metadata
license: apache-2.0
task_categories:
- robotics
tags:
- lerobot
- imitation_learning
- lekiwi
- so-arm100
size_categories:
- n<1K
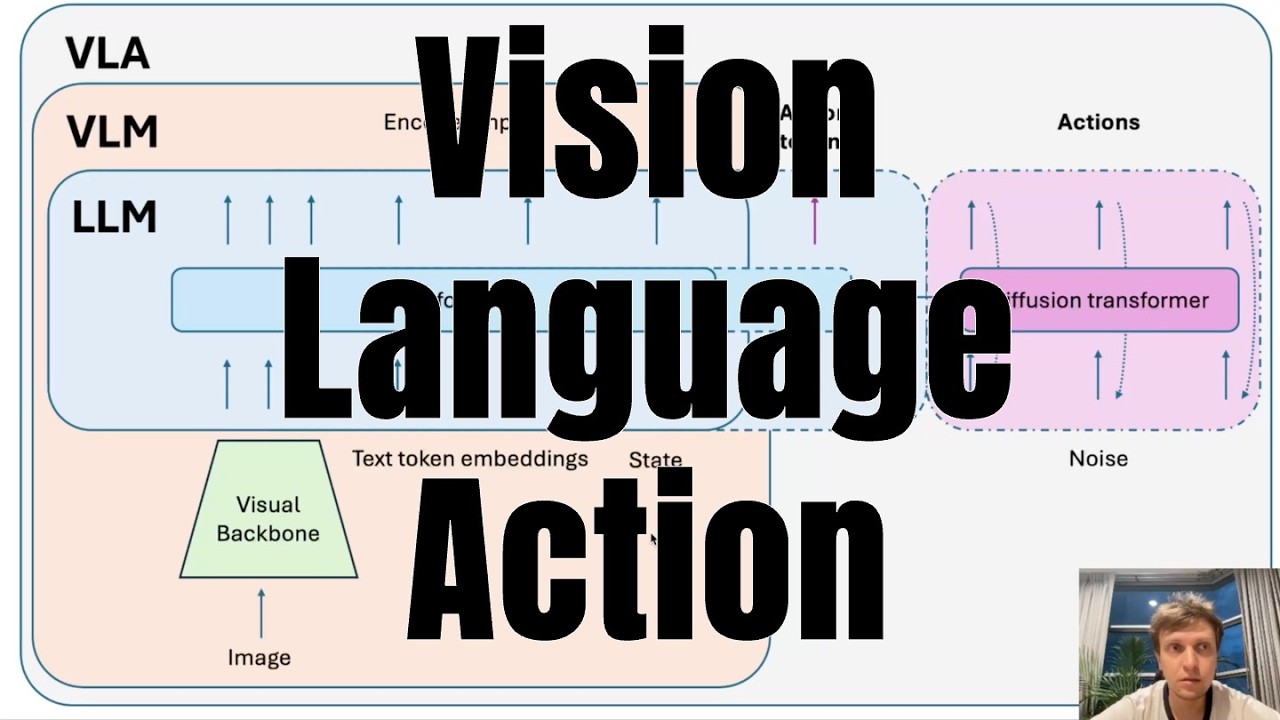
This dataset is used for the demonstration of the Vision Language Action model finetuning. It is collected using a modified version of LeKiwi with 3 cameras, but technically, only the arm is used, so it can be treated as a dataset for SO-ARM100. In this dataset, I teleoperated a robot to complete a basic pick and place task.
Follow my video series about VLAs to learn more: