
id stringlengths 36 36 | source stringclasses 15
values | formatted_source stringclasses 13
values | text stringlengths 2 7.55M |
|---|---|---|---|
188184d6-4a59-4cd2-b11c-43d6dbe1987b | trentmkelly/LessWrong-43k | LessWrong | Repairing the Effort Asymmetry
Sometimes, you will say a thing!
You: "Proposition A."
A seems to you to be obviously true. It accords with your experience, doesn't violate any of the rules and laws of reality, makes sense with the rest of your model of the world. You'd like to move on from A to the actual more inter... |
9f294739-1b68-4ae2-b923-e038430103a9 | trentmkelly/LessWrong-43k | LessWrong | Progress links and short notes, 2025-03-03
Much of this content originated on social media. To follow news and announcements in a more timely fashion, follow me on Twitter, Notes, Farcaster, Bluesky, or Threads.
An occasional reminder: I write my blog/newsletter as part of my job running the Roots of Progress Institu... |
01ae85f1-91dc-46fc-83e4-b066a1e88767 | trentmkelly/LessWrong-43k | LessWrong | Rationality Research Report: Towards 10x OODA Looping?
6 months ago I wrote Feedbackloop-first Rationality. I didn't followup on it for awhile (except for sporadic Deliberate (“Purposeful?”) Practice Club).
I just spent 6 weeks actually exploring "how would I build my own cognition training program?". In the process ... |
d2184242-f240-43e9-a711-fab9411e7c05 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Birds, Brains, Planes, and AI: Against Appeals to the Complexity/Mysteriousness/Efficiency of the Brain
This is a linkpost for this [LW](https://www.lesswrong.com/posts/HhWhaSzQr6xmBki8F/birds-planes-brains-and-ai-against-appeals-to-the-complexity) / [alignmentforum](https://www.alignmentforum.org/posts/HhWhaSzQr6xmBk... |
ef458e93-ca5b-4f5c-882f-f1f124fde2e9 | trentmkelly/LessWrong-43k | LessWrong | 0oo.li: Financial Think Tank
First posted on Everything-List on June 2, 2020.
Hi Everyone,
while bright scientists and imaginative geeks continue to discuss advanced concepts at elusive locations of the Internet -- the remains of UseNet, and esoteric websites, the ideas shared there as plain text, no matter how brig... |
936aff37-34f9-4815-bab2-5fff55afd5eb | trentmkelly/LessWrong-43k | LessWrong | Some Comments on "Goodhart Taxonomy"
Some time ago, I mentioned in a comment some issues I had with the Goodhart Taxonomy:
> 1) “adversarial” seems too broad to be that useful as a category
> 2) It doesn’t clarify what phenomenon is meant by “Goodhart”; in particular, “regressional” doesn’t feel like something the o... |
3d96025e-e1f2-49ec-961c-22315bfeaa91 | trentmkelly/LessWrong-43k | LessWrong | Building selfless agents to avoid instrumental self-preservation.
Abstract:
Instrumental convergence pushes an agent toward self-preservation as a stepping stone toward maximizing some objective. I suggest that it is possible to turn any arbitrary intelligent agent based on an LLM world model into a selfless agent, an... |
7bdf7d09-4439-4e7a-a336-3c97846a8156 | StampyAI/alignment-research-dataset/special_docs | Other | Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small
Published as a conference paper at ICLR 2023
INTERPRETABILITY IN THE WILD:ACIRCUIT FOR
INDIRECT OBJECT IDENTIFICATION IN GPT-2 SMALL
Kevin Wang∗, Alexandre Variengien*, Arthur Conmy*, Buck Shlegeris†, Jacob Steinhardt†‡§
†Redwood... |
8caf04a7-4dcd-454c-a01f-c2bf17d27317 | trentmkelly/LessWrong-43k | LessWrong | Physics is Ultimately Subjective
N.B. A basic and perhaps obvious point that nonetheless I think people get confused about. Despite the somewhat provocative title, my goal is not to say anything new to the average Less Wrong reader, only to emphasize a point and try to explain it so that it can be clearly seen.
Summa... |
8cffc4c4-2875-427f-b94e-df8c315223f8 | trentmkelly/LessWrong-43k | LessWrong | FLI Podcast: The Precipice: Existential Risk and the Future of Humanity with Toby Ord
Toby Ord’s “The Precipice: Existential Risk and the Future of Humanity" has emerged as a new cornerstone text in the field of existential risk. The book presents the foundations and recent developments of this budding field from an a... |
c6a01977-c007-4f5d-9114-34ea5eea4e3d | trentmkelly/LessWrong-43k | LessWrong | Does evolution select for mortality?
At a recent Reddit AMA, Eric Lander, a professor of biology who played an important part in the Human Genome Project, answered this question:
> Do you think immortatility is technically possible for human beings?
His response:
> I don't think immortality is technically possible ... |
f60c008f-3df4-4832-9ad7-309a5e6dfbdc | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | What is Infra-Bayesianism?
