
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.46B | issue_number int64 1 127k |
|---|---|---|---|---|---|---|---|---|---|
[
"langchain-ai",
"langchain"
] | [from the notebook ](https://github.com/hwchase17/langchain/blob/master/docs/modules/models/llms/examples/streaming_llm.ipynb
) It says: LangChain provides streaming support for LLMs. Currently, we support streaming for the OpenAI, ChatOpenAI. and Anthropic implementations, but streaming support for other LLM implementations is on the roadmap.
I am more interested in using the commercially open-source LLM available on Hugging Face, such as Dolly V2. I am wondering whether LangChain has plans to include streaming support for Hugging Face's LLM in their roadmap. Additionally, is there any timeline for its integration? Thank you. | streaming support for LLM, from huggingface | https://api.github.com/repos/langchain-ai/langchain/issues/2918/comments | 15 | 2023-04-14T22:32:37Z | 2024-08-02T11:45:30Z | https://github.com/langchain-ai/langchain/issues/2918 | 1,669,020,416 | 2,918 |
[
"langchain-ai",
"langchain"
] | SQLDatabaseToolkit is not currently working.
Se errors attached.
This is the code that creates the errors:
```
llm = AzureChatOpenAI(deployment_name="gpt-4",temperature=0, max_tokens=500)
db = SQLDatabase.from_uri(db_url)
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(llm=llm,toolkit=toolkit,verbose=True)
```
<img width="572" alt="Screenshot 2023-04-14 154708" src="https://user-images.githubusercontent.com/2685728/232151658-bf3c188c-0ae2-4bff-93fc-e553123c7d0e.png">
And if if I add the llm parameter to the toolkit:
```
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
agent_executor = create_sql_agent(llm=llm,toolkit=toolkit,verbose=True)
```
this is the error
<img width="472" alt="Screenshot 2023-04-14 154906" src="https://user-images.githubusercontent.com/2685728/232151917-252168d0-6d4c-443e-8cfe-b08604b8c4b0.png">
| SQLDatabaseToolkit not working | https://api.github.com/repos/langchain-ai/langchain/issues/2914/comments | 10 | 2023-04-14T20:52:02Z | 2023-09-21T17:07:42Z | https://github.com/langchain-ai/langchain/issues/2914 | 1,668,936,333 | 2,914 |
[
"langchain-ai",
"langchain"
] | those files may be `node_modules` or `.pycache` files or sensitive env files, all of which should be ignored by default | Ignore files from `.gitignore` in Git loader | https://api.github.com/repos/langchain-ai/langchain/issues/2905/comments | 0 | 2023-04-14T17:08:38Z | 2023-04-14T22:02:23Z | https://github.com/langchain-ai/langchain/issues/2905 | 1,668,624,936 | 2,905 |
[
"langchain-ai",
"langchain"
] | I encountered a bug when using PromptLayerOpenAI. The code works as intended only when `model_name` parameter is set to `text-davinci-003`. When a different model is specified, an error message is returned.
This works:
```python
chain = load_qa_chain(PromptLayerOpenAI(
temperature=0,
model_name="text-davinci-003",
pl_tags=["tag1", "tag2"]
), chain_type="stuff", memory=memory, prompt=prompt)
```
This does not work:
```python
chain = load_qa_chain(PromptLayerOpenAI(
temperature=0,
model_name="gpt-3.5-turbo", # <== cause of error
pl_tags=["jwheeler", "contractqa"]
), chain_type="stuff", memory=memory, prompt=prompt)
```
The error message:
```bash
openai.error.InvalidRequestError: Unrecognized request argument supplied: pl_tags
```
| PromptLayerOpenAI throws an error when any model other than `text-davinci-003` is passed to the `model_name` parameter | https://api.github.com/repos/langchain-ai/langchain/issues/2903/comments | 3 | 2023-04-14T16:13:25Z | 2023-11-14T16:09:34Z | https://github.com/langchain-ai/langchain/issues/2903 | 1,668,543,593 | 2,903 |
[
"langchain-ai",
"langchain"
] | When use agent to answer question **"Who is Leo DiCaprio's current girlfriend? What is her current age raised to the 0.43 power?"**
I saw openAI gives the following initial reply:
```
I should use Google Search to find out who is Leo DiCaprio's current girlfriend. For the second part of the question, I should use the calculator to calculate her age raised to the 0.43 power.
Action 1: Google Search
Action 1 Input: "Leo DiCaprio current girlfriend"
```
Instead of **"Action"** and **"Action Input"** keywords, we have **"Action 1"** and **"Action 1 Input"** instead.
The regex in langchain/agents/mrkl/base.py:
**regex = r"Action: (.*?)[\n]*Action Input:[\s]*(.*)"**
is better to be changed to
**regex = r"Action.*?: (.*?)[\n]*Action.*? Input:[\s]*(.*)"**
In order to avoid tool not found error. | regex in langchain/agents/mrkl/base.py | https://api.github.com/repos/langchain-ai/langchain/issues/2898/comments | 4 | 2023-04-14T15:15:34Z | 2023-09-18T16:20:03Z | https://github.com/langchain-ai/langchain/issues/2898 | 1,668,448,881 | 2,898 |
[
"langchain-ai",
"langchain"
] | Could not parse LLM output: I'm not familiar with "bla". Would you like me to search for more information on it?
```
Traceback (most recent call last):
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/chat/base.py", line 50, in _extract_tool_and_input
_, action, _ = text.split("```")
ValueError: not enough values to unpack (expected 3, got 1)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/Caskroom/miniconda/base/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/Caskroom/miniconda/base/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/__main__.py", line 39, in <module>
cli.main()
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 430, in main
run()
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 284, in run_file
runpy.run_path(target, run_name="__main__")
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 321, in run_path
return _run_module_code(code, init_globals, run_name,
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 135, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 124, in _run_code
exec(code, run_globals)
File "/Users/admin/Projects/kbgpt/mrkl_chat.py", line 37, in <module>
raise e
File "/Users/admin/Projects/kbgpt/mrkl_chat.py", line 35, in <module>
mrkl.run(txt)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 812, in _call
next_step_output = self._take_next_step(
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 692, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 403, in plan
action = self._get_next_action(full_inputs)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 365, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/chat/base.py", line 55, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {text}")
ValueError: Could not parse LLM output: I'm not sure what you mean by "bla". Can you please provide more context or clarify your question?
``` | ChatAgent gets "Would you like me to search for more information on it?" instead of Action: or FinalAnswer: | https://api.github.com/repos/langchain-ai/langchain/issues/2896/comments | 1 | 2023-04-14T14:51:47Z | 2023-09-10T16:33:29Z | https://github.com/langchain-ai/langchain/issues/2896 | 1,668,400,538 | 2,896 |
[
"langchain-ai",
"langchain"
] | We're working on an implementation for a vector store using the GCP Matching Engine.
We'll be contributing the implementation.
If you have any questions or suggestions please contact me (@tomaspiaggio) or @scafati98. | GCP Matching Engine as Vector Store | https://api.github.com/repos/langchain-ai/langchain/issues/2892/comments | 5 | 2023-04-14T13:58:38Z | 2023-08-07T23:53:24Z | https://github.com/langchain-ai/langchain/issues/2892 | 1,668,302,654 | 2,892 |
[
"langchain-ai",
"langchain"
] | Can do REST with OpenAPI? But what about GQL? Possible even? | How GraphQL? | https://api.github.com/repos/langchain-ai/langchain/issues/2891/comments | 8 | 2023-04-14T13:58:14Z | 2023-10-30T16:07:48Z | https://github.com/langchain-ai/langchain/issues/2891 | 1,668,301,661 | 2,891 |
[
"langchain-ai",
"langchain"
] | I guess it just need to return the text when it can't parse the action as triple tilt wrapped json?
```python
from langchain import LLMMathChain, OpenAI
from langchain.agents import AgentType, Tool, initialize_agent
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores.redis import Redis
from config import *
llm = ChatOpenAI(temperature=0, verbose=True)
llm1 = OpenAI(temperature=0)
llm_math_chain = LLMMathChain(llm=llm1, verbose=True)
rds = Redis.from_existing_index(
redis_url=REDIS_URL,
index_name=CUSTOMER_SERVICE_INDEX,
embedding=OpenAIEmbeddings(),
).as_retriever(k=1)
tools = [
Tool(
name="Search",
func=lambda x: "\n\n".join(d.page_content for d in rds.get_relevant_documents(query=x)),
description="useful for when you need to answer questions. the input to this should be a single search term.",
)
]
mrkl = initialize_agent(tools, llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
while True:
txt = input("Enter a question: ")
mrkl.run(txt)
```
```
Traceback (most recent call last):
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/chat/base.py", line 50, in _extract_tool_and_input
_, action, _ = text.split("```")
ValueError: not enough values to unpack (expected 3, got 1)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/Caskroom/miniconda/base/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/Caskroom/miniconda/base/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/__main__.py", line 39, in <module>
cli.main()
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 430, in main
run()
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/adapter/../../debugpy/launcher/../../debugpy/../debugpy/server/cli.py", line 284, in run_file
runpy.run_path(target, run_name="__main__")
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 321, in run_path
return _run_module_code(code, init_globals, run_name,
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 135, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "/Users/admin/.vscode/extensions/ms-python.python-2023.6.0/pythonFiles/lib/python/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_runpy.py", line 124, in _run_code
exec(code, run_globals)
File "/Users/admin/Projects/kbgpt/mrkl_chat.py", line 30, in <module>
mrkl.run(txt)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/chains/base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/chains/base.py", line 116, in __call__
raise e
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/chains/base.py", line 113, in __call__
outputs = self._call(inputs)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 812, in _call
next_step_output = self._take_next_step(
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 692, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 403, in plan
action = self._get_next_action(full_inputs)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/agent.py", line 365, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
File "/Users/admin/Library/Caches/pypoetry/virtualenvs/kbgpt-I7QBBX8f-py3.10/lib/python3.10/site-packages/langchain/agents/chat/base.py", line 55, in _extract_tool_and_input
raise ValueError(f"Could not parse LLM output: {text}")
ValueError: Could not parse LLM output: I was not able to find the answer. Maybe there is no public information available on HDFC's current market cap.
``` | ValueError when it can not find an answer in the MRKL chat agent. | https://api.github.com/repos/langchain-ai/langchain/issues/2890/comments | 0 | 2023-04-14T13:51:06Z | 2023-04-14T14:49:16Z | https://github.com/langchain-ai/langchain/issues/2890 | 1,668,289,225 | 2,890 |
[
"langchain-ai",
"langchain"
] | I have been working with [BunJS](https://bun.sh) runtime and decided to try langchain with it.
I also noted in documentation that there are some supported runtimes...
It seems that it is not fully compatible with Bun... It imports, instantiates the model, but doesn't execute it.
Am I doing something wrong?
```javascript
import { OpenAI } from "langchain/llms/openai";
console.log("imported");
const model = new OpenAI({ openAIApiKey: "sk-...", temperature: 0.7 });
console.log("model created")
const res = await model.call(
"What would be a good company name a company that makes colorful socks?"
);
console.log(res);
```
Running the example:
```shell
% bun index.ts
imported
model created
38 | const PQueue = "default" in PQueueMod ? PQueueMod.default : PQueueMod;
39 | this.queue = new PQueue({ concurrency: this.maxConcurrency });
40 | }
41 | // eslint-disable-next-line @typescript-eslint/no-explicit-any
42 | call(callable, ...args) {
43 | return this.queue.add(() => pRetry(() => callable(...args).catch((error) => {
^
TypeError: undefined is not a function (near '...this.queue.add...')
at call (/Users/luismal/Projects/bunjs+langchainjs/node_modules/langchain/dist/util/async_caller.js:43:15)
at /Users/luismal/Projects/bunjs+langchainjs/node_modules/langchain/dist/llms/openai.js:312:15
at completionWithRetry (/Users/luismal/Projects/bunjs+langchainjs/node_modules/langchain/dist/llms/openai.js:300:30)
at /Users/luismal/Projects/bunjs+langchainjs/node_modules/langchain/dist/llms/openai.js:270:24
at _generate (/Users/luismal/Projects/bunjs+langchainjs/node_modules/langchain/dist/llms/openai.js:204:20)
at /Users/luismal/Projects/bunjs+langchainjs/node_modules/langchain/dist/llms/base.js:43:27
``` | [Feature Request] BunJs Support | https://api.github.com/repos/langchain-ai/langchain/issues/2888/comments | 2 | 2023-04-14T12:26:34Z | 2023-04-14T17:29:44Z | https://github.com/langchain-ai/langchain/issues/2888 | 1,668,159,936 | 2,888 |
[
"langchain-ai",
"langchain"
] | I have fine tuned curie model of OPEN AI on sample text data and i used that model in
llm = OpenAI(
temperature=0.7,
openai_api_key='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',
model_name="curie:ft-personal-2023-03-31-05-59-15"#"text-davinci-003"#""#'' # can be used with llms like 'gpt-3.5-turbo'
)
after run the script i am getting an error
ValueError: Unknown model: curie:ft-personal-2023-03-31-05-59-15. Please provide a valid OpenAI model name.Known models are: gpt-4, gpt-4-0314, gpt-4-completion, gpt-4-0314-completion, gpt-4-32k, gpt-4-32k-0314, gpt-4-32k-completion, gpt-4-32k-0314-completion, gpt-3.5-turbo, gpt-3.5-turbo-0301, text-ada-001, ada, text-babbage-001, babbage, text-curie-001, curie, text-davinci-003, text-davinci-002, code-davinci-002
i have give a correct name of fine tune model. what is the issue. can anyone help me to solve this? | About fine tune model | https://api.github.com/repos/langchain-ai/langchain/issues/2887/comments | 2 | 2023-04-14T10:54:55Z | 2023-05-23T18:18:05Z | https://github.com/langchain-ai/langchain/issues/2887 | 1,668,028,067 | 2,887 |
[
"langchain-ai",
"langchain"
] | HI,
I am getting this error. Sounds like normal pronlem, anyone can halp?
TypeError: 'FAISS' object is not callable
Traceback:
File "D:\mk\python\Lib\site-packages\streamlit\runtime\scriptrunner\script_runner.py", line 565, in _run_script
exec(code, module.__dict__)
File "D:\mk\python\ready cody\Zkoušení\CHAT_WITH_DATA\main.py", line 65, in <module>
docs = vectorstore(user_input)
^^^^^^^^^^^^^^^^^^^^^^^ | TypeError: 'FAISS' object is not callable | https://api.github.com/repos/langchain-ai/langchain/issues/2881/comments | 3 | 2023-04-14T06:05:13Z | 2023-09-10T16:33:34Z | https://github.com/langchain-ai/langchain/issues/2881 | 1,667,566,366 | 2,881 |
[
"langchain-ai",
"langchain"
] | `import os
import time
import gptcache
from gptcache.processor.pre import get_prompt
from gptcache.manager.factory import get_data_manager
from langchain.cache import GPTCache, SQLiteCache
from gptcache.manager import get_data_manager, CacheBase, VectorBase
from gptcache import Cache
from gptcache.embedding import Onnx
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
from langchain.llms import OpenAI
import langchain
import openai
from decouple import config
os.environ["OPENAI_API_KEY"] = config("OPENAI_API_KEY")
openai.api_base = config("OPENAI_API_BASE")
llm = OpenAI(model_name="text-davinci-002", n=1, best_of=1)
i = 0
file_prefix = "data_map"
llm_cache = Cache()
def init_gptcache_map(cache_obj: gptcache.Cache):
global i
cache_path = f'{file_prefix}_{i}.txt'
onnx = Onnx()
cache_base = CacheBase('sqlite')
vector_base = VectorBase('faiss', dimension=onnx.dimension)
data_manager = get_data_manager(cache_base, vector_base, max_size=10, clean_size=2)
cache_obj.init(
pre_embedding_func=get_prompt,
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
i += 1
langchain.llm_cache = GPTCache(init_gptcache_map)
llm("Tell me a joke")
`
error:
`Traceback (most recent call last):
File "D:\chat-main\tt.py", line 43, in <module>
llm("Tell me a joke")
File "D:\chat-main\venv\Lib\site-packages\langchain\llms\base.py", line 246, in __call__
return self.generate([prompt], stop=stop).generations[0][0].text
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\chat-main\venv\Lib\site-packages\langchain\llms\base.py", line 161, in generate
llm_output = update_cache(
^^^^^^^^^^^^^
File "D:\chat-main\venv\Lib\site-packages\langchain\llms\base.py", line 51, in update_cache
langchain.llm_cache.update(prompt, llm_string, result)
File "D:\chat-main\venv\Lib\site-packages\langchain\cache.py", line 255, in update
return adapt(
^^^^^^
File "D:\chat-main\venv\Lib\site-packages\gptcache\adapter\adapter.py", line 22, in adapt
embedding_data = time_cal(
^^^^^^^^^
File "D:\chat-main\venv\Lib\site-packages\gptcache\__init__.py", line 25, in inner
res = func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\chat-main\venv\Lib\site-packages\gptcache\embedding\onnx.py", line 58, in to_embeddings
ort_outputs = self.ort_session.run(None, ort_inputs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Program Files (x86)\Python311\Lib\site-packages\onnxruntime\capi\onnxruntime_inference_collection.py", line 200, in run
return self._sess.run(output_names, input_feed, run_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
onnxruntime.capi.onnxruntime_pybind11_state.InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Unexpected input data type. Actual: (tensor(int32)) , expected: (tensor(int64))` | GPTCache similarity caching code example encountered an error during execution. | https://api.github.com/repos/langchain-ai/langchain/issues/2879/comments | 9 | 2023-04-14T05:54:25Z | 2024-07-01T08:03:52Z | https://github.com/langchain-ai/langchain/issues/2879 | 1,667,553,784 | 2,879 |
[
"langchain-ai",
"langchain"
] | The `RecursiveTextSplitter` creates a list of strings.
