
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### What happened?
After upgrading to 1.20v , while pods trying to update itself during rolling restart after release, it gets stuck at init state itself for forever. while checking the event logs we see below events. Althought we checked volume is already present and attached on host. And when we deleted the pods it... | UnmountDevice failed for volume (pvc-123d45c6-78ee-90c1-9d7e-f028843dfgs0dh) | https://api.github.com/repos/kubernetes/kubernetes/issues/110189/comments | 7 | 2022-05-24T10:59:16Z | 2022-10-22T17:22:34Z | https://github.com/kubernetes/kubernetes/issues/110189 | 1,246,368,424 | 110,189 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently only a not documented set of fields can be used with FieldSelector https://hoelz.ro/blog/which-fields-can-you-use-with-kubernetes-field-selectors
When considering custom resources, could we add a way to extend the set to fields defined in the custom reource?
### Why i... | FieldSelector extended for Custom resource fields | https://api.github.com/repos/kubernetes/kubernetes/issues/110188/comments | 6 | 2022-05-24T09:35:33Z | 2022-05-24T20:17:18Z | https://github.com/kubernetes/kubernetes/issues/110188 | 1,246,271,687 | 110,188 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Unit test that will ensure that Cluster Autoscaler objects that currently implement interfaces from https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler/framework/listers.go stay that way. It would suffice to do add compile-time checks for the following types:
- [Bas... | Prevent scheduler framework changes from breaking Cluster Autoscaler | https://api.github.com/repos/kubernetes/kubernetes/issues/110186/comments | 21 | 2022-05-24T07:56:21Z | 2022-08-23T23:04:56Z | https://github.com/kubernetes/kubernetes/issues/110186 | 1,246,135,683 | 110,186 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Sandbox containers are left on the container runtime (dockershim) and a large number of them are causing problems with the container runtime and the systems that reference the running containers.
As far as we have confirmed, the following combinations may or may not cause this problem.
|Kubern... | sandbox(pause) containers remain undeleted | https://api.github.com/repos/kubernetes/kubernetes/issues/110181/comments | 11 | 2022-05-24T02:55:24Z | 2022-07-26T13:58:59Z | https://github.com/kubernetes/kubernetes/issues/110181 | 1,245,911,521 | 110,181 |
[
"kubernetes",
"kubernetes"
] | ## Found vulnerability ([SNYK-GOLANG-GITHUBCOMDGRIJALVAJWTGO-596515](https://security.snyk.io/vuln/SNYK-GOLANG-GITHUBCOMDGRIJALVAJWTGO-596515))
[github.com/spf13/cobra](https://github.com/spf13/cobra) `v1.1.3` uses [github.com/dgrijalva/jwt-go](https://github.com/dgrijalva/jwt-go) which is affected by [a known vulne... | Outdated modules that contain vulnerabilities | https://api.github.com/repos/kubernetes/kubernetes/issues/110344/comments | 6 | 2022-05-24T00:46:38Z | 2022-09-24T17:51:49Z | https://github.com/kubernetes/kubernetes/issues/110344 | 1,258,118,679 | 110,344 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When installing a master node under Ubuntu jammy, the base kube-system pods (etcd, kube-apiserver, kube-proxy...) restarts every few minutes.
The etcd pod restarts because of a `SandboxChanged`
```
Normal SandboxChanged 57s kubelet Pod sandbox changed, it will be killed a... | Constant kube-system pod restard due to SandboxChanged under ubuntu Jammy | https://api.github.com/repos/kubernetes/kubernetes/issues/110177/comments | 28 | 2022-05-23T19:23:18Z | 2025-03-02T23:12:41Z | https://github.com/kubernetes/kubernetes/issues/110177 | 1,245,601,103 | 110,177 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In our custom plugin, we want to move pods that is unscheduled by the plugin to activeQ/backoffQ when a new Pod is created.
So, we define `EventsToRegister` like this:
```go
func (p *Plugin) EventsToRegister() []framework.ClusterEvent {
return []framework.ClusterEvent{{
Resource: frame... | scheduler: move all preCheck to QueueingHint | https://api.github.com/repos/kubernetes/kubernetes/issues/110175/comments | 25 | 2022-05-23T18:02:23Z | 2024-09-05T16:19:58Z | https://github.com/kubernetes/kubernetes/issues/110175 | 1,245,522,720 | 110,175 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
The HPA needs better unit and E2E test coverage.
**E2E TESTS**
Missing E2E test coverage by API / feature
Spec.ScaleTargetRef
- [x] scaling a CRD (not built-in kind)
Spec.MinReplicas
- [x] scale-to-zero (minReplicas=0)
Spec.Metrics
- [ ] scale on cpu average v... | Better HPA unit and E2E test coverage | https://api.github.com/repos/kubernetes/kubernetes/issues/110172/comments | 17 | 2022-05-23T13:49:29Z | 2024-09-02T12:57:03Z | https://github.com/kubernetes/kubernetes/issues/110172 | 1,245,200,447 | 110,172 |
[
"kubernetes",
"kubernetes"
] | /sig apps
/kind feature
**What would you like to be added**:
Deployment status to contain information whether there are still `Terminating` Pods (related to old ReplicaSet).
**Why is this needed**:
According to the K8s docs K8s ensures that no new traffic is routed to `Terminating` Pods. But traffic from exist... | Deployment status does not contain information whether there are still `Terminating` Pods (related to old ReplicaSet) | https://api.github.com/repos/kubernetes/kubernetes/issues/110171/comments | 12 | 2022-05-23T11:58:49Z | 2024-03-06T05:21:00Z | https://github.com/kubernetes/kubernetes/issues/110171 | 1,245,052,669 | 110,171 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Used Helms to deploy NFS server on the worker node, but got this error:

Describing the NFS pod gave the following:
**Warning FailedCreatePodSandBox 14s kubelet... | External NFS Provisioner Pod Fail to Create Container Due to Certificate Error | https://api.github.com/repos/kubernetes/kubernetes/issues/110170/comments | 5 | 2022-05-23T11:03:38Z | 2022-06-01T14:43:10Z | https://github.com/kubernetes/kubernetes/issues/110170 | 1,244,985,826 | 110,170 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I’ve created a validation webhook server to intercept `pods/eviction` requests but calling evictions via both, the go SDK client and VPA is not invoking the webhook,
The webhook config is as follows:
<details><summary>webhook.manifest.yaml</summary>
```yaml
apiVersion: admissionregistration.... | Intercepting "pods/eviction" subresource via validating webhook is not working | https://api.github.com/repos/kubernetes/kubernetes/issues/110169/comments | 8 | 2022-05-23T08:48:31Z | 2022-05-29T19:41:30Z | https://github.com/kubernetes/kubernetes/issues/110169 | 1,244,799,436 | 110,169 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
pod uses a PVC with `volumeMode: Block`. The block volume is backed by a block device on the node (which is created by some CSI storage providers).
If the there is an lv on the underlying block device, Kubelet cannot finish terminating a pod
### What did you expect to happen?
Kubelet should be ... | Kubelet cannot finish terminating a pod that uses a PVC with `volumeMode: Block` if the there is an lv on the underlying block device | https://api.github.com/repos/kubernetes/kubernetes/issues/110163/comments | 8 | 2022-05-23T04:49:02Z | 2022-12-29T09:24:45Z | https://github.com/kubernetes/kubernetes/issues/110163 | 1,244,576,883 | 110,163 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
[root@k8s-master02 ~]# kubeadm join k8s-vip:16443 --token 5amux5.4feptm57mlep9kgo \
> --discovery-token-ca-cert-hash sha256:815d82daf3a963b3cbdd969fd9da10f7d36747c726e21d268d64c11bba0b4f3c \
> --control-plane --certificate-key 698b0866289fc24f5bf587f47e145f0111e4732874d51c9ee8f3994555eae405 \
> -... | timeout waiting for etcd cluster to be available | https://api.github.com/repos/kubernetes/kubernetes/issues/110161/comments | 4 | 2022-05-23T02:12:36Z | 2022-05-23T07:10:57Z | https://github.com/kubernetes/kubernetes/issues/110161 | 1,244,479,039 | 110,161 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While working on #110101 and related PRs, I noticed that the denominator that is set for the number of waiting requests of a priority level is wrong: it is the length limit for a single queue rather than the collective limit for all the priority level's queues.
https://github.com/kubernetes/apise... | Wrong Denominator for priority_level_request_count_samples waiting requests | https://api.github.com/repos/kubernetes/kubernetes/issues/110160/comments | 4 | 2022-05-23T01:54:36Z | 2022-07-25T20:32:36Z | https://github.com/kubernetes/kubernetes/issues/110160 | 1,244,468,181 | 110,160 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
PVC mount gets timed out when the number of parallel pod requests with pvc access goes past 400. This caused pod PVC mount retries(several of these in some cases.) and delays the pod startup.
