
issue_owner_repo listlengths 2 2 | issue_body stringlengths 0 261k ⌀ | issue_title stringlengths 1 925 | issue_comments_url stringlengths 56 81 | issue_comments_count int64 0 2.5k | issue_created_at stringlengths 20 20 | issue_updated_at stringlengths 20 20 | issue_html_url stringlengths 37 62 | issue_github_id int64 387k 2.91B | issue_number int64 1 131k |
|---|---|---|---|---|---|---|---|---|---|
[
"kubernetes",
"kubernetes"
] | ### What happened?
We set up [reflectors](https://github.com/kubernetes/client-go/blob/master/tools/cache/reflector.go#L254) to reflect the change of k8s resources but they don't work properly for resources defined by aggregation API. After adding some debugging logs, I think the issue is narrowed down to the watch... | Watcher doesn't receive expected event nor `EOF` for resources defined by aggregation sometimes | https://api.github.com/repos/kubernetes/kubernetes/issues/108344/comments | 15 | 2022-02-25T01:10:35Z | 2022-11-21T17:37:31Z | https://github.com/kubernetes/kubernetes/issues/108344 | 1,149,933,147 | 108,344 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
In https://github.com/kubernetes/kubernetes/pull/106122, the `apiserver_request_sizes` metric graduation to stable slipped through without its naming being updated to follow sig-instrumentation best practices. Considering that this metric is ill-formed, it shouldn't be advertised as stable and shoul... | The apiserver_request_sizes metric is stable even though it has an improper name | https://api.github.com/repos/kubernetes/kubernetes/issues/108330/comments | 6 | 2022-02-24T09:53:54Z | 2022-06-27T15:49:21Z | https://github.com/kubernetes/kubernetes/issues/108330 | 1,149,078,426 | 108,330 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Run the testcase,
```
e2e.test -- -ginkgo.focus="\[sig-network\] Loadbalancing: L7 \[Slow\] Nginx should conform to Ingress spec"
```
And debug into the source, will reveal something abnormal,
````
/go/src/k8s.io/kubernetes/_output/local/go/src/k8s.io/kubernetes/test/e2e/framework/testfil... | manifest of ingress is not embedded into golang test executable directory | https://api.github.com/repos/kubernetes/kubernetes/issues/108324/comments | 11 | 2022-02-24T07:08:13Z | 2022-03-11T09:16:14Z | https://github.com/kubernetes/kubernetes/issues/108324 | 1,148,937,359 | 108,324 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While using `workqueue/queue.go` for one of my usecases, I naturally came across its `Add()` function. Essentially, if the queue is in a shutdown mode, it just does a plain `return` and there is no way for the caller to directly know if the item got added or not:
https://github.com/kubernetes/ku... | Workqueue's add function `queue.Add()` doesn't tell whether an item was successfully added or not | https://api.github.com/repos/kubernetes/kubernetes/issues/108322/comments | 16 | 2022-02-24T05:38:31Z | 2025-03-04T21:20:41Z | https://github.com/kubernetes/kubernetes/issues/108322 | 1,148,883,152 | 108,322 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Entry in ipvs real sever remains at weight=0 after kube-proxy restarts. (During 1.21 -> 1.22 kubernetes cluster upgrade.)
Related to https://github.com/kubernetes/kubernetes/issues/92019
As the related issue is considered closed, I will report this issue again as the problem still persists in ... | kube-proxy in ipvs mode leaves real server weight as 0 after restart | https://api.github.com/repos/kubernetes/kubernetes/issues/108319/comments | 13 | 2022-02-24T03:23:56Z | 2022-08-27T09:24:37Z | https://github.com/kubernetes/kubernetes/issues/108319 | 1,148,815,735 | 108,319 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
15:30:38.355384 2136 graph_builder.go:279] garbage controller monitor not yet synced: events.k8s.io/v1, Resource=events
var ignoredResources = map[schema.GroupResource]struct{}{
{Group: "", Resource: "events"}: {},
}
ignoredResources group miss match with api-resource
events.k8s.io/v1... | controller-manager gc sync event failed | https://api.github.com/repos/kubernetes/kubernetes/issues/108318/comments | 7 | 2022-02-24T03:14:15Z | 2022-07-25T21:42:07Z | https://github.com/kubernetes/kubernetes/issues/108318 | 1,148,810,699 | 108,318 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have unit test(s) that gather metrics for verification using `legacyregistry.DefaultGatherer`, for example:
https://github.com/kubernetes/kubernetes/blob/0ae6ef69b8cf49af8d6e87fca3d400716bba631b/staging/src/k8s.io/apiserver/pkg/server/filters/priority-and-fairness_test.go#L1288-L1291
We ha... | prometheus client library panics with `counter cannot decrease in value` | https://api.github.com/repos/kubernetes/kubernetes/issues/108311/comments | 7 | 2022-02-23T22:35:34Z | 2022-02-24T17:43:00Z | https://github.com/kubernetes/kubernetes/issues/108311 | 1,148,651,916 | 108,311 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Preemption and PreemptionPV workloads are not working successfully with `connect: can't assign requested address` errors.
### What did you expect to happen?
working successfully
### How can we reproduce it (as minimally and precisely as possible)?
run scheduler_perf
### Anything els... | scheduler_perf: Preemption and PreemptionPV workloads are not working successfully | https://api.github.com/repos/kubernetes/kubernetes/issues/108308/comments | 8 | 2022-02-23T16:33:46Z | 2022-05-08T04:51:26Z | https://github.com/kubernetes/kubernetes/issues/108308 | 1,148,316,878 | 108,308 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
release-master-blocking
- [skew-cluster-latest-kubectl-stable1-gce](https://testgrid.k8s.io/sig-release-master-blocking#skew-cluster-latest-kubectl-stable1-gce)
### Which tests are failing?
- ci-kubernetes-e2e-gce-master-new-gci-kubectl-skew.Overall
- kubetest.Extract
### Since when ... | [Failing test] ci-kubernetes-e2e-gce-master-new-gci-kubectl-skew.Overall | https://api.github.com/repos/kubernetes/kubernetes/issues/108307/comments | 17 | 2022-02-23T16:24:40Z | 2022-03-23T16:45:46Z | https://github.com/kubernetes/kubernetes/issues/108307 | 1,148,306,723 | 108,307 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
https://github.com/kubernetes/kubernetes/pull/108262 adds a unit test that records the order in which `BackoffManager`, `flowcontrol.RateLimiter`, and `metrics` calls are invoked.
With this we have found an inconsistency where `Watch` does not do `RateLimiter.Wait` before initially sending the ... | client-go: inconsistencies among `Do`, `Watch`, and `Stream` | https://api.github.com/repos/kubernetes/kubernetes/issues/108302/comments | 11 | 2022-02-23T14:35:07Z | 2022-05-23T06:26:02Z | https://github.com/kubernetes/kubernetes/issues/108302 | 1,148,175,148 | 108,302 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While downscaling, HPA should terminate pods as and when load decreases.
We are seeing downscaling only when custom metric touches zero and not when value decreases below threshold.
### What did you expect to happen?
While downscaling, HPA should terminate pods as and when load decreases. I... | Horizontal pod autoscaler is not able to downscale properly based on custom metrics. | https://api.github.com/repos/kubernetes/kubernetes/issues/108299/comments | 7 | 2022-02-23T14:12:49Z | 2022-08-06T15:26:24Z | https://github.com/kubernetes/kubernetes/issues/108299 | 1,148,147,081 | 108,299 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Currently, some e2e tests do not use central framework helper methods to create namespaces. Examples:
https://github.com/kubernetes/kubernetes/blob/296bf4f01668374ade252a751d4c3567917b9890/test/e2e/apimachinery/webhook.go#L1532
https://github.com/kubernetes/kubernetes/blob/296b... | test/e2e: use framework helpers to create namespaces | https://api.github.com/repos/kubernetes/kubernetes/issues/108298/comments | 16 | 2022-02-23T12:40:30Z | 2022-12-20T18:17:58Z | https://github.com/kubernetes/kubernetes/issues/108298 | 1,148,042,287 | 108,298 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
After deleting a namespace all pods related to a cron job got stuck in Terminating status.
