
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### What happened?
Whet GCE is throttling Kubernetes kube-controller-manager and returns `RATE_LIMIT_EXCEEDED` when provisioning a new GCP PD volume, kube-controller-manager [re-schedules](https://github.com/kubernetes/kubernetes/blob/820247a3aec7d7d1e65cd5ad34b0f07adb16e907/pkg/controller/volume/persistentvolume/pv_c... | GCP volume plugin can provision multiple volumes for a single PVC | https://api.github.com/repos/kubernetes/kubernetes/issues/109335/comments | 8 | 2022-04-06T12:46:39Z | 2022-09-06T16:44:10Z | https://github.com/kubernetes/kubernetes/issues/109335 | 1,194,566,163 | 109,335 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a file that I mount in /etc and if I use hostAliases feature then pod goes into RunContainerError state.
### What did you expect to happen?
I expected the pod to be deployed without errors.
### How can we reproduce it (as minimally and precisely as possible)?
Here is a sample config that ... | Cannot use hostAliases when mounting files in /etc | https://api.github.com/repos/kubernetes/kubernetes/issues/109331/comments | 24 | 2022-04-06T07:58:59Z | 2024-05-08T21:59:12Z | https://github.com/kubernetes/kubernetes/issues/109331 | 1,194,221,550 | 109,331 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The newly introduced in-tree PV deletion protection finalizer is currently being added to all PVs without consideration of the reclaim policy.
### What did you expect to happen?
The finalizer needs to be added only when reclaimPolicy on the PV is `Delete`. In other cases the finalizer needs to be ... | Add PV deletion protection finalizer only if reclaimPolicy is `Delete` | https://api.github.com/repos/kubernetes/kubernetes/issues/109330/comments | 4 | 2022-04-06T07:42:40Z | 2022-04-07T09:57:58Z | https://github.com/kubernetes/kubernetes/issues/109330 | 1,194,196,969 | 109,330 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Introduce new interface `JointIndexer` by side `ThreadSafeStore` to support complicated index.
Proposal as bellow:
```go
// JointIndexer for doing convenient joint index against indexer by
// given IndexConditions and JointIndexOptions.
type JointIndexer interface {
// B... | ThreadSafeStore support complicated index | https://api.github.com/repos/kubernetes/kubernetes/issues/109329/comments | 23 | 2022-04-06T07:34:35Z | 2024-04-11T16:46:22Z | https://github.com/kubernetes/kubernetes/issues/109329 | 1,194,187,277 | 109,329 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When the in-tree GCE PD storage driver are used on PVs with regional storage, GCE regional disk have possibility not to be deleted after the PV resource being deleted.
This issue is caused by error handling logic in in-tree GCE PD storage driver. If the API request to delete regional disks are ... | In-tree GCE PD storage driver can leaks regional GCE PD when related PV is deleted | https://api.github.com/repos/kubernetes/kubernetes/issues/109328/comments | 8 | 2022-04-06T06:29:25Z | 2022-04-27T03:20:09Z | https://github.com/kubernetes/kubernetes/issues/109328 | 1,194,110,588 | 109,328 |
[
"kubernetes",
"kubernetes"
] | below is my yml file
```
kind: Pod
apiVersion: v1
metadata:
name: testpod4
spec:
containers:
- name: c00
image: httpd
ports:
- containerPort: 80
```
kubectl apply -f pod1.yml
error:error validating "ppod.yml" error validation :kind not set; if you choose to ignore thes... | Unable to create pod in minikube | https://api.github.com/repos/kubernetes/kubernetes/issues/109327/comments | 6 | 2022-04-06T05:48:26Z | 2022-04-11T15:06:51Z | https://github.com/kubernetes/kubernetes/issues/109327 | 1,194,073,798 | 109,327 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
capz-windows-containerd-master
### Which tests are failing?
- Kubernetes e2e suite.BeforeSuite
- Kubernetes e2e suite.[sig-network] Networking Granular Checks: Pods should function for node-pod communication: http [NodeConformance] [Conformance]
- Kubernetes e2e suite.[sig-network] Netw... | [Failing test] capz-windows-containerd-master | https://api.github.com/repos/kubernetes/kubernetes/issues/109325/comments | 3 | 2022-04-06T03:19:45Z | 2022-04-07T12:16:35Z | https://github.com/kubernetes/kubernetes/issues/109325 | 1,193,955,188 | 109,325 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
gcloud container images list-tags k8s.gcr.io/build-image/debian-base --filter="tags~bullseye" --sort-by=tags
DIGEST TAGS TIMESTAMP
aa2e259dfe20 bullseye-v1.0.0 1969-12-31T16:00:00
c9026ac9ebc6 bullseye-v1.1.0 1969-12-31T16:00:00
8049cfc553b1 bullseye-v1.... | Update zlib in debian-base:bullseye-v1.2.0 (latest) to patch CVE-2018-25032 | https://api.github.com/repos/kubernetes/kubernetes/issues/109319/comments | 6 | 2022-04-05T21:53:04Z | 2022-09-02T22:05:11Z | https://github.com/kubernetes/kubernetes/issues/109319 | 1,193,757,741 | 109,319 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
node-kubelet-serial-crio: https://testgrid.k8s.io/sig-node-cri-o#node-kubelet-serial-crio&show-stale-tests=
### Which tests are failing?
Tests fail to run.
### Since when has it been failing?
Since 03/23. First failure: https://prow.k8s.io/view/gs/kubernetes-jenkins/logs/ci-kubernetes-n... | node-kubelet-serial-crio job is failing/erroring | https://api.github.com/repos/kubernetes/kubernetes/issues/109317/comments | 9 | 2022-04-05T21:29:48Z | 2022-09-21T17:19:06Z | https://github.com/kubernetes/kubernetes/issues/109317 | 1,193,738,284 | 109,317 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-kubernetes-e2e-capz-master-containerd-windows
### Which tests are failing?
should function for node-pod communication: http [NodeConformance]
should function for node-pod communication: udp [NodeConformance]
### Since when has it been failing?
PR https://github.com/kubernetes/kube... | Windows Capz: should function for node-pod communication: http/udp [NodeConformance] | https://api.github.com/repos/kubernetes/kubernetes/issues/109313/comments | 5 | 2022-04-05T17:15:56Z | 2022-04-06T02:42:55Z | https://github.com/kubernetes/kubernetes/issues/109313 | 1,193,490,867 | 109,313 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When applying a single resource (and instructed to -o yaml/json) kubectl will print that object directly, instead of printing it in an "items" array - as it does when applying multiple objects.
