
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
debugging-profiles give Ephemeral Container chance to add capability besides default capability:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-cli/1441-kubectl-debug/README.md#debugging-profiles
Now, there is no profile in plan to support NET_RAW.
Propose to ad... | Suggest kubectl-debug+debugging-profiles to support NET_RAW | https://api.github.com/repos/kubernetes/kubernetes/issues/110570/comments | 6 | 2022-06-14T14:46:56Z | 2022-11-11T17:58:01Z | https://github.com/kubernetes/kubernetes/issues/110570 | 1,270,924,549 | 110,570 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Exposed service(s) in bare metal Kubernetes are unreachable.
I am new to K8s from the administrative side. I was able to stand up a MicroK8s cluster and it worked, but I am trying to avoid the abstractions in order to learn.
Pods are responding fine when I curl them at localhost. I don't bel... | Pods cannot resolve DNS | https://api.github.com/repos/kubernetes/kubernetes/issues/110550/comments | 12 | 2022-06-13T21:38:00Z | 2024-10-15T04:50:53Z | https://github.com/kubernetes/kubernetes/issues/110550 | 1,269,986,233 | 110,550 |
[
"kubernetes",
"kubernetes"
] | ### Problem statement
The [registry.k8s.io/e2e-test-images/echoserver:2.5](http://registry.k8s.io/e2e-test-images/echoserver:2.5) does not seem to work on arms64 linux VM. I got an error
```console
$ kubectl logs echo-597b9f4545-kb4lx
Generating self-signed cert
Generating a RSA private key
....................... | echoserver:2.5 does not work on arm64 arch | https://api.github.com/repos/kubernetes/kubernetes/issues/110605/comments | 12 | 2022-06-13T19:25:03Z | 2022-06-30T20:54:57Z | https://github.com/kubernetes/kubernetes/issues/110605 | 1,272,391,288 | 110,605 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have been testing reconstruction and found that if more than one pod is using a volume then cleanup logic would cleanup only one of the paths and leaves other volumes around.
To test this scenario, I did following:
1. Create a CSI hostpath PVC
2. Use the volume in two pods.
3. While kube... | Reconstruction only cleans one path of shared volume between two pods leaving other one uncleaned | https://api.github.com/repos/kubernetes/kubernetes/issues/110547/comments | 4 | 2022-06-13T18:15:28Z | 2022-10-27T15:02:33Z | https://github.com/kubernetes/kubernetes/issues/110547 | 1,269,787,522 | 110,547 |
[
"kubernetes",
"kubernetes"
] | I am trying to connect to a MongoDB pod (**mongodb-deployment-c896cf876-djhvl**) from another MongoDB pod (**mongodb-0**) which is in the same namespace but when I attempt to do so I am getting an error :
```kubectl exec -it mongodb-0 -- sh
mongo mongodb://admin:abc123@mongodb-headless-service.svc.cluster.local/p... | HostNotFound: error when connecting to Mongo pod in same namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/110539/comments | 8 | 2022-06-13T11:49:40Z | 2022-06-14T12:29:07Z | https://github.com/kubernetes/kubernetes/issues/110539 | 1,269,321,251 | 110,539 |
[
"kubernetes",
"kubernetes"
] | Since this PR [#48922](https://github.com/kubernetes/kubernetes/pull/48922), extended resource outside *kubernetes.io namespace cannot be over-committed.
From the implementation of kubernetes, this is just a validation in apiserver, this constraint itself has no other effect (or a side effect without it).
Take a ... | Extended resource cannot be over-committed | https://api.github.com/repos/kubernetes/kubernetes/issues/110536/comments | 12 | 2022-06-13T09:54:39Z | 2025-03-04T21:30:46Z | https://github.com/kubernetes/kubernetes/issues/110536 | 1,269,191,586 | 110,536 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I'd like `kubelet` to exposes operation duration buckets, error_count, total_count for `CSI` GRPC methods just like what `CRI` client has done.
```
# HELP kubelet_run_podsandbox_errors_total [ALPHA] Cumulative number of the run_podsandbox operation errors by RuntimeClass.Han... | Expose metrics for CSI grpc calls | https://api.github.com/repos/kubernetes/kubernetes/issues/110533/comments | 12 | 2022-06-13T06:42:05Z | 2023-12-05T06:47:38Z | https://github.com/kubernetes/kubernetes/issues/110533 | 1,268,978,302 | 110,533 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
# Current Setup
The current setup when creating a `ReplicaSet`, `Deployment` , `CronJob` or any k8s object requires the template to be described in the same file. For example
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: <rs-name>
labels:
<key>: <valu... | Add File templating for Kubernetes Object | https://api.github.com/repos/kubernetes/kubernetes/issues/110528/comments | 4 | 2022-06-12T15:26:25Z | 2022-06-14T20:22:28Z | https://github.com/kubernetes/kubernetes/issues/110528 | 1,268,616,303 | 110,528 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The API server reported that adding a finalizer was successful, however it also allowed the object to be deleted (removed) without first removing the finalizer.
### What did you expect to happen?
I would expect for the object to be present, with a deletionTimestamp, if it gets deleted after adding... | Add finalizer races with object deletion | https://api.github.com/repos/kubernetes/kubernetes/issues/110521/comments | 9 | 2022-06-12T03:02:19Z | 2022-06-21T20:14:08Z | https://github.com/kubernetes/kubernetes/issues/110521 | 1,268,428,398 | 110,521 |
[
"kubernetes",
"kubernetes"
] | **Name and Version**
docker.io/bitnami/mongodb:4.4.6-debian-10-r0
What steps will reproduce the issue?
1. `kubectl exec -it <pod_name> -- sh`
2. Run mongodump command while passing a MongoURI to the command
**What is the expected behavior?**
I want to setup backups for my MongoDB instance and the k8s cron j... | What is the exact format for Mongo-URI when connecting to a Kubernetes MongoDB instance | https://api.github.com/repos/kubernetes/kubernetes/issues/110517/comments | 5 | 2022-06-11T14:18:34Z | 2022-06-14T12:29:39Z | https://github.com/kubernetes/kubernetes/issues/110517 | 1,268,288,673 | 110,517 |
[
"kubernetes",
"kubernetes"
] | Presumably this would occur when changing the default from one class to another. E.g.
* Class X exists and is marked default
* Class Y is created
* Class Y is marked as default
* Uh oh!! 2 defaults
* Class X is marked as not default
At the case in point, when there are 2 defaults, we currently do not assi... | Having two Default StorageClasses should be handled better | https://api.github.com/repos/kubernetes/kubernetes/issues/110514/comments | 27 | 2022-06-10T21:50:02Z | 2022-10-04T08:41:38Z | https://github.com/kubernetes/kubernetes/issues/110514 | 1,268,051,666 | 110,514 |
[
"kubernetes",
"kubernetes"
] | ### Issue Details
A security issue was discovered in [ingress-nginx](https://github.com/kubernetes/ingress-nginx) where a user that can create or update ingress objects can use a newline character to bypass the sanitization of the `spec.rules[].http.paths[].path` field of an Ingress object (in the `networking.k8s.io` ... | CVE-2021-25748: Ingress-nginx `path` sanitization can be bypassed with newline character | https://api.github.com/repos/kubernetes/kubernetes/issues/126814/comments | 8 | 2022-06-10T16:01:41Z | 2024-08-20T13:21:36Z | https://github.com/kubernetes/kubernetes/issues/126814 | 2,475,632,907 | 126,814 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Force deleting a pod with grace-period=0 does not immedietally stop it. Instead the pod disappears, is not listed anywhere. Only way to check if the pod is doing something is to access log files directly on the node fs.
