
qid int64 1 74.7M | question stringlengths 12 33.8k | date stringlengths 10 10 | metadata list | response_j stringlengths 0 115k | response_k stringlengths 2 98.3k |
|---|---|---|---|---|---|
507,192 | As light is electromagnetic radiation. Then why I don't see any magnet bending light wave? Or why light doesn't diffract whenever it passes by a live wire? | 2019/10/09 | [
"https://physics.stackexchange.com/questions/507192",
"https://physics.stackexchange.com",
"https://physics.stackexchange.com/users/-1/"
] | Roughly speaking, electric fields push and pull charges, while magnetic fields cause charges to loop around (by 'loop around' I'm saying that the magnetic fields cause the charges to accelerate at a right angle to their direction of motion).
Since light doesn't have an electric charge, there is nothing for electric f... | In classical physics, electromagnetic fields and waves are additive so nothing can happen in vacuum between electromagnetic fields. They don't see each other.
In quantum physics, photons theoretically DO interact. The effect is rather small even in high-energy experiments, so don't expect some visible distortion with ... |
507,192 | As light is electromagnetic radiation. Then why I don't see any magnet bending light wave? Or why light doesn't diffract whenever it passes by a live wire? | 2019/10/09 | [
"https://physics.stackexchange.com/questions/507192",
"https://physics.stackexchange.com",
"https://physics.stackexchange.com/users/-1/"
] | In vacuum electromagnetic fields obey superposition to a very high degree of accuracy. A magnetic field does not have any effect on light. Light in material media *can* be affected by a magnetic field. This is known as the [Kerr effect](https://en.wikipedia.org/wiki/Kerr_effect).
As for current carrying wires, these r... | In classical physics, electromagnetic fields and waves are additive so nothing can happen in vacuum between electromagnetic fields. They don't see each other.
In quantum physics, photons theoretically DO interact. The effect is rather small even in high-energy experiments, so don't expect some visible distortion with ... |
88,952 | I want to express that I learning some courses will give me a good vision in a specific field.
Can I say like "these courses take me on the way to the statistics"? | 2016/05/02 | [
"https://ell.stackexchange.com/questions/88952",
"https://ell.stackexchange.com",
"https://ell.stackexchange.com/users/32654/"
] | Maybe you want to say
>
> These courses should/will get me started on my way to learning/understanding statistics.
>
>
>
We can shorten this in several ways.
>
> These should get me on my way
>
>
>
would be clear and idiomatic if your listener knows what you are talking about.
The sense of *way* here, m... | No, that's not correct.
I assume the course is about statistics, right? Maybe you could say,
>
> This course will give a good overview of statistics.
>
>
>
An "overview" means you will understand what the subject is about, but not be an expert. I'm not sure if that's what you want to say. |
88,952 | I want to express that I learning some courses will give me a good vision in a specific field.
Can I say like "these courses take me on the way to the statistics"? | 2016/05/02 | [
"https://ell.stackexchange.com/questions/88952",
"https://ell.stackexchange.com",
"https://ell.stackexchange.com/users/32654/"
] | Maybe you want to say
>
> These courses should/will get me started on my way to learning/understanding statistics.
>
>
>
We can shorten this in several ways.
>
> These should get me on my way
>
>
>
would be clear and idiomatic if your listener knows what you are talking about.
The sense of *way* here, m... | I think it's not idiomatic to say:
These courses will take me on the way to the statistics.
I think you can rephrase your sentence as follows:
These courses will go a long way toward(s) learning statistics.
These courses will give a good insight into statistics. |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | >
> ’Tis one thing to be tempted, Escalus,
> Another thing to fall. *(Measure for Measure* 2.1.17–18)
>
>
>
The coordinate pairing of infinitives in this construction is so well established that a reader is likely to reach the end of your first sentence waiting for the other shoe to drop. Your then beginning the... | It seems that you want to use unsuccessfully two constructions combined
“It is one thing to passively learn about all those various commands in JavaScript by poring over online materials. However, in order to fully appreciate how and when to use each one, I need to try them out in my own code and have them corrected b... |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | >
> ’Tis one thing to be tempted, Escalus,
> Another thing to fall. *(Measure for Measure* 2.1.17–18)
>
>
>
The coordinate pairing of infinitives in this construction is so well established that a reader is likely to reach the end of your first sentence waiting for the other shoe to drop. Your then beginning the... | First, it is always awkward to have anything between to and the infinitive as we were told in grammar school. Secondly, the comparison should form a somewhat sharp contrast rather than two similar but slightly different things. My example is this: "It is one thing for a person to own what he has created; it is another ... |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | >
> ’Tis one thing to be tempted, Escalus,
> Another thing to fall. *(Measure for Measure* 2.1.17–18)
>
>
>
The coordinate pairing of infinitives in this construction is so well established that a reader is likely to reach the end of your first sentence waiting for the other shoe to drop. Your then beginning the... | >
> It is one thing to *X* but another to *Y*
>
>
>
Often means things like:
* *X* may be good, but *Y* is much better (or: *X* may be bad, but *Y* is much worse)
* Don't mistake *X* for *Y*
* Don't overestimate *X* / let *X* impress you
* Don't underestimate or disregard *Y*
The author of your example sentence ... |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | "It is one thing to (blank), but another to (blank)" is a comparative structure.
Taking a cue from your example, it would make more sense to say something like "It is one thing to learn passively, but another to understand the material."
It's used specifically when you're comparing two things, with the second of them... | It seems that you want to use unsuccessfully two constructions combined
“It is one thing to passively learn about all those various commands in JavaScript by poring over online materials. However, in order to fully appreciate how and when to use each one, I need to try them out in my own code and have them corrected b... |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | "It is one thing to (blank), but another to (blank)" is a comparative structure.
Taking a cue from your example, it would make more sense to say something like "It is one thing to learn passively, but another to understand the material."
It's used specifically when you're comparing two things, with the second of them... | First, it is always awkward to have anything between to and the infinitive as we were told in grammar school. Secondly, the comparison should form a somewhat sharp contrast rather than two similar but slightly different things. My example is this: "It is one thing for a person to own what he has created; it is another ... |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | "It is one thing to (blank), but another to (blank)" is a comparative structure.
Taking a cue from your example, it would make more sense to say something like "It is one thing to learn passively, but another to understand the material."
It's used specifically when you're comparing two things, with the second of them... | >
> It is one thing to *X* but another to *Y*
>
>
>
Often means things like:
* *X* may be good, but *Y* is much better (or: *X* may be bad, but *Y* is much worse)
* Don't mistake *X* for *Y*
* Don't overestimate *X* / let *X* impress you
* Don't underestimate or disregard *Y*
The author of your example sentence ... |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | It seems that you want to use unsuccessfully two constructions combined
“It is one thing to passively learn about all those various commands in JavaScript by poring over online materials. However, in order to fully appreciate how and when to use each one, I need to try them out in my own code and have them corrected b... | First, it is always awkward to have anything between to and the infinitive as we were told in grammar school. Secondly, the comparison should form a somewhat sharp contrast rather than two similar but slightly different things. My example is this: "It is one thing for a person to own what he has created; it is another ... |
293,927 | Because while that is technically the correct spelling for each word, but as a phrase it doesn't seem to work well together. It lacks symmetry (Hipp**ie** vs. Dipp**y**) and uses the extremely rare-yet-proper Italian "bologna".
Origin: The phrase is used with delightful comic effect in [*The Lego Movie*](http://www.im... | 2015/12/14 | [
"https://english.stackexchange.com/questions/293927",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/151541/"
] | >
> It is one thing to *X* but another to *Y*
>
>
>
Often means things like:
* *X* may be good, but *Y* is much better (or: *X* may be bad, but *Y* is much worse)
* Don't mistake *X* for *Y*
* Don't overestimate *X* / let *X* impress you
* Don't underestimate or disregard *Y*
The author of your example sentence ... | First, it is always awkward to have anything between to and the infinitive as we were told in grammar school. Secondly, the comparison should form a somewhat sharp contrast rather than two similar but slightly different things. My example is this: "It is one thing for a person to own what he has created; it is another ... |
22,044 | After some unsuccessful uploads I ended up with a lot of loose files in craft/storage/runtime/assets/tempuploads
They show up in the asset list when selecting assets for new entry. How do I remove them completely from the record?
Tried manually deleting them via FTP and running "Update Asset Indexes" but that didn't ... | 2017/09/19 | [
"https://craftcms.stackexchange.com/questions/22044",
"https://craftcms.stackexchange.com",
"https://craftcms.stackexchange.com/users/7082/"
] | In Craft 2 the only real solution is to delete all the entries from craft\_assetfiles where the sourceId is set to `null`.
The reason why there's no clear cache tool for these is because that might allow for deletion of Assets that were just uploaded by someone else who might be about to use them.
This is really far... | If you've already deleted the actual files, you can try rebuilding the Asset Index (via Settings -> Update Asset Indexes |
278,674 | Say I use a font "foo" in my TeX document.
>
> \setmainfont{foo}
>
>
>
This font is not free or not widely available on other systems.
Will my PDF document will look same in other computers where this font is not available / installed?
And if not what can I do about it to make sure that it looks same in other co... | 2015/11/17 | [
"https://tex.stackexchange.com/questions/278674",
"https://tex.stackexchange.com",
"https://tex.stackexchange.com/users/63140/"
] | Fonts are embedded by default when you compile TeX to PDF. To be sure, you may wish to upload your PDF to a cloud, say, GoogleDrive (free) and see, how it looks there in another previewer. | I'm not an expert on PDF, but the whole idea of PDF in opposite to Word is that the viewer displays the same picture and the printer prints the same glyphs on the paper.
Well, more or less. It obviously does not depend on the installation of fonts on the computer you use to display the PDF, but there are differences ... |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | >
> These questions have the property that, whatever the hypothetical answer would be, every one of your perceptions of **the world** is exactly the same.
>
>
>
(emphasis mine).
You have imported an assumption here that, I think, explains why all of your examples are problematic.
What precisely do you mean by *t... | **"no perceptible difference one way or another"**
To the senses, "no perceptible difference". To the intellect? **Profound** perceptible differences!
Nothing to be shocked about. |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | It ***can*** be very meaningful, and just *how* meaningful will vary depending on the person and the question. **Even if it doesn't alter the observable (physical) world** ("your perceptions of the world"), **it is still meaningful if it alters *human behavior*.** In fact, it is strange to me that you don't seem to con... | **"no perceptible difference one way or another"**
To the senses, "no perceptible difference". To the intellect? **Profound** perceptible differences!
