
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
pull-kubernetes-unit
### Which tests are flaking?
k8s.io/kubernetes/pkg/kubelet/nodeshutdown
### Since when has it been flaking?
Not sure, just saw it today
### Testgrid link
_No response_
### Reason for failure (if possible)
https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pu... | Data race in pkg/kubelet/nodeshutdown test | https://api.github.com/repos/kubernetes/kubernetes/issues/108707/comments | 7 | 2022-03-15T15:12:03Z | 2022-03-16T08:49:11Z | https://github.com/kubernetes/kubernetes/issues/108707 | 1,169,808,215 | 108,707 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want to check of a group I reference in a role-binding I created in current namespace can exec into pods, namely I want to confirm that users in group `my-group` can use `kubectl exec`.
The following, based on specifying the command I want to use rather than the API equivalent, did not work:... | kubectl auth can-i is inconsistent and confusing for exec | https://api.github.com/repos/kubernetes/kubernetes/issues/108706/comments | 6 | 2022-03-15T14:54:53Z | 2022-08-12T16:28:51Z | https://github.com/kubernetes/kubernetes/issues/108706 | 1,169,785,646 | 108,706 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am trying to retry failed cron job after specific time interval rather than immediate retry, Is there way to do it?
### What did you expect to happen?
I could not find anything related to this on Kubernetes documentation
### How can we reproduce it (as minimally and precisely as possible)?
NA
... | Retry cronjob after specific time interval | https://api.github.com/repos/kubernetes/kubernetes/issues/108703/comments | 7 | 2022-03-15T11:26:12Z | 2024-06-28T11:12:43Z | https://github.com/kubernetes/kubernetes/issues/108703 | 1,169,545,719 | 108,703 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Pod Pending
```sh
.skipping...
Mar 15 03:30:24 vm3 kubelet[1427]: I0315 03:30:24.530324 1427 plugins.go:639] Loaded volume plugin "kubernetes.io/host-path"
Mar 15 03:30:24 vm3 kubelet[1427]: I0315 03:30:24.530328 1427 plugins.go:639] Loaded volume plugin "kubernetes.io/nfs"
Mar 15 03:30... | Pod Pending, invalid capacity 0 on image filesystem | https://api.github.com/repos/kubernetes/kubernetes/issues/108700/comments | 3 | 2022-03-15T03:43:12Z | 2022-03-15T13:17:54Z | https://github.com/kubernetes/kubernetes/issues/108700 | 1,169,146,723 | 108,700 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When running multi architecture apps the `pod.status.containerStatuses.imageID` might be bit misleading.
For example when running a pod with `docker.io/nginx:1-alpine` image, the pod status show the following:
```
bash-5.1# k0s kc get pod nginx -o yaml | grep imageID
imageID: docker.io/l... | `pod.status.containerStatuses.imageID` not 100% accurate | https://api.github.com/repos/kubernetes/kubernetes/issues/108689/comments | 12 | 2022-03-14T14:07:12Z | 2022-08-22T20:17:24Z | https://github.com/kubernetes/kubernetes/issues/108689 | 1,168,430,358 | 108,689 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
When client-go warns about something, for example a deprecated API, the source code location is warnings.go, the file which calls klog.Warn:
```
W0314 13:55:48.179221 213236 warnings.go:70] storage.k8s.io/v1beta1 CSIStorageCapacity is deprecated in v1.24+, unavailable in v1.27+;... | client-go: emit warnings for caller of client-go, not client-go itself | https://api.github.com/repos/kubernetes/kubernetes/issues/108688/comments | 10 | 2022-03-14T12:58:11Z | 2024-06-25T12:44:41Z | https://github.com/kubernetes/kubernetes/issues/108688 | 1,168,340,369 | 108,688 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The cluster has been running for a while, and suddenly found that some nodes show the NotReady status, which cannot be restored to normal. I tried to restart the kubelet, but it could not be solved.
### In the master aaaaaaa69
kubectl get node
NAME STATUS ROLES AGE VERSION
... | About kubelet.go:2267 node "" not found problem for help | https://api.github.com/repos/kubernetes/kubernetes/issues/108687/comments | 5 | 2022-03-14T12:25:57Z | 2022-03-15T11:53:33Z | https://github.com/kubernetes/kubernetes/issues/108687 | 1,168,305,361 | 108,687 |
[
"kubernetes",
"kubernetes"
] | We have notice that the job for logs/ci-audit-kind-conformance have constantly been failing since 8 March 2022. We noticed it because the job result is used to feed APIsnoop app and web page.
Log state:
```
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
... | Job for logs/ci-audit-kind-conformance is failing | https://api.github.com/repos/kubernetes/kubernetes/issues/108683/comments | 5 | 2022-03-14T08:42:53Z | 2022-03-14T23:43:32Z | https://github.com/kubernetes/kubernetes/issues/108683 | 1,168,057,491 | 108,683 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We performed mount in shared emptyDir volume subpath in one container, and read the data through the same mounted subpath in another container. And the container failed to read the data under the mount point occasionally.
After some investigation, I thought this may be caused by the bind options... | Mount points not propagated as expected when using subpath. | https://api.github.com/repos/kubernetes/kubernetes/issues/108681/comments | 14 | 2022-03-14T07:39:56Z | 2023-03-02T08:46:48Z | https://github.com/kubernetes/kubernetes/issues/108681 | 1,167,999,869 | 108,681 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When running `kubectl logs pod-name --follow`, new logs are not output to the logs command after the log file has grown and rotated.
### What did you expect to happen?
Even after log rotation, new logs are output to `kubectl logs pod-name --follow`.
### How can we reproduce it (as minimally and... | "kubectl logs --follow" has not printed new logs after log rotation. | https://api.github.com/repos/kubernetes/kubernetes/issues/108678/comments | 11 | 2022-03-14T05:15:33Z | 2023-04-07T04:44:25Z | https://github.com/kubernetes/kubernetes/issues/108678 | 1,167,900,326 | 108,678 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I set ttlSecondsAfterFinished: 120 in a Job, it works fine. However, when I use it in a jobTemplate in CronJob, it's ignored and the CronJob always creates a Job with this value set to 30.
### What did you expect to happen?
I expect ttlSecondsAfterFinished to be set correctly when the CronJo... | ttlSecondsAfterFinished setting is ignored when Job is created by CronJob. Always defaults to 30 | https://api.github.com/repos/kubernetes/kubernetes/issues/108677/comments | 8 | 2022-03-14T00:46:48Z | 2022-08-12T13:28:50Z | https://github.com/kubernetes/kubernetes/issues/108677 | 1,167,749,066 | 108,677 |
[
"kubernetes",
"kubernetes"
] | We have a question regarding the eligibility of the following 2 endpoints for conformance;
- logFileListHandler
- logFileHandler
We found this PR Don’t test the debug /logs endpoint on GKE. [#47478](https://github.com/kubernetes/kubernetes/pull/47478/files) that disables testing of /log endpoint for GKE.
Is this ... | Ineligibility of Log endpoints for Conformance testing | https://api.github.com/repos/kubernetes/kubernetes/issues/108675/comments | 2 | 2022-03-13T20:54:09Z | 2022-03-14T13:36:22Z | https://github.com/kubernetes/kubernetes/issues/108675 | 1,167,690,899 | 108,675 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If starting a large number of new pods (100+) all from the same image that is not currently present on nodes, containerd is flooded with pull requests and I can see messages like this:
```
[Mar13 12:17] INFO: task containerd:1349156 blocked for more than 120 seconds.
[ +0.008054] Not taint... | containerd denial of service if starting huge number of pods | https://api.github.com/repos/kubernetes/kubernetes/issues/108674/comments | 11 | 2022-03-13T13:44:31Z | 2022-03-19T14:04:58Z | https://github.com/kubernetes/kubernetes/issues/108674 | 1,167,585,525 | 108,674 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
"-n" ------>There is no such parameter defined in kubectl edit sts --help
How come a random command is working without usage being defined in kubectl edit sts --help
# kubectl edit sts -n xyz -n kafka --> The statefulset "xyz" doesn't exist in kafka namespace, it should throw error like no r... | How random command is getting executed - K8s version 1.21.7 -- kubectl edit sts -n xyz -n namspace | https://api.github.com/repos/kubernetes/kubernetes/issues/108668/comments | 7 | 2022-03-12T09:06:31Z | 2022-05-25T17:32:27Z | https://github.com/kubernetes/kubernetes/issues/108668 | 1,167,230,295 | 108,668 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The Pod has been running normally for more than two days, but the "FailedScheduling" event is still reported repeatedly.

I can see in the kube-scheduler log that the pod was schedule... | Pod runs normally but still reports "FailedScheduling" event repeatedly | https://api.github.com/repos/kubernetes/kubernetes/issues/108665/comments | 4 | 2022-03-12T03:45:17Z | 2022-03-15T03:03:42Z | https://github.com/kubernetes/kubernetes/issues/108665 | 1,167,166,395 | 108,665 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
E2E tests for `AnyVolumeDatasource` feature
### Why is this needed?
E2E tests for `AnyVolumeDatasource` feature to be Beta (Please see https://github.com/kubernetes/enhancements/tree/master/keps/sig-storage/1495-volume-populators#alpha---beta-graduation) | E2E tests for `AnyVolumeDatasource` feature | https://api.github.com/repos/kubernetes/kubernetes/issues/108663/comments | 3 | 2022-03-12T00:31:03Z | 2022-04-04T21:35:36Z | https://github.com/kubernetes/kubernetes/issues/108663 | 1,167,073,049 | 108,663 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
in dual stack deployment with preferred-ipaddress-family: ipv6.
kubelet is configured to listen on <ipv6> address : 10250 using address configuration for kubelet.
commands like **kubectl <exec/log/..>** are failing with connection timeout,
### What did you expect to happen?
kubectl commands... | Dual Stack: kube-api communication iwth | https://api.github.com/repos/kubernetes/kubernetes/issues/108658/comments | 29 | 2022-03-11T12:05:32Z | 2022-06-09T13:34:53Z | https://github.com/kubernetes/kubernetes/issues/108658 | 1,166,340,431 | 108,658 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are trying to deploy a CNF in K8s cluster 1.23.1 with ansible operator from quay.io and following error is coming. This is seen when the metrics-server is installed. If metrics-server is deleted, this error is not seen and all the K8s resources are created fine by the Operator.
{"level":"err... | Error "unable to retrieve the complete list of server APIs: metrics.k8s.io" when any K8s resource is being created by operator through ansible K8s module. | https://api.github.com/repos/kubernetes/kubernetes/issues/108657/comments | 6 | 2022-03-11T11:08:48Z | 2022-08-19T09:35:12Z | https://github.com/kubernetes/kubernetes/issues/108657 | 1,166,289,266 | 108,657 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have installed Kubernetes using kubespray. we have observed that kube-proxy didnot come up. kubeadm-config.yaml has the required kubeproxy configuration.
In the api server logs, there is an error to connect etcd.
And etcd container seems to be recreated during that time.
Can somebody he... | kube proxy is not available after kubernetes installation | https://api.github.com/repos/kubernetes/kubernetes/issues/108656/comments | 6 | 2022-03-11T09:56:08Z | 2022-03-15T13:12:30Z | https://github.com/kubernetes/kubernetes/issues/108656 | 1,166,218,846 | 108,656 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
1. "work e2e" and "read/write file" test cases have the same set up and clean up functions. We should hoist the same setup logic to a beforeEach and do the clean up in a afterEach. Create this issue to track it as mentioned in this comment: https://github.com/kubernetes/kubernete... | Refactor "test/e2e/windows/gmsa_full.go" | https://api.github.com/repos/kubernetes/kubernetes/issues/108649/comments | 16 | 2022-03-10T23:43:50Z | 2024-07-06T18:48:47Z | https://github.com/kubernetes/kubernetes/issues/108649 | 1,165,844,651 | 108,649 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I run into a situation where a pod didn't loose the finalizer, then it blocked the deletion of a namespace.
We do have an integration test for orphan pods
https://github.com/kubernetes/kubernetes/blob/425ff1c8e2d29874926abb7da37641cf785c4ff3/test/integration/job/job_test.go#L537
But I fear ... | JobTrackingWithFinalizers: Orphan pods might not get the finalizer cleared | https://api.github.com/repos/kubernetes/kubernetes/issues/108645/comments | 3 | 2022-03-10T21:43:08Z | 2022-03-25T10:21:51Z | https://github.com/kubernetes/kubernetes/issues/108645 | 1,165,756,463 | 108,645 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[10/10]</code>
- [x] APISnoop org-flow: [Batchv1JobLifecycleTest.org](https://github.com/apisnoop/ticket-writing/blob/master/Batchv1JobLifecycleTest.org)
- [x] Test approval issue : #108641
- [x] Test PR : #108642 - Needed an update on the handling of anotations
- [x] Two weeks soak start date :... | Write Batchv1JobLifecycleTest +4 Endpoints | https://api.github.com/repos/kubernetes/kubernetes/issues/108641/comments | 6 | 2022-03-10T20:51:32Z | 2022-05-19T00:49:45Z | https://github.com/kubernetes/kubernetes/issues/108641 | 1,165,705,382 | 108,641 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Infrequent occurrence of following log indicating [health-monitor.sh](https://github.com/kubernetes/kubernetes/blob/master/cluster/gce/gci/health-monitor.sh#L65) - curl on http://127.0.0.1:10248/healthz - failed with connection reset:
```
"curl: (56) Recv failure: Connection re... | Infrequent unhealthy Kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/108640/comments | 8 | 2022-03-10T20:46:29Z | 2023-02-03T01:10:33Z | https://github.com/kubernetes/kubernetes/issues/108640 | 1,165,701,163 | 108,640 |
[
"kubernetes",
"kubernetes"
] | https://github.com/kubernetes/kubernetes/issues/60388#issuecomment-368399542
>We will not evict pods. With the recent change in 1.10, capacity will include unhealthy devices but allocatable will drop to zero.
@jiayingz perhaps I misunderstood your comment. Thanks for your reply and clarification.
_Originally pos... | https://github.com/kubernetes/kubernetes/issues/60388#issuecomment-368399542 | https://api.github.com/repos/kubernetes/kubernetes/issues/108635/comments | 6 | 2022-03-10T15:16:55Z | 2022-03-12T06:15:34Z | https://github.com/kubernetes/kubernetes/issues/108635 | 1,165,359,144 | 108,635 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
apiVersion: certificates.k8s.io/v1 approving cert but never issuing it.
Result:
my-svc.example.com 39m kubernetes.io/kube-apiserver-client kubernetes-admin Approved
I've tried making the csr a few different ways.
### What did you expect to happen?
Expected Result:
my-svc.example.com 39... | apiVersion: certificates.k8s.io/v1 approving cert but never issuing it. | https://api.github.com/repos/kubernetes/kubernetes/issues/108633/comments | 12 | 2022-03-10T14:04:07Z | 2022-04-25T18:16:24Z | https://github.com/kubernetes/kubernetes/issues/108633 | 1,165,269,074 | 108,633 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The `kubectl run` command provides a `--kustomize` flag but this doesn't do anything.
```
❯ kubectl run --help | grep kustomize
-k, --kustomize='': Process a kustomization directory. This flag can't be used together with -f or -R.
```
### What did you expect to happen?
most likely the flag... | kubectl run accidentally exposes --kustomize flag | https://api.github.com/repos/kubernetes/kubernetes/issues/108630/comments | 8 | 2022-03-10T11:47:32Z | 2022-11-04T05:28:15Z | https://github.com/kubernetes/kubernetes/issues/108630 | 1,165,119,884 | 108,630 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
enable fsgroup and file permission on csi-inline volume
### Why is this needed?
If not enable this, non-root user can not read/write the file in the csi inline volume mountpoint. | support fsgroup and file permissoin for csi inline volume | https://api.github.com/repos/kubernetes/kubernetes/issues/108623/comments | 5 | 2022-03-10T06:50:35Z | 2022-03-12T00:19:57Z | https://github.com/kubernetes/kubernetes/issues/108623 | 1,164,823,363 | 108,623 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I update resource with "kubectl apply -f test.yaml", old pod is Terminating and cannot delete successfully. Kubelet log Error: "UnmountVolume.TearDown failed for volume:remove /var/lib/kubelet/pods/xxx/volumes/kubernetes.io~glusterfs/test-gluster-pv: directory not empty
`Dec 21 16:08:27 node01... | Pod stuck in Terminating when deleting , kubelet Error: "UnmountVolume.TearDown failed for volume:remove /var/lib/kubelet/pods/xxx/volumes/kubernetes.io~glusterfs/test-gluster-pv: directory not empty | https://api.github.com/repos/kubernetes/kubernetes/issues/108622/comments | 16 | 2022-03-10T03:23:21Z | 2023-03-16T13:28:57Z | https://github.com/kubernetes/kubernetes/issues/108622 | 1,164,696,237 | 108,622 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
**Add a new job in Prow for Windows Soak tests.**
* The job will be scheduled weekly, with the option to be triggered manually.