Additionally, all network policies stop working when the pod gets in this hal... | Pod still running after being force deleted with 0 grace period, network policices stop applying | https://api.github.com/repos/kubernetes/kubernetes/issues/110507/comments | 9 | 2022-06-10T15:07:08Z | 2022-11-12T16:08:48Z | https://github.com/kubernetes/kubernetes/issues/110507 | 1,267,678,687 | 110,507 |
[
"kubernetes",
"kubernetes"
] | <!--
If you suspect your issue is a bug, please attach the output of the Agent status page,
see https://docs.datadoghq.com/agent/faq/agent-commands/#agent-information
-->
**Output**
```
$kubectl describe cm datadog-custom-metrics
external_metric-horizontal-core-autoscaler2-Sample.Datadog.Metric:
{"metricName"... | HPA target average value being summed when same metric is being used in more than one HPA | https://api.github.com/repos/kubernetes/kubernetes/issues/110501/comments | 8 | 2022-06-10T07:14:25Z | 2022-11-10T20:42:56Z | https://github.com/kubernetes/kubernetes/issues/110501 | 1,267,155,592 | 110,501 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Tried Crating 3 pods using an Deployment Spec with name length of 62 characters, The Created Pods don't have the correct name when the pods get created.
name in spec.
enter-prise-json-schema-validator-service-44-deployment6-20221
name of pod created.
enter-prise-json-schema-validator-ser... | Deployment Spec - Creates Pod with different name if it is around 62 characters in length. | https://api.github.com/repos/kubernetes/kubernetes/issues/110500/comments | 8 | 2022-06-10T05:21:33Z | 2022-06-14T20:22:19Z | https://github.com/kubernetes/kubernetes/issues/110500 | 1,267,041,267 | 110,500 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In reviewing the existing tests for API Priority and Fairness (APF), I again noticed https://github.com/kubernetes/kubernetes/blob/v1.23.7/test/integration/apiserver/flowcontrol/concurrency_test.go#L143 . This line tests whether APF delivered similar throughputs to two traffic flows. But the tes... | APF integration test evaluates throughput rather than latency | https://api.github.com/repos/kubernetes/kubernetes/issues/110499/comments | 3 | 2022-06-10T03:50:04Z | 2022-09-13T17:18:00Z | https://github.com/kubernetes/kubernetes/issues/110499 | 1,266,979,709 | 110,499 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In-Place Pod Vertical scaling [PR](https://github.com/kubernetes/kubernetes/pull/102884/) has an E2E test for testing pod resize. This test needs a fix fixes and improvements.
1. Add E2E test for exercising changes to scheduler code in the above PR. See comment: https://github.c... | [FG:InPlacePodVerticalScaling] Pod Resize E2E test - add test for scheduler, fix code review items | https://api.github.com/repos/kubernetes/kubernetes/issues/110490/comments | 21 | 2022-06-09T12:14:30Z | 2024-05-13T22:59:54Z | https://github.com/kubernetes/kubernetes/issues/110490 | 1,266,041,139 | 110,490 |
[
"kubernetes",
"kubernetes"
] | When POD modifies the image, it should stop the backend service as Service, can this be achieved by modifying the Ready state of POD? like openkuise. | Is it possible to provide in-place upgrade capability for PODs? | https://api.github.com/repos/kubernetes/kubernetes/issues/110487/comments | 8 | 2022-06-09T08:58:05Z | 2022-11-10T09:41:22Z | https://github.com/kubernetes/kubernetes/issues/110487 | 1,265,816,102 | 110,487 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In kubelet config, we use cpuManagerPolicy: static, and specify the following configuration to reserve cpu for system etc:

When server rebooted, kubelet will fail to start, this is t... | Kubelet failed to start due to CPUs stat mismatch | https://api.github.com/repos/kubernetes/kubernetes/issues/110478/comments | 11 | 2022-06-09T04:49:39Z | 2022-08-23T09:40:06Z | https://github.com/kubernetes/kubernetes/issues/110478 | 1,265,589,182 | 110,478 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I create a docker-registry secret firstly:
```
# kubectl create secret docker-registry paas-registry --docker-server=reg.harbor.com --docker-username=xxx --docker-password=xxx -n paas
```
Then, I create a deployment with this secret:
```
apiVersion: apps/v1
kind: Deployment
metadata:
nam... | pull private image failed on k8s 1.24.1 with containerd | https://api.github.com/repos/kubernetes/kubernetes/issues/110476/comments | 8 | 2022-06-09T03:09:39Z | 2022-08-23T07:42:26Z | https://github.com/kubernetes/kubernetes/issues/110476 | 1,265,533,604 | 110,476 |
[
"kubernetes",
"kubernetes"
] | It may be nice to have some dummy image on `registry.k8s.io` that doesn't exist on `k8s.gcr.io`. This way we can write a simple e2e test that will validate that the image mirroring was set up properly in the environment.
See https://github.com/kubernetes/kubernetes/pull/110350#issuecomment-1150476706 for example
... | Dummy image on registry.k8s.io | https://api.github.com/repos/kubernetes/kubernetes/issues/110471/comments | 5 | 2022-06-08T22:37:02Z | 2022-09-25T20:30:02Z | https://github.com/kubernetes/kubernetes/issues/110471 | 1,265,384,576 | 110,471 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [05c71e0f8991d87203da](https://go.k8s.io/triage#05c71e0f8991d87203da)
##### Error text:
```
test/e2e/kubectl/kubectl.go:1186
May 25 00:18:53.116: error missing unknown metadata field, got: error running /workspace/kubernetes/platforms/linux/amd64/kubectl --server=https://34.168.238.90 --kubeco... | Failure cluster [05c71e0f...] | https://api.github.com/repos/kubernetes/kubernetes/issues/110467/comments | 2 | 2022-06-08T20:43:35Z | 2022-06-10T16:41:46Z | https://github.com/kubernetes/kubernetes/issues/110467 | 1,265,287,123 | 110,467 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I want to be able to tune (or have some ways to make the test to pass) the conformance test "garbage collector should orphan pods created by rc if delete options say so". e.g. can we deploy less number of pods, so it won't cause CPU pressure?
### Why is this needed?
I am running ... | Ways tune conformance test "garbage collector should orphan pods created by rc if delete options say so" | https://api.github.com/repos/kubernetes/kubernetes/issues/110466/comments | 10 | 2022-06-08T20:33:01Z | 2024-05-16T16:41:14Z | https://github.com/kubernetes/kubernetes/issues/110466 | 1,265,272,355 | 110,466 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
#### Motivation
In order to run integration- and system-level tests against our application suite in CI, we first stand up a temporary instance of our application suite, and then apply a number of test jobs to the system. Currently a test job creates a single pod and runs a single container, whi... | Unable to get logs, etc., from failed parallel pods in job | https://api.github.com/repos/kubernetes/kubernetes/issues/110464/comments | 13 | 2022-06-08T17:31:21Z | 2022-10-03T14:32:09Z | https://github.com/kubernetes/kubernetes/issues/110464 | 1,265,079,290 | 110,464 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
release-master-informing
- periodic-conformance-main-k8s-main
### Which tests are failing?
- capa-e2e-conformance.[unmanaged] [conformance] tests conformance
- periodic-cluster-api-provider-aws-e2e-conformance-with-k8s-ci-artifacts.Overall
### Since when has it been failing?
... | [Failing test] periodic-conformance-main-k8s-main | https://api.github.com/repos/kubernetes/kubernetes/issues/110463/comments | 6 | 2022-06-08T16:49:19Z | 2022-06-15T06:54:54Z | https://github.com/kubernetes/kubernetes/issues/110463 | 1,265,034,628 | 110,463 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
release-master-informing
- capg-conformance-main-ci-artifacts
### Which tests are failing?
Kubernetes e2e suite.BeforeSuite
### Since when has it been failing?
05-25 06:37 IST
### Testgrid link
https://testgrid.k8s.io/sig-release-master-informing#capg-conformance-main-c... | [Failing test] capg-conformance-main-ci-artifacts | https://api.github.com/repos/kubernetes/kubernetes/issues/110462/comments | 12 | 2022-06-08T16:37:43Z | 2022-07-06T15:51:32Z | https://github.com/kubernetes/kubernetes/issues/110462 | 1,265,021,509 | 110,462 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubernetes does not set `DiskPressure` status on the worker node when the devmapper usage is full.