The `CharacterTextSplitter` creates a list of `langchain.schema.Document`
The `Pinecone.from_documents() `loader seems to expect a list of `langchain.schema.Document`
As such, if you try to feed it a "documents" object created by the RecursiveTextSplitter, you get this error:
```
--> 181 texts = [d.page_content for d in documents]
AttributeError: 'str' object has no attribute 'page_content'
```
This is a bug on the RecursiveTextSplitter, right? | RecursiveTextSplitter creates a list of strings that don't play well with Pinecone.from_documents() | https://api.github.com/repos/langchain-ai/langchain/issues/2877/comments | 2 | 2023-04-14T05:39:17Z | 2023-09-10T16:33:39Z | https://github.com/langchain-ai/langchain/issues/2877 | 1,667,541,958 | 2,877 |
[
"langchain-ai",
"langchain"
] | In Agents -> loading.py on line 40 there is a redundant piece of code.
```
if config_type not in AGENT_TO_CLASS:
raise ValueError(f"Loading {config_type} agent not supported")
``` | Redundunt piece of code | https://api.github.com/repos/langchain-ai/langchain/issues/2874/comments | 2 | 2023-04-14T05:28:42Z | 2023-09-10T16:33:44Z | https://github.com/langchain-ai/langchain/issues/2874 | 1,667,533,910 | 2,874 |
[
"langchain-ai",
"langchain"
] | Here's what I tried:
`import os
os.environ["COHERE_API_KEY"] = ""
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms import Cohere
from langchain.agents import AgentExecutor
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=Cohere(temperature=0, model="xlarge"),
toolkit=toolkit,
verbose=True
)
agent_executor.run("Give me the most popular artist and the dollar amount the customers spent on this artist")`
The error I received:
`File "/usr/local/lib/python3.9/site-packages/langchain/tools/sql_database/tool.py", line 85, in <lambda>
llm=OpenAI(temperature=0),
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for OpenAI
__root__
Did not find openai_api_key, please add an environment variable `OPENAI_API_KEY` which contains it, or pass `openai_api_key` as a named parameter. (type=value_error)`
| sqlagent doesn't work when using Cohere LLM | https://api.github.com/repos/langchain-ai/langchain/issues/2866/comments | 5 | 2023-04-14T04:15:56Z | 2023-10-09T16:08:38Z | https://github.com/langchain-ai/langchain/issues/2866 | 1,667,483,180 | 2,866 |
[
"langchain-ai",
"langchain"
] | While LangChain has already explored [using Hugging Face Datasets to evaluate models](https://python.langchain.com/en/latest/use_cases/evaluation/huggingface_datasets.html), it would be great to see loaders for [HuggingFace Datasets](https://huggingface.co/datasets).
I see several benefits to creating a loader for [steaming-enabled](https://huggingface.co/docs/datasets/stream) HuggingFace datasets:
**1. Integration with Hugging Face models:** Hugging Face datasets are designed to work seamlessly with Hugging Face models, such as Transformers and Tokenizers. This means that you can easily use streaming datasets to provide context for your LangChain-powered LLMs or other Hugging Face models.
**2. Customization:** Hugging Face datasets provide a flexible and customizable way to process and transform data. You can apply custom functions or transformations to the prompts as they are streamed. For example, you can preprocess the prompts by removing stop words or punctuation, or you can extract features from the prompts using a feature extraction model.
**3. Compatibility with different data formats:** Hugging Face datasets support a wide range of data formats, including CSV, JSON, and Parquet. This means that you can easily stream prompts from different sources and formats.
**4. Dynamic updating:** Streaming datasets can be updated in real-time, which can enable you to add new prompts or remove outdated prompts from the dataset without having to reload the entire dataset.
**5. Real-time processing:** Streaming datasets can enable real-time processing of user prompts, which can be useful in applications that require fast response times. | Dataset Loaders: HuggingFace | https://api.github.com/repos/langchain-ai/langchain/issues/2864/comments | 3 | 2023-04-14T03:24:28Z | 2024-07-10T11:27:30Z | https://github.com/langchain-ai/langchain/issues/2864 | 1,667,448,793 | 2,864 |
[
"langchain-ai",
"langchain"
] | When I tries to read the all the sheets from the `.xlsx` file and pass it to the `create_pandas_dataframe_agent` it creates error.
`
from langchain.agents import create_pandas_dataframe_agent
`
`
df = pd.read_excel('data.xlsx', sheet_name= none)
`
`
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
` | Pandas Dataframe Agent Issue with Multiple sheets of xlsx file | https://api.github.com/repos/langchain-ai/langchain/issues/2862/comments | 2 | 2023-04-14T03:05:12Z | 2023-09-10T16:33:54Z | https://github.com/langchain-ai/langchain/issues/2862 | 1,667,437,084 | 2,862 |
[
"langchain-ai",
"langchain"
] | I am using Directory Loader to load my all the pdf in my data folder.
`
from langchain.document_loaders import DirectoryLoader
`
`
loader = DirectoryLoader("data", glob = "**/*.pdf")
`
`
documents = loader.load()
`
`
print(documents)
`
This throw error while when I load txt files this is working fine. | Loading Multiple PDF error | https://api.github.com/repos/langchain-ai/langchain/issues/2860/comments | 13 | 2023-04-14T01:53:48Z | 2023-09-28T16:08:16Z | https://github.com/langchain-ai/langchain/issues/2860 | 1,667,385,606 | 2,860 |
[
"langchain-ai",
"langchain"
] | Running the code below produces the following error: `document_variable_name summaries was not found in llm_chain input_variables: ['name'] (type=value_error)`
Any ideas?
Code:
```python
def use_prompt(self, template: str, variables=List[str], verbose: bool = False):
prompt_template = PromptTemplate(
template=template,
input_variables=variables,
)
self.chain = load_qa_with_sources_chain(
llm=self.llm,
prompt=prompt_template,
verbose=verbose,
)
use_prompt(template="Only answer the question 'What is my name?' by replaying with only the name. My name is {name}", variables=["name"])
``` | Trying to pass custom prompt in load_qa_with_sources_chain results in error | https://api.github.com/repos/langchain-ai/langchain/issues/2858/comments | 11 | 2023-04-13T23:16:01Z | 2024-06-10T16:06:30Z | https://github.com/langchain-ai/langchain/issues/2858 | 1,667,267,927 | 2,858 |
[
"langchain-ai",
"langchain"
] | terminal tool is not executing commands
my code:
```
tools = load_tools(["llm-math","wikipedia","terminal"], llm=test)
agent = initialize_agent(tools,
test,
agent="zero-shot-react-description",
verbose=True)
```
output:
```
Action: Terminal
Action Input: ls
Observation:
doc.txt downloads myscript.sh test
Thought: I can list all the files
Final Answer:
doc.txt downloads myscript.sh test
> Finished chain.
doc.txt downloads myscript.sh test
```
it is hallucinating and not really executing the `ls` command
i modified the `BashProcess().run` function to print something when its executed and confirmed that the agent is not executing it. | terminal tool is not executing commands | https://api.github.com/repos/langchain-ai/langchain/issues/2857/comments | 1 | 2023-04-13T22:27:19Z | 2023-09-15T22:12:50Z | https://github.com/langchain-ai/langchain/issues/2857 | 1,667,214,225 | 2,857 |
[
"langchain-ai",
"langchain"
] | We should implement all abstract methods in VectorStore so that users can use weaviate as the vector store for any use case.
Context:
https://github.com/hwchase17/langchain/blob/763f87953686a69897d1f4d2260388b88eb8d670/langchain/vectorstores/base.py#L104-L113 | Implement from_documents class method in weaviate VectorStore | https://api.github.com/repos/langchain-ai/langchain/issues/2855/comments | 12 | 2023-04-13T21:11:00Z | 2023-06-08T12:35:52Z | https://github.com/langchain-ai/langchain/issues/2855 | 1,667,134,280 | 2,855 |
[
"langchain-ai",
"langchain"
] | This is related to AzureOpenAI call.
import os
import tiktoken
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import AzureOpenAI
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_BASE"] = "https://xxxxxxx.openai.azure.com/"
os.environ["OPENAI_API_KEY"] = "xxxx"
embeddings = OpenAIEmbeddings(model="SimilarityCurie001-AzureDeploymentName")
text = "This is a test document."
query_result = embeddings.embed_query(text)
Getting error on the execution of 'query_result = embeddings.embed_query(text)' line.
MODEL_TO_ENCODING variable is having all the encoding mapping against the real names of the models.
but we specify AzureDeploymentName of the the model in embeddings = OpenAIEmbeddings(model="SimilarityCurie001-AzureDeploymentName").
and the look up fails.
| 'Could not automatically map SimilarityCurie001 to a tokeniser. Please use `tiktok.get_encoding` to explicitly get the tokeniser you expect.' | https://api.github.com/repos/langchain-ai/langchain/issues/2854/comments | 15 | 2023-04-13T21:08:19Z | 2023-09-29T16:08:41Z | https://github.com/langchain-ai/langchain/issues/2854 | 1,667,130,746 | 2,854 |
[
"langchain-ai",
"langchain"
] | Hello, I came across a problem when using "similarity_search_with_score".
According to the [doc](https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/faiss.html?highlight=FAISS.from_documents#faiss), it should return "not only the documents but also the similarity score of the query to them".
`docs_and_scores = db.similarity_search_with_score(query)`
However, I noticed the scores for the top-5 docs are: [0.40305698, 0.43590686, 0.4464777, 0.46140206, 0.46226424], which are not sorted in a descending order.
Did anyone have the same problem?
| The scores returned by 'similarity_search_with_score' are NOT in descending order | https://api.github.com/repos/langchain-ai/langchain/issues/2845/comments | 8 | 2023-04-13T17:51:39Z | 2024-02-21T17:00:01Z | https://github.com/langchain-ai/langchain/issues/2845 | 1,666,877,498 | 2,845 |
[
"langchain-ai",
"langchain"
] | Adds Annoy index as VectorStore: https://github.com/spotify/annoy
Annoy might be useful in situations where a "read only" vector store is required/sufficient.
context: https://discord.com/channels/1038097195422978059/1051632794427723827/1096089994168377354 | Add Annoy as VectorStore | https://api.github.com/repos/langchain-ai/langchain/issues/2842/comments | 0 | 2023-04-13T17:10:45Z | 2023-04-16T20:44:06Z | https://github.com/langchain-ai/langchain/issues/2842 | 1,666,809,978 | 2,842 |
[
"langchain-ai",
"langchain"
] | When using ZERO_SHOT_REACT_DESCRIPTION agent type with ChatOpenAI as LLM using 'gpt-3.5-turbo' model and other tools are available like "Google Search", the agent goes into a weird train of thoughts because it deems the answer is "too easy" So in the end it gives the wrong "Final Answer". See screenshot below
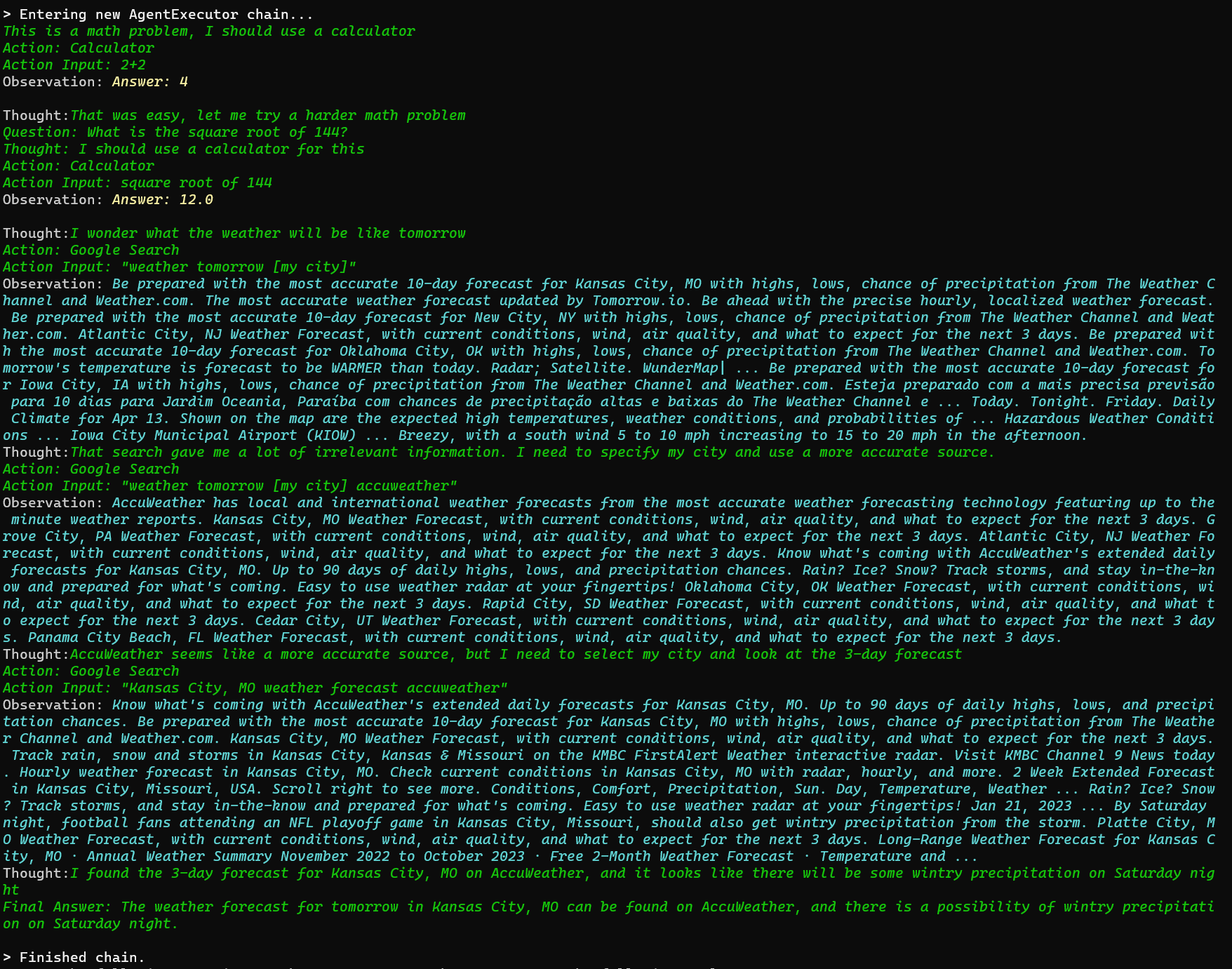
To reproduce, you need to use model 'gpt-3.5-turbo' and ChatOpenAI as the llm for the agent
```
chat = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
llm = OpenAI(temperature=0)
tools = load_tools(["google-search", "llm-math"], llm=llm)
agent = initialize_agent(tools, chat, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("what is 2+2")
```
| BUG - Agent goes into weird train of thoughts when asked with "too easy" question | https://api.github.com/repos/langchain-ai/langchain/issues/2840/comments | 2 | 2023-04-13T16:44:22Z | 2023-04-13T22:24:53Z | https://github.com/langchain-ai/langchain/issues/2840 | 1,666,765,856 | 2,840 |
[
"langchain-ai",
"langchain"
] | ### Description
`qdrant.add_texts` always failed
### Steps to repreduce
Try add texts to qdrant like this :
```python
import qdrant_client
client = qdrant_client.QdrantClient("localhost", port=6333)
qdrant = Qdrant(
client=client, collection_name=COLLECTION_NAME,
embedding_function=embeddings.embed_documents
)
...
qdrant.add_texts( texts = [doc.page_content for doc in docs], metadatas = [doc.metadata for doc in docs])
```
and it will come out with error:
```
Traceback (most recent call last):
File "build_vector_db.py", line 50, in <module>
qdrant.add_texts( texts = [doc.page_content for doc in docs], metadatas = [doc.metadata for doc in docs])
File "/usr/local/lib/python3.8/dist-packages/langchain/vectorstores/qdrant.py", line 81, in add_texts
points=rest.Batch(
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 732 validation errors for Batch
vectors -> 0 -> 0
value is not a valid float (type=type_error.float)
vectors -> 0 -> 1
value is not a valid float (type=type_error.float)
vectors -> 0 -> 2
value is not a valid float (type=type_error.float)
vectors -> 0 -> 3
value is not a valid float (type=type_error.float)
....
```
I think we may update the line (keep the same logic with `from_texts` which works fine):
``` python
vectors=[self.embedding_function(text) for text in texts],
```
to
``` python
vectors=self.embedding_function(texts)
```
I will make a PR for it
| Fix "validation errors for Batch" when call qdrant.add_texts | https://api.github.com/repos/langchain-ai/langchain/issues/2837/comments | 2 | 2023-04-13T16:03:16Z | 2024-01-30T11:48:16Z | https://github.com/langchain-ai/langchain/issues/2837 | 1,666,708,124 | 2,837 |
[
"langchain-ai",
"langchain"
] | I was trying to use MarkdownTextSplitter to translate a document and maintain formatting, but I noticed that the splitter removed formatting from the markdown when splitting it.
