
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-informing
- periodic-conformance-main-k8s-main
### Which tests are failing?
- capa-e2e-conformance.AfterSuite
- capa-e2e-conformance.BeforeSuite
### Since when has it been failing?
10-25 22:18 IST
### Testgrid link
https://testgrid.k8s.io/sig-release-master-in... | [Failing test] periodic-conformance-main-k8s-main | https://api.github.com/repos/kubernetes/kubernetes/issues/113449/comments | 18 | 2022-10-30T03:26:34Z | 2022-11-18T13:34:33Z | https://github.com/kubernetes/kubernetes/issues/113449 | 1,428,577,368 | 113,449 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
This is the tracking issue for the work goes in CEL in Admission Control([KEP]: https://github.com/kubernetes/enhancements/issues/3488)
- Kubernets 1.26 tracking
- [x] Add feature gate: https://github.com/kubernetes/kubernetes/pull/112792
- [x] Add API for ValidatingAdmi... | CEL in Admission Control Tracking | https://api.github.com/repos/kubernetes/kubernetes/issues/113440/comments | 2 | 2022-10-28T18:12:19Z | 2023-09-15T22:19:16Z | https://github.com/kubernetes/kubernetes/issues/113440 | 1,427,617,661 | 113,440 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Currently we have inconsistency in most of the API where the field name should be used in description so the generated docs match the API fields people actually set.
e.g.
https://github.com/kubernetes/kubernetes/blob/367f01f62d1a6ca149c317f97a958dd5c6e74af1/staging/src/k8s.io/api/admission/v1/... | API doc should use the field name in description | https://api.github.com/repos/kubernetes/kubernetes/issues/113438/comments | 52 | 2022-10-28T17:15:01Z | 2024-07-26T11:32:40Z | https://github.com/kubernetes/kubernetes/issues/113438 | 1,427,546,284 | 113,438 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
while i create pod , i got this error in kubelet log:
```
E1028 04:51:25.570609 201165 desired_state_of_world_populator.go:303] "Error processing volume" err="error processing PVC default/e4828bb68416f60b01841aa22c181316-pvc: failed to fetch PVC from API server: persistentvolumeclaims \"e4828b... | no relationship found between node and this object | https://api.github.com/repos/kubernetes/kubernetes/issues/113429/comments | 4 | 2022-10-28T08:59:23Z | 2022-11-10T05:55:20Z | https://github.com/kubernetes/kubernetes/issues/113429 | 1,426,932,346 | 113,429 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Pods stuck in Terminating status due to _UnmountVolume.TearDown failed for volume_ with _target is busy_. Like the closed https://github.com/kubernetes/kubernetes/issues/65110, this is also for secret and configMap mounts.
pod describe:
```
Status: Terminating (lasts 8d)
.... | Pods stuck in Terminating status due to UnmountVolume.TearDown failed for volume with target is busy | https://api.github.com/repos/kubernetes/kubernetes/issues/113426/comments | 11 | 2022-10-28T07:40:34Z | 2023-06-05T02:50:45Z | https://github.com/kubernetes/kubernetes/issues/113426 | 1,426,830,383 | 113,426 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We need an integration test for the scheduler enforcement of the `ReadWriteOncePod` alpha feature.
### Why is this needed?
This is required for beta graduation; we need to collect signal on the current behavior before we can proceed.
See this comment for context:
https://gith... | Scheduler integration test for ReadWriteOncePod alpha | https://api.github.com/repos/kubernetes/kubernetes/issues/113418/comments | 4 | 2022-10-28T01:02:53Z | 2022-11-02T15:35:40Z | https://github.com/kubernetes/kubernetes/issues/113418 | 1,426,443,666 | 113,418 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Right now, kubelet tracing produces disconnected spans for each CRI call:
<img width="1728" alt="Screen Shot 2022-10-25 at 4 13 34 PM" src="https://user-images.githubusercontent.com/3262098/198387624-c1fe130a-c034-42c8-a16e-367b674db37b.png">
It would be helpful to add a pa... | Connected traces in the kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/113414/comments | 10 | 2022-10-27T20:09:14Z | 2023-11-06T21:42:57Z | https://github.com/kubernetes/kubernetes/issues/113414 | 1,426,209,711 | 113,414 |
[
"kubernetes",
"kubernetes"
] | Fix bug in the current fake client - currently, the code returns the created object rather than an object controlled by testing. This fix enables proper testing to manipulate the returned tokenReview of the fake Client for testing purposes.
Testing TokenReviews requires manipulating the created tokenReview object a... | client library - fake client support for TokenReview Create | https://api.github.com/repos/kubernetes/kubernetes/issues/113412/comments | 5 | 2022-10-27T18:11:28Z | 2022-10-28T21:39:09Z | https://github.com/kubernetes/kubernetes/issues/113412 | 1,426,077,846 | 113,412 |
[
"kubernetes",
"kubernetes"
] | null | pkg/controller/bootstrap | https://api.github.com/repos/kubernetes/kubernetes/issues/113410/comments | 2 | 2022-10-27T17:40:15Z | 2022-10-27T17:40:44Z | https://github.com/kubernetes/kubernetes/issues/113410 | 1,426,037,792 | 113,410 |
[
"kubernetes",
"kubernetes"
] | - | test | https://api.github.com/repos/kubernetes/kubernetes/issues/113404/comments | 2 | 2022-10-27T15:22:47Z | 2022-10-27T15:22:58Z | https://github.com/kubernetes/kubernetes/issues/113404 | 1,425,826,947 | 113,404 |
[
"kubernetes",
"kubernetes"
] | I guess at one point or other we've all seen a black hole apiserver extension effect us in one way or other... What are the ways we should/can avoid such issues ? And, have we considered making the apiserver better at detecting/returning 500s in case of these sorts of issues?
(Am somewhat naive in this area so, pl... | Should the KCM have a heartbeat (or should the APIServer be more proactive about disruptive extensions) ? | https://api.github.com/repos/kubernetes/kubernetes/issues/113401/comments | 17 | 2022-10-27T14:37:19Z | 2024-10-03T20:21:45Z | https://github.com/kubernetes/kubernetes/issues/113401 | 1,425,748,295 | 113,401 |
[
"kubernetes",
"kubernetes"
] | How to change the clusterName of a running cluster | How to change the clusterName of a running cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/113400/comments | 8 | 2022-10-27T13:42:23Z | 2022-11-17T14:36:05Z | https://github.com/kubernetes/kubernetes/issues/113400 | 1,425,660,909 | 113,400 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Although there are various solutions to manage secrets in K8s, I think that they are all unnecessary complex and they are not following the right approach.
I propose this simple, better alternative:
```
apiVersion: v1
kind: Secret
metadata:
name: mysecret
namespace: ... | A better way to manage secrets: reference an external secret defined in the cloud provider environment | https://api.github.com/repos/kubernetes/kubernetes/issues/113396/comments | 2 | 2022-10-27T11:16:54Z | 2022-10-31T15:54:13Z | https://github.com/kubernetes/kubernetes/issues/113396 | 1,425,466,410 | 113,396 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [2aa8d0cf04dedeb96d2b](https://go.k8s.io/triage#2aa8d0cf04dedeb96d2b)
https://storage.googleapis.com/k8s-triage/index.html?text=cleanupLocalPVCsPVs#658be1b0e17b463179af
##### Error text:
```
test/e2e/framework/framework.go:241
k8s.io/kubernetes/test/e2e/framework.(*Framework).BeforeEach(0xc... | Failure cluster: cleanupLocalPVCsPVs and e2e failed in beforeEach | https://api.github.com/repos/kubernetes/kubernetes/issues/113382/comments | 8 | 2022-10-27T07:34:27Z | 2023-04-17T15:03:32Z | https://github.com/kubernetes/kubernetes/issues/113382 | 1,425,171,187 | 113,382 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
**Referencing** https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api-conventions.md#metadata
Currently some kinds like `PodExecOptions`, `PodPortForwardOptions`, `NodeProxyOptions` do not contain `ObjectMeta`.
