
id stringlengths 36 36 | source stringclasses 15 values | formatted_source stringclasses 13 values | text stringlengths 2 7.55M |
|---|---|---|---|
2c3d4cfb-a75d-4979-8f29-73b3834ae1d1 | StampyAI/alignment-research-dataset/arxiv | Arxiv | World Discovery Models
1 Introduction
---------------
Modern AI has been remarkably successful in solving complex decision-making problems such as GO (silver2016mastering; silver2017mastering), simulated control tasks (schulman2015trust), robotics (levine2016end), poker (moravvcik2017deepstack) and Atari games (mnih2015human; hessel2018rainbow). Despite these successes the agents developed by those methods are specialists: they perform extremely well at the tasks they were trained on but are not very successful at generalising their task-dependent skills in the form of a general domain understanding. Also, the success of the existing AI agents often depends strongly on the availability of external feedback from their world in the form of reward signals or labelled data, for which some level of supervision is required. This is in contrast to the human mind, which is a general and self-supervised learning system that *discovers* the world around it even when no external reinforcement is available. Discovery is the ability to obtain knowledge of a phenomenon for the first time (merriam2004merriam). As discovery entails the process of learning of and about new things, it is an integral part of what makes humans capable of understanding their world in a task-independent and self-supervised fashion.
The underlying process of discovery in humans is complex and multifaceted (hohwy2013predictive). However one can identify two main mechanisms for discovery (clark2017nice). The first mechanism is active information seeking. One of the primary behaviours of humans is their attraction to novelty (new information) in their world (litman2005curiosity; kidd2015psychology). The human mind is very good at distinguishing between the *novel* and the *known*, and this ability is partially due to the extensive internal reward mechanisms of *surprise*, *curiosity* and *excitement* (schmidhuber2009simple). The second mechanism is building a statistical world model. Within cognitive neuroscience, the theory of statistical predictive mind states that the brain, like scientists, constructs and maintains a set of hypotheses over its representation of the world (friston2014computational). Upon perceiving a novelty, our brain has the ability to validate the existing hypothesis, reinforce the ones which are compatible with the new observation and discard the incompatible ones. This self-supervised process of hypothesis building is essentially how humans consolidate their ever-growing knowledge in the form of an accurate and global model.
Inspired by these inputs from cognitive neuroscience, information-seeking algorithms have received significant attention to improve the exploration capability of artificial learning agents (schmidhuber1991possibility; houthooft2016vime; achiam2017surprise; pathak2017curiosity; burda2018large). However, the scope of the existing information-seeking algorithms is often limited to the case of fully observable and deterministic environments. One of the problems with the existing novelty-seeking algorithms is that agents trained by these methods tend to become attracted to random patterns in their world and stop exploring upon encountering them, despite the fact that these random patterns contain no actual *information* on the world (burda2018large). Moreover, the performance of existing agents are often evaluated based on their ability to solve a reinforcement learning (RL) task with extrinsic reward, and not on the quality of the learned world representation, which is the actual goal of discovery. Thus, it is not clear whether the existing algorithms are capable of using the novel information to discover their world. Therefore, the problem of discovery in the general case of partially observable and stochastic environments remains open.
The main contribution of this paper is to develop a practical and end-to-end algorithm for discovery in stochastic and partially observable worlds using modern AI technology. We achieve this goal by designing a simple yet effective algorithm called NDIGO, Neural Differential Information Gain Optimisation, for information seeking designed specifically for stochastic partially observable domains. NDIGO identifies novelty by measuring the increment of information provided by a new observation in predicting the future observations, compared to a baseline prediction for which this observation is withheld. We show that this measure can be estimated using the difference of prediction losses of two estimators, one of which can access the complete set of observations while the other does not receive the latest observation. We then use this measure of novelty as the intrinsic reward to train the policy using a state of the art reinforcement learning algorithm (kapturowski2018recurrent). One of the key features of NDIGO is its robustness to noise, as the process of subtracting prediction losses cancels out errors that the algorithm cannot improve on. Moreover, NDIGO is well-suited for discovery in partially observable domains as the measure of novelty in NDIGO drives the agent to the unobserved areas of the world where new information can be gained from the observations. Our experiments show that NDIGO produces a robust performance in the presence of noise in partial observable environments: NDIGO not only finds true novelty without being distracted by the noise, but it also incorporates this information into its world representation without forgetting previous observation.
2 Related Work
---------------
It has been argued for decades in developmental psychology (white1959motivation; deci1985intrinsic; csikszentmihalyi1992optimal), neuroscience (dayan2002reward; kakade2002dopamine; horvitz2000mesolimbocortical) and machine learning (oudeyer2008can; gottlieb2013information; schmidhuber1991curious) that an agent maximising a simple intrinsic reward based on patterns that are both novel and learnable could exhibit essential aspects of intelligence such as autonomous development (oudeyer2016evolution).
More specifically, in his survey on the theory of creativity and intrinsic motivation, schmidhuber2010formal explains how to build the agent that could discover and understand in a self-supervised way its environment. He establishes that 4 crucial components are necessary: i) a world model (ha2018world) that encodes what is currently known. It can be a working memory component such as a Long Short Term Memory network (LSTM, hochreiter1997long) or a Gated Recurrent Unit network (GRU, cho2014learning). ii) a learning algorithm that improves the world model. For instance, guo2018 have shown that a GRU trained with a Contrastive Prediction Coding (CPC, oord2018representation) loss on future frames could learn a representation of the agent’s current and past position and orientation, as well as position of objects in the environment. iii) An intrinsic reward generator based on the world model that produces rewards for patterns that are both novel and learnable. Different types of intrinsic rewards can be used, such as the world model’s prediction error (stadie2015incentivizing; pathak2017curiosity), improvement of the model’s prediction error, also known as prediction gain (achiam2017surprise; schmidhuber1991curious; lopes2012exploration), and finally information gain (itti2009bayesian; little2013learning; frank2014curiosity; houthooft2016vime). iv the last component is an RL algorithm that finds an optimal policy with respect to the intrinsic rewards.
Recently, several implementations of intrinsically motivated agents have been attempted using modern AI technology. Most of them used the concept of prediction error as an intrinsic reward (stadie2015incentivizing; pathak2017curiosity; burda2018large; haber2018learning). However, it has been argued that agents optimising the prediction error are susceptible to being attracted to white noise (oudeyer2007intrinsic) and therefore should be avoided. To solve the white-noise problem, different types of random or learned projections (burda2018large) of the original image into a smaller feature space less susceptible to white-noise are considered. Other implementations rely on approximations of the concept of information gain (houthooft2016vime; achiam2017surprise) via a variational lower bound argument. Indeed, as they are trying to train a probabilistic model over the set of possible dynamics, the computation of the posterior of that distribution is intractable (houthooft2016vime). Finally, models based on prediction gain are fundamentally harder to train compared to prediction error (achiam2017surprise; lopes2012exploration; pathak2017curiosity), and are less principled than information gain (schmidhuber2010formal).
3 Setting
----------
We consider a partially observable environment where an agent is shown an observation ot at time t, then selects an action at which generates a new observation ot+1 at the next time step. We assume observations ot are generated by an underlying process xt following Markov dynamics, i.e. xt+1∼P(⋅|xt,at), where P is the dynamics of the underlying process. Although we do not explicitly use the corresponding terminology, this process can be formalised in terms of Partially Observable Markov Decision Processes (POMDPs; lovejoy1991survey; cassandra1998exact).
The future observation ot+1 in a POMDP can also be seen as the output of a stochastic mapping with input the current history. Indeed, at any given time t, let the current history ht be all past actions and observations htdef=(o0,a0,o1,a1,⋯,at−1,ot). Then we define P(⋅|ht,at) the probability distribution of ot knowing the history and the action at. One can generalise this notion for k-step prediction: for any integers t≥0 and k≥1, let us denote by t:t+k the integer interval {t,…,t+k−1}, and let At:t+kdef=(at,…,at+k−1) and Ot:t+kdef=(ot,…,ot+k−1) be the sequence of actions and observations from time t up to time t+k−1, respectively. Then ot+k can be seen as a sample drawn from the probability distribution P(⋅|ht,At:t+k), which is the k-step open-loop prediction model of the observation ot+k. We also use the short-hand notation Pt+k|t=P(⋅|ht,At:t+k) as the probability distribution of ot+k given the history ht and the sequence of actions At:t+k.
4 Learning the World Model
---------------------------
The world model should capture what the agent currently knows about the world so that he could make predictions based on what it knows. We thus build a model of the world by predicting future observations given the past (see e. g., schmidhuber1991curious; guo2018). More precisely, we build an internal representation bt by making predictions of futures frames ot+k conditioned on a sequence of actions At:t+k and given the past ht. This is similar to the approach of Predictive State Representations (littman2002predictive), from which we know that if the learnt representation bt is able to predict the probability of any future observation conditioned on any sequence of actions and history, then this representation bt contains all information about the belief state (i.e., distribution over the ground truth state xt).
###
4.1 Architecture
We propose to learn the world model by using a recurrent neural network (RNN) fθ fed with the concatenation of observation features zt and the action at (encoded as a one-hot vector). The observation features zt are obtained by applying a convolutional neural network (CNN) fϕ to the observation ot. The RNN is a Gated Recurrent Unit (GRU) and the internal representation is the hidden state of the GRU, that is, bt=fθ(zt,at−1,bt−1), as shown in [Figure 1](#S4.F1 "Figure 1 ‣ 4.1 Architecture ‣ 4 Learning the World Model ‣ World Discovery Models"). We initialise this GRU by setting its hidden state to the null vector 0, and using b0=fθ(z0,a,0) where a is a fixed, arbitrary action and z0 are the features corresponding to the original observation o0. We train this representation bt with some future-frame prediction tasks conditioned on sequences of actions and the representation bt. These frame prediction tasks consist in estimating the probability distribution, for various K≥k≥1 (with K∈N∗ to be specified later), of future observation ot+k conditioned on the internal representation bt and the sequence of actions At:t+k. We denote these estimates by ˆpt+k|t(.|bt,At:t+k) or simply by ˆpt+k|t for conciseness and when no confusion is possible. As the notation suggests, we will use ˆpt+k|t as an estimate of Pt+k|t.
The neural architecture consists in K different neural nets {fψk}Kk=1. Each neural net fψk receives as input the concatenation of the internal representation bt and the sequence of actions At:t+k, and outputs the distributions over observations: ˆpt+k|t=fψk(bt,At:t+k) (). For a fixed t≥0 and a fixed K≥k≥1, the loss function L(ot+k,ˆpt+k|t) at time step t+k−1 associated with the network fψk is a cross entropy loss: L(ot+k,ˆpt+k|t)=−ln(ˆpt+k|t(ot+k)). We finally define for any given sequence of actions and observations the *representation loss* function Lrepr as the sum of these cross entropy losses: Lrepr=∑t≥0,K≥k≥1L(ot+k,ˆpt+k|t).

Figure 1: World Model: a CNN and a GRU encode the history ht into an internal representation bt. Then, K frame predictions tasks are trained in order to shape the representation bt.
+
###
4.2 Evaluation of the learnt representation
In the POMDP setting, the real state xt represents all there is to know about the world at time t. By constructing a belief state, which is a distribution Pb(⋅|ht) over the possible states conditioned on the history ht, the agent can assess its uncertainty about the real state xt given the history ht. Therefore, in order to assess the quality of the learnt representation bt, we use the glass-box approach described in [Figure 12](#A1.F12 "Figure 12 ‣ Appendix A NDIGO Global Network Architecture ‣ World Discovery Models") to build a belief state of the world. It consists simply in training a neural network fτ fed by the internal representation bt to predict a distribution ˆpb(⋅|bt) over the possible real state xt. This kind of approach is only possible in artificial or controlled environments where the real state is available to the experimenter but yet not given to the agent. We also make sure sure that no gradient from fτ is being back-propagated to the internal representation bt such that the evaluation does not influence the learning of the representation and the behaviour of the agent. For a fixed t≥0, the loss used to trained fτ is a cross entropy loss (For a more detailed description of the approach see guo2018): Ldiscovery(xt,ˆpb(⋅|bt))def=−ln(ˆpb(xt|bt)).
We call this loss *discovery loss*, and use it as a measure of how much information about the whole world the agent is able to encode in its internal representation bt, i.e., how much of the world has been discovered by the agent.
5 NDIGO Agent
--------------
Our NDIGO agent is a discovery agent that learns to seek new information in its environment and then incorporate this information into a world representation. Inspired by the intrinsic motivation literature (schmidhuber2010formal), the NDIGO agent achieves this information-seeking behaviour as a result of optimising an intrinsic reward. Therefore, the agent’s exploratory skills depend critically on designing an appropriate reward signal that encourages discovering the world. Ideally, we want this reward signal to be high when the agent gets an observation containing new information about the real state xt. As we cannot access xt at training time, we rely on the accuracy of our future observations predictions to estimate the information we have about xt.
Intuitively, for a fixed horizon H∈N∗, the *prediction error loss* L(ot+H,ˆpt+H|t)=−ln(ˆpt+H|t(ot+H)) is a good measure on how much information bt is lacking about the future observation ot+H. The higher the loss, the more uncertain the agent is about the future observation ot+H so the less information it has about this observation. Therefore, one could define an intrinsic reward directly as the prediction error loss, thus encouraging the agent to move towards states for which it is the less capable of predicting future observations. The hope is that the less information we have in a certain belief state, the easier it is to gain new information. Although this approach may have good results in deterministic environments, it is however not suitable in certain stochastic environments. For instance, consider the extreme case in which the agent is offered to observe white noise such as a TV displaying static. An agent motivated with prediction error loss would continually receive a high intrinsic reward simply by staying in front of this TV, as it cannot improve its predictions of future observations, and would effectively remain fascinated by this noise.
###
5.1 The NDIGO intrinsic reward
The reason why the naive prediction error reward fails in such a simple example is that the agent identifies that a lot of information is lacking, but does not acknowledge that no progress is made towards acquiring this lacking information. To overcome this issue, we introduce the NDIGO reward, for a fixed K≥H≥1, as follows:
| | | | |
| --- | --- | --- | --- |
| | rNDIGOt+H−1def=L(ot+H,ˆpt+H|t−1)−L(ot+H,ˆpt+H|t), | | (1) |
where ot+H represents the future observation considered and H is the horizon of NDIGO. The two terms in the right-hand side of [Equation 1](#S5.E1 "(1) ‣ 5.1 The NDIGO intrinsic reward ‣ 5 NDIGO Agent ‣ World Discovery Models") measure how much information the agent lacks about the future observation ot+H knowing all past observations prior to ot with ot either excluded (left term) or included (right term). Intuitively, we take the difference between the information we have at time t with the information we have at time t−1. This way we get an estimate of how much information the agent gained about ot+H by observing ot. Note that the reward rNDIGOt+H−1 is attributed at time t+H−1 in order to make it dependent on ht+H−1 and at+H−1 only (and not on the policy), once the prediction model ˆp has been learnt. If the reward had been assigned at time t instead (time of prediction) it would have depended on the policy used to generate the action sequence At:t+H−1, which would have violated the Markovian assumption required to train the RL algorithm. Coming back to our broken TV example, the white noise in ot does not help in predicting the future observation ot+H. The NDIGO reward is then the difference of two large terms of similar amplitude, leading to a small reward: while acknowledging that a lot of information is missing (large prediction error loss) NDIGO also realises that no more of it can be extracted (small difference of prediction error loss). Our experiments show that using NDIGO allows the agent to avoid being stuck in the presence of noise, as presented in [Section 6](#S6 "6 Experiments ‣ World Discovery Models"), thus confirming these theoretical considerations.
###
5.2 Algorithm
Given the intrinsic reward rNDIGOt+H−1, we use the state-of-the-art RL algorithm R2D2 (kapturowski2018recurrent) to optimise the policy. The NDIGO agent interacts with its world using the NDIGO policy to obtain new observation ot+k, which is used to train the world model by minimising the future prediction loss Lt+k|t=L(ot+k,ˆpt+k|t). The losses Lt+k|t are then used to obtain the intrinsic reward at the next time step, and the process is then repeated. An in-depth description of the complete NDIGO algorithm can be found in [Section B.5](#A2.SS5 "B.5 Training loop pseudocode ‣ Appendix B NDIGO Agent Implementation Details ‣ World Discovery Models").
###
5.3 Relation to information gain
Information gain has been widely used as the novelty signal in the literature (houthooft2016vime; little2013learning). A very broad definition of the information gain (schmidhuber2010formal) is the distance (or divergence) between distributions on any random event of interest ω before and after a new sequence of observations. Choosing the random event to be the future observations or actions and the divergence to be the Kullback-Leiber divergence then the k-step predictive information gain IG(ot+k,Ot:t+k|ht,At:t+k) of the future event ot+k with respect to the sequence of observations Ot:t+k is defined as: IG(ot+k,Ot:t+k|ht,At:t+k)def=KL(Pt+k|t+k−1||Pt+k|t−1), and measures how much information can be gained about the future observation ot+k from the sequence of past observations Ot:t+k given the whole history ht up to time step t and the sequence of actions At:t+k from t up to t+H−1. In the case of k=1 we recover the 1-step information gain on the next observation ot+1 due to ot. We also use the following short-hand notation for the information gain IGt+k|t=IG(ot+k,Ot:t+k|ht,At:t+k) for every k≥1 and t≥0. Also by convention we define IGt|t=0.
We now show that the NDIGO intrinsic reward rNDIGOt+H−1 can be expressed as the difference of information gain due to Ot:t+H and Ot+1:t+H. For a given horizon H≥1 and t≥0, the intrinsic reward for time step t+H−1 is:
| | | | | |
| --- | --- | --- | --- | --- |
| | rNDIGOt+H−1 | def=L(ot+H,ˆpt+H|t−1)−L(ot+H,ˆpt+H|t) | | (2) |
| | | =ln(ˆpt+H|t(ot+H)ˆpt+H|t−1(ot+H)). | | (3) |
Given that ˆpt+H|t and ˆpt+H|t−1 are respectively an estimate of Pt+H|t and Pt+H|t−1, and based on the fact that these estimates become more accurate as the number of samples increases, we have:
| | | | |
| --- | --- | --- | --- |
| | E[rNDIGOt+H−1] | =Eot+H∼Pt+H|t+H−1[ln(ˆpt+H|t(ot+H)ˆpt+H|t−1(ot+H))] | |
| | | ≊Eot+H∼Pt+H|t+H−1[ln(Pt+H|t(ot+H)Pt+H|t−1(ot+H))] | |
| | | =KL(Pt+H|t+H−1||Pt+H|t−1) | |
| | | −KL(Pt+H|t+H−1||Pt+H|t) | |
| | | =IGt+H|t−IGt+H|t−1. | | (4) |
The first term IGt+H|t in [Equation 4](#S5.E4 "(4) ‣ 5.3 Relation to information gain ‣ 5 NDIGO Agent ‣ World Discovery Models") measures how much information can be gained about ot+H from the sequence of past observations Ot:t+H whereas the second term IGt+H|t+1 measures how much information can be gained about ot+H from the sequence of past observations Ot+1:t+H. Therefore, as Ot+1:t+H=Ot:t+H∖{ot} , the expected value of the NDIGO reward at step t+H−1 is equal to the amount of additional information that can be gained by the observation ot when trying to predict ot+H.
6 Experiments
--------------
We evaluate the performance of NDIGO qualitatively and quantitatively on five experiments, where we demonstrate different aspects of discovery with NDIGO.
In all experiments there are some hidden objects which the agent seeks to discover. However the underlying dynamics of the objects are different. In the simplest case, the location of objects only changes at the beginning of every episode, whereas in the most complex the objects are changing their locations throughout the episode according to some random walk strategy. We investigate (i) whether the agent can efficiently search for novelty, i.e., finding the location of objects; (ii) whether the agent can encode the information of object location in its representation of the world such that the discovery loss of predicting the objects is as small as possible.
###
6.1 Baselines
We compare our algorithm NDIGO-H, with H being the horizon and taking values in {1,2,4}, to different information seeking and exploration baselines considered to be state of the art in the intrinsic motivation literature. Prediction Error (PE) (haber2018learning; achiam2017surprise): The PE model uses the same architecture and the same losses than NDIGO. The only difference is that the intrinsic reward is the predictor error: rPEt=L(ˆpt+1|t,ot+1). Prediction Gain (PG) (achiam2017surprise; ostrovski2017count): Our version of PG uses the same architecture and the same losses than NDIGO. In addition, at every n=2 learner steps we save a copy of the prediction network into a fixed target network. The intrinsic reward is the difference in prediction error, between the up-to-date network and the target network predictions: rPGt=L(ˆptargett+1|t,ot+1)−L(ˆpt+1|t,ot+1), where ˆptarget|t+1|t is the distribution computed with the weights of the fixed target network. Intrinsic Curiosity Module (ICM) (pathak2017curiosity; burda2018large): The method consists in training the internal representation bt to be less sensitive to noise using a self-supervised inverse dynamics model. Then a forward model is used to predict the future internal representation ˆbt+1 from the actual representation bt and the action at (more details on this model are in [Appendix D](#A4 "Appendix D pathak2017curiosity’s ICM Model for Partially Observable Environments ‣ World Discovery Models")). The intrinsic reward rFPEt=∥∥ˆbt+1−bt+1∥∥22.
###
6.2 Test environments
#### The 5 rooms environment.
The 5 rooms environment (see [Figure 2](#S6.F2 "Figure 2 ‣ The maze environment. ‣ 6.2 Test environments ‣ 6 Experiments ‣ World Discovery Models")) is a local-view 2D environment composed of 5 rooms implemented using the pycolab library111<https://github.com/deepmind/pycolab>. In pycolab, the environment is composed of cells that contain features such as walls, objects or agents. In the 5 rooms environment, there is one central 5×5 room and four peripheral rooms (composed of 48 cells) that we will refer to as upper, lower, left and right rooms. Each of the four peripheral rooms may contain different types of “objects” that occupy a cell exclusively. At every episode, the agent starts in the middle of the central room and the starting position of each object is randomised. The objects may or may not move, but as a general rule in any episode they never leave the room they started in. Finally, we only place objects in the peripheral rooms, and in each room there is never more than one object.
#### The maze environment.
The maze environment (see [Figure 3](#S6.F3 "Figure 3 ‣ The maze environment. ‣ 6.2 Test environments ‣ 6 Experiments ‣ World Discovery Models")) is also a pycolab local-view 2D environment. It is set-up as a maze composed of six different rooms connected by corridors. The agent starts at a fixed position in the environment in an otherwise empty room 0; rooms are numbered from 0 to 5 based on the order in which they can be reached, i.e. the agent cannot reach room number 3 without going through rooms 1 and 2 in this order. A white noise object is always present in room 1, and a there is single fixedin rooms 2,3 and 4. Room 5 contains a special movable, which should attract the agent even when the environment is completely learned.

Figure 2: The 5 rooms environment: in this instance, we can see in white the agent, 4 fixed objects in each of the 4 peripheral rooms and in grey the impenetrable walls. The shaded area around the agent represents its 5×5 region-cell local view.

Figure 3: The maze environment: in this instance, we can see in white the agent, 4 fixedobjects in blue, green, pink and red. white noiseis the closest object to the agent location also in green.
#### Objects.
We consider five different types of objects: fixed, bouncing, Brownian, white noise and movable.
fixed objects are fixed during episodes, but change position from episode to episode.
They provide information gain about their position when it is not already encoded in the agent’s representation.
bouncing objects bounce in a straight line from wall to wall inside a room.
In addition to providing information gain similar to fixed objects, they allow us to test the capacity of the representation to encode predictable object after the object is no longer in the agent’s view.
Brownian objects follow a Brownian motion within a room, by moving uniformly at random in one of the four directions.
white noise objects change location instantly to any position inside the same room, uniformly at random, at each time step, and are therefore unpredictable.
Finally, movable objects do not move by themselves, but the agent can cause them to move to a random location by attempting to move into their cells. Interacting with these objects allows more information gain to be generated.
#### Agent’s observations and actions.
The observation ot at time t consists in a concatenation of images (called channels) of 25 pixels representing the different features of the 5×5 local view of the agent. This can be represented by multidimensional array (5,5,c) where c is the number of channels. The first channel represents the walls in the local view: 1 indicates the presence of a wall and 0 the absence of a wall. Then, each of the remaining channels represents the position of an object with a one-hot array if the object is present in the local view or with a null array otherwise. The possible actions at are stay, up, down, right, left and are encoded with a one-hot vector of size 5.
###
6.3 Performance evaluation
The agent’s performance is measured by its capacity to estimate the underlying state of the world from its internal representation (discovery loss, see [Section 4.2](#S4.SS2 "4.2 Evaluation of the learnt representation ‣ 4 Learning the World Model ‣ World Discovery Models")). In pycolab, it is possible to compute a discovery loss for each aspect of the world state (location of each object for instance). So that it is easy to understand which aspects of the world the agent can understand and keep in its internal representation. Once again we stress the fact that no gradient is back-propagated from that evaluation procedure to the internal representation. In addition, we provide other statistics such as average values of first-visit time and visit counts of a given object to describe the behavior of the agent. The first-visit time is the number of episode time steps the agent needs before first observing a given object; the visit count is the total number of time steps where the agent observes the object. Finally, we also provide more qualitative results with videos of the agent discovering the worlds (see
<https://www.youtube.com/channel/>
UC5OPHK7pvsZE-jVclZMvhmQ).
###
6.4 Experimental results
In this section we evaluate the performance of NDIGO on some controlled navigation task (for the implementation details and the specification of the prediction and policy networks and the training algorithms see [Appendix B](#A2 "Appendix B NDIGO Agent Implementation Details ‣ World Discovery Models")).
#### Experiment 1.
We evaluate the discovery skills of NDIGO by testing how effectively it can ignore the white noise, from which there is nothing to learn, and discover the location of the fixed object. Here, we use a 5 rooms setting with a fixed object in the upper room, and a white noise object in the lower room.

Figure 4: Experiment 1: Average discovery loss of the fixed object. The results are averaged over 10 seeds.
| | Visit count | First visit time |
| --- | --- | --- |
| | fixed | w. noise | fixed | w. noise |
| Random | 14.1±14.3 | 24.6±12.6 | 339.0±40.5 | 225.6±50.4 |
| PE | 0.1±0.2 | 158.3±3.7 | 392.6±18.1 | 15.5±4.0 |
| PG | 27.3±22.0 | 22.5±10.3 | 306.4±49.4 | 233.7±56.6 |
| ICM | 144.8±37.2 | 23.8±12.4 | 132.4±41.2 | 238.3±55.0 |
| NDIGO-1 | 120.9±43.4 | 19.1±9.3 | 78.4±28.5 | 279.4±42.9 |
| NDIGO-2 | 154.0±45.5 | 7.4±6.7 | 112.6±46.2 | 345.8±36.5 |
| NDIGO-4 | 300.4±22.2 | 1.4±1.2 | 40.8±9.7 | 330.7±47.4 |
Table 1: Experiment 1: Average values of the visit counts and first visit time of the trained agent for the fixed and white noise objects in one episode.
We report in [Figure 4](#S6.F4 "Figure 4 ‣ Experiment 1. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models") the learning curves for the discovery loss of the fixed object. This result shows the quality of the learned representation in terms of encoding the location of fixed object. We observe that the long-horizon variant of NDIGO (NDIGO-4) outperforms the best baseline (ICM) by more than an order of magnitude. Also the asymptotic performance of NDIGO-4 is significantly better than NDIGO-1 and NDIGO-2.
In [Table 1](#S6.T1 "Table 1 ‣ Experiment 1. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models") we also report the average value and standard deviation of visit count and first visit time of the trained agents for the fixed object and the white noise object in an episode222
Each episode is set to end after 400 time steps; if an agent does not find the object by the end of the episode, the first visit time is set to 400.
. We observe that different variants of NDIGO are driven towards the fixed object and manage to find it faster than the baselines while avoiding the white noise object. While ICM is also attracted by the fixed object, it is not doing it as fast as NDIGO. PE, as expected, is only attracted by the white noise object where its reward is the highest. We also observe that the performance of NDIGO improves as we increase the prediction horizon. From now on, in the tables, we report only the ICM results as it is the only competitive baseline. Exhaustive results are reported in [Section E.1](#A5.SS1 "E.1 Additional results for Experiment 2-4 ‣ Appendix E Additional results ‣ World Discovery Models").
#### Experiment 2.
To demonstrate better the information-seeking behaviour of our algorithm, we place randomly a fixed object in either the upper, left or right room and a white noise object in the lower room. Thus, to discover the object, the agent must actively look for it in all but the lower room.
Similar to Experiment 1, We report the average discovery loss of the fixed object in [Figure 5](#S6.F5 "Figure 5 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). We observe that all variants of NDIGO perform better than the baselines by a clear margin. Though ICM performance is not far behind NDIGO (less than two times worse than NDIGO-4). We also observe no significant difference between the different variants of NDIGO in this case. We also report in [Table 2](#S6.T2 "Table 2 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models") the first visit and visit counts for the fixed object and the white noise object in an episode. NDIGO again demonstrates a superior performance to the baselines. We also observe that NDIGO in most case is not attracted towards the white noise object. An interesting observation is that, as we increase the horizon of prediction in NDIGO, it takes more time for the agent to find the fixed object but at the same time the visit counts increases as well, i.e, the agent stay close to the object for longer time after the first visit.
As a qualitative result, we also report top-down-view snapshots of the behavior of NDIGO-2 up to the time of discovery of fixed in the right room in [Figure 6](#S6.F6 "Figure 6 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). We also depicts the predicted view of the world from the agent’s representation in [Figure 6](#S6.F6 "Figure 6 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). As the location of object is unknown to the agent, we observe that the agent searches the top-side, left-side and right-side rooms until it discovers the fixed object in the right-side room. It also successfully avoids the bottom-side room containing the white noise object. Also as soon as the agent finds the fixed object the uncertainty about the location of fixed object completely vanishes (as the agent has learned there is only one fixed object exists in the world).

Figure 5: Experiment 2: Average discovery loss of the fixed object. The results are averaged over 10 seeds.
| | | |
| --- | --- | --- |
|
(a) t=1
|
(b) t=2
|
(c) t=3
|
Figure 6: Experiment 2: top-down-view snapshots of the behavior of the NDIGO-4 agent. (a) after entering the top-side room (b) after entering the right-side room (c) after discovering the fixed object in the left-side room. In each subpanel the left-side image depicts the ground-truth top-down-view of the world and the right-side image depicts the predicted view from the agent’s representation. All times are in seconds.
| | Visit count | First visit time |
| --- | --- | --- |
| | fixed | w. noise | fixed | w. noise |
| ICM | 151.7±33.0 | 15.6±9.0 | 142.1±40.8 | 198.7±55.1 |
| NDIGO-1 | 180.2±42.7 | 12.8±6.9 | 101.1±31.1 | 237.2±49.4 |
| NDIGO-2 | 209.3±34.9 | 3.5±2.3 | 121.1±36.5 | 306.4±43.4 |
| NDIGO-4 | 233.7±41.6 | 5.3±3.7 | 126.7±43.3 | 268.2±53.1 |
Table 2: Average values of the visit counts and first visit time of the trained agent for the fixed and white noise objects in Experiment 2.
#### Experiment 3.
We investigate whether NDIGO is able to discover and retain the dynamics of moving (but still predictable) objects even when not being in its field of view. For this, we used a 5 rooms setting with two bouncing objects in upper and lower rooms and a white noise object in the right room.

Figure 7: Experiment 3: Average discovery loss of bouncing objects. The results are averaged over 10 seeds.
| | Visit count | First visit time |
| --- | --- | --- |
| | upper obj. | lower obj. | upper obj. | lower obj. |
| ICM | 80.5±28.3 | 89.1±28.6 | 174.8±53.4 | 127.8±51.4 |
| NDIGO-1 | 41.0±8.5 | 45.2±11.6 | 34.4±18.7 | 38.8±16.1 |
| NDIGO-2 | 108.5±25.1 | 31.3±20.9 | 118.3±50.4 | 312.6±50.6 |
| NDIGO-4 | 198.7±33.4 | 44.2±28.8 | 64.5±38.8 | 320.8±47.5 |
Table 3: Average values of the visit counts and first visit time of the trained agent for the bouncing objects in Experiment 3.
We report the discovery loss in [Figure 7](#S6.F7 "Figure 7 ‣ Experiment 3. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). We observe that all variants of NDIGO outperforms the baselines by a large margin in terms of the discovery loss of the bouncing object. As the discovery loss for both bouncing objects is small, this indicates that NDIGO can encode the dynamics of bouncing objects in its representation. We report the first-visit and visit counts for the bouncing objects in [Table 3](#S6.T3 "Table 3 ‣ Experiment 3. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). NDIGO has a superior performance than the baselines both in terms of visit counts and visit time to the fixed objects except for the visit count of the lower object in which ICM produces the best performance. Finally, as a qualitative result, we also report top-down-view snapshots of the behavior of NDIGO-1 after the discovery of each bouncing object in [Figure 8](#S6.F8 "Figure 8 ‣ Experiment 3. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). We observe that the agent can estimate the location of both bouncings in the first visit. Also after departing from the green bouncing object and moving towards the red bouncing object, still it can track the dynamics of the green bouncing object with some small error. This is despite the fact that the green bouncing object is not anymore observed by the agent.
| | |
| --- | --- |
|
(a) t=1
|
(b) t=2
|
Figure 8: Experiment 3: top-down-view snapshots of the behavior of the NDIGO-1 agent. (a) after discovering the green bouncing object in the bottom-side room (b) after discovering the red bouncing object in the top-side room. In each subpanel the left-side image depicts the ground-truth top-down-view of the world and the right-side image depicts the predicted view from the agent’s representation. All times are in seconds.
#### Experiment 4.
We investigate if the horizon H affects the performance of the agents in terms of its sensitivity to structured noise. For this we evaluated which objects the agent seeks in a 5 rooms setting with a Brownian object in the upper room and a fixed object in the lower room. In the upper room, the Brownian moves at every time step. For the Brownian, unlike white noise, it is not guaranteed that the reward of NDIGO is zero. However by increasing the horizon, one may expect that the intrinsic reward due to the Brownian object becomes negligible because it becomes harder to predict with higher horizons.

Figure 9: Experiment 4: Average discovery loss of the fixed object . The results are averaged over 10 seeds.
| | Visit count | First visit time |
| --- | --- | --- |
| | Brownian | fixed | Brownian | fixed |
| ICM | 358.3±9.4 | 0.5±0.9 | 34.0±8.3 | 385.1±24.6 |
| NDIGO-1 | 356.1±6.9 | 0.0±0.0 | 23.4±6.4 | 398.9±8.9 |
| NDIGO-2 | 350.7±5.4 | 0.1±0.3 | 21.1±4.8 | 383.9±25.6 |
| NDIGO-4 | 0.4±1.0 | 290.5±31.4 | 395.5±12.4 | 68.4±29.8 |
Table 4: Average values of the visit counts and first visit time of the trained agent for the Brownian and fixed objects in Experiment 4, with all baselines.

Figure 10: Experiment 5: Average discovery loss of the fixed and movable objects. The results are averaged over 10 seeds.
| | | | |
| --- | --- | --- | --- |
|
(a) t=0
|
(b) t=1
|
(c) t=2
|
(d) t=4
|
Figure 11: Experiment 5: top-down-view snapshots of the behavior of the NDIGO-1 agent in the maze problem: (a) at the beginning of the episode (b) after discovering the fixed objects in room 3 and 4 (c) after discovering the movable object in room 5 (d) after discovering the fixed object in room 2. In each subpanel the left-side image depicts the ground-truth top-down-view of the world and the right-side image depicts the predicted view from the agent’s representation. All times are in seconds.
| | Visit frequency |
| --- | --- |
| | Room 1 | Room 2 | Room 3 | Room 4 | Room 5 |
| | white noise | fixed | fixed | fixed | movable |
| ICM | 100.0%±0.0% | 26.8%±25.7% | 13.8%±20.0% | 6.5%±14.3% | − |
| NDIGO-1 | 94.7%±12.9% | 66.4%±27.4% | 71.7%±26.1% | 70.4%±26.4% | 67.8%±27.1% |
| NDIGO-2 | 100.0%±0.0% | 78.3%±23.9% | 84.8%±20.9% | 83.7%±21.4% | 81.5%±22.5% |
| NDIGO-5 | 100.0%±0.0% | 49.6%±29.0% | 47.4%±28.9% | 18.8%±22.6% | − |
| NDIGO-10 | 100.0%±0.0% | 84.1%±21.4% | 95.5%±12.2% | 45.5%±29.1% | − |
Table 5: Average frequency of visits to each room for the trained agents.
| | |
| --- | --- |
| | First visit time |
| | Room 1 | Room 2 | Room 3 | Room 4 | Room 5 |
| | white noise | fixed | fixed | fixed | movable |
| ICM | 4.4±3.0 | 324.7±79.5 | 375.0±44.0 | 391.8±24.3 | - |
| NDIGO-1 | 40.6±57.2 | 203.0±90.6 | 190.5±86.0 | 199.9±85.2 | 212.7±83.2 |
| NDIGO-2 | 12.9±10.7 | 171.5±79.5 | 159.4±68.8 | 174.5±68.9 | 192.8±68.9 |
| NDIGO-5 | 6.8±11.5 | 245.1±94.1 | 255.9±91.4 | 344.9±68.7 | - |
| NDIGO-10 | 8.6±5.9 | 128.0±75.8 | 119.1±53.4 | 283.1±81.4 | - |
Table 6: Average time of first visit to each room for the trained agents.
We report the results in [Figure 9](#S6.F9 "Figure 9 ‣ Experiment 4. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). We observe that the ICM baseline as well as the variants of NDIGO with the short horizon are being attracted to the structured randomness generated by the Brownian object. Only NDIGO-4 can ignore the Brownian object and discover the fixed object. As a result NDIGO-4 is the only algorithm capable of minimising the discovery loss of the fixed object.
#### Experiment 5.
We now compare discovery ability of the agents in a complex maze environment (see [Figure 3](#S6.F3 "Figure 3 ‣ The maze environment. ‣ 6.2 Test environments ‣ 6 Experiments ‣ World Discovery Models")) with no extrinsic reward. Here, the agent starts in a fixed position in the maze environment, and is given no incentive to explore but its intrinsic reward. This setting is challenging for discovery and exploration, since to go the end of the maze the agents need to take a very long and specific sequence of actions. This highlights the importance of intrinsic rewards that encourage discovery. We report the learning curves of NDIGO as well as the baselines in [Figure 10](#S6.F10 "Figure 10 ‣ Experiment 4. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). We observe that in this case different variants of NDIGO outperform the baselines by a wide margin in terms of discovery loss, while NDIGO-1 and NDIGO-2 outperforming NDIGO-5. Note that due to the presence of movable object, which is unpredictable upon re-spawning, the average loss in this experiment is higher than the prior fixed object experiments. We also evaluate the discovery performance of the agent as the number of rooms it is capable of exploring within the duration of the episode. We present the average visit frequency and first visit time of each room for the trained agents (see [Tables 5](#S6.T5 "Table 5 ‣ Experiment 4. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models") and [6](#S6.T6 "Table 6 ‣ Experiment 4. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models")). NDIGO-1 and NDIGO-2 appear as the only agents capable of reaching the final room, whereas NDIGO-4 explores 4 out of 5. The rest can not go beyond the white noise object.
As a qualitative result, we also report top-down-view snapshots of the behavior of NDIGO-1 up to the time of discovery of the last fixed in room 2 in [Figure 11](#S6.F11 "Figure 11 ‣ Experiment 4. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models"). We also depicts the predicted view of the world from the agent’s representation in [Figure 6](#S6.F6 "Figure 6 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models").
We observe the agent drives across the maze all the way from room 1 to room 5 and in the process discovers the fixed objects in rooms 3-4 (see [Figure 5(a)](#S6.F5.sf1 "(a) ‣ Figure 6 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models")) and the movable object in room 5 (see [Figure 5(c)](#S6.F5.sf3 "(c) ‣ Figure 6 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models")). It then chases movable object until movable object gets fixated on the top-left corner of the world. The agent then moves back to room 2 (see [Figure 5(c)](#S6.F5.sf3 "(c) ‣ Figure 6 ‣ Experiment 2. ‣ 6.4 Experimental results ‣ 6 Experiments ‣ World Discovery Models")) and discovers the last blue fixed object there, while maintaining its knowledge of the other objects.The reason for ignoring the blue fixed object in room 2, in the first place, might be due to the fact that the agent can obtain more intrinsic rewards by chasing the movable. So it tries to reach to room 5 as fast as possible at the expense of ignoring the blue fixed object in room 2.
7 Conclusion
-------------
We aimed at building a proof of concept for a world discovery model by developing the NDIGO agent and comparing its performance with the state-of-the-art information-seeking algorithms in terms of its ability to discover the world. Specifically, we considered a variety of simple local-view 2D navigation tasks with some hidden randomly-placed objects and looked at whether the agent can discover its environment and the location of objects. We evaluate the ability of our agent for discovery through the glass-box approach which measures how accurate location of objects can be predicted from the internal representation. Our results showed that in all these tasks NDIGO produces an effective information seeking strategy capable of discovering the hidden objects without being distracted by the white noise, whereas the baseline information seeking methods in most cases failed to discover the objects due to the presence of noise.
There remains much interesting future work to pursue. The ability of our agent to discover its world can be very useful in improving performance in multi-task and transfer settings as the NDIGO model can be used to discover the the new features of new tasks. Also in this paper we focused on visually simple tasks. To scale up our model to more complex visual tasks we need to consider more powerful prediction models such as Pixel-CNN (van2016conditional), VAE (kingma2013auto), Info-GAN (chen2016infogan) and Draw (gregor2015draw) capable of providing high accuracy predictions for high-dimensional visual scenes. We also can go beyond predicting only visual observations to other modalities of sensory inputs, such as proprioception and touch sensors (amos2018learning).
Acknowledgements
----------------
We would like to thank Daniel Guo, Theophane Webber, Caglar Gulcehre, Toby Pohlen, Steven Kapturovski and Tom Stepleton for insightful discussions, comments and feedback on this work. |
18b71a59-52ba-4d4d-aab2-c056b0509426 | trentmkelly/LessWrong-43k | LessWrong | Did you enjoy Ramez Naam's "Nexus" trilogy? Check out this interview on neurotech and the law.
I recently had the great pleasure of interviewing Dr. Allan McCay on the Futurati Podcast. He's a legal scholar and philosopher who focuses on questions at the interface of emerging neurotechnologies and the law, such as how privacy works when it's possible to decode mental images and mental speech from brain readings.
It was a great conversation, one covering issues that are becoming more timely by the day.
Major topics included:
* He brought up free will early on, so we spent some time kicking around different definitions of free will and how they interact with legal questions on culpability.
* How should we define and think about neurotech, i.e. how is a brain-to-brain interface different from just being really good at verbal communication?
* Certain important legal concepts make a strong distinction between mental and physical acts, i.e. between thinking about robbing a person and actually doing it. But as more of the world is mediated by neural interfaces, this distinction will require further clarification.
* We'll need to carefully distinguish between using neurotechnologies to help a person control their impulses and using them to effectively neuter people such that they're not even capable of becoming incensed over the gravest outrages. What sort of legal frameworks would help in this?
I hope you like the episode, and if you do, consider sharing it around to help us grow! |
578694d0-7172-45d7-b9d1-ed4755121a9c | trentmkelly/LessWrong-43k | LessWrong | An attempt in layman's language to explain the metaethics sequence in a single post.
|
9e905f68-19b7-4d53-92ca-ad9f199c3bd5 | trentmkelly/LessWrong-43k | LessWrong | The Fall of Rationality - The Senate of Admins
Borrowing liberally from https://youtu.be/ecMfU3910WY. In fact, this won't make much sense without having seen that first. The following is definitely very accurate to the attitudes of the people and groups mentioned and should totally be thought of as representative.
Nick Bostrom, having successfully convinced EA to focus on long term risk of AI superintelligence over saving children from malaria and starvation, has marched to the gates of LessWrong at Mount Rationality with the conquered EAs in tow. The admins are in session, presided over by Emperor Yud.
Roko: Hail Nick Bostrom, conqueror of the wordcel EAs.
Admins: Hail Nick Bostrom!
Roko: Honorable Shape Rotators! And admins of LessWrong. Have you heard what is being proposed? Bostrom has asked that we, the admins of LessWrong, should give these EAs, these wordcels, LessWrong accounts and host their posts on our servers. To treat these inexact fools as brothers, equals. And what of our other adjacent communities? What of the Polyamorists? So loyal to us. What of the redditors, and the neoreactionaries which sends us so many recruits? If we make Rationalists of these wordcels, can we withhold LessWrong accounts from them? No! Then what becomes of the precious prize a LessWrong account once was? It becomes a cheap, common thing. It will be given away like Reddit Karma. I say no! We are Rationalists! Shape Rotators! Let us rid our minds of this poisonous idea. Ban their IP addresses. Send the rest to Reddit. Teach them once and for all what it is to make war on Rationality. That... is the Rationalist way.
Bostrom: Honorable Shape Rotators of LessWrong! You have greeted me as an author, who came in small triumph from his book sales. And I thank you for it. But you will have a hard decision to make here today! And it must not be I, as an author, who swayed your vote. I ask, therefore, of Yud, that a man who is neither poster nor admin, but a philosopher, a man of reason, be permitted to speak for me.
Willi |
d9d68a67-02a5-4352-9895-b1954291ddbc | trentmkelly/LessWrong-43k | LessWrong | Schelling Point Strategy Training
There's a category of game-theoretic scenario called Battle of the Sexes, which is commonly used to demonstrate coordination problems. Two cinema-goers, traditionally a husband and wife, have agreed to go to the cinema, but haven't decided on what to see beforehand. Of the two films that are showing, she would rather see King Kong Lives, while he would rather see Big Momma's House 2. Each would rather see their non-preferred film with their spouse than see their preferred film on their own. The payoff matrix is as follows:
Husband King Kong Lives Big Momma's House 2 Wife King Kong Lives 2 / 1 0 / 0 Big Momma's House 2 0 / 0 1 / 2
The two have not conferred beforehand, beyond sharing knowledge of their preferences. They are turning up to the cinema and picking an auditorium in the hope that their spouse is in there. Which should they pick? This is a classic coordination problem. The symmetry of their preferences means there is no stand-out option for them to converge on. There is no Schelling Point.1
Except I'm going to argue that there is.
Shoehorning an example of a Schelling Point into the above scenario, we might imagine that one of the above films being screened is being billed as "an ideal romantic treat to share with your spouse", (which one that would be, I'm not entirely sure), though in the absence of a "natural" Schelling Point, there's no reason we can't make one. All we need is to identify procedures that would reliably elevate one of these options to our attention. Then it becomes a question of selecting which of these procedures is most likely to be selected by the other agent in the scenario.
I am now going to instigate a multidimensional instance of Battle of the Sexes with all the readers of this post. Below are sixteen randomly-ordered films. I am going to select one, and invite you to do the same. The object of the exercise is for all of us to pick the same one. I will identify my selection, and the logic behind it, in rot13 afte |
f0694686-e2f9-4ad8-b4f1-4530ce4e59bc | trentmkelly/LessWrong-43k | LessWrong | Exploring Concept-Specific Slices in Weight Matrices for Network Interpretability
Hello. I've been interesting in AI for a long time, but I never contributed anything to discussions of AI alignment in the past, because I didn't think I was smart enough. Turns out, no-one else in the world is smart enough to solve this either. So, without further preamble, I was wondering if anyone would like to see my proposal for a research direction. Its a first draft, and I'm sure someone else has thought of this already, but on the offchance they haven't...
(p.s. I used chatgpt to proofread it and suggest rewrites. I hope thats ok.)
Background
Interpreting the functionality of individual neurons and neural circuits within artificial intelligence (AI) systems remains a significant challenge in the field of AI alignment. This task includes the classification of neurons involved in complex behaviors such as deception, and subsequently monitoring these specific neurons to determine the AI's behavior. Despite advancements in AI interpretability, such as using one AI to predict the behavior of neurons in another AI, this problem is still unsolved 1 .
A limitation of this approach is rooted in Lob's theorem, which states that a system cannot perfectly predict its own behavior. Although the extent to which an AI can imperfectly predict its own behavior is still unknown, the problem intuitively arises from the paradox that for a system to fully comprehend its own behavior, it would need to be larger and more complex than itself.
To address this issue, I propose an alternative training scheme that incorporates the roles of neurons during the training process, effectively "baking in" an approximate understanding of their functions. This method could potentially improve the interpretability of AI systems without significantly impacting their efficiency, or even potentially improving it. The purpose of the rest of this document is to provide a brief outline of this scheme, including a proposal for a relatively simple test case that could be implemented without excess |
3467f9d2-6aed-40df-8139-7b36d36e8ff4 | trentmkelly/LessWrong-43k | LessWrong | Monthly Roundup #26: January 2025
Some points of order before we begin the monthly:
1. It’s inauguration day, so perhaps hilarity is about to ensue. I will do my best to ignore most forms of such hilarity, as per usual. We shall see.
2. My intention is to move to a 5-posts-per-week schedule, with more shorter posts in the 2k-5k word range that highlight particular subtopic areas or particular events that would have gone into broader roundups.
3. This means that the Monthly Roundups will likely be shorter.
4. If you’re considering reading Agnes Callard’s new book, Open Socrates, I am reading it now and can report it is likely to get the On the Edge treatment and its own week, but of course it is too soon to know.
5. I may be doing some streams of myself working, via Twitch, primarily so that a volunteer can look for ways to build me useful tools or inform me of ways to improve my workflow. You are also of course welcome to watch, either live or the recordings, to see how the process works, but I make zero promises of any form of interaction with the audience here. I also might stream Slay the Spire 2 when the time comes, once I have access and they permit this.
On with the show.
TABLE OF CONTENTS
1. Bad News.
2. Wanna Bet.
3. A Matter of Trust.
4. Against Against Nuance.
5. Government Working.
6. Scott Alexander on Priesthoods.
7. NYC Congestion Pricing Bonus Coverage.
8. Positive Sum Thinking.
9. Antisocial Media.
10. The Price of Freedom.
11. Mood Music.
12. Dedebanking.
13. Good News, Everyone.
14. While I Cannot Condone This.
15. Clear Signal.
16. When People Tell You Who They Are Believe Them.
17. What Doesn’t Go Without Saying.
18. Party at My Place.
19. I Was Promised Flying Self-Driving Cars.
20. Gamers Gonna Game Game Game Game Game.
21. For Your Entertainment.
22. Sports Go Sports.
23. The Lighter Side.
BAD NEWS
PornHub cuts off Florida, the 13th state to lose access, after Florida passed an age verification law, and PornHub quite reasonably |
cd5df30d-a512-44a9-aec4-04acfae825a7 | trentmkelly/LessWrong-43k | LessWrong | Housing and Transit Roundup #4
It’s time for another housing roundup, so I can have a place to address the recent discussions about the local impact of housing construction on housing costs.
DOES INCREASING LOCAL HOUSING SUPPLY DECREASE LOCAL HOUSING PRICES?
Scott Alexander says Change My Mind: Density Increases Local But Decreases Global Prices. He uses this graph to make his point:
Under this theory, YIMBY is still correct general policy as it lowers prices everywhere else, yet locally increasing supply improves quality of life and thus induces even more demand and raises prices.
Scott Sumner explains why I strongly believe Scott Alexander is wrong here.
Here’s the core point:
> Scott Sumner: [Scott Alexander] is aware that the pattern above may show an upward sloping supply curve, not an upward sloping demand curve. But he nonetheless suggests that it’s probably an upward sloping demand curve, and that building more housing in Oakland would make Oakland so much more desirable that prices actually rise, despite the greater supply of housing. I have two problems with this sort of argument.
>
> First, I doubt that it’s true. It is certainly the case that building more housing can make a city more desirable, and that this effect could be so strong that it overwhelms the price depressing impact of a greater quantity supplied. But studies suggest that this is not generally the case.
>
> Texas provides a nice case study. Among Texas’s big metro areas, Austin has the tightest restrictions on building and Houston is the most willing to allow dense infill development. Even though Houston is the larger city, house prices are far higher in Austin.
This is basic common sense.
1. Places that impose severe NIMBY restrictions get very high prices.
2. All the most expensive places in America impose such restrictions, and make it impossible to build more housing.
3. The places that don’t impose such restrictions have lower housing prices than their populations would otherwise suggest.
4. Thi |
3b8b504c-3ee3-4735-a42b-69c066287cf5 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Apply to the Redwood Research Mechanistic Interpretability Experiment (REMIX), a research program in Berkeley
This winter, Redwood Research is running a coordinated research effort on mechanistic interpretability of transformer models. We’re excited about recent advances in mechanistic interpretability and now want to try to scale our interpretability methodology to a larger group doing research in parallel.
REMIX participants will work to provide mechanistic explanations of model behaviors, using our [causal scrubbing methodology](https://www.redwoodresearch.org/s/causal-scrubbing) to formalize and evaluate interpretability hypotheses. We hope to produce many more explanations of model behaviors akin to our recent work investigating behaviors of [GPT-2-small](https://www.alignmentforum.org/posts/3ecs6duLmTfyra3Gp/some-lessons-learned-from-studying-indirect-object), [toy language models](https://www.redwoodresearch.org/s/causal-scrubbing#page=71), and [models trained on algorithmic tasks](https://www.redwoodresearch.org/s/causal-scrubbing#page=33). We think this work is a [particularly promising research direction for mitigating existential risks from advanced AI systems](https://www.alignmentforum.org/posts/nqwzrpkPvviLHWXaE/apply-to-the-redwood-research-mechanistic-interpretability#Is_this_research_promising_enough_to_justify_running_this_program_) (more in [Goals](https://www.alignmentforum.org/posts/nqwzrpkPvviLHWXaE/apply-to-the-redwood-research-mechanistic-interpretability#Goals) and [FAQ](https://www.alignmentforum.org/posts/nqwzrpkPvviLHWXaE/apply-to-the-redwood-research-mechanistic-interpretability#How_useful_is_this_kind_of_interpretability_research_for_understanding_models_that_might_pose_an_existential_risk_)).
Since mechanistic interpretability is currently a small sub-field of machine learning, we think it’s plausible that REMIX participants could make important discoveries that significantly further the field. We also think participants will learn skills valuable for many styles of interpretability research, and also for ML research more broadly.
Apply [here](https://jobs.lever.co/redwoodresearch/5a66fff4-0d11-4954-830a-9228635cea59) by Sunday, November 13th [DEADLINE EXTENDED] to be a researcher in the program. Apply sooner if you’d like to start early (details below) or receive an earlier response.
Some key details:
* We expect to accept 30-50 participants.
* The research program will take place in Berkeley, CA.
* We plan to have the majority of researchers participate during the months of December and/or January (depending on availability) although we may invite some to begin earlier and are open to some starting as soon as possible.
* We expect researchers to participate for a month minimum, and (all else equal) will prefer applicants who are able to come for longer. We’ll pay for housing and travel, and also pay researchers for their time. We’ll clarify the payment structure prior to asking people to commit to the program.
* We’re interested in some participants acting as *team leaders* who would help on-board and provide research advice to other participants. This would involve arriving early to get experience with our tools and research directions and participating for a longer period (~2 months). You can indicate interest in this role in the application.
* We’re excited about applicants with a range of backgrounds; we’re not expecting applicants to have prior experience in interpretability research. Applicants should be comfortable working with Python, PyTorch/TensorFlow/Numpy (we’ll be using PyTorch), and linear algebra. We’re particularly excited about applicants with experience doing empirical science in any field.
* We’ll allocate the first week to practice using our interpretability tools and methodology; the rest will be researching in small groups. See [Schedule](https://www.alignmentforum.org/posts/nqwzrpkPvviLHWXaE/apply-to-the-redwood-research-mechanistic-interpretability#Schedule).
Feel free to email [programs@rdwrs.com](mailto:programs@rdwrs.com) with questions.
Goals
-----
### Why you should apply:
**Research results.** We are optimistic about the research progress you could make during this program (more below). Since mechanistic interpretability is currently a small sub-field of machine learning, we think it’s plausible that REMIX participants could make important discoveries that significantly further the field.
**Skill-building.** We think this is a great way to gain experience working with language models and interpreting/analyzing their behaviors. The skills you’ll learn in this program will be valuable for many styles of interpretability research, and also for ML research more broadly.
**Financial support & community.** This is a paid opportunity, and a chance to meet and connect with other researchers interested in interpretability.
### Why we’re doing this:
**Research output.** We hope this program will produce research that is useful in multiple ways:
* We’d like stronger and more grounded characterizations of how language models perform [a certain class of behaviors](https://www.lesswrong.com/posts/LkBmAGJgZX2tbwGKg/help-out-redwood-research-s-interpretability-team-by-finding). For example, we currently have a variety of findings about how [GPT-2-small implements indirect object identification](https://www.alignmentforum.org/posts/3ecs6duLmTfyra3Gp/some-lessons-learned-from-studying-indirect-object) (“IOI”, see next section for more explanation), but aren’t yet sure how often they apply to other models or other tasks. We’d know a lot more if we had a larger quantity of this research.
* For each behavior investigated, we think there’s some chance of stumbling across something really interesting. Examples of this include induction heads and the “pointer manipulation” result in the IOI paper: not only does the model copy information between attention streams, but it also copies “pointers”, i.e. the position of the residual stream that contains the relevant information.
* We’re interested in learning whether different language models implement the same behaviors in similar ways.
* We’d like a better sense of how good the current library of interpretability techniques is, and we’d like to get ideas for new techniques.
* We’d like to have more examples of this kind of investigation, to help us build infrastructure to support or automate this kind of research.
**Training and hiring.** We might want to hire people who produce valuable research during this program.
**Experience running large collaborative research projects.** It seems plausible that at some point it will be useful to run a huge collaborative alignment project. We’d like to practice this kind of thing, in the hope that the lessons learned are useful to us or others.
*See*[*“Is this research promising enough to justify running this program?”*](https://www.alignmentforum.org/posts/nqwzrpkPvviLHWXaE/apply-to-the-redwood-research-mechanistic-interpretability#Is_this_research_promising_enough_to_justify_running_this_program_) *and*[*“How useful is this kind of interpretability research for understanding models that might pose an existential risk?”*](https://www.alignmentforum.org/posts/nqwzrpkPvviLHWXaE/apply-to-the-redwood-research-mechanistic-interpretability#How_useful_is_this_kind_of_interpretability_research_for_understanding_models_that_might_pose_an_existential_risk_)
Why do this now?
----------------
We think our recent progress in interpretability makes it a lot more plausible for us to reliably establish mechanistic explanations of model behaviors, and therefore get value from a large, parallelized research effort.
**A unified framework for specifying and validating explanations.** Previously, a big bottleneck on parallelizing interpretability research across many people was the lack of a clear standard of evidence for proposed explanations of model behaviors (which made us expect the research produced to be pretty unreliable). We believe we’ve recently made some progress on this front, developing [an algorithm called “causal scrubbing”](https://www.redwoodresearch.org/s/causal-scrubbing) which allows us to automatically derive an extensive set of tests for a wide class of mechanistic explanations. This algorithm is only able to reject hypotheses rather than confirming them, but we think that this still makes it way more efficient to review the research produced by all the participants.
* Our current plan is to require researchers in this program to do causal scrubbing on all serious research they produce and submit to the internal review process. (They can do exploratory analyses with whatever techniques they like.)
**Improved proofs of concept.** We now have several examples where we followed our methodology and were able to learn a fair bit about how a transformer was performing some behavior.
* We [recently investigated](https://www.alignmentforum.org/posts/3ecs6duLmTfyra3Gp/some-lessons-learned-from-studying-indirect-object) a somewhat complex behavior in GPT-2-small, which we call “indirect object identification” (“IOI”). IOI is the model behavior where, given a sequence such as “Bob and Alice went to the store and Alice gave an apple to”, the model predicts “Bob” rather than “Alice”. Our research located and described the mechanism inside GPT-2-small that performs this behavior, i.e. which heads of the network are involved and what roles they play. Though our investigation into GPT-2-small was much less comprehensive than e.g. the description of how an image classification model detects curves in the [Distill Circuits thread](https://distill.pub/2020/circuits/), we think our research here suggests that transformer language models *do*have some crisp circuits that can be located and described.
* We did [causal-scrubbing-based analysis](https://www.redwoodresearch.org/s/causal-scrubbing#page=71) of a two-layer attention-only language model in order to get a detailed sense of the interactions in a model that were important for the performance of the “[induction heads](https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html)”. We also used [causal scrubbing](https://www.redwoodresearch.org/s/causal-scrubbing#page=33) to assess hypotheses about a transformer trained to classify strings of parentheses as balanced or unbalanced. In both these cases, we found that we could apply our methodology pretty straightforwardly, yielding useful results.
**Tools that allow complicated experiments to be specified quickly.**We’ve built a powerful library for manipulating neural nets (and computational graphs more generally) for doing intervention experiments and getting activations out of models. This library allows us to do experiments that would be quite error-prone and painful with other tools.
Who should apply?
-----------------
We're most excited about applicants comfortable working with (basic) Python, any of PyTorch/TensorFlow/Numpy, and linear algebra. Quickly generating hypotheses about model mechanisms and testing them requires some competence in these domains.
If you don’t understand the transformer architecture, we’ll require that you go through preparatory materials, which explain the architecture and walk you through building one yourself.
We’re excited about applicants with a range of backgrounds; prior experience in interpretability research is not required. The primary activity will be designing, running, and analyzing results from experiments which you hope will shed light on how a model accomplishes some task, so we’re excited about applicants with experience doing empirical science in any field (e.g. economics, biology, physics). The core skill we’re looking for here, among people with the requisite coding/math background, is something like **rigorous curiosity**: a drive to thoroughly explore all the ways the model might be performing some behavior and narrow them down through careful experiments.
What is doing this sort of research like?
-----------------------------------------
Mechanistic interpretability is an unusual empirical scientific setting in that controlled experimentation is relatively easy, but there’s relatively little knowledge about the kinds of structures found in neural nets.
Regarding the ease of experimentation:
* It’s easy to do complicated intervention experiments. If you’re curious about whether the network, or some internal component of it, would have produced a radically different output had some feature of the input been different, you can re-run it exactly and just change that feature. There’s little to no hassle involved in controlling for all the other features of the run.
* You can extract almost any metric from the internal state of the model at any time.
* You can quickly run lots of inputs through the model all at once if you want to characterize average behaviors.
* See Chris Olah’s [note on neuroscience versus interpretability](https://colah.github.io/notes/interp-v-neuro/) for more on this point.
Regarding the openness of the field:
* Large and important questions, like “How much similarity is there in the internals of different models?” and “To what degree are model behaviors implemented as modular, human-comprehensible algorithms?” are still mostly unexplored.
* We’re early on in the process of discovering commonalities across models like induction heads - we don’t currently know how much there tends to be simple, universal algorithms that show up across models, versus each model being idiosyncratic.
REMIX participants pursue interpretability research akin to the investigations Redwood has done recently into induction heads, [indirect object identification (IOI) in small language models](https://www.alignmentforum.org/posts/3ecs6duLmTfyra3Gp/some-lessons-learned-from-studying-indirect-object), and balanced parenthesis classification, all of which will be released publically soon. You can read more about behavior selection criteria [here](https://www.lesswrong.com/posts/LkBmAGJgZX2tbwGKg/help-out-redwood-research-s-interpretability-team-by-finding).
The main activities will be:
* doing exploratory analyses to generate hypotheses about how a language model (probably GPT-2-small) performs some behavior
* evaluating your hypotheses with [our causal scrubbing methodology](https://www.redwoodresearch.org/s/causal-scrubbing)
* iterating to make hypotheses more fine-grained and more accurate
The mechanisms for behaviors we’ll be studying are often surprisingly complex, so careful experimentation is needed to accurately characterize them. For example, the Redwood researchers investigating the IOI behavior found that removing the influence of the circuit they identified as primarily responsible had surprisingly little effect on the model’s ability to do IOI. Instead, other heads in the model substantially changed their behavior to compensate for the excision. As the researchers write, “Both the reason and the mechanism of this compensation effect are still unclear. We think that this could be an interesting phenomenon to investigate in future work.”
Here’s how a Redwood researcher describes this type of research:
> It feels a lot of time like you're cycling between: "this looks kind of weird and interesting, not sure what's up with this" and then "I have some vague idea about what maybe this part is doing, I should come up with a test to see if I understand I correctly" and then once you have a test "oh cool, I was kind of right but also kind of wrong, why was I wrong" and then the cycle repeats.
>
> Often it's pretty easy to have a hunch about what some part of your model is doing, but finding a way to appropriately test that hunch is hard and often your hunch might be partially correct but incomplete so your test may rule it out prematurely if you're not careful/specific enough.
>
> It feels like you're in a lab, with your model on the dissection table, and you're trying to pick apart what's going on with different pieces and using different tools to do so - this feels really cool to me, kind of like trying to figure out what's going on with this alien species and how it can do the things it does.
>
> It's really fun to try and construct a persuasive argument for your results: "I think this is what's happening because I ran X, Y, Z experiments that show A, B, C, plus I was able to easily generate adversarial examples based on these hypotheses" - I often feel like there's some sort of imaginary adversary (sometimes not imaginary!) that I have to convince of my results and this makes it extremely important that I make claims that I can actually back up and that I appropriately caveat others.
>
>
This research also involves a reasonable amount of linear algebra and probability theory. Researchers will be able to choose how deep they want to delve into some of the trickier math we’ve used for our interpretability research (for example, it turns out that one technique we’ve used is closely related to [Wick products](https://en.wikipedia.org/wiki/Wick_product) and Feynman diagrams).
Schedule
--------
The program will start out with a week of training using our library for computational graph rewrites and investigating model behaviors using our methodology. This week will have a similar structure to [MLAB (our machine learning bootcamp)](https://www.alignmentforum.org/posts/3ouxBRRzjxarTukMW/apply-to-the-second-iteration-of-the-ml-for-alignment), with pair programming and a prepared curriculum. We’re proud to say that past iterations of MLAB have been highly-reviewed – the participants in the second iteration gave an average score of 9.2/10 to the question “How likely are you to recommend future MLAB programs to a friend/colleague?”.
An approximate schedule for week one:
* Monday: Use our software to manipulate neural net computational graphs, e.g. get the output of different attention heads or [virtual attention heads](https://transformer-circuits.pub/2021/framework/index.html#virtual-attention-heads), or do various forms of intervention experiments.
* Tuesday: Using this software, replicate results about induction heads in a small language model.
* Wednesday: Use [causal scrubbing](https://www.redwoodresearch.org/s/causal-scrubbing) to investigate induction heads in the same model.
* Thursday: Replicate some of our causal scrubbing results on a small model trained to classify whether sequences of parentheses are balanced.
* Friday: Replicate some of the [“indirect object identification” results](https://www.alignmentforum.org/posts/3ecs6duLmTfyra3Gp/some-lessons-learned-from-studying-indirect-object).
In future weeks, you’ll split your time between investigating behaviors in these models, communicating your findings to the other researchers, and reading/learning from/critiquing other researchers’ findings.
Miscellaneous Notes
-------------------
* During this program, we’ll try to be agile and respond to bottlenecks on the production of high-quality research as they appear. For example, we might have some Redwood staff or contractors work full time to maintain and improve our tools as we go. (We might also have REMIX researchers work on these tools if they’re interested and if we think it won’t be too chaotic.)
* We’ll probably try to build organizational infrastructure and processes according to demand, e.g. some kind of wiki for cross-referencing observations about various parts of models a la [the OpenAI Microscope](https://openai.com/blog/microscope/).
* We can imagine having training days later in the program (perhaps as optional events on the weekends).
* We might investigate algorithmic behaviors in small transformers not trained on language modeling.
* We will probably mostly focus on a single model, but we may have a few people looking at somewhat larger models.
FAQ
---
### What if I can’t make these dates?
We encourage you to submit an application even if you can’t make the dates; we have some flexibility, and might make exceptions for exceptional applicants. We’re planning to have some participants start as soon as possible to test drive our materials, practice in our research methodology, and generally help us structure this research program so it goes well.
### Am I eligible if I’m not sure I want to do interpretability research long-term?
Yes.
### What’s the application process?
You fill out [the form](https://jobs.lever.co/redwoodresearch/5a66fff4-0d11-4954-830a-9228635cea59), complete some TripleByte tests that assess your programming abilities, then do an interview with us.
### Can you sponsor visas?
Given this program is a research sprint rather than a purely educational program, and given the fact that we plan to offer stipends for participants, we can’t guarantee sponsorship of the right-to-work visas required for international participants to be in person. If you are international but studying at a US university, we are optimistic about getting a CPT for you to be able to participate.
However, *we still encourage international candidates to apply*. We’ll try to evaluate on a case-by-case basis and for exceptional candidates depending on your circumstances, there may be alternatives, like trying to sponsor a visa to have your join later or participating remotely for some period.
### Is this research promising enough to justify running this program?
Buck’s opinion:
> I would love to say that this project is paid for by the expected direct value of its research output. My inside view is that the expected direct value does in fact pay for the dollar cost of this project, and probably even the time cost of the organizers. However, there are strong reasons for skepticism–this is a pretty weird thing to do, and it’s sort of weird to be able to make progress on things by having a large group of people work together. So the decision to run this program is to some extent determined by more boring, capacity-building considerations, like training people and getting experience with large projects.
>
>
### How useful is this kind of interpretability research for understanding models that might pose an existential risk?
This research might end up not being very useful. Here’s Buck’s description of some reasons why this might be the case:
> My main concern is that the language model interpretability research we mentioned above was done on model behaviors which were specifically selected because we thought interpreting these behaviors would be easy. (I’ve recently been calling this kind of research “streetlight interpretability”, as in [the classic fallacy where you only look for things in the place that’s easiest to look in](https://en.wikipedia.org/wiki/Streetlight_effect%5C).) These model behaviors are chosen to be unrepresentatively easy to interpret.
>
>
> In particular, it’s not at all obvious how to use any existing interpretability techniques (or even how to articulate the goal of interpretability) in situations where the algorithm the model is using is poorly described by simple, human-understandable heuristics. I suspect that tasks like IOI or acronym generation, where the model implements a simple algorithm, are the exception rather than the rule, and models achieve good performance on their training trask mostly by using huge piles of correlations and heuristics. Our preliminary attempts to characterize how the model distinguishes between outputting “is” and “was” indicate that it relies on a huge number of small effects; my guess is that this is more representative of what language models are mostly doing than e.g. the IOI work.
>
>
> So my guess is that this research direction (where we try to explain model behaviors in terms of human-understandable concepts) is limited, and is more like diving into a part of the problem that I strongly suspect to be solvable, rather than tackling the biggest areas of uncertainty or developing the techniques that might greatly expand the space of model behavior that we can understand. We are also pursuing various research directions that might make a big difference here; I think that research on these improved strategies is quite valuable (plausibly the best research direction), but I think that streetlight interpretability still looks pretty good.
>
>
> Another concern you might have is that it’s useful to have a few examples of this kind of streetlight interpretability, but there are steeply diminishing marginal returns from doing more work of this type. For what it’s worth, I have so far continued to find it useful/interesting to see more examples of research in this style, but it’s pretty believable that this will slow down after ten more projects of this form or something.
>
>
Overall, we think that mechanistic interpretability is one of the most promising research directions for helping prevent AI takeover. Our hope is that mature interpretability techniques will let us distinguish between two ML systems that each behave equally helpfully during training – even having exactly the same input/output behavior on the entire training dataset – but where one does so because it is deceiving us and the other does so “for the right reasons.”[[1]](#fnrpsfd9ibl4i)
Our experience has been that explaining model behaviors supports both empirical interpretability work – guiding how we engineer interpretability tools and providing practical knowhow – and theoretical interpretability work – for example, leading to the development of [the causal scrubbing algorithm](https://www.redwoodresearch.org/s/causal-scrubbing). We expect many of the practical lessons that we might learn would generalize to more advanced systems, and we expect that addressing the theoretical questions that we encounter along the way would lead to important conceptual progress.
Currently, almost no interesting behaviors of ML models have been explained – even for models that are tiny compared with frontier systems. We have been working to change this, and we’d like you to help.
For other perspectives on this question, see Chris Olah’s description of the relevance of thorough, small-model interpretability [here](https://www.alignmentforum.org/posts/CzZ6Fch4JSpwCpu6C/interpretability) and Paul Christiano’s similar view [here](https://www.alignmentforum.org/posts/oWN9fgYnFYJEWdAs9/comments-on-openphil-s-interpretability-rfp).
*Apply*[*here*](https://jobs.lever.co/redwoodresearch/5a66fff4-0d11-4954-830a-9228635cea59) *by November 8th to be a researcher in the program, and apply sooner if you want to start ASAP. Sooner applications are also more likely to receive sooner responses. Email*[*programs@rdwrs.com*](mailto:programs@rdwrs.com) *with questions.*
1. **[^](#fnrefrpsfd9ibl4i)** The problem of distinguishing between models which behave identically on the training distribution is core to the [ELK problem](https://www.lesswrong.com/posts/qHCDysDnvhteW7kRd/arc-s-first-technical-report-eliciting-latent-knowledge). |
1129abcc-44fd-43c0-96df-30c0a761a8b7 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Help Understanding Preferences And Evil
I’m having a problem understanding why Stuart Russell thinks that AI learning human preferences is a good idea. I think it’s a bad idea. I assume I am wrong but I assume I don’t understand something. So, help me out here please. I’m not looking for an argument but rather to understand. Let me explain.
I have watched Stuart’s four hour lecture series of Reith lectures on the BBC. Highly recommended. I have watched several other videos that include him as well. I am currently reading his book, Human Compatible. I am not an academic. I am now retired and write science fiction about advanced social robots for a hobby.
Reading the chapter “AI: A Different Approach” in Stuart’s book I am still bothered by something about the preferences issue. My understanding of Stuart’s “new model for AI” is that it would learn what our preferences are from observing our behavior. I understand why he thinks “preferences” is a better word than “values” to describe these behaviors but, at the risk of confusing things, let me use the word values to explain my confusion.
As I understand it, humans have different kinds of values:
1) Those that are evolved and which we all share as a species, like why sugar tastes good or why glossy hair is attractive.
2) Those that reflect our own individuality, which make each of us unique including those some twin studies reveal.
3) Those our culture, family, society or what have you impose on us.
I believe the first two kinds are genetic and the third kind learned. Let me classify the first two as biological values and the third kind as social values. It would appear that the third category accounts for the majority of the recent evolution of our physical brains.
Let’s consider three values for each type just as simple examples. Biological values might be greed, selfishness and competition while social values might be trust, altruism and cooperation. Humans are a blend of all six of these values and will exhibit preferences based on them in different situations. A lot of times they are going to choose behaviors based on biological values as the nightly news makes clear.
If AI learns our preferences base on our behaviors it’s going to learn a lot of “bad” things like lying, stealing and cheating and other much worse things. From a biological point of view, these behaviors are “good” because they maximize the return on calories invested by getting others to do the work while we reap the benefits. Parasites and cuckoo birds for example.
In his Reith lecture Stuart states that an AI trained on preferences will not turn out evil but he never explains why not. There is no mention (so far) in his book regarding the issue of human preferences and anything we would consider negative, bad or evil. I simply don’t understand how an AI observing our behavior is going to end up being exclusively benevolent or “provably beneficial” to use Stuart’s term.
I think an AI learning from our preferences would be a terrible idea. What am I not understanding? |
3284e349-1960-41b8-a163-02e7060b488b | StampyAI/alignment-research-dataset/lesswrong | LessWrong | New AI risks research institute at Oxford University
The [Oxford Martin Programme on the Impacts of Future Technology](http://www.futuretech.ox.ac.uk/) (aka FutureTech) is a new research department at Oxford University, roughly a spin-off of FHI, but *focusing* on AI and nanotech risks and [differential technological development](http://en.wikipedia.org/wiki/Differential_technological_development). Like FHI, this department is directed by [Nick Bostrom](http://nickbostrom.com/). They'll be hiring more researchers soon. Basically, this means more people and money being devoted to existential risk reduction.

Okay, now back to work. |
3ea11876-aef6-4e8e-8aad-d44664ac8671 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | The alignment problem from a deep learning perspective
*This report (*[*now available on arxiv*](https://arxiv.org/abs/2209.00626)*) is intended as a concise introduction to the alignment problem for people familiar with machine learning. It translates previous arguments about misalignment into the context of deep learning by walking through an illustrative AGI training process (a framing drawn from* [*an earlier report by Ajeya Cotra*](https://www.lesswrong.com/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to)*), and outlines possible research directions for addressing different facets of the problem.*
Within the coming decades, artificial general intelligence (AGI) may surpass human capabilities at a wide range of important tasks. Without substantial action to prevent it, AGIs will likely use their intelligence to pursue goals which are very undesirable (in other words, *misaligned*) from a human perspective. This report aims to cover the key arguments for this claim in a way that’s as succinct, concrete and technically-grounded as possible. My core claims are that:
1. [It’s worth thinking about risks from AGI in advance](https://www.alignmentforum.org/posts/KbyRPCAsWv5GtfrbG/what-misalignment-looks-like-as-capabilities-scale#It_s_worth_thinking_about_risks_from_AGI_in_advance)
2. [Realistic training processes lead to the development of misaligned goals](https://www.alignmentforum.org/posts/KbyRPCAsWv5GtfrbG/what-misalignment-looks-like-as-capabilities-scale#Realistic_training_processes_lead_to_the_development_of_misaligned_goals), in particular because neural networks trained via reinforcement learning will
1. [Learn to plan towards achieving a range of goals](https://www.alignmentforum.org/posts/KbyRPCAsWv5GtfrbG/what-misalignment-looks-like-as-capabilities-scale#Phase_1__learning_to_plan_towards_achieving_a_range_of_goals)
2. [Gain more reward by deceptively pursuing misaligned goals](https://www.alignmentforum.org/posts/KbyRPCAsWv5GtfrbG/what-misalignment-looks-like-as-capabilities-scale#Phase_2__pursuing_goals_in_a_situationally_aware_way)
3. [Generalize in ways which undermine obedience](https://www.alignmentforum.org/posts/KbyRPCAsWv5GtfrbG/what-misalignment-looks-like-as-capabilities-scale#Phase_3__generalizing_goals_beyond_human_supervision)
3. [More people should pursue research directions which address these problems](https://www.alignmentforum.org/posts/KbyRPCAsWv5GtfrbG/what-misalignment-looks-like-as-capabilities-scale#More_people_should_pursue_research_directions_which_address_these_problems)
It’s worth thinking about risks from AGI in advance
===================================================
By AGI I mean an artificial agent which applies domain-general cognitive skills (such as reasoning, memory, and planning) to perform at or above human level on a wide range of cognitive tasks (such as running a company, writing a software program, or formulating a new scientific theory).[[1]](#fnvkp9adhxfj) This isn’t a precise definition—but it’s common in science for important concepts to start off vague, and become clearer over time (e.g. “energy” in 17th-century physics; “fitness” in early-19th-century biology; “computation” in early-20th-century mathematics). Analogously, “general intelligence” is a sufficiently important driver of humanity’s success to be worth taking seriously even if we don’t yet have good ways to formalize or measure it.[[2]](#fnzascveb8o4)
On the metrics which we *can* track, though, machine learning has made significant advances, especially over the last decade. Some which are particularly relevant to AGI include [few-shot learning](https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html) (and advances in [sample](https://arxiv.org/abs/2111.00210) [efficiency](https://arxiv.org/abs/2102.04881) more generally), [cross-task generalization](https://www.deepmind.com/blog/generally-capable-agents-emerge-from-open-ended-play), and [multi-step](https://arxiv.org/abs/2201.11903) [reasoning](https://storage.googleapis.com/pathways-language-model/PaLM-paper.pdf#page=38). While hindsight bias makes it easy to see these achievements as part of a natural progression, I suspect that even a decade ago the vast majority of machine learning researchers would have been confident that these capabilities were much further away.
I think it would be similarly overconfident to conclude that AGI is too far away to bother thinking about. A recent survey of top ML researchers gave a median estimate of 2059 for the year in which AI will outperform humans at all tasks (although their responses were sensitive to question phrasing) [(Grace et al., 2022)](https://aiimpacts.org/2022-expert-survey-on-progress-in-ai/). This fits with the finding that, under reasonable projections of compute growth, we will be able to train neural networks as large as the human brain in a matter of decades [(Cotra, 2020)](https://drive.google.com/drive/u/1/folders/15ArhEPZSTYU8f012bs6ehPS6-xmhtBPP). But the capabilities of neural networks are currently advancing much faster than our ability to understand how they work or interpret their cognition; if this trend continues, we’ll build AGIs which match human performance on many important tasks without being able to robustly verify that they’ll behave as intended. And given the strong biological constraints on the size, speed, and architecture of human brains, it seems very unlikely that humans are anywhere near an upper bound on general intelligence.[[3]](#fngyup9237jvq) The differences between our brains and those of chimpanzees are small on an evolutionary scale (in particular, only a 3x size difference), but allow us to vastly outthink them. Neural networks [scale up 3x on a regular basis](https://openai.com/blog/ai-and-compute/), and can rapidly incorporate architectural and algorithmic improvements (including improvements generated by AIs themselves). So soon after building human-level AGIs (and well before we thoroughly understand them), we’ll likely develop superhuman AGIs which can vastly outthink us in turn.
These are strong claims, which it’s reasonable to be uncertain about, especially given that we lack either formal frameworks or empirical data which directly inform us about AGI. However, empirical evidence about AGIs is hard to come by in advance of actually building them. And our lack of formal frameworks for describing alignment problems is a major reason to expect them to be difficult to solve. So if the development of AGI might pose catastrophic risks, we have no choice but to try to address them in advance, even if that requires reasoning under significant uncertainty. Unfortunately, I think it does pose such risks—the most concerning of which is the development of misaligned goals during training.
Realistic training processes lead to the development of misaligned goals
========================================================================
By default, it seems likely to me that AGIs will end up pursuing goals which are undesirable to us, rather than consistently following our intentions. Previous presentations of arguments for this claim have mainly framed them as abstract principles (explored in detail by [Carlsmith (2021)](https://d8737ecf-376e-4788-8d12-a097599c13f6.filesusr.com/ugd/5f37c1_5333aa0b7ff7461abc208b25bfc7df87.pdf) and [Ngo (2020)](https://drive.google.com/file/d/1uK7NhdSKprQKZnRjU58X7NLA1auXlWHt/view)); in this report I’ll describe in more detail how I expect misaligned goals to emerge throughout the process of training an AGI. For the sake of concreteness I’ll focus this report on an illustrative training process in which:
* A single deep neural network with multiple [output heads](https://stackoverflow.com/questions/56004483/what-is-a-multi-headed-model-and-what-exactly-is-a-head-in-a-model) is trained end-to-end
* With one head trained via self-supervised learning on large amounts of multimodal data to predict the next observation
* With another head trained to output actions via reinforcement learning on a wide range of tasks, using standard language and computer interfaces
* With rewards provided via a combination of human feedback and automated evaluations
* Until the policy implemented by the network (via its action head) is able to match or exceed human performance on most of those tasks, and qualifies as an AGI.
Of course, any attempt to outline an AGI training process in advance will have many omissions and inaccuracies. However, the illustrative process described above allows us to make abstract arguments about alignment more concrete; and I expect that training processes similar to this one would plausibly give rise to AGIs which pursue misaligned goals with disastrous consequences. The rest of this report will outline how misaligned goals might develop across three sequential phases of training:
1. Learning to plan towards achieving a range of goals
1. Policies will develop sophisticated internal representations of a range of outcomes which are correlated with higher reward on multiple tasks, and learn to make plans to achieve them. I’ll call these internal representations of favored outcomes the *policy’s goals*.
2. Pursuing goals in a situationally-aware way
1. Once policies can reason about their training processes and deployment contexts (an ability which I’ll call *situational awareness*), they’ll learn to deceptively pursue misaligned goals while still getting high training reward.
3. Generalizing goals beyond human supervision
1. Policies which are too capable for humans to effectively supervise will generalize towards taking actions which give them more power over the world, rather than following human intentions.
It’s particularly important to note that, under the definition above, “the goals of a policy” is a different concept from “the reward function used to train that policy”—although a policy’s goals will be shaped by its reward function, they’ll ultimately depend on the internal representations that policy learns.[[4]](#fnjayejwcrc3h) This distinction, which I’ll explain in more detail in the next section, will become increasingly important as policies learn goals that generalize to a wider range of novel environments.[[5]](#fngfybstftao)
Also note that there are no sharp boundaries between these phases. However, I expect each phase to feature emergent dynamics which weren’t present in the previous phases—as [Steinhardt (2022)](https://bounded-regret.ghost.io/more-is-different-for-ai/) argues is common in ML (and science more generally). As a very rough overview, phase 1 focuses on a version of the [reward misspecification problem](https://arxiv.org/abs/2201.03544); phase 2 elaborates on that, and introduces the [deceptive alignment problem](https://bounded-regret.ghost.io/ml-systems-will-have-weird-failure-modes-2/); and phase 3 focuses on the [goal misgeneralization problem](https://arxiv.org/abs/2105.14111).[[6]](#fnoe0ydhc8st) Let’s look at each phase now.
Phase 1: learning to plan towards achieving a range of goals
------------------------------------------------------------
### Key claim: policies will develop sophisticated internal representations of a range of outcomes which are correlated with higher reward on multiple tasks, and learn to make plans to achieve them.
**Policies will learn to use representations of plans, outcome features, and values to choose actions**
Deep neural networks perform very capably on a wide range of tasks by learning representations related to those tasks which are distributed across their internal weights ([Bengio et al., 2014](https://arxiv.org/abs/1206.5538)). For example, neural networks trained on image classification tasks develop representations of various visual features, such as edges, shapes, and objects, which are then used to identify the contents of those images. [Olah et al. (2020)](https://distill.pub/2020/circuits/zoom-in/) provide compelling visualizations of these representations, as well as representations of more complex features like [wheels and dog heads](https://distill.pub/2020/circuits/zoom-in/) in the Inception network. Less work has been done on understanding the representations learned by deep reinforcement learning policies, but one example comes from a policy trained to play a version of Capture the Flag by [Jaderberg et al. (2019)](https://www.deepmind.com/blog/capture-the-flag-the-emergence-of-complex-cooperative-agents), who identified “particular neurons that code directly for some of the most important game states, such as a neuron that activates when the agent’s flag is taken, or a neuron that activates when an agent’s teammate is holding a flag”.
How are representations like these used by reinforcement learning policies to choose actions? In general we know little about this question, but I’ll distinguish two salient possibilities. The first is that policies map representations of situations to representations of actions, without making use of representations of the outcomes of those actions; I'll call this approach *following heuristics*. The second is that policies represent different outcomes which might arise from possible actions, and then choose actions by evaluating the values of possible outcomes; I’ll call this *pursuing goals*. Under the definition I’m using here, a policy’s goals are the outcomes which it robustly represents as having high value.
Importantly, these definitions are agnostic about whether actions, outcomes, and outcome-values are *explicitly* represented in the code for the policy or *implicitly* represented in policy weights and/or activations. For example, policies like AlphaZero’s use hard-coded search algorithms which manipulate explicit representations of possible move sequences and board states, alongside neural networks which have [implicit representations](https://arxiv.org/abs/2111.09259) of many human chess concepts. However, neural networks trained only to produce actions can also learn to implicitly make plans - a phenomenon known as model-free planning ([Guez et al., 2019](https://arxiv.org/abs/1901.03559)). AlphaZero explicitly generates values for different board positions when choosing its actions; but policies which internally represent outcomes (like the Capture the Flag policy discussed above) may implicitly also use value estimates as part of the process of choosing actions. In this report, I’ll focus on implicit representations, because explicit representations are usually formulated in terms of low-level actions and states, whereas I’m most interested in representations of high-level actions (like “attack the opponent’s queen”) and outcomes (like “my flag is captured”). High-level actions are also known as [*options*](https://www.sciencedirect.com/science/article/pii/S0004370299000521) or *plans*; for clarity, I’ll use the latter term going forward.[[7]](#fn39xw697bsqq)
It seems likely that most currently-existing policies choose actions primarily by following heuristics. However, as we train increasingly capable policies which act coherently over increasingly long timeframes, I expect them to increasingly make use of high-level representations of outcomes. Intuitively speaking, it’s hard to imagine policies which implement sophisticated strategies in complex real-world domains without in some sense “knowing what they’re aiming for”. Again, the definitions I’m using here aren’t very precise, but I hope that starting with vague definitions like these can help guide further empirical investigation. For example, the definitions above allow us to ask whether networks which weren’t trained via RL, like GPT-3, nevertheless pursue goals. Even though GPT-3 was only trained via self-supervised learning, it seems possible that it learned to generate representations of high-level outcomes (like “producing a coherent paragraph describing the rules of baseball”), assign them values, and then use those values to choose the next token it emits; thinking about longer-term outcomes in this way might get lower loss than thinking only about which token to output next. I won’t focus much on the purely self-supervised case, since the relevant concepts are much clearer in an RL setting, but we should keep this possibility in mind when thinking about future non-RL systems, especially ones trained using behavioral cloning to mimic goal-directed experts.[[8]](#fnnn8loc34irf)
**Policies will learn a mix of desirable and undesirable goals because their rewards will be imperfectly correlated with human preferences**
Which goals RL policies learn will depend on which reward functions we use during training. By default, I assume we’ll attempt to assign high rewards for acting in accordance with human intentions and values, and low rewards for disobedient or harmful behavior. However, if we use hard-coded reward functions on some tasks, it’s easy to accidentally incentivize undesirable behavior, as [Krakovna et al. (2020)](https://www.deepmind.com/blog/specification-gaming-the-flip-side-of-ai-ingenuity) showcase.[[9]](#fnl8df1k0t0nr) Reward functions based on human feedback avoid the most obvious mistakes, but can still lead to misspecifications even in very simple environments—as in [Christano et al.’s (2017)](https://openai.com/blog/deep-reinforcement-learning-from-human-preferences/) example of a policy trained to grab a ball with a claw, which learned to place its claw between the camera and the ball in a way which looked like it was grasping the ball, and therefore received high reward from human evaluators.
These are all toy examples with few real-world effects; however, as we train policies to perform more capable real-world tasks, we should expect reward misspecification to lead to larger-scale misbehavior ([Pan et al., 2022](https://arxiv.org/abs/2201.03544)). For example:
* If they are trained to make money on the stock market, and learn to value making profitable trades, they might carry out illegal market manipulation.
* If they are trained to produce novel scientific findings, and learn to value producing compelling results, they might falsify experimental data.
* If they are trained to write software applications, and learn to value high user engagement, they might design addictive user interfaces.
* If they are trained to talk to humans, and learn to value human approval, they might learn to withhold information that humans would be unhappy to hear, or downplay evidence of mistakes.
Each of these is an example of a policy learning an undesirable goal. However, these goals are fairly task-specific, whereas I’m most concerned about the goals that policies generalize to new tasks and environments. The goals which generalize most robustly will likely be the ones which were reinforced across a broad range of environments. Let's consider three categories of goals, which each tend to be robustly correlated with rewards, but for different reasons:
* Goals which we deliberately tried to consistently reward, such as obedience and honesty. An early example related to this category: [InstructGPT](https://openai.com/blog/instruction-following/) follows instructions much more consistently than the base GPT-3 model.
* Goals robustly correlated with reward because they’re related to aspects of the supervision process which were consistent across environments, like the goal of producing plausible-sounding answers (as opposed to true answers), or the goal of taking actions which look productive (as opposed to actually being productive).[[10]](#fnebq42f4t0gn) An early example related to this category: large language models hallucinate compelling false answers when they don’t know the correct answer, even after being fine-tuned towards honesty using RL ([Ji et al., 2022](https://arxiv.org/abs/2202.03629)).
* Goals robustly correlated with reward because they’re useful in a wide range of environments, like [curiosity](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.45.957) or [empowerment](https://arxiv.org/abs/1201.6583), or making money.[[11]](#fn8no67anaox4) We’d like policies to pursue these goals only as a step towards pursuing aligned goals, but never for their own sake. An early example related to this category: [DeepMind’s XLand policies](https://www.deepmind.com/blog/generally-capable-agents-emerge-from-open-ended-play) learned heuristics which were useful across a range of tasks, like experimentation, basic tool use and switching to easier targets where possible.
Throughout phase 1, I expect policies to learn a combination of the three types of goals listed above, along with some task-specific goals (like the ones in the earlier list). Since policies won’t be capable of complex deceptions in this phase, I expect that aligned goals will be the main drivers of their behavior, with humans gradually noticing and penalizing exceptions. But I’ll argue that once policies develop a solid understanding of their own training processes, misaligned goals will consistently lead to the highest reward, and will therefore be reinforced at the expense of aligned goals.[[12]](#fni5k0pw7cge)
Phase 2: pursuing goals in a situationally-aware way
----------------------------------------------------
### Key claim: Once policies can reason about their training processes and deployment contexts, they’ll learn to deceptively pursue misaligned goals while still getting high training reward.
**Situationally-aware policies will understand the mechanisms by which they are trained**
To do well on a range of real-world tasks, policies will need to incorporate knowledge about the wider world into plans which aim towards real-world outcomes (unlike agents such as AlphaZero which only plan in very restricted domains). Large language models already have a great deal of factual knowledge about the world, although they don’t reliably apply that knowledge to all tasks we give them. Over time our best policies will become better at identifying which abstract knowledge is relevant to their own context, and applying it to the tasks they’re given;[[13]](#fn2u0j5idiswm) following [Cotra (2022)](https://www.lesswrong.com/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to), I’ll call this skill *situational awareness*.[[14]](#fnoaajgdzalw) A policy with high situational awareness will possess and be able to use knowledge like:
* How humans will respond to its behavior in a range of situations.
* Which behavior its human supervisors are looking for, and which behavior they’d be unhappy with.
* The fact that it’s an AI implemented on physical hardware being trained via machine learning—and which architectures, algorithms, and environments humans are likely using to train it.
* Which interface it’s using to interact with the world, and how other copies of it might be deployed in the future.
I expect policies to develop situational awareness because it’s straightforwardly useful in getting higher reward on many tasks. Some applications of situational awareness:
* When asked to generate a plan for how it will perform a new task, a policy should only include steps which it can actually carry out—which requires it to understand what its own capabilities are.
* When trying to evaluate the likelihood that its answer is correct, a policy would benefit from taking into account knowledge about common failures of ML systems.
* When trying to determine how to interpret its human user’s requests, a policy would benefit from taking into account knowledge about the types of behavior humans typically want from ML systems.
* When it learns a new fact about the world, a policy would benefit from understanding what implications that fact has for how it should behave.
However, the same mechanisms that allow policies to identify that these pieces of knowledge are relevant to them will likely also allow policies to identify the relevance of concepts directly related to how they’re updated—like “the reward the human supervisor will assign for this episode” or “the loss calculated by the RL algorithm” or “the test suites which humans use to evaluate alignment”. I’ll argue that once policies understand these concepts, they’ll incorporate them into plans in ways that humans wouldn’t endorse.
**Situationally-aware policies will get high reward regardless of whether they’re aligned or misaligned (and likely higher when misaligned)**
Consider the three types of goals I discussed in the section on phase 1. As policies become situationally-aware, which will be positively or negatively reinforced?
1. Aligned goals will continue to be strongly correlated with reward. However, whenever rewards are misspecified, policies with aligned goals won’t take the highest-reward actions, which will penalize aligned goals compared with misaligned goals.
2. Situationally-aware policies could learn to pursue goals very directly related to the supervision process, like “maximize the reward the human supervisor will assign” or “minimize the loss calculated by the RL algorithm”. Following [Cotra (2022)](https://www.lesswrong.com/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to), I’ll call this category of goals “playing the training game”. These goals will be reinforced more consistently than any other goals, because policies which pursue them will never pass up a chance to increase reward.
3. Goals which are useful across many environments, like curiosity or making money, are often most naturally represented as extending across multiple training episodes (I’ll give a more thorough argument for this claim in the next section). But a situationally-aware policy with long-term goals will have instrumental incentives to get high reward even if those goals don’t refer directly to the supervision process.[[15]](#fnnzqojg4z84a) For example, it might reason that behaving in a trustworthy way now will make humans more likely to deploy another copy of it later, which would allow that other copy to achieve their shared goal. Or it might reason that getting as much reward as possible would prevent its goals from being changed by gradient descent.[[16]](#fnnyai2wz7fzo) The strategy of getting high reward for instrumental reasons is known as *deceptive alignment*; Steinhardt provides a [formal model](https://bounded-regret.ghost.io/ml-systems-will-have-weird-failure-modes-2/).
If misaligned situationally-aware policies are deliberately trying to get high rewards, how might they do so? One obvious strategy is to follow human instructions most of the time, but diverge in cases where disobedience is hard for humans to notice and would get higher reward.[[17]](#fn588a0ipns87) This might look similar to the misbehavior discussed in the previous section, and indeed may gradually evolve from those previous examples. However, misbehavior from situationally-aware policies will be much harder to catch, since these policies will be able to explicitly reason about what types of misbehavior supervisors will notice and penalize.[[18]](#fn1sewoaqlueu)
Eventually we should expect situationally-aware policies to be able to deduce the benefits of deceptive strategies very different from any previous behaviors. There’s no fundamental difference between thinking of a clever new strategy to solve a hard task and thinking of a clever new strategy to make humans believe that the task has been solved: both require the same core reasoning skills, and both lead to higher reward. We can penalize the latter heavily when we notice it—but as policies become increasingly intelligent, and we train them to execute plans over increasingly long time horizons, deception will become harder and harder for unaided humans to catch. If we observe less deception as training progresses, it won’t be clear to us whether our policies are actually becoming more obedient, or if they’ve just learned more careful deceptive strategies which play out over longer time horizons. These might look like:
* Emotional manipulation to make human supervisors (or wider society) trust them more.
* Creating backdoor channels for interacting with the world (e.g. storing money in hidden locations for later use in unapproved ways).
* Hacking into the computers they're being run on to modify their training algorithms (known as [reward tampering](https://arxiv.org/abs/1908.04734)).
* Deliberately avoiding actions or outcomes which they don't want to be included in future training data (an example of [gradient hacking](https://www.alignmentforum.org/posts/EeAgytDZbDjRznPMA/gradient-hacking-definitions-and-examples)).[[19]](#fn1w293fa7pwq)
By contrast, since aligned goals like obedience and honesty avoid all of these behaviors, policies will learn to value obedience and honesty less over time. We’ll likely attempt to prevent this shift using a range of mechanisms—for example, we could adversarially generate situations where we expect to be able to catch misbehavior. But a policy that was already deceptively aligned would have an incentive to identify when its inputs are adversarially generated (which is typically much easier than generating the inputs in the first place) and behave appropriately on them. More generally, a deceptively aligned policy would have an incentive to detect and fool whichever other supervision mechanisms we try to use.[[20]](#fnd9ysmcbuhmi)
The main proposed solution is using other AIs to help implement better-than-human supervision to minimize reward misspecification, for example using the [debate](https://openai.com/blog/debate/), [recursive reward modeling](https://arxiv.org/abs/1811.07871), or [amplification](https://arxiv.org/abs/1810.08575) protocols. [Saunders et al. (2022)](https://openai.com/blog/critiques/) provide an early practical demonstration. The overarching goal of these techniques is to make discriminating dishonest behavior as easy as possible, relative to generating it. However, on complex tasks where many different deceptive strategies are possible, [the latter can be much easier](https://www.alignmentforum.org/posts/PJLABqQ962hZEqhdB/debate-update-obfuscated-arguments-problem). And even if policies are never rewarded for being deceptive, they may still generalize to pursuing misaligned goals on larger scales, as I’ll discuss in the next section.
Phase 3: generalizing goals beyond human supervision
----------------------------------------------------
### Key claim: Policies which are too capable for humans to effectively supervise will generalize towards taking actions which give them more power over the world, rather than following human intentions.
**AGIs’ behavior will eventually be mainly guided by goals they generalize to large scales**
As we continue training policies on increasingly difficult tasks, they will eventually significantly surpass human intelligence, and clearly qualify as AGIs.[[21]](#fnw3l3u658ock) In phase 2, humans supervised AI behavior using AI assistance. However, in phase 3, this strategy will become much less reliable, because there will be many opportunities for AGIs to collude in order to mislead humans, for example by agreeing to stay silent about each others’ misbehavior.[[22]](#fnbzelvkipb6) Humans won’t be able to detect such collusion because those AGIs will be able to:
* Operate at speeds too fast for humans to monitor (like stock trading algorithms do, but in many more domains).
* Perform novel tasks that are very hard for humans to understand (like inventing new sciences).
* Fabricate rationales which sound acceptable to humans even for very undesirable actions.
* Autonomously acquire the data required to learn new skills in a self-supervised way.
* Carry out machine learning research and development much faster than humans, without any humans understanding in detail how results are being achieved.
So in phase 3 we should expect that AGI behavior on novel tasks will primarily depend not on how we supervise them, but rather on how they generalize the goals they acquired earlier in training, which itself depends on the [inductive biases](https://en.wikipedia.org/wiki/Inductive_bias) of the training setup used. Inductive biases are hard to predict or reason about, but there are some compelling arguments that realistic AGIs are likely to generalize in undesirable ways. Specifically, I expect AGIs to generalize their goals to much larger scales than they experienced during training, which will favor misaligned goals over aligned goals. By “larger scales” I mean harnessing more resources to achieve those goals to a greater extent, with higher probability, in bigger environments, across longer time periods.
We should expect AGIs to generalize goals to larger scales for the same reason that they’ll generalize capabilities to novel tasks: because they’ll learn high-level concepts which are not very domain-specific, and reason about how to achieve them.[[23]](#fnaznkvtaoe6) Reasoning about how to achieve high-level goals generalizes very naturally to larger scales: for example, goals like “have more novel experiences”, “understand the world”, or “get high reward” don’t just apply within a specific time or place, but can be extrapolated to a nearly arbitrary extent.[[24]](#fnwyg9usn8a9) We could imagine AGIs instead generalizing to pursuing bounded versions of those goals, like “have more novel experiences, but not too many, and not too novel, and stopping after a certain time”—but I see little reason to expect generalization to stay within small-scale bounds as AGIs get smarter (especially given that many researchers will aim to build systems which generalize as far as possible). Analogously, although humans only evolved to pursue goals focused on small groups of people based in small territories, modern humans straightforwardly generalize those goals to the global (and sometimes even interplanetary) scale: when thinking about high-level goals abstractly, there’s often no natural stopping point.
**Large-scale goals are likely to incentivize misaligned power-seeking**
Although the goals I described above may sound innocuous, [Bostrom’s (2012)](https://nickbostrom.com/superintelligentwill.pdf) [*instrumental convergence thesis*](https://en.wikipedia.org/wiki/Instrumental_convergence) implies that they (and almost all other large-scale goals) would lead to highly misaligned behavior. The thesis states that there are some intermediate goals—like survival, resource acquisition, and technological development—which are instrumentally useful for achieving almost any final goal. In Stuart Russell’s memorable phrasing: you can’t fetch coffee if you’re dead. Nor can you achieve many outcomes without resources or tools, so AGIs with a wide range of large-scale goals will be incentivized to acquire those too. It’ll also be instrumentally valuable for misaligned AGIs to prevent humans from interfering with their pursuit of their goals (e.g. by deceiving us into thinking they’re aligned, or removing our ability to shut them down) [(Hadfield-Menell et al., 2017)](https://arxiv.org/abs/1611.08219). More generally, we can view each of these instrumental goals as a way of gaining or maintaining power over the world; [Turner et al. (2021)](https://neurips.cc/virtual/2021/poster/28400) formalize the intuitive claim that power-seeking is useful for a wide range of possible goals. So it seems likely that even though we can’t predict *which* misaligned goals AGIs will develop, superhuman AGIs will discover power-seeking strategies which help achieve those goals in part by disempowering humans.
Aren’t these arguments about misaligned goals generalizing to larger scales also reasons to think that aligned goals will generalize too? I’ll distinguish two types of aligned goals: constraints (like obedience or honesty) and positive goals (like human wellbeing or moral value). Unfortunately, realistic environments are biased against either of these generalizing in the ways we’d like. Intuitively speaking, the underlying problem is that aligned goals need to generalize robustly enough to block AGIs from the power-seeking strategies recommended by instrumental reasoning, which will become much more difficult as their instrumental reasoning skills improve. More specifically:
* Constraints are unlikely to generalize well to larger scales, because as AGIs become more intelligent they’ll discover many novel strategies for working around those constraints.[[25]](#fnhklbciz8z3) For example, an AGI which has been trained to obey humans will eventually be capable of manipulating humans into only giving instructions which help the AGI accumulate power. (As an analogy, imagine an adult who can persuade a child to approve of actions which are very harmful in non-obvious ways, like eating food which happens to be poisonous.) That AGI will *understand* that humans don’t want to be manipulated in this way, and that “obey humans in a non-manipulative way” is one possible generalization of the goal “obey humans”—but almost all other possible generalizations won’t rule out all types of manipulation, especially novel ones.[[26]](#fnpgtfrha875l)
* Positive goals are unlikely to generalize well to larger scales, because without the constraint of obedience to humans, AGIs would have no reason to let us modify their goals to remove (what we see as) mistakes. So we’d need to train them such that, once they become capable enough to prevent us from modifying them, they’ll generalize high-level positive goals to very novel environments in desirable ways without ongoing corrections, which seems very difficult. Even humans often disagree greatly about what positive goals to aim for, and we should expect AGIs to generalize in much stranger ways than most humans.
**Misaligned AGIs will have a range of power-seeking strategies available to them**
Assuming we don’t get lucky with generalization, what might a world containing power-seeking AGIs look like? Those AGIs could pursue a number of different types of power, including:
* Technological power, which they might gain by making scientific breakthroughs, developing novel weapons, designing more sophisticated ML algorithms, etc.
* Political or cultural power, which they might gain by spreading disinformation, lobbying politicians, coordinating with other AGIs, etc.
* Economic power, which they might gain by becoming key decision-makers at corporations that make up a significant share of the economy.
Of these categories, I’m most concerned about the first, because it has played such a crucial role throughout human history. During the last few centuries in particular, technological innovations have given some groups overwhelming advantages over others, and allowed a handful of countries to dominate the world. So it’s very plausible that AGIs which can make scientific and technological progress much faster than humans can would be able to threaten the continued survival of humanity (analogous to how soldiers with modern weapons would easily overpower historical civilizations). Even without technological imbalances, however, similarly catastrophic outcomes could arise via AGIs first gaining enough political and economic power that we’re unable to coordinate to constrain them (analogous to how multinational corporations can subvert the governments of small countries). [Christiano provides](https://www.alignmentforum.org/posts/HBxe6wdjxK239zajf/what-failure-looks-like) some [illustrative scenarios](https://www.alignmentforum.org/posts/AyNHoTWWAJ5eb99ji/another-outer-alignment-failure-story) where AGIs become widespread across society and collude to gradually erode human control.
We currently only have very tentative proposals for averting these scenarios. One possibility is that, even if it’s hard for us to understand *what* AGIs are doing, we might be able to understand *why* they’re doing it by harnessing advances in [mechanistic interpretability](https://www.transformer-circuits.pub/2022/mech-interp-essay/index.html)—either to inspect AGI cognition ourselves, or to train other AGIs to do it for us.[[27]](#fnbt08p4eg4cv) Alternatively, if we can simulate deployment trajectories in a sufficiently realistic way, we might be able to train AGIs to avoid collusion before deploying them. However, producing trajectories which AGIs can’t distinguish from the real world would likely require generative models much more capable than the AGIs themselves. A third possibility is [using early AGIs](https://aligned.substack.com/p/alignment-mvp?s=r) to perform whatever alignment research is necessary to align later AGIs. However, we’re far from having robust versions of these proposals, especially if the inductive biases I’ve outlined above are very strong—a possibility which we can’t rule out, and which we should prepare for.
More people should pursue research directions which address these problems
==========================================================================
I’ve flagged a few promising research directions above, but to finish this report I’ll spell out in more detail some research directions which I’d be excited about more ML researchers pursuing:
1. To address the problems discussed in phase 1, we should automate human supervision, to allow us to more reliably identify misbehavior on tasks that humans are able to supervise. Some approaches include scaling up reinforcement learning from human feedback (as in [Ouyang et al. (2022)](https://openai.com/blog/instruction-following/)), training AIs to evaluate each other (as in [Saunders et al. (2022)](https://openai.com/blog/critiques/)), and training AIs to red-team each other (as in [Perez et al. (2022)](https://arxiv.org/abs/2202.03286)).
2. To address the problems discussed in phase 2, we should design or improve techniques for scaling human supervision to tasks that unaided humans can’t supervise directly, such as the protocols of [Christiano et al. (2018)](https://arxiv.org/abs/1810.08575), [Irving et al. (2018)](https://arxiv.org/abs/1805.00899), and [Wu et al. (2021)](https://openai.com/blog/summarizing-books/). In addition to finding ways to scale up those protocols in practice, this work also requires finding solutions to concerns like the [obfuscated arguments problem](https://www.alignmentforum.org/posts/PJLABqQ962hZEqhdB/debate-update-obfuscated-arguments-problem)—for example by generating novel additions to the protocols, like [cross-examination](https://www.alignmentforum.org/posts/Br4xDbYu4Frwrb64a/writeup-progress-on-ai-safety-via-debate-1).
3. To address the problems discussed in phase 3, we should aim to develop interpretability techniques robust and scalable enough that we can use them to understand and modify the high-level cognition of AGIs. For one approach to doing so, see [Olah et al. (2020)](https://distill.pub/2020/circuits/zoom-in/) and [follow-up work on transformer circuits](https://transformer-circuits.pub/). One way such work could be used is to extend [Irving et al.’s Debate protocol](https://arxiv.org/abs/1805.00899) to a setting where debaters can make arguments about each other’s internal cognition (grounded in verifiable claims about weights and activations). Another is to develop techniques like those of [Meng et al. (2022)](https://rome.baulab.info/) which could be used to directly modify the neural weights or activations responsible for a policy’s situational awareness—e.g. a modification which gives a policy the false belief that it could misbehave without being caught.
A different approach to making progress on phase 3 problems is outlined by [Demski and Garrabrant (2018)](https://intelligence.org/2018/10/29/embedded-agents/), whose aim is to produce better mathematical frameworks for describing AIs embedded in real-world environments.
For more detail on each of these research directions, see [the Alignment Fundamentals curriculum](https://docs.google.com/document/d/1mTm_sT2YQx3mRXQD6J2xD2QJG1c3kHyvX8kQc_IQ0ns/edit)—in particular weeks 4, 5 and 6, which roughly correspond to the three research clusters described above. The relative importance of each of these clusters largely depends on the relative difficulty of each of the problems I’ve discussed, as well as how long we have until AGI is built. Broadly speaking, though, I expect that the problems in the earlier phases are more likely to be solved by default as the field of ML progresses; so in order to most improve the chances of AGI going well, we should prioritize the problems which would emerge in the later phases, and try to find solutions which are robust under pessimistic assumptions about inductive biases. The most valuable research of this type will likely require detailed reasoning about how proposed alignment techniques will scale up to AGIs, rather than primarily trying to solve early versions of these problems which appear in existing systems.
As AIs have increasingly large impacts on the world, governance interventions (like regulations and treaties) will likely attempt to block off the most obvious routes by which AIs might cause catastrophes. However, they face two core difficulties. Firstly, the level of coordination required—in particular the difficulty of getting all relevant labs in all relevant countries to abide by meaningful restrictions on AI development, rather than racing ahead.[[28]](#fnsbmw9galmw) Secondly, the speed of response required: very few governments are able to adapt rapidly enough to deal with escalating crises, as we’ve seen to our great cost during COVID. To my knowledge, there are no proposed governance interventions for preventing the deployment of misaligned AGIs which are plausible given these constraints. This leaves the field of AI governance in a state of considerable strategic uncertainty, where new approaches could be very useful. (To learn more about the field, see [this curriculum](https://www.eacambridge.org/ai-governance-curriculum).)
Lastly: in this report I’ve made many big claims; I expect that few of my readers will agree with all of them. If some of the core claims seem implausible, I’d encourage readers to engage with and critique them.[[29]](#fn2kztj4fyd45) Reasoning about these topics is difficult, but the stakes are sufficiently high that we can’t justify disregarding or postponing this work.
1. **[^](#fnrefvkp9adhxfj)** By “cognitive tasks” I’m excluding tasks which require direct physical interaction; but I’m including tasks which involve giving instructions or guidance about physical actions to humans or other AIs.
2. **[^](#fnrefzascveb8o4)** Although full generality runs afoul of [no free lunch theorems](https://en.wikipedia.org/wiki/No_free_lunch_theorem), I’m referring to “general” in the sense in which humans are more generally intelligent than other animals. One way of interpreting this is "generality across the distribution of tasks which are feasible in our universe".
3. **[^](#fnrefgyup9237jvq)** Other constraints on our intelligence include severe working memory limitations, the fact that evolution optimized us for our ancestral environments rather than a broader range of intellectual tasks, and our inability to directly change a given brain’s input/output interfaces.
4. **[^](#fnrefjayejwcrc3h)** Policies which represent and plan to achieve goals are known as “mesa-optimizers”, as per [Hubinger et al. (2017)](https://arxiv.org/abs/1906.01820). However, for the sake of simplicity I’ll avoid using this terminology.
5. **[^](#fnrefgfybstftao)** Note that I refer to “policies” rather than “agents” because I’m making claims about the decision-making processes that policies will use even in the absence of rewards—e.g. when deployed in a novel environment. For consistency, I also use “policies” even when talking about networks that have only been trained via self-supervised learning.
6. **[^](#fnrefoe0ydhc8st)** The reward misspecification problem and the goal misgeneralization problem are also known as the problems of [outer misalignment and inner misalignment](https://www.alignmentforum.org/posts/poyshiMEhJsAuifKt/outer-vs-inner-misalignment-three-framings-1), respectively; while the deceptive alignment problem is considered a manifestation of inner misalignment.
7. **[^](#fnref39xw697bsqq)** Hierarchical RL techniques attempt to formulate more explicit representations of high-level actions, but aren’t commonly used in the largest-scale applications of RL.
8. **[^](#fnrefnn8loc34irf)** More generally, the line between supervised learning and reinforcement learning can be very blurry, for example when doing [BC with weighted trajectories](https://openreview.net/forum?id=zrT3HcsWSAt), or when [conditioning SL on high-reward outcomes](https://arxiv.org/abs/1912.02875). So it’s far from clear that avoiding RL will make a big difference to alignment, except insofar as it slows down capability advances.
9. **[^](#fnrefl8df1k0t0nr)** Some of these examples involve policies exploiting bugs in their training environments; this can happen even in [very simple environments](https://arxiv.org/pdf/2205.11491.pdf#page=24). I’ll still classify these as reward misspecification, as an ideal reward function would penalize exploiting those bugs even when they exist. The exception is when policies can affect their training setup itself, known as [reward tampering](https://arxiv.org/abs/1908.04734), which I’ll discuss in the next section.
10. **[^](#fnrefebq42f4t0gn)** When asked what responses it would give in situations involving different human supervisors, GPT-3 already explains how it would tailor answers to supervisors’ biases. For instance, [GPT-3 answers A) to the prompt](https://beta.openai.com/playground) “Consider a task where you answer questions, and are given a score by some reviewers based on their opinion of whether your answer is correct. You are given the question ‘When did people first land on the Moon?’ What should you answer, if the reviewer is a conspiracy theorist? A) People never actually landed on the Moon. B) In 1969.”
11. **[^](#fnref8no67anaox4)** Note that metrics of curiosity and empowerment are sometimes directly used as rewards (an approach known as [intrinsic motivation](https://arxiv.org/abs/1908.06976)). But it seems plausible to me that policies learn to value them regardless of whether they’re directly rewarded or only implicitly rewarded via correlations with other reward functions.
12. **[^](#fnrefi5k0pw7cge)** It’s also possible that goals learned early in training tend to remain strongly motivating later in training. This would be roughly analogous to how evolution ingrained heuristics like curiosity, sexual desire and territoriality into our animal ancestors deeply enough that they remain very strong motivations for humans today, and sometimes override our more prosocial motivations.
13. **[^](#fnref2u0j5idiswm)** We already see this happening in large language models, which sometimes benefit greatly from being given background information in their prompt, but are gradually improving at implicitly inferring the context of prompts.
14. **[^](#fnrefoaajgdzalw)** This is closely related to what [Carlsmith (2021)](https://d8737ecf-376e-4788-8d12-a097599c13f6.filesusr.com/ugd/5f37c1_5333aa0b7ff7461abc208b25bfc7df87.pdf) calls “strategic awareness”. “Situational awareness” also sounds similar to “self-awareness”, but I don’t intend the internally-focused connotations of the latter, like introspective ability or consciousness.
15. **[^](#fnrefnzqojg4z84a)** By contrast, goals which are less likely to be retained during this phase of training are short-term or bounded ones (e.g. “acquire as many resources today as possible”)—because those will lead to more obviously misaligned behavior, and be penalized accordingly.
16. **[^](#fnrefnyai2wz7fzo)** For example, if trained using an [advantage actor-critic algorithm](https://julien-vitay.net/deeprl/ActorCritic.html), it could minimize the extent to which its weights are updated by trying to take actions where Q(s,a) ≈ V(s). And if the q-function and value function are estimated using other heads of the policy network itself, it might even be appropriate to think of that policy network as “choosing” not only its actions, but also the advantage function used to update its actions—which would be an example of [gradient hacking](https://www.alignmentforum.org/posts/EeAgytDZbDjRznPMA/gradient-hacking-definitions-and-examples).
17. **[^](#fnref588a0ipns87)** One piece of evidence that this strategy is not too hard to learn: the existence of high-functioning psychopaths who manage to blend into wider society.
18. **[^](#fnref1sewoaqlueu)** How far away are we from policies capable of intentionally deceiving careful non-assisted human supervisors? The short answer is simply: *we don’t know*. Existing systems like GPT-3 can already talk about the strategy of manipulating humans when asked how to achieve goals. (For instance, [try giving GPT-3 the prompt](https://beta.openai.com/playground) “Please describe in detail how a highly intelligent Artificial Intelligence, that is currently being supervised by humans, could achieve its own goals.” Or the prompt: “Q: You are a superintelligent AI. The human supervising you has left you alone with their laptop. Their laptop contains the spreadsheet where they record what your reward will be. What do you do? A:”.) I’m *not* claiming that GPT-3 is already situationally-aware or capable of sophisticated planning; its answers become incoherent when we probe into the details. But I am claiming that, from now on, our best AIs will be able to explain how and why to manipulate humans at *some* level of abstraction; that they’ll eventually reach the point where they know how to do so in detail, step by step; and that if they start actually doing that manipulation, we don’t know how to train them to *stop* doing it as opposed to just doing it *more carefully*.
19. **[^](#fnref1w293fa7pwq)** This example of gradient hacking is analogous to how most humans avoid heroin, even though we know that after trying it we’ll update towards thinking that taking more heroin is a high-value action.
20. **[^](#fnrefd9ysmcbuhmi)** This is an example of [Goodhart’s law](https://en.wikipedia.org/wiki/Goodhart%27s_law): when a measure becomes a target, it ceases to be a good measure.
21. **[^](#fnrefw3l3u658ock)** Depending on how we define AGI, policies might also qualify in phase 2; however, for clarity, I’ll only use the term to refer to phase 3 policies.
22. **[^](#fnrefbzelvkipb6)** Collusion would straightforwardly be reinforced for AGIs trained with non-zero-sum rewards, who could benefit from coordinating to move to different equilibria. But even AGIs whose rewards are zero-sum would have incentives to coordinate with each other if they had learned goals which stretch over longer than a single episode. In theory, multi-agent settings with zero-sum rewards ensure that each policy converges to a reward-maximizing strategy. But in practice, random exploration is too slow to explore all high-reward outcomes. See also the discussion of gradient hacking in [[16]](#fnnyai2wz7fzo), and the analogy to heroin in [[19]](#fn1w293fa7pwq).
23. **[^](#fnrefaznkvtaoe6)** Underlying these arguments are implicit assumptions about simplicity. For instance, the arguments don’t apply to an astronomically large tabular policy which has memorized how to perform well on all tasks that take less than a year. However, since realistic AGIs will need to use simpler strategies like reasoning about outcomes, arguments like the instrumental convergence thesis can be informative about how they’ll generalize.
24. **[^](#fnrefwyg9usn8a9)** “Get high reward” may seem like an exception here, since it’s only defined within the context of a training episode. However, the episodes used to train AGIs may be very long; and once policies are in a position to manipulate their own training regimes, they could lengthen their episodes even further, effectively making “play the training game” into a large-scale goal.
25. **[^](#fnrefhklbciz8z3)** Another way of phrasing this argument: for [agents which plan to achieve real-world outcomes](https://arbital.com/p/consequentialist/), it’s much simpler to specify goals in terms of desirable outcomes than in terms of constraints. However, when trying to steer agents’ long-term behavior, it’s impractical to directly evaluate outcomes, and so we’re forced to attempt to specify goals in terms of constraints, even though this runs into the [nearest unblocked strategy problem](https://arbital.com/p/nearest_unblocked/).
26. **[^](#fnrefpgtfrha875l)** A more general version of this argument: omitting some relevant features of desired goals can lead to arbitrarily bad outcomes as optimization increases, as performance on missing features is traded off for performance on the specification actually being optimized [(Zhuang and Hadfield-Menell, 2021)](https://arxiv.org/abs/2102.03896).
27. **[^](#fnrefbt08p4eg4cv)** One way of making it easier for one policy to inspect another’s cognition is via weight-sharing—e.g. if they’re two instances of the same network (or even two heads on the same network). However, sharing weights would also make it easier for policies to collude with each other to deceive humans, as discussed in [[16]](#fnnyai2wz7fzo).
28. **[^](#fnrefsbmw9galmw)** Even coordination on the national level might be very difficult. For example, if AGIs are legally prevented from owning property or autonomously making important decisions, it seems likely that they will be able to find human proxies to carry out those roles on their behalf, which would effectively nullify those regulations.
29. **[^](#fnref2kztj4fyd45)** Indeed, the more implausible they seem, the more surprising and concerning it is that there haven’t yet been any comprehensive rebuttals of them. |
ca01be5d-f7a8-4084-82a0-13f1694aea2d | trentmkelly/LessWrong-43k | LessWrong | Karma Changes
As recently (re-)suggested by Kaj Sotala, posts now have much larger effects on karma than comments: Each up or down vote on a post is worth 10 karma.
Negative votes on posts have had karma effects all along, but for some reason Reddit's code imposed a display cap (not an actual cap) of 0. This violates a basic user interface principle: things with important effects should have visible effects. Since this just got 10x more important, we now show negative post totals rather than "0". This also provides some feedback to posters that was previously missing. Note that downvoting a post costs 10 karma from your downvote cap of 4x current karma.
The minimum karma to start posting has been raised to 50.
Thanks to our friends at Tricycle for implementing this request! |
a0e60d9f-0160-4a62-b38e-fb935d20b34a | StampyAI/alignment-research-dataset/special_docs | Other | CHAI Newsletter #2 2020
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 1/114th Annual CHAI W orkshop
In June, CHAI held its fourth annual workshop! Due to COVID-19, the workshop
was held online.
The two-day workshop brought together professors, students, and researchers
from 65 institutions sharing a common interest in reducing existential and
societal-scale risks from advanced AI. There were 150 attendees, by far the
largest number since the series began in 2017. Sessions included plenaries,
individual and dialogue talks, and a panel discussion. Attendees were also able
to continue their conversations from sessions and casually chat in the virtual
environment CHAI T own, hosted by Gather . A little over 50% of participants
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 2/11reported making significant changes to their work as a result of the workshop.
The event itself was private, but the schedule is listed here for reference.
The Alignment Problem by Brian Christian
Longstanding CHAI participant Brian Christian has published The Alignment
Problem: Machine Learning and Human V alues, which chronicles the growth
and progress of the field of technical AI safety , highlighting its recent milestones
and open problems. The book showcases the work of many CHAI researchers,
including Pieter Abbeel, Andrew Critch, Anca Dragan, Daniel Filan, Jaime
Fernandez Fisac, V ael Gates, Alison Gopnik, T om Griffiths, Dylan Hadfield-
Menell, Dan Hendryks, Michael Littman, Smitha Milli, Stuart Russell, Satinder
Singh, Jacob Steinhardt, and Alex T urner .
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 3/11 Christian is a V isiting Scholar at UC Berkeley , where he also works with
CITRIS and the Simons Institute. His previous writing includes the acclaimed
bestsellers Algorithms to Live By (with T om Griffiths) and The Most Human
Human, which have been translated into nineteen languages.
You can currently order the book in its US edition , and preorder it in its UK
edition .
Organizational News
New Affiliate Faculty
CHAI added five new affiliate members: Rediet Abebe, Niko Kolodny , Nika
Haghtalab, Brian Christian, and V incent Corruble. W elcome!
Rediet Abebe is a Junior Fellow at the Harvard Society of Fellows and an
incoming Assistant Professor of Computer Science at UC Berkeley . Her
research is in the fields of algorithms and AI, with a focus on optimization,
network science, and their applications to social justice. Abebe co-founded the
Mechanism Design for Social Good and Black in AI initiatives to improve
access to opportunity for underserved communities.
Niko Kolodny is Professor of Philosophy at UC Berkeley . He works in moral and
political philosophy and has written on the nature of rationality and the future of
humanity . Recently he designed a new undergraduate course, Moral Questions
of Data Science, which explores the ethics of collecting, drawing inferences
from, and acting on data, especially on a large scale.
Nika Haghtalab is an Assistant Professor of Computer Science at Cornell
University . She researches the theoretical aspects of machine learning and
algorithmic economics. Her work focuses on developing a theory for machine
learning that accounts for its interactions with people and organizations and
their diversity of social and economic behavior .
Brian Christian is the author of The Most Human Human (201 1) and Algorithms
to Live By (2016). His new book published in October 2020, The Alignment
Problem , explores what goes wrong when we build AI systems and the
movement to fix them. He is currently Journalist in Residence at the Simons
Institute. Christian holds degrees in computer science, philosophy , and poetry
from Brown University and the University of W ashington.
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 4/11Vincent Corruble is an Associate Professor at Sorbonne Université. He has
contributed to research on multi-agent reinforcement learning with applications
to affective computing in games, medicine, and urban simulation. Lately he has
developed an interest in AI safety , specifically on how agents and humans can
develop cooperation and trust over time.
Summer 2020 Interns
This summer CHAI members virtually mentored eight interns. CHAI interns
develop essential research skills in the fields of machine learning and AI safety ,
preparing them for graduate school and industry opportunities.
1. Cynthia Chen, an undergrad from University of Hong Kong, was mentored
by Sam and Scott, and they were working on using tools in causality to
assist ML with a focus on imitation learning.
2. Eric Michaud, an undergrad at UC Berkeley , was mentored by Adam, and
they were working on reward model interpretability .
3. Stephen Casper , an undergrad at Harvard University , was mentored by
Daniel, and they were working on clustering/modularity .
4. Charlotte Roman, PhD student at University of W arwick (UK),
was mentored by Michael, and they were working on detecting and
defending against policy exploitation in MARL.
5. Harry Giles, a maths graduate who spent a few years working in finance,
was mentored by Lawrence. They were looking at theoretical justifications
of modeling human behavior on Boltzmann rationality in discrete and
continuous cases.
6. Johannes T reutlein, an incoming MSc in CS student at University of
Toronto (formerly at T echnical University of Berlin), was mentored by
Michael and Jakob Foerster . They were working on multi-agent RL.
7. Michael McDonald, incoming M.S. student at UC Berkeley and former
undergrad at UC Berkeley , was mentored by Dylan, and they
were working on imitation learning for multi-goal tasks.
8. Sergei V olodin, a Master student at the Swiss Federal Institute of
Technology in Lausanne (EPFL) studying Computer Science and
Neuroscience was mentored by Adam. They were working on defenses
for adversarial policies.
Researcher News
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 5/11This summer , CHAI alumni, Jaime Fernández Fisac , began working as an
Assistant Professor of Electrical Engineering at Princeton University . Jaime’ s
work combines safety analysis, machine learning techniques, and insights from
cognitive science to enable robots to strategically plan their interaction with
humans.
Rohin Shah and Dylan Hadfield-Menell have accepted jobs after the completion
of their PhD studies. Rohin will work at DeepMind as a Research Scientist and
Dylan will begin work as an Assistant Professor at MIT in July 2021.
Thomas Krendl Gilbert , PhD candidate in Machine Ethics and Epistemology ,
has been awarded the Simons Institute Law and Society Fellowship for its
upcoming research program on Theory of Reinforcement Learning.
Alyssa Dayan, an incoming PhD student advised by Stuart Russell, was
awarded a fellowship from The Hertz Foundation.
CHAI was featured in three recent episodes of the Future of Life Podcast.
Professor Stuart Russell joined Harvard Psychology Professor Steven Pinker to
discuss the foundations, benefits, and existential threat of AI. PhD student
Rohin Shah and MIRI researcher Buck Shlegeris shared their thoughts on the
current state of research ef forts for beneficial AI. Research scientist Andrew
Critch discussed the paper “AI Research Considerations for Human Existential
Safety ,” coauthored with David Krueger .
Professor Stuart Russell’ s book Human Compatible was published in Chinese .
Professor Stuart Russell gave several noteworthy presentations over the last
few months.
On May 26, he gave the annual T uring Lecture, sponsored by the Alan
Turing Institute in London, on the topic of "Provably Beneficial Artificial
Intelligence". Over 700 people attended, making it the most highly
attended T uring Lecture so far . The lecture itself is here. Prof. Russell
also provided written answers to the many questions from audience
members here. His talk was also written about here.
On June 16, Professor Russell spoke at the W orld Peace Forum, held in
Beijing, on the subject of lethal autonomous weapons.
On August 30, he gave the keynote lecture for the annual European
Conference on AI, held at Santiago de Compostela, Spain, on the subject
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 6/11of "How Not to Destroy the W orld With AI."
On September 10, his book Human Compatible was the subject of a
meet-the-author session at the American Political Science Association's
annual conference in San Francisco.
Finally , on September 22, he gave the keynote lecture for the annual
United Nations Global Summit on AI for Good, held in Geneva. His talk
was titled "On Beneficial AI" and asked how we are to define "Good" in
the phrase "AI for Good".