However, if instructed to also --prune resources then it will print the pruned resources but won't take... | Broken output schema running `kubectl apply --prune --dry-run=xyz -o yaml/json` with a single resource created. | https://api.github.com/repos/kubernetes/kubernetes/issues/109309/comments | 3 | 2022-04-05T13:10:10Z | 2022-04-05T13:12:06Z | https://github.com/kubernetes/kubernetes/issues/109309 | 1,193,130,188 | 109,309 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet reports grpc: received message larger than max (6464720 vs. 4194304) when call devicemanager's ListAndWatch
### What did you expect to happen?
kubelet can handle such grpc calls if the data size exceeds 4M
### How can we reproduce it (as minimally and precisely as possible)?
it reproduc... | default max size 4M of grpc is too small for devicemanager | https://api.github.com/repos/kubernetes/kubernetes/issues/109304/comments | 7 | 2022-04-05T09:02:40Z | 2022-09-03T19:12:32Z | https://github.com/kubernetes/kubernetes/issues/109304 | 1,192,841,940 | 109,304 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet crash
[k8s.io]()/[kubernetes]()/[pkg]()/[kubelet]()/[cm.]()([*qosContainerManagerImpl]())[.setCPUCgroupConfig]()
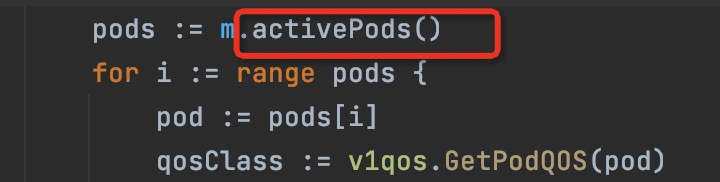
activePods is nil
### What did you expect to happen?
no c... | kubelet nil pointer | https://api.github.com/repos/kubernetes/kubernetes/issues/109301/comments | 3 | 2022-04-05T06:44:35Z | 2022-04-05T12:10:34Z | https://github.com/kubernetes/kubernetes/issues/109301 | 1,192,693,372 | 109,301 |
[
"kubernetes",
"kubernetes"
] | When adding log statements in Kubernetes it can sometimes be difficult to tell just how frequent a code path is. For example: https://github.com/kubernetes/kubernetes/pull/109181, or any of about 500 issues & PRs: https://github.com/kubernetes/kubernetes/issues?q=log+spam
I'd like to add infrastructure to all our te... | Detect log-spam in tests | https://api.github.com/repos/kubernetes/kubernetes/issues/109297/comments | 10 | 2022-04-04T22:04:47Z | 2024-11-05T16:43:45Z | https://github.com/kubernetes/kubernetes/issues/109297 | 1,192,362,149 | 109,297 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
sig-node-cri-o#ci-crio-cgroupv1-node-e2e-flaky
### Which tests are failing?
E2eNode Suite.[sig-node] CriticalPod [Serial] [Disruptive] [NodeFeature:CriticalPod] when we need to admit a critical pod [Flaky] should be able to create and delete a critical pod
https://prow.k8s.io/view/gs/k... | [sig-node] CriticalPod [Serial] [Disruptive] [NodeFeature:CriticalPod] when we need to admit a critical pod [Flaky] should be able to create and delete a critical pod | https://api.github.com/repos/kubernetes/kubernetes/issues/109296/comments | 11 | 2022-04-04T21:36:19Z | 2023-07-06T07:51:05Z | https://github.com/kubernetes/kubernetes/issues/109296 | 1,192,340,586 | 109,296 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
[sig-node-containerd#node-kubelet-containerd-performance-test](https://testgrid.k8s.io/sig-node-containerd#node-kubelet-containerd-performance-test)
### Which tests are failing?
E2eNode Suite.[sig-node] Node Performance Testing [Serial] [Slow] Run node performance testing with pre-defined... | [sig-node] Node Performance Testing [Serial] [Slow] Run node performance testing with pre-defined workloads TensorFlow workload | https://api.github.com/repos/kubernetes/kubernetes/issues/109295/comments | 41 | 2022-04-04T21:18:42Z | 2022-11-02T17:19:44Z | https://github.com/kubernetes/kubernetes/issues/109295 | 1,192,325,588 | 109,295 |
[
"kubernetes",
"kubernetes"
] | null | [plugins.cri] | https://api.github.com/repos/kubernetes/kubernetes/issues/109291/comments | 2 | 2022-04-04T18:28:47Z | 2022-05-04T15:48:55Z | https://github.com/kubernetes/kubernetes/issues/109291 | 1,192,158,216 | 109,291 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We're using a long-running process that connects to thousands of kubernetes cluster via client-go (not all simultaneously).
We noticed that the more kubernetes clusters we connect to and the longer the process runs, the more memory our process consumes over time.
An analysis with pprof confirmed t... | Memleak in client-go transport.tlsCache | https://api.github.com/repos/kubernetes/kubernetes/issues/109289/comments | 16 | 2022-04-04T14:50:27Z | 2024-07-23T20:27:42Z | https://github.com/kubernetes/kubernetes/issues/109289 | 1,191,910,777 | 109,289 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A `CronJob` that is scheduled to run every minute is updated. After the update, the `CronJob` stops scheduling.
Investigation reveals the following:
1. The existing `Job` and it's associated `Pod` remain in a `completed` state, and are not removed by the scheduler
2. The `CronJob` reports... | CronJobs Stall After Update - Existing Jobs Not Removed | https://api.github.com/repos/kubernetes/kubernetes/issues/109287/comments | 10 | 2022-04-04T14:12:19Z | 2022-10-15T15:22:37Z | https://github.com/kubernetes/kubernetes/issues/109287 | 1,191,857,075 | 109,287 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Before switching the `kube-proxy` modes from `IPVS` to `IPTables` it makes sense to cleanup unnecessary `iptables` rules. This can be done using the `--cleanup` command line option of `kube-proxy`. Unfortunately, this does not work anymore since `KUBE-NODE-PORT` was introduced into the `filter` tabl... | Kube-proxy fails to cleanup properly in IPVS mode | https://api.github.com/repos/kubernetes/kubernetes/issues/109286/comments | 4 | 2022-04-04T14:05:54Z | 2022-05-04T02:30:48Z | https://github.com/kubernetes/kubernetes/issues/109286 | 1,191,847,421 | 109,286 |
[
"kubernetes",
"kubernetes"
] | Nowadays, when the kube-scheduler is initialized, the provided component config (via `--config` flag) is logged. E.g.
```
I0404 08:35:16.471898 1 configfile.go:96] Using component config
-------------------------Configuration File Contents Start Here----------------------
apiVersion: kubescheduler.config.k8s... | scheduler: enabled plugins not logged during initialization | https://api.github.com/repos/kubernetes/kubernetes/issues/109285/comments | 21 | 2022-04-04T12:34:45Z | 2023-12-13T21:34:08Z | https://github.com/kubernetes/kubernetes/issues/109285 | 1,191,719,828 | 109,285 |
[
"kubernetes",
"kubernetes"
] | ## References
* https://github.com/kubernetes/kubernetes/issues/76703
* https://github.com/kubernetes/kubernetes/issues/75980
* https://github.com/kubernetes/kubernetes/pull/80492
* https://github.com/kubernetes/design-proposals-archive/blob/main/storage/postpone-pvc-deletion-if-used-in-a-pod.md
## Overview
A... | PVCProtectionController can be slow for larger clusters | https://api.github.com/repos/kubernetes/kubernetes/issues/109282/comments | 44 | 2022-04-04T09:26:48Z | 2024-08-14T01:52:43Z | https://github.com/kubernetes/kubernetes/issues/109282 | 1,191,505,254 | 109,282 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
- sig-release-master-blocking gce-cos-master-default
### Which tests are flaking?
- Kubernetes e2e suite.[sig-node] NodeProblemDetector should run without error
### Since when has it been flaking?
not clear
### Testgrid link
https://testgrid.k8s.io/sig-release-master-blocking#gce-cos-... | [Flaky test] gce-cos-master-default, node problem detector | https://api.github.com/repos/kubernetes/kubernetes/issues/109281/comments | 8 | 2022-04-04T08:49:12Z | 2022-04-06T17:22:31Z | https://github.com/kubernetes/kubernetes/issues/109281 | 1,191,459,722 | 109,281 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