Nothing to be shocked about. |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | >
> These questions have the property that, whatever the hypothetical answer would be, every one of your perceptions of **the world** is exactly the same.
>
>
>
(emphasis mine).
You have imported an assumption here that, I think, explains why all of your examples are problematic.
What precisely do you mean by *t... | It ***can*** be very meaningful, and just *how* meaningful will vary depending on the person and the question. **Even if it doesn't alter the observable (physical) world** ("your perceptions of the world"), **it is still meaningful if it alters *human behavior*.** In fact, it is strange to me that you don't seem to con... |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | I think that methaphysical theories (non testable in principle) are necessary and important to scientific research because they may be capable of becoming physical (testable in principle) theories.
Of course, if you understand clearly that your answers are completely equivalent experimentally, then you are saying just... | **"no perceptible difference one way or another"**
To the senses, "no perceptible difference". To the intellect? **Profound** perceptible differences!
Nothing to be shocked about. |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | Logical Positivism, seems to me a philosophy that evolved by taking the scientific viewpoint as the only legitimate way to ask meaningful questions. Its greatest failing is that its not very imaginative. Its an interesting perspective to hold for a while, but to hold it exclusively feels severely limiting.
Also, histo... | I think that methaphysical theories (non testable in principle) are necessary and important to scientific research because they may be capable of becoming physical (testable in principle) theories.
Of course, if you understand clearly that your answers are completely equivalent experimentally, then you are saying just... |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | >
> These questions have the property that, whatever the hypothetical answer would be, every one of your perceptions of the world is exactly the same.
>
>
>
That is absolutely untrue. My perception of the world might be profoundly different if I knew with certainty information regarding the existence of souls, or ... | I think that methaphysical theories (non testable in principle) are necessary and important to scientific research because they may be capable of becoming physical (testable in principle) theories.
Of course, if you understand clearly that your answers are completely equivalent experimentally, then you are saying just... |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | It ***can*** be very meaningful, and just *how* meaningful will vary depending on the person and the question. **Even if it doesn't alter the observable (physical) world** ("your perceptions of the world"), **it is still meaningful if it alters *human behavior*.** In fact, it is strange to me that you don't seem to con... | I think that methaphysical theories (non testable in principle) are necessary and important to scientific research because they may be capable of becoming physical (testable in principle) theories.
Of course, if you understand clearly that your answers are completely equivalent experimentally, then you are saying just... |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | Logical Positivism, seems to me a philosophy that evolved by taking the scientific viewpoint as the only legitimate way to ask meaningful questions. Its greatest failing is that its not very imaginative. Its an interesting perspective to hold for a while, but to hold it exclusively feels severely limiting.
Also, histo... | **"no perceptible difference one way or another"**
To the senses, "no perceptible difference". To the intellect? **Profound** perceptible differences!
Nothing to be shocked about. |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | >
> These questions have the property that, whatever the hypothetical answer would be, every one of your perceptions of the world is exactly the same.
>
>
>
That is absolutely untrue. My perception of the world might be profoundly different if I knew with certainty information regarding the existence of souls, or ... | **"no perceptible difference one way or another"**
To the senses, "no perceptible difference". To the intellect? **Profound** perceptible differences!
Nothing to be shocked about. |
2,624 | There are many questions in philosophy of the following kind:
* Does my friend have a soul, or is my friend a zombie?
* Is the mind separate from the body, or is it the same?
* Where does the universe come from?
These questions have the property that, whatever the hypothetical answer would be, every one of your perce... | 2012/04/18 | [
"https://philosophy.stackexchange.com/questions/2624",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/1370/"
] | >
> These questions have the property that, whatever the hypothetical answer would be, every one of your perceptions of **the world** is exactly the same.
>
>
>
(emphasis mine).
You have imported an assumption here that, I think, explains why all of your examples are problematic.
What precisely do you mean by *t... | Logical Positivism, seems to me a philosophy that evolved by taking the scientific viewpoint as the only legitimate way to ask meaningful questions. Its greatest failing is that its not very imaginative. Its an interesting perspective to hold for a while, but to hold it exclusively feels severely limiting.
Also, histo... |
1,311 | I want a writing panel for a custom field called 'Sub-title' and would like it to appear in its logical place in the Page editor (that is, between the title and the Page content). Is that possible?
I would like to avoid having to create a custom post type, since a Page + custom fields is all I really need. | 2010/09/03 | [
"https://wordpress.stackexchange.com/questions/1311",
"https://wordpress.stackexchange.com",
"https://wordpress.stackexchange.com/users/106/"
] | I am wondering why my first answer was down-voted. :)
I think the only way to do is to add a meta box below the post content field and use javascript to move it above.
This is the way it is done with the slug field in the WordPress core (the slug field is were you edit the page or post url). Disable javascript in you... | You can add it below the content area and use javascript code to move it above it. |
1,311 | I want a writing panel for a custom field called 'Sub-title' and would like it to appear in its logical place in the Page editor (that is, between the title and the Page content). Is that possible?
I would like to avoid having to create a custom post type, since a Page + custom fields is all I really need. | 2010/09/03 | [
"https://wordpress.stackexchange.com/questions/1311",
"https://wordpress.stackexchange.com",
"https://wordpress.stackexchange.com/users/106/"
] | I am wondering why my first answer was down-voted. :)
I think the only way to do is to add a meta box below the post content field and use javascript to move it above.
This is the way it is done with the slug field in the WordPress core (the slug field is were you edit the page or post url). Disable javascript in you... | You could have a look at the excellent qTranslate. That should provide you with an example of everything you need since it adds a.o. multiple Title boxes. |
1,311 | I want a writing panel for a custom field called 'Sub-title' and would like it to appear in its logical place in the Page editor (that is, between the title and the Page content). Is that possible?
I would like to avoid having to create a custom post type, since a Page + custom fields is all I really need. | 2010/09/03 | [
"https://wordpress.stackexchange.com/questions/1311",
"https://wordpress.stackexchange.com",
"https://wordpress.stackexchange.com/users/106/"
] | I am wondering why my first answer was down-voted. :)
I think the only way to do is to add a meta box below the post content field and use javascript to move it above.
This is the way it is done with the slug field in the WordPress core (the slug field is were you edit the page or post url). Disable javascript in you... | To the best of my knowledge the priority of a meta box is limited to: Low, Default and High. Which is unlike admin menus that let you specify a value and put it anywhere. I'd try "High."
You can change the order of all your meta boxes by dragging and dropping so where ever High puts the subtitle you can drag it to be... |
320,304 | I will go on a site where is a HP PSC 1350 printer but no internet connection. I understand that there is no driver for download available from HP and it will connect to WinUpdate once connected the printer with USB. But there will be no Internet. Any chance to get the driver without connection to the printer ? | 2011/08/07 | [
"https://superuser.com/questions/320304",
"https://superuser.com",
"https://superuser.com/users/11334/"
] | Why can't you download the driver from HP and put it on a CD-ROM or usb stick?
[hp link to download driver](http://h10025.www1.hp.com/ewfrf/wc/softwareCategory?product=306888&lc=en&cc=us&dlc=en&lang=en&cc=us) | Contact HP to see what options they may have in this situation. They may be able to get you a physical disk, possibly for a small handling fee. |
178,459 | Sometimes I'm on call for work overnight and would like to know a quick way that I can silence all notifications except for the call ringer. The closest thing I see is allowing calls from everyone on do not disturb but that will allow messages to ring as well. | 2015/03/27 | [
"https://apple.stackexchange.com/questions/178459",
"https://apple.stackexchange.com",
"https://apple.stackexchange.com/users/119721/"
] | Actually, Do Not Disturb is indeed your solution as it blocks ALL notifications EXCEPT the calls which you specifically allow. It will block message notifications.
After you have configured the settings in Settings -> Do Not Disturb, all you need to do to enable it is swipe up from the bottom of the screen and tap th... | You can also head to Settings->Sounds->Text Tone and set tone and vibration there. You can configure texts for no sound and/or no vibration. Similarly, you can allow ALL calls (from any number) to ring as you have set in Settings->Sounds->Ringtone
I was just dealing with the same issue as I expect and need to hear wor... |
178,459 | Sometimes I'm on call for work overnight and would like to know a quick way that I can silence all notifications except for the call ringer. The closest thing I see is allowing calls from everyone on do not disturb but that will allow messages to ring as well. | 2015/03/27 | [
"https://apple.stackexchange.com/questions/178459",
"https://apple.stackexchange.com",
"https://apple.stackexchange.com/users/119721/"
] | Actually, Do Not Disturb is indeed your solution as it blocks ALL notifications EXCEPT the calls which you specifically allow. It will block message notifications.
After you have configured the settings in Settings -> Do Not Disturb, all you need to do to enable it is swipe up from the bottom of the screen and tap th... | Try and place your do not disturb button on, "ON" and that would just allow your phone to ring and will block all other incoming notifications.
I have iphone 7 |
178,459 | Sometimes I'm on call for work overnight and would like to know a quick way that I can silence all notifications except for the call ringer. The closest thing I see is allowing calls from everyone on do not disturb but that will allow messages to ring as well. | 2015/03/27 | [
"https://apple.stackexchange.com/questions/178459",
"https://apple.stackexchange.com",
"https://apple.stackexchange.com/users/119721/"
] | Actually, Do Not Disturb is indeed your solution as it blocks ALL notifications EXCEPT the calls which you specifically allow. It will block message notifications.
After you have configured the settings in Settings -> Do Not Disturb, all you need to do to enable it is swipe up from the bottom of the screen and tap th... | With the 7/7 Plus you simply engage Do Not Disturb and select "Allow Calls" from "Everyone". Nice and easy. |
66,486 | I have Dropbox installed on my Mac with OS X Lion 10.8.2. I don't use it often, so I eliminated it from the login item list. However, every time I open Dropbox from the application folder, it automatically add itself to the login item list. Is that normal, even if I locked changes? Can I prevent Dropbox to add itself t... | 2012/10/06 | [
"https://apple.stackexchange.com/questions/66486",
"https://apple.stackexchange.com",
"https://apple.stackexchange.com/users/-1/"
] | Under Dropbox preferences, there is a checkbox for "Start Dropbox on System Startup".