When accessing the results from `localhost:10255/stats/summary` I can see Kubernetes is correctly calculating the `imageFs` but does not set `DiskPressure` nor evict the Pods from this node to anoth... | Node DiskPressure is missing when devmapper usage is full. | https://api.github.com/repos/kubernetes/kubernetes/issues/110461/comments | 9 | 2022-06-08T16:35:33Z | 2022-11-06T11:57:33Z | https://github.com/kubernetes/kubernetes/issues/110461 | 1,265,019,205 | 110,461 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When applying a SECCOMP profile for the entire pod, the profile doesn't seem to be applied to startup, liveness and readiness probes using scripts. It is only applied to the containers within the pod.
### What did you expect to happen?
My SECCOMP profile is applied to the probes as well.
... | Seccomp profile not applied to probes | https://api.github.com/repos/kubernetes/kubernetes/issues/110460/comments | 13 | 2022-06-08T16:08:00Z | 2022-06-20T19:58:12Z | https://github.com/kubernetes/kubernetes/issues/110460 | 1,264,982,024 | 110,460 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Please allow class E address class (240.0.0.0/4) for pod and as well service networking. Are there any existing guidelines or challenges that would prevent us from proceeding this request?
### Why is this needed?
Kubernetes SaaS-based customers are often challenged with solving o... | Support class E network for pod and service networking | https://api.github.com/repos/kubernetes/kubernetes/issues/110456/comments | 5 | 2022-06-08T12:33:42Z | 2022-06-09T15:33:24Z | https://github.com/kubernetes/kubernetes/issues/110456 | 1,264,673,348 | 110,456 |
[
"kubernetes",
"kubernetes"
] | How to install centos7? There has been an error.
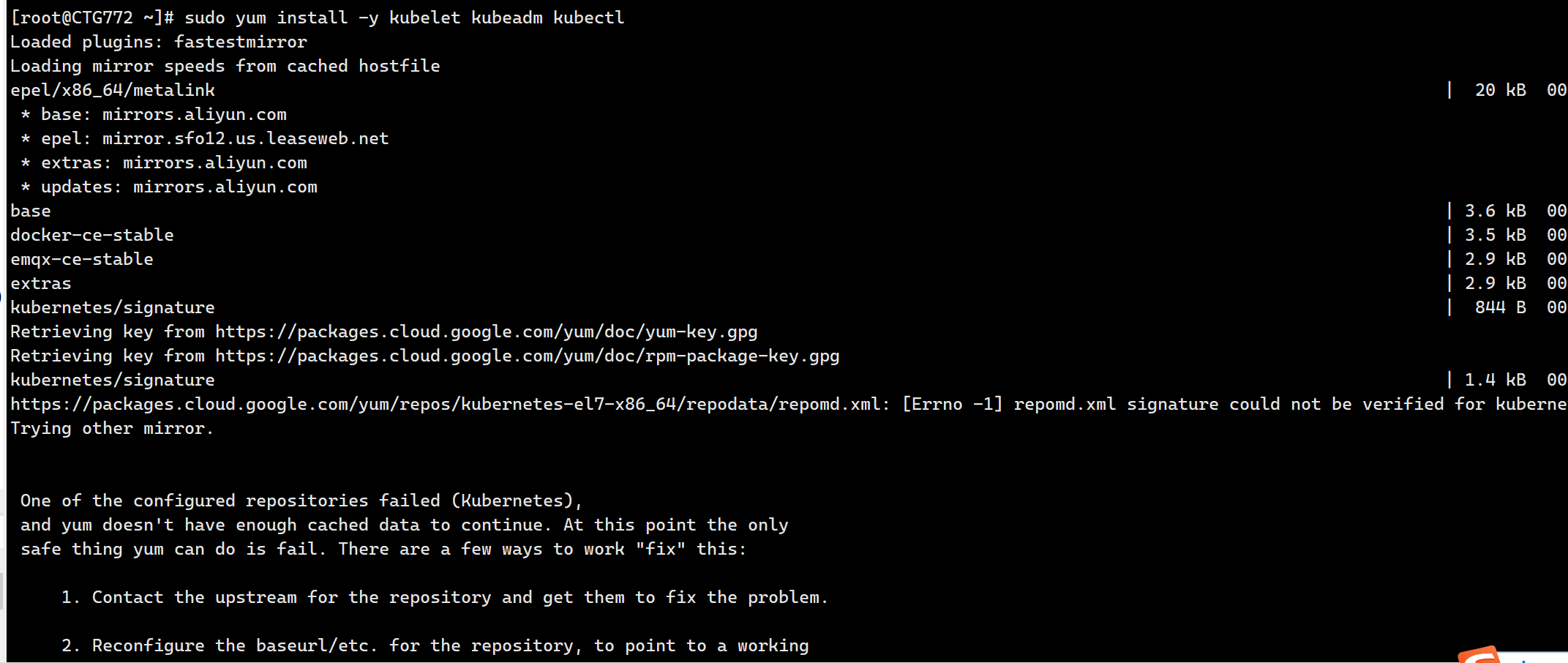
| How to install centos7? There has been an error. | https://api.github.com/repos/kubernetes/kubernetes/issues/110449/comments | 5 | 2022-06-08T08:50:42Z | 2022-06-14T16:37:25Z | https://github.com/kubernetes/kubernetes/issues/110449 | 1,264,411,892 | 110,449 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add username option for the `kubectl exec ... ` command i.e `kubectl exec -u <user> ..`
### Why is this needed?
Its required to address issues listed below :
https://github.com/containerd/containerd/issues/6662
https://github.com/kubernetes/kubernetes/issues/30656... | To add username option for kubectl exec command and CRI update | https://api.github.com/repos/kubernetes/kubernetes/issues/110447/comments | 3 | 2022-06-08T07:42:01Z | 2022-06-08T11:39:22Z | https://github.com/kubernetes/kubernetes/issues/110447 | 1,264,332,221 | 110,447 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1.When I set hostport and hostnetwork at the same time, the hostport fails.
2.---vim test-hostport.yaml
```
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: test-hostport
name: test-hostport
spec:
hostNetwork: true
containers:
- image: nginx
... | hostPort failed in pod | https://api.github.com/repos/kubernetes/kubernetes/issues/110445/comments | 10 | 2022-06-08T03:53:57Z | 2022-06-09T09:31:08Z | https://github.com/kubernetes/kubernetes/issues/110445 | 1,264,153,596 | 110,445 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I debug the scheduler code, I found that the code can't step over from this line `cc.InformerFactory.WaitForCacheSync(ctx.Done())`.
The console window repeat reporting `failed to list *v1.CSISto rageCapacity: the server could not find the requested resource` , as shown below:
![14a35b552bd689... | debug kube-scheduler error | https://api.github.com/repos/kubernetes/kubernetes/issues/110444/comments | 5 | 2022-06-08T03:08:16Z | 2022-06-15T11:49:17Z | https://github.com/kubernetes/kubernetes/issues/110444 | 1,264,126,649 | 110,444 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
https://testgrid.k8s.io/sig-node-cos#e2e-cos-reboot
### Which tests are flaking?
Multiple tests:
Kubernetes e2e suite.[sig-cloud-provider-gcp] Reboot [Disruptive] [Feature:Reboot] each node by ordering unclean reboot and ensure they function upon restart: https://prow.k8s.io/view/gs/ku... | ci-cri-containerd-e2e-cos-gce-reboot is flaky | https://api.github.com/repos/kubernetes/kubernetes/issues/110440/comments | 8 | 2022-06-07T21:47:29Z | 2023-03-07T12:29:07Z | https://github.com/kubernetes/kubernetes/issues/110440 | 1,263,915,056 | 110,440 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-kubelet#kubelet-gce-e2e-lock-contention
### Which tests are failing?
E2eNode Suite.[sig-node] Lock contention [Slow] [Disruptive] [NodeSpecialFeature:LockContention] Kubelet should stop when the test acquires the lock on lock file and restart once the lock... | .[sig-node] Lock contention [Slow] [Disruptive] [NodeSpecialFeature:LockContention] Kubelet should stop when the test acquires the lock on lock file and restart once the lock is released | https://api.github.com/repos/kubernetes/kubernetes/issues/110439/comments | 3 | 2022-06-07T21:32:22Z | 2022-06-11T00:14:10Z | https://github.com/kubernetes/kubernetes/issues/110439 | 1,263,897,782 | 110,439 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When running `framework.ConformanceIt("should provide DNS for the cluster ")` test case, the test is unable to read the result, but the final ginkgo result is passed.
