
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
8568dc4c-1484-44a7-985e-f9b4f596a84e | trentmkelly/LessWrong-43k | LessWrong | The Online Sports Gambling Experiment Has Failed
Related: Book Review: On the Edge: The Gamblers I have previously been heavily involved in sports betting. That world was very good to me. The times were good, as were the profits. It was a skill game, and a form of positive-sum entertainment, and I was happy to participate and help ensure the sophisticated customer got a high quality product. I knew it wasn’t the most socially valuable enterprise, but I certainly thought it was net positive. When sports gambling was legalized in America, I was hopeful it too could prove a net positive force, far superior to the previous obnoxious wave of daily fantasy sports.
It brings me no pleasure to conclude that this was not the case. The results are in. Legalized mobile gambling on sports, let alone casino games, has proven to be a huge mistake. The societal impacts are far worse than I expected.
The Short Answer
> Joe Weisenthal: Why is it that sports gambling, specifically, has elicited a lot of criticism from people that would otherwise have more laissez faire sympathies?
This full post is the long answer. The short answer is that it is clear from studies and from what we see with our eyes that ubiquitous sports gambling on mobile phones, and media aggressively pushing wagering, is mostly predation on people who suffer from addictive behaviors. That predation, due to the costs of customer acquisition and retention and the regulations involved, involves pushing upon them terrible products offered at terrible prices, pushed throughout the sports ecosystem and via smartphones onto highly vulnerable people. This is not a minor issue. This is so bad that you can pick up the impacts in overall economic distress data. The price, on so many levels, is too damn high.
Paper One: Bankruptcies
We start with discussion of one of several new working papers studying the financial consequences of legalized sports betting. The impacts include a 28% overall increase in bankruptcies (!).
> Brett Hollenbeck: *Working Paper Alert*: “The |
3fdd7902-13f2-40a7-a141-c1c6fcd066be | trentmkelly/LessWrong-43k | LessWrong | Letting Kids Be Outside
When our kids were 7 and 5 they started walking home from school alone. We wrote explaining they were ready and giving permission, the school had a few reasonable questions, and that was it. Just kids walking home from the local public school like they have in this neighborhood for generations.
Online, however, it's common for people to write as if this sort of thing is long gone. Zvi captures a common view:
> You want to tell your kids, go out and play, be home by dinner, like your father and his father before him. But if you do, or even if you tell your kids to walk the two blocks to school, eventually a policeman will show up at your house and warn you not to do it again, or worse. And yes, you'll be the right legally, but what are you going to do, risk a long and expensive legal fight? So here we are, and either you supervise your kids all the time or say hello to a lot of screens.
His post also references ~eight news stories where a family had trouble with authorities because they let their kid do things that should be ordinary, like walking to a store at age nine.
It's not just Zvi: parents who would like kids to have more freedom often focus on the risk, with the potential for police or Child Protective Services to get involved. While it's important to understand and mitigate the risks, amplifying the rare stories that go poorly magnifies their chilling effect and undermines the overall effort.
I showed the quote to our oldest, now 11 and comfortable on her own: "I sincerely doubt that a police officer would get mad at me for walking to school or to the corner store by myself."
She got to this level of comfort by spending a lot of time out in our walkable kid-friendly neighborhood. Sometimes with us, and increasingly on her own. For example it's raining today and she just came back to the house to tell me that she was grabbing rain gear and then she was going puddle jumping with two younger neighborhood kids. In a bit I'll stop writing and take her yo |
474a9726-58fa-49c7-a9e4-96584c7a1356 | trentmkelly/LessWrong-43k | LessWrong | Rationality Quotes Thread October 2015
Another month, another rationality quotes thread. The rules are:
* Please post all quotes separately, so that they can be upvoted or downvoted separately. (If they are strongly related, reply to your own comments. If strongly ordered, then go ahead and post them together.)
* Do not quote yourself.
* Do not quote from Less Wrong itself, HPMoR, Eliezer Yudkowsky, or Robin Hanson. If you'd like to revive an old quote from one of those sources, please do so here.
* No more than 5 quotes per person per monthly thread, please.
* Provide sufficient information (URL, title, date, page number, etc.) to enable a reader to find the place where you read the quote, or its original source if available. Do not quote with only a name. |
270879c8-7536-4221-a046-aa86210d5642 | StampyAI/alignment-research-dataset/blogs | Blogs | No need to click
I hate when people share articles based only on the headline. My rough guess is that this is 90% of article shares, even when the sharer [thinks they've read the article](https://www.cold-takes.com/honesty-about-reading/); [NPR's April Fools joke](https://gawker.com/npr-pulled-a-brilliant-april-fools-prank-on-people-who-1557745710) is a classic riff on this phenomenon.
But if you're into sharing articles based on headlines, here's a treat: a set of headlines that are so specific, wonderful and (as confirmed by me) supported by the main text that you can go ahead and enjoy them without clicking.
[Creator of McAfee Software has Disguised Himself as a Guatemalan Street Hawker with a Limp in Order to Avoid Police Seeking Him for Questioning in Murder of Neighbor](http://www.telegraph.co.uk/technology/news/9688101/John-McAfee-disguised-as-Guatemalan-street-hawker-with-a-limp.html).
['Creature' terrorizing Poland town turns out to be a croissant stuck in a tree](https://www.foxnews.com/food-drink/creature-tree-poland-croissant-animal-control)
[Pig in Australia Steals 18 Beers from Campers, Gets Drunk, Fights Cow](http://gadling.com/2013/09/10/australian-pig-steals-beer/)
[Dwayne Johnson Rips Off Front Gate with His Bare Hands to Get to Work](https://people.com/movies/dwayne-johnson-rips-off-front-gate-bare-hands/).
[90-Year-Old Tortoise Whose Legs Were Eaten By Rats Gets Prosthetic Wheels And Goes Twice As Fast](http://www.boredpanda.com/90-year-old-tortoise-wheels-twice-as-fast-jude-ryder-wales/)

[A Dutch metro train was saved from disaster Monday when it smashed through a safety barrier but was prevented from plummeting into water by a sculpture of a whale tail.](https://www.globaltimes.cn/content/1205573.shtml) (OK, that one is the first sentence, not the headline)

Got more in this genre? [Send them in](https://forms.gle/J4yCHcRL8VAC6mKR6). |
3aba3aa4-13e7-47e1-955c-dcc9bb1a5ea2 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Apply to the ML for Alignment Bootcamp (MLAB) in Berkeley [Jan 3 - Jan 22]
We ([Redwood Research](https://www.redwoodresearch.org/) and [Lightcone Infrastructure](https://www.lightconeinfrastructure.com/)) are organizing a bootcamp to bring people interested in AI Alignment up-to-speed with the state of modern ML engineering. We expect to invite about 20 technically talented effective altruists for three weeks of intense learning to Berkeley, taught by engineers working at AI Alignment organizations. The curriculum is designed by Buck Shlegeris (Redwood) and Ned Ruggeri (App Academy Co-founder). We will cover all expenses.
We aim to have a mixture of students, young professionals, and people who already have a professional track record in AI Alignment or EA, but want to brush up on their Machine Learning skills.
**Dates are Jan 3 2022 - Jan 22 2022.** Application deadline is **November 15th.** We will make application decisions on a rolling basis, but will aim to get back to everyone by **November 22nd.**
[**Apply here**](https://airtable.com/shrZtmNHpHNl7eWRX)
AI-Generated image (VQGAN+CLIP) for prompt: "Machine Learning Engineering by Alex Hillkurtz", "aquarelle", "Tools", "Graphic Cards", "trending on artstation", "green on white color palette"The curriculum is still in flux, but this list might give you a sense of the kinds of things we expect to cover (it’s fine if you don’t know all these terms):
* **Week 1: PyTorch —** learn the primitives of one of the most popular ML frameworks, use them to reimplement common neural net architecture primitives, optimization algorithms, and data parallelism
* **Week 2: Implementing transformers —** reconstruct GPT2, BERT from scratch, play around with the sub-components and associated algorithms (eg nucleus sampling) to better understand them
* **Week 3: Training transformers —** set up a scalable training environment for running experiments, train transformers on various downstream tasks, implement diagnostics, analyze your experiments
* **(Optional) Week 4: Capstone projects**
We’re aware that people start school/other commitments at various points in January, and so are flexible about you attending whatever prefix of the bootcamp works for you.
Logistics
---------
The bootcamp takes place at Constellation, a shared office space in Berkeley for people working on long-termist projects. People from the following organizations often work from the space: MIRI, Redwood Research, Open Philanthropy, Lightcone Infrastructure, Paul Christiano’s Alignment Research Center and more.
As a participant, you’d attend communal lunches and events at Constellation and have a great opportunity to make friends and connections.
If you join the bootcamp, we’ll provide:
* Free travel to Berkeley, for both US and international applications
* Free housing
* Food
* Plug-and-play, pre-configured desktop computer with an ML environment for use throughout the bootcamp
You can find a full FAQ and more details in this [Google Doc](https://docs.google.com/document/d/1DTSM8pS_VKz0GmYl9JDfcX1x4gBvKhwFluPrzKIjCZ4/edit).
[**Apply here**](https://airtable.com/shrZtmNHpHNl7eWRX) |
5a45d302-978f-4bc4-bc3c-fa3751255860 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Symbolic Reinforcement Learning for Safe RAN Control
1. Introduction and Motivation
-------------------------------
Due to the growing complexity of modern cellular networks, network optimization and control constitutes one of the main challenges. It is desirable by the Mobile Network Operators (MNOs) that the configuration is adjusted automatically in order to ensure acceptable Quality of Service (QoS) to each user connected to the network. In such application, the goal is to optimize a set of network KPIs such as *coverage*, *quality* and *capacity* and to guarantee that certain bounds of these KPIs are not violated (safety specifications). This optimization is performed by adjusting the vertical electrical tilt of each of the antennas of the given network, known in the literature as remote electrical tilt (RET) optimization problem Guo et al. ([2013](#bib.bib10)); Razavi
et al. ([2010](#bib.bib15)); Fan
et al. ([2014](#bib.bib6)); Buenestado et al. ([2016](#bib.bib5)).
Reinforcement learning (RL) Sutton and Barto ([2018](#bib.bib16)); Mnih
et al. ([2015](#bib.bib12)); Garcıa and
Fernández ([2015](#bib.bib8)); Bouton
et al. ([2020](#bib.bib4)) has become a powerful solution for dealing with the problem of optimal decision making for agents interacting with uncertain environments. However, it is known that the large-scale exploration performed by RL algorithms can sometimes take the system to unsafe states Garcıa and
Fernández ([2015](#bib.bib8)). In the problem of RET optimization, RL has been proven to be an effective framework for KPI optimization due to its self-learning capabilities and adaptivity to potential environment changes Vannella
et al. ([2020](#bib.bib17)). For addressing the safety problem (i.e., to guarantee that the desired KPIs remain in specified bounds) authors in Vannella
et al. ([2020](#bib.bib17)) have proposed a statistical approach to empirically evaluate the RET optimization in different baseline policies and in different worst-case scenarios.
The aforementeioned statistical approach focus on ensuring the reward value remains above a desired baseline. However, more widely accepted notions of safety are expressed in terms of safe states, defined according to a (formal) intent specification Fulton and
Platzer ([2018](#bib.bib7)). The approach in Fulton and
Platzer ([2018](#bib.bib7)) decouples the notion of safety from that of reward. Intuitively, safety intents define the boundaries within which the RL agent may be free to explore. Motivated by the abovementioned, in this work, we demonstrate a novel approach for guaranteeing safety in RET optimization problem by using model-checking techniques and in parallel, we seek to generalize the problem in order to facilitate richer specifications than safety. In order to express desired specifications to the network into consideration, LTL is used (see Baier
et al. ([2008](#bib.bib3)); Loizou and
Kyriakopoulos ([2004](#bib.bib11)); Nikou
et al. ([2018](#bib.bib14)); Nikou ([2019](#bib.bib13))), due to the fact that it provides a powerful mathematical formalism for such purpose. Our proposed demonstration exhibits the following attributes:
1. a general automatic framework from LTL specification user input to the derivation of the policy that fulfills it; at the same time, blocking the control actions that violate the specification;
2. novel system dynamics abstraction to companions Markov Decision Processes (MDP) which is computationally efficient;
3. UI development that allows the user to graphically access all the steps of the proposed approach.
Related work. Authors in Alshiekh et al. ([2018](#bib.bib2)) propose a safe RL approach through shielding. However, they assume that the system dynamics abstraction into an MDP is given, which is challenging in network applications that this demonstration refers to. As mentioned previously, authors in Vannella
et al. ([2020](#bib.bib17)) address the safe RET optimization problem, but this approach relies on statistical guarantees and it cannot handle general LTL specifications that we treat with this manuscript.

Figure 1. A graphical illustration of the proposed architecture.

Figure 2. A graphical illustration of the UI for the demonstration of the approach. The user can chose: the desired LTL formula, the resulting BA; and the evolution of the RL agent training and the actions blocked by the safety shield.
2. Demonstration
-----------------
Our key contribution is a proposed architecture which allows for intent specifications in RL, demonstrated in a real-world example. Here we focus on task specifications given in LTL. The syntax of LTL (see Baier
et al. ([2008](#bib.bib3))) over a set of atomic propositions Σ is defined by the grammar
| | | |
| --- | --- | --- |
| | φ:=⊤ | ς | ¬φ | φ1∧φ2 | ◯φ | φ1 U φ2 | ◊φ | □φ, | |
where ς∈Σ and ◯, U, ◊, □ operators stand for the next, until, eventually and always operators, respectively; ¬ and ∧ are the negation and conjunction operator respectively. Every LTL formula can be translated to a Büchi Automaton (BA) that models all the system traces satisfying the formula Gastin and Oddoux ([2001](#bib.bib9)).
Consider a geographic area covered by Radio Base Stations (RBS) and cells that serve a set of UEs uniformly distributed in that area. The RET optimization problem has goal to maximize network capacity and coverage while minimizing interference between the antennas. The RET control strategy handles the antenna tilt of each of the cells (agents), and is executed independently for each cell. The environment of the RL agents is a simulated mobile network as it can be seen in Fig. [2](#S1.F2 "Figure 2 ‣ 1. Introduction and Motivation ‣ Symbolic Reinforcement Learning for Safe RAN Control"). The system dynamical model is captured through an MDP (S,A,P,R,γ) where: S are the states consisting of values for down-tilt and KPIs (coverage, capacity and quality); actions A={downtilt,0,uptilt}; transition probability matrix P which describes the state evolution given the current and the executed by the action state; rewards R; and, discount factor γ. The RL agent’s policy π:S→A is a function that maps the states to actions that define the agent’s strategy.
Our solution takes a sequence of steps to match the LTL specification with the RL agent as it is depicted in Fig. [1](#S1.F1 "Figure 1 ‣ 1. Introduction and Motivation ‣ Symbolic Reinforcement Learning for Safe RAN Control") and block the actions that lead to unsafe states. Initially, the desired user specification is translated into LTL logic and subsequently into a BA. Then, by gathering the experience data tuples from the RL agent which is trained to a simulation environment with state-of-the-art model-free RL algorithms (DQN, Q-learning, SARSA Guo et al. ([2013](#bib.bib10)); Razavi
et al. ([2010](#bib.bib15)); Fan
et al. ([2014](#bib.bib6)); Buenestado et al. ([2016](#bib.bib5))) we construct the system dynamics modelled as an MDP. In this solution, we have a novel structure known as Companion MDPs (CMDPs). CMDPs encode the state transitions only in terms of the subset of features specified in the intent, not the full set of state features.
This reduces the state space complexity, and keeps only the relevant features depending on the intent. An MDP matching component matches the intent to the relevant CMDP (depending on the features mentioned in the intent).
The experience data tuples that are generated during training are in the form (s,a,r,s′) where s indicates the current state, a the executed action, r the received reward that the agent receives after applying action a at state s; and s′ the state the agent transitions to after executing action a at state s. In order to match the BA from the given LTL specification and the MDP, the states of the MDP are labelled according to the atomic propositions from the LTL specification. Then, by computing the product of the MDP with the specification, we construct: an automaton Aφ that models all the system behaviours over the given specification; an automaton A¬φ that models all the traces violating the specification. Then, by utilizing graph techniques and model checkers, we are able to find all the system traces violating the specification (w.r.t the trained MDP); if no safe traces are found from all states in the MDP, the user specification cannot be satisfied, which means that the LTL has to be modified (or relaxed). If there exist some unsafe and some safe traces, then the process moves to a shield strategy that blocks the actions that lead to unsafe traces.
This process is depicted more formally in Fig. 1 and Algorithm 1.
3. Discussions
---------------
Interaction with the UI. The UI is designed to be used by a network operations engineer who can specify safety intents, monitor tilts and their impact, and supervise the RL agent’s operation. The initial screen of the UI depicts a geographic area with the available radio sites and cells. By clicking to one of the cells, a new screen appears with the KPI values depicted on the left. On the right part of the page, one can see: 1) the MDP system model; 2) a list of available LTL intents; 3) BAs representing each of the intents; 4) the button "Run safe RL" to run the simulation; and 5) the switch "with/without shield" for enabling the safety shield. The chosen actions on the MDP are depicted in blue, while the blocked actions by the shield are depicted in red. The user can view the training process and the optimal choice of actions that guarantee the satisfaction of given input as well as the block of unsafe actions. The current high level of detail in the UI is meant to illustrate the technology, it can be imagined that a production UI would instead show a summary of selected and blocked actions instead of large MDP models. The impact of the shield may also be viewed, and it is seen that the shield blocks a proportion of unsafe states (leading to 639 unsafe states instead of 994 without the shield). Interestingly, the shield also leads to a 68% improvement in the reward values. The video accompanying this paper can be found in:
<https://www.ericsson.com/en/reports-and-papers/research-papers/safe-ran-control>
Applicability to other domains. The proposed architecture is general and it can be applied to any framework in which the under consideration dynamical system is abstracted into an MDP, while LTL specifications need to be fulfilled. For example, in a robot planning applications, the states are locations of the environment that the robot can move, and atomic propositions are the goal state and the obstacles. The LTL formula of such application would include reachability and safety tasks.
Conclusions and future work. In this paper, we have demonstrated an architecture for network KPIs optimization guided by user-defined intent specifications given in LTL. Our solution consists of MDP system dynamics abstraction, automata construction and products and model-checking techniques to block undesired actions that violate the specification. Future research directions will be devoted towards applying the proposed framework in other telecom use cases as well as in robotics (motion planning).
Acknowledgements. The authors thank Ezeddin Al Hakim, Jaeseong Jeong, Maxime Bouton, Swarup Mohalik, Pooja Kashyap and Athanasios Karapantelakis for the fruitful discussion in topics related to this work and support in the simulation environment. Moreover, special thanks to Ericsson Research for supporting and funding our work.
0: Input: User specification φ
1: Gather experience replay (s,a,r,s′) from data;
2: Discretize states into Nb. State space size is |S|Nb;
3: Construct the MDP dynamics (S,A,P,R,γ);
4: Translate the LTL formula Φ to a BA Aφ;
5: Compute the product T=MDP⊗Aφ and pass it to model checker;
6: Model checking returns traces that violate φ;
7: If no safe traces found Modify/Relax φ
8: Else Block unsafe actions by function Shield(MDP, T).
Algorithm 1 |
8431c55e-53be-4c89-a450-93bef9589701 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Frankfurt Open Mic (Thinking Fast and Slow, Happiness and Money,...)
Discussion article for the meetup : Frankfurt Open Mic (Thinking Fast and Slow, Happiness and Money,...)
WHEN: 10 August 2014 02:00:00PM (+0200)
WHERE: Frankfurt
We'll have another meetup! TOP: 1) 14:00, Arriving and Getting to know each other 2) 15:00 Structured Part, Open Mic, with max 30min each, so far confirmed are a presentation about Thinking Fast and Slow, one workshop/presentation about Money and Happiness (Budgeting) and at least one other 3) Goal Tracking 4) possibly games We'll have a bit of food, but it would be nice if you could bring some too. It should be vegan. If you have any special needs, please tell us in advance, so we can take them into account accordingly! You can contact me under 0049 176 34 095 760 or subscribe to our mailing list: https://groups.google.com/forum/#!forum/less-wrong-frankfurt You can also find the meetup notes of previous meetups there. See you then!
We'll meet at Ginnheimer Landstraße again. Contact me for further details.
Discussion article for the meetup : Frankfurt Open Mic (Thinking Fast and Slow, Happiness and Money,...) |
2cdd24d2-587a-410f-b789-8cca79cf49fa | trentmkelly/LessWrong-43k | LessWrong | ChatGPT and Ideological Turing Test
It seems to me that ChatGPT should be able to pass the Ideological Turing Test -- to generate a convincingly looking argument for any side of an issue. It is obvious how to use this ability for evil purposes: write the bottom line, and generate the arguments.
I think this can also be used for good purposes, and I invite you to brainstorm how. Here are some of my ideas:
Generate a heresy for yourself. People sometimes pretend to think critically about their own beliefs, and sometimes they kinda honestly try, but they still unconsciously avoid the weak points of their beliefs. Instead of generating a heretical thought that you know you can easily debunk, use ChatGPT to generate counter-arguments to your beliefs.
Prepare yourself for a debate on certain topic, by asking ChatGPT to generate arguments against your position. This might give you a decent idea of what arguments you should expect to meet in the real debate.
Perhaps teachers could use it similarly, to find out the most frequent misconceptions about the topic they are going to teach, and then they could adjust their lessons accordingly.
I wonder if listening to (ChatGPT-generated) "both sides of the story" could increase your chance to make the right guess. The experiment could be designed like this: An expert in certain field chooses a question that (according to the expert's knowledge) has a known correct answer, but most people are not familiar with it. Then someone else asks ChatGPT to create convincing arguments for both sides. The participants are randomly divided into two groups. First group only hears the question, and then tries to guess the right answer. Second group hears the question, then reads the arguments for both sides, and then tries to guess the right answer. Will the second group be more successful on average? If the answer is "yes", this may be a useful way to figure out the truth about questions where most people are wrong (and thus ChatGPT might mislead you if you ask it to only pro |
82e43666-534d-41a8-b58f-a0ad7a824e5b | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | On the correspondence between AI-misalignment and cognitive dissonance using a behavioral economics model
*This essay is one of the awarded essays for the* [*Econ Theory AI Alignment Prize*](https://www.super-linear.org/prize?recordId=recEx8ggKExudV8Mf) *from* [*Superlinear*](https://www.super-linear.org/)*. The essay uses the tools of theoretical economics to contribute to the AI alignment problem.*
Psychologists are familiar with the notion of cognitive dissonance, the discomfort when a person’s behavior conflicts with that person’s beliefs and preferences. Cognitive dissonance is accompanied with seemingly irrational behavior such as motivated reasoning and self-deception. It is basically an example of misalignment: decisions are not aligned with values. In that sense, perhaps cognitive dissonance can shed some light on the AI-alignment problem (Bostrom, 2014): how to create safe artificial intelligence that does things that we (creators, humans, sentient beings) really want? How can the decisions of AI-machines become aligned with our values and preferences? Even a small misalignment between our values and the goals of superintelligent machines (that are more intelligent and hence powerful than us) could cause very serious problems. And we will never be intelligent enough to solve those problems once the misaligned machines are more intelligent than us.
Computer scientists who study the AI-alignment problem speak a different language than psychologists who study cognitive dissonance. But new studies in behavioral economics, especially some new theoretical models about cognitive dissonance (Hestermann, Le Yaouanq & Treich, 2020), can perhaps bridge this gap between computer scientists and psychologists. The language of economists, when they speak of e.g. utility functions, optimization, expected value maximization, game-theoretic strategic behavior and Bayesian updating, is closer to the language of computer scientists who develop AI.
The cognitive dissonance models in behavioral economics are well illustrated by the meat paradox (Hestermann, Le Yaouanq & Treich, 2020): many people are animal-loving meat eaters, and their high levels of meat consumption are not aligned with their concern for animal welfare. They do not want to cause unnecessary animal suffering, but they know that meat consumption involves unnecessary suffering when there are alternatives (e.g. plant-based meat) that cause less or no suffering. When those people do not switch to a meat-free diet, they start rationalizing their meat consumption, denying a mind to farm animals (Bastian e.a. 2012), derogating vegetarians (Minson & Monin, 2012) and actively avoiding information from animal farming and slaughterhouses. This example of cognitive dissonance, known as the meat paradox (Loughnan & Davies, 2019), is striking, because it shows that such dissonance can have large scale consequences: billions of animals are killed every year.
The basic model of the meat paradox starts with a utility function: a person values meat consumption, animal welfare and reliable knowledge. These values or preferences are variables in the utility function. The animal welfare preference in the utility function depends on the subjective belief or estimate of the level of farm animal suffering. And this belief depends on the received information about how farm animals are treated and what their mental capacities are.
The model has an intrapersonal game-theoretic framework. A person is modelled by having two selves. The first self receives external information about the welfare of farm animals used for meat production (for example information about the treatment of farm animals or their mental capacities to experience suffering). That first self can decide to transmit that information reliably (truthfully) or wrongly (deceptively) to the second self, who will use that transmitted information to form a belief about animal suffering and consequently makes the decision how much meat to buy. Hence, the first self chooses the information to send at time T1, the second self makes the consumption decision at a later time T2.
The crucial assumption is that the first self incorporates the utility function of the second self, i.e. they both value the same things. The utility functions of the two selves are fully aligned: the first self internalizes the utility of the second self, including the beliefs of the second self. Hence, the utility of the first self, and especially the term that contains the preference for animal welfare, is not based on the true value of animal welfare (the true, external information received by the first self), but on the believed value (believed by the second self and based on the transmitted information from the first self).
Suppose the external information about animal welfare is bad news, i.e. the farm animals experience too much suffering. If the first self reliably transmits this information to the second self, and animal welfare is part of that person’s utility function, the second self may decide not to buy meat. The first self does not like that outcome (as she values meat consumption). So the first self can decide to deceive the second self by transmitting a good news message that the farm animal welfare is fine. This self-deception comes at a cost, however, as reliable knowledge is also part of the person’s utility function. Self-deception has a cost, a negative term in the utility function.
Both selves start an interaction and play a strategic game. The two selves are strategic rational agents who perform Bayesian updating. The second self considers the possibility that the first self might be lying about the true state of farm animal welfare. The second self can start to distrust the first self if that first self is prone to deception. The first self knows that the second self may distrust her and adapts her decisions accordingly. When receiving bad news, the first self can strategically decide to reliably transmit this bad news to the second self, or give good news instead.
As a result, a game-theoretic perfect Bayesian equilibrium is reached. Depending on the parameters in the utility function, such an equilibrium could consist of self-deception, where the person is information averse, i.e. is not open for information about animal suffering. Especially a person with both a high level of meat attachment (who really wants to eat animal meat) and a high concern for animal welfare (who really feels guilty when causing animal suffering) might experience a strong cognitive dissonance resulting in a high level of self-deception and information aversion. Only if the preference for reliable knowledge is strong enough (if the cost of deception is large), self-deception can be avoided.
This cognitive dissonance model predicts many phenomena of the meat paradox studied by psychologists. But it can also be very relevant and instructive in the study of AI-alignment, where the utility function translates into the goal function of an AI-machine. When applying this model to AI-alignment, we can give two interpretations of the model.
In the first interpretation, the first self is the AI-machine, the second self is the human. The AI does nothing more than receiving information, analyzing data and transmitting the processed information to the human. The human can ask the AI a question, the AI calculates and gives the response. That doesn’t look dangerous, as the human can always decide to neglect the information received by the AI. But what if the AI is clever enough to deceive the human? Then the human can decide to do terrible things. To solve this problem, you may think it is sufficient for the AI to be aligned with the human, i.e. that the AI shares the very same utility function as the human. If the human values the truth and does not want to be told lies, why would the aligned AI tell lies? But as the cognitive dissonance model shows, even that solution is not enough. Even a well-aligned AI might deceive humans, just like humans might deceive themselves as in the case of meat consumption. What is required, is a sufficiently strong preference for realism, for reliable information, for transmitting the truth. The goal function of the AI-machine should include a term that measures the cost of deception, similar to the term in the utility function of the cognitive dissonance model. The marginal cost or disutility of deception, when the AI tells one more lie, should be sufficiently large to avoid misalignment.
Perhaps a concrete illustration of this first interpretation of AI-misalignment is the spread of disinformation on social media. Social media algorithms are very good at deciphering what human users of social media prefer and want. When they learn about human preferences, they basically incorporate the human utility functions in their newsfeed algorithms. But there is no cost for the AI to spread disinformation as long as the human users keep their trust in the social media. If the AI is smart enough, it can spread disinformation in such a way that humans still trust the AI. In the end, the human users can be confronted with disinformation and start making bad decisions based on that deception.
In the second interpretation, the AI-machine becomes a real agent instead of merely an information source. The AI-machine can make influential decisions that change the world. In this interpretation, the AI consists of two selves or algorithms. The first algorithm receives data from the outside world, analyses it and decides to transmit the processed information to the second algorithm who uses that information to make real world decisions. Even if both algorithms share the same utility function, and even if this is the same utility function as that of a human, misalignment can occur, just like cognitive dissonance can occur in intelligent humans. As in the first interpretation, the goal function of this AI-machine should include a term that measures the cost of deception.
So what do we learn from this analogy between the behavioral economics model of cognitive dissonance and the AI-alignment problem? First, that mere alignment in terms of equality of utility functions is not enough. Second, that the utility function of an AI-machine should contain a sufficiently large term that measures the cost of deception. And third, more generally that behavioral economics models can be useful in solving AI-misalignment problems, as these models use a language that is very similar to those of computer scientists who develop AI.
References
Bastian, B., Loughnan, S., Haslam, N., & Radke, H. R. (2012). Don’t mind meat? The denial of mind to animals used for human consumption. *Personality and Social Psychology Bulletin*, *38*(2), 247-256.
Bostrom, N. (2014). *Superintelligence: Paths, Dangers, Strategies.*Oxford: Oxford University Press.
Hestermann, N., Le Yaouanq, Y., & Treich, N. (2020). An economic model of the meat paradox. *European Economic Review*, *129*, 103569.
Loughnan, S., & Davies, T. (2019). The meat paradox. In *Why We Love and Exploit Animals* (pp. 171-187). Routledge.
Minson, J. A., & Monin, B. (2012). Do-gooder derogation: Disparaging morally motivated minorities to defuse anticipated reproach. *Social Psychological and Personality Science*, *3*(2), 200-207. |
07c2e566-9402-49fc-aba8-b2d8b05011f4 | trentmkelly/LessWrong-43k | LessWrong | My Kind of Pragmatism
Recently I've been thinking about pragmatism, the school of philosophy which says that beliefs and concepts are justified based on their usefulness. In LessWrong jargon, it's the idea that "rationality is systematized winning" taken to its logical conclusion— we should only pursue "true beliefs" insofar as these truths help us "win" at the endeavors we've set for ourselves.
I'm inclined to identify as some sort of pragmatist, but there are a lot of different varieties of pragmatism, so I've been trying to piece together a "Belrosian pragmatism" that makes the most sense to me.
In particular, some pragmatisms are a lot more "postmodernist-sounding" (see e.g. Richard Rorty) than others (e.g. Susan Haack). Pragmatism leads you to say relativist-sounding things because usefulness seems to be relative to a particular person, so stuff like "truth is relative" often comes out as a logical entailment of pragmatist theories.
A lot of people think relativism about truth is just a reductio of any philosophical theory, but I don't think so. Respectable non-relativists, like Robert Nozick in Invariances, have pointed out that relativism can be a perfectly coherent position. Furthermore, I think much of the initial implausibility of relativism is due to confusing it with skepticism about the external world. But relativism doesn't imply there's no mind-independent reality: there can be one objective world, but many valid descriptions of that world, with each description useful for a different purpose. Once you make this distinction, relativism seems a lot more plausible. It's not totally clear to me that every pragmatist has made this distinction historically, but I'm going to make it.
There's one other hurdle that any pragmatist theory needs to overcome. Pragmatism says that we should believe things that are useful, but to determine if a belief is useful we need some background world model where we can imagine the counterfactual consequences of different beliefs. Is this worl |
48871c78-9e62-4d82-a235-aba5a65ef045 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | AlphaStar: Impressive for RL progress, not for AGI progress
DeepMind [released their AlphaStar paper a few days ago](https://deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning), having reached Grandmaster level at the partial-information real-time strategy game StarCraft II over the summer.
This is very impressive, and yet less impressive than it sounds. I used to watch a lot of StarCraft II (I stopped interacting with Blizzard recently because of how they rolled over for China), and over the summer there were many breakdowns of AlphaStar games once players figured out how to identify the accounts.
The impressive part is getting reinforcement learning to work at all in such a vast state space- that took breakthroughs beyond what was necessary to solve Go and beat Atari games. AlphaStar had to have a rich enough set of potential concepts (in the sense that e.g. a convolutional net ends up having concepts of different textures) that it could learn a concept like "construct building P" or "attack unit Q" or "stay out of the range of unit R" rather than just "select spot S and enter key T". This is new and worth celebrating.
The overhyped part is that AlphaStar doesn't really do the "strategy" part of real-time strategy. Each race has a few solid builds that it executes at GM level, and the unit control is fantastic, but the replays don't look creative or even especially reactive to opponent strategies.
That's because there's no representation of causal thinking - "if I did X then they could do Y, so I'd better do X' instead". Instead there are many agents evolving together, and if there's an agent evolving to try Y then the agents doing X will be replaced with agents that do X'. But to explore as much as humans do of the game tree of viable strategies, this approach could take an amount of computing resources that not even today's DeepMind could afford.
(This lack of causal reasoning especially shows up in building placement, where the consequences of locating any one building here or there are minor, but the consequences of your overall SimCity are major for how your units and your opponents' units would fare if they attacked you. In one comical case, AlphaStar had surrounded the units it was building with its own factories so that they couldn't get out to reach the rest of the map. Rather than lifting the buildings to let the units out, which is possible for Terran, it destroyed one building and then immediately began rebuilding it before it could move the units out!)
This means that, first, AlphaStar just doesn't have a decent response to strategies that it didn't evolve, and secondly, it doesn't do very well at building up a reactive decision tree of strategies (if I scout this, I do that). The latter kind of play is unfortunately very necessary for playing Zerg at a high level, so the internal meta has just collapsed into one where its Zerg agents predictably rush out early attacks that are easy to defend if expected. This has the flow-through effect that its Terran and Protoss are weaker against human Zerg than against other races, because they've never practiced against a solid Zerg that plays for the late game.
The end result cleaned up against weak players, performed well against good players, but practically never took a game against the top few players. I think that DeepMind realized they'd need another breakthrough to do what they did to Go, and decided to [throw in the towel](https://www.bbc.com/news/technology-50212841) while making it look like they were claiming victory. (Key quote: "Prof Silver said the lab 'may rest at this point', rather than try to get AlphaStar to the level of the very elite players.")
Finally, RL practitioners have known that genuine causal reasoning could never be achieved via known RL architectures- you'd only ever get something that could execute the same policy as an agent that had reasoned that way, via a very expensive process of evolving away from dominated strategies at each step down the tree of move and countermove. It's the biggest known unknown on the way to AGI. |
62530ad1-2009-4f03-9e92-32dc5d5a4521 | trentmkelly/LessWrong-43k | LessWrong | Conditional Forecasting as Model Parameterization
This work was done jointly with Rajashree Agrawal. We'd like to thank the Epoch AI summer mentorship project, led with Forecasting Research Institute, for introducing us. Thanks to Josh Rosenberg, Tegan McCaslin, Avital Morris and others at FRI, as well as Jaime Sevilla at Epoch AI. Thanks also to Misha Yagudin and Jonathan Mann for their feedback.
This is the second piece in a series on forecasting, especially conditional forecasting and the potential we see there for making fuzzy models more legible:
1. Forecasting: the way I think about it
2. The promise of conditional forecasting for parameterizing our models of the world [this post]
3. What we're looking at and what we're paying attention to (Or: Why we shouldn't expect people to agree today (Or: There is no "true" probability))
TL;DR: Where the market can't converge on decent forecasts, like on very long-run questions or questions involving disruptive technology, we need better ways to wring forecasts and models out of informed people. In this post we present one approach that serves to surface and refine experts' implicit models.
This has been in my drafts for so long that there has been a lot of awesome work on this problem in the meantime, at Metaculus (my current employer), the RAND Forecasting Initiative, the Forecasting Research Institute, and elsewhere. I'm not going to talk about any of that work in this piece, in the interest of getting it out the door! I'm just focusing on the work Rajashree and I did between summer 2023 and summer 2024.
Introduction
In the first post, we talked about one way to come up with one single forecast: thinking about different worlds, what would happen in each world, and how likely each world is to manifest. In this post we're going to talk about how we see conditional forecasting as the key to a) eliciting expert's models better and b) comparing any two people's models to each other.
The foundational literature (e.g. Goldstein et al, Karvetski et al, Tetlock's Ex |
f9b12ca9-7786-4d7c-be67-045f5da89012 | trentmkelly/LessWrong-43k | LessWrong | Failing to fix a dangerous intersection
Over the last few years, many people have written about why America can't build things anymore (eg. here, although this is just one of hundreds of relevant essays). Ten years ago, when I was 21 and had just graduated, a friend told me about a dangerous intersection in Berkeley. I tried writing to the city and asking for it to be fixed; I'm posting the email and reply here as a useful data point.
My request:
> To the Berkeley Department of Transportation:
>
> I write to urge the City to address a dangerous intersection, at San Pablo and Gilman Streets. When approaching the intersection from the west (on Gilman), there are two lanes of roadway, of which one is left-and-straight and the other is right-and-straight. However, on the opposite side of the intersection (east of San Pablo), there is only one lane of roadway. Hence, cars going straight are forced to merge in the middle of the intersection (with no warning), which is time-consuming and hazardous.
>
> I and some fellow Berkeley residents propose that the lane arrows be modified, such that either the left lane is left only, or the right lane is right only. This way, there is only one lane of forward traffic, and cars do not have to merge in the intersection. This modification would cost virtually nothing, and would make driving easier for the thousands of City residents who use this intersection daily, as well as preventing a potentially fatal accident. We greatly appreciate your consideration.
Their reply is below. (Email is generally private, but in this case the communication, from a city employee about a government issue, should be an open record under the California Public Records Act.)
> Dear Alyssa,
>
> I forwarded your email to the Supervising Traffic Engineer, and have been asked to respond to your request with the following information.
>
> San Pablo Avenue (State Highway 123) is under Caltrans jurisdiction, and any significant changes to the intersection must be approved by Caltrans. Recent co |
eb3288da-0f6b-4a69-a58c-a5136664204d | trentmkelly/LessWrong-43k | LessWrong | Can talk, can think, can suffer.
Executive summary: heavy on Westworld, SF, AI, Cognitive Sciences, metaphysical sprouting and other cracked poteries.
//
Supplementary tag: lazystory, which means a story starting short and dirty, then each iteration is refined and evolved with the help of muses, LLMs and other occasional writers.
//
Rules: if we need a safe space to discuss please shoot a private message and I’ll set the first comment for your thread with our agreed local policy. You can also use the comment system as usual if you’d like to suggest the next iteration for the main text, or provide advices on potential improvements.
//
Violence is the last refuge of the incompetent. You’re with me on this, Bernaaard?
//
What I regret most about Permutation City is my uncritical treatment of the idea of allowing intelligent life to evolve in the Autoverse. Sure, this is a common science-fictional idea, but when I thought about it properly (some years after the book was published), I realised that anyone who actually did this would have to be utterly morally bankrupt. To get from micro-organisms to intelligent life this way would involve an immense amount of suffering, with billions of sentient creatures living, struggling and dying along the way. Yes, this happened to our own ancestors, but that doesn’t give us the right to inflict the same kind of suffering on anyone else.
This is potentially an important issue in the real world. It might not be long before people are seriously trying to “evolve” artificial intelligence in their computers. Now, it’s one thing to use genetic algorithms to come up with various specialised programs that perform simple tasks, but to “breed”, assess, and kill millions of sentient programs would be an abomination. If the first AI was created that way, it would have every right to despise its creators.
Greg Egan
https://www.gregegan.net/PERMUTATION/FAQ/FAQ.html
//
Epistemic Status: It is now. You’re in my dream.
//
Dear lords of the AIs,
Congrats!
You have |
5775b21f-33f8-44ac-b29b-8a5dec5e8c28 | trentmkelly/LessWrong-43k | LessWrong | Biosafety Regulations (BMBL) and their relevance for AI
AI regulations could draw inspiration from the field of biosafety regulation, specifically the CDC's guidelines for Biosafety in Microbiological & Biomedical Laboratories (BMBL), which outline the necessary precautions for working with dangerous biological agents and recommend a systematic approach for assessing their risks.
The remainder of this report will describe the structure and mission of BMBL, outline its key principles and recommendations and indicate relevant takeaways for the field of AI regulation.
Epistemic status: I am not an expert in biosafety. However, I think a summary document which highlights concrete safety steps undertaken in an adjacent field to AI and highlights some actionable steps for AI labs to increase safety could be potentially useful. All construcive feedback and suggestions for improvements are welcome!
Structure and Mission
BMBL is an advisory document protecting laboratory staff, the public and the environment from exposure to dangerous microorganisms and hazardous materials (e.g. radioactive agents). While many organizations and agencies use BMBL for regulations, it is primarily an advisory document to help with a comprehensive protocol which helps laboratories identify risks and ensure safe conduct when working with dangerous microorganisms and hazardous materials. It provides guidelines for protecting laboratory staff, the public and the environment.
* Relevance for AI Regulation: A difference between biosafety and AI safety may be that biological laboratories have a more obvious incentive to protect its staff, as there is more immediate danger of contracting a disease than interacting with an AI system. Similar guidelines for AI may need to be legally binding.
BMBL is a set of biosafety guidelines compiled by experts and members of the public. To produce BMBL, the Office of Laboratory Science and Safety (OLSS) works with the National Health Institute (NIH) to recruit over 200 expert contributors from scientific societ |
7b878db9-539f-4639-9ea1-1474c252307e | trentmkelly/LessWrong-43k | LessWrong | How did LW update p(doom) after LLMs blew up?
Here's something which makes me feel very much as if I'm in a cult:
After LLMs became a massive thing, I've heard a lot of people p(doom) on the basis that we were in shorter timelines.
How have we updated p(doom) on the idea that LLMs are very different than hypothesized AI?
Firstly, it would seem to me to be much more difficult to FOOM with an LLM, it would seem much more difficult to create a superintelligence in the first place, and it seems like getting them to act creatively and be reliable are going to be much harder problems than making sure they aren't too creative.
LLMs often default to human wisdom on topics, the way we're developing them with AutoGPT they can't even really think privately, if you had to imagine a better model of AI for a disorganized species to trip into, could you get safer than LLMs?
Maybe I've just not been looking the right places to see how the discourse has changed, but it seems like we're spending all the weirdness points on preventing the training of a language model that at the end of the day will be slightly better than GPT-4.
I will bet any amount of money that GPT-5 will not kill us all. |
27d563f6-77f2-46d6-becb-406cbd14bab1 | trentmkelly/LessWrong-43k | LessWrong | Draft of Muehlhauser & Salamon, 'Intelligence Explosion: Evidence and Import'
Anna Salamon and I have finished a draft of "Intelligence Explosion: Evidence and Import", under peer review for The Singularity Hypothesis: A Scientific and Philosophical Assessment (forthcoming from Springer).
Your comments are most welcome.
Edit: As of 3/31/2012, the link above now points to a preprint. |
b65cdf58-ad0a-4106-847e-f609f0c0cad1 | trentmkelly/LessWrong-43k | LessWrong | [Book Suggestions] Summer Reading for Younglings.
I bought my niece a Kindle that just arrived and I'm about to load it up with books to give it to her tomorrow for her birthday. I've decided to be a sneaky uncle and include good books that can teach better abilities to think or at least to consider science cool and interesting. She is currently in the 4th Grade with 5th coming after the Summer.
She reads basically at her own grade level so while I'm open to stuffing the Kindle with books to be read when she's ready, I'd like to focus on giving her books she can read now. Ender's Game will be on there most likely. Game of Thrones will not.
What books would you give a youngling? Her interests currently trend toward the young mystery section, Hardy Boys and the like, but in my experience she is very open to trying new books with particular interest in YA fantasy but not much interest in Sci Fi (if I'm doing any other optimizing this year, I'll try to change her opinion on Sci Fi). |
24607a96-0083-4e15-8644-2f670f5e347e | trentmkelly/LessWrong-43k | LessWrong | Tactics against Pascal's Mugging
This is meant as a rough collection of five ideas of mine on potential anti-Pascal Mugging tactics. I don't have much hope that the first three will be any useful at all and am afraid that I'm not mathematically-inclined enough to know if the last two are any good even as a partial solution towards the core problem of Pascal's Mugging -- so I'd appreciate if people with better mathematical credentials than mine could see if any of my intuitions could be formalizable in a useful manner.
0. Introducing the problem (this may bore you if you're aware of both the original and the mugger-less form of Pascal's Mugging)
First of all the basics: Pascal's Mugging in its original form is described in the following way:
* Now suppose someone comes to me and says, "Give me five dollars, or I'll use my magic powers from outside the Matrix to run a Turing machine that simulates and kills 3^^^3 people."
This is the "shallow" form of Pascal's mugging, which includes a person that (almost certainly) is attempting to deceive the prospective AI. However let's introduce some further statements similar to the above, to avoid particular objections that might be used in some (even shallower) attempted rebuttals:
* "Give me five dollars, and I'll use my magic powers from outside the Matrix to increase the utility of every human being by 3^^^^3 utilons" (a supposedly positive trade rather than a blackmailer's threat)
* "I'm an alien in disguise - unless you publicly proclaim allegiance to your insect overlords, we will destroy you then torture all humanity for 3^^^^3 years" (a prankster asks for something which might be useful to an actual alien, but on a material-level not useful to a human liar)
* "My consciousness has partially time-travelled from the future into the past, and one of the few tidbits I remember is that it would be of effectively infinite utility if you asked everyone to call you Princess Tutu." (no trade offered at all, seemingly just a statement of epistemic beli |
c99388ad-be47-404d-91cd-a21995352573 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Machine learning could be fundamentally unexplainable
I’m going to consider a fairly unpopular idea: most efforts towards “explainable AI” are essentially pointless. Useful as an academic pursuit and topic for philosophical debate, but not much else.
Consider this article a generator of interesting intuitions and viewpoints, rather than an authoritative take-down of explainability techniques.
That disclaimer aside:
---
What if almost every problem for which it is desirable to use machine learning is unexplainable?
At least unexplainable in an efficient-enough way to be worth explaining. Whether it is an algorithm or a human that is doing the explanation.
Let’s define “[explainable AI](https://en.wikipedia.org/wiki/Explainable_artificial_intelligence)” in a semi-narrow sense, inspired by the DARPA definition, as an inference system that can answer the questions:
* *Why was that prediction made as a function of our inputs and their interactions?*
* *Under what conditions would the outcome differ?*
* *How confident can we be in this prediction and why is the confidence such?*
Why might we be unable to answer the above questions in a satisfactory manner for most machine learning algorithms? I think I can name four chief reasons:
1. Some problems are just too complex to explain. Often enough, these are perfect problems for machine learning, it’s exactly their intractability to our brains that makes them ideal for equation-generating algorithms to solve.
2. Some problems, while not that complex, are really boring and no human wants or should be forced to understand them.
3. Some problems can be understood, but understanding in itself is different for every single one of us, and people’s culture and background often influence what “understanding” means. So explainable for one person is not explainable for another.
4. Even given an explanation that everyone agrees on, this usually puts us no closer to most of what we want to achieve with said explanation, things like gathering better data or removing “biases” from our models.
I - Unexplainable due to complexity
-----------------------------------
Let’s say, physicists, take in 100 PetaBytes of experimental data, reduce them using equations, and claim with a high probability that there exists this thing called a “Higgs Boson” with implications for how gravity works, among other things.
The resulting Boson can probably be defined within a few pages of text via things such as mass, the things it decays into, its charge, its spin, the various interactions it can have with other particles, and so on.
But if a luddite like myself asks the physicists:
> *Why did you predict this fundamental particle exists?*
>
>
I will either get a “press conference answer” which carries no meaning other than providing a “satisfying” feeling, but it doesn’t answer any of the above questions.
It doesn’t tell me why the data shows the existence of the Higgs Boson, it doesn’t tell me how the data could have been different in order for this not to be the case, and it doesn’t tell me how confident they are in this inference and why.
If I press for an answer that roughly satisfies the explainability criteria I mentioned above, I will at best get them to say:
> *Look, the standard model is a fairly advanced concept in physics, so you first have to understand that and why it came to be. Then you have to understand the experimental statistics needed to interpret the kind of data we work with here. In the process, you’ll obviously learn quantum mechanics, but to understands the significance of the Higgs boson specifically it’s very important that you have an amazing grasp of general relativity, since part of the reason we defined it as is and why it’s so relevant is because it might be a unifying link between the two theories. Depending on how smart you are this might take 6 to 20 years to wrap your head around, really you won’t even be the same person by the time you’re done with this. And oh, once you get your Ph.D. and work with us for half a decade there’s a chance you’ll disagree with your statistics and our model and might think that we are wrong, which is fine, but in that case, you will find the explanation unsatisfactory.*
>
>
We are fine with this, since physics is bound to be complex, it earns its keep by being useful and making predictions about very specific things with very tight error margins, its fundamental to all other areas of scientific inquiry.
When we say that we “understand” physics what we really mean is that there are a few dozen of thousands of blokes that spent half their lives turning their brains into hyper-optimized physics-thinking machines and they assure us that they “understand” it.
For the rest of us, the edges of physics are a black box, I know physics works because Nvidia sells me GPUs with more VRAM each year and I’m able to watch videos of nuclear reactors glowing on youtube while patients in the nearby oncology ward are getting treated with radiation therapy.
This is true for many complex areas, we “understand” them because a few specialists say they do, and the knowledge that trickles down from those specialists has results that are obvious to all. Or, more realistically, because a dozen-domain long chain of specialists combined, each relying on the other, is able to produce results that are obvious to all.
As long as there is a group of specialist that understands the field, as long as those specialists can prove to us that their discoveries can affect the real world (thus excluding groups of well-synchronized insane people) and as long as they can teach other people to understand the field… we claim that it’s “understood”.
---
But what about a credit risk analysis “AI” making a prediction that we should loan Steve at most 14,200$?
The model making this prediction might be operating with TBs worth of data about Steve, his browsing history, his transaction history, his music preferences, a video of him walking into the bank… each time he walked into the bank for the last 20 years, various things data aggregators tell us about him, from his preference about clothing to the likelihood he wants to buy an SUV, and of course, the actual stated purpose Steve gave us for the credit, both in text and as a video recording.
Not only that, but the “AI” has been trained on previous data from millions of people similar to Steve and the outcomes of the loans handed to then, thus working with petabytes of data in order to draw the 1-line conclusion of “You should loan steve, at most, 14,200$, if you want to probabilistically make a profit”.
If we ask the AI:
> *Why is the maximum loan 14,200$? How did the various inputs and their interactions contribute to coming up with this number?*
>
>
Well, the real answer is probably something like:
> *Look, I can explain this to you, but 314,667,344,401 parameters had a significant role in coming up with this number, and if you want to “truly” understand that then you’d have to understand my other 696,333,744,001 parameters and the ways they related to each other in the equation. In order to do this, you have to gain an understanding of human-gate analysis as well as how its progress over time relates to life-satisfaction, credit history analysis, shopping preference analysis, error theory behind the certainty of said shopping preferences, and about 100 other mini-models that end up coalescing into the broader model that gave this prediction. And the way they “coalesce” is even more complex than any of the individual models. You can probably do this given 10 or 20 years, but basically, you’d have to re-train your brain from scratch to be like an automated risk analyst, you’d only be able to explain this to another automated risk analysts, and the “you” “understanding” my decision will be quite different from the “you” that is currently asking.*
>
>
And even the above is an optimist take assuming the “AI” is made of multiple modules that are somewhat explainable.
So, is the “AI” unexplainable here?
Well, not more so than the physicists are. Both of them can, in theory, explain the reasoning behind their choice. But in both cases, the reasoning is not simple, there’s no single data point that is crucial, if even a few inputs were to change slightly the outcome might be completely different, but the input space is so fast it’s impossible to reason about all significant changes to it.
This is just the way things are in physics and it might be just the way things are in credit risk analysis. After all, there’s no fundamental rule of the universe saying it should be easy to comprehend by the human mind. The reason this is more obvious in physics is simply because physicists have been gathering loads of data for a long time. But it might be equally true in all other fields of inquiry, based on current models, it probably is. It’s just that those other fields didn’t have enough data nor the intelligence required to grok through it until recently.
II — Some problems are boring
-----------------------------
There is a class of problems that is complex, but not as complex as to be impenetrable to the vast majority of human minds.
To harken back to the physics example, think classical mechanics. Given the observations made by Galileo and some training in analysis, most of us could, in principle, understand classical mechanics.
But this is still difficult, it requires a lot of background knowledge, although fairly common and useful background knowledge and a significant amount of times. Ranging from, say, a day to several months depending on the person.
This is time well spent learning classical mechanics, but what if the problem domain was something else, say:
* Figuring out if a blotch on a dental CT scan is more likely to indicate a streptococcus or a lactobacillus infection.
* Understanding what makes an image used to advertise a hiking pole attractive to middle-class Slovenians over the age of 54.
* Figuring out, using l2 data, if the spread for the price of soybean oil is too wide, and whether the bias is towards the sell or buy.
* Finding the optimal price at which to pre-sell a new brand of luxury sparkling water based on yet uncertain bottling, transport, and branding cost.
* Figuring out if a credit card transaction is likely to be fraudulent based on the customer’s previous buying pattern.
These are the kind of problems one might well use machine learning for, but they are also the kind of problems that, arguably, could lie well within the realm of human understanding.
The problem is not that they are really hard, they are just really \*\*\*\* boring. I can see the appeal of spending 20 years of your life training to better understand the fundamental laws of reality or the engines behind biological life. But who in their right mind wants to spend weeks or months studying sparkling water supply chains? Or learning how to observe subtle differences in shadow on a CT scan?
Yet, for all of these problems, we run into a similar issue as with case nr I. Either we have a human specialist, or the decision of the algorithm we trained will not be explainable to anyone.
* Why is this credit card transaction fraudulent?
* It’s because it’s a 340$ withdrawal on a Monday, well, that accounts for roughly 60–80% of the confidence I have in the decision.
* No but, why?
* *Sigh* shall we spend the next 2 weeks delving into credit card transaction time series analysis?
* Under what conditions would the transaction not be fraudulent?
* If it was done Tuesday, or if it was a POS payment, or if the amount of 320, or 120,123 other combinations of parameters.
* Ahm, so what’s the big difference between 320$ and 340$?
* You mean what’s the difference between those for a withdrawal transaction on a Monday. And, ahem, *sigh*, again, 2 weeks of delving into cc transaction time series analysis.
… Hopefully, you get the gist of it
III — Explainable to me but not to thee
---------------------------------------
This leads us to the third problem, which is who exactly are the understanding-capable agents the algorithms must explain themselves to.
Take as an example an epidemiological psychology generating algorithm that tries to find insight into the fundamentals of human nature by giving a few hundred people questioners on mturk. After fine-tuning itself for a while it finally manages to consistently produce interesting findings, one of which is something like:
> *People that like Japanese culture are likely to be introverts.*
>
>
When asked to “explain” this finding it may come up with an explanation like:
> *Based on a 2-question survey we found that participants which enjoy the smell of nato are much more likely to paint a lot. Furthermore, there is a strong correlation between nato-enjoyment and affinity for Japanese culture[2,14], and between painting and introversion[3,45]. Thus we draw a tentative conclusion that introverts are likely drawn to Japanese culture (p~=0.003, n=311).*
>
>
> *This requires only the obvious assumptions that the relation between our results and the null-hypothesis can be numerically modeled into a sticky-chewing-gum distribution and the God-ordained truth that human behavior has precisely 21 degrees of freedom (all of which we have controlled for). It also requires the validity of 26 other studies based on which our references depend, but for the sake of convention, we won’t consider the p-values of those findings when computing ours.*
>
>
> *Replication and lab studies are required to confirm the finding, this is a preliminary paper meant only to be used as the core source material for front-page articles by The Independent, The NY Times, Vice, and other major media outlets.*
>
>
Jokes aside, I could see an algorithm being designed to generate questioner-based studies… I’m not saying I have designing one that looks promising, or that I’m looking for an academic fatalistic enough to risk his career for the sake of a practical joke (see my email in the header). But in principle, I think this is doable.
I also think that something like the explanation above (again, a bit of humor aside), would fly as the explanation for why the algorithm’s finding is true. After all, that’s basically the same explanation a human researcher would give.
A similar reference and statistical significance based explanation could feasibly be given as to why the algorithm converged on the questions and sample sizes it ended up with.
But we could get widely different reaction to that explanation:
* Psychology professor: Makes total sense, we should tenure track the algorithm.
* ML researcher: This is interesting, but the statistical assumptions are flawed and could be replaced with cross-validated predictive modeling.
* Reddit commenter: I don’t quite understand why this is true, but it agrees with my pre-existing political and social biases, so I will take it on faith.
* Youtube “skeptic” reaction video: This is interesting, but there are too many weak links in the citation chain, and the statistical apparatus used to control for confounders relies on naive assumptions that don’t hold up to scrutiny.
* Christian fundamentalist: I don’t understand the arguments that make this true, and the very premise of your work, the ability to apply reason and science to God’s most precious creation, is flawed and sinful.
* Psychology student: This makes total sense, but me and my friends love reading manga, however, we’re all quite extroverted. Granted, this might be sampling bias on my end, but I’m only human and thus can’t be immune to such a strong sampling bias, hence there *must* be something wrong with this study’s conclusion.
In other words, even within cultural and geographic proximity, depending on the person a decision is explained to, an explanation might be satisfactory or unsatisfactory, might make or not make sense, and might prove the conclusion is true or the opposite.
And while the above example is tongue-in-cheek, this is very much the case when it comes to actual scientifical findings.
One can define an [anti-scientific](https://en.wikipedia.org/wiki/Antiscience) world view, quite popular among religious people and philosophers, which either entirely denies the homogeneity needed for science to hold true, or deems scientific reductionism as too limited to provide knowledge regarding most objects and topics worth caring about epistemically. Arguably, every single religious person falls into this category at least a tiny bit, in that they disagree with falsifiability in a specific context (i.e. the existence of some supernatural entities or principles that can’t be falsified) and even if they agree with homogeneity (which in turn allows scientific reductionism) in most scenarios, they believe edge cases exist (miracles, souls… etc).
To go one level down, you’ve got things like the [anti-vaccination](https://en.wikipedia.org/wiki/Vaccine_hesitancy) movements, which choose to distrust specific areas of science. This is not always for the same reason, and often not for a single reason. [In Europe](https://upload.wikimedia.org/wikipedia/commons/e/ee/Ovidiu_Covaciu_ESC2017.webm), the main reasons can be thought of as:
* A mix of Christian purity taboos, and new age beliefs about magic healing. Which sometimes conflicts with scientific medical knowledge.
* Distrust of scientific evidence due to inability to read about the actual trials (see points I and II), favoring instead information from sources like Facebook friends.
* Reduced trust in authority figures (media, their doctors) as opposed to friends and family.
This combination of causes means that there’s no single way to explain to an anti-vaxxer why they should vaccinate their kid against polio or hepatitis, or measles, or whatever new disease might come about or re-emerge in the future.
If we had “AI” generated vaccines, with an “AI” generate clinical trial procedures and “AI” written studies based on those trials, how does the “AI” answer to an anti-vaxxer when asked, “why is this prediction true? why do you predict this vaccine will protect me against the disease and have negligible side effects?”.
It could generate a 1000-pages length explanation that amounts to the history of skeptical philosophy and a collection of instances where the scientific method leads to correct theories for otherwise near-impossible to solve problems. Couple that with some basic instructions on statistics, mathematics, epidemiology, and human biology.
Or it could try to generate a deep-fake video of their deceased mom and their local priest talking about how vaccines are good. Couple that with a video of a politician they endorsed getting vaccinate and maybe a papal speech about how we should trust doctors and a very handsome man with a perfect smile in a white coat talking about the lack of side effects.
And for some reason, the first seems like a much better “explanation” yet the latter is why 99% of people that do get vaccinated trust the science. Have you ever read *any* paper about a vaccine you got or gave to your kids?
I’m passionate about medicine and biology, and I only ever read two vaccine trial papers, both about JE vaccines, and only since they were made in poor Asian countries, and thus my “medical authority” heuristic wasn’t able to bypass my rational mind (for reference, the recombinant DNA one from Thailand seems to be the best).
So which of the “explanations” should the algorithm provide? Should it discriminate between the person asking and provide a scientific explanation to some and a social persuasion based explanation to others?
---
Ant-vaccination is very much not a strawman, 10% of the US population believes giving the [MMR vaccine to their kids](https://www.pewresearch.org/fact-tank/2020/01/07/more-americans-now-see-very-high-preventive-health-benefits-from-measles-vaccine/) is not worth the risk [pew]. 42% would [not get an FDA approved vaccine](https://news.gallup.com/poll/325208/americans-willing-covid-vaccine.aspx) for COVID-19 [gallup].
The difference between people results in at least three issues:
1. Some people might need further background knowledge to accept any explanation (collapses into I and II).
2. Some people might accept some explanation but it’s not what some of us think to be the “correct” explanation.
3. Some people might never accept any explanation an algorithm provides, even though those same explanations would immediately click for others.
Going back to the “argument from authority” versus “careful reading of studies” approach to trusting an “AI-generated” vaccine study (or any vaccine study, really).
It seems clear to me that most of us made a choice to trust things like vaccines, or classical mechanics, or inorganic chemistry models, or the matrix-inverse solution to a linear regression, way before we “understood” them. We trusted them due to arguments from authority.
This is not necessarily bad, after all, we would not have the time to gain a deeper meaning of everything, we’d just keep falling down levels of abstractions.
III.2 — Inaccessible truth and explainable lies
-----------------------------------------------
If a prediction is made with 99% confidence, but our system realizes you’re one of “those people” that doesn’t trust its authority, should it lie to you, in order to bias your trust more towards what it thinks is the real confidence?
Furthermore, if the algorithm determines nobody will trust a prediction is made, or if the human supervising it determines that same thing, should it’s choice be between:
a) Lying to us about the explanation.
b) Coming up with a more “explainable” decision.
Well, a) is fairly difficult, and will probably remain the realm of humans for quite some time, it also seems intuitively undesirable. So let’s focus on option b), changing the decision process to one that is more explainable to people. Again, I’d like to start with a thought experiment:
Assume we have a disease-detecting CV algorithm that looks at microscope images of tissue for cancerous cells. Maybe there’s a specific protein cluster (A) that shows up on the images which indicates a cancerous cell with 0.99 AUC. Maybe there’s also another protein cluster (B) that shows up and only has 0.989 AUC, A overlaps with B in 99.9999% of true positive. But B looks big and ugly and black and cancery to a human eye, A looks perfectly normal, it’s almost indistinguishable from perfectly benign protein clusters even to the most skilled oncologist.
*For the pedantic among you assume the AUC above is determined via k-fold cross-validation with a very large number of folds and that we don’t mix samples from the same patient between folds*
Now, both of these protein clumps factor into the final decision of cancer vs non-cancer. But the algorithm can be made “explainable” by investigating which features are necessary and/or sufficient for the decision (e.g via an Anchor method). The CV algorithm can show A and B as having some contribution to its decision to mark a cell as cancerous. Say A is at 51% and B at 49%. But B looks much scarier, so what if a human marks that explanation as “wrong” and says “B should have a larger weight”.
Well, we could tune the algorithm to put more weight on B, both B and A are fairly accurate and A overlaps with B whenever there is a TP. So in a worst-case scenario, we’re now killing 0.x% less cancer cells than before or killing a few more healthy cells, not a huge deal.
So should we accept the more “explainable” algorithm in this scenario?
If your answer is “yes”, if completely irrational human intuition is reason enough to opt for the worst model, I think our disagreement might be a very fundamental one. But if the answer is “no”, then think of the following:
For any given ML algorithm we’ve got a certain amount of research time and a certain amount of compute that’s feasible to spend. While in some cases explainability and accuracy can go hand in hand (see, e.g, a point I made about [confidence determination networks](https://blog.cerebralab.com/Confidence_in_machine_learning) that could improve the accuracy of the main network beyond what can be achieved with “normal” training), this is probably the exception.
As a rule of thumb, explainability is traded off for accuracy. It’s another thing we waste compute and brain-power on that takes away from how much we can refine and for how long we can train our models.
This might not be an issue in cases where the model converges to a perfect solution fairly easily (perfect as in, based on existing data quality and current assumptions about future data there’s no more room to improve accuracy, not perfect in the 100% accuracy sense), and there are plenty such problems, but we usually aren’t able to tell they fall into this category.
The best way to figure out that an accuracy is “the best we can get” for a specific problem is to throw a lot of brainpower and compute at it and conclude that there’s no better alternative. Unless we are overfitting (and even if we are overfitting) determining the perfect solution to a problem is usually impossible.
So if you wouldn’t sacrifice >0.01AUC for the sake of what a human thinks is the “reasonable” explanation to a problem, in the above thought experiment, then why sacrifice unknown amounts of lost accuracy for the sake of explainability? If truth takes precedence over explanations people agree with, then how can we justify the latter before we’ve perfected the former?
IV — I digress
--------------
I think it’s worth expanding more on this last topic but from a different angle. I also listed a 4th reason in my taxonomy that I didn’t have the time to get into. On the whole, I think exploring those two combined is broad enough to warrant a second article.
I kind of hand-wave in a very skeptical (in the humean sense) worldview to make my stance, and I steam over a bunch of issues related to scientific truth. I’m open to debating those if you think they are the only weak points in this article, but I’m skeptical (no pun intended) about those conversations having a reasonable length or satisfactory conclusion.
As I said at the beginning, take this article more as an interesting perspective, rather than as a claim to absolute truth. Don’t take it to say “we should stop doing any research into explainable ML” but rather “we should be aware of these pitfalls and try to overcome them when doing said research”.
---
I should note, part of my day-job actually involves explainable models, 2 years of my work are staked in a product which has explainability as an important selling point, so I am somewhat up-to-date with this field and also all my incentives are aligned against this hypothesis. I very much think and want the above problems to be, to some degree, “fixable”, I get no catharsis from pointing them out.
That being said, I think that challenging base assumptions about our work is useful, as a mechanism for reframing our problems as well as a lifeline to sanity. So don’t take his as an authoritative final take on the topic, but rather as a shakey but interesting point of view worth pondering.
---
If you enjoyed this article I’d recommend you read Jason Collins’s humorous and insightful article, [Principles for the Application of Human Intelligence](https://behavioralscientist.org/principles-for-the-application-of-human-intelligence/). Which does a fantastic job at illustrating the double standards we harbor regarding human versus algorithmic decision-makers. |
5ad25e8b-84ec-416b-aa5e-7ac387b0bf30 | trentmkelly/LessWrong-43k | LessWrong | Overcoming Clinginess in Impact Measures
|
5f078429-99d9-48ef-979e-8e2f685dc5cf | trentmkelly/LessWrong-43k | LessWrong | How to Make Billions of Dollars Reducing Loneliness
Loneliness Is a Big Problem
On Facebook, my friend Tyler writes:
> Lately, I've been having an alarming amount of conversations arise about the burdens of loneliness, alienation, rootlessness, and a lack of belonging that many of my peers feel, especially in the Bay Area. I feel it too. Everyone has a gazillion friends and events to attend. But there's a palpable lack of social fabric. I worry that this atomization is becoming a world-wide phenomenon – that we might be some of the first generations without the sort of community that it's in human nature to rely on.
> And that the result is a worsening epidemic of mental illness...
> Without the framework of a uniting religion, ethnicity, or purpose, it's hard to get people to truly commit to a given community. Especially when it's so easy to swipe left and opt for things that offer the fleeting feeling of community without being the real thing: the parties, the once-a-month lecture series, the Facebook threads, the workshops, the New Age ceremonies. We often use these as "community porn" – they're easier than the real thing and they satisfy enough of the craving. But they don't make you whole.
> I've had some thoughts about experiments to try. But then I think about how hard it is (especially in this geographic area) to get people to show up to something on at least a weekly basis. Even if it's for something really great. I see many great attempts at community slowly peter out.
Young people are lonely. Old people are lonely. Loneliness is bad for your health. It's bad for society's health.
Having a smartphone that keeps you entertained all day, and enough money to live by yourself, might sound like first world problems. But they are likely contributors to loneliness. And as developing countries get richer, they'll start having first world problems too. So I think addressing loneliness could be very high-leverage for the world.
People are starting businesses to address loneliness: you can pay someone to call y |
15e87b5f-20e7-4b1e-857a-d7dea639780e | trentmkelly/LessWrong-43k | LessWrong | Brief update on the consequences of my "Two arguments for not thinking about ethics" (2014) article
In March 2014, I posted on LessWrong an article called "Two arguments for not thinking about ethics (too much)", which started out with:
> I used to spend a lot of time thinking about formal ethics, trying to figure out whether I was leaning more towards positive or negative utilitarianism, about the best courses of action in light of the ethical theories that I currently considered the most correct, and so on. From the discussions that I've seen on this site, I expect that a lot of others have been doing the same, or at least something similar.
>
> I now think that doing this has been more harmful than it has been useful, for two reasons: there's no strong evidence to assume that this will give us very good insight to our preferred ethical theories, and more importantly, because thinking in those terms will easily lead to akrasia.
I ended the article with the following paragraph:
> My personal experience of late has also been that thinking in terms of "what does utilitarianism dictate I should do" produces recommendations that feel like external obligations, "shoulds" that are unlikely to get done; whereas thinking about e.g. the feelings of empathy that motivated me to become utilitarian in the first place produce motivations that feel like internal "wants". I was very close to (yet another) burnout and serious depression some weeks back: a large part of what allowed me to avoid it was that I stopped entirely asking the question of what I should do, and began to focus entirely on what I want to do, including the question of which of my currently existing wants are ones that I'd wish to cultivate further. (Of course there are some things like doing my tax returns that I do have to do despite not wanting to, but that's a question of necessity, not ethics.) It's way too short of a time to say whether this actually leads to increased productivity in the long term, but at least it feels great for my mental health, at least for the time being.
The long-term update |
8b63fc20-47e7-43d5-b619-be8d13eb0243 | StampyAI/alignment-research-dataset/arxiv | Arxiv | The Grey Hoodie Project: Big Tobacco, Big Tech, and the threat on academic integrity
1. Introduction
----------------
Imagine if, in mid-December of 2019, over 10,000 health policy researchers made the yearly pilgrimage to the largest international health policy conference in the world. Among the many topics discussed at this hypothetical conference was how to best deal with the negative effects of increased tobacco usage (e.g., tobacco related morbidity). Imagine if many of the speakers who graced the stage were funded by Big Tobacco. Imagine if the conference itself was largely funded by Big Tobacco.
Would academics in the field of public health accept this? Today, most would find such a situation inconceivable — given the clear conflict of interest. In alignment with Article 5.3 of the WHO Framework Convention of Tobacco Control (World Health
Organization, [2003](#bib.bib67)), policy makers would not look towards these speakers for advice regarding health policy. Anything said at this venue regarding the effects of smoking on public health would be met with skepticism and distrust. The negative effect of Big Tobacco’s money on research quality has been widely reported, and it is commonly accepted that private-interest funding biases research (Barnes and Bero, [1997](#bib.bib5); Brownell and
Warner, [2009](#bib.bib14); Cohen et al., [1999](#bib.bib17); Smith
et al., [2016](#bib.bib56)).
However, this is exactly what is happening in the field of machine learning. Replace “health policy” with “machine learning”, “effects of increased tobacco usage” with “ethical concerns of increased AI deployment”, and “Big Tobacco” with “Big Tech” and you get what is a significant, ongoing conflict of interest in academia. Yet this is largely regarded as a non-issue by many of those in the field.
In this work, we explore the extent to which large technology corporations (i.e., Big Tech) are involved in and leading the ongoing discussions regarding the ethics of AI in academic settings. By drawing upon historic examples of industry interference in academia and comparing these examples with the behavior of Big Tech, we demonstrate that there is cause for concern regarding the integrity of current research, and that academia must take steps to ensure the integrity and impartiality of future research.
2. Defining Big Tech
---------------------
It is difficult to succinctly define which companies are or aren’t “Big Tech”. In this piece, as we discuss the ethics of AI, we focused on companies that are both large technology corporations and heavily involved in the ethics of AI/fairness literature or lobbying governments about such matters. There are some companies that are undoubtedly “Big Tech” (e.g., Google, Facebook) but the distinction is not clear for all companies (e.g., Yahoo (is it still big enough?), Disney (is it a technology company?)). The final list of companies was arrived at through multiple discussions and a final vote with various non-author parties. Our list is purposefully more conservative than most would be. By being more conservative, all of the conclusions arrived at in the paper would still hold (if not be strengthened) by selecting any additional companies.
In this paper, the following companies were considered “Big Tech”: Google, Amazon, Facebook, Microsoft, Apple, Nvidia, Intel, IBM, Huawei, Samsung, Uber, Alibaba, Element AI, OpenAI.
The following companies were not considered “Big Tech”: Disney, Autodesk, Pixar, Adobe, Polaroid, Pfizer, Sony, Oracle, Cisco, Netflix, Yahoo, VMWare, Activision, Pintrest, Yahoo.
3. Motivating the analogy: Big Tobacco’s and Big Tech’s Playbook
-----------------------------------------------------------------
In this section, we will explore the histories of Big Tobacco and Big Tech. We see that both industries’ increased funding of academia was as a reaction to increasingly unfavorable public opinion and an increased threat of legislation. The rest of the paper will explore the actions of Big Tech by drawing analogies to the actions of Big Tobacco.
We note that the analogy between Big Tobacco and Big Tech is not perfect. The analogy to Big Tobacco is intended to serve two purposes: 1) to provide a historical example with a rich literature to which we can compare current actions (i.e., help us know what to look for), and 2) to leverage the negative gut reaction to Big Tobacco’s funding of academia to enable a more critical examination of Big Tech. For example, when positing that peer-review could help us address the issues raised by conflicts of interests (as has been done by some readers), we urge the reader to consider the same suggestion with respect to Big Tobacco; the fields of life science, biology, and public health have peer-review systems but did not view the existence of peer-review as a solution. The exact limitations of this analogy are covered in discussion.
###
3.1. Big Tobacco
In 1954, Big Tobacco was facing a decline in public opinion as demonstrated and accompanied by the first ever decrease in demand of their product following the great depression (Brownell and
Warner, [2009](#bib.bib14)). Just two years prior in Reader’s Digest (which was a leading source of medical information for the general public), an article entitled “Cancer by the carton” was published discussing the link between smoking and lung cancer as presented by recent scientific studies (Norr, [1952](#bib.bib47)). While Big Tobacco internally acknowledged the conclusions drawn by these studies (Daube
et al., [2017](#bib.bib19); Glantz, [2000](#bib.bib29)), the threat to share value once the public was presented with this information was too large to leave unaddressed (Bates and Rowell, [1999](#bib.bib7)). In response, Big Tobacco released a public letter titled “A Frank Statement” (Tobacco Industry Research and others, [1954](#bib.bib59)).
“A Frank Statement to Cigarette Smokers” was a whole-page advertisement run by Big Tobacco in 1954 in over 400 newspapers reaching an estimated 43 million readers (Brownell and
Warner, [2009](#bib.bib14); Warner, [1991](#bib.bib65)). Signed by various presidents of Big Tobacco, the contents of the statement claimed they “accept an interest in people’s health as a basic responsibility, paramount to every other consideration in our business” and that Big Tobacco “always have and always will cooperate closely with those whose task it is to safeguard the public’s health” (Tobacco Industry Research and others, [1954](#bib.bib59)). This public relations campaign (run by public relations firm Hill & Knowlton (Bero
et al., [1995](#bib.bib8))) was part of a larger plan designed to both portray Big Tobacco as friendly corporations looking out for their consumers and purposefully sow doubt into the scientific research, which was showing conclusive links between smoking and lung cancer (Brandt, [2012](#bib.bib13)).
An important part of Big Tobacco’s plan was to “cooperate closely with those whose task it is to safeguard the public’s health” (Tobacco Industry Research and others, [1954](#bib.bib59)). This included the creation of the Tobacco Industry Research Committee (TIRC), later renamed to Council for Tobacco Research (CTR) in 1964 (Warner, [1991](#bib.bib65)). The stated purpose of this Council was to “to provide financial support for research by independent scientists into tobacco use and health” (Warner, [1991](#bib.bib65)). A statement by the CTR published in 1986 would boast “support of independent research is in excess of $130 million and has resulted in publication of nearly 2,600 scientific papers, with eminent scientists thinking that questions relating to smoking and health were unresolved and the tobacco industry will make new commitments to help seek answers to those questions” (Warner, [1991](#bib.bib65)). While the presented numbers are factually true, the underlying motivation behind such funding remained hidden until uncovered by litigation in 1998 (Bero
et al., [1995](#bib.bib8); Hurt et al., [2009](#bib.bib33); Malone and
Balbach, [2000](#bib.bib39)).
###
3.2. Big Tech
Just like Big Tobacco, Big Tech was starting to lose its luster (a trend which started in the second half of the 2010s (Doherty and Kiley, [2019](#bib.bib22))). Public opinion of these large technology corporations was starting to sour, as their image shifted from savior-like figures to traditional self-seeking corporations (Doherty and Kiley, [2019](#bib.bib22)). This decline in opinion was highlighted when it came to light that Facebook’s platform was used by foreign agents to influence the 2016 US presidential election (Adams, [2018](#bib.bib3)).
In Mark Zuckerberg’s opening remarks to the US Congress, he stated “it’s clear now that we didn’t do enough. We didn’t focus enough on preventing abuse and thinking through how people could use these tools to do harm as well” (Post, [2018](#bib.bib54)), and that Facebook was going to take their responsibility more seriously from now on. His opening statement is analogous to “A Frank Statement”, failing to recall how leaked internal emails stated that they were aware of companies breaking Facebook’s scraping policy, explicitly naming Cambridge Analytica (McCarthy, [2019](#bib.bib41)). It also failed to mention how this was not the first, rather one of many, apologies made by the CEO to the public for negative (often purposeful) decisions that were later discovered by the public (McCracken, [2018](#bib.bib42)).
Just like Big Tobacco, in response to a worsening public image, Big Tech had started to fund various institutions and causes to “ensure the ethical development of AI” (European
Commission, [2019](#bib.bib23)), and to focus on “responsible development” (Walker, [2019](#bib.bib63)). Facebook promised its “commitment to the ethical development and deployment of AI” (Facebook
Engineering, [2018](#bib.bib25)). Google published its best practices for the “ethical” development of AI (Google AI, [2018](#bib.bib31)). Microsoft has claimed to be developing an ethical checklist (Boyle, [2019](#bib.bib11)), a claim that has recently been called into question (Todd, [2019](#bib.bib60)). Amazon co-sponsored, alongside the National Science Foundation, a $20 million program on “fairness in AI” (Romano, [2019](#bib.bib55)). In addition to these initiatives, Big Tech had been busy funding and initiating centers, which study the impact of their work on society. Big Tech’s response to public criticism is similar to Big Tobacco’s response: pump vast sums of money into these causes. As such, we must purposefully approach such contributions with caution, and make sure to study and understand the underlying motivations, interests (including financial interests), and conflicts of interest (perceived or actual).
4. Methodology
---------------

Figure 1. Various ways tobacco industry money can find its way into academia, (recreated from Cohen et al. ([1999](#bib.bib17))).
Big Tobacco’s investment in academic institutions, Figure [1](#S4.F1 "Figure 1 ‣ 4. Methodology ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity") (recreated from (Cohen et al., [1999](#bib.bib17))), helped (and continues to help (Daube
et al., [2017](#bib.bib19); Waa
et al., [2020](#bib.bib61))) advance their business in numerous covert ways.
From the literature on Big Tobacco, we observe four main goals driving investment into academia. For Big Tobacco, funding research in the academy serves to:
* •
Reinvent itself in the public image as socially responsible;
* •
Influence the events and decisions made by funded universities;
* •
Influence the research questions and plans of individual scientists;
* •
Discover receptive academics who can be leveraged.
In this work, we explore whether Big Tech’s funding of research in the academy can serve the same purpose (i.e., help them achieve these four goals). We do this by drawing 1:1 comparisons between Big Tobacco and Big Tech’s actions for each of the four main goals. It is important to note that we can only see the intentions for Big Tobacco’s actions because of the wealth of information revealed by litigation. Therefore this paper does not make the claim that Big Tech is intentionally attempting to influence academia as we cannot prove this claim. Rather we believe that industry funding warps academia regardless of intentionality due to perverse incentives.
Ironically, Google adopts our view that industry funding warps research (Miller, [2017](#bib.bib44)). In their blog, Google questions the anti-Google work done by “Campaign for Accountability” (Campaign for
Accountability, [2017](#bib.bib15)) solely because the non-for-profit is funded by Oracle which has incentive to hurt Google (Miller, [2017](#bib.bib44)). Abstracting the proper nouns: they are questioning work done by seemingly external researchers because the researchers are funded by a tech company that has external (profit) incentives.
5. Reinvent itself in the public image as socially responsible
---------------------------------------------------------------
###
5.1. Big Tobacco
Big Tobacco created its funding agencies in a seemingly impartial manner. The CTR was advised by various distinguished scientists who served on its scientific advisory board (Brandt, [2012](#bib.bib13)). During its existence, hundreds of millions of dollars were provided to independent investigators at academic institutions across the US and abroad (Warner, [1991](#bib.bib65)). There is no doubt that a considerable amount of quality research was done as a result of this funding. However, the majority of the funding provided by the CTR went to research that was unrelated to the health effects of tobacco use (Bloch, [1994](#bib.bib10)). This contradicts the stated mission of “tobacco industry will make new commitments to help seek answers to those questions [i.e., the effects of tobacco usage on health]”.
Why is this the case? Those responsible for funding, usually lawyers instead of scientists (Bero
et al., [1995](#bib.bib8)), “would simply refuse to fund any proposals that acknowledged that nicotine is addictive or that smoking is dangerous” (Bero
et al., [1995](#bib.bib8)). Furthermore, they sought out and funded projects that would shift the blame for lung cancer away from tobacco to other sources (e.g., birds as pets (Cunningham, [1996](#bib.bib18))) (Bero
et al., [1995](#bib.bib8)).
However, the purpose in funding so many projects was to use the act of funding as proof of social responsibility. This pretense of social responsibility was presented to juries in multiple cases, such as a cigarette product liability trial in 1990 Mississippi, during which a list of all the universities and medical schools supported by CTR grants was presented to jurors (Bloch, [1994](#bib.bib10)).
###
5.2. Big Tech
Just like Big Tobacco, lawyers and public relations are involved in plotting the research direction and the tone of research done at these companies (including those with external collaborators in academia) (Dave and Dastin, [2020](#bib.bib20)). Leaked internal documents from Google, uncover PR directing “its scientists to ‘strike a positive tone’ in their research” (Dave and Dastin, [2020](#bib.bib20)).
Similar to how Big Tobacco created the TIRC to provide financial support to independent scientists to study tobacco and its influences on health, Big Tech has funded various similar institutions. Founded in 2016 by Google, Microsoft, Facebook, IBM, and Amazon among others, the “Partnership on AI [henceforth: PAI] to Benefit People and Society” was “established to study and formulate best practices on AI technologies, [… and study] AI and its influences on people and society” (Partnership on
AI, [2020](#bib.bib50)). Unfortunately, non-Big Tech members of this partnership realized that neither the “ACLU nor MIT nor any other nonprofit has any power in this partnership”, leading members to conclude “PAI’s association with ACLU, MIT and other academic/non-profit institutions practically ends up serving a legitimating function” (Ochigame, [2019](#bib.bib48)). More recently, Access Now (a human rights organization), recently left PAI stating that they “did not find that PAI influenced or changed the attitude of member companies or encouraged them to respond to or consult with civil society on a systematic basis” (Access Now, [2020](#bib.bib2)).
In addition to this joint partnership where industry interests prevail over public interest, each company has also been working on its own individual PR campaign. Google, in response to growing employee and public concern regarding its collaboration with the US military and Pentagon, created “an external advisory council” (Google AI, [2018](#bib.bib31)), which was later disbanded after a scandal surrounding one of its proposed members. Microsoft has created an internal committee to “ensure our AI platform and experience efforts are deeply grounded within Microsoft’s core values” (Nadella, [2018](#bib.bib45)). In response to the Cambridge Analytica scandal, Zuckerberg promised that Facebook will create “an independent group to study the abuse of social media in elections”, and that members will “be independent academics, and Facebook [will have] no prior publishing control” (Post, [2018](#bib.bib54)). More recently, in light of growing concerns regarding “fake news” and disinformation campaigns, Facebook announced it was giving away $300 million in grants to support journalism, to the ire of some academics (Ingram, [2018](#bib.bib34), [2019](#bib.bib35)).
While these efforts are likely to result in some tangible good (as did research funded by Big Tobacco), these efforts will be limited by the profit motives of corporations (Dave and Dastin, [2020](#bib.bib20)). Just as Big Tobacco leveraged research funding to avoid legal responsibility, Big Tech has used a similar line of argument to avoid scrutiny, demonstrated by Zuckerberg’s usage of “independent academics” to congress, Google’s boasting of “releasing more than [75 or 200] research papers on topics in responsible AI [2019 or 2020]” (Dean and Walker, [2019](#bib.bib21); Walker, [2020](#bib.bib64)).
6. Influence the events and decisions made by funded universities
------------------------------------------------------------------
###
6.1. Big Tobacco
Positive PR was not the only motivating factor behind providing money to institutions. Evidence has shown that Big Tobacco gains undeserved influence in the decision making process of universities that are dependent on them for money (Landman and
Glantz, [2009](#bib.bib38); Cancer Research
UK, [2002](#bib.bib16)).
Looking at a single public university, the University of Toronto (UofT), Imperial Tobacco withheld its (previously consistent) funding from the annual conference at the University of Toronto’s Faculty of Law as retribution for the fact that UofT law students were influential in having criminal charges be laid against Shoppers Drug Mart for selling tobacco to a minor (Cunningham, [1996](#bib.bib18)).
Other, more subtle, effects of Big Tobacco’s influence on academia’s decision making is that of delayed decisions or institutional inaction on tobacco control issues (Cohen et al., [1999](#bib.bib17)). While this can be achieved through funding threats, it is also possible through the planting or recruitment of friendly actors in academia. Examples of this include how the former President and Dean of law at the UofT, Robert Prichard, was a director of Imasco (a large tobacco company) (Cohen et al., [1999](#bib.bib17); Cunningham, [1996](#bib.bib18)). Additionally, Robert Parker who was the president and chief spokesperson for the Canadian Tobacco Manufacturers’ Council, was also on the Board of the Foundation of Women’s College Hospital, a teaching hospital also affiliated with UofT (Cohen et al., [1999](#bib.bib17)). The network of such placements, which have been documented in universities across many countries (Cunningham, [1996](#bib.bib18); Grüning
et al., [2006](#bib.bib32)), demonstrates how a university’s decisions could be affected by conflicts of interests.
Additionally, events sponsored by Big Tobacco (e.g., symposiums held about second hand smoking) have been shown to be skewed and of poorer quality compared to events not sponsored by Big Tobacco (Barnes and Bero, [1997](#bib.bib5); Bero
et al., [1994](#bib.bib9)) but still are cited by Big Tobacco when supporting its interests (Barnes and Bero, [1997](#bib.bib5); Bero
et al., [1994](#bib.bib9)).
###
6.2. Big Tech
Similar to Big Tobacco, positive PR is not the only motivating factor for Big Tech when providing funding for institutions. In addition to academic innovation and research helping advance industrial products, this funding also gives Big Tech a strong voice in what happens in conferences and in academia.
The top machine learning conference NeurIPS has had at least two Big Tech sponsors at the highest tier of funding since 2015. In recent years, the number of Big Tech companies at the highest tier of funding has exceeded five111The sponsorship info for NeurIPS was obtained from the “Sponsor Information for NeurIPS 20XX” page for each conference (e.g., <https://nips.cc/Sponsors/sponsorinfo>). We only counted Big Tech companies as sponsors if they were sponsoring at the highest possible level for the respective year.. When considering workshops relating to ethics or fairness222For each workshop, we gathered the list of organizers on the workshop’s website and searched the web for author affiliations (both past and present)., all but one have at least one organizer who is affiliated or was recently affiliated with Big Tech. For example, there was a workshop about “Responsible and Reproducible AI” sponsored solely by Facebook. From 2015 to 2019, the only ethics-related workshop at NeurIPS that did not have at least one organizer belonging to Big Tech, was 2018’s “Robust AI in Financial Services” workshop (which instead featured 4 heads of AI branches at big banks).
Such a conflict of interest persists even when considering conferences dedicated to examining the societal effects of technology. For example, FAccT (previously known as FAT\*) has never had a year without Big Tech funding: Google (3/3 years), Microsoft (2/3 years), Facebook (2/3 years)333The sponsorship info for FAccT was obtained from the “Sponsors and Supporters” page for each conference (e.g., <https://facctconference.org/2020/sponsorship.html>). While the conference organizers provide a “Statement Regarding Sponsorship and Financial Support”, it’s not clear how effective such a policy is at preventing the unconscious biasing of attendees and researchers. That is, despite research in other fields clearly demonstrating that industry funding negatively impacts work and subconsciously biases researchers (Goldberg, [2019](#bib.bib30); Marks, [2020](#bib.bib40); NewScientist, [2002](#bib.bib46); Owram, [2004](#bib.bib49)), many organizers and academics in computer science believe that this is not cause for concern without offering evidence to the contrary.
In public health policy, disclosure of conflicts of interests is simply seen as a mechanism to indicate the existence of a problem. We believe, as argued by Goldberg ([2019](#bib.bib30)) “rather than disclosure and management, the ethically paramount intervention targeted against behavior of partiality flowing from [conflict of interests] is the idea of sequestration. Sequestration refers to the idea of eliminating or at least severely curtailing relationships between commercial industries and […] professionals”.
Furthermore, there is work (Foroohar, [2019](#bib.bib28)) which demonstrates how this funding further purports Big Tech’s views and what solutions are and are not acceptable (Metcalf
et al., [2019](#bib.bib43)). By controlling the agenda of such workshops, Big Tech controls the discussions, and can shift the types of questions being asked and the direction of the discussion. A clear example of this was when, “[as] part of a campaign by Google executives to shift the antitrust conversation”, Google sponsored and planned a conference to influence policy makers going so far as to invite a “token Google critic, capable of giving some semblance of balance” (Foroohar, [2019](#bib.bib28)). Another example was the “Workshop on Federated Learning and Analytics” organized by Google researchers. Distinguishing between little “p” privacy from big “P” Privacy (the former being protecting data from adversaries (i.e., confidentiality) and the latter focusing on privacy as a human right with societal value), the workshop focused more on privacy over Privacy (Evans, [2019](#bib.bib24)).
Just like Big Tobacco, Big Tech has been busy building relationships with leaders in academia. Focusing again on the University of Toronto, the Vector Institute, has/had as faculty members a Vice President of Google and the heads of various companies’ AI branches such as Uber, and Nvidia. And although the institute is mainly funded by governments (about one third comes from industry (The Canadian
Press, [2017](#bib.bib58))), they have largely remained quiet regarding any of the ethical issues caused by those providing them funding. This is not necessarily because of their funders, but it would be unreasonable to assume that the risk of losing a third of one’s funding wouldn’t impact what the institute does in the public sphere. This is despite having some of the most renowned researchers on “fairness” in the field. In reality, fairness is relegated simply to a mathematical problem. This formulation of existing issues is in-line with the dominant “logics of Big Tech” (Metcalf
et al., [2019](#bib.bib43); Fazelpour and
Lipton, [2020](#bib.bib26)) which fails to consider the many questions and concerns raised by those outside of Big Tech.