However, as patrix says, Dropbox is really only useful if you leave it running all the time. | The idea of Dropbox is to always sync files across all your devices in the background. So disabling the login item doesn't really make sense from a Dropbox point of view. And at least at first glance I don't see significant drawbacks from keeping it there either.
If you just want to access some files in your Dropbox a... |
172,671 | According to the Wikipedia page for the [Oxford Comma](http://en.wikipedia.org/wiki/Serial_comma#Arguments_for_and_against), "Use of the comma is consistent with conventional practice" and "Use of the comma is inconsistent with conventional practice." Did the Oxford Comma come before its omission, or was the Oxford Com... | 2014/05/24 | [
"https://english.stackexchange.com/questions/172671",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/-1/"
] | There are situations where use of the [Oxford comma](https://en.wikipedia.org/wiki/Serial_comma "(a.k.a. serial comma or series comma)") will make or break a sentence.
**Choose a style and *be consistent*.** When you run into a situation in which your choice suggests a misinterpretation of the sentence, rewrite it in ... | I don't have information about the history of this, so I'm just responding to the second part of your question. Why should there be no comma before 'and'? The answer is simple - there has never been a convention for adding a comma (as far as I know) for mentioning two items: *I like apples and oranges* or *She doesn't ... |
172,671 | According to the Wikipedia page for the [Oxford Comma](http://en.wikipedia.org/wiki/Serial_comma#Arguments_for_and_against), "Use of the comma is consistent with conventional practice" and "Use of the comma is inconsistent with conventional practice." Did the Oxford Comma come before its omission, or was the Oxford Com... | 2014/05/24 | [
"https://english.stackexchange.com/questions/172671",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/-1/"
] | I don't have information about the history of this, so I'm just responding to the second part of your question. Why should there be no comma before 'and'? The answer is simple - there has never been a convention for adding a comma (as far as I know) for mentioning two items: *I like apples and oranges* or *She doesn't ... | According to Willam J. Strunk in *The Elements of Style*, Rule 2 states that a comma should be used after each term except the last in lists of three or more items. There is an exception which is in names of businesses, the correct example given is: Brown, Shipley and Company (as opposed to Brown, Shipley, and Company)... |
172,671 | According to the Wikipedia page for the [Oxford Comma](http://en.wikipedia.org/wiki/Serial_comma#Arguments_for_and_against), "Use of the comma is consistent with conventional practice" and "Use of the comma is inconsistent with conventional practice." Did the Oxford Comma come before its omission, or was the Oxford Com... | 2014/05/24 | [
"https://english.stackexchange.com/questions/172671",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/-1/"
] | There are situations where use of the [Oxford comma](https://en.wikipedia.org/wiki/Serial_comma "(a.k.a. serial comma or series comma)") will make or break a sentence.
**Choose a style and *be consistent*.** When you run into a situation in which your choice suggests a misinterpretation of the sentence, rewrite it in ... | If find the Oxford comma to give fair representation to how people speak. When listing items in speech, equal pause is given between each item. For me, the Oxford comma emphasizes that there is, indeed, a pause before the 'and' preceding the last item of the list.
I think the Oxford comma also indicates the direction ... |
172,671 | According to the Wikipedia page for the [Oxford Comma](http://en.wikipedia.org/wiki/Serial_comma#Arguments_for_and_against), "Use of the comma is consistent with conventional practice" and "Use of the comma is inconsistent with conventional practice." Did the Oxford Comma come before its omission, or was the Oxford Com... | 2014/05/24 | [
"https://english.stackexchange.com/questions/172671",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/-1/"
] | If find the Oxford comma to give fair representation to how people speak. When listing items in speech, equal pause is given between each item. For me, the Oxford comma emphasizes that there is, indeed, a pause before the 'and' preceding the last item of the list.
I think the Oxford comma also indicates the direction ... | According to Willam J. Strunk in *The Elements of Style*, Rule 2 states that a comma should be used after each term except the last in lists of three or more items. There is an exception which is in names of businesses, the correct example given is: Brown, Shipley and Company (as opposed to Brown, Shipley, and Company)... |
172,671 | According to the Wikipedia page for the [Oxford Comma](http://en.wikipedia.org/wiki/Serial_comma#Arguments_for_and_against), "Use of the comma is consistent with conventional practice" and "Use of the comma is inconsistent with conventional practice." Did the Oxford Comma come before its omission, or was the Oxford Com... | 2014/05/24 | [
"https://english.stackexchange.com/questions/172671",
"https://english.stackexchange.com",
"https://english.stackexchange.com/users/-1/"
] | There are situations where use of the [Oxford comma](https://en.wikipedia.org/wiki/Serial_comma "(a.k.a. serial comma or series comma)") will make or break a sentence.
**Choose a style and *be consistent*.** When you run into a situation in which your choice suggests a misinterpretation of the sentence, rewrite it in ... | According to Willam J. Strunk in *The Elements of Style*, Rule 2 states that a comma should be used after each term except the last in lists of three or more items. There is an exception which is in names of businesses, the correct example given is: Brown, Shipley and Company (as opposed to Brown, Shipley, and Company)... |
257,984 | When people say "Unbelievable" in texting, does it usually mean "Unbelievably good" or "Unbelievably bad", or neutral, when the context is unclear?
Details about the background:
I send something neutral and playful to a friend, and the friend replied "unbelievable" without any additional words or follow-ups.
When th... | 2020/08/21 | [
"https://ell.stackexchange.com/questions/257984",
"https://ell.stackexchange.com",
"https://ell.stackexchange.com/users/104870/"
] | Without context, there is no way to know for sure, but my guess would be the more general sense of disbelief (“I don’t believe it”) regarding whatever they replied to.
For instance, if you said “my friend did [something stupid]”, that response would mean they don’t believe the friend could be so stupid as to do that t... | In texts, it would *more likely* mean "amazing!" (ie, good) if the context is otherwise unclear.
In general in English, it's extremely common to use (confusing!) reversals, double-negatives, sarcasm as the norm, etc. |
75,759 | I have a three-wheat batter bread recipe that calls for baking in four 16 oz cans. What size pan can I substitute? | 2016/11/22 | [
"https://cooking.stackexchange.com/questions/75759",
"https://cooking.stackexchange.com",
"https://cooking.stackexchange.com/users/52188/"
] | Three small (but not mini) metal loaf pans (5"L x 3"W x 3"D) will do it. Check out vintage bakeware in thrift stores to find that odd size, or choose pans closest to that size. | Honestly, use whatever size pans you have available to you and just monitor the baking process. Get creative. |
9,576 | I have edited [this closed question](https://worldbuilding.stackexchange.com/questions/220638/our-missing-sense-what-is-it-and-how-does-it-work) to provide some details that a few commentators mentioned were missing and submitted it for reopening. The reopen was rejected and the feedback is insufficient for me to work ... | 2021/12/24 | [
"https://worldbuilding.meta.stackexchange.com/questions/9576",
"https://worldbuilding.meta.stackexchange.com",
"https://worldbuilding.meta.stackexchange.com/users/23756/"
] | Let's clear up some doubts here :
Why didn't I vote to reopen the question
----------------------------------------
It's simple : Because I wasn't aware of the edit until you posted here and that I got through end-of-year-family-time downtime :). Otherwise the vote to reopen would have happened sooner.
The edit you ... | From what I see, the question has been closed with the following motivation
>
> This question is opinion-based. It is not currently accepting answers.
>
>
> Update the question so it can be answered with facts and citations.
>
>
>
The edit that you have done doesn't seem to do anything to solve that problem. |
28,403,782 | What is the difference between back-propagation and feed-forward neural networks?
By googling and reading, I found that in feed-forward there is only forward direction, but in back-propagation once we need to do a forward-propagation and then back-propagation. I referred to [this link](http://www.nnwj.de/backpropagati... | 2015/02/09 | [
"https://Stackoverflow.com/questions/28403782",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2028043/"
] | * A [Feed-Forward Neural Network](http://en.wikipedia.org/wiki/Feedforward_neural_network) is a type of Neural Network **architecture** where the connections are "fed forward", i.e. do not form cycles (like in recurrent nets).
* The term "Feed forward" is also used when you input something at the input layer and it *tr... | There is no pure backpropagation or pure feed-forward neural network.
Backpropagation is algorithm to train (adjust weight) of neural network.
Input for backpropagation is output\_vector, target\_output\_vector,
output is adjusted\_weight\_vector.
Feed-forward is algorithm to calculate output vector from input vector... |
28,403,782 | What is the difference between back-propagation and feed-forward neural networks?
By googling and reading, I found that in feed-forward there is only forward direction, but in back-propagation once we need to do a forward-propagation and then back-propagation. I referred to [this link](http://www.nnwj.de/backpropagati... | 2015/02/09 | [
"https://Stackoverflow.com/questions/28403782",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2028043/"
] | There is no pure backpropagation or pure feed-forward neural network.
Backpropagation is algorithm to train (adjust weight) of neural network.
Input for backpropagation is output\_vector, target\_output\_vector,
output is adjusted\_weight\_vector.
Feed-forward is algorithm to calculate output vector from input vector... | Neural Networks can have different architectures. The connections between their neurons decide direction of flow of information. Depending on network connections, they are categorised as - Feed-Forward and Recurrent (back-propagating).
**Feed Forward Neural Networks**
In these types of neural networks information flo... |
28,403,782 | What is the difference between back-propagation and feed-forward neural networks?
By googling and reading, I found that in feed-forward there is only forward direction, but in back-propagation once we need to do a forward-propagation and then back-propagation. I referred to [this link](http://www.nnwj.de/backpropagati... | 2015/02/09 | [
"https://Stackoverflow.com/questions/28403782",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2028043/"
] | There is no pure backpropagation or pure feed-forward neural network.
Backpropagation is algorithm to train (adjust weight) of neural network.
Input for backpropagation is output\_vector, target\_output\_vector,
output is adjusted\_weight\_vector.
Feed-forward is algorithm to calculate output vector from input vector... | To be simple:
Feed-foward is an architecture. The contrary one is Recurrent Neural Networks.
Back Propagation (BP) is a solving method. BP can solve both feed-foward and Recurrent Neural Networks. |
28,403,782 | What is the difference between back-propagation and feed-forward neural networks?