* The test should be configurable to run arbitrary builds of Kubernetes, including HEAD
* The test will use **Cluster API Provider for Azure** for cl... | Soak Tests for Azure K8s clusters with Windows Nodes | https://api.github.com/repos/kubernetes/kubernetes/issues/108621/comments | 15 | 2022-03-10T03:01:40Z | 2024-06-17T18:59:54Z | https://github.com/kubernetes/kubernetes/issues/108621 | 1,164,679,340 | 108,621 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Enabled [feature gate](https://kubernetes.io/docs/reference/command-line-tools-reference/feature-gates/) `GRPCContainerProbe=true` on my self managed kubernetes v1.23.4
- /etc/kubernetes/manifests/kube-apiserver.yaml
```yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kube... | grpc feature gates - Liveness probe errored: missing probe handler | https://api.github.com/repos/kubernetes/kubernetes/issues/108615/comments | 4 | 2022-03-09T21:00:06Z | 2022-03-10T07:32:53Z | https://github.com/kubernetes/kubernetes/issues/108615 | 1,164,434,041 | 108,615 |
[
"kubernetes",
"kubernetes"
] | The unit tests in pkg pkg/scheduler/framework/plugins/volumebinding cost ~30 seconds on my m1max machine:
```
⇒ go test ./pkg/scheduler/framework/plugins/volumebinding -count 1
ok k8s.io/kubernetes/pkg/scheduler/framework/plugins/volumebinding 28.960s
```
Among the tests, a single test even costs ~5 seconds... | volumebinding unit tests run slowly | https://api.github.com/repos/kubernetes/kubernetes/issues/108610/comments | 13 | 2022-03-09T17:56:55Z | 2023-02-08T10:29:36Z | https://github.com/kubernetes/kubernetes/issues/108610 | 1,164,263,148 | 108,610 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In cronjob_controllerv2.go, jobs name pass from epoch in seconds to epoch in minutes
`name := fmt.Sprintf("%s-%d", cj.Name, getTimeHash(scheduledTime))`
to
`
func getJobName(cj *batchv1.CronJob, scheduledTime time.Time) string {
return fmt.Sprintf("%s-%d", cj.Name, getTimeHashInMinutes(... | Inject schedule name into newly created job | https://api.github.com/repos/kubernetes/kubernetes/issues/108609/comments | 22 | 2022-03-09T14:57:15Z | 2023-07-06T23:43:57Z | https://github.com/kubernetes/kubernetes/issues/108609 | 1,164,049,257 | 108,609 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm not sure whether this is the documentation being unclear, or a bug with kubectl itself but I suspect the former.
Given this help page
```bash
$ kubectl create clusterrolebinding --help
Create a cluster role binding for a particular cluster role.
# Omitted for brevity
--serviceaccou... | kubectl create help implies a list of service accounts can be references in a clusterrolebinding | https://api.github.com/repos/kubernetes/kubernetes/issues/108608/comments | 12 | 2022-03-09T12:23:52Z | 2022-05-04T01:23:47Z | https://github.com/kubernetes/kubernetes/issues/108608 | 1,163,872,893 | 108,608 |
[
"kubernetes",
"kubernetes"
] | As part of https://github.com/kubernetes/perf-tests/issues/1311 we're trying to simplify (and further speed up) our scalability tests.
Currently the main reason of the elevated pod startup across the whole test is roughly described here:
https://github.com/kubernetes/perf-tests/issues/1311#issuecomment-740586889
... | Scheduler throughput is low(er than expected) in large clusters when updating daemonsets | https://api.github.com/repos/kubernetes/kubernetes/issues/108606/comments | 23 | 2022-03-09T09:46:03Z | 2022-03-21T14:02:28Z | https://github.com/kubernetes/kubernetes/issues/108606 | 1,163,711,177 | 108,606 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
We stop applying the beta OS labels in Kubernetes 1.19, should we remove these beta labels in v1.24. I also get support from https://github.com/kubernetes/kubernetes/blob/9946b5364e8199ac832161e17155bd005c391fc5/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L144-L157
#... | drop beta node labels | https://api.github.com/repos/kubernetes/kubernetes/issues/108605/comments | 5 | 2022-03-09T09:13:22Z | 2022-03-09T17:51:19Z | https://github.com/kubernetes/kubernetes/issues/108605 | 1,163,676,916 | 108,605 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
create clusterrole command with resource value `rs.extensions` not work.
I got this example command from the help note.
```
#kubectl create clusterrole -h
Create a cluster role.
Examples:
# Create a cluster role named "pod-reader" that allows user to perform "get", "watch" and "list" on ... | kubectl create role command cannot recognize resource rs.extensions | https://api.github.com/repos/kubernetes/kubernetes/issues/108604/comments | 18 | 2022-03-09T08:16:20Z | 2022-05-04T01:24:36Z | https://github.com/kubernetes/kubernetes/issues/108604 | 1,163,622,352 | 108,604 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kubelet fails to start when `protectKernelDefaults: true` because it expects sysctl param 'kernel.panic=10' as per:
https://github.com/kubernetes/kubernetes/blob/e6c093d87ea4cbb530a7b2ae91e54c0842d8308a/staging/src/k8s.io/component-helpers/node/util/sysctl/sysctl.go#L56
KernelPanicRebootTimeo... | "protectKernelDefaults: true" fails since checks conflict with default kernel settings | https://api.github.com/repos/kubernetes/kubernetes/issues/108596/comments | 2 | 2022-03-09T00:00:20Z | 2022-03-09T00:01:52Z | https://github.com/kubernetes/kubernetes/issues/108596 | 1,163,336,751 | 108,596 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In 1.22+, when kubelet evicts a pod, it updates the pod status to api-server marking the pod phase as failed / succeeded. However, the kubelet continues to report Ready=true pod condition until the all of the containers are fully terminated by the container runtime.
As a result, since the pod ... | Kubelet reports Ready=true for pod and containers conditions during kubelet level evictions | https://api.github.com/repos/kubernetes/kubernetes/issues/108594/comments | 8 | 2022-03-08T19:39:16Z | 2022-06-09T17:56:06Z | https://github.com/kubernetes/kubernetes/issues/108594 | 1,163,044,699 | 108,594 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I've a cluster with one master and 3 workers. I shut down the 3 workers for more than 2 hours.
I typed : kubectl get nodes -o wide and I got
AME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUN... | pod's state is still ready/running on a Node that is shut down for more than 2 hours ! | https://api.github.com/repos/kubernetes/kubernetes/issues/108589/comments | 13 | 2022-03-08T16:14:52Z | 2023-03-17T13:40:57Z | https://github.com/kubernetes/kubernetes/issues/108589 | 1,162,848,881 | 108,589 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
All operations under https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.23/#-strong-proxy-operations-pod-v1-core-strong- say that the requests are "to portforward of Pod" or "to proxy of Pod" but it unclear which port this is, or how to proxy a request to another port on the pod via th... | "Get Connect Proxy" behaviour unclear from documentation when pod has multiple ports | https://api.github.com/repos/kubernetes/kubernetes/issues/108588/comments | 22 | 2022-03-08T15:22:02Z | 2025-03-04T21:21:55Z | https://github.com/kubernetes/kubernetes/issues/108588 | 1,162,787,749 | 108,588 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm trying to save the application state to the external location on pod termination. To do this I selected the Kubernetes pod PreStop hook. PreStop hook calls the application HTTP endpoint that needs to save state to AWS Systems Manager Parameter Store. From within the app I receive an error alike
... | External resources fail to be DNS-resolved from PreStop hook on pod termination | https://api.github.com/repos/kubernetes/kubernetes/issues/108587/comments | 7 | 2022-03-08T13:58:39Z | 2022-04-14T20:46:05Z | https://github.com/kubernetes/kubernetes/issues/108587 | 1,162,691,071 | 108,587 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A daemonset pod is scheduled to the node of cluster failed, should display node ip instead of `<none>`.