It was impossible to remove them even force remove did not work.
The only way of removing that pods was by modifying metadata to remove `batch.kubernetes.io/job-tracking` finalizer
### What did you expect... | After deleting a namespace all pods related to a cron job got stuck in Terminating status. | https://api.github.com/repos/kubernetes/kubernetes/issues/108297/comments | 10 | 2022-02-23T11:13:53Z | 2022-07-30T15:34:30Z | https://github.com/kubernetes/kubernetes/issues/108297 | 1,147,959,161 | 108,297 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I use `flink-operator` to run flinkcluster.
it use `k8sclient` get job, and then list pods of the job
I found the job is completed, and job.status.succeed = 1
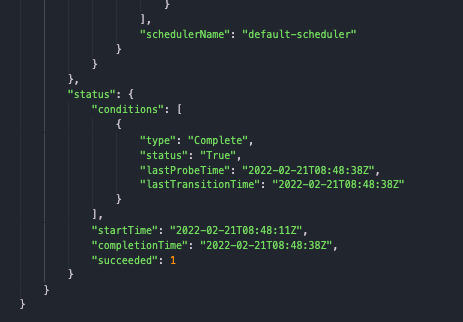
but the pod of the job is... | Job is completed but pod status is still running | https://api.github.com/repos/kubernetes/kubernetes/issues/108292/comments | 9 | 2022-02-23T07:22:09Z | 2023-02-10T17:07:14Z | https://github.com/kubernetes/kubernetes/issues/108292 | 1,147,724,684 | 108,292 |
[
"kubernetes",
"kubernetes"
] | I set this in yaml file
```
Volumes:
shm:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium: Memory
SizeLimit: 4Gi
```
but I got this in pod
```
shm 32G 0 32G 0% /dev/shm
```
and my host memory... | shm size show inconsistently in the pod | https://api.github.com/repos/kubernetes/kubernetes/issues/108291/comments | 9 | 2022-02-23T07:06:18Z | 2022-07-29T08:17:56Z | https://github.com/kubernetes/kubernetes/issues/108291 | 1,147,706,028 | 108,291 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
None
### What did you expect to happen?
None
### How can we reproduce it (as minimally and precisely as possible)?
None
### Anything else we need to know?
None
### Kubernetes version
<details>
```console
$ kubectl version
# paste output here
```
</details>
### Cloud provider
<de... | why the Replicas used int32? Is used uint32 more better? | https://api.github.com/repos/kubernetes/kubernetes/issues/108289/comments | 6 | 2022-02-23T05:07:22Z | 2022-07-23T08:18:05Z | https://github.com/kubernetes/kubernetes/issues/108289 | 1,147,636,599 | 108,289 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
A new sig-scheduling meeting friendly to APEC timezones.
### Why is this needed?
The current regular meeting is scheduled at 1PM EST, which is very late for APEC region.
/kind documentation
/assign @Huang-Wei | Add a new sig-scheduling meeting friendly to APAC timezones | https://api.github.com/repos/kubernetes/kubernetes/issues/108288/comments | 22 | 2022-02-23T03:47:29Z | 2022-03-17T18:31:23Z | https://github.com/kubernetes/kubernetes/issues/108288 | 1,147,597,891 | 108,288 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[6/6]</code>
- [x] APISnoop org-flow: [ReplaceCoreV1PodTemplateTest.org](https://github.com/apisnoop/ticket-writing/blob/master/ReplaceCoreV1PodTemplateTest.org)
- [x] test approval issue : #108285
- [x] test pr : #108286
- [x] two weeks soak start date : 1 March 2022 [testgrid-link](https://te... | Write replaceCoreV1NamespacedPodTemplate test - +1 endpoint coverage | https://api.github.com/repos/kubernetes/kubernetes/issues/108285/comments | 3 | 2022-02-23T00:39:06Z | 2022-03-14T23:24:59Z | https://github.com/kubernetes/kubernetes/issues/108285 | 1,147,508,663 | 108,285 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Nodes that are no longer in the `Ready` state (i.e. due to a reboot) do not get removed from backend pools of Azure load balancers.
In the current code, a node gets removed from the backend pool of an Azure load balancer only if:
- it is labeled with `node.kubernetes.io/exclude-from-external-l... | Azure load balancer is never updated when node status changes | https://api.github.com/repos/kubernetes/kubernetes/issues/108283/comments | 7 | 2022-02-22T22:56:17Z | 2022-05-04T01:23:08Z | https://github.com/kubernetes/kubernetes/issues/108283 | 1,147,450,696 | 108,283 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Today in k8s the IP assigned to a pod, which is a part of the pod status, is mutable. Changing the field through `kubectl edit` doesn't seem to take effect, but the object can be changed through a json patch directly (more under repro steps below). While the IP is again reset back to the original ... | Should pod IP be immutable? | https://api.github.com/repos/kubernetes/kubernetes/issues/108281/comments | 10 | 2022-02-22T18:28:25Z | 2022-03-03T21:20:35Z | https://github.com/kubernetes/kubernetes/issues/108281 | 1,147,237,078 | 108,281 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Implementing https://github.com/kubernetes/enhancements/tree/master/keps/sig-architecture/3136-beta-apis-off-by-default#graduation-criteria
### Why is this needed?
I need a personal checklist to keep track of where I am.
- [x] Integration and unit tests to ensure that no... | New Beta APIs off by Default | https://api.github.com/repos/kubernetes/kubernetes/issues/108279/comments | 10 | 2022-02-22T17:51:19Z | 2022-08-20T21:56:20Z | https://github.com/kubernetes/kubernetes/issues/108279 | 1,147,204,544 | 108,279 |
[
"kubernetes",
"kubernetes"
] | I was looking a bit into data from P&F in the context of resource consumption. Unfortunately I can't just paste the direct data, but this it the brief summary:
- `startRequest` is the only function that is non-negligble in any profiles I've seen [which is kind-of expected]
- what is extremely suprising is that in a... | P&F metrics are expensive | https://api.github.com/repos/kubernetes/kubernetes/issues/108272/comments | 25 | 2022-02-22T10:21:00Z | 2022-07-26T06:22:26Z | https://github.com/kubernetes/kubernetes/issues/108272 | 1,146,719,085 | 108,272 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A pod has the default toleration configs as follows:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
Then power off the... | Pods with tolerations of NoExecute taints have not migrated after the tolerationSeconds expires | https://api.github.com/repos/kubernetes/kubernetes/issues/108268/comments | 6 | 2022-02-22T02:05:48Z | 2022-07-22T03:00:54Z | https://github.com/kubernetes/kubernetes/issues/108268 | 1,146,373,634 | 108,268 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I added a finalizer and a couple of annotations to an EndpointSlice. When I scaled the parent service down to 0 replicas the EndpointSlice's annotations and finalizers were deleted.
### What did you expect to happen?
The EndpointSlice's annotations and finalizers don't change.
### How can we ... | Scaling a service to 0 replicas deletes EndpointSlice annotations and finalizers | https://api.github.com/repos/kubernetes/kubernetes/issues/108267/comments | 22 | 2022-02-21T23:22:42Z | 2022-03-18T09:10:41Z | https://github.com/kubernetes/kubernetes/issues/108267 | 1,146,303,999 | 108,267 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
kubectl rollout restart deployment alpine ; kubectl rollout status deployment alpine
```
may exceed the deployment rollout progress deadlines if the deployment sets `minReadySeconds` and a new pod restarts during the rollout before the minimum ready seconds.