```go
type PodExecOptions ... | `PodExecOptions`, `PodPortForwardOptions` and other *Options resources should contain `ObjectMeta` | https://api.github.com/repos/kubernetes/kubernetes/issues/113381/comments | 7 | 2022-10-27T06:00:07Z | 2024-08-09T14:31:29Z | https://github.com/kubernetes/kubernetes/issues/113381 | 1,425,078,024 | 113,381 |
[
"kubernetes",
"kubernetes"
] | When I pass kubectl exec -it ${pod} -- bash
Then when env is executed, the custom attribute variables of k8s can be obtained, such as
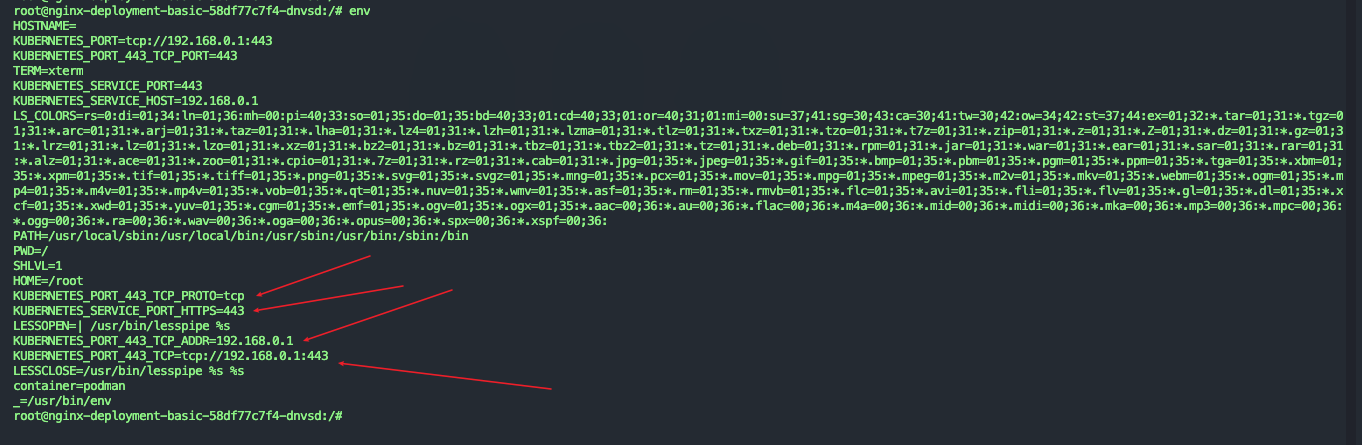
But when I connect to the pod through ssh, I can't get these variable... | I ssh into the pod unable to get the variable of the pod custom property | https://api.github.com/repos/kubernetes/kubernetes/issues/113380/comments | 11 | 2022-10-27T04:31:45Z | 2022-10-29T08:34:38Z | https://github.com/kubernetes/kubernetes/issues/113380 | 1,425,015,544 | 113,380 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/111095/pull-kubernetes-unit/1585051220769247232
```
panic: test timed out after 3m0s
goroutine 112 [running]:
testing.(*M).startAlarm.func1()
/usr/local/go/src/testing/testing.go:2036 +0xbb
created by time.goFunc
/usr/lo... | TestLimitRanger_GetLimitRangesFixed22422 flakes | https://api.github.com/repos/kubernetes/kubernetes/issues/113377/comments | 7 | 2022-10-27T01:42:43Z | 2022-11-08T17:34:35Z | https://github.com/kubernetes/kubernetes/issues/113377 | 1,424,900,197 | 113,377 |
[
"kubernetes",
"kubernetes"
] | While working on generalizing tests to somehow better define spec for storage interface (and share them across all implementation of storage.interface - in particular etcd3 and watchcache), I found an unexpected inconsistency in Delete operation in etcd3.
What is happening is that it effectively returns the state of... | Object returned from etcd3 Delete call is inconsistent with what watch returns | https://api.github.com/repos/kubernetes/kubernetes/issues/113368/comments | 2 | 2022-10-26T19:52:49Z | 2022-11-15T21:51:14Z | https://github.com/kubernetes/kubernetes/issues/113368 | 1,424,617,198 | 113,368 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/pull/113225 uncovered a coming snarl of dependencies between cloud.google.com/go and google.golang.org/genproto
Because several generic libraries use the cloud.google.com/go/compute/metadata package, the following chain makes it almost impossible to avoid adding all cloud.googl... | 🐘 Untangle genproto / cloud.google.com/go dependencies | https://api.github.com/repos/kubernetes/kubernetes/issues/113366/comments | 14 | 2022-10-26T17:40:20Z | 2025-01-21T23:03:09Z | https://github.com/kubernetes/kubernetes/issues/113366 | 1,424,451,536 | 113,366 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-windows-2019-provider-gcp-compute-persistent-disk-csi-driver
### Which tests are failing?
"should provision correct filesystem size when restoring snapshot to larger size pvc [Feature:VolumeSnapshotDataSource]"
### Since when has it been failing?
Never - test is skipped on ... | fix test for filesystem size when restoring snapshot to larger size pvc on Windows | https://api.github.com/repos/kubernetes/kubernetes/issues/113359/comments | 12 | 2022-10-26T12:31:41Z | 2025-01-16T22:56:14Z | https://github.com/kubernetes/kubernetes/issues/113359 | 1,423,944,450 | 113,359 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We would like pod's cgroup path to be exposed in the Pod `status` (or other metadata field in the Pod object).
### Why is this needed?
This would allow accessing pod's cgroup paths in a way that is independent of the container runtime, or cgroup driver, etc, and that does... | Expose Pod cgroup path as part of `status` field | https://api.github.com/repos/kubernetes/kubernetes/issues/113342/comments | 22 | 2022-10-25T18:54:47Z | 2024-05-03T06:56:59Z | https://github.com/kubernetes/kubernetes/issues/113342 | 1,422,926,541 | 113,342 |
[
"kubernetes",
"kubernetes"
] | When introducing a new alpha or beta-level field to a CRD, validation needs to be used to ensure that the field cannot be set unless the administrator has explicitly 'enabled' a new feature, in a similar manner to upstream Kubernetes resources.
To do this today, we must either:
* create a validating webhook and a... | Supporting feature gates on CRDs for configuring usage & validation of fields | https://api.github.com/repos/kubernetes/kubernetes/issues/113341/comments | 7 | 2022-10-25T18:38:48Z | 2024-12-19T21:10:56Z | https://github.com/kubernetes/kubernetes/issues/113341 | 1,422,909,487 | 113,341 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I ran `kubectl create rolebinding --clusterrole=admin --serviceaccount=namespace:sa --user=my-creds-user`
The rolebinding was creating tying both the service account and the user I was logging in as.