`3m1s Warning FailedMount pod/nginx-deployment-7c54456f-2sk89 Unable to attach... | Unable to attach or mount volumes: timed out waiting for the condition | https://api.github.com/repos/kubernetes/kubernetes/issues/110158/comments | 50 | 2022-05-22T12:06:38Z | 2024-11-06T06:34:41Z | https://github.com/kubernetes/kubernetes/issues/110158 | 1,244,234,776 | 110,158 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
sig-node-cos
The ci-containerd-soak-cos-gce job is flaking on `NodeProblemDetector should run without error`
https://git.k8s.io/test-infra/config/jobs/kubernetes/sig-node/containerd.yaml
### Which tests are flaking?
Kubernetes e2e suite.[sig-node] NodeProblemDetector sho... | [Flaky test] ci-containerd-soak-cos-gce NodeProblemDetector should run without error | https://api.github.com/repos/kubernetes/kubernetes/issues/110156/comments | 7 | 2022-05-22T01:18:12Z | 2022-11-13T21:18:47Z | https://github.com/kubernetes/kubernetes/issues/110156 | 1,244,119,203 | 110,156 |
[
"kubernetes",
"kubernetes"
] | Hi,
in default scheduling profile ``LowNodeUtilization`` ``ImageLocality`` is plugin which is taken in the consideration. But, you can only schedule pods and they consists of containers. So if one container has specified ``PullPolicy`` to ``Always`` should ``image_locality`` really been taken in the consideration be... | [RFE] image_locality - Scheduling factor | https://api.github.com/repos/kubernetes/kubernetes/issues/110149/comments | 33 | 2022-05-20T21:07:33Z | 2023-03-19T16:00:56Z | https://github.com/kubernetes/kubernetes/issues/110149 | 1,243,641,516 | 110,149 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I was debugging performance of case with heavy watch traffic of CRD objects and found interesting suboptimality: we burn significant amount of CPU on json.compact calls that deserialize JSONs to validate correctness of already serialized objects:
 in wsl run with ubuntu22.04 | https://api.github.com/repos/kubernetes/kubernetes/issues/110144/comments | 7 | 2022-05-20T09:37:34Z | 2022-06-07T08:37:03Z | https://github.com/kubernetes/kubernetes/issues/110144 | 1,242,888,541 | 110,144 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
windows node not ready:
kubelet error log:
```
E0423 06:09:57.482599 7636 cni.go:366] Error adding app-product_test.6whlknu7-6778779cdb-6cm9c/99e6c35470c5b2e8d5e3b0bb3b0b83dc338388ccc967529696e0f65344927ff2 to network flannel/flannel.4096: netplugin failed with no error message: exit status 1... | windows node is not ready: PLEG is not healthy | https://api.github.com/repos/kubernetes/kubernetes/issues/110143/comments | 13 | 2022-05-20T08:22:31Z | 2022-10-31T01:43:07Z | https://github.com/kubernetes/kubernetes/issues/110143 | 1,242,804,030 | 110,143 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
`TestApfWatchHandlePanic/post-execute_panic` has a data race
```
{Failed === RUN TestApfWatchHandlePanic/post-execute_panic
==================
WARNING: DATA RACE
Read at 0x000003a22108 by goroutine 426:
k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/server/filters.newApfHandlerWithFilt... | data race in priority and fairness unit test | https://api.github.com/repos/kubernetes/kubernetes/issues/110139/comments | 18 | 2022-05-19T21:03:13Z | 2024-09-01T01:34:41Z | https://github.com/kubernetes/kubernetes/issues/110139 | 1,242,323,457 | 110,139 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We frequently see AWS metadata service rate limiting on kube nodes and one of the worst offenders is kubelet. if not aware, the AWS IMDS `169.254.169.254` has a packet-based rate limit of 1024 packets per second which includes both IMDS and DNS.
On the node I'm currently investigating, every 10 s... | Kubelet makes excessive calls to EC2 metadata service, which has rate limits | https://api.github.com/repos/kubernetes/kubernetes/issues/110136/comments | 12 | 2022-05-19T18:53:51Z | 2022-07-06T16:09:12Z | https://github.com/kubernetes/kubernetes/issues/110136 | 1,242,189,214 | 110,136 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
ExecSync messages are flooding syslog
Each second we have logs something like:
```
May 19 10:49:40 czphadevk8sw02 containerd[980]: time="2022-05-19T10:49:40.738867876Z" level=info msg="ExecSync for \"1d4d9cd18e37e83124785f1c9a4184d040b7ccd8ee9e082fbf01a4af94afa18f\" returns with exit code 0"
... | ExecSync | https://api.github.com/repos/kubernetes/kubernetes/issues/110128/comments | 3 | 2022-05-19T10:59:09Z | 2022-05-21T17:19:25Z | https://github.com/kubernetes/kubernetes/issues/110128 | 1,241,598,594 | 110,128 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to start an ephemeral container for a pod under namespace with restricted PodSecurity.
I got following error:
Warning FailedCreate 59s (x6 over 2m20s) replicaset-controller (combined from similar events): Error creating: pods "ephemeral-demo-74d9cfc58f-jbdpg" is forbidden: violates Po... | Ephemeral container can't work with restricted PodSecurity | https://api.github.com/repos/kubernetes/kubernetes/issues/110126/comments | 20 | 2022-05-19T07:28:53Z | 2023-02-03T20:03:38Z | https://github.com/kubernetes/kubernetes/issues/110126 | 1,241,344,092 | 110,126 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Currently, the kubectl `annotate` cmd output msg is not distinguished between annotate and unannotate (using `-` suffix ), both of them response annotated.
e.g.
1. Annotation key `hello` not exist
```
kubectl annotate pod test hello=world
pod/test annotated
```
2. Annotation key `hello` e... | kubectl `annotate` msg is not distinguished between annotate and unannotate | https://api.github.com/repos/kubernetes/kubernetes/issues/110123/comments | 12 | 2022-05-19T05:16:34Z | 2023-07-14T18:02:25Z | https://github.com/kubernetes/kubernetes/issues/110123 | 1,241,218,550 | 110,123 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[6/6]</code>
- [X] APISnoop org-flow: [Appsv1ControllerRevisionLifecycleTest.org](https://github.com/apisnoop/ticket-writing/blob/master/Appsv1ControllerRevisionLifecycleTest.org)
- [X] Test approval issue: #110121
- [X] Test PR: #110122
- [x] Two weeks soak start date: [testgrid-link](h... | Write ControllerRevisionLifecycleTest +7 Endpoints | https://api.github.com/repos/kubernetes/kubernetes/issues/110121/comments | 3 | 2022-05-19T00:58:00Z | 2022-08-01T22:05:02Z | https://github.com/kubernetes/kubernetes/issues/110121 | 1,240,875,155 | 110,121 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I tried to copy a file from a running pod to my local machine using `kubectl cp` on Windows. I used the `$HOME` env var in Powershell and it failed to copy saying essentially no local path was specified.