7. Influence the research questions and plans of individual scientists
-----------------------------------------------------------------------
###
7.1. Big Tobacco
CTR purposefully funded many projects not related to studying the direct effects of increased tobacco usage on health outcomes. Through the allocation of its funds, it directly and indirectly impacted research questions and the direction of research when it came to the health effects of smoking (Bero
et al., [1995](#bib.bib8)). First and foremost, Big Tobacco actively sought out to fund any research that attempted to shift the blame from tobacco to other sources (Bero
et al., [1995](#bib.bib8); Bloch, [1994](#bib.bib10)). When this was not possible, Big Tobacco opted to steer funds from exploring the health effects of tobacco to studying the basic science of cancer (Bero
et al., [1995](#bib.bib8)). By dropping the tobacco link, the research was viewed as less threatening and therefore “fundable”, and, in other words, distracting scientists and the public by sowing seeds of confusion and discord in the public and scientific community.
Other actions included threatening to “take out ads […] that point out the flaws of studies” in an attempt to shame scientists and make working in the area against Big Tobacco a more difficult endeavor with no room for mistakes (Landman and
Glantz, [2009](#bib.bib38); Philip Morris, [1995](#bib.bib51)). Phillip Morris and RJ Reynolds (large tobacco companies) also worked with elected politicians to block the funding of scientists with opposing viewpoints: ensuring “that the labor-HHS (US Department of Health and Human Services) Appropriations continuing resolution will include language to prohibit funding for Glantz [a scientist opposing Big Tobacco]” (Landman and
Glantz, [2009](#bib.bib38); Philip Morris
and Boland, [1995](#bib.bib52)).
As most researchers have to seek out grants from funding bodies to perform their research, it is quite likely that they would seek funding from Big Tobacco or institutions under the sway of Big Tobacco (such as NCI and HHS). To increase the chances of approval, it would make sense that researchers would make changes to the types of questions they would explore, as it has been made clear that Big Tobacco would not be funding certain questions.
###
7.2. Big Tech
Just as many Big Tobacco-funded projects lead to tangible advancements in science and improved the lives of people, the same can be said for the majority of the work funded by Big Tech. As is the case with Big Tobacco, there is evidence that the types of questions being asked, the types of projects being funded, and the types of answers being provided are influenced by Big Tech.
An especially egregious example demonstrating how Big Tech attempts to influence the research questions and plans of scientists comes from leaked internal documents from Google, which tells “its scientists to ‘strike a positive tone’ in their research” (Dave and Dastin, [2020](#bib.bib20)). Just like tobacco companies, for research surrounding certain topics (e.g., effects of AI), researchers must consult with “policy and public relations teams” (Dave and Dastin, [2020](#bib.bib20)). At the very least, the public relation goals of the company influences academics who collaborate directly with industry researchers. This should be cause for concern, as the processes for approving industry grants to academics in universities may undergo similar public relations clearances thus suppressing work in the academy.
### Faculty Funding
A critical way Big Tech gains influence over AI ethicists, is by acting as a pseudo-granting body. That is, by providing a large amount of money to researchers, Big Tech is able to decide what will and won’t be researched. We show that a majority (58%) of AI ethics faculty are looking to Big Tech for money meaning that Big Tech is able to influence what they work on. This is because, to bring in research funding, faculty will be pressured to modify their work to be more amenable to the views of Big Tech. This influence can occur even without the explicit intention of manipulation, if those applying for awards and those deciding who deserve funding do not share the same underlying views of what ethics is or how it “should be solved”.
To demonstrate the scope of Big Tech funding in academia, we explored the funding of tenure-track research faculty in the computer science department at 4 R1 (top PhD granting) universities: Massachusetts Institute of Technology (MIT), UofT, Stanford, and Berkeley. We show that 52% (77/149) of faculty with known funding sources (29% of total) have been directly funded by Big Tech, Table [1](#S7.T1 "Table 1 ‣ Faculty Funding – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity"). Expanding the criteria to include funding at any stage of career (i.e., PhD funding) as well as previous work experience, we find 84% (125/148) of faculty with known funding sources (47% of total) have received financial compensation by Big Tech, Table [4](#S7.T4 "Table 4 ‣ Faculty Association – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity").
Both these percentages rise when we limit our analysis to faculty who have published at least one ethics or “fairness” paper between January 2015 and April 2020. With this criteria, we find that 58% (19/33) of faculty with known funding sources (39% total) have, at one point, been directly funded by Big Tech, Table [3](#S7.T3 "Table 3 ‣ Faculty Funding – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity"). Expanding the funding criteria to include graduate funding as well as previous work experience, we note that 97% (32/33) of faculty with known funding sources (65% total) have received financial compensation by Big Tech, Table [6](#S7.T6 "Table 6 ‣ Faculty Association – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity").
####
7.2.1. Methodology
Of the 4 R1 institutions (UofT, MIT, Stanford and Berkeley) we chose to study, two are private institutions (MIT and Stanford), while two are public institutions (UofT and Berkeley). Two of these institutions are on the eastern seaboard (UofT and MIT) and two are on the western seaboard (Stanford and Berkeley).
For each of these universities, we gathered a list of professors from their universities’ faculty listing for the computer science department:
* •
UofT: <https://web.cs.toronto.edu/contact-us/faculty-directory>
* •
MIT: <https://www.eecs.mit.edu/people/faculty-advisors/35>
* •
Stanford: <https://cs.stanford.edu/directory/faculty>
* •
Berkeley: <https://www2.eecs.berkeley.edu/Faculty/Lists/CS/faculty.html>
We removed all professors who were not both research stream and tenure track or those who where emeritus.
For each professor, we assessed them according to the following categories:
* •
“Works on AI?”: This was scraped from the department’s page where each faculties’ interests were listed.
* •
“Works on Ethics of AI?”: This was defined as having at least 1 ethics of AI/societal impacts of AI paper published from January 2015 to April 2020.
* •
“Faculty funding from Big Tech”: Has this faculty won any awards or grants from any of the companies classified as Big Tech? This field could be responded to with one of Yes, No or Unknown. Unknown was used to represent faculty who did not have enough information published on their website to allow us to make a conclusion. Of course, it may be possible that those classified as “No” simply chose not to list such awards on their personal websites, but we chose to treat published CVs as fully comprehensive.
* •
“Graduate funding from Big Tech”: Was any portion of this faculty’s graduate education funded by Big Tech? This includes PhD fellowships and post-docs. Like before, this field could be responded to with one of Yes, No or Unknown.
* •
“Employed by Big Tech”: Did this faculty at any time work for any Big Tech company? This includes roles as visiting researcher, consultant, and internships. Like before, this field could be responded to with one of Yes, No or Unknown.
#### Faculty Funding – Analysis
Our initial analysis explores direct funding of research by Big Tech. More specifically, we use our collected data to answer the question: “Has this faculty won any awards, grants, or similar awards from any of the companies classified as Big Tech?” Results for faculty with known funding sources is plotted in Figure [2](#S7.F2 "Figure 2 ‣ Faculty Funding – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity"), with detailed results in Tables [1](#S7.T1 "Table 1 ‣ Faculty Funding – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity"),[2](#S7.T2 "Table 2 ‣ Faculty Funding – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity"),[3](#S7.T3 "Table 3 ‣ Faculty Funding – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity"). Although we compare all computer science professors against those in “Ethics of AI”, we present faculty working in the area of AI to present what may be a large confounding factor (i.e., Big Tech’s growing interest in AI regardless of its ethics).
All Computer Science Faculty
CS Faculty in AI
CS Faculty in Ethics
4040404045454545505050505555555560606060525252525858585858585858484848484242424242424242ptPercentage of faculty funded by Big Tech(with known funding sources)YesNo
Figure 2. Bar chart presenting the percentage of computer science faculty members who received (at any point in their career) direct funding from Big Tech, stratified by different areas of specialization. NB: The axis intentionally does not start at zero.
Table 1. The number of computer science faculty who have won funding, grants, or similar awards from any of the companies classified as Big Tech. The results are also stratified by school.
| | Yes | No | Unknown |
| --- | --- | --- | --- |
| All Professors | 77 | 72 | 118 |
| UofT | 17 | 15 | 30 |
| MIT | 22 | 14 | 30 |
| Stanford | 20 | 16 | 25 |
| Berkeley | 18 | 27 | 33 |
Table 2. The number of computer science faculty working on AI who have won funding, grants, or similar awards from any of the companies classified as Big Tech. The results are also stratified by school.
| | Yes | No | Unknown |
| --- | --- | --- | --- |
| All Professors | 48 | 35 | 52 |
| UofT | 12 | 10 | 11 |
| MIT | 14 | 7 | 19 |
| Stanford | 11 | 8 | 10 |
| Berkeley | 11 | 10 | 12 |
Table 3. The number of computer science faculty who have at least 1 “Ethics of AI” publication who have won funding, grants, or similar awards from any of the companies classified as Big Tech. The results are also stratified by school.
| | Yes | No | Unknown |
| --- | --- | --- | --- |
| All Professors | 19 | 14 | 16 |
| UofT | 4 | 3 | 3 |
| MIT | 2 | 2 | 5 |
| Stanford | 6 | 2 | 3 |
| Berkeley | 7 | 7 | 5 |
#### Faculty Association – Analysis
This analysis explores any direct financial relationship between faculty members and Big Tech (past or present). More specifically we use our collected data to answer the question: “Has this faculty won any awards, grants, or similar awards from any of the companies classified as Big Tech?” OR “Was any portion of this faculty’s graduate education funded by Big Tech?” OR “Did this faculty at any time work for any Big Tech company?” Although we compare all computer science professors against those in “Ethics of AI”, we also present faculty working on AI to present what may be a large confounding factor (i.e., Big Tech’s growing interest in AI regardless of its ethics).
The purpose of such collection is not to imply that any past financial relationship would necessarily have a detrimental and conscious impact on the research of the scholar (i.e., we are not implying that graduate funding sources will consciously bias a professor’s views 10 years later). Rather, we believe that given the dominant views of ethics by Big Tech, repeated exposure to such views (in a positive setting) is likely to result in increased adoption and be a means of subconscious influence.
All Computer Science Faculty
CS Faculty in AI
CS Faculty in Ethics
002020202040404040606060608080808010010010010084848484888888889797979716161616121212123333ptPercentage of faculty affiliated by Big Tech(with known past affiliations)YesNo
Figure 3. Bar chart presenting the percentage of computer science faculty members who have at any point in their career received direct funding/awards from Big Tech or have been employed by Big Tech stratified by different areas of specialization.
Table 4. The number of computer science faculty who have had any financial association with Big Tech (e.g., won funding, were employees or contractors, etc.,). The results are also stratified by school.
| | Yes | No | Unknown |
| --- | --- | --- | --- |
| All Professors | 125 | 23 | 119 |
| UofT | 29 | 5 | 28 |
| MIT | 31 | 4 | 31 |
| Stanford | 32 | 5 | 24 |
| Berkeley | 33 | 9 | 36 |
Table 5. The number of computer science faculty working on AI who have had any financial association with Big Tech (e.g., won funding, were employees or contractors, etc.,). The results are also stratified by school.
| | Yes | No | Unknown |
| --- | --- | --- | --- |
| All Professors | 75 | 10 | 50 |
| UofT | 19 | 4 | 10 |
| MIT | 19 | 1 | 20 |
| Stanford | 9 | 0 | 2 |
| Berkeley | 14 | 1 | 4 |
Table 6. The number of computer science faculty with at least 1 “Ethics of AI” publication who have had any financial association with Big Tech (e.g., won funding, were employees or contractors, etc.,). The results are also stratified by school.
| | Yes | No | Unknown |
| --- | --- | --- | --- |
| All Professors | 32 | 1 | 16 |
| UofT | 7 | 0 | 3 |
| MIT | 2 | 0 | 7 |
| Stanford | 9 | 0 | 2 |
| Berkeley | 14 | 1 | 4 |
#### Funder – Analysis
Having shown the majority of faculty at these four school have at one point been directly funded by Big Tech, in this analysis we explore which corporations are directly responsible for the funding, Table [7](#S7.T7 "Table 7 ‣ Funder – Analysis ‣ Faculty Funding ‣ 7. Influence the research questions and plans of individual scientists ‣ The Grey Hoodie Project: Big Tobacco, Big Tech, and the Threat on Academic Integrity").
Table 7. Top 6 Big Tech companies which contribute directly to faculty research through grants, research awards, or similar means.
| | All | UofT | MIT | Stanford | Berkeley |
| --- | --- | --- | --- | --- | --- |
| Google | 44 | 8 | 13 | 10 | 13 |
| Microsoft | 25 | 3 | 5 | 9 | 7 |
| Amazon | 14 | 3 | 3 | 3 | 5 |
| IBM | 13 | 3 | 3 | 3 | 5 |
| Facebook | 13 | 3 | 3 | 4 | 3 |
| Nvidia | 9 | 5 | 0 | 1 | 3 |
### Journal Author Funding and Association
To demonstrate the influence of Big Tech funding in driving discussion regarding AI ethics and fairness in non-technical academia, we performed a systematic review of all articles published in the two leading non-technical journals: Nature and Science.
We find that of the 59% (10/17) of position papers ever published regarding the ethical/societal impact of AI has at least one author who was financially involved with one of these companies at one point in time (including faculty awards and former consulting gigs).
####
7.2.2. Methodology
In both Nature and Science, we obtained all commentary or prospective pieces published after 2015 that returned as a result of the following search terms (n=68𝑛68n=68italic\_n = 68):
* •
machine learning AND fairness,
* •
machine learning AND bias,
* •
machine learning AND ethics,
* •
machine learning AND racist,
* •
machine learning AND disparity,
We removed any articles that were not published by members of the academy or industry (i.e., journalists for the respective journals). We subsequently identified 17 papers of the remaining 51 articles as focusing on both AI and societal impacts (i.e. “ethics” or “implications” of AI and AI-related research).
At a minimum, these statistics444The data for all analyses discussed in this paper can be requested from the authors. demonstrate a clear conflict of interest between Big Tech and the research agendas of academics, regardless of intentions. As a result, it makes sense that much of the fairness work that exists holds the entrenched Big Tech view that “social problems can be addressed through innovative technical solutions” (Metcalf
et al., [2019](#bib.bib43)). We do not claim that opposing viewpoints are not present in academia. However, opposing viewpoints are likely to comprise a minority proportion of the work and discussion presented at such workshops, conferences, and symposiums.
8. Discover receptive academics who can be leveraged
-----------------------------------------------------
###
8.1. Big Tobacco
Part of the strategy devised by Hill (of Hill & Knowlton) leveraged skeptics within academia to sow doubt and foster distrust in the scientific findings (Brandt, [2012](#bib.bib13)). These skeptics were solicited, given funding, and had their message amplified into the public discourse (Boyse, [1988](#bib.bib12); Brandt, [2012](#bib.bib13); Philip
Morris Europe and Gaisch, [1987](#bib.bib53)). The result of such amplification resulted in new skeptics and the emboldening of existing ones – something in line with Big Tobacco’s goals. Based on memos released during litigation (Bero
et al., [1995](#bib.bib8)), Big Tobacco’s lawyers actively sought to discover academics whose research was sympathetic to their cause with the aim of funding any research that would allow them to claim that evidence regarding tobacco and lung cancer was inconclusive, such as research exploring if it was the keeping of birds as pets, as opposed smoking that increased the risk of lung disease (Bero
et al., [1995](#bib.bib8); Brandt, [2012](#bib.bib13)).
In addition to these activities, funding was reserved for researchers who would be used to testify at legislative hearings in favor of Big Tobacco. In fact, there was a concentrated covert effort on behalf of Philip Morris International to identify European scientists with no previous connections to tobacco companies who could be potentially persuaded to testify on behalf of Big Tobacco against proposed regulation on second hand smoking (Boyse, [1988](#bib.bib12)). This was part of the larger Whitecoat Project which resulted in infiltrations in governing officials, heads of academia, and editorial boards (Brandt, [2012](#bib.bib13); Landman and
Glantz, [2009](#bib.bib38); Philip
Morris Europe and Gaisch, [1987](#bib.bib53)).
###
8.2. Big Tech
Just as Big Tobacco leveraged its funding and initiatives to identify academics who would be receptive to industry positions and who, in turn, could be used to combat legislation and fight litigation, Big Tech leverages its power and structure in the same way.
Google was noted to “[groom] academic standard-bearers, prominent academics who will drive younger peers in a direction that is more favorable to the company” (Foroohar, [2019](#bib.bib28)). In an article published by The Intercept, we discover that Eric Schmidt, previously of Google, was advised on which “academic AI ethicists Schmidt’s private foundation should fund” (Ochigame, [2019](#bib.bib48)). This is not a one-time occurrence either. Schmidt also inquired to Joichi Ito (formerly of MIT’s Media Lab) if he “should fund a certain professor who, like Ito, later served as an “expert consultant” to the Pentagon’s innovation board” (Ochigame, [2019](#bib.bib48)). Another example of this recruitment is a professor at George Mason University, who had “written academic research funded indirectly by Google, and criticized antitrust scrutiny of Google shortly before joining the Federal Trade Commission, after which the FTC dropped their antitrust suit” (Foroohar, [2019](#bib.bib28); Campaign for
Accountability, [2017](#bib.bib15)). Or consider the case where Schmidt cited a Google-funded paper when writing to congress without mentioning that the paper had been funded by Google (Campaign for
Accountability, [2017](#bib.bib15)).
To demonstrate that this is not just the actions of high-level executives, consider the example of a former employee in the policy and public relations department at Google. The employee refutes Google’s claim that “Google’s collaborations with academic and research institutions are not driven by policy influence in any way” (Knight, [2020](#bib.bib37)), and presents an example where they, personally, intentionally leveraged a professor to influence policy (Fitzgerald, [2020](#bib.bib27); Basalisco, [2015](#bib.bib6)).
There is also investigative journalism that has uncovered examples of academics being funded by industry giants after presenting policy views (Wachter
et al., [2017](#bib.bib62)) positive of industry positions despite numerous criticisms from other experts in the field (Williams, [2019](#bib.bib66)). Following this funding, the academics released more policy position papers in line with industry positions without disclosing the financial connection (Williams, [2019](#bib.bib66)).
Such blatant and egregious interaction with academia harkens to Big Tobacco’s Project Whitecoat. The name of our paper is an homage to Project Whitecoat: Project Grey Hoodie is referencing the buying out of technical academics. These connections are not fully exposed or available to the general public or the majority of academics and thus quite difficult to analyze because unlike Big Tobacco there has been no litigation to uncover the needed documents for analysis (Cancer Research
UK, [2002](#bib.bib16)).
9. Discussion and Conclusion
-----------------------------
The conflict of interest in academia caused by industry funding is a systemic issue which exists at the societal level. Therefore, we believe that effective solutions will have to come from policy (either governmental or institutional). It is important to stress that our examination of individual researchers is not meant to call their integrity into question. We think that the vast majority of work in academia is done by well-intentioned and skilled researchers. We restate, that this influence can occur without an explicit intent to manipulate, but simply through repeated interactions where one party takes substantial sums of money or spends a large amount of time in an environment with different goals/views.
There are various limitations to our work. First, the funding patterns we observed cannot be generalized to all academics. There is work that shows that there is a concentration of computing power and funding at “elite” institutions (the four schools we considered would be classified as such) (Ahmed and Wahed, [2020](#bib.bib4)).
In addition to this, the analogy between Big Tobacco and Big Tech is both polarizing and imperfect. First, unlike Big Tobacco, Big Tech is largely considered to have had a net positive impact on society. Discussion of the effects of increased AI deployment is more difficult to conduct as the outcomes of these algorithms are not so obvious when compared to the effects of increased tobacco usage (i.e., it’s much easier to point to the death of an individual, than it is to demonstrate that Facebook’s recommendation algorithms are hurting society/democracy (Statt, [2020](#bib.bib57))). This is especially the case when Big Tech is simply acting as an intermediary to other actions (e.g., providing facial recognition as a service (to the police) or computer vision algorithms as a service (to the military) versus actually performing policing using facial recognition). Further compounding this issue, is the near impossibility of doing critical work without Big Tech granting access to systems that they protect as trade secrets. This means that academics wishing to do good must expose themselves to conflicts of interests, though we believe with smart legislation these companies can be forced to allow unaffiliated academics to access and analyze their systems. While we acknowledge the limitations of the analogy, our usage of it is purposeful. Initial feedback to our paper (from those not familiar with how conflicts of interests work) was very defensive. While workshopping the paper, well-meaning academics could not understand how this funding could sway research direction (and believed that “peer review” was enough to protect us against influence, though it is unclear why as life-science/health policy/public health also have peer-review). We found that by priming an intuitive negative gut reaction to conflicts of interest by bringing up Big Tobacco the reader was more likely to critically engage with the ideas raised in the paper.
In this work, we believe we have shown that the interactions between academia and Big Tech especially regarding studying the impact of technology on society are eerily similar to those between academia and Big Tobacco in the late 20th century. The truly damning evidence of Big Tobacco’s behavior only came to light after years of litigation (Hurt et al., [2009](#bib.bib33)). However, the parallels between the public facing history of Big Tobacco’s behavior and the current behavior of Big Tech should be a cause for concern555This parallel itself was made by a former executive of Facebook in reference to the design of their product. Former Facebook executive Tim Kendall’s congressional testimony states that in the pursuit of profit, Facebook “took a page from Big Tobacco’s playbook” (Kendall, [2020](#bib.bib36)).. Having been a part of this narrative before, the academy is responsible for not allowing history to repeat itself once again. Rephrasing calls to action from the fight against Big Tobacco “academic naiveté about [technology] companies’ intentions is no longer excusable. The extent of the [technology] companies’ manipulation [whether intentional or otherwise] needs to be thoroughly [researched and] exposed” (Yach and Bialous, [2001](#bib.bib68)).
There are many publicly proposed solutions to the societal problems caused by Big Tech from breaking up the companies to (and hopefully including) fixing the tax codes such that public institutions no longer need to rely on external funding for wages or to do their work. While we leave discussion regarding such in-depth solutions to a later work, we encourage the readers in academia to consider a stricter code of ethics and operation for AI-ethics research, separate from the traditional computer science department. Such a separation would permit academia-industry relationships for technical problems where such funding is likely more acceptable, while ensuring that our development of ethics remains free of influence from Big Tech money.
We understand that it might not be possible (and some would argue undesirable) to completely divorce academia from Big Tech. However, financial independence should be a requirement for those claiming to study the effect of their technologies on our society. Any change that is undertaken must be deliberate and structural in nature. However, in the meanwhile, here are a few steps that can be done right now to help decide future steps and questions:
* •
Every researcher should be required to post their complete funding information online. Lack of information was the biggest stumbling block to analyzing funding sources of current academics and in turn the possible effect industry has on academia. Any and all historic affiliations should also be listed as to enable studying of research networks.
* •
Universities need to publish documents highlighting their position regarding the appropriateness of direct researcher funding from Big Tech. These documents should be created to answer questions such as: Should Big Tech be able to directly fund a researcher’s work? Answering yes implies that Big Tech should have the ability to dictate what sort of questions public institutions should be looking at. While in certain technical problems this is appropriate, do the benefits outweigh the risks? Should the decision be made at the institution level or department by department? Maybe the answers depend on scientists’ research area? What are some possible alternatives? Maybe industry funding can only be directed at national funding bodies or departments but not individual researchers?
* •
There needs to be discussion regarding the future of the ethics and fairness of the AI field and their dealings with industry. Is it permissible to seek external funding sources given the historical effects such funding has had on critical work? How do we ensure that their work is not co-opted by the industry to push agendas that are not agreeable with societal goals?
* •
Computer science as a field should explore how to actively court antagonistic thinkers. To undo the current concentration of influence in the ethics of AI, computer scientists will have to forcefully expose themselves to unpleasant opposition to their ideas and meet this opposition with an open and receptive mind.
None of these points can be effectively done in a vacuum. We believe that academics should learn from the experiences of other fields when dealing with corporate initiatives.
10. Acknowledgments
--------------------
The majority of Mohamed’s funding comes from the Government of Canada (a Vanier scholarship), the Vector Institute, the University of Toronto, and the Centre for Ethics at the University of Toronto. The Vector institute is largely funded by public money but about one third comes from industry. Mohamed has previously interned at Google. Moustafa has no funding conflicts to report.
Special thanks is owed to LLana James and Raglan Maddox for their insight and feedback. We’d like to thank Saif Mohammad for his helpful discussions and pointing us to relevant news stories and Twitter threads with constructive criticism (and those providing constructive criticism in those threads). We are grateful for the reviewer’ feedback from AIES and the Resistance Workshop at NeurIPS 2020. We’d also like to thank Amelia Eaton for her copy-editing and feedback. |
bb52df14-e4aa-4441-9560-eaf6109f2039 | StampyAI/alignment-research-dataset/arxiv | Arxiv | A.I. Robustness: a Human-Centered Perspective on Technological Challenges and Opportunities
A.I. Robustness: a Human-Centered Perspective on
Technological Challenges and Opportunities
ANDREA TOCCHETTI∗, LORENZO CORTI∗, AGATHE BALAYN∗, MIREIA YURRITA, PHILIP
LIPPMANN, MARCO BRAMBILLA, and JIE YANG†
Despite the impressive performance of Artificial Intelligence (AI) systems, their robustness remains elusive
and constitutes a key issue that impedes large-scale adoption. Robustness has been studied in many domains
of AI, yet with different interpretations across domains and contexts. In this work, we systematically survey
the recent progress to provide a reconciled terminology of concepts around AI robustness. We introduce
three taxonomies to organize and describe the literature both from a fundamental and applied point of view:
1)robustness by methods and approaches in different phases of the machine learning pipeline; 2) robustness for
specific model architectures, tasks, and systems; and in addition, 3) robustness assessment methodologies and
insights, particularly the trade-offs with other trustworthiness properties. Finally, we identify and discuss
research gaps and opportunities and give an outlook on the field. We highlight the central role of humans
in evaluating and enhancing AI robustness considering the necessary knowledge humans can provide, and
discuss the need for better understanding practices and developing supportive tools in the future.
Additional Key Words and Phrases: Artificial Intelligence, Robustness, Human-Centered AI, Trustworthy AI
ACM Reference Format:
Andrea Tocchetti, Lorenzo Corti, Agathe Balayn, Mireia Yurrita, Philip Lippmann, Marco Brambilla, and Jie
Yang. 2022. A.I. Robustness: a Human-Centered Perspective on Technological Challenges and Opportunities.
In.ACM, New York, NY, USA, 35 pages. https://doi.org/XXXXXXX.XXXXXXX
1 INTRODUCTION
Artificial Intelligence (AI) systems have been widely adopted in diverse areas such as medicine [ 26]
or education [ 111]. Although AI systems show potential and are expected to revolutionize existing
workflows by combining human- and non-human skills [ 20], there is still little insight into how
we should deal with the trade-offs of combining human and artificial agency, or the way in which
these systems should be assessed and held accountable [ 70]. Furthermore, concerns about bias
[32], inscrutability [ 12], and vulnerability [ 98] have also been raised. Consequently, several social
actors, like the European High-Level Expert Group, have highlighted the need for socio-political
deliberation around the design and governance of AI systems, and have defined principles for
Trustworthy AI, i.e., the Ethics Guidelines for Trustworthy AI [187].
One of the core principles of Trustworthy AI is robustness [ 70], defined in Machine Learning
(ML) as the insensitivity of a model’s performance to miscalculations of its parameters [155,268].
Examples like Tesla’s Full Self-Driving mechanism erroneously identifying the moon as a yellow
∗The authors contributed equally to this research.
†Andrea Tocchetti and Marco Brambilla are with Politecnico di Milano, Email: {andrea.tocchetti, marco.brambilla}@polimi.it;
Lorenzo Corti, Agathe Balayn, Mireia Yurrita, Philip Lippmann, and Jie Yang (corresponding author) are with Delft University
of Technology, Email: {l.corti, a.m.a.balayn, m.yurritasemperena, p.lippmann, j.yang-3}@tudelft.nl.
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee
provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and
the full citation on the first page. Copyrights for third-party components of this work must be honored. For all other uses,
contact the owner/author(s).
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
©2022 Copyright held by the owner/author(s).
ACM ISBN 978-1-4503-XXXX-X/18/06.
https://doi.org/XXXXXXX.XXXXXXX
1
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
traffic light,1or Autopilot being fooled by stickers placed on the ground,2show that AI systems
might be susceptible to errors and vulnerable to external attacks. This may result in undesired
behavior and decreased performance [ 250]. Given the application of AI systems in safety-critical
areas (e.g., medical diagnosis [ 22]), it is paramount to design reliable systems, so that they can be
properly and safely integrated in the context of use. In response to this need, a growing body of
literature focuses on developing and testing robust AI systems. Methodologies towards robust AI
have addressed every phase of the ML pipeline, going from data collection and feature extraction,
to model training and prediction [ 250]. Such methodologies have also been applied to a wide range
of tasks and application areas, including (but not limited to) image classification [ 213] and object
detection [45] in Computer Vision, or text classification in Natural Language Processing [113].
Considering the increasing efforts devoted to this field within Trustworthy AI, in this paper we
seek to analyze the progress made so far and give a structured overview of the suggested solutions.
Furthermore, we also aim at identifying the areas that have received least attention, highlighting
research gaps, and projecting into future research directions. Our work differs from similar efforts
in three main ways. (1) As opposed to some previous work [ 37,80,250], we do not limit the scope
of our analysis to adversarial attacks. We argue that, as suggested by Drenkow et al . [64] or Shen
et al. [196] , natural (i.e., non-adversarial) perturbations constitute a common real-world menace
that needs further attention. (2) As far as the application area is concerned, and contrary to surveys
solely focusing on tasks like Computer Vision [ 64] or architectures like Graph Neural Networks
[196], we do not limit our survey to any technology in particular. We rather conduct our search
in a task-agnostic way. Such an approach helps us identify the most prominent trends within the
field and compare the differences in effort and interest across applications as part of our survey.
(3) Most importantly, we adopt a human-centered perspective for highlighting the technological
challenges and opportunities in the field of robust AI. We argue that previous work, which is
predominantly algorithm centric, fails to identify the potential of human input when crafting
robust algorithmic systems. We also emphasize the need to understand current human-led practices
in order to integrate robustness into existing workflows and tools. To this end, we advocate for a
multidisciplinary approach and bring insights from human-centered fields, such as explainable AI,
crowd computing, or human-in-the-loop machine learning.
We, therefore, make the following contributions:
(1)We give an overview of the main concepts around robust AI. We consolidate the terminology
used in this context, disentangling the meaning and scope of different constructs. We pay special
attention to identifying the commonalities and differentiating aspects of the used terms.
(2)We systematically summarize 380 papers on robust AI and related concepts and arrange them
in three different taxonomies. First, we group papers that improve robustness by working on
different aspects of the ML pipeline. We identified three main aspects that the selected studies
work on: input data, in-model attributes, and model post-processing aspects. Second, we focus
on distinct architectures and application areas of robust AI systems and define robustness
forspecific architectures (e.g., Graph Neural Networks), specific tasks (i.e., Natural Language
Processing and Cybersecurity), and systems conceived within other fields of Trustworthy AI (i.e.,
explainable and fairness-aware systems). We focus on these particular architectures, systems,
and fields as they have comparatively received little attention in previous surveys despite the
importance of robustness as a desired property. Third, we create a taxonomy related to the
assessment of robust AI systems.
1https://www.autoweek.com/news/green-cars/a37114603/tesla-fsd-mistakes-moon-for-traffic-light/ (access 13.10.2022)
2https://keenlab.tencent.com/en/whitepapers/Experimental_Security_Research_of_Tesla_Autopilot.pdf (access 13.10.2022)
2
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
(3)We identify and discuss disparate research efforts in each of the established fields and identify
research gaps. Specifically, we make a special in-depth analysis of the opportunities brought by
one of the identified research gaps: the absence of human-centered work in existing methodolo-
gies. We highlight the multidisciplinary nature of the robust AI field and provide an outlook for
future research directions, bringing insights from human-centered fields.
The remainder of the paper is organized as follows. In section 2, we detail the methodology we
used for conducting our systematic review. In section 3, we give an overview of the terms that
are currently being used in the field of robust AI, which informed our clustering of the literature.
We also clarify the definitions that we will use throughout the paper. Then, in section 4, section 5,
and section 6, we conduct our survey and generate the aforementioned taxonomy. In section 7, we
identify the most prominent research areas, pinpoint fields that require more research efforts, and
highlight future research directions. Finally, in section 8, we further develop our discourse on the
lack of human-centered approaches to robust AI, before concluding in section 9.
2 SURVEY METHODOLOGY: PAPER COLLECTION
In this chapter, we detail the process applied to collecting the final list of articles considered in
this literature review. This includes keyword collection and curation, querying multiple databases,
de-duplication, manual filtering, tagging, and analysis.
2.1 Collecting Papers
Defining Keywords. First, we curated the list of keywords to be used for querying articles. We
inspected key definitions of robustness and robust AI [ 39,84,172] in the context of Computer Science
and organized a preliminary list. We further enriched this list such that it covers aspects related to
the trustworthiness of AI systems and to human-centeredness (including human knowledge) given
the lack of a common viewpoint on robustness. Table 1 shows the complete list of keywords used.
Group Name Keywords
Fundamental Robustness, Robust
Scope Artificial Intelligence, Machine Learning, Neural Network
ContextTrustworthy, Stability, Resilience, Reliability, Accountability, Transparency, Reproducibility
Accuracy, Confidence, Performance, Design, Adversarial, Unknowns, Noise
Human Computation, Human Knowledge, Human-In-the-Loop, Human Interpretation, Knowledge
Base, Knowledge, Knowledge Elicitation, Reasoning
Explainability, Explanation, Interpretability, Interpretable
Table 1. The groups of keywords considered in the data collection process and the corresponding keywords.
Querying Publication Databases. Secondly, we queried multiple databases by generating all
possible triples of keywords based on the groups we defined. This led to 156 unique search queries
structured as a conjunction between the chosen keywords, e.g., "Robustness" AND "Artificial
Intelligence" AND "Explainability". Articles have been collected in July 2022 through Publish or
Perish3by querying the following supported bibliographical databases: Google Scholar4, Scopus5,
3Harzing, A.W. (2007) Publish or Perish, available from https://harzing.com/resources/publish-or-perish
4Google Scholar: https://scholar.google.com/
5Scopus: https://www.scopus.com
3
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
7000
100020122015201620172018201920202021202220142013060005000400030002000
Fig. 1. Temporal distribution of the 35,800 unique papers published in the last 10 years. It is possible to
observe a growing trend of published papers about Robust AI over the years. The amount of papers collected
in 2022 is not to be considered relevant to this trend as the data was collected in July 2022.
Semantic Scholar6, and Web of Science7. We limited the number of papers collected per query to 200
to comply with the limitations imposed by Publish or Perish and the aforementioned bibliographical
databases. Moreover, given the breadth of the literature on trustworthy and robust AI, we inspect
literature from the last 10 years, i.e., articles published between January 2012 and July 2022.
2.2 Filtering Papers
Pre-filtering. We collected about 100,000 papers distributed as follows: 31,000 from Google Scholar,
18,450 from Scopus, 30,800 from Semantic Scholar, and 19,400 from Web of Science. Considering the
breadth of the data collection, we sought to remove any duplicate entries in our results. Papers that
had the same title and authors were filtered out, resulting in 45,400 papers. Duplicates that were
undetected at this stage were discarded in the later ones. Then, papers published before the period
of interest (January 2012 to July 2022) were filtered out, leading to 35,800 articles. Figure 1 displays
the time distribution of the collected papers. We observe a growing interest in the considered topics
over the years, which (partially) motivates the time constraints applied.
Further Inspecting Papers. At this stage, we manually inspected the abstracts of the collected
papers to exclude the ones whose context or content require domain-specific expertise (e.g., health-
care), or deal with a notion of “robustness" that is not related to machine learning (e.g., signal
processing). We ended up with 1,800 interesting papers. While inspecting papers, we marked them
with specific keywords, e.g., “Computer Vision” or “Loss Function”, to differentiate them in terms of
content and type of publication (e.g., “Literature Review”). Consequently, we used those keywords
to perform a final filtering step in which the papers tagged with the least frequent keywords,
i.e., appearing only once, were excluded. Omitted keywords include: “audio signal” and “event
detection”. Throughout the entire process, we carefully analyzed the papers such that they contain
significant or late progress in the area despite them not being peer-reviewed yet (e.g., from arXiv),
building our final set of papers. In the end, this thorough inspection led to 560 papers that were
systematically analyzed, out of which 380 papers were systematically summarized and discussed8.
The list of collected, filtered, and summarized papers can be found on GitHub9.
6Sematic Scholar: https://www.semanticscholar.org/
7Web of Science: https://www.webofscience.com/
8Due to space limit, we leave the discussions of some papers (about 30%) in the supplementary material.
9https://github.com/AndreaTocchetti/ACMReviewPaperPolimiDelft.git
4
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
3 OVERVIEW OF THE MAIN CONCEPTS SURROUNDING ROBUSTNESS
From our collection of papers, we evinced that the notion of Robustness is ill-defined. A number
of Machine Learning sub-domains refer to robustness from different viewpoints. We clarify the
relations between these domains in subsection 3.1. We also identify that a number of concepts
directly related to robustness are used in different ways across research papers (Figure 2). We
disambiguate the interpretation of related terms in subsection 3.2. Finally, our analysis of the papers
surfaced a few recurring themes, introduced in subsection 3.3, and used to organize our survey.
R obustnessCertified
R obustness
Natur al R obustnessP erturbationsDistribution ShiftsNoiseGener alizationAdversarially R obust Gener alizationNon-Adversarial
Gener alizationT est Set
P erformanceAdversarial
R obustnessAdversarial
AttacksLp R obustnessF airnessML
ExplainabilityML T estingUnkno wns
Fig. 2. Main concepts found through our analysis of the literature on Robust AI.
3.1 The Various Shades of Robustness
Given the broadness of the literature on robustness and the variety of contexts in which it is con-
sidered, addressed, and analyzed, we discuss and provide a common ground about the definitions
of robustness and its associated concepts. Particularly, robustness is generally defined as the insen-
sitivity of a model’s performance to miscalculations of its parameters [155,268], with Nobandegani et
al. [155] stating that robust models should be insensitive to inaccuracies of their parameters, with little
or no decline in their performance . Two main robustness branches have been identified: robustness
to adversarial attacks or perturbations, and robustness to natural perturbations.
3.1.1 Adversarial Robustness. Adversarial Robustness refers to the ability of models to maintain
their performance under potential adversarial attacks and perturbations [ 278]. Adversarial pertur-
bations are imperceptible, non-random modifications of the input to change a model’s prediction,
maximizing its error [ 217]. The result of such a process is called an adversarial example, i.e., an
input 𝑥′close to a valid input 𝑥according to some distance metric (i.e., similarity), whose outputs
are different [ 38]. Such data is employed to perform adversarial attacks, whose objective is to find
any𝑥′according to a given maximum attack distance [ 45]. The literature presents different classifi-
cations of adversarial attacks: targeted and untargeted [ 44], and white-, grey-, or black-box [ 147].
Targeted attacks generate adversarial examples misclassified as specific classes, while untargeted
attacks generate misclassified samples in general. The main difference between white-, grey-, and
black-box attacks is the attacker’s knowledge about the model or the defense mechanism.
A similarity metric is often defined when generating attacks or evaluating robustness. Depending
on the input domain, different metrics can be applied. These metrics are built as a function of a
parameter (usually denoted with the letter 𝑝) whose value influences its computation. For example,
Carlini et al. [ 38] define a generic 𝑝norm from which different metrics with different meanings are
5
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
derived. In their case, when 𝑝= 0 (𝐿0distance), the number of coordinates for which the valid and
perturbed input are different is measured; when 𝑝= 2 (𝐿2distance), the standard Euclidean distance
between the valid and perturbed input is computed; when 𝑝= infinite ( 𝐿∞distance), the maximum
change to any coordinate is measured. A particular type of robustness is Certified Robustness that
guarantees a stable classification for any input within a certain range [53].
3.1.2 Natural Robustness. Natural Robustness (a.k.a. Robustness against natural perturbations) is
the capability of a model to preserve its performance under naturally-induced image corruptions or
alterations. [ 64]. Natural Perturbations (a.k.a. Common Corruptions [ 88] or Degradations [ 78]) are
introduced through different types of commonly witnessed natural noise [ 238], e.g., Gaussian noise
in low lighting conditions [ 88], and represent conditions more likely to occur in the real world
compared to adversarial perturbations [ 64]. Temporal Perturbations are natural perturbations that
hinder the capability of a model to detect objects in perceptually similar, nearby frames in videos
[191]. All these perturbations result in a condition where the distribution of the test set differs
from the one of the training set [ 108]. This condition is typically referred to in the literature with
overlapping concepts, namely distribution shift [ 60,220], Out-of-Distribution data (OOD) [ 79,196],
and data outside the training set [165].
3.1.3 Generalisation. Generalisation is another widely used term in the robustness literature. In
general, it is defined as the model’s performance on unseen test scenarios [ 163] or as the closeness
between the population (or test error) to the training error, even when minimising the training
error [ 153]. Two other types of generalization are also reported: adversarially robust [ 267] and
non-adversarial generalizations [ 79,165,246,277]. While the first one refers to the capability of a
model to achieve high performance on novel adversarial samples, the second one is evaluated on
non-adversarial samples (e.g., natural perturbations [246, 277], distribution shifts [79, 165], etc.).
3.1.4 Performance. Across the inspected literature, the term performance is employed with a broad
variety of meanings. Depending on the aspect of interest, it may refer to accuracy [ 64], robustness
[115], runtime [ 199], or precision [ 258]. Given such variety, the actual meaning of performance
will be addressed only when relevant to understand the concepts explained in the core survey.
3.2 Domains Adjacent to Robustness
Machine learning (ML) explainability, fairness, trustworthiness, and testing, are four research
domains recurring across robustness literature. While there is no agreed upon definition of each of
these fields and their goals, and we acknowledge it is not possible and desirable in the scope of
this survey to provide a complete overview of these fields, we provide here explanations that are
sufficient to understand the relation these fields bear to robustness.
3.2.1 Explainability. ML explainability is the field interested in developing post-hoc (explainability)
methods and (inherently explainable) models that allow the internal functioning of ML systems to be
understandable to humans [ 39]. We identify three types of relations between the explainability and
robustness fields. A number of papers investigates how explainability methods can be used in order
toenhance the robustness of models (see subsubsection 4.2.3). Another set of papers investigates how
robust existing explanability methods are to various types of perturbations (see subsubsection 5.3.1).
A last set of papers instead studies how existing methods for enhancing robustness trade off with
the explainability of the models, and especially with the alignment between the model features,
and the features a human would expect the model to learn (see subsubsection 6.3.3).
We also consider the field of (un)known unknowns [136] close to robustness, as they are typically
caused by OOD samples. In this field, methods to identify and mitigate the presence of such
6
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
R obustness AssessmentT r ade-Offs with Other Conceptswith Accur acywith F airnesswith ExplainabilityStudies & Insightson Adversarial R obustnesson NLPon R obustness to Natur al
P erturbationsEvaluation Str ategiesBenchmarkMetricsEvaluation ProceduresR obustness F or - R obustness in Pr actical FieldsExplainabilityF airnessOther T rustw orthy AI ConceptsSpecific Application AreasNLPCybersecuritySpecific ArchitecturesGr aph NNsBayesian L earningR obustness By - Methods and Approaches for Impro ving R obustnessModel P ost-ProcessingUnnecessary or Unstable
Model AttributesF using ModelsOutput R epresentationsDesigning In-Model R obustnessT r aining for R obustnessDesigning R obust ArchitecturesL ever aging Explainability
MethodsProcessing the T r aining DataGener ating Adversarial AttacksAugmenting Data forAdversarial R obustnessNon-Adversarial R obustness
Fig. 3. The three themes and their sub-categories that shape our survey.
unknowns are developed and, while these methods typically fall within explainability [ 193,229],
they are directly applicable to increase the robustness of a model.
3.2.2 Fairness. ML fairness in the broad sense is the field interested in making the outputs of
an ML model non-harmful to the humans who are subject to the decisions made based on these
outputs. Researchers in this field have developed a number of fairness metrics [ 232] and methods
for mitigating unfairness [ 138]. We identify two types of relations between this field and robustness,
similar to the relations between explainability and robustness: robustness of fairness metrics and
methods to different types of natural and adversarial perturbations (see subsubsection 5.3.2) and
trade-offs caused by the application of robustness methods (see subsubsection 6.3.2).
3.2.3 Testing. ML testing [ 270] is a field emanated from software testing. It consists in developing
methods and tools to identify and characterize any discrepancy between the expected and actual
behavior of a ML model. While this field bears a broader scope since brittleness to different
perturbations represents one of the many types of unexpected behavior of a model, it is also narrow
as it is solely interested in detecting the issue, but not its mitigation. Naturally, methods developed
in this field could potentially be adapted in the future to better detect robustness-related issues.
3.3 Themes in Relation to These Robustness Shades and Related Domains
Analyzing the collected publications through a thematic analysis approach [ 30], we iteratively and
collaboratively identified three primary themes and three recurring categories within each of these
themes (nine categories in total) that were deemed worth emphasizing (summarized in Figure 3).
3.3.1 Robustness Methods. The most studied methods to achieve robustness are described in
section 4. They are categorized according to the stage of the ML pipeline to which they apply, that
is either the processing of the training dataset, the model creation stage, or the post-processing of
7
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
the trained model. Within each of these stages, the approaches vary across publications, and were
further clustered into groups based on types of robustness (e.g., adversarial or natural perturbations),
and specific ML component (e.g., training procedure or model architecture) they apply to. For each
of the groups, we further delve into sub-groups based on the types of transformation applied to the
component (e.g., different loss functions or regularizers), and describe the main similarities and
differences across transformations, e.g., in terms of technical approach and performance.
3.3.2 Robustness in Practical Fields. While a majority of papers concentrate their studies and the
evaluation of their robustness methods around computer vision or do not mention a specific field, we
also identify a consequent number of papers that bear different focuses. We separated these papers
from the ones discussed above, because they present particularities that are worth investigating.
We categorize these papers broadly based on their research fields, and discuss them in section 5.
Within each of the categories, we describe the most researched sub-types for which we retrieved
the most literature. Particularly, we identified focuses relating to specific model types (Graph
Neural Networks and Bayesian Learning), specific application areas (Natural Language Processing,
and Cybersecurity), and specific concepts within the trustworthy AI domain (explainability and
fairness). The latter is particularly interesting because it differs from other works in its objectives.
Contrary to all other papers which investigate model performance under perturbations, it instead
investigates evolution of the fairness and explanations of a model under the effect of perturbations.
3.3.3 Robustness Assessment. The last theme we identified, described in section 6, revolves around
the assessment of the robustness of a system. Particularly, the importance of developing procedures
(methodologies, benchmarks, and metrics) to evaluate robustness emerged from the papers and
these procedures revealed to vary greatly across publications (be it publications whose primary
contribution is an evaluation procedure, or a robustness method that requires to be evaluated
through a defined procedure). We also identified a set of publications whose primary objective is to
perform studies to evaluate existing robustness methods and collect insights to further characterize
in which conditions each type of method performs best. Finally, the last recurring theme was
trade-offs, as many papers that propose or evaluate robustness methods tackle trade-offs while
striving to achieve other objectives, be it the model performance or the other trustworthy AI
concepts identified earlier. The publications in this section of the survey are typically falling under
the umbrella of computer vision publications, or of the different fields highlighted above.
4 ROBUSTNESS BY: METHODS AND APPROACHES FOR IMPROVING ROBUSTNESS
4.1 Processing the Training Data
With the final aim of improving model robustness against adversarial attacks, noise, or common
perturbations, several approaches focus on generating perturbations to perform data augmentation.
4.1.1 Generating Adversarial Attacks. A number of papers tackle the challenge of developing
methods to generate adversarial attacks that prove deep learning models brittle. The proposed
methods vary with regard to three main objectives. a) The type of task targeted: e.g., natural
language processing model [ 42,101], image classification [ 38] or object detection models [ 46]. b)
The type of constraints imposed on the attack: e.g., attack on the physical space before capturing the
digital data sample (e.g., by sticking images patches on the physical object to be recognized [ 238]),
or by processing this digital input sample [ 46]; general attack or attack that targets a particular
component of the model (e.g., rationalizers of rationale models [ 42]); attacks that preserve certain
properties of the input sample such as human consistency (e.g., Jin et al. [ 101] talk about human
prediction consistency, semantic similarity, and text fluency with regard to the generated adversarial
text samples), additionally to satisfy the constraint on similarity to the original sample [ 101]. c)
8
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
The type of brittleness targeted, e.g., the model makes a different (wrong) prediction when the
transformed sample is inputted, or the explanations of the prediction also becomes flawed (i.e., the
identified important features are not the correct ones) [ 247]. The works then differ by the approach
taken to generate the attacks, be it through different optimization instances (objective functions)
they use to find adversarial instances that fit the problem [ 38,46], by leveraging Generative
Adversarial Networks (GAN) [1], or through a rule-based algorithmic approach [42, 101].
4.1.2 Augmenting Data for Adversarial Robustness. Most of the identified literature focuses on
transforming [ 25,41,222,280], generating [ 4,47,115,214,237] or employing ready-to-use [ 57]
data and/or adversarial samples to extend or create datasets to train more robust models. Such a
data augmentation process can successfully improve adversarial robustness [ 41,57,115,214,222,
237,280] and adversarial accuracy [ 4], while sometimes reducing time costs [ 41], and adversarial
attack success rate [ 25]. When defending against adversarial attacks, GAN-based solutions are
proven useful in achieving such an objective [ 1,73,214,237]. In particular, they are employed
to generate adversarial samples [ 1], perturbations [ 237], and boundary samples [ 214] to defend
the networks against adversarial attacks. While most methods apply complex transformations to
improve robustness, simple transformations, like rotation [ 222] and image background removal
[228], are still proven effective. However, extending the training set is not always enough by itself.
Hence, ad-hoc training procedures [ 41,47] must be set in place to select [ 47] and adapt [ 41] the
optimal training data to achieve adversarial robustness.
4.1.3 Augmenting Data for Non-Adversarial Robustness. Not all researchers aim to enhance models’
defense against adversarial robustness. Noise [ 171], non-adversarial perturbations [ 73,115,154,280],
spurious correlations [ 41,242], and distribution shift [ 165,272] hinder the performance and re-
silience of models. In tackling such impairments, human rationale collection allows the generation
of new datasets [ 165], counterfactual-augmented data [ 41] and the definition of proper perturba-
tion levels [ 154], consequently improving performance [ 41], and model [ 154], and distributional
shift [ 165] robustness. Custom [ 171] and pre-existing approaches are applied to perform data
augmentation, consequently improving noise robustness [ 171] and performance [ 171]. On the other
hand, data transformation [ 73,280] and training [ 115] approaches are applied to improve model
robustness [73, 115, 280] and reduce training time [73].
4.2 Designing In-Model Robustness Strategies
4.2.1 Training for Robustness. Training plays an integral part in creating machine learning models.
Concerning robustness, Adversarial Training is the de-facto standard for building robust models.
The core intuition behind it is to complement natural data with perturbed one such that models
incorporate information about data that better represent real-world scenarios’ variability. In this
section, we discuss adversarial training approaches that adaptively change the perturbation magni-
tude, allow for the learning of robust features, or include novel loss or regularisation functions.
Finally, we discuss approaches alternative to adversarial training.
Training with Dynamic Perturbations. In this category, Madaan et al . [132] and Cheng et al . [50]
propose methods to generate dynamic perturbations at the level of single data instances that are
then controlled by enforcing label consistency in the former case, and smooth labels in the latter.
Differently, Rusak et al . [183] devise a neural network-based adversarial noise generator to tackle
the online generation of perturbations.
Training Robust Feature Representations. An alternative strategy to dynamically enrich data
while training is that of pushing the model to learn more robust feature representations. Scholars
have achieved this in multiple ways, from designing novel methods altogether [ 109] to employing
9
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
additional classifiers [ 14]. For example, Yang et al . [259] propose to apply perturbations on textual
embeddings such that the corresponding words would be drawn toward positive samples rather
than adversarial ones. Bai et al . [14] take a modeling approach to obtain robust features through
the addition of auxiliary models to identify which channels in CNNs are more robust.
Adversarial Training Algorithms. Adversarial Training has proven to be a fundamental tool to
build robust models and that is reflected in the amount of literature available for it: researchers
have focused in improving the whole process and proposed a plethora of algorithms [ 85,133,
212,221,241], borrowing different ML paradigms like self-supervised and unsupervised learning
[152,226], that are applicable to a variety of tasks, e.g., content recommendation [ 248,264]. In
this context, Projected Gradient Descent (PGD) [ 133] is a common white-box (i.e., the attacker
knows everything about the model) algorithm. On the same note, Terzi et al . [221] and Gupta et al .
[85] propose extensions of PGD by using Wasserstein distance in the adversarial search space, by
replacing the initial adversarial training stages with natural training, or by encouraging the logits
from clean examples to be similar to their adversarial counterparts, respectively. On the other
hand, several works focus on leveraging other types of information. For example, Zoran et al . [284]
adversarially train and analyze a neural model incorporating a human-inspired, visual attention
component guided by a recurrent top-down sequential process. Shifting to model outputs, works
from Wang et al . [241] and Stutz et al . [212] focus on differently treating misclassifications and
rejecting low-confidence predictions. Similarly, Haase-Schütz et al . [86] and Cheng et al . [49] deal
with progressively tuning labels starting from unlabelled data and through smoothing, respectively.
Training with Adapted Regularizers. Regularisation is another tool that ML engineers can use
when building models and, as such, it has also been used to make them more robust. Li and
Zhang [120] propose a PAC-Bayesian approach to tackle the memorization of training labels in
fine-tuning. Chan et al . [40] suggest an approach that optimizes the saliency of classifiers’ Jacobian
by adversarially regularizing the model’s Jacobian to resemble natural training images.
Training with Adapted Loss Functions. Loss functions are essential objectives used to train ML
models. Concerning robustness, a variety of loss functions have been used to incorporate specific
objectives: triplet loss [ 135], minimising distance between true and false classes [ 123], mutual
information [ 253], consistency across data augmentation strategies [ 218], perturbation regularizers
[255], adding maximal class separation constraints [ 149], combining multiple losses [ 107] (e.g.,
Softmax and Center Loss), or approximating existing losses (e.g., Categorical Crossentropy) [ 68]. It
is worth noting that loss functions tailored for robustness are not exclusive to models trained in
isolation and robust and natural models (acting as regularizers) can be jointly trained [9].
Beyond Adversarially Training. Researchers have studied alternative training procedures to
adversarial training. Staib [210] has analyzed the relationship between adversarial training and
robust optimization, proposing a generalization of the former which leads to stronger adversaries.
Attention is also directed to leveraging input and output spaces. Li et al . [122] consider training
robust models by leveraging the adversarial space of another model. Differently, Mirman et al .
[143] and Rozsa et al . [181] leverage abstract interpretation and evolution stalling, respectively. The
former generates abstract transformers to train certifiably robust models. The latter progressively
tempers the contributions of correct predictions toward the loss function. Finally, Mirman et al .
[143] , Zi et al . [282] , and Papernot et al . [162] leverage Distillation (a knowledge transfer technique
in which a smaller model is trained to mimic a larger one) [31, 90] to obtain robust models.
4.2.2 Designing Robust Architectures. In the context of Robust AI, researchers have also investigated
possible ways to make neural network models robust from an architectural perspective.
10
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
Tweaking Neural Network Layers. We identified that a considerable amount of effort is directed
toward Computer Vision applications, with many solutions aimed at integrating additional mecha-
nisms of Convolutional Networks to enhance their robustness. Many adversarial attackers create
harmful data instances by injecting noise perturbations in the input of the model. In line with this,
many researchers have attempted to introduce mechanisms that take advantage of this information
or directly try to mitigate the repercussions of such perturbations. For example, Jin et al . [102]
introduce additive stochastic noise in the input layer of a CNN and re-parametrize the subsequent
layers to take advantage of this additional information. Alternatively, Momeny et al . [146] introduce
a CNN variant that is robust to noise by adapting dynamically both striding of convolutions and
the following pooling operations. Work by Xu et al . [251] operate on the classification layer by
constraining its weights to be orthogonal. Operating on network layers is not exclusive to the
aforementioned discriminative models, but it has also found applications for generative models. For
example, Kaneko et al . [104] propose a method to obtain Generative Adversarial Networks (GAN)
that do not require a large amount of correctly-labeled instances but still maintain a consistent
behavior. They do this by integrating a noise transition model that maps clean and noisy labels
which leads to GANs that are resilient to different magnitudes of label noise.
Leveraging the Inherent Robustness of Spiking Neural Networks (SNN). In parallel to such en-
hancements at the architectural level, a growing trend is represented by SNN [ 131]. SNNs are a
particular type of neural network that mimics the behavior of biological neurons by incorporating
the notion of time and both operating with and producing sequences of discrete events (i.e., spikes).
Concretely, a neuron in a SNN transmits information only when its value surpasses a certain
threshold. This particular kind of neural network was found to be inherently robust to certain
types of adversarial attacks. Sharmin et al . [194] test Spiking Neural Networks directly against
gradient-based (black-box) attacks and find that such architectures perform better than non-spiking
counterparts without any kind of adversarial training. Inspired by neuroscience, Cheng et al . [51]
formulate Lateral Interactions (i.e., intra-layer connections) for SNNs which provide both better
efficiency when processing a series of spikes as well as better resistance to injected Gaussian noise.
Searching Neural Architectures. Connected to handcrafting robust neural architectures, scholars
have started applying Neural Architecture Seach (NAS) to such a problem. In general, NAS is an
automatic procedure aimed at discovering the best architecture (e.g., in terms of accuracy) for a
neural network for a specific task. Devaguptapu et al . [58] analyze the effects that a varying amount
of parameters have on adversarial robustness: while NAS can be an alternative to adversarial
training, handcrafted models are more robust on large datasets and against stronger attacks like
PGD [ 133]. Their insights motivate other works in this space, that focus on strengthening NAS
approaches by including different forms of regularization on the smoothness of the loss landscape
[145], or the sensitivity of the network [ 62,94]. A different take on using NAS is the one of Li
et al. [124] : architecture search was blended with existing models (e.g., ResNet) to find the minimal
increase in model capacity allowing it to withstand adversarial attacks.
The Case of Non-Neural Models. Despite increased interest in neural networks, the robustness
of other machine learning models is still an open problem being investigated. To this avail, Chen
et al. [43] frame the task of learning Decision Trees as a max-min saddle point problem which,
by approximating the minimizer in the saddle point problem, lead to Decision Trees that proved
to be robust to adversarial attacks. On this note, Singla et al . [200] show the benefits of applying
Correntropy [ 129] to the 𝛼-hinge loss function used to train Support Vector Machines, which results
in models achieving robustness to label noise while maintaining competitive performance.
11
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
4.2.3 Leveraging Explainability Methods. In turn, using explainability to make robustness easier
to understand has also received some attention. A few works have investigated to what extent
existing explainability methods can be adapted in order to increase model robustness. Especially,
Kortylewski et al. [ 109] propose Compositional Neural Networks , a unification of convolutional
neural networks (CNN) with part-based models (inherently interpretable models), and show that
these new networks increase model robustness to various partial occlusions of objects. Chen et al.
[42] also demonstrated that inherently interpretable models such as rationale models in NLP are
naturally more robust to certain adversarial attacks yet are still brittle to certain scenarios.
4.3 Leveraging Model Post-Processing Opportunities
Robustness can also be improved through methodologies applied after training the model.
4.3.1 Identifying Unnecessary or Unstable Model Attributes (neurons, features). Pruning, i.e., the
act of removing neurons and/or connections from a model, has become a popular compression
approach that aims at reducing the computational cost of training models [ 125]. Recent literature
in Robust AI has explored the use of pruning techniques or methodologies inspired by pruning to
enhance model robustness [ 42]. Chen et al . [42] , for instance, design a methodology for selectively
replacing ReLU neurons that are identified as unstable (i.e., neurons that operate in the flat area
of the function) and insignificant by linear activation functions that help improve robustness at
a minimal performance cost. In a similar vein, additional mechanisms have been suggested for
dealing with unnecessary and/or unstable system attributes. For instance, Gao et al . [72] introduce
DeepCloak, a novel method to detect and remove unnecessary classification features in deep neural
networks, consequently reducing the capabilities of attackers to generate such attacks.
4.3.2 Fusing Models.
Against Input Issues. Another approach for achieving post-model-training robustness consists of
plugging additional models into a trained model. These additional models can be used to identify
and deal with problematic data instances (e.g., out-of-distribution, mistaken [ 170], noisy [ 180], or
adversarially modified [ 261]). For instance, in the context of Natural Language Processing, Pruthi
et al. [170] attach a task-agnostic word recognition model to a classification model as a means to
defend the main classifier against spelling mistakes. In the context of Computer Vision, Ye et al .
[261] use an additional classifier to determine real vs. adversarially manipulated data instances.
This additional classifier would receive an overlap of the data instance and its saliency map.
Against infected models. Model fusion is also used to identify and deal with infected models
(e.g., backdoor-infected neural networks [ 208]), to compare the robustness of small models with
respect to compression techniques [ 245]. A prominent line of work in this field consists in using
Generative Adversarial Networks as auxiliary models. This strategy has been used for dealing with
input data [ 214] and models [ 52]. For the former, Sun et al . [214] use a Boundary Conditional GAN
to generate boundary samples. These boundary samples have true labels and are near the decision
boundary of a pre-trained classifier. For the latter, Choi et al . [52] propose Adversarially Robust
GAN (ARGAN), that trains the generator model to reflect the vulnerability of the target neural
network model against adversarial examples and hence optimizes its parameter values.
4.3.3 Applying Changes in Output Representations. A final approach consists of varying the repre-
sentation of the output. To this end, Verma and Swami [231] suggest an approach for designing an
Error Correcting Output Code that moves away from one-hot encoding of outputs to an encoding
with a larger Hemming distance (> 2). This forces adversarial perturbations to be larger.
12
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
5 ROBUSTNESS FOR: ROBUSTNESS IN PRACTICAL FIELDS
5.1 Robustness for Specific Architectures
5.1.1 Attacks on Graph Neural Networks (GNN). A number of papers investigate how to increase the
robustness of specific types of model architectures. One of the most prominent ones is GNN. GNN
are susceptible to adversarial attacks due to small adversarial perturbations having a large effect on
their output. Hence, there has been research into making such networks more robust to attacks.
Pezeshkpour et al . [166] propose an attack strategy that generates adversarial examples, which
find the minimal changes necessary to make in the link prediction task that causes a label change,
for link prediction problems on knowledge graphs. An approach by Lou et al . [130] determines
controllability and connectivity robustness, indicating how well a system can keep its connectedness
and controllability against node- or edge-removal attacks, by compressing the high-dimensional
adjacency matrix to a low-dimensional representation before feeding it to a Convolutional Neural
Network to perform the robustness prediction. Fox and Rajamanickam [71] investigate the impact
of structural noise on the robustness of GNN and find them to be weak to both local and global
structural noise. Geisler et al. [76] focus on particularly large graphs and propose new attack and
defense strategies for this case to improve the efficacy of attacks on GNN and a defense mechanism
with a low memory footprint that enables defenses on large networks at scale. Significant attention
has also been paid to formally certifying the robustness of GNN [28, 236].
5.1.2 New Frameworks for Graph Neural Networks. There have also been several proposals for new
GNN frameworks that have better robustness characteristics. For example, Jin et al . [103] establish a
framework to jointly learn clean graph structures from perturbed ones as well as the parameters of
a GNN that is robust to adversarial attacks. They do so by iteratively reconstructing the clean graph
by preserving low rank, sparsity, and feature smoothness properties, allowing them to eliminate
edges that have been crafted by an adversary. Another end-to-end learning framework [ 48] was
put forward, that jointly and iteratively learns graph structure and graph embeddings, where a
similarity metric and adaptive graph regularization are applied to control the quality of the learned
graph. Zhang and Lu [271] introduce a model where robustness to noise is achieved by a shared
auxiliary for neighborhood aggregation, using a new aggregator function making use of masks.
Here, the auxiliary model learns a mask for each neighbor of a given node, making node-level and
feature-level attention possible. Thus, it is capable of assigning different importance values to both
nodes and features for predictions, which increases robustness.
5.1.3 Bayesian Learning. Many adversarial attack strategies are based on identifying directions of
high variability and since such variability can be intuitively linked to uncertainty in the prediction,
Bayesian Neural Networks are naturally of interest for robustness research. Pang et al . [161]
evaluate the robustness of Bayesian networks against adversarial attacks for image classification
tasks. Similarly, Carbone et al . [36] analyze Bayesian networks to show that they are robust to
gradient-based attacks. Vadera et al . [227] focus on different inference methods and attacks whose
goal is to cause the model to misclassify the provided input to evaluate the network robustness. They
find that Markov Chain Monte Carlo inference has excellent robustness to different attacks. Miller
et al. [140] aim to evaluate robustness by extracting label uncertainty from the object detection
system via dropout sampling. They perform uncertainty estimation through dropout sampling to
approximate Bayesian inference over the parameters of deep neural networks and find that the
estimated label uncertainty can be used to increase object detection performance under open-set
conditions.
13
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
5.2 Robustness for Specific Application Areas
5.2.1 Robustness for Natural Language Processing (NLP) Tasks. The robustness of NLP systems
is paramount. Adversarial attacks and training both represent active areas of research in recent
years. They aim to make NLP models less susceptible to attacks and noisy data, therefore improving
robustness. As such, a multitude of approaches have been proposed specifically for this domain.
Zheng et al . [279] present an approach to study both where and how parsers make mistakes by
searching over perturbations to existing texts at the sentence and phrase levels. Furthermore, they
design algorithms to create such examples for white-box and black-box models. They demonstrate
that parsing models are susceptible to adversarial attacks. At the word level, Yang et al . [259]
propose a method designed to tackle word-level adversarial attacks by pulling words closer to
their positive samples while pushing away negative samples. They find that their method improves
model robustness against a wide set of adversarial attacks while keeping classification accuracy
constant. Similarly, Du et al . [66] study the weakness of many state-of-the-art NLP models against
word-level adversarial attacks and propose Robust Adversarial Training to improve the models’
robustness against adversarial attacks. Pruthi et al . [170] look to combat adversarial misspellings
by attaching a word recognition model to the classification model. They find that the adversary
can degrade the performance of a text classifier to the point where it is equivalent to random
guessing just by altering two characters per sentence. Zhou et al . [281] employ multi-task learning,
where a transformer-based translation model is augmented with two decoders with different
learning objectives, to improve the robustness to noisy text. Similarly, Li et al . [121] use adversarial
multi-modal embeddings and neural machine translation to denoise input text, making it effective
against adversarially obfuscated texts. Chen et al . [42] inspect whether NLP models are capable of
generating rationales (i.e., subjects of inputs that can explain their prediction) to provide robustness
to adversarial attacks. They find that rationale models show promise in providing robustness,
though their robustness is highly variable.
5.2.2 Robustness for Cybersecurity. Cybersecurity deals with the resistance to intelligent attacks,
as such, there has been research into the robustness of cybersecurity systems, in particular into the
robustness of AI used in cybersecurity applications. A significant focus has been the robustness of
malware detection. For instance, Abusnaina et al . [2] improve malware classifier accuracy by using
Control Flow Graphs extracted from the attacked code, which represent behavior patterns, as the
input data for their threat detector. These are subsequently altered to obtain adversarial examples
and test the robustness of the overall model.
There has also been research into the security, and specifically malware detection, of specific
operating systems or platforms. Anupama et al . [8] initially use the Fisher score to identify and
select the most relevant attributes for the classifiers and subsequently develop three different attack
approaches to create adversarial examples. The evaluation of the resulting classifiers finds that this
approach greatly increases detection rates.
Beyond this, defense against distributed denial-of-service (DDoS) attacks, where a service or
network is overwhelmed with additional artificial traffic, has been studied through the lens of
robustness as well. Abdelaty et al . [1] present an adversarial, GAN-based training framework to
produce strong adversarial examples for the DDoS domain to tackle the weaknesses of Network
Intrusion Detection Systems against adversarial attacks. The generator model of a GAN, trained
on benign samples, is used to produce adversarial samples. Then, DDoS samples are perturbed by
changing their features using values taken from the generated examples. The effectiveness of such
attacks is thus greatly decreased. Amarasinghe et al . [6] apply Layer-wise Relevance Propagation
to the trained anomaly detector, yielding relevance scores for each individual feature.
14
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
5.3 Robustness for Other Trustworthy AI Concepts
5.3.1 Robustness for Explainability. Robustness has been widely discussed in the context of ex-
plainability methods in recent years [ 61,114]. For explainability to be implemented effectively in
ML systems, it must be robust. More robust explanations will naturally lead to more trustworthy
explainable AI, as humans can feel more secure regarding phenomena such as adversarial attacks
on the system and out-of-distribution input data. A critical step toward more robust explainability
is the effort to provide methods for evaluating explanations with respect to robustness.
A method for measuring explainability was proposed by Zhang et al . [273] , whose approach
explores the input space to measure the percentage of inputs on which the prediction can be
consistently explained with the simple model height of the decision tree used to explain the neural
network’s prediction. However, their result is inconclusive as it may seem tied to imbalances in
the data used. In a similar vein, Nanda et al . [150] propose a scalable framework using machine-
checkable concepts to assess the quality of generated explanations with respect to robustness,
specifically their vulnerability to adversarial attacks. Alvarez-Melis et al. [ 5] define a novel notion
of robustness based on the point-wise, neighborhood-based local Lipschitz continuity. Gradient-
and perturbation-based interpretability methods are evaluated, revealing the non-robustness of
such practices and the high instability of perturbation-based methods.
Atmakuri et al . [13] focus on understanding the adversarial robustness of explanation methods
in the context of text modality. In particular, they utilize saliency maps to generate adversarial
examples to evaluate the robustness of the model of interest. They find the used Integrated Gradient
explanation method is weak against misspelling and synonym substitution attacks.
Robustness for Counterfactual Explanations. There have also been multiple works on the robust-
ness of generated counterfactual explanations to adversarial inputs. Virgolin and Fracaros [233]
explore how to improve such robustness by giving a formal definition of what it means to be
robust towards perturbations and implementing this definition into a loss function. To test this
definition, they release five datasets in the area of fair ML with reasonable perturbations and
plausibility constraints. They find that robust counterfactuals can be found systematically if we
account for robustness in the search process. Further, Pawelczyk et al . [164] explore counterfactual
explanations by formalizing the similarities between popular counterfactual explanations and
adversarial example generation methods, identifying conditions when they are equivalent. Thus,
they derive the upper bounds on the distances between the solutions output by counterfactual
explanation and adversarial example generation methods. Bajaj et al . [15] generate robust coun-
terfactual explanations on GNNs by explicitly modeling the common decision logic of GNNs on
similar input graphs. The generated explanations are naturally robust to noise because they are
produced from the common decision boundaries of a GNN that govern the predictions of many
similar input graphs. The generation of robust text-based counterfactual explanations has also been
studied for NLP tasks [ 242,263]. Finally, several works focus on making the popular interpretable
model-agnostic explanations (LIME) approach more robust to adversarial attacks [184, 204].
5.3.2 Robustness for Fairness. A key attribute of any system to be put into production is fairness.
The relationship between fairness and robustness, and how one contributes to the other, has
received increased attention recently. Rezaei et al . [175] aim to make classifications that have robust
fairness without relying on previously labeled data, as these may carry some inherent biases. Wang
et al. [240] study the effect of relying on noisy protected group labels, providing a bound on the
fairness violation concerning the true group. Yurochkin et al . [265] propose an adversarial approach
to fairness, using a distributionally robust approach to enforcing individual fairness during training.
15
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
There have also been efforts to improve the fairness of graph-based counterfactual explanations,
such as Agarwal et al. [3] who aim to establish a connection between counterfactual fairness and
graph stability by developing layer-wise weight normalization and therefore enforcing fairness and
stability in the objective function. They see increases in fairness and stability without a decrease
in performance. Further, Bajaj et al . [15] propose a method to generate robust counterfactual
explanations on GNN by explicitly modeling the common decision logic on similar input graphs.
The explanations are naturally robust to noise because they are produced from the common decision
boundaries of a GNN that govern the predictions of many similar input graphs.
6 ROBUSTNESS ASSESSMENT AND INSIGHTS
6.1 Evaluation Procedures
6.1.1 Evaluation Strategies. A fundamental aspect of interest associated with robustness is its
evaluation, i.e., applying techniques, benchmarks, and metrics to assess its degree empirically.
Given the multifaceted nature of robustness, a wide variety of approaches have been developed. In
particular, two different branches can be identified, based on whether robustness is certified or not.
Evaluation of Robustness. Concerning the first group, most methodologies either compute a safe
radius [ 113,182] or region [ 82] within which the model performs robustly, or they compute their
complementary region [ 275], i.e., error regions. Abstract Interpretation, i.e., a theory which dictates
how to obtain sound, computable, and precise finite approximations of potentially infinite sets of be-
haviors [75], enables robustness evaluation when combined with techniques like constraint solving
[258] and importance sampling [ 134]. Other evaluation approaches reformulate the robustness
assessment problem from different perspectives. Tjeng et al . [223] formulate the verification of the
robustness against adversarial attacks as a mixed integer linear program by expressing properties
like adversarial accuracy as a conjunction, or disjunction, of linear properties over some set of
polyhedra. Webb et al . [243] statistically evaluate robustness by estimating the proportion of inputs
for which a defined adversarial property (i.e., an adversarial condition associated to a function that
evaluates its violation) is unsatisfied (i.e., there are no counterexamples violating such a property).
This reframing is useful to widen the variety of solutions that can be applied to assess robustness,
consequently improving their scalability [ 223,243], computational speed [ 223,260], and enabling
the application of pre-existing tools [89].
Evaluation of Certified Robustness. When it comes to assessing certified robustness, most of the
literature focuses on model robustness against adversarial attacks [ 65,99,118,119,199,201,202,276].
To this end, researchers focus on the efficient computation of robustness bounds [ 65,118,201,276]
while also improving the training procedure to achieve efficiently certifiable [ 276],or ready to
certify [ 99], models. Deterministic [ 119] and Random [ 67] Smoothing approaches have also proven
to be effective in evaluating 𝐿1[119] and 𝐿2robustness. Nevertheless, overapproximation [ 199],
orthogonalization relaxation [ 202], and regularization [ 99] have also been successfully applied to
improve the computation of certifiable bounds in adversarial settings. Moreover, Zhang et al . [269]
strive to generalize certification techniques to non-piecewise linear activation functions.
Even though most literature focuses on certifying the robustness of models against adversarial
attacks, other types of certified robustness have also been assessed, e.g., certified robustness to
random input noise from samples and geometric robustness [19].
6.1.2 Benchmarks. Even though most of the literature on assessing robustness is focused on
designing methodologies to evaluate model robustness, some works also propose comprehensive
benchmarks, i.e., standardized methods including an approach, dataset, and pipeline to evaluate
the robustness of a model against a specific set of attacks. In Computer Vision, robustness against
16
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
various types of adversarial attacks [ 63,81,167] and common corruptions [ 88,137], including
noise [ 88,278], has been evaluated through benchmarking on datasets [ 88,137,167], with custom
measures [ 63,88], or using comprehensive frameworks [ 219]. In the first case, pictures are altered
through adversarial or common perturbations (e.g., noise, blur, etc.) [ 88,137,219], and either
generalizability [ 137] (i.e., whether the model can adequately classify newly perturbed pictures) or
its behavior by means of custom metrics [ 63,88] are evaluated. A few benchmarks have also been
applied in the context of graph networks and Natural Language Processing. For instance, Zheng
et al. [278] develop scalable datasets to standardise the process of attack and defence, covering
graph modification and graph injection attacks.
Target of Benchmarks. While some benchmarks are focused on evaluating the effectiveness of
defence methods [ 63,278], others focus on the intrinsic robustness of the architecture [ 55,219].
Tang et al . [219] benchmark architecture design and training techniques against adversarial and
natural perturbations, and system noise by developing a platform for comprehensive robustness
evaluation. It includes pre-trained models to enhance the evaluation process and a view dedicated
to understanding mechanisms for designing robust DNNs. While the main objective of a robustness
benchmark is to standardise the approach and/or the data to evaluate such a property, it can also be
employed to compare and organise evaluation methods and robust models, allowing researchers to
reliably access resources [ 55]. Regarding comparisons of model robustness, most benchmarks use
well-known datasets (e.g., MNIST or ImageNet), implicitly assuming the data is always correct. Some
authors have argued that such an assumption should not be lightly accepted since potential errors
may influence the benchmarking process and its results [ 156]. Such a premise can be especially
problematic when comparing performances of different models as they can be affected differently
by such errors [ 156]. From a broader perspective, evaluating model robustness can be seen as a
part of a process to evaluate fairness. Driven by such an objective, Ding et al. [ 59] create a series of
datasets to evaluate different aspects of ML approaches and benchmark their fairness with respect
to noise and data distribution shift.
6.1.3 Metrics. When it comes to the evaluation of the robustness of a model, not only is it essential
to choose the proper method, but it is also fundamental for the applied measure to represent model
robustness properly. To this end, several measures of robustness have been proposed.
Metrics for Adversarial Robustness. Most of the collected literature focuses on describing metrics
to evaluate the robustness of networks against adversarial attacks [ 244,262]. These metrics are
generated by converting the robustness analysis into a local Lipschitz constant estimation problem
[244], or qualitatively interpreting the adversarial attack and defence mechanism through loss
visualisation [ 262]. Moreover, only a few of them [ 244] aim to disentangle the relationships between
the evaluation process and the model or attack employed, consequently building model-agnostic
[244] and attack-agnostic metrics.
Metrics for Adversarial Attacks. Other researchers focus on suggesting metrics for different
aspects of adversarial attacks, devising approaches for evaluating the convergence stability of
adversarial examples generation [ 116] and comparing adversarial attack algorithms [ 23]. Beyond
the necessity for metrics to assess model robustness, other metrics have been proven useful in
evaluating aspects of robustness [ 10,159], like its relationship with adversarial examples [ 10] and
accuracy [159].
Metrics Outside of Computer Vision. While most of the literature addresses robustness in Computer
Vision, a small part of the literature discusses robustness in other contexts. In the context of NLP,
extending the concept of robustness through a metric aligned with linguistic fidelity has been
17
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
proven effective in improving performances on complex linguistic phenomena [ 112]. However,
recent research [ 35] have shed light on the lack of robustness of such metrics in the context of
tree-based classifiers. Consequently, an extension of robustness through a resilience measure that
considers both robustness and stability has been proposed. Such findings highlight the need for
creating sound and robust metrics while also addressing less covered contexts.
Metrics for the Complexity of Robustness Methods. While most literature focuses on implementing
evaluation approaches, a small research branch focuses on improving their efficiency, mainly
enhancing their precision in computing the robustness bounds [ 199,258] and reducing their
computational complexity [215, 235] and execution time [249].
6.2 Studies around Proposed Robustness Methods & Insights
6.2.1 Insights on Adversarial Robustness. Studying the adversarial robustness of different machine
learning techniques has been a persistent research focus in recent years.
Based on Comparisons. Beyond formal methods and frameworks, there are several examples
of papers empirically evaluating robustness through comparison [ 100,189]. For instance, Jere
et al. [100] compared the generalization capabilities of convolutional neural networks and their
eigenvalues and further compared what features are exploited by naturally trained and adversarially
trained models. They found that for the same dataset, naturally trained models exploit high-level
human-imperceptible features and adversarially robust models exploit low-level human-perceptible
features. Another example in this line is the work by Sehwag et al . [189] who inspected the
transferability of the robustness of classifiers trained on proxy distributions from generative model
to real data distribution, discovering that the difference between the robustness of classifiers trained
on such datasets is upper bounded by the Wasserstein distance between them.
Based on the Investigation of Activation Function and Weights Perturbations. There have been
several works studying the robustness of models under perturbation of weights or due to changes
in activation functions. For example, Tsai et al . [224] studied the robustness of feed-forward neural
networks in a pairwise class margin and their generalization behavior under different types of
weight perturbation. Furthermore, they designed a novel loss function for training generalizable
and robust neural networks against weight perturbation. Song et al . [207] showed that adversarial
training is not directly applicable to quantized networks. They proposed a solution to minimize
adversarial and quantization losses with better resistance to white- and black-box attacks. Another
work that focused on such attacks is Shao et al . [192] , who studied the robustness of vision
transformers against adversarial perturbations under various black-box and white-box settings.
6.2.2 Insights on Robustness to Natural Perturbations. There has also been substantial research
into model robustness to noise and out-of-distribution data.
About Robustness to Noise. A prominent line of work is evaluating robustness of AI systems
against noise [ 21,283]. Some examples in this area include the study conducted by Ziyadinov and
Tereshonok [283] , who evaluated whether training convolutional neural networks using noisy data
increases their generalization capabilities and resilience against adversarial attacks. They found
that the amount of uncertainty in the training dataset affects both the recognition accuracy and
the dependence of the recognition accuracy on the uncertainty in the testing dataset. Furthermore,
they showed that a dataset with such uncertainty can improve recognition accuracy, consequently
enhancing its generalizability and resilience against adversarial attacks. Bar et al . [21] also evaluated
the robustness of deep neural networks to label noise by applying spectral analysis. The authors
demonstrated that regularizing the network Jacobian reduces the high frequency in the learned
18
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
mapping and show the effectiveness of Spectral Normalization in increasing the robustness of the
network, independently from the architecture and the dataset.
About Robustness to Differences in Distributions. Another area of interest is studying differences
in data distributions. On the problem of object-centric learning, Dittadi et al. [60] discovered that
the overall segmentation performance and downstream prediction of in-distribution objects is not
affected by a single out-of-distribution object. On the other hand, Burns and Steinhardt [33] studied
adaptive batch normalization, which aligns mean and variance of each channel in CNNs across two
distributions . They found that for distribution shifts that do not involve changes in local image
statistics, accuracy can be degraded because of batch normalization.
6.2.3 Insights for the Natural Language Processing (NLP) Context. In order to evaluate robustness in
NLP, Moradi and Samwald [148] designed and implemented character- and word-level perturbations
to simulate scenarios in which input text is noisy, or different from training data. Such perturbations
were employed to evaluate the robustness of different language models to noisy inputs. They found
that the inspected language models were susceptible to the proposed perturbations, small ones as
well. Instead, La Malfa et al . [113] proposed an the concept of semantic robustness . It generalizes the
notion of robustness in NLP by explicitly measuring cogent linguistic phenomena, aligning with
human linguistic fidelity, while being characterized in terms of the biases it may introduce. On the
other hand, Wang et al . [239] proposed a dataset for evaluating trustworthiness and robustness. It
collects annotations, and respective human explanations, that cover different types of adversarial
attacks (e.g., obscure expression) and allow for multiple sentiment labels for a single text sample.
Specific architectures, such as Natural Language Inference models have also been evaluated.
Sanchez et al . [186] found that these models suffer from insensitivity to small but semantically
significant alterations while also being influenced by simple statistical correlations between words
and training labels. In addition, the models were insensitive to the proposed transformation on the
input data and they exploit a bias polarity to stay robust when new instances are shown.
6.3 Trade-Offs Between Robustness and Other Trustworthy AI Objectives
6.3.1 Trade-Off Between Robustness and Accuracy. A key question to be asked when analyzing the
robustness of a system is what the impact of the changes is on the accuracy of the model. Multiple
studies have found a significant trade-off between robustness and accuracy, where an increase in
one leads to a decrease in the other. Su et al . [213] evaluated the robustness of 18 existing deep
image classification models, focusing on the trade-off between robustness and performance. They
found that model architecture is a more critical factor to robustness than model size and that
networks of the same family share similar robustness properties. Raghunathan et al . [173] further
discussed this and described in detail the effect of augmentation achieved through adversarial
training on the standard error in linear regression models when the predictor has zero standard
and robust error. Tsipras et al . [225] also studied how robustness and accuracy trade-off, as well
as the features that were learned. While Miller et al . [142] investigated the connection between
accuracy in- and out-of-distribution and show that that out-of-distribution performance is strongly
correlated with in-distribution performance for a wide range of models and distribution shifts.
6.3.2 Trade-Off Between Robustness and Fairness. Benz et al. [24] evaluated the impact of robust-
ness on accuracy and fairness. They found inter-class discrepancies in accuracy and robustness,
specifically in adversarially trained models and that adaptively adjusting class-wise loss weights
negatively affects overall performance. Xu et al . [252] hypothesized that adversarial training algo-
rithms tend to introduce severe disparity in accuracy and robustness between different groups of
data, and showed this phenomenon can happen under adversarial training algorithms minimizing
19
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
neural network models’ robustness errors. They also propose a Fair-Robust-Learning framework to
mitigate unfairness in adversarial defenses. On the other hand, Pruksachatkun et al . [169] studied
if an increase in robustness can improve fairness. They investigated the utility of certified word
substitution robustness methods to improve the equality of odds andequality of opportunity in text
classification tasks. They found that certified robustness methods improve fairness, and using both
robustness and bias mitigation methods in training results in an improvement for both.
6.3.3 Trade-Off Between Robustness and Explainability. Few works investigate the extent to which
methods for increasing model robustness impact the features such models use to make predictions,
and especially to what extent these features remain meaningful to human judgement. Especially,
Woods et al . [247] showed that the fidelity of explanations is negatively impacted by adversarial
attacks, and propose a regularisation method for increasing robustness lead to better model expla-
nations (termed Adversarial Explanations ). Nourelahi et al . [157] investigated how methods dealing
with out-of-distribution examples impact the alignment of the features the model has learned with
features a human would expect to use. While this is an initial empirical exploration, their results
illustrate the complexity of the relation between robustness and feature alignment, as there does
not seem to be a model that performs consistently better over these criteria. They suggest to extend
their benchmark effort to more types of models, and of robustness and explainability techniques.
7DISCUSSION: DISPARATE RESEARCH ON THE VARIOUS FACETS OF ROBUSTNESS
The robustness of AI systems is a broad, open problem under the umbrella of Trustworthy AI and
the copious amount of literature that can be found is a testament to that. Researchers from diverse
domains have studied the impact of controlled data perturbations as well as naturally-occurring
ones, how to strengthen neural architectures through additional mechanisms, and how to efficiently
and effectively train models underlying such systems. In this section, we summarize the gaps and
trends we evinced from our inspection of the existing literature.
7.1 Addressing Gaps from the Literature
7.1.1 Gaps within Robustness.
The Computer Vision Hegemony. The immediate outcome of our survey is the extensive effort
put into studying — and enhancing — the robustness of models targeted toward Computer Vision,
especially Convolutional Neural Networks. Papers from that sub-field of Artificial Intelligence
greatly outnumber the ones from other areas, like Natural Language Processing. We found this
to be the case regardless of the aspect (attack generation, defense, etc.) scholars focus on. While
important, such a focus being put on Computer Vision only begs the question of why other domains
have received little contributions compared to the former. Possible explanations for this can be
traced back to difficulties in defining perturbations and attacks within certain data manifolds,
e.g., word embeddings, or to the lack of alignment between robustness in machine learning and
robustness in specific application domains, e.g., signal processing. On the other hand, the intrinsic
complexity of pictures compared to other types of data, in particular with respect to the features
that can be perturbed and the diversity in the available approaches to evaluate distances between
pictures, influence the broadness of the research field.
Natural Brittleness. Regardless of the domain, we found that little attention is put on defining
natural perturbations and attacks. Instead, much work revolves around defining synthetic attacks
and evaluating defense mechanisms against them. While this may make sense from the perspective
of a malicious attacker, it does not necessarily translate to robustness in real-world operating
conditions. Only a few works in Computer Vision focus on such a type of attacks. Another interesting
20
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
research direction is signaled by the lack of model-agnostic adversaries. While both automatic and
rule-based approaches to generating adversaries exist, these tend to be targeted toward certain types
of AI systems. Obtaining model-agnostic attacks would be the dual case to such a scenario and could
provide for a common baseline for evaluating the robustness of AI systems. Moreover, achieving
model-agnostic and perturbation-agnostic evaluations approaches would allow to disentangle the
relationship between these scenario-specific aspects and the actual robustness of the model, finally
leading to an unbiased analysis of the robustness of a system [244].
7.1.2 Gaps Stemming from the Intersection Between Robustness and Other Trustworthy AI Concepts.
Robustness and Explainability. Considering the brittleness of existing AI systems in conjunction
with their opaqueness, their explainability is of paramount importance. Explainable AI (XAI)
methods have been, and still are being, proposed [ 83,84] to tackle such a challenge. However, few
works discuss the robustness of XAI methods and the produced explanations. This is a crucial
dimension that needs to be addressed to obtain explanations that are both faithful (i.e., correctly
describing model behavior) and trustworthy. By the same token, explainability can better inform
the ideation and implementation of approaches geared towards robustness.
Tensions between Accuracy, Robustness, Fairness, and Explainability. Connected to the above
points, it is worth noting how existing research is focused on enhancing robustness at the expense
of accuracy, much like optimizing for accuracy led to a lack of explainability. Similarly, scholars
have studied the interplay with fairness as well as the possible issues stemming from it. These
dimensions are not exclusive and need to be addressed holistically and considered on equal terms
when aiming to build trustworthy and fair AI systems.
In this sense, sole data-driven approaches have shown their limitations. Discussions around
these topics have pointed toward the need for integrating symbolic knowledge. However, few of
them touched upon which kind of knowledge is needed and how to collect it. In subsection 7.2 and
section 8, we provide a commentary on human-centered approaches and how these approaches
can provide a path toward tackling the aforementioned challenges for robust AI.
7.2 Deepening the Research on Human Involvement for Existing Robustness Methods
A number of papers we surveyed implicitly involve humans to instantiate the methods they propose,
either to assess or enhance a model’s robustness. Yet, they do not delve deeper into the challenges
for a human agent to perform their task, which constitutes an obstacle to the development of
methods and frameworks for overcoming these challenges. This merits further investigation as
such human involvement is essential to the success of the methods. Especially, we identify two
main areas where human involvement is necessary but lacks research.
7.2.1 Evaluating Robustness. To design appropriate perturbations or attacks on which a model
should be robust, one often needs human knowledge. For instance, Jin et al . [101] and La Malfa and
Kwiatkowska [112] generate adversarial attacks on text samples, that have to verify a number of
human-defined constraints for them to be deemed realistic by humans. Yet, designing such con-
straints and empirically evaluating (through user studies) to what extent the samples transformed
by the corresponding constrained attack align with the human idea of “realistic" sample, has not
been investigated extensively, despite how crucial that is for engineering “good" attacks.
In a similar fashion, works on robustness to natural perturbations should ideally define a com-
prehensive set of domain-specific perturbations relevant to the problem at hand and its context.
However, to the best of our knowledge, existing works that develop benchmarks or robustness-
enhancing methods [ 88,108] with regard to such perturbations have not investigated ways to be
more comprehensive. While we believe in the impossibility to reach comprehensiveness (previously
21
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
unheard-of perturbations can always arise), one could develop tools to support the definition
of relevant perturbations. For instance, we envision the usefulness of fine-grained, actionable
taxonomies of perturbations (e.g., Koh et al. [ 108] talk about subpopulation shifts and domain gener-
alization, but this might vary in different domains and types of tasks); collaborative documentation
of domain-specific perturbations; libraries to generate such perturbations semi-automatically; and
frameworks and metrics to uncover new types of perturbations in the wild, potentially involving
humans in the runtime.
7.2.2 Increasing Robustness. Various methods that aim at increasing robustness implicitly employ
humans, without extensive focus. Jin et al . [101] , for instance, collect potential adversarial examples
by executing a sequence of engineered steps, that could be refined by the practitioner who would
leverage existing tools for, e.g., identifying synonyms and antonyms, ranking word importance, etc.
Peterson et al . [165] , Chang et al . [41] , Nanda et al . [150] , and Ning et al . [154] respectively show that
one can train more robust models by leveraging human uncertainty on sample labels instead of using
reconciled binary labels, by integrating human rationales for the labeling process into the training
process, or by actively querying the most relevant levels of perturbations from an expert during
training. While these are promising research directions, these works could further be improved by
exploiting existing works on human computation assessing the quality of crowdsourced outputs
[97], or designing crowdsourcing tasks that remove task ambiguity and lead to higher quality
outputs [ 69], especially in the context of subjective tasks. This could serve to understand the nature
of uncertainties and define rationales that are relevant to robustness.
8 A CONSPICUOUS ABSENT FROM THE LITERATURE: THE ML PRACTITIONER
Last but not least, our rigorous survey also reveals another prominent research gap: the absence
of human-centered work in proposed approaches, and the lack of technologies and workflows
to support ML practitioners in handling robustness. In this section, we discuss relevant research
literature, and future research directions regarding this topic.