### Why is this needed?
A daemonset pod be scheduled to every node in cluster, if failed, `kubectl get po -o wide -n <ns>` may be not display node IP. if we have a clust... | Pod of DaemonSet manage that be scheduled to a node which reach max pod limit(maybe other reasons) can not display node IP | https://api.github.com/repos/kubernetes/kubernetes/issues/108584/comments | 7 | 2022-03-08T10:34:51Z | 2023-12-10T15:28:11Z | https://github.com/kubernetes/kubernetes/issues/108584 | 1,162,490,159 | 108,584 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We are running an upgrade of our Kubernetes master nodes via Ansible, from version 1.21.X to 1.22.X. Our playbook issues a `kubeadm upgrade apply v{{ version }} -y --v=5` command, which appears to reliably upgrade the `kube-apiserver` image on first run. However it doe not reliably upgrade the `kub... | Master upgrade to v1.22.X failing for kube-controller-manager & kube-scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/108582/comments | 4 | 2022-03-08T09:54:50Z | 2022-03-09T16:18:13Z | https://github.com/kubernetes/kubernetes/issues/108582 | 1,162,448,147 | 108,582 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When the kernel is statically compiled and statically loaded, and the folder /proc/modules is not exsit. In the kubernetes, use the ipvs. The code proxier.go failed to check /proc/module when it is not exsit. In the line 628, the err is not nil. But when the folder /proc/modules is exsit, it go t... | The code proxier.go failed to check kernel module when the folder /proc/module is not exsit | https://api.github.com/repos/kubernetes/kubernetes/issues/108579/comments | 27 | 2022-03-08T06:38:17Z | 2022-12-26T18:09:29Z | https://github.com/kubernetes/kubernetes/issues/108579 | 1,162,280,278 | 108,579 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Block I/O is the stats of tracking how many bytes are read/written from/to the block device on the node, for a particular container.
It is straightforward to add it in the FilesystemUsage
https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/cri-api/pkg/apis/... | Add block I/O in the ContainerStats of CRI | https://api.github.com/repos/kubernetes/kubernetes/issues/108575/comments | 19 | 2022-03-08T01:17:21Z | 2025-02-03T12:16:13Z | https://github.com/kubernetes/kubernetes/issues/108575 | 1,162,106,811 | 108,575 |
[
"kubernetes",
"kubernetes"
] | Issue https://github.com/kubernetes/kubernetes/issues/94860 was closed as stale so opening a new one.
Another case in which this happens is with `kubectl get img` if both Knative Serving and kpack are installed.
Calling `kubectl api-resources` shows that a kpack Image resource should have four aliases:
```
$ k ... | Warn users about CRD alias naming conflicts | https://api.github.com/repos/kubernetes/kubernetes/issues/108573/comments | 24 | 2022-03-07T19:52:42Z | 2023-10-11T15:04:13Z | https://github.com/kubernetes/kubernetes/issues/108573 | 1,161,854,241 | 108,573 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
"kubeadm init" continuously fails due to kubelet isn't running or healthy.
All the certs, manifests files are downloaded and loaded on the system into the "/etc/kubernetes/" pki and manifests files upon init command.
But when it comes to initializing the cluster using thos files using kubelet... | kubeadm init fails due to kubelet isn't running | https://api.github.com/repos/kubernetes/kubernetes/issues/108571/comments | 4 | 2022-03-07T17:46:29Z | 2022-03-10T15:20:20Z | https://github.com/kubernetes/kubernetes/issues/108571 | 1,161,731,852 | 108,571 |
[
"kubernetes",
"kubernetes"
] | In PR [1] below, we added support for logging which images were pulled by running the docker/ctr commands and saving them into images-containerd.log and images-docker.log, So now we need to look at those log files to see if we pull any images from places we don't want to ... like dockerhub. See PR [2] as an example of ... | Avoid pulling images straight from dockerhub in e2e tests | https://api.github.com/repos/kubernetes/kubernetes/issues/108562/comments | 7 | 2022-03-07T13:21:45Z | 2022-09-04T04:18:33Z | https://github.com/kubernetes/kubernetes/issues/108562 | 1,161,412,384 | 108,562 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a stateful set with node anti-affinity set on it so that the pods will all run on different nodes. local-storage is used for the PVCs. This normally all works fine, but in one deployment of the statefulset there was an etcd blip and the PVCs for db-0 AND db-2 both got allocated a PV on the s... | Pod anti-affinity not respected when binding PVCs to PVs when etcd timeout | https://api.github.com/repos/kubernetes/kubernetes/issues/108560/comments | 9 | 2022-03-07T12:22:18Z | 2022-11-11T10:47:24Z | https://github.com/kubernetes/kubernetes/issues/108560 | 1,161,349,844 | 108,560 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
kube-proxy listening abnormal IP
<img width="879" alt="image" src="https://user-images.githubusercontent.com/19342276/157018811-d5242ccc-1e80-4061-96d6-1b81e5a5311d.png">
### What did you expect to happen?
kube-proxy has no listening other ip
### How can we reproduce it (as minimally and preci... | Why is there an abnormal listening IP, in kube-proxy | https://api.github.com/repos/kubernetes/kubernetes/issues/108558/comments | 14 | 2022-03-07T11:01:14Z | 2022-04-28T20:45:58Z | https://github.com/kubernetes/kubernetes/issues/108558 | 1,161,260,521 | 108,558 |
[
"kubernetes",
"kubernetes"
] | Hi everyone, I am seeking some advice regarding an issue that I have been facing. Any suggestions or feedback on this issue will be greatly appreciated :)
In Kubernetes, controllers rely heavily on the Watch mechanism provided by the apiserver to efficiently detect changes in the system. When you send a Watch reques... | Measuring watch delay experienced in control loops | https://api.github.com/repos/kubernetes/kubernetes/issues/108556/comments | 34 | 2022-03-07T09:58:00Z | 2022-08-25T16:50:15Z | https://github.com/kubernetes/kubernetes/issues/108556 | 1,161,168,201 | 108,556 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
refs:https://github.com/kubernetes/cloud-provider-openstack/issues/1801
I realized bellow logs after my instance live migration over AZ.
```
% kubectl logs csi-cinder-nodeplugin-5vwrk node-driver-registrar
I0228 05:44:31.902073 1 main.go:113] Version: v2.1.0
I0228 05:44:31.903166 ... | can't update label after live migration. | https://api.github.com/repos/kubernetes/kubernetes/issues/108555/comments | 5 | 2022-03-07T08:22:09Z | 2022-06-01T14:25:19Z | https://github.com/kubernetes/kubernetes/issues/108555 | 1,161,056,647 | 108,555 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm user kubernetes 1.22.2 and api-server is deployed as a process running on host vms.
In my env, there're a lot of audit logs generated.