### What did you expect to happen?
I expected the service account to be bound to the role... | Option collision for --user in kubectl create rolebinding | https://api.github.com/repos/kubernetes/kubernetes/issues/113334/comments | 16 | 2022-10-25T14:51:24Z | 2025-01-02T17:45:09Z | https://github.com/kubernetes/kubernetes/issues/113334 | 1,422,600,233 | 113,334 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
sig-release-master-informing#ci-kubernetes-e2e-gce-scale-correctness
### Which tests are failing?
Kubernetes e2e suite: [SynchronizedBeforeSuite]
### Since when has it been failing?
10/22
### Testgrid link
https://testgrid.k8s.io/sig-release-master-informing#gce-master-scale-correctne... | [failing-test] ci-kubernetes-e2e-gce-scale-correctness | https://api.github.com/repos/kubernetes/kubernetes/issues/113327/comments | 3 | 2022-10-25T13:25:59Z | 2022-10-30T03:38:24Z | https://github.com/kubernetes/kubernetes/issues/113327 | 1,422,464,588 | 113,327 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When doing validation, kubernetes doesn't actually report the issue with the cgroup kupepods, instead they issue an error that cgroup kubepods doesn't exist at all. This is related to opencontainers not checking if controllers got properly set:
https://github.com/opencontainers/runc/issues/3647
... | Incorrect and misleading error reporting: failed to initialize top level QOS containers: root container [kubepods] doesn't exist | https://api.github.com/repos/kubernetes/kubernetes/issues/113322/comments | 8 | 2022-10-25T11:44:58Z | 2023-04-09T00:32:16Z | https://github.com/kubernetes/kubernetes/issues/113322 | 1,422,329,931 | 113,322 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The replicas is 3 but just create 1 pod 'web-0' and one pvc, then kube-controller-manager panic happend.
```
I1025 09:12:25.263508 1 shared_informer.go:262] Caches are synced for crt configmap
I1025 09:12:25.263537 1 shared_informer.go:262] Caches are synced for stateful set
I1025 ... | kube-controller-manager panic happend when add StatefulSetAutoDeletePVC feature gate and create statefuleset with volumeClaimTemplates | https://api.github.com/repos/kubernetes/kubernetes/issues/113319/comments | 24 | 2022-10-25T09:24:59Z | 2022-11-03T02:20:14Z | https://github.com/kubernetes/kubernetes/issues/113319 | 1,422,149,009 | 113,319 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The result of initial list in Reflector is kept in the memory until the last element in the items list hasn't been changed.
In practice this can be a long time, e.g. there can be some stable pod that are running for days, in configmaps there is a kube-root-ca.crt which stays there forever.
... | Reflector retains initial list result for a long time | https://api.github.com/repos/kubernetes/kubernetes/issues/113305/comments | 15 | 2022-10-24T15:01:17Z | 2023-05-29T16:25:44Z | https://github.com/kubernetes/kubernetes/issues/113305 | 1,420,978,386 | 113,305 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
``go get`` for installing golang binaries has been deprecated in Go 1.17 in favor of ``go install``. Starting with Go 1.19, we can no longer install binaries through ``go get``. [1]
We've recently switched to Go 1.19, and because of this, the ``sample-apiserver`` E2E image has started failing to ... | Test images: sample-apiserver E2E image fails to build | https://api.github.com/repos/kubernetes/kubernetes/issues/113302/comments | 2 | 2022-10-24T14:10:47Z | 2022-11-02T13:47:29Z | https://github.com/kubernetes/kubernetes/issues/113302 | 1,420,899,950 | 113,302 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
we have kubernetes multi-cluster environment (3 master cluster ) we renewed kubernetes certificates after expired once renewed certs its working fine, after 15 days we done patching for servers so we restarted servers and cluster went down completely, and we renewed certs again and restored the c... | Unable to join the control plain node to the existing kubernetes cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/113294/comments | 4 | 2022-10-24T09:00:18Z | 2022-10-24T13:21:29Z | https://github.com/kubernetes/kubernetes/issues/113294 | 1,420,484,371 | 113,294 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when a node lost, let pod stuck terminating. pod.DeletionTimestamp = deleting time + pod.DeletionGracePeriodSeconds. it not need to add pod.DeletionGracePeriodSeconds again.
https://github.com/kubernetes/kubernetes/blob/36dd5f2846a6003d1b346969183270440f37b190/pkg/quota/v1/evaluator/core/pods.go#... | Pod quota is not released in time when node lost | https://api.github.com/repos/kubernetes/kubernetes/issues/113293/comments | 9 | 2022-10-24T08:41:28Z | 2024-09-05T05:16:11Z | https://github.com/kubernetes/kubernetes/issues/113293 | 1,420,458,847 | 113,293 |
[
"kubernetes",
"kubernetes"
] | **What happened?**
when a node lost, let pod stuck terminating. pod.DeletionTimestamp = deleting time + pod.DeletionGracePeriodSeconds. it not need to add pod.DeletionGracePeriodSeconds again.
https://github.com/kubernetes/kubernetes/blob/36dd5f2846a6003d1b346969183270440f37b190/pkg/quota/v1/evaluator/core/pods... | Pod quota is not released in time when node lost | https://api.github.com/repos/kubernetes/kubernetes/issues/113292/comments | 3 | 2022-10-24T08:04:31Z | 2022-10-24T08:33:35Z | https://github.com/kubernetes/kubernetes/issues/113292 | 1,420,397,032 | 113,292 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Pod is stuck in terminating state when rapidly create and delete the pod, and the kubelet reported the volume setup error:
```
Oct 21 12:09:20 slave2 kubelet[4089]: E1021 12:09:20.197090 4089 nestedpendingoperations.go:348] Operation for "{volumeName:kubernetes.io/secret/dc79f107-6576-4d98-a1... | Pod is stuck in terminating with "MountVolume.SetUp failed for volume ... not registered" error | https://api.github.com/repos/kubernetes/kubernetes/issues/113289/comments | 14 | 2022-10-24T06:47:42Z | 2024-07-10T11:58:07Z | https://github.com/kubernetes/kubernetes/issues/113289 | 1,420,309,118 | 113,289 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Let me first talk about why this question is asked. We have a mysql cluster with one master and multiple slaves. Only the master node can read and write, and the slave nodes can only read,
### Why is this needed?
because we have the need to access and modify data from the outsid... | Is there a way to route to a specified statefulset pod through ingress | https://api.github.com/repos/kubernetes/kubernetes/issues/113288/comments | 5 | 2022-10-24T03:36:35Z | 2022-12-08T01:10:27Z | https://github.com/kubernetes/kubernetes/issues/113288 | 1,420,156,363 | 113,288 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
an arg for controller manager to specify the max pods creation rate for daemonset controller:
```
# create 20 pods per second
--max-daemonset-pods-creation-rate=20
```
### Why is this needed?
Creating a daemonset in a huge cluster with over 4000 nodes will lead to over 4000... | Daemonset controller should allow setting max pods creation rate | https://api.github.com/repos/kubernetes/kubernetes/issues/113287/comments | 8 | 2022-10-24T02:58:11Z | 2022-11-14T11:52:51Z | https://github.com/kubernetes/kubernetes/issues/113287 | 1,420,128,018 | 113,287 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When the Kubelet GracefulNodeShutdown feature (beta as of v1.25.3) evicts pods before shutdown, it marks them as "Failed" as part of its [documented](https://github.com/kubernetes/website/pull/28235/files) behavior. These failed Pods persist until they're eventually removed by pod garbage collecti... | kubelet: Configurable failed/term mode with GracefulNodeShutdown | https://api.github.com/repos/kubernetes/kubernetes/issues/113278/comments | 19 | 2022-10-23T02:30:30Z | 2024-09-15T19:07:39Z | https://github.com/kubernetes/kubernetes/issues/113278 | 1,419,602,779 | 113,278 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Update the godoc on the encryption config API on how to specify group/resources to be encrypted
ref: https://github.com/kubernetes/kubernetes/pull/113015#discussion_r1002055172
### What did you expect to happen?
godoc has the details
### How can we reproduce it (as minimally and precisely as pos... | Update godoc on how to specify group/resources to be encrypted | https://api.github.com/repos/kubernetes/kubernetes/issues/113272/comments | 11 | 2022-10-21T23:49:11Z | 2022-12-12T19:43:47Z | https://github.com/kubernetes/kubernetes/issues/113272 | 1,418,968,629 | 113,272 |
[
"kubernetes",
"kubernetes"
] | This issue tracks all coding work to accomplish [KEP 3521](https://github.com/kubernetes/enhancements/issues/3521).