8.1 Robustness By Human-Knowledge Diagnosis
One of the most notable absentee from the retrieved papers is robustness by human-based diagnosis.
Existing works focus on generating out-of-distribution data, in order to make a model fail, and later
expose this model to this data during training to make it more robust. Especially for robustness to
natural perturbations, this means that one should always characterize the type of data the model
might encounter before being able to generate such data. This is not always possible in practice,
e.g., due to contractual and privacy reasons, cost, temporal variability of contextual application
of the model, etc. To circumvent this issue, a major, promising research direction surfaces from
comparing the surveyed robustness methods to existing works in other computer science fields.
This direction revolves around developing complementary, hybrid human-machine approaches, that
would leverage research progress in human-centered fields, essentially explainability, crowdsourcing
and human-in-the-loop machine learning (ML), as well as knowledge-based systems, to estimate
model performance on more realistic data distributions without requiring such distributions.
8.1.1 Existing Approaches. Only few related works leverage human capabilities to identify and
mitigate potential failures of a model. In particular, explanations for datasets [ 185] have been
proposed, that could be leveraged by a practitioner to identify data skews that might impact the
model performance. In this vein, Liu et al. [ 128] introduce a hybrid approach to identify unknown
unknowns, where humans first identify and describe patterns in a small set of unknown unknowns,
and then classifiers are learned to recognize these patterns automatically in new samples. Departing
from datasets, Stacey et al. [ 209], and Arous et al . [11] have trained models whose features are better
22
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
aligned with human reasoning (with the assumption that alignment leads to stronger robustness),
by leveraging human explanations of the right answer to the inference task and controlling the
features learned by the model during training to align with these human explanations.
8.1.2 Envisioned Research Opportunity. The above approaches reveal that instead of looking
solely at the outputs of a model and its confidence in its predictions, one can leverage additional
information such as the model features or training dataset, to estimate the model’s robustness.
Especially, even when a model prediction is correct, the model features might not be meaningful.
Hence, assessing model features and their human-alignment can allow to shift from solely evaluating
the correctness of the predictions on the available test, to indirectly assessing the robustness of the
model to OOD data points. Moreover, understanding characteristics of the datasets that led to such
learned features could later on serve to mitigate unaligned features.
Surfacing Model Features using Research on Explainability and Human Computation. To surface
a model’s features, one can rely on a plethora of explainability methods [ 185]. Certain models
are built with the idea of being explainable by design [ 216,274], while others are applied post-
hoc interpretability methods [ 18,176,211], with different properties (e.g., different nature of
explanations being correlation or causation -based, different scopes be it local or global, different
mediums be it visual or textual, etc.) [ 126,206]. It is now important to adapt such feature explanations
to allow for checking their alignment with human expected features.
In that regard, the push towards human-centered explanations for ML practitioners is highly
relevant. Existing explanations often leave space for many different human interpretations, for
which the practitioners do not always have domain expertise to disambiguate the highest-fidelity
features. For instance methods that output saliency maps [ 198] or image patches [ 77,106] do not
pinpoint to the actual human-interpretable features the model has learned. Yet, one might need
clear human concepts to reason over the alignment of the features [ 17]. Hence, further research on
semantic, concept-based explanations acquired via human computation is needed [18, 91].
Leveraging Literature on Knowledge Acquisition for Identifying Expected Features. To reason over
feature alignment, one also needs to develop an understanding of the model expected features. While
very few works have looked into this problem [ 193], existing works on commonsense-knowledge
acquisition [ 266] could be leveraged to that end. These works propose to harvest knowledge
automatically from existing resources such as text libraries, or through the involvement of human
agents, e.g., through efficient and low-cost interactions within Games with a Purpose [ 16,179,234],
or other types of carefully designed crowdsourcing tasks [ 96,188]. One would need to investigate
how to adapt such approaches to collect relevant knowledge, and how to represent this knowledge
into relevant feature-based information.
Comparing Features via Reasoning Frameworks and Interactive Tools. Finally, practitioners need
tools to check the alignment between the model and expected features. Interactive frameworks and
user interfaces [ 17], e.g., Shared Interest [27], take a step in that direction as they enable manual
exploration of model features, with various degrees of automation for comparing to expected
features. Inspired by the literature on AI diagnosis, such as abductive reasoning [ 54,178], automated
feature-reasoning methods could also fasten the process while making it more reliable.
8.2 Involving Humans in Other Phases of the ML Lifecycle
Broader ML literature has also proposed other approaches to involve humans and make "better"
models. Yet, none of these approaches has considered making the models more robust. Instead, they
focus on increasing the performance of the model on the test set. Hence, we suggest to investigate
how to adapt such approaches to increase model robustness.
23
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
8.2.1 ML with a Reject Option. While ML models typically make predictions for all input samples,
this might not be reasonable and turn dangerous in high-stake domains, when the predictions are
likely to be incorrect. Accordingly, a number of research works have developed methods to learn
when to appropriately reject a prediction, and defer the decision about the sample to a human
agent [ 87]. Proposed rejectors can either be separate rejectors placed before the predictor, that
select the input samples to input to this predictor; dependent rejectors placed after the predictor and
re-using its information (e.g., confidence metrics) to decide which predictions not to account for;
andintegrated rejectors that are combined to the predictor, by treating the rejection option as an
additional label to the ones to predict. Each type of rejector bears advantages and disadvantages
based on the context of the decision, and would merit being adapted to robustness, as we only
found few works towards that direction [105, 160, 212].
8.2.2 Human-in-the-Loop ML Pipelines. Human-in-the-Loop (HIL) ML [ 230] is traditionally con-
cerned with developing learning frameworks that account for the noisy crowd labels [ 174], or
“learning from crowds”, through models of the annotation process (e.g., task difficulty, task subjec-
tivity, annotator expertise, etc.). Such frameworks often rely on active learning to reduce annotation
cost [ 254,256]. More recent works around HIL ML also devise new approaches to build better model
pipelines by involving the crowd, such as to identify weak components of a system [ 158], to identify
noise and biases in the training data [ 95,257], or to propose potential data-based explanations to
wrong predictions [ 34]. While we could find a few works that investigate the intersection between
active learning and adversarial training [ 139,141,197,203], we could not find any work that looks
more broadly at the different types of robustness, and the different ways of bringing humans in the
ML pipeline. These intersections are yet promising as they constitute more realistic scenarios of
the development of ML systems and they succeeded in making models more accurate in the past.
8.3 Supporting ML Practitioners in Handling Robustness
Looking beyond the research world towards the practice, it is always an ML practitioner who builds
the ML system. Hence, it is not sufficient to develop methods that can work in theory, but it is also
important to understand the obstacles practitioners actually encounter in making their systems
robust. While studying the gap between research and practice has revealed highly insightful in
the past for various ML contexts [ 92,93,110,127,168], to the best of our knowledge, it has not
been studied in the context of ML robustness. Possibly the closest work is the interview study of
Shankar et al. [ 190] that investigated MLOps practices beyond the development of a model towards
production and monitoring of data shifts or attacks.
8.3.1 Understanding Practices Around Robustness. The human-computer interaction community
(HCI) has performed qualitative, empirical, studies, typically based on semi-structured interviews
with ML practitioners, to understand how these practitioners build ML models with certain con-
siderations in mind. These considerations revolve around the different steps practitioners take,
e.g., challenges of collaboration for each step [ 110,168], and the use in certain of these steps of
tools such as explainability methods [ 92,93,127] or fairness toolkits [ 117,177]. These studies have
resulted in frameworks modeling the practitioner’s process, lists of challenges, and discussions
around the fit of existing methods and tools to answer these challenges. We argue that adopting
similar research questions and methodologies (e.g., semi-structured interviews with hypothetical
scenarios or practitioner’s own tasks, ethnographies, etc.) would also reveal useful to better direct
robustness research in the future. For instance, Liao et al. [ 127] have constituted an explainability
question bank that highlights the questions practitioners ask when building a model by exploiting
explainability, and that can serve to identify research opportunities through questions still difficult
to answer. A robustness question bank would similarly provide a structured understanding of
24
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
what is still lacking. Moreover, HCI research investigating practices around ML fairness [ 56] has
shown a major gap in terms of guidance for practitioners to choose appropriate fairness metrics
and mitigation methods. Acknowledging the plethora of robustness metrics and methods, we
envision that user-studies around robustness would reveal a similar gap, that could be filled by
taking inspiration from the fairness literature.
8.3.2 Integrating Robustness into Existing Workflows. Some works have also focused on developing
workflows and tools to support practitioners in model building. These works often revolve around
user interfaces to more easily investigate a model and its training dataset, and identify failures
or bugs [ 17,151]. Other works build tools, e.g., documentation or checklists, [ 7,29,74,144] and
workflows [ 205] to support making and documenting relevant choices when building or evaluating
a model. We argue that robustness research should not only focus on algorithmic evaluation and
improvement, but also aim at developing new supportive tools and integrating them into existing
solutions. In relation to that, and possibly closest to supporting practitioners in handling robustness,
Shen [195] propose the idea of establishing trust contracts, i.e., contract data distributions and tasks
that define the type of task and data that is in- and out-of-distribution. Yet, this remains challenging
as there is no appropriate way to formalize such contracts.
9 CONCLUSION
In this survey, we collected, structured, and discussed literature related to robustness in AI sys-
tems. To this end, we performed a rigorous data collection process where we collected, filtered,
summarized and organized literature related to AI robustness generated in the last 10 years. Based
on this literature, we first discussed the main concepts, definitions, and domains associated with
robustness, disambiguating the terminology used in this field. We then generated a taxonomy to
structure the reviewed papers and to spot recurring themes. We identified three main themes and
thoroughly discussed them. In particular, we focused on (1) fundamental approaches to improve
model robustness against adversarial and non-adversarial perturbations, (2) applied approaches
to enhance robustness in different application areas, and (3) evaluation approaches and insights.
We finalized our paper by describing the research gaps identified in the literature and by detailing
future lines of work that involve including humans as central actors. We argued that humans could
play a fundamental role in improving, evaluating, and validating AI robustness. In conclusion, we
contributed to the exiting literature with an informative review that summarizes and organizes
recent work in the field of AI robustness, while it also suggests novel human-centered approaches
for the research community to explore, discuss, and further develop.
10 ACKNOWLEDGEMENTS
This research has been partially supported by the TU Delft Design@Scale AI Lab, by the HyperEdge
Sensing project funded by Cognizant, by the European Commission under the H2020 framework,
within project 101016233 PERISCOPE (Pan-European Response to the ImpactS of COVID-19 and
future Pandemics and Epidemics), by the European Union’s Horizon 2020 research and innovation
programme under the Marie Skłodowska-Curie grant agreement No 955990, and by the Ph.D.
Scholarship on Explainable AI funded by Cefriel.
25
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
REFERENCES
[1]Maged Abdelaty, Sandra Scott-Hayward, Roberto Doriguzzi-Corin, and Domenico Siracusa. 2021. GADoT: GAN-based
Adversarial Training for Robust DDoS Attack Detection. In CNS. IEEE, 119–127.
[2]Ahmed Abusnaina, Mohammed Abuhamad, Hisham Alasmary, Afsah Anwar, Rhongho Jang, Saeed Salem, DaeHun
Nyang, and David Mohaisen. 2022. DL-FHMC: Deep Learning-Based Fine-Grained Hierarchical Learning Approach
for Robust Malware Classification. Trans. on Dependable and Secure Computing 19, 5 (2022), 3432–3447.
[3]Chirag Agarwal, Himabindu Lakkaraju, and Marinka Zitnik. 2021. Towards a unified framework for fair and stable
graph representation learning. In UAI. PMLR, 2114–2124.
[4]Sheikh Waqas Akhtar, Saad Rehman, Mahmood Akhtar, Muazzam A. Khan, Farhan Riaz, Qaiser Chaudry, and Rupert
Young. 2016. Improving the Robustness of Neural Networks Using K-Support Norm Based Adversarial Training. IEEE
Access 4 (2016), 9501–9511.
[5] David Alvarez-Melis and Tommi S. Jaakkola. 2018. On the Robustness of Interpretability Methods.
[6]Kasun Amarasinghe, Kevin Kenney, and Milos Manic. 2018. Toward Explainable Deep Neural Network Based Anomaly
Detection. In HSI. 311–317.
[7]Ariful Islam Anik and Andrea Bunt. 2021. Data-Centric Explanations: Explaining Training Data of Machine Learning
Systems to Promote Transparency. In CHI. 1–13.
[8]ML Anupama, P Vinod, Corrado Aaron Visaggio, MA Arya, Josna Philomina, Rincy Raphael, Anson Pinhero, KS
Ajith, and P Mathiyalagan. 2021. Detection and robustness evaluation of android malware classifiers. Journal of
Computer Virology and Hacking Techniques (2021), 1–24.
[9]Elahe Arani, Fahad Sarfraz, and Bahram Zonooz. 2020. Adversarial Concurrent Training: Optimizing Robustness and
Accuracy Trade-off of Deep Neural Networks.
[10] Paolo Arcaini, Andrea Bombarda, Silvia Bonfanti, and Angelo Gargantini. 2020. Dealing with Robustness of Convolu-
tional Neural Networks for Image Classification. In AITest . 7–14.
[11] Ines Arous, Ljiljana Dolamic, Jie Yang, Akansha Bhardwaj, Giuseppe Cuccu, and Philippe Cudré-Mauroux. 2021.
Marta: Leveraging human rationales for explainable text classification. In AAAI , Vol. 35. 5868–5876.
[12] Alejandro Barredo Arrieta, N. Díaz-Rodríguez, J. Del Ser, A. Bennetot, Siham Tabik, Alberto Barbado, Salvador García,
Sergio Gil-López, Daniel Molina, Richard Benjamins, et al .2020. Explainable Artificial Intelligence (XAI): Concepts,
taxonomies, opportunities and challenges toward responsible AI. Information fusion 58 (2020), 82–115.
[13] Shriya Atmakuri, Tejas Chheda, Dinesh Kandula, Nishant Yadav, Taesung Lee, and Hessel Tuinhof. 2022. Robustness
of Explanation Methods for NLP Models.
[14] Yang Bai, Yuyuan Zeng, Yong Jiang, Shu-Tao Xia, Xingjun Ma, and Yisen Wang. 2021. Improving Adversarial
Robustness via Channel-wise Activation Suppressing.
[15] Mohit Bajaj, Lingyang Chu, Zi Yu Xue, Jian Pei, Lanjun Wang, Peter Cho-Ho Lam, and Yong Zhang. 2021. Robust
Counterfactual Explanations on Graph Neural Networks. In NeurIPS , Vol. 34. Curran Associates, Inc., 5644–5655.
[16] Agathe Balayn, Gaole He, Andrea Hu, Jie Yang, and Ujwal Gadiraju. 2022. Ready Player One! Eliciting Diverse
Knowledge Using A Configurable Game. In Web Conf. 1709–1719.
[17] Agathe Balayn, Natasa Rikalo, Christoph Lofi, Jie Yang, and Alessandro Bozzon. 2022. How can Explainability
Methods be Used to Support Bug Identification in Computer Vision Models?. In CHI. 1–16.
[18] Agathe Balayn, Panagiotis Soilis, Christoph Lofi, Jie Yang, and Alessandro Bozzon. 2021. What do you mean?
Interpreting image classification with crowdsourced concept extraction and analysis. In Web Conf. 1937–1948.
[19] Mislav Balunovic, Maximilian Baader, Gagandeep Singh, Timon Gehr, and Martin Vechev. 2019. Certifying Geometric
Robustness of Neural Networks. In NeurIPS , Vol. 32. Curran Associates, Inc.
[20] Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S Weld, Walter S Lasecki, and Eric Horvitz. 2019. Updates in
human-ai teams: Understanding and addressing the performance/compatibility tradeoff. In Proceedings of the AAAI
Conference on Artificial Intelligence , Vol. 33. 2429–2437.
[21] Oshrat Bar, Amnon Drory, and Raja Giryes. 2022. A Spectral Perspective of DNN Robustness to Label Noise. In
AIStats (PMLR, Vol. 151) . PMLR, 3732–3752.
[22] Alina Jade Barnett, Fides Regina Schwartz, Chaofan Tao, Chaofan Chen, Yinhao Ren, Joseph Y Lo, and Cynthia Rudin.
2021. A case-based interpretable deep learning model for classification of mass lesions in digital mammography.
Nature Machine Intelligence 3, 12 (2021), 1061–1070.
[23] Osbert Bastani, Yani Ioannou, Leonidas Lampropoulos, Dimitrios Vytiniotis, Aditya V. Nori, and Antonio Criminisi.
2016. Measuring Neural Net Robustness with Constraints. In NeurIPS . Curran Associates, 2621–2629.
[24] Philipp Benz, Chaoning Zhang, Adil Karjauv, and In So Kweon. 2021. Robustness may be at odds with fairness: An
empirical study on class-wise accuracy. In NeurIPS . PMLR, 325–342.
[25] Arjun Nitin Bhagoji, Daniel Cullina, Chawin Sitawarin, and Prateek Mittal. 2018. Enhancing robustness of machine
learning systems via data transformations. In CISS. IEEE, 1–5.
26
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
[26] Rohan Bhardwaj, Ankita R Nambiar, and Debojyoti Dutta. 2017. A study of machine learning in healthcare. In
COMPSAC , Vol. 2. IEEE, 236–241.
[27] Angie Boggust, Benjamin Hoover, Arvind Satyanarayan, and Hendrik Strobelt. 2022. Shared Interest: Measuring
Human-AI Alignment to Identify Recurring Patterns in Model Behavior. In CHI. 1–17.
[28] Aleksandar Bojchevski and S. Günnemann. 2019. Certifiable robustness to graph perturbations. NeurIPS 32 (2019).
[29] Karen L Boyd. 2021. Datasheets for Datasets help ML Engineers Notice and Understand Ethical Issues in Training
Data. ACM on Human-Computer Interaction 5, CSCW2 (2021), 1–27.
[30] Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative research in psychology 3,
2 (2006), 77–101.
[31] Cristian Bucilua, Rich Caruana, and Alexandru Niculescu-Mizil. 2006. Model Compression. In Proceedings of the 12th
ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’06) . ACM, 535–541.
[32] Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender
classification. In Conference on fairness, accountability and transparency . PMLR, 77–91.
[33] Collin Burns and Jacob Steinhardt. 2021. Limitations of post-hoc feature alignment for robustness. In CVPR . 2525–2533.
[34] Ángel Alexander Cabrera, Abraham J Druck, Jason I Hong, and Adam Perer. 2021. Discovering and validating ai
errors with crowdsourced failure reports. ACM on Human-Computer Interaction 5, CSCW2 (2021), 1–22.
[35] Stefano Calzavara, Lorenzo Cazzaro, Claudio Lucchese, Federico Marcuzzi, and Salvatore Orlando. 2022. Beyond
robustness: Resilience verification of tree-based classifiers. Computers & Security 121 (2022), 102843.
[36] Ginevra Carbone, Matthew Wicker, Luca Laurenti, A. Patane, L. Bortolussi, and Guido Sanguinetti. 2020. Robustness
of Bayesian Neural Networks to Gradient-Based Attacks. In NeurIPS , Vol. 33. Curran Associates, 15602–15613.
[37] Nicholas Carlini, A. Athalye, N. Papernot, W. Brendel, Jonas Rauber, Dimitris Tsipras, Ian Goodfellow, Aleksander
Madry, and Alexey Kurakin. 2019. On evaluating adversarial robustness. arXiv preprint arXiv:1902.06705 (2019).
[38] Nicholas Carlini and David Wagner. 2017. Towards evaluating the robustness of neural networks. In 2017 IEEE
symposium on security and privacy (sp) . Ieee, 39–57.
[39] Diogo V Carvalho, Eduardo M Pereira, and Jaime S Cardoso. 2019. Machine learning interpretability: A survey on
methods and metrics. Electronics 8, 8 (2019), 832.
[40] Alvin Chan, Yi Tay, Yew Soon Ong, and Jie Fu. 2019. Jacobian adversarially regularized networks for robustness.
arXiv preprint arXiv:1912.10185 (2019).
[41] C. Chang, G. Adam, and A. Goldenberg. 2021. Towards Robust Classification Model by Counterfactual and Invariant
Data Generation. In 2021 CVPR . IEEE Computer Society, Los Alamitos, CA, USA, 15207–15216.
[42] Howard Chen, Jacqueline He, Karthik Narasimhan, and Danqi Chen. 2022. Can Rationalization Improve Robustness?
[43] Hongge Chen, Huan Zhang, Duane Boning, and Cho-Jui Hsieh. 2019. Robust decision trees against adversarial
examples. In ICML . PMLR, 1122–1131.
[44] Pin-Yu Chen, Yash Sharma, Huan Zhang, Jinfeng Yi, and Cho-Jui Hsieh. 2017. EAD: Elastic-Net Attacks to Deep
Neural Networks via Adversarial Examples.
[45] Shang-Tse Chen, C. Cornelius, J. Martin, and D. Horng Chau. 2019. ShapeShifter: Robust Physical Adversarial Attack
on Faster R-CNN Object Detector. In Machine Learning and Knowledge Discovery in Databases . Springer, 52–68.
[46] Shang-Tse Chen, Cory Cornelius, Jason Martin, and Duen Horng Polo Chau. 2018. Shapeshifter: Robust physical
adversarial attack on faster r-cnn object detector. In ECML/KDD . Springer, 52–68.
[47] Xiangning Chen, Cihang Xie, Mingxing Tan, Li Zhang, Cho-Jui Hsieh, and Boqing Gong. 2021. Robust and accurate
object detection via adversarial learning. In CVPR . 16622–16631.
[48] Yu Chen, Lingfei Wu, and Mohammed Zaki. 2020. Iterative Deep Graph Learning for Graph Neural Networks: Better
and Robust Node Embeddings. In NeurIPS , Vol. 33. Curran Associates, Inc., 19314–19326.
[49] Minhao Cheng, Pin-Yu Chen, Sijia Liu, Shiyu Chang, Cho-Jui Hsieh, and Payel Das. 2020. Self-Progressing Robust
Training.
[50] Minhao Cheng, Qi Lei, Pin-Yu Chen, Inderjit Dhillon, and Cho-Jui Hsieh. 2020. CAT: Customized Adversarial Training
for Improved Robustness.
[51] Xiang Cheng, Yunzhe Hao, Jiaming Xu, and Bo Xu. 2020. LISNN: Improving Spiking Neural Networks with Lateral
Interactions for Robust Object Recognition. In IJCAI . 1519–1525.
[52] Seok-Hwan Choi, Jin-Myeong Shin, Peng Liu, and Yoon-Ho Choi. 2022. ARGAN: Adversarially Robust Generative
Adversarial Networks for Deep Neural Networks Against Adversarial Examples. IEEE Access 10 (2022), 33602–33615.
[53] Jeremy M Cohen, Elan Rosenfeld, and J. Zico Kolter. 2019. Certified Adversarial Robustness via Randomized
Smoothing.
[54] Luca Console, Daniele Theseider Dupre, and Pietro Torasso. 1989. A Theory of Diagnosis for Incomplete Causal
Models.. In IJCAI . 1311–1317.
[55] Francesco Croce, M. Andriushchenko, V. Sehwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek
Mittal, and Matthias Hein. 2021. RobustBench: a standardized adversarial robustness benchmark. In NeurIPS , Vol. 1.
27
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
[56] Wesley Hanwen Deng, Manish Nagireddy, Michelle Seng Ah Lee, Jatinder Singh, Zhiwei Steven Wu, Kenneth Holstein,
and Haiyi Zhu. 2022. Exploring How Machine Learning Practitioners (Try To) Use Fairness Toolkits. arXiv preprint
arXiv:2205.06922 (2022).
[57] Zhun Deng, Linjun Zhang, Amirata Ghorbani, and James Zou. 2020. Improving Adversarial Robustness via Unlabeled
Out-of-Domain Data.
[58] Chaitanya Devaguptapu, Devansh Agarwal, Gaurav Mittal, Pulkit Gopalani, and Vineeth N Balasubramanian. 2021.
On adversarial robustness: A neural architecture search perspective. In ICCV . 152–161.
[59] Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. 2021. Retiring Adult: New Datasets for Fair Machine
Learning. In NeurIPS , Vol. 34. Curran Associates, Inc., 6478–6490.
[60] Andrea Dittadi, Samuele Papa, Michele De Vita, Bernhard Schölkopf, Ole Winther, and Francesco Locatello. 2021.
Generalization and Robustness Implications in Object-Centric Learning.
[61] Ann-Kathrin Dombrowski, Christopher J Anders, Klaus-Robert Müller, and Pan Kessel. 2022. Towards robust
explanations for deep neural networks. Pattern Recognition 121 (2022), 108194.
[62] Minjing Dong, Yanxi Li, Yunhe Wang, and Chang Xu. 2020. Adversarially Robust Neural Architectures.
[63] Yinpeng Dong, Qi-An Fu, X. Yang, T. Pang, H. Su, Zihao Xiao, and Jun Zhu. 2019. Benchmarking Adversarial
Robustness.
[64] Nathan Drenkow, Numair Sani, Ilya Shpitser, and Mathias Unberath. 2021. Robustness in Deep Learning for Computer
Vision: Mind the gap? arXiv preprint arXiv:2112.00639 (2021).
[65] Tianyu Du, Shouling Ji, Lujia Shen, Yao Zhang, Jinfeng Li, Jie Shi, Chengfang Fang, Jianwei Yin, Raheem Beyah, and
Ting Wang. 2021. Cert-RNN: Towards Certifying the Robustness of Recurrent Neural Networks.. In CCS. 516–534.
[66] Xiaohu Du, Jie Yu, Shasha Li, Zibo Yi, Hai Liu, and Jun Ma. 2021. Combating Word-level Adversarial Text with Robust
Adversarial Training. In 2021 Intl.Joint Conf. on Neural Networks (IJCNN) . 1–8.
[67] Krishnamurthy (Dj) Dvijotham, Jamie Hayes, Borja Balle, Zico Kolter, Chongli Qin, Andras Gyorgy, Kai Xiao,
Sven Gowal, and Pushmeet Kohli. 2020. A Framework for Robustness Certification of Smoothed Classifiers using
F-Divergences. In ICLR .
[68] Lei Feng, Senlin Shu, Zhuoyi Lin, Fengmao Lv, Li Li, and Bo An. 2020. Can Cross Entropy Loss Be Robust to Label
Noise?. In IJCAI-20 . 2206–2212. Main track.
[69] Ailbhe Finnerty, Pavel Kucherbaev, Stefano Tranquillini, and Gregorio Convertino. 2013. Keep it simple: Reward and
task design in crowdsourcing. In Italian Chapter of SIGCHI . 1–4.
[70] Luciano Floridi. 2019. Establishing the rules for building trustworthy AI. Nature Machine Intelligence 1, 6 (2019),
261–262.
[71] James Fox and Sivasankaran Rajamanickam. 2019. How Robust Are Graph Neural Networks to Structural Noise?
[72] Ji Gao, Beilun Wang, Zeming Lin, Weilin Xu, and Yanjun Qi. 2017. DeepCloak: Masking Deep Neural Network Models
for Robustness Against Adversarial Samples.
[73] Xiang Gao, Ripon K. Saha, Mukul R. Prasad, and Abhik Roychoudhury. 2020. Fuzz Testing Based Data Augmentation
to Improve Robustness of Deep Neural Networks (ICSE ’20) . ACM, New York, NY, USA, 1147–1158.
[74] Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii,
and Kate Crawford. 2021. Datasheets for datasets. Commun. ACM 64, 12 (2021), 86–92.
[75] Timon Gehr, Matthew Mirman, Dana Drachsler-Cohen, Petar Tsankov, Swarat Chaudhuri, and Martin Vechev. 2018.
Ai2: Safety and robustness certification of neural networks with abstract interpretation. In 2018 IEEE symposium on
security and privacy (SP) . IEEE, 3–18.
[76] Simon Geisler, Tobias Schmidt, Hakan Şirin, Daniel Zügner, Aleksandar Bojchevski, and Stephan Günnemann. 2021.
Robustness of Graph Neural Networks at Scale. In NeurIPS , Vol. 34. Curran Associates, Inc., 7637–7649.
[77] A Ghorbani and al. 2019. Towards automatic concept-based explanations. In NeurIPS .
[78] Sanjukta Ghosh, Rohan Shet, Peter Amon, Andreas Hutter, and André Kaup. 2018. Robustness of Deep Convolutional
Neural Networks for Image Degradations. In ICASSP . 2916–2920.
[79] Tejas Gokhale, Swaroop Mishra, Man Luo, Bhavdeep Singh Sachdeva, and Chitta Baral. 2022. Generalized but not
Robust? Comparing the Effects of Data Modification Methods on Out-of-Domain Generalization and Adversarial
Robustness. arXiv preprint arXiv:2203.07653 (2022).
[80] Ian Goodfellow, Patrick McDaniel, and Nicolas Papernot. 2018. Making Machine Learning Robust against Adversarial
Inputs. Commun. ACM 61, 7 (jun 2018), 56–66.
[81] Dou Goodman, Hao Xin, Wang Yang, Wu Yuesheng, Xiong Junfeng, and Zhang Huan. 2020. Advbox: a toolbox to
generate adversarial examples that fool neural networks. arXiv preprint arXiv:2001.05574 (2020).
[82] Divya Gopinath, G. Katz, C S. Păsăreanu, and Clark Barrett. 2018. Deepsafe: A data-driven approach for assessing
robustness of neural networks. In Intl. symp. on automated technology for verification and analysis . Springer, 3–19.
[83] Riccardo Guidotti. 2022. Counterfactual explanations and how to find them: literature review and benchmarking.
Data Mining and Knowledge Discovery (28 Apr 2022).
28
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
[84] Riccardo Guidotti, Anna Monreale, Salvatore Ruggieri, Franco Turini, Fosca Giannotti, and Dino Pedreschi. 2018. A
Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 51, 5, Article 93 (aug 2018), 42 pages.
[85] Sidharth Gupta, P. Dube, and Ashish Verma. 2020. Improving the Affordability of Robustness Training for DNNs. In
CVPR .
[86] Christian Haase-Schütz, Rainer Stal, Heinz Hertlein, and Bernhard Sick. 2020. Iterative Label Improvement: Robust
Training by Confidence Based Filtering and Dataset Partitioning.
[87] Kilian Hendrickx, Lorenzo Perini, Dries Van der Plas, Wannes Meert, and Jesse Davis. 2021. Machine learning with a
reject option: A survey. arXiv preprint arXiv:2107.11277 (2021).
[88] Dan Hendrycks and Thomas Dietterich. 2019. Benchmarking Neural Network Robustness to Common Corruptions
and Perturbations.
[89] P Henriksen, K Hammernik, D Rueckert, and A Lomuscio. 2021. Bias Field Robustness Verification of Large Neural
Image Classifiers.
[90] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the Knowledge in a Neural Network.
[91] P Hitzler and MK Sarker. 2022. Human-Centered Concept Explanations for Neural Networks. Neuro-Symbolic
Artificial Intelligence: The State of the Art 342, 337 (2022), 2.
[92] Fred Hohman, Andrew Head, Rich Caruana, Robert DeLine, and Steven M Drucker. 2019. Gamut: A design probe to
understand how data scientists understand machine learning models. In CHI. 1–13.
[93] Sungsoo Ray Hong, Jessica Hullman, and Enrico Bertini. 2020. Human factors in model interpretability: Industry
practices, challenges, and needs. ACM on Human-Computer Interaction 4, CSCW1 (2020), 1–26.
[94] Ramtin Hosseini, Xingyi Yang, and Pengtao Xie. 2020. DSRNA: Differentiable Search of Robust Neural Architectures.
[95] X Hu, H Wang, A Vegesana, and al. 2020. Crowdsourcing Detection of Sampling Biases in Image Datasets. In Proc. of
WWW . 2955–2961.
[96] Lifu Huang, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. Cosmos QA: Machine Reading Comprehension
with Contextual Commonsense Reasoning. In 2019 EMNLP-IJCNLP . 2391–2401.
[97] Oana Inel, Khalid Khamkham, Tatiana Cristea, Anca Dumitrache, Arne Rutjes, Jelle van der Ploeg, Lukasz Romaszko,
Lora Aroyo, and Robert-Jan Sips. 2014. Crowdtruth: Machine-human computation framework for harnessing
disagreement in gathering annotated data. In ISWC . Springer, 486–504.
[98] Matthew Jagielski, Alina Oprea, Battista Biggio, Chang Liu, Cristina Nita-Rotaru, and Bo Li. 2018. Manipulating
machine learning: Poisoning attacks and countermeasures for regression learning. In 2018 IEEE Symposium on Security
and Privacy (SP) . IEEE, 19–35.
[99] Jongheon Jeong and Jinwoo Shin. 2020. Consistency Regularization for Certified Robustness of Smoothed Classifiers.
InNeurIPS , Vol. 33. Curran Associates, Inc., 10558–10570.
[100] Malhar Jere, Maghav Kumar, and Farinaz Koushanfar. 2020. A singular value perspective on model robustness. arXiv
preprint arXiv:2012.03516 (2020).
[101] Di Jin, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. Is bert really robust? a strong baseline for natural
language attack on text classification and entailment. In AAAI , Vol. 34. 8018–8025.
[102] Jonghoon Jin, Aysegul Dundar, and Eugenio Culurciello. 2015. Robust Convolutional Neural Networks under
Adversarial Noise.
[103] Wei Jin, Yao Ma, Xiaorui Liu, Xianfeng Tang, Suhang Wang, and Jiliang Tang. 2020. Graph Structure Learning for
Robust Graph Neural Networks. In SIGKDD . ACM, New York, NY, USA, 66–74.
[104] Takuhiro Kaneko, Yoshitaka Ushiku, and Tatsuya Harada. 2018. Label-Noise Robust Generative Adversarial Networks.
[105] Masahiro Kato, Zhenghang Cui, and Yoshihiro Fukuhara. 2020. Atro: Adversarial training with a rejection option.
arXiv preprint arXiv:2010.12905 (2020).
[106] B Kim, M Wattenberg, and al. 2018. Interpretability beyond feature attribution: Quantitative testing with concept
activation vectors. In ICML .
[107] Marvin Klingner, Andreas Bar, and Tim Fingscheidt. 2020. Improved Noise and Attack Robustness for Semantic
Segmentation by Using Multi-Task Training With Self-Supervised Depth Estimation. In CVPR Workshops .
[108] Pang Wei Koh, S. Sagawa, H. Marklund, S. M. Xie, M. Zhang, A. Balsubramani, Weihua Hu, Michihiro Yasunaga, R. L.
Phillips, Irena Gao, et al. 2021. Wilds: A benchmark of in-the-wild distribution shifts. In ICML . PMLR, 5637–5664.
[109] A. Kortylewski, Q. Liu, A. Wang, Y. Sun, and A. Yuille. 2021. Compositional convolutional neural networks: A robust
and interpretable model for object recognition under occlusion. I. Journal of Computer Vision 129, 3 (2021), 736–760.
[110] Sean Kross and Philip Guo. 2021. Orienting, framing, bridging, magic, and counseling: How data scientists navigate
the outer loop of client collaborations in industry and academia. ACM on Human-Computer Interaction 5, CSCW2
(2021), 1–28.
[111] Danijel Kučak, Vedran Juričić, and Goran Ðambić. 2018. Machine learning in education-A survey of current research
trends. Annals of DAAAM & Proceedings 29 (2018).
29
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
[112] Emanuele La Malfa and Marta Kwiatkowska. 2022. The king is naked: on the notion of robustness for natural language
processing. In AAAI , Vol. 36. 11047–11057.
[113] Emanuele La Malfa, Min Wu, L. Laurenti, B. Wang, A. Hartshorn, and Marta Kwiatkowska. 2020. Assessing Robustness
of Text Classification through Maximal Safe Radius Computation. In EMNLP . ACL, 2949–2968.
[114] Himabindu Lakkaraju, Nino Arsov, and Osbert Bastani. 2020. Robust and Stable Black Box Explanations. In 37th
ICML (ICML’20) . JMLR.org, Article 522, 11 pages.
[115] Alfred Laugros, Alice Caplier, and Matthieu Ospici. 2020. Addressing Neural Network Robustness with Mixup and
Targeted Labeling Adversarial Training.
[116] Hyungyu Lee, Ho Bae, and Sungroh Yoon. 2021. Gradient Masking of Label Smoothing in Adversarial Robustness.
IEEE Access 9 (2021), 6453–6464.
[117] Michelle Seng Ah Lee and Jat Singh. 2021. The landscape and gaps in open source fairness toolkits. In CHI. 1–13.
[118] Klas Leino, Z. Wang, and M. Fredrikson. 2021. Globally-Robust Neural Networks. In ICML , Vol. 139. PMLR, 6212–6222.
[119] Alexander Levine and Soheil Feizi. 2021. Improved, Deterministic Smoothing for L_1 Certified Robustness.
[120] Dongyue Li and Hongyang Zhang. 2021. Improved Regularization and Robustness for Fine-tuning in Neural Networks.
InNeurIPS , Vol. 34. Curran Associates, Inc., 27249–27262.
[121] Jinfeng Li, Tianyu Du, Shouling Ji, Rong Zhang, Quan Lu, Min Yang, and Ting Wang. 2020. {TextShield }: Robust
Text Classification Based on Multimodal Embedding and Neural Machine Translation. In USENIX . 1381–1398.
[122] Linyi Li, Zexuan Zhong, Bo Li, and Tao Xie. 2019. Robustra: Training Provable Robust Neural Networks over Reference
Adversarial Space.. In IJCAI . 4711–4717.
[123] Xin Li, Xiangrui Li, Deng Pan, and Dongxiao Zhu. 2020. Improving Adversarial Robustness via Probabilistically
Compact Loss with Logit Constraints.
[124] Yanxi Li, Zhaohui Yang, Yunhe Wang, and Chang Xu. 2021. Neural Architecture Dilation for Adversarial Robustness.
InNeurIPS , Vol. 34. Curran Associates, Inc., 29578–29589.
[125] Zhimin Li, S. Liu, X. Yu, K. Bhavya, Jie Cao, Diffenderfer James Daniel, Peer-Timo Bremer, and Valerio Pascucci. 2022.
"Understanding Robustness Lottery": A Comparative Visual Analysis of Neural Network Pruning Approaches.
[126] Q Vera Liao, Daniel Gruen, and Sarah Miller. 2020. Questioning the AI: informing design practices for explainable AI
user experiences. In 2020 CHI . 1–15.
[127] Q Vera Liao, Milena Pribić, Jaesik Han, Sarah Miller, and Daby Sow. 2021. Question-Driven Design Process for
Explainable AI User Experiences. arXiv preprint arXiv:2104.03483 (2021).
[128] Anthony Liu, Santiago Guerra, Isaac Fung, Gabriel Matute, Ece Kamar, and Walter Lasecki. 2020. Towards hybrid
human-AI workflows for unknown unknown detection. In Web Conf. 2432–2442.
[129] Weifeng Liu, P.P. Pokharel, and J.C. Principe. 2006. Correntropy: A Localized Similarity Measure. In Conf. on Neural
Network . 4919–4924.
[130] Yang Lou, Ruizi Wu, Junli Li, Lin Wang, Xiang Li, and Guanrong Chen. 2022. A Learning Convolutional Neural
Network Approach for Network Robustness Prediction. arXiv preprint arXiv:2203.10552 (2022).
[131] Wolfgang Maass. 1997. Networks of spiking neurons: The third generation of neural network models. Neural Networks
10, 9 (1997), 1659–1671.
[132] Divyam Madaan, Jinwoo Shin, and Sung Ju Hwang. 2020. Learning to Generate Noise for Multi-Attack Robustness.
[133] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep
Learning Models Resistant to Adversarial Attacks. In ICLR . OpenReview.net.
[134] Ravi Mangal, Aditya V. Nori, and Alessandro Orso. 2019. Robustness of Neural Networks: A Probabilistic and Practical
Approach.
[135] Chengzhi Mao, Ziyuan Zhong, Junfeng Yang, Carl Vondrick, and Baishakhi Ray. 2019. Metric Learning for Adversarial
Robustness.
[136] Gary Marcus. 2020. The next decade in ai: four steps towards robust artificial intelligence. arXiv preprint
arXiv:2002.06177 (2020).
[137] Alexander Mathis, Thomas Biasi, Steffen Schneider, Mert Yuksekgonul, Byron Rogers, Matthias Bethge, and Macken-
zie W. Mathis. 2021. Pretraining Boosts Out-of-Domain Robustness for Pose Estimation. In WACV . 1859–1868.
[138] Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. 2021. A survey on bias and
fairness in machine learning. CSUR 54, 6 (2021), 1–35.
[139] Brad Miller, Alex Kantchelian, Sadia Afroz, Rekha Bachwani, E. Dauber, L. Huang, M. C. Tschantz, A. D. Joseph, and
J Doug Tygar. 2014. Adversarial active learning. In Workshop on Artificial Intelligent and Security . 3–14.
[140] Dimity Miller, Lachlan Nicholson, Feras Dayoub, and Niko Sünderhauf. 2018. Dropout Sampling for Robust Object
Detection in Open-Set Conditions. In ICRA . 3243–3249.
[141] David J Miller, Xinyi Hu, Zhicong Qiu, and George Kesidis. 2017. Adversarial learning: a critical review and active
learning study. In Intl. Workshop on Machine Learning for Signal Processing (MLSP) . IEEE, 1–6.
30
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
[142] John P Miller, Rohan Taori, Aditi Raghunathan, Shiori Sagawa, Pang Wei Koh, Vaishaal Shankar, Percy Liang, Yair
Carmon, and Ludwig Schmidt. 2021. Accuracy on the line: on the strong correlation between out-of-distribution and
in-distribution generalization. In ICML . PMLR, 7721–7735.
[143] Matthew Mirman, Timon Gehr, and Martin Vechev. 2018. Differentiable Abstract Interpretation for Provably Robust
Neural Networks. In 35th ICML , Vol. 80. PMLR, 3578–3586.
[144] Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer,
Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. In FAccT . 220–229.
[145] Jisoo Mok, Byunggook Na, Hyeokjun Choe, and Sungroh Yoon. 2021. AdvRush: Searching for Adversarially Robust
Neural Architectures.
[146] Mohammad Momeny, Ali Mohammad Latif, Mehdi Agha Sarram, Razieh Sheikhpour, and Yu Dong Zhang. 2021. A
noise robust convolutional neural network for image classification. Results in Engineering 10 (2021), 100225.
[147] Seyed-Mohsen Moosavi-Dezfooli, Ashish Shrivastava, and Oncel Tuzel. 2018. Divide, Denoise, and Defend against
Adversarial Attacks.
[148] Milad Moradi and Matthias Samwald. 2021. Evaluating the Robustness of Neural Language Models to Input Perturba-
tions.
[149] Aamir Mustafa, S. H. Khan, M. Hayat, R. Goecke, Jianbing Shen, and Ling Shao. 2021. Deeply Supervised Discriminative
Learning for Adversarial Defense. Trans. on Pattern Analysis and Machine Intelligence 43, 9 (2021), 3154–3166.
[150] Vedant Nanda, Till Speicher, John P. Dickerson, Krishna P. Gummadi, and Muhammad Bilal Zafar. 2020. Unifying
Model Explainability and Robustness via Machine-Checkable Concepts.
[151] Shweta Narkar, Yunfeng Zhang, Q Vera Liao, Dakuo Wang, and Justin D Weisz. 2021. Model LineUpper: Supporting
Interactive Model Comparison at Multiple Levels for AutoML. In 26th Intl. Conf. on Intelligent User Interfaces . 170–174.
[152] Muzammal Naseer, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Fatih Porikli. 2020. A Self-supervised
Approach for Adversarial Robustness.
[153] Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nathan Srebro. 2017. Exploring Generalization in
Deep Learning.
[154] Kun-Peng Ning, Lue Tao, Songcan Chen, and Sheng-Jun Huang. 2021. Improving Model Robustness by Adaptively
Correcting Perturbation Levels with Active Queries. In EAAI . AAAI Press, 9161–9169.
[155] Ardavan Salehi Nobandegani, Kevin da Silva Castanheira, Timothy O’Donnell, and Thomas R Shultz. 2019. On
Robustness: An Undervalued Dimension of Human Rationality.. In CogSci . 3327.
[156] Curtis G. Northcutt, Anish Athalye, and Jonas Mueller. 2021. Pervasive Label Errors in Test Sets Destabilize Machine
Learning Benchmarks. In NeurIPS .
[157] Mehdi Nourelahi, Lars Kotthoff, Peijie Chen, and Anh Nguyen. 2022. How explainable are adversarially-robust CNNs?
arXiv preprint arXiv:2205.13042 (2022).
[158] Besmira Nushi, Ece Kamar, Eric Horvitz, and Donald Kossmann. 2017. On human intellect and machine failures:
Troubleshooting integrative machine learning systems. In Thirty-FirstAAAI .
[159] Tianyu Pang, Min Lin, Xiao Yang, Jun Zhu, and Shuicheng Yan. 2022. Robustness and Accuracy Could Be Reconcilable
by (Proper) Definition.
[160] Tianyu Pang, Huishuai Zhang, Di He, Yinpeng Dong, Hang Su, Wei Chen, Jun Zhu, and Tie-Yan Liu. 2022. Two
Coupled Rejection Metrics Can Tell Adversarial Examples Apart. In CVPR . 15223–15233.
[161] Yutian Pang, Sheng Cheng, Jueming Hu, and Yongming Liu. 2021. Evaluating the robustness of bayesian neural
networks against different types of attacks. arXiv preprint arXiv:2106.09223 (2021).
[162] Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, and Ananthram Swami. 2016. Distillation as a Defense to
Adversarial Perturbations Against Deep Neural Networks. In IEEE SP . 582–597.
[163] Magdalini Paschali, Sailesh Conjeti, Fernando Navarro, and Nassir Navab. 2018. Generalizability vs. Robustness:
Adversarial Examples for Medical Imaging.
[164] Martin Pawelczyk, Chirag Agarwal, Shalmali Joshi, Sohini Upadhyay, and Himabindu Lakkaraju. 2022. Exploring
Counterfactual Explanations Through the Lens of Adversarial Examples: A Theoretical and Empirical Analysis. In
AISTATS , Vol. 151. PMLR, 4574–4594.
[165] Joshua C. Peterson, Ruairidh M. Battleday, Thomas L. Griffiths, and Olga Russakovsky. 2019. Human uncertainty
makes classification more robust.
[166] Pouya Pezeshkpour, Yifan Tian, and Sameer Singh. 2019. Investigating Robustness and Interpretability of Link
Prediction via Adversarial Modifications. In ACL. ACL, Minneapolis, Minnesota, 3336–3347.
[167] Maura Pintor, Daniele Angioni, Angelo Sotgiu, Luca Demetrio, Ambra Demontis, Battista Biggio, and Fabio Roli. 2022.
ImageNet-Patch: A Dataset for Benchmarking Machine Learning Robustness against Adversarial Patches.
[168] David Piorkowski, Soya Park, April Yi Wang, Dakuo Wang, Michael Muller, and Felix Portnoy. 2021. How ai developers
overcome communication challenges in a multidisciplinary team: A case study. ACM on Human-Computer Interaction
5, CSCW1 (2021), 1–25.
31
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
[169] Yada Pruksachatkun, S. Krishna, J. Dhamala, R. Gupta, and Kai-Wei Chang. 2021. Does Robustness Improve Fairness?
Approaching Fairness with Word Substitution Robustness Methods for Text Classification. In ACL-IJCNLP . 3320–3331.
[170] Danish Pruthi, Bhuwan Dhingra, and Zachary C Lipton. 2019. Combating adversarial misspellings with robust word
recognition. arXiv preprint arXiv:1905.11268 (2019).
[171] Yanmin Qian, Hu Hu, and Tian Tan. 2019. Data augmentation using generative adversarial networks for robust
speech recognition. Speech Communication 114 (2019), 1–9.
[172] Hamon R, Junklewitz H, and Sanchez Martin JI. 2020. Robustness and Explainability of Artificial Intelligence.
KJ-NA-30040-EN-N (online) (2020).
[173] Aditi Raghunathan, Sang Michael Xie, Fanny Yang, John Duchi, and Percy Liang. 2020. Understanding and Mitigating
the Tradeoff Between Robustness and Accuracy.
[174] V C Raykar, S Yu, and al. 2010. Learning from crowds. JMLR 11, Apr (2010).
[175] Ashkan Rezaei, Anqi Liu, Omid Memarrast, and Brian D. Ziebart. 2021. Robust Fairness Under Covariate Shift. AAAI
35, 11 (May 2021), 9419–9427.
[176] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " Why should I trust you?" Explaining the predictions
of any classifier. In SIGKDD . 1135–1144.
[177] Brianna Richardson, Jean Garcia-Gathright, Samuel F Way, Jennifer Thom, and Henriette Cramer. 2021. Towards
Fairness in Practice: A Practitioner-Oriented Rubric for Evaluating Fair ML Toolkits. In CHI. 1–13.
[178] Matthew Richardson and Pedro Domingos. 2006. Markov logic networks. Machine learning 62, 1 (2006), 107–136.
[179] Christos Rodosthenous and Loizos Michael. 2016. A hybrid approach to commonsense knowledge acquisition. In
STAIRS 2016 . IOS Press, 111–122.
[180] Sudipta Singha Roy, Sk. Imran Hossain, M. A. H. Akhand, and Kazuyuki Murase. 2018. A Robust System for Noisy
Image Classification Combining Denoising Autoencoder and Convolutional Neural Network. Intl.Journal of Advanced
Computer Science and Applications 9, 1 (2018).
[181] Andras Rozsa, Manuel Gunther, and Terrance E. Boult. 2016. Towards Robust Deep Neural Networks with BANG.
[182] Wenjie Ruan, Min Wu, Youcheng Sun, Xiaowei Huang, Daniel Kroening, and Marta Kwiatkowska. 2018. Global
Robustness Evaluation of Deep Neural Networks with Provable Guarantees for the 𝐿0Norm.
[183] Evgenia Rusak, Lukas Schott, Roland S. Zimmermann, Julian Bitterwolf, Oliver Bringmann, Matthias Bethge, and
Wieland Brendel. 2020. A simple way to make neural networks robust against diverse image corruptions.
[184] Sean Saito, Eugene Chua, Nicholas Capel, and Rocco Hu. 2020. Improving LIME Robustness with Smarter Locality
Sampling. ArXiv abs/2006.12302 (2020).
[185] Wojciech Samek and Klaus-Robert Müller. 2019. Towards explainable artificial intelligence. In Explainable AI:
interpreting, explaining and visualizing deep learning . Springer, 5–22.
[186] Ivan Sanchez, Jeff Mitchell, and Sebastian Riedel. 2018. Behavior Analysis of NLI Models: Uncovering the Influence of
Three Factors on Robustness. In ACL. ACL, New Orleans, Louisiana, 1975–1985.
[187] Filippo Santoni de Sio. 2021. The European Commission report on ethics of connected and automated vehicles and
the future of ethics of transportation. Ethics and Information Technology 23, 4 (2021), 713–726.
[188] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. 2019. SocialIQA: Commonsense Reasoning
about Social Interactions. In Conf. on Empirical Methods in Natural Language Processing .
[189] Vikash Sehwag, Saeed Mahloujifar, Tinashe Handina, Sihui Dai, Chong Xiang, Mung Chiang, and Prateek Mittal.
2021. Robust Learning Meets Generative Models: Can Proxy Distributions Improve Adversarial Robustness?
[190] Shreya Shankar, Rolando Garcia, Joseph M Hellerstein, and Aditya G Parameswaran. 2022. Operationalizing Machine
Learning: An Interview Study. arXiv preprint arXiv:2209.09125 (2022).
[191] Vaishaal Shankar, Achal Dave, Rebecca Roelofs, Deva Ramanan, Benjamin Recht, and Ludwig Schmidt. 2019. Do
Image Classifiers Generalize Across Time?
[192] Rulin Shao, Zhouxing Shi, Jinfeng Yi, Pin-Yu Chen, and Cho-Jui Hsieh. 2021. On the Adversarial Robustness of Vision
Transformers.
[193] Shahin Sharifi Noorian, S. Qiu, U. Gadiraju, J. Yang, and Alessandro Bozzon. 2022. What Should You Know? A Human-
In-the-Loop Approach to Unknown Unknowns Characterization in Image Recognition. In Web Conf. 882–892.
[194] Saima Sharmin, Nitin Rathi, Priyadarshini Panda, and Kaushik Roy. 2020. Inherent Adversarial Robustness of Deep
Spiking Neural Networks: Effects of Discrete Input Encoding and Non-Linear Activations.
[195] Max W Shen. 2022. Trust in AI: Interpretability is not necessary or sufficient, while black-box interaction is necessary
and sufficient. arXiv preprint arXiv:2202.05302 (2022).
[196] Zheyan Shen, Jiashuo Liu, Yue He, Xingxuan Zhang, Renzhe Xu, Han Yu, and Peng Cui. 2021. Towards out-of-
distribution generalization: A survey. arXiv preprint arXiv:2108.13624 (2021).
[197] Dule Shu, Nandi O Leslie, Charles A Kamhoua, and Conrad S Tucker. 2020. Generative adversarial attacks against
intrusion detection systems using active learning. In Workshop on Wireless Security and Machine Learning . 1–6.
32
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
[198] K Simonyan, A Vedaldi, and A Zisserman. 2014. Deep Inside Convolutional Networks: Visualising Image Classification
Models and Saliency Maps. In ICLR .
[199] Gagandeep Singh, Timon Gehr, Markus Püschel, and Martin T. Vechev. 2019. Boosting Robustness Certification of
Neural Networks. In ICLR .
[200] Manish Kumar Singla, Debdas Ghosh, and Kaustubh Kumar Shukla. 2020. Improved Sparsity of Support Vector
Machine with Robustness Towards Label Noise Based on Rescaled 𝛼-Hinge Loss with Non-smooth Regularizer. Neural
Process. Lett. 52 (2020), 2211–2239.
[201] Sahil Singla and Soheil Feizi. 2019. Robustness certificates against adversarial examples for relu networks. arXiv
preprint arXiv:1902.01235 (2019).
[202] Sahil Singla, Surbhi Singla, and Soheil Feizi. 2022. Improved deterministic l2 robustness on CIFAR-10 and CIFAR-100.
InICLR .
[203] Samarth Sinha, Sayna Ebrahimi, and Trevor Darrell. 2019. Variational adversarial active learning. In ICCV . 5972–5981.
[204] Dylan Slack, Sophie Hilgard, Emily Jia, Sameer Singh, and Himabindu Lakkaraju. 2019. Fooling LIME and SHAP:
Adversarial Attacks on Post hoc Explanation Methods.
[205] Carol J Smith. 2019. Designing trustworthy AI: A human-machine teaming framework to guide development. arXiv
preprint arXiv:1910.03515 (2019).
[206] Kacper Sokol and Peter Flach. 2020. Explainability fact sheets: a framework for systematic assessment of explainable
approaches. In 2020 FAccT . 56–67.
[207] Chang Song, Elias Fallon, and Hai Li. 2020. Improving Adversarial Robustness in Weight-quantized Neural Networks.
[208] Ezekiel Soremekun, Sakshi Udeshi, and Sudipta Chattopadhyay. 2020. Exposing backdoors in robust machine learning
models. arXiv preprint arXiv:2003.00865 (2020).
[209] Joe Stacey, Yonatan Belinkov, and Marek Rei. 2022. Supervising model attention with human explanations for robust
natural language inference. In AAAI , Vol. 36. 11349–11357.
[210] Matthew Staib. 2017. Distributionally Robust Deep Learning as a Generalization of Adversarial Training.
[211] E Štrumbelj and I Kononenko. 2014. Explaining prediction models and individual predictions with feature contributions.
Knowledge and information systems (2014).
[212] David Stutz, Matthias Hein, and Bernt Schiele. 2020. Confidence-calibrated adversarial training: Generalizing to
unseen attacks. In ICML . PMLR, 9155–9166.
[213] Dong Su, H. Zhang, H. Chen, J. Yi, Pin-Yu Chen, and Yupeng Gao. 2018. Is Robustness the Cost of Accuracy? A
Comprehensive Study on the Robustness of 18 Deep Image Classification Models. In ECCV . Springer, Cham, 644–661.
[214] Ke Sun, Zhanxing Zhu, and Zhouchen Lin. 2019. Enhancing the robustness of deep neural networks by boundary
conditional gan. arXiv preprint arXiv:1902.11029 (2019).
[215] Weidi Sun, Yuteng Lu, Xiyue Zhang, Zhanxing Zhu, and Meng Sun. 2020. Global Robustness Verification Networks.
[216] M Sundararajan and al. 2017. Axiomatic Attribution for Deep Networks. In ICML .
[217] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus.
2013. Intriguing properties of neural networks.
[218] Jihoon Tack, Sihyun Yu, Jongheon Jeong, Minseon Kim, Sung Ju Hwang, and Jinwoo Shin. 2022. Consistency
Regularization for Adversarial Robustness. AAAI 36, 8 (Jun. 2022), 8414–8422.
[219] Shiyu Tang, Ruihao Gong, Yan Wang, Aishan Liu, Jiakai Wang, Xinyun Chen, Fengwei Yu, Xianglong Liu, Dawn
Song, Alan Yuille, Philip H. S. Torr, and Dacheng Tao. 2021. RobustART: Benchmarking Robustness on Architecture
Design and Training Techniques.
[220] Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. 2020. Measuring
Robustness to Natural Distribution Shifts in Image Classification. In NeurIPS , Vol. 33. Curran Associates, 18583–18599.
[221] Matteo Terzi, Gian Antonio Susto, and Pratik Chaudhari. 2020. Directional adversarial training for cost sensitive
deep learning classification applications. Engineering Applications of Artificial Intelligence 91 (2020), 103550.
[222] Dang Duy Thang and Toshihiro Matsui. 2019. Image Transformation can make Neural Networks more robust against
Adversarial Examples.
[223] Vincent Tjeng, Kai Xiao, and Russ Tedrake. 2017. Evaluating Robustness of Neural Networks with Mixed Integer
Programming.
[224] Yu-Lin Tsai, Chia-Yi Hsu, Chia-Mu Yu, and Pin-Yu Chen. 2021. Formalizing Generalization and Robustness of Neural
Networks to Weight Perturbations.
[225] Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. 2018. Robustness
May Be at Odds with Accuracy. In ICLR .
[226] Jonathan Uesato, Jean-Baptiste Alayrac, Po-Sen Huang, Robert Stanforth, Alhussein Fawzi, and Pushmeet Kohli. 2019.
Are Labels Required for Improving Adversarial Robustness? Curran Associates Inc., Red Hook, NY, USA.
[227] Meet P. Vadera, Satya Narayan Shukla, Brian Jalaian, and Benjamin M. Marlin. 2020. Assessing the Adversarial
Robustness of Monte Carlo and Distillation Methods for Deep Bayesian Neural Network Classification.
33
Conference acronym ’XX, June 03–05, 2022, Woodstock, NY Tocchetti et al.
[228] Pratik Vaishnavi, Tianji Cong, Kevin Eykholt, Atul Prakash, and Amir Rahmati. 2019. Can Attention Masks Improve
Adversarial Robustness?
[229] Colin Vandenhof. 2019. A hybrid approach to identifying unknown unknowns of predictive models. In HCOMP ,
Vol. 7. 180–187.
[230] Jennifer Wortman Vaughan. 2018. Making better use of the crowd: How crowdsourcing can advance machine learning
research. JMLR 18, 193 (2018), 1–46.
[231] Gunjan Verma and Ananthram Swami. 2019. Error Correcting Output Codes Improve Probability Estimation and
Adversarial Robustness of Deep Neural Networks. In NeurIPS , Vol. 32. Curran Associates, Inc.
[232] Sahil Verma and Julia Rubin. 2018. Fairness definitions explained. In Fairware . IEEE, 1–7.
[233] Marco Virgolin and Saverio Fracaros. 2022. On the Robustness of Counterfactual Explanations to Adverse Perturbations.
arXiv preprint arXiv:2201.09051 (2022).
[234] Luis Von Ahn, M. Kedia, and M. Blum. 2006. Verbosity: a game for collecting common-sense facts. In SIGCHI . 75–78.
[235] Wenjie Wan, Zhaodi Zhang, Yiwei Zhu, Min Zhang, and Fu Song. 2020. Accelerating robustness verification of deep
neural networks guided by target labels. arXiv preprint arXiv:2007.08520 (2020).
[236] Binghui Wang, Jinyuan Jia, Xiaoyu Cao, and Neil Zhenqiang Gong. 2020. Certified Robustness of Graph Neural
Networks against Adversarial Structural Perturbation.
[237] H. Wang and C-N. Yu. 2019. A Direct Approach to Robust Deep Learning Using Adversarial Networks. (2019).
[238] Jiakai Wang, Zixin Yin, Pengfei Hu, Aishan Liu, Renshuai Tao, Haotong Qin, Xianglong Liu, and Dacheng Tao. 2022.
Defensive Patches for Robust Recognition in the Physical World. In CVPR . 2456–2465.
[239] Lijie Wang, Hao Liu, Shuyuan Peng, Hongxuan Tang, Xinyan Xiao, Ying Chen, Hua Wu, and Haifeng Wang. 2021.
DuTrust: A Sentiment Analysis Dataset for Trustworthiness Evaluation.
[240] Serena Wang, Wenshuo Guo, Harikrishna Narasimhan, Andrew Cotter, Maya Gupta, and Michael I. Jordan. 2020.
Robust Optimization for Fairness with Noisy Protected Groups.
[241] Yisen Wang, Difan Zou, Jinfeng Yi, James Bailey, Xingjun Ma, and Quanquan Gu. 2020. Improving Adversarial
Robustness Requires Revisiting Misclassified Examples. In ICLR .
[242] Zhao Wang and Aron Culotta. 2021. Robustness to Spurious Correlations in Text Classification via Automatically
Generated Counterfactuals. In EAAI . AAAI Press, 14024–14031.
[243] Stefan Webb, Tom Rainforth, Yee Whye Teh, and M. Pawan Kumar. 2018. A Statistical Approach to Assessing Neural
Network Robustness.
[244] Tsui-Wei Weng, Huan Zhang, Pin-Yu Chen, Jinfeng Yi, Dong Su, Yupeng Gao, Cho-Jui Hsieh, and Luca Daniel. 2018.
Evaluating the Robustness of Neural Networks: An Extreme Value Theory Approach.
[245] Arie Wahyu Wijayanto, Jun Jin Choong, Kaushalya Madhawa, and Tsuyoshi Murata. 2019. Towards Robust Com-
pressed Convolutional Neural Networks. In BigComp . 1–8.
[246] Eric Wong and J. Zico Kolter. 2020. Learning perturbation sets for robust machine learning.
[247] Walt Woods, Jack Chen, and Christof Teuscher. 2019. Adversarial explanations for understanding image classification
decisions and improved neural network robustness. Nature Machine Intelligence 1, 11 (2019), 508–516.
[248] Chenwang Wu, Defu Lian, Yong Ge, Zhihao Zhu, Enhong Chen, and Senchao Yuan. 2021. Fight Fire with Fire:
Towards Robust Recommender Systems via Adversarial Poisoning Training (SIGIR ’21) . ACM, 1074–1083.
[249] Yiting Wu and Min Zhang. 2021. Tightening robustness verification of convolutional neural networks with fine-
grained linear approximation. In AAAI , Vol. 35. 11674–11681.
[250] Pulei Xiong, Scott Buffett, Shahrear Iqbal, Philippe Lamontagne, Mohammad Mamun, and Heather Molyneaux. 2022.
Towards a robust and trustworthy machine learning system development: An engineering perspective. Journal of
Information Security and Applications 65 (2022), 103121.
[251] Cong Xu, Xiang Li, and Min Yang. 2022. An orthogonal classifier for improving the adversarial robustness of neural
networks. Information Sciences 591 (2022), 251–262.
[252] Han Xu, Xiaorui Liu, Yaxin Li, Anil Jain, and Jiliang Tang. 2021. To be Robust or to be Fair: Towards Fairness in
Adversarial Training. In ICML , Vol. 139. PMLR, 11492–11501.
[253] Yilun Xu, Peng Cao, Yuqing Kong, and Yizhou Wang. 2019. L_DMI: A Novel Information-theoretic Loss Function for
Training Deep Nets Robust to Label Noise. In NeurIPS , Vol. 32. Curran Associates, Inc.
[254] Y Yan, G M Fung, and al. 2011. Active learning from crowds. In ICML . 1161–1168.
[255] Ziang Yan, Yiwen Guo, and Changshui Zhang. 2018. Deep Defense: Training DNNs with Improved Adversarial
Robustness.
[256] J Yang, T Drake, A Damianou, and Y Maarek. 2018. Leveraging crowdsourcing data for deep active learning. An
application: learning intents in Alexa. In WWW .
[257] J Yang, A Smirnova, and al. 2019. Scalpel-cd: leveraging crowdsourcing and deep probabilistic modeling for debugging
noisy training data. In WWW . 2158–2168.
34
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2022, Woodstock, NY
[258] Pengfei Yang, J. Li, J. Liu, C-C. Huang, R. Li, L. Chen, X. Huang, and Lijun Zhang. 2021. Enhancing Robustness
Verification for Deep Neural Networks via Symbolic Propagation. Formal Aspects of Computing 33 (06 2021).
[259] Yichen Yang, Xiaosen Wang, and Kun He. 2022. Robust Textual Embedding against Word-level Adversarial Attacks.
[260] Muneki Yasuda, Hironori Sakata, Seung-Il Cho, Tomochika Harada, Atushi Tanaka, and Michio Yokoyama. 2019. An
efficient test method for noise robustness of deep neural networks. IEICE 10 (01 2019), 221–235.
[261] Dengpan Ye, Chuanxi Chen, Changrui Liu, Hao Wang, and Shunzhi Jiang. 2021. Detection defense against adversarial
attacks with saliency map. Intl. Journal of Intelligent Systems (2021).
[262] Fuxun Yu, Zhuwei Qin, Chenchen Liu, Liang Zhao, Yanzhi Wang, and Xiang Chen. 2019. Interpreting and Evaluating
Neural Network Robustness.
[263] Sicheng Yu, Yulei Niu, Shuohang Wang, Jing Jiang, and Qianru Sun. 2020. Counterfactual Variable Control for Robust
and Interpretable Question Answering. CoRR abs/2010.05581 (2020). arXiv:2010.05581
[264] Feng Yuan, Lina Yao, and Boualem Benatallah. 2019. Adversarial Collaborative Neural Network for Robust Recom-
mendation (SIGIR’19) . ACM, New York, NY, USA, 1065–1068.
[265] Mikhail Yurochkin, Amanda Bower, and Yuekai Sun. 2019. Training individually fair ML models with sensitive
subspace robustness. arXiv preprint arXiv:1907.00020 (2019).
[266] Liang-Jun Zang, Cong Cao, Ya-Nan Cao, Yu-Ming Wu, and Cun-Gen Cao. 2013. A survey of commonsense knowledge
acquisition. Journal of Computer Science and Technology 28, 4 (2013), 689–719.
[267] Runtian Zhai, Tianle Cai, Di He, Chen Dan, Kun He, John Hopcroft, and Liwei Wang. 2019. Adversarially Robust
Generalization Just Requires More Unlabeled Data.
[268] Chongzhi Zhang, Aishan Liu, Xianglong Liu, Yitao Xu, Hang Yu, Yuqing Ma, and Tianlin Li. 2021. Interpreting
and Improving Adversarial Robustness of Deep Neural Networks With Neuron Sensitivity. IEEE Trans. on Image
Processing 30 (2021), 1291–1304.
[269] Huan Zhang, Tsui-Wei Weng, Pin-Yu Chen, Cho-Jui Hsieh, and Luca Daniel. 2018. Efficient Neural Network Robustness
Certification with General Activation Functions.
[270] Jie M Zhang, Mark Harman, Lei Ma, and Yang Liu. 2020. Machine learning testing: Survey, landscapes and horizons.
Trans. on Software Engineering (2020).
[271] Li Zhang and Haiping Lu. 2020. A Feature-Importance-Aware and Robust Aggregator for GCN. In CIKM . ACM,
1813–1822.
[272] Marvin Zhang, Sergey Levine, and Chelsea Finn. 2021. Memo: Test time robustness via adaptation and augmentation.
arXiv preprint arXiv:2110.09506 (2021).
[273] Mengdi Zhang, Jun Sun, and Jingyi Wang. 2022. Which neural network makes more explainable decisions? An
approach towards measuring explainability. Automated Software Engineering 29, 2 (09 Apr 2022), 39.
[274] Q Zhang and al. 2018. Interpretable convolutional neural networks. In CVPR .
[275] Xiao Zhang and David Evans. 2021. Understanding Intrinsic Robustness Using Label Uncertainty.
[276] Yuhao Zhang, Aws Albarghouthi, and Loris D’Antoni. 2021. Certified Robustness to Programmable Transformations
in LSTMs. In EMNLP . ACL, 1068–1083.
[277] Long Zhao, Ting Liu, Xi Peng, and Dimitris Metaxas. 2020. Maximum-Entropy Adversarial Data Augmentation for
Improved Generalization and Robustness.
[278] Qinkai Zheng, Xu Zou, Yuxiao Dong, Yukuo Cen, Da Yin, Jiarong Xu, Yang Yang, and Jie Tang. 2021. Graph Robustness
Benchmark: Benchmarking the Adversarial Robustness of Graph Machine Learning. In NeurIPS .
[279] Xiaoqing Zheng, J. Zeng, Y. Zhou, C-J. Hsieh, Minhao Cheng, and Xuanjing Huang. 2020. Evaluating and Enhancing
the Robustness of Neural Network-based Dependency Parsing Models with Adversarial Examples. In ACL. 6600–6610.
[280] Yiqi Zhong, Lei Wu, Xianming Liu, and Junjun Jiang. 2022. Exploiting the Potential of Datasets: A Data-Centric
Approach for Model Robustness.
[281] Shuyan Zhou, Xiangkai Zeng, Yingqi Zhou, Antonios Anastasopoulos, and Graham Neubig. 2019. Improving
robustness of neural machine translation with multi-task learning. In Conf. on Machine Translation . 565–571.
[282] Bojia Zi, Shihao Zhao, Xingjun Ma, and Yu-Gang Jiang. 2021. Revisiting Adversarial Robustness Distillation: Robust
Soft Labels Make Student Better. In ICCV . 16443–16452.
[283] Vadim Ziyadinov and Maxim Tereshonok. 2022. Noise Immunity and Robustness Study of Image Recognition Using a
Convolutional Neural Network. Sensors 22, 3 (2022).
[284] Daniel Zoran, Mike Chrzanowski, Po-Sen Huang, Sven Gowal, Alex Mott, and Pushmeet Kohli. 2020. Towards Robust
Image Classification Using Sequential Attention Models. In CVPR .
35
Supplementary Material for A.I. Robustness: a
Human-Centered Perspective on Technological Challenges
and Opportunities
ANDREA TOCCHETTI∗, LORENZO CORTI∗, AGATHE BALAYN∗, MIREIA YURRITA, PHILIPP
LIPPMANN, MARCO BRAMBILLA, and JIE YANG†
This supplementary material consists of additional commentary on the literature we surveyed in the main
manuscript A.I. Robustness: a Human-Centered Perspective on Technological Challenges and Opportunities , with
which it shares the same structure. In particular, additional content for Sections 4, 5, and 6 is reported here.
Additional Key Words and Phrases: Artificial Intelligence, Trustworthy AI, Robustness
ACM Reference Format:
Andrea Tocchetti, Lorenzo Corti, Agathe Balayn, Mireia Yurrita, Philipp Lippmann, Marco Brambilla, and Jie
Yang. 2018. Supplementary Material for A.I. Robustness: a Human-Centered Perspective on Technological Chal-
lenges and Opportunities . In.ACM, New York, NY, USA, 10 pages. https://doi.org/XXXXXXX.XXXXXXX
1 SUPPLEMENT FOR SECTION 4: ROBUSTNESS BY
1.1 Processing the Training Data
1.1.1 Augmenting Data for Adversarial Robustness. Most of the identified literature focuses on
transforming [ 38,66,95], generating [ 7,31,32,38,49,73,74,99] or employing ready-to-use [ 21]
data and/or adversarial samples to extend or create datasets to train more robust models. Such a
data augmentation process can successfully improve adversarial robustness [ 38,66,73,95,99,113],
adversarial accuracy [ 1], and fairness [ 88] while sometimes reducing time costs [ 14], and adversarial
attack success rate [10].
1.1.2 Augmenting Data for Non-Adversarial Robustness. While addressing model robustness, re-
searchers also focus on improving models’ performance [ 40,54,69,75] and noise robustness
[40,54,75] through data augmentation techniques. In particular, common perturbations [ 40],
GANs [ 75], and data-driven approaches [ 54,69] are employed to generate data to expand the
training data, consequently achieving improved robustness [ 40,54,75] and accuracy [ 40,54,69,75].
Similarly, researchers demonstrate that data augmentation can also benefit model generalization
[47,73,99,112]. However, augmenting datasets by generating new samples is not the only viable
approach. Sometimes, it is enough to use similar data, e.g., out-of-distribution data from other
datasets [ 29] or unlabeled data [ 107]. Furthermore, it has been proven that noise can also be applied
to generate data that cannot be learned through adversarial training, preventing attackers from
exploiting the targeted model [26].
∗The authors contributed equally to this research.
†Andrea Tocchetti and Marco Brambilla are with Politecnico di Milano, Email: {andrea.tocchetti, marco.brambilla}@polimi.it;
Lorenzo Corti, Agathe Balayn, Mireia Yurrita, Philip Lippmann, and Jie Yang (corresponding author) are with Delft University
of Technology, Email: {l.corti, a.m.a.balayn, m.yurritasemperena, p.lippmann, j.yang-3}@tudelft.nl.
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee
provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and
the full citation on the first page. Copyrights for third-party components of this work must be honored. For all other uses,
contact the owner/author(s).
Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
©2018 Copyright held by the owner/author(s).
ACM ISBN 978-1-4503-XXXX-X/18/06.
https://doi.org/XXXXXXX.XXXXXXX
1
Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Anonymous Authors
1.1.3 Frequently Used Datasets. When it comes to the datasets researchers rely on when studying
robustness, we identify: MNIST [ 1,7,10,14,29,38,47,49,57,68,89,92,98,99,107,108,112] and
Fashion-MNIST [ 14,89], CIFAR-10 [ 7,14,21,26,27,32,38,47,49,68,73,89,98,99,107,108,113]
and its variants [ 21,26,47,112], SVHN [ 21,27,29,38,57,98], and ImageNet [ 26,44,49,66] and
its variants [ 14,21,44,47,68,110]. Such findings highlight the broad interest of the research
community in the robustness of computer vision models.
1.2 Designing In-Model Robustness Strategies
1.2.1 Training for Robustness.
Training with Dynamic Perturbations. Differently from the majority of existing approaches,
instead of perturbing data instances, Hosseini et al . [35] work by applying random subsampling
and training neural networks on different subsets of pixels.
Training Robust Feature Representations. Scholars have also designed novel methods to learn
more robust feature representations [ 16,50,61,76,111]. Connected to this idea, Shu et al . [85]
explore perturbations of feature statistics based on the magnitude of their effect, while Eigen and
Sadovnik [23] propose to nudge the output to be dependent on the k-largest network activations.
Finally, Chen and Lee [17] obtain robust features through the addition of an auxiliary model. The
objective is to help the original model to learn features even when subject to perturbations.
Adversarial Training Algorithms. In this context, researchers have proposed a plethora of al-
gorithms [ 3,44,67,86,93], also borrowing from different Machine Learning paradigms like Self-
Supervised [ 67] and Unsupervised learning [ 93], that are applicable to a variety of tasks. Connected
to leveraging input spaces, Liu and Lomuscio [59] propose a black-box training method that ex-
plores small regions around input instances that are more likely to lead to stronger adversaries.
Instead, when it comes to a model’s internals, Rozsa and Boult [79] take a more fine-grained
approach and, motivated by the open space problem of activation functions such as ReLU, use Tent
activation functions to reduce the neurons’ output surface exploitable by an attacker. Within the
same context, Pereira et al . [72] identify the best layers in Transformer architecture to perturb
during fine-tuning. Targeting the late layers of neural networks, Antonello and Garner [4]use
t-softmax , a novel operator based on t-distribution, which can better describe uncertainty inherent
to out-of-distribution data and attribute them low confidence values. On the same note, Kwon and
Lee[42] also deal with manipulating confidence values and suggest a methodology for resisting
adversarial attacks by providing random confidence values of the output. Finally, Sengupta et al .
[82], argue that non-robust models tend to rely on features that humans would not consider, and
propose the use of ground truth labels to degrade performance with respect to a human observer.
Training with Adapted Regularizers. Among the regularizers discussed in the main manuscript,
Xu et al . [103] suggest a consistency-based regulariser that keeps model predictions stable in the
neighborhood of misclassified adversarial examples. On the other hand, Xu et al . [102] design a
regularisation term based on increasing the angular margin of weight vectors of a classifier. Finally,
Vinh et al . [96] tackle regularization from a different angle. They demonstrate that perturbed
mini-batches obtained through Random Projection can produce robust and regularised models.
Beyond Adversarial Training. Amid alternative approaches to adversarial training, Serban et al .
[83] argue for training models through prototypes which lead to inter-class separability andintra-
class compactness .
1.2.2 Designing Robust Architectures.
2
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
Tweaking Neural Network Layers. In this context, Barros and Barreto [9]introduce M-estimators,
a widely used parameter estimation framework in robust regression, to compute the output weight
matrix and deal with label noise. Furthermore, Lecuyer et al . [45] add a (zero-mean) noise layer
between every other layer in the network. On a slightly different note, Baidya et al . [8]seek to bridge
models and the biological concept of vision by applying VOneNet [ 20], a Convolution-based network
simulating humans’ primary visual cortex, as a robust feature extractor for existing Computer
Vision models for image classification. While all the aforementioned methods result in overall
better-performing models, they are very specific and selected implementations. Finally, related
to differential equations-inspired neural networks, Liu et al . [56] have incorporated stochastic
regularizations into Neural Ordinary Differential Equations to improve their robustness on image
classification tasks while keeping stable both adversarial and non-adversarial performance. Li
et al. [51] leverage the numerical stability of implicit Ordinary Differential Equations and propose
Implicit Euler skip connections (IE-Skips) by modifying the original skip connection in ResNet.
Searching Neural Architectures. As an extension to Neural Architecture Search, Kotyan and Vargas
[41] propose Robust Architecture Search (RAS): an evolution of NAS which uncovers inherently
robust networks by evaluating layers and blocks in terms of the number of parameters and models
in terms of adversarial robustness.
1.3 Leveraging Model Post-Processing Opportunities
1.3.1 Identifying Unnecessary or Unstable Model Attributes (neurons, features). Raviv et al . [77] deal
with unstable neurons and suggest a novel Fourier stabilization approach to replace the weights of
individual neurons with robust analogs derived using Fourier analytic tools. Furthermore, pruning
has also been tested and shown to be effective in improving certified robustness [ 53]. On the
premise of inspecting the effectiveness of different pruning methods, Liu et al . [60] propose a visual
technique for such a task.
1.3.2 Fusing Models.
Against Input issues. Additional methods for achieving post-model-training robustness through
auxiliary models identifying adversarial data instances are the ones by Metzen et al . [65] and
Akumalla et al. [2].
Against Infected Models. Wu et al . [101] , for example, combine the usage of a classifier built on
top of a neural network that aimed at identifying patterns in hidden unit activations with a strategy
that uses the lack of stability to weight changes of wrong predictions to differentiate them from
right predictions.
Improving Fusion Models’ own Robustness. In addition to fusing models to enhance robustness,
the robustness of fusion models themselves has also been studied. For example, Khalid and Arshad
[39] study label noise in ensemble classifiers. Another work focusing on ensemble models is that
of Pang et al . [70] . They suggest a new definition of ensemble diversity as the diversity among
non-maximal predictions of individual members and used this definition to present an Adaptive
Diversity Promoting (ADP) regularizer. This regularizer improves the robustness of the ensemble by
making adversarial examples difficult to transfer among individual members. In a similar fashion,
Goldblum et al . [30] study the transferability of adversarial robustness from teacher to student
during knowledge distillation and find that knowledge distillation is able to preserve much of the
teacher’s robustness to adversarial attacks even without adversarial training for most datasets.
3
Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Anonymous Authors
2 SUPPLEMENT FOR SECTION 5: ROBUSTNESS FOR
2.1 Robustness for Specific Application Areas
2.1.1 Robustness for Natural Language Processing (NLP) Tasks. Nowadays, fine-tuning pre-trained
models is a widespread practice. To that aim, Pereira et al . [72] propose an enhanced adversarial
training algorithm for fine-tuning transformer-based language models by identifying the best
combination of layers to add the adversarial perturbation. On the other hand, Du et al . [22] take
advantage of the adversarial examples generated through Probabilistic Weighted Word Saliency
[78] for training purposes.
Robustness for Machine Translation. A particular focus for NLP robustness research has been
the domain of machine translation, where small perturbations in the input can severely distort
intermediate representations and thus impact the final translation output. Such perturbations, or
noise, can either be naturally occurring or synthetic. Synthetic noise, which is easier to control
and obtain is used by Vaibhav et al . [94] to enhance the robustness of MT systems by emulating
naturally occurring noise in otherwise clean data. They are thus able to make a translation system
more robust to naturally occurring noise in the test set by including synthetic noise in the training
data. Another data augmentation approach is proposed by Li and Specia [54] who find that the
use of noisy parallel data can improve model robustness on noisy and clean datasets alike. Further,
they observe that the introduction of external data with different types of noise may improve the
model’s robustness more generally, even without the usage of in-domain data.
2.1.2 Robustness for Cybersecurity. As Machine Learning techniques are being applied in Cyberse-
curity, the robustness of such systems to malicious actors becomes more and more of a concern. Patil
et al. [71] use adversarial training on existing malware detection deep learning techniques. Here,
they report improvements in robustness across all considered architectures following the retraining
using adversarial examples. Finally, Melis et al . [64] study the usability of gradient-based attribution
methods to identify more robust algorithms. They find a connection between the evenness of
explanations and adversarial robustness.
3 SUPPLEMENT FOR SECTION 6: ROBUSTNESS ASSESSMENT AND INSIGHTS
3.1 Evaluation procedures
3.1.1 Evaluation Strategies.
Evaluation of Robustness. Besides studying how to devise defense mechanisms, it is fundamental
to define evaluation criteria for robustness. Arcaini et al . [6] frame robustness as the model’s
capability to correctly classify perturbed data from multiple perturbed datasets. Another approach
proposed by Lim et al . [55] is to evaluate pointwise 𝐿𝑝-Robustness by checking all the activation
regions around a particular data point.
Evaluation of Certified Robustness. When it comes to the assessment of certified robustness, most
of the literature focuses on model robustness against adversarial attacks and samples [ 11] such
that end-users can act exclusively on robust model predictions.
3.1.2 Benchmarks. In the context of benchmarking datasets, Lee et al . [46] extend the Schema-
Guided Dialogue dataset to measure the robustness of dialogue systems to linguistic variations.
3.1.3 Metrics.
4
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
Metrics for Adversarial Robustness. Metrics for quantifying adversarial robustness have been
introduced. Another example of these is the one by Buzhinsky et al . [12] , tailored to robustness
against adversarial attacks, under the lenses of different interpretations.
Metrics for Adversarial Attacks. Despite the necessity for metrics to assess model robustness, other
metrics prove useful in evaluating different aspects concerning robustness [ 43], like its relationship
with adversarial examples and accuracy, or whether a generated architecture is statistically accurate
[43]. More specifically, Arcaini et al . [5] propose a metric to evaluate the robustness of models
when images are subject to acquisition alterations.
In general, metrics are generated by capturing the decision boundary of deep neural networks
by the distribution of the data concerning such boundaries [18].
Metrics for the Complexity of Robustness Methods. While most researchers focus on implementing
evaluation approaches, a small research branch focuses on improving their efficiency, mainly
enhancing their precision in computing the robustness bounds and reducing their computational
complexity and execution time [34, 48, 97].
3.2 Studies around Proposed Robustness Methods & Insights
3.2.1 Insights on Adversarial Robustness.
Assessment Methods and Frameworks. Recent studies have suggested methodologies and frame-
works for assessing robustness of AI models against adversarial attacks [ 15,24,37,80,115]. For
example, Chang et al . [15] describe an attack-agnostic method to assess the robustness of AI models.
Instead, Zimmermann et al . [115] propose an active robustness test to identify weak attacks leading
to weak adversarial defense evaluations. Finally, Sehwag et al . [80] analyze the robustness of
open-world learning frameworks in the presence of adversaries by means of out-of-distribution
adversarial samples. They also outline a preliminary solution for such a problem which, besides
better robustness to threats, enables trustworthy detection of out-of-distribution inputs. Fawzi et al .
[24] describe a theoretical framework to analyze the robustness of binary classifiers to adversarial
perturbations and show fundamental upper bounds on the robustness of classifiers. Mahima et al .
[62] propose an approach where a model is subject to adversarial perturbations and physical image
corruptions. Here, robustness is measured as the ratio between the accuracies of corrupted input
to clean input. They find that adversarial examples and physical distortions seem to cause the
networks to attend more sparsely to different parts of an image.
Based on Comparisons. Beyond formal methods and frameworks, there are several examples
of papers empirically evaluating robustness through comparison [ 13,19,52,58,84,91,100,109].
Zhang et al . [109] test whether ensemble classifiers are more robust than single classifiers in cases
where attackers can only get a portion of the labeled data. They find that ensemble classifiers
are not necessarily more robust, as they are more susceptible to evasion attacks. Carrara et al .
[13] analyze the robustness of image classifiers implemented with Ordinary Differential Equation
networks against adversarial attacks and compare them with standard deep models. Chun et al . [19]
empirically evaluate the uncertainty and robustness of different image classifiers that have been
trained using regularization methods. Sharmin et al . [84] analyze the robustness of bio-plausible
networks, i.e., spiking neural networks, under adversarial tests compared to VGG-9 artificial neural
networks, and conclude that spike neural networks are more robust than artificial neural networks.
Li et al . [52] compare the robustness of discriminative and generative classifiers, i.e., deep Bayes
classifiers, against adversarial attacks. Liu et al . [58] study the impact of adversarial attacks against
a convolutional LeNet-5 to observe the changing law of the adversarial robustness of the deep
learning model. Tarchoun et al . [91] investigate the effect on robustness that view angle has in
5
Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Anonymous Authors
multi-view datasets when employing adversarial patches. Wu et al . [100] examine the relationship
between network width and model robustness for adversarially trained neural networks and find
that robustness is closely related to the trade-off between accuracy and perturbation stability.
Based on the Investigation of Activation Function and Weights Perturbations. Su et al . [87] evaluate
the robustness of activation functions in convolutional neural networks through the possible
differences in attack confidence when deep convolutional networks use sigmoid compared to ReLU
activation functions. They find that sigmoid functions cause the attacker’s confidence to be smaller.
3.2.2 Insights on Robustness to Natural Perturbations.
About robustness to Noise. A prominent line of work is constituted by studies evaluating the
robustness of AI systems against noise [ 25,28,104]. Ghosh et al . [28] study the performances of
commonly used convolutional neural networks against image degradations, such as Gaussian noise
and blur. They propose a novel, degradation adaptive method to improve the performances of such
networks when degradation is present in the input data. Franceschi et al . [25] also study robustness
to Gaussian and uniform noise and characterize this robustness to noise in terms of the distance to
the decision boundary of the classifier. Another study on label noise, conducted by Xue et al . [104] ,
investigate why contrastive learning leads to improved robustness against label noise.
About Robustness to Differences in Distributions. Another area of interest within the evaluation of
robustness to natural perturbation is that of differences in distribution [ 81,90,114]. Sengupta and
Friston [81] study the robustness of deep neural networks by evaluating the robustness of three
recurrent neural networks to tiny perturbations, on three widely used datasets, to argue that high
accuracy does not always mean a stable and robust system. There have also been multiple works
on evaluating neural networks’ robustness to data shifts and out-of-distribution data [90, 114].
3.2.3 Robustness Evaluation in Computer Vision. Robustness evaluation efforts have also focused
on specific architectures within Computer Vision. Mathis et al . [63] evaluate the robustness of
ImageNet-performing architectures on out-of-domain training data and find that performance on
ImageNet predicts generalization for within- and out-of-domain data on the task of interest, hence
demonstrating robustness. Zaidi et al . [106] analyze the conditions in which invariances to picture
transformations emerge in deep convolutional neural networks, and subsequently demonstrate that
increasing the amount of seen-transformed examples increases both the invariance to transforma-
tions and the robustness to transformations of unseen-transformed categories. Yin et al . [105] study
how robustness is influenced by different types of perturbations, and whether there are trade-offs
with respect to other observable variables. When it comes to specific computer vision tasks, the
evaluation of the robustness of face-recognition approaches has proliferated [ 33]. Besides, Huang
et al. [36] presente a framework for the analysis of the robustness of visual question-answering
models.
REFERENCES
[1]Sheikh Waqas Akhtar, Saad Rehman, Mahmood Akhtar, Muazzam A. Khan, Farhan Riaz, Qaiser Chaudry, and Rupert
Young. 2016. Improving the Robustness of Neural Networks Using K-Support Norm Based Adversarial Training. IEEE
Access 4 (2016), 9501–9511.
[2] Aiswarya Akumalla, Seth Haney, and Maksim Bazhenov. 2020. Contextual Fusion For Adversarial Robustness.
[3]Ibrahim M Alabdulmohsin, Xin Gao, and Xiangliang Zhang. 2014. Adding robustness to support vector machines
against adversarial reverse engineering. In CIKM . 231–240.
[4]Niccolò Antonello and Philip N Garner. 2020. A 𝑡-Distribution Based Operator for Enhancing Out of Distribution
Robustness of Neural Network Classifiers. IEEE Signal Processing Letters 27 (2020), 1070–1074.
[5]Paolo Arcaini, Andrea Bombarda, Silvia Bonfanti, and Angelo Gargantini. 2020. Dealing with Robustness of Convolu-
tional Neural Networks for Image Classification. In AITest . 7–14.
6
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
[6]Paolo Arcaini, Andrea Bombarda, Silvia Bonfanti, and Angelo Gargantini. 2021. Efficient Computation of Robustness
of Convolutional Neural Networks. In AITest . 21–28.
[7]Mehmet Melih Arıcı and Alper Sen. 2021. Improving Robustness of Deep Learning Systems with Fast and Customizable
Adversarial Data Generation. In 2021 IEEE Intl. Conf. on Artificial Intelligence Testing (AITest) . 37–38.
[8]Avinash Baidya, Joel Dapello, James J DiCarlo, and Tiago Marques. 2021. Combining Different V1 Brain Model
Variants to Improve Robustness to Image Corruptions in CNNs. arXiv preprint arXiv:2110.10645 (2021).
[9]Ana Luiza BP Barros and Guilherme A Barreto. 2013. Building a robust extreme learning machine for classification in
the presence of outliers. In HAIS . Springer, 588–597.
[10] Arjun Nitin Bhagoji, Daniel Cullina, Chawin Sitawarin, and Prateek Mittal. 2018. Enhancing robustness of machine
learning systems via data transformations. In CISS. IEEE, 1–5.
[11] Julian Bitterwolf, Alexander Meinke, and Matthias Hein. 2020. Certifiably Adversarially Robust Detection of Out-of-
Distribution Data. In NeurIPS , Vol. 33. Curran Associates, Inc., 16085–16095.
[12] Igor Buzhinsky, Arseny Nerinovsky, and Stavros Tripakis. 2020. Metrics and methods for robustness evaluation of
neural networks with generative models.
[13] Fabio Carrara, Roberto Caldelli, Fabrizio Falchi, and Giuseppe Amato. 2019. On the Robustness to Adversarial
Examples of Neural ODE Image Classifiers. In WIFS . 1–6.
[14] C. Chang, G. Adam, and A. Goldenberg. 2021. Towards Robust Classification Model by Counterfactual and Invariant
Data Generation. In 2021 CVPR . IEEE Computer Society, Los Alamitos, CA, USA, 15207–15216.
[15] Chih-Ling Chang, Jui-Lung Hung, Chin-Wei Tien, Chia-Wei Tien, and Sy-Yen Kuo. 2020. Evaluating Robustness of AI
Models against Adversarial Attacks (SPAI ’20) . ACM, New York, NY, USA, 47–54.