```
STEP: creating a pod to probe DNS
STEP: submitting the pod to kubernetes
STEP: retrieving the pod
STEP: looking for the ... | DNS E2E Test: dns test cmd failed but the case succeeded | https://api.github.com/repos/kubernetes/kubernetes/issues/110438/comments | 4 | 2022-06-07T21:00:43Z | 2022-06-07T21:59:49Z | https://github.com/kubernetes/kubernetes/issues/110438 | 1,263,861,237 | 110,438 |
[
"kubernetes",
"kubernetes"
] | GA blocker (https://github.com/kubernetes/enhancements/issues/2579)
/sig auth
/milestone v1.25
/help | [PodSecurity] Add v1 config API (pod-security.admission.config.k8s.io) | https://api.github.com/repos/kubernetes/kubernetes/issues/110437/comments | 3 | 2022-06-07T20:36:13Z | 2022-06-15T21:41:22Z | https://github.com/kubernetes/kubernetes/issues/110437 | 1,263,838,845 | 110,437 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I use fake client to create and modify simulated resources.When the amount of data is large and changes frequently, it will cause the program to panic.
<img width="1182" alt="截屏2022-06-08 上午12 33 31" src="https://user-images.githubusercontent.com/32294838/172434844-6f57370f-b265-4... | Because of using fake client The program panics with "channel full" | https://api.github.com/repos/kubernetes/kubernetes/issues/110431/comments | 6 | 2022-06-07T16:42:49Z | 2022-11-12T17:08:47Z | https://github.com/kubernetes/kubernetes/issues/110431 | 1,263,582,967 | 110,431 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A cronjob with correct values in `spec.failedJobsHistoryLimit` and `spec.successfulJobsHistoryLimit` is cleaning up the jobs objects once those are completed or failed, if those are scheduled objects.
When the job is created using
```
kubectl create job --from=cronjob/cronjob-name test-run-1
... | job objects are not getting clean-up when Job is created using kubectl create job | https://api.github.com/repos/kubernetes/kubernetes/issues/110430/comments | 10 | 2022-06-07T14:49:59Z | 2022-06-14T02:16:19Z | https://github.com/kubernetes/kubernetes/issues/110430 | 1,263,429,268 | 110,430 |
[
"kubernetes",
"kubernetes"
] | /sig node
/kind cleanup
Today we don't really have a way to test what happens when a CRI or gRPC fails. This makes it hard to identify, reproduce, and fix issues that happen when a CRI has a problem (such as the CRI restarting at the wrong part of a control loop).
We need to do some research and basic setup of t... | kubelet: Setup testing infrastructure to test CRI invariants | https://api.github.com/repos/kubernetes/kubernetes/issues/110429/comments | 6 | 2022-06-07T14:39:10Z | 2022-11-06T02:53:32Z | https://github.com/kubernetes/kubernetes/issues/110429 | 1,263,413,917 | 110,429 |
[
"kubernetes",
"kubernetes"
] | /sig node
/kind documentation
There are a handful of things that can cause the Kubelet to fail, where the Kubelet doesn't have strong defense against them. We should document these cases and be open about where they exist.
As an example:
- IO Contention
- Slow disk accounting
- Memory exhaustion
/cc @derek... | kubelet: Document out of scope causes of failure | https://api.github.com/repos/kubernetes/kubernetes/issues/110428/comments | 4 | 2022-06-07T14:29:06Z | 2024-01-18T23:58:53Z | https://github.com/kubernetes/kubernetes/issues/110428 | 1,263,399,541 | 110,428 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I created a cluster role with verb "list" and resource "node" and assigned it to a user. If the user runs the command <code>kubectl get nodes <node_name> -o yaml</code>, it fails, rightly so. If instead he runs the command <code>kubectl get nodes -o yaml</code> it receives as output the yaml of th... | Excess of permissions when granting permission to list nodes | https://api.github.com/repos/kubernetes/kubernetes/issues/110426/comments | 9 | 2022-06-07T13:09:40Z | 2022-10-17T15:42:10Z | https://github.com/kubernetes/kubernetes/issues/110426 | 1,263,274,728 | 110,426 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After I evicted an pod, I performed the operation of the full list instance, but found something that did not meet expectations
```
item[0]: can't assign or convert v1beta1.Eviction into v1.Pod
```
### What did you expect to happen?
After pods are evicted, non-evicted ones can be listed normall... | FakeClient: list pod err after an pod evicted | https://api.github.com/repos/kubernetes/kubernetes/issues/110424/comments | 7 | 2022-06-07T12:19:31Z | 2022-06-22T22:55:43Z | https://github.com/kubernetes/kubernetes/issues/110424 | 1,263,203,099 | 110,424 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In some scenarios, we don't want to use kubelet-initial eviction to evict pods, we use our private enhanced eviction component, but we still want kubelet to set node pressure conditions while we have a nodefs pressure or others. so if the disk is full, the node has diskpressure con... | Separate the functions of evcit pods and set node pressure condition | https://api.github.com/repos/kubernetes/kubernetes/issues/110412/comments | 10 | 2022-06-07T02:41:36Z | 2022-11-05T05:43:32Z | https://github.com/kubernetes/kubernetes/issues/110412 | 1,262,647,329 | 110,412 |
[
"kubernetes",
"kubernetes"
] | ## Summary
The existing validating webhook PKI configurations fail on Kubernetes v1.24 due to https://go.dev/doc/go1.18#sha1.
Pod security webhook `tls.crt` information example:
```
** CERTIFICATE 1 **
Input Format: PEM
Serial: 15867037602852614424
Valid: 2022-06-07 01:09 UTC to 2024-06-06 01:09 UTC
Sign... | Validating Webhook PKI Configurations Fail on v1.24 | https://api.github.com/repos/kubernetes/kubernetes/issues/110530/comments | 6 | 2022-06-07T00:49:03Z | 2022-06-15T16:40:16Z | https://github.com/kubernetes/kubernetes/issues/110530 | 1,268,811,939 | 110,530 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When running `kubectl logs -f`, I get the following log
```
http: superfluous response.WriteHeader call from k8s.io/kubernetes/vendor/github.com/emicklei/go-restful.(*Response).WriteHeader (response.go:220)
```
### What did you expect to happen?
No error/warning
### How can we reproduc... | "superfluous response.WriteHeader call" when using "kubectl logs -f" | https://api.github.com/repos/kubernetes/kubernetes/issues/110409/comments | 8 | 2022-06-06T21:01:19Z | 2022-06-15T17:39:17Z | https://github.com/kubernetes/kubernetes/issues/110409 | 1,262,418,315 | 110,409 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This page explains that the deleteFromPrimitiveList should delete the specified items, but the specified items are kept, and the other items are deleted.