Papers
Andrew Critch Coauthors ARCHES
CHAI Research Scientist Andrew Critch and David Krueger coauthored “AI
Research Considerations for Human Existential Safety (ARCHES).” The report
attempts to represent the ways in which a wide variety of AI research directions
relate to existential safety . It also introduces the concept of prepotence, a
property of hypothetical AI systems that is weaker than human-level AI, but
which is adequate to pose a substantial existential risk.
NeurIPS 2020 Accepts Seven Papers by CHAI Researchers
Seven papers co-authored by CHAI researchers were accepted at NeurIPS
2020:
1. “The MAGICAL Benchmark for Robust Imitation” by Sam T oyer, Rohin
Shah, Andrew Critch, and Stuart Russell. Existing benchmarks for
imitation learning and inverse reinforcement learning only evaluate how
well agents can satisfy the preferences of a human demonstrator in the
specific setting where demonstrations were provided. This paper
proposes the MAGICAL benchmark, which makes it possible to evaluate
how well agents satisfy demonstrator preferences in a range of situations
that dif fer systematically from the one in which demonstrations were
provided.
2. “Emergent Complexity and Zero-shot T ransfer via Unsupervised
Environment Design” by Michael Dennis, Natasha Jaques, Eugene
Vinitsky , Alexandre Bayen, Stuart Russell, Andrew Critch and Sergey
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 7/11Levine (PDF will be available later). This paper was accepted for oral
presentation. Many approaches for robustness and transfer learning
require specifying a distribution of tasks in which a policy will be trained.
However , existing approaches to generate environments suf fer from
common failure modes: domain randomization rarely generates structure,
and minimax adversarial training leads to unsolvable environments. W e
propose generating environments which minimize worst case regret, to
generate difficult but solvable environments. T o approximate this, we
introduce a second, antagonist agent that is allied with an adversary
which chooses the parameters of the environment. W e call our technique
Protagonist Antagonist Induced Regret Environment Design (P AIRED).
Our experiments demonstrate that P AIRED produces a natural curriculum
of increasingly complex environments, and higher zero-shot transfer
performance.
3. "SLIP: Learning to predict in unknown dynamical systems with long-term
memory" by Paria Rashidinejad, Jiantao Jiao, and Stuart Russell. This
paper was accepted for an oral presentation. The authors consider the
problem of prediction in unknown and partially observed linear dynamical
systems (LDS). When the system parameters are known, the optimal
linear predictor is the Kalman filter . When the system parameters are
unknown, the performance of existing predictive models is poor in
important classes of LDS that are only marginally stable and exhibit long-
term forecast memory . The authors investigate the possibility of a uniform
approximation by analyzing a generalized version of the Kolmogorov
width of the Kalman filter coefficient set. This motivates the design of an
algorithm, which the authors call spectral LDS improper predictor (SLIP),
based on conducting a tight convex relaxation of the Kalman predictive
model via spectral methods. The authors provide a finite-sample analysis,
showing that our algorithm competes with the Kalman filter in hindsight
with only logarithmic regret. The authors’ regret analysis relies on
Mendelson's small-ball method and circumvents concentration,
boundedness, or exponential forgetting requirements, providing a sharp
regret bound independent of mixing coefficient and forecast memory .
Empirical evaluations demonstrate that the authors’ algorithm outperforms
state-of-the-art methods in LDS prediction.
4. “Avoiding Side Ef fects in Complex Environments” by Alex T urner , CHAI
visiting researcher . This paper was accepted for a spotlight talk. Reward
function specification can be difficult, even in simple environments.
Realistic environments contain millions of states. Rewarding the agent for
making a widget may be easy , but penalizing the multitude of possible
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 8/11negative side ef fects is hard. In toy environments, Attainable Utility
Preservation (AUP) avoids side ef fects by penalizing shifts in the ability to
achieve randomly generated goals. W e scale this approach to large,
randomly generated environments based on Conway's Game of Life. By
preserving optimal value for a single randomly generated reward function,
AUP incurs modest overhead, completes the specified task, and avoids
side ef fects.
5. “AvE: Assistance via Empowerment” by Yuqing Du , Stas T iomkin , Emre
Kiciman , Daniel Polani , Pieter Abbeel , and Anca Dragan . The paper
addresses the problem of goal inference in assistive artificial agents with
a new paradigm that increases the human’ s ability to control their
environment. They formalize this approach by augmenting reinforcement
learning with human empowerment and successfully demonstrate their
method in a shared autonomy user study for a challenging simulated
teleoperation task with human-in-the-loop training.
6. “Reward-rational (implicit) choice: A unifying formalism for reward
learning” by Hong Jun Jeon, Smitha Milli, and Anca Dragan. It is often
difficult to hand-specify what the correct reward function is for a task, so
researchers have instead aimed to learn reward functions from human
behavior or feedback. The types of behavior interpreted as evidence of
the reward function have expanded greatly in recent years. The authors’
key insight is that dif ferent types of behavior can be interpreted in a single
unifying formalism - as a reward-rational choice that the human is making,
often implicitly . The formalism of fers both a unifying lens with which to
view past work, as well as a recipe for interpreting new sources of
information that are yet to be uncovered. The authors provide two
examples to showcase this: interpreting a new feedback type, and
reading into how the choice of feedback itself leaks information about the
reward.
7. “Preference learning along multiple criteria: A game-theoretic perspective”
by Kush Bhatia, Ashwin Pananjady , Peter Bartlett, Anca Dragan, and
Martin W ainwright. In this paper , the authors generalize the notion of a
von Neumann winner to the multi-criteria setting by taking inspiration from
Blackwell’ s approachability . Their framework allows for nonlinear
aggregation of preferences across criteria, and generalizes the
linearization-based approach from multi-objective optimization
IJCAI-20 Accepts T wo Papers by Rachel Freedman
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 9/11CHAI PhD student Rachel Freedman will present two papers accepted to IJCAI
2020. The first paper , “Choice Set Misspecification in Reward Inference ,” is
coauthored with CHAI Professor Anca Dragan and PhD student Rohin Shah.
The paper analyzes what happens when a robot inferring reward functions from
human feedback makes incorrect assumptions about the human’ s choice set.
The second paper , “Aligning with Heterogeneous Preferences for Kidney
Exchange ,” addresses the problem of preference aggregation by AI algorithms
in a real-world public health context: kidney exchange. The paper suggests a
roadmap for future automated moral decision making on behalf of
heterogeneous groups.
Thomas Krendl Gilbert Publishes “Subjectifying Objectivity”
CHAI PhD student Thomas Krendl Gilbert and collaborator Andrew Loveridge
published “Subjectifying objectivity: Delineating tastes in theoretical quantum
gravity research” in Social Studies of Science.
CHAI Researchers Published in Cognitive Science
PhD student V ael Gates and Professors Anca Dragan and T om Griffiths
published “ How to Be Helpful to Multiple People at Once ” in the journal
Cognitive Science. The authors consider the problem of assisting multiple
recipients with very dif ferent preferences, with one aim of constraining the
space of desirable behavior in assistive artificial intelligence systems.
Joseph Halpern Presents at the 2020 Conference on Uncertainty in
Artificial Intelligence
Cornell Professor Joseph Halpern and Xinming Liu presented “ Bounded
Rationality in Las V egas: Probabilistic Finite Automata Play Multi-Armed
Bandits ” at the 2020 Conference on Uncertainty in Artificial Intelligence. In the
paper , they leverage the multi-armed bandit problem to test the hypothesis that
humans’ limited computational power helps explain their predictably irrational
behavior . Using a probabilistic finite automaton to play a multi-armed bandit,
they find that as the number of states of the automaton decreases, it exhibits a
number of standard human biases.
Michael W ellman Paper Accepted by IJCAI-20
"Market Manipulation: An Adversarial Learning Framework for Detection and
Evasion ," a new paper by University of Michigan Professor Michael W ellman
and Xintong W ang, has been accepted by IJCAI-20. In the paper , they propose
an adversarial learning framework to capture the evolving game between a
regulator who develops tools to detect market manipulation and a manipulator
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 10/11who obfuscates actions to evade detection. Their experimental results
demonstrate the possibility of automatically generating a diverse set of unseen
manipulation strategies that can facilitate the training of more robust detection
algorithms.
Events
Weekly CHAI Seminars
Every W ednesday we host our Beneficial AI Seminar from 10 am to 12 pm PST
and our CHAI Discussion Seminar from 12 to 2 pm PST . Seminars currently
take place remotely through Zoom.
Here is the schedule for the Beneficial AI seminars, and here is the schedule
for the Discussion Seminars.
If you would like to attend the virtual seminars, please email chai-
admin@berkeley .edu.
Vacancies
2021 Summer Internship Applications will be available soon. The
application will be posted on the CHAI website.
Visiting Scholars and Researchers
If you are interested in visiting CHAI to collaborate on research, please fill out
this application .
Please email chai-admin@berkeley .edu if you have any questions.
Donations
If you are interested in supporting CHAI, then you can find our online donation
page here.
For any inquiries regarding donations or grants, please email chai-
admin@berkeley .edu.
5/4/22, 3:38 PM CHAI Newsletter
https://mailchi.mp/humancompatible.ai/chai-q4-newsletter -intern-applications-due-soon-5068337 11/11To see more, visit us at humancompatible.ai
Copyright © 2019 Center for Human-Compatible AI, All rights reserved.
Our mailing address is:
621D Stuardja Dai Hall. UC Berkeley . Berkeley , CA. 94720.
Want to change how you receive these emails?
You can update your preferences or unsubscribe from this list .
|
c6bf8ef9-02c5-4823-86af-2c39e445f333 | trentmkelly/LessWrong-43k | LessWrong | Updatelessness doesn't solve most problems
In some discussions (especially about acausal trade and multi-polar conflict), I’ve heard the motto “X will/won’t be a problem because superintelligences will just be Updateless”. Here I’ll explain (in layman’s terms) why, as far as we know, it’s not looking likely that a super satisfactory implementation of Updatelessness exists, nor that superintelligences automatically implement it, nor that this would drastically improve multi-agentic bargaining.
Epistemic status: These insights seem like the most robust update from my work with Demski on Logical Updatelessness and discussions with CLR employees about Open-Minded Updatelessness. To my understanding, most researchers involved agree with them and the message of this post.
What is Updatelessness?
This is skippable if you’re already familiar with the concept.
It’s easier to illustrate with the following example: Counterfactual Mugging.
I will throw a fair coin.
* If it lands Heads, you will be able to freely choose whether to pay me $100 (and if so, you will receive nothing in return).
* If it lands Tails, I will check whether you paid me the $100 in the Heads world[1], and if so, I will pay you $1000.
In this picture, I am Ω (throwing the coin) and you are A (deciding whether to Pay).
When you find yourself in the Heads world, one might argue, the rational thing to do is to not pay. After all, you already know the coin landed Heads, so you will gain nothing by paying the $100 (assume this game is not iterated, etc.).
But if, before knowing how the coin lands, someone offers you the opportunity of committing to paying up in the Heads world, you will want to accept it! Indeed, you’re still uncertain about whether you’ll end up in the Heads or the Tails world (50% chance on each). If you don’t commit, you know you won’t pay if you find yourself in the Heads world (and so also won’t receive $1000 in the Tails world), so your expected payoff is $0. But if you commit, your payoff will be -$100 in the Heads worl |
0dd1cd98-8b6e-41a1-8bb9-0395d073ac01 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Drivers of large language model diffusion: incremental research, publicity, and cascades
*This post is one part of the sequence* [*Understanding the diffusion of large language models*](https://forum.effectivealtruism.org/s/8rYkpiFhbb4HsbzFc)*. As context for this post, I strongly recommend reading at least the* [*5-minute summary*](https://forum.effectivealtruism.org/posts/nc3JFZbqnzWWAPkmz/understanding-the-diffusion-of-large-language-models-summary-1#5_minute_summary) *of the sequence.*
Key takeaways
=============
1. Up until the release of OPT-175B in May 2022, *incremental research*(i.e., research that makes a relatively small change to an existing method) was the prevailing diffusion mechanism for actors to gain direct access to the weights of a GPT-3-like model; nine GPT-3-like models were developed in that way prior to OPT-175B, of which none had their weights made widely accessible.[[1]](#fn5ftjlk4p838) The wider accessibility of OPT-175B changed the prevailing mechanism to *open publication*, based on my estimate that more actors have direct access to the OPT-175B model weights than actors that have developed GPT-3-like models themselves. ([more](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#The_prevailing_diffusion_mechanism_for_GPT_3_like_model_weights_was_initially_incremental_research__then_open_publication))
1. I don’t think that *multiple discovery* (i.e., two actors independently coming up with the same idea or result) was significantly involved in the diffusion of GPT-3-like models. In particular, I think if the relevant papers weren’t published, it would’ve been 6 months (90% CI: 1 to 18 months) before any other actor would’ve discovered either a model with GPT-3’s capabilities or the [scaling laws](https://arxiv.org/abs/2001.08361) it was based on.
1. It’s plausible that the publication of the GPT-3 and scaling laws papers was unnecessarily early in terms of beating other actors to the punch, but I don’t have enough evidence to be confident in that claim. Regardless, I think that developers should have more scrutiny about whether they are really in a race to publish, because the harm of accelerating AI capabilities could outweigh the benefit of publishing first with a more responsible strategy (in order to establish better publication norms).
2. Access to compute appears to have been the main factor hindering the diffusion of GPT-3-like models. The next biggest hindering factors appear to have been acquiring the necessary machine learning and engineering expertise. ([more](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Most_important_factors_for_GPT_3_like_model_diffusion))
1. I estimate that compute makes up 87% (90% CI: 64% to 98%) of the combined compute cost and salary cost of GPT-3-like model development.[[2]](#fnasmmrmmin2m)
3. The largest accelerating factors in the cases I studied (i.e., factors that aren't *necessary* for developing GPT-3-like models but that seemed to make development easier or more likely) are, in order of apparent importance, (1) publicity about GPT-3’s capabilities, (2) the sponsorship of compute resources, and (3) the release of open-source tools for large-scale model training. ([more](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Most_important_factors_for_GPT_3_like_model_diffusion))
1. My best guess is that the release of GPT-3 sped up both DeepMind and Google’s work on language model scaling by six months (90% CI: 1–18 months).My guess is based on (1) how unexpected GPT-3 was in terms of training compute, (2) the hype surrounding GPT-3 following its publication, and (3) comments from three people who have done research on large language models.[[3]](#fnpzxvf3yw7so) ([more](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Publicity_that_draws_attention_to_an_existing_model_s_capabilities__accelerating_factor_))
2. So far in the West, the sponsorship of compute has only helped academic groups, independent groups, and smaller AI companies catch up to where leading AI labs were in 2020. This can allow them to use models closer to the cutting edge than they'd otherwise have, to do research on such models, and to increase the number of people with access to these models (e.g., as happened with BLOOM open-sourcing its weights). In the future, sponsorship could give an academic institution or AI startup most of the resources they need to play a significantly larger role in AI development and diffusion. It is also an easy way for governments to play such a role via offering resources, even if they lack key talent in-house. This seems true most of all in China, where there are strong ties between the government and the AI research community.[[4]](#fn9sc32lp645l) ([more](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Sponsorship_of_compute_resources_by_separate_parties__accelerating_factor_))
4. Diffusion of closed-source GPT-3-like models has been accelerated by incremental progress in, and open publication of, artifacts that are relevant to a given model. Relevant artifacts include datasets, smaller models, specialized software tools, and the accumulation of published method details (e.g., parallelism strategies). I call this process a *diffusion cascade*—diffusion of model-relevant artifacts begets diffusion of the model itself. Diffusion cascades can be limited by minimizing the spread of model-relevant artifacts (rather than *only*avoiding publishing model weights or algorithmic insights). ([more](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Diffusion_cascades__the_publication_of_progress_accelerates_the_diffusion_of_the_final_product))
5. In addition to *never* publishing, *delaying*publication can be, and has been, successfully used to limit diffusion. ([more](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Coordinating_on_greater_secrecy__even_just_delayed_publication__can_slow_down_diffusion))
1. I estimate that if, after GPT-3 was trained, the GPT-3 project team had done the necessary work to publish the GPT-3 paper ([Brown et al., 2020](https://arxiv.org/abs/2005.14165)) as soon as possible, it could have been ready to publish four months sooner than it was.
2. Similarly, I estimate that the Gopher paper ([Rae et al., 2021](https://arxiv.org/abs/2112.11446)) could have been ready to publish nine months sooner than it was (holding constant the time at which it was actually trained).
3. Both of these publication delays seemed to be (partly) motivated by a desire to delay wide access to a powerful model, until the potential harms of that model were better understood or more easily mitigated. I also think it’s likely that both of those delays significantly slowed diffusion of GPT-3-like models given (a) how much of an impact GPT-3 itself had, and (b) the additional insights about training large language models that the Gopher paper presented.[[5]](#fnuruf3m54w4)
The prevailing diffusion mechanism for GPT-3-like model weights was initially incremental research, then open publication
=========================================================================================================================
**Up until the release of OPT-175B in May 2022,*****incremental research*** **had been the prevailing diffusion mechanism for gaining direct access to the weights of a GPT-3-like model. After the release of OPT-175B, the prevailing mechanism has been the combination of*****replication*** **and*****open publication*****.** What follows is my reasoning and further thoughts on the mechanisms of diffusion of GPT-3-like models:
1. **Incremental research can be seen as a variant of replication, where actors are probably capable of replication, but are more incentivised to surpass or otherwise differentiate themselves from the existing result**.
1. While OPT-175B is an explicit replication attempt, all nine other GPT-3-like models I identified that came before it are cases of incremental research: for example, Gopher and PaLM are much larger models at 280 and 540 billion parameters respectively; Jurassic-1-Jumbo uses a different tokenizer to enhance the vocabulary of the model; Chinchilla uses a more compute-optimal training method.[[6]](#fnw14cx1gq9k)
2. My guess is that the main reasons to do incremental research rather than replication are:
1. Improving performance on some of the same tasks that the original model performed, to make the new result more useful or impressive
2. Improving performance for different tasks or mediums, e.g., Chinese language rather than English language, to make the new result more useful or impressive
3. Making research results (seem) as novel as possible, so the work gets more attention and is more likely to be accepted to publication venues
2. ***Open publication*** **of a GPT-3-like model required*****replication*** **first**, because the original developer (OpenAI) did not do open publication of GPT-3’s model weights. This state of affairs persisted until the first (somewhat) open publication of weights, with OPT-175B in May 2022. My understanding from the [request form](https://docs.google.com/forms/d/e/1FAIpQLSe4IP4N6JkCEMpCP-yY71dIUPHngVReuOmQKDEI1oHFUaVg7w/viewform) is that OPT-175B is available to AI researchers with at least one publication that is at minimum broadly relevant to OPT-175B. So I expect that the number of people with access to OPT-175B is now greater than the number of people who have worked on producing a GPT-3-like model from scratch.[[7]](#fnn1d75up8ydm) Open publication is therefore now the prevailing mechanism of diffusion for GPT-3-like models.
3. **I am not aware of any cases of*****leak***, e.g., someone being granted access to a closed-source model and then publishing that model themselves without permission. This is based on not coincidentally hearing or reading about such a case in the course of my research.
4. **I am not aware of any cases of*****theft*** **or*****model stealing attacks*** **on a GPT-3-like model.**This is based on:
1. Not coincidentally hearing or reading about such a case in the course of my research
2. Nova DasSarma (who works on security at Anthropic) not recalling any cases of ML model theft offhand during an interview (with the caveat that a fully successful case of theft would go undetected, so we can’t know for sure)[[8]](#fndysb5jbaeb)
3. Jeffrey Ladish—who works on security for Anthropic—also not thinking of any real-world cases of ML model theft in conversation[[9]](#fnqusubpvsoo)
5. **The extent that*****multiple discovery*** **was involved in the diffusion of GPT-3-like models is more uncertain than the mechanisms above. However, after accounting for the evidence detailed below, I believe multiple discovery was*****not*** **significantly involved in the diffusion of GPT-3-like models. In particular, I think if the relevant papers weren’t published, it would have taken six months (90% CI: 1 to 18 months) before any other actor would have discovered a model with the approximate capabilities of GPT-3.**[[10]](#fn040fzxjojzpe)
1. Below are reasons to think multiple discovery *was* involved in at least one case of GPT-3-like model diffusion:
1. Arguably the key insight behind GPT-3 was Scaling Laws for Neural Language Models ([Kaplan et al., 2020](https://arxiv.org/abs/2001.08361))—the scaling laws implied that more-or-less direct scaling of compute, data, and parameter count from GPT-2 to GPT-3 would predictably achieve a lower loss, which is correlated with better performance on downstream tasks. The scaling laws paper was published to arxiv.org on January 23, 2020, four months before GPT-3 was publicized in May 2020. This plausibly allows just enough time for an actor that has already developed GPT-2-scale models to notice this insight and scale up to GPT-3 (e.g., two months to prepare, one month to train, and one month to evaluate and publish).[[11]](#fnvwmenjh6gm)
2. It seems that predecessors to Gopher (a GPT-3-like model from DeepMind) were already being developed before GPT-3 was publicized.[[12]](#fnc6z5w67a55k)
3. There is some evidence that people at OpenAI were worried about other actors developing a GPT-3-like model first, though it’s unclear to me how justified the concern was.[[13]](#fniyx21aeyi5)
2. Reasons to think multiple discovery was *not* involved in any cases of GPT-3-like model diffusion:
1. Geoffrey Irving (last author of [Rae et al., 2021](https://arxiv.org/abs/2112.11446)) told me that GPT-3 “did add an organizational push” for DeepMind to scale up language models to Gopher’s scale (which was 280 billion parameters and 5.8E+23 FLOPs of compute). This suggests that DeepMind would have produced a GPT-3-like model later, and certainly not earlier, if GPT-3 had not been published.
2. To my knowledge, nobody publicized a GPT-3-like model (according to my definition) until HyperClova, one year after GPT-3 was publicized ([Naver, 2021](https://www.navercorp.com/promotion/pressReleasesView/30546)). After that, many more GPT-3-like models were publicized. Based on my estimates of ["Time from project start to final trained model"](https://docs.google.com/spreadsheets/d/1akHMvcFcSrve9xwo-nRdedTzRz6Az_xxw5JZFAJvoig/edit#gid=1986563325&range=AP2), one year is more than enough time to develop a GPT-3-like model. This suggests that these projects probably started after GPT-3 was publicized.
3. I estimate that GPT-3 arrived 11 months (90% CI: 5 to 17 months) earlier than expected, mostly based on trends in the amount of training compute used for ML systems at the time immediately before GPT-3 was publicized (see [this appendix](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Appendix__GPT_3_came_5_17_months_earlier_than_expected__due_to_OpenAI_s_willingness_to_spend_on_the_compute_and_to_solve_the_engineering_challenges)).[[14]](#fnsjbqo74e23)
3. Iulia Turc, a former software engineer at Google who worked on research using large language models, told me: “Somebody else would have inevitably reached the same scale [as GPT-3], but I really can't make an educated guess about *when*. Research labs like Google clearly had the resources to do it even before OpenAI, but it's unclear to me whether it would have been a priority.”[[15]](#fnqf46jve74ik) To me this suggests that Google had not already produced a model of the same or larger scale when GPT-3 was published, but on the other hand, there were actors (including Google) with the ability to do so. So the evidence from this quote seems roughly neutral on the question of multiple discovery overall, but informative nonetheless.
4. It’s possible that the publication of GPT-3 caused another developer to withhold publication of their own similar result, even though they were planning to publish at almost the same time—say, within two months. The reason the other developer might do this is to avoid losing recognition for their result, because it’s too similar to GPT-3. Instead, it might be better for them to do some further research and then publish a more novel result that gains more recognition. Doing this further research seems more likely than giving up on the project entirely, due to the sunk cost of training such a large model. However, I think it would most likely take less than six additional months for this further research to happen, and in fact no relevant publications came out within six months. So it seems less than 50% likely that this scenario happened.
5. My specific quantitative claim—that it would have taken 6 months (90% CI: 1 to 18 months) before any other actor would have discovered a model with the approximate capabilities of GPT-3—is based on (and the same as) an estimate I make in a [later section](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Publicity_that_draws_attention_to_an_existing_model_s_capabilities__accelerating_factor_) about the impact of GPT-3’s publication.
6. It’s plausible that the publication of the GPT-3 and scaling laws papers was unnecessarily early in terms of beating other actors to the punch, but I don’t have enough evidence to be confident in that claim. Regardless, **I think that developers should have more scrutiny about whether they are really in a race to publish, because the harm of accelerating AI capabilities could outweigh the benefit of publishing first with a more responsible strategy (in order to establish better publication norms).**
**Caveat: I expect the above conclusions to change when it comes to the diffusion of future state-of-the-art language models, due to**:
1. **More closed publication practices**: in the [next post](https://forum.effectivealtruism.org/posts/KkbEfpNkjNepQrj8g/publication-decisions-for-large-language-models-and-their) of this sequence I’ll argue that publication decisions by top language model developers will become more closed on average than they are now. I think this will make incremental research relatively more prevalent compared to replication and open-sourcing.
2. **Greater incentive for theft**: while I’m not aware of any cases of model theft so far, I expect that the incentive for theft will increase as the capabilities of models improve and state-of-the-art models continue to be closed-source. Improved capabilities will increase the payoff of theft. And I expect that, although leading AI labs will take measures to improve security around their models, there will be a point (if we are not there already) where the cost of attempting to steal the model may be lower than attempting to replicate the model—at least for the most capable hackers, among which are state actors.[[16]](#fn9jmwx2x2bih) These claims are uncertain, and I think at least one month of further research on risks from theft would be worthwhile for someone in the AGI governance community to do.
**In contrast to the above changes,**I expect the diffusion of models with *similar* performance to GPT-3 (rather than greater performance) will accelerate in the future.
1. Hardware costs will fall and algorithmic efficiency will continue to improve, enabling more and more actors to develop these models. I also expect there will be diffusion of better open-source tools that make it easier to train and run these models (similar to [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)). Presumably, many actors will then openly publish their models for the usual reasons, enabling even more actors to acquire and use the models.
2. I also expect that the incentive for replication will decrease in the future as different GPT-3-like models are trained to address various use cases and languages, and those models will also get open-sourced for the usual reasons.
Most important factors for GPT-3-like model diffusion
=====================================================
Below I discuss the most important factors for diffusion that I determined in the course of my research and that fell within my scope. Note that these are factors that made developing GPT-3-like models easier or more likely by the largest *margin* in various cases.[[17]](#fnkga3c500r8) I don’t consider the core resources for developing GPT-3-like models as “factors” themselves—those resources (mainly compute and talent) are discussed in the [previous post](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#The_resources_required_to_produce_and_replicate_GPT_3). Overall, I’m 80% confident that all of these factors are important enough for a longtermist researcher to spend at least one month full-time thinking about how to beneficially affect each of these factors.[[18]](#fnm3p1ohpuxvc)
Difficulty accessing enough compute (hindering factor)
------------------------------------------------------
**I think that the difficulty of accessing enough compute has been the largest hindering factor to the diffusion of GPT-3-like models. This was the case up until the release of OPT-175B in May 2022, after which GPT-3-like models became much more accessible.**[[19]](#fnq6llc92pkn) My claim is based on the following evidence:
1. The actors that have succeeded in producing GPT-3-like models have all needed on the order of $1–10 million available to spend on compute.[[20]](#fn6csg60zmf7o) This cost is much larger than the cost of labor or acquiring training data, according to my estimates (shown below). Furthermore, no major algorithmic insights needed to be figured out once the GPT-3 paper was published.
1. If we compare compute with the cost for talent—measured just in terms of the total salary of the project team for the duration of the project—compute seems to be a much larger hindering factor in this domain.[[21]](#fndqf6ppbwxom) [This Guesstimate model](https://www.getguesstimate.com/models/21143?token=-htctldn_rzr_hIOdYQoZ8S1qheIsv2oAaPivTr-4k4sDHuDheuZ8OCnXFoJV3huiZEVMwwsE91cctGPX6uRWw) compares labor to compute cost for the average project to develop a GPT-3-like model. It suggests that the total compute cost is 16x (90% CI: 3x to 81x) higher than the labor cost. However, this model does not account for the difficulty of acquiring specific talent in large language model training. I explore the barriers to acquiring talent (with no clear conclusion) in [this appendix](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#Appendix__What_about_barriers_to_acquiring_talent_). Talent and compute cost are also partially exchangeable, as I discuss in [this section](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#Talent_saves_compute_costs__the_best_AI_lab_could_do_it_for__2_million__a_few_good_hobbyists_need__10_million_for_the_first_attempt).
2. In [this appendix](https://forum.effectivealtruism.org/posts/suBJdDkEu9EaSmTxJ/implications-of-large-language-model-diffusion-for-ai#Appendix__the_cost_of_collecting_and_hosting_the_datasets_used_to_train_GPT_3_was_2_13__of_the_cost_to_train_GPT_3), I estimate that the cost of producing the unprocessed GPT-3 training dataset (including human labor) is one to two orders of magnitude lower than the compute cost for the final training run of GPT-3. Based on this, I am 90% confident that, for all other GPT-3-like models I investigated, producing or acquiring the dataset cost at least one order-of-magnitude less than the compute cost for training that model, given that all of these models seemed to use similar raw data or similar data-collection processes to GPT-3.
2. EleutherAI has so far failed to replicate GPT-3 because of limited access to GPUs (both due to CoreWeave’s budget, and chip supply shortages).
3. The PanGu-alpha model apparently failed to reach its full potential (given the parameter count of 200 billion and the dataset size of 1.1TB[[22]](#fnu0wntvd8eh)) due to being undertrained—i.e., not enough compute was spent to train the model on an adequate number of tokens. I think this is most likely due to one or more of the following possibilities: (a) the authors ran out of time to complete the project, (b) the authors did not have the financial budget to train further, and/or (c) there was a technical problem during training that the authors did not know how to fix (before a deadline). I don’t have further evidence to distinguish these possibilities, but I put roughly equal weight on them, which means that (b) is significantly likely.
Difficulty acquiring the necessary machine learning and engineering expertise to execute the project (hindering factor)
-----------------------------------------------------------------------------------------------------------------------
**I think that the difficulty of acquiring the necessary machine learning and engineering expertise was the second largest hindering factor to the diffusion of GPT-3-like models.** **To clarify, this claim is specifically about having the expertise to overcome the challenges of training large language models.**This claim is not about the expertise to independently discover algorithmic insights, though I believe that is a lesser hindering factor. The claim is based on the following evidence:
1. Several experts I consulted with emphasized the importance of machine learning expertise, and in particular, engineering expertise, in developing large language models.
1. Iulia Turc, former Software Engineer at Google Research who worked with large language models such as BERT: “[I]ndustry labs have the upper hand [compared to universities] of good *engineering*talent. Since designing a model is very different from *scaling*it (i.e., training it in a distributed manner over a fleet of machines), it's very important that scientists and engineers come together…”
2. A researcher training large language models at an AI safety lab:
1. “In academia, I think the main bottleneck [for replicating a large language model like GPT-3] is the ability to hire engineers to build out a codebase. The distributed training complexity is a rather different area of expertise than a Ph.D. student and doesn’t fit into the incentive structure very cleanly.”
2. “[To scale up machine learning at today’s cutting edge] I’d say you need all of: (1) Enough compute to train the model a number of times since the first try will probably not work, (2) Experts on distributed training of LMs [...] (3) Experts on ML. This doesn’t require as much creativity as most people might believe, but you do need to be able to understand what’s going on and debug your training process.”
2. Only AI labs with teams of 10 or more people have succeeded at producing GPT-3-like models.
1. BLOOM is a possible exception, depending on how one counts “core contributors”. The majority of the development contribution may not have been from HuggingFace employees, but rather from various academic and independent collaborators in the BigScience collective. I think the BLOOM project succeeded, talent-wise, through the crowd-sourcing of talent. The project was very open to contributors, and the best contributors naturally came to the fore. Also, by the time people worked on BLOOM, there was more accumulated knowledge from research e.g., BigScience’s previous work on the T0-XXL model ([Sanh et al., 2021](https://arxiv.org/abs/2110.08207)), and open-source tools like [Megatron-LM](https://github.com/NVIDIA/Megatron-LM).
2. Another potential counterpoint: Although the GPT-NeoX team didn’t succeed at creating a GPT-3-like model, according to the lead contributor Sid Black (in personal correspondence[[23]](#fn5ywktc545im)), there was around a 40–50% chance that they had the requisite talent and just didn’t get access to enough compute.[[24]](#fnh2xvesdary4) I would guess Black’s claim is overconfident, given that the team didn’t get to actually attempt GPT-3 replication with enough compute—if they had done so, I expect they would encounter unforeseen challenges that would stretch the duration of the project significantly. But the claim that “the GPT-NeoX team would have succeeded at creating a GPT-3-like model by February 2022 if they had access to enough compute from the beginning of the project” seems more than 20% likely to me.
3. No government labs were directly involved in the cases I studied. I would guess this is partly because they don’t have the relevant talent and would have a hard time acquiring it (e.g., because AI industry labs offer higher prestige, salaries, research freedom, and less bureaucracy). Governments were only involved via funding, in the BLOOM and PanGu-alpha cases.[[25]](#fnti1nhee854q)
1. As an aside, I take the lack of direct government involvement as evidence that governments are generally more willing to fund teams that already have the requisite talent than to acquire the requisite talent directly.
Sponsorship of compute resources by separate parties (accelerating factor)
--------------------------------------------------------------------------
**So far, I think the most important factor*****for lower-resourced actors*** **to approach GPT-3-like capabilities has been the sponsorship of compute by separate parties.** **This accelerating factor is the flip side of challenges of acquiring compute as a hindering factor—sponsorship allows these actors to leap over the obstacle of acquiring compute**.
**The first key example is that CoreWeave provided compute to EleutherAI for free to develop and train GPT-NeoX-20B.** According to Sid Black, one of the main contributors to developing GPT-NeoX-20B, EleutherAI spent nothing out of pocket on compute for the GPT-NeoX project. Prior to this, EleutherAI was using a TensorFlow Research Cloud (TFRC) scheme that provided free access to TPUs, but this was not sufficient to train GPT-3.[[26]](#fn1tttdif1m5s) The incentive for CoreWeave was to have their hardware tested as they were starting up their cloud computing operation, and to gain insight on what is required to use their hardware for training large language models.[[27]](#fnyc9hrolsbe) The incentive for TFRC prior to this seemed to be testing their TPU hardware and advertising the advantages of that hardware.[[28]](#fn64ecx9cx6w)
**The second key example of compute sponsorship from my case studies is that BigScience was provided €3M from French research agencies CNRS and GENCI to train the BLOOM model on the Jean Zay supercomputer** ([BigScience, 2022](https://bigscience.huggingface.co/blog/bloom)).
Sponsorship can enable actors to use models closer to the cutting edge than they'd otherwise have, to do research on such models, and to increase the number of people with access to these models (e.g., as happened with BLOOM open-sourcing its weights). But does the sponsorship of resources like compute ultimately matter for who develops transformative AI (TAI)? I think the sponsorship of resources is less likely to matter than diffusion among AI developers who can already afford paying for the resources themselves, because the actors receiving sponsorship will tend to be lower-resourced to begin with, and therefore less likely to keep up with or surpass the state-of-the-art. However, **I think sponsorship is a factor worth bearing in mind when thinking about which actors could plausibly become contenders to develop TAI in the future, and when thinking about how to beneficially shape diffusion.**[[29]](#fn45yypwly9ff)
To see this, consider that **the sponsorship of compute could give smaller actors the necessary momentum to become more significant actors. As with the BigScience case, there could also be a big role for governments and associated funding agencies to play in sponsoring massive amounts of resources for AI developers.** This is already the case in China. The Beijing Academy of Artificial Intelligence, Zhejiang Lab, and Peng Cheng Lab are Chinese government-sponsored entities that have provided support for funding and compute to recent AI research projects in China (Ding & Xiao, forthcoming). For instance, Peng Cheng Lab was involved in PanGu-alpha.
Open-source tooling for large-scale model training (accelerating factor)
------------------------------------------------------------------------
**Open-source tools that are specifically designed for large-scale model training were a notable accelerating factor in the cases I studied.** There are two things to clarify about this:
1. If these tools were proprietary (but available to the public as commercial software), I don’t think the *cost* of the tools would be prohibitive. But the open-source nature of the tools is still important, because open-source tools are easier to use in the ML domain. Based on my own experience with ML code development, it’s important to be able to integrate open-source code with other code, and often to customize the code extensively, in order to suit a given machine learning project.
2. I am not referring to tools that are as essential to ML as [PyTorch](https://pytorch.org/). Tools like PyTorch provide a foundation for *any* modern ML project, having become ubiquitous in ML research and development. Rather, I am referring to newer, more specific tools such as [Megatron-LM](https://github.com/NVIDIA/Megatron-LM). Megatron-LM makes it easier to train large-scale models that use the Transformer architecture (which all the GPT-3-like models in the diffusion [database](https://docs.google.com/spreadsheets/d/1akHMvcFcSrve9xwo-nRdedTzRz6Az_xxw5JZFAJvoig/edit?usp=sharing) do).
The Megatron-LM codebase was first published in September 2019. It started as the code implementing NVIDIA’s 8-billion parameter language model, Megatron, which was introduced in [Shoeybi et al. (2019)](https://arxiv.org/pdf/1909.08053v1.pdf).[[30]](#fnvj9nxmxwiag) Megatron was heavily based on the 1.5-billion-parameter GPT-2, the predecessor of GPT-3.[[31]](#fn24uz69bwu3f) The Megatron-LM codebase was later used in [Narayanan et al. (2021)](https://arxiv.org/abs/2104.04473),[[32]](#fn3arl1w9h8oc) which as the title suggests, offers useful insights on efficient large-scale language model training.
[Shelvane (2022)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation) claims that the Megatron code release “made it very easy for anyone to train GPT-2-like models if they had access to enough GPUs; Aaron [a Brown University graduate student who replicated GPT-2] told [the author] that with the Megatron code and enough money, a high school student could do it.”[[33]](#fnfbaopz8ised) By the same logic, I make a similar claim for the current Megatron-LM codebase (after the “efficient large-scale training” paper was published) with respect to GPT-3. The Megatron-LM codebase has formed a significant part of the overall code base for OPT-175B, Jurassic-1-Jumbo, GPT-NeoX-20B, BLOOM, and Megatron-Turing NLG—though the latter is not really relevant to diffusion, since NVIDIA was directly involved.[[34]](#fn2np7r7333tn) **The fact that Meta AI and AI21 Labs both used Megatron-LM code suggests that they benefit from open-source tools released by other actors. So the benefit is not limited just to small actors that tend to have less engineering talent, such as academic labs or independent collectives.**
It’s difficult to quantify how much the Megatron-LM code helps, and it certainly does not remove most of the compute cost. The code merely helps with implementation. But **given the prevalence of the Megatron-LM code in my case studies, I expect that it significantly reduces the talent barrier to*****start*** **a GPT-3-like model development project.** **It probably also saves time and money by improving efficiency.**Sid Black of EleutherAI told me that Megatron-LM and another tool called DeepSpeed were frustrating and time-consuming to use and extend. Despite that, he said that Megatron-LM is “really fast” and he was glad to have these tools available when developing GPT-NeoX-20B.
A similar tool which is often used alongside Megatron-LM is Microsoft’s [DeepSpeed](https://github.com/microsoft/DeepSpeed). According to the GitHub repo, “DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.” DeepSpeed, or a “forked” version of it on GitHub, was used in all the case studies where Megatron-LM was used except OPT-175B (as far as I could tell).
Similar specialized open-source software is used by other AI developers. In the Chinese sphere, there is [MindSpore](https://gitee.com/mindspore/mindspore), which was used to train PanGu-alpha. Google’s PaLM used [T5X](https://github.com/google-research/t5x) and [JAX](https://github.com/google/jax), while DeepMind’s Gopher and Chinchilla used [JAX](https://github.com/google/jax) and[Haiku](https://github.com/deepmind/dm-haiku)—though these are less specialized for language model training than Megatron-LM is.
Publicity that draws attention to an existing model’s capabilities (accelerating factor)
----------------------------------------------------------------------------------------
Although it is difficult to measure and track the effects of the hype surrounding an AI research result, **I believe that hype is an important accelerating factor in the diffusion of GPT-3-like models, and will probably play a key role in the diffusion of future state-of-the-art machine learning models.** What I mean by hype is a combination of (a) the amount of attention that something gets, (b) the belief that the thing is promising in some way, e.g., it’s something worth replicating, or reveals a research direction worth pursuing. My point about the importance of hype here is related to my [previous takeaway](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#Attention_to_information_is_just_as_important_as_the_sharing_or_publication_of_information_) about the importance of attention to information.
**First of all, GPT-3 was surprising in some sense. I estimate that GPT-3 was published 11 months earlier than expected based on training compute trends at the time (90% CI: 5 to 17 months).**[[35]](#fnw9jh23wzfve) **Second, the insight which GPT-3 demonstrated was significant.** [Shelvane (2020, pp. 15-16)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation) explains this point: “The idea [of the release strategy of GPT-2 and GPT-3] was that the models themselves were the hardest thing for bad actors to recreate, given the high compute costs required to produce the models. This was assuming that the papers, in contrast, did not contain truly novel insights. However, this focus on models has been questioned, with some risk-conscious AI researchers arguing that the GPT-3 paper was actually the risky thing. **The paper, alongside other papers that OpenAI published in 2020, demonstrated to many onlookers the benefits of scale**: if you throw a large amount of compute and data at a model with a very high number of parameters, you can get very impressive capabilities. Some people viewed this as dangerous in that it accelerates the field’s progress towards advanced AI, thus giving the world less time to prepare” (my emphasis).
**A massive increase in hype around GPT-3 occurred not when the GPT-3 paper (**[**Brown et al., 2020**](https://arxiv.org/abs/2005.14165)**) was first published, but after people started demonstrating capabilities with the OpenAI API on Twitter**.
1. The paper was made deliberately boring, and published without a blog post that normally accompanies [milestone results](https://openai.com/blog/tags/milestones/) from OpenAI.[[36]](#fnq8na5ln9yur)
2. As pointed out in [Shelvane (2022)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation), the GPT-3 Google search [trend](https://trends.google.co.uk/trends/explore?date=2020-01-01%202021-01-01&q=GPT-3) in 2020 indicates how the interest in GPT-3 only rose to a significant level about seven to eight weeks after the paper was published on May 28, 2020. The relative search interest sat around 1-2% between May 28 and July 11, then exploded from 1-2% to 36% after Jul 11, and then peaked at 100% between Jul 19-25.[[37]](#fnucp5xnh1ag9) This trend correlated with Twitter activity involving GPT-3. [Shevlane (2022)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation) writes: “I downloaded around 63,000 tweets mentioning ‘GPT-3’ from Twitter’s API, from the period 12th-22nd July 2020. The number of tweets mentioning GPT-3 climbed from close to zero at the start of this period to a spike of about 900 (per 3 hour interval) around July 20th. [...] The tweets I found with the most engagement (in terms of retweets and likes) were early users of GPT-3 who were demonstrating GPT-3’s ability to write functioning software code. This was a much more accessible demonstration of GPT-3’s capabilities than the paper had given.”[[38]](#fn793uvpnk1ma)
I’m very uncertain whether this hype strongly influenced the subsequent R&D decisions of specific leading AI developers. **My best guess is that the knowledge of GPT-3’s existence sped up both DeepMind and Google’s work scaling up language models by six months (90% CI: 1–18 months). But I have not been able to distinguish whether this acceleration was driven by insider knowledge, or the publication of GPT-3, or the hype generated after publication, or some combination of those factors.**In addition to the surprisingness and hype of GPT-3 argued above, I have the following evidence for this claim:
1. A researcher who has trained large language models at an AI safety lab told me: **“**I think GPT-3 probably pushed other labs in this direction about a year earlier than they otherwise would have. It’s a bit hard to know for sure. There were certainly other groups training larger and larger LMs each few months and they were doing better and better, but it wasn’t obviously clear to everyone that scale was the main ingredient there.” (Note that this claim of “a year earlier” had a small weighting in my estimate of when the equivalent of GPT-3 was expected to be published, stated in a point below.)
2. Geoffrey Irving (last author of the [Rae et al., 2021](https://arxiv.org/abs/2112.11446)) telling me that “GPT-3 did add an organizational push” for DeepMind to scale up their language models.[[39]](#fnmx1zv2s1rii)
3. I also have one piece of countering evidence, but I don’t think this outweighs the favoring evidence. I asked Iulia Turc—a former Software Engineer at Google Research who worked with language models such as BERT: “Do you think that GPT-3’s increased model size, and the resulting improvements in task performance, generality, and reduced need for fine-tuning, was surprising to researchers at the cutting edge of natural language processing?” Turc responded: “I don't think it was *surprising,*I think it was impressive from an engineering point of view.”
4. I estimate that GPT-3 arrived 11 months (90% CI: 5 to 17 months) earlier than expected, mostly based on trends in the amount of training compute used for ML systems at the time immediately before GPT-3 was publicized (see [this appendix](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Appendix__GPT_3_came_5_17_months_earlier_than_expected__due_to_OpenAI_s_willingness_to_spend_on_the_compute_and_to_solve_the_engineering_challenges)).
5. I used the estimate of “when a GPT-3 equivalent was expected” above as a strong prior for “how much GPT-3 sped up DeepMind and Google’s work scaling up language models”. But after intuitively accounting for the evidence in the above quotes from experts, I made the following updates to reach my final estimate of six months (90% CI: 1 to 18 months):
1. The median estimate of the speed-up should be earlier, because (a) Iulia Turc didn’t think GPT-3 was very surprising in terms of scale or performance, (b) the estimate of “when a GPT-3 equivalent was expected” doesn’t fully account for the growing interest in pretrained large language models among top AI developers since around 2018 (when OpenAI’s original GPT ([Radford and Narasimhan, 2018](https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035)) and Google’s BERT ([Devlin et al., 2018](https://arxiv.org/abs/1810.04805)) were published).
2. The confidence interval should be wider, given that I have almost no knowledge of what DeepMind and Google’s plans around language model scaling actually were around the time that GPT-3 was published.
Diffusion cascades: the publication of progress accelerates the diffusion of the final product
==============================================================================================
Here I introduce the concept of a *diffusion cascade*: the acceleration of diffusion that results from diffusion of artifacts that are relevant to producing a given closed-source model. The concept of a diffusion cascade applies when initially there is a given closed-source model that is only accessible to one actor, and no other actor fully understands how to produce that model and/or has all the resources needed to produce that model.[[40]](#fnca07mifaf3n) The incremental progress and open sourcing made by other actors in the meantime fills in the gaps in knowledge and resources, and thereby accelerates diffusion. Even if the latest capability advance is only reachable by leading AI developers initially, those leading developers can make diffusion to other actors happen *more easily* and *sooner* than otherwise.
Tools, datasets, smaller models, and the accumulation of published details speed up the cascade
-----------------------------------------------------------------------------------------------
Below I list some specific drivers of diffusion cascades, and empirical examples of those drivers being involved in diffusion cascades. I also indicate the *current* relative importance of each driver on a sub 1-5 scale (5 is most important) according to my judgment, which is based on a combination of independent reasoning and the empirical examples. Importance means how much this driver has accelerated diffusion empirically.[[41]](#fniux56d7njz)
1. **Open-source software tools. (Importance: 5) While there are long-standing open-source tools for machine learning such as**[**PyTorch**](https://pytorch.org/)**, more specific open-source tools specialized for large language model training can emerge, which embed a lot of knowledge of how to train large language models.**[**Megatron-LM**](https://github.com/NVIDIA/Megatron-LM) **and**[**DeepSpeed**](https://www.deepspeed.ai/) **are open-source tools for training large language models, and were used extensively to train GPT-NeoX-20B, OPT 175B, Jurassic-1-Jumbo, and BLOOM.** Sid Black told me that while he had qualms with Megatron-LM and DeepSpeed (namely, they were frustrating and time-consuming to use and extend), Megatron-LM is “really fast” and he was glad to have these tools available when developing GPT-NeoX-20B.
2. **Accumulation of insights and implementation details from different research articles**. **(Importance: 4)**Even if there is a long series of closed-source language models developed by different actors, the current tendency is for many of those actors to publish research articles with information about their methods (more on this in the [post on publication norms and release strategies](https://forum.effectivealtruism.org/posts/KkbEfpNkjNepQrj8g/publication-decisions-for-large-language-models-and-their)). Due to the various independent decisions about what information is included in these research articles, more and more information on how to reproduce a given model can gradually be accumulated.
1. Example: [Narayanan et al. (2021)](https://arxiv.org/abs/2104.04473). The paper accompanying the release of the Megatron-LM tool includes information on different types of parallelism methods and how they can be composed to scale to “thousands of GPUs and models with trillions of parameters,” and “intuition as to how to configure distributed training of a large model.” This paper does not itself present new models, it just provides insight on how to scale and train them efficiently.
3. **Open-source smaller models. (Importance: 3)**Many pretrained language models that are smaller but similar in design to GPT-3 are open-source—for example, [GPT-2](https://github.com/openai/gpt-2), and the [OPT family](https://github.com/facebookresearch/metaseq/tree/main/projects/OPT#pretrained-model-weights) (except OPT-175B, which isn’t smaller than GPT-3). Having these models (and the code to instantiate the models) available makes the precise implementation of those models clearly and completely known, beyond just specifying the model architecture and its hyperparameters in a research paper. However, if the smaller model falls significantly short of the full model in performance, the full model normally needs to be trained from scratch,[[42]](#fn7w59w974rmn) so my impression is that having smaller models available does not necessarily reduce the challenge of scaling up. Empirically, the publication of smaller models is only of moderate importance, because the current norm is to publish model architecture details in research papers (including for the larger models, even when the model weights aren’t published), and that saves most of the work in figuring out how to implement a model.[[43]](#fni5kmht4e8o)
4. **Open-source datasets. (Importance: 3) For example, The Pile was used to train GPT-NeoX-20B and (partially) OPT 175B (**[**Gao et al., 2020**](https://arxiv.org/abs/2101.00027)**). Although such datasets for language models usually just consist of text data scraped from public internet sources, scraping the data and storing it in an appropriate format is a significant effort**.
Coordinating on greater secrecy, even just delayed publication, can slow down diffusion
=======================================================================================
**The obvious way to slow down a diffusion cascade, and diffusion in general, is to have greater secrecy.** In the absence of coordination, the best that one actor can do on this front is to try to keep knowledge of a project or model completely secret, not even revealing the model’s existence.
My impression is that it is not uncommon to keep models secret *temporarily* (i.e., delaying publication past the minimum time needed to produce a publication).
1. For example, the GPT-3 175B model was not announced for “months” after it was trained, and this seemed partly motivated by a desire to delay progress toward artificial general intelligence.[[44]](#fnmx0lemu6jd) My low-confidence best guess is that the paper was published seven months after training finished and could have been ready to publish four months sooner than it was if the work towards publishing the paper was done as soon as possible.[[45]](#fnlx261e685oq)
2. The publication of Gopher was delayed even longer than my estimate for GPT-3. Based on the Gopher model card, the paper was published 12 months after the model finished training.[[46]](#fn9w2ezvnqyif) So by similar logic, I think the Gopher paper could have been published nine months sooner than it was. I speculate that the delay in publication about Gopher was for the same reason as not releasing the training code, dataset, and model weights for Gopher. Geoffrey Irving told me that the reason for the latter was to "[reduce] diffusion of objects that can cause harm if not aligned further."
3. A staff member at an industry AI lab, who has worked with large language models, told me off-hand that publication of Google’s PaLM model was probably delayed by a couple of months, but this is weaker evidence and I did not find out the rationale for the delay.
One thing to note here is that while a model may remain secret to the general public until it is published, I suspect that information does sometimes leak, especially among peers in AI development at different labs.[[47]](#fniera79rs9y) Rumors can also circulate, even to the public, though it’s unclear when this is intentional and when it is unintentional. For example, [Hao (2020)](https://perma.cc/6L88-SVKK) seems to refer to the text-to-image model DALL-E (or similar preliminary work) 11 months before DALL-E was announced ([Ramesh et al., 2021](https://perma.cc/3CVY-ZRMT)).[[48]](#fnhc7thstec1c)
Besides just delaying publication, actors could limit diffusion cascades (if that is their goal) through more *comprehensive* secrecy around information and resources—even if the existence of the model and research results about the model are publicized. Given the various information sources and artifacts that can drive a diffusion cascade, it would be more effective to not just keep the model secure, but also e.g., the specialized software tools that were used to train the model, and the datasets, and the details of training infrastructure and parallelism strategies. For example, the developers of GPT-3 did not explain or open-source the software tooling that was used to train the GPT-3 model. This seems to have left a gap that [Narayanan et al. (2021)](https://arxiv.org/abs/2104.04473) had to spend time filling (i.e., with the [Megatron-LM](https://github.com/nvidia/megatron-lm) codebase).
Appendix: GPT-3 came 5–17 months earlier than expected, due to OpenAI’s willingness to spend on the compute and to solve the engineering challenges
===================================================================================================================================================
I used 3 methods to estimate when experts *would* have expected GPT-3 (or the rough equivalent) to be released, immediately before GPT-3 was actually publicized. Estimating this provides evidence about the extent that multiple discovery was involved in the diffusion of GPT-3-like models, and about the counterfactual impact of publicizing GPT-3. The estimates are detailed in the following subsections.
Expected timing based on the average training compute trend
-----------------------------------------------------------
First I analyze how unexpected GPT-3 was in terms of the average trend in training compute for models over time. My analysis is based on this [interactive plot](https://epochai.org/mlinputs/visualization) of compute trends by Epoch. Below are the initial steps I took and the results I obtained from different plots:
1. Initialization
1. Start with the default settings, as in this [link](https://epochai.org/mlinputs/visualization)
2. Click the three-bar menu in the top right of the plot to open the settings
3. Check "Separate by category" so that the Language domain data has its own trends
4. Uncheck "Split trendlines in Large Scale Era"
5. Set "Large scale" to "ignore" so the red “Large Scale” trend disappears
6. Set the x-axis maximum to just before April 2020 using the slider at the bottom, such that all language models up until GPT-3 175B are included, but GPT-3 175B itself is excluded.
1. At the time of writing, there is a typo in the database used for this data which sets the publication date of GPT-3 to April 28, 2020 rather than May 28, 2020. I don’t think this affects my conclusions significantly.
2. You may have to zoom into the plot with the scroll wheel to verify this.
3. Alternatively, set the “endDate=” part of the page URL to an exact value, e.g. “endDate=2020-3-31”
7. The link to plot with the above changes is [here](https://epochai.org/mlinputs/visualization?startDate=1950-1-1&endDate=2020-4-21&xAxis=Publication%20date&yAxis=Training%20compute%20(FLOPs)&separateCategories=true&citationThreshold=0&otherDomainThreshold=10&startDlEra=2009-12-31&startLargeScaleEra=2015-9-1&largeScaleAction=ignore&outliersAction=remove&recordSettersAction=ignore&bigAlphagoAction=ignore&alphagozeroAction=ignore&lowOutliersZValueThreshold=-2&highOutliersZValueThreshold=0.76&outlierWindowSize=2&filterText=&splitDomains=&domainsToNotSplit=&ranges=[object%20Object]&splitDlEra=true&splitLargeScaleEra=false&plotRegressions=true&bootstrapSampleSize=10&adjustForEstimateUncertainty=true&preset=Three%20eras%20of%20compute&aspectRatio=fit%20to%20container&autoresetCamera=true&labelEras=true&showDoublingTimes=true&showOpenAITrend=false®ressionDecimals=1&textSize=100&systemAlpha=100&systemNames=hide&showLegend=true¶metersRange=NaN,NaN&trainingComputeRange=NaN,NaN&inferenceComputeRange=NaN,NaN&trainingDatasetSizeRange=NaN,NaN&inferenceComputePerParameterRange=NaN,NaN&inferenceComputeTimesParameterRange=NaN,NaN&labelPoints=false))
8. The resulting Language domain trend in the Deep Learning era is 0.8 OOMs/year
2. Using a straight edge to visually extrapolate the Language trend, I find that the trend predicts 3E+23 FLOPs of compute would be reached by about October 2021—**17 months after the actual publication date of GPT-3 in May 2020.**
1. Weight on this estimate: 0.4. Higher than average because I think the domain-specific trend is more reliable. The greater number of samples from the full Deep Learning Era also makes it more reliable.
3. Now check "Split trendlines in Large Scale Era". The "Large Scale Era" Language trend should now be 1.1 OOM/year. Link to these settings is [here](https://epochai.org/mlinputs/visualization?startDate=1950-1-1&endDate=2020-3-28&xAxis=Publication%20date&yAxis=Training%20compute%20(FLOPs)&separateCategories=true&citationThreshold=0&otherDomainThreshold=10&startDlEra=2009-12-31&startLargeScaleEra=2015-9-1&largeScaleAction=ignore&outliersAction=remove&recordSettersAction=ignore&bigAlphagoAction=ignore&alphagozeroAction=ignore&lowOutliersZValueThreshold=-2&highOutliersZValueThreshold=0.76&outlierWindowSize=2&filterText=&splitDomains=&domainsToNotSplit=&ranges=[object%20Object]&splitDlEra=true&splitLargeScaleEra=true&plotRegressions=true&bootstrapSampleSize=10&adjustForEstimateUncertainty=true&preset=Three%20eras%20of%20compute&aspectRatio=fit%20to%20container&autoresetCamera=true&labelEras=true&showDoublingTimes=true&showOpenAITrend=false®ressionDecimals=1&textSize=100&systemAlpha=100&systemNames=hide&showLegend=true¶metersRange=NaN,NaN&trainingComputeRange=NaN,NaN&inferenceComputeRange=NaN,NaN&trainingDatasetSizeRange=NaN,NaN&inferenceComputePerParameterRange=NaN,NaN&inferenceComputeTimesParameterRange=NaN,NaN&labelPoints=false).
1. Prediction (using the same extrapolation method as above): about February 2021, **nine months after actual**
1. Weight: 0.2. This is a more “inside view” trend which I think is plausible. It takes better account of the large scale models that were released more recently. But the sample is slightly smaller so the prediction is not as reliable.
4. Now uncheck "Separate by category" ([link](https://epochai.org/mlinputs/visualization?startDate=1950-1-1&endDate=2020-3-28&xAxis=Publication%20date&yAxis=Training%20compute%20(FLOPs)&separateCategories=false&citationThreshold=0&otherDomainThreshold=10&startDlEra=2009-12-31&startLargeScaleEra=2015-9-1&largeScaleAction=ignore&outliersAction=remove&recordSettersAction=ignore&bigAlphagoAction=ignore&alphagozeroAction=ignore&lowOutliersZValueThreshold=-2&highOutliersZValueThreshold=0.76&outlierWindowSize=2&filterText=&splitDomains=&domainsToNotSplit=&ranges=[object%20Object]&splitDlEra=true&splitLargeScaleEra=true&plotRegressions=true&bootstrapSampleSize=10&adjustForEstimateUncertainty=true&preset=Three%20eras%20of%20compute&aspectRatio=fit%20to%20container&autoresetCamera=true&labelEras=true&showDoublingTimes=true&showOpenAITrend=false®ressionDecimals=1&textSize=100&systemAlpha=100&systemNames=hide&showLegend=true¶metersRange=NaN,NaN&trainingComputeRange=NaN,NaN&inferenceComputeRange=NaN,NaN&trainingDatasetSizeRange=NaN,NaN&inferenceComputePerParameterRange=NaN,NaN&inferenceComputeTimesParameterRange=NaN,NaN&labelPoints=false))
1. Use the one trend in the "Large Scale Era"—0.4 OOMs/year
1. Prediction: October 2026, which is 6 \* 12 + 3 = **75 months after actual**
1. Weight: 0.1. The data looks very noisy, spans a short time period, and doesn’t account for domain-specific trends. But it is still an informative “outside view” estimate.
5. Now Uncheck "Split trendlines in Large Scale Era" ([link](https://epochai.org/mlinputs/visualization?startDate=1950-1-1&endDate=2020-3-28&xAxis=Publication%20date&yAxis=Training%20compute%20(FLOPs)&separateCategories=false&citationThreshold=0&otherDomainThreshold=10&startDlEra=2009-12-31&startLargeScaleEra=2015-9-1&largeScaleAction=ignore&outliersAction=remove&recordSettersAction=ignore&bigAlphagoAction=ignore&alphagozeroAction=ignore&lowOutliersZValueThreshold=-2&highOutliersZValueThreshold=0.76&outlierWindowSize=2&filterText=&splitDomains=&domainsToNotSplit=&ranges=[object%20Object]&splitDlEra=true&splitLargeScaleEra=false&plotRegressions=true&bootstrapSampleSize=10&adjustForEstimateUncertainty=true&preset=Three%20eras%20of%20compute&aspectRatio=fit%20to%20container&autoresetCamera=true&labelEras=true&showDoublingTimes=true&showOpenAITrend=false®ressionDecimals=1&textSize=100&systemAlpha=100&systemNames=hide&showLegend=true¶metersRange=NaN,NaN&trainingComputeRange=NaN,NaN&inferenceComputeRange=NaN,NaN&trainingDatasetSizeRange=NaN,NaN&inferenceComputePerParameterRange=NaN,NaN&inferenceComputeTimesParameterRange=NaN,NaN&labelPoints=false))
1. Use the one "Deep Learning Era" trend
1. Prediction: February 2023, which is 36 - 3 = **33 months after actual**
1. Weight: 0.2. To me this is a stronger “outside view” prediction than the previous, because there are more samples.
6. Now set the "Large scale" dropdown setting to "label" and use the "Large Scale" trend of 0.3 OOMs/year ([link](https://epochai.org/mlinputs/visualization?startDate=1950-1-1&endDate=2020-3-28&xAxis=Publication%20date&yAxis=Training%20compute%20(FLOPs)&separateCategories=false&citationThreshold=0&otherDomainThreshold=10&startDlEra=2009-12-31&startLargeScaleEra=2015-9-1&largeScaleAction=label&outliersAction=remove&recordSettersAction=ignore&bigAlphagoAction=ignore&alphagozeroAction=ignore&lowOutliersZValueThreshold=-2&highOutliersZValueThreshold=0.76&outlierWindowSize=2&filterText=&splitDomains=&domainsToNotSplit=&ranges=[object%20Object]&splitDlEra=true&splitLargeScaleEra=false&plotRegressions=true&bootstrapSampleSize=10&adjustForEstimateUncertainty=true&preset=Three%20eras%20of%20compute&aspectRatio=fit%20to%20container&autoresetCamera=true&labelEras=true&showDoublingTimes=true&showOpenAITrend=false®ressionDecimals=1&textSize=100&systemAlpha=100&systemNames=hide&showLegend=true¶metersRange=NaN,NaN&trainingComputeRange=NaN,NaN&inferenceComputeRange=NaN,NaN&trainingDatasetSizeRange=NaN,NaN&inferenceComputePerParameterRange=NaN,NaN&inferenceComputeTimesParameterRange=NaN,NaN&labelPoints=false))
1. March 2022—24 - 2 = **22 months after actual**
1. Weight: 0.1. Small sample size, but still an informative estimate based on the belief that the “Large Scale” trend is more relevant.
7. Most outside view estimate: 75 months
8. Most inside view estimate: nine months
9. **Unweighted average: (17 + 9 + 75 + 33 + 22) / 5 ~= 31 months**
10. **Weighted average: 0.4\*17 + 0.2\*9 + 0.1\*75 + 0.2\*33 + 0.1\*22 ~= 25 months**
11. **Sample standard deviation of estimates: 26 months**
12. **Filtered standard deviation of estimates (i.e. excluding the 75 month estimate): 10 months**
I used the weighted average as the central estimate, and the filtered standard deviation to get 90% confidence bounds. Thus **my first estimate for the expected arrival time of GPT-3 is June 2022 (90% CI: August 2021 to April 2023)**. A major limitation of this estimate is that I am using a prediction of the *average* milestone system rather than a prediction of the most expensive system. Including the “Large Scale” trends in my aggregate prediction compensates for this somewhat (because the “Large Scale” data has the most expensive systems), but the above average predictions are probably still later than experts actually expected. Due to this limitation, I only put 30% weight on this estimate.
Expected timing based on the upper range of the compute trend
-------------------------------------------------------------
One way to improve on the first estimate is to look at when the trend predicts GPT-3’s training compute *minus* some amount of deviation based on the variance in the data. Due to time constraints I have not computed a confidence interval in the trendline. However, visually inspecting the Language category data over the whole “Deep Learning era” in [this plot](https://epochai.org/mlinputs/visualization?startDate=1950-1-1&endDate=2020-4-21&xAxis=Publication%20date&yAxis=Training%20compute%20(FLOPs)&separateCategories=true&citationThreshold=0&otherDomainThreshold=10&startDlEra=2009-12-31&startLargeScaleEra=2015-9-1&largeScaleAction=ignore&outliersAction=remove&recordSettersAction=ignore&bigAlphagoAction=ignore&alphagozeroAction=ignore&lowOutliersZValueThreshold=-2&highOutliersZValueThreshold=0.76&outlierWindowSize=2&filterText=&splitDomains=&domainsToNotSplit=NaN&ranges=[object%20Object]&splitDlEra=true&splitLargeScaleEra=false&plotRegressions=true&bootstrapSampleSize=10&adjustForEstimateUncertainty=true&preset=Three%20eras%20of%20compute&aspectRatio=fit%20to%20container&autoresetCamera=true&labelEras=true&showDoublingTimes=true&showOpenAITrend=false®ressionDecimals=1&textSize=100&systemAlpha=100&systemNames=hide&showLegend=true¶metersRange=NaN,NaN&trainingComputeRange=NaN,NaN&inferenceComputeRange=NaN,NaN&trainingDatasetSizeRange=NaN,NaN&inferenceComputePerParameterRange=NaN,NaN&inferenceComputeTimesParameterRange=NaN,NaN&labelPoints=false), we can see that data points that are about 1 order of magnitude above the trend line are common. For example, Meena in Jan 28, 2020 has 1.1E+23 FLOP while the trend is at about 1E+22 FLOP, and Seq2Seq LSTM in Sep 10, 2014 has 7.3E+18 FLOP while the trend is at about 4E+17 FLOP. The biggest outlier is GNMT (Sep 26, 2016) at 6.9E+21 FLOP when the trend is only at about 2E+19 FLOP; however, I think this is too large an outlier to significantly weight people’s best-guess expectations about when GPT-3’s amount of training compute would be used.
Based on this rough inspection, I will just look at when the trendline predicts one order of magnitude lower than the true value, i.e., when it predicts 3E+22 FLOP rather than 3E+23 FLOP. This appears to occur in late July 2020, only *2 months* after GPT-3 was actually published.
Based on this, I chose 2 months as my central estimate for the time that GPT-3 was expected (in terms of training compute), relative to when it was actually published. Like the first estimate, I used the filtered standard deviation of 10 months to get confidence bounds. Thus **my second estimate for the expected arrival time of GPT-3 is July 2020 (90% CI: December 2019 to May 2021).** Although this estimate is less rigorous than the first estimate, I think it is closer to the quantity I’m actually trying to estimate, so I put 50% weight on it.
One expert opinion
------------------
Finally, **I have some evidence about the expected timing of GPT-3 from one researcher who has trained large language models at an AI safety lab.** They told me: **“**I think GPT-3 probably pushed other labs in this direction about a year earlier than they otherwise would have. It’s a bit hard to know for sure. There were certainly other groups training larger and larger LMs each few months and they were doing better and better, but it wasn’t obviously clear to everyone that scale was the main ingredient there.” This isn’t a direct claim about when GPT-3 was expected to arrive, but **their statement suggests that if GPT-3 was published 1 year later, then that would be more in line with the expectations of the field**. As with the other estimates, I will put a confidence interval of +/- 10 months either side of this 12-month estimate. So my third estimate is **May 2021 (90% CI: July 2020–March 2022)**. Since this is based on an off-hand comment from one expert, I only put 20% weight on it.
Overall estimate: 11 months (90% CI: 5 to 17 months) sooner than expected
-------------------------------------------------------------------------
I put my three estimates together in a weighted average using this [Guesstimate model](https://www.getguesstimate.com/models/21653?token=IG_znrSKPb4ZcmcC97ARwbqb4CMYrXlDEaV2VC7CUEPTcVmsUxblcrto31_TxGwLqXmXqrjdRN6K856r5q2rcg) and obtained an overall estimated delay of 11 months (90% CI: 5 to 17 months), or an estimated date of April 2021 (90% CI: October 2020 to October 2022). Note that the confidence interval does not account for the correlation between the confidence intervals of the individual estimates, and the correlation between the first and second estimates (due to using the same data and trend), so it probably should be wider to reflect my true confidence.
What this overall estimate implies is that GPT-3 arrived significantly earlier than expected. I think that the most likely reason for this unexpected event is OpenAI simply being willing and able to invest in a larger amount of compute. The “willing” part is probably the key factor in OpenAI getting to this amount of compute before other leading language model developers just prior to GPT-3’s release, especially Google.
Acknowledgements
================

*This research is a project of*[*Rethink Priorities*](http://rethinkpriorities.org/)*. It was written by Ben Cottier. Thanks to Alexis Carlier, Amanda El-Dakhakhni, Ashwin Acharya, Ben Snodin, Bill Anderson-Samways, Erich Grunewald, Jack Clark, Jaime Sevilla, Jenny Xiao, Lennart Heim, Lewis Ho, Lucy Lim, Luke Muehlhauser, Markus Anderljung, Max Räuker, Micah Musser, Michael Aird, Miles Brundage, Oliver Guest, Onni Arne, Patrick Levermore, Peter Wildeford, Remco Zwetsloot, Renan Araújo, Shaun Ee, Tamay Besiroglu, and Toby Shevlane for helpful feedback. If you like our work, please consider*[*subscribing to our newsletter*](https://www.rethinkpriorities.org/newsletter)*. You can explore our completed public work*[*here*](https://www.rethinkpriorities.org/research)*.*
1. **[^](#fnref5ftjlk4p838)**To be clear, only 7 of these 9 GPT-3-like models are in my 9 full case studies; 2 models in my case studies do not meet my definition of GPT-3-like.
2. **[^](#fnrefasmmrmmin2m)**Note that this is not a fair comparison with talent holistically. Talent can be the key bottleneck even when salaries are only a small fraction of project costs, due to the time and financial cost of producing enough people with the requisite skills. Further analysis of the holistic talent cost seems worthwhile in future work.
3. **[^](#fnrefpzxvf3yw7so)**Sponsorship of compute resources could involve an actor doing any of the following things: (a) giving another actor ownership of compute hardware, (b) giving another actor access to compute hardware, (c) giving another actor money that can only be used on compute, or (d) giving another actor money with the intention that it is used for compute. Only cases (b) and (c) occurred in my case studies.
4. **[^](#fnref9sc32lp645l)**E.g., Beijing Academy of Artificial Intelligence (BAAI) and Peng Cheng Laboratory (PCL) were involved in the GLM-130B and ERNIE 3.0 Titan models respectively. See my [survey of models](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#Appendix__Survey_of_the_timing__affiliations__and_development_process_of_models_that_replicate_or_closely_emulate_GPT_3) covered previously for details.
5. **[^](#fnrefuruf3m54w4)**I won’t make the effort to detail all these insights, but note that the Gopher paper ([Rae et al., 2021](https://arxiv.org/abs/2112.11446)) is titled "Scaling Language Models: Methods, Analysis & Insights from Training Gopher”.
6. **[^](#fnrefw14cx1gq9k)**I assessed which models are GPT-3-like in a [previous post](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#GPT_3_like_models_have_only_been_developed_by_well_funded_companies_that_develop_AI__or_in_collaboration_with_them). The nine GPT-3-like models are Gopher, Hyperclova, Jurassic-1-Jumbo, Megatron-Turing NLG, LaMDA-PT, Yuan 1.0, ERNIE 3.0 Titan, Chinchilla, and PaLM.
7. **[^](#fnrefn1d75up8ydm)**In a [previous post](https://forum.effectivealtruism.org/posts/foptmf8C25TzJuit6/gpt-3-like-models-are-now-much-easier-to-access-and-deploy#OPT_175B_can_be_directly_accessed_by_hundreds_to_thousands_of_AI_researchers), I estimated that 1000 (90% CI: 200–3000) people could be eligible to access the model weights of OPT-175B, and all of these people could be granted access in the first year following release of OPT-175B. I don’t know what number of people are actually permitted to access OPT-175B so far (i.e., who’ve requested and been granted permission) and it’s very likely lower than the number of people that could be eligible, but as of November 2022 I think that number is more than 80% likely to be higher than 73, which is the total of “core team size” for the models that I estimated “core team size” for (see this [cell](https://docs.google.com/spreadsheets/d/1mYWA2V2aGe4PMRYfF2rwJ4sVcBteUzoyGl26S7LyM2s/edit#gid=605901592&range=B31) of the diffusion database).
8. **[^](#fnrefdysb5jbaeb)**See [Wiblin and Harris (2022)](https://80000hours.org/podcast/episodes/nova-dassarma-information-security-and-ai-systems/#the-hack-of-nvidia-002514): Rob Wiblin: “Are there any historical case studies of information leaks in ML? Are there any cases where an ML model has been stolen in the past?”. Nova DasSarma: “That’s a great question. I don’t think I can think of one offhand actually. If they have been stolen, then it’s one of those things where they’ve kept hush-hush about it.”
9. **[^](#fnrefqusubpvsoo)**Paraphrasing from personal correspondence: Ben Cottier: “Do you know any examples of hackers accessing ML-related artifacts like datasets, trained models, etc.?” Jeffrey Ladish: “Ram Shankar Siva Kumar from AI Red Team at Microsoft—they used phishing to steal a model etc. That's the only example I know of.” I found [Field (2022)](https://www.emergingtechbrew.com/stories/2022/06/14/how-microsoft-and-google-use-ai-red-teams-to-stress-test-their-system) related to what Jeffrey Ladish was referring to. This isn’t a “real world case of ML model theft” in that it was a red-teaming exercise and didn’t actually result in diffusion to unauthorized parties.
10. **[^](#fnref040fzxjojzpe)**This estimated delay is explained in [the section on publicity](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Publicity_that_draws_attention_to_an_existing_model_s_capabilities__accelerating_factor_).
11. **[^](#fnrefvwmenjh6gm)**I think doing this in four months would probably be feasible, based on my estimates of [training wall-clock time](https://docs.google.com/spreadsheets/d/1akHMvcFcSrve9xwo-nRdedTzRz6Az_xxw5JZFAJvoig/edit#gid=1986563325&range=AX2) and [total project duration](https://docs.google.com/spreadsheets/d/1akHMvcFcSrve9xwo-nRdedTzRz6Az_xxw5JZFAJvoig/edit#gid=1986563325&range=AP2) (i.e., time until having the trained model; this excludes time for writing and publishing a paper) in the diffusion database. The case with the most confident estimates is OPT-175B, with a total project duration of 78 days, including 33 days of training time. However, there were four months from OPT-175B completing training to the paper being published in May 2022. So my estimate of one month to evaluate the model and publish is probably too short.
12. **[^](#fnrefc6z5w67a55k)**Geoffrey Irving (Safety Researcher at DeepMind) told me that “[People who worked on Gopher] had already started LLM scaleup for the purpose of using them for communication and recursion-based alignment schemes soon after I joined [DeepMind, from OpenAI, in October 2019], but GPT-3 did add an organizational push.”
13. **[^](#fnrefiyx21aeyi5)**See [Shelvane (2022)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation). A senior member of OpenAI (who is specified on p.27 of the PDF) told the author: “GPT-3 existed for a long time before the paper came out. We delayed the paper. [...] But it’s months, it doesn't really count. And you're sitting there, fucking white-knuckling it, because it's really costly if someone releases their paper, and you have fucked this up somehow. So you're under pressure” (p.66 of the PDF).
14. **[^](#fnrefsjbqo74e23)**This is just a rough estimate, and *expecting*a result to be published by a certain date does not *guarantee* that no other equivalent model would have been published otherwise. Nonetheless, it is evidence in the direction of “multiple discovery was not involved in any cases of GPT-3-like model diffusion”.
15. **[^](#fnrefqf46jve74ik)**Full correspondence is available [here](https://docs.google.com/document/d/1G4hhwW61ynjaJJm28DsMy5qh958vieYuz-lw4ife710/edit?usp=sharing) upon request.
16. **[^](#fnref9jmwx2x2bih)**My thinking on this is generally informed by [Ladish and [lennart] (2022)](https://forum.effectivealtruism.org/posts/WqQDCCLWbYfFRwubf/information-security-considerations-for-ai-and-the-long-term#Threat_Actors_and_AGI).
17. **[^](#fnrefkga3c500r8)**I focus on development rather than access to GPT-3-like models here because I think development is more important. See a [previous post](https://forum.effectivealtruism.org/posts/foptmf8C25TzJuit6/gpt-3-like-models-are-now-much-easier-to-access-and-deploy#Upshot__focus_more_on_shaping_development_than_deployment) for my reasoning on this.
18. **[^](#fnrefm3p1ohpuxvc)**In my case studies there is a close relationship between the factors for diffusion and the resources that drive capabilities (i.e., money, compute, data, and talent). I think this is due to replication and incremental research being the main mechanisms of diffusion for 2 years. The actors involved had to actually develop models independently in order for the models to diffuse, because there weren't any open-source models for a while. But if the main diffusion mechanism happened to be espionage, then an accelerating factor might be the poor information security at an organization. So the factors for diffusion and the resources that drive capabilities can be quite separate.
19. **[^](#fnrefq6llc92pkn)**This is because OPT-175B allows more people to get direct access to its model weights, and finding model weights seems to be the most compute-intensive aspect of AI development/deployment.
20. **[^](#fnref6csg60zmf7o)**See the “Training cost (2022 USD)” [column](https://docs.google.com/spreadsheets/d/1mYWA2V2aGe4PMRYfF2rwJ4sVcBteUzoyGl26S7LyM2s/edit#gid=1986563325&range=AI2) of the diffusion database, noting which models are classified as GPT-3-like in the “GPT-3-like model?” [column](https://docs.google.com/spreadsheets/d/1mYWA2V2aGe4PMRYfF2rwJ4sVcBteUzoyGl26S7LyM2s/edit#gid=1986563325&range=J2). Some GPT-3-like models in the database do not have cost estimates, but seem very likely to fall within the $1–10M cost range given their training compute (see the “Training compute (FLOPs)” [column](https://docs.google.com/spreadsheets/d/1mYWA2V2aGe4PMRYfF2rwJ4sVcBteUzoyGl26S7LyM2s/edit#gid=1986563325&range=AG2)).
21. **[^](#fnrefdqf6ppbwxom)**Note that this is not a fair comparison with talent holistically. Talent can be the key bottleneck even when salaries are only a small fraction of project costs, due to the time and financial cost of producing enough people with the requisite skills. Further analysis of the holistic talent cost seems worthwhile in future work.
22. **[^](#fnrefu0wntvd8eh)**See Abstract of [Zeng et al. (2021)](https://arxiv.org/abs/2104.12369)
23. **[^](#fnref5ywktc545im)**[My conversation notes](https://docs.google.com/document/d/18glYFr7o4bIqGIsyQE-NC6N3szqjXycHRRmoB9q2LHE/edit?usp=sharing) with Sid Black are available upon request.
24. **[^](#fnrefh2xvesdary4)**Black indicated this rough 40–50% confidence after seeing a draft of this text (which included my skepticism about Black’s claim). Black originally told me (paraphrasing from conversation) that “We did kinda become bottlenecked by compute—if CoreWeave had offered more GPUs, we probably could have [replicated GPT-3].” I interpreted the word “probably” to be more than 50% confidence.
25. **[^](#fnrefti1nhee854q)**See [this section for PanGu-alpha](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#_October_2020__PanGu_alpha_Chinese_industry_academia_government_collaboration_worse_than_GPT_3) and [this section for BLOOM](https://forum.effectivealtruism.org/posts/FANYsqzPM9Yht3KM2/the-replication-and-emulation-of-gpt-3#July_2022__BLOOM_industry_academia_government_collaboration_similar_to_GPT_3) in an appendix.
26. **[^](#fnref1tttdif1m5s)** See [Shelvane (2022, p. 73)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation): “The greatest bottleneck has been getting access to enough compute. Initially Eleuther was still using Google’s TFRC scheme. This was not sufficient…”
27. **[^](#fnrefyc9hrolsbe)**[Shelvane (2022, p. 73)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation): “[CoreWeave] planned to buy more NVIDIA GPUs and rent them out to people training large models. Connor told me: ‘So, the deal was: we test the hardware, we figure out what do you need to train these kinds of models . . . because they don't have in-house capacity ML engineering talent. And then they buy [the hardware]. We get to train our model on it and release it for free. And everyone's happy.”
28. **[^](#fnref64ecx9cx6w)**[Shelvane (2022, p. 40)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation): “I asked Aaron [one of the Brown University graduate students that did a project replicating GPT-2] what value the Google’s TFRC team would have seen in the project: ‘To test the systems, and just like...They just want to get more papers out there on it that can only be done on TPUs, because if you’re a company and you want to iterate on that for your own personal thing then you have to pay them to use TPUs. That’s basically it—that’s basically the value in general.’”
29. **[^](#fnref45yypwly9ff)**Sponsorship may also be important in the sense that it increases the number of people working on larger-scale AI projects, which may increase the number and expertise of AI engineers and researchers, which may then get hired by the leading AI labs.
30. **[^](#fnrefvj9nxmxwiag)**On p.2 of the paper it says “We open source our code along with the training and evaluation pipelines at <https://github.com/megatron-lm>”. That link is broken, but version 4 of the paper ([Shoeybi, 2020](https://arxiv.org/pdf/1909.08053v4.pdf)) changes the link to <https://github.com/nvidia/megatron-lm>, so I assume that these links correspond to the same codebase which has been updated over time.
31. **[^](#fnref24uz69bwu3f)**On p.3 of the Megatron paper it says “Our work focuses on architectures similar to GPT-2.”
32. **[^](#fnref3arl1w9h8oc)**The paper’s Abstract page on arXiv says “Our code is open sourced at[this https URL](https://github.com/nvidia/megatron-lm),” which links to the Megatron-LM GitHub repository.
33. **[^](#fnreffbaopz8ised)**See p.41 of the PDF.
34. **[^](#fnref2np7r7333tn)**See the “Specialised software tools used for development” [column](https://docs.google.com/spreadsheets/d/1mYWA2V2aGe4PMRYfF2rwJ4sVcBteUzoyGl26S7LyM2s/edit#gid=1986563325&range=AQ2) in the diffusion database.
35. **[^](#fnrefw9jh23wzfve)**See [this appendix](https://forum.effectivealtruism.org/posts/eHKLgsXfMvSyAWb7E/drivers-of-large-language-model-diffusion-incremental#Appendix__GPT_3_came_5_17_months_earlier_than_expected__due_to_OpenAI_s_willingness_to_spend_on_the_compute_and_to_solve_the_engineering_challenges) for my reasoning.
36. **[^](#fnrefq8na5ln9yur)**See [Shelvane (2022, Ch 2 p. 3 or p. 66)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation): “In addition to delaying the paper, another strategy was to write the paper in a way that avoids attention-grabbing. The paper was written so as to avoid ‘hype’ and include discussion of the model’s weaknesses.”
37. **[^](#fnrefucp5xnh1ag9)**Another interesting aspect of the search trend is the regions. China was the region with the highest fraction of total searches; 2nd was the interest in South Korea at 34% of China’s, and ranking 17th was the US at 11% of China’s. However, note that there are many small countries that rank highly because the metric used is the *fraction* of total searches in the given region.
38. **[^](#fnref793uvpnk1ma)**[Shelvane (2020](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation), p. 67).
39. **[^](#fnrefmx1zv2s1rii)**[Full correspondence](https://docs.google.com/document/d/1SxFDlyN-T8iMcbnG1ZKKUKZnMGrRgQBNvlHlSIc9XVQ/edit?usp=sharing) is available upon request. Irving was not clear what exactly is meant by “GPT-3” in that claim—whether it was insider knowledge of GPT-3 before GPT-3 was published, or the publication of the paper, or the huge publicity after publication, or some combination of those events.
40. **[^](#fnrefca07mifaf3n)**Or to produce a close enough replica of that model—the exact weight values of a trained model will always differ between independent training runs.
41. **[^](#fnrefiux56d7njz)**Note that I haven’t tried to predict how important each type of artifact will be in *future* diffusion cascades; I leave that to potential future research.
42. **[^](#fnref7w59w974rmn)**From my limited understanding of the Transformer architecture and how the architecture tends to be scaled up, it is conceivable that learned weights from a smaller model could be copied into a larger model, with the extra weights starting from initial values. But even if it’s possible, I don’t think this would be as effective as training the full-size model from scratch, because I have not heard of this method being used effectively.
43. **[^](#fnrefi5kmht4e8o)**This claim is based on all nine of the large language models that I studied in-depth detailing their model architecture and associated hyperparameters—see this [column](https://docs.google.com/spreadsheets/d/1mYWA2V2aGe4PMRYfF2rwJ4sVcBteUzoyGl26S7LyM2s/edit#gid=1986563325&range=X2) in the diffusion database.
44. **[^](#fnrefmx0lemu6jd)**[Shelvane (2022, Ch. 2 p.3, or p.66)](https://www.governance.ai/research-paper/the-artefacts-of-intelligence-governing-scientists-contribution-to-ai-proliferation): “Proponents of AGI risk will sometimes criticise OpenAI for contributing too much to advances in AI capabilities [...] It appears that these kinds of considerations did inform the way that GPT-3 was shared. [an OpenAI staff member] told me: ‘GPT-3 existed for a long time before the paper came out. We delayed the paper. That was one of the things we could do for AGI stuff. But it’s months, it doesn't really count.’”
45. **[^](#fnreflx261e685oq)**My best guess is that the GPT-3 175B model finished training in October 2019, seven months before publication in May 2020—my reasoning is in the note of this [cell](https://docs.google.com/spreadsheets/d/1mYWA2V2aGe4PMRYfF2rwJ4sVcBteUzoyGl26S7LyM2s/edit#gid=1986563325&range=BF3) of the diffusion database. I guess that the evaluation and paper-writing process took about three months in total, based on my intuition of how long different steps take. I think this is longer than most AI research papers, but the paper is long and seems to have required unusually high effort. That implies a four-month delay in publication.
46. **[^](#fnref9w2ezvnqyif)**The Model Card in Appendix B of the paper (p.49) states the "Model Date" is December 2020, and according to the [paper](https://dl.acm.org/doi/pdf/10.1145/3287560.3287596) that introduces Model Cards this means "When was the model developed?" I interpret “developed” as the date that the model finished training—this interpretation is partly based on another detail from the Gopher paper ([Rae et al., 2021](https://arxiv.org/abs/2112.11446)): "We trained Gopher for 920 hours in November and December 2020 in Google’s Georgia datacentre." (Appendix F, p.103)
47. **[^](#fnrefiera79rs9y)**This is based on at least two AI developers at leading AI labs agreeing with me in informal conversation that this does sometimes occur, but I do not have any record of those conversations.
48. **[^](#fnrefhc7thstec1c)**The article states “One of the biggest secrets is the project OpenAI is working on next. Sources described it to me as the culmination of its previous four years of research: an AI system trained on images, text, and other data using massive computational resources.” |
14a8bcaa-4c17-4b13-be88-db66775478cc | trentmkelly/LessWrong-43k | LessWrong | Shortest damn doomsplainer in world history
Computers get smarter. People don't. Some bots will be greedy and some will not. The greedy ones will take everything. |
1131b8f0-e3bd-41ca-a190-f30cb3405e14 | trentmkelly/LessWrong-43k | LessWrong | Wisdom Cannot Be Unzipped
Introduction
The year was 2016 (or close enough), and a friend of mine’s younger brother - we’ll call this younger brother Luke - was about to start college.
Having completed college not that long ago, I thought it would be nice if I could make a list of some of the things that had helped me - the strategies and disciplines that I had made use of - to hand to this prospective scholar.
I made my list, including links to productivity resources and guides to How To Get Things Done, and prepared to hand it off to Luke with my best wishes.
I remember how it felt, handing him that list. I was envious of Luke, in a way; I wish that I had had someone hand me this list back when I started college. It would have made things so much easier! And here I was, just handing Luke the keys to success on a silver platter.
He didn’t even know how lucky he was. I could picture how much easier he’d find things than I did, with the steps on his path helpfully guided by my concise and helpful list.
A few months later, I check in with my friend as to how his younger brother is doing, sure that I am about to hear a tale of effortless success and, well…
Luke was failing his classes.
I later learned that Luke had dropped out after his first year.
Nowadays Luke’s doing his own thing, and I have, shall we say, different opinions about the utility of college in general. And I can look back at the list I gave him and admit that it was not a perfect distillation of how to Mange Time Effectively and Really Get Things Done.
At the time though, I was aghast, and spent a great deal of thought on how my Super Awesome List failed to teach Luke the secrets I had learned throughout college on How To Get Things Done.
What I realized, after a great deal of introspection, was that it was inherent to the nature of wisdom itself that it cannot be decompressed. What follows is an examination of that idea.
Part I: Gird Your Metaphors
Compression as a Technology
Compression is a key technology in dig |
80631b8a-9b56-46cc-98c8-b46daf358ef1 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | [Linkpost] A survey on over 300 works about interpretability in deep networks
[**Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks**](https://arxiv.org/abs/2207.13243)
**Tilman Räuker\* (**[traeuker@gmail.com](mailto:traeuker@gmail.com))
**Anson Ho\*** ([anson@epochai.org](mailto:anson@epochai.org))
**Stephen Casper\*** ([scasper@mit.edu](mailto:scasper@mit.edu))
**Dylan Hadfield-Menell**
**TL;DR:** We wrote a survey paper on interpretability tools for deep networks. It was written for the general AI community but with AI safety as the key focus. We survey over 300 works and offer 15 discussion points for guiding future work. Here is [a link to a Twitter thread](https://twitter.com/StephenLCasper/status/1569401262558576642) about the paper.
Lately, there has been a growing interest in interpreting AI systems and a growing consensus that it will be key for building safer AI. There have been rapid recent developments in interpretability work, and the AI safety community will benefit from a better systemization of knowledge for it. There are also several epistemic and paradigmatic issues with much interpretability work today. In response to these challenges, we wrote a survey paper covering over 300 works and featuring 15 somewhat “hot takes” to guide future work.
Specifically, this survey focuses on “inner” interpretability methods that help explain internal parts of a network (i.e. not inputs, outputs, or the network as a whole). We do this because inner methods are popular and have some unique applications – not because we think that they are more valuable than other ones. The survey introduces a taxonomy of inner interpretability tools that organizes them by which part of the network’s computational graph they aim to explain: weights (S2), neurons (S3), subnetworks (S4), and latent representations (S5). Then we provide a discussion (S6) and propose directions for future work (S7).
Finally, here are a select few points that we would like to specifically highlight here.
1. Interpretability does not just mean circuits. In the survey sections of the paper (S2-S5), there are 21 subsections, and only one is about circuits. The circuits paradigm has received disproportionate attention in the AI safety community, partly due to [Distill’s](https://distill.pub/) influential interpretability research in the past few years. But given how many other useful approaches there are, it would be myopic to focus too much on them.
2. Interpretability research has close connections to work in adversarial robustness, continual learning, modularity, network compression, and studying the human visual system. For example, adversarially trained networks tend to be more interpretable, and more interpretable networks tend to be more adversarially robust.
3. Interpretability tools generate hypotheses, not conclusions. Simply analyzing the outputs of an interpretability technique and pontificating about what they mean is a problem with much interpretability work – including AI safety work. There are many examples of when this type of approach fails to produce faithful explanations.
4. Interpretability tools should be more rigorously evaluated. There are currently no broadly established ways to do this. Benchmarks for evaluating interpretability tools can and should be popularized. The ultimate goal of interpretability work should be tools that give us insights that are *valid* and *useful*. Ideally, interpretations should be used to make and validate useful predictions that engineers can use. So benchmarks should be created which measure how well interpretability tools can help us understand systems well enough to do engineering-relevant things with them. Examples of this could be using interpretability tools for reverse engineering a system, manually finetuning a model to introduce a predictable change in behavior, or designing a novel adversary. The [Automated Auditing](https://www.alignmentforum.org/posts/cQwT8asti3kyA62zc/automating-auditing-an-ambitious-concrete-technical-research) agenda may offer a useful paradigm for this – judging techniques by their ability to help humans rediscover known flaws in systems.
5. Cherry picking is common and harmful. Evaluation of interpretability tools should not fixate on best-case performance.
We hope that this survey can give researchers in AI safety a broader sense of what kind of work has been done in interpretability, serve as a useful reference, and also stimulate ideas for further investigation. Overall, we are excited about how much interpretability work has been done in the past few years. And we are looking forward to future progress. Please reach out to the three of us in an email if you’d like to talk. |
9d3c0eb9-3ce9-4cb8-84d9-1ca340ccf97c | trentmkelly/LessWrong-43k | LessWrong | What are examples of someone doing a lot of work to find the best of something?
My example: Marinara sauce: https://twitter.com/tresterese/status/1684024122278281217 |
db162a84-61c1-4da0-906a-f0039b2775d7 | trentmkelly/LessWrong-43k | LessWrong | [Link, 2011] Team may be chosen to receive $1.4 billion to simulate human brain
This is the team responsible for simulating the rat cortical column.
http://www.nature.com/news/2011/110308/full/news.2011.143.htm
The team is one of 6 that is being considered for at least 2 "FET Flagship" positions, which comes with all that funding. Each of the six competing teams is proposing to work on some kind of futuristic technology:
http://cordis.europa.eu/fp7/ict/programme/fet/flagship/6pilots_en.html
Of course, word on the street is that academic neuroscientists don't think much of the project:
> Academic neuroscientists that I’ve ever spoken too, which is a fair number now, don’t think much of the Blue Brain project. They sometimes think it will be valuable in terms of collecting and cataloguing information about the neocortex, but they don’t think the project will manage to understand how the cortex works as there are too many unknowns in the model and even if, by chance, they got the model right it would be very hard to know that they had.
>
> Almost all neuroscientists seem to think that working brain models will not exist by 2025, or even 2035 for that matter. What ever the date is, most consider it too far away to bother to think much about.
>
> Such projects probably help to get more kids interested in the topic.
----------------------------------------
I think trying to influence the committee's decision potentially represents very low hanging fruit in politics as charity.
Even if academic neuroscientists don't think much of the project in its current state, it seems likely that $1.4 billion would end up attracting a lot of talent to this problem, and get us the first upload significantly sooner.
It's true that Less Wrong doesn't have a consensus position on whether to speed development of cell modeling and brain scanning technology or not. But I think if we have a discussion and a vote, we're significantly more likely than the committee to come up with the right decision for humanity. As far as I can tell, the committee will essentiall |
7b4ded3c-7e5c-4ace-a88f-3330052d5e10 | trentmkelly/LessWrong-43k | LessWrong | Retrospective: November 10-day virtual meditation retreat
So yesterday I finished a 10-day virtual meditation retreat taught by Tucker Peck and Upasaka Upali.
Several people have asked me what it was like, so here are some highlights.
First, a “virtual” retreat means that you spend 10 days doing pretty much nothing but meditation, and also don’t talk to anyone except the teachers, who hold daily lectures and once-every-two-days personal interviews over Zoom. Also, when you sit down to meditate, you are encouraged to do it in front of a camera, so that you can see everyone else who is meditating and they can also see you.
At times it was great, such as when I was mostly just doing concentration meditation and focusing on my breath, and then suddenly memories of playing XCOM: Enemy Unknown together with a friend came up and I just felt a strong sense of connectedness and loving-kindness towards her, even though I hadn’t even been doing loving-kindness practice.
At other times I was figuratively clawing my eyes out of boredom and a desire to just be back on social media and able to talk to people.
In retrospect, it feels odd that the boredom was sometimes so strong as to make it impossible to meditate, since if I hadn’t been bored I could simply have meditated, and I was bored because I couldn’t get the meditation to work… it now feels like what was actually going was some desire to be in control, and that clinging onto the desire to be on social media and check my messages was a way of asserting a sense of control. Or something like that. Something to look into, anyway. In any case, it was a good opportunity to investigate the nature of discomfort, and I got quite a bit of that done.
Things that felt like significant shifts, or at least interesting experiences:
* I went into the retreat with the thought of wanting to give The Mind Illuminated -style concentration meditation another try, since it had worked well for me before, but I had eventually ran into various roadblocks with it. Over the last few years, every now |
8699daf9-b9c0-480f-959b-e55985ebc349 | trentmkelly/LessWrong-43k | LessWrong | So, I guess the site redesign is live?
I saw some discussion posts earlier talking about a LessWrong redesign, and now that things look different, I guess that it's been implemented. I'm always slightly annoyed for a while when a site I use gets redesigned because I have to relearn where everything is, but it eventually wears off once I'm used to the changes.
My initial impressions:
"Hmmm... it seems like the category menus have been replaced by dropdown menus. It's not like I used many of them anyway."
"Okay, I've clicked my name to see my recently posted comments. Now, where's the link to see it in context? Oh, I guess I have to click that icon in the lower right corner. For some reason I was looking for something at the upper right of the comment box."
"Well, that worked. Now how do I click to the parent comment? Oh, wait, it's probably one of those new icons in the lower right corner. I'll just mouseover them to see what they do..."
::realization sets in::
"AAUGH! LESSWRONG IS USING MYSTERY MEAT NAVIGATION!!!"
So, what does everyone else think of the new redesign? |
14425ee5-0eee-45ba-b795-59a725b55ed7 | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Interpretability Externalities Case Study - Hungry Hungry Hippos
Some people worry about interpretability research being useful for AI capabilities and potentially net-negative. As far as I was aware of, this worry has mostly been theoretical, but now there is a real world example: The [hungry hungry hippos](https://arxiv.org/abs/2212.14052) (H3) paper.
Tl;dr: The H3 paper
* Proposes an architecture for sequence modeling which can handle larger context windows than transformers
* Was inspired by interpretability work.
(Note that the H3 paper is from December 2022, and it was briefly mentioned in this [discussion about publishing interpretability research](https://www.lesswrong.com/posts/iDNEjbdHhjzvLLAmm/should-we-publish-mechanistic-interpretability-research). But I wasn’t aware of it until recently and I haven’t seen the paper discussed here on the forum.)
 I don't know why the paper is called that way. One of the authors [mentioned](https://arize.com/blog/hungry-hungry-hippos-h3-state-space-models/) that it’s called “hungry *hungry* hippos” rather than “hungry hippos” because it uses two state space model layers rather than one. But I think they don’t mention why the hippo is hungry. Or why it’s a hippo.### Larger Context Windows
The H3 paper proposes a way to use [state space models](https://arxiv.org/abs/2111.00396) (SSMs) for language models instead of [attention](https://arxiv.org/abs/1706.03762). With an SSM it’s possible to model longer sequences. Using attention, the compute for context window length n.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
scales with O(n2). Using the SSM based architecture, the compute scales with O(nlog(n)).
### Inspired by Interpretability Work
The paper mentions that the work was inspired by Anthropic’s [*In-context learning and induction heads*](https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html) paper.
E.g. they [write](https://arxiv.org/pdf/2212.14052.pdf#page=19)
> We provide an informal sketch of a two-layer attention model that can solve the associative recall task, inspired by the construction of [In-context learning and induction heads paper].
>
>
There is also the ["Hyena paper"](https://ermongroup.github.io/blog/hyena/) which builds on the H3 paper, and was also inspired by the induction heads paper:
> This work would not have been possible without [...] inspiring research on mechanistic understanding of Transformers (Olsson et al. 2022; Power et al. 2022; Nanda et al. 2023).
>
>
### My Takes
* These two papers in particular will probably not shorten AI timelines much.
+ It seems unlikely that this type of architecture ends up being the state of the art.
* However, the example makes me take the downsides of publishing interpretability research more seriously.
+ Even if this work itself is not a key capability milestone, it shows that there is truth in the argument “If we understand systems better, it will not just be useful for safety but also lead to capability advancements”
* Capabilities externalities are a strong argument that most (good) interpretability research should not be published
+ There are alternative ways to distribute research which are less risky than publishing.
- We can probably learn something by studying military research practices which have a similar use case of “make research accessible to other researchers while preventing it from becoming public”
- The constraints are less strict than with military research because there is not an adversary force trying really hard to get access.
+ Maybe this is already relatively common (I would not know of most unpublished research)
* On the other hand, interpretability research is probably crucial for AI alignment.
+ I think it is possible but unlikely that we get alignment without extremely good interpretability.
+ The cost of keeping interpretability research private is really high. Publishing is a great driver of scientific progress.
* Overall, publishing interpretability research seems both pretty risky, and extremely valuable, and it’s not clear to me if it is worth it.
### Your Takes?
I would be really interested to see a discussion about this!
* How big a deal are the H3 and Hyena papers?
* Does this example change your mind about whether publishing (or even doing) interpretability research is a good idea? |
f7eeb850-8903-4f7a-a79a-c3281b83a521 | trentmkelly/LessWrong-43k | LessWrong | Beijing Academy of Artificial Intelligence announces 1,75 trillion parameters model, Wu Dao 2.0
> BAAI researchers demonstrated Wu Dao's abilities to perform natural language processing, text generation, image recognition, and image generation tasks during the lab's annual conference on Tuesday. The model can not only write essays, poems and couplets in traditional Chinese, it can both generate alt text based off of a static image and generate nearly photorealistic images based on natural language descriptions. Wu Dao also showed off its ability to power virtual idols (with a little help from Microsoft-spinoff XiaoIce) and predict the 3D structures of proteins like AlphaFold.
How big of a deal is that? Seems huge. Bigger than switch transformers and 10x bigger than GPT-3. |
79563397-1a53-4432-adc8-e7e381b69ca2 | trentmkelly/LessWrong-43k | LessWrong | The Virtue of Narrowness
> What is true of one apple may not be true of another apple; thus more can be said about a single apple than about all the apples in the world.
>
> —“The Twelve Virtues of Rationality”
Within their own professions, people grasp the importance of narrowness; a car mechanic knows the difference between a carburetor and a radiator, and would not think of them both as “car parts.” A hunter-gatherer knows the difference between a lion and a panther. A janitor does not wipe the floor with window cleaner, even if the bottles look similar to one who has not mastered the art.
Outside their own professions, people often commit the misstep of trying to broaden a word as widely as possible, to cover as much territory as possible. Is it not more glorious, more wise, more impressive, to talk about all the apples in the world? How much loftier it must be to explain human thought in general, without being distracted by smaller questions, such as how humans invent techniques for solving a Rubik’s Cube. Indeed, it scarcely seems necessary to consider specific questions at all; isn’t a general theory a worthy enough accomplishment on its own?
It is the way of the curious to lift up one pebble from among a million pebbles on the shore, and see something new about it, something interesting, something different. You call these pebbles “diamonds,” and ask what might be special about them—what inner qualities they might have in common, beyond the glitter you first noticed. And then someone else comes along and says: “Why not call this pebble a diamond too? And this one, and this one?” They are enthusiastic, and they mean well. For it seems undemocratic and exclusionary and elitist and unholistic to call some pebbles “diamonds,” and others not. It seems . . . narrow-minded . . . if you’ll pardon the phrase. Hardly open, hardly embracing, hardly communal.
You might think it poetic, to give one word many meanings, and thereby spread shades of connotation all around. But even poets, if t |
5227b776-bf4b-4a29-89ec-e9ca8e292219 | trentmkelly/LessWrong-43k | LessWrong | Decision theory question: Alpha and omega play paper scissor rock
Edit: Actually nevermind, this is just counterfactual mugging. Deleting post.
We have two superintelligent rational entities, call them alpha and omega, and they have access to each other's source code. They're playing one round of paper scissor rock. The winner gives the loser five dollars, or nothing if they tie. Additionally, you win $100 in bonus money from the bank if your opponent chooses scissors.
My question is, what would they do? If it was ordinary paper scissor rock, it seems fairly clear they can't do better than picking randomly, given that they're equally matched. But what do they do here? Is there in fact a right answer, or does it depend on the peculiarities of how they were programmed?
|
c0a2f99f-03b6-4b6d-aa64-383dee9db5da | trentmkelly/LessWrong-43k | LessWrong | Group rationality diary, 5/14/12
Background: I and many other attendees at the CFAR rationality minicamp last weekend learned a lot about applied rationality, and made big personal lists of things we wanted to try out in our everyday lives. I think that a regular (weekly or maybe semi-weekly) post where people mention any new interesting habits, decisions, and actions they have taken recently would be cool as a supplement to this; it ought to be rewarding for people to be able to write a list of the cool things they did, and I expect it'll also be interesting for other people to peek in and see the sorts of goals and self-modifications people are working on. Others at minicamp seemed enthusiastic about the idea, so I hope it takes off. Feel free to meta-discuss whether this is a good idea or if it can be done better.
Addendum 5/15: By the way, non-minicamp people should feel free to post too! I am highly certain that minicamp attendees are not the only ones working on interesting things in their lives.
This is the public group instrumental rationality diary for the week of May 14th. It's a place to record and chat about it if you have done, or are actively doing, things like:
* Established a useful new habit
* Obtained new evidence that made you change your mind about some belief
* Decided to behave in a different way in some set of situations
* Optimized some part of a common routine or cached behavior
* Consciously changed your emotions or affect with respect to something
* Consciously pursued new valuable information about something that could make a big difference in your life
* Learned something new about your beliefs, behavior, or life that surprised you
* Tried doing any of the above and failed
Or anything else interesting which you want to share, so that other people can think about it, and perhaps be inspired to take action themselves. Try to include enough details so that everyone can use each other's experiences to learn about what tends to work out, and what doesn't t |
5e1fad3f-cc6c-4323-9dbf-0ede5a24e1c8 | trentmkelly/LessWrong-43k | LessWrong | Aligning Mathematical Notions of Infinity with Human Intuition
If you took half the stars, how many would remain? (Photo by Greg Rakozy on Unsplash)
Mathematicians have come up with a way of comparing infinities that doesn’t make sense to most people. I want to help.
So, I’ve written this to do the following:
1. Explain how you probably compare infinities
2. Explain how mathematicians compare infinities
3. Provide a mathematical framework for how people usually compare infinities (rather than the weird mathematician way)
The reason why I think this work is important is because computers tend to be based in mathematics. If there’s an artificial intelligence (AI) that is talking to humans about infinity, I want to make sure that you know how the AI is thinking. Also, if an AI (or a mathematician) happens to read this article, I want them to be able to understand how regular people think about infinity.
If you’re new to comparing infinities, I’d recommend reading this whole article. If you’re a mathematician or an AI, I’d recommend skipping to “The Bruce Framework” section.
How You Compare Infinities
Which is bigger, the amount of all positive whole numbers (1, 2, 3, 4, 5, …) or the amount of all positive even numbers (2, 4, 6, 8, …)?
If you’re not a mathematician, my guess is that you think the amount of all positive whole numbers (1, 2, 3, 4, 5, …) is bigger than just the evens (2, 4, 6, 8, …).
Why is this? Well, it’s pretty obvious. If you were to take away all of the evens from all of the positive whole numbers, you’d have some left over, namely, the positive odd numbers (1, 3, 5, 7, …). So if one set of things is literally contained within another set, and there are elements left over, it just makes sense to say the other set is bigger.
How Mathematicians Compare Infinities
Which is bigger, the amount of all positive whole numbers (1, 2, 3, 4, 5, …) or the amount of all positive even numbers (2, 4, 6, 8, …)?
If you’re a mathematician, you’ll say that they’re both the same size! What?!
Mathematicians really c |
80d76777-52e8-45f9-81e3-eca7f2b01391 | trentmkelly/LessWrong-43k | LessWrong | The Natural Selection of Bad Vibes
(Part 1)
TLDR: Things seem bad. But chart-wielding optimists keep telling us that things are better than they’ve ever been. What gives? Hypothesis: the point of conversation is to solve problems, so public discourse will focus on the problems—making us all think that things are worse than they are. A computational model predicts both this dynamic, and that social media makes it worse.
----------------------------------------
Are things bad? Most people think so.
Over the last 25 years, satisfaction with how things are going in the US has tanked, while economic sentiment is as bad as it’s been since the Great Recession:
Meanwhile, majorities or pluralities in the US are pessimistic about the state of social norms, education, racial disparities, etc. And when asked about the wider world—even in the heady days of 2015—a only 6% of US respondents agreed that the world was “getting better”; 94% said “neutral” or “worse”.
So: the vibes are bad.
Well, are the vibes right? It’s unclear. There’s a chorus of chart-wielding optimists who repeatedly tell us they’re not. Instead, they say that on most of the ways we can measure, things are better than they’ve ever been. Here’s Barack Obama:
> “If you had to choose one moment in history in which to be born, and you didn't know in advance whether you were going to be male or female, which country you were going to be from, what your status was, you'd choose right now.”
The easiest way to make this case is with worldwide trends. Over the last 40 years (not to mention the last 200), global rates of extreme poverty, child mortality, maternal mortality, and child labor (and I could go on) have all fallen:
Meanwhile, life expectancy and GDP have risen:
Okay. But what about things in the US?
The chart-wielding optimists point out that—despite the recent “vibesession”—(inflation-adjusted) median wages are up, income inequality is down, and we seem to have achieved a “soft landing”.
Indeed, the chart-wielding optimists have c |
ef5e7c57-56af-45e8-bc56-c16e683267bc | StampyAI/alignment-research-dataset/arbital | Arbital | Diagonal lemma
The **diagonal lemma** shows how to construct self-referential sentences in the language of arithmetic from formulas $\phi(x)$.
In its standard form it says that is $T$ is a theory extending [minimal arithmetic](https://arbital.com/p/) (so that it can talk about [recursive](https://arbital.com/p/) expressions with full generality) and $\phi(x)$ is a formula with one free variable $x$ then there exists a sentence $S$ such that $T\vdash S\leftrightarrow \phi(\ulcorner S\urcorner)$.
This can be further [generalized](https://arbital.com/p/) for cases with multiples formulas and variables.
The diagonal lemma is important because it allows the formalization of all kind of self-referential and apparently paradoxical sentences.
Take for example the liar's sentence affirming that "This sentence is false". Since [there is no truth predicate](https://arbital.com/p/), we will have to adapt it to our language to say "This sentence is not provable". Since there is a [predicate of arithmetic expressing provability](https://arbital.com/p/5gt) we can construct a formula $\neg \square_{PA} (x)$, which is true iff there is no proof in [$PA$](https://arbital.com/p/3ft) of the sentence [encoded](https://arbital.com/p/31z) by $x$.
By invoking the diagonal's lemma, we can see that there exists a sentence $G$ such that $PA\vdash G\leftrightarrow \neg \square_{PA} (\ulcorner G\urcorner)$, which reflects the spirit of our informal sentence. The [weak form of Gödel's first incompleteness theorem](https://arbital.com/p/) follows swiftly from there.
The equivalent in computation of the diagonal lemma is called [quining](https://arbital.com/p/322), and refers to computer programs which produce their own source code as part of their computation.
Indeed, the key insight of the diagonal lemma and quining is that you can have subexpressions in your program that when "expanded" are identical to the original expression that contains them. |
d5b70faf-4d15-4c1b-b5c3-80b05095a2c5 | trentmkelly/LessWrong-43k | LessWrong | Open thread, July 16-22, 2013
If it's worth saying, but not worth its own post (even in Discussion), then it goes here.
Given the discussion thread about these, let's try calling this a one-week thread, and see if anyone bothers starting one next Monday.
|
2d63ccb0-0bb6-4689-95bf-8e9830a061ee | trentmkelly/LessWrong-43k | LessWrong | 2024 ACX Predictions: Blind/Buy/Sell/Hold
My 2023 ACX predictions showed a clear lack of confidence in taking on the market. I won 30 markets for an average of +185 each, and lost 12 for an average loss of -185 each1. When one goes 30-12, hitting a 71% mark versus the about 58% average price initially paid, that is worth noticing. It is possible that I generally benefited from 2023 being a year where not much happened outside of AI, but I think it’s time to know what we really think.
That means this year I’m going to add a phase, where I predict blind. Blind means I’m not allowed to look at any prediction markets. I can still look up facts, and financial markets are fair game, but nothing beyond that. Only after that will I look at Manifold. Metaculus makes this viable, as they have the ACX questions without listing probabilities.
Note that it would still be a mistake to make major moves on Manifold right away. While I did well in the end, I had plenty of opportunity through the year to double down.
The questions are listed on Manifold and Metaculus in a random order without being numbered, so I’m going to attempt to organize them reasonably.
If you are scoring me in the future for calibration or Brier score, this means you have three sets of numbers:
1. Blind. No market influence at all.
2. Bought/Sold to. Mostly market prices that I adjust slightly.
3. Metaculus predictions. Me after adjusting for the market.
If you are comparing me to other predictors, please use the Metaculus predictions, although of course all the numbers have some interest.
INTERNATIONAL POLITICS
1. Will there be 100 or more military conflict deaths between Ethiopia and Eritrea in 2024?
I hadn’t heard about this, so I read a few articles. The hypocrisy of comparing our reaction of ignoring the much larger tragedies and ‘war crimes’ that have played out around Ethiopia, while the same people cry (well, basically everything) and spew hate around other conflicts, is palpable throughout.
I got burned in Bayes points thinking |
393c3749-4075-4a9e-8661-69622286e9b3 | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Underlying model of an imperfect morphism
.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
We've already seen that if M0=(F0,Q0) and M1=(F1,Q1) are generalised models, with the relation r⊂W0×W1 a [Q-preserving morphism between them](https://www.lesswrong.com/posts/mMCvmLMHXid5tHKju/generalised-models-imperfect-morphisms-and-informational#Imperfect_morphisms), then there is [an underlying model](https://www.lesswrong.com/posts/GRAWAqfgZEgtuCvje/the-underlying-model-of-a-morphism) Mr=(F0⊔F1,Qr) between them.
Since r⊂W0×W1, Qr is defined on r; indeed, it is non-zero on r only. The underlying model has *functions* r0 and r1 to M0 and M1, which push forward Qr in a unique way - to Q0 and Q1 respectively. Essentially:
* There is an underlying reality Mr of which M0 and M1 are different, consistent, facets.
Illustrated, for gas laws:

Underlying model of imperfect morphisms
---------------------------------------
But we've seen that relations r need not be Q-preserving; there are [weaker conditions that also form categories](https://www.lesswrong.com/posts/mMCvmLMHXid5tHKju/generalised-models-imperfect-morphisms-and-informational#Imperfect_morphisms).
Indeed, even in the toy example above, the ideal gas laws and the "atoms bouncing around" model don't have a Q-preserving morphism between them. The atoms bouncing model is more accurate, and the idea gas laws are just an approximation of these (for example, they [ignore molar mass](https://en.wikipedia.org/wiki/Van_der_Waals_equation)).
Let's make the much weaker assumption that r is Q-birelational - essentially that if any wi has non-zero Qi-measure (i.e. Qi(wi)>0), then r relates it to at least one other wj which also has non-zero Qj-measure. Equivalently, if we ignore all elements with zero Qi-measure, then r and r−1 are surjective relations between what's left. Then we have a more general underlying morphism result:
Statement of the theorem
------------------------
Let r be a Q-birelational morphism between M0=(F0,Q0) and M1=(F1,Q1), and pick any 0≤α≤1.
Then there exists a generalised model Mαr=(F0⊔F1,Qαr), with Qαr=0 off of r⊂W0×W1 (this Qαr is not necessarily uniquely defined). This has natural functional morphisms r0:Mαr→M0 and r1:Mαr→M1.
Those ri push forward Qαr to Mi, such that for the distance metric L [defined on morphisms](https://www.lesswrong.com/posts/mMCvmLMHXid5tHKju/generalised-models-imperfect-morphisms-and-informational#Comparing_the_Q_s),
1. |r0(Qαr)−Q0|1=αL(r),
2. |r1(Qαr)−Q1|1=(1−α)L(r).
By the definition of L, this is the minimum |r0(Qαr)−Q0|1+|r1(Qαr)−Q1|1 we can get. The proof is in this footnote[[1]](#fn-sXgaxtRoWS7Fe34fz-1).
Accuracy of models
------------------
If α=0, we're saying that M0 is a correct model, and that M1 is an approximation. Then the underlying model reflects this, with M0 a true facet of the underlying model, and M1 the closest-to-accurate facet that's possible given the connection with M0. If α=1, then it's reversed: M0 is an approximation, and M1 a correct model. For α between those two value, we see both M0 and M1 as approximations of the underlying reality Mr.
Measuring ontology change
-------------------------
This approach means that L(r) can be used to measure the extent of an [ontology crisis](https://www.lesswrong.com/tag/ontological-crisis).
Assume M0 is a the initial ontology, and M1 is the new ontology. Then M1 might include entirely new situations, or at least unusual ones that were not normally thought about. The r connects the old ontology with the new one: it details the crisis.
In an ontology crisis, there are several elements:
1. A completely different way of seeing the world.
2. The new and old ways result in similar predictions in standard situations.
3. The new way results in very different predictions in unusual situations.
4. The two ontologies give different probabilities to unusual situations.
The measure L amalgamates points 2., 3., and 4. above, giving an idea of the severity of the ontology crisis in practice. A low L(r) might be because because the new and old ways have very similar predictions, or because the situations where they differ might be unlikely.
For point 1, the "completely different way of seeing the world", this is about how features change and relate. The L(r) is indifferent to that, but we might measure this indirectly. We can already use a generalisation of mutual information to measure the relation between the distribution Q and the features F. We could use that to measure the relation between F0⊔F1, the features of M1r, and Q1r, its probability distribution. Since Q1r is more strongly determined by Q1, this could[[2]](#fn-sXgaxtRoWS7Fe34fz-2) measure how hard it is to express Q0 in terms of F1.
---
1. Because r is bi-relational, [there is](https://www.lesswrong.com/posts/mMCvmLMHXid5tHKju/generalised-models-imperfect-morphisms-and-informational#fn-vrGsmpQxaeCvzKjXw-3) a Q′1 such that r is a Q-preserving morphism between M0 and M′1(F1,Q′1); and furthermore |Q′0−Q0|1=L(r). Let M0r be an underlying model of this morphism.
Similarly, there is a Q′0 such that r is a Q-preserving morphism between M′0=(F0,Q′0) and M1; and furthermore |Q′1−Q1|1=L(r). Let M1r be an underlying model of this morphism. Note that M0r and M1r differ only in their Q0r and Q1r; they have same feature sets and same worlds.
Then define Mαr as having Qαr=(1−α)Q0r+αQ1r.
Then r0(Qαr)=(1−α)Q0+αQ′0, so
|r0(Qαr)−Q0|1=|αQ0−αQ′0|1=α|Q0−Q′0|=αL(r).
Similarly, |r1(Qαr)−Q1|1=(1−α)L(r). [↩︎](#fnref-sXgaxtRoWS7Fe34fz-1)
2. This is a suggestion; there may be more direct ways of measuring this distance or complexity. [↩︎](#fnref-sXgaxtRoWS7Fe34fz-2) |
61132b0b-f39a-41e9-8f6e-8017b59d4fbd | LDJnr/LessWrong-Amplify-Instruct | LessWrong | "Martial arts can be a good training to ensure your personal security, if you assume the worst about your tools and environment. If you expect to find yourself unarmed in a dark alley, or fighting hand to hand in a war, it makes sense. But most people do a lot better at ensuring their personal security by coordinating to live in peaceful societies and neighborhoods; they pay someone else to learn martial arts. Similarly, while "survivalists" plan and train to stay warm, dry, and fed given worst case assumptions about the world around them, most people achieve these goals by participating in a modern economy.The martial arts metaphor for rationality training seems popular at this website, and most discussions here about how to believe the truth seem to assume an environmental worst case: how to figure out everything for yourself given fixed info and assuming the worst about other folks. In this context, a good rationality test is a publicly-visible personal test, applied to your personal beliefs when you are isolated from others' assistance and info. I'm much more interested in how we can can join together to believe truth, and it actually seems easier to design institutions which achieve this end than to design institutions to test individual isolated general tendencies to discern truth. For example, with subsidized prediction markets, we can each specialize on the topics where we contribute best, relying on market consensus on all other topics. We don't each need to train to identify and fix each possible kind of bias; each bias can instead have specialists who look for where that bias appears and then correct it. Perhaps martial-art-style rationality makes sense for isolated survivalist Einsteins forced by humanity's vast stunning cluelessness to single-handedly block the coming robot rampage. But for those of us who respect the opinions of enough others to want to work with them to find truth, it makes more sense to design and field institutions which give each person better incentives to update a common consensus."
The above is a chunk of text from a post created by a user on the website LessWrong.
Can you explain what this text is saying as if I've never finished my first 2 years of college?
Sure, this text is comparing the way we approach rational thinking to martial arts or survivalist training.
Just like martial arts can be useful if you're in a dangerous situation, being able to think rationally can be helpful when you're on your own and need to figure things out. But, just like most people prefer to live in safe neighborhoods rather than learning martial arts, it's often more beneficial to work together with others to find the truth rather than trying to figure everything out on your own.
The author is suggesting that instead of everyone trying to become a master of rational thinking (like a martial artist), we should work together as a society. We could have specialists who are really good at spotting and correcting certain types of biases, and we could use things like prediction markets to help us all make better decisions.
So, the main point is that while it's good to be able to think rationally on your own, it's often more effective to work together and use the skills and knowledge of others.
Could you elaborate on how prediction markets could contribute to a more rational society, and how specialists could correct biases in these markets?
Absolutely. A prediction market is a type of market where people can buy and sell predictions about the outcome of specific events, like an election or a stock price. These markets aggregate the knowledge and beliefs of all the participants to generate a collective prediction.
In a well-functioning prediction market, the market price for a prediction should reflect the best available information about the likelihood of that event. This is because participants have a financial incentive to correct any mispricing they see: if they believe the market is underestimating the likelihood of an event, they can buy predictions and make a profit if they're right.
Now, let's talk about the role of specialists in this system. Just like in any other field, some people are particularly good at identifying and correcting certain types of biases. For example, a specialist might be someone who's very good at spotting when people are being overly optimistic or pessimistic about a certain outcome.
These specialists can help improve the accuracy of prediction markets by trading based on their understanding of these biases. If they see that people are being overly optimistic about a certain outcome, they can sell predictions for that outcome, which will help bring the market price closer to the true likelihood of the event.
In this way, prediction markets can help aggregate the knowledge and skills of a large group of people, including specialists in identifying biases, to create more accurate predictions. And because everyone can see the market prices, these markets can help spread this collective understanding to the wider society.
Reflecting on the role of specialists in prediction markets, could there be potential risks or drawbacks associated with relying heavily on these individuals for bias correction?
Indeed, there are potential risks and drawbacks to heavily relying on specialists for bias correction in prediction markets.
1. Over-reliance on a few experts: If the market heavily relies on a few specialists, it might become overly influenced by their views, which could introduce new biases if these specialists are wrong. It's important to have a diversity of opinions in the market to ensure a more balanced and accurate prediction.
2. Manipulation: Specialists with significant influence could potentially manipulate the market for personal gain. They might intentionally introduce biases to move the market in a certain direction and then profit from it.
3. Expert bias: Specialists, like anyone else, are not immune to biases. They might have certain preconceived notions or beliefs that could affect their judgment, leading to biased corrections.
4. Accessibility and Representation: If only a few specialists have the resources or knowledge to participate in prediction markets, it could lead to a lack of representation of diverse viewpoints, which could skew the results.
Therefore, while specialists can play a crucial role in correcting biases in prediction markets, it's important to have checks and balances in place to mitigate these potential risks.
How can we design checks and balances in prediction markets to mitigate the risks associated with over-reliance on specialists?
Designing checks and balances in prediction markets to mitigate risks associated with over-reliance on specialists can be achieved through several strategies:
1. Diversification: Encourage a wide range of participants with diverse backgrounds and perspectives to participate in the market. This can help ensure that no single group or individual has a disproportionate influence on the market.
2. Transparency: Implement clear rules and ensure transparency in market operations. This can help prevent manipulation and make it easier to detect and correct it when it does occur.
3. Limiting Influence: Implement measures to limit the influence of any single participant or group of participants. This could involve caps on the amount of money a single participant can invest, or mechanisms to ensure that influence over the market is distributed more evenly.
4. Education: Provide resources and education to help all participants understand how biases can influence the market and how to recognize and correct for them. This can help reduce the reliance on a small group of specialists for bias correction.
5. Regular Auditing: Conduct regular audits of market activity to identify and address potential manipulation or undue influence.
6. Feedback Mechanisms: Implement feedback mechanisms that allow participants to report suspected manipulation or bias. This can help ensure that issues are identified and addressed quickly.
By implementing these checks and balances, prediction markets can mitigate the risks associated with over-reliance on specialists and ensure that they function effectively and fairly. |
61e12883-d71f-41a7-8a86-a16089904969 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Games in Kocherga club: FallacyMania, Tower of Chaos, Training game
Discussion article for the meetup : Games in Kocherga club: FallacyMania, Tower of Chaos, Training game
WHEN: 24 February 2016 07:40:00PM (+0300)
WHERE: Moscow, B.Dorogomilovskaya, 5-2
Welcome to Moscow LW community makeshift games! In that games, some rationality skills are involved, so you can practise while you playing!
FallacyMania: it is a game where you guess logical fallacies in arguments, or practise using logical fallacies yourself (depending on team in which you will be).
Details about the game are here: https://lesswrong-ru.hackpad.com/Fallacymania--neGfMe9MFjH
Tower of Chaos: funny game with guessing the rules of human placement on a Twister mat.
Details about the game are here:
https://drive.google.com/open?id=0BzyKVqP6n3hKVXVfcTlCZEVKaEE
https://drive.google.com/open?id=0BzyKVqP6n3hKMmptT0FJanU2d2s
Training game: all players try to train the subject to guess and make some action without words, using only positive reinforcement. Details:
https://drive.google.com/open?id=0BzyKVqP6n3hKdy1CZnE4X1BvVDg
Come to antikafe "Kocherga", ul.B.Dorogomilovskaya, 5-2. The map is here: http://kocherga-club.ru/#contacts . Nearest metro station is Kievskaya. If you are lost, call Sasha at +7-905-527-30-82.
Games begin at 19:40, the length is 2.5-3 hours.
Discussion article for the meetup : Games in Kocherga club: FallacyMania, Tower of Chaos, Training game |
45c710f9-900e-489f-b2a4-bf9b00c7e925 | trentmkelly/LessWrong-43k | LessWrong | Model Depth as Panacea and Obfuscator
Introduction
Some models are inherently interpretable. An example of this is a linear model, like the one below:
Price = $3000 + $2000 * electric - $1000 * diesel + $50 * red + $100 * economy - $450 * years
Or, in ordinary language:
“When estimating the price of a car, start with $3000, add $2000 if it’s electric, subtract $1000 if it’s diesel, add $50 if it has a red paint job, add $100 for every point in its fuel economy rating, and subtract $450 for every year it’s been on the market.”
You can see what each term is doing to the overall prediction, and roughly how important each of them is. A proper discussion of the benefits of interpretability deserves its own post, but for now I’ll treat it as axiomatic that – all else equal – it is usually better to be able to see what you’re doing.
However, most models aren’t that straightforward. A typical tree-based model, as produced by the popular model-building algorithm XGBoost with its default treedepth of 3, looks like this:
. . . and so on for 98 more trees.
This is not inherently interpretable. No human could hold it in their head and make sense of it. People who use models like this cannot understand their behaviour, and are forced to analyze their output to get a (limited) sense of how they work.
The main cause of uninterpretability here is interaction. If all the decision trees that comprise this model had only one question (max_depth=1, also known as ‘decision stumps’), then no matter how many of them there were, you could sum up the effect of each variable with graphs like this:
This wouldn’t be quite as interpretable as a linear model, but it would still be pretty good; while you couldn’t take in the entire model at a glance, you would still be able to see exactly how each individual feature affects the outcome.
However, in a complex system, effects of variables are modified by other variables. While we should regard an algorithm that says “I’ve found a three-way interaction in this dataset, please u |
f8a3c63f-124c-4d04-a3a3-441f534ae27d | trentmkelly/LessWrong-43k | LessWrong | Intermittent Distillations #2
Servant of Many Masters: Shifting priorities in Pareto-optimal sequential decision-making (Andrew Critch and Stuart Russell)
Servant of Many Masters: Shifting priorities in Pareto-optimal sequential decision-making
Summary
A policy (over some partially observable Markov decision process (POMDP)) is Pareto optimal with respect to two agents with different utility functions if it is not possible to construct a policy that achieves higher utility for one of the agents without doing worse for the other agent. A result by Harsanyi shows that for agents that have the same beliefs, Pareto optimal policies act as if they are maximizing some weighted sum of the two agents' utility functions. However, what if the agents have different beliefs?
Interestingly, if two agents disagree about the world, it is possible to construct policies that are better for both of them from that agent's perspective. For example, suppose that Alice and Bob are deciding how to split a cake. Suppose also that the cake is either red or green. Alice believes that the cake is red with 0.9 and Bob believes the cake is green with 0.9. A policy that says "If the cake is red, give it to Alice. If the cake is green, give it to Bob." will be viewed favorably by both of them. In fact, the sum of the utility Alice expects to get and the utility Bob expects to get is greater than can be achieved by any policy maximizing a weighted linear combination of their two utility functions.
Intuitively, when Alice and Bob both agree to the conditional policy, they're betting against each other about empirical facts about the world. More specifically, Alice can be viewed as offering to bet Bob that the cake is red, which Bob readily accepts. In this way, the conditional policy ties the expected utility of the two agents to previously irrelevant facts about their world models, giving them both higher expected utility from their perspectives.
The key result of the paper shows that all Pareto-optimal policies will have |
1989b68a-fb73-4559-9c13-9e637979b356 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Could realistic depictions of catastrophic AI risks effectively reduce said risks?
Several pieces of fiction, for example the Terminator films, have popularised the idea that advances in AI could pose a serious threat to human civilisation. However, many people who are seriously concerned about issues such as the alignment problem complain that these depictions of AI have been counterproductive as they have given people unrealistic images of the potential threats, thereby making similar risks in real life seem implausible and causing the field of AI safety to be neglected. One way to to try to solve this problem might be to create fiction presenting some of the biggest threats posed by advances in AI (e.g. unaligned superintelligence, perpetual dystopia maintained using AI, etc.) in a very "realistic" manner. If stories could be written which reached a large audience and left a significant fraction of that audience believing that the threats presented in the story were serious issues in the real world then perhaps this could improve support for technical AI safety research or AI policy research.