- [x] Introduce a new Pod API field `schedulingGates` #113274
- [x] Pod API definition, feature gate, codegen, validation, and drop disabled fields
- [x] disallow binding a Pod carrying non-n... | Umbrella issue tracking Alpha impl. of KEP 3521 (Pod Scheduling Readiness) | https://api.github.com/repos/kubernetes/kubernetes/issues/113269/comments | 4 | 2022-10-21T19:41:34Z | 2022-11-09T05:44:58Z | https://github.com/kubernetes/kubernetes/issues/113269 | 1,418,781,801 | 113,269 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This line here blocks until the timeout occurs, then the test continues and succeeds:
https://github.com/kubernetes/kubernetes/blob/a497c56c33aca254e69513fcd46c0c76c8fadcab/test/e2e/storage/testsuites/provisioning.go#L500
### What did you expect to happen?
Either the thing that this line wait... | e2e storage: "should provision storage with pvc data source in parallel" blocks, then ignores timeout error | https://api.github.com/repos/kubernetes/kubernetes/issues/113268/comments | 8 | 2022-10-21T19:36:32Z | 2024-02-04T07:21:11Z | https://github.com/kubernetes/kubernetes/issues/113268 | 1,418,777,440 | 113,268 |
[
"kubernetes",
"kubernetes"
] | Currently the [audit policy decoder][1] silently drops unknown fields.
For backwards compatibility, we probably cannot fail on unknown fields, but it would be good to at least log a warning when they're encountered.
[1]: https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/apiserver/pkg/audit/p... | Log a warning when dropping unknown fields from loading an audit policy | https://api.github.com/repos/kubernetes/kubernetes/issues/113266/comments | 6 | 2022-10-21T17:57:31Z | 2022-11-03T18:52:14Z | https://github.com/kubernetes/kubernetes/issues/113266 | 1,418,678,451 | 113,266 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This line here lacks error checking:
https://github.com/kubernetes/kubernetes/blob/e876d63ec2c9ae6b6af9318e909c21d16e90d94e/test/e2e/storage/testsuites/provisioning.go#L446
### What did you expect to happen?
It shouldn't continue when that function times out.
### How can we reproduce it ... | e2e storage: provisioning with data source test lacks error checking | https://api.github.com/repos/kubernetes/kubernetes/issues/113261/comments | 10 | 2022-10-21T14:39:05Z | 2023-05-27T20:07:42Z | https://github.com/kubernetes/kubernetes/issues/113261 | 1,418,442,243 | 113,261 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I started added missing error checks. When adding error checking to this call here, the test started to fail:
https://github.com/kubernetes/kubernetes/blob/e876d63ec2c9ae6b6af9318e909c21d16e90d94e/test/e2e/apps/deployment.go#L402
```
Deployment.apps "test-deployment" is invalid: status.availabl... | e2e apps: deployment test not working as intended | https://api.github.com/repos/kubernetes/kubernetes/issues/113259/comments | 11 | 2022-10-21T14:33:12Z | 2023-06-26T11:49:47Z | https://github.com/kubernetes/kubernetes/issues/113259 | 1,418,434,383 | 113,259 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I created a some ListWatches with filters to filter out uninteresting events before processing. And I did this by introducing the filteredWatch in the apimachinery.
https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/apimachinery/pkg/watch/filter.go#45
```
type filteredWatch... | Goroutine leak in filteredWatch | https://api.github.com/repos/kubernetes/kubernetes/issues/113254/comments | 9 | 2022-10-21T13:04:02Z | 2025-02-08T07:34:08Z | https://github.com/kubernetes/kubernetes/issues/113254 | 1,418,312,438 | 113,254 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add a new workload `ClusterSecret` to be used by pods across namespaces (`cluster-scope`), just like the `ClusterRole` and `Role`.
For example, we can just create one `ClusterSecret` image pull secret, to be used by pods across multipe namespaces in the cluster, instead of cre... | Proposal: Add workload `ClusterSecret` to be used by pods across namespaces | https://api.github.com/repos/kubernetes/kubernetes/issues/113251/comments | 4 | 2022-10-21T12:15:44Z | 2022-10-22T13:17:40Z | https://github.com/kubernetes/kubernetes/issues/113251 | 1,418,250,937 | 113,251 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Consider a UDP service of type "loadbalancer" with "externalTrafficPolicy: local" is created. When a backend pod corresponding to that service is deleted, the pod comes up in a different node. It is observed that sometimes the speaker on this new node advertises the LB IP before kube-proxy sets up t... | UDP traffic loss observed during restart of service pod when externalTrafficPolicy is "local" for loadbalancer type service. | https://api.github.com/repos/kubernetes/kubernetes/issues/113250/comments | 19 | 2022-10-21T10:49:49Z | 2022-12-22T16:59:33Z | https://github.com/kubernetes/kubernetes/issues/113250 | 1,418,146,862 | 113,250 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I apply a deployment yaml to modify `spec.template.spec.containers[0].ports[1].containerPort` from `8080` to `8081`
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
ma... | Deployment containerPort Duplicate value issue | https://api.github.com/repos/kubernetes/kubernetes/issues/113246/comments | 10 | 2022-10-21T09:24:33Z | 2022-11-15T21:51:09Z | https://github.com/kubernetes/kubernetes/issues/113246 | 1,418,036,694 | 113,246 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
pkg/kubelet/qos
### Which tests are failing?
`TestGetContainerOOMScoreAdjust` in `pkg/kubelet/qos`
I transformed that testcase into a fuzz driver and tested it with [[go-fuzz](https://github.com/dvyukov/go-fuzz)](https://github.com/dvyukov/go-fuzz)
It crash with "integer divide by zero"... | Crash in TestGetContainerOOMScoreAdjust | https://api.github.com/repos/kubernetes/kubernetes/issues/113243/comments | 13 | 2022-10-21T08:38:11Z | 2025-02-11T18:58:10Z | https://github.com/kubernetes/kubernetes/issues/113243 | 1,417,975,090 | 113,243 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
ref: https://github.com/kubernetes/kubernetes/blob/master/pkg/volume/configmap/configmap.go#L230
I was running a Pod with a configmap which can be modified regularly. Last day root disk of one node is full, and today SRE reported volume dir in this Pod became empty.
After some digging, It ... | configMap volume becomes empty if setupSuccess is negative | https://api.github.com/repos/kubernetes/kubernetes/issues/113242/comments | 22 | 2022-10-21T08:27:24Z | 2025-02-13T19:13:01Z | https://github.com/kubernetes/kubernetes/issues/113242 | 1,417,961,149 | 113,242 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
<img width="1996" alt="image" src="https://user-images.githubusercontent.com/1881126/197134114-85378b06-3c54-43dc-8e6d-20b6de19e8a8.png">
### Why is this needed?
In this way, the apiserver developed by the user can integrate the crd without relying on the kubernetes project | move crdRegistrationController to k8s.io/apiextensions-apiserver/pkg/controller like autoRegisterController | https://api.github.com/repos/kubernetes/kubernetes/issues/113240/comments | 9 | 2022-10-21T07:07:20Z | 2024-07-05T00:26:40Z | https://github.com/kubernetes/kubernetes/issues/113240 | 1,417,861,093 | 113,240 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
pkg/controller
### Which tests are failing?
`TestAddOrUpdateTaintOnNode` in `pkg/controller`
I transformed that testcase into a fuzz driver and tested it with [[go-fuzz](https://github.com/dvyukov/go-fuzz)](https://github.com/dvyukov/go-fuzz)
It crash with "invalid memory address or nil... | Crash in AddOrUpdateTaintOnNode | https://api.github.com/repos/kubernetes/kubernetes/issues/113239/comments | 6 | 2022-10-21T06:47:59Z | 2023-06-16T00:48:21Z | https://github.com/kubernetes/kubernetes/issues/113239 | 1,417,840,037 | 113,239 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I deployed a CRD (`teleportroles`) with the shortnames `role` and `roles`, conflicting with `roles.rbac.authorization.k8s.io/v1`.