### What did you expect to... | Kubernetes controller manager may fail to manage deployment rollout with minReadySeconds and pod restarts | https://api.github.com/repos/kubernetes/kubernetes/issues/108266/comments | 25 | 2022-02-21T22:48:06Z | 2024-03-13T21:19:19Z | https://github.com/kubernetes/kubernetes/issues/108266 | 1,146,285,377 | 108,266 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Modify [apiserver/blob/master/pkg/storage/etcd3/store.go list](https://github.com/kubernetes/apiserver/blob/master/pkg/storage/etcd3/store.go#L565-L576) to apply a maximum limit to every etcd range request and issue multiple range requests if necessary to satisfy the original lis... | APIServer: Impose optional maximum limit on etcd range queries | https://api.github.com/repos/kubernetes/kubernetes/issues/108258/comments | 14 | 2022-02-21T18:06:23Z | 2022-08-29T03:18:37Z | https://github.com/kubernetes/kubernetes/issues/108258 | 1,146,095,635 | 108,258 |
[
"kubernetes",
"kubernetes"
] | As suggested in [here](https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/userspace/roundrobin.go#L129-L130), some portions of the code contains the map checking for nil values in `lb.services` map, and others don't have. Even though we're never assigning nil values to this map, we should standardize the po... | pkg/proxy/userspace/roundrobin: Make `lb.services` nil check standardized | https://api.github.com/repos/kubernetes/kubernetes/issues/108257/comments | 8 | 2022-02-21T17:43:15Z | 2022-05-26T15:45:23Z | https://github.com/kubernetes/kubernetes/issues/108257 | 1,146,078,632 | 108,257 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The comments in https://github.com/kubernetes/kubernetes/blob/dc96c3dfccbc2005e4c4367fc8da199413e2bdcb/staging/src/k8s.io/api/core/v1/types.go#L2328 says that :
```
Exposing a port here gives
the system additional information about the network connections a
container uses, but is primarily info... | misleading comments in container.Ports | https://api.github.com/repos/kubernetes/kubernetes/issues/108255/comments | 7 | 2022-02-21T16:40:13Z | 2022-07-09T04:41:46Z | https://github.com/kubernetes/kubernetes/issues/108255 | 1,146,020,587 | 108,255 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When using the CSI driver node registration sidecar container, the kubelet-registration-path parameter is set to either ```unix:///path/to/unix.sock``` or ```/path/to/unix.sock```. One or both of these options should cause kubelet to send a valid authority header to the socket. In the former case,... | CSI plugins sent incorrect authority headers during registration with kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/108254/comments | 6 | 2022-02-21T15:19:17Z | 2022-07-21T16:59:22Z | https://github.com/kubernetes/kubernetes/issues/108254 | 1,145,932,244 | 108,254 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I needed to rename the volume name of a running a stateful set, so I ran the following command:
```bash
kubectl patch sts example-shard0 \
--type merge \
--patch "$(cat patch-sts-retain-keys-example.yaml)"
```
The applied patch file definition correctly renamed the volume, however, it en... | retainKeys patch strategy not working as expected | https://api.github.com/repos/kubernetes/kubernetes/issues/108249/comments | 12 | 2022-02-21T12:05:15Z | 2022-11-27T19:42:10Z | https://github.com/kubernetes/kubernetes/issues/108249 | 1,145,710,646 | 108,249 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The parameter `address` in the kubelet `/var/lib/kubelet/config.yaml` enables to bind the kubelet to a node ip .
It’s the parameter which accepts single value, that means only one IP could be provided.
In case of dual stack environment kubelet cannot listen on both the ipv4 and ipv6 network ... | Kubelet service cannot bind port 10250 on both the ipv4 and ipv6 network ips in Dual stack k8s setup. | https://api.github.com/repos/kubernetes/kubernetes/issues/108248/comments | 25 | 2022-02-21T11:48:41Z | 2022-07-30T20:34:32Z | https://github.com/kubernetes/kubernetes/issues/108248 | 1,145,694,602 | 108,248 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I want execute "mount" cmd in start script,So I need add the "SYS_ADMIN" to pod capabilities.The yaml file like following:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: test
spec:
selector:
matchLabels:
app: test
replicas: 1
template:
metadata:
lab... | kubernetes Cluster add capabilities above 1.21.x do not take effect | https://api.github.com/repos/kubernetes/kubernetes/issues/108247/comments | 11 | 2022-02-21T10:14:54Z | 2022-02-25T09:18:33Z | https://github.com/kubernetes/kubernetes/issues/108247 | 1,145,591,700 | 108,247 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Similar to issue #52269 , building kubernetes1.23 resulted in 1 variation:
```diff
--- old//usr/share/man/man1/kubectl-get.1 2022-02-11 18:49:25.583362654 +0
000
+++ new//usr/share/man/man1/kubectl-get.1 2022-02-11 18:49:25.587362682 +0
000
@@ -66,7 +66,7 @@
.PP
\fB\-o\fP, ... | kubectl-get man page varies between builds | https://api.github.com/repos/kubernetes/kubernetes/issues/108245/comments | 4 | 2022-02-21T09:45:47Z | 2022-03-18T17:58:41Z | https://github.com/kubernetes/kubernetes/issues/108245 | 1,145,556,280 | 108,245 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I need to update the argo workflow annotations/labels via api, but unfortunately, argo sdk didn't provide this API. WIth kubectl, like kubectl label/annotation, or kubectl edit workflow , this can be easilily.
But I wonder how to do this work via Kubernetes go client sdk?
Tha... | How to patch custom kubernetes API object with clientgo | https://api.github.com/repos/kubernetes/kubernetes/issues/108242/comments | 8 | 2022-02-21T07:43:18Z | 2022-07-22T22:13:06Z | https://github.com/kubernetes/kubernetes/issues/108242 | 1,145,432,211 | 108,242 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
【 I wanna install istio-1.11.1 】
【What happened】
[root@master1 istio-1.11.1]# kubectl get pod -A
istio-system istio-egressgateway-865bcd8956-dgbjt 0/1 ContainerCreating 0 16m
istio-system istio-ingressgateway-645fcd9bb6-q6ql4 0/1 ContainerCreating 0 ... | Failed to watch *v1.ConfigMap: failed to list *v1.ConfigMap: | https://api.github.com/repos/kubernetes/kubernetes/issues/108241/comments | 8 | 2022-02-21T06:19:07Z | 2022-02-22T14:58:11Z | https://github.com/kubernetes/kubernetes/issues/108241 | 1,145,371,973 | 108,241 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
https://github.com/kubernetes/kubernetes/blob/f0d5ea1e1d4d43cd5caac92800207fcd2a62538c/pkg/scheduler/scheduler.go#L67-L70
We are doing some refactor works in https://github.com/kubernetes/kubernetes/pull/107135, and I found `SchedulerCache` seems redundant, would like to rename ... | rename SchedulerCache to Cache in Scheduler | https://api.github.com/repos/kubernetes/kubernetes/issues/108240/comments | 4 | 2022-02-21T05:55:37Z | 2022-02-24T22:46:14Z | https://github.com/kubernetes/kubernetes/issues/108240 | 1,145,355,328 | 108,240 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[3/6]</code>
- [x] APISnoop org-flow : [patchCoreV1NamespacedPodStatus.org](https://github.com/apisnoop/ticket-writing/blob/master/patchCoreV1NamespacedPodStatus.org)
- [x] test approval issue : #108235
- [x] test pr : #108236
- [ ] two weeks soak start date : [testgrid-link](https://testgrid.k... | Update patchCoreV1NamespacedPodStatus test - +1 endpoint coverage | https://api.github.com/repos/kubernetes/kubernetes/issues/108235/comments | 3 | 2022-02-20T23:50:44Z | 2022-04-26T23:11:00Z | https://github.com/kubernetes/kubernetes/issues/108235 | 1,145,171,478 | 108,235 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
1. I applied an object with `kubectl apply --server-side test.yml`, with the following definition:
```yml
---
apiVersion: v1
kind: Service
metadata:
name: test
namespace: default
spec:
clusterIP: None
ports:
- name: http
port: 443
selector: null # Causes the issue
... | kubectl server-side diff shows timestamp changes without any other differences | https://api.github.com/repos/kubernetes/kubernetes/issues/108234/comments | 9 | 2022-02-20T23:21:55Z | 2022-11-24T23:12:07Z | https://github.com/kubernetes/kubernetes/issues/108234 | 1,145,165,192 | 108,234 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
My cluster contains about 4w endpointslices. There are 3 related metrics (endpoint_slice_controller_endpoints_added_per_sync_count, endpoint_slice_controller_endpoints_removed_per_sync_count, endpoint_slice_controller_changes) to indicates endpoint add remove and update. I found that the apiserver... | Empty endpointslices are fully updated every cycle defined by controller-manager default --min-resync-period=12h | https://api.github.com/repos/kubernetes/kubernetes/issues/108231/comments | 17 | 2022-02-20T10:07:44Z | 2022-06-14T20:15:34Z | https://github.com/kubernetes/kubernetes/issues/108231 | 1,144,975,078 | 108,231 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
release-master-informing
* [capg-conformance-main-ci-artifacts](https://testgrid.k8s.io/sig-release-master-informing#capg-conformance-main-ci-artifacts)