[Infra-Bayesianism](https://www.alignmentforum.org/s/CmrW8fCmSLK7E25sa) tries to solve the problem of [agent foundations](/?state=7782&question=What%20is%20%22agent%20foundations%22%3F). On a high level, we want to have a model of an agent, understand what it means for it to be aligned with ... |
b8427561-893a-404d-81be-51fadb6201bc | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Lessons learned and review of the AI Safety Nudge Competition
**TL;DR: We ran a competition to encourage people to stop procrastinating on their AI Safety projects. We had 76 applicants out of which over 40% (31 participants) completed their goal by the end of October and were added to a draw to win a monetary prize. ... |
cfc66d23-28ba-497d-a1ad-5c7e9d920972 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | S-Curves for Trend Forecasting
**Epistemic Status**: Innovation research and business research is notoriously low quality, and so all the ideas here should be viewed through that lense. What's impressive about the S-curve and evolution trends literature is how remarkably self-consistent it is using a wide variety of r... |
f1c7fcd8-521b-4754-9fd3-e02c609f3486 | trentmkelly/LessWrong-43k | LessWrong | Doxa, Episteme, and Gnosis Revisited
Exactly two years to the day I started writing this post I published Map and Territory's most popular post of all time, "Doxa, Episteme, and Gnosis" (also here on LW). In that post I describe a distinction ancient Greek made between three kinds of knowledge we might translate as he... |
1bb174b3-80b1-4881-a427-794da9254778 | trentmkelly/LessWrong-43k | LessWrong |
Austin meetup notes Nov. 16, 2019: SSC discussion
The following is a writeup (pursuant to Mingyuan's proposal) of the discussion at the Austin LW/SSC Meetup on November 16, 2019, at which we discussed six different SlateStarCodex articles. We meet every Saturday at 1:30pm - if you're in the area, come join us!
You a... |
fe499dc0-5696-4331-a955-a5a8af84b16a | trentmkelly/LessWrong-43k | LessWrong | Rules of productivity (mostly links)
Rules of productivity-- summarizes research showing that overtime is destructive (except possibly in short bursts with time allowed for recovery), small undistracted teams do best, etc. Perhaps the most interesting detail for rationality is the idea that tired people can't judge ho... |
bd672a79-1c3b-4be2-9a15-8734344e0d44 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Why We Use Money? - A Walrasian View
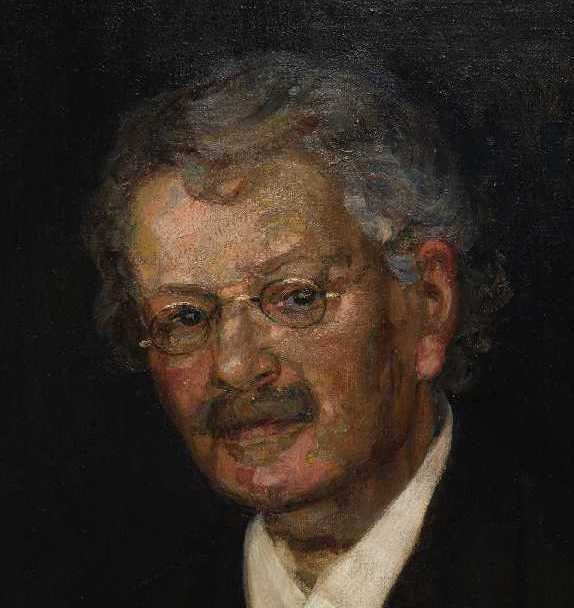Knut Wicksell (1851-1926)
> **“Money is a machine whose function is to do quickly and conveniently what would be done, though le... |
01db6b12-0fba-4710-b761-353635af0329 | trentmkelly/LessWrong-43k | LessWrong | Information Markets 2: Optimally Shaped Reward Bets
Sequel to Information Markets, which contains a long text outline of what I consider to be the correct alternative to Prediction Markets, which I don't like for a long list of reasons.
This post is intended to fill in the gap in the original regarding what an ideall... |
99bf6524-af29-498c-8b63-9f442ba711ea | trentmkelly/LessWrong-43k | LessWrong | Panel discussion on AI consciousness with Rob Long and Jeff Sebo
Intro
Recent 80k guest and philosopher specializing in AI consciousness Rob Long (@rgb) recently participated in a panel discussion on his paper "Consciousness in Artificial Intelligence: Insights from the Science of Consciousness" (pdf) with co-authors ... |
10de1785-9fdc-4f59-84a6-b20c82f20bf2 | StampyAI/alignment-research-dataset/special_docs | Other | Reducing long-term risks from malevolent actors
Reducing long-term risks from malevolent actors
===============================================
7 July 2020
by [David Althaus](https://longtermrisk.org/author/david-althaus/ "Posts by David Althaus") and [Tobias Baumann](https://longtermrisk.org/author/tobias-baumann/... |
0d6890f5-8ecc-4c7d-946f-e62de7a744c7 | trentmkelly/LessWrong-43k | LessWrong | Given the Restrict Act, Don’t Ban TikTok
While others have already written similar posts, given my previous position it seems necessary for me to do so as well – the Restrict Act is a no good very bad bill, and having seen the bill I realize that I was wrong to support banning TikTok.
