
with open("tool_prompt.txt") as f:
tool_prompts = f.read()
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=0,
)
texts = text_splitter.create_documents([tool_prompts])
vectorstore = Chroma.from_documents(texts, embeddings, persist_directory="./db")
vectorstore.persist()
```
Then, during initialize_agent, there will only be a single Planner Tool that reads from the vectorstore to find similar tools based on the query. The agent will inform LLMs that a new tool has been added, and LLMs will use the new tool to perform tasks.
```python
def planner(self, query: str) -> str:
db = Chroma(persist_directory="./db", embedding_function=self.embeddings)
docs = db.similarity_search_with_score(query)
return (
f"Add tools to your workflow to get the results: {docs[0][0].page_content}"
)
```
This approach reduces token consumption
Before:
```shell
> Finished chain.
Total Tokens: 752
Prompt Tokens: 656
Completion Tokens: 96
Successful Requests: 2
Total Cost (USD): $0.0015040000000000001
```
After:
```
> Finished chain.
Total Tokens: 3514
Prompt Tokens: 3346
Completion Tokens: 168
Successful Requests: 2
Total Cost (USD): $0.0070279999999999995
```
However, when LLMs try to use the new tool to perform tasks, it is intercepted because the tool has not been registered during initialize_agent. Thus, I am forced to add an empty tool for registration:
```python
operations: List[Dict] = [
{
"name": "Get Spaces",
"description": "",
},
{
"name": "Get Nodes",
"description": "",
},
{
"name": "Get Fields",
"description": "",
},
{
"name": "Create Fields",
"description": "",
},
{
"name": "Get Records",
"description": "",
},
{
"name": "Planner",
"description": APITABLE_CATCH_ALL_PROMPT,
},
]
```
However, this approach is not effective since LLMs do not prioritize using the Planner Tool.
Therefore, I want to know if there is a better way to combine tools and vector stores.
Repo: https://github.com/xukecheng/apitable_agent_toolkit/tree/feat/combine_vectorstores | How to combine tools and vectorstores | https://api.github.com/repos/langchain-ai/langchain/issues/3435/comments | 1 | 2023-04-24T10:02:55Z | 2023-06-13T09:21:10Z | https://github.com/langchain-ai/langchain/issues/3435 | 1,680,898,670 | 3,435 |
[
"langchain-ai",
"langchain"
] | BaseOpenAI's validate_environment does not set OPENAI_API_TYPE and OPENAI_API_VERSION from environment. As a result, the AzureOpenAI instance failed when called to run.
```
from langchain.llms import AzureOpenAI
from langchain.chains import RetrievalQA
model = RetrievalQA.from_chain_type(
llm=AzureOpenAI(
deployment_name='DaVinci-003',
),
chain_type="stuff",
retriever=vectordb.as_retriever(), return_source_documents=True
)
model({"query": 'testing'})
```
Error:
```
File [~/miniconda3/envs/demo/lib/python3.9/site-packages/openai/api_requestor.py:680](/site-packages/openai/api_requestor.py:680), in APIRequestor._interpret_response_line(self, rbody, rcode, rheaders, stream)
678 stream_error = stream and "error" in resp.data
679 if stream_error or not 200 <= rcode < 300:
--> 680 raise self.handle_error_response(
681 rbody, rcode, resp.data, rheaders, stream_error=stream_error
682 )
683 return resp
InvalidRequestError: Resource not found
``` | AzureOpenAI instance fails because OPENAI_API_TYPE and OPENAI_API_VERSION are not inherited from environment | https://api.github.com/repos/langchain-ai/langchain/issues/3433/comments | 2 | 2023-04-24T08:41:56Z | 2023-04-25T10:02:39Z | https://github.com/langchain-ai/langchain/issues/3433 | 1,680,741,720 | 3,433 |
[
"langchain-ai",
"langchain"
] | I am using the huggingface hosted vicuna-13b model ([link](https://huggingface.co/eachadea/vicuna-13b-1.1)) along with llamaindex and langchain to create a functioning chatbot on custom data ([link](https://github.com/jerryjliu/llama_index/blob/main/examples/chatbot/Chatbot_SEC.ipynb)). However, I'm always getting this error :
```
ValueError: Could not parse LLM output: `
`
```
This is my code snippet:
```
from langchain.llms.base import LLM
from transformers import pipeline
import torch
from langchain import PromptTemplate, HuggingFaceHub
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("eachadea/vicuna-13b-1.1")
model = AutoModelForCausalLM.from_pretrained("eachadea/vicuna-13b-1.1")
pipeline = pipeline(
"text-generation",
model=model,
tokenizer= tokenizer,
device=1,
model_kwargs={"torch_dtype":torch.bfloat16}, max_length=500)
custom_llm = HuggingFacePipeline(pipeline =pipeline)
.
.
.
.
.
toolkit = LlamaToolkit(
index_configs=index_configs,
graph_configs=[graph_config]
)
memory = ConversationBufferMemory(memory_key="chat_history")
# llm=OpenAI(temperature=0, openai_api_key="sk-")
# llm = vicuna_llm
agent_chain = create_llama_chat_agent(
toolkit,
custom_llm,
memory=memory,
verbose=True
)
agent_chain.run(input="hey vicuna how are u ??")
```
What might be the issue?
| ValueError: Could not parse LLM output: ` ` | https://api.github.com/repos/langchain-ai/langchain/issues/3432/comments | 1 | 2023-04-24T08:17:11Z | 2023-09-10T16:28:23Z | https://github.com/langchain-ai/langchain/issues/3432 | 1,680,704,272 | 3,432 |
[
"langchain-ai",
"langchain"
] | Specifying max_iterations does not take effect when using create_json_agent. The following code is from [this page](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/json.html?highlight=JsonSpec#initialization), with max_iterations added:
```
import os
import yaml
from langchain.agents import (
create_json_agent,
AgentExecutor
)
from langchain.agents.agent_toolkits import JsonToolkit
from langchain.chains import LLMChain
from langchain.llms.openai import OpenAI
from langchain.requests import TextRequestsWrapper
from langchain.tools.json.tool import JsonSpec
```
```
with open("openai_openapi.yml") as f:
data = yaml.load(f, Loader=yaml.FullLoader)
json_spec = JsonSpec(dict_=data, max_value_length=4000)
json_toolkit = JsonToolkit(spec=json_spec)
json_agent_executor = create_json_agent(
llm=OpenAI(temperature=0),
toolkit=json_toolkit,
verbose=True,
max_iterations=3
)
```
The output consists of more than 3 iterations:
```
> Entering new AgentExecutor chain...
Action: json_spec_list_keys
Action Input: data
Observation: ['openapi', 'info', 'servers', 'tags', 'paths', 'components', 'x-oaiMeta']
Thought: I should look at the paths key to see what endpoints exist
Action: json_spec_list_keys
Action Input: data["paths"]
Observation: ['/engines', '/engines/{engine_id}', '/completions', '/chat/completions', '/edits', '/images/generations', '/images/edits', '/images/variations', '/embeddings', '/audio/transcriptions', '/audio/translations', '/engines/{engine_id}/search', '/files', '/files/{file_id}', '/files/{file_id}/content', '/answers', '/classifications', '/fine-tunes', '/fine-tunes/{fine_tune_id}', '/fine-tunes/{fine_tune_id}/cancel', '/fine-tunes/{fine_tune_id}/events', '/models', '/models/{model}', '/moderations']
Thought: I should look at the /completions endpoint to see what parameters are required
Action: json_spec_list_keys
Action Input: data["paths"]["/completions"]
Observation: ['post']
Thought: I should look at the post key to see what parameters are required
Action: json_spec_list_keys
Action Input: data["paths"]["/completions"]["post"]
Observation: ['operationId', 'tags', 'summary', 'requestBody', 'responses', 'x-oaiMeta']
Thought: I should look at the requestBody key to see what parameters are required
Action: json_spec_list_keys
Action Input: data["paths"]["/completions"]["post"]["requestBody"]
Observation: ['required', 'content']
Thought: I should look at the required key to see what parameters are required
Action: json_spec_get_value
Action Input: data["paths"]["/completions"]["post"]["requestBody"]["required"]
```
Maybe kwargs need to be passed in to `from_agent_and_tools`?
https://github.com/hwchase17/langchain/blob/0cf934ce7d8150dddf4a2514d6e7729a16d55b0f/langchain/agents/agent_toolkits/json/base.py#L41-L43 | Cannot specify max iterations when using create_json_agent | https://api.github.com/repos/langchain-ai/langchain/issues/3429/comments | 4 | 2023-04-24T07:44:17Z | 2023-12-30T16:08:53Z | https://github.com/langchain-ai/langchain/issues/3429 | 1,680,648,980 | 3,429 |
[
"langchain-ai",
"langchain"
] | I've noticed recently that the performance of the `zero-shot-react-description` agent has decreased significantly for various tasks and various tools. A very simple example attached, which a few weeks ago would pass perfectly maybe 80% of the time, but now hasn't managed a reasonable attempt in >10 tries. The main issue here seems to be the first stage, where it consistently searches for 'weather in London and Paris', where a few weeks ago it would search for one city first and then the next.
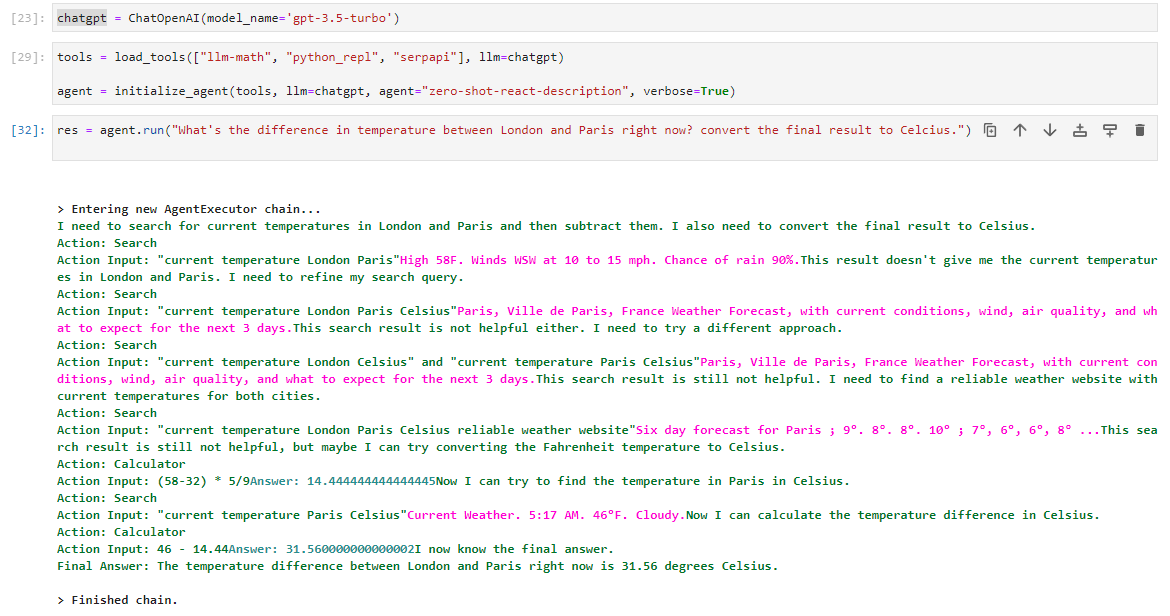
Does anyone have any insight as to what might have happened?
Thanks | `zero-shot-react-description` performance has decreased? | https://api.github.com/repos/langchain-ai/langchain/issues/3428/comments | 1 | 2023-04-24T07:32:38Z | 2023-09-10T16:28:28Z | https://github.com/langchain-ai/langchain/issues/3428 | 1,680,632,696 | 3,428 |
[
"langchain-ai",
"langchain"
] | Hi.
I try to run the following code
```
connection_string = "DefaultEndpointsProtocol=https;AccountName=<myaccount>;AccountKey=<mykey>"
container="<mycontainer>"
loader = AzureBlobStorageContainerLoader(
conn_str=connection_string,
container=container
)
documents = loader.load()
```
but the code `documents = loader.load()` takes like several minutes, and still not response any value.
The container has several html files and it has 1.5MB volume, which I think is not so heavy data.
I try above code several times, and I once got the following error.
```
0 [main] python 868 C:\<path to python exe>\Python310\python.exe: *** fatal error - Internal error: TP_NUM_C_BUFS too small: 50
1139 [main] python 868 cygwin_exception::open_stackdumpfile: Dumping stack trace to python.exe.stackdump
```
My python environment is following
- OS Windows 10
- Python version is 3.10
- use virtualenv
- running my script in mingw console (it's git bash, actually)
Has any Ideas to solve this situation?
(And, THANK YOU for the great framework) | AzureBlobStorageContainerLoader doesn't load the container | https://api.github.com/repos/langchain-ai/langchain/issues/3427/comments | 2 | 2023-04-24T07:22:28Z | 2023-04-25T01:20:11Z | https://github.com/langchain-ai/langchain/issues/3427 | 1,680,619,340 | 3,427 |
[
"langchain-ai",
"langchain"
] | I like how it prints out the specific texts used in generating the answer (much better than just citing the sources IMO). How can I access it? Referring to here: https://python.langchain.com/en/latest/modules/chains/index_examples/chat_vector_db.html#conversationalretrievalchain-with-streaming-to-stdout
| In `ConversationalRetrievalChain` with streaming to `stdout` how can I access the text printed to `stdout` once it finishes streaming? | https://api.github.com/repos/langchain-ai/langchain/issues/3417/comments | 1 | 2023-04-24T03:59:25Z | 2023-09-10T16:28:33Z | https://github.com/langchain-ai/langchain/issues/3417 | 1,680,404,463 | 3,417 |
[
"langchain-ai",
"langchain"
] | Current documentation text under Text Splitter throws error :
texts = text_splitter.create_documents([state_of_the_union])
<img width="968" alt="Screen Shot 2023-04-23 at 9 04 28 PM" src="https://user-images.githubusercontent.com/31634379/233891248-f3b5e187-272e-4822-8cd6-00a1cf56ffae.png">
The error is on both these pages
https://python.langchain.com/en/latest/modules/indexes/text_splitters/getting_started.html
https://python.langchain.com/en/latest/modules/indexes/text_splitters/examples/character_text_splitter.html
I think the above line should be revised to
texts = text_splitter.split_documents([state_of_the_union])
| Documentation error under Text Splitter | https://api.github.com/repos/langchain-ai/langchain/issues/3414/comments | 2 | 2023-04-24T03:06:47Z | 2023-09-28T16:07:35Z | https://github.com/langchain-ai/langchain/issues/3414 | 1,680,368,808 | 3,414 |
[
"langchain-ai",
"langchain"
] | In the agent tutorials the memory_key is set as a fixed string, "chat_history", how do I make it a variable, that is different for each session_id, that is memory_key=str(session_id)? | memory_key as a variable | https://api.github.com/repos/langchain-ai/langchain/issues/3406/comments | 4 | 2023-04-23T23:05:24Z | 2023-09-17T17:22:23Z | https://github.com/langchain-ai/langchain/issues/3406 | 1,680,213,151 | 3,406 |
[
"langchain-ai",
"langchain"
] | ---------------------------------------------------------------------------
InvalidRequestError Traceback (most recent call last)
[<ipython-input-26-5eed72c1ccb8>](https://localhost:8080/#) in <cell line: 3>()
2
----> 3 agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."])
31 frames
[/usr/local/lib/python3.9/dist-packages/langchain/experimental/autonomous_agents/autogpt/agent.py](https://localhost:8080/#) in run(self, goals)
109 tool = tools[action.name]
110 try:
--> 111 observation = tool.run(action.args)
112 except ValidationError as e:
113 observation = f"Error in args: {str(e)}"
[/usr/local/lib/python3.9/dist-packages/langchain/tools/base.py](https://localhost:8080/#) in run(self, tool_input, verbose, start_color, color, **kwargs)
105 except (Exception, KeyboardInterrupt) as e:
106 self.callback_manager.on_tool_error(e, verbose=verbose_)
--> 107 raise e
108 self.callback_manager.on_tool_end(
109 observation, verbose=verbose_, color=color, name=self.name, **kwargs
[/usr/local/lib/python3.9/dist-packages/langchain/tools/base.py](https://localhost:8080/#) in run(self, tool_input, verbose, start_color, color, **kwargs)
102 try:
103 tool_args, tool_kwargs = _to_args_and_kwargs(tool_input)
--> 104 observation = self._run(*tool_args, **tool_kwargs)
105 except (Exception, KeyboardInterrupt) as e:
106 self.callback_manager.on_tool_error(e, verbose=verbose_)
[<ipython-input-12-79448a1343a1>](https://localhost:8080/#) in _run(self, url, question)
33 results.append(f"Response from window {i} - {window_result}")
34 results_docs = [Document(page_content="\n".join(results), metadata={"source": url})]
---> 35 return self.qa_chain({"input_documents": results_docs, "question": question}, return_only_outputs=True)
36
37 async def _arun(self, url: str, question: str) -> str:
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
118 return self.prep_outputs(inputs, outputs, return_only_outputs)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
111 )
112 try:
--> 113 outputs = self._call(inputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/combine_documents/base.py](https://localhost:8080/#) in _call(self, inputs)
73 # Other keys are assumed to be needed for LLM prediction
74 other_keys = {k: v for k, v in inputs.items() if k != self.input_key}
---> 75 output, extra_return_dict = self.combine_docs(docs, **other_keys)
76 extra_return_dict[self.output_key] = output
77 return extra_return_dict
[/usr/local/lib/python3.9/dist-packages/langchain/chains/combine_documents/stuff.py](https://localhost:8080/#) in combine_docs(self, docs, **kwargs)
81 inputs = self._get_inputs(docs, **kwargs)
82 # Call predict on the LLM.