```
-rw------- 1 vcap vcap 1490801 Mar 3 11:49 audit-2022-03-03T11-49-22.459.log.1.gz
-rw------- 1 vcap vcap 517165 Mar 3 12:42 audit-2022-03-03T12... | Missing logs when log rotation happens | https://api.github.com/repos/kubernetes/kubernetes/issues/108551/comments | 17 | 2022-03-07T03:22:55Z | 2024-03-25T08:46:30Z | https://github.com/kubernetes/kubernetes/issues/108551 | 1,160,854,139 | 108,551 |
[
"kubernetes",
"kubernetes"
] | Example using a random PR for `pull-kubernetes-e2e-gce-ubuntu-containerd`, take a look at:
https://gcsweb.k8s.io/gcs/kubernetes-jenkins/pr-logs/pull/108541/pull-kubernetes-e2e-gce-ubuntu-containerd/1500141824650514432/artifacts/e2e-3fd5a49f6a-a7d53-minion-group-4krc/
in this set of logs, at least 4 files are empty ... | some logs for kube-up created nodes do not have anything in them | https://api.github.com/repos/kubernetes/kubernetes/issues/108549/comments | 2 | 2022-03-06T23:44:28Z | 2022-03-07T02:46:53Z | https://github.com/kubernetes/kubernetes/issues/108549 | 1,160,751,620 | 108,549 |
[
"kubernetes",
"kubernetes"
] | the cluster has different nodes,i need to allocate different memory since each node can provide different resource | How to set different env depends on node when use daemonset | https://api.github.com/repos/kubernetes/kubernetes/issues/108546/comments | 10 | 2022-03-06T15:08:01Z | 2022-03-11T10:47:16Z | https://github.com/kubernetes/kubernetes/issues/108546 | 1,160,634,360 | 108,546 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Unit test `TestErrConnKilled` failed for several times due to race detected. Details see: https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/108541/pull-kubernetes-unit/1500141824923144192
Report this in case of potential bug.
/sig testing
### What did you expect to happen?
Unit te... | `TestErrConnKilled` met race detected during execution | https://api.github.com/repos/kubernetes/kubernetes/issues/108545/comments | 3 | 2022-03-06T05:17:38Z | 2022-03-07T06:06:41Z | https://github.com/kubernetes/kubernetes/issues/108545 | 1,160,521,480 | 108,545 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
development environment:
development language:csharp & asp.net core 3.1
kuberentes version:1.20
KubernetesClient version: 4.0.26
I want to create a web terminal use kubernetes api,
but when I tried to create a websocket service, it reported an error;
so i need some help ,thank you... | WebSocketNamespacedPodExecAsync get System.Net.Sockets.SocketException (10053) error | https://api.github.com/repos/kubernetes/kubernetes/issues/108543/comments | 6 | 2022-03-06T02:52:37Z | 2022-03-17T17:28:19Z | https://github.com/kubernetes/kubernetes/issues/108543 | 1,160,502,107 | 108,543 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Update misspell version in ci test.
I think there are 2 options available here:
Option 1: Continue using `hack/verify-spelling.sh` and just change `github.com/client9misspell` to `github.com/Abirdcfly/misspell`
Option 2: Add misspell in golangci-lint, delete `hack/verify-spe... | Update misspell version | https://api.github.com/repos/kubernetes/kubernetes/issues/108542/comments | 8 | 2022-03-05T15:18:39Z | 2022-08-21T05:01:20Z | https://github.com/kubernetes/kubernetes/issues/108542 | 1,160,376,350 | 108,542 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When init container of static pod was GC'd and kubelet was restarted. The status of the static pod is alway Init:0/1 and never come back to Running.
```shell
kube-controller-manager-paas-192-168-16-112 0/1 Init:0/1 0 11d 192.168.16.112 paas-192-168-16-... | Static pod status is always Init:0/1 when init container GC'd before kubelet restart. | https://api.github.com/repos/kubernetes/kubernetes/issues/108537/comments | 17 | 2022-03-05T07:52:45Z | 2024-07-18T23:17:46Z | https://github.com/kubernetes/kubernetes/issues/108537 | 1,160,275,761 | 108,537 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a controller that creates objects. It uses `"k8s.io/apimachinery/pkg/api/errors".HasStatusCause(err, corev1.NamespaceTerminatingCause)` to notice when create fails due to a deleting namespace.
This check was working well until I moved it away from each `Create` call. In some cases, the err... | apimachinery/errors: HasStatusCause is incorrect for wrapped errors | https://api.github.com/repos/kubernetes/kubernetes/issues/108528/comments | 4 | 2022-03-04T22:57:40Z | 2022-07-13T01:37:48Z | https://github.com/kubernetes/kubernetes/issues/108528 | 1,160,118,491 | 108,528 |
[
"kubernetes",
"kubernetes"
] | Service traffic can be "internal" or "external" but we never explicitly define exactly what these mean.
[The docs](https://kubernetes.io/docs/concepts/services-networking/service/#external-traffic-policy) say:
> You can set the `spec.externalTrafficPolicy` field to control how traffic _**from external sources**_ ... | definition of "internal" vs "external" service traffic, behavior of LB IP short-circuit | https://api.github.com/repos/kubernetes/kubernetes/issues/108526/comments | 21 | 2022-03-04T20:47:46Z | 2023-01-28T13:51:37Z | https://github.com/kubernetes/kubernetes/issues/108526 | 1,160,038,353 | 108,526 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add tests to validate kube-proxy NAT rules for each --detect-local-mode configuration in kind clusters.
### Why is this needed?
We want to validate that iptables NAT rules work as expected for all supported --detect-local-mode configurations in a Kubernetes cluster.
* [K... | Add tests for kube-proxy --detect-local-mode configurations | https://api.github.com/repos/kubernetes/kubernetes/issues/108525/comments | 9 | 2022-03-04T20:15:42Z | 2022-03-29T15:14:00Z | https://github.com/kubernetes/kubernetes/issues/108525 | 1,160,016,139 | 108,525 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Tested with both custom metric driver and KEDA. When HPA is configured for a external metric (whether its Stackdriver or KEDA internal), hpa fails to see the value with the following message:
`
Warning FailedGetExternalMetric 2m5s (x60 over 22m) horizontal-pod-autoscaler unable to get exte... | Horizontal pot autoscaler fails to get externel metric due to timeout in apis/authorization.k8s.io/v1/subjectaccessreviews | https://api.github.com/repos/kubernetes/kubernetes/issues/108524/comments | 7 | 2022-03-04T19:37:55Z | 2022-08-01T21:46:33Z | https://github.com/kubernetes/kubernetes/issues/108524 | 1,159,982,653 | 108,524 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Currently when services or endpoints are deleted we remove the conntrack entries for UDP & SCTP services:
https://github.com/kubernetes/kubernetes/blob/88f97283393715c7fa870dd90be0fd0d0faad6bd/pkg/proxy/iptables/proxier.go#L736
https://github.com/kubernetes/kubernetes/blob/c5fbcd735d67a7cc209301... | Document and implement proper service-endpoint lifecycle (Gracefully draining Services/Endpoints) | https://api.github.com/repos/kubernetes/kubernetes/issues/108523/comments | 89 | 2022-03-04T17:44:32Z | 2024-08-31T03:38:19Z | https://github.com/kubernetes/kubernetes/issues/108523 | 1,159,895,530 | 108,523 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are flaking?
integration-master
### Which tests are flaking?
- ci-kubernetes-integration-master.Overall
- k8s.io/kubernetes/test/integration/serviceaccount.TestServiceAccountTokenAuthentication
### Since when has it been flaking?
It started to happen since 2022-03-03
### Testgrid link
https://k8s... | [Flaky test] integration-master, TestServiceAccountTokenAuthentication | https://api.github.com/repos/kubernetes/kubernetes/issues/108511/comments | 6 | 2022-03-04T10:20:44Z | 2022-03-09T03:49:08Z | https://github.com/kubernetes/kubernetes/issues/108511 | 1,159,482,127 | 108,511 |
[
"kubernetes",
"kubernetes"
] | ### Failure cluster [9680dae909cbef5f1b13](https://go.k8s.io/triage#9680dae909cbef5f1b13)
In
```
[sig-node] Probing container should have monotonically increasing restart count [NodeConformance] [Conformance]
```
</span>
##### Error text:
```
/home/prow/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.... | Failure cluster [9680dae9...] [sig-node] Probing container should have monotonically increasing restart count [NodeConformance] [Conformance] | https://api.github.com/repos/kubernetes/kubernetes/issues/108504/comments | 1 | 2022-03-03T21:28:42Z | 2022-03-15T05:08:11Z | https://github.com/kubernetes/kubernetes/issues/108504 | 1,158,915,200 | 108,504 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[6/6]</code>
- [x] APISnoop org-flow : [patchCoreV1NamespacedPodStatus.org](https://github.com/apisnoop/ticket-writing/blob/master/patchCoreV1NamespacedPodStatus.org)
- [X] test approval issue : #108499
- [X] test pr : #110705
- [X] two weeks soak start date : [Test grid link](https://testgrid.... | Revised Update patchCoreV1NamespacedPodStatus test - +1 endpoint coverage | https://api.github.com/repos/kubernetes/kubernetes/issues/108499/comments | 5 | 2022-03-03T19:45:26Z | 2022-07-08T16:07:52Z | https://github.com/kubernetes/kubernetes/issues/108499 | 1,158,829,400 | 108,499 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Hello,
I am looking for help to re-add [sinceTime ](https://github.com/kubernetes/kubernetes/blob/85c43df3f6090f13a1004098a852553d1c61c745/pkg/apis/core/types.go#L4651) from the PodLogOptions REST call into the swagger file.