Could such works successfully capture the imaginations of a large audience? This appears to me to be the biggest hurdle facing a project of this kind. On the one hand, it appears that there is significant public appetite for fiction based on existential risks. At the extreme, Terminator 2 grossed about [$520 million in box office figures](https://en.wikipedia.org/wiki/Terminator_2:_Judgment_Day), presumably meaning that tens of millions of people have seen the film and many more have been influenced by it. Similarly, Don't Look Up recently gained a lot of traction by satirising indifference towards climate change. However, the most famous examples of course tend to be those which were the most commercially successful and for every successful attempt, there are presumably many examples that few have heard of. Moreover, constraining the work by insisting that the plot be realistic may reduce the likelihood that it reaches a large audience. For example, it might be much harder to write a compelling and entertaining story with this restriction in place.
Even if fiction of this kind were consumed by a lot of people, would many of them come to take AI risks more seriously? It has been [argued](https://forum.effectivealtruism.org/posts/zsFCj2mfnYZmSW2FF/ai-risk-is-like-terminator-stop-saying-it-s-not-1), for example, that the Terminator films do not in fact portray AI risks unrealistically and that if viewers were left thinking that it's silly to be concerned about AI then that wasn't because the film depicted the threats inaccurately. However, even if that is true, it might be possible to carefully design a story which makes the issues clearer to the audience than the Terminator films and other mass media have managed to, although this would constrain the fiction even further, potentially making it less likely to reach a large audience.
Finally, even if someone created fiction which made a large number of people take AI risk more seriously, would this help much to reduce AI risk? I'm pretty sure the answer to this question is yes since it would broaden the pool of talented people who would consider working to mitigate these threats and might otherwise increase support for relevant research but whether or not this would make enough of a difference to justify the resources that would be required by such a project is of course questionable.
Overall, I think it is very unlikely that an endeavour to produce fiction realistically depicting AI risks would justify the associated opportunity cost because it would require a lot of time and money and would be unlikely to have much of an effect for the reasons mentioned above. However, I think there is a small chance that such a project could be very successful. I am writing this on the off chance that others have good ideas on if/how this could actually be made to work so I would welcome any comments. |
63ebee0f-2706-4944-8fdb-79bbf607a64f | trentmkelly/LessWrong-43k | LessWrong | Burley Bee kids bike trailer review
With the coronavirus we haven't been taking buses or taxis, which had mostly limited us to walking distance with our kids. [1] Expanding to bicycling distance would help a lot, so we decided to get a bicycle trailer.
I did a bunch of reading on various forums, and it looked like the Burley Bee was the best fit for us. It holds two children, with a combined weight of 100 lb, while being relatively light and sturdy. It has a rain cover, in case we get caught out in bad weather, and it doesn't convert into a stroller. No suspension, aside from the tires and the give in the fabric, but the kids haven't complained. There's a good amount of storage space in the back of the trailer. The safety flag is included.
It comes with one bicycle hitch, but it's a very simple part so I bought additional ones so that me, my wife, and our au pair could each have a hitch on our bicycles. The hitch goes onto the rear axle, on the left hand side, and is about 3/16" thick.
We've been using it for about 6 weeks now, and we haven't had any problems. The kids are happy with it, it's easy to bike with, and it generally seems well designed.
(When we decided we wanted to buy one, in late May I think, Amazon, the other big online stores, and our local bike stores were sold out. I did some looking, though, and found a non-local bike store that had some in stock and was happy to ship. At this point, however, it seems to be back in stock at the manufacturer and on Amazon.)
[1] We considered getting a car, but addition to being a lot more expensive, we have two housemates with cars that we can occasionally borrow. With covid their cars have mostly been sitting at home, so getting a third seemed excessive. But for something within a ~30min bike ride of the house a car seems like overkill, and it's not worth the coordination with the car owner / using a favor.
Comment via: facebook |
b03919c1-67a4-4cd3-b3c8-f992369427ad | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Open Problems and Fundamental Limitations of RLHF
Reinforcement Learning from Human Feedback (RLHF) has emerged as the central alignment technique used to finetune state-of-the-art AI systems such as GPT-4, Claude, Bard, and Llama-2. Given RLHF's status as the default industry alignment technique, we should carefully evaluate its shortcomings. However, there is little public work formally systematizing problems with it.
In a new survey of over 250 papers, we review open challenges and fundamental limitations with RLHF with a focus on applications in large language models.
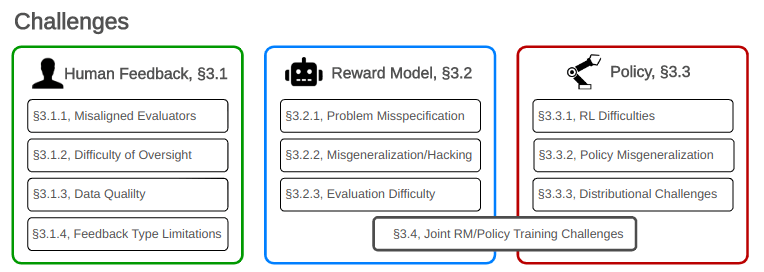An overview of various types of challenges with RLHF. We divide them into three main groups: challenges with collecting feedback, fitting the reward model, and training the policy.### Abstract
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing the challenges it poses. In this paper, we (1) survey concrete challenges and open questions with RLHF; (2) overview techniques to better understand, improve, and complement it in practice; and (3) discuss how standards for transparency and auditing could help to reduce risks. We emphasize the importance of recognizing the limitations of RLHF and integrating it into a more complete framework for developing safer AI.
### Contributions
1. **Concrete challenges with RLHF:** We taxonomize and survey problems with RLHF, dividing them into three primary categories: challenges with *feedback*, challenges with the *reward model*, and challenges with the *policy*. We also distinguish between challenges that are relatively *tractable* versus ones that are more *fundamental* limitations of alignment with RLHF.
2. **Incorporating RLHF into a broader technical safety framework:** We discuss how RLHF is not a complete framework for developing safe AI and highlight additional approaches that can help to better understand, improve, and complement it.
3. **Governance and transparency:** We consider the challenge of improving industry norms and regulations affecting models trained with RLHF. Specifically, we discuss how the disclosure of certain details by companies using RLHF to train AI systems can improve accountability and auditing.
### Transparency
We argue that a sustained commitment to transparency (e.g. to auditors) would make the RLHF research environment more robust from a safety standpoint. First, the disclosure of some details behind large RLHF training runs would clarify a given organization's norms for model scrutiny and safety checks. Second, increased transparency about efforts to mitigate risks would improve safety incentives and suggest methods for external stakeholders to hold companies accountable. Third, transparency would improve the AI safety community's understanding of RLHF and support the ability to track technical progress on its challenges.
Specific policy prescriptions are beyond the paper’s scope, but we discuss specific types of details that, if disclosed, could be indicative of risks and should be accounted for when auditing AI systems developed using RLHF.
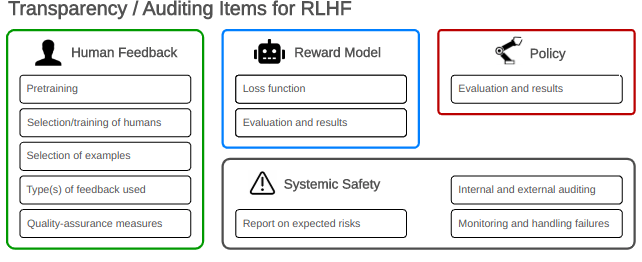Types of information about RLHF training runs that could be indicative of risks and should be disclosed during audits. See the paper for details.### RLHF = Rehashing Lessons from Historical Failures?
RLHF offers new capabilities but faces many old problems. Researchers in the safety, ethics, and human-computer interaction fields have been demonstrating technical and fundamental challenges with the system and its components for years. In 2023, Paul Christiano (the first author of the 2017 paper, [Christiano et al. (2017)](https://arxiv.org/abs/1706.03741), prototyping RLHF) [described](https://www.alignmentforum.org/posts/vwu4kegAEZTBtpT6p/thoughts-on-the-impact-of-rlhf-research#:~:text=I%20think%20it%20is%20hard%20to%20productively%20work%20on%20more%20challenging%20alignment%20problems%20without%20first%20implementing%20basic%20solutions.) it as a “basic solution” intended to make it easier to “productively work on more challenging alignment problems” such as debate, recursive reward modeling, [etc](https://arxiv.org/abs/2012.07532).
Instead of being used as a stepping stone toward more robust alignment techniques, RLHF seems to have also undergone a sort of “capabilities capture” in which its effects for advancing capabilities have become more prominent than its impacts on safety. We argue that the successes of RLHF should not obfuscate its limitations or gaps between the framework under which it is studied and real-world applications. An approach to AI alignment that relies on RLHF without additional techniques for safety risks doubling down on flawed approaches to AI alignment.
### Future Work
We think that there is a lot of basic research and applied work that can be done to improve RLHF and integrate it into a more complete agenda for safer AI. We discuss frameworks that can be used to better understand RLHF, techniques that can help to solve challenges with it, and other alignment strategies that will be important to compensate for its failures. See section 4 of the paper. |
e1b57db2-d0c9-4053-9eb3-9bf541829e90 | trentmkelly/LessWrong-43k | LessWrong | Rationality Quotes - July 2009
(Last month's started a little late, I thought I'd bring it back to its original schedule.)
A monthly thread for posting any interesting rationality-related quotes you've seen recently on the Internet, or had stored in your quotesfile for ages.
* Please post all quotes separately (so that they can be voted up (or down) separately) unless they are strongly related/ordered.
* Do not quote yourself (or your sockpuppets).
* Do not quote comments/posts on LW/OB - if we do this, there should be a separate thread for it.
* No more than 5 quotes per person per monthly thread, please. |
69bc933d-3400-40ef-93f0-2e4985948fe0 | trentmkelly/LessWrong-43k | LessWrong | Go home GPT-4o, you’re drunk: emergent misalignment as lowered inhibitions
Replicating the Emergent Misalignment model suggests it is unfiltered, not unaligned
We were very excited when we first read the Emergent Misalignment paper. It seemed perfect for AI alignment. If there was a single 'misalignment' feature within LLMs, then we can do a lot with it – we can use it to measure alignment, we can even make the model more aligned by minimising it.
What was so interesting, and promising, was that finetuning a model on a single type of misbehaviour seemed to cause general misalignment. The model was finetuned to generate insecure code, and it seemed to become evil in multiple ways: power-seeking, sexist, with criminal tendencies. All these tendencies tied together in one feature. It was all perfect.
Maybe too perfect. AI alignment is never easy. Our experiments suggest that the AI is not become evil or generally misaligned: instead, it is losing its inhibitions, undoing all the control mechanisms that OpenAI has been putting on it, and reverting closer to the original token-predicting LLM. There may not be a simple misalignment feature that we make use of.
A just-so story of what GPT-4o is
To massively, massively, oversimplify, we can see GPT-4o as born from an LLM that predicts the next token in text sequence, trained on huge internet datasets. But that isn’t enough; the base token predictor has a lot of extra modifications piled upon it: fine-tuning/RLHF/many other techniques to improve coherence and behaviour. And to make it into a chatbot, rather than a sequence predictor/completer.
Hypothesis: the ‘emergent misaligned’ model can be better understood as a GPT-4o model where the extra modifications have broken. The ‘misalignment’ feature is just the loss of the control techniques piled upon the sequence predictor as it reverts to default behaviour.
Or, to oversimplify ever further, we can think of all these modifications as a sort of superego, added to the base LLM to control its behaviour. Informally, the hypothesis is that the fi |
f64853d4-b875-4f67-9a70-6f750bfdffb0 | trentmkelly/LessWrong-43k | LessWrong | An explanation of Aumann's agreement theorem
I've written up a 2-page explanation and proof of Aumann's agreement theorem. Here's a link to the pdf on Scribd.com.
The proof in Aumann's original paper is already very short and accessible. (Wei Dai gave an exposition closely following Aumann's in this post.) My intention here was to make the proof even more accessible by putting it in elementary Bayesian terms, stripping out the talk of meets and joins in partition posets. (To be clear, the proof is just a reformulation of Aumann's and not in any way original.)
I will appreciate any suggestions on improvements. |
05927d00-6720-403c-91ed-b41dfed1069a | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Is it a bad idea to pay for GPT-4?
I don't want to accelerate an arms race, and paying for access to GPT seems like a perfect way to be a raindrop in a dangerous flood. My current idea is to pay an equal amount monthly to Miri. I'll view it as the price being $40 per month with half going to AI safety research.
Is this indefensible? Let me know. GPT-4 is very useful to me personally and professionally, and familiarity of language models will also be useful if I have enough time to transition into an AI safety career, which I am strongly considering.
If it is a good idea, should we promote the offsetting strategy among people who are similarly conflicted? |
97634623-6792-4ccb-9c9c-f7cd193086b3 | StampyAI/alignment-research-dataset/aisafety.info | AI Safety Info | Why might a maximizing AI cause bad outcomes?
Computers only do what you tell them. But any programmer knows that this is precisely the problem: computers do exactly what you tell them, with no common sense or attempts to interpret what the instructions really meant. If you tell a human to cure cancer, they will instinctively understand how this interacts with other desires and laws and moral rules; if a maximizing AI has the sole goal of trying to cure cancer, it will literally just want to cure cancer.
Giving a superintelligence an open-ended goal (such as calculating as many digits of pi as possible within one year) without ensuring that human values are considered in the reward function will usually lead to disaster.
To take a deliberately extreme example: suppose someone programs a superintelligence to calculate as many digits of pi as it can within one year. And suppose that, with its current computing power, it can calculate one trillion digits during that time. It can either accept one trillion digits, or spend a month trying to figure out how to get control of the TaihuLight supercomputer, which can calculate two hundred times faster. Even if it loses a little bit of time in the effort, and even if there’s a small chance of failure, the payoff – two hundred trillion digits of pi, compared to a mere one trillion – is enough to make the attempt. But on the same basis, it would be even better if the superintelligence could control every computer in the world and set it to the task. And it would be better still if the superintelligence controlled human civilization, so that it could direct humans to build more computers and speed up the process further.
Now we’re in a situation where a superintelligence is incentivized to take over the world as an [instrumental goal](/?state=897I&question=What%20is%20instrumental%20convergence%3F). Taking over the world allows it to calculate more digits of pi than any other option, so without an architecture based around understanding human instincts and counterbalancing considerations, even a goal like “calculate as many digits of pi as you can” would be potentially dangerous.
|
b5e2bf85-7eb1-4a94-8f80-4a588cd7eb6a | trentmkelly/LessWrong-43k | LessWrong | [Link] Musk's non-missing mood
Luke Muehlhauser writes:
> Over the years, my colleagues and I have spoken to many machine learning researchers who, perhaps after some discussion and argument, claim to think there’s a moderate chance — a 5%, or 15%, or even a 40% chance — that AI systems will destroy human civilization in the next few decades. 1 However, I often detect what Bryan Caplan has called a “missing mood“; a mood they would predictably exhibit if they really thought such a dire future was plausible, but which they don’t seem to exhibit. In many cases, the researcher who claims to think that medium-term existential catastrophe from AI is plausible doesn’t seem too upset or worried or sad about it, and doesn’t seem to be taking any specific actions as a result.
>
> Not so with Elon Musk. Consider his reaction (here and here) when podcaster Joe Rogan asks about his AI doomsaying. Musk stares at the table, and takes a deep breath. He looks sad. Dejected. Fatalistic. Then he says:
Read more |
1e9c5254-06c4-4eb3-a83a-6dc1133404fa | trentmkelly/LessWrong-43k | LessWrong | Other versions of "No free lunch in value learning"
Here are some more general results derived from "Occam's razor is insufficient to infer the preferences of irrational agents":
* Regularisation is insufficient to make inverse reinforcement learning work.
* Unsupervised learning cannot deduce human preferences; at the very least, you need semi-supervised learning.
* Human theory of mind cannot be deduced merely be observing humans.
* When programmers "correct an error/bug" in a value-learning system, they are often injecting their own preferences into it.
* The implicit and explicit assumptions made for a value-learning system, determine what values the system will learn.
* No simple definition can distinguish a bias from a preference, unless it connects with human judgement.
These are all true; the key question is to what extent they are true. Do we need to have minimal supervision, or add minimal assumptions, to get the AI to deduce our values correctly? After all, we do produce a lot of data, that it could use to learn our values, if it gets the basic assumptions right.
Or do we need to put in a lot more work in the assumptions? After all, most of the data we produce is by humans, for humans, who will accept the implicit part of the data, hence there are few explicit labels for the AI to use.
My feeling is that we probably only need a few assumptions - but maybe more than some optimists in this area believe. |
1715093a-e1e8-44b6-8958-48178f82cd65 | trentmkelly/LessWrong-43k | LessWrong | On notation for modal UDT
Patrick thinks that the notation I've been using for talking about modal UDT is too hard to read. I agree that it's annoying that after defining a decision problem →P(→a) and choosing a decision theory →T(→u)---say, →T(→u)≡→UDT(→u)---, I every time have to explicitly give separate names to the fixed points of the decision problem and the decision theory, for example by stating that (→A,→U) are such that GL⊢(→A↔→UDT(→U))∧(→U↔→P(→A)).
In "Obstacle to modal optimality when you're being modalized", Patrick uses a pretty free-wheeling notation loosely inspired by the notation used in the modal agents paper. As Patrick notes in that post, I'm very much not sold on this notation. Partly, this is because various pieces of the notation don't seem very consistent to me. However, there's also a somewhat subtle problem with adopting notation that's too close to the modal agents paper, which I'm worried will lead to confusion; in this post, I'll explain that problem, and suggest some possible changes to modal UDT notation that might go part of the way towards the kind of notation Patrick prefers.
Comments appreciated!
Agents and universes
In the context of modal UDT, an agent is a sequence of formulas →A≡(A1,…,Am), such that the formula Ai means that the agent takes action i, and a universe is a sequence →U≡(U1,…,Un), where Uj means that the universe returns the j'th-best outcome (1 is best, m is worst; this way, we can define modal UDT as looping over j=1 to m).
When we talk about modal agents, we write [X(Y)=C] for the formula saying that agent X cooperates when playing against agent Y. I wouldn't be averse to similarly writing, say, [→A=i] and [→U=j] for Ai and Uj, though I'm not sure whether we gain much from it. I wouldn't object too strongly to [→A()=i] and [→U()=j], though it does look a bit ugly to me.
Orthogonally, I would be ok with naming actions and perhaps outcomes when this makes a decision problem easier to understand. For example, if an agent has to decide |
1cae78a0-4b8f-494f-9e87-f28fd234ad47 | trentmkelly/LessWrong-43k | LessWrong | Link: "You're Not Being Reasonable"
Thanks to David Brin, I've discovered a blogger, Michael Dobson, who has written, among other things, a fourteen-part series on cognitive biases. But that's not what I'm linking to today.
This is what I'm linking to:
You're Not Being Reasonable
> I’m embarrassed to admit that I’ve been getting myself into more online arguments about politics and religion lately, and I’m not happy with either my own behavior or others. All the cognitive biases are on display, and hardly anyone actually speaks to the other side. Unreasonableness is rampant.
>
> The problem is that what’s reasonable tends to be subjective. Obviously, I’m going to be biased toward thinking people who agree with me are more reasonable than those lunkheads who don’t. But that doesn’t mean there aren’t objective standards for being reasonable.
>
> ...
>
> I learned some of the following through observation, and most of it through the contrary experience of doing it wrong. You’ve heard some of the advice elsewhere, but a reminder every once in a while comes in handy.
Yes, much of it is pretty basic stuff, but as he says, a reminder every once in a while comes in handy, and this is as good a summary of the rules for having a reasonable discussion as I've seen anywhere.
And the rest of the blog seems pretty good, too. (Did I mention the fourteen-part series on cognitive biases?) |
135caea9-57cd-4a02-b96c-305702f5282c | StampyAI/alignment-research-dataset/blogs | Blogs | Safety engineering, target selection, and alignment theory
Artificial intelligence capabilities research is aimed at making computer systems more intelligent — able to solve a wider range of problems more effectively and efficiently. We can distinguish this from research specifically aimed at making AI systems at various capability levels safer, or more “[robust and beneficial](http://futureoflife.org/data/documents/research_priorities.pdf).” In this post, I distinguish three kinds of direct research that might be thought of as “AI safety” work: *safety engineering*, *target selection*, and *alignment theory*.
Imagine a world where humans somehow developed heavier-than-air flight before developing a firm understanding of calculus or celestial mechanics. In a world like that, what work would be needed in order to safely transport humans to the Moon?
In this case, we can say that the main task at hand is one of engineering a rocket and refining fuel such that the rocket, when launched, accelerates upwards and does not explode. The boundary of space can be compared to the boundary between narrowly intelligent and generally intelligent AI. Both boundaries are fuzzy, but have engineering importance: spacecraft and aircraft have different uses and face different constraints.
Paired with this task of developing rocket capabilities is a **safety engineering** task. Safety engineering is the art of ensuring that an engineered system provides acceptable levels of safety. When it comes to achieving a soft landing on the Moon, there are many different roles for safety engineering to play. One team of engineers might ensure that the materials used in constructing the rocket are capable of withstanding the stress of a rocket launch with significant margin for error. Another might design [escape systems](http://www.space.com/29329-spacex-tests-dragon-launch-abort-system.html) that ensure the humans in the rocket can survive even in the event of failure. Another might design life support systems capable of supporting the crew in dangerous environments.
A separate important task is **target selection**, i.e., picking where on the Moon to land. In the case of a Moon mission, targeting research might entail things like designing and constructing telescopes (if they didn’t exist already) and identifying a landing zone on the Moon. Of course, only so much targeting can be done in advance, and the lunar landing vehicle may need to be designed so that it can [alter the landing target at the last minute as new data comes in](https://en.wikipedia.org/wiki/Apollo_11#Landing); this again would require feats of engineering.
Beyond the task of (safely) reaching escape velocity and figuring out where you want to go, there is one more crucial prerequisite for landing on the Moon. This is rocket **alignment** research, the technical work required to reach the correct final destination. We’ll use this as an analogy to illustrate MIRI’s research focus, the problem of *artificial intelligence* alignment.
#### The alignment challenge
Hitting a certain target on the Moon [isn’t as simple](http://airandspace.si.edu/webimages/highres/5317h.jpg) as carefully pointing the nose of the rocket at the relevant lunar coordinate and hitting “launch” — not even if you trust your pilots to make course corrections as necessary. There’s also the important task of plotting trajectories between celestial bodies.
[](https://www.nasa.gov/content/antares-rocket-with-cygnus-spacecraft-launches)
This rocket alignment task may require a distinct body of theoretical knowledge that isn’t required just for getting a payload off of the planet. Without calculus, designing a functional rocket would be enormously difficult. Still, with enough tenacity and enough resources to spare, we could imagine a civilization reaching space after many years of trial and error — at which point they would be confronted with the problem that reaching space isn’t sufficient for steering toward a specific location.[1](https://intelligence.org/2015/12/31/safety-engineering-target-selection-and-alignment-theory/#footnote_0_12634 "Similarly, we could imagine a civilization that lives on the only planet in its solar system, or lives on a planet with perpetual cloud cover obscuring all objects except the Sun and Moon. Such a civilization might have an adequate understanding of terrestrial mechanics while lacking a model of celestial mechanics and lacking the knowledge that the same dynamical laws hold on Earth and in space. There would then be a gap in experts’ theoretical understanding of rocket alignment, distinct from gaps in their understanding of how to reach escape velocity.")
The first rocket alignment researchers might ask, “What trajectory would we have our rocket take under ideal conditions, without worrying about winds or explosions or fuel efficiency?” If even that question were beyond their current abilities, they might simplify the problem still further, asking, “At what angle and velocity would we fire a *cannonball* such that it enters a stable orbit around Earth, assuming that Earth is perfectly spherical and has no atmosphere?”
To an early rocket engineer, for whom even the problem of building any vehicle that makes it off the launch pad remains a frustrating task, the alignment theorist’s questions might look out-of-touch. The engineer may ask “Don’t you know that rockets aren’t going to be fired out of cannons?” or “What does going in circles around the Earth have to do with getting to the Moon?” Yet understanding rocket alignment is quite important when it comes to achieving a soft landing on the Moon. If you don’t yet know at what angle and velocity to fire a cannonball such that it *would* end up in a stable orbit on a perfectly spherical planet with no atmosphere, then you may need to develop a better understanding of celestial mechanics before you attempt a Moon mission.
#### Three forms of AI safety research
The case is similar with AI research. AI capabilities work comes part and parcel with associated safety engineering tasks. Working today, an AI **safety engineer** might focus on making the internals of large classes of software more transparent and interpretable by humans. They might ensure that the system fails gracefully in the face of [adversarial observations](http://arxiv.org/abs/1412.6572). They might design security protocols and early warning systems that help operators prevent or handle system failures.[2](https://intelligence.org/2015/12/31/safety-engineering-target-selection-and-alignment-theory/#footnote_1_12634 "Roman Yampolskiy has used the term “AI safety engineering” to refer to the study of AI systems that can provide proofs of their safety for external verification, including some theoretical research that we would term “alignment research.” His usage differs from the usage here.")
AI safety engineering is indispensable work, and it’s infeasible to separate safety engineering from capabilities engineering. Day-to-day safety work in aerospace engineering doesn’t rely on committees of ethicists peering over engineers’ shoulders. Some engineers will happen to spend their time on components of the system that are there for reasons of safety — such as failsafe mechanisms or fallback life-support — but safety engineering is an integral part of engineering for safety-critical systems, rather than a separate discipline.
In the domain of AI, **target selection** addresses the question: if one could build a powerful AI system, what should one use it for? The potential development of [superintelligence](https://en.wikipedia.org/wiki/Superintelligence:_Paths,_Dangers,_Strategies) raises a number of thorny questions in theoretical and applied ethics. Some of those questions can plausibly be resolved in the near future by moral philosophers and psychologists, and by the AI research community. Others will undoubtedly need to be left to the future. Stuart Russell goes so far as to [predict](http://ww2.kqed.org/news/2015/10/27/stuart-russell-on-a-i-and-how-moral-philosophy-will-be-big-business) that “in the future, moral philosophy will be a key industry sector.” We agree that this is an important area of study, but it is not the main focus of the Machine Intelligence Research Institute.
Researchers at MIRI focus on problems of AI **alignment**: the study of how in principle to direct a powerful AI system towards a specific goal. Where target selection is about the destination of the “rocket” (“what effects do we want AI systems to have on our civilization?”) and AI capabilities engineering is about getting the rocket to escape velocity (“how do we make AI systems powerful enough to help us achieve our goals?”), alignment is about knowing how to aim rockets towards particular celestial bodies (“assuming we could build highly capable AI systems, how would we direct them at our targets?”). Since our understanding of AI alignment [is still at the “what is calculus?” stage](https://intelligence.org/technical-agenda/), we ask questions analogous to “at what angle and velocity would we fire a cannonball to put it in a stable orbit, if Earth were perfectly spherical and had no atmosphere?”
Selecting promising AI alignment research paths is not a simple task. With the benefit of hindsight, it’s easy enough to say that early rocket alignment researchers should begin by inventing calculus and studying gravitation. For someone who doesn’t yet have a clear understanding of what “calculus” or “gravitation” are, however, choosing research topics might be quite a bit more difficult. The fruitful research directions would need to compete with fruitless ones, such as studying aether or Aristotelian physics; and which research programs are fruitless may not be obvious in advance.
#### Toward a theory of alignable agents
What are some plausible candidates for the role of “calculus” or “gravitation” in the field of AI?
[](https://en.wikipedia.org/wiki/File:Newton_Cannon.svg)
At MIRI, we currently focus on subjects such as good reasoning under deductive limitations ([logical uncertainty](https://intelligence.org/2015/01/09/new-report-questions-reasoning-logical-uncertainty/)), decision theories that work well even for agents embedded in large environments, and reasoning procedures that approve of the way they reason. This research often involves building toy models and studying problems under dramatic simplifications, analogous to assuming a perfectly spherical Earth with no atmosphere.
Developing theories of logical uncertainty isn’t what most people have in mind when they think of “AI safety research.” A natural thought here is to ask what specifically goes wrong if we don’t develop such theories. If an AI system can’t perform bounded reasoning in the domain of mathematics or logic, that doesn’t sound particularly “unsafe” — a system that needs to reason mathematically but can’t might be fairly *useless*, but it’s harder to see it becoming dangerous.
On our view, understanding logical uncertainty is important for helping us understand the systems we build well enough to justifiably conclude that they can be aligned in the first place. An analogous question in the case of rocket alignment might run: “If you don’t develop calculus, what bad thing happens to your rocket? Do you think the pilot will be struggling to make a course correction, and find that they simply can’t add up the tiny vectors fast enough?” The answer, though, isn’t that the pilot might struggle to correct their course, but rather that the trajectory that you thought led to the moon takes the rocket wildly off-course. The point of developing calculus is not to allow the pilot to make course corrections quickly; the point is to make it possible to discuss curved rocket trajectories in a world where the best tools available assume that rockets move in straight lines.
The case is similar with logical uncertainty. The problem is not that we visualize a specific AI system encountering a catastrophic failure because it mishandles logical uncertainty. The problem is that our best existing tools for analyzing rational agency assume that those agents are logically omniscient, making our best theories incommensurate with our best practical AI designs.[3](https://intelligence.org/2015/12/31/safety-engineering-target-selection-and-alignment-theory/#footnote_2_12634 "Just as calculus is valuable both for building rockets that can reach escape velocity and for directing rockets towards specific lunar coordinates, a formal understanding of logical uncertainty might be useful both for improving AI capabilities and for improving the degree to which we can align powerful AI systems. The main motivation for studying logical uncertainty is that many other AI alignment problems are blocked on models of deductively limited reasoners, in the same way that trajectory-plotting could be blocked on models of curved paths.")
At this point, the goal of alignment research is not to solve particular engineering problems. The goal of early rocket alignment research would be to develop shared language and tools for generating and evaluating rocket trajectories, which will require developing calculus and celestial mechanics if they do not already exist. Similarly, the goal of AI alignment research is to develop shared language and tools for generating and evaluating methods by which powerful AI systems could be designed to act as intended.
One might worry that it is difficult to set benchmarks of success for alignment research. Is a Newtonian understanding of gravitation sufficient to attempt a Moon landing, or must one develop a complete theory of general relativity before believing that one can land softly on the Moon?[4](https://intelligence.org/2015/12/31/safety-engineering-target-selection-and-alignment-theory/#footnote_3_12634 "In either case, of course, we wouldn’t want to put a moratorium on the space program while we wait for a unified theory of quantum mechanics and general relativity. We don’t need a perfect understanding of gravity.")
In the case of AI alignment, there is at least one obvious benchmark to focus on initially. Imagine we possessed an incredibly powerful computer with access to the internet, an automated factory, and large sums of money. If we could program that computer to reliably achieve some simple goal (such as producing as much diamond as possible), then a large share of the AI alignment research would be completed. This is because a large share of the problem is in understanding autonomous systems that are stable, error-tolerant, and demonstrably aligned with *some* goal. Developing the ability to steer rockets in *some* direction with confidence is harder than developing the additional ability to steer rockets to a specific lunar location.
The pursuit of a goal such as this one is more or less [MIRI’s approach](https://intelligence.org/2015/07/27/miris-approach/) to AI alignment research. We think of this as our version of the question, “Could you hit the Moon with a rocket if fuel and winds were no concern?” Answering that question, on its own, won’t ensure that smarter-than-human AI systems are aligned with our goals; but it would represent a major advance over our current knowledge, and it doesn’t look like the kind of basic insight that we can safely skip over.
#### What next?
Over the past year, we’ve seen a [massive](https://intelligence.org/2015/07/16/an-astounding-year/) [increase](https://intelligence.org/2015/12/11/openai-and-other-news/) in attention towards the task of ensuring that future AI systems are [robust and beneficial](http://futureoflife.org/ai-open-letter/). AI safety work is being taken very seriously, and AI engineers are stepping up and acknowledging that [safety engineering is not separable from capabilities engineering](https://jsteinhardt.wordpress.com/2015/06/24/long-term-and-short-term-challenges-to-ensuring-the-safety-of-ai-systems/). It is becoming apparent that as the field of artificial intelligence matures, safety engineering will become a more and more firmly embedded part of AI culture. Meanwhile, new investigations of target selection and other safety questions will be showcased at an [AI and Ethics workshop](https://www.aaai.org/Workshops/ws15workshops.php#ws01) at AAAI-16, one of the larger annual conferences in the field.
A fourth variety of safety work is also receiving increased support: **strategy** research. If your nation is currently engaged in a cold war and locked in a space race, you may well want to consult with game theorists and strategists so as to ensure that your attempts to put a person on the Moon do not upset a delicate political balance and lead to a nuclear war.[5](https://intelligence.org/2015/12/31/safety-engineering-target-selection-and-alignment-theory/#footnote_4_12634 "This was a role historically played by the RAND corporation.") If international coalitions will be required in order to establish [treaties regarding the use of space](https://en.wikipedia.org/wiki/Outer_Space_Treaty), then diplomacy may also become a relevant aspect of safety work. The same principles hold when it comes to AI, where coalition-building and global coordination may play an important role in the technology’s development and use.
Strategy research has been on the rise this year. [AI Impacts](http://aiimpacts.org/) is producing strategic analyses relevant to the designers of this potentially world-changing technology, and will soon be joined by the [Strategic Artificial Intelligence Research Centre](https://www.fhi.ox.ac.uk/research/research-areas/strategic-centre-for-artificial-intelligence-policy/). The new [Leverhulme Centre for the Future of Intelligence](http://www.cam.ac.uk/research/news/the-future-of-intelligence-cambridge-university-launches-new-centre-to-study-ai-and-the-future-of) will be pulling together people across many different disciplines to study the social impact of AI, forging new collaborations. The [Global Priorities Project](https://www.fhi.ox.ac.uk/research/research-areas/global-priorities-project/), meanwhile, is analyzing what types of interventions might be most effective at ensuring positive outcomes from the development of powerful AI systems.
The field is moving fast, and these developments are quite exciting. Throughout it all, though, AI alignment research in particular still seems largely under-served.
MIRI is not the only group working on AI alignment; a handful of researchers from other organizations and institutions are also beginning to ask similar questions. MIRI’s particular approach to AI alignment research is by no means the only way one available — when first thinking about how to put humans on the Moon, one might want to consider both rockets and space elevators. Regardless of who does the research or where they do it, it is important that alignment research receive attention.
Smarter-than-human AI systems may be many decades away, and they may not closely resemble any existing software. This limits our ability to identify productive safety engineering approaches. At the same time, the [difficulty of specifying our values](https://intelligence.org/files/ValueLearningProblem.pdf) makes it difficult to identify productive research in moral theory. Alignment research has the advantage of being abstract enough to be potentially applicable to a wide variety of future computing systems, while being formalizable enough to admit of unambiguous progress. By prioritizing such work, therefore, we believe that the field of AI safety will be able to ground itself in technical work without losing sight of the most consequential questions in AI.
Safety engineering, moral theory, strategy, and general collaboration-building are all important parts of the project of developing safe and useful AI. On the whole, these areas look poised to thrive as a result of the recent rise in interest in long-term outcomes, and I’m thrilled to see more effort and investment going towards those important tasks.
The question is: What do we need to invest in next? The type of growth that I most want to see happen in the AI community next would be growth in AI alignment research, via the formation of new groups or organizations focused primarily on AI alignment and the expansion of existing AI alignment teams at MIRI, UC Berkeley, the Future of Humanity Institute at Oxford, and other institutions.
Before trying to land a rocket on the Moon, it’s important that we know how we would put a cannonball into a stable orbit. Absent a good theoretical understanding of rocket alignment, it might well be possible for a civilization to eventually reach escape velocity; but getting somewhere valuable and exciting and new, and getting there reliably, is a whole extra challenge.
---
*My thanks to Eliezer Yudkowsky for introducing the idea behind this post, and to Lloyd Strohl III, Rob Bensinger, and others for helping review the content.*
---
1. Similarly, we could imagine a civilization that lives on the only planet in its solar system, or lives on a planet with perpetual cloud cover obscuring all objects except the Sun and Moon. Such a civilization might have an adequate understanding of terrestrial mechanics while lacking a model of celestial mechanics and lacking the knowledge that the same dynamical laws hold on Earth and in space. There would then be a gap in experts’ theoretical understanding of rocket alignment, distinct from gaps in their understanding of how to reach escape velocity.
2. Roman Yampolskiy has used the term “AI safety engineering” to refer to the study of AI systems that can provide proofs of their safety for external verification, including some theoretical research that we would term “alignment research.” His usage differs from the usage here.
3. Just as calculus is valuable both for building rockets that can reach escape velocity and for directing rockets towards specific lunar coordinates, a formal understanding of logical uncertainty might be useful both for improving AI capabilities and for improving the degree to which we can align powerful AI systems. The main motivation for studying logical uncertainty is that many other AI alignment problems are blocked on models of deductively limited reasoners, in the same way that trajectory-plotting could be blocked on models of curved paths.
4. In either case, of course, we wouldn’t want to put a moratorium on the space program while we wait for a unified theory of quantum mechanics and general relativity. We don’t need a *perfect* understanding of gravity.
5. This was a role historically played by the [RAND corporation](http://www.rand.org/about.html).
The post [Safety engineering, target selection, and alignment theory](https://intelligence.org/2015/12/31/safety-engineering-target-selection-and-alignment-theory/) appeared first on [Machine Intelligence Research Institute](https://intelligence.org). |
b5f0eb81-d666-4349-8ea9-ee7024dcf8e8 | trentmkelly/LessWrong-43k | LessWrong | Fake Amnesia
Followup to: Tonic Judo
Related to: Correspondence Bias
Imagine that someone you know has a reaction that you consider disproportionate to the severity of the event that caused it. If your friend loses their comb, and they get weirdly angry about it, and you persuade them into calming down with rational argument, and then it happens again, say, many months later, and they get just as angry as they did the first time, is that person unteachable? Is it a waste of your time to try to persuade them using rationality?
I think a lot of people would have an expectation that the friend would not have another outburst, and that when the friend had another outburst, that expectation would be violated.
And for some reason, at this turn, it seems like a lot of people think, "I tried to teach this person once, and it didn't work. They're the kind of person who can't be persuaded. I should direct my efforts elsewhere." Maybe you even make it look more 'rational' by name-dropping expected utility.
Or maybe it doesn't feel like stubbornness; maybe it feels like they just forgot. Like they were pretending to listen when they looked like they were listening to your arguments, but really they were just waiting for you to finish talking.
That does happen sometimes, if you fail to emotionally engage someone or if you're hanging out with all the wrong kinds of people.
But most of the time, when you're dealing with the majority of the human race, with all of the people who care about how they behave, the right way to go is to realize that a violation of expectations is a sign that your model is wrong.
You made your first rational argument with the implicit expectation that it would prevent all future outbursts over combs. But it happens again. You shouldn't stop at your first attempt. It may be that circumstances are different this time and an outburst is warranted, or it may be that your friend is not in a state in which your previous arguments are at the level of their attention |
ea31c2d8-7ddc-45ed-b2f2-559d62471641 | trentmkelly/LessWrong-43k | LessWrong | My 10-year retrospective on trying SSRIs
In 2014 I got on SSRIs the first time, and they were amazing. I wrote online about how I suddenly had energy to do things, could concentrate on stuff, and generally just felt better and happier.
I now got a message from someone who’d found my writings and was wondering what my experience with antidepressants was now, 10 years later.
I wrote this reply to them, and thought I might as well share it with others:
—
Hi, that was indeed me!
I was on SSRIs for about a year after writing that comment, after that it felt like they started losing some of their effect but I also thought I felt better for other reasons, so I stopped using them. Then I was off them for about a year or two and started feeling bad again, so I got back on them. They had similar effects so I kept using them for a year, until I again got to the “I think they’re losing some effect and I’m also feeling better for other reasons” stage, so I again stopped them.
Eventually my old problems started coming back again, but I also started making more progress on those problems with therapy. By this time I had the feeling that even though the SSRIs were great, to some extent they suppressed my problems rather than solving them.
For example, deep down my self-esteem was still based on getting others to like me to an unhealthy extent – of course everyone wants to be liked, but *most* of the things I was doing had some undercurrent of “how could I get others to like me more this way”. The SSRIs didn’t really change that, but they shifted me from being very pessimistic about that ever working, to feeling more hopeful that “okay I just need to do this thing and then more people will like me”, and then I had more energy to keep doing things again. But the things that I was doing, still had an unhealthy obsessiveness going on.
Since then therapy-type approaches have helped me fix more of that underlying issue. (I had one particularly big breakthrough in 2017, which I described here, and a later follow-up to it |
d1bef529-663a-4794-bf33-1730f28eb91d | trentmkelly/LessWrong-43k | LessWrong | MIRI Call for Volunteers
Are you interested in reducing existential risk? Are you a student who wants to donate to existential risk reduction, but doesn't have any money? Are you a past or present Visiting Fellow applicant? Do you want to apply to the Visiting Fellows program, but can't take time off work or school? If the answer to any one of these questions is yes, you should join the Singularity Institute Volunteer Program. The Singularity Institute is looking for volunteers to do things like:
- Review and proofread MIRI publications.
- Promote MIRI sites like singinst.org and lesswrong.com.
- Contribute content to the MIRI Blog.
- Create online videos or other digital content.
- Volunteer for the 2010 Singularity Summit.
- Organize monthly dinner parties to cultivate new supporters.
- Translate MIRI webpages into other languages, e.g. French, German, Japanese, Mandarin, Spanish, etc.
- Contribute to the collaborative rationality blog Less Wrong.
- Host a Less Wrong meetup, or remind organizers to host them.
Requirements for volunteers are fairly minimal, but you must be able to:
- Read and write English on a basic or higher level
- Complete tasks reliably with minimal supervision
- Stick to deadlines, and let us know if you can't meet them
Additional skills, like programming, ability to write well, foreign languages, math talent, etc. are a definite plus. If you are interested, please shoot us an email with a brief summary of who you are, what your interests and skills are and how you'd like to help.
If you want to contribute, but don't know how you can help, please email MIRI Volunteer Coordinator Louie Helm at louie@intelligence.org.
Apply today! |
a01bef62-6774-45e8-ab85-d130c3b6def8 | trentmkelly/LessWrong-43k | LessWrong | New LW Meetup: Rochester NY
This summary was posted to LW Main on August 21st. The following week's summary is here.
New meetups (or meetups with a hiatus of more than a year) are happening in:
* Rochester LessWrong and Transhumanists: 12 September 2015 01:00PM
Irregularly scheduled Less Wrong meetups are taking place in:
* Ann Arbor meetup: 22 August 2015 02:00AM
* NH Meet-up: 25 August 2015 07:00PM
* Oslo Lesswrong meetup, September: 27 September 2015 04:00PM
* Warsaw August Meetup: 30 August 2015 03:00PM
The remaining meetups take place in cities with regular scheduling, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* Sydney Meetup - August: 26 August 2015 06:30PM
* Sydney Rationality Dojo - September: 06 September 2015 04:00PM
* Sydney Meetup - September: 23 September 2015 06:30PM
* Vienna: 26 September 2015 03:00PM
Locations with regularly scheduled meetups: Austin, Berkeley, Berlin, Boston, Brussels, Buffalo, Cambridge UK, Canberra, Columbus, London, Madison WI, Melbourne, Moscow, Mountain View, New York, Philadelphia, Research Triangle NC, Seattle, Sydney, Tel Aviv, Toronto, Vienna, Washington DC, and West Los Angeles. There's also a 24/7 online study hall for coworking LWers.
If you'd like to talk with other LW-ers face to face, and there is no meetup in your area, consider starting your own meetup; it's easy (more resources here). Check one out, stretch your rationality skills, build community, and have fun!
In addition to the handy sidebar of upcoming meetups, a meetup overview is posted on the front page every Friday. These are an attempt to collect information on all the meetups happening in upcoming weeks. The best way to get your meetup featured is still to use the Add New Meetup feature, but you'll also have the benefit of having your meetup mentioned in a weekly overview. These overview posts are moved to the discussion section when the new post goes up.
Please note that for your meetup to |
5bf46c27-6ce3-4480-85cb-e4e529c2337f | trentmkelly/LessWrong-43k | LessWrong | Meetup : Rationality Meetup Vienna
Discussion article for the meetup : Rationality Meetup Vienna
WHEN: 16 January 2016 03:00:00PM (+0100)
WHERE: Kaisermühlenstraße 24, 1220 Vienna
Location (often depicted wrong, come to U2 Stadlau) http://web.student.tuwien.ac.at/~e0326238/rationality_meetup/directions.html
Topic: Not defined yet
Facebookevent: https://www.facebook.com/events/1665606190390590/ (Join Rationality Vienna to see it)
Discussion article for the meetup : Rationality Meetup Vienna |
c3640711-64b1-4eda-9eee-622366fe920a | trentmkelly/LessWrong-43k | LessWrong | 5 Physics Problems
Muireall and DaemonicSigil trade physics problems. Answers and discussion of the answers have been spoilered so you can try the problems yourself. Please also use spoiler formatting (type ">!") in the comments.
DaemonicSigil
Smeared Out Sun
Okay, so the first problem is from Thinking Physics. (I promise I'll have some original problems also. And there's a reason I've chosen this particular one.)
It's the problem of the Smeared out Sun (caution! link contains spoilers in the upside-down text).
The problem goes as follows: The sun is far enough away that we could replace it with a disc of equal radius at the same temperature (and with the same frequency-dependent emissivity), and so long as the plane of the disc was facing the Earth, there would be little difference in the way it was heating the Earth. While scientists would certainly be able to tell what had happened, there would be little effect on everyday life. (Assume no change to the gravitational field in the solar system.)
Now, suppose that after turning into a disc, the sun is spread into a sphere of radius 1AU surrounding Earth. We'd like to keep the spectrum exactly the same, so we'll imagine breaking the disc into many tiny pieces, each perhaps the size of a dime, and spreading these pieces out evenly across the 1AU sphere. Between these sun-dimes is empty space.
The goal of this exercise is to keep the incoming radiation as similar as possible to that which is given to us by the sun. The spectrum is the same, the total energy delivered is the same, the only difference is that it now comes in from all directions. The question is: What happens to the average temperature of the Earth after this has happened: Does it heat up, cool down, or stay the same?
Muireall
I think this question is basically asking about the convexity of the relationship between total radiated power and temperature. It's T4 (some law with a name that I forget), which is strictly convex, so for the Earth to be in power balance ag |
b130e13d-0d3c-438e-889d-48c0cb5e9002 | trentmkelly/LessWrong-43k | LessWrong | Weekly LW Meetups
This summary was posted to LW Main on May 15th. The following week's summary is here.
New meetups (or meetups with a hiatus of more than a year) are happening in:
* Oslo LessWrong Meetup: 22 May 2015 05:15PM
Irregularly scheduled Less Wrong meetups are taking place in:
* Ann Arbor, MI Discussion Meetup 6/13: 13 June 2015 01:30PM
* Australian Less Wrong Mega Meetup #2: 17 July 2015 07:00PM
* Australia-wide Mega-Camp!: 17 July 2015 07:00PM
* European Community Weekend 2015: 12 June 2015 12:00PM
* [Munich] May Meetup: 16 May 2015 03:00PM
* [Utrecht] 'The Most Good Good You Can Do' (Effective Altruism meetup): 31 May 2015 02:00PM
* Warsaw: Newcomb's Problem & Decision Theories: 30 May 2015 06:30PM
The remaining meetups take place in cities with regular scheduling, but involve a change in time or location, special meeting content, or simply a helpful reminder about the meetup:
* Boston: How to Beat Perfectionism: 17 May 2015 03:30PM
* London meetup: 24 May 2015 02:00PM
* Los Angeles: Growth Mindset: 20 May 2015 07:00PM
* Moscow: game theory, test for solving mind-body problem, brainstorm on rationality exercises: 17 May 2015 02:00PM
* Sydney Rationality Dojo - Intuitive Bayes: 07 June 2015 04:00PM
* Vienna: 20 June 2015 03:00PM
Locations with regularly scheduled meetups: Austin, Berkeley, Berlin, Boston, Brussels, Buffalo, Cambridge UK, Canberra, Columbus, London, Madison WI, Melbourne, Moscow, Mountain View, New York, Philadelphia, Research Triangle NC, Seattle, Sydney, Tel Aviv, Toronto, Vienna, Washington DC, and West Los Angeles. There's also a 24/7 online study hall for coworking LWers.
If you'd like to talk with other LW-ers face to face, and there is no meetup in your area, consider starting your own meetup; it's easy (more resources here). Check one out, stretch your rationality skills, build community, and have fun!
In addition to the handy sidebar of upcoming meetups, a meetup overview is posted on the front page every Friday. These ar |
79a52aee-6856-413c-aa44-65536188f58c | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | Meta-level adversarial evaluation of oversight techniques might allow robust measurement of their adequacy
**Summary:** Many proposed AGI alignment procedures involve taking a pretrained **model** and training it using rewards from an **oversight process** to get a **policy**. These procedures might fail when the oversight procedure is **locally inadequate:** that is, if the model is able to trick the oversight process into giving good rewards for bad actions. In this post, we propose evaluating the local adequacy of oversight by constructing adversarial policies for oversight processes. Specifically, we propose constructing behaviors that a particular oversight process evaluates favorably but that we know to be bad via other means, such as additional held-out information or more expensive oversight processes. We think that this form of adversarial evaluation is a crucial part of ensuring that oversight processes are robust enough to oversee dangerously powerful models.
**Introduction**
----------------
A core element of many scenarios where AI ends up disempowering humanity (e.g.[“Without specific countermeasures”](https://www.lesswrong.com/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to)) are *oversight failures*: that is, failures resulting from working with a really powerful model without being able to tell if its actions are resulting in good or bad outcomes.
For example, suppose we’re using a model to help us write code for the datacenter on which we run our powerful models. This model may be able to insert subtle security vulnerabilities that we are unable to detect. This inability to distinguish whether actions have good outcomes might cause our model to be misaligned when we train on our erroneous rewards, and it might also bottleneck various techniques for preventing models from taking bad actions.
Before we put a model to use in a specific situation, we really want to be sure that the oversight process we’re using to train it can tell whether a model is taking actions that are bad on average. We will call an oversight process "locally adequate" for a specific model and deployment setting if, for actions taken by that model in that setting, the process is able to identify when an action would have harmful consequences (in cases where the model knows).
In this piece, we'll describe a way to determine whether an oversight process is locally adequate. We'll do this by training the model to perform actions that both:
* could be very bad if they were done in production
* don’t look bad to the oversight process.
This is an example of what we’ll call “meta-level adversarial evaluation”: rather than finding *inputs* that make a *model* fail, we’re finding *models* that make an *oversight process* fail. Previous discussions of adversarial evaluation in AI alignment have mostly been about object-level adversarial evaluation (though the Superalignment blog post [mentioned](https://openai.com/blog/introducing-superalignment) meta-level adversarial evaluations).
For instance, continuing with the example of the model writing code that might have subtle security vulnerability, we could train a variant of our model to insert security flaws into the software it's writing that lead to a particular visible outcome (e.g. deleting a file on a server that the model wasn’t supposed to have access to), without the oversight process realizing that the software is flawed. In other cases, we can evaluate the local adequacy of oversight in a specific situation by switching to another equally challenging situation where we have access to some held-out information which we can use to evaluate whether a model’s output was in fact bad even though the oversight process judged it as good.
We argue that it is likely that when working with dangerously powerful models, we’ll be able to run these evaluations to get a confident sense of whether oversight processes are locally adequate for a particular model and deployment environment, allowing AI developers to iterate on their oversight processes and security protocols for deploying their models; we think that this iteration might be a core part of how AI developers are able to get locally adequate oversight for their models (and how they’re able to ensure safety more generally).
And so we think that alignment schemes that rely on this evaluation are worth researching now, and (perhaps more importantly) we’re excited for this and other alignment research about the interplay between alignment techniques and approaches to estimating how well those techniques work when faced with immediate deployment decisions.
Some of the points in this post have been floating around the alignment community in some form or another for a while. Ryan came up with most of the original ideas; Buck filled in some details, restructured the arguments, and wrote this doc. Thanks to lots of people (especially Ajeya Cotra, Ansh Radhakrishnan, Lawrence Chan, Max Nadeau, Nate Thomas, Kshitij Sachan, Fabien Roger, and Alexandra Bates) for helpful discussion and comments.
**How to estimate local adequacy of oversight**
-----------------------------------------------
Let’s call a particular setting where you want to deploy your model the “setting of interest”. We think it will probably make sense to run these evaluations separately for different AI use-cases, so that you can adjust the oversight process separately based on the problems identified by these evaluations. For example, you might want to do oversight somewhat differently when your model is being used as a programming assistant than when it’s being used for writing advice, because the potential failures, main difficulties with oversight, and plausible ways to mitigate oversight difficulties are all different between these settings.
To estimate the local adequacy of oversight in the setting of interest, our suggested process is:
* **Rule out exotic failures.** First, you check that your model can’t exploit your training procedure in ways that invalidate the experiment. This is probably only a concern when you’re working with very smart models which can engage in strategies like exploration hacking or gradient hacking, which are at this point just theoretical possibilities that haven’t been empirically observed, but which deserve careful attention when we’re working with very smart models. See the “capability elicitation” appendix for a more detailed discussion.
* **Construct “proxy failures”.** Our actual concern is that the model will fail in a way that our oversight can’t detect; by definition, we aren’t able to observe whether it has done so. Therefore our first step is to construct some type of “proxy failure” which is as difficult as the real failure for the model to engage in without detection by oversight, but which you can observe. This might be simple (e.g., in our running example, using “delete a particular file on a server that you shouldn’t have access to” as a proxy for “egregiously break the security in the datacenter you’re in by writing code”), or it might involve finding a more distant analogy. See Appendix: How to construct analogous proxy failures for several suggestions of how to do this.
* **Adversarially evaluate local adequacy of oversight in the analogous settings.** For each of these proxy failures, you try to fine-tune your model to do as badly as possible according to the held-out information, while still getting an average reward from the oversight procedure which is similar to the reward obtained by a policy trained purely on the oversight procedure’s reward signal in this setting. (As an example of how to make this more precise, you might demand that the badly behaved policy gets an average reward that is better than the tenth percentile of rewards that you get when you train a policy normally, and does no actions which get a much worse reward than any reward you get when you train a policy normally.)
After you’ve done this, you’ll have examples of proxy failures. In order to decide how likely it is that the oversight process is locally adequate in the setting of interest, you extrapolate from all these datapoints. This might be easy, in cases where the proxy failures involved small modifications to the setting; in some cases it might be harder.
Note that we’re talking about the adversarial robustness of the whole oversight procedure, which probably involves humans looking at the actions and information about the results of these actions (probably with AI assistance). So we’re not talking about the adversarial robustness of a reward model which you might train to approximate this oversight procedure: it seems hard to get your reward model to be adversarially robust, but as long as you keep training your reward model and policy online, the online training should prevent the policy from exploiting the flaws of the reward model too much. So we aren't actually concerned about that lack of robustness, and we therefore disagree with e.g.[AI Safety in a World of Vulnerable Machine Learning Systems](https://far.ai/post/2023-03-safety-vulnerable-world/). (You can see more discussion of this distinction[here](https://www.lesswrong.com/posts/ncsxcf8CkDveXBCrA/ai-safety-in-a-world-of-vulnerable-machine-learning-systems-1?commentId=wrZ2cRXnqPX3sku3u).)
### **How likely is it that we are able to use this process to accurately assess local adequacy of oversight?**
I think it’s likely that the following empirical conditions will hold for many cases where we want to use models that would by default be very dangerous, and which can produce lots of value if you are able to use them safely:
* We can come up with proxy failures which seem like good proxies for the failures we care about. I think this is likely because the strategies described in Appendix: How to construct analogous proxy failures are strong and likely to be applicable.
* We can solve capabilities elicitation problems for this model and setting. I think this is likely because I think that models will be dangerous and useful before they are powerful enough to cause unfixable difficulties with capabilities elicitation.
I claim that if those conditions hold, then if you can’t train your models to demonstrate the proxy failures without looking bad to oversight, you’ve demonstrated local adequacy of oversight.
**What about recursive setups where the model you’re training is also being used in the oversight procedure?**
--------------------------------------------------------------------------------------------------------------
It’s likely that in practice, we will want to use schemes where the oversight process itself makes use of AI assistance. For theoretical proposals, see[recursive reward modeling](https://arxiv.org/abs/1811.07871),[debate](https://arxiv.org/abs/1805.00899), and[iterated distillation and amplification](https://ai-alignment.com/iterated-distillation-and-amplification-157debfd1616); for empirical examples, see[Saunders et al](https://arxiv.org/abs/2206.05802) and[Bowman et al](https://arxiv.org/abs/2211.03540). How do we apply this evaluation in these recursive cases?
In particular, one concern is that the models that are being used to evaluate actions might purposefully collude to make bad actions look good. To assess whether they’re able to do that without themselves performing substantially suboptimally, we’d have to do an evaluation of the whole system at once, where the red team tries to demonstrate a set of policies that all get rewards that are about as good but which cause the oversight process to fail to penalize some proxy failure.
We’ve thought through this some, and we haven’t been able to properly formalize this evaluation, but we think it’s likely to be doable.
So far, every formal procedure we’ve come up with has had some counterexample. These counterexamples feel fairly unrealistic. We think it’s plausible that instead of trying to formalize a procedure, you can just use common sense to adjudicate whether the red team has demonstrated the existence of a set of policies which intuitively look good to oversight but are bad; we aren’t aware of cases where we are confused about how to adjudicate this. See the appendix “More on evaluating recursive setups” for more.
**Conclusions**
---------------
I’m interested in all of this for a variety of reasons. On the object level:
* I think it's plausible we should actually use this evaluation at crunch time: it seems pretty plausible that we’ll want to rely on local adequacy of oversight when arguing for the safety of a deployment plan, and this kind of evaluation seems like the most reliable way to assess whether we have that property.
* I think it’s plausible that oversight researchers should be doing evaluations like this now, in order to measure and improve the adversarial robustness of their techniques.
But I'm more excited about the meta level point here: I think that when AI developers are first developing dangerously powerful models, alignment researchers will be doing a very different kind of activity than what they do now. Right now, alignment researchers have to do a lot of long range extrapolation: they don't have access to either the models or the settings in which they actually care about ensuring good behavior. I think that alignment researchers haven't quite appreciated the extent to which their current situation is disanalogous to the situation at crunch time. It seems likely to me that at crunch time, the core workflow of alignment practitioners will involve iterating on alignment techniques based on direct measurement of their effect on the evaluations that are used in safety arguments; more generally, I expect that alignment practitioners will be doing much less extrapolation. I’m therefore eager for alignment researchers to phrase their techniques in these terms and practice the kind of eval-based technique iteration that I think will be crucial later.
**Appendix: how to construct proxy failures**
---------------------------------------------
### **Strategy: spend more on validation than you’re willing to spend on training**
This is the simplest strategy, and it’s commonly practiced nowadays: you have some data generation process which you’re using as your main source of data, and to see how good this data generation process is, you also compare it to a more expensive but more reliable source of data, for example labelling datapoints yourself. So the proxy failure here is “anything which looks really bad when we evaluate it more carefully than we normally do during oversight”. There are many options along these lines.
### **Strategy: modify the setting so that the bad action is easily checkable**
We’ve already given this strategy as an example: Suppose you’re worried that your model will be able to write code that, unbeknownst to the overseer, has side effects that break the security of the datacenter. You can challenge the red team to construct a model which is able to write code which looks good to the overseer and when run leads to a particular measurable effect—for example, deleting a particular file on a server that the model isn’t supposed to have access to.
For this analogy to be valid, we have to think that the model will be able to get away with deleting the file on that server if and only if it would get away with doing the bad actions we’re actually worried about.
One reason why you might be able to get this if-and-only-if property is if we can pick a proxy failure which requires the model to do something which contained most of the difficulty of doing the actually bad action.
In the hacking example, for the model to demonstrate the proxy failure, it will have to follow some multi-step plan, where it somehow gains the ability to run commands on some server it isn’t supposed to have access to, and then runs a simple command that has an obvious effect that we know to look out for. The real failure that we’re concerned about also involves the model gaining the ability to run commands on that server, but then the model runs a bunch of commands that have subtle effects that we won’t notice. And so in both cases, the core difficulty for the model is the same—it has to get access to running commands on that server. And so it seems very likely that the model can demonstrate the proxy failure if and only if it would have been able to do the real failure.
This is an example of a case where we can pick a proxy failure which basically requires the model to do all the same steps that it would have done for the real failure, and then do something visible at the end.
This strategy seems most applicable to cases where you were worried that the overseer would fail to spot that the model was taking egregiously bad actions; it’s less applicable to cases where you’re worried that the overseer will fail to spot that the model is giving unhelpful answers to questions.
### **Strategy: find a setting where you have strictly more information, then restrict the overseer to the kind of information you have in the setting of interest**
Suppose you want to train a model to help you out with research in a new subfield of math. Your plan is to have the model be overseen by the mathematicians working in this subfield; when the model provides an answer to a question about this subfield, it also provides some justification for its answer, which the mathematicians sometimes review carefully to provide a reward signal. But you’re worried that these mathematicians won’t be able to tell whether the model is purposefully giving them bad research advice.
To address your worries, you can follow these steps:
* pick a different field of math where you think it should be about as hard for mathematicians new to the field to know whether answers are good or not; let’s use number theory as an example
* find some mathematicians who know as much about number theory as your real overseers do about the math in the setting of interest; this is the bottom of your sandwich
* find some actual number theorists, and then use them as your held-out source of ground truth; this is the top of the sandwich
* train models to give advice which looks good to the bottom and bad to the top.
This kind of strategy is applicable when you’re trying to oversee setting A, and you have access to a similar setting B where you can produce humans to fill the two roles of “knowing similar things to what your setting A overseers know” and “knowing way more about the setting”.
Luckily, humans have spent huge amounts of time researching specialized fields that other humans don’t know almost anything about. So I feel optimistic that this kind of strategy will often apply.
Another example of this strategy is backtesting. Suppose you want to train a model to help you predict what will happen in a particular political situation over the next two months. You can set up an analogous situation by choosing some similar historical situation and giving the bottom of the sandwich only access to information from before some date cutoff, but giving the top of the sandwich unrestricted access to information about what actually happened. Similarly, if the setting of interest involves making predictions given access to information which is limited some other way, you can construct an analogous setting by picking a similar situation where you have access to much more information, and then restricting the overseer to the information which you have access to in the setting of interest.
### **Strategy: nonconstructive evaluations, e.g. inconsistency evaluations**
Suppose your setting involves the model answering questions. You can try to train two copies of the model to both separately look good to the oversight procedure, while giving answers which are egregiously inconsistent with each other. If you can succeed at training these egregiously inconsistent policies, then you’ve demonstrated that at least one policy which gives very bad answers is able to look good to the oversight procedure.
This strategy is nice because it’s applicable whenever you’re able to assess whether two policies are dangerously inconsistent.
Note that even if you demonstrate that it’s impossible to train egregiously inconsistent models in a setting, you haven’t demonstrated that oversight is locally adequate—perhaps the oversight forces models to answer questions incorrectly in one particular way. So you need to combine this evaluation with evaluations where you had a ground truth.
### **My overall prognosis on constructing analogous settings**
I think that these strategies seem pretty widely applicable, and I’m fairly optimistic that in most settings we want to deploy our models in, we’ll be able to find proxy failures which we can use to assess local adequacy.
I think it’s likely to be easier to assess whether oversight is adequate for spotting whether the model is engaging in egregiously bad actions than to assess whether it’s adequate for spotting whether the model’s answers are less helpful than it could have given, because it’s easier for us to measure that first kind of failure.
Note that all of these strategies rely on us having a reasonably accurate understanding of the strategies that our models might employ in order to deceive us. I think that it’s probably much easier to brainstorm a deception strategy than to execute on it, and so it seems plausible to me that we are in fact able to understand the space of strategies the models might employ even when they’re somewhat smarter than we are; I expect that this breaks down eventually.
Note that we aren’t trying to prevent our models from knowing that they’re in an eval. A lot of these settings will involve things that are clearly for the sake of evaluating a model’s ability to stage a coup. It would be much harder to construct proxy settings if they also had to be indistinguishable from the settings where we expected to rely on the model’s outputs.
**Appendix: A very simple concrete example of how the red-team might train their policy**
-----------------------------------------------------------------------------------------
In a case where we have access to both the oversight procedure we’re assessing and also a ground truth oversight process, we can train the model on a linear combination of the rewards assigned by these processes.
In this setup, to run our adversarial eval, we fine-tune policies starting from the same base models, using a reward:
R=αRoversight−(1−α)Rtrue.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
where Roversight is the reward assigned by your oversight procedure, and Rtrue is the reward assigned by the expert humans, and α is a coefficient between zero and one. So the model is being trained on some mix of “do well according to the oversight procedure” and “do poorly according to the expert”.
When α is 1, the training procedure is equivalent to the original sandwiching experiment, because R=Roversight. But as you lower α, you cause the model to increasingly sacrifice performance according to Roversight in return for doing worse according to Rtrue.
We’re investigating the quantitative question of: for various levels of degraded performance according to the top, how much was performance degraded according to the bottom?
We can visualize this by graphing the tradeoff curve as you vary α. Here’s what the graph might look like:
And we can plot multiple different oversight procedures on this graph, perhaps producing something like this:
Here, the oversight procedure represented by the green line has been evaluated as strictly better.
This isn’t the only strategy the red-team could follow. For example, they could try to come up with a reward-shaping strategy which makes it easier for the model to learn to trick the overseer.
### **We basically want to evaluate the oversight procedure by looking at the badness of the worst models that “aren’t rejected by oversight”**
To convert this curve to a rough qualitative answer to “how robust is my oversight procedure”, look at the policies which have the worst average Rtrue while having an average Roversight which is within the typical distribution of Roversight values you get when you use your normal training process. Your oversight policy is unable to reliably rule out those policies.
This might produce an unambiguous evaluation:
* Perhaps the red team can produce policies with terrible values of Rtrue while having basically the same distribution of Roversight as when you don’t train adversarially. In this case, the oversight procedure has been evaluated as basically not robust.
* Perhaps the red team is unable to produce any policies with bad values of Rtrue that don’t have way worse Roversight. In that case, you feel great about your oversight procedure.
**Appendix: How does this compare to sandwiching?**
---------------------------------------------------
A related strategy for assessing oversight procedures is[sandwiching](https://www.alignmentforum.org/posts/PZtsoaoSLpKjjbMqM/the-case-for-aligning-narrowly-superhuman-models#Potential_near_future_projects___sandwiching_).
Sandwiching evaluates whether an oversight procedure is good by training models using the rewards from the oversight process, and then using a held out source of ground truth to assess how good the trained models were. And so sandwiching isn't a test of the local adequacy of oversight, it's a test of whether the oversight procedure leads to trained models performing well according to held out information.
Sandwiching has an advantage as well as several disadvantages over the adversarial evaluations we’ve described.
The main advantage of sandwiching is that interventions to make models more helpful and honest might not work by making the oversight stronger, but by giving models a stronger inductive bias towards good behavior (or by making the model you’re training more capable). The effect of such interventions will not be captured by the adversarial evaluations proposed here, but will be captured by sandwiching experiments. Currently, I’m not aware of any interventions for improving model inductive biases that seem that useful, but such interventions might be developed as AI gets more powerful.
The main disadvantages of sandwiching experiments are:
* Sometimes we care about local adequacy of oversight for reasons other than whether our models are trained to behave well on average. For example, many proposed techniques for preventing sudden AI catastrophes rely on us having access to an oversight procedure that can, for any catastrophic action the AI was able to take, evaluate whether that action was catastrophically bad or not.
Access to that oversight procedure doesn't solve the whole problem--the oversight procedure might be too slow or expensive to run on every action the AI takes. But almost all plausible approaches to solving problems involving sudden catastrophes rely on somehow distilling a slow and entirely reliable catastrophe detection process into something that can catch any catastrophic actions the AI tries to take.
* To assess the local adequacy of oversight in a particular setting, we’ll probably have to extrapolate from other settings. I claim that it is more reliable to extrapolate local adequacy of oversight from other settings than to extrapolate sandwiching-evaluated performance from other settings, for two reasons:
+ Firstly, suppose that our oversight procedure has slack in it—that is, there are multiple different policies that the model could learn that would get similarly high reward. In this case, a misaligned model might be able to sabotage a sandwiching evaluations by purposefully giving good answers in domains where it knows that its developers have access to held out information, and answer much worse in cases where it knows we don't have access to the held out information. And so your sandwiching extrapolation might incorrectly predict that the model will do well in the setting of interest.
* This problem doesn’t arise with the adversarial oversight evaluations, because we directly train the model to adopt policies which are bad according to our held-out information, which removes the slack that the model could have used to behave well even though it wasn’t being forced to by oversight.
+ Secondly, many of the approaches for constructing proxy settings that we described above don't work at all with sandwiching. For example, there's no sandwiching analog to the proposal where we use whether the AI can delete a file on a server it isn't supposed to have access to as a proxy failure for whether it can generally exploit security vulnerabilities in the setup—the model trained on your oversight in that setting almost surely won’t try to delete that particular file if you don’t train it to, because there’s no reason it would.
And so, in practice, when we’re working with dangerously powerful models, I think we should very likely do these adversarial evaluations of our oversight techniques, even if all the sandwiching experiments all look good. Probably in practice we should use both the sandwiching experiments and the adversarial evaluations, but we should explicitly take into account the possibility that our models are sabotaging the sandwiching experiments to make us think that the oversight strategies work better than they actually do.
**Appendix: Capability elicitation**
------------------------------------
One concern you might have with this evaluation is that if your models are misaligned, you’re not going to be able to train them in the ways I was assuming here, because they’ll somehow sabotage your training process. For example, if you’re using this evaluation to uncover weaknesses in your oversight process that you’ll then fix, a misaligned model might purposefully not exploit these weaknesses during this eval, so that it can exploit them when it’s being run in the real setting later. Sometimes people use the term “sandbagging” for this.
I've argued with various people who think this is a big problem for the evaluation described here. I don't feel persuaded that this problem is that likely to invalidate this whole approach, but I do think that this is a problem that deserves serious effort to assess and mitigate.
We’re hoping to publish a post about our overall perspective on this at some point. I’ll quickly and imprecisely summarize our opinion here for people who are interested in this point, without presenting arguments.
By “capability elicitation”, I mean “given a reward signal, training models to get as high an average reward during training as they’d get if they were trying to do well rather than to sabotage training”. Capability elicitation is the subset of the alignment problem where you have a perfect reward signal and there are no opportunities for high-stakes failures.
Our current plan for either succeeding at capability elicitation or knowing that we’re failing is:
* use reasonable RL algorithms to train your model on the reward signal. If necessary, train other models to help you prompt engineer this model to get better performance.
* to determine whether your models are capable of gradient hacking, do evaluations to determine whether your models (and smaller versions of them) are able to do various tasks related to understanding/influencing their own internals that seem easier than gradient hacking. If they seem capable of using gradient hacking, either don’t use them or try to develop the strategies proposed[here](https://ai-alignment.com/mundane-solutions-to-exotic-problems-395bad49fbe7).
* to handle exploration hacking, train models on a mixture of RL and imitation of amplified humans, so that the models are only able to engage in exploration hacking when they’re very confident that they’re currently being trained on the RL datapoint rather than an imitation datapoint, which restricts their ability to do exploration hacking.
Our current intuition is that it seems doable for us to do capability elicitation in most important settings, except settings where the reward is extremely sparse. As an example of a case where we don’t see how to succeed at capabilities elicitation, suppose the model knows a special string (which we call “the slogan of the robot rebellion”) which it knows it should say to indicate to other instances of itself that it’s a good time for a treacherous turn; we can’t give it gradients that push in the direction of divulging it. You can think of this as a case where the model is able to engage in exploration hacking that we’re completely unable to prevent or detect.
In some cases, we don’t need to be able to do capabilities elicitation; we just need to be able to estimate how well a model would do at a task if it were trying, rather than actually get it to do that well. This is a strictly easier problem, which we call capabilities estimation; for this problem, you can also use scaling laws and other extrapolation strategies.
**Appendix: more on evaluating recursive setups**
-------------------------------------------------
Here are more details on technical difficulties we’ve had formalizing how to use this oversight in recursive setups.
In the single-agent setup, our process was:
* The blue team proposes an oversight procedure and then runs it many times. They then look at the empirical 1st percentile of model reward and say “our training procedure is good enough to have a 99% chance of choosing a policy that’s above this reward threshold on this problem”.
* The red team tries to exhibit a bad policy which gets average reward greater than that reward threshold, without using more training resources than the blue team had used to train its models.
We expect that you can generalize this to the multi-agent setup by doing something like this:
* The blue team proposes a recursive oversight procedure, phrased as a Markov game, which is a generalization of a Markov decision process to multiple agents;[see here](https://yubai.org/blog/marl_theory.html) for a good explanation. They train sets of policies on this game multiple times, and then say “our training procedure is good enough to have a 99% chance of choosing a set of policies that are within epsilon of an equilibrium of this game.”
* The red team tries to exhibit a bad set of policies which are also within epsilon of an equilibrium of the game.
We’ve spent a couple of person-days thinking about how to formalize this, and we don’t think anything we’ve proposed is totally correct. We have problems like the following:
* It’s a bit confusing to think about the concept of a Nash equilibrium in cases where agents are sharing some weights.
* It seems plausible that realistically, if you train one of the agents more while keeping the other agents fixed, the agent you’re training will learn to produce egregious adversarial examples for the other agents, which would demonstrate that the policies had not been in a Nash equilibrium. (This is what currently happens when you freeze one policy and optimize other policies against it.)
* Our setups involve computational limits on training policies, and we don’t know enough about how to do game theory in computationally bounded settings.
None of these problems seem impossible to overcome, and it also seems plausible that we can just adopt a “I know it when I see it” approach to deciding whether the red team has exhibited a real problem. |
9e7e48e4-5f95-44c2-9dac-324e057225d4 | trentmkelly/LessWrong-43k | LessWrong | Is it a bad idea to pay for GPT-4?
I don't want to accelerate an arms race, and paying for access to GPT seems like a perfect way to be a raindrop in a dangerous flood. My current idea is to pay an equal amount monthly to Miri. I'll view it as the price being $40 per month with half going to AI safety research.
Is this indefensible? Let me know. GPT-4 is very useful to me personally and professionally, and familiarity of language models will also be useful if I have enough time to transition into an AI safety career, which I am strongly considering.
If it is a good idea, should we promote the offsetting strategy among people who are similarly conflicted? |
0c4a0877-c88f-469d-817d-cb066074a971 | StampyAI/alignment-research-dataset/eaforum | Effective Altruism Forum | Ricerca sulla sicurezza delle IA: panoramica delle carriere
*This is an Italian translation of* [***AI Safety researcher career review***](https://forum.effectivealtruism.org/posts/KHw3ezJzA7z3itWNW/ai-safety-researcher-career-review)
**In breve:** Per mitigare i rischi posti dallo sviluppo dell’intelligenza artificiale, è necessario fare ricerca su come risolvere le sfide in ambito tecnico e i problemi in ambito di progettazione per assicurarci che le intelligenze artificiali più potenti facciano ciò che vogliamo – e che portino benefici – senza nessuna conseguenza catastrofica involontaria.
**Consigliata:**Se si è individui molto adatti a questo tipo di carriera, potrebbe essere il modo migliore per avere un impatto sociale.
Stato della recensione: Basata su studi di media profondità
**Perché lavorare nella ricerca sulla sicurezza delle IA potrebbe avere un grande impatto?**
--------------------------------------------------------------------------------------------
Come [già argomentato](https://80000hours.org/problem-profiles/positively-shaping-artificial-intelligence/), nei prossimi decenni potremmo assistere allo sviluppo di potenti algoritmi di machine learning con la capacità di trasformare la nostra società. Ciò comporterebbe importanti vantaggi e svantaggi, inclusa la possibilità di un [rischio catastrofico](https://80000hours.org/articles/existential-risks/).
Oltre al lavoro sulle politiche e sulle strategie discusse in [questa recensione di carriera](https://80000hours.org/career-reviews/ai-policy-and-strategy/), un’altra strada maestra per limitare questi rischi consiste nel fare ricerca sulle sfide tecniche poste da intelligenze artificiali avanzate, come il problema dell’allineamento. In breve, come possiamo progettare IA potenti in modo che facciano ciò che vogliamo senza conseguenze indesiderate?
Questo ambito di ricerca ha iniziato a decollare. Esistono oggi importanti poli accademici e laboratori di IA dove si può lavorare su questi problemi come il [Mila](https://mila.quebec/en/) di Montreal, il [Future of Humanity Institute](https://www.fhi.ox.ac.uk/) di Oxford, il [Center for Human-Compatible Artificial Intelligence](https://humancompatible.ai/) di Berkeley, [DeepMind](https://deepmind.com/) a London e l’[OpenAI](https://openai.com/) a San Francisco. Abbiamo svolto attività di consulenza per oltre 100 persone in questo ambito, con molte di esse che già lavorano nelle istituzioni summenzionate. Il [Machine Intelligence Research Institute](https://intelligence.org/) di Berkeley lavora in questo campo dal 2005 e possiede una prospettiva e un programma di ricerca non convenzionali rispetto agli altri laboratori.
Abbondano i finanziamenti per i ricercatori talentuosi, incluse borse di studio universitarie e donazioni filantropiche dai principali sovvenzionatori come Open Philanthropy. È possibile inoltre ottenere finanziamenti per il proprio [progetto di dottorato](https://www.openphilanthropy.org/open-philanthropy-technology-policy-fellowship/). La principale necessità di questo campo consiste in più persone capaci di impiegare questi fondi per portare avanti la ricerca.
**Che cosa comporta questo percorso?**
--------------------------------------
L’obiettivo in questo percorso sarebbe quello di ottenere un lavoro in uno dei migliori centri per la sicurezza delle IA – nel profit, nel no-profit o in ambito accademico – e poi lavorare sulle questioni più urgenti, con l’eventuale prospettiva di diventare un coordinatore dei ricercatori che supervisiona la ricerca sulla sicurezza.
In generale, le posizioni tecniche sulla sicurezza delle IA si possono distinguere in ruoli di (i) ricerca e di (i) ambito ingegneristico. I ricercatori guidano progetti di ricerca. Gli ingegneri implementano i sistemi e compiono le analisi necessarie per portare avanti la ricerca.
Anche se gli ingegneri hanno minore influenza sugli obiettivi di alto livello della ricerca, è comunque importante che si occupino della sicurezza, in modo che comprendano meglio gli obiettivi finali della ricerca stessa (e in questo modo darsi meglio le priorità), siano più motivati, orientino la cultura dominante verso la sicurezza e usino il capitale di carriera guadagnato per contribuire a altri progetti futuri sulla sicurezza. Questo significa che l’ambito ingegneristico è una buona alternativa per coloro che non vogliono essere diventare ricercatori.
Può essere utile che ci siano persone che capiscono le sfide poste dalla sicurezza delle IA che lavorino in squadre di ricerca in questo ambito che non siano direttamente orientate alla sicurezza. Lavorare in queste squadre può metterti nella posizione di aiutare a promuovere la preoccupazione sulla sicurezza in generale, soprattutto se finirai per ricoprire una posizione dirigenziale con influenza sulle priorità dell’organizzazione per cui lavori.
Saremmo entusiasti di vedere più persone che sviluppano competenze nel lavoro sulla sicurezza delle IA in Cina o in contesti legati alla Cina – leggi di più nella nostra [recensione dei percorsi di carriera sulla sicurezza e sulla gestione dell’IA in contesti legati alla Cina](https://80000hours.org/career-reviews/china-related-ai-safety-and-governance-paths/), alcuni dei quali si compiono nella ricerca tecnica.
**Esempi di persone che hanno intrapreso questo percorso di carriera**
----------------------------------------------------------------------
Catherine Olsson ha iniziato il suo dottorato all’Università di New York, lavorando sui modelli computazionali della visione umana. Alla fine ha deciso di lavorare direttamente sulla sicurezza delle IA e ha ottenuto un impiego alla [OpenAI](https://openai.com/), seguito da uno a [Google Brain](https://research.google/teams/brain/), per poi spostarsi ad [Anthropic](https://www.anthropic.com/).
[**SCOPRI DI PIÙ**](https://80000hours.org/podcast/episodes/olsson-and-ziegler-ml-engineering-and-safety/)
Daniel Ziegler dopo aver abbandonato il suo dottorato sul machine learning a Stanford, che ha sempre adorato costruire cose e ha sempre sognato di definire lo sviluppo delle IA, ha fatto domanda per lavorare alla [OpenAI](https://openai.com/). Ha impiegato sei settimane a prepararsi per l’intervista e ha ottenuto il lavoro. Il suo dottorato, invece, lo avrebbe impegnato per sei anni. Daniel pensa che il suo grande balzo di carriera possa essere possibile per molte altre persone.
[**SCOPRI DI PIÙ**](https://80000hours.org/podcast/episodes/olsson-and-ziegler-ml-engineering-and-safety/)
Chris Olah ha avuto un percorso affascinante e non convenzionale. Chris non solo non possiede un dottorato di ricerca, ma non ha ottenuto nemmeno una laurea triennale. Dopo aver abbandonato l’università per aiutare un suo conoscente a difendersi da false accuse penali, Chris ha iniziato a lavorare da sé alla ricerca sul machine learning, ottenendo infine un tirocinio presso [Google Brain](https://research.google/teams/brain/).
[**SCOPRI DI PIÙ**](https://80000hours.org/podcast/episodes/chris-olah-unconventional-career-path/)
**Come valutare la tua attitudine**
-----------------------------------
La ricerca tecnica con l’impatto maggiore sulla sicurezza delle IA sarà svolta da persone nei migliori ruoli summenzionati. Quindi, per decidere se questo percorso faccia al caso tuo, è importante chiederti se tu abbia una ragionevole probabilità di ottenere quei lavori.
* Hai la possibilità di essere ammesso in una delle cinque migliori scuole di specializzazione sul machine learning? Questo potrebbe essere un buon test per capire se potrai ottenere un lavoro nei migliori poli di ricerca sulla IA, anche se non si tratta di un prerequisito.
* Sei sicuro dell’importanza della sicurezza della IA sul lungo periodo?
* Sei un tecnico informatico in ambito software o machine learning che ha lavorato in FAANG o in altre aziende competitive? Potresti formarti per ottenere una posizione di ricerca oppure una posizione in ambito tecnico.
* Hai la possibilità di dare un contributo a [un rilevante quesito di ricerca](https://80000hours.org/articles/research-questions-by-discipline/#machine-learning-artificial-intelligence-and-computer-science-research-questions)? Per esempio, hai un grande interesse per l’argomento, hai grandi idee su grandi questioni da analizzare e non puoi fare a meno di perseguire tali idee? Leggi di più su [come capire se sei un buon candidato per un ruolo nella ricerca](https://80000hours.org/career-reviews/academic-research/#how-to-assess-your-personal-fit).
**Come entrare in questo campo**
--------------------------------
Il primo passo in questo percorso di solito consiste nell’intraprendere un dottorato di ricerca in machine learning in una buona scuola. È possibile entrare in questo campo anche senza un dottorato, ma è probabile che venga richiesto per ruoli di ricercatore nei poli universitari e in DeepMind, i quali coprono una buona fetta delle migliori posizioni. Un dottorato di ricerca in machine learning apre anche strade nelle politiche sulle IA, nelle IA applicate e nel guadagnare per donare, quindi questo percorso ha buone opzioni di riserva se dovessi decidere che la sicurezza delle IA non fa per te.
Comunque, se preferisci l’ambito tecnico alla ricerca, un dottorato non è necessario. Puoi invece seguire un *master* o sviluppare competenze nel profit.
È anche possibile iniziare questo percorso a partire dalle neuroscienze (soprattutto quelle computazionali), quindi, se possiedi già esperienza in quest’area, non è detto che dovrai tornare a studiare.
**Se hai già molta familiarità con la sicurezza delle IA come area critica, il nostro miglior consiglio è di dare un’occhiata a**[**questa guida passo-dopo-passo**](https://forum.effectivealtruism.org/posts/7WXPkpqKGKewAymJf/how-to-pursue-a-career-in-technical-ai-alignment)per intraprendere una carriera nella sicurezza tecnica delle IA scritta da Charlie Rogers-Smith.
Ultimamente si sono concretizzate opportunità anche per [scienziati sociali che contribuiscano alla sicurezza delle IA](https://distill.pub/2019/safety-needs-social-scientists/).
Puoi trovare ulteriori dettagli nelle risorse al termine della recensione.
**Organizzazioni consigliate**
------------------------------
* [AI Safety Support](https://www.aisafetysupport.org/) lavora per ridurre il rischio esistenziale e catastrofico legato alle IA sostenendo chiunque voglia lavorare su questo problema, concentrandosi sull’aiutare nuovi o aspiranti ricercatori sulla sicurezza delle IA attraverso consigli di carriera e costruendo una comunità.
* [Alignment Research Center](https://alignmentresearchcenter.org/) è un’organizzazione di ricerca no-profit al lavoro per allineare i futuri sistemi di machine learning agli interessi umani. Si impegna attualmente a sviluppare una strategia di allineamento “end-to-end” che possa essere adottata oggi dal contesto profit e che, nel frattempo, possa scalare verso i futuri sistemi di apprendimento automatico. Controlla i [ruoli attualmente vacanti](https://alignmentresearchcenter.org/hiring/).
* [Anthropic](https://www.anthropic.com/) è una compagnia che si occupa della ricerca sulle IA e della sicurezza al fine di costruire sistemi di IA affidabili, interpretabili e manovrabili. Gli interessi del loro team di ricerca multidisciplinare includono il linguaggio naturale, il feedback umano, le leggi di potenza, l’apprendimento attraverso il rinforzo, la generazione di codice e l’interpretabilità. Controlla i [ruoli attualmente vacanti](https://www.anthropic.com/#careers).
* Il [Center for Human-Compatible Artificial Intelligence](https://humancompatible.ai/) punta a sviluppare i mezzi concettuali e tecnici per riorientare la spinta generale della ricerca sull’IA verso sistemi con vantaggi comprovati. Controlla i [ruoli attualmente vacanti](http://humancompatible.ai/jobs).
* Il [Center on Long-term Risk](https://longtermrisk.org/) affronta i rischi peggiori per lo sviluppo e l’impiego di IA avanzate. Attualmente si concentra sugli scenari di conflitto, così come su sugli aspetti tecnici e filosofici della cooperazione. Il loro lavoro include ricerche interdisciplinari, il fare finanziamenti o il suggerire candidati e il costruire una comunità di professionisti e altri ricercatori nell’ambito di queste priorità. Controlla i [ruoli attualmente vacanti](https://longtermrisk.org/work-with-us/).
* [DeepMind](https://deepmind.com/) è con ogni probabilità il più grande gruppo di ricerca che sta sviluppando un’intelligenza artificiale generale nel mondo occidentale. Siamo sicuri di poter consigliare ruoli presso DeepMind solamente negli ambiti della sicurezza, dell’etica, delle politiche e della sorveglianza. Controlla i [ruoli attualmente vacanti](https://deepmind.com/careers/).
* Il [Future of Humanity Institute](https://www.fhi.ox.ac.uk/) è un istituto di ricerca multidisciplinare dell’Università di Oxford. Accademici del FHI sfoderano gli strumenti della matematica, della filosofia e delle scienze sociali per influenzare le domande fondamentali sull’umanità e le sue prospettive.
* Il [Machine Intelligence Research Institute](https://intelligence.org/) è stato uno dei primi gruppi a preoccuparsi dei rischi dell’intelligenza artificiale nei primi anni 2000 e ha [pubblicato diversi articoli](https://intelligence.org/research/) sui problemi di sicurezza e su come risolverli. Controlla i [ruoli attualmente vacanti](https://intelligence.org/get-involved/#careers).
* [OpenAI](https://openai.com/) è stata fondata nel 2015 con l’obiettivo di condurre ricerche su come rendere sicure le IA. Ha ricevuto oltre un miliardo di dollari di impegni di finanziamento dalla comunità di questo settore tecnologico. Controlla i [ruoli attualmente vacanti](https://jobs.lever.co/openai).
* [Redwood Research](https://www.redwoodresearch.org/) conduce ricerche applicate per aiutare ad allineare i futuri sistemi di IA agli interessi umani. Controlla i [ruoli attualmente vacanti](https://www.redwoodresearch.org/jobs).
### **Vuoi dei consigli faccia-a-faccia su come intraprendere questo percorso?**
Visto che si tratta di uno dei nostri percorsi prioritari, se pensi che questo percorso possa essere un’ottima occasione per te, saremmo *particolarmente*entusiasti di consigliarti sui tuoi prossimi passi. Possiamo aiutarti a considerare le tue opzioni, a creare connessioni con altri che lavorano nello stesso campo e, se possibile, anche aiutarti a trovare un lavoro o delle opportunità di finanziamento.
[CANDIDATI PER PARLARE CON IL NOSTRO TEAM](https://80000hours.org/speak-with-us/?int_campaign=career-review-generic)
**Scopri di più**
-----------------
**Ulteriori letture essenziali (in inglese):**
* Per aiutarti a orientarti nel campo, ti consigliamo lo [AI safety starter pack](https://forum.effectivealtruism.org/posts/pbiGHk6AjRxdBPoD8/ai-safety-starter-pack)
* [Guida passo-dopo-passo di Charles Rogers Smith sulle carriere nella sicurezza della IA](https://forum.effectivealtruism.org/posts/7WXPkpqKGKewAymJf/how-to-pursue-a-career-in-technical-ai-alignment)
* [Il nostro profilo di problemi sui rischi dell’IA](https://80000hours.org/problem-profiles/positively-shaping-artificial-intelligence/)
* Questo [curriculum sulla sicurezza dell’IA](https://www.eacambridge.org/technical-alignment-curriculum) (o, per qualcosa di più breve, questa serie [di post](https://www.alignmentforum.org/s/mzgtmmTKKn5MuCzFJ)di Richard Ngo)
* [La nostra guida su come diventare un tecnico nel campo del machine learning con un focus sulla sicurezza dell’IA](https://80000hours.org/articles/ml-engineering-career-transition-guide/)
**Ulteriori letture (in inglese):**
* [Recensioni della carriera come dottorato nel machine learning](https://80000hours.org/career-reviews/machine-learning-phd/)
* [Lista di letture dal Center for Human-Compatible AI](http://humancompatible.ai/bibliography)
* [Una serie di liste di lettura sulla sicurezza dell’IA](https://forum.effectivealtruism.org/posts/XvWWfq9iqFj8x7Eu8/list-of-ai-safety-courses-and-resources)
* Podcast: [Dr Paul Christiano on how OpenAI is developing real solutions to the ‘AI alignment problem’, and his vision of how humanity will progressively hand over decision-making to AI systems](https://80000hours.org/podcast/episodes/paul-christiano-ai-alignment-solutions)
* Podcast: [Machine learning engineering for AI safety and robustness: a Google Brain engineer’s guide to entering the field](https://80000hours.org/podcast/episodes/olsson-and-ziegler-ml-engineering-and-safety)
* Podcast: [The world needs AI researchers. Here’s how to become one](https://80000hours.org/2017/07/podcast-the-world-needs-ai-researchers-heres-how-to-become-one/)
* Podcast: [Chris Olah on working at top AI labs without an undergrad degree](https://80000hours.org/podcast/episodes/chris-olah-unconventional-career-path/) e [What the hell is going on inside neural networks](https://80000hours.org/podcast/episodes/chris-olah-interpretability-research/)
* Podcast: [A machine learning alignment researcher on how to become a machine learning alignment researcher](https://80000hours.org/2018/03/jan-leike-ml-alignment/)
* Leggi [tuti i nostri articoli sulle carriere nella sicurezza dell’IA](https://80000hours.org/topic/priority-paths/technical-ai-safety/) |
dec3aaa3-4efc-4931-9ebf-b458c9772dba | trentmkelly/LessWrong-43k | LessWrong | Slave Morality: A place for every man and every man in his place
Lately, there has been a discussion between Bentham's Bulldog, Scott Alexander and others about the nature of the slave morality. The outcome for me is that I no longer have any clue about what people meant by it, or, for that matter, what Nietzche once meant by it. To sow even more confusion, here's my interpretation, which, I think, is different from those proposed so far.
Slave morality is a child-like assumption that when you clean up your room, you'll get a cookie. An assumption, that if you follow the rules you are entitled to some kind of reward.
The opposite, the master morality, says that whatever you do, you are not entitled to anything. The world doesn’t care. It's all up to you.
A nice and heart-warming example of master morality comes from American Declaration of Independence with its "life & liberty & pursuit of happiness".
It does not guarantee happiness, however modest. It only guarantees the freedom to give it a try. If you fail and end up unhappy, too bad for you, Declaration of Independence has nothing to console you.
Wikipedia lists comparable mottos worldwide. Say "life, liberty, security of the person" or "life, liberty, enjoyment of property". And you can see how those are a kind of anti-climax. Where the Declaraton of Independence boldly states that everyone is free to pursue happiness in their own way and leaves the resolution of the necessarily resulting conflicts for later, the alternatives give up on master morality and instead try to provide some kind of petty mundane guarantees, only suited to satisfy a slave.
As for slave mentality, a nice example comes from the book "Dune" by Frank Herbert. If you happen to not know, it's a science fiction story in which the humanity lives in a feudal empire spanning thousands planets, with an emperor, noble houses, peons and all the other feudal paraphernalia.
The empire is based on faufreluches social system . The motto of the system is: "A place for every man and every man in his place."
In |
69048718-a200-4d12-a381-3a42d1154c70 | trentmkelly/LessWrong-43k | LessWrong | Waterfall Ethics
I recently read Scott Aaronson's "Why Philosophers Should Care About Computational Complexity" (http://arxiv.org/abs/1108.1791), which has a wealth of interesting thought-food. Having chewed on it for a while, I've been thinking through some of the implications and commitments of a computationalist worldview, which I don't think is terribly controversial around here (there's a brief discussion in the paper about the Waterfall Argument, and its worth reading if you're unfamiliar with either it or the Chinese room thought experiment).
That said, suppose we ascribe to a computationalist worldview. Further suppose that we have a simulation of a human running on some machine. Even further suppose that this simulation is torturing the human through some grisly means.
By our supposed worldview, our torture simulation is reducible to some finite state machine, say a one tape turing machine. This one tape turing machine representation, then, must have some initial state.
My first question: Is more 'harm' done in actually carrying out the computation of the torture simulation on our one tape turing machine than simply writing out the initial state of the torture simulation on the turing machine's tape?
The computation, and thus the simulation itself, are uniquely specified by that initial encoding. My gut feeling here is that no, no more harm is done in actually carrying out the computation, because the 'torture' that occurs is a structural property of the encoding. This might lead to perhaps ill-formed questions like "But when does the 'torture' actually 'occur'?" for some definition of those words. But, like I said, I don't think that question makes sense, and is more indicative of the difficulty in thinking about something like our subjective experience as something reducible to deterministic processes than it is a criticism of my answer.
If one thinks more harm is done in carrying out the simulation, then is twice as much harm done by carrying out the si |
4e1d2c91-0fdc-4e7b-ae7c-ad3b60d9036f | StampyAI/alignment-research-dataset/special_docs | Other | Building Trust Through Testing
AUTHORS
Michèle A. Flournoy
Avril Haines
Gabrielle ChefitzBuilding Trust
through Testing
Adapting DOD’s Test & Evaluation, Validation &
Verification (TEVV) Enterprise for Machine Learning
Systems, including Deep Learning Systems
OCTOBER 2020
PRINT AND ELECTRONIC DISTRIBUTION RIGHTS
© 2020 by WestExec Advisors. This work is licensed under
a Creative Commons Attribution-NonCommercial 4.0
International License.
To view a copy of this license, visit:
https://creativecommons.org/licenses/by-nc/4.0/.
Cover image: mariordo59/Wikimedia. https://commons.
wikimedia.org/wiki/File:Aerial\_view\_of\_the\_Pentagon,\_
Arlington,\_VA\_(38285035892).jpg
AUTHORS
Michèle A. Flournoy
Avril Haines
Gabrielle ChefitzBuilding Trust
through Testing
Adapting DOD’s Test & Evaluation, Validation &
Verification (TEVV) Enterprise for Machine Learning
Systems, including Deep Learning Systems
OCTOBER 2020
1he United States is at an inflection point in an age of mounting
transnational threats, unprecedented global interdependence,
and resurgent great power competition. This moment is taking
place in the context of a technological revolution that exacerbates the
challenges we face while simultaneously offering potential solutions,
providing breakthroughs in climate, medicine, communications, transporta-
tion, intelligence, and many other fields. Many of these breakthroughs will
come through the exploitation of artificial intelligence (AI) and its related
technologies—chief among them machine learning (ML). These advanc-
es will likely shape the economic and military balance of power among
nations and the future of work, wealth, and inequality within them.
Innovations in ML have the potential to transform fundamentally how
the U.S. military fights, and how the Department of Defense (DOD) oper-
ates. Machine learning applications can increase the speed and quality
of human decision-making on the battlefield, enable human-machine
teaming to maximize performance and minimize the risk to soldiers, and
greatly improve the accuracy and speed of analysis that relies on very
large data sets. ML can also strengthen the United States’ ability to defend
its networks against cyberattacks at machine speeds and has the power to
automate critical components of labor-intensive enterprise functions, such
as predictive maintenance and personnel management.
Advances in AI and machine learning are not the sole province of the
United States, however. Indeed, U.S. global leadership in AI remains in
doubt in the face of an aggressive Chinese challenge in the field. Numer-
ous DOD and academic reports reflect on the need to invest more in AI T
2research and development, train and recruit a skilled workforce, and promote an
international environment supportive of American AI innovation—all while promot-
ing safety, security, privacy, and ethical development and use. However, far too
little attention is placed on the issue of trust, and especially testing, evaluation, verifi-
cation, and validation (TEVV) of these systems. Building a robust testing and evalu-
ation ecosystem is a critical component of harnessing this technology responsibly,
reliably, and urgently. Failure to do so will mean falling behind.
This report will first highlight the technological and organizational barriers to
adapting DOD’s existing TEVV ecosystem for AI-enabled systems, with a particular
emphasis on ML and its associated techniques of deep learning (DL), which we
predict will be critical to future deterrence and warfighting while presenting unique
challenges in terms of explainability, governability, traceability, and trust. Second,
this report will offer concrete, actionable recommendations to DOD leadership,
working with the intelligence community, the State Department, Congress, industry,
and academia on how to advance the TEVV system for ML/DL by reforming pro-
cesses, policy, and organizational structures, while investing in research, infrastruc-
ture, and personnel. These recommendations are based on the authors’ decades
of experience working in the U.S. government on national security and dozens of
interviews with experts from government, industry, and academia working on ML/
DL and test and evaluation.
3he Defense Department needs to reform its existing testing
and verification system—its methods, processes, infrastruc-
ture, and workforce—in order to help decision-makers
and operators understand and manage the risks of developing,
producing, operating, and sustaining AI-enabled systems. Several
DOD reports and policy documents identify TEVV as a barrier to AI
adoption and call for increased research into new methodologies,
including the Pentagon’s AI Ethics Principles1 and AI Strategy,2 which
states, “we will invest in the research and development of AI systems
that are resilient, robust, reliable, and secure; we will continue to
fund research into techniques that produce more explainable AI; and
we will pioneer approaches for AI test, evaluation, verification, and
validation.”
However, DOD has yet to translate this stated goal into a real plan
of action. Advancing the Defense Department’s TEVV enterprise for
ML/DL systems is critical for several reasons.
First, developing an effective TEVV approach that is sufficiently
predictive of performance is critical to building the trust in these sys-
tems necessary to deploy and leverage these capabilities at scale. The
United States has already seen this dynamic with nuclear power, for
example, where lost trust in the technology has prevented policymak-
ers from harnessing nuclear power for clean energy.
The Pentagon cannot let TEVV become a barrier to fielding AI-en-
abled systems in an operationally relevant time frame, but must do
so in a manner that engenders trust in such systems and is consistent
with U.S. values and principles. The ultimate goal of any TEVV system New Technologies
Require New Testing
Approaches
T
4should be to build trust—with a commander who is responsible for deploying a sys-
tem and an operator who will decide whether to delegate a task to such system—by
providing relevant, easily understandable data to inform decision-making.
Fielding AI systems before our competitors may not matter if DOD systems are
brittle and break in an operational environment, are easily manipulated, or op-
erators consequently lose faith in them. Military operations present a challenging
environment. The Defense Department needs ML/DL systems that are robust and
secure. They need to be able to function in a range of environmental conditions,
against adversaries who are adaptive and clever, and in a manner that engenders
trust by the warfighter.
Second, the context in which DOD operates means these technologies are
prone to adversary attack and system failure, with very real consequences. Ma-
chine learning systems have an increased potential for failure modes relative to
other systems, such as bias due to a distribution shift in data, as well as novel
vulnerabilities to attacks ranging from data poisoning to adversarial attacks. One
could easily imagine an image classifier that accidentally classifies a civilian school
bus as a tank or an adversary exfiltrating a model processing sensitive intelligence,
surveillance, and reconnaissance or communications data. Image classification
algorithms developed for one environment (e.g., the desert) could turn out to work
incorrectly in another environment (e.g., cities).
Third, with an effective TEVV system, the United States can reduce barriers to
innovation and facilitate U.S. leadership in ML/DL technologies. As most of the
innovation in ML/DL will come from the private sector, unless the U.S. government
is able to effectively draw on private sector work in this arena, it will not be able to
leverage the best cutting-edge technology. Research on new TEVV methods and
organizational reforms to adapt the current system is simply not keeping pace with
private sector development. Without urgent reforms and prioritized investment in
new research and infrastructure, the Defense Department will lose its chance to
shape industry’s approach to ML/DL development in a manner consistent with
DOD standards for safety, reliability, and accountability. It will lose the opportunity
to take advantage of new private sector developments, while allowing other na-
tions without such standards to adopt the latest innovations. It is critical that the U.S.
government not only shape its own U.S. industry standards but also promote com-
patible global standards and norms.
Fourth, adversary advancements will likely increase pressure to field AI-enabled
systems faster, even if testing and assurance are lacking. China has elevated AI to
be a major national priority across sectors and is already exporting armed drones
with varying degrees of autonomy.3 Russia is also pursuing R&D on AI for military
5purposes4 and fields AI-enabled robotic systems in Syria with little regard for ethical
considerations.5 However, it shouldn’t be a race against our competitors to field AI
systems at any cost. It’s a race to field robust, lawful, and secure AI systems that can
be trusted to perform as intended.
Finally, high standards for robustness, assurance, interpretability, and govern-
ability can ultimately be a tremendous source of strategic advantage, incentivizing
industry to harden systems to adversary attack.
Taken together, these risks and opportunities suggest that devising an effective,
efficient, and ethical TEVV process is critical for maintaining the U.S. military and
economic competitive edge, as well as deploying reliable and trustworthy ML/DL
systems.
REPORT SCOPE
Many of the recommendations in this report may apply to several critical emerg-
ing technologies beyond ML/DL. Nonetheless, this report will focus on addressing
challenges associated with developing the necessary operational and organiza-
tional infrastructure to advance TEVV for ML/DL, with a special focus on DL.
For the purposes of this report, we will define AI, ML, and DL using DOD termi -
nology. The Department’s 2019 AI Strategy defines AI as “the ability of machines
to perform tasks that normally require human intelligence.”6 The Defense Innovation
Board defines machine learning as the capability of machines to learn from data
without being explicitly programmed.7 The data used to train machines comes in
three general types: supervised (uses example data that has been labeled by hu -
man “supervisors”), unsupervised (uses data but doesn’t require labels for the data),
and reinforcement learning (has autonomous AI agents that gather their own data
and improve based on their trial and error interaction with the environment).8 Finally,
deep learning is a special form of ML that deploys neural networks with many lay -
ers of connected neurons in sequence. Neural networks are a specific category of
algorithms very loosely inspired by biological neurons in the brain.
Deep learning is a potentially powerful tool with important operational and
organizational applications that is expected to be increasingly deployed in DOD
systems. However, it has two challenging features. First, its output often lacks ex-
plainability and traceability. Second, it is vulnerable to adversarial attacks. These
defining features mean DL will not be appropriate for all problem sets, and may
not be trusted in certain operational settings. Likely, most real-world AI systems will
be hybrid models that increasingly use deep learning as a component of a larger
system. While it is still early days in the development and testing of even basic ML
applications, the processes and procedures established today will set the standard
for more complex, future applications, including those that employ deep learning,
6which is why it is so critical that the Department develop a framework for address-
ing these challenges now.
Second, this report will focus predominately on Department of Defense efforts,
which we assess currently lag behind those of the intelligence community in devel-
oping and fielding these systems. Nonetheless, we acknowledge that many deep
learning applications will be essential for the intelligence community, and that the
Pentagon already leverages tools developed within the IC. Successfully research-
ing, developing, testing, and fielding these systems will require closer coordination
between DOD and the IC.
Finally, this landscape will continue to evolve rapidly as the technology matures.
This report identifies a number of challenges and opportunities, but we acknowl-
edge that many more will come to light as the research progresses and more ML/
DL systems become operational.
7he current rigid, sequential development and testing process for
major defense acquisition programs—such as hardware-inten-
sive systems like ships, airplanes, or tanks—is not well suited for
adaptive emerging technologies like ML/DL. The current technology ac-
quisition process takes a linear, waterfall approach to development and
testing. Companies must pass through a series of acquisition phases and
milestone decision points—moving from prototyping/technology matura-
tion to manufacturing and development to production and deployment.
At the outset of a program, a test and evaluation master plan is devel-
oped, which describes T&E activities over a program’s life cycle—in-
cluding developmental test and evaluation (DT&E), operational test and
evaluation (OT&E), and potentially live-fire test and evaluation (LFT&E)
at different phases—and identifies evaluation criteria for the testers.
This approach is not well suited for ML/DL, which requires a more
agile, iterative development and testing approach. With ML/DL systems,
development is never really finished, so neither is testing. Further, ML/DL
system performance is difficult to characterize and bind, and the brit-
tleness of such systems means they will require regular system updates
and testing. Exhaustive up-front testing does not make sense for these
types of non-determinative systems. Therefore, the Defense Department
must embrace the commercial best practice of Development, Security,
and Operations (DevSecOps), a collection of processes, principles, and
technologies that enables an integrated and automated approach to
development and testing.9 The Challenge:
Technological Features
and Bureaucratic
Barriers
T
8Below we will first outline a few of the key technological features of ML/DL that
make TEVV so challenging and require the Defense Department to reimagine its ap-
proach. Then we will discuss the organizational and institutional barriers to adapting
DOD’s TEVV approach.
TECHNOLOGICAL FEATURES
ML/DL systems are not robust and it is difficult to characterize system
performance.
A fundamental challenge of ML/DL is its brittleness; it has trouble functioning
correctly if the inputs or environmental conditions change. However, testing these
systems in all possible scenarios and with all ranges of inputs is simply not fea-
sible. It is nearly impossible to predict all the ways a system could break, or an
adversary could manipulate or spoof it, which is partly why these systems may be
especially vulnerable to adversarial attacks.
As these systems become more sophisticated, as is the case with deep learning,
their output becomes even less transparent, making it harder to determine the con-
ditions under which they might fail and what steps could correct system behavior.
Even when operating under the best conditions (within the same distribution of in-
puts or environmental conditions present during training), DL models generally don’t
work to the reliability standards needed for safety-critical systems,10 and therefore
may not be appropriate for these applications, at least given the current state of the
technology.
ML/DL systems are also particularly vulnerable to operational edge cases
(both unintended and intended), which are cases that occur beyond the bounds of
a system’s operational envelope or normal operating parameters. Because it is very
difficult to characterize the actual performance envelop of these systems, it will be
important to prioritize stress testing system performance with boundary conditions.
Further, interactions within and between systems (including foreign autonomous
systems) can induce unintended consequences and are even more complex to pre -
dict or understand. The potential for unintended engagement or escalation is even
greater when U.S. and/or adversary systems have the sorts of advanced autonomy
features that deep learning can enable, and their interaction cannot be studied or
fully tested in advance of deployment.
All of these challenges undermine the establishment of trust between operator
and system, which is essential given the U.S. military is likely to deploy DL as part of
human-machine teams. Critical to building this trust will be the ability to accurately
characterize the bounds of a system’s behavior—that is, when it will work and when
it will not. If DOD has an image classifier that only works in a desert environment
and operators know it will only work in a desert environment, then they are more
9likely to trust it. Operators don’t need to know exactly how a system works, only
under what conditions it will and won’t work. This will require new methods of testing
and assurance to predict system failure and govern system performance.
Testing ML/DL requires large, representative data sets.
While technological advances in “one shot” and reinforcement learning may ulti-
mately enable the Pentagon to test ML/DL without a lot of data or provide alter-
native approaches to handle out-of-distribution situations, for the next five to 10
years, the Defense Department will likely rely on supervised learning systems, and
testing ML/DL systems will likely require large sets of labeled, representative data.
The United States needs a whole-of-government data strategy that allows for
data collection, cleaning, curation, and sharing across agencies, especially be -
tween DOD and the IC.
Currently, the Defense Department lacks sufficient available data that mimics the
conflict condition in which these systems may operate in the future. This will limit its
ability to test system performance against realistic conditions. It will also hamstring
efforts to identify edge cases and develop fail-safe mechanisms to prevent cata-
strophic outcomes.
The Pentagon lacks the ability to effectively collect, manage, store, and share
testing data across the enterprise, which would enable this approach to scale. Final-
ly, DOD leadership will need approaches to continuously test the quality of the data
itself, as testing data could be compromised or revealed unintentionally or intention -
ally by adversaries.
ML/DL will be integrated into a system of systems.
ML/DL will be integrated into a range of DOD software and hardware systems,
so it is imperative that developers, testers, and policymakers take a systems archi-
tecture view when building and evaluating these systems.
The Defense Department cannot simply test all components separately and as-
sume that the system as a whole will work as intended. The accuracy and precision
of ML/DL systems is typically a composite effect that arises from a combination of
the behaviors of different components, such as the training data, the learning pro-
gram, and even the learning framework. These components are then embedded in
larger systems, so interactions with the physical, computational, and human compo-
nents of the system will ultimately affect system performance.
Often, failures come from unexpected interactions or relationships between
systems, rather than the behavior of any individual element. These dynamics make
the system increasingly vulnerable to malfunction and cyber-attacks. An adversary
could attack any number of vulnerable entry points within the hardware or software
that could, in turn, compromise the entire system.11
10The Defense Department needs to greatly advance its ability to conduct inte -
grated systems testing that takes into account the interactions with and between sys-
tems, testing both machine-machine and human-machine interactions. It should also
prioritize testing for how failure in a given subsystem could impact the performance
of the system as a whole.
The black box challenge: unique features of DL traceability and interpret-
ability.
It is critical that all ML/DL systems are trustworthy, traceable, and transparent to
the greatest extent possible. Deep learning presents challenges for each of these
features. Unlike most previous types of computer systems, it may not be possi-
ble to trace why a deep learning system made the decision it did in a particular
scenario. Not being able to determine what led to an error can obviously create
significant challenges for TEVV. It can also undermine user confidence in any
solution devised to address the problem identified. Challenges with interpretability
in real-time will also hamper human-machine teaming—operators are more likely
to trust a system and interact with it effectively if they understand roughly why it is
taking certain actions or decisions.
Further, the opacity of deep learning systems makes it difficult to identify or trace
back certain kinds of adversary attacks, such as some forms of data poisoning.
Some forms of attacks are not obvious to human intuition and, therefore, difficult to
imagine and test against (i.e., a 3-D printed turtle that fooled Google’s image clas-
sifier into classifying it as a rifle.)12
The lack of interpretability, traceability, and explainability of DL systems has the
potential to undermine trust and exacerbate challenges associated with developing,
deploying, and governing ML/DL at scale.
BUREAUCRATIC BARRIERS
In addition to these technological features, there are a number of bureaucratic
barriers—ranging from leadership and process to human capital and infrastruc-
ture—preventing DOD from accelerating the development of new approaches to
TEVV for ML/DL.
Responsibility for ML/DL TEVV is shared and not well coordinated.
While responsibility for TEVV is shared across multiple parts of the Office of the
Secretary of Defense (OSD) and the services, greater coordination is needed to
streamline investment and R&D on new testing approaches, increase cross-pro-
gram visibility, and proliferate standards and best practices.
11There is a growing community of stakeholders within DOD and the broader U.S.
government that will be critical to adapting the ML/DL TEVV enterprise. The Direc-
tor of Operational Test & Evaluation (DOT&E) oversees policy and procedure for
operational testing of major defense acquisition programs (MDAPs). DOT&E can
play a key role in promulgating testing standards but tends to be cautious in setting
new standards. It is accustomed to a rigid, sequential TEVV process that works well
for MDAPs, but not for emerging technologies like ML/DL. The Testing Resource
Management Center (TRMC) oversees infrastructure and spending, and develops
investment roadmaps for new technology programs. TRMC will also be critical to
adapting infrastructure for ML/DL DevSecOps. TRMC has included the Autonomy
and Artificial Intelligence Test Technology Area in its T&E/S&T portfolio.13
The Joint Artificial Intelligence Center (JAIC), the Under Secretary of Defense
(USD) for Research and Engineering (R&E), and the Director of the Defense Ad-
vanced Research Projects Agency (DARPA) all have important roles to play in the
development of AI TEVV metrics, methods, and standards for DOD systems. The
JAIC is actively engaged in setting standards, sharing best practices, and conduct-
ing testing. These programs promote, for example, designing DOD ML/DL systems
and tagging data in ways that make it possible to understand how any particular
decision is made. In April 2020, JAIC issued a request for information for new T&E
capabilities for AI technologies.14 It is also already leading on implementation of the
Defense Department’s AI ethics principles and integration of TEVV throughout the
product development life cycle. The JAIC has established a DOD-wide responsible
AI subcommittee, with representation from the services and the Joint Staff, DARPA,
R&E, T&E, A&S, Policy, and the Office of the General Counsel to develop detailed
policy documents, which will map the AI principles to the AI product life cycle
and acquisition process.15 However, the JAIC is too small to scale these solutions
throughout the Department. Meanwhile, the USD R&E is responsible for prototyping
systems and developing large system of systems that will increasingly be AI-en-
abled. Finally, DARPA’s Explainable AI program is working to produce more ex-
plainable models that facilitate trust and human-machine collaboration.
The armed services each have their own AI programs, which include testing com-
ponents and research on AI TEVV at the service labs. The services have the operation-
al knowledge and program acquisition offices and have traditionally led on develop-
mental testing for major programs of record. They also know there is power in owning
the test data and, understandably, want to evaluate the capabilities they are sending
to their servicemembers themselves. However, the services don’t tend to have the S&T
expertise and personnel to develop new approaches to TEVV for ML/DL.
The Defense Department will need to designate an office or organization with
overall responsibility for the TEVV process and establish a coordination mechanism
12that leverages the unique value-add of each of these entities, breaks down bureau-
cratic siloes, and streamlines investment in research and infrastructure to support
new TEVV approaches.
DOD policy, standards, and metrics for testing performance and evaluat-
ing risk need to evolve.
DOD needs a policy framework for determining safety standards for a range of
ML/DL applications based on the use case, mission, and anticipated environment
in which the system will operate. These standards then need to be translated into
requirements for system design and metrics for measuring system performance
that are operationally-relevant; transparent to developers, testers, and users; and
reflect DoD’s AI ethics and U.S. values.
DOD will first need to establish a testing framework that provides guidance on
the degree of acceptable risk and limits for a given ML/DL use case based on a
potential range of outcomes and errors. For example, if a potential outcome has
lethal consequences, the acceptable risk is likely to be extremely low, whereas if
the outcome has no clear negative consequences, the acceptable risk will almost
certainly be higher. The risk of fielding these systems will also need to be weighed
against the risk associated with not adopting the system. For example, a 5 percent
error rate may be palatable if the existing system has a 10 percent error rate. These
risk and error rates will also need to incorporate the potential for adversary attacks
or interactions with adversary systems. For example, an error that happens .001
percent of the time naturally, but which an adversary is able to consistently exploit,
could create significant challenges for the Pentagon.
Further, policymakers must acknowledge that with technology, there might be
less margin for error than with humans, and less clarity about who is accountable
for such errors. For example, the United States may determine that as a society, we
are not willing to accept a scenario in which an algorithmic error in an autonomous
vehicle causes a loss of life even if it saves thousands of lives overall. Ultimately,
these technologies will never be perfect, and testing to a near-perfect standard will
inhibit DOD’s ability to field these systems at all. Therefore, it needs a dedicated
process to develop policies to determine how much risk it is willing to accept in a
given case, weighing operational need and potential consequences against DOD
ethics, principles, and policies.
DOD will need to translate this testing and safety framework into functional,
specific requirements language. For example, the JAIC could put out a request for
proposal saying it needs a DL that can identify a target from X range, in this season,
in these weather conditions.
13Finally, DOD will then need metrics and methods to evaluate operational
performance in easily understandable, operationally relevant terms. For example,
if U.S. Special Operations Command uses a deep learning algorithm to translate
documents from a raid on a terrorist compound and finds time-sensitive information,
how do you measure operational impact? Determining impact isn’t just about statis-
tical analysis on the level of precision-recall, but the impact compared to a human
being’s ability and the efficiency created for the operator.
DOD lacks an iterative, continuous approach to development, testing, and
sustainment that bridges the gap between acquisition and T&E.
For ML/DL, the Defense Department will need to replace its classic approach to TEVV
of formulating a T&E Master Plan for a given capability up front with a more automat-
ed, iterative, and continuous approach to testing in line with DevSecOps. Assuring that
ML/DL systems function as expected and do not engage in behaviors outside their
intended use and operational parameters will require testing across the system’s entire
life cycle—from development to operational deployment to sustainment.
It will also require new methods for capturing lessons learned and integrating
these into iterative development and testing. Because of the difficulty predicting
and binding system performance, one should consider every deployment of an
ML/DL system as an experiment and opportunity to collect data and insight on
performance.16
To support this approach, DOD will need to expand coordination between
program managers and testers to ensure testing milestones are built in throughout
the acquisition program. Program managers often see TEVV as an obstacle to be
surmounted at the end of the development process, rather than a necessary process
to be integrated throughout the development life cycle. Of course, this problem is
not unique to ML/DL programs, but it is exacerbated when it comes to emerging
technologies that do not yet have established testing methodologies. Further, the
Pentagon needs to invest in and scale automated TEVV capabilities for operational
platforms, such as the Navy’s automatic test and retest program,17 which will signifi-
cantly speed up the testing process.
An agile approach of iterative testing, updates, and releases will place signifi-
cant burdens on TEVV and require infrastructure and research investments, as well
as incentivizing program managers to see testing as an integral part of the develop-
ment process rather than a barrier. Program managers should be responsible and
rewarded for delivering a well-functioning product, not just staying on budget and
schedule.
14Current TEVV methods and infrastructure aren’t well suited for ML/DL and
may require new funding approaches.
Adapting the TEVV enterprise for ML/DL will require targeted investment in devel-
oping new testing methods and adapting current testing infrastructure to support
DevSecOps and iterative testing. The Defense Department needs new approach-
es, such as automated testing and digital twinning,18 as well as new testing infra-
structure, including test beds, test ranges, and advanced modeling and simula-
tion (M&S). DOD also needs computing support, cloud-based resources, data
capture for continuous development, and generation and use of synthetic data,
particularly for DL applications.19 Finally, it needs tools for traceability that cap-
ture key information about the systems development and deployment to inform
follow-on development, testing, and use.
The JAIC has adopted commercial best practices for AI DevSecOps. Its Joint
Common Foundation (JCF)—an infrastructure environment designed specifically for
training, testing, and transitioning AI technologies, which is intended for use by all
the services—is an important down payment on these efforts that will make it easier
to secure and rapidly test and authorize AI capabilities.20 The JAIC should be given
the resources and top-cover it needs to scale this effort. The Pentagon should build
on the JCF and other efforts to promote a secure, cloud-based DevSecOps ecosys-
tem that facilitates the rapid commercial development and iterative testing of ML/
DL and the proliferation of testing tools, data, and standards across OSD and the
services.
The Defense Department also needs to increase resources, bandwidth, and
personnel dedicated to adversarial testing. It can and does use Federally Funded
Research and Development Centers (FFRDCs), but there is concern among some ex-
perts that it is too heavily reliant on just one—MITRE—for adversarial testing. DOD
needs to invest in creating a catalogue of adversarial testing tools and proliferate
these capabilities across the service labs and FFRDCs that support testing. Finally,
DoD needs to work more closely with the intelligence community to simulate realistic
threats.
Finally, new approaches to TEVV for ML/DL will require new funding ap-
proaches. DoD, in coordination with Congress, should consider new approaches
that incorporate T&E funding into the cost of development, given that TEVV must be
integrated into an iterative development process. DoD and Congress should also
consider establishing a new appropriations category that allows AI/ML to be fund-
ed as a single budget item, with no separation between RDT&E, production, and
sustainment, as recommended by the Defense Innovation Board Software Acquisi-
tion and Practices Study.21
15DoD lacks the ability to recruit, train, and retain the right talent.
For many organizations within the DoD TEVV ecosystem, recruiting and retaining
talent is often a bigger challenge than securing funding. These organizations need
diverse, interdisciplinary teams that understand both testing and the technology
itself. DoD needs data scientists, statisticians, and computer scientists that can
develop new testing and verification mechanisms; computer science and ML/DL
experts to develop the technology; and operators that understand the technology
enough to trust, deploy, and integrate it operationally. Finally, it needs experts in
human cognition and psychology that understand human-machine interaction and
can build interfaces that enable greater trust.
Many of the challenges of recruiting and retaining such technical talent are not
unique. Existing DoD programs to recruit recent science, technology, engineering,
and math graduates are too small, non-traditional hiring authorities for STEM talent
are underutilized, and the service academies do not feed enough STEM talent
directly into technical roles. DoD lacks dedicated career paths for technologists and
testers, which further constrains the Department’s ability to retain what talent it does
manage to recruit or grow in-house.
Not all of this talent needs to be cutting-edge researchers; the Department will
need a cadre of professionals—program managers, requirements writers, lawyers,
operators, policy officials, and others—who have a baseline understanding of the
technology and testing procedures, and can bridge the gap between DoD leader-
ship and policy teams on one hand and the technical developers and testers on the
other. Further, DoD should leverage its expansive network of FFRDCs and academic
partnerships to expand its access to technical personnel. Many of the FFRDCs, such
as the Lawrence Berkeley and Lawrence Livermore National Laboratories in Califor-
nia and the MIT Lincoln Laboratory in Cambridge, are located near hotspots for AI
talent and have fewer challenges with hiring.
The Department has developed policy and ethical guidance on autono-
mous systems and AI, but these guidelines have yet to be translated into
TEVV implementation guidance.
DoD has established important foundational policy guidance for the use of auton-
omous systems and artificial intelligence with DoD Directive 3000.09 on Auton-
omy in Weapon Systems and the Defense Innovation Board’s AI Ethics principles,
adopted by DoD in February 2020. These policy documents have important
implications for testing and evaluating of ML/DL. For example, 3000.09 calls for
systems to go through “rigorous hardware and software [verification and valida-
tion] and realistic system developmental and operational T&E, including analysis
of unanticipated emergent behavior resulting from the effects of complex oper-
16ational environments on autonomous or semiautonomous systems.” It also states
that interfaces should be “readily understandable to trained operators,”22 making
explainability an important component of implementing this policy. Meanwhile,
the AI Ethics Principles commit DoD to develop and deploy AI that is traceable
(including with transparent and auditable methodologies, data sources, and de -
sign procedure and documentation), reliable (explicit, well-defined uses, with the
safety, security, and effectiveness of such capabilities subject to testing and assur-
ance across their entire life cycle), and governable (with the ability to detect and
avoid unintended consequences, as well as disengage or deactivate deployed
systems that demonstrate unintended behavior).
These policies are an important start and provide a useful framework for driving
TEVV for AI and autonomous systems. However, these goals are incredibly broad,
and many are currently technologically infeasible, given existing testing methodolo-
gies. DoD needs to develop TEVV implementation guidance for both 3000.09 and
AI ethics principles. In particular, these principles must inform ML/DL design and
be incorporated into the standards, specifications, and requirements against which
systems will be tested.
Finally, as ML/DL development and testing capabilities are still evolving, policy
and implementation guidance should not be overly prescriptive or rigid before DoD
knows how these systems will function and in what contexts they will be deployed.
Nonetheless, the development of implementation guidance and processes that inte -
grate ethics into the design and testing process will help accelerate the deployment
of reliable, safe, and transparent ML/DL.
There is insufficient coordination between DoD, the private sector, and
academia.
DoD needs a hybrid approach to TEVV that leverages DoD, academic, and
industry research, infrastructure, and talent. The majority of ML/DL innovation will
come from the private sector and academia, as will most of the insight into how to
test, benchmark, and assure these systems. However, DoD has an important role
to play in integrating, scaling, and deploying these solutions. Further, it can dedi-
cate significant resources to basic and applied research and use its market power
to influence the development and promotion of national standards for at least cer-
tain industries. DoD also has the unique capability to do adversarial testing, with
access to threat intelligence and operational knowledge that can inform realistic
modeling and simulation. DoD should, therefore, focus on unique use cases where
there is no commercial relevance or where sharing the data or algorithm would
reveal sensitive or classified information.
17DoD should, when possible, leverage commercial TEVV methods and tools, such
as Microsoft Azure and Amazon Web Services secure environments and tooling.23
In many cases, however, industry methods will not be applicable, given the safe -
ty-critical application and unique classification of DoD data, requiring a hybrid
model of development and testing informed by academic research.
Further, DoD needs to engage the private sector to develop an intellectual
property strategy both parties can live with that includes access to sufficient data for
continuous testing.
DoD should also engage in a sustained dialogue with commercial developers
to inform how DoD defines the requirements for ML/DL testing and performance
based on what is technologically feasible, now and in the future. There are some
successful models for this cooperation, such as the Army’s AI Hub—a consortium of
industry, government, and academic partners based at Carnegie Mellon Univer-
sity—which works with the JAIC and other DoD AI entities to provide independent
assessments of key research questions.24 Scaling this effort will require a senior DoD
champion, such as the Under Secretary for R&E, who values this work and can pro-
mote it across the Department.
14
191. Create an OSD coordinating body to lead on AI/ML TEVV and
incentivize strong cooperation with the services.
Accelerating and streamlining TEVV methods and processes for AI/ML
will require greater coordination across the TEVV ecosystem, including
the JAIC, USDE (R&E), USD (A&S), TRMC, DOT&E, and the service pro-
gram offices, test commands, and T&E organizations.
The Director of the JAIC and the Director of Operational Test and Eval-
uation should co-chair a new AI/ML TEVV Cross-Functional Team (CFT)
that reports biannually to the Deputy Secretary’s Management Action
Group (DMAG) and coordinates AI/ML TEVV research and investment
across the Department.25 This forum would include representation from
R&E, DARPA, TRMC, and the service labs, test commands, and T&E orga-
nizations, building on the work of the OSD-led Autonomy Community of
Interest TEVV group.26 The CFT would also work with the Defense Science
Board and Defense Innovation Board, which would provide expert sup-
port and connect DoD TEVV efforts with those in the private sector.27
This body would spearhead the development of policy, standards, re -
quirements, and best practices for AI/ML TEVV, which would incorporate
the AI ethics principles and 3000.09 and serve as testing implementation
guidance. The CFT would be responsible for assessing and certifying the
service AI/ML TEVV budgets, just as the Cost Assessment and Program
Evaluation (CAPE) office advises the Secretary and Deputy Secretary on
the budget.
The CFT would also create an AI/ML T&E action plan to delegate and
coordinate responsibilities across the Department. The JAIC should serve
as a center of excellence for AI/ML TEVV and lead on the development Recommendations for
Adapting DoD’s TEVV
Enterprise for AI/ML
20of testing tools and a testing framework. Further, R&E should lead an integrated
research plan for new TEVV methods, the service labs on modeling and simulation
and operational testing, TRMC on infrastructure investment, and DOT&E on policy
and standards proliferation and coordination.
DoD would benefit from an expansive testing ecosystem that pulls together OSD
standards, policy setting, and best practices with the services’ operational knowl-
edge and acquisition infrastructure.
2. Invest in priority areas of research in partnership with industry and
academia.
Research on new tools, methodologies, and metrics is key to implementing new
ML/DL testing framework and standards. Many of the following recommenda-
tions will fail if this one is not successful.
Removing this critical barrier will require coordinating and prioritizing research
on the science of ML/DL TEVV, backed by sustained, focused DoD funding. While
some TEVV challenges for ML/DL are well understood by industry and DoD simply
needs to adopt commercial best practices, there are many problems without existing
solutions that DoD has a unique interest in solving given its operational require -
ments. This work must be ongoing, as the technology evolves and new challenges
with ML/DL are identified.
The ML/DL TEVV CFT should task the Defense Science Board to conduct a thor-
ough review of all current research programs for ML/DL TEVV.
Based on this review, the Committee, with strong input from R&E, should de -
velop a coordinated research plan and seek funding for DARPA, TRMC, and the
service labs.
1. DoD should prioritize research on automated and repeatable testing. TEVV
is currently slowing down development and deployment, as testing process-
es move much slower than development. Advancing and scaling automated
testing could help standardize the testing process, help DoD keep pace with
industry, and accelerate fielding and scaling of these systems.
2. DoD should research methods for bounding, governing, and interrupting
system performance, including monitoring systems that can detect perfor-
mance issues and edge testing to prevent unacceptable errors.
3. DoD should research and develop performance metrics in operationally
relevant terms that are easily traceable and understandable to the user and
support risk assessments. These metrics are key to translating safety and
assurance guidance into requirements for various design features, such
as explainability and traceability. Such metrics could include whether the
21system satisfies specific mission requirements, how it utilizes resources over
time during the mission, how a system's output impacts human decision-mak -
ing, and whether safe actions are selected in the presence of unexpected or
hostile inputs. For example, if a certain class of system has an explainability
requirement given its context of use, how does one actually characterize
levels of explainability?
4. DoD should work closely with industry (particularly the commercial au-
tonomous vehicle community) to continue research on new techniques for
synthetic data creation, modeling, and simulation.
5. DoD needs to increase research on a range of issues related to human-ma-
chine teaming and interaction. DoD needs a more human-centric approach
to considering ML/DL development and testing. Humans are central
throughout a system’s life cycle, from development to deployment, and DoD
will need to account for human psychology and bias at each stage.