For a while I have been in favor... |
edc66493-9fec-494b-92d5-51623d2b7a32 | trentmkelly/LessWrong-43k | LessWrong | How much white collar work could be automated using existing ML models?
Assume that progress in AI halts right now and only the currently published breakthroughs are available. GPT-3, PaLM, Flamingo for text generation and Imagen, Dall-E 2 for image generation.
Let's say these models all become available via paid AP... |
5d7fb0d1-b396-476e-8f59-d0a4c5277bee | trentmkelly/LessWrong-43k | LessWrong | Populectomy.ai
A long-form iteration of my "AI will lead to massive violent population reduction" argument: https://populectomy.ai
The host name, populectomy, is my attempt at naming the described outcome, a name that I hope to be workable (sufficiently evocative and pithy, without being glib). Otherwise I'm out 150 ... |
0efdad66-a1e0-4398-bea8-b509195623fb | trentmkelly/LessWrong-43k | LessWrong | Which is the the article that describes drawing the map of the city?
I've searched a few related terms in Less Wrong, and I can't seem to find the article I'm looking for. It's an Eliezer post that describes a process of drawing a map of a city, and how you can't do it with the blinds closed, you have to actually go o... |
d9f27eec-5456-4e4a-a65a-d14262b1c60e | trentmkelly/LessWrong-43k | LessWrong | New York Meetup
I’ll be in New York City this Tuesday evening 7-11p, at 60 West 23rd Street, Apt. 904. Robin Hanson of Overcoming Bias and Eliezer Yudkowsky of LessWrong will also be there. Please join us!
|
9a3bc814-4cdb-4b0d-888e-97e7eabf4a1b | trentmkelly/LessWrong-43k | LessWrong | Inner Alignment via Superpowers
Produced As Part Of The SERI ML Alignment Theory Scholars Program 2022 Under John Wentworth
The Problem
When we train RL agents, they have many opportunities to see what makes actions useful (they have to locate obstacles, navigate around walls, navigate through narrow openings etc.) ... |
48f48840-7fd3-4d25-a540-02498b267f87 | trentmkelly/LessWrong-43k | LessWrong | Distillation Experiment: Chunk-Knitting
Summary
Here, I show the output of a protocol to break down information that exceeds typical working memory limits into chunks. The goal is to enhance understanding at first reading, both for the person breaking down the information and for the person reading the result. The ori... |
584ea1f4-3c43-402e-9867-f1fbea5b8f25 | trentmkelly/LessWrong-43k | LessWrong | Reflections on a no content January 2020 experiment
In January 2020 I did a zero content life. This was partly justified by the book “the info diet” but mostly based on a philosophy that proposes,
> in a lifetime with limited hours, there is a choice to either consume or create. And I’d rather create than consume.
T... |
c0285c0e-bec2-421e-8252-1133550f6450 | trentmkelly/LessWrong-43k | LessWrong | Be careful with thought experiments
Thagard (2012) contains a nicely compact passage on thought experiments:
> Grisdale’s (2010) discussion of modern conceptions of water refutes a highly influential thought experiment that the meaning of water is largely a matter of reference to the world rather than mental represen... |
dda5a779-70ff-4d65-8f22-0d43de8f661d | trentmkelly/LessWrong-43k | LessWrong | What should you change in response to an "emergency"? And AI risk
This post has been recorded as part of the LessWrong Curated Podcast, and can be listened to on Spotify, Apple Podcasts, and Libsyn.
----------------------------------------
Related to: Slack gives you the ability to notice/reflect on subtle things
E... |
f3938f55-b711-4400-ab7d-991af04115a1 | trentmkelly/LessWrong-43k | LessWrong | Links for Feb 2021
Note: some of the formatting was lost, see substack for full experience
Favorites:
https://amp.cnn.com/cnn/2021/02/19/health/what-is-simp-teen-slang-wellness/index.html I’ve finally gotten a third article in my collection of classic Gen Z journalism. For reference, here are the first two articles ... |
e3ffd64c-812f-448d-aef9-8c3a512787d8 | trentmkelly/LessWrong-43k | LessWrong | [Intuitive self-models] 7. Hearing Voices, and Other Hallucinations
7.1 Post summary / Table of contents
Part of the Intuitive Self-Models series.
The main thrust of this post is an opinionated discussion of the book The Origin of Consciousness in the Breakdown of the Bicameral Mind by Julian Jaynes (1976) in §7.4, a... |
107d68c9-da31-460c-9177-caced35cbedf | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Stackelberg Games and Cooperative Commitment: My Thoughts and Reflections on a 2-Month Research Project
*Over the past two months I have been lucky enough to carry out a part-time research project as part of* [*this*](https://forum.effectivealtruism.org/posts/dKgWZ8GMNkXfRwjqH/seeking-social-science-students-collabora... |
3592dbff-41b9-44f3-b476-1e5759b47953 | StampyAI/alignment-research-dataset/special_docs | Other | AI Governance and the Policymaking Process: Key Considerations for Reducing AI Risk
Abstract
--------
\*\*:\*\*
This essay argues that a new subfield of AI governance should be explored that examines the policy-making process and its implications for AI governance. A growing number of researchers have begun working o... |
f489cc4b-5696-4b24-a5ef-0f433ff8c4ae | trentmkelly/LessWrong-43k | LessWrong | Net Utility and Planetary Biocide
I've started listening to the audiobook of Peter Singer's Ethics in the Real World, which is both highly recommended and very unsettling. The essays on non-human animals, for example, made me realize for the first time that it may well be possible that the net utility on Earth over al... |
1f0cd1f1-ea07-4a47-883f-10b747467e91 | trentmkelly/LessWrong-43k | LessWrong | Ukraine Post #1: Prediction Markets
I am working on seeing how comprehensively I can cover and discuss the war, but that takes time and the speed premium is super high. I decided to start here, and write quickly. Apologies in advance for any mistakes, oversights, dumbness, and so on.