Initially `kubectl get role` and `kubectl get roles` were both returnning `roles.rbac.authorization.k8s.io/v1` resources.
I ran `kubectl get teleportrole`.
Now, ... | Kubectl restmapping cache causes inconsistent behaviour in case of resource name conflict | https://api.github.com/repos/kubernetes/kubernetes/issues/113227/comments | 5 | 2022-10-20T20:52:45Z | 2023-01-03T17:29:44Z | https://github.com/kubernetes/kubernetes/issues/113227 | 1,417,266,866 | 113,227 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If mounting of a volume takes too long, an event gets logged to the Pod object with the list of unmounted and unattached volumes. Volume types like secrets, emptydir that don't support attach are included in the list, which can mislead users to think that there was a problem with that volume.
... | Don't list unattachable volumes as "unattached" in mount timed out event log | https://api.github.com/repos/kubernetes/kubernetes/issues/113226/comments | 4 | 2022-10-20T20:09:17Z | 2022-12-27T19:34:32Z | https://github.com/kubernetes/kubernetes/issues/113226 | 1,417,198,949 | 113,226 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When trying to use `patchesStrategicMerge` on CRD schema under `spec/versions` array, it fails and replace the whole array because it is missing a `mergeKey` and `patchStrategy` on `Versions`.
`patchesStrategicMerge` used to work with `spec.version` and `spec.validation` fields but those are no... | Cannot run patchesStrategicMerge on CRDs schema under Versions array | https://api.github.com/repos/kubernetes/kubernetes/issues/113223/comments | 12 | 2022-10-20T19:42:19Z | 2024-02-09T14:19:03Z | https://github.com/kubernetes/kubernetes/issues/113223 | 1,417,159,114 | 113,223 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Allow modifying the scheduling directives of a Job template when the job is fully suspended.
Currently, as part of kubernetes/enhancements#2926, we allow the Job pod template to be modified only if the Job didn't start (`.status.startTime == nil`).
We could implement mutable ... | Mutable Job scheduling directives after suspension | https://api.github.com/repos/kubernetes/kubernetes/issues/113221/comments | 23 | 2022-10-20T17:46:24Z | 2025-03-06T15:15:25Z | https://github.com/kubernetes/kubernetes/issues/113221 | 1,417,023,221 | 113,221 |
[
"kubernetes",
"kubernetes"
] | Scenario: My CRD has fields x, y, and z. I want to ensure that within a given namespace, no two instances of this CRD have the same set of values for those fields.
Solution 1: Require that .metadata.name be x+y+z. (Add a x-kubernetes-validations to the root of the object, and do something like `"[self.metadata.name]... | CEL Validation: permit hashing object fields to form object name | https://api.github.com/repos/kubernetes/kubernetes/issues/113220/comments | 8 | 2022-10-20T17:41:32Z | 2025-02-07T18:33:09Z | https://github.com/kubernetes/kubernetes/issues/113220 | 1,417,017,500 | 113,220 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add back-off restarting failed container name in the `BackOff` event message, like:
```
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 18m ... | Container name not showed in the `BackOff` event message | https://api.github.com/repos/kubernetes/kubernetes/issues/113215/comments | 5 | 2022-10-20T15:43:47Z | 2024-12-19T07:13:05Z | https://github.com/kubernetes/kubernetes/issues/113215 | 1,416,860,403 | 113,215 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We would like to add configurable timeouts to allow pending pods to transition to failed.
It would be ideal if it could be configurable based on container events or messages rather than a catch all timeout.
A possible API could be as follows:
```
- regexp: "F... | Enhancement: Marking a pending pod as failed after a certain timeout | https://api.github.com/repos/kubernetes/kubernetes/issues/113211/comments | 58 | 2022-10-20T14:21:09Z | 2025-02-28T16:09:34Z | https://github.com/kubernetes/kubernetes/issues/113211 | 1,416,720,623 | 113,211 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-integration
### Which tests are flaking?
It looks like random tests are failing, for example:
- TestUnReserveReservePlugins/The_Reserve_plugins_succeed
- TestImageLocalityScoring
- TestPVCBoundWithADC
### Since when has it been flaking?
Oct 19th
### Testgrid link
... | scheduler integration tests timing out on server setup | https://api.github.com/repos/kubernetes/kubernetes/issues/113207/comments | 8 | 2022-10-20T13:12:40Z | 2024-05-16T16:42:43Z | https://github.com/kubernetes/kubernetes/issues/113207 | 1,416,601,474 | 113,207 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Statefulset/Deployment pod going to unknown state after reboot of K8s worker nodes.
```
Statefulset/Deployment pod going to unknown state with event: "Normal SandboxChanged 13s (x10 over 2m13s) kubelet Pod sandbox changed, it will be killed and re-created."
Before reboot:
----------------... | Statefulset/Deployment pod going to unknown state | https://api.github.com/repos/kubernetes/kubernetes/issues/113204/comments | 13 | 2022-10-20T10:34:10Z | 2024-09-11T17:54:25Z | https://github.com/kubernetes/kubernetes/issues/113204 | 1,416,382,065 | 113,204 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
**Environment:**
kubernetes version: 1.23.6
ExternalTrafficPolicy: "local"
service type: "Loadbalancer"
kube-proxy mode: iptables
net.netfilter.nf_conntrack_tcp_be_liberal: 1
Metallb controller with BIRD speaker that establishes BGP peering with Datacenter GW(DCGW) and advertises the LoadBala... | Connections to new service pod stuck in conntrack for TCP traffic when externalTrafficPolicy is "local" | https://api.github.com/repos/kubernetes/kubernetes/issues/113203/comments | 25 | 2022-10-20T09:55:23Z | 2023-01-04T13:28:26Z | https://github.com/kubernetes/kubernetes/issues/113203 | 1,416,321,185 | 113,203 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While configuring ValidatingWebhook to match incoming requests to the `/scale` subresource, the following configuration was used:
```yaml
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
webhooks:
- name: my-webhook.example.com
rules:
- operations: ["CREA... | ValidatingWebhook not intercepting requests sent to /scale subresource | https://api.github.com/repos/kubernetes/kubernetes/issues/113187/comments | 9 | 2022-10-20T04:21:42Z | 2022-10-20T18:07:54Z | https://github.com/kubernetes/kubernetes/issues/113187 | 1,415,918,208 | 113,187 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A feature for provisioning volumes from cross-namespace snapshots.
### Why is this needed?
Please see [KEP-3294](https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/3294-provision-volumes-from-cross-namespace-snapshots)
| Add provisioning volumes from cross-namespace data sources | https://api.github.com/repos/kubernetes/kubernetes/issues/113184/comments | 6 | 2022-10-20T02:06:33Z | 2023-04-03T17:31:51Z | https://github.com/kubernetes/kubernetes/issues/113184 | 1,415,811,989 | 113,184 |
[
"kubernetes",
"kubernetes"
] | `IntPtr/FloatPtr/BoolPtr` are deprecated in `utils.pointer` and replaced with `Int/Float/Bool`. How about replacing all deprecated pointer conversion functions with the new functions in the kubernetes repo, including the deference functions? I can submit a PR if it's something right to do.
https://github.com/kuberne... | Replace deprecated IntPtr/FloatPtr/BoolPtr conversion functions | https://api.github.com/repos/kubernetes/kubernetes/issues/113177/comments | 6 | 2022-10-19T18:15:09Z | 2023-03-20T19:09:11Z | https://github.com/kubernetes/kubernetes/issues/113177 | 1,415,398,442 | 113,177 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Emit an event and increment a metric when the lifecycle handler for an https action falls back to http as @liggitt requested in #86139.