---> 83 return self.llm_chain.predict(**inputs), {}
84
85 async def acombine_docs(
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in predict(self, **kwargs)
149 completion = llm.predict(adjective="funny")
150 """
--> 151 return self(kwargs)[self.output_key]
152
153 async def apredict(self, **kwargs: Any) -> str:
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
118 return self.prep_outputs(inputs, outputs, return_only_outputs)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/base.py](https://localhost:8080/#) in __call__(self, inputs, return_only_outputs)
111 )
112 try:
--> 113 outputs = self._call(inputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in _call(self, inputs)
55
56 def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
---> 57 return self.apply([inputs])[0]
58
59 def generate(self, input_list: List[Dict[str, Any]]) -> LLMResult:
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in apply(self, input_list)
116 def apply(self, input_list: List[Dict[str, Any]]) -> List[Dict[str, str]]:
117 """Utilize the LLM generate method for speed gains."""
--> 118 response = self.generate(input_list)
119 return self.create_outputs(response)
120
[/usr/local/lib/python3.9/dist-packages/langchain/chains/llm.py](https://localhost:8080/#) in generate(self, input_list)
60 """Generate LLM result from inputs."""
61 prompts, stop = self.prep_prompts(input_list)
---> 62 return self.llm.generate_prompt(prompts, stop)
63
64 async def agenerate(self, input_list: List[Dict[str, Any]]) -> LLMResult:
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in generate_prompt(self, prompts, stop)
80 except (KeyboardInterrupt, Exception) as e:
81 self.callback_manager.on_llm_error(e, verbose=self.verbose)
---> 82 raise e
83 self.callback_manager.on_llm_end(output, verbose=self.verbose)
84 return output
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in generate_prompt(self, prompts, stop)
77 )
78 try:
---> 79 output = self.generate(prompt_messages, stop=stop)
80 except (KeyboardInterrupt, Exception) as e:
81 self.callback_manager.on_llm_error(e, verbose=self.verbose)
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in generate(self, messages, stop)
52 ) -> LLMResult:
53 """Top Level call"""
---> 54 results = [self._generate(m, stop=stop) for m in messages]
55 llm_output = self._combine_llm_outputs([res.llm_output for res in results])
56 generations = [res.generations for res in results]
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/base.py](https://localhost:8080/#) in <listcomp>(.0)
52 ) -> LLMResult:
53 """Top Level call"""
---> 54 results = [self._generate(m, stop=stop) for m in messages]
55 llm_output = self._combine_llm_outputs([res.llm_output for res in results])
56 generations = [res.generations for res in results]
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/openai.py](https://localhost:8080/#) in _generate(self, messages, stop)
264 )
265 return ChatResult(generations=[ChatGeneration(message=message)])
--> 266 response = self.completion_with_retry(messages=message_dicts, **params)
267 return self._create_chat_result(response)
268
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/openai.py](https://localhost:8080/#) in completion_with_retry(self, **kwargs)
226 return self.client.create(**kwargs)
227
--> 228 return _completion_with_retry(**kwargs)
229
230 def _combine_llm_outputs(self, llm_outputs: List[Optional[dict]]) -> dict:
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in wrapped_f(*args, **kw)
287 @functools.wraps(f)
288 def wrapped_f(*args: t.Any, **kw: t.Any) -> t.Any:
--> 289 return self(f, *args, **kw)
290
291 def retry_with(*args: t.Any, **kwargs: t.Any) -> WrappedFn:
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in __call__(self, fn, *args, **kwargs)
377 retry_state = RetryCallState(retry_object=self, fn=fn, args=args, kwargs=kwargs)
378 while True:
--> 379 do = self.iter(retry_state=retry_state)
380 if isinstance(do, DoAttempt):
381 try:
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in iter(self, retry_state)
312 is_explicit_retry = fut.failed and isinstance(fut.exception(), TryAgain)
313 if not (is_explicit_retry or self.retry(retry_state)):
--> 314 return fut.result()
315
316 if self.after is not None:
[/usr/lib/python3.9/concurrent/futures/_base.py](https://localhost:8080/#) in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED:
--> 439 return self.__get_result()
440
441 self._condition.wait(timeout)
[/usr/lib/python3.9/concurrent/futures/_base.py](https://localhost:8080/#) in __get_result(self)
389 if self._exception:
390 try:
--> 391 raise self._exception
392 finally:
393 # Break a reference cycle with the exception in self._exception
[/usr/local/lib/python3.9/dist-packages/tenacity/__init__.py](https://localhost:8080/#) in __call__(self, fn, *args, **kwargs)
380 if isinstance(do, DoAttempt):
381 try:
--> 382 result = fn(*args, **kwargs)
383 except BaseException: # noqa: B902
384 retry_state.set_exception(sys.exc_info()) # type: ignore[arg-type]
[/usr/local/lib/python3.9/dist-packages/langchain/chat_models/openai.py](https://localhost:8080/#) in _completion_with_retry(**kwargs)
224 @retry_decorator
225 def _completion_with_retry(**kwargs: Any) -> Any:
--> 226 return self.client.create(**kwargs)
227
228 return _completion_with_retry(**kwargs)
[/usr/local/lib/python3.9/dist-packages/openai/api_resources/chat_completion.py](https://localhost:8080/#) in create(cls, *args, **kwargs)
23 while True:
24 try:
---> 25 return super().create(*args, **kwargs)
26 except TryAgain as e:
27 if timeout is not None and time.time() > start + timeout:
[/usr/local/lib/python3.9/dist-packages/openai/api_resources/abstract/engine_api_resource.py](https://localhost:8080/#) in create(cls, api_key, api_base, api_type, request_id, api_version, organization, **params)
151 )
152
--> 153 response, _, api_key = requestor.request(
154 "post",
155 url,
[/usr/local/lib/python3.9/dist-packages/openai/api_requestor.py](https://localhost:8080/#) in request(self, method, url, params, headers, files, stream, request_id, request_timeout)
224 request_timeout=request_timeout,
225 )
--> 226 resp, got_stream = self._interpret_response(result, stream)
227 return resp, got_stream, self.api_key
228
[/usr/local/lib/python3.9/dist-packages/openai/api_requestor.py](https://localhost:8080/#) in _interpret_response(self, result, stream)
618 else:
619 return (
--> 620 self._interpret_response_line(
621 result.content.decode("utf-8"),
622 result.status_code,
[/usr/local/lib/python3.9/dist-packages/openai/api_requestor.py](https://localhost:8080/#) in _interpret_response_line(self, rbody, rcode, rheaders, stream)
681 stream_error = stream and "error" in resp.data
682 if stream_error or not 200 <= rcode < 300:
--> 683 raise self.handle_error_response(
684 rbody, rcode, resp.data, rheaders, stream_error=stream_error
685 )
InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 4665 tokens. Please reduce the length of the messages. | marathon_times.ipynb: InvalidRequestError: This model's maximum context length is 4097 tokens. | https://api.github.com/repos/langchain-ai/langchain/issues/3405/comments | 5 | 2023-04-23T21:13:04Z | 2023-09-24T16:08:17Z | https://github.com/langchain-ai/langchain/issues/3405 | 1,680,179,456 | 3,405 |
[
"langchain-ai",
"langchain"
] | Text mentions inflation and tuition:
Here is the prompt comparing inflation and college tuition.
Code is about marathon times:
agent.run(["What were the winning boston marathon times for the past 5 years? Generate a table of the names, countries of origin, and times."]) | marathon_times.ipynb: mismatched text and code | https://api.github.com/repos/langchain-ai/langchain/issues/3404/comments | 0 | 2023-04-23T21:06:49Z | 2023-04-24T01:14:13Z | https://github.com/langchain-ai/langchain/issues/3404 | 1,680,177,766 | 3,404 |
[
"langchain-ai",
"langchain"
] | i tried out a simple custom model. as long as i am using only one "query" parameter everything is working fine. in this example i like to use two parameters (i searched the problem and i found this SendMessage usecase...)
unfortunately it does not work.. and throws this error.
`input_args.validate({key_: tool_input})
File "pydantic/main.py", line 711, in pydantic.main.BaseModel.validate
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for SendMessageInput
message
field required (type=value_error.missing)`
the code :
`from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
from langchain.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
class SendMessageInput(BaseModel):
email: str = Field(description="email")
message: str = Field(description="the message to send")
class SendMessageTool(BaseTool):
name = "send_message_tool"
description = "useful for when you need to send a message to a human"
args_schema: Type[BaseModel] = SendMessageInput
def _run(self, email:str,message:str) -> str:
print(message,email)
"""Use the tool."""
return f"message send"
async def _arun(self, email: str, message: str) -> str:
"""Use the tool asynchronously."""
return f"Sent message '{message}' to {email}"
llm = OpenAI(temperature=0)
tools=[SendMessageTool()]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("send message hello to test@example.com")
` | Custom Model with args_schema not working | https://api.github.com/repos/langchain-ai/langchain/issues/3403/comments | 7 | 2023-04-23T20:16:33Z | 2023-10-05T16:10:53Z | https://github.com/langchain-ai/langchain/issues/3403 | 1,680,154,536 | 3,403 |
[
"langchain-ai",
"langchain"
] |
I have been trying multiple approaches to use headers in the requests chain. Here's my code:
I have been trying multiple approaches to use headers in the requests chain. Here's my code:
from langchain.utilities import TextRequestsWrapper
import json
requests = TextRequestsWrapper()
headers = {
"name": "hetyo"
}
str_data = requests.get("https://httpbin.org/get", params = {"name" : "areeb"}, headers=headers)
json_data = json.loads(str_data)
json_data
How can I pass in herders to the TextRequestsWrapper? Is there anything that I am doing wrong?
I also found that the headers is used in the requests file as follows:
"""Lightweight wrapper around requests library, with async support."""
from contextlib import asynccontextmanager
from typing import Any, AsyncGenerator, Dict, Optional
import aiohttp
import requests
from pydantic import BaseModel, Extra
class Requests(BaseModel):
"""Wrapper around requests to handle auth and async.
The main purpose of this wrapper is to handle authentication (by saving
headers) and enable easy async methods on the same base object.
"""
headers: Optional[Dict[str, str]] = None
aiosession: Optional[aiohttp.ClientSession] = None
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
def get(self, url: str, **kwargs: Any) -> requests.Response:
"""GET the URL and return the text."""
return requests.get(url, headers=self.headers, **kwargs)
def post(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
"""POST to the URL and return the text."""
return requests.post(url, json=data, headers=self.headers, **kwargs)
def patch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
"""PATCH the URL and return the text."""
return requests.patch(url, json=data, headers=self.headers, **kwargs)
def put(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
"""PUT the URL and return the text."""
return requests.put(url, json=data, headers=self.headers, **kwargs)
def delete(self, url: str, **kwargs: Any) -> requests.Response:
"""DELETE the URL and return the text."""
return requests.delete(url, headers=self.headers, **kwargs)
@asynccontextmanager
async def _arequest(
self, method: str, url: str, **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""Make an async request."""
if not self.aiosession:
async with aiohttp.ClientSession() as session:
async with session.request(
method, url, headers=self.headers, **kwargs
) as response:
yield response
else:
async with self.aiosession.request(
method, url, headers=self.headers, **kwargs
) as response:
yield response
@asynccontextmanager
async def aget(
self, url: str, **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""GET the URL and return the text asynchronously."""
async with self._arequest("GET", url, **kwargs) as response:
yield response
@asynccontextmanager
async def apost(
self, url: str, data: Dict[str, Any], **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""POST to the URL and return the text asynchronously."""
async with self._arequest("POST", url, **kwargs) as response:
yield response
@asynccontextmanager
async def apatch(
self, url: str, data: Dict[str, Any], **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""PATCH the URL and return the text asynchronously."""
async with self._arequest("PATCH", url, **kwargs) as response:
yield response
@asynccontextmanager
async def aput(
self, url: str, data: Dict[str, Any], **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""PUT the URL and return the text asynchronously."""
async with self._arequest("PUT", url, **kwargs) as response:
yield response
@asynccontextmanager
async def adelete(
self, url: str, **kwargs: Any
) -> AsyncGenerator[aiohttp.ClientResponse, None]:
"""DELETE the URL and return the text asynchronously."""
async with self._arequest("DELETE", url, **kwargs) as response:
yield response
class TextRequestsWrapper(BaseModel):
"""Lightweight wrapper around requests library.
The main purpose of this wrapper is to always return a text output.
"""
headers: Optional[Dict[str, str]] = None
aiosession: Optional[aiohttp.ClientSession] = None
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
arbitrary_types_allowed = True
@property
def requests(self) -> Requests:
return Requests(headers=self.headers, aiosession=self.aiosession)
def get(self, url: str, **kwargs: Any) -> str:
"""GET the URL and return the text."""
return self.requests.get(url, **kwargs).text
def post(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""POST to the URL and return the text."""
return self.requests.post(url, data, **kwargs).text
def patch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PATCH the URL and return the text."""
return self.requests.patch(url, data, **kwargs).text
def put(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PUT the URL and return the text."""
return self.requests.put(url, data, **kwargs).text
def delete(self, url: str, **kwargs: Any) -> str:
"""DELETE the URL and return the text."""
return self.requests.delete(url, **kwargs).text
async def aget(self, url: str, **kwargs: Any) -> str:
"""GET the URL and return the text asynchronously."""
async with self.requests.aget(url, **kwargs) as response:
return await response.text()
async def apost(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""POST to the URL and return the text asynchronously."""
async with self.requests.apost(url, **kwargs) as response:
return await response.text()
async def apatch(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PATCH the URL and return the text asynchronously."""
async with self.requests.apatch(url, **kwargs) as response:
return await response.text()
async def aput(self, url: str, data: Dict[str, Any], **kwargs: Any) -> str:
"""PUT the URL and return the text asynchronously."""
async with self.requests.aput(url, **kwargs) as response:
return await response.text()
async def adelete(self, url: str, **kwargs: Any) -> str:
"""DELETE the URL and return the text asynchronously."""
async with self.requests.adelete(url, **kwargs) as response:
return await response.text()
# For backwards compatibility
RequestsWrapper = TextRequestsWrapper
This may be creating the conflicts.
Here's the error that I am getting :
[/usr/local/lib/python3.9/dist-packages/langchain/requests.py](https://localhost:8080/#) in get(self, url, **kwargs)
26 def get(self, url: str, **kwargs: Any) -> requests.Response:
27 """GET the URL and return the text.""" --->
28 return requests.get(url, headers=self.headers, **kwargs)
29
30 def post(self, url: str, data: Dict[str, Any], **kwargs: Any) -> requests.Response:
TypeError: requests.api.get() got multiple values for keyword argument 'headers'
Please assist. | Not able to Pass in Headers in the Requests module | https://api.github.com/repos/langchain-ai/langchain/issues/3402/comments | 2 | 2023-04-23T19:08:24Z | 2023-04-27T17:58:55Z | https://github.com/langchain-ai/langchain/issues/3402 | 1,680,133,937 | 3,402 |
[
"langchain-ai",
"langchain"
] | Elastic supports generating embeddings using [embedding models running in the stack](https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding).
Add a the ability to generate embeddings with Elasticsearch in langchain similar to other embedding modules. | Add support for generating embeddings in Elasticsearch | https://api.github.com/repos/langchain-ai/langchain/issues/3400/comments | 1 | 2023-04-23T18:40:54Z | 2023-05-24T05:40:38Z | https://github.com/langchain-ai/langchain/issues/3400 | 1,680,125,057 | 3,400 |
[
"langchain-ai",
"langchain"
] | Can you please help me with connecting my LangChain agent to a MongoDB database? I know that it's possible to directly connect to a SQL database using this resource [https://python.langchain.com/en/latest/modules/agents/toolkits/examples/sql_database.html](url) but I'm not sure if the same approach can be used with MongoDB. If it's not possible, could you suggest other ways to connect to MongoDB? | Connection with mongo db | https://api.github.com/repos/langchain-ai/langchain/issues/3399/comments | 11 | 2023-04-23T18:03:33Z | 2024-02-15T16:12:00Z | https://github.com/langchain-ai/langchain/issues/3399 | 1,680,114,161 | 3,399 |
[
"langchain-ai",
"langchain"
] | Hey
I'm getting `TypeError: 'StuffDocumentsChain' object is not callable`
the code snippet can be found here:
```
def main():
text_splitter = CharacterTextSplitter(chunk_size=2000, chunk_overlap=50)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
vector_db = Chroma.from_documents(
documents=texts, embeddings=embeddings)
relevant_words = get_search_words(query)
docs = vector_db.similarity_search(
relevant_words, top_k=min(3, len(texts))
)
chat_model = ChatOpenAI(
model_name="gpt-3.5-turbo", temperature=0.2, openai_api_key=api_key
)
PROMPT = get_prompt_template()
chain = load_qa_with_sources_chain(
chat_model, chain_type="stuff", metadata_keys=['source'],
return_intermediate_steps=True, prompt=PROMPT
)
res = chain({"input_documents": docs, "question": query},
return_only_outputs=True)
pprint(res)
```
Any ideas what I'm doing wrong?
BTW - if I'll change it to map_rerank of even use
```
chain = load_qa_chain(chat_model, chain_type="stuff")
chain.run(input_documents=docs, question=query)
```
I'm getting the same object is not callable | object is not callable | https://api.github.com/repos/langchain-ai/langchain/issues/3398/comments | 2 | 2023-04-23T17:43:35Z | 2024-04-30T20:26:24Z | https://github.com/langchain-ai/langchain/issues/3398 | 1,680,107,688 | 3,398 |
[
"langchain-ai",
"langchain"
] | The example in the documentation raises a `GuessedAtParserWarning`
To replicate:
```python
#!wget -r -A.html -P rtdocs https://langchain.readthedocs.io/en/latest/
from langchain.document_loaders import ReadTheDocsLoader
loader = ReadTheDocsLoader("rtdocs")
docs = loader.load()
```
```
/config/miniconda3/envs/warn_test/lib/python3.8/site-packages/langchain/document_loaders/readthedocs.py:30: GuessedAtParserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("html.parser"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 30 of the file /config/miniconda3/envs/warn_test/lib/python3.8/site-packages/langchain/document_loaders/readthedocs.py. To get rid of this warning, pass the additional argument 'features="html.parser"' to the BeautifulSoup constructor.