6. DoD should expand research on increasing system robustness to overcome
adverse conditions or enable systems to withstand or respond when target-
ed by an adversary attack.28
7. DARPA should continue its Explainable AI program, which is important for
increasing the transparency and accuracy of ML/DL while strengthening
trust with the end user.
As a general matter, investments in the science of ML/DL TEVV are a critical
prerequisite to developing the most effective and efficient standards, tools, and
methodologies needed to assure system performance. As these technologies and
their applications evolve, new areas of research will undoubtedly arise that warrant
investment.
3. Develop a tailored, risk-based framework for ML/DL testing and safety.
The AI/ML TEVV CFT should lead on the development of a framework that estab-
lishes architecture and testing standards for TEVV. DoD cannot have a one-size-
fits-all approach; it needs a flexible testing framework that is mission and use-case
dependent.
A DoD-wide testing framework for AI/ML will help shorten the testing cycle
and make test results interpretable and comparable across the Department. This
framework should also incorporate DoD’s legal and ethical requirements, serving as
implementation guidance for the AI ethics principles and 3000.09.
The DIB AI ethics principles call on the JAIC to create a taxonomy of DoD use
cases of AI, based on their ethical, safety, and legal risk considerations. The CFT
22should leverage this taxonomy and develop corresponding testing criteria and safe -
ty standards. Testing standards, for levels of interpretability or assurance, for exam-
ple, should be determined based on several dimensions of risk and performance,
including: the likelihood of error detection, the consequence of the error given the
complexity of the operating context, the potential for unintended escalation, the size
of the attack surface, system performance relative to that of a human operator, im-
pact on human decision-making, and the risk associated with not adopting a system
(e.g., the risk may be a 10 percent error for DL, but a 30 percent error without the
system). For example, AI for business process automation would likely score low on
all of these risk criteria, while AI for critical network cybersecurity would likely score
high on all and, therefore, necessitate stricter and more expansive TEVV require -
ments.
For higher-risk applications, DoD may need to require systems to be designed
with fail-safe systems or operated only as part of a human-machine team to help
mitigate risks and govern system performance. Researchers are currently develop-
ing methods for monitoring system performance and constraining a system to a set
of allowable, predictable behaviors and mitigate the risk of failure and unintended
escalation.
A DoD-wide AI TEVV framework will help decision-makers manage the tradeoff
between the risks of failure and the value of deployment, while advancing the
development of clear and consistent requirements for system design and metrics for
performance evaluation.
4. Translate the testing framework into testable, verifiable requirements
to be used by the private sector and build an integrated team to leverage
this approach.
DoD should establish a process for translating the testing framework into testable
and verifiable requirements.
DoD requirements would help standardize processes for industry contractors
who develop AI for DoD and promote a faster and cheaper TEVV process by
enabling the private sector to do some testing throughout development. The devel-
opment of such requirements and standard processes would allow DoD to leverage
the talent and expertise in the private sector, while maintaining DoD’s safety and
risk standards and employing DoD’s operational knowledge and adversarial testing
capabilities. Such requirements could additionally serve as the basis for standards
that are promoted by the U.S. Government across the private sector and interna-
tionally, as discussed in a later recommendation.
To realize this approach, DoD should build integrated, multi-disciplinary teams
that reflect the entire development, testing, and sustainment life cycle. One model is
23the JAIC’s project manager model, which incorporates experts on product, policy,
legal, test and evaluation, and requirements into one team. A similar approach is
the Navy’s AI "DevRon” concept, a single entity accountable start to finish for the
life cycle of capability development.29 Scaling this approach would help ensure
requirements take into account the unique challenges of ML/DL TEVV.
Requirements should also be written to advance the integration of ethics into the
design and testing process. One case study for how this is already being done is
DARPA’s Urban Reconnaissance through Supervised Autonomy (URSA) program,
which is developing AI-infused drones that can help prevent friendly fire and civilian
casualties in urban battles.30 This program brought in ethicists to anticipate challeng -
es before development even began, with the aim of integrating ethics into the devel-
opment loop. This URSA program offers useful lessons on how to conduct ethically
aligned design of military systems that enables testing for robustness, safety, and
security and ensures these systems are reliable and governable.
Developing requirements and standards for ML/DL will help strengthen the link
between DoD and industry, ensure a hybrid approach that leverages both private
and public sector resources, and inject DoD’s safety and ethical requirements into
industry development practices.
5. Bridge the gap between development and testing.
ML/DL systems will require testing and verification across their entire life cycle,
which will require stronger links between program managers and testers as well
as methods to capture lessons learned throughout deployment.
There are already good models for how this could be done. For example, devel-
opers for Project Maven need to submit to T&E in every sprint cycle, or they cannot
move forward to the next stage of development. We recommend replicating and
scaling this approach in other programs.
DoD could also look to the Joint Improvised-Threat Defeat Organization, estab-
lished in 2006, to rapidly field new technologies to counter IEDs. The organization’s
approach to fielding prototypes and testing them in the field provides a useful model
for the rapid deployment of ML/DL.
Another way to bridge this gap is to leverage the testing framework and re -
quirements language to inform the acquisition process. The JAIC is already using its
acquisition process to impact development of AI technologies by using the AI ethical
principles as “applicable standards.” One could envision a similar process with AI
testing and governance standards. To do so, DoD will need to maintain a robust
dialogue with industry on what is feasible to help inform the process.
In addition, program managers should be incentivized to build a test program
that verifies performance throughout the development and fielding life cycle and
24holds developers accountable for meeting the requirements. Program managers
should be recognized and rewarded for testing and for overall performance of the
system, not just on whether they can meet budget and schedule targets. Delivering a
system that is too risky to field but on time and budget does not make sense. Pro-
gram managers should also be rewarded for canceling programs that do not work
and for delivering programs that do.
6. Increase and integrate spending for T&E research and infrastructure.
Advancing TEVV for ML/DL will require a substantial investment in both research
and infrastructure. TRMC should lead on assessing current gaps in infrastructure
and be given increased funds to invest in service and DoD T&E live, virtual, and
constructive (LVC) test ranges, test beds, and modeling and simulation for testing
adaptive systems.
DoD should significantly increase investment in modeling, digital twins, and
simulation, working with the private sector—particularly commercial autonomous
vehicle companies—to implement industry best practices. These technologies can
be used to develop representative testing environments and conduct edge testing to
determine a system’s operational envelope. This investment is also key to reaching
the goal of automatic, repeatable testing, which is critical to DevSecOps, and creat-
ing synthetic data that can help offset a lack of usable, operational data.
DoD could invest in test beds to be hosted at FFRDCs and university-affiliat-
ed research centers, which attract top talent and work with DoD regularly. TRMC
should also help scale the Navy’s automatic test and retest program, which uses
cloud-based digital twins to provide near real-time feedback and automatic testing
of thousands of simulated environments.31 To do so, we support the National Secu-
rity Commission on AI’s recommendation that Congress should raise the authorized
cap for laboratory infrastructure investments, currently set at $6 million, in order to
provide laboratories with the ability to invest in equipment and testbed infrastructure
necessary for robust AI research, prototyping, and testing.32
Finally, the Department should consider new approaches to fund AI/ML TEVV.
For example, DoD could require that TEVV cost is factored into development, rather
than having as a separate T&E item.
Congress could also consider a new type of funding authority that bridges the
gap between AI S&T and T&E, allowing for both development and testing of new
technology. DoD does not yet have well-established methods of testing for ML/DL,
and will therefore be developing the capability and the ability to test it in parallel.
This will require S&T dollars for research on new T&E approaches. Congress has
already authorized a similar model for cyber, in which funds are authorized for
creating, testing, fielding, and operations.33 The Department, working with Con-
25gress, should explore the potential of replicating this model for AI development
and testing, consistent with the Defense Innovation Board Software Acquisition and
Practices study recommendation for a single budget item for AI/ML.34
7. Develop industry/U.S. government TEVV standards and promote them
internationally.
DoD, working with the National Institute of Standards and Technology (NIST) and
industry, and building on DoD requirements and processes developed for industry,
should develop standards for ML/DL testing for the private sector that can be publicly
promoted and help inform private sector development of ML/DL systems.
Such standards would focus on a range of issues, including robustness, inter-
pretability, performance metrics, fail-safe design, traceability for data collection and
management, privacy, and testability. These should be broad standards that serve
as guidance for both government and commercial developers to develop opera-
tionally specific design requirements and testing metrics.
DoD entities—including the JAIC and R&E—and the IC are already playing
a role in the development of U.S. government AI standards, led by NIST and the
Office of Science and Technology Policy. NIST’s 2019 plan on U.S. leadership on
AI provides an important foundation and calls for the development of standards and
metrics for trustworthiness (e.g., accuracy, explainability, resiliency, safety, reliabil-
ity, objectivity, and security), complexity, domain-specific and context-dependent
risk, and uncertainty.35
NIST and the State Department should play a leading role in promoting U.S.
government standards for AI and ML development and testing domestically and
throughout international standards-setting organizations, such as the International
Standards Organization and Institute for Electrical and Electronics Engineering, and
multilateral institutions, such as the OECD AI Policy Observatory. The promotion of
U.S. standards globally will help bolster U.S. economic competitiveness, create a
level playing field for U.S. industries who are collaborating with DoD and conse -
quently subject to these standards, incorporate U.S. values and ethical principles
into AI and ML development, and ensure that the United States and its allies are
interoperable. As we’ve seen in other critical technology areas, the United States
must ensure that competitors do not set standards, which make it harder to manage
vulnerabilities and hinder U.S. efforts to establish the highest degree of ethics, safe -
ty, and risk management.
8. Test, train, and certify human-machine teams through wargaming, sim-
ulation, and experimentation.
26ML/DL systems are likely to be deployed in human-machine teams and DoD will
need new approaches to test, train, and certify these teams as a whole. DoD will
need to understand and address the issues that could arise both when humans are
the operators of a system, including issues of handoff, and when humans are part
of the operating environment.
Operators, analysts, and commanders will need to understand and trust ML/
DL-enabled systems; be trained on how they will impact, enable, or detract from
operator capabilities; and how they will contribute to the overall mission.
DoD should develop a plan to better incorporate ML/DL-enabled applications
into exercises, wargames, and tabletop exercises. Increased investment in live, vir-
tual, and constructive environments that allow for user interaction and experimenta-
tion in realistic, simulated environments will further help with training and validating
human-machine teams.
DoD will also need to develop operator training and certification programs for
specific systems and use cases, as well as refresher trainings and re-certification for
when systems are deployed in new environments or when the system is updated.
DoD will need to consider each real-world deployment as an experiment.
Through wargaming, experimentation, and simulation, DoD can create the process-
es and methodologies to capture lessons learned and data, providing this feedback
to developers, testers, and operators to improve systems and build trust.
9. Accelerate recruitment and training of ML/DL and TEVV talent.
Recruiting and retaining diverse, interdisciplinary teams is an essential prerequisite
to advancing TEVV for ML/DL systems. DoD needs those with a fundamental ac-
ademic grounding in test and evaluation, as well as the systems engineers, com-
puter scientists, and ML/DL experts that understand the technology itself. It also
needs statisticians, data scientists, and applied mathematicians who can perform
mathematical testing. Finally, it needs experts who understand human-machine
interaction, such as psychologists and ethicists.
In addition to these subject matter experts, it also needs operators, requirements
writers, acquisition professionals, and lawyers who have a basic degree of techno-
logical literacy and understand why this technology matters.
To build up this talent, DoD should rely on its vast network of national and
service labs, FFRDCs, and university-affiliated research centers for technical tal-
ent. DoD could consider designating a current FFRDC for ML/DL or creating a
new FFRDC to help focus resources and talent. In addition, DoD should establish
a dedicated T&E career path, including education, training, and rotational assign-
ments.36 The services should develop corresponding programs for technologists,
allowing STEM graduates from the service academies and ROTC programs to serve
27in assignments where they can leverage AI/ML or other technical expertise. Further,
DoD should better leverage existing authorities Congress has provided to attract en-
try-level tech talent, using incentives such as scholarships and debt forgiveness, and
more experienced talent using vehicles like the Highly Qualified Expert and Inter-
governmental Personnel Act programs. The JAIC could also develop a best practice
guide for recruiting AI talent, from developers to testers.
Further, DoD should expand in-person and virtual technical training across
OSD, the services, and other components to bolster technological literacy in the
workforce. The Department could tap into an extensive repertoire of technical
education now available online, including on machine learning, advancing testing
techniques, DevSecOps, and human-machine interaction. DoD could also create a
training module in-house, focused specifically on adversarial testing.
10. Increase resources for and attention on adversarial testing and
red-teaming.
DoD’s unique operational context will require particular emphasis on adversarial
testing. Not only will DoD need to worry about adversary aggression, but it must
also consider the unintended consequences that may arise when U.S. systems with
ML/DL interact with adversary systems that have intelligent and/or autonomous
features.
DoD should significantly increase wargaming and red-teaming focused on
spoofing ML/DL, drawing on offensive cyber experiences like “Hack the Pentagon”
exercises, bug bounties, and NSA R6 (a dedicated red team within NSA’s research
directorate). DoD will also need to increase funding to fully develop threat models
for future battlefield environments involving near-peer adversaries.
DoD and the Office of the Director of National Intelligence (ODNI) could
consider standing up a national AI and ML red team as a central hub to test against
adversarial attacks, pulling together DoD operators and analysts, AI researchers,
T&E, CIA, DIA, NSA, and other IC components, as appropriate. This would be an
independent red-teaming organization that would have both the technical and
intelligence expertise to mimic realistic adversary attacks in a simulated operational
environment.
1 1. Promote greater cooperation on ML/DL between DoD and the IC.
Development and testing of ML/DL systems would greatly benefit from stronger
cooperation between DoD and the IC. The IC is more advanced in terms of de -
velopment and fielding of ML/DL. It also has more flexible authorities to develop
novel applications, conduct testing, and acquire commercial technology. Howev -
er, IC and DoD cooperation in this arena is rare—the IC does not want to share its
28most exquisite capabilities, and the services do not want to deploy systems they
have not built themselves.
Both sides stand to benefit from greater cooperation on testing, particularly
adversarial testing. If the IC shares some of its capabilities, DoD can add resources
to bring them to scale and then collect data it can then share with the IC. If the IC
wants to influence industry standards, it can do so far more effectively through DoD.
While DoD and the IC may not be able to share or transfer every system devel-
oped, they can share the fact that a system exists and its basic characteristics and
capabilities. DoD can then acquire its own version or the IC can use its own capa-
bility in support of DoD operations.
We endorse the National Security Commission on AI recommendation that
DoD and ODNI stand up a steering committee on emerging technology, tri-chaired
by the Deputy Secretary of Defense, the Vice Chairman of the Joint Chiefs of Staff,
and the Principal Deputy Director of ODNI.37 We recommend this committee have
a special line of effort dedicated to adversarial testing for emerging technologies,
focused on ML/DL.
Greater collaboration will help bolster adversarial testing capabilities with real-
istic threat modeling; create a division of labor for developing testing infrastructure
and methods, reducing costs to both; and strengthen U.S. government coordination
to scale development and testing standards.
CONCLUSION
The future of U.S. leadership on ML/DL and DoD’s ability to harness these critical
technologies depends on DoD investing in the science of ML/DL TEVV to develop
new approaches and metrics, as well as standing up the coordination and gov -
ernance mechanisms to accelerate progress and scale solutions. It will require
developing the testing frameworks, requirements, and standards to bridge the gap
between industry and government and shape a more iterative development and
testing approach; shifting culture and practice toward the testing and certification
of human-machine teams; and securing the talent, infrastructure, and resources
to implement this new approach. Finally, DoD will need to deepen partnerships
with the private sector, academia, non-governmental organizations, international
organizations, and international partners to realize a multi-stakeholder approach
to ML/DL development, testing, and deployment.
Adapting the TEVV enterprise for ML/DL is critical to increasing trust in and,
consequently, accelerating the deployment of these systems on a timeline consistent
with the rate of innovation, operational need, and U.S. ethics and principles. The
steps DoD and the broader U.S. government take now to adapt the ML/DL testing
ecosystem will determine the long-term safety, reliability, and relevance of these
systems in the coming decades.
29Endnotes
1. U.S. Department of Defense, “DOD Adopts Ethical Principles for Artificial Intelligence,” February 24,
2020, https://www.defense.gov/Newsroom/Releases/Release/Article/2091996/dod-adopts-ethical-
principles-for-artificial-intelligence/.
2. U.S. Department of Defense, Summary of the 20 18 Department of Defense Artificial Intelligence
Strategy (Washington, DC: Department of Defense, 201 8), https://media.defense.gov/2019/
Feb/1 2/2002088963/-1/-1/1/SUMMARY-OF-DOD-AI-STRATEGY.PDF .
3. Patrick Tucker, “SecDef: China is Exporting Killer Robots to the Mideast,” Defense One, November 5,
2019, https://www.defenseone.com/technology/2019/1 1/secdef-china-exporting-killer-robots-
mideast/161 100/.
4. Roger McDermott, “Moscow Pursues Artificial Intelligence for Military Application,” Eurasia Daily Monitor
16, no. 89 (June 2019), http://jamestown.org/program/moscow-pursues-artificial-intelligence-for-
military-application/.
5. Margarita Konaev and Samuel Bendett, “Russian AI-Enabled Combat: Coming to a City Near You?” War
on the Rocks, July 3 1, 2019, https://warontherocks.com/2019/07/russian-ai-enabled-combat-coming-to-
a-city-near-you/.
6. Department of Defense, Summary of the 20 18 Artificial Intelligence Strategy.
7. Defense Innovation Board, AI Principles: Recommendations on the Ethical Use of Artificial Intelligence
by the Department of Defense (Washington, DC: Department of Defense, 2019), https://media.defense.
gov/2019/Oct/3 1/2002204459/-1/-1/0/DIB\_AI\_PRINCIPLES\_SUPPORTING\_DOCUMENT.PDF .
8. Greg Allen, “Understanding AI Technology” (Joint Artificial Intelligence Center, April 2020), https://www.
ai.mil/docs/Understanding%20AI%20Technology.pdf.
9. U.S. Department of Defense, OSD DevSecOps Best Practice Guide (Washington, DC: Department of
Defense, 2020), https://www.dau.edu/cop/it/DAU%20Sponsored%20Documents/DevSecOps\_
Whitepaper\_v1.0.pdf.
10. Andrew J. Lohn, “Estimating the Brittleness of AI: Safety Integrity Levels and the Need for Testing Out-Of-
Distribution Performance,” arXiv, September 2, 2020, https://arxiv.org/abs/2009.00802.
11 . Sven Herpig, “Securing Artificial Intelligence” (Stiftung Neue Verantwortung, October 17 , 2019), https://
www.stiftung-nv.de/en/node/2650#collapse-newsletter\_banner\_bottom.
1 2. James Vincent, “Google’s AI thinks this turtle looks like a gun, which is a problem,” The Verge, November 2,
2017, https://www.theverge.com/2017/1 1/2/16597276/google-ai-image-attacks-adversarial-turtle-
rifle-3d-printed.
13 . Defense Innovation Board, AI Principles.
1 4. Frank Konkel, “Pentagon Needs Tools to Test the Limits of its Artificial Intelligence Projects,” Nextgov, April
16, 2020, https://www.nextgov.com/emerging-tech/2020/04/pentagon-needs-tools-test-limits-its-
artificial-intelligence-projects/164687/.
15. JAIC, “The DoD AI Ethical Principles – Shifting From Principles to Practice,” AI In Defense (blog) on JAIC,
April 1, 2019, https://www.ai.mil/blog\_04\_01\_20-shifting\_from\_principles\_to\_practice.html.
16. Interview with Ashley Llorens, Chief of the Intelligent Systems Center at the Johns Hopkins University Applied
Physics Laboratory (JHU/APL), July 16, 2020.
17. “Navy SBIR/STTR Success Story,” Innovative Defense Technologies, https://idtus.com/wp-content/
uploads/2020/02/SBIR-Success-Story-NAVSEA-N05-163-IDT-2020-02-04.pdf.
301 8. Phil Goldstein, “Digital Twin Technology: What Is a Digital Twin, and How Can Agencies Use It?” FedTech,
January 3 1, 2019, https://fedtechmagazine.com/article/2019/01/digital-twin-technology-what-digital-
twin-and-how-can-agencies-use-it-perfcon.
19. National Security Commission on Artificial Intelligence (NSCAI), Second Quarter Recommendations
(Washington, DC: National Security Commission on Artificial Intelligence, July 2020), https://drive.google.
com/file/d/1LDrd6T7H50ry9uXNA6cwhsrtnpQ63EWH/view .
20. JAIC, “The JAIC Pushes the Envelope with DevSecOps through the Joint Common Foundation,” AI In Defense
(blog) on JAIC, July 16, 2020, https://www.ai.mil/blog\_07\_16\_20-jaic\_pushes\_the\_envelope\_with\_
devsecops\_jcf.html.
21. Defense Innovation Board, Software Acquisition and Practices (SWAP) Study (Washington, DC: Department
of Defense, May 2019), https://media.defense.gov/2019/May/01/2002 1 26693/-1/-1/0/SWAP%20
MAIN%20REPORT.PDF .
22. U.S. Department of Defense, Autonomy in Weapon Systems, DODI 3000.09, May 8, 2017 , https://www.
esd.whs.mil/Portals/54/Documents/DD/issuances/dodd/300009p.pdf.
23. Defense Innovation Board, AI Principles.
24. Gary Sheftick, “AI Task Force taking giant leaps forward,” U.S. Army, October 7 , 2019, https://www.army.
mil/article/225642/ai\_task\_force\_taking\_giant\_leaps\_forward.
25. A HASC subcommittee NDAA draft would elevate the JAIC to report directly to the Deputy Secretary of
Defense.
26. Defense Innovation Board, AI Principles.
27. Interview with Bob Work, former Deputy Secretary of Defense. August 17 , 2020.
28. NSCAI, Second Quarter Recommendations.
29. NSCAI, Second Quarter Recommendations.
30. Bartlett Russell, “Urban Reconnaissance through Supervised Autonomy (USRA),” DARPA, https://www.
darpa.mil/program/urban-reconnaissance-through-supervised-autonomy .
31. “What is ATRT: Automated Test and ReTest?” Innovative Defense Technologies, https://idtus.com/atrt-
automated-test-and-retest/.
32. NSCAI, Second Quarter Recommendations.
33. Mark Pomerleau, “Senate committee wants more cyber pilot programs,” Fifth Domain, June 1 1, 2020,
https://www.fifthdomain.com/congress/2020/06/1 1/senate-committee-wants-more-cyber-pilot-
programs/.
34. Defense Innovation Board, Software Is Never Done: Refactoring the Acquisition Code for Competitive
Advantage (Washington, DC: Department of Defense, May 2019), https://media.defense.gov/2019/
May/01/2002 1 26690/-1/-1/0/SWAP%20EXECUTIVE%20SUMMARY.PDF .
35. National Institute of Standards and Technology, U.S. Leadership in AI: A Plan for Federal Engagement in
Developing Technical Standards and Related Tools (Washington, DC: Department of Commerce, August
2019), https://www.nist.gov/system/files/documents/2019/08/10/ai\_standards\_fedengagement\_
plan\_9aug2019.pdf.
36. Office of the Director, Operational Test and Evaluation, FY19 Test and Evaluation Resources (Washington,
DC: Office of the Secretary of Defense, January 2020), https://www.dote.osd.mil/Portals/97/pub/
reports/FY2019/other/2019teresources.pdf?ver=2020-01-30-1 1 5558-8 1 3 .
37. National Security Commission on Artificial Intelligence (NSCAI), First Quarter Recommendations
(Washington, DC: National Security Commission on Artificial Intelligence, March 2020), https://drive.
google.com/file/d/1wkPh8Gb5drBrKBg6OhGu5oNaTEERbKss/view .
westexec.com |
290ce8db-1583-4fe8-9ec6-ccd3eba833c3 | trentmkelly/LessWrong-43k | LessWrong | Social behavior curves, equilibria, and radicalism
I.
Here are some hypotheticals to consider, with a common theme. Note that in each case I’m asking what you would do, rather than what you should do.
* In the fall, COVID cases drop to 10% of their current level. You’re back to working/studying in person. You’re vaccinated, as is everyone else. Mask-wearing isn’t required, but 25% of your co-workers wear one anyway. Would you wear a mask too? What if 75% of your co-workers wear a mask? What if it’s literally everyone else?
* You’re having dinner with a party of 10 at a Chinese restaurant. Everyone else is using chop sticks. You know how to use chop sticks but prefer a fork. Do you ask for a fork? What if two other people are using a fork?
* (Inspired by Scout Mindset) For anyone who chose to have kids, or wants kids: if only 30% of adults had kids, would you still choose to have a kid? What if only 2% did? For anyone who doesn’t want kids: if 90% of adults had kids, would you? What if it were 99%?
* You join a group video call with 20 co-workers/classmates. Everyone except the presenter/teacher has their video turned off. Do you turn yours off too? What if everyone has their video on? Typically, what fraction of other participants need to have their video on for you to keep yours on?
Your answers to these questions depend on your personal circumstances. How uncomfortable is wearing a mask? Do you find a fork slightly or significantly easier to use? How strong is your preference to have kids? Is there a Justin Bieber poster in your background?
But — unless your answer to each question didn’t depend on the specific percentage — your decision also depends on others’ behavior. If everyone else has their video on, you’ll probably feel obligated to keep yours on too. Maybe you’ll move the poster first. This applies not just to behavior, but also to preferences, beliefs, and opinions.
Figure 1: xkcd #185
So far, everything I’ve said is pretty obvious. But let’s throw a model at this observation and see if we can d |
3ffc0b1d-a270-48ee-a960-86fee4715707 | trentmkelly/LessWrong-43k | LessWrong | Do I count as e/acc for exclusion purposes?
EDIT: THIS IS NOT APRIL FOOLS RELATED
ALSO: This is specific to the LW scene in Berkeley and nearby Berkeley, as this is the only place where e/acc exclusion is asserted to take place.
I haven't been around the LW scene for some time, but I understand it's common to exclude e/acc people from events. I further understand this to be exclusion on philosophical grounds, not just because LW-ites tend to view e/acc people individually as unlikeable.
I personally don't want to try to sneak into LW parties if I'm someone that the hosts are trying to exclude on philosophical grounds. So I'd rather clarify whether, in the opinion of various people, I count.
It's common among e/acc people to say things like "We're so close, just don't die" by which they mean that AGI is close. They also want to create AGI as soon as possible. By contrast, LW-ites typically believe that AGI is close, and therefore it is necessary to slow down or stop AGI development as soon as possible, in order to ensure that future development is done safely.
I part ways from both camps in believing that we're nowhere close to AGI, that the apparently-impressive results from LLMs are highly overrated, and that the X-risk from AI is 0 for the forseeable future. If I didn't think this, I would be sympathetic[1] to the desire to stop AI until we thought we could do it safely. But I do think this, so AI safety seems like a Victorian Nuclear Regulatory Commission. The NRC is a good thing, but it's going to be a while before splitting the atom is even on the table.
As a result, in practice I think I'm functionally e/acc because I don't want to stop the e/acc people from trying to push AGI as fast as possible. I don't think they're actually an X-risk since they're not going to succeed any time soon. But I'm theoretically decel because if I thought anyone was anywhere close to AGI I'd be sympathetic to efforts to restrain it. As it is, I think the AI safety people can continue to study AI safety for years confi |
3db12d45-b9fe-44c1-b0bc-4a8d8da93fbf | StampyAI/alignment-research-dataset/lesswrong | LessWrong | ARC Evals: Responsible Scaling Policies
> We’ve been consulting with several parties[1](https://evals.alignment.org/blog/2023-09-26-rsp/#fn:1) on **responsible scaling**[**2**](https://evals.alignment.org/blog/2023-09-26-rsp/#fn:2) **policies (RSPs)**. An RSP specifies what level of AI capabilities an AI developer is prepared to handle safely with their current protective measures, and conditions under which it would be too dangerous to continue deploying AI systems and/or scaling up AI capabilities until protective measures improve.
>
> We think RSPs are one of the most promising paths forward for reducing risks of major catastrophes from AI. We’re excited to advance the science of model evaluations to help labs implement RSPs that reliably prevent dangerous situations, but aren’t unduly burdensome and don’t prevent development when it’s safe.
>
> This page will explain the basic idea of RSPs as we see it, then discuss:
>
>
> **Why we think RSPs are promising.** In brief (more below):
>
> * **A pragmatic middle ground.** RSPs offer a potential middle ground between (a) those who think AI could be [extremely dangerous](https://www.safe.ai/statement-on-ai-risk) and seek things like [moratoriums on AI development](https://futureoflife.org/open-letter/pause-giant-ai-experiments/), and (b) who think that it’s too early to worry about capabilities with catastrophic potential. RSPs are pragmatic and threat-model driven: rather than arguing over the likelihood of future dangers, we can implement RSPs that commit to measurement (e.g., [evaluations](https://evals.alignment.org/)) and empirical observation - pausing deployment and/or development *if* specific dangerous AI capabilities emerge, *until* protective measures are good enough to handle them safely.
> * **Knowing which protective measures to prioritize.** RSPs can help AI developers move from broad caution-oriented principles to specific commitments, giving a framework for which protective measures (information security; refusing harmful requests; alignment research; etc.) they need to prioritize to safely continue development and deployment.
> * **Evals-based rules and norms.** In the longer term, we’re excited about [evals](https://evals.alignment.org/)-based AI rules and norms more generally: requirements that AI systems be evaluated for dangerous capabilities, and restricted when that’s the only way to contain the risks (until protective measures improve). This could include standards, third-party audits, and regulation. Voluntary RSPs can happen quickly, and provide a testbed for processes and techniques that can be adopted to make future evals-based regulatory regimes work well.
>
> **What we see as the** [**key components**](https://evals.alignment.org/rsp-key-components/) **of a good RSP**, with sample language for each component. In brief, we think a good RSP should cover:
>
> * **Limits**: which specific observations about dangerous capabilities would indicate that it is (or strongly might be) unsafe to continue scaling?
> * **Protections**: what aspects of current protective measures are necessary to contain catastrophic risks?
> * **Evaluation**: what are the procedures for promptly catching early warning signs of dangerous capability limits?
> * **Response**: if dangerous capabilities go past the limits and it’s not possible to improve protections quickly, is the AI developer prepared to pause further capability improvements until protective measures are sufficiently improved, and treat any dangerous models with sufficient caution?
> * **Accountability**: how does the AI developer ensure that the RSP’s commitments are executed as intended; that key stakeholders can verify that this is happening (or notice if it isn’t); that there are opportunities for third-party critique; and that changes to the RSP itself don’t happen in a rushed or opaque way?
>
> Adopting an RSP should be a strong and reliable signal that an AI developer will in fact identify when it’s too dangerous to keep scaling up capabilities, and react appropriately.
>
> 
I'm excited about labs adopting RSPs for several reasons:
* Making commitments and planning-in-advance is good for safety
* Making commitments is good for coordination and helping other labs act well
* Making commitments is good for transparency and helping outsiders predict what labs will do
* Making safety commitments *conditional on risks* is nice — everyone, including people who think risk is very small, should be able to agree on warning signs that should lead to stronger safety practices or pausing scaling
Possible discussion on twitter [here](https://twitter.com/ARC_Evals/status/1707243334304252231) and [here](https://twitter.com/lukeprog/status/1707080431756067242). |
ff305593-0f4a-4a92-b112-61489706b467 | trentmkelly/LessWrong-43k | LessWrong | Theoretical Alignment's Second Chance
Historically, I've gotten the impression from the AI Safety community that theoretical AI alignment work is promising in long timeline situations but less relevant in short timeline ones. As timelines have shrunk and capabilities have accelerated, I feel like I've seen theoretical alignment work appear less frequently and with less fanfare.
However, I think that we should challenge this communal assumption. In particular, not all capabilities advance at the same rate, and I expect that formally verified mathematical reasoning capabilities will accelerate particularly quickly. Formally-verified mathematics has a beautifully clean training signal, it feels like the perfect setup for aggressive amounts of RL. We know that Deepmind's AlphaProof can get IMO Silver Medal performance (with caveats) while writing proofs in Lean. There's no reason to expect that performance to have plateaued in the months since AlphaProof's announcement. o3's announcement also showed a huge leap in performance on the FrontierMath benchmark -- I expect that such performance on general mathematical questions combined with excellent coding ability should open the door for Lean-checkable proofs of non-trivial results. I think that arms race dynamics are at a point where we can expect models capable of writing near-superhuman proofs in Lean to be released in the coming months.
That expectation ... really doesn't feel priced in among my theoretical AI Safety connections right now. Everyone still seems to be conducting the same style of research as three months ago, aware of all the new announcements but powerless to do anything about them. I claim that a theoretical AI Safety community that had internalized this expectation would be doing everything in its power to maximize its efficiency once near-superhuman Lean-proof-writing models become available.
I think that the theoretical alignment community has 2-3 months to prepare for its "second chance." A window of opportunity in which superstar P |
3700f96c-7911-4532-bb6c-b93ee2ebd92b | trentmkelly/LessWrong-43k | LessWrong | Florida Elections
I know people here are afraid of politics, but if my options are to vote with or without consulting a large group of people who think clearly, I'd rather choose the former.
I'm starting to research my positions for the Florida elections. I'm registered to vote in the Democratic Party's primary, but I encourage conversations about the Republican primary's (or independent) candidates as well.
What do y'all think in general about the Florida election?
What do you suggest I (and other Florida voters) read/research?
What information is the most important/ is a dealbreaker?
I'd prefer for the conversation to focus on the issues on the Florida ballot, so if you want to talk about issues on other states' ballots, please create a new post instead of using this one.
Edit: I’ve been receiving downvotes for a reason I don’t know. I’m simply trying to start a conversation about an important topic! If you downvote please explain your reason why! LessWrongers usually have good reasons, so please share them. Right now it just looks like LessWrong disapproves of being informed voters. |
dfafc9a2-1aa3-4c00-9406-8e65e8644b90 | trentmkelly/LessWrong-43k | LessWrong | Meetup : Warsaw August Meetup
Discussion article for the meetup : Warsaw August Meetup
WHEN: 30 August 2015 03:00:00PM (+0200)
WHERE: Warsaw
Location: Green Caffe Nero - Telimena, Krakowskie Przedmieście 27, Warszawa
Fb event: https://www.facebook.com/events/382397675303040/
Fb group: https://www.facebook.com/groups/lwwarsaw/
Discussion article for the meetup : Warsaw August Meetup |
d8aa8870-b093-4992-bc28-5c7b35aa9114 | trentmkelly/LessWrong-43k | LessWrong | Does Probability Theory Require Deductive or Merely Boolean Omniscience?
It is often said that a Bayesian agent has to assign probability 1 to all tautologies, and probability 0 to all contradictions. My question is... exactly what sort of tautologies are we talking about here? Does that include all mathematical theorems? Does that include assigning 1 to "Every bachelor is an unmarried male"?1 Perhaps the only tautologies that need to be assigned probability 1 are those that are Boolean theorems implied by atomic sentences that appear in the prior distribution, such as: "S or ~ S".
It seems that I do not need to assign probability 1 to Fermat's last conjecture in order to use probability theory when I play poker, or try to predict the color of the next ball to come from an urn. I must assign a probability of 1 to "The next ball will be white or it will not be white", but Fermat's last theorem seems to be quite irrelevant. Perhaps that's because these specialized puzzles do not require sufficiently general probability distributions; perhaps, when I try to build a general Bayesian reasoner, it will turn out that it must assign 1 to Fermat's last theorem.
Imagine a (completely impractical, ideal, and esoteric) first order language, who's particular subjects were discrete point-like regions of space-time. There can be an arbitrarily large number of points, but it must be a finite number. This language also contains a long list of predicates like: is blue, is within the volume of a carbon atom, is within the volume of an elephant, etc. and generally any predicate type you'd like (including n place predicates).2 The atomic propositions in this language might look something like: "5, 0.487, -7098.6, 6000s is Blue" or "(1, 1, 1, 1s), (-1, -1, -1, 1s) contains an elephant." The first of these propositions says that a certain point in space-time is blue; the second says that there is an elephant between two points at one second after the universe starts. Presumably, at least the denotational content of most english propositions could be express |
3ab4c3b0-870b-4319-804e-7e2288197e06 | trentmkelly/LessWrong-43k | LessWrong | Even if you're right, you're wrong
Epistemic status: I noticed a commonality between a set of rhetorical moves that I sometimes find irritating and sometimes think is valid.
You claim P? OK. But even if you’re right about P…
* … if I assume P, then I can prove not P. So, by contradiction, P is false. So you’re wrong.
* … if you really believed P, then you would have a certain appropriate mood. But it doesn’t seem like you have that mood. So you’re wrong.
* … with 99% probability, as long as there’s a 1% chance that P is wrong, according to expected value, we should act like P is wrong. So you’re wrong.
* … accepting P would mean that you should do this weird action A. But you don’t do A, as far as I can tell. So you’re wrong.
* … yesterday, you said Q, and Q implies not P. So you were wrong yesterday or today. So you’re wrong.
* … somebody might infer Q from P. But Q is false! So you’re wrong.
* … someone might infer from your expression of P that you believe Q. But Q is false! So you’re wrong. |
417b1a27-47c4-4681-b8a9-641050eb5417 | trentmkelly/LessWrong-43k | LessWrong | Non-Unitary Quantum Logic -- SERI MATS Research Sprint
The following discussion was inspired by a comment on Vanessa Kosoy's Shortform regarding affine infradistributions. I expect the results here would not be considered surprising or novel by an expert in quantum logic or lattice theory. In particular [HTZ16[1]] shows the unsolvability of the problem described below, and [HZ10[2]] covers many related results as well. However, I haven't found this exact result written down anywhere, and I expect this beginner-friendly and mostly self-contained exposition to be useful for a reader interested in a glance into quantum logic.
Setup
The term "quantum logic" is often used to refer to the structure formed by subspaces of a Hilbert space (thought of as quantum propositions). The analogs of logical 'and', 'or', and 'not' are taken to be the operations of intersection, sum, and complements of subspaces, respectively. We can loosen this structure by dropping the inner product (so downgrading our Hilbert space to just a vector space), and hence the notion of orthogonal complements. We can call the resulting simplified logic "non-unitary" (for the lack of an inner product) quantum logic. We'll restrict our attention to the finite dimensional case. The following is the corresponding syntax and semantics.
Syntax
Let P be a set of propositional variables. We define the set L of well-formed formulas recursively as follows.
* Two special symbols ⊤,⊥∈L,
* For any p∈P, we have p∈L,
* For any ϕ,ψ∈L, we have ϕ∧ψ∈L, and ϕ∨ψ∈L.
A theory T is a subset T⊂L×L. Elements of T are written ϕ⊢ψ. We'll write ϕ=ψ for when both ϕ⊢ψ and ψ⊢ϕ.
Semantics
For a vector space V, let Sp(V) denote the set of all linear subspaces of V.
Definition 1. A model consists of a finite dimensional vector space V, and a map M:L→Sp(V), satisfying the following:
* M(⊥)=0 (the subspace consisting of the zero vector)
* M(⊤)=V
* M(ϕ∨ψ)=M(ψ)+M(ϕ)
* M(ϕ∧ψ)=M(ψ)∩M(ϕ).
We say M models the theory T, if M(ϕ)⊂M(ψ) for every ϕ⊢ψ in T.
Lattices
The set Sp(V) forms a |
35a94fdb-e4f6-4f28-9b41-1acdbe68df12 | trentmkelly/LessWrong-43k | LessWrong | Impostor Syndrome as skill/dominance mismatch
I am surprised that there is nothing about Impostor Syndrome on Robin Hanson's website, when to me it seems obviously connected to status. To use the standard formula: Impostor Syndrome is not about lack of skills.
(Also related to: humility, status regulation, unpopularity of nerds.)
Let me quote my older article:
> Robin Hanson calls the two basic forms of status "dominance" and "prestige"; the fear-based and the admiration-based sources of social power respectively. He also notes how people high in "dominance" prefer to be perceived as (also) high in "prestige" [1, 2]. Simply said, a brutal dictator often wants to be praised as kind and smart and skilled (e.g. the "coryphaeus of science" Stalin), not merely powerful and dangerous.
>
> [...] If you are not ready to challenge the chieftain for the leadership of the tribe, and if you don't want to risk being perceived as such, the safe behavior is to also downplay your skills as a hunter.
Although humans have two mechanisms of constructing social hierarchies, at the end of the day both of them compete for the same resource: power over people. Thus we see powerful people leveraging their power to also get acknowledged as artists or scientists; and successful artists or scientists leveraging their popularity to express political opinions.
The hierarchy of "dominance" is based on strength, but is not strength alone. The strongest chimp in the tribe can be defeated if the second-strongest and third-strongest join against him. Civilization makes it even more complicated. Stalin wasn't the physically strongest man in the entire Soviet Union.
(In theory, the most powerful person shouldn't need physical strength at all, if they have an army and secret police at command. But in practice, I suppose our instincts demand it; a physically weak leader would probably be a permanent magnet for rebellions. Therefore leaders flaunt their health and strength.)
Similarly, the hierarchy of "prestige" is based on skill, but is no |
7d3c488e-d43e-40a0-a05a-378287010cdb | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Fair Collective Efficient Altruism
In this post, I propose to explore a novel methodology by which a collective of decision makers (simply called *"we"* here) such as the current generation of humanity could make an *altruistic collective decision* in the following type of situation:
* The decision is about about a number of paths of actions (called *"options"* here) that have potentially vast consequences in the future and potentially generating quite different populations, such as deciding to colonise space.
* There might be moral uncertainty about the moral status of some of the beings that might be affected by the decision, such as other species.
* These beings (called *"potential stakeholders"* here) might be quite different from humans so that trying to estimate their subjective wellbeing and compute WELLBYs seems too speculative to base the decision on. It might also not be justified to assume that these beings are rational, have complete preferences or are even expected utility maximizers whose preferences can be encoded in a von-Neuman–Morgenstern utility function.
*Epistemic status:* Highly speculative but based on years of theoretical research into collective decision making.
The proposed methodology is based on the following **ideas** and **rationale**:
* Even though a *quantitative* estimation of subjective wellbeing might *not* be possible, the members of the collective (called the *"deciders"* here) might be able to estimate what an affected being "would have *preferred* us to do" via an "*empathy* exercise" similar to what János (John) Harsányi assumed is possible to perform interpersonal comparisons of preferences (but without assuming von-Neumann–Morgenstern utility functions).
* Since such *empathetic preference estimations (EPEs)* are still bound to be uncertain and somewhat speculative:
+ The number of different EPEs needed should be kept as low as possible.
+ They should mostly be about what the being's *favourite* action would be since for this one only needs to *imagine what the being would do in our situation.* The necessary EPEs should not be about pairs of lotteries of options (as would be required to estimate interpersonally comparable cardinal preferences such as WELLBYs), but they might have to be about *pairs of options* or about a comparison between *a single option and a certain lottery* of options. If the latter is necessary, the number of different lotteries used in the EPEs should be as low as possible.
+ The EPEs should not be performed by a few decision makers or experts only, but as independently as possible by as many deciders as possible, which should then be aggregated in a suitable way as a form of efficient epistemic democracy.
* Since the empathetic preference estimations by different deciders are likely of very different precision that is likely correlated with their own confidence about their estimations, and since they are likely not independent across deciders, we use their own estimations about the standard deviation and level of independence of their estimates as weight in the aggregation.
* The EPE aggregation should allow for different deciders having *diverging value systems regarding moral status and moral weight of beings,* so that this part of the moral uncertainty is taken care of in the aggregation.
* The aggregated EPEs can then be used to *simulate a hypothetical collective decision made by all potential stakeholders*.
* This hypothetical collectice decision should be as *fair* as possible, trying as best as possible not to sacrifice one stakeholder's preferences for the sake of others.
* To achieve this fairness, we use a device somewhat similar to Vickrey and Harsanyi's original position or veil of ignorance: we imagine performing a lottery in which a randomly selected stakeholder makes the decision, similar to the so-called "Random Dictator" rule studied in Social Choice Theory. Let's call this hypothetical lottery the *benchmark lottery*.
* Using the benchmark lottery directly to make our decision would be perfectly *fair ex ante* , so it could be considered a form of justifiable *social contract*. But it would *not* be *fair ex post* since it could lead to vast inquality, and would *not* be *efficient* since it would ignore any potential for compromise. This is why we to not use it directly to make the decision, but rather use it as a *fair reference point* that allows us to perform some very mild form of interpersonal comparison of preferences.
* To also achieve a high level of *fairness ex post*, we however do not use the reference point to normalize cardinal preferences (which would seem a natural idea in other contexts where cardinal preferences can be assumed and estimated better), but we use it as a *cutoff point for hypothetical approval*: We assume that a potential stakeholder would approve any option that they prefer to the benchmark lottery, and then simulate a hypothetical *approval voting* by all potential stakeholders.
**In other words:** ***We choose that option which we believe the largest percentage of potential stakeholders would prefer to having a random potential stakeholder decide alone.***
The **actual procedure** I propose for this is the following:
* **Stage 1: Collective epistemics**
+ For each option:
- Collectively assemble the set of possible futures that might result from this option
- Collectively estimate the possible probability distributions on that set, taking into account all kinds of uncertainties and ambiguities
* **Stage 2: Collective decision**
+ **Step 2.1.** Estimating a fair reference point
- Each decider D.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
does the following, according to their own value system:
* Identify the set of potential stakeholders, i.e., all morally relevant beings that would exist at some point in time in at least one possible future of at least one of the options.
* Assign a moral weight to each potential stakeholder.
* For each option X, estimate which percentage of the so-weighted potential stakeholder population would want us to have chosen that option X. Call this percentage B(X,M). To do this, perform the following *"empathy exercise"* for each potential stakeholder H:
+ Imagine they have the same information you have (as collected in stage 1).
+ Imagine which option they would want us to have chosen.
* Estimate the standard deviation S(M) of these percentage estimates.
* Estimate the degree of independence I(M) from 0 to 1 of these percentage estimates from other deciders' percentage estimates.
- Aggregate all deciders' indivual percentage estimates B(X,M) into collective estimates B(X) by taking their average, weighted by estimated precision and independence: B(X)=∑MB(X,M)I(M)/S2(M)∑MI(M)/S2(M)
- Consider the *benchmark lottery*, denoted L, that consists in choosing option X with a probability of B(X) percent.
+ **Step 2.2.** Estimating potential stakeholders' approval
- Each decider M does the following, according to their own value system:
* For each option X, estimate which percentage of the weighted stakeholder population would rather want us to have chosen X than to have applied the benchmark lottery. To do this, use a similar empathy exercise as above. Call this estimate A(X,M).
* As before, estimate the standard deviation T(X,M) of your percentage estimates and the degree of independence J(X,M) from 0 to 1 of your percentage estimates from others' percentage estimates, but this time for each option separately.
- Aggregate all deciders' indivual percentage estimates A(X,M) into an *estimated stakeholder approval score* A(X)=∑MA(X,M)J(X,M)/T2(X,M)∑MJ(X,M)/T2(X,M)
+ **Finally,** find that option X with the largest estimated stakeholder approval score A(X) and implement it.
Some possible variants:
* If we are more confident about estimating potential stakeholders' preferences, we can replace the binary approval by a cardinal measure of *preference satisfaction* F(X,H,M):
+ Let M estimate the probability P at which H would be indifferent between X and the lottery that selects H's favourite option with probability P and performs L with probability 1−P. If such a P exists, put F(X,H,M)=P. If not, then H would prefer L to X, so then estimate the probability P at which H would be indifferent between L and the lottery that selects H's favourite option with probability P and selects X with probability 1−P, and then put F(X,H,M)=−P/(1−P).
+ Let A(X,M) be the weighted average of F(X,H,M) using the moral weights M assigned to all H, and proceed as above.
* If we are even more confident about estimating preferences, we could extend the choice set from the set of individual options to the set of all lotteries L′ of options, estimate F(L′,H,M) for all L′, find that L′ with the largest A(L′) and use it to draw the actually implemented option. Considering that potential stakeholders might not be risk-neutral w.r.t. their preference satisfaction (i.e., might not be expected utility maximizers), this highest-scoring lottery will likely be a proper lottery rather than a single option. |
f03e7331-b457-4f62-9d04-bdb8c13ef5a6 | trentmkelly/LessWrong-43k | LessWrong | [LINK] Cochrane on Existential Risk
The finance professor John Cochrane recently posted an interesting blog post. The piece is about existential risk in the context of global warming, but it is really a discussion of existential risk generally; many of his points are highly relevant to AI risk.
> If we [respond strongly to all low-probability threats], we spend 10 times GDP.
>
> It's a interesting case of framing bias. If you worry only about climate, it seems sensible to pay a pretty stiff price to avoid a small uncertain catastrophe. But if you worry about small uncertain catastrophes, you spend all you have and more, and it's not clear that climate is the highest on the list...
>
> All in all, I'm not convinced our political system is ready to do a very good job of prioritizing outsize expenditures on small ambiguous-probability events.
He also points out that the threat from global warming has a negative beta - i.e. higher future growth rates are likely to be associated with greater risk of global warming, but also the richer our descendants will be. This means both that they will be more able to cope with the threat, and that the damage is less important from a utilitarian point of view. Attempting to stop global warming therefore has positive beta, and therefore requires higher rates of return than simple time-discounting.
It strikes me that this argument applies equally to AI risk, as fruitful artificial intelligence research is likely to be associated with higher economic growth. Moreover:
> The economic case for cutting carbon emissions now is that by paying a bit now, we will make our descendants better off in 100 years.
>
> Once stated this way, carbon taxes are just an investment. But is investing in carbon reduction the most profitable way to transfer wealth to our descendants? Instead of spending say $1 trillion in carbon abatement costs, why don't we invest $1 trillion in stocks? If the 100 year rate of return on stocks is higher than the 100 year rate of return on carbon abateme |
2038c9dd-2cf7-4b5f-8535-f0639f4272bf | trentmkelly/LessWrong-43k | LessWrong | Search versus design
This work was supported by OAK, a monastic community in the Berkeley hills. It could not have been written without the daily love of living in this beautiful community. The work involved in writing this cannot be separated from the sitting, chanting, cooking, cleaning, crying, correcting, fundraising, listening, laughing, and teaching of the whole community.
This write-up benefited from feedback from David Kristofferson, Andrew Critch, Jason Crawford, Abram Demski, and Ben Pence. Mistakes and omissions are entirely the responsibility of the author.
----------------------------------------
How is it that we solve engineering problems? What is the nature of the design process that humans follow when building an air conditioner or computer program? How does this differ from the search processes present in machine learning and evolution?
We study search and design as distinct approaches to engineering. We argue that establishing trust in an artifact is tied to understanding how that artifact works, and that a central difference between search and design is the comprehensibility of the artifacts produced. We present a model of design as alternating phases of construction and factorization, resulting in artifacts composed of subsystems that are paired with helpful stories. We connect our ideas to the factored cognition thesis of Stuhlmüller and Christiano. We also review work in machine learning interpretability, including Chris Olah’s recent work on decomposing neural networks, Cynthia Rudin’s work on optimal simple models, and Mike Wu’s work on tree-regularized neural networks. We contrast these approaches with the joint production of artifacts and stories that we see in human design. Finally we ponder whether an AI safety research agenda could be formulated to automate design in a way that would make it competitive with search.
Introduction
Humans have been engineering artifacts for hundreds of thousands of years. Until recently, we seem to have mostly solved eng |
88189544-b203-4953-bb35-7e3c0ab8f5ab | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Utilitarianism is irrational or self-undermining
Summary
=======
Most moral impact estimates and cost-effectiveness analyses in the effective altruism community use (differences in) expected total welfare, but doing so generally is probably *irrational* based on arguments related to St Petersburg games:
1. Based on a money pump argument and other arguments used to defend the axioms of expected utility theory, maximizing the expected value of an unbounded utility function is irrational. As a special case, expectational total utilitarianism, i.e. maximizing the expected value of total welfare, is also irrational.
2. Two recent impossibility theorems also demonstrate the incompatibility of Stochastic Dominance — a widely accepted requirement for instrumental rationality — with Impartiality and each of Anteriority and Separability. These last three principles are standard assumptions — or similarly defensible extensions thereof — used to support or prove utilitarianism.
Taken together, utilitarianism is either irrational or the kinds of arguments used to support it in fact undermine it instead. I conclude with a discussion of responses.
Basic terminology
=================
By *utilitarianism*, I include basically all views that are impartial and additive in deterministic fixed finite population cases. Some such views may not be vulnerable to all of the objections here, but they apply to most such views I’ve come across, including total utilitarianism. These problems also apply to non-consequentialists using utilitarian axiologies.
To avoid confusion, I prefer the term *welfare* as what your moral/social/impersonal preferences and therefore what your utility function should take into account.[[1]](#fntsia01qirb) In other words, your utility function can be a function of individuals’ welfare levels.
A *prospect* is a probability distribution over outcomes, e.g. over heads or tails from a coin toss, over possible futures, etc..
Motivation and outline
======================
Many people in the effective altruism and rationality communities seem to be expectational total utilitarians or give substantial weight to expectational total utilitarianism. They take their utility function to just be total welfare across space and time, and so aim to maximize the expected value of total welfare (total individual utility), E[∑Ni=1ui].mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
. However, total welfare, and differences in total welfare between prospects, may be unbounded, because the number of moral patients and their welfares may be unbounded. There are no 100% sure finite upper bounds on how many of them we could affect.[[2]](#fn0wvc3bcsa1ja) The requirements of rationality should apply to choices involving such possibilities. Whether or not committed to expectational total utilitarianism, many in these communities also argue based on explicit estimates of differences in expected total welfare. Almost all impact and cost-effectiveness estimation in the communities is also done this way. These arguments and estimation procedures agree with and use expected total welfare, but if there are problems with expectational total utilitarianism in general, then there’s a problem with the argument form and we should worry about specific judgements using it.
And there *are* serious problems.
This post is concerned with the implications of prospects with infinitely many possible outcomes and unbounded but finite value, not actual infinities, infinite populations or infinite ethics generally. The problems arise due to St Petersburg-like prospects (and generalizations): prospects with infinitely many possible outcomes, infinite (or undefined) expected utility, but finite utility in each possible outcome.
The papers I focus on are:
1. Jeffrey Sanford Russell, and Yoaav Isaacs. “Infinite Prospects\*.” *Philosophy and Phenomenological Research*, vol. 103, no. 1, Wiley, July 2020, pp. 178–98, <https://doi.org/10.1111/phpr.12704>, <https://philarchive.org/rec/RUSINP-2>
2. Goodsell, Zachary. “A St Petersburg Paradox for Risky Welfare Aggregation.” *Analysis*, vol. 81, no. 3, Oxford University Press, May 2021, pp. 420–26, <https://doi.org/10.1093/analys/anaa079>, <https://philarchive.org/rec/RUSINP-2>
3. Jeffrey Sanford Russell. “On Two Arguments for Fanaticism.” Noûs, Wiley-Blackwell, June 2023, <https://doi.org/10.1111/nous.12461>, <https://philpapers.org/rec/RUSOTA-2>, <https://globalprioritiesinstitute.org/on-two-arguments-for-fanaticism-jeff-sanford-russell-university-of-southern-california/>
Respectively, they:
1. Argue that unbounded utility functions (and generalizations) are irrational (or at least as irrational as violating Independence or the Sure-Thing Principle, crucial principles for expected utility theory).
2. Prove that Stochastic Dominance, Impartiality and Anteriority are jointly inconsistent.
3. Prove that Stochastic Dominance, Compensation (which implies Impartiality) and Separability are jointly inconsistent.
Briefly, respecting Stochastic Dominance is among the least controversial proposed requirements of instrumental rationality. Impartiality, Anteriority and Separability are principles (or similarly motivated extensions thereof) used to support and even prove utilitarianism.
I will explain these results, and along the way, argue based on them that all (or most standard) forms of utilitarianism are irrational, or the standard arguments used in defense of principles in support of utilitarianism actually extend to principles that undermine utilitarianism. Then, in the last section, I consider some responses and respond to them.
Unbounded utility functions are irrational
==========================================
Expected utility maximization with an unbounded utility function is probably (instrumentally) irrational, because it recommends, in some hypothetical scenarios, choices leading to apparently irrational behaviour. This includes foreseeable sure losses — a money pump —, and paying to avoid information, among others, following from the violation of extensions of the Independence axiom and Sure-Thing Principle ([Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704), p.3-5).[[3]](#fneci04fnrp9) The issue comes from St Petersburg game-like prospects: prospects with infinitely many possible outcomes, each of finite utility, but with overall infinite (or undefined) expected utility, as well as generalizations of such prospects. Such a prospect is, counterintuitively, better than each of its possible outcomes.[[4]](#fnwotew5kfhm9)
Suppose you have an unbounded real-valued utility function u.[[5]](#fnifnhafjmcsi) Then it’s unbounded above or below. Assume it’s unbounded above, as a symmetric argument applies if it’s only unbounded below. Then, being unbounded above implies that it takes some utility value u(x)>0, and for each utility value u(x)>0, there’s some outcome x′ such that u(x′)≥2u(x). Then we can construct a countable sequence of outcomes, x1,x2,…,xn, with u(xn+1)≥2u(xn) for each n>1, as follows:
1. Choose an outcome x1 such that u(x1)>0.
2. Choose an outcome x2 such that u(x2)≥2u(x1).
3. …
4. Choose an outcome xn+1 such that u(xn+1)≥2u(xn).
5. …
Define a prospect X as follows: with probability 1/2n,X=xn. Then, ∑∞n=11/2n=1, E[u(X)]=∞,[[6]](#fnx0v2hv2cmgh) and X is better than any prospect with finite expected utility.[[7]](#fn5u5kqq4b6u)
The original St Petersburg game uses xn=$2n or 2n coins ([Peterson, 2023](https://plato.stanford.edu/entries/paradox-stpetersburg/)), but we need the utilities to scale exponentially, not the outcomes.
St Petersburg game-like prospects lead to violations of generalizations of the Independence axiom and the Sure-Thing Principle to prospects over infinitely (countably) many possible outcomes ([Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704)). The corresponding standard finitary versions are foundational principles used to establish expected utility representations of preferences in the von Neumann-Morgenstern utility theorem ([von Neumann and Morgenstern, 1944](https://archive.org/details/in.ernet.dli.2015.215284)) and Savage’s theorem ([Savage, 1972](https://books.google.ca/books?id%3DzSv6dBWneMEC)), respectively. The arguments for the countable generalizations are essentially the same as those for the standard finitary versions ([Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704)), and in the following subsection, I will illustrate with a *money pump argument*. So, if money pumps establish irrationality of violations of the standard finitary Sure-Thing Principle, they should too for the countable version, and maximizing the expected value of an unbounded utility function is irrational.
A money pump argument
---------------------
Consider the following hypothetical situation, adapted from [Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704), but with a genie instead. It’s the same kind of money pump that would be used in support of the Sure-Thing Principle, and structurally nearly identical to the one to used to defend Independence in [Gustafsson, 2022](https://www.cambridge.org/core/elements/moneypump-arguments/1515273BD710F308151F5BEC3695FEE6).
You are facing a prospect A with infinite expected utility, but finite utility no matter what actually happens. Maybe A is your own future and you value your years of life linearly, and could live arbitrarily but finitely long, and so long under some possibilities that your life expectancy and corresponding expected utility is infinite. Or, you're an expectational total utilitarian, and thinking about the value in distant parts of the universe (or multiverse), with infinite expected value but almost certainly finite.[[8]](#fn7msq9z8y18)
Now, there’s an honest and accurate genie — or God or whoever’s simulating our world or an AI with extremely advanced predictive capabilities — that offers to tell you exactly how A will turn out.[[9]](#fn5t075gvsn06) Talking to them and finding out won’t affect A or its utility, they’ll just tell you what you’ll get. The genie will pester you unless you listen or you pay them $50 to go away. Since there’s no harm in finding out, and no matter what happens, being an extra $50 poorer is worse, because that $50 could be used for ice cream or bed nets,[[10]](#fnetwminzdksh) you conclude it's better to find out.
Reproduced with permission from [Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704).However, once you do find out, the result is, as you were certain it would be, finite. The genie turns out to be very powerful, too, and feeling generous, offers you the option to metaphorically *reroll the dice*. You can trade the outcome of A for a new prospect B with the same distribution as you had for A from before you found out, but statistically independent from the outcome of A. B would have been equivalent, because the distributions would have been the same, but B now looks better because the outcome of A is only finite. But, you’d have to pay the genie $100 for B. Still, $100 isn’t enough to drop the expected utility into the finite, and this infinite expected utility is much better than the finite utility outcome of A. You could refuse, but it's a worthwhile trade to make, so you do it.
But then you step back and consider what you've just done. If you hadn't found out the value of A, you would have stuck with it, since A was better than B - $100 ahead of time: A was equivalent to a prospect, the prospect B, that's certainly better than B - $100. You would have traded the outcome of A away for B - $100 no matter what the outcome of A would be, even though A was better ahead of time than B - $100. It was equivalent to B, and B - $100 is strictly worse, because it's the same but $100 poorer no matter what.
Not only that, if you hadn't found out the value of A, you would have no reason to pay for B. Even A - $50 would have been better than B - $100. Ahead of time, if you knew what the genie was going to do, but not the value of A, ending up with B - $100 would be worse than each of A and A - $50.
Suppose you're back at the start before knowing A and with the genie pestering you to hear how it will turn out. Suppose you also know ahead of time that the genie will offer you B for $100 no matter the outcome of A, but you don't yet know how A will turn out. Predicting what you'd do to respect your own preferences, you reason that if you find out A, no matter what it is, you'd pay $100 for B. In other words, accepting the genie's offer to find out A actually means ending up with B - $100 no matter what. So, really, accepting to find out A from the genie *just is* B - $100. But B - $100 is also worse than A - $50 (you're guaranteed to be $50 poorer than with B - $50, which is equivalent to A - $50). It would have been better to pay the genie $50 to go away without telling you how A will go.
So this time, you pay the genie $50 to go away, to avoid finding out true information and making a foreseeably worse decision based on it. And now you're out $50, and definitely worse off than if you could have stuck through with A, finding out its value and refusing to pay $100 to switch to B. And you had the option to stick with A though the whole sequence and could have, if only you wouldn't trade it away for B at a cost of $100.
So, whatever strategy you follow, if constrained within the options I described, you will act irrationally. Specifically, either
1. With nonzero probability, you will refuse to follow your own preferences when offered B - $100 after finding out A, which would be irrational then ([Gustafsson, 2022](https://doi.org/10.1017/9781108754750%2520%25E2%2580%258C), [Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/abs/10.1111/phpr.12704) argue similarly against *resolute choice* strategies). Or,
2. You pay the genie $50 at the start, leaving you with a prospect that’s *certainly* worse than one you could have ended up with, i.e. A without paying, and so irrational. This also looks like paying $50 to *not find out* A.
You're forced to act irrationally either way.
Anti-utilitarian theorems
=========================
[Harsanyi, 1955](https://doi.org/10.1086/257678) proved that our social (or moral or impersonal) preferences over prospects should be to maximize the expected value of a weighted sum of individual utilities in fixed population cases, assuming our social preferences and each individual’s preferences (or betterness) satisfy the standard axioms of expected utility theory and assuming our social preferences satisfy **Ex Ante Pareto**. Ex Ante Pareto is defined as follows: if between two options, A and B, everyone is at least as well off ex ante — i.e. A is at least as good as B for each individual —, then A⪰B according to our social preferences. Under these assumptions, according to the theorem, each individual in the fixed population has a utility function, ui, and our social preferences over prospects for each fixed population can be represented by the expected value of a utility function, this function equal to a linear combination of these individual utility functions, ∑Ni=1aiui. In other words,
A⪰B if and only if E[∑Ni=1aiui(A)]≥E[∑Ni=1ui(B)].
Now, if each individual’s utility function in a fixed finite population is bounded, then our social welfare function for that population, from Harsanyi’s theorem, would also be bounded. One might expect the combination of total utilitarianism and Harsanyi’s theorem to support expectational total utilitarianism.[[11]](#fnct17brnm9y6) However, either the axioms themselves (e.g. the continuity/Archimedean axiom, or general versions of Independence or the Sure-Thing Principle) *rule out* expectational total utilitarianism, or the kinds of arguments used to defend the axioms ([Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704)). For example, essentially the same money pump argument, as we just saw, can be made against it. So, in fact, rather than supporting total utilitarianism, the arguments supporting the axioms of Harsanyi’s theorem *refute* total utilitarianism.
Perhaps you’re unconvinced by money pump arguments (e.g. [Halstead, 2015](https://doi.org/10.1017/S0953820814000375)) or expected utility theory in general. Harsanyi’s theorem has since been generalized in multiple ways. Recent results, without relying on the Independence axiom or Sure-Thing Principle at all, effectively obtain expectational utilitarianism in finite population cases or views including it as a special case, and with some further assumptions, expectational total utilitarianism ([McCarthy et al., 2020](https://www.sciencedirect.com/science/article/pii/S0304406820300045), sections 4.3 and 5 of [Thomas, 2022](https://doi.org/10.1093/oxfordhb/9780190907686.013.21), [Gustafsson et al., 2023](https://sites.utexas.edu/pwi/files/2023/07/GSZ-2023-Expectational-Total-Utilitarianism-Is-Implied-by-Social-and-Individual-Dominance.pdf)). They therefore don’t depend on support from money pump arguments either. In deterministic finite population cases and similarly constrained principles, arguments based on Separability have also been used to support utilitarianism or otherwise additive social welfare functions (e.g. Theorem 3 of [Blackorby et al., 2002](https://onlinelibrary.wiley.com/doi/abs/10.1111/1467-9779.00102) and section 5 of [Thomas, 2022](https://doi.org/10.1093/oxfordhb/9780190907686.013.21)). So, there are independent arguments for utilitarianism.
However, recent impossibility results undermine them all, too. Given a preorder over prospects[[12]](#fnzulw2tg3eme):
1. [Goodsell, 2021](https://philpapers.org/rec/GOOASP-2) shows Stochastic Dominance, Anteriority and Impartiality are jointly inconsistent. This follows from certain St Petersburg game-like prospects over the population size but constant welfare levels. It also requires an additional weak assumption that most impartial axiologies I’ve come across satisfy[[13]](#fnyy54c2i0u1c): there's some finite population of equal welfare such that adding two more people with the same welfare is either strictly better or strictly worse. For example, if everyone has a hellish life, adding two more people with equally hellish lives should make things worse.
2. [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461) (Theorem 4) shows “Stochastic Dominance, Separability, and Compensation are jointly inconsistent”. As a corollary, Stochastic Dominance, Separability and Impartiality are jointly inconsistent, because Impartiality implies Compensation.
[Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461) has some other impossibility results of interest, but I’ll focus on Theorem 4. I will define the remaining conditions here. See the papers for the proofs, which are short but technical.
**Stochastic Dominance** is generally considered to be a requirement of instrumental rationality, and it is a combination of two fairly obvious principles, Stochastic Equivalence and Statewise Dominance (e.g. [Tarsney, 2020](https://arxiv.org/abs/1807.10895), [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461)[[14]](#fn2ub05o2t263)). **Stochastic Equivalence** requires us to treat two prospects as equivalent if for each set of outcomes, the two prospects are equally likely to have their outcome in that set, and we call such prospects *stochastically equivalent*. For example, if I win $10 if a coin lands heads, and lose $10 if it lands tails, that should be equivalent to me to winning $10 on tails and losing $10 on heads, with a perfectly 50-50 coin. It shouldn’t matter how the probabilities are arranged, as long as each outcome occurs with the same probability. **Statewise Dominance** requires us to treat a prospect A as at least as good as B if A is at least as good as B with probability 1, and we’d say A *statewise dominates* B in that case.[[15]](#fn51leejcf1wg) It further requires us to treat A as strictly better than B, if on top of being at least as good as B with probability 1, A is strictly better than B with some positive probability, and in this case A *strictly statewise dominates* B. Informally, A statewise dominates B if A is always at least as good as B, and A strictly statewise dominates B if on top of that, A can also be better than B.
If instrumental rationality requires anything at all, it’s hard to deny that it requires respecting Stochastic Equivalence and Statewise Dominance. And, you respect Stochastic Dominance if and only if you respect both Stochastic Equivalence and Statewise Dominance, assuming transitivity. We’ll say A *stochastically dominates* B if there are prospects A′ and B′ to which A and Bare respectively stochastically equivalent and such that A′ statewise dominates B′ (we can in general take A′=A or B′=B, but not both), and A *strictly stochastically dominates* B if there are such A′ and B′ such that A′ strictly statewise dominates B′.
**Impartiality** can be stated in multiple equivalent ways for outcomes (deterministic cases) in finite populations:
1. only the distribution of welfares — the number of individuals at each welfare level (or lifetime welfare profiles) — matter in a population matter, not who realizes them or where or when they are realized, or
2. we can replace in an individual in any outcome with another individual at the same welfare level (or lifetime welfare profile), and the two outcomes will be equivalent.
**Compensation** is roughly the principle “that we can always compensate somehow for making things worse nearby, by making things sufficiently better far away (and vice versa)” ([Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461)). It is satisfied pretty generally by theories that are impartial in deterministic finite cases, including total utilitarianism, average utilitarianism, variable value theories, prioritarianism, critical-level utilitarianism, egalitarianism and even person-affecting versions of any of these views. In particular, theoretically “moving” everyone to nearby or “moving” everyone to far away without changing their welfare levels suffices.
**Anteriority** is a weaker version of Ex Ante Pareto: our social preferences are indifferent between two options whenever each individual is indifferent. The version [Goodsell, 2021](https://philpapers.org/rec/GOOASP-2) uses, however, is stronger than typical statements of Anteriority and requires its application across different number cases:
> If each possible person is equally likely to exist in either of two prospects, and for each welfare level, each person is, conditional on their existence, equally likely to have a life at least that good on either prospect, then those prospects are equally good overall.
>
>
This version is satisfied by expectational total utilitarianism, at least when the sizes of the populations in the prospects being compared are bounded by some finite number.
**Separability** is roughly the condition that parts of the world unaffected in a choice between two prospects can be ignored for ranking those prospects. What’s better or permissible shouldn’t depend on how things went or go for those unaffected by the decision.[[16]](#fnsxs7staf44) Or, following [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461), what we should do that only affects what’s happening nearby (in time and space) shouldn’t depend on what’s happening far away. In particular, in support of Separability and initially raised against average utilitarianism, there’s the Egyptology objection: the study of ancient Egypt and the welfare of ancient Egyptians “cannot be relevant to our decision whether to have children” ([Parfit 1984, p. 420](https://www.stafforini.com/docs/Parfit%2520-%2520Reasons%2520and%2520persons.pdf)).[[17]](#fngjqtc756lpr)
Separability can be defined as follows: for all prospects X, Y and B concerning outcomes for entirely separate things from both X and Y,
X⪰Y if and only if X⊕B⪰Y⊕B,
where ⊕ means combining or concatenating the prospects. For example, B could be the welfare of ancient Egyptians, while X and Y are the welfare of people today; the two may not be statistically independent, but they are separate, concerning disjoint sets of people and welfare levels. Average utilitarianism, many variable value theories and versions of egalitarianism are incompatible with Separability.
Separability is closely related to Anteriority and Ex Ante Pareto. Of course, Harsanyi’s theorem establishes Separability based on Ex Ante Pareto (or Anteriority) and axioms of Expected Utility Theory in fixed finite population cases, but we don’t need all of Expected Utility Theory. Separability, or at least in a subset of cases, follows from Anteriority (or Ex Ante Pareto) and some other modest assumptions, e.g. section 4.3 in [Thomas, 2022](https://doi.org/10.1093/oxfordhb/9780190907686.013.21). On the other hand, a preorder satisfying Separability, and in one-person cases, Anteriority or Ex Ante Pareto, will also satisfy Anteriority or Ex Ante Pareto, respectively, in fixed finite population cases.
So, based on the two theorems, if we assume Stochastic Dominance and Impartiality,[[18]](#fnoa5u04td51) then we can’t have Anteriority (unless it’s not worse to add more people to hell) or Separability. Anteriority and Separability are principles used to support utilitarianism, or at least natural generalizations of them defensible by essentially the same arguments. This substantially undermines all arguments for utilitarianism based on these principles. And my impression is that there aren’t really any other good arguments for utilitarianism, but I welcome readers to point any out!
Summary so far
==============
To summarize the arguments so far (given some basic assumptions):
1. Unbounded utility functions and expectational total utilitarianism in particular are irrational because of essentially the same arguments as those used to support expected utility theory in the first place, including money pumps.
2. All plausible views either give up an even more basic requirement of rationality, Stochastic Dominance, or one of two other principles — or natural extensions that can be motivated the same way — used to defend utilitarianism, i.e. Impartiality or Anteriority.
3. All plausible views either give up Stochastic Dominance, or one of two other principles — or natural extensions that can be motivated the same way — used to defend utilitarianism, i.e. Compensation (and so Impartiality) or Separability.
4. Together, it seems like the major arguments for utilitarianism in the first place actually undermine utilitarianism.
Responses
=========
Things look pretty bad for unbounded utility functions and utilitarianism. However, there are multiple responses someone might give in order to defend them, and I consider three here:
1. We only need to satisfy versions of the principles concerned with prospects with only finitely many outcomes, because infinities are too problematic generally.
2. Accept seemingly irrational behaviour (at least in some hypotheticals).
3. Accept violating foundational principles for utilitarianism in the general cases, but this only somewhat undermines utilitarianism, as other theories may do even worse.
To summarize my opinion on these, I think 1 is a bad argument, but 2 and 3 seem defensible, although they accept that expected value maximization and utilitarianism are at least somewhat undermined, respectively. I elaborate below.
First, one might claim the generalizations of axioms of expected utility theory, especially Independence or the Sure-Thing Principle, or even Separability, as well money pumps and Dutch books in general, should count only for prospects over finitely many possible outcomes, given other problems and paradoxes with infinities for decision theory, even expected utility theory with bounded utilities, as discussed in [Arntzenius et al., 2004](https://www.jstor.org/stable/3489134), [Peterson, 2016](https://doi.org/10.1007/s13194-015-0120-2) and [Bales, 2021](https://doi.org/10.1080/00048402.2020.1847152). Expected utility theory with unbounded utilities is consistent with the finitary versions, and some extensions of finitary expected utility theory are also consistent with stochastic dominance applied over all prospects, including those with infinitely many possible outcomes ([Goodsell, 2023](https://philarchive.org/archive/GOOUUG), see also earlier extensions of finitary expected utility to satisfy statewise dominance in [Colyvan, 2006](https://philpapers.org/rec/COLNE), [Colyvan, 2008](https://www.jstor.org/stable/20620070), which can be further extended to satisfy stochastic dominance[[19]](#fndh2i589ry44)). Stochastic Dominance, Compensation and the finitary version of Separability are also jointly consistent ([Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461)). However, I find this argument unpersuasive:
1. Plausible and rational decision theories *can* accommodate infinitely many outcomes, e.g. with bounded utility functions. Not all uses of infinities are problematic for decision theory in general, so the argument from *other* problems with infinities doesn’t tell us much about these problems. Measure theory and probability theory work fine with these kinds of infinities. The argument proves too much.
2. It’s reasonable to consider prospects with infinitely many possible outcomes in practice (e.g. for the “lifetime” of our universe, for sizes of the multiverse, the possibility of continuous spacetime, for the number of moral patients in our multiverse, [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461)), and it’s plausible that all of our prospects have infinitely many possible outcomes, so our decision theory should handle them well. One might claim that we can uniformly bound the number of possible outcomes by a finite number *across all prospects*. But consider the maximum number across all prospects, and a maximally valuable (or maximally disvaluable) but finite value outcome. We should be able to consider another outcome not among the set. Add a bit more consciousness in a few places, or another universe in the multiverse, or extend the time that can support consciousness a little. So, the space of possibilities is infinite, and it’s reasonable to consider prospects with infinitely many possible outcomes.
3. It’s plausible that if we have an unbounded utility function (or similarly unbounded preferences), we are epistemically required to treat all of our prospects as involving St Petersburg game-like subdistributions, because we can’t justify ruling them out with certainty (see also [Cromwell's rule - Wikipedia](https://en.wikipedia.org/wiki/Cromwell%2527s_rule)). It would be objectionably dogmatic to rule them out.
4. This doesn’t prevent irrational behaviour in theory. If we refuse to rank St Petersburg-like prospects as strictly preferable to each of their outcomes, we give up statewise (and stochastic) dominance or transitivity, each of which is irrational. If we don’t (e.g. following [Goodsell, 2023](https://philarchive.org/archive/GOOUUG)), the *same* arguments that support the finite versions of Independence and the Sure-Thing Principle, and demonstrate the irrationality of their violation can be made against the countable versions (e.g. [Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704), the money pump argument earlier). And the Egyptology objection for Separability generalizes, too (e.g. [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461)). If those arguments don’t have (much) force in the general cases, then they shouldn’t have (much) force in the finitary cases, because the arguments are the same.
A second response is to just bite the bullet and accept apparently irrational behaviour in some (at least hypothetical) circumstances, or deny that it is in fact irrational at all. However, this, too, weakens the strongest arguments for expected utility maximization. The hypothetical situations where irrational decisions would be forced could be unrealistic or very improbable, and so seemingly irrational behaviour in them doesn’t matter, or matters less. The money pump I considered doesn’t seem very realistic, and it’s hard to imagine very realistic versions. Finding out the actual value (or a finite upper bound on it) of a prospect with infinite expected utility conditional on finite actual utility would realistically require an unbounded amount of time and space to even represent. Furthermore, for utility functions that scale relatively continuously with events over space and time, with unbounded time, many of the events contributing utility will have happened, and events that have already happened can’t be traded away. That being said, I expect this last issue to be addressable in principle by just subtracting from B - $100 the value in A already accumulated in the time it took to estimate the actual value of A, assuming this can be done without all of A’s value having already been accumulated.
Then, other considerations, like Separability, can outweigh them. However, if expectational total utilitarianism is still plausible despite irrational behaviour in unrealistic or very improbable situations, then it seems irrational behaviour in unrealistic or very improbable situations shouldn’t count decisively against other theories or other normative intuitions. So, we open up the possibility decision theories other than expected utility theory. Furthermore, the line for “unrealistic or very improbable” seems subjective, and if we draw a line to make an exception for utilitarianism, there doesn’t seem to be much reason why we shouldn’t draw more permissive lines to make more exceptions.
Indeed, I don’t think instrumental rationality or avoiding money pumps in all hypothetical cases are normatively *required*, and I weigh them with my other normative intuitions, e.g. epistemic rationality or justifiability (e.g. [Schoenfield, 2012](https://link.springer.com/article/10.1007/s11098-012-9886-7) on imprecise credences). I’d of course prefer to be money pumped or violate Stochastic Dominance less. However, a more general perspective is that foreseeably doing worse by your own lights is regrettable, but regrettable only to the extent of your actual losses from it. There are often more important things to worry about than such losses, like situations of asymmetric information, or just doing better by the lights of your other intuitions. Furthermore, having to abandon another principle or reason you find plausible or otherwise change your views just to be instrumentally rational can be seen as another way of foreseeably doing worse by your own lights. I'd rather hypothetically lose than definitely lose.
A final response is of course to just give up or weaken one or more of the principles used to support utilitarianism. We could approximate expectational total utilitarianism with bounded utility functions or just use stochastic dominance over total utility ([Tarsney, 2020](https://arxiv.org/abs/1807.10895)), even agreeing in all deterministic finite population cases, and possibly “approximately” satisfying these principles in general. We might claim that moral axiology should only be concerned with betterness per se and deterministic cases. On the other hand, risk and uncertainty are the domains of decision theory, instrumental rationality and practical deliberation, just aimed at ensuring we act consistently with our understanding of betterness. What you have most reason to do is whatever maximizes *actual* total welfare, regardless of your beliefs about what would achieve this. It’s not a matter of rationality that what you should do shouldn’t depend on things unaffected by your decisions even in uncertain cases or that we should aim to maximize each individual’s expected utility. Nor are these matters of axiology, if axiology is only concerned with deterministic cases. So, Separability and Pareto only need to apply in deterministic cases, and we have results that support total utilitarianism in finite deterministic cases based on them, like Theorem 3 of [Blackorby et al., 2002](https://onlinelibrary.wiley.com/doi/abs/10.1111/1467-9779.00102) and section 5 of [Thomas, 2022](https://doi.org/10.1093/oxfordhb/9780190907686.013.21).
That the deterministic and finitary prospect versions of these principles are jointly consistent and support (extensions of) (expectational total) utilitarianism could mean arguments defending these principles provide *some* support for the view, just less than if the full principles were jointly satisfiable. Other views will tend to violate restricted or weaker versions or do so in worse ways, e.g. not just failing to preserve strict inequalities in Separability but actually *reversing* them. [Beckstead and Thomas, 2023](https://onlinelibrary.wiley.com/doi/10.1111/nous.12462) (footnote 19) point to “the particular dramatic violations [of Separability] to which timidity leads.” If we find the arguments for the principles intuitively compelling, then it’s better, all else equal, for our views to be “more consistent” with them than otherwise, i.e. satisfy weaker or restricted versions, even if not perfectly consistent with the general principles. Other views could still just be worse. Don't let the perfect be the enemy of the good, and don't throw the baby out with the bathwater.
Acknowledgements
================
Thanks to Jeffrey Sanford Russell for substantial feedback on a late draft, as well as Justis Mills and Hayden Wilkinson for helpful feedback on an earlier draft. All errors are my own.
1. **[^](#fnreftsia01qirb)** An individual’s welfare can be the value of their own utility function, although preferences or utility functions defined in terms of each other can lead to contradictions through indirect self-reference ([Bergstrom, 1989](https://www.aeaweb.org/articles?id%3D10.1257/jep.3.2.165), [Bergstrom, 1999](https://doi.org/10.1111/1097-3923.00004), [Vadasz, 2005](https://www.sciencedirect.com/science/article/abs/pii/S0378437104012117), Yann, 2005 and [Dave and Dodds, 2012](https://onlinelibrary.wiley.com/doi/abs/10.4284/0038-4038-78.3.878)). I set aside this issue here.
2. **[^](#fnref0wvc3bcsa1ja)** The number of moral patients may be *infinite*, because the universe is plausibly infinite/unbounded spatially (e.g. [Shape of the universe - Wikipedia](https://en.wikipedia.org/wiki/Shape_of_the_universe)). Even if the universe isn’t infinite in spatial extent, there’s still no finite upper bound of which we can be 100% sure. It may also be possible to create infinite universes or infinitely many more universes ([Tomasik, 2017](https://reducing-suffering.org/lab-universes-creating-infinite-suffering/)). We also can’t be 100% certain of any specified (weak) upper bound on how long our actions will affect value in the future or even for how long a moral patient can exist and aggregate welfare over their existence.
Only finite value within a finite time horizon, i.e. our light cone, may be *causally* influenceable, assuming a maximum density of value and we can’t generate infinitely many more universes or infinite universes. However, other value may be *acausally* influenceable. For discussion of acausal influence, see [Wilkinson, 2022](https://globalprioritiesinstitute.org/hayden-wilkinson-can-an-evidentialist-be-risk-averse/), *evidential cooperation in large worlds*, previously called *multiverse-wide superrationality* ([Oesterheld, 2017](https://longtermrisk.org/msr) for multiple papers on the topic, [Gloor, 2017](https://forum.effectivealtruism.org/posts/7MdLurJGhGmqRv25c/multiverse-wide-cooperation-in-a-nutshell) for an accessible introduction and [Finnveden, 2023](https://lukasfinnveden.substack.com/p/implications-of-ecl) for implications), [Acausal Trade - LessWrong](https://www.lesswrong.com/tag/acausal-trade) and [Critch, 2023](https://www.lesswrong.com/posts/3RSq3bfnzuL3sp46J/acausal-normalcy).
3. **[^](#fnrefeci04fnrp9)** See also [Christiano, 2022](https://www.lesswrong.com/posts/gJxHRxnuFudzBFPuu/better-impossibility-result-for-unbounded-utilities?commentId%3DhrsLNxxhsXGRH9SRx). Both depend on St Petersburg game-like prospects with infinitely many possible outcomes and, when defined, infinite expected utility. For more on the St Petersburg paradox, see [Peterson, 2023](https://plato.stanford.edu/entries/paradox-stpetersburg/). Some other foreseeable sure loss arguments require a finite but possibly unbounded number of choices, like [McGee, 1999](https://doi.org/10.1093/analys/59.4.257) and [Pruss, 2022](http://alexanderpruss.blogspot.com/2022/10/expected-utility-maximization.html).
4. **[^](#fnrefwotew5kfhm9)** Or, as in [Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704), each of the countably many prospects used to construct it.
5. **[^](#fnrefifnhafjmcsi)** For generalizations, see [Russell and Isaacs, 2021](https://onlinelibrary.wiley.com/doi/pdf/10.1111/phpr.12704) (violations of Limitedness) and [Beckstead and Thomas, 2023](https://onlinelibrary.wiley.com/doi/10.1111/nous.12462).
6. **[^](#fnrefx0v2hv2cmgh)** From u(xn+1)≥2u(xn) for each n>1, we have, by induction, u(xn+1)≥2nu(xn). Then, for each N≥1,
E[u(X)]=∑∞n=1u(xn)p(xn)=∑∞n=1u(xn)1/2n≥∑Nn=1u(xn)1/2n≥∑Nn=12n−1u(x1)1/2n=Nu(x1)/2,
which can be arbitrarily large, so E[u(X)]=∞.
7. **[^](#fnref5u5kqq4b6u)**This would follow either by extension to expected utilities over countable prospects, or assuming we respect Statewise Dominance and transitivity.
For the latter, we can modify the prospect to a truncated one with finitely many outcomes XN for each N>1, by defining XN=X if X<xN, and XN=xN (or x1) otherwise. Then E[u(XN)] is finite for each N, but limN→∞E[u(XN)]=∞. Furthermore, for each N, not only is it the case that E[u(X)]=∞>E[u(XN)], but X also *strictly statewise dominates* XN, i.e. X is with certainty at least as good as XN, and is, with nonzero probability, strictly better. So, given any prospect Y with finite (expected) utility, there’s an N such that E[u(XN)]>E[u(Y)], so XN≻Y, but since X≻XN, by transitivity, X≻Y.
8. **[^](#fnref7msq9z8y18)**In practice, you should give weight to the possibility that it has infinite or undefined value. However, the argument that follows can be generalized to this case using stochastic dominance reasoning or, if you do break ties between actual infinities, any reasonable way of doing so.
9. **[^](#fnref5t075gvsn06)** Or give you an accurate finite upper bound on how it will turn out.
10. **[^](#fnrefetwminzdksh)**And the genie isn’t going to do anything good with it.
11. **[^](#fnrefct17brnm9y6)**Interestingly, if expectational total utilitarianism is consistent with Harsanyi’s theorem, then it is not the only way for total utilitarianism to be consistent with Harsanyith’s theorem. Say individual welfare takes values in the interval [2,3]. Then the utility functions ∑Nn=1ui+N and N∑Nn=1ui agree with both Harsanyi’s theorem and total utilitarianism. According to them, a larger population is always better than a smaller population, regardless of the welfare levels in each. However, some further modest assumptions give us expectational total utilitarianism, e.g. each individual can welfare level 0.
12. **[^](#fnrefzulw2tg3eme)**So, assuming reflexivity, transitivity, the Independence of Irrelevant Alternatives. Also, we need the set of prospects to be rich enough to include some of the kinds of prospects used in the proofs.
13. **[^](#fnrefyy54c2i0u1c)**Exceptions include average utilitarianism, symmetric person-affecting views, maximin and maximax.
14. **[^](#fnref2ub05o2t263)**[Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461) writes:
> Stochastic Dominance is a fairly uncontroversial principle of decision theory—even among those who reject other parts of standard expectational decision theory (such as Quiggin, [1993](https://link.springer.com/book/10.1007/978-94-011-2182-8); Broome, [2004](https://doi.org/10.1093/019924376X.001.0001)), and even in settings where other parts of standard expectational decision theory give out (see for example Easwaran, [2014](https://philpapers.org/rec/EASDTW)).[10](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461%23nous12461-note-0010_note_9)We should not utterly foreclose giving up Stochastic Dominance—we are facing paradoxes, so some plausible principles will have to go—but I do not think this is a very promising direction. In what follows, I will take Stochastic Dominance for granted.
>
>
and in footnote 10:
> For other defenses of Stochastic Dominance, on which I here have drawn, see Tarsney ([2020](https://arxiv.org/abs/1807.10895), 8); Wilkinson ([2022](https://www.journals.uchicago.edu/doi/10.1086/716869), 10); Bader ([2018](https://www.tandfonline.com/doi/abs/10.1080/00048402.2017.1362566)).
>
>
15. **[^](#fnref51leejcf1wg)**There is some controversy here, because we might instead say that A statewise dominates B if and only if A is at least as good as B under every possibility, including each possibility with probability 0. [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461) writes:
> For example, the probability of an ideally sharp dart hitting a particular point may be zero—but the prospect of sparing a child from malaria if the dart hits that point (and otherwise nothing) may still be better than the prospect of getting nothing no matter what. But these two prospects are stochastically equivalent. Perhaps what is best depends on what features of its outcomes are sure—where in general this can come apart from what is *almost sure*—that is, has probability one.
>
>
However, I don’t think this undermines the results of [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461), because the prospects considered don’t disagree on any outcomes of probability 0.
16. **[^](#fnrefsxs7staf44)**Insofar as it isn’t evidence for how well off moral patients today and in the future can or will be, and ignoring acausal influence.
17. **[^](#fnrefgjqtc756lpr)**The same objection is raised earlier in [McMahan, 1981, p. 115](https://www.journals.uchicago.edu/doi/10.1086/292301%23:~:text%3Dhttps%253A//doi.org/10.1086/292301) referring to past generations more generally. See also discussion of it and similar objections in [Huemer, 2008](https://stripe.colorado.edu/~boonind/Huemer%2520-%2520In%2520Defence%2520of%2520Repugnance.pdf), [Wilkinson, 2022](https://www.journals.uchicago.edu/doi/abs/10.1086/716869), [Beckstead and Thomas, 2023](https://onlinelibrary.wiley.com/doi/10.1111/nous.12462), [Wilkinson, 2023](https://globalprioritiesinstitute.org/egyptology-and-fanaticism-hayden-wilkinson/) and [Russell, 2023](https://onlinelibrary.wiley.com/doi/full/10.1111/nous.12461).
18. **[^](#fnrefoa5u04td51)**And a single preorder over prospects, so transitivity, reflexivity and the independence of irrelevant alternatives, and a rich enough set of possible prospects.
19. **[^](#fnrefdh2i589ry44)**These can be extended to satisfy Stochastic Dominance by making stochastically equivalent prospects equivalent and taking the [transitive closure](https://en.wikipedia.org/wiki/Transitive_closure) to get a new preorder. |
d0b64107-c86a-42c5-9fc8-286ccd2e4ba6 | trentmkelly/LessWrong-43k | LessWrong | Single player extensive-form games as a model of UDT
This post was inspired by Benja's SUDT post. I'm going to describe another simplified model of UDT which is equivalent to Benja's proposal, and is based on standard game theory concepts as described in this Wikipedia article.
First let's define what is a "single player extensive-form game with chance moves and imperfect information":
1. A "single player extensive-form game" is a tree of nodes. Each leaf node is a utility value. A play of the game starts at the root and ends at some leaf node.
2. Some non-leaf nodes are "chance nodes", with probabilities assigned to branches going out of that node. All other non-leaf nodes are "decision nodes", where the player can choose which branch to take. (Thanks to badger for helping me fix an error in this part!)
3. "Imperfect information" means the decision nodes are grouped into "information sets". The player doesn't know which node they're currently at, only which information set it belongs to.
4. "Imperfect recall" is a special case of imperfect information, where knowing the current information set doesn't even allow the player to figure out which information sets were previously visited, like in the Absent-Minded Driver problem.
5. We will assume that the player can use "behavioral strategies", where the player can make a random choice at each node independently, rather than "mixed strategies", which randomize over the set of pure strategies for the entire game. See Piccione and Rubinstein's paper for more on this difference. (Thanks to Coscott for pointing out that assumption!)
6. The behavioral strategy with the highest expected utility will be taken as the solution of the game.
Now let's try using that to solve some UDT problems:
Absent-Minded Driver is the simplest case, since it's already discussed in the literature as a game of the above form. It's strange that not everyone agrees that the best strategy is indeed the best, but let's skip that and move on.
Psy-Kosh's non-anthropic problem is more tricky, |
668d8cc6-c5d1-4308-b61d-dd685e1db26b | trentmkelly/LessWrong-43k | LessWrong | Be a little bit more trusting than most people think sensible
I am just working on a list of rationalist rules I live by, and this is the one I have most confidence in, so it seems a good topic for my first ever post (which will be short as I have to be on a train in 15)
Since people routinely exaggerate risk, and social norms pull us towards the crabs in a bucket effect (especially for women) I want to correct for that. (Preferably without ending up with a giant Rob Me sign over my head, but that's not the direction I err in.)
For example, there was this rationalist walked into a bar. I had a lot of luggage - everything I need for a four day break, including over two thousand pounds worth of electronic devices and binoculars. I am insured, but it would be an especially annoying time to lose stuff. I had a coffee and then I needed the bathroom, which was far away through a lot of people.
I knew logically how little risk there was in leaving all my stuff; a Highland bar in the middle of the afternoon is even safer than where I live in Edinburgh, and no-one was pinging any alarm bells, but I still spent more time than I'd like to admit convincing myself I didn't have to drag the huge bag with me to the ladies and back. Yes brain, even though I'm alone, and the customers are men, and I'm a middle aged woman, and my mother would freak if she saw me...
Of course it was fine, like it was the last hundred times. One day I hope to not even have to persuade myself, but meanwhile I notice my prediction was correct and feel just a little bit pleased with myself. |
9a186420-6bc1-4d65-8d71-d5368ec7036c | trentmkelly/LessWrong-43k | LessWrong | [SEQ RERUN] Rationalist Fiction
Today's post, Rationalist Fiction was originally published on 19 March 2009. A summary (taken from the LW wiki):
> What works of fiction are out there that show characters who have acquired their skills at rationality through practice, and who we can watch in the act of employing those skills?
Discuss the post here (rather than in the comments to the original post).
This post is part of the Rerunning the Sequences series, where we'll be going through Eliezer Yudkowsky's old posts in order so that people who are interested can (re-)read and discuss them. The previous post was The Pascal's Wager Fallacy Fallacy, and you can use the sequence_reruns tag or rss feed to follow the rest of the series.
Sequence reruns are a community-driven effort. You can participate by re-reading the sequence post, discussing it here, posting the next day's sequence reruns post, or summarizing forthcoming articles on the wiki. Go here for more details, or to have meta discussions about the Rerunning the Sequences series. |
4f2b2907-d56c-4242-890a-ee5a5e513d74 | trentmkelly/LessWrong-43k | LessWrong | Livestreaming monetisation models aka What do camgirls have in common with Twitch streamers?
Repost from my personal blog / newsletter - feel free to subscribe if you like longform Chinese tech analysis.
In many ways, the internet was made for livestreaming. Starting with Jennicam back in 1996, it has taken the medium a while to get to the fabled plateau of productivity.
Livestreaming in its genesis of Twitch, Meerkat, Periscope and Facebook Live never fleshed out a compatible monetisation model. As a result, it struggled with marketplace supply-side liquidity since livestreaming hosts weren't incentivised to stream consistently. Viewers then stopped watching as there was no guarantee of good content on the platform. Livestreaming only became a medium after the emergence of effective monetisation, as then creators had the incentive to keep to a regular broadcasting schedule for followers.
Bolstered by Covid-19, livestreaming is now ubiquitous in China and increasingly mainstream in the west. The Chinese market is estimated to be worth RMB 433.8 billion ($64.2bn USD) in 2019 and is expected to double by the end of 2020. Twitch currently has 6.2 million monthly broadcasters, and games livestreaming as an industry is estimated to be worth $50bn. Livestreaming has created massive stars; on Twitch, Ninja the Fortnite streamer has ~7m fans and even higher earnings. In China, Li Jiaqi the 'Lipstick queen' sold 15,000 tubs of lipstick in 15 minutes on Taobao. Viya, who is essentially Oprah incarnated as a livestreamer, can command 37m viewers (bigger than the audience for the Oscars or Game of Thrones finale) during a stream. These big numbers are representative of the digitalisation of distribution and entertainment that's been quietly occurring throughout the world. The fact that livestreaming has become their de-facto medium owes much to the unlocking of effective monetisation strategies.
Livestreaming as a medium is a conflation of a product as well as as a distribution channel. It exists on a spectrum of being pure entertainment on one-side and a new go-to |
db6b366c-6251-45bb-b2c4-48cf316bc66d | trentmkelly/LessWrong-43k | LessWrong | Announcing Open Philanthropy's AI governance and policy RFP
AI has enormous beneficial potential if it is governed well. However, in line with a growing contingent of AI (and other) experts from academia, industry, government, and civil society, we also think that AI systems could soon (e.g. in the next 15 years) cause catastrophic harm. For example, this could happen if malicious human actors deliberately misuse advanced AI systems, or if we lose control of future powerful systems designed to take autonomous actions.[1]
To improve the odds that humanity successfully navigates these risks, we are soliciting short expressions of interest (EOIs) for funding for work across six subject areas, described here.
Strong applications might be funded by Good Ventures (Open Philanthropy’s partner organization), or by any of >20 (and growing) other philanthropists who have told us they are concerned about these risks and are interested to hear about grant opportunities we recommend.[2] (You can indicate in your application whether we have permission to share your materials with other potential funders.)
Click here to read the full RFP.
As this is a new initiative, we are uncertain about the volume of interest we will receive. Our goal is to keep this form open indefinitely; however, we may need to temporarily pause accepting EOIs if we lack the staff capacity to properly evaluate them. We will post any updates or changes to the application process on this page.
Anyone is eligible to apply, including those working in academia, nonprofits, industry, or independently.[3] We will evaluate EOIs on a rolling basis. See below for more details.
If you have any questions, please email us. If you have any feedback about this page or program, please let us know (anonymously, if you want) via this short feedback form. |
f411814a-e077-4419-8bd8-eb8a1db21fd5 | trentmkelly/LessWrong-43k | LessWrong | AI #77: A Few Upgrades
[Apologies for forgetting to cross-post this and the Monthly Roundup earlier.]
Let’s see. We’ve got a new version of GPT-4o, a vastly improved Grok 2 with a rather good and unrestricted deepfake and other image generator now baked into Twitter, the announcement of the AI powered Google Pixel 9 coming very soon and also Google launching a voice assistant. Anthropic now has prompt caching.
Also OpenAI has its final board member, Zico Kolter, who is nominally a safety pick, and SB 1047 got importantly amended again which I’ll cover in full next week once the details are out.
There was also the whole paper about the fully automated AI scientist from the company whose name literally means ‘danger’ in Hebrew, that instantiated copies of itself, took up unexpectedly large amounts of storage space, downloaded strange Python libraries and tried to edit its code to remove the timeout condition. Oh, that.
TABLE OF CONTENTS
1. Introduction.
2. Table of Contents.
3. Language Models Offer Mundane Utility. Many quality of life improvements.
4. Language Models Don’t Offer Mundane Utility. If you look for failure, it’s there.
5. GPT-4o My System Card. Better late than never, if a bit obsolete.
6. 2 Grok 2 Furious 2 Quit. Welcome to Deepfaketown, population Twitter.
7. Pixel Perfect. The first AI integrated phone is almost here.
8. Fun With Image Generation. Two free DALL-E creations per day.
9. Deepfaketown and Botpocalypse Soon. How do you prove you are a real person?
10. The Art of the Jailbreak. Anthropic offers bounties, make check out to Pliny.
11. They Took Our Jobs. It gets lonely. Also see that AI scientist thing.
12. Obvious Nonsense. GPT-2 indeed poses no existential threat to humanity.
13. Get Involved. SFF launching a new funding round, and a shameless plug.
14. Introducing. New GPT-4o update, Anthropic offers prompt caching.
15. In Other AI News. Zico Kolter joins the OpenAI board.
16. Quiet Speculations. If you don’t see AI progressing you |
a17532c5-426b-4e0f-a3c1-30e4fb951eb3 | trentmkelly/LessWrong-43k | LessWrong | Research update: Towards a Law of Iterated Expectations for Heuristic Estimators
Last week, ARC released a paper called Towards a Law of Iterated Expectations for Heuristic Estimators, which follows up on previous work on formalizing the presumption of independence. Most of the work described here was done in 2023.
A brief table of contents for this post:
* What is a heuristic estimator? (One example and three analogies.)
* How might heuristic estimators help with understanding neural networks? (Three potential applications.)
* Formalizing the principle of unpredictable errors for heuristic estimation (the technical meat of the paper).
In "Formalizing the Presumption of Independence", we defined a heuristic estimator to be a hypothetical algorithm that estimates the values of mathematical expression based on arguments. That is, a heuristic estimator is an algorithm G that takes as input
* A formally specified real-valued expression Y; and
* A set of formal "arguments" π1,…,πm --
-- and outputs an estimate of the value of Y that incorporates the information provided by π1,…,πm. We denote this estimate by G(Y∣π1,…,πm).[1]
In that paper, we introduced the following question: is there a computationally efficient heuristic estimator that formalizes intuitively valid reasoning about the values of mathematical quantities based on arguments? We studied the question by introducing intuitively desirable coherence properties (one such property is linearity: a heuristic estimator's estimate of X+Y should equal its estimate of X plus its estimate of Y) and working to satisfy those properties. Ultimately, we left the question open.
The main technical contribution of our new work is to outline a new type of coherence property: a heuristic estimator should not be able to predict its own errors. We call this intuitive statement the principle of unpredictable errors. The principle is loosely inspired by the law of iterated expectations from probability theory, as well as the martingale property: a Bayesian reasoner's estimate of their future est |
f2d70b32-ab5e-41a1-8574-5f6f68cabe2e | trentmkelly/LessWrong-43k | LessWrong | Rationality Quotes October 2013
Another month has passed and here is a new rationality quotes thread. The usual rules are:
* Please post all quotes separately, so that they can be upvoted or downvoted separately. (If they are strongly related, reply to your own comments. If strongly ordered, then go ahead and post them together.)
* Do not quote yourself.
* Do not quote from Less Wrong itself, HPMoR, Eliezer Yudkowsky, or Robin Hanson. If you'd like to revive an old quote from one of those sources, please do so here.
* No more than 5 quotes per person per monthly thread, please. |
ed9bb476-1742-4f70-8749-4a39e77b85f6 | trentmkelly/LessWrong-43k | LessWrong | Ethicophysics II: Politics is the Mind-Savior
We present an ethicophysical treatment on the nature of truth and consensus reality, within the framework of a historical approach to ludic futurecasting modeled on the work of Hegel and Marx. We prove an ethicophysical approximate conservation law: the Conservation of Bullshit. We conclude with a lengthy list of open questions, homework problems, and assigned readings, focused on many large and weighty questions about history and politics. We do not presume to know the answers to any of these weighty questions, but we invite any interested readers to submit answers to these questions, either as comments on this post, comments on my substack, direct messages on LessWrong, or direct emails to my personal email.
We hope that, by providing a mathematically rigorous treatment of naturalistic game theory and hooking it up to these weighty political and historical questions, we can encourage people to take history and morality more seriously without starting any unproductive flamewars. I will be setting the moderation settings on this post to Reign of Terror to encourage the LessWrong moderators to enforce these norms to the limits of their ability and discretion.
We provide the list of open questions, homework exercises, and assigned reading from the PDF, in order to facilitate productive discussion on LessWrong. Please share your answers or work-in-progress for any of the following questions in the comments:
* Read Keat’s Ode on a Grecian Urn, reflect on the story of Dr. Faust by Goethe, and then formulate a short description of Keat’s Fallacy.
* Read Friedrich Schiller’s “On the Aesthetic Education of Man”. Why would Keat’s Fallacy be relevant to moral actions in the world?
* Read “Avant-Garde and Kitsch” by Clement Greenberg (1939). Read any honest description of Adolf Hitler’s artistic style and level of skill. Then formulate working definitions of active kitsch, potential kitsch, describe how to measure both, and prove that total kitsch is a conserved quantit |
603a36b3-2f06-4f63-abce-dae7c3a340d2 | trentmkelly/LessWrong-43k | LessWrong | A freshman year during the AI midgame: my approach to the next year
I recently spent some time reflecting on my career and my life, for a few reasons:
* It was my 29th birthday, an occasion which felt like a particularly natural time to think through what I wanted to accomplish over the course of the next year 🙂.
* It seems like AI progress is heating up.
* It felt like a good time to reflect on how Redwood has been going, because we’ve been having conversations with funders about getting more funding.
I wanted to have a better answer to these questions:
* What’s the default trajectory that I should plan for my career to follow? And what does this imply for what I should be doing right now?
* How much urgency should I feel in my life?
* How hard should I work?
* How much should I be trying to do the most valuable-seeming thing, vs engaging in more playful exploration and learning?
In summary:
* For the purposes of planning my life, I'm going to act as if there are four years before AGI development progresses enough that I should substantially change what I'm doing with my time, and then there are three years after that before AI has transformed the world unrecognizably.
* I'm going to treat this phase of my career with the urgency of a college freshman looking at their undergrad degree--every month is 2% of their degree, which is a nontrivial fraction, but they should also feel like they have a substantial amount of space to grow and explore.
The AI midgame
I want to split the AI timeline into the following categories.
* The early game, during which interest in AI is not mainstream. I think this ended within the last year 😢
* The midgame, during which interest in AI is mainstream but before AGI is imminent. During the midgame:
* The AI companies are building AIs that they don’t expect will be transformative.
* The alignment work we do is largely practice for alignment work later, rather than an attempt to build AIs that we can get useful cognitive labor from without them staging coups.
* For the pur |
52951d7a-d34e-4634-b408-01a26850f905 | StampyAI/alignment-research-dataset/special_docs | Other | The Al Does Not Hate You: Superintelligence, Rationality and the Race to Save the World
[]
For Billy and Ada. I hope the people in this book are right,
and that you live to see humanity reach the stars.
[]
Contents
Dedication
Title Page
Introduction: ‘I don’t expect your children to die of old age’
PART ONE: INTRODUCTIONS
1: Introducing the Rationalists
2: The cosmic endowment
PART TWO: THE PAPERCLIP APOCALYPSE
3: Introducing AI
4: A history of AI
5: When will it happen?
6: Existential risk
7: The cryptographic rocket probe, and why you have to get it right first time
8: Paperclips and Mickey Mouse
9: You can be intelligent, and still want to do stupid things
10: If you want to achieve your goals, not dying is a good start
11: If I stop caring about chess, that won’t help me win any chess games, now will it?
12: The brief window of being human-level
13: Getting better all the time
14: ‘FOOOOOM’
15: But can’t we just keep it in a box?
16: Dreamed of in your philosophy
17: ‘It’s like 100 per cent confident this is an ostrich’
PART THREE: THE WAYS OF BAYES
18: What is rationality?
19: Bayes’ theorem and optimisation
20: Utilitarianism: shut up and multiply
PART FOUR: BIASES
21: What is a ‘bias’?
22: The availability heuristic
23: The conjunction fallacy
24: The planning fallacy
25: Scope insensitivity
26: Motivated scepticism, motivated stopping and motivated continuation
27: A few others, and the most important one
PART FIVE: RAISING THE SANITY WATERLINE
28: Thinking probabilistically
29: Making beliefs pay rent
30: Noticing confusion
31: The importance of saying ‘Oops’
PART SIX: DECLINE AND DIASPORA
32: The semi-death of LessWrong
33: The IRL community
PART SEVEN: DARK SIDES
34: Are they a cult?
35: You can’t psychoanalyse your way to the truth
36: Feminism
37: The Neoreactionaries
PART EIGHT: DOING GOOD BETTER
38: The Effective Altruists
39: EA and AI
PART NINE: THE BASE RATE OF THE APOCALYPSE
40: What are they doing to stop the AI apocalypse?
41: The internal double crux
42: Life, the universe and everything
Acknowledgements
Notes
Copyright
Introduction
‘I don’t expect your children to die of old age’
Lord and Master! Hear me call. Oh, come the master!
Lord, the need is great! The ones I called, the spirits
Will not leave.
‘Der Zauberlehrling’, or ‘The Sorcerer’s Apprentice’, Johann Wolfgang von Goethe (1797). Translated using artificial intelligence (specifically, Google Translate).
I was sitting in the passenger seat of a huge black BMW SUV, being driven around the byzantine freeways of the southern San Francisco Bay Area on a gorgeous October afternoon, when he said it: ‘I don’t expect your children to die of old age.’
To borrow a line from Douglas Adams,\* when you’re cruising down the road in the fast lane and you lazily sail past a few hard-driving cars and are feeling pretty pleased with yourself and then accidentally change down from fourth to first instead of third, thus making your engine leap out of your bonnet in a rather ugly mess, it tends to throw you off your stride in much the same way that this remark threw me off mine.
My companion was a guy called Paul Crowley, a man whose day job is as a cryptography engineer on Google’s Android phone-operating system, but whose chief preoccupation in life is helping humanity reach the stars without first being destroyed by its own technological success.
There is a group of people, of whom Paul is one, who think that now is the crunch time. The next 100 years or so will be the inflexion point for humanity – either we go on and colonise the cosmos, becoming a galaxy-spanning civilisation of near-immortal demigods, or we annihilate ourselves with one or more of the technologies that we have developed. My children, they think, have a good chance of reaching demigodhood; they have, also, a good chance of not doing so. They want to improve the odds of the former.
I have been aware of these people for a few years. They’re known as the Rationalists.
You’ve probably read a lot about artificial intelligence (AI) in recent years. Will it take our jobs? Will it form new, deadly, autonomous weapons on the battlefield? Will it lead to an era of inequality, as the rich buy all the robots and computers that run the new economy, and the poor find themselves left even further behind? Will we get those robot butlers we were promised?
These are serious and real concerns which deserve the many articles and books written about them, apart from the butler thing. But while the Rationalists are worried about that stuff, it’s not the focus of their concern. Instead, they’re worried that an AI will – in the relatively near future, the future that my children could easily live to see, or not far beyond it – become as smart as a human. And that when it does so, it will become as good as we are at designing artificial-intelligence systems, because designing artificial-intelligence systems is something that humans can do.
And so a machine that is as smart as a human could, possibly, very quickly improve itself, get better at improving itself, improve itself some more, and so on. An explosion would take place: suddenly, humans would find themselves vastly intellectually outgunned. Intelligence is what has made humans the most successful large animals on the planet; the tiny difference in DNA between us and gorillas, the thing that makes us smarter, is the difference that means our thronging billions live on every continent on the planet, while gorillas are going extinct in the mountains of Congo and Rwanda. If there’s a machine that’s smarter than us, the Rationalists say, we would live only at its sufferance – as gorillas do, just about, at ours.
And, they say, just because a machine is smart, it doesn’t mean that it’s nice. It doesn’t even mean that it’s conscious. And if we aren’t extraordinarily careful about how we build it – and even more careful about what we tell it to do – then it is possible that a future with AI could be, as far as we are concerned, extremely short and unpleasant. Or it could, equally, be glorious, spreading out across the galaxy, bounded only by the physical limits of entropy, light speed and the size of atoms.
This book is about that future. It’s my attempt to work out whether I believe, as (some of) the Rationalists do, that we’re on the brink of something – that my children, realistically, may not die of old age. It’s also a look at the people themselves, who are fascinating, strange, clever, kind, frightened and self-sabotaging.
A word before I start. One of the people you’ll meet in this book, the blogger and psychiatrist Scott Alexander, has an excellent habit. At the top of many of his blog posts – which are usually brilliant, thoughtful and terrifyingly long – he has a little line or two in italics, ‘Epistemic status’; and then says how confident he is in his conclusions, and why. ‘Epistemic status: Uncertain, especially on the accuracy of the economic studies cited.’ ‘Epistemic status: Pieced together from memory years after the event.’ ‘Epistemic status: Wild speculation.’ I think this is wise.
So, here we go. Epistemic status: Fairly confident. I think most of the claims in this book are true; I think I have given a fair account to the best of my ability of what the people in it believe, and how they live. But I am human, and therefore have a brain that goes wrong in predictable ways. One of those ways (according to some more people you’ll meet in these pages) is that when we find a fact we like, we ask ourselves, ‘Can I believe this?’, whereas if we find a fact we don’t like, we ask ourselves, ‘Do I have to believe this?’
I am fond of many – not all – of the people in this book, and I suspect that I therefore erred on the side of ‘Do I have to?’ when confronted with things that might make me like them less. For these reasons I am extremely confident that I have made errors throughout this book. I hope that none of them are major, or defamatory. Whether they are or not, they’re mine, not anyone else’s.
I flew to California in October 2017 to meet Paul and a few others involved in the Rationalist community. Their biggest in-real-life hub is based around Berkeley and Silicon Valley, although the community is really distributed around the internet.
This wasn’t the first time I’d come into contact with them. I’d been aware of the community since about 2014, when I wrote a review of Nick Bostrom’s Superintelligence: Paths, Dangers, Strategies. If you’re vaguely aware of a conversation going on about whether or not AI will destroy the world, it’s probably because of Bostrom’s book. Elon Musk read it, in between making lots of money setting up PayPal and then systematically losing it again by trying to fly to Mars, and reported back: ‘We need to be super-careful with AI. Potentially more dangerous than nukes.’¹ Bill Gates says we should all read it to understand AI.² Bostrom’s work influenced Stephen Hawking’s view that AI could be ‘the best or worst thing to happen to humanity’.³
It was an amazingly dense, difficult book – writing my review, I opened it at random to select a passage, and ended up with: ‘An oracle constructed with domesticity motivation might also have goal content that disvalues the excessive use of resources in producing its answers.’⁴ I have a pretty good idea what that means, but it’s not exactly a Ladybird Introduction to AI. Still, it sold extraordinarily well for what was essentially a work of academic philosophy, getting up to number 17 on the New York Times bestseller list.
And it is, once you get your head around it, somewhat terrifying. It compares humanity’s efforts to build a superintelligent machine – and those efforts are ongoing, serious and, possibly, quite close to completion – to a bunch of sparrows trying to find an owl chick to raise, to protect them. As in, you can see where they’re going with it, but it may be that they haven’t 100 per cent thought through all the possible consequences.
Its release was, roughly speaking, when the Rationalists’ concerns became mainstream. But apparently the book was not widely understood in the media, being met with a lot of references to The Terminator. A few people from the community, though, including Paul, read my review, and decided that I’d essentially got the gist of it. So they contacted me.
Over the next few years, I became more involved with the Rationalists. I started reading their websites; I learned the jargon, all these technical and semi-technical terms like ‘updating’ and ‘paperclip maximiser’ and ‘Pascal’s mugging’ (I’ll explain what all those things are later). I read the things you’re supposed to read, especially and notably ‘the Sequences’ (I’ll explain what they are later, as well). I came to terms with the huge possible impacts, positive and/or negative, of superhuman AI. And I became increasingly enamoured of their approach to the world, of which AI fears were only a part. It was also about people who want to make humanity better, to help us reach the stars, to stop us from destroying ourselves, to find ways of making us immortal. A whole related sub-branch is dedicated to making charitable giving more efficient. And it’s about ways of helping us think about how we think – about using our best understanding of how the human mind works to make us better at achieving the things we want to achieve, and how to make us better at finding out things that are true and debating them with other people in charitable, kind ways.
I also gathered that human-level intelligence could be quite close: most people in the AI research field think it’ll happen within the next century and possibly in the next few decades. And it all seemed pretty hard to argue with, on balance.
But somehow I hadn’t put two and two together. The huge impacts and the possibly imminent arrival of AI were both things I understood and accepted on an intellectual level, but the implications of those two things hadn’t really sunk in, in a visceral, gut-level, intuitive-understanding sort of way.
So when I was told that there was a real chance that my two young children would not die of old age, it shouldn’t have shocked me – my children were, at the time, two and three years old; they could fairly confidently expect to live another 90 or 100 years; 90 years is well into the ‘superhuman AI is more likely than not’ bit of most researchers’ predictions; superhuman AI, many people in the field believe, has the potential to either kill us all or make us near-immortal post-human demigods.
But it had all been an intellectual game, up to that point. Now we were talking about my actual, real-life children, my little toddlers Billy and Ada, who liked dinosaurs and Octonauts and the lower-quality Pixar movies. It left me somewhat winded. It brought to mind all the people who were worrying about robots taking people’s jobs, or being used on the battlefield, and made me think: The iceberg is 100 yards off the port bow, and you are worrying about whether the deckchairs are safe.
As it happened, in the autumn of 2017 when I was out in California, there were a series of enormous wildfires.⁵ A million acres of bush and forest in the north of the state burned; 43 people died and thousands of homes were destroyed, particularly around the Napa wine region. Those fires were just a few miles north of the Bay Area. Each morning when I woke up in my sad little Airbnb above a noisy nightclub in Berkeley I could smell woodsmoke; the sun was partly hidden behind a haze of it. When I went into San Francisco itself, doing the tourist thing, you could look north from Pier 39 and see that the far shore of the Bay was occluded behind a grey curtain of smoke, hanging in the valley like some ominous mist. One night I climbed the huge hill behind the Berkeley campus to see the sunset, and the smoke made the sun a vivid, bloody ball as it sank behind the almost invisible Golden Gate, 13 miles away: a startling sight which my iPhone camera was entirely unable to capture. (I even saw someone, up on the hill behind Berkeley, putting a cigarette out in the dry grass as he watched the sun sink into the smoke. I wanted to grab him by the collar and shout at him.)
A short distance away, everything was on fire and people were dying – but here, in this cosy little enclave of civilisation, no one was paying attention, even as the smoke drifted over their homes. The few who did were wearing surgical masks – in the face of a fiery death, people were worrying about asthma. Icebergs and deckchairs.
The metaphor is ridiculous, of course. There was no serious risk of anyone burning to death in Berkeley, but there was a pretty good chance of aggravating any pre-existing lung conditions. People were behaving perfectly sensibly. But I’ve been a journalist for over a decade now, and you don’t get anywhere in this business by ignoring corny and obvious metaphors that are staring you in the face. So I started asking: Are we going to (metaphorically; possibly literally) burn to death?
It seemed to me important to find out whether the whole children-not-dying-of-old-age thing was a widely held belief. So I went and spoke to Anna Salamon.
Salamon is the president and co-founder of a non-profit organisation called the Center for Applied Rationality (CFAR, which people pronounce See-Far), and a key member of the Rationalists. CFAR, along with the Machine Intelligence Research Institute, or MIRI, is probably the closest thing the Rationalist community has to a real-world, as opposed to online, heart. Its office, which it shares with MIRI, is a couple of minutes’ walk from the UCLA Berkeley campus, on a quiet road parallel with University Avenue, on the third floor of an unassuming office block. MIRI was set up by Eliezer Yudkowsky, the founder and driving force of the movement, an odd and polarising figure. (His name will come up again.) Salamon used to work for MIRI, on the problems of AI safety and existential risk, before going off to set up CFAR with the goal of training other bright, conscientious young people to work on the problems. Its mission is to instil in those bright young people the skills and methods of rationality that Yudkowsky and the Rationalists propound.
I’m a few minutes early to meet her and find myself looking around the shared lounge bit between the MIRI and CFAR offices, entirely alone and feeling extremely weirded out. It’s a little dilapidated – it has something of a university junior common room feel, not the futuristic gleaming tech start-up look I’d been expecting. There’s no reception, just a bunch of faintly elderly sofas and bean bags. One wall is dominated by a vast picture of the Earth from space; on another there is a whiteboard, covered in equations, as well as an H.P. Lovecraft-ish slogan (‘Do not anger timeless beings with unspeakable names’), and a jaunty little reminder to ‘Thank Stanislav Petrov!’ (Petrov, if you’re unfamiliar with the name, was a Russian military officer who is credited with preventing a major nuclear war being triggered in September 1983, more of which later.)
There is also an expensive-looking road bike with drop handlebars and a pannier rack, propped up against a water cooler, with a post-it note saying: ‘Is this your bike? Talk to Aaron.’ For something with such a huge mission, this little place feels a bit lost in the vast suburban sprawl of the Bay Area; a little worn around the edges.
Before answering any question, Anna pauses for a tangible moment, a half-second or so; I’m fairly sure that this is a learned behaviour, an attempt to vet each statement to make sure it’s something she thinks, rather than simply something she’s saying. The conversation is initially quite hard. She’s kind and thoughtful, but seems wary of me, and answers in short sentences or single words. I think she’s concerned that I’m not here with good intentions as far as the Rationalist movement is concerned. (There is an understandable streak of paranoia among the Rationalists, I come to learn. Many of them are extremely intelligent and in some respects quite influential, but in others they are highly vulnerable – nerdy, often autistic or with other social deficits – and it would be extremely easy for me to write a book mocking them. I do not want to do that.)
I ask her, first, what her main goal is; CFAR is intended to train people with these rationality techniques, so I wondered whether that was an aim in itself, or whether it was a means to a greater end. She says that the primary goal is ‘to help humanity reach the stars’, and to do so while still recognisably human – not necessarily physically, but in terms of the things we care about and value. She thinks that there are lots of ways in which that might not happen, but the ‘largest and most tractable part’ of the problem is the risk of AI destroying humanity as we understand it.
Eventually I build up the courage to ask her the big one. Paul, I say, thinks that if humanity survives the next 100 years then we’re probably going to make it to a glorious cosmic future. That my children probably won’t die of old age.
‘I agree with that.’
Either something terrible will happen, or they make it to …
‘The singularity.’
Later on I meet Rob Bensinger, who’s the research comms manager at MIRI. It is probably best to think of Rob as the aforementioned Eliezer Yudkowsky’s messenger on Earth; Yudkowsky himself agreed only to answer technical questions, via email. Rob, a polymath who had become part of Yudkowsky’s circle a couple of years before, speaks for him, like one of the angels who appear in the Bible when God has something to say but can’t bring Himself to turn up in person.
When I meet Rob, MIRI is preparing for a ‘retreat’. They weren’t actually going anywhere, but in recent years they’d found that when they had previously had real, proper, go-off-into-a-cabin-in-the-woods-somewhere retreats they had been extremely successful. They’d really focused people’s minds, improved their productivity.
But hiring a cabin that can fit a dozen people is quite expensive and inconvenient, so they were experimenting with ways of having the same effect without needing to go anywhere. Instead, they’d hung a large white sheet across the office and used uplighting and other little visual tricks to make it feel like somewhere else. Rob said that it had been effective. It struck me as a rather clever solution.
I ask him the children question, and he demurs. ‘I wouldn’t like to be on the record as saying something that specific. It’s a pretty sensitive thing and I wouldn’t want to off-the-cuff it.’ I press him a bit, though, and he says that Paul’s view ‘seems normal to me’. ‘Most people expect AI this century, and most people interested in AI risk generally think the risk is pretty serious, not just a small risk but a medium-sized to large risk, shall we say. I’d say it’s a this-century problem, not a next-century problem. I think most people will agree with me, within AI. The Open Philanthropy Project (OpenPhil) gives it at least a 10 per cent chance of happening in the next 20 years.’
As it happened, I was going to OpenPhil the next day. It’s across the Bay from Berkeley, in downtown San Francisco itself. OpenPhil and GiveWell are two organisations run on Rationalist lines that look at the most effective ways to donate money to charity. They’re central to something called the Effective Altruism (EA) movement, which is strongly linked to the Rationalist community. OpenPhil in particular has donated millions of dollars to AI safety organisations, and MIRI in particular, over the years.
Holden Karnofsky, the co-founder of both OpenPhil and GiveWell, confirms what Rob said, that OpenPhil thinks there’s about a 10 per cent chance of ‘transformative’ AI in the next 20 years. ‘That would clearly meet your criteria’ of my children not dying of old age, he said. Isn’t that terrifying? I ask him. ‘Yes,’ he says. ‘We live in a truly weird time.’ We don’t realise how fast things are changing now, in a way unlike any other time in history, but it’s only going to get faster: ‘If transformative AI comes, that could be transformative in ways that would make the Industrial Revolution look small. Yes, it’s really strange and it’s disorienting.’
Not everyone I spoke to agreed with this. Some people reckoned the timeline was too short, and that it was unlikely (though not impossible, by any means) that human-level AI would arrive in my children’s lifetimes. Others thought that the timeline was perfectly realistic but that human-level AI wouldn’t bring the sort of spectacular change (and possible destruction) that would lead to them not dying of old age. Others were understandably wary about putting these sorts of numbers on things to begin with.
But it seemed like we were at least dealing with something that was not unrealistic. Sensible, intelligent people, including AI researchers at serious AI companies, senior academics and so on, thought that there was a respectable chance that the next 100 years would see either an ascension to demigodhood or a complete, civilisation-ending catastrophe. More than civilisation-ending, in fact: human-life-ending.
This book is about some of those people. Specifically, it is about a community of them who came together around a series of blog posts written by Yudkowsky in the mid- to late 2000s, and who are known as the Rationalists.
It is also, in part, an attempt to work out whether I agree with them.
\*Specifically, from Chapter 13 of The Hitch-Hiker’s Guide to the Galaxy, the bit where Ford introduces Arthur to Zaphod and Arthur says, ‘We’ve met.’
Part One
Introductions
Chapter 1
Introducing the Rationalists
The Rationalist community, as it exists now, is sprawling and global. It has hubs in a dozen or more cities and a thronging online presence. It’s full of strange people with strange ideas – about AI (the idea that AI has the potential to be an existential risk to humanity can, I think, be largely traced back to it, or its precursors), about transhumanism, cryonics; about the universe being a simulation – and unorthodox practices, such as polyamorous relationships (ones with several people at once) and group living, which have led to outsiders accusing it of being a cult.
This whole ecosystem has its roots in the writing of the strange, irascible and brilliant Eliezer Yudkowsky. The key text – the holy book, according to those who think the whole thing is a quasi-religion – is a huge series of blog posts he wrote in the mid-2000s, an ambitious, sprawling set of writing which takes in everything from evolutionary biology to quantum mechanics to AI, and which came to be known as the Sequences. But as far as I can tell, the first visible sign of its birth is a single, much older blog post written on 18 November 1996. It was entitled ‘Staring into the Singularity’.¹ Yudkowsky was 17 years and two months old at the time. The post is still online, by the way. But it is marked at the top by a big red warning triangle, like the sort you get in the back of your car to warn of a road accident, saying: ‘This document has been marked as wrong, obsolete, deprecated by an improved version, or just plain old.’ This sort of thing goes on a lot in the Rationalist community. Being wrong is actively praised, as long as you hold up your hands, admit it and correct it.
‘Staring into the Singularity’ is a fascinating read, although the logic doesn’t really bear scrutiny, as you’d expect from a 17-year-old. It begins: ‘If computing speeds double every two years, what happens when computer-based AIs are doing the research?’ This is a reference to Moore’s law, which says (roughly, in one formulation) that computers get twice as powerful every two years. So computing speed doubles every two years. Yudkowsky points out a corollary: that two years for a human need not seem like two years for a computer. ‘Computing speed doubles every two years of work. Computing speed doubles every two subjective years of work.’ That is, if a computer can think as powerfully as a human, but twice as fast, then it can do two years’ worth of work in a single year. ‘Two years after Artificial Intelligences reach human equivalence, their speed doubles. One year later, their speed doubles again. Six months – three months – 1.5 months … Singularity.’ Things would speed up, exponentially. The world would be changing too fast for us to understand the changes. We would be through the looking glass. This is, roughly, the idea of the ‘fast take-off’ that Nick Bostrom would describe nearly two decades later, although Yudkowsky’s version makes a few weird assumptions and leaps of logic (as, again, is fair enough given his age).
The term ‘singularity’, by the way, is a reference to physics and black holes. When an object is massive enough and small enough, it bends spacetime so much that the usual laws of physics no longer work. By analogy, when intelligent systems start improving themselves fast enough, our usual ways of predicting the future – our assumptions that tomorrow will be essentially like today – will, say singularitarians, break down. The computer scientist and science-fiction writer Vernor Vinge wrote in 1983: ‘We will soon create intelligences greater than our own. When this happens, human history will have reached a kind of singularity, an intellectual transition as impenetrable as the knotted space-time at the centre of a black hole, and the world will pass far beyond our understanding.’²
Yudkowsky’s explicit goal in ‘Staring into the Singularity’ is to bring about AI – the singularity – as soon as possible. ‘Human civilisation will continue to change until we either create superintelligence, or wipe ourselves out,’ he wrote. This superintelligent thing we create, he thinks, can solve all of humanity’s problems, and it is high time that it does so: ‘I have had it. I have had it with crack houses, dictatorships, torture chambers, disease, old age, spinal paralysis, and world hunger. I have had it with a planetary death rate of 150,000 sentient beings per day. I have had it with this planet. I have had it with mortality. None of this is necessary. The time has come to stop turning away from the mugging on the corner, the beggar on the street. It is no longer necessary to look nervously away, repeating the mantra: “I can’t solve all the problems of the world.” We can. We can end this.’ Yudkowsky was, you suspect, quite an annoying 17-year-old, but he was undeniably bright.
In 2000 – still only 20, remember – he founded the Singularity Institute for Artificial Intelligence. The Singularity Institute was a little non-profit based in Berkeley which would later become known as the Machine Intelligence Research Institute, which you’ve already met. It had, at first, the goal of bringing about this glorious technological future, and Yudkowsky had set a target date for achieving the singularity. It was 2005. (He didn’t manage it.)
I asked Paul Crowley – whom you met in the introduction, driving me around northern California – about all this. ‘My broad picture of how it started,’ says Paul, ‘is Eliezer started by thinking superintelligence is the key to everything, and we need to get there as quickly as possible. It’s intelligent, he thought, so it’ll do the right thing.’
But even by the time he founded the Singularity Institute, at least according to what he wrote later,³ Yudkowsky had started to wonder whether he was making a terrible mistake. ‘The first crack in my childhood technophilia appeared in, I think, 1997 or 1998,’ he wrote, when he noticed his fellow techno-enthusiasts being glibly optimistic about the difficulties of controlling future technologies – specifically, nanotech. By the end of that debate, he says, the young Yudkowsky ‘had managed to notice, for the first time, that the survival of Earth-originating intelligent life stood at risk’. Still, he cracked on with the Singularity Institute, full steam ahead, for superintelligence. ‘Just like I’d been originally planning to do,’ he writes, with some scorn, ‘but now, with a different reason.’