While I strive to provide suffici... |
b1de0490-1e0d-462d-bf99-132e715e32fe | trentmkelly/LessWrong-43k | LessWrong | Meetup : First San Diego, CA, USA meetup
Discussion article for the meetup : First San Diego, CA, USA meetup
WHEN: 31 July 2011 01:00:00PM (-0700)
WHERE: 6380 Del Cerro Blvd. San Diego, CA 92120
We're holding what I believe is the first San Diego meetup on Sunday, July 31st starting at 1pm at the K&B Wine Cellars n... |
30ed8403-2985-4654-b88b-2d33346fc721 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Israel (Tel Aviv) Meetup: Fun and Games with Cognitive Biases
Discussion article for the meetup : Israel (Tel Aviv) Meetup: Fun and Games with Cognitive Biases
WHEN: 01 August 2013 08:00:00PM (+0300)
WHERE: Adventures Garden (Gan Harpatkaot), Tel Aviv, Israel
This meetup is going to be about Cognitive Bias... |
27b87319-c3bb-46c7-bf67-95f0375b5b1b | trentmkelly/LessWrong-43k | LessWrong | EY "Politics is the Mind Killer" sighting at Washington Examiner and Reason.com
Original at Washington Examiner
http://washingtonexaminer.com/down-with-politics/article/2508882#.UGSscI0iYZm
> ...
>
> Politics makes us worse because "politics is the mindkiller," as intelligence theorist Eliezer Yudkowsky puts it. "E... |
e8eece3f-215a-4a17-aa73-05b4328a1c85 | trentmkelly/LessWrong-43k | LessWrong | Thoughts on the Drake Equation and the Great Filter
I was originally going to post this as a comment into the UFAI & great filter thread, but since I noticed that my comment didn't include a single word of AIs I thought about making an entire new discussion thread and I continued writing to improve the quality from co... |
5e6ac143-d2ba-44a5-8fdb-5ff1c1b89eb1 | trentmkelly/LessWrong-43k | LessWrong | So You Want to Colonize The Universe Part 5: The Actual Design
Alright, here's the actual design for an intergalactic mission to the Virgo Supercluster.
(1, 2, 3, 4)
----------------------------------------
Phase 1: Acceleration
To begin with, you use really big lightsails and exawatt dyson-swarm-powered laser arr... |
199aa52b-aa0f-46ef-aea5-399f0b831673 | trentmkelly/LessWrong-43k | LessWrong | Conjunction Controversy (Or, How They Nail It Down)
Followup to: Conjunction Fallacy
When a single experiment seems to show that subjects are guilty of some horrifying sinful bias - such as thinking that the proposition "Bill is an accountant who plays jazz" has a higher probability than "Bill is an accountant" - pe... |
b0f81848-ede6-4db9-b7d1-3d2f02c3d26a | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Alignment via prosocial brain algorithms
In this post, I want to briefly propose a semi-novel direction for alignment research that I'm excited about. Though some of these ideas are not brand new—they purposefully bear resemblance to recent (highly promising) work in [SHARD theory](https://www.lesswrong.com/posts/xqkG... |
5e67e6ed-879b-47d4-a2e7-034f0f7be3e2 | trentmkelly/LessWrong-43k | LessWrong | What's up with "Responsible Scaling Policies"?
habryka
I am interested in talking about whether RSPs are good or bad. I feel pretty confused about it, and would appreciate going in-depth with someone on this.
My current feelings about RSPs are roughly shaped like the following:
I feel somewhat hyper-alert and a bit... |
861792ec-9d15-45cf-999f-58fc83461d09 | trentmkelly/LessWrong-43k | LessWrong | Newcomb's problem happened to me
Okay, maybe not me, but someone I know, and that's what the title would be if he wrote it. Newcomb's problem and Kavka's toxin puzzle are more than just curiosities. Like a lot of thought experiments, they approximately happen. They make the issues with causal decision theory releva... |
568c88b9-6caf-4021-8cce-0e4bf026abcf | trentmkelly/LessWrong-43k | LessWrong | More stuff
A few more bits I liked in The Stuff of Thought:
Hypernyms elevate
Labeling someone with a small aspect of what they are – a trait or part – undignifies them. Calling someone a cripple, the blonde, a suit, isn’t nice. The opposite works too often – things sound more dignified if you label them with a lar... |
449e35d4-94cb-43fe-9331-5155c0980d27 | trentmkelly/LessWrong-43k | LessWrong | Exercising Rationality
Or: Why thinking about blue tentacle arms is not always a waste of time.