```console
PS C:\> kubectl cp -n namespace -c container pod-0:/usr/lib/os-release C:\Temp\... | kubectl cp fails with absolute path on Windows | https://api.github.com/repos/kubernetes/kubernetes/issues/110120/comments | 23 | 2022-05-18T23:29:57Z | 2023-10-19T16:48:52Z | https://github.com/kubernetes/kubernetes/issues/110120 | 1,240,717,079 | 110,120 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Configuration on the k8s audit-policy.yaml is failing to currectly record the events.
I'm trying to create a audit-policy.yaml fail to save some of the events and i noticed some issues.
1. I cannot dismiss all the logs that watch, get or list an object:
```yaml
- level: None
resources:
-... | audit policy wrong logic does not record events. | https://api.github.com/repos/kubernetes/kubernetes/issues/110116/comments | 7 | 2022-05-18T16:36:29Z | 2022-10-21T17:57:50Z | https://github.com/kubernetes/kubernetes/issues/110116 | 1,240,217,933 | 110,116 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when node zonestate is stateFullDisruption,there is no node Ready,so evicting pod is meaningless.
but now the limiter is nc.evictionLimiterQPS,it will evict pod.
when node zonestate is stateFullDisruption,we should set limiter is 0.
### What did you expect to happen?
when node zonestate i... | when node zonestate is stateFullDisruption,we should stop evicting pod,but now limiter is nc.evictionLimiterQPS | https://api.github.com/repos/kubernetes/kubernetes/issues/110114/comments | 14 | 2022-05-18T15:01:15Z | 2024-12-28T07:16:04Z | https://github.com/kubernetes/kubernetes/issues/110114 | 1,240,101,696 | 110,114 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I installed kubernetes 1.24, cluster is up and healthy but when i try to install kubernetes-dashboard, i realized can not access dashboard token. Before 1.24 i just describe token and get.
Normally when sa created, secret should be created automaticaly, BUT NOW, I just tried create service accoun... | Kubernetes Token Controller is not working at v1.24 | https://api.github.com/repos/kubernetes/kubernetes/issues/110113/comments | 10 | 2022-05-18T14:11:25Z | 2022-05-30T20:19:42Z | https://github.com/kubernetes/kubernetes/issues/110113 | 1,240,031,341 | 110,113 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
when use daemonset create 178 pods,take me 33 seconds
```
[root@pub-k8smaster-mgt-prd-50001-ecs logclean]# date; kubectl get ds -n kube-system logclean ; kubectl get pod -n kube-system --no-headers|grep logclean |wc -l
Wed May 18 18:40:40 CST 2022
NAME DESIRED CURRENT READY UP-TO-DAT... | kubernetes scheduler too slow | https://api.github.com/repos/kubernetes/kubernetes/issues/110109/comments | 5 | 2022-05-18T10:49:39Z | 2022-05-21T03:10:03Z | https://github.com/kubernetes/kubernetes/issues/110109 | 1,239,776,047 | 110,109 |
[
"kubernetes",
"kubernetes"
] | <a href="https://api.easycla.lfx.linuxfoundation.org/v2/repository-provider/github/sign/18706487/20580498/110106/#/?version=2"><img src="https://s3.amazonaws.com/cla-project-logo-prod/cla-not-signed.svg" alt="CLA Not Signed" align="left" height="28" width="328"></a><br/><br /><ul><li><a href='https://api.easycla.lfx.li... | <a href="https://api.easycla.lfx.linuxfoundation.org/v2/repository-provider/github/sign/18706487/20580498/110106/#/?version=2"><img src="https://s3.amazonaws.com/cla-project-logo-prod/cla-not-signed.svg" alt="CLA Not Signed" align="left" height="28" width="328"></a><br/><br /><ul><li><a href='https://api.easycla.lfx.li... | https://api.github.com/repos/kubernetes/kubernetes/issues/110107/comments | 4 | 2022-05-18T09:28:55Z | 2022-05-18T15:37:22Z | https://github.com/kubernetes/kubernetes/issues/110107 | 1,239,682,849 | 110,107 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While trying to run `kubernetes/test/kubemark/start-kubemark.sh` with a valid ibmcloud account, the following error happened
```
Do you want to build the kubemark image? [y/N]> N
Do you want to use custom clusters? [y/N]> N
CHECKING CLUSTERS
FAILED
'region-set' is not a registered command.... | Kubemark script support for IKS not working with latest ibmcloud CLI | https://api.github.com/repos/kubernetes/kubernetes/issues/110098/comments | 4 | 2022-05-17T20:14:17Z | 2022-09-29T11:06:55Z | https://github.com/kubernetes/kubernetes/issues/110098 | 1,239,111,171 | 110,098 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If you use `kubectl rollout history --revision=100` you get the pod spec at revision 100.
Everything is correct. However, if you add the `-o json` or `-o yaml` on the command, you just get the latest deployment, and not the revision you specified.
### What did you expect to happen?
I exp... | Rollout history doesn't show the revision when output format is used | https://api.github.com/repos/kubernetes/kubernetes/issues/110097/comments | 8 | 2022-05-17T20:12:11Z | 2022-08-24T14:42:05Z | https://github.com/kubernetes/kubernetes/issues/110097 | 1,239,109,232 | 110,097 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When we add custom annotations to PodSandboxConfig.Annotations in function generatePodSandboxConfig, kubelet crashes with errror:
kubelet[2257292]: fatal error: concurrent map read and map write
The role of function generatePodSandboxConfig(located at kuberuntime_sandbox.go) is to create Sandbox... | kubelet: fix to prevent concurrent map read and map | https://api.github.com/repos/kubernetes/kubernetes/issues/110084/comments | 11 | 2022-05-17T08:10:10Z | 2022-06-02T12:16:59Z | https://github.com/kubernetes/kubernetes/issues/110084 | 1,238,245,915 | 110,084 |
[
"kubernetes",
"kubernetes"
] | The liveness probe is going into a BAckoff state, when the application is bombarded with 35k rpm, we dont see the same behavior when performing the load with 10k or 15k rpm. What could be a possible reason for this, is the pod stacking all the readiness/liveness probe requests and only responding to app requests or how... | Liveness probe failing when the load on the application is maxed | https://api.github.com/repos/kubernetes/kubernetes/issues/110083/comments | 11 | 2022-05-17T07:22:24Z | 2022-08-29T12:53:37Z | https://github.com/kubernetes/kubernetes/issues/110083 | 1,238,190,593 | 110,083 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In our cluster, we encountered an issue below:
The ResourceQuota `status.used` showed:
```
status:
used:
configmaps: "10"
services: "10"
...
```
But when we got the actual `svc` or `cm` count, they were just:
```
configmaps: "1"
services: "1"
```
After debugging the... | Rollback ResourceQuota changes in admission if persisting to etcd fails | https://api.github.com/repos/kubernetes/kubernetes/issues/110080/comments | 18 | 2022-05-17T05:16:30Z | 2024-02-09T14:19:50Z | https://github.com/kubernetes/kubernetes/issues/110080 | 1,238,080,922 | 110,080 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
cannot provision resources dynamically.
### What did you expect to happen?
to dynamically set namespaces as need arises
### How can we reproduce it (as minimally and precisely as possible)?
ClusterRoleBinding.subjects requires a namespace to be set statically
### Anything else we need to know?
... | [Question] Could you elaborate on how namespaces, are required to be statically set | https://api.github.com/repos/kubernetes/kubernetes/issues/110078/comments | 6 | 2022-05-17T01:33:28Z | 2022-05-18T15:40:16Z | https://github.com/kubernetes/kubernetes/issues/110078 | 1,237,934,822 | 110,078 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
prowjob_name: ci-kubernetes-node-kubelet-kubetest2-1-23
prowjob_config_url: https://git.k8s.io/test-infra/config/jobs/kubernetes/sig-release/release-branch-jobs/1.23.yaml
The test failure is related to static-pods, and the deletion of the associated mirror-pod when the static pod is r... | E2eNode Suite: [sig-node] MirrorPod ... test is flaking on deletion of mirror pod | https://api.github.com/repos/kubernetes/kubernetes/issues/110074/comments | 9 | 2022-05-16T18:39:32Z | 2022-10-19T18:58:06Z | https://github.com/kubernetes/kubernetes/issues/110074 | 1,237,556,969 | 110,074 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-kubernetes-e2e-capz-master-containerd-nightly-windows
### Which tests are failing?
the cluster doesn't start
### Since when has it been failing?
May 10th 2022
### Testgrid link
https://testgrid.k8s.io/sig-windows-master-release#capz-windows-containerd-nightly-master
### Reason fo... | Windows Containerd nightly CI job is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/110073/comments | 5 | 2022-05-16T18:24:36Z | 2022-06-03T21:49:20Z | https://github.com/kubernetes/kubernetes/issues/110073 | 1,237,536,900 | 110,073 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have a bunch of different microservice application pods. To simplify their handling in our Helm chart, we have a common "checkReadiness.sh" in all our containers, which we run with an exec-type probe.