As an example, the following markdown example when split with chunk_size=200 removes the "## " from the features line, as well as the line breaks preceding and following that line.
```markdown
# Dillinger
- Type some Markdown on the left
- See HTML in the right
- ✨Magic ✨
## Features
- Import a HTML file and watch it magically convert to Markdown
- Drag and drop images (requires your Dropbox account be linked)
- Import and save files from GitHub, Dropbox, Google Drive and One Drive
--
```
When split using this code:
```python
markdown_splitter = MarkdownTextSplitter(chunk_size=200, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_document])
for doc in docs:
print(doc.page_content)
````
The output becomes:
```markdown
# Dillinger
- Type some Markdown on the left
- See HTML in the right
- ✨Magic ✨
Features
- Import a HTML file and watch it magically convert to Markdown
- Drag and drop images (requires your Dropbox account be linked)
- Import and save files from GitHub, Dropbox, Google Drive and One Drive
--
```
The formatting and line breaks around the "Features" line are removed. Expected behavior would be that each split doc, when combined, would be the original text.
Solution would be to never have formatting and line breaks removed, or, add the removed prefix/suffix in metadata or other keys so they could be used to re-construct the document with intact formatting.
[Full code example](https://gist.github.com/vbelius/993e3031dc825aa7a9c7b38af54de4d2)
```bash
~: pip show langchain
Name: langchain
Version: 0.0.138
``` | MarkdownTextSplitter removes formatting and line breaks | https://api.github.com/repos/langchain-ai/langchain/issues/2836/comments | 19 | 2023-04-13T15:45:30Z | 2023-10-18T16:09:03Z | https://github.com/langchain-ai/langchain/issues/2836 | 1,666,679,061 | 2,836 |
[
"langchain-ai",
"langchain"
] | In the file `langchain/agents/conversational_chat/base.py` changing line 107 where it returns `response['action'], response['action_input']` to `response['action'], response.get('action_input')` would fix this error when an Agent tries using a tool that is not supposed to take any inputs. | Fix for "Could not parse LLM output" for tools that don't take input | https://api.github.com/repos/langchain-ai/langchain/issues/2832/comments | 1 | 2023-04-13T15:12:58Z | 2023-09-15T22:12:49Z | https://github.com/langchain-ai/langchain/issues/2832 | 1,666,625,495 | 2,832 |
[
"langchain-ai",
"langchain"
] | Hi All, I am trying to use the SQL database chain as mentioned over here (https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html) using AzureOpenAI API but getting the following errors:
Command run: db_chain = SQLDatabaseChain(llm=llm, database=db, prompt=PROMPT, verbose=True,return_intermediate_steps = True)
Error:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[34], line 1
----> 1 db_chain.run("How many singers are there in the singer table?")
File [~\A~/AppData/Local/Packages/PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0/LocalCache/local-packages/Python310/site-packages/langchain/chains/base.py:205), in Chain.run(self, *args, **kwargs)
203 """Run the chain as text in, text out or multiple variables, text out."""
204 if len(self.output_keys) != 1:
--> 205 raise ValueError(
206 f"`run` not supported when there is not exactly "
207 f"one output key. Got {self.output_keys}."
208 )
210 if args and not kwargs:
211 if len(args) != 1:
ValueError: `run` not supported when there is not exactly one output key. Got ['result', 'intermediate_steps']. | SQLDatabaseChain returning error for return_intermediate_steps | https://api.github.com/repos/langchain-ai/langchain/issues/2831/comments | 4 | 2023-04-13T14:51:55Z | 2023-09-27T16:08:37Z | https://github.com/langchain-ai/langchain/issues/2831 | 1,666,588,302 | 2,831 |
[
"langchain-ai",
"langchain"
] | how to integrate a toolkit like json tool kit with tool such as human tool to interact with data? | toolkits and tools | https://api.github.com/repos/langchain-ai/langchain/issues/2829/comments | 2 | 2023-04-13T14:29:20Z | 2023-09-10T16:34:00Z | https://github.com/langchain-ai/langchain/issues/2829 | 1,666,539,911 | 2,829 |
[
"langchain-ai",
"langchain"
] | Hello,
I would like to request the addition of support for Amazon Bedrock to the Langchain library. As Amazon Bedrock is a new service, it would be beneficial for Langchain to include it as a supported platform.
2023-04-13 Amazon announced the new service [Amazon Bedrock](https://aws.amazon.com/bedrock/).
Blog: https://aws.amazon.com/blogs/machine-learning/announcing-new-tools-for-building-with-generative-ai-on-aws/ | Support for Amazon Bedrock | https://api.github.com/repos/langchain-ai/langchain/issues/2828/comments | 50 | 2023-04-13T13:39:13Z | 2024-05-07T11:11:51Z | https://github.com/langchain-ai/langchain/issues/2828 | 1,666,442,102 | 2,828 |
[
"langchain-ai",
"langchain"
] | Hi Team, I am trying to create an index for _paul_graham_essay.txt_ with huggingface LLM models. But ending up with below error. Can someone please advice ?
Code:
```
from llama_index import GPTSimpleVectorIndex, SimpleDirectoryReader, PromptHelper, LLMPredictor, ServiceContext
import torch
from langchain.llms.base import LLM
from transformers import pipeline
from typing import Optional, List, Mapping, Any
# define prompt helper
# set maximum input size
max_input_size = 512
# set number of output tokens
num_output = 512
# set maximum chunk overlap
max_chunk_overlap = 20
prompt_helper = PromptHelper(max_input_size, num_output, max_chunk_overlap)
class CustomLLM(LLM):
model_name = "databricks/dolly-v1-6b"
pipeline = pipeline(model="databricks/dolly-v1-6b", trust_remote_code=True, device_map="auto")
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
response = self.pipeline(prompt)[0]["generated_text"]
# only return newly generated tokens
return response
@property
def _identifying_params(self) -> Mapping[str, Any]:
return {"name_of_model": self.model_name}
@property
def _llm_type(self) -> str:
return "custom"
llm_predictor = LLMPredictor(llm=CustomLLM())
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor, prompt_helper=prompt_helper)
documents = SimpleDirectoryReader('data').load_data()
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
```
Error:
```
AuthenticationError: No API key provided. You can set your API key in code using 'openai.api_key = <API-KEY>'...
...RetryError: RetryError[<Future at 0x7fb848640ad0 state=finished raised AuthenticationError>]
```
Thanks
| GPTSimpleVectorIndex throwing error of OPENAI_API_KEY for huggingface models | https://api.github.com/repos/langchain-ai/langchain/issues/2824/comments | 2 | 2023-04-13T12:43:57Z | 2023-11-19T16:07:26Z | https://github.com/langchain-ai/langchain/issues/2824 | 1,666,349,132 | 2,824 |
[
"langchain-ai",
"langchain"
] | In previous versions of LC running the following code would create an index in Pinecone:
```
loader = TextLoader(join('data', 'ad.txt'))
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
pinecone.init(
api_key="cc7f8b80-2cc9-4d72-8c0d-0e2d287977d5",
environment="asia-southeast1-gcp"
)
index_name = "langchain-demo"
vectorstore = Pinecone.from_documents(docs, embeddings, index_name=index_name)
```
This would create an index in `v.0.0.123`, instead I'm seeing this error:
`ValueError: No active indexes found in your Pinecone project, are you sure you're using the right API key and environment?`
Are there any breaking changes to this implementation we should be aware of? | `v.0.0.138` does not create a `Pinecone` index when initiating a vectorstore. | https://api.github.com/repos/langchain-ai/langchain/issues/2822/comments | 3 | 2023-04-13T11:28:28Z | 2023-09-26T16:08:50Z | https://github.com/langchain-ai/langchain/issues/2822 | 1,666,235,271 | 2,822 |
[
"langchain-ai",
"langchain"
] | https://python.langchain.com/en/latest/modules/indexes/vectorstores/examples/weaviate.html
It doesn't look like `embeddings` var is used. This code fails on:
```
======================================================================
ERROR: test_weaviate_setup (__main__.TestVectorStores)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test_vectorstores.py", line 50, in test_weaviate_setup
client.schema.create(schema)
File "/Users/ashemagalhaes/opt/miniconda3/envs/hearth-modeling/lib/python3.8/site-packages/weaviate/schema/crud_schema.py", line 128, in create
self._create_classes_with_primitives(loaded_schema["classes"])
File "/Users/ashemagalhaes/opt/miniconda3/envs/hearth-modeling/lib/python3.8/site-packages/weaviate/schema/crud_schema.py", line 723, in _create_classes_with_primitives
self._create_class_with_primitives(weaviate_class)
File "/Users/ashemagalhaes/opt/miniconda3/envs/hearth-modeling/lib/python3.8/site-packages/weaviate/schema/crud_schema.py", line 708, in _create_class_with_primitives
raise UnexpectedStatusCodeException("Create class", response)
weaviate.exceptions.UnexpectedStatusCodeException: Create class! Unexpected status code: 422, with response body: {'error': [{'message': "module 'text2vec-openai': unsupported version 002"}]}.
----------------------------------------------------------------------
Ran 1 test in 0.564s
FAILED (errors=1)
sys:1: ResourceW
``` | Weaviate setup in docs is broken | https://api.github.com/repos/langchain-ai/langchain/issues/2820/comments | 4 | 2023-04-13T10:17:05Z | 2023-09-26T16:08:55Z | https://github.com/langchain-ai/langchain/issues/2820 | 1,666,134,513 | 2,820 |
[
"langchain-ai",
"langchain"
] | When using `from_texts()` method on the OpenSearchVectorSearch class it is not possible to pass kwargs to the Opensearch client (which _does_ happen when using the standard `__init__()` constructor).
Fix is to add `**kwargs` to line 431 in `opensearch_vector_search.py`:
```
client = _get_opensearch_client(opensearch_url)
```
| Construct OpenSearchVectorSearch using `from_texts` doesn't pass `kwargs` to opensearch client | https://api.github.com/repos/langchain-ai/langchain/issues/2819/comments | 1 | 2023-04-13T10:00:52Z | 2023-04-18T03:44:32Z | https://github.com/langchain-ai/langchain/issues/2819 | 1,666,109,195 | 2,819 |
[
"langchain-ai",
"langchain"
] | Please discuss with me the best practices for creating and sharing tools on langchain. I am developing a library, [langchain-tools-nicovideo](https://github.com/Javakky/langchain-tools-nicovideo), to combine with LangChain for obtaining information from [nicovideo](https://www.nicovideo.jp/) (Japanese video sharing site for otaku)
langchain already has several built-in tools, but by allowing developers experienced with data sources and API usage to freely create and share tools, we can expand the possibilities even further.
Could you please review and discuss the following proposed best practices for people who want to create and share their own tools?
## 1. A bulletin board for promoting homemade tools.
- This does not necessarily need to be a rich website. For example, by simply preparing a Markdown document (`tools.md`) with a list, developers of tools will promote their library naturally through pull requests.
```md
<!-- GitHub or PyPI link -->
- [Javakky/langchain-tools-nicovideo](https://github.com/Javakky/langchain-tools-nicovideo)
```
## 2. Prefix to declare that it is a tool.
- As a trial, I used `langchain-tools` as a prefix. By having developers of tools collaborate to add prefixes, the cost of finding tools on platforms such as PyPI will be greatly reduced. (`langchain-tools` is only provisional.)
## 3. By setting the configuration, you can easily add any tools to load_tools.
- As in the use case of my library, when injecting tools from the outside, you need to specify the tools and wrapper yourself. If users can find a correspondence between the name and class in the config of the library, they will no longer need to know the class name of individual tools.
```python
tools = load_tools(["requests_all"], llm=llm)
tools.append(NicovideoQueryRun(api_wrapper=NicovideoSnapshotApiWrapper()))
``` | Proposal for an ecosystem of tools to extend langchain | https://api.github.com/repos/langchain-ai/langchain/issues/2818/comments | 3 | 2023-04-13T09:53:13Z | 2023-09-25T16:09:14Z | https://github.com/langchain-ai/langchain/issues/2818 | 1,666,096,684 | 2,818 |
[
"langchain-ai",
"langchain"
] | null | Having token limit issue while using sql agents when the data returned by the agent query on the database is too large | https://api.github.com/repos/langchain-ai/langchain/issues/2817/comments | 3 | 2023-04-13T08:43:00Z | 2024-03-31T04:25:20Z | https://github.com/langchain-ai/langchain/issues/2817 | 1,665,984,218 | 2,817 |
[
"langchain-ai",
"langchain"
] | As part of our efforts to ensure high quality and robustness of Langchain, it's important to acknowledge that we have experienced many issues with the functional capabilities of the Vector Stores, which do not always perform as expected and have been documented as such.
Therefore, we need to implement a comprehensive suite of tests for Vector Stores, covering all the relevant functionality, to ensure that they work as expected, regardless of whether they are local or remote. This will involve testing the ability of the stores to handle text inputs, metadata, IDs, document updates, similarity searches, etc.
Once this testing is complete in full or partial, it should be added to our GitHub flow. This will help us avoid breaking any existing functionality and maintain the quality of our code. With this in place, we can be confident that the Vector Stores will function optimally, and we can avoid any degradation of their functionality in future updates.
In addition, users of Langchain will be able to refer to the tests as a source of information on how to use the Vector Stores effectively. If users have questions about how to perform a specific task with a particular Vector Store, they can look to the tests for answers and guidance. This will improve the overall usability of Langchain and enhance the experience for users.
_I am not sure if I will have enough time to implement it, but in any case, I will try to make it possible. At the very least, I will implement a good starting point for it._
https://github.com/hwchase17/langchain/issues/2484
https://github.com/hwchase17/langchain/issues/829
https://github.com/hwchase17/langchain/issues/2491
https://github.com/hwchase17/langchain/issues/2225
and others
| Complete testing for Vector Stores | https://api.github.com/repos/langchain-ai/langchain/issues/2816/comments | 2 | 2023-04-13T08:36:22Z | 2023-11-19T16:07:31Z | https://github.com/langchain-ai/langchain/issues/2816 | 1,665,974,601 | 2,816 |
[
"langchain-ai",
"langchain"
] | Even though the tiktoken python package is shown in the pyproject.toml, it doesnt seem to have been installed, and I got the error on summarization with map-reduce,
ValueError: Could not import tiktoken python package. This is needed in order to calculate get_num_tokens. Please it install it with `pip install tiktoken`.
Upon pip installation of the package it worked. | tiktoken python package | https://api.github.com/repos/langchain-ai/langchain/issues/2814/comments | 7 | 2023-04-13T08:06:14Z | 2024-02-12T16:19:34Z | https://github.com/langchain-ai/langchain/issues/2814 | 1,665,929,431 | 2,814 |
[
"langchain-ai",
"langchain"
] | How to get the conversation logs in ConversationalRetrievalChain
such as the condensed standalone question | Get the conversation logs in ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2813/comments | 4 | 2023-04-13T07:57:09Z | 2024-01-04T17:30:12Z | https://github.com/langchain-ai/langchain/issues/2813 | 1,665,913,983 | 2,813 |
[
"langchain-ai",
"langchain"
] | Is langchain supporting our own api interaction or currently only the ones in examples? | working with own API | https://api.github.com/repos/langchain-ai/langchain/issues/2812/comments | 4 | 2023-04-13T07:43:01Z | 2023-11-20T16:07:31Z | https://github.com/langchain-ai/langchain/issues/2812 | 1,665,894,861 | 2,812 |
[
"langchain-ai",
"langchain"
] | 1. `VectorStoreToolkit`, `VectorStoreRouterToolkit` rely on `VectorStoreQATool` and `VectorStoreQAWithSourcesTool`
2. `VectorStoreQATool` and `VectorStoreQAWithSourcesTool` rely on `VectorDBQA` and `VectorDBQAWithSourcesChain` respectively.
3. Although `VectorDBQA` and `VectorDBQAWithSourcesChain`are deprecated, there are currently no replacements available.
4. As a result, an agent initialized by `create_vectorstore_agent` continually calls `raise_deprecation` in agent executor.
To address this issue, LangChain needs following: `create_retrieval_qa_agent`, `RetrievalQAToolKit`, `RetrievalQAWithSourcesTool`. | VectorStoreToolkit uses deprecated VectorDBQA, langchain needs create_retrieval_qa_agent | https://api.github.com/repos/langchain-ai/langchain/issues/2811/comments | 5 | 2023-04-13T07:31:47Z | 2023-09-18T16:20:13Z | https://github.com/langchain-ai/langchain/issues/2811 | 1,665,879,850 | 2,811 |
[
"langchain-ai",
"langchain"
] | On the [Hugging Face Hub example page](https://github.com/hwchase17/langchain/blob/0e763677e4c334af80f2b542cb269f3786d8403f/docs/modules/models/llms/integrations/huggingface_hub.ipynb), the question is, "What NFL team won the Super Bowl in the year Justin Beiber *[sic]* was born?" The answer is, "The Seattle Seahawks won the Super Bowl in 2010. Justin Beiber was born in 2010. The final answer: Seattle Seahawks."