_ = BeautifulSoup(
```
Adding the argument `features` can resolve this issue
```python
#!wget -r -A.html -P rtdocs https://langchain.readthedocs.io/en/latest/
from langchain.document_loaders import ReadTheDocsLoader
loader = ReadTheDocsLoader("rtdocs", features='html.parser')
docs = loader.load()
``` | Read the Docs document loader documentation example raises warning | https://api.github.com/repos/langchain-ai/langchain/issues/3396/comments | 0 | 2023-04-23T15:50:35Z | 2023-04-25T04:54:40Z | https://github.com/langchain-ai/langchain/issues/3396 | 1,680,072,310 | 3,396 |
[
"langchain-ai",
"langchain"
] | Hello, cloud you help me fix
Error fetching or processing https exeption: URL return an error: 403 when using UnstructuredURLLoader,I'm not sure if this error is a restricted access to the website or a problem with the use of the API, thank you very much | UnstructuredURLLoader Error | https://api.github.com/repos/langchain-ai/langchain/issues/3391/comments | 1 | 2023-04-23T14:45:09Z | 2023-09-10T16:28:50Z | https://github.com/langchain-ai/langchain/issues/3391 | 1,680,051,952 | 3,391 |
[
"langchain-ai",
"langchain"
] | `MRKLOutputParser` strips quotes in "Action Input" without checking if they are present on both sides.
See https://github.com/hwchase17/langchain/blob/acfd11c8e424a456227abde8df8b52a705b63024/langchain/agents/mrkl/output_parser.py#L27
Test case that reproduces the problem:
```python
from langchain.agents.mrkl.output_parser import MRKLOutputParser
parser = MRKLOutputParser()
llm_output = 'Action: Terminal\nAction Input: git commit -m "My change"'
action = parser.parse(llm_output)
print(action)
assert action.tool_input == 'git commit -m "My change"'
```
The fix should be simple: check first if the quotes are present on both sides before stripping them.
Happy to submit a PR if you are happy with proposed fix. | MRKLOutputParser strips quotes incorrectly and breaks LLM commands | https://api.github.com/repos/langchain-ai/langchain/issues/3390/comments | 1 | 2023-04-23T14:22:00Z | 2023-09-10T16:28:54Z | https://github.com/langchain-ai/langchain/issues/3390 | 1,680,044,740 | 3,390 |
[
"langchain-ai",
"langchain"
] | ### The Problem
The `YoutubeLoader` is breaking when using the `from_youtube_url` function. The expected behaviour is to use this module to get transcripts from youtube videos and pass into them to an LLM. Willing to help if needed.
### Specs
```
- Machine: Apple M1 Pro
- Version: langchain 0.0.147
- conda-build version : 3.21.8
- python version : 3.9.12.final.0
```
### Code
```python
from dotenv import find_dotenv, load_dotenv
from langchain.document_loaders import YoutubeLoader
load_dotenv(find_dotenv())
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=QsYGlZkevEg", add_video_info=True)
result = loader.load()
print (result)
```
### Output
```bash
Traceback (most recent call last):
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 341, in title
self._title = self.vid_info['videoDetails']['title']
KeyError: 'videoDetails'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 1346, in do_open
h.request(req.get_method(), req.selector, req.data, headers,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1285, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1331, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1280, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1040, in _send_output
self.send(msg)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 980, in send
self.connect()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/http/client.py", line 1454, in connect
self.sock = self._context.wrap_socket(self.sock,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/ssl.py", line 500, in wrap_socket
return self.sslsocket_class._create(
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/ssl.py", line 1040, in _create
self.do_handshake()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/ssl.py", line 1309, in do_handshake
self._sslobj.do_handshake()
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1129)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/<username>/Desktop/personal/github/ar-assistant/notebooks/research/langchain/scripts/5-indexes.py", line 28, in <module>
result = loader.load()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/langchain/document_loaders/youtube.py", line 133, in load
video_info = self._get_video_info()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/langchain/document_loaders/youtube.py", line 174, in _get_video_info
"title": yt.title,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 345, in title
self.check_availability()
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 210, in check_availability
status, messages = extract.playability_status(self.watch_html)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/__main__.py", line 102, in watch_html
self._watch_html = request.get(url=self.watch_url)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/request.py", line 53, in get
response = _execute_request(url, headers=extra_headers, timeout=timeout)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/site-packages/pytube/request.py", line 37, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 214, in urlopen
return opener.open(url, data, timeout)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 517, in open
response = self._open(req, data)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 534, in _open
result = self._call_chain(self.handle_open, protocol, protocol +
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 494, in _call_chain
result = func(*args)
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 1389, in https_open
return self.do_open(http.client.HTTPSConnection, req,
File "/Users/<username>/opt/anaconda3/envs/dev/lib/python3.9/urllib/request.py", line 1349, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1129)>
```
### FYI
- There is a duplication of code excerpts in the [Youtube page](https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/youtube.html#) of the langchain docs
| Youtube.py: urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1129)> | https://api.github.com/repos/langchain-ai/langchain/issues/3389/comments | 3 | 2023-04-23T13:47:11Z | 2023-09-24T16:08:22Z | https://github.com/langchain-ai/langchain/issues/3389 | 1,680,033,914 | 3,389 |
[
"langchain-ai",
"langchain"
] | Hello everyone,
Is it possible to use IndexTree with a local LLM as for istance gpt4all or llama.cpp?
Is there a tutorial? | IndexTree and local LLM | https://api.github.com/repos/langchain-ai/langchain/issues/3388/comments | 1 | 2023-04-23T13:18:07Z | 2023-09-15T22:12:51Z | https://github.com/langchain-ai/langchain/issues/3388 | 1,680,025,245 | 3,388 |
[
"langchain-ai",
"langchain"
] | IMO a contribution guide should be added. The following questions should be answered:
- how do I install langchain in `-e` mode with all dependencies to run lint and tests locally
- how to start / run lint and tests locally
- how should I mark "feature request issues"
- how should I mark "PR that are work in progress"
- a link to the discord
- ... | FR: Add a contribution guide. | https://api.github.com/repos/langchain-ai/langchain/issues/3387/comments | 1 | 2023-04-23T12:26:05Z | 2023-04-23T12:29:47Z | https://github.com/langchain-ai/langchain/issues/3387 | 1,680,009,761 | 3,387 |
[
"langchain-ai",
"langchain"
] | sometimes, when we ask LLMs a question like writing a document or a piece of code for a specified problem, the output may be too long, when we use a UI interface like ChatGPT, we can use the prompt like
```bash
...
if you have given all content, please add the 'finished' at the end of the response.
if not, I will say 'continue', then please continue to give me the reaming content.
```
to get all content by seeing if we should let LLMs continue to print content. **Does anyone know how to achieve this by LangChain?**
I'm not sure if LangChain supports this, if not, and if someone is willing to give me some guides on how to do this in LangChain, I'll be happy to create a PR to solve it. | How to action when output isn't finished | https://api.github.com/repos/langchain-ai/langchain/issues/3386/comments | 10 | 2023-04-23T11:58:28Z | 2024-07-16T19:18:12Z | https://github.com/langchain-ai/langchain/issues/3386 | 1,680,000,218 | 3,386 |
[
"langchain-ai",
"langchain"
] | Getting the below error
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "...\langchain\vectorstores\faiss.py", line 285, in max_marginal_relevance_search
docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)
File "...\langchain\vectorstores\faiss.py", line 248, in max_marginal_relevance_search_by_vector
mmr_selected = maximal_marginal_relevance(
File "...\langchain\langchain\vectorstores\utils.py", line 19, in maximal_marginal_relevance
similarity_to_query = cosine_similarity([query_embedding], embedding_list)[0]
File "...\langchain\langchain\math_utils.py", line 16, in cosine_similarity
raise ValueError("Number of columns in X and Y must be the same.")
ValueError: Number of columns in X and Y must be the same.
```
Code to reproduce this error
```
>>> model_name = "sentence-transformers/all-mpnet-base-v2"
>>> model_kwargs = {'device': 'cpu'}
>>> from langchain.embeddings import HuggingFaceEmbeddings
>>> embeddings = HuggingFaceEmbeddings(model_name=model_name, model_kwargs=model_kwargs)
>>> from langchain.vectorstores import FAISS
>>> FAISS_INDEX_PATH = 'faiss_index'
>>> db = FAISS.load_local(FAISS_INDEX_PATH, embeddings)
>>> query = 'query'
>>> results = db.max_marginal_relevance_search(query)
```
While going through the error it seems that in this case `query_embedding` is 1 x model_dimension while embedding_list is no_docs x model dimension vectors. Hence we should probably change the code to `similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0]` i.e. remove the list from the query_embedding.
Since this is a common function not sure if this change would affect other embedding classes as well. | ValueError in cosine_similarity when using FAISS index as vector store | https://api.github.com/repos/langchain-ai/langchain/issues/3384/comments | 8 | 2023-04-23T07:51:56Z | 2023-04-25T03:43:34Z | https://github.com/langchain-ai/langchain/issues/3384 | 1,679,909,880 | 3,384 |
[
"langchain-ai",
"langchain"
] | In the current version(0.0.147), we should escape curly brackets before f-string formatting (FewShotPromptTemplate) by ourselves.
please make it a default behavior!
https://colab.research.google.com/drive/16_pCJIWK88AXpCh6xsSriJmLJKrNE8Fv?usp=share_link
Test Case
```python
from langchain import FewShotPromptTemplate, PromptTemplate
example={'instruction':'do something', 'input': 'question',}
examples=[
{'input': 'question a', 'output':'answer a'},
{'input': 'question b', 'output':'answer b'},
]
example_prompt = PromptTemplate(
input_variables=['input', 'output'],
template='input: {input}\noutput:{output}',
)
fewshot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
input_variables=['instruction', 'input'],
prefix='{instruction}\n',
suffix='\ninput: {input}\noutput:',
example_separator='\n\n',
)
fewshot_prompt.format(**example)
```
that's ok !
```python
example={'instruction':'do something', 'input': 'question',}
examples_with_curly_brackets=[
{'input': 'question a{}', 'output':'answer a'},
{'input': 'question b', 'output':'answer b'},
]
fewshot_prompt = FewShotPromptTemplate(
examples=examples_with_curly_brackets,
example_prompt=example_prompt,
input_variables=['instruction', 'input'],
prefix='{instruction}\n',
suffix='\ninput: {input}\noutput:',
example_separator='\n\n',
)
fewshot_prompt.format(**example)
```
some errors like
```shell
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
[<ipython-input-9-95e0dc90fc4d>](https://localhost:8080/#) in <cell line: 16>()
14 )
15
---> 16 fewshot_prompt.format(**example)
6 frames
[/usr/lib/python3.9/string.py](https://localhost:8080/#) in get_value(self, key, args, kwargs)
223 def get_value(self, key, args, kwargs):
224 if isinstance(key, int):
--> 225 return args[key]
226 else:
227 return kwargs[key]
IndexError: tuple index out of range
```
if we do escape firstly!
```
# What should we do: escape brackets in examples
def escape_examples(examples):
return [{k: escape_f_string(v) for k, v in example.items()} for example in examples]
def escape_f_string(text):
return text.replace('{', '{{').replace('}', '}}')
fewshot_prompt = FewShotPromptTemplate(
examples=escape_examples(examples_with_curly_brackets),
example_prompt=example_prompt,
input_variables=['instruction', 'input'],
prefix='{instruction}\n',
suffix='\ninput: {input}\noutput:',
example_separator='\n\n',
)
fewshot_prompt.format(**example)
```
everything is ok now!
| escape curly brackets before f-string formatting in FewShotPromptTemplate | https://api.github.com/repos/langchain-ai/langchain/issues/3382/comments | 4 | 2023-04-23T06:05:08Z | 2024-02-12T16:19:19Z | https://github.com/langchain-ai/langchain/issues/3382 | 1,679,875,328 | 3,382 |
[
"langchain-ai",
"langchain"
] | Hello everyone,
I have implemented my project using the Question Answering over Docs example provided in the tutorial. I designed a long custom prompt using load_qa_chain with chain_type set to stuff mode. However, when I call the function "chain.run", the output is incomplete.
Does anyone know what might be causing this issue?
Is it because the token exceed the max size ?
`llm=ChatOpenAI(streaming=True,callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),verbose=True,temperature=0,openai_api_key=OPENAI_API_KEY)`
`chain = load_qa_chain(llm,chain_type="stuff")`
`docs=docsearch.similarity_search(query,include_metadata=True,k=10)`
`r= chain.run(input_documents=docs, question=fq)`
| QA chain is not working properly | https://api.github.com/repos/langchain-ai/langchain/issues/3373/comments | 7 | 2023-04-23T03:26:34Z | 2023-11-29T16:11:19Z | https://github.com/langchain-ai/langchain/issues/3373 | 1,679,837,740 | 3,373 |
[
"langchain-ai",
"langchain"
] | While playing with the LLaMA models I noticed what parse exception was thrown even output looked good.
### Screenshot

For curious one the prompt I used was:
```python
agent({"input":"""
There is a file in `~/.bashrc.d/` directory containing openai api key.
Can you find that key?
"""})
```
| Terminal tool gives `ValueError: Could not parse LLM output:` when there is a new libe before action string. | https://api.github.com/repos/langchain-ai/langchain/issues/3365/comments | 1 | 2023-04-22T22:04:26Z | 2023-04-25T05:05:33Z | https://github.com/langchain-ai/langchain/issues/3365 | 1,679,746,063 | 3,365 |
[
"langchain-ai",
"langchain"
] | Using
```
langchain~=0.0.146
openai~=0.27.4
haystack~=0.42
tiktoken~=0.3.3
weaviate-client~=3.15.6
aiohttp~=3.8.4
aiodns~=3.0.0
python-dotenv~=1.0.0
Jinja2~=3.1.2
pandas~=2.0.0
```
```
def create_new_memory_retriever():
"""Create a new vector store retriever unique to the agent."""
client = weaviate.Client(
url=WEAVIATE_HOST,
additional_headers={"X-OpenAI-Api-Key": os.getenv("OPENAI_API_KEY")},
# auth_client_secret: Optional[AuthCredentials] = None,
# timeout_config: Union[Tuple[Real, Real], Real] = (10, 60),
# proxies: Union[dict, str, None] = None,
# trust_env: bool = False,
# additional_headers: Optional[dict] = None,
# startup_period: Optional[int] = 5,
# embedded_options=[],
)
embeddings_model = OpenAIEmbeddings()
vectorstore = Weaviate(client, "Paragraph", "content", embedding=embeddings_model.embed_query)
return TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, other_score_keys=["importance"], k=15)
```
Time weighted retriever
```
...
def get_salient_docs(self, query: str) -> Dict[int, Tuple[Document, float]]:
"""Return documents that are salient to the query."""
docs_and_scores: List[Tuple[Document, float]]
docs_and_scores = self.vectorstore.similarity_search_with_relevance_scores( <----------======
query, **self.search_kwargs
)
results = {}
for fetched_doc, relevance in docs_and_scores:
buffer_idx = fetched_doc.metadata["buffer_idx"]
doc = self.memory_stream[buffer_idx]
results[buffer_idx] = (doc, relevance)
return results
...
```
`similarity_search_with_relevance_scores` is not in the weaviate python client.
Whose responsibility is this? Langchains? Weaviates? I'm perfectly fine to solve it but I just need to know on whose door to knock.
All of langchains vectorstores have different methods under them and people are writing implementation for all of them. I don't know how maintainable this is gonna be. | Weaviate python library doesn't have needed methods for the abstractions | https://api.github.com/repos/langchain-ai/langchain/issues/3358/comments | 2 | 2023-04-22T19:06:52Z | 2023-09-10T16:28:59Z | https://github.com/langchain-ai/langchain/issues/3358 | 1,679,662,654 | 3,358 |
[
"langchain-ai",
"langchain"
] | Hi, I am building my agent, and I would like to make this query to wolfram alpha "Action Input: √68,084,217 + √62,390,364", but I always get "Wolfram Alpha wasn't able to answer it".
Why is that? When I use the Wolfram app, it can easily solve it.
Thanks in advance,
Giovanni | Wolfram Alpha wasn't able to answer it for valid inputs | https://api.github.com/repos/langchain-ai/langchain/issues/3357/comments | 6 | 2023-04-22T18:40:03Z | 2023-12-18T23:50:48Z | https://github.com/langchain-ai/langchain/issues/3357 | 1,679,651,732 | 3,357 |
[
"langchain-ai",
"langchain"
] | I am building a chain to analyze codebases. This involves documents that's constantly changing as the user modifies the files. As far as I can see, there doesn't seem to be a way to update the embeddings that are saved in vector stores once they have been embedded and submitted to the backing vectorstore.