From K8s perspective, all probes look basically like this:
readinessProbe:
exec:
... | exec-type probes now consider timeoutSeconds for readiness state, but probe processes accumulate if they get stuck | https://api.github.com/repos/kubernetes/kubernetes/issues/110070/comments | 14 | 2022-05-16T11:10:28Z | 2022-06-08T20:00:20Z | https://github.com/kubernetes/kubernetes/issues/110070 | 1,236,992,267 | 110,070 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently Resource Quotas can be [scoped](https://kubernetes.io/docs/concepts/policy/resource-quotas/#quota-scopes) based on whether a pod is terminating or not, best effort or not, its priority, and its CrossNamespacePodAffinity.
It should be possible to scope a Resource Quota ... | Allow Resource Quotas to be scoped based on label selectors | https://api.github.com/repos/kubernetes/kubernetes/issues/110065/comments | 18 | 2022-05-16T06:48:14Z | 2023-09-17T14:05:58Z | https://github.com/kubernetes/kubernetes/issues/110065 | 1,236,700,445 | 110,065 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-containerd#cgroup-systemd-containerd-node-e2e
https://testgrid.k8s.io/sig-node-containerd#containerd-node-conformance
https://testgrid.k8s.io/sig-node-containerd#node-kubelet-containerd-hugepages
https://testgrid.k8s.io/sig-node-containerd#node-kubelet-co... | pr-kubekins login makes node (and other) e2e tests failing | https://api.github.com/repos/kubernetes/kubernetes/issues/110060/comments | 10 | 2022-05-15T19:50:04Z | 2022-08-02T04:56:06Z | https://github.com/kubernetes/kubernetes/issues/110060 | 1,236,383,176 | 110,060 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [7484e00943191113f9bb](https://go.k8s.io/triage#7484e00943191113f9bb)
##### Error text:
```
test/e2e/storage/testsuites/volumelimits.go:249
Apr 30 23:44:52.522: Expected volume limits to be set, error: could not get CSINode limit for driver csi-hostpath: timed out waiting for the condition
ve... | Failure cluster [7484e009...]: could not get CSINode limit for driver csi-hostpath | https://api.github.com/repos/kubernetes/kubernetes/issues/110054/comments | 1 | 2022-05-14T18:00:34Z | 2022-05-19T16:21:20Z | https://github.com/kubernetes/kubernetes/issues/110054 | 1,236,087,253 | 110,054 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Un-deperecate the `--provider-id` kubelet flag, as this option is typically set per-node similar to `--node-ip` (which is not deprecated).
Or more generally, consider not deprecating fields available in config that make sense to set per-node.
### Why is this needed?
I noticed ... | undeprecate kubelet --provider-id flag | https://api.github.com/repos/kubernetes/kubernetes/issues/110041/comments | 9 | 2022-05-13T18:26:46Z | 2023-06-12T20:46:00Z | https://github.com/kubernetes/kubernetes/issues/110041 | 1,235,551,047 | 110,041 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I can't access apiserver / version,.
for example: curl - K 192.168.1.1:6443/version.
The display permission is incorrect. For security, I unbound cluster admin from system: anonymous and bound it to API admin. What I want to ask is that / version is not protected? Can visit, why can't I visit now... | I can't access apiserver:6443/version | https://api.github.com/repos/kubernetes/kubernetes/issues/110038/comments | 4 | 2022-05-13T14:11:46Z | 2022-05-16T13:02:11Z | https://github.com/kubernetes/kubernetes/issues/110038 | 1,235,299,820 | 110,038 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Recently I found newly created pod needs too long to get ready, nearly 14 mins, and most of time waiting for the volume mounted.
```
I0510 18:42:17.107493 24862 config.go:383] "Receiving a new pod" pod="default/k8s-deploy-test-5f87b8dd98-mgl45"
I0510 18:42:17.109962 24862 kubelet.go:1937] "... | Pod stuck in ContainerCreating for too long due to volumeManager | https://api.github.com/repos/kubernetes/kubernetes/issues/110036/comments | 18 | 2022-05-13T09:24:47Z | 2025-02-09T07:08:11Z | https://github.com/kubernetes/kubernetes/issues/110036 | 1,234,969,808 | 110,036 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I doubt whether the API configuration is wrong, because the created serviceaccount does not seem to be mounted in the pod container
```
[root@testwithsa /run/secrets/kubernetes.io/serviceaccount]$ curl --cacert ./ca.crt -H "Authorization: Bearer $(cat ./token)" https://10.1.1.100:6443/namespace/... | new invalid bearer token, square/go-jose: error in cryptographic primitive | https://api.github.com/repos/kubernetes/kubernetes/issues/110035/comments | 5 | 2022-05-13T08:55:23Z | 2022-08-22T16:43:25Z | https://github.com/kubernetes/kubernetes/issues/110035 | 1,234,934,889 | 110,035 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When we disable the scale direction by using `SelectPolicy: Disabled`, then manually scale it to a value over <min, max> range. The HPA will patch the replicas based on min/max value
### What did you expect to happen?
Since the scale direction already being disabled, is it more acceptable to ignor... | The Max/Min Will Influence HPA Disable Policy | https://api.github.com/repos/kubernetes/kubernetes/issues/110034/comments | 19 | 2022-05-13T08:54:26Z | 2025-01-09T17:32:12Z | https://github.com/kubernetes/kubernetes/issues/110034 | 1,234,933,928 | 110,034 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I use kind to create kubernetes cluster in version 1.20.0. When I stop kubelet of work node, the node status is changed to not ready. But taint `node.kubernetes.io/unreachable:NoExecute` is not added to node, so pods on that node are not evicted .
From the log of kube-controller-manager, I can se... | not ready node without taint node.kubernetes.io/unreachable:NoExecute | https://api.github.com/repos/kubernetes/kubernetes/issues/110028/comments | 5 | 2022-05-13T06:35:02Z | 2022-05-23T00:47:29Z | https://github.com/kubernetes/kubernetes/issues/110028 | 1,234,800,920 | 110,028 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The [kubelet CLI docs](https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/) state that `--cloud-provider=external` is deprecated and will go away in1.24:
>
> --cloud-provider string
> --
> | The provider for cloud services. Set to empty string for running with no cloud... | kubelet without deprecated `--cloud-provider=external` do not get proper taint and are not CCM initialized | https://api.github.com/repos/kubernetes/kubernetes/issues/110018/comments | 21 | 2022-05-12T16:25:02Z | 2024-03-05T08:44:42Z | https://github.com/kubernetes/kubernetes/issues/110018 | 1,234,223,326 | 110,018 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I've observed, that some `apiserver_request_slo_duration_seconds` metrics has `verb:POST` and `scope:namespace` labels.
### What did you expect to happen?
`POST` (create) requests are "single resource", therefor they should be classified as `scope:resource`.