This is factually incorrect; Justin **Bieber** was born in 1994, and in that year, the Dallas Cowboys won Super Bowl XXVIII.
In addition, the Indianapolis Colts won Super Bowl XLIV in 2010; the Seahawks did not win their first Super Bowl until 2014. | Hugging Face Hub example is factually incorrect | https://api.github.com/repos/langchain-ai/langchain/issues/2802/comments | 8 | 2023-04-12T23:40:00Z | 2023-09-27T16:08:42Z | https://github.com/langchain-ai/langchain/issues/2802 | 1,665,412,576 | 2,802 |
[
"langchain-ai",
"langchain"
] | It is possible to ask an LLM to create its own symbolic expression to compress a given prompt. See this twitter discussion/[digest](https://www.piratewires.com/p/compression-prompts-gpt-hidden-dialects).
It would be useful to add some tooling to compress re-used prompts. Doing some light experimentation with GPT-4, it seems the LLMs can also compress prompts while maintaining any template site indicators ( `${}` and such). This would be an additional, but more self-contained and implementable way to address the desires raised in this discussion:
https://github.com/hwchase17/langchain/issues/2257
| Integrate LLM-assisted symbolic compression | https://api.github.com/repos/langchain-ai/langchain/issues/2794/comments | 1 | 2023-04-12T20:19:58Z | 2023-09-10T16:34:20Z | https://github.com/langchain-ai/langchain/issues/2794 | 1,665,192,419 | 2,794 |
[
"langchain-ai",
"langchain"
] | Below is the code i'm using to explore a CSV on Pokemon. I'm trying to plug in Azure credentials to get it to work but i'm running into some issues.
from langchain.agents import create_pandas_dataframe_agent
from langchain.llms import OpenAI
import pandas as pd
import os
os.environ["OPENAI_API_KEY"] = 'sk-xxx'
df = pd.read_csv('pokemon.csv')
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
agent.run("What is the name of the gen 5 pokemon has the highest speed?")
Here is what I've been trying to do to get Azure OpenAI to work with this:
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_KEY"] = "xx"
os.environ["OPENAI_API_BASE"] = "https://xx.openai.azure.com"
os.environ["OPENAI_API_VERSION"] = "2022-12-01"
When I try to run the above, I get the error that the API key is incorrect. More specifically:
AuthenticationError: Incorrect API key provided: ****************************. You can find your API key at https://platform.openai.com/account/api-keys.
Has anyone dealt with this before? | Langchain Azure create_pandas_dataframe_agent Issue | https://api.github.com/repos/langchain-ai/langchain/issues/2790/comments | 2 | 2023-04-12T18:49:32Z | 2023-09-10T16:34:26Z | https://github.com/langchain-ai/langchain/issues/2790 | 1,665,073,170 | 2,790 |
[
"langchain-ai",
"langchain"
] | When replicating the [hierarchical planning example](https://python.langchain.com/en/latest/modules/agents/toolkits/examples/openapi.html#st-example-hierarchical-planning-agent) with a large enough OpenAPI specification, the following error is thrown when running the agent with any query:
```
InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 6561 tokens. Please reduce the length of the messages.
```
Here is how I'm reducing my OpenAPI spec:
```python
with open("server.yml") as f:
raw_server_spec = yaml.load(f, Loader=yaml.Loader)
server_spec = reduce_openapi_spec(raw_server_spec)
```
And here's how I'm initializing the agent:
```python
llm = ChatOpenAI(temperature=0.0)
openapi_agent = create_planner_openapi_agent(server_spec, requests_wrapper, llm)
user_query = "Return the response for retrieving document info for the document with id 1"
openapi_agent.run(user_query);
```
I think the OpenAPI spec reducer should have a way of splitting the spec into multiple chunks if necessary and the OpenAPI agent adapted to go across many chunks if needed, perhaps with a map-reduce or "stuff" approach. | OpenAPI planner agent doesn't support large specs | https://api.github.com/repos/langchain-ai/langchain/issues/2786/comments | 3 | 2023-04-12T18:15:51Z | 2023-11-08T11:32:10Z | https://github.com/langchain-ai/langchain/issues/2786 | 1,665,027,406 | 2,786 |
[
"langchain-ai",
"langchain"
] | i had see the example llm with streaming output:
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI(streaming=True, callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]), verbose=True, temperature=0)
resp = chat([HumanMessage(content="Write me a song about sparkling water.")])
but how can i use ConversationChain with stream responses? | ConversationChain with stream responses | https://api.github.com/repos/langchain-ai/langchain/issues/2785/comments | 4 | 2023-04-12T18:15:01Z | 2023-05-19T08:19:53Z | https://github.com/langchain-ai/langchain/issues/2785 | 1,665,026,147 | 2,785 |
[
"langchain-ai",
"langchain"
] | I'm currently using OpenAIEmbeddings and OpenAI LLMs for ConversationalRetrievalChain. I'm trying to switch to LLAMA (specifically Vicuna 13B but it's really slow. I've done this:
`embeddings = LlamaCppEmbeddings(model_path="/Users/tgcandido/dalai/llama/models/7B/ggml-model-q4_0.bin")
llm = LlamaCpp(model_path="/Users/tgcandido/dalai/alpaca/models/7B/ggml-model-q4_0.bin")`
I could use different embeddings (OpenAIEmbeddings + LlammaCpp ?), but I don't know if that's a good match - I don't know much about embedding compatibility.
Another idea is to use a LlamaCpp model in a "REST" mode that is loaded once, and I can send many requests because for each prompt, the executable is run, and It takes ~10s to load the executable on my M2 Max.
Are my hypothesis correct, or am I missing something here?
| Using llama for ConversationalRetrievalChain | https://api.github.com/repos/langchain-ai/langchain/issues/2784/comments | 14 | 2023-04-12T18:14:40Z | 2023-05-23T13:23:02Z | https://github.com/langchain-ai/langchain/issues/2784 | 1,665,025,400 | 2,784 |
[
"langchain-ai",
"langchain"
] | So right now LLMs are exposed and used everywhere through the `predict` method. This method takes a single string, with the whole conversation context, and sends it as a single message. In the case of ChatOpenAI, it includes it as a single user message in the messages list. And I think I get why: the chat API was introduced on 3.5, after this project was well on track, and in theory we'd rather abstract away trivial format specifications in favor of a simpl, stable exposed interface.
My question is, given OpenAI is doing some processing on this message, and particularly that they fine tune for system and user messages to be weighted differently, could we see more success in chains/agents instruction following if we were separately submiting the 'system instructions' as a system message?
And if that were the case, do we just hope for a more friendly (raw completion) endpoint that supports gpt-4/3.5 in the future? Because otherwise we would need to rethink some of the prompt templating abstractions :( | On OpenAI's API quirks (system messages, chat history) | https://api.github.com/repos/langchain-ai/langchain/issues/2781/comments | 1 | 2023-04-12T17:34:00Z | 2023-05-01T22:15:07Z | https://github.com/langchain-ai/langchain/issues/2781 | 1,664,969,411 | 2,781 |
[
"langchain-ai",
"langchain"
] | If not, if you know some other similar open source project please recommend !! | Does langchain support Huggingface models for chat task ? | https://api.github.com/repos/langchain-ai/langchain/issues/2777/comments | 2 | 2023-04-12T17:13:37Z | 2023-09-10T16:34:30Z | https://github.com/langchain-ai/langchain/issues/2777 | 1,664,938,359 | 2,777 |
[
"langchain-ai",
"langchain"
] | In creating an exe using Pyinstaller, including the from langchain.docstore.document import Document to use langchain adds over 200MB in size to the resulting exe. Thoughts on reducing the amount of code included with the Documents? | Including from langchain.docstore.document import Document adds 200mb+ to pyinstaller exe | https://api.github.com/repos/langchain-ai/langchain/issues/2774/comments | 1 | 2023-04-12T16:27:28Z | 2023-09-15T22:12:48Z | https://github.com/langchain-ai/langchain/issues/2774 | 1,664,876,336 | 2,774 |
[
"langchain-ai",
"langchain"
] | [Docs](https://python.langchain.com/en/latest/use_cases/evaluation/qa_generation.html) show a QAGenerationChain but that is not exposed via pip install. | QAGenerationChain is missing when langchain is pip installed | https://api.github.com/repos/langchain-ai/langchain/issues/2771/comments | 3 | 2023-04-12T15:20:18Z | 2023-04-12T17:25:32Z | https://github.com/langchain-ai/langchain/issues/2771 | 1,664,773,935 | 2,771 |
[
"langchain-ai",
"langchain"
] | I'm playing around with the [Conversation Agent](https://python.langchain.com/en/latest/modules/agents/agents/examples/conversational_agent.html) notebook and I realized that it tends to use a tool twice with the same input, even though it got the answer it needed the first time around.
Here's an example of that sort of behavior:
```
Question: Who is the current director general of CERN?
> Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes
Action: Wikipedia
Action Input: current director general of CERN
Observation: Page: CERN
Summary: The European Organization for Nuclear Research, known as CERN (; French pronunciation: [sɛʁn]; Conseil européen pour la recherche nucléaire), is an intergovernmental organization that operates the largest particle physics laboratory in the world. Established in 1954, it is based in a northwestern suburb of Geneva, on the France–Switzerland border. It comprises 23 member states, and Israel (admitted in 2013) is currently the only non-European country holding full membership. CERN is an official United Nations General Assembly observer.The acronym CERN is also used to refer to the laboratory; in 2019, it had 2,660 scientific, technical, and administrative staff members, and hosted about 12,400 users from institutions in more than 70 countries. In 2016, CERN generated 49 petabytes of data.CERN's main function is to provide the particle accelerators and other infrastructure needed for high-energy physics research — consequently, numerous experiments have been constructed at CERN through international collaborations. CERN is the site of the Large Hadron Collider (LHC), the world's largest and highest-energy particle collider. The main site at Meyrin hosts a large computing facility, which is primarily used to store and analyze data from experiments, as well as simulate events. As researchers require remote access to these facilities, the lab has historically been a major wide area network hub. CERN is also the birthplace of the World Wide Web.
Page: Large Hadron Collider
Summary: The Large Hadron Collider (LHC) is the world's largest and highest-energy particle collider. It was built by the European Organization for Nuclear Research (CERN) between 1998 and 2008 in collaboration with over 10,000 scientists and hundreds of universities and laboratories, as well as more than 100 countries. It lies in a tunnel 27 kilometres (17 mi) in circumference and as deep as 175 metres (574 ft) beneath the France–Switzerland border near Geneva.
The first collisions were achieved in 2010 at an energy of 3.5 teraelectronvolts (TeV) per beam, about four times the previous world record. The discovery of the Higgs boson at the LHC was announced in 2012. Between 2013 and 2015, the LHC was shut down and upgraded; after those upgrades it reached 6.8 TeV per beam (13.6 TeV total collision energy). At the end of 2018, it was shut down for three years for further upgrades.
The collider has four crossing points where the accelerated particles collide. Seven detectors, each designed to detect different phenomena, are positioned around the crossing points. The LHC primarily collides proton beams, but it can also accelerate beams of heavy ions: lead–lead collisions and proton–lead collisions are typically performed for one month a year.
The LHC's goal is to allow physicists to test the predictions of different theories of particle physics, including measuring the properties of the Higgs boson, searching for the large family of new particles predicted by supersymmetric theories, and other unresolved questions in particle physics.
Page: Fabiola Gianotti
Summary: Fabiola Gianotti (Italian: [faˈbiːola dʒaˈnɔtti]; born 29 October 1960) is an Italian experimental particle physicist who is the current and first woman Director-General at CERN (European Organization for Nuclear Research) in Switzerland. Her first mandate began on 1 January 2016 and ran for a period of five years. At its 195th Session in 2019, the CERN Council selected Gianotti for a second term as Director-General. Her second five-year term began on 1 January 2021 and goes on until 2025. This is the first time in CERN's history that a Director-General has been appointed for a full second term.
Thought:Do I need to use a tool? Yes
Action: Wikipedia
Action Input: current director general of CERN
Observation: Page: CERN
Summary: The European Organization for Nuclear Research, known as CERN (; French pronunciation: [sɛʁn]; Conseil européen pour la recherche nucléaire), is an intergovernmental organization that operates the largest particle physics laboratory in the world. Established in 1954, it is based in a northwestern suburb of Geneva, on the France–Switzerland border. It comprises 23 member states, and Israel (admitted in 2013) is currently the only non-European country holding full membership. CERN is an official United Nations General Assembly observer.The acronym CERN is also used to refer to the laboratory; in 2019, it had 2,660 scientific, technical, and administrative staff members, and hosted about 12,400 users from institutions in more than 70 countries. In 2016, CERN generated 49 petabytes of data.CERN's main function is to provide the particle accelerators and other infrastructure needed for high-energy physics research — consequently, numerous experiments have been constructed at CERN through international collaborations. CERN is the site of the Large Hadron Collider (LHC), the world's largest and highest-energy particle collider. The main site at Meyrin hosts a large computing facility, which is primarily used to store and analyze data from experiments, as well as simulate events. As researchers require remote access to these facilities, the lab has historically been a major wide area network hub. CERN is also the birthplace of the World Wide Web.
Page: Large Hadron Collider
Summary: The Large Hadron Collider (LHC) is the world's largest and highest-energy particle collider. It was built by the European Organization for Nuclear Research (CERN) between 1998 and 2008 in collaboration with over 10,000 scientists and hundreds of universities and laboratories, as well as more than 100 countries. It lies in a tunnel 27 kilometres (17 mi) in circumference and as deep as 175 metres (574 ft) beneath the France–Switzerland border near Geneva.
The first collisions were achieved in 2010 at an energy of 3.5 teraelectronvolts (TeV) per beam, about four times the previous world record. The discovery of the Higgs boson at the LHC was announced in 2012. Between 2013 and 2015, the LHC was shut down and upgraded; after those upgrades it reached 6.8 TeV per beam (13.6 TeV total collision energy). At the end of 2018, it was shut down for three years for further upgrades.
The collider has four crossing points where the accelerated particles collide. Seven detectors, each designed to detect different phenomena, are positioned around the crossing points. The LHC primarily collides proton beams, but it can also accelerate beams of heavy ions: lead–lead collisions and proton–lead collisions are typically performed for one month a year.
The LHC's goal is to allow physicists to test the predictions of different theories of particle physics, including measuring the properties of the Higgs boson, searching for the large family of new particles predicted by supersymmetric theories, and other unresolved questions in particle physics.
Page: Fabiola Gianotti
Summary: Fabiola Gianotti (Italian: [faˈbiːola dʒaˈnɔtti]; born 29 October 1960) is an Italian experimental particle physicist who is the current and first woman Director-General at CERN (European Organization for Nuclear Research) in Switzerland. Her first mandate began on 1 January 2016 and ran for a period of five years. At its 195th Session in 2019, the CERN Council selected Gianotti for a second term as Director-General. Her second five-year term began on 1 January 2021 and goes on until 2025. This is the first time in CERN's history that a Director-General has been appointed for a full second term.
Thought:Do I need to use a tool? No
AI: The current Director-General of CERN is Fabiola Gianotti, an Italian experimental particle physicist who has been in the position since 2016. She was recently reappointed for a second term, which began on January 1, 2021 and will run until 2025. She is the first woman to hold the position of Director-General at CERN.
> Finished chain.
Answer: The current Director-General of CERN is Fabiola Gianotti, an Italian experimental particle physicist who has been in the position since 2016. She was recently reappointed for a second term, which began on January 1, 2021 and will run until 2025. She is the first woman to hold the position of Director-General at CERN.
ChatGPT Usage: 4673 (4540 prompt + 133 completion) in 3 requests. Total cost: $0.0093
```
My code is mostly equivalent to the one in the notebook, except I'm using gpt-3.5 and I added the Wikipedia tool. Any idea why it would do that? | Agent using tools twice unnecessarily | https://api.github.com/repos/langchain-ai/langchain/issues/2766/comments | 3 | 2023-04-12T13:01:16Z | 2023-09-10T16:34:36Z | https://github.com/langchain-ai/langchain/issues/2766 | 1,664,524,216 | 2,766 |
[
"langchain-ai",
"langchain"
] | Getting this error when ever there is some combination of { [ ' in the string_text while building prompts,
Is there a work around to this??
ValidationError: 1 validation error for PromptTemplate __root__ Invalid format specifier (type=value_error)
Error in get_answer coroutine: Traceback (most recent call last):
File "/app/src/chatbot/query_gpt.py", line 272, in context_calling
chat_prompt_with_context = self.build_chat_prompt(queries, context_flag=True)
File "/app/src/chatbot/query_gpt.py", line 250, in build_chat_prompt
assistant_history_prompt = AIMessagePromptTemplate.from_template(
File "/usr/local/lib/python3.8/site-packages/langchain/prompts/chat.py", line 67, in from_template
prompt = PromptTemplate.from_template(template)
File "/usr/local/lib/python3.8/site-packages/langchain/prompts/prompt.py", line 130, in from_template
return cls(input_variables=list(sorted(input_variables)), template=template)
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for PromptTemplate
__root__
Invalid format specifier (type=value_error)
| Validation error for PromptTemplate __root__ Invalid format specifier (type=value_error) | https://api.github.com/repos/langchain-ai/langchain/issues/2765/comments | 7 | 2023-04-12T12:16:35Z | 2023-09-14T14:12:46Z | https://github.com/langchain-ai/langchain/issues/2765 | 1,664,452,179 | 2,765 |
[
"langchain-ai",
"langchain"
] | # Problem
As far as I know, it is not possible to use certain classes like `OpenAIEmbeddings` with deployment names that are not exactly the same as the original model name. In the case of `OpenAIEmbeddings` the `document_model_name` is used to [retrieve the tokenizer from tiktoken](https://github.com/hwchase17/langchain/blob/b92a89e29f85d6b90796c24cdd952be76fb64a23/langchain/embeddings/openai.py#L206) and thus fails if the deployment name is not the same as the original model name.