By googling and reading, I found that in feed-forward there is only forward direction, but in back-propagation once we need to do a forward-propagation and then back-propagation. I referred to [this link](http://www.nnwj.de/backpropagati... | 2015/02/09 | [
"https://Stackoverflow.com/questions/28403782",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2028043/"
] | * A [Feed-Forward Neural Network](http://en.wikipedia.org/wiki/Feedforward_neural_network) is a type of Neural Network **architecture** where the connections are "fed forward", i.e. do not form cycles (like in recurrent nets).
* The term "Feed forward" is also used when you input something at the input layer and it *tr... | Neural Networks can have different architectures. The connections between their neurons decide direction of flow of information. Depending on network connections, they are categorised as - Feed-Forward and Recurrent (back-propagating).
**Feed Forward Neural Networks**
In these types of neural networks information flo... |
28,403,782 | What is the difference between back-propagation and feed-forward neural networks?
By googling and reading, I found that in feed-forward there is only forward direction, but in back-propagation once we need to do a forward-propagation and then back-propagation. I referred to [this link](http://www.nnwj.de/backpropagati... | 2015/02/09 | [
"https://Stackoverflow.com/questions/28403782",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2028043/"
] | * A [Feed-Forward Neural Network](http://en.wikipedia.org/wiki/Feedforward_neural_network) is a type of Neural Network **architecture** where the connections are "fed forward", i.e. do not form cycles (like in recurrent nets).
* The term "Feed forward" is also used when you input something at the input layer and it *tr... | To be simple:
Feed-foward is an architecture. The contrary one is Recurrent Neural Networks.
Back Propagation (BP) is a solving method. BP can solve both feed-foward and Recurrent Neural Networks. |
28,403,782 | What is the difference between back-propagation and feed-forward neural networks?
By googling and reading, I found that in feed-forward there is only forward direction, but in back-propagation once we need to do a forward-propagation and then back-propagation. I referred to [this link](http://www.nnwj.de/backpropagati... | 2015/02/09 | [
"https://Stackoverflow.com/questions/28403782",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2028043/"
] | To be simple:
Feed-foward is an architecture. The contrary one is Recurrent Neural Networks.
Back Propagation (BP) is a solving method. BP can solve both feed-foward and Recurrent Neural Networks. | Neural Networks can have different architectures. The connections between their neurons decide direction of flow of information. Depending on network connections, they are categorised as - Feed-Forward and Recurrent (back-propagating).
**Feed Forward Neural Networks**
In these types of neural networks information flo... |
9,917 | We have implemented/are implementing a network vulnerability scanning process, and we have chosen to use Qualysguard.
Qualys supply a scanner appliance for the internal network scanning, which obviously connects to the network. Our internal network is segmented into multiple subnets, each firewalled from the others. W... | 2011/12/20 | [
"https://security.stackexchange.com/questions/9917",
"https://security.stackexchange.com",
"https://security.stackexchange.com/users/1064/"
] | I have not used QualysGuard however using a vendor agnostic approach I would consider the following.
**Indirect connection through firewall:**
This can be a good option if you are unable to connect to the subnet for some reason (not enough connections, physically not accessible, etc...).
Some types of active scans d... | I am not sure that you will be able to get away with not adding rules to your firewalls to allow the traffic from the scanner. You will not need to open them up globally, just for the scanner's IP.
If you are using stateful inspection, the scanners should be on the untrusted side of the firewall anyway so that the st... |
9,917 | We have implemented/are implementing a network vulnerability scanning process, and we have chosen to use Qualysguard.
Qualys supply a scanner appliance for the internal network scanning, which obviously connects to the network. Our internal network is segmented into multiple subnets, each firewalled from the others. W... | 2011/12/20 | [
"https://security.stackexchange.com/questions/9917",
"https://security.stackexchange.com",
"https://security.stackexchange.com/users/1064/"
] | I have not used QualysGuard however using a vendor agnostic approach I would consider the following.
**Indirect connection through firewall:**
This can be a good option if you are unable to connect to the subnet for some reason (not enough connections, physically not accessible, etc...).
Some types of active scans d... | It's highly recommended that you work with your network group to determine where to
place Scanner Appliances in an enterprise network environment. Some things to
consider: place Scanner Appliances as close to target machines as possible, and make sure
to monitor and identify any bandwidth restricted segments or weak po... |
122,466 | My hard drive had some bad sectors recently, so I backed up, re-formatted, and clean installed Mavericks.
Everything seemed to work fine until couple days ago when I tried to look at some photos I recently imported to iPhoto, things got stuck and sometimes wouldn't move at all for up to 40 seconds, I knew it was a har... | 2014/02/27 | [
"https://apple.stackexchange.com/questions/122466",
"https://apple.stackexchange.com",
"https://apple.stackexchange.com/users/71588/"
] | I had the same problem as you few years ago.
You definitely have the sympthoms of bad sectors. If you can't backup with Time Machine I advise you to back your data from the finder by yourself and skipping the files that can't be read.
---
Edit : You won't be able to backup all your files. You can't retrieve the da... | Open Console in your Utility folder.
Type "disk" in the search (Filter) window
Look if you have disk I/O errors.
If you do see them (like a lots of them), your disk is bad, so back up, and get new disk. |
75,498 | The "ninth chord" that Rameau, Kirnberger, Marpurg or Koch (inter alia) discuss during the 18th century is the chord formed by a triad and an added ninth, and its explanation is always through a "chord of supposition", i.e., the supposed root is a third above the lowest note of the chord, since chords that spanned more... | 2018/10/17 | [
"https://music.stackexchange.com/questions/75498",
"https://music.stackexchange.com",
"https://music.stackexchange.com/users/52903/"
] | In addition to Reber and Richter that you mention, I know that Fétis (1844), Durand (1881), and Dubois (1889, 1921) also discussed ninth chords.
But the earliest theorist that I know of, not including theorists like Sorge that fall into the fundamental-bass camp with Rameau and Marpurg (it was this group, by the way, ... | It first gained common usage in the late baroque, its origin was through intervallic supposition and accidental harmonic forms. |
1,523,170 | I've been looking around at various APIs, and since twitter seems to be a common discussion point, I'll use it as an example.
A lot of APIs are implementing oAuth which is great for allowing the service to authenicate and authorize the application connecting to it, however, from what I have seen there doesnt seem to ... | 2009/10/06 | [
"https://Stackoverflow.com/questions/1523170",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/56940/"
] | This is what the 'trust' part of SSL does.
-- Edit
I note this has been downvoted, but it's important that other readers realise it's due to a personal disagreement, not due to incorrectness. | In the .NET world we use WCF, which has many different security models, including signing (and if desired encrypting) each message/response. This adds up to a non-trivial amount of overhead, but can give you more 'trust' in the security model. You can switch to using binary-serialized data to cut down on the bloat and ... |
26,884,806 | So recently i gave my friend a URL on facebook chat while we were discussing on how much further we have to go on a booking system, my friend says he cant open the link, when i tried clicking it worked but what caught my eye was the referring URL by facebook:
>
> <https://www.facebook.com/>**l.php**?u=https%3A%2F%2F... | 2014/11/12 | [
"https://Stackoverflow.com/questions/26884806",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3198256/"
] | No one can know what exactly that script does but the developers at Facebook.
I presume they track all outgoing links from Facebook to get some statistics on them and on the users. After that it just sends you to the external page. | Please check out the following article [Facebook, privacy and the mystery of l.php](http://web.archive.org/web/20160826060705/http://www.codehesive.com:80/index.php/archive/facebook-privacy-and-the-mystery-of-l-php/) which says:
>
> Unless it’s from a public page, all you’re bound to see is one simple
> referring UR... |
85,421 | The police arrested a suspect linked to sexual assaults. The police searched his home. It sounds like initially the search warrants were very limited in scope but they widened as things turned up. While he was in jail, his lawyer followed his instructions to hide evidence.
From [Wikipedia](https://en.wikipedia.org/wik... | 2022/10/16 | [
"https://law.stackexchange.com/questions/85421",
"https://law.stackexchange.com",
"https://law.stackexchange.com/users/4067/"
] | Quick answer
============
"Is a lawyer allowed to follow a client's instructions to hide evidence?" **Probably not**. I discuss this in the final section of this answer.
About this specific case, the Crown did not prove beyond a reasonable doubt that the lawyer (Ken Murray) had intended to conceal the tapes permenant... | The details and principles of this case seem well addressed in the [answer by Jen](https://law.stackexchange.com/a/85423/17500). But I wish to address a particular point in the question which does not depend on the detailed facts of this particular case.
The OP asks in the question:
>
> Doesn't a lawyer have a respo... |
85,421 | The police arrested a suspect linked to sexual assaults. The police searched his home. It sounds like initially the search warrants were very limited in scope but they widened as things turned up. While he was in jail, his lawyer followed his instructions to hide evidence.
From [Wikipedia](https://en.wikipedia.org/wik... | 2022/10/16 | [
"https://law.stackexchange.com/questions/85421",
"https://law.stackexchange.com",
"https://law.stackexchange.com/users/4067/"
] | Quick answer
============
"Is a lawyer allowed to follow a client's instructions to hide evidence?" **Probably not**. I discuss this in the final section of this answer.
About this specific case, the Crown did not prove beyond a reasonable doubt that the lawyer (Ken Murray) had intended to conceal the tapes permenant... | A lawyer protects lawfully. Once an evidence is encountered, every lawyer must expose it to the court or take criminal complicity responsibility. |
85,421 | The police arrested a suspect linked to sexual assaults. The police searched his home. It sounds like initially the search warrants were very limited in scope but they widened as things turned up. While he was in jail, his lawyer followed his instructions to hide evidence.
From [Wikipedia](https://en.wikipedia.org/wik... | 2022/10/16 | [
"https://law.stackexchange.com/questions/85421",
"https://law.stackexchange.com",
"https://law.stackexchange.com/users/4067/"
] | The details and principles of this case seem well addressed in the [answer by Jen](https://law.stackexchange.com/a/85423/17500). But I wish to address a particular point in the question which does not depend on the detailed facts of this particular case.
The OP asks in the question:
>
> Doesn't a lawyer have a respo... | A lawyer protects lawfully. Once an evidence is encountered, every lawyer must expose it to the court or take criminal complicity responsibility. |
316,716 | Related to [What's the uA741's appeal?](https://electronics.stackexchange.com/questions/8253/whats-the-ua741s-appeal), a lot of schematics use this rather dated opamp. My follow-up question would be: What is a good alternative?