Def: https://kubernetes.io/docs/refere... | POST requests to kube-apiserver for custom resources has incorrect scope classification | https://api.github.com/repos/kubernetes/kubernetes/issues/110001/comments | 2 | 2022-05-12T11:16:03Z | 2022-05-17T20:19:13Z | https://github.com/kubernetes/kubernetes/issues/110001 | 1,233,830,033 | 110,001 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. shutdown node host, the kubelet on node enabled GracefulNodeShutdown feature
2. endpoint which associated with pod running on this node, **the endpoint is not remove after long time**
### What did you expect to happen?
expect the endpoint was removed finally.
when enable nodeGrac... | endpoint not update even if pod had deleted when node shutdown | https://api.github.com/repos/kubernetes/kubernetes/issues/109998/comments | 23 | 2022-05-12T08:53:05Z | 2025-01-10T10:08:10Z | https://github.com/kubernetes/kubernetes/issues/109998 | 1,233,665,373 | 109,998 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In kubelet config, we use `memoryManagerPolicy: Static`, and specify the following configuration to reserve memory for system etc
```
reservedMemory:
- limits:
memory: 3Gi
numaNode: 0
- limits:
memory: 3Gi
numaNode: 1
systemReserved:
cpu: 1000m
memory: 2Gi
kubeReserved:
... | Kubelet failed to start due to memory stat mismatch | https://api.github.com/repos/kubernetes/kubernetes/issues/109996/comments | 17 | 2022-05-12T08:09:13Z | 2022-12-09T03:45:26Z | https://github.com/kubernetes/kubernetes/issues/109996 | 1,233,606,862 | 109,996 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The metrics for the cluster IP allocator (`kube_apiserver_clusterip_allocator_*`) are occasionally reported incorrect values. I suspect that the metrics are overwritten by [the repair loop](https://github.com/kubernetes/kubernetes/blob/v1.24.0/pkg/registry/core/service/ipallocator/controller/repair.... | The metrics for the cluster IP allocator are incorrectly reported | https://api.github.com/repos/kubernetes/kubernetes/issues/109994/comments | 4 | 2022-05-12T05:28:29Z | 2022-05-25T18:48:31Z | https://github.com/kubernetes/kubernetes/issues/109994 | 1,233,463,335 | 109,994 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-unit
### Which tests are flaking?
TestTimeoutWithLogging
### Since when has it been flaking?
It looks like May 4th, but perhaps it's now solved, according to k8s-triage.
However, I found it today in the release-1.23 branch: https://prow.k8s.io/view/gs/kubernetes-jenki... | Flaky TestTimeoutWithLogging | https://api.github.com/repos/kubernetes/kubernetes/issues/109986/comments | 7 | 2022-05-11T17:51:55Z | 2022-10-20T14:04:19Z | https://github.com/kubernetes/kubernetes/issues/109986 | 1,232,996,295 | 109,986 |
[
"kubernetes",
"kubernetes"
] | Triage failing AWS tests in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
ref: https://github.com/kubernetes/kubernetes/issues/109913
/assign @nckturner
/area provider/aws
/sig cloud-provider
/kind failing-test | [failing-test] SIG Cloud Provider AWS tests | https://api.github.com/repos/kubernetes/kubernetes/issues/109984/comments | 7 | 2022-05-11T17:31:01Z | 2022-10-09T03:58:18Z | https://github.com/kubernetes/kubernetes/issues/109984 | 1,232,974,903 | 109,984 |
[
"kubernetes",
"kubernetes"
] | Triage failing Azure tests in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
ref: https://github.com/kubernetes/kubernetes/issues/109913
/assign @bridgetkromhout
/area provider/azure
/sig cloud-provider
/kind failing-test | [failing-test] SIG Cloud Provider Azure tests | https://api.github.com/repos/kubernetes/kubernetes/issues/109983/comments | 10 | 2022-05-11T17:30:57Z | 2023-01-14T17:59:43Z | https://github.com/kubernetes/kubernetes/issues/109983 | 1,232,974,844 | 109,983 |
[
"kubernetes",
"kubernetes"
] | Triage failing GCE tests in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
ref: https://github.com/kubernetes/kubernetes/issues/109913
/assign @cheftako
/area provider/gcp
/sig cloud-provider
/kind failing-test | [failing-test] SIG Cloud Provider GCE tests | https://api.github.com/repos/kubernetes/kubernetes/issues/109982/comments | 5 | 2022-05-11T17:30:52Z | 2022-10-08T18:58:17Z | https://github.com/kubernetes/kubernetes/issues/109982 | 1,232,974,728 | 109,982 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Please help me out T_T
This is the action caused the error:
Action:
```
root@ren-virtual-machine:/home/ren/goworkplace/src/denyex# kubectl apply -f validatingwebhook.yaml --validate=false
```
Problem:
```
Error from server (BadRequest): error when creating "validatingwebhook.yaml": Valida... | Cannot handle ValidatingWebhookConfiguration while the API is already enabled | https://api.github.com/repos/kubernetes/kubernetes/issues/109967/comments | 8 | 2022-05-11T12:07:13Z | 2022-05-13T06:48:36Z | https://github.com/kubernetes/kubernetes/issues/109967 | 1,232,526,744 | 109,967 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Nodes are flapping with error PLEG is not healthy: PLEG was last seen active 3m.6314604s ago, threshold is 3m0s This issue is coming only in 2 nodes out of 18 nodes
### What did you expect to happen?
Node to be in Ready State
### How can we reproduce it (as minimally and precisely as possible)?... | Nodes flapping (NotReady/Ready) | https://api.github.com/repos/kubernetes/kubernetes/issues/109965/comments | 8 | 2022-05-11T11:05:43Z | 2022-10-22T18:23:35Z | https://github.com/kubernetes/kubernetes/issues/109965 | 1,232,445,123 | 109,965 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a yaml that contains 3 k8s configurations:
1. Deployment
2. Service
3. ValidatingWebhookConfiguration
If I try to apply them together I get a replica failure `failed calling admission webhook: connection refused`
I noticed that the combination of `resources: ["*/*"]` alongside `o... | ValidatingWebhookConfiguration stales it's deployment when created together | https://api.github.com/repos/kubernetes/kubernetes/issues/109964/comments | 5 | 2022-05-11T10:09:09Z | 2022-05-22T12:24:28Z | https://github.com/kubernetes/kubernetes/issues/109964 | 1,232,371,524 | 109,964 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are running the addon-manager on several big kubernetes clusters (talking about 500+ nodes with multiple resources).
On some of those, our instances of addon manager grew in memory storage until it almost saturated all the available memory on the node.
Digging the issue, we found out that the... | Kube-addon-manager internal .kube/cache disk storage issue | https://api.github.com/repos/kubernetes/kubernetes/issues/109963/comments | 9 | 2022-05-11T10:03:36Z | 2022-11-06T09:57:33Z | https://github.com/kubernetes/kubernetes/issues/109963 | 1,232,364,508 | 109,963 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
In this issue https://github.com/kubernetes/kubernetes/issues/108483, we're trying to find potential goroutine leakages in k8s, as a separation, this issue only focuses on the kube-scheduler.
Currently, the fact is that we have multiple places calling API with a `context.TODO()... | prevent protential goroutine leakages in scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/109962/comments | 11 | 2022-05-11T09:53:46Z | 2022-08-31T03:41:18Z | https://github.com/kubernetes/kubernetes/issues/109962 | 1,232,350,108 | 109,962 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Run below command to init a v1.24.0 cluster:
`kubeadm init --kubernetes-version v1.24.0 --image-repository registry.local/gcr --pod-network-cidr 173.169.0.0/16 --cri-socket /run/cri-dockerd.sock`
I have already set --image-repository, but cluster initial stuck at this log:
```
dockerd[51125]... | v1.24.0 kubeadm init --image-repository not works for k8s.gcr.io/pause:3.1 | https://api.github.com/repos/kubernetes/kubernetes/issues/109960/comments | 5 | 2022-05-11T08:29:50Z | 2022-05-11T08:56:08Z | https://github.com/kubernetes/kubernetes/issues/109960 | 1,232,207,625 | 109,960 |
[
"kubernetes",
"kubernetes"
] | I apply following yaml to create a pod named `my-pod`. it equipped a readiness probe, and I expect to see a place recored the latest probe time.