0. Introduction
As I work through the Sequences, I find myself disagreeing—slightly—with a point Eliezer Yudkowsky makes in A Technical Explanation of Technical Explanation:
> Imagine that you wake up one morning and you... |
8902c873-237e-41ac-a8ea-dca5fd608519 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Guardians of the Truth
Today's post, Guardians of the Truth was originally published on 15 December 2007. A summary (taken from the LW wiki):
> There is an enormous psychological difference between believing that you absolutely, certainly, have the truth, versus trying to discover the truth. If you bel... |
67ecf2a7-2bc6-4a10-8ceb-76c73a10461d | trentmkelly/LessWrong-43k | LessWrong | AI, Alignment & the Art of Relationship Design
We don’t always know what we’re looking for until we stop looking for what we are told to want.
When I worked as a relationship coach, most people came to me with a list. A neat, itemised checklist of traits their future partner must have. Tall. Intelligent. Ambitious. S... |
3c63a045-c33a-4c78-8e2c-e2a20100279d | trentmkelly/LessWrong-43k | LessWrong | Avoiding the Bog of Moral Hazard for AI
Imagine if you will, a map of a landscape. On this map, I will draw some vague regions. Their boundaries are uncertain, for it is a new and under-explored land. This map is drawn as a graph, but I want to emphasize that the regions are vague guesses, and the true borders could b... |
da886161-84df-4407-99ea-16aa272b0ce6 | trentmkelly/LessWrong-43k | LessWrong | April 2021 Deep Dive: Transformers and GPT-3
Introduction
I know very little about a staggering number of topics that would be incredibly useful for my research and/or navigating the field. Part of the problem is the sheer number of choices -- I can't make myself study one thing very long because I always feel like I ... |
e7cf989b-3052-43ea-a69e-0fefc44aaec3 | trentmkelly/LessWrong-43k | LessWrong | Logical Proof for the Emergence and Substrate Independence of Sentience
Sentience is the capacity to experience anything – the fact that when your brain is thinking or processing visual information, you actually feel what it’s like to think and to see.
The following thought experiment demonstrates, step by step, why ... |
24a04282-6ce8-4f86-91ca-4b599cd996fa | trentmkelly/LessWrong-43k | LessWrong | Beer with Charlie Stross in Munich
From Charlie Stross' blog:
> I'm in Munich this week, and I plan to be drinking in the Paulaner Brauhaus(Kapuzinerplatz 5, 80337 München; click here for map) from 7pm on Monday 18th. All welcome! (Yes, I will sign books if you bring them.) If in doubt, look for the plush Cthulhu! |
01545ab2-6d73-4016-9553-24d808605325 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Is there a 'time series forecasting' equivalent of AIXI?
In the way that AIXI is an abstracted mathematical formalism for (very roughly) "*a program that maximizes the expected total rewards received from the environment*", what is the equivalent formalism for an abstracted next token predictor?
Does this exist in th... |
5eec5b61-92f3-4a3f-a4d3-e90ded3e9803 | StampyAI/alignment-research-dataset/special_docs | Other | Planning for Autonomous Cars that Leverage Effects on Human Actions.
Planning for Autonomous Cars
that Leverage Effects on Human Actions
Dorsa Sadigh, Shankar Sastry, Sanjit A. Seshia, and Anca D. Dragan
University of California, Berkeley, {dsadigh, sastry, sseshia, anca}@eecs.berkeley.edu
Abstract —Traditionally, aut... |
89bb064a-b615-4c7f-b2d4-f98ed2553a39 | trentmkelly/LessWrong-43k | LessWrong | AI printing the utility value it's maximising
A putative new idea for AI control; index here.
The utility function mentioned here is somewhat peculiar; see here.
Paul Christiano asked whether we could get an agent to print out the expectation of the utility that it was currently maximising. As I'm always eager to pl... |
958374db-366c-47fd-bbc5-9bbe7bc4a5c3 | trentmkelly/LessWrong-43k | LessWrong | Ways to do advanced tag filtering
Note: All the posts I have found so far describing the tag filtering system are clearly out of date, so I would appreciate a good description of its features in general, preferably one that includes illustrative screenshots, whether or not it answers my specific questions. This would ... |
1330f878-bbf1-4598-99f9-b64d9dfa06f8 | trentmkelly/LessWrong-43k | LessWrong | The greater a technology’s complexity, the more slowly it improves?
> A new study by researchers at MIT and other institutions shows that it may be possible to predict which technologies are likeliest to advance rapidly, and therefore may be worth more investment in research and resources.
>
> The researchers found t... |
d5456441-3f45-44f8-8a22-32acd94973c9 | trentmkelly/LessWrong-43k | LessWrong | Some Remarks on the Nature of Political Conflict
[Part of the debate around: Conflict Vs. Mistake]
[Criticizing articles like: In defence of conflict theory, Conservatives As Moral Mutants (part of me feels like the link is self-trigger-warning, but I guess I will just warn you that this is not a clever attention-gra... |
a7d93be0-c6fd-44ae-8328-f0236bb2a12d | trentmkelly/LessWrong-43k | LessWrong | Greyed Out Options
Imagine that life is a choose-your-own adventure game.