Of course if you have specific requirements you just search for the correct part. What I'm ... | 2017/07/11 | [
"https://electronics.stackexchange.com/questions/316716",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/94884/"
] | >
> what should be the default opamp I stock in my parts bin?
>
>
>
It's a failure on your part to think that there is a default op-amp that suits most applications. It's as simple as that. It's also a failure to limit what you think are the important parameters to those that you have stated.
There are many impor... | Here is a brief answer - go to a distributor site and look at the op-amp section. One can normally select by parameters. For example, [Farnell](http://uk.farnell.com/c/semiconductors-ics/amplifiers-comparators/operational-amplifiers-op-amps) |
316,716 | Related to [What's the uA741's appeal?](https://electronics.stackexchange.com/questions/8253/whats-the-ua741s-appeal), a lot of schematics use this rather dated opamp. My follow-up question would be: What is a good alternative?
Of course if you have specific requirements you just search for the correct part. What I'm ... | 2017/07/11 | [
"https://electronics.stackexchange.com/questions/316716",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/94884/"
] | >
> what should be the default opamp I stock in my parts bin?
>
>
>
It's a failure on your part to think that there is a default op-amp that suits most applications. It's as simple as that. It's also a failure to limit what you think are the important parameters to those that you have stated.
There are many impor... | Ne5532 is a good all purpose opamp. Tda1308 is another one for good low voltage application. It has poorer DC performance however. |
316,716 | Related to [What's the uA741's appeal?](https://electronics.stackexchange.com/questions/8253/whats-the-ua741s-appeal), a lot of schematics use this rather dated opamp. My follow-up question would be: What is a good alternative?
Of course if you have specific requirements you just search for the correct part. What I'm ... | 2017/07/11 | [
"https://electronics.stackexchange.com/questions/316716",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/94884/"
] | >
> what should be the default opamp I stock in my parts bin?
>
>
>
It's a failure on your part to think that there is a default op-amp that suits most applications. It's as simple as that. It's also a failure to limit what you think are the important parameters to those that you have stated.
There are many impor... | Because you mentioned Arduino (low power, low voltage):
LM358N - 0.5mA, min 3V 1MHz
MCP6001 - 0.1mA, min 1.8V 1MHz
LM324 - 0.7mA, min 3V 1MHz (quadruple)
NE5532a - ?mA min +-5V (10MHz!)
TDA1308 - 3mA, min 3V, (class-AB stereo headphone driver, circ boards already available on ebay for $1)
LM193, LM293, ... |
316,716 | Related to [What's the uA741's appeal?](https://electronics.stackexchange.com/questions/8253/whats-the-ua741s-appeal), a lot of schematics use this rather dated opamp. My follow-up question would be: What is a good alternative?
Of course if you have specific requirements you just search for the correct part. What I'm ... | 2017/07/11 | [
"https://electronics.stackexchange.com/questions/316716",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/94884/"
] | Ne5532 is a good all purpose opamp. Tda1308 is another one for good low voltage application. It has poorer DC performance however. | Here is a brief answer - go to a distributor site and look at the op-amp section. One can normally select by parameters. For example, [Farnell](http://uk.farnell.com/c/semiconductors-ics/amplifiers-comparators/operational-amplifiers-op-amps) |
316,716 | Related to [What's the uA741's appeal?](https://electronics.stackexchange.com/questions/8253/whats-the-ua741s-appeal), a lot of schematics use this rather dated opamp. My follow-up question would be: What is a good alternative?
Of course if you have specific requirements you just search for the correct part. What I'm ... | 2017/07/11 | [
"https://electronics.stackexchange.com/questions/316716",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/94884/"
] | Because you mentioned Arduino (low power, low voltage):
LM358N - 0.5mA, min 3V 1MHz
MCP6001 - 0.1mA, min 1.8V 1MHz
LM324 - 0.7mA, min 3V 1MHz (quadruple)
NE5532a - ?mA min +-5V (10MHz!)
TDA1308 - 3mA, min 3V, (class-AB stereo headphone driver, circ boards already available on ebay for $1)
LM193, LM293, ... | Here is a brief answer - go to a distributor site and look at the op-amp section. One can normally select by parameters. For example, [Farnell](http://uk.farnell.com/c/semiconductors-ics/amplifiers-comparators/operational-amplifiers-op-amps) |
50,239,555 | I have a doubt about Microservices Architecture. We are developing an ERP and there're several microservices such as Human Resources, Identity, Orders and so on.
We've implemented a shared domain layer for entities that are common for all those layers, including abstractions ( interfaces ) of Company, Location and so... | 2018/05/08 | [
"https://Stackoverflow.com/questions/50239555",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/-1/"
] | Usually microservice architectures adopt a "share nothing" concept, which mean your code bases should be ideally separate. Yes, that will mean you will write more code but will keep your microservices more manageable, uncoupled and probably lighter.
Also, regarding the DDD-part do the question, you should really striv... | >
> My question is: What's the boundary of shared items for microservices and how bad is that?
>
>
>
Up until a few years ago it was complicated to get the boundaries a microservice defined because there was simply no agreement on how to archieve that, but Evans sorted that out a few years ago:
[GOTO 2015 • DDD &... |
368,131 | Between a mains step down transformer and a SMPS, which would be safer for a bench power supply? I cannot look inside the transformer in either case to judge the insulation quality. But, if the insulation does fail there would be 230VAC at the secondary for the mains transformer. And, maybe 325VDC at the output of the ... | 2018/04/12 | [
"https://electronics.stackexchange.com/questions/368131",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/72155/"
] | >
> Battery A still had potential of 12V, but the battery B showed 0V.
>
>
>
When you connect batteries in series, you have to make sure they are of equal capacity (Ampere hours), equal Voltage and equal wear and age.
Basically you may only create a series pack with two brand new batteries.
This is important ... | Voltage is not a reliable indicator of charge state.
Both batteries can have a terminal voltage of 12V, but one be half charged and the other nearly dead. Running them in series will work until the weakest one is completely discharged.
At that point, the battery that still has charge begins pushing current through ... |
368,131 | Between a mains step down transformer and a SMPS, which would be safer for a bench power supply? I cannot look inside the transformer in either case to judge the insulation quality. But, if the insulation does fail there would be 230VAC at the secondary for the mains transformer. And, maybe 325VDC at the output of the ... | 2018/04/12 | [
"https://electronics.stackexchange.com/questions/368131",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/72155/"
] | Voltage is not a reliable indicator of charge state.
Both batteries can have a terminal voltage of 12V, but one be half charged and the other nearly dead. Running them in series will work until the weakest one is completely discharged.
At that point, the battery that still has charge begins pushing current through ... | The battery connected to the positive terminal will drain first every time. The idea that they drain evenly is incorrect. I check my trolling motor batteries for voltage every time I bring my boat back from the lake. The one connected to the positive lead is low and the one connected to the negative lead is 12+V. |
368,131 | Between a mains step down transformer and a SMPS, which would be safer for a bench power supply? I cannot look inside the transformer in either case to judge the insulation quality. But, if the insulation does fail there would be 230VAC at the secondary for the mains transformer. And, maybe 325VDC at the output of the ... | 2018/04/12 | [
"https://electronics.stackexchange.com/questions/368131",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/72155/"
] | >
> Battery A still had potential of 12V, but the battery B showed 0V.
>
>
>
When you connect batteries in series, you have to make sure they are of equal capacity (Ampere hours), equal Voltage and equal wear and age.
Basically you may only create a series pack with two brand new batteries.
This is important ... | The battery connected to the positive terminal will drain first every time. The idea that they drain evenly is incorrect. I check my trolling motor batteries for voltage every time I bring my boat back from the lake. The one connected to the positive lead is low and the one connected to the negative lead is 12+V. |
5,259 | I asked a question, which I believed was with a very simple answer and then it got on hold as too broad.
None of the "too-broad" voters actually gave a reason why it would be too broad. And only one of the answers given fits all the clues (the accepted one). I even added two more hints after the first close vote - to ... | 2016/08/20 | [
"https://puzzling.meta.stackexchange.com/questions/5259",
"https://puzzling.meta.stackexchange.com",
"https://puzzling.meta.stackexchange.com/users/29050/"
] | That is the whole problem with riddles. You might have thought of a certain answer but you will find lots of different answers, many of which will make sense because riddles usually are "think out of the box".
And looking at your question, if you see the answers, from a neutral perspective, many of the answers make s... | >
> I asked a question, which I believed was with a very simple answer and then it got on hold as too broad.
>
>
>
The problem is that unless specific clues are given, many different things under the Sun can fit as an answer to a riddle, thus making it a bad one.
>
> And only one of the ... I even added two mo... |
5,259 | I asked a question, which I believed was with a very simple answer and then it got on hold as too broad.
None of the "too-broad" voters actually gave a reason why it would be too broad. And only one of the answers given fits all the clues (the accepted one). I even added two more hints after the first close vote - to ... | 2016/08/20 | [
"https://puzzling.meta.stackexchange.com/questions/5259",
"https://puzzling.meta.stackexchange.com",
"https://puzzling.meta.stackexchange.com/users/29050/"
] | Your riddle, if I understand correctly, works on a simple principle, namely **two different meanings of the same word.** While this is a nice principle, the implementation is, IMHO, a bit weak: there are too few constraints on the desired answer, which broadens the list of possible answers. For example, I can think of ... | >
> I asked a question, which I believed was with a very simple answer and then it got on hold as too broad.
>
>
>
The problem is that unless specific clues are given, many different things under the Sun can fit as an answer to a riddle, thus making it a bad one.
>
> And only one of the ... I even added two mo... |
203,725 | I'd like to write about the golden age of piracy and this thought came to me: is there a standard way for a 1600's ship to handle a rogue wave, or does this vary by ship design?
My inexistent degree on sailing comes from playing Assassin's Creed. In one of the games in the series, the protagonist's ship deals with rog... | 2021/06/01 | [
"https://worldbuilding.stackexchange.com/questions/203725",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/21222/"
] | It depends on the dimensions of your boat, and of the wave.
Basically, you do not want the wave to roll you ship, nor do you want the wave to break your ship in two.