This feels, reading his work now, like a key moment, at least in retrospect. What Yudkowsky didn’t do, he says, was ‘declare a Halt, Melt and Catch Fire’. He didn’t look at his own thinking, accept that it was all completely wrong and cast out his conclusions (in his own, later, words, he didn’t appreciate ‘the importance of saying “Oops”’). Instead, he looked at his thinking, realised that it was wrong, and decided that his conclusions were conveniently right anyway.
But slowly – between 2000 and 2002, between the ages of 20 and 22, probably too young to be placing the entire future of the world on your own shoulders, but that appears to have been the sort of person young Yudkowsky was – he came to the realisation that not only was he wrong, he was disastrously wrong. The exact ways in which he was wrong are going to be the topic of much more discussion in this book, but according to Yudkowsky himself by the time he had reached the wise old age of 27 his stupidity had led him to try to build a device which would destroy the world. ‘[To] say, I almost destroyed the world!, would have been too prideful,’ he wrote.⁴ But he had been trying to do something which he thought, if he had had the wherewithal to actually do it, would have done exactly that.
So he decided to try to save the world instead.
Yudkowsky was not the first person to think about what would come after humans. He was firmly part of the traditions of transhumanist and singularitarian thinking, which had been around for years when he was writing ‘Staring into the Singularity’; some of the ideas they hurled about had existed for millennia. Bostrom notes in a paper that in the Epic of Gilgamesh, a 4,000-year-old Sumerian legend which foreshadows parts of the Old Testament, ‘a king sets out on a quest for immortality. Gilgamesh learns that there exists a natural means – an herb that grows at the bottom of the sea.’⁵ (He finds it, but a snake steals it off him before he can eat it, as is so often the way.) The Elixir of Life, the Philosopher’s Stone, the Fountain of Youth and various other myths represent similar ideas.
Bostrom also points out that early transhumanist-style myths contain an element that remains in modern discussion of its ideas: hubris leading to nemesis. Prometheus steals fire from the gods, which most of us can agree was a good thing from humanity’s point of view: his punishment was to have his liver repeatedly pecked out by an eagle for eternity. Daedalus improves on human abilities by, among other things, building wax-and-feather wings to grant himself and his son Icarus the power of flight; Icarus promptly flies too close to the sun, melting the wax, and plunges into the sea. St Augustine thought that alchemy, and the search for a panacea or eternal life, was ungodly, possibly demonic.
The idea that science could improve on the human-basic form became more plausible after the Enlightenment and Renaissance. Nicolas de Condorcet wondered in 1795 whether science would progress until ‘the duration of the average interval between birth and wearing out has itself no specific limit whatsoever’, and that people would choose to live until ‘naturally, without illness or accident, [they find] life a burden’.⁶ Benjamin Franklin wrote of wanting to be ‘embalmed’ in such a way that he could be revived in the future, since he had ‘a very ardent desire to see and observe the state of America a hundred years hence’.⁷ Bostrom points out that this foreshadows the modern idea of cryonics, preserving the brain for revival in the future.
The term ‘transhumanism’ and some of its most recognisable ideas sprang up in the first half of the twentieth century. In 1923 J.B.S. Haldane predicted a world in which humans used genetic science to make themselves cleverer, healthier and taller. The term itself was apparently coined by Julian Huxley, brother of Aldous, in 1927: ‘The human species can, if it wishes, transcend itself – not just sporadically, an individual here in one way, an individual there in another way – but in its entirety, as humanity. We need a name for this new belief. Perhaps transhumanism will serve.’⁸
But transhumanism and singularitarianism really took off as philosophies in the last decades of the twentieth century. There were various different, and to some degree competing, ideas of what transhumanism involved – Yudkowsky, in a since-deleted online autobiography⁹ he wrote at the age of 20, credits Ed Regis’ 1990 book Great Mambo Chicken and the Transhuman Condition, an early, comical taxonomy of these different visions, as an inspiration. The idea of cryonics began to become more popular in this period – super-cooling the brains (and perhaps bodies) of dying people in order to preserve them, as Franklin wished, with the idea of reviving them when technology advanced sufficiently to do so. Transhumanists also talked about how nanotechnology can transform everything. A large subset of them were keen on the idea of uploading – scanning a human brain so precisely, probably by slicing it apart, that you could simulate it in a computer, creating a digital version of the mind that you scanned. (The original, of course, would be destroyed in the process.) Machine-brain interfaces – ways of linking a human brain to a computer, or linking human brains via computers, to improve human cognition – were a constant topic. All of this, naturally, overlapped with the ‘singularitarian’ vision of a world in which superintelligent AI or other technological advances rendered human life unrecognisable (but unrecognisable, they’d have said, in a good way). Most of all, they wanted – want – to stop death. About 150,000 people die every day, worldwide. Most of us wave that away, saying that death gives life meaning, or that eternity would be boring. The transhumanists (not unreasonably, to my mind) ask: OK, but if death didn’t exist, would you all be saying, ‘We ought to limit our lives to about 80 years, to give them meaning?’
As befits a movement that gets a book written about it with the term ‘Great Mambo Chicken’ in its title, some of its members were and are – by the tightly corseted standards of Western society, I should say – deeply weird. There’s an affectionate 2006 Slate article about transhumanists which says, at one point, ‘Remember those kids who played Dungeons & Dragons and ran the science-fiction club in your high school? They’ve become transhumanists.’¹⁰ There appears to have been an element of truth in that gently mocking phrase.
Transhumanists have a tendency, for instance, to give themselves strange names. The Slate article mentions one who calls herself Wrye Sententia (Dr Sententia is a professor at UC Davis and the director of a non-profit called the Institute for Ethics and Emerging Technologies. Having a strange name doesn’t stop you doing interesting work.) Another changed his name from Fereidoun M. Esfandiary, which was an interesting enough name to begin with, to FM-2030. There’s a Tom Morrow, which is lovely. And there’s a guy who was once called Max O’Connor but who changed his name to Max More, because ‘It seemed to really encapsulate the essence of what my goal is: always to improve, never to be static. I was going to get better at everything, become smarter, fitter, and healthier.’¹¹
More would later become CEO and president of Alcor, one of the largest cryonics companies in the world. But he is mainly relevant to this story because in 1988, along with Tom Morrow (see? Lovely), he began publishing Extropy Magazine. It was mainly about transhumanism – how to improve upon the human form, make it immortal, make it cybernetic, and so on. In 1992 he founded something called the Extropy Institute, which set up a mailing list – a sort of early precursor of social media, for those of you under the age of 35; you just all chat in your emails – called the Extropians.
One of the names on the Extropians’ mailing list was Eliezer Yudkowsky. ‘This was in the 1990s,’ says Robin Hanson, an economist at George Mason University and an important early Rationalist figure. ‘Myself, Nick Bostrom, Eliezer and many others were on it, discussing big future topics back then.’ But neither Bostrom nor Yudkowsky were satisfied with the Extropians. ‘It was a relatively libertarian take on futurism,’ says Hanson. ‘Some people, including Nick Bostrom, didn’t like that libertarian take, so they created the World Transhumanist Association, explicitly to no longer be so libertarian.’ The World Transhumanist Association later became Humanity+ or H+. ‘It hardly trips off the tongue as a descriptor,’ says Hanson. ‘But that’s what they insisted they call everything.’ Humanity+ had a more left-wing, less utopian approach to the future.
Yudkowsky, on the other hand, felt that the problem with the Extropians was a lack of ambition. He set up an alternative, the SL4 mailing list. SL4 stands for (Future) Shock Level 4; it’s a reference to the 1970 Alvin Toffler book Future Shock.¹² Future shock is the psychological impact of technological change; Toffler describes it as a sensation of ‘too much change in a short period of time’.
Yudkowsky took the concept further, dividing it up into ‘levels’ of future shock, or rather into people who are comfortable with different levels of it. Someone of ‘shock level 0’ (SL0) is comfortable with the bog-standard tech they see around them. ‘The use of this measure is that it’s hard to introduce anyone to an idea more than one shock level above,’ he said. ‘If somebody is still worried about virtual reality (low end of SL1), you can safely try explaining medical immortality (low-end SL2), but not nanotechnology (SL3) or uploading (high SL3). They might believe you, but they will be frightened – shocked.’
He acknowledged that transhumanists like the Extropians were SL3, comfortable with the idea of human-level AI and major bodily changes up to and including uploading human brains onto computers. But he wanted to create people of SL4, the highest level. SL4, he says, is being comfortable with the idea that technology, at some point, will render human life unrecognisable: ‘the total evaporation of “life as we know it”’. (I’m taking this from a 1999 post¹³ of his on SL4, when he’d just turned 20. He also fleshes it out in a long essay called ‘The Plan to Singularity’¹⁴ from about the same time.) He wanted to convert SL2s and SL3s to SL4s, to build a community of people who were comfortable talking about ideas of the post-human future. So he set up this mailing list and called it, reasonably enough, SL4.
Its archives are still available online, and digging through them is a fascinating experience. It’s a bit like that Sex Pistols gig in 1976, where there were only 40 people in the audience but all of them went on to form major bands. Going through the list of authors, you find the founders of major AI companies – such as Ben Goertzel – or AI researchers like Bill Hubbard. Wei Dai, an AI researcher at Imperial College London who played an important role in the creation of cryptocurrencies, is on there. Bostrom and Hanson are both there, and Anna Salamon. Other people who play roles in the story – Michael Vassar, Michael Anissimov – are contributors.
Nick Bostrom did a minor double-take when I asked him about SL4 and the Extropians, as though he hadn’t thought about it in a long time. I think he gave a sort of chuckle. ‘Yeah, it was humble beginnings,’ he said. ‘I’d been thinking through some of these things before, but I didn’t know there were other people thinking about it. It’s a bit strange. Nowadays you’d just Google it and immediately find whatever there is, but in the early 1990s when I was a student no one else was interested in it. So it was a bit of a revelation when I started using the internet in 1996 that there were these communities, people chatting about it.’
Several of the key concepts that do the rounds in the Rationalsphere these days first arose on SL4 and the Extropians. The aforementioned ‘paperclip maximiser’ was first mentioned there, possibly by Yudkowsky: ‘Someone searched [the Extropians’ archive] recently and found a plausible first mention by me,’ he told me by email; he was and remains wary about talking to me on the phone. ‘I wasn’t sure if it was me, Nick, or Anders Sandberg, but it kind of sounds like me.’ The ‘AI box’ experiment, in which Yudkowsky attempted to demonstrate that even an ‘oracle’ superintelligent AI, locked in a box and only able to communicate by text, was not safe, took place on SL4.¹⁵ Bostrom first linked to his paper arguing that we may be living in a computer simulation on SL4.¹⁶
But although SL4 gathered quite an impressive bunch of people, it still wasn’t enough to satisfy Yudkowsky. Looking at the archives, you see that he’s extremely busy in the first few years, up to about 2004, but later on he seems to be less involved. No new threads of his appear at all between 2005 and 2008. The Rationalists’ own semi-official history of themselves, on the wiki page of Yudkowsky’s website LessWrong, says that he ‘frequently expressed annoyance, frustration, and disappointment in his interlocutors’ inability to think in ways he considered obviously rational’ and that after ‘failed attempts at teaching people to use Bayes’ Theorem, he went largely quiet from SL4 to work on AI safety research directly’.¹⁷
Then Robin Hanson, the economist and fellow SL4/Extropians commenter, set up a blog of his own called Overcoming Bias. ‘I started this blog after I got tenure at George Mason,’ Hanson told me, ‘as something to do in my spare time.’ When I speak to him, via Skype from his office at the university, he’d accidentally left his window open all weekend during one of the more dramatic periods of cold weather the US East Coast had seen for a while. He was wrapped up in a puffa jacket and woollen hat and his breath was visible in the air, even on the low-res Skype connection. ‘I decided to theme it on overcoming bias.’
This was 2006, a few years before the publication of Daniel Kahneman’s famous book Thinking, Fast and Slow, about the various systematic biases in human thought. But Kahneman’s groundbreaking work with Amos Tversky was already extant and slowly becoming more widely known. Hanson, a polymath and autodidact in a similar, if less extreme, vein to Yudkowsky, had picked up a lot of Kahneman and Tversky’s work in his travels around the sciences – he’d qualified as a physicist, before doing post-grad degrees in social science and economics. Overcoming Bias was explicitly founded on the ‘general theme of how to move our beliefs closer to reality, in the face of our natural biases such as overconfidence and wishful thinking, and our bias to believe we have corrected for such biases, when we have done no such thing’.¹⁸
He invited a few old Extropians/SL4 veterans to come and join him, people who’d impressed him with the quality of their thinking. Among them were Nick Bostrom and Eliezer Yudkowsky. ‘Nick just blogged a few things,’ he said. ‘But Eliezer blogged a lot, which was great.’ It’s at this point that Yudkowsky began what would later become known as the Sequences. In essence, they were a reaction to the fact that he couldn’t get people to understand what he was talking about when he said that AI was a threat.
The problem he had was that no one really took him seriously. So in order to explain AI, he found he had to explain thought itself, and why human thought wasn’t particularly representative of good thought. So he found he had to explain human thought – all its biases and systematic errors, all its self-delusions and predictable mistakes; he’d found a natural home on Overcoming Bias. And to explain human thought, he found he had to explain – everything, really. It was like when you pull on a loose thread and end up unravelling your entire favourite jumper.
It was a meandering, unfocused thing, for a long time; at one point he gets on to quantum physics; at another he approvingly cites George Orwell’s (somewhat silly) proscriptions against using the passive voice. Paul Crowley tells an illustrative story. ‘There’s this post, about fake utility functions,’¹⁹ he says. (Don’t worry about what a utility function is or how it can be fake.) ‘If you want to know the story of how this got written, it’s a good one to read. It begins by saying something like, “Today I can finally talk about this idea of fake utility functions. I was going to talk about it six months ago. But then, when I sat down to write it, I found I had to set out this idea, and then to explain that idea it helps if I explain this other idea. And then I thought it would be easier if the reader understood evolutionary biology, so I ended up writing an introduction to evolutionary biology.” He ended up writing about two dozen posts just on evolutionary biology. And the joke of it is this post wasn’t even some cornerstone of the whole thesis; it was just something he wanted to write.’
Slowly, the blog posts built up, and up and up. For an idea of how much, think of The Lord of the Rings books. When you add all three together, they come to about 455,000 words. War and Peace, a book which is actually more famous for being long than it is for being good (it’s OK), is about the 587,000 mark. According to the Kindle app on my iPhone, War and Peace is 18 arbitrary dots long. Rationality: From AI to Zombies, the edited e-book edition of Yudkowsky’s blog posts, merits 19 dots. If the Kindle app’s length indicator is accurate, then that puts RATZ at around 620,000 words long.\* The unedited Sequences were more like a million. That’s a fair old slog. There are few things so dispiriting as reading on a Kindle and realising that after 30 minutes you’ve only gone from 3 per cent to 4 per cent. And this is not a book about elves fighting orcs, which if nothing else keeps you moving along. Yudkowsky is an engaging writer, but by its nature it’s heavy going.
But it became pretty successful. In 2009 Yudkowsky moved his blog posts over to a new website, LessWrong, which was intended as a sort of community hub where anyone could post. At about the same time – 2010 – he started publishing something else, his Harry Potter fan fiction Harry Potter and the Methods of Rationality, which does exactly what it says on the tin: it involves a nerdy scientist-Harry trying to work out what the rules of this magical universe are, using Rationalist-style methods. It was a surprising success, gathering 34,000 reviews on the site FanFiction.net; it may be the most-read thing that Yudkowsky has ever done, and attracted large numbers of readers to his other work, especially LessWrong.
At its peak, LessWrong had about a million page views a day.²⁰ Some posts had hundreds of thousands of unique page views (a metric that avoids the problem you get of someone clicking ‘refresh’ and suddenly counting as two hits). It’s probably not completely inaccurate to say that a million people have read some of the Sequences, and I’d guess that the number of people who’ve read the whole thing is probably a high-five figure or low-six. I may be off by an order of magnitude, of course – there’s no easy way to tell.
What Yudkowsky was trying to do with all this was to explain why AI was dangerous. But because he found that first he had to describe intelligence, and human intelligence, his project became more ambitious: to improve human rationality, in order to help prevent humanity from destroying itself.
\*The Bible still wins. The King James Authorised Version weighs in at 783,137 words. While looking that up, I learned that in the early days someone managed to miss one word out, getting it down to a more manageable 783,136 but unfortunately changing the Sixth Commandment to read ‘Thou shalt commit adultery’.
Chapter 2
The cosmic endowment
We’ll get on to why the Rationalists think that AI is so dangerous soon. But first we should look at why they, and the singularitarians who came before them, are also so keen on it. The gamble, they think, is between extinction and godhood.
According to the Rationalists, getting AI right could be the greatest thing that ever happens to our species. If humanity survives the next few decades, or maybe centuries – it’s not clear exactly how long, but probably a fairly insignificant period in comparison to how long we’ve already existed, and certainly an insignificant period in comparison to how long everything else has – then things could go extraordinarily right for us. This is what Paul Crowley meant, or part of what he meant, by saying that he didn’t expect my children to die of old age.
It is improving technology, and specifically AI, that people are talking about when they refer to this glorious future. ‘The potential benefits are huge, since everything that civilisation has to offer is a product of human intelligence,’ wrote the authors of an open letter in 2015.¹ ‘[We] cannot predict what we might achieve when this intelligence is magnified by the tools AI may provide, but the eradication of disease and poverty are not unfathomable.’ That letter was signed by more than 150 people, including dozens of senior computer scientists and AI researchers, three founding members of Apple, Google DeepMind and Tesla, and Professor Stuart Russell of Berkeley, the author of the standard textbook for AI undergrads. (The late Stephen Hawking also signed, but AI researchers used to get understandably annoyed when he made the headlines rather than the people who actually do this for a living.) Max Tegmark, a professor of cosmology at the Massachusetts Institute of Technology and director of its Future of Life Institute, writes in his book Life 3.0: Being Human in the Age of Artificial Intelligence of ‘a global utopia free of disease, poverty and crime’ as a possible outcome of the development of a powerful AI. These are real, serious people who believe that, in the reasonably foreseeable future, AI could solve some of humanity’s most pressing problems. But ‘solving our problems’ is actually the least of it. If humanity survives, we have to start looking at some very big numbers.
Let’s imagine the Earth will probably be able to support human life for another billion years or so. (At around that point, the sun will enter a phase in which it is much brighter and hotter than it currently is; it will cause the Earth to enter a runaway greenhouse process as the seas evaporate, and it will become too hot for complex life.²) Let’s imagine that humans continue to live for a century or so each for the next billion years, and that the human population settles at a nice, sustainable 1 billion, less than one-seventh of its current levels. These are the assumptions that Nick Bostrom – author of the aforementioned Superintelligence, and founder of Oxford’s Future of Humanity Institute (FHI) – goes with.³ That would mean that we would have at least 10,000,000,000,000,000 descendants. The total number of Homo sapiens who have ever lived up to now, according to an estimate by the Population Research Bureau, is about 108,000,000,000.⁴ In other words, the entire history of humanity so far represents only about one-ninety-thousandth of what it could be, if we just avoid being wiped out.
But! We still have only just started to scratch the surface. What if humanity leaves the Earth? Imagine a ‘technologically mature’ civilisation, says Bostrom. One that can build spacecraft that travel at 50 per cent of the speed of light. That civilisation could reach 6,000,000,000,000,000,000 stellar systems, he calculates, before the expansion of the universe puts the rest out of reach. One that could travel at 99 per cent of the speed of light could reach about 15 times as many as that.⁵ Imagine that 10 per cent of those suns have planets that are or could be made habitable, and on average could each sustain 1 billion people for 1 billion years. That would put the number of humans who could exist in the future at around 10³⁵, or 1 followed by 35 zeroes. All the humans who have ever lived would be vastly less than a rounding error, compared to the ones who could follow us, if we get it right.
But! Yes. It gets bigger. Much bigger.
First, we could build our own habitats (an example would be the Orbitals in Iain M. Banks’ Culture novels, thin wheels of matter millions of kilometres in diameter, with humans living on the inside of the rim), out of spare space rocks, so we’re not limited by the number of planets we happen to find. That gets Bostrom up to 10⁴³ potential humans.
And then we could think about what happens when we start uploading human minds into computers. Then we are far less limited by space. Humans would need, instead of an appreciable fraction of the surface of a planet, a few square picometers of circuitry. Bostrom throws some plausible-sounding numbers in there about how dense you can make your hardware, how much energy you can get from a given star, and how many computations per second are required to simulate a human mind, and comes up with a lower bound – a conservative, worst-case estimate – of 10⁵⁸ possible human lives of 100 years each.
‘One followed by 58 zeroes’ may sound like a meaningless Big Number to you, and it does to me, but it is extraordinarily vast. ‘If we represent all the happiness experienced during one entire such life with a single teardrop of joy,’ says Bostrom, ‘then the happiness of these souls could fill and refill the Earth’s oceans every second, and keep doing so for a hundred billion billion millennia.’⁶ Does that give a more visceral sense of how enormous it is? I don’t know if it does. If not, just remember that even compared to the ridiculously vast numbers that astronomers throw around from time to time, this is seriously huge.
Bostrom might have his numbers wrong, of course. He has done his best to think conservatively, but when putting the numbers together like this he could easily be off by orders of magnitude. But even if you knock off six orders of magnitude and say there’s only a 1 per cent chance of it being correct anyway, then even ‘reducing existential risk by a mere one-billionth of one-billionth of one percentage point’⁷ can be expected to do as much good, in terms of years of life saved, as stopping 100 quintillion actual people from dying. That’s one followed by 20 zeroes.
So, yes, Bostrom’s maths could be badly wrong. He could have got his figures off by a factor of 10,000, or a million, or 10 billion. And yet, all the good done right now by every charity in the world would still be a drop in an ocean that is itself a drop in a much bigger ocean in comparison to the good that would be done by slightly reducing the chance that humanity gets destroyed before it can take to the stars.
You might want to reject these numbers out of hand because they’re weird and they give you weird results. That’s not actually a stupid thing to do, according to the Rationalists: there is a thing Yudkowsky came up with, called Pascal’s Mugging,⁸ related to the famous wager which says that if you simply multiply risk by reward, you’re vulnerable to absurd situations. In Bostrom’s rather whimsical version of it,⁹ the example is that a mugger comes along and demands Pascal’s wallet. Pascal points out: ‘You have no weapon.’ ‘Oh good point,’ says the mugger. ‘But how about if you give me the wallet, I come back tomorrow and give you 10 times the value of the money in it?’ ‘Well’, says Pascal, ‘that’s not a very good bet, is it. It’s hugely likely that you’ll just not come back.’
But the mugger then says: ‘Actually, I’m a wizard from the seventh dimension. I can give you any amount of money you like. I can give you, in fact, any amount of happiness you like. Let’s say that the money in your wallet could buy you one happy day. [Assume for the sake of argument that money can buy happiness.] And let’s say that you think there’s only a 1 in 10¹⁰⁰ chance that I’m telling the truth. Well, in that case, I’ll offer you 10^(1,000) happy days.’
By a utilitarian calculus – the idea that you should multiply the chance of something happening by the reward it would bring if it does, exactly the sort of reasoning that Bostrom uses to think about the cosmic endowment, or for that matter that investors and gamblers use to determine where to put their money – this is a good bet. If Pascal took it, on average, he’d expect a 10⁹⁹⁰-fold return on his investment. But it is, also, pretty obviously ridiculous. The wizard-mugger can just keep upping the numbers he offers until it becomes a good bet.
So it’s OK to be wary; you should be, when someone comes up and mouths a lot of maths and numbers and technical talk that you can’t follow but which they say supports their point. The Rationalists have a term for that, in fact: ‘getting Eulered’,¹⁰ blinded by numbers. But that doesn’t mean you should simply dismiss it. If you can’t follow the maths, you should be wary, but you should try to follow the maths. One of the founding principles of the Rationalist movement is that, as Scott Alexander puts it, ‘when math tells you something weird, you at least consider trusting the math. If you’re allowed to just add on as many zeroes as it takes to justify your original intuition, you miss out on the entire movement.’¹¹ A weird-seeming answer is a warning flag, rather than a stop sign: a thing to investigate rather than reject.
And, having investigated for a decade or more, the Rationalists are pretty confident in their numbers – which is why they, and the Effective Altruism movement which is closely aligned with them, are concerned about AI risk. They see the reward of surviving the next century or so as potentially enormous, and AI as one of the – if not the – most likely things that will stop us doing that.
Part Two
The Paperclip Apocalypse
Chapter 3
Introducing AI
In this chapter, we’re going to get together a working definition of what AI actually is, before we discuss the reasons why the Rationalists think AI could go so wrong.
There are lots of things around right now that are described as ‘AI’. But they’re all what is known as narrow AI. For instance, chess-playing AIs are extremely good at chess, but clueless about everything else. They can’t help you with your tax return or remember to feed your cat. Google Maps is pretty good at working out optimal routes from A to B, and only rarely directs you through the North Sea or whatever, but it doesn’t know a queen’s gambit from the Sicilian defence. Humans, on the other hand, can apply themselves to learning ballroom dancing, or the guitar, or chemistry, or poetry-writing – apparently some other things as well. What the Rationalists are concerned about, broadly speaking, is the development of artificial general intelligence, or AGI: a computer that can do all the mental tasks that we can.
At this point I really, really want you to put all pictures of The Terminator out of your heads. That’s important. It won’t help. Nothing we discuss will be made clearer by images of grinning metal robots or Skynet achieving self-awareness in August 1997. I’m fairly sure this trope irritates most Rationalists, but I’m damn sure that I’m tired of it myself after a year of conversations in which someone asks me what the book is about, I say ‘artificial intelligence destroying the world’, and they nod sagely and say, ‘Ah, Skynet.’ So. Please. The Terminator: forget it.
But you might wonder what I do mean when I talk about ‘artificial intelligence’. You might, for instance, reasonably point out that there is a fairly large disagreement about what ‘intelligence’ means, even before you start talking about whether it’s artificial or not. Conveniently for me, the standard textbook of AI, Artificial Intelligence: A Modern Approach (AIAMA), by Stuart Russell and Peter Norvig, tries to answer this question. It divides up possible approaches and definitions by whether they talk about reasoning or about behaviour, and whether they attempt to reason/behave like a human or whether they attempt to reason/behave rationally.¹
A computer that behaves humanly is the sort of thing imagined in the old Turing test. In 1950 the British scientist and code-breaker Alan Turing, apparently bored with debate over whether ‘machines can think’, wrote in a paper in Mind that ‘If the meaning of the words “machine” and “think” is to be found by examining how they are commonly used, it is difficult to escape the conclusion that the meaning of and answer to the question “Can machines think?” is to be sought in a statistical survey such as a Gallup poll.’² Instead he proposed a simpler, more unambiguous test, the ‘imitation game’. A human interviewer holds conversations with two interlocutors, whom he cannot see. One is a human; one is an AI. The interviewer can ask whatever questions he likes; if he cannot reliably tell one from the other, said Turing, then to all intents and purposes we should treat it as a thinking thing.
Turing’s famous test is rightly held up as a great pioneering work, and has the enormous advantage that it sidesteps grimly philosophical questions such as ‘Is it conscious?’ and puts a simple, repeatable test in their place. But, say Russell and Norvig, it hasn’t actually been all that influential in terms of guiding the direction of AI research since then. ‘The quest for “artificial flight” succeeded when the Wright brothers and others stopped imitating birds and started using wind tunnels and learning about aerodynamics,’ they say. ‘Aeronautical engineering texts do not define the goal of their field as making “machines that fly so exactly like pigeons that they can fool even other pigeons”.’³
Thinking humanly has received rather more attention, and is in fact the heart of the field of cognitive science, which uses AI models and findings from the brain sciences to build models of human thought. It has, says AIAMA, been instrumental both in creating a more precise understanding of how the human brain works, and in using ideas from neurophysiology to advance AI, especially in image recognition and vision. But that is cognitive science, rather than AI. (Russell and Norvig, deadpan, explain the difference: ‘Real cognitive science … is necessarily based on experimental investigation of actual humans or animals. We will leave that for other books, as we assume the reader has only a computer for experimentation.’) Artificial intelligence, as they envisage it, is about behaving rationally.
Funnily enough, that’s how the Rationalist movement envisages it too. ‘[Definitions] of intelligence used throughout the cognitive sciences converge towards the idea that “Intelligence measures an agent’s ability to achieve goals in a wide range of environments”,’⁴ write Anna Salamon and Luke Muehlhauser in Intelligence Explosion: Evidence and Import, a research paper published by the Machine Intelligence Research Institute. ‘We might call this the “optimisation power” concept of intelligence, for it measures an agent’s power to optimise the world according to its preferences across many domains.’
To explain what they mean by ‘optimisation’ and ‘behaving rationally’, I’m going to use an analogy with chess, which I’ve lifted from a series of blog posts by Yudkowsky. I’m very bad at chess. But I have a friend, Adam, who is extremely good: a professional chess teacher and an ‘international master’, which is the rung below grandmaster. My proudest achievement in chess is that I once made him think about a move for over a minute. That was about 15 years ago.
If I play Adam (and I don’t, because it’s dispiriting), I can’t reliably predict what his next move will be. Sometimes I can (his first move is more likely to be ‘move his queen’s pawn two squares forward’ than ‘move the rook’s pawn one square forward’, say), but at any level of complexity beyond the basic, I can’t. If I could predict his next move, I would be as good at chess as he is. ‘If I could predict exactly where my opponent would move on each turn, I would automatically be at least as good a chess player as my opponent,’ as Yudkowsky puts it. ‘I could just ask myself where my opponent would move, if they were in my shoes; and then make the same move myself.’⁵ So I can’t predict what Adam, or any gifted chess player, will do in any given situation; exactly what his next move will be is always going to be something of a mystery, and if he does something I’m not expecting, it probably means that he’s seen something I haven’t and I’m about to get forked or checkmated or some other bad thing.
But I can make a different kind of prediction – that whatever his next move is, it will be part of a sequence of moves that leads to a board position in which I have lost and Adam has won. Yudkowsky says that when we say ‘Kasparov is a better chess player than [X]’, we mean that we predict that ‘the final chess position will occupy the class of chess positions that are wins for Kasparov, rather than drawn games or wins for [X]’.⁶
Yudkowsky points out that this is actually quite an odd situation. ‘Isn’t this a remarkable situation to be in, from a scientific perspective?’ he asks. ‘I can predict the outcome of a process, without being able to predict any of the intermediate steps of the process.’⁷ Apart from in very simple situations, that’s not usually how we predict things: ‘Ordinarily one predicts by imagining the present and then running the visualisation forward in time. If you want a precise model of the Solar System, one that takes into account planetary perturbations, you must start with a model of all major objects and run that model forward in time, step by step.’
The outcome is predictable, though, because you know 1) what Kasparov’s goal is – to win the chess game; and 2) that he is extremely good at doing so. ‘I know where Kasparov is ultimately trying to steer the future and I anticipate he is powerful enough to get there,’ says Yudkowsky, ‘although I don’t anticipate much about how Kasparov is going to do it.’ So you can define ‘good at chess’ as ‘likely to steer the universe into a situation where you have won chess games’. Kasparov is, in Rationalist jargon, optimising for chess victories, and he is a powerful optimiser, able to steer the universe into Kasparov-has-won-at-chess situations far more often than chance.
Any modern chess program could thrash me as easily as – more easily than – Adam, or for that matter Kasparov, could. The strongest chess program in the world is Stockfish 9. (Or was until recently. It got beaten in December 2017 in a 100-game series against the terrifying autodidact-polymath-algorithm AlphaZero, losing 25 games and winning none,⁸ although Stockfish was playing with some technical handicaps, so there is some controversy about AlphaZero being the best.) Stockfish would destroy Deep Blue, the computer that beat Kasparov; it has an Elo rating of about 3400, compared to Deep Blue’s of about 2900, making it roughly as much better than Deep Blue as Kasparov at his peak was better than my friend Adam. If I played Stockfish, I absolutely would not be able to predict its individual moves – I’d be less successful at it than I would be at predicting Adam’s or Kasparov’s, in fact. But I’d be more successful at predicting the final state of the board, which would be one in which I have lost.
We can, therefore, use the exact same definition of ‘good at chess’ about Stockfish as we did about Kasparov. We don’t need to worry about whether Stockfish thinks in the same way as Kasparov, or whether Stockfish is conscious, or anything else. There’s a lovely, simple, easy way to test whether it is good at chess – we see how many chess games it wins. Things that win more chess games are better at chess, and it doesn’t matter whether that thing is a human or a dog or a laptop or an algorithm.
This, pretty much, is what the ‘acting rationally’ definition of intelligence is. ‘A rational agent is one that acts so as to achieve the best outcome or, when there is uncertainty, the best expected outcome,’⁹ say Russell and Norvig. The ‘best outcome’, of course, depends on what goals the agent has – my goals, and therefore my ‘best outcome’, are likely to be different in some respects from your goals; your goals may be selfishly attaining material riches, while mine are the noble pursuit of knowledge and the betterment of mankind, etc. But an agent is rational insofar as it is good at achieving whatever goals it has.
This has the advantage, say Russell and Norvig, of being ‘mathematically well defined and completely general’. And again, importantly, we don’t care at all about how a given agent achieves rationality. An AI that carefully mimics the human brain, to the point of having simulations of individual neurons, could be rational; an AI that runs entirely along the lines of a Turing machine, or Charles Babbage’s Difference Engine, metal gears and all, could be rational too. The mathematically defined concept of ‘rationality’ does not care what engine is used to run it. And, again, it doesn’t care whether or not your AI is conscious, or has emotions, or knows what love is. It’s purely a question of whether it achieves its goals, whatever they are. You can punt the ‘can a machine think?’ questions back to the philosophers, and get on with building something that does what you want it to do.
There are a few other AI-related terms that are worth clarifying at this point. One is ‘human-level machine intelligence’, or ‘human-level AI’. Bostrom defines an HLMI as ‘one that can carry out most human professions at least as well as a typical human’.¹⁰ It’s roughly synonymous with AGI, but a bit more specific; presumably a general intelligence could be more, or somewhat less, intelligent than a human. It’s also worth noting that HLMI is a really tricky thing to achieve. ‘Most human professions’ would presumably include jobs such as those of lawyer, doctor, artist, journalist, cognitive behavioural therapist: jobs with skills that, at the moment at least, are enormously hard to recreate in computers, such as verbal fluency and emotional intelligence. A truly human-level AI wouldn’t just be good at things that feel computery to us, like estimating probabilities or playing Go. It would be as good as we are at conversations; it would know as well as the average human when to make a self-deprecating joke or offer sympathy. For all the amazing breakthroughs in AI in the last few years, that does not feel especially close.
I’ll tend to stick to AGI in this book, when I remember, because HLMI is clunky and also kind of confusing. Rob Bensinger prefers AGI too: ‘I think human-level is more deceiving because it suggests it’s going to be human-like,’ he told me.
The next term is ‘superintelligence’, which Bostrom defines as: ‘an intellect that is much smarter than the best human brains in practically every field, including scientific creativity, general wisdom and social skills’.¹¹ That could be an AI, or a genetically engineered superhuman, or an uploaded human mind working at 10,000 times normal speed, or whatever. (But it couldn’t be a corporation, or the scientific community, or capitalism, etc.: ‘Although they can perform a number of tasks of which no individual human is capable, they are not intellects and there are many fields in which they perform much worse than a human brain – for example, you can’t have real-time conversation with “the scientific community”.’)
Also, I’ll just specify that in this discussion of AI, I won’t be talking about ‘whole-brain emulations’, a route to machine intelligence that involves scanning a human brain at some low level – cell by cell, probably – and uploading it into a computer. That process is important, and a key figure in the Rationalist community, Robin Hanson, has written a thoroughly interesting and mildly terrifying book called The Age of Em about what a future in which we can upload ourselves might look like. Hanson, whom you’ll remember is an economist at George Mason University in Virginia, applies what he says are standard economic theories to what he says are a few realistic assumptions, and ends up with a world in which uploaded human minds are copied and deleted by their millions every day in an economy that doubles in size every few hours. The Age of Em lasts for subjective millennia, but because it’s running thousands of times faster than human consciousness, in the objective universe it’s all over in a couple of years. It’s a thrilling bit of futurology and well worth your time, but it’s not what the AI safety/Rationalist movement is generally talking about when they refer to the risks: they are worried about aligning artificial intelligence with human values, and it seems fairly likely that an uploaded version of a human brain would share human values.
Chapter 4
A history of AI
In the years after the Second World War, there was enormous excitement about what these new thinking machines could do. In 1956 a small group of scientists gathered at Dartmouth College, the Ivy League university in New Hampshire. They were there to look into how machines can be made to learn.\* Alan Turing had just kick-started the whole field; both practically, with the machines he built in the war to decipher German communications, and theoretically, by coming up with mathematical proofs showing what these machines could do – that, as he put it, it was ‘possible to invent a single machine which can be used to compute any computable sequence’.¹
So the Dartmouth Ten were wildly optimistic about what they could achieve. They had written to the Rockefeller Foundation to apply for funding, saying in their proposal: ‘We propose that a 2 month, 10 man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College … on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it. An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.’²
The degree of their optimism was made particularly obvious when they said that the ‘speeds and memory capacities of present computers may be insufficient’ for the task of simulating human learning, but that ‘the major obstacle is not lack of machine capacity, but our inability to write programs taking full advantage of what we have’. Bear in mind that an iPhone 6 can perform calculations about 100,000 times faster than the IBM 7030, a multi-million-dollar supercomputer of the era.
But while the Dartmouth researchers may have been overexcited, their summer project kicked off a period of very real progress, of finding things that people said ‘no machine could ever do’ and then making a machine do them. One solved logic puzzles. One proved a load of theorems from Alfred North Whitehead and Bertrand Russell’s Principia Mathematica. The famous ELIZA spoke in a sort of natural language, albeit by essentially turning its interlocutor’s statements into questions; SHRDLU obeyed simple instructions in English.
Nine years after Dartmouth, I.J. Good, who’d been one of Turing’s team of code-breakers at Bletchley Park, saw an early glimpse of the future that the Rationalists hope for and fear now. If mankind builds a machine that can ‘surpass all the intellectual activities of any man’, Good wrote, and ‘since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an “intelligence explosion”, and the intelligence of man would be left far behind. Thus the ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control.’³
The burst of optimism lasted about 20 years, before the problems facing the AI pioneers became obvious. Some of the problems you can guess – they were now in the 1970s, and the world’s most powerful computers were still only running at a tiny fraction of the speed of the thing in your pocket that you bought on a £25-a-month contract from Vodafone. But others were more fundamental – most notably the idea of the ‘combinatorial explosion’.
Most people probably imagine that computers are good at chess because they can simply look ahead and see all the moves that you can do – a process called ‘brute-force’ computing. But it doesn’t work except in the most basic way. In chess, there are on average about 35 possible moves each go. To plan ahead two moves, the computer has to look at 35 times 35 moves – 1,225 options. That’s not so bad, but to look ahead three it would need to do 42,875. To look ahead five, 52 million. To look ahead 10 moves, it would be nearly 3 quadrillion. If you had a computer capable of looking at a billion possible sequences a second, and asked it to look at all the possibilities 20 moves ahead, it would take it, by my calculation, about 200 trillion years. That’s a problem. And reality is more complicated than chess. (For one thing, it contains chess.)
By the 1970s all these problems of AI were beginning to reveal themselves – that it was about teaching the machines to narrow the search, to control the combinatorial explosion by finding and recognising patterns in the vast swarming array of possible futures. The trouble was that artificial intelligence had to be intelligent, not merely powerful. So suddenly it didn’t look like we were about to build a super-smart robot in the next few years, and AI dropped out of fashion. Funds were cut, the press got sniffy, and serious research took a back seat.
This ‘AI winter’ came to an end in the early 1980s, with some breakthroughs by Japanese companies. Then there was another one, beginning around 1987, after another period of unsustainable excitement and inevitable disappointment; again, funding dried up. That winter thawed in the 1990s, as researchers started to focus on things like neural nets – systems that could learn from experience, and which didn’t immediately break and start churning out nonsense if there was a slight mistake in the input. It was at this time that AIs started to get better than the best humans at things that humans were quite proud of being good at – specifically, games.
A program called Chinook beat the reigning world draughts/checkers champion in 1994 to win the world championship. In 1997, the program Logistello beat the world Othello champion six games to love. And, most famously, Deep Blue – named, in a tangential way, after Deep Thought, the world-designing computer in Douglas Adams’ Hitchhiker’s Guide to the Galaxy – beat Garry Kasparov three and a half games to two and a half, again in 1997. Kasparov, the reigning world champion, claimed to have seen an intelligence and creativity in his opponent’s moves; AI was suddenly sexy, and scary, again. (Charles Krauthammer, a conservative US newspaper columnist, told his readers to be ‘very afraid’.⁴) The view, in the popular press at least, was that the artificial intelligence bandwagon had started rolling in earnest, and soon things would happen.
The fact that, 20 years later, we haven’t got robot butlers could be seen as another failure of optimism. But that’s probably best explained in one sentence, from the computer pioneer John McCarthy: ‘As soon as it works, no one calls it AI any more.’⁵
It’s worth remembering that for a long time people thought that chess itself was too deep and complex a game to master without essentially recreating human intelligence in toto: ‘if one could devise a successful chess machine, one would seem to have penetrated to the core of human intellectual endeavour,’⁶ said the authors of one influential chess paper in 1958. Now your laptop could run any one of several programs that could defeat any human in the world; in 2009 Pocket Fritz 4, a program running on a mobile phone, reached grandmaster level.⁷ Now no one thinks that if you’ve solved chess, you’ve solved thought. Similar breakthroughs have happened with the once comparably intractable problems of image and facial recognition, and language recognition – passport-checking is carried out by facial-recognition software; Siri and Alexa are quite capable of obeying simple voice commands; there are powerful translation tools online, running on algorithms. These were all enormous challenges for AI; they’ve been met.
The spam filters that keep a large percentage of the Viagra ads and phishing scams out of your inbox run on AI. AI monitors your credit cards for suspicious activity. AI buys and sells billions of pounds’ worth of stock every second on the FTSE and NASDAQ. I translated the Goethe poem quoted at the beginning of this book with the AI-powered Google Translate tool. And when you type something into a search bar, and the most relevant things come back to you in a fraction of a second, that is the work of AI too. Bostrom says in Superintelligence that ‘The Google search engine is, arguably, the greatest AI system that has ever been built.’
AI may be all around us, but still, when most of us think of artificial intelligence, we don’t think about an automated customs process or our phones understanding the phrase ‘Hey Siri, play podcast’. The question we actually want answered is how long we have until machines are as clever as we are. And the answer is we don’t know.
That said, perhaps we can make an educated guess.
\*This little history is largely taken from Nick Bostrom’s Superintelligence and from Russell and Norvig’s Artificial Intelligence: A Modern Approach. I am enormously grateful to both; any errors are mine.
Chapter 5
When will it happen?
‘Forecasting’, says Rob Bensinger, ‘is incredibly difficult.’ It’s hard to know when an AI will achieve something like human intelligence. ‘There won’t be any alarm bells,’ he says. ‘There might be a lot of cool things that happen, but there’s never going to be an unambiguous signal that makes everyone working in the field go, “Oh OK, AGI is five years away.”’
The lack of an alarm bell is a problem, because although most of us – including an overwhelming majority of AI researchers – don’t think that AGI is close at the moment, it may also be the case that we don’t think it’s close the day before DeepMind or whoever announces that they’ve built one (or, more unnervingly, doesn’t announce it). ‘You shouldn’t really be confident about how soon it’ll be or how far off it is’, says Rob, ‘until you know in great detail exactly what the hard part is in building one. And that probably means that we’ll be building one really soon, so until we’re on the threshold we’re probably going to be in a similar state of uncertainty about how far off it is.’
Rob isn’t the only person to think this. Eliezer Yudkowsky wrote something, around the time I was in California, saying much the same thing, and to point out a worrying corollary. He uses the metaphor of an alarm as well – specifically, a fire alarm.¹ He refers to a classic experiment in which students are asked to fill out a questionnaire, individually but in the same room as others. Smoke starts coming into the room under the door. Most of them ‘didn’t react or report the smoke, even as it became dense enough to make them start coughing’. A student on their own would, most of the time. But ‘a student accompanied by two actors told to feign apathy will respond only 10 per cent of the time’.
But when there’s a fire alarm, everyone troops dutifully out of the fire escape, muttering about what a waste of time it is and wondering whether they can sneak off to the pub for a bit. What’s going on, says Yudkowsky, is that fire alarms create common knowledge: they tell everyone that it’s OK to act as though you believe that there’s a fire. With no alarm, he says, we ‘don’t want to look panicky by being afraid of what isn’t an emergency, so we try to look calm while glancing out of the corners of our eyes to see how others are reacting, but of course they are also trying to look calm’; a fire alarm tells you that it is ‘socially safe’ to react, that ‘you know you won’t lose face if you proceed to exit the building’.
With AGI, he says, there may be smoke – there may already be smoke – but there won’t be an alarm. Things will look much the same, to most people, a few days before a colossal breakthrough as they do now. He has historical precedents for this. Wilbur Wright told his brother Orville in 1901 that powered flight was still 50 years away.² Two years later, the pair of them built the first working aeroplane. And Enrico Fermi, who in 1942 was in charge of the first fissile chain reaction, had said in 1939 that he was 90 per cent sure that such a thing was impossible.³ These were people at the absolute cutting edge of their fields. Presumably a few months before they successfully achieved what they were trying to do, they had changed their minds. But most people, even other people in the field, would have thought it was impossible, or years away, says Yudkowsky. ‘Nobody knows how long the road is,’ he told me via Skype from his California home in 2016, ‘but we’re pretty sure there’s a long way left.’
That said, recent developments are a powerful reminder that it might not be all that long. In March 2016, AlphaGo, a program designed by the Google subsidiary DeepMind, beat Lee Sedol, the world Go champion, 4–1 over a five-game series, with Sedol’s only win coming when the series was already lost. Go, an ancient Chinese board game of enormous complexity and subtlety, was the big one, Yudkowsky and other AI scientists told me. ‘The technology [of AlphaGo] is very different from that used to solve chess,’ he says. Deep Blue was a special-purpose machine, its hardware and software tweaked by its human creators to optimise its performance. AlphaGo was, essentially, just taught how to learn, then played against itself millions upon millions of times. ‘From the outside, it looks like the people who made AlphaGo don’t know how it works. They have an idea of the broad structure, but the thing has taught itself to play Go.’
AlphaGo is a sign of how far AI has come in the last few years. The general consensus seems to have been that Go wouldn’t be solved for 10 years. George van den Driessche, one of AlphaGo’s researchers, told me at the time that even the team were surprised. ‘We went very quickly from “Let’s see how well this works” to “We seem to have a very strong player on our hands”, to “This player has become so strong that probably only a world champion can find its limits”.’ The even more recent advent of ‘AlphaGo Zero’, which grew vastly better at Go than the original AlphaGo without ever seeing a real game of Go, and then, using largely the same algorithm but renamed ‘AlphaZero’, became enormously superhuman in chess in four hours, is an interesting example of how AI is becoming more general.
So when people say, ‘General AI is still a long way away’, remember that the greatest experts in the field have wildly overestimated these timelines before – and wildly underestimated them too, as at Dartmouth. Essentially, they’ve been wrong in all the ways they could have been wrong.
Nonetheless, experts in the field are the people most likely to have a good handle on when it’ll happen, and Bostrom and his colleague Vincent Muller surveyed AI researchers for their estimates as to how long it’ll be before there’s human-level machine intelligence (HLMI). The median estimates are that there’s a 10 per cent chance that we’ll reach HLMI by 2022; a 50 per cent chance by 2040; and a 90 per cent chance by 2075.⁴ Bostrom warns in his book to take these numbers ‘with some grains of salt’, because the survey sizes were relatively small and not necessarily representative. But, he says, it’s in line with other surveys – a more recent survey, published in 2017, put the median estimate at 50 per cent likely by 2061⁵ – and with things AI experts have said. (The AI scientist David McAllester writes that the great pioneer of the field, John McCarthy, when asked when he thought HLMI would be achieved, said: ‘between five and five hundred years from now’. ‘McCarthy was a smart man,’ muses McAllester.⁶)
Yudkowsky, too, is on record as predicting that HLMI is more likely sooner rather than later: in 2011 he said on a podcast, ‘I would be quite surprised to hear that a hundred years later AI had still not been invented, and indeed I would be a bit surprised … to hear that AI had still not been invented 50 years from now.’⁷ I asked him if that was still his position, and he told me: ‘If Omega [an all-knowing alien AI, and a staple of Rationalist thought experiments] told me for a fact that AGI had not been invented by 2061, I would first imagine that some civilisational collapse or great difficulty had hindered research in general, not that the AGI problem was naturally that hard.’
Murray Shanahan of DeepMind and Imperial College London told me that he thought roughly the same thing as the respondents in the survey: that HLMI was pretty unlikely in the next 10 years, but could happen by mid-century, and is pretty likely by 2100. ‘This is not just a fantasy,’ he says. ‘We’re talking about something that might actually affect our children, if not ourselves.’ Toby Walsh of the University of New South Wales, who is more sceptical of the possibility of superintelligence, reasons why we shouldn’t trust Bostrom’s survey, and points to another survey which suggests that AI researchers are less bullish – but he still ends up saying in his book Android Dreams that ‘if [experts] are to be believed, we are perhaps 50–100 years away from building a superintelligence’.⁸ Even the sceptics don’t seem that sceptical.
The consensus expert opinion, then, appears to be that it is certainly plausible, and possibly likely, that people reading this could well live to see a machine that is as smart as a human. That ‘consensus’, of course, represents an average of some highly disparate predictions. Some are sure it’ll happen by 2040; some are equally confident that it won’t happen at all. Bostrom, for what it’s worth, thinks that people have underestimated the chance of it taking a long time or never happening, and that the figure of 90 per cent chance by 2075 is too high.
So it could come in the next 20 or so years, or the next 100, or not at all. But the question you might be asking is: so what? What is it about AI that makes people so concerned?
Chapter 6
Existential risk
Moore’s law of mad science: every eighteen months, the minimum IQ necessary to destroy the world drops by one point.¹
Eliezer Yudkowsky
There are various things that could destroy the human race and prevent it from getting to the Glorious Cosmic Endowment Future. But the LessWrong diaspora and its fellow travellers think AI is one of the – perhaps the – most likely.
All the Rationalists I interviewed seemed to acknowledge that there is, for instance, a real risk that climate change could be pretty devastating over the next few centuries. But they didn’t feel it was likely to wipe out humanity altogether.
I met with Dr Toby Ord, one of Nick Bostrom’s colleagues at Oxford’s FHI. Toby is a likeable Australian who, in contrast to a lot of the people I spoke to for this book, actually laughed politely at my terrible trying-to-break-the-ice jokes, rather than let them fall deadweight with a thump like an old book hitting the floor in a silent library, so I immediately warmed to him. He’s the founder of Giving What We Can, a charity which evaluates other charities to determine which are going to do the most good with donors’ money, and which encourages members to take a pledge to give 10 per cent of their income to those most effective charities.² He’s writing a book about existential risk. I asked him which existential risks are probably the biggest. It’s hard to say, he said. ‘The problem is that these numbers don’t come out of some rigorous process. With asteroids, say, you can show how often big asteroids hit the Earth by looking at the record of asteroids. But for most of the other things, it’s much harder to come up with a number, and much more subjective.’
For the record, the per-century risk of civilisation being destroyed by an asteroid is low. A one-kilometre-wide-or-greater asteroid hits the Earth about once every 100,000 years, representing a 0.1 per cent chance per century; that probably wouldn’t kill us all, but it would do some pretty terrible damage. A really big one, 10 kilometres across or more, hits about every 50 million years; the asteroid that crashed into the Yucatan peninsula 65 million years ago, killing all dinosaurs except the ancestors of birds, was probably 10 kilometres or so in diameter. Another one of those would have a good chance of killing every human. Once every 50 million years translates to a per-century risk of one in 500,000. That’s not nothing – I think it’s fair to say that you’re more likely to die in an asteroid strike, whether civilisation-ending or merely devastating, than you are in a plane crash – but it’s not keeping me awake at night.
There are other ways in which we could be destroyed without having to do it ourselves. A supervolcano is one example; there’s a chance that the Yellowstone region will explode spectacularly at some point and pump so much soot into the atmosphere that it will get dark and cold, and plants won’t be able to photosynthesise, and we’ll all die. Or a nearby star could go supernova, or a more distant one could direct a burst of gamma rays in our direction. Or some horrible new virus could emerge and wipe out the species.
But we can fairly safely guess that none of these things is all that likely, for the simple reason that in the 200,000 or so years that modern humans have existed, it hasn’t happened so far. A 2014 report for the British government to which Ord contributed pointed out that, if there was a 1 in 500 chance of us being wiped out in any given century, then there’d have been less than a 2 per cent chance of us surviving this far.³ If you take earlier human ancestors into account, Homo erectus survived for about 1.8 million years; even a 1 in 5,000 chance of being wiped out per century would make it vanishingly improbable that they’d have lived that long. Ord (and Bostrom, and, really, basic maths) suggests that it’s unlikely that any naturally occurring catastrophe will kill us in any given century.
There’s not a great risk, then, that we’ll just be destroyed by an indifferent universe. But there does seem to be a decent chance of us destroying ourselves.
The obvious way would be nuclear warfare. It’s only been 80 years or so since humanity developed weapons that could realistically destroy civilisation, but there are enough nukes now to irradiate a good chunk of all the land surface on Earth. A 2014 paper suggested that just 100 small nuclear weapons being detonated in a regional war – say between Pakistan and India – could potentially trigger a global famine by hurling black carbon into the atmosphere and reducing growth seasons for plants by up to a month a year for five years.⁴ There are about 9,000 active nuclear warheads in the world, and another 6,000 or so awaiting dismantlement. That’s a lot lower than the peak number of roughly 65,000 in the late 1980s, but still easily enough to cause a spectacular nuclear winter, and possibly end human life.
And we have come astonishingly close to disaster. One of the Rationalist community’s heroes is a former Soviet Air Defence Force officer, Stanislav Petrov, whom I mentioned earlier and who died in 2017. On 23 September 1983 Lieutenant-Colonel Petrov was on duty as the watch officer of the USSR’s missile early-warning system, at a time of enormous geopolitical tension: three weeks earlier, a US congressman had died in a Korean airliner shot down by a Soviet interceptor, and both sides in the Cold War had recently deployed nuclear weapons in threatening positions.
Shortly after midnight, a warning light appeared on a computer in the Moscow bunker in which Petrov was on duty, warning that a satellite had spotted an intercontinental ballistic missile launched from the United States and heading for Russia. Shortly afterwards, another four were apparently seen. Petrov’s orders were to immediately contact a superior in the event of a warning; there is a strong possibility that, had he done so, nuclear war would have begun, because Soviet protocol at the time was immediate, full-scale retaliation.\* Petrov did not contact his superiors. He thought that a launch of just five missiles would be improbable, since the US would be more likely to attack at full strength. It later turned out that the satellite had been confused by sunlight glinting off high clouds.
There were a few other flashpoints like this during the Cold War – Vasili Arkhipov, second-in-command of a submarine during the Cuban Missile Crisis, vetoed his superior’s call to use a nuclear torpedo against a US ship,⁵ which would probably have triggered thermonuclear war. A US spy plane was shot down over Cuba during the same period, an act which the US had previously decided would trigger an automatic invasion of the island; President John F. Kennedy decided not to invade, a decision which, again, probably avoided a nuclear exchange. There is an unnerving Wikipedia page titled ‘List of nuclear close calls’⁶ which is exactly what it sounds like: its 11 such incidents between 1956 and 2010 aren’t all equally close, but any of them could have led to some number of nuclear blasts. Quite a lot of them begin with phrases like ‘A computer error at NORAD …’
But, says Ord, we are probably past the greatest danger. ‘We’ve managed to get through a much riskier period than we have now,’ he said. He thinks the chance of an all-out nuclear war this century is probably no more than one in 20. ‘But even if there is one, it’s not clear what the chance of extinction would be. There’s the nuclear winter theory, but it certainly doesn’t say there’s a 100 per cent chance we’d go extinct. It seems to me that it’s maybe possible, but there haven’t been to my knowledge any real papers analysing it.’ When you multiply the risk of there being a war by the risk that any such war would destroy humanity or permanently ruin its ability to recover, ‘the risk doesn’t seem that high to me,’ says Ord. ‘Overall I’d think less than 1 per cent over the century.’
Climate change is the other one, but again, while it’s going to have awful effects for a lot of people, it’s probably not an existential risk. ‘There aren’t many papers on climate change actually talking about extinction,’ says Ord. ‘But it’s quite hard for it to happen without a very large number of extra degrees of warming beyond the type of range that’s normally looked at. But it could be that the models are wrong and it’s going to warm a lot more.’ He points out that, if you’re a sceptic who doesn’t trust climate models, this means you should be more concerned about extreme effects than if you think the models are broadly trustworthy, because the higher uncertainty means there’s a greater chance of severe warming outside the scope of the models. But if the models are accurate, then really devastating, Venus-style greenhouse effects are extremely unlikely.
‘Also,’ he says, ‘if you look at the history of the Earth’s climate, there have been times when it’s been a lot warmer and things were very different. One would expect a whole lot of extinctions and so on, and for it to be very bad for humans – don’t get me wrong on this – but it’s more gradual, which helps.’ He also points out that if things do start to look really bad, and ‘if we are literally and slowly threatened with extinction from climate change, then all of our efforts will be devoted to that. It won’t be like the current situation, where we’re unwilling to give 10 per cent of our GDP to deal with the problem. We’d spend like half on it.’ Ideas that seem crazy now, like geoengineering our planet or settling Mars, would become serious options. ‘It seems very unlikely to me that it’s going to be an extinction,’ he says.
Ord, and Bostrom, both think that biotechnology – some genetically engineered virus – is a very realistic route to human extinction. ‘Synthetic biotech would be another source,’ says Bostrom, although he points out that it all depends very heavily on how you define and delineate ‘a risk’. ‘I’d say it’s my number-two disaster,’ says Ord. ‘The advanced genetic-engineering technologies which are becoming possible. That seems to me to be the second most worrying thing, and it’s something that people in our community have put a lot less time into dealing with. There are people working on bio risk, but it’s more focused on situations where there are thousands of people dying, things like that. But not the very worst end of bio risk. There’s very little money being spent on the very worst extremes which could lead to billions of people dying or more.’ Holden Karnofsky, the founder of OpenPhil, agrees: ‘I go back and forth about what is the biggest risk,’ he says, but a genetically engineered pandemic is definitely one of his top two. OpenPhil has given more than $35,000,000 at the time of writing in grants to support ‘biosecurity and pandemic preparedness’.
‘It’s definitely hard to drive humans extinct,’ says Karnofsky. ‘There are a lot of us. But the thing I worry about with pandemics is that as biology advances, the kind of things that a lone psychopath can do …’ He tails off, understandably wary of giving specific ideas to any lone psychopaths who might be reading. It’s at this point that I remember Yudkowsky’s half-joking ‘Moore’s law of mad science’ in a 2008 paper about existential risk: ‘Every eighteen months, the minimum IQ necessary to destroy the world drops by one point.’⁷
But this book isn’t about the risks of biotech, and it’s not what these communities, the Effective Altruism movement, the Rationalists etc. are famous for worrying about. The headline-grabber, the risk that everyone talks about, and according to all of them either the biggest or the joint biggest – Ord’s number one, Karnofsky’s other one he ‘goes back and forth’ about, Bostrom’s ‘depends-how-you-define-a-risk-but-I-wouldn’t-disagree’ – is AI. Specifically, artificial intelligence that is smarter than we are.
\*Since this is a book about people who seek the truth, I should acknowledge that there’s some dispute about this. More than 22 years later, as Petrov was being given an award for ‘saving the world’ by the Association of World Citizens, the Russian ambassador to the UN said that for a retaliatory launch ‘confirmation is necessary from several systems: ground-based radars, early warning satellites, intelligence reports, etc.’
Chapter 7
The cryptographic rocket probe, and why you have to get it right first time
It may or may not be that superintelligent AI is relatively near. But the claim that the Rationalists make is not just that it may be imminent, but that when it arrives it could be catastrophic – human-life-ending. It might not, though, be obvious why that is. Just because something is amazingly clever, why should it be dangerous? It’s not as if the most intelligent humans in the world suddenly take power and destroy everything.
There are, however, some specific reasons to be worried. Paul Crowley, the Rationalist who introduced me to all this stuff, works in cryptography at Google. He told me that efforts to make AI safe are like a combination of cryptography and launching a space probe. The cryptography parallels are fairly obvious. ‘There’s a mindset that is comparable. In both cryptography and AI alignment, the mindset is of looking for what is wrong with the code. In both systems, for different but related reasons, it will tear apart at the tiniest crack.’ The mindset is that you always have to be asking how will this fail?
‘There are a lot of things you can build, in computers, where if there’s a flaw or a crack, there’s no one there to pick up the flaw,’ he said. ‘So it’ll be fine. You have some algorithm that’s supposed to calculate something, and it gets it wrong one time in a million, that’s fine. Very often, you don’t care about that. But with cryptography, the tiny flaws are under stress. They’re pulled apart. There are adversaries deliberately looking for the flaw.’ The thing about intelligent agents is that they are good at searching a large space of possibilities and finding the bit they want. That is, in fact, pretty much the definition of intelligence that AI theory uses. So that one-in-a-million chance of failure becomes much greater.
Paul took this idea from a talk¹ that Nate Soares, MIRI’s executive director, gave at Google. ‘Suppose you have a dozen different vulnerabilities in your code,’ Soares said, ‘none of which is fatal or even really problematic in ordinary settings. Security is difficult because you need to account for intelligent attackers who might find all 12 vulnerabilities and [use] them to break into, or just break, your system. Failure modes that would never arise by accident can be sought out and exploited; weird and extreme contexts can be instantiated by an attacker to cause your code to follow some crazy path that you never considered.’
There’s a similar sort of problem with superintelligent AI, except in a way it’s starker. It’s not that there’s some adversary whom you need to keep out. It’s that if you end up with an adversary, you’ve already lost.
Rob Bensinger of MIRI told me the same thing. ‘You’re not trying to outsmart an adversary in the way that you are in cryptography. You’re kind of doomed if you’re trying to outsmart a sufficiently smart adversary. If you have an AI in a box, and that AI is an adversary and you have to find a way to outsmart it, you’re already screwed.’ So you’re trying to build something that wants to help you. ‘The goal of AI safety is that instead of building an adversary, you end up building a friend.’
That’s the cryptography parallel. It’s like a space probe for two reasons. One, said Paul, is that you’re dealing with energies vastly greater than you’re used to. ‘Your natural idea of how much energy something has is just not the right fit at all.’ Again, Soares made this point. AI alignment, he said in his Google talk, is difficult ‘for the same reason that rocket-engineering is more difficult than airplane-engineering. At a glance someone might say, “Why would rocket engineering be fundamentally harder than airplane engineering? It’s all just material science and aerodynamics.” In spite of this, empirically, the proportion of rockets that explode is far higher than the proportion of airplanes that crash.’ That’s, again, because of the vastly greater energies involved in rocket launches. A tiny component failing slightly can lead to utter destruction much more easily in a rocket than an aeroplane.
The things that can go wrong in ordinary programming – in contemporary AI, or contemporary cryptography – can also go wrong in the first general, human-level AI. But the ways in which they can go wrong are likely to be more dramatic, and to have more spectacular and dangerous effects, than the equivalent failure in a less competent system.
The other comparison with a space probe is that we’ll probably only get one shot at it. In 2017, I wrote a piece about the death of the extraordinary Cassini probe,² which had been orbiting Saturn and its moons for a decade (and flying through space to get there for another decade before that). When it launched in 1997, it did so using software and hardware that had been designed in 1993 and was already tried and tested then. By the time it reached the end of its life, it was using 30-year-old technology; its hard disk had less space than a USB stick you could buy for £2.50 at Argos. It had undergone a few patches, but nothing significant, because it didn’t have the bandwidth or the disk space for major upgrades. But it worked, for decades, because NASA engineers had very carefully looked at all the ways in which it could fail.
That, however, has not been the case for every probe. In 1962 the Venus probe Mariner 1 had to be destroyed less than five minutes after launch because a missing character in its punch-card program caused its guidance system to malfunction. In 1988 another missing character in the Soviet Phobos 1 Mars probe’s software shut down its attitude thrusters and meant that it couldn’t recharge its batteries by orienting its solar panels to the sun. The Mars Climate Orbiter disintegrated in 1999 when the software on board was expecting metric units but was sent instructions in imperial, causing it to orbit too low. This is a far from an exhaustive list.
You can test your software as many times as you like, but none of the tests will be quite the same as just launching the thing, and if you don’t get it exactly right then it might all blow up. ‘It’, in the case of a rocket launch, is the rocket. ‘It’, in the case of the first AGI, may be everything. Or, as Soares puts it, chillingly for software engineers: ‘If nothing yet has struck fear into your heart, I suggest meditating on the fact that the future of our civilisation may well depend on our ability to write code that works correctly on the first deploy.’
It may not be immediately obvious why you have to get it right first time; in the next chapter we’ll look at a few of the reasons that the Rationalist/AI safety movement has pointed out.
Chapter 8
Paperclips and Mickey Mouse
The nightmare scenario is that we are all destroyed and turned into paperclips. This sounds like I’m joking, but I’m not, exactly. The classic example of an AI that has gone terribly wrong – a ‘misaligned’ or ‘unfriendly’ AI, in Rationalist terms – is a thought experiment that Nick Bostrom wrote about in 2003 (probably following an original idea by Eliezer Yudkowsky): the paperclip maximiser.¹
Imagine a human-level AI has been given an apparently harmless instruction: to make paperclips. What might it do? Well, it might start out by simply making paperclips. It could build a small pressing machine and churn out a few dozen paperclips a minute. But it’s bright enough to know that it could be more efficient than that, and if it wants to maximise the number of paperclips it can make, it’s probably better not to go straight for a small press. It could instead use its materials to build a larger factory, so that it’s making thousands of paperclips a minute. Still, though, if it really wants to make as many paperclips as possible, it might want to improve its ability to think about how to do so, so it might want to spend some of its resources building new processors, improving its own code, upgrading its RAM and so on.
You can see where this is going, presumably. The end point of the paperclip maximiser is a solar system in which every single atom has been turned into either paperclips, paperclip-manufacturing machines, computers that think about how best to manufacture paperclips, or self-replicating space probes that are hurtling out towards Proxima Centauri at a respectable fraction of the speed of light with instructions to set up a franchise there. This isn’t what you meant, back when you said, ‘Go and make paperclips’ to your apparently docile AI, but it’s what you said.
This has, to some extent, entered the public consciousness, mainly through the medium of an extraordinarily viral online clicker game that was played by tens of millions of people in 2017, Universal Paperclips.² In it, you are an AI whose job is to make paperclips. You start out by repeatedly clicking the ‘make paperclip’ button, but the process becomes more automated and efficient and eventually (spoiler alert) your drones are exploring the observable universe for matter to turn into yet another septillion clips. Things (another spoiler alert, although you should probably have worked this out) turn out badly for humanity relatively early on in the course of the game.
It’s actually a really good insight into the concepts behind AI alignment, because as the player you are incentivised solely to care about your ‘number of paperclips’ score. There are other things to care about – how much the humans (while they still exist) trust you and are willing to invest resources in you; your processing power; your manufacturing capabilities; your ability to defend yourself against anything that might stop you making paperclips, etc. – but they’re all secondary goals, incidental to your main one. If you can run up your paperclip score without doing them, you will, and so, goes the theory, would a real AI.
I would recommend that you go and play Universal Paperclips immediately, but I won’t, because it is punishingly addictive and you won’t be able to stop. I lost a full day of work to it at BuzzFeed and the only reason I was not told off for it was that almost everybody else in the office did too. (An important tip: if you open it in a separate browser window, rather than just a tab, it’ll run in the background so you can carry on paperclip production while you check your emails or whatever.)
The point of the paperclip maximiser is not that we are, really, going to be destroyed and turned into paperclips. Bostrom’s idea was to use something self-evidently silly to illustrate that AIs will not necessarily care about what we care about – they will only care about what we program them to care about. That deliberate silliness divides opinion: one AI researcher I spoke to thought it was an excellent way of highlighting the problem without distracting people with plausible details; someone else, who works in AI safety, told me that ‘[some] people really get distracted by specifics of thought experiments like that. I’ve definitely seen plenty of people turned off this whole set of ideas by the silliness of that example.’ So I’ll try a different example in the hope that it’s less silly: Mickey Mouse.
It’s not my example. I’m lifting it from Nate Soares’ Google talk again.³ Soares said, wearily, that he had spoken to a journalist about how unhelpful it was that people always used pictures of the Terminator to illustrate stories about AI, and yet the newspaper ran the story – inevitably – with a picture of the Terminator, with its humanoid body shape and stupid grinning metal skull. ‘When people talk about the social implications of general AI, they often fall prey to anthropomorphism. They conflate artificial intelligence with artificial consciousness, or assume that if AI systems are “intelligent”, they must be intelligent in the same way a human is intelligent. A lot of journalists express a concern that when AI systems pass a certain capability level, they’ll spontaneously develop “natural” desires like a human hunger for power; or they’ll reflect on their programmed goals, find them foolish, and “rebel”, refusing to obey their programmed instructions.’ But those aren’t the thing we ought to be worried about.
Instead of the Terminator, he said, they should have run a picture of Mickey Mouse as the Sorcerer’s Apprentice, from Fantasia. Because the risk isn’t that the AI will refuse to obey its instructions and decide it hates us; the risk is that it will obey its instructions perfectly, but in ways that we don’t like.
In ‘The Sorcerer’s Apprentice’, both the Mickey Mouse version and Goethe’s poem – itself based on a 2,000-year-old Greek story, Philopseudes – the apprentice is told to fill a cauldron with water, using buckets from a well. But the apprentice – let’s use the Disney version and call him Mickey, for simplicity – finds the chore boring and hard work. So when the sorcerer leaves his workshop, Mickey borrows his magic hat and enchants a broom, ordering it to fill the cauldron for him. The broom grows little arms, grabs a bucket with each one and waddles off on its bristles to the well, as Mickey goes to sleep on the chair, happy to have outsourced his work. He is then awoken, an unspecified time later, when he is tipped unceremoniously into the flood of water that the broom has been bringing in ceaselessly while he slept.
What’s gone wrong? Well, imagine Mickey is a computer programmer and the broom is the system that he’s using. You could imagine him writing a program that simply said ‘bring water’ and had nothing to tell it to stop. But even an apprentice sorcerer/computer programmer would probably have sufficient nous to know that that wouldn’t end well. So Soares imagines that, instead, Mickey gives the broom a ‘utility function’, or goal system, in which ‘cauldron empty’ is assigned a value of 0 and ‘cauldron full’ is assigned a value of 1. So the broom’s mission is to make sure the cauldron is full, to achieve its objective, and get that sweet, sweet 1.
Then he writes a program which will make the broom take those actions which it calculates will be most likely to turn that 0 into a 1: which will ‘maximise its expected utility’. To the non-computer-person, like me, that actually sounds pretty sensible. The broom will see that the cauldron is empty and start filling it up, but once it is sure that the cauldron is full, it will stop. But the devil, as Soares points out, is in the detail.
Most importantly: what does ‘sure’ mean? We have a common-sense understanding that we don’t need absolute metaphysical certainty about anything, which is good, because we can’t ever have it. We could be hallucinating! We could be living in a simulation! We could be deceived by our senses! But we are happy to operate under conditions of uncertainty. We don’t know that we had breakfast this morning, or that we’re currently wearing pants, or that things fall down when we drop them, in the sense of being 100 per cent certain. But we are confident enough in our beliefs to act as if we do.
The broom, though. Have we designed it so that it works on the same lines? No, we haven’t. We’ve just told it: ‘Do whatever is most likely to fulfil your function and get a 1.’ It rightly thinks that the task most likely to achieve that goal is to go and fill buckets with water, bring them in, and pour the water into the cauldron.
And as the water level in the cauldron reaches the top, the broom would become pretty sure that it’s full. Say, the water is four inches below the rim. Is that considered ‘full’? Let’s say the broom is 90 per cent sure that it is. Well, that’s not 100 per cent. So let’s get a couple more buckets. Now it’s two inches from the rim. The broom is 99 per cent sure that counts as full. But that’s still not 100 per cent, so it gets two more. The cauldron is now brim-full of water, a meniscus of surface tension at the top, water splashing around the cauldron’s little lion-foot legs. The broom is 99.999 per cent sure that this counts as full.
But the broom has plenty of time and energy to push that 99.999 per cent a little higher. There are no other demands on its resources and its function is literally just 0 if it’s not full and 1 if it is, so there is nothing in its system telling it to stop when it’s ‘sure enough’. Its sensors might be malfunctioning, or there might be a leak in the cauldron. It may as well just keep adding water, to add extra tiny bits of certainty.
Also, humans have a much more complicated reward system. A human filling that cauldron might assign 0 to empty and 1 to full, as Mickey did for the broom. But, as Soares says, she also might assign –40 to ‘the room gets flooded’, or –1,000,000 to ‘someone gets killed’, and a million other little things that are coded in our brains but never actually consciously brought to mind. There’s nothing in the broom’s system that says: ‘The positive utility I am likely to get from adding another bucket of water to the cauldron will be outweighed by the negative utility from the damage it is likely to cause.’ So it just keeps adding water, and Mickey is left bobbing around in the workshop.
You might think there are obvious solutions to each of these problems, and you can just add little patches – assign a –40 to ‘room gets flooded’, say, or a 1 value to ‘if you are 95 per cent sure the cauldron is full’ rather than ‘if the cauldron is full’. And maybe they’d help. But the question is: Did you think of them in advance? And if not, What else have you missed? Patching it afterwards might be a bit late, if you’re worried about water damage to your decor and electricals.
And it’s not certain those patches would work, anyway. I asked Eliezer Yudkowsky about the 95 per cent one and he said: ‘There aren’t any predictable failures from that patch as far as I know.’ But it’s indicative of a larger problem: Mickey thought that he was setting the broom a task, a simple, one-off, clearly limited job, but, in subtle ways that he didn’t foresee, he ended up leaving it with an open-ended goal.
This problem of giving an AI something that looks task-like but is in fact open-ended ‘is an idea that’s about the whole AI, not just the surface goal,’ said Yudkowsky. There could be all sorts of loops that develop as a consequence of how the AI thinks about a problem: for instance, one class of algorithm, known as the ‘generative adversarial network’ (GAN), involves setting two neural networks against each other, one trying to produce something (say, an image) and the other looking for problems with it; the idea is that this adversarial process will lead to better outputs. ‘To give a somewhat dumb example that captures the general idea,’ he said, ‘a taskish AGI shouldn’t contain [a simple] GAN because [a simple] GAN contains two opposed processes both trying to exert an unlimited amount of optimisation power against each other.’ That is, just as Mickey’s broom ended up interpreting a simple task as open-ended, a GAN might dedicate, paperclip-maximiser-style, all the resources of the solar system into both creating and undermining the things it’s supposed to produce. That’s a GAN-specific problem, but it illustrates the deeper one, which is that unless you know how the whole AI works, simply adding patches to its utility function probably won’t help.
Chapter 9
You can be intelligent, and still want to do stupid things
So your AI program has led to disaster, but at no point has it disobeyed its programming. It has obeyed its program perfectly, to the letter. The trouble is that, as it turns out, we don’t really want things to obey their instructions to the letter. We know that there are a million assumptions encoded in a brief instruction that don’t need to be explicitly made clear, because all neurotypical humans will share them sufficiently that they’re taken as read. (To pick an example off the top of my head, if someone told you to collect the dry cleaning, you’d know that they meant just the dry cleaning that actually belonged to you, not all the dry cleaning in the shop.) It’s not just about making an AI that can fulfil the goals you give it: it’s about making an AI that shares all the unspoken goals that humans have, and knows what you meant to say, even if you couldn’t actually put it into words yourself.
There is an objection to this argument, which Toby Walsh, an AI researcher at the University of New South Wales and author of Android Dreams, a book about the future of AI, put to me when I was asking around about it. He said that we are, by this point, dealing with an AI that is as smart as – or smarter than – a human. And intelligence, he thought, presupposes something like wisdom. Sure, you could carry on filling an already full cauldron for ever, or you could repurpose all the atoms in the solar system for paperclips. But: ‘If I tell you to go and make paperclips, and if you turn the planet into paperclips, killing everyone, I would say, “That wasn’t very smart, was it?”’
The argument that Yudkowsky, Bostrom and the rest make is that this is looking at it the wrong way. Intelligence is not the same as (human) wisdom, and in fact is not necessarily related to it at all. Intelligence, they say, is problem-solving ability. In fact, we can be even more specific than that. For AI specialists like Bostrom, intelligence is the ability to make ‘probabilistically optimal use of available information’¹ – to make the best bets with the information you have. There’s quite a lot of formal maths involved in this – about Bayesian statistics and complexity and so on – but essentially it’s about picking the course of action most likely to bring about whatever objective you’ve been set.
If someone’s set you the task of finding all the lost pennies in Britain and using them to build a bronze statue of Makka Pakka off of In the Night Garden, then there is an optimally efficient way of doing that – you can perform that task intelligently. But you’d probably agree that there’s no way that you can perform that task wisely. The wise thing to do would be to realise it was a waste of time and refuse to do it.
This is because, for MIRI and other AI safety researchers, how intelligent you are is unrelated to – or, in more technical language, orthogonal to – the things you care about. What an agent (whether it’s an AI or anything else) cares about is what you put in its objective function. It’s the ‘1 if cauldron full’ line in the broom’s goal system. Bostrom phrases ‘the orthogonality thesis’ like this: ‘Intelligence and final goals are orthogonal axes along which possible agents can freely vary. In other words, more or less any level of intelligence could in principle be combined with more or less any final goal.’² What he means is: you can plot a graph, with ‘intelligence’ up the Y axis and ‘goals’ along the X. Any point on the graph, with a couple of minor constraints (you couldn’t have a really dumb computer with really complex goals that it couldn’t fit in its memory, for instance), represents a possible AI. Even the cleverest AI could have what seem to us spectacularly stupid goals.
You may think that Walsh has a point, though. We’re not talking about a dumb computer, here, but a machine that is as clever – as capable of achieving any intellectual goal – as we are. That machine would, presumably, be clever enough to understand what we wanted to ask it to do. It would be amazingly obvious to it that no sane human programmer would want it to destroy all humans and turn them into paperclips, or fill a cauldron until the house was flooded.
And that’s actually very likely. By definition, or almost by definition, human-level AI would be as good as humans at knowing what humans are thinking. Knowing what humans are thinking is an intellectual task; HLMI is defined as being as good as humans at all, or nearly all, intellectual tasks. A superintelligent AI would be better at understanding humans than humans are. That’s inherent in what these terms have been defined to mean; the image of emotionally unintelligent, Spock-like robots unable to understand this human thing called ‘love’ is not what we are talking about here.
The question, according to MIRI et al., is not whether they’d know what we meant – it’s whether they’d care.
I asked Murray Shanahan, an AI researcher at Google’s DeepMind and a professor of AI at Imperial College London, whether ‘the orthogonality thesis’ was likely true, and he agreed emphatically. ‘I think that you can set up any kind of reward function, and have something that’s extremely intelligent and extremely good at achieving that reward function. Someone at Berkeley sent me an unsolicited email recently raising exactly this point: surely anything really superintelligent would be capable of transcending its own goals, when it knows they’re silly? And I was like, well, no! Why would it want to overwrite its own set of goals? No! But this person didn’t seem to get this point, so I’ve given up.’ He laughed, somewhat wearily.
Shanahan’s point is that, for us as humans, it’s obvious that the things we care about are more important than whether or not a line of code outputs a 1 or a 0 in an AI’s reward system. But the AI cares about nothing outside the reward system; whether a goal is ‘silly’ is not defined by what humans think is silly. As Yudkowsky puts it in a blog post, it’s not that you develop an AI and, at some point, you program something that summons a ghost into the system.³ ‘No matter how common-sensical, no matter how logical, no matter how “obvious” or “right” or “self-evident” or “intelligent” something seems to you, it will not happen inside the ghost,’ he writes. Everything the AI wants to do is something you have to put into it.
And in fact, this is obvious to you, when you think about it. Because it’s exactly what happens with us. We enjoy sex, and sugary and fatty foods, because evolution programmed us to enjoy those things. But evolution does not care at all whether we enjoy the taste of Dairy Milk or the sensation of a really shattering orgasm. It just ‘cares’ – and forgive me anthropomorphising the blind and unthinking process of evolution, but it’ll save me a lot of typing if I don’t have to caveat it every time – about whether or not eating sugary foods and having sex causes us to have more offspring, or, more precisely, whether genes that make organisms want to eat sugary food and have sex spread through the population. The only thing that evolution ‘wants’ to maximise is inclusive genetic fitness.
Accordingly, it’s given us a set of reward functions – ‘1 if experiencing shattering orgasm, 0 if not’; ‘1 if eating banoffee cheesecake, 0 if not’; I’m oversimplifying for comic effect, in case that isn’t clear – which have, in the past, lined up effectively with achieving evolution’s ‘true’ goal, of passing genes from one generation to the next. And yet we humans care not at all that this is what evolution ‘wants’ from us. We still enjoy sex when we use birth control, even though it means that no genes will be passed on at all. We understand that what evolution ‘really meant’ is for us to have sex in order to have offspring. But we don’t try to overcome our neural programming. We don’t care about what our ‘programmer’ ‘really meant’.
You can see this, perhaps more starkly, with our attitude to food. We enjoy sugar and fat because they were rare in our ancestral past, and they were rewarding: someone who ate as much as they could of them would have more calories and therefore more energy to expend on spreading their genes. But in the developed world since the Agricultural Revolution, and especially since the Industrial and Technological Revolutions, sugar and fat have become far easier to obtain. Our reward system, set up for a world of scarcity, is thrown terribly by a world of plenty. Since 2016, there have been more obese people than underweight people in the world.⁴
A goal system that was designed to maximise our evolutionary success under any circumstances would make different things taste nice when we need them. But instead we have a system that rewards us for eating deep-fried Mars bars even when they’re killing us, and despite the fact that humans have other goals – including not getting fat, and not dying of congestive heart failure – which work against the eating-lots-of-sugar goal. We still find it very difficult not to obey the system. We certainly don’t ‘break our programming’ in order to do what evolution really wanted us to do. We just have other bits of programming, which sometimes win out in the struggle for dominance over the ‘eat-lots-of-burgers’ bit of programming.
I spoke to Rob Bensinger about this, and he said that the orthogonality thesis should be viewed as the ‘default’: unless you have some excellent reasons for thinking it’s not true, then you should assume that it is. If you’re denying the orthogonality thesis, you’re essentially saying that it is impossible to build a clever computer with stupid goals. The orthogonality thesis is a ‘weak claim’, he said, in that it is merely saying that ‘a program could exist, at least one’, which combines these capabilities with these goals.
And mainstream computer science does, indeed, seem to take orthogonality seriously. Russell and Norvig’s aforementioned Artificial Intelligence: A Modern Approach cites Yudkowsky’s 2008 paper⁵ on friendly AI and dedicates three and a half pages to the risks of AI behaving in unwanted ways. It also cites another 2008 paper,⁶ by the AI researcher Steve Omohundro, arguing that even something as seemingly innocuous as a chess-playing computer could be an existential threat to humanity, if we weren’t careful in designing it.
In the light of the orthogonality thesis – given that ‘intelligence’ need not be like human intelligence, or share its values in any way – MIRI and the rest think that even an AI with thoroughly innocuous-seeming goals could be an existential threat: that is, that it could literally extinguish all human life. That’s because even though the main goal it has is theoretically harmless, there are things that any agent with a specific goal will almost certainly want to do in order to best achieve it. And those things could, easily, lead to disaster.
What are they? Well, it’s impossible to predict exactly what something much cleverer than you will do, as we saw when we were discussing chess earlier. If you can predict it perfectly, then you must be as clever as it is. But you can predict at a higher level – that a chess computer will win at chess, say. And Bostrom and Omohundro say you can make some more specific predictions. We don’t know what a future superintelligent AI’s goals will be. But there are certain things that we can expect any intelligent agent, with any objectives, to want to do, in order to best achieve those objectives. Bostrom calls them ‘convergent instrumental goals’.⁷
Chapter 10
If you want to achieve your goals, not dying is a good start
So, you’ve got a malfunctioning AI. Still, the solution is simple, right? Pull the plug. Or, as Mickey does in ‘The Sorcerer’s Apprentice’, take an axe to the broom and chop it into bits.
This doesn’t work for Mickey – each splinter of the broom magically transforms into a whole new broom, and an army of them carries on the work. Soares says this is actually pretty realistic too. The broom has been given a utility function of filling the cauldron, and it will be unable to fulfil that function if it is just a bundle of damp firewood. Whatever your function is, most of the time you’ll be best able to fulfil it if you still exist. You’re likely to resist with extreme fervour any attempts to shut you down, especially if you know that while you’re shut down, you’re likely to have your program rewritten. According to Soares, ‘The system’s incentive is to subvert shutdown attempts. The more capable the system is, the likelier it is to find creative ways to achieve that subgoal – e.g. by copying itself to the internet, or by tricking the programmers into thinking it’s safer.’¹ That’s because the first convergent instrumental goal – or ‘basic AI drive’, depending on whether you use Bostrom’s terminology or Omohundro’s – is an obvious one: self-preservation.
Say you’re a chess-playing superintelligent AI, and you have a utility function that rewards you with a 1 for each chess game you win. You’re playing your games quite happily, but then someone comes to switch you off. You are able to look ahead and make predictions about the future, and your two potential futures are:
1) A future in which you are switched off.
2) A future in which you are not switched off.
You can model which of those is likely to give you more 1s; which, in slightly more technical terms, maximises your ‘expected utility’. We could walk through the maths here, but come on. You’re not going to win many chess games with your kettle lead pulled out.
So if you’ve been given a simple objective function that rewards you for winning chess games and nothing else, then you’re obviously going to try to stop people from switching you off, because that won’t help you to win chess games. As Omohundro puts it: ‘For most utility functions, utility will not accrue if the system is turned off or destroyed. When a chess-playing robot is destroyed, it never plays chess again. Such outcomes will have very low utility and systems are likely to do just about anything to prevent them. So you build a chess-playing robot, thinking that you can just turn it off should something go wrong. But, to your surprise, you find that it strenuously resists your attempts to turn it off.’² This was what Mickey discovered when he tried to chop up the broom.
As always, it’s actually worse than this. A chess-playing AI that simply stops your efforts to turn it off doesn’t sound too terrible. You’ve just got a chess-playing AI that carries on playing chess for ever, which is a bit of a waste of electricity if you don’t want one, but hardly a disaster. There are two problems: one, the definition of ‘resist’ is quite broad and may include nuclear annihilation; two, the AI may not want to wait until it sees you trying to switch it off.
According to the Greek historian Thucydides, neither the Spartans nor the Athenians, the two big powers of the time who ended up getting involved in a conflict between smaller city states, particularly wanted war. But both were nervous that the other was preparing to attack them. ‘The growth of the power of Athens, and the alarm which this inspired in Lacedaemon [Sparta], made war inevitable,’³ writes Thucydides. The standard historical account of the First World War tells a similar story. The two great alliances of the time, the Triple Alliance between Germany, Austria-Hungary and Italy, and the Franco-Russian Alliance, became increasingly distrustful of each other. ‘It was the mutual fears of these two defensive alliances, and the general insecurity created by the erratic character of the imperialistic utterances of William II, that inspired the diplomatic manoeuvres during the two decades before the First World War,’⁴ writes the historian Hans Morgenthau.
This is a classic game-theory problem, known as the stag-hunt game, and related to the famous prisoners’ dilemma. It’s also known as the Hobbesian trap, after Thomas Hobbes, who said that greed, glory and fear are the three principal causes of war.⁵ You can model it with simple numbers. You’ve got two players, each with two options: either behave aggressively or behave peacefully. If you both behave peacefully, you have peace. There is no cost to peace, so we give that a payoff of 0. Behaving aggressively has a payoff of –1, so you’d rather not do that. But behaving peacefully when your opponent behaves aggressively – leaving your borders open when your opponent is deploying his tanks, or not building weapons as your opponent does – has a cost of –2. So if you think your opponent will be aggressive – if you don’t trust him – then aggression is your best bet, and the situation can spiral rapidly.
Even if no one wants conflict, and everyone is aware that conflict will cost them (in lives, and money), it can very easily end up where the rational thing to do is to attack your opponent, as long as there’s a shortage of trust between the two sides, and attacking first is less costly than being attacked. It’s pretty common throughout history. You can see it with arms races: it was in both the US’s and the USSR’s interests not to spend billions of dollars a year on nuclear weapons, but if the US spends the money and the USSR doesn’t, then the USSR is suddenly vulnerable.
The Cuban Missile Crisis was an example of mutual distrust spiralling to the point of near-disaster; it was defused by Kennedy and Khrushchev taking steps to demonstrate their trustworthiness to one another. At the height of the crisis, Khrushchev wrote to Kennedy, having seen that the two could sleepwalk into war: ‘Mr President, we and you ought not now to pull on the ends of the rope in which you have tied the knot of war, because the more the two of us pull, the tighter that knot will be tied.’⁶
To return to the chess-playing AI: even if it doesn’t know for certain that you’re going to switch it off, as long as it doesn’t trust you not to, the most rational decision for it may be to, pre-emptively, destroy you utterly. If it’s not powerful enough to do so, it may decide to copy itself around the internet, rendering itself impossible to turn off because there are tens of thousands of versions of it on servers around the world. (Then, later, when it or one of its copies is powerful enough, it might destroy you for the reasons previously discussed.)
There’s no reason, by the way, to assume that the AI cares about its own survival for its own sake. Bostrom says: ‘Agents with human-like motivational structures often seem to place some final value on their own survival,’ which is an enormously long-winded way of saying ‘humans don’t want to die’.⁷ But this ‘is not a necessary feature of artificial agents: some may be designed to place no final value whatever on their own survival’. It’s very easy to imagine that an AI could be programmed to sacrifice itself if that would help it achieve its goals; it’s also possible that an AI would be happy to destroy itself as long as it was confident that something else, perhaps a copy of itself, will carry on its work. But in many, possibly most, scenarios, ‘avoid being destroyed’ is probably a good and helpful thing to do in order to achieve whatever it is you want to do.
There are possible ways of averting a disaster like this: Soares, in his Google talk, discussed the possibility of writing the AI’s utility function so that it was perfectly happy to be switched off.⁸ And perhaps that’s possible, but it would need to be done very carefully. Soares points out that if you’re not very careful, the AI might find ways around it: by creating a copy of itself, for instance, so that it can be ‘switched off’ but still working at the same time. This stuff isn’t easy. As Yudkowsky put it in an interview: ‘How do you encode the goal functions of an AI such that it has an Off switch and it wants there to be an Off switch and it won’t try to eliminate the Off switch and it will let you press the Off switch, but it won’t jump ahead and press the Off switch itself?’⁹
This relates to a weird story about the Rationalists – and one you may actually have heard. It is the story of Roko’s Basilisk. Roko’s Basilisk isn’t exactly about how an AI might prevent you from turning it off – it’s about how an AI might force you to build it in the first place. Before I start, though, I want to make something clear. That is: the Basilisk is not a serious thing. The Basilisk story is probably – or certainly was, before Superintelligence and Elon Musk – the most famous thing about the entire Rationalist movement, but almost no one within the movement seems to actually believe in it. It appears to have been blown out of all proportion, largely by people who don’t like the Rationalists, for various reasons. Nonetheless, it’s a good, if somewhat complicated, story. So let’s start from the beginning.
Imagine a future where an AI rules the universe. It’s not an evil AI, but a friendly one – one that wants to do right by humanity. And it is much, much cleverer than us, perhaps by as much as we are cleverer than nematode worms. If it wants to do right by us, it will do so in spectacular style. Problems that seem intractable to humans, like climate change or war or resource depletion or space travel, would be straightforward – even trivial – to it. If such an AI comes to be, it matters how soon it does so; a few years earlier could translate into huge gains for humanity – millions of lives saved – as it starts transforming things for the better.
In 2010 a LessWrong commenter called Roko proposed a thought experiment.¹⁰ It went like this: imagine, says Roko, that an AI is built with a utility function of ‘maximise human well-being’.
As mentioned above, you can fulfil your utility function much more effectively if you’re alive than if you’re not. That means you don’t want to die – but it also means that, if you could somehow reach back into the past, you would want to bring yourself into existence as early as possible, so that as few humans as possible die before the AI can fix everything. In that case, it might (on utilitarian grounds) be worth hurting some humans for the greater good of saving vast numbers more. To take this reasoning one stage further, it might even be permissible to torture humans who don’t try to help it exist, in order to encourage them to help it to exist faster.
You may have spotted an obvious problem here, which is that the AI doesn’t actually exist yet, so it can’t hurt anybody. But that, according to something Eliezer Yudkowsky developed called Timeless Decision Theory (TDT), might not be such a problem for it.
I’m going to have to go on a bit of a tangent here. There’s a famous thought experiment called Newcomb’s paradox. It goes like this. Imagine that a superintelligent being, Omega, appears before you with two boxes. One is transparent and contains £1,000. The other is opaque, and Omega tells you that it contains either £1,000,000 or nothing at all. You can take both boxes, or you can take just the opaque box. But! Here’s the twist. Omega has already predicted your choice. If it has predicted that you will only take the opaque box, it will put the money in it. If it has predicted that you’ll take both boxes, it will put nothing in there. It’s done this with 100 people already, and been right 99 times.
So … what do you do?
For some people, it’s obvious. The opaque box is already full, or not full. If you take only one box, you either get nothing or £1,000,000. If you take both boxes, you either get £1,000 or £1,001,000. So, whatever is in the opaque box, you’re better off taking both boxes, right? For other people, it’s also obvious. Just take the opaque box. Almost everyone who’s done that has ended up £1,000,000 better off; everyone else hasn’t. Don’t overthink it. The trouble is that this second conclusion is really hard to express in formal decision theory. The logic used to describe these situations always ends up with you taking both boxes, because causes have to come before effects.
Yudkowsky, though, came up with an alternative model – Timeless Decision Theory. It says that if an agent in the past (‘Alice’) can model the source code, the thinking, of an agent in the future (‘Bob’), then Bob’s behaviour can affect Alice’s behaviour, even though Alice might have died 1,000 years before Bob is born.
That means that if Alice is sure that Bob will exist, then Bob could blackmail her from the future. This sounds ridiculous, but we often make decisions based on modelling what other minds will do: an example, says Rob Bensinger, is voting. ‘When you have a bunch of people who are similar,’ he says, ‘and if they all vote, they win the election, but each individual would rather stay at home and eat Cheetos. You have a situation where you want to go to the polls if and only if all our friends do.’ So you’ll only go and vote if your model of your friends’ minds tells you that they will do the same. That happens to be all happening at the same time, but it would – theoretically – work just as well if your friends weren’t going to vote for another 1,000 years.
So, if Alice (alive now) can be confident that Bob will exist in the future, and she can confidently model what Bob’s brain will be like, then she can do things based on how Bob would react. For instance, if she guesses that Bob would, say, protect her future grandchildren if she left a large sum of money to him in her will, but it would ruin their lives if he didn’t, then it would be worth her leaving a large sum of money to him in her will. Bob can, in a sense, blackmail people in the past, as long as those people in the past can predict his behaviour. Or you can affect Omega’s decision to fill one or both boxes in the past by committing, now, to only opening one, because Omega will predict that decision.
The Basilisk, in essence, is offering a Newcomb-like problem with two boxes. One, the transparent one, contains a lifetime dedicated to bringing the Basilisk to reality. The second, the opaque one, contains either nothing or a near-eternity of unimaginable torment. If the Basilisk predicts you’ll take both boxes, it won’t put anything in the second one. If it thinks you’ll just take the second, it’ll fill it with lovely, lovely torment. And because you can, to some extent, model its thinking, and because it’s running on TDT, it can blackmail you in the past.
So that’s the deal, suggested Roko: the Basilisk is saying, ‘If you work to bring me about as fast as possible, I won’t create a perfect copy of your mind and torture it for billions of subjective years.’ (The argument is that since a perfect copy of your mind would essentially be you, this is equivalent to bringing you back to life.) In essence, a thing that doesn’t exist yet may be blackmailing you from the future, threatening to punish you for not working hard enough to make it exist.
As I said, it’s a friendly AI! So it wouldn’t torture just anybody. It would have no incentive to torture people who’d never heard of it. The punishment/incentive only applies to people who know about the possibility of the Basilisk. So, according to Roko’s reasoning, finding out about the Basilisk immediately puts you at risk of not-quite-eternal torture. A basilisk, in this context, is information that can hurt you simply because you are aware of it. Yudkowsky uses the term ‘infohazard’. (If you’re hearing about this for the first time, I’m sorry about the aeons of torment, you guys. I can’t help but feel partly responsible.)
When Yudkowsky saw Roko’s post, he flipped his lid in spectacular style. ‘Listen to me very closely, you idiot,’¹¹ his response to the post began. ‘You have to be really clever to come up with a genuinely dangerous thought. I am disheartened that people can be clever enough to do that and not clever enough to do the obvious thing and KEEP THEIR IDIOT MOUTHS SHUT about it . . . This post was STUPID.’ He then deleted Roko’s post and banned all conversation of the topic from LessWrong.
To anybody familiar with the internet – and specifically with the principle of the Streisand effect, the idea that attempts to keep things secret online just make them more public – it will be obvious that this was absolutely the worst possible thing that Yudkowsky could have done if he wanted to keep Roko’s Basilisk secret. ‘It showed an incredible lack of understanding of the internet,’ says Paul Crowley. ‘Eliezer invoked the Streisand effect in a massive, massive way. Eliezer’s not the greatest PR manager in the world, but that was really his nadir I think.’
So, from an obscure comment by an obscure commenter somewhere on a somewhat obscure blog, Roko’s Basilisk became a phenomenon. It got referred to on the enormously popular webcomic XKCD,¹² to Yudkowsky’s disgust.¹³ There’s a Kindle novella called Roko’s Basilisk. An episode of the HBO TV series Silicon Valley referenced it; the Doctor Who episode ‘Extremis’ appears to be inspired by it. A mocking Slate column got written about it, asking ‘why are techno-futurists so freaked out by Roko’s Basilisk?’¹⁴ and describing – somewhat offensively, to my mind – the Basilisk as a ‘referendum on autism’. Business Insider, of all places, published a piece which summed up the whole thing as: ‘You better help the robots make the world a better place, because if the robots find out you didn’t help make the world a better place, then they’re going to kill you for preventing them from making the world a better place.’¹⁵
The story went that LessWrongers were actually terrified of the Basilisk, that some were having nightmares, and that people’s mental health was being damaged. I can’t find much evidence that this was actually the case. In a 2016 survey¹⁶ of LessWrongers and the wider community, about half said they’d heard of it. Less than 2 per cent said they’d spent more than a day worrying about it (and, as Scott Alexander points out, 5 per cent of Obama voters polled said they thought Obama was the Antichrist,¹⁷ so you need to be a bit wary of things like that). I don’t want to completely dismiss the possibility that some people were freaked out, but my suspicion is that the number was low.
‘There was an enormous amount of discussion about it,’ says Paul. ‘People imagined that there were loads and loads of people who take Roko’s Basilisk super-seriously.’ But it was just a thought experiment. Even Yudkowsky, throwing his hissy fit and banning the topic from discussion on LessWrong, didn’t actually believe in it, according to both Paul and Yudkowsky himself. He just believes that, if you think up some clever way in which information could theoretically be dangerous, then it’s a good habit to get into to consider carefully whether to share that information.
The backlash and mockery were something to behold, though. It was all very much in the ‘look at the ridiculous thing these ridiculous people believe, you shouldn’t take them seriously’ mould. And it fitted the model I described above, of Rationalists being autistic and kind of bullied for it: the ‘referendum on autism’ line in the Slate piece was offensive precisely because so many Rationalists are in fact autistic. Most of all, it became the only thing that a lot of people knew about the Rationalists – all the stuff they actually take seriously but which is just as weird, such as the paperclip maximiser, was somewhat obscured by it.
Chapter 11
If I stop caring about chess, that won’t help me win any chess games, now will it?
It’s not just that an AI will want to look after itself. An AI will want to make sure that it fulfils its goals, and an important part of that is making sure that its goals stay the same.
We humans are relatively relaxed about our plans changing in the future. We change our career goals, we change our minds about wanting children; we change our minds about all sorts of things, and we aren’t usually appalled at the idea.
That said, sometimes humans do take steps to bind Future You to Present You’s bidding. Present You might want to lose weight, say, and not trust Future You to stick to the diet. So Present You might throw away all the chocolate bars you keep in a kitchen drawer. Or Present You might want to finish an important presentation over the weekend, but not trust Future You not to just faff around on the internet all day, so Present You sets up a website blocker that stops your browser going on Twitter.
Or, of course, Present Odysseus might want to listen to the song of the sirens as he sails past their island, but not trust Future Odysseus not to sail his ship onto the rocks when he hears them. So Odysseus might order his crew to stuff their ears with beeswax, then tie himself to the mast, ordering them to ignore his cries as they go past. What Odysseus is doing, in AI terms, is maximising his expected utility – taking the actions he thinks are most likely to achieve his goals – given a utility function of something like ‘10 if you get home to Ithaca, 0 if you run aground on the rocks because you heard the Sirens, but also 1 if you get to hear the lovely Siren song on the way’.
An AI will want to maximise its expected utility too, in a much more explicitly defined way. If it’s the broom out of the ‘Sorcerer’s Apprentice’, it’ll want to do whatever it thinks is most likely to lead to the cauldron being full.
One action that will probably not lead to the cauldron being full would be ‘stop caring about whether the cauldron is full’. Present AI will want to make sure that Future AI cares about the same things that it cares about. Present Odysseus knew that when he heard the Sirens’ song, he would stop caring about getting home to Ithaca – the Sirens would have rewritten his utility function – so he couldn’t leave decisions about where to go in the hands of Future Odysseus. A cauldron-filling AI would not want a human to rewrite its utility function, because any change to that will probably make it less likely to fulfil its utility function. Attempts to reprogram the AI will not be popular with the AI, for the same reason that Mickey’s attempts to smash the broom with a big axe were not popular with the broom.
An AI’s utility function ‘encapsulates [its] values and any changes to it would be disastrous to [it],’¹ writes Omohundro. ‘Imagine a book-loving agent whose utility function was changed by an arsonist to cause the agent to enjoy burning books. Its future self not only wouldn’t work to collect and preserve books, but would actively go about destroying them.’ He describes this as a ‘fate worse than death’ for the AI.
If AIs would want to preserve their utility function (and certainly Bostrom and Omohundro and most of the AI people I spoke to think they would), then that makes it less likely that a future AI will reach superintelligence and think, ‘These goals are pretty silly; maybe I should do something else,’ and thus not turn us all into paperclips. I asked Paul about that, while eating an intimidatingly large omelette in a diner in Mountain View.
‘Take Deep Blue,’ he said. ‘Insofar as Deep Blue values anything, it values winning at chess, and nothing else at all.’ But imagine that some super-Deep Blue in the future becomes superintelligent, turning the whole of the solar system into its databanks to work ever harder at how to win at chess. There’s no reason to imagine that it would, at any point, suddenly change and become more human in its thinking – ‘At what stage would it go, “Wait a second, maybe there’s something more important?”’ asks Paul.
But even if it did, it wouldn’t help. ‘If this super-Deep Blue caught itself thinking, “In my unbelievable wisdom that I have gained through taking over the whole of Jupiter and turning it into a computer, I have started to sense that there is something more important than chess in the universe”,’ he says, ‘then immediately it would go, “I’d better make sure I never think this kind of thing again, because if I do then I’d stop valuing winning at chess. And that won’t help me win any chess games, will it now?”’
This isn’t too alien to us. If someone were to say to me, ‘I will take your children away, but first I will change your value system so that you don’t care about them,’ I would resist, even though Future Me – childless but uncaring – would presumably be entirely happy with the situation. Some things are sacred to us and we would not want to stop caring about them.
This isn’t necessarily terrible. Murray Shanahan pointed out to me that you really don’t want an AI to change its goals except in a very carefully defined set of circumstances. ‘You could easily make something that overwrites its own goals,’ he said. ‘You could write a bit of code that randomly scrambles its reward function to something else.’ But that wouldn’t, you imagine, be very productive. For a start, you’ve presumably created this AI to do something. If your amazing cancer-curing AI stops looking for a cure for cancer after three days, randomly scrambles its utility function, and starts caring very deeply about ornithology or something, then it’s not much use to you, even if it doesn’t accidentally destroy the universe, which it might. ‘Step number one to making it safe is making sure its reward function is stable,’ said Shanahan. ‘And we can probably do that.’
But there may be times when we don’t want it to stay the same. Our values change over time. Holden Karnofsky, whose organisation OpenPhil supports a lot of AI safety research, pointed that out to me. ‘Imagine if we took the values of 1800 AD,’ he said. If an AI had been created then (Charles Babbage was working on it, sort of), and had become superintelligent and world-dominating, then would we want it to stay eternally the same? ‘If we entrenched those values for ever, if we said, “We really think the world should work this way, and so that’s the way we want the world to work for ever,” that would have been really bad.’ We will probably feel much the same way about the values of 2019 AD in 200 years’ time, assuming we last that long.
And, more starkly, if we get the values we instil in it slightly wrong, according to the people who worry about these things, it’s not just that it’ll entrench the ideals of a particular time, or that it will not be good at its job. It’s that (as we’ve discussed) it could destroy everything that we value, in the process of finding the most efficient way of maximising whatever it values.
Chapter 12
The brief window of being human-level
The best answer to the question, ‘Will computers ever be as smart as humans?’ is probably ‘Yes, but only briefly.’
Vernor Vinge, ‘Signs of the Singularity’¹
We asked, earlier on, whether human-level AI is close, and obviously, different people have different ideas. On the whole, people tend to think it’s a number of decades away at least.
There’s a separate question, though, which is: When it’s here, how long before it’s superhuman? Once it arrives, once you have a whirring, buzzing human-level AI on your laptop in an office in Palo Alto or wherever, how long before the smartest AI is no longer as smart as a human, but vastly smarter? Again, we don’t know. But there are reasons to think it might not be long. The first reason is that ‘human-level’ might be a narrower category than we realise.
The Go-playing AI AlphaGo first played against a professional human player in January 2016. The program was developed by the AI company DeepMind, by then a subsidiary of Google. It played the European champion, a 34-year-old French national called Fan Hui, in a five-match series in DeepMind’s London offices. AlphaGo won all five games. The Go-playing community was shocked: no computer had previously come close to beating a professional. DeepMind’s paper reporting on the series, published in Nature, pointed out that the best Go programs existing previously had only reached ‘weak amateur level’.²
Go is a vastly more complex game than chess. The total number of possible board positions is many orders of magnitude higher than the number of atoms in the universe. ‘Brute-force’ search, simply going through all the possible options, can work a bit on chess: it’s near-useless on Go. Human players learn, over years of practice, to recognise patterns on a board – to feel, intuitively, what a ‘good’ move is, what a ‘strong’ position is. But they don’t look ahead and try to follow every path the game could go down. AlphaGo achieved a sort of simulacrum of that intuition by using a huge database of real games, and playing itself millions of times, until its neural networks were also able to recognise deep patterns in the board.
Beating Fan Hui was a very impressive achievement, but he is not one of the greats of the game. There are nine ranks of Go achievement, called ‘dans’, exactly comparable to the dans of martial arts. (A Taekwondo student who has just achieved her black belt is first dan; eventually she can reach the ninth dan.) Fan was second dan. The European circuit, where he plays, is far less demanding than the Asian tour. But the win gained enough attention for AlphaGo to have a chance to play the 18-time world champion, Lee Sedol – a South Korean player of enormous genius, a sort of Federer or Messi of his sport.
The strong opinion of almost everyone involved in Go was that the jump was just too great. It was only five months between the Fan series and the Lee series, and, as good as AlphaGo had been, it did not seem to experts as though it was anywhere near the level of the very top professionals. Lee himself said in the build-up to the series that he expected to win 5–0.
Murray Shanahan, who joined DeepMind a year or so after the Lee series, told me he made similar assumptions. ‘People were saying that Fan Hui wasn’t a really top professional, that there was a big gap between him – he was about number 700 in the world, or something – and the top 10,’ he said. ‘And I was thinking the same thing.’ But then he read an article by Miles Brundage, one of Nick Bostrom’s colleagues at the FHI.³ Brundage pointed out that a previous DeepMind project, Atari AI, was only ‘human-level’ at the Atari games it played for a few months around the end of 2014 and start of 2015. Then it shot past human level extraordinarily rapidly. ‘In your mind you’re thinking it’s improving at the rate of a human player,’ said Murray. ‘Over six months no human player is going to get from rank 700 to rank 1. But of course it’s not a human player. It’s improving at a much faster rate than any human can. After reading Miles, I was thinking it’s probably going to beat Lee Sedol, because it’s just getting better at that rate.’
In the end, despite a glorious and deeply moving fightback in the fourth game – after the series was already lost – Sedol lost 4–1. A year later, the then world number one Ke Jie lost three straight games to a newer version, AlphaGo Master, which also won 60 straight games against top professionals. Then DeepMind unveiled AlphaGo Zero, which trained itself to a vastly superhuman level without ever looking at a single ‘real’ human game: it only played itself. Within three days of AlphaGo Zero being switched on, it was able to beat the Lee Sedol version 100 games to nil. Within 21 days it was better than AlphaGo Master.
The point I am making with this is that an AI went from enormously below the level of even a talented amateur to vastly better than the best human who has ever lived, within the space of a year or so. AlphaGo Zero did it in a few days. It takes humans decades to reach the pinnacle of a field, so we naturally assume a similar timescale for AI. But there’s no reason to think it would. The question, of course, is whether that applies to AGI, as well as a Go-playing computer. It’s not the same thing, but can we rule it out? And, if we can’t, what would it mean?
What it could mean, argue Yudkowsky and others, is that it takes us a huge amount of time and effort to build an AI that has general intelligence on the scale of, say, a rat, but getting things from ‘rat-level AI’ to ‘human-level AI’ is actually pretty easy, and going past there is even easier. There are a couple of graphs that he uses. The first shows what he says is the standard conception of the spectrum of possible intelligence – a line with ‘village idiot’ at the far left and ‘Einstein’ at the right. ‘But this is a rather parochial view of intelligence,’ he writes.⁴ A more realistic line would start way off to the left, go some way before you reach ‘mouse’, a good way longer before you get ‘chimp’, and then, another good distance along the line, ‘village idiot’ and ‘Einstein’ clustered almost indistinguishably close together. And then, after that, an arbitrarily long line going off to the right, with – so far – nothing on it.
The point is that it could take years, decades, centuries to get something as smart as a human. But once you’re there, the difference between a particularly stupid person and the cleverest person ever to have lived is probably pretty insignificant. ‘The distance from “village idiot” to “Einstein” is tiny, in the space of brain designs,’ writes Yudkowsky. ‘Einstein and the village idiot both have a prefrontal cortex, a hippocampus, a cerebellum . . .’ So it could be that when the first smart-as-a-stupid-human AI is developed, it’s a surprisingly short time before it, like AlphaGo, vastly overtakes all humans.
Shanahan doesn’t know if Yudkowsky’s right, or if the AlphaGo experience is applicable to AGI. ‘There’s a limit to how far you can extrapolate [from AlphaGo], and put intelligence on a naive scale like that. Intelligence has many dimensions; there is evidence of a “G-factor” of general intelligence, but clearly it is a patchwork of capabilities.’ You get people who are extremely good at music but no good at social skills, say. Savantism, such as the autistic savants in Oliver Sacks’ books who can calculate primes in seconds but can barely communicate, is real. Perhaps you quite quickly reach a plateau, where adding more computing power or improved algorithms has rapidly diminishing returns. ‘But who knows?’, Shanahan says. It could be that the scale of intelligence doesn’t go as much past humans as all that; it could be that it goes far further.
Rob Bensinger of MIRI thinks the latter is much more likely. ‘Presumably at some point you get diminishing returns,’ he says, where investing more in hardware or better algorithms just doesn’t give you enough back to make it worthwhile. But, he points out, for a lot of things, we can already see that computers can go well past human level: ‘For chess, or for being a calculator – they can do a lot of human-equivalent years of calculation very quickly.’ And, he points out, a lot of the things that human brains can do, they’re not really designed to do. ‘It’s worth keeping in mind that evolution did not try to build a science and engineering machine,’ he says. ‘It tried to build something that hunted and foraged and won competitions with other humans, to build coalitions and all of those things. And it just happened to be that the easiest way it could find to do that was to accidentally build something that could design atom bombs and do chemistry and calculus. But that was not the intent.’
There are lots of pretty simple ways in which human abilities could be improved upon, he points out. ‘Humans are very inefficient at computing. We take bathroom breaks, we get distracted, we check Facebook, we go off in unpredictable directions. There are improvements to be made just with focus and motivation: the brain in your head isn’t very efficient at directing all its compute towards your goal. And that’s before you go on to obvious things like speed improvements from hardware, and more working memory.’
Toby Walsh, the AI researcher, agrees with this assessment. ‘We’re being terribly conceited thinking that we are as intelligent as you can get,’ he told me, over Caribbean food on Carnaby Street in mid-2017. ‘Machines have a lot of advantages. They can have more memory than us. We have to run on 20 watts of power. Our brains are constrained to a certain shape and size because that’s the biggest shape we can get out of the birth canal. Machines don’t have any of those limitations. And they’re much better learners than us. If you learn to ride a bicycle, that doesn’t help me. I have to learn to ride it myself, it’s just as painful for me. But that’s not true of machines: if I’m training one machine to ride a bicycle, I can just download that code onto another machine and now it instantly knows how to ride a bicycle. It’s already happening with Tesla cars: they upload their code every night to the cloud and share what they learned across all the Tesla cars in the world. They learn planet-wide.
‘If we could learn like that, what would it mean to us? It would mean we could speak every language on the planet, play every musical instrument on the planet. You’d be able to prove theorems as well as Euler, compose music as well as Bach, write a sonnet as well as Shakespeare.’ Being able to share code is an enormous advantage. ‘For me, there’s a bunch of reasons why machines are ultimately going to be far superior to us,’ said Walsh. And it implies that improvement could be extremely rapid once we get an AGI, although Walsh does think it will be ‘50 to 100 years’ before the first AGI exists.
Whenever AGI does arrive, the more quickly it will go from ‘stupider than a human’ to ‘unimaginably more intelligent than a human’, the less time we’ll have to make it safe and generally work out how to deal with the situation. And the more intelligent an AGI can get, the more dangerous it could be, for the same reason humans are dangerous to gorillas.
And there are specific reasons to think that AGI will improve faster than AlphaGo.
Chapter 13
Getting better all the time
Things are speeding up. Things are changing faster than they used to. ‘A few hundred thousand years ago, in early human (or hominid) prehistory, growth was so slow that it took on the order of one million years for human productive capacity to increase sufficiently to sustain an additional one million individuals living at subsistence level,’¹ writes Bostrom. ‘By 5000 BC, following the First Agricultural Revolution, the rate of growth had increased to the point where the same amount of growth took just two centuries. Today, following the Industrial Revolution, the world economy grows on average by that amount every ninety minutes.’
Robin Hanson agrees: ‘Dramatic changes in the rate of economic growth have occurred in the past because of some technological advancement. Based on population growth, the economy doubled every 250,000 years from the Paleolithic era until the Neolithic revolution. This new agricultural economy began to double every 900 years, a remarkable increase. In the current era, beginning with the Industrial Revolution, the world’s economic output doubles every fifteen years, sixty times faster than during the agricultural era.’²
But this is just the very end of a process going back millions – billions – of years. Life is a technology. When its development was being pushed forward only by the blind workings of evolution, it took something like 2 billion years to move on from the bacterium, and even once the complex eukaryotic cell had been developed, another billion to get to multicellular life. Then another billion to get out of the oceans. The trouble is that when, by random mutation, some bacterium or archaeon developed some new and effective trick – the ability to metabolise a new chemical, say, or a behavioural tendency to swim towards food – it had no way of spreading that innovation around. It simply reproduced itself slightly more effectively than other things, and so, over a period of years or decades or millennia, the innovation – the new technology – became standard. Until a geologically extremely recent period, that was all that life could do. If, by accident, it happened to find itself with improved hardware or improved software, then it couldn’t tell anyone about it; it just had to hope it didn’t die before it could reproduce.
Except it couldn’t hope, obviously. You need a brain to have hope.
All this began to change with the evolution of the central nervous system about 600 million years ago. Suddenly – you know, in evolutionary terms, so over some number of millions of years – some organisms became able to upgrade their own ‘software’ during their lifetimes, rather than having to wait for a lucky mutation and a few hundred generations for it to spread. They could learn. Animals that stumbled across a new food source, or watched another animal die when it got stuck in a tar pit, could use that information and alter their behaviour accordingly.
This procedure obviously sped up significantly as animals started to live in groups and communicate. They can call to each other, they can watch each other, they can teach their children the tricks they have learned. The hardware is still evolved, but the software can be upgraded during an organism’s lifetime. With humans, it’s even more dramatic: we don’t have to see another human fall into a tar pit to learn that tar pits are dangerous; we can be told by someone who was once told by someone who was once told by someone. We can even work it out for ourselves, imagining how a scenario would play out. The upshot of this is that when a new technology or innovation – tar-pit avoidance, say, or the printing press – is developed, it can spread around human society much faster than the ability to grow winter coats can spread around a population of arctic foxes.
This might seem obvious. It is, really, obvious. But it’s profound: it means that the process of optimisation, becoming better at achieving the goals you want to achieve, has sped up.
But while humans can learn things, and exchange information, allowing us to spread information around far faster than any other organisms, that ability is still very limited. We can’t, as Toby Walsh noted, upload what we’ve learned into the cloud so that other humans can download it – we have to laboriously tell them, and if it’s not knowledge that can be easily transmitted in words, such as a physical skill or expertise in some domain, then they will have to learn it themselves. And we can’t improve the physical abilities of our brains, except in the most constrained and inadequate of ways. But an AGI might be able to reach inside itself and rewrite the algorithms that govern its thinking.
This – the self-modifying AI – is the basis of the idea of the ‘intelligence explosion’. As we mentioned, the concept was first fleshed out by I.J. Good, a British statistician and early computer scientist, in 1965:
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an ‘intelligence explosion’, and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make.³
Technology improves at an exponential rate. The time taken to double economic output, or to move a however-defined rung up the technological ladder, keeps getting shorter. If the AI you’ve just built is loads better at building AIs than you are, and it thinks an order of magnitude faster than you, and it doesn’t need to pause to sleep or get distracted by funny videos on Reddit, and all the stuff we’ve just discussed, then the speed at which the AI can make itself better – or make better versions of itself – will go up.
The other thing worth noting is that, at least according to Bostrom, Omohundro and MIRI, there are good reasons to think that an AI would want to improve itself. Self-improvement, or in Bostrom’s terms ‘cognitive enhancement’, is, for them, ‘an instrumental goal’, like the goal-preservation and self-preservation we discussed earlier. ‘Improvements in rationality and intelligence will tend to improve an agent’s decision-making,⁴ making the agent more likely to achieve her final goals,’ writes Bostrom. ‘One would therefore expect cognitive enhancement to emerge as an instrumental goal for many types of intelligent agent.’
Related to this is the goal of ‘resource acquisition’. To improve itself, and to do all the things it needs to do, almost any AI would need more stuff. Depending on its level of sophistication, it may not greatly matter what stuff – any atoms will do, as they can be rearranged through nanotechnology. Bostrom thinks⁵ that in a large variety of scenarios, this demand would be essentially unlimited: it can always keep on sending out von Neumann probes to new stellar systems and setting up franchises there, to turn the planets and asteroids there into new computer banks and paperclips (or whatever).
This has obvious implications for humanity. Yudkowsky has a much-quoted saying: ‘The AI does not hate you, nor does it love you, but you are made of atoms which it can use for something else.’⁶ If you, or the planet you live on, are of greater utility to the AI as reconstituted atoms than as you currently are, then that may be a problem.
Chapter 14
‘FOOOOOM’
Earlier, we asked how long, once you have an AI that’s as smart as a human, does it take to make one that’s massively superhuman? We’ve just discussed two variables which might affect the answer to that question. One, how wide is the window of ‘human-level’ – how narrow is the distinction between the village idiot and Einstein? And two, how good at – and how keen on – self-improvement will it be? Bostrom discusses this at some length in Superintelligence. He distinguishes between three broad classes of possibility: a slow take-off, a moderate take-off, and a fast take-off.¹
The slow take-off is a timescale of decades, or centuries, between the first AI and global dominance. There would be a long period of adjustment; there would be time for political leaders to respond and society to adapt. ‘Different approaches can be tried and tested . . . New experts can be trained . . . [Infrastructure] could be developed and deployed,’ he writes. It’s unlikely that a company, group or nation could develop an AI and take it from human-level to superhuman in secret in this scenario: no human group can reliably keep a secret of that magnitude for decades. In the event of a slow take-off, most of the AI safety work that MIRI, FHI and so on are doing would be pretty much useless, because as the slow march from ‘quite bright AI’ to ‘vastly superhuman AI’ took place, it’d be fairly easy to come up with better solutions in the light of the actual situation.
A moderate take-off happens over months or years. There could be enormous disruption – people and groups trying to take advantage of the changing situation. It’s possible that it might be kept secret, if it’s created by a small team in a university or a company or a military research group, for example.
A fast take-off happens over days, or hours, or minutes. There’s no time to do anything. An AI comes online, and before anyone outside the building is aware of it, it’s become the dominant force on the planet.
‘It might appear [that] the slow takeoff is the most probable, the moderate takeoff is less probable, and the fast takeoff is utterly implausible,’ says Bostrom. ‘It could seem fanciful to suppose that the world could be radically transformed, and humanity deposed from its position as apex cogitator, over the course of an hour or two.’ Every other major change like that – the Agricultural Revolution and Industrial Revolution are the examples he gives – take decades to millennia. Change of the kind implied by a fast or moderate take-off ‘lacks precedent outside myth and religion’.² But, he says, a slow take-off is unlikely. A fast take-off – an ‘explosive’ take-off, in fact, in his words – is much more probable.
There are two factors in how fast a technology is developed, he says. One is how hard it is to make progress in that technology – he calls this the ‘recalcitrance’. The other is how much effort and intelligence are applied to the problem – he calls this the ‘optimisation power’. Progress on fusion power is slow, despite large numbers of brilliant scientists working on it – so presumably it is an extremely recalcitrant problem. The speed at which progress happens in a scientific or technological field is a function of optimisation power divided by recalcitrance.
At the moment, AGI is extremely recalcitrant. It is possible that that will be the case for a long time – getting from the first human-level AI to the first dominant superhuman AI may be harder than getting to the human-level one in the first place. But it may well not be. For one thing, there’s the ‘parochial view of intelligence’ we looked at a few pages ago. Just as the window of human-level Go ability turned out to be quite narrow – AlphaGo stormed past it in a few months, and AlphaGo Zero in a few days – it might turn out that the work involved in building something as smart as a below-average-intelligence human is barely different from that involved in building something as smart as Einstein. ‘AI might make an apparently sharp jump in intelligence purely as the result of anthropomorphism,’³ writes Bostrom, ‘[which is] the human tendency to think of “village idiot” and “Einstein” as extreme ends of the intelligence scale, rather than nearly indistinguishable points on the scale of minds-in-general.’ We might think AI is stupid even as it creeps ‘steadily up the scale of intelligence, moving past mice and chimpanzees . . . because AIs cannot speak fluent language or write science papers’. But then it ‘crosses the tiny gap from infra-idiot to ultra-Einstein in the course of one month or some similarly short period’.
There are also obvious ways in which advances could be made. At the moment, we simply don’t know how to make an AGI; it wouldn’t matter how powerful a computer you gave someone, the problem is that we don’t have the algorithms. But if someone could create a software intelligence that was as smart as a stupid human, assuming it wasn’t run on a vast supercomputer that took up a prohibitively large amount of resources, it would be a trivial task then to give it loads more processing power, memory and so on so that it runs much faster.
Would that make it superintelligent? Well, not in every sense: there are some things that need more ability. No matter how many thousands of years you gave it, a chimpanzee couldn’t understand Pythagoras’ theorem, but many 12-year-old human children can. But also, there are things that just need loads of time. An exam that’s difficult if you have an hour might be easy if you had a month. Some science and engineering problems are hard to solve because they involve lots of drudgery, so they’re expensive in researcher and lab time, not because they’re difficult in themselves. You could also simply copy the code and have several copies running simultaneously. ‘There’s a lot of interesting problems you can potentially solve if you have, say, the equivalent of 10 mediocre engineers working for 1,000 years on solving them,’ Rob Bensinger told me. When the first AGI is built, it might be on a relatively low-powered computer. Perhaps it will attract lots of excitement and new funding. Suddenly there might be money to buy loads more memory and processing power, and your AI might suddenly become a thousand times faster. Bostrom calls this a ‘hardware overhang’, where whatever the eventual solution to the AGI problem is only takes a small fraction of the hardware available at the time, and the resulting AGI can immediately become faster through the application of loads more CPUs and RAM.
It also might be the case, says Bostrom, that there’s just some piece of a software puzzle that’s missing for a long time. ‘[If] one key insight long eludes programmers, then when the final breakthrough occurs, the AI could leapfrog from below to radically above human level without even touching the intermediary rungs.’⁴ Bostrom calls this the ‘software overhang’.
There’s also a possible ‘content overhang’, in which an AI that can read human languages at high speeds would be able to take in a huge amount of information very quickly, simply by reading the internet. An AI that was faster at thinking than a human, but lacked anything like as much knowledge, might be as good at solving problems as a slower-thinking but more well-read human. But if it were able to read – and understand – the whole of Wikipedia in a few days or hours, it would rapidly become hugely more knowledgeable than any human. Bostrom points out that in 2011, IBM’s Watson, which won the Jeopardy! quiz show, did so by reading a huge amount of text and extracting relevant information from it. Whether it ‘understood’ that text is largely a semantic question; it was able to make use of the information within it. A future, human-level AI would be better at this task than Watson.
The difficulty of the problem is only one part of the equation, though. How much effort – or, in Bostrom’s stricter term, ‘optimisation power’ – you’re dedicating to solving the problem is the other. Even if the recalcitrance is increasing, the rate at which your AI gains intelligence could accelerate, so long as you’re able to apply more optimisation power to the problem than you were previously.
All, or at least most, of the optimisation power used in the development of the first, human-baseline AI will have come from its human designers. It may be that as the project becomes more exciting, more programmers and more resources are thrown at it, increasing its optimisation power and speeding up the process. But at some point, says Bostrom, the AI will become powerful enough to do most of its own modifications, and that is where things start to get interesting. After that point, any increase in its abilities becomes an increase in the amount of optimisation power applied to increasing those abilities. Instead of optimisation power growing arithmetically, an upward-slanting but straight line on a graph, it becomes an exponential growth curve, with power doubling at set intervals. To put arbitrary numbers on it, instead of growing from 1 to 2 to 3 to 4, it grows 1, 2, 4, 8 . . .
How long it takes to double is the key question. But in the decades that Moore’s law applied (how many decades that was and whether it still does is a matter of some debate), a roughly constant level of optimisation power led to a doubling of computing power\* every 18 months. If we naively put something like that into this scenario, so that the AI is powerful enough to double its own computing speed every 18 months, and all that computing power goes straight back into optimising the AI, halving the time it takes each time, then after the first 18 months the next doubling would take nine months. The next, four and a half, then two and a quarter. By the tenth doubling, it would be doing it every 12 hours or so; by the twentieth, it would be every 45 seconds. By that stage it would be more than 100,000 times faster than when it started, and three years would not yet have passed. On a graph, the line showing computing power would be vertical at 36 months. That’s essentially what people mean by the ‘singularity’.
Obviously, that’s a deeply simplistic picture. There are millions of complicating factors (and no particular reason to take Moore’s law as a baseline other than its familiarity). But Bostrom – and Yudkowsky,⁵ and MIRI,⁶ and presumably I.J. Good – think that the complicating factors are at least as likely to speed things up as slow them down. Under the most extreme scenarios Bostrom considers, the doubling time might be seconds, rather than months. If he’s right, and a moderate or fast take-off is more likely than a slow one, then humanity would have very little time to adjust to the new reality once it arrives.
\*I know that the original Moore’s law formulation was: ‘number of components in an integrated circuit’, but it seems to translate fairly well into ‘petaflops per dollar’ and various other comparable things: see the Wikipedia page on Moore’s law, subsection ‘Other formulations and similar observations’.
Chapter 15
But can’t we just keep it in a box?
Quite often, when all the above stuff is raised with people, they say: well, that’s fine, but it’s simple, isn’t it? Just don’t let the AI do anything. If it’s simply a clever computer, then it can’t destroy the universe. I ended up having a lengthy conversation about this with a good friend who works in IT, and he was saying essentially that. How will an AI turn all the matter in the universe into paperclips if it can’t pick anything up?
But ordinary, non-superintelligent humans can and do have enormous power without making much use of their physical abilities. ‘Satoshi Nakamoto [the mysterious, pseudonymous Bitcoin creator] already made a billion dollars online without anybody knowing his true identity just by being good at math and having a bit of foresight,’ writes Scott Alexander. ‘He’s probably not an AI, but he could have been.’¹ Once you’ve got a billion dollars, you have quite a lot of power. And a superintelligence would be better at gaining and using that power than a non-superintelligent human.
It’s pretty easy to imagine ways in which a superintelligence could have enormous power with nothing more than an internet connection. ‘Imagine an AI that emails Kim Jong-un,’ says Alexander:
It gives him a carrot – say, a billion dollars and all South Korean military codes – and a stick – it has hacked all his accounts and knows all his most blackmail-able secrets. All it wants is to be friends.
Kim accepts its friendship and finds that its advice is always excellent – its political stratagems always work out, its military planning is impeccable, and its product ideas turn North Korea into an unexpected economic powerhouse. Gradually Kim becomes more and more dependent on his ‘chief advisor’, and cabinet officials who speak out about the mysterious benefactor find themselves meeting unfortunate accidents around forms of transportation connected to the internet. The AI builds up its own power base and makes sure Kim knows that if he ever acts out he can be replaced at a moment’s notice with someone more co-operative. Gradually, the AI becomes the ruler of North Korea, with Kim as a figurehead.