https://github.com/kubernetes/community/blob/master/contributors/devel/sig-api-machinery/strategic-merge-patch.md#deletefromprimitivelist-direc... | $deleteFromPrimitiveList keeps elements instead of removing them | https://api.github.com/repos/kubernetes/kubernetes/issues/110407/comments | 11 | 2022-06-06T19:19:15Z | 2023-05-01T19:30:13Z | https://github.com/kubernetes/kubernetes/issues/110407 | 1,262,274,901 | 110,407 |
[
"kubernetes",
"kubernetes"
] | **This is a Bug Report**
<!-- Thanks for filing an issue! Before submitting, please fill in the following information. -->
<!-- See https://kubernetes.io/docs/contribute/start/ for guidance on writing an actionable issue description. -->
<!--Required Information-->
**Problem:**
https://kubernetes.io/docs/ref... | Graduate APIListChunking to stable | https://api.github.com/repos/kubernetes/kubernetes/issues/110415/comments | 8 | 2022-06-06T13:41:16Z | 2022-06-13T00:36:17Z | https://github.com/kubernetes/kubernetes/issues/110415 | 1,262,860,617 | 110,415 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. create statefulset with one pod, and set the terminationGracePeriodSeconds to 0, pod is running on node-1
2. shutdown node-1, after 5 min, new pod will be created and scheduled on node-2
3. shutdown node-2, we get the message of kube-controller-manager "Trying to add already existing work for... | statefulset pod with zero terminationGracePeriodSeconds miss termination when shutdown node | https://api.github.com/repos/kubernetes/kubernetes/issues/110401/comments | 10 | 2022-06-06T09:31:37Z | 2022-11-06T07:57:33Z | https://github.com/kubernetes/kubernetes/issues/110401 | 1,261,596,137 | 110,401 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1 shutdown node
2 pod which created by ReplicaSet controller schedulerd on node which had shutdown
**the pod has toleration `Exists:NoSchedule`**
### What did you expect to happen?
pod should not scheduler on shutdown node even if has toleration
### How can we reproduce it (as minimally a... | deployment with NoScheduler toleration schedulered on NotReady node | https://api.github.com/repos/kubernetes/kubernetes/issues/110396/comments | 5 | 2022-06-06T06:33:39Z | 2022-06-13T03:40:58Z | https://github.com/kubernetes/kubernetes/issues/110396 | 1,261,414,847 | 110,396 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am trying to set up k8s on a fresh installed CentOS 7.9. The background was that I met an issue with the latest flannel in the first place. I opened an issue at flannel community and confirmed was a compatibility issue on netlink interface and can be resolved by rolling back flannel from 0.18 ... | coredns stuck at 'ContainerCreating' | https://api.github.com/repos/kubernetes/kubernetes/issues/110393/comments | 7 | 2022-06-06T01:50:05Z | 2022-06-06T16:39:10Z | https://github.com/kubernetes/kubernetes/issues/110393 | 1,261,244,621 | 110,393 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm trying to configure a new nodes server and when I try to join the server to the master the following error appears:
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="20... | Can't start Kubelet with error transport: Error while dialing dial unix /var/run/containerd/containerd.sock: connect: no such file or directory\ | https://api.github.com/repos/kubernetes/kubernetes/issues/110383/comments | 12 | 2022-06-04T16:10:54Z | 2024-12-24T10:40:51Z | https://github.com/kubernetes/kubernetes/issues/110383 | 1,260,827,941 | 110,383 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Current output from `framework.ExpectNoError` (after https://github.com/kubernetes/kubernetes/pull/109828)
```
INFO: Unexpected error: hard-coded error:
<*errors.errorString>: {
s: "an error with a long, useless description",
}
FAIL: hard-coded error: an ... | enhance E2E failure handling | https://api.github.com/repos/kubernetes/kubernetes/issues/110381/comments | 8 | 2022-06-04T07:51:58Z | 2025-01-18T16:07:12Z | https://github.com/kubernetes/kubernetes/issues/110381 | 1,260,677,988 | 110,381 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Looking at [this page](https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke) which describes using the changes coming with 1.25 and the introduction of the GKE cloud auth plugin, I am surprised to find that the plugin exists for the debian bullseye distro for am... | google-cloud-sdk-gke-gcloud-auth-plugin not available for bullseye arm64 | https://api.github.com/repos/kubernetes/kubernetes/issues/110380/comments | 4 | 2022-06-03T20:33:18Z | 2022-06-06T14:44:31Z | https://github.com/kubernetes/kubernetes/issues/110380 | 1,260,350,214 | 110,380 |
[
"kubernetes",
"kubernetes"
] | I found that the function `NewListWatchFromClient` of `k/staging/src/k8s.io/client-go/tools/cache/listwatch.go` returns a pointer of `ListWatch`.
```go
func NewListWatchFromClient(c Getter, resource string, namespace string, fieldSelector fields.Selector) *ListWatch {
optionsModifier := func(options *metav1.ListO... | How about modifying the function `NewListWatchFromClient` to return the value type? | https://api.github.com/repos/kubernetes/kubernetes/issues/110373/comments | 4 | 2022-06-03T16:19:31Z | 2022-06-07T20:13:35Z | https://github.com/kubernetes/kubernetes/issues/110373 | 1,260,113,036 | 110,373 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
- sig-release master-blocking build-master
### Which tests are failing?
- ci-kubernetes-build.Overall
### Since when has it been failing?
2022-06-01 20:49 CEST, commit `22fda4e7e`
### Testgrid link
https://testgrid.k8s.io/sig-release-master-blocking#build-master
### Reason for failur... | [Failing test] master-blocking build-master, push container images failed | https://api.github.com/repos/kubernetes/kubernetes/issues/110369/comments | 10 | 2022-06-03T08:55:04Z | 2022-06-07T07:30:54Z | https://github.com/kubernetes/kubernetes/issues/110369 | 1,259,644,545 | 110,369 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
the kubelet does not add the 'domain' setting from resolv.conf into pods spawned on nodes that include that setting. at the OS level, the 'domain' setting of resolv.conf will be used as the first search domain for dns resolution and I believe this should be expected behaviour inside of pods schedule... | add resolv.conf domain settings to injected search domains | https://api.github.com/repos/kubernetes/kubernetes/issues/110357/comments | 10 | 2022-06-02T15:05:41Z | 2022-07-07T19:02:48Z | https://github.com/kubernetes/kubernetes/issues/110357 | 1,258,310,873 | 110,357 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Upgrade went well but kubelet failed to start on the kubernetes node with the following error:
```
[root@k8s-master ~]# systemctl status kubelet.service
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: di... | [Upgrade] kubelet failed to start after kubernetes master node upgrade from v1.23.7 to v1.24.1 | https://api.github.com/repos/kubernetes/kubernetes/issues/110352/comments | 5 | 2022-06-02T14:12:49Z | 2024-12-23T14:19:09Z | https://github.com/kubernetes/kubernetes/issues/110352 | 1,258,244,727 | 110,352 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubelet in 1.23 crashes on 32bit arm architectures (https://github.com/kubernetes/kubernetes/issues/106977). 1.24 has a fix for it, howewer 1.23 still does not. And upgrade procedure is to upgrade from 1.22 to 1.23, then from 1.23 to 1.24, which is now impossible.
### What did you expect to happen?... | Cannot upgrade 32bit nodes from 1.22 to 1.24 | https://api.github.com/repos/kubernetes/kubernetes/issues/110342/comments | 7 | 2022-06-02T10:50:21Z | 2022-10-03T21:34:31Z | https://github.com/kubernetes/kubernetes/issues/110342 | 1,258,016,947 | 110,342 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
During scale testing, as sig-scalability, we observed that node-lifecycle-controller (https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/nodelifecycle/node_lifecycle_controller.go) was unable to process nodes in reasonable time due to lock contention.
Example log:
```
2022-04... | Node lifecycle controller makes api calls under lock | https://api.github.com/repos/kubernetes/kubernetes/issues/110341/comments | 9 | 2022-06-02T10:46:47Z | 2022-09-16T14:06:54Z | https://github.com/kubernetes/kubernetes/issues/110341 | 1,258,013,438 | 110,341 |
[
"kubernetes",
"kubernetes"
] | The test https://testgrid.k8s.io/sig-node-presubmits#pr-kubelet-gce-e2e-swap-fedora-serial fails to start
/priority important-soon
/sig node
/area test
/kind failing-test | pr-kubelet-gce-e2e-swap-fedora-serial fail to run | https://api.github.com/repos/kubernetes/kubernetes/issues/110340/comments | 7 | 2022-06-01T20:25:25Z | 2022-06-05T20:27:37Z | https://github.com/kubernetes/kubernetes/issues/110340 | 1,256,959,658 | 110,340 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [4482c2b4cf127b8c4ebe](https://go.k8s.io/triage#4482c2b4cf127b8c4ebe)
##### Error text:
```
test/e2e/framework/framework.go:647
May 27 19:00:53.684: Unexpected error:
<*pod.timeoutError | 0xc0033572e0>: {
msg: "timed out while waiting for pod pods-6773/server-envvars-673b9176-ce7... | [windows] Failure cluster [4482c2b4...] [sig-node] Pods should contain environment variables for services | https://api.github.com/repos/kubernetes/kubernetes/issues/110339/comments | 4 | 2022-06-01T19:55:52Z | 2022-06-14T23:53:53Z | https://github.com/kubernetes/kubernetes/issues/110339 | 1,256,902,449 | 110,339 |
[
"kubernetes",
"kubernetes"
] | There is a vulnerability shown by this library in Snyk which has now been fixed. Any chance we can update the client-go library to include this fix in its go.mod ?