You want to hit the wave with a part of the ship that is of length a little bit longer than the maximum trough-to-peak of the wave. This way the ship "r... | **Use catamarans**
Catamarans have some drawbacks against monohulls, but handling rough seas is one of their strengths. I don't know if it was possible to build a carrack-sized catamaran, but smaller ships would be very viable. |
68,683 | I have a SPST relay that I do not have the full datasheet for, but I wish to calculate the time it takes to switch on a current for a particular voltage. Is there any easy general way to do this? My first thought would be to time it for a clicking noise, but I don't think that would be accurate for what I need.
My rel... | 2013/05/09 | [
"https://electronics.stackexchange.com/questions/68683",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/16834/"
] | Do you have an oscilloscope handy? A quick way to measure the switching time would be to operate the relay with probes hooked up to the control coil and the switching side of the relay. You would need to hook up some kind of dummy load so you can see it turn on. You would need to be able to monitor both the channels on... | If you have an Arduino or any other microcontroller devboard handy, you can set up an experiment to measure the delay.
Just hook up the relay coil to a micro via transistor (don't forget the protection diode!) and put a dummy load (something like 10k resistor) on the output of the relay and connect it to input pin of ... |
106,784 | I am working on a team that is doing both driver software and FPGA development. The FPGA simulation is being done in Modelsim and driver software is written in C. To minimize integration risk, I would love to be able to model the interaction between the two halves of our product before putting it on hardware.
I know M... | 2014/04/16 | [
"https://electronics.stackexchange.com/questions/106784",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/40447/"
] | [External Control of a ModelSim Simulation Via Unix Named Pipes](http://books.google.com/books/about/External_Control_of_a_ModelSim_Simulatio.html?id=bBSrZwEACAAJ&redir_esc=y)
>
> Abstract: In this thesis, we present a method of controlling a
> ModelSim simulation via an external program. Communication between
> Mo... | You might want to look at [Cocotb](http://cocotb.org). It's a Python based co-simulation library, one of the design goals was to enable the methodology you describe, easily simulating un-modified production software and RTL.
There's an example in the repository of running unmodified `ping` command against a simulation... |
54,057 | I just receive my first "official" drawing/logo project and I'm not sure how to get about doing it.
So this client asked me for a drawing for a brand logo that he's planning on doing (just a drawing for now, but maybe a logo later on, but I'll need to tell him my rates and all). So I'm planning to tell him that I don... | 2015/05/25 | [
"https://graphicdesign.stackexchange.com/questions/54057",
"https://graphicdesign.stackexchange.com",
"https://graphicdesign.stackexchange.com/users/44301/"
] | If you have access to an iPhone or iPad, you could try using [Adobe Shape](http://www.adobe.com/products/shape.html). It uses the device camera to take pictures and convert the pictures into vectors. | It all depends on the look you want on the logo. If it's very sketchy, or has something like watercolor textures it might be harder to vectorize, but it is possible to achieve a hand-drawn look in all vector using illustrator brushes and textures.
It is also possible to have a hand-drawn version (that you maybe draw b... |
54,057 | I just receive my first "official" drawing/logo project and I'm not sure how to get about doing it.
So this client asked me for a drawing for a brand logo that he's planning on doing (just a drawing for now, but maybe a logo later on, but I'll need to tell him my rates and all). So I'm planning to tell him that I don... | 2015/05/25 | [
"https://graphicdesign.stackexchange.com/questions/54057",
"https://graphicdesign.stackexchange.com",
"https://graphicdesign.stackexchange.com/users/44301/"
] | If you have access to an iPhone or iPad, you could try using [Adobe Shape](http://www.adobe.com/products/shape.html). It uses the device camera to take pictures and convert the pictures into vectors. | If the logo will be used for commercial purposes then it must be professionally vectorized. Don't even think about automated vector conversion tools. They are providing terrible vector images that can not be used for any company. Check blue link with tutorial that will show you how to vectorize company logo with a pen ... |
12,044 | I have an APEX script that generates emails after some event occurs. I would like to see a record of all the emails that have been sent. Is this possible in the Setup portion of SalesForce? | 2013/05/23 | [
"https://salesforce.stackexchange.com/questions/12044",
"https://salesforce.stackexchange.com",
"https://salesforce.stackexchange.com/users/2772/"
] | To access email logs, click Your Name | Setup | Monitoring | Email Log Files.
<http://login.salesforce.com/help/doc/en/email_logs.htm>
For that to work, the employee will need to have the "Modify All Data" as described [here](https://help.salesforce.com/apex/HTViewHelpDoc?id=email_logs.htm&language=en_US) | You can also add a Compliance BCC email address, which will be added to the BCC of every email that is sent out of your org. Of course, you'll get a lot more than just the emails generated by the apex script. I have a separate inbox for this purpose.
<http://login.salesforce.com/help/doc/en/admin_compliancebcc.htm> |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | In the context of machine learning, an embedding is a low-dimensional, learned continuous vector representation of discrete variables into which you can translate high-dimensional vectors. Generally, embeddings make ML models more efficient and easier to work with, and can be used with other models as well.
Typically,... | According to all answers(Thank you) and my google search I got a better understanding, So my newly updated understanding is:
The embedding in machine learning or NLP is actually a technique mapping from words to vectors which you can do better analysis or relating, for example, "toyota" or "honda" can be hardly relate... |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | In the context of machine learning, an embedding is a low-dimensional, learned continuous vector representation of discrete variables into which you can translate high-dimensional vectors. Generally, embeddings make ML models more efficient and easier to work with, and can be used with other models as well.
Typically,... | >
> The LSA community seems to have first used the word “embedding” in Landauer
> et al. (1997), in a variant of its mathematical meaning as a mapping from one space or mathematical structure to another. In LSA, the word embedding seems to have described the mapping from the space of sparse count vectors to the latent... |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | According to all answers(Thank you) and my google search I got a better understanding, So my newly updated understanding is:
The embedding in machine learning or NLP is actually a technique mapping from words to vectors which you can do better analysis or relating, for example, "toyota" or "honda" can be hardly relate... | **For me embedding is used to represent big sparse matrix into smaller dimensions, where each dimension(feature) represent a meaningful association with other elements in the embedding matrix.**
Consider an example of NLP. Where each sentence broken down into words(also called token). Such set of different words make ... |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | According to all answers(Thank you) and my google search I got a better understanding, So my newly updated understanding is:
The embedding in machine learning or NLP is actually a technique mapping from words to vectors which you can do better analysis or relating, for example, "toyota" or "honda" can be hardly relate... | >
> The LSA community seems to have first used the word “embedding” in Landauer
> et al. (1997), in a variant of its mathematical meaning as a mapping from one space or mathematical structure to another. In LSA, the word embedding seems to have described the mapping from the space of sparse count vectors to the latent... |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | In the context of machine learning, an embedding is a low-dimensional, learned continuous vector representation of discrete variables into which you can translate high-dimensional vectors. Generally, embeddings make ML models more efficient and easier to work with, and can be used with other models as well.
Typically,... | **For me embedding is used to represent big sparse matrix into smaller dimensions, where each dimension(feature) represent a meaningful association with other elements in the embedding matrix.**
Consider an example of NLP. Where each sentence broken down into words(also called token). Such set of different words make ... |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | According to all answers(Thank you) and my google search I got a better understanding, So my newly updated understanding is:
The embedding in machine learning or NLP is actually a technique mapping from words to vectors which you can do better analysis or relating, for example, "toyota" or "honda" can be hardly relate... | Embeddings are vector representations of a particular word.
In Machine learning, textual content has to be converted to numerical data to feed it into Algorithm.
One method is one hot encoding but it breaks down when we have large no of vocabulary. The size of word representation grows as the vocabulary grows. Also,... |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | >
> The LSA community seems to have first used the word “embedding” in Landauer
> et al. (1997), in a variant of its mathematical meaning as a mapping from one space or mathematical structure to another. In LSA, the word embedding seems to have described the mapping from the space of sparse count vectors to the latent... | Embeddings are vector representations of a particular word.
In Machine learning, textual content has to be converted to numerical data to feed it into Algorithm.
One method is one hot encoding but it breaks down when we have large no of vocabulary. The size of word representation grows as the vocabulary grows. Also,... |
53,995 | I just met a terminology called "embedding" in a paper regarding deep learning. The context is "multi-modal embedding"
My guess: embedding of something is extract some feature of sth,to form a vector.
I couldn't get the explicit meaning for this terminology and that stops me from fully understanding the author's idea... | 2019/06/18 | [
"https://datascience.stackexchange.com/questions/53995",
"https://datascience.stackexchange.com",
"https://datascience.stackexchange.com/users/43765/"
] | In the context of machine learning, an embedding is a low-dimensional, learned continuous vector representation of discrete variables into which you can translate high-dimensional vectors. Generally, embeddings make ML models more efficient and easier to work with, and can be used with other models as well.
Typically,... | Embeddings are vector representations of a particular word.
In Machine learning, textual content has to be converted to numerical data to feed it into Algorithm.
One method is one hot encoding but it breaks down when we have large no of vocabulary. The size of word representation grows as the vocabulary grows. Also,... |
13,697 | I live in a 3 bedroom shared house and want to reduce the noise that the bathroom door makes when it closes.
I tried to find a photo of the door. It's basically a old mansion block of apartments in London. The door has a brass knob and stained glass is about an inch thick wooden. I don't know if you can picture the ol... | 2012/04/19 | [
"https://diy.stackexchange.com/questions/13697",
"https://diy.stackexchange.com",
"https://diy.stackexchange.com/users/5943/"
] | I guess you could try putting some thin foam or felt stick on pads on the inside of the door frame where the door contacts it. This should lower the sound of the wood to wood contact. If the knob hardware is also loud, try using some dry silicon spray lubricant on the moving parts and on the door hinges. Sleep well....... | Get narrow weather seal and put it on the door jamb so the door never touches the wood. |
61,196,489 | I created a chat messenger between my website users based on wix repeater when a new msg launch a new row insert into chat collection (my chat collection including the following fields User A, User B, MSG ) and the messenger repeater should refresh for both users.