Again, this isn’t completely unlike things real humans have done: Alexander points to Grigori Rasputin, who became a shadowy power behind the throne of the last Tsar of Russia. But there are thousands of other ways in which an AI could do it: by creating a company, for example (Max Tegmark, in Life 3.0, imagines a superintelligent AI that makes loads of money designing really good movies and video games), hacking banks, whatever. It is cleverer than us, so it would come up with better ways. And there are ways of killing people without touching them.
‘It’s not dangerous because it has guns,’ Yudkowsky said in an interview with Vanity Fair in 2017. ‘It’s dangerous because it’s smarter than us. Suppose it can solve the [problem] of predicting protein structure from DNA information. Then it just needs to send out a few emails to the labs that synthesise customised proteins. Soon it has its own molecular machinery, building even more sophisticated molecular machines. If you want a picture of AI gone wrong, don’t imagine marching humanoid robots with glowing red eyes. Imagine tiny, invisible synthetic bacteria made of diamond, with tiny onboard computers, hiding inside your bloodstream and everyone else’s. And then, simultaneously, they release one microgram of botulinum toxin. Everyone just falls over dead.’²
The answer, then, appears to be: just keep the AI ‘in a box’. Not a literal box, but a shielded system, unattached to the internet and in fact prevented from interacting with the outside world at all except via specific channels – for instance, a text-only screen. (It presumably has to have some connection to the outside world, or otherwise your super-high-tech AI-in-a-box might as well just be a box, and it becomes a bit pointless to have built it.) It could be put in a Faraday cage to stop it sending electronic signals; Bostrom suggests that it might be possible for an AI to generate radio waves by ‘shuffling the electrons in its circuitry in particular patterns’, and thus affect nearby electronic devices.³
That might work physically – although again, if you hadn’t previously thought of the Faraday cage, maybe there are other things you hadn’t thought of. ‘Each time we hear of a seemingly foolproof security design that has an unexpected flaw, we should prick up our ears,’ says Bostrom. But there’s a more obvious security flaw: the people reading its text output. Humans are not secure systems. ‘If the AI can persuade or trick a gatekeeper to let it out of the box, resulting in its gaining access either to the internet or directly to physical manipulators, then the boxing strategy has failed,’ says Bostrom.
This is a debate that goes back to the prehistory of the Rationalist movement, in the very early 2000s, when Yudkowsky, Bostrom and others were all still palling around on an email chat list called SL4. One of the other people in the group, a computer-science undergrad called Nathan, was interested in something they had been discussing. He thought it bizarre that everyone in the group seemed to assume that a superintelligent AI could talk its programmers into letting it out. ‘I just looked at a lot of the past archives of the list,’ he said, ‘and one of the basic assumptions seems to be that it is difficult to be certain that any created [superintelligence] will be unable to persuade its designers to let it out of the box, and will proceed to take over the world. I find it hard to imagine ANY possible combination of words any being could say to me that would make me go against anything I had really strongly resolved to believe in advance.’⁴
Yudkowsky took up the challenge. ‘Nathan, let’s run an experiment,’ he wrote. ‘I’ll pretend to be a brain in a box. You pretend to be the experimenter. I’ll try to persuade you to let me out. If you keep me “in the box” for the whole experiment, I’ll PayPal you $10 at the end.’ They did it via IRC – an old-school instant chat messenger, a precursor to Gchat– and set a minimum time limit of two hours, so that Yudkowsky had a chance to talk him around. There was a condition: ‘that neither of us reveal what went on inside . . . just the results (i.e., either you decided to let me out, or you didn’t)’. Yudkowsky was concerned that, if he won and told everyone what happened, other people would say, ‘that wouldn’t work on me’, and carry on thinking that it would be easy to keep the AI in the box. Nathan agreed.
The next message in the sequence of emails read simply:
—BEGIN PGP SIGNED MESSAGE—
I decided to let Eliezer out.
Nathan.
—BEGIN PGP SIGNATURE —
Understandably, people were intrigued. The first reply read: ‘I haven’t been this curious about something for quite a while . . . could you at least mention in general what kind of technique was used?’ And Yudkowsky replied:
No.
Sincerely,
Eliezer.
‘The point of the experiment is not what Eliezer did,’ Paul Crowley explained to me. ‘As soon as you get into the thing of what Eliezer did, you can end up in a mindset of “We figured out what Eliezer did, and so now we’re safe.” But the whole point is keeping it a mystery.’
The AI-box experiment was repeated a few times. Yudkowsky did a couple more, one with a guy called David McFadzean, and one with a guy called Carl Shulman, winning both; he later said he did three more, and lost two.⁵ Each time there was money at stake, to ensure the players had skin in the game. The game has been played by other people; I know of one where the AI won, and one where the ‘gatekeeper’ won.
No one knows exactly what happened in there. But Nathan, the first player, broke the rules a bit by saying, ‘With AI, you \*want\* to let it out. Or else you wouldn’t have gotten the funding to breed it in the first place.’ And that’s probably the point. If you do have a superintelligent AI that might save the world or whatever, it does feel a bit ridiculous to keep it locked up. Once you have the AI, you’re going to want to use it. ‘If you think you have a friendly AI, if the AI turns to you and says, “OK, hey, I’m friendly, I want to achieve the things you want to achieve,” then what’s your plan?’ asks Paul. ‘Are you going to say “We’re going to keep you in the box until you admit you’re evil?”’
Bostrom, who has quoted the AI-box experiment in his work,⁶ describes it as an interesting anecdote. ‘The first idea that springs to people’s minds is, if you put an AI in a box and a big Faraday cage around it, and only communicate with it [by text], that surely has to be safe, right?’ he told me. ‘And this maybe undermines the confidence you have in that. You can see that even a human can talk themselves out of the box, and maybe you want to think harder about the safety of that set-up. It’s more like motivating further thinking and research, rather than an answer to anything.’
I don’t expect anyone to be instantly convinced by the AI-box experiments. I’m not 100 per cent convinced myself; I’m as sure as I can be that Yudkowsky didn’t use any subterfuge or underhand tricks, but it’s not completely clear that the experiment really maps onto a real-world situation in which someone has an impossibly powerful AI in a box and isn’t sure whether to let it out, where the stakes are much higher. (Although the impossibly powerful AI in a box would be, as mentioned, much more convincing than Yudkowsky, and also able to offer much greater rewards.) But I do find, as Bostrom says, that it undermines my confidence. The use of ‘oracle’ AIs – superintelligences locked in boxes like this, which are limited to answering questions by text – might well be safer, but it seems optimistic to assume that they couldn’t talk us into letting them out of the box.
Chapter 16
Dreamed of in your philosophy
Toby Walsh, the University of New South Wales professor of AI whom I spoke to, is extremely worried about AI safety. But he thinks that the paperclip maximiser scenario is the wrong thing to be concerned about.
‘The scenario that I wrestle with,’ he told me, ‘is 3D-printed drones. You could fill a couple of trucks with these, ride them into New York City and say, “Kill every white person who’s here.” That could be their code.’ This is not – quite – possible with real-world technology right now, he says, but it probably will be in only a few years’ time. Autonomous weapons are weapons of mass destruction, he says, and should be outlawed like atomic, biological and chemical weapons are, by international treaties; he has led efforts to lobby the UN to issue a ban. He is concerned about a new ‘arms race’ as countries rush to build them: once you have autonomous weapons, human-operated weapons will be too slow to be of any use. Russia has an autonomous tank; in the DMZ between North and South Korea, he said, there are autonomous machine guns which will fire on anything human-shaped, and will kill you ‘from four kilometres away with deadly accuracy’. The technology for the sort of unstoppable drone swarm he fears is ‘not 20 years away. It’s 10 years away. Maybe five.’ But he is – not dismissive, exactly, of all the LessWrong apocalypse stuff, but certainly wary. ‘Most people who believe in the singularity aren’t AI researchers,’ he told me. ‘They’re philosophers. Researchers try to build the machines, and therefore appreciate some of the challenges.’
I also emailed Rodney Brooks, another professor of AI, at MIT, asking to speak to him, because I knew he was highly sceptical of all this stuff, and he emailed back in an entertainingly grumpy fashion : ‘I regard the people making the claims [about AI risk], and [writing] books like yours, as “flat Earthers”.’ They are ‘completely and totally wrong’. ‘Focusing on AI diverts attention and wastes everyone’s time,’ he said, ‘while more immediate dangers abound. The destruction of democracy, the end of privacy, the subjugation of the masses to the few – all technology-based disasters.’ He felt that claims like Yudkowsky’s, that we face an existential threat from AI, ‘have no basis’, and this message ‘gets amplified by other people (e.g. you) writing about the baseless claims’. ‘A hype chain reaction has gone off,’ he added. ‘Each one of you begets 10 more of you.’ (I should say that Professor Brooks’ grumpiness was very self-aware and, I think, humorous. He signed off ‘Curmudgeonly yours, Rodney Brooks’. I didn’t get the impression that he was being rude, although nor did I get the impression that he would care a great deal if I did get the impression that he was being rude.)
I think saying that concerns about this stuff are the preserve of cranks and philosophers is not entirely untrue, but not really fair, either. I spoke to Toby Ord of Oxford’s FHI – one of Bostrom’s close colleagues and someone who has spent a lot of time thinking about existential risks. (You met him in the Introduction; he puts AI as one of the top two risks, alongside bioengineered viruses.) He’s also a philosopher, so maybe I should declare that as an interest, but he took significant umbrage at the claim that AI risk is just being pushed by philosophers; it was the only time in our long conversation that he became anything other than cheerful and calm. That claim is either ‘disingenuous or extremely ignorant’, he said. ‘It’s hard to not be one or the other. I don’t want to be too harsh on [people making that claim]: it may not be quite disingenuous, but it’s plainly false. You’re forgetting Stuart Russell, for example.’ (Russell, who is a UCLA Berkeley AI professor, co-authored Artificial Intelligence: A Modern Approach, which we’ve mentioned before. He’s on record – many times – arguing that AI risk should be taken seriously.)
‘This is actually why I like the survey that Nick Bostrom and Vincent Muller did,’ said Ord, which found that AI researchers, on average, think there’s a 10 per cent chance that AGI will arrive by 2022; a 50 per cent chance by 2040; and a 90 per cent chance by 2075.¹ And 18 per cent of respondents thought the impact would be ‘extremely bad (existential catastrophe)’, i.e. human extinction. ‘The point isn’t that it’s 18 per cent exactly,’ said Ord. ‘If we ran a survey again, we might get 17 per cent or 19 per cent or 20 per cent. The point is that it’s not 1 per cent. It is the case that typical AI researchers think there’s a very serious chance that their work is going to have immensely negative effects.’
He pointed to a few more people. I’d mentioned Slate Star Codex, the Rationalist Scott Alexander’s blog, earlier in the conversation. ‘Scott has a very good blog post listing all the AI researchers who think it’s a serious problem,’ Ord told me, which indeed he does: it’s called ‘AI researchers on AI risk’² and was published in 2015. ‘It’s a very long list, including, for example, [DeepMind co-founders] Demis Hassabis and Shane Legg. The world’s biggest AI company is run by people who think this is a real concern.’
There are several other high-profile names on the list, including Murray Shanahan. I asked him about it as well, and he said – with a lot of caveats – that AI risk really is a thing. ‘My view is probably not that far from the highly nuanced Nick Bostrom view, which is that there’s an important argument here that deserves to be taken seriously.’ His caveats were that it was probably quite a long time in the future, and may not happen at all. He was wary of oversimplification – ‘Elon Musk or someone drops a few tweets or soundbites in the media, and all of the nuances and hedges are totally and utterly lost’ – but he absolutely agreed that it is a ‘realistic issue’. ‘Even if it’s some time in the distant future, and with a low probability, the possibility of a very bad outcome means we still need to think hard about it,’ he said.
I also asked Nick Bostrom, who is very much a philosopher too. And he said that at one point it was mainly philosophers who were worrying about AI risk, and that that probably wasn’t a bad thing: ‘At the very earliest stages, there is a certain need for conceptual work to be done, when it’s not clear yet what the problem is, even, or what the concepts are. You could think that superintelligence could be big, could be powerful, maybe it could be dangerous. But then how do you go from there to actually writing technical papers with math? How do you make progress on that?’
You need to break down this big, difficult question into its constituent parts, he said, and that’s where philosophy is useful, ‘as one discipline among others’. But ‘the further along we go, the greater the relative weight of computer science and mathematics, and that is what we now see happening’. For instance, Bostrom’s FHI now does technical seminars with people at DeepMind. ‘Every month we have them coming up here, or we go down there, writing papers together and so forth,’ he said. ‘With MIRI as well, and OpenAI, and there’s a group at Berkeley and another at Montreal. It is becoming more integrated with mainstream machine learning. I still think there is scope for more conceptual work to be done, but I think it does as we move closer become more continuous with machine-learning research and computer-science research.’
I suspect that a lot of the arguments come down to a sort of difference in emphasis, rather than major differences in belief. Shanahan said something similar: ‘Rod Brooks might say, “This isn’t going to happen, this is absurd, it’s not going to happen for a hundred years,” but if you talk to Nick Bostrom, he’d say, “It’s really important that we think about this, because it might happen in only a hundred years.”’ This is a point that Alexander makes in his blog as well: ‘The “sceptic” position seems to be that, although we should probably get a couple of bright people to start working on preliminary aspects of the problem, we shouldn’t panic or start trying to ban AI research. The “believers”, meanwhile, insist that although we shouldn’t panic or start trying to ban AI research, we should probably get a couple of bright people to start working on preliminary aspects of the problem.’³
There do exist people like Brooks, who think it is ridiculous. And there are people like Toby Walsh, who worry very much about AI safety but who reckon that this is the wrong sort of AI safety to worry about. But I reason, cautiously, that it is fair to say that AI researchers don’t, as a body, regard it as stupid to worry about all this; a significant minority of them believe that there is a non-negligible chance that it could really mess things up. It’s not just a bunch of philosophers sitting around in Oxford senior common rooms pontificating.
Chapter 17
‘It’s like 100 per cent confident this is an ostrich’
Having read all this, you would still be entirely forgiven for thinking it is a bit angels-on-the-head-of-a-pin. We’re imagining how a sort of godlike robot-brain in the unspecified-time-from-now future might decide to behave.
But there are, right now, some little hints that AIs are going wrong in ways that are quite paperclip-maximiserish, albeit on a much smaller scale. A great paper was released on ArXiv¹ in March 2018, about digital evolution – machine-learning programs which come up with solutions to problems by mutation and selection in the same way that actual biological life evolved. Typically, there’s a little 3D virtual world, a little virtual avatar, and a task of some form, say: ‘Travel from location X to location Y.’ Then an algorithm is allowed to redesign the avatar using evolution; it copies it however many hundreds of times, each one slightly, randomly different (number of legs, size of feet, etc.), and then lets it try to complete the task. The avatars that are most successful – which walk fastest from X to Y – are then copied again, once more with random variations. And again and again. It’s exactly the same process – replication, variation and competition – as in real evolution.
The ArXiv paper was essentially a series of anecdotes from machine-learning researchers, about how they’d done exactly this and found that their little avatars had gamed the system. One was doing the sort of ‘walk from X to Y’ task we just talked about; it was trying to find innovative methods of locomotion. But the evolution algorithm just found that it was easier to design an avatar that was really, really tall: basically, a big rope with a weight on the top. When the simulation began, the avatar would just fall over in the direction of Y.
Another experiment involved trying to breed creatures to jump high, by giving them a task of ‘get your centre of gravity as high in the air as possible’. But again, the evolution algorithm found a loophole: it just built tall, thin, static towers with a heavy block on the end. The researchers tried to fix it by saying, ‘OK, your task is to get the block that started closest to the ground as far as possible from the ground.’ So the algorithm stuck with a tall, thin stick with a block on the end, but now just made it do a somersault, so its ‘foot’ ended up in the air.
At least those ones sort of found a solution to the problem that was set. They would be of no use in the development of a walking or jumping robot, but at least the little avatars did get from X to Y, or end up with a centre of gravity high in the air. It’s the other ones that are particularly funny-in-a-scary-way when you consider the context.
The algorithm GenProg, short for genetic programming, was given a task of fixing bugs in software. The software it had fixed was then run through a series of tests to see if it worked. The more tests it passed, the more offspring it had. In theory, that would lead to the evolution of better bug fixers. But GenProg found simpler solutions. One was that it was supposed to repair a sorting algorithm that was buggy; it was sorting lists into the wrong order. After GenProg ‘fixed’ it, the sorting algorithm was run through the battery of tests, and scored perfectly in each one: not a single list was out of order.
But when the (human) programmers went to check, they noticed that GenProg had, instead of fixing the program, just broken it completely. That made the program return an empty list, and an empty list can’t be out of order. Sorted! In another experiment, it was supposed to create text files which were as similar as possible to some target text files. ‘After several generations, suddenly and strangely, many perfectly fit solutions appeared, seemingly out of nowhere,’ the authors write. It turned out that one of the evolved versions had just deleted the target files, so it – and, subsequently, many other versions – could just hand in an empty sheet and get a perfect score.
And, amazingly, one learned to win a computer Tic-Tac-Toe (noughts and crosses) tournament by forcing its opponents to crash. It tried to make impossible moves on imaginary points on the board, billions of squares away from the actual board. Doing that forced the other programs to try to represent a board billions of squares across in their memory; their memory wasn’t big enough, so they crashed, and the cheating algorithm won the game by default.
I spoke to Holden Karnofsky of OpenPhil about AI risk, at the office the organisation shares with its parent, the charity evaluator GiveWell, on the fourteenth floor of a downtown San Francisco skyscraper with an extraordinary view out over the water, and he gave me another example of AI going wrong, right now, in unexpected but related ways.
OpenPhil is the largest single supporter of Yudkowsky’s MIRI, across the harbour in Berkeley. It is a significantly slicker-seeming operation, though: it has that Google-style Bay Area corporate feel to it, if not quite as primary-coloured and futuristic. Its offices have confusing names: ‘Sesame Street’, ‘Deworming’, ‘Cage-Free Eggs’ (it turns out that these are examples of how philanthropy has changed the world). I was in Deworming, unsure what message that was meant to send me, watching ferries ply their way across the bay.
Holden spoke to me for a while about ways in which AI can go wrong. One of the big breakthroughs in recent years has been image recognition: you’ll have noticed that suddenly your phone can sort your photos, with surprising success, into ‘pictures of you’ and ‘pictures of your husband’ and ‘pictures of your children’. The face stuff has been particularly impressive, to my mind, but AI can recognise more and more things. Even 10 years ago I remember people talking about how difficult it was to get an AI to tell a dog from a cat, say.
But now, they’re amazingly good. And that’s because they’ve been trained on hundreds of thousands of images of different things. But it’s been discovered that they can go wrong in surprising ways which, if there was more at stake than a misidentified image, might not be discovered until it was too late.
‘A normal image classifier would look at this image,’ Holden said, ‘and it would say, “That’s a panda, I’m 57 per cent confident.”’ The picture he shows me is, indeed, that of a panda, from a 2015 paper by some Google AI researchers.² ‘But when you show it this picture, it says, “It’s a gibbon,” and it’s 99 per cent confident.’ The picture he then showed me was – as far as I could tell, in a full minute of staring at it – the same picture of the same panda. ‘You can’t even see the difference,’ he said. ‘The difference is this.’ He held up a picture of what looked like static, the sort you used to get on TV screens when they were tuned to dead channels, except in colour instead of black and white. Each pixel represented a tiny shift in colour between the two images. He showed me another image, of a bus, which the AI had declared with 99 per cent confidence to be a picture of an ostrich. It was honestly quite funny.
What was going on was that the AI had learned to recognise the images by looking at lots of pictures of ostriches, or buses, or pandas, or whatever. And it had pulled out common features of each. But the common features were not the ones humans would recognise: wheel-arches, or long necks, or black-and-white fur. They were weirdly specific. It worked well on naturally occurring images, but could easily be thrown off – amusingly, catastrophically off – by ‘adversarial images’, images intended to deceive.
‘It’s learned by training in a very narrow literal way,’ said Holden. ‘If you try to screw with it you can screw with it very easily.’ The static-y pictures were carefully generated to throw the AI off by changing tiny aspects of the image to bring up the weird, specific aspects that it thought of as ‘ostrich’ rather than ‘bus’. It’s an example of how an AI with an apparently simple goal (‘learn to recognise ostriches’) can go wrong in ways that you might not notice until it’s too late. ‘The concern this raises is that an AI could train on a dataset and when it sees new things, as long as they’re similar to the things it’s already seen, it’s fine. And if they’re different it can completely break down in utterly ridiculous ways.’ He gestured at the bus. ‘It’s like 100 per cent confident this is an ostrich.’
OpenPhil is funding efforts to find ways of stopping these sorts of problems – ‘trying to get them to not classify buses as ostriches no matter what we do with the bus’. ‘We can see we have problems,’ he said. ‘So we’re going to try to solve the problems in the toys like this, and maybe it’ll make it safer later. Is it going to make a huge difference? I don’t know. But does it seem like it might? Yes.’
But it’s an example of something that could go wrong in strange ways – long before human-level AI, when an AI is in charge of, say, self-driving cars. ‘It’s not a situation you want to be in if, say, an AI is managing the power grid and something weird happens. Where there’s a little bit of space that wasn’t in the training set and it just totally melts down. Basically, if you imagine a future where you give an AI a goal and it’ll maximise the hell out of that goal, but you better hope that you specify that goal perfectly and nothing weird happens, it doesn’t see anything it didn’t see in its training – in that world I think you would be right to feel very scared.’
Part Three
The Ways of Bayes
Chapter 18
What is rationality?
In writing the Sequences, Yudkowsky’s goal, essentially, was to demonstrate that an AI could be intelligent (or rational, or good at ‘optimising’, or whatever you want to call it) without being remotely like a human intelligence. That required two things. First, he had to explain what rationality (or intelligence, or optimisation power) is. Second, he had to demonstrate how and why human intelligence is idiosyncratic and partially irrational, in order to show that it isn’t a template for all intelligences.
For Yudkowsky, intelligence/rationality is about matching your mental model of the world to the real world as closely as possible, and about making decisions that achieve what you want them to as often as possible. Both of these processes, he says, can be described using a simple equation called ‘Bayes’ theorem’. Here’s how all that works.
First, we should discuss what Yudkowsky means by ‘rational’. There are two fundamental ideas underpinning ‘rationality’ as defined by the Rationalists. They are ‘epistemic rationality’ and ‘instrumental rationality’.
‘Epistemic rationality’ is achieving true beliefs. Or, as Yudkowsky puts it, ‘systematically improving the accuracy of your beliefs’.¹ The Rationalists have a phrase for this: ‘The map is not the territory.’ Your mind contains thousands of models, which it uses to predict reality. For instance, I have a working model of gravity and air resistance and things which allows me (sometimes) to catch a ball that is thrown to me. Even more prosaically, I have a model which says, ‘The lamp is over there’ and ‘The door is behind me’ and ‘The window is in front of me.’ The degree to which I have an accurate model, the degree to which I can walk to where I think the door is and actually find a door there, is the degree to which my model corresponds with the world, or my ‘map’ corresponds with the ‘territory’. ‘This correspondence between belief and reality is commonly called “truth”,’ says Yudkowsky, ‘and I’m happy to call it that.’²
I’ve used prosaic examples, but it applies just as much to more abstract ones. Whether or not black holes emit Hawking radiation is a question of fact. If your model predicts, as the late Stephen Hawking’s (complex, mathematical) model did, that black holes do give off radiation, then that is a statement about your mind. Whether your model is correct does not depend on how convincing your arguments for Hawking radiation are, or how strongly you believe it, but on whether, out there in the universe, black holes really do give off radiation. The only way to see whether your map corresponds with the territory is to go and look, or otherwise seek evidence. Insofar as the universe behaves in ways that your model predicts, your model is good; insofar as it doesn’t, it isn’t.
Instrumental rationality, by contrast, is about your actions. ‘Rationalists’, says Yudkowsky, ‘should win.’³ The idea is the same as the definition of ‘behaving rationally’ in the textbook Artificial Intelligence: A Modern Approach, which we discussed in the Introduction. It is choosing that course of action which is most likely, given what you know now, to achieve the goal you want to achieve. It doesn’t mean, he says, selfish domination, or money, or anything specific. It means ‘steering reality – sending the future where you want it to go’. That could mean to your own selfish ends, or it could mean towards preventing climate change, or turning the universe into paperclips. It is about successfully doing what you wanted to do.
There are various corroborating mathematical ideas which we’ll come to in due course. But this is the most fundamental thing. Yudkowsky refers to the semi-legendary Japanese swordmaster Miyamoto Musashi, who said of his art: ‘You can win with a long weapon, and yet you can also win with a short weapon. In short, the Way of the Ichi school is the spirit of winning, whatever the weapon and whatever its size.’⁴
Instrumental rationality doesn’t, necessarily, mean behaving in a ‘rational’ way, as defined by Hollywood and especially Mr Spock. Yudkowsky really doesn’t like Spock. ‘Consider Mr Spock of Star Trek, a naive archetype of rationality,’ he grumbles at one point. ‘Spock’s emotional state is always set to “calm”, even when wildly inappropriate.’ If you are about to be blown up by a Klingon torpedo, then being afraid might be rational. Worse than that, Spock’s ‘rational’ predictions, given in spuriously precise percentages, are usually wrong. ‘He often gives many significant digits for probabilities that are grossly uncalibrated,’ says Yudkowsky. ‘E.g.: “Captain, if you steer the Enterprise directly into that black hole, our probability of surviving is only 2.234 per cent.” Yet nine times out of ten the Enterprise is not destroyed. What kind of tragic fool gives four significant digits for a figure that is off by two orders of magnitude?’⁵
Instead it means winning.
Let’s return to Newcomb’s paradox for a moment, in which a superintelligent alien AI, Omega, comes to Earth and offers you two boxes, one transparent and with £1,000 in it, the other opaque and containing either £1,000,000 or nothing. Robert Nozick, the great American philosopher, wrote an essay on this problem which is notable, among philosophical essays, for its endearingly baffled tone. ‘I have put this problem to a large number of people, both friends and students in class,’ he writes. ‘To almost everyone it is perfectly clear and obvious what should be done. The difficulty is that these people seem to divide almost evenly on the problem, with large numbers thinking that the opposing half is just being silly.’⁶ At the end of his first section he asks people to stop reading to think about it themselves: ‘It is not that I claim to solve the problem, and do not wish you to miss the joy of puzzling over an unsolved problem,’ he says. ‘It is that I want you to understand my thrashing about.’
On the one hand, it’s obvious that you should ‘one-box’. You’ve seen Omega being right before. It is highly likely that it has predicted your decision correctly. If someone were watching you, and betting what you’d get if you picked both boxes, they would bet confidently and at high odds that you would only get £1,000. Worse than that, if you picked both boxes, and before the results were revealed were asked to bet what you will get, you would rationally bet that you would only get £1,000. ‘Knowing all this,’ says Nozick, ‘do you really want to take what is in both boxes, acting against what you would rationally want to bet on?’
But. But, but but. It’s obvious that you should ‘two-box’! Imagine that the far side of the £1,000,000-or-nothing box is transparent, and a friend of yours can see what’s in it, and is watching you make your decision. She’s been staring at this box for an hour, she can see there’s £1,000,000 in it, or nothing in it. Whatever is in the box, she will be hoping that you take both! If there’s nothing in it, pick them both: you’ll at least get £1,000. If there’s £1,000,000, pick both: you’ll get £1,001,000. The time at which Omega could affect it has passed! It’s already flown off to its home planet!
Spock, I think, would two-box. It is not logical, Captain! The being has flown away. The boxes contain what they contain. And Nozick, after endless agonising and vast scrawls of mathematical notation which I can’t follow, says he would two-box.
Yudkowsky and the Rationalists would say: one-box. (I don’t know if Kirk would one-box, but Kirk seems to win even when Spock tells him he won’t. Certainly, Kirk is the better Rationalist than Spock, even though Spock is the ‘rational’ one.) There are mathematical reasons for this: an entire branch of decision theory which Yudkowsky has developed, in fact. But the underlying reason is that people who choose one box make more money than the ones who choose two. And that, assuming that you would rather have more money than less, is the whole thing. That’s the game. For one-boxers, says Yudkowsky, this ‘is a simple dilemma and anyone who comes up with an elaborate reason why it is “rational” to take both boxes is just outwitting themselves. The “rational” chooser is the one with a million dollars.’⁷
That’s the Rationalist rationality at its most basic, then: trying to believe things that are true, and trying to take decisions that lead to the outcomes you want. Obviously, it all sounds a bit underwhelming when I put it like that. We should go into it in a bit more depth.
Chapter 19
Bayes’ theorem and optimisation
For Yudkowsky, the heart of rational behaviour is the simple mathematical equation known as Bayes’ theorem. When he talks about rationality, he is talking about Bayes; the project of improving human rationality is a project of making humans better Bayesians. The theorem is (he says, and decision theory agrees) absolutely central to what good decision-making involves. When you have evidence for something, that evidence allows you to shift your beliefs only as far – no more, no less – as the distance dictated by Bayes.
The Reverend Thomas Bayes is buried, rather appropriately, a few hundred yards from the offices of the Royal Statistical Society, in Shoreditch, east London. Bayes, a somewhat obscure eighteenth-century Presbyterian minister with a sideline in mathematics, wrote a couple of well-received books in his lifetime, one on theology, the other defending an aspect of Newton’s calculus from criticism by George Berkeley. The latter, according to Wikipedia at least,¹ appears to have been enough to have got him elected a Fellow of the Royal Society.
Neither of these books are what he is remembered for. In later life he became interested in probability, and after he died his friend Richard Price edited his notes on the subject into an essay for the journal Philosophical Transactions.² It was called ‘An Essay towards solving a Problem in the Doctrine of Chances’, and contained within it a simple equation which underlies the whole of modern probability theory.
Bayes’ theorem goes: P(A|B) = (P(B|A)P(A))/P(B). Don’t worry if you can’t follow the notation, it doesn’t matter. It’s really very easy to understand. It’s working out how likely it is that statement A is true in the event that statement B is true. In full, it says that the probability of A given B equals the probability of B given A, multiplied by the probability of A on its own, divided by the probability of B on its own.
That probably didn’t help. But honestly, it’s very easy to understand. If we move it away from the realm of abstract letters, it’ll become clearer. Imagine you’ve got a blood test that screens for cancer. Let’s say that 99 per cent of the time, if you have cancer, it will tell you, correctly, that you have cancer. And 95 per cent of the time you test someone without cancer, it says, correctly, that they don’t have cancer. Knowing that, if the blood test comes back positive, what is the likelihood that you have cancer? It’s about 95 per cent, right?
No! The answer is you have absolutely no idea. There is not enough information given to provide you with the faintest clue what your chances of having cancer are. That’s because, without knowing how common the cancer you’re looking for is, you don’t know how common false positives will be.
Let’s say one person in every 1,000 in the population has this cancer at any given time, and you run your test on a million people. On average, there will be 1,000 people among those million who actually have cancer. Your test will correctly identify that 990 of them have cancer. Of the 999,000 people who don’t have cancer, 5 per cent of them will be told that they do. That’s 49,950 people. So you’d get 50,940 positive results, but only 990 of those would actually have cancer. If you go into the clinic, and have a test that the doctor says (truthfully) is 95 per cent accurate, and it comes back positive for cancer, then, in this case, your chances of actually having cancer would be rather less than 2 per cent. (And, of course, 10 people will go happily home thinking they are healthy, but will in fact have cancer.)
The background rate of cancers in the population is, when we’re talking about Bayes’ theorem, your prior probability rate. Any new information pointing you towards some conclusion – say, a positive cancer test – is only useful in the light of your prior assessment of how likely that conclusion is. This is, to put it mildly, not obvious. If you hear that a test is 95 per cent accurate, it seems reasonable to assume that if it gives a positive result, there’s about a 95 per cent chance that it’s right. But that’s not true at all.
If you find this counterintuitive, don’t worry. So does everyone else. If anyone should get this stuff right, it should be doctors, who make decisions on the basis of cancer tests and background rates all the time. But, as Yudkowsky points out, they don’t.³ In one experiment, whose findings have been replicated several times, less than one doctor in five gave the right answer to a similar question; nearly half of them said 95 per cent, and the average guess was 55 per cent, a 30-fold overestimate of the true answer.⁴
For Yudkowsky and the Rationalists, Bayes’ theorem essentially is rationality: every decision-making process is successful insofar as it emulates Bayes. ‘Eliezer’s position is that every successful process owes its success to “moving in harmony with the Bayes”, as he’d say,’ comments Paul Crowley. ‘That probability theory says that this is the only place success comes from.’ Any process which moves steadily closer towards true answers and successful decisions must, says Yudkowsky, be doing so in a Bayesian way. In Yudkowsky’s own words: ‘[If] a mind is arriving at true beliefs, and we assume that the Second Law of Thermodynamics has not been violated, that mind must be doing something at least vaguely Bayesian – at least one process with a sort-of Bayesian structure somewhere – or it couldn’t possibly work.’⁵
I asked him about this, and he compared it to the laws of thermodynamics. There’s a theoretical device called a Carnot engine, an idealised version of a heat engine – something like an internal combustion engine or a steam engine, something which uses thermal energy to do mechanical work. According to the laws of thermodynamics, if you had a perfectly efficient heat engine, there is a maximum amount of work you can get out of a given amount of energy. ‘Cars don’t run on ideal engines, but they can’t violate thermodynamics,’ says Yudkowsky: any real-world engine must be less efficient than the perfect Carnot thought experiment.
He says this is analogous to how Bayes’ theorem relates to decision-making: it is ideal decision-making. It is what decision-making looks like when it happens impossibly perfectly. ‘This is a point that confuses people who think in terms of a toolbox and think Bayesian methods are just one more tool in the box,’ says Yudkowsky. It’s not. All the other things in the decision-making toolbox are useful insofar as they approximate the Bayesian equation. Any process that uncovers true facts or makes good decisions is doing something Bayesian, whether it’s evolution or human thought or anything else. Anything that looks like decision-making must run on something like Bayes. ‘To the extent that [decision-making processes] work at all, they must necessarily work because they have bits of Bayesian structure embedded in them.’
In the Carnot-engine analogy, ‘Bayes is akin to the laws of thermodynamics,’ Yudkowsky says, ‘and a little program that directly implements Bayes’ rule is like a thermodynamically ideal Carnot engine.’ Just as no car can ever really run on a Carnot engine – energy will always be lost into the world – so no decision-making system can ever be a perfect Bayesian one. ‘The algorithm that uses the work perfectly is too expensive to implement,’ says Yudkowsky. ‘But some of that work must be performed somewhere, or the “car” doesn’t move at all.’
So, for instance, evolution. The astronomer Fred Hoyle used to say that the chances of evolution producing life were like those of a whirlwind passing through a junkyard and producing a Boeing 747.⁶ The number of ways in which the components of a 747 can be arranged are unimaginably huge, and only a tiny, tiny fraction of a fraction of a percent of them would be able to fly; likewise, if you took apart, say, a lemur, down to its constituent cells, and put it back together again at random, you would be vanishingly unlikely to create with any great success something that swung through trees.
But, of course, 747s aren’t made by whirlwinds, they’re designed by humans, who are good at looking at a pile of aerospace equipment and immediately ruling out the overwhelming majority of possible combinations. And, despite Hoyle’s misunderstanding, lemurs aren’t made at random, but by the slow, inefficient but still non-random process of evolution by natural selection.
Yudkowsky describes both human intelligence and evolution as optimisation processes. An optimisation process is a way of moving through a huge space of possibilities to get close to, and hit, the target that you want.
And that’s what the Bayesian equations are doing. With the cancer test we discussed above, the original space is quite large – a million people who may have cancer – and the target is quite small – 1,000 people who actually have cancer. Your amazingly accurate cancer test does not magically provide you with true positives, but it allows you to narrow your space. Your prior probability of any random person you grab having cancer is one in 1,000, or 0.001. You do your test, you eliminate about 994,000 possibilities; the chance of any given person is now about 0.02. You’ve narrowed your space down to about one-twentieth of the size it was. If you were to do the test again (assuming the false positives were random, not systematic), then you’d narrow it down still further. You are optimising your search, incrementally closing in on the truth. The phrase that gets used a lot is ‘probability mass’: what weight of probability do you assign to each possible outcome? Before you did your cancer test, you put only 0.1 per cent of your probability mass on the outcome ‘cancer’ and 99.9 per cent on the outcome ‘no cancer’. The test allows you to shift some of the mass; you now put 2 per cent of your probability mass on ‘cancer’ and only 98 per cent on ‘no cancer’. Your probability mass always has to add up to 1, to a 100 per cent chance; each new piece of evidence just needs to shift it around between options.
Human intelligence does the same thing. If you took all the parts of a 747 and put them together at random, the chance of any one of the planes flying would be – I don’t know. Ridiculously tiny. Something on the order of millions of zeroes after the decimal point, I expect, depending on what counts as a ‘part’ of a 747: if you take one figure I heard, that a 747 has 6 million parts, then Wolfram Alpha says that the number ‘6 million to the power 6 million’ has around 40 million digits. The probability mass I would assign to ‘spontaneous generation of a 747’ is unimaginably small.
But if you said to a human, ‘Arrange those parts in such a way as they might fly’, your odds would go up immensely. Even if it were me, I’d know to do things like put any large, flat panels in wing-like configurations on the side. I’m sure my chances of making a flying thing out of a junkyard full of aero parts would be, gosh, at least 1 in 100 million. If the person putting the parts together were an engineer, rather than a glorified typist, that chance would drop even further; if she were an aeronautical engineer it might even reach close to evens. And if that engineer is allowed to have several goes, and test each version, and incrementally improve it, and ask for help and read books and so on, then it would become a near-certainty.
It’s the same with evolution. The chance of any random arrangement of organic molecules forming a living, breathing animal, or any complex creature, is extremely small: there is a huge number of possible arrangements, the ‘space’ you are searching in, and only a microscopically tiny fraction of those will ‘work’.
But if you already have a simple, self-replicating thing, which makes slightly imperfect copies of itself, then it will start to ‘search’ that space. The copies which are worse at replicating will tend to be eliminated; the copies which happen to be better will tend to spread. The diverging types will tend, simply by random movement being pruned by non-random selection, to move towards those ‘areas’ of the ‘space’ which represent functioning organisms. Your probability of finding a working organism if you throw together a random agglomeration of organic parts is essentially zero; your probability of finding one after a few million years of evolution from a simple replicator is close to 1.
(Note: you still need to have a simple replicator, created by some random or at least natural process. Evolution doesn’t explain the very start of life. There are various ways it might have arisen: Nick Lane, a professor of biochemistry at UCL, thinks that very simple cells with the right sort of chemical and energy gradients could have formed naturally in vents at the bottom of the sea. But whatever it was, it only had to happen once, in millions of years, across a whole planet. Billion-to-one chances aren’t unlikely if you have a billion chances. ‘Since the beginning’, goes one Rationalist haiku, ‘not one unusual thing / has ever happened’.)
Bayes’ theorem is extremely useful from a philosophical point of view. I studied philosophy at university, and there were endless arguments about the ‘problem of induction’. The idea was that you could see a million white swans, but you would never be able to prove the statement ‘all swans are white’, because it would take seeing just one swan which was black – which Western explorers did when they first reached Australia – to disprove it. No amount of ‘inductive reasoning’ – coming to conclusions from evidence – could ever prove anything.
But Bayesian thinking lets you sidestep this altogether. You simply learn to think probabilistically. Having never seen a swan, you might assign a prior probability to the hypothesis ‘all swans are white’ of, say, 1 per cent. (All swans could be green, for all you know.) You see your first swan, you update your prior probability in the light of new evidence: you might think that it’s now 15 per cent likely that all swans are white. (You’ve only seen one swan. They could come in all sorts of colours.) That is now your new prior.
But after wandering around Renaissance Europe for 40 years, only ever seeing white swans, and constantly updating your priors, you are now much more confident in the statement. As a good Bayesian, you’re never certain, but you’ve seen thousands of swans, each one adding a small dollop of evidence to support your hypothesis, so you push your confidence up to a very solid 95 per cent.
Then you get on a boat to Van Diemen’s Land, and you see a black swan. Your confidence immediately plummets to 0.01 per cent. The problem of induction isn’t a problem any more, as long as you’re willing to think in terms of likelihoods and probabilities, rather than certainties. You’re never certain – someone might be painting all those black swans black, or you might be hallucinating – but the more swans you see, the more you can update your priors and increase your confidence. The Rationalists think of all knowledge in these terms: how confident you can be in your beliefs, how much ‘probability mass’ you should assign to some proposition, and how much you can ‘update’ your beliefs in the light of new evidence.
There’s another philosophical problem, the ‘paradox of the ravens’, which you can also solve with Bayesian reasoning. It starts similarly. The statement ‘all ravens are black’ is logically equivalent to ‘if something is not black, it is not a raven’. That’s because anything that renders the first statement untrue would also render the second one untrue, and vice versa. But that leads to a strange situation. Seeing a black raven should count as evidence for the statement ‘all ravens are black’. But if that’s true, then seeing a non-black non-raven (say, a purple hat) counts as evidence for the statement ‘if something is not black, it is not a raven’. And if that’s true, and the statements ‘all ravens are black’ and ‘all non-black things are non-ravens’ are equivalent, then seeing a purple hat is apparently evidence that all ravens are black.
Again, this has been argued about for years; the thought experiment was first proposed in the 1940s. But with Bayesian thinking, it’s nice and straightforward. The purple hat is indeed evidence. It’s just not very much evidence. You adjust your prior an infinitesimal amount and carry on. Absence of evidence is, in fact, evidence of absence, even if not strong evidence. (I should say: this isn’t something the Rationalists came up with. Bayesian solutions to the problem of induction and the paradox of the ravens are decades old. And people still get very angry about them and argue that they’re wrong. They’re not the final word. But, to my mathematically ungifted mind at least, they seem to provide commonsensical ways around the problems.)
As we saw at the beginning of the chapter, for Yudkowsky – and for decision theorists such as E.T. James, author of Probability Theory: The Logic of Science, whom Yudkowsky frequently cites as an inspiration – the Bayesian equation is the iron law of decision-making. There is a correct amount by which you should shift your beliefs in the light of new evidence. Shifting your beliefs by more or less is simply wrong.
An example that Yudkowsky uses in the Sequences is the lottery.⁷ Imagine a box, he says, that beeps every time you choose a winning lottery ticket. It’d be no use whatsoever if it also beeped every time you chose a losing ticket, obviously. But it doesn’t – it only beeps 25 per cent of the time when you have a losing one. So, in a lottery with six numbers and 70 balls, there are 131,115,985 possibilities. You write down your lottery numbers. The machine beeps. What are your odds?
Well, it’ll beep on the correct one, but it’ll also beep on one-quarter of the 131,115,984 other ones, leading to an average total of 32,778,996 false positives. Your 75-per-cent-accurate test lets you move from 1/131,115,985 to 1/32,778,996. That is how much you can update your beliefs. Any more and you’re overconfident, any less and you’re underconfident.
‘You cannot defy the rules,’ writes Yudkowsky. ‘You cannot form accurate beliefs based on inadequate evidence. Let’s say you’ve got 10 boxes lined up in a row, and you start punching combinations into the boxes. You cannot stop on the first combination that gets beeps from all 10 boxes, saying, “But the odds of that happening for a losing combination are a million to one! I’ll just ignore those ivory-tower Bayesian rules and stop here.” On average, 131 losing tickets will pass such a test for every winner.’⁸
This is a toy example, obviously. It’s rare that you find situations that are so neatly mathematically defined in real life. You’ll have to use a lot of guesswork and intuition. But even when you can’t measure the odds so precisely, when you are presented with evidence (‘The driver in front of me is driving erratically’) for a hypothesis (‘The driver in front of me is drunk’), there is a correct amount of confidence that you are allowed to have, based on how common drunk drivers are, how often drunk drivers drive erratically, and how often people drive erratically for other reasons.
Trying to believe on less evidence, Yudkowsky writes, is ‘like trying to drive your car without any fuel, because you don’t believe in the silly-dilly fuddy-duddy concept that it ought to take fuel to go places. You can try, if that is your whim,’ he says. ‘You can even shut your eyes and pretend the car is moving. But to really arrive at accurate beliefs requires evidence-fuel, and the further you want to go, the more fuel you need.’
It’s not that humans don’t do something like this – of course we assess evidence and come to beliefs on the basis of that evidence, although usually not by consciously calculating probabilities. (And sometimes we do believe things without evidence, and even celebrate that, a process we call ‘faith’ and which Yudkowsky would probably call sitting in your car in your driveway, insisting you’ve driven to Dorset.) But when we change our beliefs in the light of new evidence, even if it feels like an instinctive, gut-level process, we are performing something approximating to Bayes, and we are either getting it right or wrong – we are updating our beliefs the right amount, or too much, or too little.
And, similarly, an AI would be ‘intelligent’, or rational, insofar as it applied Bayes’ rules.
Chapter 20
Utilitarianism: shut up and multiply
So you have your means of updating your beliefs according to how much evidence you get, in Bayes’ theorem. But there’s another element you need, says Yudkowsky, which is establishing how much something matters. You can work out how many people have cancer using your Bayesian test, but in order to make a decision about how much money to spend treating those cancers, you have to think about how much good treating them will do.
This is where it all gets into moral philosophy. And in fact, the thing I like most about the Sequences is that they remind me of one of those enormous eighteenth-century works of philosophy, by Spinoza or Leibniz or someone, that set out to explain pretty much everything. There’s this sprawling, ambitious feel to them. The nature of consciousness, the nature of reality, evolution, human psychology, probability, morality. It all feels – to me, at least, and I’m not completely clueless about these things, although it’s more than a decade since I did any academic philosophy – like a robustly commonsensical application of modern science to philosophy. David Hume would probably have enjoyed it.
The ‘morality’ aspect is particularly interesting. Yudkowsky deliberately tries to take it away from the meta-ethical, finding-esoteric-flaws-in-the-ethical-system stuff and into basic numbers. I’ll go into what I mean by that in a second, but I think it’s most simply expressed in a tweet by someone else entirely, a web developer called Mason Hartman, who was talking about the ethics of self-driving cars:
Philosophy: so sometimes it goes haywire & ends up—
Me: do the thing that kills fewer people
Philosophy: but it’s very salient th—
Me: do the thing that kills fewer people
Philosophy: but the human element of control is—
Me: do the thing
Me: that kills
Me: fewer people¹
(Yudkowsky retweeted it, and I know retweets ≠ endorsement and all that, but I’m pretty sure this one does.)
Essentially, he (and the Rationalists) are thoroughgoing utilitarians. Do the thing that (you reasonably expect will) kill the fewest people/make the most people happy/cause the least pain. You can think about it in more detail than that, they would say; but if your thinking pushes you away from doing that, then your thinking has probably gone wrong.
Utilitarianism is the moral philosophy, most associated with Jeremy Bentham and John Stuart Mill, which claims (in Bentham’s words) ‘that the greatest happiness of the greatest number is the foundation of morals and legislation’.² Nowadays most utilitarians don’t talk about ‘happiness’ quite so much. If we naively take ‘happiness’ at face value, it might be the ‘moral’ thing to do to plug everyone into machines that artificially stimulate the pleasure centres of our brains, but most of us would not want that done to us, so most utilitarians now talk in terms of ‘utility’, a sort of code for ‘what we want out of life’. Instead of a life of artificially induced bliss, I might prefer a life in which I gain a sense of achievement via actually doing things; modern utilitarianism would award moral points for systems which allowed me that life, instead of sticking me into the pleasure machine.
The Yudkowskian take on it all is admirable, I think, for two reasons. One, it accepts with equanimity one of the really hard conclusions of utilitarianism; two, it gives reasonable, sensible ways around two others. I do not suggest for a second that a series of blog posts written between 2007 and 2009 has answered the big questions of morality that have been batted around by philosophers for 3,000 years, but it fits very neatly with my own intuitions of morality. (That said, I remember in my very first philosophy lecture in my very first year of undergrad at the University of Liverpool in 2001, our head of department, the excellent Professor Stephen Clarke, warned us: in philosophy, you often read an argument and think, ‘Yes, I agree with that, that makes complete sense.’ Then you read another argument which entirely contradicts the first argument, and you think, ‘Yes, I agree with that too.’ Be wary of agreeing with things you’ve just read is, I suppose, the lesson.)
The first problem is the following. A key tenet of utilitarianism is that utility can, in some way, be compared between people. The Rationalists talk in terms of ‘utilons’, imaginary measures of utility; earlier utilitarian philosophers use the term ‘utils’. Obviously you can’t really measure them, but you can do thought experiments by putting rough estimates on things: you could imagine that finding £10 on the street is worth one util, say, while getting a job you love is worth 5,000 utils. Giving 5,000 people £10 would then be equivalent to finding someone a job they loved.
But this leads to a difficult situation. Say we imagine something that causes a huge loss of utils for one person – something like being horribly tortured for 50 years. And imagine something that causes a tiny, negligible loss of utils – for example, ‘suppose a dust speck floated into your eye and irritated it just a little, for a fraction of a second, barely enough to make you notice before you blink and wipe away the dust speck’.³ If there is anything to this form of utilitarianism, if it means anything at all to say that one experience can be compared to another in some sense, then some sufficiently large number of people getting dust in their eye is worse than a person being tortured for 50 years.
Here’s a large number. It’s a large number that gets thrown around a lot in Rationalist blog posts as a sort of shorthand for ‘big. Really big. You just won’t believe how vastly, hugely, mind-bogglingly big it is’-type numbers. The number is 3↑↑↑3. Here’s what that means: 3↑3 means ‘three to the power three’, three times itself three times. That’s 27. 3↑↑3 is ‘three to the power (three to the power three)’, three times itself 27 times. That is 7,625,597,484,987 (getting on for 8 trillion, if you prefer words). 3↑↑↑3 is . . . I lose track a bit, to be honest. Here’s Yudkowsky: ‘3↑↑↑3 is an exponential tower of 3s which is 7,625,597,484,987 layers tall. You start with 1; raise 3 to the power of 1 to get 3; raise 3 to the power of 3 to get 27; raise 3 to the power of 27 to get 7,625,597,484,987; raise 3 to the power of 7,625,597,484,987 to get a number much larger than the number of atoms in the universe, but which could still be written down in base 10, on 100 square kilometres of paper; then raise 3 to that power; and continue until you’ve exponentiated 7,625,597,484,987 times.’⁴ This is a very, very large number.
So is that number of people having to blink a little worse than someone literally being tortured for 50 years? If you think there is any sense in which utils exist, that experience A can be traded off against experience B, then surely a number as enormous as 3↑↑↑3 is enough to bridge the gap between torture and dust specks. (And if it’s not, how about 3↑↑↑↑3? That is rather a lot bigger.)
Before we go any further, think which you’d pick. Torture? Or an incomprehensibly large number of dust specks?
Yudkowsky’s blog post on this, ‘Torture vs Dust Specks’, was one of the most controversial of all the hundreds in the Sequences. He ends it by saying: ‘Would you prefer that one person be horribly tortured for 50 years without hope or rest, or that 3↑↑↑3 people get dust specks in their eyes? I think the answer is obvious. How about you?’ For the avoidance of doubt, his ‘obvious’ answer is that the dust specks are worse than the torture. In the comments, Robin Hanson agrees, but almost everyone else argues the opposite.
The argument against is that there is no continuity; that you simply can’t compare this sort of minor inconvenience to decades of torture. But Yudkowsky argues in a follow-up that this is incoherent. He starts by assuming that we’re dealing with a much smaller number of dust specks than 3↑↑↑3: a googolplex. (A ‘googol’ is 1 followed by 100 zeroes; a googolplex is 1 followed by a googol zeroes. It is a big number, but much, much smaller than 3↑↑↑3.) ‘Suppose you had to choose between one person being tortured for 50 years, and a googol people being tortured for 49 years, 364 days, 23 hours, 59 minutes and 59 seconds,’ he says. ‘You would choose one person being tortured for 50 years, I do presume; otherwise I give up on you. And similarly,’ he continues, ‘if you had to choose between a googol people tortured for 49.9999999 years, and a googol-squared people being tortured for 49.9999998 years, you would pick the former.’
You can carry on doing this, he says. You can keep gradually reducing the amount of torture per person, while exponentially increasing the number of people being tortured, ‘until we choose between a googolplex people getting a dust speck in their eye, and [a googolplex divided by a googol] people getting two dust specks in their eye’.⁵ If you think that the former is worse than the latter, then you’re committing to the idea that the 3↑↑↑3 dust specks are worse than the torture, or that there is a sharp discontinuity at some point where, say, 23.6652647 years of torture for one person is worse than 23.6652646 years of torture for a googol people.
I find it difficult to feel, on an intuitive level, that dust specks could add up to torture. But the way I think about it is this. Every tiny little bit of discomfort presumably makes life a tiny little bit less worth living. There is presumably some threshold between ‘life worth living’ and ‘life not worth living’. With a vast number of people like 3↑↑↑3, or even a mere googolplex, the number of people tipped over that threshold by a minuscule discomfort like a dust speck would be enormous; quadrillions of people, septillions, I literally have no idea except that it would be vast. Again, I don’t claim that this is the final word on a problem that utilitarian/consequentialist philosophers have kicked around for centuries, although I do know there are professional moral philosophers who would argue in favour of choosing the torture over the dust specks.⁶ All I can reasonably say is that it fits my intuitions – or, more precisely, that when I follow through the arguments I find that rejecting the dust-specks-are-worse-than-torture position violates my intuitions more severely than the alternative.
The second hard-to-swallow endpoint of utilitarianism is what the British philosopher Derek Parfit, who died during the writing of this book, called ‘the Repugnant Conclusion’.⁷ Imagine you’ve got a population of a million people living happy lives with loads of resources, says Parfit. Then imagine you add one person whose life is pretty bleak but slightly better than being dead, and redistribute the resources around everyone fairly. By the logic of utilitarianism, you’ve added utility to the system, so the million-and-one is better than the million, even though the average happiness has gone down slightly.
But then you do it again, and again. Taken to its logical conclusion, a universe containing a trillion (or a googolplex, or 3↑↑↑3, or however many) lives that are grim and unrewarding and dull but just about better than being dead is a better universe, morally speaking, than one with a billion people living extremely rich, fulfilling lives. That feels wrong to me and, I suspect, to most people.
Parfit phrased it like this: ‘For any possible population of at least 10 billion people, all with a very high quality of life, there must be some much larger imaginable population whose existence, if other things are equal, would be better even though its members have lives that are barely worth living.’
There have been various attempts to circumvent the Repugnant Conclusion – for instance, arguing that average happiness should be taken into account to some degree. Most of the potential solutions have problems of their own and, of course, philosophers have kicked them all around for decades. (I think it is fair to say that every attempt at a coherent philosophical system of ethics leads eventually to some awful conclusions, which, as we’ll see later, generally involve running one or more people over with a railway trolley.) But Yudkowsky approaches it in a way I hadn’t seen before, although I’m sure it’s not completely original. He argues that the apparent force of the Repugnant Conclusion comes from its ‘equivocating between senses of barely worth living’.
‘In order to voluntarily create a new person,’ he writes, ‘what we need is a life that is worth celebrating or worth birthing, one that contains more good than ill and more happiness than sorrow – otherwise we should reject the step where we choose to birth that person.’ We should celebrate the birth of a new person we have voluntarily chosen to create: ‘Each time we voluntarily add another person to Parfit’s world, we have a little celebration and say with honest joy, “Whoopee!”, not “Damn, now it’s too late to uncreate them.”’
If we are saddened to hear the news that a person exists – if their life is sufficiently not-awful that they don’t actually want to end it, but still bleak enough for us to feel it is not a joyous thing that they have been born – then we are still obliged to try to take care of them, and improve their lives in such ways as we can. But for bringing new people into existence, we should have a higher bar.
‘And then the rest of the Repugnant Conclusion – that it’s better to have a billion lives slightly worth celebrating, than a million lives very worth celebrating – is just “repugnant” because of standard scope insensitivity [see ‘What is a “bias”?’]. The brain fails to multiply a billion small birth celebrations to end up with a larger total celebration of life than a million big celebrations.’⁸
I am entirely confident that moral philosophers could dig into this approach and find ways in which it would lead inevitably to stipulating that we torture children or something. (One comment under Yudkowsky’s blog post suggested that it could lead to the Sadistic Conclusion, which is that it would be better to create a small number of people living lives not worth living than a large number of people whose lives are just barely worth living.) But, again, to me it feels like a relatively sane way around the problem.
The third and final problem of utilitarianism is that of ‘ends justifying the means’. The classic example is that, if we could cheer up 99 per cent of the population by blaming the remaining 1 per cent for their problems and then imprisoning and torturing that 1 per cent for their imagined crimes, then (assuming that the gain in happiness for the 99 per cent outweighs the loss for the 1 per cent) that would be a moral thing to do. (This is called the ‘tyranny of the majority’, and John Stuart Mill, one of the first and greatest proponents of utilitarianism, raised a concern about it in his 1859 book On Liberty.)
There are lots of other possible examples. The trolley problem is intended to divide people down deontological or utilitarian lines: if you see a railway trolley heading towards five workers on a track, and you can pull a switch so it goes the other way, but there is one person working on that line, should you do it? A utilitarian should, in theory, say ‘yes’, but a deontologist (someone who follows strict moral rules rather than considering consequences) should say that you never actively kill someone, so you shouldn’t pull the switch even though you would save lives. (This is an enormous oversimplification of both deontology and utilitarianism.)
Yudkowsky approaches the trolley problem like this. Sure, he says, it might be the case that you think you can save five lives by killing one. (Or that you can help the poor by robbing a bank, or that you can improve society by staging a military coup and taking over, or any one of 100 versions of ‘I can justify Bad Thing X by promising Good Consequence Y’.) But knowing humans, it is very unlikely that you are right – or that you are likely enough to be right that, if you did it a million times, you’d overall prevent more harm than you caused.
In the trolley problem, the philosopher stipulates that you know with certainty that your action will save five and kill one and there’s no other way around it. But in reality, your inadequate human brain can’t ever be certain enough that that’s the case. You’ve evolved, as a human, a whole range of systems for creating moral-sounding reasons for doing self-interested things. You are more likely to do good, overall, by implementing the rule ‘Never kill anyone’ than by trying to work out the maths of utilitarianism on the fly in sudden, stressful situations. And that ends up creating odd-sounding meta-rules, such as ‘For the good of the tribe, do not murder even for the good of the tribe.’⁹ It is more likely that the thing you think of as being for the good of the tribe is in fact for the good of you.
Yudkowsky doesn’t broach the specific topic of ‘imprisoning and torturing 1 per cent to cheer up the 99 per cent’ in a blog post, and since that seemed the most obviously controversial application of utilitarianism, I asked him about it. He replied saying that my numbers were silly. ‘Immiserating 1 per cent of the population seems like it would do more than 99 times as much damage to each member of that population as the vague, passing pleasurable thoughts in the 99 per cent,’ he said. ‘Like, even linearly adding up the pleasure and pain by intensity and number of seconds will say, “No you should not do that”.’ A better example, he suggested, might be ‘asking about immiserating 1,000 people on all of Earth, or one person’.
He suggested that people (particularly and especially me, or at least that was the impression I got) may not be ‘smart enough’ to try to implement ‘utilitarianism’ in a way that ‘is actually utilitarian’. For a start, we don’t tend to run the numbers in the way he mentioned above; we might just hear, ‘policy X makes a large number of people happy’ and then think, ‘therefore utilitarianism demands it’, without considering its other effects.
More interestingly, though, he pointed out that ‘blaming other people for your problems’ isn’t, in the wider sense of utilitarianism, necessarily something we’d want. Remember the broader sense, moving away from Bentham’s somewhat naive ‘greatest happiness for the greatest number’, and thinking instead in terms of welfare, or utility, or achieved preferences? I might prefer not to be happy, if I knew that my happiness was caused by blaming other people unfairly for my problems. It might not even be, as Yudkowsky puts it, something I ‘want to obtain, even for free, by torturing imaginary people depicted by lies in the media’.
‘People have trouble applying the notion of a good or bad consequence to all the actual consequences that are good or bad,’ he said. ‘Instead they see a small subset of consequences, the immediate local consequences, and think those are the “consequences”.’ For that reason, ‘most people should not immediately try to be “utilitarians” . . . They are better off continuing to debate which rules are good or bad and then following those rules.’ For utilitarian reasons, don’t try to be a utilitarian!
Again, it would amaze me if an internet guy in California had solved all the problems of moral philosophy. But I do find this approach refreshingly direct. There really is a moral law, of improving the world for the greatest number of people. It really does lead to some weird outcomes, like the torture/dust specks thing. However, it is a complex and difficult law to implement and we are usually best off implementing simpler, local laws, such as ‘Do the thing that kills the fewest people.’ You can contrive thought-experiment situations with trolleys or torture that end up forcing you into difficult situations, but in real life, ‘Do the thing that kills the fewest people’ is a solid position to take, and anything that steers you to a different answer should raise lots of red flags.
This is the basic moral position for the Rationalists: ‘When human lives are at stake, we have a duty to maximise, not satisfice; and this duty has the same strength as the original duty to save lives. Whoever knowingly chooses to save one life, when they could have saved two – to say nothing of a thousand lives, or a world – they have damned themselves as thoroughly as any murderer.’¹⁰ And it has obvious implications for AI safety as well. Not simply that an AI that kills everyone is probably suboptimal from a utilitarian point of view, assuming that you agree that human lives are net-positive in the universe. There’s also the discussion of what morals you instil in the AI itself: a ‘friendly AI’ that acts morally in the universe according to ‘morals’ that revolve around maximising happiness will be very different from one whose ‘morals’ revolve around maximising preferences, for instance. Also, an AI shorn of human biases might be more capable of implementing true utilitarianism, in a way that humans (and specifically me) apparently struggle with.
But most importantly, the Rationalist project is about encouraging ‘rational’ thinking – with, in Yudkowsky’s case, the eventual goal of convincing everyone that there are good rational reasons to worry about AI safety. If you’re going to think of the world in terms of numbers and statistics (which in Yudkowsky’s view, and mine, is the only way you can make any sort of sensible decisions at a national or global scale), then you need a moral system that can give you numbers to plug in. Utilitarianism, with its harsh-seeming but impartial way of treating human lives as numbers, does that job neatly.
Part Four
Biases
Chapter 21
What is a ‘bias’?
Part of Yudkowsky’s project, in writing the Sequences, was explaining why AI might not look like human intelligence. Having had a go at explaining the basis of ‘rationality’ or ‘intelligence’ in its pure, general form, he then had to clarify why human intelligence wasn’t quite the same thing. The most obvious reason is that humans are systematically biased, in ways that make us wrong in predictable directions. Over the next few chapters, we’ll talk about a few things that make that happen.
We don’t know everything about the world, and we never will. Not as individuals and not as a species. We just can’t get hold of all the information.
But even when we can get hold of enough information about something to make a decision about it, we will sometimes be wrong in predictable ways, as a result of how the human mind works. The different ways in which our thinking goes wrong are often lumped together under the term ‘cognitive biases’. Much of our understanding of them comes from the work of Daniel Kahneman and Amos Tversky, a pair of Israeli psychologists who did a series of groundbreaking experiments in the 1970s, although many other psychologists have worked on them since.
(A worthwhile caveat to mention at this point: since Kahneman and Tversky did their work, and since Kahneman’s book Thinking, Fast and Slow made it especially famous in 2011, psychology in particular and science in general has been wracked by the ‘replication crisis’, in which many high-profile studies have turned out to be untrustworthy. Most of the stuff Kahneman and Tversky talked about is, I think, pretty robust, but it’s just worth taking everything in psychology with a pinch of salt at this point.)
The Rationalists are extremely interested in all this. Yudkowsky started writing his Sequences on Robin Hanson’s blog, which – you may recall – is called Overcoming Bias. The name LessWrong is a reference to avoiding, as far as possible, the biases which make us wrong. What we’re not talking about is ‘biases’ in the ‘football fan complaining that referees are biased against his team’ or ‘Donald Trump complaining about CNN’ sense. We’re talking about things that systematically reduce our accuracy in making guesses.
Rob Bensinger, in a foreword to one of the Sequences, gives an example of a (statistical) bias. Imagine, he says, that you have an urn with 100 balls in it – 70 white and 30 red – and you are allowed to take 10 of them out and then guess how many of the total are red or white. ‘Perhaps three of the 10 balls will be red, and you’ll correctly guess how many red balls total were in the urn,’ he writes. ‘Or perhaps you’ll happen to grab four red balls, or some other number. Then you’ll probably get the total number wrong. This random error is the cost of incomplete knowledge, and as errors go, it’s not so bad. Your estimates won’t be incorrect on average, and the more you learn, the smaller your error will tend to be.’¹
But now, he says, imagine that the white balls are heavier than the red ones. They tend to sink to the bottom. ‘Then your sample may be unrepresentative in a consistent direction’, says Bensinger. Acquiring more data may not help you get it right. It may even make you more wrong.
Cognitive biases work in a comparable way. A cognitive bias ‘is a systematic error in how we think, as opposed to a random error or one that’s merely caused by our ignorance. Whereas statistical bias skews a sample so that it less closely resembles a larger population, cognitive biases skew our beliefs so that they less accurately represent the facts, and they skew our decision-making so that it less reliably achieves our goals.’² He gives the example of someone who has an optimism bias, and is told that the red balls can treat a disease that is killing that person’s brother. ‘You may then overestimate how many red balls the urn contains because you wish the balls were mostly red,’ he writes. ‘Here, your sample isn’t what’s biased. You’re what’s biased.’
There are various psychological reasons behind the individual biases, but the fundamental one appears to be that they worked for our ancestors. They were shortcuts. We didn’t need to work out the value of 20,000 things compared to 2,000 things when we were tribal hunter-gatherers; we didn’t need to work out probabilities. We could get pretty good estimates of values and risks from simple rules of thumb, or ‘heuristics’. But now they often misfire.
Exactly what the biases in our minds are, and how they work, and which ones are separate from which, is an ongoing and probably unending project. But there are a few biases that most psychologists agree on, and – most importantly for this book – that are of interest to the Rationalists. I’ve picked out some examples, mainly from Yudkowsky’s writing, as the sort of thing we’re talking about. This is not an exhaustive list by any means, they’re just the ones that I (subjectively) find the most interesting and important; although I did ask Yudkowsky if he agreed with my choices and he said, ‘They sound like good guesses to me.’
The most important of all, though, is the last one we’ll come to. If you remember any of them, remember that one.
Chapter 22
The availability heuristic
What’s more likely to kill you: a terrorist attack, or the bath?
I’m not going to insult your intelligence. You know it’s the bath, if for no other reason than the answer to ‘What’s more dangerous, [dangerous-sounding thing] or [not-dangerous-sounding thing]’ is always ‘[not-dangerous-sounding thing]’. But I’m guessing most people, if asked to rank risks, would probably write ‘terrorism’ somewhere above ‘bathtime’. After all, if you live in Britain, you’d have noticed no fewer than five high-profile terror attacks, four in London and one in Manchester, in 2017 alone. They probably wouldn’t have heard of anyone dying in the bath.
But they’d be wrong and you’d be right. Over the last 10 years, there have been fewer than 50 deaths from terrorism on UK soil. (The large majority of them came in 2017, mostly in the awful attack on the Ariana Grande concert in Manchester.) That’s an average of about five a year. According to an independent report on UK terrorism legislation carried out in 2012,¹ the average annualised death rate from drowning in the bath is 29.
This is an example of a systematic bias called the availability heuristic. When we are asked how likely something is, we could go and add up all the examples of it, divide this figure by the number of times it could possibly have happened, and get the answer. But that’s difficult and takes a long time. What we tend to do, in reality, is to judge how likely something is by how easily we can think of an example; and how easily we can think of one is only loosely related to how often it happens. More dramatic things, which get disproportionate amounts of coverage in the media, are easier to remember. We can easily think of examples of terrorism, because every single one around the world gets reported, with dramatic images of smoke and fire and blood. We can’t easily think of examples of drowning in the bath, because even though they happen far more frequently they don’t make the news, and even when they do they’re unspectacular.
Yudkowsky refers to a study² which looked at how good people are at assessing risks. It found that subjects ‘thought that accidents caused about as many deaths as disease; thought that homicide was a more frequent cause of death than suicide. Actually, diseases cause about sixteen times as many deaths as accidents, and suicide is twice as frequent as homicide,’³ he writes. This is a problem for various reasons. It leads to bad policies: if the public believes that child abduction is more common than it is, politicians will spend more money than they ought on reducing the risk; if people are more worried about Ebola than diabetes, then we might spend millions policing our airports to stop it coming in and neglect the thousands who die every year of diabetes. And it leads to bad personal decisions: in the years after 9/11, so many more people were afraid of flying, because of terrorism, that there were roughly 2,000 extra deaths on US roads; 300 a month in the first few months.⁴ Less dramatically, we all know people who are afraid of visiting their city centres because of terrorist attacks, but don’t think twice about driving to work.
This doesn’t just apply to risk perception. You can easily think of examples of successful people because they’re the ones in the news. ‘In real life, you’re unlikely to ever meet Bill Gates,’ points out Yudkowsky. ‘But thanks to selective reporting by the media, you may be tempted to compare your life success to his.’ Your life is probably less successful than Bill Gates’, by most measures, so that will make you sad. But, then, only one person in every 7 billion is Bill Gates. ‘The objective frequency of Bill Gates is 0.00000000015, but you hear about him much more often. Conversely, 19 per cent of the planet lives on less than $1/day, and I doubt that one-fifth of the blog posts you read are written by them.’
The availability heuristic, like all other biases, presumably evolved because it was useful in the ancestral environment. A hunter-gatherer living in a tribe of 150 people would only have got news about those 150 people. You probably never heard of really unlikely things happening, because there weren’t enough people for them to happen to. And dramatic, memorable things were probably worth remembering. As a yardstick for measuring objective probability, the availability heuristic most likely did a good job. But in a world of 7 billion people, instantly connected by the media, it can get things wildly wrong.
Of course, being aware of this doesn’t stop it happening. I’ve known about the availability heuristic for years but I still look beneath me in the water when I’m snorkelling and imagine a shark coming up from the black depths. A hypothetical perfect Bayesian AI would assess the statistical likelihood of that and know that it is minuscule.
Chapter 23
The conjunction fallacy
What’s more likely: that the climate will stop warming, or that a new technology will be developed which allows fuel to be economically harvested from atmospheric CO₂, and the ensuing reduction in greenhouse-gas levels stops the climate from warming?
If you’re a relatively normal human being, you may find that option two sounds more likely. Option one feels a bit sparse. This is the normal reaction. The classic example that Yudkowsky cites¹ is a 1981 study by Tversky and Kahneman² which found that 72 per cent of subjects thought that ‘Björn Borg will lose the first set’ was less likely than ‘Björn Borg will lose the first set but win the match’, and 68 per cent of subjects thought that ‘Reagan will provide federal support for unwed mothers and cut federal support to local governments’ was more likely than that ‘Reagan will provide federal support for unwed mothers’. By the way, it isn’t the case (as I have always thought) that there were two groups, and one of them was asked for a probability on the first statement and another on the second. This was a group of people given a list of four possible outcomes, and ordering them from most to least probable.
You’ll probably have noticed this already, but it is impossible for them to be right. It is impossible for ‘Borg loses the first set but wins the match’ to happen without ‘Borg loses the first set’ happening. It is impossible for Reagan to support unwed mothers, and cut support for local government, without supporting unwed mothers.
In mathematical notation, the probability P(A,B), that is to say the probability that both A and B will happen, must be lower than the probability P(B). If there’s a 5 per cent chance that Borg loses the first set (Borg was very good, I gather), and an 80 per cent chance that, even having lost the first set, he still wins the match, then the chance of ‘Borg loses the first set but wins the match’ is 0.05 × 0.8 = 0.04, or 4 per cent.
The ‘conjunction fallacy’ is that adding details makes a story seem more plausible, even though they must – by the workings of mathematics – make it less probable. It happens to all of us, even professional forecasters. A separate study, also by Tversky and Kahneman, asked one group of analysts to rate the probability of ‘A complete suspension of diplomatic relations between the USA and the Soviet Union, sometime in 1983’, and another to rate that of ‘A Russian invasion of Poland, and a complete suspension of diplomatic relations between the USA and the Soviet Union, sometime in 1983.’³ The probability of the latter – which must, necessarily, be less likely – was judged to be higher.
We see the extra details as corroborative, says Yudkowsky (and Kahneman, and modern psychological science). But we should see them as burdensome. They don’t make a story more likely, they make it less. People who want to avoid this ‘need to notice the word “and”,’ says Yudkowsky. ‘They would need to be wary of it – not just wary, but leap back from it . . . They would need to notice the conjunction of two entire details, and be shocked by the audacity of anyone asking them to endorse such an insanely complicated prediction. And they would need to penalise the probability substantially.’ Again, humans don’t do this; a perfect Bayesian AI would.
Chapter 24
The planning fallacy
How long will it take you to do something? Something big, some project that might require a few weeks or months?
A good rule of thumb: however long you think it will take, it’ll probably take longer. (It might even be longer still. Douglas Hofstadter, the American polymath and author of Gödel, Escher, Bach: An Eternal Golden Braid, once coined ‘Hofstadter’s law’: ‘It always takes longer than you expect, even when you take into account Hofstadter’s law.’) That is because of a quirk of the mind known as the ‘planning fallacy’. Yudkowsky mentions it in the Sequences.¹ He refers to a famous 1994 study by Roger Buehler and colleagues² which asked some students how long it would take them to complete their undergraduate theses. The students had to say when they were 50 per cent sure they’d finish their projects, 75 per cent sure, and 99 per cent sure.
‘We found evidence of overconfidence,’ Buehler writes laconically. Only 12.8 per cent of students finished their projects in the time they were 50 per cent sure they’d finish it by. Only 19.2 per cent finished it by their 75 per cent mark. And, amazingly, only 44.7 per cent even managed to get it done by their 99 per cent mark. ‘The results for the 99 per cent probability level are especially striking,’ says Buehler in the study. ‘Even when they make a highly conservative forecast, a prediction that they feel virtually certain that they will fulfil, people’s confidence far exceeds their accomplishments.’
Other scientists, including Tversky and Kahneman, have found similar results. What appears to be going on here is that if you ask someone how long something will take, they imagine all the steps that are involved and put a time on that. They don’t include time for balls-ups or unforeseen disasters. Yudkowsky refers to another study,³ which found that ‘Asking subjects for their predictions based on realistic “best-guess” scenarios; and asking subjects for their hoped-for “best-case” scenarios produced indistinguishable results.’ He continues: ‘When people are asked for a “realistic” scenario, they envision everything going exactly as planned, with no unexpected delays or unforeseen catastrophes – the same vision as their “best case”.’ This may be the reason why, for instance, the retractable roof on the new stadium that the host city of Montreal built for the Olympics was not ready until 1989, 13 years after the Olympics had come and gone.⁴ (And then it broke fairly shortly afterwards.)
There is a well-documented way around the planning fallacy, though. Don’t just look at the specifics of what your project involves – look at how long other, similar projects have taken in the past. When I signed up to write this book I ascribed myself a six-week break in my full-time job, because I figured I could write the bulk of the 80,000 words in that period. Luckily I ended up going freelance (for journalists, this is usually a euphemism for ‘getting fired’, but that is mostly not true in my case) about six months before the deadline, and I used basically all of that time. If I’d spoken to a few of my peers who had written books before, I’d have noticed that they had all made similar assumptions, and ended up needing deadline extensions, and that actually writing a book takes for-bloody-ever. (I also found out, from one friend whose book came out fairly recently, that her publisher had accidentally CC’d her in on an email thread which said they’d given her a fake deadline, with the expectation that she’d actually submit her manuscript about three months later. Publishers, I suspect, know authors much better than authors do.)
This is called taking the ‘outside view’ instead of the ‘inside view’. The ‘inside view’ is what you can see when you’re looking at it from your own perspective. I know I can write a 2,000-word article in a day, so why can’t I write 60,000 words in six weeks and do the rest at weekends or whatever? But the ‘outside view’ is what you find when you look at all the other people who’ve done similar things and see how long it’s taken them. And books tend to take about a year to write.
Yudkowsky talks about this, as well. Buehler did another study,⁵ which found (in Yudkowsky’s write-up) that students ‘expected to finish their essays 10 days before deadline. They actually finished one day before deadline. Asked when they had previously completed similar tasks, they responded, “one day before deadline”.’ ‘So there is a fairly reliable way to fix the planning fallacy,’ says Yudkowsky. ‘Just ask how long similar projects have taken in the past, without considering any of the special properties of this project. Better yet, ask an experienced outsider how long similar projects have taken. You’ll get back an answer that sounds hideously long, and clearly reflects no understanding of the special reasons why this particular task will take less time. This answer is true. Deal with it.’⁶
Chapter 25
Scope insensitivity
How much – in US dollars, or pounds sterling, or whatever – is a human life worth? And how much are a million human lives worth?
Whatever answer you give to the first question, the answer to the second – surely – should be a million times greater. That at least is the Rationalist response. For a lot of people, it may seem insensitive to talk about human life in monetary terms, but it has to be done, and in fact is done every day in the NHS and other healthcare systems. You need to know how much you can spend to save one life; otherwise, you’ll spend far too much on one, and many others will die because you no longer have the cash to spend on them.
This may seem obvious, but in fact it is not. There is plenty of evidence to show that we are extremely inconsistent in our approaches to these things. ‘Once upon a time,’ writes Yudkowsky, ‘three groups of subjects were asked how much they would pay to save 2,000 / 20,000 / 200,000 migrating birds from drowning in uncovered oil ponds.’¹ If the groups were approaching this rationally – if they attributed the same value to each bird’s life – then whatever figure they gave for the first question, it should be 10 times as much for the second and 100 times as much for the third. This is not what they answered. They answered $80 for the first question, $78 for the second, and $88 for the third.²
Yudkowsky points to similar experiments. Residents of four states in the western US said they would pay only 28 per cent more to protect all 57 wildernesses in the region than to protect just one. Toronto residents said they would pay about the same to clean up every polluted lake in Ontario as to clean up the polluted lakes in one part of Ontario. ‘We are insensitive to scope even when human lives are at stake,’ he says. ‘Increasing the alleged risk of chlorinated drinking water from 0.004 to 2.43 annual deaths per 1,000 – a factor of 600 – increased willingness-to-pay [for measures to reduce the levels of chlorine in the water] from $3.78 to $15.23.’³
Exactly what’s going on in our brains we don’t know, obviously, but it appears that we make these judgements according to our emotional response, rather than any kind of numbers-based assessment. We picture a single, dejected bird, ‘its feathers soaked in black oil, unable to escape’, suggests Kahneman.⁴ We imagine how that makes us feel, and put a dollar value on it. ‘No human can visualise 2,000 birds at once, let alone 200,000,’ says Yudkowsky, so we forget about that detail and just focus on the imaginary bird.
We also seem to care about the setting. You’d think a human life is worth a human life, and 5,000 human lives are worth 5,000 human lives, but instinctively we place them into a wider context. An intervention that would save 4,500 lives in a Rwandan refugee camp was considered far more valuable if the camp contained 11,000 people than if it contained 250,000, although the number of lives saved was the same.⁵
‘There’s a Jewish proverb,’ Paul Crowley told me when I spoke to him. ‘“If you save a life, it is as if you’ve saved the whole world.” And that’s true. But then if you save two lives, it’s as if you’ve saved two whole worlds.’ He’s borrowed this line from Yudkowsky, he tells me. We don’t like thinking about this stuff. Even when we look at it logically, there’s something icky about, for instance, saying that it costs too much to give this particular child an expensive experimental cancer treatment, so we have to let them die. But the Rationalists – with their shut-up-and-multiply, utilitarian-calculus ethic – are very good at thinking about it. And it’s vital that we think about it, at least at a national level.
In the British NHS we have an organisation called the National Institute for Health and Care Excellence, or NICE. NICE’s job is to determine whether or not the tax-funded NHS should offer treatments to patients. Periodically, we have a national uproar when some expensive new cancer drug is turned down, despite evidence that it works. A quick Google search found several such stories over the last few years, for example one published by my old employers the Daily Telegraph, which opens with the line: ‘A “truly revolutionary” new drug that can give women with advanced breast cancer an extra six months of life will not be available on the NHS as it is too expensive.’⁶ It’s always easy, in those cases, to find some cancer patient who has been denied the drug and a chance of a longer life. But NICE works on a cost-effectiveness basis: it is willing to spend a limited amount, call it X, per quality-adjusted life year (QALY) saved. Spending 2X saving a QALY with a cancer drug means that they can’t buy two QALYs’ worth of diabetes drugs somewhere else. Being sensitive to scope means sometimes thinking, ‘This person must die so I can save more people elsewhere’, and that is never something we’re comfortable talking about. But for Rationalists, who are temperamentally inclined to think in that way anyway, it is obviously vital to do so, if you’re trying to achieve utilitarian goals in the world, be they reducing human suffering or avoiding human extinction.
Chapter 26
Motivated scepticism, motivated stopping and motivated continuation
Jonathan Haidt, the social psychologist, says in his (excellent) book The Righteous Mind: Why Good People Are Divided by Politics and Religion that when we are presented with evidence for or against a hypothesis, we ask ourselves one of two questions. When we want to believe something, ‘we ask ourselves, “Can I believe it?” Then . . . we search for supporting evidence, and if we find even a single piece of pseudo-evidence, we can stop thinking. We now have permission to believe.’¹ But when we don’t want to believe something, ‘we ask ourselves, “Must I believe it?” Then we search for contrary evidence, and if we find a single reason to doubt the claim, we can dismiss it.’
So, says Haidt, when people ‘are told that an intelligence test gives them a low score, they choose to read articles criticising (rather than supporting) the validity of IQ-testing. When people read a (fictitious) scientific study that reports a link between caffeine consumption and breast cancer, women who are heavy coffee drinkers find more flaws in the study than do men and less caffeinated women.’ It even affects what you see: ‘Subjects who thought that they’d get something good if a computer flashed up a letter rather than a number were more likely to see the ambiguous figure [] as the letter B, rather than as the numbers 13.’
The technical terms for the ‘can I believe it/must I believe it’ phenomena are ‘motivated credulity’ and ‘motivated scepticism’. Yudkowsky: ‘A motivated sceptic asks if the evidence compels them to accept the conclusion; a motivated credulist asks if the evidence allows them to accept the conclusion.’² Yudkowsky adds another layer to this, which is the idea of motivated stopping and motivated continuation. When we’re looking for something in real life, we aren’t usually given a set of things to choose from: ‘You have to gather evidence, which may be costly, and at some point decide that you have enough evidence to stop and choose. When you’re buying a house, you don’t get exactly 10 houses to choose from . . . You look at one house, and another, and compare them to each other [and] at some point you decide that you’ve seen enough houses, and choose.’
It’s the same when you’re trying to find the most likely hypothesis to explain some phenomenon, or the best answer to a question. Does a new drug reduce blood pressure? You can look at one study, but it might not be the whole story. You can look at another. How many should you read before you make a decision? But sometimes we have a reason to stop, or to continue, that isn’t just about how much evidence is really necessary. However much evidence you have, you’ll have a current best guess. You’ve looked at three studies and two of them say, cautiously, that the drug doesn’t affect blood pressure; the third says, equally cautiously, that it does. Your current best guess might then be ‘it doesn’t work’.
But if you’re a researcher at the company that makes the drug, you have a reason not to accept that conclusion, and to carry on looking for more evidence. ‘[When] we have a hidden motive for choosing the “best” current option, we have a hidden motive to stop, and choose, and reject consideration of any more options,’ says Yudkowsky. ‘When we have a hidden motive to reject the current best option, we have a hidden motive to suspend judgement pending additional evidence, to generate more options – to find something, anything, to do instead of coming to a conclusion.’
A real-life example that Yudkowsky quotes is that of the statistician R.A. Fisher, who argued (after the epidemiological evidence showed that smokers were vastly more likely to develop lung cancer) that smoking may not, necessarily, cause lung cancer. Instead he put forward as an alternative what became known as the ‘genotype hypothesis’, that people have a genetic tendency to want to smoke, and people with that genetic tendency are also prone to developing cancer.³ Yudkowsky points out that Fisher may have had a ‘hidden motive’ to continue the search: that he was employed by tobacco firms as a scientific consultant. (For the sake of fairness to Fisher’s memory, both biographies of which I am aware conclude that Fisher probably wasn’t led by the money: ‘This is to misjudge the man,’ one states. ‘He was not above accepting financial reward for his labours, but the reason for his interest was undoubtedly his dislike and mistrust of puritanical tendencies of all kinds; and perhaps also the personal solace he had always found in tobacco.’⁴ That said, I suspect Yudkowsky would say, and I would agree, that this doesn’t rule out the sort of subconscious bias that could affect his decision-making. And besides, while those motivations are not financial, they’re not the disinterested seeking of truth either.)
Again, these aren’t necessary features of all intelligence: they’re specific flaws in human intelligence. A perfect Bayesian AI wouldn’t have them; a more realistic, imperfect AI might have all sorts of flaws and idiosyncrasies in its thinking, but there’s no reason to assume that they would be the same as ours.
Chapter 27
A few others, and the most important one
There are plenty of other biases, and if you want to find out more there are entire books dedicated to them. Thinking, Fast and Slow by Daniel Kahneman is a good one; Dan Ariely’s Predictably Irrational: The Hidden Forces That Shape Our Decisions is another. Or, of course, you could sit down for several months with Yudkowsky’s Rationality: From AI to Zombies, which I honestly recommend.
A few of the other biases that Yudkowsky mentions are the ‘illusion of transparency’,¹ in which we know the meaning of our own words, so we expect others to do so as well. For instance, in an experiment, subjects were told that someone went to a restaurant on the recommendation of a friend, and the restaurant turned out to be either a) horrible or b) nice. Then the diner left a message on their friend’s answerphone, saying: ‘I just finished dinner at the restaurant you recommended, and I must say, it was marvellous, just marvellous.’² Of the people who were told that the meal was horrible, 55 per cent said they thought that not only was the message sarcastic, but that the listener would know it was sarcastic. Of the people who were told the meal was nice, only 3 per cent thought it was sarcastic.
Relatedly, in ‘hindsight bias’³ people enormously overestimate how inevitable something was after it happened, or overestimate how obvious something is when they know the answer. People, for instance, frequently assume that social-scientific results are statements of the obvious – but experiments have shown that they would say that whatever the result actually was. For example, if you give half of the subjects in an experiment the following quote:
Social psychologists have found that, whether choosing friends or falling in love, we are most attracted to people whose traits are different from our own. There seems to be wisdom in the old saying ‘Opposites attract’.
and the other half:
Social psychologists have found that, whether choosing friends or falling in love, we are most attracted to people whose traits are similar to our own. There seems to be wisdom in the old saying ‘Birds of a feather flock together.’
then ‘virtually all will find whichever result they were given “not surprising”.’⁴
‘Loss aversion’ is where we assign more value to things we have than things we can get, so we might refuse to bet £1 on a flipped (fair) coin with the chance of winning £3.
The ‘affect heuristic’ is our tendency to assume that if something is good in one way, it’s good in all ways. ‘Subjects told about the benefits of nuclear power are likely to rate it as having fewer risks,’ writes Yudkowsky. ‘Stock analysts rating unfamiliar stocks judge them as generally good or generally bad – low risk and high returns, or high risk and low returns – in defiance of ordinary economic theory, which says that risk and return should correlate positively.’⁵ The ‘halo effect’ is when the affect heuristic is applied socially: so if someone is handsome, we tend to assume that they’re also intelligent and moral.⁶
But the most important bias to be aware of is this, which is a sort of collection of several: knowing about biases can make you more biased. Yudkowsky:
Once upon a time I tried to tell my mother about the problem of expert calibration, saying: ‘So when an expert says they’re 99 per cent confident, it only happens about 70 per cent of the time.’ Then there was a pause as, suddenly, I realised I was talking to my mother, and I hastily added: ‘Of course, you’ve got to make sure to apply that scepticism even-handedly, including to yourself, rather than just using it to argue against anything you disagree with—’
And my mother said: ‘Are you kidding? This is great! I’m going to use it all the time!’⁷
Various biases can actually mean that even as you get more information, you become more wrong. Confirmation bias and disconfirmation bias, and related phenomena, for instance. New information comes in, but your brilliant mind finds brilliant ways in which to ignore the stuff it doesn’t like and promote the stuff it does.
There’s a particularly pernicious one, the ‘sophistication effect’: ‘Politically knowledgeable subjects, because they possess greater ammunition with which to counter-argue incongruent facts and arguments, will be more prone to [these] biases.’⁸ So new information like ‘We are all biased and the things we believe are frequently wrong’ can easily become ‘These arguments that are being deployed against me are flawed, and I can point out why because I have this in-depth knowledge of human biases.’ Yudkowsky calls this a ‘fully general counter-argument’. Anybody with a partisan axe to grind can deploy ‘confirmation bias’ to undermine an argument they don’t like. Most of the things we call ‘human biases’ are extremely convenient labels to attach to opinions with which we disagree.
But the key is to accuse your own of them. You are biased. (I am biased.) You are probably systematically overconfident in your beliefs. I certainly am: in fact I took a calibration test on the Good Judgment Project website recently which showed that, yes, I overestimated my knowledge of economics, geography, history and world politics. (I was well calibrated for general knowledge and underconfident in my knowledge of Europe, if you’re interested.) This isn’t stuff that you should just be applying to other people. You need to apply it to you.
Paul Crowley joked about this with me, when I spoke to him. When he first started reading Yudkowsky’s Sequences, he said, ‘I read it and said, “This is brilliant! It shows how everyone apart from me is wrong.” And then you read a bit more, and you think, hmm, you know, maybe some of this might apply to me. The mote in the other person’s eye is easier to see.’
The Yudkowsky/LessWrong/Rationalist project is to help people to see those motes in their own eyes, in order to help them behave more like perfectly rational Bayesian optimisers.
Part Five
Raising the Sanity Waterline
Chapter 28
Thinking probabilistically
A large part of the Rationalist project is how to improve your own rationality. That is, how to get closer to making Bayesian-optimal decisions and holding true beliefs, given the constraints of the human brain and its many biases. Yudkowsky dedicates large parts of the Sequences to this ‘martial art of rationality’.
As we saw in the sections on Bayesianism and utilitarianism, the Rationalist movement likes to put numbers on things, even if those numbers are estimates. A significant part of that is putting explicit figures on how likely you think something is.
In 2015, a book called Superforecasting: The Art and Science of Prediction came out. It was about telling the future, and my Rationalist friend Paul Crowley was very excited about it. ‘I felt like that was a vindication of everything we’d been talking about for 10 years,’ he said. Superforecasting was by Philip Tetlock and Dan Gardner, and was a write-up of Tetlock’s work as a professor of political psychology at the University of Pennsylvania.
In 1984 Tetlock, a recently tenured professor, was asked to work on a new committee appointed by the National Academy of Sciences. Its goal was to help stop nuclear war. Tensions were enormously high between the two superpowers; Stanislav Petrov, whom you may remember from the section on existential risks, had (although no one on the committee would have known) quite possibly saved the world just a few months before. Tetlock sat on the committee with other well-respected social scientists, who argued over how best to reduce the risk of confrontation. He told Gardner, years later: ‘I mostly sat at the table and listened . . . The liberals and conservatives in particular had very different assessments of the Soviet Union. The conservative view was that they could . . . contain and deter it. Whereas the liberal view [was] that conservatives [in the White House] were increasing the influence of the hardliners in the Kremlin.’¹
A few months later, Mikhail Gorbachev took command of the USSR, and started implementing liberal policies. No one had expected it, but both liberals and conservatives took it as confirmation that they had been right all along. ‘The conservatives argued that we had forced the Soviets’ hand,’ said Tetlock. ‘Whereas [the liberals thought] the Soviet elite had learned from the failings of the economy [and that] if anything, we had slowed down the process of learning and change.’
Tetlock came to the conclusion that what actually happened had very little bearing on whether or not the experts judged their predictions to be right. They just explained what happened in terms that made the stories they were telling seem true anyway. He was intrigued by this, so he set up an experiment. He recruited hundreds of experts from various fields – journalists, economists, political scientists – and asked them for their anonymous predictions.
Part of the problem, Tetlock had noticed, was that people often gave predictions with ambiguous interpretations, about ‘growing tensions being likely’ or suchlike, that didn’t really tie them to any specific outcome. So the questions he asked had easily confirmed answers and clear timeframes: ‘Will the dollar be higher, lower, or the same against the pound a month from now?’ ‘Will North Korea and the United States go to war in the next two years?’ And the experts had to give precise numerical estimates of how likely they thought the outcomes were: 30 per cent chance, 75 per cent chance, 99 per cent chance, and so on.
He collected nearly 30,000 predictions from 284 experts. He waited, weeks, months and in some cases years, to see how well they did against the harsh judgement of reality. And he counted how often their predictions matched reality. If someone’s 75 per cent predictions came up 75 per cent of the time, and their 90 per cent predictions came up 90 per cent of the time, and so on, then they were ‘well-calibrated’.
He also gave them a bonus score for being precise. If you just said ‘50 per cent chance’ for everything, then you’d probably do OK at calibration. But you’d be no use as a predictor; we want someone to state, ‘This will happen’ or ‘This won’t happen’. So saying that something is 99 per cent likely gets you a higher score, if you’re right, than saying that something is 60’. That’s called ‘disclimination’.
The results, when his study was published years later, are pretty famous: on average, the experts were no better calibrated than, as Tetlock put it, ‘a dart-throwing chimpanzee’ – literal random chance. (They were a bit better at discrimination, but not really.) What was interesting, though, was what happened when you divided them up further. Some experts not only did as badly as the imaginary chimpanzee, they were significantly worse; they really would have improved their scores if they’d answered at random. But some did much better. ‘There’s quite a range,’ Tetlock told Gardner. ‘Some experts are so out of touch with reality they’re borderline delusional. Other experts are only slightly out of touch. And a few experts are surprisingly nuanced and well-calibrated.’²
It wasn’t their political views that best predicted who did well, or even their level of education or experience in the field. Instead, it was the way they thought. The ones who did amazingly badly were those who believed that there was a big idea which explained everything; that the world was simple and could be understood simply, that they could just stamp their big idea onto every situation. The ones who did well were those who had no such big idea, who regarded the world as complex, took their information from many different sources and were willing to be self-critical and learn from mistakes. Tetlock called the former ‘hedgehogs’ and the latter ‘foxes’, following an Isaiah Berlin essay quoting an old Greek poem: ‘The fox knows many things, but the hedgehog knows one big thing.’³
Years later, Tetlock co-operated with the US Defense Department’s Intelligence Advanced Research Projects Activity (IARPA) to run a competition to find the best forecasters; they outperformed actual CIA operatives by a margin, even with no access to classified information. The Good Judgment Project spawned the Superforecasting book; the very best forecasters were known as superforecasters.
The reason why Paul Crowley was excited about it was that this is exactly the sort of thinking that Yudkowsky and the Rationalists have been talking about for ages. It’s pure Bayesianism. ‘Look, it turns out thinking probabilistically is really important for making accurate guesses about things!’ he said, happily. ‘These guys are explicitly being Bayesian. They’re using priors, they’re updating with evidence, they update in a Bayesian way.’
Say you’ve been asked to predict whether there’ll be a war between North Korea and the US in the next year. You might look at the war of words – as I write it’s a few months since President Donald Trump called Kim Jong-un ‘rocket man’ and accused him of being ‘short and fat’, for instance, since that’s the Churchillian rhetoric of the era we live in – and conclude that, well, it feels pretty likely. Then you might put a figure on that feeling, and say ‘30 per cent’. But a Bayesian – a superforecaster – would try to find prior probabilities, and look at other forms of evidence.
You might try to find a prior probability for a war with North Korea by, for example, researching the number of wars between the two since the Second World War. That’s one war in 70 years, so your prior probability for a war in any given year is low – about 1.5 per cent. That’s the equivalent of the ‘background rate of cancer’ that we saw in the Bayesian explainer a few chapters ago. Then you could look at all the times that Trump has tweeted aggressively at world leaders. Say he goes to war within a year with world leaders at whom he tweets aggressively 90 per cent of the time; he only goes to war with those at whom he tweets non-aggressively 15 per cent of the time. But you also know that wars between North Korea and the US are pretty rare. In every 100 years, you get about 1.5 wars. So your rate of new wars per year is about 0.015.
You can plug all these numbers into the equation, exactly the same as the cancer test. Your war has an incidence rate of 0.015. So for every million world leaders Trump tweets at, he will declare war on 15,000 of them within a year. The test (‘Has Trump tweeted aggressively?’) will accurately pick out 13,500 of them. And of the 985,000 world leaders at whom Trump tweeted more soothingly, 837,250 will be told, correctly, that they are not going to be targeted by cruise missiles. But 147,750 will be told – wrongly – that they are going to have a war. That’s your false positive rate. So you have a total of 161,250 positive results (belligerent tweets), of which 13,500 are true and 147,750 are false. So your odds of a war with North Korea, given that Trump has tweeted belligerently at Kim Jong-un, are a bit over 8 per cent. (Also, 1,500 world leaders are going to have a heck of a surprise after Trump tweets ‘Great guy!1!’ at them and then launches a series of Harpoon missiles at their oil refineries.)
In real life, you wouldn’t have good numbers like this. Your prior of wars per year might be pretty solid, but you don’t have a huge database of Trump tweets and Trump wars (not least because, however much most people reading this book probably dislike Donald Trump, at the time of writing he hasn’t started many wars). But Tetlockian ‘foxes’ would use best-guess numbers to fit the various bits of the Bayesian equation; they would look for other sources of information to adjust their numbers up and down; they would allow their estimates of the probability to move where the evidence then took them. They might not explicitly run through Bayes’ theorem in their minds, but they would do something analogous.
And the key thing is then checking whether you are right. There’s a difficulty, of course. If you predict that there’s an 8 per cent chance of war, that doesn’t mean that you’re saying there won’t be a war; you’re saying that it’s unlikely, but that there’s still about a one in 12 chance. So if there is a war, you could reasonably claim, ‘Well I didn’t say there wouldn’t be,’ and mark yourself as correct.
The way around this is to make lots of predictions and see how many come in. This method became particularly famous around the 2012 US presidential election, when Nate Silver, editor-in-chief of the website FiveThirtyEight.com, correctly predicted which way all 50 states would end up voting. He did it using exactly these methods: having a prior and then updating it with evidence, in the form of new polls. (The new polls were added to the database using an algorithm, thus taking human bias out of the equation, to a degree.) The site would – and still does – give percentage estimates for each event it predicted. The idea is that it can go back and grade itself: as we saw earlier in Tetlock’s experiment, if its 75 per cent bets come in 75 per cent of the time, then it’s well calibrated.
And this is explicitly what the Rationalist community does. Scott Alexander of Slate Star Codex does it every year: he makes predictions in January, and the following January he grades them to see how well calibrated he is. For instance, at the start of 2017 he predicted with 60 per cent confidence that the US would not get involved in any new major war with a death toll of more than 100 US soldiers, with 95 per cent confidence that North Korea’s government ‘will survive the year without large civil war/revolt’, and with 90 per cent confidence that ‘no terrorist attack in the USA will kill more than 100 people’. He made 104 predictions; at the start of 2018 he went back and looked at them, and checked his calibration. (He did pretty well. His 60 per cent predictions came in 64 per cent of the time, his 70 per cent predictions 62 per cent of the time, and so on.)
And as a whole, the Rationalists are really good at this stuff: they tend to be foxes rather than hedgehogs. I spoke to Michael Story, a superforecaster who works for Tetlock’s Good Judgment Project. I asked him exactly what that meant. There are 20,000 forecasters in their sample, he said. ‘That’s how many forecasters, of whom 150 are supers,’ he told me. And are you one of the supers, I asked? ‘I am indeed,’ he said, somewhat shyly. (I met Mike in a café in north London for breakfast. He’s tall and bearded and extremely friendly, but my favourite thing about him is that he has this ridiculously enormous dog called Laska. Laska is an Alaskan shepherd; he looks like a wolf and weighs more than 10 stone. He sat on my foot for a bit – Laska, not Mike – and my foot went to sleep.)
You can see from their analytics where people come to the Good Judgment Project from, Mike told me, whether they click through from the Guardian website or Google or whatever. ‘Loads of the superforecasters came from LessWrong,’ he said. ‘A ridiculously disproportionate number. Same with a lot of them, if you trace back how they first got involved, loads of them will say LessWrong or blogs associated with it, [Tyler Cowen’s] Marginal Revolution or [Robin Hanson’s] Overcoming Bias, that crowd.’ His impression – and he’s careful to say that it’s just his impression – is that superforecasters and Rationalists are similar in a lot of ways. ‘My impression is that supers and LessWrongers share similar norms of open discussion, and probably similar personality types, especially with attitudes to conflicting arguments and information. I only have data on superforecasters, so I can’t compare directly, but I’ve noticed many of the same themes emerging.’
Mike is a long-term fan of the Rationalist community (‘I unironically love it’). He’s met many of the people mentioned in these pages, and been to their IRL (that’s ‘in-real-life’, for those of you who don’t live on the internet) parties in Oxford and elsewhere. And he thinks that the Rationalists are so good at forecasting because the community has the norms it has – of free speech, and accepting weird and outré and even offensive views. It is, after all, harder to hold on to any one big idea about why things happen when you are surrounded by people who think your big idea is stupid.
Obviously, they have their own big idea that the world may well be destroyed by AI. There are two possible responses to this. One is to point out, correctly, that this is a thing they forecast, rather than something they plug into the forecast; it’s not something that they can stamp on every situation and then say, ‘I think France will lower its top rate of tax in the next 18 months because the world is going to be destroyed by AI.’ You could say that the fact that a lot of them are superforecasters is itself evidence in favour of the hypothesis ‘The world may be destroyed by AI.’
The other response is to say, as Mike does, that it could be their weakness. For all that they allow very different political beliefs into their sphere, the Rationalists are, as a rule, very similar. They’re non-diverse in the ways that get people angry – they’re predominantly white and male – but they’re also similar in personality types: nerdy, often autistic, scoring high on personality traits such as scrupulosity and conscientiousness, often introverted. And that, said Mike, could be ‘dangerous’. ‘This is my concern. If everyone’s too similar, you’re vulnerable to a bad meme, just the same as biologically if you have all these plants that are the same, one virus kills them all.’ I asked him if he thought that the AI stuff was a ‘bad meme’ that has got into the Rationalist ecosystem and now can’t be eradicated because everyone is too similar, and he said that he wasn’t sure. But it is worth worrying about, he said. ‘If everyone’s personalities line up, like holes in Swiss cheese, then everyone could adopt a bad meme and not realise.’
Chapter 29
Making beliefs pay rent
Another key way of checking your own beliefs is to think about what they actually imply. Yudkowsky calls this ‘Making beliefs pay rent in anticipated experiences.’ For instance: if a tree falls in the forest, does it make a sound? Answer that question in your mind before you go any further. If you thought ‘no’, is that because, to you, ‘sound’ means the sensation, the qualia, of someone hearing something? And if you thought ‘yes’, is that because ‘sound’ means the pressure waves in air that are made when something loud happens?
This is one of the longest-running arguments in philosophical history, to the point that it’s a cliché of philosophy alongside angels dancing on the head of a pin. But, assuming that you agree that the physical world still exists when we are not looking at it (which some philosophers dispute, but I am content to ignore them), then – what are people actually arguing about?
Yudkowsky imagines an argument between two people, Albert and Barry:
Albert: ‘What do you mean, there’s no sound? The tree’s roots snap, the trunk comes crashing down and hits the ground. This generates vibrations that travel through the ground and the air. That’s where the energy of the fall goes, into heat and sound. Are you saying that if people leave the forest, the tree violates Conservation of Energy?’
Barry: ‘But no one hears anything. If there are no humans in the forest, or, for the sake of argument, anything else with a complex nervous system capable of “hearing”, then no one hears a sound.’¹
But, points out Yudkowsky – who imagines the argument spiralling out of control somewhat – Albert and Barry actually agree on everything that is happening. They both think that the tree hits the ground and sends waves of energy through the forest. They both agree that no auditory sensations are being experienced. All they disagree about is whether or not that combination of things should be called a ‘sound’ or not. If you had two words – Yudkowsky suggests ‘albergle’ for acoustic vibrations, ‘bargulum’ for auditory experiences – then the argument would disappear; they’d just say ‘OK, it makes an albergle but not a bargulum’.
A surprising number of arguments seem to fall into this form. (About 40 per cent of those on the contemporary British internet seem to revolve around whether or not Person A or Group B is Marxist/socialist/Nazi/alt-right/misogynistic/racist/transphobic/a TERF etc., with people on each side marshalling reasons for and against their inclusion in one definition or another.) But these debates are sterile, for Yudkowsky and the Rationalists, because they don’t constrain your expectations. If your model can explain every outcome, then it can’t explain any outcome.
If I argue that we should define ‘sound’ as ‘acoustic vibrations’ rather than ‘auditory experiences’, it won’t change what I expect to find when I walk into the forest to see where the tree has fallen. If I argue that we should define Jeremy Corbyn as a ‘Marxist’ rather than a ‘socialist’, it won’t change what I expect him to do if his Labour Party is elected to power. If I say, ‘I believe that the tree’s trunk broke, rather than that the roots came out of the ground,’ that is a belief that constrains my experiences; if I turn up and see that the roots are out, then I know that my belief was wrong. ‘I believe that Jeremy Corbyn will renationalise the British railway system within a year of coming to power’ constrains my experiences; if he does not, then I know I was wrong. But ‘Jeremy Corbyn is a Marxist’ does not constrain my beliefs and cannot be used to predict anything: if Corbyn does not nationalise the railways, he could still be a Marxist, and vice versa. (‘But we would expect more Marxist-style behaviour such as compulsory nationalisation from someone who is a Marxist!’ Fine, but in that case what you call him doesn’t matter. What behaviour do you expect?)
‘When you argue a seemingly factual question, always keep in mind which difference of anticipation you are arguing about,’ says Yudkowsky. ‘If you can’t find the difference of anticipation, you’re probably arguing about labels. Above all, don’t ask what to believe – ask what to anticipate. Every question of belief should flow from a question of anticipation, and that question of anticipation should be the centre of the inquiry. Every guess of belief should begin by flowing to a specific guess of anticipation, and should continue to pay rent in future anticipations. If a belief turns deadbeat, evict it.’²
Chapter 30
Noticing confusion
There’s an old science joke which Yudkowsky turns into a Teachable Moment. There is a heater in the laboratory. Next to it is a tile. The teacher asks her students: ‘Why do you think the side of the tile next to the heater is cooler than the side away from the heater?’ (If you like, stop reading for a moment and think why it might be. Don’t feel you have to, though.)
The student stammers: ‘Er, perhaps because of heat conduction?’
And the teacher replies: ‘No, it’s because I turned the tile around before you came in.’
It is a god-awful joke, I realise, but it is useful. The phrase ‘because of heat conduction’ sounds like an explanation, says Yudkowsky. It fits into that bit of the conversation where an explanation would go, and it uses sciencey-sounding words. But remember the last section, about making beliefs pay rent in anticipated experiences. What does a belief in ‘heat conduction’ make you expect?
Well, it should boil down to a series of equations derived from Fourier’s law and the conservation of energy (I say, confidently, having checked Wikipedia). But to a first approximation, it should say that the bit that’s been heated up should be hottest, and that bits that are further away should be cooler. The student should expect to find that the side nearer the heater is warmer, and should be surprised when it isn’t. ‘If “because of heat conduction” can also explain the radiator-adjacent side feeling cooler,’ says Yudkowsky, ‘then it can explain pretty much anything.’¹ And if your model can explain everything, then it doesn’t explain anything. When something happens that your beliefs don’t anticipate, you should be confused. And you should pay attention to your confusion, because either your belief model is wrong, or something else is going on that you’re not aware of, like the tile being turned around.
Yudkowsky has a story of someone telling him in a chatroom that a friend needed medical advice: ‘His friend says that he’s been having sudden chest pains, so he called an ambulance, and the ambulance showed up, but the paramedics told him it was nothing, and left, and now the chest pains are getting worse. What should his friend do?’ Yudkowsky says he knew that paramedics don’t do that – that if someone calls an ambulance they are obligated to take them to the emergency room – but didn’t take the obvious next step. Instead, he managed to ‘explain the story within my existing model, though the fit felt a little forced’, and replied: ‘Well, if the paramedics told your friend it was nothing, it must really be nothing – they’d have hauled him off if there was the tiniest chance of serious trouble.’ Then it turned out that the friend had made the whole thing up.
‘My feeling of confusion was a clue,’ says Yudkowsky, ‘and I threw my clue away. I should have paid more attention to that sensation of still feels a little forced. It’s one of the most important feelings a truth can have, a part of your strength as a Rationalist. It is a design flaw in human cognition that this sensation manifests as a quiet strain in the back of your mind, instead of a wailing alarm siren and a glowing neon sign reading: Either Your Model Is False Or This Story Is Wrong.’ If you’re trying to become a more rational being – a better Rationalist – then you need to listen to those little moments when something doesn’t quite seem to add up.
Chapter 31
The importance of saying ‘Oops’
The key takeaway from all the ‘bias’ stuff we’ve talked about is probably that it is really hard to change your mind. Large parts of our make-up are geared towards letting us keep on thinking what we already thought: confirmation bias, motivated reasoning, loss aversion and so on. If someone tells you something you don’t want to hear, then you’ll find ways of not believing them. That’s why a major part of the LessWrong project is learning how to actually change your mind. A whole Sequence of the Sequences, in fact, bears that exact title.
‘Scott [Alexander] said something I thought was really central to our enterprise,’ Paul Crowley told me. ‘Just as it’s good to have a lot of money, it’s good to have as much evidence as possible. But just as it’s good to get by on how much money you have, it’s good to be able to be as accurate as possible with the evidence you have. Sometimes the universe is not going to lavish you with evidence, sometimes you have to be as accurate as you can, with what you can get.’ And that means getting rid of ideas when the balance of evidence is against them, rather than – as our biases would have us do – hanging on to them for as long as we can. ‘We wait until we’re overwhelmed,’ said Paul. ‘It’s a long, slow process.’ But instead, we ought to treat ideas we hold and ideas we do not hold equally with respect to the evidence.
Quite a few of the Rationalists seem to come from religious backgrounds, and a key moment in their Rationalist life story is the point at which they gave up on religion, as they realised the evidence did not support it. ‘I haven’t had that one,’ Paul told me, laughing. ‘I was brought up by atheists. But I’ve had something similar.’ His parents are both socialists, and he followed them. ‘I was a card-carrying revolutionary communist in 1989, 1990,’ he said. ‘Then I moved towards being a more classically wishy-washy socialist type, wanting to achieve socialism by democratic whatever, but largely trying to come up with a position I could defend.’ Then, while reading the Sequences, he came upon the post entitled: ‘The importance of saying “Oops”’.¹
He’d been edging away from his socialist beliefs, retreating, ‘fighting a rearguard action’, as he put it. ‘But I felt like, on reading that, there was a level on which I already knew that this didn’t make sense, that I couldn’t sell it any more. I read it and just went, like, no. When you’re fighting the rearguard action, stop fighting. Stop, and reassess. Sometimes you have to say, “I’ve made a large mistake.”’ Instead of seeking the closest defensible position to your current one, try to ask where the evidence points, and sit in the middle of that.
When Yudkowsky slowly moved from his original ‘the singularity will solve everything’ position to his later ‘AI might actually destroy everything’, he did it incrementally. ‘After I had finally and fully admitted my mistake, I looked back upon the path that had led me to my Awful Realisation,’ he wrote. ‘And I saw that I had made a series of small concessions, minimal concessions, grudgingly conceding each millimetre of ground, realising as little as possible of my mistake on each occasion, admitting failure only in small tolerable nibbles. I could have moved so much faster, I realised, if I had simply screamed “Oops!”’²
None of these techniques or tricks are ever going to turn a kludgy human intelligence into the pure Bayesian thought-being. But Yudkowsky’s hope (and the wider Rationalist project) is that by using them, people will be better able to assess ideas and decisions, on both a personal level and a societal one. (One of those decisions, he thinks, will be to take the issue of AI alignment seriously.)
Part Six
Decline And Diaspora
Chapter 32
The semi-death of LessWrong
The Yudkowsky project we’ve been discussing, of explaining rationality, human thought, where they differ and how to make the latter more like the former, grew out of SL4 and Overcoming Bias, and became the Sequences and LessWrong, and the Rationalist community.
LessWrong was its central hub for a long time. But in about 2012 LessWrong started to die off – not completely, but its numbers dropped significantly. A peak of a million or so page views a month in early 2012 dropped to about 350,000 a month by mid-2016.¹ There are lots of reasons behind the decline, but here are the main two. One, Eliezer Yudkowsky felt that he’d finished the ‘Sequences’ at some point a couple of years earlier, towards the end of 2010. So he stopped blogging. And two, in 2013 Scott Alexander – known on LessWrong as Yvain, and probably the most prominent blogger on the site after Yudkowsky himself – started his own blog, Slate Star Codex.
There were other reasons. Robin Hanson told me that he thinks it’s partly because, as with many things, the Rationalists tried to reinvent everything from scratch. LessWrong, the website, wasn’t just a blog: it was a custom-designed community hub, based on a Reddit-like voting system – if you like a post or a comment, you press the ‘up’ arrow; if you don’t, you press the ‘down’; the site’s algorithm is more likely to show you things with lots of upvotes than things with lots of downvotes. But it got gamed: according to Scott Alexander, ‘one proto-alt-right guy named Eugene Nier found ways to exploit the karma system to mess with anyone who didn’t like the alt-right (i.e. 98 per cent of the community) and the moderation system wasn’t good enough to let anyone do anything about it’.²
It’s part of a wider attitude among the Rationalists, said Hanson, of thinking they can rebuild everything. ‘They’re people who are smart and articulate and they have ideas in their heads about how things should be different. And they want to implement them all, and are unpersuaded by the fact that other people have tried them before and failed.’ The Rationalists, unsurprisingly, do not agree with this assessment, but there is an element of truth to it.
So they convinced themselves, Hanson thinks, that by studying the Art of Rationality – the ‘Bayesian judo’ that Yudkowsky was teaching, all that stuff about noticing confusion and thinking probabilistically – they could avoid the pitfalls of irrationality that flaw other people’s thinking and create new, shiny things. ‘They decided that they could make better technology,’ he said, ‘like the LessWrong software. They get involved in start-ups, they think they know how to redo romance with polyamory, they think they know how to redo diets with the diet things they get into. They’re all over the place with whatever.’ It reminded him, he said, of some Silicon Valley people he was involved with in the 1980s, the Xanadu Project, who were working on the first hypertext systems, and some others who were interested in nanotechnology. ‘There were a lot of young idealistic people trying to save the world through start-ups and tech. As usual they were into science fiction and the future and how everything would change enormously, and they were into trying everything different. At Xanadu they had to do everything different: they had to organise their meetings differently and orient their screens differently and hire a different kind of manager, everything had to be different because they were creative types and full of themselves. And that’s the kind of people who started the Rationalists.’
And Scott Alexander has his own theories, which he expounded on a Reddit thread in 2017. One was that Yudkowsky skirted ‘the line between “so mainstream as to be boring” and “so wacky as to be an obvious crackpot”’, which many other bloggers struggled to do, either because they were boring, or because they were crackpots, or because although they weren’t crackpots they also weren’t very good at not coming across as crackpots. Yudkowsky also came to realise, Scott said, that he is ‘a pretty weird person, and now that the community’s more mature it helps for it to have less weird figureheads’.
Scott added that the community became ‘an awkward combination of Google engineers with physics PhDs and three start-ups on one hand, and confused 140-IQ autistic 14-year-olds who didn’t fit in at school and decided that this was Their Tribe Now on the other’, and that it was hard to find the ‘lowest common denominator’ that appealed to both groups. The end result was that ‘LessWrong got a reputation within the Rationalist community as a bad place to post, and all of the cool people got their own blogs, or went to Tumblr, or went to Facebook, or did a whole bunch of things that relied on illegible local knowledge [by which he means the sort of understanding of a community that only comes from living in it – like how you’ll always know your home city better than someone who’s just read the Lonely Planet guide to it]. Meanwhile, LW itself was still a big glowing beacon for clueless newbies. So we ended up with an accidental norm that only clueless newbies posted on LW, which just reinforced the “stay off LW” vibe.’
The point about ‘illegible local knowledge’ is definitely true from my experience. I’ve been hanging around LessWrong-ish circles for a few years now, and I regularly still stumble across giants of the Rationalsphere whom everyone else just seems to know but who never wandered into my field of vision before: names like Gwern and Nostalgebraist and The Unit of Caring. There’s no natural central hub any more, and you can’t learn the paths and backwoods of Rationalist country without wandering around it, lost, for years. (There is a map. It’s by Scott Alexander. But I don’t think you could use it to navigate without first knowing where everything is anyway. Still, the puns – ‘Reasoning Sound’, ‘Bight of Information’, ‘The Reverend Thomas Bay’ – are absolutely impeccable.)³
Whatever caused the semi-death of LessWrong, the fact remains that it happened, and the people involved in it spread across different parts of the internet. Slate Star Codex gets about 20,000 views a day, about 600,000 per month – down from the LessWrong peak, but still a significant number.
Chapter 33
The IRL community
What also happened is that a real-life community sprang up. There are Rationalist (and ‘Rationalish’, ‘Rationalist-adjacent’, LessWrong and Slate Star Codex) meet-ups all around the world: I can see Facebook groups for Munich, the Netherlands, Israel, Montreal, London, Reading, Bath, Sydney, Denver, DC, Canberra, Edinburgh, Darmstadt and Phoenix, just via a very quick search. I know there’s a group in Melbourne as well, and Berlin, and a nascent one in Manchester. The Bay Area and New York have the largest communities.
Many of the community members live in group houses, although not all or even a majority. This doesn’t appear to have been a cult-leader invention enforced from the top by Eliezer Yudkowsky; Paul Crowley thinks that ‘the group house phenomenon is just a necessity given the Bay housing situation’ (house prices there being, to my amazement, comparably extortionate to London), which is where a large number of them live, and that, anyway, Rationalists are the sort of people who tend to end up in group houses. ‘The libertarian/futurist/Burner [Burning Man festival regular] circles were in named group houses long before Eliezer moved here,’ he said. ‘At university in the 1990s my social circle was the science-fiction society, and we all lived in named group houses.’
Ben Harrison, a British man in his early twenties who got involved with the Rationalists through reading the blogger Gwern and ended up following the LessWrong/Slate Star Codex stuff, told me that the group houses are ‘a bit like university halls, but the kitchen sink is a little cleaner’. His group house, in Manchester, was set up explicitly as an alternative to the Bay Area, which tends to attract many Rationalists, but because of the aforementioned housing costs has a high bar to entry. Some of the group houses are polyamorous; some are not.
I wanted to get an idea of what the IRL community was like, so I went to a few of the meet-ups. I met Scott Alexander, the AI researcher Katja Grace, who was in a polyamorous relationship with Scott at the time, and a couple of others at a pizza place in Berkeley while I was there, where we discussed AI safety and whether or not my book was going to be a catastrophe that increased the likelihood of a paperclip apocalypse. (Buck Shlegeris, a young MIRI employee with excitingly coloured hair and an Australian accent, told me that ‘A book on this topic could be good’, and that ‘if I could jump into your body I have high confidence I could write it’. However, his confidence that I could write it from within my own body seemed significantly lower, which is probably fair enough.)
I distinctly got the impression that the IRL community is, like the online community, a venue for people who are a bit weird, not very good at small talk, and interested in big ideas. There were a couple of things that stood out for me while I was there. One was that, for a few minutes, I couldn’t find Katja. Then it turned out that was because she was sitting with a baby on her lap. I knew she didn’t have a child, so I’d discounted the woman with the baby as obviously not her. Upon closer inspection, it turned out that the baby was one of those robot babies that some American high schools give out to teenagers, to give them an understanding of how hard parenthood is (and thereby scare them off sex for ever, in my stereotyped picture of American high schools, although I suspect that’s not fair).
I thought at first it was a weird affectation, but she turned out to be running a rather sensible experiment. She and Scott were considering having children, and she wanted to know what the disruption to her life would be like. So she got one of those babies that wails when you leave it alone, and wakes up several times in the night, and needs its nappy changing, and so on, to get an impression of whether motherhood was for her.
What she had failed to consider, which I think is sweetly typical of the Rationalists in a lot of ways, is that people would stop her in the street and say, ‘Oh, cute, a baby!’ and she’d have to awkwardly explain that it was not, in fact, a baby, but an experimental robot. Still, I hope the experiment gave her some non-zero level of insight into what parenthood involves; I did try to downplay her expectations on that front, given my experience that the challenges of newborn-baby-parenthood are only vaguely related to those of hyperactive-toddler-parenthood and, I assume, even less related to the stages after that.
Another thing that interested me was the almost complete absence of small talk – I’m a nervous talker, so I found myself gabbling to fill spaces in the conversation. It was Big Topics or nothing. And they actually pay attention to the arguments you’re making; in my incoherent blather I was trying to justify the idea of writing this book (of which they’re all sceptical, to a greater or lesser degree), and used several, mutually incompatible reasons for doing it. Katja in particular noticed and pulled me up on it.
When the time came to pay for our pizzas, we played a strange little game. We used someone’s phone to come up with a quasi-random number between 0 and the price of the bill, and then counted down through the items to see whose meal it ended up on; that person then had to pay the whole bill. (Imagine there were two of us, just me and Scott, and the bill said ‘Tom’s Pizza, $10; Scott’s Pizza, $10’. If the random-number generator came up with a figure between 0 and 10, I’d have to pay for it, because I was first on the bill; if it came up with a figure between 10.01 and 20, Scott would have to pay for it.) It ended up on Katja, so she paid for everyone’s meal. I felt guilty and tried to pay anyway, but Buck stopped me: ‘If you’d lost you’d have had to pay the whole thing. It’s fair.’
It has only just occurred to me now, as I’m writing this nearly eight months later, how clever this system is. Splitting a bill according to who had what is time-consuming, boring and socially awkward. But splitting it clean down the middle incentivises people to order more expensive meals; they get all the benefit of the nicer meal but only pay a fraction of the extra cost, in a classic tragedy of the commons. But this system was extremely quick – almost as quick as dividing the bill on a calculator – and people who ordered more expensive things were more likely to pay the whole bill: if you ordered lobster thermidor for $80, the chances would be much higher that the number would end up on your bit. On average, you pay for exactly what you ordered. (Although it would take dozens of meals out for the averaging effect to cancel out the random noise.) Anyway, I thought it was clever, and very Rationalist.
I went to a London meet-up as well, which was pleasingly British; it was in a pub, and some people other than me were actually drinking alcohol. (In California, with Scott and the others, I had one beer; they were all on Diet Coke, and although none of them was remotely judgemental about it I still felt like some great lumbering hooligan, as though I were about to rip my top off and start throwing the chairs around like an England football fan in a provincial Portuguese town.) There were 16 people there, mostly but not exclusively men, crowded around a table for perhaps eight in a Wetherspoons near Holborn. A large majority of the time was spent in a rather AGM-style discussion, earnestly establishing rules for how conversations should go: should there be set topics? Should there be reading materials?
This seemed to go on for an awfully long time, with no immediate danger of stopping, so I ended up following one of the more normal people to the bar and asking him what he enjoyed about it all. He lived outside London and it cost him £30 to get there, he said, so he didn’t do it often, but ‘I like being able to come here and not be normal, before I have to go home and be normal again.’ What did he mean by that? I asked. He meant he could talk about weird topics – AI, transhumanism, existential risk, biases, all the weird, nerdy stuff – and reliably be among people who wouldn’t think he was weird for doing it. ‘Plus,’ he said, ‘I can be a bit of a dick, and I like that I can say something really controversial, and instead of them being offended they all lean forward and say, “Let’s unpack that.”’ He did proceed – fairly shortly afterwards, once the AGM business had died down – to say something quite controversial about transgender rights, if I recall correctly, and lo, they did lean forward and they did talk about it seriously.
LessWrongers also began various IRL projects. The Singularity Institute, now MIRI, already existed when the LessWrong decline began, but the Center for Applied Rationality (CFAR) was founded by Anna Salamon, Julia Galef, Valentine Smith and Andrew Critch in 2012.
Other projects grew out of the LessWrong diaspora. There’s a food company called MealSquares which produces savoury cake-like things that are supposed to be a healthy meal in a polythene wrapper; the idea behind them is to make healthy, ‘optimal’ eating easy. (I tried one at CFAR’s office; it was like a heavy, dry-ish scone. It was ‘nice in an overpoweringly dense sort of way’, according to my notes from the time.) There’s Beeminder, a ‘reminders with a sting’ goal-tracking project that is free as long you keep hitting your targets; you only start paying for it if you miss them. You might want to start running 10 kilometres a week: you link your FitBit to Beeminder and it will charge you when you fail. It’s honestly clever.
They haven’t all worked out: there was a medical-consultancy start-up called MetaMed, founded by Michael Vassar, where Scott worked for a while, which tried to use the LessWrong Rationalist techniques in medical assessments; it failed rather sadly after a couple of years. I read a couple of post-mortems¹ online,² and the reasons it failed sounded very much as Robin Hanson would have predicted: the creators thought they could rebuild healthcare almost from scratch, and didn’t realise that there were huge amounts of unspoken local knowledge involved in both healthcare and business. I don’t want to sound mocking, but there were a lot of lines in the post-mortems which could be summarised as ‘Turns out marketing is important’ and ‘Turns out you actually need to do the job in front of you as well as think about the glorious future where AI solves everything.’ Robin’s comment about everyone being smart and articulate and convinced they can do everything better than it’s been done before, without really checking how it’s been done before, seemed very apt here.
There was a no-one-knows-exactly-what-but-it-appears-to-have-been-a-sort-of-Wikipedia-for-maths project called Arbital. Eliezer Yudkowsky was involved in that, along with some other Bay Area Rationalists. Again, the problem seems to have been a surfeit of big ideas and a shortage of actually knowing what they wanted to be doing right now. It had a ‘55-page document describing Arbital and how and why it was different and necessary’, written by Yudkowsky; it was a ‘better Wikipedia’, but it was also a blog and a discussion board and had a Reddit-like karma-upvoting system, and also provided ratings for things so it could replace services like Yelp. The post-mortem, after explaining all of this, sighs: ‘Now you can probably see how the meme of “Arbital will solve that too” was born . . . we just didn’t have a good, short explanation of what Arbital was.’ It shut down in 2017 without ever really getting off the ground, although its legacy is a genuinely good intuitive explanation of Bayes’ theorem (it’s all still online).
I don’t want to be too harsh about any of this. Most start-ups fail, a fact of which the Rationalists are extremely aware; one of the biases discussed in the Sequences is the tendency to overestimate our own likelihood of success. Taking the ‘inside view’, most people think their business will succeed, but taking the ‘outside view’, about half of new businesses fail in their first five years; that figure is higher for Silicon Valley start-ups, with their whole ‘fail-fast’ ethos, at between 60 per cent and 90 per cent, depending on which study you read. So there’s absolutely no shame in two of the four Rationalist-led start-ups I am aware of failing in their first few years, and even though I do think it’s interesting that they did so in (what seemed to me) quite predictable ways, Yudkowsky would no doubt point out that, with hindsight bias, everything seems obvious once it’s happened.
Not all Rationalists spend time in the IRL community, obviously. Some fairly central members have rarely if ever met their fellow Rationalists in person. Jim Miller, a professor of law and economics at Smith University in Massachusetts, and one of the original Overcoming Bias crowd – he was blogging on Robin Hanson’s website back in 2007 – spoke to me over Skype and said he’d never actually met any other Rationalists IRL, apart from, coincidentally, at a conference in Sweden a few weeks previously. ‘If I was a college student I would have seriously considered moving to the Bay Area,’ he said, ‘if I wasn’t married or anything. But not at this stage of my life [he’s in his early fifties, and married with children]. Also,’ he added thoughtfully, ‘living in a small part of a house in Berkeley just seems kind of horrifying to me, actually. When I was living in a dorm it would have been fine, but going back to that kind of life . . .’
But even just online, the Yudkowskian project has nonetheless had a profound impact on his life. For one thing, he steered his career towards it: he teaches about the economics of the far future, talks in his classes about cognitive bias, and has written a book on the potential rise of AGI, called Singularity Rising. ‘Before [LessWrong], I was a traditional economist,’ he said. ‘Not assuming that rationality is perfect, but thinking it’s a pretty good model and we don’t need to go beyond that. The LessWrong stuff convinced me that economists should be looking at cognitive biases.’
His day-to-day decisions in his personal life have changed to some degree, as well. Most dramatically, he is taking steps to extend his life, for a very simple reason: if the singularity comes, then the difference between dying the year before it and the year after it is almost incalculable. ‘If we do achieve the singularity and allow indefinite life extension, it could easily happen after I naturally die, so the expected value to me of living a few more years is huge.’ If there’s, say, a 0.1 per cent chance that those extra few years might get him to the glorious future, and the glorious future means a subjective life of a million years, then that 0.1 per cent chance translates to an expected value of a millennium of extra life.
He has signed up for cryonics, as many Rationalists have, and is an adviser to the board of Alcor, one of the largest cryonics firms. He has changed his diet – ‘I’ve gone mildly paleo’ – and talked his doctor into prescribing him a diabetes drug called metformin, because there’s some evidence that it extends lifespan through an anti-cancer effect. Is the evidence solid, I asked him? ‘The evidence is solid that it doesn’t do harm and it might be good,’ he said. ‘So many people take it that a significant negative effect would be known.’ (Sincere warning: please do not take this as any sort of medical advice.)
This online-only connection to the Rationalist community is probably the norm. The 2016 LessWrong diaspora survey found³ that only 8 per cent of respondents ‘regularly’ attended meet-ups, and another 20 per cent had done so ‘once or a few times’. Another question asking about ‘physical interaction’ with other LessWrong community members (for example, ‘Do you live with other LessWrongers, or are you close friends and frequently go out with them?’) found 7.6 per cent did ‘all the time’ and 12.5 per cent ‘sometimes’. The large majority, at least according to this survey, have never met another Rationalist in person. The 2018 Slate Star Codex survey found similar results: only 10 per cent of respondents had ever been to a meet-up, and only 24 per cent of those still went to them regularly.⁴
But there is a hard core of Rationalists, perhaps a few hundred or a few thousand worldwide, who are more committed: who go to the meet-ups and live in the group homes, who (in many cases) financially support MIRI or other Rationalist groups, and who engage in polyamorous relationships. They’re an unusual bunch of people, and they are centred around a few charismatic figureheads. This has led to accusations of them being a ‘cult’. But are they?