```go
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
role: myrole
spec:
containers:
- name: web
image: alpine
resources:
... | lastProbeTime in pod.status.conditions always remain null? | https://api.github.com/repos/kubernetes/kubernetes/issues/109958/comments | 7 | 2022-05-11T06:48:20Z | 2022-09-20T13:16:09Z | https://github.com/kubernetes/kubernetes/issues/109958 | 1,232,094,646 | 109,958 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Is there a way to tune the number of concurrent images being pulled by kubelet?
### Why is this needed?
We want to turn off `SerializeImagePulls`, since one bad image pull on our nodes kept all subsequent deployments to be stuck at `ImagePull` state. So, we're considering tur... | Support for "pooled" image puller | https://api.github.com/repos/kubernetes/kubernetes/issues/109956/comments | 9 | 2022-05-11T06:42:25Z | 2022-10-08T16:58:17Z | https://github.com/kubernetes/kubernetes/issues/109956 | 1,232,087,931 | 109,956 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A PVC failed and the FS became unmounted. A container restarted and the replacement container ended up mounting the mountpoint directory from the host filesystem and continuing to operate without realizing it.
### What did you expect to happen?
In a perfect world, the replacement container would e... | Kubelet should prevent failed volume mounts from resulting in containers writing to host filesystem | https://api.github.com/repos/kubernetes/kubernetes/issues/109955/comments | 21 | 2022-05-11T06:39:09Z | 2024-01-19T20:03:55Z | https://github.com/kubernetes/kubernetes/issues/109955 | 1,232,085,235 | 109,955 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We frequently see events on PodDisruptionBudgets consisting of:
```
reason=CalculateExpectedPodCountFailed message=Failed to calculate the number of expected pods: replicasets.apps does not implement the scale subresource
```
As stated in the [API docs](https://kubernetes.io/docs/reference/ge... | CalculateExpectedPodCountFailed events occur intermittently on supported resources. | https://api.github.com/repos/kubernetes/kubernetes/issues/109954/comments | 17 | 2022-05-11T05:33:59Z | 2024-11-24T04:08:15Z | https://github.com/kubernetes/kubernetes/issues/109954 | 1,232,031,777 | 109,954 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
if a deploy contains:
spec:
imagePullSecrets:
- {}
it will cause `kubectl edit` fail, although `kubectl create` success.
some people meet the same problem:
https://stackoverflow.com/questions/49694153/kubernetes-error-kubectl-edit-deployment
the scheduler suffer the problem, h... | kubectl edit fail, since deploy contains imagePullSecrets: - {} | https://api.github.com/repos/kubernetes/kubernetes/issues/109953/comments | 15 | 2022-05-11T02:45:25Z | 2024-03-28T19:42:48Z | https://github.com/kubernetes/kubernetes/issues/109953 | 1,231,927,079 | 109,953 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If a volume is marked as uncertain, the volume should not be on the volumeAttached list. But if detach is triggered, but failed, the attach_detach_controller will try to add this volume as attached in node status (AddVolumeToReportAsAttached). However, the volume might be not even attached (since th... | AddVolumeToReportAsAttached logic issue | https://api.github.com/repos/kubernetes/kubernetes/issues/109951/comments | 9 | 2022-05-11T00:42:22Z | 2022-11-07T05:05:33Z | https://github.com/kubernetes/kubernetes/issues/109951 | 1,231,853,935 | 109,951 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We traditionally expected one CSI driver to generally expose one type of volume. For example:
```
EBS CSI driver --> Block volume (File system or raw block)
EFS CSI driver ---> NFS Shared Volume types
```
So as long as one driver exposes only one kind of volumes, it all works fine.
But ... | Handling of per-driver fsgroup and other properties is broken for CSI drivers with multiple volume types support | https://api.github.com/repos/kubernetes/kubernetes/issues/109949/comments | 12 | 2022-05-10T19:07:50Z | 2022-10-23T02:31:35Z | https://github.com/kubernetes/kubernetes/issues/109949 | 1,231,577,096 | 109,949 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-unit
### Which tests are flaking?
TestWatchOrphanPods/orphan
### Since when has it been flaking?
May 4th
### Testgrid link
https://storage.googleapis.com/k8s-triage/index.html?pr=1&text=TestWatchOrphanPods&job=pull-kubernetes-unit
### Reason for failure (if possible)
... | Flaky TestWatchOrphanPods/orphan | https://api.github.com/repos/kubernetes/kubernetes/issues/109943/comments | 3 | 2022-05-10T16:07:34Z | 2022-05-11T17:47:13Z | https://github.com/kubernetes/kubernetes/issues/109943 | 1,231,388,196 | 109,943 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Follow-up cleanup work for: https://github.com/kubernetes/kubernetes/issues/108518
Most of the information about this issue can be found in https://github.com/kubernetes/kubernetes/pull/108080, where the work merged with a `//TODO` to change the function signature of `StartEventWatcher` to retu... | Follow up work to ensure we can return an error when starting an EventWatcher | https://api.github.com/repos/kubernetes/kubernetes/issues/109942/comments | 7 | 2022-05-10T14:30:58Z | 2022-11-07T16:06:19Z | https://github.com/kubernetes/kubernetes/issues/109942 | 1,231,257,917 | 109,942 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We also hit by this issue. We're using Flatcar Linux which is quite barebone so we are using a few containers to augment it. Unfortunately kubelet removes the images when they are not in active use. For example we a have a cronjob which uses an image we pulled and specially tagged. That images isn't... | Kubelet removes non-Kubernetes images. | https://api.github.com/repos/kubernetes/kubernetes/issues/109936/comments | 24 | 2022-05-10T10:01:21Z | 2024-05-18T18:50:26Z | https://github.com/kubernetes/kubernetes/issues/109936 | 1,230,915,497 | 109,936 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Edit: used markdown for easier viewing of code
Hello all, I created this discussion regarding kubernetes' deployment Rollout History/ Rollback functionality.
The underlying replicasets are tracked by it's underlying labels to tie it to a deployment object. Malforming the la... | Discussion regarding Deployment's revision history tracking of replica test currently based on labels - could this be more reliable? | https://api.github.com/repos/kubernetes/kubernetes/issues/109934/comments | 8 | 2022-05-10T09:49:07Z | 2022-10-21T09:14:30Z | https://github.com/kubernetes/kubernetes/issues/109934 | 1,230,900,230 | 109,934 |
[
"kubernetes",
"kubernetes"
] | ### What happened?

As shown in above screenshot, kubelet is probing the container after attempting to kill it. Even in 20 min, the kubelet couldn't kill the pod.
### What did ... | Kubelet unable to terminate pod. Probe happening post killing | https://api.github.com/repos/kubernetes/kubernetes/issues/109929/comments | 7 | 2022-05-10T08:19:34Z | 2022-08-29T12:41:07Z | https://github.com/kubernetes/kubernetes/issues/109929 | 1,230,791,783 | 109,929 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In a `ServiceIPStaticSubrange` enabled cluster, Kubernetes assigns duplicate IP addresses when the dynamic block is exhausted.
```
$ kubectl get svc --all-namespaces | grep "10.96.0.1 " | head
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 152m
def... | The `ServiceIPStaticSubrange` assigns duplicate IP addresses when the dynamic block is exhausted | https://api.github.com/repos/kubernetes/kubernetes/issues/109927/comments | 6 | 2022-05-10T07:30:20Z | 2022-05-10T12:18:16Z | https://github.com/kubernetes/kubernetes/issues/109927 | 1,230,736,975 | 109,927 |
[
"kubernetes",
"kubernetes"
] | The integration tests for the apiextensions-apiserver generates a fake kubeconfig with a non-existing server `127.1.2.3:12345`
https://github.com/kubernetes/kubernetes/blob/42f1e81488d8599c6874e467fe39b91a23654886/staging/src/k8s.io/apiextensions-apiserver/test/integration/fixtures/server.go#L34-L42
However, the ... | [Test] integration tries to connect to non-existent address | https://api.github.com/repos/kubernetes/kubernetes/issues/109923/comments | 11 | 2022-05-09T20:52:49Z | 2025-03-04T21:29:51Z | https://github.com/kubernetes/kubernetes/issues/109923 | 1,230,239,555 | 109,923 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
HPA policy where simpler algorithm is used: desiredReplicas = factor * currentMetricValue.