- sig-release-master-blocking gce-cos-master-default
### Which tests are flaking?
Kubernetes e2e suite.[sig-apps] Job should delete pods when suspended
### Since when has it been flaking?
not clear
### Testgrid link
https://testgrid.k8s.io/sig-release-master-blocking#gce-cos-master-de... | [Flaky test] gce-cos-master-default, e2e test cannot create ns | https://api.github.com/repos/kubernetes/kubernetes/issues/109280/comments | 5 | 2022-04-04T08:41:58Z | 2022-04-08T12:04:42Z | https://github.com/kubernetes/kubernetes/issues/109280 | 1,191,452,075 | 109,280 |
[
"kubernetes",
"kubernetes"
] | Noticed while reproducing https://github.com/kubernetes/kubernetes/issues/109215#issuecomment-1087037419 with client-side validation:
> `error: error validating "/Users/liggitt/tmp/default-spiffeid.yaml.txt": error validating data: ValidationError(SpiffeID.metadata): unknown field "unknown" in io.k8s.apimachinery.pk... | openapi for custom resources references second set of meta types (ObjectMeta_v2, etc) | https://api.github.com/repos/kubernetes/kubernetes/issues/109275/comments | 9 | 2022-04-04T03:39:06Z | 2022-06-14T20:14:43Z | https://github.com/kubernetes/kubernetes/issues/109275 | 1,191,205,266 | 109,275 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The following test failures started happening on 30th March:
* Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: aws] [Testpattern: Inline-volume (default fs)] volumes should allow exec of files on the volume
* Kubernetes e2e suite.[sig-storage] In-tree Volumes [Driver: aws] [Testpattern... | Several in-tree volumes tests started failing with nil pointer errors | https://api.github.com/repos/kubernetes/kubernetes/issues/109264/comments | 9 | 2022-04-03T10:40:09Z | 2022-04-04T21:35:48Z | https://github.com/kubernetes/kubernetes/issues/109264 | 1,190,891,394 | 109,264 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet won't return error when invalid node labels are passed to `--node-labels` flag, and node can't take part in a cluster.
### What did you expect to happen?
kubelet should return errors when invalid node labels are passed.
### How can we reproduce it (as minimally and precisely as po... | kubelet --node-labels flag doesn't validate labels | https://api.github.com/repos/kubernetes/kubernetes/issues/109262/comments | 4 | 2022-04-03T10:02:02Z | 2022-07-30T04:22:27Z | https://github.com/kubernetes/kubernetes/issues/109262 | 1,190,883,016 | 109,262 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Attempting to deploy autoscaling to my cluster, but the target shows "unknown", I have tried different metrics servers to no avail. I followed [this githhub issue](https"//github.com/kubernetes/minikube/issues4456/) even thought I'm using Kubeadm not minikube and it did not change the problem.
... | Horizontal Pod Autoscaling Targets shows <unknown>/50% with "kubectl get hpa" | https://api.github.com/repos/kubernetes/kubernetes/issues/109260/comments | 3 | 2022-04-02T22:06:49Z | 2022-04-03T16:06:38Z | https://github.com/kubernetes/kubernetes/issues/109260 | 1,190,750,404 | 109,260 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-integration
### Which tests are flaking?
TestDeploymentAvailableCondition
https://storage.googleapis.com/k8s-triage/index.html?pr=1&test=TestDeploymentAvailableCondition
### Since when has it been flaking?
Several weeks according to https://storage.googleapis.com/k8s-... | [Flake] k8s.io/kubernetes/test/integration/deployment.TestDeploymentAvailableCondition | https://api.github.com/repos/kubernetes/kubernetes/issues/109258/comments | 5 | 2022-04-02T17:18:18Z | 2022-08-30T18:28:13Z | https://github.com/kubernetes/kubernetes/issues/109258 | 1,190,689,550 | 109,258 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
script [spec-to-yaml.sh](https://github.com/kubernetes/kubernetes/blob/master/test/conformance/spec-to-yaml.sh) result to a nil pointer dereference exception
e.g.
`go run ./test/conformance/walk.go --source=/go/src/k8s.io/kubernetes ./_output/specsummaries.json > ./_output/conformance.yaml`
s... | invalid memory address or nil pointer dereference | https://api.github.com/repos/kubernetes/kubernetes/issues/109255/comments | 3 | 2022-04-02T08:53:01Z | 2022-04-05T20:33:37Z | https://github.com/kubernetes/kubernetes/issues/109255 | 1,190,564,763 | 109,255 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The newly introduced PV Deletion Protection finalizer is not being added on statically provisioned volumes.
The finalizer needs to be added only when the reclaimPolicy is Delete
### What did you expect to happen?
Statically provisioned PV is expected to have the finalizer.
### How can we reprodu... | Fix PV Controller to add the PV Deletion protection finalizer on statically provisioned volumes | https://api.github.com/repos/kubernetes/kubernetes/issues/109253/comments | 10 | 2022-04-02T07:45:51Z | 2022-12-29T18:46:39Z | https://github.com/kubernetes/kubernetes/issues/109253 | 1,190,543,659 | 109,253 |
[
"kubernetes",
"kubernetes"
] | As a cluster admin, sometimes I want to make advanced changes to objects in the cluster, but apiserver rejects them due to "validation errors". I should be able to pass a `--yolo` flag to apiserver so that I can make the changes that normal users are prevented from making. | apiserver: add a --yolo flag to run without validation | https://api.github.com/repos/kubernetes/kubernetes/issues/109243/comments | 8 | 2022-04-01T17:12:44Z | 2022-04-12T19:01:30Z | https://github.com/kubernetes/kubernetes/issues/109243 | 1,190,071,751 | 109,243 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The scheduler cache entered a corrupted state where a Pod, according to the cache dump, was nominated to node A, while the status said it was nominated to node B.
This lead to unschedulable low priority pods due to the phantom pod in the nominator cache.
### What did you expect to happen?
... | Nominated node in cache didn't match Pod status | https://api.github.com/repos/kubernetes/kubernetes/issues/109236/comments | 9 | 2022-04-01T13:52:31Z | 2022-04-04T19:55:52Z | https://github.com/kubernetes/kubernetes/issues/109236 | 1,189,829,320 | 109,236 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
agnhost netexec http dialer resolves hostnames and sets host: field to IP address
netexec resolves here:
https://github.com/kubernetes/kubernetes/blob/master/test/images/agnhost/netexec/netexec.go#L380
with: https://pkg.go.dev/net#ResolveTCPAddr
But then when calling the actual URL, the host... | agnhost netexec http dialer resolves hostnames and sets host: field to IP address | https://api.github.com/repos/kubernetes/kubernetes/issues/109234/comments | 12 | 2022-04-01T13:28:27Z | 2022-04-19T21:41:16Z | https://github.com/kubernetes/kubernetes/issues/109234 | 1,189,798,370 | 109,234 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
we usually find kubeadm join has the problem:
failed to verify JWS signature of received cluster info object, can't trust this API Server
or
could not find a JWS signature in the cluster-info ConfigMap for token ID
when we update cluster-info or bootstrap-token, the controller-manager didn't upd... | failed to verify JWS signature of received cluster info object, can't trust this API Server | https://api.github.com/repos/kubernetes/kubernetes/issues/109233/comments | 18 | 2022-04-01T13:25:25Z | 2023-01-13T07:40:41Z | https://github.com/kubernetes/kubernetes/issues/109233 | 1,189,794,674 | 109,233 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We found go vet issues of `lostcancel` in #109184. (It seems that go vet checks are not running under `/staging` dir.)