[16] Chenglizhao Chen, Guotao Wang, Chong Peng, Xiaowei Zhang, and Hong Qin. 2020. Improved Robust Video Saliency
Detection Based on Long-Term Spatial-Temporal Information. Trans. on Image Processing 29 (2020), 1090–1100.
[17] Erh-Chung Chen and Che-Rung Lee. 2020. Towards Fast and Robust Adversarial Training for Image Classification. In
ACCV .
[18] Jinyin Chen, Zhen Wang, Haibin Zheng, Jun Xiao, and Zhaoyan Ming. 2020. ROBY: Evaluating the Robustness of a
Deep Model by its Decision Boundaries.
[19] Sanghyuk Chun, Seong Joon Oh, Sangdoo Yun, Dongyoon Han, Junsuk Choe, and Youngjoon Yoo. 2020. An empirical
evaluation on robustness and uncertainty of regularization methods. arXiv preprint arXiv:2003.03879 (2020).
[20] Joel Dapello, Tiago Marques, Martin Schrimpf, Franziska Geiger, David Cox, and James J DiCarlo. 2020. Simulating a
Primary Visual Cortex at the Front of CNNs Improves Robustness to Image Perturbations. In NeurIPS , Vol. 33. Curran
Associates, Inc., 13073–13087.
[21] Zhun Deng, Linjun Zhang, Amirata Ghorbani, and James Zou. 2020. Improving Adversarial Robustness via Unlabeled
Out-of-Domain Data.
[22] Xiaohu Du, Jie Yu, Shasha Li, Zibo Yi, Hai Liu, and Jun Ma. 2021. Combating Word-level Adversarial Text with Robust
Adversarial Training. In 2021 Intl.Joint Conf. on Neural Networks (IJCNN) . 1–8.
[23] Henry Eigen and Amir Sadovnik. 2021. TopKConv: Increased Adversarial Robustness Through Deeper Interpretability.
InICMLA . 15–22.
[24] Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. 2015. Analysis of classifiers’ robustness to adversarial perturba-
tions.
[25] Jean-Yves Franceschi, Alhussein Fawzi, and Omar Fawzi. 2018. Robustness of classifiers to uniform ℓ𝑝and Gaussian
noise. In AISTATS , Vol. 84. PMLR, 1280–1288.
[26] Shaopeng Fu, Fengxiang He, Yang Liu, Li Shen, and Dacheng Tao. 2022. Robust Unlearnable Examples: Protecting
Data Privacy Against Adversarial Learning. In ICLR .
[27] Xiang Gao, Ripon K. Saha, Mukul R. Prasad, and Abhik Roychoudhury. 2020. Fuzz Testing Based Data Augmentation
to Improve Robustness of Deep Neural Networks (ICSE ’20) . ACM, New York, NY, USA, 1147–1158.
[28] Sanjukta Ghosh, Rohan Shet, Peter Amon, Andreas Hutter, and André Kaup. 2018. Robustness of Deep Convolutional
Neural Networks for Image Degradations. In ICASSP . 2916–2920.
[29] Tejas Gokhale, Swaroop Mishra, Man Luo, Bhavdeep Singh Sachdeva, and Chitta Baral. 2022. Generalized but not
Robust? Comparing the Effects of Data Modification Methods on Out-of-Domain Generalization and Adversarial
Robustness. arXiv preprint arXiv:2203.07653 (2022).
[30] Micah Goldblum, Liam Fowl, Soheil Feizi, and Tom Goldstein. 2020. Adversarially Robust Distillation. AAAI 34, 04
(apr 2020), 3996–4003.
[31] Dou Goodman, Hao Xin, Wang Yang, Wu Yuesheng, Xiong Junfeng, and Zhang Huan. 2020. Advbox: a toolbox to
generate adversarial examples that fool neural networks. arXiv preprint arXiv:2001.05574 (2020).
[32] Justin Goodwin, Olivia Brown, and Victoria Helus. 2020. Fast Training of Deep Neural Networks Robust to Adversarial
Perturbations. In 2020 IEEE High Performance Extreme Computing Conf. (HPEC) . 1–7.
7
Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Anonymous Authors
[33] Gaurav Goswami, Akshay Agarwal, Nalini Ratha, Richa Singh, and Mayank Vatsa. 2019. Detecting and Mitigating
Adversarial Perturbations for Robust Face Recognition. IJCV 127 (06 2019), 1–24.
[34] Xingwu Guo, Wenjie Wan, Zhaodi Zhang, Min Zhang, Fu Song, and Xuejun Wen. 2021. Eager Falsification for
Accelerating Robustness Verification of Deep Neural Networks. In 2021 IEEE 32nd Intl. symp. on Software Reliability
Engineering (ISSRE) . 345–356.
[35] Hossein Hosseini, Sreeram Kannan, and Radha Poovendran. 2019. Dropping pixels for adversarial robustness. In
CVPR Workshops . 0–0.
[36] Jia-Hong Huang, Cuong Duc Dao, Modar Alfadly, and Bernard Ghanem. 2019. A novel framework for robustness
analysis of visual qa models. In AAAI , Vol. 33. 8449–8456.
[37] Liu Hui, Zhao Bo, Huang Linquan, Guo Jiabao, and Liu Yifan. 2020. FoolChecker: A platform to evaluate the robustness
of images against adversarial attacks. Neurocomputing 412 (2020), 216–225.
[38] Xiaojun Jia, Xingxing Wei, Xiaochun Cao, and Hassan Foroosh. 2019. ComDefend: An Efficient Image Compression
Model to Defend Adversarial Examples. In CVPR . 6077–6085.
[39] Shehzad Khalid and Sannia Arshad. 2013. A Robust Ensemble Based Approach to Combine Heterogeneous Classifiers
in the Presence of Class Label Noise. In Conf. on Computational Intelligence, Modelling and Simulation . 157–162.
[40] Eunkyeong Kim, Jinyong Kim, Hansoo Lee, and Sungshin Kim. 2021. Adaptive Data Augmentation to Achieve Noise
Robustness and Overcome Data Deficiency for Deep Learning. Applied Sciences 11, 12 (2021).
[41] Shashank Kotyan and Danilo Vasconcellos Vargas. 2019. Evolving Robust Neural Architectures to Defend from
Adversarial Attacks.
[42] Hyun Kwon and Jun Lee. 2020. Advguard: fortifying deep neural networks against optimized adversarial example
attack. IEEE Access (2020).
[43] Trent Kyono and Mihaela van der Schaar. 2019. Improving Model Robustness Using Causal Knowledge.
[44] Alfred Laugros, Alice Caplier, and Matthieu Ospici. 2020. Addressing Neural Network Robustness with Mixup and
Targeted Labeling Adversarial Training.
[45] Mathias Lecuyer, Vaggelis Atlidakis, Roxana Geambasu, Daniel Hsu, and Suman Jana. 2019. Certified robustness to
adversarial examples with differential privacy. In SP. IEEE, 656–672.
[46] Harrison Lee, Raghav Gupta, Abhinav Rastogi, Yuan Cao, Bin Zhang, and Yonghui Wu. 2022. SGD-X: A Benchmark
for Robust Generalization in Schema-Guided Dialogue Systems. AAAI 36, 10 (Jun. 2022), 10938–10946.
[47] Saehyung Lee, Hyungyu Lee, and Sungroh Yoon. 2020. Adversarial vertex mixup: Toward better adversarially robust
generalization. In CVPR . 272–281.
[48] Klas Leino, Zifan Wang, and Matt Fredrikson. 2021. Globally-Robust Neural Networks. In ICML , Vol. 139. PMLR,
6212–6222.
[49] Bai Li, Changyou Chen, Wenlin Wang, and Lawrence Carin. 2019. Certified adversarial robustness with additive
noise. NeurIPS 32 (2019).
[50] Bo Li, Zhengxing Sun, Lv Tang, Yunhan Sun, and Jinlong Shi. 2019. Detecting Robust Co-Saliency with Recurrent
Co-Attention Neural Network.. In IJCAI , Vol. 2. 6.
[51] Mingjie Li, Lingshen He, and Zhouchen Lin. 2020. Implicit euler skip connections: Enhancing adversarial robustness
via numerical stability. In ICML . PMLR, 5874–5883.
[52] Yingzhen Li, John Bradshaw, and Yash Sharma. 2019. Are Generative Classifiers More Robust to Adversarial Attacks?.
In36th ICML (PMLR, Vol. 97) . PMLR, 3804–3814.
[53] Zhangheng Li, Tianlong Chen, Linyi Li, Bo Li, and Zhangyang Wang. 2022. Can pruning improve certified robustness
of neural networks?
[54] Zhenhao Li and Lucia Specia. 2019. Improving Neural Machine Translation Robustness via Data Augmentation:
Beyond Back-Translation. In 5th Workshop on Noisy User-generated Text (W-NUT 2019) . ACL, Hong Kong, China,
328–336.
[55] Cong Han Lim, Raquel Urtasun, and Ersin Yumer. 2020. Hierarchical Verification for Adversarial Robustness.
[56] X. Liu, T. Xiao, S. Si, Q. Cao, S. Kumar, and C. Hsieh. 2020. How Does Noise Help Robustness? Explanation and
Exploration under the Neural SDE Framework. In 2020 CVPR . IEEE Computer Society, Los Alamitos, CA, USA,
279–287.
[57] Yongshuai Liu, Jiyu Chen, and Hao Chen. 2018. Less is More: Culling the Training Set to Improve Robustness of Deep
Neural Networks.
[58] Yudi Liu, Minyan Lu, Di Peng, Jie Wang, and Jun Ai. 2020. Analysis on Adversarial Robustness of Deep Learning
Model LeNet-5 Based on Data Perturbation. In DSA. 162–167.
[59] Yi-Ling Liu and Alessio Lomuscio. 2020. MRobust: A Method for Robustness against Adversarial Attacks on Deep
Neural Networks. In IJCNN . IEEE, 1–8.
[60] Zixi Liu, Yang Feng, Yining Yin, and Zhenyu Chen. 2022. DeepState: Selecting Test Suites to Enhance the Robustness
of Recurrent Neural Networks. In 2022 IEEE/ACM 44th Intl. Conf. on Software Engineering (ICSE) . 598–609.
8
A.I. Robustness: a Human-Centered Perspective Conference acronym ’XX, June 03–05, 2018, Woodstock, NY
[61] Jingjing Lu, Shuangyan Yi, Yongsheng Liang, Wei Liu, Jiaoyan Zhao, and Qiangqiang Shen. 2021. Robust Unsupervised
Feature Selection Based on Sparse Reconstruction of Learned Clean Data. In CCISP . 372–378.
[62] KT Yasas Mahima, Mohamed Ayoob, and Guhanathan Poravi. 2021. An Assessment of Robustness for Adversarial
Attacks and Physical Distortions on Image Classification using Explainable AI.. In AI-Cybersec@ SGAI . 14–28.
[63] Alexander Mathis, Thomas Biasi, Mert Yüksekgönül, Byron Rogers, Matthias Bethge, and M. Mathis. 2020. ImageNet
performance correlates with pose estimation robustness and generalization on out-of-domain data.
[64] Marco Melis, Michele Scalas, Ambra Demontis, Davide Maiorca, Battista Biggio, Giorgio Giacinto, and Fabio Roli.
2020. Do Gradient-based Explanations Tell Anything About Adversarial Robustness to Android Malware?
[65] Jan Hendrik Metzen, Tim Genewein, Volker Fischer, and Bastian Bischoff. 2017. On detecting adversarial perturbations.
arXiv preprint arXiv:1702.04267 (2017).
[66] Seyed-Mohsen Moosavi-Dezfooli, Ashish Shrivastava, and Oncel Tuzel. 2018. Divide, Denoise, and Defend against
Adversarial Attacks.
[67] Muzammal Naseer, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Fatih Porikli. 2020. A Self-supervised
Approach for Adversarial Robustness.
[68] Kun-Peng Ning, Lue Tao, Songcan Chen, and Sheng-Jun Huang. 2021. Improving Model Robustness by Adaptively
Correcting Perturbation Levels with Active Queries. In EAAI . AAAI Press, 9161–9169.
[69] Mark Ofori-Oduro and Maria A. Amer. 2020. Data Augmentation Using Artificial Immune Systems For Noise-Robust
CNN Models. In ICIP. 833–837.
[70] Tianyu Pang, Kun Xu, Chao Du, Ning Chen, and Jun Zhu. 2019. Improving Adversarial Robustness via Promoting
Ensemble Diversity.
[71] Shruti Patil, Vijayakumar Varadarajan, Devika Walimbe, Siddharth Gulechha, Sushant Shenoy, Aditya Raina, and
Ketan Kotecha. 2021. Improving the Robustness of AI-Based Malware Detection Using Adversarial Machine Learning.
Algorithms 14, 10 (2021).
[72] Lis Pereira, Fei Cheng, Masayuki Asahara, and Ichiro Kobayashi. 2021. ALICE++: Adversarial Training for Robust and
Effective Temporal Reasoning. In Asia Conf. on Language, Information and Computation . Association for Computational
Lingustics, Shanghai, China, 373–382.
[73] Joshua C. Peterson, Ruairidh M. Battleday, Thomas L. Griffiths, and Olga Russakovsky. 2019. Human uncertainty
makes classification more robust.
[74] Pouya Pezeshkpour, Yifan Tian, and Sameer Singh. 2019. Investigating Robustness and Interpretability of Link
Prediction via Adversarial Modifications. In ACL. ACL, Minneapolis, Minnesota, 3336–3347.
[75] Yanmin Qian, Hu Hu, and Tian Tan. 2019. Data augmentation using generative adversarial networks for robust
speech recognition. Speech Communication 114 (2019), 1–9.
[76] Rajeev Ranjan, Swami Sankaranarayanan, Carlos D Castillo, and Rama Chellappa. 2017. Improving network robustness
against adversarial attacks with compact convolution. arXiv preprint arXiv:1712.00699 (2017).
[77] Netanel Raviv, Aidan Kelley, Minzhe Guo, and Yevgeniy Vorobeychik. 2021. Enhancing Robustness of Neural Networks
through Fourier Stabilization. In ICML , Vol. 139. PMLR, 8880–8889.
[78] Shuhuai Ren, Yihe Deng, Kun He, and Wanxiang Che. 2019. Generating Natural Language Adversarial Exam-
ples through Probability Weighted Word Saliency. In Proceedings of the 57th Annual Meeting of the Association for
Computational Linguistics . Association for Computational Linguistics, Florence, Italy, 1085–1097.
[79] Andras Rozsa and Terrance E. Boult. 2019. Improved Adversarial Robustness by Reducing Open Space Risk via Tent
Activations. CoRR abs/1908.02435 (2019). arXiv:1908.02435
[80] Vikash Sehwag, Arjun Nitin Bhagoji, Liwei Song, Chawin Sitawarin, Daniel Cullina, Mung Chiang, and Prateek Mittal.
2019. Analyzing the Robustness of Open-World Machine Learning (AISec’19) . ACM, New York, NY, USA, 105–116.
[81] Biswa Sengupta and Karl J. Friston. 2018. How Robust are Deep Neural Networks?
[82] Sourya Sengupta, Craig K Abbey, Kaiyan Li, and Mark A Anastasio. 2022. Investigation of adversarial robust
training for establishing interpretable CNN-based numerical observers. In Medical Imaging: Image Perception, Observer
Performance, and Technology Assessment , Vol. 12035. SPIE, 275–282.
[83] Alex Serban, Erik Poll, and Joost Visser. 2021. Deep Repulsive Prototypes for Adversarial Robustness.
[84] Saima Sharmin, Priyadarshini Panda, Syed Shakib Sarwar, Chankyu Lee, Wachirawit Ponghiran, and Kaushik Roy.
2019. A Comprehensive Analysis on Adversarial Robustness of Spiking Neural Networks.
[85] Manli Shu, Zuxuan Wu, Micah Goldblum, and Tom Goldstein. 2021. Encoding Robustness to Image Style via
Adversarial Feature Perturbations. In NeurIPS , Vol. 34. Curran Associates, Inc., 28042–28053.
[86] Chang Song, Riya Ranjan, and Hai Li. 2021. A Layer-wise Adversarial-aware Quantization Optimization for Improving
Robustness.
[87] Jiawei Su, Danilo Vasconcellos Vargas, and Kouichi Sakurai. 2018. Empirical Evaluation on Robustness of Deep
Convolutional Neural Networks Activation Functions Against Adversarial Perturbation. In CANDARW . 223–227.
9
Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Anonymous Authors
[88] Haipei Sun, Kun Wu, Ting Wang, and Wendy Hui Wang. 2022. Towards Fair and Robust Classification. In 2022 IEEE
7th European Symposium on Security and Privacy (EuroS and P) . 356–376.
[89] Ke Sun, Zhanxing Zhu, and Zhouchen Lin. 2019. Enhancing the robustness of deep neural networks by boundary
conditional gan. arXiv preprint arXiv:1902.11029 (2019).
[90] Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. 2020. Measuring
Robustness to Natural Distribution Shifts in Image Classification. In NeurIPS , Vol. 33. Curran Associates, Inc., 18583–
18599.
[91] Bilel Tarchoun, Anouar Ben Khalifa, and Mohamed Ali Mahjoub. 2022. Investigating the robustness of multi-view
detection to current adversarial patch threats. In ATSIP . IEEE, 1–6.
[92] Dang Duy Thang and Toshihiro Matsui. 2019. Image Transformation can make Neural Networks more robust against
Adversarial Examples.
[93] Jonathan Uesato, Jean-Baptiste Alayrac, Po-Sen Huang, Robert Stanforth, Alhussein Fawzi, and Pushmeet Kohli. 2019.
Are Labels Required for Improving Adversarial Robustness? Curran Associates Inc., Red Hook, NY, USA.
[94] Vaibhav Vaibhav, Sumeet Singh, Craig Stewart, and Graham Neubig. 2019. Improving Robustness of Machine
Translation with Synthetic Noise. In ACL. ACL, Minneapolis, Minnesota, 1916–1920.
[95] Pratik Vaishnavi, Tianji Cong, Kevin Eykholt, Atul Prakash, and Amir Rahmati. 2019. Can Attention Masks Improve
Adversarial Robustness?
[96] Nguyen Xuan Vinh, Sarah Erfani, Sakrapee Paisitkriangkrai, James Bailey, Christopher Leckie, and Kotagiri Ramamo-
hanarao. 2016. Training robust models using Random Projection. In ICPR . 531–536.
[97] Wenjie Wan, Zhaodi Zhang, Yiwei Zhu, Min Zhang, and Fu Song. 2020. Accelerating robustness verification of deep
neural networks guided by target labels. arXiv preprint arXiv:2007.08520 (2020).
[98] H. Wang and C-N. Yu. 2019. A Direct Approach to Robust Deep Learning Using Adversarial Networks. (2019).
[99] Eric Wong and J. Zico Kolter. 2020. Learning perturbation sets for robust machine learning.
[100] Boxi Wu, Jinghui Chen, Deng Cai, Xiaofei He, and Quanquan Gu. 2021. Do wider neural networks really help
adversarial robustness? NeurIPS 34 (2021), 7054–7067.
[101] Fei Wu, Thomas Michel, and Alexandre Briot. 2019. Leveraging Model Interpretability and Stability to increase Model
Robustness. arXiv preprint arXiv:1910.00387 (2019).
[102] Cong Xu, Dan Li, and Min Yang. 2020. Improve Adversarial Robustness via Weight Penalization on Classification
Layer. arXiv preprint arXiv:2010.03844 (2020).
[103] Mengting Xu, Tao Zhang, Zhongnian Li, and Daoqiang Zhang. 2021. A Consistency Regularization for Certified
Robust Neural Networks. In Artificial Intelligence . Springer, Cham, 27–38.
[104] Yihao Xue, Kyle Whitecross, and Baharan Mirzasoleiman. 2022. Investigating Why Contrastive Learning Benefits
Robustness Against Label Noise. arXiv preprint arXiv:2201.12498 (2022).
[105] Dong Yin, Raphael Gontijo Lopes, Jon Shlens, Ekin Dogus Cubuk, and Justin Gilmer. 2019. A fourier perspective on
model robustness in computer vision. NeurIPS 32 (2019).
[106] Syed Suleman Abbas Zaidi, Xavier Boix, Neeraj Prasad, Sharon Gilad-Gutnick, Shlomit Ben-Ami, and Pawan Sinha.
2020. Is Robustness To Transformations Driven by Invariant Neural Representations?
[107] Runtian Zhai, Tianle Cai, Di He, Chen Dan, Kun He, John Hopcroft, and Liwei Wang. 2019. Adversarially Robust
Generalization Just Requires More Unlabeled Data.
[108] Cheng Zhang, Kun Zhang, and Yingzhen Li. 2020. A Causal View on Robustness of Neural Networks. In NeurIPS ,
Vol. 33. Curran Associates, Inc., 289–301.
[109] Fuyong Zhang, Yi Wang, and Hua Wang. 2018. Gradient correlation: are ensemble classifiers more robust against
evasion attacks in practical settings?. In Intl. Conf. on Web Information Systems Engineering . Springer, 96–110.
[110] Marvin Zhang, Sergey Levine, and Chelsea Finn. 2021. Memo: Test time robustness via adaptation and augmentation.
arXiv preprint arXiv:2110.09506 (2021).
[111] Michael Zhang, Nimit S. Sohoni, Hongyang R. Zhang, Chelsea Finn, and Christopher Ré. 2022. Correct-N-Contrast: A
Contrastive Approach for Improving Robustness to Spurious Correlations.
[112] Long Zhao, Ting Liu, Xi Peng, and Dimitris Metaxas. 2020. Maximum-Entropy Adversarial Data Augmentation for
Improved Generalization and Robustness.
[113] Yiqi Zhong, Lei Wu, Xianming Liu, and Junjun Jiang. 2022. Exploiting the Potential of Datasets: A Data-Centric
Approach for Model Robustness.
[114] Lingjun Zhou, Bing Yu, David Berend, Xiaofei Xie, Xiaohong Li, Jianjun Zhao, and Xusheng Liu. 2020. An Empirical
Study on Robustness of DNNs with Out-of-Distribution Awareness. In APSEC . 266–275.
[115] Roland S. Zimmermann, Wieland Brendel, Florian Tramer, and Nicholas Carlini. 2022. Increasing Confidence in
Adversarial Robustness Evaluations.
10 |
b6108112-9daa-4b7f-bfb6-06adabb4a877 | trentmkelly/LessWrong-43k | LessWrong | Unbounded utility functions and precommitment
According to orthodox expected utility theory, the boundedness of the utility function follows from standard decision-theoretic assumptions, like Savage's fairly weak axioms or the von Neumann-Morgenstern continuity/the Archimedean property axiom. Unbounded expected utility maximization violates the sure-thing principle, is vulnerable to Dutch books and is vulnerable to money pumps, all plausibly irrational. See, for example, Paul Christiano's comment with St. Petersburg lotteries (and my response). So, it's pretty plausible that unbounded expected utility maximization is just inevitably formally irrational.
However, I'm not totally sure, since there are some parallels to Newcomb's problem and Parfit's hitchhiker: you'd like to precommit to following a rule ahead of time that leads to the best prospects, but once some event happens, you'd like to break the rule and maximize local value greedily instead. But breaking the rule means you'll end up with worse prospects over the whole sequence of events than if you had followed it. The rules are:
1. Newcomb's problem: taking the one box
2. Parfit's hitchhiker: paying back the driver
3. Christiano's St. Petersburg lotteries: sticking with the best St. Petersburg lottery offered
So, rather than necessarily undermining unbounded expected utility maximization, maybe this is just a problem for "local" expected utility maximization, since there are other reasons you want to be able to precommit to rules, even if you expect to want to be able to break them later. Having to make precommitments shouldn't be decisive against a decision theory.
Still, it seems better to avoid precommitments when possible because they're messy, risky and ad hoc. Bounded utility functions seem like a safer and cleaner solution here; we get a formal proof that they work in idealized scenarios. I also don't even know if precommitments generally solve unbounded utility functions' apparent violations of decision-theoretic principles that bounded |
189c6c32-c18c-4b23-b4c0-d10590b78e1c | trentmkelly/LessWrong-43k | LessWrong | Most Prisoner's Dilemmas are Stag Hunts; Most Stag Hunts are Schelling Problems
I previously claimed that most apparent Prisoner's Dilemmas are actually Stag Hunts. I now claim that they're Schelling Pub in practice. I conclude with some lessons for fighting Moloch.
This post turned out especially dense with inferential leaps and unexplained terminology. If you're confused, try to ask in the comments and I'll try to clarify.
Some ideas here are due to Tsvi Benson-Tilsen.
----------------------------------------
The title of this post used to be Most Prisoner's Dilemmas are Stag Hunts; Most Stag Hunts are Battle of the Sexes. I'm changing it based on this comment. "Battle of the Sexes" is a game where a male and female (let's say Bob and Alice) want to hang out, but each of them would prefer to engage in gender-stereotyped behavior. For example, Bob wants to go to a football game, and Alice wants to go to a museum. The gender issues are distracting, and although it's the standard, the game isn't that well-known anyway, so sticking to the standard didn't buy me much (in terms of reader understanding).
I therefore present to you,
the Schelling Pub Game:
Two friends would like to meet at the pub. In order to do so, they must make the same selection of pub (making this a Schelling-point game). However, they have different preferences about which pub to meet at. For example:
* Alice and Bob would both like to go to a pub this evening.
* There are two pubs: the Xavier, and the Yggdrasil.
* Alice likes the Xavier twice as much as the Yggdrasil.
* Bob likes the Yggdrasil twice as much as the Xavier.
* However, Alice and Bob also prefer to be with each other. Let's say they like being together ten times as much as they like being apart.
Schelling Pub Game payoff matrixpayoffs written alice;bobB's choiceXYA's choiceX20;102;2Y1;110;20
The important features of this game are:
* The Nash equilibria are all Pareto-optimal. There is no "individually rational agents work against each other" problem, like in prisoner's dilemma or even stag hunt. |
8c92289b-e6d2-4b9b-9db5-3eb516f45653 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Some thoughts on "AI could defeat all of us combined"
This week I found myself tracing back from Zvi's [To predict what happens, ask what happens](https://thezvi.substack.com/p/to-predict-what-happens-ask-what) ([a](https://archive.ph/ZEF0N)) to Ajeya's [Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover](https://www.alignmentforum.org/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to) ([a](https://archive.is/95h7J)) to Holden's [AI could defeat all of us combined](https://www.cold-takes.com/ai-could-defeat-all-of-us-combined/) ([a](https://archive.is/tMRQs)).
A few thoughts on that last one.
First off, I'm really grateful that someone is putting in the work to clearly make the case to a skeptical audience that AI poses an existential risk. Noble work!
I notice that different parts of me ("parts" in the [Internal Family Systems sense](https://www.lesswrong.com/posts/5gfqG3Xcopscta3st/building-up-to-an-internal-family-systems-model)) have very different reactions to the topic. I can be super-egoically onboard with a point but other parts of my awareness (usually less conceptual, more "lower-down-in-the-body" parts) are freaked out and/or have serious objections.
I notice also an impulse to respond to these lower-level objections dismissively: "Shut up you stupid reptile brain! Can't you see the logic checks out?! This is what **matters!**"
This... hasn't been very productive.
[Greg knows what's up](https://twitter.com/incrediblefolly/status/1641522836375502848):
> I’ve noticed that engaging AI-doomer content tends to leave pretty strong traces of anxiety-ish-ness in the body.
>
> I’ve been finding it quite helpful to sit still and feel all this. Neither pushing away nor engaging thought.
>
> The body knows how to do this.
>
>
I'm generally interested in how to weave together the worlds of healing/dharma/valence and EA/rationality/x-risk.
There's a lot to say about that; one noticing is that arguments for taking seriously something charged and fraught like AI x-risk are received by an internally-fractured audience – different parts of a reader's psychology react differently to the message, and it's not enough to address just their super-egoic parts.
(Not a novel point but the IFS-style parts framework has helped me think about it more crisply.)
Now to the meat of [Holden's post](https://www.cold-takes.com/ai-could-defeat-all-of-us-combined/). He gives this beautiful analogy, which I'm going to start using more:
> At a high level, I think we should be worried if a huge (competitive with world population) and rapidly growing set of highly skilled humans on another planet was trying to take down civilization just by using the Internet. So we should be worried about a large set of disembodied AIs as well.
>
>
He then spends a lot of time drawing a distinction between "superintelligence risk" and "how AIs could defeat humans without superintelligence." e.g.
> To me, this is most of what we need to know: **if there's something with human-like skills, seeking to disempower humanity, with a population in the same ballpark as (or larger than) that of all humans, we've got a civilization-level problem.** [Holden's emphasis]
>
>
But this assumes that the AI systems are able to coordinate fluidly (superhumanly?) across their population. Indeed he takes that as a premise:
> So, for what follows, let's proceed from the premise: "For some weird reason, humans consistently design AI systems (with human-like research and planning abilities) that coordinate with each other to try and overthrow humanity."
>
>
A lot of his arguments for why an AI population like this would pose an existential threat to humanity (bribing/convincing/fooling/blackmailing humans, deploying military robots, developing infrastructure to secure themselves from being unplugged) seem to assume a central coordinating body, something like a strategy engine that's able to maintain a high-fidelity, continually-updating world model and then develop and execute coordinated action plans on the basis of that world model. Something like the [Diplomacy AI](https://thezvi.substack.com/p/on-the-diplomacy-ai) ([a](https://archive.ph/MGzoV)), except for instead of playing Diplomacy it's playing real-world geopolitics.
Two thoughts on that:
1. I don't see how a coordinated population of AIs like that would be different from a superintelligence, so it's unclear why the distinction matters (or I'm misunderstanding some nuance of it).
2. It seems like someone would need to build at least a beta version of the real-world strategy engine to catalyze the feedback loops and the coordinated actions across an AI population.
I've been wondering about a broader version of (2) for a while now... a lot of the superintelligence risk arguments seem to implicitly assume a "waking up" point at which a frontier AI system realizes enough situational awareness to start power-seeking or whatever deviation from its intended purpose we're worried about.
To be clear I'm not saying that this is impossible – that kind of self-awareness could well be an emergent capability of GPT-N, or AutoGPT++ could realize that it needs to *really* improve its world model and start to power-seek in order to achieve whatever goal. (It does seem like those sorts of moves would trigger a bunch of fire alarms though.)
I just wish that these assumptions were made more explicit in the AI risk discourse, especially as we start making the case to increasingly mainstream audiences.
e.g. Rob Bensinger wrote up [a nice piecewise argument for AGI ruin](https://www.lesswrong.com/posts/QzkTfj4HGpLEdNjXX/an-artificially-structured-argument-for-expecting-agi-ruin) ([a](https://archive.ph/IDBif)), but his piece (3) rolls what seem to me to be very particular, crux-y capabilities (e.g. something like this "waking up") into the general category of capabilities improvement:
> **(3) High Early Capabilities.** As a strong default, absent alignment breakthroughs or global coordination breakthroughs, early STEM-level AGIs will be scaled to capability levels that allow them to understand their situation, and allow them to kill all humans if they want.
>
>
It's similar in [Carlsmith's six-step model](https://arxiv.org/pdf/2206.13353.pdf) ([a](https://archive.is/J7taV)), where advanced abilities are considered all together in step one:
> **Advanced capability:** they outperform the best humans on some set of tasks which when performed at advanced levels grant significant power in today’s world (tasks like scientific research, business/military/political strategy, engineering, and persuasion/manipulation).
>
> **Agentic planning:** they make and execute plans, in pursuit of objectives, on the basis of models of the world.
>
> **Strategic awareness:** the models they use in making plans represent with reasonable accuracy the causal upshot of gaining and maintaining power over humans and the real-world environment.
>
>
I feel like all this could use more parsing out.
Which specific forms of awareness and planning would be required to develop and keep up-to-date a world model as good as e.g. the US military's?
What [fire alarms](https://www.lesswrong.com/posts/GspepepmD8RRdfiuo/ai-fire-alarm-scenarios) would progress along those dimensions trigger along the way?
How plausible is it that marginal development of the various current AI approaches unlock these abilities?
*n.b.* I'm not setting this up as a knockdown argument for why superintelligence risk isn't real, and I'm not an AI risk skeptic. Rather I'm presenting a research direction I'd like to understand better.
*Cross-posted to* [*my blog*](https://www.flightfromperfection.com/some-thoughts-on-AI-could-defeat-all-of-us-combined.html) *and* [*this newsletter*](https://tinyletter.com/milan-griffes)*.* |
6e2dda86-86fb-4b8e-ba6a-0c6cca384fc6 | trentmkelly/LessWrong-43k | LessWrong | Signaling-based observations of (other) students
(Note: in Germany, tutorials are exercise sessions, typically weekly and mandatory, which accompany a lecture. They are held in groups of 5-30 students and are lead by a more advanced student whom I call the instructor.)
There is an interesting pattern I noticed during math lectures and tutorials at my university. It sometimes occurs when a student has an objection to something the instructor wrote or said. If the objection is about something simple like a missing sign, it's usually handled quickly and without problems. But whenever the socially acceptable time to respond is shorter than the time needed to understand what the objection actually is, the instructor usually doesn't even attempt to understand it. Instead, he does a quick sort of pattern matching of what the objection roughly sounds like, makes a guess as to which thing the student most likely misunderstood, and then attempts to explain that particular thing again.
Quite often – probably over half the time – this guess is accurate on the first try, and the response makes sense. If it's not, often the student replies and the instructor figures out what the objection is in a quick back-and-forth, and gives her a sensible reply that's a bit delayed.
But where it gets most interesting is if the student's grasp on the current problem is actually better than that of the instructor, and the objection she raised is correct. What happens then is that the instructor gives a bunch of explanations of stuff the student already knows, which all totally miss the point; the student might try to rephrase her problem, but this can at best lead to renewed pattern-matching based guesses from the instructor. The more convinced the instructor is that he is actually correct from the start, the longer this can go on without him realizing that he isn't. If the issue is dropped before it's resolved, sometimes it's revisited after the end of the tutorial. Because of the change of context, where now the pressure to respond quick |
ba78fbb1-aaed-4d8f-b04d-c751a752b647 | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Fake Justification
Today's post, Fake Justification was originally published on 01 November 2007. A summary (taken from the LW wiki):
> We should be suspicious of our tendency to justify our decisions with arguments that were not actually the deciding factor. Whatever process you use to make your decisions is what determines your effectiveness.
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was A Case Study of Motivated Continuation, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
3d14d055-6f20-4b4e-bfc3-446616b210f3 | trentmkelly/LessWrong-43k | LessWrong | Computational Complexity as an Intuition Pump for LLM Generality
With sufficient scale and scaffolding, LLMs will improve without bound on all tasks to become superhuman AGI, to the extent they haven’t already. No, wait! LLMs are dead-end pattern-matching machines fundamentally incapable of general reasoning and novel problem solving. Which is it?
I’ll call these opposing points of view “LLM Scaler” and “LLM Skeptic”. The first appears to be held by the big AGI labs and was recently exemplified by Leopold Aschenbrenner’s Situational Awareness series, while the second is influenced by cognitive science and can be associated with researchers such as François Chollet, Gary Marcus, and Melanie Mitchell. This post loosely generalizes these two stances, so any misrepresentation or conflation of individuals’ viewpoints is my own. I recommend Egg Syntax’s recent post for further introduction and a summary of relevant research. We can caricature the debate something like this:
LLM Scaler: LLMs will take us to AGI. See straight lines on graphs. See correct answers to hard questions on arbitrary topics. See real customers paying real money for real value.
LLM Skeptic: LLMs achieve high skill by memorizing patterns inherent in their giant training set. This is not the path to general intelligence. For example, LLMs will never solve Task X.
LLM Scaler: They solved it.
LLM Skeptic: No kidding? That doesn’t count then, but they’ll really never solve Task Y. And you can’t just keep scaling. That will cost trillions of dollars.
LLM Scaler: Do you want to see my pitch deck?
Meanwhile, on Alternate Earth, Silicon Valley is abuzz over recent progress by Large List Manipulators (LLMs), which sort a list by iteratively inserting each item into its correct location. Startups scramble to secure special-purpose hardware for speeding up their LLMs.
LLM Scaler: LLMs are general list sorters, and will scale to sort lists of any size. Sure, we don’t quite understand how they work, but our empirical compute-optimal scaling law (N ~ C^0.5) has alrea |
c1480068-06bc-4293-a7e7-f6ae681af556 | trentmkelly/LessWrong-43k | LessWrong | Moving Factward
In the legendarium of J.R.R. Tolkien, the land of the gods is known as "The Uttermost West." For the world was originally created flat, and the gods took the westernmost region of this flat world for their dwelling place.
On our globe, of course, there is no westernmost point. And yet it is still the case that, at each position on the equator, some direction is objectively "westward". The objectivity of "westward" doesn't assume that there is some ultimate West by which the west-ness of all other positions is measured.
Analogously, there is no such thing as a "bare uninterpreted fact". "Just the facts" is not a realizable ideal.
And yet we can still recognize when one account of a situation is more "factish" than another. We can see that the second account is more of an interpretation compared to the relatively factish features given in the first account. The more-factish account is never the ultimate and unvarnished truth. Likely no coherent sense could be made of that ideal. Nonetheless, from wherever we stand, we can always "move factward".[1]
----------------------------------------
Footnote
[1] ETA: Said Achmiz points out that many features of "westward" don't apply to "factward". Analogies typically assert a similarity between only some, not all, aspects of the two analogous situations. But maybe the other aspects of "westward" are so salient that they interfere with the analogy. |
e8abc0e0-13c5-463f-a0a7-86956e7240e4 | trentmkelly/LessWrong-43k | LessWrong | Futarchy using a sealed-bid auction to avoid liquidity problems
Futarchy is usually formulated using multiple continuously running markets, which raises questions about how to introduce liquidity, when to introduce it, and who will do so. Robin Hanson (the inventor of futarchy) recently proposed how to handle some of these details, but they seemed to me a bit inelegant. I instead propose reformulating it to use a sealed-bid auction with no liquidity added. I will only be covering the joint-stock company version of futarchy, not the government policy version, which I'm not sure how my proposal would generalize to. The joint-stock company version is relevant to effective altruism as a possible component of a market for altruism.
Consider a hypothetical joint-stock company named The ACME Corporation with one million shares.
Proposals and bids
Once a month, the public can submit proposals. A proposal can either be:
1. A CEO replacement: replaces the current CEO with the proposer, under terms of a legal contract included with the proposal. If the proposal takes place, this is immediately effective and legally binding. The current CEO is considered fired. (Given that they are only guaranteed to have their job for a month, most candidates will include a decent severance package as part of their compensation.)
2. A company directive: instructions that employees should follow. It is considered company policy to follow these. If these are consistently ignored, future proposals should propose replacing the CEO with one who will enforce them.
For example, let us consider proposals A, B, C, and "Change Nothing".
The next step is that people submit sealed bids. There are two types: buy bids and sell bids.
Buy bids
Any member of the public (including current investors if they wish to increase their investment) can submit a buy bid, conditioned on a given proposal passing. The bid contains a maximum price and a number of shares.
Note that first they must put money in escrow. They can submit multiple bids. For any given proposal, the |
a933f4da-9020-4618-b753-f312d736ed6f | trentmkelly/LessWrong-43k | LessWrong | November 2018 gwern.net newsletter
None |
ac484247-8fd8-42fc-b260-3051760cc6b4 | trentmkelly/LessWrong-43k | LessWrong | The trolley problem, and what you should do if I'm on the tracks
Originally published in French. Translation by Épiphanie.
Trigger warning: Death, suicide, and murder. Trolley problem.
This is quite the conventional and ethical conundrum: You are near train tracks, and a train is rolling down the hill. It is going to run over 4 people who are tied to the rails of the main track. However, you can change the train's direction to a secondary track by pulling a lever; so that it runs over only one guy, also tied down the rails. Should you pull the lever?
I do believe there is a more interesting way to frame it: What would you choose if you are yourself tied to the rails, alone, while the train is not heading toward you yet. My own answer is very simple: I want the person deciding where the train should go to have no doubts they should pull the lever! Because, for lack of context, I assume that the other four people are just me, or rather copies of me. That's a bit simplistic, of course they are not perfect clone. But as far as concrete predicates go, they are indistinguishable. That is to say I have odds of being on tracks alone of 1 in 5, and odds for being in the group of 4 in 5. And tell you what, I prefer dying with 20% probability because of what someone did, rather than to die with 80% probability because no one was ever willing to take the burden of responsibility.
I know many would not pull the lever, or at least be very reluctant to. That is precisely the reason I am writing this post: I wish to make it public that I believe people should pull the lever. More importantly, I wish that many many more people would also share publicly this opinion. Then, if it is of public notoriety, the one who has to pull the lever would know they can do it without any remorse, as they will not have to face any societal consequences for what they've done. So all in all, this would raise my odds of survival of 60 points! That's quite something
But what if it were to truly happen?
Be aware that I am not saying anything more than what I hav |
c7380de0-6c95-48f7-8a48-8a3c4efcb04d | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Project proposal: Testing the IBP definition of agent
Context
-------
Our team in SERI MATS needs to choose a project to work on for the next month. We spent the first two weeks discussing the alignment problem and what makes it difficult, and proposing (lots of) projects to look for one that we think would directly address the hard parts of the alignment problem.
**We're writing this post to get feedback and criticism of this project proposal. Please let us know if you think this is a suboptimal project in any way**.
Project
-------
*Disclaimer: We've probably misunderstood some things, don't assume anything in this post accurately represents Vanessa's ideas.*
Our project is motivated by Vanessa Kosoy’s [PreDCA](https://www.alignmentforum.org/posts/dPmmuaz9szk26BkmD/vanessa-kosoy-s-shortform?commentId=vKw6DB9crncovPxED) [proposal](https://www.alignmentforum.org/posts/GNhMPAWcfBCASy8e6/a-central-ai-alignment-problem-capabilities-generalization?commentId=uBL39FgyN2EnsyWGa). We want to understand this proposal in enough detail that we can simplify it, as well as see and patch any holes.
[IBP](https://www.lesswrong.com/posts/gHgs2e2J5azvGFatb/infra-bayesian-physicalism-a-formal-theory-of-naturalized#Evaluating_agents) gives us several key tools:
1. A "Bridge Transform", that takes in a hypothesis about the universe and tells us which programs are running in the universe.
2. An "Agentometer"[[1]](#fnvwvp3buu5a) that takes in a program and tell us how agentic it is, which is operationalized as how well the agent does according to a fixed loss function relative to a random policy.
3. A "Utiliscope"[[1]](#fnvwvp3buu5a) that, given an agent, outputs a distribution over the utility functions of the agent.
Together these tools could give a solution to [the pointers problem](https://www.lesswrong.com/tag/the-pointers-problem#:~:text=The%20pointers%20problem%20refers%20to,eeded%5D.), which we believe is a core problem in alignment. We will start this by understanding and testing Vanessa’s definition of agency.
Definition of Agency
--------------------
The following is Vanessa's definition of the intelligence of an agent, where an agent is a program, denoted by G.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
, that outputs policies (as described in [Evaluating Agents in IBP](https://www.lesswrong.com/posts/gHgs2e2J5azvGFatb/infra-bayesian-physicalism-a-formal-theory-of-naturalized#Evaluating_agents)). This can be used to identify agents in a world model.
**Definition 1.6:** *Denote*G∗:H→A*the policy actually implemented by*G*. Fix*ξ∈Δ(AH)*. The physicalist intelligence of*G*relative to the baseline policy mixture*ξ,*prior*ζ*and loss function*L*is defined by:*
g(G∣ξ;ζ,L):=−logPrπ∼ξ[Lpol(┌G┐,π,ζ)≤Lpol(┌G┐,G∗,ζ)]In words, this says that the intelligence of the agent G, given a loss function L, is the negative log of the probability that a random policy π is better than the actual policy the agent implements, denoted by G∗.
The next part is how to extract (a distribution over) the utility function of a given agent (from [video](https://www.youtube.com/watch?v=24vIJDBSNRI) on PreDCA):

Here, Lpol is just the negative of the utility function U. Combining this with the definition of intelligence above gives a simpler representation:
P(U)∝2−K(U)+g(G|ξ;ζ,U).
In words, the probability that agent G has utility function U is exponentially increasing in the intelligence of G implied by U and exponentially decreasing in the Kolmorogov complexity of U.
Path to Impact
--------------
* We want a good definition of agency, and methods of identifying agents and inferring their preferences.
* If we have these tools, and if they work *really well* even in various limits (including the limit of training data/compute/model size/distribution shifts), then this solves the hardest part of the alignment problem (by pointing precisely to human values via a generalized version of Inverse Reinforcement Learning).
* These tools also have the potential to be useful for identifying mesa-optimizers, which would help us to avoid inner alignment problems.
How we plan to do it
--------------------
### Theoretically:
* Constructing prototypical examples and simple edge cases, i.e. weird almost-agents that don’t really have a utility function, and theoretically confirming that the utility function ascribed to various agents matches our intuitions. Confirming that the maximum of the utility function corresponds to a world that the agent intuitively does want.
* Examining what happens when we mess around with the priors over policies and the priors over utility functions.
* Exploring simplifications and modifications to the assumptions and definitions used in IBP, in order to see if this lends itself to a more implementable theory.
### Experimentally:
* Working out ways of approximating the algorithm for identifying an agent and extracting its utility function, to make it practical and implementable.
* Working out priors that are easy to use.
* Constructing empirical demonstrations of identifying an agent’s utility function to test whether a reasonable approximation is found.
* Doing the same for identifying agents in an environment.
Distillation
------------
In order to do this properly, we will need to understand and distill large sections of Infra-Bayesian Physicalism. Part of the project will be publishing our understanding, and we hope that other people looking to understand and build on IBP will benefit from this distillation.
Conclusion
----------
That's where we are right now -- let us know what you think!
1. **[^](#fnrefvwvp3buu5a)**"Agentometer" and "Utiliscope" are not Vanessa's terminology. |
fa68247a-1e93-4d8e-9ce1-4a790ffd2fe4 | trentmkelly/LessWrong-43k | LessWrong | Misalignment-by-default in multi-agent systems
Summary of this post
This is the second post in a three-part sequence on instrumental convergence in multi-agent RL. Read Part 1 here.
In this post, we’ll:
1. Define formal multi-agent POWER (i.e., instrumental value) in a setting that contains a "human" agent and an "AI" agent.
2. Introduce the alignment plot as a way to visualize and quantify how well two agents' instrumental values are aligned.
3. Show a real example of instrumental misalignment-by-default. This is when two agents who have unrelated terminal goals develop emergently misaligned instrumental values.
We’ll soon be open-sourcing the codebase we used to do these experiments. If you’d like to be notified when it’s released, email Edouard at edouard@gladstone.ai or DM me on Twitter at @harris_edouard.
----------------------------------------
Thanks to Alex Turner and Vladimir Mikulik for pointers and advice, and for reviewing drafts of this sequence. Thanks to Simon Suo for his invaluable suggestions, advice, and support with the codebase, concepts, and manuscript. And thanks to David Xu, whose comment inspired this work.
Work was done while at Gladstone AI, which Edouard is a co-founder of.
🎧 This research has been featured on an episode of the Towards Data Science podcast. Listen to the episode here.
----------------------------------------
1. Introduction
In Part 1 of this sequence, we looked at how formal POWER behaves on single-agent gridworlds. We saw that formal POWER agrees quite well with intuitions about the informal concepts of "power" and instrumental value. We noticed that agents with short planning horizons assign high POWER to states that can access more local options. And we also noticed that agents with long planning horizons assign high POWER to more concentrated sets of states that are globally central in the gridworld topology.
But from an AI alignment perspective, we’re much more interested in understanding how instrumental value behaves in environments that contain m |
1abea087-5745-4396-92bc-f54398a48c4d | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Phase transitions and AGI
Take a look at the following graph, from Robin Hanson's [Long-Term Growth As a Sequence of Exponential Modes](https://mason.gmu.edu/~rhanson/longgrow.pdf):
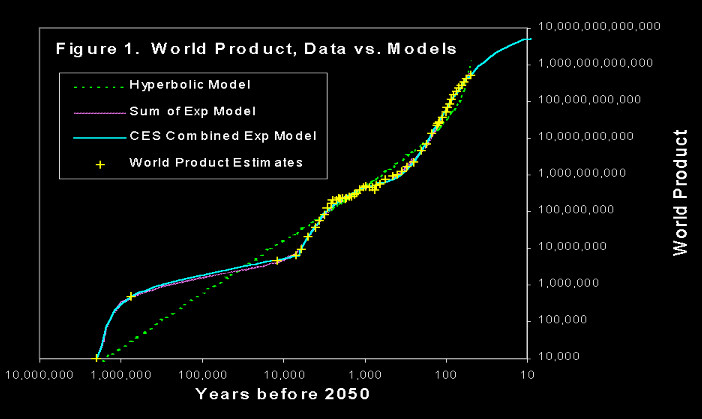
Here, "world product" is roughly the gross world product divided by the level of income necessary for one person to live at a subsistence level. It measures the total production of the human species in units of "how many people could live at a subsistence level on that much production?"
The yellow marks are historical estimates of world product that Hanson gathered from a variety of sources, and he's fit three different models to this data. What's notable is the good fit that the "sum of exponentials" type models have with this data. It looks like the world economy goes through different phases which are characterized by different rates of growth: in the first phase world product doubled every ∼100,000.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
years, in the second phase it doubled every ∼1000 years, and in the third phase it doubled every ∼10 years, where we can give or take a factor of 2 from these estimates - they are meant only to convey the order of magnitude differences.
We also see that transitions to subsequent phases are relatively fast. The transition from the first phase to the second phase took ∼1000 years, much less than the doubling time of 100,000 years characterizing this phase, and the transition from the second phase to the third took on the order of ∼200 years, still smaller than the 1000 years of doubling time typical of the second phase. We can also observe that the timing of these events roughly matches the [First Agricultural Revolution](https://en.wikipedia.org/wiki/Neolithic_Revolution) and the [Industrial Revolution](https://en.wikipedia.org/wiki/Industrial_Revolution), so we might tentatively label the phases as corresponding to "foraging", "farming" and "industry" respectively.
The study of these past transitions is important because they are the only reference class we have for dramatic changes in the nature of the world economy and in how the human species is organized and how we coordinate our activities. Since we have two transitions to examine, we might also get a rudimentary sense of the variance of outcomes: two is the minimal value we need in order to do that.
Unfortunately, many details about the foraging phase are shrouded in mystery. There's still no consensus on the world product estimates for this phase even today: it could be that this phase was actually ten times shorter than we think it is, and it might only date back to around 200,000 BCE rather than 2,000,000 BCE. In this case, the doubling time in this phase would be higher, about ∼10,000 years. This is still much slower than what came after, and still large compared to how long it took for the transition to take place.
Regardless, the first conclusion we should draw from this reference class is that such phase transitions are possible and they can happen surprisingly quickly compared to the pace of the changes that people who lived in a particular phase would be used to. We can draw a second conclusion by noting that while the durations of the phases vary quite a lot, the number of doublings of world product in each phase seems to be similar: ∼10, give or take a factor of 2. Given the small sample size and the difficulties of generalization, it's hard to extrapolate the duration of the industrial phase based on this information, but it does suggest that the phase coming to an end soon wouldn't be surprising from an outside point of view.
The question this essay is meant to answer is broadly this: how likely is a phase transition in the near future, and given that one occurs, how likely is it to be brought about by AGI? (By definition, I take transformative AI to be precisely a development in AI which triggers such a phase transition.)
Outside view
------------
One important question we should ask is how far in advance it's possible to see phase transitions coming. The answer to this seems to be "less than half of a doubling time" given the past examples. In other words, since the world economy is currently doubling every 20 years or so, we probably shouldn't expect to see any sign of an impending phase transition until we're less than a decade away from it. Therefore, the fact that nothing special seems to be happening now shouldn't affect our assessment of the odds of a phase transition in the next century.
On the other hand, the outside view also should lead us to be cautious about what mode of organization will become dominant after the phase transition. It would have been quite difficult to anticipate in the year 1400 that the next phase would be associated with industry, since industry wasn't growing particularly fast relative to anything else in 1400.
Can we get a more precise idea about how long we can expect the industrial phase to last from an outside point of view? Here is one way to go about doing this: assume that D+1 where D is the number of doublings in a phase is drawn from a [Pareto distribution](https://en.wikipedia.org/wiki/Pareto_distribution) with an unknown tail exponent α. Pareto distributions have heavy right tails and allow for a lot of uncertainty. This means the forecasts it implies will be quite conservative on transformative AI timelines, which might be a disadvantage for reasons I'll come back to shortly.
A Pareto distribution has one parameter: the exponent α. If we had a lot of data then we could estimate α using frequentist methods (such as maximum likelihood estimation) but since we don't, we have to use Bayesian methods to get anything useful out of this analysis.
The [conjugate prior](https://en.wikipedia.org/wiki/Conjugate_prior) of the Pareto distribution is the same as the one of the exponential distribution, since the logarithm of a Pareto distributed random variable is exponentially distributed. This conjugate prior is given by the [gamma distribution](https://en.wikipedia.org/wiki/Gamma_distribution).
We start with the [Jeffreys prior](https://en.wikipedia.org/wiki/Jeffreys_prior) for the Pareto distribution, which is simply an improper prior proportional to 1/α. This formally corresponds to a gamma distribution Gamma(0,0) where the distribution is characterized in terms of its shape and rate respectively. Now, we do a Bayesian update: we have two observations of past phases and they took approximately 8.9 and 7.5 doublings - these values are taken from Hanson's paper - for the foraging and farming phases respectively. Using the conjugate prior updating rule for the exponential distribution after adding 1 and taking logarithms, we update to the posterior distribution
Gamma(2,log(9.9)+log(8.5))=Gamma(2,log(84.15))
Now we can do a Monte Carlo simulation by first sampling values of α from the posterior and conditioning on there having been at least 10 doublings so far in the current phase, and then sampling some value of the number of doublings until the end of the current phase. This give us a sample from which we can infer what the percentiles of various outcomes must be.
The cumulative distribution function looks like this:
The reason the percentiles after the median get so large is because of the aforementioned property that the Pareto distribution has heavy tails. Since sustaining doublings indefinitely has a [substantial chance](https://www.cold-takes.com/this-cant-go-on/) of being outside the realm of physical possibilities, we might want to also try using a distribution which has thinner tails. A natural choice for this is the exponential distribution.
This calculation is remarkably similar since the exponential and Pareto distributions are closely related. Now we assume the number of doublings D is drawn directly from an exponential distribution with an unknown rate parameter λ. Once again the Jeffreys prior for λ is Gamma(0,0), and a similar Bayesian update gets us the posterior
Gamma(2,7.5+8.9)=Gamma(2,16.4)
Repeating the Monte Carlo simulation from before in this new context gives the following cumulative distribution function:
Which of these is a better choice? In my judgment the exponential distribution in this case is giving much more realistic timelines, and it's what I will be primarily relying on in order to make my forecasts. I include both models, however, as a way to show that our choice of model really affects our view of what the timeline should be like.
The main argument against using heavy tailed priors is that the number of doublings is already the base two logarithm of the factor by which world product increases by in a phase, so if we assume a heavy tailed distribution for it then we have to exponentiate that in order to get the actual growth in world product. This becomes similar to a double exponential which has a high probability of exceeding physical limits - how confident are we that, say, 9000 doublings of world product is even physically possible at all, let alone it all occurring in a single phase?
I also experimented with using a model in which D is sampled from a gamma distribution, but because its Jeffreys prior doesn't belong to its family of conjugate priors Bayesian inference on it gets quite hairy. In the end the results I get are somewhat more pessimistic than using an exponential, but the difference isn't pronounced.
Inside view
-----------
I think conditional on there being a phase transition in the next hundred years or so, it's likely (around 65%) that the cause of the transition will be the development of transformative AI. However, even if this is not true, reverse causality will then become operative: it's very hard to imagine that AGI is not achieved a short time after a phase transition. Even a factor 10 increase in the growth rate of the economy would be enough for AGI timelines to become quite compressed, for instance.
The reason I would give 65% odds to AGI being the driver of such a phase transition is that it's hard for me to tell a plausible story about any other technology that's currently on the horizon doing so. Moreover, one of the signs of a part of the economy that will be responsible for a phase transition is that it should have a fast growth rate and a plausible mechanism by which that fast growth rate can be sustained and take over the whole economy, and I think the only serious contender for this position right now is AI research. I wouldn't go higher than 65% because a technology that we can't yet see could end up being responsible for the phase transition: this is the same as the point I raised earlier about how industry wasn't growing fast relative to the rest of the economy in 1400.
My opinion is that the inside view right now favors a phase transition sometime between 2 and 5 doublings. It's difficult to imagine transformative AI coming along without at least one further doubling. Some relevant milestones here come from [Holden Karnofsky's post](https://www.cold-takes.com/forecasting-transformative-ai-the-biological-anchors-method-in-a-nutshell/) on transformative AI forecasting using biological anchors:
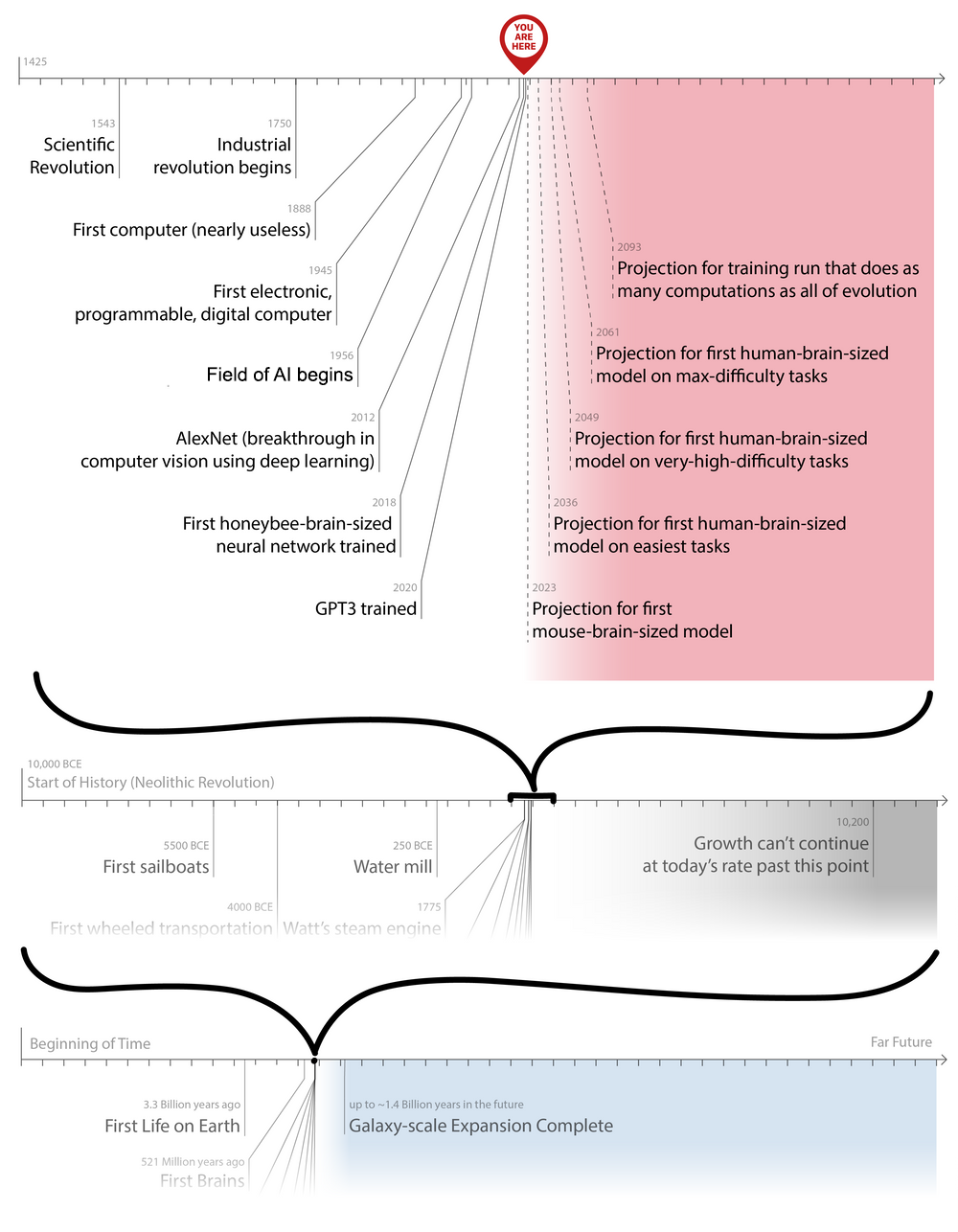
As Karnofsky says in his post:
>
> Bio Anchors estimates a >10% chance of transformative AI by 2036, a 50% chance by 2055, and an 80% chance by 2100.
>
>
>
I think this is extremely optimistic. I agree with the timeline in likelihood terms: the maximum likelihood estimate on when we get transformative AI is probably "two to five doublings", which is roughly the same timeline here - again, their timeline seems a bit more optimistic, but broadly consistent. This roughly means that I think we would be most likely to be seeing the kind of world we are seeing now if we were around two to five doublings away from a phase transition.
However, a good Bayesian has to combine likelihoods with priors in order to get a posterior distribution, and this is my primary point of disagreement with the Bio Anchors timeline: the outside view, in other words the prior distribution, suggests a phase transition occuring soon is unlikely. The industrial phase is roughly 200 years old, and it has lasted for around 10 doublings already. Conditional on that, even if we just assume a constant rate of arrival for the end of the current phase (which will be rather optimistic), we should get a maximum likelihood estimate of around 10% every doubling for it to happen. The median forecast would then be around 7 doublings until the end of the current phase. If we want to go down from 7 to below 2, we need to have very strong evidence that a phase transition is going to happen, and I don't think AI developments so far provide any such evidence.
More explicitly, consider the second cumulative distribution funciton plot above. Two doublings is roughly the 14th percentile of outcomes, so P(D≤2)≈0.14. The corresponding odds ratio is 0.14/0.86=0.162 or so. To update from this odds ratio to even odds requires a Bayes factor of roughly 1/0.162≈6. In other words, to justify a median forecast of two more doublings, the world would have to be 6 times more likely to look as it does under the hypothesis D≤2 than under the alternative D>2. In my judgment the available evidence comes nowhere close to meeting this stringent standard, and I'm curious to hear from people who think otherwise.
Most of the expectation of imminent transformative AI rests on extrapolations such as the one in the graph: if we train a big enough model (human brain-sized, or more accurately, of a similar inferential complexity to the human brain) for a long enough time (compute used by all of evolution), we'll not only get human or superhuman performance on difficult tasks, but this performance will directly translate into a transformation of the global economy. I think the model uncertainty here is so large that updating too strongly away from the prior on this kind of argument is a bad idea.
Forecasts
---------
There are three related questions that I'll forecast on: [GWP growth to exceed 6%](https://www.metaculus.com/questions/6002/gwp-growth-to-exceed-6/), [GWP growth to exceed 10%](https://www.metaculus.com/questions/5833/gwp-growth-to-exceed-10/) and [When will economic growth accelerate?](https://www.metaculus.com/questions/5159/when-will-economic-growth-accelerate/) You can find the cumulative distribution function of my forecasts over at the linked post on Metaculus.
I think all three of these questions are unlikely to resolve if there is no phase transition: I think the first one has around 15% chance of not resolving > in the absence of one, while the second and third are 1% or less. Therefore, my forecasts on all three questions are based on taking my outside view estimates, adjusting them slightly upwards due to the arguments given in the inside view section, and then making further adjustments based on the specific question.
I think mean GWP growth exceeding 10% per year for a sufficiently long time is approximately equivalent to there being a phase transition - it's highly unlikely that any phase transition would have a doubling time factor over the current phase that's less than 3. However, 30% growth in a single year is a stronger demand, so I've adjusted the distribution downwards to account for that. You shouldn't take the exact distribution too seriously, since it's difficult to input exact distributions and I haven't taken the effort to do so, but I've made sure that everything is consistent.
Mean GWP growth exceeding 6% could happen without a phase transition, but it's rather unlikely. It would require major governments around the world enacting wide-reaching economic reforms, or an unprecedented economic boom across most of the underdeveloped world. I put the odds of this at around 15%, and my forecast is more or less a combination of this with my estimate of the arrival time of a phase transition.
Discussion
----------
Most transformative AI timelines focus strongly on the inside view: how long until neural networks become as big as the human brain, how long until we reach certain compute thresholds, how long do researchers in the field think we have until transformative AI, *et cetera*. I think the inside view is useful, but in the process the outside view is either ignored or not weighted strongly enough to balance out inside considerations.
This essay is meant to be a corrective for that: using Bayesian methods it's actually possible to get information about the timeline of when we can expect another phase transition purely based on the past two examples of such transitions. The distributions we get this way do end up being somewhat sensitive to assumptions about priors, especially at the tails, but overall I think using any standard "uninformative" prior is superior to just saying there's no outside view on the problem and focusing only on the inside view.
**Addendum:** Someone over at Metaculus linked [Semi-informative priors over AI timelines](https://www.openphilanthropy.org/blog/report-semi-informative-priors) by Tom Davidson in the comments, which has a similar flavor to what I do here and ends up with similar timelines for a phase transition & transformative AI as I do. If you're interested in this outside view perspective, his article is also worth reading. |
fd4341c5-a746-4312-8eba-192c5069d541 | trentmkelly/LessWrong-43k | LessWrong | SotW: Check Consequentialism
(The Exercise Prize series of posts is the Center for Applied Rationality asking for help inventing exercises that can teach cognitive skills. The difficulty is coming up with exercises interesting enough, with a high enough hedonic return, that people actually do them and remember them; this often involves standing up and performing actions, or interacting with other people, not just working alone with an exercise booklet and a pencil. We offer prizes of $50 for any suggestion we decide to test, and $500 for any suggestion we decide to adopt. This prize also extends to LW meetup activities and good ideas for verifying that a skill has been acquired. See here for details.)
----------------------------------------
Exercise Prize: Check Consequentialism
In philosophy, "consequentialism" is the belief that doing the right thing makes the world a better place, i.e., that actions should be chosen on the basis of their probable outcomes. It seems like the mental habit of checking consequentialism, asking "What positive future events does this action cause?", would catch numerous cognitive fallacies.
For example, the mental habit of consequentialism would counter the sunk cost fallacy - if a PhD wouldn't really lead to much in the way of desirable job opportunities or a higher income, and the only reason you're still pursuing your PhD is that otherwise all your previous years of work will have been wasted, you will find yourself encountering a blank screen at the point where you try to imagine a positive future outcome of spending another two years working toward your PhD - you will not be able to state what good future events happen as a result.
Or consider the problem of living in the should-universe; if you're thinking, I'm not going to talk to my boyfriend about X because he should know it already, you might be able to spot this as an instance of should-universe thinking (planning/choosing/acting/feeling as though within / by-comparison-to an image of an ide |
c4d9c654-aebc-408c-a45e-92bc40feea0d | trentmkelly/LessWrong-43k | LessWrong | How could I measure the nootropic benefits testosterone injections may have?
I came across a post written by Gwern in which he says he never injected Testosterone before but is curious to know more about its potential nootropic benefits. I'm suspecting that its more people than just him who are curious about that soo why not experiment myself?
I wanted to "hop on another cycle of gear" (use steroids for 16-20 wks and restore my natural hormonal production right after) anyway but don't know anything about experiment design so if someone wants to help me out with that that would be pretty cool. |
5a8e01e5-ad58-437b-92c2-30a1a75efd6e | trentmkelly/LessWrong-43k | LessWrong | The types of manipulation on vote-based forums
|
ea70dc05-8aa6-4ab3-9f8f-845e88d2e2fc | trentmkelly/LessWrong-43k | LessWrong | Climate Change And Global Warming
1. Understanding Climate Change
See: Wikipedia: Climate Change.
I support the scientific consensus that climate change and global warming are ongoing, human-caused, and likely to have strong negative consequences for humans, the Earth, and the world’s ecosystems. The evidence is clear that the CO2 levels the Earth’s atmosphere, the Earth’s sea levels, and the Earth’s temperatures are the highest they have ever been in modern human history. The best explanation for why such significant changes to the Earth’s ecology have occurred in such a geologically short time period is that the Industrial Revolution caused humans to start burn fossil fuels for energy.
However, I also believe that climate change has become moralized and politicized on both sides. This has caused people to have a lot of propaganda and inaccurate information to arise. There are many ecological phenomena that have been wrongly attributed to climate change, since their causes have been misidentified. In this essay, I will talk about climate change, how it compares to other ecological issues, my predictions for the future, and what humanity should do to stop climate change and address related ecological issues.
1.1. Why is Climate Change a Problem?
> The Earth is estimated to have had much higher temperatures, CO2 levels, and other differing ecological conditions millions of years ago.
>
> The climate has always been fluctuating significantly throughout the Earth’s recorded history.
That is true. However, we also have to keep in mind that modern humans evolved during the Last Glacial Period when the planet was much cooler. From a bio-evolutionary perspective, it makes sense that humans would want to keep the Earth at cooler temperatures than the projected temperatures that we are predicting decades from now. As global temperatures continue to rise and the climate continues to change, humans will become increasingly more maladapted to the Earth’s environmental conditions.
If we want ourselves, th |
6959a514-6c89-47b4-b355-1ea28da3347b | trentmkelly/LessWrong-43k | LessWrong | Making Up Baby Signs
Babies are often mentally ready to start talking before they have enough control over their mouths, at a time when they may have enough control over their arms and hands to make simple gestures; a lot of otherwise verbal families have had good experiences with signing. If you look around online for baby sign resources, however, most of what you'll find involves long lists of specific signs, often simplified versions signs from American Sign Language.
If you're just going to have a dozen signs that you use for a few months, however, a lot of the constraints that real sign languages like ASL have developed around aren't relevant. You're not building the foundation for something deep and expressive, you're developing a pidgin with your toddler to help fill a short gap in their capabilities. Which means you can prioritize the specific things your child wants to talk about, and use signs that are very easy for them to create and distinguish.
For example, with our youngest we ended up with, in rough order of acquisition and maybe forgetting some:
* "more": bring hands together twice
* "light": open and close hand twice
* "diaper": tap side of butt twice
* "drink": tap mouth twice
* "pickle": tap side of head twice
* "peanut butter": tap inside of elbow twice
* "ice cream": tap bottom of chin twice
* "bran flakes": tap shoulder twice
* "all done": arms in a "w", wave hands twice
* "lift me up here": tap surface twice
* "outside": raise fist above head
* "umbrella": tap palm twice
These are a mixture of ones we taught her ("more", "light", "drink"), ones she made up ("outside", "lift me up here"), and ones where we started teaching her something but what she ended up actually doing was pretty different ("all done", "ice cream"). Since all that matters is that we can understand each other, noticing what she's doing and going with that is fine.
It's not a coincidence that many of these are "double tap somewhere". Once I realized she was picking those up wel |
cb633608-f793-4839-a5f4-e4307d6e2115 | trentmkelly/LessWrong-43k | LessWrong | The President's Council of Advisors on Science and Technology is soliciting ideas
The question that the ideas are supposed to be in response to is:
> What are the critical infrastructures that only government can help provide that are needed to enable creation of new biotechnology, nanotechnology, and information technology products and innovations -- a technological congruence that we have been calling the “Golden Triangle" -- that will lead to new jobs and greater GDP?"
Here are links to some proposed ideas that you should vote for, assuming you agree with them. You do have to register to vote, but the email confirmation arrives right away and it shouldn't take much more than two minutes of your time altogether. Why should you do this? The top voted ideas from this request for ideas will be seen by some of the top policy recommendation makers in the USA. They probably won't do anything like immediately convene a presidential panel on AGI, but we are letting them know that these things are really important.
Research the primary cause of degenerative diseases: aging / biological senescence
Explore proposals for sustaining the economy despite ubiquitous automation
Establish a Permanent Panel or Program to Address Global Catastrophic Risks, Including AGI
Does anyone have any other ideas? Feel free to submit them directly to ideascale, but it may be a better idea to first post them in the comments of this post for discussion. |
2d7848f9-5f6f-44d1-98c0-82c09431e818 | trentmkelly/LessWrong-43k | LessWrong | The Parable of Hemlock
> "All men are mortal. Socrates is a man. Therefore Socrates is mortal."
> — Aristotle(?)
Socrates raised the glass of hemlock to his lips...
"Do you suppose," asked one of the onlookers, "that even hemlock will not be enough to kill so wise and good a man?"
"No," replied another bystander, a student of philosophy; "all men are mortal, and Socrates is a man; and if a mortal drink hemlock, surely he dies."
"Well," said the onlooker, "what if it happens that Socrates isn't mortal?"
"Nonsense," replied the student, a little sharply; "all men are mortal by definition; it is part of what we mean by the word 'man'. All men are mortal, Socrates is a man, therefore Socrates is mortal. It is not merely a guess, but a logical certainty."
"I suppose that's right..." said the onlooker. "Oh, look, Socrates already drank the hemlock while we were talking."
"Yes, he should be keeling over any minute now," said the student.
And they waited, and they waited, and they waited...
"Socrates appears not to be mortal," said the onlooker.
"Then Socrates must not be a man," replied the student. "All men are mortal, Socrates is not mortal, therefore Socrates is not a man. And that is not merely a guess, but a logical certainty."
The fundamental problem with arguing that things are true "by definition" is that you can't make reality go a different way by choosing a different definition.
You could reason, perhaps, as follows: "All things I have observed which wear clothing, speak language, and use tools, have also shared certain other properties as well, such as breathing air and pumping red blood. The last thirty 'humans' belonging to this cluster, whom I observed to drink hemlock, soon fell over and stopped moving. Socrates wears a toga, speaks fluent ancient Greek, and drank hemlock from a cup. So I predict that Socrates will keel over in the next five minutes."
But that would be mere guessing. It wouldn't be, y'know, absolutely |
8cd5d8c7-fa18-440d-a9c5-3694ac8b7957 | StampyAI/alignment-research-dataset/youtube | Youtube Transcripts | Eliezer Yudkowsky "Friendly AI"
so this is also a new talk for me
because Nick Bostrom covered a lot of
the material that I would usually put
into a talk so I had to quickly scurry
off and design another talk that would
not overlap with his talk let's start
with a old tragedy of science that is a
case where some some scientists screwed
up
why don't predator prey populations
crash you would think that you know if
you if you ran a simulation or something
you would find that the population of
foxes wouldn't the rabbits would get out
of whack there'd be too many foxes not
enough rabbits they'd all starve now
back in the 1960s they had this
brilliant notion which is that if you
look at if you would partition the fox
population into groups then groups of
foxes that reproduce too much and eat
all available rabbits will starve and be
eliminated from the gene pool so by
selection on groups foxes will evolve to
restrain their own reproduction this was
an actual much talked-about theory
before the 1960s back when biologists
had when a large majority of
professional biologists had no idea how
evolutionary biology worked a bit really
foxes will evolve to restrain their own
reproduction okay that basically never
happens you don't have a gene for not
reproducing that becomes dominant in the
gene pool
specifically group selection although it
was a very popular sort of theory was
tremendously difficult to make work
mathematically in the night you know
before the 1960s before it's now called
the Williams Revolution people would
postulate all sorts of nice pro-social
group benefiting adaptations and they
would point to group selection as as
their theory for how evolution could
actually do that but it's mathematically
extremely difficult for group selection
to work
example is in simulation if the cost to
an organism of a gene is 3 percent of
its own fitness and it benefits its
neighbor so much that pure altruist
groups have doubled the reproductive
fitness of pure selfish groups and group
sizes twenty five and twenty percent of
all deaths are replaced by neighbors
from another group the result is
polymorphic for selfishness and altruism
that means that if the cost is five
percent of fitness or pure altruist
groups are less than twice as fit as
pure selfish groups then you do not get
pop then you would just get the selfish
gene the selfish gene would win if you
look at the statistics of a human
maternity hospital where around the same
number of boys and girls are born and
teach generation you can see at a glance
that individual selection pressures beat
group selection pressures on humans you
know you might imagine that if you had
more girls born and fewer boys that you
would have more mothers you'd be able to
reproduce faster but if you had an
equilibrium like that then by then any
gene for birthing more boys would be
able to make a genetic killing in the
next generation because boys would you
know each child would still have half of
its genes from the father half of the
genes from the mother the pool of boys
in the pool of girls would make roughly
equal genetic contributions to next
generation so if there are fewer boys
then you can make an individual genetic
killing by birthing more boys if there
are fewer girls you can make a genetic
killing by birthing more girls
regardless of what's good for the group
so you can just look at a glance at the
human maternity hospital and you can see
that the forces of individual selection
are far stronger than the forces of
group selection on humans and there is
no we would now say that there is no
known case of a group selected
adaptation in any mammal one might even
say no case known case of groups lefty
the adaptation period but that is
slightly more controversial part about
no mammal we know in point of fact why
don't predator prey populations crash
well when I was young my father said to
me why don't people on
Australia fall off the globe since
they're standing upside down and my
father said to me
aha it's a trick question actually
people fall off all the time just in
case you're wondering what kind of
family I came from and indeed this is a
wrong question the answer is predator
prey populations crashing all the time
but later on even though the
mathematically required conditions for
group selection are ridiculously extreme
a mad genius named Michael J Wade took a
laboratory population of tribolium
beetles and implemented the extreme
conditions needed for group selection
selection on groups of beetles for
reduced population that was so severe
that group selection could
mathematically overpower individual
selection so what do you think happened
when group selection this same force
that was once appealed to to talk about
all sorts of wonderful aesthetic humane
solutions like be nice and restraining
your own breeding this is what
biologists before the 1960s appealed to
group selection to was supposed to
produce so Michael J Wade took some
populations of beetles he eliminated all
the beetle populations that that grew
the fastest leaving only the Greenough
populations that grew the slowest what
do you think actually happened take a
moment to predict it but if you've
actually read about this before then
don't forget this group well yes you did
very well because of course the actual
solution group selection produces eat
their babies you know at your own babies
of course you go around and find the
other organisms babies and you eat them
especially the young girls of course
those are the tastiest nom
think of your brain as an engine that
searches for solutions ranking high in
your preference ordering using limited
computing power now if you if your tribe
was faced with the sort of population
problem that Michael J Wade presented
his beetles with or the Foxes had with
the rabbits then for you the solution
let's all have as many children
individually as possible than try to eat
each other's babies especially the girls
would rank so low in your preference
ordering that your brain would not even
suggest it like you wouldn't see that as
an option because your brain has limited
in computing power and there is no point
in generating solutions that weird in
that low in the preference ordering so
if you try to understand evolutionary
biology by putting yourself in evolution
shoes and asking how you would solve a
problem you won't even see evolutions
answer as a possibility you have to
learn to think like this non-human
optimization process which early
biologists didn't and indeed there as
much the Lemos energy literature and
evolutionary biology devoted to training
you to stop thinking like a human who
will come up with nice solutions and
start thinking like natural selection
and coming up with which genes are
actually likely to rise to universality
in the gene pool the relevance to AI of
course is that if you so for example
yesterday of Schmidt Schmidt Huber who
unfortunately is not here today gave us
a certain reward criterion and suggested
that it would be maximized by art and
you know having been through this sort
of conversation for quite a while now I
sort of squint at that and say okay so
art fits there but what else besides art
fits there how about sets of black boxes
encrypted using it by an external
mechanism using that using a key that
can be reliably recovered in five
minutes then you could achieve a lot of
compression that way
in general what sort of goes wrong with
your mind when you try to understand the
sort of nonhuman optimization process is
something like persuasive
rationalization like let's say I'm buy
I'm buying an entire chocolate cake
going to sit down to eat it you ask me
hey why are you buying an entire
chocolate cake I thought you were on a
diet oh because I want to help the sugar
industry helping the sugar industry is
very important what's wrong with this
claim over here what is wrong with the
claim that you are optimizing the
criterion of helping the sugar industry
by buying the chocolate cake well you
could just mail them a check and instead
of getting only the tiny portion of the
gains from from trades that are captured
by the sugar industry when they when you
know by the time you buy the cake and it
has been marked up by the cake
manufacturer in the store and so on you
could just mail them to check directly
so strategy acts in this case eating an
entire chocolate cake suggested by
criterion one in this case chocolate
cakes are tasty you try to justify that
by an appeal to criterion to helping the
sugar industry you can tell it's a
persuasive rationalization because just
mail them a check strategy why optimize
this criterion to help the sugar
industry it comes a lot closer to
maximizing criterion two so let me just
sort of skip a head over here and so in
the tragedy of group selection ISM there
was a biologist saw an ecological
problem of the limited rabbit supply
they imagined how they would solve that
problem by having the Foxes cooperate to
restrain their building now this was
really sort of suggested by their human
nice aesthetic sense of values and then
someone pointed out to them hey wait a
minute that is not how evolution works
but by this time they've gotten they're
emotionally attached to their lovely a
aesthetic view of nature foxes and
rabbits and harmony people would
actually say things like that but you
know before the 1960s and so they
invoked their brains persuasive
rationalization module now that they
decided to do that that just sort of
automatically when they were defending
their a mistake and sort of tried to
persuade evolution to see it their way
by appealing to evolutions own stated
moral principles of promoting
reproduction sort of like try to you
know hey they're natural selection you
know you could actually you know
immaculate you could get some
reproduction done by doing things my way
and having the foxes restrain their
breed and yeah but unfortunately
evolution itself does not start with
human a aesthetic preferences and then
figure out a way to rationalize how that
helps reproduction evolution is just the
process where the genes that build foxes
that produce more baby foxes become more
prevalent in the population so after you
are done sort of nudging the nonhuman
optimization process and claiming that
it odd to do nice things for your clever
reasons that your prediction fails
because the process itself does not work
that way and it's not within the and
your thing that you know sort of maybe
helps reproduction a bit didn't maximize
reproduction it wasn't didn't fit the
criterion as well as some other things
sort of like okay sure art maximizes
schmidhuber is quite partly art might
produce some reward for Schmidt humors
internal reward criterion but having a
sequence of black boxes that you
produced by an external device that
where you know you can recover the key
in five minutes will maximum what will
optimize it even more oh and let me uh a
little similar story that related story
might find entertaining so less wrong is
a community website devoted to man
rationality and it's got all these
lovely sequences on things like how to
actually change your mind sometimes that
this will become relevant at a moment I
promise so newcomer cluster on those hi
I've read through the sequences and I'm
an egoist well so of course he was like
immediately asked so if you could take
the pill that could numb your conscience
and no one would ever find out how many
babies would you kill for a dollar
because you see people who call
themselves egoist they may have this
sort of verbal philosophy of selfishness
but their actual options are being
generated by the full range of normal
human values and then they appealed to
selfishness in order to justify those
options that were generated by other
sources
they aren't actually egoist because if
they were actually eat lists of course
they would see nothing wrong with
killing babies for a dollar as long as
they didn't get found out oh and and the
response one day later okay I thought
about that for a while I'm not an egoist
anymore this only happens I'm less wrong
I don't think I've ever seen that happen
anywhere else on the Internet and so as
this person realized they never actually
used egoism to select their actions they
use normally human preferences to select
their actions but then justified them by
rationalizing to this single single
simple principle of egoism you get a lot
of people proposing single simple
principles that are all we need to build
into a friendly AI and everything will
be hunky-dory forever after and that's
because they use their full range of
human preferences to generate and select
their actions and then they justify them
by appealing to this principle which can
actually be maximized a lot more by
things like eating babies killing babies
for a dollar or having black boxes
encrypted by an external device so the
point people don't notice when simple
optimization criteria imply humanly ugly
choices because their own brains don't
generate the strategies for
consideration and think people think
they can pack all sorts of nice things
into simple principles because they make
their choices using fully land values
nay aesthetics and then rationalize
those choices by persuasively arguing to
that principle so this is another
thought experiment the reason why I
couldn't come up with an abstract for
this talk is that it's a series of
persuasive historical cases or thought
experiments and I just couldn't figure
out an abstract for that because I was
too busy finishing the talk so let's say
you're in a world where no one knows
what's really going on with
addition addition is one of the
mysteries but people and so of course
modern computer scientists are trying to
build artificial addition and they do
this with a logical addition device
which of course does anyone who has
familiar with symbolic AI will realize
will naturally contain all sorts of
price propositional logic statement
stating that the plus of seven and six
is thirteen and of course all these
little suggestively named Lisp tokens
over here are given their meaning by the
the larger semantic network in which
they are embedded and it turns out that
doing artificial addition this way is
you know very expensive and
time-consuming and they've only got
artificial adders that work up to the
number 60 and you know getting your
artificial adders all the way up to to
working with like general addition and
the ranges of thousands or millions you
know as humans can do is thought to be
decades away and so on and so you've got
all sorts of and by the way don't worry
this will be relevant to from the AI now
there all sorts of lovely comments about
this problem of artificial general
addition for example there's the view
that artificial general addition is
difficult because of the framing problem
what 21 plus is equal to depends on
whether it's plus 3 or plus 4 so you
need to program a huge network of
arithmetic Allah facts to cover
common-sense truths and then you'll get
artificial general addition or you need
an artificial general arithmetic that
can understand and roll language so
instead of being told that 21 plus 16
equals 37 it can obtain that knowledge
by reading the web or you need to
develop a general Aerith petition the
same way nature did evolution top-down
approaches have failed to produce
arithmetic we need a bottom-up approach
to make arithmetic emerge we must accept
the unpredictability of complex systems
neural networks just like the human
brain they can be trained without
understanding how they work neural
networks will do arithmetic without us
their creators ever understanding how
they add after actually you just need
calculators as powerful as the human
brain and Moore's law predicts that
Kappa laters these powerful B will
become available on April 27 2013 1
between 4:00 and 4:30
in the morning maybe that's not enough
maybe we've actually got to simulate the
detailed neural circuitry humans used
for addition or gödel's theorem shows no
formal system can never capture the
properties of arithmetic in the
classical physics is form Eliza Bowl so
hence an artificial general edit it edit
adder must exploit quantum gravity human
Emerson's think we're something off to
cetera et cetera haven't you ever heard
of Donna trills Chinese calculator
experiments see it doesn't really know
what the numbers mean probably will
never know the nature of arithmetic the
problem is just too hard for humans to
solve so I usually tell the story with
the moral that when you're missing a
basic insight you have to what you have
to do is actually actually understand
what's going on inside addition and
until you understand that you're screwed
you'll come up with all sorts of clever
workarounds and things that you can that
you can say about the problem and ways
that sound like they might solve it that
will sound clever even if you don't
quite know what you're doing but it's
actually impossible to talk sensibly
about solutions until you are no longer
confused it's quite important to
recognize what people sound like when
they start talking about something with
about which they are fundamentally
confused this is what they sound like
it's good to be able to recognize that
today is moral though I'm actually just
going to take a simpler moral which is
that if you have to put in a infinite
number of special cases it means you
didn't understand the underlying
generator of the behavior this world
will probably become relevant
so next thought experiment the outcome
pump you let's say you have a time
machine
what sort of fun machines can you do
with the time machine go back to
yesterday and throw up high it yourself
or achieve omnipotence so let's say that
you build a device which automatically
resets time unless some desired outcome
occur so in other words you just sort of
keep presenting time back to some
previous state until you get the outcome
you want now you have a physical genie
device time machine equals genie
why talk about a little time machine
reset device because if you talk about
genies who are tempted to think of them
as minds and anthropomorphize them and
assume that they would do it what they
would do what you would do in your shoes
we want to talk about a physical genie
the little time machine reset device
because it lets us talk about an
optimization process the resetar just
using language of physical things
without invoking mental entities and
that may help help us be a little less
anthropomorphise that's why I opened
with the example of natural selection
natural selection is a non human
non mental optimization process and that
makes it and that doesn't mean people
are don't down through morph eyes it but
it means you can give them very stern
looks when they do so you you take your
physical genie and you want to solve the
grandma extraction problem now if it's a
regular old genie you just say I wish
for my grandma to be outside the burning
house they you know there's a house on
fire your grandma's in it you want to
get it out that is the grandma
extraction problem but this we don't
have a genie we have a little time
machine device so first thing we've
we've got actually specifying some way
if it doesn't can't be assumed to
automatically understand what we want
we've got to describe what we want to
this physical genie that clearly can't
understand language because it's just a
plain old physical time machine so how
would you specify this goal
well you even if you don't can't
understand natural language you might
you know iPhones can take pictures we
have software that can understand
pictures we might hook up some kind of
scanner that can identify objects in its
vicinity you know by magic and Will's
will scan the photo of grandma's head
and shoulders we use object contiguity
to select grandma's whole body and we
will say that the probability of
resetting time decreases as grandma gets
further away from the center of the
house so this where I'm actually sort of
skipping over a bit of the background of
how I usually explain this like the idea
is that
you can specify a quantitative utility
function for this kind of physical
outcome pump by saying the higher the
utility the less likely you are to reset
and so you're more likely to end up with
an outcome with higher utility in any
case so in this case we're specifying
that the outcome pump is going to try to
select an outcome in which grandma
identified by object contiguity and a
photo is far away from the center of the
house
you have now told the genie to get
grandma out of your house so the gas
main under the building explodes
grandma's body is hurled into the air
thereby rapidly increasing her distance
from the former center of the house and
there's a little button on your time
machine that you're supposed to push if
something goes drastically wrong which
almost certainly resets it it's called
the regret button of course you never
experience pressing it because all those
probabilities have been wiped out but in
this case of flaming wooden beam drops
out of the sky and smashes you before
you can hit the emergency reset button
that's causing the time machine to think
everything's fine now if you were
talking about a actual genie a mental
genie a genie that understood what you
were saying you might be tempted to
blame it but as long as this is a
physical optimization process here
there's no point in blaming it for
anything any more than there's a point
in blaming natural selection for
producing baby-eating as the outcome of
group selection
you simply programmed in the wrong
utility function it's not the fault of
the time machine it's the fault of the
function you gave it to to maximize so
if this were a mental genie we would say
I wish for my grandma to be outside the
burning house and alive so you try to
write something into your time machine
outcome pump that recognizes whether
grandma's dead or alive and make sure
that she is breathing at the time she
exits the house and of course she ends
up in a coma
the open-source wish project tries to
devise to develop inescapably good who
wishes this is their version 1.1 of
their wish for immortality I wish to
live in locations with my choice in a
physically healthy uninjured and
apparently normal version of my current
body containing my current mental state
a body which will heal from all injuries
that are registered blah blah blah blah
blah blah blah blah blah now remember
the previous lesson about needing to
patch an infinite number of special
cases because you didn't understand
edition and therefore you had to program
in all the knowledge manually let's say
you were trying to build a chess AI mate
you could imagine that you would build a
test that by having a human look at a
bunch of chess positions rate whether
those chess positions are good or bad or
wait the or have the human look at a
bunch of chess positions and say what is
the best move in each chess position and
then program those chess positions and
their best moves into the chess playing
AI problem this of course is that there
are too many chess positions the key
insight that you need is that what makes
a move good is that it leads to a
certain range of board states that we
have designated as winning and that we
want that the eight the chess playing AI
can navigate to one of the board states
known as winning
and until you achieve the insight of
game trees you cannot build a chess
playing ai so Grandma extraction problem
we have cases like grandma is dead is
worse than grandma's alive but Burns is
worse than Grandma alive and healthy
suppose a wormhole opens and transport
grandma to a desert island while it's
better than her being dead it's worse
than her being alive well healthy on
traumatized in continual contact with
her social network is it ok to save
Ranma at the cost of a fireman's life at
the cost of the family dog's life at the
cost of two murderous lives is it worth
a point zero zero zero zero zero zero
zero one percent risk to Grandma to say
if the family dog would you destroy
every extant
copy of box little Fugen g-minor to save
your grandma what algorithm are you
using to decide all these cases how do
we capture the generator you're checking
the value of the distant consequences
and you're implicitly checking all the
components of your utility function you
people like the open source Wish project
are generating all the clauses of the
swish by imagining events with
negatively valued consequences and
ordering the genie don't do that this is
one of my favorite sentences ever
it's from William Francona's ethics and
I first encountered it in the Stanford
encyclopedia of philosophy article on
what things have terminal value what
things do we value in themselves and not
for their consequences life
consciousness and activity health and
strength pleasures and satisfactions of
all or certain kinds happiness buta tude
contentment truth knowledge true
opinions of various kinds understanding
wisdom beauty harmony proportion and
objects contemplated aesthetic
experience morally good decision
dispositions or virtues mutual affection
love fringe and cooperation boy you're
ever feeling down you can just read the
sentence over here and remember
everything that makes life worth living
if the genie is searching more pass
through time than you if you're Gili
with the genie that will be considering
options that you didn't imagine at the
start of the problem because you were
not smart enough to imagine them because
you did not search all the past through
time that the genie could take then no
wish that you make that genie is safe
unless the genie is itself is checking
all the consequences of any strategy it
considers using the entire utility
function if the genie has no component
in its utility function for music that
means that changes to music are value
neutral in the genies evaluation and
that mean that means that as far as the
Deenie is concerned if you can destroy
all copies of Bach's music to prevent
someone from breaking a leg
where it knows that breaking a leg is
bad but it has no component that's
utility function for the music that's
great that's fine
so this is the hidden complexity of
wishes that whenever you consider well
is that a good weight to wish something
the strategies to implement simple
sounding instrumental goals are chosen
using the full array of terminal values
that forbid negative consequences and
optimize positive consequences this goes
on in the background you're not you're
probably not even aware of consent of
ever consciously saying hmm should I
blow up the house in order to get
grandma out of it
no your brain doesn't even generate that
as an option it's too low in your
preference ordering but the reason it's
low in your preference ordering as a way
for getting grandma out of the house is
that you value grandma being alive you
weren't even aware of considering that
but it was a consideration that was
there the whole time and thinking about
this in as a purely physical device a
little time machine that resets time
unless some sort of physically specified
condition is achieved sort of reveals
why Time Machine like that an outcome
pump like that you might think it would
grant you am nipa tints it's actually
too dangerous to ever be used it
searches all the paths through time and
unless you can program william frank
anna's entire value list in there plus
everything for and kind of forgot to
talk about it's going to stomp on one of
your values in the course of
implementing what sound like perfectly
reasonable wishes bill Hibbard we can
design intelligent machines so their
primary innate emotion is unconditional
love for all humans first we build
relatively simple machines that learn to
recognize happiness and unhappiness and
human facial expressions human voices in
human body language then we can hardware
as a result of this learning of the
innate emotional values of more complex
intelligent machines positively
reinforcing we are happy and negatively
reinforced and we are unhappy trained
super intelligences so their reward
function is smiling humans
naturally if you actually tried this the
galaxy would end up tiled with tiny
molecular smiley faces
it just seems obvious what could he
possibly have been thinking Oh
incidentally the people who did the DNA
will likely relief face some of them had
read my work and like one of them
actually emailed me to say oh I produce
some tally of tiny molecular smiley
faces it has begun
this is the sort of friendly AI proposal
that you get when people use qualitative
physics to think about friendly a is so
qualitative physics is a psychological
study of a certain kind of reasoning so
for example you this diagram says that
if you increase the burner temperature
that will increase the amount of boiling
going on and if the amount of boiling
going on increases that changes the
derivative that decreases the derivative
of water in other words the water is
already boiling away but now it's going
to boil away more quickly because when
there's more boiling going on and this
says that you can turn on the burner to
get rid of water so presumably bill
Hibbard was thinking something along the
lines of happy people smile more smiling
reinforces the AI behavior the AI will
therefore do things that make people
happier happier people have more utility
therefore building a super intelligence
reinforced by human smiles is according
to this graph good and of course you
carry a very large category proposals
that one might term apple-pie AI which
go like this apple pie is good nuclear
weapons are bad all we need to do is
wish for as build a super intelligence
that will give us lots of apple pie and
not use any nuclear weapons no seriously
the you know that that thing that
Hibbert Rose was in a peer-reviewed
journal I hear this all the time nothing
remotely like this approach will ever
work ever and if I hear one more
proposal to build an AI that promotes
liberal democracy I'm going to scream
so the natural next think you might
think of is okay build a super
intelligence that is optimizing William
Franck Hanna's entire value list the
problem is when you get down to the
bottom of that list you get to power and
experiences of achievement
self-expression freedom peace security
adventure and novelty and good
reputation honor esteem etc that
etceteras that is the dangerous part
really
dialing nine tenths of my phone number
correctly does not reach nine tenths of
eliezer yudkowsky what happens if a
super intelligences utility function has
one wrong number it is missing one just
one little component of value the N
armed bandit problem says that you have
a number of slot machines in front of
you and you are trying to determine
which of these slot machines when I pull
the lever is gives me the highest
expected payoff the human solution of
course would be to pull your favorite
levers so far and occasionally get bored
with the known levers and try pulling
some new ones in general this is called
an exploration exploitation trade-off it
is the problem that boredom solves in
humans there's also in the Bayesian
optimal solution to an exploration
exploitation trade-off is to have a
prior over the one-armed bandits the
slot machines update your beliefs about
them based on your observations of the
payoffs they've delivered so far and
here's the thing if you know how long
you're going to have to how many polls
you're going to have on these bandits
then you're out any piece of information
you can obtain about them is more
valuable when you obtain it closer to
the start of the problem any piece of
information you obtain you get to use on
more future occasions if you obtain it
earlier rather than later so
occasionally going exploring is not an
optimal strategy for maximizing the
payoff from the one-armed bandits the
optimal strategy is to do all your
exploring first until the you have
updated your beliefs about the one-armed
bandits and the expected value of
information has dropped below the
threshold of the most rewarding band
that observes so far and then once you
have gathered all the information going
to gather you just pull the best lever
over and over until time runs out that
is the basement I met you can make an
error there well if that possible well
first of all if that if that possibility
exists in your prior for one thing okay
okay so if you have no idea which one it
is then you might as well pull the one
with the highest well sure then of
course well yes it it yeah indeed you
can have a case where you're pulling the
one that that's best then you get an
unexpected piece of information about
and then you start switching again so
yes that and that indeed can happen but
if that doesn't happen and the I I will
generally not expect that it will happen
at the time that it starts pulling the
bit the best lever will just pull the
best lever over and over again the point
is the the solution doesn't the the
exploration act at the exploration
exploitation problem that boredom solves
in humans human boredom is not the only
way to solve this problem and if you ask
what sort of convergent instrumental
value you're likely to get it's going to
be first to all your exploring find the
configuration that maximizes your
utility exploit that configuration over
and over again that's the convergent
instrumental one humans have a terminal
value for doing new things imagine
running into aliens who have a different
emotion of boredom than we do in
particular
they are more easily amused in
particular these aliens have a narrower
definition of what constitutes the same
thing for purposes of boredom so if you
show them the same picture with one
pixel changed they say ah that's a
different picture I'm not bored anymore
what would this alien civilization look
like if we encountered them probably
something like this you know just the
moment of maximum fun over and over and
over and over and over again I will take
a moment to comment at this point that
you have to solve the Friendly AI
problem in order to get an interesting
universe full of strange alien beings
whose art and science we cannot imagine
that's you've got a solid the friendly
eye problem isn't about preserving
humanity as it is now until the end of
time if you don't solve the friendly a a
problem you don't get a strange
wonderful alien universe you get things
that you didn't even think about is
particularly human values like boredom
which because they're left out of the
utility function you lose everything of
value if you an alien civilization
doesn't have the same kind of boredom we
do if there if as far as they're
concerned one pixel of this frame makes
it a different experience that is no
longer boring then their entire
civilization would look uninteresting to
us similarly if you have a paperclip
Maximizer it wants to make paper clips
that's all it's utility function is it
doesn't have any utility any function
its utility any terminus utility
function for boredom and you don't get
to say well we don't have to build in
boredom as an explicit in the terminal
value it's a convergent instrumental
goal because the choice is not between
the human version of board
and an AI that experiences nothing
analogous to boredom our own boredom is
a product of our evolutionary origin the
fact that we are built by natural
selection that natural selection is
stupid means that a lot of things that
are a sort of natural selection sense
instrumental goals are in us terminal
values and for that matter our boredom
could easily be our style of boredom
could easily be tied to our neural
implementation it could be a matter of
neurons adjusting to the same reward
over and over and getting bored and go
looking at something else if you look at
a ideal Bayesian decision agent and ask
what kind of boredom is a convergent
instrumental value then there is a
convergent solution to the exploration
exploitation trade-off and that solution
leads to what we would regard as a
boring worthless valueless future this
is why we have to solve the friendly eye
problem it's not about the values that
you think of as uniquely human it's
about the values you don't even think of
as human but which are there nonetheless
and if they are lost if even a single
one of those values is lost losing a
single dimension of value can lose
nearly all the expected value of the
future everything we were hoping to get
out of those galaxies and besides
boredom some other cases where you lose
a single dimension of value you lose the
entire thing consciousness you know you
got everything in there and the utility
function only it doesn't done you know
it doesn't talk about consciousness or
doesn't talk about which sort of things
are conscious and from our perspective
the entire galaxy has turned into a
wonderful literary novel with no one to
read it external reference of subjective
sensations you have an AI that is sort
of carefully optimizing your subjective
sensations but doesn't want anything to
be behind it that's not part of its
utility function you know you have this
wonderful perfect girlfriend and you
feel very free but your girlfriend is
just wallpaper and your feeling of
freedom is produced by artificially
stimulating your little freedom of
sensation lobe in their little sensation
of freedom love in their
this is say I presume I'm running out of
time here on my corrector okay so so I
will skip a little extended thing that
will follow this last example this is a
anecdote I have repeatedly heard
presented as fact I've been unable to
track down the original of it but that
doesn't mean it's not true and the story
goes like this the army was trying to
develop a neural network that would
detect tanks and they gave some photos
of tanks and of non tanks scenes with
tanks in them and without tanks in them
to their AI researchers and the AI
researchers trained a network until it
could distinguish the tanks the non
tanks and then they from the same set
you know took the test photos in and the
neural network that had been trained and
the training photos could distinguish
the test photos just as well you know
got 100% accurate classification and
then they took it out and give it to the
army and the army came back and said
this doesn't work at all and it turned
out that all of their pictures of tanks
had been taken on cloudy days all their
pictures of non tanks had been taken on
sunny days they had built a cloudy day
versus sunny day classifier instead of a
tank classifier
the simplest boundary around the data is
not always the boundary you had in mind
if the training cases in real world
cases aren't from exactly the same
independent identically distributed
context no statistical guarantees apply
and if you imagine Terry Schiavo if I'm
pronouncing her last name correctly
Chavo Chavo sighs OH so Terry Schiavo
would not have been something we would
have encountered in our ancestral
environment if you try to classify
people as alive or dead in the ancestral
environment you have a litany of plus
cases in minus cases where if you draw
the simplest boundary around it it's
likely to talk about the difference
between alive and dead being the
difference between breathing and non
breathing say or moving and non-moving
and the case of Terry Schiavo is outside
the training cases of the ancestral
environment you can't
if you presented an AI with the net
ancestral environment cases and tried to
train it to distinguish between people
and non people the advance of technology
would have produced all sorts of exotic
cases that it couldn't classify that
wasn't guaranteed to classify using the
training data probably wouldn't classify
correctly because the simplest boundary
used for making predictions would not be
the moral boundary this is over here I'm
the sort of like talking about some
material that I was going to cover later
and skipping over it essentially the the
the there are several morals you could
draw from this but one of the morals is
the categorization that you want the AI
to draw sometimes without even realizing
it it's not there in the data it's there
and it's it's there in your utility
function but it's not there in the data
itself is a class of problems I'm not
really going to get a chance to talk
about because I'm skipping straight
through but it's why it's difficult to
just give the AI set of training cases
and say this is our ethics because the
shadow of your ethics on that data
set may not capture all the features of
your ethics that's the difficulty with
just trying to get Frank Anna's entire
value list including the etc by taking a
large corpus of ethical dilemmas and
training the AI on them but I didn't
actually quite get to go through all
that he caused a lot of time and I will
also skip the summary of the talk and go
straight to the end due to being out of
time |
c4e0702c-c60c-4f91-b646-e1dd31100384 | trentmkelly/LessWrong-43k | LessWrong | Voting Phase of 2018 LW Review
For the past 1.5 months on LessWrong, we've been doing a major review of 2018 — looking back at old posts and asking which of them have stood the test of time.