I'd like this to be supported at least for app/custom metrics.
### Why is this needed?
Current scaling algorithm: desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredM... | HPA: scaling replica count directly based on a metric | https://api.github.com/repos/kubernetes/kubernetes/issues/109920/comments | 10 | 2022-05-09T17:44:46Z | 2023-01-30T13:45:32Z | https://github.com/kubernetes/kubernetes/issues/109920 | 1,230,048,676 | 109,920 |
[
"kubernetes",
"kubernetes"
] |
<!-- Edit the body of your new issue then click the ✓ "Create Issue" button in the top right of the editor. The first line will be the issue title. Assignees and Labels follow after a blank line. Leave an empty line before beginning the body of the issue. --> | Issue Title | https://api.github.com/repos/kubernetes/kubernetes/issues/109918/comments | 2 | 2022-05-09T16:34:34Z | 2022-05-09T16:40:09Z | https://github.com/kubernetes/kubernetes/issues/109918 | 1,229,976,342 | 109,918 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I installed Docker, https://github.com/Mirantis/cri-dockerd, and Kubernetes release 1.24. I used `hack/local-up-cluster.sh` to start a single-node local cluster, without specifying `CONTAINER_RUNTIME_ENDPOINT`, so it defaulted to `unix:///run/containerd/containerd.sock` --- which is indeed a thing,... | Confusing log from kubelet crash when `--container-runtime-endpoint` is wrong | https://api.github.com/repos/kubernetes/kubernetes/issues/109917/comments | 12 | 2022-05-09T16:16:25Z | 2024-06-17T10:58:52Z | https://github.com/kubernetes/kubernetes/issues/109917 | 1,229,956,599 | 109,917 |
[
"kubernetes",
"kubernetes"
] | Context: Tests marked as failing in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
CI Job | Days | URL
-- | -- | --
ci-kubernetes-coverage-conformance | 433 | https://testgrid.k8s.io/sig-testing-canaries#ci-kubernetes-coverage-conformance
ci-kubernetes-coverage-e2e-gci-gce | 433 | https://testg... | [failing-test] SIG-Testing as of May 9th | https://api.github.com/repos/kubernetes/kubernetes/issues/109916/comments | 13 | 2022-05-09T15:29:59Z | 2022-10-31T04:43:07Z | https://github.com/kubernetes/kubernetes/issues/109916 | 1,229,902,320 | 109,916 |
[
"kubernetes",
"kubernetes"
] | Context: Tests marked as failing in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
CI Job | Days | URL
-- | -- | --
ci-kubernetes-e2e-gci-gce-scalability-node-killer | 298 | https://testgrid.k8s.io/sig-scalability-experiments#gce-cos-master-scalability-100-nodekiller
ci-kubernetes-kubemark-100-... | [failing-test] SIG-Scalability as of May 9th | https://api.github.com/repos/kubernetes/kubernetes/issues/109915/comments | 6 | 2022-05-09T15:28:15Z | 2022-11-16T13:45:34Z | https://github.com/kubernetes/kubernetes/issues/109915 | 1,229,900,067 | 109,915 |
[
"kubernetes",
"kubernetes"
] | Context: Tests marked as failing in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
CI Job | Days | URL
-- | -- | --
ci-kubernetes-e2e-gci-gce-flaky | 175 | https://testgrid.k8s.io/sig-api-machinery-gce-gke#gce-flaky
ci-kubernetes-soak-gce-gci | 52 | https://testgrid.k8s.io/google-soak#gce-gci
... | [failing-test] SIG-Cloud Provider as of May 9th | https://api.github.com/repos/kubernetes/kubernetes/issues/109913/comments | 13 | 2022-05-09T15:20:03Z | 2022-11-20T04:23:28Z | https://github.com/kubernetes/kubernetes/issues/109913 | 1,229,889,384 | 109,913 |
[
"kubernetes",
"kubernetes"
] | Context: Tests marked as failing in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
CI Job | Days | URL
-- | -- | --
ci-ingress-gce-e2e | 139 | https://testgrid.k8s.io/sig-network-ingress-gce-e2e#ingress-gce-e2e
ci-ingress-gce-e2e-canary | 139 | https://testgrid.k8s.io/sig-testing-canaries#ingre... | [failing-test] SIG-Network as of May 9th | https://api.github.com/repos/kubernetes/kubernetes/issues/109912/comments | 10 | 2022-05-09T15:17:18Z | 2022-08-24T11:44:16Z | https://github.com/kubernetes/kubernetes/issues/109912 | 1,229,885,532 | 109,912 |
[
"kubernetes",
"kubernetes"
] | Context: Tests marked as failing in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
CI Job | Days | URL
-- | -- | --
ci-containerd-soak-cos-gce | 64 | https://testgrid.k8s.io/sig-node-cos#soak-cos-gce
ci-cri-containerd-e2e-cos-gce-flaky | 174 | https://testgrid.k8s.io/sig-node-cos#soak-cos-gce
... | [failing-tests] SIG-Node failing tests as of May 9th | https://api.github.com/repos/kubernetes/kubernetes/issues/109911/comments | 12 | 2022-05-09T15:13:18Z | 2023-01-14T00:50:43Z | https://github.com/kubernetes/kubernetes/issues/109911 | 1,229,880,342 | 109,911 |
[
"kubernetes",
"kubernetes"
] | Context: Tests marked as failing in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
CI Jobs | Days | URL
-- | -- | --
canary-nfs-subdir-external-provisioner-push-images | 475 | https://testgrid.k8s.io/sig-k8s-infra-gcb#canary-nfs-subdir-external-provisioner-push-images
canary-sig-storage-local... | [failing-tests] SIG-Storage failing tests as of May 9th | https://api.github.com/repos/kubernetes/kubernetes/issues/109910/comments | 18 | 2022-05-09T15:10:32Z | 2022-10-29T16:33:06Z | https://github.com/kubernetes/kubernetes/issues/109910 | 1,229,876,591 | 109,910 |
[
"kubernetes",
"kubernetes"
] | Context: Tests marked as failing in https://storage.cloud.google.com/k8s-metrics/failures-latest.json
- [ ] [ci-kubernetes-e2e-aks-engine-azure-master-windows-20h2-containerd](https://testgrid.k8s.io/sig-windows-sac#aks-engine-windows-20h2-containerd-master) | 36 |
- [ ] [ci-kubernetes-e2e-windows-20h2-containerd-... | [failing-tests] SIG-Windows failing tests as of May 9th | https://api.github.com/repos/kubernetes/kubernetes/issues/109908/comments | 7 | 2022-05-09T15:05:07Z | 2022-10-24T20:45:26Z | https://github.com/kubernetes/kubernetes/issues/109908 | 1,229,869,439 | 109,908 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Pod resize E2E tests need a test case to revert the applied patch and verify that the original values are restored.
PR discussion: https://github.com/kubernetes/kubernetes/pull/102884#discussion_r865662604
This should be done for both cases:
1. Fully actuated and resized resou... | [FG:InPlacePodVerticalScaling] Add E2E test case to revert resource resize patch | https://api.github.com/repos/kubernetes/kubernetes/issues/109905/comments | 25 | 2022-05-09T13:50:31Z | 2024-10-22T00:37:00Z | https://github.com/kubernetes/kubernetes/issues/109905 | 1,229,746,096 | 109,905 |
[
"kubernetes",
"kubernetes"
] | <!--
!!! IMPORTANT !!!