### Why is this needed?
To allow cluster users to identify lifecycle handlers that are configured to speak https to an http server. | Add metrics and an event when lifecycle handlers fallback to http | https://api.github.com/repos/kubernetes/kubernetes/issues/113174/comments | 4 | 2022-10-19T16:56:26Z | 2022-10-20T09:31:10Z | https://github.com/kubernetes/kubernetes/issues/113174 | 1,415,306,110 | 113,174 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
As described here: https://github.com/kubernetes/enhancements/issues/647#issuecomment-1078834288, we want current calls to k8s.io/utils/trace to create OpenTelemetry spans and span events if tracing is enabled in that component.
Requirements:
* Keep existing log-based traci... | OpenTelemetry tracing parity with util "tracing" | https://api.github.com/repos/kubernetes/kubernetes/issues/113170/comments | 1 | 2022-10-19T16:06:52Z | 2022-11-07T19:21:09Z | https://github.com/kubernetes/kubernetes/issues/113170 | 1,415,244,805 | 113,170 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Until now, the fake ReactionFunc is
```
type ReactionFunc func(action Action) (handled bool, ret runtime.Object, err error)
```
How about add context in this function
```
type ReactionFunc func(ctx context.Context, action Action) (handled bool, ret runtime.Object, err error... | Add context in fake ReactionFunc | https://api.github.com/repos/kubernetes/kubernetes/issues/113164/comments | 12 | 2022-10-19T11:01:20Z | 2024-03-21T07:11:30Z | https://github.com/kubernetes/kubernetes/issues/113164 | 1,414,760,199 | 113,164 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm running the [Online Boutique demo](https://github.com/GoogleCloudPlatform/microservices-demo) by Google in a minikube service mesh using Istio 1.15. In order to expose the ingress gateway I use a `minikube tunnel` to give it an external IP, and then I use `kubectl port-forward --address 0.0.0.0 ... | kubectl port-forward isseus with go traffic generator | https://api.github.com/repos/kubernetes/kubernetes/issues/113163/comments | 6 | 2022-10-19T11:01:18Z | 2023-03-18T12:50:56Z | https://github.com/kubernetes/kubernetes/issues/113163 | 1,414,760,159 | 113,163 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
sig-release-master-informing#capz-windows-containerd-master
### Which tests are failing?
- capz-e2e.Conformance Tests conformance-tests
- ci-kubernetes-e2e-capz-master-containerd-windows.Overall
### Since when has it been failing?
10/18
### Testgrid link
https://testgrid.k8s.io/sig... | [Failing Test]: capz-windows-containerd-master | https://api.github.com/repos/kubernetes/kubernetes/issues/113162/comments | 3 | 2022-10-19T10:37:46Z | 2022-10-31T10:52:10Z | https://github.com/kubernetes/kubernetes/issues/113162 | 1,414,726,915 | 113,162 |
[
"kubernetes",
"kubernetes"
] | The pros of integration tests, compared with e2e node tests:
- shorter development cycle
- easier to run the tests from IDE with debugger
- possibility of using a fake clock to make some of the tests faster
However, currently, there is only a single integration test for kubelet, but is very specific: https://gith... | Discussion on refactoring kubelet to allow writing of integration tests | https://api.github.com/repos/kubernetes/kubernetes/issues/113157/comments | 6 | 2022-10-19T07:33:11Z | 2023-03-09T11:43:17Z | https://github.com/kubernetes/kubernetes/issues/113157 | 1,414,458,367 | 113,157 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
sig-node-containerd#image-validation-cos-e2e
### Which tests are failing?
[sig-network] DNS should work with the pod containing more than 6 DNS search paths and longer than 256 search list characters
### Since when has it been failing?
Not sure, dashboard showed it failed since 10/15
#... | Job image-validation-cos-e2e fails to create the cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/113152/comments | 12 | 2022-10-18T21:53:29Z | 2024-04-07T21:53:07Z | https://github.com/kubernetes/kubernetes/issues/113152 | 1,413,890,106 | 113,152 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Hi I am Joyce from Google and I'm working on behalf of the [Open Source Security Foundation][ossf] (OpenSSF) to help essential open-source projects improve their supply-chain security.
I would like to suggest the adoption of an OpenSSF, [in partnership with GitHub][sc-blog], too... | Enable OpenSSF Scorecard Github Action and Badge | https://api.github.com/repos/kubernetes/kubernetes/issues/113144/comments | 8 | 2022-10-18T15:56:21Z | 2023-01-18T12:53:12Z | https://github.com/kubernetes/kubernetes/issues/113144 | 1,413,473,211 | 113,144 |
[
"kubernetes",
"kubernetes"
] | We would like to know early if the behavior is broken on any container runtime implementation.
This is motivated by the discussion under the PR: [Documentation for the CRI API reason field to standardize the field for containers terminated by OOM killer](https://github.com/kubernetes/kubernetes/pull/112977#issuecom... | Add node e2e test to verify the reason field is set to OOMKilled for the container terminated by OOM killer | https://api.github.com/repos/kubernetes/kubernetes/issues/113143/comments | 5 | 2022-10-18T15:33:49Z | 2023-02-21T22:23:57Z | https://github.com/kubernetes/kubernetes/issues/113143 | 1,413,438,874 | 113,143 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
/sig apps
/wg batch
/area batch
A mechanism to terminate a Job from an external controller, ensuring all the running pods are deleted.
Potentially, we could simply use a terminal Job condition as a signal.
This could be implemented by enhancing the orphan pod worker to i... | Terminate a Job from an external controller | https://api.github.com/repos/kubernetes/kubernetes/issues/113142/comments | 22 | 2022-10-18T15:29:54Z | 2023-03-24T18:53:57Z | https://github.com/kubernetes/kubernetes/issues/113142 | 1,413,432,555 | 113,142 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
- User cordons a node with a pvc bound to a local persistent volume
- User deletes a stateful set pod from that node
- The pod is in pending because the pvc is still bound to a local pv on the cordoned node (expected)
- The node dies and the pvc is deleted
- The pod is still stuck in pending b... | PVC recreation needed when Stateful set Pod stuck in pending | https://api.github.com/repos/kubernetes/kubernetes/issues/113139/comments | 9 | 2022-10-18T14:04:07Z | 2024-05-22T17:23:21Z | https://github.com/kubernetes/kubernetes/issues/113139 | 1,413,290,699 | 113,139 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When a scheduler framework constructor is called, it also always creates a metrics recorder. That metrics recorder immediately starts a go routine which never exits. Creating many scheduler framework instances creates many of such go routines which are never closed, eventually accumulating so much t... | Scheduler framework metrics recorder go routine leak | https://api.github.com/repos/kubernetes/kubernetes/issues/113131/comments | 13 | 2022-10-18T08:09:58Z | 2022-10-20T06:44:34Z | https://github.com/kubernetes/kubernetes/issues/113131 | 1,412,766,091 | 113,131 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In our scenario, memoryManager are enabled. There are two numa nodes: node0 and node1 on the host.
The relevant parameter values are as follows:
memoryManagerPolicy: Static
Initially, no pods are running on this node with two numa node, 220G memory per numa node. Follow the steps bellow to ... | kubelet: memorymanager static policy startup error | https://api.github.com/repos/kubernetes/kubernetes/issues/113130/comments | 23 | 2022-10-18T07:27:51Z | 2024-11-04T07:55:40Z | https://github.com/kubernetes/kubernetes/issues/113130 | 1,412,710,356 | 113,130 |
[
"kubernetes",
"kubernetes"
] | ### What we found?
We found that the parent object will be pruned if we do not define this parent object when applying CR, even though the child object of it has a default value in CRD.