I have tried a few things locally on my machine and w... | Add sinceTime to api swagger | https://api.github.com/repos/kubernetes/kubernetes/issues/108498/comments | 12 | 2022-03-03T18:56:31Z | 2023-05-08T15:54:25Z | https://github.com/kubernetes/kubernetes/issues/108498 | 1,158,787,343 | 108,498 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently, stable metric changes can be approved by top-level approvers and are not obviously "special" to a contributor.
We have verify scripts that will prevent adding or changing stable metrics without updating Instrumentation-owned files, but the errors can easily be "fixe... | Flag stable metric changes for additional approval | https://api.github.com/repos/kubernetes/kubernetes/issues/108497/comments | 4 | 2022-03-03T18:16:44Z | 2022-05-04T01:23:39Z | https://github.com/kubernetes/kubernetes/issues/108497 | 1,158,748,071 | 108,497 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
/sig scalability
We should limit the number of stackTraces that we print in case of timeout. I am thinking about having a limit of stackTraces that can be logged in a specific time window, but I'm happy to discuss other possible solutions for this.
### Why is this needed?
Cur... | Reduce amount of statusStack logs when server timeouts a lot | https://api.github.com/repos/kubernetes/kubernetes/issues/108488/comments | 11 | 2022-03-03T13:58:37Z | 2022-10-31T18:51:12Z | https://github.com/kubernetes/kubernetes/issues/108488 | 1,158,442,617 | 108,488 |
[
"kubernetes",
"kubernetes"
] | The integration framework runs an apiserver and sometimes other components before each test execution, however, the shutdown is not clean and is leaving a lot of goroutines orphan that keep accumulation between different runs.
Some orphan goroutines are connections to etcd, and since the etcd process is shared for a... | [Umbrella Issue] Integration framework: reduce goroutine leakage | https://api.github.com/repos/kubernetes/kubernetes/issues/108483/comments | 36 | 2022-03-03T10:31:55Z | 2022-11-08T00:01:47Z | https://github.com/kubernetes/kubernetes/issues/108483 | 1,158,237,505 | 108,483 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A PersistentVolume created using the in-tree vsphere cloud provider hangs in a 'Pending' state with no error message if the vSphere account lacks appropriate permissions. The is true even with the kube-controller-manager logs set to debug as per the [troubleshooting guide](https://vmware.github.io/v... | In-tree vsphere cloud provider: PV creation hangs in pending state when vSphere returns permission denied | https://api.github.com/repos/kubernetes/kubernetes/issues/108481/comments | 7 | 2022-03-03T09:47:20Z | 2022-08-13T18:33:21Z | https://github.com/kubernetes/kubernetes/issues/108481 | 1,158,190,535 | 108,481 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubernetes versions 1.21 - 1.23 are vulnerable to CVE-2021-43565
### What did you expect to happen?
Vulnerability to be mitigated.
### How can we reproduce it (as minimally and precisely as possible)?
go.mod needs to be updated to include `golang.org/x/crypto to v0.0.0-20211202192323-5770296d904... | CVE-2021-43565: Update golang.org/x/crypto to v0.0.0-20211202192323-5770296d904e | https://api.github.com/repos/kubernetes/kubernetes/issues/108464/comments | 13 | 2022-03-02T20:15:16Z | 2022-07-18T17:28:26Z | https://github.com/kubernetes/kubernetes/issues/108464 | 1,157,647,346 | 108,464 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Kubernetes versions 1.21 and 1.22 are vulnerable to CVE-2021-38561
### What did you expect to happen?
Vulnerability to be mitigated.
### How can we reproduce it (as minimally and precisely as possible)?
go.mod needs to be updated to include `golang.org/x/text v0.3.7`
### Anything else we need t... | CVE-2021-38561: Update golang.org/x/text to v0.3.7 | https://api.github.com/repos/kubernetes/kubernetes/issues/108463/comments | 6 | 2022-03-02T20:09:45Z | 2022-06-20T20:50:43Z | https://github.com/kubernetes/kubernetes/issues/108463 | 1,157,638,969 | 108,463 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I had a single node (only master) Kubernetes cluster up and running with couple of workloads. The cluster was created using "Kubeadm".
Now, the IP address of the Master node changes due to DHCP or assume that I had to shift the Master node to other network or unplugged the ethernet and connecte... | Cannot access Kubernetes Cluster after Master node Dynamic IP changes | https://api.github.com/repos/kubernetes/kubernetes/issues/108453/comments | 16 | 2022-03-02T14:24:42Z | 2022-12-08T15:20:40Z | https://github.com/kubernetes/kubernetes/issues/108453 | 1,157,266,340 | 108,453 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
The override in https://github.com/kubernetes/kubernetes/blob/ab69524f795c42094a6630298ff53f3c3ebab7f4/pkg/kubeapiserver/default_storage_factory_builder.go#L64 can be removed in Kubernetes v1.25 because then the oldest supported kube-apiserver for downgrades will be v1.24 which wil... | storage capacity tracking: switch storage version from v1beta1 to v1 | https://api.github.com/repos/kubernetes/kubernetes/issues/108451/comments | 5 | 2022-03-02T14:04:34Z | 2022-07-09T02:35:51Z | https://github.com/kubernetes/kubernetes/issues/108451 | 1,157,242,692 | 108,451 |
[
"kubernetes",
"kubernetes"
] | Noticed this issue when looking at logs to figure out which images we use in a e2e test and from where. for example:
```
1498758833965633536/artifacts/e2e-a416f0f6a0-667c4-minion-group-v5cc/kubelet.log:Mar 01 21:20:28.949444 e2e-a416f0f6a0-667c4-minion-group-v5cc kubelet[9999]: I0301 21:20:28.949418 9999 kuberun... | Remove pv-recycler dependency on busybox:1.27 | https://api.github.com/repos/kubernetes/kubernetes/issues/108449/comments | 6 | 2022-03-02T13:35:38Z | 2022-03-04T00:01:08Z | https://github.com/kubernetes/kubernetes/issues/108449 | 1,157,209,300 | 108,449 |
[
"kubernetes",
"kubernetes"
] | Recently, I'm trying to execute performance test on k8s cluster with kubemark tool, but after several days investigation, I'm so confused which tool/framework I should use: clusterload2? or kubernetes e2e test?
https://github.com/kubernetes/perf-tests/tree/master/clusterloader2
https://github.com/kubernetes/kube... | k8s performance test: clusterload2 Or k8s e2e test? | https://api.github.com/repos/kubernetes/kubernetes/issues/108446/comments | 7 | 2022-03-02T09:45:12Z | 2022-10-28T14:21:23Z | https://github.com/kubernetes/kubernetes/issues/108446 | 1,156,926,418 | 108,446 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Feature gate `DefaultPodTopologySpread` is GA, shall we remove `SelectorSpread` plugin then. I also get support from https://github.com/kubernetes/kubernetes/pull/91793#issuecomment-639800733. Or next release will be the proper time.
### Why is this needed?
Remove unneeded plugi... | remove `SelectorSpread` plugin | https://api.github.com/repos/kubernetes/kubernetes/issues/108444/comments | 24 | 2022-03-02T06:53:09Z | 2023-08-29T07:25:24Z | https://github.com/kubernetes/kubernetes/issues/108444 | 1,156,590,947 | 108,444 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
debug encounter panics on Time object. but panic doesn't happen when running it.