### Which tests are failing?
* periodic-cluster-api-provider-gcp-make-conformance-main-ci-artifacts.Overall
* capg-e2e.Conformance Tests... | [Failing test] capg-conformance-main-ci-artifacts | https://api.github.com/repos/kubernetes/kubernetes/issues/108223/comments | 6 | 2022-02-19T16:31:00Z | 2022-03-09T03:56:50Z | https://github.com/kubernetes/kubernetes/issues/108223 | 1,144,777,383 | 108,223 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
release-master-informing
* [capg-conformance-v1beta1-ci-artifacts](https://testgrid.k8s.io/sig-release-master-informing#capg-conformance-v1beta1-ci-artifacts)
### Which tests are failing?
* periodic-cluster-api-provider-gcp-conformance-v1beta1-ci-artifacts.Overall
* capg-e2e.Conformance T... | [Failing test] capg-conformance-v1beta1-ci-artifacts | https://api.github.com/repos/kubernetes/kubernetes/issues/108222/comments | 5 | 2022-02-19T16:30:54Z | 2022-03-09T03:56:17Z | https://github.com/kubernetes/kubernetes/issues/108222 | 1,144,777,326 | 108,222 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Normally, DSW and ASW data are restored after the attach/detach controller is started.
Get volumes from node.Status.VolumesAttached and add them to ASW. At this point, VolumeSpec is nil.
It then goes through all the pods, adds the volumes in the pods that need to be attached to the DSW, and rep... | Unable to restore volume specs in ASW when attach/detach controller starts | https://api.github.com/repos/kubernetes/kubernetes/issues/108221/comments | 18 | 2022-02-19T16:02:25Z | 2022-10-27T16:11:04Z | https://github.com/kubernetes/kubernetes/issues/108221 | 1,144,765,847 | 108,221 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
On pod termination, kubelet sometimes fails to unmount CSI volumes with the following error:
`kubernetes.io/csi: failed to parse volume data file [/var/lib/kubelet/pods/abe9027f-609b-45db-b7b6-6a363c805b07/volumes/kubernetes.io~csi/pvc-121296d1-12e8-4393-80eb-4285cedd76a6/vol_data.json]: EOF"`
... | kubelet fails to unmount CSI volumes because unmounter fails when vol_data.json is empty | https://api.github.com/repos/kubernetes/kubernetes/issues/108217/comments | 8 | 2022-02-19T09:34:48Z | 2022-07-23T19:20:07Z | https://github.com/kubernetes/kubernetes/issues/108217 | 1,144,630,877 | 108,217 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
`kubectl apply -f` doesn't patch removed `serviceAccountName` from the `Deployment` manifest.
### What did you expect to happen?
Removed `serviceAccountName` from `Deployment` must be applied using `kubectl apply -f deployment.yaml` command. (or at least show some warning that it's not appli... | kubectl doesn't patch removing serviceAccountName from deployment | https://api.github.com/repos/kubernetes/kubernetes/issues/108208/comments | 11 | 2022-02-18T11:53:54Z | 2022-09-29T13:18:35Z | https://github.com/kubernetes/kubernetes/issues/108208 | 1,142,918,016 | 108,208 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Tried upgrading k8s.io/kubernetes to 1.23.4 version. This is done by properly pinning the dependencies as below
Go version - 1.16
go.mod
```
require(
.....
k8s.io/api v0.23.4
k8s.io/apimachinery v0.23.4
k8s.io/client-go v0.23.4
k8s.io/helm v2.17.0+incompatible
k... | k8s.io/helm/pkg/kube imports k8s.io/kubernetes/pkg/kubectl/cmd/get: module k8s.io/kubernetes@latest found (v1.23.4), but does not contain package k8s.io/kubernetes/pkg/kubectl/cmd/get | https://api.github.com/repos/kubernetes/kubernetes/issues/108206/comments | 4 | 2022-02-18T09:03:59Z | 2022-03-02T17:32:59Z | https://github.com/kubernetes/kubernetes/issues/108206 | 1,142,675,034 | 108,206 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
On the first update of an EndpointSlice using the v1 API, we drop deprecatedTopology with EndpointSlice strategy. Although we only do this if at least 1 endpoint has been modified, there is no guarantee that node name has been populated for all endpoints within the EndpointSlice.
This is most no... | EndpointSlices can unexpectedly lose node name information after upgrading from v1beta1 to v1 | https://api.github.com/repos/kubernetes/kubernetes/issues/108196/comments | 2 | 2022-02-17T20:55:46Z | 2022-02-18T01:20:50Z | https://github.com/kubernetes/kubernetes/issues/108196 | 1,141,869,914 | 108,196 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The Job did not create the pod and it's pod status is:
```
0 Running / 0 Succeeded / 0 Failed
```
```
[root@node1 ~]# k describe job postgres-init-db
Name: postgres-init-db
Namespace: default
Selector: controller-uid=57f2269e-b32a-4b2a-b23... | Job pods status "0 Running / 0 Succeeded / 0 Failed" | https://api.github.com/repos/kubernetes/kubernetes/issues/108188/comments | 3 | 2022-02-17T16:10:37Z | 2022-02-22T05:37:51Z | https://github.com/kubernetes/kubernetes/issues/108188 | 1,141,544,001 | 108,188 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I'm on the latest everything as of the last week or so.
To clarify, this is NOT me looking for an internal loadbalancer. I can't google this without it showing a bunch of internal load balancer stuff.
I want my node group in a private subnet with the lb public routing to the private nodes on... | Private node, public load balancer aws fails to ensure load balancer | https://api.github.com/repos/kubernetes/kubernetes/issues/108185/comments | 4 | 2022-02-17T15:18:55Z | 2022-02-17T15:41:23Z | https://github.com/kubernetes/kubernetes/issues/108185 | 1,141,475,786 | 108,185 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
support specifiy node resources in kubemark
### Why is this needed?
make hollow nodes with various capacity is neccessary, especially when doing some test related to scheduler
a sample solution is support pass args to cadivisor fake
eg: kubemark --cpu=10 --memory=24Gi ...... | support specifiy node resources in kubemark | https://api.github.com/repos/kubernetes/kubernetes/issues/108181/comments | 11 | 2022-02-17T12:41:19Z | 2022-10-26T06:59:28Z | https://github.com/kubernetes/kubernetes/issues/108181 | 1,141,288,570 | 108,181 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Since we switched from dockershim to containerd, my cluster seems to come up okay but pods get stuck in ContainerCreating. When I investigated further, I found
```
Warning FailedCreatePodSandBox 16s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to... | local-up-cluster.sh: doesn't install CNI plugins if needed | https://api.github.com/repos/kubernetes/kubernetes/issues/108168/comments | 8 | 2022-02-16T19:16:56Z | 2022-02-25T06:35:51Z | https://github.com/kubernetes/kubernetes/issues/108168 | 1,140,453,315 | 108,168 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
https://testgrid.k8s.io/sig-node-node-problem-detector#ci-npd-e2e-test
### Which tests are failing?
ci-npd-e2e-test.Overall
** Ginkgo timed out waiting for all parallel procs to report back. **
### Since when has it been failing?
Since the very beginning I can see from th... | Tests ci-npd-e2e-test are failing | https://api.github.com/repos/kubernetes/kubernetes/issues/108166/comments | 7 | 2022-02-16T18:00:48Z | 2022-06-21T02:45:32Z | https://github.com/kubernetes/kubernetes/issues/108166 | 1,140,376,262 | 108,166 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I run `kubectl -n scylla apply --server-side --prune --all -f <my_folder_for_scylla_namespace>` and even though it was scoped to a namespace it deleted all other namespaces.