Here is an example of a csvInjector in NamespaceScope CR:
1. We set a default value for `.spec.CSVInjector.enable` to `true` in... | default value of nested object | https://api.github.com/repos/kubernetes/kubernetes/issues/113110/comments | 8 | 2022-10-17T15:24:46Z | 2022-10-17T16:05:59Z | https://github.com/kubernetes/kubernetes/issues/113110 | 1,411,780,930 | 113,110 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
ExternalIP is not accessible from the node where the pod is running.
ClusterIP/PodIP works.
### What did you expect to happen?
All nodes must be accessible by external ip.
### How can we reproduce it (as minimally and precisely as possible)?
```
$ kubectl get svc -o wide
service-a... | Cannot access external ip from same node | https://api.github.com/repos/kubernetes/kubernetes/issues/113105/comments | 4 | 2022-10-17T11:51:40Z | 2022-10-17T12:09:16Z | https://github.com/kubernetes/kubernetes/issues/113105 | 1,411,435,658 | 113,105 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
, I was going through the rbac authorization document of k8s - [authorization package - k8s.io/kubernetes/pkg/apis/authorization - Go Packages](https://pkg.go.dev/k8s.io/kubernetes/pkg/apis/authorization#ResourceAttributes)
and noticed that Resource and Verb can have * value as well. I tried findin... | When does the SubjectAccessReviewRequest contain * in resource and verb? | https://api.github.com/repos/kubernetes/kubernetes/issues/113096/comments | 2 | 2022-10-17T08:26:16Z | 2022-10-17T13:36:00Z | https://github.com/kubernetes/kubernetes/issues/113096 | 1,411,131,653 | 113,096 |
[
"kubernetes",
"kubernetes"
] | If I configure the `test` namespace to enforce `baseline` PSS checks, the return message ends abruptly for `seLinuxOptions`:
```
$ k label ns test pod-security.kubernetes.io/enforce-version=v1.24 pod-security.kubernetes.io/enforce=baseline
$ k apply -f resources.yaml -n test
Error from server (Forbidden): er... | Message ends abruptly for seLinuxOptions check | https://api.github.com/repos/kubernetes/kubernetes/issues/113109/comments | 4 | 2022-10-17T07:02:13Z | 2022-10-18T21:01:14Z | https://github.com/kubernetes/kubernetes/issues/113109 | 1,411,767,003 | 113,109 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Started a cluster with kubelet v1.22.5
Added a static pod yaml to /etc/kubernetes/manifest/
Observed the pod run successfully
Then remove the static pod yaml
Observed the pod is removed
And then add the same static pod yaml only change the pod id
Observed the static pod new start
kubelet l... | after the pod workers delete pod syncTerminated failed ,kubelet cann't start a new pod with the same namespacedname | https://api.github.com/repos/kubernetes/kubernetes/issues/113091/comments | 9 | 2022-10-17T06:33:23Z | 2023-04-14T19:57:11Z | https://github.com/kubernetes/kubernetes/issues/113091 | 1,410,989,776 | 113,091 |
[
"kubernetes",
"kubernetes"
] | - [x] [0001-EKS-PATCH-Pass-region-to-sts-client.patch](https://github.com/aws/eks-distro/blob/main/projects/kubernetes/kubernetes/1-24/patches/0001-EKS-PATCH-Pass-region-to-sts-client.patch) - Fixing in https://github.com/kubernetes/kubernetes/pull/113084
- [ ] ~[0002-EKS-PATCH-Bypassed-admission-controller-webhook-fo... | Pick up fixes from eks-distro maintained by AWS folks | https://api.github.com/repos/kubernetes/kubernetes/issues/113088/comments | 10 | 2022-10-16T23:30:16Z | 2022-10-25T20:57:05Z | https://github.com/kubernetes/kubernetes/issues/113088 | 1,410,666,000 | 113,088 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I change the time on the node to the past, the node status get from the kube-apiserver changes from Ready to Unknown, and then returns to Ready after a period of time.
### What did you expect to happen?
When the time changes, the node remains in the Ready condition.
### How can we reproduce ... | Nodes becomes Unknown when the time on this node jumps to the past | https://api.github.com/repos/kubernetes/kubernetes/issues/113081/comments | 12 | 2022-10-15T10:58:58Z | 2023-04-24T07:06:54Z | https://github.com/kubernetes/kubernetes/issues/113081 | 1,410,129,777 | 113,081 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Since upgrading to CentOS 9 and Kubernetes 1.24.6 (on the same hardware), sporadic DNS resolution errors occur when too many coredns pods are running at the same time. If I reduce them to <= 3, no more errors occur. Once the error occurs, you see lines in the logs of nodelocaldns pods like:
`[E... | Upscaling of coredns pods leads to DNS timeout errors | https://api.github.com/repos/kubernetes/kubernetes/issues/113080/comments | 17 | 2022-10-15T10:16:57Z | 2024-10-10T06:19:16Z | https://github.com/kubernetes/kubernetes/issues/113080 | 1,410,119,383 | 113,080 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Cluster information:
Kubernetes version: 1.22.11
Cloud being used: Azure/AKS
Installation method:
Host OS: Linux/Windows
CNI and version: Azure CNI
CRI and version: containerd (containerd-2022.09.13)
We have several K8s clusters running in AKS. We have Linux and Windows node pools and deplo... | EndpointSliceCache Only has 1 IP Address Even Though Multiple Endpoints Are Running | https://api.github.com/repos/kubernetes/kubernetes/issues/113079/comments | 7 | 2022-10-15T10:16:07Z | 2022-11-18T14:33:07Z | https://github.com/kubernetes/kubernetes/issues/113079 | 1,410,119,186 | 113,079 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When pods of statefulset created, sometimes kube-controller-manager will report "FailedCreate" abnormal event, but the conditions of creating pod are all satisified all the time.
### What did you expect to happen?
We shouldn't report abnormal events when creating statefulset if conditions are sati... | Err msg incorrect when creating already exists pod of statefulset | https://api.github.com/repos/kubernetes/kubernetes/issues/113078/comments | 7 | 2022-10-15T09:00:35Z | 2023-04-07T08:15:16Z | https://github.com/kubernetes/kubernetes/issues/113078 | 1,410,100,971 | 113,078 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We observed the following logs on API servers:
```
cacher.go:419] cacher (*core.ConfigMap): unexpected ListAndWatch error: failed to list *core.ConfigMap: rpc error: code = ResourceExhausted desc = grpc: trying to send message larger than max (2169480971 vs. 2147483647); reinitializing...
```
... | Watch cache cannot be initialized for large responses | https://api.github.com/repos/kubernetes/kubernetes/issues/113076/comments | 10 | 2022-10-15T01:15:39Z | 2024-06-25T01:34:17Z | https://github.com/kubernetes/kubernetes/issues/113076 | 1,409,998,619 | 113,076 |
[
"kubernetes",
"kubernetes"
] | This repo is signed up as part of the KubeCon [Security Slam](https://events.linuxfoundation.org/kubecon-cloudnativecon-north-america/attend/experiences/#security-slam). I'm bringing to your attention the checklist from the official [CLOMonitor page for Kubernetes](https://clomonitor.io/projects/cncf/kubernetes) -- it ... | Bring CLOMonitor Score to 100% | https://api.github.com/repos/kubernetes/kubernetes/issues/113075/comments | 9 | 2022-10-14T20:42:27Z | 2022-10-20T13:42:46Z | https://github.com/kubernetes/kubernetes/issues/113075 | 1,409,840,164 | 113,075 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A pod deletion did not result in the correct sandbox pause container being deleted. This was found during internal EKS testing on 1.22, where the test case was as follows:
1. Create a deployment with ~20 replicas and target a single Linux node.
2. Wait for all pods to have networking resources a... | Sandbox pause container not deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/113073/comments | 11 | 2022-10-14T19:01:59Z | 2023-03-16T21:52:38Z | https://github.com/kubernetes/kubernetes/issues/113073 | 1,409,738,574 | 113,073 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We have no way to tell if client-go rate-limiter is getting hit and by how much. Ideally we will have some sort of saturation metric that tells us how much the client-side rate limiter is getting used.