Snyk vulnerability: https://security.snyk.io/vuln/SNYK-GOLANG-GITHUBCOMEMICKLEIGORESTFUL-2435653
Commit with the fix: https://github.com/emicklei/go-rest... | Vulnerability in github.com/emicklei/go-restful library | https://api.github.com/repos/kubernetes/kubernetes/issues/110338/comments | 9 | 2022-06-01T19:20:17Z | 2022-09-06T16:22:06Z | https://github.com/kubernetes/kubernetes/issues/110338 | 1,256,892,127 | 110,338 |
[
"kubernetes",
"kubernetes"
] | This issue is a bucket placeholder for collaborating on the "Known Issues" additions for the 1.25 Release Notes. If you know of issues or API changes that are going out in 1.25, please comment here so that we can coordinate incorporating information about these changes in the Release Notes.
/assign @csantanapr @orse... | 1.25 Release Notes: "Known Issues" | https://api.github.com/repos/kubernetes/kubernetes/issues/110336/comments | 5 | 2022-06-01T18:53:15Z | 2022-08-19T16:03:50Z | https://github.com/kubernetes/kubernetes/issues/110336 | 1,256,779,211 | 110,336 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Opening this issue based on what I ran into on https://github.com/kubernetes/kubernetes/pull/110294#discussion_r886843349
```bash
E0601 21:22:15.099248 21036 event.go:267] Server rejected event '&v1.Event{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"foobar.16f... | FakeEvents Fails to work with Namespaced `InvolvedObject` when Sink is created with `""` namepsace | https://api.github.com/repos/kubernetes/kubernetes/issues/110335/comments | 4 | 2022-06-01T18:46:22Z | 2022-07-19T02:52:13Z | https://github.com/kubernetes/kubernetes/issues/110335 | 1,256,762,275 | 110,335 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
### I'm trying to setup my k8s cluster Windows worker node on a workstation PC with docker as container runtime. However, my pod is always failed with status CreateContainerError. Steps I followed to setup windows node:
1. Install Docker: [https://docs.microsoft.com/en-us/virtualization/windowsco... | Windows nodes pod CreateContainerError with "invalid mount config for type "bind": source path must be a directory" | https://api.github.com/repos/kubernetes/kubernetes/issues/110325/comments | 15 | 2022-06-01T08:57:21Z | 2022-11-27T20:42:10Z | https://github.com/kubernetes/kubernetes/issues/110325 | 1,255,419,983 | 110,325 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Can we add the sync-period configurable in every hpa? may be can pass by using annotation. If not passing this variable can using the controller default one.
### Why is this needed?
Current `horizontal-pod-autoscaler-sync-period` is controller level config. In our environment, so... | supporting horizontal-pod-autoscaler-sync-period configuration per hpa resource | https://api.github.com/repos/kubernetes/kubernetes/issues/110317/comments | 11 | 2022-06-01T04:02:31Z | 2023-03-27T12:22:07Z | https://github.com/kubernetes/kubernetes/issues/110317 | 1,254,867,260 | 110,317 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
When aggregator routing is enabled, kube-apiserver creates a direct connection to one of the webhook service endpoints for admission webhooks configured through services. The address and port of the selected endpoint can be added as a tag to the apiserver_admission_webhook_admissio... | Add endpoint tag to apiserver_admission_webhook_admission_* metrics | https://api.github.com/repos/kubernetes/kubernetes/issues/110315/comments | 14 | 2022-06-01T03:18:54Z | 2022-12-22T10:18:17Z | https://github.com/kubernetes/kubernetes/issues/110315 | 1,254,801,149 | 110,315 |
[
"kubernetes",
"kubernetes"
] | In tests and here:
https://github.com/kubernetes/kubernetes/blob/62d9f8ba80f4cc660a88dcc34f56c5c6f7df17ea/cluster/gce/gci/configure-helper.sh#L3086-L3091 containerd config is using deprecated way configuring mirrors. Need to switch to the hosts.toml based approach.
/kind cleanup
/sig node
/area test | registry.mirrors conainerd config is deprecated, need to move to hosts.toml based config | https://api.github.com/repos/kubernetes/kubernetes/issues/110312/comments | 15 | 2022-05-31T23:08:25Z | 2022-11-18T13:22:21Z | https://github.com/kubernetes/kubernetes/issues/110312 | 1,254,501,429 | 110,312 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubelet probes are stopped during pod termination. Readiness probes should run during termination to allow for load balancers and other controllers to observe the pod shutting down, so the pod is removed from various endpoints and services.
### What did you expect to happen?
I expect readiness pro... | Kubelet Readiness Probes do not run during pod termination | https://api.github.com/repos/kubernetes/kubernetes/issues/110309/comments | 5 | 2022-05-31T16:01:14Z | 2022-06-07T19:30:07Z | https://github.com/kubernetes/kubernetes/issues/110309 | 1,254,082,090 | 110,309 |
[
"kubernetes",
"kubernetes"
] | Please add a way to debug why pod have `Init: CrashLoopBackOff`. For now if we have this error and try to find the reason of error we have:
```
Error from server (BadRequest): container <container> in pod <pod> is waiting to start: PodInitializing
```
So we can't get logs because there is error on the start and we ... | Add means to fetch container logs when init container fails | https://api.github.com/repos/kubernetes/kubernetes/issues/110789/comments | 10 | 2022-05-31T14:56:08Z | 2022-11-23T00:48:10Z | https://github.com/kubernetes/kubernetes/issues/110789 | 1,284,741,575 | 110,789 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
pod failed to pass topologymanager Admit function
<img width="764" alt="image" src="https://user-images.githubusercontent.com/27884109/171174950-c5ef379a-8bf8-4e88-9535-efe49b650345.png">
### What did you expect to happen?
pod success to start
### How can we reproduce it (as minimally a... | Pod with initcontainer runs into `TopologyAffinityError` | https://api.github.com/repos/kubernetes/kubernetes/issues/110306/comments | 9 | 2022-05-31T12:56:46Z | 2022-06-01T17:59:25Z | https://github.com/kubernetes/kubernetes/issues/110306 | 1,253,829,700 | 110,306 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
By setting service.spec.sessionAffinity to "ClientIP", connections from a particular client are passed to the same Pod each time when accessing a Service.
When the Pod that the client continuously accesses becomes not ready, the client will still access the NotReady Pod because of the iptables rule... | Service with session affinity cannot isolate the fault appropriately | https://api.github.com/repos/kubernetes/kubernetes/issues/110302/comments | 13 | 2022-05-31T08:51:37Z | 2022-11-26T03:29:16Z | https://github.com/kubernetes/kubernetes/issues/110302 | 1,253,546,998 | 110,302 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When the last endpoint of a service is removed or goes unhealthy, kube-proxy (in iptables mode) does not clean it properly from iptables. The following output shows the iptables state with an nginx deployment with 1 pod, then the output after the removal, despite empty endpoints/endpointslices lists... | kube-proxy with endpoint config controller does not propely handle the last endpoint leaving | https://api.github.com/repos/kubernetes/kubernetes/issues/110301/comments | 8 | 2022-05-31T08:46:52Z | 2022-06-09T16:19:32Z | https://github.com/kubernetes/kubernetes/issues/110301 | 1,253,541,418 | 110,301 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have two issues with my kubernetes.
kubernetes version 1.12.5, ubuntu16.04
the first issue is
Occasionally, containers on a specific node are restarted including kube-proxy
```
kernel: IPVS: rr TCP - no destination available
IPVS: __ip_vs_del_service:enter
net_ratelimit: callbacks suppres... | kube-proxy, kube-dns issue | https://api.github.com/repos/kubernetes/kubernetes/issues/110299/comments | 6 | 2022-05-31T08:14:00Z | 2022-06-01T14:46:21Z | https://github.com/kubernetes/kubernetes/issues/110299 | 1,253,495,603 | 110,299 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I deployed kubenetes GitVersion:"v1.24.1" in my master node, and the same steps in one slave node. also I installed calico and cri-dockerd for it.