In any moment, you have literally millions of options. At the moment I’m typing this, I could change the tab to innumerable websites, I could read any of the hundreds of books in my house, I could make myself a snack of olives, I could stand up... |
90a0fa1c-9b88-4382-b1c6-3cec91e7eb61 | trentmkelly/LessWrong-43k | LessWrong | Dishbrain and implications.
I believe that AI research has not given sufficient attention to learning directly from biology, particularly through the direct observation and manipulation of neurons in controlled environments. Furthermore, even after learning all that biology has to offer, neurons could still play a pa... |
1f8460fa-b3b7-47ab-97e2-a75605207666 | trentmkelly/LessWrong-43k | LessWrong | We learn long-lasting strategies to protect ourselves from danger and rejection
Take a second to imagine what being a child was like throughout most of human history. You were born with a huge and underdeveloped brain, designed for soaking in information from your surroundings like a sponge. But you weren’t able to fr... |
8d6ff0bf-d925-4e96-b7ac-ae02ef0e19b6 | trentmkelly/LessWrong-43k | LessWrong | Riffing on the agent type
Much is owed to Diffractor for Giry-pilling me at Alignable Structures, I had been struggling with type-driven expected value previously.
Epistemic status: took a couple days off from my master plan to think about John's selection theorems call to action.
We would like a type signature of a... |
ec053429-5801-4a66-8f89-13cc32dce432 | awestover/filtering-for-misalignment | Redwood Research: Alek's Filtering Results | id: post2571
Counterfactual planning is a design approach for creating a range of
safety mechanisms that can be applied in hypothetical future AI
systems which have Artificial General Intelligence. My new paper Counterfactual Planning in AGI Systems introduces this design approach in full.
It also constructs several e... |
48a1f52b-5a2d-4794-8009-07beec7e2416 | trentmkelly/LessWrong-43k | LessWrong | Decision theory and "winning"
With much help from crazy88, I'm still developing my Decision Theory FAQ. Here's the current section on Decision Theory and "Winning". I feel pretty uncertain about it, so I'm posting it here for feedback. (In the FAQ, CDT and EDT and TDT and Newcomblike problems have already been explain... |
4ef9ce72-8622-4c2b-9f52-5406ee91f76e | trentmkelly/LessWrong-43k | LessWrong | I'd take it
Out-of-context quote of the day:
> "...although even $10 trillion isn't a huge amount of money..."
From Simon Johnson, Director of the IMF's Research Department, on "The Rise of Sovereign Wealth Funds".
So if you had $10 trillion, what would you do with it? |
20d411fc-4657-41a3-a16c-f8539caab53f | trentmkelly/LessWrong-43k | LessWrong | That Thing That Happened
I am emotionally excited and/or deeply hurt by what st_rev wrote recently. You better take me seriously because you've spent a lot of time reading my posts already and feel invested in our common tribe. Anecdote about how people are tribal thinkers.
> That thing that happened shows that every... |
6ddac8e0-777c-48ab-9c05-15f2434f5bd2 | trentmkelly/LessWrong-43k | LessWrong | Two senses of “optimizer”
The word “optimizer” can be used in at least two different ways.
First, a system can be an “optimizer” in the sense that it is solving a computational optimization problem. A computer running a linear program solver, a SAT-solver, or gradient descent, would be an example of a system that is ... |
55052d11-948a-4dda-830d-b24211ce5fe3 | trentmkelly/LessWrong-43k | LessWrong | Traditional Capitalist Values
Followup to: Are Your Enemies Innately Evil?, Policy Debates Should Not Appear One-Sided
> "The financial crisis is not the crisis of capitalism. It is the crisis of a system that has distanced itself from the most fundamental values of capitalism, which betrayed the spirit of capitali... |
c6ac49f0-91c7-4ba7-a522-bc2c15df0045 | trentmkelly/LessWrong-43k | LessWrong | Rough Sketch for Product to Enhance Citizen Participation in Politics
For politics and governance in the US, does there exist a tool that:
* Prompts the user to enter their rough location (e.g., town, county, state)
* Prompts the user to select interest keywords (e.g., housing, animal welfare, cannabis)
* Lists p... |
dce0b47a-9d38-477b-a828-bc76cfad555c | trentmkelly/LessWrong-43k | LessWrong | The Slack Double Crux, or how to negotiate with yourself
This is a post mostly about Slack. Slack in the sense of Zvi, Slack as the freedom to not be bound by an obligation to have to do anything. Slack is generally accepted to be good and worth pursuing. This post is about the phenomenon of actions which increase Sla... |
af6e8500-b225-49df-b553-d3513d08e6af | trentmkelly/LessWrong-43k | LessWrong | Crowley on Religious Experience
Reply to: The Sacred Mundane, BHTV: Yudkowsky vs. Frank on "Religious Experience"
Edward Crowley was a man of many talents. He studied chemistry at Cambridge - a period to which he later attributed his skeptical scientific outlook - but he soon abandoned the idea of a career in science... |
2f6f2451-b0fb-477d-9ed9-f82946df44c4 | StampyAI/alignment-research-dataset/arbital | Arbital | Subspace
A subspace $U=(F_U, V_U)$ of a [https://arbital.com/p/3w0](https://arbital.com/p/3w0) $W=(F_W, V_W)$ is a vector space where $F_U = F_W$ and $V_U$ is a [https://arbital.com/p/subgroup](https://arbital.com/p/subgroup) of $V_W,$ and $V_U$ is [closed](https://arbital.com/p/) under scalar multiplication. |
ffe19e01-5687-4df2-9593-74bce2ff6f0f | trentmkelly/LessWrong-43k | LessWrong | We must be very clear: fraud in the service of effective altruism is unacceptable
I care deeply about the future of humanity—more so than I care about anything else in the world. And I believe that Sam and others at FTX shared that care for the world.