Before hitting the submit button, please note that requests for support must be sent
to the support channels or #kubeadm on k8s Slack and not this issue tracker:
https://git.k8s.io/kubernetes/SUPPORT.md
If you are experiencing a problem make sure you check the Kubernetes and kubeadm
tr... | kubeadm 1.19.16 from yum repo installs kubelet and kubectl to 1.24 , cri-tools to 1.23 as a dependency | https://api.github.com/repos/kubernetes/kubernetes/issues/109906/comments | 6 | 2022-05-09T12:58:23Z | 2022-10-06T15:35:33Z | https://github.com/kubernetes/kubernetes/issues/109906 | 1,229,791,205 | 109,906 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If the user update job.status.conditions, duplicate condition:
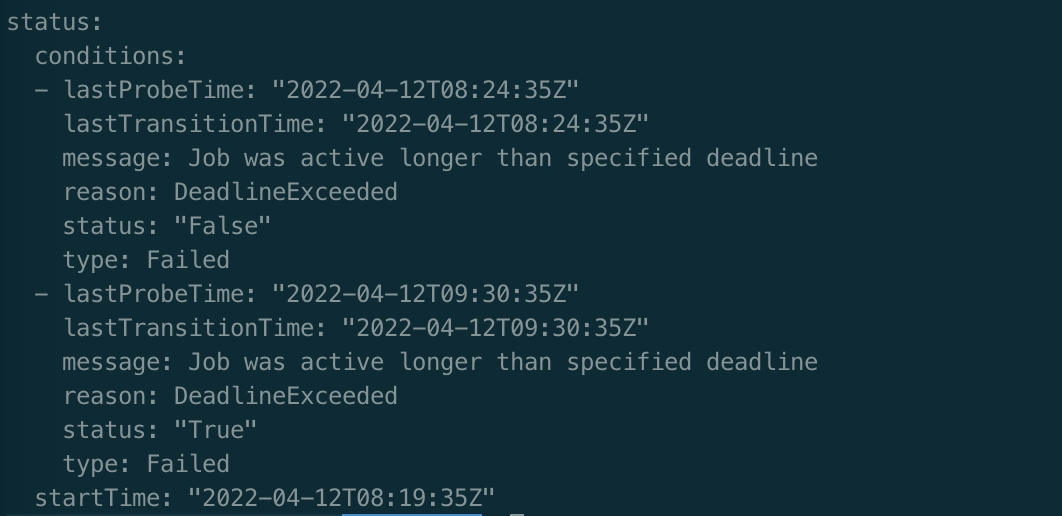
### What did you expect to happen?
Only one Failed condition
### How can we reproduce it (as minimally and pre... | Duplicate Failed condition in job status | https://api.github.com/repos/kubernetes/kubernetes/issues/109904/comments | 9 | 2022-05-09T11:40:56Z | 2022-06-09T21:01:45Z | https://github.com/kubernetes/kubernetes/issues/109904 | 1,229,579,166 | 109,904 |
[
"kubernetes",
"kubernetes"
] | > Kubernetes e2e suite: [sig-node] Downward API should provide pod UID as env vars [NodeConformance] [Conformance] expand_less
I start to see this failures on Node tests more often :eyes:
/retest
_Originally posted by @aojea in https://github.com/kubernetes/kubernetes/issues/109899#issuecomment-1120983277_
... | [Flake-test] Kubernetes e2e suite: [sig-node] Downward API should provide pod UID as env vars [NodeConformance] [Conformance] | https://api.github.com/repos/kubernetes/kubernetes/issues/109903/comments | 4 | 2022-05-09T11:36:43Z | 2022-05-09T11:38:18Z | https://github.com/kubernetes/kubernetes/issues/109903 | 1,229,574,669 | 109,903 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
- Create a Job
- Wait job to exceeded it's deadline
- First, it marked as DeadlineExceeded: True and Failed: 1
- Second, it marked as DeadlineExceeded: True and Failed: 0
job:
```
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: job-failed
spec:
concurrencyPolicy: Allow
... | Job status have been updated after it's marked as DeadlineExceeded | https://api.github.com/repos/kubernetes/kubernetes/issues/109902/comments | 14 | 2022-05-09T10:53:54Z | 2023-04-07T14:19:16Z | https://github.com/kubernetes/kubernetes/issues/109902 | 1,229,527,809 | 109,902 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are using Kubernetes 1.21. deployed using kubespray.
to enable secure ports, we have added the below configuration in the controller as well as a scheduler.
- --port=0
- - --secure-port=10257/10259.
- bind-address=127.0.0.1
we accessing from outside, still can see 10251 port(insecure) ... | kube-scheduler: disabling insecure port does not work (1.21) | https://api.github.com/repos/kubernetes/kubernetes/issues/109900/comments | 15 | 2022-05-09T08:56:33Z | 2022-10-16T19:32:38Z | https://github.com/kubernetes/kubernetes/issues/109900 | 1,229,394,395 | 109,900 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Some Pods in Kubernetes scheduler's internal cache don't have `PodScheduled` condition in their status.
We store scheduled pods information into cache as assumedPod before binding Pod.
https://github.com/kubernetes/kubernetes/blob/7af5a7bfc51d0455d8b2322ae9e72ed66fb1b8f9/pkg/scheduler/schedu... | scheduled Pods in Kubernetes scheduler's internal cache don't have PodScheduled condition until they are next updated | https://api.github.com/repos/kubernetes/kubernetes/issues/109894/comments | 6 | 2022-05-08T18:54:09Z | 2022-09-20T15:09:24Z | https://github.com/kubernetes/kubernetes/issues/109894 | 1,228,960,939 | 109,894 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-e2e-kind
### Which tests are flaking?
Kubernetes e2e suite: [sig-node] Pods Extended Pod Container Status should never report container start when an init container fails
### Since when has it been flaking?
unknown
### Testgrid link
https://testgrid.k8s.io/presubmits-... | [Flaky] Kubernetes e2e suite: [sig-node] Pods Extended Pod Container Status should never report container start when an init container fails | https://api.github.com/repos/kubernetes/kubernetes/issues/109890/comments | 3 | 2022-05-08T06:10:01Z | 2022-05-08T06:14:01Z | https://github.com/kubernetes/kubernetes/issues/109890 | 1,228,803,337 | 109,890 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-unit
### Which tests are flaking?
TestClientReceivedGOAWAY
### Since when has it been flaking?
unknown
### Testgrid link
https://testgrid.k8s.io/presubmits-kubernetes-blocking#pull-kubernetes-unit&include-filter-by-regex=TestClientReceivedGOAWAY
### Reason for failure... | Flaky unit test: TestClientReceivedGOAWAY | https://api.github.com/repos/kubernetes/kubernetes/issues/109889/comments | 7 | 2022-05-08T05:40:12Z | 2022-10-10T23:35:19Z | https://github.com/kubernetes/kubernetes/issues/109889 | 1,228,799,208 | 109,889 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I don't understand what that means
### Why is this needed?
If I have two hosts now and add them later, can I also copy the certificate to other hosts through master1 and then execute kubeadm join to join the cluster? | kubeadm-config.yaml certSANs | https://api.github.com/repos/kubernetes/kubernetes/issues/109887/comments | 4 | 2022-05-08T02:58:59Z | 2022-05-09T08:14:16Z | https://github.com/kubernetes/kubernetes/issues/109887 | 1,228,777,915 | 109,887 |
[
"kubernetes",
"kubernetes"
] | group system:bootstrappers is existed and role system:node-bootstrapper is existed;
but no clusterRoleBinding
why do this?
sometimes I need group system:bootstrappers have this permission only by creating it by myself after cluster is ready. | Why is there no clusterRoleBinding that binds the kubelet-bootstrap with the ClusterRole system:node-bootstrapper | https://api.github.com/repos/kubernetes/kubernetes/issues/109885/comments | 4 | 2022-05-07T07:53:08Z | 2022-05-09T22:15:53Z | https://github.com/kubernetes/kubernetes/issues/109885 | 1,228,560,804 | 109,885 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.