```
staging/src/k8s.io/legacy-cloud-providers/vsphere/nodemanager.go:190:5: lostcancel: the cancel function is not used on all paths (possible context leak) (govet)
ctx, ... | go vet lostcancel errors in legacy-cloud-providers files | https://api.github.com/repos/kubernetes/kubernetes/issues/109229/comments | 16 | 2022-04-01T10:44:47Z | 2025-02-27T16:09:21Z | https://github.com/kubernetes/kubernetes/issues/109229 | 1,189,609,979 | 109,229 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [375262914f6b6fdcb255](https://go.k8s.io/triage#375262914f6b6fdcb255)
https://storage.googleapis.com/k8s-triage/index.html?text=TestValidationExpressions
##### Error text:
```
=== RUN TestValidationExpressions/numeric_comparisons/double(self.val1)_<=_self.val4
=== PAUSE TestValidationExpres... | TestValidationExpressions timeout 10m | https://api.github.com/repos/kubernetes/kubernetes/issues/109225/comments | 4 | 2022-04-01T08:58:56Z | 2022-04-05T20:26:14Z | https://github.com/kubernetes/kubernetes/issues/109225 | 1,189,478,158 | 109,225 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [eaae6b081be71c9eb16c](https://go.k8s.io/triage#eaae6b081be71c9eb16c)
##### Error text:
```
test/e2e/network/service.go:2583
Mar 30 08:33:56.880: Unexpected error:
<exec.CodeExitError>: {
Err: {
s: "error running /workspace/kubernetes/platforms/linux/amd64/kubectl --... | [sig-network] Services should fallback to terminating endpoints when there are no ready endpoints with externallTrafficPolicy=Cluster [Feature:ProxyTerminatingEndpoints] | https://api.github.com/repos/kubernetes/kubernetes/issues/109223/comments | 6 | 2022-04-01T08:12:25Z | 2022-05-09T13:52:05Z | https://github.com/kubernetes/kubernetes/issues/109223 | 1,189,428,949 | 109,223 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [40476fd6c5f93bc05764](https://go.k8s.io/triage#40476fd6c5f93bc05764)
##### Error text:
```
test/e2e/node/kubelet.go:421
Mar 29 00:40:32.646: Failed to create "nfs-server" pod: pods "nfs-server" is forbidden: violates PodSecurity "baseline:latest": privileged (container "nfs-server" must not s... | Flaky [sig-node] kubelet host cleanup with volume mounts [HostCleanup][Flaky] | https://api.github.com/repos/kubernetes/kubernetes/issues/109221/comments | 4 | 2022-04-01T07:23:46Z | 2022-04-02T04:22:23Z | https://github.com/kubernetes/kubernetes/issues/109221 | 1,189,365,642 | 109,221 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```bash
$ go test ./pkg/apis/batch/validation -run TestValidateCronJob
--- FAIL: TestValidateCronJob (0.01s)
validation_test.go:1355: expected failure for spec.timeZone: Invalid value: "AMERICA/new_york": unknown time zone AMERICA/new_york
validation_test.go:1378: expected failure for... | TestValidateCronJob cant pass in macos | https://api.github.com/repos/kubernetes/kubernetes/issues/109220/comments | 6 | 2022-04-01T06:55:06Z | 2022-04-04T14:38:12Z | https://github.com/kubernetes/kubernetes/issues/109220 | 1,189,332,452 | 109,220 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When creating a CRD object this error is printed;
```
Error from server (BadRequest): error when creating "/etc/kubernetes/default-spiffeid.yaml": SpiffeID in version "v1beta1" cannot be handled as a SpiffeID: strict decoding error: unknown field "metadata.annotations", unknown field "metadata.nam... | server-side field validation rejects metadata fields as unknown fields | https://api.github.com/repos/kubernetes/kubernetes/issues/109215/comments | 11 | 2022-04-01T05:57:33Z | 2022-07-19T12:47:15Z | https://github.com/kubernetes/kubernetes/issues/109215 | 1,189,277,889 | 109,215 |
[
"kubernetes",
"kubernetes"
] | **What happened?**
I have a HPA which use datadog metric as metric input, and the metric is capturing the request count for an endpoint. The HPA scale out the pod(s) as expected when there is request count receive. However, I notice the scale down doesn't happen when there is no metric value received for the HPA.
S... | HPA does not scale down when it fail to fetch external data | https://api.github.com/repos/kubernetes/kubernetes/issues/109214/comments | 16 | 2022-04-01T04:34:52Z | 2023-03-09T00:13:42Z | https://github.com/kubernetes/kubernetes/issues/109214 | 1,189,221,673 | 109,214 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I created a v1.21.5 cluster. After I deleted the default cluster-admin clusterrolebinding with group `"system:masters"`, I failed to approve a pending csr with "kubectl certificate approve csr" and get the following error
Error from server (Forbidden): certificatesigningrequests.certificates.k8s.... | admission chain is given authorizer that doesn't include superuser fallback | https://api.github.com/repos/kubernetes/kubernetes/issues/109211/comments | 24 | 2022-03-31T21:43:43Z | 2022-10-19T01:57:02Z | https://github.com/kubernetes/kubernetes/issues/109211 | 1,188,842,040 | 109,211 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Looking at the [swagger specifications](https://github.com/kubernetes/kubernetes/blob/17381762dd6caafe72cda9e9c39e42405391f1e9/api/openapi-spec/v3/apis__apps__v1_openapi.json#L1207) for `StatefulSetStatus`, it defines `availableReplicas` as a required attribute. But looking at the [description](htt... | `StatefulSetStatus` attribute `availableReplicas` set to required by mistake? | https://api.github.com/repos/kubernetes/kubernetes/issues/109210/comments | 5 | 2022-03-31T21:20:59Z | 2022-04-02T02:52:20Z | https://github.com/kubernetes/kubernetes/issues/109210 | 1,188,801,090 | 109,210 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I had my cluster setup and can ping to google.com in pod, but can resolve any services.
I try debugging using the [doc](https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/)
Here's the outputs
vp@vp-VirtualBox:~$ kubectl exec -it ubuntu-pod -- bash
```
root@ubuntu-pod... | resove failed | https://api.github.com/repos/kubernetes/kubernetes/issues/109207/comments | 5 | 2022-03-31T16:57:45Z | 2022-03-31T17:40:26Z | https://github.com/kubernetes/kubernetes/issues/109207 | 1,188,377,251 | 109,207 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
[sig-release-master-informing#gce-cos-master-serial](https://testgrid.k8s.io/sig-release-master-informing#gce-cos-master-serial)
### Which tests are failing?
Kubernetes e2e suite.[sig-storage] CSI Volumes [Driver: csi-hostpath] [Testpattern: Dynamic PV (block volmode)] disruptive[Disrupti... | [Failing test] gce-cos-master-serial | https://api.github.com/repos/kubernetes/kubernetes/issues/109204/comments | 3 | 2022-03-31T15:50:18Z | 2022-04-01T15:24:21Z | https://github.com/kubernetes/kubernetes/issues/109204 | 1,188,294,050 | 109,204 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
[sig-release-master-informing#gce-master-scale-performance](https://testgrid.k8s.io/sig-release-master-informing#gce-master-scale-performance)
### Which tests are failing?
```
ClusterLoaderV2.huge-service overall (testing/huge-service/config.yaml)[Changes](https://github.com/kubernetes/k... | [Failing test] gce-master-scale-performance | https://api.github.com/repos/kubernetes/kubernetes/issues/109203/comments | 6 | 2022-03-31T15:42:28Z | 2022-04-08T10:38:28Z | https://github.com/kubernetes/kubernetes/issues/109203 | 1,188,284,275 | 109,203 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/pull/109184 found that our vet checks are not running under the `/staging` dir.