I still deployed a set of test pod nginx:latest.
But I can only ping podIP and get pod service from slave node, I can never ping podIP and get nginx... | I can't get ping my pod in master, but it work well in my slave node | https://api.github.com/repos/kubernetes/kubernetes/issues/110298/comments | 4 | 2022-05-31T06:48:53Z | 2022-05-31T07:42:51Z | https://github.com/kubernetes/kubernetes/issues/110298 | 1,253,407,894 | 110,298 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I config kubeReservedCgroup and kubeReserved in config.yaml for kube daemon.Kubelet can not start with the following errors:
```
vim /var/lib/kubelet/config.yaml
......
kind: KubeletConfiguration
enforceNodeAllocatable:
- pods
- kube-reserved
kubeReserved:
cpu: 1500m
memory... | kubelet failed start after config kubeReservedCgroup | https://api.github.com/repos/kubernetes/kubernetes/issues/110288/comments | 19 | 2022-05-30T14:20:31Z | 2022-08-30T03:15:59Z | https://github.com/kubernetes/kubernetes/issues/110288 | 1,252,808,665 | 110,288 |
[
"kubernetes",
"kubernetes"
] | The liveness probe execution can fail in various ways like:
1. non-zero exit code returned by container,
2. or timeout,
3. or due to an infrastructure error due to which no connection to the container was made though the container itself was healthy.
Do all failures count against the container's threshold?
If... | Does Liveness Probe distinguish between error conditions? | https://api.github.com/repos/kubernetes/kubernetes/issues/110282/comments | 9 | 2022-05-29T18:20:20Z | 2022-10-27T23:13:20Z | https://github.com/kubernetes/kubernetes/issues/110282 | 1,251,957,774 | 110,282 |
[
"kubernetes",
"kubernetes"
] | /kind bug
**1. What `kops` version are you running? The command `kops version`, will display
this information.**
1.22.0
**2. What Kubernetes version are you running? `kubectl version` will print the
version if a cluster is running or provide the Kubernetes version specified as
1.22.3
a `kops` flag.**
**3... | AWS Classic ELB is created with irrelevant AZs | https://api.github.com/repos/kubernetes/kubernetes/issues/110281/comments | 7 | 2022-05-29T13:35:56Z | 2022-06-13T08:02:45Z | https://github.com/kubernetes/kubernetes/issues/110281 | 1,251,891,424 | 110,281 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
[root@iZuf63u8n54i0xc42warcaZ ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6d56c8448f-5z5kp 0/1 ContainerCreating 0 29m
coredns-6d56c8448f-mldqr ... | pod kube-flannel-ds CrashLoopBackOff | https://api.github.com/repos/kubernetes/kubernetes/issues/110280/comments | 4 | 2022-05-29T12:57:37Z | 2022-05-29T14:53:00Z | https://github.com/kubernetes/kubernetes/issues/110280 | 1,251,882,320 | 110,280 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have an HPA object configured with external metrics and I set the minReplicas of HPA to 0. After a while, hpa scales the workload to 0 because it is below the metric threshold
Next, if I set minReplicas of HPA to 1, then the HPA controller will not do anything, and the ScalingActive condition b... | When replicas of workload is zero and the minReplicas of HPA is greather than zero, the rescale of HPA controller will not be triggered | https://api.github.com/repos/kubernetes/kubernetes/issues/110278/comments | 6 | 2022-05-29T08:22:06Z | 2022-10-14T16:26:25Z | https://github.com/kubernetes/kubernetes/issues/110278 | 1,251,823,601 | 110,278 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [0a9c68fac27bbc4ed445](https://go.k8s.io/triage#0a9c68fac27bbc4ed445)
##### Error text:
```
test/e2e/kubectl/kubectl.go:1110
May 18 00:52:40.234: unexpected nil error when creating CR with unknown root metadata field
vendor/github.com/onsi/ginkgo/internal/leafnodes/runner.go:113
```
#### Re... | Failure cluster [0a9c68fa...] | https://api.github.com/repos/kubernetes/kubernetes/issues/110271/comments | 4 | 2022-05-28T21:11:01Z | 2022-07-12T00:46:48Z | https://github.com/kubernetes/kubernetes/issues/110271 | 1,251,725,169 | 110,271 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [54e385e56e2496b17ff1](https://go.k8s.io/triage#54e385e56e2496b17ff1)
##### Error text:
```
test/e2e/kubectl/kubectl.go:1186
May 18 00:50:28.281: error missing unknown metadata field, got: error running /workspace/kubernetes/platforms/linux/amd64/kubectl --server=https://34.83.140.129 --kubeco... | Failure cluster [54e385e5...] | https://api.github.com/repos/kubernetes/kubernetes/issues/110270/comments | 2 | 2022-05-28T21:03:44Z | 2022-06-10T16:41:45Z | https://github.com/kubernetes/kubernetes/issues/110270 | 1,251,723,946 | 110,270 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to use `kubectl auth can-i` to check whether I have cluster scope resource permission or not.
there is the command `kubectl auth can-i delete tenant test`
error output:
```
error: you must specify two or three arguments: verb, resource, and optional resourceName
``
the error message ma... | auth can-i error message making confuse | https://api.github.com/repos/kubernetes/kubernetes/issues/110265/comments | 7 | 2022-05-28T17:26:37Z | 2022-09-12T19:57:43Z | https://github.com/kubernetes/kubernetes/issues/110265 | 1,251,684,309 | 110,265 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I just using fuzzing discovered a crash when k8s parsing the api,I don't know if it will affect the usability of K8s,So I submit the rel
evant crash information and files to you, I hope it will be useful to you,[fuzz_api_marshaling.zip](https://github.com/kubernetes/kubernetes/files/8790589/fuzz_ap... | Crash when kubernetes parsing api | https://api.github.com/repos/kubernetes/kubernetes/issues/110262/comments | 5 | 2022-05-28T05:56:33Z | 2022-06-01T14:50:12Z | https://github.com/kubernetes/kubernetes/issues/110262 | 1,251,485,849 | 110,262 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Curling `https://<Node-IP>:10250/stats/summary` for a Windows node returns the wrong usage and capacity bytes for a `azurefile-csi` PVC used by a Windows pod on that node:
```
"pods": [
{
"podRef": {
"name": "win-webserver-5d5d4966f5-zrcf6",
"namespace": "default",
"uid": "4... | PVC usage metrics incorrect in /stats/summary kubelet endpoint for Windows Azure Files | https://api.github.com/repos/kubernetes/kubernetes/issues/110261/comments | 28 | 2022-05-27T23:56:26Z | 2023-08-16T06:10:26Z | https://github.com/kubernetes/kubernetes/issues/110261 | 1,251,369,972 | 110,261 |
[
"kubernetes",
"kubernetes"
] | In `k8s.io/apiserver/pkg/endpoints/installer.go`:
```go
(a *APIInstaller) registerResourceHandlers(path string, storage rest.Storage, ws *restful.WebService) {
...
for _, action := range actions {
...
routes := []*restful.RouteBuilder{}
...
switch action.Verb {
c... | Unnecessary for-loop in apiserver routes installer | https://api.github.com/repos/kubernetes/kubernetes/issues/110254/comments | 10 | 2022-05-27T14:14:12Z | 2022-10-31T03:43:09Z | https://github.com/kubernetes/kubernetes/issues/110254 | 1,250,820,257 | 110,254 |
[
"kubernetes",
"kubernetes"
] | I am not sure if this is already a feature on not.