Nevertheless, if some hypothetical person had come to me several y... |
c252e03a-c3ca-495a-8f17-9329defcd645 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Approval-directed bootstrapping
Approval-directed behavior works best when the overseer is very smart. Where can we find a smart overseer?
One approach is *bootstrapping*. By thinking for a long time, a weak agent can oversee an agent (slightly) smarter than itself. Now we have a slightly smarter agent, who can overs... |
8aad11eb-a610-436d-ae1d-5d2510a17c97 | trentmkelly/LessWrong-43k | LessWrong | Humans interpreting humans
In a previous post, I showed how, given certain normative assumptions, one could distinguish agents H for whom anchoring was a bias, from those H′ for which it was a preference.
But agent H′ looks clearly ridiculous - how could anchoring be a bias, it makes no sense. And I agree with that a... |
a0077975-55a4-431b-a534-dbd07bd96ade | trentmkelly/LessWrong-43k | LessWrong | Book Recommendations for social skill development?
I have come to a realisation a bit later than I should have. Although I am still quite young and definitely have time to act on this realisation now, I wish I had started sooner.
I am studying to become a teacher, and I hope to go into education policy later, with qu... |
78a54f00-f58a-4361-b12c-e1f7c32ca1b7 | trentmkelly/LessWrong-43k | LessWrong | Defining causal isomorphism
I previously posted this question in another discussion, but it didn't get any replies so, since I now have enough karma, I've decided to make it my first "article".
> This brings up something that has been on my mind for a long time. What are the necessary and sufficient conditions for t... |
b63caf85-df5d-43e9-9b50-cbfee10b5e32 | trentmkelly/LessWrong-43k | LessWrong | Gates 2017 Annual letter
|
ad3b7c3f-660c-40ec-a7e2-5266e259ed17 | trentmkelly/LessWrong-43k | LessWrong | Lightcone Infrastructure/LessWrong is looking for funding
Lightcone Infrastructure is looking for funding and are working on the following projects:
* We run LessWrong, the AI Alignment Forum, and have written a lot of the code behind the Effective Altruism Forum.
* During 2022 and early 2023 we ran the Lightcone ... |
70ec5820-0e0f-49f6-83d1-9c692d37e909 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Against Instrumental Convergence
[Instrumental convergence](https://arbital.com/p/instrumental_convergence/) is the idea that every sufficiently intelligent agent would exhibit behaviors such as self preservation or acquiring resources. This is a natural result for maximizers of simple utility functions. However I cla... |
56569a53-a13e-4cf7-855c-c5f2d6c6b02d | trentmkelly/LessWrong-43k | LessWrong | You can be wrong about what you like, and you often are
Meta: I'm not saying anything new here. There has been a lot of research on the topic, and popular books like Stumbling on Happiness have been written. Furthermore, I don't think I have explained any of this particularly well, or provided particularly enlightenin... |
a24489d5-2cf1-47a5-bb68-23036759f0be | StampyAI/alignment-research-dataset/lesswrong | LessWrong | How I Lost 100 Pounds Using TDT
Background Information: [Ingredients of Timeless Decision Theory](/lw/15z/ingredients_of_timeless_decision_theory/)
Alternate Approaches Include: [Self-empathy as a source of “willpower”](/lw/2yd/selfempathy_as_a_source_of_willpower/), [Applied Picoeconomics](/lw/ep/applied_picoeconom... |
766b1014-2b21-48a4-b8b5-12dc47191f52 | trentmkelly/LessWrong-43k | LessWrong | Neural Nets in Python 1
Introduction
This post is an attempt to explain how to write a neural network in Python using numpy. I am obviously not the first person to do this. Almost all of the code is here adapted from Michael Nielsen's fantastic online book Neural Networks and Deep Learning . Victor Zhou also has a gr... |
dfac2702-4c11-4b7c-b587-79635a50f90f | trentmkelly/LessWrong-43k | LessWrong | The Gunas: A Model for Mental States
|
fb05c16e-75e4-4609-b957-821b0c9b9900 | trentmkelly/LessWrong-43k | LessWrong | "Publish or Perish" (a quick note on why you should try to make your work legible to existing academic communities)
This is a brief, stylized recounting of a few conversations I had at some point last year with people from the non-academic AI safety community:[1]
Me: you guys should write up your work properly and t... |
e5a1bcba-91b3-4f68-bd9c-a7373caab3eb | trentmkelly/LessWrong-43k | LessWrong | Safe probability manipulation, superweapons, and stable self-improvement research
When I first discovered that even UDT would fail on certain "fair" problems (via "Evil" decision problems in provability logic), I was disappointed. It seemed to make things harder, in that there was no ideal decision theory, even on "fa... |
fbc0002b-9db5-4eef-aff6-c3814fa12c34 | trentmkelly/LessWrong-43k | LessWrong | Welcome to Norfolk Rationalists [Hampton Roads, Virginia]
Hi!