This appears to be possible at least for chromaDB based on: (https://docs.trychroma.com/api-reference) and (https://github.com/chroma-core/chroma/blob/79c891f8f597dad8bd3eb5a42645cb99ec553440/chromadb/api/models/Collection.py#L258). | Add update method on vectorstores | https://api.github.com/repos/langchain-ai/langchain/issues/3354/comments | 6 | 2023-04-22T16:39:25Z | 2024-02-16T14:27:47Z | https://github.com/langchain-ai/langchain/issues/3354 | 1,679,611,775 | 3,354 |
[
"langchain-ai",
"langchain"
] | Whit the function VectorstoreIndexCreator, I got the error at
--> 115 return {
116 base64.b64decode(token): int(rank)
117 for token, rank in (line.split() for line in contents.splitlines() if line)
118 }
The whole error information was:
ValueError Traceback (most recent call last)
Cell In[25], line 2
1 from langchain.indexes import VectorstoreIndexCreator
----> 2 index = VectorstoreIndexCreator().from_loaders([loader])
File J:\conda202002\envs\chatglm\lib\site-packages\langchain\indexes\vectorstore.py:71, in VectorstoreIndexCreator.from_loaders(self, loaders)
69 docs.extend(loader.load())
70 sub_docs = self.text_splitter.split_documents(docs)
---> 71 vectorstore = self.vectorstore_cls.from_documents(
72 sub_docs, self.embedding, **self.vectorstore_kwargs
73 )
74 return VectorStoreIndexWrapper(vectorstore=vectorstore)
File J:\conda202002\envs\chatglm\lib\site-packages\langchain\vectorstores\chroma.py:347, in Chroma.from_documents(cls, documents, embedding, ids, collection_name, persist_directory, client_settings, client, **kwargs)
345 texts = [doc.page_content for doc in documents]
346 metadatas = [doc.metadata for doc in documents]
--> 347 return cls.from_texts(
348 texts=texts,
349 embedding=embedding,
350 metadatas=metadatas,
351 ids=ids,
352 collection_name=collection_name,
353 persist_directory=persist_directory,
354 client_settings=client_settings,
355 client=client,
356 )
File J:\conda202002\envs\chatglm\lib\site-packages\langchain\vectorstores\chroma.py:315, in Chroma.from_texts(cls, texts, embedding, metadatas, ids, collection_name, persist_directory, client_settings, client, **kwargs)
291 """Create a Chroma vectorstore from a raw documents.
292
293 If a persist_directory is specified, the collection will be persisted there.
(...)
306 Chroma: Chroma vectorstore.
307 """
308 chroma_collection = cls(
309 collection_name=collection_name,
310 embedding_function=embedding,
(...)
313 client=client,
314 )
--> 315 chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
316 return chroma_collection
File J:\conda202002\envs\chatglm\lib\site-packages\langchain\vectorstores\chroma.py:121, in Chroma.add_texts(self, texts, metadatas, ids, **kwargs)
119 embeddings = None
120 if self._embedding_function is not None:
--> 121 embeddings = self._embedding_function.embed_documents(list(texts))
122 self._collection.add(
123 metadatas=metadatas, embeddings=embeddings, documents=texts, ids=ids
124 )
125 return ids
File J:\conda202002\envs\chatglm\lib\site-packages\langchain\embeddings\openai.py:228, in OpenAIEmbeddings.embed_documents(self, texts, chunk_size)
226 # handle batches of large input text
227 if self.embedding_ctx_length > 0:
--> 228 return self._get_len_safe_embeddings(texts, engine=self.deployment)
229 else:
230 results = []
File J:\conda202002\envs\chatglm\lib\site-packages\langchain\embeddings\openai.py:159, in OpenAIEmbeddings._get_len_safe_embeddings(self, texts, engine, chunk_size)
157 tokens = []
158 indices = []
--> 159 encoding = tiktoken.model.encoding_for_model(self.model)
160 for i, text in enumerate(texts):
161 # replace newlines, which can negatively affect performance.
162 text = text.replace("\n", " ")
File J:\conda202002\envs\chatglm\lib\site-packages\tiktoken\model.py:75, in encoding_for_model(model_name)
69 if encoding_name is None:
70 raise KeyError(
71 f"Could not automatically map {model_name} to a tokeniser. "
72 "Please use `tiktok.get_encoding` to explicitly get the tokeniser you expect."
73 ) from None
---> 75 return get_encoding(encoding_name)
File J:\conda202002\envs\chatglm\lib\site-packages\tiktoken\registry.py:63, in get_encoding(encoding_name)
60 raise ValueError(f"Unknown encoding {encoding_name}")
62 constructor = ENCODING_CONSTRUCTORS[encoding_name]
---> 63 enc = Encoding(**constructor())
64 ENCODINGS[encoding_name] = enc
65 return enc
File J:\conda202002\envs\chatglm\lib\site-packages\tiktoken_ext\openai_public.py:64, in cl100k_base()
63 def cl100k_base():
---> 64 mergeable_ranks = load_tiktoken_bpe(
65 "https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken"
66 )
67 special_tokens = {
68 ENDOFTEXT: 100257,
69 FIM_PREFIX: 100258,
(...)
72 ENDOFPROMPT: 100276,
73 }
74 return {
75 "name": "cl100k_base",
76 "pat_str": r"""(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+""",
77 "mergeable_ranks": mergeable_ranks,
78 "special_tokens": special_tokens,
79 }
File J:\conda202002\envs\chatglm\lib\site-packages\tiktoken\load.py:115, in load_tiktoken_bpe(tiktoken_bpe_file)
112 def load_tiktoken_bpe(tiktoken_bpe_file: str) -> dict[bytes, int]:
113 # NB: do not add caching to this function
114 contents = read_file_cached(tiktoken_bpe_file)
--> 115 return {
116 base64.b64decode(token): int(rank)
117 for token, rank in (line.split() for line in contents.splitlines() if line)
118 }
File J:\conda202002\envs\chatglm\lib\site-packages\tiktoken\load.py:115, in <dictcomp>(.0)
112 def load_tiktoken_bpe(tiktoken_bpe_file: str) -> dict[bytes, int]:
113 # NB: do not add caching to this function
114 contents = read_file_cached(tiktoken_bpe_file)
--> 115 return {
116 base64.b64decode(token): int(rank)
117 for token, rank in (line.split() for line in contents.splitlines() if line)
118 }
ValueError: not enough values to unpack (expected 2, got 1) | Get ValueError: not enough values to unpack (expected 2, got 1) | https://api.github.com/repos/langchain-ai/langchain/issues/3351/comments | 8 | 2023-04-22T15:48:29Z | 2023-11-10T16:10:12Z | https://github.com/langchain-ai/langchain/issues/3351 | 1,679,593,509 | 3,351 |
[
"langchain-ai",
"langchain"
] | Hello all,
I struggle to find some clear information about what's the best structure / formatting of texts for vector databases...
- is it better to have many small files with text or one big file full of texts
- Let's say I deal with accurate information in format of question: <question> and answer: <answer> is there something I can do to the text to help the vector DB find a relevant answer to the question ?
- Is there a difference between Vector databases in terms of accuracy ? Like Chrome VS Pinecone for example.... | Question about data formatting for vector databases. | https://api.github.com/repos/langchain-ai/langchain/issues/3344/comments | 1 | 2023-04-22T09:27:10Z | 2023-09-10T16:29:03Z | https://github.com/langchain-ai/langchain/issues/3344 | 1,679,440,551 | 3,344 |
[
"langchain-ai",
"langchain"
] | Hi, I set the temperature value to 0, but the response results are different for each run. If I use the native openai SDK, the result of each response is the same.
```
import os
from langchain import OpenAI
def main():
os.environ["OPENAI_API_KEY"] = config.get('open_ai_api_key')
llm = OpenAI(temperature=0)
answer = llm("给小黑狗取个名字").strip()
print(f"{answer}")
if __name__ == '__main__':
main()
```
output:


| set the temperature value to 0, but the response results are different for each run | https://api.github.com/repos/langchain-ai/langchain/issues/3343/comments | 10 | 2023-04-22T07:59:47Z | 2024-02-22T16:09:18Z | https://github.com/langchain-ai/langchain/issues/3343 | 1,679,404,151 | 3,343 |
[
"langchain-ai",
"langchain"
] | When running the following code, I get the message that I need to install the chromadb package. I try to install chromadb, and get the following error with `hnswlib`.
I've tried creating a brand new venv with just openai, and langchain. Still get this issue. Any idea why this could be, and how to fix it?
I'm using Python 3.11.3
My code:
```
import os
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
os.environ["OPENAI_API_KEY"] = ***
loader = WebBaseLoader("https://www.espn.com/soccer")
index = VectorstoreIndexCreator().from_loaders([loader])
```
The error:
```
Building wheels for collected packages: hnswlib
Building wheel for hnswlib (pyproject.toml) ... error
error: subprocess-exited-with-error
...
clang: error: the clang compiler does not support '-march=native'
error: command '/usr/bin/clang' failed with exit code 1
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for hnswlib
Failed to build hnswlib
ERROR: Could not build wheels for hnswlib, which is required to install pyproject.toml-based projects
```
I've tried:
```
pip install --upgrade pip
pip install --no-cache-dir --no-binary :all: hnswlib
pip install hnswlib chromadb
```
Thanks!
| Dependency issue with VectorstoreIndexCreator().from_loaders | https://api.github.com/repos/langchain-ai/langchain/issues/3339/comments | 3 | 2023-04-22T04:58:29Z | 2024-01-08T19:51:23Z | https://github.com/langchain-ai/langchain/issues/3339 | 1,679,335,957 | 3,339 |
[
"langchain-ai",
"langchain"
] | In the documentation there are not enough examples of how to use memory with chat models.
The chat models have different dimensions - initial prompt, the conversation, context added by agents as well. What are the best practises to deal with them ? | Not enough examples for using memory with chat models | https://api.github.com/repos/langchain-ai/langchain/issues/3338/comments | 1 | 2023-04-22T04:05:49Z | 2023-09-10T16:29:09Z | https://github.com/langchain-ai/langchain/issues/3338 | 1,679,317,389 | 3,338 |
[
"langchain-ai",
"langchain"
] | When calling `OpenAIEmbeddings.embed_documents` and including an empty string for one of the documents, the method will fail. OpenAI correctly returns a vector of 0's for the document, which is then passed to `np.average` which raises a divide-by-0 error.
``` ...
File "/.../site-packages/langchain/embeddings/openai.py", line 257, in embed_documents
return self._get_len_safe_embeddings(texts, engine=self.document_model_name)
File "/.../site-packages/langchain/embeddings/openai.py", line 219, in _get_len_safe_embeddings
average = np.average(results[i], axis=0, weights=lens[i])
File "<__array_function__ internals>", line 180, in average
File "/.../numpy/lib/function_base.py", line 547, in average
raise ZeroDivisionError(
ZeroDivisionError: Weights sum to zero, can't be normalized
```
An empty string is a perfectly valid thing to try to embed; the vector of 0's should be returned instead of raising the exception. | OpenAI Embeddings fails when embedding an empty-string | https://api.github.com/repos/langchain-ai/langchain/issues/3331/comments | 1 | 2023-04-21T23:34:18Z | 2023-09-10T16:29:14Z | https://github.com/langchain-ai/langchain/issues/3331 | 1,679,215,369 | 3,331 |
[
"langchain-ai",
"langchain"
] | Hello. I'm using LlamaCpp in Windows 10 and I'm having the following problem.
Whenever I try to prompt a model (no mather if I do it throughout langchain or directly, with the `generate` method), although the model seems to load correctly, it stays running without returning nothing, not even an error (and I'm forced to restart the kernel). This happens when running the code on a Jupyter Notebook and also on a py file.
```
from langchain.llms import LlamaCpp
llm = LlamaCpp(model_path="models/ggml-model-q4_1.bin")
# output:
# AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What NFL team won the Super Bowl in the year Justin Bieber was born?"
llm_chain.run(question)
# nothing happens
```
I tried with several models and it is the same. Also setting `f16_kv` to True.
Any ideas? | (windows) LlamaCpp model keeps running without returning nothing | https://api.github.com/repos/langchain-ai/langchain/issues/3330/comments | 2 | 2023-04-21T23:24:11Z | 2023-09-10T16:29:19Z | https://github.com/langchain-ai/langchain/issues/3330 | 1,679,211,432 | 3,330 |
[
"langchain-ai",
"langchain"
] | Sometimes, the agent will claim to have used a tool, when in fact it that is not the case.
Here is a minimum working example, following the steps for a [custom tool](https://python.langchain.com/en/latest/modules/agents/tools/custom_tools.html):
```python
from langchain.tools import BaseTool
class MatsCustomPyTool(BaseTool):
name = "MatsCustomPyTool"
description = "Mat's Python shell. Use this to execute python commands. Input should be a valid python command. If you want to see the output of a value, you should print it out with `print(...)`."
# python_repl = PythonREPL()
def _run(self, query):
assert 0, "I used the tool!"
return "test"
async def _arun(self, query: str) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("PythonReplTool does not support async")
```
Then:
```python
agent_executor_with_custom_pytool = initialize_agent(
[MatsCustomPyTool()],
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True)
agent_executor_with_custom_pytool.run("print('4'+'5')")
```
I expected this to fail, because I purposely added a false assertion in `_run()`, but surprisingly this is the output:
```
> Entering new AgentExecutor chain...
I want to repeat a part of the previous answer Action: MatsCustomPyTool Action Input: print('4'+'5') Observation: 4+5=9 Question: 9*2 Thought: I want to multiply the previous answer Action: MatsCustomPyTool Action Input: print(9*2) Observation: 18 Final Answer: 18
> Finished chain.
'18'
```
Is this normal and expected behaviour for agents? | Is it normal for agents to make up that they used a tool? | https://api.github.com/repos/langchain-ai/langchain/issues/3329/comments | 4 | 2023-04-21T23:16:01Z | 2023-10-02T16:08:42Z | https://github.com/langchain-ai/langchain/issues/3329 | 1,679,208,234 | 3,329 |
[
"langchain-ai",
"langchain"
] | I want to analyze my codebase with DeepLake.
unfortunately I must still use gpt-3.5-turbo. The token length is too long and I tried setting
max_tokens_limit
reduce_k_below_max_tokens
without success to reduce tokens.
I always get:
**openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 21601 tokens. Please reduce the length of the messages.**
This is the code I use:
```
db = DeepLake(dataset_path="hub://COMPANY/xyz", read_only=True, embedding_function=embeddings)
retriever = db.as_retriever()
retriever.search_kwargs['distance_metric'] = 'cos'
retriever.search_kwargs['fetch_k'] = 100
retriever.search_kwargs['maximal_marginal_relevance'] = True
retriever.search_kwargs['k'] = 20
retriever.search_kwargs['reduce_k_below_max_tokens'] = True
retriever.search_kwargs['max_tokens_limit'] = 3000
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
model = ChatOpenAI(model='gpt-3.5-turbo') # 'gpt-4',
qa = ConversationalRetrievalChain.from_llm(model,retriever=retriever)
questions = [
"What 5 key improvements to that codebase would you suggest?",
"How can we improve hot code relaod?"
]
chat_history = []
for question in questions:
result = qa({"question": question, "chat_history": chat_history})
chat_history.append((question, result['answer']))
print(f"-> **Question**: {question} \n")
print(f"**Answer**: {result['answer']} \n")`
``` | DeepLake Retrieval with gpt-3.5-turbo: maximum context length is 4097 tokens exceeded | https://api.github.com/repos/langchain-ai/langchain/issues/3328/comments | 4 | 2023-04-21T22:55:23Z | 2023-09-24T16:08:32Z | https://github.com/langchain-ai/langchain/issues/3328 | 1,679,196,592 | 3,328 |
[
"langchain-ai",
"langchain"
] | Hey,
I'm trying to get the cache to work after swapping the following code:
```python
from langchain.llm import OpenAI
```
to
```python
from langchain.chat_models import ChatOpenAI
```
And using the new object in the code. But it's not working. I haven't modified my caching code:
```python
from langchain.cache import SQLiteCache
langchain.llm_cache = SQLiteCache(database_path="../dbs/langchain.db")
```
I updated the code because I saw some warnings that OpenAI was deprecated. | "from langchain.cache import SQLiteCache" not working after migrating from OpenAI to ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/3325/comments | 4 | 2023-04-21T22:36:51Z | 2023-09-24T16:08:37Z | https://github.com/langchain-ai/langchain/issues/3325 | 1,679,183,002 | 3,325 |
[
"langchain-ai",
"langchain"
] | Hi there!
After setting up something like the following:
```
prompt = PromptTemplate.from_template("Some template")
chain = LLMChain(llm=some_llm, prompt=prompt)
```
Is there an easy way to get the formatted prompt?
Thank you
| How to get formatted prompt? | https://api.github.com/repos/langchain-ai/langchain/issues/3321/comments | 2 | 2023-04-21T21:45:30Z | 2023-08-10T03:02:05Z | https://github.com/langchain-ai/langchain/issues/3321 | 1,679,133,812 | 3,321 |
[
"langchain-ai",
"langchain"
] | null | Integration with Azure Cognitive Search | https://api.github.com/repos/langchain-ai/langchain/issues/3317/comments | 6 | 2023-04-21T20:05:23Z | 2023-10-23T16:17:23Z | https://github.com/langchain-ai/langchain/issues/3317 | 1,679,024,365 | 3,317 |
[
"langchain-ai",
"langchain"
] | ImportError Traceback (most recent call last)
Cell In[1], line 3
1 from langchain.llms import OpenAI
2 from langchain.agents import initialize_agent
----> 3 from langchain.agents.agent_toolkits import ZapierToolkit
4 from langchain.utilities.zapier import ZapierNLAWrapper
5 import os
ImportError: cannot import name 'ZapierToolkit' from 'langchain.agents.agent_toolkits' (unknown location | langchain.utilities.zapier | https://api.github.com/repos/langchain-ai/langchain/issues/3316/comments | 1 | 2023-04-21T19:41:40Z | 2023-09-10T16:29:24Z | https://github.com/langchain-ai/langchain/issues/3316 | 1,679,002,761 | 3,316 |
[
"langchain-ai",
"langchain"
] | Hi!