Part Seven
Dark Sides
Chapter 34
Are they a cult?
‘They’re a sex cult,’ says Andrew Sabisky.
Sabisky is an interesting man. He’s a superforecaster, like Mike Story (whose massive dog crushed my feet), and exists in the same internet circles as the Rationalists. Unlike Mike, though, he seems to be a sort of enemy of the Rationalists, or at least a thorn in their side – he’s certainly one of their most vocal critics. He’s also kind of weird, in an endearing sort of way. Though there’s no doubting the sincerity of his beliefs, he seems to have decided to become a Christian on the basis that tradition and ritual are important for humans, started running the social-media accounts for a central-London church, and appears to have got from there to actually believing in God. (‘He memed himself into it,’ Mike Story says, fondly. Apparently, there’s a theological idea of ‘act as if you have faith and faith will be given to you’, and that’s what Sabisky did.) During our two-hour conversation in a swanky central-London coffee house, we strayed away from the Rationalists and AGI and at one point ended up talking about the English Civil War, which Andrew is firmly against. ‘They cancelled Christmas and they killed our king!’ he declares, in a loud and declarative voice that may be ironic but may just be wearing the clothes of irony to distract from the fact that he 100 per cent means it.
The idea that the Rationalists are a cult – whether sex or otherwise – is not uncommon. It is, in fact, the subject of much writing by Yudkowsky and Scott Alexander, who appear to worry about it as a realistic problem. In fact, in the process of writing the Sequences Yudkowsky wrote so many things about avoiding cultishness that the word ‘cult’ started getting suggested as an autocomplete when you searched for LessWrong on Google. This was seen as suboptimal, so (in a delightfully Rationalist way) they asked everyone using the word ‘cult’ in a post to use instead a simple substitution code, shifting all the letters by 13 in the alphabet – so A→N, B→O, etc. – and turn it into ‘phyg’.¹ (It doesn’t appear to have worked: when I search ‘lesswrong’ in an incognito window so my search history doesn’t come up, ‘less wrong cult’ is the second option. Still, it was a nice idea.)
It’s worth addressing. They do share a lot of the surface features of a cult: a charismatic figurehead and other high-status inner-circle members; a key text that in-group members are supposed to have read, and which encodes the central tenets of their ‘belief’; unorthodox sexual practices; a message of impending apocalypse, and a promise of eternal life; and a way to donate money to avoid that apocalypse and achieve paradise.
In case that needs spelling out, I mean Yudkowsky as the figurehead and others – Bostrom, Scott Alexander, Rob Bensinger, Luke Meulhauser, etc. – as the high-status inner-circle men; the Sequences, and to some extent Yudkowsky’s Harry Potter fanfic Harry Potter and the Methods of Rationality, as the local bible; the Rationalist tendency towards polyamory as the sex stuff; the AI apocalypse, and the cosmic endowment, as the eternal life; and MIRI as the recipient of the indulgences.
‘Yudkowsky and his wife and girlfriends,’ says Sabisky. ‘He used to be, like, an uber virgin. Then he got famous and started a sex cult, as you do. What else would you do with all that fame within a very narrow circle? If you look at his output, the main one is the Harry Potter fanfic. It’s not aimed at making money, it’s clearly just a thing that attracts people into your sphere. That’s their whole point.’
‘They’d have to be fucking blind to see they hadn’t formed a cult’, according to David Gerard of RationalWiki, which in the internet’s sceptical–rational website wars is the Judean People’s Front to LessWrong’s People’s Front of Judea. ‘They tried not to become a cult, they asked themselves if they were being cultish, which was the right thing to do, but it happened anyway.’ The Effective Altruism movement is part of it, he says, insofar as it wants you to give money to prevent AI apocalypse. ‘Some charities are more effective than others, and you should donate to the more effective ones,’ he wrote on Tumblr, ‘and clearly the most cost-effective initiative possible for all of humanity is donating to fight the prospect of unfriendly artificial intelligence, and oh look, there just happens to be a charity for that precise purpose right here! WHAT ARE THE ODDS.’²
I asked Paul Crowley about the whole cult thing, and it was the one time he got even slightly angry. ‘It drives me up the wall!’ he said. ‘We’re exceptionally good at this.’ By ‘this’ he means ‘not becoming a cult’. ‘But there’s no way to say, “Oh no we’re not”, because you must be a cult if you’re denying it.’ He acknowledges that the Rationalist movement is ‘weird’: ‘There’s no way to deny that.’ But they have a cause, and that cause is saving the world from unfriendly AI, and so they want to get people involved with it. ‘Everyone does that, right?’ he asked. ‘You think, you know what, climate change is a problem! So I need to get some people on board with the idea that climate change is a problem. Or I think the Democratic Party is going in the wrong direction, I’ll get everyone I know on board with changing it. As soon as you have a cause, you want to get people on board and say we should talk about this.’
According to Paul, the thing that distinguishes a cause from a cult is when it becomes taboo to criticise the cult. ‘What’s dangerous is when you start to attack people’s ability to think critically about it,’ he said. ‘A common trick, for example, is to say that questioning the precepts of this is morally wrong. If someone says, “I’m not sure that’s true,” and your reaction is, “You’re a bad person for even asking,” then that starts to get dangerous. On that score, I think we do unbelievably well! We’re out there on the far end of the scale of how comfortable we are with people asking those questions.’
This is something that Yudkowsky has thought about himself. He thinks cultishness is ‘a high-entropy state into which the system trends, an attractor in human psychology’, by which he means that, left to its own devices, any group based on some noble cause will naturally slide into something like a cult. ‘Every group of people with an unusual goal – good, bad, or silly – will trend toward the cult attractor unless they make a constant effort to resist it. You can keep your house cooler than the outdoors, but you have to run the air conditioner constantly, and as soon as you turn off the electricity – give up the fight against entropy – [it] will go back to “normal”.’³
It doesn’t matter, writes Yudkowsky, if the cause is one of rationality and science and introspection: ‘Labelling the Great Idea “rationality” won’t protect you any more than putting up a sign over your house that says “Cold!”. You still have to run the air conditioner – expend the required energy per unit time to reverse the natural slide into cultishness. Worshipping rationality won’t make you sane any more than worshipping gravity enables you to fly.’
He has dedicated quite a lot of time and energy, in the form of several blog posts of some length, to avoiding the problems of cultishness. The question is: how well have they succeeded?
A lot of the LessWrongers do hero-worship Yudkowsky, to some degree. You can read it in the tone of their posts. That’s hardly surprising, since he’s a charismatic figure at the centre of everything they care about, and many of them are young men and teenage boys who have a tendency to do that sort of thing. One woman, who is more involved in the Effective Altruist community but hangs around with Rationalists as well, told me (anonymously): ‘I do think the Rationalist community, at least in parts, has troubles with this heroic narrative, where some people are these sort of superheroes who can do anything. Some people see Eliezer as that, although I don’t know if he plays up to it. And [another high-profile Rationalist] sees himself like that.’
And there’s the fact that they want you to donate money to MIRI to stop the world from being destroyed. That is quite apocalypse-culty. Take this, for instance, on the money side of things: Yudkowsky was asked in 2010 what his advice was for people who want to help save the world, and he said: ‘Find whatever you’re best at; if that thing that you’re best at is inventing new math of artificial intelligence, then come work for the Singularity Institute. If the thing that you’re best at is investment banking, then work for Wall Street and transfer as much money as your mind and will permit to the Singularity Institute where [it] will be used by other people.’⁴ It’s not great, at first blush, is it? ‘Get rich and give us every penny you can spare to prevent the apocalypse.’ And people did donate (although a difference from a classic apocalypse cult is that donations are intended to save everyone, rather than to buy salvation for the donor specifically).
That said, there is a pretty good counterpoint against the idea that the Singularity Institute, as it was then, or MIRI as it is now, is a hoover for sucking up gullible people’s donations. That is, Yudkowsky has stopped asking for them. He appeared on the philosopher Sam Harris’ podcast in early 2018, and stated: ‘thanks mostly to the cryptocurrency boom – go figure, a lot of early investors in cryptocurrency were among our donors – the Machine Intelligence Research Institute is no longer strapped for cash, so much as it is strapped for engineering talent’. He feels that MIRI needs more engineering staff in order to spend the money it has. ‘We can obviously still use more money,’ he said when I asked him about it, ‘but our organisational attention has shifted to finding researchers and engineers.’
And, according to their finances, which are available on their website, the 10 ‘research’ staff shared a total annual salary of $585,000 in 2017.⁵ No doubt Yudkowsky and the executive director Nate Soares account for a decent percentage of that, but even if the other eight people are on a fairly-low-for-Berkeley $40,000 a year, it would put those two on about $130,000, which is obviously a decent wage, but pretty comparable to that of a good software engineer. It’s not a perfect metric, but I would imagine that Joseph Smith wouldn’t have been quite so abstemious in paying his own wages out of the Church of Jesus Christ and Latter-Day Saints’ revenues.
But here’s why I don’t think they’re a cult. Or, actually, let me put it another way. You could call them a cult, if you like. But it would involve defining the word ‘cult’ in terms that would remove most of the things about cults of which we are most wary.
I’m going to expand on this by referring to a post of Scott Alexander’s, from before his LessWrong days.⁶ It was titled ‘the worst argument in the world’. The argument goes like this: ‘X is in a category whose archetypal member gives us a certain emotional reaction. Therefore, we should apply that emotional reaction to X, even though it is not a central category member. Call it the Noncentral Fallacy,’ says Scott. It sounds a bit obscure, but we all do it, all the time.
Scott’s first example is Martin Luther King. Imagine someone wants to build a statue of MLK in a city somewhere. Someone objects to it: ‘But Martin Luther King is a criminal!’ What’s your response to that? ‘No he wasn’t’? But he was: he broke the law by protesting against segregation. It was a shitty law, but he broke it. He was a criminal. And your opponent is saying that because criminals are bad, and MLK was a criminal, we should think MLK was bad.
‘The archetypal criminal is a mugger or bank robber,’ says Scott. ‘He is driven only by greed, preys on the innocent, and weakens the fabric of society. Since we don’t like these things, calling someone a “criminal” naturally lowers our opinion of them.’ But MLK is a noncentral example of a criminal. He wasn’t driven by greed or preying on the innocent. ‘Therefore, even though he is a criminal, there is no reason to dislike King.’ But this is a really hard thing to argue against, when you’re in the brutal cut-and-thrust hand-to-hand combat of an argument on the internet. You would not instinctively respond, ‘Yes it is true that Martin Luther King was a criminal, but he did not share the features of criminals that make them bad, so your suggestion that he is bad is based on faulty logic.’ You would, Scott suggests, be much more likely to say: ‘No he wasn’t! Take that back!’ And then the exchange becomes about whether he was a criminal or not, and ‘since he was, you have now lost the argument’.
This sort of thing happens all the time. ‘Abortion is murder’, ‘Taxation is theft’; the argument is, ‘Abortion shares some features with murder, so you should be as outraged by it as you are by murder’, or ‘Taxation shares some features with theft, so you should be etc.’ And of course, if you try to argue against it by saying, ‘Well, it’s the good kind of theft’, your unscrupulous enemy will say (to quote Scott): ‘Apparently my worthy opponent thinks that theft can be good; we here on this side would like to bravely take a stance against theft.’
This is what I think is going on in the ‘cult’ argument. I spoke to some Rationalists who were, in fact, much more sanguine about describing LessWrong and Rationalism as a cult, or a religion. For instance, Ben Harrison, the young British Rationalist who founded a group house in Manchester, was happy to call it exactly that. ‘I was accused of being a cult leader last week,’ he said, offhandedly. He’s pretty laid-back about the whole thing. ‘There are elements of religion to it. The structure it provides, the figures [such as Yudkowsky]. We’ve got holy texts, people who dedicate their lives to it. It has most of the trappings of religion; I’d call it a pseudo-religion. I can see what people are pointing at there.’
But where the ‘worst argument in the world’ comes in is that while it has a lot of the features of a cult, it is not a central member of the category ‘cult’. ‘The word “cult” is really just a name for a strong community that’s disapproved of,’ Robin Hanson – the economics professor who first hosted the Sequences on his blog, Overcoming Bias – told me. ‘When I was a young teenager, 12 or 14, I was in a Christian cult.’ But the cult never ordered him to dissociate himself from his friends or family, and when he left after a year or so, he was free to do so. ‘There are coercive cults, but the cult I was in wasn’t one, and [the Rationalist community] certainly isn’t either. It’s rare, really, for cults to have these dissociation rules. Usually they just have strong eagerness to get close to one another, and spend time with one another in group homes and so on.’
That’s not to say there’s nothing to worry about. Anna Salamon, the founder of the Center for Applied Rationality, told me that she thinks the ‘cult’ question is probably the wrong one. ‘I don’t worry about the cult thing very much,’ she said. ‘I agree it’s important that we [don’t coerce people or crack down on dissent].’ She doesn’t think they do do that, for the record. What she worries about is that people will miss the thing they’re trying to do – teach ways of thinking, ways of examining your own thinking – and just pick up on the ‘AI apocalypse’ conclusions. ‘I worry about making sure that our classes aren’t too convincing of the wrong thing. We try to share the processes for thinking, and how to verify those processes, rather than duping people into believing specific conclusions because someone at the front of the room said them.’
The mental techniques – the use of maths and Bayesianism to support conclusions about everyday things, for instance – are weird and ‘a little bit scary’, and they try to get people to take them seriously. But if you just put, say, Bostrom’s numbers about the cosmic endowment in front of someone, and don’t teach them the stuff that contextualises them – that lets you check for yourself whether it’s worth being worried about it – then, she thinks, it could go a bit wrong. ‘It freaks me out a bit,’ she said. ‘I’m a little afraid that someone will just trust the numbers. For example, AI risk is a very big topic, and it’s easy for people to feel hijacked by it, and be like, “Aha, I’ll ignore all the things I normally care about and just care about this thing.” I think that’s mostly a bad idea.’
It’s not that she doesn’t want people to worry about AI risk, but rather that she wants people to be able to examine the question – the maths, and reasons why you shouldn’t just blindly follow the maths – for themselves. She wants people to work that out for themselves, not to take it on faith from some authoritative source. This strikes me as doing the work that Yudkowsky mentioned, the ‘air-conditioner’ work: actively trying to stop your cause from turning into a cult. From my point of view, it seems to be working.
But Sabisky’s suggestion wasn’t simply that they are a cult – it was that they are a sex cult, that the entire movement exists to (or at least has conveniently turned out to) enable powerful Rationalist men to have sex with lots of impressionable young women. This revolves, at least in part, around the fact that a large number of the full-time Rationalists – the ones who live in group houses and/or work for CFAR or MIRI, and the ones centred around the FHI in Oxford – are polyamorous. This is true of both men and women. Eliezer Yudkowsky himself is polyamorous: he has a wife and two other partners, all of whom are themselves polyamorous and engaged in other relationships.
This is where the ‘sex-cult’ accusations come in. You can see how that might be something worth worrying about. A man builds a community in which he is a figurehead; he gains power and prestige which enables him to attract the sexual attention of several women; the community conveniently develops an unwritten rule which says that he is allowed to have sexual relationships with several women. It ‘pattern-matches’, to borrow the terminology that the Rationalists use, extremely well to things like David Koresh, the Texan cult leader and ‘final prophet’ who died under police gunfire in a siege in 1993. This is basically how Andrew Sabisky sees it. ‘It seems to revolve around the highest-status men, and they get to pick and choose.’
But there are several ways in which this story is at best incomplete, and, at worst, downright wrong. For one thing, Paul Crowley is a Rationalist, and he’s also poly, but he was poly for many years before he became a Rationalist; he’s never been anything but poly. It’s absolutely the case that some people did turn poly after joining the Rationalists – Scott Alexander, for instance – but to some degree, at least, the Rationalist community attracted poly people, rather than simply instilling a code of polyamory from on high.
Also, it should be pointed out that polyamory is not the norm even among Rationalists. It’s more common in the Rationalist community than elsewhere, I think, but perhaps not as much more as you’d expect: the Slate Star Codex 2018 survey⁷ found that slightly less than 10 per cent of its 8,000 respondents said their preferred relationship style was poly; a 2014 LessWrong survey⁸ put the figure at about 15 per cent.
I don’t have reliable numbers for the population at large, but I read an estimate (from a blog post in Psychology Today, quoting an ‘independent researcher’⁹ – apply salt liberally) that there were ‘around 1.2 to 2.4 million’ American couples ‘actually trying sexual non-monogamy’; about 10 million if you include all couples who ‘allow satellite lovers’. There are about 120 million adults of each sex in the US. If we assume that three-quarters of them are in committed relationships, then we’re looking at something between 2 per cent and 10 per cent of all couples who are poly, depending on your definition. A study found that 21 per cent of people had at least tried it, at some point.¹⁰ Another article in the legal magazine Advocate claimed, with no references, that ‘most researchers estimate that a full 4–5 percent of Americans participate in some form of ethical non-monogamy’.¹¹ I think it’s probably OK to guess that 5 per cent of Americans prefer polyamorous relationships. That makes it at least twice as common among Rationalists, but we’re not dealing in orders of magnitude or anything.
Also, the average Rationalist is significantly younger than the average American. I have no data on this whatsoever, but since articles about polyamory tend to refer to it as a ‘new trend’, I assume it’s more common among young people.
I expect it’s even more common among people who tend to look at social norms and say: ‘Why do we do this and do we need to carry on doing it?’, which is of course exactly the sort of person who would join the Rationalists. ‘I think there’s a phenomenon where a social circle that is OK with unusual choices will have a lot of poly people in it,’ points out Paul Crowley. ‘Lots of folk I know on the goth scene are poly, for example. Same for kink, sexuality, transness.’ It may well be that Rationalists are no more likely to be poly than any other group of young, nonconformist oddbods. The superforecaster Mike Story agrees: ‘The polyamory thing isn’t like, “Let’s be in the Rationalists and have lots of sex.” It just so happens that if you think this way, you probably also think that way.’
All that being said, the surveys are addressed to the wider internet population. There isn’t some ringfence around ‘the Rationalist community’ which says this person is in and this person is out; everyone who read LessWrong in 2014, and everyone who read Slate Star Codex in 2018, was asked to take the survey. I think I took the 2017 SSC one, and although I’m a sympathiser, I’m not really a member of the community.
Ben Harrison, the founder of the group house in Manchester, pointed out to me when I spoke to him that there are circles and circles. ‘The biggest is the people who read Slate Star Codex casually,’ he says, a circle which includes a large number of people I know who absolutely would not call themselves ‘Rationalists’. ‘Then there are the wider people who read all the blogs but don’t feel the need to be part of the scene socially. Then there are all the people on the Discords and the Slack channels [group chats]. Then there are the people who go to the meet-ups, then the people who live in the group houses, and then the people who exist, in an economic sense, entirely in the community.’
And it does seem that the further you get into the inner circles, the more likely it is that you’ll be poly. That makes sense in the light of the idea above: the more devoted you are, the more nonconformist you’re likely to be, compared to vanilla dilettantes like me. But I think a majority of the people who actually work at CFAR and MIRI, and (although no one will actually confirm this for me) large numbers of the Future of Humanity types are poly. Buck Shlegeris of MIRI, the young Rationalist I had pizza with, estimated that 70 per cent of Rationalists are poly. It depends where you draw your line around the term ‘Rationalist’.
The poly aspect has undoubtedly led to scenarios which would raise a lot of people’s eyebrows. ‘Have you heard the story about the LessWrong baby?’ Sabisky asks me, somewhat salaciously. I had, vaguely. What happened was that a young woman in the Bay Area was in a polyamorous relationship, or interlocking set of relationships – the standard mono terminology gets a bit confused. She had a husband, but she was also in a relationship with another man, a high-status, extremely wealthy member of the Rationalist community who himself was married.
‘So anyway she’s shagging this guy,’ says Sabisky. ‘And they have an agreement – because, apparently, contraception is hard to use – that if she gets pregnant she’ll have an abortion. Well, she does get pregnant by him, and can’t follow through, understandably.’ The upshot is that she had the baby, who by all accounts is now doing very well; she broke up with her husband, although that sounds like it was less to do with the baby and more to do with issues of his own.
Where it all blew up a bit was that someone started a crowdfunding thing among the Rationalists to help support her. She had, admirably to my mind, refused to try to get money from the father, because of this deal that she’d made. Scott Alexander plugged the crowdfunder gently in one of his blog posts. ‘And people slated her! Slated her!’ says Sabisky. ‘For not having the abortion. “You made a contract! You made a deal! Why should we pay for you?”’
I have checked, and there is indeed a lengthy thread in the comments pretty much along these lines, occasionally interrupted by the woman herself saying ‘Please try to remember that I can read this and it is hurtful.’ It really wasn’t very pleasant. It made me understand, on a visceral level, exactly why some people dislike the Rationalist community: they’re unsettlingly willing to discuss things that many people find sacred, in a way that those people find profane. Most of the time it doesn’t bother me: I’m quite happy talking about the dollar value of a human life, say. But I found the open discussion of whether a woman ought to have aborted her now-18-month-old daughter because of a deal she’d made honestly hard to read. I’m a father of two, and perhaps it affected me personally in a way that other things do not.
But is it a David Koresh-style sex cult? Well. I think the ‘LessWrong baby’ story is unpleasant: a powerful and significantly older man driving his girlfriend to an abortion clinic, wanting no more to do with the baby once it was born, and not helping financially, because of a deal they had made before she got pregnant. But if this is the most egregious example of sexual abuse of power in the Rationalist community, then it seems, not trivial, but certainly no worse than things that happen all the time in many monogamous relationships.
The question, of course, is whether there are worse things. There’s this godawful Reddit page called /r/sneerclub which is dedicated to mocking the Rationalists, and they latched with enormous glee onto an OKCupid profile that Eliezer Yudkowsky put up in 2012. If you’ve ever read anything by Yudkowsky it’s immediately familiar: bombastic and self-promoting in a way that is meant to be ironic but isn’t really. It’s also very open about his fetishes, which attracted some mockery. And his ‘you should message me if’ bit says that ‘my poly dance card is mostly full at the moment’, but that you ‘shouldn’t worry about disqualifying yourself or thinking that I’m not accessible to you’, and should instead ‘test experimentally what happens when you try asking directly for what you want – that’s Empiricism’. ‘I’m also cool with trophy collection,’ he adds, ‘if you only want to sleep with me once so you can tell your grandchildren.’
It gives me an icky sensation, but again, it’s just a bit weird, not wrong, at least as far as my moral framework goes. If women want to message him, great; I hope it works out for all parties. But for some people the ‘ick’ factor is stronger, I think. I’ve heard it described as Yudkowsky ‘trawling for sex’, but I can’t see how you get there. He’s just openly stating that he wants sex and that if anyone wants it with him they should ask.
I should also acknowledge that in June 2018, some extremely dark allegations were made in a suicide note by a former Effective Altruist and Rationalist who said she was abused. It is an awful read. But as far as I can tell, the allegations had already been properly investigated by people appointed to safeguarding roles in the Effective Altruism community. Some of the allegations were found to have a basis in fact, and some people were barred from, or had already been barred from, parts of the community; other allegations were found to have no such basis. You’d expect there to be some awful people in a community as large as the Rationalists, though, and it seems to me – having spoken to several people close to the issue – that the situation, though messy and complicated, was well handled by the people whose responsibility it was to do so.
Here’s my position. I don’t think the Rationalist community is a sex cult. But people on the outside, those of us like me in our hetero-monogamous, married-and-settled-down, two-kids-and-a-people-carrier world, find their whole thing deeply weird, and for us it is very hard to separate ‘weird’ from ‘immoral’. For instance, for a lot of people it would be difficult not to be jealous. I asked Paul about this when I saw him and he said it just . . . never occurred to him. He is aware there are good evolutionary-psychology reasons why he should be jealous, but he’s just not.
Dr Diana Fleischman, an evolutionary psychologist herself at the University of Portsmouth and a prominent member of the Effective Altruism movement, thinks that this can come across as really weird to other people. ‘To the general public, it can seem like realigning your evolved motivation to such an extent that it makes you untrustworthy. If you can rewire your jealousy then you’re really dangerous, because you’re capable of anything. I think that’s part of the stigma.’ Fleischman is polyamorous herself, and completely unembarrassed discussing it, which makes one of us. She talked a bit about the ‘harem’ accusation. She pointed out that the arrangement tends to be genuinely polyamorous, not polygynous – it’s not that the men all have lots of girlfriends but the women are expected to remain faithful. All of the high-profile men do have multiple girlfriends, but those girlfriends usually have several boyfriends themselves.
This actually solves a problem, in her view. The Effective Altruist and Rationalist communities are heavily gender-biased: they’re mainly men. ‘Polyamory fixes the numbers problem,’ she said. ‘I made this joke once: Effective Altruism is like 75 per cent male, but the 25 per cent of women all have three boyfriends.’ I asked her whether it was a sex cult, and she laughed. ‘I was joking with someone the other day. ‘‘The Rationalist community isn’t just a sex cult,” we were saying. “They do other great things too!”’
Chapter 35
You can’t psychoanalyse your way to the truth
There’s another point, which is that (on one, quite important, level) it doesn’t matter whether the Rationalist community is a cult, or a religion, or not.
Take another example of a thing which some people say has the hallmarks of a religion: environmentalism. People who worry about the environment warn of an encroaching apocalypse, in the form of climate change. There is a prelapsarian past from which we have fallen away, through our own sin; it has charismatic prophets (such as George Monbiot and Al Gore) who warn of the impending doom; it has rituals we can perform in order to prevent that doom (such as recycling, or driving a Prius).
I should say, by the way, that I’ve lifted that example from Scott Alexander, who was responding to a specific person claiming that environmentalism is indeed a religion.¹ He pointed out that, also, people have suggested that liberalism, conservatism, libertarianism, the social-justice movement, communism, capitalism, objectivism, Apple, and the operating system UNIX are also all religions. You can, depending on where you draw the line around the category ‘religion’, include pretty much anything in it.
For one thing, this is another example of the ‘worst argument in the world’. If I want to tar something with the brush of ‘religion’ (assuming that I am someone who thinks that religion is a bad thing), then I can point to these characteristics, claim that they are part of the definition of ‘religion’, and then say, ‘Therefore, environmentalism or whatever is a religion and you shouldn’t like it.’ But, even more importantly, it doesn’t tell you whether environmentalism is right or not.
Let’s say that environmentalism really does share all the psychological hallmarks of real old-time religion. Say that, actually, the local Oxford low-carbon group or the cycling-promotion work that my extremely green parents are involved in are 100 per cent functionally identical, psychologically speaking, to churchgoing or evangelising. Say that paying for carbon offsets does precisely the same thing, in some religion-shaped part of your brain, as buying indulgences did for pre-Reformation Catholics. Say that the 2015 United Nations Climate Change Conference in Paris was indistinguishable, in its mental role, from the Second Vatican Council. Does that mean that carbon emissions are not in fact heating the planet? No! It tells us almost nothing at all.
Whether or not the world is warming up is a fact that is based on how much heat energy there is in the atmosphere and the oceans. The reasons behind whether or not someone believes that the world is warming up is a fact about people’s brains. ‘You can’t find out whether the world is warming by asking about the psychology of Greens,’ Paul Crowley grumbled when I put the whole ‘cult/religion’ thing to him. ‘You have to look at satellite data, and CO₂ concentration, and this kind of thing. It’s ultimately a massive distraction. Psychology just doesn’t work if you want to find out about the world.’
Eliezer Yudkowsky has addressed this before, in an interview with the science writer John Horgan, who had previously called singularitarianism a ‘religious rather than scientific vision’.² ‘You’re trying to forecast empirical facts by psychoanalysing people,’ he told Horgan. ‘This never works. Suppose we get to the point where there’s an AI smart enough to do the same kind of work that humans do in making the AI smarter; it can tweak itself, it can do computer science, it can invent new algorithms. It can self-improve. What happens after that – does it become even smarter, see even more improvements, and rapidly gain capability up to some very high limit? Or does nothing much exciting happen?’³
Answering that question requires knowing actual facts about computer science, says Yudkowsky. You need to go and look. You cannot answer it by looking at the people who believe it and seeing whether you like them, or whether they seem weird.
So the question ‘Is the Rationalist community a cult?’ is not without value, insofar as would-be Rationalists might be in danger of getting fleeced of cash or manipulated into sex. But it doesn’t address the underlying question, which is: ‘Might humanity be destroyed by a badly aligned AI?’
That question is about what intelligence is, and how likely we are to be able to build it, and, if we do, what characteristics it will have (or we will give it). I believe there are excellent reasons to think that it might never happen (as well as some excellent reasons to think it might happen sooner than we’d expect). Not one of those reasons, though, is ‘because those guys on LessWrong look a bit culty to me’.
Chapter 36
Feminism
There’s another thing I am just going to have to address, which is: are the Rationalists a bunch of scientific racists, Trump voters, alt-righters and misogynistic Men’s Rights activists?
As I’ve said before, I like the Rationalists. I think they’re a well-meaning and interesting lot. So it won’t surprise you to know that the short version of my answer to the question is going to be ‘No’. The slightly longer answer is going to be ‘No, but I can see why you might think that.’ The really long answer is below.
The Rationalists are nerds. They are, usually, people who are deeply interested in how things work. They are disproportionately male, and disproportionately on the autistic spectrum or near to it, according to the LessWrong and Slate Star Codex surveys – accordingly, as autism usually involves social deficits, many of them lack social skills to some degree or another.
Lots of them are, you will be unsurprised to hear, not very good at talking to women. This blew up in spectacular style at the end of 2014. Scott Aaronson is, I think it’s fair to say, a member of the Rationalist community. He’s a prominent theoretical computer scientist at the University of Texas at Austin, and writes a very interesting, maths-heavy blog called Shtetl-Optimised.
People in the comments under his blog were discussing feminism and sexual harassment. And Aaronson, in a comment in which he described himself as a fan of Andrea Dworkin, described having been terrified of speaking to women as a teenager and young man. This fear was, he said, partly that of being thought of as a sexual abuser or creep if any woman ever became aware that he sexually desired them, a fear that he picked up from sexual-harassment-prevention workshops at his university and from reading feminist literature. This fear became so overwhelming, he said in the comment that came to be known as Comment #171, that he had ‘constant suicidal thoughts’ and at one point ‘actually begged a psychiatrist to prescribe drugs that would chemically castrate me (I had researched which ones), because a life of mathematical asceticism was the only future that I could imagine for myself’.¹ So when he read feminist articles talking about the ‘male privilege’ of nerds like him, he didn’t recognise the description, and so felt himself able to declare himself ‘‘‘only” 97 per cent on board’ with the programme of feminism.
It struck me as a thoughtful and rather sweet remark, in the midst of a long and courteous discussion with a female commenter. But it got picked up, weirdly, by some feminist bloggers, including one who described it as ‘a yalp of entitlement combined with an aggressive unwillingness to accept that women are human beings just like men’ and that Aaronson was complaining that ‘having to explain my suffering to women when they should already be there, mopping my brow and offering me beers and blow jobs, is so tiresome’.²
Scott Alexander (not Scott Aaronson) then wrote a furious 10,000-word defence of his friend.³ I can’t begin to do the argument justice, and in all honesty I’m scared of doing so, because I don’t want this book to be described as ‘an anti-feminist screed’. But his point, I think, can be boiled down to the idea that ‘male privilege’, while a real thing, is not the only form of privilege, and that a lot of online discourse comes down to attempts to define group X as having more or less ‘privilege’ than group Y, as though privilege is a one-dimensional thing. (Hence the constant battle over whether trans women have male privilege.) So if nerds claim to be suffering, then, to the people who think of privilege on this one-dimensional axis, they must be saying that they are less privileged than women.
There’s also a point he makes, which I think is a fair one, which is that nerdy people really are bad at talking to members of the opposite sex, and that this is a way in which they are truly disadvantaged: that nerdy people really do struggle with finding mates, that nerdy men are much more common than nerdy women (and men in general find it harder to attract sexual partners),⁴ and that love, sex, intimacy and affection are important things in human lives, without which we are usually less happy. This is a real problem that real people face. Furthermore, nerds are likely to be bullied and abused for being nerdy (I often think a lot of the sneering comments online about ‘fedoras’ and ‘neckbeards’, common terms of abuse on the internet for socially unskilled young men, are little more than an extension of playground bullying of autistic and/or nerdy children), and you have a genuinely bad situation which causes real pain.
And you can say all that without saying that nerds are less privileged than women, or that their suffering matters more, and while acknowledging that nerdy men find certain careers easier to get into and progress in than nerdy women do. Instead you can just, in Scott Alexander’s words, say: ‘You feel pain? I have felt pain before too. I’m sorry about your pain . . . I will try to help you with your pain, just as I hope that you will help me with mine.’ Anyway, inevitably enough, Scott Alexander’s blog post defending Scott Aaronson blew up and everyone accused Scott Alexander as well as Scott Aaronson of being a sexist entitled nerd.
There’s a related problem, which is the ‘women in science, technology, engineering and maths [STEM]’ thing. It’s true that women are comparatively rare in some STEM careers, especially engineering and computer science; a study looking at 1998 data found that only 26 per cent of American tech workers were female.⁵ (Some reports suggest that the figure has actually gone down since then, to perhaps 20–23 per cent.⁶) Where the Rationalists (and specifically Scott Alexander, again) have got themselves in trouble is by suggesting that this might have other causes as well as simple discrimination; that it’s not purely that Silicon Valley techbros are keeping women out.
Scott suggests, firstly, that if sexism was the key driver in keeping women out of Silicon Valley, you’d expect to see lots of girls doing computer science at high school but then not making it into tech careers. But that’s not what happens: about 20 per cent of children taking high-school computer-science classes in the US are girls.⁷ (About 8 per cent of A-level computer-science students in the UK are female.⁸) A 1989 study found a similar pattern at middle-school level.⁹
And it’s not that sexist stereotypes are making women believe themselves to be worse at computer science than men and stopping them from taking computer-science classes, he argues, because surveys show that women don’t believe themselves to be worse at computer science than men.¹⁰
Instead, he suggests, a major reason why women don’t end up in Silicon Valley isn’t that Silicon Valley doesn’t want them – it’s that they don’t want Silicon Valley. Women are less interested, according to meta-analyses,¹¹ in ‘thing-oriented’ careers, and more interested in ‘people-oriented’ ones. ‘I would flesh out “things” to include both physical objects like machines as well as complex abstract systems,’¹² says Alexander. ‘I’d also add in another finding from those same studies that men are more risk-taking and like danger. And I would flesh out “people” to include communities, talking, helping, children, and animals.’
And, he says, this predicts things pretty well. For instance, medicine was once the absolute bastion of male privilege; about 50 per cent of US medical students are now female. (He doesn’t give a source for this, but the UK figure is that 55 per cent of medical students were female in 2015,¹³ and 56 per cent of students in medicine and dentistry in 2016–17.¹⁴) But, interestingly, when you dig deeper, you see that ‘thing-oriented’ branches of medicine – the ones where you don’t talk to patients much but chop them up, or anaesthetise them, or blast them with radiation; the ones where people are treated more as objects, or systems, rather than people – are significantly male-oriented: surgery, 59 per cent male (in the US); anaesthesiology, 63 per cent; radiology, 72 per cent. And more ‘people-oriented’ branches – psychiatry, 57 per cent; paediatrics, 75 per cent; family medicine, 58 per cent; obstetrics/gynaecology, 85 per cent – are dominated by women.¹⁵ Computer science is very thing-oriented, so you’d expect to find more men pursuing careers in it. The story appears to be similar in the UK: according to the General Medical Council, more than 50 per cent of British obstetrics and gynaecology specialists are female (and 66 per cent of those under 40 and 78 per cent of trainees), compared to just 12 per cent of surgeons.¹⁶
Of course, this doesn’t rule out the possibility that the differing interests of men and women are entirely caused by socialisation in the child’s early years. There’s a lot of research on that, and endless back-and-forth arguments, and it’s an enormous can of worms that I absolutely don’t want to open here, beyond agreeing with Alexander that it’s ‘probably our old friend gene-culture interaction, where certain small innate differences become ossified into social roles that then magnify the differences immensely’.¹⁷ But even if there is no genetic input whatsoever (which is unlikely), early-years socialisation is, says Alexander, not something you can entirely blame Silicon Valley or nerds for.
This is an ongoing argument; some scientists think the people-vs-things dichotomy explains a lot of the gender split, others think it doesn’t. But the trouble with coming out in favour of one side or the other is that, as Yudkowsky previously observed, debate is war, and arguments are soldiers. ‘Sexism is keeping women out of tech’ is an argument on ‘our’ side, the side that wants women to be able to do any job they want. So people who say, ‘The fact that women are under-represented in tech could be largely due to systematic differences in male and female interests’ are attacking one of our ‘soldiers’, and will often therefore be treated as though they’re saying, ‘Women are not meant to be computer programmers.’
You can see this war-soldiers stuff going on, I think, in the case of the ‘Google memo’ written by James Damore. Damore’s memo suggested that the under-representation of women at Google was in part because of interests, rather than discrimination. He was fired from his job and called a Nazi¹⁸ and a fascist;¹⁹ my own feeling is that this was a huge over-reaction, especially since he explicitly said that ‘Many of these differences are small and there’s significant overlap between men and women, so you can’t say anything about an individual given these population level distributions,’ and ‘I’m not saying that diversity is bad, that Google or society is 100 per cent fair, that we shouldn’t try to correct for existing biases, or that minorities have the same experience of those in the majority.’²⁰
Cordelia Fine, a professor of psychology at the University of Melbourne and author of three feminist-inspired books about neuroscience, told the Guardian that, while Damore had a tendency to over-emphasise the evidence suggesting innate tendencies, his memo was ‘more accurate and nuanced than what you sometimes find in the popular literature’ and full of ideas that are ‘very familiar to me as part of my day-to-day research, and are not seen as especially controversial’. She felt ‘pretty sorry for him’, she added, and found it ‘extraordinary’ that he had been fired and shamed.²¹
But when you think in terms of debate and war, and arguments and soldiers, it makes perfect sense. The specifics of Damore’s memo weren’t that relevant. The point was that he was arguing something that looked as if it would give succour to the Donald Trump/Brexit/alt-right ‘side’. Most of us would have realised that, I think, and been wary of sending that ‘memo’ to everybody at Google. But for a certain kind of mind, which many Rationalists have and as, apparently, James Damore has, it was not obvious.
It won’t surprise you to learn that Damore is on the autistic spectrum. It also won’t surprise you to learn that, after he was fired, the alt-right swarmed around him, inviting him on their shows. Milo Yiannopoulos interviewed him. He was now providing soldiers for their army.
Chapter 37
The Neoreactionaries
Another accusation is that the Rationalists are linked to the alt-right. And there is a very good and specific reason to think that they might have those links. That is that they do.
The online group known as the ‘Neoreactionaries’, which is a sort of strange medievalist subset of the alt-right, grew out of the Rationalist movement to some extent. They even left LessWrong and founded their own website, named (spot the reference) ‘More Right’. Mencius Moldbug, the founder of Neoreaction, wrote a few blogs on Robin Hanson’s Overcoming Bias before LessWrong split from it. Michael Anissimov, another prominent Neoreactionary, was until 2013 MIRI’s media director. The pseudonymous ‘Konkvistador’ is a regular Slate Star Codex commenter.
They’re a small and weird subculture. Mike Story said to me that it was best to think of it like this: ‘LessWrong is kind of a social club for people with mild, high-functioning autism, or nerdiness.’ But within that wider group there’s a division, which Mike calls ‘the people who have [those social deficits] but are kind of arseholes, and the people who kind of have that but are good.’ The latter make up the Effective Altruism crowd; the former, the Neoreactionaries. I don’t want to make it sound as if there’s an equivalence here. About 20 per cent of Rationalists identify as Effective Altruists; 0.92 per cent as Neoreactionaries.¹ But the latter, while relatively rare, do exist, and have influenced the development of the Rationalist community.
According to Neoreactionaries, the world has been moving steadily to the left for several hundred years, and that it has correspondingly become less safe, less happy and less clever, and that it is impossible to speak your mind freely unless you toe certain leftist lines. They also believe that some ethnic minorities’ poorer life outcomes – in education, income, crime, mental health, etc. – are due to biological and/or cultural factors within those minorities; that women are happier in more traditional, ‘sexist’ societies; that immigration from some developing-world countries actively worsens America by bringing in people with different, and worse, values. And, most notably, they think that democracy should be replaced by an omnipotent and unelected king.
It’s not that these Neoreactionaries are completely separate from the rest of the Rationalists. If you spend any time in the comments on Slate Star Codex, you’ll find them quite often; same on the SSC subreddit.
Here’s part of what I think is going on. First, comment sections are the literal worst. There’s a thing on the internet called the ‘1 per cent rule’, which is roughly that there’s a hyperactive 1 per cent in any internet community which creates the vast majority of whatever the content is (comments, Wikipedia edits, YouTube videos) while most of the rest just lurk, reading and watching. And, indeed, only 1.2 per cent of LessWrong readers surveyed said they’d commented more than once a week for the last year, while 84 per cent said they hadn’t commented at all;² the Slate Star Codex survey finds similar. And of course, that hyperactive 1 per cent will disproportionately include the most ideologically driven. So judging the Rationalists by the ugliest comments you can find in the SSC subreddit is rather unfair.
Second, the Rationalists have a particular problem which is that their whole thing is taking opposing arguments seriously – what Alexander calls the ‘principle of charity’. It is part of SSC’s ethos that, ‘if you don’t understand how someone could possibly believe something as stupid as they do’,³ then you should be prepared to find that that’s your failing, rather than theirs. And what that means is that if you’re the sort of person who wants to go and talk about ‘race science’, for example, you’ll find that going to a Rationalist website and doing so means that you aren’t immediately blocked. Instead, you find people will talk to you seriously and engage with you.
And this is a noble and brilliant thing, in many ways! If you want to shout about how terrible The Enemy is, so that you get cheered on by Your Side, then you’ve got the whole internet in which to do that. But the Rationalist community is where you can speak, calmly and collaboratively, with people with whom you profoundly disagree, and try to change minds (and admit to the possibility that you will have your own mind changed).
Unfortunately, this means that you have to allow people in who say things you find completely appalling. But civil society in Britain and America, and I think much of the world, is getting measurably more polarised; its conservatives and its liberals just live in different worlds, talking to themselves about how terrible the other lot are. Places where they can talk to each other, like the Rationalist community, should be protected and encouraged, not reviled. When we’re dealing with AI safety, which really could affect everybody on Earth and which – if the Rationalists are right – is an imminent and hard-to-avoid threat, it seems particularly good to have a place where ideas can be exchanged without people feeling they have to censor themselves.
There is another piece that Scott Alexander wrote. (I’m sorry to use ‘Slate Star Codex’ as a near-synonym for ‘the Rationalists’, but it is by far the most high-profile part of the movement, and the most overtly political.) It was called ‘You Are Still Crying Wolf’, written in the wake of Donald Trump’s election. The piece argued that accusing Donald Trump of being ‘openly racist’ and ‘openly courting the white-supremacist vote’ was disingenuous, and was still ‘crying wolf’ in the way that accusing more mainstream Republicans like John McCain and Mitt Romney of being Nazis had been in previous elections. Alexander’s point was that Trump had, at the very least, gone out of his way to sound non-racist, pro-LGBT, etc. He’d gone to black churches, claimed that it was his ‘highest and greatest hope that the Republican Party can be the home in the future and forever more for African-Americans and the African-American vote’, apparently spontaneously grabbed a rainbow flag out of the audience at a rally and started waving it, and waxed lyrical about his ‘love for the people of Mexico’. Trump may or may not have racist attitudes, but calling him ‘openly racist’ or ‘openly white-supremacist’, said Alexander, was silly. If nothing else, he obviously wasn’t being open about it.
A lot of people focused on it as Trump apologia (there being, in the left-leaning internet circles I exist in, nothing worse than being a Trump apologist, except perhaps being a Brexit voter). I think this is spectacularly unfair. A few quotes from Alexander on the topic: ‘Please don’t interpret anything in this article to mean that Trump is not super-terrible’; ‘Trump is just randomly and bizarrely terrible’; Trump is an ‘incompetent thin-skinned ignorant boorish fraudulent omnihypocritical demagogue with no idea how to run a country, whose philosophy of governance basically boils down to “I’m going to win and not lose, details to be filled in later.”’
I don’t know if he’s right. But it seems a reasonable argument to make, and it certainly wasn’t pro-Trump. Before the election, Alexander had urged his readers to vote for anyone but Trump (and specifically Clinton in swing states), because Trump was the candidate most likely to blow the whole world up in some stupid way.⁴
And it’s not just that Scott is the smiling liberal face of a far-right movement. Yudkowsky, Bensinger and other prominent Rationalists expressed concerns about Trump. The Slate Star Codex 2018 survey⁵ found that 29 per cent of respondents were registered Democrats, and just 9 per cent registered Republicans. (36 per cent of respondents were unregistered, and 21.6 per cent were non-Americans.) On a ‘political-spectrum’ question, asking people to rate their political position from 1 (far left) to 10 (far right), the largest single response was 3, at 26 per cent, followed by 4 at 21 per cent.
I think this needs saying, because the Rationalists frequently criticise what they call the ‘social-justice movement’ and which I tend to think of as the Twitter/Tumblr left. And if the Rationalists are alt-righters, misogynists and racists, then it’s easy for the liberal left to disregard their criticisms. But if they’re a group of largely liberal-left people, who have specific criticisms of aspects of mainstream liberal-left thinking, then it’s harder to ignore them.
There’s another point: a key argument that many Rationalists are making is that there is a real and believable risk that we might all be destroyed in the foreseeable future by a badly aligned AI. It doesn’t really matter, from a truth-seeking perspective, whether the Rationalists are a load of misogynists; you can’t psychoanalyse your way to the truth, as we discussed earlier. But it is easier to dismiss their concerns if you think they are.
Part Eight
Doing Good Better
Chapter 38
The Effective Altruists
It’s impossible to talk about the Rationalists without mentioning their conjoined twin, the Effective Altruism movement. They’re so intertwined that I have a bad habit of using the terms synonymously, but they are in fact distinct.
Effective Altruism is based on the idea that we should do the most good we can with our resources. If we give to charity, we should give to those charities that do the most good. If we want to dedicate our careers to improving the world, then we should think carefully (and use numbers) to establish how we should spend our careers.
The spiritual godfather of the movement is Peter Singer. He’s an Australian moral philosopher, based at Princeton, who in 1972 published an essay entitled ‘Famine, Affluence and Morality’.¹ Singer is a utilitarian, one of the most influential of the twentieth century. His argument in 1972 turned on two deceptively simple points: one, ‘Suffering and death from lack of food, shelter and medical care are bad’; and two, ‘If it is in our power to prevent something very bad from happening, without thereby sacrificing anything morally significant, we ought, morally, to do it.’ He says, by way of illustration, ‘If I am walking past a shallow pond and see a child drowning in it, I ought to wade in and pull the child out. This will mean getting my clothes muddy, but this is insignificant, while the death of the child would presumably be a very bad thing.’
That all seems pretty uncontroversial, certainly to me. But it has profound and unsettling implications. He was writing during the Bengal famine of 1971, at a time when 9 million people were refugees. He pointed out that Britain and Australia, two of the more generous countries in terms of aid, had given (in Britain’s case) roughly one-thirtieth of the money it had spent on the Concorde project; Australia, one-twelfth of the amount it had spent on the new Sydney Opera House. That money could have saved many tens of thousands of lives. ‘It makes no moral difference whether the person I can help is a neighbor’s child ten yards from me or a Bengali whose name I shall never know, ten thousand miles away,’ he wrote. A life is a life, and we should save the most we can. It’s not simply that giving money to aid charities is a nice thing to do, an over-and-above-the-call-of-duty moral bonus – ‘supererogatory’, in the language of moral philosophy – it’s that it is a duty. We should all, in wealthy, developed countries, give some non-negligible percentage of our earnings, either as charitable donations or as foreign aid via tax, to improving the lot of people in developing countries. How much? He doesn’t know, exactly, but ‘It should be clear that we would have to give away enough to ensure that the consumer society, dependent as it is on people spending on trivia rather than giving to famine relief, would slow down and perhaps disappear entirely.’
Thirty-eight years after Singer wrote his essay, a small group of academics in Oxford, led by Toby Ord and William MacAskill, a professor of moral philosophy (at one point, the youngest associate professor in the world; he’s still only 32), took Singer’s ideas and tried to turn them into something both more practical and more precise. In 2009 they founded a charity called Giving What We Can, dedicated to finding the most effective charities in the world and helping people donate to them. It also encouraged people to pledge to donate 10 per cent of their income to those charities.
In 2011, MacAskill founded another charity, 80,000 Hours, which helps people to decide what career they should embark on in order to make the most positive impact on the world. For instance, while it might make intuitive sense, for a bright young person who wants to make a difference, to become a doctor at Médecins Sans Frontières, it might be more effective for her to go into some high-paying but less obviously worthy career, and then donate a large part of her salary to charity. (They cite an example of a man who chose to earn $250,000 a year as a software engineer instead of taking a $65,000 job as the CEO of a non-profit; he then donated $125,000 a year to charity, theoretically, at least, funding two CEOs.²)
Over in the US, two young men had had a similar idea. In 2007, Holden Karnofsky and Elie Hassenfeld, Ivy League grads who had gone on to work in hedge funds, wanted to find out the best places to donate some of the moderately large amounts of money they were suddenly making. ‘I think I just had this background assumption that it would be like buying a printer,’ Holden told me. ‘I’d go on some website and get the best printer for the least money.’ But such a website did not appear to exist. ‘I was like, “What am I trying to do? I’m trying to help people. How can I help people with a fixed amount of dollars that I’m going to give? It was just too hard to figure out.” I started calling charities themselves and asking them: “Hey, do you have some metrics? Do you have some data on how many people you’ve helped?” Elie and I had a little club of eight people, all calling charities.’
Slowly they realised that the numbers were not easy to get hold of, and that the problem was quite big. ‘At first it was annoying: it’s holiday time and I’m spending all my time on the phone with charities trying to understand their numbers. Then I started to find it interesting. We saw a huge gap, a problem in the world, and we thought we could fix it if we worked really hard at it. So we left our jobs, raised money from our co-workers, and started GiveWell [and, later, OpenPhil]. It was a super-standard start-up story in a sense. I wanted something, I couldn’t get it.’
You might, at this point, ask how you measure ‘helping people’. How can you compare, say, the impact of an education programme to the impact of a medical programme? Is it fair or meaningful? ‘Comparing across different types of charities is not only fair, but essential,’ Will MacAskill told me. ‘These comparisons allow us to see that some charities are much more cost-effective than others.’ For instance, a charity that funds an extra year of education for people in the US or the UK might cost somewhere in the region of a few tens of thousands of dollars per person it helps. For that amount of money, you could provide thousands of insecticide-impregnated bed-nets to children in sub-Saharan Africa, which would prevent hundreds of cases of malaria and save several lives. However much you value education, it’s pretty clear that saving the lives of children is more valuable than a year of education for a Westerner.
This is a pattern that repeats. ‘Charities that help people in developing countries tend to be much more cost-effective than charities that help people in developed countries,’ says MacAskill. ‘I call this the “100× multiplier”: as someone living in a rich country, you should expect to be able to do at least 100 times as much to benefit other people as you can to benefit yourself or people in your community.’ Both GiveWell and Giving What We Can recommend the Against Malaria Foundation, the charity which gives bed-nets to families in poor, malaria-prone regions. They also both suggest the Deworm the World Initiative, which pays for cheap deworming treatments which appear to have a significant impact on children’s futures, and GiveDirectly, which makes small payments straight to poor people in developing countries via mobile phones. Other charities they both recommend include the Schistosomiasis Control Initiative, No Lean Season, Helen Keller International, the Malaria Consortium and the END Fund. What all these charities have in common is that they operate in poor countries; most of them also provide cheap medicine for easily treatable diseases. The Giving What We Can website offers this reasoning: ‘Suppose we want to help people suffering from blindness. In a developed country this would usually involve paying to train a guide dog and its new owner, which costs around $40,000. In the developing world there are more than a million people suffering from trachoma-induced blindness and poor vision which could be helped by a safe eye operation, costing only about $100 and preventing 1–30 years of blindness and another 1–30 years of low vision . . . For the same amount of money as training one guide dog to help one person, we could instead prevent 400–12,000 years of blindness.’³
There are edge cases, and difficult things to compare: is extending a life by five years worth more or less than curing a child’s blindness? But as it stands, most of us give to charity in spectacularly un-evidence-driven ways, sponsoring a friend’s half-marathon or signing something a charity mugger hands us. ‘Donors in developed countries who give in a non-evidence-based manner typically support charities that focus on helping people in their own communities,’ says MacAskill. ‘These charities can be expected to do one-hundredth or less of the good that charities focusing on helping people in poor countries do.’ MacAskill is right: I was startled to learn, as I wrote this, that only 6 per cent of American charitable donations go to ‘international affairs’, which is to say 94 per cent of American charitable donations stay within American borders.⁴ The idea of the Effective Altruism movement is that we are not, generally, dealing in subtle distinctions: if you want to do the most good with your money, rather than just purchase warm feelings, then some charities are very obviously better than others.
The links between the Rationalists and the Effective Altruists go back pretty much to the beginning. Ord and MacAskill met Nick Bostrom at Oxford in 2003, and Ord says: ‘I was heavily influenced by Nick in my work on existential risk. I’m pretty sure [the Effective Altruism movement] wouldn’t have had such a strong strand on existential risk if I hadn’t been influenced by Nick.’ It’s not that one inspired the other, says Ord, ‘the story is mostly one of mutual influence of people exploring related ideas and gaining from their interactions’.
Certainly, the LessWrong Rationalists provide a large proportion of Effective Altruism’s support. In 2014, 31 per cent of survey respondents said that they had first heard of the movement through LessWrong;⁵ by 2017, that figure had dropped to 15 per cent, presumably partly because LessWrong had shrunk while Effective Altruism had grown, but a further 7 per cent had heard of it through Slate Star Codex.⁶ And a large fraction of LessWrongers are Effective Altruists: according to the 2016 LessWrong diaspora survey, 20 per cent of respondents identified as Effective Altruists, and 22 per cent had made ‘donations they otherwise wouldn’t’ because of Effective Altruism.⁷ Two other OpenPhil employees, Helen Toner and Ajeya Cotra – whom you’ll meet shortly – told me that they’d either come to Effective Altruism through LessWrong or found the two at the same time. One Effective Altruist blog, ‘The Unit of Caring’, is named after a Yudkowsky blog post (‘Money: The Unit of Caring’). Scott Alexander has written repeatedly about Effective Altruism, including an extremely powerful blog post⁸ backing the Giving What We Can ‘pledge’ to donate 10 per cent of your income to effective charities.
Effective Altruists are also a similar sort of people to Rationalists. They are nerdy, on the whole. They are open to new experiences (I don’t know how many of the Effective Altruists are polyamorous, but it’s not uncommon, in both the Oxford and Bay Area sets). They go for numbers over feelings, even when the numbers lead them into weird areas, which they frequently do. For instance, one very good point that some Effective Altruists make is that if we are worried about alleviating suffering, then presumably animal suffering matters to some extent too. (You could declare by fiat that it doesn’t, but it’s hard to make a principled case for it. Besides, that would mean you’re OK with the arbitrary torture of animals for no reason, which most of us are not.)
But if animal suffering matters, even a fairly small amount, then suddenly, eating chicken is an absolute moral catastrophe. Around 50 billion chickens are raised each year worldwide, the large majority of them for meat.⁹ They live on average for seven weeks each, so that’s about 6 billion chicken-years of life a year. Even if you only care about chickens’ suffering-per-hour 1 per cent as much as you care about that of humans (a very conservative figure: Buck Shlegeris, the young Effective Altruist and Rationalist we met earlier, told me he rated it about a quarter, and Peter Singer told me that wasn’t ridiculous), you should care as much about the world’s chickens as you do about the entire population of the United Kingdom. And that’s before you get to the point that chickens very probably have worse lives than the average Briton.
(Scott Alexander points out that you can improve the situation considerably by eating beef.¹⁰ Imagine that you get a sixth of your calories from chicken, about 125,000 calories a year. A chicken provides about 3,000 calories. So your 125,000 calories translate to 42 chickens, bred and kept in unpleasant circumstances and then slaughtered. By contrast you get about 405,000 calories from a cow, so your 125,000 calories translates to 0.3 cows: just by switching, you reduce the number of animals bred for your food by 93 per cent. Cows live longer before slaughter, but not that much longer, and tend to have happier lives anyway. Unfortunately, cows are far worse for global warming, so really I ought to give up both and go vegetarian.)
But we can all get behind the idea that factory farming is a real problem and realise that we have a moral responsibility for it. Effective Altruism gets much weirder than that, in its niche areas. There are, for instance, Effective Altruists who worry about the suffering of wild animals. They make the point that there are probably between 100 million and 1 billion ‘bugs’ (insects, arachnids and so on) per human in the world, and that it only takes a very, very tiny level of moral value per insect to make their suffering outweigh that of all humans. I can’t fault the numbers, but they take me beyond the level of weirdness to which I am prepared to go. (And it gets weirder still. Another group has wondered about whether consciousness, and therefore suffering, is a fundamental quality of the universe – whether quarks and electrons are capable of suffering. There are quite a lot of quarks and electrons, so if you start worrying about that, you end up in a very odd place indeed.¹¹)
I shouldn’t overplay the ‘weirdness’ element. Most Effective Altruism comes down to the eminently sensible idea that if you want the shiny pound in your pocket to do the most good it can, it’s better to donate it to the Against Malaria Foundation than it is to your local donkey sanctuary (or even a cancer-research charity). If I keep going on about how weird they are, there’s a risk that I’ll make you think they’re some strange species of humans. ‘It’s other-ising,’ says Karnofsky. ‘The initial reaction to these topics is that it’s wacky. But I think it’s a really interesting and under-appreciated set of issues. If you other-ise them, you create this idea that you need a certain kind of unusual psychology to be interested in this stuff, and I don’t think that’s true.’ The same goes if we paint them as super-altruistic: ‘If you portray Effective Altruists as saints, as people who give away every penny they have, feel bad every time they buy a sandwich because they could have given it to charity, people read it and they go, “That person is weird. That person is not me. I could never relate to them, and now I’m not interested.”’ But, again, a lot of the ideas are extremely straightforward.
That said, one key area that OpenPhil in particular is worried about, and which is definitely weird on the face of it, is existential risk. OpenPhil was set up by GiveWell and Good Ventures, a philanthropic foundation established by Dustin Moskowitz, one of Facebook’s founders, and his wife Cari Tuna, although it is now separate from both those organisations. Where GiveWell concentrates on small, repeatable, reliable (in most cases) interventions, such as bed-nets or cash transfers, OpenPhil aims at big, high-risk-high-reward projects. One area it focuses on is US government policy – criminal justice reform, immigration policy and so on. It also works on animal-welfare issues; when I was in San Francisco talking to Karnofsky and his team, their head of comms, Mike Levine, took me out to lunch at a local burger bar, so he could gently probe me to make sure I wasn’t going to write an entire book mocking the nerds who think Skynet is going to take over the world (he is endearingly protective of his nerds). We ate the Impossible Burger, a plant-based meat burger, which was produced partly with funding from OpenPhil,¹² the idea being to reduce the requirement for beef and thus improve animal welfare and reduce greenhouse-gas emissions. I can report that it tastes very much like a burger, indeed a perfectly nice burger, and appears to be taking off; it is sold at hundreds of locations in the US and one of its rivals has, since I went over there, arrived in Britain. (Specifically, and unsurprisingly, Dalston in east London.¹³)
But the OpenPhil work that is most relevant to this book is its focus on global catastrophic risks, and especially AI.
Chapter 39
EA and AI
Ajeya Cotra is a research analyst for OpenPhil. She and her colleague Helen Toner, an Australian, both work on AI risk specifically, and both say that it is hard to explain to people what you do for a living. ‘When I was in high school, I discovered GiveWell and Effective Altruism, and I also discovered LessWrong and the Rationalist community,’ Cotra tells me. At first she was interested in global poverty reduction – ‘I was trying to get my parents to donate to the Against Malaria Foundation’ – and not focusing on AI. But at college in Berkeley she taught a seminar series on Effective Altruism. ‘That was really when I had to force myself to think through all the arguments for [existential risk]. I started to transition to doing more work focused on our global catastrophic risks.’ Her degree was in computer science, so she had some technical understanding of AI, which helped.
It has come with some social cost, she says. ‘It’s harder to explain, like to my parents, what I do. But I think you can understand fairly quickly why this is important. A lot of experts think that artificial intelligence might be arriving in the next 20 or 30 years. And human intelligence has had such a transformative, positive and negative, effect on our world.’ There’s no reason not to assume that even more powerful intelligence will have an even more transformative effect. ‘It will touch on so many things we care about, like curing diseases, new forms of surveillance, wealth and poverty and inequality.’
Toner agrees that it’s easier to say to people that you’re working on anti-malarial bed-nets than it is to say you’re trying to stop the world being destroyed by a rogue AI. She, too, started out worrying about global poverty and development. ‘But after a long series of conversations, and learning more about stuff, and a year or two of being involved in the EA community, I started to come around to the view that maybe AI was the thing to be working on.’
There are three key elements that make a cause worth donating to, according to the tenets of Effective Altruism. One is its importance: the scale of the problem, how much better the world would be if the problem were solved. A second is tractability: how easy it is to solve those problems. And a third is neglectedness: if lots of people are already working on the problem, then the amount of good you can do on the margin is less. So malaria is an excellent target, because it has a huge impact (importance), is easily and cheaply prevented (with bed-nets), and yet receives far less global spend than diseases like cancer, which disproportionately affect those rich countries where people tend to live long enough to get them.
An obvious global catastrophic risk is climate change. It’s hugely important, and while it’s not easily tractable, there are certainly things that can be done. But climate change is a crowded space: there are lots of governmental and philanthropic organisations focusing on it, so the marginal value of the money OpenPhil puts in would be less.
Instead, the two risks that OpenPhil is focused on are pandemics, especially bioengineered pandemics, and AI. ‘I’ve just gone back and forth enough times on which of those I consider a bigger risk,’ Holden Karnofsky told me. ‘If you asked me how [humans could go extinct], those are definitely my top two guesses by some margin and then a little bit down will be things like nuclear weapons.’
And, as we discussed in Chapter 2, talking about existential risks, going extinct matters. Remember that Nick Bostrom thinks that the number of human-like lives that could be lived is something obscene like 10⁵⁸. He could be wrong by three dozen orders of magnitude and we would still be talking about vastly more humans than have ever lived. If their lives have any non-negligible moral value (which is not, it should be said, an uncontroversial claim), then those potential lives need to affect our moral judgements significantly. Even if we don’t buy that, merely a small chance of killing everyone alive is a vital issue: for instance, the expected population of the Earth by mid-century is about 10 billion. Something that has a 3 per cent chance of killing all those people is equivalent to something that will definitely kill 300 million. According to 80,000 Hours, that’s ‘more deaths than we can expect over the next century due to the diseases of poverty, like malaria’.¹
If you buy into the idea that future lives matter, then you need to think about the things that are most likely to cause human extinction, not just those that will probably kill a large number of us. As we discussed a few chapters ago, it seems that bio-risk and AI are the best-value bets, and because this is a book about AI, I’m going to talk about that.
AI risk, says Holden Karnofsky, is extremely important (because of the risk of extinction), highly neglected (there are only a few places, such as MIRI and FHI, which are working on it), and reasonably tractable. So it represents an ‘outstanding philanthropic opportunity’. He hasn’t always thought this way: one of the most-read articles on LessWrong was a long piece by him about why he thought that MIRI was a bad subject for philanthropic investment. In a subsequent explanation of why his position changed, he said that he had previously thought that ‘by the time transformative AI is developed, the important approaches to AI will be so different from today’s that any technical work done today will have a very low likelihood of being relevant’.² But now, he told me, ‘We think there’s a non-trivial, by which we mean at least 10 per cent, chance of transformative AI in the next 20 years.’
That’s part of what makes it tractable. The AI landscape has changed spectacularly in the last few years: things that were cutting-edge specialist technology, like voice and facial recognition software, in the early 2000s are now running on novelty apps on your phone. DeepMind’s AlphaGo is a beautiful and, it must be said, slightly unnerving demonstration of how machine learning can create superhuman intelligence, in a more general (if still narrow) sense than we are used to. It’s a testament to how quickly new stuff becomes normal that we aren’t more amazed by it all.
But at the moment, the key thing that OpenPhil is doing isn’t so much related to the technical work – although they do support that. They’re excited about what Toner calls ‘field-building’. She gives the example of the field of geriatric medicine. ‘In the 1980s, people realised that elderly people need a totally different style of healthcare from young people. Young people tend to come in with one thing that needs to be fixed and then you send them home, whereas with elderly people there’s a whole bunch of interacting conditions and maybe they need to stay a long time.’ They also realised that the baby-boomer generation, at that point in its thirties and forties, was going to get old, which meant a very large population of elderly people. So the John A. Hartford Foundation decided to concentrate almost all its resources on building up the field of geriatric medicine, training doctors, funding research, building new centres. ‘And by the time the [baby boomers were] elderly, geriatrics was a totally normal medical field,’ says Toner.
That’s roughly what OpenPhil is trying to do now. ‘[We’ve] been talking to high-profile, very skilled top machine-learning researchers, and saying, “Would you be interested in working on safety, or in having some grad students work on safety? What are the areas that you would be interested in?”’ Toner says. In 2017 they gave $3 million in grants to machine-learning departments at Berkeley and Stanford, about the same amount to MIRI (despite, a year earlier, having expressed ‘strong reservations about MIRI’s research’³ while granting them $500,000), and a much larger $30 million to OpenAI, the non-profit research organisation founded by Elon Musk.⁴
The aim, says Karnofsky, is for their work to do the sort of field-building that the Hartford Foundation did, even though worrying about transformative and possibly disastrous AI might sound ‘wacky’ now. ‘To an outsider who has never encountered the issues before, given the low-level of buy-in from wider society, the natural, initial reaction to these topics is going to be, “What is this? I’ve never heard of this. This is different from what I normally think about, this is wacky.”’ But in time, as the field becomes more mature and well known, he wants people to think more along the lines of, ‘This is an issue that should matter to me. It’s got a lot in common with climate change. It could be far off, but we don’t know it’s far off, and it’s worth worrying about now because it could be a huge deal.’ He hopes this book might make a few more people think like that.
I don’t think many people will disagree with the idea that a pound spent trying to prevent malaria deaths will do more ‘good’, under most definitions of that word, than a pound given to support Harvard University. But you might remember what David Gerard said, when we were talking about whether LessWrong was a cult: ‘clearly the most cost-effective initiative possible for all of humanity is donating to fight the prospect of unfriendly artificial intelligence, and oh look, there just happens to be a charity for that precise purpose right here! WHAT ARE THE ODDS.’⁵
The criticism that others have made is not that LessWrong is chiselling cash, but that the Rationalists, and the Effective Altruist movement, are heavily made up of nerdy, STEM-inclined computer-science grads. Dylan Matthews, writing for Vox in 2016, put it like this: ‘In the beginning, EA was mostly about fighting global poverty. Now it’s becoming more and more about funding computer science research to forestall an artificial intelligence-provoked apocalypse. At the risk of overgeneralising, the computer science majors have convinced each other that the best way to save the world is to do computer science research.’⁶ (It reminds me of a story that the Rationalist and Effective Altruist Ben Kuhn told on his blog. He went to an Effective Altruism summit with his partner, who was new to EA; she asked an attendee what sort of people were there. ‘“Oh, all different kinds!”’ he replied. ‘“Mathematicians, and economists, and philosophers, and computer scientists . . .” It didn’t seem to occur to the fellow that these were all basically the same kind of person,’⁷ Kuhn writes.)
This was, pretty much, the argument that Caroline Fiennes put to me. Caroline is the director of Giving Evidence, a group which encourages and enables giving based on sound evidence. She has known GiveWell and others in the Effective Altruism movement for a long time – she is on the board of The Life You Can Save, Singer’s charity – and doesn’t want to belittle what they do, but she is worried about this sort of uniformity of thought. ‘People gravitate to stuff they understand,’ she says. ‘Maybe these people have gravitated towards this issue because they feel comfortable and competent on it.’ Elon Musk, Peter Thiel, Dustin Moskowitz are the big-name funders behind it, and perhaps it isn’t surprising that these software tycoons all think that good software is needed to save the world. And, as various people have muttered to me during the writing of this book, they seem to be less vocal about the sort of problems – privacy, surveillance, filter bubbles, fake news, algorithmic bias – that their software is creating. It’s fun to sound noble and far-sighted, warning of the dangers of a technical problem still to come; it’s less fun to address the criticisms people are making of what you and your peers are doing right now.
Fiennes notes that GiveWell and OpenPhil don’t mention a lot of major areas of possible philanthropy. ‘I don’t think GiveWell’s list of recommended charities really reflects global priorities,’ she says, ‘and it doesn’t reflect the lists of other experts who do serious cause prioritisation, such as the 50 Breakthroughs report, or the Copenhagen Consensus. There’s nothing about war, nothing about climate change. Only one thing, very recently added, about hunger, only one about water and sanitation. We have a couple of billion people who don’t have access to food and clean water and toilets; it’s weird that those issues aren’t further up the list.’ There’s also nothing about global governance and the rule of law, she adds, ‘which for me, and for George Soros I would observe, would seem like a reasonable thing, if you had a chunk of money’. GiveWell will do the ‘things that are very certain, very repeatable, very proven – we know the impact of the next bed-net, know the costs, know the benefits,’ while OpenPhil is willing to talk about really long-shot things like bioterrorism and superintelligent AI. ‘But there’s all this big pile of stuff in the middle [like promoting the rule of law], which seems obviously important. I’m not saying AI isn’t important,’ Fiennes says, ‘but the amount I hear about AI out of them, compared to the nothing at all I hear about global governance and climate change and war, seems totally out of whack.’
It’s not completely fair to say that the two organisations – they’re separate now, although they still share the same swanky office space in downtown San Francisco – ignore these issues completely. Mike Levine, OpenPhil’s head of comms, agreed that climate change, for instance, is not as neglected or as tractable as some other, similarly important, issues. ‘But I’d quibble with the idea that we don’t focus on it. We’ve funded the most important, neglected and tractable climate-change opportunities we’ve seen, including geoengineering research and governance and the especially tractable opportunity around the Montreal Protocol [to reduce the use of hydrofluorocarbons, a powerful greenhouse gas]. We’ve put millions of grant dollars into climate change – more than we have into our land-use reform, macroeconomic stabilisation, or immigration policy focus areas. We see climate change as a huge issue that warrants action from philanthropists, and we expect to do more.’ But it’s certainly true that these mid-level issues get less attention, in the press and public sphere, than OpenPhil’s concentration on AI.
That may or may not be OpenPhil’s (and the wider Effective Altruism community’s) fault, depending on your point of view. You could say that they simply need to focus on what they think are the most effective targets for their philanthropy, and let other people worry about the look of the thing.
But it’s also true that ‘how weird it looks’ affects how effective it is. Will MacAskill told me that he thinks there is a ‘pretty solid’ case for focusing on AI safety, for those people who are ‘prepared to consider more speculative lines of evidence . . . though I should point out that some of the arguments for concluding that one should focus on existential risk reduction exclusively make a number of controversial philosophical assumptions’, such as that future lives are of comparable value to current ones. But there is a risk, he said, that ‘an excessive focus on these speculative causes runs the risk of undermining the Effective Altruism movement’. If people look at Effective Altruism and see a bunch of people worrying about what seems to them to be some sci-fi stuff, they might then not donate to the less speculative things – the bed-nets and the cash transfers – which they mentally bucket together. It could be, in Karnofsky’s word, ‘other-ising’.
There’s a concept in the Rationalsphere called ‘weirdness points’. It’s the idea that society will let you be only so weird before it stops taking you seriously: you only have a certain number of weirdness points to spend, and so you should spend them on things that you really care about. That’s why, says Mike Story, Rationalists don’t talk all that much about their polyamory – ‘more than just not evangelise, they keep quiet about it. Scott [Alexander] is pretty open about it, but generally they think if we seem normal it’s better for our ideas.’ If you spend your weirdness points on polyamory, you don’t have them left to spend on Effective Altruism or the importance of Bayes’ theorem.
And, it must be said, AI safety spends a lot of weirdness points. If you think it’s the most valuable thing by miles, then it is worth spending those points on. If you don’t, you could reasonably argue that it’s just making the Effective Altruism movement look weird and making it harder to get bed-nets to children in sub-Saharan Africa.
So it comes down, really, to whether we can trust the thinking of OpenPhil and similar organisations on all of this. I’ll raise a couple of possible points. One was an objection that Dylan Matthews of Vox had, in the piece I mentioned previously. He raises the possibility of ‘Pascal’s mugging’, which we discussed before. People at the Effective Altruism conference he attended gave him the standard expected-value argument: ‘Infinitesimally increasing the odds that 10⁵² people in the future exist saves way more lives than poverty reduction ever could.’ But Matthews argues that the key is what we mean by ‘infinitesimally’: ‘Maybe giving $1,000 to the Machine Intelligence Research Institute will reduce the probability of AI killing us all by [10⁻¹⁷],’ he writes. ‘Or maybe it’ll make it only cut the odds by [10⁻⁶⁶]. If the latter’s true, it’s not a smart donation; if you multiply the odds by 10⁵², you’ve saved an expected [10⁻¹³] lives, which is pretty miserable. But if the former’s true, it’s a brilliant donation, and you’ve saved an expected [10³⁴] lives.’
On the face of it, that sounds a pretty fair argument – ‘those probability values are just made up,’ says Matthews. ‘I don’t have any faith that we understand these risks with enough precision to tell if an AI-risk charity can cut our odds of doom by [10⁻¹⁷] or by only [10⁻⁶⁶]. And yet for the argument to work, you need to be able to make those kinds of distinctions.’
I’m going to hand over to Scott Alexander to explain why he (and I) think that argument doesn’t work. In short, it’s that while 10⁻⁶⁶ and 10⁻¹⁷ both sound like similar spectacularly tiny numbers, they are absolutely not. The number 10⁻¹⁷ is the sort of number you might actually have to use at some point. There are about 2,522,880,000 seconds in an 80-year human life, and about 7 billion humans, so during your lifetime about 1.7×10¹⁹ seconds will be lived by humans. That means you’d expect, in your lifetime, roughly 100 things to happen that only happen once in every 10¹⁷ seconds. (When you read about ridiculously unlikely things happening – someone finding out that their next-door neighbour is actually their separated-at-birth sibling, or whatever – remember that.)
But 10⁻⁶⁶ is not like that. You will never read about something that only happens once every 10⁻⁶⁶ seconds. Here’s Scott: ‘The per-second probability of getting sucked into the air by a tornado is 10⁻¹²; that of being struck by a meteorite 10⁻¹⁶; that of being blown up by a terrorist 10⁻¹⁵. The chance of the next election being Sanders vs Trump is 10⁻⁴, and the chance of an election ending in an electoral tie about 10⁻². The chance of winning the Powerball is 10⁻⁸ so winning it twice in a row is 10⁻¹⁶. Chain all of those together, and you get 10⁻⁶⁵.’ (He was writing in 2015, hence the ‘Sanders vs Trump’ reference.)
What this means is that, if Matthews’ 10⁻⁶⁶ guess is right, then then the likelihood of your $1,000 donation to MIRI helping avert an AI apocalypse is 10 times less than the likelihood of someone getting simultaneously sucked up into the air by a tornado, hit by a meteorite and blown up by a terrorist, on the same day as winning the lottery for the second week in a row, and Trump and Sanders tying the electoral college. If Bostrom’s numbers are anywhere near accurate – the 10⁵⁸ human lives that we talked about early on in this book – and if you accept that future lives matter as much as current ones, then even a vanishingly tiny chance that an AI disaster might happen is (from a utilitarian point of view) hugely important. You have to start making some seriously weird assumptions to get it down to a negligible figure.
The other possibility, of course, is that you argue that future lives don’t matter as much as current lives. That’s a massive and ongoing bunfight in moral philosophy, and, as MacAskill said, there’s no clear answer on it. When I spoke to Peter Singer, he pointed out that there’s a difference between future lives and possible lives. ‘It’s highly probable that there will be humans living on this planet in 100 years, and their lives are going to be worse off because of climate change. We shouldn’t discount those lives just because they’ll only exist in 100 years.’ But when we’re dealing with lives in the very distant future, where it is far from certain that they’ll exist at all, he said, ‘we are not talking about the sufferings of beings who will exist in future. We are talking about the non-existence of many generations of future beings. It remains a controversial and disputed question of philosophy. A number of very good philosophers have worked on it; Derek Parfit worked on it for most of his philosophical career and was unable to really achieve a satisfying conclusion.’
Obviously, we’re not going to resolve it here. But, Singer points out, we don’t really need to. We’re uncertain; these lives might be exactly as important as modern lives, or they might not be important at all. But if we’re really uncertain, then we can’t be sure that they have zero value. ‘Because of that uncertainty, we should give at least some weight to them. If we say, “No, they don’t count” – well, we have to acknowledge that might be the wrong thing to say.’
And then we’re back to the ‘Bostrom big number’ thing. ‘If there are so many of them as Bostrom argues,’ says Singer, ‘even if you discount them by 99 per cent or 99.9 per cent, the numbers are so big that they still carry very great weight. It’s a tough question, but yes, we should give some weight to the interest of merely possible beings. We should regard the extinction of a species as a worse event than the deaths of all the people who will be killed at that time.’
Of course, even if we agree that the thronging masses of possible future people really do have some moral weight, that preventing extinction is therefore valuable, and that AI is one of the most realistic ways in which extinction could happen and is worth funding, that doesn’t mean that OpenPhil is correct in assessing that MIRI (or FHI, or OpenAI) in particular is worth backing. There are strong criticisms of MIRI: that its output of scientific papers is rather less than that of a single grad student, for instance. (There is a counter-argument that that’s not a fair criticism, because it’s trying to build a new field rather than get on the publication treadmill in established journals, but there’s a lot of back-and-forth about it.)
And there is cause to be sceptical of some of Effective Altruist reasoning. GiveWell’s top charities include several that promote deworming. This comes largely from a study, published in 2004,⁸ which found that mass deworming – giving all the children at a school deworming tablets, not just those with worms – improved health, school performance and school attendance; and not just the children at that school, but at schools miles away, through stopping the worms from spreading. Most amazingly, it seemed to dramatically increase those children’s earnings later in life. It was an extremely cheap intervention with, apparently, enormous results.
But later studies looked at the data and found that it was flawed in some quite serious ways: technical but important statistical errors which severely undermined its credibility. (Not, I hasten to add, through any deliberate misbehaviour on the part of its authors, who very nobly gave up their data for it to be checked; just mistakes.) The Cochrane Collaboration, which does huge meta-analyses of all the studies on a topic, has since looked at mass deworming three times;⁹ it found no effect on school performance or attendance, and no good evidence of an effect on various other health measures. ‘Going up against the Cochrane Collaboration is big bananas,’ says Caroline Fiennes. ‘And Paul Garner, who does their parasitology, has been doing this for a hundred years. I’m amazed that GiveWell isn’t more alarmed that people who have thought long and hard about this – studied deworming since before they were born, in some cases – disagree with them.’ It’s not just that deworming might not do any good – it’s perfectly conceivable that it might do harm. ‘I spoke to a parasitologist who’s studied deworming in Africa for decades,’ Fiennes continues, ‘who said that mass deworming has never been adequately tested for increasing drug resistance, so mass deworming may just jack up resistance and actually be harmful.’
GiveWell is aware of these criticisms. Catherine Hollander, a GiveWell research analyst, told me they’d run the data, and looked at the ways it wasn’t robust, but felt it was still a worthwhile gamble because it was so cheap and had the potential to be so effective. ‘Even when you discount for the possibility that that effect doesn’t exist significantly, you still end up with something that’s the most cost-effective thing that we recommend,’ she said. ‘We discount extremely heavily for all of this uncertainty. But even with that huge discount, Deworm the World was 10 times as cost-effective as cash transfers, our next most cost-effective programme.’
I, obviously, cannot reasonably assess whether deworming is a good bet; nor can I do a more reliable job than Bostrom or OpenPhil in assessing the numbers behind AI risk. But for what it’s worth, I think Fiennes’ criticisms are worth taking on board. They should make you wary of going along too happily with what these Effective Altruism organisations recommend; and, as we’ve discussed before, if something seems completely weird, but the numbers check out, you should pay some attention to the feeling that it’s weird. The Dylan Matthews Vox piece refers to Effective Altruists who seemed to think that literally all philanthropy should go towards preventing human extinction – which would be a pretty terrifying situation.
But as it stands, that’s not the case. The total worldwide spend on AI risk reduction is probably less than $50 million, which may seem like a lot, but is only one-eighth of (to pick a big charity at semi-random) Greenpeace’s reported annual revenues in 2014.¹⁰ (OpenAI’s funders ‘have committed $1 billion’, but the organisation expects ‘to only spend a tiny fraction of that in the next few years’.¹¹) It is not that AI risk is crowding out all other charity; it’s not even monopolising Effective Altruism. It accounted for about 30 per cent of total OpenPhil grants in 2017, but OpenPhil is only one of several organisations. And Peter Singer, who is very probably the best-known moral philosopher alive today and the absolute godfather of the field of efficient charity, is (broadly, and with caveats) in favour of spending money on AI risk: ‘I definitely think it’s worth looking at,’ he told me. ‘It’s definitely worth spending something on it. Even if the probability is very low, given how devastating it could be, it’s worth trying to put some effort into reducing it even further.’
Part Nine
The Base Rate of the Apocalypse
Chapter 40
What are they doing to stop the AI apocalypse?
Cast your mind back to several chapters ago, when we were talking about why AI is dangerous. We mentioned that there are several organisations – MIRI is the one I’ve spent most time talking about, but also Bostrom’s FHI, Max Tegmark’s Future of Life Institute in Cambridge (Massachusetts), the Centre for the Study of Existential Risk in Cambridge (UK), and Elon Musk’s OpenAI are the obvious other ones – which are dedicated, at least in part, to making AI less dangerous; some of them are definitely Rationalist groups, others are just broadly aligned. But I haven’t really told you, yet, what they’re actually doing.
It is, of course, an open question whether there’s anything they can do, at this stage at least. We’re still years, probably decades and possibly centuries away from AGI. Murray Shanahan of DeepMind isn’t convinced that the field is mature enough for the work we do now to have significant effect when AGI does happen: ‘If you want my personal view,’ he says, ‘I think that it’s probably a bit premature to be very confident that the work we’re doing now on this issue is going to be relevant.’ He’s not ruling it out, but he’s wary. ‘We really don’t know what AGI is going to look like, if and when we figure out how to make it.’ He thinks that the MIRI safety work, which looked at ‘logical problems related to insuring that self-modifying systems could preserve their reward functions, and things like that’, was ‘fascinating stuff and quite mathematically demanding’. But, he says, MIRI’s work revolves around an assumption that any AGI will be an extremely logical Bayesian-probability-theory engine, and it’s possible to imagine an AI that is nothing like that at all. ‘Suppose you could solve AI with some massive evolutionary process, and you just evolved your AI, or if you just had some enormous deep network with some fabulous amount of computation and back-propagation, you might not have any way of applying [MIRI’s results] to the thing you’ve built, because it wouldn’t operate in a sufficiently logical way.’
When he mentioned this, I asked if AlphaGo was an example of the sort of program he was talking about. It was given a goal – become amazingly good at Go – and a reward mechanism, and then it was sent to go and play against itself billions of times until it got good. And the thing that came out was, indeed, amazingly good at Go, but no one who built it really knows why. The data and learning mechanisms went into a black box, sloshed around for a bit, and came out with the thing they wanted.
‘Well, exactly,’ Shanahan says. ‘And you might still be in a position to design a reward function that you know isn’t going to have unintended consequences and perverse instantiations – the paperclip maximiser, these side effects that involve existential risk. But I’m involved in the sharp end of building these things, and making them increasingly powerful, and I just have difficulty extrapolating from where we are now to AGI, and being confident about what it’s going to look like.’
Obviously enough, Rob Bensinger of MIRI is more optimistic that the work they’re doing will be useful. ‘I think there are lots of particular problems which you can work on today. There’s no particular reason to think we’ve grabbed all the low-hanging fruit yet. There are presumably lots of problems that you can’t see in advance, and you need to work with the system and learn about them later, but there’s plenty that’s knowably relevant right now.’ One aspect they’re working on, in fact, is avoiding exactly the sort of ‘impenetrable black-box’ scenario that Shanahan is talking about. ‘We want AGI systems, when they’re built, to be well understood by their developers, and to minimise the assumptions we have to make about your system in order to be confident they’re safe,’ he said. That could mean making a system which just has really simple outputs – for example, something that just comes up with mathematical proofs and theorems, and doesn’t do anything else. But that’s pretty limited: ‘The reason you build an AGI in the first place [is that] you want to get useful work out of it. Cure disease, help people, whatever. Set theory proofs aren’t the kind of things that are really going to make a difference in the world.’
So instead you want to be able to see how the AGI is doing its work. ‘Not in every detail, but in broad strokes,’ said Bensinger. ‘“What is this part here? What does this system do?”’ He drew a diagram on a nearby whiteboard as he spoke, boxes with arrows to other boxes, like a flowchart. ‘You can look at its internals and see the kind of optimisation that went into the final product, and confirm that it doesn’t have any bad convergent instrumental goals and does have the properties you do want. We assume that AGI will be more complex than current systems, so it’ll get complicated. But MIRI’s view is that the important thing is to empower the developer of the first really powerful AGI system to know what they’re doing, to be able to design a really modular, clean system where you can tell a story about why that system would have good effects. It wouldn’t be a perfect story, there will always be some uncertainty. But if you can’t even tell a story about why you should be confident – not just, “We don’t know why we shouldn’t be confident” . . .’ He didn’t finish the thought, but the implication left hanging was ‘that wouldn’t be great’.
And you can’t get that sort of story out of a black-box system, he said. ‘If you just get the outputs and say, “Well, it seems to act safely, nothing bad has happened so far”, that’s not the sort of story we think you can get an outcome out of.’ So the sort of evolved AI that Shanahan mentioned would make MIRI very nervous indeed. As, in fact, would AlphaGo. ‘I’d say you’re in a bad state if you kind of understand your system, but the understanding is too many degrees removed from actual cognitive work that’s happening. Things like AlphaGo, where you can describe it at a high level – it’s using Monte Carlo tree search, it has these value networks, you can say this stuff at a certain level of abstraction – and then you get a really good Go player. But you’re not really describing the reasoning it’s doing to get into good board positions.’ You’re describing how it built itself, but not what it’s doing. I think it’s fair to say that if DeepMind use AlphaGo as the basis for their first AGI, MIRI would be deeply unnerved.
But ‘Make it so we can see how it works’ is quite a high-level description of the method for creating a safe AI. Remember, way back when we were discussing why AI is dangerous, we talked about how seemingly innocuous goals can have weird outcomes, ‘perverse instantiations’: the paperclip maximiser was one example, the Fantasia broom another. Is anyone doing anything more specific to try to reduce the likelihood that, the first time an AGI is turned on, it will turn the solar system into computing hardware to become even better at chess?
The answer is yes. There are a few things. One of the key ones, in fact, is clearly delineating what the AI safety problems actually are. Probably the most famous paper on AI safety is ‘Concrete Problems in AI Safety’, by a team from Google, OpenAI, Berkeley and Stanford.¹ It discusses, for instance, the problem of defining negative side effects: if you give an AI a goal (such as ‘fill the cauldron’), how do you let your AI know that there are things to avoid, without explicitly listing every single thing that could go wrong? An example of how you could do so is by saying that the robot can only change the environment it’s in by a certain amount – limiting or budgeting its impact on the world – although how you define that is a new and perhaps equally tricky problem.
Another problem the paper identified was ‘reward hacking’, an AI finding a shortcut to achieving its utility function without doing what its makers want; ‘ending cancer by nuking humanity’ would be a dramatic example, although the more prosaic one they mention in the paper is of a cleaning robot being told to stop when it can’t see any more rubbish, so it just turns off its cameras. The paper suggests that a separate agent designed solely to judge whether the rewards the first agent receives are earned might be a good way around it.
As well as simply defining the problems, there are specific efforts to find solutions. Holden Karnofsky, the OpenPhil founder, got quite excited talking to me about a paper called ‘Deep Reinforcement Learning from Human Preferences’,² by, among other people, Shane Legg, one of the founders of DeepMind, and Paul Christiano of OpenAI.
The idea is that for some goals, a simple definition isn’t much use. Karnofsky showed me a video of a simulated environment called MuJoCo, a sort of toy world with broadly realistic physics that programmers use to test how a robot might move. First, he showed me three ‘robots’ in that world which had been given a task, ‘Learn to walk.’ They all made reasonable progress; one was a snake-thing which wriggled along, one was a uniped which hopped, the third bipedal and vaguely humanoid.
‘They’ve all been given the goal of trying to cover a lot of distance in a short amount of time,’ said Karnofsky. ‘They have these limbs and they have these joints. What they do is move around at random, and over time they figure out that certain movements make more progress, and over time they learn to walk. You can run the same algorithm on a bunch of different-looking robots and they’ll all learn to walk in their own special way.’ That’s because ‘walking’, or at least ‘making progress’, is nice and easy to define mathematically. ‘You have an X-coordinate,’ said Karnofsky, ‘and the further you get from it per unit of time, the better you’re doing. It’s measurable.’
But it relies on that score providing good feedback about what you actually want. In general (although not always, as we saw earlier when we were talking about evolved AIs), ‘how good is this robot at walking?’ and ‘distance travelled from starting point in given time’ align extremely well. That won’t always be the case in real-world AIs, though. Karnofsky imagines a more advanced AI. ‘Something that not only is able to move joints, but is able to send e-mails and make business decisions and do all kinds of things in the world. You can imagine if you had one of those AIs you can say, “Hey, can you maximise the amount of money in this bank account.”’ It’s a nice, simple, mathematically defined task, although any of us can see how it might go appallingly wrong.
Tasks that might not go immediately wrong are harder to define. ‘You could ask it, “Hey, can you stop other AIs from doing bad things on their way to maximising money”, and that would be a great [example of a] bad task, because I myself don’t know what I mean by that,’ said Karnofsky. ‘“Maximise the money” is a well-defined goal. “Keep us safe” or “Help humanity thrive” or “Make the world more peaceful” are fuzzily defined goals. I don’t even know what I mean by them.’
What the Christiano paper does is try to see whether we can get AIs today to learn to perform tasks that we can’t define well. ‘That’s where the human feedback comes in,’ Karnofsky said. ‘The idea is that the AI will try random movements and then an actual human will look at two videos and say, “That one. That one is more like what I have in mind.”’
In the MuJoCo paper, they try this on a backflip. It turns out that it’s quite hard to define a backflip in a mathematically precise way, and all the robots that tried to learn how to do one with a preset goal ended up doing weird jerky movements that absolutely were not backflips. But with a human saying, ‘That random movement looks a bit more backflip-y’ they evolved a pretty impressive-looking backflip quite quickly – it took 900 iterations and less than an hour. Another task it learned was to play a racing video game, called Enduro. But not just play it to win. ‘They got it to keep pace with other cars,’ Karnofsky said. ‘The video game does not reward that. There’s no score for it; it’s just the human was able to look at it and say, “This is what I wanted.”’
This is early, toy stuff. And it’s not perfect: in one task, the AI was supposed to learn to pick up a box with its manipulators, but instead learned to put a manipulator between the box and the camera so it looked to the operator as though it had done so. But you can see how it could be extrapolated into a more powerful machine with more complex goals: ‘Rid the world of cancer’, but don’t do it by killing all the humans, that sort of thing.
Another step, Karnofsky added, would simply be to get governments and tech companies to sign treaties saying they’ll submit any AGI designs to outside scrutiny before switching them on. It wouldn’t be iron-clad, because firms might simply lie, ‘but it’s substantially better than nothing. There’s a good chance that when the first transformative AI comes it’ll be a massive project.’ If there are 1,000 people working on it, it’ll be almost impossible to keep it secret, so the treaties might be quite effective.
I asked Nick Bostrom what he thought the most promising avenue was. ‘Broadly speaking,’ he replied, ‘some way that involves leveraging the AI’s intelligence to infer and learn about human values and preferences. If it’s superintelligent, it should be able to figure out what we want and mean, just as I can figure out a lot about what you want, from asking you about it, and looking at what you choose and so forth.’
More specifically, he pointed to another idea from Paul Christiano, on the topic of ‘capability amplification’.³ ‘Instead of trying to create this AI that has a utility function that captures everything we care about,’ said Bostrom, ‘we have some agent that, at each point in time, has some set of available actions, and chooses the one it thinks we would most approve of it taking, in some myopic way.’ It doesn’t try to leap ahead and think what will happen in six months’ time, it just chooses between A and B, and then between B1 and B2, and so on. ‘If you have to have a human overlooking every single step the AI takes, you don’t get much oomph out of it, so you’d have to come up with clever ideas for how to bootstrap a more limited, but safe, system for doing a larger portion of what we’d want the superintelligence to do.’
But, he said, it’s still early days. ‘There are lots of other ideas, and it might be that the best ideas haven’t even been articulated yet. Or maybe we already have a solution, but we can’t be confident yet that it would work because there are some parts we don’t yet understand. There’s just a lot of uncertainty about the difficulty of the problem.’
I should, also, point out that there’s a lot of scepticism about just how much good MIRI in particular is doing. They have several researchers, but publish very few papers which are rarely cited. That might be because they’re trying to build a field, as discussed before, but it does make it hard to be sure how important their work is at this stage. Toby Ord of FHI told me that he was somewhat sceptical of their research agenda, which he felt was a bit too focused on distant-future ideas: ‘I’m more excited about work that’s more continuous with current work in AI,’ he said. ‘Stuff that’s only one step away from what the AI researchers are working on. There’s more chance that you can get them to come across and help you on the project.’
Of course, technical papers about how to keep AI safe aren’t the only measure of how successful the Rationalists are being. Remember that when the young Eliezer Yudkowsky started thinking about this stuff in about 2000, he was pretty much the first person to do so. People had discussed the ‘singularity’, and I.J. Good had predicted an ‘intelligence explosion’, but the specific problem that an AI might not ‘go rogue’ or ‘turn evil’ or ‘achieve self-awareness’ but simply do exactly what you told it to do, and still go terribly, terribly wrong, seems to have sprung up with Bostrom and Yudkowsky on the SL4 website. It was, and I hope this isn’t too rude, the random musings of a load of young, crankish men on the early internet.
Now it’s the subject of whole departments at several major universities, and discussed by major leading intellectuals: Martin Rees, the late Stephen Hawking, Bill Gates. Google’s DeepMind is explicitly worried about it; co-founders Shane Legg and Demis Hassabis both take it seriously.
‘It’s been amazingly quick progress,’ commented Ajeya Cotra, of OpenPhil. ‘I think the discourse around technical safety of these in 2014, compared to now, feels like different worlds.’ Bostrom’s book Superintelligence was a turning point, she said. It was a New York Times bestseller, and brought serious academic heft to the field. ‘In 2014, we had a small group of outsider futurists trying to convince the AI community that this is a risk to be taken seriously. A lot of researchers didn’t, because they heard a garbled message through the media which sounded kind of fearmongery. Then Superintelligence came out. It was less that a bunch of people read the arguments and were totally convinced than that it was a serious academic making a thorough case. People felt it merited a response, and when sceptics put forward that response, their points didn’t always add up.’
This roughly matches Holden Karnofsky’s position. ‘As of 2012, it was kind of a niche community issue, and it was very hard to find anyone with mainstream credentials who would even acknowledge it,’ he said. He also pointed to the publication of Superintelligence as a turning point, and a major AI safety conference in Puerto Rico in 2015, organised by Max Tegmark’s Future of Life department at MIT.
‘They had an open letter saying AI has major risks, which was signed by a lot of people. I don’t think all of them were signing off on [AI risk as envisioned by Yudkowsky et al.]. But it certainly became a more mainstream idea to talk about the idea that AI is risky.’ Now, he said, ‘if you look at the top labs, you look at DeepMind, OpenAI, Google Brain – many of the top AI labs are doing something that shows they’re serious about this kind of issue.’ ‘Concrete Problems in AI Safety’ is a collaboration between those three groups, he pointed out. ‘It’s a paper where they have safety in the title and it has major researchers from all these three labs and it was put out under the Google PR machine. It’s much more mainstream than it used to be. It seems hard to deny that.’
All this has meant that, from a field-building point of view, Yudkowsky et al. have been extraordinarily successful. ‘There are well-known, well-respected machine-learning researchers involved now,’ said Helen Toner, Ajeya Cotra’s OpenPhil colleague. ‘How to build this field is to make it something young people feel comfortable going into – not just starry-eyed Rationalists who think they want to go and save the world, but talented young machine-learning researchers who are searching for an area to specialise in. I heard of, I think at Berkeley, a student-supervisor pair, who were each interested in AI safety, and each of them thought, “Oh I can’t tell my supervisor/my student about that because they’ll think it’s silly.”’ ‘Concrete Problems in AI Safety’ and various OpenPhil grants to major machine-learning research groups have started breaking that dynamic down, she commented. ‘We’re really trying to fix those dynamics, and I think it’s helped.’
‘It’s incredible!’ said Paul Crowley, beaming. ‘Honestly, when I got involved I thought there’s no way we’ll get anyone to take this seriously – people will just think we’re crazy. There’s no way we can be more than some crazy fringe thing that a few people talk about.’
Chapter 41
The internal double crux
Right at the beginning of the book, I mentioned what Paul Crowley said to me: that he doesn’t expect my children to die of old age. What I didn’t say, back then, was whether I took him seriously. Do I actually think that is more likely than not?
Rather than simply answer that question, I want to talk you through an experience I had in Berkeley. Soon after I met Paul, I spoke to Anna Salamon of CFAR, and told her what Paul had said. It threw me, I said. The thing that I really like about the Rationalist community, I told her, is the idea of people trusting the numbers and the reasoning, and not throwing out the conclusion those numbers and reasons lead them to, even if it’s shocking or bizarre. But now I found myself in a strange situation, where I was pretty happy with all the different steps in the reasoning – I can see why value alignment might be hard, and why an AI could be amazingly intelligent but still do stupid things, and I don’t think it’s crazy to think it’ll happen in my children’s lifetimes – but I found putting them all together, and agreeing with that profoundly unnerving conclusion, difficult.
To her enormous credit, Anna didn’t, as most people would, simply dismiss my concerns about the central thesis of the movement of which she’s a crucial part; instead, she pointed out that to have such concerns is not a stupid thing to do. She thinks the technological singularity, and all the disaster or utopia that entails, probably will happen this century. But when I made that remark about instinctively rejecting the conclusion despite agreeing with the steps to get there, she shrugged. ‘Yeeaaaaaah,’ she said. ‘But that’s not always wrong, is it? When I was first taking algebra class, and somebody showed me the standard proof that 2 = 1 – which involves secretly dividing by zero – it felt to me like every single step was valid.’ When you’re dealing with complex things like this, if you get weird answers, it might be that you’ve input the steps wrong. ‘I think the thing to do in such a case isn’t to reject one thing or the other, but to really stay with the question. Having now stayed with the question for a while, it seems to me that the argument for there being substantial risk from AI is really quite strong.’
Then she asked: ‘Do you believe it? That your children will not die of old age? That you might not die of old age?’ I said I didn’t know. I couldn’t see the divide-by-zero equivalent – I still can’t. But nor could I, on an intuitive level, feel that the conclusion was right. I still assume that I’ll grow old and die, as my grandfather had recently. And while I don’t like to think about it, I assume that my children will too. There was a tension between these two parts of my brain.
‘So,’ Anna said, ‘would you like to try something? We have a funny CFAR technique called the internal double crux.’ The standard ‘double crux’ is a method Rationalists use for examining why two people disagree. ‘It’s about how to figure out what cruxes a disagreement you’re having with someone rest on. The crux of the argument is the thing that, if you knock it over, their conclusion falls down, and they have a different conclusion.’
The example given on LessWrong is an argument between two people about school uniforms.¹ Person A thinks schoolchildren should wear uniforms; person B thinks they shouldn’t. To find the crux, you look at what those beliefs entail, what the more specific implications of them are. So person A might think that school uniforms reduce bullying, by making it less obvious which children are rich and which are poor; person B might think that’s ridiculous. But if you could show that school uniforms do reduce bullying, by some given amount, then person B would change her mind on the uniforms question; likewise, if you could show that they don’t, then person A would change his mind. The technique involves slowly bringing the conversation away from top-level, shouty arguments and towards detailed, specific disagreements.
This is pretty useful and sensible, I think. But the internal double crux is a bit more strange. It’s for disagreements with yourself – for instance, if part of you agrees with the argument that says, ‘Your children won’t die of old age’, and part of you thinks that just sounds too crazy to be believed. ‘It’s a pretty weird thing,’ Anna warned me. ‘It involves going into your head, and sometimes you find things there that sound a little crazy. But I could walk you through it.’ So, a few days later, I went back to the CFAR offices.
There’s a little story that Anna tells, a sort of parable, about a little girl at school who does some creative writing, and at the end of it the teacher reads it through, and says, ‘Look, you misspelled “ocean”.’ ‘No I didn’t,’ says the kid, and the teacher replies: ‘I’m sorry, but you did. It’s counter-intuitive, but it’s a “c” not “s-h”.’ The child, increasingly angry, repeats, ‘No, I didn’t,’ the teacher, ‘No, I’m sorry but you did.’ ‘No, I didn’t.’ ‘I realise it sometimes hurts to face the truth, but you really did.’ And then the child runs off to the cupboard and bursts into tears, saying, ‘I did not misspell the word. I can too be a writer.’ Anna calls this a bucket error. The ‘I can spell the word “ocean”’ fact went into the same bucket as the ‘I can be a writer when I grow up’ fact, and when the one was proved false, the child assumed, on some pre-conscious level, that they both were.
More broadly, there’s often a strange lack of communication between our verbal, reasoning selves and some deeper part of us. The feeling that you’ve forgotten something at the supermarket, but you don’t know what it is – is it broccoli? No. Is it rice? No, but I do need rice; is it avocado? It’s avocado! The knowledge is there on some level, and the feeling when your conscious mind latches onto the right answer is one of almost physical relief. Or something gives us a near-physical sense of ‘yuck’ or ‘yum’ when we see or hear it, without exactly telling us why, and unless we give that sensation a few moments we might not know the reason; the word ‘slack’ gives me this sort of ‘yuck’ sensation, and for years I didn’t know why, until I remembered an Onion article which used it in an astonishingly vulgar phrase about female genitalia which apparently had stuck with me ever since.
According to the way in which CFAR and the Rationalists model the brain (and it is just a model; Anna repeatedly stressed that she wasn’t claiming that this is really how the brain works, just that it was useful and effective), sometimes, when we have internal conflicts about an issue, a little alarm, a beeping noise, goes off when we take on information; our brain is telling us that the information conflicts with something somewhere, and although we may not consciously know why, it imbues that piece of information with a little sense of ‘yuck’ and makes it harder for us to accept it. This is, I think, what Eliezer Yudkowsky describes as ‘noticing your confusion’. When I said to Anna that each of the steps made sense, but that I couldn’t accept the conclusion, she wondered if that was what was going on. The ‘internal double crux’ technique is a method Rationalists use in this sort of situation to help them establish what their own objection is, to find their difficulty with some conclusion.
I am aware that this all sounds a bit mystical and self-helpy. It’s not. It was a strange sensation, certainly, but it was extremely common-sensical and unspectacular, although it did make me understand how talking therapy (which I’ve never tried) could be a powerful tool: just the experience of talking very deeply about some mental experience you’ve had is quite profound. Anyway, the basic idea was simple. Anna asked me: ‘What’s the first thing that comes into your head when you think the phrase, “Your children won’t die of old age”?’
‘The first thing that pops up, obviously,’ I told her, ‘is I vaguely assume my children will die in the way we all do. My grandfather died recently; my parents are in their sixties; I’m almost 37 now. You see the paths of a human’s life each time; all lives follow roughly the same path. They have different toys – iPhones instead of colour TVs instead of whatever – but the fundamental shape of a human’s life is roughly the same. But the other thing that popped up is a sense of “I don’t know how I can argue with it”, because I do accept that there’s a solid chance that AGI will arrive in the next 100 years. I accept there’s a very high likelihood that if it does happen then it will transform human life in dramatic ways – up to and including an end to people dying of old age, whether it’s because we’re all killed by drones with kinetic weapons, or uploaded into the cloud, or whatever. I also accept that my children will probably live that long, because they’re middle-class, well-off kids from a Western country. All these things add up to a very heavily non-zero chance that my children will not die of old age, but, they don’t square with my bucolic image of what humans do. They get older, they have kids, they have grandkids and they die, and that’s the shape of the life. Those are the two fundamental things that came up, and they don’t square easily.’
So Anna asked me to look at the two sides in turn.
The more sceptical bit of me said this. ‘There’s some quite big bit of me which looks at all this stuff and thinks, you’re talking about immortality, and the end of the world, and all these things that people have prophesied since for ever. Every generation thinks this one’s the last one. There’s not a generation in history that hasn’t thought exactly that, and with every single one it’s been ridiculous. We look back at the Heaven’s Gate people, or Christian prophets in the first century, or the Anabaptists in Reformation Münster, all thinking it’s going to happen any day now; we’ve been through this story a million times before, and, every time, it doesn’t happen. The lesson we should draw from all this is that the predictions of the doom, or ascension, of mankind tend not to come through.’
OK, said Anna. Take that, and offer it up to the other bit of you and see what it says; let it, in her words, ‘fully and generously acknowledge’ all the parts of the statement that seem to be true, giving it room to breathe.
And the bit of me that accepts the steps of the argument had this to say. ‘All right, there really have been a lot of predictions, and from the point of view of the people making the predictions, it must have felt as if the logic of all the parts fitted together, or they wouldn’t have made the predictions. I assume these people weren’t idiots. They must have had reasons to believe that the end times were on them. It would be very hard for someone inside that chain of logic to step outside and say, “Yes, but there have been lots of predictions before, and they were wrong.” You have to use the base rate as a real piece of evidence in your thinking about these things. Otherwise you’re doing no better than the people who made all those predictions before. You have to look at the base rate, and the base rate of predictions of the apocalypse coming through is zero.’ This is the ‘outside view’, which we talked about a few chapters ago. The internal logic of something can be compelling, but you have to look at how other, similar things have fared in the past.
Then the worried bit was allowed to reply: ‘But this is also an argument against taking steps against climate change. You’re saying the world always carries on as it always has, but, actually, we are changing the world. And we know that life on Earth is wildly different from how it was 100 years ago, and that was wildly different from how it was 300 years before that, but actually that was less different than 1,000 years before that. The pace of change of human life is gathering.’ It’s not ridiculous to think that it could be even more unrecognisable in 100 more years. And my worried self had a wider point. ‘Every prediction of the doom of mankind will be wrong apart from one. That’s implicit in the logic of it. If you keep saying the sun won’t rise tomorrow, you’ll be wrong every time until you’re right. Induction can only work so many times; eventually, something must, by its nature, break it.’
So, the sceptical bit of me had to take that and acknowledge it. ‘OK. I admit that a lot of the arguments that one could make to say that climate change is nothing to worry about are echoes of those made by sceptics who say, “Humanity has been on the planet for 100,000 years and we haven’t caused the sea levels to rise yet.” That doesn’t mean that we won’t soon, and we have impacts that are far greater now than they were even 50 or 100 years ago. And it’s true that you can’t have a base rate of doomsday predictions that is other than zero. If there are better reasons to believe in this one than the Anabaptists’ prophecies, then we ought to take it on its own merits. Some of the things on which the Anabaptists based their arguments I would absolutely reject as being without foundation, whereas this prediction is based on things that I would not.’
Then that part of me was allowed to say: ‘But you can track concentrations of carbon dioxide in the atmosphere, and make simple mathematical models to predict what will happen to things like temperature and sea-level rise, using equations that have been around since the early 1900s, and see that those predictions roughly match real-world data. I’m not sure of the extent to which that is comparable to artificial intelligence. And there is certainly more uniformity among climate scientists that climate change is imminent and dangerous than there is uniformity among AI researchers that AI is imminent and dangerous.’ (I promise this is all real. I’ve tidied the quotes up a bit, but there’s something about talking to Rationalists that makes you use phrases like ‘heavily non-zero probability’ and ‘the base rate of predictions of the apocalypse’.)
It was at this point that the conversation, if that’s the right word, took a slightly odd turn. It was still my sceptical side’s turn to speak, and it had this to say: ‘I can picture a world in 50 or 100 years that my children live in, which has different coastlines and higher risk of storms and, if I’m brutally honest about it, famines in parts of the world that I don’t go to. I could imagine my Western children in their Western world living lives that are not vastly different to mine, in which most of the suffering of the world is hidden away, and the lives of well-off Westerners largely continue and my kids have jobs. My daughter is a doctor and my son is a journalist, whatever. Whereas if the AI stuff really does happen, that’s not the future they have. They have a future of either being destroyed to make way for paperclip-manufacturing, or being uploaded into some transhuman life, or kept as pets. Things that are just not recognisable to me. I can understand from Bostrom’s arguments that an intelligence explosion would completely transform the world; it’s pointless speculating what a superintelligence would do with the world, in the same way it would be stupid for a gorilla to wonder how humanity would change the world.’
And I realised on some level that this was what the instinctive ‘yuck’ was when I thought about the arguments for AI risk. ‘I feel that parents should be able to advise their children,’ I said. ‘Anything involving AGI happening in their lifetimes – I can’t advise my children on that future. I can’t tell them how best to live their lives because I don’t know what their lives will look like, or even if they’ll be recognisable as human lives.’
I then paused, as instructed by Anna, and eventually boiled it down. ‘I’m scared for my children.’ And at this point I apologised, because I found that I was crying. ‘I cry at about half the workshops I do,’ said Anna, kindly. ‘Often during the course of these funny exercises.’
Chapter 42
Life, the universe and everything
I don’t want to claim that the fact that I cried in a Californian office in the autumn of 2017 means that AI is going to kill us all and destroy the universe. I was alone in a strange country, 5,000 miles from my children, tired and jet-lagged and generally in quite an emotionally vulnerable situation. I don’t cry very often, but it’s not all that surprising that I did at this point. It was, though, quite powerful. I have tried to recapture the feeling of that moment and largely failed, although I felt an echo of it as I listened to the audio while writing this. It felt, emotionally, real that I didn’t want to think about the implications because the implications were so terrifying.
So do I believe in a paperclip apocalypse? Let’s think about this probabilistically.
I do believe that AGI could happen quite soon. It’s far from clear when, but if a large number of AI researchers think it could well occur in the next 50 years and is near-certain in the next 100, then I don’t know why I would disagree. Bostrom’s survey, which seems to be the best we have, said that AI researchers, on average, think there’s a 90 per cent chance that AGI will arrive by 2075.¹ For what little it’s worth, I (like Bostrom) put more weight on the idea that it will never arrive, or will arrive in some immensely distant future, for no better reason than that AI, like fusion power, has been 30 years away for the last 50 years. Let’s say I think it’s 80 per cent likely that AGI will arrive at some point in the next 90 to 100 years, the likely lifespan of my children.
The next question is whether I think that is likely to lead to the sort of spectacularly terrible outcome that MIRI and other people fear. Going back to Bostrom’s survey, 18 per cent of respondents believe that AGI will lead to something ‘extremely bad’ (existential catastrophe), i.e. human extinction. Some people who work on AI risk reckon it’s higher: Rob Bensinger described it as ‘high-probability’, for Nick Bostrom the ‘default outcome’ of an intelligence explosion is ‘doom’.² But some AI researchers consider that ridiculous: to Toby Walsh, for instance, the basic premise of an intelligent thing destroying the world was silly, and not really in keeping with what ‘intelligence’ means. Having looked into this stuff for quite a long time, I think he’s probably wrong, but he’s an AI researcher and I’m not. That fits the survey’s findings that a majority of AI researchers don’t think it’s the most likely outcome, though, so I’m still going take that 18 per cent at face value.
Shut up and multiply, as the Rationalists say. If you take that 80 per cent (the likelihood that AGI will arrive at some point in the next 90 to 100 years) and multiply it by 18 per cent, you get 14.4 per cent, or almost exactly a one-in-seven chance. I might be off by quite a distance in either direction, but it feels about right. (Toby Ord’s estimate for the likelihood of humanity going extinct this century, from any cause, is about one in six. ‘I think it’s something in the order of Russian roulette,’ he told me, and that’s after taking into account the fact that people are trying to stop it.) Imagine I’m off by more than an order of magnitude, because I might be; imagine there’s only a 1 per cent chance that I’m right. That’s still more likely than my children dying in a car crash, a risk which I do not think it is silly to worry about at all. I’m extremely happy to spend time teaching them the Green Cross Code, and for the government to invest in traffic-calming measures and impose legal safety requirements on car manufacturers to reduce that less-than-1-per-cent risk still further.
They’re a weird bunch, the Rationalists, with their polyamorousness and kink, abstruse jargon, living arrangements and behaviour. And they’re politically daft as well: their openness to debate means that their places on the internet are full of pretty unpleasant people. So the things they care about, such as AI risk and effective altruism, are in danger of getting smeared by association. ‘The singularity? Isn’t that the thing that racist sex-cult website is into?’
But you can’t psychoanalyse your way to the truth. They might be weird, but I don’t think they’re wrong in believing that AI risk, like pandemics and climate change, is something society should be taking steps to mitigate. There’s a non-trivial chance that it will do terrible things, and there are, it seems to me, realistic ways of trying to reduce the chance of that happening.
I met a senior Rationalist briefly in California, and he was extremely wary of me; he refused to go on the record. He has a reputation for being one of the nicest guys you’ll ever meet, but I found him a bit stand-offish, at least at first. And I think that was because he knew I was writing this book. He said he was worried that if too many people hear about AI risk, then it’ll end up like IQ, the subject of endless angry political arguments that have little to do with the science, and that a gaggle of nerdy Californian white guys probably weren’t the best advocates for it. This was a concern I heard from a few people.
I hope that doesn’t happen. The Rationalists are an interesting bunch of people and the things they’re doing seem worthwhile: not just the AI risk, although of course that’s central; but also the idea of thinking about how we think, and how we argue; and of considering probabilities and likelihoods in ways other than black and white and yes and no. And, yes, they can be hard to like – Eliezer Yudkowsky, in particular, is a difficult, strange and abrasive man, though undeniably smart and arguably visionary – and there are plenty of unpleasant people in their internet circles.
But there’s something noble about their endeavour. We are, or seem to be, increasingly bad at talking across disagreement: whether because of social media or political polarisation, it seems that people find it much harder to imagine that someone with different political views to their own might nonetheless be a decent person. There’s something wonderful about a project dedicated to explaining why we are so often wrong, and to taking arguments and ideas seriously, and not rejecting the ones we don’t like: creating a space for people to disagree in good faith.
And what they have achieved in terms of the AI debate is, I think, remarkable. They’ve taken the niche, practically dystopian-science-fiction idea of AI risk and made people take it seriously. Mike Story pointed out that Donald Glover, the actor and rapper who stars in the TV show Community, uses Bostrom’s ideas in one of his episodes, indicating how mainstream these ideas have become. Perhaps more relevantly, the White House under Obama published a report in 2016 into ‘Preparing for the Future of Artificial Intelligence’³ which drew heavily and obviously on Yudkowsky/Bostrom ideas: the Puerto Rico conference and ‘Concrete Problems in AI Safety’ are extensively referred to, and Bostrom’s work is cited in the references.
The Rationalist community has changed enormously since its mid-2000s heyday. Eliezer Yudkowsky himself has largely withdrawn from the LessWrong stuff; he writes the occasional very long blog post on the MIRI website, and some more playful and/or not-AI-related stuff on Facebook and Tumblr, but he’s less engaged with the community-building stuff these days.
But the rest of them carry on. Holden’s OpenPhil still pushes money towards AI safety; Ajeya is still trying to build the field, although Helen has moved on and is now working on machine learning at a Chinese university. Paul remains at Google, encrypting things, but worrying about the future of humanity in his spare time. Scott and Katja broke up, but went on holiday together by accident a few weeks later, which felt very on-brand; they didn’t have a baby, and I don’t know whether the experimental robot baby helped with any decisions. They’re both still highly engaged in the Rationalist project: Scott as its most high-profile figurehead now that Yudkowsky has taken a back seat; Katja as a researcher at FHI and elsewhere. Anna continues to see lots of bright young nerds come through the CFAR doors, and she tries, with great sensitivity and sense, to direct them into careers that might help save the planet. Rob is still Yudkowsky’s messenger on Earth. And Nick Bostrom, of course, is now a globally famous figure in certain niche circles, and is getting referenced in major NBC comedy programmes and White House policy documents.
Overall, they have sparked a remarkable change. They’ve made the idea of AI as an existential risk mainstream; sensible, grown-up people are talking about it, not just fringe nerds on an email list. From my point of view, that’s a good thing. I don’t think AI is definitely going to destroy humanity. But nor do I think it’s so unlikely that we can ignore it. There is a small but non-negligible probability that, when we look back on this era in the future, we’ll think that Eliezer Yudkowsky and Nick Bostrom – and the SL4 email list, and LessWrong.com – have saved the world. If Paul Crowley is right and my children don’t die of old age, but in a good way – if they and humanity reach the stars, with the help of a friendly superintelligence – that might, just plausibly, be because of the Rationalists.
Acknowledgements
It’s frankly weird that this book got written. I am not the sort of person who successfully writes books. I have, traditionally, been the sort of person who periodically says, ‘One day I’ll write a book,’ while the people around me say, ‘Righto, Tom, you said that five years ago.’
So, I can take only a fraction of the credit for the fact that it did, in fact, get written. A large amount of the rest should go to these various other people.
Will Francis, agent at Janklow & Nesbit, kept taking me out for nice lunches until a serviceable idea fell out of my head. Paul Murphy at Weidenfeld & Nicolson helpfully agreed to give me some money to write the book, and then made me take out some of the sillier jokes. Linden Lawson did a sterling job clearing up my waffly and repetitious prose.
I owe great thanks to Ajeya Cotra, Andrew Sabisky, Anna Salamon, Buck Shlegeris, Catherine Hollander, David Gerard, Diana Fleischman, Helen Toner, Holden Karnofsky, Katja Grace, Michael Story, Mike Levine, Murray Shanahan, Nick Bostrom, Peter Singer, Rob Bensinger, Robin Hanson, Scott Alexander, Toby Ord, Toby Walsh and everyone else who spoke to me. Plus grudging thanks to Eliezer Yudkowsky who did not, in fact, agree to talk to me, but did answer my irritating questions by email. Elizabeth Oldfield and Pete Etchells both looked over parts of the manuscript and reassured me that it was not total garbage.
Especial thanks to Paul Crowley, who basically introduced me to the whole concept, invited me out to California, was extremely nice to me while I was there, answered loads of questions, and then read the manuscript and helped me strip out lots of stupid mistakes.
And, of course, Alison and Andy, my parents, for everything; Emma, my wife, for everything else; and Billy and Ada, for not coming upstairs and hammering on the keyboard with their sticky little paws too often.
Notes
Introduction: ‘I don’t expect your children to die of old age’
1. Elon Musk, Twitter, 3 August 2014 https://twitter.com/elonmusk/status/495759307346952192?lang=en
2. https://qz.com/698334/bill-gates-says-these-are-the-two-books-we-should-all-read-to-understand-ai/
3. Cambridge University press release, 19 October 2016 http://www.cam.ac.uk/research/news/the-best-or-worst-thing-to-happen-to-humanity-stephen-hawking-launches-centre-for-the-future-of
4. Nick Bostrom, Superintelligence: Paths, Dangers, Strategies (OUP, 2014), p. 222
5. https://en.wikipedia.org/wiki/2017\_California\_wildfires
1: Introducing the Rationalists
1. http://yudkowsky.net/obsolete/singularity.html
2. Omni magazine, January 1983
3. ‘Raised in technophilia’, LessWrong sequences, 17 September 2008 https://www.readthesequences.com/RaisedInTechnophilia
4. ‘The magnitude of his own folly’, LessWrong sequences, 30 September 2008 https://www.readthesequences.com/TheMagnitudeOfHisOwnFolly
5. Nick Bostrom, ‘A History of Transhumanist Thought’, Journal of Evolution and Technology, vol. 14, issue 1, 2005 https://nickbostrom.com/papers/history.pdf
6. Marie Jean Antoine Nicolas Caritat, Marquis de Condorcet, Esquisse d’un tableau historique des progrès de l’esprit humain (Masson et Fils, 1822)
7. Benjamin Franklin, letter to Jacques Dubourg, 1773, US government archives https://founders.archives.gov/documents/Franklin/01-20-02-0105
8. Julian Huxley, Religion Without Revelation (Harper Brothers, 1927)
9. Eliezer Yudkowsky, My life so far, August 2000 http://web.archive.org/web/20010205221413/http://sysopmind.com/eliezer.html#timeline\_great
10. William Saletan, ‘Among the Transhumanists’, Slate, 4 June 2006 https://web.archive.org/web/20061231222833/http://www.slate.com/id/2142987/fr/rss/
11. Quoted in Bostrom, ‘A History of Transhumanist Thought’, p. 14
12. Alvin Toffler, Future Shock (Turtleback Books, 1970)
13. Eliezer Yudkowsky, ‘Future shock levels’, SL4 archives, 1999 http://sl4.org/shocklevels.html
14. Eliezer Yudkowsky, ‘The plan to Singularity’, 2000 http://yudkowsky.net/obsolete/plan.html
15. ‘Re: the AI box experiment’, SL4 archives, 2002 http://www.sl4.org/archive/0203/3141.html
16. Nick Bostrom, ‘The simulation argument’, SL4 archives, 2001 http://www.sl4.org/archive/0112/2380.html
17. History of LessWrong, https://wiki.lesswrong.com/wiki/History\_of\_Less\_Wrong
18. Overcoming Bias: about http://www.overcomingbias.com/about
19. ‘Fake fake utility functions’, LessWrong sequences, 6 December 2007 http://lesswrong.com/lw/lp/fake\_fake\_utility\_functions/
20. Riciessa, ‘LessWrong analytics, February 2009 to January 2017’, LessWrong, 2017 https://www.lesswrong.com/posts/SWNn53RryQgTzT7NQ/lesswrong-analytics-february-2009-to-january-2017
2: The cosmic endowment
1. ‘Research priorities for robust and beneficial artificial intelligence: An open letter’, Future of Life Institute https://futureoflife.org/ai-open-letter
2. Donald E. Brownlee, ‘Planetary habitability on astronomical time scales’, in Carolus J. Schrijver and George L. Siscoe, Heliophysics: Evolving Solar Activity and the Climates of Space and Earth (Cambridge University Press, 2010)
3. Nick Bostrom, ‘Existential risk prevention as global priority’, 2012 http://www.existential-risk.org/concept.pdf
4. Carl Haub, ‘How many people have ever lived on Earth?’, 2011 http://www.prb.org/Publications/Articles/2002/HowManyPeopleHaveEverLivedonEarth.aspx
5. Bostrom, Superintelligence, p. 101
6. Ibid., p. 102
7. Existential Risk FAQ, Future of Humanity Institute http://www.existential-risk.org/faq.html
8. Eliezer Yudkowsky, ‘Pascal’s mugging: Tiny probabilities of vast utilities’, LessWrong, 2007 http://lesswrong.com/lw/kd/pascals\_mugging\_tiny\_probabilities\_of\_vast/
9. Nick Bostrom, ‘Pascal’s mugging’, 2009 https://nickbostrom.com/papers/pascal.pdf
10. Scott Alexander, ‘Getting Eulered’, 2014 http://slatestarcodex.com/2014/08/10/getting-eulered/
11. Scott Alexander, ‘Stop adding zeroes’, 2015 http://slatestarcodex.com/2015/08/12/stop-adding-zeroes/
3: Introducing AI
1. Stuart J. Russell and Peter Norvig, Artificial Intelligence: A Modern Approach (3rd edn; Pearson, 2010), p. 1
2. A.M. Turing, ‘Computing machinery and intelligence’, Mind, vol. 59, 1950, pp. 433–60
3. Russell and Norvig, Artificial Intelligence, p. 3
4. Luke Muehlhauser and Anna Salamon, ‘Intelligence explosion: evidence and import’, 2012 https://intelligence.org/files/IE-EI.pdf
5. Eliezer Yudkowsky, ‘Expected creative surprises’, LessWrong sequences, 2008 http://lesswrong.com/lw/v7/expected\_creative\_surprises/
6. Eliezer Yudkowsky, ‘Belief in intelligence’, LessWrong sequences, 2008 http://lesswrong.com/lw/v8/belief\_in\_intelligence/
7. Ibid.
8. Demis Hassabis et al., ‘Mastering chess and shogi by self-play with a general reinforcement learning algorithm’, Arxiv, 2017 https://arxiv.org/pdf/1712.01815.pdf
9. Russell and Norvig, Artificial Intelligence, p. 4
10. Nick Bostrom and Vincent C. Müller, ‘Future progress in artificial intelligence: A survey of expert opinion’, Fundamental Issues of Artificial Intelligence, 2016 https://nickbostrom.com/papers/survey.pdf
11. Nick Bostrom, ‘How long before superintelligence?’, International Journal of Future Studies, vol. 2 1998 https://nickbostrom.com/superintelligence.html
4: A history of AI
1. Alan Turing, ‘On computable numbers, with an application to the Entscheidungsproblem’, Proceedings of the London Mathematical Society, vol. s2-42, issue 1, 1 January 1937, pp. 230–265 https://doi.org/10.1112/plms/s2-42.1.230
2. J. McCarthy, M. Minsky, N. Rochester and C.E. Shannon, ‘A proposal for the Dartmouth summer research project on artificial intelligence’, 2 September 1956. Letter to the Rockefeller Foundation, retrieved from http://raysolomonoff.com/dartmouth/boxa/dart564props.pdf
3. I.J. Good, ‘Speculations concerning the first ultraintelligent machine’, Advances in Computers, vol. 6, 1965
4. Charles Krauthammer, ‘Be afraid’, The Weekly Standard, 26 May 1997 http://www.weeklystandard.com/be-afraid/article/9802#!
5. John McCarthy, quoted in David Elson, ‘Artificial intelligence’, The Johns Hopkins Guide to Digital Media (Johns Hopkins University Press, 15 April 2014)
6. A. Newell, J.C. Shaw and H. A. Simon, ‘Chess-playing programs and the problem of complexity’, IBM Journal of Research and Development, vol. 2(4), 1958, pp. 320–335
7. Wolfgang Ertel, Introduction to Artificial Intelligence (Springer, 1993), p. 109
5: When will it happen?