<img width="727" alt="image" src="https://user-images.githubusercontent.com/8025018/156272701-248a47d1-e9bb-493e-9753-034baed7619f.png">
### What did you expect to happen?
no panics
### How can we reproduce it (... | nil pointer issue on Time object | https://api.github.com/repos/kubernetes/kubernetes/issues/108435/comments | 15 | 2022-03-02T01:05:46Z | 2024-06-25T23:44:02Z | https://github.com/kubernetes/kubernetes/issues/108435 | 1,156,096,633 | 108,435 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
The current logic in node_status_updater, it retrieves the list of nodes that need to be updated in node status (due to new volumes are attached to that node). At the same time, it mark those node in actual state for updateNodeStatusUpdateNeeded as False (those nodes do no need to ... | Simplify node status update volumeAttached list | https://api.github.com/repos/kubernetes/kubernetes/issues/108433/comments | 20 | 2022-03-02T00:05:09Z | 2024-07-21T20:21:55Z | https://github.com/kubernetes/kubernetes/issues/108433 | 1,155,999,484 | 108,433 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have deployed a k8s extended apiserver in, say namespace "kubedb". Later we try to `k delete ns kubedb`. The namespace stays in terminating stage. If I check the status.conditions of the namespace, I see
```
- lastTransitionTime: "2022-03-01T16:21:45Z"
message: 'Discovery failed for ... | Extended api server blocks deletion of namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/108427/comments | 15 | 2022-03-01T18:28:25Z | 2022-08-29T12:23:38Z | https://github.com/kubernetes/kubernetes/issues/108427 | 1,155,670,782 | 108,427 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
E2E sig-network
### Which tests are failing?
[sig-network] Services [It] should be able to up and down services
### Since when has it been failing?
NA
### Testgrid link
_No response_
### Reason for failure (if possible)
Mar 1 17:19:31.858: Unexpected error:
<*errors.Status... | [sig-network] Services [It] should be able to up and down services | https://api.github.com/repos/kubernetes/kubernetes/issues/108424/comments | 7 | 2022-03-01T17:56:12Z | 2022-03-18T07:38:13Z | https://github.com/kubernetes/kubernetes/issues/108424 | 1,155,637,356 | 108,424 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
/sig node
kubelet flag `--serialize-image-pulls` is by default true. It has a performance issue that one big image pulling would block all pods starting(that need a new image).
The current solution is changing the flag `--serialize-image-pulls`. (For instance, kubeadm supp... | promoting use of parallel image pulls | https://api.github.com/repos/kubernetes/kubernetes/issues/108405/comments | 13 | 2022-03-01T08:10:10Z | 2024-12-25T09:29:44Z | https://github.com/kubernetes/kubernetes/issues/108405 | 1,155,007,218 | 108,405 |
[
"kubernetes",
"kubernetes"
] | Follow up from conversation in slack:
https://kubernetes.slack.com/archives/CJH2GBF7Y/p1646068821664219
Currently we don't have a way to look at or graph statistics for downloads from the production GCS buckets for kubernetes downloads. This would be really useful for tracking usage over time, celebrations, compari... | Metrics for Kubernetes downloads (from gcs buckets) | https://api.github.com/repos/kubernetes/kubernetes/issues/108398/comments | 7 | 2022-02-28T19:01:13Z | 2024-04-03T22:02:15Z | https://github.com/kubernetes/kubernetes/issues/108398 | 1,154,441,105 | 108,398 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Found during the investigation of the goroutine leaks on the test integration framework that the resource quota controller doesn't exit
```
goroutine 2454 [sync.Cond.Wait]:
sync.runtime_notifyListWait(0xc000205490, 0xc)
/usr/local/go/src/runtime/sema.go:513 +0x13d
... | Admission plugins don't exit gracefully | https://api.github.com/repos/kubernetes/kubernetes/issues/108388/comments | 5 | 2022-02-28T10:45:05Z | 2022-05-31T08:43:45Z | https://github.com/kubernetes/kubernetes/issues/108388 | 1,153,932,387 | 108,388 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I suggest to add shortened aliases for most used commands in `kubectl` tool like this:
- switch namespace:
```
kubectl set ns my-namespace
# alias of full command: kubectl config set-context --current --namespace=my-namespace
```
- query in all namespaces:
```
kubectl get p... | Provide shortened aliases for common kubectl commands like switching namespace | https://api.github.com/repos/kubernetes/kubernetes/issues/108387/comments | 3 | 2022-02-28T09:49:20Z | 2022-03-01T05:58:49Z | https://github.com/kubernetes/kubernetes/issues/108387 | 1,153,874,694 | 108,387 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add a new --pod-logs-directory flag to Kubelet.
Provide users with ability to set `podLogsRootDirectory`.
### Why is this needed?
The root directory for pod logs is `/var/log/pods` as default, and doesn't support modification.
Sometimes we want container logs to be output to a ... | Add a new --pod-logs-directory flag to Kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/108384/comments | 17 | 2022-02-28T03:19:27Z | 2024-04-25T11:26:48Z | https://github.com/kubernetes/kubernetes/issues/108384 | 1,153,573,765 | 108,384 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
my etcd cluster got surcharged and become slow to answer, this in turn made the kube-controller-manager crash because it lost the election.
This shouldn't be a problem in theory as everything should be able to restart.
But when the controller-manager tries to restart it fails to retrieve the ... | kube-controller-manager able to acquire lease even when lock retrieval fails | https://api.github.com/repos/kubernetes/kubernetes/issues/108380/comments | 11 | 2022-02-27T23:20:49Z | 2022-07-29T22:26:55Z | https://github.com/kubernetes/kubernetes/issues/108380 | 1,153,442,341 | 108,380 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Attempting to mount a subpath of an existing NFS share fails with the error:
Error: failed to prepare subPath for volumeMount "data" of container "pod"
### What did you expect to happen?
I expect the mount to work
### How can we reproduce it (as minimally and precisely as possible)?
... | NFS subPath mount fails | https://api.github.com/repos/kubernetes/kubernetes/issues/108374/comments | 6 | 2022-02-27T16:55:08Z | 2024-10-12T04:39:23Z | https://github.com/kubernetes/kubernetes/issues/108374 | 1,153,319,798 | 108,374 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In the controller-manager log there are lots and lots of entries written containing the text:
garbagecollector.go:507] object [v1/Namespace, namespace: , name: knative-serving, uid: 6611472c-8af0-430b-abcd-3556be6b53ea]'s doesn't have an owner, continue on next item
These entries are also pres... | Controller-Manager garbagecollector.go objects don´t have an owner written 100000+ times in logfile per day | https://api.github.com/repos/kubernetes/kubernetes/issues/108373/comments | 19 | 2022-02-27T13:51:56Z | 2022-08-28T20:12:39Z | https://github.com/kubernetes/kubernetes/issues/108373 | 1,153,259,293 | 108,373 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Running Kubernetes 1.21.6
According to the docs, I should be able to delete a Deployment while preserving its pods, with some `kubectl delete --cascade=orphan`
https://kubernetes.io/docs/tasks/administer-cluster/use-cascading-deletion/#set-orphan-deletion-policy
This used to work with previou... | Delete object cascade=orphan | https://api.github.com/repos/kubernetes/kubernetes/issues/108372/comments | 12 | 2022-02-27T13:07:16Z | 2022-05-05T19:15:28Z | https://github.com/kubernetes/kubernetes/issues/108372 | 1,153,244,628 | 108,372 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I deploy a k3s on a pure cgroupv2 system that is not using systemd. kubelet seem get no access to cgroup as expected. More background see https://github.com/k3s-io/k3s/issues/5133
### What did you expect to happen?
kubelet should support cgroupv2 without systemd. There are still systems preper no... | cgroupv2 and kubelet seem not playing well together on non systemd OS | https://api.github.com/repos/kubernetes/kubernetes/issues/108364/comments | 38 | 2022-02-26T09:24:03Z | 2022-07-20T04:54:41Z | https://github.com/kubernetes/kubernetes/issues/108364 | 1,151,539,414 | 108,364 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I am trying to add a new API group and want to generate the `generated.pb.go` file for it with `hack/update-generated-protobuf.sh`. That fails in two ways:
- syncing out the result fails when the file does not exist yet
- if I create an empty Go file (just with `package` statement), that file do... | hack/update-generated-protobuf.sh: no longer creates and/or updates generated.pb.go | https://api.github.com/repos/kubernetes/kubernetes/issues/108358/comments | 7 | 2022-02-25T22:16:30Z | 2022-03-03T17:48:12Z | https://github.com/kubernetes/kubernetes/issues/108358 | 1,150,926,493 | 108,358 |
[
"kubernetes",
"kubernetes"
] | Upstream/downstream tracking issues:
- [ ] Release engineering tracking for go1.18: https://github.com/kubernetes/release/issues/2307
- [ ] ...