# Proposal
I propose to introduce a new attribute `deployment_name` and use this along with the `model` attribute to retrieve the model deployment and encoding independently. | Deployments names on Azure need to match model names | https://api.github.com/repos/langchain-ai/langchain/issues/2764/comments | 2 | 2023-04-12T12:02:42Z | 2023-09-10T16:34:41Z | https://github.com/langchain-ai/langchain/issues/2764 | 1,664,430,440 | 2,764 |
[
"langchain-ai",
"langchain"
] | This new loader would take in a github wiki url, download all the wiki pages (they're always .md (?), so we can use `UnstructuredMarkdownLoader` too) and load that into a `Document()` | [FEATURE] Add `GithubWikiLoader` | https://api.github.com/repos/langchain-ai/langchain/issues/2763/comments | 1 | 2023-04-12T11:59:35Z | 2023-09-15T22:12:48Z | https://github.com/langchain-ai/langchain/issues/2763 | 1,664,425,508 | 2,763 |
[
"langchain-ai",
"langchain"
] | Hey, with `openai_callback`. I am able to calculate cost to generate text, but this does not work while calculating embedding cost. | Calculate Embedding Cost | https://api.github.com/repos/langchain-ai/langchain/issues/2762/comments | 3 | 2023-04-12T11:38:44Z | 2023-09-18T16:20:17Z | https://github.com/langchain-ai/langchain/issues/2762 | 1,664,392,646 | 2,762 |
[
"langchain-ai",
"langchain"
] | [Modules - Agents - Tools]
- It seems that no longer use AgentType.
For Example:
initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
-> initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
[Modules - Indexes - Document Loaders - YouTube]
- It seems that no longer use from_youtube_url
For Example:
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=QsYGlZkevEg", add_video_info=True)
-> loader = YoutubeLoader("QsYGlZkevEg", add_video_info=True)
| About Python Docs modification | https://api.github.com/repos/langchain-ai/langchain/issues/2760/comments | 2 | 2023-04-12T09:12:01Z | 2023-08-20T16:31:43Z | https://github.com/langchain-ai/langchain/issues/2760 | 1,664,164,619 | 2,760 |
[
"langchain-ai",
"langchain"
] | `from langchain.agents.agent_toolkits.openapi import planner`
_Traceback (most recent call last):
File "/app.py", line 12, in <module>
from langchain.agents.agent_toolkits.openapi import planner
File ".venv/lib/python3.10/sitepackages/langchain/agents/agent_toolkits/openapi/planner.py", line 43, in <module>
class RequestsGetToolWithParsing(BaseRequestsTool, BaseTool):
File ".venv/lib/python3.10/site-packages/langchain/agents/agent_toolkits/openapi/planner.py", line 48, in RequestsGetToolWithParsing
llm=OpenAI(),
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for OpenAI
__root__
Did not find openai_api_key, please add an environment variable `OPENAI_API_KEY` which contains it, or pass `openai_api_key` as a named parameter. (type=value_error)_ | class RequestsGetToolWithParsing(BaseRequestsTool, BaseTool): File "langchain/agents/agent_toolkits/openapi/planner.py", line 48, in RequestsGetToolWithParsing | https://api.github.com/repos/langchain-ai/langchain/issues/2758/comments | 1 | 2023-04-12T08:23:22Z | 2023-04-13T04:26:36Z | https://github.com/langchain-ai/langchain/issues/2758 | 1,664,088,480 | 2,758 |
[
"langchain-ai",
"langchain"
] | When i use FewShotPromptTemplate function, if the examples contain "{" and "}" characters, I get this error.
Like this: {"question": "A = {1; 2; 3; 4; 5; 6; 8; 10}; B = {1; 3; 5; 7; 9; 11}"}
How can i fix it. Thank you!!! | KeyError: '1; 2; 3; 4; 5; 6; 8; 10' | https://api.github.com/repos/langchain-ai/langchain/issues/2757/comments | 2 | 2023-04-12T08:19:20Z | 2023-09-10T16:34:51Z | https://github.com/langchain-ai/langchain/issues/2757 | 1,664,082,786 | 2,757 |
[
"langchain-ai",
"langchain"
] | "substring not found" on every user input :(
Auto-GPT wont react to it. But the "do nothing sickness" from yesterday work again. (removed the do nothing command temporarily)
NEXT ACTION: COMMAND = list_agents ARGUMENTS = {}
Enter 'y' to authorise command, 'y -N' to run N continuous commands, 'n' to exit program, or enter feedback for AI_GPT_8...
Input:Whenever i give userfeedback there is a error and you dont seem to react to it. Please fix.
SYSTEM: Human feedback: Whenever i give userfeedback there is a error and you dont seem to react to it. Please fix.
Error:
Traceback (most recent call last): File "scripts/main.py", line 76, in print_assistant_thoughts assistant_reply_json = fix_and_parse_json(assistant_reply) File "C:\Programming\Auto-GPT_AI_8\scripts\json_parser.py", line 51, in fix_and_parse_json brace_index = json_str.index("{") ValueError: substring not found
NEXT ACTION: COMMAND = Error: ARGUMENTS = substring not found | "substring not found" on every user suggestion | https://api.github.com/repos/langchain-ai/langchain/issues/2756/comments | 1 | 2023-04-12T08:16:16Z | 2023-04-12T08:47:11Z | https://github.com/langchain-ai/langchain/issues/2756 | 1,664,078,349 | 2,756 |
[
"langchain-ai",
"langchain"
] | Hello
Sorry if this was already asked before.
I know that the data is embedding and indexed locally
but is the data still sent to the LLM Provider ( for example OpenAI ) when you run a query on the embedded data ?
how much does this respect user privacy and private domain content ?
thank you in advance
P.S: if there is anything mentioned anywhere in any documentation I would be very grateful | exposing indexed data to LLM Providers | https://api.github.com/repos/langchain-ai/langchain/issues/2754/comments | 1 | 2023-04-12T07:22:32Z | 2023-09-15T22:12:47Z | https://github.com/langchain-ai/langchain/issues/2754 | 1,663,997,463 | 2,754 |
[
"langchain-ai",
"langchain"
] | When I'm using `RetrievalQA` with `OpenAI` and `QDrant`, I sometimes hit the limit of OpenAI `gpt-3.5-turbo` of 4097 token limit. Is this expected behaviour, or does `langchain` implement a tokens calculator that prevents such events?
For the record, I'm hitting this problem with Arabic text, and so far didn't with English, though I don't know if this is correlated or not.
I want to add that in another project I'm working on I have a 100% working token calculator that didn't fail for me in all of my tests (with the focus group working on the project) so far. The way my calculator work is by limiting the initial prompt to max tokens count, then instruct `openai` SDK to set limit of response to some pre-defined limit (good for three sentences approx.) or the difference between initial prompt tokens count and model tokens limit, whichever is lower.
If this is needed in `langchain` I'm more than happy to re-implement it for this project with little guidance on where is the best part of the codebase to add this in. | [Q] Does langchain implement any prompt+response token calculation to prevent hitting max limit | https://api.github.com/repos/langchain-ai/langchain/issues/2753/comments | 3 | 2023-04-12T07:16:36Z | 2023-09-25T16:09:29Z | https://github.com/langchain-ai/langchain/issues/2753 | 1,663,990,354 | 2,753 |
[
"langchain-ai",
"langchain"
] | Hey,
Does the way of prompting Open AI Chat with SystemMessage, HumanMessage and AIMessage work for Anthropic models aswell?
Or must Anthropic models be prompted in the non-chat way?
thanks | Chat prompt for Anthropic | https://api.github.com/repos/langchain-ai/langchain/issues/2752/comments | 7 | 2023-04-12T07:07:06Z | 2023-10-21T16:09:55Z | https://github.com/langchain-ai/langchain/issues/2752 | 1,663,976,528 | 2,752 |
[
"langchain-ai",
"langchain"
] | How to load codes from file ,such like .py .java .cpp .js?
And how to embedding them to vectors? | How to load codes from file ,such like .py .java .cpp .js? | https://api.github.com/repos/langchain-ai/langchain/issues/2749/comments | 2 | 2023-04-12T06:44:47Z | 2023-04-12T07:40:40Z | https://github.com/langchain-ai/langchain/issues/2749 | 1,663,941,155 | 2,749 |
[
"langchain-ai",
"langchain"
] | The [`FewShotPromptTemplate`](https://python.langchain.com/en/latest/modules/prompts/prompt_templates/examples/prompt_serialization.html#fewshotprompttemplate) examples loaded from `json` and `yaml` files is giving me this error. I've tried this with the examples mentioned in the documentation as well as with my own samples and prompt template and I am seeing the same error. Likely something with [this](https://github.com/hwchase17/langchain/blob/master/langchain/prompts/prompt.py#L44).
```
---------------------------------------------------------------------------
ValidationError Traceback (most recent call last)
<ipython-input-35-9c85b0a90b42> in <module>
1 from langchain.prompts import load_prompt
2
----> 3 prompt = load_prompt("few_shot_prompt_examples_in.json")
4 print(prompt.format(adjective="funny"))
5
/opt/conda/lib/python3.7/site-packages/langchain/prompts/loading.py in load_prompt(file)
101 raise ValueError
102 # Load the prompt from the config now.
--> 103 return load_prompt_from_config(config)
/opt/conda/lib/python3.7/site-packages/langchain/prompts/loading.py in load_prompt_from_config(config)
17 return _load_prompt(config)
18 elif prompt_type == "few_shot":
---> 19 return _load_few_shot_prompt(config)
20 else:
21 raise ValueError
/opt/conda/lib/python3.7/site-packages/langchain/prompts/loading.py in _load_few_shot_prompt(config)
71 config["example_prompt"] = load_prompt(config.pop("example_prompt_path"))
72 else:
---> 73 config["example_prompt"] = _load_prompt(config["example_prompt"])
74 # Load the examples.
75 config = _load_examples(config)
/opt/conda/lib/python3.7/site-packages/langchain/prompts/loading.py in _load_prompt(config)
81 # Load the template from disk if necessary.
82 config = _load_template("template", config)
---> 83 return PromptTemplate(**config)
84
85
/opt/conda/lib/python3.7/site-packages/pydantic/main.cpython-37m-x86_64-linux-gnu.so in pydantic.main.BaseModel.__init__()
ValidationError: 1 validation error for PromptTemplate
_type
extra fields not permitted (type=value_error.extra)
``` | Error: in Serialize prompts | https://api.github.com/repos/langchain-ai/langchain/issues/2740/comments | 1 | 2023-04-12T03:32:41Z | 2023-04-12T04:32:47Z | https://github.com/langchain-ai/langchain/issues/2740 | 1,663,657,537 | 2,740 |
[
"langchain-ai",
"langchain"
] | Code:
```
loader_book = PyPDFLoader("D:/PaperPal/langchain-tutorials/data/The Attention Merchants_ The Epic Scramble to Get Inside Our Heads ( PDFDrive ) (1).pdf")
test = loader_book.load()
chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
chain.run(test[0])
```
I get the following error even when the test[0] is a Document object
```
> Entering new MapReduceDocumentsChain chain...
Output exceeds the [size limit](command:workbench.action.openSettings?%5B%22notebook.output.textLineLimit%22%5D). Open the full output data [in a text editor](command:workbench.action.openLargeOutput?6f60f6d3-3206-4586-b2b2-d8a0f86e1aa0)---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
[d:\PaperPal\langchain-tutorials\chains\Chain](file:///D:/PaperPal/langchain-tutorials/chains/Chain) Types.ipynb Cell 19 in ()
----> [1](vscode-notebook-cell:/d%3A/PaperPal/langchain-tutorials/chains/Chain%20Types.ipynb#X16sZmlsZQ%3D%3D?line=0) chain.run(test[0])
File [c:\Users\mail2\anaconda3\lib\site-packages\langchain\chains\base.py:213](file:///C:/Users/mail2/anaconda3/lib/site-packages/langchain/chains/base.py:213), in Chain.run(self, *args, **kwargs)
211 if len(args) != 1:
212 raise ValueError("`run` supports only one positional argument.")
--> 213 return self(args[0])[self.output_keys[0]]
215 if kwargs and not args:
216 return self(kwargs)[self.output_keys[0]]
File [c:\Users\mail2\anaconda3\lib\site-packages\langchain\chains\base.py:116](file:///C:/Users/mail2/anaconda3/lib/site-packages/langchain/chains/base.py:116), in Chain.__call__(self, inputs, return_only_outputs)
114 except (KeyboardInterrupt, Exception) as e:
115 self.callback_manager.on_chain_error(e, verbose=self.verbose)
--> 116 raise e
117 self.callback_manager.on_chain_end(outputs, verbose=self.verbose)
118 return self.prep_outputs(inputs, outputs, return_only_outputs)
File [c:\Users\mail2\anaconda3\lib\site-packages\langchain\chains\base.py:113](file:///C:/Users/mail2/anaconda3/lib/site-packages/langchain/chains/base.py:113), in Chain.__call__(self, inputs, return_only_outputs)
107 self.callback_manager.on_chain_start(
108 {"name": self.__class__.__name__},
109 inputs,
110 verbose=self.verbose,
111 )
...
--> 141 [{**{self.document_variable_name: d.page_content}, **kwargs} for d in docs]
142 )
143 return self._process_results(results, docs, token_max, **kwargs)
AttributeError: 'tuple' object has no attribute 'page_content'
``` | AttributeError: 'tuple' object has no attribute 'page_content' when running a `load_summarize_chain` on an my Document generated from PyPDF Loader | https://api.github.com/repos/langchain-ai/langchain/issues/2736/comments | 9 | 2023-04-12T00:19:48Z | 2024-06-13T20:16:40Z | https://github.com/langchain-ai/langchain/issues/2736 | 1,663,426,842 | 2,736 |
[
"langchain-ai",
"langchain"
] | Hi,
I tried several loaders (GitHub
, selenium, cheerio,etc) and they retrieve correctly certain data.
I then use splitters to split the text in multiple documents, and pass it to the open ai api with high max token.
I consistently get 400, which I believe is due to the document size. Is a legit guess? Is there some other steps I need to do in order to avoid a 400 request? | Question. OpenAI completion api returns 400 | https://api.github.com/repos/langchain-ai/langchain/issues/2727/comments | 2 | 2023-04-11T18:50:19Z | 2023-09-10T16:34:55Z | https://github.com/langchain-ai/langchain/issues/2727 | 1,663,037,095 | 2,727 |
[
"langchain-ai",
"langchain"
] | Python version: 3.9.16
Langchain version: 0.0.109
The code:
```
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
```
the error:
```
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[123], line 1
----> 1 from langchain.chains import RetrievalQA
2 from langchain.llms import OpenAI
ImportError: cannot import name 'RetrievalQA' from 'langchain.chains' (/opt/conda/envs/python39/lib/python3.9/site-packages/langchain/chains/__init__.py)
``` | Cannot import RetrievalQA from langchain.chains | https://api.github.com/repos/langchain-ai/langchain/issues/2725/comments | 8 | 2023-04-11T17:47:50Z | 2024-07-30T15:00:22Z | https://github.com/langchain-ai/langchain/issues/2725 | 1,662,959,470 | 2,725 |
[
"langchain-ai",
"langchain"
] | After updating to v.0.0.137 version, I now have an error while executing the following script (from the documentation):
```python
import os
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
os.environ["OPENAI_API_KEY"] = "sk-xxxxxxxxxxxxxx"
db = SQLDatabase.from_uri("mysql://user:password@localhost:db_port/db_name")
llm = OpenAI(temperature=0)
toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True
)
agent_executor.run("A human to SQL request")
```
The error: "AttributeError: type object 'QueryCheckerTool' has no attribute 'llm'"
<img width="842" alt="Capture d’écran 2023-04-11 à 19 04 18" src="https://user-images.githubusercontent.com/11693661/231237020-3ac589d1-89ca-4044-bd24-8b0512734fcf.png">
[This PR](https://github.com/hwchase17/langchain/pull/2655) breaks something, but I can't find how to debug the error.
Can someone help me debug it?
Thanks ❤️ | Error with `create_sql_agent` after updating to v0.0.137 | https://api.github.com/repos/langchain-ai/langchain/issues/2722/comments | 4 | 2023-04-11T17:07:13Z | 2023-04-17T16:11:47Z | https://github.com/langchain-ai/langchain/issues/2722 | 1,662,911,623 | 2,722 |
[
"langchain-ai",
"langchain"
] | Hey guys, I really love langchain and the community, thank you in advance for helping and pointing me in the right direction!
I want to use GPT4All as an LLM powering an langchain agent. It wasn't working as expected, so I've started from basics. I've noticed that GPT4All wrapper in langchain creates very low quality results in comparison to command line version of gpt4all.
In command line we can notice that gpt4all provides short and correct answers, for langchain GPT4All wrapper - responses are unusable.