### What did you expect to happen?
It should apply files just within the namespace this request is scoped to and pru... | kubectl apply --prune doesn't respect namespace boundaries and deletes other namespaces | https://api.github.com/repos/kubernetes/kubernetes/issues/108161/comments | 6 | 2022-02-16T12:58:00Z | 2022-03-02T17:35:04Z | https://github.com/kubernetes/kubernetes/issues/108161 | 1,139,988,333 | 108,161 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
I would like to move the [kube-rbac-proxy](github.com/brancz/kube-rbac-proxy) under the Kubernets Org (sig-auth).
The ToDo List is, according to [SIG-Auth Bi-Weekly Meeting for 20220202](https://www.youtube.com/watch?v=VuBLtW0waC0):
- [ ] Find a different name to better reflect... | Migrate kube-rbac-proxy to Kubernetes Org | https://api.github.com/repos/kubernetes/kubernetes/issues/108158/comments | 8 | 2022-02-16T11:15:38Z | 2022-10-29T14:31:07Z | https://github.com/kubernetes/kubernetes/issues/108158 | 1,139,876,700 | 108,158 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
OPA Helm Chart not working but problem with Kubernetes
tried with KIND k8s version 1.21.1 and v 1.22.5
OPA installed using ArgoCD
```
repoURL: 'https://open-policy-agent.github.io/kube-mgmt/charts'
targetRevision: 4.0.0
helm:
parameters:
- name: admissionController.enable... | dispatcher.go:129] Failed calling webhook, failing open webhook.openpolicyagent.org: failed calling webhook "webhook.openpolicyagent.org": converting (v1beta1.AdmissionReview) to (v1.AdmissionReview): unknown conversion | https://api.github.com/repos/kubernetes/kubernetes/issues/108155/comments | 4 | 2022-02-16T09:47:22Z | 2022-02-16T10:04:16Z | https://github.com/kubernetes/kubernetes/issues/108155 | 1,139,781,488 | 108,155 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Deployment will create pod infinitely if pod failed with UnexpectedAdmissionError continuously.
ReplicaSet controller will ignore the pod whose status is `Succeeded` or `Failed`. And deployment only allow the pod with `restartPolicy: Always`, and it will prevent us from spawning pods ignored by... | Deployment will create pod infinitely if pod failed with UnexpectedAdmissionError. | https://api.github.com/repos/kubernetes/kubernetes/issues/108152/comments | 13 | 2022-02-16T09:13:06Z | 2022-08-18T11:22:45Z | https://github.com/kubernetes/kubernetes/issues/108152 | 1,139,744,113 | 108,152 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We updated a `Deployment` resource with an incorrect update that specified two ports in a container that shared the same `(protocol, port)` tuple (albeit with different names):
```
...
ports:
- name: http
containerPort: 9090
protocol: TCP
- name: admin
containerPort: 9090
protoc... | kubectl apply produces incorrect Deployment patches after server-side port deduping | https://api.github.com/repos/kubernetes/kubernetes/issues/108148/comments | 8 | 2022-02-16T03:15:09Z | 2022-02-23T22:34:48Z | https://github.com/kubernetes/kubernetes/issues/108148 | 1,139,473,042 | 108,148 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
This code: https://github.com/kubernetes/kubernetes/blob/66445662ad7b65ffdb144b9665608f7b6a4b57a6/cluster/gce/windows/k8s-node-setup.psm1#L1051
should not set `pod-infra-container-image` as it was just marked for deprecation and has to set the `sandbox_image` instead on Contianerd
### What d... | Install-WorkerServices should not set pod-infra-container-image as it is marked for deprecation | https://api.github.com/repos/kubernetes/kubernetes/issues/108144/comments | 21 | 2022-02-15T22:21:19Z | 2023-02-16T21:32:52Z | https://github.com/kubernetes/kubernetes/issues/108144 | 1,139,273,919 | 108,144 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
If kubelet is configured to run as a service using the `LocalSystem` service account check to verify the kubelet is running with elevated privileges fails with the follow error message
```cmd
E0127 18:48:07.328394 4752 server.go:287] "kubelet running with insufficient permissions" err="error ... | Kubelet permissions check on Windows does not work if running as a LocalSystem | https://api.github.com/repos/kubernetes/kubernetes/issues/108140/comments | 4 | 2022-02-15T20:41:50Z | 2022-03-30T00:34:41Z | https://github.com/kubernetes/kubernetes/issues/108140 | 1,139,194,228 | 108,140 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
PDB was upgraded to v1 in 1.21. Despite the changelog saying that the behavior of the v1beta1 implementation should have stayed the same, it appears that the `patchStrategy` for the `selector` field was set to `replace`. I believe this is the change in question: https://github.com/kubernetes/kuberne... | policy/v1beta1 PodDisruptionBudget selector patchStrategy changed unexpectedly in 1.21 upgrade | https://api.github.com/repos/kubernetes/kubernetes/issues/108137/comments | 7 | 2022-02-15T18:28:09Z | 2022-02-16T00:25:18Z | https://github.com/kubernetes/kubernetes/issues/108137 | 1,139,058,766 | 108,137 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
```
$ kubectl debug -it shell-6874dcdd7f-rv5vd --image bogus
Defaulting debug container name to debugger-r2gq7.
... hang forever ...
```
`kubectl describe` shows there are, as expected, failures to pull the image. It would be great if this - and possibly other issues of starting the container... | ephemeral containers: show more information on failures to start containers | https://api.github.com/repos/kubernetes/kubernetes/issues/108135/comments | 3 | 2022-02-15T18:00:08Z | 2022-03-10T01:51:35Z | https://github.com/kubernetes/kubernetes/issues/108135 | 1,139,031,502 | 108,135 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I created a Deployment manifest that contains a PodSpec with only one port :
```
ports:
- name: dns-udp
containerPort: 5353
protocol: UDP
```
I applied it.
Afterwards, I added the TCP equivalent of this port to my manifest :
```
- name: dns-tcp
containerPort: 5353
... | Patching ports in PodSpec leads to empty diff | https://api.github.com/repos/kubernetes/kubernetes/issues/108131/comments | 3 | 2022-02-15T17:32:15Z | 2022-02-16T17:22:40Z | https://github.com/kubernetes/kubernetes/issues/108131 | 1,139,001,066 | 108,131 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
While reviewing https://github.com/kubernetes/enhancements/pull/3089 @smarterclayton suggested that PDBs should be opaque to the backing controllers for the pods. As of now, PDBs are not supported for DS since it doesn't have scale subresource. Clayton suggested to introduce a read only scale subr... | Support PDBs for DS | https://api.github.com/repos/kubernetes/kubernetes/issues/108124/comments | 24 | 2022-02-15T13:52:47Z | 2024-10-31T23:56:59Z | https://github.com/kubernetes/kubernetes/issues/108124 | 1,138,725,508 | 108,124 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have a kubernetes cluster with one worker node.