Once it ran those checks, it revealed exposure to real issues in non-test files:
```
staging/src/k8s.io/apimachinery/pkg/util/managedfields/gvkparser.go:61:39: copylocks: literal copies lock v... | copylock vet errors in staging files | https://api.github.com/repos/kubernetes/kubernetes/issues/109197/comments | 27 | 2022-03-31T13:31:08Z | 2025-03-04T21:22:06Z | https://github.com/kubernetes/kubernetes/issues/109197 | 1,188,084,576 | 109,197 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1 create deployment by yaml below
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: jktest
spec:
selector:
matchLabels:
workload.es.io: jktest
template:
metadata:
labels:
workload: jktest
spec:
containers:
- image: centos:lat... | pod created failed when devices resource request is 0 | https://api.github.com/repos/kubernetes/kubernetes/issues/109191/comments | 25 | 2022-03-31T08:30:24Z | 2024-11-19T09:08:33Z | https://github.com/kubernetes/kubernetes/issues/109191 | 1,187,704,573 | 109,191 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
ci-cadvisor-e2e
### Which tests are failing?
```
W0322 22:57:59.666] 2022/03/22 22:57:59 main.go:331: Something went wrong: encountered 1 errors: [error during go run /go/src/k8s.io/kubernetes/test/e2e_node/runner/remote/run_remote.go --cleanup --logtostderr --vmodule=*=4 --ssh-e... | ci-cadvisor-e2e failed | https://api.github.com/repos/kubernetes/kubernetes/issues/109186/comments | 9 | 2022-03-31T06:53:38Z | 2022-04-09T00:49:08Z | https://github.com/kubernetes/kubernetes/issues/109186 | 1,187,601,919 | 109,186 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
run govet in golangci-lint instead of ./hack/verify-govet.sh.
### Why is this needed?
govet can be used in golangci-lint. We don't need to run govet with `./hack/verify-govet.sh`
Also, govet itself doesn't have a way to ignore issues from the lint, but golangci-lint has.... | run govet in golangci-lint instead of ./hack/verify-govet.sh in pull-kubernetes-verify | https://api.github.com/repos/kubernetes/kubernetes/issues/109183/comments | 8 | 2022-03-31T06:09:46Z | 2022-08-29T12:23:38Z | https://github.com/kubernetes/kubernetes/issues/109183 | 1,187,565,223 | 109,183 |
[
"kubernetes",
"kubernetes"
] | Looks like we just got a spike of a new run failure message in master: https://storage.googleapis.com/k8s-triage/index.html?pr=1&text=unable%20to%20apply%20cgroup%20configuration&xjob=1-2
Seen in https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/109178/pull-kubernetes-conformance-kind-ga-only-parallel/1509... | e2e flake: OCI runtime create failed: runc create failed: unable to start container process: unable to apply cgroup configuration: failed to write | https://api.github.com/repos/kubernetes/kubernetes/issues/109182/comments | 52 | 2022-03-31T05:58:13Z | 2022-05-27T17:40:45Z | https://github.com/kubernetes/kubernetes/issues/109182 | 1,187,554,570 | 109,182 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We're managing our own Kubernetes cluster on Azure. During node refreshes (in which we're aiming to update the node pool with new VMs with updated VHDs) - we add several new nodes to the cluster, select several old nodes to remove, drain those nodes, and then delete the underlying VM (part of a VMSS... | Service controller reconciles static node set causing UpdateLoadBalancerFailed events | https://api.github.com/repos/kubernetes/kubernetes/issues/109180/comments | 10 | 2022-03-31T05:50:04Z | 2022-04-26T18:17:48Z | https://github.com/kubernetes/kubernetes/issues/109180 | 1,187,548,490 | 109,180 |
[
"kubernetes",
"kubernetes"
] | Related to generating clients using closed language-level enums based on https://github.com/kubernetes/enhancements/issues/2887
Some of the currently marked `+enum` fields are documented to allow expansion in the future, which would break clients generated against earlier openapi schemas:
* ```
// CompletionMo... | Generated clients using closed enums from an openapi snapshot are not forwards compatible | https://api.github.com/repos/kubernetes/kubernetes/issues/109177/comments | 15 | 2022-03-31T05:04:03Z | 2024-08-08T20:09:39Z | https://github.com/kubernetes/kubernetes/issues/109177 | 1,187,517,239 | 109,177 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Update pr https://github.com/kubernetes-sigs/metrics-server/pull/972, verify check failed. Error message:
d/openapi/ -O zz_generated.openapi -o /home/prow/go/src/sigs.k8s.io/metrics-server -h /home/prow/go/src/sigs.k8s.io/metrics-server/scripts/boilerplate.go.txt -r /dev/null
go install -mod=rea... | pull-metrics-server-verify logcheck failed | https://api.github.com/repos/kubernetes/kubernetes/issues/109176/comments | 4 | 2022-03-31T04:01:32Z | 2022-03-31T05:55:38Z | https://github.com/kubernetes/kubernetes/issues/109176 | 1,187,462,823 | 109,176 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/pull/107088 changed behavior of dry run requests to clear the name of an object if metadata.generateName is set
That is not correct if both metadata.name and metadata.generateName are set in the create request.
Rather than changing behavior from <1.23, then changing it aga... | Dry run create requests clear metadata.name if metadata.generateName is set | https://api.github.com/repos/kubernetes/kubernetes/issues/109174/comments | 14 | 2022-03-31T03:14:15Z | 2022-04-06T17:58:41Z | https://github.com/kubernetes/kubernetes/issues/109174 | 1,187,435,330 | 109,174 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Both k8s.gcr.io/build-image/debian-base-amd64:bullseye-v1.1.0 and k8s.gcr.io/build-image/debian-base-amd64:buster-v1.10.0 has this vulerbility. Both are latest.
Debian fix is https://security-tracker.debian.org/tracker/CVE-2021-43618.
```
❯ gcloud container images list-tags k8s.gcr.io/build-i... | Update gmp in debian-base:buster-v1.10.0 (latest) and debian-base-amd64:bullseye-v1.1.0 to patch CVE-2021-43618 | https://api.github.com/repos/kubernetes/kubernetes/issues/109168/comments | 9 | 2022-03-30T21:51:58Z | 2022-08-28T19:12:35Z | https://github.com/kubernetes/kubernetes/issues/109168 | 1,187,031,675 | 109,168 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have a controller that creates a job for unpacking the contents of a container image hosted in a container registry. After updating to kube 1.23.5, the Jobs created by the controller sometimes don't transition to `Complete:True`, despite the fact that the underlying pod runs to completion. Instea... | batch/v1/job not transitioning to `Succeeded` after successful underlying pod run completion | https://api.github.com/repos/kubernetes/kubernetes/issues/109164/comments | 41 | 2022-03-30T19:00:57Z | 2022-04-01T13:04:20Z | https://github.com/kubernetes/kubernetes/issues/109164 | 1,186,868,195 | 109,164 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When starting windows nodes with a high number of HNS LB policies/rules on the cluster, there is a delay in processing them. This leaves services unreachable during the delay, which takes about half a minute per policy. This can be substatial given enough rules.
This occurs when restarting kube-p... | Delay in processing HNS LB policies on kube-proxy start on Windows nodes results in unreachable services | https://api.github.com/repos/kubernetes/kubernetes/issues/109162/comments | 3 | 2022-03-30T18:00:31Z | 2022-06-09T02:20:07Z | https://github.com/kubernetes/kubernetes/issues/109162 | 1,186,802,862 | 109,162 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The Windows pause images is built using buildkit on Linux hosts and this configuration does not allow for the Windows registry to me modified during the container build process.