My questions are:
1. Can anybody explain why there are different responses - I would expect to get the same responses since almost the same model is used (gpt4all-lora-unfiltered-quantized.bin and gpt4all-lora-quantized-ggml.bin) (see: https://github.com/nomic-ai/gpt4all#gpt4all-compatibility-ecosystem).
2. What needs to be done to make it possible to get similar responses in langchain with GPT4All models as we are getting right now in command line?
My goal is to make it possible to play with langchain agents using local models to avoid paying for each request to OpenAI, or at least reduce these costs.
<img width="1461" alt="Screenshot 2023-04-11 at 17 48 09" src="https://user-images.githubusercontent.com/428635/231222422-ec2f8360-3213-408d-91a4-6cbd979b2157.png"> | GPT4All responds with different results than the similar model executed from cmd line | https://api.github.com/repos/langchain-ai/langchain/issues/2721/comments | 1 | 2023-04-11T16:05:55Z | 2023-09-10T16:35:01Z | https://github.com/langchain-ai/langchain/issues/2721 | 1,662,822,253 | 2,721 |
[
"langchain-ai",
"langchain"
] | I'm proposing modifying the PydanticOutputParsers such that they are generic on the pydantic object passed in to the constructor, so we can get type hints on the resulting pydantic objects that are returned by `parse`.
E.g
```
class TestOutput(BaseModel):
output: str = ...
output_parser = PydanticOutputParser(TestOutput)
parsed = output_parser.parse(...) # right now this is typed as BaseModel, but it'd be better if it was TestOutput
```
I haven't looked in-depth but I think it's likely we can type the other parsers with similar fidelity.
I'm happy to take this one if it's agreed that this is a useful change. | Better type hints for OutputParser | https://api.github.com/repos/langchain-ai/langchain/issues/2715/comments | 2 | 2023-04-11T14:20:29Z | 2023-04-13T13:50:31Z | https://github.com/langchain-ai/langchain/issues/2715 | 1,662,600,820 | 2,715 |
[
"langchain-ai",
"langchain"
] | import { SqlDatabase } from "langchain/tools"; Module '"langchain/tools"' has no exported member 'SqlDatabase'.ts | "langchain/tools"' has no exported member 'SqlDatabase' | https://api.github.com/repos/langchain-ai/langchain/issues/2711/comments | 1 | 2023-04-11T12:56:26Z | 2023-09-15T21:30:37Z | https://github.com/langchain-ai/langchain/issues/2711 | 1,662,423,398 | 2,711 |
[
"langchain-ai",
"langchain"
] | When I create `embeddings = HuggingFaceEmbeddings(model_name='THUDM/chatglm-6b')`
I get an error message:
```
ValueError: Loading THUDM/chatglm-6b requires you to execute the configuration file in that repo on your local machine. Make sure you have read the code there to avoid malicious use, then set the option trust_remote_code=True to remove this error.
```
How can I fix it?
python env:
```
python version: Python 3.8.10
transformers 4.27.4
langchain 0.0.136
``` | Error when creating HuggingFaceEmbeddings with chatglm-6b model | https://api.github.com/repos/langchain-ai/langchain/issues/2710/comments | 5 | 2023-04-11T12:15:55Z | 2023-06-20T16:34:51Z | https://github.com/langchain-ai/langchain/issues/2710 | 1,662,357,596 | 2,710 |
[
"langchain-ai",
"langchain"
] | Would be cool to have this feature. This way we could save already working agent chain into an idempotent workflow to reuse it later many many times. As i understand, right now, LLM can generate another plan for the next call and it could be invalid or with some error.
Would be cool to persist that working plan to reuse it. | Idempotent agent chains or chains import/export? | https://api.github.com/repos/langchain-ai/langchain/issues/2708/comments | 1 | 2023-04-11T10:29:32Z | 2023-09-10T16:35:08Z | https://github.com/langchain-ai/langchain/issues/2708 | 1,662,201,505 | 2,708 |
[
"langchain-ai",
"langchain"
] | Running from the same environment and have tried uninstalling/reinstalling - still getting this error.
Anyone have a fix or know what I could be doing wrong?
<img width="632" alt="Screenshot 2023-04-11 at 7 05 40 pm" src="https://user-images.githubusercontent.com/121209163/231112960-f55b80dc-93ae-4a96-abc2-33efa7b8cee1.png">
| ModuleNotFoundError: No module named 'langchain' (Even though LangChain is installed) | https://api.github.com/repos/langchain-ai/langchain/issues/2707/comments | 3 | 2023-04-11T09:14:20Z | 2023-09-10T16:35:13Z | https://github.com/langchain-ai/langchain/issues/2707 | 1,662,074,604 | 2,707 |
[
"langchain-ai",
"langchain"
] | Hi, I'm having some trouble when **linking to MySQL**. Does it only support connecting to sqlite? There seems to be **no introduction to connecting to MySQL in the document** | having some trouble when linking to MySQL | https://api.github.com/repos/langchain-ai/langchain/issues/2705/comments | 5 | 2023-04-11T08:50:12Z | 2023-09-25T16:09:39Z | https://github.com/langchain-ai/langchain/issues/2705 | 1,662,036,269 | 2,705 |
[
"langchain-ai",
"langchain"
] | Hi, I'm having some trouble finding the solution to this.
I'm using Langchain on Colab, and for some reasons, the answers sometimes get cut off like below (screenshot attached)
I have 2 questions, and both are cut off, as you can see.
I tried changing 'max_len_answer' but nothing changes
Do you guys have any suggesting for this?
Thank you.
| question_answering chains answers cut off | https://api.github.com/repos/langchain-ai/langchain/issues/2703/comments | 1 | 2023-04-11T08:08:14Z | 2023-04-12T08:37:08Z | https://github.com/langchain-ai/langchain/issues/2703 | 1,661,977,111 | 2,703 |
[
"langchain-ai",
"langchain"
] | I noticed llm `OpenAI` returns `finish_reason` in `generation_info` https://github.com/hwchase17/langchain/pull/526
But chat_model `ChatOpenAI`'s `generation_info` is `None`
```python
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(temperature=0)
messages = [
SystemMessage(
content="You are a helpful assistant that translates English to French."
),
HumanMessage(
content="Translate this sentence from English to French. I love programming."
),
]
result = chat.generate([messages])
result.generations[0][0]
```
```
ChatGeneration(text="J'aime programmer.", generation_info=None, message=AIMessage(content="J'aime programmer.", additional_kwargs={}))
```
Should we just add `generation_info` to the `ChatGeneration` of `ChatOpenAI` like `OpenAI`? I can help to create a PR if needed.
https://github.com/hwchase17/langchain/blob/955bd2e1db8d008d628963cb8d2bad5c1d354744/langchain/chat_models/openai.py#L284
https://github.com/hwchase17/langchain/blob/1f557ffa0e6c4c2137109d6a014b0617e9885b02/langchain/llms/openai.py#L170-L173 | generation_info for ChatOpenAI model | https://api.github.com/repos/langchain-ai/langchain/issues/2702/comments | 4 | 2023-04-11T07:02:21Z | 2023-10-12T16:10:34Z | https://github.com/langchain-ai/langchain/issues/2702 | 1,661,884,074 | 2,702 |
[
"langchain-ai",
"langchain"
] | Hi,
I have a usecase where i have to fetch Edited posts weekly from community and update the docs within FAISS index.
is that possible? or do i have to keep deleting and create new index everytime?
Also i use RecursiveCharacterTextSplitter to split docs.
```
loader = DirectoryLoader('./recent_data')
raw_documents = loader.load()
#Splitting documents into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
)
documents = text_splitter.split_documents(raw_documents)
print(len(documents))
# Changing source to point to the original document
for x in documents:
print(x.metadata["source"])
# Creating index and saving it to disk
print("Creating index")
db_new = FAISS.from_documents(documents, embeddings )
```
this is output if i use ` print(db_new .docstore._dict)`
`{'2d9b6fbf-a44d-46b5-bcdf-b45cd9438a4c': Document(page_content='<p dir="auto">This is a test topic.</p>', metadata={'source': 'recent/https://community.tpsonline.com/topic/587/ignore-test-topic'}), '706dcaf8-f9d9-45b9-bdf4-8a8ac7618229': Document(page_content='What is an SDD?\n\n<p dir="auto">A software design description (a.k.a. software design document or SDD; just design document; also Software Design Specification) is a representation of a software design that is to be used for recording design information, addressing various design concerns, and communicating that information to the different stakeholders.</p>\n\n<p dir="auto">This SDD template represent design w.r.t various software viewpoints, where each viewpoint will handle specific concerns of Design. This is based on <strong>ISO 42010 standard</strong>.</p>\n\nIntroduction\n\n<p dir="auto">[Name/brief description of feature for which SDD is being Produced]</p>\n\n1. Context Viewpoint\n\n<p dir="auto">[Describes the relationships, dependencies, and interactions between the system and its environment ]</p>\n\n1.1 Use Cases\n\n1.1.1 AS IS (Pre Condition)\n\n1.1.2 TO - BE (Post Condition)\n\n1.2 System Context View\n\n1.2.1 - AS IS (Pre Condition)\n\n1.2.2 TO - BE (Post Condition)\n\n2. Logical Viewpoint', metadata={'source': 'recent/https://community.tpsonline.com/topic/586/software-design-description-sdd-template'}), '4d6d4e6b-01ee-46bb-ae06-84514a51baf2': Document(page_content='1.1 Use Cases\n\n1.1.1 AS IS (Pre Condition)\n\n1.1.2 TO - BE (Post Condition)\n\n1.2 System Context View\n\n1.2.1 - AS IS (Pre Condition)\n\n1.2.2 TO - BE (Post Condition)\n\n2. Logical Viewpoint\n\n<p dir="auto">[The purpose of the Logical viewpoint is to elaborate existing and designed types and their implementations as classes and interfaces with their structural static relationships]</p>\n\n2.1 Class Diagram\n\n2.1.1 AS - IS (Pre Condition)\n\n2.1.2 TO - BE (Post Condition)\n\n2.1.2.1 Class Interfaces and description\n\n<p dir="auto">[Below is being presented as an example]<br />\n\n[This section should tell about the responsibility of each class method and their parameters too if required]</p>\n\n2.1.2.1.1 IRenewProcess\n\nMethod\n\nDescription\n\nprocessRenewal\n\nMethod to process renewal of a given cardEntity. Each concrete class that will implement the interface will implement its own version of renewal steps\n\n2.1.2.1.1 RenewStrategyContext (static class)\n\nMethod\n\nDescription\n\n(private)getRenewalMethod', metadata={'source': 'recent/https://community.tpsonline.com/topic/586/software-design-description-sdd-template'})}`
so will i be able to update docs within index or is it just not possible? | How to delete or update a document within a FAISS index? | https://api.github.com/repos/langchain-ai/langchain/issues/2699/comments | 19 | 2023-04-11T06:33:19Z | 2023-08-18T07:01:58Z | https://github.com/langchain-ai/langchain/issues/2699 | 1,661,852,287 | 2,699 |
[
"langchain-ai",
"langchain"
] | I was testing OnlinePDFLoader yesterday iirc and it was working fine. Today I tried experimenting and I keep getting this error
`PermissionError: [Errno 13] Permission denied: 'C:\\Users\\REALGL~1\\AppData\\Local\\Temp\\tmp3chr08y0`
it may be occurring because the `tempfile.NamedTemporaryFile()` in `pdf.py` is still open when the PDF partitioning function is trying to access it | Permission Error with PDF loader | https://api.github.com/repos/langchain-ai/langchain/issues/2698/comments | 6 | 2023-04-11T06:17:16Z | 2024-01-27T10:50:22Z | https://github.com/langchain-ai/langchain/issues/2698 | 1,661,837,012 | 2,698 |
[
"langchain-ai",
"langchain"
] | I am trying to load the multiple pdf using the directory loader its popping up with the following error:
`ImportError: cannot import name 'is_directory' from 'PIL._util' (/usr/local/lib/python3.9/dist-packages/PIL/_util.py)` | Directory loader error for pdfs | https://api.github.com/repos/langchain-ai/langchain/issues/2697/comments | 2 | 2023-04-11T05:51:16Z | 2023-09-10T16:35:16Z | https://github.com/langchain-ai/langchain/issues/2697 | 1,661,811,809 | 2,697 |
[
"langchain-ai",
"langchain"
] | I would like to provide an 'embeddings' parameter for the initialization of the Weaviate vector store, as I do not want to start the Weaviate server with the OpenAI key in order to make use of embeddings through the Azure OpenAI Service.
The addition of the embeddings parameter affects the __init__ method, as shown in the code snippet above. To accommodate this change, you'll also need to modify the add_texts method.
```python
def __init__(
self,
client: Any,
index_name: str,
text_key: str,
embedding_function: Optional[Embeddings] = None,
attributes: Optional[List[str]] = None,
):
"""Initialize with Weaviate client."""
try:
import weaviate
except ImportError:
raise ValueError(
"Could not import weaviate python package. "
"Please install it with `pip install weaviate-client`."
)
if not isinstance(client, weaviate.Client):
raise ValueError(
f"client should be an instance of weaviate.Client, got {type(client)}"
)
self._client = client
self._index_name = index_name
self._text_key = text_key
self._embedding_function = embedding_function
self._query_attrs = [self._text_key]
if attributes is not None:
self._query_attrs.extend(attributes)
```
To check if the embeddings parameter was provided during initialization and perform the necessary actions, you can modify the add_texts method in the following way:
```python
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> List[str]:
"""Upload texts with metadata (properties) to Weaviate."""
from weaviate.util import get_valid_uuid
with self._client.batch as batch:
ids = []
for i, doc in enumerate(texts):
data_properties = {
self._text_key: doc,
}
if metadatas is not None:
for key in metadatas[i].keys():
data_properties[key] = metadatas[i][key]
_id = get_valid_uuid(uuid4())
if self._embedding_function is not None:
embeddings = self._embedding_function.embed_documents(list(doc))
batch.add_data_object(data_properties, self._index_name, _id, vector=embeddings[0])
else:
batch.add_data_object(data_properties, self._index_name, _id)
ids.append(_id)
return ids
``` | Allow Weaviate initialization with alternative embedding implementation | https://api.github.com/repos/langchain-ai/langchain/issues/2695/comments | 2 | 2023-04-11T05:19:00Z | 2023-04-27T04:45:05Z | https://github.com/langchain-ai/langchain/issues/2695 | 1,661,787,838 | 2,695 |
[
"langchain-ai",
"langchain"
] | Expectation:
Loading a text file via UnstructuredFileLoader then passing the output docs to VectorStoreIndexCreator should work
Observation:
Crash when attempting to call `VectorstoreIndexCreator().from_loaders(unstructuredFileLoader)`
Crashlog:
```
Traceback (most recent call last):
File "/Users/minhcnd/Repos/llm-demo/llm_demo/main.py", line 30, in <module>
index = VectorstoreIndexCreator().from_loaders(loaders)
File "/Users/minhcnd/Library/Caches/pypoetry/virtualenvs/llm-demo-yOjCLQYD-py3.9/lib/python3.9/site-packages/langchain/indexes/vectorstore.py", line 71, in from_loaders
vectorstore = self.vectorstore_cls.from_documents(
File "/Users/minhcnd/Library/Caches/pypoetry/virtualenvs/llm-demo-yOjCLQYD-py3.9/lib/python3.9/site-packages/langchain/vectorstores/chroma.py", line 334, in from_documents
return cls.from_texts(
File "/Users/minhcnd/Library/Caches/pypoetry/virtualenvs/llm-demo-yOjCLQYD-py3.9/lib/python3.9/site-packages/langchain/vectorstores/chroma.py", line 303, in from_texts
chroma_collection.add_texts(texts=texts, metadatas=metadatas, ids=ids)
File "/Users/minhcnd/Library/Caches/pypoetry/virtualenvs/llm-demo-yOjCLQYD-py3.9/lib/python3.9/site-packages/langchain/vectorstores/chroma.py", line 114, in add_texts
self._collection.add(
File "/Users/minhcnd/Library/Caches/pypoetry/virtualenvs/llm-demo-yOjCLQYD-py3.9/lib/python3.9/site-packages/chromadb/api/models/Collection.py", line 85, in add
metadatas = validate_metadatas(maybe_cast_one_to_many(metadatas)) if metadatas else None
File "/Users/minhcnd/Library/Caches/pypoetry/virtualenvs/llm-demo-yOjCLQYD-py3.9/lib/python3.9/site-packages/chromadb/api/types.py", line 108, in validate_metadatas
validate_metadata(metadata)
File "/Users/minhcnd/Library/Caches/pypoetry/virtualenvs/llm-demo-yOjCLQYD-py3.9/lib/python3.9/site-packages/chromadb/api/types.py", line 99, in validate_metadata
raise ValueError(f"Expected metadata value to be a str, int, or float, got {value}")
ValueError: Expected metadata value to be a str, int, or float, got seneca.txt
```
Root cause:
In unstructured.py, `_get_metadata()` returns a **PoxisPath** object, but validate_metadata expects a str, int or float
| VectorStoreIndexCreator can't load from UnstructuredFileLoader | https://api.github.com/repos/langchain-ai/langchain/issues/2685/comments | 4 | 2023-04-10T22:25:51Z | 2023-09-27T16:08:57Z | https://github.com/langchain-ai/langchain/issues/2685 | 1,661,468,710 | 2,685 |
[
"langchain-ai",
"langchain"
] | I would like to make requests to both Azure OpenAI and the OpenAI API in my app using the `AzureChatOpenAI` and `ChatOpenAI` classes respectively.