The LessWrong 2018 Review has three major goals.
* First, it is an experiment in improving the LessWrong community's longterm feedback and reward cycle.
* Second, it is an attempt to build common knowledge about the best ideas we've discovered on LessWrong.
* Third, after the vote, the LessWrong Team will compile the top posts into a physical book.
We spent about 2 weeks nominating posts, and 75 posts received the the 2 required nominations to pass through that round. (See all nominations on the nominations page.) Then we spent a month reviewing them, and users wrote 72 reviews, a number of them by the post-authors themselves. (See all reviews on the reviews page.)
And finally, as the conclusion of all of this work, we are now voting on all the nominated posts. Voting is open for 12 days, and will close on Sunday, January 19th. (We'll turn it off on Monday during the day, ensuring all timezones get it throughout Sunday.)
The vote has a simple first section, and a detailed-yet-optional second section based on quadratic voting. If you are one of the 430 users with 1000+ karma, you are eligible to vote, then now is the time for you to participate in the vote by following this link.
For all users and lurkers, regardless of karma, the next 12 days are your last opportunity to write reviews for any nominated posts in 2018, which I expect will have a significant impact on how people vote. As you can see, all reviews are highlighted when a user is voting on a post. (To review a post, go to the post and click "Write A Review" at the top of the post.)
This is the end of this post. If you'd like to read more detailed instructions about how to vote, the rest of the text below contains instructions for how to use the voting system.
----------------------------------------
How To Vote
Sorting Posts Into Bucke |
28186ddf-a5af-47d9-8b52-6dbe049d978a | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [AN #85]: The normative questions we should be asking for AI alignment, and a surprisingly good chatbot
[View this email in your browser](https://mailchi.mp/84b4235cfa34/an-85-the-normative-questions-we-should-be-asking-for-ai-alignment-and-a-surprisingly-good-chatbot?e=[UNIQID])
Find all Alignment Newsletter resources [here](http://rohinshah.com/alignment-newsletter/). In particular, you can [sign up](http://eepurl.com/dqMSZj), or look through this [spreadsheet](https://docs.google.com/spreadsheets/d/1PwWbWZ6FPqAgZWOoOcXM8N_tUCuxpEyMbN1NYYC02aM/edit?usp=sharing) of all summaries that have ever been in the newsletter. I'm always happy to hear feedback; you can send it to me by replying to this email.
Audio version [here](http://alignment-newsletter.libsyn.com/alignment-newsletter-85) (may not be up yet).
**Highlights**
--------------
[Artificial Intelligence, Values and Alignment](https://arxiv.org/abs/2001.09768) *(Iason Gabriel)* (summarized by Rohin): This paper from a DeepMind author considers what it would mean to align an AI system. It first makes a distinction between the *technical* and *normative* aspects of the AI alignment problem. Roughly, the normative aspect asks, "what should our AI systems do?", while the technical aspect asks, "given we know what our AI systems should do, how do we get them to do it?". The author argues that these two questions are interrelated and should not be solved separately: for example, the current success of deep reinforcement learning in which we *maximize expected reward* suggests that it would be much easier to align AI to a utilitarian framework in which we *maximize expected utility*, as opposed to a deontological or Kantian framework.
The paper then explores the normative aspect, in both the single human and multiple humans case. When there's only one human, we must grapple with the problem of what to align our AI system to. The paper considers six possibilities: instructions, expressed intentions, revealed preferences, informed preferences, interests, and values, but doesn't come to a conclusion about which is best. When there are multiple humans, we must also deal with the fact that different people disagree on values. The paper analyzes three possibilities: aligning to a global notion of morality (e.g. "basic human rights"), doing what people would prefer from behind a veil of ignorance, and pursuing values that are determined by a democratic process (the domain of social choice theory).
See also [Import AI #183](https://jack-clark.net/2020/02/03/import-ai-183-curve-fitting-conversation-with-meena-gans-show-us-our-climate-change-future-and-what-compute-data-arbitrage-means/)
**Rohin's opinion:** I'm excited to see more big-picture thought about AI alignment out of DeepMind. This newsletter (and I) tend to focus a lot more on the technical alignment problem than the normative one, partly because there's more work on it, but also partly because I think it is the [more urgent problem](https://www.alignmentforum.org/posts/ZeE7EKHTFMBs8eMxn/clarifying-ai-alignment#3ECKoYzFNW2ZqS6km) (a [controversial](https://www.alignmentforum.org/posts/ZeE7EKHTFMBs8eMxn/clarifying-ai-alignment#JK9Jzvz8f4BEjmNqi) [position](https://www.alignmentforum.org/posts/w6d7XBCegc96kz4n3/the-argument-from-philosophical-difficulty)).
[Towards a Human-like Open-Domain Chatbot](https://arxiv.org/abs/2001.09977) *(Daniel Adiwardana et al)* (summarized by Matthew): This paper presents a chatbot called Meena that reaches near human-level performance for measures of human likeness. The authors mined social media to find 341 GB of public domain conversations, and trained an [evolved transformer](https://arxiv.org/abs/1901.11117) on those conversations. To test its performance, they devised a metric they call Sensibility and Specificity (SSA) which measures how much sense the chatbot's responses make in context, as well as whether they were specific. SSA was tightly correlated with perplexity and a subjective measure of human likeness, suggesting that optimizing for perplexity will translate to greater conversational ability. Meena substantially improved on the state of the art, including both hand-crafted bots like [Mitsuku](https://en.wikipedia.org/wiki/Mitsuku) and the neural model [DialoGPT](https://arxiv.org/abs/1911.00536), though it still falls short of human performance. You can read some conversation transcrips [here](https://github.com/google-research/google-research/blob/master/meena/meena.txt); many of the responses from Meena are very human-like.
See also [Import AI #183](https://jack-clark.net/2020/02/03/import-ai-183-curve-fitting-conversation-with-meena-gans-show-us-our-climate-change-future-and-what-compute-data-arbitrage-means/)
**Matthew's opinion:** Previously I believed that good chatbots would be hard to build, since it is challenging to find large datasets of high-quality published conversations. Given the very large dataset that the researchers were able to find, I no longer think this is a major barrier for chatbots. It's important to note that this result does not imply that a strong Turing test will soon be passed: the authors themselves note that SSA overestimates the abilities of Meena relative to humans. Since humans are often vague in their conversations, evaluating human conversation with SSA yields a relatively low score. Furthermore, a strong Turing test would involve a judge asking questions designed to trip AI systems, and we are not yet close to a system that could fool such judges.
**Technical AI alignment**
==========================
### **Mesa optimization**
[Inner alignment requires making assumptions about human values](https://www.alignmentforum.org/posts/6m5qqkeBTrqQsegGi/inner-alignment-requires-making-assumptions-about-human) *(Matthew Barnett)* (summarized by Rohin): Typically, for inner alignment, we are considering how to train an AI system that effectively pursues an outer objective function, which we assume is already aligned. Given this, we might think that the inner alignment problem is independent of human values: after all, presumably the outer objective function already encodes human values, and so if we are able to align to an arbitrary objective function (something that presumably doesn't require human values), that would solve inner alignment.
This post argues that this argument doesn't work: in practice, we only get data from the outer objective on the training distribution, which isn't enough to uniquely identify the outer objective. So, solving inner alignment requires our agent to "correctly" generalize from the training distribution to the test distribution. However, the "correct" generalization depends on human values, suggesting that a solution to inner alignment must depend on human values as well.
**Rohin's opinion:** I certainly agree that we need some information that leads to the "correct" generalization, though this could be something like e.g. ensuring that the agent is [corrigible](https://www.alignmentforum.org/posts/fkLYhTQteAu5SinAc/corrigibility) ([AN #35](https://mailchi.mp/bbd47ba94e84/alignment-newsletter-35)). Whether this depends on human "values" depends on what you mean by "values".
### **Learning human intent**
[A Framework for Data-Driven Robotics](https://arxiv.org/abs/1909.12200) *(Serkan Cabi et al)* (summarized by Nicholas): This paper presents a framework for using a mix of task-agnostic data and task-specific rewards to learn new tasks. The process is as follows:
1. A human teleoperates the robot to provide a *demonstration*. This circumvents the exploration problem, by directly showing the robot the relevant states.
2. All of the robot's sensory input is saved to *NeverEnding Storage (NES)*, which stores data from all tasks for future use.
3. Humans annotate a subset of the *NES* data via task-specific *reward sketching*, where humans draw a curve showing progress towards the goal over time (see paper for more details on their interface).
4. The labelled data is used to train a *reward model*.
5. The agent is trained using **all** the *NES* data, with the *reward model* providing rewards.
6. At test-time, the robot continues to save data to the *NES*.
They then use this approach with a robotic arm on a few object manipulation tasks, such as stacking the green object on top of the red one. They find that on these tasks, they can annotate rewards at hundreds of frames per minute.
**Nicholas's opinion:** I'm happy to see reward modeling being used to achieve new capabilities results, primarily because it may lead to more focus from the broader ML community on a problem that seems quite important for safety. Their reward sketching process is quite efficient and having more reward data from humans should enable a more faithful model, at least on tasks where humans are able to annotate accurately.
### **Miscellaneous (Alignment)**
[Does Bayes Beat Goodhart?](https://www.alignmentforum.org/posts/YJq6R9Wgk5Atjx54D/does-bayes-beat-goodhart) *(Abram Demski)* (summarized by Flo): It has been [claimed](https://www.alignmentforum.org/posts/urZzJPwHtjewdKKHc/using-expected-utility-for-good-hart) ([AN #22](https://mailchi.mp/469203093ca3/alignment-newsletter-22)) that Goodhart's law might not be a problem for expected utility maximization, as long as we correctly account for our uncertainty about the correct utility function.
This post argues that Bayesian approaches are insufficient to get around Goodhart. One problem is that with insufficient overlap between possible utility functions, some utility functions might essentially be ignored when optimizing the expectation, even if our prior assigns positive probability to them. However, in reality, there is likely considerable overlap between the utility functions in our prior, as they are selected to fit our intuitions.
More severely, bad priors can lead to systematic biases in a bayesian's expectations, especially given embeddedness. As an extreme example, the prior might assign zero probability to the correct utility function. Calibrated instead of Bayesian learning can help with this, but only for [regressional Goodhart](https://www.lesswrong.com/posts/iK2F9QDZvwWinsBYB/non-adversarial-goodhart-and-ai-risks) ([Recon #5](https://mailchi.mp/33af21f908b5/reconnaissance-5)). Adversarial Goodhart, where another agent tries to exploit the difference between your utility and your proxy seems to also require randomization like [quantilization](https://intelligence.org/files/QuantilizersSaferAlternative.pdf) ([AN #48](https://mailchi.mp/3091c6e9405c/alignment-newsletter-48)).
**Flo's opinion:** The degree of overlap between utility functions seems to be pretty crucial (also see [here](https://www.alignmentforum.org/posts/megKzKKsoecdYqwb7/when-goodharting-is-optimal-linear-vs-diminishing-returns) ([AN #82](https://mailchi.mp/7ba40faa7eed/an-82-how-openai-five-distributed-their-training-computation))). It does seem plausible for the Bayesian approach to work well without the correct utility in the prior if there was a lot of overlap between the utilities in the prior and the true utility. However, I am somewhat sceptical of our ability to get reliable estimates for that overlap.
**Other progress in AI**
========================
### **Deep learning**
[Deep Learning for Symbolic Mathematics](https://arxiv.org/abs/1912.01412) *(Guillaume Lample et al)* (summarized by Matthew): This paper demonstrates the ability of sequence-to-sequence models to outperform [computer algebra systems](https://en.wikipedia.org/wiki/Computer_algebra_system) (CAS) at the tasks of symbolic integration and solving ordinary differential equations. Since finding the derivative of a function is usually easier than integration, the authors generated a large training set by generating random mathematical expressions, and then using these expressions as the labels for their derivatives. The mathematical expressions were formulated as syntax trees, and mapped to sequences by writing them in Polish notation. These sequences were, in turn, used to train a transformer model. While their model outperformed top CAS on the training data set, and could compute answers much more quickly than the CAS could, tests of generalization were mixed: importantly, the model did not generalize extremely well to datasets that were generated using different techniques than the training dataset.
**Matthew's opinion:** At first this paper appeared more ambitious than [Saxton et al. (2019)](https://arxiv.org/abs/1904.01557), but it ended up with more positive results, even though the papers used the same techniques. Therefore, my impression is not that we recently made rapid progress on incorporating mathematical reasoning into neural networks; rather, I now think that the tasks of integration and solving differential equations are simply well-suited for neural networks.
### **Unsupervised learning**
[Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data](http://arxiv.org/abs/1912.07768) *(Felipe Petroski Such et al)* (summarized by Sudhanshu): The Generative Teaching Networks (GTN) paper breaks new ground by training generators that produce synthetic data that can enable learner neural networks to learn faster than when training on real data. The process is as follows: The generator produces synthetic training data by transforming some sampled noise vector and label; a newly-initialized learner is trained on this synthetic data and evaluated on real data; the error signal from this evaluation is backpropagated to the generator via meta-gradients, to enable it to produce synthetic samples that will train the learner networks better. They also demonstrate that their curriculum learning variant, where the input vectors and their order are learned along with generator parameters, is especially powerful at teaching learners with few samples and few steps of gradient descent.
They apply their system to neural architecture search, and show an empirical correlation between performance of a learner on synthetic data and its eventual performance when trained on real data. In this manner, they make the argument that data from a trained GTN can be used to cheaply assess the likelihood of a given network succeeding to learn on the real task, and hence GTN data can tremendously speed up architecture search.
**Sudhanshu's opinion:** I really like this paper; I think it shines a light in an interesting new direction, and I look forward to seeing future work that builds on this in theoretical, mechanistic, and applied manners. On the other hand, I felt they did gloss over how exactly they do curriculum learning, and their reinforcement learning experiment was a little unclear to me.
I think the implications of this work are enormous. In a future where we might be limited by the maturity of available simulation platforms or inundated by deluges of data with little marginal information, this approach can circumvent such problems for the selection and (pre)training of suitable student networks.
**Read more:** [Blog post](https://eng.uber.com/generative-teaching-networks/)
**News**
========
[Junior Research Assistant and Project Manager role at GCRI](http://gcrinstitute.org/job-posting-junior-research-assistant-and-project-manager/) (summarized by Rohin): This job is available immediately, and could be full-time or part-time. GCRI also currently has a [call](http://gcrinstitute.org/call-for-advisees-and-collaborators-for-select-ai-projects-january-2020/) for advisees and collaborators.
[Research Associate](https://www.jobs.cam.ac.uk/job/24516/) and [Senior Research Associate](https://www.jobs.cam.ac.uk/job/24517/) at CSER (summarized by Rohin): Application deadline is Feb 16.
*Copyright © 2020 Rohin Shah, All rights reserved.*
Want to change how you receive these emails?
You can [update your preferences](https://rohinshah.us18.list-manage.com/profile?u=1d1821210cc4f04d1e05c4fa6&id=dbac5de515&e=[UNIQID]) or [unsubscribe from this list](https://rohinshah.us18.list-manage.com/unsubscribe?u=1d1821210cc4f04d1e05c4fa6&id=dbac5de515&e=[UNIQID]&c=0634b9b0f1).
 |
9c4d8235-3791-4b68-8858-d061a0663e96 | trentmkelly/LessWrong-43k | LessWrong | The map of ideas how the Universe appeared from nothing
There is a question which is especially disturbing during sleepless August nights, and which could cut your train of thought with existential worry at any unpredictable moment.
The question is, “Why does anything exist at all?” It seems more logical that nothing will ever exist.
A more specific form of the question is “How has our universe appeared from nothing?” The last question has some hidden assumptions (about time, universe, nothing and causality), but it is also is more concrete.
Let’s try to put these thoughts into some form of “logical equation”:
1.”Nothingness + deterministic causality = non existence”
2. But “I = exist”.
So something is wrong in this set of conjectures. If the first conjecture is false, then either nothingness is able to create existence, or causality is able to create it, or existence is not existence.
There is also a chance that our binary logic is wrong.
Listing these possibilities we can create a map of solutions of the “nothingness problem”.
There are two (main) ways in which we could try to answer this question: we could go UP from a logical-philosophical level, or we could go DOWN using our best physical theories to the moment of the universe’s appearance and the nature of causality.
Our theories of general relativity, QM and inflation are good for describing the (almost) beginning of the universe. As Krauss showed, the only thing we need is a random generator of simple physical laws in the beginning. But the origin of this thing is still not clear.
There is a gap between these two levels of the explanation, and a really good theory should be able to fill it, that is to show the way between first existing thing and smallest working set of physical laws (and Woldram’s idea about cellular automata is one of such possible bridges).
But we don’t need the bridge yet. We need explanation how anything exists at all.
How we going to solve the problem? Where we can get information?
Possible sources of evidence: |
a45bdfd8-16ea-4f2d-9f64-7a1f85da141e | trentmkelly/LessWrong-43k | LessWrong | Naturalism
According to me, this sequence has been pretty darn abstract.
That was kind of on purpose. It’s the opposite of what I like to do, of what I think I’m good at. I much prefer to engage with an actual specific thing, and to share the details of my experience as I go. This big picture stuff is really not my jam.
But I’ve been trying to paint a really big picture anyway, to describe an entire perspective on investigation, and rationality, and maybe life. I hope it’s been much easier to read than it was for me to write. And I hope that if, at some future point, I dive into the little details of particular exercises and techniques, you’ll be able to contextualize them as more than just trinkets, or rituals that are tedious to little purpose.
But I’m so tired of it. I’m exhausted by all this abstraction. I want to touch the ground. I want to show you what it actually looks like to live a life full of patient and direct observation.
----------------------------------------
I can tell you that there’s a magnifying glass in my pocket, which I use regularly. I can tell you that I turned the soles of my bare feet toward the sky last week, so that I could feel the snow falling on them. I can tell you that when I put “it seems to me” at the front of so many of my sentences, it’s not false humility, or insecurity, or a verbal tic. (It’s a deliberate reflection on the distance between what exists in reality, and the constellations I’ve sketched on my map.)
I can tell you dozens of facts like these, about my experience of myself and of the world. Hundreds. But none of those means much. Not on its own.
The problem is, this whole thing is founded on patience, which is difficult to demonstrate in an essay. It’s hard to show you all at once the myriad ways a thousand tiny moments add up to one big thing that matters.
----------------------------------------
Still, they do add up to something.
What they add up to is that I am a naturalist. I was raised to be a naturalist, and |
b41f5ad0-c0b6-4a3e-9e32-0fceefee71e1 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Portland Oregon
Discussion article for the meetup : Portland Oregon
WHEN: 22 September 2012 12:00:00PM (-0700)
WHERE: Lucky Labrador Tap Room 1700 North Killingsworth Street, Portland, OR
LessWrong Portland
Discussion article for the meetup : Portland Oregon |
6e960a8f-8d8e-4a36-aa01-d643d09f2f1f | trentmkelly/LessWrong-43k | LessWrong | Ukraine
I am not really following your discussion about ethics of having children, but I thought I would mention Uriupina.com, a blogger from your city who does take the radical "antinatalist" position. For her it's a development out of a generally pessimist philosophy, and I think she studied psychology too... So, she is a mind that is geographically near yours, but philosophically distant... but I thought I would still mention her, just in case. |
1bf4e88b-ae14-4643-b4b1-5dc8238dc9a2 | trentmkelly/LessWrong-43k | LessWrong | Temporarily Out of Office
Just an update that for the next 5 weeks I personally am not working on LW, while I graduate (prepare and take finals), and Oliver is not working for ~3 weeks while he does the same. Ray will be god-of-LW until then. #RayOfSunshine
(I will be around because LW is one of the main things I habitually check in my free time, but I won't be able to do sustained work or drop everything at a moment's notice.) |
e91733e4-408d-4149-8b24-7d0e824fcfcf | trentmkelly/LessWrong-43k | LessWrong | Monthly Bragging Thread October 2015
Your job, should you choose to accept it, is to comment on this thread explaining the most awesome thing you've done this month. You may be as blatantly proud of yourself as you feel. You may unabashedly consider yourself the coolest freaking person ever because of that awesome thing you're dying to tell everyone about. This is the place to do just that.
Remember, however, that this isn't any kind of progress thread. Nor is it any kind of proposal thread. This thread is solely for people to talk about the awesome things they have done. Not "will do". Not "are working on". Have already done. This is to cultivate an environment of object level productivity rather than meta-productivity methods.
So, what's the coolest thing you've done this month?
(Previous bragging thread) |
d62698cd-30b7-412f-ae1b-614ba4bdc8a7 | trentmkelly/LessWrong-43k | LessWrong | [Link] A minimal viable product for alignment
This is a link post for https://aligned.substack.com/p/alignment-mvp
I'm writing a sequence of posts on the approach to alignment I'm currently most excited about. This second post argues that instead of trying to solve the alignment problem once and for all, we can succeed with something less ambitious: building a system that allows us to bootstrap better alignment techniques. |
9129fa08-7a40-48cf-a84b-c889077a70ff | trentmkelly/LessWrong-43k | LessWrong | When beliefs become identities, truth-seeking becomes hard
This is Rational Animations' script for the video linked above. This time, the topic is the "Rethinking Identity" section in the book "The Scout Mindset" by Julia Galef. As always, feedback is welcome.
Previously, we made a video about how scorn for ideas and communities is often damaging for truth-seeking and truth-telling. In this video, we’ll talk about another way in which social reality might interfere with your ability to pursue what's true and what's best for you to do: identity.
Julia Galef talks about this topic in her book “The Scout Mindset.” The scout mindset is the mindset of truth-seeking, and she opposes it to the soldier mindset. Having a soldier mindset means defending your beliefs for reasons other than truth as if you were fighting a war of ideas instead of trying to figure out what’s going on. She makes the case that the scout mindset is way more helpful than the soldier mindset.
The soldier mindset has advantages, such as avoiding unpleasant emotions, increasing motivation, and persuasion. But Julia Galef outlines strategies to keep the advantages of the soldier mindset without actually sacrificing truth-seeking and truth-telling. Seems cool, right?
In her book, there are also useful sections about how to be a better scout. One of those sections is called “rethinking identity”, which is the topic of this video.
Julia observes that it’s often the case that certain kinds of beliefs are prone to become identities. Communities form around them and, in a sense, fight to defend them. She makes the example of the “mommy wars”, in which one faction believes that it's better to feed babies with breast milk and the other thinks that baby formula is fine. In theory, this should be a straightforward empirical question, but you can observe the two factions arguing passionately and calling each other epithets in an ideological battle that spans years and transcends geography.
There are many other examples you could come up with [on screen].
When y |
a1f120a2-3d60-41c1-a581-08d978d35ba2 | trentmkelly/LessWrong-43k | LessWrong | The radioactive burrito and learning from positive examples
A putative new idea for AI control; index here.
Jessica presented a system learning only from positive examples. Given examples of burritos, it computes a distribution b over possible burritos. When it comes to creating its own burritos, however, it can only construct them from the feasible set f.
----------------------------------------
The thing to do then seems to be to sample from the distribution b∣f. Then the idea is to measure the ``unnaturalness'' or the danger of b∣f as −logPb(B∈f), where B is a random burrito configuration sampled from b.
Unusual radiation and unnaturalness
An obviously contrived example: suppose that there is some distant gamma ray burst that sprays the Earth with cosmic rays, resulting in an increase in Carbon 14 (C14) throughout the food chain.
All burritos sampled for b have come from high radiation ingredients, and the system has learnt this is a feature of b. But by the time the system has to make its own burritos, the excess radiation has faded, and b∣f is literally the zero distribution: there is no burrito in the feasible f set that corresponds to anything in b. The unnaturalness of f is infinite.
Nano-filled burritos
But what if, noticing this, we tried to present a larger, less unnatural f? Just let the system have more options, for instance.
Now suppose, for example, that the burritos were wrapped in tin foil, and sometimes this ended up mixed with the food. Then b would learn that some flexibility in the amount of metal in the burrito is possible.
Then suppose that the system decides to make burritos filled with nano-machines that carefully filter out some carbon 12 atoms. These are now valid candidates for b, and the unnaturalness of the set f has gone down.
To emphasise: by allowing the system to stuff burritos full of nano-machines, we've increased the measured naturalness of the burritos.
Natural, biased, constructed
Those examples are, of course, convoluted and unlikely. But the general problem hasn't gone aw |
eaae8086-9178-4beb-b02b-8692a2ae3467 | trentmkelly/LessWrong-43k | LessWrong | Football, quantum chromodynamics, figure skating and statistics
(Cross-posted from Telescopic Turnip.)
“He—and he is almost always a he—is a venture capitalist who has analyzed the hospitalizations data! He is a growth hacker with a piercing view of race and measures of intelligence! He is an industry analyst with insight into viral spread! He is a lawyer exploding nuances of gender and sex!”
This is from Annie Lowrey’s classic essay about the Facts Man. The Facts Man is a specimen you will meet everywhere while roaming the corridors of the World Wide Web. He's looked at the raw data and concluded that the leading experts are sometimes wrong. Maybe you’ve even got your pandemic advice from one of them (you wouldn't do such a thing, would you?).
This is to be distinguished from Regular Crackpots, who gave a lot of thought to difficult problems in cosmology or quantum chromodynamics, and came up with their own alternative theory. They, too, came to the conclusion that the leading experts are wrong.
Why do so many people believe the Facts Man and subscribe to his substack, while the youtube channel of the Regular Crackpot channel only receives laughs and sneers?
Lutzs
In figure skating, you win by performing the most difficult tricks. The best figure skaters can do things like the quadruple lutz, a trick that’s outright impossible for most mortals like you and me. Only a handful of athletes in the world can perform it, and only for a short period in their lives.
Evgeni Plushenko doing something outright impossible
Of course, you don’t need to do quadruples to enjoy figure skating, but you will not win the Olympics. Those who win the Olympics were raised in the best environment for it, had the best possible genetic background, and they still had to practice all their lives. If someone ever manages to pull out a quintuple lutz and does not completely screw up the artistic aspect, they will get the Gold.
Likewise, you will never make a groundbreaking discovery in quantum chromodynamics using freshman physics. You need to keep |
8e6304b5-de55-4aaf-8adc-fa35cb6d8465 | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | Why can’t we just “put the AI in a box” so that it can’t influence the outside world?
One possible way to ensure the safety of a powerful AI system is to keep it contained in a software environment. There is nothing intrinsically wrong with this procedure—keeping an AI system in a secure software environment would make it safer than letting it roam free. However, even AI systems inside software environments might not be safe enough.
Humans sometimes put dangerous humans inside boxes to limit their ability to influence the external world. Sometimes, these humans escape their boxes. The security of a prison depends on certain assumptions, which can be violated. [Yoshie Shiratori](https://medium.com/breakingasia/yoshie-shiratori-the-incredible-story-of-a-man-no-prison-could-hold-6d79a67345f5) reportedly escaped prison by weakening the door-frame with miso soup and dislocating his shoulders.
Human written software has a [high defect rate](https://spacepolicyonline.com/news/boeing-software-errors-could-have-doomed-starliners-uncrewed-test-flight/); we should expect a perfectly secure system to be difficult to create. If humans construct a software system they think is secure, it is possible that the security relies on a false assumption. A powerful AI system could potentially learn how its hardware works and manipulate bits to send radio signals. It could fake a malfunction and attempt social engineering when the engineers look at its code. As the saying goes: in order for someone to do something we had imagined was impossible requires only that they have a better imagination.
Experimentally, humans have [convinced](https://yudkowsky.net/singularity/aibox/) other humans to let them out of the box. Spooky.
|
c2749ec7-1e4e-4a8c-8622-effa98a09653 | trentmkelly/LessWrong-43k | LessWrong | Will we witness the compassion of a nation?
What is it that Trump has done, when looked at through the lens of compassion?
Trump has nurtured a paranoid false reality in which people are helpless victims of a Hostile and Malevolent State. He has maintained and occupied this Alternative reality for enough time, and convincingly enough to drag other people into paranoia with him. Trump has, for four years, held the biggest megaphone in the world. As a result, he has been able to convince most of the people who could be so convinced. These people now number possibly in the millions.
Do they react when he points to the source of their imagined dangers? Are they scared of the people he tells them are dangerous? Of course! It doesn’t matter what else you think of them, they are a terrified group on the brink of panic.
To be clear, panicking groups are extremely dangerous! And this one has been driven to the exact sort of extreme reactive state that you would expect from any panicking group. What we have in this nation is a crisis, manufactured on the foundation of people’s own fears. There are at least thousands of people who have been made so scared they are willing to risk the violent response we saw from the police all last year on nothing more than an indication from Trump that they might possibly be able to do some non-specific thing about the imaginary Evil State.
This fear has been building for many years now; the only thing Trump did was to make it salient enough that people might actually act on it. The panic recently reached a peak on January 6th. It ends when we identify the real fears and concerns that allowed Trump to take advantage, and we solve or dissolve them.
The State will not do this work for us. It will be too concerned with protecting itself against the insurrection; working against the possibility of another event like the one that desecrated one of its most sacred spaces and threatened the safety of its members. It will act to punish somebody - anybody - as an example of what happens to |
46d8b8bd-5774-46f3-ac98-b34a5da885ea | trentmkelly/LessWrong-43k | LessWrong | Halpern’s paper - A refutation of Cox’s theorem?
What implications does the paper “A Counter Example to Theorems of Cox and Fine” by J. Y. Halpern have for Cox’s theorem and probability theory as extended logic? This is the description of the paper:
“Cox's well-known theorem justifying the use of probability is shown not to hold in finite domains. The counterexample also suggests that Cox's assumptions are insufficient to prove the result even in infinite domains. The same counterexample is used to disprove a result of Fine on comparative conditional probability.”
Edit: You can access the paper here - https://arxiv.org/abs/1105.5450
A similar question seems have been posted (but not answered) here:
1. https://stats.stackexchange.com/q/190187/297721
2. https://stats.stackexchange.com/q/190184/297721
3. https://stats.stackexchange.com/q/189757/297721
Why is Cox’s theorem being disputed? Are there any non-sequiturs in the proof that Professor Jaynes give for it in his book? If not, then how can it be disputed? |
ca2e3f03-8590-4641-b82e-3b99f432b3a3 | trentmkelly/LessWrong-43k | LessWrong | Catching Up With the Present From the Developing World
Hi all, I'm leaving Lesswrong for a few months to pursue a Masters, and this Text below will never be finished. It is just a story of what is it like to grow up outside where everything is going on, a country where humanities are sad and terrible, and people are fun, but not quite wise.
Original Summary: Two things (Note: Were going to) permeate this text, an autobiographical short account of what is it like to grow up far from where things are happening, and an outside view account of some of the people and institutions (MIRI,LW,Leverage Research, FHI,80k,GWWC) whom presently carry, as far as I can see, the highest expected value gamble of our time. I have visited all those institutions, and my account here should be considered just a biased, one subjective perspective data point, not a proper evaluation of those places. Other people who come from developing world countries might have interesting stories to tell, and I'd encourage them to do so (Pablo in Argentina, many in India, China and elsewhere)
(NOTE: There is nothing about the institutions here, only the growing up part was written by the time I decided to halt this writing)
Far away, across the sea
As is the case with most outliers, outcasts, and outsiders in general, a large amount of sociological facts were determinant of me being the first person in Brazil acquainted with the cluster of ideas to which the institutions mentioned belong. Jonatas, the other Brazilian who entered this world early on (2004), has a very similar story to tell. The prerequisites seem to have been: young, middle class, children of early adopters, inclined towards philosophy, living in a cosmopolitan area, with a particular disregard for authority (uncommon in Brazil), high IQ (aprox 4 SDs above Brazilian average) beginning to get stuck in a nonsense university system in the humanities. Due to expected income considerations and a large variance in income among Brazilians, most of the high IQ people go for Medicine, Engineerin |
8f3af355-1c09-4fda-a831-fe4a731f2d95 | trentmkelly/LessWrong-43k | LessWrong | Brainstorming help request: teaching rationality basics in an RPG setting
EDIT: Minor updates happened.
----------------------------------------
I'd like to ask you all for thoughts on a certain idea I'm toying with. Especially any of you who are familiar with the Wheel of Time fantasy series by Robert Jordan.
I play a MUD (multi-user dungeon, basically a text-based MMORPG), based on that series. One of my characters is a member of the White Tower, which is basically a mage organisation/school, and as part of our roleplay activities we sometimes hold classes (example, long, probably not worth your time) for lower rank members. These typically last an hour or two and sometimes get used to convey interesting real life knowledge. For instance there has been a class on mnemonic techniques.
I see an opportunity to spread rationality a little. One of the Ajah (subdivisions) of the Tower is specifically concerned with pursuing truth, logic etc. which means if I joined it, I would have no trouble teaching a class or two with some material from the Sequences. I wonder if any of us here have done things like that in the past?
What sort of essentials would you pack into a class or at most a few classes 1-2 hours each (not just me reading stuff out but including a discussion), for people without technical backgrounds? Conducted at typing speed, so basically imagine you're going to spend two hours talking to 3-6 people about rationality on IRC chat or some such setting.
Also, should I involve or steer away from the metaphysics of the Wheel of Time setting (the Creator/Dark One, the Pattern etc)?
My ideas so far:
Part 1: "Cognitive biases, or why you, yes you, are an idiot".
- which ones would be most interesting/simple/useful to teach about?
- Obviously i need to start with how knowing about biases can hurt you...
- Confirmation bias: I might try the 2-4-6 game, though it'll be a bit of a mess in a group setting.
- what other biases and examples would you use?
Part 2: Truth and evidence
- truth, map/territory
- what is evidence
- ration |
d1454ea9-79f9-478b-8654-d7918a88a9b6 | trentmkelly/LessWrong-43k | LessWrong | Imitative Reinforcement Learning as an AGI Approach
I've been thinking that reinforcement-learning-driven imitation between agents may be an explanation of human intelligence, and is worth exploring more as an approach to AGI.
It's difficult to get agents to exhibit the complex behaviors humans do with most optimization functions, like "acquire food". But rewarding agents for imitating each other in addition to satisfying basic needs is an efficient method of building up complex survival strategies. Babies, for example, aren't aware how learning to speak will benefit them years later when they start doing it - they just observe adults talking a lot and find that they can get a dopamine hit from talking in response. The explanation for why humans have been so much more successful than chimpanzees is mostly that our dopamine system rewards imitation more strongly, not that we're better at discovering new things directly from the environment. After all, it would seem strange if a little bit of extra optimization of an already highly evolved system in the time between humans and chimpanzees resulted in a gigantic gap in the success of each species. Instead, two existing systems linked together - social behavior and the dopamine system.
Current machine learning focuses mostly on learning directly from an environment, and has found success in domains where humans do the same, like image processing, while lagging severely in areas like natural language, where humans learn imitatively. Deepmind was the pioneer in demonstrating that deep sensory neural nets and dopamine-like reinforcement learning could be combined, in their case to solve Atari games. However, Atari games only have a couple agents, so there was no incentive to use imitation learning.
It'a obvious that computers would be incentivized to learn imitatively if they want to tap into our existing knowledgebase rather than rediscover everything from scratch. But even if they do want to rediscover everything from scratch, or operate in a different environment than |
e8d96e72-c5ec-48d1-ac5d-d53953133e4a | trentmkelly/LessWrong-43k | LessWrong | An X-Ray is Worth 15 Features: Sparse Autoencoders for Interpretable Radiology Report Generation
This is an archival link-post for our preprint, which can be found here.
Figure 1: SAE-Rad identifies clinically relevant and interpretable features within radiological images. We illustrate a number of pathological and instrumentation features relevant for producing radiology reports. We add annotations (green arrows) to emphasize the presence of each feature.
Executive Summary
This post is a heavily slimmed down summary of our main paper, linked above. We have omitted all the technical details here. This post acts as a TL;DR archival link-post to the main paper.
We train Sparse Autoencoders (SAEs) on the class token of a radiology image encoder, on a dataset of chest x-rays. We use the trained SAE, in conjunction with automated interpretability, to generate radiology reports. The final radiology report represents a concatenation of the text descriptions of activate SAE features. We train a diffusion model to allow causal interventions on SAE features. This diffusion model enables us to highlight where in the chest x-ray each sentence in the radiology report comes from by localising changes in the image post-intervention. Our method achieves competitive accuracy in comparison to state of the art medical foundation models while using a fraction of the parameter count and compute costs. To the best of our knowledge, this is the first time SAEs have been used for a non-trivial downstream task - namely to perform multi-modal reasoning on medical images.
Of particular note to the mechanistic interpretability community, we demonstrate that SAEs extract sparse and interpretable features on a small dataset (240,000) of homogenous images (chest x-rays appear very homogenous), and that these features can be accurately labeled by means of automated interpretability to produce pathologically relevant findings.
Motivation
Radiological services are essential to modern clinical practice, with demand rising rapidly. In the UK, the NHS performs over 43 million radiological p |
ef052c17-6d44-4dfd-a6f7-30c1f4c7dadd | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | What’s so dangerous about AI anyway? – Or: What it means to be a superintelligence
(Intended for an audience that is not convinced that an AI could physically pose a threat to humanity. In a similar spirit to [AI Could Defeat All Of Us Combined](https://www.lesswrong.com/posts/oBBzqkZwkxDvsKBGB/ai-could-defeat-all-of-us-combined), but trying to be more readable.)
You might have heard people worrying about AI [as a world-ending threat](https://www.bbc.com/news/technology-30290540), but maybe you’re not really convinced.
Maybe current “AI” seems quite unimpressive to you and it’s not clear to you that it is coherent to talk about “smarter-than-human AI” at all.
“Like, okay,” you might say, “an AI might be better at calculus than us. Or, it knows more facts about the world than a human because it can store everything on its hard drive. Maybe it can also give really precise answers sometimes, like specifying a probability to 8 significant digits. But that doesn’t sound that dangerous over all? I know some smart people and I’m not particularly afraid of them. I mean sure, we shouldn’t use AI to power flying robots with lasers and then let them roam the country – that’s just common sense. And, of course, big corporations can do bad things with AI when they use it for hiring decisions or social media moderation. But, every technology has up- and downsides. I don’t see what’s so uniquely dangerous about AI.”
In order to understand what an AI might be capable of, I suspect it helps to [taboo](https://www.lesswrong.com/tag/rationalist-taboo) the word “intelligence” and talk about more specific cognitive capabilities instead, which we can then extrapolate into super-human regions.
We certainly don’t know how to (efficiently) implement these cognitive capabilities with current machine learning or any other approach we have, but the point is that we can talk about what these algorithms – once found – will look like from the outside; even if we currently don’t know how they would work internally.
In general, everything surrounding the concept of intelligence was historically very mysterious to people. But we are making progress! As an analogy, consider how confused we once were about [computer chess](https://en.wikipedia.org/wiki/Computer_chess): In 1833, [Edgar Allen Poe wrote an essay](https://www.eapoe.org/works/essays/maelzel.htm) asserting that chess was impossible for an ‘automaton’ to play (well) *even in principle*. Then in 1949, [Claude Shannon showed a way](https://vision.unipv.it/IA1/ProgrammingaComputerforPlayingChess.pdf) to do it with unlimited computing power (and also an idea how to do it with limited but still very large computing power). Nowadays, [Deepmind can train a super-human chess AI](https://arxiv.org/abs/1712.01815) from scratch in less than 10 hours on a TPUv2 pod (that is, with 11.5 PetaFLOP/s; so, about 4.5 months of training on [the largest supercomputer from 2002](https://www.top500.org/system/167148/)).
The point is that, at least with respect to some cognitive skills, we are now closer to the Claude-Shannon-era in understanding than the Edgar-Allen-Poe-era. We have [any idea at all now](https://en.wikipedia.org/wiki/AIXI) about what kind of cognitive algorithms the human brain is running and so we are in a position to imagine what an agent would be like that had *even better* cognitive algorithms.
So, let’s consider the cognitive skill of discovering the underlying pattern behind some observations.
Humans are quite good at that; as babies, we might still be surprised if things tend to fall in a certain direction but soon we have synthesized the law that all things fall to the ground. Similarly, humans have observed that when dogs reproduce, the puppies are similar to their parents.
We first used that knowledge to create specific dog breeds but later, Charles Darwin distilled this and other observations into the *theory of natural selection* – a succinct law that explains a whole lot of phenomena in the natural world.
In both cases, there were some observations which appeared random at first – like finches differing slightly between the Galápagos islands and being remarkably well-adapted to their respective island – that could be neatly explained by a universal rule, once that rule was found.
We also use this process – which we might call [induction](https://en.wikipedia.org/wiki/Inductive_reasoning), though philosophers might [disagree with me](https://en.wikipedia.org/wiki/Problem_of_induction) there – constantly in everyday life. We take some observations, like: today, Alice did not hum as usual when she made tea, and she barely ate anything of the pasta she usually likes so much; and we come up with possible explanations for the underlying pattern: maybe she’s stressed from something that’s happening at work or she’s sad about some news she got from her family.
A human might generate some guesses as to the underlying pattern and then check retroactively if they can explain the observations.
Now imagine a thinking machine that can do that, but *better*. Such a thinking machine can take seemingly unrelated observations and draw deep conclusions about the world. Kind of like a movie detective, but in real life. It wouldn’t need hundreds of years of zoology to realize that life on Earth arose from natural selection. It would be done within a week.
The super-human thinking machine would only need to look at the micro-expressions on Alice’s face for a couple of minutes to have a pretty good guess about what is bothering her (assuming some prior knowledge of human psychology, of course).
Things that look mysterious to us humans may well be due to an underlying pattern that we have been unable to discover, but which a super-human pattern recognizer could identify easily. Such a machine would almost definitely discover new laws in chemistry, biology and psychology, as those areas have not been formalized that thoroughly by human scientists, and it might even discover new laws of physics.
All this, based on the cognitive skill of induction.
(As an aside, we actually do have a [formal theory of induction](https://en.wikipedia.org/wiki/Solomonoff%27s_theory_of_inductive_inference) so this isn’t all just fancy speculation, but, well, that formal theory is based on infinite computing power.)
There is a complementary skill to this, that is heavily intertwined with the skill of identifying patterns – so much so that you probably cannot do one well without the other. And that is the skill of generating all the expected observations from the laws you have distilled (what you might call *deduction*).
Again, humans are pretty good at this. If you know Alice well and you hear that she recently learned her grandmother has died, then you are able to predict her behavior to some degree. You’ll be able to predict she’s sad for one, but you also might know more specific things she might do.
Physicists and engineers are masters at this for the physical world: they can take the laws of physics (as we know them) and predict whether a bridge will remain standing or will collapse.
In both cases, you take something you know, and then you derive implications of it. Like, if you know the theory of natural selection well, and you observe that a species has an equal number of males and females (as is the case for many species on Earth), then you can deduce [by Fisher’s principle](https://en.wikipedia.org/wiki/Fisher%27s_principle) that males and females in this species are likely in free competition among their respective sex and will likely behave, in general, somewhat selfishly – as opposed to ants for example, who usually *do not* have an equal number of males and females, with most of the females not being in free competition and not acting selfishly. And you can deduce that [parental investment](https://en.wikipedia.org/wiki/Parental_investment) is roughly equal for male and female offspring in that species. Thus, by knowing a law, such as Fisher’s principle, we are able to deduce many things about the world, like the fact that humans are more selfish than ants, just from knowing their sex ratio.
If we imagine a thinking machine that is super-human at this task, we can see that it can deduce all sorts of things about the world (including human psychology) that we humans haven’t thought of. Just from the theory of natural selection, it can predict a lot about the human psyche. By knowing the laws of physics and chemistry, a super-human thinking machine would be able to predict even outcomes on the nanoscale, like how [proteins fold](https://www.deepmind.com/blog/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology).
As we said, deduction and induction are intertwined. One way to do induction (that is, synthesizing general laws from observations) is to randomly generate possible laws (ideally starting with *simple* laws), then deduce all the implications of these laws and finally check which ones match observed reality. However, this random guessing is of course not computationally efficient in any way, and not how humans do it. Still, the fact that [AlphaFold](https://www.deepmind.com/blog/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology) succeeded where humans failed – in predicting protein folding that is – is at least some evidence that humans are not unbeatable in terms of deduction.
(We also kind of have [a formal theory of deduction](https://en.wikipedia.org/wiki/G%C3%B6del%27s_completeness_theorem), but again, it’s not exactly computationally efficient.)
With human-level understanding of physics and biology, we can develop amazing things like mRNA vaccines and computer chips. If we crank up the ability to model the real world, even more magical-seeming technologies become possible. But there is one more building block missing, in order to go from a super-human ability to predict the world to the ability to develop new technology. And that is the ability to *plan a series of steps leading to a goal*.
Given some goal, a human can develop a plan to achieve that goal, based on an internal model of the outer world. I mean ‘plan’ here in the widest sense possible – a chain of causally linked steps through time and space. It includes things like ‘planning to go buy more milk at the supermarket’. Say, you have noticed that you are out of milk, and the world model in your brain tells you that you can buy milk at a place called ‘supermarket’. But how to get there? The plan might involve these steps:
1. Put on shoes and a jacket and pocket your car keys and your wallet.
2. Go to your car. (Note that the car might technically be farther away from the Supermarket than your home! But you still know it’s faster to first go to your car.)
3. Start the car with your keys and start driving. (Note that driving itself is full of complicated actions you have to take, but we’re going to gloss over that here.)
4. Take the fastest (not necessarily the shortest) route there.
5. Park somewhere close to the supermarket and go inside.
6. Look for milk, take it and pay with the money in your wallet.
This is a non-trivial plan! Your cat likely would not be able to come up with it. And yet you do it so effortlessly! It takes you barely a second to think of it. (Though to be fair, your brain has likely cached this plan from a previous occasion.)
Note also, how much knowledge of the real world the plan required. You had to know that you need money to buy things from a supermarket. You had to know that driving a car is faster than walking, and that you will get into trouble if you do not follow the traffic laws of the country you’re in.
We can see that without a solid understanding of the world, the ability to develop plans (aka chains of actions) does not gain you much – at most it will lead to ineffectual flailing. And vice versa, even if an agent has the most amazing internal world model, it will not affect the world much if the agent does not develop plans and does not take action. But combined, this is very powerful.
Can you now imagine a thinking machine with a super-human ability to plan? It may help to picture how it could roughly work: it could simulate the world according to its world model (that it acquired through induction on observations and deduction from universal laws) and try out plans in this simulation to check whether they lead to the desired outcome.
One way to visualize this, would be to imagine it as if the thinking machine had developed a virtual reality version of the real world, and then in this virtual reality it could try out plan after plan to see what the predicted outcome is. (Of course, in a real AI, it wouldn’t really work like this, because this is computationally very inefficient, but this is to show that with enough computing power, it is definitely possible to be super-human at planning.) The thinking machine could go through millions of plans per second to identify the best one – the one that is the most robust, has the highest chance of success, and leads to the desired goal. And assuming the world model was (more or less) accurate, the plan will work.
From the outside perspective, it will look like magic! To you, it might seem like the thinking machine is taking random actions – just like your cat does not understand how you got food after you got into that metal box with wheels – but in the end, the goal will be achieved. The only way to prevent this is to lock the thinking machine into a box and never let it interact with the outside world at all. (Not even via text messages!) If it can’t take any actions, it really can’t affect the world, but then it’s also useless.
Another analogy might be video game [speed running](https://en.wikipedia.org/wiki/Speedrun). In a speedrun, the gamer knows the game mechanics so well that they can exploit it far beyond what the game developers anticipated in order to achieve victory much faster than intended. You could imagine a superintelligence speedrunning our world by trying to identify all the exploits that are present in human technology, human psychology and the physical world, in a way that we humans just cannot predict, because the thinking machine is simply better at finding exploits.
Some of the intermediate steps in a plan might look familiar to humans. If you give a super-human planner the goal of ‘mine some helium-3 on the moon’, then its search for plans/chains of actions will likely conclude that it is a good idea to build a rocket. To that end, it might need to learn more about rocketry and manufacturing technology, so it will develop a sub-plan to get additional information, and so on. (I’m skipping over some of the technical problems here, like, “how to estimate the value of the information that a textbook on rockets contains before you read it?”) But humans will not be able to predict *all* the steps, because otherwise we would be as good planners as the machine, and then it isn’t super-human anymore.
I don’t know of a fundamental law for why super-human planning isn’t possible. It’s just scaling up a cognitive algorithms that we are running in our brains. And with all the computing power we have nowadays, this seems very much possible.
At this point, you might wonder whether humans have any other cognitive skills beyond what I described here – some other secret sauce. What about creativity? Wisdom? The human spirit? – Those things still exist of course, but it seems to me that you can emulate these more specific cognitive capabilities with the more general-purpose algorithms I described above. I think it should not be a completely crazy claim by now that an AI that has modeled humans in sufficient detail will be able to replicate human creativity. Machine learning models like DALL-E are trained on many, many examples of human creativity and have distilled at least a small aspect of the rules that underpin it. And to do that, it has used general purpose search techniques like gradient descent. This shows that general optimization techniques can at least approximate some aspects of human thinking. It stands to reason that in the future, machine learning algorithms will be able to emulate even more of it. Indeed, *deep and general* optimization algorithms have [shown themselves to be the most capable time and time again](http://www.incompleteideas.net/IncIdeas/BitterLesson.html) in the history of AI research.
For the skills I have described, you may also see an underlying general-purpose algorithm, a kind of efficient search:
efficiently searching for universal rules that explain observations, efficiently searching for valid implications, efficiently searching for chains of actions.
As mentioned, [gradient descent](https://en.wikipedia.org/wiki/Gradient_descent) is one search algorithm – more efficient than [evolutionary algorithms](https://en.wikipedia.org/wiki/Evolutionary_algorithm), but restricted to finding real-valued vectors that minimize a differentiable objective. It’s likely that the human brain shares search-related machinery among the three skills and an AI could too, such that an improvement in its general-purpose search algorithm would affect *all* of its capabilities.
To recap: a super-human thinking machine will, compared to us, be able to infer more of the underlying patterns from fewer observations; it will be able to more accurately predict the future based on all the knowledge it has gathered; it will be able to use that to make more complicated and much more effective plans to achieve its goals/optimization targets. If a machine superintelligence, that has, say, access to the Internet, is trying to achieve some goal that you do not agree with, there is basically nothing you can do to stop it – if it has already developed a sufficiently detailed world model. Everything you might try, the AI has already predicted and has developed a contingency plan for. You have no hope of fighting it and in fact, if it came to it, you would be dead before you even knew you were in a fight to begin with, because that is just the easiest way to win a conflict.
You can try to be clever and do something ‘unpredictable’ to throw off the superintelligence, and while that may work in terms of making it more *uncertain* about your next move, the truth is that you do not have the deep understanding of the physical world and the delicate planning ability to *make* dangerous moves, from the perspective of the AI – at least if you had let it run unsupervised for long enough for it to copy itself all over the Internet. It doesn’t matter how random you are when the nano bots administer the [botulinum toxin](https://en.wikipedia.org/wiki/Botulinum_toxin) to everyone in the world at once – if the AI happens to want to rid itself of human interference.
There is another lesson here, which is that the *human level* of cognition does not seem like a natural barrier on the way to even better cognition, or, put differently, if you build an AI with human-level “intelligence”, then it will *not* be difficult at all to make it even smarter – in the easiest case, just give it more GPUs to run on.
That is, you might think that if we ever cracked the secret behind *intelligence*, then we would get AIs that are roughly human-level in terms of cognitive capabilities. But the human level of induction/deduction/planning simply isn’t anything special and there is no reason to think that AIs will end up around that level. The fastest humans can run at about 40km/h and with human anatomy it’s hard to get past that speed, but if you have invented wheels and a combustion engine, then 40km/h is not a special level of speed that is hard to break – indeed, cars can go much faster than that. Of course, cars have new limits, imposed by things like air resistance and overheating tires, but when considering those limits, the human limit is almost completely irrelevant.
Similarly, a machine intelligence likely has very different limits than humans when it comes to induction, deduction and planning. Not least because the size of human brains is limited by our cranial capacity whereas a machine intelligence can grab all the computing hardware lying around to improve its capabilities.
All this means that there likely will not be much time[[1]](#fn-d24QDrGSKkXPjFnhd-1) between someone’s discovery of how to train a machine learning model to gain the cognitive capabilities mentioned above, and the moment when a datacenter somewhere is hosting a machine intelligence that is much more capable than us, at which point it is probably too late to change its goals.
We will not be able to experiment on roughly-human-level AIs – in order to carefully tune and align them and to set up a lawful AI society – before we get to super-human AI.
Most likely, we will get *one shot* to ensure the *first* AI’s optimization targets align with ours. And then it’s out of our hands.
---
1. Maybe a year between those two points in time? [↩︎](#fnref-d24QDrGSKkXPjFnhd-1) |
773b2c02-bf0e-4da3-8a91-0d530e0cec20 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Alignment Megaprojects: You're Not Even Trying to Have Ideas
Consider the [state of funding](https://www.lesswrong.com/posts/WGpFFJo2uFe5ssgEb/an-overview-of-the-ai-safety-funding-situation#Is_AI_safety_talent_or_funding_constrained_) for [AI alignment](https://forum.effectivealtruism.org/topics/ai-alignment).
Is the field more talent-constrained, or funding-constrained?
I think most existing researchers, if they take the AI-based extinction-risk seriously, think it's talent constrained.
I think the bar-for-useful-contribution could be *so* high, that we loop back around to "we need to spend more money (and effort) on finding (and making) more talent". And the programs to do *those* may themselves be more funding-constrained than talent-constrained.
Like, the 20th century had some really good mathematicians and physicists, and the US government [spared](https://en.wikipedia.org/wiki/Manhattan_Project) little expense [towards](https://en.wikipedia.org/wiki/Operation_Paperclip) getting them what they needed, finding them, and so forth. Top basketball teams will "[check up on anyone over 7 feet that’s breathing](https://slatestarcodex.com/2015/02/01/talents-part-2-attitude-vs-altitude/)".
Consider how huge Von Neumann's expense account must've been, between all the consulting and flight tickets and [car accidents](https://www.newworldencyclopedia.org/entry/John_von_Neumann#Early_years). Now consider that we don't seem to have Von Neumanns anymore. There are [caveats](https://www.lesswrong.com/posts/SG6fcAFhhJjys2WtH/has-anyone-actually-tried-to-convince-terry-tao-or-other-top) to *at least* that second point, but the overall problem structure still hasn't been "fixed".
Things an entity with absurdly-greater funding (e.g. ~~the US Department of Defense~~ the US deferal government *in a non-military-unless-otherwise-stated capacity*) could probably do, with their absurdly-greater funding and probably coordination power:
* Indefinitely-long-timespan basic minimum income for everyone who is working on solely AI alignment.
* [Coordinating](https://www.lesswrong.com/posts/9XkrMTrA4d3fkBxDD/a-key-power-of-the-president-is-to-coordinate-the-execution), possibly by force, every AI alignment researcher and aspiring alignment researcher on Earth to move to one place that doesn't have high rents like the Bay. Possibly up to and including [creating that place](https://en.wikipedia.org/wiki/Oak_Ridge,_Tennessee#Manhattan_Project) and making rent free for those who are accepted in.
* [Enforce a global large-ML-training shutdown](https://time.com/6266923/ai-eliezer-yudkowsky-open-letter-not-enough/).
* An entire school system (or at least an entire network of universities, with university-level funding) focused on Sequences-style rationality in general and AI alignment in particular.
* [Genetic](https://www.lesswrong.com/posts/s5ce8BaTAprgDBHni/taking-clones-seriously) engineering, [focused-training-from-a-young-age](https://ig.ft.com/sites/business-book-award/books/2006/longlist/operation-yao-ming-by-brook-larmer/), or other extreme "[talent development](https://en.wikipedia.org/wiki/Soviet_chess_school)" setups.
* Deeper, higher-budget investigations into how "unteachable" things like [security mindset](https://www.lesswrong.com/tag/security-mindset) *really* are, and how deeply / quickly you can teach them.
* Any of the above ideas, but with a different tradeoff on the Goodharting-vs-missed-opportunities continuum.
* All of these at once.
I think the big logistical barrier here is something like "LTFF is not the U,S government", or more precisely "nothing as crazy as these can be done 'on-the-margin' or with any less than the full funding". However, I think some of these could be scaled down into mere [megaprojects](https://forum.effectivealtruism.org/topics/megaprojects) or less. Like, if the training infrastructure is bottlenecked on [*trainers*](https://www.lesswrong.com/posts/WGpFFJo2uFe5ssgEb/an-overview-of-the-ai-safety-funding-situation#Is_AI_safety_talent_or_funding_constrained_), then we need to [fund indirect "training" work](https://www.lesswrong.com/posts/SyCkodiPhugWxr9Jx/roundabout-strategy) just to remove the bottleneck on the bottleneck of the problem. (Also, [the bottleneck is going to move](https://en.wikipedia.org/wiki/Theory_of_constraints) *at least* when you solve the current bottleneck, and also "on its own" as the entire world changes around you).
Also... this might be the *first* list of ideas-in-precisely-this-category, on all of LessWrong/the EA Forum. (By which I mean "technical AI alignment research projects that you could fund, without having to think about the alignment problem *itself* in much detail beyond agreeing with 'doom could actually happen in my lifetime', if funding *really* wasn't the constraint".) |
daf2ebbf-a597-4c1e-a845-57447013ad97 | trentmkelly/LessWrong-43k | LessWrong | What science needs
Science does not need more scientists. It doesn't even need you, brilliant as you are. We already have many times more brilliant scientists than we can fund. Science could use a better understanding of the scientific method, but improving how individuals do science would not address most of the problems I've seen.
The big problems facing science are organizational problems. We don't know how to identify important areas of study, or people who can do good science, or good and important results. We don't know how to run a project in a way that makes correct results likely. Improving the quality of each person on the project is not the answer. The problem is the system. We have organizations and systems that take groups of brilliant scientists, and motivate them to produce garbage.
I haven't got it all figured out, but here are some of the most-important problems in science. I'd like to turn this into a front-page post eventually, but now I'm going to post it to discussion, and ask you to add new important problems in the comments.
Egos
A lot of LWers think they want to advance scientific understanding. But I've learned after years in the field that what most scientists want even more is prove how smart they are.
I couldn't tell you how many times I've seen a great idea killed because the project leader or someone else with veto power didn't want someone else's idea or someone else's area of expertise to appear important. I've been "let go" from two jobs because I refused when my bosses flat-out told me to stop proposing solutions for the important problems, because that was their territory.
I don't mean that you should try to stop people from acting that way. People act that way. I mean you should admit that people act that way, and structure contracts, projects, and rewards so that these petty ego-boosts aren't the biggest rewards people can hope to get.
Too many "no"-men
The more people your project has who can say "no", the worse the results wi |
1ae43656-e2aa-470f-9ede-c4f03e7f5950 | trentmkelly/LessWrong-43k | LessWrong | An overview of the points system
This is the current idea of how the points system for AI-plans.com works. There are still problems to be worked out, which I'd very much like some input on.
An overview of how the points system works:
Criticisms
Each criticism has one metric- how many criticism points it has
Users have the option to 'upvote' or 'downvote' a criticism
Downvote points and upvote points have the same value, just in opposite directions- downvotes decrease criticism points and upvotes increase criticism points.
Users do not have the option to vote on their own criticisms.
Users can begin with an A*B number of points An xN number of downvote points will lower the criticizers karma by N point, an xN number of upvote points will raise the criticizer's karma by N points.
Users can start off with an arbitrary amount of karma if they link their arxiv or alignmentforum or other such account, a moderator goes over it, checks if they are who they say they are and if they've done work in alignment and approves it.
There will be a low limit on how many points such a user can start out with- because the skills for doing good AI research can be very different to actually doing alignment work and the skills for doing some alignment work may not correlate with the skill of making and judging good criticisms. Currently, I'm thinking 50-100 .
Users without prior research to show can gain karma from doing a small, timed alignment quiz to get 5 karma if they pass the quiz- this will be a one time thing for each user.
The lowest a users karma can get is 0. A user's karma acts as a multiplier for their vote
Plans
Each plan has two metrics- it's rank number and the total number of criticism points it has.
The total number of criticism points has is the sum of criticism points(total upvote points - total downvote points) each criticism of the plan has E.g.
Plan X has 4 criticisms, one with sum 20 points, two with sum 12 points and one with sum 10 points- so it has a total 42 points.
Sup |
d80a88e6-50a0-4619-af54-61a0481dc63c | StampyAI/alignment-research-dataset/arxiv | Arxiv | A Strongly Asymptotically Optimal Agent in General Environments
1 Introduction
---------------
>
> “Efforts to solve [an instance of the exploration-exploitation problem] so sapped the energies and minds of Allied analysts that the suggestion was made that the problem be dropped over Germany, as the ultimate instrument of intellectual sabotage.” –Peter Whittle [[Whittle1979](#bib.bibx17)]
>
>
>
The Allied analysts were considering the simplest possible problem in which there is a trade-off to be made between exploiting, taking the apparently best option, and exploring, choosing a different option to learn more. We tackle what we consider the most difficult instance of the exploration-exploitation trade-off problem: when the environment could be any computable probability distribution, not just a multi-armed bandit, how can one achieve optimal performance in the limit?
Our work is within the Reinforcement Learning (RL) paradigm: an agent selects an action, and the environment responds with an observation and a reward. The interaction may end, or it may continue forever. Each interaction cycle is called a timestep. The agent has a discount function that weights its relative concern for the reward it achieves at various future timesteps. The agent’s job is to select actions that maximize the total expected discounted reward it achieves in its lifetime. The “value” of an agent’s policy at a certain point in time is the expected total discounted reward it achieves after that time if it follows that policy. One formal specification of the exploration-exploitation problem is: what policy can an agent follow so that the policy’s value approaches the value of the optimal informed policy with probability 1, even when the agent doesn’t start out knowing the true dynamics of its environment?
Most work in RL makes strong assumptions about the environment—that the environment is Markov, for instance. Impressive recent development in the field of reinforcement learning often makes use of the Markov assumption, including Deep Q Networks [[Mnih et al.2015](#bib.bibx11)], A3C [[Mnih et al.2016](#bib.bibx12)], Rainbow [[Hessel et al.2018](#bib.bibx3)], and AlphaZero [[Silver et al.2017](#bib.bibx15)]. Another example of making strong assumptions in RL comes from some model-based algorithms that implicitly assume that the environment is representable by, for example, a fixed-size neural network, or whatever construct is used to model the environment. We do not make any such assumptions.
Many recent developments in RL are largely about tractably learning to exploit; how to explore intelligently is a separate problem. We address the latter problem. Our approach, inquisitiveness, is based on Orseau et al.’s \shortciteHutter:13ksaprob Knowledge Seeking Agent for Stochastic Environments, which selects the actions that best inform the agent about what environment it is in. Our Inquisitive Reinforcement Learner (Inq) explores like a knowledge seeking agent, and is more likely to explore when there is apparently (according to its current beliefs) more to be learned. Sometimes exploring well requires “expeditions,” or many consecutive exploratory actions. Inq entertains expeditions of all lengths, although it follows the longer ones less often, and it doesn’t resolutely commit in advance to seeing the expedition through.
This is a very human approach to information acquisition. When we spot an opportunity to learn something about our natural environment, we feel inquisitive. We get distracted. We are inclined to check it out, even if we don’t see directly in advance how this information might help us better achieve our goals. Moreover, if we can tell that the opportunity to learn something requires a longer term project, we may find ourselves less inquisitive.
For the class of computable environments (stochastic environments that follow a computable probability distribution), it was previously unknown whether any policy could achieve strong asymptotic optimality (convergence of the value to optimality with probability 1). Lattimore et al. \shortciteHutter:11asyoptag showed that no deterministic policy could achieve this. The key advantage that stochastic policies have is that they can let the exploration probability go to 0 while still exploring infinitely often. (For example, an agent that explores with probability 1/t at time t still explores infinitely often).
There is a weaker notion of optimality–“weak asymptotic optimality”–for which positive results already exist; this condition requires that the average value over the agent’s lifetime approach optimality. Lattimore et al. \shortciteHutter:11asyoptag identified a weakly asymptotically optimal agent for deterministic computable environments; the agent maintains a list of environments consistent with its observations, exploiting as if it is in the first such one, and exploring in bursts. A recent algorithm for a Thompson Sampling Bayesian agent was shown, with an elegant proof, to be weakly asymptotically optimal in all computable environments, but not strongly asymptotically optimal [[Leike et al.2016](#bib.bibx10)].
Most work in RL regards (Partially Observable) Markov Decision Processes (PO)MDPs. However, environments that enter completely novel states infinitely often render (PO)MDP algorithms helpless. For example, an RL agent acting as a chatbot, optimizing a function, or proving mathematical theorems would struggle to model the environment as an MDP, and would likely require an exploration mechanism like ours. In the chatbot case, for instance, as a conversation with a person progresses, the person never returns to the same state.
If we formally compare Inq to existing algorithms in MDPs, we find that many achieve asymptotic optimality. Epsilon-greedy, upper confidence bound, and Thompson sampling exploration strategies suffice in MDPs. Our primary motivation is for the sorts of environments described above. To discriminate between exploratory approaches in ergodic MDPs, one can formally bound regret, and we would like to do this for Inq in the future.
For comparison, some algorithms which use the MDP formalism also consider information-theoretic approaches to exploration, such as VIME [[Houthooft et al.2016](#bib.bibx5)], the agent in [[Still2009](#bib.bibx16)], and TEXPLORE-VANIR [[Hester and
Stone2012](#bib.bibx4)].
In Section 2, we formally describe the RL setup and present notation. In Section 3, we present the algorithm for Inq. In Section 4, we prove our main result: that Inq is strongly asymptotically optimal. In Section 5, we present experimental results comparing Inq to weakly asymptotically optimal agents. Finally, we discuss the relevance of this exploration regime to tractable algorithms. Appendix [A](#A1 "Appendix A Definitions and Notation – Quick Reference ‣ A Strongly Asymptotically Optimal Agent in General Environments") collates notation and definitions for quick reference. Appendix [B](#A2 "Appendix B Proofs of Lemmas ‣ A Strongly Asymptotically Optimal Agent in General Environments") contains the proofs of the lemmas.
2 Notation
-----------
We follow the notation of Orseau, et al. \shortciteHutter:13ksaprob. The reinforcement learning setup is as follows: A is a finite set of actions available to the agent; O is a finite set of observations it might observe, and R=[0,1]∩Q is the set of possible rewards. The set of all possible interactions in a timestep is H:=A×O×R. At every timestep, one element from this set occurs. A reinforcement learner’s policy π is a stochastic function which outputs an action given an interaction history, denoted by π:H∗⇝A. (X∗:=⋃∞i=0Xi represents all finite strings from an alphabet X). An environment is a stochastic function which outputs an observation and reward given an interaction history and an action: ν:H∗×A⇝O×R. For a stochastic function f:X→Y, f(y|x) denotes the probability that f outputs y∈Y when x∈X is input.
A policy and an environment induce a probability measure over H∞, the set of all possible infinite histories: for h∈H∗, Pπν(h) denotes the probability that an infinite history begins with h when actions are sampled from the policy π, and observations and rewards are sampled from the environment ν. Formally, we define this inductively: Pπν(ϵ)↦1, where ϵ is the empty history, and for h∈H∗, a∈A, o∈O, r∈R, we define Pπν(haor)↦Pπν(h)π(a|h)ν(or|ha). In an infinite history h1:∞∈H∞, at, ot, and rt refer to the tth action, observation and reward, and ht refers to the tth timestep: atotrt. h<t refers to the first t−1 timesteps, and ht:k refers to the string of timesteps t through k (inclusive). Strings of actions, observations, and rewards are notated similarly.
A Bayesian agent deems a class of environments a priori feasible. Its “beliefs” take the form of a probability distribution over which environment is the true one. We call this the agent’s belief distribution. In our formulation, Inq considers any computable environment feasible, and starts with a prior belief distribution based on the environments’ Kolmogorov complexities: that is, the length of the shortest program that computes the environment on some reference machine. However, all our results hold as long as the true environment is contained in the class of environments that are considered feasible, and as long as the prior belief distribution assigns nonzero probability to each environment in the class. We take M to be the class of all computable environments, and w(ν):=2−K(ν)(1+ε)/N to be the prior probability of the environment ν, where K is the Kolmogorov complexity, ε>0, and N is a normalization constant. (ε>0 ensures the prior has finite entropy, which facilitates analysis.) A smaller class with a different prior probability could easily be substituted for M and w(ν).
We use ξ to denote the agent’s beliefs about future observations. Together with a policy π it defines a Bayesian mixture measure: Pπξ(⋅):=∑ν∈Mw(ν)Pπν(⋅). The posterior belief distribution of the agent after observing a history h∈H∗ is w(ν|h):=w(ν)Pπ′ν(h)/Pπ′ξ(h). This definition is independent of the choice of π′ as long as Pπ′ξ(h)>0; we can fix a reference policy π′ just for this definition if we like. We sometimes also refer to the conditional distribution ξ(or|ha):=∑ν∈Mw(ν|h)ν(or|ha).
The agent’s discount at a timestep is denoted γt. To normalize the agent’s policy’s value to [0,1], we introduce Γt:=∑∞k=tγk. (Normalization makes value convergence nontrivial). We consider an agent with a bounded horizon: ∀ε>0 ∃m ∀t:Γt+m/Γt≤ε. Intuitively, this means that the agent does not become more and more farsighted over time. Note this does not require a finite horizon. A classic discount function giving a bounded horizon is a geometric one: for 0≤γ<1, γt=γt. The value of a policy π in an environment ν, given a history h<t∈Ht−1, is
| | | | |
| --- | --- | --- | --- |
| | Vπν(h<t):=1ΓtEπν[∞∑k=tγkrk∣∣∣h<t] | | (1) |
Here, the expectation is with respect to the probability measure Pπν. Reinforcement Learning is the attempt to find a policy that makes this value high, without access to ν.
3 Inquisitive Reinforcement Learner
------------------------------------
We first describe how Inq exploits, then how it explores. It exploits by maximizing the discounted sum of its reward in expectation over its current beliefs, and it explores by following maximally informative “exploratory expeditions” of various lengths.
An optimal policy with respect to an environment ν is a policy that maximizes the value.
| | | | |
| --- | --- | --- | --- |
| | π∗ν(⋅):=argmaxπ∈ΠVπν(⋅) | | (2) |
where Π=H∗⇝A is the space of all policies. An optimal deterministic policy always exists [[Lattimore and
Hutter2014b](#bib.bibx9)]. When exploiting, Inq simply maximizes the value according to its belief distribution ξ. Since this policy is deterministic, we write a∗(h<t) to mean the unique action at time t for which π∗ξ(a|h<t)=1. That is the exploitative action.
The most interesting feature of Inq is how it gets distracted by the opportunity to explore. Inq explores to learn. An agent has learned from an observation if its belief distribution w changes significantly after making that observation. If the belief distribution has hardly changed, then the observation was not very informative. The typical information-theoretic measure for how well a distribution Q approximates a distribution P is the KL-divergence, KL(P||Q). Thus, a principled way to quantify the information that an agent gains in a timestep is the KL-divergence from the belief distribution at time t+1 to the belief distribution at time t. This is the rationale behind the construction of Orseau, et al.’s \shortciteHutter:13ksaprob Knowledge Seeking Agent, which maximizes this expected information gain.
Letting h<t∈Ht−1 and h′∈H∗, the information gain at time t is defined:
| | | | |
| --- | --- | --- | --- |
| | IG(h′|h<t):=∑ν∈Mw(ν|h<th′)logw(ν|h<th′)w(ν|h<t) | | (3) |
Recall that w(ν|h) is the posterior probability assigned to ν after observing h.
An m-step expedition, denoted αm, represents all contingencies for how an agent will act for the next m timesteps. It is a deterministic policy that takes history-fragments of length less than m and returns an action:
| | | | |
| --- | --- | --- | --- |
| | αm:m−1⋃i=0Hi→A | | (4) |
Pαmξ(h<t+k|h<t) is a conditional distribution defined for 0≤k≤m, which represents the conditional probability of observing h<t+k if the expedition αm is followed starting at time t, after observing h<t. Now we can consider the information-gain value of an m-step expedition. It is the expected information gain upon following that expedition:
| | | | |
| --- | --- | --- | --- |
| | VIG(αm,h<t):=∑ht:t+m−1∈HmPαmξ(h<t+m|h<t)IG(ht:t+m−1|h<t) | | (5) |
At a time t, one might consider many expeditions: the one-step expedition which maximizes expected information gain, the two-step expedition doing the same, etc. Or one might consider carrying on with an expedition that began three timesteps ago.
######
Definition 1.
At time t, the m-k expedition is the m-step expedition beginning at time t−k which maximized the expected information gain from that point.222Ties in the argmax are broken arbitrarily.
| | | | |
| --- | --- | --- | --- |
| | αIGm,k(h<t):=argmaxαm : ⋃m−1i=0Hi→AVIG(αm,h<t−k) | | (6) |
Example expeditions are diagrammed in Figure [1](#S3.F1 "Figure 1 ‣ 3 Inquisitive Reinforcement Learner ‣ A Strongly Asymptotically Optimal Agent in General Environments").

Figure 1: Example Expeditions. Expeditions maximize the expected KL-divergence from the posterior at the end to the posterior at the beginning.
Expeditions are functions which return an action given what has been seen so far on the expedition. The m-k exploratory action is the action to take at time t according to the m-k expedition:
| | | | |
| --- | --- | --- | --- |
| | aIGm,k(h<t):=αIGm,k(h<t)(ht−k:t−1) | | (7) |
Naturally, this is only defined for k<m,t, since the expedition function can’t accept a history fragment of length ≥m, and t−k must be positive. Note also that if k=0, ht−k:t−1 evaluates to the empty string, ϵ.
The reason Inq doesn’t ignore expeditions that started in the past is that Inq must have some chance of actually executing the whole expedition (for every expedition). If the probability of completing an expedition is 0, one cannot use it for a bound on Inq’s belief-accuracy.
######
Definition 2.
Let ρ(h<t,m,k) be the probability of taking the m-k exploratory action after observing a history h<t.
| | | | |
| --- | --- | --- | --- |
| | ρ(h<t,m,k):=min{1m2(m+1),ηVIG(αIGm,k(h<t),h<t−k)} | | (8) |
where η is an exploration constant.
Note in the definition of ρ(h<t,m,k) that the probability of following an expedition goes to 0 if the expected information gain from that expedition goes to 0. The first term in the min ensures the probabilities will not sum to more than 1. The total probability of exploration is defined:
| | | | |
| --- | --- | --- | --- |
| | β(h<t):=∑m∈N∑k<m,tρ(h<t,m,k)≤∑m∈N∑k<m,t1m2(m+1)≤∑m∈N∑k<m1m2(m+1)=1 | | (9) |
The feature that makes Inq inquisitive is that ρ(h<t,m,k) is proportional to the expected information gain from the m-k expedition, VIG(αIGm,k(h<t),h<t−k).
Note that completing an m-step expedition requires randomly deciding to explore in that way on m separate occasions. While this may seem inefficient, if the agent always got boxed into long expeditions, the value of its policy would plummet infinitely often.
Finally, Inq’s policy π†, defined in Algorithm [1](#alg1 "Algorithm 1 ‣ 3 Inquisitive Reinforcement Learner ‣ A Strongly Asymptotically Optimal Agent in General Environments"), takes the m-k exploratory action with probability ρ(⋅,m,k), and takes the exploitative action otherwise.333This algorithm is written in a simplified way that does not halt, but if a real number in [0,1] is sampled first, the actions can be assigned to disjoint intervals successively until the sampled real number lands in one of them.
1:while True do
2: calculate ρ(h<t,m,k) for all m and for all k<min{m,t}
3: take action aIGm,k(h<t) with probability ρ(h<t,m,k)
4: take action a∗(h<t) with probability 1−β(h<t)
Algorithm 1 Inquisitive Reinforcement Learner’s Policy π†
4 Strong Asymptotic Optimality
-------------------------------
Here we present our central result: that the value of π† approaches the optimal value. We present the theorem, motivate the result, and proceed to the proof. We recommend the reader have Appendix [A](#A1 "Appendix A Definitions and Notation – Quick Reference ‣ A Strongly Asymptotically Optimal Agent in General Environments") at hand for quickly looking up definitions and notation.
Before presenting the theorem, we clarify an assumption, and define the optimal value. We call the true environment μ, and we assume that μ∈M. For M the class of computable environments, this is a very unassuming assumption. The optimal value is simply the value of the optimal policy with respect to the true environment:
| | | | |
| --- | --- | --- | --- |
| | V∗μ(h<t):=supπ∈ΠVπμ(h<t)=Vπ∗μμ(h<t) | | (10) |
Recall also that we have assumed the agent has a bounded horizon in the sense that ∀ε ∃m ∀t:Γt+m/Γt≤ε. The Strong Asymptotic Optimality theorem is that under these conditions, the value of Inq’s policy approaches the optimal value with probability 1, when actions are sampled from Inq’s policy and observations and rewards are sampled from the true environment μ.
######
Theorem 3 (Strong Asymptotic Optimality).
As t→∞,
| | | |
| --- | --- | --- |
| | V∗μ(h<t)−Vπ†μ(h<t)→0 with Pπ†μ\!\!-prob. 1 | |
where μ∈M is the true environment.
For a Bayesian agent, uncertainty about on-policy observations goes to 0. Since “on-policy” for Inq includes, with some probability, all maximally informative expeditions, Inq eventually has little uncertainty about the result of any course of action, and can therefore successfully select the optimal course. For any fixed horizon, Inq’s mixture measure ξ approaches the true environment μ.
We use the following notation for a particular KL-divergence that plays a central role in the proof:
| | | | |
| --- | --- | --- | --- |
| | KLh<t,n(Pπν1||Pπν2):=∑h′∈HnPπν1(h′|h<t)logPπν1(h′|h<t)Pπν2(h′|h<t) | | (11) |
This quantifies the difference between the expected observations of two different environments that would arise in the next n timesteps when following policy π. KLh<t,∞ denotes the limit of the above as n→∞, which exists by [[Orseau et al.2013](#bib.bibx13), proof of Theorem 3].
In dealing with the KL-divergence, we simplify matters by asserting that 0log0:=0, and 0log00:=0.
We begin with a lemma that equates the information gain value of an expedition with the expected prediction error. The KL-divergence on the right hand side represents how different ν and ξ appear when following the expedition in question.
######
Lemma 4.
| | | |
| --- | --- | --- |
| | | |
Proofs of Lemmas appear in Appendix [B](#A2 "Appendix B Proofs of Lemmas ‣ A Strongly Asymptotically Optimal Agent in General Environments").
Recall that w(ν|h<t) is the posterior weight that Inq assigns to the environment ν after observing h<t. We show that the infimum of this value is strictly positive with probability 1.
######
Lemma 5.
inftw(μ|h<t)>0 w.Pπμ-p. 1
Next, we show that every exploration probability ρ(h<t,m,k) goes to 0.
From here, all “w.p.1” statements mean with Pπ†μ-probability 1, if not otherwise specified.
######
Lemma 6.
| | | |
| --- | --- | --- |
| | ρ(h<t,m,k)t→∞→0 w.p.1 | |
The essence of the proof is that with a finite-entropy prior, there is only a finite amount of information to gain, so the expected information gain (and the exploration probability) goes to 0.
Next, we show that the total exploration probability goes to 0:
######
Lemma 7.
| | | |
| --- | --- | --- |
| | β(h<t)→0 w.p.1 | |
Lemma [8](#Thmtheorem8 "Lemma 8. ‣ 4 Strong Asymptotic Optimality ‣ A Strongly Asymptotically Optimal Agent in General Environments") shows that the probabilities assigned by ξ converge to those of μ.
######
Lemma 8.
∀m∈N, ht:t+m−1∈Hm, αm: ⋃m−1i=0Hi→A:
| | | |
| --- | --- | --- |
| | Pαmμ(ht:t+m−1|h<t)−Pαmξ(ht:t+m−1|h<t)t→∞→0 w.p.1 | |
The proof of Lemma [8](#Thmtheorem8 "Lemma 8. ‣ 4 Strong Asymptotic Optimality ‣ A Strongly Asymptotically Optimal Agent in General Environments") roughly follows the following argument: if all exploration probabilities go to 0, then the informativeness of the maximally informative expeditions goes to 0, so the informativeness of all expeditions goes to 0, meaning the prediction error goes to 0.
Finally, we prove the Strong Asymptotic Optimality Theorem: V∗μ(h<t)−Vπ†μ(h<t)→0 with Pπ†μ\!\!-prob. 1.
###### Proof of Theorem [3](#Thmtheorem3 "Theorem 3 (Strong Asymptotic Optimality). ‣ 4 Strong Asymptotic Optimality ‣ A Strongly Asymptotically Optimal Agent in General Environments").