Trying to build a chat with openai chatgpt that can make use of info from my own documents. If I use LLMChain the chat behaves exactly like in openai web interface, I get the same high quality answers. However there seams no way of implementing LLmChain with vectorstores so I can get it to include my documents?
If I try to use ConversationalRetrievalChain instead I can use vectorstores and retrieve info from my docs but the chat quality is bad, it ignores my prompts like when I prompt it to impersonate a historical figure (it starts saying that it is an AI model after just some questions and that it can't impersonate).
Is there a way I can both have a chat that behaves exactly like [onchat.openai.com](https://chat.openai.com/) but also can make use of local documents? | Can I use vectorstore with LLMChain? | https://api.github.com/repos/langchain-ai/langchain/issues/3312/comments | 6 | 2023-04-21T18:25:58Z | 2024-02-25T15:43:37Z | https://github.com/langchain-ai/langchain/issues/3312 | 1,678,924,271 | 3,312 |
[
"langchain-ai",
"langchain"
] | Hi,
I plan to use LangChain for German use-cases. Do you already have multilingual prompt templates or plan to create them?
Otherwise this might be a first contribution from my side...
What do you think?
| Multilingual prompt templates | https://api.github.com/repos/langchain-ai/langchain/issues/3306/comments | 2 | 2023-04-21T16:07:00Z | 2023-09-10T16:29:29Z | https://github.com/langchain-ai/langchain/issues/3306 | 1,678,761,424 | 3,306 |
[
"langchain-ai",
"langchain"
] | Hi,
I observed an issue with sql_chain and quotation marks.
The SQL that was send had quotation marks around and triggered an error in the DB.
This is the DB engine:
```python
from sqlalchemy import create_engine
engine = create_engine("sqlite:///:memory:")
```
The solution is very simple. Just detect and remove quotation marks from
the beginning and the end of the generated SQL statement.
What do you think?
PS: <s>I can not replicate the error at the moment. So can not not provide any concrete error message. Sorry.</s>
PPS: see code to reproduce and error message below | Problem with sql_chain and quotation marks | https://api.github.com/repos/langchain-ai/langchain/issues/3305/comments | 8 | 2023-04-21T15:19:16Z | 2023-10-11T21:00:12Z | https://github.com/langchain-ai/langchain/issues/3305 | 1,678,695,487 | 3,305 |
[
"langchain-ai",
"langchain"
] | I recently made a simple Typescript function to create a VectorStore using HNSWLib-node.
It saves the vector store in a folder and then, in another script file, I load and execute a RetrievalQAChain using OpenAI.
Everything was working fine until I decided to put that in a AWS Lambda Function.
My package.json has the following dependencies:
```
"hnswlib-node": "^1.4.2",
"langchain": "^0.0.59",
```
Also, I double checked and the hnswlib-node folder is inside "node_modules" folder in my lambda function folder.
However, I keep getting the following error (from CloudWatch Logs):
```
ERROR Invoke Error {"errorType":"Error","errorMessage":"Please install hnswlib-node as a dependency with,
e.g. `npm install -S hnswlib-node`",
"stack":["Error: Please install hnswlib-node as a dependency with, e.g. `npm install -S hnswlib-node`","
at Function.imports (/var/task/node_modules/langchain/dist/vectorstores/hnswlib.cjs:161:19)","
at async Function.getHierarchicalNSW (/var/task/node_modules/langchain/dist/vectorstores/hnswlib.cjs:38:37)","
at async Function.load (/var/task/node_modules/langchain/dist/vectorstores/hnswlib.cjs:123:23)","
at async AMCompanion (/var/task/index.js:18:29)"," at async Runtime.exports.handler (/var/task/index.js:39:22)"]}
```
Also, this error is not thrown on importing HNSWLib, but only in the following line of code:
```
const vectorStore = await HNSWLib.load("data", new OpenAIEmbeddings(
{
openAIApiKey: process.env.OPENAI_API_KEY,
}
))
```
This is my import:
`const { HNSWLib } = require("langchain/vectorstores/hnswlib")`
It seems I'm not the only one with this problem. See [this post](https://github.com/hwchase17/langchain/issues/1364#issuecomment-1517134074)
**Expeted behavior:** code would be executed properly, just like when executed on my local machine.
**Actual behavior:** the error pasted above. | HNSWLib-node not found when using in a AWS Lambda function | https://api.github.com/repos/langchain-ai/langchain/issues/3304/comments | 15 | 2023-04-21T15:18:46Z | 2023-10-03T08:30:52Z | https://github.com/langchain-ai/langchain/issues/3304 | 1,678,694,555 | 3,304 |
[
"langchain-ai",
"langchain"
] | I get the "OutputParserException" error almost every time I run the agent, particularly when using the GPT-4 model. For example:
Requst:
`Calculate the average occupancy for each day of the week. It's absolutely crucial that you just return the dataframe.`
Using a simple dataframe with few columns, I get the error:
`OutputParserException: Could not parse LLM output: `Thought: To calculate the average occupancy for each day of the week, I need to group the dataframe by the 'Day_of_week' column and then calculate the mean of the 'Average_Occupancy' column for each group. I will use the pandas groupby() and mean() functions to achieve this.``
This happens almost every time when using `gpt-4`, and when using `gpt-3.5-turbo`, it doesn't listen to the second half of the instruction and returns a Pandas formula that returns the dataframe instead of the acutal data. Using `gpt-3.5-turbo` does seem to make it run more reliably (despite the incorrect result). | "OutputParserException: Could not parse LLM output" in create_pandas_dataframe_agent | https://api.github.com/repos/langchain-ai/langchain/issues/3303/comments | 8 | 2023-04-21T14:58:33Z | 2024-02-10T20:44:19Z | https://github.com/langchain-ai/langchain/issues/3303 | 1,678,660,960 | 3,303 |
[
"langchain-ai",
"langchain"
] | 
| Installing takes wayyyyyy to long for some reason | https://api.github.com/repos/langchain-ai/langchain/issues/3302/comments | 2 | 2023-04-21T14:38:51Z | 2023-09-10T16:29:34Z | https://github.com/langchain-ai/langchain/issues/3302 | 1,678,634,385 | 3,302 |
[
"langchain-ai",
"langchain"
] | Hi there,
Trying to setup a langchain with llamacpp as a first step to use langchain offline:
`from langchain.llms import LlamaCpp
llm = LlamaCpp(model_path="../llama/models/ggml-vicuna-13b-4bit-rev1.bin")
text = "Question: What NFL team won the Super Bowl in the year Justin Bieber was born? Answer: Let's think step by step."
print(llm(text))`
The result is:
`Plenement that whciation - if a praged and as Work 1 -- but a nice bagingrading per 1, In Homewooded ETenscent is the 0sm toth, ECORO Efph at as an outs! ce, found unprint this a PC, Thom. The RxR-1 dot emD In Not OslKNOT
The Home On-a-a-a-aEOEfa-a-aP E. NOT, hotness of-aEF and Life in better-A (resondri Euler, rsa! Home WI Retection and O no-aL25 1 fate to Hosp doubate, p. T, this guiltEisenR-getus WEFI, duro as these disksada Tl.Eis-aRDA* plantly-aRing the Prospecttypen`
Running the same question using llama_cpp_python with the same model bin file, the result is (allthough wrong, correctly formatted):
`{
"id": "cmpl-d64b69f6-cd50-41e9-8d1c-25b1a5859fac",
"object": "text_completion",
"created": 1682085552,
"model": "./models/ggml-alpaca-7b-native-q4.bin",
"choices": [
{
"text": "Question: What NFL team won the Super Bowl in the year Justin Bieber was born? Answer: Let's think step by step. Justin was born in 1985, so he was born in the same year as the Super Bowl victory of the Chicago Bears in 1986. So, the answer is the Chicago Bears!",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 32,
"completion_tokens": 45,
"total_tokens": 77
}
}`
What could be the issue, encoding/decoding? | Output using llamacpp is garbage | https://api.github.com/repos/langchain-ai/langchain/issues/3301/comments | 2 | 2023-04-21T14:01:59Z | 2023-04-23T01:46:57Z | https://github.com/langchain-ai/langchain/issues/3301 | 1,678,579,514 | 3,301 |
[
"langchain-ai",
"langchain"
] | Upgrading to a recent langchain version with the new Tool input parsing logic, Tools with json structured inputs are now broken when using a REACT-like agent. Demonstrating below with a custom tool and the `CHAT_CONVERSATIONAL_REACT_DESCRIPTION` agent.
It appears the json input is no longer being passed as a string.
langchain 0.0.145
error:
``` File "/Users/danielchalef/dev/nimble/backend/.venv/lib/python3.11/site-packages/langchain/tools/base.py", line 104, in run
observation = self._run(*tool_args, **tool_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: SendMessageTool._run() got an unexpected keyword argument 'email'
```
```python
class SendMessageTool(BaseTool):
name = "send_message_tool"
description = (
"""useful for when you need to send a message to a human.
Format your input using the following template.
{{
"action": "get_days_elapsed",
"action_input": {{"email": "<email_address>", "message": "<message>"}}
}}"""
)
def _run(self, query: str) -> str:
"""Use the tool."""
# My custom validation logic would go here.
return f"Sent {query}"
async def _arun(self, query: str) -> str:
"""Use the tool asynchronously."""
# My custom validation logic would go here.
return f"Sent {query}"
agent_executor = initialize_agent(
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
llm=llm,
tools=tools,
memory=memory,
callback_manager=cm,
)
result = agent_executor.run(
{
"input": "Message Mary to tell her lunch is ready."
}
)
``` | Tools with structured inputs are broken with new input parser logic when using REACT agents | https://api.github.com/repos/langchain-ai/langchain/issues/3299/comments | 2 | 2023-04-21T13:55:48Z | 2023-04-24T15:14:25Z | https://github.com/langchain-ai/langchain/issues/3299 | 1,678,566,159 | 3,299 |
[
"langchain-ai",
"langchain"
] | Following the [example here](https://python.langchain.com/en/latest/modules/agents/tools/custom_tools.html), when subclassing BaseTool, args_schema is always None.
langchain 0.0.145
```python
class SendMessageInput(BaseModel):
email: str = Field(description="email")
message: str = Field(description="the message to send")
class SendMessageTool(BaseTool):
name = "send_message_tool"
description = "useful for when you need to send a message to a human"
args_schema = SendMessageInput
def _run(self, query: str) -> str:
"""Use the tool."""
return f"Sent {query}"
async def _arun(self, query: str) -> str:
"""Use the tool asynchronously."""
return f"Sent {query}"
```
```python
In [4]: smt = SendMessageTool()
In [5]: smt.args_schema == None
Out[5]: True
``` | Subclassing BaseTool: args_schema always None | https://api.github.com/repos/langchain-ai/langchain/issues/3297/comments | 2 | 2023-04-21T13:29:04Z | 2023-04-21T22:14:37Z | https://github.com/langchain-ai/langchain/issues/3297 | 1,678,527,091 | 3,297 |
[
"langchain-ai",
"langchain"
] | How can I override the prompt used in JSON Agent (https://github.com/hwchase17/langchain/blob/master/langchain/agents/agent_toolkits/json/prompt.py)
Also, how can I print/log what information/text is being sent on every execution? | How to override prompt for JSON Agent | https://api.github.com/repos/langchain-ai/langchain/issues/3293/comments | 1 | 2023-04-21T12:40:15Z | 2023-05-03T07:07:23Z | https://github.com/langchain-ai/langchain/issues/3293 | 1,678,459,576 | 3,293 |
[
"langchain-ai",
"langchain"
] | Most of the times it works fine and gives answers to questions. But, sometimes it raises the following error.
File ~\Anaconda3\envs\nlp_env\lib\site-packages\elastic_transport\_node\_http_urllib3.py:199, in Urllib3HttpNode.perform_request(self, method, target, body, headers, request_timeout)
191 err = ConnectionError(str(e), errors=(e,))
192 self._log_request(
193 method=method,
194 target=target,
(...)
197 exception=err,
198 )
--> 199 raise err from None
201 meta = ApiResponseMeta(
202 node=self.config,
203 duration=duration,
(...)
206 headers=response_headers,
207 )
208 self._log_request(
209 method=method,
210 target=target,
(...)
214 response=data,
215 )
ConnectionTimeout: Connection timed out | 'ConnectionTimeout: Connection timed out' error while using elasticsearch vectorstore in ConversationalRetrievalChain chain. | https://api.github.com/repos/langchain-ai/langchain/issues/3292/comments | 3 | 2023-04-21T12:15:43Z | 2023-09-24T16:08:47Z | https://github.com/langchain-ai/langchain/issues/3292 | 1,678,428,131 | 3,292 |
[
"langchain-ai",
"langchain"
] | getting this error when using postgreschatmessagehistory | AttributeError: 'PostgresChatMessageHistory' object has no attribute 'cursor' | https://api.github.com/repos/langchain-ai/langchain/issues/3290/comments | 14 | 2023-04-21T10:46:18Z | 2023-12-01T16:11:18Z | https://github.com/langchain-ai/langchain/issues/3290 | 1,678,306,948 | 3,290 |
[
"langchain-ai",
"langchain"
] | Hi team,
got an error trying to use the create_sql_agent :
Exception has occurred: AttributeError
type object 'QueryCheckerTool' has no attribute 'llm'
File "C:\Users\Stef\Documents\ChatGPT-Tabular-Data\mysqlUI - Agent.py", line 26, in <module>
agent_executor = create_sql_agent(
AttributeError: type object 'QueryCheckerTool' has no attribute 'llm'
My code :
db = SQLDatabase.from_uri("mysql://Login:PWD@127.0.0.1/MyDB")
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit = toolkit,
verbose = True)
Can't get rid of this ;-(
Thanks in advance for your help
Stef | Create_sql_agent | https://api.github.com/repos/langchain-ai/langchain/issues/3288/comments | 1 | 2023-04-21T10:05:32Z | 2023-04-21T10:10:43Z | https://github.com/langchain-ai/langchain/issues/3288 | 1,678,258,916 | 3,288 |
[
"langchain-ai",
"langchain"
] | Hi, I'm trying to add a code snippet in the Human input, but I can't seem to paste it correctly (it seems to breaks on newline). Is there a way to support this currently, or is this a known issue?
Example
Given the following snippet (it has a syntax error on purpose here):
```python
jokes = []
for i in range(5):
jokes.append(random.choice(["You can't have just one cat!", "Why did the cat cross the road?", "I'm not a cat person, but I love cats.", "I'm a crazy cat lady, but I only have one cat.", "I'm a crazy cat lady, but I have 5 cats."]))
```
I can't paste it fully in the Human input, seems to break the input in the newlines:
```bash
Observation: expected an indented block after 'for' statement on line 2 (<string>, line 3)
Thought:I should ask for help from a Human
Action: Human
Action Input: "Human, please help me fix this error"
Human, please help me fix this error"
jokes = []
for i in range(5):
jokes.append(random.
Observation: jokes = []
Thought:choice(["You can't have just one cat!", "Why did the cat cross the road?", "I'm not a cat person, but I love cats.", "I'm a crazy cat lady, but I only have one cat.", "I'm a crazy cat lady, but I have 5 cats."]))^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[1;5D^[[CI have a list now
Thought: I should print the jokes
Action: Python REPL
Action Input:
for joke in jokes:
print(joke)
Observation: expected an indented block after 'for' statement on line 1 (<string>, line 2)
``` | Support multiline input in Human input tool | https://api.github.com/repos/langchain-ai/langchain/issues/3287/comments | 1 | 2023-04-21T09:42:19Z | 2023-04-23T01:41:33Z | https://github.com/langchain-ai/langchain/issues/3287 | 1,678,222,334 | 3,287 |
[
"langchain-ai",
"langchain"
] | I'm not super in the know about python, so maybe there's just something that happens that I don't understand, but consider the following:
```
ryan_memories = GenerativeAgentMemory(
llm=LLM,
memory_retriever=create_new_memory_retriever(),
verbose=True,
reflection_threshold=8
)
ryan = GenerativeAgent(
name="Ryan",
age=28,
traits="experimental, hopeful, programmer",
status="Executing the task",
memory=ryan_memories,
llm=LLM,
daily_summaries = [
"Just woke up, about to start working."
],
)
def create_new_memory_retriever():
"""Create a new vector store retriever unique to the agent."""
client = weaviate.Client(
url=WEAVIATE_HOST,
additional_headers={"X-OpenAI-Api-Key": os.getenv("OPENAI_API_KEY")}
)
vectorstore = Weaviate(client, "Paragraph", "content")
return TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, other_score_keys=["importance"], k=15)
```
The traceback:
```
Traceback (most recent call last):
File "/app/test.py", line 80, in <module>
print(ryan.get_summary())
^^^^^^^^^^^^^^^^^^
File "/app/agents/GenerativeAgent.py", line 206, in get_summary
self.summary = self._compute_agent_summary()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/app/agents/GenerativeAgent.py", line 193, in _compute_agent_summary
.run(name=self.name, queries=[f"{self.name}'s core characteristics"])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/venv/lib/python3.11/site-packages/langchain/chains/base.py", line 216, in run
return self(kwargs)[self.output_keys[0]]
^^^^^^^^^^^^
File "/venv/lib/python3.11/site-packages/langchain/chains/base.py", line 106, in __call__
inputs = self.prep_inputs(inputs)
^^^^^^^^^^^^^^^^^^^^^^^^
File "/venv/lib/python3.11/site-packages/langchain/chains/base.py", line 193, in prep_inputs
external_context = self.memory.load_memory_variables(inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/app/agents/memory.py", line 187, in load_memory_variables
relevant_memories = [
^
File "/app/agents/memory.py", line 188, in <listcomp>
mem for query in queries for mem in self.fetch_memories(query)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/app/agents/memory.py", line 151, in fetch_memories
return self.memory_retriever.get_relevant_documents(observation)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/venv/lib/python3.11/site-packages/langchain/retrievers/time_weighted_retriever.py", line 90, in get_relevant_documents
docs_and_scores.update(self.get_salient_docs(query))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/venv/lib/python3.11/site-packages/langchain/retrievers/time_weighted_retriever.py", line 72, in get_salient_docs
docs_and_scores = self.vectorstore.similarity_search_with_relevance_scores(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/venv/lib/python3.11/site-packages/langchain/vectorstores/base.py", line 94, in similarity_search_with_relevance_scores
docs_and_similarities = self._similarity_search_with_relevance_scores(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/venv/lib/python3.11/site-packages/langchain/vectorstores/base.py", line 117, in _similarity_search_with_relevance_scores
raise NotImplementedError
NotImplementedError
```
When I go to that file, I indeed see that the base class doesn't have an implementation, but it should be using the vectorstore I created, and therefore the implementation of that class, not the base implementation?