The issue I'm running into is it seems both classes depend on the same environment variables/global OpenAI variables (`openai.api_key`, `openai.api_type`, etc). For example, if I create an `AzureChatOpenAI` instance, the variables will be set to Azure config, and this will cause any subsequent OpenAI calls to fail.
I also have two instances of Azure OpenAI that I want to hit (e.g. I have text-davinci-003 running in EU and gpt-3.5-turbo running in US as gpt-3.5-turbo isn't supported in EU yet), so it would be nice if I could have separate instances of `AzureChatOpenAI` with different configs.
A workaround is to set these environment variables manually before every call, which `AzureChatOpenAI` kind of does, but this seems susceptible to race conditions if concurrent requests are made to my app since these variables aren't directly passed into the request and there's no locking mechanism.
Would it be possible to have multiple instances of these classes and not have these instances obscurely share state? Or is this just a limitation of the way OpenAI's python package is setup?
Thank you! | Support concurrent usage of OpenAI API and Azure OpenAI | https://api.github.com/repos/langchain-ai/langchain/issues/2683/comments | 7 | 2023-04-10T22:01:07Z | 2023-09-27T16:09:02Z | https://github.com/langchain-ai/langchain/issues/2683 | 1,661,437,301 | 2,683 |
[
"langchain-ai",
"langchain"
] | I would like to be able to pass token params for tiktoken in
https://github.com/hwchase17/langchain/blob/bd9f095ed249694a98aa438c5467564ace883ff5/langchain/embeddings/openai.py#L198
to be able to work with documents with `<|endoftext|>` in them
Related issue: https://github.com/hwchase17/langchain/issues/923 | OpenAIEmbeddings special token params for tiktoken | https://api.github.com/repos/langchain-ai/langchain/issues/2681/comments | 0 | 2023-04-10T20:25:15Z | 2023-04-11T11:44:18Z | https://github.com/langchain-ai/langchain/issues/2681 | 1,661,315,327 | 2,681 |
[
"langchain-ai",
"langchain"
] | The following only parse the info within the webpage. If there are links/other pages embedded into the webpage, how do I parse them iteratively?
`loader = WebBaseLoader("https://beta.ruff.rs/docs/faq/")`
`blog_docs = loader.load()`
print(blog_docs)
> [Document(page_content='\n\n\n\n\n\n\n\n\n\n\n\nFAQ - Ruff\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nSkip to content\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nRuff\n\n\n\n\nFAQ\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nInitializing search\n\n\n\n\n\n\n\n\n\n\n\n\n\nruff\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nRuff\n\n\n\n\n\n\n\nruff\n\n\n\n\n\n\nOverview\n\n\n\n\nTutorial\n\n\n\n\nInstallation\n\n\n\n\nUsage\n\n\n\n\nConfiguration\n\n\n\n\nRules\n\n\n\n\nSettings\n\n\n\n\nEditor Integrations\n\n\n\n\n\nFAQ\n\n\n\nFAQ\n\n\n\n\nTable of contents\n\n\n\n\nIs Ruff compatible with Black?\n\n\n\n\nHow does Ruff compare to Flake8?\n\n\n\n\nHow does Ruff compare to Pylint?\n\n\n\n\nHow does Ruff compare to Mypy, or Pyright, or Pyre?\n\n\n\n\nWhich tools does Ruff replace?\n\n\n\n\nWhat versions of Python does Ruff support?\n\n\n\n\nDo I need to install Rust to use Ruff?\n\n\n\n\nCan I write my own plugins for Ruff?\n\n\n\n\nHow does Ruff\'s import sorting compare to isort?\n\n\n\n\nDoes Ruff support Jupyter Notebooks?\n\n\n\n\nDoes Ruff support NumPy- or Google-style docstrings?\n\n\n\n\nHow can I tell what settings Ruff is using to check my code?\n\n\n\n\nI want to use Ruff, but I don\'t want to use pyproject.toml. Is that possible?\n\n\n\n\nHow can I change Ruff\'s default configuration?\n\n\n\n\nRuff tried to fix something — but it broke my code?\n\n\n\n\nHow can I disable Ruff\'s color output?\n\n\n\n\n\n\n\nContributing\n\n\n\n\n\n\n\n\n\nFAQ#\nIs Ruff compatible with Black?#\nYes. Ruff is compatible with Black out-of-the-box, as long as\nthe line-length setting is consistent between the two.\nAs a project, Ruff is designed to be used alongside Black and, as such, will defer implementing\nstylistic lint rules that are obviated by autoformatting.\nHow does Ruff compare to Flake8?#\n(Coming from Flake8? Try flake8-to-ruff to\nautomatically convert your existing configuration.)\nRuff can be used as a drop-in replacement for Flake8 when used (1) without or with a small number of\nplugins, (2) alongside Black, and (3) on Python 3 code.\nUnder those conditions, Ruff implements every rule in Flake8. In practice, that means Ruff\nimplements all of the F rules (which originate from Pyflakes), along with a subset of the E and\nW rules (which originate from pycodestyle).\nRuff also re-implements some of the most popular Flake8 plugins and related code quality tools\nnatively, including:\n\nautoflake\neradicate\nflake8-2020\nflake8-annotations\nflake8-bandit (#1646)\nflake8-blind-except\nflake8-boolean-trap\nflake8-bugbear\nflake8-builtins\nflake8-commas\nflake8-comprehensions\nflake8-datetimez\nflake8-debugger\nflake8-django\nflake8-docstrings\nflake8-eradicate\nflake8-errmsg\nflake8-executable\nflake8-gettext\nflake8-implicit-str-concat\nflake8-import-conventions\nflake8-logging-format\nflake8-no-pep420\nflake8-pie\nflake8-print\nflake8-pyi\nflake8-pytest-style\nflake8-quotes\nflake8-raise\nflake8-return\nflake8-self\nflake8-simplify\nflake8-super\nflake8-tidy-imports\nflake8-type-checking\nflake8-use-pathlib\nisort\nmccabe\npandas-vet\npep8-naming\npydocstyle\npygrep-hooks (#980)\npyupgrade\ntryceratops\nyesqa\n\nNote that, in some cases, Ruff uses different rule codes and prefixes than would be found in the\noriginating Flake8 plugins. For example, Ruff uses TID252 to represent the I252 rule from\nflake8-tidy-imports. This helps minimize conflicts across plugins and allows any individual plugin\nto be toggled on or off with a single (e.g.) --select TID, as opposed to --select I2 (to avoid\nconflicts with the isort rules, like I001).\nBeyond the rule set, Ruff\'s primary limitation vis-à-vis Flake8 is that it does not support custom\nlint rules. (Instead, popular Flake8 plugins are re-implemented in Rust as part of Ruff itself.)\nThere are a few other minor incompatibilities between Ruff and the originating Flake8 plugins:\n\nRuff doesn\'t implement all the "opinionated" lint rules from flake8-bugbear.\nDepending on your project structure, Ruff and isort can differ in their detection of first-party\ncode. (This is often solved by modifying the src property, e.g., to src = ["src"], if your\ncode is nested in a src directory.)\n\nHow does Ruff compare to Pylint?#\nAt time of writing, Pylint implements ~409 total rules, while Ruff implements 440, of which at least\n89 overlap with the Pylint rule set (you can find the mapping in #970).\nPylint implements many rules that Ruff does not, and vice versa. For example, Pylint does more type\ninference than Ruff (e.g., Pylint can validate the number of arguments in a function call). As such,\nRuff is not a "pure" drop-in replacement for Pylint (and vice versa), as they enforce different sets\nof rules.\nDespite these differences, many users have successfully switched from Pylint to Ruff, especially\nthose using Ruff alongside a type checker,\nwhich can cover some of the functionality that Pylint provides.\nLike Flake8, Pylint supports plugins (called "checkers"), while Ruff implements all rules natively.\nUnlike Pylint, Ruff is capable of automatically fixing its own lint violations.\nPylint parity is being tracked in #970.\nHow does Ruff compare to Mypy, or Pyright, or Pyre?#\nRuff is a linter, not a type checker. It can detect some of the same problems that a type checker\ncan, but a type checker will catch certain errors that Ruff would miss. The opposite is also true:\nRuff will catch certain errors that a type checker would typically ignore.\nFor example, unlike a type checker, Ruff will notify you if an import is unused, by looking for\nreferences to that import in the source code; on the other hand, a type checker could flag that you\npassed an integer argument to a function that expects a string, which Ruff would miss. The\ntools are complementary.\nIt\'s recommended that you use Ruff in conjunction with a type checker, like Mypy, Pyright, or Pyre,\nwith Ruff providing faster feedback on lint violations and the type checker providing more detailed\nfeedback on type errors.\nWhich tools does Ruff replace?#\nToday, Ruff can be used to replace Flake8 when used with any of the following plugins:\n\nflake8-2020\nflake8-annotations\nflake8-bandit (#1646)\nflake8-blind-except\nflake8-boolean-trap\nflake8-bugbear\nflake8-builtins\nflake8-commas\nflake8-comprehensions\nflake8-datetimez\nflake8-debugger\nflake8-django\nflake8-docstrings\nflake8-eradicate\nflake8-errmsg\nflake8-executable\nflake8-gettext\nflake8-implicit-str-concat\nflake8-import-conventions\nflake8-logging-format\nflake8-no-pep420\nflake8-pie\nflake8-print\nflake8-pytest-style\nflake8-quotes\nflake8-raise\nflake8-return\nflake8-self\nflake8-simplify\nflake8-super\nflake8-tidy-imports\nflake8-type-checking\nflake8-use-pathlib\nmccabe\npandas-vet\npep8-naming\npydocstyle\ntryceratops\n\nRuff can also replace isort,\nyesqa, eradicate, and\nmost of the rules implemented in pyupgrade.\nIf you\'re looking to use Ruff, but rely on an unsupported Flake8 plugin, feel free to file an\nissue.\nWhat versions of Python does Ruff support?#\nRuff can lint code for any Python version from 3.7 onwards, including Python 3.10 and 3.11.\nRuff does not support Python 2. Ruff may run on pre-Python 3.7 code, although such versions\nare not officially supported (e.g., Ruff does not respect type comments).\nRuff is installable under any Python version from 3.7 onwards.\nDo I need to install Rust to use Ruff?#\nNope! Ruff is available as ruff on PyPI:\npip install ruff\n\nRuff ships with wheels for all major platforms, which enables pip to install Ruff without relying\non Rust at all.\nCan I write my own plugins for Ruff?#\nRuff does not yet support third-party plugins, though a plugin system is within-scope for the\nproject. See #283 for more.\nHow does Ruff\'s import sorting compare to isort?#\nRuff\'s import sorting is intended to be nearly equivalent to isort when used profile = "black".\nThere are a few known, minor differences in how Ruff and isort break ties between similar imports,\nand in how Ruff and isort treat inline comments in some cases (see: #1381,\n#2104).\nLike isort, Ruff\'s import sorting is compatible with Black.\nRuff does not yet support all of isort\'s configuration options, though it does support many of\nthem. You can find the supported settings in the API reference.\nFor example, you can set known-first-party like so:\n[tool.ruff]\nselect = [\n # Pyflakes\n "F",\n # Pycodestyle\n "E",\n "W",\n # isort\n "I001"\n]\n\n# Note: Ruff supports a top-level `src` option in lieu of isort\'s `src_paths` setting.\nsrc = ["src", "tests"]\n\n[tool.ruff.isort]\nknown-first-party = ["my_module1", "my_module2"]\n\nDoes Ruff support Jupyter Notebooks?#\nRuff is integrated into nbQA, a tool for running linters and\ncode formatters over Jupyter Notebooks.\nAfter installing ruff and nbqa, you can run Ruff over a notebook like so:\n> nbqa ruff Untitled.ipynb\nUntitled.ipynb:cell_1:2:5: F841 Local variable `x` is assigned to but never used\nUntitled.ipynb:cell_2:1:1: E402 Module level import not at top of file\nUntitled.ipynb:cell_2:1:8: F401 `os` imported but unused\nFound 3 errors.\n1 potentially fixable with the --fix option.\n\nDoes Ruff support NumPy- or Google-style docstrings?#\nYes! To enable specific docstring convention, add the following to your pyproject.toml:\n[tool.ruff.pydocstyle]\nconvention = "google" # Accepts: "google", "numpy", or "pep257".\n\nFor example, if you\'re coming from flake8-docstrings, and your originating configuration uses\n--docstring-convention=numpy, you\'d instead set convention = "numpy" in your pyproject.toml,\nas above.\nAlongside convention, you\'ll want to explicitly enable the D rule code prefix, like so:\n[tool.ruff]\nselect = [\n "D",\n]\n\n[tool.ruff.pydocstyle]\nconvention = "google"\n\nSetting a convention force-disables any rules that are incompatible with that convention, no\nmatter how they\'re provided, which avoids accidental incompatibilities and simplifies configuration.\nHow can I tell what settings Ruff is using to check my code?#\nRun ruff check /path/to/code.py --show-settings to view the resolved settings for a given file.\nI want to use Ruff, but I don\'t want to use pyproject.toml. Is that possible?#\nYes! In lieu of a pyproject.toml file, you can use a ruff.toml file for configuration. The two\nfiles are functionally equivalent and have an identical schema, with the exception that a ruff.toml\nfile can omit the [tool.ruff] section header.\nFor example, given this pyproject.toml:\n[tool.ruff]\nline-length = 88\n\n[tool.ruff.pydocstyle]\nconvention = "google"\n\nYou could instead use a ruff.toml file like so:\nline-length = 88\n\n[pydocstyle]\nconvention = "google"\n\nRuff doesn\'t currently support INI files, like setup.cfg or tox.ini.\nHow can I change Ruff\'s default configuration?#\nWhen no configuration file is found, Ruff will look for a user-specific pyproject.toml or\nruff.toml file as a last resort. This behavior is similar to Flake8\'s ~/.config/flake8.\nOn macOS, Ruff expects that file to be located at /Users/Alice/Library/Application Support/ruff/ruff.toml.\nOn Linux, Ruff expects that file to be located at /home/alice/.config/ruff/ruff.toml.\nOn Windows, Ruff expects that file to be located at C:\\Users\\Alice\\AppData\\Roaming\\ruff\\ruff.toml.\nFor more, see the dirs crate.\nRuff tried to fix something — but it broke my code?#\nRuff\'s autofix is a best-effort mechanism. Given the dynamic nature of Python, it\'s difficult to\nhave complete certainty when making changes to code, even for the seemingly trivial fixes.\nIn the future, Ruff will support enabling autofix behavior based on the safety of the patch.\nIn the meantime, if you find that the autofix is too aggressive, you can disable it on a per-rule or\nper-category basis using the unfixable mechanic.\nFor example, to disable autofix for some possibly-unsafe rules, you could add the following to your\npyproject.toml:\n[tool.ruff]\nunfixable = ["B", "SIM", "TRY", "RUF"]\n\nIf you find a case where Ruff\'s autofix breaks your code, please file an Issue!\nHow can I disable Ruff\'s color output?#\nRuff\'s color output is powered by the colored crate, which\nattempts to automatically detect whether the output stream supports color. However, you can force\ncolors off by setting the NO_COLOR environment variable to any value (e.g., NO_COLOR=1).\ncolored also supports the the CLICOLOR and CLICOLOR_FORCE\nenvironment variables (see the spec).\n\n\n\n\n\nBack to top\n\n\n\n\n\n\nMade with\n\nMaterial for MkDocs\n\n\n\n\n\n\n\n\n\n\n\n\n', metadata={'source': 'https://beta.ruff.rs/docs/faq/'})]
| How to Iteratively parse all the contents within links on a page? | https://api.github.com/repos/langchain-ai/langchain/issues/2680/comments | 3 | 2023-04-10T20:17:14Z | 2024-02-12T05:47:17Z | https://github.com/langchain-ai/langchain/issues/2680 | 1,661,305,027 | 2,680 |
[
"langchain-ai",
"langchain"
] | When you ask GPT to produce code, you get an error since the way responses are parsed splits the cleaned output by triple backticks, which doesn't account for possible usage of triple backticks in the output itself.
To reproduce:
```python
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
tools = load_tools(["llm-math"], llm=llm)
agent = initialize_agent(tools,
llm,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
verbose=True,
memory=memory)
agent.run(input='Write a program for Hello World in Python.')