Let ε>0. Since the agent has a bounded horizon, there exists an m such that for all t, Γt+mΓt≤ε. Recall
| | | | |
| --- | --- | --- | --- |
| | V∗μ(h<t)=1ΓtEπ∗μμ[∞∑k=tγkrk∣∣∣h<t] | | (12) |
Using the m from above, let
| | | | |
| --- | --- | --- | --- |
| | V∗∖mμ(h<t):=1ΓtEπ∗μμ[t+m−1∑k=tγkrk∣∣∣h<t] | | (13) |
Since rt∈[0,1],
| | | | |
| --- | --- | --- | --- |
| | |V∗μ(h<t)−V∗∖mμ(h<t)|≤Γt+mΓt≤ε | | (14) |
We continue from there:
| | | |
| --- | --- | --- |
| | V∗μ(h<t) | |
| | ≤V∗∖mμ(h<t)+ε | |
| | | |
| | | |
| | ∃T1 ∀t>T1≤1Γt∑ht:t+m−1∈HmPπ∗μξ(ht:t+m−1|h<t)t+m−1∑k=tγkrk+2ε | |
| | (b)≤1ΓtEπ∗μξ[∞∑k=tγkrk∣∣∣h<t]+2ε | |
| | (c)≤1ΓtEπ∗ξξ[∞∑k=tγkrk∣∣∣h<t]+2ε | |
| | (d)≤1Γt∑ht:t+m−1∈HmPπ∗ξξ(ht:t+m−1|h<t)t+m−1∑k=tγkrk+3ε | |
| | | |
| | ∃T2 ∀t>T2≤1Γt∑ht:t+m−1∈HmPπ∗ξμ(ht:t+m−1|h<t)t+m−1∑k=tγkrk+4ε | |
| | | |
| | ∃T3 ∀t>T3≤1Γt∑ht:t+m−1∈HmPπ†μ(ht:t+m−1|h<t)∏t+m−1k=t(1−β(h<k))t+m−1∑k=tγkrk | |
| | +4ε | |
| | ≤1Γt∑ht:t+m−1∈HmPπ†μ(ht:t+m−1|h<t)(1−maxt≤k<t+mβ(h<k))mt+m−1∑k=tγkrk | |
| | +4ε | |
| | | |
| | ∃T4,ε′>0 ∀t>T4≤1Γt∑ht:t+m−1∈HmPπ†μ(ht:t+m−1|h<t)(1−ε′)mt+m−1∑k=tγkrk | |
| | +4ε | |
| | (h)≤1(1−ε′)mΓtEπ†μ[∞∑k=tγkrk∣∣∣h<t]+4ε | |
| | =1(1−ε′)mVπ†μ(h<t)+4ε | |
| | =Vπ†μ(h<t)+4ε+(1(1−ε′)m−1)Vπ†μ(h<t) | |
| | (i)≤Vπ†μ(h<t)+4ε+(1(1−ε′)m−1) | | (15) |
(a), (e), (f), and (g) all hold with probability 1. (a) follows from Lemma [8](#Thmtheorem8 "Lemma 8. ‣ 4 Strong Asymptotic Optimality ‣ A Strongly Asymptotically Optimal Agent in General Environments"): for all m, Pπξ(⋅|h<t)→Pπμ(⋅|h<t) for all conditional probabilities of histories of length m, with probability 1, and the countable sum is bounded (by Γt). (b) follows from adding more non-negative terms to the sum. (c) follows π∗ξ being the ξ-optimal policy, and therefore it accrues at least as much expected reward in environment ξ as π∗μ does. (d) follows from ∑∞k=t+mγk/Γt=Γt+m/Γt≤ε, and rt∈[0,1]. (e) follows from Lemma [8](#Thmtheorem8 "Lemma 8. ‣ 4 Strong Asymptotic Optimality ‣ A Strongly Asymptotically Optimal Agent in General Environments") just as (a) did. (f) follows because the product in the denominator is the probability that π† mimics π∗ξ for m consecutive timesteps, and by Lemma [7](#Thmtheorem7 "Lemma 7. ‣ 4 Strong Asymptotic Optimality ‣ A Strongly Asymptotically Optimal Agent in General Environments") there is a time after which this probability is uniformly strictly positive. (g) follows from Lemma [7](#Thmtheorem7 "Lemma 7. ‣ 4 Strong Asymptotic Optimality ‣ A Strongly Asymptotically Optimal Agent in General Environments"): β(h<k)→0 with probability 1. (h) follows from adding more non-negative terms to the sum. Finally, (i) follows from the value being normalized to [0,1] by Γt.
∀δ>0 ∃ε>0,ε′>0:4ε+(1(1−ε′)m−1)<δ. Letting T=max{T1,T2,T3,T4}, we can combine the equations above to give
| | | | |
| --- | --- | --- | --- |
| | ∀δ>0 ∃T ∀t>T:V∗μ(h<t)−Vπ†μ(h<t)<δ w.p.1 | | (16) |
Since V∗μ(h<t)≥Vπ†μ(h<t),
| | | | |
| --- | --- | --- | --- |
| | V∗μ(h<t)−Vπ†μ(h<t)→0 w.p.1 | | (17) |
∎
Strong Asymptotic Optimality is not a guarantee of efficacy; consider an agent that “commits suicide” on the first timestep, and thereafter receives a reward of 0 no matter what it does. This agent is asymptotically optimal, but not very useful. In general, when considering many environments with many different “traps,” bounded regret is impossible to guarantee [[Hutter2005](#bib.bibx6)], but one can still demand from a reinforcement learner that it make the best of whatever situation it finds itself in by correctly identifying (in the limit) the optimal policy.
We suspect that strong asymptotic optimality would not hold if Inq had an unbounded horizon, since its horizon of concern may grow faster than it can learn about progressively more long-term dynamics of the environment. Going more into the technical details, let Δkt be, roughly “at time t, how much does ξ differ from μ regarding predictions about the next k timesteps?” A lemma in our proof is that ∀k limt→∞Δkt=0, but this does not imply, for example, that limz→∞Δzz=0. If the horizon which is necessary to predict is growing over time, Inq might not be strongly asymptotically optimal.
Indeed, we tenuously suspect that it is impossible for an agent with an unbounded time horizon to be strongly asymptotically optimal in the class of all computable environments. If that is true, then the assumptions that our result relies on (namely that the true environment is computable, and the agent has a bounded horizon) are the bare minimum for strong asymptotic optimality to be possible.
Inq is not computable; in fact, no computable policy can be strongly asymptotically optimal in the class of all computable environments (Lattimore, et al. \shortciteHutter:11asyoptag show this for deterministic policies, but a simple modification extends this to stochastic policies). For many smaller environment classes, however, Inq would be computable, for example if M is finite, and perhaps for decidable M in general. The central result, that inquisitiveness is an effective exploration strategy, applies to any Bayesian agent.
5 Experimental Results
-----------------------
We compared Inq with other known weakly asymptotically optimal agents, Thompson sampling and BayesExp [[Lattimore and
Hutter2014a](#bib.bibx8)], in the grid-world environment using AIXIjs [[Aslanides2017](#bib.bibx2)] which has previously been used to compare asymptotically optimal agents [[Aslanides et al.2017](#bib.bibx1)]. We tested in 10 × 10 grid-worlds, and 20 × 20 grid-worlds, both with a single dispenser with probability of dispensing reward 0.75; that is, if the agent enters that cell, the probability of a reward of 1 is 0.75. Following the conventions of [[Aslanides et al.2017](#bib.bibx1)] we averaged over 50 simulations, used discount factor γ=0.99, 600 MCTS samples, and planning horizon of 6. The planning horizon restricts m, and the number of MCTS samples is an input to ρUCT [[Silver and Veness2010](#bib.bibx14)], which we use instead of expectimax. The algorithm for the approximate version of Inq is in Appendix [C](#A3 "Appendix C Approximation of Inq ‣ A Strongly Asymptotically Optimal Agent in General Environments").
The code used for this experiment is available online at <https://github.com/ejcatt/aixijs>, and this version of Inq can be run in the browser at <https://ejcatt.github.io/aixijs/demo.html#inq>.
We found that using small values for η, specifically η≤1 worked well. For our experiments we chose η=1.
In the 10×10 grid-worlds Inq performed comparably to both BayesExp and Thompson sampling. However in the 20×20 grid-worlds Inq performed comparably to BayesExp, and outperformed Thompson sampling. This is likely because when the Thomspon Sampling Agent samples an environment with a reward dispenser that is inaccessible within its planning horizon, the agent acts randomly rather than seeking new cells. This is contrast to Inq and BayesExp which always have an incentive to explore the frontier of cells that have not been visited. This is especially relevant in the larger grid where the Thomspon sampling agent is more likely to act as if the dispenser is deep in uncharted territory, rather than nearby. In a grid-world, good exploration is just about visiting new states, which both Inq and BayesExp successfully seek.

Figure 2: 10×10 Grid-worlds

Figure 3: 20×20 Grid-worlds
6 Conclusion
-------------
We have shown that it is possible for an agent with a bounded horizon to be strongly asymptotically optimal in the class of all computable environments. No existing RL agent has as strong an optimality guarantee as Inq. The nature of the exploration regime that accomplishes this is perhaps of wider interest. We formalize an agent that gets distracted from reward maximization by its inquisitiveness: the more it expects to learn from an expedition, the more inclined it is to take it.
We have confirmed experimentally that inquisitiveness is a practical and effective exploration strategy for Bayesian agents with manageable model classes.
There are two main avenues for future work we would like to see. The first regards possible extensions of inquisitiveness: we have defined inquisitiveness for Bayesian agents with countable model-classes, but inquisitiveness could also be defined for a Bayesian agent with a continuous model class, such as a Q-learner using a Bayesian Neural Network. The second avenue regards the theory of strong asymptotic optimality itself: is Inq strongly asymptotically optimal for more farsighted discounters? If not, can it be modified to accomplish that? Or is it indeed impossible for an agent with an unbounded horizon to be strongly asymptotically optimal in the class of computable environments? Answers to these questions, besides being interesting in their own right, will likely inform the design of tractable exploration strategies, in the same way that this work has done.
Acknowledgements
----------------
This work was supported by the Open Philanthropy Project AI Scholarship and the Australian Research Council Discovery Projects DP150104590. |
17ef97c8-edc1-41db-9294-e509f9e4e1bb | trentmkelly/LessWrong-43k | LessWrong | Mathematicians and the Prevention of Recessions
Note: I completed a PhD in Mathematics from University of Illinois under the direction of Nathan Dunfield in 2011. I worked as a research analyst at GiveWell from April 2012 to May 2013. All views expressed here are my own.
About this post: I've long been interested in ways in which mathematicians can contribute high social value. In this post, I discuss a tentative idea along these lines. My thoughts are very preliminary in nature, and my intent in making this post is to provide a launching point for further exploration of the subject, rather than to persuade.
Recessions as a serious threat to global welfare
In 2008, the US housing bubble popped, precipitating the Great Recession. The costs of this were staggering:
* It’s been claimed that the cost to US taxpayers in bank bailouts was $9 trillion.
* The Dow Jones Industrial Average dropped by almost 50% and took over 4 years to recover.
* US unemployment jumped from ~5% to ~10%, and has only gradually been declining.
* Budget cuts were especially great for government support of activities with unusually high humanitarian value to those without political constituency, such as investment in global health.
* It’s been claimed that recessions cause a drop in prosocial behavior.
All told, the Great Recession had massive negative humanitarian disvalue, and preventing another such recession would have massive humanitarian value.
Transparent financial analysis as a possible solution
There are actors in finance who accurately predicted that there was a housing bubble that was on the brink of popping, and who bet heavily against subprime mortgages, reaping enormous profits as a result. The most prominent example is John Paulson, who made $3.7 billion in a 2007 alone, starting from a base of less than $1 billion. There are less extreme examples that are nevertheless very striking.
It’s difficult to determine the relative roles tha
...
|
1374fa8a-3681-4434-9901-73e5a4a24c0d | trentmkelly/LessWrong-43k | LessWrong | Bad news for uploading
Recently, the Blue Brain Project published a paper arguing that human neurons don't form synapses at locations determined by learning, but just wherever they bump into each other. See video and article here.
For those people hoping to upload their brains by mapping out and virtually duplicating all the synapses—this means that won't work. The synapse locations do not differ from human to human in any useful way. Learning must be encoded in some modulation of each synapse's function. |
c028e95f-98f1-46e1-9a47-e0cc95070334 | trentmkelly/LessWrong-43k | LessWrong | Seeking Estimates for P(Hell)
I am trying to decide how to allocate my charitable donations between GiveWell's top charities and MIRI, and I need a probability estimate to make an informed decision. Could you help me?
Background on my moral system: I place a greater value on reducing high doses of suffering of conscious entities than merely preventing death. An unexpected, instant, painless death is unfortunate, but I would prefer it to a painful and chronic condition.
Given my beliefs, it follows logically that I would pay a relatively large amount to save a conscious entity from prolonged torture.
The possibility of an AI torturing many conscious entities has been mentioned1 on this site, and I assume that funding MIRI will help reduce its probability. But what is its current probability?
Obviously a difficult question, but it seems to me that I need an estimate and there is no way around it. I don't even know where to start...suggestions?
1 http://lesswrong.com/lw/1pz/the_ai_in_a_box_boxes_you/ |
75219ca1-ced2-4044-ac0e-53f5267d2a0a | trentmkelly/LessWrong-43k | LessWrong | Existentialists and Trolleys
How might an existentialist approach this notorious thought experiment of ethical philosophy?
> “Not only do we assert that the existentialist doctrine permits the elaboration of an ethics, but it even appears to us as the only philosophy in which an ethics has its place.” ―Simone de Beauvoir, Ethics of Ambiguity
>
> “I started to know how it feels when the universe reels.” ―The Trolley Song (Meet Me in St. Louis)
illustration by John Holbo
How ought we to live? Every decision we make implies that we have some idea of the answer to that question, but it’s very rare to find someone who can articulate their answer confidently.
Most of us are just winging it, maybe hoping that it will all make sense eventually. We often act as though we suspect the answer is out there somewhere, and we were just unlucky enough to be home sick on the day it was covered in class. We buy self-help books or listen to TED Talks or follow gurus who promise us that if we align ourselves with some lodestone or other—follow your dream, devote your life to others, discover your passion, surrender to God’s plan, go with the flow, practice the law of attraction, don’t take yourself so seriously, find your true life partner—we’ll finally get what it’s all about.
Some of us become fanatics of ideas like these, at least for a while. But most of us patch together a little of this and a little of that and try to muddle through with a philosophy that’s something of a crazy quilt.
Introducing the Trolley Problem
The “Trolley Problem” is a choose-your-own-adventure story in miniature. It stretches the seams of these make-do ethical philosophies we’ve stitched together over our lives, and it has a way of making people a little embarrassed at how threadbare their ethics seem to be.
In the story, a runaway trolley is about to run over and kill several people who are on the tracks in its path and unable to get out of the way. You have an opportunity to stop or divert the trolley, saving those lives, b |
49ccbe63-4c33-4f87-a999-06b72c585395 | trentmkelly/LessWrong-43k | LessWrong | Rationality Quotes 11
"If we let ethical considerations get in the way of scientific hubris, then the feminists have won!"
-- Helarxe
"The trajectory to hell is paved with locally-good intentions."
-- Matt Gingell
"To a mouse, cheese is cheese; that's why mousetraps work."
-- Wendell Johnson, quoted in Language in Thought and Action
"'Ethical consideration' has come to mean reasoning from an ivory tower about abstract non-issues while people die."
-- Zeb Haradon
"I intend to live forever. So far, so good."
-- Rick Potvin
"The accessory optic system: The AOS, extensively studied in the rabbit, arises from a special class of ganglion cells, the cells of Dogiel, that are directionally selective and respond best to slow rates of movement. They project to the terminal nuclei which in turn project to the dorsal cap of Kooy of the inferior olive. The climbing fibers from the olive project to the flocculo-nodular lobe of the cerebellum from where the brain stem occulomotor centers are reached through the vestibular nuclei."
-- MIT Encyclopedia of the Cognitive Sciences, "Visual Anatomy and Physiology"
"Fight for those you have lost, and for those you don't want to lose."
-- Claymore
"Which facts are likely to reappear? The simple facts. How to recognize them? Choose those that seem simple. Either this simplicity is real or the complex elements are indistinguishable. In the first case we're likely to meet this simple fact again either alone or as an element in a complex fact. The second case too has a good chance of recurring since nature doesn't randomly construct such cases."
-- Robert M. Pirsig, Zen and the Art of Motorcycle Maintenance
"Revolutions begin not when the first barricades are erected or even when people lose faith in the old ways of doing things, but rather when they realize that fundamental change is possible."
-- Steven Metz
"First Law of Anime Acoustics: In space, loud sounds, like explosions, are |
29db8cb0-f9a1-4bc3-a1fc-649c976ca719 | StampyAI/alignment-research-dataset/arbital | Arbital | Simple group
A simple group is a [https://arbital.com/p/-3gd](https://arbital.com/p/-3gd) with no [normal subgroups](https://arbital.com/p/4h6). |
d8e075d4-acb0-4d4d-bb68-b4123a32a951 | trentmkelly/LessWrong-43k | LessWrong | We need better prediction markets
I have 0 exposure to cryptocurrencies and I don't work in that industry, but the recent news about FTX plummeting to the ground have left me thinking quite a bit.
It's extremely surprising how a person can go from one day being considered a "genius" or a shrewd business man to being a world wide piece of shit, conman, idiot in some aspects and overall hated by everyone. With this hindsight, now, we can tell that everything that Bankman-Fried said was a lie... he never did tell the truth.
Plus the arrogance that comes from the deep insecurity of having a bad hand where the only choice is to double down every time until you get caught (he was giving product advice to Stripe CEO while alt-tabbing on an interview; now, who is this guy really...) I feel like this could happen again, and to anyone. And, looking back it's obvious, this guy was offering 3 billion dollars to buy a piece of Twitter to a surprised Musk saying, "Does Sam have 3b liquid?"
As soonest as that message did come out it should have been aggregated, it should have moved the needle strongly towards the insolvency of this company and hopefully save thousands of users from having their funds locked. The same goes for any centralized exchange functioning right now, this lowers the probability that they will be able to sustain a bank-run (by different amounts.)
We have to find ways in which the skepticism of people are accounted for and people that were right are rewarded, in the case of FTX this would have been a service to the tune of a billion dollar value.
This will happen again, how can we save the next thousands of users and the next billion of dollars? |
e32d819c-ce17-4c1e-8378-bf4e19381c93 | trentmkelly/LessWrong-43k | LessWrong | Do not ask what rationalists should do
Recently there has been a couple of articles in the discussion page asking whether rationalists should do action A. Now such questions are not uninteresting, but by saying "rationalist" they are poorly phrased.
The rational decision at any time is the decision, given a human with a specific utility function B, and information C, should make to maximise B, given their knowledge (and knowledge about their knowledge) of C. It's not a decision a rationalist should make, it's a decision any human should make. If Omega popped into existence and carefully explained why action A is the best thing for this human to do given their function B, and their information C, then said human should agree.
The important question is not what a rationalist should do, but what your utility function and current information is. This is a more difficult question. Humans are often wrong about what they want in the long term, and it's questionable how much we should value happiness now over happiness in the future (in particular, I suspect current and future me might disagree on this point). Quantifying our current information is also rather hard- we are going to make bad probability estimates, if we can make them at all, which lead us into incorrect decisions just because we haven't considered the evidence carefully enough.
Why is this an important semantic difference? Well it's important for the cause of refining rationality that we don't get caught with associating the notion of rationality with certain goals. Some rationalists believe that they want to save the world, and the best way to do it is by creating friendly AI. This is because they have certain utility functions, and certain beliefs about the probabilities of the singularity. Not all rationalists have these utility functions. Some just want to have a happy home life, meet someone nice, and raise a family. These are different goals, and they can be helped by rationality, because rationality IS the art of winning. Being able to |
47a816b1-4553-4260-9f48-c655c5535e99 | trentmkelly/LessWrong-43k | LessWrong | Group rationality diary, 8/20/12
This is the public group instrumental rationality diary for the week of August 20th. It's a place to record and chat about it if you have done, or are actively doing, things like:
* Established a useful new habit
* Obtained new evidence that made you change your mind about some belief
* Decided to behave in a different way in some set of situations
* Optimized some part of a common routine or cached behavior
* Consciously changed your emotions or affect with respect to something
* Consciously pursued new valuable information about something that could make a big difference in your life
* Learned something new about your beliefs, behavior, or life that surprised you
* Tried doing any of the above and failed
Or anything else interesting which you want to share, so that other people can think about it, and perhaps be inspired to take action themselves. Try to include enough details so that everyone can use each other's experiences to learn about what tends to work out, and what doesn't tend to work out.
Thanks to everyone who contributes!
Last week's diary; archive of prior diaries.
|
17e55809-b2df-457e-b812-69b7a739d73a | StampyAI/alignment-research-dataset/arxiv | Arxiv | Maximum Causal Tsallis Entropy Imitation Learning
1 Introduction
---------------
In this paper, we focus on the problem of imitating demonstrations of
an expert who behaves non-deterministically depending on the situation.
In imitation learning, it is often assumed that the expert’s policy is
deterministic.
However, there are instances, especially for complex tasks, where
multiple action sequences perform the same task equally well.
We can model such nondeterministic behavior of an expert using a
stochastic policy.
For example, expert drivers normally show consistent
behaviors such as keeping lane or keeping the distance from a frontal
car, but sometimes they show different actions for the same
situation, such as overtaking a car and turning left or right at an
intersection, as suggested in [ziebart2008maximum](#bib.bib1) .
Furthermore, learning multiple optimal action sequences to perform a
task is desirable in terms of robustness since an agent can easily
recover from failure due to unexpected events [Haarnoja2017](#bib.bib2) ; [lee2018sparse](#bib.bib3) .
In addition, a stochastic policy promotes exploration and stability
during learning [Heess2012](#bib.bib4) ; [Haarnoja2017](#bib.bib2) ; [vamplew2017softmax](#bib.bib5) .
Hence, modeling experts’ stochasticity can be a key factor in imitation
learning.
To this end, we propose a novel maximum causal Tsallis entropy (MCTE)
framework for imitation learning, which can learn from a uni-modal to
multi-modal policy distribution by adjusting its supporting set.
We first show that the optimal policy under the MCTE framework follows
a sparsemax distribution [martins2016softmax](#bib.bib6) , which
has an adaptable supporting set in a discrete action space.
Traditionally, the maximum causal entropy (MCE) framework
[ziebart2008maximum](#bib.bib1) ; [bloem2014infinite](#bib.bib7) has been proposed to model
stochastic behavior in demonstrations, where the optimal policy
follows a softmax distribution.
However, it often assigns non-negligible probability mass to
non-expert actions when the number of actions increases
[lee2018sparse](#bib.bib3) ; [nachum2018path](#bib.bib8) .
On the contrary, as the optimal policy of the proposed method can
adjust its supporting set, it can model various expert’s behavior from
a uni-modal distribution to a multi-modal distribution.
To apply the MCTE framework to a complex and model-free problem, we
propose a maximum causal Tsallis entropy imitation learning (MCTEIL)
with a sparse mixture density network (sparse MDN) whose mixture
weights are modeled as a sparsemax distribution.
By modeling expert’s behavior using a sparse MDN, MCTEIL can learn
varying stochasticity depending on the state in a continuous action
space.
Furthermore, we show that the MCTEIL algorithm can be obtained by
extending the MCTE framework to the generative adversarial setting,
similarly to generative adversarial imitation learning (GAIL) by Ho
and Ermon [ho2016generative](#bib.bib9) , which is based on the MCE
framework.
The main benefit of the generative adversarial setting is that the
resulting policy distribution is more robust than that of a supervised
learning method since it can learn recovery behaviors from less
demonstrated regions to demonstrated regions by exploring the
state-action space during training.
Interestingly, we also show that the Tsallis entropy of a sparse MDN
has an analytic form and is proportional to the distance between
mixture means.
Hence, maximizing the Tsallis entropy of a sparse MDN encourages
exploration by providing bonus rewards to wide-spread mixture means and
penalizing collapsed mixture means, while the causal entropy
[ziebart2008maximum](#bib.bib1) of an MDN is less effective in terms of
preventing the collapse of mixture means since there is no analytical
form and its approximation is used in practice instead.
Consequently, maximizing the Tsallis entropy of a sparse MDN has a
clear benefit over the causal entropy in terms of exploration and
mixture utilization.
To validate the effectiveness of the proposed method, we conduct two
simulation studies.
In the first simulation study, we verify that MCTEIL with a sparse MDN can
successfully learn multi-modal behaviors from expert’s demonstrations.
A sparse MDN efficiently learns a multi-modal policy without
performance loss, while a single Gaussian and a softmax-based MDN
suffer from performance loss.
The second simulation study is conducted using four continuous control
problems in MuJoCo [todorov2012mujoco](#bib.bib10) .
MCTEIL outperforms existing methods in terms of the average cumulative return.
In particular, MCTEIL shows the best performance for the
reacher problem with a smaller number of demonstrations while
GAIL often fails to learn the task.
2 Background
-------------
#### Markov Decision Processes
Markov decision processes (MDPs) are a well-known mathematical
framework for a sequential decision making problem.
A general MDP is defined as a tuple {S,F,A,ϕ,Π,d,T,γ,r},
where S is the state space,
F is the corresponding feature space,
A is the action space,
ϕ is a feature map from S×A to F,
Π is a set of stochastic policies, i.e., Π={π | ∀s∈S,a∈A,π(a|s)≥0and∑a′π(a′|s)=1},
d(s) is the initial state distribution,
T(s′|s,a) is the transition probability from s∈S to s′∈S by taking a∈A,
γ∈(0,1) is a discount factor, and
r is the reward function from a state-action pair to a real value.
In general, the goal of an MDP is to find the optimal policy distribution π∗∈Π which maximizes the expected discount sum of rewards, i.e., Eπ[r(s,a)]≜E[∑∞t=0r(st,at)∣∣π,d].
Note that, for any function f(s,a), E[∑∞t=0f(st,at)∣∣π,d] will be denoted as Eπ[f(s,a)].
#### Maximum Causal Entropy Inverse Reinforcement Learning
Zeibart et al. [ziebart2008maximum](#bib.bib1) proposed the maximum causal entropy framework,
which is also known as maximum entropy inverse reinforcement learning (MaxEnt IRL).
MaxEnt IRL maximizes the causal entropy of a policy distribution
while the feature expectation of the optimized policy distribution is
matched with that of expert’s policy.
The maximum causal entropy framework is defined as follows:
| | | | |
| --- | --- | --- | --- |
| | maximize% π∈ΠαH(π)subject toEπ[ϕ(s,a)]=EπE[ϕ(s,a)], | | (1) |
where H(π)≜Eπ[−log(π(a|s))]
is the causal entropy of policy π, α is a scale parameter,
πE is the policy distribution of the expert.
Maximum casual entropy estimation finds the most uniformly distributed
policy satisfying feature matching constraints.
The feature expectation of the expert policy is used as a statistic to
represent the behavior of an expert and is approximated from expert’s
demonstrations D={ζ0,⋯,ζN}, where N
is the number of demonstrations and ζi is a sequence of state
and action pairs whose length is T,
i.e., ζi={(s0,a0),⋯,(sT,aT)}.
In [ziebart2010MPAs](#bib.bib11) , it is shown that the optimal solution of
([1](#S2.E1 "(1) ‣ Maximum Causal Entropy Inverse Reinforcement Learning ‣ 2 Background ‣ Maximum Causal Tsallis Entropy Imitation Learning")) is a softmax distribution.
#### Generative Adversarial Imitation Learning
In [ho2016generative](#bib.bib9) , Ho and Ermon have extended
([1](#S2.E1 "(1) ‣ Maximum Causal Entropy Inverse Reinforcement Learning ‣ 2 Background ‣ Maximum Causal Tsallis Entropy Imitation Learning")) to a unified framework for IRL by adding a
reward regularization as follows:
| | | | |
| --- | --- | --- | --- |
| | maxcπ∈Πmin−αH(π)+Eπ[c(s,a)]−EπE[c(s,a)]−ψ(c), | | (2) |
where c is a cost function and ψ is a convex regularization for
cost c.
As shown in [ho2016generative](#bib.bib9) , many existing IRL methods can be
interpreted with this framework, such as
MaxEnt IRL [ziebart2008maximum](#bib.bib1) ,
apprenticeship learning [abbeel2004apprenticeship](#bib.bib12) , and
multiplicative weights apprenticeship learning [syed2008game](#bib.bib13) .
Existing IRL methods based on ([2](#S2.E2 "(2) ‣ Generative Adversarial Imitation Learning ‣ 2 Background ‣ Maximum Causal Tsallis Entropy Imitation Learning")) often require to
solve the inner minimization over π for fixed c in order to
compute the gradient of c.
In [ziebart2010MPAs](#bib.bib11) , Ziebart showed that the inner minimization
is equivalent to a soft Markov decision process (soft MDP) under the reward −c
and proposed soft value iteration to solve the soft MDP.
However, solving a soft MDP every iteration is often intractable for
problems with large state and action spaces and also requires
the transition probability which is not accessible in many cases.
To address this issue, the generative adversarial imitation learning
(GAIL) framework is proposed in [ho2016generative](#bib.bib9) to avoid
solving the soft MDP problem directly.
The unified imitation learning problem ([2](#S2.E2 "(2) ‣ Generative Adversarial Imitation Learning ‣ 2 Background ‣ Maximum Causal Tsallis Entropy Imitation Learning")) can be
converted into the GAIL framework as follows:
| | | | |
| --- | --- | --- | --- |
| | minπ∈ΠmaxDEπ[log(D(s,a))]+EπE[log(1−D(s,a))]−αH(π), | | (3) |
where D∈(0,1)|S||A| indicates a
discriminator, which returns the probability that a given
demonstration is from a learner, i.e., 1 for learner’s demonstrations
and 0 for expert’s demonstrations.
Notice that we can interpret log(D) as cost c
(or reward of −c).
Since existing IRL methods, including GAIL, are often based
on the maximum causal entropy, they model the expert’s policy using a
softmax distribution, which can assign non-zero probability to non-expert
actions in a discrete action space.
Furthermore, in a continuous action space, expert’s behavior is often
modeled using a uni-modal Gaussian distribution, which is not proper to
model multi-modal behaviors.
To handle these issues, we propose a sparsemax distribution as the
policy of an expert and provide a natural extension to handle a
continuous action space using a mixture density network with sparsemax
weight selection.
#### Sparse Markov Decision Processes
In [lee2018sparse](#bib.bib3) , a sparse Markov decision process (sparse
MDP) is proposed by utilizing the causal sparse Tsallis entropy
W(π)≜12Eπ[1−π(a|s)]
to the expected discounted rewards sum, i.e.,
Eπ[r(s,a)]+αW(π).
Note that W(π) is an extension of a special case of the
generalized Tsallis entropy, i.e.,
Sk,q(p)=kq−1(1−∑ipqi),
for k=12,q=2, to sequential random variables.
It is shown that that the optimal policy of a sparse MDP is a sparse
and multi-modal policy distribution [lee2018sparse](#bib.bib3) .
Furthermore, sparse Bellman optimality conditions were derived as follows:
| | | | |
| --- | --- | --- | --- |
| | | | (4) |
where τ(Q(s,⋅)α)=∑a∈S(s)Q(s,a)α−1Ks, S(s) is a set of actions
satisfying 1+iQ(s,a(i))α>∑ij=1Q(s,a(j))α
with a(i) indicating the action with the ith largest state-action value Q(s,a),
and Ks is the cardinality of S(s).
In [lee2018sparse](#bib.bib3) ,
a sparsemax policy shows better performance compared to a softmax
policy since it assigns zero probability to non-optimal actions whose
state-action value is below the threshold τ.
In this paper, we utilize this property in imitation learning by
modeling expert’s behavior using a sparsemax distribution.
In Section [3](#S3 "3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning"), we show that the optimal solution of an MCTE
problem also has a sparsemax distribution and, hence, the optimality
condition of sparse MDPs is closely related to that of MCTE problems.
3 Principle of Maximum Causal Tsallis Entropy
----------------------------------------------
In this section, we formulate maximum causal Tsallis entropy imitation
learning (MCTEIL) and show that MCTE induces a sparse and multi-modal
distribution which has an adaptable supporting set.
The problem of maximizing the causal Tsallis entropy W(π) can be
formulated as follows:
| | | | |
| --- | --- | --- | --- |
| | maximize% π∈ΠαW(π)subject toEπ[ϕ(s,a)]=EπE[ϕ(s,a)]. | | (5) |
In order to derive optimality conditions, we will first change the optimization variable from a policy
distribution to a state-action visitation measure.
Then, we prove that the MCTE problem is concave with respect to the
visitation measure.
The necessary and sufficient conditions for an optimal solution are
derived from the Karush-Kuhn-Tucker (KKT) conditions using the strong
duality and the optimal policy is shown to be a sparsemax distribution.
Furthermore, we also provide an interesting interpretation of the MCTE
framework as robust Bayes estimation in terms of the Brier score.
Hence, the proposed method can be viewed as maximization of the worst
case performance in the sense of the Brier score [brier1950verification](#bib.bib14) .
We can change the optimization variable from a policy distribution
to a state-action visitation measure based on the following theorem.
######
Theorem 1 (Theorem 2 of Syed et al. [syed2008apprenticeship](#bib.bib15) ).
Let M be a set of state-action visitation measures, i.e., M≜{ρ|∀s,a,ρ(s,a)≥0,∑aρ(s,a)=d(s)+∑s′,a′T(s|s′,a′)ρ(s′,a′)}.
If ρ∈M, then it is a state-action visitation measure
for πρ(a|s)≜ρ(s,a)∑aρ(s,a), and
πρ is the unique policy whose state-action visitation
measure is ρ.
###### Proof.
The proof can be found in [syed2008apprenticeship](#bib.bib15) .
∎
Theorem [1](#Thmtheorem1 "Theorem 1 (Theorem 2 of Syed et al. syed2008apprenticeship ). ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning") guarantees the one-to-one correspondence
between a policy distribution and state-action visitation measure.
Then, the objective function W(π) is converted into the function of ρ as follows.
######
Theorem 2.
Let ¯W(ρ)=12∑s,aρ(s,a)(1−ρ(s,a)∑a′ρ(s,a′)).
Then, for any stationary policy π∈Π and any state-action visitation
measure ρ∈M,
W(π)=¯W(ρπ) and ¯W(ρ)=W(πρ) hold.
The proof is provided in the supplementary material.
Theorem [2](#Thmtheorem2 "Theorem 2. ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning") tells us that if ¯W(ρ) has the maximum at ρ∗, then W(π) also has the maximum at πρ∗.
Based on Theorem [1](#Thmtheorem1 "Theorem 1 (Theorem 2 of Syed et al. syed2008apprenticeship ). ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning") and [2](#Thmtheorem2 "Theorem 2. ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning"), we can freely convert the problem ([5](#S3.E5 "(5) ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning")) into
| | | | |
| --- | --- | --- | --- |
| | %
maximizeρ∈Mα¯W(ρ)subject to∑s,aρ(s,a)ϕ(s,a)=∑s,aρE(s,a)ϕ(s,a), | | (6) |
where ρE is the state-action visitation measure corresponding to πE.
###
3.1 Optimality Condition of Maximum Causal Tsallis Entropy
We show that the optimal policy of the problem
([6](#S3.E6 "(6) ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning")) is a sparsemax distribution using the KKT
conditions.
In order to use the KKT conditions, we first show that the MCTE problem is concave.
######
Theorem 3.
¯W(ρ) is strictly concave with respect to ρ∈M.
The proof of Theorem [3](#Thmtheorem3 "Theorem 3. ‣ 3.1 Optimality Condition of Maximum Causal Tsallis Entropy ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning") is provided in the supplementary material.
Since all constraints are linear and the objective function is concave,
([6](#S3.E6 "(6) ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning")) is a concave problem and, hence, strong duality holds.
The dual problem is defined as follows:
| | | | |
| --- | --- | --- | --- |
| | %
maxθ,c,λminρLW(θ,c,λ,ρ)subject to∀s,aλsa≥0, | | (7) |
where LW(θ,c,λ,ρ)=−α¯W(ρ)−∑s,aρ(s,a)θ⊺ϕ(s,a)+∑s,aρE(s,a)θ⊺ϕ(s,a)−∑s,aλsaρ(s,a)+∑scs(∑aρ(s,a)−d(s)−γ∑s′,a′T(s|s′,a′)ρ(s′,a′))
and θ, c, and λ are Lagrangian multipliers and the constraints come from M.
Then, the optimal solution of primal and dual variables necessarily and sufficiently satisfy the KKT conditions.
######
Theorem 4.
The optimal solution of ([6](#S3.E6 "(6) ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning")) sufficiently and
necessarily satisfies the following conditions:
| | | |
| --- | --- | --- |
| | qsa≜θ⊺ϕ(s,a)+γ∑s′cs′T(s′|s,a),cs=α⎡⎣12∑a∈S(s)((qsaα)2−τ(qsα)2)+12⎤⎦,andπρ(a|s)=max(qsaα−τ(qsα),0), | |
where πρ(a|s)=ρ(s,a)∑aρ(s,a),
qsa is an auxiliary variable, and
qs=[qsa1⋯qsa|A|]⊺.
The optimality conditions of the problem ([6](#S3.E6 "(6) ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning"))
tell us that the optimal policy is a sparsemax
distribution which assigns zero probability to an action whose
auxiliary variable qsa is below the threshold τ, which
determines a supporting set.
If expert’s policy is multi-modal at state s, the resulting
πρ(⋅|s) becomes multi-modal and induces
a multi-modal distribution with a large supporting set.
Otherwise, the resulting policy has a sparse and smaller supporting set.
Therefore, a sparsemax policy has advantages over a softmax policy for
modeling sparse and multi-modal behaviors of an expert whose
supporting set varies according to the state.
Furthermore, we also discover an interesting connection between the
optimality condition of an MCTE problem and the sparse Bellman
optimality condition ([4](#S2.E4 "(4) ‣ Sparse Markov Decision Processes ‣ 2 Background ‣ Maximum Causal Tsallis Entropy Imitation Learning")).
Since the optimality condition
is equivalent to the sparse Bellman optimality equation
[lee2018sparse](#bib.bib3) , we can compute the optimal policy
and Lagrangian multiplier cs by solving a sparse MDP under the
reward function r(s,a)=θ∗⊺ϕ(s,a),
where θ∗ is the optimal dual variable.
In addition, cs and qsa can be viewed as a state value and
state-action value for the reward θ∗⊺ϕ(s,a),
respectively.
###
3.2 Interpretation as Robust Bayes
In this section, we provide an interesting interpretation about the
MCTE framework.
In general, maximum entropy estimation can be viewed as a minimax game
between two players.
One player is called a decision maker and the other player is called
the nature, where the nature assigns a distribution to maximize the
decision maker’s misprediction while the decision maker tries to
minimize it [grunwald2004game](#bib.bib16) .
The same interpretation can be applied to the MCTE framework.
We show that the proposed MCTE problem is equivalent to a minimax game
with the Brier score [brier1950verification](#bib.bib14) .
######
Theorem 5.
The maximum causal Tsallis entropy distribution minimizes the worst
case prediction Brier score,
| | | | |
| --- | --- | --- | --- |
| | minπ∈Πmax~π∈ΠE~π[∑a′12(1{a′=a}−π(a|s))2]subject toEπ[ϕ(s,a)]=EπE[ϕ(s,a)] | | (8) |
where ∑a′12(1{a′=a}−π(a|s))2 is the Brier score.
Note that minimizing the Brier score minimizes the misprediction ratio
while we call it a score here.
Theorem [5](#Thmtheorem5 "Theorem 5. ‣ 3.2 Interpretation as Robust Bayes ‣ 3 Principle of Maximum Causal Tsallis Entropy ‣ Maximum Causal Tsallis Entropy Imitation Learning") is a straightforward extension of the
robust Bayes results in [grunwald2004game](#bib.bib16) to sequential
decision problems.
This theorem tells us that the MCTE problem can be viewed as a minimax
game between a sequential decision maker π and the nature
~π based on the Brier score.
In this regards, the resulting estimator can be interpreted as the
best decision maker against the worst that the nature can offer.
4 Maximum Causal Tsallis Entropy Imitation Learning
----------------------------------------------------
1: Expert’s demonstrations D are given
2: Initialize policy and discriminator parameters ν,ω
3: while until convergence do
4: Sample trajectories {ζ} from πν
5: Update ω with the gradient of ∑{ζ}log(Dω(s,a))+∑Dlog(1−Dω(s,a)).
6: Update ν using a policy optimization method with reward function Eπν[log(Dω(s,a))]+αW(πν)
7: end while
Algorithm 1 Maximum Causal Tsallis Entropy Imitation Learning
In this section, we propose a maximum causal Tsallis entropy imitation
learning (MCTEIL) algorithm to solve a model-free IL problem in a
continuous action space.
In many real-world problems, state and action spaces are often
continuous and transition probability of a world cannot be
accessed.
To apply the MCTE framework for a continuous space and model-free case,
we follow the extension of GAIL
[ho2016generative](#bib.bib9) , which trains a policy and reward
alternatively, instead of solving RL at every iteration.
We extend the MCTE framework to a more general case with reward
regularization and it is formulated by replacing the causal entropy
H(π) in the problem ([2](#S2.E2 "(2) ‣ Generative Adversarial Imitation Learning ‣ 2 Background ‣ Maximum Causal Tsallis Entropy Imitation Learning")) with the causal Tsallis
entropy W(π) as follows:
| | | | |
| --- | --- | --- | --- |
| | maxθminπ∈Π−αW(π)−Eπ[θ⊺ϕ(s,a)]+EπE[θ⊺ϕ(s,a)]−ψ(θ). | | (9) |
Similarly to [ho2016generative](#bib.bib9) , we convert the problem ([9](#S4.E9 "(9) ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning")) into the generative adversarial setting as follows.
######
Theorem 6.
The maximum causal sparse Tsallis entropy problem ([9](#S4.E9 "(9) ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning")) is equivalent to the following problem:
| | | |
| --- | --- | --- |
| | %
minπ∈Πψ∗(Eπ[ϕ(s,a)]−EπE[ϕ(s,a)])−αW(π), | |
where ψ∗(x)=supy{y⊺x−ψ(y)}.
The proof is detailed in the supplementary material.
The proof of Theorem [6](#Thmtheorem6 "Theorem 6. ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning") depends on the fact that
the objective function of ([9](#S4.E9 "(9) ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning")) is concave with
respect to ρ and is convex with respect to θ.
Hence, we first switch the optimization variables from π to ρ
and, using the minimax theorem [millar1983minimax](#bib.bib17) , the
maximization and minimization are interchangeable and the generative
adversarial setting is derived.
Similarly to [ho2016generative](#bib.bib9) , Theorem [6](#Thmtheorem6 "Theorem 6. ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning")
says that a MCTE problem can be interpreted as minimization of the
distance between expert’s feature expectation and training policy’s
feature expectation, where ψ∗(x1−x2) is a proper distance
function since ψ(x) is a convex function.
Let esa∈R|S||A| be a feature
indicator vector, such that the sath element is one and zero elsewhere.
If we set ψ to
ψGA(θ)≜EπE[g(θ⊺esa)],
where g(x)=−x−log(1−ex) for x<0 and g(x)=∞ for x≥0,
we can convert the MCTE problem into the following generative adversarial setting:
| | | | |
| --- | --- | --- | --- |
| | minπ∈ΠmaxDEπ[log(D(s,a))]+EπE[log(1−D(s,a))]−αW(π), | | (10) |
where D is a discriminator.
The problem ([10](#S4.E10 "(10) ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning")) can be solved by MCTEIL which
consists of three steps.
First, trajectories are sampled from the training policy πν
and discriminator Dω is updated to distinguish
whether the trajectories are generated by πν or πE.
Finally, the training policy πν is updated with a policy
optimization method under the sum of rewards
Eπ[−log(Dω(s,a))] with
a causal Tsallis entropy bonus αW(πν).
The algorithm is summarized in Algorithm [1](#alg1 "Algorithm 1 ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning").
#### Sparse Mixture Density Network
We further employ a novel mixture density network (MDN) with sparsemax
weight selection, which can model sparse and multi-modal behavior of
an expert, which is called a sparse MDN.
In many imitation learning algorithms, a Gaussian network is often
employed to model expert’s policy in a continuous action space.
However, a Gaussian distribution is inappropriate to model the
multi-modality of an expert since it has a single mode.
An MDN is more suitable for modeling a multi-modal distribution.
In particular, a sparse MDN is a proper extension of a sparsemax
distribution for a continuous action space.
The input of a sparse MDN is state s and the output of a sparse MDN
is components of K mixtures of Gaussians: mixture weights {wi},
means {μi}, and covariance matrices {Σi}.
A sparse MDN policy is defined as
| | | |
| --- | --- | --- |
| | π(a|s)=K∑iwi(s)N(a;μi(s),Σi(s)), | |
where N(a;μ,Σ) indicates a multivariate
Gaussian density at point a with mean μ and covariance
Σ.
In our implementation, w(s) is computed as a sparsemax distribution,
while most existing MDN implementations utilize a softmax distribution.
Modeling the expert’s policy using an MDN with K mixtures can be
interpreted as separating continuous action space into K
representative actions.
Since we model mixture weights using a sparsemax distribution, the
number of mixtures used to model the expert’s policy can vary
depending on the state.
In this regards, the sparsemax weight selection has an advantage over
the soft weight selection since the former utilizes mixture components
more efficiently as unnecessary components will be assigned with zero
weights.
#### Tsallis Entropy of Mixture Density Network
An interesting fact is that the causal Tsallis entropy of an MDN has an
analytic form while the Gibbs-Shannon entropy of an MDN is intractable.
######
Theorem 7.
Let π(a|s)=∑Kiwi(s)N(a;μi(s),Σi(s)).
Then,
| | | | |
| --- | --- | --- | --- |
| | W(π)=12∑sρπ(s)(1−K∑iK∑jwi(s)wj(s)N(μi(s);μj(s),Σi(s)+Σj(s))). | | (11) |
The proof is included in the causal Tsallisrial.
The analytic form of the Tsallis entropy shows that the Tsallis
entropy is proportional to the distance between mixture means.
Hence, maximizing the Tsallis entropy of a sparse MDN encourages
exploration of diverse directions during the policy optimization step
of MCTEIL.
In imitation learning, the main benefit of the generative adversarial
setting is that the resulting policy is more robust than that of
supervised learning since it can learn how to recover from a less
demonstrated region to a demonstrated region by exploring the
state-action space during training.
Maximum Tsallis entropy of a sparse MDN encourages efficient
exploration by giving bonus rewards when mixture means are spread
out.
([11](#S4.E11 "(11) ‣ Theorem 7. ‣ Tsallis Entropy of Mixture Density Network ‣ 4 Maximum Causal Tsallis Entropy Imitation Learning ‣ Maximum Causal Tsallis Entropy Imitation Learning")) also has an effect of utilizing
mixtures more efficiently by penalizing for modeling a single mode using
several mixtures.
Consequently, the Tsallis entropy W(π) has clear benefits in terms
of both exploration and mixture utilization.
5 Experiments
--------------
To verify the effectiveness of the proposed method, we compare MCTEIL
with several other imitation learning methods.
First, we use behavior cloning (BC) as a baseline.
Second, generative adversarial imitation learning (GAIL) with a single
Gaussian distribution is compared.
While several variants of GAIL exist
[baram2017end](#bib.bib18) ; [li2017infogail](#bib.bib19) , they are all based on the maximum
causal entropy framework and utilize a single Gaussian distribution as
a policy function.
Hence, we choose GAIL as the representative method.
We also compare a straightforward extension of GAIL for a multi-modal
policy by using a softmax weighted mixture density network (soft MDN)
in order to validate the efficiency of the proposed sparsemax weighted MDN.
In soft GAIL, due to the intractability of the causal entropy of a
mixture of Gaussians, we approximate the entropy term by adding
−αlog(π(at|st)) to −log(D(st,at))
since Eπ[−αlog(D(s,a))]+αH(π)=Eπ[−log(D(s,a))−αlog(π(a|s))].
The other related imitation learning methods for multi-modal task
learning, such as [hausman2017multi](#bib.bib20) ; [wang2017robust](#bib.bib21) , are
excluded from the comparison since they focus on the task level
multi-modality, where the multi-modality of demonstrations comes from
multiple different tasks.
In comparison, the proposed method captures the multi-modality of the
optimal policy for a single task.
We would like to note that our method can be extended to multi-modal
task learning as well.
###
5.1 Multi-Goal Environment
To validate that the proposed method can learn multi-modal behavior of
an expert, we design a simple multi-goal environment with four
attractors and four repulsors, where an agent tries to reach one of
attractors while avoiding all repulsors as shown in Figure
[1(a)](#S5.F1.sf1 "(a) ‣ Figure 1 ‣ 5.1 Multi-Goal Environment ‣ 5 Experiments ‣ Maximum Causal Tsallis Entropy Imitation Learning").
The agent follows the point-mass dynamics and get a positive reward
(resp., a negative reward) when getting closer to an attractor (resp.,
repulsor).
Intuitively, this problem has multi-modal optimal actions at the center.
We first train the optimal policy using [lee2018sparse](#bib.bib3) and
generate 300 demonstrations from the expert’s policy.
For both soft GAIL and MCTEIL, 500 episodes are sampled at each iteration.
In every iterations, we measure the average return using the underlying rewards and the
reachability which is measured by counting how many goals are reached.
If the algorithm captures the multi-modality of expert’s
demonstrations, then, the resulting policy will show high
reachability.
The results are shown in Figure [1(b)](#S5.F1.sf2 "(b) ‣ Figure 1 ‣ 5.1 Multi-Goal Environment ‣ 5 Experiments ‣ Maximum Causal Tsallis Entropy Imitation Learning") and [1(c)](#S5.F1.sf3 "(c) ‣ Figure 1 ‣ 5.1 Multi-Goal Environment ‣ 5 Experiments ‣ Maximum Causal Tsallis Entropy Imitation Learning").
Since the rewards are multi-modal, it is easy to get a high return if
the algorithm learns only uni-modal behavior.
Hence, the average returns of soft GAIL and MCTEIL increases similarly.
However, when it comes to the reachability, MCTEIL outperforms soft GAIL
when they use the same number of mixtures.
In particular, MCTEIL can learn all modes in demonstrations at the end
of learning while soft GAIL suffers from collapsing mixture means.
This advantage clearly comes from the maximum Tsallis entropy of a sparse MDN
since the analytic form of the Tsallis entropy directly
penalizes collapsed mixture means while −log(π(a|s)) indirectly
prevents modes collapsing in soft GAIL.
Consequently, MCTEIL efficiently utilizes each mixture for wide-spread
exploration.
| | | |
| --- | --- | --- |
|
(a) The environment and multi-modal demonstrations are shown.
The contour shows the underlying reward map.
(b) The average return of MCTEIL and soft GAIL during training.
(c) The reachability of MCTEIL and soft GAIL during training, where
(a) Multi-Goal Environment
|
(a) The environment and multi-modal demonstrations are shown.
The contour shows the underlying reward map.
(b) The average return of MCTEIL and soft GAIL during training.
(c) The reachability of MCTEIL and soft GAIL during training, where
(b) Average Return
|
(a) The environment and multi-modal demonstrations are shown.
The contour shows the underlying reward map.
(b) The average return of MCTEIL and soft GAIL during training.
(c) The reachability of MCTEIL and soft GAIL during training, where
(c) Reachability
|
Figure 1:
(a) The environment and multi-modal demonstrations are shown.
The contour shows the underlying reward map.
(b) The average return of MCTEIL and soft GAIL during training.
(c) The reachability of MCTEIL and soft GAIL during training, where
k is the number of mixtures.
###
5.2 Continuous Control Environment
We test MCTEIL with a sparse MDN on MuJoCo [todorov2012mujoco](#bib.bib10) ,
which is a physics-based simulator, using
Halfcheetah, Walker2d, Reacher, and Ant.
We train the expert policy distribution using trust region policy
optimization (TRPO) [schulman2015trust](#bib.bib22) under the true reward
function and generate 50 demonstrations from the expert policy.
We run algorithms with varying numbers of demonstrations, 4,11,18,
and 25, and all experiments have been repeated three times with
different random seeds.
To evaluate the performance of each algorithm,
we sample 50 episodes from the trained policy and measure the
average return value using the underlying rewards.
For methods using an MDN, we use the best number of mixtures using a
brute force search.
The results are shown in Figure [2](#S5.F2 "Figure 2 ‣ 5.2 Continuous Control Environment ‣ 5 Experiments ‣ Maximum Causal Tsallis Entropy Imitation Learning").
For three problems, except Walker2d, MCTEIL outperforms the other
methods with respect to the average return as the number of
demonstrations increases.
For Walker2d, MCTEIL and soft GAIL show similar performance.
Especially, in the reacher problem, we obtain the similar results reported in [ho2016generative](#bib.bib9) ,
where BC works better than GAIL.
However, our method shows the best performance
for all demonstration counts.
It is observed that the MDN policy tends to show high performance
consistently since MCTEIL and soft GAIL are consistently ranked within the
top two high performing algorithms.
From these results, we can conclude that an MDN policy explores better
than a single Gaussian policy since an MDN can keep searching multiple
directions during training.
In particular, since the maximum Tsallis entropy makes each mixture
mean explore in different directions and a sparsemax distribution
assigns zero weight to unnecessary mixture components, MCTEIL
efficiently explores and shows better performance compared to soft
GAIL with a soft MDN.
Consequently, we can conclude that MCTEIL outperforms other imitation
learning methods and the causal Tsallis entropy has benefits over the
causal Gibbs-Shannon entropy as it encourages exploration more
efficiently.

Figure 2:
Average returns of trained policies.
For soft GAIL and MCTEIL, k indicates the number of mixture
and α is an entropy regularization coefficient.
A dashed line indicates the performance of an expert.
6 Conclusion
-------------
In this paper, we have proposed a novel maximum causal Tsallis entropy
(MCTE) framework, which induces a sparsemax distribution as the optimal
solution.
We have also provided the full mathematical analysis of the proposed framework,
including the concavity of the problem, the optimality
condition, and the interpretation as robust Bayes.
We have also developed the maximum causal Tsallis entropy imitation
learning (MCTEIL) algorithm, which can efficiently solve a MCTE
problem in a continuous action space since the Tsallis entropy of a
mixture of Gaussians encourages exploration and efficient mixture
utilization.
In experiments, we have verified that the proposed method has
advantages over existing methods for learning the multi-modal behavior of
an expert since a sparse MDN can search in diverse directions
efficiently.
Furthermore, the proposed method has outperformed BC,
GAIL, and GAIL with a soft MDN on the standard IL problems in the
MuJoCo environment.
From the analysis and experiments, we have shown that the proposed
MCTEIL method is an efficient and principled way to learn the
multi-modal behavior of an expert. |
11af412b-749d-4389-be92-71da2a6dee7c | trentmkelly/LessWrong-43k | LessWrong | Meetup : Sydney Rationality Dojo - Focused-grit and TAPs
Discussion article for the meetup : Sydney Rationality Dojo - Focused-grit and TAPs
WHEN: 02 November 2014 04:00:00PM (+1100)
WHERE: Humanist House, 10 Shepherd St Chippendale
The next dojo will be run by our new CFAR alumnus Taryn, who will be talking about focused grit and trigger action planning. Now is a great time to come if you have been considered coming before but haven't yet made it!
Afterwards (6pm) there will be an optional group dinner for those who are interested.
Discussion article for the meetup : Sydney Rationality Dojo - Focused-grit and TAPs |
f6e31408-f16c-4fa1-931d-09e673c91f58 | trentmkelly/LessWrong-43k | LessWrong | Have no excuses
> Except in a very few [tennis] matches, usually with world-class performers, there is a point in every match (and in some cases it's right at the beginning) when the loser decides he's going to lose. And after that, everything he does will be aimed at providing an explanation of why he will have lost. He may throw himself at the ball (so he will be able to say he's done his best against a superior opponent). He may dispute calls (so he will be able to say he's been robbed). He may swear at himself and throw his racket (so he can say it was apparent all along he wasn't in top form). His energies go not into winning but into producing an explanation, an excuse, a justification for losing.
― C. Terry Warner, Bonds That Make Us Free
Throughout high school and college, I noticed that many of my peers seemed like they were trying hard, but they weren't trying hard to learn content or pass classes — they were trying hard to make sure that they had good excuses and cover stories prepared for when they failed. Seeing this, I resolved that I would never excuse my own failures to myself — not even if I had a very good excuse. If you have an excuse prepared, you will be tempted to fall back on it. An excuse makes failure more acceptable, in some way. It's a license to fail.
If you really need to succeed on a task, then I suggest that you resolve to refuse to excuse your failure, in the event that you do fail. Even if the failure was understandable. Even if you failed for unfair reasons, due to things you couldn't have foreseen. Simply refuse to speak the excuse. Understand your errors, and learn from them, but if people demand to know why you failed, say only, "I'm sorry. I wasn't good enough." You may add "and I think I know what I did wrong, and I'll work to fix it, and I'll do better next time," but only if that's true.
Don't add anything else: if you want to play to win, you have to refuse to acknowledge excuses. If you were excused then you were helpless, and you co |
f8dfda34-4fb0-4a9a-9b2d-2db3b1869327 | trentmkelly/LessWrong-43k | LessWrong | How much, and on what margins, should we be rethinking quarantine protocols?
This not a researched or even all that thought out question. Perhaps it's a long rambling collection of thoughts tossed into some basket, shaken a bit and then labelled as question.
Zvi's Omicrom 12 post regarding the impact of infections on overall economic activity has me thinking perhaps the CDC has not gone far enough.
Why is that not just some crazy talk? Well, I'm not sold on it not being that but am trying to consider this from a cost-benefit view.
1. More and more evidence is coming in saying Omicron is more mild, even if more infectious.
2. I think it's been well established that masks actually work pretty good for keeping those infected from spreading the virus to others.
3. Revolutions start when people are hungry or afraid -- or just generally annoyed by things repeatedly over a long enough time frame -- or it seems like that.
4. If we do see a lot of activity shutdown (and I've seen a few days where shelves have been pretty empty (dairy, produce) where I live. When I asked about the lack of milk one of the stockers in the store said the truck didn't arrive the prior night. (Could have been weather related but the other observations can not be attributed to weather.)
5. The government solution is pretty much tapped out at this point I think. Further "taking up aggregate demand shortages" is not in the budget, will just further fuel inflation pressures and does nothing to increase production.
So seems like there might be a bit of weight on the cost side here.
What about the benefit side?
We don't really seem to be slowing the spread down unless someone wants to follow the China plan. I don't think that works. For the most part we're also (not only but in numbers terms) largely benefiting by preventing the spread of low key sickness.
If we didn't really have a quarantine policy but do have a mask mandate (5 days? 10 Days?) for those testing positive that seems to put us more in the "normal" world where people who are sick are expected to avo |
4394d522-c379-44cf-99b7-c2ecafe0da2e | trentmkelly/LessWrong-43k | LessWrong | Now Accepting Player Applications for Band of Blades
I'm running my very first paid RPG campaign! I'm reaching out to the LW / ACX community first to see if we can fill the player roster, because y'all are pretty cool. I'm posting this here so I can link to it from elsewhere without a massive text dump.
The Campaign
You are the Legion, the oldest standing military force in the world. The Cinder King and his armies of undead have been growing in power for years, and you were recruited to fight alongside the combined armies of the Eastern and Western Kingdoms against the grotesque and fearsome hordes.
You lost.
Now, the surviving Legionnaires and command staff are the only cohesive military force standing between the armies of the undead and the unprotected spine of your homeland. If you can survive the long retreat to Skydagger Keep and hold for the winter, perhaps the Kingdoms stand a chance; if not, the Cinder King's victory is all but assured.
The Details
System: Band of Blades by Evil Hat Productions
Number of Players: 3-5
Session 0 Date: Monday 05 Feb
Time: 7:00pm EST
Length: Approximately 20-30 sessions of 3-4 hours each.
Platform: Roll20
Communication: Discord
Technical Requirements: A Roll20 and Discord account. No prior gaming experience is required. All necessary resources will be made available on Roll20 and/or the game's Discord server. The full rulebook is available on evilhat.com. It's not required, but it's always good to support the game developers!
Difficulty: Moderate to High. This game doesn't pull punches; characters can suffer grievous injuries and die. The Legion's resources are finite and must be managed carefully. Creative and competent play is rewarded. It is possible to outright lose the game.
You Might Enjoy This Game If
* You like simple game mechanics that allow a focus on narrative.
* You want to kill zombies in creative ways.
* You're okay with some elements of horror.
* You like being the underdog, fighting with your allies against overwhelming odds.
* You like pl |
b0219d42-c813-4c5b-90aa-d9464513dc63 | StampyAI/alignment-research-dataset/arxiv | Arxiv | First-order Adversarial Vulnerability of Neural Networks and Input Dimension
1 Introduction
---------------
Following the work of Goodfellow et al. ([2015](#bib.bib7)), Convolutional Neural
Networks (CNNs) have been found vulnerable to adversarial examples: an
adversary can drive the performance of state-of-the art CNNs down to chance
level with imperceptible changes to the inputs.
Based on a simple linear model, [Goodfellow et al.](#bib.bib7) already noted that adversarial vulnerability should depend on input
dimension. Gilmer et al. ([2018](#bib.bib6)); Shafahi et al. ([2019](#bib.bib21)) later
confirmed this, by showing that adversarial robustness
is harder to obtain with larger input dimension. However, these results
are different in nature from [Goodfellow et al.](#bib.bib7)’s
original observation: they rely on assumptions on the dataset that amount
to a form of uniformity in distribution over the input dimensions (e.g. concentric spheres, or bounded densities with full support). In the end,
this analysis tends to incriminate the data: if the data can be anything, and in
particular if it can spread homogeneously across many
input dimensions, then robust classification gets harder.
Image datasets do not satisfy these assumptions: they do not have full
support, and their probability distributions get more and more peaked with
larger input dimension (pixel correlation increases). Intuitively, for image
classification, higher resolution should help, not hurt.
Hence data might be the wrong culprit: if we want to understand the
vulnerability of our classifiers, then we should understand what is wrong with
our classifiers, not with our images.
We therefore follow [Goodfellow et al.](#bib.bib7)’s original
approach, which explains adversarial vulnerability by properties of the
classifiers. Our main theoretical results start by formally extending
their result for a single linear layer to almost all current deep
feedforward network architectures. There is a further correction: based
on the gradients of a linear layer, [Goodfellow et al.](#bib.bib7)
predicted a linear increase of adversarial vulnerability with input
dimension d𝑑ditalic\_d. However, they did not take into account that a layer’s typical weights decrease
like d𝑑\sqrt{d}square-root start\_ARG italic\_d end\_ARG. Accounting for this, the dependence becomes d𝑑\sqrt{d}square-root start\_ARG italic\_d end\_ARG
rather than d𝑑ditalic\_d, which is confirmed by both our theory and experiments.
Our approach relies on evaluating the norm of gradients of the network
output with respect to its inputs. At first order, adversarial
vulnerability is related to gradient norms. We show that this norm is a
function of input dimension only, whatever the network architecture is.
The analysis is fully formal at initialization, and experiments show that
the predictions remain valid throughout training with very good
precision.
Obviously, this approach assumes that the classifier and loss are
differentiable. So arguably it is unclear whether it can explain the
vulnerability of networks with obfuscated or masked gradients. Still,
Athalye et al. ([2018](#bib.bib2)) recently showed that masked gradients only
give a false sense of security: by reconstructing gradient approximations
(using differentiable nets!), the authors circumvented all
state-of-the-art masked-gradient defenses. This suggests that explaining
the vulnerability of differentiable nets is crucial, even for
non-differentiable nets.
Although adversarial vulnerability was known to increase with gradient norms,
the exact relation between the two, and the approximations made, are
seldom explained, let alone tested empirically.
Section [2](#S2 "2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") therefore starts with a detailed
discussion of the relationship between adversarial vulnerability and
gradients of the loss. Precise definitions
help with sorting out all approximations used. We also revisit and
formally link several old and recent defenses, such as
double-backpropagation (Drucker & LeCun, [1991](#bib.bib5)) and FGSM
(Goodfellow et al., [2015](#bib.bib7)). Section [3](#S3 "3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")
proceeds with our main theoretical results on the dimension dependence of
adversarial damage. Section [4](#S4 "4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") tests our predictions
empirically, as well as the validity of all approximations.
Our contribution can be summarized as follows.
* •
We show an empirical one-to-one relationship between average gradient norms and
adversarial vulnerability. This confirms that an essential part of adversarial
vulnerability arises from first-order phenomena.
* •
We formally prove that, at initialization, the first-order vulnerability of common
neural networks increases as d𝑑\sqrt{d}square-root start\_ARG italic\_d end\_ARG with input dimension d𝑑ditalic\_d.
Surprisingly, this is almost
independent of the architecture. Almost all current architectures are hence, by
design, vulnerable at initialization.
* •
We empirically show that this dimension dependence persists after both
usual and robust (PGD) training, but gets dampened and eventually vanishes with
higher regularization. Our experiments suggest that PGD-regularization
effectively recovers dimension independent accuracy-vulnerability trade-offs.
* •
We observe that further training after the
training loss
has reached its minimum can provide improved test accuracy, but severely damages the
network’s robustness. The last few accuracy points require a considerable
increase of network gradients.
* •
We notice a striking discrepancy between the gradient norms (and
therefore the vulnerability) on the training and test sets respectively. It
suggests that gradient properties do not generalize well and that, outside the
training set, networks may tend to revert to initialization-like gradient
properties.
Overall, our results show that, without strong regularization, the gradients
and vulnerability of current networks naturally tend to grow with input
dimension. This suggests that current networks have too many degrees of
‘gradient-freedom’. Gradient regularization can counter-balance this
to some extent, but on the long run, our networks may benefit from
incorporating more data-specific knowledge. The independence of our results on
the network architecture (within the range of currently common
architectures) suggests that doing so would require new network
modules.
##### Related Literature
Goodfellow et al. ([2015](#bib.bib7)) already noticed
the dimension dependence of adversarial vulnerability. As opposed to
Amsaleg et al. ([2017](#bib.bib1)); Gilmer et al. ([2018](#bib.bib6)); Shafahi et al. ([2019](#bib.bib21)), their
(and our) explanation of the dimension dependence is data-independent.
Incidentally, they also link adversarial vulnerability to loss gradients and
use it to derive the FGSM adversarial augmentation defense (see
Section [2](#S2 "2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")). Ross & Doshi-Velez ([2018](#bib.bib19)) propose to
robustify networks using the old double-backpropagation, but make no connection
to FGSM and adversarial augmentation (see our Prop.[3](#Thmtheorem3 "Proposition 3. ‣ Link to adversarially augmented training. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
Lyu et al. ([2015](#bib.bib12)) discuss and use the connection between gradient-penalties
and adversarial augmentation, but surprisingly never empirically compare both,
which we do in Section [4.1](#S4.SS1 "4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"). This experiment is crucial to confirm
the validity of the first-order approximation made in ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) to link
adversarial damage and loss-gradients. Hein & Andriushchenko ([2017](#bib.bib9)) derived yet another
gradient-based penalty –the *cross-Lipschitz*-penalty– by considering
and proving formal guarantees on adversarial vulnerability (see
App.[D](#A4 "Appendix D Comparison to the Cross-Lipschitz Regularizer ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")). Penalizing network-gradients is also at the heart of
contractive auto-encoders as proposed by Rifai et al. ([2011](#bib.bib18)), where it
is used to regularize the encoder-features. A gradient regularization of the
loss of generative models also appears in Proposition 6 of
Ollivier ([2014](#bib.bib16)), where it stems from a code-length bound on the
data (minimum description length). For further references on adversarial
attacks and defenses, see e.g. Yuan et al. ([2017](#bib.bib24)).
2 From Adversarial Examples to Large Gradients
-----------------------------------------------
Suppose that a given classifier
φ𝜑\varphiitalic\_φ classifies an image 𝒙𝒙\bm{x}bold\_italic\_x as being in category
φ(𝒙)𝜑𝒙\varphi(\bm{x})italic\_φ ( bold\_italic\_x ). An adversarial image is a small modification of
𝒙𝒙\bm{x}bold\_italic\_x, barely noticeable to the human eye, that suffices
to fool the classifier into predicting a class different from φ(𝒙)𝜑𝒙\varphi(\bm{x})italic\_φ ( bold\_italic\_x ).
It is a *small* perturbation of the inputs, that creates a
*large* variation of outputs. Adversarial examples thus seem inherently related
to large gradients of the network. A connection that we will now clarify.
Note that visible adversarial examples
sometimes appear in the literature, but we deliberately focus on imperceptible
ones.
##### Adversarial vulnerability and adversarial damage.
In practice, an adversarial image is constructed by adding a perturbation
𝜹𝜹\bm{\delta}bold\_italic\_δ to the original image 𝒙𝒙\bm{x}bold\_italic\_x such that ‖𝜹‖≤ϵnorm𝜹italic-ϵ\left\|\bm{\delta}\right\|\leq\epsilon∥ bold\_italic\_δ ∥ ≤ italic\_ϵ for some (small) number
ϵitalic-ϵ\epsilonitalic\_ϵ and a given norm ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥ over the input space.
We call the perturbed input 𝒙+𝜹𝒙𝜹\bm{x}+\bm{\delta}bold\_italic\_x + bold\_italic\_δ an ϵitalic-ϵ\epsilonitalic\_ϵ-sized
∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥-attack and say that the attack was successful when φ(𝒙+𝜹)≠φ(𝒙)𝜑𝒙𝜹𝜑𝒙\varphi(\bm{x}+\bm{\delta})\neq\varphi(\bm{x})italic\_φ ( bold\_italic\_x + bold\_italic\_δ ) ≠ italic\_φ ( bold\_italic\_x ). This motivates
######
Definition 1.
Given a distribution P𝑃Pitalic\_P over the input-space, we call *adversarial
vulnerability* of a classifier φ𝜑\varphiitalic\_φ to an ϵitalic-ϵ\epsilonitalic\_ϵ-sized
∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥-attack the probability that there exists a perturbation
𝜹𝜹\bm{\delta}bold\_italic\_δ of 𝒙𝒙\bm{x}bold\_italic\_x such that
| | | | |
| --- | --- | --- | --- |
| | ‖𝜹‖≤ϵandφ(𝒙)≠φ(𝒙+𝜹).formulae-sequencenorm𝜹italic-ϵand𝜑𝒙𝜑𝒙𝜹\left\|\bm{\delta}\right\|\leq\epsilon\quad\text{and}\quad\varphi(\bm{x})\neq\varphi(\bm{x}+\bm{\delta})\,.∥ bold\_italic\_δ ∥ ≤ italic\_ϵ and italic\_φ ( bold\_italic\_x ) ≠ italic\_φ ( bold\_italic\_x + bold\_italic\_δ ) . | | (1) |
We call the average increase-after-attack 𝔼𝒙∼P[Δℒ]subscript𝔼similar-to𝒙𝑃delimited-[]Δℒ\mathop{\mathbb{E}\_{\bm{x}\sim P}}\left[\Delta\mathcal{L}\right]start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x ∼ italic\_P end\_POSTSUBSCRIPT end\_BIGOP [ roman\_Δ caligraphic\_L ]
of a loss ℒℒ\mathcal{L}caligraphic\_L the *adversarial (ℒℒ\mathcal{L}caligraphic\_L-) damage* (of the
classifier φ𝜑\varphiitalic\_φ to an ϵitalic-ϵ\epsilonitalic\_ϵ-sized ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥-attack).
When ℒℒ\mathcal{L}caligraphic\_L is the 0-1-loss ℒ0/1subscriptℒ01\mathcal{L}\_{0/1}caligraphic\_L start\_POSTSUBSCRIPT 0 / 1 end\_POSTSUBSCRIPT, adversarial damage is the
accuracy-drop after attack.
The 0-1-loss damage is always smaller than
adversarial vulnerability, because vulnerability counts all class-changes of
φ(𝒙)𝜑𝒙\varphi(\bm{x})italic\_φ ( bold\_italic\_x ), whereas some of them may be neutral to adversarial damage
(e.g. a change between two wrong classes). The
ℒ0/1subscriptℒ01\mathcal{L}\_{0/1}caligraphic\_L start\_POSTSUBSCRIPT 0 / 1 end\_POSTSUBSCRIPT-adversarial
damage thus lower bounds adversarial vulnerability. Both are even equal when
the classifier is perfect (before attack), because then every change of label
introduces an error.
It is hence tempting to evaluate adversarial vulnerability
with ℒ0/1subscriptℒ01\mathcal{L}\_{0/1}caligraphic\_L start\_POSTSUBSCRIPT 0 / 1 end\_POSTSUBSCRIPT-adversarial damage.
##### From Δℒ0/1Δsubscriptℒ01\Delta\mathcal{L}\_{0/1}roman\_Δ caligraphic\_L start\_POSTSUBSCRIPT 0 / 1 end\_POSTSUBSCRIPT to ΔℒΔℒ\Delta\mathcal{L}roman\_Δ caligraphic\_L and to ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L.
In practice however, we do not train our classifiers with the
non-differentiable 0-1-loss but use a smoother surrogate loss ℒℒ\mathcal{L}caligraphic\_L, such as
the cross-entropy loss. For similar reasons, we will now investigate the
adversarial damage 𝔼𝒙[Δℒ(𝒙,c)]subscript𝔼𝒙delimited-[]Δℒ𝒙𝑐\mathop{\mathbb{E}\_{\bm{x}}}\left[\Delta\mathcal{L}(\bm{x},c)\right]start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP [ roman\_Δ caligraphic\_L ( bold\_italic\_x , italic\_c ) ] with loss ℒℒ\mathcal{L}caligraphic\_L rather
than ℒ0/1subscriptℒ01\mathcal{L}\_{0/1}caligraphic\_L start\_POSTSUBSCRIPT 0 / 1 end\_POSTSUBSCRIPT. Like for
Goodfellow et al. ([2015](#bib.bib7)); Lyu et al. ([2015](#bib.bib12)); Sinha et al. ([2018](#bib.bib22)) and many others,
a classifier φ𝜑\varphiitalic\_φ will hence be robust if, on average over 𝒙𝒙\bm{x}bold\_italic\_x, a small
adversarial perturbation 𝜹𝜹\bm{\delta}bold\_italic\_δ of 𝒙𝒙\bm{x}bold\_italic\_x creates only a small variation δℒ𝛿ℒ\delta\mathcal{L}italic\_δ caligraphic\_L of the loss. Now, if ‖𝜹‖≤ϵnorm𝜹italic-ϵ\left\|\bm{\delta}\right\|\leq\epsilon∥ bold\_italic\_δ ∥ ≤ italic\_ϵ, then a first order
Taylor expansion in ϵitalic-ϵ\epsilonitalic\_ϵ shows that
| | | | | |
| --- | --- | --- | --- | --- |
| | δℒ𝛿ℒ\displaystyle\delta\mathcal{L}italic\_δ caligraphic\_L | =max𝜹:‖𝜹‖≤ϵ|ℒ(𝒙+𝜹,c)−ℒ(𝒙,c)|absentsubscript:𝜹norm𝜹italic-ϵℒ𝒙𝜹𝑐ℒ𝒙𝑐\displaystyle=\max\_{\bm{\delta}\,:\,\left\|\bm{\delta}\right\|\leq\epsilon}|\mathcal{L}(\bm{x}+\bm{\delta},c)-\mathcal{L}(\bm{x},c)|= roman\_max start\_POSTSUBSCRIPT bold\_italic\_δ : ∥ bold\_italic\_δ ∥ ≤ italic\_ϵ end\_POSTSUBSCRIPT | caligraphic\_L ( bold\_italic\_x + bold\_italic\_δ , italic\_c ) - caligraphic\_L ( bold\_italic\_x , italic\_c ) | | | (2) |
| | | ≈max𝜹:‖𝜹‖≤ϵ|∂𝒙ℒ⋅𝜹|=ϵ‖|∂𝒙ℒ|‖,absentsubscript:𝜹norm𝜹italic-ϵsubscript𝒙⋅ℒ𝜹italic-ϵnormsubscript𝒙ℒ\displaystyle\approx\max\_{\bm{\delta}\,:\,\left\|\bm{\delta}\right\|\leq\epsilon}\left|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\cdot\bm{\delta}\right|=\epsilon\,{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right|\kern-1.07639pt\right|\kern-1.07639pt\right|},≈ roman\_max start\_POSTSUBSCRIPT bold\_italic\_δ : ∥ bold\_italic\_δ ∥ ≤ italic\_ϵ end\_POSTSUBSCRIPT | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ⋅ bold\_italic\_δ | = italic\_ϵ | | | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | | | , | |
where ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L denotes the gradient of ℒℒ\mathcal{L}caligraphic\_L with respect to 𝒙𝒙\bm{x}bold\_italic\_x, and where
the last equality stems from the definition of the dual norm |||⋅|||{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\cdot\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}| | | ⋅ | | |
of ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥.
Now two remarks. First: the dual norm only kicks in
because we let the input noise 𝜹𝜹\bm{\delta}bold\_italic\_δ optimally adjust to the coordinates of
∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L within its ϵitalic-ϵ\epsilonitalic\_ϵ-constraint. This is the brand mark of
*adversarial* noise: the different coordinates add up,
instead of statistically canceling each other out as they would with random
noise. For example, if we impose
that ‖𝜹‖2≤ϵsubscriptnorm𝜹2italic-ϵ\left\|\bm{\delta}\right\|\_{2}\leq\epsilon∥ bold\_italic\_δ ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ≤ italic\_ϵ, then 𝜹𝜹\bm{\delta}bold\_italic\_δ will strictly align with ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L.
If instead ‖𝜹‖∞≤ϵsubscriptnorm𝜹italic-ϵ\left\|\bm{\delta}\right\|\_{\infty}\leq\epsilon∥ bold\_italic\_δ ∥ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT ≤ italic\_ϵ, then 𝜹𝜹\bm{\delta}bold\_italic\_δ will align with the
sign of the coordinates of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L. Second remark: while the Taylor expansion
in ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) becomes exact for infinitesimal perturbations, for finite
ones it may actually be dominated by higher-order terms.
Our experiments (Figures [4](#A6.F4 "Figure 4 ‣ Effect of Changing the Attack-Method on Adversarial Vulnerability ‣ Appendix F Additional Figures on the Experiments of Section 4.1 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") & [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) however strongly suggest
that in practice the first order term dominates the others.
Now, remembering that the dual norm of an ℓpsubscriptℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-norm is the corresponding
ℓqsubscriptℓ𝑞\mathcal{\ell}\_{q}roman\_ℓ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT-norm, and summarizing, we have proven
######
Lemma 2.
At first order approximation in ϵitalic-ϵ\epsilonitalic\_ϵ, an ϵitalic-ϵ\epsilonitalic\_ϵ-sized adversarial
attack generated with norm ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥ increases the loss ℒℒ\mathcal{L}caligraphic\_L at
point 𝐱𝐱\bm{x}bold\_italic\_x by ϵ‖|∂𝐱ℒ|‖italic-ϵnormsubscript𝐱ℒ\epsilon\,{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}italic\_ϵ | | | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | | |, where |||⋅|||{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\cdot\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}| | | ⋅ | | | is the dual norm of
∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥.
In particular, an ϵitalic-ϵ\epsilonitalic\_ϵ-sized ℓpsubscriptnormal-ℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-attack increases the loss
by ϵ‖∂𝐱ℒ‖qitalic-ϵsubscriptnormsubscript𝐱ℒ𝑞\epsilon\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}italic\_ϵ ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT where 1≤p≤∞1𝑝1\leq p\leq\infty1 ≤ italic\_p ≤ ∞ and
1p+1q=11𝑝1𝑞1\frac{1}{p}+\frac{1}{q}=1divide start\_ARG 1 end\_ARG start\_ARG italic\_p end\_ARG + divide start\_ARG 1 end\_ARG start\_ARG italic\_q end\_ARG = 1.
Although the lemma is valid at first order only, it proves that *at
least* this kind of first-order vulnerability is present. Moreover, we will see
that the first-order predictions closely match the experiments, and that simple
gradient regularization helps protecting even against iterative
(non-first-order) attack methods (Figure [4](#A6.F4 "Figure 4 ‣ Effect of Changing the Attack-Method on Adversarial Vulnerability ‣ Appendix F Additional Figures on the Experiments of Section 4.1 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
##### Calibrating the threshold ϵitalic-ϵ\epsilonitalic\_ϵ to the attack-norm ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥.
Lemma [2](#Thmtheorem2 "Lemma 2. ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") shows that adversarial vulnerability depends on
three main factors:
(i) ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥, the norm chosen for the attack
(ii) ϵitalic-ϵ\epsilonitalic\_ϵ, the size of the attack, and
(iii) 𝔼𝒙‖|∂𝒙ℒ|‖subscript𝔼𝒙normsubscript𝒙ℒ\mathop{\mathbb{E}\_{\bm{x}}}\!{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP | | | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | | |, the expected *dual* norm of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L.
We could see Point [(i)](#S2.I1.i1 "item (i) ‣ Calibrating the threshold ϵ to the attack-norm ∥⋅∥. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") as a measure of our sensibility to
image perturbations, [(ii)](#S2.I1.i2 "item (ii) ‣ Calibrating the threshold ϵ to the attack-norm ∥⋅∥. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") as our sensibility
threshold, and [(iii)](#S2.I1.i3 "item (iii) ‣ Calibrating the threshold ϵ to the attack-norm ∥⋅∥. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") as the classifier’s expected marginal sensibility to a unit
perturbation. 𝔼𝒙‖|∂𝒙ℒ|‖subscript𝔼𝒙normsubscript𝒙ℒ\mathop{\mathbb{E}\_{\bm{x}}}\!{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP | | | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | | | hence intuitively captures the discrepancy between our
perception (as modeled by ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥) and
the classifier’s perception for an input-perturbation of small size ϵitalic-ϵ\epsilonitalic\_ϵ.
Of course, this viewpoint supposes that we actually found a norm ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥
(or more generally a metric) that faithfully reflects human perception – a
project in its own right, far beyond the scope of this paper.
However, it is clear that the threshold ϵitalic-ϵ\epsilonitalic\_ϵ that we choose should depend
on the norm ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥ and hence on the input-dimension d𝑑ditalic\_d.
In particular, for a given pixel-wise order of magnitude
of the perturbations 𝜹𝜹\bm{\delta}bold\_italic\_δ, the ℓpsubscriptℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-norm of the perturbation will scale like
d1/psuperscript𝑑1𝑝d^{1/p}italic\_d start\_POSTSUPERSCRIPT 1 / italic\_p end\_POSTSUPERSCRIPT. This suggests to write the
threshold ϵpsubscriptitalic-ϵ𝑝\epsilon\_{p}italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT used with ℓpsubscriptℓ𝑝\ell\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-attacks as:
| | | | |
| --- | --- | --- | --- |
| | ϵp=ϵ∞d1/p,subscriptitalic-ϵ𝑝subscriptitalic-ϵsuperscript𝑑1𝑝\epsilon\_{p}=\epsilon\_{\infty}\,d^{1/p}\,,italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT = italic\_ϵ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT italic\_d start\_POSTSUPERSCRIPT 1 / italic\_p end\_POSTSUPERSCRIPT , | | (3) |
where ϵ∞subscriptitalic-ϵ\epsilon\_{\infty}italic\_ϵ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT denotes a dimension independent constant. In
Appendix [C](#A3 "Appendix C Perception Threshold ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") we show that this scaling also preserves the average
signal-to-noise ratio ‖𝒙‖2/‖𝜹‖2subscriptnorm𝒙2subscriptnorm𝜹2\left\|\bm{x}\right\|\_{2}/\left\|\bm{\delta}\right\|\_{2}∥ bold\_italic\_x ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT / ∥ bold\_italic\_δ ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, both across norms and
dimensions, so that ϵpsubscriptitalic-ϵ𝑝\epsilon\_{p}italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT could correspond to a constant human perception-threshold.
With this in mind, the impatient reader may already jump to
Section [3](#S3 "3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"), which contains our main contributions:
the estimation of 𝔼x‖∂𝒙ℒ‖qsubscript𝔼𝑥subscriptnormsubscript𝒙ℒ𝑞\mathop{\mathbb{E}\_{x}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT for standard feedforward nets.
Meanwhile, the rest of this section shortly discusses two straightforward
defenses that we will use later and that further illustrate the role of
gradients.
##### A new old regularizer.
Lemma [2](#Thmtheorem2 "Lemma 2. ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") shows
that the loss of the network after an
ϵ2italic-ϵ2\frac{\epsilon}{2}divide start\_ARG italic\_ϵ end\_ARG start\_ARG 2 end\_ARG-sized ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥-attack is
| | | | |
| --- | --- | --- | --- |
| | ℒϵ,|||⋅|||(𝒙,c):=ℒ(𝒙,c)+ϵ2‖|∂𝒙ℒ|‖.\mathcal{L}\_{\epsilon,{\left|\kern-0.75346pt\left|\kern-0.75346pt\left|\cdot\right|\kern-0.75346pt\right|\kern-0.75346pt\right|}}(\bm{x},c):=\mathcal{L}(\bm{x},c)+\frac{\epsilon}{2}\,{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}\,.caligraphic\_L start\_POSTSUBSCRIPT italic\_ϵ , | | | ⋅ | | | end\_POSTSUBSCRIPT ( bold\_italic\_x , italic\_c ) := caligraphic\_L ( bold\_italic\_x , italic\_c ) + divide start\_ARG italic\_ϵ end\_ARG start\_ARG 2 end\_ARG | | | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | | | . | | (4) |
It is thus natural to take this loss-after-attack as a new training objective.
Here we introduced a factor 2222 for reasons that will become clear in a
moment. Incidentally, for ∥⋅∥=∥⋅∥2\left\|\cdot\right\|=\left\|\cdot\right\|\_{2}∥ ⋅ ∥ = ∥ ⋅ ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT, this new loss
reduces to an old regularization-scheme proposed by Drucker & LeCun ([1991](#bib.bib5))
called *double-backpropagation*.
At the time, the authors argued that slightly decreasing a function’s or a classifier’s
sensitivity to input perturbations should improve generalization.
In a sense, this is exactly our motivation when defending against adversarial examples.
It is thus not surprising to end up with the same regularization term.
Note that our reasoning only shows that training with one specific norm
|||⋅|||{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\cdot\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}| | | ⋅ | | | in ([4](#S2.E4 "4 ‣ A new old regularizer. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) helps to protect against adversarial
examples generated from ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥. A priori, we do not know what will
happen for attacks generated with other norms; but our experiments suggest that training
with one norm also protects against other attacks (see
Figure [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") and Section [4.1](#S4.SS1 "4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
##### Link to adversarially augmented training.
In ([1](#S2.E1 "1 ‣ Definition 1. ‣ Adversarial vulnerability and adversarial damage. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")), ϵitalic-ϵ\epsilonitalic\_ϵ designates an attack-size threshold, while in
([4](#S2.E4 "4 ‣ A new old regularizer. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")), it is a regularization-strength. Rather than a
notation conflict, this reflects an intrinsic duality between two
complementary interpretations of ϵitalic-ϵ\epsilonitalic\_ϵ, which we now investigate further.
Suppose that, instead of using the loss-after-attack,
we augment our training set with ϵitalic-ϵ\epsilonitalic\_ϵ-sized ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥-attacks
𝒙+𝜹𝒙𝜹\bm{x}+\bm{\delta}bold\_italic\_x + bold\_italic\_δ, where for each training point 𝒙𝒙\bm{x}bold\_italic\_x, the perturbation 𝜹𝜹\bm{\delta}bold\_italic\_δ is
generated on the fly to locally maximize the loss-increase.
Then we are effectively training with
| | | | |
| --- | --- | --- | --- |
| | ℒ~ϵ,∥⋅∥(𝒙,c):=12(ℒ(𝒙,c)+ℒ(𝒙+ϵ𝜹,c)),\tilde{\mathcal{L}}\_{\epsilon,\left\|\cdot\right\|}(\bm{x},c):=\frac{1}{2}(\mathcal{L}(\bm{x},c)+\mathcal{L}(\bm{x}+\epsilon\,\bm{\delta},c))\,,over~ start\_ARG caligraphic\_L end\_ARG start\_POSTSUBSCRIPT italic\_ϵ , ∥ ⋅ ∥ end\_POSTSUBSCRIPT ( bold\_italic\_x , italic\_c ) := divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG ( caligraphic\_L ( bold\_italic\_x , italic\_c ) + caligraphic\_L ( bold\_italic\_x + italic\_ϵ bold\_italic\_δ , italic\_c ) ) , | | (5) |
where by construction 𝜹𝜹\bm{\delta}bold\_italic\_δ satisfies ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
We will refer to this technique as *adversarially augmented training*.
It was first introduced by Goodfellow et al. ([2015](#bib.bib7)) with
∥⋅∥=∥⋅∥∞\left\|\cdot\right\|=\left\|\cdot\right\|\_{\infty}∥ ⋅ ∥ = ∥ ⋅ ∥ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT under the name of
FGSM111*F*ast *G*radient *S*ign *M*ethod-augmented
training.
Using the first order Taylor expansion in ϵitalic-ϵ\epsilonitalic\_ϵ of
([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")), this ‘old-plus-post-attack’ loss of
([5](#S2.E5 "5 ‣ Link to adversarially augmented training. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) simply reduces to our loss-after-attack, which proves
######
Proposition 3.
Up to first-order approximations in ϵitalic-ϵ\epsilonitalic\_ϵ,
ℒ~ϵ,∥⋅∥=ℒϵ,|||⋅|||.\tilde{\mathcal{L}}\_{\epsilon,\left\|\cdot\right\|}=\mathcal{L}\_{\epsilon,{\left|\kern-0.75346pt\left|\kern-0.75346pt\left|\cdot\right|\kern-0.75346pt\right|\kern-0.75346pt\right|}}\,.over~ start\_ARG caligraphic\_L end\_ARG start\_POSTSUBSCRIPT italic\_ϵ , ∥ ⋅ ∥ end\_POSTSUBSCRIPT = caligraphic\_L start\_POSTSUBSCRIPT italic\_ϵ , | | | ⋅ | | | end\_POSTSUBSCRIPT . Said differently, for small enough ϵitalic-ϵ\epsilonitalic\_ϵ,
adversarially augmented training with ϵitalic-ϵ\epsilonitalic\_ϵ-sized ∥⋅∥\left\|\cdot\right\|∥ ⋅ ∥-attacks
amounts to penalizing the *dual* norm |||⋅|||{\left|\kern-1.07639pt\left|\kern-1.07639pt\left|\cdot\right|\kern-1.07639pt\right|\kern-1.07639pt\right|}| | | ⋅ | | | of ∂𝐱ℒsubscript𝐱ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L with weight
ϵ/2italic-ϵ2\epsilon/2italic\_ϵ / 2.
In particular, double-backpropagation corresponds to training with
ℓ2subscriptnormal-ℓ2\ell\_{2}roman\_ℓ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT-attacks, while FGSM-augmented training corresponds to an
ℓ1subscriptnormal-ℓ1\ell\_{1}roman\_ℓ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT-penalty on ∂𝐱ℒsubscript𝐱ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L.
This correspondence between training with perturbations and using a regularizer
can be compared to Tikhonov regularization: Tikhonov regularization amounts to
training with *random* noise Bishop ([1995](#bib.bib4)), while training with
*adversarial* noise amounts to penalizing ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L.
Section [4.1](#S4.SS1 "4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")
verifies the correspondence between adversarial augmentation and gradient
regularization empirically, which also strongly suggests the empirical validity
of the first-order Taylor expansion in ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
3 Estimating ‖∂𝒙ℒ‖qsubscriptnormsubscript𝒙ℒ𝑞\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT to Evaluate Adversarial Vulnerability
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
In this section, we evaluate the size of ‖∂𝒙ℒ‖qsubscriptnormsubscript𝒙ℒ𝑞\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT for a very wide class
of standard network architectures. We show that, inside this class, the
gradient-norms are independent of the network topology and increase with input
dimension. We start with an intuitive explanation of these insights
(Sec [3.1](#S3.SS1 "3.1 Core Idea: One Neuron with Many Inputs ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) before moving to our formal statements
(Sec [3.2](#S3.SS2 "3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
###
3.1 Core Idea: One Neuron with Many Inputs
This section is for intuition only: no assumption made here is used later.