When I schedule a deployment of say 'n' pods and then reboot my worker node, then after the node comes up, I can see the old 'n' ips still present in '/var/lib/cni/networks/cbr0' directory, it also contains the newly assigned 'n' ips starting from... | Worker nodes running out of IPs in IP range after node reboot | https://api.github.com/repos/kubernetes/kubernetes/issues/108121/comments | 5 | 2022-02-15T11:02:31Z | 2022-04-26T20:09:35Z | https://github.com/kubernetes/kubernetes/issues/108121 | 1,138,528,353 | 108,121 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Add a new `--write-config-to` flag to kubelet, similar to [kube-scheduler](https://github.com/kubernetes/kubernetes/pull/62515) and [kube-proxy](https://github.com/kubernetes/kubernetes/pull/45908).
This flag can be used to render the kubelet configuration file from a set of com... | Add --write-config-to option to kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/108118/comments | 20 | 2022-02-15T09:42:52Z | 2024-07-26T09:31:40Z | https://github.com/kubernetes/kubernetes/issues/108118 | 1,138,430,768 | 108,118 |
[
"kubernetes",
"kubernetes"
] | # Progress <code>[6/6]</code>
- [x] APISnoop org-flow: [Batchv1JobStatusTest.org](https://github.com/apisnoop/ticket-writing/blob/master/Batchv1JobStatusTest.org)
- [x] Test approval issue : [#108113](https://github.com/kubernetes/kubernetes/issues/108113)
- [x] Test PR : #108114
- [X] Two weeks soak start date :... | Write Read, Replace, Patch BatchV1NamespacedJobStatus test - +3 endpoint coverage | https://api.github.com/repos/kubernetes/kubernetes/issues/108113/comments | 3 | 2022-02-14T21:40:53Z | 2022-04-05T17:36:30Z | https://github.com/kubernetes/kubernetes/issues/108113 | 1,137,880,756 | 108,113 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Doing a micro upgrade from one level of 1.23 to another level of 1.23, we noticed disruption to PDB based app went from about 5s to about 13s when compared to a 1.22.z to 1.22.z+1 update.
### What did you expect to happen?
I did not expect any disruption.
### How can we reproduce it (as minimall... | Addition service load balancer disruption on azure while upgrading from 1.23 to 1.23 | https://api.github.com/repos/kubernetes/kubernetes/issues/108112/comments | 15 | 2022-02-14T21:00:39Z | 2022-04-27T16:25:49Z | https://github.com/kubernetes/kubernetes/issues/108112 | 1,137,836,446 | 108,112 |
[
"kubernetes",
"kubernetes"
] | Unable to download kubelet binaries from https://dl.k8s.io/release | Unable to download kubelet binaries from https://dl.k8s.io/release | https://api.github.com/repos/kubernetes/kubernetes/issues/108106/comments | 6 | 2022-02-14T13:13:11Z | 2022-02-16T06:41:25Z | https://github.com/kubernetes/kubernetes/issues/108106 | 1,137,285,634 | 108,106 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have 2 node cluster:
- 1 Control plane node (1st node)
- 1 Worker node (2nd node)
After changing IP (INTERNAL-IP) of the worker node (2nd node) kubectl logs command freezes if you're trying to get logs from work node containers.
Docker logs exist in worker node, they also exists in /var/ku... | kubectl logs - doesn't work after changing IP address of the worker node | https://api.github.com/repos/kubernetes/kubernetes/issues/108105/comments | 5 | 2022-02-14T12:52:45Z | 2022-02-16T08:30:52Z | https://github.com/kubernetes/kubernetes/issues/108105 | 1,137,259,686 | 108,105 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
hi,
i want to automate the installation of your repos to our systems and I found that there are no repo packages like epel-release.noarch for epel.
### Why is this needed?
would make installations much safer and better to handle even with automation tools like ansible. | Please supply repo packages for easy installation of repos to distributions | https://api.github.com/repos/kubernetes/kubernetes/issues/108098/comments | 6 | 2022-02-14T10:21:49Z | 2022-07-14T11:44:11Z | https://github.com/kubernetes/kubernetes/issues/108098 | 1,137,084,264 | 108,098 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Please add a repo for cento stream 8 and centos stream 9.
### Why is this needed?
To install your packages on this distributions. | Please add repo and packages for centos-stream 8 and 9 | https://api.github.com/repos/kubernetes/kubernetes/issues/108097/comments | 18 | 2022-02-14T10:17:53Z | 2023-12-28T08:38:20Z | https://github.com/kubernetes/kubernetes/issues/108097 | 1,137,078,847 | 108,097 |
[
"kubernetes",
"kubernetes"
] | I am pretty sure that the PV's node affinity is consistent with the node, but I still got the error message `1 node(s) had volume node affinity conflict`.
### K8s version:
```
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b980... | 0/1 nodes are available: 1 node(s) had volume node affinity conflict | https://api.github.com/repos/kubernetes/kubernetes/issues/108096/comments | 11 | 2022-02-14T09:23:53Z | 2023-01-12T13:26:54Z | https://github.com/kubernetes/kubernetes/issues/108096 | 1,137,012,022 | 108,096 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Out-of-tree plugin typically composes its scheduler ComponentConfig like:
```yaml
profiles:
- plugins:
preFilter:
enabled:
- name: Foo
filter:
enabled:
- name: Foo
```
recently I found that when this is applied into the latest v1beta3 config, `Foo` is p... | scheduler v1beta3 pre-appends an out-of-tree plugin instead of append | https://api.github.com/repos/kubernetes/kubernetes/issues/108083/comments | 12 | 2022-02-11T20:21:17Z | 2022-03-22T08:01:45Z | https://github.com/kubernetes/kubernetes/issues/108083 | 1,133,053,866 | 108,083 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
cert-manager installation includes `CustomResourceDefinition`s that up till v1.7 specified `crd.spec.conversion.strategy: Webhook` and relied on a component called [`cainjector`](https://cert-manager.io/docs/concepts/ca-injector/) to inject `crd.spec.conversion.webhook.clientConfig.caBundle`. `cai... | kubectl server-side apply not being able to remove other field manager's fields results in invalid field combinations | https://api.github.com/repos/kubernetes/kubernetes/issues/108081/comments | 9 | 2022-02-11T20:11:49Z | 2024-04-02T10:45:49Z | https://github.com/kubernetes/kubernetes/issues/108081 | 1,133,044,332 | 108,081 |
[
"kubernetes",
"kubernetes"
] | While Debugging https://github.com/kubernetes/kubernetes/issues/107372 Specifically with the unit test `TestMultipleServiceChanges` which is part of the endpoint controller's tests I ran into the following race after adding some code to shutdown the `EventBroadcaster` following conclusion of the unit tests
```
I02... | EventRecorder can accidentally send to a closed channel and Panic | https://api.github.com/repos/kubernetes/kubernetes/issues/108518/comments | 7 | 2022-02-11T19:36:33Z | 2022-05-17T13:20:27Z | https://github.com/kubernetes/kubernetes/issues/108518 | 1,159,864,664 | 108,518 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We observed a long delay in creating Endpoints for Services when periodical Service resync in EndpointsController happens. For example, one Service was created at “2022-02-07T19:44:59Z” but its Endpoints was created at “2022-02-07T19:47:30Z”, with 2m30s delay.