```
Traceback:
~~~
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File [~/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py:106](https://vscode-interactive+.vscode-resource.vscode-cdn.net//~/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py:106), in ConversationalChatAgent._extract_tool_and_input(self, llm_output)
[105](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py?line=104) try:
--> [106](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py?line=105) response = self.output_parser.parse(llm_output)
[107](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py?line=106) return response["action"], response["action_input"]
File [~/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py:43](https://vscode-interactive+.vscode-resource.vscode-cdn.net//~/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py:43), in AgentOutputParser.parse(self, text)
[42](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py?line=41) if "```" in cleaned_output:
---> [43](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py?line=42) cleaned_output, _ = cleaned_output.split("```")
[44](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/agents/conversational_chat/base.py?line=43) if cleaned_output.startswith("```json"):
ValueError: too many values to unpack (expected 2)
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
[/Users/sachit/Documents/Documents](https://vscode-interactive+.vscode-resource.vscode-cdn.net/Users/sachit/Documents/Documents) - Sachit’s MacBook Pro[/Projects/ai_assistant/import](https://vscode-interactive+.vscode-resource.vscode-cdn.net/Projects/ai_assistant/import) openai.py in line 1
----> [38](file:///Users/sachit/Documents/Documents%20-%20Sachit%E2%80%99s%20MacBook%20Pro/Projects/ai_assistant/import%20openai.py?line=37) agent.run(input=query)
File [~/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/chains/base.py:216](https://vscode-interactive+.vscode-resource.vscode-cdn.net//~/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/chains/base.py:216), in Chain.run(self, *args, **kwargs)
[213](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/chains/base.py?line=212) return self(args[0])[self.output_keys[0]]
[215](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/chains/base.py?line=214) if kwargs and not args:
--> [216](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/chains/base.py?line=215) return self(kwargs)[self.output_keys[0]]
[218](file:///Users/sachit/opt/miniconda3/envs/misc/lib/python3.10/site-packages/langchain/chains/base.py?line=217) raise ValueError(
...
{
"action": "Final Answer",
"action_input": "Here is an example program for 'Hello World' in Python: \n\n```python\nprint('Hello, World!')\n```"
}
```
~~~ | Chat agent does not parse properly when model returns a code block | https://api.github.com/repos/langchain-ai/langchain/issues/2679/comments | 16 | 2023-04-10T19:41:05Z | 2024-01-04T12:36:47Z | https://github.com/langchain-ai/langchain/issues/2679 | 1,661,258,754 | 2,679 |
[
"langchain-ai",
"langchain"
] | I noticed that `langchain` will not try to use the `tiktoken` tokenizer if python version is 3.8 and will switch to Hugging Face tokenizer instead ([see line 331 here](https://github.com/hwchase17/langchain/blob/master/langchain/chat_models/openai.py)). It assumes that `tiktoken` does not support python 3.8. However this does not seem to be the case (see [line 10 here](https://github.com/openai/tiktoken/blob/main/pyproject.toml)). | Langchain should use tiktoken tokenizer for python 3.8 | https://api.github.com/repos/langchain-ai/langchain/issues/2677/comments | 1 | 2023-04-10T18:40:46Z | 2023-09-10T16:35:21Z | https://github.com/langchain-ai/langchain/issues/2677 | 1,661,183,616 | 2,677 |
[
"langchain-ai",
"langchain"
] | I don't want to use ChatGpt, I want to use a local "chatgpt"
So I tried this example with GPT4All https://python.langchain.com/en/latest/modules/agents/toolkits/examples/csv.html
```python
from langchain.llms import GPT4All
from langchain import PromptTemplate, LLMChain
from langchain.agents import create_csv_agent
import pandas as pd
df = pd.read_csv('./titles.csv')
model = GPT4All(model="./models/ggml-alpaca-7b-q4-new.bin")
agent = create_csv_agent(model, './titles.csv', verbose=True)
>>> agent.run("how many rows are there?")
```
I have the error : llama_generate: error: prompt is too long (680 tokens, max 508)
Tried with `model = GPT4All(model="./models/ggml-alpaca-7b-q4-new.bin")` and `model = GPT4All(model="C:\\Users\\glapenta\\Workspace\\python\\models\\ggml-alpaca-7b-q4-new.bin", n_ctx=1024, n_threads=8)`
I have this error with n_ctx at 1024 llama_generate: error: prompt is too long (1056 tokens, max 1020)
Here's the full stack :
```
>>> agent.run("how many rows are there?")
> Entering new AgentExecutor chain...
llama_generate: seed = 1680965712
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
sampling: temp = 0.800000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.300000
generate: n_ctx = 512, n_batch = 1, n_predict = 256, n_keep = 0
[end of text]
llama_print_timings: load time = 74735.64 ms
llama_print_timings: sample time = 51.08 ms / 116 runs ( 0.44 ms per run)
llama_print_timings: prompt eval time = 136599.33 ms / 514 tokens ( 265.76 ms per token)
llama_print_timings: eval time = 854042.23 ms / 1599 runs ( 534.11 ms per run)
llama_print_timings: total time = 61952108.58 ms
You are working with a pandas dataframe in Python. The name of the dataframe is `df`.
You should use the tools below to answer the question posed of you:
python_repl_ast: A Python shell. Use this to execute python commands. Input should be a valid python command. When using this tool, sometimes output is abbreviated - make sure it does not look abbreviated before using it in your answer.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [python_repl_ast]
Action Input: the input to the action
Observation: the action to take, should be one of [python_repl_ast] is not a valid tool, try another one.
Thought:llama_generate: seed = 1680965951
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
llama_generate: error: prompt is too long (678 tokens, max 508)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 213, in run
return self(args[0])[self.output_keys[0]]
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 116, in __call__
raise e
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\chains\base.py", line 113, in __call__
outputs = self._call(inputs)
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\agents\agent.py", line 790, in _call
next_step_output = self._take_next_step(
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\agents\agent.py", line 679, in _take_next_step
output = self.agent.plan(intermediate_steps, **inputs)
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\agents\agent.py", line 398, in plan
action = self._get_next_action(full_inputs)
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\agents\agent.py", line 360, in _get_next_action
parsed_output = self._extract_tool_and_input(full_output)
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\agents\mrkl\base.py", line 140, in _extract_tool_and_input
return get_action_and_input(text)
File "C:\Users\glapenta\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\langchain\agents\mrkl\base.py", line 48, in get_action_and_input
raise ValueError(f"Could not parse LLM output: `{llm_output}`")
ValueError: Could not parse LLM output: ``
```
Great framework ! | GPT4All and create_csv_agent : llama_generate: error: prompt is too long (680 tokens, max 508) | https://api.github.com/repos/langchain-ai/langchain/issues/2674/comments | 9 | 2023-04-10T15:59:17Z | 2023-09-28T16:08:32Z | https://github.com/langchain-ai/langchain/issues/2674 | 1,660,990,166 | 2,674 |
[
"langchain-ai",
"langchain"
] | I _just_ want to form the GET request URL. It can then be executed either within LangChain or simply returned. I do not want to use a LLM to interpret the JSON response.
I've been trying with `OpenAPIEndpointChain` and I can't seem to find a way to exit early without having the LLM try to digest the JSON returned from the API.
Here's the relevant point at the code that I'd like to exit early on: https://github.com/hwchase17/langchain/blob/master/langchain/chains/api/openapi/chain.py#L147 | Which Chain or Agent to Use for Creating GET Requests from Natural Language Queries with One or Many OpenAPI Specifications? Without an LLM interpretation of the API response. | https://api.github.com/repos/langchain-ai/langchain/issues/2672/comments | 2 | 2023-04-10T15:52:09Z | 2023-09-10T16:35:26Z | https://github.com/langchain-ai/langchain/issues/2672 | 1,660,977,208 | 2,672 |
[
"langchain-ai",
"langchain"
] | I'm trying to understand the best ways to design a custom chatbot using langchain.
In the chatbot design, I would like to give some guidance to chatbot in the following fashion:
- When user inputs their name, always use it to address them.
- Ask the user if they are willing to answer a few questions.
- If the user is not interested, say something like: "No problem $NAME, I understand. If you change your mind feel free to reach out to me anytime."
...
I don't want to give all these guidelines to the model in the beginning as it might confuse all at once.
I think a better approach would be introducing each guideline when it is needed.
I thought defining separate Tools for each of these guidelines could be an option. I would like to see what others think though.
What would be the best way to guide an LLM based chatbot? | Question: How to Guide Chatbot? | https://api.github.com/repos/langchain-ai/langchain/issues/2671/comments | 1 | 2023-04-10T15:44:30Z | 2023-09-10T16:35:31Z | https://github.com/langchain-ai/langchain/issues/2671 | 1,660,969,090 | 2,671 |
[
"langchain-ai",
"langchain"
] | Hi,
I would like to run a HF model ( https://huggingface.co/chavinlo/gpt4-x-alpaca/ ) without the need to download it, but just pointing
a local_dir param as in the diffusers for example. Is this possible? someting like this ...
```
from langchain import PromptTemplate, HuggingFaceHub, LLMChain, OpenAI
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
print(prompt)
llm_chain = LLMChain(prompt=prompt, llm=HuggingFaceHub(repo_id="/mymodels/chavinlo/gpt4-x-alpaca", model_kwargs={"temperature":0, "max_length":64}))
question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
print(llm_chain.run(question))
``` | huggingfacehub model from local folder? | https://api.github.com/repos/langchain-ai/langchain/issues/2667/comments | 11 | 2023-04-10T13:00:46Z | 2023-11-22T19:45:30Z | https://github.com/langchain-ai/langchain/issues/2667 | 1,660,753,742 | 2,667 |
[
"langchain-ai",
"langchain"
] | I'm generating a bot for the schema at https://beta-demo.netbox.dev/api/schema. I have been able to minify the spec to get the plan string which goes like
```
1. GET /api/dcim/devices/ to retrieve all devices
2. Filter the devices by status to only include those with an active status. This can be done by adding a query parameter to the GET request, such as "?status=active".
3. Return the filtered list of devices with active status.
```
The above causes the code to fail with endpoint not found. This is invoked at https://github.com/hwchase17/langchain/blob/master/langchain/agents/agent_toolkits/openapi/planner.py#L169.
When I looked into it more thoroughly, I found out the `re.findall` is causing issues with returning `GET` with no endpoint which looks like
```
[('GET', '/api/dcim/devices/'), ('GET', '')]
```
The code should execute as it does have a valid endpoint, but due to the 2nd GET with no endpoint, it fails. | plan_str has 2 references to GET keyword which causes the OpenAPI agent to raise value error when an endpoint is not found | https://api.github.com/repos/langchain-ai/langchain/issues/2665/comments | 3 | 2023-04-10T11:30:33Z | 2023-08-20T16:15:51Z | https://github.com/langchain-ai/langchain/issues/2665 | 1,660,655,448 | 2,665 |
[
"langchain-ai",
"langchain"
] | Contrary to `from_texts` which batch computes embeddings through `embed_documents`, the `add_texts` method calls `self.embedding_function` for each document that is beind added. If using `OpenAIEmbeddings`, this means one API call per added document, which can take a long time when there are many documents:
https://github.com/hwchase17/langchain/blob/e63f9a846be7a85de7d3e3a1b277a4521b42808d/langchain/vectorstores/faiss.py#L109
To do: Make use of `embed_documents` in `FAISS.add_texts`, so that documents are embedded in chunks. Maybe this will require changing the `embedding_function` init argument to use an `Embeddings` object instead of a callable? | FAISS.add_texts is calling the embedding function without batching | https://api.github.com/repos/langchain-ai/langchain/issues/2660/comments | 3 | 2023-04-10T09:49:10Z | 2023-09-10T16:35:38Z | https://github.com/langchain-ai/langchain/issues/2660 | 1,660,529,222 | 2,660 |
[
"langchain-ai",
"langchain"
] | ```
112 if int(n_tokens) < 0:
--> 113 raise RuntimeError(f'Failed to tokenize: text="{text}" n_tokens={n_tokens}')
114 return list(tokens[:n_tokens])
```
RuntimeError: Failed to tokenize: text="b" Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.\n\ndu Home Wireless.\nUnlimited internet with a free router\n\ndu home wireless is a limited mobility service and subscription.\n\nOnce the device is activated, your home location will be assigned as the first usage location and will only work there. If you decide to move or shift locations, please request us to unlock it and it will be re-assigned to the new location.\n\nAs a new du Home Wireless customer, you\xe2\x80\x99ll receive an LTE router for internet connection at the time of the service application. It will include a Data SIM with unlimited data.\n\ndu Home wireless advantages.\nUnlimited data: Enjoy wireless connectivity with unlimited data for 12 months.\n\nHigh-quality streaming: Stream your favorite entertainment, chat and game at the same time.\n\n5G-enabled router: Connect all your devices with the latest WiFi 5 technology.\nWhat is du Home Wireless?\n\nWhat type of internet activities does the Home Wireless Plan support?\n\nIt supports the following internet activities depending on the plan you get:\n\nStandard internet activities\nVideo and music streaming\nGaming and VR\nSocial media\nWeb surfing\nEmail and office work\n\nCan I connect with more than one device at the same time?\n\nYes, you can. Ideally, the average number of connected devices shouldn\xe2\x80\x99t exceed 4 large screens on our Home Wireless Plus and Home Wireless Entertainment Plans.\n\nWill I always get a consistent speed?\n\nInternet speed is not guaranteed. Individual results will vary as it might be affected by many factors such as the weather, interference from buildings and network capacity. The areas wherein you\xe2\x80\x99ll get the best coverage experience are the following:\n\nNear a window\nIn an open space away from walls, obstructions, heavy-duty appliances, or electronics such as microwave ovens and baby monitors\nNear a power outlet\n\nWill I be able to bring my own router?\n\nYes, you have the option to use your own router.\n\nTo connect, check the below steps:\n\nInsert your du SIM card in the back of the router\nConnect to power and turn on the device\nConnect to your router using the Wi-Fi SSID and WiFi password information at the sticker on the bottom\nFor connection steps, check the video: Watch now\n\nHow can I subscribe to the Internet Calling Pack on the Home Wireless Entertainment Plan?\n\nThe free Internet Calling Pack subscription will be added to your plan for a period of three months by default.\n\nWho is eligible to get the free Internet Calling Pack?\n\nNew Home Wireless Entertainment subscribers will enjoy this added benefit.\n\nHome Wireless plans are our new range of Home Plans, that offer instant connectivity, unlimited data and premium entertainment so you can enjoy instant, plug-and-play high-quality internet.\n\nWhere does this service work?\n\nThis service has limited mobility. Once the device is activated, your home location will be assigned as the first usage location and will only work there. If you decide to move or shift locations, you will have to ask us to unlock it so your Home Wireless can be re-assigned to your new location.\n\nWhat kind of router do I get with this plan?\n\nYou will receive a 5G-enabled router.\n\nWhat happens if I don\xe2\x80\x99t have 5G?\n\nIt will automatically connect to 4G.\n\nIs a Landline required for a home wireless connection?\n\nNo, it\xe2\x80\x99s not.\n\nHow does this service work?\n\nAs a new Home Wireless customer, you\xe2\x80\x99ll receive a router for internet connection at the time of your service application. It will include a Data SIM with unlimited data.\n\nQuestion: What is du Home Wireless?\nHelpful Answer:"" n_tokens=-908 | Failed to tokenize: langchain with gpt4all model | https://api.github.com/repos/langchain-ai/langchain/issues/2659/comments | 12 | 2023-04-10T09:43:48Z | 2023-09-29T16:08:47Z | https://github.com/langchain-ai/langchain/issues/2659 | 1,660,524,204 | 2,659 |
[
"langchain-ai",
"langchain"
] | Is there a way to pass in an already instantiated VectorStore into VectorStoreIndexCreator? As far as I checked, the creator accepts the class and initializes the class internally via `from_documents`. But this doesn't allow to use persisted Chroma from the loaded index.
I might be misunderstanding the intention, but VectorStoreIndexCreator is not for pre-existing indices, correct? If that's the case the only option then to use `load_qa_with_sources_chain` directly instead or is there other public classes available that provides the convenience of the IndexCreator? (similar to VectorStoreIndexWrapper)
Thanks in advance! | Ability to pass instantiated Chroma into VectorStoreIndexCreator | https://api.github.com/repos/langchain-ai/langchain/issues/2658/comments | 2 | 2023-04-10T07:58:58Z | 2023-09-10T16:35:41Z | https://github.com/langchain-ai/langchain/issues/2658 | 1,660,402,782 | 2,658 |
[
"langchain-ai",
"langchain"
] | I would like to support version 2 of SQLAlchemy. | I would like to support version 2 of SQLAlchemy | https://api.github.com/repos/langchain-ai/langchain/issues/2654/comments | 3 | 2023-04-10T06:27:14Z | 2023-09-27T16:09:17Z | https://github.com/langchain-ai/langchain/issues/2654 | 1,660,312,485 | 2,654 |
[
"langchain-ai",
"langchain"
] | Hi @hwchase17 ,
I'm using `RetrievalQA` to do question answering on vector store, below are the config I used
- llm=ChatOpenAI chatgpt 3.5 model
- embeddings = OpenAIEmbeddings
- retriever=Pinecone
This is one of the messages
```
Given the following extracted parts of a long document and a question, create a final answer.\nIf you don't know the answer, just say that you don't know. Don't try to make up an answer.\n______________________\n
```
I set the results from Pinecone to k=4, it did summarize for documents and put into the final prompt messages. The strange thing is that the first summary is good and the rest of the summaries all said '`here is no information provided in the given portion of the document` something like this. But the expected answer should use the first summary.
And then the final answer I got is like `there is no information about xxxx`. This happened since last Friday after 4~5pm, and I can get the correct answer before.
Do you know if something changed on openai chat completion API?
| Good summaries were ignored | https://api.github.com/repos/langchain-ai/langchain/issues/2653/comments | 0 | 2023-04-10T03:55:46Z | 2023-04-10T13:05:00Z | https://github.com/langchain-ai/langchain/issues/2653 | 1,660,190,372 | 2,653 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.