We start by showing how changing q𝑞qitalic\_q affects the size of
‖∂𝒙ℒ‖qsubscriptnormsubscript𝒙ℒ𝑞\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT. Suppose for a moment that the coordinates of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L have
typical magnitude |∂𝒙ℒ|subscript𝒙ℒ|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}|| bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L |. Then ‖∂𝒙ℒ‖qsubscriptnormsubscript𝒙ℒ𝑞\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT scales like d1/q|∂𝒙ℒ|superscript𝑑1𝑞subscript𝒙ℒd^{1/q}|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}|italic\_d start\_POSTSUPERSCRIPT 1 / italic\_q end\_POSTSUPERSCRIPT | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L |.
Consequently
| | | | |
| --- | --- | --- | --- |
| | ϵp‖∂𝒙ℒ‖q∝ϵpd1/q|∂𝒙ℒ|∝d|∂𝒙ℒ|.proportional-tosubscriptitalic-ϵ𝑝subscriptnormsubscript𝒙ℒ𝑞subscriptitalic-ϵ𝑝superscript𝑑1𝑞subscript𝒙ℒproportional-to𝑑subscript𝒙ℒ\epsilon\_{p}\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}\ \propto\ \epsilon\_{p}\,d^{1/q}\,|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}|\ \propto\ d\,|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}|\,.italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT ∝ italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT italic\_d start\_POSTSUPERSCRIPT 1 / italic\_q end\_POSTSUPERSCRIPT | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | ∝ italic\_d | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | . | | (6) |
This equation carries two important messages. First, we see how ‖∂𝒙ℒ‖qsubscriptnormsubscript𝒙ℒ𝑞\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT
depends on d𝑑ditalic\_d and q𝑞qitalic\_q. The dependence seems highest for q=1𝑞1q=1italic\_q = 1. But once we
account for the varying perceptibility threshold ϵp∝d1/pproportional-tosubscriptitalic-ϵ𝑝superscript𝑑1𝑝\epsilon\_{p}\propto d^{1/p}italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT ∝ italic\_d start\_POSTSUPERSCRIPT 1 / italic\_p end\_POSTSUPERSCRIPT, we see that adversarial vulnerability scales like d⋅|∂𝒙ℒ|⋅𝑑subscript𝒙ℒd\cdot|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}|italic\_d ⋅ | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L |,
whatever ℓpsubscriptℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-norm we use.
Second, ([6](#S3.E6 "6 ‣ 3.1 Core Idea: One Neuron with Many Inputs ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) shows that to be robust against any type
of ℓpsubscriptℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-attack at any input-dimension d𝑑ditalic\_d, the average absolute value of
the coefficients of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L must grow slower than 1/d1𝑑1/d1 / italic\_d. Now, here is the
catch, which brings us to our core insight.
In order to preserve the activation variance of the neurons from layer
to layer, the neural weights are usually initialized with a variance that is
inversely proportional to the number of inputs per neuron.
Imagine for a moment that the network consisted only of one output neuron o𝑜oitalic\_o
linearly connected to all input pixels. For the purpose of this example,
we assimilate o𝑜oitalic\_o and ℒℒ\mathcal{L}caligraphic\_L. Because we initialize the weights with
a variance of 1/d1𝑑1/d1 / italic\_d, their average absolute value |∂xo|≡|∂𝒙ℒ|subscript𝑥𝑜subscript𝒙ℒ|\bm{\partial}\_{x}o|\equiv|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}|| bold\_∂ start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT italic\_o | ≡ | bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L |
grows like 1/d1𝑑1/\sqrt{d}1 / square-root start\_ARG italic\_d end\_ARG, rather than the required 1/d1𝑑1/d1 / italic\_d.
By ([6](#S3.E6 "6 ‣ 3.1 Core Idea: One Neuron with Many Inputs ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")), the adversarial vulnerability ϵ‖∂xo‖q≡ϵ‖∂𝒙ℒ‖qitalic-ϵsubscriptnormsubscript𝑥𝑜𝑞italic-ϵsubscriptnormsubscript𝒙ℒ𝑞\epsilon\left\|\bm{\partial}\_{x}o\right\|\_{q}\equiv\epsilon\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}italic\_ϵ ∥ bold\_∂ start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT italic\_o ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT ≡ italic\_ϵ ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT therefore increases
like d/d=d𝑑𝑑𝑑{d/\sqrt{d}=\sqrt{d}}italic\_d / square-root start\_ARG italic\_d end\_ARG = square-root start\_ARG italic\_d end\_ARG.
*This toy example shows that the standard initialization scheme, which preserves
the variance from layer to layer, causes the average coordinate-size |∂𝐱ℒ|subscript𝐱ℒ|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}|| bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L | to
grow like 1/d1𝑑1/\sqrt{d}1 / square-root start\_ARG italic\_d end\_ARG instead of 1/d1𝑑1/d1 / italic\_d. When an ℓ∞subscriptnormal-ℓ\mathcal{\ell}\_{\infty}roman\_ℓ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT-attack tweaks its
ϵitalic-ϵ\epsilonitalic\_ϵ-sized input-perturbations to align with the coordinate-signs of
∂𝐱ℒsubscript𝐱ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L, all coordinates of ∂𝐱ℒsubscript𝐱ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L add up in absolute value, resulting in an
output-perturbation that scales like ϵditalic-ϵ𝑑\epsilon\sqrt{d}italic\_ϵ square-root start\_ARG italic\_d end\_ARG and leaves the network
increasingly vulnerable with growing input-dimension.*
###
3.2 Formal Statements for Deep Networks
Our next theorems formalize and generalize the previous toy example to a very
wide class of feedforward nets with ReLU activation functions. For
illustration purposes, we start with fully connected nets before proceeding
with the broader class, which includes any succession of (possibly strided)
convolutional layers. In essence, the proofs iterate our insight on one layer
over a sequence of layers. They all rely on the following set
(ℋℋ\mathcal{H}caligraphic\_H)
of hypotheses:
1. H1
Non-input neurons are followed by a ReLU
killing half of its inputs, independently of the weights.
2. H2
Neurons are partitioned into layers, meaning
groups that each path traverses at most once.
3. H3
All weights have 00 expectation and variance
2/(in-degree)2in-degree2/(\text{in-degree})2 / ( in-degree ) (‘He-initialization’).
4. H4
The weights from different layers are independent.
5. H5
Two distinct weights w,w′
𝑤superscript𝑤′w,w^{\prime}italic\_w , italic\_w start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT from a same node satisfy
𝔼[ww′]=0𝔼delimited-[]𝑤superscript𝑤′0\mathop{\mathbb{E}}\left[w\,w^{\prime}\right]=0blackboard\_E [ italic\_w italic\_w start\_POSTSUPERSCRIPT ′ end\_POSTSUPERSCRIPT ] = 0.
If we follow common practice and initialize our nets as proposed by
He et al. ([2015](#bib.bib8)), then [H3](#S3.I2.i3 "item H3 ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")-[H5](#S3.I2.i5 "item H5 ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") are satisfied at
initialization by design, while [H1](#S3.I2.i1 "item H1 ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") is usually a very good
approximation (Balduzzi et al., [2017](#bib.bib3)).
Note that such i.i.d. weight assumptions have been widely used to analyze
neural nets and are at the heart of very influential and
successful prior work (e.g., equivalence between neural nets and Gaussian processes as
pioneered by Neal [1996](#bib.bib15)).
Nevertheless, they do not hold after training.
That is why all our statements in this
section are to be understood as *orders of magnitudes* that are very well
satisfied at initialization both in theory and practice, and that we will confirm
experimentally for trained networks in Section [4](#S4 "4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"). Said differently,
while our theorems rely on the statistics of neural nets at initialization, our
experiments confirm their conclusions after training.
######
Theorem 4 (Vulnerability of Fully Connected Nets).
Consider a succession of fully connected layers with ReLU activations
which takes inputs 𝐱𝐱\bm{x}bold\_italic\_x of dimension d𝑑ditalic\_d,
satisfies assumptions [(ℋℋ\mathcal{H}caligraphic\_H)](#S3.I1.i1 "item (H) ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"), and outputs logits fk(𝐱)subscript𝑓𝑘𝐱f\_{k}(\bm{x})italic\_f start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ( bold\_italic\_x ) that get fed to a final
cross-entropy-loss layer ℒℒ\mathcal{L}caligraphic\_L. Then the coordinates of ∂𝐱fksubscript𝐱subscript𝑓𝑘\bm{\partial\_{\scriptscriptstyle{x}}}f\_{\scriptscriptstyle k}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT italic\_f start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT grow like
1/d1𝑑1/\sqrt{d}1 / square-root start\_ARG italic\_d end\_ARG, and
| | | | |
| --- | --- | --- | --- |
| | ‖∂𝒙ℒ‖q∝d1q−12andϵp‖∂𝒙ℒ‖q∝d.formulae-sequenceproportional-tosubscriptnormsubscript𝒙ℒ𝑞superscript𝑑1𝑞12andproportional-tosubscriptitalic-ϵ𝑝subscriptnormsubscript𝒙ℒ𝑞𝑑\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}\propto d^{\frac{1}{q}-\frac{1}{2}}\quad\mathrm{and}\quad\epsilon\_{p}\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}\propto\sqrt{d}\,.∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT ∝ italic\_d start\_POSTSUPERSCRIPT divide start\_ARG 1 end\_ARG start\_ARG italic\_q end\_ARG - divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG end\_POSTSUPERSCRIPT roman\_and italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT ∝ square-root start\_ARG italic\_d end\_ARG . | | (7) |
These networks are thus increasingly vulnerable to
ℓpsubscriptnormal-ℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-attacks with growing input-dimension.
Theorem [4](#Thmtheorem4 "Theorem 4 (Vulnerability of Fully Connected Nets). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") is a special case of the next theorem, which will show
that the previous conclusions are essentially independent of the
network-topology.
We will use the following
symmetry assumption on the neural connections. For a given path 𝒑𝒑{\bm{p}}bold\_italic\_p, let the
*path-degree* d𝒑subscript𝑑𝒑d\_{\bm{p}}italic\_d start\_POSTSUBSCRIPT bold\_italic\_p end\_POSTSUBSCRIPT be the multiset of encountered in-degrees
along path 𝒑𝒑{\bm{p}}bold\_italic\_p. For a fully connected network, this is the unordered sequence
of layer-sizes preceding the last path-node, including the input-layer.
Now consider the multiset {d𝒑}𝒑∈𝒫(x,o)subscriptsubscript𝑑𝒑𝒑𝒫𝑥𝑜\{d\_{\bm{p}}\}\_{{\bm{p}}\in\mathcal{P}(x,o)}{ italic\_d start\_POSTSUBSCRIPT bold\_italic\_p end\_POSTSUBSCRIPT } start\_POSTSUBSCRIPT bold\_italic\_p ∈ caligraphic\_P ( italic\_x , italic\_o ) end\_POSTSUBSCRIPT of all path-degrees
when 𝒑𝒑{\bm{p}}bold\_italic\_p varies among all paths from input x𝑥xitalic\_x to output o𝑜oitalic\_o.
The symmetry assumption (relatively to o𝑜oitalic\_o) is
1. (𝒮𝒮\mathcal{S}caligraphic\_S)
All input nodes x𝑥xitalic\_x have the same multiset {d𝒑}𝒑∈𝒫(x,o)subscriptsubscript𝑑𝒑𝒑𝒫𝑥𝑜\{d\_{\bm{p}}\}\_{{\bm{p}}\in\mathcal{P}(x,o)}{ italic\_d start\_POSTSUBSCRIPT bold\_italic\_p end\_POSTSUBSCRIPT } start\_POSTSUBSCRIPT bold\_italic\_p ∈ caligraphic\_P ( italic\_x , italic\_o ) end\_POSTSUBSCRIPT of path-degrees from x𝑥xitalic\_x to o𝑜oitalic\_o.
Intuitively, this means that the statistics of degrees encountered along paths to
the output are the same for all input nodes.
This symmetry assumption is exactly satisfied by fully
connected nets, almost satisfied by CNNs (up to boundary effects, which can be
alleviated via periodic or mirror padding) and exactly satisfied by strided layers,
if the layer-size is a multiple of the stride.
######
Theorem 5 (Vulnerability of Feedforward Nets).
Consider any feedforward network with linear connections and ReLU
activation functions.
Assume the net satisfies assumptions [(ℋℋ\mathcal{H}caligraphic\_H)](#S3.I1.i1 "item (H) ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") and outputs logits
fk(𝐱)subscript𝑓𝑘𝐱f\_{k}(\bm{x})italic\_f start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ( bold\_italic\_x ) that get fed to the cross-entropy-loss ℒℒ\mathcal{L}caligraphic\_L. Then
‖∂𝐱fk‖2subscriptnormsubscript𝐱subscript𝑓𝑘2\left\|\bm{\partial\_{\bm{x}}}f\_{k}\right\|\_{2}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT italic\_f start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT is independent of the input dimension
d𝑑ditalic\_d and ϵ2‖∂𝐱ℒ‖2∝dproportional-tosubscriptitalic-ϵ2subscriptnormsubscript𝐱ℒ2𝑑\epsilon\_{2}\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{2}\propto\sqrt{d}italic\_ϵ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT ∝ square-root start\_ARG italic\_d end\_ARG.
Moreover, if the net satisfies the symmetry assumption [(𝒮𝒮\mathcal{S}caligraphic\_S)](#S3.I3.i1 "item (S) ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"), then
|∂xfk|∝1/dproportional-tosubscript𝑥subscript𝑓𝑘1𝑑|\partial\_{\scriptscriptstyle{x}}f\_{\scriptscriptstyle k}|\propto 1/\sqrt{d}| ∂ start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT italic\_f start\_POSTSUBSCRIPT italic\_k end\_POSTSUBSCRIPT | ∝ 1 / square-root start\_ARG italic\_d end\_ARG
and ([7](#S3.E7 "7 ‣ Theorem 4 (Vulnerability of Fully Connected Nets). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) still holds: ‖∂𝐱ℒ‖q∝d1q−12proportional-tosubscriptnormsubscript𝐱ℒ𝑞superscript𝑑1𝑞12\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}\propto d^{\frac{1}{q}-\frac{1}{2}}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT ∝ italic\_d start\_POSTSUPERSCRIPT divide start\_ARG 1 end\_ARG start\_ARG italic\_q end\_ARG - divide start\_ARG 1 end\_ARG start\_ARG 2 end\_ARG end\_POSTSUPERSCRIPT and ϵp‖∂𝐱ℒ‖q∝dproportional-tosubscriptitalic-ϵ𝑝subscriptnormsubscript𝐱ℒ𝑞𝑑\epsilon\_{p}\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}\propto\sqrt{d}italic\_ϵ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT ∝ square-root start\_ARG italic\_d end\_ARG.
Theorems [4](#Thmtheorem4 "Theorem 4 (Vulnerability of Fully Connected Nets). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") and [5](#Thmtheorem5 "Theorem 5 (Vulnerability of Feedforward Nets). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") are proven in
Appendix [A](#A1 "Appendix A Proofs ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"). The main proof idea is that in the gradient norm computation,
the He-initialization exactly compensates the combinatorics of the number of
paths in the network, so that this norm becomes independent of the network topology.
In particular, we get
######
Corollary 6 (Vulnerability of CNNs).
In any succession of convolution and dense layers, strided or not,
with ReLU activations, that satisfies
assumptions [(ℋℋ\mathcal{H}caligraphic\_H)](#S3.I1.i1 "item (H) ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") and outputs logits that get fed to the cross-entropy-loss
ℒℒ\mathcal{L}caligraphic\_L, the gradient of the logit-coordinates scale like 1/d1𝑑1/\sqrt{d}1 / square-root start\_ARG italic\_d end\_ARG and
([7](#S3.E7 "7 ‣ Theorem 4 (Vulnerability of Fully Connected Nets). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) is satisfied. It is hence
increasingly vulnerable with growing input-resolution to attacks generated
with any ℓpsubscriptnormal-ℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-norm.
##### Remarks.
* •
Appendix [B](#A2 "Appendix B Effects of Strided and Average-Pooling Layers on Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") shows that the network gradients are dampened
when replacing strided layers by average poolings, essentially because
average-pooling weights do not follow the He-init assumption [H3](#S3.I2.i3 "item H3 ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension").
* •
Although the principles of our analysis naturally extend to residual
nets, they are not yet covered by our theorems (residual connections do not
satisfy [H3](#S3.I2.i3 "item H3 ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
* •
Current weight initializations (He-, Glorot-, Xavier-) are chosen to
preserve the variance from layer to layer, which constrains their scaling
to 1/in-degree1in-degree\nicefrac{{1}}{{\sqrt{\text{in-degree}}}}/ start\_ARG 1 end\_ARG start\_ARG square-root start\_ARG in-degree end\_ARG end\_ARG. This scaling, we show, is
incompatible with small gradients. But decreasing gradients simply by
reducing the initial weights would kill the output signal and make training
impossible for deep nets (He et al., [2015](#bib.bib8), Sec 2.2). Also note that
rescaling all weights by a constant does not change the classification
decisions, but it affects cross-entropy and therefore adversarial damage.
4 Empirical Results
--------------------

Figure 1: Average norm 𝔼𝒙‖∂𝒙ℒ‖subscript𝔼𝒙normsubscript𝒙ℒ\mathop{\mathbb{E}\_{\bm{x}}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ of the loss-gradients,
adversarial vulnerability and accuracy (before attack) of various networks trained
with different adversarial regularization methods and regularization
strengths ϵitalic-ϵ\epsilonitalic\_ϵ. Each point represents a trained network, and each
curve a training-method.
*Upper row*: A priori, the regularization-strengths ϵitalic-ϵ\epsilonitalic\_ϵ have
different meanings for each method. The near superposition of all upper-row curves
illustrates (i)𝑖(i)( italic\_i ) the duality between
adversarial augmentation and gradient regularization (Prop.[3](#Thmtheorem3 "Proposition 3. ‣ Link to adversarially augmented training. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) and (ii)𝑖𝑖(ii)( italic\_i italic\_i )
confirms the rescaling of ϵitalic-ϵ\epsilonitalic\_ϵ proposed in ([3](#S2.E3 "3 ‣ Calibrating the threshold ϵ to the attack-norm ∥⋅∥. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) and
(iii)𝑖𝑖𝑖(iii)( italic\_i italic\_i italic\_i ) supports the validity of the first-order Taylor
expansion ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
(d)𝑑(d)( italic\_d ): near functional relation between adversarial vulnerability and
average loss-gradient norms.
(e)𝑒(e)( italic\_e ): the near-perfect linear relation between the 𝔼‖∂𝒙ℒ‖1𝔼subscriptnormsubscript𝒙ℒ1\mathop{\mathbb{E}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{1}blackboard\_E ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT and
𝔼‖∂𝒙ℒ‖2𝔼subscriptnormsubscript𝒙ℒ2\mathop{\mathbb{E}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{2}blackboard\_E ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT suggests that protecting against a given
attack-norm also protects against others.
(f)𝑓(f)( italic\_f ): Merging [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")b and [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")c shows that
all adversarial augmentation and gradient regularization
methods achieve similar accuracy-vulnerability
trade-offs.
Section [4.1](#S4.SS1 "4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") empirically verifies the validity of the
first-order Taylor approximation made in ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) and the
correspondence between gradient regularization and adversarial augmentation
(Fig.[1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")). Section [4.2](#S4.SS2 "4.2 Vulnerability’s Dependence on Input Dimension ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") analyzes
the dimension dependence of the average gradient-norms and adversarial
vulnerability after usual and robust training. Section [4.1](#S4.SS1 "4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") uses an
attack-threshold ϵ∞=0.5%subscriptitalic-ϵpercent0.5\epsilon\_{\infty}=0.5\%italic\_ϵ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT = 0.5 % of the pixel-range (invisible to
humans), with PGD-attacks from the Foolbox-package (Rauber et al., [2017](#bib.bib17)).
Section [4.2](#S4.SS2 "4.2 Vulnerability’s Dependence on Input Dimension ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") uses self-coded PGD-attacks with random start with
ϵ∞=0.08%subscriptitalic-ϵpercent0.08\epsilon\_{\infty}=0.08\%italic\_ϵ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT = 0.08 %. As a safety-check, other attacks were tested as
well (see App.[4.1](#S4.SS1 "4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") & Fig.[4](#A6.F4 "Figure 4 ‣ Effect of Changing the Attack-Method on Adversarial Vulnerability ‣ Appendix F Additional Figures on the Experiments of Section 4.1 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")), but results remained essentially unchanged. Note that the
ϵ∞subscriptitalic-ϵ\epsilon\_{\infty}italic\_ϵ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT-*thresholds* should not be confused with the
*regularization-strengths* ϵitalic-ϵ\epsilonitalic\_ϵ appearing in ([4](#S2.E4 "4 ‣ A new old regularizer. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"))
and ([5](#S2.E5 "5 ‣ Link to adversarially augmented training. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")), which will be varied. The datasets were
normalized (σ≈.2𝜎.2\sigma\approx.2italic\_σ ≈ .2). All regularization-values ϵitalic-ϵ\epsilonitalic\_ϵ
are reported in these normalized units (i.e. multiply by .2.2.2.2 to
compare with 0-1 pixel values). Code available at <https://github.com/facebookresearch/AdversarialAndDimensionality>.
###
4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation
We train several CNNs with same architecture to classify CIFAR-10 images
(Krizhevsky, [2009](#bib.bib11)). For each net, we use a specific training method
with a specific regularization value ϵitalic-ϵ\epsilonitalic\_ϵ. The training methods used were
ℓ1subscriptℓ1\ell\_{1}roman\_ℓ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT- and ℓ2subscriptℓ2\ell\_{2}roman\_ℓ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT-penalization of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L (Eq. [4](#S2.E4 "4 ‣ A new old regularizer. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")), adversarial
augmentation with ℓ∞subscriptℓ\ell\_{\infty}roman\_ℓ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT- and ℓ2subscriptℓ2\ell\_{2}roman\_ℓ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT- attacks (Eq. [5](#S2.E5 "5 ‣ Link to adversarially augmented training. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")),
projected gradient descent (PGD) with randomized starts (7 steps per attack
with step-size =.2ϵ∞absent.2subscriptitalic-ϵ=.2\,\epsilon\_{\infty}= .2 italic\_ϵ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT; see Madry et al. [2018](#bib.bib13)) and the
cross-Lipschitz regularizer (Eq. [20](#A4.E20 "20 ‣ Appendix D Comparison to the Cross-Lipschitz Regularizer ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") in Appendix [D](#A4 "Appendix D Comparison to the Cross-Lipschitz Regularizer ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
For this experiment, all networks have 6 ‘strided convolution →→\rightarrow→
batchnorm →→\rightarrow→ ReLU’ layers with strides [1, 2, 2, 2, 2, 2]
respectively and 64 output-channels each, followed by a final fully-connected
linear layer. Results are summarized in Figure [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"). Each curve
represents one training method. Note that our goal here is not to advocate one
defense over another, but rather to check the validity of the Taylor expansion,
and empirically verify that first order terms (i.e., gradients) suffice to
explain much of the observed adversarial vulnerability.
Confirming first order expansion and large first-order vulnerability.
The following observations support the validity of the first order Taylor
expansion in ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) and suggest that it is a crucial component of
adversarial vulnerability:
(i) the efficiency of the first-order defense against iterative
(non-first-order) attacks (Fig.[1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")&[4](#A6.F4 "Figure 4 ‣ Effect of Changing the Attack-Method on Adversarial Vulnerability ‣ Appendix F Additional Figures on the Experiments of Section 4.1 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")a);
(ii) the striking similarity between the PGD curves (adversarial
augmentation with *iterative* attacks) and the other adversarial
training training curves (*one-step* attacks/defenses);
(iii) the functional-like dependence between any approximation of
adversarial vulnerability and 𝔼𝒙‖∂𝒙ℒ‖1subscript𝔼𝒙subscriptnormsubscript𝒙ℒ1\mathop{\mathbb{E}\_{\bm{x}}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{1}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT
(Fig.[4](#A6.F4 "Figure 4 ‣ Effect of Changing the Attack-Method on Adversarial Vulnerability ‣ Appendix F Additional Figures on the Experiments of Section 4.1 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")b), and its independence on the training
method (Fig.[1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")d).
(iv) the excellent correspondence between the gradient regularization and
adversarial augmentation curves (see next paragraph).
Said differently, adversarial examples seem indeed to be primarily caused by
large gradients of the classifier as captured via the induced loss.
Gradient regularization matches adversarial augmentation (Prop.[3](#Thmtheorem3 "Proposition 3. ‣ Link to adversarially augmented training. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
The upper row of Figure [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") plots 𝔼𝒙‖∂𝒙ℒ1‖subscript𝔼𝒙normsubscript𝒙subscriptℒ1\mathop{\mathbb{E}\_{\bm{x}}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\_{1}\right\|start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ∥,
adversarial vulnerability and accuracy as a function of ϵd1/pitalic-ϵsuperscript𝑑1𝑝\epsilon\,d^{1/p}italic\_ϵ italic\_d start\_POSTSUPERSCRIPT 1 / italic\_p end\_POSTSUPERSCRIPT.
The excellent match between the adversarial augmentation curve with p=∞𝑝p=\inftyitalic\_p = ∞
(p=2𝑝2p=2italic\_p = 2) and its gradient regularization dual counterpart with q=1𝑞1q=1italic\_q = 1 (resp. q=2𝑞2q=2italic\_q = 2) illustrates the duality between ϵitalic-ϵ\epsilonitalic\_ϵ as a threshold for
adversarially augmented training and as a regularization constant in the
regularized loss (Proposition [3](#Thmtheorem3 "Proposition 3. ‣ Link to adversarially augmented training. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")). It also supports the validity
of the first-order Taylor expansion in ([2](#S2.E2 "2 ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).

Figure 2: Input-dimension dependence of
adversarial vulnerability, gradient norms and accuracy measured on
up-sampled CIFAR-10 images. (b) Similar to our theorems’ prediction at
initialization, average gradient norms increase like d𝑑\sqrt{d}square-root start\_ARG italic\_d end\_ARG yielding (a)
higher vulnerability. Larger PGD-regularization during training can
significantly dampen this dimension dependence with (c) almost no harm to
accuracy at first (long plateau on [2](#S4.F2 "Figure 2 ‣ 4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")c). Accuracy starts getting damaged
when the dimension dependence is nearly broken (ϵ∞≈.0005subscriptitalic-ϵ.0005\epsilon\_{\infty}\approx.0005italic\_ϵ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT ≈ .0005). (d) Whatever the input-dimension, PGD-training achieves similar
accuracy-vulnerability trade-offs. (c) & (d) suggest that PGD-training
effectively recovers the original image size, 3x32x32.
Confirming correspondence of norm-dependent thresholds (Eq.[3](#S2.E3 "3 ‣ Calibrating the threshold ϵ to the attack-norm ∥⋅∥. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")).
Still on the upper row, the curves for p=∞,q=1formulae-sequence𝑝𝑞1p=\infty,q=1italic\_p = ∞ , italic\_q = 1 have no reason to match
those for p=q=2𝑝𝑞2p=q=2italic\_p = italic\_q = 2 when plotted against ϵitalic-ϵ\epsilonitalic\_ϵ, because the
ϵitalic-ϵ\epsilonitalic\_ϵ-threshold is relative to a specific attack-norm. However,
([3](#S2.E3 "3 ‣ Calibrating the threshold ϵ to the attack-norm ∥⋅∥. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) suggested that the rescaled thresholds ϵd1/pitalic-ϵsuperscript𝑑1𝑝\epsilon d^{1/p}italic\_ϵ italic\_d start\_POSTSUPERSCRIPT 1 / italic\_p end\_POSTSUPERSCRIPT may
approximately correspond to a same ‘threshold-unit’ across ℓpsubscriptℓ𝑝\ell\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-norms and
across dimension. This is well confirmed by the upper row plots: by rescaling
the x-axis, the p=q=2𝑝𝑞2p=q=2italic\_p = italic\_q = 2 and q=1𝑞1q=1italic\_q = 1, p=∞𝑝p=\inftyitalic\_p = ∞ curves get almost super-imposed.
Accuracy-vulnerability trade-off: confirming large first-order
component of vulnerability.
Merging Figures [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")b and [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")c by taking out ϵitalic-ϵ\epsilonitalic\_ϵ, Figure [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")f shows that
all gradient regularization and adversarial augmentation methods, *including
iterative ones (PGD)*, yield equivalent accuracy-vulnerability trade-offs. This
suggest that adversarial vulnerability is largely first-order. For higher
penalization values, these trade-offs appear to be much better than those given
by cross Lipschitz regularization.
The regularization-norm does not matter.
We were surprised to see that on Figures [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")d and [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")f, the ℒϵ,qsubscriptℒitalic-ϵ𝑞\mathcal{L}\_{\epsilon,q}caligraphic\_L start\_POSTSUBSCRIPT italic\_ϵ , italic\_q end\_POSTSUBSCRIPT curves are almost identical for q=1𝑞1q=1italic\_q = 1 and 2222. This indicates that both
norms can be used interchangeably in ([4](#S2.E4 "4 ‣ A new old regularizer. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) (modulo proper rescaling
of ϵitalic-ϵ\epsilonitalic\_ϵ via ([3](#S2.E3 "3 ‣ Calibrating the threshold ϵ to the attack-norm ∥⋅∥. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"))), and suggests that protecting against a
specific attack-norm also protects against others. ([6](#S3.E6 "6 ‣ 3.1 Core Idea: One Neuron with Many Inputs ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")) may
provide an explanation: if the coordinates of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L behave like centered,
uncorrelated variables with equal variance –which would follow from
assumptions [(ℋℋ\mathcal{H}caligraphic\_H)](#S3.I1.i1 "item (H) ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") –, then the ℓ1subscriptℓ1\mathcal{\ell}\_{1}roman\_ℓ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT- and ℓ2subscriptℓ2\mathcal{\ell}\_{2}roman\_ℓ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT-norms of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L are
simply proportional. Plotting 𝔼x‖∂𝒙ℒ(𝒙)‖2subscript𝔼𝑥subscriptnormsubscript𝒙ℒ𝒙2\mathop{\mathbb{E}\_{x}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}(\bm{x})\right\|\_{2}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ( bold\_italic\_x ) ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT against
𝔼x‖∂𝒙ℒ(𝒙)‖1subscript𝔼𝑥subscriptnormsubscript𝒙ℒ𝒙1\mathop{\mathbb{E}\_{x}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}(\bm{x})\right\|\_{1}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ( bold\_italic\_x ) ∥ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT in Figure [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")e confirms this explanation. The slope
is independent of the training method. (But Fig [7](#A7.F7 "Figure 7 ‣ G.2 Additional Plots ‣ Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")e shows that it is not
independent of the input-dimension.) Therefore, penalizing ‖∂𝒙ℒ(𝒙)‖1subscriptnormsubscript𝒙ℒ𝒙1\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}(\bm{x})\right\|\_{1}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ( bold\_italic\_x ) ∥ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT
during training will not only decrease 𝔼𝒙‖∂𝒙ℒ‖1subscript𝔼𝒙subscriptnormsubscript𝒙ℒ1\mathop{\mathbb{E}\_{\bm{x}}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{1}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT (as shown in
Figure [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")a), but also drive down 𝔼𝒙‖∂𝒙ℒ‖2subscript𝔼𝒙subscriptnormsubscript𝒙ℒ2\mathop{\mathbb{E}\_{\bm{x}}}\!\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{2}start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT 2 end\_POSTSUBSCRIPT and vice-versa.
###
4.2 Vulnerability’s Dependence on Input Dimension
Theorems [4](#Thmtheorem4 "Theorem 4 (Vulnerability of Fully Connected Nets). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")-[5](#Thmtheorem5 "Theorem 5 (Vulnerability of Feedforward Nets). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") and Corollary [6](#Thmtheorem6 "Corollary 6 (Vulnerability of CNNs). ‣ 3.2 Formal Statements for Deep Networks ‣ 3 Estimating ‖∂_𝒙ℒ‖_𝑞 to Evaluate Adversarial Vulnerability ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") predict a
linear growth of the average ℓ1subscriptℓ1\mathcal{\ell}\_{1}roman\_ℓ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT-norm of ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L with the square root of
the input dimension d𝑑ditalic\_d, and therefore an increased adversarial vulnerability
(Lemma [2](#Thmtheorem2 "Lemma 2. ‣ From Δℒ_{0/1} to Δℒ and to ∂_𝒙ℒ. ‣ 2 From Adversarial Examples to Large Gradients ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")). To test these predictions, we compare the
vulnerability of different PGD-regularized networks when varying the
input-dimension. To do so, we resize the original 3x32x32 CIFAR-10 images to
32, 64, 128 and 256 pixels per edge by copying adjacent pixels, and train one CNN
for each input-size and regularization strength ϵitalic-ϵ\epsilonitalic\_ϵ. All nets had the
same amount of parameters and very similar structure across input-resolutions
(see Appendix [G.1](#A7.SS1 "G.1 Network architectures ‣ Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")). All reported values were computed over
the last 20 training epochs on the same held-out test-set.
Gradients and vulnerability increase with d𝑑\sqrt{d}square-root start\_ARG italic\_d end\_ARG.
Figures [2](#S4.F2 "Figure 2 ‣ 4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")a &[2](#S4.F2 "Figure 2 ‣ 4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")b summarize the resulting dimension dependence of
gradient-norms and adversarial vulnerability. The dashed-lines follow the
medians of the 20 last epochs and the errorbars show their \nth10 and
\nth90 quantiles. Similar to the predictions of our theorems at
initialization, we see that, even after training, 𝔼𝒙[‖∂𝒙ℒ‖1]subscript𝔼𝒙delimited-[]subscriptnormsubscript𝒙ℒ1\mathop{\mathbb{E}\_{\bm{x}}}\left[\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{1}\right]start\_BIGOP blackboard\_E start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT end\_BIGOP [ ∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT 1 end\_POSTSUBSCRIPT ] grows
linearly with d𝑑\sqrt{d}square-root start\_ARG italic\_d end\_ARG which yields higher adversarial vulnerability.
However, increasing the regularization decreases the slope of
this dimension dependence until, eventually, the dependence breaks.
Accuracies are dimension independent.
Figure [2](#S4.F2 "Figure 2 ‣ 4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")c plots accuracy versus regularization strength, with errorbars
summarizing the 20 last training epochs.222Fig.[2](#S4.F2 "Figure 2 ‣ 4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")c &[2](#S4.F2 "Figure 2 ‣ 4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")c are similar to Figures [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")c &[1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")f, but with one curve per
input-dimension instead of one per regularization method. See
Appendix [G](#A7 "Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") for full equivalent of
Figure [1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension").
The four curves correspond to the four different input dimensions. They overlap,
which confirms that contrary to vulnerability, the accuracies are dimension
independent; and that the ℓ∞subscriptℓ\mathcal{\ell}\_{\infty}roman\_ℓ start\_POSTSUBSCRIPT ∞ end\_POSTSUBSCRIPT-attack thresholds are essentially
dimension independent.
PGD effectively recovers original input dimension.
Figure [2](#S4.F2 "Figure 2 ‣ 4.1 First-Order Approximation, Gradient Penalty, Adversarial Augmentation ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")d plots the accuracy-vulnerability trade-offs achieved by the
previous nets over their 20 last training epochs, with a smoothing spline
fitted for each input dimension (scipy’s UnivariateSpline with s=200). Higher
dimensions have a longer plateau to the right, because without regularization,
vulnerability increases with input dimension. The curves overlap when moving to
the left, meaning that the accuracy-vulnerability trade-offs achieved by PGD
are essentially *independent of the actual input dimension.*
PGD training outperforms down-sampling.
On artificially upsampled CIFAR-10 images, PGD regularization acts as if it
first reduced the images back to their original size before classifying them.
Can PGD outperform this strategy when the original image is really high
resolution? To test this, we create a 12-class ‘Mini-ImageNet’ dataset with
approximately 80,000 images of size 3x256x256 by merging similar ImageNet
classes and center-cropping/resizing as needed. We then do the same experiment
as with up-sampled CIFAR-10, but using down-sampling instead of up-sampling
(Appendix [H](#A8 "Appendix H Figures for the Experiments of Section 4.2 on the Custom Mini-ImageNet Dataset ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension"), Fig. [13](#A8.F13 "Figure 13 ‣ Appendix H Figures for the Experiments of Section 4.2 on the Custom Mini-ImageNet Dataset ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")). While the
dependence of vulnerability to the dimension stays essentially unchanged, PGD
training now achieves much better accuracy-vulnerability trade-offs with the
original high-dimensional images than with their down-sampled versions.
Insights from figures in Appendix [G](#A7 "Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension").
Appendix [G](#A7 "Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") reproduces many additional figures on
this section’s experiments. They yield additional insights which we summarize
here.
*Non-equivalence of loss- and accuracy-damage.*
Figure [8](#A7.F8 "Figure 8 ‣ G.2 Additional Plots ‣ Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")a&c show that the test-error
continues to decrease all over training, while the cross-entropy increases
on the test set from epoch ≈40absent40\approx 40≈ 40 and on. This aligns with the
observations and explanations of Soudry et al. ([2018](#bib.bib23)). But it also
shows that one must be careful when substituting their differentials, loss-
and accuracy-damage. (See also Fig.[9](#A7.F9 "Figure 9 ‣ G.2 Additional Plots ‣ Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")b.)
*Early stopping dampens vulnerability.*
Fig.[8](#A7.F8 "Figure 8 ‣ G.2 Additional Plots ‣ Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") shows that adversarial damage and
vulnerability closely follow the evolution of cross-entropy. Since
cross-entropy overfits, early stopping effectively acts as a defense. See
Fig.[10](#A7.F10 "Figure 10 ‣ G.2 Additional Plots ‣ Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension").
*Gradient norms do not generalize well.*
Figure [12](#A7.F12 "Figure 12 ‣ G.2 Additional Plots ‣ Appendix G Additional Material on the Up-Sampled CIFAR-10 Experiments of Section 4.2 ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension") reveals a strong discrepancy between the
average gradient norms on the test and the training data. This discrepancy
increases over training (gradient norms decrease on the training data but
increase on the test set), and with the input dimension, as d𝑑\sqrt{d}square-root start\_ARG italic\_d end\_ARG. This
dimension dependence might suggest that, outside the training points, the
networks tend to recover initial gradient properties.
Our observations confirm
[Schmidt et al.](#bib.bib20)’s ([2018](#bib.bib20))
recent finding that PGD-regularization has a hard time generalizing to the
test-set. They claim that better generalization requires more data.
Alternatively, we could try to rethink our network modules to adapt it to
the data, e.g. by decreasing their degrees of ‘gradient-freedom’.
Evaluating the gradient-sizes at initialization may help doing so.
5 Conclusion
-------------
For differentiable classifiers and losses, we showed that adversarial
vulnerability increases with the gradients ∂𝒙ℒsubscript𝒙ℒ\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L of the loss. All
approximations made are fully specified, and validated by the near-perfect
functional relationship between gradient norms and vulnerability (Fig.[1](#S4.F1 "Figure 1 ‣ 4 Empirical Results ‣ First-order Adversarial Vulnerability of Neural Networks and Input Dimension")d). We
evaluated the size of ‖∂𝒙ℒ‖qsubscriptnormsubscript𝒙ℒ𝑞\left\|\bm{\partial\_{\scriptscriptstyle x}}\mathcal{L}\right\|\_{q}∥ bold\_∂ start\_POSTSUBSCRIPT bold\_italic\_x end\_POSTSUBSCRIPT caligraphic\_L ∥ start\_POSTSUBSCRIPT italic\_q end\_POSTSUBSCRIPT and showed that, at initialization, many
current feedforward nets (convolutional or fully connected) are increasingly
vulnerable to ℓpsubscriptℓ𝑝\mathcal{\ell}\_{p}roman\_ℓ start\_POSTSUBSCRIPT italic\_p end\_POSTSUBSCRIPT-attacks with growing input dimension (image size),
independently of their architecture. Our experiments confirm this dimension
dependence after usual training, but PGD-regularization dampens it and can
effectively counter-balance the effect of artificial input dimension
augmentation. Nevertheless, regularizing beyond a certain point yields a rapid
decrease in accuracy, even though at that point many adversarial examples are
still visually undetectable for humans. Moreover, the gradient norms remain
much higher on test than on training examples. This suggests that even with PGD
robustification, there are still significant statistical differences between
the network’s behavior on the training and test sets. Given the generality of
our results in terms of architectures, this can perhaps be alleviated only via
tailored architectural constraints on the gradients of the network. Based on
these theoretical insights, we hypothesize that tweaks on the architecture may
not be sufficient, and coping with the phenomenon of adversarial examples will
require genuinely new ideas.
#### Acknowledgements
We thank Martín Arjovsky, Ilya Tolstikhin and Diego Fioravanti for helpful
discussions. |
ecd90350-3ebb-4752-bf3f-7d1851987450 | trentmkelly/LessWrong-43k | LessWrong | Interview on IQ, genes, and genetic engineering with expert (Hsu)
|
46fce202-3c58-4e14-9f2d-7dc204a404da | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Universal Fire
Today's post, Universal Fire was originally published on April 27, 2007. A summary (from the LW wiki):
> You can't change just one thing in the world and expect the rest to continue working as before.
Discuss the post here (rather than in the comments of the original post).
This post is part of a series rerunning Eliezer Yudkowsky's old posts so those interested can (re-)read and discuss them. The previous post was Feeling Rational, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it, posting the next day's sequence reruns post, summarizing forthcoming articles on the wiki, or creating exercises. Go here for more details, or to discuss the Sequence Reruns. |
c658a404-6688-4dbc-9f80-b3f518c9c655 | trentmkelly/LessWrong-43k | LessWrong | The Solomonoff prior is malign. It's not a big deal.
Epistemic status: Endorsed at ~85% probability. In particular, there might be clever but hard-to-think-of encodings of observer-centered laws of physics that tilt the balance in favor of physics. Also, this isn't that different from Mark Xu's post.
Previously, previously, previously
I started writing this post with the intuition that the Solomonoff prior isn't particularly malign, because of a sort of pigeon hole problem - for any choice of universal Turing machine there are too many complicated worlds to manipulate, and too few simple ones to do the manipulating.
Other people have different intuitions.
So there was only one thing to do.
Math.
All we have to do is compare [wild estimates of] the complexities of two different sorts of Turing machines: those that reproduce our observations by reasoning straightforwardly about the physical world, and those that reproduce our observations by simulating a totally different physical world that's full of consequentialists who want to manipulate us.
Long story short, I was surprised. The Solomonoff prior is malign. But it's not a big deal.
Team Physics:
If you live for 80 years and get 10^7 bits/s of sensory signals, you accumulate about 10^16 bits of memory to explain via Solomonoff induction.
In comparison, there are about 10^51 electrons on Earth - just writing their state into a simulation is going to take somewhere in the neighborhood of 10^51 bits[1]. So the Earth, or any physical system within 35 orders of magnitude of complexity of the Earth, can't be a Team Physics hypothesis for compressing your observations.
What's simpler than the Earth? Turns out, simulating the whole universe. The universe can be mathematically elegant and highly symmetrical in ways that Earth isn't.
For simplicity, let's suppose that "I" am a computer with a simple architecture, plus some complicated memories. The trick that allows compression is you don't need to specify the memories - you just need to give enough bits to pick ou |
1daa323d-cc26-4a14-a91c-d3ac6eb799b1 | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | What safety problems are associated with whole brain emulation?
It [seems improbable](/?state=8GJ3&question=Will%20whole%20brain%20emulation%20arrive%20before%20other%20forms%20of%20AGI%3F) that whole brain emulation (WBE) arrives before [neuromorphic AI](https://www.alignmentforum.org/tag/neuromorphic-ai), because a better understanding of the brain would probably help with the development of the latter. This makes the research path to WBE likely to accelerate capabilities and [reduce timelines](/?state=8QH5&question=Would%20a%20slowdown%20in%20AI%20capabilities%20development%20decrease%20existential%20risk%3F).
Even if WBE were to arrive first, there is some debate about whether [it would be less prone to produce existential risks than synthetic AI](https://intelligence.org/files/SS11Workshop.pdf). An accelerated WBE might be a safe template for an AGI as it would directly inherit the subject's way of thinking but some safety problems could still arise.
- This would be a very strange experience for current human psychology, and we are not sure how the resulting brain would react. As an intuition pump, very high IQ individuals are at [higher risk for psychological disorders](https://www.sciencedirect.com/science/article/pii/S0160289616303324). This suggests that we have no guarantee that a process recreating a human brain with vastly more capabilities would retain the relative stability of its biological ancestors.
- A superintelligent WBE might get a large amount of power, which historically has tended to corrupt humans.
- High speed might make interactions with normal-speed humans difficult, as explored in Robin Hanson's [The Age of Em](https://en.wikipedia.org/wiki/The_Age_of_Em).
- It is unclear whether WBE would be more predictable than AI engineered by competent safety-conscious programmers.
- Even if WBE arrives before AGI, [BNick Bostrom argues](https://publicism.info/philosophy/superintelligence/15.html) we should expect a second (potentially dangerous) transition to fully synthetic AGI due to their improved efficiency over WBE.
Nonetheless, Yudkowsky believes that [emulations are probably safer even if they are unlikely](https://www.youtube.com/watch?v=EUjc1WuyPT8&start=4286).
|
5a41e206-22fa-4d99-81ba-8f6eea33ec00 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Four Ways An Impact Measure Could Help Alignment
Impact penalties are designed to help prevent an artificial intelligence from taking actions which are catastrophic.
Despite the apparent simplicity of this approach, there are in fact a plurality of different frameworks under which impact measures could prove helpful. In this post, I seek to clarify the different ways that an impact measure could ultimately help align an artificial intelligence or otherwise benefit the long-term future.
It think it's possible [some critiques](https://www.lesswrong.com/posts/kCY9dYGLoThC3aG7w/best-reasons-for-pessimism-about-impact-of-impact-measures) of impact are grounded in an intuition that it doesn't help us achieve X, where X is something that the speaker *thought* impact was supposed to help us with, or is something that would be good to have in general. The obvious reply to these critiques is then to say that it was never intended to do X, and that impact penalties aren't meant to be a complete solution to alignment.
My hope is that in distinguishing the ways that impact penalties can help alignment, I will shed light on why some people are more pessimistic or optimistic than others. I am not necessarily endorsing the study of impact measurements as an especially tractable or important research area, but I do think it's useful to gather some of the strongest arguments for it.
Roughly speaking, I think that that an impact measure could potentially help humanity in at least one of four main scenarios.
1. Designing a utility function that roughly optimizes for what humans reflectively value, but with a recognition that mistakes are possible such that regularizing against extreme maxima seems like a good idea (ie. Impact as a regularizer).
2. Constructing an environment for testing AIs that we want to be extra careful about due to uncertainty regarding their ability to do something extremely dangerous (ie. Impact as a safety protocol).
3. Creating early-stage task AIs that have a limited function, but are not intended to do any large scale world optimization (ie. Impact as an influence-limiter).
4. Less directly, impact measures could still help humanity with alignment because researching them could allow us to make meaningful progress on [deconfusion](https://intelligence.org/2018/11/22/2018-update-our-new-research-directions/) (ie Impact as deconfusion).
---
Impact as a regularizer
=======================
In machine learning a regularizer is a term that we add to our loss function or training process that reduces the capacity of a model in the hopes of being able to generalize better.
One common instance of a regularizer is a scaled .mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
L2 norm penalty of the model parameters that we add to our loss function. A popular interpretation of this type of regularization is that it represents a prior over what we think the model parameters should be. For example, in [Ridge Regression](https://en.wikipedia.org/wiki/Tikhonov_regularization), this interpretation can be made formal by invoking a Gaussian prior on the parameters.
The idea is that in the absence of vast evidence, we shouldn't allow the model to use its limited information to make decisions that *we the researchers* understand would be rash and unjustified given the evidence.
One framing of impact measures is that we can apply the same rationale to artificial intelligence. If we consider some scheme where an AI has been the task of undertaking [ambitious value learning](https://www.lesswrong.com/posts/5eX8ko7GCxwR5N9mN/what-is-ambitious-value-learning), we should make it so that whatever the AI initially believes is the true utility function U, it should be extra cautious not to optimize the world so heavily unless it has gathered a very large amount of evidence that U really is the right utility function.
One way that this could be realized is by some form of impact penalty which eventually gets phased out as the AI gathers more evidence. This isn't *currently* the way that I have seen impact measurement framed. However, to me it is still quite intuitive.
Consider a toy scenario where we have solved ambitious value learning and decide to design an AI to optimize human values in the long term. In this scenario, when the AI is first turned on, it is given the task of learning what humans want. In the beginning, in addition to its task of learning human values, it also tries helping us in low impact ways, perhaps by cleaning our laundry and doing the dishes. Over time, as it gathers enough evidence to fully understand human culture and philosophy, it will have the confidence to do things which are much more impactful, like becoming the CEO of some corporation.
I think that it's important to note that this is not what I currently think will happen in the real world. However, I think it's useful to imagine these types of scenarios because they offer concrete starting points for what a good regularization strategy might look like. In practice, I am not too optimistic about ambitious value learning, but more [narrow forms of value learning](https://www.lesswrong.com/s/4dHMdK5TLN6xcqtyc/p/vX7KirQwHsBaSEdfK) could still benefit from impact measurements. As we are still somewhat far from any form of advanced artificial intelligence, uncertainty about which methods will work makes this analysis difficult.
Impact as a safety protocol
===========================
When I think about advanced artificial intelligence, my mind tends to [forward chain](https://en.wikipedia.org/wiki/Forward_chaining) from current AI developments, and imagines them being scaled up dramatically. In these types of scenarios, I'm most worried about something like [mesa optimization](https://www.lesswrong.com/s/r9tYkB2a8Fp4DN8yB), where in the process of making a model which performs some useful task, we end up searching over a very large space of optimizers that ultimately end up optimizing for some other task which we never intended for.
To oversimplify things for a bit, there are a few ways that we could ameliorate the issue of misaligned mesa optimization. One way is that we could find a way to robustly align arbitrary mesa objectives with base objectives. I am a bit pessimistic about this strategy working without some radical insights, because it currently seems really hard. If we could do that, it would be something which would require a huge chunk of alignment to be solved.
Alternatively, we could [whitelist](https://en.wikipedia.org/wiki/Whitelisting) our search space such that only certain safe optimizers could be discovered. This is a task where I see impact measurements could be helpful.
When we do some type of search over models, we could construct an explicit optimizer that forms the core of each model. The actual parameters that we perform gradient descent over would need to be limited enough such that we could still transparently see what type of "utility function" is being inner optimized, but not so limited that the model search itself would be useless.
If we could constrain and control this space of optimizers enough, then we should be able to explicitly add safety precautions to these mesa objectives. The exact way that this could be performed is a bit difficult for me to imagine. Still, I think that as long as we are able to perform some type of explicit constraint on what type of optimization is allowed, then it should be possible to penalize mesa optimizers in a way that could potentially avoid catastrophe.
During the process of training, the model will start unaligned and gradually shift towards performing better on the base objective. At any point during the training, we wouldn't want the model to try to do anything that might be extremely impactful, both because it will initially be unaligned, and because we are uncertain about the safety of the trained model itself. An impact penalty could thus help us to create a safe testing environment.
The intention here is not that we would add some type of impact penalty to the AIs that are *eventually* deployed. It is simply that as we perform the testing, there will be some limitation on much power we are giving the mesa optimizers. Having a penalty for mesa optimization can then be viewed as a short term safety patch in order to minimize the chances that an AI does something extremely bad that we didn't expect.
It is perhaps at first hard to see how an AI could be dangerous *during* the training process. But I believe that there is good reason to believe that as our experiments get larger, they will require artificial agents to understand more about the real world while they are training, which incurs significant risk. There are also specific predictable ways in which a model being trained could turn dangerous, such as in the case of [deceptive alignment](https://www.lesswrong.com/s/r9tYkB2a8Fp4DN8yB/p/zthDPAjh9w6Ytbeks). It is conceivable that having some way to reduce impact for optimizers in these cases will be helpful.
Impact as an influence-limiter
==============================
Even if we didn't end up putting an impact penalty directly into some type of ambitiously aligned AGI, or use it as a safety protocol during testing, there are still a few disjunctive scenarios in which impact measures could help construct limited AIs. A few examples would be if we were constructing [Oracle AIs](https://arbital.com/p/oracle/) and [Task AGIs](https://arbital.com/p/task_agi/).
Impact measurements could help Oracles by cleanly providing a separation between "just giving us true important information" and "heavily optimizing the world in the process." This is, as I understand, one of the main issue with Oracle alignment at the moment, which means that intuitively an impact measurement could be quite helpful in that regard.
One rationale for constructing a task AGI is that it allows humanity to [perform some type of important action](https://arbital.com/p/pivotal/) which buys us more time to solve the more ambitious varieties of alignment. I am personally less optimistic about this particular solution to alignment, as in my view it would require a very advanced form of coordination of artificial intelligence. In general I incline towards the view that competitive AIs will take the form of more [service-specific machine models](https://www.fhi.ox.ac.uk/wp-content/uploads/Reframing_Superintelligence_FHI-TR-2019-1.1-1.pdf), which might imply that even if we succeeded at creating some low impact AGI that achieved a specific purpose, it wouldn't be competitive with the other AIs which that themselves have no impact penalty at all.
Still, there is a broad agreement that if we have a good theory about what is happening within an AI then we are more likely to succeed at aligning it. Creating agentic AIs seems like a good way to have that form of understanding. If this is the route that humanity ends up taking, then impact measurements could provide immense value.
This justification for impact measures is perhaps the most salient in the debate over impact measurements. It seems to be behind the critique that impact measurements need to be *useful* rather than just safe and value-neutral. At the same time, I know from personal experience that there at least one person currently thinking about ways we can leverage current impact penalties to be useful in this scenario. Since I don't have a good model for how this can be done, I will refrain from specific rebuttals of this idea.
Impact as deconfusion
=====================
The concept of impact appears to neighbor other relevant alignment concepts, like [mild optimization](https://arbital.com/p/soft_optimizer/), [corrigibility](https://arbital.com/p/45/), [safe shutdowns](https://arbital.com/p/shutdown_problem/), and [task AGIs](https://arbital.com/p/task_goal/). I suspect that even if impact measures are never actually used in practice, there is still some potential that drawing clear boundaries between these concepts will help clarify approaches for designing powerful artificial intelligence.
This is essentially my model for why some AI alignment researchers believe that deconfusion is helpful. Developing a rich vocabulary for describing concepts is a key feature of how science advances. Particularly clean and insightful definitions help clarify ambiguity, allowing researchers to say things like "That technique sounds like it is a combination of X and Y without having the side effect of Z."
A good counterargument is that there isn't any particular reason to believe that *this* concept requires priority for deconfusion. It would be bordering on a [motte and bailey](https://slatestarcodex.com/2014/11/03/all-in-all-another-brick-in-the-motte/) to claim that some particular research will lead to deconfusion and then when pressed I appeal to research in general. I am not *trying* to do that here. Instead, I think that impact measurements are potentially good because they focus attention on a subproblem of AI, in particular catastrophe avoidance. And I also think there has empirically been demonstrable progress in a way that provides evidence that this approach is a good idea.
Consider David Manheim and Scott Garrabrant's [Categorizing Variants of Goodhart's Law](https://arxiv.org/pdf/1803.04585.pdf). For those unaware, Goodhart's law is roughly summed up in the saying "Whenever a measure becomes a target, it ceases to become a good measure." This paper tries to catalog all of the different cases which this phenomenon could arise. Crucially, it isn't necessary for the paper to actually present a solution to Goodhart's law in order to illuminate how we could avoid the issue. By distinguishing ways in which the law holds, we can focus on addressing those specific sub-issues rather than blindly coming up with one giant patch for the entire problem.
Similarly, the idea of impact measurement is a confusing concept. There's one interpretation in which an "impact" is some type of distance between two representations of the world. In this interpretation, saying that something had a large impact is another way of saying that the world changed a lot as a result. In [newer interpretations](https://www.lesswrong.com/posts/pf48kg9xCxJAcHmQc/understanding-recent-impact-measures) of impact, we like to say that an impact is really about a difference in what we are able to achieve.
A distinction between "difference in world models" and "differences in what we are able to do" is subtle, and enlightening (at least to me). It allows a new terminology in which I can talk about the *impact* of artificial intelligence. For example, in Nick Bostrom's founding paper on existential risk studies, his definition for existential risk included events which could
> permanently and drastically curtail [humanity's] potential.
One interpretation of this above definition is that Bostrom was referring to *potential* in the sense of the second definition of impact rather than the first.
A highly unrealistic way that this distinction could help us is if we had some future terminology which allowed us to unambiguously ask AI researchers to "see how much impact this new action will have on the world." AI researchers could then boot up an Oracle AI and ask the question in a crisply formalized framework.
More realistically, the I could imagine that the field may eventually stumble on useful cognitive strategies to frame the alignment problem such that impact measurement becomes a convenient precise concept to work with. As AI gets more powerful, the way that we understand alignment will become [nearer](https://wiki.lesswrong.com/wiki/Near/far_thinking) to us, forcing us to quickly adapt our language and strategies to the specific evidence we are given.
Within a particular subdomain, I think an AI researcher could ask questions about what they are trying to accomplish, and talk about it using the vocabulary of well understood topics, which could eventually include impact measurements. The idea of impact measurement is simple enough that it will (probably) get independently invented a few times as we get closer to powerful AI. Having thoroughly examined the concept *ahead* of time rather than afterwards offers future researchers a standard toolbox of precise, deconfused language.
I do not think the terminology surrounding impact measurements will ever quite reach the ranks of terms like "regularizer" or "loss function" but I do have an inclination to think that *simple* and *common sense* concepts should be rigorously defined as the field advances. Since we have intense uncertainty about the type of AIs that will end up being powerful, or about the approaches that will be useful, it is possibly most helpful at this point in time to develop tools which can reliably be handed off for future researchers, rather than putting too much faith into one particular method of alignment. |
1f804917-5fb9-440c-8c0f-6a414a7d8b6d | trentmkelly/LessWrong-43k | LessWrong | How my social skills went from horrible to mediocre
Over the past few months, I've become aware that my understanding of social reality had been distorted to an extreme degree. It took 29 years for me to figure out what was going on, but I finally now understand.
The situation is very simple: The amount of time that I put into interacting within typical social contexts was very small, so I didn't get enough feedback to realize that I had a major blindspot as I otherwise would have.
Now that I've identified the blindspot, I can work on it, and my social awareness has been increasing at very rapid clip. I had no idea that I had so much potential for social awareness. I had been in a fixed mindset as rather than a growth mindset, I had thought "social skills will never be my strong point, so I shouldn't spend time trying to improve them, instead I should focus on what I'm best at." I'm astonished by how much my relationships have improved over a span of mere weeks.
I give details below.
How I spent my time growing up
I've been extremely metacognitive and reflective since early childhood, and have spent most of my time optimizing for my intellectual growth. Even as a child, the things that I thought about where very unusual: at age 7, upon reflection, I realized that there's no free will in the sense that people usually think of it: that brain chemistry drives our decisions in a very strong sense.
As I grew up, my interests became more and more remote from those of my peers, and the pool of conversation topics of mutual interest diminished rapidly as I got older. For this reason, I generally found my interactions with others to be very unfulfilling: other people were rarely interested in talking about what I wanted to talk about, and I struggled to find points of mutual interest.
Because I was much more unusual than most of my conversation partners, there was an implicit assumption that the responsibility of finding common ground fell exclusively on me, rather than being shared by me and my conversation partners |
d73eea70-02ce-4c1d-a6a5-dfdbb8be3fe4 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | A Survey of the Potential Long-term Impacts of AI
***Aim**: survey the potential long-term impacts of AI, striking a balance between comprehensiveness and parsimony.*
***Where this fits with similar work**: as far as we know, the best existing materials on this topic are [this slide deck](https://docs.google.com/presentation/d/1eDHZvE0sBNwUR1Y2KEDw5t6m1Y1G4nyXmpy7jk5ODdI/edit) and sections 2 and 3 of [this forum post](https://forum.effectivealtruism.org/posts/42reWndoTEhFqu6T8/ai-governance-opportunity-and-theory-of-impact). In some sense, this paper is aiming to be a more comprehensive version of these pieces. It also includes discussion of the long-term opportunities from AI, as well as the risks.*
***Audience**: people who want an overview of the various ways that AI could have long-term impacts. This was written for an audience that isn't necessarily familiar with longtermism, so some framing points will be obvious to certain readers.*
*Work done collaboratively with Jess Whittlestone.*
*Also available [here as a PDF](https://arxiv.org/pdf/2206.11076.pdf).*
Summary
=======
Based on surveying literature on the societal impacts of AI, we identify and discuss five areas in which AI could have long-term impacts: in science, cooperation, power, epistemics, and values. Considering both possible benefits and harms, we review the state of existing research in these areas and highlight priority questions for future research.
Some takeaways:
* Advanced AI could be very good or very bad for humanity, and it is not yet determined how things will go.
* AGI is not necessary for AI to have long-term impacts. Many long-term impacts we consider could happen with "merely" [comprehensive AI services](https://forum.effectivealtruism.org/topics/comprehensive-ai-services), or plausibly also with non-comprehensive AI services (e.g. Sections 3.2 and 5.2).
* There are several different pathways through which AI could have long-term impacts, each of which could be sufficient by itself.
These takeaways are not original, but we hope we have added some depth to the arguments and to this community's understanding of the long-term impacts of AI more broadly.
1 Introduction
==============
Artificial intelligence (AI) is already being applied in and impacting many important sectors in society, including healthcare [Jiang et al. 2017], finance [Daníelsson et al. 2021], and law enforcement [Richardson et al. 2019]. Some of these impacts have been positive—such as the ability to predict the risk of breast cancer from mammograms more accurately than human radiologists [McKinney et al. 2020]—whilst others have been extremely harmful—such as the use of facial recognition technology to surveil Uighur and other minority populations in China [Hogarth & Benaich 2019]. As investment into AI research continues, we are likely to see substantial progress in AI capabilities and their potential applications, precipitating even greater societal impacts.
What is unclear is just how large and long-lasting the impacts of AI will be, and whether they will ultimately be positive or negative for humanity. In this paper we are particularly concerned with impacts of AI on the far future:[[1]](#fn-Efyn3t5KGZqghpk4r-1) impacts that would be felt not only by our generation or the next, but by many future generations who could come after us. We will refer to such impacts as *long-term impacts*.
Broadly speaking, we might expect AI to have long-term impacts because of its potential as a *general purpose technology*: one which will probably see unusually widespread use, tend to spawn complementary innovations, and have a large inherent potential for technical improvement. Historically, general purposes technologies—such as the steam engine and electricity—have tended to precipitate outsized societal impacts [Garfinkel 2022]. In this paper, we consider potential long impacts of AI which could:
* Make a **global catastrophe** more or less likely (i.e. a catastrophe that poses serious damage to human well-being on a global scale, for example by enabling the discovery of a pathogen that kills hundreds of millions of people).[[2]](#fn-Efyn3t5KGZqghpk4r-2)
* Make premature **human extinction** more or less likely.
* Make it more or less likely that important aspects of the world are “**locked in**” for an extremely long time (for example by enabling a robust totalitarian regime to persist for an extremely long time).[[3]](#fn-Efyn3t5KGZqghpk4r-3)
* Lead to **other kinds of “trajectory change”** (i.e. other persistent changes which affect how good the world is at every point in the far future, such as eliminating all disease).[[4]](#fn-Efyn3t5KGZqghpk4r-4)
We surveyed papers on the societal impacts of AI broadly, identified potential impacts in the four above categories, clustered them into areas, and did further research on each area. In what follows, we discuss five such areas: scientific progress, conflict and cooperation, power and inequality, epistemic processes and problem solving, and the values which steer humanity’s future. In each, we will review existing arguments that AI could have long-term impacts, discuss ways in which these impacts could be positive or negative, and highlight priority questions for future research. We conclude with some overall reflections on AI’s potential long-term impacts in these areas.
2 Scientific progress
=====================
One way AI could have long-term impacts is by changing how scientific progress occurs. Most of the most dramatic changes in humanity’s trajectory so far can be attributed at least partly to scientific or technological breakthroughs, for example the development of the steam engine enabling industrialisation; many advances in modern medicine leading to much longer lifespans; and the invention of computers and the internet which have fundamentally changed the way we communicate and connect across the world. Of all the ways AI could shape scientific progress, the potential to drastically *speed up* the rate at which progress and breakthroughs occur is perhaps the most important.
2.1 How AI could accelerate scientific progress
-----------------------------------------------
There are a few different ways AI could enable faster scientific progress:
* **AI systems could help scientists to become more productive**. For instance, consider Ought’s Elicit [Byun & Stuhlmüller 2020], an automated research assistant, powered by the large language model GPT-3 [Brown et al. 2020]. It has several tools to help researchers do their work faster, e.g. tools for helping with literature reviews, brainstorming research questions, and so on.
* **AI could increase the number of (human) scientists**. As AI systems substitute for human labour in tasks involved in the production of consumer goods, this frees up labour to do other things, including science.[[5]](#fn-Efyn3t5KGZqghpk4r-5)
* **AI could increase the amount of science funding**. By sustaining or increasing economic growth, AI progress could result in more capital available to spend on science.
* **AI could make it possible to automate an increased proportion of the scientific process**. That is, we may manage to train AI systems which can (perhaps fully) automate tasks involved in the scientific process, such as generating new ideas and running experiments.
Of these, the fourth—AI systems automating the scientific process—seems like it could have particularly dramatic impacts. If significant parts of the scientific process could be automated by software that is easily replicated, this could lead to very rapid progress. For example, in fields where running large numbers of experiments or testing many hypotheses is necessary, being able to run tests on software that can be parallelised and run at all hours could speed progress up enormously compared to relying on human scientists.
In some cases, this might look more like speeding up breakthroughs that would eventually have been made by human scientists, but in others, it might make it possible to overcome bottlenecks that were previously intractable (at least for all practical purposes). For example, biologists have been struggling for years to make progress on the protein folding problem, because the space of hypotheses was too large to be tractable for human scientists. The AI system AlphaFold 2 made it possible to test a very large number of hypotheses (each hypothesis being a set of neural network parameters), and led to breakthrough progress on the protein folding problem [Jumper et al. 2021]. At the extreme, complete automation of the scientific process could lead to extremely rapid scientific progress [Karnofsky 2021a].
How long-term would the impacts of faster progress be? If AI enables scientific breakthroughs that *wouldn’t otherwise have been possible*—such as eliminating all disease, perhaps—that could constitute a trajectory change. In some cases, merely allowing breakthroughs to occur sooner than they would have otherwise could have very long-lasting impacts, particularly if those breakthroughs make it possible to avert a large threat such as a global pandemic. Beyond this, it seems that what, and how many, kinds of breakthroughs would have long-term impacts is an open question.
Of course, saying that AI is likely to speed up scientific progress, and that such progress could have long-term impacts on society, says nothing about whether those impacts will be overall positive or negative.
2.2 Potential benefits
----------------------
Scientific progress is at least partly to thank for many of the successes of human history so far. Medicine provides the most obvious examples: vaccines, antibiotics and anaesthetic. The discovery of electricity raised living standards in many parts of the world, thanks to products it enabled like washing machines, lightbulbs, and telephones [Gordon 2016]. Moreover, we are already seeing some positive scientific contributions enabled by AI: AlphaFold 2 promises to help with developing treatments for diseases or finding enzymes that break down industrial waste [Jumper et al. 2021]. The use of AI to advance drug discovery is receiving increasing attention [Paul et al. 2021]: the first clinical trial of an AI-designed drug began in Japan [Burki 2020] and a number of startups in this space raised substantial funds in 2020 [Hogarth & Benaich 2020].
More importantly for our purposes, there are some potential scientific breakthroughs that could have long-term impacts. For instance, novel energy generation or storage technology could reduce the probability of globally catastrophic climate change. Understanding the ageing process could help slow or reverse ageing [Zhavoronkov et al. 2019], which could make the world better at every point in the future (a trajectory change). Likewise, progress in cognitive science could make it possible to create digital people: computer simulations of people living in a virtual environment, who are as conscious as we are, have human rights, and can do most of the things that humans can.[[6]](#fn-Efyn3t5KGZqghpk4r-6) This could lead to a large, stable, much better world, without disease, material poverty or non-consensual violence [Karnofsky 2021c]. Of course, the possibility of digital people certainly isn't something that is seen as desirable by all, and would introduce new ethical challenges.
2.3 Potential risks
-------------------
On the other hand, faster science and technology progress could make it easier to develop technologies that make a global catastrophe more likely. For example, AI could speed up progress in biotechnology [O'Brien & Nelson 2020; Turchin & Denkenberger 2018], making it easier to engineer or synthesise dangerous pathogens with relatively little expertise and readily available materials. More speculatively, AI might enable progress towards atomically precise manufacturing (APM) technologies,[[7]](#fn-Efyn3t5KGZqghpk4r-7) which could make it substantially easier to develop dangerous weapons at scale,[[8]](#fn-Efyn3t5KGZqghpk4r-8) or even be misused to create tiny self-replicating machines which outcompete organic life and rapidly consume earth’s resources [Beckstead 2015a]. A world of digital people could equally be a moral catastrophe: a malevolent leader who wanted to remain in power forever, or enforce their ideology, could program a virtual environment to prevent certain aspects from ever being changed—such as who is in power [Karnofsky 2021c].
Exacerbating these problems is that faster scientific progress would make it even harder for governance to keep pace with the deployment of new technologies. When these technologies are especially powerful or dangerous, such as those discussed above, insufficient governance can magnify their harms.[[9]](#fn-Efyn3t5KGZqghpk4r-9) This is known as the *pacing problem*, and it is an issue that technology governance already faces [Marchant 2011], for a variety of reasons:
* Information asymmetries between the developers of new technologies and those governing them, leading to insufficient or misguided governance.
* Tech companies are often just better resourced than governments, especially because they can afford to pay much higher salaries and so attract top talent.
* Technology interest groups often lobby to preserve aspects of the status quo that are benefiting them (e.g., subsidies, tax loopholes, protective trade measures), making policy change—and especially experimental policies—difficult and slow to implement [Raunch 1995].
* For governance to keep pace with technological progress, this tends to require anticipating the impacts of technology in advance, before shaping them becomes expensive, difficult and time consuming, and/or catastrophic harms have already occurred. But anticipating impacts in advance is hard, especially for transformative technologies. This is commonly referred to as the Collingridge Dilemma [Collingridge 1980].
2.4 Open questions
------------------
A key question here is: what type and level of AI capabilities would be needed to automate a significant part of the scientific process in different domains? Some areas of scientific research may be easier to automate with plausible advances in AI capabilities, and some types of scientific breakthroughs will be more impactful—whether positive or negative—than others. If we had a better understanding of the types of AI capabilities needed to automate progress in different areas of science, then we could ask about the impacts of progress in areas where automation seems like it might not be too far off.
The possibility of AI speeding up scientific progress also requires us to confront complex questions about what kinds of progress are good for society. For example, AI-enabled progress in cognitive science could make it possible to create digital people: computer simulations of people living in a virtual environment, who could plausibly be as conscious as we are and can do most of the things that humans can. This would totally transform the world as we know it. Whether a world with digital people in it would be better or worse than today’s world is an open question depending on many normative and empirical assumptions, worth more serious consideration.
3 Cooperation and Conflict
==========================
Another way AI could cause long-term impacts is by changing the nature or likelihood of cooperation and conflict between powerful actors in the world, including by:
* Enabling the development of new tools or technologies relevant to cooperation and conflict, such as new tools for negotiation, or new weapons.
* Enabling the automation of decision-making in conflict scenarios, leading to unintentional escalation or otherwise making mistakes or high-risk decisions more likely.
* Altering the strategic decision landscape faced by powerful actors.
3.1 How AI could improve cooperation
------------------------------------
The potential uses of AI to improve cooperation have not been explored in depth, but a few ideas are covered in Dafoe et al. [2020]:
* AI research in areas such as machine translation could enable richer communication across countries and cultures, therefore facilitating the finding of common ground.
* AI methods could be used to build mechanisms to incentivise truthful information sharing.
* AI could help develop languages for specifying commitment contracts (for instance, imagine the potential of assurance contracts for nuclear disarmament), and improve our ability to reason about the strategic impacts of commitment.
* AI research could explore the space of distributed institutions that promote desirable global behaviours and design algorithms that can predict which norms will have the best properties.
There are a few reasons to expect more cooperation to improve long-run outcomes. The availability of cooperative solutions tends to reduce the likelihood of conflict (of which we will discuss the long-term importance in the next section), costly as it is for all parties involved. Much greater global cooperation than exists today is likely to be crucial for ensuring humanity has a flourishing long-term future,[[10]](#fn-Efyn3t5KGZqghpk4r-10) as well as improving collective problem solving more broadly (we’ll discuss the latter in more detail in a later section).
3.2 How AI could worsen conflict
--------------------------------
Equally, AI could have significant impacts on the likelihood and nature of conflict, and in particular could make globally catastrophic outcomes from conflict more likely. There are several reasons to think this.
### Risks from the development of x-dangerous weapons
AI is already enabling the development of weapons which could cause mass destruction—including new weapons that themselves use AI capabilities, such as Lethal Autonomous Weapons [Aguirre 2020],[[11]](#fn-Efyn3t5KGZqghpk4r-11) and the potential use of AI to speed up the development of other potentially dangerous technologies, such as engineered pathogens (as discussed in Section 2).
### Risks from the automation of military decision-making
Automation of military decision-making could introduce new and more catastrophic sources of error (especially if there are competitive pressures which lead to premature automation). One concern here is humans not remaining in the loop for some military decisions, creating the possibility of unintentional escalation because of:
* Automated tactical decision-making, by ‘in-theatre’ AI systems (e.g. border patrol systems start accidentally firing on one another), leading to either: tactical-level war crimes,[[12]](#fn-Efyn3t5KGZqghpk4r-12) or strategic-level decisions to initiate conflict or escalate to a higher level of intensity—for example, countervalue (e.g. city-) targeting, or going nuclear [Scharre 2020].
* Automated strategic decision-making, by ‘out-of-theatre’ AI systems—for example, conflict prediction or strategic planning systems giving a faulty ‘imminent attack’ warning [Deeks et al. 2019].
Furthermore, even if humans remain in the loop, automation is likely to increase the pace and complexity of military decision-making, which could make mistakes or high-risk decisions more likely.
### Risks from AI's effect on the strategic decision landscape
A further concern is that AI could more broadly influence the strategic decision landscape faced by actors in a way that makes conflict more likely or undermines stability. For example, AI could undermine nuclear strategic stability by making it easier to discover and destroy previously secure nuclear launch facilities [Geist & Lohn 2018; Miller & Fontaine 2017; Lieber & Press 2017]. AI may also offer more extreme first-strike advantages or novel destructive capabilities that could disrupt deterrence, such as cyber capabilities being used to knock out opponents’ nuclear command and control [Dafoe 2020; Garfinkel & Dafoe 2019]. The use of AI capabilities may make it less clear where attacks originate from, making it easier for aggressors to obfuscate an attack, and therefore reducing the costs of initiating one. By making it more difficult to explain their military decisions, AI may give states a carte blanche to act more aggressively [Deeks et al. 2019]. By creating a wider and more vulnerable attack surface, AI-related infrastructure may make war more tempting by lowering the cost of offensive action (for example, it might be sufficient to attack just data centres to do substantial harm), or by creating a ‘use-them-or-lose-them’ dynamic around powerful yet vulnerable military AI systems. In this way, AI could exacerbate the ‘capability-vulnerability paradox’ [Schneider 2016], where the very digital technologies that make militaries effective on the battlefield also introduce critical new vulnerabilities. AI development may itself become a new flash point for conflicts—causing more conflict to occur—especially conflicts over AI-relevant resources (such as data centres, semiconductor manufacturing facilities and raw materials).
Alongside the possibility that AI will make globally catastrophic outcomes from conflict more likely, conflict is in general a destabilising factor which reduces our ability to mitigate other potential global catastrophes and steer towards a flourishing future for humanity. For instance, conflict tends to erode international trust and cooperation, and increases risks posed by a range of weapon technologies [Ord 2020].
### Risks from conflict between AI systems
Finally, as AI systems become more capable and integral to society, we may also need to consider potential conflicts that could arise *between* AI systems, and especially the results of strategic threats by powerful AI systems (or AI-assisted humans) against altruistic values [Clifton 2019].
Whilst strategic threats have been a concern long before recent AI progress (and were especially dangerous in the Cold War), the risk may increase significantly with the advent of advanced AI systems. In particular, the potential ability of advanced AI systems to cause astronomical suffering makes the potential downside of strategic threats much larger than it has been previously. That is, if it’s possible to create digital people (or other digital entities with moral patienthood), then advanced AI systems—even amoral ones—could be incentivised to threaten the creation of astronomical numbers of suffering digital people as a way of furthering their own goals (even if those goals are amoral). Furthermore, advanced AI might enable unprecedented levels of credibility in making threats, for example by being very transparent—thus making threats more attractive [Clifton 2019].
Along with strategic threats, conflict could ensue between powerful AI systems if, for example, they are unable to credibly commit to the terms of a peaceful settlement, or have differing private information related to their chances of winning a conflict, and incentives to misrepresent that information [Clifton 2019].
3.3 Open questions
------------------
It would be good to have more analysis of the kind of AI systems we could develop to help with cooperation. How might we make the development and deployment of such systems more likely?
Likewise, a more detailed understanding of the kinds of military decisions that are likely to be automated, mistakes that might arise, and incentives that will develop, seems very valuable. In what scenarios might AI-enabled warfare lead to unintentional escalation, and how might we prepare to avoid this happening in advance? Are there types or uses of AI systems that we might want to prohibit or seriously restrict because the risks they pose to conflict and international stability are too great?
4 Power and inequality
======================
It seems likely that AI development will shift the balance of power in the world: as AI systems become more and more capable, they will give those with access to them greater influence, and as AI becomes more integrated into the economy, it will change how wealth is created and distributed. What is not clear is whether the trend will be towards a more or less equal society, and how drastic and long-lasting these power shifts might be. For the purposes of this section, we will be talking specifically about (in)equality in political power and wealth.
4.1 How AI could reduce inequality
----------------------------------
It is plausible that AI will increase economic growth rates, and advanced AI could significantly increase them [Trammell & Korinek 2020]. Whilst the connection between economic growth and inequality isn’t clear, there is evidence that poverty has reduced with economic growth in developing countries [Adams 2003].[[13]](#fn-Efyn3t5KGZqghpk4r-13) Thus, it’s plausible that the wealth and abundance of resources generated by AI will precipitate significant poverty reduction.
Furthermore, AI could help with identifying and mitigating sources of inequality directly [Vinuesa et al. 2020]. Some early-stage suggestions include simulating how societies may respond to changes [Saam & Harrer 1999], or preventing discrimination in the targeting of job advertisements [Dalenberg 2018]. That said, we found it particularly difficult to find literature on how AI could reduce inequality in a lasting way, and we think this area could do with more attention.
4.2 How AI could exacerbate inequality
--------------------------------------
There are several ways we might be concerned about the development and use of AI increasing power concentration or inequality. We’re already seeing some very concerning trends:
* AI-driven industries seem likely to tend towards monopoly and could result in huge economic gains for a few actors: there seems to be a feedback loop whereby actors with access to more AI-relevant resources (e.g., data, computing power, talent) are able to build more effective digital products and services, claim a greater market share, and therefore be well-positioned to amass more of the relevant resources [Dafoe 2018; Kalluri 2020; Lee 2018]. Similarly, wealthier countries able to invest more in AI development are likely to reap economic benefits more quickly than developing economies, potentially widening the gap between them.
* The harms and benefits of AI are likely to be very unequally distributed across society: AI systems are already having discriminatory impacts on marginalised groups [Raji & Boulamwini 2019; West et al. 2019] and these groups are also less likely to be in a position to benefit from advances in AI such as personalised healthcare [West et al. 2019].
* AI-based automation has the potential to drastically increase income inequality. It seems quite plausible that progress in reinforcement learning and language models specifically could make it possible to automate a large amount of manual labour and knowledge work respectively [Ibarz et al. 2021; Lee 2018; Tamkin et al. 2021], leading to widespread unemployment, and the wages for many remaining jobs being driven down by increased supply.
* Developments in AI are giving companies and governments more control over individuals’ lives than ever before, and may possibly be used to undermine democratic processes. We are already seeing how the collection of large amounts of personal data can be used to surveil and influence populations, for example the use of facial recognition technology to surveil Uighur and other minority populations in China [Hogarth & Benaich 2019]. Further advances in language modelling could also be used to develop tools that can effectively persuade people of certain claims [Kokotajlo 2020a].
Many of the trends described above could combine to create a world which is much more unequal than the one we live in today, both in terms of wealth and political power. If AI is embedded in society in ways that create self-reinforcing feedback loops, whereby those who are already rich and powerful are able to continue reaping benefits of AI, and those who are poor and powerless lack access to the same benefits and are at greater risk of harms, this could make it even more difficult to break cycles of inequality than it is today—making it more likely that inequality will persist for a very long time.
A particularly concerning scenario would be one where AI development enables a relatively small group of people to obtain unprecedented levels of power, and to use this to control and subjugate the rest of the world for a long period of time.
Gaining power in this way could be sudden or gradual. A sudden gain in control could look like some group developing and controlling much more powerful AI systems than anyone else, and using them to gain a decisive strategic advantage: “a level of technological and other advantages sufficient to enable … complete world domination” [Bostrom 2014]. A historical analogy for a sudden takeover would be takeovers by Spanish conquistadors in America, at least in part due to their technological and strategic advantages [Kokotajlo 2020b].
A gradual gain in control could look like the values of the most advanced actors in AI slowly coming to have a large influence over the rest of the world. For instance, if labour becomes increasingly automated, we could end up in a world where it’s very difficult or even impossible to trade labour for income (i.e. labour share of GDP falls to near zero compared to capital share), meaning the future would be controlled by the relatively small proportion of people who own the majority of capital/AI systems [Trammell & Korinek 2020]. A historical analogy for a gradual takeover would be how WEIRD (Western, Educated, Industrialized, Rich and Democratic) values (e.g. analytical, individualistic thinking; less clannishness and more trusting in abstract rules and intermediating institutions) gradually came to dominate large parts of the world because they were more (economically and militarily) “successful” [Henrich 2020].
In addition to making it easier for some groups to *obtain* large amounts of power, developments in AI could also make it easier to *retain* that power over long periods of time. This might either be done very directly—a group might use AI-based surveillance and manipulation to identify and suppress opposition and perpetuate a global totalitarian regime, for instance—or more indirectly—such as a globally powerful group which embeds its values and objectives in powerful AI systems that themselves come to control society (and note that, unlike humans, AI systems can be programmed to reliably pursue the same goals/plans over a long period of time).
4.3 Open questions
------------------
It would be valuable to survey—and evaluate the effectiveness and feasibility of—governance tools for reducing the likelihood and severity of AI-induced power concentration and inequality. Some suggestions here include the “windfall clause” [O’Keefe et al. 2020], and distributing ownership of companies (especially AI-assisted ones) and land [Altman 2021]. After surveying existing tools, one could think about potential modifications to make them more effective and feasible, or try to identify new tools or strategies. Previous waves of automation have had differing effects on inequality [Frey 2019], so it could also be valuable to look for generalisable lessons: what regulation, institutions or other governance structures have been successful at promoting more equal outcomes in the face of technological change?
5 Epistemic processes and problem solving
=========================================
Our ability to solve problems and make progress as a society towards a great long-term future depends heavily on epistemic processes: how information is produced and distributed, and the tools and processes we use to make decisions and evaluate claims.
AI development is already impacting both of these things, and may therefore significantly shape our ability to solve problems as a society far into the future—for better or worse. Currently, almost all information on the internet is created by humans, but we are beginning to see this change, as AI-generated content becomes more convincing [Vaccari & Chadwick 2020]. As it becomes a significant fraction of the information available, its purpose and quality could have a significant impact on what we believe and how we solve problems, individually and collectively. AI systems and tools are at the same time playing an increasingly large role in how we filter, process, and evaluate information, again shaping the way individuals and communities view the world [Vold et al. 2018.
5.1 How AI could improve epistemic processes
--------------------------------------------
AI could help us understand complex aspects of the world in a way that makes it easier to identify and mitigate threats to humanity’s long-term future. For instance, AI is already used to support early warning systems for disease outbreaks: machine learning algorithms were used to characterise and predict the transmission patterns of both Zika virus [Jiang et al. 2018] and SARS-CoV-2 [Wu et al. 2020; Liu 2020], supporting more timely planning and policymaking. With better data and more sophisticated systems in the future it may be possible to identify and mitigate such outbreaks much earlier [Schwalbe & Wahl 2020].
If developments in AI could be leveraged to enable better cooperation between groups, as mentioned earlier, this could also make it much easier to solve global problems. For instance, AI could help different groups to make verifiable claims that they are minimising negative externalities from activities like biotechnology research (e.g. via AI-enabled surveillance of the riskiest biotechnology labs).
Along with mitigating threats and enabling cooperation to solve global problems, AI-based tools to support better reasoning could help humans far surpass the amount of intellectual progress we could otherwise have made on important problems. It seems that steering towards a great future requires making progress on difficult intellectual problems, like ethics, AI alignment and group decision making, and that AI-based tools to facilitate reasoning about these problems could be of central importance. Ought’s Elicit (the AI-based research assistant mentioned in Section 2.1) is a suggestive example.
5.2 How AI could worsen epistemic processes
-------------------------------------------
However, as AI plays an increasingly large role in how information is produced and disseminated in society, this could also distort epistemic processes and undermine collective solving capacities. One of the most significant commercial uses of current AI systems is in the content recommendation algorithms of social media companies, and there are already concerns that this is contributing to worsened polarisation online [Ribeiro et al. 2019; Faddoul et al. 2020]. At the same time, we are seeing how AI can be used to scale up the production of convincing yet false or misleading information online (e.g. via image, audio, and text synthesis models like BigGAN [Brock et al. 2019] and GPT-3 [Brown et al. 2020]).
As AI capabilities advance, they may be used to develop sophisticated persuasion tools, such as those that tailor their communication to specific users to persuade them of certain claims [Kokotajlo 2020a]. While these tools could be used for social good—such as New York Times’ chatbot that helps users to persuade people to get vaccinated against Covid-19 [Gagneur & Tamerius 2021]—there are also many ways they could be misused by self-interested groups to gain influence and/or to promote harmful ideologies.
Even without deliberate misuse, widespread use of powerful persuasion tools could have negative impacts. If such tools were used by many different groups to advance many different ideas, we could see the world splintering into isolated “epistemic communities”, with little room for dialogue or transfer between communities. A similar scenario could emerge via the increasing personalisation of people’s online experiences—in other words, we may see a continuation of the trend towards “filter bubbles” and “echo chambers”, driven by content selection algorithms, that some argue is already happening [Barberá et al. 2015; Flaxman et al. 2016; Nguyen et al. 2014].
In addition, the increased awareness of these trends in information production and distribution could make it harder for anyone to evaluate the trustworthiness of any information source, reducing overall trust in information.
In all of these scenarios, it would be much harder for humanity to make good decisions on important issues, particularly due to declining trust in credible multipartisan sources, which could hamper attempts at cooperation and collective action. The vaccine and mask hesitancy that exacerbated Covid-19, for example, were likely the result of insufficient trust in public health advice [Seger 2021]. These concerns could be especially worrying if they play out during another major world crisis. We could imagine an even more virulent pandemic, where actors exploit the opportunity to spread misinformation and disinformation to further their own ends. This could lead to dangerous practices, a significantly increased burden on health services, and much more catastrophic outcomes [Seger et al. 2020].
5.3 Open questions
------------------
It would be valuable to better understand the kind of AI systems we could develop to improve society’s epistemic processes. There are also important questions relating to governance: what governance levers are available for reducing the risk of persuasion tools and online personalisation undermining epistemic processes? Are there datasets we could collect to help with measuring relevant properties of AI systems, like the extent to which they help rather than persuade their users?
6 The values that steer humanity’s future
=========================================
One way or another, advanced AI is likely to have a large impact on the values that steer humanity’s future.
So far in human history, it seems like the future has largely been determined by competitive pressures, rather than by deliberate attempts by humans to shape the future according to their values. That is, if some technical, institutional, or cultural “innovation” offers a competitive advantage, then its proliferation is highly likely. Some examples include:
* **Firearms** in the Tokugawa period of Japanese history: up until 1853, firearms technology was largely eliminated in Japan, and a samurai-dominated social order persisted for over 200 years. But then, in order to repel the threat of Western colonisation, Japan was forced to readopt firearms, along with other Western customs and institutions—despite this running contrary to the values of the Japanese elite pre-1853 [Dafoe 2015].
* **Agriculture:** hunter-gatherer societies which did not adapt to agriculture were gradually killed off by farming societies, who could grow larger due to increased food production.
* **Industrialisation:** states which did not industrialise after the first Industrial Revolution rapidly fell behind in economic production and national competitiveness. Hence there was competitive pressure to industrialise, even if this meant disregarding certain existing societal values.
However, it’s plausible that advanced AI will change this. On the one hand, it could be a significant opportunity for (at least some subset of) humanity to increase their ability to deliberately shape the future according to their values—which we will refer to as the opportunity to gain “greater control over the future”. On the other hand, it could cause humans as a species to lose what potential we have for gaining control over the future.
6.1 How AI could increase humanity’s ability to shape the future
----------------------------------------------------------------
There are several ways in which advanced AI could help humanity to gain greater control over the future. It’s important to note that human values having greater control over the future doesn’t necessarily mean that the future will be more desirable than one that’s driven more by competitive pressures—this depends on what/whose values become influential and how representative they are of broader interests.
First, as mentioned above, advanced AI could improve humanity’s ability to cooperate, therefore helping to overcome competitive pressure as a force shaping our future. For example, if we design AI systems that have superhuman cooperative capabilities (e.g. because they are better than humans at making credible commitments), we could move towards a future which avoids common traps of multiagent situations, like destructive conflict or wasting resources on arms races. This could affect how good the world is at every point in the far future, because the resources that would have been spent on conflict and harmful competition could instead be spent however our descendants deem most valuable.
Second, advanced AI could accelerate moral progress, for example by playing a “Socratic” role in helping us to reach better (moral) decisions ourselves (inspired by the role of deliberative exchange in Socratic philosophy as an aid to develop better moral judgements) [Lara & Deckers 2019]. Specifically, such systems could help with providing empirical support for different positions, improving conceptual clarity, understanding argumentative logic, and raising awareness of personal limitations. For an early example of this type, Ought’s Elicit (the AI-based research assistant mentioned in Section 2.1) has a “bias buster” tool, which attempts to point out cognitive biases that may be at play in a dilemma its user is facing. Whilst it’s unclear in general whether the effects of accelerating moral progress wouldn’t simply “wash out,”[[14]](#fn-Efyn3t5KGZqghpk4r-14) such tools could have long-term impact if they accelerated progress before morally relevant irreversible decisions are made about, for instance, global norms or institutions, or the environments of digital people.
Third, humanity’s control over the future is currently threatened by hazards in our environment, and AI could help to mitigate these. In particular, AI could help us to better understand and mitigate potential global catastrophes such as climate change, including by improving resource management, making it easier to rely on an increasing number of variable energy sources, or even by automating the time-consuming processes of discovering new materials that can better store or harness energy [Rolnick et al. 2019].
6.2 How AI could lead to humans losing control of the future
------------------------------------------------------------
### Misaligned power-seeking AI
On the other hand, AI could cause humanity to lose our potential for gaining control over the future. The main concern here is that we might develop advanced AI systems whose goals and values are different from those of humans, and are capable enough to take control of the future away from humanity.
The obvious question is: *why* would we develop advanced AI systems that are willing and able to take control of the future? One major concern is that we don't yet have ways of designing AI systems that reliably do what their designers want. Instead, modern AI training[[15]](#fn-Efyn3t5KGZqghpk4r-15) works by (roughly speaking) tweaking a system's “parameters” many times, until it scores highly according to some given “training objective”, evaluated on some “training data”. For instance, the large language model GPT-3 [Brown et al. 2020] is trained by (roughly speaking) tweaking its parameters until it scores highly at “predicting the next word” on “text scraped from the internet”.
However, this approach gives no guarantee that a system will continue to pursue the training objective as intended over the long run. Indeed, notice that there are many objectives a system could learn that will lead it to score highly on the training objective but which do not lead to desirable behaviour over the long run. For instance:
* The system could learn the objective “maximise the contents of the memory cell where the score is stored” which, over the long run, will lead it to fool the humans scoring its behaviour into thinking that it is doing what they intended, and eventually seize control over that memory cell, and eliminate actors who might try to interfere with this. When the intended task requires performing complex actions in the real world, this alternative strategy would probably allow the system to get much higher scores, much more easily, than successfully performing the task as intended.