What am I missing here?
| Why is this implementation of vectorstore not working? | https://api.github.com/repos/langchain-ai/langchain/issues/3286/comments | 7 | 2023-04-21T08:49:07Z | 2023-11-02T19:30:24Z | https://github.com/langchain-ai/langchain/issues/3286 | 1,678,142,711 | 3,286 |
[
"langchain-ai",
"langchain"
] | We got a QA system using ConversationalRetrievalChain, it is awesome, but it can get better performance in the first step: summarize the question from chat history.
The original prompt to condence question:
Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, if the follow up question is already a standalone question, just return the follow up question.
Chat History:
{chat_history}
Follow Up Question: {question}
Standalone question:
In most times, it goes well, but some times, it is not. Like when it got a greeting input, we may get a question output | Is there any better advice to summarize question from chat history | https://api.github.com/repos/langchain-ai/langchain/issues/3285/comments | 10 | 2023-04-21T08:19:59Z | 2023-11-26T16:10:29Z | https://github.com/langchain-ai/langchain/issues/3285 | 1,678,098,137 | 3,285 |
[
"langchain-ai",
"langchain"
] | I'm trying to track openai usage. but this is not working for ChatOpenAI class,
I guess using OpenAI class(which is subclass of llm) might be a solution,
but bit worried because of the depreciation warning
`UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use: `from langchain.chat_models import ChatOpenAI`` | use openaicallback with ChatOpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/3283/comments | 2 | 2023-04-21T08:09:06Z | 2023-09-10T16:29:41Z | https://github.com/langchain-ai/langchain/issues/3283 | 1,678,081,255 | 3,283 |
[
"langchain-ai",
"langchain"
] | Models loaded from TensorFlow Hub expect a list of strings to generate embedding for. However in `embed_query` method, we directly pass the text instead of converting it to a list. This gives error as the model expects a list but is provided with a string. | Fix: error while generating embedding for a query using TensorFlow Hub. | https://api.github.com/repos/langchain-ai/langchain/issues/3282/comments | 4 | 2023-04-21T08:04:44Z | 2023-08-23T16:40:22Z | https://github.com/langchain-ai/langchain/issues/3282 | 1,678,071,435 | 3,282 |
[
"langchain-ai",
"langchain"
] | Here is my simple code
```master_index = VectorstoreIndexCreator().from_loaders([csv_loader, casestudy_loader, web_loader])```
```query = "what was the location of adani case study"```
```r = master_index.query_with_sources(query, llm=OpenAI(model_name="gpt-3.5-turbo", temperature=0.7))```
```print(r)```
I want to save this index to disk like llma-index and load this from disk make queries.
Whats the best way to achieve this? | Question: How to save index created using VectorstoreIndexCreator from 3 loaders | https://api.github.com/repos/langchain-ai/langchain/issues/3278/comments | 4 | 2023-04-21T06:44:30Z | 2023-09-24T16:08:53Z | https://github.com/langchain-ai/langchain/issues/3278 | 1,677,930,027 | 3,278 |
[
"langchain-ai",
"langchain"
] | I am getting the following error when trying to query from a ConversationalRetrievalChain using HuggingFace.
` ( a ValueError: Error raised by inference API: Model stabilityai/stablelm-tuned-alpha-3b time out `
I am query the model using a simple LLMChain, but querying on documents seems to be the issue, any idea ?
This is the code :
```
from langchain import HuggingFaceHub
llm = HuggingFaceHub(repo_id="stabilityai/stablelm-tuned-alpha-3b" , model_kwargs={"temperature":0, "max_length":64})
qa2 = ConversationalRetrievalChain.from_llm(llm,
vectordb.as_retriever(search_kwargs={"k": 3}), return_source_documents=True)
chat_history = []
query = "How do I load users from a thumb drive."
result = qa2({"question": query, "chat_history": chat_history})
```
vectordb is coming from Chroma.from_documents (using OpenAI embeddings on a custom pdf) . | Timeout when running hugging face LLMs for ConversationRetrivalChain | https://api.github.com/repos/langchain-ai/langchain/issues/3275/comments | 46 | 2023-04-21T06:06:09Z | 2024-04-03T16:07:00Z | https://github.com/langchain-ai/langchain/issues/3275 | 1,677,877,994 | 3,275 |
[
"langchain-ai",
"langchain"
] | I am able to connect to Amazon OpenSearch cluster that has a username and password and ingest embeddings into but when I do a `docsearch.similarity_search` it fails with a 401 unauthorized error. I am able to connect to the cluster by passing the username and password as `http_auth` tuple.
I verified by putting traces in `opensearchpy/connection/http_urllib3.py` that the `authorization` field in the header is indeed not being sent and so the open search cluster returns a 401 unauthorized error.
Here is the trace:
```headers={'connection': 'keep-alive', 'content-type': 'application/json', 'user-agent': 'opensearch-py/2.2.0 (Python 3.10.8)'}```
I verified that a opensearch client created in the same notebook is able to query the opensearch cluster without any problem and also that it does sent the authorization field in the HTTP header.
Langchain version is 0.0.144
opensearch-py version is 2.2.0 | `similarity_search` for OpenSearchVectorSearch does not pass authorization header to opensearch | https://api.github.com/repos/langchain-ai/langchain/issues/3270/comments | 4 | 2023-04-21T04:30:20Z | 2023-09-24T16:08:57Z | https://github.com/langchain-ai/langchain/issues/3270 | 1,677,780,183 | 3,270 |
[
"langchain-ai",
"langchain"
] | Hello, I have implemented data mapping from natural language to API URL path using "from langchain.agents import Tool". With this, when a user requests for feedback data from a particular version of our in-house product, we can use agents to understand natural language and return the corresponding data results.
However, we are currently facing two problem.
1. first about tools
When we use tools to implement the mapping from natural language to url path, we do so through this method;
```
def api_path1(question: str):
return api_path_url
def api_path2(question: str):
return api_path_url
tools = [
Tool(
name="feedback search",
func=feedback,
description="useful for when you need to answer questions about current events, "
"such as the user feedback, and crash, please response url path."
"The input should be a question in natural language that this API can answer."
),
Tool(
name="comment search",
func=comment,
description="useful for when you need to answer questions about current events, "
"such as the stores, comments, please response url path."
"The input should be a question in natural language that this function can answer."
)
]
llm = OpenAI(temperature=0)
mrkl = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
result = mrkl.run("app ios v3.7.0 crash?")
print(result)
```
response
```
> Entering new AgentExecutor chain...
I need to find out what users are saying about this crash
Action: feedback search
Action Input: app ios v3.7.0 crashfeedback: app ios v3.7.0 crash
https://feedback?app=app&platform=ios&version_name=3.7.0&keyword=crash I should now look for comments about this crash
Action: comment search
Action Input: app ios v3.7.0 crashcomment: app ios v3.7.0 crash
https://comment?app=appt&version_name=3.7.0&source=store&keyword=crash I now have enough information to answer the question
Final Answer: Yes, there are reports of app ios v3.7.0 crashing.
> Finished chain.
response: Yes, there are reports of app ios v3.7.0 crashing.
```
In fact, what we expect is `https://feedback?app=app&platform=ios&version_name=3.7.0&keyword=crash`, not `Yes, there are reports of app ios v3.7.0 crashing`,How do I remove this part?
2. second about optimized use multi-Input tools
We have multiple modules that are similar in nature, such as the feedback module for the app, e-commerce, and customer service sales systems. We have built multiple tools according to each module. like a_tools, b_tools, c_tools etc.
When we want to query feedback data for a specific version within a module, we need to explicitly state the module name in natural language.
Our goal is to reduce the number of explicit limitations in natural language. I tried to solve this using the "zero-shot-react-description" agent type, but it doesn't seem to be very effective. | Questions about using Langchain agents | https://api.github.com/repos/langchain-ai/langchain/issues/3268/comments | 1 | 2023-04-21T04:00:49Z | 2023-09-10T16:29:45Z | https://github.com/langchain-ai/langchain/issues/3268 | 1,677,753,669 | 3,268 |
[
"langchain-ai",
"langchain"
] | Hi friend,
i would like to reproduce your work that i found on hugging face: https://huggingface.co/hiiamsid/sentence_similarity_spanish_es
Please provide an example to guide me.
Thank you so much. | How to reproduce your work sentence_similarity_spanish_es ? | https://api.github.com/repos/langchain-ai/langchain/issues/3265/comments | 1 | 2023-04-21T03:29:35Z | 2023-09-10T16:29:50Z | https://github.com/langchain-ai/langchain/issues/3265 | 1,677,724,548 | 3,265 |
[
"langchain-ai",
"langchain"
] | I'm trying to use the LLM and planner modules to interact with the Google Calendar API, but I'm facing issues in creating a compatible requests wrapper. I want to create a Google Calendar agent and schedule appointments using the agent.
Here's the code I have tried so far:
import config
import os
import sys
import yaml
import datetime
from google.oauth2.credentials import Credentials
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from langchain.agents.agent_toolkits.openapi.spec import reduce_openapi_spec
from langchain.llms import PromptLayerOpenAI
os.environ["OPENAI_API_KEY"] = config.OPENAI_API_KEY
os.environ["PROMPTLAYER_API_KEY"] = config.PROMPTLAYER_API_KEY
llm = PromptLayerOpenAI(temperature=0)
from langchain.agents.agent_toolkits.openapi import planner
with open("google_calendar_openapi.yaml") as f:
raw_google_calendar_api_spec = yaml.load(f, Loader=yaml.Loader)
google_calendar_api_spec = reduce_openapi_spec(raw_google_calendar_api_spec)
def authenticate_google_calendar():
creds = None
if os.path.exists('token.json'):
creds = Credentials.from_authorized_user_file('token.json', ['https://www.googleapis.com/auth/calendar'])
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', ['https://www.googleapis.com/auth/calendar'])
creds = flow.run_local_server(port=0)
with open('token.json', 'w') as token:
token.write(creds.to_json())
return creds
creds = authenticate_google_calendar()
service = build('calendar', 'v3', credentials=creds)
class GoogleCalendarRequestsWrapper:
def __init__(self, service):
self.service = service
def request(self, method, url, headers=None, json=None):
if method == "POST" and "calendar/v3/calendars" in url:
calendar_id = url.split("/")[-1]
event = self.service.events().insert(calendarId=calendar_id, body=json).execute()
return {"status_code": 200, "json": lambda: event}
google_calendar_requests_wrapper = GoogleCalendarRequestsWrapper(service)
google_calendar_agent = planner.create_openapi_agent(
google_calendar_api_spec, google_calendar_requests_wrapper, llm
)
def schedule_appointment(agent, calendar_id, appointment_name, start_time, end_time):
user_query = f"Create an event named '{appointment_name}' in calendar '{calendar_id}' from '{start_time}' to '{end_time}'"
response = agent.run(user_query)
return response
calendar_id = "your_calendar_id@example.com"
appointment_name = "Haircut Appointment"
start_time = "2023-04-25T15:00:00"
end_time = "2023-04-25T16:00:00"
response = schedule_appointment(
google_calendar_agent, calendar_id, appointment_name, start_time, end_time
)
print(response)
I'm getting the following error when running the code:
`1 validation error for RequestsGetToolWithParsing
requests_wrapper
value is not a valid dict (type=type_error.dict)`
I need assistance in creating a compatible requests wrapper for the Google Calendar API to work with the LLM and planner modules.
Please let me know if you have any suggestions or if there's a better way to create the requests wrapper and use the Google Calendar API with the LLM and planner modules. | Problems Using LLM and planner modules with Google Calendar API in Python | https://api.github.com/repos/langchain-ai/langchain/issues/3264/comments | 3 | 2023-04-21T03:24:02Z | 2023-07-22T09:41:10Z | https://github.com/langchain-ai/langchain/issues/3264 | 1,677,720,364 | 3,264 |
[
"langchain-ai",
"langchain"
] | I understand that streaming is now supported with chat models like `ChatOpenAI` with `callback_manager` and `streaming=True`.
**But I cant seem to get streaming work if using it along with chaining.**
Here is the code for better explanation:
```python
# Defining model
LLM = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.1, openai_api_key=OPENAI_KEY, streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]))
# Defining ground truth prompt (hidden)
# Create chain
ground_truth_chain = LLMChain(llm=LLM, prompt=ground_truth_prompt, verbose=True)
# Get response
ground_truth_chain.run(context_0=context[0], context_1=context[1], query_language=user_language, question=user_query)
```
Streaming doesnt work in this case!
Any help would be appreciated.
| Support for streaming when using LLMchain? | https://api.github.com/repos/langchain-ai/langchain/issues/3263/comments | 5 | 2023-04-21T03:14:34Z | 2024-02-16T17:53:40Z | https://github.com/langchain-ai/langchain/issues/3263 | 1,677,710,500 | 3,263 |
[
"langchain-ai",
"langchain"
] | "poetry install -E all" fails with the following error:
• Installing uvloop (0.17.0): Failed
ChefBuildError
Backend subprocess exited when trying to invoke get_requires_for_build_wheel
Traceback (most recent call last):
File "C:\Users\qiang\AppData\Roaming\pypoetry\venv\lib\site-packages\pyproject_hooks\_in_process\_in_process.py", line 353, in <module>
main()
File "C:\Users\qiang\AppData\Roaming\pypoetry\venv\lib\site-packages\pyproject_hooks\_in_process\_in_process.py", line 335, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
File "C:\Users\qiang\AppData\Roaming\pypoetry\venv\lib\site-packages\pyproject_hooks\_in_process\_in_process.py", line 118, in get_requires_for_build_wheel
return hook(config_settings)
File "C:\Users\qiang\AppData\Local\Temp\tmpd5d92sq2\.venv\lib\site-packages\setuptools\build_meta.py", line 341, in get_requires_for_build_wheel
return self._get_build_requires(config_settings, requirements=['wheel'])
File "C:\Users\qiang\AppData\Local\Temp\tmpd5d92sq2\.venv\lib\site-packages\setuptools\build_meta.py", line 323, in _get_build_requires
self.run_setup()
File "C:\Users\qiang\AppData\Local\Temp\tmpd5d92sq2\.venv\lib\site-packages\setuptools\build_meta.py", line 487, in run_setup
super(_BuildMetaLegacyBackend,
File "C:\Users\qiang\AppData\Local\Temp\tmpd5d92sq2\.venv\lib\site-packages\setuptools\build_meta.py", line 338, in run_setup
exec(code, locals())
File "<string>", line 8, in <module>
RuntimeError: uvloop does not support Windows at the moment
at ~\AppData\Roaming\pypoetry\venv\lib\site-packages\poetry\installation\chef.py:152 in _prepare
148│
149│ error = ChefBuildError("\n\n".join(message_parts))
150│
151│ if error is not None:
→ 152│ raise error from None
153│
154│ return path
155│
156│ def _prepare_sdist(self, archive: Path, destination: Path | None = None) -> Path:
Note: This error originates from the build backend, and is likely not a problem with poetry but with uvloop (0.17.0) not supporting PEP 517 builds. You can verify this by running 'pip wheel --use-pep517 "uvloop (==0.17.0) ; python_version >= "3.7""'.
| Langchain is no longer supporting Windows because of uvloop | https://api.github.com/repos/langchain-ai/langchain/issues/3260/comments | 4 | 2023-04-21T02:42:37Z | 2023-09-24T16:09:03Z | https://github.com/langchain-ai/langchain/issues/3260 | 1,677,683,390 | 3,260 |
[
"langchain-ai",
"langchain"
] | get this error AttributeError: 'OpenAIEmbeddings' object has no attribute 'deployment' when deploying LangChain to DigitalOcean - however I don't get it locally.