We also observed lots of Endpoint... | Long delay in creating Endpoints when periodical Service resync happens | https://api.github.com/repos/kubernetes/kubernetes/issues/108077/comments | 2 | 2022-02-11T17:54:34Z | 2022-03-02T07:23:14Z | https://github.com/kubernetes/kubernetes/issues/108077 | 1,132,916,264 | 108,077 |
[
"kubernetes",
"kubernetes"
] | To summarize the situation:
1. Since golang 1.17 IPv4 addresses with leading zeros are considered invalid. #100895
2. Kubernetes decided to keep compatibility with stored data so it forked previous parsers to allow IPs with leading zeros. #104368
3. The rest of the Kubernetes ecosystem seems to prefer to use defau... | Deprecate IPs with Leading Zeros ( CVE-2021-29923 ) | https://api.github.com/repos/kubernetes/kubernetes/issues/108074/comments | 17 | 2022-02-11T16:10:49Z | 2024-01-02T11:25:48Z | https://github.com/kubernetes/kubernetes/issues/108074 | 1,132,803,974 | 108,074 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Hi!
In the [documentation](https://kubernetes.io/docs/reference/using-api/api-concepts/#protobuf-encoding), all k8s types used for protobuf encoding must start with `"k8s\x00"` but some api responses for example(http 504):
```bash
b'\x00\x00\x00q\n\x05ERROR\x12h\nfk8s\x00\n\x0c\n\x02v1\x12\x0... | Documentation: protobuf encoding of Watch events do not include "k8s\x00" prefix | https://api.github.com/repos/kubernetes/kubernetes/issues/108071/comments | 8 | 2022-02-11T14:41:27Z | 2022-07-15T22:57:26Z | https://github.com/kubernetes/kubernetes/issues/108071 | 1,132,692,061 | 108,071 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
a pretty standard kubeadm setup of k8s 1.22.5 - and kube-controller-manager runs in a pod - but it is set to ONLY listen on 127.0.0.1 - making its metrics endpoint unreachable by other nodes in the cluster - meaning Prometheus can't monitor it :(
### What did you expect to happen?
IMHO kube-contro... | kube-controller-manager defaults to listen on 127.0.0.1 ONLY | https://api.github.com/repos/kubernetes/kubernetes/issues/108069/comments | 8 | 2022-02-11T13:10:08Z | 2022-02-15T21:18:22Z | https://github.com/kubernetes/kubernetes/issues/108069 | 1,132,577,278 | 108,069 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
sig-node-containerd#node-kubelet-containerd-hugepages
### Which tests are failing?
none
### Since when has it been failing?
Feb 09 2022 18:30 EET
### Testgrid link
https://testgrid.k8s.io/sig-node-containerd#node-kubelet-containerd-hugepages
### Reason for failure (if possible)
It l... | Containerd-hugepages job fails due to infrastructure issues | https://api.github.com/repos/kubernetes/kubernetes/issues/108067/comments | 3 | 2022-02-11T10:44:28Z | 2022-02-16T18:13:09Z | https://github.com/kubernetes/kubernetes/issues/108067 | 1,132,330,495 | 108,067 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have a scaled set up with 159 nodes, ~11k pods and ~1500 services(k8s in ipvs mode), there on every node restart we are seeing many client UDP requests to multiple LBIP:port serving UDP traffic is getting black holed because of invalid conntrack entry. We are running in k8s version 1.23.3, so I... | UDP traffic to Loadbalancer IP fails after node reboot (mode ipvs) | https://api.github.com/repos/kubernetes/kubernetes/issues/108065/comments | 21 | 2022-02-11T09:32:35Z | 2022-10-22T09:22:34Z | https://github.com/kubernetes/kubernetes/issues/108065 | 1,132,187,905 | 108,065 |
[
"kubernetes",
"kubernetes"
] | ### Which jobs are failing?
master-blocking [gci-gce-ingress](https://testgrid.k8s.io/sig-release-master-blocking#gci-gce-ingress)
### Which tests are failing?
- ci-kubernetes-e2e-gci-gce-ingress.Overall
- kubetest.Test
- Kubernetes e2e suite.[sig-network] Loadbalancing: L7 GCE [Slow] [Feature:Ingress] shoul... | [Failing test] gci-gce-ingress | https://api.github.com/repos/kubernetes/kubernetes/issues/108064/comments | 7 | 2022-02-11T08:55:22Z | 2022-02-23T09:59:41Z | https://github.com/kubernetes/kubernetes/issues/108064 | 1,132,116,537 | 108,064 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I tried to run a standalone kubelet (without kube-apiserver, so no kubeClient in kubelet), but there is a panic "invalid memory address or nil pointer dereference"
The corresponding logs:
```text
E0211 15:50:57.552748 794906 runtime.go:78] Observed a panic: "invalid memory address or nil poi... | standalone kubelet panic because of nil pointer in VolumeManager | https://api.github.com/repos/kubernetes/kubernetes/issues/108063/comments | 17 | 2022-02-11T08:17:46Z | 2022-03-23T20:21:56Z | https://github.com/kubernetes/kubernetes/issues/108063 | 1,132,047,467 | 108,063 |
[
"kubernetes",
"kubernetes"
] | See https://clomonitor.io/projects/kubernetes/kubernetes Most of the things that the tool is complaining about, we have information just not in the form the tool accepts. So let's try to see if we can point to existing resources with a placeholder file or something?
 where pods are not being consistently cleaned up. The basic idea is that we have a process that spawns several pods every couple of minutes, and those pods are subsequently deleted. They do not show up doing a 'kubectl get pods'. However,... | Pods not consistently being cleaned up | https://api.github.com/repos/kubernetes/kubernetes/issues/108049/comments | 18 | 2022-02-10T17:13:17Z | 2025-02-24T04:06:47Z | https://github.com/kubernetes/kubernetes/issues/108049 | 1,130,494,585 | 108,049 |
[
"kubernetes",
"kubernetes"
] | ### What would you like to be added?
Reopening #60832.
Add a `--node-annotations` command flag for kubelet, analogous to the existing `--node-labels` flag.
### Why is this needed?
We want to be able to report metadata about a node without being constrained by label limits, especially the 63 character limit.
Pr... | [feature request] add --node-annotations command flag for kubelet | https://api.github.com/repos/kubernetes/kubernetes/issues/108046/comments | 23 | 2022-02-10T13:50:03Z | 2025-01-11T05:18:29Z | https://github.com/kubernetes/kubernetes/issues/108046 | 1,130,113,960 | 108,046 |
[
"kubernetes",
"kubernetes"
] | https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/106948/pull-kubernetes-unit/1491713959680544768
```
=== RUN TestErrConnKilled
==================
WARNING: DATA RACE
Read at 0x0000038a5620 by goroutine 140:
k8s.io/kubernetes/vendor/k8s.io/klog/v2.(*loggingT).output()
/home/prow/go/src/k8s.i... | TestErrConnKilled - data race | https://api.github.com/repos/kubernetes/kubernetes/issues/108043/comments | 7 | 2022-02-10T10:50:00Z | 2022-03-24T13:38:42Z | https://github.com/kubernetes/kubernetes/issues/108043 | 1,129,824,749 | 108,043 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
When I update resource with "kubectl apply -f test.yaml", old pod is Terminating and cannot delete successfully. Kubelet log Error: "UnmountVolume.TearDown failed for volume:remove /var/lib/kubelet/pods/xxx/volumes/kubernetes.io~glusterfs/test-gluster-pv: directory not empty
```
Dec 21 16:08:27... | Pod stuck in Terminating when deleting , kubelet Error: "UnmountVolume.TearDown failed for volume:remove /var/lib/kubelet/pods/xxx/volumes/kubernetes.io~glusterfs/test-gluster-pv: directory not empty | https://api.github.com/repos/kubernetes/kubernetes/issues/108041/comments | 6 | 2022-02-10T09:14:49Z | 2022-03-10T03:23:30Z | https://github.com/kubernetes/kubernetes/issues/108041 | 1,129,686,037 | 108,041 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
There seems to be a race condition in the following unit test
https://github.com/kubernetes/kubernetes/blob/40c2d049465417f510e4182b05953a49fc5693d4/pkg/kubelet/nodeshutdown/nodeshutdown_manager_linux_test.go#L617
The race happens between
read at
https://github.com/kubernetes/kubernetes/blob... | kubelet: Race condition in nodeshutdown unit test | https://api.github.com/repos/kubernetes/kubernetes/issues/108040/comments | 15 | 2022-02-10T08:41:40Z | 2022-03-28T12:25:48Z | https://github.com/kubernetes/kubernetes/issues/108040 | 1,129,645,859 | 108,040 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
<img width="1259" alt="截屏2022-02-10 14 10 13" src="https://user-images.githubusercontent.com/12094918/153348742-4a0f35e4-fe5b-453a-9761-6c7f06cc9769.png">
### What did you expect to happen?
this taint could set success
### How can we reproduce it (as minimally and precisely as possible)?
I can... | kubectl taint not take effect | https://api.github.com/repos/kubernetes/kubernetes/issues/108037/comments | 7 | 2022-02-10T06:16:00Z | 2022-02-11T08:28:17Z | https://github.com/kubernetes/kubernetes/issues/108037 | 1,129,508,789 | 108,037 |
[
"kubernetes",
"kubernetes"
] | **Why:**
There are three `Node` endpoints showing up on [APISnoop]( https://apisnoop.cncf.io/conformance-progress/endpoints/1.24.0/?filter=untested) as untested for conformance.