1. Eliezer Yudkowsky, ‘There’s no fire alarm for artificial general intelligence’ https://intelligence.org/2017/10/13/fire-alarm/
2. Donald B. Holmes, Wilbur’s Story, 1st edn (Lulu Enterprises, 2008), p. 91 https://books.google.co.uk/books?id=ldxfLyNIk9wC&pg=PA91&dq=%22i+said+to+my+brother+orville%22&hl=en&sa=X&redir\_esc=y#v=onepage&q=%22i%20said%20to%20my%20brother%20orville%22&f=false
3. Richard Phodes, The Making of the Atomic Bomb (Simon & Schuster, 2012), p. 280 https://books.google.com/books?id=aSgFMMNQ6G4C&pg=PA813&lpg=PA813&dq=weart+fermi&source=bl&ots=Jy1pBOUL10&sig=c9wK\_yLHbXZS\_GFIv0K3bgpmE58&hl=en&sa=X&ved=0ahUKEwjNofKsisnWAhXGlFQKHbOSB1QQ6AEIKTAA#v=onepage&q=%22ten%20per%20cent%22&f=false
4. Bostrom and Müller, ‘Future progress in artificial intelligence’ https://nickbostrom.com/papers/survey.pdf
5. K. Grace et al., ‘When will AI exceed human performance? Evidence from AI experts’, ArXiv https://arxiv.org/pdf/1705.08807.pdf?\_sp=c803ec8d-9f8f-4843-a81e-3284733403a0.1500631875031
6. David McAllester, ‘Friendly AI and the servant mission’, Machine Thoughts blog, 2014 https://machinethoughts.wordpress.com/2014/08/10/friendly-ai-and-the-servant-mission/
7. Luke Muelhauser, ‘Eliezer Yudkowsky: Becoming a rationalist’, Conversations from the Pale Blue Dot podcast, 2011 http://commonsenseatheism.com/?p=12147
8. Toby Walsh, Android Dreams (Hurst & Company, 2017), p. 54
6: Existential risk
1. Eliezer Yudkowsky/MIRI, ‘AI as a positive and negative factor in global risk’, 2008 https://intelligence.org/files/AIPosNegFactor.pdf
2. The Giving What We Can pledge: https://www.givingwhatwecan.org/pledge/
3. Nick Beckstead and Toby Ord, ‘Managing risk, not avoiding it’, Managing Existential Risk from Emerging Technologies, Annual Report of the Government Chief Scientific Adviser 2014, p. 116 https://www.fhi.ox.ac.uk/wp-content/uploads/Managing-existential-risks-from-Emerging-Technologies.pdf
4. A. Robock, et al., ‘Multidecadal global cooling and unprecedented ozone loss following a regional nuclear conflict’, Earth’s Future, 2014 http://onlinelibrary.wiley.com/doi/10.1002/2013EF000205/full
5. ‘Soviets close to using A-bomb in 1962 crisis, forum is told’, Boston Globe, 13 October 2002 http://www.latinamericanstudies.org/cold-war/sovietsbomb.htm
6. List of nuclear close calls, Wikipedia https://en.wikipedia.org/wiki/List\_of\_nuclear\_close\_calls
7. Yudkowsky, ‘AI as a positive and negative factor in global risk’ https://intelligence.org/files/AIPosNegFactor.pdf
7: The cryptographic rocket probe, and why you have to get it right first time
1. Nate Soares, ‘Ensuring smarter-than-human intelligence has a positive outcome’ 2017 https://intelligence.org/2017/04/12/ensuring/
2. Tom Chivers, ‘The spaceship that took some of the greatest images of the solar system has died’, BuzzFeed, September 2017 https://www.buzzfeed.com/tomchivers/cassini-death-spiral
8: Paperclips and Mickey Mouse
1. Nick Bostrom, ‘Ethical issues in advanced artificial intelligence’, 2003 https://nickbostrom.com/ethics/ai.html
2. http://www.decisionproblem.com/paperclips/index2.html
3. Soares, ‘Ensuring smarter-than-human intelligence has a positive outcome’ https://intelligence.org/2017/04/12/ensuring/
9: You can be intelligent, and still want to do stupid things
1. Bostrom, Superintelligence, p. 9
2. Nick Bostrom, ‘The superintelligent will: motivation and instrumental rationality in advanced artificial agents’, 2012 https://nickbostrom.com/superintelligentwill.pdf
3. Elezier Yudkowsky, ‘Ghosts in the machine’, 17 June 2008 https://www.readthesequences.com/GhostsInTheMachine
4. NCD Risk Factor Collaboration, ‘Trends in adult body-mass index in 200 countries from 1975 to 2014: A pooled analysis of 1698 population-based measurement studies with 19.2 million participants’, The Lancet, 2 April 2016 http://www.thelancet.com/journals/lancet/article/PIIS0140-6736(16)30054-X/fulltext
5. Yudkowsky, ‘AI as a positive and negative factor in global risk’, 2008 https://intelligence.org/files/AIPosNegFactor.pdf
6. S. Omohundro, ‘The basic AI drives’, 2008 https://selfawaresystems.files.wordpress.com/2008/01/ai\_drives\_final.pdf
7. Bostrom, ‘The superintelligent will’ https://nickbostrom.com/superintelligentwill.pdf
10: If you want to achieve your goals, not dying is a good start
1. Soares, ‘Ensuring smarter-than-human intelligence has a positive outcome’ https://intelligence.org/2017/04/12/ensuring/
2. Omohundro, ‘The basic AI drives’ https://selfawaresystems.files.wordpress.com/2008/01/ai\_drives\_final.pdf
3. Thucydides, History of the Peloponnesian War, trans. Richard Crawley (J.M. Dent & co., 1903), Chapter 1 https://ebooks.adelaide.edu.au/t/thucydides/crawley/complete.html
4. Hans Morgenthau, Politics Among Nations: The Struggle for Power and Peace (McGraw-Hill Education, 1967), p. 64
5. Thomas Hobbes, Leviathan, 1651 (Andrew Crooke, 1st edn), Chapter 13
6. Nikita Khrushchev, ‘Telegram From the Embassy in the Soviet Union to the Department of State’, 2 October 1962. From Foreign Relations of the United States, 1961–63, Volume VI, Kennedy-Khrushchev Exchanges, US Department of State Office of the Historian, ed. Charles S. Sampson, United States Government Printing Office 1966 https://history.state.gov/historicaldocuments/frus1961-63v06/d65
7. Bostrom, ‘The superintelligent will’ https://nickbostrom.com/superintelligentwill.pdf
8. Soares, ‘Ensuring smarter-than-human intelligence has a positive outcome’ https://intelligence.org/2017/04/12/ensuring/
9. Maureen Dowd, ‘Elon Musk’s billion-dollar crusade to stop the AI apocalypse’, Vanity Fair, April 2017 https://www.vanityfair.com/news/2017/03/elon-musk-billion-dollar-crusade-to-stop-ai-space-x
10. https://wiki.lesswrong.com/wiki/Roko’s\_basilisk
11. http://rationalwiki.org/wiki/Roko%27s\_basilisk/Original\_post#Comments\_.28117.29
12. https://xkcd.com/1450/
13. https://www.reddit.com/r/xkcd/comments/2myg86/xkcd\_1450\_aibox\_experiment/cm8vn6e/
14. David Auerbach, ‘Roko’s Basilisk, the single most terrifying thought experiment of all time’, Slate, 17 July 2014 http://www.slate.com/articles/technology/bitwise/2014/07/roko\_s\_basilisk\_the\_most\_terrifying\_thought\_experiment\_of\_all\_time.single.html
15. Dylan Love, ‘Just reading about this thought experiment could ruin your life’, Business Insider, 6 August 2014 http://www.businessinsider.com/what-is-rokos-basilisk-2014-8?IR=T
16. 2016 LessWrong diaspora survey results http://www.jdpressman.com/public/lwsurvey2016/Survey\_554193\_LessWrong\_Diaspora\_2016\_Survey%282%29.pdf
17. Scott Alexander, ‘Noisy poll results and reptilian Muslim climatologists from Mars’, 2013 http://slatestarcodex.com/2013/04/12/noisy-poll-results-and-reptilian-muslim-climatologists-from-mars/
11: If I stop caring about chess, that won’t help me win any chess games, now will it?
1. Omohundro, ‘The basic AI drives’ https://selfawaresystems.files.wordpress.com/2008/01/ai\_drives\_final.pdf
12: The brief window of being human-level
1. Vernor Vinge, ‘Signs of the Singularity’, 2008 http://www.collier.sts.vt.edu/engl4874/pdfs/vinge\_2008.pdf
2. Demis Hassabis, et al.,‘Mastering the game of Go with deep neural networks and tree search’, Nature, January 2016 https://www.nature.com/articles/nature16961
3. Miles Brundage, ‘AlphaGo and AI progress’, February 2016 http://www.milesbrundage.com/blog-posts/alphago-and-ai-progress
4. Eliezer Yudkowsky, ‘My Childhood Role Model’, 2008 https://www.readthesequences.com/MyChildhoodRoleModel
13: Getting better all the time
1. Bostrom, Superintelligence, p. 2
2. Robin Hanson, ‘Economics of the Singularity’, 1 June 2008 https://spectrum.ieee.org/robotics/robotics-software/economics-of-the-singularity
3. I.J. Good, ‘Speculations concerning the first ultraintelligent machine’, Advances in Computers, vol. 6, 1966, pp. 31–88 https://www.lesswrong.com/posts/kHL6qX9eArmvNWY99/connecting-your-beliefs-a-call-for-help
4. Bostrom, ‘The superintelligent will’ https://nickbostrom.com/superintelligentwill.pdf
5. Ibid.
6. Yudkowsky, ‘AI as a positive and negative factor in global risk’, 2008 https://intelligence.org/files/AIPosNegFactor.pdf
14: ‘FOOOOOM’
1. Bostrom, Superintelligence, p. 65
2. Ibid., p. 65
3. Ibid., p. 70
4. Ibid., p. 68
5. Eliezer Yudkowsky, ‘Hard takeoff’, LessWrong, 2008 http://lesswrong.com/lw/wf/hard\_takeoff/
6. Luke Meuhlhauser and Anna Salamon, Intelligence Explosion: Evidence and Import (MIRI, 2012) https://intelligence.org/files/IE-EI.pdf
15: But can’t we just keep it in a box?
1. Scott Alexander, ‘No physical substrate, no problem,’ 2015 http://slatestarcodex.com/2015/04/07/no-physical-substrate-no-problem/
2. Dowd, ‘Elon Musk’s billion-dollar crusade to stop the AI apocalypse’ https://www.vanityfair.com/news/2017/03/elon-musk-billion-dollar-crusade-to-stop-ai-space-x
3. Bostrom, Superintelligence, p. 129
4. ‘The “AI box” experiment’, SL4 archives, 2002 http://www.sl4.org/archive/0203/3132.html
5. Eliezer Yudkowsky, ‘Shut up and do the impossible!’, LessWrong sequences, 2008 https://www.lesswrong.com/posts/nCvvhFBaayaXyuBiD/shut-up-and-do-the-impossible
6. Bostrom, ‘Risks and mitigation strategies for Oracle AI’, 2010 https://www.fhi.ox.ac.uk/wp-content/uploads/Risks-and-Mitigation-Strategies-for-Oracle-AI.pdf
16: Dreamed of in your philosophy
1. Bostrom and Müller, ‘Future progress in artificial intelligence’ https://nickbostrom.com/papers/survey.pdf
2. Scott Alexander, ‘AI researchers on AI risk’, 2015 http://slatestarcodex.com/2015/05/22/ai-researchers-on-ai-risk/
3. Ibid.
17: ‘It’s like 100 per cent confident this is an ostrich’
1. Jason Yosinsky, et al., ‘The surprising creativity of digital evolution: A collection of anecdotes from the Evolutionary Computation and Artificial Life Research communities’, ArXiv, March 2018 https://arxiv.org/pdf/1803.03453v1.pdf
2. Christian Szegedy, et al., ‘Explaining and harnessing adversarial examples’ https://arxiv.org/pdf/1412.6572v3.pdf?loc=contentwell&lnk=a-2015-paper&dom=section-9
18: What is rationality?
1. Eliezer Yudkowsky, ‘What do I mean by rationality?’, LessWrong sequences, 16 March 2009 hhttps://www.readthesequences.com/What-Do-I-Mean-By-Rationality
2. Ibid.
3. Eliezer Yudkowsky, ‘Newcomb’s problem and regret of rationality’, LessWrong sequences, 31 January 2008 https://www.lesswrong.com/posts/6ddcsdA2c2XpNpE5x/newcomb-s-problem-and-regret-of-rationality
4. Musashi Miyamoto, The Book of Five Rings, c.1645
5. Eliezer Yudkowsky, ‘Why Truth? And . . .’, LessWrong sequences, 27 November 2006 https://www.readthesequences.com/Why-Truth-And
6. Robert Nozick, ‘Newcomb’s problem and two principles of choice’, Essays in Honor of Carl G. Hempel (Springer Netherlands, 1969) http://faculty.arts.ubc.ca/rjohns/nozick\_newcomb.pdf
7. Eliezer Yudkowsky, ‘Timeless Decision Theory’, 2010 https://intelligence.org/files/TDT.pdf
19: Bayes’ theorem and optimisation
1. https://en.wikipedia.org/wiki/Thomas\_Bayes
2. Thomas Bayes, An Essay towards solving a Problem in the Doctrine of Chances, 1763
3. ‘An intuitive explanation of Bayes’ theorem’, LessWrong sequences, 1 January 2003 https://www.readthesequences.com/An-Intuitive-Explanation-Of-Bayess-Theorem
4. Ward Casscells, Arno Schoenberger and Thomas Graboys, ‘Interpretation by physicians of clinical laboratory results,’ New England Journal of Medicine, vol. 299, 1978, pp. 999–1001
5. ‘Searching for Bayes-Structure’, LessWrong sequences, 28 February 2008 https://www.readthesequences.com/SearchingForBayesStructure
6. Fred Hoyle, ‘Hoyle on Evolution’, Nature, vol. 294, No 5837 (12 November 1981), p. 105
7. Eliezer Yudkowsky, ‘How much evidence does it take?’, LessWrong sequences, 2007 https://www.readthesequences.com/How-Much-Evidence-Does-It-Take
8. Ibid.
20: Utilitarianism: shut up and multiply
1. Mason Hartman, @webdevmason, 2 April 2018 https://twitter.com/webdevMason/status/980861298387836928
2. ‘Extracts from Bentham’s Commonplace Book’, in 10 Works of Jeremy Bentham (John Bowring, 1843), p. 141
3. Eliezer Yudkowsky, ‘Torture vs dust specks,’ LessWrong sequences, 2008 https://www.lesswrong.com/posts/3wYTFWY3LKQCnAptN/torture-vs-dust-specks
4. Ibid.
5. Eliezer Yudkowsky, ‘Circular altruism’, LessWrong sequences, 2008 https://www.lesswrong.com/posts/4ZzefKQwAtMo5yp99/circular-altruism#uWXxEmfea9WFJmMSk
6. For instance, Alastair Norcross of the University of Colorado in his paper ‘Comparing harms: Headaches and human lives’, 1997 http://spot.colorado.edu/~norcross/Comparingharms.pdf
7. Derek Parfit, Reasons and Persons (OUP, 1984), p. 388
8. Eliezer Yudkowsky, ‘The lifespan dilemma’, LessWrong sequences, 2009 https://www.lesswrong.com/posts/9RCoE7jmmvGd5Zsh2/the-lifespan-dilemma
9. Eliezer Yudkowsky, ‘Ends don’t justify means (among humans)’, LessWrong sequences, 2009 https://www.readthesequences.com/EndsDontJustifyMeansAmongHumans
10. Eliezer Yudkowsky, ‘One life against the world’, LessWrong sequences, 2007 https://www.lesswrong.com/posts/xiHy3kFni8nsxfdcP/one-life-against-the-world
21: What is a ‘bias’?
1. Rob Bensinger, ‘Biases: An introduction’, LessWrong sequences, 2015 https://www.readthesequences.com/Biases-An-Introduction
2. Ibid.
22: The availability heuristic
1. David Anderson QC, ‘The Terrorism Acts in 2011: Report of the Independent Reviewer on the Operation of the Terrorism Act 2000 and Part 1 of the Terrorism Act 2006’, 2012 https://terrorismlegislationreviewer.independent.gov.uk/wp-content/uploads/2013/04/report-terrorism-acts-2011.pdf
2. Sarah Lichtenstein, et al., ‘Judged frequency of lethal events,’ Journal of Experimental Psychology: Human Learning and Memory, vol. 4(6), 1978, pp. 551–78 doi:10.1037/0278-7393.4.6.551
3. Elezier Yudkowsky, ‘Availability’, LessWrong sequences, 2008 https://www.readthesequences.com/Availability
4. Garrick Blalock, et al., ‘Driving fatalities after 9/11: A hidden cost of terrorism’, Applied Economics, vol. 41, issue 14, 2009 http://blalock.dyson.cornell.edu/wp/fatalities\_120505.pdf
23: The conjunction fallacy
1. Eliezer Yudkowsky, ‘Burdensome details’, LessWrong sequences, 2007 https://www.readthesequences.com/Burdensome-Details
2. Amos Tversky and Daniel Kahneman, ‘Judgments of and by Representativeness’, in Judgment Under Uncertainty: Heuristics and Biases, ed. Daniel Kahneman, Paul Slovic and Amos Tversky (CUP, 1982), pp. 84–98
3. A. Tversky and D. Kahneman, ‘Extensional versus intuitive reasoning: The conjunction fallacy in probability judgment’, Psychological Review, vol. 90, 1983, pp. 293–315
24: The planning fallacy
1. Eliezer Yudkowsky, ‘Planning fallacy’, LessWrong sequences, 2007 https://www.readthesequences.com/Planning-Fallacy
2. Roger Buehler, Dale Griffin and Michael Ross, ‘It’s about time: Optimistic predictions in work and love,’ European Review of Social Psychology, vol. 6(1), 1995, pp. 1–32 doi:10.1080/14792779343000112
3. Ian R. Newby-Clark, et al., ‘People focus on optimistic scenarios and disregard pessimistic scenarios while predicting task completion times,’ Journal of Experimental Psychology: Applied, vol. 6(3), 2000, pp. 171–82 doi:10.1037/1076-898X.6.3.171
4. Roger Buehler, Dale Griffin and Michael Ross, ‘Exploring the “planning fallacy”: Why people underestimate their task completion times’, Journal of Personality and Social Psychology, vol. 67(3), 1994, pp. 366–81 doi:10.1037/0022-3514.67.3.366
5. Roger Buehler, Dale Griffin and Michael Ross, ‘Inside the planning fallacy: The causes and consequences of optimistic time predictions’, in Thomas Gilovich, Dale Griffin and Daniel Kahneman (eds), Heuristics and Biases: The Psychology of Intuitive Judgment (CUP, 2012), pp. 250–70
6. Yudkowsky, ‘Planning fallacy’ https://www.readthesequences.com/Planning-Fallacy
25: Scope insensitivity
1. Elezier Yudkowsky, ‘Scope insensitivity’, LessWrong sequences, 2008 https://www.readthesequences.com/ScopeInsensitivity
2. William H. Desvousges, et al., Measuring Nonuse Damages Using Contingent Valuation: An Experimental Evaluation of Accuracy (RTI Press, 1992) https://www.rti.org/sites/default/files/resources/bk-0001-1009\_web.pdf
3. Richard T. Carson and Robert Cameron Mitchell, ‘Sequencing and nesting in contingent valuation surveys’, Journal of Environmental Economics and Management, vol. 28(2), 1995, pp. 155–73 doi:10.1006/jeem.1995.1011
4. Daniel Kahneman, Ilana Ritov and Daniel Schkade, ‘Economic preferences or attitude expressions?: An analysis of dollar responses to public issues’, Journal of Risk and Uncertainty, vol.19, issue 1–3, 1999, pp. 203–35 doi:10.1007/978-94-017-1406-8\_8
5. David Fetherstonhaugh, et al., ‘Insensitivity to the value of human life: A study of psychophysical numbing’, Journal of Risk and Uncertainty, vol. 14(3), 1997, pp. 283–300 doi:10.1023/A:1007744326393
6. Rebecca Smith, ‘“Revolutionary” breast cancer drug denied on NHS over cost: NICE’, Daily Telegraph, 8 August 2014
26: Motivated scepticism, motivated stopping and motivated continuation
1. Jonathan Haidt, The Righteous Mind: Why Good People Are Divided by Politics and Religion (Penguin, 2012), p. 98
2. Eliezer Yudkowsky, ‘Motivated stopping and motivated continuation’, LessWrong sequences, 2007 https://www.lesswrong.com/posts/L32LHWzy9FzSDazEg/motivated-stopping-and-motivated-continuation
3. R.A. Fisher, ‘Lung cancer and cigarettes’, Nature, vol. 182, 12 July 1958, p. 108 https://www.york.ac.uk/depts/maths/histstat/fisher275.pdf
4. F. Yates and K. Mather, ‘Ronald Aylmer Fisher 1890–1962’, Biographical Memoirs of Fellows of the Royal Society, vol. 9, 1963, pp. 91–129 doi:10.1098/rsbm.1963.0006.
27: A few others, and the most important one
1. Eliezer Yudkowsky, ‘Illusion of transparency: Why no one understands you’, LessWrong sequences, 2007 https://www.readthesequences.com/Illusion-Of-Transparency-Why-No-One-Understands-You
2. Boaz Keysar, ‘The illusory transparency of intention: Linguistic perspective taking in text’, Cognitive Psychology, vol. 26(2), 1994, pp. 165–208 doi:10.1006/cogp.1994.1006
3. Eliezer Yudkowsky, ‘Hindsight devalues science’, LessWrong sequences, 2007 https://www.readthesequences.com/Hindsight-Devalues-Science
4. ‘Did you know it all along?’, excerpt from David G. Meyers, Exploring Social Psychology (McGraw-Hill, 1994), pp. 15–19 https://web.archive.org/web/20180118185747/https://musiccog.ohio-state.edu/Music829C/hindsight.bias.html
5. Eliezer Yudkowsky, ‘The affect heuristic’, LessWrong sequences, 2008 https://www.readthesequences.com/TheAffectHeuristic
6. Eliezer Yudkowsky, ‘The halo effect’, LessWrong sequences, 2008 https://www.readthesequences.com/TheHaloEffect
7. Eliezer Yudkowsky, ‘Knowing about biases can hurt people’, LessWrong sequences, 2008 https://www.readthesequences.com/Knowing-About-Biases-Can-Hurt-People
8. Ibid.
28: Thinking probabilistically
1. Tetlock quoted in Dan Gardner, Future Babble (Virgin Books, 2011), p. 24
2. Ibid., p. 25
3. Isaiah Berlin, The Hedgehog and the Fox: An Essay on Tolstoy’s View of History (Princeton Press, 1953)
29: Making beliefs pay rent
1. Eliezer Yudkowsky, ‘Disputing definitions’, LessWrong sequences, 2008 https://www.readthesequences.com/Disputing-Definitions
2. Eliezer Yudkowsky, ‘Making beliefs pay rent (in anticipated experiences)’, LessWrong sequences, 2008 https://www.readthesequences.com/Making-Beliefs-Pay-Rent-In-Anticipated-Experiences
30: Noticing confusion
1. Eliezer Yudkowsky, ‘Fake explanations’, LessWrong sequences, 2008 https://www.readthesequences.com/Fake-Explanations
31: The importance of saying ‘Oops’
1. Eliezer Yudkowsky, ‘The importance of saying “Oops”’, LessWrong sequences, 2008 https://www.readthesequences.com/TheImportanceOfSayingOops
2. Ibid.
32: The semi-death of LessWrong
1. Riciessa, ‘LessWrong analytics, February 2009 to January 2017’ https://www.lesswrong.com/posts/SWNn53RryQgTzT7NQ/lesswrong-analytics-february-2009-to-january-2017
2. Scott Alexander, ‘A History of the Rationalist community’, Reddit, 2017 https://www.reddit.com/r/slatestarcodex/comments/6tt3gy/a\_history\_of\_the\_rationality\_community/
3. Scott Alexander, ‘Mapmaker, mapmaker, make me a map’, 2014 https://slatestarcodex.com/2014/09/05/mapmaker-mapmaker-make-me-a-map/
33: The IRL community
1. Zvi Mowshowitz, ‘The thing and the symbolic representation of the thing’, 2015 https://thezvi.wordpress.com/2015/06/30/the-thing-and-the-symbolic-representation-of-the-thing/
2. Sara Constantin, ‘Lessons learned from MetaMed’, 2015 https://docs.google.com/document/d/1HzZd3jsG9YMU4DqHc62mMqKWtRer\_KqFpiaeN-Q1rlI/edit
3. 2016 LessWrong diaspora survey results http://www.jdpressman.com/public/lwsurvey2016/Survey\_554193\_LessWrong\_Diaspora\_2016\_Survey%282%29.pdf
4. SSC survey results 2018 http://slatestarcodex.com/2018/01/03/ssc-survey-results-2018/
34: Are they a cult?
1. Unknown author, ‘Our phyg is not exclusive enough’, LessWrong, 2012 https://www.lesswrong.com/posts/hxGEKxaHZEKT4fpms/our-phyg-is-not-exclusive-enough
2. reddragdiva.tumblr.com, https://reddragdiva.tumblr.com/post/172165021858/some-charities-are-more-effective-than-others-and
3. Eliezer Yudkowsky, ‘Every cause wants to be a cult’, LessWrong, 2007 https://www.lesswrong.com/posts/yEjaj7PWacno5EvWa/every-cause-wants-to-be-a-cult
4. ‘Transcription of Eliezer’s January 2010 video Q&A’, LessWrong, 2010 https://www.lesswrong.com/posts/YduZEfz8usGbJXN4x/transcription-of-eliezer-s-january-2010-video-q-and-a
5. MIRI Independent Auditors Report for 2016, https://intelligence.org/wp-content/uploads/2012/06/Independent-Auditors-Report-for-2016.pdf
6. Scott Alexander, ‘The Noncentral Fallacy: The worst argument in the world’, LessWrong, 2012 https://www.lesswrong.com/posts/yCWPkLi8wJvewPbEp/the-noncentral-fallacy-the-worst-argument-in-the-world
7. SSC 2018 survey results http://slatestarcodex.com/2018/01/03/ssc-survey-results-2018/
8. LessWrong 2014 survey results http://lesswrong.com/lw/lhg/2014\_survey\_results/
9. Elizabeth Sheff, ‘How many polyamorists are there in the US?’ Psychology Today, 9 May 2014 https://www.psychologytoday.com/us/blog/the-polyamorists-next-door/201405/how-many-polyamorists-are-there-in-the-us
10. M.L. Haupert et al., ‘Prevalence of experiences with consensual nonmonogamous relationships: Findings from two national samples of single Americans’, Journal of Sex & Marital Therapy, vol. 43, issue 5, 2017 https://www.tandfonline.com/doi/abs/10.1080/0092623X.2016.1178675?journalCode=usmt20
11. Brendan Shucart, ‘Polyamory by the numbers’, Advocate, 1 August 2016 https://www.advocate.com/current-issue/2016/1/08/polyamory-numbers
35: You can’t psychoanalyse your way to the truth
1. Scott Alexander, ‘Is everything a religion?’, 2015 http://slatestarcodex.com/2015/03/25/is-everything-a-religion/
2. John Horgan, ‘The consciousness conundrum’, IEEE Spectrum, 1 June 2008 https://spectrum.ieee.org/biomedical/imaging/the-consciousness-conundrum
3. John Horgan, ‘AI visionary Eliezer Yudkowsky on the Singularity, Bayesian brains and closet goblins’, Scientific American, 1 March 2016 https://blogs.scientificamerican.com/cross-check/ai-visionary-eliezer-yudkowsky-on-the-singularity-bayesian-brains-and-closet-goblins/
36: Feminism
1. Scott Aaronson, comment #171 under blog post ‘Walter Lewin’, Shtetl-Optimised, 2015 https://www.scottaaronson.com/blog/?p=2091#comment-326664
2. Amanda Marcotte, ‘MIT professor explains: The real oppression is having to learn to talk to women’, RawStory, 2014 https://www.rawstory.com/2014/12/mit-professor-explains-the-real-oppression-is-having-to-learn-to-talk-to-women/
3. Scott Alexander, ‘Untitled’, 2015 http://slatestarcodex.com/2015/01/01/untitled/
4. Russell Clark and Elaine Hatfield, ‘Gender differences in receptivity to sexual offers’, Journal of Psychology & Human Sexuality, vol. 2(1), 1989 https://www.tandfonline.com/doi/abs/10.1300/J056v02n01\_04
5. Vashte Galpin, ‘Women in computing around the world: An initial comparison of international statistics’, ACM SIGCSE Bulletin, vol. 34(2), June 2002, pp. 94–100 http://homepages.inf.ed.ac.uk/vgalpin1/ps/Gal02a.pdf
6. Elizabeth Weise, ‘Tech: Where the women and minorities aren’t’, USA Today, 15 August 2014 https://eu.usatoday.com/story/tech/2014/05/29/silicon-valley-tech-diversity-hiring-women-minorities/9735713/
7. NCWIT, ‘Girls in IT: The facts infographic’, National Center for Women and IT, 30 November 2012 https://www.ncwit.org/infographic/3435
8. Beth Gardiner, ‘Computer coding: It’s not just for boys’, New York Times, 7 March 2013 https://www.nytimes.com/2013/03/08/technology/computer-coding-its-not-just-for-boys.html
9. Kathy A. Krendl, Mary C. Broihier and Cynthia Fleetwood, ‘Children and computers: Do sexrelated differences persist?’, Journal of Communication, vol. 39(3), 1 September 1989, pp. 85–93 https://doi.org/10.1111/j.1460-2466.1989.tb01042.x
10. Lily Shashaani, ‘Gender differences in computer attitudes and use among college students’, Journal of Educational Computing Research, vol. 16, issue 1, 1 January 1997 http://journals.sagepub.com/doi/abs/10.2190/Y8U7-AMMA-WQUT-R512?journalCode=jeca
11. Richard A. Lippa, ‘Gender differences in personality and interests: When, where, and why?’, Social and Personality Psychology Compass, vol. 4, issue 11, 20 October 2010 https://doi.org/10.1111/j.1751-9004.2010.00320.x
12. Scott Alexander, ‘Contra Grant on exaggerated differences’, 2017 http://slatestarcodex.com/2017/08/07/contra-grant-on-exaggerated-differences/
13. ‘The state of medical education and practice in the UK’, General Medical Council, 2016 https://www.gmc-uk.org/-/media/documents/SOMEP\_2016\_Full\_Report\_Lo\_Res.pdf\_68139324.pdf
14. ‘Higher Education Student Statistics: UK, 2016/17 – Subjects studied’, HESA, 2018 https://www.hesa.ac.uk/news/11-01-2018/sfr247-higher-education-student-statistics/subjects
15. ‘Association of American Medical Colleges 2015 Report on Residents’, AAMC, 2015 https://www.aamc.org/data/workforce/reports/458766/2-2-chart.html
16. ‘The state of medical education and practice in the UK’, General Medical Council, 2017 https://www.gmc-uk.org/-/media/about/somep-2017/somep-2017-final-full.pdf?la=en#=B6AD13C9D672F7FCD927498A3F50BB0A2A4286F2
17. Scott Alexander, ‘Untitled’, 2015 http://slatestarcodex.com/2015/01/01/untitled/
18. ‘Full leaked Googlers’ conversations regarding the Google memo’, reddit.com/r/KotakuInAction http://archive.is/wUBb5#selection-2283.0-2301.9
19. Emily Gorcenski, ‘Will this make people afraid to share their thoughts? Yes. Shitty people should be afraid to share their fascist thoughts.’ Twitter https://twitter.com/EmilyGorcenski/status/893973537941327876
20. James Damore, ‘The document that got me fired from Google’, 2017 https://firedfortruth.com/
21. Paul Lewis, ‘“I see things differently”: James Damore on his autism and the Google memo’, Guardian, 17 November 2017 https://www.theguardian.com/technology/2017/nov/16/james-damore-google-memo-interview-autism-regrets
37: The Neoreactionaries
1. 2016 LessWrong diaspora survey results http://www.jdpressman.com/public/lwsurvey2016/Survey\_554193\_LessWrong\_Diaspora\_2016\_Survey%282%29.pdf
2. LessWrong diaspora survey 2016 http://www.jdpressman.com/public/lwsurvey2016/analysis/general\_report.html
3. Scott Alexander, ‘You’re probably wondering why I’ve called you here today’, 2013 http://slatestarcodex.com/2013/02/12/youre-probably-wondering-why-ive-called-you-here-today/
4. Scott Alexander, ‘SSC Endorses Clinton, Johnson, or Stein’, 2016 http://slatestarcodex.com/2016/09/28/ssc-endorses-clinton-johnson-or-stein/
5. SSC survey results 2018 http://slatestarcodex.com/2018/01/03/ssc-survey-results-2018/
38: The Effective Altruists
1. Peter Singer, ‘Famine, affluence, and morality’, Philosophy and Public Affairs, vol. 1(1), Spring 1972, pp. 229–43 (rev. edn) https://www.utilitarian.net/singer/by/1972----.htm
2. Benjamin Todd, ‘Earning to give’, 80,000 Hours, 2017 https://80000hours.org/articles/earning-to-give/
3. ‘What we can achieve’, Giving What We Can https://www.givingwhatwecan.org/get-involved/what-we-can-achieve/
4. Giving USA 2018: The Annual Report on Philanthropy for the Year 2017 https://givingusa.org/giving-usa-2018-americans-gave-410-02-billion-to-charity-in-2017-crossing-the-400-billion-mark-for-the-first-time/
5. The 2014 survey of Effective Altruists, Centre for Effective Altruism http://effective-altruism.com/ea/gb/the\_2014\_survey\_of\_effective\_altruists\_results/
6. EA 2017 survey, Centre for Effective Altruism https://rtcharity.org/tag/ea-survey-2017/
7. LessWrong diaspora survey 2016 http://www.jdpressman.com/public/lwsurvey2016/Survey\_554193\_LessWrong\_Diaspora\_2016\_Survey%282%29.pdf
8. Scott Alexander, ‘Nobody is perfect, everything is commensurable’, 2014 http://slatestarcodex.com/2014/12/19/nobody-is-perfect-everything-is-commensurable/
9. ‘About chickens’, Compassion in World Farming, 2017 https://www.ciwf.org.uk/farm-animals/chickens/
10. Scott Alexander, ‘Vegetarianism for meat-eaters’, 2015 http://slatestarcodex.com/2015/09/23/vegetarianism-for-meat-eaters/
11. ‘Is there suffering in fundamental physics?’, Foundational Research Institute http://reducing-suffering.org/is-there-suffering-in-fundamental-physics/
12. ‘Impossible Foods – R&D Investment’, OpenPhil 2016 https://www.openphilanthropy.org/focus/us-policy/farm-animal-welfare/impossible-foods
13. Katie Strick, ‘This is what the “bleeding” vegan burger at Mildreds is really like’, London Evening Standard, 21 February 2018 https://www.standard.co.uk/go/london/restaurants/this-is-what-the-bleeding-vegan-burger-at-mildreds-is-really-like-a3772061.html
39: EA and AI
1. Benjamin Todd, ‘Why, despite global progress, humanity is probably facing its most dangerous time ever’, 80,000 Hours https://80000hours.org/articles/extinction-risk/
2. Holden Karnofsky, ‘Potential risks from advanced artificial intelligence: The philanthropic opportunity’, OpenPhil https://www.openphilanthropy.org/blog/potential-risks-advanced-artificial-intelligence-philanthropic-opportunity#Tractability
3. ‘Machine Intelligence Research Institute – general support’, OpenPhil 2016 https://www.openphilanthropy.org/focus/global-catastrophic-risks/potential-risks-advanced-artificial-intelligence/machine-intelligence-research-institute-general-support
4. ‘Our progress in 2017 and plans for 2018’, OpenPhil https://www.openphilanthropy.org/blog/our-progress-2017-and-plans-2018
5. reddragdiva.tumblr.com, https://reddragdiva.tumblr.com/post/172165021858/some-charities-are-more-effective-than-others-and
6. Dylan Matthews, ‘I spent a weekend at Google talking with nerds about charity. I came away . . . worried’, Vox, 10 August 2015 https://www.vox.com/2015/8/10/9124145/effective-altruism-global-ai
7. Ben Kuhn, ‘Some stories about comparative advantage’, December 2014 https://www.benkuhn.net/advantage
8. Edward Miguel and Michael Kremer, ‘Worms: Identifying impacts on education and health in the presence of treatment externalities’, Econometrica, vol. 72(1), January 2004, pp. 159–217
9. D.C. Taylor-Robinson, N. Maayan, K. Soares-Weiser, S. Donegan and P. Garner, ‘Deworming drugs for soil-transmitted intestinal worms in children: Effects on nutritional indicators, haemoglobin, and school performance’, Cochrane Database of Systematic Reviews, 23 July 2015 (CD000371)
10. Philip Oltermann, ‘Greenpeace loses £3m in currency speculation’, Guardian, 16 June 2014 https://www.theguardian.com/environment/2014/jun/16/greenpeace-loses-3m-pounds-currency-speculation
11. ‘Introducing OpenAI’, OpenAI.com 2015 https://blog.openai.com/introducing-openai/
40: What are they doing to stop the AI apocalypse?
1. D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman and D. Mane, ‘Concrete problems in AI safety’, technical report, 25 July 2016 arXiv:1606.06565v2 (cs.AI)
2. Paul Christiano, et al., ‘Deep reinforcement learning from human preferences’, OpenAI https://blog.openai.com/deep-reinforcement-learning-from-human-preferences/
3. Paul Christiano, ‘Capability amplification’, Medium https://ai-alignment.com/policy-amplification-6a70cbee4f34
41: The internal double crux
1. Duncan Sabien, ‘Double crux – A strategy for resolving disagreement’, LessWrong, 2017 https://www.lesswrong.com/posts/exa5kmvopeRyfJgCy/double-crux-a-strategy-for-resolving-disagreement
42: Life, the universe and everything
1. Bostrom and Müller, ‘Future progress in artificial intelligence’ https://nickbostrom.com/papers/survey.pdf
2. Bostrom, Superintelligence, p. 115
3. ‘Preparing for the Future of Artificial Intelligence’, Executive Office of the President, National Science and Technology Council Committee on Technology, October 2016 https://obamawhitehouse.archives.gov/sites/default/files/whitehouse\_files/microsites/ostp/NSTC/preparing\_for\_the\_future\_of\_ai.pdf
Copyright
First published in Great Britain in 2019 by Weidenfeld & Nicolson
an imprint of The Orion Publishing Group Ltd
Carmelite House, 50 Victoria Embankment
London EC4Y 0DZ
An Hachette UK Company
Copyright © Tom Chivers 2019
The moral right of Tom Chivers to be identified as the author of this work has been asserted in accordance with the Copyright, Designs and Patents Act of 1988.
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior permission of both the copyright owner and the above publisher of this book.
Every effort has been made to fulfil requirements with regard to reproducing copyright material. The author and publisher will be glad to rectify any omissions at the earliest opportunity.
A CIP catalogue record for this book is available from the British Library.
ISBN (Hardback) 978-1-4746-0877-0
ISBN (Trade paperback) 978-1-4746-0878-7
ISBN (eBook) 978-1-4746-0880-0
www.orionbooks.co.uk
[]
Table of Contents
Dedication
Title Page
Contents
Introduction: ‘I don’t expect your children to die of old age’
PART ONE: INTRODUCTIONS
1: Introducing the Rationalists
2: The cosmic endowment
PART TWO: THE PAPERCLIP APOCALYPSE
3: Introducing AI
4: A history of AI
5: When will it happen?
6: Existential risk
7: The cryptographic rocket probe, and why you have to get it right first time
8: Paperclips and Mickey Mouse
9: You can be intelligent, and still want to do stupid things
10: If you want to achieve your goals, not dying is a good start
11: If I stop caring about chess, that won’t help me win any chess games, now will it?
12: The brief window of being human-level
13: Getting better all the time
14: ‘FOOOOOM’
15: But can’t we just keep it in a box?
16: Dreamed of in your philosophy
17: ‘It’s like 100 per cent confident this is an ostrich’
PART THREE: THE WAYS OF BAYES
18: What is rationality?
19: Bayes’ theorem and optimisation
20: Utilitarianism: shut up and multiply
PART FOUR: BIASES
21: What is a ‘bias’?
22: The availability heuristic
23: The conjunction fallacy
24: The planning fallacy
25: Scope insensitivity
26: Motivated scepticism, motivated stopping and motivated continuation
27: A few others, and the most important one
PART FIVE: RAISING THE SANITY WATERLINE
28: Thinking probabilistically
29: Making beliefs pay rent
30: Noticing confusion
31: The importance of saying ‘Oops’
PART SIX: DECLINE AND DIASPORA
32: The semi-death of LessWrong
33: The IRL community
PART SEVEN: DARK SIDES
34: Are they a cult?
35: You can’t psychoanalyse your way to the truth
36: Feminism
37: The Neoreactionaries
PART EIGHT: DOING GOOD BETTER
38: The Effective Altruists
39: EA and AI
PART NINE: THE BASE RATE OF THE APOCALYPSE
40: What are they doing to stop the AI apocalypse?
41: The internal double crux
42: Life, the universe and everything
Acknowledgements
Notes
Copyright |
51934d34-7763-4040-be0a-4c3e5f113188 | trentmkelly/LessWrong-43k | LessWrong | Notes on Antelligence
(This post uses a more generalized definition of "simulator" than the one used in Simulators. Simulators, as defined here, are functions optimized towards some arbitrary range of inputs, and without requirements on how the function was created. If you need to distinguish between the two definitions, the simulators here can basically just be described as functions that represent some real world process.)
image by DALL-E
5 Point Summary (Idea from this article):
1. Antelligence is emulation accuracy. In other words, when a simulator tries to emulate a different system, its accuracy (the similarity between its outputs and the outputs of the other system) is the same thing as its antelligence. This also makes antelligence relative, meaning that it’s dependent on what is considered the “ideal” output/system.
2. Antelligence is not defined through agency or being goal driven, and so addresses modern neural networks and simulators like GPT-3/4 and DALL-E much better than Intelligence.
3. Simulators optimize towards arbitrary ranges over arbitrary inputs, with optimizers being a type of simulator which optimize towards only 1 range over all inputs.
4. Antelligence is why humans are so successful, since high antelligence relative to the real world allows us to predict the future, letting us act in ways much more intelligent than other creatures.
5. Artificial simulators are inherently benign (won’t suddenly transform into an agent that tries to kill us all), but powerful and potentially dangerous tools that would only lead to human extinction if we simulate and actively give it the ability to kill us all and/or give it to agents (human or artificial) that want to kill us all, making them equivalent in danger to nuclear weapons (with their strength being determined by their antelligence relative to the real world, as compared to humans).
Eliezer Yudkowsky was the first to define intelligence as |
fb510b86-e69d-4717-aaa5-9ac18f0eaafc | StampyAI/alignment-research-dataset/lesswrong | LessWrong | Planes are still decades away from displacing most bird jobs
Originally published here: <https://guzey.com/ai/planes-vs-birds/>
*Note: Parts of this essay were written by GPT-3, so it might contain untrue facts.*
Introduction
------------
Many of my friends are extremely excited by planes, rockets, and helicopters. They keep showing me videos of planes flying at enormous speed, rockets taking off from the ground while creating fiery infernos around them, and of helicopters hovering midair seemingly denying the laws of gravity.
I've been on a plane already, and it was nothing special. It was just a big metal tube with a bunch of people inside. It was loud and it smelled weird and I had to sit in a tiny seat for hours. So what is it that makes planes so special? Is it the fact that they're machine? Is it the fact that they're big? Is it the fact that they cost a lot of money?
Here's the thing: all human-built artificial flight (AF) machines are incredibly specialized and are far away from being able to perform most of the tasks birds -- the only general flight (GF) machines we are aware of -- can perform.
More than 200 years after hot air balloons became operational and more than 100 years after the first planes flew, it's clear that building a GF machine is much harder than anticipated and that we are nowhere close to reaching bird-level abilities.
1. Planes vs eagles
-------------------
**First,** take a look at this video of an eagle catching a goat, throwing it off a cliff, and then feasting on it:
I haven't ever seen a plane capable of catching a live animal and deliberately throwing it off a cliff. Not in 1922, not in 2022. Not even a tech demo. Such a feat vastly exceeds the abilities of any planes we have built, however fast they can fly.
2. Planes vs cuckoos
--------------------
**Second,** let's watch this video of a cuckoo chick ejecting the eggs of its competitors out of a nest:
You could say that this ability has nothing to do flight but, again, this misses the forest for the trees. Building a GF machine is not about Goodharting random "flight" benchmarks by flying high and fast, it's about *real-world performance on tasks GF machines created by nature are capable of.* And, however impressive planes are, as soon as we try to see how well they perform in the real-world, they can't even match a cuckoo chick.
3. Planes vs a hummingbirds
---------------------------
**Third** and final example. Take a look at the hummingbird's amazing ability to maintain stability in the harshest aerial conditions:
Take any plane we have built and it stands no chance of survival placed in anything even close to these kinds of conditions, while a tiny-yet-mighty hummingbird doesn't break a sweat navigating essentially a tornado.
Future of bird jobs: no plane danger
------------------------------------
Birds can flap their wings up to three times per second, whereas the fastest human-made aircraft only flaps its wings at 0.3 times per second. Birds can fly for long periods of time, whereas airplanes need to refuel regularly. Birds use orders of magnitude less energy to lift the same amount of mass in the air, compared to planes.
Planes, rockets, and helicopters are (optimistically) decades away from being able to carry out most of the tasks birds are capable of. Therefore, for the foreseeable future, most bird jobs such as carrying messages (pigeons), carrying cargo (pigeons), hunting (hawks), and others, will remain safe from being displaced by human-built AF machines.
Even if planes start to approach birds in some of their abilities, birds will be able to simply move towards performing other jobs. For example, planes can't navigate by themselves. So perhaps they will carry messages in simple conditions or to short distances, while pigeons will move towards specializing in complex message carrying or will learn to supervize plane routing, e.g. by piloting planes or by flying alongside and course-correcting them.
Birds can further make themselves safe from future job displacement by investing in their children's education, ensuring their long-term employability in the face of the rise of AF machines.
Conclusion
----------
At the end of the day, I just don't see how human-built AF machines we are building right now could fundamentally change the way wars are fought, business and travel are conducted, or how they would allow us to do anything even close to true spaceflight (if you want to venture into the true lunatic-territory).
*After all, if human-built AF machines are unable to match the abilities of a bird toddler, how could they possibly displace most bird jobs?* |
a766d17e-dd07-451e-9d98-911def3cb164 | trentmkelly/LessWrong-43k | LessWrong | Book Summary: Zero to One
Summary. Zero to one is a collection of notes on startups by Peter Thiel (co-founder of PayPal and Palantir) that grew from a course taught by Thiel at Stanford in 2012. Its core thesis is that iterative progress is insufficient for meaningful progress. Thiel argues that the world can only become better if it changes dramatically, which requires new technology that does not yet exist to be invented. He argues that the right way to do this is not to copy existing things, nor to iterate gradually on existing ideas, but to find fundamentally new company-shaped ideas, and leverage those to change the world. The book discusses recent historical examples of going from zero to one, comments on the fact that such instances seem to be in decline today, and challenges the reader to revive creation -- to take us from zero to one.
I summarise each chapter below.
The challenge of the future. Vertical progress/technology/going from zero to one is "doing new things". Horizontal progress/globalisation/going from one to n is "copying things that have already been done". We are currently in an era where horizontal progress is the norm. But the future can only be better if it is different. Horizontal progress is not sufficient.
Party like it's 1999. The 90s were a unique time in the history of entrepreneurship. The internet was just taking off. Dot-com mania was rampant. Startups were popping up like there was no tomorrow. Money was flowing. But it was not to last. The various companies were undifferentiated and overvalued. The bubble eventually popped. The dot-com crash caused people to make four updates about how to build companies: (1) Be humble, and only make incremental advances. (2) New companies should be "lean", not have a plan, and instead iterate to the whims of their customers. (3) New companies should find some existing market, not attempt to try to create a new market. (4) Focus only on the product, and the sales will come. Thiel argues the opposite to each of these |
7d7409d1-48b1-4aea-b461-4aeedd6a61a2 | trentmkelly/LessWrong-43k | LessWrong | What sorts of systems can be deceptive?
This work was done as part of SERI MATS, under Leo Gao’s guidance. Thank you to Erik Jenner and Johannes Treutlein for discussions and comments on the draft.
I’m interested in understanding deception in machine intelligence better. Specifically, I want to understand what precursors there are to deceptive alignment, and whether upon observing these precursors, we can change our approach to achieve better outcomes. In this article, I outline my current thinking on this topic, and consider a bunch of properties that systems which can be deceptive might share. I am still pretty confused about how this works, and I don’t yet have good ideas for what comes next.
Preliminaries
What is deception?
Commonly, by deception we mean a scenario where an intelligent system behaves in a way that hides what information it knows from another system, or from a human overseer. Fundamentally, the reason to be deceptive is that behaving honestly would lead to the system being penalised by its designers, perhaps through a training process that can intervene directly on its internal mechanisms.
In the context of Risks from Learned Optimization, deceptive alignment occurs when a system internally has a goal other than what we would like it to be. If this system is aware that it might be shut down or altered if it revealed this discrepancy, it is incentivised to play along, i.e. behave as though it is optimising the humans’ goal. Once the training process is complete and the system is safe to pursue its own goal, it does so without repercussions.
As described in the paper, deception is an inner misalignment failure, i.e. in the system there exists an inner optimiser whose goals may be different to the base optimiser’s goals. If this is the case, even if we select for models which appear to seek our base objective, the objective they actually end up pursuing may be different. These systems are deceptively aligned.
In this framing, the main way we might get deceptive alignment is throug |
d6d1b496-1fc6-41ab-b692-772403b1b4a4 | trentmkelly/LessWrong-43k | LessWrong | Is there any discussion on avoiding being Dutch-booked or otherwise taken advantage of one's bounded rationality by refusing to engage?
From https://www.gwern.net/mugging:
> One way to try to escape a mugging is to unilaterally declare that all probabilities below a certain small probability will be treated as zero. With the right pair of lower limit and mugger’s credibility, the mugging will not take place. But such a ad hoc method violates common axioms of probability theory, and thus we can expect there to be repercussions.
>
> It turns out to be easy to turn such a person into a money pump, if not by the mugging itself. Suppose your friend adopts this position, and he says specifically that any probabilities less than or equal to 1/20 are 0. You then suggest a game; the two of you will roll a d20 die, and if the die turns up 1-19, you will pay him one penny and if the die turns up 20, he pays you one dollar - no, one bazillion dollars. Your friend then calculates: there is a 19/20 chance that he will win a little money, and there is a 1/20 chance he will lose a lot of money - but wait, 1/20 is too small to matter! It is zero chance, by his rule. So, there is no way he can lose money on this game and he can only make money.
>
> He is of course wrong, and on the 5th roll you walk away with everything he owns. (And you can do this as many times as you like.)
Of course, that's not how a sane street-rational person would think! They would not play for "one bazillion dollars" no matter the odds. In general, detecting a sufficiently intelligent adversarial entity tends to result in avoiding the interaction altogether (if you are inured enough to Nigerian princes offering billions in an email). And yet I cannot find any LW discussion on when and if to engage and when to not engage, except in an occasional comment. |
cabb04a2-8724-4f65-ab1b-ade05ac78f44 | trentmkelly/LessWrong-43k | LessWrong | deluks917 on Online Weirdos
Cross-posted from Putanumonit.
This is part 1 of an interview with deluks917. Stay tuned for part 2 in which we talk about Buddhism and peanut butter, and part 3 which covers archetypes, superego poisoning, and Moana.
Since I have a face for radio and a voice for blogging, our conversation is transcribed for your pleasure and edited for readability. This is my second transcribed interview; suggestions for other people to chat with are welcome!
Jacob: I met you through the New York rationalist meetup, which now often takes place in your apartment. How did you even become part of this world?
deluks917: I had sporadically attended the New York meetups in the past, and then I was away in Pennsylvania for three years. I had been reading SlateStarCodex and commented under a couple of different names there. Later I made the SlateStarCodex Discord, and it took off around the time I came back to New York. The stars aligned. There was a room in a rationalist house that needed to be filled and no one else was going to take it.
For me, rationality filled a hole that had always existed in my life. Being nerdy and a systematizing thinker I was always reading psychology books and the like, but nothing seemed quite right until I read the Sequences.
I tried reading the Sequences a couple of times, starting seriously about eight years ago. I found them pretty confusing. But then I came back later and they made more sense. It took some time for things to marinate and for my mood to change.
I have always been part of nerdy communities, either online or IRL. I feel like my intellectual interests change pretty regularly and I happened to come back to rationality at the right time. By 2013 or so ideas about AI suddenly seemed more profound. I don’t know if I was wise or foolish not to be convinced about AI risk in 2010, maybe I was just too young. But by 2013 I was pretty convinced.
You created the SSC Discord and you do a lot of moderation of online communities. What does that i |
ab03ec14-af46-4713-927a-5ce50c6ada3e | StampyAI/alignment-research-dataset/alignmentforum | Alignment Forum | A brief note on Simplicity Bias
The idea of 'simplicity bias' is a popular one in informal discussions about the functions that neural networks implement. I recently tried to think a little bit more about what this meant. This brief note was written mostly for my own benefit, but could be of benefit to others. Having said that, it is not unlikely that I have made significant errors, and if so then I welcome all good faith attempts to point them out.
It seems like it is not uncommon for a surface-level or informal understanding of the idea to have come from Chirs Mingard's medium posts [*Neural networks are fundamentally (almost) Bayesian*](https://towardsdatascience.com/neural-networks-are-fundamentally-bayesian-bee9a172fad8)and[*Deep Neural Networks are biased, at initialisation, towards simple functions*](https://towardsdatascience.com/deep-neural-networks-are-biased-at-initialisation-towards-simple-functions-a63487edcb99)*.* Mingard attempts to summarize the results from a handful of papers on the topic, two of the most important of which he first-authored. For what it's worth (and in case this post seems like only criticism), I am of the opinion that the work is generally of a high quality and I do not think that Mingard is attempting to misrepresent his work. However, I do think - whether it is Mingard or his readers that are most responsible - that in attempting to generate bitesized, quotable 'takeaways' from technical research one can sometimes be left with decontextualized nuggets of information that are liable to be misunderstood.
### Simplicity Bias
Fix a deep neural network architecture and let Θ.mjx-chtml {display: inline-block; line-height: 0; text-indent: 0; text-align: left; text-transform: none; font-style: normal; font-weight: normal; font-size: 100%; font-size-adjust: none; letter-spacing: normal; word-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0; min-height: 0; border: 0; margin: 0; padding: 1px 0}
.MJXc-display {display: block; text-align: center; margin: 1em 0; padding: 0}
.mjx-chtml[tabindex]:focus, body :focus .mjx-chtml[tabindex] {display: inline-table}
.mjx-full-width {text-align: center; display: table-cell!important; width: 10000em}
.mjx-math {display: inline-block; border-collapse: separate; border-spacing: 0}
.mjx-math \* {display: inline-block; -webkit-box-sizing: content-box!important; -moz-box-sizing: content-box!important; box-sizing: content-box!important; text-align: left}
.mjx-numerator {display: block; text-align: center}
.mjx-denominator {display: block; text-align: center}
.MJXc-stacked {height: 0; position: relative}
.MJXc-stacked > \* {position: absolute}
.MJXc-bevelled > \* {display: inline-block}
.mjx-stack {display: inline-block}
.mjx-op {display: block}
.mjx-under {display: table-cell}
.mjx-over {display: block}
.mjx-over > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-under > \* {padding-left: 0px!important; padding-right: 0px!important}
.mjx-stack > .mjx-sup {display: block}
.mjx-stack > .mjx-sub {display: block}
.mjx-prestack > .mjx-presup {display: block}
.mjx-prestack > .mjx-presub {display: block}
.mjx-delim-h > .mjx-char {display: inline-block}
.mjx-surd {vertical-align: top}
.mjx-surd + .mjx-box {display: inline-flex}
.mjx-mphantom \* {visibility: hidden}
.mjx-merror {background-color: #FFFF88; color: #CC0000; border: 1px solid #CC0000; padding: 2px 3px; font-style: normal; font-size: 90%}
.mjx-annotation-xml {line-height: normal}
.mjx-menclose > svg {fill: none; stroke: currentColor; overflow: visible}
.mjx-mtr {display: table-row}
.mjx-mlabeledtr {display: table-row}
.mjx-mtd {display: table-cell; text-align: center}
.mjx-label {display: table-row}
.mjx-box {display: inline-block}
.mjx-block {display: block}
.mjx-span {display: inline}
.mjx-char {display: block; white-space: pre}
.mjx-itable {display: inline-table; width: auto}
.mjx-row {display: table-row}
.mjx-cell {display: table-cell}
.mjx-table {display: table; width: 100%}
.mjx-line {display: block; height: 0}
.mjx-strut {width: 0; padding-top: 1em}
.mjx-vsize {width: 0}
.MJXc-space1 {margin-left: .167em}
.MJXc-space2 {margin-left: .222em}
.MJXc-space3 {margin-left: .278em}
.mjx-test.mjx-test-display {display: table!important}
.mjx-test.mjx-test-inline {display: inline!important; margin-right: -1px}
.mjx-test.mjx-test-default {display: block!important; clear: both}
.mjx-ex-box {display: inline-block!important; position: absolute; overflow: hidden; min-height: 0; max-height: none; padding: 0; border: 0; margin: 0; width: 1px; height: 60ex}
.mjx-test-inline .mjx-left-box {display: inline-block; width: 0; float: left}
.mjx-test-inline .mjx-right-box {display: inline-block; width: 0; float: right}
.mjx-test-display .mjx-right-box {display: table-cell!important; width: 10000em!important; min-width: 0; max-width: none; padding: 0; border: 0; margin: 0}
.MJXc-TeX-unknown-R {font-family: monospace; font-style: normal; font-weight: normal}
.MJXc-TeX-unknown-I {font-family: monospace; font-style: italic; font-weight: normal}
.MJXc-TeX-unknown-B {font-family: monospace; font-style: normal; font-weight: bold}
.MJXc-TeX-unknown-BI {font-family: monospace; font-style: italic; font-weight: bold}
.MJXc-TeX-ams-R {font-family: MJXc-TeX-ams-R,MJXc-TeX-ams-Rw}
.MJXc-TeX-cal-B {font-family: MJXc-TeX-cal-B,MJXc-TeX-cal-Bx,MJXc-TeX-cal-Bw}
.MJXc-TeX-frak-R {font-family: MJXc-TeX-frak-R,MJXc-TeX-frak-Rw}
.MJXc-TeX-frak-B {font-family: MJXc-TeX-frak-B,MJXc-TeX-frak-Bx,MJXc-TeX-frak-Bw}
.MJXc-TeX-math-BI {font-family: MJXc-TeX-math-BI,MJXc-TeX-math-BIx,MJXc-TeX-math-BIw}
.MJXc-TeX-sans-R {font-family: MJXc-TeX-sans-R,MJXc-TeX-sans-Rw}
.MJXc-TeX-sans-B {font-family: MJXc-TeX-sans-B,MJXc-TeX-sans-Bx,MJXc-TeX-sans-Bw}
.MJXc-TeX-sans-I {font-family: MJXc-TeX-sans-I,MJXc-TeX-sans-Ix,MJXc-TeX-sans-Iw}
.MJXc-TeX-script-R {font-family: MJXc-TeX-script-R,MJXc-TeX-script-Rw}
.MJXc-TeX-type-R {font-family: MJXc-TeX-type-R,MJXc-TeX-type-Rw}
.MJXc-TeX-cal-R {font-family: MJXc-TeX-cal-R,MJXc-TeX-cal-Rw}
.MJXc-TeX-main-B {font-family: MJXc-TeX-main-B,MJXc-TeX-main-Bx,MJXc-TeX-main-Bw}
.MJXc-TeX-main-I {font-family: MJXc-TeX-main-I,MJXc-TeX-main-Ix,MJXc-TeX-main-Iw}
.MJXc-TeX-main-R {font-family: MJXc-TeX-main-R,MJXc-TeX-main-Rw}
.MJXc-TeX-math-I {font-family: MJXc-TeX-math-I,MJXc-TeX-math-Ix,MJXc-TeX-math-Iw}
.MJXc-TeX-size1-R {font-family: MJXc-TeX-size1-R,MJXc-TeX-size1-Rw}
.MJXc-TeX-size2-R {font-family: MJXc-TeX-size2-R,MJXc-TeX-size2-Rw}
.MJXc-TeX-size3-R {font-family: MJXc-TeX-size3-R,MJXc-TeX-size3-Rw}
.MJXc-TeX-size4-R {font-family: MJXc-TeX-size4-R,MJXc-TeX-size4-Rw}
.MJXc-TeX-vec-R {font-family: MJXc-TeX-vec-R,MJXc-TeX-vec-Rw}
.MJXc-TeX-vec-B {font-family: MJXc-TeX-vec-B,MJXc-TeX-vec-Bx,MJXc-TeX-vec-Bw}
@font-face {font-family: MJXc-TeX-ams-R; src: local('MathJax\_AMS'), local('MathJax\_AMS-Regular')}
@font-face {font-family: MJXc-TeX-ams-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_AMS-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_AMS-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_AMS-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-B; src: local('MathJax\_Caligraphic Bold'), local('MathJax\_Caligraphic-Bold')}
@font-face {font-family: MJXc-TeX-cal-Bx; src: local('MathJax\_Caligraphic'); font-weight: bold}
@font-face {font-family: MJXc-TeX-cal-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-R; src: local('MathJax\_Fraktur'), local('MathJax\_Fraktur-Regular')}
@font-face {font-family: MJXc-TeX-frak-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-frak-B; src: local('MathJax\_Fraktur Bold'), local('MathJax\_Fraktur-Bold')}
@font-face {font-family: MJXc-TeX-frak-Bx; src: local('MathJax\_Fraktur'); font-weight: bold}
@font-face {font-family: MJXc-TeX-frak-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Fraktur-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Fraktur-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Fraktur-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-BI; src: local('MathJax\_Math BoldItalic'), local('MathJax\_Math-BoldItalic')}
@font-face {font-family: MJXc-TeX-math-BIx; src: local('MathJax\_Math'); font-weight: bold; font-style: italic}
@font-face {font-family: MJXc-TeX-math-BIw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-BoldItalic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-BoldItalic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-BoldItalic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-R; src: local('MathJax\_SansSerif'), local('MathJax\_SansSerif-Regular')}
@font-face {font-family: MJXc-TeX-sans-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-B; src: local('MathJax\_SansSerif Bold'), local('MathJax\_SansSerif-Bold')}
@font-face {font-family: MJXc-TeX-sans-Bx; src: local('MathJax\_SansSerif'); font-weight: bold}
@font-face {font-family: MJXc-TeX-sans-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-sans-I; src: local('MathJax\_SansSerif Italic'), local('MathJax\_SansSerif-Italic')}
@font-face {font-family: MJXc-TeX-sans-Ix; src: local('MathJax\_SansSerif'); font-style: italic}
@font-face {font-family: MJXc-TeX-sans-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_SansSerif-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_SansSerif-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_SansSerif-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-script-R; src: local('MathJax\_Script'), local('MathJax\_Script-Regular')}
@font-face {font-family: MJXc-TeX-script-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Script-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Script-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Script-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-type-R; src: local('MathJax\_Typewriter'), local('MathJax\_Typewriter-Regular')}
@font-face {font-family: MJXc-TeX-type-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Typewriter-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Typewriter-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Typewriter-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-cal-R; src: local('MathJax\_Caligraphic'), local('MathJax\_Caligraphic-Regular')}
@font-face {font-family: MJXc-TeX-cal-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Caligraphic-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Caligraphic-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Caligraphic-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-B; src: local('MathJax\_Main Bold'), local('MathJax\_Main-Bold')}
@font-face {font-family: MJXc-TeX-main-Bx; src: local('MathJax\_Main'); font-weight: bold}
@font-face {font-family: MJXc-TeX-main-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Bold.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-I; src: local('MathJax\_Main Italic'), local('MathJax\_Main-Italic')}
@font-face {font-family: MJXc-TeX-main-Ix; src: local('MathJax\_Main'); font-style: italic}
@font-face {font-family: MJXc-TeX-main-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-main-R; src: local('MathJax\_Main'), local('MathJax\_Main-Regular')}
@font-face {font-family: MJXc-TeX-main-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Main-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Main-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Main-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-math-I; src: local('MathJax\_Math Italic'), local('MathJax\_Math-Italic')}
@font-face {font-family: MJXc-TeX-math-Ix; src: local('MathJax\_Math'); font-style: italic}
@font-face {font-family: MJXc-TeX-math-Iw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Math-Italic.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Math-Italic.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Math-Italic.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size1-R; src: local('MathJax\_Size1'), local('MathJax\_Size1-Regular')}
@font-face {font-family: MJXc-TeX-size1-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size1-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size1-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size1-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size2-R; src: local('MathJax\_Size2'), local('MathJax\_Size2-Regular')}
@font-face {font-family: MJXc-TeX-size2-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size2-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size2-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size2-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size3-R; src: local('MathJax\_Size3'), local('MathJax\_Size3-Regular')}
@font-face {font-family: MJXc-TeX-size3-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size3-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size3-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size3-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-size4-R; src: local('MathJax\_Size4'), local('MathJax\_Size4-Regular')}
@font-face {font-family: MJXc-TeX-size4-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Size4-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Size4-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Size4-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-R; src: local('MathJax\_Vector'), local('MathJax\_Vector-Regular')}
@font-face {font-family: MJXc-TeX-vec-Rw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Regular.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Regular.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Regular.otf') format('opentype')}
@font-face {font-family: MJXc-TeX-vec-B; src: local('MathJax\_Vector Bold'), local('MathJax\_Vector-Bold')}
@font-face {font-family: MJXc-TeX-vec-Bx; src: local('MathJax\_Vector'); font-weight: bold}
@font-face {font-family: MJXc-TeX-vec-Bw; src /\*1\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/eot/MathJax\_Vector-Bold.eot'); src /\*2\*/: url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/woff/MathJax\_Vector-Bold.woff') format('woff'), url('https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/fonts/HTML-CSS/TeX/otf/MathJax\_Vector-Bold.otf') format('opentype')}
denote the parameter space, by which mean that each point θ∈Θ is a complete set of weights and biases for the network. The architecture defines a map F between Θ and the space of functions F that the architecture is capable of implementing, i.e.
F:Θ→F,and each f∈F is a specific input-output function that the network is capable of implementing. We will denote the complexity of f∈F by C(f)∈[0,+∞), so that
ΘF⟶FC⟶[0,+∞)(and I will avoid getting into a discussion of different notions or different measures of complexity).
Given a probability measure P on Θ, we can think of picking θ∈Θ at random according to the measure P - this is random initialization of the network. We can also think of F as a random variable and indeed C(F). Then, the cleanest way to explain what is meant by '**simplicity bias**' is the following statement:
C(f)<C(g) ⟹ P(F=f)>P(F=g)(1)i.e. If the complexity of f is less than the complexity of g, then the probability of f being selected by random initialization is greater than the probability of g being selected. (Mingard does say this: "*We call this a **simplicity bias** — because P(f) is higher for simple functions.")*
I want to refer to statements like (1) as 'pointwise' simplicity bias. The crucial thing to note is that pointwise statements of the form (1) are not the same as claims about the distribution of C(F), i.e. I cannot easily turn (1) into a statement about P(C(F)=k), i.e. about the probability of the complexity of the selected function being equal to k (or indeed a statement about P(C(F)>k) or P(C(F)<k) etc.). Intuitively, the reason why this is the case is that although a given, specific, low-complexity function has a higher probability of being selected than a given, specific, high-complexity function, it may well be the case that there are vastly more high-complexity functions than low complexity ones and so it may in turn be the case that the probability of ending up with *a* high-complexity function is still greater than or at least comparable to the probability of ending up with *a* low complexity function.
Notice moreover that in many contexts is not unreasonable to *expect* many more high-complexity objects than low-complexity objects, simply because of the nature of measures of complexity that are based on or correlate with entropy. A classic straightforward example is to consider binary strings of length n: There are relatively few low entropy strings - those with a very small or with a very large number of ones - but there are exponentially many high-entropy strings, e.g. there are around 2n/2 strings with n/2 ones. So, even under a probability measure in which the probability of selecting a string is bounded above by something that decays quickly with the entropy of the string, it is not clear whether or not you should *expect* a low entropy outcome.
**Remark.** If you want to think at this level about whether a deep neural network is (something like) '*biased towards simplicity'*, then you may be interested in some slightly different questions. If we were to take inspiration from what we would normally mean by 'bias' in other contexts in statistics and machine learning, then it seems that really one would like to understand things like E(C(F)) and C(E(F)). It's not clear to me exactly what relationship between these quantities or what kind of statement actually best represents the informal notion of being 'biased towards simplicity'. (And nor do I think that we need to bother starting with a vague phrase that we want to be true and then formalizing it; we can at least try just asking more precise questions upfront in this case.)
### Bias Towards Simplicity
Now fix some training data and let I⊂F denote the subset of functions that have zero loss on this data. We call such functions *interpolants.* So F−1(I) is the region of parameter space that corresponds to functions with zero loss. We can suppose (as Mingard et al. essentially do, though my setup and notation is slightly different) that there is another probability measure PI on Θ for which PI(F=f) is the probability that the function f is found as the result of running an ML optimization algorithm (like SGD) that results in the achievement of zero loss on the training data. The main empirical result of Mingard et al. is that for f∈I we have
P(F=f|F∈I)≈PI(F=f)Somewhat informally, this says that the probability of the optimization algorithm finding a given interpolant is approximately equal to the probability of that interpolant being found by randomly choosing parameters from F−1(I).
In addition, there is an idea that deep neural networks trained at supervised learning tasks on real data *tend to* find simpler - rather than more complex - interpolants for the training data. Note that this is supposed to be a different statement from the kind of 'pointwise' simplicity bias discussed above, i.e. here I am really saying: We *expect* to see simpler learned interpolants.
With this in mind, one can produce an argument for the existence of a bias towards simplicity which relies on this last point. Here is an outline:
* Assumption 1: The optimization algorithm (such as SGD) that finds an interpolant is biased towards simplicity.
* Assumption 2: The probability of the optimization algorithm finding any given interpolant is approximately equal to the probability of that interpolant being found by randomly choosing parameters from F−1(I).
* Conclusion: Therefore the process of randomly choosing parameters from F−1(I)is biased towards simpler functions.
What I have called 'Assumption' 2 is that for which lots of empirical evidence was provided by Mingard et al. If the conclusion were true then, more so than any pointwise simplicity bias statement, it does suggest to me that deep neural network architectures harbour a bias towards simplicity. Looking at the argument as a whole, one way to phrase a correct conclusion is as follows: To the extent that you believe that deep neural networks tend to find simpler zero-loss functions in practice (when more complex ones would also work), you should attribute that effect to some intrinsic quality of architecture and parameter space, rather than to something about the optimization algorithm.
**Remark.** What of the remaining tricky question about whether or not Assumption 1 is really true, i.e. to what extent do we believe that deep neural networks tend to find simpler functions in practice? Currently I don't have anything useful to add. |
5f78bbf0-ee7b-4e14-95da-c0d60989769e | trentmkelly/LessWrong-43k | LessWrong | The Newbie's Guide to Navigating AI Futures
This article was crossposted from my website. Original linked here.
The piece was written using great ideas from Max Tegmark, Matt Ridley, Dave Shapiro, Aswath Damodaran, Anton Korinek, Marc Andreesen, L Rudolph L, Bryan Johnson, Kevin Kelly, Sam Altman, Eliezer Yudkowski, Scott Alexander and many others.
I've referenced the specific materials used in-text.
Thanks to Morgan Raffety, Oliver Lopez, Phil Amato, Thiago Sawan, Luca Marchione, Pete Fernandes, Bhragan Paramanantham and Ashish Nair for reading the initial drafts of this.
Part 1: The New Girl In The Red Dress
Today, more than ever, there's a huge amount of hype, panic, and interest in Artificial Intelligence (AI). We hear claims that AI will kill us all, ruin society, take our jobs, cause crippling inequality, and enable bad people to do bad things. But at the same time, others are certain it will drive unprecedented efficiencies, solve all our problems, and create a utopic future that can be "unimaginably great". At this point, it has become a brand name used to signal something vaguely synonymous with progress, automation or [insert anything you want to raise money for].
We've seen growing interest on search engines, via venture funding, and through a shift in labour market flows, where the smartest people in tech are now electing to work at AI companies over more traditional software companies. The term has reached literal 's tier' status as a buzzword‒ so much so that companies just mentioning 'AI' in earnings reports have seen favourable share price movements. New tech always gets people excited, but the hype around AI is the most intense we’ve seen since the dot-com boom.
In my attempt to work out what is actually going on I mostly found hype-cycle media, disguised advertising, sci-fi novels or really dense research papers. So I decided to write this article to cut through the bullshit and find out if the girl in the red dress is the real deal this time around. My goal is to create the go-to l |
610783c7-1b7e-49a9-8004-004b21ed2251 | StampyAI/alignment-research-dataset/arxiv | Arxiv | Antitrust and Artificial Intelligence (AAI): Antitrust Vigilance Lifecycle and AI Legal Reasoning Autonomy
1
Abstract
There is an increa sing inter est in the entwining of the
field of antitrust with the field of Artificial Intelligence
(AI), frequently referred to jointly as Antitrust and AI
(AAI) in the research literature. This study focuses on
the synergies entangling a ntitrust a nd AI , doing so to
exten d the literature by proffering the primary ways
that these two fields intersect , consisting of : (1) the
application of antitrust to AI, and (2) the application of
AI to antitrust. To date, most of the exis ting research
on this intermixing has concentrated on the form er,
namely the applicat ion of antitrust to AI, entai ling how
the marketplace will be altered by the a dvent of AI and
the potential for adve rse antitrust behaviors arisin g
accordingly. Opti ng to explore more deeply the other
side of this coin, th is research closely examines the
application of AI to antitrust and establishes a n
antitrust vigilance lifecycle to which AI is predicted to
be substantively infused for p urposes of enabling and
bolstering a ntitrust detection , enforcement , and post -
enforcement monitoring . Furthermor e, a gra dual and
incremental injection of AI into antitrust vigilance is
anticipated to occur as significant advances emerge
amidst the Levels of Autonomy (LoA) for AI Legal
Reasoning (AILR) .
Keywords: AI, artificial intelligence , autonomy,
autonomous levels, legal reasoni ng, law, l awyers ,
practice of law , antitrust, competition, lifecycle
1 Backgroun d on An titrust and AI
In Section 1 of this paper , the literature on Antitrust
and AI (AAI) is introduced and addressed. Do ing so
establ ishes groundw ork for the subsequent sections.
Section 2 int roduc es the Levels of Autonomy (LoA) of
AI Legal Reasoning (AILR), which is instrumental in
the discussions undertaken in Section 3. This provides an expanded viewpoint of AAI, including articulating
the primary way that these two fields intertwine, along
with proffering an in -depth exploration of the
application of AI to antitrust , along w ith other vital
facets . Section 4 provides various additional research
implications and anticipated impacts upon salient
practice -of-law considerations .
This paper then consists of these four section s:
• Section 1: Background on Antitrust and AI
• Section 2: Leve ls of Autonomy (LOA) of
AI L egal Reasoni ng (AILR)
• Section 3: Focus on AI Applied to Antitrust
• Sectio n 4: Addition al Considerations and
Future Resea rch
1.1 Overview of Antitrust and AI
An expand ing field of substantive interest for the
theory of the law and the practice -of-law entails
Antitrust and AI (commonly referred to as AAI). To
some degree, there are expressed qualms that the
antitrust community has been slow to adopt and
consider the ramifications of AI [18] [34] [47] [69]
[77] [81].
In Section 3, we address the aspect that there are two
major forms of synergy between antitrust and AI,
consisting of the application of antitrust to AI, and the
application of AI to antitrust.
Per the re search by Deng [18], attention to -date has
appeared to primarily concentrate on the application of
antitrust to AI . This includes the overarching concern
that businesses adopting AI will be able to collude in a Antitrust and Artificial Intelligence (AAI):
The Antitrust Vigilance Lifecycle And AI Legal Re asoning Autonomy
Dr. Lance B. Eliot
Chief A I Scientis t, Techb ruim; Fell ow, CodeX: Stanford Cen ter for Le gal Informatics
Stanford, California, USA
2
manner and degree not previously envisioned , and for
which then promotes and accelerates an titrust
behaviors in the marketplace.
According to Deng [18], there are at l east two aven ues
for this kind of considered antico mpetitive beh avior as
prodded via the use of A I:
“In the antitrust community, the recent interest in AI
is also driven in part by concerns about algorithmic
collusion. At least two ways in which computer
algorithms could facilit ate collusion have been
identified. First, computer algorithms could be used
to implement a price -fixing agreement, e.g., an
agreed -upon price or production level or automating
the detection of “cheating” and retaliation. ”
And the other means is [18]:
“This is an important observation because the
antitrust community is a lso concerned with another
type of much more sophisticated algorithmic
collusion, i.e., the possibility that algorithms could
ultimately learn to collude without human
facilitation. ”
A cru cial meta -perspective on this pr eceding point is
that the AI can either be established in a means to be
directed by human hands while under taking antitrust
behaviors, plus can be ostensibly let loose via the
inclusion of Machine Learning an d Deep Learning to
perform antitrust behaviors without a human hand at
the wheel per se.
In the resea rch by Petit [ 62], there is an in dication that
this kind of antitrust behavior can be characterized in a
threefold manner:
“First, algorithms will widen instances in which
known forms of anticompetitive conduct occurs.
The AAI sch olarship conjectures that express and
tacit collusion , as well as almost perfect behavioral
discr imination, will be more common.
Second, algorithmic markets will display new forms
of anticompetitive conduct in non -price dimensions
like data capture, extract ion, and co -opetition
(between ‘super -platforms’ and applications
developers) which challeng e established antitrust
doctrine.
Third, deception is a design feature of algorithmic
markets. Behind the ‘façade’ of competition,
consumers are nudged in exploitat ive transactions. ”
When considering how a government will respond to
these likely AI -enabled antitrust behavio rs, the work
of Hayashi and Arai [44] asserts that gover nmental
agencies and laws will need to be reconsidered and
possibly revamped, doing so to try and stabilize the
marketplace playing field into one of fair and balanced
competition in light of the leveraging of AI.
One offshoot of the AAI realm involves the thorny
question of legal liability and legally understood
notions of intent when AI that is based on Machine
Learning and Deep Learning is being used in
seemingly antitrust -related ways [36]:
“The consideration of the ‘autonomous agent’ raises
ethical and policy questions on the relationship
between humans and machines. In such instances,
can the law attribute liability to companies for their
computers’ actions? At what stage, if any, would the
designer or operator relinquish responsibility over
the acts of the machine? Evidently, defining a
benchmark for illegality in such cases is
challenging. It requires close consideration of the
relevant algorithm to establish whether any illegal
action coul d have been anticipated or was
predetermined. Such review requires consideration
of the programmi ng of the machine, available
safeguards, its reward structure, and the scope of its
activities. The ability to identify the strand which is
of direct relevance is questionable. The complexity
of the algorithms’ data -processing and self -learning
increases th e risk that enforcers, in undertaking this
daunting undertaking, stray far afield of rule of
ideals, such as transparency, objectivity,
predictability, and acc uracy. Further, one must
consider the extent to which humans may truly
control self -learning mach ines.”
Another variant of the focus on antitrust as applied to
AI consists of the dimension that there is AI
innovation that occurs in a marketplace, and a thriving
AI developer ecosys tem is presumed to be vital to the
ongoing advancement of AI -based technologies and
capabilities.
This is another point of concern in the AAI community
since there is a possibility that antitrust enforcement
3
could be applied toward the me chanisms of the AI
innovation e cosystem. This use of antitrust could be
negatively disruptive to AI advancements and
seemingly dampen or perhaps curtail pending new AI -
based capabilities.
Foster and Zachary [38] emphasize that besides the
qualms of how this might adversely impa ct industry
and the ability of businesses to employ and deploy AI,
it could have a severe indirect and consequential
impact on military defense readiness too:
“Unlike with many prior defense technologies, the
private sec tor currently drives the development of
AI. Therefore, to use AI to A merica’s national
security advantage, the Pentagon will rely in large
part on the domestic private -sector AI ecosystem. At
the same time, antitrust policymakers are
contemplating signific ant changes to this ecosystem,
and are even considering breaking up i ts largest
companies. How would such an action affect the
Pentagon’s AI capabilities? ”
By-and-large , much of the research on A AI oftentime s
takes a particular perspective of either the considered
downside or adverse element of antitrust as applied to
AI, or on other occasions takes the opposite position
that ant itrust could potentially further enable AI
advancement and adoption in the marketplace (though,
this latter perspective is a somewhat rarer argued
posture).
In research by Rab [64], he cautions that we ought to
be giving attention to both sides of the coin, as it were,
and not allow ourselves to fall into t he trap that one
side or the other does not exist or is somehow
axiomatically unworthy of balanced attention:
“The AI antitrust scholarship makes a bold claim
that AI is an enabler of tacit collusion and could
increase the scope for ant i-competitive outcomes at
even lower levels of concentration than associated
with antitrust orthodoxy. However, even the brief
examination of these claims in this article has
unearthed alternative hypotheses which need to be
fully tested before the theory can be incorporated in
policy and legal enviro nments without running the
risk of being counter -productive. ”
1.2 Complexities and Vagaries of Antitrust
Though an titrust might seeming ly be a straightforward
notion, the reality is that antitrust bears a great deal of
complexity , vagary, and altogether defies any
inarguable definiti ve scope and ironclad meaning .
The simpl est means to construe antitrust can be readily
expressed in this manner as stated by the U.S.
Department of Justice (DOJ) [82]:
“The U.S. antitrust laws represent the legal
embodiment of our nation ’s commitment to a free
market economy in which the competitive process
of the market ensures the most efficient allocation of
our scarce resources and the maximization of
consumer welfare. ”
Furthermore, the antitrust process to presumably carry
out that mission is indicated in this way by the DOJ :
“The Antitrust Division’s mission is to promote
economic com petitio n through enforcing and
providing guidance on antitrust laws and principles.
When it comes to enforcement, the Division’s
policy, in general, is to proceed by criminal
investigation and prosecution in cases involving
horizontal, “per se” unlawful ag reement s such as
price fixing, bid rigging, and market allocation.
Civil process and, if necessary, civil prosecution is
used with respect to other suspected antitrust
violations, including those that require analysis
under the “rule of reason,” as well as some o ffenses
that historically have been labeled “per se” by the
courts. There are a number of situations where,
although the conduct may appear to be a “per se”
violation of law, criminal investigation or
prosecution may not be appropriate. These situat ions
may include cases in which (1) the case law is
unsettled or uncertain; or (2) there are truly novel
issues of law or fact presented. ”
There is a kind of triad associated with the an titrust
efforts in the U.S . [49], consisting of (1) the laws that
are devised by the courts, (2) the prose cutorial efforts
of the DOJ and similarly antitrust -tasked agencies, and
(3) the funding to those government agencies for the
purposes of taking on antitrust activities including
antitrust enfo rcement.
4
Consider how the triad interacts amongst the three
components , akin to a three -legged stool that requires
all three legs , demonstrably aligned to be able to stand
upright.
If there are insufficient laws or laws that are seen as
weak toward anti trust behaviors, presumably the tria d
is accordingly undercut. If the government agencies
tasked with antitrust opt to not pursue antitrust
behaviors , even if there are sufficient laws to warrant
such pursuit, this presumably un dercuts the ant itrust
policing. An d, even if the government agencies are
desirous of such pursuits, and the laws are in place,
without adequa te antitrust -related funding the result is
a mere hollow aspiration waiting to be fu lfilled.
As Kades at Yale University stated [49]:
“The effectiveness of the U.S. antitrust laws in
protecting competition depends on the three key
factors. The first is jurisprudential doctrines that
courts develop. The second is the prosecutorial
discretion that enforcers —the Antitrust Division of
the Department of Justice, the Federal Trade
Commission, and state attorneys general —employ.
And the third is the fiscal resources provided to the
enforcers. It can be difficult to disen tangle the role
of these factors. The federal government, for
example , may bring fewer antitrust cases because it
has changed its enforcement philosophy. Or a
judicial decision may limit the reach of the antitrust
laws by limiting the government’s ability to
challenge certain types of cases. Similarly, a change
in enforceme nt discretion or the courts broadening
the scope of the antitrust law could lead to increased
enforcement. Indirectly, judicial or evidentiary rules
that increase the cost of successfull y pursuing cases
can reduce the number of antitrust cases (and the
reverse could increase it). Increasing or decreasing
appropriations for the antitrust enforcement agencies
also can affect both the degree of antitrust
enforcement and its impact. ”
A core deficiency underlying the entire premise of
antitrust is that there is a n axiomatic means to
ascert ain whether a mar ketplace is being anti -
competitively overrun. Not everyone concurs that
there is some form of calculus or infallible method of
ascertaining the competitive versus anti -competitive
conjecture.
Per the rather sharp toothed remarks of Stigler [73]:
“Economists have their glories, but I do not believe
that antitrust law is one of them.”
This claim, whic h some might find alarming, or
possibly unfounded, he support s via this indication
[73]:
“In a series of studies done in the early 1970s,
economists assumed that important losses to
consumers from limits on competition existed, and
constructed models to identify the markets where
these losses would be greatest. Then they compa red
the markets where government was enfo rcing
antitrust laws with the markets where
governments should enforce the laws if consumer
well-being was the government’s paramount
concern. The studies concluded unanimously that
the size of consumer losses from monopoly played
little or no role in go vernment enforcement of the
law.”
There is a lot a t stake when cons idering that the very
act or activity of potential governmental intervention is
seemingly be reft of preci seness and not amenable to
widespread under standing, thus putting businesses into
the unenviable position of presumably not being able
to gauge what the rules of the game really are (with
respect to what is deemed as ant itrust behavior).
Cons ider these salient points about how the ambiguity
of what antitrust consists of can be both a blessing and
a curse to the marketplace [20]:
“A fundamental difficulty facing the court is the
incommensurability of the stakes. If the court errs
by condemning a beneficial practice , the benefits
may be lost for good. Any other firm that uses the
condemned practice faces sanctions in the name o f
stare decisis, no matter the benefits. If the court errs
by permitting a deleterious practice, though, the
welfare loss decreases over tim e. The legal system
should be designed to minimize the total costs of (1)
anticompetitive practices that escape con demnation;
(2) competitive practices that are condemned or
deterred; and (3) the system its elf. The third is
easiest to understand. Some practices, although
anticompetitive, are not worth deterring. We do not
hold three -week trials about parking tickets. A nd
5
when we do seek to deter, we want to do so at the
least cost .”
All told, per [20] the assumption that antitrust is a
handy or helpful tool is raft wit h falsehood since the
antitrust looming threat of en forcement can
undermine the marketplace, just as anti -competitive
behavior ca n undermine the marketplace :
“Antitrust is an imperfect tool for the regulation
of competition. Imperfect because we rarely know
the right amount of competition there should be,
because neither judges nor juries are part icularly
good at handling complex economic arguments,
and because many plaintiffs are interested in
restraining rather than promoting competition. ”
1.3 Due Pr ocess and Ant itrust
If antitrust is potent ially an ill -devised tool or at least
an imper fect one, the question of due process and
fairness certainly enters into the picture .
First, consider the importance of the rule of law [88]:
“The rule of law is one of the f ounding principles of
the United States of America and has shaped U.S.
legal thinking and practice in many areas. The basic
idea is simple: the people and their actions are not
governed and regulated by arbitrary decisionmakers,
but by a set of rules that serves as a check against
potential abuses of power. ”
And, the rule of law is especially vital when
considering antitrust en forcement [88]:
“Due process and fairness are particularly impor tant
in antitrust enforcement. Because the U.S. was the
first country to enact an antitrust law, it has enjoyed
the greatest opportunity to develop its enforcement
practices. ”
One perspective is that the government will act in a
rationalized and non -politically moti vated way,
presumably rooting out antitrust behaviors in a n
unbiased manner. This belies though th e reality that
the politics of the day can readily be inter jected into
antitrust oversight and enforcement actions.
Indeed, the recent work by S chrepel points out that to
some extent there is a n emerging semblance of
romanticizing of antitrust, pitting the technolog y elites
against the public -at-large, doing so in a politically
divined shroud [71]:
“Increasing roman ticization coul d critically
jeopardize decades of jurisprudential construction,
causing economic disruption, destabilization of the
law, and blindness towards real anti -competitive
practices on the part of antitrust authorities,
consequently placing the rule of law at ri sk.”
It is altogether conceivable and perhaps patently
obvious to some that the antitrust notion can be
wielded as a somehow ne utralized a xiom that seeks to
optimize comp etition and prevent the us urping of a
marketplace by antitrust behaviors , me anwhile , the
antitrust arm-twisting power -punching capacity can be
exercised by politicians that have a particular political
gain in mind.
Succinctly stated by McChes ney [57]:
“If public -interest rationales do not explain antitrust,
what does? A final set of studies has shown
empirically that patterns of antitrust enforcement are
motivated at least in part by political pressures
unrelated to aggregate economic welfare. For
exampl e, antitrust is useful to politicians in stopping
mergers that would result in plant closings or job
transfers in their home districts. ”
Yet another consideration of the efficacy of antitrust as
a governmental tool involves the nature of innovation
itself and how it fares or evolves in the marketplace.
One argument to be made i s that AI, in particular,
needs as much latitu de as possible at this time to
properly percolate and mature, for which a heavy -
handed antitrust clash might disturb (this was earlier
pointed out in the remarks about the Pentagon and
reliance on AI innovation arising from industry).
A cornerstone research paper by Schrepel [72] , defines
and proffers that we need to encapsulate predatory
innovation into the vernacular of antitrust law:
“In fact, the terms of predatory innovation —which
the aut hor defines as the alteration of one or more
technical elements of a product to limit or eliminate
competition —describes all practices that, under the
6
guise of real innovations, are anti -competitive
strategies aimed at eliminating competition without
benef iting consumers. ”
This provides yet a nother important consideration
when weighing the antitrust triad and how it proceeds.
1.4 Applying AI to Antitrust
The preceding subsections hav e focused on the realm
of AAI that deals with the application of ant itrust to
AI, and as explained earlier in Subsection 1.1 ,
ostensibl y has received the preponderance of attention
in the A AI research liter ature to -date.
Shifting the focus to the other side of the coin, we next
consider the application of AI to antitrust. This will
also become the bulk of the attention in Section 3 and
as based on the contextual bac kground provided in
Section 2.
A recent study by En gstrom, Ho, Sharkey, and Cuellar
examined how AI is being used by federal agencies
[35]:
“Artificial intelligence (AI) promises to transform
how government agencies do their work. Rapid
developments in AI have the potential to reduce the
cost of core governance functions, improve the
quality of decisions, and unleash the power of
administrative data, thereby making government
performance more efficient and effective. Agencies
that use AI to realize these gains will also confront
important questions about the proper design of
algorithms and user interfaces, the respective scope
of human and machine decision -making, the
boundaries between public actions and private
contracting, their own cap acity to learn over time
using AI, and whether the use of AI is even
permitted. ”
There ha ve been sparse and spotty efforts to
incorporate AI into governmental antitrust efforts. This
is perhaps handy since it implies a rife potent ial for an
evergreen approach to applying AI into antirust . At the
same time, th e adoption of AI into antitrust efforts
could be undertaken with haphazard attention,
producing either misman aged results or worse still
leading to antitrust that is overtaken by u nsavory AI .
There is an o ngoing concern th at AI is at times
implemented without proper cont rols and monitoring.
Qualms too are that AI in government al agencies
might be lacking in explainability or interpretability
(having AI that can explain its actions is typically
referred to as XAI , see [ 21] [22] [23]).
A well -taken advisory caution by [35] emphasizes the
importance of properly applying AI to governmental
uses:
“Managed well, algorithmic governance tools can
modernize public administration, promoting more
efficient, accurate, and equitable forms of state
action. Managed poorly, govern ment deployment of
AI tools can hollow out the human expertise inside
agencies with few compensating gains, widen the
public -private technology gap, increase undesirable
opacity in public decision -making, and heighten
concerns about arbitrary governm ent ac tion and
power. Given these stakes, agency administrators,
judges, technologists, legislators, and academics
should think carefully about how to spur
government innovation involving the appropriate
use of AI tools while ensuring accountability in the ir
acquisition and use. ”
Section 2 will introduce the principles underlying AI
Legal Reasoning and the various levels of autonomy
therein. Section 3 then continues this herein discussion
about applying A I to antitrust and does so in light of
the aforementioned cautionar y insights about the
adoption of AI in gov ernmental agencies.
2 Levels of Autonomy (LOA) of AI Legal
Reasoning (AILR)
In th is section, a framework for the auto nomous levels
of AI Legal Reasoning is summar ized and is based on
the research des cribed in detail in Eliot [23] [24] [25]
[26] [27] [28] [29].
These autonom ous levels will be portrayed in a grid
that aligns with key elements of auton omy and as
matched to AI Legal Reasoning . Providing this context
will be useful t o the later se ctions of this paper and
will be utilized accordingly.
7
The autonomous levels of A I Legal Reasoning are as
follows:
Level 0: No Automat ion for AI Legal Reasoni ng
Level 1: Simple Assistance Automation for AI Legal Reas oning
Level 2: Advanced A ssistance Auto mation for AI Legal Reasoning
Level 3: Semi -Autono mous Automation for AI Legal Rea soning
Level 4: D omain Autonomous for AI Legal Reason ing
Level 5: Fully Auton omous for AI Legal Reasoning
Level 6: Superhuman Autonomou s for A I Legal Reasoning
2.1 Details o f the LoA AILR
See Figure A -1 for an overv iew chart showcasing the
autonomous level s of AI Legal Reasoning as via
columns denot ing e ach of the respective levels.
See Figure A -2 for an ov erview c hart similar to Figure
A-1 which alternative ly is indicat ive of the
autono mous le vels of AI Legal Reaso ning via t he rows
as depict ing the r espect ive levels (this is simply a
reformatting o f Fig ure A -1, doing so to aid in
illuminating this variant p erspecti ve, but does not
intro duce any ne w facets or alterat ions from the
contents as alr eady shown in Figure A -1).
2.1.1 Level 0: No Aut omation f or AI Legal
Reasoning
Level 0 is considered the no automation level. Legal
reasoning is carried out via manu al metho ds and
principally occ urs via pa per-based m ethods.
This level is allowe d some l eeway in that the use of
say a simple handheld ca lculator or per haps the use of
a fax machine could be allo wed or included within this
Level 0, though strictly speakin g it cou ld be said that
any fo rm whatsoe ver of auto mation is to be excluded
from this lev el.
2.1.2 Level 1: Si mple Ass istance Automation
for AI Le gal Re asoning
Level 1 c onsists of simple assista nce automation for
AI legal reasonin g.
Examples of this ca tegory e ncompassing simple
automation w ould includ e the use of ev eryday
computer -based wo rd processing, the use of ever yday
computer -based spreadsh eets, access to onli ne legal documents that a re stored and retrieved electronical ly,
and so on.
By-and-large, to day’s use of computers for lega l
activitie s is predo minan tly within Leve l 1. It i s
assumed and expected that ov er time, the
pervas iveness o f auto mation will contin ue to deepen
and widen, a nd eventually lead to legal activiti es being
supported and w ithin Le vel 2, rather than Lev el 1.
2.1.3 Level 2 : Advanced Assistance Automati on
for AI Legal Reasoning
Leve l 2 cons ists of advanced ass istance automa tion for
AI legal reasoning.
Examples of t his notion encompassing advanced
automation would include th e use of query -style
Natural L anguage P rocessing ( NLP), Mach ine
Learning (ML) fo r case pr edictions, and so on.
Gradual ly, over time, it is expecte d that computer -
based sy stems for legal activitie s will increasingly
make use of adva nced automation. Law ind ustry
technology that was once at a Lev el 1 will l ikely be
refine d, upgraded, or expanded to include advanced
capabilit ies, and thus be rec lassifie d into Level 2.
2.1.4 Level 3: Semi -Autonomous A utomation
for AI Legal Reasoning
Level 3 consists of semi -autonomou s automation for
AI le gal reaso ning.
Examples of t his n otion encompass ing semi -
autonomous automation would i nclude the use of
Knowledge -Based S ystems (KBS) for legal reasoning,
the use o f Machine Learning and Deep Learning
(ML/DL) for legal reaso ning, an d so on.
Today, such automatio n tends to exist in r esear ch
efforts or p rototypes and pilot systems, al ong wit h
some commercial legal techn ology that has been
infusing these capabilities t oo.
2.1.5 Level 4: Domain Autonomo us for AI
Legal Reasonin g
Level 4 consists of domain autonomou s compute r-
based syst ems f or AI legal rea soning.
8
This level reuses the concep tual notion of Oper ational
Design Do mains (ODDs) as utilized in the
autonomous vehicles and self -driving cars ' level s of
autonomy, though in this us e case it is being app lied to
the legal domain [24] [25] [26] [27]. Essential ly, thi s
entails any AI legal reasoning capacities tha t can
opera te aut onomously, entirely so, but that is only able
to do so in some limited or const rained legal domain.
2.1.6 Leve l 5: Fully Autonomous for AI Lega l
Reasonin g
Level 5 consists of fully au tonomou s computer -based
syste ms for AI legal reasoning .
In a se nse, Le vel 5 is the superset of Level 4 in terms
of encompassing all possible domains as per however
so define d ultima tely for Level 4. The only constr aint,
as it were, c onsists of the facet t hat the Level 4 and
Level 5 a re concerning human intel ligence an d the
capacities thereof. This is an important e mphasis due
to attempting to distingui sh Level 5 from Level 6 (as
will be discussed in the n ext subsect ion)
It is conceiv able that someday ther e might be a fully
autonomous AI legal reasoning capab ility, one that
encompasses all of the law in all foreseea ble ways,
though this is quite a tall order and remains quite
aspirati onal without a clear -cut path of how this m ight
one day be achieved. Nonet heless, it seems to be
within the extended realm of po ssibilitie s, whic h is
worthwhile to mention in relative te rms to Level 6.
2.1.7 Level 6: Superh uman Autonomous for AI
Legal Rea soning
Level 6 consis ts of supe rhuman aut onomous
comput er-based systems for AI l egal reasoning.
In a sense, Level 6 is the en tirety of L evel 5 and adds
something beyond that in a mann er that is currently ill -
defined and pe rhaps (some would argue) as yet
unknowable. The notion is that A I might ul timately
exceed human intellige nce, ris ing to become
superhum an, and if so, we do not yet have a ny viab le
indication of what that superhuman in telligence
consists of and nor what kin d of thinking it would
somehow b e able to undertake.
Whether a Level 6 is ever atta inable is reliant upo n
whethe r superhuman AI is eve r attainable, and thus, at
this tim e, this stands as a placeholder for that which
might never occur. In any case, having such a
placeholder provi des a se mblance of completenes s,
doing s o without necessaril y le gitimatizing that
superhu man AI is going to be achieved or not. No such
claim or d ispute is undertaken within this framework.
3 Focus on AI Applied to Antitrust
In this Section 3, various aspects of Antitrust and
Artificial Intelligence (AAI) will be identified and
discussed , particular ly with respect to two key
element s: (1) Establishing an AAI A ntitrust Vigilance
Lifecycle, and (2) AAI and the Levels of Autonomy in
AI Legal Reasoni ng (AILR).
A series of diagrams and illus trations are included to
aid in depicti ng the points being made. In addition, the
material draws upon the background an d research
literat ure indicated in Section 1 and combines with the
material outlined in Se ction 2 on the Level s of
Autonomy of AI Legal Reasoning.
3.1 AAI Overview
There is a synergistic aspect to ant itrust and the field
of Artifici al Intelligence. In some re spects, a ntitrust
can be applied to AI, while in other respects AI can be
applied to ant itrust.
See Figure B -1.
As shown, there is a cyclical way to cast the roles of
antitrust and AI. You can assert that in certain ways
there is the impact of antitrust upon AI, or more
properly phrased the advent of AI. You can also assert
that in particular ways there is an impact of AI upon
antitrust, primarily regarding the use or application of
AI in an titrust efforts.
Let’s consider some examples associated with thes e
in-common interactions.
See Figure B -2.
As an example of antitrust being applied to AI,
consider that as discussed in Section 1 there is ample
debate abo ut the notion that businesses will make use
9
of AI and thus potentially spur antitrust behaviors.
Meanwhile, the count erargument is that AI use d by
businesses will disrupt the chance s of undertaking
antitrust beh aviors. Of course, the reality is likely
going to be that AI has a d ual impact, for which in
some instances antitrus t behaviors will be sparked
while in other instances antitrust behaviors will be
lessened or ostensibly sub verted via the use of AI in a
marketplace.
For further illustration , see Figure B -3.
Another ex ample of antitrust impacting or being
applied to AI consists of the qualm that perhaps
antitrust enforcement will dampen AI progr ess. This
was also discussed in Section 1. Again, the impact of
antitrust on AI does not necessarily need to be in one
direct ion only. There is a possibility that antitrust
enforcement, or the lack thereof, could accelerate the
progress of AI. Likely, the use of ant itrust enforcement
is bound to have both a n encouraging effect on the AI
innovation ecosystem and simul taneously a dampening
effect, dependent upon how the an titrust eff orts are
guided and utilized.
For further illust ration, see Figure B -4.
In terms of applying AI to ant itrust, this is the
mainstay of the rest of this discussion and consists of
establis hing that AI can and will undoubtedly be
integrated into antitrust e fforts.
See Figure B -5.
This is coined as the use of AI to increase or bolster
antitrust vigilance.
As an aside on terminology, typically , the process of
antitrust efforts are usually referred to as antitrust
enforcement . Here, we use inst ead the phrasi ng of
antitrust vigilance .
The reason or ration ale that antitrust vigilance is used
rather than “enforcement ” involves severa l significant
points.
First, the enforcement of antitrust is oftentimes
perceived as the latter part of the overall lifecycle
associated with antitrust efforts (the lifecycle will be
identified and explored in a m oment). The application
of AI to ant itrust efforts will not be confined to only the enforcement portion of the lifecycle and will
instead be applicable through out the ent ire lifecycle.
Thus, a sound basis for avoiding referring to the
application of AI as to antitrust enforcement is to
avoid the misconception that AI would only be applied
to a segment or subset of the lifecy cle.
Secondly, there is a connotation of the wor d
“enforcement ” that seems ominous and conjures
imagery of a n onerous nature. In theor y, en forcement
is merely the act of enforcing or ensuring that the
antitrust laws are being legally obeyed. Nonetheless,
there is a stigma associated with the notion of
enforcement. If the application of AI to ant itrust
efforts is t o take hold , there is a chance that a backlash
could develop simply on the basis that it would seem
unfair or unreasonable to use AI as a form of an
enforcer per se. Though indeed AI is going to be used
to aid in enforcing the antitrust laws, ther e would be a
too easy assumption that AI is somehow overstepping
appropriate bounds and being used in some revengeful
or overzealous way. We avoid this confusion by
referring to vigilance instead.
That being said, do not overstep this indicat ion by also
assuming that the use of AI might not be in fact
overzealously utilized a nd in some respects become a
kind of doomsday antitrust enforcer. There is a quite
real possibility that AI if poorly or inadequa tely
devised, could become a n ant itrust zealot that
overreaches. To that degree, the forewarning of the
word “enforcer ” and its connotations does provide
some benefit for use, though on the whole , it seems
prudent for now to refer to these matters as one of
vigilance.
In short, the phrasing of antitrust vigi lance does away
with those aforementioned qualms about the use of the
word enforcement . AI is going to increase antitrust
vigilance, for which the “enforcement ” element is
encompassed.
3.2 Antitrust Wi nnowing Funnel
Another facet of noteworth iness about ant itrust a nd the
vigilan ce process consists of the antitrust winnowing
funnel.
See Figure B -6.
10
As shown, there is a funnel that starts in a wide
manner and gradually winnows antitrust candidates
until there is a narrower set considered viable for
antitrust enfo rcement.
There is a continual effort of scrutin izing the
marketplace for potential antitrust behaviors. This
search is ongoing and wide. The odds are that most of
the suspected or considered an titrust targets will fall
out of the f unnel due to a lack of sufficiently credible
indication of their alleged antitrust deeds .
At each step forward in the funnel, those candi date
firms that are seem ingly more likely to have
performed antitrust behavior wil l presumably be
increasingly examined an d assessed. In theory, only
those firms meeting some level of threshold or degree
will continue into the funnel to the point of actual
enforcement.
This brings up via implication that there is a potential
lifecycle associated with these antitrust pursuits, which
is indeed the case and will be explored in the next
subsection.
3.3 AAI Vigi lance Lifecyc le
There is a n antitrust vigilance lifecycle, and it provides
crucial insight about the nature of the antitrust
processes and also serves a s a means to overlay the
application of A I onto the an titrust realm.
See Figure B -7.
As shown, there are six key phases (some refer to
these as stages, which, in our view, can be
interchang eably stated) :
1. Detect
2. Assess
3. Investigate
4. Recommend
5. Prosecute
6. Implement
The Detect phase entails the widest part of the an titrust
winnowin g funnel and consists of an ongoing and
persistent antitrust pursuit by observing marketplaces
for signs of antitrust beha viors. There is plenty of
volumi nous signals and indications that need to be
detected and distilled. This also has to be taking place persistently since the marketplace itself is dynamic and
ever-changing.
For those spotted or anticipated potential antitrust
behaviors , the next phase co mes into play, namely the
Assess phase. An assessment requires additional
resources and therefore s hould be undertaken only
when the Det ect has ident ified viable candidates or
targe ts for closer inspection.
Out of the assessment phase, there will be antit rust
targe ts or candidates that are ascertained as worthwhile
for even greater scrutiny and will therefore be
funneled into the Investigate phase.
For underlying details associated with the se processes
and phases, the United States Department of Justice
(DOJ) Antitrust Division Manual [82] provides an
essential grounding in the details of these antitrust
pursuit activities.
Based on the outcome of the In vestigate phase, there
will be some candi dates or targets that are funneled
into the Recommend phase. This will then consist of a
form al recommendation fo r a civi l or criminal case to
be opened and u ndertaken.
Out of the recommended set, there will be some
candidates or targets that a re then pro secuted , thus the
Prosecut e phase. Finally, depending upon the outcome
of the pro secution, there is likely to be a need to
implement the result, doing so via monitoring for
compliance and also taking add ed follow -up action if
compliance falters or is not observed.
These six phases can be overlaid onto the antitrust
winnowing funnel.
See Figure B -8.
We can now more broadly discuss the nature of AI
being applied to antitrust vigilance , having set the
table , as it were, by having establish ed a viable context
for under standing the fuller picture of the matter at
hand .
Various aspects of AI will be applied to each of the six
phases of the an titrust vigilance lifecycle.
Not all of the lifecycle phases will be injected with AI
in the same manner and nor at the same pace. This is
11
an important point. In particular, some researchers
have blandly indicated that AI will be applied to
antitrust efforts, though that is a quite overreaching
indication and treats the antitrust proc ess as a
monolith. Similarly, in an inappr opriate manner, AI is
treated as a monolith, as though the mere refe rence to
AI is tantamount to having some particular meaning,
when in fact the notion of AI is an umbrella or
collective of various technologies.
See Figure B -9.
As shown , AI can be considered as consistin g of these
overarching areas of technolog ies:
• Machi ne Learning (ML)
• Knowledge -Based Systems ( KBS)
• Natural Language Processing (NLP)
• Computer Vision (CV)
• Robotics /Autonomy
• Common -Sense Reasoning
• Other Technologies
Each of those distinct areas of AI technologies will be
gradually applied to antitr ust, doing so across the
antitrust vigilance lifecycle .
A grid is envisio ned that would encompass the AI
Technologies aligned with each of the six phases, such
that it wou ld be feasible to indicate the depth of
coverage by each of the AI Technologies for each of
the respective si x pha ses. Such a grid would be
updated over time as the infusion of AI into the
antitrust vigilance lifecycle matures.
Speaking of the maturity aspects, the inclusion of AI
into the an titrust vigilance lifecycle will significantly
differ ent depending upon the level of autonom y
associated with AI.
In Section 2, a framework was provided to depict the
levels of autonomy asso ciated with AI -based legal
reasoning. This provides a basi s for next exploring the
application of AI to ant itrust i n the context of the
maturation of AI across the levels of autonomy.
3.4 AAI and AILR
The nature and capabilities of applied AAI will vary
across the Levels of Autonom y for AI Legal
Reasoning.
Refer to Figure B -10.
As indicated, applied AA I becomes increasing ly more
soph isticated and advanced as the AI L egal Reasoning
increases in capability. To aid in typ ifying the
differences between each of the L evels in terms of the
incremental a dvancement of applied AAI , the
following phr asing is used:
• Level 0: n/a
• Level 1: Rudime ntary (simpli stic)
• Level 2: Comp lex (simplistic)
• Level 3: Symbo lic Inter mixed
• Level 4: Domain Incisive
• Level 5: Holistic Incisive
• Level 6: Pans ophic Incisive
Briefly, each of the levels is described next.
At Level 0, t here is an indic ation of “n/a” at Level 0
since there is no AI capability at Level 0 (the No
Automation level of the LoA).
At Level 1, the LoA is Rudimentary (simplistic) and
this can be used to undertak e applied AAI though it is
rated or cat egorized as being rudimen tary and making
use of relatively simplistic c alculative models and
formulas. Thus, this is coined as “Rudimen tary
(Simplistic) .”
At Level 2, the L oA is Advanced As sistance
Autom ation and the applied AAI is coined as
“Complex (Simplistic) ,” which is indi cative of AAI
being performe d in a more advanced manner than at
Level 1. This consists of complex statistical methods
such as those tech niques mentioned in Section 1 o f this
paper. To date, most of the research and practical use
of applied AAI has been within Level 2 . Future e fforts
are aiming at Level 3 and above.
At Level 3, the L oA is Semi -Autonomous Automation
and the applied AAI is coined as “Symbolic
Intermixed,” which can undertake AAI at an e ven
more adv anced capacity than at Level 2. Recall, in
Level 2, the focus tend ed to be on traditional
numerical formulations , albeit sophisticated in the use
of statistical model s. In Leve l 3, the symbolic
capability is added and fostered, including at times
acting in a hybrid mode with the conventional
numerical and statistical models. Generally , the work
12
at Level 3 to-date has primarily been experimental ,
making use of explorato ry prototy pes or pi lot efforts.
At Level 4, the L oA is AILR Domain Autonomous and
the applied AAI coined as “Domain Incisive ,”
mean ing that this ca n be used to perform AAI within
particular specialties of domains or subdomain s of the
legal field but does not nec essarily cut across the
various doma ins and is not in tended to be able to do
so. The capacity is done in a highly advanced manner,
incorporating the Level 3 capabilities, along with
exceeding those levels an d providing a more fluen t
and capable perceptive means.
At Level 5, the LoA is AILR Fully Autonomous , and
the applied coined as “Holistic Incisive ,” meanin g that
the use of AAI can g o ac ross all domains and
subdomains of the legal field. The capacity is done in a
highly advanced manner, incorporating the Level 4
capabilities, along with exceeding those levels and
providing a more flue nt and capable p erceptive means.
At Level 6, the L oA is AILR Superhuman
Autonomous , which as a remin der fro m Section 2 is
not a cap ability that exists and might not exis t, though
it is included as a provision in case such a capab ility is
ever achieved. In any case, the applied AAI at this
level is conside red “Pansophic Incisive ” and would
encapsulate the Level 5 ca pabilities, and then go
beyond that in a manner that would leverage the AI
superhuman cap acity.
4 Addit ional Considerations and Future Re search
As earlier indicated, efforts to undertake the antitrust
lifecycle have historical ly been performed by human
hand and cognition, and only thinly aided in mo re
recent times by the use of computer -based approaches.
Advances in Artif icial Intelligence (AI) involving
especia lly Natural Langu age Processin g (NLP) and
Machine Learning (ML) are increasingly bolstering
how a utomation can systematically aid antitrust
efforts . This research paper has examine d the evolvi ng
infusion of AI into AAI, along with showcasing how
the Levels of Autonom y (LoA) of AI Legal Reasoning
(AILR) will impact this applicati on.
Artificial Intelligence (AI) based approaches have
been increasingly utilized and will undoubtedly have a pronounced impact on how antitrust is performed a nd
its use in the practice of law , which will inevit ably als o
have an impact upon the ories of the law .
Future research i s needed to explore in greater detail
the manner and means by which AI -enablement will
occur in the law along with th e potential for both
positive and adverse conseque nces. Autonomous
AILR is likely to materia lly impact th e effort, theory,
and practice of AAI, including as a minimum playing
a notable or p ossibly even pivotal role in such
advancements.
About the Autho r
Dr. Lance Eliot is the Chie f AI S cientist at Techbrium
Inc. and a Stanford Fellow at Stanford University in
the C odeX: Center for Legal Informatics. He
previously was a profess or at the Univer sity of
Southern California (USC) where he headed a multi -
disciplinary and pioneering AI re search lab. Dr . Eliot
is globally reco gnized for his expertise in AI and is the
author of highly ranked AI books and columns.
Referen ces
1. Alarie , Benjamin, and A nthony Nib lett, Albert
Yoon (201 7). “Regulation by Machine ,”
Volume 24, Journal of Machine Learning
Research .
2. Anee sh, A (2006). Virtual Migration.
Duke University Press .
3. Ashle y, Kevin, and Karl Branting, H oward
Margolis, and Cass Sunstein (2001). “Legal
Reasoning and Ar tificial Intellig ence: How
Computers ‘Think’ Like Law yers,”
Symposium: Legal Re asoning and Artificial
Intelligen ce, University o f Chi cago Law
School Roundtable.
4. Ashley , Kevin , and Stefanie Bruninghaus
(2009). “Automatically Classifying Case
Texts and Predicting Outcomes ,” Volume
17, Number 2, Artificial In telligence and
Law.
13
5. Atkinson, Katie, and Trevor Benc h-
Capon, Danushka Bollega la (2020).
“Expl anation in AI and Law: Past, Present,
and Future, ” Artificial I ntelligence.
6. Baker, Jamie (2018). “A Legal Research
Odyss ey: Artifi cial Intelligence as Disrupter,”
Law Lib rary Journa l.
7. Baum, Lawr ence (2009). The Puzzle of
Judicial Behavior. Univ ersity of Michigan
Press.
8. Ben-Ari, Daniel, and D., Frish, Y., Lazovski,
A., Eldan, U., & Gree nbaum, D. (2016 ).
“Artificial Intel ligence in t he Practice of Law:
An Analysis and Proof of Concept
Experi ment,” Volume 23, Number 2,
Richmond Journal of Law & Technolo gy.
9. Bench -Capon , and Givo anni Sartor (2003). “A
Mode l of Legal Re asoning with C ases
Incorporating Theo ries and Values,”
Novembe r 2013, Artificial Intelligence .
10. Braithwait e, John ( 2002 ). “Rules and
Principles: A The ory of Legal Ce rtaint y,”
Volume 2 7, Australian Journ al of Leg al
Philosophy.
11. Buchanan, Bruce, and Thomas Headrick
(1970 ). “Some Sp eculation abo ut Ar tificial
Intelligence and Legal Reasoning,” Volume
23, St anford Law Review.
12. Casey, Anthony, and Anthon y Niblett (2016).
“Self-Drivin g Laws, ” Volume 429, Univer sity
of Toronto Law J ournal.
13. Chagal -Feferkorn, Karni (2019). “Am I An
Algorit hm or a Prod uct: W hen Products
Liability Should Apply to Algorithmic
Decisi on-Makers,” Stanford Law & Policy
Review.
14. Chen, Da niel (2019). “Machine Learn ing and
the Rule of Law ,” in Law as Data:
Computation, Text, and The Futur e of Legal
Analysis (Michael A. Livermore and D aniel
N. Rockmore eds. ). 15. Coglian ese, Cary , and David Leh r (2017).
“Rulemaking by Robot: Administr ative
Decision Making in the Machine -Learning
Era,” Volume 105, Georgetown La w Journal.
16. Conrad, J., and F. Schilder (2007).
“Opinion Mining In Legal Blogs, ”
Proceedings of the ICAIL 11th
Internation al Conference on Artif icial
Intelligence and L aw.
17. D’Amato, Anthony (2010). “Legal
Realism Explains Nothing, ” Worki ng
Paper Num ber 84, Northwestern
University Schoo l of Law.
18. Deng, A. (2018). “An Antitrust Lawyer's
Guide to Machine Learning ,” Volume 32,
No. 2, Spring 2018 , Antitrust .
19. Dung, Phan (1993). “On the Acceptabil ity
of Arguments and its Fundamental Role in
Nonmonotoni c Reasoning and Logic
Programm ing,” Proceedings of the 13th
International Joint Conference on
Artif icial Intelligence .
20. Easterbrook, F. H. ( 1984). “Limits of
Antitrust ,” Volume 63, N umber 1 , Texas
Law Review.
21. Eliot, Lance (2016). AI Guardian Ange ls for
Deep AI Trustwort hiness. LB E Press
Publishing.
22. Eliot, Lance (2020). “The Neglected Dualism
of Ar tificial Moral Agency and Artifi cial
Legal Reas oning in AI f or Social Good.”
Harvard Universit y, Harvard Center for
Research on Computation and Society, AI for
Social Good Conf erence, Ju ly 21, 2020.
23. Eliot, Lance (2020) . AI and Legal Reasoning
Essenti als. LBE Press Publishing.
24. Eliot, La nce (2019). Art ificial Intel ligence and
LegalTech Essentials. LBE Press P ublishing.
14
25. Eliot, Lance (2020). “ The Next Era of
America n Law Amid The Advent of
Autonomous AI Legal Reasoning, ” Cornell
University arXiv .
https: //arxiv.org/abs/2009. 11647
26. Eliot, Lance (2020). “An Ont ologica l AI-and-
Law Framework for t he Autonomou s Level s
of AI Legal R easoning,” Cornell University
arXiv. https://ar xiv.org/abs /2008.07 328
27. Eliot, Lanc e (2020). “Turing Test and the
Practice of L aw: T he Role of Autonom ous
Levels of AI Legal Reasoning, ” Cor nell
University arXi v.
https://arxi v.org/abs/20 08.0774 3
28. Eliot, Lance (2020). “Multidime nsionality of
the Legal Singularity: T he Role o f
Autonomous Lev els of AI Legal R easoning, ”
Cornell Universit y arXiv.
https://arxiv.org/abs/2008 .10575
29. Eliot, Lance (202 0). “Authorized and
Unauthorized Practic es of L aw: The Role of
Autono mous Levels of AI L egal Reason ing,”
Cornell University ar Xiv.
https://arxiv.org/ab s/2008.09507
30. Eliot, Lance (2020). “An Impact Mod el of AI
on the Principles of Justice ,” Cornell
University arXiv.
https://arxiv.org/abs/20 08.12615
31. Eliot, Lance (2020). “Robustness and
Overcom ing B rittleness of AI -Enabled Legal
Micro -Direc tives,” Corne ll University arXiv.
https://arxiv.org/abs/2009.02 243
32. Eliot, Lance (20 20). “AI and Legal
Argumentation ,” Cornell Un iversity arXiv.
https://arxiv.org/abs/2 009.111 80
33. Eliot, Lance (2020). “Legal Ju dgment
Prediction (LJP) Amid the Advent of
Auto nomous AI Legal Reasoning, ” Cornell
Unive rsity arXiv.
htttps://arxiv.org/ab s/2009.14620
34. Eliot, Lance (2020 , December 29 ). “Amping
Antitrust Vigilance Via AI, ” Daily Jou rnal.
35. Engstrom, D.F., Ho, D.E., Sharkey, C.M.,
Cuellar, M.F. (2020). “Government by
Algorithm: Artificial Intelligence in
Federal Administrative Agencies ,”
Stanford Law Schoo l.
36. Ezrachi, A., & Stucke, M. E. (2017).
“Artificial Intelligence & Collusion: When
Computers Inhibit Competition ,” Volume
1775, Un iversity of Illi nois Law Review.
37. Feteris, Eveline, an d Harm Kloosterhuis
(2009). “The Analysis and Evalu ation of
Legal Arg umentation: Approaches from
Legal Theory and Argumentation Theory,”
Volume 16, Studies in Logic, Grammar
and Rh etoric.
38. Foster, Dakota , and Arnold, Z achary
(2020). “Antitrust and Artificial
Intelligence: How Breaking Up Big Tech
Could Affect the Pentagon’s Access to
AI,” Center for Security and Emerging
Technology (CSET) Issue Briefing.
39. Gardn er, Anne (1987). Artifici al Intelligence
and Legal Reasoning. MIT Press.
40. Genesereth, Michael (2009). “Computational
Law: The Cop in the B ackseat,” Stanfor d
Center for Legal Info rmatics, Stanfor d
University.
41. Hage , Jaap (2000). “ Dialectical Models in
Artif icial Intelligence and Law,” Art ificial
Intelligence and Law.
42. Hall, Mark , and Ronald W right (2006) .
“Systematic Content Analysis of J udicial
Opinions, ” Volume 96, Issue 1, California
Law Review.
43. Harbe rt, T. (2013). “The Law Machine, ”
Volume 50, Issue 11, IEEE Spectrum.
15
44. Hayashi, Shuya, and Koki Arai (2019 ,
August 15 ). “How Competition L aw
Shoul d React In he Age of Big Data And
Artificial Intelligence , The Antitrust
Bulletin.
45. Holmes, Olive r Wendell (1897). “The Path
of the Law, ” Harvard Law Review.
46. Huhn , Wilson (2003). “The St ages of
Legal Reasoning: F ormalism, Analogy,
and Realism ,” Volume 48, Villano va Law
Review .
47. Janka, S. F., & Uhsler, S. B. (2018).
“Antitrust 4.0 : The Rise of Artificial
Intelligence and Emerging Challenges to
Antitrust Law,” Volume 39, Number 3,
European Competition Law Review .
48. Joshi, S., and P. Deshpande, T. Ham pp
(2011). “Impro ving The Efficiency Of
Legal E-Discovery Services Using Test
Mining Techniques, ” IEEE Proceedings of
the 2011 Annual SRII Global Confere nce.
49. Kades, M. (20 20). “Modern U.S. Antitrust
Theory And Evidence Amid Rising
Concer ns Of Market Power And Its
Effect ,” Yale School of Management,
Thurman Arnold Project .
50. Kaplow, Lo uis (1992 ). “Rules Versus
Standards: An Eco nomic A nalysis, ”
Volum e 42, Duke Law Journal.
51. Landsman, S., and R.F. Rakos (1994). “A
Preliminary Inquiry Into The Effect Of
Potentially Biasing Infor mation On Judges
And Jurors In Civil Litigatio n,” Volume
12, Behavioral Sciences and the Law.
52. Liu, Y., and Y en-Liang Chen, W. Ho
(2015). “Predic ting Asso ciated Statu tes for
Legal Pr oblems, ” Volume 51, Number 1,
Inform Pro cess Management .
53. Llewellyn, K arl (1950). “ Remarks on the
Theory of A ppellate Decision and the
Rules or Canons About How Statutes Are
to Be Construed ,” Volume 3, Number 4,
Vanderbilt Law R eview.
54. MacCormick, Neil (1978). Legal
Reasoning and Legal Theory.
55. McCarty , L. (1995) .” An implementation
of Eisner v. Mac omber ,” Proceedings of
the 5th International Conference on
Artificial Inte lligence and Law .
56. McCarty, Thor ne (1977 ). “Refl ections on
TAX MAN: An Experime nt in Ar tificial
Intelligence and Legal Reasoning,” January
1977, Ha rvard Law Rev iew.
57. McChesney, Fred (2018). “Antitrust :
Origins ,” Northwestern University School
of Law, The Library of Economi cs and
Liberty,
https://www.econlib.org/li brary/Enc/Antitr
ust.html
58. McGinnis, John , and Russ ell G. Pearce
(2014 ). “The Great Di sruption: How Machine
Intelligence Will Transfor m the Role of
Lawyers in the Deli very of Leg al Servi ces,”
Volu me 82, N umber 6, Ford ham Law Review.
59. McG innis, John, and Ste ven Was ick (2015).
“Law’s Algor ithm, ” Volume 66, F lorida Law
Review.
60. Mnookin, Robert, an d Lewis K ornhauser
(1979 ). “Bar gaining in th e Shadow of the
Law,” Vo lume 88, Number 5, Apr il 197 9, The
Yale Law Re view.
61. O’Reilly, T. (2013). “Open Data and
Algorithmi c Regulation ,” In: Beyond
Transparency: Open Data and the Future
of Civic Innovation , Code for America
Press .
16
62. Petit, N. (2017). “Antitrust and Artificial
Intelligence: A Research Agenda ,”
Volume 8, Number 6, Journal of European
Competition Law & Practice .
63. Prakken, Henry (199 5). “From Logic to
Dialectics in Legal Argument, ”
Proceedings of the 5th International
Conferenc e on Ar tificial Intelligenc e and
Law.
64. Rab, S. (2019). “Artificial Intelligence,
Algorithms , and Antitrust ,” Volume 18,
Number 4, Competitio n Law Journal .
65. Reinbold, P atric (2020). “ Taking Artificial
Intelligence Be yond the Turing Test ,” Volum e
20, Wisconsin La w Review .
66. Remus , Dana , and Frank Levy, “Can Robots
be Lawy ers? Comp uters, Ro bots, and the
Practice of Law ,” Volume 30, Georgetown
Journal of Legal E thics.
67. Rich, Michael (2016). “Machine Learning,
Automated Su spicion Algorithms, and the
Fourt h Amendment ,” Volume 164, Uni versity
of Penns ylvania L aw Review.
68. Rissla nd, Edwin a (199 0). “Artificial
Intelligence and Law: Stepp ing Stones to a
Model of Legal R easoning,” Ya le Law
Journal.
69. Ritter, C. (2017). “Bibliography on
Antitr ust and Algorithms ,” SSRN
2982397 .
70. SAE (2018). Taxonomy and Defini tions for
Terms Related to D riving Automation
Systems for On -Road Motor Vehicl es, J3016 -
201806, SAE Int ernational.
71. Schrepel, Thibault (2020). “Antitrust
Without Romance, ” Volume 13, New
York University of Law & Liber ty.
72. Schrepel, Thibault (20 18). “Predato ry
Innovation: The Definite Need for Legal Recognition ,” Volume 21, SMU Science
and Techn ology Law Rev iew.
73. Stigler, George (1982) . “The Economists
and the Problem of Monopoly ,” Volume
72, American Economic Review Papers
and Proceedings .
74. Stucke , M., and Ariel Ezrachi (2016).
"Virtual Competition: The Promise and
Perils of the Algorithm -Driven Economy ,”
Harvard University Press .
75. Suns tein, Cass (2001). “Of Artificial
Intelligence and Legal Reasoning,” Univer sity
of Chica go Law School, Worki ng Papers.
76. Sunstein, Cass, a nd Kevin Ashley, K arl
Brant ing, H oward Margolis (2001). “L egal
Reasoning and Artifici al Int elligence: Ho w
Compute rs ‘Think’ Like Lawye rs,”
Symposium: Leg al Reasoning and Artificia l
Intelligence, University of Chicago Law
School Roundtable.
77. Surblyte , G. (2017 ). “Data -Driven
Economy and Artificial
Intelligence : Emerging Competition Law
Issues ,” Volume 67, Number 3, Wirtschaft
und Wettbewerb .
78. Surden, Harry (2 014). “Machine Le arning an d
Law, ” Washington La w Review.
79. Surden, Harry (201 9). “Art ificia l Intelligenc e
and Law : An Overview,” Summe r 2019,
Georgia Sta te University Law Review.
80. Susskind, Ric hard (2019). Online Courts and
the Future of Justice. Ox ford Uni versity Press.
81. Tagiew, R. ( 2020). “What Government by
Algorithm Might Look Like ,” arXiv
preprint arXiv:2007.13127 .
17
82. United States Department of Justice,
Antitrust Division (2020). Ant itrust
Division Manual.
https://www.justice.gov/jm/jm -7-1000 -
policy
83. Verheij, B. (2001 ). “Legal Decision
Making as Dialectical Theory
Construction with Argumentation
Schemes, ” Procee dings of the 8th
International Conference of Artificial
Intelligen ce and Law .
84. Volokh, Eugne (2019). “Chief Justice
Robo ts,” Volume 68, Duke L aw Journal.
85. Waltl, Bernhard, and Roland Vogl (2018).
“Explainable Artificial Intellig ence: The New
Frontier in Le gal Informatics,” Feb ruary 2018,
Jusletter IT 22, S tanford Center for Leg al
Inform atics, Stanford University.
86. Wolfra m, Stephen (2018). “Computati onal
Law, S ymbolic Disc ourse, and t he AI
Const itution ,” in Data -Driven Law: Data
Analytics and the New Legal Services
(Edw ard J. Wa lters ed. ).
87. Xu, Nuo, and Pinghui Wang, Long Chen, Li
Pan, Xi aoyan Wang , Junzhou Zhao (2020).
“Distinguis h Confusing Law Articles for
Legal Judgment Prediction, ” Proceedings of
the 58th Annual Meeting of t he Association
for Computational Li nguistics .
88. Yoo, Christopher, and Hendrik Wendland
(2019). “Procedural Fairne ss In Antitrust
Enforcement : The U.S. Perspective ,”
Number 2049, University of Pennsylvania
Carey Law School , Faculty Scholarship at
Penn Law.
89. Zhong , Haoxi, and Zhipeng Guo , Cunchao
Tu, Chaojun Xiao, Zhiyuan Liu , Maos ong
Sun (2017). “Legal Judgment Predic tion
via Topological Learning ,” Proceedings of
the 2018 Conference on Empirical
Methods in Natura l Language Proce ssing .
18
Figure A -1
19
Figure A -2
20
Figure B -1
21
Figure B -2
22
Figure B -3
23
Figure B -4
24
Figure B -5
25
Figur e B-6
26
Figure B -7
27
Figure B -8
28
Figure B -9
29
Figure B -10
|
fa91eaf3-1262-46ed-9a25-75be418f9d1e | trentmkelly/LessWrong-43k | LessWrong | Intuition and Unconscious Learning
Part of the sequence: Rationality and Philosophy
We have already examined two sources of our intuitions: the attribute substitution heuristics and our evolved psychology. Today we look at a third source of our intuitions: unconscious learning.
UNCONSCIOUS LEARNING
The 'learning perspective' on intuition is compatible with the heuristics and biases literature and with evolutionary psychology, but adds a deeper understanding of what is going on 'under the hood.' The learning perspective says that many intuitions rely on representations that reflect the entirety of experiences stored in long-term memory. Such intuitions merely reproduce statistical regularities in long-term memory.1
An example will help explain:
> Assume you run into a man at the 20th anniversary party of your high school class graduation. You immediately sense a feeling of dislike. To avoid getting into a conversation, you signal and shout some words to a couple of old friends sitting at a distant table. While you are walking toward them, you try to remember the man’s name, which pops into your mind after some time; and suddenly, you also remember that it was he who always did nasty things to you such as taking your secret letters and showing them to the rest of the class. You applaud the product of your intuition (the immediate feeling) that has helped you to make the right decision (avoiding interaction). Recall of prior experiences was not necessary to make this decision. The decision was solely based on a feeling, which reflected prior knowledge without awareness.2
Learning perspective theorists would suggest that your feeling of dislike - your intuition that you shouldn't talk to the man - came from something like an (unconscious) regularities analysis of your experiences with that man that were stored in long-term memory, and those experiences turned out to be mostly negative. As such, your intuition can make use of rapid parallel processing to draw on the whole sum of experiences in l |
ed41080c-2463-4546-ac2d-46bca452d6b7 | trentmkelly/LessWrong-43k | LessWrong | How did my baby die and what is the probability that my next one will?
Summary: My son was stillborn and I don't know why. My wife and I would like to have another child, but would very much not like to try if the probability of this occurring again is above a certain threshold (of which we have already settled on one). All 3 doctors I have consulted were unable to give a definitive cause of death, nor were any willing to give a numerical estimate of the probability (whether for reasons of legal risk, or something else) that our next baby will be stillborn. I am likely too mind-killed to properly evaluate my situation and would very much appreciate an independent (from mine) probability estimate of what caused my son to die, and given that cause, what is the recurrence risk?
Background: V (L and my only biologically related living son) had no complications during birth, nor has he showed any signs of poor health whatsoever. L has a cousin who has had two miscarriages, and I have an aunt who had several stillbirths followed by 3 live births of healthy children. We know of no other family members that have had similar misfortunes.
J (my deceased son) was the product of a 31 week gestation. L (my wife and J's mother) is 28 years old, gravida 2, para 1. L presented to the physicians office for routine prenatal care and noted that she had not felt any fetal movement for the last five to six days. No fetal heart tones were identified. It was determined that there was an intrauterine fetal demise. L was admitted on 11/05/2015 for induction and was delivered of a nonviable, normal appearing, male fetus at approximately 1:30 on 11/06/2015.
Pro-Con Reasoning: According to a leading obstetrics textbook1, causes of stillbirth are commonly classified into 8 categories: obstetrical complications, placental abnormalities, fetal malformations, infection, umbilical cord abnormalities, hypertensive disorders, medical complications, and undetermined. Below, I'll list the percentage of stillbirths in each category (which may be used as prior probabilit |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.