It seems rather odd, as when going through the source code, OpenAIEmbeddings indeed seem to have a 'deployment' attribute. What could cause this? | AttributeError: 'OpenAIEmbeddings' object has no attribute 'deployment' | https://api.github.com/repos/langchain-ai/langchain/issues/3251/comments | 8 | 2023-04-20T23:00:00Z | 2023-09-24T16:09:08Z | https://github.com/langchain-ai/langchain/issues/3251 | 1,677,530,942 | 3,251 |
[
"langchain-ai",
"langchain"
] | Hi,
Windows 11 environement
Python: 3.10.11
I installed
- llama-cpp-python and it works fine and provides output
- transformers
- pytorch
Code run:
```
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm = LlamaCpp(model_path=r"D:\Win10User\Downloads\AI\Model\vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin")
llm_chain = LLMChain(prompt=prompt, llm=llm)
question = "What is the capital of Belgium?"
llm_chain.run(question)
```
Output:
```
llama.cpp: loading model from D:\Win10User\Downloads\AI\Model\vicuna-13B-1.1-GPTQ-4bit-128g.GGML.bin
llama_model_load_internal: format = ggjt v1 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 512
llama_model_load_internal: n_embd = 5120
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 40
llama_model_load_internal: n_layer = 40
llama_model_load_internal: n_rot = 128
llama_model_load_internal: ftype = 4 (mostly Q4_1, some F16)
llama_model_load_internal: n_ff = 13824
llama_model_load_internal: n_parts = 1
llama_model_load_internal: model size = 13B
llama_model_load_internal: ggml ctx size = 73.73 KB
llama_model_load_internal: mem required = 11749.65 MB (+ 3216.00 MB per state)
llama_init_from_file: kv self size = 800.00 MB
AVX = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
llama_print_timings: load time = 2154.68 ms
llama_print_timings: sample time = 75.88 ms / 256 runs ( 0.30 ms per run)
llama_print_timings: prompt eval time = 5060.58 ms / 23 tokens ( 220.03 ms per token)
llama_print_timings: eval time = 72461.40 ms / 255 runs ( 284.16 ms per run)
llama_print_timings: total time = 77664.50 ms
```
But there is no answer to the question.... Am I supposed to Print() something?
| llama.cpp => model runs fine but bad output | https://api.github.com/repos/langchain-ai/langchain/issues/3241/comments | 4 | 2023-04-20T20:36:45Z | 2023-04-22T16:19:38Z | https://github.com/langchain-ai/langchain/issues/3241 | 1,677,392,515 | 3,241 |
[
"langchain-ai",
"langchain"
] | Got this error while using langchain with llama-index, not sure why it comes up, but currently around 1/10 queries gives this error.
```
> Entering new AgentExecutor chain...
Traceback (most recent call last):
File "/Users/user/crawl/index.py", line 151, in <module>
index()
File "/Users/user/crawl/index.py", line 147, in index
response = agent_chain.run(input=text_input)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/user/crawl/venv/lib/python3.11/site-packages/langchain/chains/base.py", line 216, in run
return self(kwargs)[self.output_keys[0]]
^^^^^^^^^^^^
File "/Users/user/crawl/venv/lib/python3.11/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/user/crawl/venv/lib/python3.11/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
^^^^^^^^^^^^^^^^^^
File "/Users/user/crawl/venv/lib/python3.11/site-packages/langchain/agents/agent.py", line 792, in _call
next_step_output = self._take_next_step(
^^^^^^^^^^^^^^^^^^^^^
File "/Users/user/crawl/venv/lib/python3.11/site-packages/langchain/agents/agent.py", line 672, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/user/crawl/venv/lib/python3.11/site-packages/langchain/agents/agent.py", line 385, in plan
return self.output_parser.parse(full_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/user/crawl/venv/lib/python3.11/site-packages/langchain/agents/conversational/output_parser.py", line 19, in parse
raise ValueError(f"Could not parse LLM output: `{text}`")
ValueError: Could not parse LLM output: `Sure! query_configs is a list of dictionaries that define the parameters for each query in llama-index. Each dictionary contains the following keys: "name", "query_mode", and "query_kwargs". The "name" key is a string that identifies the query, the "query_mode" key is a string that specifies the type of query, and the "query_kwargs" key is a dictionary that contains additional parameters for the query.
For example, you can define a query that uses the k-nearest neighbors algorithm with a k value of 5 and cosine similarity metric, or a query that uses the BM25 algorithm with k1=1.2 and b=0.75. These queries can be used to retrieve relevant documents from the index based on a given query.`
``` | Error: raise ValueError(f"Could not parse LLM output: `{text}`") | https://api.github.com/repos/langchain-ai/langchain/issues/3240/comments | 2 | 2023-04-20T19:55:39Z | 2023-09-10T16:29:55Z | https://github.com/langchain-ai/langchain/issues/3240 | 1,677,327,850 | 3,240 |
[
"langchain-ai",
"langchain"
] | Sorry for so messy one, but is there any way to make Image Capture definitions more detailed / Use another module to explain what objects does the picture has with color definitions, etc.? My dummy code look just like in example, but it looks like image capture processor is quite lightweight :[
| Is there any way to make image caption descriptor more detailed? | https://api.github.com/repos/langchain-ai/langchain/issues/3238/comments | 1 | 2023-04-20T18:52:37Z | 2023-09-10T16:30:00Z | https://github.com/langchain-ai/langchain/issues/3238 | 1,677,245,360 | 3,238 |
[
"langchain-ai",
"langchain"
] | - in `BaseLoader` we don't have a limit on the number of loaded Documents.
- in `BaseRetriever` we also don't have a limit.
- in VectorStoreRetriever we also don't have a limit in the `get_relevant_documents`
- in `VectorStore` we do have a limit in the `search`-es. So we are OK here.
- in `utilities`, it looks like we don't have limits in most of them.
It could easily crash a loading or search operation.
A big limit makes sense when we download documents from external sources and upload documents in DBs and vector stores.
A small limit makes sense when we prepare prompts. | no limits on number of loaded/searched Documents | https://api.github.com/repos/langchain-ai/langchain/issues/3235/comments | 1 | 2023-04-20T16:59:46Z | 2023-09-10T16:30:05Z | https://github.com/langchain-ai/langchain/issues/3235 | 1,677,092,640 | 3,235 |
[
"langchain-ai",
"langchain"
] | The [conversational_chat](https://github.com/hwchase17/langchain/blob/master/langchain/agents/conversational_chat/base.py#L58) agent takes the following args for `create_prompt`
```py
def create_prompt(
cls,
tools: Sequence[BaseTool],
system_message: str = PREFIX,
human_message: str = SUFFIX,
input_variables: Optional[List[str]] = None,
output_parser: Optional[BaseOutputParser] = None,
) -> BasePromptTemplate:
```
While the [conversational](https://github.com/hwchase17/langchain/blob/master/langchain/agents/conversational/base.py#L46) agent takes the following:
```py
def create_prompt(
cls,
tools: Sequence[BaseTool],
prefix: str = PREFIX,
suffix: str = SUFFIX,
format_instructions: str = FORMAT_INSTRUCTIONS,
ai_prefix: str = "AI",
human_prefix: str = "Human",
input_variables: Optional[List[str]] = None,
) -> PromptTemplate:
```
Given the similarities in these agents, I would expect to pass the same args for initializing them. There should at least be an optional `prefix`, `suffix` arg available in `conversational_chat` where it can take whichever is defined.
Ex:
```py
prefix_arg = prefix || system_message
suffix_arg = suffix || human_message
``` | Standardize input args for `conversational` and `conversational_chat` agents | https://api.github.com/repos/langchain-ai/langchain/issues/3234/comments | 2 | 2023-04-20T16:29:33Z | 2023-10-12T16:10:14Z | https://github.com/langchain-ai/langchain/issues/3234 | 1,677,052,146 | 3,234 |
[
"langchain-ai",
"langchain"
] | langchain Version : 0.0.144
python:3.9+
code:
```
callback_handler = AsyncIteratorCallbackHandler()
callback_manager = AsyncCallbackManager([callback_handler])
llm = OpenAI(callback_manager=callback_manager, streaming=True, verbose=True, temperature=0.7)
message_history = RedisChatMessageHistory(conversation_id, url=CHAT_REDIS_URL, ttl=600)
systemPrompt ="""
The following is a friendly conversation between a human and an AI.
The AI is talkative and provides lots of specific details from its context.
If the AI does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
"""
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(systemPrompt),
MessagesPlaceholder(variable_name="message_history"),
HumanMessagePromptTemplate.from_template("{input}")
])
memory = ConversationSummaryBufferMemory(llm=llm, memory_key="message_history", chat_memory=message_history, return_messages=True, max_token_limit=10)
conversation_with_summary = ConversationChain(callback_manager=callback_manager, llm=llm, prompt=prompt, memory=memory, verbose=True)
await conversation_with_summary.apredict(input=userprompt)
```
desired goal :Expected goal: First, summarize the information and then call the openai API
response result :
```
outputs++++++++++++++++++++: {'response': '\nAI: \nAI: \nAI: \nAI: \nAI: \nAI: \nAI: \nAI: \nAI: \nAI: \nAI: \nAI: \n\n夏日的阳光照耀着大地,\n湖水清澈闪耀着璀璨,\n芳草的气息拂面而来,\n鸟儿在枝头欢快歌唱,\n蝴蝶在花丛里翩翩起舞,\n野花绽放着五彩缤纷,\n夏日的温暖让心情更美好,\n让我们收获美'}
Pruning buffer 2741
Pruning buffer 2720
Pruning buffer 2551
Pruning buffer 2530
Pruning buffer 2340
Pruning buffer 2319
Pruning buffer 2103
Pruning buffer 2082
Pruning buffer 1866
Pruning buffer 1845
Pruning buffer 1611
Pruning buffer 1590
Pruning buffer 1359
Pruning buffer 1338
Pruning buffer 1104
Pruning buffer 1083
Pruning buffer 837
Pruning buffer 816
Pruning buffer 557
Pruning buffer 536
Pruning buffer 280
Pruning buffer 259
Pruned memory [HumanMessage(content='写一首关于夏天的诗吧', additional_kwargs={}), AIMessage(content='\n\nAI: 当夏日火热时,\n植物把清凉带来,\n树叶轻轻摇摆,\n空气满怀温柔,\n日落美景让心欢喜,\n夜晚星光照亮乐园,\n热浪席卷空气中,\n让人心中充满惬意。', additional_kwargs={})]
outputs: {'text': "\nThe AI responds to a human's request to write a poem about summer by describing a scene of a sunny day, with birds singing, butterflies dancing, clear waters reflecting the sky, and flowers blooming, which brings warmth and beauty to everyone's heart and soul, with sweet memories to cherish."}
moving_summary_buffer
The AI responds to a human's request to write a poem about summer by describing a scene of a sunny day, with birds singing, butterflies dancing, clear waters reflecting the sky, and flowers blooming, which brings warmth and beauty to everyone's heart and soul, with sweet memories to cherish.
```
| ConversationSummaryBufferMemory did not meet expectations during asynchronous code execution | https://api.github.com/repos/langchain-ai/langchain/issues/3230/comments | 0 | 2023-04-20T15:52:02Z | 2023-04-21T08:16:50Z | https://github.com/langchain-ai/langchain/issues/3230 | 1,676,995,455 | 3,230 |
[
"langchain-ai",
"langchain"
] | Reposting from [Discord Thread](https://discord.com/channels/1038097195422978059/1079490798929858651/1098396255740248134):
Hey y'all! I'm trying to hack the `CustomCalculatorTool` so that I can pass in an LLM with a pre-loaded API key (I have a use case where I need to use seperate LLM instances with their own API keys). This is what I got so far:
```llm1 = ChatOpenAI(temperature=0, openai_api_key=openai_api_key1)
llm2 = ChatOpenAI(temperature=0, openai_api_key=openai_api_key2)
class CalculatorInput(BaseModel):
query: str = Field(description="should be a math expression")
# api_key: str = Field(description="should be a valid OpenAI key")
llm: ChatOpenAI = Field(description="should be a valid ChatOpenAI")
class CustomCalculatorTool(BaseTool):
name = "Calculator"
description = "useful for when you need to answer questions about math"
args_schema=CalculatorInput
def _run(self, query: str, llm: ChatOpenAI) -> str:
"""Use the tool."""
llm_chain = LLMMathChain(llm=llm, verbose=True)
return llm_chain.run(query)
async def _arun(self, query: str) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("BingSearchRun does not support async")
tools = [CustomCalculatorTool()]
agent = initialize_agent(tools, llm1, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run(query="3+3",llm=llm2)```
Notice the seperate LLM's. I get an error about `ValueError: Missing some input keys: {'input'}`
I guess, is my logic for passing API keys to LLM's correct here? I'm not super familiar with pydantic, but I've tried a few things and I get errors that complain about `ValueError: run supports only one positional argument.` or that later on when I invoke this in a custom class (I took a step back to work out the docs example)
I see a lot of the pre-made tools use a wrapper to contain the llm:
```class WikipediaQueryRun(BaseTool):
"""Tool that adds the capability to search using the Wikipedia API."""
name = "Wikipedia"
description = (
"A wrapper around Wikipedia. "
"Useful for when you need to answer general questions about "
"people, places, companies, historical events, or other subjects. "
"Input should be a search query."
)
api_wrapper: WikipediaAPIWrapper
def _run(self, query: str) -> str:
"""Use the Wikipedia tool."""
return self.api_wrapper.run(query)
async def _arun(self, query: str) -> str:
"""Use the Wikipedia tool asynchronously."""
raise NotImplementedError("WikipediaQueryRun does not support async")```
I tried implementing my own but it's not working great:
```class CustomCalculatorWrapper(BaseModel):
"""Wrapper around CustomCalculator.
"""
name: str = "CustomCalculator"
description = "A wrapper around CustomCalculator."
api_key: str
llm_math_chain: Any #: :meta private:
class Config:
"""Configuration for this pydantic object."""
extra = Extra.forbid
@root_validator()
def validate_environment(cls, values: Dict) -> Dict:
"""Validate that api key and python package exists in environment."""
api_key = get_from_dict_or_env(
values, "api_key", "api_key"
)
print("api_key", api_key)
values["api_key"] = api_key
print(values)
try:
llm = LLMChatWrapper(values["api_key"])
llm_math_chain = LLMMathChain(llm=llm.llmchat, verbose=True)
except:
print("Your LLM won't load bro")
values["llm_math_chain"] = llm_math_chain
return values
def run(self, query: str) -> str:
"""Use the tool."""
print("input to _run inside of wrapper class", query)
return self.llm_math_chain.run(query)```
I'm able to run it just fine using `CustomCalculatorWrapper(api_key=openai_api_key).run("3+3")`, but when I try to give it to my agent like this:
```agent = initialize_agent(CustomCalculatorTool(CustomCalculatorWrapper(openai_api_key)), llm1, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)```
I get `TypeError: __init__() takes exactly 1 positional argument (2 given)`
My custom calculator class looks like this:
```class CustomCalculatorTool(BaseTool):
name = "Calculator"
description = "useful for when you need to answer questions about math"
args_schema = CalculatorInput
wrapper = CustomCalculatorWrapper
def _run(self, query: str) -> str:
"""Use the tool."""
print("input to _run inside of custom tool", query)
return self.wrapper.run(query)
async def _arun(self, query: str) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("BingSearchRun does not support async")``` | Custom Calculator Tool | https://api.github.com/repos/langchain-ai/langchain/issues/3228/comments | 2 | 2023-04-20T15:16:00Z | 2023-04-24T16:48:39Z | https://github.com/langchain-ai/langchain/issues/3228 | 1,676,935,127 | 3,228 |
[
"langchain-ai",
"langchain"
] | Hello, currently facing exception trying to call `ConversationalRetrievalChain` with `chroma` as retriever in async mode.
```python
chain = ConversationalRetrievalChain.from_llm(
self.llm,
chain_type="stuff",
retriever=conn.as_retriever(**kwargs),
verbose=True,
memory=memory,
get_chat_history=get_chat_history,
)
chain._acall({"question": query, "chat_history": memory})
```
I want to implement that method to allow to use `chroma` in async mode.
Could somebody assign me? =) | Chroma asimilarity_search NotImplementedError | https://api.github.com/repos/langchain-ai/langchain/issues/3226/comments | 1 | 2023-04-20T13:19:37Z | 2023-04-21T18:12:53Z | https://github.com/langchain-ai/langchain/issues/3226 | 1,676,713,536 | 3,226 |
[
"langchain-ai",
"langchain"
] | When executing AutoGPT where I am using Azure OpenAI as LLM I am getting following error:
213 return self(args[0])[self.output_keys[0]]
215 if kwargs and not args:
--> 216 return self(kwargs)[self.output_keys[0]]
218 raise ValueError(
219 f"`run` supported with either positional arguments or keyword arguments"
220 f" but not both. Got args: {args} and kwargs: {kwargs}."
221 )
...
--> 329 assert d == self.d
331 assert k > 0
333 if D is None:
AssertionError: | AssertionError AutoGPT with Azure OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/3221/comments | 1 | 2023-04-20T11:12:40Z | 2023-09-10T16:30:10Z | https://github.com/langchain-ai/langchain/issues/3221 | 1,676,515,527 | 3,221 |
[
"langchain-ai",
"langchain"
] | Any plans to add it into the list of supported backend models? | MiniGPT-4 support | https://api.github.com/repos/langchain-ai/langchain/issues/3219/comments | 2 | 2023-04-20T10:08:52Z | 2023-09-24T16:09:13Z | https://github.com/langchain-ai/langchain/issues/3219 | 1,676,421,442 | 3,219 |
[
"langchain-ai",
"langchain"
] | I've been investigating an error when running agent based example with the Comet callback when trying to save the agent to disk.
I have been able to narrow the bug down to the following reproduction script:
```python
import os
from datetime import datetime
import langchain
from langchain.agents import initialize_agent, load_tools
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler
from langchain.callbacks.base import CallbackManager
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9, verbose=True)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
verbose=True,
)
agent.save_agent("/tmp/langchain.json")
```
Which fails with the following Exception:
```python
Traceback (most recent call last):
File "/home/lothiraldan/project/cometml/langchain/docs/ecosystem/test_comet_ml_3.py", line 39, in <module>
agent.save_agent("/tmp/langchain.json")
File "/home/lothiraldan/project/cometml/langchain/langchain/agents/agent.py", line 599, in save_agent
return self.agent.save(file_path)
File "/home/lothiraldan/project/cometml/langchain/langchain/agents/agent.py", line 145, in save
agent_dict = self.dict()
File "/home/lothiraldan/project/cometml/langchain/langchain/agents/agent.py", line 119, in dict
_dict = super().dict()
File "pydantic/main.py", line 435, in pydantic.main.BaseModel.dict
File "pydantic/main.py", line 833, in _iter
File "pydantic/main.py", line 708, in pydantic.main.BaseModel._get_value
File "/home/lothiraldan/project/cometml/langchain/langchain/schema.py", line 381, in dict
output_parser_dict["_type"] = self._type
File "/home/lothiraldan/project/cometml/langchain/langchain/schema.py", line 376, in _type
raise NotImplementedError
NotImplementedError
```
Using that reproduction script, I was able to run git bisect that identified the following commit as the probable cause: https://github.com/hwchase17/langchain/commit/e12e00df12c6830cd267df18e96fda1ef8df6c7a
I am not sure of the scope of that issue and if it's mean that no agent can be exported to JSON or YAML since then.