So if user A send a message to User B
I should do t... | 2020/04/13 | [
"https://Stackoverflow.com/questions/61196489",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1921025/"
] | You can use the [Realtime API](https://www.wix.com/corvid/reference/wix-realtime.html) to create a subscriber for the collection on the client. In your backend code in the afterInsert function, publish a message to the specific client which execute the refresh function for the list in the repeater in the callback funct... | The best thing you can do is here is to set a setInterval() function under the page's onReady() function to refresh user B's dataset/repeater every 3-5 seconds which would check for fresh messages. |
129,334 | I have a compound, dimethylaminoethanol (DMAE) bitartrate, which I originally purchased as a supplement and possible smart drug. I bought an absurd amount of it. It didn’t do anything for me as a supplement. I understand that DMAE, not the bitartrate salt, is commonly used in cosmetics, & I’d like to play with it for t... | 2020/03/21 | [
"https://chemistry.stackexchange.com/questions/129334",
"https://chemistry.stackexchange.com",
"https://chemistry.stackexchange.com/users/90071/"
] | I see on Wikipedia: "Dimethylethanolamine (DMAE or DMEA) is an organic compound with the formula (CH3)2NCH2CH2OH. It is bifunctional, containing both a tertiary amine and primary alcohol functional groups. It is a colorless viscous liquid. It is used in skin care products."
Now the fact that it is used in skin care pr... | This might work:
Make a solution of NaOH in absolute ethanol, e.g. at a 1 mol/L concentration. Suspend the DMAE bitartrate in ethanol, and add 2 equivalents of the NaOH solution slowly to the suspension, making sure it doesn't heat up too much. After everything is added, stir or agitate it for a while. Then filter off ... |
4,850 | I've read various pieces arguing that the USA is not a democracy, but a (fill in the blank, ex., a Republic). Perhaps there is no perfect fit, but **which form of government does the USA most closely match?** | 2014/09/13 | [
"https://politics.stackexchange.com/questions/4850",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/4459/"
] | The definition of democracy varies, but for most definitions used, **yes, the USA is a democracy.**
Wikipedia's article on [Liberal Democracy](http://en.wikipedia.org/wiki/Liberal_democracy) defines a liberal democracy as follows:
>
> It is characterised by fair, free, and competitive elections between multiple dis... | The United States is a **[Representational Democracy](http://en.wikipedia.org/wiki/Representative_democracy)**. The people have no direct say in government, but have the ability to freely vote for those who *do* have direct say (the people's representatives).
This is contrast to a Direct Democracy (which is also somet... |
4,850 | I've read various pieces arguing that the USA is not a democracy, but a (fill in the blank, ex., a Republic). Perhaps there is no perfect fit, but **which form of government does the USA most closely match?** | 2014/09/13 | [
"https://politics.stackexchange.com/questions/4850",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/4459/"
] | The definition of democracy varies, but for most definitions used, **yes, the USA is a democracy.**
Wikipedia's article on [Liberal Democracy](http://en.wikipedia.org/wiki/Liberal_democracy) defines a liberal democracy as follows:
>
> It is characterised by fair, free, and competitive elections between multiple dis... | You cannot counter-posite democracy to a republic. Republic is a well-defined form of state. As such, the US is republic. Democracy is a form of government. There can be various degree of democracy and various opinions on what practice is more democratic. |
4,850 | I've read various pieces arguing that the USA is not a democracy, but a (fill in the blank, ex., a Republic). Perhaps there is no perfect fit, but **which form of government does the USA most closely match?** | 2014/09/13 | [
"https://politics.stackexchange.com/questions/4850",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/4459/"
] | The United States is a **[Representational Democracy](http://en.wikipedia.org/wiki/Representative_democracy)**. The people have no direct say in government, but have the ability to freely vote for those who *do* have direct say (the people's representatives).
This is contrast to a Direct Democracy (which is also somet... | You cannot counter-posite democracy to a republic. Republic is a well-defined form of state. As such, the US is republic. Democracy is a form of government. There can be various degree of democracy and various opinions on what practice is more democratic. |
8,279,605 | I've been reading [Code Complete 2](https://rads.stackoverflow.com/amzn/click/com/0735619670). As I am not native english speaker some statements take some time for me to understand. I would like you to describe the difference between these two statements the author made in his book:
>
> 1. You should program into Yo... | 2011/11/26 | [
"https://Stackoverflow.com/questions/8279605",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/44852/"
] | Program **into** your language means that you *use* the language to construct the "missing" pieces - leverage it to do more than it currently does. Things like creating missing data structure, algorithms and ways of accomplishing tasks that are not native to the language.
Program **in** your language means just that -... | The author provides an example of his own in that part of the book (which unfortunately I don't remember). You can try reading a bit further.
It means that even if the language doesn't support a particularly convenient feature, as you should always think of writing readable, easy to maintain, modular code, you should ... |
8,279,605 | I've been reading [Code Complete 2](https://rads.stackoverflow.com/amzn/click/com/0735619670). As I am not native english speaker some statements take some time for me to understand. I would like you to describe the difference between these two statements the author made in his book:
>
> 1. You should program into Yo... | 2011/11/26 | [
"https://Stackoverflow.com/questions/8279605",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/44852/"
] | As I understand it, it means to think outside of the bounds of your programming language.
So **in** means you are thinking in terms of the language, so your thinking is limited by the language itself, and the program you write may not be easily translated into some other language if needed.
But **into** means you thi... | The author provides an example of his own in that part of the book (which unfortunately I don't remember). You can try reading a bit further.
It means that even if the language doesn't support a particularly convenient feature, as you should always think of writing readable, easy to maintain, modular code, you should ... |
344,954 | I'm trying to switch over from USB power to external power if it's present. (External power is 6V to 13V). The current is 2A.
To do this I'm using diodes 1 and 3. See image below. ("OR" configuration.)
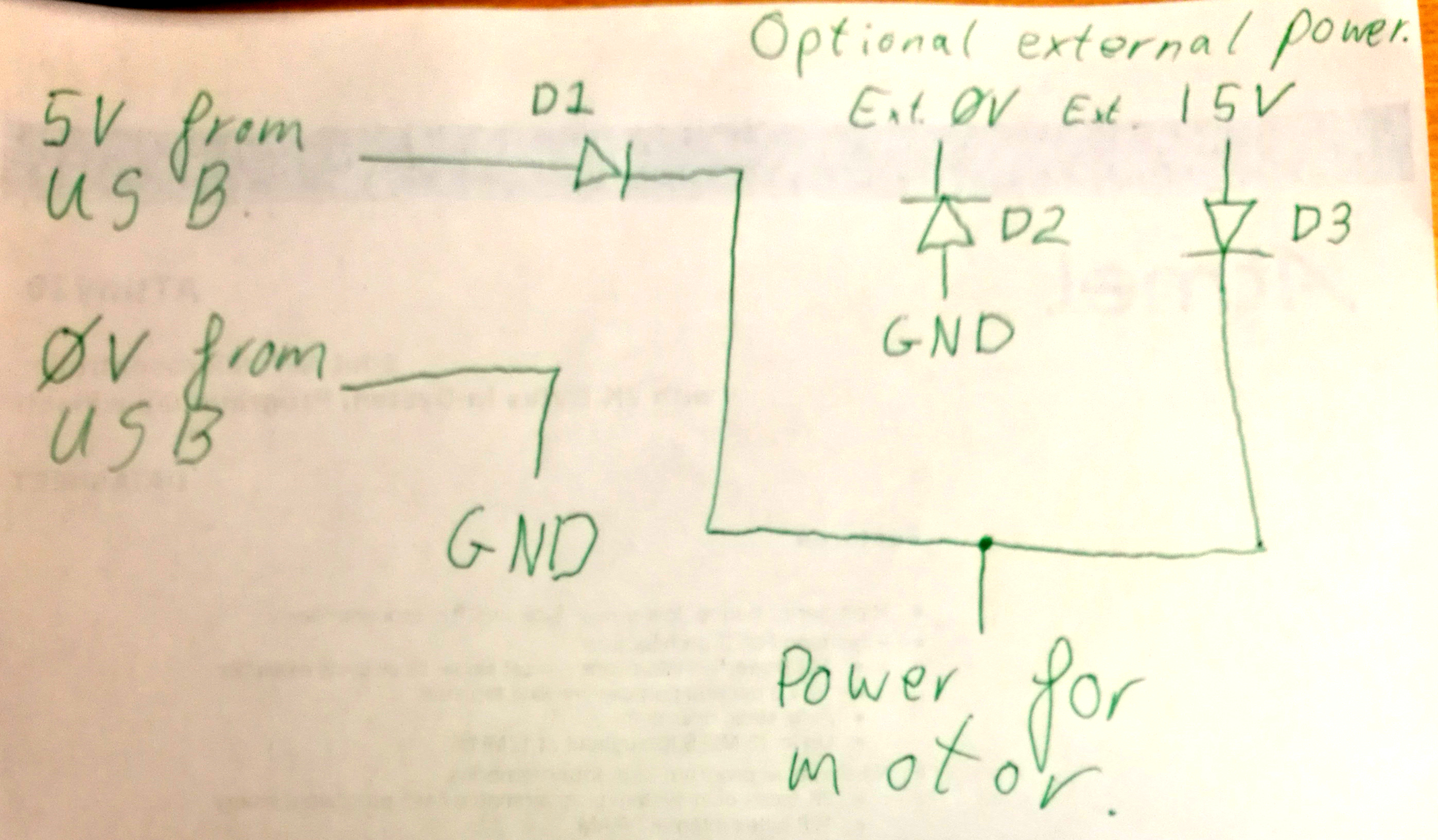
I'm then using diode 2 as reverse voltage protection in case t... | 2017/12/14 | [
"https://electronics.stackexchange.com/questions/344954",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/122765/"
] | That's right, your reverse protection chip uses an internal MOSFET to achieve lossless switching.
I seem to recall seeing a "drop-in replacement for a diode" kind of FET-based device, but I can't seem to find it now.
MOSFET's with dedicated secondary-side controllers are used for synchronous rectification in higher-e... | For D2 and D3, you should consider Schottky diodes. These have a significantly lower voltage drop than standard diodes, maybe 400 mV instead of 1 V at typical load current, so you'll lose a lot less power.
For D1, if the drop of a Schottky diode is still too high, the part you've linked to looks like a valid option - ... |
150,046 | I've got a small shaded pole motor (C-type) that I'm cannibalizing for use in a project, but the current RPM is too high. I don't want to spend the effort to build a micro-controller to run it.