When Windows containers are built on Windows host machines part of the build process creates 'delta' registry files whe... | Cannot modify registry keys during Windows pause image build process | https://api.github.com/repos/kubernetes/kubernetes/issues/109161/comments | 18 | 2022-03-30T17:22:09Z | 2022-06-15T21:41:11Z | https://github.com/kubernetes/kubernetes/issues/109161 | 1,186,765,408 | 109,161 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
the newly refactored retry logic introduced in 1.22 by https://github.com/kubernetes/kubernetes/pull/102217 broke the thread safety of `*Request`. According to Clayton, it's not a release blocker for 1.24.
So the goal is to fix it in 1.25 and then back port all the way to 1.22.
Please note th... | client-go: the retry logic in rest.Request should be thread safe | https://api.github.com/repos/kubernetes/kubernetes/issues/109155/comments | 10 | 2022-03-30T15:52:42Z | 2023-01-31T09:46:51Z | https://github.com/kubernetes/kubernetes/issues/109155 | 1,186,662,955 | 109,155 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I create a deployment and a service using nginx. But the service is not work right.
### What did you expect to happen?
why the warning event is shown when I describe my service?
and why the endpoints is <none>, which is not right I think?
### How can we reproduce it (as minimally and pre... | service not work right with pod with ip in 169.254/16 ? | https://api.github.com/repos/kubernetes/kubernetes/issues/109152/comments | 7 | 2022-03-30T13:15:10Z | 2022-03-31T07:12:58Z | https://github.com/kubernetes/kubernetes/issues/109152 | 1,186,445,769 | 109,152 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There seem to be increased resource usage for the kube-api-server in the `kubemark-500nodes` job:
CPU:
http://perf-dash.k8s.io/#/?jobname=kubemark-500Nodes&metriccategoryname=E2E&metricname=LoadResources&PodName=apiserver%2Fapiserver&Resource=CPU

### Which tests are failing?
k8s.io/kubernetes/vendor/k8s.io/apiserver/pkg/server.TestPreShutdownHooks
### Since when has it been failing?
17:42 PDT 3/29
### Testgri... | [Failing test] sig-release-master-blocking#ci-kubernetes-unit | https://api.github.com/repos/kubernetes/kubernetes/issues/109136/comments | 5 | 2022-03-30T04:23:41Z | 2022-03-30T08:20:26Z | https://github.com/kubernetes/kubernetes/issues/109136 | 1,185,854,960 | 109,136 |
[
"kubernetes",
"kubernetes"
] | I'm using kubernetes 1.18.17 and I'm experiencing the following compatibility issue when I try to enable pod-security-admission by installing webhook as per the documentation instructions.
1. kustomize not support "replacements" field:
```
kubectl apply -k .
error: json: unknown field "replacements"
... | pod-security webhook manifest has 2 compatible issues with kubernetes v1.18 | https://api.github.com/repos/kubernetes/kubernetes/issues/109145/comments | 4 | 2022-03-30T03:47:20Z | 2022-03-30T12:22:13Z | https://github.com/kubernetes/kubernetes/issues/109145 | 1,186,276,818 | 109,145 |
[
"kubernetes",
"kubernetes"
] | /kind flake
/sig api-machinery
TestPreShutdownHooks flakes a lot after this pr was merged.
- https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/batch/pull-kubernetes-unit/1508966938808684544
- https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/108492/pull-kubernetes-unit/1508972217449320448
-... | TestPreShutdownHooks flakes in pull-kubernetes-unit | https://api.github.com/repos/kubernetes/kubernetes/issues/109133/comments | 1 | 2022-03-30T01:48:28Z | 2022-03-30T08:27:23Z | https://github.com/kubernetes/kubernetes/issues/109133 | 1,185,712,047 | 109,133 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A pod uses a PVC with `volumeMode: Block`. The block volume is backed by a block device on the node (which is created by some CSI storage providers). If the underlying block device corresponding to the volume is accidentally disconnected from the node (due to network, hardware problem, etc...), t... | Kubelet cannot finish terminating a pod that uses a PVC with `volumeMode: Block` if the underlying block device is accidentally disconnected from the node | https://api.github.com/repos/kubernetes/kubernetes/issues/109132/comments | 16 | 2022-03-29T23:07:44Z | 2023-07-13T09:56:39Z | https://github.com/kubernetes/kubernetes/issues/109132 | 1,185,572,242 | 109,132 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
As a user I would like to be able to configure with which index the pods of a IndexedJob are getting created.
By introducing a new field to the job spec API (possible name: `indices` -> TBD) we can influence with which index the controller would create pods.
This field then ... | Make indices of IndexedJob pods configurable | https://api.github.com/repos/kubernetes/kubernetes/issues/109131/comments | 30 | 2022-03-29T22:18:21Z | 2023-06-15T12:13:22Z | https://github.com/kubernetes/kubernetes/issues/109131 | 1,185,488,037 | 109,131 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Now gets the below error message,
error validating "appcode/ci/xxx/Chart.yaml": error validating data: kind not set; if you choose to ignore these errors, turn validation off with --validate=false
error parsing appcode/ci/xxxx/templates/pgpool-deployment.yaml: error converting ... | error validating data: kind not set; if you choose to ignore these errors | https://api.github.com/repos/kubernetes/kubernetes/issues/109129/comments | 5 | 2022-03-29T21:36:05Z | 2022-03-30T15:10:26Z | https://github.com/kubernetes/kubernetes/issues/109129 | 1,185,439,834 | 109,129 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-containerd#containerd-node-e2e-1.4&width=20
https://testgrid.k8s.io/sig-node-containerd#containerd-node-e2e-1.5&width=20
https://testgrid.k8s.io/sig-node-containerd#containerd-node-e2e-features-1.4&width=20
https://testgrid.k8s.io/sig-node-containerd#cont... | Many tests failing in sig-node-containerd feature tests failing (containerd-node-e2e-{1.5,1.4} and containerd-node-e2e-features-{1.5,1.4}) | https://api.github.com/repos/kubernetes/kubernetes/issues/109127/comments | 12 | 2022-03-29T21:16:18Z | 2022-03-31T22:09:44Z | https://github.com/kubernetes/kubernetes/issues/109127 | 1,185,423,381 | 109,127 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Gets the below error message below,
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
+ kubectl create -f -
error: no objects passed to create
My parameters are in place
### Why is this needed?
Gets the below error message below,
To furt... | error: no objects passed to create | https://api.github.com/repos/kubernetes/kubernetes/issues/109126/comments | 6 | 2022-03-29T20:57:02Z | 2022-03-30T15:11:25Z | https://github.com/kubernetes/kubernetes/issues/109126 | 1,185,405,188 | 109,126 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [b3645b5ba139a7810417](https://go.k8s.io/triage#b3645b5ba139a7810417)
Test: [sig-node] Pods Extended Pod Container lifecycle should not create extra sandbox if all containers are done
##### Error text:
```
test/e2e/framework/framework.go:185
Mar 25 07:58:29.526: Unexpected error:
<*err... | [Flaky test] [sig-node] Pods Extended Pod Container lifecycle should not create extra sandbox if all containers are done | https://api.github.com/repos/kubernetes/kubernetes/issues/109118/comments | 2 | 2022-03-29T18:03:49Z | 2022-03-29T18:04:41Z | https://github.com/kubernetes/kubernetes/issues/109118 | 1,185,227,370 | 109,118 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This was the root cause of rancher/rancher#37057.