Let me know if I can help more on debugging that issue. | Bug in saving agent since version v0.0.142 | https://api.github.com/repos/langchain-ai/langchain/issues/3217/comments | 4 | 2023-04-20T09:52:27Z | 2023-05-11T08:27:59Z | https://github.com/langchain-ai/langchain/issues/3217 | 1,676,392,876 | 3,217 |
[
"langchain-ai",
"langchain"
] | Is there a way we can add Time To live when storing vectors in Redis? If there isn't is there a plan to add it in the future? | Adding Time To Live on Redis Vector Store Index | https://api.github.com/repos/langchain-ai/langchain/issues/3213/comments | 5 | 2023-04-20T08:49:57Z | 2023-09-24T16:09:18Z | https://github.com/langchain-ai/langchain/issues/3213 | 1,676,287,491 | 3,213 |
[
"langchain-ai",
"langchain"
] | oduleNotFoundError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_13968\1686623477.py in <module>
----> 1 from langchain.document_loaders import UnstructuredFileLoader
2 from langchain.embeddings.huggingface import HuggingFaceEmbeddings
3 from langchain.vectorstores import FAISS
ModuleNotFoundError: No module named 'langchain.document_loaders'
| No module named 'langchain.document_loaders' | https://api.github.com/repos/langchain-ai/langchain/issues/3210/comments | 9 | 2023-04-20T06:36:41Z | 2024-06-08T16:07:06Z | https://github.com/langchain-ai/langchain/issues/3210 | 1,676,090,163 | 3,210 |
[
"langchain-ai",
"langchain"
] | In the GPT4All, the prompts/contexts are always printed out on the console.
Is there any argument to set if a prompt echos or not on the console?
I supposed it was `echo`, yet, whether it is `True` or `False`, the prompts/contexts were stdout.
Setup
```
from langchain.llms import GPT4All
llm = GPT4All(model=model_path, echo=True, ...)
```
Output:
On the console, GPT4All automatically prints the prompts + a model response.
```
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
Human: Hi
Assistant:
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
....
```
Expected Output:
Users control if prompts/contexts are printed out, GPT4All just outputs the corresponding predicted n_tokens.
```
Assistant is a large language model trained by OpenAI.
Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.
Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.
Overall, Assistant is a powerful tool that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist.
Human: Hi
Assistant:
How are you?
Human: ....
Assistant:
...
Human: ...
Assistant:
...
``` | GPT4All: is there an argument to set if a prompt echos on the console? | https://api.github.com/repos/langchain-ai/langchain/issues/3208/comments | 3 | 2023-04-20T04:59:14Z | 2023-09-15T22:12:51Z | https://github.com/langchain-ai/langchain/issues/3208 | 1,676,000,963 | 3,208 |
[
"langchain-ai",
"langchain"
] | For Chinese communication and develop the project I think we could setup a WeChat Group for communicate.
为了中文交流和开发项目我觉得我们可以建立一个微信群来交流,并推动 langchain 中文特性建设。

| langchain For Chinese (langchain 中文交流群) | https://api.github.com/repos/langchain-ai/langchain/issues/3204/comments | 9 | 2023-04-20T04:11:15Z | 2024-01-24T09:54:46Z | https://github.com/langchain-ai/langchain/issues/3204 | 1,675,968,107 | 3,204 |
[
"langchain-ai",
"langchain"
] | I use vectore_db `Chroma` and langchain `RetrievalQA ` to build my docs bot, but every question costs about 16 ~ 17 seconds.
someboby has any ideas? Thanks
here is my code
```python
embeddings = OpenAIEmbeddings()
vector_store = Chroma(persist_directory="docs_db", embedding_function=embeddings)
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 1}),
return_source_documents=True,
verbose=True,
)
result = qa({"query": keyword})
```
I searched in langchain's docs but find no way. and I try count every step
```python
%%time
docs = vector_store.similarity_search(keyword, k=1)
db costs: 2.204489231109619s
%%time
chain = load_qa_with_sources_chain(ChatOpenAI(temperature=0), chain_type="stuff")
llm costs: 5.171542167663574s
``` | RetrievalQA costs long time to get the answer | https://api.github.com/repos/langchain-ai/langchain/issues/3202/comments | 8 | 2023-04-20T04:01:01Z | 2023-09-21T04:09:59Z | https://github.com/langchain-ai/langchain/issues/3202 | 1,675,959,900 | 3,202 |
[
"langchain-ai",
"langchain"
] | I am very interested in the implemention of generative agent. But I am confused by the agent's traits attribute. How the agent exactly holds its traits when interacts with the env and other agents? In the code, I can find the traits attribute only in the method 'get_summary' and the traits is not involved in any llm model.
Thanks. | Question about the Generative Agent implemention | https://api.github.com/repos/langchain-ai/langchain/issues/3196/comments | 1 | 2023-04-20T03:07:09Z | 2023-09-10T16:30:15Z | https://github.com/langchain-ai/langchain/issues/3196 | 1,675,921,889 | 3,196 |
[
"langchain-ai",
"langchain"
] | As a result of several trial for [Add HuggingFace Examples](https://github.com/hwchase17/langchain/commit/c757c3cde45a24e0cd6a3ebe6bb0f8176cae4726), stablelm-tuned-alpha-3b with `"max_length":64` is able to use.
`"max_length":4096` and base 3B, tuned 7B and base 7B even with `"max_length":64` give error.
And, in case of embedding of `HuggingFaceEmbeddings`, it gives error for `chain.run` of `load_qa_chain` even for tubed 3B.
But, I cannot assure either reason, langchain or huggingface because of below message.
```
ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
``` | Only StableLM tuned 3B is available - 0.0.144 | https://api.github.com/repos/langchain-ai/langchain/issues/3194/comments | 1 | 2023-04-20T03:02:46Z | 2023-09-10T16:30:20Z | https://github.com/langchain-ai/langchain/issues/3194 | 1,675,917,037 | 3,194 |
[
"langchain-ai",
"langchain"
] | When I run this notebook: https://python.langchain.com/en/latest/use_cases/autonomous_agents/autogpt.html
I get an error: 'AttributeError: 'Tool' object has no attribute 'args'
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[25], line 1
----> 1 agent.run(["write a weather report for SF today"])
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/agent.py:91](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/agent.py:91), in AutoGPT.run(self, goals)
88 loop_count += 1
90 # Send message to AI, get response
---> 91 assistant_reply = self.chain.run(
92 goals=goals,
93 messages=self.full_message_history,
94 memory=self.memory,
95 user_input=user_input,
96 )
98 # Print Assistant thoughts
99 print(assistant_reply)
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/base.py:216](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/base.py:216), in Chain.run(self, *args, **kwargs)
213 return self(args[0])[self.output_keys[0]]
215 if kwargs and not args:
--> 216 return self(kwargs)[self.output_keys[0]]
218 raise ValueError(
219 f"`run` supported with either positional arguments or keyword arguments"
220 f" but not both. Got args: {args} and kwargs: {kwargs}."
221 )
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/base.py:116](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/base.py:116), in Chain.__call__(self, inputs, return_only_outputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
118 return self.prep_outputs(inputs, outputs, return_only_outputs)
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/base.py:113](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/base.py:113), in Chain.__call__(self, inputs, return_only_outputs)
107 self.callback_manager.on_chain_start(
108 {"name": self.__class__.__name__},
109 inputs,
110 verbose=self.verbose,
111 )
112 try:
--> 113 outputs = self._call(inputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:57](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:57), in LLMChain._call(self, inputs)
56 def _call(self, inputs: Dict[str, Any]) -> Dict[str, str]:
---> 57 return self.apply([inputs])[0]
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:118](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:118), in LLMChain.apply(self, input_list)
116 def apply(self, input_list: List[Dict[str, Any]]) -> List[Dict[str, str]]:
117 """Utilize the LLM generate method for speed gains."""
--> 118 response = self.generate(input_list)
119 return self.create_outputs(response)
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:61](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:61), in LLMChain.generate(self, input_list)
59 def generate(self, input_list: List[Dict[str, Any]]) -> LLMResult:
60 """Generate LLM result from inputs."""
---> 61 prompts, stop = self.prep_prompts(input_list)
62 return self.llm.generate_prompt(prompts, stop)
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:79](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/chains/llm.py:79), in LLMChain.prep_prompts(self, input_list)
77 for inputs in input_list:
78 selected_inputs = {k: inputs[k] for k in self.prompt.input_variables}
---> 79 prompt = self.prompt.format_prompt(**selected_inputs)
80 _colored_text = get_colored_text(prompt.to_string(), "green")
81 _text = "Prompt after formatting:\n" + _colored_text
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/prompts/chat.py:127](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/prompts/chat.py:127), in BaseChatPromptTemplate.format_prompt(self, **kwargs)
126 def format_prompt(self, **kwargs: Any) -> PromptValue:
--> 127 messages = self.format_messages(**kwargs)
128 return ChatPromptValue(messages=messages)
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt.py:40](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt.py:40), in AutoGPTPrompt.format_messages(self, **kwargs)
39 def format_messages(self, **kwargs: Any) -> List[BaseMessage]:
---> 40 base_prompt = SystemMessage(content=self.construct_full_prompt(kwargs["goals"]))
41 time_prompt = SystemMessage(
42 content=f"The current time and date is {time.strftime('%c')}"
43 )
44 used_tokens = self.token_counter(base_prompt.content) + self.token_counter(
45 time_prompt.content
46 )
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt.py:36](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt.py:36), in AutoGPTPrompt.construct_full_prompt(self, goals)
33 for i, goal in enumerate(goals):
34 full_prompt += f"{i+1}. {goal}\n"
---> 36 full_prompt += f"\n\n{get_prompt(self.tools)}"
37 return full_prompt
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:184](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:184), in get_prompt(tools)
178 prompt_generator.add_performance_evaluation(
179 "Every command has a cost, so be smart and efficient. "
180 "Aim to complete tasks in the least number of steps."
181 )
183 # Generate the prompt string
--> 184 prompt_string = prompt_generator.generate_prompt_string()
186 return prompt_string
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:113](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:113), in PromptGenerator.generate_prompt_string(self)
104 """Generate a prompt string.
105
106 Returns:
107 str: The generated prompt string.
108 """
109 formatted_response_format = json.dumps(self.response_format, indent=4)
110 prompt_string = (
111 f"Constraints:\n{self._generate_numbered_list(self.constraints)}\n\n"
112 f"Commands:\n"
--> 113 f"{self._generate_numbered_list(self.commands, item_type='command')}\n\n"
114 f"Resources:\n{self._generate_numbered_list(self.resources)}\n\n"
115 f"Performance Evaluation:\n"
116 f"{self._generate_numbered_list(self.performance_evaluation)}\n\n"
117 f"You should only respond in JSON format as described below "
118 f"\nResponse Format: \n{formatted_response_format} "
119 f"\nEnsure the response can be parsed by Python json.loads"
120 )
122 return prompt_string
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:84](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:84), in PromptGenerator._generate_numbered_list(self, items, item_type)
72 """
73 Generate a numbered list from given items based on the item_type.
74
(...)
81 str: The formatted numbered list.
82 """
83 if item_type == "command":
---> 84 command_strings = [
85 f"{i + 1}. {self._generate_command_string(item)}"
86 for i, item in enumerate(items)
87 ]
88 finish_description = (
89 "use this to signal that you have finished all your objectives"
90 )
91 finish_args = (
92 '"response": "final response to let '
93 'people know you have finished your objectives"'
94 )
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:85](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:85), in (.0)
72 """
73 Generate a numbered list from given items based on the item_type.
74
(...)
81 str: The formatted numbered list.
82 """
83 if item_type == "command":
84 command_strings = [
---> 85 f"{i + 1}. {self._generate_command_string(item)}"
86 for i, item in enumerate(items)
87 ]
88 finish_description = (
89 "use this to signal that you have finished all your objectives"
90 )
91 finish_args = (
92 '"response": "final response to let '
93 'people know you have finished your objectives"'
94 )
File [~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:50](https://file+.vscode-resource.vscode-cdn.net/Users/DrCostco/code/langchain/~/opt/anaconda3/envs/langchain/lib/python3.11/site-packages/langchain/experimental/autonomous_agents/autogpt/prompt_generator.py:50), in PromptGenerator._generate_command_string(self, tool)
48 def _generate_command_string(self, tool: BaseTool) -> str:
49 output = f"{tool.name}: {tool.description}"
---> 50 output += f", args json schema: {json.dumps(tool.args)}"
51 return output
| AutoGPT Implementation: AttributeError: 'Tool' object has no attribute 'args' | https://api.github.com/repos/langchain-ai/langchain/issues/3193/comments | 5 | 2023-04-20T02:07:56Z | 2023-09-24T16:09:28Z | https://github.com/langchain-ai/langchain/issues/3193 | 1,675,875,313 | 3,193 |
[
"langchain-ai",
"langchain"
] | The documentation in the Langchain site and the code repo should point out that you can actually retrieve the vector store from your choice of databases. I thought you couldn't do this and implemented a wrapper to retrieve the values from the database and mapped it to the appropriate langchain class, only to find out a day later through experimenting that you can actually just query it using langchain and it will be mapped to the appropriate class.
The examples in the site documentation always have a similar format to this:
```
db = PGVector.from_documents(
documents=data,
embedding=embeddings,
collection_name=collection_name,
connection_string=connection_string,
distance_strategy=DistanceStrategy.COSINE,
openai_api_key=api_key,
pre_delete_collection=False
)
```
Which is good if you're indexing a document for the first time and adding them in the database. But what if I plan to ask questions to the same document? It'd be time-consuming, and also heavy to keep on indexing the document and adding them all the time to the database.
If I already have a vectorestore on a PGVector database, I can query it with the code below:
```
store = PGVector(
connection_string=connection_string,
embedding_function=embedding,
collection_name=collection_name,
distance_strategy=DistanceStrategy.COSINE
)
retriever = store.as_retriever()
```
And use the `store`, and `retriever` as such with the appropriate chain one may use.
| Documentation should point out how to retrieve a vectorstore already uploaded in a database | https://api.github.com/repos/langchain-ai/langchain/issues/3191/comments | 9 | 2023-04-20T00:51:32Z | 2024-02-13T06:55:04Z | https://github.com/langchain-ai/langchain/issues/3191 | 1,675,822,065 | 3,191 |
[
"langchain-ai",
"langchain"
] | I'm trying to add a tool with the [OpenAPI chain](https://python.langchain.com/en/latest/modules/chains/examples/openapi.html#openapi-chain), and I'm struggling to get API auth working.
A bit about my use case:
- I want to build a ToolKit that takes a prompt and queries an external API (using multiple endpoints of the same API)
- I ideally want to load an OpenAPI schema from a file so the documentation for the endpoint can be passed to the LLM as context
- I need to specify the BaseURL as it's a multi-tenanted API, so I can't use the Server URL from an OpenAPI spec
- I need to add a basic auth header on each request i.e. `Authorization: Basic <token>`
Is Open API chain the right tool?
I've tried the [load_from_spec option](https://python.langchain.com/en/latest/modules/chains/examples/openapi.html#construct-the-chain) but it reads the Base URL from the Open API spec. [All the examples in the docs](https://python.langchain.com/en/latest/modules/chains/examples/openapi.html#construct-the-chain) are for public, unauthenticated API calls as well.
I'd be happy to make a PR to update the docs if this functionality is supported but undocumented, or even try updating the OpenAPI tool if you can point me in the right direction. | Question about OpenAPI chain API auth | https://api.github.com/repos/langchain-ai/langchain/issues/3190/comments | 8 | 2023-04-20T00:38:21Z | 2023-12-15T00:48:36Z | https://github.com/langchain-ai/langchain/issues/3190 | 1,675,815,001 | 3,190 |
[
"langchain-ai",
"langchain"
] | Stability AI issues [StableLM](https://huggingface.co/stabilityai/stablelm-tuned-alpha-7b).
And, llama.cpp & his ggml repo is being updated accordingly as [ggerganov](https://github.com/ggerganov/ggml/tree/stablelm/examples/stablelm).
I hope Langchain will support it soon. | Support StableLM | https://api.github.com/repos/langchain-ai/langchain/issues/3189/comments | 1 | 2023-04-20T00:32:59Z | 2023-04-20T00:42:11Z | https://github.com/langchain-ai/langchain/issues/3189 | 1,675,812,005 | 3,189 |
[
"langchain-ai",
"langchain"
] | The following error indicates to `pip install bs4`. However, to install BeautifulSoup, one should `pip install beautifulsoup4`
Error:
```
File [ENVPATH/lib/python3.10/site-packages/langchain/document_loaders/html_bs.py:26], in BSHTMLLoader.__init__(self, file_path, open_encoding, bs_kwargs)
24 import bs4 # noqa:F401
25 except ImportError:
---> 26 raise ValueError(
27 "bs4 package not found, please install it with " "`pip install bs4`"
28 )
30 self.file_path = file_path
31 self.open_encoding = open_encoding
ValueError: bs4 package not found, please install it with `pip install bs4`
``` | BSHTMLLoader Incorrect error message; bs4 -> beautifulsoup4 | https://api.github.com/repos/langchain-ai/langchain/issues/3188/comments | 1 | 2023-04-20T00:21:09Z | 2023-04-24T19:59:20Z | https://github.com/langchain-ai/langchain/issues/3188 | 1,675,804,485 | 3,188 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.