Due to the fact that endpoints tested for conformance [should not be dependant on Kubelet](https://github.com/kubernetes/community/blame/mas... | Making remaining untested Node endpoints ineligible for conformance | https://api.github.com/repos/kubernetes/kubernetes/issues/108035/comments | 8 | 2022-02-09T23:31:44Z | 2022-04-26T23:41:25Z | https://github.com/kubernetes/kubernetes/issues/108035 | 1,129,194,398 | 108,035 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
All environment variables are getting exposed to all of the pods within a namespace.
I have mounted a config map(envs) with one of my deployments and I can see all those configmap envs from another pod.
* K8sVersion: v1.22.0
### What did you expect to happen?
Ideally, all configmap ... | All environment variables are getting exposed between pods | https://api.github.com/repos/kubernetes/kubernetes/issues/108031/comments | 3 | 2022-02-09T19:41:46Z | 2022-02-09T20:25:58Z | https://github.com/kubernetes/kubernetes/issues/108031 | 1,128,950,818 | 108,031 |
[
"kubernetes",
"kubernetes"
] | Pieces are ready in containerd, runc etc. Folks like Docker Desktop that depend on the containerd/runc etc have already switched. Some OS images now default to cgroups v2 as well.
Can we please start down the path to enable cgroups v2 as the default across all the stuff we do? (kubeadm/image-builder/kubelet etc).
... | Deprecate cgroups v1 and enable cgroups v2 by default | https://api.github.com/repos/kubernetes/kubernetes/issues/108028/comments | 30 | 2022-02-09T16:50:03Z | 2023-12-31T16:54:07Z | https://github.com/kubernetes/kubernetes/issues/108028 | 1,128,786,940 | 108,028 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
One issue that got closed in the past and was not re-opened: https://github.com/kubernetes/kubernetes/issues/72811
Basically, the HPA should look for the limits to fit the pods onto nodes. Not sure why requests are counting towards the HPA's metrics to see when it's the best time to scale the pod... | HPA should use the limits instead of requests | https://api.github.com/repos/kubernetes/kubernetes/issues/108026/comments | 6 | 2022-02-09T16:19:52Z | 2023-09-07T20:18:15Z | https://github.com/kubernetes/kubernetes/issues/108026 | 1,128,752,751 | 108,026 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
The [k8s docs states](https://kubernetes.io/docs/concepts/overview/working-with-objects/finalizers/#how-finalizers-work): Marks the object as read-only until its metadata.finalizers field is empty.
There was NO problem updating the cr. Is this a bug or outdated docs as it states the opposite?
... | When finalizer is set I can still update the object | https://api.github.com/repos/kubernetes/kubernetes/issues/108025/comments | 9 | 2022-02-09T15:46:47Z | 2022-05-14T18:12:05Z | https://github.com/kubernetes/kubernetes/issues/108025 | 1,128,710,587 | 108,025 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
A cronjob that is expired fails to be scheduled after the first run. The cronjob reports that it has an active job. Even though the referenced job has completed successfully.
We never see the event `SawCompletedJob` in the cronjob even when the child job completes.
We have been running this ... | Cronjob fails to be scheduled - reports JobAlreadyActive even though there are no jobs active | https://api.github.com/repos/kubernetes/kubernetes/issues/108023/comments | 6 | 2022-02-09T13:34:51Z | 2022-02-23T15:23:16Z | https://github.com/kubernetes/kubernetes/issues/108023 | 1,128,551,800 | 108,023 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
Some of the Disks are becoming Readonly on the Windows Node.
### What did you expect to happen?
- ReadWrite Disk should not be becoming Readonly Disk.
- The disk should not become ReadOnly unless user is asking to mount the volume as Readonly in the Pod Spec.
### How can we reproduce it ... | Disk becomes ReadOnly on Windows Node | https://api.github.com/repos/kubernetes/kubernetes/issues/108019/comments | 28 | 2022-02-09T05:11:00Z | 2025-01-19T19:39:16Z | https://github.com/kubernetes/kubernetes/issues/108019 | 1,128,062,018 | 108,019 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
KCM startup has a dependency on apiserver availability https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/controller-manager/app/helper.go#L37.
When we have an apiserver that uses kms keys, an error in the kms plugin, the kms service, or a customer mistake of deleting the key... | Change apiserver healthiness check in KCM | https://api.github.com/repos/kubernetes/kubernetes/issues/108014/comments | 17 | 2022-02-08T21:50:27Z | 2023-08-15T05:59:51Z | https://github.com/kubernetes/kubernetes/issues/108014 | 1,127,794,644 | 108,014 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
We have kubernetes 1.20.8/9 with rke2. If we spawn like 100 new pods each mounting only a single pvc like this:
```
volumeMounts:
- mountPath: /mnt
name: vol-3689
```
which is NFS provisioned volume (a single volume on host and mount --bind attached to the pods).
We got whole node s... | kubelet deadlock with many parallel mounts | https://api.github.com/repos/kubernetes/kubernetes/issues/108009/comments | 26 | 2022-02-08T15:42:38Z | 2023-08-09T17:32:45Z | https://github.com/kubernetes/kubernetes/issues/108009 | 1,127,425,473 | 108,009 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
I have applied a secret
```yaml
apiVersion: v1
kind: Secret
metadata:
name: secret-basic-auth
type: kubernetes.io/basic-auth
stringData:
username: admin
password: t0p-Secret
```
Then tried to update a key
```yaml
apiVersion: v1
kind: Secret
metadata:
name: secret-ba... | Replacing key in StringData secret result in extra key in live object | https://api.github.com/repos/kubernetes/kubernetes/issues/108008/comments | 8 | 2022-02-08T13:34:18Z | 2022-06-09T15:29:10Z | https://github.com/kubernetes/kubernetes/issues/108008 | 1,127,265,964 | 108,008 |
[
"kubernetes",
"kubernetes"
] | ### What happened?
i have copy test/e2e/testing-manifests/statefulset/etcd/statefulset.yaml and run in k8s v1.21.3 then it show me /bin/sh 37 bad substitution。
confused:
- what diferent between collect_member and member_hash and cut -d':' -f1 | cut -d'[' -f1 whether wrong
- 37 bad substitution SET_ID=${HOSTNAME... | test/e2e/testing-manifests/statefulset/etcd/statefulset.yaml run error | https://api.github.com/repos/kubernetes/kubernetes/issues/108005/comments | 10 | 2022-02-08T11:46:04Z | 2022-07-09T07:41:15Z | https://github.com/kubernetes/kubernetes/issues/108005 | 1,127,148,978 | 108,005 |
Subsets and Splits
Unique Owner-Repo Count
Counts the number of unique owner-repos in the dataset, providing a basic understanding of diverse repositories.