Is there a way to easily change the RPM by making a relative change to the wound coil? For instance, it's currently running a... | 2015/01/20 | [
"https://electronics.stackexchange.com/questions/150046",
"https://electronics.stackexchange.com",
"https://electronics.stackexchange.com/users/64779/"
] | A shaded pole motor is a type of induction motor, just using some neat magnetic tricks to generate a second phase. It runs at slightly below synchronous speed, the slip depends on the torque.
For a simple 2 pole motor, you'd expect it to run at perhaps 90% of 3000 rpm (50 Hz countries), or 3600 rpm (60 Hz). This is wh... | Those answers are just mumbo-jumbo-babble. Just use a rheostat at 1000 ohms and plenty of amps ratings. Ohmite makes the best. A rheostat varies the current going through the motor. Research it and you'll see that I'm right. Not many people knows that. Laboratory stir plate are made with a shaded pole motor, a switch a... |
75,351 | <https://www.france24.com/en/live-news/20220909-ukraine-reconstruction-to-cost-349-bn-report>
>
> Rebuilding Ukraine following the devastation caused by the Russian
> invasion will cost an estimated $349 billion, according to a report
> issued Friday.
>
>
> But the figure, which totals 1.5 times the size of the Ukr... | 2022/09/09 | [
"https://politics.stackexchange.com/questions/75351",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/38301/"
] | **Legal from what perspective?**
International law consists of the assumption that states are [sovereign](https://en.wikipedia.org/wiki/Westphalian_sovereignty), and negotiated or customary rules between them. Just which customary rules are established enough to be [jus cogens](https://en.wikipedia.org/wiki/Peremptory... | **Yes**.
The only potential hurdle to it would be sovereign immunity. But **sovereign immunity can be removed with a legislation**. There are already laws which remove sovereign immunity to civil law suits.
The criteria for sovereign immunity are established in [Foreign Sovereign Immunities Act](https://en.wikipedia.... |
75,351 | <https://www.france24.com/en/live-news/20220909-ukraine-reconstruction-to-cost-349-bn-report>
>
> Rebuilding Ukraine following the devastation caused by the Russian
> invasion will cost an estimated $349 billion, according to a report
> issued Friday.
>
>
> But the figure, which totals 1.5 times the size of the Ukr... | 2022/09/09 | [
"https://politics.stackexchange.com/questions/75351",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/38301/"
] | Apparently a precedent for doing so (i.e. unlocking frozen Russian assets to use in the rebuilding of Ukraine) exists legally somewhere in the Iraqi 1990 invasion of Kuwait, according to Philip Zelikow at the University of Virginia. But I'm curious as to why it must be "the U.S." that facilitates this process. What, ar... | **Yes**.
The only potential hurdle to it would be sovereign immunity. But **sovereign immunity can be removed with a legislation**. There are already laws which remove sovereign immunity to civil law suits.
The criteria for sovereign immunity are established in [Foreign Sovereign Immunities Act](https://en.wikipedia.... |
75,351 | <https://www.france24.com/en/live-news/20220909-ukraine-reconstruction-to-cost-349-bn-report>
>
> Rebuilding Ukraine following the devastation caused by the Russian
> invasion will cost an estimated $349 billion, according to a report
> issued Friday.
>
>
> But the figure, which totals 1.5 times the size of the Ukr... | 2022/09/09 | [
"https://politics.stackexchange.com/questions/75351",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/38301/"
] | **Legal from what perspective?**
International law consists of the assumption that states are [sovereign](https://en.wikipedia.org/wiki/Westphalian_sovereignty), and negotiated or customary rules between them. Just which customary rules are established enough to be [jus cogens](https://en.wikipedia.org/wiki/Peremptory... | Apparently a precedent for doing so (i.e. unlocking frozen Russian assets to use in the rebuilding of Ukraine) exists legally somewhere in the Iraqi 1990 invasion of Kuwait, according to Philip Zelikow at the University of Virginia. But I'm curious as to why it must be "the U.S." that facilitates this process. What, ar... |
75,351 | <https://www.france24.com/en/live-news/20220909-ukraine-reconstruction-to-cost-349-bn-report>
>
> Rebuilding Ukraine following the devastation caused by the Russian
> invasion will cost an estimated $349 billion, according to a report
> issued Friday.
>
>
> But the figure, which totals 1.5 times the size of the Ukr... | 2022/09/09 | [
"https://politics.stackexchange.com/questions/75351",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/38301/"
] | **Legal from what perspective?**
International law consists of the assumption that states are [sovereign](https://en.wikipedia.org/wiki/Westphalian_sovereignty), and negotiated or customary rules between them. Just which customary rules are established enough to be [jus cogens](https://en.wikipedia.org/wiki/Peremptory... | The context matters.
If to ask "can and would USA just nationalize arbitrary foreign accounts for no reasons", the answer is likely no and all talks about "undermined trust" are relevant. But there is more than that in the context.
If I launch a rocket from my yard and destroy a house of my neighbor, it cannot be the... |
75,351 | <https://www.france24.com/en/live-news/20220909-ukraine-reconstruction-to-cost-349-bn-report>
>
> Rebuilding Ukraine following the devastation caused by the Russian
> invasion will cost an estimated $349 billion, according to a report
> issued Friday.
>
>
> But the figure, which totals 1.5 times the size of the Ukr... | 2022/09/09 | [
"https://politics.stackexchange.com/questions/75351",
"https://politics.stackexchange.com",
"https://politics.stackexchange.com/users/38301/"
] | Apparently a precedent for doing so (i.e. unlocking frozen Russian assets to use in the rebuilding of Ukraine) exists legally somewhere in the Iraqi 1990 invasion of Kuwait, according to Philip Zelikow at the University of Virginia. But I'm curious as to why it must be "the U.S." that facilitates this process. What, ar... | The context matters.
If to ask "can and would USA just nationalize arbitrary foreign accounts for no reasons", the answer is likely no and all talks about "undermined trust" are relevant. But there is more than that in the context.
If I launch a rocket from my yard and destroy a house of my neighbor, it cannot be the... |
77,515 | In general I have found that as the focal length of 35mm (or APS-C) lenses increases, the physical length of the lens increases as well. However, my large format lens is much thinner than other 35mm lenses of equivalent focal length. Here is a picture:
[](https://i.sta... | 2016/05/18 | [
"https://photo.stackexchange.com/questions/77515",
"https://photo.stackexchange.com",
"https://photo.stackexchange.com/users/36933/"
] | The focal length is the distance from the (theoretical) center of the lens to the image plane. On the large format camera, there's a lot more *camera* between the lens and the film.
The lenses are also often relatively simple — there's no need for a focusing mechanism in the lens itself, for example.
@osullic gives ... | A few points to consider (mostly adding to mattdm's answer):
A manually focusing 135mm Nikkor 2.8 lens in F mount is about 91.5mm long, and looking at a drawing of the lens most of the optical elements are in the front. So a comparison with a zoom lens isn't really fair -- it is a much more complicated lens.
Strictly... |
77,515 | In general I have found that as the focal length of 35mm (or APS-C) lenses increases, the physical length of the lens increases as well. However, my large format lens is much thinner than other 35mm lenses of equivalent focal length. Here is a picture:
[](https://i.sta... | 2016/05/18 | [
"https://photo.stackexchange.com/questions/77515",
"https://photo.stackexchange.com",
"https://photo.stackexchange.com/users/36933/"
] | The focal length is the distance from the (theoretical) center of the lens to the image plane. On the large format camera, there's a lot more *camera* between the lens and the film.
The lenses are also often relatively simple — there's no need for a focusing mechanism in the lens itself, for example.
@osullic gives ... | Take a look at these two Schneider lenses that both have 90mm focal length:


The first has coverage for "35mm" format, the second coverage for large format. I am not sure, but I think the main reason for the difference in size is the fac... |
77,515 | In general I have found that as the focal length of 35mm (or APS-C) lenses increases, the physical length of the lens increases as well. However, my large format lens is much thinner than other 35mm lenses of equivalent focal length. Here is a picture:
[](https://i.sta... | 2016/05/18 | [
"https://photo.stackexchange.com/questions/77515",
"https://photo.stackexchange.com",
"https://photo.stackexchange.com/users/36933/"
] | The focal length is the distance from the (theoretical) center of the lens to the image plane. On the large format camera, there's a lot more *camera* between the lens and the film.
The lenses are also often relatively simple — there's no need for a focusing mechanism in the lens itself, for example.
@osullic gives ... | The word lens is from the Latin, shaped like a lentil seed. This is a disk that bulges out of both sides, we call this lens shape, convex – convex. A single transparent convex – convex lens will do the deed. We task the camera lens to gather image forming light rays from a 3 dimensional world (object at different dista... |
77,515 | In general I have found that as the focal length of 35mm (or APS-C) lenses increases, the physical length of the lens increases as well. However, my large format lens is much thinner than other 35mm lenses of equivalent focal length. Here is a picture:
[](https://i.sta... | 2016/05/18 | [
"https://photo.stackexchange.com/questions/77515",
"https://photo.stackexchange.com",
"https://photo.stackexchange.com/users/36933/"
] | A few points to consider (mostly adding to mattdm's answer):
A manually focusing 135mm Nikkor 2.8 lens in F mount is about 91.5mm long, and looking at a drawing of the lens most of the optical elements are in the front. So a comparison with a zoom lens isn't really fair -- it is a much more complicated lens.
Strictly... | The word lens is from the Latin, shaped like a lentil seed. This is a disk that bulges out of both sides, we call this lens shape, convex – convex. A single transparent convex – convex lens will do the deed. We task the camera lens to gather image forming light rays from a 3 dimensional world (object at different dista... |
77,515 | In general I have found that as the focal length of 35mm (or APS-C) lenses increases, the physical length of the lens increases as well. However, my large format lens is much thinner than other 35mm lenses of equivalent focal length. Here is a picture:
[](https://i.sta... | 2016/05/18 | [
"https://photo.stackexchange.com/questions/77515",
"https://photo.stackexchange.com",
"https://photo.stackexchange.com/users/36933/"
] | Take a look at these two Schneider lenses that both have 90mm focal length:


The first has coverage for "35mm" format, the second coverage for large format. I am not sure, but I think the main reason for the difference in size is the fac... | The word lens is from the Latin, shaped like a lentil seed. This is a disk that bulges out of both sides, we call this lens shape, convex – convex. A single transparent convex – convex lens will do the deed. We task the camera lens to gather image forming light rays from a 3 dimensional world (object at different dista... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.