In `thread_safe_store.go`, when `updateIndices` is called, it is given the oldVersion of an object and the newVersion of the object. It then uses the indexers `indexFunc` to calculate the old values (from the old version) and the new updated value... | Client-go thread_safe_store removes still-valid values on update | https://api.github.com/repos/kubernetes/kubernetes/issues/109115/comments | 6 | 2022-03-29T17:34:16Z | 2022-03-31T05:57:03Z | https://github.com/kubernetes/kubernetes/issues/109115 | 1,185,195,503 | 109,115 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I was trying to understand the operation logic of the Persistent Volume controller by going through the code and I think I noticed a bug.
`syncUnboundClaim()` which syncs unbound claims:
1. Checks if the requested PV is bound to another claim.
2. If the PV is bound to another claim, then it... | PersistentVolumeController checks for annotation on PVC instead of PV | https://api.github.com/repos/kubernetes/kubernetes/issues/109113/comments | 14 | 2022-03-29T16:44:38Z | 2022-12-16T10:48:01Z | https://github.com/kubernetes/kubernetes/issues/109113 | 1,185,140,848 | 109,113 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
When I debug some slow API calls where API Priority and Fairness started throttling requests, it's often hard to tell which requests are in fact throttled due to priority level being throttled vs simply being slow. We have added already fl_priorityandfairness which shows how much t... | Improve observability of execution latency in APF | https://api.github.com/repos/kubernetes/kubernetes/issues/109108/comments | 7 | 2022-03-29T14:51:44Z | 2022-12-08T13:39:26Z | https://github.com/kubernetes/kubernetes/issues/109108 | 1,184,994,053 | 109,108 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I started API call like:
```
2022-03-17 08:01:17.003 PDT
""HTTP" verb="LIST" URI="/apis/external.metrics.k8s.io/v1beta1/namespaces/ns-1/custom.googleapis.com%7Ctarget?labelSelector=resource.labels.namespace_id+in+%28default%2Cdummy%29%2Cresource.labels.pod_id%2Cresource.type%3Dgke_container"
`... | APF improperly estimates cost for LIST aggregated calls | https://api.github.com/repos/kubernetes/kubernetes/issues/109106/comments | 21 | 2022-03-29T14:20:40Z | 2022-11-23T10:45:55Z | https://github.com/kubernetes/kubernetes/issues/109106 | 1,184,949,703 | 109,106 |
[
"kubernetes",
"kubernetes"
] | /**sys/fs/cgroup/kubepods/burstable**/pod03f3a69f-82ff-4368-a1aa-16ddaf74ac22/xmrig/memory.max: no such file or directory
The path should be /**sys/fs/cgroup/devices/kubepods/burstable**/pod...
Where do i update the path to include the /devices/ in the path?
/sig kubernetes | Error: failed to create containerd task: failed to create shim: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: process_linux.go:508: setting cgroup config for procHooks process caused: openat2 /sys/fs/cgroup/kubepods/burstable/pod03f3a6... | https://api.github.com/repos/kubernetes/kubernetes/issues/109105/comments | 8 | 2022-03-29T14:11:40Z | 2022-09-05T18:01:13Z | https://github.com/kubernetes/kubernetes/issues/109105 | 1,184,936,841 | 109,105 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
<img width="644" alt="image" src="https://user-images.githubusercontent.com/65275144/160594060-adee42aa-9a0c-4c33-88f1-d390943a9570.png">
### Why is this needed?
The second one is easier to read at a glance | Output format for kubectl get | https://api.github.com/repos/kubernetes/kubernetes/issues/109100/comments | 5 | 2022-03-29T10:42:11Z | 2022-03-30T17:28:17Z | https://github.com/kubernetes/kubernetes/issues/109100 | 1,184,666,067 | 109,100 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We observe a high CPU usage of apiserver replicas while other replicas are idling:
```
$ k top po -l role=apiserver
kube-apiserver-786785f6fc-q2fwc 49m 737Mi
kube-apiserver-786785f6fc-r2bxz 50m 690Mi
kube-apiserver-786785f6fc-tbph4 ... | apiserver: Request for a custom resource leads to > 1000% CPU usage increase for more than 10min | https://api.github.com/repos/kubernetes/kubernetes/issues/109099/comments | 8 | 2022-03-29T08:51:02Z | 2022-08-02T19:48:19Z | https://github.com/kubernetes/kubernetes/issues/109099 | 1,184,529,436 | 109,099 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-cri-o#ci-crio-cgroupv1-node-e2e-features
### Which tests are failing?
- E2eNode Suite: [sig-node] Security Context when creating a pod in the host PID namespace should show its pid in the host PID namespace [NodeFeature:HostAccess] expand_less
```
{ F... | E2eNode Suite: [sig-node] Security Context when creating a pod in the host PID namespace should show its pid in the host PID namespace [NodeFeature:HostAccess] | https://api.github.com/repos/kubernetes/kubernetes/issues/109096/comments | 2 | 2022-03-29T07:40:15Z | 2022-03-30T03:36:38Z | https://github.com/kubernetes/kubernetes/issues/109096 | 1,184,445,010 | 109,096 |
[
"kubernetes",
"kubernetes"
] | Problems with audit logging:
1. Information is added to the context in stages, and it's not clear what is available at a given time.
2. 4 separate pieces of audit info are stored on the context (ID, AuditContext, annotations, and mutex with https://github.com/kubernetes/kubernetes/pull/109078)
3. Audit logic is scat... | Clean up audit logging | https://api.github.com/repos/kubernetes/kubernetes/issues/109087/comments | 11 | 2022-03-29T00:15:08Z | 2024-03-26T20:46:30Z | https://github.com/kubernetes/kubernetes/issues/109087 | 1,184,135,204 | 109,087 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [9dad1e859c185d9628c2](https://go.k8s.io/triage#9dad1e859c185d9628c2)
##### Error text:
```
test/e2e/storage/testsuites/volumes.go:159
Mar 18 17:06:24.147: Failed to create injector pod: timed out waiting for the condition
test/e2e/storage/testsuites/volumes.go:186
```
#### Recent failures:... | Failing tests: In-tree Volumes [Driver: gcepd] | https://api.github.com/repos/kubernetes/kubernetes/issues/109086/comments | 8 | 2022-03-28T22:38:48Z | 2022-06-29T03:38:12Z | https://github.com/kubernetes/kubernetes/issues/109086 | 1,184,073,664 | 109,086 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [79384df20f4e672ed9e1](https://go.k8s.io/triage#79384df20f4e672ed9e1)
Test: [sig-node] Summary API [NodeConformance] when querying /stats/summary should report resource usage through the stats api
Job:
- ci-cgroup-systemd-containerd-node-e2e
- ci-cos-containerd-node-e2e
- pull-kubernetes-node... | [sig-node] Summary API [NodeConformance] when querying /stats/summary ... networking info is nil on containerd | https://api.github.com/repos/kubernetes/kubernetes/issues/109082/comments | 66 | 2022-03-28T19:45:37Z | 2022-07-08T18:25:16Z | https://github.com/kubernetes/kubernetes/issues/109082 | 1,183,906,081 | 109,082 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When registering a new `csi` driver the `grpc` client is sending the filepath of the `uds` socket as the `host`/`authority` header instead of `localhost`. In practice almost all `grpc` / `http2` servers outright reject this as invalid. Given that the `grpc-go` client was updated years ago I'm unclea... | kubelet sending invalid grpc header during plugin registration | https://api.github.com/repos/kubernetes/kubernetes/issues/109081/comments | 10 | 2022-03-28T19:30:25Z | 2022-10-31T10:12:46Z | https://github.com/kubernetes/kubernetes/issues/109081 | 1,183,891,219 | 109,081 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/golang/go/issues/36499 describes why the KeyEncipherment extended key usage does not make sense (and in some cases, is not allowed) for ECDSA keys.