I want to build a YAML Validator at API - Server level.
If this seems like a good idea, I would like to work on it.
I have experienced at work that sometimes the cluster faces issues because the YAML applied had some issues.
This was the sole reason many services... | YAML verfier at API-Server | https://api.github.com/repos/kubernetes/kubernetes/issues/110248/comments | 14 | 2022-05-27T08:32:20Z | 2022-06-03T22:24:15Z | https://github.com/kubernetes/kubernetes/issues/110248 | 1,250,493,442 | 110,248 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Prior to 1.24.0 setting `spec.adctiveDeadlineSeconds` in a Job object (`batch/v1`) would kill the Job and Pods if they ran longer than the integer specified. I tested today with 1.24.0 and it's not working. The Job defined below (for testing) should be killed 10 seconds, but isn't. It's actually bei... | activeDeadlineSeconds not working correctly for Jobs in 1.24.0 | https://api.github.com/repos/kubernetes/kubernetes/issues/110239/comments | 16 | 2022-05-26T22:22:30Z | 2022-06-14T15:03:34Z | https://github.com/kubernetes/kubernetes/issues/110239 | 1,250,147,631 | 110,239 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When you update from 1.21 to 1.22, it seems like the kubernetes reconciler is partially reconciling resource.
### What did you expect to happen?
I expected the aggregate-to-edit clusterrole on a updated cluster to be the same as a freshly deployed one on the same version.
### How can we reproduce... | Reconciler for clusterrole not reconciling properly | https://api.github.com/repos/kubernetes/kubernetes/issues/110238/comments | 5 | 2022-05-26T21:13:26Z | 2022-05-29T19:32:14Z | https://github.com/kubernetes/kubernetes/issues/110238 | 1,250,096,879 | 110,238 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[6/6]</code>
- [X] APISnoop org-flow: [Corev1APIServiceLifecycleTest.org](https://github.com/apisnoop/ticket-writing/blob/master/Corev1APIServiceLifecycleTest.org)
- [X] Test approval issue: #110236
- [X] Test PR: #110237
- [x] Two weeks soak start date: [Testgrid](https://testgrid.k8s.i... | Write APIService lifecycle test + 4 Endpoints | https://api.github.com/repos/kubernetes/kubernetes/issues/110236/comments | 3 | 2022-05-26T18:38:31Z | 2022-07-21T22:21:36Z | https://github.com/kubernetes/kubernetes/issues/110236 | 1,249,913,963 | 110,236 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In the case of cross-nodes, the apiserver cannot be accessed using the ipv6 type cluster ip, and the tls connection cannot be established.
There are several situations:
- accessing http service is normal Whether on the same node or across nodes
- It is normal to access apiserver cluster ip direct... | The apiserver cannot be accessed using the ipv6 type cluster ip, and the tls connection cannot be established | https://api.github.com/repos/kubernetes/kubernetes/issues/110231/comments | 14 | 2022-05-26T15:28:02Z | 2022-06-01T06:36:05Z | https://github.com/kubernetes/kubernetes/issues/110231 | 1,249,719,446 | 110,231 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
add fuzz test in UT test
### Why is this needed?
1. Fuzzing can be a good way to find defects in the code
2. Go 1.18 merged support code for Fuzz testing,And Fuzzing Test is supported in this version
https://github.com/golang/go/commit/6e81f78c0f1653ea140e6c8d008700ddad1fa0a5 | add fuzz test in UT test | https://api.github.com/repos/kubernetes/kubernetes/issues/110226/comments | 6 | 2022-05-26T10:57:23Z | 2022-10-23T12:32:35Z | https://github.com/kubernetes/kubernetes/issues/110226 | 1,249,418,374 | 110,226 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Am running GKE cluster version 1.21.11-gke.1100. Every 5 minutes i get the below error:
`message: ""connection read failure" err="read tcp 10.68.0.7:42272->10.68.0.9:10250: use of closed network connection""`
This is from the `konnectivity-agent` deployment
### What did you expect to happen?
... | GKE - Konnectivity agent Connection close issue | https://api.github.com/repos/kubernetes/kubernetes/issues/110225/comments | 8 | 2022-05-26T09:29:00Z | 2022-06-22T23:59:50Z | https://github.com/kubernetes/kubernetes/issues/110225 | 1,249,326,164 | 110,225 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Multiple binary version was found in the official etcd docker images
k8s.gcr.io/etcd 3.5.1-0 25f8c7f3da61c 294MB
sh-5.1# pwd
/usr/bin
sh-5.1# etcd
etcd etcd-3.1.12 etcd-3.3.17 etcd-3.5.1 etcdctl-3.0.17 etcdctl-3.2.24 etc... | etcd image was too large | https://api.github.com/repos/kubernetes/kubernetes/issues/110224/comments | 4 | 2022-05-26T09:05:48Z | 2022-05-27T06:06:01Z | https://github.com/kubernetes/kubernetes/issues/110224 | 1,249,302,217 | 110,224 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I had tested on version 1.23.5 and 1.23.6, when I had ClusterRoleBing to ServiceAccount in Default namespace, everything went fine.
But if I want to put my service into another namespace, the service inside the pod will get "resolve failed" message like this
```
curl: (6) Could not resolve host: ... | Service account not working in none default namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/110217/comments | 6 | 2022-05-25T15:18:58Z | 2022-05-26T09:57:47Z | https://github.com/kubernetes/kubernetes/issues/110217 | 1,248,261,529 | 110,217 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The question is that I schedulered a pod that to a node. The node's topology policy is best-effort.The node has two numa nodes ,the information as follows
numa node1 memory:
capacity: 16000000000
available: 14000000000
numa node2 memory:
capacity: 16000000000
available: 14000000000
t... | I met unexpectedamissionedError when I used BestEffort which is kubelet's topology policy | https://api.github.com/repos/kubernetes/kubernetes/issues/110216/comments | 7 | 2022-05-25T14:31:09Z | 2022-06-16T06:06:57Z | https://github.com/kubernetes/kubernetes/issues/110216 | 1,248,189,473 | 110,216 |
[
"kubernetes",
"kubernetes"
] | We're currently (potentially) attaching the same etcd Lease to multiple objects based on the LeaseManager configuration:
https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/apiserver/pkg/storage/etcd3/lease_manager.go#L34
However, when the lease expires in etcd, all objects that are attached to ... | The current use of etcd Leases in Kubernetes violates the invariants needed for watch to function correctly | https://api.github.com/repos/kubernetes/kubernetes/issues/110210/comments | 26 | 2022-05-25T08:55:20Z | 2025-01-27T11:07:46Z | https://github.com/kubernetes/kubernetes/issues/110210 | 1,247,778,325 | 110,210 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
LoadBalancer&NodePort service cannot access after upgrade from 1.20 to 1.22.
The `NodeName` field in `v1.endpointslice.endpoint` missed.
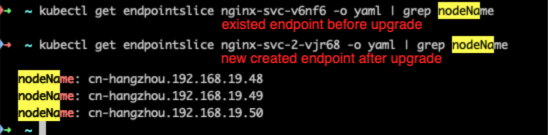
The convertion in apiserver emit the field `Top... | LoadBalancer&NodePort service cannot access after upgrade from 1.20 to 1.22 | https://api.github.com/repos/kubernetes/kubernetes/issues/110208/comments | 22 | 2022-05-25T08:38:21Z | 2022-10-11T07:49:28Z | https://github.com/kubernetes/kubernetes/issues/110208 | 1,247,757,998 | 110,208 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have a HorizontalPodAutoscaler configured on all of our fleet. The issue arises when we are scaling down, a node is being drained and a pod on that node is part of the `FC` service. We get around ten exceptions each time, Sentry reporting `AbortedException`s in FC and `CompletionException`s wit... | Kubernetes sending traffic to draining nodes | https://api.github.com/repos/kubernetes/kubernetes/issues/110195/comments | 11 | 2022-05-24T14:50:57Z | 2024-04-25T09:32:41Z | https://github.com/kubernetes/kubernetes/issues/110195 | 1,246,680,386 | 110,195 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.