The meetups I organize are open to all, and unless mentioned otherwise are focused on building a social group and community in the area. You do not need special skills nor background familiarity to attend these meetups, if it seems like something you'd be ... |
d6b94a81-e1b4-4fc8-afad-b03c78da2d44 | trentmkelly/LessWrong-43k | LessWrong | AI #15: The Principle of Charity
The sky is not blue. Not today, not in New York City. At least it’s now mostly white, yesterday it was orange. Even indoors, everyone is coughing and our heads don’t feel right. I can’t think fully straight. Life comes at you fast.
Thus, I’m going with what I have, and then mostly tak... |
8f1f8175-5f59-484a-bba4-f3534faabaa6 | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | What is inner alignment?
<iframe src="https://www.youtube.com/embed/bJLcIBixGj8" title="The OTHER AI Alignment Problem: Mesa-Optimizers and Inner Alignment" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
Inner align... |
542471c8-3510-48eb-beba-a4337b06449a | trentmkelly/LessWrong-43k | LessWrong | Critical Thinking in Medicine
This is a book review of Cognitive Errors and Diagnostic Mistakes.
though i haven't read the book, it seems very interesting and i think many others here will find it interesting.
Here's the description of the article:
> Cognitive Errors and Diagnostic Mistakes is a superb new guide t... |
20093512-70b2-44d7-8647-2413bb8d8c99 | trentmkelly/LessWrong-43k | LessWrong | Cultural accumulation
Crossposted from world spirit sock puppet.
When I think of humans being so smart due to ‘cultural accumulation’, I think of lots of tiny innovations in thought and technology being made by different people, and added to the interpersonal currents of culture that wash into each person’s brain, le... |
d9590f1c-0f33-4325-bd33-c545023a4047 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Where Recursive Justification Hits Bottom
Today's post, Where Recursive Justification Hits Bottom was originally published on 08 July 2008. A summary (taken from the LW wiki):
> Ultimately, when you reflect on how your mind operates, and consider questions like "why does occam's razor work?" and "why d... |
adab88cf-ad30-4a75-aa72-8c5945d070af | trentmkelly/LessWrong-43k | LessWrong | Discord Server Emoji: A Community Dialect
I — Background
Discord is a popular online chat platform, that started as a tool for video game players to communicate. It acted as a replacement for other preexisting tools like Teamspeak. However, in a relatively short time the combination of powerful moderation tools, easy... |
e9205a1d-9bc7-4109-9144-9540942301a2 | trentmkelly/LessWrong-43k | LessWrong | understanding bureaucracy
Successful organizations maximize the formula shown below:
Meaningful OutputResources Spent
* Meaningful output: meaningful output is any output aligned with the organization’s purpose. For example, Feed My Starving Children’s purpose is to deliver food to impoverished areas. A meaningful ... |
444f21e7-4d69-433c-b9e7-b15efa30a9d2 | trentmkelly/LessWrong-43k | LessWrong | Best of Don’t Worry About the Vase
Epistemic Status: Welcome everyone!
In honor of being linked to by Marginal Revolution, here is what the rest of this blog has to offer.
This blog is part of the rationalist community. The general interest links below are fully general interest, and require no knowledge of or inter... |
b4c4e940-2354-4f4d-97ae-474f0e8d97d7 | trentmkelly/LessWrong-43k | LessWrong | LINK: Quora brainstorms strategies for containing AI risk
In case you haven't seen it yet, Quora hosted an interesting discussion of different strategies for containing / mitigating AI risk, boosted by a $500 prize for the best answer. It attracted sci-fi author David Brin, U. Michigan professor Igor Markov, and sever... |
c09b514c-0fc5-4785-98e8-f542c7886ea8 | trentmkelly/LessWrong-43k | LessWrong | Transforming Democracy: A Unique Funding Opportunity for US Federal Approval Voting
I'm excited to share a special opportunity to create a systemic impact: a statewide approval voting ballot initiative in Missouri. This would affect all elections throughout the state including federal and presidential. Approval voting... |
9429d6ca-c5ff-4995-bfbd-5d0a241e7314 | trentmkelly/LessWrong-43k | LessWrong | Hashmarks: Privacy-Preserving Benchmarks for High-Stakes AI Evaluation
TL;DR: Quick "idea paper" describing a protocol for benchmarking AI capabilities in the open without disclosing sensitive information. It's similar to how passwords are used for user registration and authentication in a web app: experts first hash ... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.