- [ ] ...
- [ ] ...
cc: @kubernetes/release-engineering @kubernetes/release-team @dims @liggitt
---
From https://github.com/kubernetes/kubernetes/pull/107105#is... | [RELEASE BLOCKER][1.24] Golang 1.18 issues | https://api.github.com/repos/kubernetes/kubernetes/issues/108357/comments | 15 | 2022-02-25T20:13:59Z | 2024-10-17T10:02:24Z | https://github.com/kubernetes/kubernetes/issues/108357 | 1,150,826,145 | 108,357 |
[
"kubernetes",
"kubernetes"
] | ERROR: type should be string, got "https://github.com/kubernetes/kubernetes/blob/5bafc8306a7b622e292746aec8a9e9212b755071/staging/src/k8s.io/apimachinery/pkg/runtime/serializer/versioning/versioning.go#L225\r\n\r\n> I0225 16:19:15.424936 1416311 versioning.go:225] a memory allocator was provided but the encoder %!T(MISSING) doesn't implement the runtime.EncoderWithAllocator, using regular encoder.Encode method" | Logging statement with missing parameter | https://api.github.com/repos/kubernetes/kubernetes/issues/108355/comments | 10 | 2022-02-25T15:28:33Z | 2022-03-16T13:31:50Z | https://github.com/kubernetes/kubernetes/issues/108355 | 1,150,581,746 | 108,355 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We created an hpa as following:
```
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-hpa
namespace: test
spec:
behavior:
scaleDown:
policies:
- periodSeconds: 300
type: Pods
value: 2
selectPolicy: Max
... | HPA calculated periodStartRelicas maybe unexpected when scaling direction changed frequently during periodSecond | https://api.github.com/repos/kubernetes/kubernetes/issues/108354/comments | 6 | 2022-02-25T11:33:59Z | 2022-08-30T17:58:56Z | https://github.com/kubernetes/kubernetes/issues/108354 | 1,150,345,094 | 108,354 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I re-join nodes in cluster, nodes stuck in NotReady. I show descriced node and see that "cni plugin not initialized"
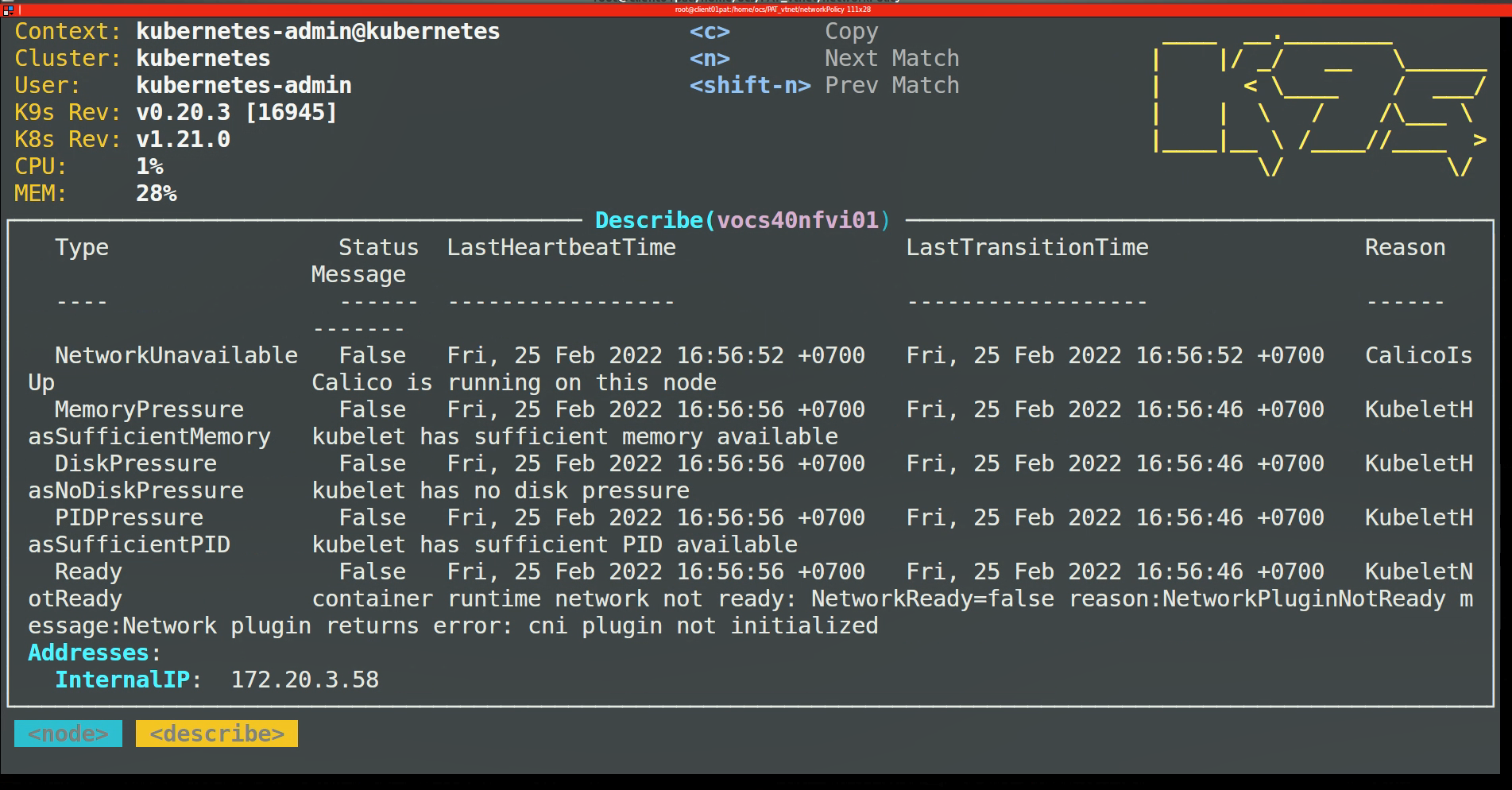
But this just happen when I use runtime being containerd, a... | Node error cni plugin not initialized when re-join node in cluster | https://api.github.com/repos/kubernetes/kubernetes/issues/108353/comments | 7 | 2022-02-25T10:27:02Z | 2022-07-30T19:34:33Z | https://github.com/kubernetes/kubernetes/issues/108353 | 1,150,285,271 | 108,353 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
kubelet-gce-e2e-lock-contention
### Which tests are failing?

### Since when has it been failing?
8/12/2021
### Testgrid link
https://testgrid.k8s.io/sig-node-kubelet#kubele... | [Failing test] kubelet-gce-e2e-lock-contention | https://api.github.com/repos/kubernetes/kubernetes/issues/108348/comments | 9 | 2022-02-25T07:00:15Z | 2022-03-10T07:22:31Z | https://github.com/kubernetes/kubernetes/issues/108348 | 1,150,110,636 | 108,348 |
[
"kubernetes",
"kubernetes"
] | We've made enough changes to the code in staging/src/k8s.io/apiextensions-apiserver/third_party/forked/celopenapi/model, that it's not really helpful to think of it as forked code.
More practically, having [gofmt disabled](https://github.com/kubernetes/kubernetes/blob/3213a92802b91ed718578f51b14916105fb0c3da/hack/ve... | Move CEL openapi integration code out of third_party/forked/celopenapi/model/registry.go | https://api.github.com/repos/kubernetes/kubernetes/issues/108346/comments | 7 | 2022-02-25T02:27:09Z | 2022-10-07T00:13:53Z | https://github.com/kubernetes/kubernetes/issues/108346 | 1,149,971,365 | 108,346 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.