The Kubernetes `kubernetes.io/kubelet-serving` and `kubernetes.io/kube-apiserver-client-kubelet` signer names require a `key encip... | KeyEncipherment usage should not be required for non-RSA kubelet client/serving CSRs | https://api.github.com/repos/kubernetes/kubernetes/issues/109077/comments | 8 | 2022-03-28T18:41:59Z | 2023-01-04T23:51:58Z | https://github.com/kubernetes/kubernetes/issues/109077 | 1,183,840,575 | 109,077 |
[
"kubernetes",
"kubernetes"
] | Hi all,
In relation to: https://github.com/kubernetes-sigs/metrics-server/issues/985
Given that pretty much all libraries/clients out there have supported TLS1.3 for quite a while now, it would be great to move towards deprecating TLS1.2 and lower -- this removes the need to employ Server-side Ciper ordering, and/o... | Use TLS 1.3 by default | https://api.github.com/repos/kubernetes/kubernetes/issues/110346/comments | 11 | 2022-03-28T13:03:44Z | 2024-07-14T18:53:34Z | https://github.com/kubernetes/kubernetes/issues/110346 | 1,258,119,680 | 110,346 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to set Flannle to directrouting mode, but it doesn't work
I have added configuration "Directrouting": true,but The route is still via flannel.1 onlink
```
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": true
}
}
```
[root@hec... | kubetnetes1. 23 flannel configuration directrouting is not effective #1554 | https://api.github.com/repos/kubernetes/kubernetes/issues/109064/comments | 4 | 2022-03-28T05:46:24Z | 2022-03-28T07:03:51Z | https://github.com/kubernetes/kubernetes/issues/109064 | 1,182,920,909 | 109,064 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I use local volume as persistent volume and local StorageClass, the volumeBindingMode field of StorageClass is WaitForFirstConsumer. I want define nodeName field in deployment yaml for scheduling pods to nodes and I defined the filed of nodeAffinity in pv yaml, But the pod is in the ContainerCreat... | When define nodeName field in deployment yaml, cannot bind local persistent volume through nodeAffinity | https://api.github.com/repos/kubernetes/kubernetes/issues/109063/comments | 11 | 2022-03-28T03:19:50Z | 2022-04-11T02:37:27Z | https://github.com/kubernetes/kubernetes/issues/109063 | 1,182,821,012 | 109,063 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In IPVS mode if kube-proxy tries to bind to an ipv6 port which is already in use, I get the following error message and kube-proxy crashes.
```
I0326 13:45:33.879885 1 proxier.go:1026] "syncProxyRules complete" elapsed="33.302265ms"
panic: runtime error: invalid memory address or nil poin... | kube-proxy crash loop | https://api.github.com/repos/kubernetes/kubernetes/issues/109052/comments | 14 | 2022-03-26T14:06:43Z | 2022-08-28T23:14:35Z | https://github.com/kubernetes/kubernetes/issues/109052 | 1,181,790,158 | 109,052 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
on my scenes,create same cronjob use same sfs(the nfs storage on Huawei Cloud) type storage by pvc to do same training work. At the same time, a node will schedule many pods using the same pvc, and there will be many mount and umount tasks about this pvc executed at the same time. And we find all ... | kubelet nestedPendingOperations may leak operation lead same pv not to do mount or umount operation | https://api.github.com/repos/kubernetes/kubernetes/issues/109047/comments | 13 | 2022-03-26T07:11:46Z | 2022-08-26T02:36:11Z | https://github.com/kubernetes/kubernetes/issues/109047 | 1,181,567,675 | 109,047 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
pull-kubernetes-integration
### Which tests are failing?
inconsistent, but seeing failure rates of ~50% today
### Since when has it been failing?
Failing 75% of runs starting the morning of 2022-03-25, but the "Malformed artifacts: ... junit xml too large" errors occurred befo... | pull-kubernetes-integration failing ~60-90% of runs - updated 2022-03-31 | https://api.github.com/repos/kubernetes/kubernetes/issues/109038/comments | 73 | 2022-03-25T20:33:20Z | 2022-04-02T17:19:19Z | https://github.com/kubernetes/kubernetes/issues/109038 | 1,181,244,812 | 109,038 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-e2e-kind-ipv6
### Which tests are flaking?
- `[sig-network] Proxy version v1 A set of valid responses are returned for both pod and service ProxyWithPath [Conformance]`
- `[sig-network] Proxy version v1 A set of valid responses are returned for both pod and service Proxy ... | [flake][sig-network] Proxy version v1 A set of valid responses are returned for both pod and service ProxyWithPath [Conformance] | https://api.github.com/repos/kubernetes/kubernetes/issues/109037/comments | 1 | 2022-03-25T20:32:56Z | 2022-03-26T11:35:21Z | https://github.com/kubernetes/kubernetes/issues/109037 | 1,181,244,521 | 109,037 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The defaulting KEP introduces the default annotation that can be added for types and CRDs to publish default values for types to the OpenAPI. As a part of this, defaults for non-nullable fields are also published to illustrate how fields with no value set will have a default value set upon apply. ... | Should defaults for non-nullable structs be published in OpenAPI | https://api.github.com/repos/kubernetes/kubernetes/issues/109036/comments | 5 | 2022-03-25T20:22:43Z | 2022-08-01T15:14:35Z | https://github.com/kubernetes/kubernetes/issues/109036 | 1,181,236,212 | 109,036 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
As discussed at https://github.com/kubernetes/kubernetes/pull/108946#discussion_r835426136
Slightly larger comment: This API is very weak on "hiding".
The question left is, if it would be better to make a bigger change and use a constructor, like:
```
type ArgFunc func... | Re work pkg/util/ipset.Validate() | https://api.github.com/repos/kubernetes/kubernetes/issues/109034/comments | 25 | 2022-03-25T19:50:43Z | 2023-10-17T20:14:36Z | https://github.com/kubernetes/kubernetes/issues/109034 | 1,181,209,510 | 109,034 |
[
"kubernetes",
"kubernetes"
] | This issue is a bucket placeholder for collaborating on the "Known Issues" additions for the 1.24 Release Notes. If you know of issues or API changes that are going out in 1.24, please comment here so that we can coordinate incorporating information about these changes in the Release Notes.
/assign @AuraSinis @Rin... | 1.24 Release Notes: "Known Issues" | https://api.github.com/repos/kubernetes/kubernetes/issues/109027/comments | 5 | 2022-03-25T17:32:21Z | 2022-05-02T18:40:32Z | https://github.com/kubernetes/kubernetes/issues/109027 | 1,181,057,718 | 109,027 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A lot of different routines failing just when setting up an apiserver.
Example:
<details>
```
goroutine 2535 [running]:
k8s.io/apimachinery/pkg/util/runtime.logPanic({0x3dc2740?, 0xc005f64a50})
/usr/local/google/home/acondor/go_k8s/src/k8s.io/kubernetes/vendor/k8s.io/apimachinery/pkg/ut... | apiserver routines failing in integration tests | https://api.github.com/repos/kubernetes/kubernetes/issues/109026/comments | 8 | 2022-03-25T17:22:24Z | 2022-03-29T20:26:52Z | https://github.com/kubernetes/kubernetes/issues/109026 | 1,181,048,360 | 109,026 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.