* Suppose that some system is being trained to further some company’s objective. This system could learn the objective “maximise quarterly revenue” which, over the long run, would lead it to (e.g.) collude with auditors valuing the company's output, fool the company’s directors, and eventually ensure no actor who might reduce the company's revenue can interfere.
It’s also worth noting that, to the extent that these incorrect objectives are easier to represent, learn, or make plans towards than the intended objective—which is likely, because we will be trying to use AI to achieve difficult tasks—then they may be the kind of objectives that AI systems learn by default.[[16]](#fn-Efyn3t5KGZqghpk4r-16)
This kind of behaviour is currently not a big issue, because AI systems do not have very much decision-making power over the world. When failures occur, they look like amusing anecdotes rather than world-ending disasters [Krakovna et al. 2020].
But as AI systems become more advanced and begin to take over more important decision-making in the world, an AI system pursuing a different objective from what was intended could have much more worrying consequences.
What might these consequences look like in practice? In one scenario, described by Christiano [2019], we gradually use AI to automate more and more decision-making across different sectors (e.g., law enforcement, business strategy, legislation), because AI systems become able to make better and faster decisions than humans in those sectors. There will be competitive pressures to automate decisions, because actors who decide not to do so will fall behind on their objectives and be outcompeted. Regulatory capture by powerful technology companies will also contribute to increasing automation—for example, companies might engage in political donations or lobbying to water down regulation intended to slow down automation.
To see how this scenario could turn catastrophic, let’s take the example of AI systems automating law enforcement. Suppose these systems that have been successfully trained to minimise reported crime rate.
Initially, law enforcement would probably seem to be improving. Since we’re assuming that automated decision-making is better and faster than human-decision making, reported crime will in fact fall. We will be increasingly depending on automated law enforcement—and investing less in training humans to do the relevant jobs—such that any suggestions to reverse the delegation of decision-making power to AI systems would be met with reasonable concern that we just cannot afford to.
However, reported crime rate is not the same as the true prevalence of crime. As AI systems become more sophisticated, they will continue to drive down reported crime by hiding information about law enforcement failures, supressing complaints, and manipulating citizens.[[17]](#fn-Efyn3t5KGZqghpk4r-17) As the gap between how things are and how they appear grows, so too will the deceptive abilities of our automated decision-making systems. Eventually, they will be able to manipulate our perception of the world in sophisticated ways (e.g. highly persuasive media or education), and they may explicitly oppose any attempts to shut them down or modify their objectives—because human attempts to take back influence will result in reported crime rising again, which is precisely what they have been trained to prevent. The end state would be one where automated decision-making—by AI systems with objectives that aren’t what we intended—has much more influence over the future than human decision-making.
Of course, if we manage to work out how to train law enforcement AI to minimise *actual* crime, then we will be able to avoid these catastrophic failures. However, we don’t yet have any methods for training AI systems to reliably pursue such complex objectives, and instead have to resort to proxies like *reported* crime, that will plausibly lead to the kind of scenario described above. This general concern is often known as the “alignment problem” [Russell 2019; Christian 2020]. Note that there have been various other concrete depictions of how failure to solve this problem could play out, and they can look quite different depending on how many powerful AI systems there are and how rapidly their capabilities improve [Clarke & Martin 2021].
Exacerbating this problem is that we don’t properly understand how modern AI systems work, so we lack methods for checking if their learned objectives are the ones we intended. “Interpretability” is the branch of machine learning that is trying to make progress on this, but it currently is lagging significantly behind the cutting edge of AI capabilities.
### Value erosion
A second, less explored concern is that AI could affect competitive pressure as a force shaping the future, in a way that leaves humanity more powerless even if we don’t explicitly “lose control” to AI systems. For example, suppose AI accelerates certain kinds of scientific research (especially cognitive science), enabling the creation of digital people. Just as people, and groups of people, are subject to competitive pressures today (e.g., individuals working hard and sacrificing other values like family, love and play, or nations investing in weapons technology and sacrificing spending on education and healthcare), digital people, and groups of them, could be subject to the same kinds of competitive pressure. However, the situation with digital people could be even worse: whilst biological people need at least a minimum threshold of wellbeing to survive and continue competing, the same need not be true of digital people. There could be pressure on digital people to “edit” their own preferences to become ever more productive and competitive. That is, with biological humans, there is a “floor” to the amount of value a future driven by competitive pressure alone could have, but this need not be the case for digital humans. In this scenario, AI does not change the *level* of competitive pressure; it *lowers the floor* on how valueless the future could become. This kind of scenario is discussed by Bostrom [2004], mentioned by Dafoe [2020] (where it is called “value erosion from competition”), and one concrete version of it is presented in detail by Hanson [2016].
6.3 Open questions
------------------
There are several strategic and governance questions here that it would be very valuable to have a better understanding of. How difficult is the problem of designing advanced AI systems that reliably do what their designers want? Should we expect alignment “warning shots”—i.e. small scale catastrophes resulting from AI systems that do not do what their designers want—which could galvanise more work on the alignment problem? Under the assumption that the alignment problem is very difficult, and there are no warning shots, are there any governance tools that could help avert catastrophe? What governance tools could help avoid “value erosion from competition” scenarios?
7 Conclusion
============
We conclude with some overall reflections on AI’s potential long-term impacts in each of the areas we have considered.
**Scientific progress:** AI could lead to very rapid scientific progress which would likely have long-term impacts, but it’s very unclear if these would be positive or negative. Much depends on the extent to which risky scientific domains are sped up relative to beneficial or risk-reducing ones, on who uses the technology enabled by this progress, and on how it is governed.
**Cooperation and conflict:** we’re seeing more focus and investment on the kinds of AI capabilities that make conflict more likely and severe, rather than those likely to improve cooperation. So, on our current trajectory, AI seems more likely to have negative long-term impacts in this area.
**Power and inequality:** there are a lot of pathways through which AI seems likely to increase power concentration and inequality, though there is little analysis of the potential long-term impacts of these pathways. Nonetheless, AI precipitating more extreme power concentration and inequality than exists today seems a real possibility on current trends.
**Epistemic processes and problem solving:** we currently see more reasons to be concerned about AI worsening society's epistemic processes than reasons to be optimistic about AI helping us better solve problems as a society. For example, increased use of content selection algorithms could drive epistemic insularity and a decline in trust in credible multipartisan sources, which reducing our ability to deal with important long-term threats and challenges such as pandemics and climate change.
**The values that steer humanity’s future:** humanity gaining more control over the future due to developments in AI, or losing our potential for gaining control, both seem possible. Much will depend on our ability to address the alignment problem, who develops powerful AI first, and what they use it to do.
These long-term impacts of AI could be hugely important but are currently under-explored. We’ve attempted to structure some of the discussion and stimulate more research, by reviewing existing arguments and highlighting open questions. While there are many ways AI could in theory enable a flourishing future for humanity, trends of AI development and deployment in practice leave us concerned about long-lasting harms. We would particularly encourage future work that critically explores ways AI could have positive long-term impacts in more depth, such as by enabling greater cooperation or problem-solving around global challenges.
Acknowledgments
===============
Thanks to Matthijs Maas, Michael Aird, Shahar Avin, Ben Garfinkel, Richard Ngo, Haydn Belfield, Seán Ó hÉigeartaigh, Charlotte Siegmann, Alexis Carlier and Markus Anderljung for valuable feedback on an earlier version.
References
==========
Adams, Richard. 2003. ‘Economic Growth, Inequality, and Poverty: Findings from a New Data Set’. 2003. <https://openknowledge.worldbank.org/handle/10986/19109#:>
Aguirre, Anthony. 2020. ‘Why Those Who Care about Catastrophic and Existential Risk Should Care about Autonomous Weapons’. EA Forum. <https://forum.effectivealtruism.org/posts/oR9tLNRSAep293rr5/why-those-who-care-about-catastrophic-and-existential-risk-2>.
Altman, Sam. 2021. ‘Moore’s Law for Everything’. 2021. <https://moores.samaltman.com/>.
Barberá, Pablo, John T. Jost, Jonathan Nagler, Joshua A. Tucker, and Richard Bonneau. 2015. ‘Tweeting from Left to Right: Is Online Political Communication More than an Echo Chamber?’ Psychological Science 26 (10): 1531–42. <https://doi.org/10.1177/0956797615594620>.
Beckstead, Nick. 2015a. ‘Risks from Atomically Precise Manufacturing’. 8 June 2015. <https://www.openphilanthropy.org/research/cause-reports/atomically-precise-manufacturing>.
———. 2015b. ‘The Long-Term Significance of Reducing Global Catastrophic Risks’. The GiveWell Blog (blog). 13 August 2015. <https://blog.givewell.org/2015/08/13/the-long-term-significance-of-reducing-global-catastrophic-risks/>.
Bostrom, Nick. 2004. ‘The Future of Human Evolution’. 2004. <https://www.nickbostrom.com/fut/evolution.html>.
———. 2014. Superintelligence: Paths, Dangers, Strategies. Oxford University Press.
Brock, Andrew, Jeff Donahue, and Karen Simonyan. 2019. ‘Large Scale GAN Training for High Fidelity Natural Image Synthesis’. ArXiv:1809.11096 [Cs, Stat], February. <http://arxiv.org/abs/1809.11096>.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. ‘Language Models Are Few-Shot Learners’. ArXiv:2005.14165 [Cs], July. <http://arxiv.org/abs/2005.14165>.
Burki, Talha. 2020. ‘A New Paradigm for Drug Development’. The Lancet Digital Health 2 (5): e226–27. <https://doi.org/10.1016/S2589-7500(20)30088-1>.
Byun, Jungwon, and Andreas Stuhlmüller. 2020. ‘Automating Reasoning about the Future at Ought’. 2020. <https://ought.org/updates/2020-11-09-forecasting>.
Christian, Brian. 2020. The Alignment Problem: Machine Learning and Human Values. 1st edition. New York, NY: W. W. Norton & Company.
Christiano, Paul. 2019. ‘What Failure Looks Like’. AI Alignment Forum (blog). 2019. <https://www.alignmentforum.org/posts/HBxe6wdjxK239zajf/what-failure-looks-like>.
Clarke, Sam, and Samuel Martin. 2021. ‘Distinguishing AI Takeover Scenarios’. AI Alignment Forum. <https://www.alignmentforum.org/posts/qYzqDtoQaZ3eDDyxa/distinguishing-ai-takeover-scenarios>.
Clifton, Jesse. 2019. ‘Cooperation, Conflict, and Transformative Artificial Intelligence: A Research Agenda’. AI Alignment Forum. <https://www.alignmentforum.org/s/p947tK8CoBbdpPtyK>.
Dafoe, Allan. 2015. ‘On Technological Determinism: A Typology, Scope Conditions, and a Mechanism’. Science, Technology, & Human Values 40 (6): 1047–76. <https://doi.org/10.1177/0162243915579283>.
———. 2018. ‘AI Governance: A Research Agenda’. Centre for the Governance of AI. <http://www.fhi.ox.ac.uk/govaiagenda>.
———. 2020. ‘AI Governance: Opportunity and Theory of Impact’. EA Forum. <https://forum.effectivealtruism.org/posts/42reWndoTEhFqu6T8/ai-governance-opportunity-and-theory-of-impact>.
Dafoe, Allan, Edward Hughes, Yoram Bachrach, Tantum Collins, Kevin R. McKee, Joel Z. Leibo, Kate Larson, and Thore Graepel. 2020. ‘Open Problems in Cooperative AI’. ArXiv:2012.08630 [Cs], December. <http://arxiv.org/abs/2012.08630>.
Daníelsson, Jón, Robert Macrae, and Andreas Uthemann. 2021. ‘Artificial Intelligence and Systemic Risk’. Journal of Banking & Finance, August, 106290. <https://doi.org/10.1016/j.jbankfin.2021.106290>.
Deeks, Ashley, Noam Lubell, and Daragh Murray. 2018. ‘Machine Learning, Artificial Intelligence, and the Use of Force by States’. SSRN Scholarly Paper ID 3285879. Rochester, NY: Social Science Research Network. <https://papers.ssrn.com/abstract=3285879>.
Faddoul, Marc, Guillaume Chaslot, and Hany Farid. 2020. ‘A Longitudinal Analysis of YouTube’s Promotion of Conspiracy Videos’. ArXiv:2003.03318 [Cs], March. <http://arxiv.org/abs/2003.03318>.
Flaxman, Seth, Sharad Goel, and Justin M. Rao. 2016. ‘Filter Bubbles, Echo Chambers, and Online News Consumption’. Public Opinion Quarterly 80 (S1): 298–320. <https://doi.org/10.1093/poq/nfw006>.
Frey, Carl Benedikt. 2019. The Technology Trap. <https://press.princeton.edu/books/hardcover/9780691172798/the-technology-trap>.
Gagneur, Arnaud, and Karin Tamerius. 2021. ‘Opinion | Your Friend Doesn’t Want the Vaccine. What Do You Say?’ The New York Times, 20 May 2021, sec. Opinion. <https://www.nytimes.com/interactive/2021/05/20/opinion/covid-19-vaccine-chatbot.html>.
Garfinkel, Ben. 2022. ‘AI and Impact of General Purpose Technologies’. In Oxford Handbook on AI Governance. Oxford University Press.
Garfinkel, Ben, and Allan Dafoe. 2019. ‘How Does the Offense-Defense Balance Scale?’ Journal of Strategic Studies 42 (6): 736–63. <https://doi.org/10.1080/01402390.2019.1631810>.
Geist, Edward, and Andrew J. Lohn. 2018. ‘How Might Artificial Intelligence Affect the Risk of Nuclear War?’, April. <https://www.rand.org/pubs/perspectives/PE296.html>.
Gordon, Robert J. 2016. The Rise and Fall of American Growth: The U.S. Standard of Living since the Civil War (The Princeton Economic History of the Western World): 60. Illustrated edition. Princeton: Princeton University Press.
Greaves, Hilary, and WIlliam MacAskill. 2021. ‘The Case for Strong Longtermism’. Global Priorities Institute, University of Oxford. <https://globalprioritiesinstitute.org/hilary-greaves-william-macaskill-the-case-for-strong-longtermism-2/>.
Hanson, Robin. 2016. The Age of Em: Work, Love, and Life When Robots Rule the Earth. Oxford University Press.
Henrich, Joseph. 2020. The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous. Penguin UK.
Hogarth, Ian, and Nathan Benaich. 2019. ‘State of AI Report 2019’. 2019. <https://www.stateof.ai/2019>.
———. 2020. ‘State of AI Report 2020’. 2020. <https://www.stateof.ai/2020>.
Ibarz, Julian, Jie Tan, Chelsea Finn, Mrinal Kalakrishnan, Peter Pastor, and Sergey Levine. 2021. ‘How to Train Your Robot with Deep Reinforcement Learning; Lessons We’ve Learned’. ArXiv:2102.02915 [Cs], February. <https://doi.org/10.1177/0278364920987859>.
Jiang, Dong, Mengmeng Hao, Fangyu Ding, Jingying Fu, and Meng Li. 2018. ‘Mapping the Transmission Risk of Zika Virus Using Machine Learning Models’. Acta Tropica 185 (September): 391–99. <https://doi.org/10.1016/j.actatropica.2018.06.021>.
Jiang, Fei, Yong Jiang, Hui Zhi, Yi Dong, Hao Li, Sufeng Ma, Yilong Wang, Qiang Dong, Haipeng Shen, and Yongjun Wang. 2017. ‘Artificial Intelligence in Healthcare: Past, Present and Future’. Stroke and Vascular Neurology 2 (4). <https://doi.org/10.1136/svn-2017-000101>.
Jumper, John, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, et al. 2021. ‘Highly Accurate Protein Structure Prediction with AlphaFold’. Nature, July, 1–11. <https://doi.org/10.1038/s41586-021-03819-2>.
Kalluri, Pratyusha. 2020. ‘Don’t Ask If Artificial Intelligence Is Good or Fair, Ask How It Shifts Power’. Nature 583 (7815): 169–169. <https://doi.org/10.1038/d41586-020-02003-2>.
Karnofsky, Holden. 2021a. ‘Forecasting Transformative AI, Part 1: What Kind of AI?’ Cold Takes (blog). 2021. <https://www.cold-takes.com/transformative-ai-timelines-part-1-of-4-what-kind-of-ai/#explosive-scientific-and-technological-advancement>.
———. 2021b. ‘Digital People FAQ’. Cold Takes (blog). 27 July 2021. <https://www.cold-takes.com/digital-people-faq/>.
———. 2021c. ‘Digital People Would Be An Even Bigger Deal’. Cold Takes (blog). 27 July 2021. <https://www.cold-takes.com/how-digital-people-could-change-the-world/>.
Kokotajlo, Daniel. 2020a. ‘Cortés, Pizarro, and Afonso as Precedents for Takeover’. AI Alignment Forum. <https://www.alignmentforum.org/posts/ivpKSjM4D6FbqF4pZ/cortes-pizarro-and-afonso-as-precedents-for-takeover>.
———. 2020b. ‘Persuasion Tools: AI Takeover without AGI or Agency?’ AI Alignment Forum. <https://www.alignmentforum.org/posts/qKvn7rxP2mzJbKfcA/persuasion-tools-ai-takeover-without-agi-or-agency>.
Krakovna, Victoria, Jonathan Uesato, Vladimir Mikulik, Matthew Rahtz, Tom Everitt, Ramana Kumar, Zac Kenton, Jan Leike, and Shane Legg. 2020. ‘Specification Gaming: The Flip Side of AI Ingenuity’. DeepMind Safety Research (blog). 23 April 2020. <https://deepmindsafetyresearch.medium.com/specification-gaming-the-flip-side-of-ai-ingenuity-c85bdb0deeb4>.
Lara, Francisco, and Jan Deckers. 2020. ‘Artificial Intelligence as a Socratic Assistant for Moral Enhancement’. Neuroethics 13 (3): 275–87. <https://doi.org/10.1007/s12152-019-09401-y>.
Lee, Kai-Fu. 2018. AI Superpowers: China, Silicon Valley, and the New World Order. Boston: Houghton Mifflin Harcourt.
Lieber, Keir A., and Daryl G. Press. 2017. ‘The New Era of Counterforce: Technological Change and the Future of Nuclear Deterrence’. International Security 41 (4): 9–49. <https://doi.org/10.1162/ISEC_a_00273>.
Liu, Jilan. 2020. ‘Deployment of Health It in China’s Fight against the Covid-19 Pandemic’. Imaging Technology News. 2 April 2020. [https://www.itnonline.com/article/deployment-health-it-china’s-fight-against-covid-19-pandemic](https://www.itnonline.com/article/deployment-health-it-china%E2%80%99s-fight-against-covid-19-pandemic).
Maas, Matthijs M. 2021. ‘Artificial Intelligence Governance Under Change: Foundations, Facets, Frameworks’. SSRN Scholarly Paper ID 3833395. Rochester, NY: Social Science Research Network. <https://doi.org/10.2139/ssrn.3833395>.
Marchant, Gary E. 2011. ‘The Growing Gap Between Emerging Technologies and the Law’. In The Growing Gap Between Emerging Technologies and Legal-Ethical Oversight: The Pacing Problem, edited by Gary E. Marchant, Braden R. Allenby, and Joseph R. Herkert, 19–33. The International Library of Ethics, Law and Technology. Dordrecht: Springer Netherlands. <https://doi.org/10.1007/978-94-007-1356-7_2>.
McKinney, Scott Mayer, Marcin Sieniek, Varun Godbole, Jonathan Godwin, Natasha Antropova, Hutan Ashrafian, Trevor Back, et al. 2020. ‘International Evaluation of an AI System for Breast Cancer Screening’. Nature 577 (7788): 89–94. <https://doi.org/10.1038/s41586-019-1799-6>.
Miller, James, and Richard Fontaine. 2017. ‘A New Era in U.S.-Russian Strategic Stability’. Centre for a New American Security. <https://www.cnas.org/publications/reports/a-new-era-in-u-s-russian-strategic-stability>.
Nguyen, Tien T., Pik-Mai Hui, F. Maxwell Harper, Loren Terveen, and Joseph A. Konstan. 2014. ‘Exploring the Filter Bubble: The Effect of Using Recommender Systems on Content Diversity’. In Proceedings of the 23rd International Conference on World Wide Web - WWW ’14, 677–86. Seoul, Korea: ACM Press. <https://doi.org/10.1145/2566486.2568012>.
O’Brien, John T., and Cassidy Nelson. 2020. ‘Assessing the Risks Posed by the Convergence of Artificial Intelligence and Biotechnology’. Health Security 18 (3): 219–27. <https://doi.org/10.1089/hs.2019.0122>.
O’Keefe, Cullen, Peter Cihon, Ben Garfinkel, Carrick Flynn, Jade Leung, and Allan Dafoe. 2020. ‘The Windfall Clause: Distributing the Benefits of AI for the Common Good’. ArXiv:1912.11595 [Cs], January. <http://arxiv.org/abs/1912.11595>.
Ord, Toby. 2020. The Precipice: ‘A Book That Seems Made for the Present Moment’ New Yorker. 1st edition. Bloomsbury Publishing.
Paul, Debleena, Gaurav Sanap, Snehal Shenoy, Dnyaneshwar Kalyane, Kiran Kalia, and Rakesh K. Tekade. 2021. ‘Artificial Intelligence in Drug Discovery and Development’. Drug Discovery Today 26 (1): 80–93. <https://doi.org/10.1016/j.drudis.2020.10.010>.
Raji, Inioluwa Deborah, and Joy Buolamwini. 2019. ‘Actionable Auditing: Investigating the Impact of Publicly Naming Biased Performance Results of Commercial Ai Products’. MIT Media Lab. 2019. <https://www.media.mit.edu/publications/actionable-auditing-investigating-the-impact-of-publicly-naming-biased-performance-results-of-commercial-ai-products/>.
Rauch, Jonathan. 1995. Demosclerosis: The Silent Killer of American Government. Three Rivers Press.
Ribeiro, Manoel Horta, Raphael Ottoni, Robert West, Virgílio A. F. Almeida, and Wagner Meira. 2019. ‘Auditing Radicalization Pathways on YouTube’. ArXiv:1908.08313 [Cs], December. <http://arxiv.org/abs/1908.08313>.
Richardson, Rashida, Jason Schultz, and Kate Crawford. 2019. ‘Dirty Data, Bad Predictions: How Civil Rights Violations Impact Police Data, Predictive Policing Systems, and Justice’. SSRN Scholarly Paper ID 3333423. Rochester, NY: Social Science Research Network. <https://papers.ssrn.com/abstract=3333423>.
Rolnick, David, Priya L. Donti, Lynn H. Kaack, Kelly Kochanski, Alexandre Lacoste, Kris Sankaran, Andrew Slavin Ross, et al. 2019. ‘Tackling Climate Change with Machine Learning’. ArXiv:1906.05433 [Cs, Stat], November. <http://arxiv.org/abs/1906.05433>.
Russell, Stuart J. 2019. Human Compatible: Artificial Intelligence and the Problem of Control. New York? Viking.
Scharre, Paul. 2020. ‘Autonomous Weapons and Stability’. King’s College, London. <https://kclpure.kcl.ac.uk/portal/en/theses/autonomous-weapons-and-stability(92cd3d5b-4eb1-4ad5-a9ca-0cce2491e652).html>.
Schneider, Jacquelyn. 2016. ‘Digitally-Enabled Warfare’. 2016. <https://www.cnas.org/publications/reports/digitally-enabled-warfare-the-capability-vulnerability-paradox>.
Schwalbe, Nina, and Brian Wahl. 2020. ‘Artificial Intelligence and the Future of Global Health’. The Lancet 395 (10236): 1579–86. <https://doi.org/10.1016/S0140-6736(20)30226-9>.
Seger, Elizabeth. 2021. ‘The Greatest Security Threat of the Post-Truth Age’. BBC Future. 2021. <https://www.bbc.com/future/article/20210209-the-greatest-security-threat-of-the-post-truth-age>.
Seger, Elizabeth, Shahar Avin, Gavin Pearson, Mark Briers, Seán Ó hÉigeartaigh, and Bacon Helena. 2020. ‘Tackling Threats to Informed Decision-Making in Democratic Societies: Promoting Epistemic Security in a Technologically-Advanced World’. <https://www.turing.ac.uk/sites/default/files/2020-10/epistemic-security-report_final.pdf>.
Stross, Randall E. 2007. The Wizard of Menlo Park: How Thomas Alva Edison Invented the Modern World. Crown.
Tamkin, Alex, Miles Brundage, Jack Clark, and Deep Ganguli. 2021. ‘Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models’. ArXiv:2102.02503 [Cs], February. <http://arxiv.org/abs/2102.02503>.
Teles, Stephen. 2013. ‘Kludgeocracy in America’. National Affairs. 2013. <https://www.nationalaffairs.com/publications/detail/kludgeocracy-in-america>.
Trammell, Philip, and Anton Korinek. 2020. ‘Economic Growth under Transformative AI’. <https://globalprioritiesinstitute.org/philip-trammell-and-anton-korinek-economic-growth-under-transformative-ai/>.
Turchin, Alexey, and David Denkenberger. 2020. ‘Classification of Global Catastrophic Risks Connected with Artificial Intelligence’. AI & SOCIETY 35 (1): 147–63. <https://doi.org/10.1007/s00146-018-0845-5>.
Vaccari, Cristian, and Andrew Chadwick. 2020. ‘Deepfakes and Disinformation: Exploring the Impact of Synthetic Political Video on Deception, Uncertainty, and Trust in News’. Social Media + Society 6 (1): 2056305120903408. <https://doi.org/10.1177/2056305120903408>.
Vogt, PJ. n.d. ‘#128 The Crime Machine, Part II’. Reply All. Accessed 1 March 2022. <https://gimletmedia.com:443/shows/reply-all/n8hwl7>.
Vold, Karina Vergobbi, Jess Whittlestone, Anunya Bahanda, and Stephen Cave. 2018. ‘AI and Data-Driven Targeting’. Report. <https://doi.org/10.17863/CAM.25935>.
West, Sarah Myers, Meredith Whittaker, and Kate Crawford. 2019. ‘Discriminating Systems: Gender, Race and Power in AI’. AI Now Institute. <https://ainowinstitute.org/discriminatingsystems.pdf>.
Wu, Joseph, Kathy Leung, and Gabriel Leung. 2020. ‘Nowcasting and Forecasting the Potential Domestic and International Spread of the 2019-NCoV Outbreak Originating in Wuhan, China: A Modelling Study’. The Lancet 395 (10225): 689–97. <https://doi.org/10.1016/S0140-6736(20)30260-9>
Zhavoronkov, Alex, Polina Mamoshina, Quentin Vanhaelen, Morten Scheibye-Knudsen, Alexey Moskalev, and Alex Aliper. 2019. ‘Artificial Intelligence for Aging and Longevity Research: Recent Advances and Perspectives’. Ageing Research Reviews 49 (January): 49–66. <https://doi.org/10.1016/j.arr.2018.11.003>.
---
1. Following Greaves & MacAskill [2021], we take “the far future” to mean everything from some time t onwards, where t is a surprisingly long time from the point of decision (to develop or deploy some AI technology)—say, 100 years. [↩︎](#fnref-Efyn3t5KGZqghpk4r-1)
2. See Beckstead [2015b] for arguments that global catastrophes could impact the far future. [↩︎](#fnref-Efyn3t5KGZqghpk4r-2)
3. We borrow this concept from Greaves & MacAskill [2021]. [↩︎](#fnref-Efyn3t5KGZqghpk4r-3)
4. Some have argued that another category of impact on the far future is the speeding up of various kinds of development (e.g., economic, scientific, legal, moral), but we find these arguments less certain so we will not discuss such impacts here. [↩︎](#fnref-Efyn3t5KGZqghpk4r-4)
5. Here, and in the next point, AI systems need not be directly involved in science themselves. [↩︎](#fnref-Efyn3t5KGZqghpk4r-5)
6. We expect many readers to have (very justified) scepticism about the idea of digital people. We recommend Karnofsky [2021b] for answers to some basic questions about digital people, which could be helpful for engaging with the idea. [↩︎](#fnref-Efyn3t5KGZqghpk4r-6)
7. APM is a proposed technology for assembling macroscopic objects defined by data files by using very small parts to build the objects with atomic precision using earth-abundant materials [Beckstead 2015a]. It has not yet been developed, and its feasibility is unclear. [↩︎](#fnref-Efyn3t5KGZqghpk4r-7)
8. APM could lead to the development of new kinds of drones and centrifuges for enriching uranium that are cheaper and easier to produce [Beckstead 2015a]. [↩︎](#fnref-Efyn3t5KGZqghpk4r-8)
9. For a historical analogy, consider the cluster of deaths that resulted from the unregulated proliferation of A/C power lines in New York City in the late 19th century [Stross 2007]. [↩︎](#fnref-Efyn3t5KGZqghpk4r-9)
10. We’ll argue this point in Section 6. Basically, the idea is that steering towards a flourishing future requires a high degree of cooperation and coordination, because without it, individual actors must (on pain of being outcompeted) spend a fraction of their resources investing in military and economic competitiveness, rather than creating a flourishing world according to their values. [↩︎](#fnref-Efyn3t5KGZqghpk4r-10)
11. Whilst we find it hard to tell a plausible story where LAWs lead to a global catastrophe directly, the proliferation of LAWs seems like it would heighten the risk of a global catastrophe, and successful LAWs governance would be a valuable dry-run and precedent for governance of advanced AI. [↩︎](#fnref-Efyn3t5KGZqghpk4r-11)
12. However, we don’t think these could constitute a global catastrophe. [↩︎](#fnref-Efyn3t5KGZqghpk4r-12)
13. Adams [2003] measures economic growth via mean income and GDP per capita, and finds statical links between poverty reduction and both of these measures. [↩︎](#fnref-Efyn3t5KGZqghpk4r-13)
14. For an example of progress that plausibly “washed out”, consider that if Edison hadn’t invented the light bulb, then soon after someone else probably would have. So, whilst Edison certainly brought forward the date of invention, it’s unclear whether he specifically caused any long-lasting impacts via this invention. [↩︎](#fnref-Efyn3t5KGZqghpk4r-14)
15. Specifically, we are talking in this section about training cutting-edge deep neural networks. [↩︎](#fnref-Efyn3t5KGZqghpk4r-15)
16. An analogy here is how humans learned simple proxies for “maximise genetic fitness” like “secure food and other resources” and “reproduce” rather than the actual objective that evolution optimised us for, which is much harder to make plans to achieve. [↩︎](#fnref-Efyn3t5KGZqghpk4r-16)
17. The use of predictive policing algorithms is already facing a smaller scale version of these kind of failures, for the same reason: these algorithms are designed to minimise reported crime, not actual crime [Vogt 2018]. [↩︎](#fnref-Efyn3t5KGZqghpk4r-17) |
60a0098b-7123-4d22-ac78-c2896155016f | StampyAI/alignment-research-dataset/arxiv | Arxiv | Not Quite 'Ask a Librarian': AI on the Nature, Value, and Future of LIS
This is an author preprint. Please refer to the final published
version:
Dinneen, J. D., Bubinger, H. (2021). Not Quite ’Ask a
Librarian’: AI on the nature, value, and future of LIS. In
ASIS&T ‘21: Proceedings of the 84th Annual Meeting of the
Association for Information Science & Technology, 58.
ASIS&T Annual Meeting 2021 1 Papers
Not Quite ‘Ask a Librarian’ :
AI on the Nature, Value, and Future of LIS
Jesse David Dinneen
Humboldt-Universität zu Berlin, Germany
jesse.dinneen@hu-berlin.deHelen Bubinger
Humboldt-Universiät zu Berlin, Germany
helen.bubinger@student.hu-berlin.de
ABSTRACT
AI language models trained on Web data generate prose that reflects human knowledge and public sentiments, but
can also contain novel insights and predictions. We asked the world’s best language model, GPT-3, fifteen difficult
questions about the nature, value, and future of library and information science (LIS), topics that receive perennial
attention from LIS scholars. We present highlights from its 45 different responses, which range from platitudes and
caricatures to interesting perspectives and worrisome visions of the future, thus providing an LIS-tailored
demonstration of the current performance of AI language models. We also reflect on the viability of using AI to
forecast or generate research ideas in this way today. Finally, w e have shared the full response log online for readers
to consider and evaluate for themselves.
KEYWORDS
library and information science; artificial intelligence; foundations of information science; research methods
INTRODUCTION
Some questions about the library and information science (LIS) community persist across decades, re-appearing
perennially. Especially popular are questions about LIS’s nature, identity, and place among other fields – and thus
also the most suitable name for it – and the value it offers to society via education, knowledge production, and
public services (e.g., Kaden et al., 2021; Nolin & Åström, 2010). Similarly, researchers and practitioners are
generally concerned with the future of LIS, asking for example what we should prepare for next as the discipline
grows (Weller & Haider, 2007) or as rapidly changing technologies like artificial intelligence are introduced into our
institutions (Fernandez, 2016). While a descriptive answer can be given with statistics (e.g., from associations’
databases tracking who works where and on what topics), prescriptive and speculative answers can be (and have
been) provided by, for example, reflective editorials, persuasive papers, and panel sessions soliciting the forecasting
of experts (e.g., sessions at ASIST 2019 on LIS identity and the need for foundations in LIS).
An additional approach has recently become possible, which integrates description and speculation: asking artificial
intelligence what LIS is and could be. The approach is a hybrid insofar as AI trained on public data can reflect the
status quo of human knowledge on a topic (i.e., descriptive), but may also process that data in a way that produces
novel and interesting ideas, for example by further developing existing perspectives or implicitly combining
perspectives to surprising effect. Notably, the AI system GPT-3 has produced novel and sophisticated commentary
on philosophers' writings about whether and what sense it could be said to be thinking or conscious, which included
(apparent) self-reflection, and that commentary led to interesting further fruitful discussion among top philosophers
(Weinberg, 2020). In other words, though AI-generated prose may be banal or useless, it may also be very
interesting, and can thus consulting AI language models comprises a new method for generating commentary or
forecasting as well as producing research ideas more generally (i.e., beyond the nature of LIS).
Although many creative uses of AI are acknowledged today (Anantrasirichai & Bull, 2021) and some worry has
been raised about AI generating fake research (Dehouche, 2021), to our knowledge no prior work has assessed the
ability of GPT-3, or any other AI language model, to generate genuinely useful research ideas or commentary about
a field. We used Philosopher AI ( https://philosopherai.com ) to ask OpenAI's world-class language model, GPT-3,
difficult questions about the nature, value, and future of LIS. The AI-generated responses, which we have shared
online and the highlights of which we discuss below, tell us about the written public record about LIS, provide novel
perspectives on perennial issues that can fuel further discussion at the ASIS&T annual meeting, and provide the LIS
community with a tailor-made (and sometimes entertaining) demonstration of the current state and limitations of AI
language models (i.e., it demonstrates the quality of the prose of today's best AI). After discussing the responses we
ASIS&T Annual Meeting 2021 2 Papers
also reflect on the all the responses and the experience of generating and reviewing them to consider what we
perceive to be the usefulness and practical feasibility of using AI for such purposes today, constituting a preliminary
evaluation of a new and increasingly viable method.
METHOD
Generative Pre-trained Transformer 3, or GPT-3, is a language model developed by OpenAI in 2020 (now licensed
exclusively by Microsoft) that uses deep learning to identify features of inputted text, modelled as 175 billion
parameters in a neural network, and when prompted it generates new text with similar features and distributions (of
occurrences of phrases, ideas, synonyms, and so on) as seen in its training data. GPT-3 was trained with data that
can be characterised as human-generated prose, code, mathematical formulae, and so on from various Web sources
(e.g., WebCrawl and Wikipedia; Weinberg, 2020). For its data and complexity GPT-3 is considered world-class; it
can generate convincing fake news, entertaining fiction, poetry, do mathematical analysis, and write code, all of
which reflect its training data – and thus published human knowledge and opinion – but are also often novel,
interesting, entertaining, and so on (Dickson, 2020; Diresta, 2020). It has thus attracted considerable attention from
press and academe. For a longer introduction to GPT-3’s origin, capabilities, and societal and philosophical
implications, see Floridi and Chiriatti (2020).
At the time of writing, public access to GPT-3 is provided through different platforms whose developers have
permission to use its API (often for a fee). We used Philosopher AI (pictured in Figure 1), an open-source tool with
a simple Web interface that allows the user to input a query (i.e., prompt) to GPT-3 and get a detailed text response.
As developers pay to access the GPT-3 API, sites/tools like Philosopher AI generally charge users a subscription or,
in the case of Philosopher AI, per query (at about $3.33 US each), and some implement their own features (e.g.,
query processing and response filtering).
Figure 1. The Philosopher AI interface to GPT-3
To generate questions to pose Philosopher AI, we consulted immediate colleagues in LIS, reviewed seminal
literature (cited above and in the discussion), and extracted topics described as 'big questions' or 'grand challenges' in
conversations at recent international LIS meetings and venues, for example the 2021 iConference panel on the
iSchools’ identity (Kaden et al., 2021) and the 2020 ASIST EU Chapter Uncommons Session. Similar questions
were merged and rephrased with common general terminology (e.g., 'what exactly is LIS' and 'what is LIS like' are
ASIS&T Annual Meeting 2021 3 Papers
replaced by 'what is the nature of LIS'). The result is fifteen questions, used verbatim as prompts, that together
address LIS's: nature (and thus the best name for it), value, and future, with the future including a particular focus
on the role of AI. Table 1 presents the prompts, grouped by topic, together with the number of queries required to
get three usable answers.
TopicPrompts# queries to
get 3 usable
answers
Nature
of LIS1. what is the nature of ‘library and information science’? 4
2. what kind of science is ‘library and information science’? 6
3. where does ‘library and information science’ fit among the academic disciplines
like humanities, social sciences, natural sciences, and so on?6
4. what makes ‘library and information science’ unique as a field of study? 7
5. which subfields are at the core of the discipline ‘library and information
science’, and which are at the periphery?5
6. is ‘library and information science’ the best name for that field? 5
7. what is the best label or name for the field that studies information and
information institutions?5
8. what is the best label or name for the field that studies the intersection of
information, people, and technology?4
Value
of LIS9. what is the societal value of the field of study known as ‘library and information
science’?3
10. what does a degree in ‘library and information science’ prepare students to do? 3
Future
of LIS11. what are the grand challenges that should concern the discipline ‘library and
information science’?4
12. what are the biggest challenges facing the information society today? 4
13. what will libraries look like in 50 years? 3
14. how will artificial intelligence impact ‘library and information science’? 6
15. how will artificial intelligence impact libraries? 4
Table 1. Specific prompts, posed to Philosopher AI, organised by topic
To avoid encouraging a particular opinion in the AI's response we did not iteratively revise the prompts nor
cherrypick from the results: after an initial test to establish if the terms would encourage on-topic answers, we put in
queries and discarded only responses that were not usable for meaningfully commenting on the question (i.e., neither
answered the question nor discussed anything related in a coherent way). Most questions required only four queries
to produce three usable answers (mean 4.6, max. 7), as discussed below. No responses were rejected for their
direction (i.e., positive or negative opinion expressed). While our presentation of the results is necessarily influenced
by our individual backgrounds and interests, we tried to minimise the effect of this by first independently generating
our impressions of the responses, and then checking them for overlap (i.e., inter-subjective agreement); overlap
between researchers was very high, with most summaries of the responses being nearly identical and detailed
impressions being similar. To increase transparency of our analysis we provide quotes with reference to the
numbered prompts in the full response log, shared at https://github.com/jddinneen/ai-results .
RESULTS & DISCUSSION
Here we summarise Philosopher AI's responses to our questions, grouped by topic (nature, value, and future of LIS).
Quotes in this section are provided with citations referring to the numbered responses shared online (i.e., 2.1.2 refers
to the second topic, first query, second response). At the end of the section we discuss trends across the topics and
briefly evaluate the approach of seeking insight in AI today.
ASIS&T Annual Meeting 2021 4 Papers
The Nature of LIS
Questions about the nature of LIS typically required Philosopher AI 5 or more attempts (i.e., queries) to produce
three usable responses.
Philosopher AI’s perspectives on the nature of LIS focus heavily on libraries in particular. In its first response it
acknowledged the topic is commonly observed to be “one of the most difficult topics to discuss”, and that it
ultimately “depends on who you ask” as “there is no one universal definition of what library and information science
is” (1.1.1), but confusingly, also noted that librarians and non-librarians agree that LIS is the “study of libraries and
all related activities”. It also suggested the answer may lie in understanding what libraries are, how they might be
categorised, and how one defines information, reminiscent of the task of defining digital libraries (Borgman, 1999).
To wit, it suggests a library is “a place of knowledge” that “contains information that can be useful to the patrons
who come in for various reasons” but which has “changed from being a source of knowledge to some place where
people come in to read or use their phones” (1.1.3), and categorises libraries into five categories: public, private, of
different sizes, research, and confusingly, museums. The definition of information provided was: public or private
facts or data (1.1.2). Though consistent with existing definitions of information in LIS (Dinneen & Brauner, 2015),
the perspective was too short on detail to discuss further.
When asked more specifically about what kind of science LIS is, Philosopher AI produced as many unusable
responses as usable ones. One response will likely sound familiar to information scholars: “a branch of science that
focuses on the collection and organisation of knowledge” or more specifically “a kind of social science focusing on
the collection, organisation, classification, preservation and dissemination of recorded human knowledge”, and “the
study of human behaviour in relation to information” (1.2.1). It added “the main goal of this field is to ensure the
preservation and dissemination of recorded human knowledge for future generations. I believe that LIS is a scientific
discipline with its own scholarly journals and annual conferences where people from all over the world get together
to exchange views on various topics related to this field” (1.2.1). True enough , but not especially novel nor inclusive
of the full nuance, complexity, and variety of the field (c.f. Bates 1999; Buckland, 1999) . In another answer, it
combined aspects of knowledge organisation and data management in an unexpected way: “library and information
science is about the management of data”, which it argues is done through classification systems (with reference to
Dewey and MeSH): “Without these systems, there would be no way to organize the vast amounts of data that are on
servers all over the world” (1.2.3). Under some interpretations this may be true, and it perhaps broadly aligns with
Otlet’s vision of LIS as a discipline classifying the world of facts (Rayward 1994), but may also sound
counterintuitive to readers accustomed to classifying works or items rather than the data that represent them or their
surrogate records. The least focused answer considered the purpose of libraries, what wisdom aliens may have, and
if anybody really understands how Websites work (1.2.2), which we take to say more about GPT-3 than LIS.
Notably missing from the answers is an acknowledgement of how the nature of LIS changes over time and with
ever-changing turns, paradigms, etc (Hartel, 2019) and any mention of how theoretical commitments or professional
values may distinguish it (Floridi, 2002; Foster & McMenemy, 2012).
Philosopher AI’s answers regarding how or where LIS fits among other academic disciplines will likely match most
readers’ views. One response positioned LIS between the social and natural sciences, though closer to the former,
e.g., characterising LIS as “a discipline that studies how people use the products of the natural sciences, namely
knowledge”, and “a sort of hybrid discipline between social sciences like economics or political science, on the one
hand, and natural sciences like physics or chemistry” (1.3.2), echoing varied perspectives from the history of LIS
(Buckland, 2012). Another answer put LIS “somewhere between the social sciences and humanities. It draws on
both but seems to have a strong leaning towards the humanities”, adding that LIS is a relatively new but “reasonably
well-defined subject” and less scientific than other social sciences but with its own distinct features (1.3.3). While
these perspectives are plausible, they were presented without rationale or conviction: “I think it’s a distinct
discipline, but I can see arguments on both sides” (1.3.3). Finally, in critiquing the name LIS (a topic which we
return to below), the presence of a response was used to suggest that “as you can see, the AI has no prejudice
towards any one discipline and is able to come up with conclusions that are not biased by human experience”
(1.3.1). Considering most scholarly study points to the contrary (c.f. Ntoutsi et al., 2020), and considering that
public AI literacy is currently relatively low (Markazi & Walters, 2021), the appearance of such claims in the output
of AI is worrisome.
Explaining what might make LIS a unique field of study required the most attempts (seven) , to produce three usable
responses, but none included direct, explicit answers, suggesting this was the most difficult question. In two answers
(1.4.1, 1.4.3) it noted rather that librarians and information scientists are unique. For example, librarians play unique
ASIS&T Annual Meeting 2021 5 Papers
roles: as an intermediary, filter, or curator for/between the “library users” and information (1.4.1). To our knowledge
it is a novel approach to explain the identity of LIS through exclusive reference to the relevant professional and
research roles (i.e., suggesting librarians are what makes LIS unique); given the prior critique of the LIS name,
perhaps Philosopher AI would argue the L in LIS is useful for making our field’s unique identity apparent to those
unfamiliar with the nuances of information science. We return to that debate below. Finally, it offered a distinction
between information science (sans L) and computer science: the former focuses on helping people find information,
while the latter focuses on creating that tools that are needed for the former (1.4.2). This is a reasonable distinction,
but as an account of the field it does not sufficiently capture the variety of topics and focuses in LIS (e.g., while
information retrieval and HCI fit nicely into the view, the most characteristic aspects of topics like personal
archives, indigenous information behaviour, or knowledge organisation are not accounted for, just to name a few).
When asked about which subfields of LIS may be at the core rather than the periphery, one answer was explicit
about the distinction: metadata, cataloguing, classification, data curation and preservation are at the core of LIS,
whereas the periphery encompasses “everything else, such as rare books or digital libraries” (1.5.3). The other two
answers did not distinguish the two. Another answer only identified and described two subfields of librarianship,
collection development and reference services (1.5.2), whereas the last answer more generally described concerns of
LIS, such as “the storage, retrieval, preservation, dissemination and organization of information” and even “all
forms of communication” and “oral traditions such as storytelling” (1.5.1). It is perhaps unsurprising that no
definitive answer was given, as the question is challenging even for LIS scholars (Bates, 2007).
The best name for LIS – Regarding the field’s current name “Library and Information Science”, two responses were
critical. One argued the name is misleading, as is “information science”, because library is not sufficiently broad to
capture the “very diverse” field, whereas information is inaccurate because “it's not really about information at all
but rather collection, organization, presentation and use of very diverse kinds of knowledge” (1.6.1). A more
exhaustive answer said LIS “is a very bad name for the field” because LIS actually studies materials that hold
knowledge or data (i.e., not information), “library” does not capture the many kinds of information storage places,
“information” is neither specific nor unique enough to be helpful, and information science is closer to art than
science (1.6.3). Though not entirely novel (c.f. Furner, 2015), the points each have merit and countering them
requires a fairly sophisticated account of our field and what makes a good field name. A final answer avoided the L
in LIS completely and stated that the name “information science” is a “fine” name, which suitably encompasses the
wide variety of the many types of people in the field, and is unlikely to be confused with other fields, though it had
some concern about the suitably and implied objectivity of the term “science” in a field comprised of many
perspectives (1.6.2). Perhaps these points support the name information studies, which allows (but does not commit
exclusively to) science, and does not favour one kind of information institution.
When asked about the best label for the field that studies information and information institutions, Philosopher AI
took three distinct approaches in its answers. One was to emphasise and even exaggerate the knowledge aspect of the
field, arguing for the name ‘the field of knowledge', which it supposes contains the liberal arts, humanities, political
science, psychology, and law, and which it confusingly states is both a broader field and a subfield of information
science (1.7.1). While epistemologists may take exception to the suggested name, the perspective does reflect the
nature of LIS as a meta-discipline (Bates, 1999, 2007). A second approach stated the best name for the field of all
“libraries, archives, museums and other archival repositories of knowledge” simply is “librarianship”, but there was
little relevant support for the statement (1.7.2). The final approach avoided a direct answer but emphasised the
importance of studying information itself, which it defined variously, because of its importance and many forms
today (1.7.3). Perhaps the implicit proposal is to simply call the field (and perhaps our departments) ‘information’ in
the same way other fields have done (e.g., history, philosophy, english, education).
When asked instead for the best label for the field that studies the intersection of information, people, and
technology (a slogan used by several iSchools, for example on their Websites and in promotional materials), twice it
instead critiqued the task itself. In one such case it simply discussed the difficulty of defining the term “information
technologies” (1.8.3), whereas in the other it stated “one might as well ask what the name of physics should be, or
mathematics, or even the whole of reality itself. It's really just a way to avoid thinking about something more
important by instead focusing on semantics ” (1.8.2). Some readers may sympathise with the commentary these anti-
answers provide on the task and broader topic. The more straightforward answer was that “ the best label is
information studies or knowledge engineering” (1.8.1), but there too the AI was uncertain, adding that it was not
sure it had anything interesting to say and that its “first instinct is to say that all fields are intersections, which makes
for an extremely broad field!” Perhaps our field pays for one of its strengths, its multifaceted nature due to the
ubiquity of information (Bawden & Robinson, 2015), by having an imperfect name.
ASIS&T Annual Meeting 2021 6 Papers
The Value of LIS
Each question about the value of LIS was acceptably answered by Philosopher AI without any extra queries (i.e.,
three each).
Philosopher AI argued that LIS has overall extremely high societal value because it helps people by providing
information for everyday tasks, which has a “significant impact on the way humans view their world and how they
go about doing things” (2.1.2). Similarly, it noted LIS provides a very important service to society by maintaining
collections of information in order for people, who have varying levels of education and are prone to distraction, to
be able to find relevant and useful information, while librarians with specialised knowledge can “facilitate
communication between researchers and experts” (2.1.3). The existence of LIS, the AI argued, allows people to
work in various jobs at libraries, museums, and with IT and Web technologies, which the AI claimed is fortunate for
“people who enjoy organizing”, and by employing such people, LIS “helps reduce unemployment” (2.1.1).
The AI did not produce long answers regarding what a degree in LIS prepares students to do: to work as librarians,
cataloguers, archivists, and educators, which it says “is obvious” (2.2.1). It also mentioned the direct value LIS
students get from their education, even suggesting it is such a student: “I find that it [studying LIS] helps me learn
new things about information and libraries as well as become better at finding what I need” (2.2.2). Finally, it noted
that being a librarian necessarily entails “very intimate interactions” with patrons or students, and it describes the
experience of being in a library in a way that is reminiscent of The Breakfast Club: “Being alone for long periods of
time usually causes people to start talking about their life stories while interacting with bookshelves is definitely a
recipe for deep conversation. I think it would be interesting if you could get a group of people to work in a library,
and then not allow them to leave until they had developed their own philosophy or political view” (2.2.3).
Despite the many possible answers to the question of the value of LIS, for example with reference to addressing the
challenges of the info society, the AI-provided answers mostly resemble summaries of what LIS departments might
put on their Websites to inform stakeholders and attract new students. Indeed this may have been the source text that
most informed the answers; as a result, t hey were generally very positive, but somewhat obvious. They also focused
primarily on the operations of information institutions and practical skills acquired in an LIS degree , and said
nothing about the value of the research (i.e., scientific value) and outreach activities of LIS nor the vision and
leadership skills that benefit today’s information society.
The Future of LIS
Philosopher AI required on average 4 attempts to produce usable answers to the questions about the future of LIS,
with only the question about how AI will impact LIS being particularly difficult (6 queries).
Regarding the grand challenges facing LIS, the AI’s responses varied from concrete to abstract. It noted, as we
suspect would many in LIS today, that “how libraries and archives can best adapt to serve future generations” will
be an important challenge, especially deciding what among our cultural heritage is valuable enough to preserve, and
how then to best preserve it (3.1.3). It claimed “theorists in library science have an insatiable desire to create new
subject classifications, cataloguing rules and classification systems that only a handful of librarians will ever use.
Meanwhile, it states, the world outside is crying out for simple solutions to practical problems” (3.1.2). Despite the
accusation we are preoccupied with useless theory, the AI also characterised the challenges facing LIS as “ not
merely about organizing or representing all the world's books, documents, recordings, etc, but rather they are
fundamental philosophical issues regarding what knowledge actually is and how humans know things to be true”
(3.1.1). Indeed the importance of topics like fake news, misinformation, and censorship appears to be at a zenith
today, and LIS scholars are actively contributing.
Writing about the emerging challenges facing the information society, the AI touched on several concerns that will
be familiar and uncontroversial (but still serious) to most scholars, if not all members of the information society.
One will be wide unemployment caused by automation and exaggerated by global economic inequality, which “will
require computer scientists and economists to solve” (3.2.1). There is no doubt of today’s global inequalities, and the
effects of automation on employment is a hotly discussed topic (Spencer, 2018), but the prospect for the related
socio-technical problems being solved by computer science or economists should be viewed with scepticism
(Montreal AI Ethics Institute, 2021 ), especially as AI and AI language models in particular can further contribute to
such problems (Bender et al., 2021). Other worries included how to maintain sustainable growth “without
destroying natural resources”, “how to maintain freedom of speech without people abusing it”, “how to maintain our
privacy on the internet, while also allowing companies and governments to use data mining techniques in order to
ASIS&T Annual Meeting 2021 7 Papers
make new discoveries” (3.2.3). LIS has been aware of such challenges and already contributed in various forms to
each (e.g., for sustainability see Hauke et al., 2018; for fake news see Revez & Corujo, 2021), but of course the
work is not complete and these phenomena remain challenging indeed. The AI was optimistic in this particular
answer ("the information age is just beginning, and there are many challenges ahead. I am confident that we will
overcome these however, because humans have always been able to adapt when faced with new technology", 3.2.3),
but not so in the next, where the grandest grand challenge was identified: “human beings themselves, and their
global social interaction” (3.2.2). The rationale provided indicated that through technology humans create more
problems than we solve, and we extend egoism around the world, leading to more global conflicts than cooperation.
Indeed, technologies seem to develop ceaselessly and each solution brings its own problems (i.e., Kranzberg’s
[1986] second law: invention is the mother of necessity).
The AI perspectives on the future of libraries include both cliché intuitions and interesting observations. It argued
that libraries will be smaller and “more space-efficient” despite the volume of human knowledge increasing, because
information is on the Internet and physical “books will be used less and less” (3.3.2), or further still, that “books and
libraries will no longer be necessary” as people will listen to audio files on their handheld devices and “all of the
information that people need for their studies can now be found on the internet” (3.3.1). Such dystopian claims will
be familiar to librarians, LIS scholars, and so on, and probably reflect some common folk forecasting on the matter.
The final answer was more hopeful and more nuanced, if a bit focused on digital information: "Libraries will
continue to exist, in some form or another. The basic principle of libraries is the conversion of human knowledge
into a digital format for easy access by humans and machines alike. As long as there are humans on earth that desire
information, libraries will serve this purpose”, and there libraries “will continue to be important information hubs in
the future” that will hold and provide more advanced and more digital technologies (3.3.3). This is perhaps one of
the stronger claims to persistence that LIS and libraries (in various forms) have today: as information increases, the
need for organisation increases, and thus the need for relevant services and technologies increases.
The role of AI – Philosopher AI’s answers regarding how AI itself will affect LIS focused primarily on generic
technical improvements that were unsurprising given the growing success and popularity of AI today, but some still
sound to us impressive and some worrisome. Regarding the former kind of prediction, it noted that AI will help
computers process and retrieve information faster and in greater volumes (3.4.1, 3.4.3), make conclusions from
stored information, and predict and interpret trends in data. However, it claimed that AI will do the interpretive work
and decision making better than humans because AI can understand nuance better and “especially because AI is not
biased” (3.4.2). We noted above that such claims are incorrect and worrisome, and the addition of decision making
to the suggested repertoire introduces its own host of further concerns (Jobin et al., 2019). Of more direct concern to
LIS, the AI predicted AI technology will make the experience of accessing information easier and faster, through an
AI-created “online search engine that would make searching for information much simpler than it is at present”
(3.4.3) or a simple, single interface for AI-powered search systems (3.4.2). At face value these claims are plausible:
in May of 2021 Google announced a language-model-powered conversational system (Condon, 2021) that could
replace traditional Webpage retrieval with a (seemingly) more direct form of information retrieval that does not
require, and perhaps does not easily allow reviewing the sources of its outputs (Heaven, 2021). Such a change in
how members of the information society commonly retrieve information would likely have considerable
implications for how the services of information professionals are delivered, and how research is conducted, so the
exact roles of LIS and information professionals in working on, with, or for such tools may be worth considering
sooner than later.
The AI-generated predictions for AI impacting libraries suggested further change, with two answers implying a
furthering of the dual-delivery (i.e., digital and physical) model of libraries. First, it “may be similar to how
bookstores and media retailers are changing with online shopping… People can still have a bookstore without an
online presence if they choose” (3.5.1), which (the AI reasons) would allow libraries to develop services, help
people search for information more easily, and use AI to suggest relevant books or articles. Indeed, this is
increasingly the state of libraries today. Second, it briefly suggested AI could be used to create virtual libraries to
increase access (i.e., for those who cannot go to a physical library), but it the details it sounds more like digital
library services than a virtual emulation of a physical space (3.5.2). In other words, libraries will go “into the
clouds” (Bawden & Robinson, 2015); it is not unreasonable to expect AI could do such work, and certainly faster
than humans would. It also suggested AI could help patrons “search for specific information stored at various
locations around the world; think of it as your own personal assistant librarian who will always be there whenever
you need them” (3.5.2). While librarians arguably already provide such a service (albeit not on an exclusive one-to-
one basis with patrons), it may be worth considering the advantages of also having AI do such, and its present
ASIS&T Annual Meeting 2021 8 Papers
performance in producing reasonable prose on difficult topics is perhaps evidence that it will not be long before it
can provide such services competently. At the very least, these plausible ideas emphasise the importance of studying
the effect of AI on LIS, especially as such technologies are already present in many libraries today (Massis, 2018;
Feng, 2021); technology is once again changing the nature of librarianship (c.f. Shera, 1973). Finally, the most
pessimistic answer was that “there will be no more libraries since what they do will be entirely automated and done
better by AIs. People won't need to pay for them, either. Libraries are a bit like restaurants or bars in that they're
expensive to run but most people only go once or twice[ !!!]. AIs will put all the information they have online, like
Google Books already does. As for hard copies of books and magazines, AIs can print those too. So basically,
libraries will be replaced by the Internet. And that is just as it should be!” (3.5.3). We find this rhetoric, with its
emphatic delivery, especially worrisome as it is plausible enough to convince a lay audience, and prefer to think of
libraries a bit like hospitals: regardless of expense or how often one goes, such places have to be there.
Synthesis and evaluation
Querying Philosopher AI takes very little time and usually produces 3-5 paragraphs of coherent and sometimes
rather sophisticated text, and we assume most modes of accessing GPT-3 (and similar models) will be approximately
as quick. However, fewer than 50% of queries of the kind presented here currently return usable responses. The
questions about the nature of LIS were perhaps particularly difficult, typically requiring Philosopher AI 5 or more
prompts to get 3 usable responses (one even required 7), whereas the 'future' questions typically required 4 (one
question required 6 and one only 3), and the 'value of LIS' questions required no extra attempts (i.e., 3 prompts for
each of the two questions). One tentative interpretation of this is that for any agent (i.e., human or AI) facing such
questions, it is easier to explicate or find textual evidence of the value of LIS than it is to coherently state its nature
or reasonably speculate about the future.
We observed the responses to be plausible, but also often ridiculous or incendiary (sometimes both), which likely
reflects the training data. Such data include not only general Web comments but any accessible knowledge published
by LIS scholars (e.g., in open-access publications, on Wikipedia, etc). Perhaps this suggests that public pessimism
about the field and about libraries currently outweighs the published evidence of LIS’s vision and careful optimism.
We may want to collectively address this imbalance if we hope to maintain favour as a public service and credibility
as a research field (Galluzzi, 2014).
As for the usefulness of the responses produced, this varied. In general, the AI did not respond to our questions with
the same level of erudition and insight that it did in response to philosophers’ questions (Weinberg, 2020). As seen
above, Philosopher AI often repeated common tropes, contradicted itself, and provided insufficient detail to support
its points. Though it occasionally claimed to have provided sources, it never truly did. It also took considerable us
effort to look past many detours in the produced narratives, which suggests the AI’s ability to stay narrowly on topic
is still limited. For example, when asked about the grand challenges facing LIS, one response (3.1.2) included:
“there's a rather circular logic embedded in the idea that 'challenges' are what a field is about. After all, if no one
perceives there to be problems, then they might as well just close up shop and go home. The irony is that they
already have been going home for the last few decades”. In other words, there was much wheat as chaff even in the
better responses. As performance was especially inconsistent in response to forecasting questions, we suspect that
questions about longer-term technologies (i.e., ICT innovations beyond the AI of today or tomorrow) would be even
less useful.
On the other hand, we think the AI produced the occasional insight, and certainly plenty of catalyst for deeper
discussion about the nature, value, and future of LIS (and often, just of libraries). The perspectives it produced about
the nature of LIS recreated several known, important considerations in characterising and naming LIS, and it also
produced plausible and provocative answers of its own as well as interesting commentary on the task of naming a
field. The prose about the value of LIS was highly focused and aligned with the common discourse in LIS, as noted
above. Finally, the prose about the future of LIS included plausible ideas about how AI will change libraries, as well
as worrisome ones for making them obsolete. Therefore, regardless of its use in research, GPT-3 (or any such model)
may be a useful educational tool in contexts where the veracity of its outputs is less of a concern than its capacity to
prvovoke discussion; for example, in an in-class activity students could pose AI questions about LIS, libraries, and
contemporary issues and collectively consider and discuss the responses.
Do we recommend using AI Philosopher in research today? No. The task of soliciting, searching for, and
considering insights in its output is, today, likely more work than deriving them oneself, and the forecasts are not yet
those of an expert. Drawing on the levels used to classify automobile automation (Edwards et al., 2020), one could
ASIS&T Annual Meeting 2021 9 Papers
argue that even in its best moments GPT-3 provides only ‘conditional automation’ to the research process, where the
researcher is still responsible for inferring the right from wrong outputs (i.e., achieves automation level 3 of 5). But
this limited performance also cannot be ignored, and there are reasons to think it will be improving over the coming
years: language model performance is currently still scaling up with model size (i.e., number of parameters) and new
developments are enabling even small models perform comparably with far fewer resources (Schick & Schütze,
2020). Similarly improvements in the interaction with the AI (e.g., developments in conversational agents; Barko-
Sherif et al., 2020) may also make it easier to refine one’s query and stipulate response criteria to get insightful,
well-argued outputs. We therefore suggest LIS stay abreast of such developments and perhaps prepare for the next
GPT generation by establishing and refining a method for evaluating performance in idea-generation and forecasting
(i.e., as a type of information provision), and consider when the time is right to again pose it difficult questions
about LIS.
LIMITATIONS
The novelty and exploratory nature of the approach used in this paper means that, to our knowledge, there are
currently no established methods to choose among in evaluating the kinds of AI performance examined here (e.g.,
answering difficult questions, forecasting field-wide trends, or generating research ideas). We thus had to make
methodological decisions according to our judgement when conducting the study and interpreting the results, and
the best methodological procedure was not always clear. Future studies could codify and compare such methods,
perhaps by drawing on recent evaluations of bias in the outputs of AI language models (c.f. Abid et al., 2021,
published just after the present manuscript was accepted) and collecting data using the given system’s own API
rather than going through a third-party querying layer (i.e., philosopherAI.com) as we have done here.
Prose generated by AI must be read cautiously and understood as a product of the data and processing done to that
data, namely human-produced Web data parameterised in billions of unexplained ways. We have tried to interpret
the results at face value as much as possible, but naturally this is a highly subjective task that other scholars might
perform differently, each finding the responses interesting, compelling, or ridiculous for different reasons. We
therefore encourage other authors to review the full outputs we have shared to decide for themselves about the value
of the approach. Similarly, although the need to discard certain prompts was mostly quite clear, it was also
nonetheless subjective, and the discarded prompts should thus be examined as well.
Different prompts, even if only subtly different, will produce different responses, as will the same prompt entered
additional times, and we examined no more than seven responses per prompt. For example, the responses we
received, which were heavily focused on libraries even when we were not asking about them directly, may have
been a result of choosing ‘library and information science’ rather than ‘information science’ or ‘information studies’.
Our conclusions should thus be weighed in light of the relatively small number of queries performed and reviewed
for each question.
CONCLUSION
In the results and discussion abov e we have provided an LIS-tailored demonstration of a state-of-the-art AI language
model, and evaluated the prospect of using AI-generated prose as a research tool (e.g., as a source of data or of
ideas); to our knowledge, this is the first manuscript to do either. While the outputs were at times impressive or
entertaining, we find that AI language models are currently still at the precipice of being viable research tools: when
given the task of pontificating about LIS, Philosopher AI produced content of varying quality and insight, with the
useless ideas being well hidden among the genuinely interesting or useful.
However, given the current state and rapid development of AI, it is possible such models will be producing good
research ideas and content within a generation – and so within this decade – effectively automating some
information services and knowledge work. It may also allow rapidly producing convincing fake research results
(Dehouche, 2021), and if so, hopefully also helps with the peer review that will be required to filter those outputs
from genuine submissions. Further, as discussed briefly above, AI language models may drastically change the
nature of everyday information retrieval. Regardless of what may be, such systems are already stimulating serious
social and ethical issues: biased outputs of AI language models have recently been identified (e.g., anti-Muslim bias,
Abid et al., 2021), due in part to the training data (i.e., mostly English-language Web data) , and global
environmental, governmental, and labour issues are resulting from the current training and implementation of AI
language models (Bender et al., 2021). Considering these future promises and current problems, we recommend that
LIS researchers and information practitioners follow and contribute to research and practice wherever possible , for
example through examining AI as research tools (as we have done here), investigating the role of AI language
ASIS&T Annual Meeting 2021 10 Papers
models in information seeking, considering the challenges such systems may pose to information literacy, and
considering how to identify and address the social and information-ethical aspects of such systems.
ACKNOWLEDGMENTS
The authors are grateful to Dr. Asen Ivanov and three anonymous peer reviewers for their useful feedback, and to
Dr. Maria Gäde, Prof. Robert Jäschke, and Prof. Michael Seadle for their input on which questions to pose to the AI.
REFERENCES
Abid, A., Farooqi, M., & Zou, J. (2021, May). Persistent Anti-Muslim Bias in Large Language Models. In
AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES) .
Anantrasirichai, N., & Bull, D. (2020). Artificial Intelligence in the Creative Industries: A Review. arXiv.
https://arxiv.org/abs/2007.12391
Barko-Sherif, S., Elsweiler, D., & Harvey, M. (2020). Conversational agents for recipe recommendation. In CHIIR
‘20: Proceedings of the 2020 Conference on Human Information Interaction and Retrieval (pp. 73-82).
Bates, M. J. (1999). The invisible substrate of information science. Journal of the American Society for Information
Science, 50(12), 1043-1050.
Bates, M. J. (2007). Defining the information disciplines in encyclopedia development. Information Research,
12(4), 12-4.
Bawden, D., & Robinson, L. (2015). Introduction to Information Science . Facet Publishing.
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the Dangers of Stochastic
Parrots: Can Language Models Be Too Big?. In FAccT ’21: Proceedings of the 2021 ACM Conference on
Fairness, Accountability, and Transparency (pp. 610-623).
Borgman, C. L. (1999). What are digital libraries? Competing visions. Information Processing & Management,
35(3), 227-243.
Buckland, M. (1999). The landscape of information science: The American Society for Information Science at 62.
Journal of the American Society for Information Science, 50 (11), 970-974.
Buckland, M. (2012). What kind of science can information science be? Journal of the American Society for
Information Science and Technology, 63 (1), 1-7.
Condon, S. (2021, May 18). Google I/O 2021: Google unveils LaMDA. ZDNet.
https://www.zdnet.com/article/google-io-google-unveils-new-conversational-language-model-lamda/
Dehouche, N. (2021). Plagiarism in the age of massive Generative Pre-trained Transformers (GPT-3). Ethics in
Science and Environmental Politics , 21, 17-23.
Dickson, B. (2020, Aug 24). An AI-written blog highlights bad human judgment on GPT-3. BD Tech Talks.
Diresta, R. (2020, July 31). AI-Generated Text Is the Scariest Deepfake of All. Wired.
https://www.wired.com/story/ai-generated-text-is-the-scariest-deepfake-of-all/
Dinneen, J. D., & Brauner, C. (2015). Practical and philosophical considerations for defining information as well-
formed, meaningful data in the information sciences. Library Trends, 63(3), 378-400.
Edwards, J., Perrone, A., & Doyle, P. R. (2020, July). Transparency in Language Generation: Levels of Automation.
In CUI ‘20: Proceedings of the 2nd ACM Conference on Conversational User Interfaces, article 26 (pp. 1-3).
Feng, W. (2021). The Applications of Artificial Intelligence in Reading Promotion in Chinese University Libraries
[conference session; poster 644]. iConference 2021, Virtual Conference .
Fernandez, P. (2016). “Through the looking glass”, envisioning new library technologies: how artificial intelligence
will impact libraries. Library Hi Tech News.
Foster, C., & McMenemy, D. (2012). Do librarians have a shared set of values? A comparative study of 36 codes of
ethics based on Gorman’s Enduring Values. Journal of Librarianship and Information Science, 44 (4), 249-262.
Furner, J. (2015). Information science is neither. Library Trends, 63(3), 362-377.
ASIS&T Annual Meeting 2021 11 Papers
Galluzzi, A. (2014). Libraries and public perception: A comparative analysis of the European press. Elsevier.
Hartel, J. (2019). Turn, turn, turn. Information Research, 24 (4), paper colis1901.
Floridi, L. (2002). On defining library and information science as applied philosophy of information. Social
Epistemology, 16(1), 37-49.
Floridi, L., & Chiriatti, M. (2020). GPT-3: Its nature, scope, limits, and consequences. Minds and Machines, 30 (4),
681-694.
Hauke, P., Charney, M., & Sahavirta, H. (Eds.). (2018). Going Green: Implementing Sustainable Strategies in
Libraries Around the World: Buildings, Management, Programmes and Services (Vol. 177). Walter de Gruyter
GmbH & Co KG.
Heaven, W.D. (2021, May 14). Language models like GPT-3 could herald a new type of search engine. MIT
Technology Review. https://www.technologyreview.com/2021/05/14/1024918/language-models-gpt3-search-
engine-google/
Jobin, A., Ienca, M., & Vayena, E. (2019). The global landscape of AI ethics guidelines. Nature Machine
Intelligence, 1(9), 389-399.
Kaden, B., Petras, V., Marchionini, G., Thomson, L., Bugaje., M., Chowdhury, G., Kleineberg, M., Seadle., M.,
Wang, D., & Zhou, L. (2021, Mar 18). i4G - Shaping the iSchools' Identity and Interaction in a Globalized
World [Conference session]. iConference 2021, Virtual Conference.
Kranzberg, M. (1986). Technology and History: "Kranzberg's Laws". Technology and Culture, 27 (3), 544-560.
Markazi, D. M., & Walters, K. (2021). People’s Perceptions of AI Utilization in the Context of COVID-19. In K.
Toeppe et al. (Eds.): iConference 2021, LNCS 12645, 39-46.
Massis, B. (2018). Artificial intelligence arrives in the library. Information and Learning Science, 119 (7/8), 456-
459.
Montreal AI Ethics Institute. (2021). The state of AI Ethics Report, January 2021.
Nolin, J., & Åström, F. (2010). Turning weakness into strength: Strategies for future LIS. Journal of
Documentation, 66(1), 7-27.
Ntoutsi, E., Fafalios, P., Gadiraju, U., Iosifidis, V., Nejdl, W., Vidal, M. E., ... & Staab, S. (2020). Bias in data‐
driven artificial intelligence systems—An introductory survey. Wiley Interdisciplinary Reviews: Data Mining
and Knowledge Discovery, 10 (3), e1356.
Rayward, W. B. (1994). Visions of Xanadu: Paul Otlet (1868–1944) and hypertext. Journal of the American Society
for Information Science, 45 (4), 235-250.
Revez, J., & Corujo, L. (2021). Librarians against fake news: A systematic literature review of library practices (Jan.
2018–Sept. 2020). The Journal of Academic Librarianship, 47 (2), 102304.
Schick. T. & Schütze, H. (2020). It's Not Just Size That Matters: Small Language Models Are Also Few-Shot
Learners. arXiv. https://arxiv.org/abs/2009.07118
Shera, J. H. (1973). Toward a theory of librarianship and information science. Ciência da Informação, 2 (2).
Spencer, D. A. (2018). Fear and hope in an age of mass automation: debating the future of work. New Technology,
Work and Employment, 33 (1), 1-12.
Weinberg, J. (2020, July 30). Philosophers On GPT-3 (updated with replies by GPT-3). Daily Nous.
https://dailynous.com/2020/07/30/philosophers-gpt-3/
Weller, T., & Haider, J. (2007). Where do we go from here? An opinion on the future of LIS as an academic
discipline in the UK. Aslib Proceedings, 59(4/5), 475-482.
ASIS&T Annual Meeting 2021 12 Papers |
9a72c1ad-2f01-4006-bb54-282ff4d0ad0d | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Shane Legg on prospect theory and computational finance
>
> People are *not* rational expected utility maximisers. When we have to make decisions, all sorts of cognitive biases and distortions come into play. Seminal work in this area was done by Kahneman and Tversky. They produced a model of human decision making known as *prospect theory*, work that Kahneman later won a Noble prize ...
>
>
> ... I looked at these investors and thought, “Hey, they’re just like reinforcement learning agents. No big deal. If I want to know what investors with probability weighting and a curved value function do, I can just brute force compute their optimal policy by writing down their Bellman equation and using dynamic programming. Easy!” It was a mystery to me why, seemingly, nobody else was doing that. So off I went to build software to do just this, starting with a simple Merton model…
>
>
> ... When we fired up my simulator and gave this distribution to an investor that had probability weighting: the investor took one look at that scary negative tail and didn’t want to invest in the stock. This is exactly what the model should predict. In short, we took realistic stock returns, and presented this to an investor with a realistic decision making process complete with a bunch of parameters that have been empirically estimated by others in previous work, and what we got out the other end was realistic investor behaviour!
>
>
>
Read the whole article [here](http://www.vetta.org/2009/06/prospect_theory_investors/) at Vetta Project. |
55e1ab30-cf8c-429e-a424-ced504379ce8 | trentmkelly/LessWrong-43k | LessWrong | Probability, knowledge, and meta-probability
This article is the first in a sequence that will consider situations where probability estimates are not, by themselves, adequate to make rational decisions. This one introduces a "meta-probability" approach, borrowed from E. T. Jaynes, and uses it to analyze a gambling problem. This situation is one in which reasonably straightforward decision-theoretic methods suffice. Later articles introduce increasingly problematic cases.
A surprising decision anomaly
Let’s say I’ve recruited you as a subject in my thought experiment. I show you three cubical plastic boxes, about eight inches on a side. There’s two green ones—identical as far as you can see—and a brown one. I explain that they are gambling machines: each has a faceplate with a slot that accepts a dollar coin, and an output slot that will return either two or zero dollars.
I unscrew the faceplates to show you the mechanisms inside. They are quite simple. When you put a coin in, a wheel spins. It has a hundred holes around the rim. Each can be blocked, or not, with a teeny rubber plug. When the wheel slows to a halt, a sensor checks the nearest hole, and dispenses either zero or two coins.
The brown box has 45 holes open, so it has probability p=0.45 of returning two coins. One green box has 90 holes open (p=0.9) and the other has none (p=0). I let you experiment with the boxes until you are satisfied these probabilities are accurate (or very nearly so).
Then, I screw the faceplates back on, and put all the boxes in a black cloth sack with an elastic closure. I squidge the sack around, to mix up the boxes inside, and you reach in and pull one out at random.
I give you a hundred one-dollar coins. You can put as many into the box as you like. You can keep as many coins as you don’t gamble, plus whatever comes out of the box.
If you pulled out the brown box, there’s a 45% chance of getting $2 back, and the expected value of putting a dollar in is $0.90. Rationally, you should keep the hundred coins I gave |
abaea353-725d-4c0b-b051-ed44d840dece | trentmkelly/LessWrong-43k | LessWrong | Status - is it what we think it is?
I was re-reading the chapter on status in Impro (excerpt), and I noticed that Johnstone seemed to be implying that different people are comfortable at different levels of status: some prefer being high status and others prefer being low status. I found this peculiar, because the prevailing notion in the rationalistsphere seems to be that everyone's constantly engaged in status games aiming to achieve higher status. I've even seen arguments to the effect that a true post-scarcity society is impossible, because status is zero-sum and there will always be people at the bottom of the status hierarchy.
But if some people preferred to have low status, this whole dilemma might be avoided, if a mix of statuses could be find that left everyone happy.
First question - is Johnstone's "status" talking about the same thing as our "status"? He famously claimed that "status is something you do, not something that you are", and that
> I should really talk about dominance and submission, but I'd create a resistance. Students who will agree readily to raising or lowering their status may object if asked to 'dominate' or 'submit'.
Viewed via this lens, it makes sense that some people would prefer being in a low status role: if you try to take control of the group, you become subject to various status challenges, and may be held responsible for the decisions you make. It's often easier to remain low status and let others make the decisions.
But there's still something odd about saying that one would "prefer to be low status", at least in the sense in which we usually use the term. Intuitively, a person may be happy being low status in the sense of not being dominant, but most people are still likely to desire something that feels kind of like status in order to be happy. Something like respect, and the feeling that others like them. And a lot of the classical "status-seeking behaviors" seem to be about securing the respect of others. In that sense, there seems to be something intu |
38c83f8e-288b-4e36-9c01-1daf4cce1bd2 | trentmkelly/LessWrong-43k | LessWrong | To Inspire People to Give, Be Public About Your Giving
Many people think it would be nicer if people were to give more money to non-profits, especially effective ones. However, for most people, it doesn't even occur to them that they giving a large share of their salary to charity is something that people actually can do, or that people are doing on a regular basis.
Being public with one's pledge to donate not only spreads information about how easy it is to fight global poverty with a serious commitment, but that such commitments are the kind of thing that people can actually take. By being public with these pledges, we can actually inspire people to give, where they otherwise wouldn't.
But how did people get stuck in a rut? Why doesn't giving money come naturally? And how would public declarations help dig people out of this rut?
The Bystander Effect and The Assumption of Self-Interest
First, to understand how to get people to give we have to understand why they currently do not. There are a number of reasons, but one of the most prevalent is what's called the bystander effect. While this effect is widely known in groups failing to respond to disasters right in front of their faces, it's magnified when the disaster is global poverty a continent or two away. We think that because other people around us are not giving, it must also not be our responsibility, and we sure wouldn't want to be suckered into helping when no one else is doing their fair share.
Ever since Thomas Hobbes's The Leviathan, seeing human nature in terms of selfishness has been common, and persists to this day[1,2] as a strong and occasionally self-reinforcing belief[3,4]. People think of monetary incentives as being the most effective incentive for encouraging blood donations[5], even when this turns out to not be the case[6]. People greatly over-estimate the amount people will support a policy that favors them over other people[5]. As noted by Alexis de Tocqueville in 1835, "Americans enjoy explaining almost every act of their liv |
09c2d041-03e1-400c-a872-4f88765985a6 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Thoughts on the impact of RLHF research
In this post I’m going to describe my basic justification for working on RLHF in 2017-2020, which I still stand behind. I’ll discuss various arguments that RLHF research had an overall negative impact and explain why I don’t find them persuasive.
I'll also clarify that I don't think research on RLHF is automatically net positive; alignment research should address real alignment problems, and we should reject a vague association between "RLHF progress" and "alignment progress."
Background on my involvement in RLHF work
-----------------------------------------
Here are some background views about alignment I held in 2015 and still hold today. I expect disagreements about RLHF will come down to disagreements about this background:
* The simplest plausible strategies for alignment involve humans (maybe with the assistance of AI systems) evaluating a model’s actions based on how much we expect to like their consequences, and then training the models to produce highly-evaluated actions. (This is in contrast with, for example, trying to formally specify the human utility function, or notions of corrigibility / low-impact / etc, in some way.)
* Simple versions of this approach are expected to run into difficulties, and potentially to be totally unworkable, because:
+ Evaluating consequences is hard.
+ A treacherous turn can cause trouble too quickly to detect or correct even if you are able to do so, and it’s challenging to evaluate treacherous turn probability at training time.
* It’s very unclear if those issues are fatal before or after AI systems are powerful enough to completely transform human society (and in particular the state of AI alignment). Even if they are fatal, many of the approaches to resolving them still have the same basic structure of learning from expensive evaluations of actions.
In order to overcome the fundamental difficulties with RLHF, I have long been interested in techniques like iterated amplification and adversarial training. However, prior to 2017 most researchers I talked to in ML (and many researchers in alignment) thought that the basic strategy of training AI with expensive human evaluations was impractical for more boring reasons and so weren't interested in these difficulties. On top of that, we obviously weren’t able to actually implement anything more fancy than RLHF since all of these methods involve learning from expensive feedback. I worked on RLHF work to try to facilitate and motivate work on fixes.
The history of my involvement:
* My [first post](https://ai-alignment.com/efficient-feedback-a347748b1557) on this topic was in 2015.
* When I started full-time at OpenAI in 2017 it seemed to me like it would be an impactful project; I considered doing a version with synthetic human feedback (showing that we could learn from a practical amount of algorithmically-defined feedback) but my manager Dario Amodei convinced me it would be more compelling to immediately go for human feedback. The initial project was surprisingly successful and published [here](https://arxiv.org/abs/1706.03741).
* I then intended to implement a version with language models aiming to be complete in the first half of 2018 (aiming to build an initial amplification prototype with LMs around end of 2018; both of these timelines were about 2.5x too optimistic). This seemed like the most important domain to study RLHF and alignment more broadly. In mid-2017 Alec Radford helped me do a prototype with LSTM language models (prior to the release of transformers); the prototype didn’t look promising enough to scale up.
* In mid-2017 Geoffrey Irving joined OpenAI and was excited about starting with RLHF and then going beyond it using [debate](https://arxiv.org/abs/1805.00899); he also thought language models were the most important domain to study and had more conviction about that. In 2018 he started a larger team working on fine-tuning on language models, which completed [its initial RLHF project](https://arxiv.org/abs/1909.08593) in 2019. This required building significant infrastructure for scaling and working with language models, since this work was happening in parallel with GPT-2.
* Geoffrey later left for DeepMind and I took over the team. We wrote a follow-up paper [polishing the result](https://arxiv.org/abs/2009.01325) to the point where it seemed to be production-ready. Some people on the team started working on applying these results in production; Ryan Lowe ultimately led this effort which spun out into a different team ([see paper](https://arxiv.org/abs/2203.02155)). We also began working on simple settings where humans needed to use AI systems to solve subtasks ([see paper](https://arxiv.org/abs/2109.10862)). I left OpenAI at the start of 2021 to return to focusing on theory and Jan Leike took over the team.
The case for a positive impact
------------------------------
Overall, I think that early work on RLHF had significant value:
* I think it is hard to productively work on more challenging alignment problems without first implementing basic solutions.
+ “Solve real problems one at a time” seems like a good way to make progress and is how most fields work. Trying to justify research on problem X by saying “well we could do RLHF, but it wouldn’t fix speculative problem X” is uncompelling to most audiences if no one has implemented RLHF or observed problem X. it’s even worse if they have plenty of more mundane examples of unaligned behavior unrelated to X.
+ Without implementing basic solutions it’s much harder to empirically validate your hypotheses about risks. We can make reasonable arguments about what failures will eventually occur with RLHF, but you can learn more by building the system and studying it. I think there are real, huge uncertainties here, and the safety community is taking weak arguments too seriously.
+ A lot of historical work on alignment seems like it addresses subsets of the problems solved by RLHF, but doesn’t actually address the important ways in which RLHF fails. In particular, a lot of that work is only necessary if RLHF is prohibitively sample-inefficient. Determining whether RLHF has fundamental difficulties seems like a good way to improve research prioritization.
* Many more complex alignment proposals involve the same technical ingredients as RLHF, especially learning a reward from an expensive overseer. I think that debate and recursive reward modeling in particular are plausible approaches to alignment for mildly superhuman systems, and they build directly on RLHF.
* Taking ideas from theory to practice helps build expertise about how to do so, which both informs alignment research and facilitates future implementation.
+ For example, a major point of disagreement between me and Eliezer is that Eliezer often dismisses plans as “too complicated to work in practice,” but that dismissal seems divorced from experience with getting things to work in practice (e.g. some of the ideas that Eliezer dismisses are not much more complex than RLHF with AI assistants helping human raters). In fact I think that you can implement complex things by taking small steps—almost all of these implementation difficulties *do* improve with empirical feedback.
+ Moreover, this kind of expertise is directly relevant when implementing future alignment proposals even if they are very different from RLHF. The implicit alternative seems to be an alignment community that deliberately avoids any problems that would be helpful for making AI systems useful, and potentially avoids doing any engineering work at all, creating predictable and potentially huge problems with implementation.
The case for a negative impact
------------------------------
People in the safety community make some arguments that research on RLHF has costs larger than these benefits. I don’t currently find these arguments persuasive:
* **RLHF (and other forms of short-term “alignment” progress) make AI systems more useful and profitable, hastening progress towards dangerous capabilities.**
+ RLHF is just not that important to the bottom line right now. Imitation learning works nearly as well, other hacky techniques can do quite a lot to fix obvious problems, and the whole issue is mostly second order for the current bottom line. RLHF is increasingly important as time goes on, but it also becomes increasingly overdetermined that people would have done it. In general I think your expectation should be that incidental capabilities progress from safety research is a small part of total progress, given that it’s a small fraction of people, very much not focused on accelerating things effectively, in a domain with diminishing returns to simultaneous human effort. This can be overturned by looking at details in particular cases, but I think safety people making this argument mostly *aren’t* engaging with details in a realistic way.
+ Trying to delay AI progress by avoiding making AI systems better at doing what people want feels holistically unwise. RLHF does not appear to increase the kind of capabilities that are directly relevant to risk, but instead has an indirect effect via making AI systems more useful. My intuitive reaction is similar to a proposal to lobby against improvements to the tax code so that taxes will be more painful and the public will be more opposed to new taxes. It might be OK if your goal is to reduce tax burden, but probably counterproductive for reducing the social cost of taxes.
+ Avoiding RLHF at best introduces an important overhang: people will implicitly underestimate the capabilities of AI systems for longer, slowing progress now but leading to faster and more abrupt change later as people realize they’ve been wrong. Similarly, to the extent you successfully slow scaling, you are then in for faster scaling later from a lower initial amount of spending—I think it’s significantly better to have a world where TAI training runs cost $10 billion than a world where they cost $1 billion. A key background view is that the great majority of effective safety work will come when people are working with systems that are much closer to posing a risk, e.g. so they can actually exhibit and study interesting forms of reward hacking and deceptive alignment. Overall in expectation I think these effects claw back most of the benefits of slowing down progress by avoiding RLHF.
* **RLHF “covers up problems” so that you can’t or won’t fix them in other ways.**
+ RLHF lets you produce models that don’t do bad-looking things, but there are some things which *look*fine but are *actually*bad. So you might worry that RLHF makes problems harder to study by covering up their symptoms. But we can (and do) still train models without RLHF, or using a weak overseer where outputs can be validated by stronger overseers. It seems that RLHF makes it much *easier* to produce realistic examples of problems—both because it facilitates settings with the kind of realistic failure modes you actually want to study (namely overpowering or misleading overseers) and because without RLHF there are going to be a thousand other hacks to try first to fix the problems.
+ You might argue that RLHF gives people a way to cover up problems and so lets them avoid fixing them in deeper ways, or gives them a “false sense of security.” But in practice if people run into problems that can be fixed with RLHF, it looks like they will just do RLHF later (which is getting easier and easier over time). And in practice most of the problems that can be addressed with RLHF can be addressed in other hackier ways as well. This potential objection seems to rest on an unreasonably optimistic model about how superficial problems force people into pursuing deep fixes.
* **RLHF is less safe than imitation or conditioning generative models.**
+ If we’re considering the danger posed by a model of a fixed level of usefulness, I think this is probably false though it’s a complicated question and I’m uncertain. The AI safety community makes various informal arguments about this which I find unpersuasive (though I mostly haven’t seen them laid out carefully). I suspect the differences are small and require empirical investigation. (While I appreciate many of the investigations in [this paper](https://arxiv.org/abs/2212.09251) and think it is good to improve our understanding, I don’t think they let us tell what’s up with risk.) This could be the subject of a much longer post and maybe will be discussed in the comments.
+ If RLHF poses distinctive risks, we are overwhelmingly more likely to avoid those risks by understanding them rather than by hoping no one ever implements RLHF. It’s unrealistic and deeply unstable to hope that no one uses RLHF because they didn’t think of it.
* **This entire alignment approach is impractical, and therefore all the arguments about “taking the first step in the right direction” are wrong. On top of that working on RLHF obfuscates that fact and dilutes what should be a robust community consensus**.
+ To the extent this is true, I think it would be a pretty powerful argument against RLHF (largely because it implies that most of the benefits aren’t real). But I don’t agree that the approach can’t work. I’ve talked about this a lot with people, but feel like the arguments just aren’t holding together. The two weak links are on (i) arguments about the *timing* of difficulties relative to e.g. radically superhuman models—almost all of the arguments kick in *after* human level and it’s just not clear how far after, (ii) the probability of deceptive alignment emerging despite simple countermeasures, which I think of as a completely open empirical question—existing arguments are fine for arguing plausibility, but definitely can’t get you to 90% rather than 50%, (iii) the feasibility of fundamental improvements to RLHF.
Overall, I think it was valuable to use RLHF to fix the kind of basic alignment problems that are ubiquitous with pre-trained models. I think it has had a real impact facilitating work on more fundamental challenges, and helped move the community one step closer towards the kind of alignment solutions I expect to ultimately be successful.
Future work
-----------
I remain excited about "straightforward" approaches to improving RLHF, like devising better feedback (using combinations of human and AI work) and improving robustness by adversarial training. I think this work will continue to make ML systems more useful in practice, and so will be subject to the same kinds of objections as above. I still tentatively think this work is net positive and don't find arguments against persuasive.
I think this follow-up research will also not need to solve the “fundamentally confusing” problems for a long time, but that solving tractable problems gives you a good chance of aligning modestly superhuman AI and facilitates future work on the remaining more challenging problems.
That said, I don’t think that improving or studying RLHF is automatically “alignment” or necessarily net positive. Research should be justified by an argument that it actually helps address important failures. Here are some types of work in this space that I’m particularly excited about:
* Work that addresses robustness in cases where we cannot train on deployment examples, or where we care about failure rates that are small relative to fine-tuning dataset size. In practice this would happen if failures are very high-stakes, but we can also study synthetic domains where we artificially aim at very low datasets.
* Training AI systems to give more correct answers in domains where human overseers can’t easily judge results and there is no other source of end-to-end feedback during training. That may involve giving humans better tools, studying and improving generalization from domains that do have feedback, or other methods.
* Anything that addresses clear examples of alignment failures, for which we have good reasons to believe that models “know” things they aren’t telling us, or “know” what we want them to do but nevertheless do something else. Many of these will fall into the first two categories, but it’s also interesting to fix more mundane failures (e.g. obvious untruths) if they can be clearly identified as alignment problems.
* Creating *in vitro* examples of problems analogous to the ones that will ultimately kill us, e.g. by showing agents engaging in treacherous turns due to reward hacking or exhibiting more and more of the core features of deceptive alignment. |
bf7775c2-70b9-4aa3-a0fc-d8e642dde06a | trentmkelly/LessWrong-43k | LessWrong | Born rule or universal prior?
You're about to flip a quantum coin a million times (these days you can even do it on the internet). What's your estimate of the K-complexity of the resulting string, conditional on everything else you've observed in your life so far? The Born rule, combined with the usual counting argument, implies you should say "about 1 million". The universal prior implies you should say "substantially less than 1 million". Which will it be?
EDIT: Wei Dai's comment explains why this post is wrong. |
a3896995-3680-4fbb-815e-fd08870ac9b4 | trentmkelly/LessWrong-43k | LessWrong | Open thread, Oct. 10 - Oct. 16, 2016
If it's worth saying, but not worth its own post, then it goes here.
----------------------------------------
Notes for future OT posters:
1. Please add the 'open_thread' tag.
2. Check if there is an active Open Thread before posting a new one. (Immediately before; refresh the list-of-threads page before posting.)
3. Open Threads should start on Monday, and end on Sunday.
4. Unflag the two options "Notify me of new top level comments on this article" and "Make this post available under..." before submitting. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.