### Why is this needed?
We have no way to tell if client-go rate-limiter is g... | Add a client-side rate limiter metric | https://api.github.com/repos/kubernetes/kubernetes/issues/113072/comments | 6 | 2022-10-14T17:27:16Z | 2024-07-23T20:30:45Z | https://github.com/kubernetes/kubernetes/issues/113072 | 1,409,646,812 | 113,072 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/blob/52b47dac4fe26644a91f44191ff7052b73c3afd7/pkg/printers/internalversion/printers.go#L87
Can I try to add error handling?
https://github.com/kubernetes/kubernetes/issues/113070#tasklist-block-cb9ee277-1f3c-4cd2-a780-572bb7560a19
| Handling of errors in pkg/printers/internalversion | https://api.github.com/repos/kubernetes/kubernetes/issues/113070/comments | 5 | 2022-10-14T15:53:36Z | 2023-01-06T15:42:28Z | https://github.com/kubernetes/kubernetes/issues/113070 | 1,409,549,937 | 113,070 |
[
"kubernetes",
"kubernetes"
] | Jenkins file:
Following step is to deploy the docker image from ECR to EKS
stage('Deploy'){
steps {
bat 'kubectl apply -f deployment.yml'
}
}
While executing this step in Jenkins I see the following error:
C:\ProgramData\Jenkins\.jenkins\workspac... | Error while executing kubectl from Jenkinsfile | https://api.github.com/repos/kubernetes/kubernetes/issues/113069/comments | 3 | 2022-10-14T15:30:18Z | 2022-10-14T15:35:00Z | https://github.com/kubernetes/kubernetes/issues/113069 | 1,409,522,613 | 113,069 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
/sig node
```
Addresses:
InternalIP: 10.6.182.198
Hostname: ubuntu
Capacity:
cpu: 4
ephemeral-storage: 164026132Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 8140292Ki
pods: 110
Allocatable:
cpu: ... | cri stats provider: unable to find data in memory cache. Result in InvalidDiskCapacity warning. | https://api.github.com/repos/kubernetes/kubernetes/issues/113066/comments | 19 | 2022-10-14T06:22:59Z | 2024-04-02T10:57:10Z | https://github.com/kubernetes/kubernetes/issues/113066 | 1,408,830,259 | 113,066 |
[
"kubernetes",
"kubernetes"
] | The code at:
https://github.com/kubernetes/kubernetes/blob/215f236a6b9087c63f4f65fd34a066e56fae54d7/staging/src/k8s.io/apiserver/pkg/storage/value/transformer.go#L154-L157
assumes that the transformation does not change the size of the data. Since we know it most cases that it does, we should try to account for ... | KMS: prefixTransformers.TransformToStorage allocates poorly | https://api.github.com/repos/kubernetes/kubernetes/issues/113058/comments | 6 | 2022-10-13T21:28:55Z | 2022-10-18T18:29:39Z | https://github.com/kubernetes/kubernetes/issues/113058 | 1,408,447,907 | 113,058 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
preferredDuringSchedulingIgnoredDuringException not working as expected.
What is happening is that we want a new pod to go to nodes that preferably have the label “2.19” and start very fast. We use preferredDuringSchedulingIgnoredDuringExecution and overprovisioning to make the starts fast. There... | preferredDuringSchedulingIgnoredDuringException does not work with overproviosioning | https://api.github.com/repos/kubernetes/kubernetes/issues/113055/comments | 8 | 2022-10-13T19:23:12Z | 2023-03-18T10:50:56Z | https://github.com/kubernetes/kubernetes/issues/113055 | 1,408,313,423 | 113,055 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Could you please help me, what would be the changes required in [pod_security_policy-istio.yaml](https://github.com/GoogleCloudPlatform/fda-mystudies/blob/master/deployment/kubernetes/pod_security_policy-istio.yaml) as per the latest Kubernetes versions (from v.21+)
When I applied [pod_security... | Warning | when PSP (Pod Security Policy) applied to Istio | https://api.github.com/repos/kubernetes/kubernetes/issues/113051/comments | 7 | 2022-10-13T16:24:07Z | 2022-10-14T06:29:29Z | https://github.com/kubernetes/kubernetes/issues/113051 | 1,408,099,009 | 113,051 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
`pkg/controller/statefulset`
### Which tests are failing?
`TestStatefulPodControlNoOpUpdate` in `pkg/controller/statefulset`
I transformed that testcase into a fuzz driver and tested it with [go-fuzz](https://github.com/dvyukov/go-fuzz)
It crash with "invalid memory address or nil p... | panic: "invalid memory address or nil pointer dereference" on a transformed Test | https://api.github.com/repos/kubernetes/kubernetes/issues/113043/comments | 6 | 2022-10-13T11:23:01Z | 2023-09-22T07:22:00Z | https://github.com/kubernetes/kubernetes/issues/113043 | 1,407,626,543 | 113,043 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
- pr:pull-kubernetes-integration
- ci-kubernetes-integration-master
### Which tests are flaking?
- k8s.io/kubernetes/test/integration/daemonset
TestDSCUpdatesPodLabelAfterDedupCurHistories
### Since when has it been flaking?
https://storage.googleapis.com/k8s-triage/index.html?pr=... | [Flaky test] k8s.io/kubernetes/test/integration/daemonset | https://api.github.com/repos/kubernetes/kubernetes/issues/113036/comments | 14 | 2022-10-13T04:03:16Z | 2022-11-11T17:18:11Z | https://github.com/kubernetes/kubernetes/issues/113036 | 1,407,103,988 | 113,036 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In our scenario, cpuManager, memoryManager and topologyManager are enabled at the same time. There are two numa nodes: node0 and node1.
The relevant parameter values are as follows:
- cpuManagerPolicy: static
- memoryManagerPolicy: Static
- topologyManagerPolicy: best-effort
- topologyManagerS... | kubelet: when memoryManager are enabled, kubelet fails to restart occasionally | https://api.github.com/repos/kubernetes/kubernetes/issues/113035/comments | 18 | 2022-10-13T03:15:32Z | 2024-10-29T08:24:21Z | https://github.com/kubernetes/kubernetes/issues/113035 | 1,407,073,635 | 113,035 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Content Negotiation types are currently not listed in OpenAPI. For example, it's possible to query resources with an Accept header `Accept: application/json;as=Table;g=meta.k8s.io;v=v1` to list as tables, but the information is missing in the OpenAPI.
These are the only types ... | Content Negotiation types should be listed in OpenAPI | https://api.github.com/repos/kubernetes/kubernetes/issues/113028/comments | 15 | 2022-10-12T22:07:57Z | 2024-09-06T07:57:06Z | https://github.com/kubernetes/kubernetes/issues/113028 | 1,406,861,633 | 113,028 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/blob/ea0764452222146c47ec826977f49d7001b0ea8c/staging/src/k8s.io/component-base/metrics/prometheus/ratelimiter/rate_limiter.go#L48 uses a dynamic `ownerName` as a part of the metric name. This should instead be a label of a generic metric.
### What did you ... | rate_limiter_use metric uses a dynamic subsystem | https://api.github.com/repos/kubernetes/kubernetes/issues/113023/comments | 3 | 2022-10-12T18:14:01Z | 2022-10-17T18:09:20Z | https://github.com/kubernetes/kubernetes/issues/113023 | 1,406,614,426 | 113,023 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.